
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_15517
|
rasdani/github-patches
|
git_diff
|
InstaPy__InstaPy-458
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unfollow end prematurelly
Hello I made the following script, but after it unfollows 19 people it neatly ends the session.
Why is it ending prematurly?
from instapy import InstaPy
import os
session = InstaPy(username='login', password='pass')
session.login()
session.set_do_follow(enabled=True, percentage=97, times=1)
##session.set_upper_follower_count(limit = 6500)
#session.set_dont_like('nsfw')
#session.set_dont_like('#exactmatch', '[startswith', ']endswith', 'broadmatch')
session.unfollow_users(amount=500)
#session.follow_by_list(accs, times=1)
session.end()
**Here is the CMD line:**
Logged in successfully!
Number of people followed automatically remaining: 776
--> Ongoing Unfollow 1, now unfollowing: b'amar_tafilovic'
--> Ongoing Unfollow 2, now unfollowing: b'super_car_heaven_'
--> Ongoing Unfollow 3, now unfollowing: b'la2natural'
--> Ongoing Unfollow 4, now unfollowing: b'lusinelusarts'
--> Ongoing Unfollow 5, now unfollowing: b'khfitfam'
--> Ongoing Unfollow 6, now unfollowing: b'nicksforzarealty'
--> Ongoing Unfollow 7, now unfollowing: b'kymu.motivation'
--> Ongoing Unfollow 8, now unfollowing: b'roger.despres'
--> Ongoing Unfollow 9, now unfollowing: b'biene141291'
--> Ongoing Unfollow 10, now unfollowing: b'trendynclassy_acce
sleeping for about 10min
--> Ongoing Unfollow 11, now unfollowing: b'lizzy.pg'
--> Ongoing Unfollow 12, now unfollowing: b'chrisprandy'
--> Ongoing Unfollow 13, now unfollowing: b'faits.n.quotes'
--> Ongoing Unfollow 14, now unfollowing: b'mindsetleader'
--> Ongoing Unfollow 15, now unfollowing: b'55totalpackage55'
--> Ongoing Unfollow 16, now unfollowing: b'sorelleshoes'
--> Ongoing Unfollow 17, now unfollowing: b'babymugglemom'
--> Ongoing Unfollow 18, now unfollowing: b'karrcomedy'
--> Ongoing Unfollow 19, now unfollowing: b'roninisgolden'
--> Total people unfollowed : 19
Session ended
-------------
Thank you in advance,
Jeffrey
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instapy/unfollow_util.py`
Content:
```
1 """Module which handles the follow features like unfollowing and following"""
2 import json
3 import csv
4 from .time_util import sleep
5 from random import randint
6 from .util import delete_line_from_file
7 from .util import scroll_bottom
8 from .print_log_writer import log_followed_pool
9
10
11 def set_automated_followed_pool(username):
12 automatedFollowedPool = []
13 try:
14 with open('./logs/' + username + '_followedPool.csv') as followedPoolFile:
15 reader = csv.reader(followedPoolFile)
16 automatedFollowedPool = [row[0] for row in reader]
17
18 print("Number of people followed automatically remaining: {}".format(len(automatedFollowedPool)))
19 followedPoolFile.close()
20
21 except BaseException as e:
22 print("set_automated_followed_pool error \n", str(e))
23
24 return automatedFollowedPool
25
26
27 def unfollow(browser, username, amount, dont_include, onlyInstapyFollowed, automatedFollowedPool):
28 """unfollows the given amount of users"""
29 unfollowNum = 0
30
31 browser.get('https://www.instagram.com/' + username)
32
33 # check how many poeple we are following
34 allfollowing = browser.find_element_by_xpath("//li[3]/a/span").text
35 allfollowing = allfollowing.replace(',', '').replace('.', '')
36 allfollowing = int(allfollowing.replace('k', '00').replace('m', '00000'))
37
38 # throw RuntimeWarning if we are 0 people following
39 if (allfollowing == 0):
40 raise RuntimeWarning('There are 0 people to unfollow')
41
42 try:
43 following_link = browser.find_elements_by_xpath('//header/div[2]//li[3]')
44 following_link[0].click()
45 except BaseException as e:
46 print("following_link error \n", str(e))
47
48 sleep(2)
49
50 # find dialog box
51
52 dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')
53
54 # scroll down the page
55 scroll_bottom(browser, dialog, allfollowing)
56
57 # get persons, unfollow buttons, and length of followed pool
58 person_list_a = dialog.find_elements_by_tag_name("a")
59 person_list = []
60
61 for person in person_list_a:
62
63 if person and hasattr(person, 'text') and person.text:
64 person_list.append(person.text)
65
66 follow_buttons = dialog.find_elements_by_tag_name('button')
67 automatedFollowedPoolLength = len(automatedFollowedPool)
68
69 # unfollow loop
70 try:
71 hasSlept = False
72
73 for button, person in zip(follow_buttons, person_list):
74 if unfollowNum >= amount:
75 print("--> Total unfollowNum reached it's amount given ", unfollowNum)
76 break
77
78 if onlyInstapyFollowed == True and unfollowNum >= automatedFollowedPoolLength:
79 print("--> Total unfollowNum exeeded the pool of automated followed ", unfollowNum)
80 break
81
82 if unfollowNum != 0 and hasSlept == False and unfollowNum % 10 == 0:
83 print('sleeping for about 10min')
84 sleep(600)
85 hasSlept = True
86 continue
87
88 if person not in dont_include:
89 if onlyInstapyFollowed == True and person in automatedFollowedPool:
90 unfollowNum += 1
91 button.click()
92 delete_line_from_file('./logs/' + username + '_followedPool.csv', person + ",\n")
93
94 print('--> Ongoing Unfollow From InstaPy ' + str(unfollowNum) + ', now unfollowing: {}'.format(
95 person.encode('utf-8')))
96 sleep(15)
97 # To only sleep once until there is the next unfollow
98 if hasSlept: hasSlept = False
99
100 continue
101
102 elif onlyInstapyFollowed != True:
103 unfollowNum += 1
104 button.click()
105
106 print('--> Ongoing Unfollow ' + str(unfollowNum) + ', now unfollowing: {}'.format(
107 person.encode('utf-8')))
108 sleep(15)
109 # To only sleep once until there is the next unfollow
110 if hasSlept: hasSlept = False
111
112 continue
113
114 else:
115 continue
116
117 except BaseException as e:
118 print("unfollow loop error \n", str(e))
119
120 return unfollowNum
121
122
123 def follow_user(browser, follow_restrict, login, user_name):
124 """Follows the user of the currently opened image"""
125
126 follow_button = browser.find_element_by_xpath("//article/header/span/button")
127 sleep(2)
128
129 if follow_button.text == 'Follow':
130 follow_button.click()
131 print('--> Now following')
132 log_followed_pool(login, user_name)
133 follow_restrict[user_name] = follow_restrict.get(user_name, 0) + 1
134 sleep(3)
135 return 1
136
137 else:
138 print('--> Already following')
139 sleep(1)
140 return 0
141
142
143 def follow_given_user(browser, acc_to_follow, follow_restrict):
144 """Follows a given user."""
145 browser.get('https://www.instagram.com/' + acc_to_follow)
146 print('--> {} instagram account is opened...'.format(acc_to_follow))
147 follow_button = browser.find_element_by_xpath("//*[contains(text(), 'Follow')]")
148 sleep(10)
149 if follow_button.text == 'Follow':
150 follow_button.click()
151 print('---> Now following: {}'.format(acc_to_follow))
152 print('*' * 20)
153 follow_restrict[acc_to_follow] = follow_restrict.get(acc_to_follow, 0) + 1
154 sleep(3)
155 return 1
156 else:
157 print('---> {} is already followed'.format(acc_to_follow))
158 print('*' * 20)
159 sleep(3)
160 return 0
161
162
163 def dump_follow_restriction(followRes):
164 """Dumps the given dictionary to a file using the json format"""
165 with open('./logs/followRestriction.json', 'w') as followResFile:
166 json.dump(followRes, followResFile)
167
168
169 def load_follow_restriction():
170 """Loads the saved """
171 with open('./logs/followRestriction.json') as followResFile:
172 return json.load(followResFile)
173
```
Path: `instapy/util.py`
Content:
```
1 from .time_util import sleep
2 from random import randint
3 from random import choice
4
5
6 def delete_line_from_file(filepath, lineToDelete):
7 try:
8 f = open(filepath, "r")
9 lines = f.readlines()
10 f.close()
11 f = open(filepath, "w")
12
13 for line in lines:
14
15 if line != lineToDelete:
16 f.write(line)
17 f.close()
18 except BaseException as e:
19 print("delete_line_from_file error \n", str(e))
20
21
22 def scroll_bottom(browser, element, range_int):
23 # put a limit to the scrolling
24 if range_int > 50: range_int = 1
25
26 for i in range(int(range_int / 2)):
27 browser.execute_script("arguments[0].scrollTop = arguments[0].scrollHeight", element)
28 sleep(1)
29
30 return
31
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instapy/unfollow_util.py b/instapy/unfollow_util.py
--- a/instapy/unfollow_util.py
+++ b/instapy/unfollow_util.py
@@ -49,7 +49,7 @@
# find dialog box
- dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')
+ dialog = browser.find_element_by_xpath('/html/body/div[4]/div/div[2]/div/div[2]/div/div[2]')
# scroll down the page
scroll_bottom(browser, dialog, allfollowing)
diff --git a/instapy/util.py b/instapy/util.py
--- a/instapy/util.py
+++ b/instapy/util.py
@@ -21,7 +21,7 @@
def scroll_bottom(browser, element, range_int):
# put a limit to the scrolling
- if range_int > 50: range_int = 1
+ if range_int > 50: range_int = 50
for i in range(int(range_int / 2)):
browser.execute_script("arguments[0].scrollTop = arguments[0].scrollHeight", element)
|
{"golden_diff": "diff --git a/instapy/unfollow_util.py b/instapy/unfollow_util.py\n--- a/instapy/unfollow_util.py\n+++ b/instapy/unfollow_util.py\n@@ -49,7 +49,7 @@\n \n # find dialog box\n \n- dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')\n+ dialog = browser.find_element_by_xpath('/html/body/div[4]/div/div[2]/div/div[2]/div/div[2]')\n \n # scroll down the page\n scroll_bottom(browser, dialog, allfollowing)\ndiff --git a/instapy/util.py b/instapy/util.py\n--- a/instapy/util.py\n+++ b/instapy/util.py\n@@ -21,7 +21,7 @@\n \n def scroll_bottom(browser, element, range_int):\n # put a limit to the scrolling\n- if range_int > 50: range_int = 1\n+ if range_int > 50: range_int = 50\n \n for i in range(int(range_int / 2)):\n browser.execute_script(\"arguments[0].scrollTop = arguments[0].scrollHeight\", element)\n", "issue": "Unfollow end prematurelly \nHello I made the following script, but after it unfollows 19 people it neatly ends the session.\r\nWhy is it ending prematurly? \r\n\r\nfrom instapy import InstaPy\r\nimport os\r\nsession = InstaPy(username='login', password='pass')\r\nsession.login()\r\nsession.set_do_follow(enabled=True, percentage=97, times=1)\r\n##session.set_upper_follower_count(limit = 6500)\r\n#session.set_dont_like('nsfw')\r\n#session.set_dont_like('#exactmatch', '[startswith', ']endswith', 'broadmatch')\r\nsession.unfollow_users(amount=500)\r\n\r\n#session.follow_by_list(accs, times=1)\r\n\r\nsession.end()\r\n\r\n\r\n**Here is the CMD line:**\r\n\r\nLogged in successfully!\r\nNumber of people followed automatically remaining: 776\r\n--> Ongoing Unfollow 1, now unfollowing: b'amar_tafilovic'\r\n--> Ongoing Unfollow 2, now unfollowing: b'super_car_heaven_'\r\n--> Ongoing Unfollow 3, now unfollowing: b'la2natural'\r\n--> Ongoing Unfollow 4, now unfollowing: b'lusinelusarts'\r\n--> Ongoing Unfollow 5, now unfollowing: b'khfitfam'\r\n--> Ongoing Unfollow 6, now unfollowing: b'nicksforzarealty'\r\n--> Ongoing Unfollow 7, now unfollowing: b'kymu.motivation'\r\n--> Ongoing Unfollow 8, now unfollowing: b'roger.despres'\r\n--> Ongoing Unfollow 9, now unfollowing: b'biene141291'\r\n--> Ongoing Unfollow 10, now unfollowing: b'trendynclassy_acce\r\nsleeping for about 10min\r\n--> Ongoing Unfollow 11, now unfollowing: b'lizzy.pg'\r\n--> Ongoing Unfollow 12, now unfollowing: b'chrisprandy'\r\n--> Ongoing Unfollow 13, now unfollowing: b'faits.n.quotes'\r\n--> Ongoing Unfollow 14, now unfollowing: b'mindsetleader'\r\n--> Ongoing Unfollow 15, now unfollowing: b'55totalpackage55'\r\n--> Ongoing Unfollow 16, now unfollowing: b'sorelleshoes'\r\n--> Ongoing Unfollow 17, now unfollowing: b'babymugglemom'\r\n--> Ongoing Unfollow 18, now unfollowing: b'karrcomedy'\r\n--> Ongoing Unfollow 19, now unfollowing: b'roninisgolden'\r\n--> Total people unfollowed : 19\r\n\r\nSession ended\r\n-------------\r\n\r\n\r\nThank you in advance,\r\nJeffrey\n", "before_files": [{"content": "\"\"\"Module which handles the follow features like unfollowing and following\"\"\"\nimport json\nimport csv\nfrom .time_util import sleep\nfrom random import randint\nfrom .util import delete_line_from_file\nfrom .util import scroll_bottom\nfrom .print_log_writer import log_followed_pool\n\n\ndef set_automated_followed_pool(username):\n automatedFollowedPool = []\n try:\n with open('./logs/' + username + '_followedPool.csv') as followedPoolFile:\n reader = csv.reader(followedPoolFile)\n automatedFollowedPool = [row[0] for row in reader]\n\n print(\"Number of people followed automatically remaining: {}\".format(len(automatedFollowedPool)))\n followedPoolFile.close()\n\n except BaseException as e:\n print(\"set_automated_followed_pool error \\n\", str(e))\n\n return automatedFollowedPool\n\n\ndef unfollow(browser, username, amount, dont_include, onlyInstapyFollowed, automatedFollowedPool):\n \"\"\"unfollows the given amount of users\"\"\"\n unfollowNum = 0\n\n browser.get('https://www.instagram.com/' + username)\n\n # check how many poeple we are following\n allfollowing = browser.find_element_by_xpath(\"//li[3]/a/span\").text\n allfollowing = allfollowing.replace(',', '').replace('.', '')\n allfollowing = int(allfollowing.replace('k', '00').replace('m', '00000'))\n\n # throw RuntimeWarning if we are 0 people following\n if (allfollowing == 0):\n raise RuntimeWarning('There are 0 people to unfollow')\n\n try:\n following_link = browser.find_elements_by_xpath('//header/div[2]//li[3]')\n following_link[0].click()\n except BaseException as e:\n print(\"following_link error \\n\", str(e))\n\n sleep(2)\n\n # find dialog box\n\n dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')\n\n # scroll down the page\n scroll_bottom(browser, dialog, allfollowing)\n\n # get persons, unfollow buttons, and length of followed pool\n person_list_a = dialog.find_elements_by_tag_name(\"a\")\n person_list = []\n\n for person in person_list_a:\n\n if person and hasattr(person, 'text') and person.text:\n person_list.append(person.text)\n\n follow_buttons = dialog.find_elements_by_tag_name('button')\n automatedFollowedPoolLength = len(automatedFollowedPool)\n\n # unfollow loop\n try:\n hasSlept = False\n\n for button, person in zip(follow_buttons, person_list):\n if unfollowNum >= amount:\n print(\"--> Total unfollowNum reached it's amount given \", unfollowNum)\n break\n\n if onlyInstapyFollowed == True and unfollowNum >= automatedFollowedPoolLength:\n print(\"--> Total unfollowNum exeeded the pool of automated followed \", unfollowNum)\n break\n\n if unfollowNum != 0 and hasSlept == False and unfollowNum % 10 == 0:\n print('sleeping for about 10min')\n sleep(600)\n hasSlept = True\n continue\n\n if person not in dont_include:\n if onlyInstapyFollowed == True and person in automatedFollowedPool:\n unfollowNum += 1\n button.click()\n delete_line_from_file('./logs/' + username + '_followedPool.csv', person + \",\\n\")\n\n print('--> Ongoing Unfollow From InstaPy ' + str(unfollowNum) + ', now unfollowing: {}'.format(\n person.encode('utf-8')))\n sleep(15)\n # To only sleep once until there is the next unfollow\n if hasSlept: hasSlept = False\n\n continue\n\n elif onlyInstapyFollowed != True:\n unfollowNum += 1\n button.click()\n\n print('--> Ongoing Unfollow ' + str(unfollowNum) + ', now unfollowing: {}'.format(\n person.encode('utf-8')))\n sleep(15)\n # To only sleep once until there is the next unfollow\n if hasSlept: hasSlept = False\n\n continue\n\n else:\n continue\n\n except BaseException as e:\n print(\"unfollow loop error \\n\", str(e))\n\n return unfollowNum\n\n\ndef follow_user(browser, follow_restrict, login, user_name):\n \"\"\"Follows the user of the currently opened image\"\"\"\n\n follow_button = browser.find_element_by_xpath(\"//article/header/span/button\")\n sleep(2)\n\n if follow_button.text == 'Follow':\n follow_button.click()\n print('--> Now following')\n log_followed_pool(login, user_name)\n follow_restrict[user_name] = follow_restrict.get(user_name, 0) + 1\n sleep(3)\n return 1\n\n else:\n print('--> Already following')\n sleep(1)\n return 0\n\n\ndef follow_given_user(browser, acc_to_follow, follow_restrict):\n \"\"\"Follows a given user.\"\"\"\n browser.get('https://www.instagram.com/' + acc_to_follow)\n print('--> {} instagram account is opened...'.format(acc_to_follow))\n follow_button = browser.find_element_by_xpath(\"//*[contains(text(), 'Follow')]\")\n sleep(10)\n if follow_button.text == 'Follow':\n follow_button.click()\n print('---> Now following: {}'.format(acc_to_follow))\n print('*' * 20)\n follow_restrict[acc_to_follow] = follow_restrict.get(acc_to_follow, 0) + 1\n sleep(3)\n return 1\n else:\n print('---> {} is already followed'.format(acc_to_follow))\n print('*' * 20)\n sleep(3)\n return 0\n\n\ndef dump_follow_restriction(followRes):\n \"\"\"Dumps the given dictionary to a file using the json format\"\"\"\n with open('./logs/followRestriction.json', 'w') as followResFile:\n json.dump(followRes, followResFile)\n\n\ndef load_follow_restriction():\n \"\"\"Loads the saved \"\"\"\n with open('./logs/followRestriction.json') as followResFile:\n return json.load(followResFile)\n", "path": "instapy/unfollow_util.py"}, {"content": "from .time_util import sleep\nfrom random import randint\nfrom random import choice\n\n\ndef delete_line_from_file(filepath, lineToDelete):\n try:\n f = open(filepath, \"r\")\n lines = f.readlines()\n f.close()\n f = open(filepath, \"w\")\n\n for line in lines:\n\n if line != lineToDelete:\n f.write(line)\n f.close()\n except BaseException as e:\n print(\"delete_line_from_file error \\n\", str(e))\n\n\ndef scroll_bottom(browser, element, range_int):\n # put a limit to the scrolling\n if range_int > 50: range_int = 1\n\n for i in range(int(range_int / 2)):\n browser.execute_script(\"arguments[0].scrollTop = arguments[0].scrollHeight\", element)\n sleep(1)\n\n return\n", "path": "instapy/util.py"}], "after_files": [{"content": "\"\"\"Module which handles the follow features like unfollowing and following\"\"\"\nimport json\nimport csv\nfrom .time_util import sleep\nfrom random import randint\nfrom .util import delete_line_from_file\nfrom .util import scroll_bottom\nfrom .print_log_writer import log_followed_pool\n\n\ndef set_automated_followed_pool(username):\n automatedFollowedPool = []\n try:\n with open('./logs/' + username + '_followedPool.csv') as followedPoolFile:\n reader = csv.reader(followedPoolFile)\n automatedFollowedPool = [row[0] for row in reader]\n\n print(\"Number of people followed automatically remaining: {}\".format(len(automatedFollowedPool)))\n followedPoolFile.close()\n\n except BaseException as e:\n print(\"set_automated_followed_pool error \\n\", str(e))\n\n return automatedFollowedPool\n\n\ndef unfollow(browser, username, amount, dont_include, onlyInstapyFollowed, automatedFollowedPool):\n \"\"\"unfollows the given amount of users\"\"\"\n unfollowNum = 0\n\n browser.get('https://www.instagram.com/' + username)\n\n # check how many poeple we are following\n allfollowing = browser.find_element_by_xpath(\"//li[3]/a/span\").text\n allfollowing = allfollowing.replace(',', '').replace('.', '')\n allfollowing = int(allfollowing.replace('k', '00').replace('m', '00000'))\n\n # throw RuntimeWarning if we are 0 people following\n if (allfollowing == 0):\n raise RuntimeWarning('There are 0 people to unfollow')\n\n try:\n following_link = browser.find_elements_by_xpath('//header/div[2]//li[3]')\n following_link[0].click()\n except BaseException as e:\n print(\"following_link error \\n\", str(e))\n\n sleep(2)\n\n # find dialog box\n\n dialog = browser.find_element_by_xpath('/html/body/div[4]/div/div[2]/div/div[2]/div/div[2]')\n\n # scroll down the page\n scroll_bottom(browser, dialog, allfollowing)\n\n # get persons, unfollow buttons, and length of followed pool\n person_list_a = dialog.find_elements_by_tag_name(\"a\")\n person_list = []\n\n for person in person_list_a:\n\n if person and hasattr(person, 'text') and person.text:\n person_list.append(person.text)\n\n follow_buttons = dialog.find_elements_by_tag_name('button')\n automatedFollowedPoolLength = len(automatedFollowedPool)\n\n # unfollow loop\n try:\n hasSlept = False\n\n for button, person in zip(follow_buttons, person_list):\n if unfollowNum >= amount:\n print(\"--> Total unfollowNum reached it's amount given \", unfollowNum)\n break\n\n if onlyInstapyFollowed == True and unfollowNum >= automatedFollowedPoolLength:\n print(\"--> Total unfollowNum exeeded the pool of automated followed \", unfollowNum)\n break\n\n if unfollowNum != 0 and hasSlept == False and unfollowNum % 10 == 0:\n print('sleeping for about 10min')\n sleep(600)\n hasSlept = True\n continue\n\n if person not in dont_include:\n if onlyInstapyFollowed == True and person in automatedFollowedPool:\n unfollowNum += 1\n button.click()\n delete_line_from_file('./logs/' + username + '_followedPool.csv', person + \",\\n\")\n\n print('--> Ongoing Unfollow From InstaPy ' + str(unfollowNum) + ', now unfollowing: {}'.format(\n person.encode('utf-8')))\n sleep(15)\n # To only sleep once until there is the next unfollow\n if hasSlept: hasSlept = False\n\n continue\n\n elif onlyInstapyFollowed != True:\n unfollowNum += 1\n button.click()\n\n print('--> Ongoing Unfollow ' + str(unfollowNum) + ', now unfollowing: {}'.format(\n person.encode('utf-8')))\n sleep(15)\n # To only sleep once until there is the next unfollow\n if hasSlept: hasSlept = False\n\n continue\n\n else:\n continue\n\n except BaseException as e:\n print(\"unfollow loop error \\n\", str(e))\n\n return unfollowNum\n\n\ndef follow_user(browser, follow_restrict, login, user_name):\n \"\"\"Follows the user of the currently opened image\"\"\"\n\n follow_button = browser.find_element_by_xpath(\"//article/header/span/button\")\n sleep(2)\n\n if follow_button.text == 'Follow':\n follow_button.click()\n print('--> Now following')\n log_followed_pool(login, user_name)\n follow_restrict[user_name] = follow_restrict.get(user_name, 0) + 1\n sleep(3)\n return 1\n\n else:\n print('--> Already following')\n sleep(1)\n return 0\n\n\ndef follow_given_user(browser, acc_to_follow, follow_restrict):\n \"\"\"Follows a given user.\"\"\"\n browser.get('https://www.instagram.com/' + acc_to_follow)\n print('--> {} instagram account is opened...'.format(acc_to_follow))\n follow_button = browser.find_element_by_xpath(\"//*[contains(text(), 'Follow')]\")\n sleep(10)\n if follow_button.text == 'Follow':\n follow_button.click()\n print('---> Now following: {}'.format(acc_to_follow))\n print('*' * 20)\n follow_restrict[acc_to_follow] = follow_restrict.get(acc_to_follow, 0) + 1\n sleep(3)\n return 1\n else:\n print('---> {} is already followed'.format(acc_to_follow))\n print('*' * 20)\n sleep(3)\n return 0\n\n\ndef dump_follow_restriction(followRes):\n \"\"\"Dumps the given dictionary to a file using the json format\"\"\"\n with open('./logs/followRestriction.json', 'w') as followResFile:\n json.dump(followRes, followResFile)\n\n\ndef load_follow_restriction():\n \"\"\"Loads the saved \"\"\"\n with open('./logs/followRestriction.json') as followResFile:\n return json.load(followResFile)\n", "path": "instapy/unfollow_util.py"}, {"content": "from .time_util import sleep\nfrom random import randint\nfrom random import choice\n\n\ndef delete_line_from_file(filepath, lineToDelete):\n try:\n f = open(filepath, \"r\")\n lines = f.readlines()\n f.close()\n f = open(filepath, \"w\")\n\n for line in lines:\n\n if line != lineToDelete:\n f.write(line)\n f.close()\n except BaseException as e:\n print(\"delete_line_from_file error \\n\", str(e))\n\n\ndef scroll_bottom(browser, element, range_int):\n # put a limit to the scrolling\n if range_int > 50: range_int = 50\n\n for i in range(int(range_int / 2)):\n browser.execute_script(\"arguments[0].scrollTop = arguments[0].scrollHeight\", element)\n sleep(1)\n\n return\n", "path": "instapy/util.py"}]}
| 2,932 | 263 |
gh_patches_debug_29153
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-249
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SIGINT (Ctrl+C) should be handled by opsdroid
When executing opsdroid in Ubuntu or in a Docker container, the following message appears:
`(Press CTRL+C to quit)`
When hitting `Ctrl+C` though, the following traceback is produced:
```
^CERROR asyncio: Task exception was never retrieved
future: <Task finished coro=<ConnectorShell.listen() done, defined at /root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py:57> exception=ConnectionResetError('Connection lost',)>
Traceback (most recent call last):
File "/usr/local/lib/python3.5/asyncio/tasks.py", line 240, in _step
result = coro.send(None)
File "/root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py", line 63, in listen
user_input = await async_input('', opsdroid.eventloop)
File "/root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py", line 37, in async_input
await writer.drain()
File "/usr/local/lib/python3.5/asyncio/streams.py", line 333, in drain
yield from self._protocol._drain_helper()
File "/usr/local/lib/python3.5/asyncio/streams.py", line 204, in _drain_helper
raise ConnectionResetError('Connection lost')
ConnectionResetError: Connection lost
ERROR asyncio: Exception in default exception handler
Traceback (most recent call last):
File "/usr/local/lib/python3.5/asyncio/base_events.py", line 1284, in call_exception_handler
self.default_exception_handler(context)
File "/usr/local/lib/python3.5/asyncio/base_events.py", line 1259, in default_exception_handler
logger.error('\n'.join(log_lines), exc_info=exc_info)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1314, in error
self._log(ERROR, msg, args, **kwargs)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1421, in _log
self.handle(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1431, in handle
self.callHandlers(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1493, in callHandlers
hdlr.handle(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 861, in handle
self.emit(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1053, in emit
self.stream = self._open()
File "/usr/local/lib/python3.5/logging/__init__.py", line 1043, in _open
return open(self.baseFilename, self.mode, encoding=self.encoding)
NameError: name 'open' is not defined
Exception ignored in: <bound method Task.__del__ of <Task finished coro=<ConnectorShell.listen() done, defined at /root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py:57> exception=ConnectionResetError('Connection lost',)>>
Traceback (most recent call last):
File "/usr/local/lib/python3.5/asyncio/tasks.py", line 93, in __del__
File "/usr/local/lib/python3.5/asyncio/futures.py", line 234, in __del__
File "/usr/local/lib/python3.5/asyncio/base_events.py", line 1290, in call_exception_handler
File "/usr/local/lib/python3.5/logging/__init__.py", line 1314, in error
File "/usr/local/lib/python3.5/logging/__init__.py", line 1421, in _log
File "/usr/local/lib/python3.5/logging/__init__.py", line 1431, in handle
File "/usr/local/lib/python3.5/logging/__init__.py", line 1493, in callHandlers
File "/usr/local/lib/python3.5/logging/__init__.py", line 861, in handle
File "/usr/local/lib/python3.5/logging/__init__.py", line 1053, in emit
File "/usr/local/lib/python3.5/logging/__init__.py", line 1043, in _open
NameError: name 'open' is not defined
ERROR asyncio: Task was destroyed but it is pending!
task: <Task pending coro=<parse_crontab() running at /usr/src/app/opsdroid/parsers/crontab.py:20> wait_for=<Future pending cb=[Task._wakeup()]>>
ERROR asyncio: Exception in default exception handler
Traceback (most recent call last):
File "/usr/local/lib/python3.5/asyncio/base_events.py", line 1284, in call_exception_handler
self.default_exception_handler(context)
File "/usr/local/lib/python3.5/asyncio/base_events.py", line 1259, in default_exception_handler
logger.error('\n'.join(log_lines), exc_info=exc_info)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1314, in error
self._log(ERROR, msg, args, **kwargs)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1421, in _log
self.handle(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1431, in handle
self.callHandlers(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1493, in callHandlers
hdlr.handle(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 861, in handle
self.emit(record)
File "/usr/local/lib/python3.5/logging/__init__.py", line 1053, in emit
self.stream = self._open()
File "/usr/local/lib/python3.5/logging/__init__.py", line 1043, in _open
return open(self.baseFilename, self.mode, encoding=self.encoding)
NameError: name 'open' is not defined
Exception ignored in: <bound method Task.__del__ of <Task pending coro=<parse_crontab() running at /usr/src/app/opsdroid/parsers/crontab.py:20> wait_for=<Future pending cb=[Task._wakeup()]>>>
Traceback (most recent call last):
File "/usr/local/lib/python3.5/asyncio/tasks.py", line 92, in __del__
File "/usr/local/lib/python3.5/asyncio/base_events.py", line 1290, in call_exception_handler
File "/usr/local/lib/python3.5/logging/__init__.py", line 1314, in error
File "/usr/local/lib/python3.5/logging/__init__.py", line 1421, in _log
File "/usr/local/lib/python3.5/logging/__init__.py", line 1431, in handle
File "/usr/local/lib/python3.5/logging/__init__.py", line 1493, in callHandlers
File "/usr/local/lib/python3.5/logging/__init__.py", line 861, in handle
File "/usr/local/lib/python3.5/logging/__init__.py", line 1053, in emit
File "/usr/local/lib/python3.5/logging/__init__.py", line 1043, in _open
NameError: name 'open' is not defined
```
This should be handled, so that opsdroid can exit gracefully without producing any tracebacks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opsdroid/core.py`
Content:
```
1 """Core components of OpsDroid."""
2
3 import copy
4 import logging
5 import sys
6 import weakref
7 import asyncio
8
9 from opsdroid.memory import Memory
10 from opsdroid.connector import Connector
11 from opsdroid.database import Database
12 from opsdroid.loader import Loader
13 from opsdroid.parsers.regex import parse_regex
14 from opsdroid.parsers.apiai import parse_apiai
15 from opsdroid.parsers.crontab import parse_crontab
16 from opsdroid.const import DEFAULT_CONFIG_PATH
17
18
19 _LOGGER = logging.getLogger(__name__)
20
21
22 class OpsDroid():
23 """Root object for opsdroid."""
24
25 # pylint: disable=too-many-instance-attributes
26 # All are reasonable in this case.
27
28 instances = []
29
30 def __init__(self):
31 """Start opsdroid."""
32 self.bot_name = 'opsdroid'
33 self.sys_status = 0
34 self.connectors = []
35 self.connector_tasks = []
36 self.eventloop = asyncio.get_event_loop()
37 self.skills = []
38 self.memory = Memory()
39 self.loader = Loader(self)
40 self.config = {}
41 self.stats = {
42 "messages_parsed": 0,
43 "webhooks_called": 0,
44 "total_response_time": 0,
45 "total_responses": 0,
46 }
47 self.web_server = None
48 self.should_restart = False
49 self.stored_path = []
50 _LOGGER.info("Created main opsdroid object")
51
52 def __enter__(self):
53 """Add self to existing instances."""
54 self.stored_path = copy.copy(sys.path)
55 if not self.__class__.instances:
56 self.__class__.instances.append(weakref.proxy(self))
57 else:
58 self.critical("opsdroid has already been started", 1)
59 return self
60
61 def __exit__(self, exc_type, exc_value, traceback):
62 """Remove self from existing instances."""
63 sys.path = self.stored_path
64 self.__class__.instances = []
65 asyncio.set_event_loop(asyncio.new_event_loop())
66
67 @property
68 def default_connector(self):
69 """Return the default connector."""
70 default_connector = None
71 for connector in self.connectors:
72 if "default" in connector.config and connector.config["default"]:
73 default_connector = connector
74 break
75 if default_connector is None:
76 default_connector = self.connectors[0]
77 return default_connector
78
79 def exit(self):
80 """Exit application."""
81 _LOGGER.info("Exiting application with return code " +
82 str(self.sys_status))
83 sys.exit(self.sys_status)
84
85 def critical(self, error, code):
86 """Exit due to unrecoverable error."""
87 self.sys_status = code
88 _LOGGER.critical(error)
89 print("Error: " + error)
90 self.exit()
91
92 def restart(self):
93 """Restart opsdroid."""
94 self.should_restart = True
95 self.stop()
96
97 def stop(self):
98 """Stop the event loop."""
99 pending = asyncio.Task.all_tasks()
100 for task in pending:
101 task.cancel()
102 self.eventloop.stop()
103
104 def load(self):
105 """Load configuration."""
106 self.config = self.loader.load_config_file([
107 "./configuration.yaml",
108 DEFAULT_CONFIG_PATH,
109 "/etc/opsdroid/configuration.yaml"
110 ])
111
112 def start_loop(self):
113 """Start the event loop."""
114 connectors, databases, skills = \
115 self.loader.load_modules_from_config(self.config)
116 _LOGGER.debug("Loaded %i skills", len(skills))
117 if databases is not None:
118 self.start_databases(databases)
119 self.setup_skills(skills)
120 self.start_connector_tasks(connectors)
121 self.eventloop.create_task(parse_crontab(self))
122 self.web_server.start()
123 try:
124 pending = asyncio.Task.all_tasks()
125 self.eventloop.run_until_complete(asyncio.gather(*pending))
126 except (KeyboardInterrupt, EOFError):
127 print('') # Prints a character return for return to shell
128 self.stop()
129 _LOGGER.info("Keyboard interrupt, exiting.")
130 except RuntimeError as error:
131 if str(error) != 'Event loop is closed':
132 raise error
133 finally:
134 self.eventloop.close()
135
136 def setup_skills(self, skills):
137 """Call the setup function on the passed in skills."""
138 for skill in skills:
139 try:
140 skill["module"].setup(self)
141 except AttributeError:
142 pass
143
144 def start_connector_tasks(self, connectors):
145 """Start the connectors."""
146 for connector_module in connectors:
147 for _, cls in connector_module["module"].__dict__.items():
148 if isinstance(cls, type) and \
149 issubclass(cls, Connector) and\
150 cls is not Connector:
151 connector = cls(connector_module["config"])
152 self.connectors.append(connector)
153
154 if connectors:
155 for connector in self.connectors:
156 self.eventloop.run_until_complete(connector.connect(self))
157 for connector in self.connectors:
158 task = self.eventloop.create_task(connector.listen(self))
159 self.connector_tasks.append(task)
160 else:
161 self.critical("All connectors failed to load", 1)
162
163 def start_databases(self, databases):
164 """Start the databases."""
165 if not databases:
166 _LOGGER.debug(databases)
167 _LOGGER.warning("All databases failed to load")
168 for database_module in databases:
169 for name, cls in database_module["module"].__dict__.items():
170 if isinstance(cls, type) and \
171 issubclass(cls, Database) and \
172 cls is not Database:
173 _LOGGER.debug("Adding database: " + name)
174 database = cls(database_module["config"])
175 self.memory.databases.append(database)
176 self.eventloop.run_until_complete(database.connect(self))
177
178 async def parse(self, message):
179 """Parse a string against all skills."""
180 self.stats["messages_parsed"] = self.stats["messages_parsed"] + 1
181 tasks = []
182 if message.text.strip() != "":
183 _LOGGER.debug("Parsing input: " + message.text)
184
185 tasks.append(
186 self.eventloop.create_task(parse_regex(self, message)))
187
188 if "parsers" in self.config:
189 _LOGGER.debug("Processing parsers")
190 parsers = self.config["parsers"]
191
192 apiai = [p for p in parsers if p["name"] == "apiai"]
193 _LOGGER.debug("Checking apiai")
194 if len(apiai) == 1 and \
195 ("enabled" not in apiai[0] or
196 apiai[0]["enabled"] is not False):
197 _LOGGER.debug("Parsing with apiai")
198 tasks.append(
199 self.eventloop.create_task(
200 parse_apiai(self, message, apiai[0])))
201 return tasks
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opsdroid/core.py b/opsdroid/core.py
--- a/opsdroid/core.py
+++ b/opsdroid/core.py
@@ -2,6 +2,7 @@
import copy
import logging
+import signal
import sys
import weakref
import asyncio
@@ -34,6 +35,8 @@
self.connectors = []
self.connector_tasks = []
self.eventloop = asyncio.get_event_loop()
+ for sig in (signal.SIGINT, signal.SIGTERM):
+ self.eventloop.add_signal_handler(sig, self.stop)
self.skills = []
self.memory = Memory()
self.loader = Loader(self)
@@ -100,6 +103,8 @@
for task in pending:
task.cancel()
self.eventloop.stop()
+ print('') # Prints a character return for return to shell
+ _LOGGER.info("Keyboard interrupt, exiting.")
def load(self):
"""Load configuration."""
@@ -123,10 +128,6 @@
try:
pending = asyncio.Task.all_tasks()
self.eventloop.run_until_complete(asyncio.gather(*pending))
- except (KeyboardInterrupt, EOFError):
- print('') # Prints a character return for return to shell
- self.stop()
- _LOGGER.info("Keyboard interrupt, exiting.")
except RuntimeError as error:
if str(error) != 'Event loop is closed':
raise error
|
{"golden_diff": "diff --git a/opsdroid/core.py b/opsdroid/core.py\n--- a/opsdroid/core.py\n+++ b/opsdroid/core.py\n@@ -2,6 +2,7 @@\n \n import copy\n import logging\n+import signal\n import sys\n import weakref\n import asyncio\n@@ -34,6 +35,8 @@\n self.connectors = []\n self.connector_tasks = []\n self.eventloop = asyncio.get_event_loop()\n+ for sig in (signal.SIGINT, signal.SIGTERM):\n+ self.eventloop.add_signal_handler(sig, self.stop)\n self.skills = []\n self.memory = Memory()\n self.loader = Loader(self)\n@@ -100,6 +103,8 @@\n for task in pending:\n task.cancel()\n self.eventloop.stop()\n+ print('') # Prints a character return for return to shell\n+ _LOGGER.info(\"Keyboard interrupt, exiting.\")\n \n def load(self):\n \"\"\"Load configuration.\"\"\"\n@@ -123,10 +128,6 @@\n try:\n pending = asyncio.Task.all_tasks()\n self.eventloop.run_until_complete(asyncio.gather(*pending))\n- except (KeyboardInterrupt, EOFError):\n- print('') # Prints a character return for return to shell\n- self.stop()\n- _LOGGER.info(\"Keyboard interrupt, exiting.\")\n except RuntimeError as error:\n if str(error) != 'Event loop is closed':\n raise error\n", "issue": "SIGINT (Ctrl+C) should be handled by opsdroid\nWhen executing opsdroid in Ubuntu or in a Docker container, the following message appears:\r\n`(Press CTRL+C to quit)`\r\n\r\nWhen hitting `Ctrl+C` though, the following traceback is produced:\r\n\r\n```\r\n^CERROR asyncio: Task exception was never retrieved\r\nfuture: <Task finished coro=<ConnectorShell.listen() done, defined at /root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py:57> exception=ConnectionResetError('Connection lost',)>\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/asyncio/tasks.py\", line 240, in _step\r\n result = coro.send(None)\r\n File \"/root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py\", line 63, in listen\r\n user_input = await async_input('', opsdroid.eventloop)\r\n File \"/root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py\", line 37, in async_input\r\n await writer.drain()\r\n File \"/usr/local/lib/python3.5/asyncio/streams.py\", line 333, in drain\r\n yield from self._protocol._drain_helper()\r\n File \"/usr/local/lib/python3.5/asyncio/streams.py\", line 204, in _drain_helper\r\n raise ConnectionResetError('Connection lost')\r\nConnectionResetError: Connection lost\r\nERROR asyncio: Exception in default exception handler\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/asyncio/base_events.py\", line 1284, in call_exception_handler\r\n self.default_exception_handler(context)\r\n File \"/usr/local/lib/python3.5/asyncio/base_events.py\", line 1259, in default_exception_handler\r\n logger.error('\\n'.join(log_lines), exc_info=exc_info)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1314, in error\r\n self._log(ERROR, msg, args, **kwargs)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1421, in _log\r\n self.handle(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1431, in handle\r\n self.callHandlers(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1493, in callHandlers\r\n hdlr.handle(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 861, in handle\r\n self.emit(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1053, in emit\r\n self.stream = self._open()\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1043, in _open\r\n return open(self.baseFilename, self.mode, encoding=self.encoding)\r\nNameError: name 'open' is not defined\r\nException ignored in: <bound method Task.__del__ of <Task finished coro=<ConnectorShell.listen() done, defined at /root/.opsdroid/modules/opsdroid-modules/connector/shell/__init__.py:57> exception=ConnectionResetError('Connection lost',)>>\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/asyncio/tasks.py\", line 93, in __del__\r\n File \"/usr/local/lib/python3.5/asyncio/futures.py\", line 234, in __del__\r\n File \"/usr/local/lib/python3.5/asyncio/base_events.py\", line 1290, in call_exception_handler\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1314, in error\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1421, in _log\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1431, in handle\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1493, in callHandlers\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 861, in handle\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1053, in emit\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1043, in _open\r\nNameError: name 'open' is not defined\r\nERROR asyncio: Task was destroyed but it is pending!\r\ntask: <Task pending coro=<parse_crontab() running at /usr/src/app/opsdroid/parsers/crontab.py:20> wait_for=<Future pending cb=[Task._wakeup()]>>\r\nERROR asyncio: Exception in default exception handler\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/asyncio/base_events.py\", line 1284, in call_exception_handler\r\n self.default_exception_handler(context)\r\n File \"/usr/local/lib/python3.5/asyncio/base_events.py\", line 1259, in default_exception_handler\r\n logger.error('\\n'.join(log_lines), exc_info=exc_info)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1314, in error\r\n self._log(ERROR, msg, args, **kwargs)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1421, in _log\r\n self.handle(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1431, in handle\r\n self.callHandlers(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1493, in callHandlers\r\n hdlr.handle(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 861, in handle\r\n self.emit(record)\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1053, in emit\r\n self.stream = self._open()\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1043, in _open\r\n return open(self.baseFilename, self.mode, encoding=self.encoding)\r\nNameError: name 'open' is not defined\r\nException ignored in: <bound method Task.__del__ of <Task pending coro=<parse_crontab() running at /usr/src/app/opsdroid/parsers/crontab.py:20> wait_for=<Future pending cb=[Task._wakeup()]>>>\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/asyncio/tasks.py\", line 92, in __del__\r\n File \"/usr/local/lib/python3.5/asyncio/base_events.py\", line 1290, in call_exception_handler\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1314, in error\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1421, in _log\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1431, in handle\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1493, in callHandlers\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 861, in handle\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1053, in emit\r\n File \"/usr/local/lib/python3.5/logging/__init__.py\", line 1043, in _open\r\nNameError: name 'open' is not defined\r\n```\r\n\r\nThis should be handled, so that opsdroid can exit gracefully without producing any tracebacks.\n", "before_files": [{"content": "\"\"\"Core components of OpsDroid.\"\"\"\n\nimport copy\nimport logging\nimport sys\nimport weakref\nimport asyncio\n\nfrom opsdroid.memory import Memory\nfrom opsdroid.connector import Connector\nfrom opsdroid.database import Database\nfrom opsdroid.loader import Loader\nfrom opsdroid.parsers.regex import parse_regex\nfrom opsdroid.parsers.apiai import parse_apiai\nfrom opsdroid.parsers.crontab import parse_crontab\nfrom opsdroid.const import DEFAULT_CONFIG_PATH\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass OpsDroid():\n \"\"\"Root object for opsdroid.\"\"\"\n\n # pylint: disable=too-many-instance-attributes\n # All are reasonable in this case.\n\n instances = []\n\n def __init__(self):\n \"\"\"Start opsdroid.\"\"\"\n self.bot_name = 'opsdroid'\n self.sys_status = 0\n self.connectors = []\n self.connector_tasks = []\n self.eventloop = asyncio.get_event_loop()\n self.skills = []\n self.memory = Memory()\n self.loader = Loader(self)\n self.config = {}\n self.stats = {\n \"messages_parsed\": 0,\n \"webhooks_called\": 0,\n \"total_response_time\": 0,\n \"total_responses\": 0,\n }\n self.web_server = None\n self.should_restart = False\n self.stored_path = []\n _LOGGER.info(\"Created main opsdroid object\")\n\n def __enter__(self):\n \"\"\"Add self to existing instances.\"\"\"\n self.stored_path = copy.copy(sys.path)\n if not self.__class__.instances:\n self.__class__.instances.append(weakref.proxy(self))\n else:\n self.critical(\"opsdroid has already been started\", 1)\n return self\n\n def __exit__(self, exc_type, exc_value, traceback):\n \"\"\"Remove self from existing instances.\"\"\"\n sys.path = self.stored_path\n self.__class__.instances = []\n asyncio.set_event_loop(asyncio.new_event_loop())\n\n @property\n def default_connector(self):\n \"\"\"Return the default connector.\"\"\"\n default_connector = None\n for connector in self.connectors:\n if \"default\" in connector.config and connector.config[\"default\"]:\n default_connector = connector\n break\n if default_connector is None:\n default_connector = self.connectors[0]\n return default_connector\n\n def exit(self):\n \"\"\"Exit application.\"\"\"\n _LOGGER.info(\"Exiting application with return code \" +\n str(self.sys_status))\n sys.exit(self.sys_status)\n\n def critical(self, error, code):\n \"\"\"Exit due to unrecoverable error.\"\"\"\n self.sys_status = code\n _LOGGER.critical(error)\n print(\"Error: \" + error)\n self.exit()\n\n def restart(self):\n \"\"\"Restart opsdroid.\"\"\"\n self.should_restart = True\n self.stop()\n\n def stop(self):\n \"\"\"Stop the event loop.\"\"\"\n pending = asyncio.Task.all_tasks()\n for task in pending:\n task.cancel()\n self.eventloop.stop()\n\n def load(self):\n \"\"\"Load configuration.\"\"\"\n self.config = self.loader.load_config_file([\n \"./configuration.yaml\",\n DEFAULT_CONFIG_PATH,\n \"/etc/opsdroid/configuration.yaml\"\n ])\n\n def start_loop(self):\n \"\"\"Start the event loop.\"\"\"\n connectors, databases, skills = \\\n self.loader.load_modules_from_config(self.config)\n _LOGGER.debug(\"Loaded %i skills\", len(skills))\n if databases is not None:\n self.start_databases(databases)\n self.setup_skills(skills)\n self.start_connector_tasks(connectors)\n self.eventloop.create_task(parse_crontab(self))\n self.web_server.start()\n try:\n pending = asyncio.Task.all_tasks()\n self.eventloop.run_until_complete(asyncio.gather(*pending))\n except (KeyboardInterrupt, EOFError):\n print('') # Prints a character return for return to shell\n self.stop()\n _LOGGER.info(\"Keyboard interrupt, exiting.\")\n except RuntimeError as error:\n if str(error) != 'Event loop is closed':\n raise error\n finally:\n self.eventloop.close()\n\n def setup_skills(self, skills):\n \"\"\"Call the setup function on the passed in skills.\"\"\"\n for skill in skills:\n try:\n skill[\"module\"].setup(self)\n except AttributeError:\n pass\n\n def start_connector_tasks(self, connectors):\n \"\"\"Start the connectors.\"\"\"\n for connector_module in connectors:\n for _, cls in connector_module[\"module\"].__dict__.items():\n if isinstance(cls, type) and \\\n issubclass(cls, Connector) and\\\n cls is not Connector:\n connector = cls(connector_module[\"config\"])\n self.connectors.append(connector)\n\n if connectors:\n for connector in self.connectors:\n self.eventloop.run_until_complete(connector.connect(self))\n for connector in self.connectors:\n task = self.eventloop.create_task(connector.listen(self))\n self.connector_tasks.append(task)\n else:\n self.critical(\"All connectors failed to load\", 1)\n\n def start_databases(self, databases):\n \"\"\"Start the databases.\"\"\"\n if not databases:\n _LOGGER.debug(databases)\n _LOGGER.warning(\"All databases failed to load\")\n for database_module in databases:\n for name, cls in database_module[\"module\"].__dict__.items():\n if isinstance(cls, type) and \\\n issubclass(cls, Database) and \\\n cls is not Database:\n _LOGGER.debug(\"Adding database: \" + name)\n database = cls(database_module[\"config\"])\n self.memory.databases.append(database)\n self.eventloop.run_until_complete(database.connect(self))\n\n async def parse(self, message):\n \"\"\"Parse a string against all skills.\"\"\"\n self.stats[\"messages_parsed\"] = self.stats[\"messages_parsed\"] + 1\n tasks = []\n if message.text.strip() != \"\":\n _LOGGER.debug(\"Parsing input: \" + message.text)\n\n tasks.append(\n self.eventloop.create_task(parse_regex(self, message)))\n\n if \"parsers\" in self.config:\n _LOGGER.debug(\"Processing parsers\")\n parsers = self.config[\"parsers\"]\n\n apiai = [p for p in parsers if p[\"name\"] == \"apiai\"]\n _LOGGER.debug(\"Checking apiai\")\n if len(apiai) == 1 and \\\n (\"enabled\" not in apiai[0] or\n apiai[0][\"enabled\"] is not False):\n _LOGGER.debug(\"Parsing with apiai\")\n tasks.append(\n self.eventloop.create_task(\n parse_apiai(self, message, apiai[0])))\n return tasks\n", "path": "opsdroid/core.py"}], "after_files": [{"content": "\"\"\"Core components of OpsDroid.\"\"\"\n\nimport copy\nimport logging\nimport signal\nimport sys\nimport weakref\nimport asyncio\n\nfrom opsdroid.memory import Memory\nfrom opsdroid.connector import Connector\nfrom opsdroid.database import Database\nfrom opsdroid.loader import Loader\nfrom opsdroid.parsers.regex import parse_regex\nfrom opsdroid.parsers.apiai import parse_apiai\nfrom opsdroid.parsers.crontab import parse_crontab\nfrom opsdroid.const import DEFAULT_CONFIG_PATH\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass OpsDroid():\n \"\"\"Root object for opsdroid.\"\"\"\n\n # pylint: disable=too-many-instance-attributes\n # All are reasonable in this case.\n\n instances = []\n\n def __init__(self):\n \"\"\"Start opsdroid.\"\"\"\n self.bot_name = 'opsdroid'\n self.sys_status = 0\n self.connectors = []\n self.connector_tasks = []\n self.eventloop = asyncio.get_event_loop()\n for sig in (signal.SIGINT, signal.SIGTERM):\n self.eventloop.add_signal_handler(sig, self.stop)\n self.skills = []\n self.memory = Memory()\n self.loader = Loader(self)\n self.config = {}\n self.stats = {\n \"messages_parsed\": 0,\n \"webhooks_called\": 0,\n \"total_response_time\": 0,\n \"total_responses\": 0,\n }\n self.web_server = None\n self.should_restart = False\n self.stored_path = []\n _LOGGER.info(\"Created main opsdroid object\")\n\n def __enter__(self):\n \"\"\"Add self to existing instances.\"\"\"\n self.stored_path = copy.copy(sys.path)\n if not self.__class__.instances:\n self.__class__.instances.append(weakref.proxy(self))\n else:\n self.critical(\"opsdroid has already been started\", 1)\n return self\n\n def __exit__(self, exc_type, exc_value, traceback):\n \"\"\"Remove self from existing instances.\"\"\"\n sys.path = self.stored_path\n self.__class__.instances = []\n asyncio.set_event_loop(asyncio.new_event_loop())\n\n @property\n def default_connector(self):\n \"\"\"Return the default connector.\"\"\"\n default_connector = None\n for connector in self.connectors:\n if \"default\" in connector.config and connector.config[\"default\"]:\n default_connector = connector\n break\n if default_connector is None:\n default_connector = self.connectors[0]\n return default_connector\n\n def exit(self):\n \"\"\"Exit application.\"\"\"\n _LOGGER.info(\"Exiting application with return code \" +\n str(self.sys_status))\n sys.exit(self.sys_status)\n\n def critical(self, error, code):\n \"\"\"Exit due to unrecoverable error.\"\"\"\n self.sys_status = code\n _LOGGER.critical(error)\n print(\"Error: \" + error)\n self.exit()\n\n def restart(self):\n \"\"\"Restart opsdroid.\"\"\"\n self.should_restart = True\n self.stop()\n\n def stop(self):\n \"\"\"Stop the event loop.\"\"\"\n pending = asyncio.Task.all_tasks()\n for task in pending:\n task.cancel()\n self.eventloop.stop()\n print('') # Prints a character return for return to shell\n _LOGGER.info(\"Keyboard interrupt, exiting.\")\n\n def load(self):\n \"\"\"Load configuration.\"\"\"\n self.config = self.loader.load_config_file([\n \"./configuration.yaml\",\n DEFAULT_CONFIG_PATH,\n \"/etc/opsdroid/configuration.yaml\"\n ])\n\n def start_loop(self):\n \"\"\"Start the event loop.\"\"\"\n connectors, databases, skills = \\\n self.loader.load_modules_from_config(self.config)\n _LOGGER.debug(\"Loaded %i skills\", len(skills))\n if databases is not None:\n self.start_databases(databases)\n self.setup_skills(skills)\n self.start_connector_tasks(connectors)\n self.eventloop.create_task(parse_crontab(self))\n self.web_server.start()\n try:\n pending = asyncio.Task.all_tasks()\n self.eventloop.run_until_complete(asyncio.gather(*pending))\n except RuntimeError as error:\n if str(error) != 'Event loop is closed':\n raise error\n finally:\n self.eventloop.close()\n\n def setup_skills(self, skills):\n \"\"\"Call the setup function on the passed in skills.\"\"\"\n for skill in skills:\n try:\n skill[\"module\"].setup(self)\n except AttributeError:\n pass\n\n def start_connector_tasks(self, connectors):\n \"\"\"Start the connectors.\"\"\"\n for connector_module in connectors:\n for _, cls in connector_module[\"module\"].__dict__.items():\n if isinstance(cls, type) and \\\n issubclass(cls, Connector) and\\\n cls is not Connector:\n connector = cls(connector_module[\"config\"])\n self.connectors.append(connector)\n\n if connectors:\n for connector in self.connectors:\n self.eventloop.run_until_complete(connector.connect(self))\n for connector in self.connectors:\n task = self.eventloop.create_task(connector.listen(self))\n self.connector_tasks.append(task)\n else:\n self.critical(\"All connectors failed to load\", 1)\n\n def start_databases(self, databases):\n \"\"\"Start the databases.\"\"\"\n if not databases:\n _LOGGER.debug(databases)\n _LOGGER.warning(\"All databases failed to load\")\n for database_module in databases:\n for name, cls in database_module[\"module\"].__dict__.items():\n if isinstance(cls, type) and \\\n issubclass(cls, Database) and \\\n cls is not Database:\n _LOGGER.debug(\"Adding database: \" + name)\n database = cls(database_module[\"config\"])\n self.memory.databases.append(database)\n self.eventloop.run_until_complete(database.connect(self))\n\n async def parse(self, message):\n \"\"\"Parse a string against all skills.\"\"\"\n self.stats[\"messages_parsed\"] = self.stats[\"messages_parsed\"] + 1\n tasks = []\n if message.text.strip() != \"\":\n _LOGGER.debug(\"Parsing input: \" + message.text)\n\n tasks.append(\n self.eventloop.create_task(parse_regex(self, message)))\n\n if \"parsers\" in self.config:\n _LOGGER.debug(\"Processing parsers\")\n parsers = self.config[\"parsers\"]\n\n apiai = [p for p in parsers if p[\"name\"] == \"apiai\"]\n _LOGGER.debug(\"Checking apiai\")\n if len(apiai) == 1 and \\\n (\"enabled\" not in apiai[0] or\n apiai[0][\"enabled\"] is not False):\n _LOGGER.debug(\"Parsing with apiai\")\n tasks.append(\n self.eventloop.create_task(\n parse_apiai(self, message, apiai[0])))\n return tasks\n", "path": "opsdroid/core.py"}]}
| 3,946 | 318 |
gh_patches_debug_42193
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-438
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Instrument non-index Elasticsearch client methods
There are many methods on the `elasticsearch-py` client class that we aren't instrumenting, for example `ping()`, because they don't operate on an index.
We should capture all these calls too - I'm sure many applications have such calls that would be good to show on traces.
https://github.com/elastic/elasticsearch-py/blob/master/elasticsearch/client/__init__.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/instruments/elasticsearch.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5
6 import wrapt
7
8 from scout_apm.core.tracked_request import TrackedRequest
9
10 try:
11 from elasticsearch import Elasticsearch, Transport
12 except ImportError: # pragma: no cover
13 Elasticsearch = None
14 Transport = None
15
16 logger = logging.getLogger(__name__)
17
18
19 def ensure_installed():
20 logger.info("Ensuring elasticsearch instrumentation is installed.")
21
22 if Elasticsearch is None:
23 logger.info("Unable to import elasticsearch.Elasticsearch")
24 else:
25 ensure_client_instrumented()
26 ensure_transport_instrumented()
27
28
29 CLIENT_METHODS = [
30 "bulk",
31 "count",
32 "create",
33 "delete",
34 "delete_by_query",
35 "exists",
36 "exists_source",
37 "explain",
38 "field_caps",
39 "get",
40 "get_source",
41 "index",
42 "mget",
43 "msearch",
44 "msearch_template",
45 "mtermvectors",
46 "reindex",
47 "reindex_rethrottle",
48 "search",
49 "search_shards",
50 "search_template",
51 "termvectors",
52 "update",
53 "update_by_query",
54 ]
55
56
57 have_patched_client = False
58
59
60 def ensure_client_instrumented():
61 global have_patched_client
62
63 if not have_patched_client:
64 for name in CLIENT_METHODS:
65 try:
66 setattr(
67 Elasticsearch,
68 name,
69 wrap_client_method(getattr(Elasticsearch, name)),
70 )
71 except Exception as exc:
72 logger.warning(
73 "Unable to instrument elasticsearch.Elasticsearch.%s: %r",
74 name,
75 exc,
76 exc_info=exc,
77 )
78
79 have_patched_client = True
80
81
82 @wrapt.decorator
83 def wrap_client_method(wrapped, instance, args, kwargs):
84 def _get_index(index, *args, **kwargs):
85 return index
86
87 try:
88 index = _get_index(*args, **kwargs)
89 except TypeError:
90 index = "Unknown"
91 else:
92 if not index:
93 index = "Unknown"
94 if isinstance(index, (list, tuple)):
95 index = ",".join(index)
96 index = index.title()
97 camel_name = "".join(c.title() for c in wrapped.__name__.split("_"))
98 operation = "Elasticsearch/{}/{}".format(index, camel_name)
99 tracked_request = TrackedRequest.instance()
100 tracked_request.start_span(operation=operation, ignore_children=True)
101
102 try:
103 return wrapped(*args, **kwargs)
104 finally:
105 tracked_request.stop_span()
106
107
108 have_patched_transport = False
109
110
111 def ensure_transport_instrumented():
112 global have_patched_transport
113
114 if not have_patched_transport:
115 try:
116 Transport.perform_request = wrapped_perform_request(
117 Transport.perform_request
118 )
119 except Exception as exc:
120 logger.warning(
121 "Unable to instrument elasticsearch.Transport.perform_request: %r",
122 exc,
123 exc_info=exc,
124 )
125
126 have_patched_transport = True
127
128
129 def _sanitize_name(name):
130 try:
131 op = name.split("/")[-1]
132 op = op[1:] # chop leading '_' from op
133 known_names = (
134 "bench",
135 "bulk",
136 "count",
137 "exists",
138 "explain",
139 "field_stats",
140 "health",
141 "mget",
142 "mlt",
143 "mpercolate",
144 "msearch",
145 "mtermvectors",
146 "percolate",
147 "query",
148 "scroll",
149 "search_shards",
150 "source",
151 "suggest",
152 "template",
153 "termvectors",
154 "update",
155 "search",
156 )
157 if op in known_names:
158 return op.title()
159 return "Unknown"
160 except Exception:
161 return "Unknown"
162
163
164 @wrapt.decorator
165 def wrapped_perform_request(wrapped, instance, args, kwargs):
166 try:
167 op = _sanitize_name(args[1])
168 except IndexError:
169 op = "Unknown"
170
171 tracked_request = TrackedRequest.instance()
172 tracked_request.start_span(
173 operation="Elasticsearch/{}".format(op), ignore_children=True
174 )
175
176 try:
177 return wrapped(*args, **kwargs)
178 finally:
179 tracked_request.stop_span()
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/scout_apm/instruments/elasticsearch.py b/src/scout_apm/instruments/elasticsearch.py
--- a/src/scout_apm/instruments/elasticsearch.py
+++ b/src/scout_apm/instruments/elasticsearch.py
@@ -2,6 +2,7 @@
from __future__ import absolute_import, division, print_function, unicode_literals
import logging
+from collections import namedtuple
import wrapt
@@ -26,31 +27,46 @@
ensure_transport_instrumented()
+ClientMethod = namedtuple("ClientMethod", ["name", "takes_index_argument"])
+
CLIENT_METHODS = [
- "bulk",
- "count",
- "create",
- "delete",
- "delete_by_query",
- "exists",
- "exists_source",
- "explain",
- "field_caps",
- "get",
- "get_source",
- "index",
- "mget",
- "msearch",
- "msearch_template",
- "mtermvectors",
- "reindex",
- "reindex_rethrottle",
- "search",
- "search_shards",
- "search_template",
- "termvectors",
- "update",
- "update_by_query",
+ ClientMethod("bulk", True),
+ ClientMethod("clear_scroll", False),
+ ClientMethod("count", True),
+ ClientMethod("create", True),
+ ClientMethod("delete", True),
+ ClientMethod("delete_by_query", True),
+ ClientMethod("delete_by_query_rethrottle", False),
+ ClientMethod("delete_script", False),
+ ClientMethod("exists", True),
+ ClientMethod("exists_source", True),
+ ClientMethod("explain", True),
+ ClientMethod("field_caps", True),
+ ClientMethod("get", True),
+ ClientMethod("get_script", False),
+ ClientMethod("get_source", True),
+ ClientMethod("index", True),
+ ClientMethod("info", False),
+ ClientMethod("mget", True),
+ ClientMethod("msearch", True),
+ ClientMethod("msearch_template", True),
+ ClientMethod("mtermvectors", True),
+ ClientMethod("ping", False),
+ ClientMethod("put_script", False),
+ ClientMethod("rank_eval", True),
+ ClientMethod("reindex", False),
+ ClientMethod("reindex_rethrottle", False),
+ ClientMethod("render_search_template", False),
+ ClientMethod("scripts_painless_context", False),
+ ClientMethod("scripts_painless_execute", False),
+ ClientMethod("scroll", False),
+ ClientMethod("search", True),
+ ClientMethod("search_shards", True),
+ ClientMethod("search_template", True),
+ ClientMethod("termvectors", True),
+ ClientMethod("update", True),
+ ClientMethod("update_by_query", True),
+ ClientMethod("update_by_query_rethrottle", False),
]
@@ -61,13 +77,14 @@
global have_patched_client
if not have_patched_client:
- for name in CLIENT_METHODS:
+ for name, takes_index_argument in CLIENT_METHODS:
try:
- setattr(
- Elasticsearch,
- name,
- wrap_client_method(getattr(Elasticsearch, name)),
- )
+ method = getattr(Elasticsearch, name)
+ if takes_index_argument:
+ wrapped = wrap_client_index_method(method)
+ else:
+ wrapped = wrap_client_method(method)
+ setattr(Elasticsearch, name, wrapped)
except Exception as exc:
logger.warning(
"Unable to instrument elasticsearch.Elasticsearch.%s: %r",
@@ -80,7 +97,7 @@
@wrapt.decorator
-def wrap_client_method(wrapped, instance, args, kwargs):
+def wrap_client_index_method(wrapped, instance, args, kwargs):
def _get_index(index, *args, **kwargs):
return index
@@ -105,6 +122,19 @@
tracked_request.stop_span()
[email protected]
+def wrap_client_method(wrapped, instance, args, kwargs):
+ camel_name = "".join(c.title() for c in wrapped.__name__.split("_"))
+ operation = "Elasticsearch/{}".format(camel_name)
+ tracked_request = TrackedRequest.instance()
+ tracked_request.start_span(operation=operation, ignore_children=True)
+
+ try:
+ return wrapped(*args, **kwargs)
+ finally:
+ tracked_request.stop_span()
+
+
have_patched_transport = False
|
{"golden_diff": "diff --git a/src/scout_apm/instruments/elasticsearch.py b/src/scout_apm/instruments/elasticsearch.py\n--- a/src/scout_apm/instruments/elasticsearch.py\n+++ b/src/scout_apm/instruments/elasticsearch.py\n@@ -2,6 +2,7 @@\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n import logging\n+from collections import namedtuple\n \n import wrapt\n \n@@ -26,31 +27,46 @@\n ensure_transport_instrumented()\n \n \n+ClientMethod = namedtuple(\"ClientMethod\", [\"name\", \"takes_index_argument\"])\n+\n CLIENT_METHODS = [\n- \"bulk\",\n- \"count\",\n- \"create\",\n- \"delete\",\n- \"delete_by_query\",\n- \"exists\",\n- \"exists_source\",\n- \"explain\",\n- \"field_caps\",\n- \"get\",\n- \"get_source\",\n- \"index\",\n- \"mget\",\n- \"msearch\",\n- \"msearch_template\",\n- \"mtermvectors\",\n- \"reindex\",\n- \"reindex_rethrottle\",\n- \"search\",\n- \"search_shards\",\n- \"search_template\",\n- \"termvectors\",\n- \"update\",\n- \"update_by_query\",\n+ ClientMethod(\"bulk\", True),\n+ ClientMethod(\"clear_scroll\", False),\n+ ClientMethod(\"count\", True),\n+ ClientMethod(\"create\", True),\n+ ClientMethod(\"delete\", True),\n+ ClientMethod(\"delete_by_query\", True),\n+ ClientMethod(\"delete_by_query_rethrottle\", False),\n+ ClientMethod(\"delete_script\", False),\n+ ClientMethod(\"exists\", True),\n+ ClientMethod(\"exists_source\", True),\n+ ClientMethod(\"explain\", True),\n+ ClientMethod(\"field_caps\", True),\n+ ClientMethod(\"get\", True),\n+ ClientMethod(\"get_script\", False),\n+ ClientMethod(\"get_source\", True),\n+ ClientMethod(\"index\", True),\n+ ClientMethod(\"info\", False),\n+ ClientMethod(\"mget\", True),\n+ ClientMethod(\"msearch\", True),\n+ ClientMethod(\"msearch_template\", True),\n+ ClientMethod(\"mtermvectors\", True),\n+ ClientMethod(\"ping\", False),\n+ ClientMethod(\"put_script\", False),\n+ ClientMethod(\"rank_eval\", True),\n+ ClientMethod(\"reindex\", False),\n+ ClientMethod(\"reindex_rethrottle\", False),\n+ ClientMethod(\"render_search_template\", False),\n+ ClientMethod(\"scripts_painless_context\", False),\n+ ClientMethod(\"scripts_painless_execute\", False),\n+ ClientMethod(\"scroll\", False),\n+ ClientMethod(\"search\", True),\n+ ClientMethod(\"search_shards\", True),\n+ ClientMethod(\"search_template\", True),\n+ ClientMethod(\"termvectors\", True),\n+ ClientMethod(\"update\", True),\n+ ClientMethod(\"update_by_query\", True),\n+ ClientMethod(\"update_by_query_rethrottle\", False),\n ]\n \n \n@@ -61,13 +77,14 @@\n global have_patched_client\n \n if not have_patched_client:\n- for name in CLIENT_METHODS:\n+ for name, takes_index_argument in CLIENT_METHODS:\n try:\n- setattr(\n- Elasticsearch,\n- name,\n- wrap_client_method(getattr(Elasticsearch, name)),\n- )\n+ method = getattr(Elasticsearch, name)\n+ if takes_index_argument:\n+ wrapped = wrap_client_index_method(method)\n+ else:\n+ wrapped = wrap_client_method(method)\n+ setattr(Elasticsearch, name, wrapped)\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n@@ -80,7 +97,7 @@\n \n \n @wrapt.decorator\n-def wrap_client_method(wrapped, instance, args, kwargs):\n+def wrap_client_index_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n \n@@ -105,6 +122,19 @@\n tracked_request.stop_span()\n \n \[email protected]\n+def wrap_client_method(wrapped, instance, args, kwargs):\n+ camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n+ operation = \"Elasticsearch/{}\".format(camel_name)\n+ tracked_request = TrackedRequest.instance()\n+ tracked_request.start_span(operation=operation, ignore_children=True)\n+\n+ try:\n+ return wrapped(*args, **kwargs)\n+ finally:\n+ tracked_request.stop_span()\n+\n+\n have_patched_transport = False\n", "issue": "Instrument non-index Elasticsearch client methods\nThere are many methods on the `elasticsearch-py` client class that we aren't instrumenting, for example `ping()`, because they don't operate on an index.\r\n\r\nWe should capture all these calls too - I'm sure many applications have such calls that would be good to show on traces.\r\n\r\nhttps://github.com/elastic/elasticsearch-py/blob/master/elasticsearch/client/__init__.py\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\n\nimport wrapt\n\nfrom scout_apm.core.tracked_request import TrackedRequest\n\ntry:\n from elasticsearch import Elasticsearch, Transport\nexcept ImportError: # pragma: no cover\n Elasticsearch = None\n Transport = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef ensure_installed():\n logger.info(\"Ensuring elasticsearch instrumentation is installed.\")\n\n if Elasticsearch is None:\n logger.info(\"Unable to import elasticsearch.Elasticsearch\")\n else:\n ensure_client_instrumented()\n ensure_transport_instrumented()\n\n\nCLIENT_METHODS = [\n \"bulk\",\n \"count\",\n \"create\",\n \"delete\",\n \"delete_by_query\",\n \"exists\",\n \"exists_source\",\n \"explain\",\n \"field_caps\",\n \"get\",\n \"get_source\",\n \"index\",\n \"mget\",\n \"msearch\",\n \"msearch_template\",\n \"mtermvectors\",\n \"reindex\",\n \"reindex_rethrottle\",\n \"search\",\n \"search_shards\",\n \"search_template\",\n \"termvectors\",\n \"update\",\n \"update_by_query\",\n]\n\n\nhave_patched_client = False\n\n\ndef ensure_client_instrumented():\n global have_patched_client\n\n if not have_patched_client:\n for name in CLIENT_METHODS:\n try:\n setattr(\n Elasticsearch,\n name,\n wrap_client_method(getattr(Elasticsearch, name)),\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n name,\n exc,\n exc_info=exc,\n )\n\n have_patched_client = True\n\n\[email protected]\ndef wrap_client_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n\n try:\n index = _get_index(*args, **kwargs)\n except TypeError:\n index = \"Unknown\"\n else:\n if not index:\n index = \"Unknown\"\n if isinstance(index, (list, tuple)):\n index = \",\".join(index)\n index = index.title()\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}/{}\".format(index, camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\nhave_patched_transport = False\n\n\ndef ensure_transport_instrumented():\n global have_patched_transport\n\n if not have_patched_transport:\n try:\n Transport.perform_request = wrapped_perform_request(\n Transport.perform_request\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Transport.perform_request: %r\",\n exc,\n exc_info=exc,\n )\n\n have_patched_transport = True\n\n\ndef _sanitize_name(name):\n try:\n op = name.split(\"/\")[-1]\n op = op[1:] # chop leading '_' from op\n known_names = (\n \"bench\",\n \"bulk\",\n \"count\",\n \"exists\",\n \"explain\",\n \"field_stats\",\n \"health\",\n \"mget\",\n \"mlt\",\n \"mpercolate\",\n \"msearch\",\n \"mtermvectors\",\n \"percolate\",\n \"query\",\n \"scroll\",\n \"search_shards\",\n \"source\",\n \"suggest\",\n \"template\",\n \"termvectors\",\n \"update\",\n \"search\",\n )\n if op in known_names:\n return op.title()\n return \"Unknown\"\n except Exception:\n return \"Unknown\"\n\n\[email protected]\ndef wrapped_perform_request(wrapped, instance, args, kwargs):\n try:\n op = _sanitize_name(args[1])\n except IndexError:\n op = \"Unknown\"\n\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(\n operation=\"Elasticsearch/{}\".format(op), ignore_children=True\n )\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n", "path": "src/scout_apm/instruments/elasticsearch.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nfrom collections import namedtuple\n\nimport wrapt\n\nfrom scout_apm.core.tracked_request import TrackedRequest\n\ntry:\n from elasticsearch import Elasticsearch, Transport\nexcept ImportError: # pragma: no cover\n Elasticsearch = None\n Transport = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef ensure_installed():\n logger.info(\"Ensuring elasticsearch instrumentation is installed.\")\n\n if Elasticsearch is None:\n logger.info(\"Unable to import elasticsearch.Elasticsearch\")\n else:\n ensure_client_instrumented()\n ensure_transport_instrumented()\n\n\nClientMethod = namedtuple(\"ClientMethod\", [\"name\", \"takes_index_argument\"])\n\nCLIENT_METHODS = [\n ClientMethod(\"bulk\", True),\n ClientMethod(\"clear_scroll\", False),\n ClientMethod(\"count\", True),\n ClientMethod(\"create\", True),\n ClientMethod(\"delete\", True),\n ClientMethod(\"delete_by_query\", True),\n ClientMethod(\"delete_by_query_rethrottle\", False),\n ClientMethod(\"delete_script\", False),\n ClientMethod(\"exists\", True),\n ClientMethod(\"exists_source\", True),\n ClientMethod(\"explain\", True),\n ClientMethod(\"field_caps\", True),\n ClientMethod(\"get\", True),\n ClientMethod(\"get_script\", False),\n ClientMethod(\"get_source\", True),\n ClientMethod(\"index\", True),\n ClientMethod(\"info\", False),\n ClientMethod(\"mget\", True),\n ClientMethod(\"msearch\", True),\n ClientMethod(\"msearch_template\", True),\n ClientMethod(\"mtermvectors\", True),\n ClientMethod(\"ping\", False),\n ClientMethod(\"put_script\", False),\n ClientMethod(\"rank_eval\", True),\n ClientMethod(\"reindex\", False),\n ClientMethod(\"reindex_rethrottle\", False),\n ClientMethod(\"render_search_template\", False),\n ClientMethod(\"scripts_painless_context\", False),\n ClientMethod(\"scripts_painless_execute\", False),\n ClientMethod(\"scroll\", False),\n ClientMethod(\"search\", True),\n ClientMethod(\"search_shards\", True),\n ClientMethod(\"search_template\", True),\n ClientMethod(\"termvectors\", True),\n ClientMethod(\"update\", True),\n ClientMethod(\"update_by_query\", True),\n ClientMethod(\"update_by_query_rethrottle\", False),\n]\n\n\nhave_patched_client = False\n\n\ndef ensure_client_instrumented():\n global have_patched_client\n\n if not have_patched_client:\n for name, takes_index_argument in CLIENT_METHODS:\n try:\n method = getattr(Elasticsearch, name)\n if takes_index_argument:\n wrapped = wrap_client_index_method(method)\n else:\n wrapped = wrap_client_method(method)\n setattr(Elasticsearch, name, wrapped)\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n name,\n exc,\n exc_info=exc,\n )\n\n have_patched_client = True\n\n\[email protected]\ndef wrap_client_index_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n\n try:\n index = _get_index(*args, **kwargs)\n except TypeError:\n index = \"Unknown\"\n else:\n if not index:\n index = \"Unknown\"\n if isinstance(index, (list, tuple)):\n index = \",\".join(index)\n index = index.title()\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}/{}\".format(index, camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\[email protected]\ndef wrap_client_method(wrapped, instance, args, kwargs):\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}\".format(camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\nhave_patched_transport = False\n\n\ndef ensure_transport_instrumented():\n global have_patched_transport\n\n if not have_patched_transport:\n try:\n Transport.perform_request = wrapped_perform_request(\n Transport.perform_request\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Transport.perform_request: %r\",\n exc,\n exc_info=exc,\n )\n\n have_patched_transport = True\n\n\ndef _sanitize_name(name):\n try:\n op = name.split(\"/\")[-1]\n op = op[1:] # chop leading '_' from op\n known_names = (\n \"bench\",\n \"bulk\",\n \"count\",\n \"exists\",\n \"explain\",\n \"field_stats\",\n \"health\",\n \"mget\",\n \"mlt\",\n \"mpercolate\",\n \"msearch\",\n \"mtermvectors\",\n \"percolate\",\n \"query\",\n \"scroll\",\n \"search_shards\",\n \"source\",\n \"suggest\",\n \"template\",\n \"termvectors\",\n \"update\",\n \"search\",\n )\n if op in known_names:\n return op.title()\n return \"Unknown\"\n except Exception:\n return \"Unknown\"\n\n\[email protected]\ndef wrapped_perform_request(wrapped, instance, args, kwargs):\n try:\n op = _sanitize_name(args[1])\n except IndexError:\n op = \"Unknown\"\n\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(\n operation=\"Elasticsearch/{}\".format(op), ignore_children=True\n )\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n", "path": "src/scout_apm/instruments/elasticsearch.py"}]}
| 1,719 | 1,023 |
gh_patches_debug_31899
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1380
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Do not save ElasticDL embedding's variables in the master
In current code, ElasticDL embedding layer create trainable variables and use them only for training under graph mode (i.e. under tf.function decorator). These variables are used for training and thus should only be created in workers.
However, now ElasticDL embedding layer creates these variables in `__init__` function. The master (or PS) creates these variables when it creates a model instance, and then save these variables in `self._model`.
I propose that ElasticDL embedding layer should not create these variables in `__init__` function. Instead, creating them before the training process only in worker is enough.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/elasticdl/layers/embedding.py`
Content:
```
1 import collections
2
3 import numpy as np
4 import tensorflow as tf
5 from tensorflow.python.keras.utils import tf_utils
6
7 from elasticdl.python.master.embedding_service import EmbeddingService
8
9 EmbeddingAndIds = collections.namedtuple(
10 "EmbeddingAndIds", ["batch_embedding", "batch_ids"]
11 )
12
13
14 class Embedding(tf.keras.layers.Layer):
15 """
16 Input: indexes for the embedding entries with a shape of
17 (batch_size, input_length). Input can be either dense tensor
18 or SparseTensor.
19 Output:
20 corresponding (combined) embeddings with a shape of
21 (batch_size, input_length, output_dim) if combiner is None
22 (batch_size, output_dim) if combiner is not None
23 Arguments:
24 output_dim: the dimension of the embedding vector
25 embedding_initializer: Initializer for embedding table
26 mask_zero: Whether or not the input value 0 is a special "padding"
27 value that should be masked out.
28 If input is SparseTensor, mask_zero must be False.
29 input_length: Length of input sequences, when it is constant.
30 This argument is required if you are going to connect
31 `Flatten` then `Dense` layers upstream
32 (without it, the shape of the dense outputs cannot be computed).
33 combiner: A string specifying the reduction op or None if not used.
34 "mean", "sqrtn" and "sum" are supported for the reduction op.
35 If input is SparseTensor, combiner must set as a reduction op.
36 """
37
38 def __init__(
39 self,
40 output_dim,
41 embedding_initializer="uniform",
42 mask_zero=False,
43 input_length=None,
44 combiner=None,
45 embedding_service_endpoint=None,
46 **kwargs
47 ):
48 if "input_shape" not in kwargs and input_length:
49 kwargs["input_shape"] = (input_length,)
50 super(Embedding, self).__init__(**kwargs)
51
52 self.output_dim = output_dim
53 self.embedding_initializer = embedding_initializer
54 self.supports_masking = mask_zero
55 self.input_length = input_length
56 self.combiner = combiner
57 self.embedding_service_endpoint = embedding_service_endpoint
58 self.tape = None
59 self.lookup_func = None
60
61 self._embedding_and_ids_eagerly = []
62
63 # BET's shape and ids' shape in `self._embedding_and_ids_graph` have
64 # `None` dimension. This is because they have different shapes in
65 # different iterations.
66 # `tf.Variable` requires initial value if shape has `None` dimension.
67 self._embedding_and_ids_graph = [
68 EmbeddingAndIds(
69 batch_embedding=tf.Variable(
70 initial_value=tf.zeros((1, self.output_dim)),
71 shape=tf.TensorShape((None, self.output_dim)),
72 dtype=tf.float32,
73 trainable=True,
74 ),
75 batch_ids=tf.Variable(
76 initial_value=tf.zeros((1, 1), dtype=tf.int64),
77 shape=tf.TensorShape(None),
78 dtype=tf.int64,
79 trainable=False,
80 ),
81 )
82 ]
83
84 @tf_utils.shape_type_conversion
85 def compute_output_shape(self, input_shape):
86 # this function is taken from
87 # tf.keras.layers.Embedding.compute_output_shape
88 # https://github.com/tensorflow/tensorflow/blob/3f3c728bf80e0fd6653744318cbbfe1454c6ddca/tensorflow/python/keras/layers/embeddings.py#L156
89 if self.input_length is None:
90 return input_shape + (self.output_dim,)
91 else:
92 if isinstance(self.input_length, (list, tuple)):
93 in_lens = list(self.input_length)
94 else:
95 in_lens = [self.input_length]
96 if len(in_lens) != len(input_shape) - 1:
97 raise ValueError(
98 '"input_length" is %s, '
99 "but received input has shape %s"
100 % (str(self.input_length), str(input_shape))
101 )
102 else:
103 for i, (s1, s2) in enumerate(zip(in_lens, input_shape[1:])):
104 if s1 is not None and s2 is not None and s1 != s2:
105 raise ValueError(
106 '"input_length" is %s, '
107 "but received input has shape %s"
108 % (str(self.input_length), str(input_shape))
109 )
110 elif s1 is None:
111 in_lens[i] = s2
112 return (input_shape[0],) + tuple(in_lens) + (self.output_dim,)
113
114 @property
115 def name(self):
116 return self._name
117
118 @staticmethod
119 def get_key(name_list):
120 return "-".join(map(str, name_list))
121
122 def lookup_embedding(self, unique_ids):
123 ids = unique_ids.numpy()
124 keys = [Embedding.get_key([self._name, id]) for id in ids]
125 (
126 embedding_vectors,
127 unknown_keys_index,
128 ) = EmbeddingService.lookup_embedding(
129 keys=keys,
130 embedding_service_endpoint=self.embedding_service_endpoint,
131 )
132
133 if unknown_keys_index:
134 # Initialize unknown_keys' embedding vectors and write into Redis.
135 unknown_keys = [keys[index] for index in unknown_keys_index]
136 initializer = tf.keras.initializers.get(self.embedding_initializer)
137 embedding_vector_init = [
138 initializer(shape=[1, self.output_dim]).numpy()
139 for _ in unknown_keys
140 ]
141 embedding_vector_init = np.concatenate(
142 embedding_vector_init, axis=0
143 )
144 EmbeddingService.update_embedding(
145 keys=unknown_keys,
146 embedding_vectors=embedding_vector_init,
147 embedding_service_endpoint=self.embedding_service_endpoint,
148 set_if_not_exist=True,
149 )
150 # Lookup unknown_keys' embedding vectors
151 (
152 embedding_vectors_new,
153 unknown_keys_idx_new,
154 ) = EmbeddingService.lookup_embedding(
155 keys=unknown_keys,
156 embedding_service_endpoint=self.embedding_service_endpoint,
157 )
158 if unknown_keys_idx_new:
159 raise Exception(
160 "Update embedding vector: %s failed."
161 % str(
162 [unknown_keys[index] for index in unknown_keys_idx_new]
163 )
164 )
165 for key_index, vector in zip(
166 unknown_keys_index, embedding_vectors_new
167 ):
168 embedding_vectors[key_index] = vector
169 embedding_vectors = np.concatenate(embedding_vectors, axis=0)
170 return embedding_vectors.reshape((len(keys), self.output_dim))
171
172 def _record_gradients(self, batch_embedding, ids):
173 if tf.executing_eagerly():
174 self.tape.watch(batch_embedding)
175 self._embedding_and_ids_eagerly.append(
176 EmbeddingAndIds(batch_embedding, ids)
177 )
178 else:
179 # In graph mode, assigning tensors to trainable variables is
180 # allowed and tape can record the gradients of trainable
181 # variables automatically.
182 embedding_and_ids = self._embedding_and_ids_graph[0]
183 embedding_and_ids.batch_embedding.assign(batch_embedding)
184 embedding_and_ids.batch_ids.assign(ids)
185 batch_embedding = embedding_and_ids.batch_embedding
186 return batch_embedding
187
188 def call(self, input):
189 input = tf.cast(input, tf.int64)
190 if isinstance(input, tf.SparseTensor):
191 return self._sparse_input_call(input)
192
193 ids = tf.convert_to_tensor(input, name="embedding_ids")
194 flat_ids = tf.reshape(ids, [-1])
195 unique_ids, idx = tf.unique(flat_ids)
196 # Gradient for `batch_embedding` is SparseTensor here due to
197 # `tf.gather` op. `tf.gather` accesses tensor slices, resulting in
198 # sparse tensor gradient.
199 batch_embedding = tf.py_function(
200 self.lookup_embedding, inp=[unique_ids], Tout=tf.float32
201 )
202 # TODO: use tf.cond rather than python if statement
203 if self.tape:
204 batch_embedding = self._record_gradients(batch_embedding, flat_ids)
205
206 outputs = tf.gather(batch_embedding, idx)
207 # tf.reshape does not support shape with None. Replace None with -1.
208 if ids.get_shape().rank == 2:
209 input_length = ids.get_shape()[1]
210 if input_length is None:
211 outputs.set_shape(shape=(None, None, self.output_dim))
212 return outputs
213 output_shape = (-1, input_length, self.output_dim)
214 else:
215 output_shape = ids.get_shape().concatenate(self.output_dim)
216 outputs = tf.reshape(outputs, output_shape)
217 # TODO: support combiner for dense input
218 return outputs
219
220 def _sparse_input_call(self, sparse_input):
221 if self.combiner not in ["sum", "mean", "sqrtn"]:
222 raise ValueError(
223 "combiner must set sum, mean or sqrtn for sparse input"
224 )
225 unique_ids, idx = tf.unique(sparse_input.values)
226 # Gradient for `batch_embedding` is dense tensor.
227 batch_embedding = tf.py_function(
228 self.lookup_embedding, inp=[unique_ids], Tout=tf.float32
229 )
230 # TODO: use tf.cond rather than python if statement
231 if self.tape:
232 batch_embedding = self._record_gradients(
233 batch_embedding, unique_ids
234 )
235
236 segment_ids = sparse_input.indices[:, 0]
237 if segment_ids.dtype != tf.int32:
238 segment_ids = tf.cast(segment_ids, tf.int32)
239
240 if self.combiner == "sum":
241 batch_embedding = tf.sparse.segment_sum(
242 batch_embedding, idx, segment_ids
243 )
244 elif self.combiner == "mean":
245 batch_embedding = tf.sparse.segment_mean(
246 batch_embedding, idx, segment_ids
247 )
248 elif self.combiner == "sqrtn":
249 batch_embedding = tf.sparse.segment_sqrt_n(
250 batch_embedding, idx, segment_ids
251 )
252 return batch_embedding
253
254 def compute_mask(self, inputs, mask=None):
255 if isinstance(input, tf.SparseTensor):
256 raise ValueError("SparseTensor inputs do not support mask_zero")
257 if not self.supports_masking:
258 return None
259 return tf.math.not_equal(inputs, 0)
260
261 def reset(self):
262 self._embedding_and_ids_eagerly = []
263 self.tape = None
264
265 def set_tape(self, tape):
266 self.tape = tape
267
268 def set_endpoint(self, endpoint):
269 self.embedding_service_endpoint = endpoint
270
271 @property
272 def embedding_and_ids(self):
273 """
274 Return bet and ids pairs.
275 """
276 if self._embedding_and_ids_eagerly:
277 return self._embedding_and_ids_eagerly
278 return self._embedding_and_ids_graph
279
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/elasticdl/layers/embedding.py b/elasticdl/python/elasticdl/layers/embedding.py
--- a/elasticdl/python/elasticdl/layers/embedding.py
+++ b/elasticdl/python/elasticdl/layers/embedding.py
@@ -64,16 +64,21 @@
# `None` dimension. This is because they have different shapes in
# different iterations.
# `tf.Variable` requires initial value if shape has `None` dimension.
+ self._embedding_and_ids_graph = []
+
+ def _init_for_graph_mode(self):
self._embedding_and_ids_graph = [
EmbeddingAndIds(
batch_embedding=tf.Variable(
- initial_value=tf.zeros((1, self.output_dim)),
+ # In some cases, `tf.Variable` requires that initial value
+ # is callable.
+ initial_value=lambda: tf.zeros((1, self.output_dim)),
shape=tf.TensorShape((None, self.output_dim)),
dtype=tf.float32,
trainable=True,
),
batch_ids=tf.Variable(
- initial_value=tf.zeros((1, 1), dtype=tf.int64),
+ initial_value=lambda: tf.zeros((1, 1), dtype=tf.int64),
shape=tf.TensorShape(None),
dtype=tf.int64,
trainable=False,
@@ -186,6 +191,13 @@
return batch_embedding
def call(self, input):
+ if (
+ self.tape
+ and not tf.executing_eagerly()
+ and not self._embedding_and_ids_graph
+ ):
+ self._init_for_graph_mode()
+
input = tf.cast(input, tf.int64)
if isinstance(input, tf.SparseTensor):
return self._sparse_input_call(input)
|
{"golden_diff": "diff --git a/elasticdl/python/elasticdl/layers/embedding.py b/elasticdl/python/elasticdl/layers/embedding.py\n--- a/elasticdl/python/elasticdl/layers/embedding.py\n+++ b/elasticdl/python/elasticdl/layers/embedding.py\n@@ -64,16 +64,21 @@\n # `None` dimension. This is because they have different shapes in\n # different iterations.\n # `tf.Variable` requires initial value if shape has `None` dimension.\n+ self._embedding_and_ids_graph = []\n+\n+ def _init_for_graph_mode(self):\n self._embedding_and_ids_graph = [\n EmbeddingAndIds(\n batch_embedding=tf.Variable(\n- initial_value=tf.zeros((1, self.output_dim)),\n+ # In some cases, `tf.Variable` requires that initial value\n+ # is callable.\n+ initial_value=lambda: tf.zeros((1, self.output_dim)),\n shape=tf.TensorShape((None, self.output_dim)),\n dtype=tf.float32,\n trainable=True,\n ),\n batch_ids=tf.Variable(\n- initial_value=tf.zeros((1, 1), dtype=tf.int64),\n+ initial_value=lambda: tf.zeros((1, 1), dtype=tf.int64),\n shape=tf.TensorShape(None),\n dtype=tf.int64,\n trainable=False,\n@@ -186,6 +191,13 @@\n return batch_embedding\n \n def call(self, input):\n+ if (\n+ self.tape\n+ and not tf.executing_eagerly()\n+ and not self._embedding_and_ids_graph\n+ ):\n+ self._init_for_graph_mode()\n+\n input = tf.cast(input, tf.int64)\n if isinstance(input, tf.SparseTensor):\n return self._sparse_input_call(input)\n", "issue": "Do not save ElasticDL embedding's variables in the master\nIn current code, ElasticDL embedding layer create trainable variables and use them only for training under graph mode (i.e. under tf.function decorator). These variables are used for training and thus should only be created in workers. \r\n\r\nHowever, now ElasticDL embedding layer creates these variables in `__init__` function. The master (or PS) creates these variables when it creates a model instance, and then save these variables in `self._model`. \r\n\r\nI propose that ElasticDL embedding layer should not create these variables in `__init__` function. Instead, creating them before the training process only in worker is enough.\n", "before_files": [{"content": "import collections\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.python.keras.utils import tf_utils\n\nfrom elasticdl.python.master.embedding_service import EmbeddingService\n\nEmbeddingAndIds = collections.namedtuple(\n \"EmbeddingAndIds\", [\"batch_embedding\", \"batch_ids\"]\n)\n\n\nclass Embedding(tf.keras.layers.Layer):\n \"\"\"\n Input: indexes for the embedding entries with a shape of\n (batch_size, input_length). Input can be either dense tensor\n or SparseTensor.\n Output:\n corresponding (combined) embeddings with a shape of\n (batch_size, input_length, output_dim) if combiner is None\n (batch_size, output_dim) if combiner is not None\n Arguments:\n output_dim: the dimension of the embedding vector\n embedding_initializer: Initializer for embedding table\n mask_zero: Whether or not the input value 0 is a special \"padding\"\n value that should be masked out.\n If input is SparseTensor, mask_zero must be False.\n input_length: Length of input sequences, when it is constant.\n This argument is required if you are going to connect\n `Flatten` then `Dense` layers upstream\n (without it, the shape of the dense outputs cannot be computed).\n combiner: A string specifying the reduction op or None if not used.\n \"mean\", \"sqrtn\" and \"sum\" are supported for the reduction op.\n If input is SparseTensor, combiner must set as a reduction op.\n \"\"\"\n\n def __init__(\n self,\n output_dim,\n embedding_initializer=\"uniform\",\n mask_zero=False,\n input_length=None,\n combiner=None,\n embedding_service_endpoint=None,\n **kwargs\n ):\n if \"input_shape\" not in kwargs and input_length:\n kwargs[\"input_shape\"] = (input_length,)\n super(Embedding, self).__init__(**kwargs)\n\n self.output_dim = output_dim\n self.embedding_initializer = embedding_initializer\n self.supports_masking = mask_zero\n self.input_length = input_length\n self.combiner = combiner\n self.embedding_service_endpoint = embedding_service_endpoint\n self.tape = None\n self.lookup_func = None\n\n self._embedding_and_ids_eagerly = []\n\n # BET's shape and ids' shape in `self._embedding_and_ids_graph` have\n # `None` dimension. This is because they have different shapes in\n # different iterations.\n # `tf.Variable` requires initial value if shape has `None` dimension.\n self._embedding_and_ids_graph = [\n EmbeddingAndIds(\n batch_embedding=tf.Variable(\n initial_value=tf.zeros((1, self.output_dim)),\n shape=tf.TensorShape((None, self.output_dim)),\n dtype=tf.float32,\n trainable=True,\n ),\n batch_ids=tf.Variable(\n initial_value=tf.zeros((1, 1), dtype=tf.int64),\n shape=tf.TensorShape(None),\n dtype=tf.int64,\n trainable=False,\n ),\n )\n ]\n\n @tf_utils.shape_type_conversion\n def compute_output_shape(self, input_shape):\n # this function is taken from\n # tf.keras.layers.Embedding.compute_output_shape\n # https://github.com/tensorflow/tensorflow/blob/3f3c728bf80e0fd6653744318cbbfe1454c6ddca/tensorflow/python/keras/layers/embeddings.py#L156\n if self.input_length is None:\n return input_shape + (self.output_dim,)\n else:\n if isinstance(self.input_length, (list, tuple)):\n in_lens = list(self.input_length)\n else:\n in_lens = [self.input_length]\n if len(in_lens) != len(input_shape) - 1:\n raise ValueError(\n '\"input_length\" is %s, '\n \"but received input has shape %s\"\n % (str(self.input_length), str(input_shape))\n )\n else:\n for i, (s1, s2) in enumerate(zip(in_lens, input_shape[1:])):\n if s1 is not None and s2 is not None and s1 != s2:\n raise ValueError(\n '\"input_length\" is %s, '\n \"but received input has shape %s\"\n % (str(self.input_length), str(input_shape))\n )\n elif s1 is None:\n in_lens[i] = s2\n return (input_shape[0],) + tuple(in_lens) + (self.output_dim,)\n\n @property\n def name(self):\n return self._name\n\n @staticmethod\n def get_key(name_list):\n return \"-\".join(map(str, name_list))\n\n def lookup_embedding(self, unique_ids):\n ids = unique_ids.numpy()\n keys = [Embedding.get_key([self._name, id]) for id in ids]\n (\n embedding_vectors,\n unknown_keys_index,\n ) = EmbeddingService.lookup_embedding(\n keys=keys,\n embedding_service_endpoint=self.embedding_service_endpoint,\n )\n\n if unknown_keys_index:\n # Initialize unknown_keys' embedding vectors and write into Redis.\n unknown_keys = [keys[index] for index in unknown_keys_index]\n initializer = tf.keras.initializers.get(self.embedding_initializer)\n embedding_vector_init = [\n initializer(shape=[1, self.output_dim]).numpy()\n for _ in unknown_keys\n ]\n embedding_vector_init = np.concatenate(\n embedding_vector_init, axis=0\n )\n EmbeddingService.update_embedding(\n keys=unknown_keys,\n embedding_vectors=embedding_vector_init,\n embedding_service_endpoint=self.embedding_service_endpoint,\n set_if_not_exist=True,\n )\n # Lookup unknown_keys' embedding vectors\n (\n embedding_vectors_new,\n unknown_keys_idx_new,\n ) = EmbeddingService.lookup_embedding(\n keys=unknown_keys,\n embedding_service_endpoint=self.embedding_service_endpoint,\n )\n if unknown_keys_idx_new:\n raise Exception(\n \"Update embedding vector: %s failed.\"\n % str(\n [unknown_keys[index] for index in unknown_keys_idx_new]\n )\n )\n for key_index, vector in zip(\n unknown_keys_index, embedding_vectors_new\n ):\n embedding_vectors[key_index] = vector\n embedding_vectors = np.concatenate(embedding_vectors, axis=0)\n return embedding_vectors.reshape((len(keys), self.output_dim))\n\n def _record_gradients(self, batch_embedding, ids):\n if tf.executing_eagerly():\n self.tape.watch(batch_embedding)\n self._embedding_and_ids_eagerly.append(\n EmbeddingAndIds(batch_embedding, ids)\n )\n else:\n # In graph mode, assigning tensors to trainable variables is\n # allowed and tape can record the gradients of trainable\n # variables automatically.\n embedding_and_ids = self._embedding_and_ids_graph[0]\n embedding_and_ids.batch_embedding.assign(batch_embedding)\n embedding_and_ids.batch_ids.assign(ids)\n batch_embedding = embedding_and_ids.batch_embedding\n return batch_embedding\n\n def call(self, input):\n input = tf.cast(input, tf.int64)\n if isinstance(input, tf.SparseTensor):\n return self._sparse_input_call(input)\n\n ids = tf.convert_to_tensor(input, name=\"embedding_ids\")\n flat_ids = tf.reshape(ids, [-1])\n unique_ids, idx = tf.unique(flat_ids)\n # Gradient for `batch_embedding` is SparseTensor here due to\n # `tf.gather` op. `tf.gather` accesses tensor slices, resulting in\n # sparse tensor gradient.\n batch_embedding = tf.py_function(\n self.lookup_embedding, inp=[unique_ids], Tout=tf.float32\n )\n # TODO: use tf.cond rather than python if statement\n if self.tape:\n batch_embedding = self._record_gradients(batch_embedding, flat_ids)\n\n outputs = tf.gather(batch_embedding, idx)\n # tf.reshape does not support shape with None. Replace None with -1.\n if ids.get_shape().rank == 2:\n input_length = ids.get_shape()[1]\n if input_length is None:\n outputs.set_shape(shape=(None, None, self.output_dim))\n return outputs\n output_shape = (-1, input_length, self.output_dim)\n else:\n output_shape = ids.get_shape().concatenate(self.output_dim)\n outputs = tf.reshape(outputs, output_shape)\n # TODO: support combiner for dense input\n return outputs\n\n def _sparse_input_call(self, sparse_input):\n if self.combiner not in [\"sum\", \"mean\", \"sqrtn\"]:\n raise ValueError(\n \"combiner must set sum, mean or sqrtn for sparse input\"\n )\n unique_ids, idx = tf.unique(sparse_input.values)\n # Gradient for `batch_embedding` is dense tensor.\n batch_embedding = tf.py_function(\n self.lookup_embedding, inp=[unique_ids], Tout=tf.float32\n )\n # TODO: use tf.cond rather than python if statement\n if self.tape:\n batch_embedding = self._record_gradients(\n batch_embedding, unique_ids\n )\n\n segment_ids = sparse_input.indices[:, 0]\n if segment_ids.dtype != tf.int32:\n segment_ids = tf.cast(segment_ids, tf.int32)\n\n if self.combiner == \"sum\":\n batch_embedding = tf.sparse.segment_sum(\n batch_embedding, idx, segment_ids\n )\n elif self.combiner == \"mean\":\n batch_embedding = tf.sparse.segment_mean(\n batch_embedding, idx, segment_ids\n )\n elif self.combiner == \"sqrtn\":\n batch_embedding = tf.sparse.segment_sqrt_n(\n batch_embedding, idx, segment_ids\n )\n return batch_embedding\n\n def compute_mask(self, inputs, mask=None):\n if isinstance(input, tf.SparseTensor):\n raise ValueError(\"SparseTensor inputs do not support mask_zero\")\n if not self.supports_masking:\n return None\n return tf.math.not_equal(inputs, 0)\n\n def reset(self):\n self._embedding_and_ids_eagerly = []\n self.tape = None\n\n def set_tape(self, tape):\n self.tape = tape\n\n def set_endpoint(self, endpoint):\n self.embedding_service_endpoint = endpoint\n\n @property\n def embedding_and_ids(self):\n \"\"\"\n Return bet and ids pairs.\n \"\"\"\n if self._embedding_and_ids_eagerly:\n return self._embedding_and_ids_eagerly\n return self._embedding_and_ids_graph\n", "path": "elasticdl/python/elasticdl/layers/embedding.py"}], "after_files": [{"content": "import collections\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.python.keras.utils import tf_utils\n\nfrom elasticdl.python.master.embedding_service import EmbeddingService\n\nEmbeddingAndIds = collections.namedtuple(\n \"EmbeddingAndIds\", [\"batch_embedding\", \"batch_ids\"]\n)\n\n\nclass Embedding(tf.keras.layers.Layer):\n \"\"\"\n Input: indexes for the embedding entries with a shape of\n (batch_size, input_length). Input can be either dense tensor\n or SparseTensor.\n Output:\n corresponding (combined) embeddings with a shape of\n (batch_size, input_length, output_dim) if combiner is None\n (batch_size, output_dim) if combiner is not None\n Arguments:\n output_dim: the dimension of the embedding vector\n embedding_initializer: Initializer for embedding table\n mask_zero: Whether or not the input value 0 is a special \"padding\"\n value that should be masked out.\n If input is SparseTensor, mask_zero must be False.\n input_length: Length of input sequences, when it is constant.\n This argument is required if you are going to connect\n `Flatten` then `Dense` layers upstream\n (without it, the shape of the dense outputs cannot be computed).\n combiner: A string specifying the reduction op or None if not used.\n \"mean\", \"sqrtn\" and \"sum\" are supported for the reduction op.\n If input is SparseTensor, combiner must set as a reduction op.\n \"\"\"\n\n def __init__(\n self,\n output_dim,\n embedding_initializer=\"uniform\",\n mask_zero=False,\n input_length=None,\n combiner=None,\n embedding_service_endpoint=None,\n **kwargs\n ):\n if \"input_shape\" not in kwargs and input_length:\n kwargs[\"input_shape\"] = (input_length,)\n super(Embedding, self).__init__(**kwargs)\n\n self.output_dim = output_dim\n self.embedding_initializer = embedding_initializer\n self.supports_masking = mask_zero\n self.input_length = input_length\n self.combiner = combiner\n self.embedding_service_endpoint = embedding_service_endpoint\n self.tape = None\n self.lookup_func = None\n\n self._embedding_and_ids_eagerly = []\n\n # BET's shape and ids' shape in `self._embedding_and_ids_graph` have\n # `None` dimension. This is because they have different shapes in\n # different iterations.\n # `tf.Variable` requires initial value if shape has `None` dimension.\n self._embedding_and_ids_graph = []\n\n def _init_for_graph_mode(self):\n self._embedding_and_ids_graph = [\n EmbeddingAndIds(\n batch_embedding=tf.Variable(\n # In some cases, `tf.Variable` requires that initial value\n # is callable.\n initial_value=lambda: tf.zeros((1, self.output_dim)),\n shape=tf.TensorShape((None, self.output_dim)),\n dtype=tf.float32,\n trainable=True,\n ),\n batch_ids=tf.Variable(\n initial_value=lambda: tf.zeros((1, 1), dtype=tf.int64),\n shape=tf.TensorShape(None),\n dtype=tf.int64,\n trainable=False,\n ),\n )\n ]\n\n @tf_utils.shape_type_conversion\n def compute_output_shape(self, input_shape):\n # this function is taken from\n # tf.keras.layers.Embedding.compute_output_shape\n # https://github.com/tensorflow/tensorflow/blob/3f3c728bf80e0fd6653744318cbbfe1454c6ddca/tensorflow/python/keras/layers/embeddings.py#L156\n if self.input_length is None:\n return input_shape + (self.output_dim,)\n else:\n if isinstance(self.input_length, (list, tuple)):\n in_lens = list(self.input_length)\n else:\n in_lens = [self.input_length]\n if len(in_lens) != len(input_shape) - 1:\n raise ValueError(\n '\"input_length\" is %s, '\n \"but received input has shape %s\"\n % (str(self.input_length), str(input_shape))\n )\n else:\n for i, (s1, s2) in enumerate(zip(in_lens, input_shape[1:])):\n if s1 is not None and s2 is not None and s1 != s2:\n raise ValueError(\n '\"input_length\" is %s, '\n \"but received input has shape %s\"\n % (str(self.input_length), str(input_shape))\n )\n elif s1 is None:\n in_lens[i] = s2\n return (input_shape[0],) + tuple(in_lens) + (self.output_dim,)\n\n @property\n def name(self):\n return self._name\n\n @staticmethod\n def get_key(name_list):\n return \"-\".join(map(str, name_list))\n\n def lookup_embedding(self, unique_ids):\n ids = unique_ids.numpy()\n keys = [Embedding.get_key([self._name, id]) for id in ids]\n (\n embedding_vectors,\n unknown_keys_index,\n ) = EmbeddingService.lookup_embedding(\n keys=keys,\n embedding_service_endpoint=self.embedding_service_endpoint,\n )\n\n if unknown_keys_index:\n # Initialize unknown_keys' embedding vectors and write into Redis.\n unknown_keys = [keys[index] for index in unknown_keys_index]\n initializer = tf.keras.initializers.get(self.embedding_initializer)\n embedding_vector_init = [\n initializer(shape=[1, self.output_dim]).numpy()\n for _ in unknown_keys\n ]\n embedding_vector_init = np.concatenate(\n embedding_vector_init, axis=0\n )\n EmbeddingService.update_embedding(\n keys=unknown_keys,\n embedding_vectors=embedding_vector_init,\n embedding_service_endpoint=self.embedding_service_endpoint,\n set_if_not_exist=True,\n )\n # Lookup unknown_keys' embedding vectors\n (\n embedding_vectors_new,\n unknown_keys_idx_new,\n ) = EmbeddingService.lookup_embedding(\n keys=unknown_keys,\n embedding_service_endpoint=self.embedding_service_endpoint,\n )\n if unknown_keys_idx_new:\n raise Exception(\n \"Update embedding vector: %s failed.\"\n % str(\n [unknown_keys[index] for index in unknown_keys_idx_new]\n )\n )\n for key_index, vector in zip(\n unknown_keys_index, embedding_vectors_new\n ):\n embedding_vectors[key_index] = vector\n embedding_vectors = np.concatenate(embedding_vectors, axis=0)\n return embedding_vectors.reshape((len(keys), self.output_dim))\n\n def _record_gradients(self, batch_embedding, ids):\n if tf.executing_eagerly():\n self.tape.watch(batch_embedding)\n self._embedding_and_ids_eagerly.append(\n EmbeddingAndIds(batch_embedding, ids)\n )\n else:\n # In graph mode, assigning tensors to trainable variables is\n # allowed and tape can record the gradients of trainable\n # variables automatically.\n embedding_and_ids = self._embedding_and_ids_graph[0]\n embedding_and_ids.batch_embedding.assign(batch_embedding)\n embedding_and_ids.batch_ids.assign(ids)\n batch_embedding = embedding_and_ids.batch_embedding\n return batch_embedding\n\n def call(self, input):\n if (\n self.tape\n and not tf.executing_eagerly()\n and not self._embedding_and_ids_graph\n ):\n self._init_for_graph_mode()\n\n input = tf.cast(input, tf.int64)\n if isinstance(input, tf.SparseTensor):\n return self._sparse_input_call(input)\n\n ids = tf.convert_to_tensor(input, name=\"embedding_ids\")\n flat_ids = tf.reshape(ids, [-1])\n unique_ids, idx = tf.unique(flat_ids)\n # Gradient for `batch_embedding` is SparseTensor here due to\n # `tf.gather` op. `tf.gather` accesses tensor slices, resulting in\n # sparse tensor gradient.\n batch_embedding = tf.py_function(\n self.lookup_embedding, inp=[unique_ids], Tout=tf.float32\n )\n # TODO: use tf.cond rather than python if statement\n if self.tape:\n batch_embedding = self._record_gradients(batch_embedding, flat_ids)\n\n outputs = tf.gather(batch_embedding, idx)\n # tf.reshape does not support shape with None. Replace None with -1.\n if ids.get_shape().rank == 2:\n input_length = ids.get_shape()[1]\n if input_length is None:\n outputs.set_shape(shape=(None, None, self.output_dim))\n return outputs\n output_shape = (-1, input_length, self.output_dim)\n else:\n output_shape = ids.get_shape().concatenate(self.output_dim)\n outputs = tf.reshape(outputs, output_shape)\n # TODO: support combiner for dense input\n return outputs\n\n def _sparse_input_call(self, sparse_input):\n if self.combiner not in [\"sum\", \"mean\", \"sqrtn\"]:\n raise ValueError(\n \"combiner must set sum, mean or sqrtn for sparse input\"\n )\n unique_ids, idx = tf.unique(sparse_input.values)\n # Gradient for `batch_embedding` is dense tensor.\n batch_embedding = tf.py_function(\n self.lookup_embedding, inp=[unique_ids], Tout=tf.float32\n )\n # TODO: use tf.cond rather than python if statement\n if self.tape:\n batch_embedding = self._record_gradients(\n batch_embedding, unique_ids\n )\n\n segment_ids = sparse_input.indices[:, 0]\n if segment_ids.dtype != tf.int32:\n segment_ids = tf.cast(segment_ids, tf.int32)\n\n if self.combiner == \"sum\":\n batch_embedding = tf.sparse.segment_sum(\n batch_embedding, idx, segment_ids\n )\n elif self.combiner == \"mean\":\n batch_embedding = tf.sparse.segment_mean(\n batch_embedding, idx, segment_ids\n )\n elif self.combiner == \"sqrtn\":\n batch_embedding = tf.sparse.segment_sqrt_n(\n batch_embedding, idx, segment_ids\n )\n return batch_embedding\n\n def compute_mask(self, inputs, mask=None):\n if isinstance(input, tf.SparseTensor):\n raise ValueError(\"SparseTensor inputs do not support mask_zero\")\n if not self.supports_masking:\n return None\n return tf.math.not_equal(inputs, 0)\n\n def reset(self):\n self._embedding_and_ids_eagerly = []\n self.tape = None\n\n def set_tape(self, tape):\n self.tape = tape\n\n def set_endpoint(self, endpoint):\n self.embedding_service_endpoint = endpoint\n\n @property\n def embedding_and_ids(self):\n \"\"\"\n Return bet and ids pairs.\n \"\"\"\n if self._embedding_and_ids_eagerly:\n return self._embedding_and_ids_eagerly\n return self._embedding_and_ids_graph\n", "path": "elasticdl/python/elasticdl/layers/embedding.py"}]}
| 3,396 | 394 |
gh_patches_debug_20404
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-5075
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Possible timezone related failure
### Describe the issue
https://github.com/ietf-tools/datatracker/actions/runs/4071644533/jobs/7013629899
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/group/factories.py`
Content:
```
1 # Copyright The IETF Trust 2015-2022, All Rights Reserved
2 import datetime
3 import debug # pyflakes:ignore
4 import factory
5
6 from typing import List # pyflakes:ignore
7
8 from django.utils import timezone
9
10 from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \
11 GroupHistory, RoleHistory
12 from ietf.review.factories import ReviewTeamSettingsFactory
13
14 class GroupFactory(factory.django.DjangoModelFactory):
15 class Meta:
16 model = Group
17 django_get_or_create = ('acronym',)
18
19 name = factory.Faker('sentence',nb_words=6)
20 acronym = factory.Sequence(lambda n: 'acronym%d' %n)
21 state_id = 'active'
22 type_id = 'wg'
23 list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)
24 uses_milestone_dates = True
25 used_roles = [] # type: List[str]
26
27 @factory.lazy_attribute
28 def parent(self):
29 if self.type_id in ['wg','ag']:
30 return GroupFactory(type_id='area')
31 elif self.type_id in ['rg','rag']:
32 return GroupFactory(acronym='irtf', type_id='irtf')
33 else:
34 return None
35
36 class ReviewTeamFactory(GroupFactory):
37
38 type_id = 'review'
39
40 @factory.post_generation
41 def settings(obj, create, extracted, **kwargs):
42 ReviewTeamSettingsFactory.create(group=obj,**kwargs)
43
44 class RoleFactory(factory.django.DjangoModelFactory):
45 class Meta:
46 model = Role
47
48 group = factory.SubFactory(GroupFactory)
49 person = factory.SubFactory('ietf.person.factories.PersonFactory')
50 email = factory.LazyAttribute(lambda obj: obj.person.email())
51
52 class GroupEventFactory(factory.django.DjangoModelFactory):
53 class Meta:
54 model = GroupEvent
55
56 group = factory.SubFactory(GroupFactory)
57 by = factory.SubFactory('ietf.person.factories.PersonFactory')
58 type = 'comment'
59 desc = factory.Faker('paragraph')
60
61 class BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):
62 class Meta:
63 model = GroupMilestone
64
65 group = factory.SubFactory(GroupFactory)
66 state_id = 'active'
67 desc = factory.Faker('sentence')
68
69 class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):
70 group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)
71 due = timezone.now()+datetime.timedelta(days=180)
72
73 class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):
74 group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)
75 order = factory.Sequence(lambda n: n)
76
77 class GroupHistoryFactory(factory.django.DjangoModelFactory):
78 class Meta:
79 model=GroupHistory
80
81 time = lambda: timezone.now()
82 group = factory.SubFactory(GroupFactory, state_id='active')
83
84 name = factory.LazyAttribute(lambda obj: obj.group.name)
85 state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)
86 type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)
87 parent = factory.LazyAttribute(lambda obj: obj.group.parent)
88 uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)
89 used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)
90 description = factory.LazyAttribute(lambda obj: obj.group.description)
91 list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory
92 list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)
93 list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)
94 comments = factory.LazyAttribute(lambda obj: obj.group.comments)
95 meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)
96 acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)
97
98 @factory.post_generation
99 def unused_states(obj, create, extracted, **kwargs):
100 if create:
101 if extracted:
102 obj.unused_states.set(extracted)
103 else:
104 obj.unused_states.set(obj.group.unused_states.all())
105 @factory.post_generation
106 def unused_tags(obj, create, extracted, **kwargs):
107 if create:
108 if extracted:
109 obj.unused_tags.set(extracted)
110 else:
111 obj.unused_tags.set(obj.group.unused_states.all())
112
113 class RoleHistoryFactory(factory.django.DjangoModelFactory):
114 class Meta:
115 model=RoleHistory
116
117 group = factory.SubFactory(GroupHistoryFactory)
118 person = factory.SubFactory('ietf.person.factories.PersonFactory')
119 email = factory.LazyAttribute(lambda obj: obj.person.email())
120
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/group/factories.py b/ietf/group/factories.py
--- a/ietf/group/factories.py
+++ b/ietf/group/factories.py
@@ -10,6 +10,8 @@
from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \
GroupHistory, RoleHistory
from ietf.review.factories import ReviewTeamSettingsFactory
+from ietf.utils.timezone import date_today
+
class GroupFactory(factory.django.DjangoModelFactory):
class Meta:
@@ -68,7 +70,7 @@
class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):
group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)
- due = timezone.now()+datetime.timedelta(days=180)
+ due = date_today() + datetime.timedelta(days=180)
class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):
group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)
|
{"golden_diff": "diff --git a/ietf/group/factories.py b/ietf/group/factories.py\n--- a/ietf/group/factories.py\n+++ b/ietf/group/factories.py\n@@ -10,6 +10,8 @@\n from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\n from ietf.review.factories import ReviewTeamSettingsFactory\n+from ietf.utils.timezone import date_today\n+\n \n class GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n@@ -68,7 +70,7 @@\n \n class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n- due = timezone.now()+datetime.timedelta(days=180)\n+ due = date_today() + datetime.timedelta(days=180)\n \n class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n", "issue": "Possible timezone related failure\n### Describe the issue\n\nhttps://github.com/ietf-tools/datatracker/actions/runs/4071644533/jobs/7013629899\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "# Copyright The IETF Trust 2015-2022, All Rights Reserved\nimport datetime\nimport debug # pyflakes:ignore\nimport factory\n\nfrom typing import List # pyflakes:ignore\n\nfrom django.utils import timezone\n\nfrom ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\nfrom ietf.review.factories import ReviewTeamSettingsFactory\n\nclass GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Group\n django_get_or_create = ('acronym',)\n\n name = factory.Faker('sentence',nb_words=6)\n acronym = factory.Sequence(lambda n: 'acronym%d' %n)\n state_id = 'active'\n type_id = 'wg'\n list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)\n uses_milestone_dates = True\n used_roles = [] # type: List[str]\n\n @factory.lazy_attribute\n def parent(self):\n if self.type_id in ['wg','ag']:\n return GroupFactory(type_id='area')\n elif self.type_id in ['rg','rag']:\n return GroupFactory(acronym='irtf', type_id='irtf')\n else:\n return None\n\nclass ReviewTeamFactory(GroupFactory):\n\n type_id = 'review'\n\n @factory.post_generation\n def settings(obj, create, extracted, **kwargs):\n ReviewTeamSettingsFactory.create(group=obj,**kwargs)\n\nclass RoleFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Role\n\n group = factory.SubFactory(GroupFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\nclass GroupEventFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupEvent\n\n group = factory.SubFactory(GroupFactory)\n by = factory.SubFactory('ietf.person.factories.PersonFactory')\n type = 'comment'\n desc = factory.Faker('paragraph')\n\nclass BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupMilestone\n\n group = factory.SubFactory(GroupFactory)\n state_id = 'active'\n desc = factory.Faker('sentence')\n\nclass DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n due = timezone.now()+datetime.timedelta(days=180)\n\nclass DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n order = factory.Sequence(lambda n: n)\n\nclass GroupHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=GroupHistory\n\n time = lambda: timezone.now()\n group = factory.SubFactory(GroupFactory, state_id='active')\n\n name = factory.LazyAttribute(lambda obj: obj.group.name)\n state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)\n type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)\n parent = factory.LazyAttribute(lambda obj: obj.group.parent)\n uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)\n used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)\n description = factory.LazyAttribute(lambda obj: obj.group.description)\n list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory\n list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)\n list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)\n comments = factory.LazyAttribute(lambda obj: obj.group.comments)\n meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)\n acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)\n\n @factory.post_generation\n def unused_states(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_states.set(extracted)\n else:\n obj.unused_states.set(obj.group.unused_states.all())\n @factory.post_generation\n def unused_tags(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_tags.set(extracted)\n else:\n obj.unused_tags.set(obj.group.unused_states.all()) \n\nclass RoleHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=RoleHistory\n\n group = factory.SubFactory(GroupHistoryFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\n", "path": "ietf/group/factories.py"}], "after_files": [{"content": "# Copyright The IETF Trust 2015-2022, All Rights Reserved\nimport datetime\nimport debug # pyflakes:ignore\nimport factory\n\nfrom typing import List # pyflakes:ignore\n\nfrom django.utils import timezone\n\nfrom ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\nfrom ietf.review.factories import ReviewTeamSettingsFactory\nfrom ietf.utils.timezone import date_today\n\n\nclass GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Group\n django_get_or_create = ('acronym',)\n\n name = factory.Faker('sentence',nb_words=6)\n acronym = factory.Sequence(lambda n: 'acronym%d' %n)\n state_id = 'active'\n type_id = 'wg'\n list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)\n uses_milestone_dates = True\n used_roles = [] # type: List[str]\n\n @factory.lazy_attribute\n def parent(self):\n if self.type_id in ['wg','ag']:\n return GroupFactory(type_id='area')\n elif self.type_id in ['rg','rag']:\n return GroupFactory(acronym='irtf', type_id='irtf')\n else:\n return None\n\nclass ReviewTeamFactory(GroupFactory):\n\n type_id = 'review'\n\n @factory.post_generation\n def settings(obj, create, extracted, **kwargs):\n ReviewTeamSettingsFactory.create(group=obj,**kwargs)\n\nclass RoleFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Role\n\n group = factory.SubFactory(GroupFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\nclass GroupEventFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupEvent\n\n group = factory.SubFactory(GroupFactory)\n by = factory.SubFactory('ietf.person.factories.PersonFactory')\n type = 'comment'\n desc = factory.Faker('paragraph')\n\nclass BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupMilestone\n\n group = factory.SubFactory(GroupFactory)\n state_id = 'active'\n desc = factory.Faker('sentence')\n\nclass DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n due = date_today() + datetime.timedelta(days=180)\n\nclass DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n order = factory.Sequence(lambda n: n)\n\nclass GroupHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=GroupHistory\n\n time = lambda: timezone.now()\n group = factory.SubFactory(GroupFactory, state_id='active')\n\n name = factory.LazyAttribute(lambda obj: obj.group.name)\n state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)\n type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)\n parent = factory.LazyAttribute(lambda obj: obj.group.parent)\n uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)\n used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)\n description = factory.LazyAttribute(lambda obj: obj.group.description)\n list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory\n list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)\n list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)\n comments = factory.LazyAttribute(lambda obj: obj.group.comments)\n meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)\n acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)\n\n @factory.post_generation\n def unused_states(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_states.set(extracted)\n else:\n obj.unused_states.set(obj.group.unused_states.all())\n @factory.post_generation\n def unused_tags(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_tags.set(extracted)\n else:\n obj.unused_tags.set(obj.group.unused_states.all()) \n\nclass RoleHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=RoleHistory\n\n group = factory.SubFactory(GroupHistoryFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\n", "path": "ietf/group/factories.py"}]}
| 1,621 | 216 |
gh_patches_debug_4593
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1189
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NpipeSocket.makefile crashes when bufsize < 0
**Original report**: https://github.com/docker/compose/issues/3901#issuecomment-244828701
Negative `bufsize` should be handled.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/transport/npipesocket.py`
Content:
```
1 import functools
2 import io
3
4 import win32file
5 import win32pipe
6
7 cSECURITY_SQOS_PRESENT = 0x100000
8 cSECURITY_ANONYMOUS = 0
9 cPIPE_READMODE_MESSAGE = 2
10
11
12 def check_closed(f):
13 @functools.wraps(f)
14 def wrapped(self, *args, **kwargs):
15 if self._closed:
16 raise RuntimeError(
17 'Can not reuse socket after connection was closed.'
18 )
19 return f(self, *args, **kwargs)
20 return wrapped
21
22
23 class NpipeSocket(object):
24 """ Partial implementation of the socket API over windows named pipes.
25 This implementation is only designed to be used as a client socket,
26 and server-specific methods (bind, listen, accept...) are not
27 implemented.
28 """
29 def __init__(self, handle=None):
30 self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT
31 self._handle = handle
32 self._closed = False
33
34 def accept(self):
35 raise NotImplementedError()
36
37 def bind(self, address):
38 raise NotImplementedError()
39
40 def close(self):
41 self._handle.Close()
42 self._closed = True
43
44 @check_closed
45 def connect(self, address):
46 win32pipe.WaitNamedPipe(address, self._timeout)
47 handle = win32file.CreateFile(
48 address,
49 win32file.GENERIC_READ | win32file.GENERIC_WRITE,
50 0,
51 None,
52 win32file.OPEN_EXISTING,
53 cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,
54 0
55 )
56 self.flags = win32pipe.GetNamedPipeInfo(handle)[0]
57
58 self._handle = handle
59 self._address = address
60
61 @check_closed
62 def connect_ex(self, address):
63 return self.connect(address)
64
65 @check_closed
66 def detach(self):
67 self._closed = True
68 return self._handle
69
70 @check_closed
71 def dup(self):
72 return NpipeSocket(self._handle)
73
74 @check_closed
75 def fileno(self):
76 return int(self._handle)
77
78 def getpeername(self):
79 return self._address
80
81 def getsockname(self):
82 return self._address
83
84 def getsockopt(self, level, optname, buflen=None):
85 raise NotImplementedError()
86
87 def ioctl(self, control, option):
88 raise NotImplementedError()
89
90 def listen(self, backlog):
91 raise NotImplementedError()
92
93 def makefile(self, mode=None, bufsize=None):
94 if mode.strip('b') != 'r':
95 raise NotImplementedError()
96 rawio = NpipeFileIOBase(self)
97 if bufsize is None:
98 bufsize = io.DEFAULT_BUFFER_SIZE
99 return io.BufferedReader(rawio, buffer_size=bufsize)
100
101 @check_closed
102 def recv(self, bufsize, flags=0):
103 err, data = win32file.ReadFile(self._handle, bufsize)
104 return data
105
106 @check_closed
107 def recvfrom(self, bufsize, flags=0):
108 data = self.recv(bufsize, flags)
109 return (data, self._address)
110
111 @check_closed
112 def recvfrom_into(self, buf, nbytes=0, flags=0):
113 return self.recv_into(buf, nbytes, flags), self._address
114
115 @check_closed
116 def recv_into(self, buf, nbytes=0):
117 readbuf = buf
118 if not isinstance(buf, memoryview):
119 readbuf = memoryview(buf)
120
121 err, data = win32file.ReadFile(
122 self._handle,
123 readbuf[:nbytes] if nbytes else readbuf
124 )
125 return len(data)
126
127 @check_closed
128 def send(self, string, flags=0):
129 err, nbytes = win32file.WriteFile(self._handle, string)
130 return nbytes
131
132 @check_closed
133 def sendall(self, string, flags=0):
134 return self.send(string, flags)
135
136 @check_closed
137 def sendto(self, string, address):
138 self.connect(address)
139 return self.send(string)
140
141 def setblocking(self, flag):
142 if flag:
143 return self.settimeout(None)
144 return self.settimeout(0)
145
146 def settimeout(self, value):
147 if value is None:
148 self._timeout = win32pipe.NMPWAIT_NOWAIT
149 elif not isinstance(value, (float, int)) or value < 0:
150 raise ValueError('Timeout value out of range')
151 elif value == 0:
152 self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT
153 else:
154 self._timeout = value
155
156 def gettimeout(self):
157 return self._timeout
158
159 def setsockopt(self, level, optname, value):
160 raise NotImplementedError()
161
162 @check_closed
163 def shutdown(self, how):
164 return self.close()
165
166
167 class NpipeFileIOBase(io.RawIOBase):
168 def __init__(self, npipe_socket):
169 self.sock = npipe_socket
170
171 def close(self):
172 super(NpipeFileIOBase, self).close()
173 self.sock = None
174
175 def fileno(self):
176 return self.sock.fileno()
177
178 def isatty(self):
179 return False
180
181 def readable(self):
182 return True
183
184 def readinto(self, buf):
185 return self.sock.recv_into(buf)
186
187 def seekable(self):
188 return False
189
190 def writable(self):
191 return False
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/transport/npipesocket.py b/docker/transport/npipesocket.py
--- a/docker/transport/npipesocket.py
+++ b/docker/transport/npipesocket.py
@@ -94,7 +94,7 @@
if mode.strip('b') != 'r':
raise NotImplementedError()
rawio = NpipeFileIOBase(self)
- if bufsize is None:
+ if bufsize is None or bufsize < 0:
bufsize = io.DEFAULT_BUFFER_SIZE
return io.BufferedReader(rawio, buffer_size=bufsize)
|
{"golden_diff": "diff --git a/docker/transport/npipesocket.py b/docker/transport/npipesocket.py\n--- a/docker/transport/npipesocket.py\n+++ b/docker/transport/npipesocket.py\n@@ -94,7 +94,7 @@\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n- if bufsize is None:\n+ if bufsize is None or bufsize < 0:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n", "issue": "NpipeSocket.makefile crashes when bufsize < 0\n**Original report**: https://github.com/docker/compose/issues/3901#issuecomment-244828701\n\nNegative `bufsize` should be handled.\n\n", "before_files": [{"content": "import functools\nimport io\n\nimport win32file\nimport win32pipe\n\ncSECURITY_SQOS_PRESENT = 0x100000\ncSECURITY_ANONYMOUS = 0\ncPIPE_READMODE_MESSAGE = 2\n\n\ndef check_closed(f):\n @functools.wraps(f)\n def wrapped(self, *args, **kwargs):\n if self._closed:\n raise RuntimeError(\n 'Can not reuse socket after connection was closed.'\n )\n return f(self, *args, **kwargs)\n return wrapped\n\n\nclass NpipeSocket(object):\n \"\"\" Partial implementation of the socket API over windows named pipes.\n This implementation is only designed to be used as a client socket,\n and server-specific methods (bind, listen, accept...) are not\n implemented.\n \"\"\"\n def __init__(self, handle=None):\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n self._handle = handle\n self._closed = False\n\n def accept(self):\n raise NotImplementedError()\n\n def bind(self, address):\n raise NotImplementedError()\n\n def close(self):\n self._handle.Close()\n self._closed = True\n\n @check_closed\n def connect(self, address):\n win32pipe.WaitNamedPipe(address, self._timeout)\n handle = win32file.CreateFile(\n address,\n win32file.GENERIC_READ | win32file.GENERIC_WRITE,\n 0,\n None,\n win32file.OPEN_EXISTING,\n cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,\n 0\n )\n self.flags = win32pipe.GetNamedPipeInfo(handle)[0]\n\n self._handle = handle\n self._address = address\n\n @check_closed\n def connect_ex(self, address):\n return self.connect(address)\n\n @check_closed\n def detach(self):\n self._closed = True\n return self._handle\n\n @check_closed\n def dup(self):\n return NpipeSocket(self._handle)\n\n @check_closed\n def fileno(self):\n return int(self._handle)\n\n def getpeername(self):\n return self._address\n\n def getsockname(self):\n return self._address\n\n def getsockopt(self, level, optname, buflen=None):\n raise NotImplementedError()\n\n def ioctl(self, control, option):\n raise NotImplementedError()\n\n def listen(self, backlog):\n raise NotImplementedError()\n\n def makefile(self, mode=None, bufsize=None):\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n if bufsize is None:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n\n @check_closed\n def recv(self, bufsize, flags=0):\n err, data = win32file.ReadFile(self._handle, bufsize)\n return data\n\n @check_closed\n def recvfrom(self, bufsize, flags=0):\n data = self.recv(bufsize, flags)\n return (data, self._address)\n\n @check_closed\n def recvfrom_into(self, buf, nbytes=0, flags=0):\n return self.recv_into(buf, nbytes, flags), self._address\n\n @check_closed\n def recv_into(self, buf, nbytes=0):\n readbuf = buf\n if not isinstance(buf, memoryview):\n readbuf = memoryview(buf)\n\n err, data = win32file.ReadFile(\n self._handle,\n readbuf[:nbytes] if nbytes else readbuf\n )\n return len(data)\n\n @check_closed\n def send(self, string, flags=0):\n err, nbytes = win32file.WriteFile(self._handle, string)\n return nbytes\n\n @check_closed\n def sendall(self, string, flags=0):\n return self.send(string, flags)\n\n @check_closed\n def sendto(self, string, address):\n self.connect(address)\n return self.send(string)\n\n def setblocking(self, flag):\n if flag:\n return self.settimeout(None)\n return self.settimeout(0)\n\n def settimeout(self, value):\n if value is None:\n self._timeout = win32pipe.NMPWAIT_NOWAIT\n elif not isinstance(value, (float, int)) or value < 0:\n raise ValueError('Timeout value out of range')\n elif value == 0:\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n else:\n self._timeout = value\n\n def gettimeout(self):\n return self._timeout\n\n def setsockopt(self, level, optname, value):\n raise NotImplementedError()\n\n @check_closed\n def shutdown(self, how):\n return self.close()\n\n\nclass NpipeFileIOBase(io.RawIOBase):\n def __init__(self, npipe_socket):\n self.sock = npipe_socket\n\n def close(self):\n super(NpipeFileIOBase, self).close()\n self.sock = None\n\n def fileno(self):\n return self.sock.fileno()\n\n def isatty(self):\n return False\n\n def readable(self):\n return True\n\n def readinto(self, buf):\n return self.sock.recv_into(buf)\n\n def seekable(self):\n return False\n\n def writable(self):\n return False\n", "path": "docker/transport/npipesocket.py"}], "after_files": [{"content": "import functools\nimport io\n\nimport win32file\nimport win32pipe\n\ncSECURITY_SQOS_PRESENT = 0x100000\ncSECURITY_ANONYMOUS = 0\ncPIPE_READMODE_MESSAGE = 2\n\n\ndef check_closed(f):\n @functools.wraps(f)\n def wrapped(self, *args, **kwargs):\n if self._closed:\n raise RuntimeError(\n 'Can not reuse socket after connection was closed.'\n )\n return f(self, *args, **kwargs)\n return wrapped\n\n\nclass NpipeSocket(object):\n \"\"\" Partial implementation of the socket API over windows named pipes.\n This implementation is only designed to be used as a client socket,\n and server-specific methods (bind, listen, accept...) are not\n implemented.\n \"\"\"\n def __init__(self, handle=None):\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n self._handle = handle\n self._closed = False\n\n def accept(self):\n raise NotImplementedError()\n\n def bind(self, address):\n raise NotImplementedError()\n\n def close(self):\n self._handle.Close()\n self._closed = True\n\n @check_closed\n def connect(self, address):\n win32pipe.WaitNamedPipe(address, self._timeout)\n handle = win32file.CreateFile(\n address,\n win32file.GENERIC_READ | win32file.GENERIC_WRITE,\n 0,\n None,\n win32file.OPEN_EXISTING,\n cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,\n 0\n )\n self.flags = win32pipe.GetNamedPipeInfo(handle)[0]\n\n self._handle = handle\n self._address = address\n\n @check_closed\n def connect_ex(self, address):\n return self.connect(address)\n\n @check_closed\n def detach(self):\n self._closed = True\n return self._handle\n\n @check_closed\n def dup(self):\n return NpipeSocket(self._handle)\n\n @check_closed\n def fileno(self):\n return int(self._handle)\n\n def getpeername(self):\n return self._address\n\n def getsockname(self):\n return self._address\n\n def getsockopt(self, level, optname, buflen=None):\n raise NotImplementedError()\n\n def ioctl(self, control, option):\n raise NotImplementedError()\n\n def listen(self, backlog):\n raise NotImplementedError()\n\n def makefile(self, mode=None, bufsize=None):\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n if bufsize is None or bufsize < 0:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n\n @check_closed\n def recv(self, bufsize, flags=0):\n err, data = win32file.ReadFile(self._handle, bufsize)\n return data\n\n @check_closed\n def recvfrom(self, bufsize, flags=0):\n data = self.recv(bufsize, flags)\n return (data, self._address)\n\n @check_closed\n def recvfrom_into(self, buf, nbytes=0, flags=0):\n return self.recv_into(buf, nbytes, flags), self._address\n\n @check_closed\n def recv_into(self, buf, nbytes=0):\n readbuf = buf\n if not isinstance(buf, memoryview):\n readbuf = memoryview(buf)\n\n err, data = win32file.ReadFile(\n self._handle,\n readbuf[:nbytes] if nbytes else readbuf\n )\n return len(data)\n\n @check_closed\n def send(self, string, flags=0):\n err, nbytes = win32file.WriteFile(self._handle, string)\n return nbytes\n\n @check_closed\n def sendall(self, string, flags=0):\n return self.send(string, flags)\n\n @check_closed\n def sendto(self, string, address):\n self.connect(address)\n return self.send(string)\n\n def setblocking(self, flag):\n if flag:\n return self.settimeout(None)\n return self.settimeout(0)\n\n def settimeout(self, value):\n if value is None:\n self._timeout = win32pipe.NMPWAIT_NOWAIT\n elif not isinstance(value, (float, int)) or value < 0:\n raise ValueError('Timeout value out of range')\n elif value == 0:\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n else:\n self._timeout = value\n\n def gettimeout(self):\n return self._timeout\n\n def setsockopt(self, level, optname, value):\n raise NotImplementedError()\n\n @check_closed\n def shutdown(self, how):\n return self.close()\n\n\nclass NpipeFileIOBase(io.RawIOBase):\n def __init__(self, npipe_socket):\n self.sock = npipe_socket\n\n def close(self):\n super(NpipeFileIOBase, self).close()\n self.sock = None\n\n def fileno(self):\n return self.sock.fileno()\n\n def isatty(self):\n return False\n\n def readable(self):\n return True\n\n def readinto(self, buf):\n return self.sock.recv_into(buf)\n\n def seekable(self):\n return False\n\n def writable(self):\n return False\n", "path": "docker/transport/npipesocket.py"}]}
| 1,969 | 122 |
gh_patches_debug_22473
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2363
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add documentation in user guide on `torch.compile` usage
- `torch.compile` "from-scratch" usage
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py/torch_tensorrt/dynamo/_settings.py`
Content:
```
1 from dataclasses import dataclass, field
2 from typing import Optional, Set
3
4 import torch
5 from torch_tensorrt._Device import Device
6 from torch_tensorrt.dynamo._defaults import (
7 DEBUG,
8 ENABLE_EXPERIMENTAL_DECOMPOSITIONS,
9 MAX_AUX_STREAMS,
10 MIN_BLOCK_SIZE,
11 OPTIMIZATION_LEVEL,
12 PASS_THROUGH_BUILD_FAILURES,
13 PRECISION,
14 REQUIRE_FULL_COMPILATION,
15 TRUNCATE_LONG_AND_DOUBLE,
16 USE_FAST_PARTITIONER,
17 USE_PYTHON_RUNTIME,
18 VERSION_COMPATIBLE,
19 WORKSPACE_SIZE,
20 default_device,
21 )
22
23
24 @dataclass
25 class CompilationSettings:
26 """Compilation settings for Torch-TensorRT Dynamo Paths
27
28 Args:
29 precision (torch.dtype): Model Layer precision
30 debug (bool): Whether to print out verbose debugging information
31 workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)
32 min_block_size (int): Minimum number of operators per TRT-Engine Block
33 torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage
34 pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)
35 max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine
36 version_compatible (bool): Provide version forward-compatibility for engine plan files
37 optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,
38 searching for more optimization options. TRT defaults to 3
39 use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime
40 based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the
41 argument as None
42 truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32
43 enable_experimental_decompositions (bool): Whether to enable all core aten decompositions
44 or only a selected subset of them
45 """
46
47 precision: torch.dtype = PRECISION
48 debug: bool = DEBUG
49 workspace_size: int = WORKSPACE_SIZE
50 min_block_size: int = MIN_BLOCK_SIZE
51 torch_executed_ops: Set[str] = field(default_factory=set)
52 pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES
53 max_aux_streams: Optional[int] = MAX_AUX_STREAMS
54 version_compatible: bool = VERSION_COMPATIBLE
55 optimization_level: Optional[int] = OPTIMIZATION_LEVEL
56 use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME
57 truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE
58 use_fast_partitioner: bool = USE_FAST_PARTITIONER
59 enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS
60 device: Device = field(default_factory=default_device)
61 require_full_compilation: bool = REQUIRE_FULL_COMPILATION
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/py/torch_tensorrt/dynamo/_settings.py b/py/torch_tensorrt/dynamo/_settings.py
--- a/py/torch_tensorrt/dynamo/_settings.py
+++ b/py/torch_tensorrt/dynamo/_settings.py
@@ -39,9 +39,13 @@
use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime
based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the
argument as None
- truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32
+ truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32
+ use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system
enable_experimental_decompositions (bool): Whether to enable all core aten decompositions
or only a selected subset of them
+ device (Device): GPU to compile the model on
+ require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.
+ Only applicable for `ir="dynamo"`; has no effect for `torch.compile` path
"""
precision: torch.dtype = PRECISION
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/_settings.py b/py/torch_tensorrt/dynamo/_settings.py\n--- a/py/torch_tensorrt/dynamo/_settings.py\n+++ b/py/torch_tensorrt/dynamo/_settings.py\n@@ -39,9 +39,13 @@\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n- truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32\n+ truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32\n+ use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n+ device (Device): GPU to compile the model on\n+ require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.\n+ Only applicable for `ir=\"dynamo\"`; has no effect for `torch.compile` path\n \"\"\"\n \n precision: torch.dtype = PRECISION\n", "issue": "Add documentation in user guide on `torch.compile` usage\n- `torch.compile` \"from-scratch\" usage\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional, Set\n\nimport torch\nfrom torch_tensorrt._Device import Device\nfrom torch_tensorrt.dynamo._defaults import (\n DEBUG,\n ENABLE_EXPERIMENTAL_DECOMPOSITIONS,\n MAX_AUX_STREAMS,\n MIN_BLOCK_SIZE,\n OPTIMIZATION_LEVEL,\n PASS_THROUGH_BUILD_FAILURES,\n PRECISION,\n REQUIRE_FULL_COMPILATION,\n TRUNCATE_LONG_AND_DOUBLE,\n USE_FAST_PARTITIONER,\n USE_PYTHON_RUNTIME,\n VERSION_COMPATIBLE,\n WORKSPACE_SIZE,\n default_device,\n)\n\n\n@dataclass\nclass CompilationSettings:\n \"\"\"Compilation settings for Torch-TensorRT Dynamo Paths\n\n Args:\n precision (torch.dtype): Model Layer precision\n debug (bool): Whether to print out verbose debugging information\n workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)\n min_block_size (int): Minimum number of operators per TRT-Engine Block\n torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage\n pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)\n max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine\n version_compatible (bool): Provide version forward-compatibility for engine plan files\n optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,\n searching for more optimization options. TRT defaults to 3\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n \"\"\"\n\n precision: torch.dtype = PRECISION\n debug: bool = DEBUG\n workspace_size: int = WORKSPACE_SIZE\n min_block_size: int = MIN_BLOCK_SIZE\n torch_executed_ops: Set[str] = field(default_factory=set)\n pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES\n max_aux_streams: Optional[int] = MAX_AUX_STREAMS\n version_compatible: bool = VERSION_COMPATIBLE\n optimization_level: Optional[int] = OPTIMIZATION_LEVEL\n use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME\n truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE\n use_fast_partitioner: bool = USE_FAST_PARTITIONER\n enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS\n device: Device = field(default_factory=default_device)\n require_full_compilation: bool = REQUIRE_FULL_COMPILATION\n", "path": "py/torch_tensorrt/dynamo/_settings.py"}], "after_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional, Set\n\nimport torch\nfrom torch_tensorrt._Device import Device\nfrom torch_tensorrt.dynamo._defaults import (\n DEBUG,\n ENABLE_EXPERIMENTAL_DECOMPOSITIONS,\n MAX_AUX_STREAMS,\n MIN_BLOCK_SIZE,\n OPTIMIZATION_LEVEL,\n PASS_THROUGH_BUILD_FAILURES,\n PRECISION,\n REQUIRE_FULL_COMPILATION,\n TRUNCATE_LONG_AND_DOUBLE,\n USE_FAST_PARTITIONER,\n USE_PYTHON_RUNTIME,\n VERSION_COMPATIBLE,\n WORKSPACE_SIZE,\n default_device,\n)\n\n\n@dataclass\nclass CompilationSettings:\n \"\"\"Compilation settings for Torch-TensorRT Dynamo Paths\n\n Args:\n precision (torch.dtype): Model Layer precision\n debug (bool): Whether to print out verbose debugging information\n workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)\n min_block_size (int): Minimum number of operators per TRT-Engine Block\n torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage\n pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)\n max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine\n version_compatible (bool): Provide version forward-compatibility for engine plan files\n optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,\n searching for more optimization options. TRT defaults to 3\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32\n use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n device (Device): GPU to compile the model on\n require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.\n Only applicable for `ir=\"dynamo\"`; has no effect for `torch.compile` path\n \"\"\"\n\n precision: torch.dtype = PRECISION\n debug: bool = DEBUG\n workspace_size: int = WORKSPACE_SIZE\n min_block_size: int = MIN_BLOCK_SIZE\n torch_executed_ops: Set[str] = field(default_factory=set)\n pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES\n max_aux_streams: Optional[int] = MAX_AUX_STREAMS\n version_compatible: bool = VERSION_COMPATIBLE\n optimization_level: Optional[int] = OPTIMIZATION_LEVEL\n use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME\n truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE\n use_fast_partitioner: bool = USE_FAST_PARTITIONER\n enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS\n device: Device = field(default_factory=default_device)\n require_full_compilation: bool = REQUIRE_FULL_COMPILATION\n", "path": "py/torch_tensorrt/dynamo/_settings.py"}]}
| 1,044 | 301 |
gh_patches_debug_59440
|
rasdani/github-patches
|
git_diff
|
Pycord-Development__pycord-576
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SlashCommand Groups Issues
This issue is to keep track of the issues since we reworked groups.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/app_commands/slash_groups.py`
Content:
```
1 import discord
2
3 bot = discord.Bot()
4
5 # If you use commands.Bot, @bot.slash_command should be used for
6 # slash commands. You can use @bot.slash_command with discord.Bot as well
7
8 math = bot.command_group(
9 "math", "Commands related to mathematics."
10 ) # create a slash command group
11
12
13 @math.command(guild_ids=[...]) # create a slash command
14 async def add(ctx, num1: int, num2: int):
15 """Get the sum of 2 integers."""
16 await ctx.respond(f"The sum of these numbers is **{num1+num2}**")
17
18
19 # another way, creating the class manually
20
21 from discord.commands import SlashCommandGroup
22
23 math = SlashCommandGroup("math", "Commands related to mathematics.")
24
25
26 @math.command(guild_ids=[...])
27 async def add(ctx, num1: int, num2: int):
28 ...
29
30
31 bot.add_application_command(math)
32
33 bot.run("TOKEN")
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/app_commands/slash_groups.py b/examples/app_commands/slash_groups.py
--- a/examples/app_commands/slash_groups.py
+++ b/examples/app_commands/slash_groups.py
@@ -5,7 +5,7 @@
# If you use commands.Bot, @bot.slash_command should be used for
# slash commands. You can use @bot.slash_command with discord.Bot as well
-math = bot.command_group(
+math = bot.create_group(
"math", "Commands related to mathematics."
) # create a slash command group
|
{"golden_diff": "diff --git a/examples/app_commands/slash_groups.py b/examples/app_commands/slash_groups.py\n--- a/examples/app_commands/slash_groups.py\n+++ b/examples/app_commands/slash_groups.py\n@@ -5,7 +5,7 @@\n # If you use commands.Bot, @bot.slash_command should be used for\r\n # slash commands. You can use @bot.slash_command with discord.Bot as well\r\n \r\n-math = bot.command_group(\r\n+math = bot.create_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n ) # create a slash command group\n", "issue": "SlashCommand Groups Issues\nThis issue is to keep track of the issues since we reworked groups.\n", "before_files": [{"content": "import discord\r\n\r\nbot = discord.Bot()\r\n\r\n# If you use commands.Bot, @bot.slash_command should be used for\r\n# slash commands. You can use @bot.slash_command with discord.Bot as well\r\n\r\nmath = bot.command_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n) # create a slash command group\r\n\r\n\r\[email protected](guild_ids=[...]) # create a slash command\r\nasync def add(ctx, num1: int, num2: int):\r\n \"\"\"Get the sum of 2 integers.\"\"\"\r\n await ctx.respond(f\"The sum of these numbers is **{num1+num2}**\")\r\n\r\n\r\n# another way, creating the class manually\r\n\r\nfrom discord.commands import SlashCommandGroup\r\n\r\nmath = SlashCommandGroup(\"math\", \"Commands related to mathematics.\")\r\n\r\n\r\[email protected](guild_ids=[...])\r\nasync def add(ctx, num1: int, num2: int):\r\n ...\r\n\r\n\r\nbot.add_application_command(math)\r\n\r\nbot.run(\"TOKEN\")\r\n", "path": "examples/app_commands/slash_groups.py"}], "after_files": [{"content": "import discord\r\n\r\nbot = discord.Bot()\r\n\r\n# If you use commands.Bot, @bot.slash_command should be used for\r\n# slash commands. You can use @bot.slash_command with discord.Bot as well\r\n\r\nmath = bot.create_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n) # create a slash command group\r\n\r\n\r\[email protected](guild_ids=[...]) # create a slash command\r\nasync def add(ctx, num1: int, num2: int):\r\n \"\"\"Get the sum of 2 integers.\"\"\"\r\n await ctx.respond(f\"The sum of these numbers is **{num1+num2}**\")\r\n\r\n\r\n# another way, creating the class manually\r\n\r\nfrom discord.commands import SlashCommandGroup\r\n\r\nmath = SlashCommandGroup(\"math\", \"Commands related to mathematics.\")\r\n\r\n\r\[email protected](guild_ids=[...])\r\nasync def add(ctx, num1: int, num2: int):\r\n ...\r\n\r\n\r\nbot.add_application_command(math)\r\n\r\nbot.run(\"TOKEN\")\r\n", "path": "examples/app_commands/slash_groups.py"}]}
| 551 | 119 |
gh_patches_debug_12195
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-5124
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HTTP 500 on /oauth/<provider>
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
The server returns HTTP 500 when a request is made to /oauth/<provider>. It is probably because I haven't configured facebook keys in the settings.
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
It shouldn't error out in any case. If something is improperly configured then it should return that message rather than the HTTP 500.
**Stacktrace**
```
INFO:werkzeug:127.0.0.1 - - [17/Jul/2018 04:40:54] "GET /v1/auth/oauth/facebook HTTP/1.1" 500 -
Traceback (most recent call last):
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2309, in __call__
return self.wsgi_app(environ, start_response)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/__init__.py", line 66, in __call__
return self.app(environ, start_response)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2295, in wsgi_app
response = self.handle_exception(e)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1741, in handle_exception
reraise(exc_type, exc_value, tb)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/api/auth.py", line 39, in redirect_uri
provider_class.get_client_id() + '&redirect_uri=' +\
TypeError: must be str, not NoneType
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/auth.py`
Content:
```
1 import base64
2 from flask import request, jsonify, make_response, Blueprint
3 from flask_jwt import current_identity as current_user, jwt_required
4 from sqlalchemy.orm.exc import NoResultFound
5 import requests
6
7 from app import get_settings
8 from app.api.helpers.db import save_to_db
9 from app.api.helpers.files import make_frontend_url
10 from app.api.helpers.mail import send_email_with_action, \
11 send_email_confirmation
12 from app.api.helpers.notification import send_notification_with_action
13
14 from app.api.helpers.utilities import get_serializer, str_generator
15 from app.models.mail import PASSWORD_RESET, PASSWORD_CHANGE, \
16 USER_REGISTER_WITH_PASSWORD
17 from app.models.notification import PASSWORD_CHANGE as PASSWORD_CHANGE_NOTIF
18 from app.models.user import User
19 from app.api.helpers.errors import UnprocessableEntityError, NotFoundError, BadRequestError
20 from app.api.helpers.third_party_auth import GoogleOAuth, FbOAuth, TwitterOAuth, InstagramOAuth
21
22 auth_routes = Blueprint('auth', __name__, url_prefix='/v1/auth')
23
24
25 @auth_routes.route('/oauth/<provider>', methods=['GET'])
26 def redirect_uri(provider):
27 if provider == 'facebook':
28 provider_class = FbOAuth()
29 elif provider == 'google':
30 provider_class = GoogleOAuth()
31 elif provider == 'twitter':
32 provider_class = TwitterOAuth()
33 elif provider == 'instagram':
34 provider_class = InstagramOAuth()
35 else:
36 return make_response(jsonify(
37 message="No support for {}".format(provider)), 404)
38 url = provider_class.get_auth_uri() + '?client_id=' +\
39 provider_class.get_client_id() + '&redirect_uri=' +\
40 provider_class.get_redirect_uri()
41 return make_response(jsonify(url=url), 200)
42
43
44 @auth_routes.route('/oauth/token/<provider>', methods=['GET'])
45 def get_token(provider):
46 if provider == 'facebook':
47 provider_class = FbOAuth()
48 payload = {
49 'grant_type': 'client_credentials',
50 'client_id': provider_class.get_client_id(),
51 'client_secret': provider_class.get_client_secret()
52 }
53 elif provider == 'google':
54 provider_class = GoogleOAuth()
55 payload = {
56 'client_id': provider_class.get_client_id(),
57 'client_secret': provider_class.get_client_secret()
58 }
59 elif provider == 'twitter':
60 provider_class = TwitterOAuth()
61 payload = {
62 'client_id': provider_class.get_client_id(),
63 'client_secret': provider_class.get_client_secret()
64 }
65 elif provider == 'instagram':
66 provider_class = InstagramOAuth()
67 payload = {
68 'client_id': provider_class.get_client_id(),
69 'client_secret': provider_class.get_client_secret()
70 }
71 else:
72 return make_response(jsonify(
73 message="No support for {}".format(provider)), 200)
74 response = requests.post(provider_class.get_token_uri(), params=payload)
75 return make_response(jsonify(token=response.json()), 200)
76
77
78 @auth_routes.route('/verify-email', methods=['POST'])
79 def verify_email():
80 token = base64.b64decode(request.json['data']['token'])
81 s = get_serializer()
82
83 try:
84 data = s.loads(token)
85 except Exception:
86 return BadRequestError({'source': ''}, 'Invalid Token').respond()
87
88 try:
89 user = User.query.filter_by(email=data[0]).one()
90 except Exception:
91 return BadRequestError({'source': ''}, 'Invalid Token').respond()
92 else:
93 user.is_verified = True
94 save_to_db(user)
95 return make_response(jsonify(message="Email Verified"), 200)
96
97
98 @auth_routes.route('/resend-verification-email', methods=['POST'])
99 def resend_verification_email():
100 try:
101 email = request.json['data']['email']
102 except TypeError:
103 return BadRequestError({'source': ''}, 'Bad Request Error').respond()
104
105 try:
106 user = User.query.filter_by(email=email).one()
107 except NoResultFound:
108 return UnprocessableEntityError(
109 {'source': ''}, 'User with email: ' + email + ' not found.').respond()
110 else:
111 serializer = get_serializer()
112 hash_ = str(base64.b64encode(str(serializer.dumps(
113 [user.email, str_generator()])).encode()), 'utf-8')
114 link = make_frontend_url(
115 '/email/verify'.format(id=user.id), {'token': hash_})
116 send_email_with_action(
117 user, USER_REGISTER_WITH_PASSWORD,
118 app_name=get_settings()['app_name'], email=user.email)
119 send_email_confirmation(user.email, link)
120
121 return make_response(jsonify(message="Verification email resent"), 200)
122
123
124 @auth_routes.route('/reset-password', methods=['POST'])
125 def reset_password_post():
126 try:
127 email = request.json['data']['email']
128 except TypeError:
129 return BadRequestError({'source': ''}, 'Bad Request Error').respond()
130
131 try:
132 user = User.query.filter_by(email=email).one()
133 except NoResultFound:
134 return UnprocessableEntityError({'source': ''}, 'User not found').respond()
135 else:
136 link = make_frontend_url('/reset-password', {'token': user.reset_password})
137 send_email_with_action(user, PASSWORD_RESET, app_name=get_settings()['app_name'], link=link)
138
139 return make_response(jsonify(message="Email Sent"), 200)
140
141
142 @auth_routes.route('/reset-password', methods=['PATCH'])
143 def reset_password_patch():
144 token = request.json['data']['token']
145 password = request.json['data']['password']
146
147 try:
148 user = User.query.filter_by(reset_password=token).one()
149 except NoResultFound:
150 return NotFoundError({'source': ''}, 'User Not Found').respond()
151 else:
152 user.password = password
153 save_to_db(user)
154
155 return jsonify({
156 "id": user.id,
157 "email": user.email,
158 "name": user.fullname if user.fullname else None
159 })
160
161
162 @auth_routes.route('/change-password', methods=['POST'])
163 @jwt_required()
164 def change_password():
165 old_password = request.json['data']['old-password']
166 new_password = request.json['data']['new-password']
167
168 try:
169 user = User.query.filter_by(id=current_user.id).one()
170 except NoResultFound:
171 return NotFoundError({'source': ''}, 'User Not Found').respond()
172 else:
173 if user.is_correct_password(old_password):
174
175 user.password = new_password
176 save_to_db(user)
177 send_email_with_action(user, PASSWORD_CHANGE,
178 app_name=get_settings()['app_name'])
179 send_notification_with_action(user, PASSWORD_CHANGE_NOTIF,
180 app_name=get_settings()['app_name'])
181 else:
182 return BadRequestError({'source': ''}, 'Wrong Password').respond()
183
184 return jsonify({
185 "id": user.id,
186 "email": user.email,
187 "name": user.fullname if user.fullname else None,
188 "password-changed": True
189 })
190
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/api/auth.py b/app/api/auth.py
--- a/app/api/auth.py
+++ b/app/api/auth.py
@@ -35,8 +35,14 @@
else:
return make_response(jsonify(
message="No support for {}".format(provider)), 404)
+
+ client_id = provider_class.get_client_id()
+ if not client_id:
+ return make_response(jsonify(
+ message="{} client id is not configured on the server".format(provider)), 404)
+
url = provider_class.get_auth_uri() + '?client_id=' +\
- provider_class.get_client_id() + '&redirect_uri=' +\
+ client_id + '&redirect_uri=' +\
provider_class.get_redirect_uri()
return make_response(jsonify(url=url), 200)
|
{"golden_diff": "diff --git a/app/api/auth.py b/app/api/auth.py\n--- a/app/api/auth.py\n+++ b/app/api/auth.py\n@@ -35,8 +35,14 @@\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 404)\n+\n+ client_id = provider_class.get_client_id()\n+ if not client_id:\n+ return make_response(jsonify(\n+ message=\"{} client id is not configured on the server\".format(provider)), 404)\n+\n url = provider_class.get_auth_uri() + '?client_id=' +\\\n- provider_class.get_client_id() + '&redirect_uri=' +\\\n+ client_id + '&redirect_uri=' +\\\n provider_class.get_redirect_uri()\n return make_response(jsonify(url=url), 200)\n", "issue": "HTTP 500 on /oauth/<provider>\n**Describe the bug**\r\n<!-- A clear and concise description of what the bug is. -->\r\nThe server returns HTTP 500 when a request is made to /oauth/<provider>. It is probably because I haven't configured facebook keys in the settings.\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nIt shouldn't error out in any case. If something is improperly configured then it should return that message rather than the HTTP 500.\r\n\r\n**Stacktrace**\r\n```\r\nINFO:werkzeug:127.0.0.1 - - [17/Jul/2018 04:40:54] \"GET /v1/auth/oauth/facebook HTTP/1.1\" 500 -\r\nTraceback (most recent call last):\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2309, in __call__\r\n return self.wsgi_app(environ, start_response)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/__init__.py\", line 66, in __call__\r\n return self.app(environ, start_response)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2295, in wsgi_app\r\n response = self.handle_exception(e)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1741, in handle_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2292, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1815, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1718, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1813, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1799, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/api/auth.py\", line 39, in redirect_uri\r\n provider_class.get_client_id() + '&redirect_uri=' +\\\r\nTypeError: must be str, not NoneType\r\n```\n", "before_files": [{"content": "import base64\nfrom flask import request, jsonify, make_response, Blueprint\nfrom flask_jwt import current_identity as current_user, jwt_required\nfrom sqlalchemy.orm.exc import NoResultFound\nimport requests\n\nfrom app import get_settings\nfrom app.api.helpers.db import save_to_db\nfrom app.api.helpers.files import make_frontend_url\nfrom app.api.helpers.mail import send_email_with_action, \\\n send_email_confirmation\nfrom app.api.helpers.notification import send_notification_with_action\n\nfrom app.api.helpers.utilities import get_serializer, str_generator\nfrom app.models.mail import PASSWORD_RESET, PASSWORD_CHANGE, \\\n USER_REGISTER_WITH_PASSWORD\nfrom app.models.notification import PASSWORD_CHANGE as PASSWORD_CHANGE_NOTIF\nfrom app.models.user import User\nfrom app.api.helpers.errors import UnprocessableEntityError, NotFoundError, BadRequestError\nfrom app.api.helpers.third_party_auth import GoogleOAuth, FbOAuth, TwitterOAuth, InstagramOAuth\n\nauth_routes = Blueprint('auth', __name__, url_prefix='/v1/auth')\n\n\n@auth_routes.route('/oauth/<provider>', methods=['GET'])\ndef redirect_uri(provider):\n if provider == 'facebook':\n provider_class = FbOAuth()\n elif provider == 'google':\n provider_class = GoogleOAuth()\n elif provider == 'twitter':\n provider_class = TwitterOAuth()\n elif provider == 'instagram':\n provider_class = InstagramOAuth()\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 404)\n url = provider_class.get_auth_uri() + '?client_id=' +\\\n provider_class.get_client_id() + '&redirect_uri=' +\\\n provider_class.get_redirect_uri()\n return make_response(jsonify(url=url), 200)\n\n\n@auth_routes.route('/oauth/token/<provider>', methods=['GET'])\ndef get_token(provider):\n if provider == 'facebook':\n provider_class = FbOAuth()\n payload = {\n 'grant_type': 'client_credentials',\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'google':\n provider_class = GoogleOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'twitter':\n provider_class = TwitterOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'instagram':\n provider_class = InstagramOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 200)\n response = requests.post(provider_class.get_token_uri(), params=payload)\n return make_response(jsonify(token=response.json()), 200)\n\n\n@auth_routes.route('/verify-email', methods=['POST'])\ndef verify_email():\n token = base64.b64decode(request.json['data']['token'])\n s = get_serializer()\n\n try:\n data = s.loads(token)\n except Exception:\n return BadRequestError({'source': ''}, 'Invalid Token').respond()\n\n try:\n user = User.query.filter_by(email=data[0]).one()\n except Exception:\n return BadRequestError({'source': ''}, 'Invalid Token').respond()\n else:\n user.is_verified = True\n save_to_db(user)\n return make_response(jsonify(message=\"Email Verified\"), 200)\n\n\n@auth_routes.route('/resend-verification-email', methods=['POST'])\ndef resend_verification_email():\n try:\n email = request.json['data']['email']\n except TypeError:\n return BadRequestError({'source': ''}, 'Bad Request Error').respond()\n\n try:\n user = User.query.filter_by(email=email).one()\n except NoResultFound:\n return UnprocessableEntityError(\n {'source': ''}, 'User with email: ' + email + ' not found.').respond()\n else:\n serializer = get_serializer()\n hash_ = str(base64.b64encode(str(serializer.dumps(\n [user.email, str_generator()])).encode()), 'utf-8')\n link = make_frontend_url(\n '/email/verify'.format(id=user.id), {'token': hash_})\n send_email_with_action(\n user, USER_REGISTER_WITH_PASSWORD,\n app_name=get_settings()['app_name'], email=user.email)\n send_email_confirmation(user.email, link)\n\n return make_response(jsonify(message=\"Verification email resent\"), 200)\n\n\n@auth_routes.route('/reset-password', methods=['POST'])\ndef reset_password_post():\n try:\n email = request.json['data']['email']\n except TypeError:\n return BadRequestError({'source': ''}, 'Bad Request Error').respond()\n\n try:\n user = User.query.filter_by(email=email).one()\n except NoResultFound:\n return UnprocessableEntityError({'source': ''}, 'User not found').respond()\n else:\n link = make_frontend_url('/reset-password', {'token': user.reset_password})\n send_email_with_action(user, PASSWORD_RESET, app_name=get_settings()['app_name'], link=link)\n\n return make_response(jsonify(message=\"Email Sent\"), 200)\n\n\n@auth_routes.route('/reset-password', methods=['PATCH'])\ndef reset_password_patch():\n token = request.json['data']['token']\n password = request.json['data']['password']\n\n try:\n user = User.query.filter_by(reset_password=token).one()\n except NoResultFound:\n return NotFoundError({'source': ''}, 'User Not Found').respond()\n else:\n user.password = password\n save_to_db(user)\n\n return jsonify({\n \"id\": user.id,\n \"email\": user.email,\n \"name\": user.fullname if user.fullname else None\n })\n\n\n@auth_routes.route('/change-password', methods=['POST'])\n@jwt_required()\ndef change_password():\n old_password = request.json['data']['old-password']\n new_password = request.json['data']['new-password']\n\n try:\n user = User.query.filter_by(id=current_user.id).one()\n except NoResultFound:\n return NotFoundError({'source': ''}, 'User Not Found').respond()\n else:\n if user.is_correct_password(old_password):\n\n user.password = new_password\n save_to_db(user)\n send_email_with_action(user, PASSWORD_CHANGE,\n app_name=get_settings()['app_name'])\n send_notification_with_action(user, PASSWORD_CHANGE_NOTIF,\n app_name=get_settings()['app_name'])\n else:\n return BadRequestError({'source': ''}, 'Wrong Password').respond()\n\n return jsonify({\n \"id\": user.id,\n \"email\": user.email,\n \"name\": user.fullname if user.fullname else None,\n \"password-changed\": True\n })\n", "path": "app/api/auth.py"}], "after_files": [{"content": "import base64\nfrom flask import request, jsonify, make_response, Blueprint\nfrom flask_jwt import current_identity as current_user, jwt_required\nfrom sqlalchemy.orm.exc import NoResultFound\nimport requests\n\nfrom app import get_settings\nfrom app.api.helpers.db import save_to_db\nfrom app.api.helpers.files import make_frontend_url\nfrom app.api.helpers.mail import send_email_with_action, \\\n send_email_confirmation\nfrom app.api.helpers.notification import send_notification_with_action\n\nfrom app.api.helpers.utilities import get_serializer, str_generator\nfrom app.models.mail import PASSWORD_RESET, PASSWORD_CHANGE, \\\n USER_REGISTER_WITH_PASSWORD\nfrom app.models.notification import PASSWORD_CHANGE as PASSWORD_CHANGE_NOTIF\nfrom app.models.user import User\nfrom app.api.helpers.errors import UnprocessableEntityError, NotFoundError, BadRequestError\nfrom app.api.helpers.third_party_auth import GoogleOAuth, FbOAuth, TwitterOAuth, InstagramOAuth\n\nauth_routes = Blueprint('auth', __name__, url_prefix='/v1/auth')\n\n\n@auth_routes.route('/oauth/<provider>', methods=['GET'])\ndef redirect_uri(provider):\n if provider == 'facebook':\n provider_class = FbOAuth()\n elif provider == 'google':\n provider_class = GoogleOAuth()\n elif provider == 'twitter':\n provider_class = TwitterOAuth()\n elif provider == 'instagram':\n provider_class = InstagramOAuth()\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 404)\n\n client_id = provider_class.get_client_id()\n if not client_id:\n return make_response(jsonify(\n message=\"{} client id is not configured on the server\".format(provider)), 404)\n\n url = provider_class.get_auth_uri() + '?client_id=' +\\\n client_id + '&redirect_uri=' +\\\n provider_class.get_redirect_uri()\n return make_response(jsonify(url=url), 200)\n\n\n@auth_routes.route('/oauth/token/<provider>', methods=['GET'])\ndef get_token(provider):\n if provider == 'facebook':\n provider_class = FbOAuth()\n payload = {\n 'grant_type': 'client_credentials',\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'google':\n provider_class = GoogleOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'twitter':\n provider_class = TwitterOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'instagram':\n provider_class = InstagramOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 200)\n response = requests.post(provider_class.get_token_uri(), params=payload)\n return make_response(jsonify(token=response.json()), 200)\n\n\n@auth_routes.route('/verify-email', methods=['POST'])\ndef verify_email():\n token = base64.b64decode(request.json['data']['token'])\n s = get_serializer()\n\n try:\n data = s.loads(token)\n except Exception:\n return BadRequestError({'source': ''}, 'Invalid Token').respond()\n\n try:\n user = User.query.filter_by(email=data[0]).one()\n except Exception:\n return BadRequestError({'source': ''}, 'Invalid Token').respond()\n else:\n user.is_verified = True\n save_to_db(user)\n return make_response(jsonify(message=\"Email Verified\"), 200)\n\n\n@auth_routes.route('/resend-verification-email', methods=['POST'])\ndef resend_verification_email():\n try:\n email = request.json['data']['email']\n except TypeError:\n return BadRequestError({'source': ''}, 'Bad Request Error').respond()\n\n try:\n user = User.query.filter_by(email=email).one()\n except NoResultFound:\n return UnprocessableEntityError(\n {'source': ''}, 'User with email: ' + email + ' not found.').respond()\n else:\n serializer = get_serializer()\n hash_ = str(base64.b64encode(str(serializer.dumps(\n [user.email, str_generator()])).encode()), 'utf-8')\n link = make_frontend_url(\n '/email/verify'.format(id=user.id), {'token': hash_})\n send_email_with_action(\n user, USER_REGISTER_WITH_PASSWORD,\n app_name=get_settings()['app_name'], email=user.email)\n send_email_confirmation(user.email, link)\n\n return make_response(jsonify(message=\"Verification email resent\"), 200)\n\n\n@auth_routes.route('/reset-password', methods=['POST'])\ndef reset_password_post():\n try:\n email = request.json['data']['email']\n except TypeError:\n return BadRequestError({'source': ''}, 'Bad Request Error').respond()\n\n try:\n user = User.query.filter_by(email=email).one()\n except NoResultFound:\n return UnprocessableEntityError({'source': ''}, 'User not found').respond()\n else:\n link = make_frontend_url('/reset-password', {'token': user.reset_password})\n send_email_with_action(user, PASSWORD_RESET, app_name=get_settings()['app_name'], link=link)\n\n return make_response(jsonify(message=\"Email Sent\"), 200)\n\n\n@auth_routes.route('/reset-password', methods=['PATCH'])\ndef reset_password_patch():\n token = request.json['data']['token']\n password = request.json['data']['password']\n\n try:\n user = User.query.filter_by(reset_password=token).one()\n except NoResultFound:\n return NotFoundError({'source': ''}, 'User Not Found').respond()\n else:\n user.password = password\n save_to_db(user)\n\n return jsonify({\n \"id\": user.id,\n \"email\": user.email,\n \"name\": user.fullname if user.fullname else None\n })\n\n\n@auth_routes.route('/change-password', methods=['POST'])\n@jwt_required()\ndef change_password():\n old_password = request.json['data']['old-password']\n new_password = request.json['data']['new-password']\n\n try:\n user = User.query.filter_by(id=current_user.id).one()\n except NoResultFound:\n return NotFoundError({'source': ''}, 'User Not Found').respond()\n else:\n if user.is_correct_password(old_password):\n\n user.password = new_password\n save_to_db(user)\n send_email_with_action(user, PASSWORD_CHANGE,\n app_name=get_settings()['app_name'])\n send_notification_with_action(user, PASSWORD_CHANGE_NOTIF,\n app_name=get_settings()['app_name'])\n else:\n return BadRequestError({'source': ''}, 'Wrong Password').respond()\n\n return jsonify({\n \"id\": user.id,\n \"email\": user.email,\n \"name\": user.fullname if user.fullname else None,\n \"password-changed\": True\n })\n", "path": "app/api/auth.py"}]}
| 3,200 | 179 |
gh_patches_debug_67111
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1619
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Scroll container not expanding to width of container
```
import toga
from toga.style import Pack
from toga.style.pack import COLUMN, ROW
class AFV(toga.App):
def startup(self):
self.main_window = toga.MainWindow(title=self.formal_name)
box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))
self.label_1 = toga.Label('TESTE 1')
self.lineEdit_1 = toga.TextInput()
self.label_2 = toga.Label('TESTE 2')
self.lineEdit_2 = toga.TextInput()
self.label_3 = toga.Label('TESTE 3')
self.lineEdit_3 = toga.TextInput()
self.label_4 = toga.Label('TESTE 4')
self.lineEdit_4 = toga.TextInput()
self.label_5 = toga.Label('TESTE 5')
self.lineEdit_5 = toga.TextInput()
box_test.add(self.label_1, self.lineEdit_1,
self.label_2, self.lineEdit_2,
self.label_3, self.lineEdit_3,
self.label_4, self.lineEdit_4,
self.label_5, self.lineEdit_5)
self.container = toga.ScrollContainer(horizontal=True, vertical=True)
self.container.content = box_test
self.main_window.content = self.container
self.main_window.show()
def main():
return AFV()
```
When using the widget it leaves the widgets in the wrong shape and size on the screen.
The ScrollContainer doesn't make the TextInput widget fill to the bottom of the screen, it measures according to the size of the Label text.

Worked on Briefcase 0.3.9; new screenshot is from Briefcase 0.3.10.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/android/toga_android/widgets/scrollcontainer.py`
Content:
```
1 from travertino.size import at_least
2
3 from toga_android.window import AndroidViewport
4
5 from ..libs.android.view import (
6 Gravity,
7 View__MeasureSpec,
8 View__OnTouchListener
9 )
10 from ..libs.android.widget import (
11 HorizontalScrollView,
12 LinearLayout__LayoutParams,
13 ScrollView
14 )
15 from .base import Widget
16
17
18 class TogaOnTouchListener(View__OnTouchListener):
19 is_scrolling_enabled = True
20
21 def __init__(self):
22 super().__init__()
23
24 def onTouch(self, view, motion_event):
25 if self.is_scrolling_enabled:
26 return view.onTouchEvent(motion_event)
27 else:
28 return True
29
30
31 class ScrollContainer(Widget):
32 vScrollListener = None
33 hScrollView = None
34 hScrollListener = None
35
36 def create(self):
37 vScrollView = ScrollView(self._native_activity)
38 vScrollView_layout_params = LinearLayout__LayoutParams(
39 LinearLayout__LayoutParams.MATCH_PARENT,
40 LinearLayout__LayoutParams.MATCH_PARENT
41 )
42 vScrollView_layout_params.gravity = Gravity.TOP
43 vScrollView.setLayoutParams(vScrollView_layout_params)
44 self.vScrollListener = TogaOnTouchListener()
45 self.vScrollListener.is_scrolling_enabled = self.interface.vertical
46 vScrollView.setOnTouchListener(self.vScrollListener)
47 self.native = vScrollView
48 self.hScrollView = HorizontalScrollView(self._native_activity)
49 hScrollView_layout_params = LinearLayout__LayoutParams(
50 LinearLayout__LayoutParams.MATCH_PARENT,
51 LinearLayout__LayoutParams.MATCH_PARENT
52 )
53 hScrollView_layout_params.gravity = Gravity.LEFT
54 self.hScrollListener = TogaOnTouchListener()
55 self.hScrollListener.is_scrolling_enabled = self.interface.horizontal
56 self.hScrollView.setOnTouchListener(self.hScrollListener)
57 vScrollView.addView(self.hScrollView, hScrollView_layout_params)
58 if self.interface.content is not None:
59 self.set_content(self.interface.content)
60
61 def set_content(self, widget):
62 widget.viewport = AndroidViewport(widget.native)
63 content_view_params = LinearLayout__LayoutParams(
64 LinearLayout__LayoutParams.MATCH_PARENT,
65 LinearLayout__LayoutParams.MATCH_PARENT
66 )
67 if widget.container:
68 widget.container = None
69 if self.interface.content:
70 self.hScrollView.removeAllViews()
71 self.hScrollView.addView(widget.native, content_view_params)
72 for child in widget.interface.children:
73 if child._impl.container:
74 child._impl.container = None
75 child._impl.container = widget
76
77 def set_vertical(self, value):
78 self.vScrollListener.is_scrolling_enabled = value
79
80 def set_horizontal(self, value):
81 self.hScrollListener.is_scrolling_enabled = value
82
83 def set_on_scroll(self, on_scroll):
84 self.interface.factory.not_implemented("ScrollContainer.set_on_scroll()")
85
86 def get_vertical_position(self):
87 self.interface.factory.not_implemented(
88 "ScrollContainer.get_vertical_position()"
89 )
90 return 0
91
92 def set_vertical_position(self, vertical_position):
93 self.interface.factory.not_implemented(
94 "ScrollContainer.set_vertical_position()"
95 )
96
97 def get_horizontal_position(self):
98 self.interface.factory.not_implemented(
99 "ScrollContainer.get_horizontal_position()"
100 )
101 return 0
102
103 def set_horizontal_position(self, horizontal_position):
104 self.interface.factory.not_implemented(
105 "ScrollContainer.set_horizontal_position()"
106 )
107
108 def rehint(self):
109 # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.
110 if not self.native.getLayoutParams():
111 return
112 self.native.measure(
113 View__MeasureSpec.UNSPECIFIED,
114 View__MeasureSpec.UNSPECIFIED,
115 )
116 self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())
117 self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/android/toga_android/widgets/scrollcontainer.py b/src/android/toga_android/widgets/scrollcontainer.py
--- a/src/android/toga_android/widgets/scrollcontainer.py
+++ b/src/android/toga_android/widgets/scrollcontainer.py
@@ -59,7 +59,7 @@
self.set_content(self.interface.content)
def set_content(self, widget):
- widget.viewport = AndroidViewport(widget.native)
+ widget.viewport = AndroidViewport(self.native)
content_view_params = LinearLayout__LayoutParams(
LinearLayout__LayoutParams.MATCH_PARENT,
LinearLayout__LayoutParams.MATCH_PARENT
|
{"golden_diff": "diff --git a/src/android/toga_android/widgets/scrollcontainer.py b/src/android/toga_android/widgets/scrollcontainer.py\n--- a/src/android/toga_android/widgets/scrollcontainer.py\n+++ b/src/android/toga_android/widgets/scrollcontainer.py\n@@ -59,7 +59,7 @@\n self.set_content(self.interface.content)\n \n def set_content(self, widget):\n- widget.viewport = AndroidViewport(widget.native)\n+ widget.viewport = AndroidViewport(self.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n", "issue": "Scroll container not expanding to width of container\n```\r\nimport toga\r\nfrom toga.style import Pack\r\nfrom toga.style.pack import COLUMN, ROW\r\n\r\nclass AFV(toga.App):\r\n\r\n def startup(self):\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n\r\n box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))\r\n self.label_1 = toga.Label('TESTE 1')\r\n self.lineEdit_1 = toga.TextInput()\r\n self.label_2 = toga.Label('TESTE 2')\r\n self.lineEdit_2 = toga.TextInput()\r\n self.label_3 = toga.Label('TESTE 3')\r\n self.lineEdit_3 = toga.TextInput()\r\n self.label_4 = toga.Label('TESTE 4')\r\n self.lineEdit_4 = toga.TextInput()\r\n self.label_5 = toga.Label('TESTE 5')\r\n self.lineEdit_5 = toga.TextInput()\r\n\r\n box_test.add(self.label_1, self.lineEdit_1, \r\n self.label_2, self.lineEdit_2, \r\n self.label_3, self.lineEdit_3, \r\n self.label_4, self.lineEdit_4, \r\n self.label_5, self.lineEdit_5)\r\n self.container = toga.ScrollContainer(horizontal=True, vertical=True)\r\n self.container.content = box_test\r\n\r\n\r\n self.main_window.content = self.container\r\n self.main_window.show()\r\n\r\n\r\ndef main():\r\n return AFV()\r\n```\r\n\r\n\r\nWhen using the widget it leaves the widgets in the wrong shape and size on the screen.\r\nThe ScrollContainer doesn't make the TextInput widget fill to the bottom of the screen, it measures according to the size of the Label text.\r\n\r\n\r\n\r\nWorked on Briefcase 0.3.9; new screenshot is from Briefcase 0.3.10.\n", "before_files": [{"content": "from travertino.size import at_least\n\nfrom toga_android.window import AndroidViewport\n\nfrom ..libs.android.view import (\n Gravity,\n View__MeasureSpec,\n View__OnTouchListener\n)\nfrom ..libs.android.widget import (\n HorizontalScrollView,\n LinearLayout__LayoutParams,\n ScrollView\n)\nfrom .base import Widget\n\n\nclass TogaOnTouchListener(View__OnTouchListener):\n is_scrolling_enabled = True\n\n def __init__(self):\n super().__init__()\n\n def onTouch(self, view, motion_event):\n if self.is_scrolling_enabled:\n return view.onTouchEvent(motion_event)\n else:\n return True\n\n\nclass ScrollContainer(Widget):\n vScrollListener = None\n hScrollView = None\n hScrollListener = None\n\n def create(self):\n vScrollView = ScrollView(self._native_activity)\n vScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n vScrollView_layout_params.gravity = Gravity.TOP\n vScrollView.setLayoutParams(vScrollView_layout_params)\n self.vScrollListener = TogaOnTouchListener()\n self.vScrollListener.is_scrolling_enabled = self.interface.vertical\n vScrollView.setOnTouchListener(self.vScrollListener)\n self.native = vScrollView\n self.hScrollView = HorizontalScrollView(self._native_activity)\n hScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n hScrollView_layout_params.gravity = Gravity.LEFT\n self.hScrollListener = TogaOnTouchListener()\n self.hScrollListener.is_scrolling_enabled = self.interface.horizontal\n self.hScrollView.setOnTouchListener(self.hScrollListener)\n vScrollView.addView(self.hScrollView, hScrollView_layout_params)\n if self.interface.content is not None:\n self.set_content(self.interface.content)\n\n def set_content(self, widget):\n widget.viewport = AndroidViewport(widget.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n if widget.container:\n widget.container = None\n if self.interface.content:\n self.hScrollView.removeAllViews()\n self.hScrollView.addView(widget.native, content_view_params)\n for child in widget.interface.children:\n if child._impl.container:\n child._impl.container = None\n child._impl.container = widget\n\n def set_vertical(self, value):\n self.vScrollListener.is_scrolling_enabled = value\n\n def set_horizontal(self, value):\n self.hScrollListener.is_scrolling_enabled = value\n\n def set_on_scroll(self, on_scroll):\n self.interface.factory.not_implemented(\"ScrollContainer.set_on_scroll()\")\n\n def get_vertical_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_vertical_position()\"\n )\n return 0\n\n def set_vertical_position(self, vertical_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_vertical_position()\"\n )\n\n def get_horizontal_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_horizontal_position()\"\n )\n return 0\n\n def set_horizontal_position(self, horizontal_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_horizontal_position()\"\n )\n\n def rehint(self):\n # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.\n if not self.native.getLayoutParams():\n return\n self.native.measure(\n View__MeasureSpec.UNSPECIFIED,\n View__MeasureSpec.UNSPECIFIED,\n )\n self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())\n self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())\n", "path": "src/android/toga_android/widgets/scrollcontainer.py"}], "after_files": [{"content": "from travertino.size import at_least\n\nfrom toga_android.window import AndroidViewport\n\nfrom ..libs.android.view import (\n Gravity,\n View__MeasureSpec,\n View__OnTouchListener\n)\nfrom ..libs.android.widget import (\n HorizontalScrollView,\n LinearLayout__LayoutParams,\n ScrollView\n)\nfrom .base import Widget\n\n\nclass TogaOnTouchListener(View__OnTouchListener):\n is_scrolling_enabled = True\n\n def __init__(self):\n super().__init__()\n\n def onTouch(self, view, motion_event):\n if self.is_scrolling_enabled:\n return view.onTouchEvent(motion_event)\n else:\n return True\n\n\nclass ScrollContainer(Widget):\n vScrollListener = None\n hScrollView = None\n hScrollListener = None\n\n def create(self):\n vScrollView = ScrollView(self._native_activity)\n vScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n vScrollView_layout_params.gravity = Gravity.TOP\n vScrollView.setLayoutParams(vScrollView_layout_params)\n self.vScrollListener = TogaOnTouchListener()\n self.vScrollListener.is_scrolling_enabled = self.interface.vertical\n vScrollView.setOnTouchListener(self.vScrollListener)\n self.native = vScrollView\n self.hScrollView = HorizontalScrollView(self._native_activity)\n hScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n hScrollView_layout_params.gravity = Gravity.LEFT\n self.hScrollListener = TogaOnTouchListener()\n self.hScrollListener.is_scrolling_enabled = self.interface.horizontal\n self.hScrollView.setOnTouchListener(self.hScrollListener)\n vScrollView.addView(self.hScrollView, hScrollView_layout_params)\n if self.interface.content is not None:\n self.set_content(self.interface.content)\n\n def set_content(self, widget):\n widget.viewport = AndroidViewport(self.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n if widget.container:\n widget.container = None\n if self.interface.content:\n self.hScrollView.removeAllViews()\n self.hScrollView.addView(widget.native, content_view_params)\n for child in widget.interface.children:\n if child._impl.container:\n child._impl.container = None\n child._impl.container = widget\n\n def set_vertical(self, value):\n self.vScrollListener.is_scrolling_enabled = value\n\n def set_horizontal(self, value):\n self.hScrollListener.is_scrolling_enabled = value\n\n def set_on_scroll(self, on_scroll):\n self.interface.factory.not_implemented(\"ScrollContainer.set_on_scroll()\")\n\n def get_vertical_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_vertical_position()\"\n )\n return 0\n\n def set_vertical_position(self, vertical_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_vertical_position()\"\n )\n\n def get_horizontal_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_horizontal_position()\"\n )\n return 0\n\n def set_horizontal_position(self, horizontal_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_horizontal_position()\"\n )\n\n def rehint(self):\n # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.\n if not self.native.getLayoutParams():\n return\n self.native.measure(\n View__MeasureSpec.UNSPECIFIED,\n View__MeasureSpec.UNSPECIFIED,\n )\n self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())\n self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())\n", "path": "src/android/toga_android/widgets/scrollcontainer.py"}]}
| 1,730 | 124 |
gh_patches_debug_17407
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1485
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Refuse account creation when using disposable email addresses.
long term it makes no sense to accept accounts which use an email address which is disposable for managing legit packages. short/near term it opens an easy door for spammers to create accounts on PyPI.
i've implemented blacklisting for account signup and email swaps which use the blacklist at https://github.com/martenson/disposable-email-domains for legacy pypi.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/accounts/forms.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12 import re
13
14 import wtforms
15 import wtforms.fields.html5
16
17 from warehouse import forms, recaptcha
18
19
20 class CredentialsMixin:
21 username = wtforms.StringField(
22 validators=[
23 wtforms.validators.DataRequired(),
24 wtforms.validators.Length(max=50),
25 ],
26 )
27
28 password = wtforms.PasswordField(
29 validators=[
30 wtforms.validators.DataRequired(),
31 ],
32 )
33
34 def __init__(self, *args, user_service, **kwargs):
35 super().__init__(*args, **kwargs)
36 self.user_service = user_service
37
38
39 # XXX: This is a naive password strength validator, but something that can
40 # easily be replicated in JS for client-side feedback.
41 # see: https://github.com/pypa/warehouse/issues/6
42 PWD_MIN_LEN = 8
43 PWD_RE = re.compile(r"""
44 ^ # start
45 (?=.*[A-Z]+.*) # >= 1 upper case
46 (?=.*[a-z]+.*) # >= 1 lower case
47 (?=.*[0-9]+.*) # >= 1 number
48 (?=.*[.*~`\!@#$%^&\*\(\)_+-={}|\[\]\\:";'<>?,\./]+.*) # >= 1 special char
49 .{""" + str(PWD_MIN_LEN) + """,} # >= 8 chars
50 $ # end
51 """, re.X)
52
53
54 class RegistrationForm(CredentialsMixin, forms.Form):
55 password_confirm = wtforms.PasswordField(
56 validators=[
57 wtforms.validators.DataRequired(),
58 wtforms.validators.EqualTo(
59 "password", "Passwords must match."
60 ),
61 ],
62 )
63
64 full_name = wtforms.StringField()
65
66 email = wtforms.fields.html5.EmailField(
67 validators=[
68 wtforms.validators.DataRequired(),
69 wtforms.validators.Email(),
70 ],
71 )
72
73 g_recaptcha_response = wtforms.StringField()
74
75 def __init__(self, *args, recaptcha_service, **kwargs):
76 super().__init__(*args, **kwargs)
77 self.recaptcha_service = recaptcha_service
78
79 def validate_username(self, field):
80 if self.user_service.find_userid(field.data) is not None:
81 raise wtforms.validators.ValidationError(
82 "Username exists.")
83
84 def validate_email(self, field):
85 if self.user_service.find_userid_by_email(field.data) is not None:
86 raise wtforms.validators.ValidationError("Email exists.")
87
88 def validate_g_recaptcha_response(self, field):
89 # do required data validation here due to enabled flag being required
90 if self.recaptcha_service.enabled and not field.data:
91 raise wtforms.validators.ValidationError("Recaptcha error.")
92 try:
93 self.recaptcha_service.verify_response(field.data)
94 except recaptcha.RecaptchaError:
95 # TODO: log error
96 # don't want to provide the user with any detail
97 raise wtforms.validators.ValidationError("Recaptcha error.")
98
99 def validate_password(self, field):
100 if not PWD_RE.match(field.data):
101 raise wtforms.validators.ValidationError(
102 "Password must contain an upper case letter, a lower case "
103 "letter, a number, a special character and be at least "
104 "%d characters in length" % PWD_MIN_LEN
105 )
106
107
108 class LoginForm(CredentialsMixin, forms.Form):
109 def validate_username(self, field):
110 userid = self.user_service.find_userid(field.data)
111
112 if userid is None:
113 raise wtforms.validators.ValidationError("Invalid user.")
114
115 def validate_password(self, field):
116 userid = self.user_service.find_userid(self.username.data)
117 if userid is not None:
118 if not self.user_service.check_password(userid, field.data):
119 raise wtforms.validators.ValidationError("Invalid password.")
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/accounts/forms.py b/warehouse/accounts/forms.py
--- a/warehouse/accounts/forms.py
+++ b/warehouse/accounts/forms.py
@@ -11,6 +11,7 @@
# limitations under the License.
import re
+import disposable_email_domains
import wtforms
import wtforms.fields.html5
@@ -84,6 +85,9 @@
def validate_email(self, field):
if self.user_service.find_userid_by_email(field.data) is not None:
raise wtforms.validators.ValidationError("Email exists.")
+ domain = field.data.split('@')[-1]
+ if domain in disposable_email_domains.blacklist:
+ raise wtforms.validators.ValidationError("Disposable email.")
def validate_g_recaptcha_response(self, field):
# do required data validation here due to enabled flag being required
|
{"golden_diff": "diff --git a/warehouse/accounts/forms.py b/warehouse/accounts/forms.py\n--- a/warehouse/accounts/forms.py\n+++ b/warehouse/accounts/forms.py\n@@ -11,6 +11,7 @@\n # limitations under the License.\n import re\n \n+import disposable_email_domains\n import wtforms\n import wtforms.fields.html5\n \n@@ -84,6 +85,9 @@\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n+ domain = field.data.split('@')[-1]\n+ if domain in disposable_email_domains.blacklist:\n+ raise wtforms.validators.ValidationError(\"Disposable email.\")\n \n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n", "issue": "Refuse account creation when using disposable email addresses.\nlong term it makes no sense to accept accounts which use an email address which is disposable for managing legit packages. short/near term it opens an easy door for spammers to create accounts on PyPI.\n\ni've implemented blacklisting for account signup and email swaps which use the blacklist at https://github.com/martenson/disposable-email-domains for legacy pypi.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport re\n\nimport wtforms\nimport wtforms.fields.html5\n\nfrom warehouse import forms, recaptcha\n\n\nclass CredentialsMixin:\n username = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Length(max=50),\n ],\n )\n\n password = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n ],\n )\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\n# XXX: This is a naive password strength validator, but something that can\n# easily be replicated in JS for client-side feedback.\n# see: https://github.com/pypa/warehouse/issues/6\nPWD_MIN_LEN = 8\nPWD_RE = re.compile(r\"\"\"\n^ # start\n(?=.*[A-Z]+.*) # >= 1 upper case\n(?=.*[a-z]+.*) # >= 1 lower case\n(?=.*[0-9]+.*) # >= 1 number\n(?=.*[.*~`\\!@#$%^&\\*\\(\\)_+-={}|\\[\\]\\\\:\";'<>?,\\./]+.*) # >= 1 special char\n.{\"\"\" + str(PWD_MIN_LEN) + \"\"\",} # >= 8 chars\n$ # end\n\"\"\", re.X)\n\n\nclass RegistrationForm(CredentialsMixin, forms.Form):\n password_confirm = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.EqualTo(\n \"password\", \"Passwords must match.\"\n ),\n ],\n )\n\n full_name = wtforms.StringField()\n\n email = wtforms.fields.html5.EmailField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Email(),\n ],\n )\n\n g_recaptcha_response = wtforms.StringField()\n\n def __init__(self, *args, recaptcha_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.recaptcha_service = recaptcha_service\n\n def validate_username(self, field):\n if self.user_service.find_userid(field.data) is not None:\n raise wtforms.validators.ValidationError(\n \"Username exists.\")\n\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n\n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n if self.recaptcha_service.enabled and not field.data:\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n try:\n self.recaptcha_service.verify_response(field.data)\n except recaptcha.RecaptchaError:\n # TODO: log error\n # don't want to provide the user with any detail\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n\n def validate_password(self, field):\n if not PWD_RE.match(field.data):\n raise wtforms.validators.ValidationError(\n \"Password must contain an upper case letter, a lower case \"\n \"letter, a number, a special character and be at least \"\n \"%d characters in length\" % PWD_MIN_LEN\n )\n\n\nclass LoginForm(CredentialsMixin, forms.Form):\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\"Invalid user.\")\n\n def validate_password(self, field):\n userid = self.user_service.find_userid(self.username.data)\n if userid is not None:\n if not self.user_service.check_password(userid, field.data):\n raise wtforms.validators.ValidationError(\"Invalid password.\")\n", "path": "warehouse/accounts/forms.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport re\n\nimport disposable_email_domains\nimport wtforms\nimport wtforms.fields.html5\n\nfrom warehouse import forms, recaptcha\n\n\nclass CredentialsMixin:\n username = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Length(max=50),\n ],\n )\n\n password = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n ],\n )\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\n# XXX: This is a naive password strength validator, but something that can\n# easily be replicated in JS for client-side feedback.\n# see: https://github.com/pypa/warehouse/issues/6\nPWD_MIN_LEN = 8\nPWD_RE = re.compile(r\"\"\"\n^ # start\n(?=.*[A-Z]+.*) # >= 1 upper case\n(?=.*[a-z]+.*) # >= 1 lower case\n(?=.*[0-9]+.*) # >= 1 number\n(?=.*[.*~`\\!@#$%^&\\*\\(\\)_+-={}|\\[\\]\\\\:\";'<>?,\\./]+.*) # >= 1 special char\n.{\"\"\" + str(PWD_MIN_LEN) + \"\"\",} # >= 8 chars\n$ # end\n\"\"\", re.X)\n\n\nclass RegistrationForm(CredentialsMixin, forms.Form):\n password_confirm = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.EqualTo(\n \"password\", \"Passwords must match.\"\n ),\n ],\n )\n\n full_name = wtforms.StringField()\n\n email = wtforms.fields.html5.EmailField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Email(),\n ],\n )\n\n g_recaptcha_response = wtforms.StringField()\n\n def __init__(self, *args, recaptcha_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.recaptcha_service = recaptcha_service\n\n def validate_username(self, field):\n if self.user_service.find_userid(field.data) is not None:\n raise wtforms.validators.ValidationError(\n \"Username exists.\")\n\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n domain = field.data.split('@')[-1]\n if domain in disposable_email_domains.blacklist:\n raise wtforms.validators.ValidationError(\"Disposable email.\")\n\n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n if self.recaptcha_service.enabled and not field.data:\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n try:\n self.recaptcha_service.verify_response(field.data)\n except recaptcha.RecaptchaError:\n # TODO: log error\n # don't want to provide the user with any detail\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n\n def validate_password(self, field):\n if not PWD_RE.match(field.data):\n raise wtforms.validators.ValidationError(\n \"Password must contain an upper case letter, a lower case \"\n \"letter, a number, a special character and be at least \"\n \"%d characters in length\" % PWD_MIN_LEN\n )\n\n\nclass LoginForm(CredentialsMixin, forms.Form):\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\"Invalid user.\")\n\n def validate_password(self, field):\n userid = self.user_service.find_userid(self.username.data)\n if userid is not None:\n if not self.user_service.check_password(userid, field.data):\n raise wtforms.validators.ValidationError(\"Invalid password.\")\n", "path": "warehouse/accounts/forms.py"}]}
| 1,497 | 176 |
gh_patches_debug_39390
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5881
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.ustvnow: pluginmatcher URL update needed
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
You need to replace the search template in ustvnow.py plugin with the one below.
```
@pluginmatcher(re.compile(
r"https?://(?:www\.)?ustvnow\.com/channel/live/(?P<chname>\w+)",
))
```
What is in the code now - does not work due to changes that have occurred on the site www.ustvnow.com
### Debug log
```text
The log cannot be retrieved because changes must be made to the template of the link it "serves"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/ustvnow.py`
Content:
```
1 """
2 $description US live TV channels. OTT service from USTVnow.
3 $url ustvnow.com
4 $type live
5 $account Required, additional subscription required by some streams
6 """
7
8 import base64
9 import json
10 import logging
11 import re
12 from urllib.parse import urljoin, urlparse
13 from uuid import uuid4
14
15 from streamlink.plugin import Plugin, PluginError, pluginargument, pluginmatcher
16 from streamlink.stream.hls import HLSStream
17 from streamlink.utils.crypto import AES, SHA256, pad, unpad
18
19
20 log = logging.getLogger(__name__)
21
22
23 @pluginmatcher(re.compile(
24 r"https?://(?:www\.)?ustvnow\.com/live/(?P<scode>\w+)/-(?P<id>\d+)",
25 ))
26 @pluginargument(
27 "username",
28 required=True,
29 requires=["password"],
30 metavar="USERNAME",
31 help="Your USTV Now account username",
32 )
33 @pluginargument(
34 "password",
35 required=True,
36 sensitive=True,
37 metavar="PASSWORD",
38 help="Your USTV Now account password",
39 )
40 class USTVNow(Plugin):
41 _main_js_re = re.compile(r"""src=['"](main\..*\.js)['"]""")
42 _enc_key_re = re.compile(r'(?P<key>AES_(?:Key|IV))\s*:\s*"(?P<value>[^"]+)"')
43
44 TENANT_CODE = "ustvnow"
45 _api_url = "https://teleupapi.revlet.net/service/api/v1/"
46 _token_url = _api_url + "get/token"
47 _signin_url = "https://www.ustvnow.com/signin"
48
49 def __init__(self, *args, **kwargs):
50 super().__init__(*args, **kwargs)
51 self._encryption_config = {}
52 self._token = None
53
54 @classmethod
55 def encrypt_data(cls, data, key, iv):
56 rkey = "".join(reversed(key)).encode("utf8")
57 riv = "".join(reversed(iv)).encode("utf8")
58
59 fkey = SHA256.new(rkey).hexdigest()[:32].encode("utf8")
60
61 cipher = AES.new(fkey, AES.MODE_CBC, riv)
62 encrypted = cipher.encrypt(pad(data, 16, "pkcs7"))
63 return base64.b64encode(encrypted)
64
65 @classmethod
66 def decrypt_data(cls, data, key, iv):
67 rkey = "".join(reversed(key)).encode("utf8")
68 riv = "".join(reversed(iv)).encode("utf8")
69
70 fkey = SHA256.new(rkey).hexdigest()[:32].encode("utf8")
71
72 cipher = AES.new(fkey, AES.MODE_CBC, riv)
73 decrypted = cipher.decrypt(base64.b64decode(data))
74 if decrypted:
75 return unpad(decrypted, 16, "pkcs7")
76 else:
77 return decrypted
78
79 def _get_encryption_config(self, url):
80 # find the path to the main.js
81 # load the main.js and extract the config
82 if not self._encryption_config:
83 res = self.session.http.get(url)
84 m = self._main_js_re.search(res.text)
85 main_js_path = m and m.group(1)
86 if main_js_path:
87 res = self.session.http.get(urljoin(url, main_js_path))
88 self._encryption_config = dict(self._enc_key_re.findall(res.text))
89
90 return self._encryption_config.get("AES_Key"), self._encryption_config.get("AES_IV")
91
92 @property
93 def box_id(self):
94 if not self.cache.get("box_id"):
95 self.cache.set("box_id", str(uuid4()))
96 return self.cache.get("box_id")
97
98 def get_token(self):
99 """
100 Get the token for USTVNow
101 :return: a valid token
102 """
103
104 if not self._token:
105 log.debug("Getting new session token")
106 res = self.session.http.get(self._token_url, params={
107 "tenant_code": self.TENANT_CODE,
108 "box_id": self.box_id,
109 "product": self.TENANT_CODE,
110 "device_id": 5,
111 "display_lang_code": "ENG",
112 "device_sub_type": "",
113 "timezone": "UTC",
114 })
115
116 data = res.json()
117 if data["status"]:
118 self._token = data["response"]["sessionId"]
119 log.debug("New token: {}".format(self._token))
120 else:
121 log.error("Token acquisition failed: {details} ({detail})".format(**data["error"]))
122 raise PluginError("could not obtain token")
123
124 return self._token
125
126 def api_request(self, path, data, metadata=None):
127 key, iv = self._get_encryption_config(self._signin_url)
128 post_data = {
129 "data": self.encrypt_data(json.dumps(data).encode("utf8"), key, iv).decode("utf8"),
130 "metadata": self.encrypt_data(json.dumps(metadata).encode("utf8"), key, iv).decode("utf8"),
131 }
132 headers = {"box-id": self.box_id,
133 "session-id": self.get_token(),
134 "tenant-code": self.TENANT_CODE,
135 "content-type": "application/json"}
136 res = self.session.http.post(self._api_url + path, data=json.dumps(post_data), headers=headers).json()
137 data = {k: v and json.loads(self.decrypt_data(v, key, iv)) for k, v in res.items()}
138 return data
139
140 def login(self, username, password):
141 log.debug("Trying to login...")
142 resp = self.api_request(
143 "send",
144 {
145 "login_id": username,
146 "login_key": password,
147 "login_mode": "1",
148 "manufacturer": "123",
149 },
150 {"request": "signin"},
151 )
152
153 return resp["data"]["status"]
154
155 def _get_streams(self):
156 """
157 Finds the streams from ustvnow.com.
158 """
159 if self.login(self.get_option("username"), self.get_option("password")):
160 path = urlparse(self.url).path.strip("/")
161 resp = self.api_request("send", {"path": path}, {"request": "page/stream"})
162 if resp["data"]["status"]:
163 for stream in resp["data"]["response"]["streams"]:
164 if stream["keys"]["licenseKey"]:
165 log.warning("Stream possibly protected by DRM")
166 yield from HLSStream.parse_variant_playlist(self.session, stream["url"]).items()
167 else:
168 log.error("Could not find any streams: {code}: {message}".format(**resp["data"]["error"]))
169 else:
170 log.error("Failed to login, check username and password")
171
172
173 __plugin__ = USTVNow
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/ustvnow.py b/src/streamlink/plugins/ustvnow.py
--- a/src/streamlink/plugins/ustvnow.py
+++ b/src/streamlink/plugins/ustvnow.py
@@ -21,7 +21,7 @@
@pluginmatcher(re.compile(
- r"https?://(?:www\.)?ustvnow\.com/live/(?P<scode>\w+)/-(?P<id>\d+)",
+ r"https?://(?:www\.)?ustvnow\.com/channel/live/(?P<chname>\w+)",
))
@pluginargument(
"username",
@@ -96,11 +96,6 @@
return self.cache.get("box_id")
def get_token(self):
- """
- Get the token for USTVNow
- :return: a valid token
- """
-
if not self._token:
log.debug("Getting new session token")
res = self.session.http.get(self._token_url, params={
@@ -114,13 +109,13 @@
})
data = res.json()
- if data["status"]:
- self._token = data["response"]["sessionId"]
- log.debug("New token: {}".format(self._token))
- else:
+ if not data["status"]:
log.error("Token acquisition failed: {details} ({detail})".format(**data["error"]))
raise PluginError("could not obtain token")
+ self._token = data["response"]["sessionId"]
+ log.debug(f"New token: {self._token}")
+
return self._token
def api_request(self, path, data, metadata=None):
@@ -153,21 +148,20 @@
return resp["data"]["status"]
def _get_streams(self):
- """
- Finds the streams from ustvnow.com.
- """
- if self.login(self.get_option("username"), self.get_option("password")):
- path = urlparse(self.url).path.strip("/")
- resp = self.api_request("send", {"path": path}, {"request": "page/stream"})
- if resp["data"]["status"]:
- for stream in resp["data"]["response"]["streams"]:
- if stream["keys"]["licenseKey"]:
- log.warning("Stream possibly protected by DRM")
- yield from HLSStream.parse_variant_playlist(self.session, stream["url"]).items()
- else:
- log.error("Could not find any streams: {code}: {message}".format(**resp["data"]["error"]))
- else:
+ if not self.login(self.get_option("username"), self.get_option("password")):
log.error("Failed to login, check username and password")
+ return
+
+ path = urlparse(self.url).path.strip("/")
+ resp = self.api_request("send", {"path": path}, {"request": "page/stream"})
+ if not resp["data"]["status"]:
+ log.error("Could not find any streams: {code}: {message}".format(**resp["data"]["error"]))
+ return
+
+ for stream in resp["data"]["response"]["streams"]:
+ if stream["keys"]["licenseKey"]:
+ log.warning("Stream possibly protected by DRM")
+ yield from HLSStream.parse_variant_playlist(self.session, stream["url"]).items()
__plugin__ = USTVNow
|
{"golden_diff": "diff --git a/src/streamlink/plugins/ustvnow.py b/src/streamlink/plugins/ustvnow.py\n--- a/src/streamlink/plugins/ustvnow.py\n+++ b/src/streamlink/plugins/ustvnow.py\n@@ -21,7 +21,7 @@\n \n \n @pluginmatcher(re.compile(\n- r\"https?://(?:www\\.)?ustvnow\\.com/live/(?P<scode>\\w+)/-(?P<id>\\d+)\",\n+ r\"https?://(?:www\\.)?ustvnow\\.com/channel/live/(?P<chname>\\w+)\",\n ))\n @pluginargument(\n \"username\",\n@@ -96,11 +96,6 @@\n return self.cache.get(\"box_id\")\n \n def get_token(self):\n- \"\"\"\n- Get the token for USTVNow\n- :return: a valid token\n- \"\"\"\n-\n if not self._token:\n log.debug(\"Getting new session token\")\n res = self.session.http.get(self._token_url, params={\n@@ -114,13 +109,13 @@\n })\n \n data = res.json()\n- if data[\"status\"]:\n- self._token = data[\"response\"][\"sessionId\"]\n- log.debug(\"New token: {}\".format(self._token))\n- else:\n+ if not data[\"status\"]:\n log.error(\"Token acquisition failed: {details} ({detail})\".format(**data[\"error\"]))\n raise PluginError(\"could not obtain token\")\n \n+ self._token = data[\"response\"][\"sessionId\"]\n+ log.debug(f\"New token: {self._token}\")\n+\n return self._token\n \n def api_request(self, path, data, metadata=None):\n@@ -153,21 +148,20 @@\n return resp[\"data\"][\"status\"]\n \n def _get_streams(self):\n- \"\"\"\n- Finds the streams from ustvnow.com.\n- \"\"\"\n- if self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n- path = urlparse(self.url).path.strip(\"/\")\n- resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n- if resp[\"data\"][\"status\"]:\n- for stream in resp[\"data\"][\"response\"][\"streams\"]:\n- if stream[\"keys\"][\"licenseKey\"]:\n- log.warning(\"Stream possibly protected by DRM\")\n- yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n- else:\n- log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n- else:\n+ if not self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n log.error(\"Failed to login, check username and password\")\n+ return\n+\n+ path = urlparse(self.url).path.strip(\"/\")\n+ resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n+ if not resp[\"data\"][\"status\"]:\n+ log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n+ return\n+\n+ for stream in resp[\"data\"][\"response\"][\"streams\"]:\n+ if stream[\"keys\"][\"licenseKey\"]:\n+ log.warning(\"Stream possibly protected by DRM\")\n+ yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n \n \n __plugin__ = USTVNow\n", "issue": "plugins.ustvnow: pluginmatcher URL update needed\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest build from the master branch\n\n### Description\n\nYou need to replace the search template in ustvnow.py plugin with the one below.\r\n\r\n```\r\n@pluginmatcher(re.compile( \r\n r\"https?://(?:www\\.)?ustvnow\\.com/channel/live/(?P<chname>\\w+)\", \r\n))\r\n```\r\nWhat is in the code now - does not work due to changes that have occurred on the site www.ustvnow.com\n\n### Debug log\n\n```text\nThe log cannot be retrieved because changes must be made to the template of the link it \"serves\"\n```\n\n", "before_files": [{"content": "\"\"\"\n$description US live TV channels. OTT service from USTVnow.\n$url ustvnow.com\n$type live\n$account Required, additional subscription required by some streams\n\"\"\"\n\nimport base64\nimport json\nimport logging\nimport re\nfrom urllib.parse import urljoin, urlparse\nfrom uuid import uuid4\n\nfrom streamlink.plugin import Plugin, PluginError, pluginargument, pluginmatcher\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.crypto import AES, SHA256, pad, unpad\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?ustvnow\\.com/live/(?P<scode>\\w+)/-(?P<id>\\d+)\",\n))\n@pluginargument(\n \"username\",\n required=True,\n requires=[\"password\"],\n metavar=\"USERNAME\",\n help=\"Your USTV Now account username\",\n)\n@pluginargument(\n \"password\",\n required=True,\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"Your USTV Now account password\",\n)\nclass USTVNow(Plugin):\n _main_js_re = re.compile(r\"\"\"src=['\"](main\\..*\\.js)['\"]\"\"\")\n _enc_key_re = re.compile(r'(?P<key>AES_(?:Key|IV))\\s*:\\s*\"(?P<value>[^\"]+)\"')\n\n TENANT_CODE = \"ustvnow\"\n _api_url = \"https://teleupapi.revlet.net/service/api/v1/\"\n _token_url = _api_url + \"get/token\"\n _signin_url = \"https://www.ustvnow.com/signin\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self._encryption_config = {}\n self._token = None\n\n @classmethod\n def encrypt_data(cls, data, key, iv):\n rkey = \"\".join(reversed(key)).encode(\"utf8\")\n riv = \"\".join(reversed(iv)).encode(\"utf8\")\n\n fkey = SHA256.new(rkey).hexdigest()[:32].encode(\"utf8\")\n\n cipher = AES.new(fkey, AES.MODE_CBC, riv)\n encrypted = cipher.encrypt(pad(data, 16, \"pkcs7\"))\n return base64.b64encode(encrypted)\n\n @classmethod\n def decrypt_data(cls, data, key, iv):\n rkey = \"\".join(reversed(key)).encode(\"utf8\")\n riv = \"\".join(reversed(iv)).encode(\"utf8\")\n\n fkey = SHA256.new(rkey).hexdigest()[:32].encode(\"utf8\")\n\n cipher = AES.new(fkey, AES.MODE_CBC, riv)\n decrypted = cipher.decrypt(base64.b64decode(data))\n if decrypted:\n return unpad(decrypted, 16, \"pkcs7\")\n else:\n return decrypted\n\n def _get_encryption_config(self, url):\n # find the path to the main.js\n # load the main.js and extract the config\n if not self._encryption_config:\n res = self.session.http.get(url)\n m = self._main_js_re.search(res.text)\n main_js_path = m and m.group(1)\n if main_js_path:\n res = self.session.http.get(urljoin(url, main_js_path))\n self._encryption_config = dict(self._enc_key_re.findall(res.text))\n\n return self._encryption_config.get(\"AES_Key\"), self._encryption_config.get(\"AES_IV\")\n\n @property\n def box_id(self):\n if not self.cache.get(\"box_id\"):\n self.cache.set(\"box_id\", str(uuid4()))\n return self.cache.get(\"box_id\")\n\n def get_token(self):\n \"\"\"\n Get the token for USTVNow\n :return: a valid token\n \"\"\"\n\n if not self._token:\n log.debug(\"Getting new session token\")\n res = self.session.http.get(self._token_url, params={\n \"tenant_code\": self.TENANT_CODE,\n \"box_id\": self.box_id,\n \"product\": self.TENANT_CODE,\n \"device_id\": 5,\n \"display_lang_code\": \"ENG\",\n \"device_sub_type\": \"\",\n \"timezone\": \"UTC\",\n })\n\n data = res.json()\n if data[\"status\"]:\n self._token = data[\"response\"][\"sessionId\"]\n log.debug(\"New token: {}\".format(self._token))\n else:\n log.error(\"Token acquisition failed: {details} ({detail})\".format(**data[\"error\"]))\n raise PluginError(\"could not obtain token\")\n\n return self._token\n\n def api_request(self, path, data, metadata=None):\n key, iv = self._get_encryption_config(self._signin_url)\n post_data = {\n \"data\": self.encrypt_data(json.dumps(data).encode(\"utf8\"), key, iv).decode(\"utf8\"),\n \"metadata\": self.encrypt_data(json.dumps(metadata).encode(\"utf8\"), key, iv).decode(\"utf8\"),\n }\n headers = {\"box-id\": self.box_id,\n \"session-id\": self.get_token(),\n \"tenant-code\": self.TENANT_CODE,\n \"content-type\": \"application/json\"}\n res = self.session.http.post(self._api_url + path, data=json.dumps(post_data), headers=headers).json()\n data = {k: v and json.loads(self.decrypt_data(v, key, iv)) for k, v in res.items()}\n return data\n\n def login(self, username, password):\n log.debug(\"Trying to login...\")\n resp = self.api_request(\n \"send\",\n {\n \"login_id\": username,\n \"login_key\": password,\n \"login_mode\": \"1\",\n \"manufacturer\": \"123\",\n },\n {\"request\": \"signin\"},\n )\n\n return resp[\"data\"][\"status\"]\n\n def _get_streams(self):\n \"\"\"\n Finds the streams from ustvnow.com.\n \"\"\"\n if self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n path = urlparse(self.url).path.strip(\"/\")\n resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n if resp[\"data\"][\"status\"]:\n for stream in resp[\"data\"][\"response\"][\"streams\"]:\n if stream[\"keys\"][\"licenseKey\"]:\n log.warning(\"Stream possibly protected by DRM\")\n yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n else:\n log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n else:\n log.error(\"Failed to login, check username and password\")\n\n\n__plugin__ = USTVNow\n", "path": "src/streamlink/plugins/ustvnow.py"}], "after_files": [{"content": "\"\"\"\n$description US live TV channels. OTT service from USTVnow.\n$url ustvnow.com\n$type live\n$account Required, additional subscription required by some streams\n\"\"\"\n\nimport base64\nimport json\nimport logging\nimport re\nfrom urllib.parse import urljoin, urlparse\nfrom uuid import uuid4\n\nfrom streamlink.plugin import Plugin, PluginError, pluginargument, pluginmatcher\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.crypto import AES, SHA256, pad, unpad\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?ustvnow\\.com/channel/live/(?P<chname>\\w+)\",\n))\n@pluginargument(\n \"username\",\n required=True,\n requires=[\"password\"],\n metavar=\"USERNAME\",\n help=\"Your USTV Now account username\",\n)\n@pluginargument(\n \"password\",\n required=True,\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"Your USTV Now account password\",\n)\nclass USTVNow(Plugin):\n _main_js_re = re.compile(r\"\"\"src=['\"](main\\..*\\.js)['\"]\"\"\")\n _enc_key_re = re.compile(r'(?P<key>AES_(?:Key|IV))\\s*:\\s*\"(?P<value>[^\"]+)\"')\n\n TENANT_CODE = \"ustvnow\"\n _api_url = \"https://teleupapi.revlet.net/service/api/v1/\"\n _token_url = _api_url + \"get/token\"\n _signin_url = \"https://www.ustvnow.com/signin\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self._encryption_config = {}\n self._token = None\n\n @classmethod\n def encrypt_data(cls, data, key, iv):\n rkey = \"\".join(reversed(key)).encode(\"utf8\")\n riv = \"\".join(reversed(iv)).encode(\"utf8\")\n\n fkey = SHA256.new(rkey).hexdigest()[:32].encode(\"utf8\")\n\n cipher = AES.new(fkey, AES.MODE_CBC, riv)\n encrypted = cipher.encrypt(pad(data, 16, \"pkcs7\"))\n return base64.b64encode(encrypted)\n\n @classmethod\n def decrypt_data(cls, data, key, iv):\n rkey = \"\".join(reversed(key)).encode(\"utf8\")\n riv = \"\".join(reversed(iv)).encode(\"utf8\")\n\n fkey = SHA256.new(rkey).hexdigest()[:32].encode(\"utf8\")\n\n cipher = AES.new(fkey, AES.MODE_CBC, riv)\n decrypted = cipher.decrypt(base64.b64decode(data))\n if decrypted:\n return unpad(decrypted, 16, \"pkcs7\")\n else:\n return decrypted\n\n def _get_encryption_config(self, url):\n # find the path to the main.js\n # load the main.js and extract the config\n if not self._encryption_config:\n res = self.session.http.get(url)\n m = self._main_js_re.search(res.text)\n main_js_path = m and m.group(1)\n if main_js_path:\n res = self.session.http.get(urljoin(url, main_js_path))\n self._encryption_config = dict(self._enc_key_re.findall(res.text))\n\n return self._encryption_config.get(\"AES_Key\"), self._encryption_config.get(\"AES_IV\")\n\n @property\n def box_id(self):\n if not self.cache.get(\"box_id\"):\n self.cache.set(\"box_id\", str(uuid4()))\n return self.cache.get(\"box_id\")\n\n def get_token(self):\n if not self._token:\n log.debug(\"Getting new session token\")\n res = self.session.http.get(self._token_url, params={\n \"tenant_code\": self.TENANT_CODE,\n \"box_id\": self.box_id,\n \"product\": self.TENANT_CODE,\n \"device_id\": 5,\n \"display_lang_code\": \"ENG\",\n \"device_sub_type\": \"\",\n \"timezone\": \"UTC\",\n })\n\n data = res.json()\n if not data[\"status\"]:\n log.error(\"Token acquisition failed: {details} ({detail})\".format(**data[\"error\"]))\n raise PluginError(\"could not obtain token\")\n\n self._token = data[\"response\"][\"sessionId\"]\n log.debug(f\"New token: {self._token}\")\n\n return self._token\n\n def api_request(self, path, data, metadata=None):\n key, iv = self._get_encryption_config(self._signin_url)\n post_data = {\n \"data\": self.encrypt_data(json.dumps(data).encode(\"utf8\"), key, iv).decode(\"utf8\"),\n \"metadata\": self.encrypt_data(json.dumps(metadata).encode(\"utf8\"), key, iv).decode(\"utf8\"),\n }\n headers = {\"box-id\": self.box_id,\n \"session-id\": self.get_token(),\n \"tenant-code\": self.TENANT_CODE,\n \"content-type\": \"application/json\"}\n res = self.session.http.post(self._api_url + path, data=json.dumps(post_data), headers=headers).json()\n data = {k: v and json.loads(self.decrypt_data(v, key, iv)) for k, v in res.items()}\n return data\n\n def login(self, username, password):\n log.debug(\"Trying to login...\")\n resp = self.api_request(\n \"send\",\n {\n \"login_id\": username,\n \"login_key\": password,\n \"login_mode\": \"1\",\n \"manufacturer\": \"123\",\n },\n {\"request\": \"signin\"},\n )\n\n return resp[\"data\"][\"status\"]\n\n def _get_streams(self):\n if not self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n log.error(\"Failed to login, check username and password\")\n return\n\n path = urlparse(self.url).path.strip(\"/\")\n resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n if not resp[\"data\"][\"status\"]:\n log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n return\n\n for stream in resp[\"data\"][\"response\"][\"streams\"]:\n if stream[\"keys\"][\"licenseKey\"]:\n log.warning(\"Stream possibly protected by DRM\")\n yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n\n\n__plugin__ = USTVNow\n", "path": "src/streamlink/plugins/ustvnow.py"}]}
| 2,410 | 736 |
gh_patches_debug_12917
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-724
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'AsyncTransport' has no attribute '_start_event_processor'
**Describe the bug**: ...
After upgrading to `elastic-apm==5.4.1` I now get an error when Celery starts:
```
<function _register_worker_signals.<locals>.worker_startup at 0x7feae4beb620> raised: AttributeError("'AsyncTransport' object has no attribute '_start_event_processor'",)
Traceback (most recent call last):
File "/venv/lib/python3.6/site-packages/celery/utils/dispatch/signal.py", line 288, in send
response = receiver(signal=self, sender=sender, **named)
File "/venv/1.37.1/lib/python3.6/site-packages/elasticapm/contrib/celery/__init__.py", line 80, in worker_startup
client._transport._start_event_processor()
AttributeError: 'AsyncTransport' object has no attribute '_start_event_processor'
```
**Environment (please complete the following information)**
- OS: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-centos-7.7.1908-Core 2020-02-18 16:24:31
- Python version: Python 3.6.8
- Framework and version:
celery 4.4.0
Django 3.0.3
- APM Server version: ?
- Agent version: 5.4.1
I see the same error mentioned in issue #704, but I don't seem to have an issue with restarting Celery workers.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/contrib/celery/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31
32 from celery import signals
33
34 from elasticapm.utils import get_name_from_func
35
36
37 class CeleryFilter(object):
38 def filter(self, record):
39 if record.funcName in ("_log_error",):
40 return 0
41 else:
42 return 1
43
44
45 def register_exception_tracking(client):
46 dispatch_uid = "elasticapm-exc-tracking"
47
48 def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):
49 client.capture_exception(
50 extra={"task_id": task_id, "task": sender, "args": args, "kwargs": kwargs}, handled=False
51 )
52
53 signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)
54 signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)
55 _register_worker_signals(client)
56
57
58 def register_instrumentation(client):
59 def begin_transaction(*args, **kwargs):
60 client.begin_transaction("celery")
61
62 def end_transaction(task_id, task, *args, **kwargs):
63 name = get_name_from_func(task)
64 client.end_transaction(name, kwargs.get("state", "None"))
65
66 dispatch_uid = "elasticapm-tracing-%s"
67
68 # unregister any existing clients
69 signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % "prerun")
70 signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % "postrun")
71
72 # register for this client
73 signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % "prerun", weak=False)
74 signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % "postrun")
75 _register_worker_signals(client)
76
77
78 def _register_worker_signals(client):
79 def worker_startup(*args, **kwargs):
80 client._transport._start_event_processor()
81
82 def worker_shutdown(*args, **kwargs):
83 client.close()
84
85 def connect_worker_process_init(*args, **kwargs):
86 signals.worker_process_init.connect(worker_startup, dispatch_uid="elasticapm-start-worker", weak=False)
87 signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid="elasticapm-shutdown-worker", weak=False)
88
89 signals.worker_init.connect(
90 connect_worker_process_init, dispatch_uid="elasticapm-connect-start-threads", weak=False
91 )
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/contrib/celery/__init__.py b/elasticapm/contrib/celery/__init__.py
--- a/elasticapm/contrib/celery/__init__.py
+++ b/elasticapm/contrib/celery/__init__.py
@@ -76,14 +76,10 @@
def _register_worker_signals(client):
- def worker_startup(*args, **kwargs):
- client._transport._start_event_processor()
-
def worker_shutdown(*args, **kwargs):
client.close()
def connect_worker_process_init(*args, **kwargs):
- signals.worker_process_init.connect(worker_startup, dispatch_uid="elasticapm-start-worker", weak=False)
signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid="elasticapm-shutdown-worker", weak=False)
signals.worker_init.connect(
|
{"golden_diff": "diff --git a/elasticapm/contrib/celery/__init__.py b/elasticapm/contrib/celery/__init__.py\n--- a/elasticapm/contrib/celery/__init__.py\n+++ b/elasticapm/contrib/celery/__init__.py\n@@ -76,14 +76,10 @@\n \n \n def _register_worker_signals(client):\n- def worker_startup(*args, **kwargs):\n- client._transport._start_event_processor()\n-\n def worker_shutdown(*args, **kwargs):\n client.close()\n \n def connect_worker_process_init(*args, **kwargs):\n- signals.worker_process_init.connect(worker_startup, dispatch_uid=\"elasticapm-start-worker\", weak=False)\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n \n signals.worker_init.connect(\n", "issue": "'AsyncTransport' has no attribute '_start_event_processor'\n**Describe the bug**: ...\r\n\r\nAfter upgrading to `elastic-apm==5.4.1` I now get an error when Celery starts:\r\n\r\n```\r\n<function _register_worker_signals.<locals>.worker_startup at 0x7feae4beb620> raised: AttributeError(\"'AsyncTransport' object has no attribute '_start_event_processor'\",)\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/celery/utils/dispatch/signal.py\", line 288, in send\r\n response = receiver(signal=self, sender=sender, **named)\r\n File \"/venv/1.37.1/lib/python3.6/site-packages/elasticapm/contrib/celery/__init__.py\", line 80, in worker_startup\r\n client._transport._start_event_processor()\r\nAttributeError: 'AsyncTransport' object has no attribute '_start_event_processor' \r\n```\r\n\r\n**Environment (please complete the following information)**\r\n- OS: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-centos-7.7.1908-Core 2020-02-18 16:24:31\r\n- Python version: Python 3.6.8\r\n- Framework and version: \r\n celery 4.4.0\r\n Django 3.0.3\r\n- APM Server version: ?\r\n- Agent version: 5.4.1\r\n\r\nI see the same error mentioned in issue #704, but I don't seem to have an issue with restarting Celery workers.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom celery import signals\n\nfrom elasticapm.utils import get_name_from_func\n\n\nclass CeleryFilter(object):\n def filter(self, record):\n if record.funcName in (\"_log_error\",):\n return 0\n else:\n return 1\n\n\ndef register_exception_tracking(client):\n dispatch_uid = \"elasticapm-exc-tracking\"\n\n def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):\n client.capture_exception(\n extra={\"task_id\": task_id, \"task\": sender, \"args\": args, \"kwargs\": kwargs}, handled=False\n )\n\n signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)\n signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)\n _register_worker_signals(client)\n\n\ndef register_instrumentation(client):\n def begin_transaction(*args, **kwargs):\n client.begin_transaction(\"celery\")\n\n def end_transaction(task_id, task, *args, **kwargs):\n name = get_name_from_func(task)\n client.end_transaction(name, kwargs.get(\"state\", \"None\"))\n\n dispatch_uid = \"elasticapm-tracing-%s\"\n\n # unregister any existing clients\n signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\")\n signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % \"postrun\")\n\n # register for this client\n signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\", weak=False)\n signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % \"postrun\")\n _register_worker_signals(client)\n\n\ndef _register_worker_signals(client):\n def worker_startup(*args, **kwargs):\n client._transport._start_event_processor()\n\n def worker_shutdown(*args, **kwargs):\n client.close()\n\n def connect_worker_process_init(*args, **kwargs):\n signals.worker_process_init.connect(worker_startup, dispatch_uid=\"elasticapm-start-worker\", weak=False)\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n\n signals.worker_init.connect(\n connect_worker_process_init, dispatch_uid=\"elasticapm-connect-start-threads\", weak=False\n )\n", "path": "elasticapm/contrib/celery/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom celery import signals\n\nfrom elasticapm.utils import get_name_from_func\n\n\nclass CeleryFilter(object):\n def filter(self, record):\n if record.funcName in (\"_log_error\",):\n return 0\n else:\n return 1\n\n\ndef register_exception_tracking(client):\n dispatch_uid = \"elasticapm-exc-tracking\"\n\n def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):\n client.capture_exception(\n extra={\"task_id\": task_id, \"task\": sender, \"args\": args, \"kwargs\": kwargs}, handled=False\n )\n\n signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)\n signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)\n _register_worker_signals(client)\n\n\ndef register_instrumentation(client):\n def begin_transaction(*args, **kwargs):\n client.begin_transaction(\"celery\")\n\n def end_transaction(task_id, task, *args, **kwargs):\n name = get_name_from_func(task)\n client.end_transaction(name, kwargs.get(\"state\", \"None\"))\n\n dispatch_uid = \"elasticapm-tracing-%s\"\n\n # unregister any existing clients\n signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\")\n signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % \"postrun\")\n\n # register for this client\n signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\", weak=False)\n signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % \"postrun\")\n _register_worker_signals(client)\n\n\ndef _register_worker_signals(client):\n def worker_shutdown(*args, **kwargs):\n client.close()\n\n def connect_worker_process_init(*args, **kwargs):\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n\n signals.worker_init.connect(\n connect_worker_process_init, dispatch_uid=\"elasticapm-connect-start-threads\", weak=False\n )\n", "path": "elasticapm/contrib/celery/__init__.py"}]}
| 1,654 | 186 |
gh_patches_debug_9210
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-3237
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DictDataset throws an internal error only in Python 3.
The following code throws an internal error only in Python 3 environment with the latest version of Chainer. (3.0.0b1, 8bcac6f)
```py
from chainer.datasets import DictDataset
def main():
a = range(10)
b = range(10, 20)
dataset = DictDataset(x=a, y=b)
print(dataset[0:5])
if __name__ == '__main__':
main()
```
In Python 3.6.1,
```sh
$ python --version
Python 3.6.1
$ python poc.py
Traceback (most recent call last):
File "poc.py", line 12, in <module>
main()
File "poc.py", line 8, in main
print(dataset[0:5])
File "/home/igarashi/projects/chainer/chainer/datasets/dict_dataset.py", line 34, in __getitem__
length = len(six.itervalues(batches).next())
AttributeError: 'dict_valueiterator' object has no attribute 'next'
```
In Python 2.7.13,
```sh
$ python --version
Python 2.7.13
$ python poc.py
[{'y': 10, 'x': 0}, {'y': 11, 'x': 1}, {'y': 12, 'x': 2}, {'y': 13, 'x': 3}, {'y': 14, 'x': 4}]
```
It is because an instance of `six.Iterator` doesn't have `next()` method in the Python 3 environment.
[Reference](http://pythonhosted.org/six/#six.Iterator)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/datasets/dict_dataset.py`
Content:
```
1 import six
2
3
4 class DictDataset(object):
5
6 """Dataset of a dictionary of datasets.
7
8 It combines multiple datasets into one dataset. Each example is represented
9 by a dictionary mapping a key to an example of the corresponding dataset.
10
11 Args:
12 datasets: Underlying datasets. The keys are used as the keys of each
13 example. All datasets must have the same length.
14
15 """
16
17 def __init__(self, **datasets):
18 if not datasets:
19 raise ValueError('no datasets are given')
20 length = None
21 for key, dataset in six.iteritems(datasets):
22 if length is None:
23 length = len(dataset)
24 elif length != len(dataset):
25 raise ValueError(
26 'dataset length conflicts at "{}"'.format(key))
27 self._datasets = datasets
28 self._length = length
29
30 def __getitem__(self, index):
31 batches = {key: dataset[index]
32 for key, dataset in six.iteritems(self._datasets)}
33 if isinstance(index, slice):
34 length = len(six.itervalues(batches).next())
35 return [{key: batch[i] for key, batch in six.iteritems(batches)}
36 for i in six.moves.range(length)]
37 else:
38 return batches
39
40 def __len__(self):
41 return self._length
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/datasets/dict_dataset.py b/chainer/datasets/dict_dataset.py
--- a/chainer/datasets/dict_dataset.py
+++ b/chainer/datasets/dict_dataset.py
@@ -31,7 +31,7 @@
batches = {key: dataset[index]
for key, dataset in six.iteritems(self._datasets)}
if isinstance(index, slice):
- length = len(six.itervalues(batches).next())
+ length = len(six.next(six.itervalues(batches)))
return [{key: batch[i] for key, batch in six.iteritems(batches)}
for i in six.moves.range(length)]
else:
|
{"golden_diff": "diff --git a/chainer/datasets/dict_dataset.py b/chainer/datasets/dict_dataset.py\n--- a/chainer/datasets/dict_dataset.py\n+++ b/chainer/datasets/dict_dataset.py\n@@ -31,7 +31,7 @@\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n- length = len(six.itervalues(batches).next())\n+ length = len(six.next(six.itervalues(batches)))\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n", "issue": "DictDataset throws an internal error only in Python 3.\nThe following code throws an internal error only in Python 3 environment with the latest version of Chainer. (3.0.0b1, 8bcac6f)\r\n```py\r\nfrom chainer.datasets import DictDataset\r\n\r\ndef main():\r\n a = range(10)\r\n b = range(10, 20)\r\n dataset = DictDataset(x=a, y=b)\r\n print(dataset[0:5])\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n\r\nIn Python 3.6.1,\r\n```sh\r\n$ python --version\r\n Python 3.6.1\r\n$ python poc.py\r\n Traceback (most recent call last):\r\n File \"poc.py\", line 12, in <module>\r\n main()\r\n File \"poc.py\", line 8, in main\r\n print(dataset[0:5])\r\n File \"/home/igarashi/projects/chainer/chainer/datasets/dict_dataset.py\", line 34, in __getitem__\r\n length = len(six.itervalues(batches).next())\r\nAttributeError: 'dict_valueiterator' object has no attribute 'next'\r\n```\r\n\r\nIn Python 2.7.13, \r\n```sh\r\n$ python --version\r\n Python 2.7.13\r\n$ python poc.py\r\n [{'y': 10, 'x': 0}, {'y': 11, 'x': 1}, {'y': 12, 'x': 2}, {'y': 13, 'x': 3}, {'y': 14, 'x': 4}]\r\n```\r\n\r\nIt is because an instance of `six.Iterator` doesn't have `next()` method in the Python 3 environment.\r\n[Reference](http://pythonhosted.org/six/#six.Iterator)\r\n\n", "before_files": [{"content": "import six\n\n\nclass DictDataset(object):\n\n \"\"\"Dataset of a dictionary of datasets.\n\n It combines multiple datasets into one dataset. Each example is represented\n by a dictionary mapping a key to an example of the corresponding dataset.\n\n Args:\n datasets: Underlying datasets. The keys are used as the keys of each\n example. All datasets must have the same length.\n\n \"\"\"\n\n def __init__(self, **datasets):\n if not datasets:\n raise ValueError('no datasets are given')\n length = None\n for key, dataset in six.iteritems(datasets):\n if length is None:\n length = len(dataset)\n elif length != len(dataset):\n raise ValueError(\n 'dataset length conflicts at \"{}\"'.format(key))\n self._datasets = datasets\n self._length = length\n\n def __getitem__(self, index):\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n length = len(six.itervalues(batches).next())\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n return batches\n\n def __len__(self):\n return self._length\n", "path": "chainer/datasets/dict_dataset.py"}], "after_files": [{"content": "import six\n\n\nclass DictDataset(object):\n\n \"\"\"Dataset of a dictionary of datasets.\n\n It combines multiple datasets into one dataset. Each example is represented\n by a dictionary mapping a key to an example of the corresponding dataset.\n\n Args:\n datasets: Underlying datasets. The keys are used as the keys of each\n example. All datasets must have the same length.\n\n \"\"\"\n\n def __init__(self, **datasets):\n if not datasets:\n raise ValueError('no datasets are given')\n length = None\n for key, dataset in six.iteritems(datasets):\n if length is None:\n length = len(dataset)\n elif length != len(dataset):\n raise ValueError(\n 'dataset length conflicts at \"{}\"'.format(key))\n self._datasets = datasets\n self._length = length\n\n def __getitem__(self, index):\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n length = len(six.next(six.itervalues(batches)))\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n return batches\n\n def __len__(self):\n return self._length\n", "path": "chainer/datasets/dict_dataset.py"}]}
| 1,007 | 145 |
gh_patches_debug_35186
|
rasdani/github-patches
|
git_diff
|
vnpy__vnpy-1795
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug:rqdata.py 中 RqdataClient 类的 to_rq_symbol 方法对连续和指数合约转换有问题
## 环境
* 操作系统: 如Windows 10
* Anaconda版本: Anaconda 18.12 Python 3.7 64位
* vn.py版本: v2.0.3
## Issue类型
三选一:Bug
## 预期程序行为
正确将合约名转换至rqdata中的合约名
## 实际程序行为
错误的将郑商所的合约连续和指数合约转换,例如将AP888会转换为AP2888,AP99会转换至AP199导致无法下载到数据。
## 重现步骤
在回测模块中下载AP88数据即可。
针对Bug类型Issue,请提供具体重现步骤以及报错截图
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vnpy/trader/rqdata.py`
Content:
```
1 from datetime import datetime, timedelta
2 from typing import List
3
4 from rqdatac import init as rqdata_init
5 from rqdatac.services.basic import all_instruments as rqdata_all_instruments
6 from rqdatac.services.get_price import get_price as rqdata_get_price
7
8 from .setting import SETTINGS
9 from .constant import Exchange, Interval
10 from .object import BarData, HistoryRequest
11
12
13 INTERVAL_VT2RQ = {
14 Interval.MINUTE: "1m",
15 Interval.HOUR: "60m",
16 Interval.DAILY: "1d",
17 }
18
19 INTERVAL_ADJUSTMENT_MAP = {
20 Interval.MINUTE: timedelta(minutes=1),
21 Interval.HOUR: timedelta(hours=1),
22 Interval.DAILY: timedelta() # no need to adjust for daily bar
23 }
24
25
26 class RqdataClient:
27 """
28 Client for querying history data from RQData.
29 """
30
31 def __init__(self):
32 """"""
33 self.username = SETTINGS["rqdata.username"]
34 self.password = SETTINGS["rqdata.password"]
35
36 self.inited = False
37 self.symbols = set()
38
39 def init(self):
40 """"""
41 if self.inited:
42 return True
43
44 if not self.username or not self.password:
45 return False
46
47 rqdata_init(self.username, self.password,
48 ('rqdatad-pro.ricequant.com', 16011))
49
50 try:
51 df = rqdata_all_instruments(date=datetime.now())
52 for ix, row in df.iterrows():
53 self.symbols.add(row['order_book_id'])
54 except RuntimeError:
55 return False
56
57 self.inited = True
58 return True
59
60 def to_rq_symbol(self, symbol: str, exchange: Exchange):
61 """
62 CZCE product of RQData has symbol like "TA1905" while
63 vt symbol is "TA905.CZCE" so need to add "1" in symbol.
64 """
65 if exchange in [Exchange.SSE, Exchange.SZSE]:
66 if exchange == Exchange.SSE:
67 rq_symbol = f"{symbol}.XSHG"
68 else:
69 rq_symbol = f"{symbol}.XSHE"
70 else:
71 if exchange is not Exchange.CZCE:
72 return symbol.upper()
73
74 for count, word in enumerate(symbol):
75 if word.isdigit():
76 break
77
78 # noinspection PyUnboundLocalVariable
79 product = symbol[:count]
80 year = symbol[count]
81 month = symbol[count + 1:]
82
83 if year == "9":
84 year = "1" + year
85 else:
86 year = "2" + year
87
88 rq_symbol = f"{product}{year}{month}".upper()
89
90 return rq_symbol
91
92 def query_history(self, req: HistoryRequest):
93 """
94 Query history bar data from RQData.
95 """
96 symbol = req.symbol
97 exchange = req.exchange
98 interval = req.interval
99 start = req.start
100 end = req.end
101
102 rq_symbol = self.to_rq_symbol(symbol, exchange)
103 if rq_symbol not in self.symbols:
104 return None
105
106 rq_interval = INTERVAL_VT2RQ.get(interval)
107 if not rq_interval:
108 return None
109
110 # For adjust timestamp from bar close point (RQData) to open point (VN Trader)
111 adjustment = INTERVAL_ADJUSTMENT_MAP[interval]
112
113 # For querying night trading period data
114 end += timedelta(1)
115
116 df = rqdata_get_price(
117 rq_symbol,
118 frequency=rq_interval,
119 fields=["open", "high", "low", "close", "volume"],
120 start_date=start,
121 end_date=end
122 )
123
124 data: List[BarData] = []
125 for ix, row in df.iterrows():
126 bar = BarData(
127 symbol=symbol,
128 exchange=exchange,
129 interval=interval,
130 datetime=row.name.to_pydatetime() - adjustment,
131 open_price=row["open"],
132 high_price=row["high"],
133 low_price=row["low"],
134 close_price=row["close"],
135 volume=row["volume"],
136 gateway_name="RQ"
137 )
138 data.append(bar)
139
140 return data
141
142
143 rqdata_client = RqdataClient()
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vnpy/trader/rqdata.py b/vnpy/trader/rqdata.py
--- a/vnpy/trader/rqdata.py
+++ b/vnpy/trader/rqdata.py
@@ -36,11 +36,15 @@
self.inited = False
self.symbols = set()
- def init(self):
+ def init(self, username="", password=""):
""""""
if self.inited:
return True
+ if username and password:
+ self.username = username
+ self.password = password
+
if not self.username or not self.password:
return False
@@ -75,6 +79,11 @@
if word.isdigit():
break
+ # Check for index symbol
+ time_str = symbol[count:]
+ if time_str in ["88", "888", "99"]:
+ return symbol
+
# noinspection PyUnboundLocalVariable
product = symbol[:count]
year = symbol[count]
@@ -118,24 +127,27 @@
frequency=rq_interval,
fields=["open", "high", "low", "close", "volume"],
start_date=start,
- end_date=end
+ end_date=end,
+ adjust_type="none"
)
data: List[BarData] = []
- for ix, row in df.iterrows():
- bar = BarData(
- symbol=symbol,
- exchange=exchange,
- interval=interval,
- datetime=row.name.to_pydatetime() - adjustment,
- open_price=row["open"],
- high_price=row["high"],
- low_price=row["low"],
- close_price=row["close"],
- volume=row["volume"],
- gateway_name="RQ"
- )
- data.append(bar)
+
+ if df is not None:
+ for ix, row in df.iterrows():
+ bar = BarData(
+ symbol=symbol,
+ exchange=exchange,
+ interval=interval,
+ datetime=row.name.to_pydatetime() - adjustment,
+ open_price=row["open"],
+ high_price=row["high"],
+ low_price=row["low"],
+ close_price=row["close"],
+ volume=row["volume"],
+ gateway_name="RQ"
+ )
+ data.append(bar)
return data
|
{"golden_diff": "diff --git a/vnpy/trader/rqdata.py b/vnpy/trader/rqdata.py\n--- a/vnpy/trader/rqdata.py\n+++ b/vnpy/trader/rqdata.py\n@@ -36,11 +36,15 @@\n self.inited = False\n self.symbols = set()\n \n- def init(self):\n+ def init(self, username=\"\", password=\"\"):\n \"\"\"\"\"\"\n if self.inited:\n return True\n \n+ if username and password:\n+ self.username = username\n+ self.password = password\n+\n if not self.username or not self.password:\n return False\n \n@@ -75,6 +79,11 @@\n if word.isdigit():\n break\n \n+ # Check for index symbol\n+ time_str = symbol[count:]\n+ if time_str in [\"88\", \"888\", \"99\"]:\n+ return symbol\n+\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n@@ -118,24 +127,27 @@\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n- end_date=end\n+ end_date=end,\n+ adjust_type=\"none\"\n )\n \n data: List[BarData] = []\n- for ix, row in df.iterrows():\n- bar = BarData(\n- symbol=symbol,\n- exchange=exchange,\n- interval=interval,\n- datetime=row.name.to_pydatetime() - adjustment,\n- open_price=row[\"open\"],\n- high_price=row[\"high\"],\n- low_price=row[\"low\"],\n- close_price=row[\"close\"],\n- volume=row[\"volume\"],\n- gateway_name=\"RQ\"\n- )\n- data.append(bar)\n+\n+ if df is not None:\n+ for ix, row in df.iterrows():\n+ bar = BarData(\n+ symbol=symbol,\n+ exchange=exchange,\n+ interval=interval,\n+ datetime=row.name.to_pydatetime() - adjustment,\n+ open_price=row[\"open\"],\n+ high_price=row[\"high\"],\n+ low_price=row[\"low\"],\n+ close_price=row[\"close\"],\n+ volume=row[\"volume\"],\n+ gateway_name=\"RQ\"\n+ )\n+ data.append(bar)\n \n return data\n", "issue": "Bug\uff1arqdata.py \u4e2d RqdataClient \u7c7b\u7684 to_rq_symbol \u65b9\u6cd5\u5bf9\u8fde\u7eed\u548c\u6307\u6570\u5408\u7ea6\u8f6c\u6362\u6709\u95ee\u9898\n## \u73af\u5883\r\n\r\n* \u64cd\u4f5c\u7cfb\u7edf: \u5982Windows 10\r\n* Anaconda\u7248\u672c: Anaconda 18.12 Python 3.7 64\u4f4d\r\n* vn.py\u7248\u672c: v2.0.3\r\n\r\n## Issue\u7c7b\u578b\r\n\u4e09\u9009\u4e00\uff1aBug\r\n\r\n## \u9884\u671f\u7a0b\u5e8f\u884c\u4e3a\r\n\u6b63\u786e\u5c06\u5408\u7ea6\u540d\u8f6c\u6362\u81f3rqdata\u4e2d\u7684\u5408\u7ea6\u540d\r\n\r\n## \u5b9e\u9645\u7a0b\u5e8f\u884c\u4e3a\r\n\u9519\u8bef\u7684\u5c06\u90d1\u5546\u6240\u7684\u5408\u7ea6\u8fde\u7eed\u548c\u6307\u6570\u5408\u7ea6\u8f6c\u6362\uff0c\u4f8b\u5982\u5c06AP888\u4f1a\u8f6c\u6362\u4e3aAP2888\uff0cAP99\u4f1a\u8f6c\u6362\u81f3AP199\u5bfc\u81f4\u65e0\u6cd5\u4e0b\u8f7d\u5230\u6570\u636e\u3002\r\n\r\n## \u91cd\u73b0\u6b65\u9aa4\r\n\u5728\u56de\u6d4b\u6a21\u5757\u4e2d\u4e0b\u8f7dAP88\u6570\u636e\u5373\u53ef\u3002\r\n\r\n\u9488\u5bf9Bug\u7c7b\u578bIssue\uff0c\u8bf7\u63d0\u4f9b\u5177\u4f53\u91cd\u73b0\u6b65\u9aa4\u4ee5\u53ca\u62a5\u9519\u622a\u56fe\r\n\r\n\r\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import List\n\nfrom rqdatac import init as rqdata_init\nfrom rqdatac.services.basic import all_instruments as rqdata_all_instruments\nfrom rqdatac.services.get_price import get_price as rqdata_get_price\n\nfrom .setting import SETTINGS\nfrom .constant import Exchange, Interval\nfrom .object import BarData, HistoryRequest\n\n\nINTERVAL_VT2RQ = {\n Interval.MINUTE: \"1m\",\n Interval.HOUR: \"60m\",\n Interval.DAILY: \"1d\",\n}\n\nINTERVAL_ADJUSTMENT_MAP = {\n Interval.MINUTE: timedelta(minutes=1),\n Interval.HOUR: timedelta(hours=1),\n Interval.DAILY: timedelta() # no need to adjust for daily bar\n}\n\n\nclass RqdataClient:\n \"\"\"\n Client for querying history data from RQData.\n \"\"\"\n\n def __init__(self):\n \"\"\"\"\"\"\n self.username = SETTINGS[\"rqdata.username\"]\n self.password = SETTINGS[\"rqdata.password\"]\n\n self.inited = False\n self.symbols = set()\n\n def init(self):\n \"\"\"\"\"\"\n if self.inited:\n return True\n\n if not self.username or not self.password:\n return False\n\n rqdata_init(self.username, self.password,\n ('rqdatad-pro.ricequant.com', 16011))\n\n try:\n df = rqdata_all_instruments(date=datetime.now())\n for ix, row in df.iterrows():\n self.symbols.add(row['order_book_id'])\n except RuntimeError:\n return False\n\n self.inited = True\n return True\n\n def to_rq_symbol(self, symbol: str, exchange: Exchange):\n \"\"\"\n CZCE product of RQData has symbol like \"TA1905\" while\n vt symbol is \"TA905.CZCE\" so need to add \"1\" in symbol.\n \"\"\"\n if exchange in [Exchange.SSE, Exchange.SZSE]:\n if exchange == Exchange.SSE:\n rq_symbol = f\"{symbol}.XSHG\"\n else:\n rq_symbol = f\"{symbol}.XSHE\"\n else:\n if exchange is not Exchange.CZCE:\n return symbol.upper()\n\n for count, word in enumerate(symbol):\n if word.isdigit():\n break\n\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n month = symbol[count + 1:]\n\n if year == \"9\":\n year = \"1\" + year\n else:\n year = \"2\" + year\n\n rq_symbol = f\"{product}{year}{month}\".upper()\n\n return rq_symbol\n\n def query_history(self, req: HistoryRequest):\n \"\"\"\n Query history bar data from RQData.\n \"\"\"\n symbol = req.symbol\n exchange = req.exchange\n interval = req.interval\n start = req.start\n end = req.end\n\n rq_symbol = self.to_rq_symbol(symbol, exchange)\n if rq_symbol not in self.symbols:\n return None\n\n rq_interval = INTERVAL_VT2RQ.get(interval)\n if not rq_interval:\n return None\n\n # For adjust timestamp from bar close point (RQData) to open point (VN Trader)\n adjustment = INTERVAL_ADJUSTMENT_MAP[interval]\n\n # For querying night trading period data\n end += timedelta(1)\n\n df = rqdata_get_price(\n rq_symbol,\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n end_date=end\n )\n\n data: List[BarData] = []\n for ix, row in df.iterrows():\n bar = BarData(\n symbol=symbol,\n exchange=exchange,\n interval=interval,\n datetime=row.name.to_pydatetime() - adjustment,\n open_price=row[\"open\"],\n high_price=row[\"high\"],\n low_price=row[\"low\"],\n close_price=row[\"close\"],\n volume=row[\"volume\"],\n gateway_name=\"RQ\"\n )\n data.append(bar)\n\n return data\n\n\nrqdata_client = RqdataClient()\n", "path": "vnpy/trader/rqdata.py"}], "after_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import List\n\nfrom rqdatac import init as rqdata_init\nfrom rqdatac.services.basic import all_instruments as rqdata_all_instruments\nfrom rqdatac.services.get_price import get_price as rqdata_get_price\n\nfrom .setting import SETTINGS\nfrom .constant import Exchange, Interval\nfrom .object import BarData, HistoryRequest\n\n\nINTERVAL_VT2RQ = {\n Interval.MINUTE: \"1m\",\n Interval.HOUR: \"60m\",\n Interval.DAILY: \"1d\",\n}\n\nINTERVAL_ADJUSTMENT_MAP = {\n Interval.MINUTE: timedelta(minutes=1),\n Interval.HOUR: timedelta(hours=1),\n Interval.DAILY: timedelta() # no need to adjust for daily bar\n}\n\n\nclass RqdataClient:\n \"\"\"\n Client for querying history data from RQData.\n \"\"\"\n\n def __init__(self):\n \"\"\"\"\"\"\n self.username = SETTINGS[\"rqdata.username\"]\n self.password = SETTINGS[\"rqdata.password\"]\n\n self.inited = False\n self.symbols = set()\n\n def init(self, username=\"\", password=\"\"):\n \"\"\"\"\"\"\n if self.inited:\n return True\n\n if username and password:\n self.username = username\n self.password = password\n\n if not self.username or not self.password:\n return False\n\n rqdata_init(self.username, self.password,\n ('rqdatad-pro.ricequant.com', 16011))\n\n try:\n df = rqdata_all_instruments(date=datetime.now())\n for ix, row in df.iterrows():\n self.symbols.add(row['order_book_id'])\n except RuntimeError:\n return False\n\n self.inited = True\n return True\n\n def to_rq_symbol(self, symbol: str, exchange: Exchange):\n \"\"\"\n CZCE product of RQData has symbol like \"TA1905\" while\n vt symbol is \"TA905.CZCE\" so need to add \"1\" in symbol.\n \"\"\"\n if exchange in [Exchange.SSE, Exchange.SZSE]:\n if exchange == Exchange.SSE:\n rq_symbol = f\"{symbol}.XSHG\"\n else:\n rq_symbol = f\"{symbol}.XSHE\"\n else:\n if exchange is not Exchange.CZCE:\n return symbol.upper()\n\n for count, word in enumerate(symbol):\n if word.isdigit():\n break\n\n # Check for index symbol\n time_str = symbol[count:]\n if time_str in [\"88\", \"888\", \"99\"]:\n return symbol\n\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n month = symbol[count + 1:]\n\n if year == \"9\":\n year = \"1\" + year\n else:\n year = \"2\" + year\n\n rq_symbol = f\"{product}{year}{month}\".upper()\n\n return rq_symbol\n\n def query_history(self, req: HistoryRequest):\n \"\"\"\n Query history bar data from RQData.\n \"\"\"\n symbol = req.symbol\n exchange = req.exchange\n interval = req.interval\n start = req.start\n end = req.end\n\n rq_symbol = self.to_rq_symbol(symbol, exchange)\n if rq_symbol not in self.symbols:\n return None\n\n rq_interval = INTERVAL_VT2RQ.get(interval)\n if not rq_interval:\n return None\n\n # For adjust timestamp from bar close point (RQData) to open point (VN Trader)\n adjustment = INTERVAL_ADJUSTMENT_MAP[interval]\n\n # For querying night trading period data\n end += timedelta(1)\n\n df = rqdata_get_price(\n rq_symbol,\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n end_date=end,\n adjust_type=\"none\"\n )\n\n data: List[BarData] = []\n\n if df is not None:\n for ix, row in df.iterrows():\n bar = BarData(\n symbol=symbol,\n exchange=exchange,\n interval=interval,\n datetime=row.name.to_pydatetime() - adjustment,\n open_price=row[\"open\"],\n high_price=row[\"high\"],\n low_price=row[\"low\"],\n close_price=row[\"close\"],\n volume=row[\"volume\"],\n gateway_name=\"RQ\"\n )\n data.append(bar)\n\n return data\n\n\nrqdata_client = RqdataClient()\n", "path": "vnpy/trader/rqdata.py"}]}
| 1,686 | 527 |
gh_patches_debug_66272
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1184
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Swagger spec still invalid
The Swagger spec is still invalid it seems
Extract:
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver:\\d+",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics:.*",
"type": "string",
"required": true,
"in": "path"
}
],
```
In this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter
The right definition should be
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics",
"type": "string",
"required": true,
"in": "path"
}
],
```
To validate that it works, you can try this small program with Smowgger to print all operations:
```python
import asyncio
from smwogger import API
async def print_operations():
async with API('http://path.to.kinto/v1/__api__') as api:
print(api.operations)
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(print_operations())
finally:
loop.close()
```
cc @gabisurita @chartjes
Swagger spec still invalid
The Swagger spec is still invalid it seems
Extract:
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver:\\d+",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics:.*",
"type": "string",
"required": true,
"in": "path"
}
],
```
In this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter
The right definition should be
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics",
"type": "string",
"required": true,
"in": "path"
}
],
```
To validate that it works, you can try this small program with Smowgger to print all operations:
```python
import asyncio
from smwogger import API
async def print_operations():
async with API('http://path.to.kinto/v1/__api__') as api:
print(api.operations)
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(print_operations())
finally:
loop.close()
```
cc @gabisurita @chartjes
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import codecs
2 import os
3 from setuptools import setup, find_packages
4
5 here = os.path.abspath(os.path.dirname(__file__))
6
7
8 def read_file(filename):
9 """Open a related file and return its content."""
10 with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:
11 content = f.read()
12 return content
13
14
15 README = read_file('README.rst')
16 CHANGELOG = read_file('CHANGELOG.rst')
17 CONTRIBUTORS = read_file('CONTRIBUTORS.rst')
18
19 REQUIREMENTS = [
20 'bcrypt',
21 'colander >= 1.3.2',
22 'cornice >= 2.4',
23 'cornice_swagger >= 0.5',
24 'jsonschema',
25 'jsonpatch',
26 'logging-color-formatter >= 1.0.1', # Message interpolations.
27 'python-dateutil',
28 'pyramid > 1.8',
29 'pyramid_multiauth >= 0.8', # User on policy selected event.
30 'transaction',
31 'pyramid_tm',
32 'requests',
33 'waitress',
34 'ujson >= 1.35'
35 ]
36
37 POSTGRESQL_REQUIRES = [
38 'SQLAlchemy',
39 'psycopg2 > 2.5',
40 'zope.sqlalchemy',
41 ]
42
43 REDIS_REQUIRES = [
44 'kinto_redis'
45 ]
46
47 SETUP_REQUIRES = [
48 'pytest-runner'
49 ]
50
51 TEST_REQUIREMENTS = [
52 'bravado_core',
53 'pytest',
54 'WebTest'
55 ]
56
57 DEPENDENCY_LINKS = [
58 ]
59
60 MONITORING_REQUIRES = [
61 'raven',
62 'statsd',
63 'newrelic',
64 'werkzeug',
65 ]
66
67 ENTRY_POINTS = {
68 'paste.app_factory': [
69 'main = kinto:main',
70 ],
71 'console_scripts': [
72 'kinto = kinto.__main__:main'
73 ],
74 }
75
76
77 setup(name='kinto',
78 version='7.0.0.dev0',
79 description='Kinto Web Service - Store, Sync, Share, and Self-Host.',
80 long_description="{}\n\n{}\n\n{}".format(README, CHANGELOG, CONTRIBUTORS),
81 license='Apache License (2.0)',
82 classifiers=[
83 "Programming Language :: Python",
84 "Programming Language :: Python :: 3",
85 "Programming Language :: Python :: 3.5",
86 "Programming Language :: Python :: 3.6",
87 "Programming Language :: Python :: Implementation :: CPython",
88 "Topic :: Internet :: WWW/HTTP",
89 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
90 "License :: OSI Approved :: Apache Software License"
91 ],
92 keywords="web sync json storage services",
93 author='Mozilla Services',
94 author_email='[email protected]',
95 url='https://github.com/Kinto/kinto',
96 packages=find_packages(),
97 package_data={'': ['*.rst', '*.py', '*.yaml']},
98 include_package_data=True,
99 zip_safe=False,
100 setup_requires=SETUP_REQUIRES,
101 tests_require=TEST_REQUIREMENTS,
102 install_requires=REQUIREMENTS,
103 extras_require={
104 'redis': REDIS_REQUIRES,
105 'postgresql': POSTGRESQL_REQUIRES,
106 'monitoring': MONITORING_REQUIRES,
107 },
108 test_suite="tests",
109 dependency_links=DEPENDENCY_LINKS,
110 entry_points=ENTRY_POINTS)
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@
'bcrypt',
'colander >= 1.3.2',
'cornice >= 2.4',
- 'cornice_swagger >= 0.5',
+ 'cornice_swagger >= 0.5.1',
'jsonschema',
'jsonpatch',
'logging-color-formatter >= 1.0.1', # Message interpolations.
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,7 @@\n 'bcrypt',\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n- 'cornice_swagger >= 0.5',\n+ 'cornice_swagger >= 0.5.1',\n 'jsonschema',\n 'jsonpatch',\n 'logging-color-formatter >= 1.0.1', # Message interpolations.\n", "issue": "Swagger spec still invalid\nThe Swagger spec is still invalid it seems\r\n\r\nExtract:\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver:\\\\d+\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics:.*\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nIn this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter\r\n\r\nThe right definition should be\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nTo validate that it works, you can try this small program with Smowgger to print all operations:\r\n\r\n```python\r\nimport asyncio\r\nfrom smwogger import API\r\n\r\n\r\nasync def print_operations():\r\n async with API('http://path.to.kinto/v1/__api__') as api:\r\n print(api.operations)\r\n\r\nloop = asyncio.get_event_loop()\r\ntry:\r\n loop.run_until_complete(print_operations())\r\nfinally:\r\n loop.close()\r\n```\r\n\r\n\r\ncc @gabisurita @chartjes \nSwagger spec still invalid\nThe Swagger spec is still invalid it seems\r\n\r\nExtract:\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver:\\\\d+\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics:.*\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nIn this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter\r\n\r\nThe right definition should be\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nTo validate that it works, you can try this small program with Smowgger to print all operations:\r\n\r\n```python\r\nimport asyncio\r\nfrom smwogger import API\r\n\r\n\r\nasync def print_operations():\r\n async with API('http://path.to.kinto/v1/__api__') as api:\r\n print(api.operations)\r\n\r\nloop = asyncio.get_event_loop()\r\ntry:\r\n loop.run_until_complete(print_operations())\r\nfinally:\r\n loop.close()\r\n```\r\n\r\n\r\ncc @gabisurita @chartjes \n", "before_files": [{"content": "import codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\nREQUIREMENTS = [\n 'bcrypt',\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n 'cornice_swagger >= 0.5',\n 'jsonschema',\n 'jsonpatch',\n 'logging-color-formatter >= 1.0.1', # Message interpolations.\n 'python-dateutil',\n 'pyramid > 1.8',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'transaction',\n 'pyramid_tm',\n 'requests',\n 'waitress',\n 'ujson >= 1.35'\n]\n\nPOSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2 > 2.5',\n 'zope.sqlalchemy',\n]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'bravado_core',\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='7.0.0.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=\"{}\\n\\n{}\\n\\n{}\".format(README, CHANGELOG, CONTRIBUTORS),\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py', '*.yaml']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}], "after_files": [{"content": "import codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\nREQUIREMENTS = [\n 'bcrypt',\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n 'cornice_swagger >= 0.5.1',\n 'jsonschema',\n 'jsonpatch',\n 'logging-color-formatter >= 1.0.1', # Message interpolations.\n 'python-dateutil',\n 'pyramid > 1.8',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'transaction',\n 'pyramid_tm',\n 'requests',\n 'waitress',\n 'ujson >= 1.35'\n]\n\nPOSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2 > 2.5',\n 'zope.sqlalchemy',\n]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'bravado_core',\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='7.0.0.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=\"{}\\n\\n{}\\n\\n{}\".format(README, CHANGELOG, CONTRIBUTORS),\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py', '*.yaml']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}]}
| 2,301 | 116 |
gh_patches_debug_28025
|
rasdani/github-patches
|
git_diff
|
twisted__twisted-12013
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Read The Docs documentation website search not working
You can test this link
https://docs.twisted.org/en/twisted-23.8.0/search.html?q=threads&check_keywords=yes&area=default#
it looks like jquery is not included
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 #
2 # Twisted documentation build configuration file, created by
3 # sphinx-quickstart on Tue Jan 14 11:31:15 2014.
4 #
5 # This file is execfile()d with the current directory set to its
6 # containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 import os
15 import pathlib
16 import subprocess
17 import sys
18 from datetime import date
19 from pprint import pprint
20
21 import sphinx_rtd_theme
22
23 # If extensions (or modules to document with autodoc) are in another directory,
24 # add these directories to sys.path here. If the directory is relative to the
25 # documentation root, use os.path.abspath to make it absolute, like shown here.
26 sys.path.insert(0, os.path.abspath("./_extensions"))
27 sys.path.insert(0, os.path.abspath(".."))
28
29 # -- General configuration ------------------------------------------------
30
31 # See pyproject.toml for the Sphinx version required to build the documentation.
32 # needs_sphinx is not use to avoid duplication and getting these values
33 # out of sync.
34
35 # Add any Sphinx extension module names here, as strings. They can be
36 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
37 # ones.
38 extensions = [
39 "sphinx.ext.intersphinx",
40 "pydoctor.sphinx_ext.build_apidocs",
41 ]
42
43 try:
44 import rst2pdf.pdfbuilder
45
46 extensions.append("rst2pdf.pdfbuilder")
47 except ImportError:
48 pass
49
50 from twisted import version as twisted_version_object
51
52 # Add any paths that contain templates here, relative to this directory.
53 templates_path = ["_templates"]
54
55 # The suffix of source filenames.
56 source_suffix = ".rst"
57
58 # The encoding of source files.
59 # source_encoding = 'utf-8-sig'
60
61 # The master toctree document.
62 master_doc = "index"
63
64 _today = date.today()
65 # General information about the project.
66 project = "Twisted"
67 copyright = "{}, Twisted Matrix Labs. Ver {}. Built on {}".format(
68 _today.year,
69 twisted_version_object.public(),
70 _today.isoformat(),
71 )
72
73 # The version info for the project you're documenting, acts as replacement for
74 # |version| and |release|, also used in various other places throughout the
75 # built documents.
76 #
77 # The short X.Y version.
78 version = "{major}.{minor}".format(
79 major=twisted_version_object.major, minor=twisted_version_object.minor
80 )
81 # The full version, including alpha/beta/rc tags.
82 release = twisted_version_object.short()
83
84 # There are two options for replacing |today|: either, you set today to some
85 # non-false value, then it is used:
86 # today = ''
87 # Else, today_fmt is used as the format for a strftime call.
88 # today_fmt = '%B %d, %Y'
89
90 # List of patterns, relative to source directory, that match files and
91 # directories to ignore when looking for source files.
92 exclude_patterns = ["_build"]
93
94 # The name of the Pygments (syntax highlighting) style to use.
95 pygments_style = "sphinx"
96
97 # -- Options for HTML output ----------------------------------------------
98
99 # Only the RTD theme is used. Both for local development and for the public site.
100 html_theme = "sphinx_rtd_theme"
101 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
102
103 # Add any paths that contain custom static files (such as style sheets) here,
104 # relative to this directory. They are copied after the builtin static files,
105 # so a file named "default.css" will overwrite the builtin "default.css".
106 html_static_path = ["_static"]
107
108
109 # These paths are either relative to html_static_path
110 # or fully qualified paths (eg. https://...)
111 html_js_files = [
112 "js/custom.js",
113 # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.
114 'https://sidecar.gitter.im/dist/sidecar.v1.js" defer hack="',
115 ]
116
117 # Output file base name for HTML help builder.
118 htmlhelp_basename = "Twisteddoc"
119
120
121 # -- Options for LaTeX output ---------------------------------------------
122
123 latex_elements = {
124 # The paper size ('letterpaper' or 'a4paper').
125 #'papersize': 'letterpaper',
126 # The font size ('10pt', '11pt' or '12pt').
127 #'pointsize': '10pt',
128 # Additional stuff for the LaTeX preamble.
129 #'preamble': '',
130 }
131
132 # Grouping the document tree into LaTeX files. List of tuples
133 # (source start file, target name, title,
134 # author, documentclass [howto, manual, or own class]).
135 latex_documents = [
136 ("index", "Twisted.tex", "Twisted Documentation", "Twisted Matrix Labs", "manual"),
137 ]
138
139
140 # -- Options for manual page output ---------------------------------------
141
142 # One entry per manual page. List of tuples
143 # (source start file, name, description, authors, manual section).
144 man_pages = [("index", "twisted", "Twisted Documentation", ["Twisted Matrix Labs"], 1)]
145
146
147 # -- Options for Texinfo output -------------------------------------------
148
149 # Grouping the document tree into Texinfo files. List of tuples
150 # (source start file, target name, title, author,
151 # dir menu entry, description, category)
152 texinfo_documents = [
153 (
154 "index",
155 "Twisted",
156 "Twisted Documentation",
157 "Twisted Matrix Labs",
158 "Twisted",
159 "One line description of project.",
160 "Miscellaneous",
161 ),
162 ]
163
164
165 # -- Options for Epub output ----------------------------------------------
166
167 # Bibliographic Dublin Core info.
168 epub_title = "Twisted"
169 epub_author = "Twisted Matrix Labs"
170 epub_publisher = "Twisted Matrix Labs"
171 epub_copyright = "2020, Twisted Matrix Labs"
172
173
174 # -- Extension configuration ----------------------------------------------
175 _git_reference = subprocess.run(
176 ["git", "rev-parse", "--abbrev-ref", "HEAD"],
177 text=True,
178 encoding="utf8",
179 capture_output=True,
180 check=True,
181 ).stdout
182
183
184 print(f"== Environment dump for {_git_reference} ===")
185 pprint(dict(os.environ))
186 print("======")
187
188
189 # Try to find URL fragment for the GitHub source page based on current
190 # branch or tag.
191
192 if _git_reference == "HEAD":
193 # It looks like the branch has no name.
194 # Fallback to commit ID.
195 _git_reference = subprocess.getoutput("git rev-parse HEAD")
196
197 if os.environ.get("READTHEDOCS", "") == "True":
198 rtd_version = os.environ.get("READTHEDOCS_VERSION", "")
199 if "." in rtd_version:
200 # It looks like we have a tag build.
201 _git_reference = rtd_version
202
203 _project_root = pathlib.Path(__file__).parent.parent
204 _source_root = _project_root / "src"
205 pydoctor_args = [
206 "--quiet",
207 # pydoctor should not fail the sphinx build, we have another tox environment for that.
208 f"--config={_project_root}/setup.cfg",
209 f"--html-viewsource-base=https://github.com/twisted/twisted/tree/{_git_reference}/src",
210 f"--project-base-dir={_source_root}",
211 f"--template-dir={_source_root}/twisted/python/_pydoctortemplates",
212 "--html-output={outdir}/api",
213 str(_source_root / "twisted"),
214 ]
215
216 pydoctor_url_path = "/en/{rtd_version}/api/"
217
218 # A dict mapping unique IDs (which can be used to disambiguate references) to a
219 # tuple of (<external sphinx documentation URI>, <inventory file location>).
220 # The inventory file may be None to use the default location at the given URI.
221 intersphinx_mapping = {
222 "py3": ("https://docs.python.org/3", None),
223 "zopeinterface": ("https://zopeinterface.readthedocs.io/en/latest", None),
224 }
225 # How long to cache remote inventories. Positive is a number of days,
226 # negative means infinite. The default is 5 days, which should be fine
227 # for standard library documentation that does not typically change
228 # significantly after release.
229 # intersphinx_cache_limit = 5
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -20,6 +20,8 @@
import sphinx_rtd_theme
+from twisted import version as twisted_version_object
+
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
@@ -37,18 +39,10 @@
# ones.
extensions = [
"sphinx.ext.intersphinx",
+ "sphinxcontrib.jquery",
"pydoctor.sphinx_ext.build_apidocs",
]
-try:
- import rst2pdf.pdfbuilder
-
- extensions.append("rst2pdf.pdfbuilder")
-except ImportError:
- pass
-
-from twisted import version as twisted_version_object
-
# Add any paths that contain templates here, relative to this directory.
templates_path = ["_templates"]
@@ -106,14 +100,6 @@
html_static_path = ["_static"]
-# These paths are either relative to html_static_path
-# or fully qualified paths (eg. https://...)
-html_js_files = [
- "js/custom.js",
- # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.
- 'https://sidecar.gitter.im/dist/sidecar.v1.js" defer hack="',
-]
-
# Output file base name for HTML help builder.
htmlhelp_basename = "Twisteddoc"
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -20,6 +20,8 @@\n \n import sphinx_rtd_theme\n \n+from twisted import version as twisted_version_object\n+\n # If extensions (or modules to document with autodoc) are in another directory,\n # add these directories to sys.path here. If the directory is relative to the\n # documentation root, use os.path.abspath to make it absolute, like shown here.\n@@ -37,18 +39,10 @@\n # ones.\n extensions = [\n \"sphinx.ext.intersphinx\",\n+ \"sphinxcontrib.jquery\",\n \"pydoctor.sphinx_ext.build_apidocs\",\n ]\n \n-try:\n- import rst2pdf.pdfbuilder\n-\n- extensions.append(\"rst2pdf.pdfbuilder\")\n-except ImportError:\n- pass\n-\n-from twisted import version as twisted_version_object\n-\n # Add any paths that contain templates here, relative to this directory.\n templates_path = [\"_templates\"]\n \n@@ -106,14 +100,6 @@\n html_static_path = [\"_static\"]\n \n \n-# These paths are either relative to html_static_path\n-# or fully qualified paths (eg. https://...)\n-html_js_files = [\n- \"js/custom.js\",\n- # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.\n- 'https://sidecar.gitter.im/dist/sidecar.v1.js\" defer hack=\"',\n-]\n-\n # Output file base name for HTML help builder.\n htmlhelp_basename = \"Twisteddoc\"\n", "issue": "Read The Docs documentation website search not working\n\r\nYou can test this link\r\n\r\nhttps://docs.twisted.org/en/twisted-23.8.0/search.html?q=threads&check_keywords=yes&area=default#\r\n\r\nit looks like jquery is not included\r\n\n", "before_files": [{"content": "#\n# Twisted documentation build configuration file, created by\n# sphinx-quickstart on Tue Jan 14 11:31:15 2014.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport pathlib\nimport subprocess\nimport sys\nfrom datetime import date\nfrom pprint import pprint\n\nimport sphinx_rtd_theme\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath(\"./_extensions\"))\nsys.path.insert(0, os.path.abspath(\"..\"))\n\n# -- General configuration ------------------------------------------------\n\n# See pyproject.toml for the Sphinx version required to build the documentation.\n# needs_sphinx is not use to avoid duplication and getting these values\n# out of sync.\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.intersphinx\",\n \"pydoctor.sphinx_ext.build_apidocs\",\n]\n\ntry:\n import rst2pdf.pdfbuilder\n\n extensions.append(\"rst2pdf.pdfbuilder\")\nexcept ImportError:\n pass\n\nfrom twisted import version as twisted_version_object\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix of source filenames.\nsource_suffix = \".rst\"\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n_today = date.today()\n# General information about the project.\nproject = \"Twisted\"\ncopyright = \"{}, Twisted Matrix Labs. Ver {}. Built on {}\".format(\n _today.year,\n twisted_version_object.public(),\n _today.isoformat(),\n)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = \"{major}.{minor}\".format(\n major=twisted_version_object.major, minor=twisted_version_object.minor\n)\n# The full version, including alpha/beta/rc tags.\nrelease = twisted_version_object.short()\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n# today = ''\n# Else, today_fmt is used as the format for a strftime call.\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\"_build\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# -- Options for HTML output ----------------------------------------------\n\n# Only the RTD theme is used. Both for local development and for the public site.\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# These paths are either relative to html_static_path\n# or fully qualified paths (eg. https://...)\nhtml_js_files = [\n \"js/custom.js\",\n # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.\n 'https://sidecar.gitter.im/dist/sidecar.v1.js\" defer hack=\"',\n]\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Twisteddoc\"\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (\"index\", \"Twisted.tex\", \"Twisted Documentation\", \"Twisted Matrix Labs\", \"manual\"),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(\"index\", \"twisted\", \"Twisted Documentation\", [\"Twisted Matrix Labs\"], 1)]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n \"index\",\n \"Twisted\",\n \"Twisted Documentation\",\n \"Twisted Matrix Labs\",\n \"Twisted\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Options for Epub output ----------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = \"Twisted\"\nepub_author = \"Twisted Matrix Labs\"\nepub_publisher = \"Twisted Matrix Labs\"\nepub_copyright = \"2020, Twisted Matrix Labs\"\n\n\n# -- Extension configuration ----------------------------------------------\n_git_reference = subprocess.run(\n [\"git\", \"rev-parse\", \"--abbrev-ref\", \"HEAD\"],\n text=True,\n encoding=\"utf8\",\n capture_output=True,\n check=True,\n).stdout\n\n\nprint(f\"== Environment dump for {_git_reference} ===\")\npprint(dict(os.environ))\nprint(\"======\")\n\n\n# Try to find URL fragment for the GitHub source page based on current\n# branch or tag.\n\nif _git_reference == \"HEAD\":\n # It looks like the branch has no name.\n # Fallback to commit ID.\n _git_reference = subprocess.getoutput(\"git rev-parse HEAD\")\n\nif os.environ.get(\"READTHEDOCS\", \"\") == \"True\":\n rtd_version = os.environ.get(\"READTHEDOCS_VERSION\", \"\")\n if \".\" in rtd_version:\n # It looks like we have a tag build.\n _git_reference = rtd_version\n\n_project_root = pathlib.Path(__file__).parent.parent\n_source_root = _project_root / \"src\"\npydoctor_args = [\n \"--quiet\",\n # pydoctor should not fail the sphinx build, we have another tox environment for that.\n f\"--config={_project_root}/setup.cfg\",\n f\"--html-viewsource-base=https://github.com/twisted/twisted/tree/{_git_reference}/src\",\n f\"--project-base-dir={_source_root}\",\n f\"--template-dir={_source_root}/twisted/python/_pydoctortemplates\",\n \"--html-output={outdir}/api\",\n str(_source_root / \"twisted\"),\n]\n\npydoctor_url_path = \"/en/{rtd_version}/api/\"\n\n# A dict mapping unique IDs (which can be used to disambiguate references) to a\n# tuple of (<external sphinx documentation URI>, <inventory file location>).\n# The inventory file may be None to use the default location at the given URI.\nintersphinx_mapping = {\n \"py3\": (\"https://docs.python.org/3\", None),\n \"zopeinterface\": (\"https://zopeinterface.readthedocs.io/en/latest\", None),\n}\n# How long to cache remote inventories. Positive is a number of days,\n# negative means infinite. The default is 5 days, which should be fine\n# for standard library documentation that does not typically change\n# significantly after release.\n# intersphinx_cache_limit = 5\n", "path": "docs/conf.py"}], "after_files": [{"content": "#\n# Twisted documentation build configuration file, created by\n# sphinx-quickstart on Tue Jan 14 11:31:15 2014.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport pathlib\nimport subprocess\nimport sys\nfrom datetime import date\nfrom pprint import pprint\n\nimport sphinx_rtd_theme\n\nfrom twisted import version as twisted_version_object\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath(\"./_extensions\"))\nsys.path.insert(0, os.path.abspath(\"..\"))\n\n# -- General configuration ------------------------------------------------\n\n# See pyproject.toml for the Sphinx version required to build the documentation.\n# needs_sphinx is not use to avoid duplication and getting these values\n# out of sync.\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.intersphinx\",\n \"sphinxcontrib.jquery\",\n \"pydoctor.sphinx_ext.build_apidocs\",\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix of source filenames.\nsource_suffix = \".rst\"\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n_today = date.today()\n# General information about the project.\nproject = \"Twisted\"\ncopyright = \"{}, Twisted Matrix Labs. Ver {}. Built on {}\".format(\n _today.year,\n twisted_version_object.public(),\n _today.isoformat(),\n)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = \"{major}.{minor}\".format(\n major=twisted_version_object.major, minor=twisted_version_object.minor\n)\n# The full version, including alpha/beta/rc tags.\nrelease = twisted_version_object.short()\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n# today = ''\n# Else, today_fmt is used as the format for a strftime call.\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\"_build\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# -- Options for HTML output ----------------------------------------------\n\n# Only the RTD theme is used. Both for local development and for the public site.\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Twisteddoc\"\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (\"index\", \"Twisted.tex\", \"Twisted Documentation\", \"Twisted Matrix Labs\", \"manual\"),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(\"index\", \"twisted\", \"Twisted Documentation\", [\"Twisted Matrix Labs\"], 1)]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n \"index\",\n \"Twisted\",\n \"Twisted Documentation\",\n \"Twisted Matrix Labs\",\n \"Twisted\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Options for Epub output ----------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = \"Twisted\"\nepub_author = \"Twisted Matrix Labs\"\nepub_publisher = \"Twisted Matrix Labs\"\nepub_copyright = \"2020, Twisted Matrix Labs\"\n\n\n# -- Extension configuration ----------------------------------------------\n_git_reference = subprocess.run(\n [\"git\", \"rev-parse\", \"--abbrev-ref\", \"HEAD\"],\n text=True,\n encoding=\"utf8\",\n capture_output=True,\n check=True,\n).stdout\n\n\nprint(f\"== Environment dump for {_git_reference} ===\")\npprint(dict(os.environ))\nprint(\"======\")\n\n\n# Try to find URL fragment for the GitHub source page based on current\n# branch or tag.\n\nif _git_reference == \"HEAD\":\n # It looks like the branch has no name.\n # Fallback to commit ID.\n _git_reference = subprocess.getoutput(\"git rev-parse HEAD\")\n\nif os.environ.get(\"READTHEDOCS\", \"\") == \"True\":\n rtd_version = os.environ.get(\"READTHEDOCS_VERSION\", \"\")\n if \".\" in rtd_version:\n # It looks like we have a tag build.\n _git_reference = rtd_version\n\n_project_root = pathlib.Path(__file__).parent.parent\n_source_root = _project_root / \"src\"\npydoctor_args = [\n \"--quiet\",\n # pydoctor should not fail the sphinx build, we have another tox environment for that.\n f\"--config={_project_root}/setup.cfg\",\n f\"--html-viewsource-base=https://github.com/twisted/twisted/tree/{_git_reference}/src\",\n f\"--project-base-dir={_source_root}\",\n f\"--template-dir={_source_root}/twisted/python/_pydoctortemplates\",\n \"--html-output={outdir}/api\",\n str(_source_root / \"twisted\"),\n]\n\npydoctor_url_path = \"/en/{rtd_version}/api/\"\n\n# A dict mapping unique IDs (which can be used to disambiguate references) to a\n# tuple of (<external sphinx documentation URI>, <inventory file location>).\n# The inventory file may be None to use the default location at the given URI.\nintersphinx_mapping = {\n \"py3\": (\"https://docs.python.org/3\", None),\n \"zopeinterface\": (\"https://zopeinterface.readthedocs.io/en/latest\", None),\n}\n# How long to cache remote inventories. Positive is a number of days,\n# negative means infinite. The default is 5 days, which should be fine\n# for standard library documentation that does not typically change\n# significantly after release.\n# intersphinx_cache_limit = 5\n", "path": "docs/conf.py"}]}
| 2,683 | 347 |
gh_patches_debug_8600
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-356
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: webargs 5.0 introduces incompatibility with Flask < 1.0
https://github.com/marshmallow-code/webargs/blob/5.0.0/webargs/flaskparser.py#L63
`_get_data_for_json` is only available since Flask >= 1.0
for Flask < 1.0, there is an error as follows:
```
File "/usr/local/lib/python2.7/site-packages/webargs/flaskparser.py", line 63, in parse_json
data = req._get_data_for_json(cache=True)
File "/usr/local/lib/python2.7/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
AttributeError: 'Request' object has no attribute '_get_data_for_json'
```
I had to downgrade webargs to 4.4.1 to get it work.
So you need to update this framework requirement https://github.com/marshmallow-code/webargs/blob/dev/setup.py#L11 or update the code for the backward compatibility.
IMHO, using `_get_data_for_json` should be avoided because it's considered private and can be changed/removed anytime.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `webargs/flaskparser.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Flask request argument parsing module.
3
4 Example: ::
5
6 from flask import Flask
7
8 from webargs import fields
9 from webargs.flaskparser import use_args
10
11 app = Flask(__name__)
12
13 hello_args = {
14 'name': fields.Str(required=True)
15 }
16
17 @app.route('/')
18 @use_args(hello_args)
19 def index(args):
20 return 'Hello ' + args['name']
21 """
22 import flask
23 from werkzeug.exceptions import HTTPException
24
25 from webargs import core
26 from webargs.core import json
27
28
29 def abort(http_status_code, exc=None, **kwargs):
30 """Raise a HTTPException for the given http_status_code. Attach any keyword
31 arguments to the exception for later processing.
32
33 From Flask-Restful. See NOTICE file for license information.
34 """
35 try:
36 flask.abort(http_status_code)
37 except HTTPException as err:
38 err.data = kwargs
39 err.exc = exc
40 raise err
41
42
43 def is_json_request(req):
44 return core.is_json(req.mimetype)
45
46
47 class FlaskParser(core.Parser):
48 """Flask request argument parser."""
49
50 __location_map__ = dict(view_args="parse_view_args", **core.Parser.__location_map__)
51
52 def parse_view_args(self, req, name, field):
53 """Pull a value from the request's ``view_args``."""
54 return core.get_value(req.view_args, name, field)
55
56 def parse_json(self, req, name, field):
57 """Pull a json value from the request."""
58 json_data = self._cache.get("json")
59 if json_data is None:
60 # We decode the json manually here instead of
61 # using req.get_json() so that we can handle
62 # JSONDecodeErrors consistently
63 data = req._get_data_for_json(cache=True)
64 try:
65 self._cache["json"] = json_data = core.parse_json(data)
66 except json.JSONDecodeError as e:
67 if e.doc == "":
68 return core.missing
69 else:
70 return self.handle_invalid_json_error(e, req)
71 return core.get_value(json_data, name, field, allow_many_nested=True)
72
73 def parse_querystring(self, req, name, field):
74 """Pull a querystring value from the request."""
75 return core.get_value(req.args, name, field)
76
77 def parse_form(self, req, name, field):
78 """Pull a form value from the request."""
79 try:
80 return core.get_value(req.form, name, field)
81 except AttributeError:
82 pass
83 return core.missing
84
85 def parse_headers(self, req, name, field):
86 """Pull a value from the header data."""
87 return core.get_value(req.headers, name, field)
88
89 def parse_cookies(self, req, name, field):
90 """Pull a value from the cookiejar."""
91 return core.get_value(req.cookies, name, field)
92
93 def parse_files(self, req, name, field):
94 """Pull a file from the request."""
95 return core.get_value(req.files, name, field)
96
97 def handle_error(self, error, req, schema, error_status_code, error_headers):
98 """Handles errors during parsing. Aborts the current HTTP request and
99 responds with a 422 error.
100 """
101 status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS
102 abort(
103 status_code,
104 exc=error,
105 messages=error.messages,
106 schema=schema,
107 headers=error_headers,
108 )
109
110 def handle_invalid_json_error(self, error, req, *args, **kwargs):
111 abort(400, exc=error, messages={"json": ["Invalid JSON body."]})
112
113 def get_default_request(self):
114 """Override to use Flask's thread-local request objec by default"""
115 return flask.request
116
117
118 parser = FlaskParser()
119 use_args = parser.use_args
120 use_kwargs = parser.use_kwargs
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/webargs/flaskparser.py b/webargs/flaskparser.py
--- a/webargs/flaskparser.py
+++ b/webargs/flaskparser.py
@@ -60,7 +60,7 @@
# We decode the json manually here instead of
# using req.get_json() so that we can handle
# JSONDecodeErrors consistently
- data = req._get_data_for_json(cache=True)
+ data = req.get_data(cache=True)
try:
self._cache["json"] = json_data = core.parse_json(data)
except json.JSONDecodeError as e:
|
{"golden_diff": "diff --git a/webargs/flaskparser.py b/webargs/flaskparser.py\n--- a/webargs/flaskparser.py\n+++ b/webargs/flaskparser.py\n@@ -60,7 +60,7 @@\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n- data = req._get_data_for_json(cache=True)\n+ data = req.get_data(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n", "issue": "bug: webargs 5.0 introduces incompatibility with Flask < 1.0\nhttps://github.com/marshmallow-code/webargs/blob/5.0.0/webargs/flaskparser.py#L63\r\n\r\n`_get_data_for_json` is only available since Flask >= 1.0\r\n\r\nfor Flask < 1.0, there is an error as follows:\r\n\r\n```\r\n File \"/usr/local/lib/python2.7/site-packages/webargs/flaskparser.py\", line 63, in parse_json\r\n data = req._get_data_for_json(cache=True)\r\n File \"/usr/local/lib/python2.7/site-packages/werkzeug/local.py\", line 347, in __getattr__\r\n return getattr(self._get_current_object(), name)\r\nAttributeError: 'Request' object has no attribute '_get_data_for_json'\r\n```\r\n\r\nI had to downgrade webargs to 4.4.1 to get it work.\r\n\r\nSo you need to update this framework requirement https://github.com/marshmallow-code/webargs/blob/dev/setup.py#L11 or update the code for the backward compatibility.\r\n\r\nIMHO, using `_get_data_for_json` should be avoided because it's considered private and can be changed/removed anytime.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n\n @app.route('/')\n @use_args(hello_args)\n def index(args):\n return 'Hello ' + args['name']\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.core import json\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(view_args=\"parse_view_args\", **core.Parser.__location_map__)\n\n def parse_view_args(self, req, name, field):\n \"\"\"Pull a value from the request's ``view_args``.\"\"\"\n return core.get_value(req.view_args, name, field)\n\n def parse_json(self, req, name, field):\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n data = req._get_data_for_json(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_querystring(self, req, name, field):\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.args, name, field)\n\n def parse_form(self, req, name, field):\n \"\"\"Pull a form value from the request.\"\"\"\n try:\n return core.get_value(req.form, name, field)\n except AttributeError:\n pass\n return core.missing\n\n def parse_headers(self, req, name, field):\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req, name, field):\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req, name, field):\n \"\"\"Pull a file from the request.\"\"\"\n return core.get_value(req.files, name, field)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request objec by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "webargs/flaskparser.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n\n @app.route('/')\n @use_args(hello_args)\n def index(args):\n return 'Hello ' + args['name']\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.core import json\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(view_args=\"parse_view_args\", **core.Parser.__location_map__)\n\n def parse_view_args(self, req, name, field):\n \"\"\"Pull a value from the request's ``view_args``.\"\"\"\n return core.get_value(req.view_args, name, field)\n\n def parse_json(self, req, name, field):\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n data = req.get_data(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_querystring(self, req, name, field):\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.args, name, field)\n\n def parse_form(self, req, name, field):\n \"\"\"Pull a form value from the request.\"\"\"\n try:\n return core.get_value(req.form, name, field)\n except AttributeError:\n pass\n return core.missing\n\n def parse_headers(self, req, name, field):\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req, name, field):\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req, name, field):\n \"\"\"Pull a file from the request.\"\"\"\n return core.get_value(req.files, name, field)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request objec by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "webargs/flaskparser.py"}]}
| 1,616 | 130 |
gh_patches_debug_12423
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-284
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API tests using wrong tables database
**Describe the bug**
The django API tests are running on the `test_mathesar_db_test_database`, which differs from the `mathesar_db_test_database` tables database we should be using. As a result, we don't have a proper reference to the database being used by the API functions, which prevents us from certain operations like installing types for a test.
**Expected behavior**
We should ensure `pytest-django` doesn't build a separate tables database.
**Additional context**
Currently blocking #276
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `config/settings.py`
Content:
```
1 """
2 Django settings for config project.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19 # Build paths inside the project like this: BASE_DIR / 'subdir'.
20 BASE_DIR = Path(__file__).resolve().parent.parent
21
22 # Application definition
23
24 INSTALLED_APPS = [
25 "django.contrib.admin",
26 "django.contrib.auth",
27 "django.contrib.contenttypes",
28 "django.contrib.sessions",
29 "django.contrib.messages",
30 "django.contrib.staticfiles",
31 "rest_framework",
32 "django_filters",
33 "django_property_filter",
34 "mathesar",
35 ]
36
37 MIDDLEWARE = [
38 "django.middleware.security.SecurityMiddleware",
39 "django.contrib.sessions.middleware.SessionMiddleware",
40 "django.middleware.common.CommonMiddleware",
41 "django.middleware.csrf.CsrfViewMiddleware",
42 "django.contrib.auth.middleware.AuthenticationMiddleware",
43 "django.contrib.messages.middleware.MessageMiddleware",
44 "django.middleware.clickjacking.XFrameOptionsMiddleware",
45 ]
46
47 ROOT_URLCONF = "config.urls"
48
49 TEMPLATES = [
50 {
51 "BACKEND": "django.template.backends.django.DjangoTemplates",
52 "DIRS": [],
53 "APP_DIRS": True,
54 "OPTIONS": {
55 "context_processors": [
56 "config.context_processors.get_settings",
57 "django.template.context_processors.debug",
58 "django.template.context_processors.request",
59 "django.contrib.auth.context_processors.auth",
60 "django.contrib.messages.context_processors.messages",
61 ],
62 },
63 },
64 ]
65
66 WSGI_APPLICATION = "config.wsgi.application"
67
68 # Database
69 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
70
71 # TODO: Add to documentation that database keys should not be than 128 characters.
72 DATABASES = {
73 decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),
74 decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
75 }
76
77
78 # Quick-start development settings - unsuitable for production
79 # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
80
81 # SECURITY WARNING: keep the secret key used in production secret!
82 SECRET_KEY = decouple_config('SECRET_KEY')
83
84 # SECURITY WARNING: don't run with debug turned on in production!
85 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
86
87 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())
88
89 # Password validation
90 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
91
92 AUTH_PASSWORD_VALIDATORS = [
93 {
94 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
95 },
96 {
97 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
98 },
99 {
100 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
101 },
102 {
103 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
104 },
105 ]
106
107
108 # Internationalization
109 # https://docs.djangoproject.com/en/3.1/topics/i18n/
110
111 LANGUAGE_CODE = "en-us"
112
113 TIME_ZONE = "UTC"
114
115 USE_I18N = True
116
117 USE_L10N = True
118
119 USE_TZ = True
120
121
122 # Static files (CSS, JavaScript, Images)
123 # https://docs.djangoproject.com/en/3.1/howto/static-files/
124
125 STATIC_URL = "/static/"
126
127 CLIENT_DEV_URL = "http://localhost:3000"
128
129
130 # Media files (uploaded by the user)
131
132 MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
133
134 MEDIA_URL = "/media/"
135
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/config/settings.py b/config/settings.py
--- a/config/settings.py
+++ b/config/settings.py
@@ -74,6 +74,13 @@
decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
}
+# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
+# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
+if decouple_config('TEST', default=False, cast=bool):
+ DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {
+ 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']
+ }
+
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
|
{"golden_diff": "diff --git a/config/settings.py b/config/settings.py\n--- a/config/settings.py\n+++ b/config/settings.py\n@@ -74,6 +74,13 @@\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n }\n \n+# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n+# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\n+if decouple_config('TEST', default=False, cast=bool):\n+ DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n+ 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n+ }\n+\n \n # Quick-start development settings - unsuitable for production\n # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n", "issue": "API tests using wrong tables database\n**Describe the bug**\r\nThe django API tests are running on the `test_mathesar_db_test_database`, which differs from the `mathesar_db_test_database` tables database we should be using. As a result, we don't have a proper reference to the database being used by the API functions, which prevents us from certain operations like installing types for a test. \r\n\r\n**Expected behavior**\r\nWe should ensure `pytest-django` doesn't build a separate tables database.\r\n\r\n**Additional context**\r\nCurrently blocking #276 \r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.get_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\nDATABASES = {\n decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n}\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\nCLIENT_DEV_URL = \"http://localhost:3000\"\n\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n", "path": "config/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.get_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\nDATABASES = {\n decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n}\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nif decouple_config('TEST', default=False, cast=bool):\n DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n }\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\nCLIENT_DEV_URL = \"http://localhost:3000\"\n\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n", "path": "config/settings.py"}]}
| 1,516 | 201 |
gh_patches_debug_9068
|
rasdani/github-patches
|
git_diff
|
techmatters__terraso-backend-368
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
feat: Handle error for SSO signup if user does not have email set
## Description
With Google and Apple SSO it seems we have a guarantee that the user will have their email set. This is good for us; the email is a required column in our user table. However, with Microsoft it seems like we do not have this guarantee, which causes us to display an ugly error message in the case where the user does not have an email defined. There are several ways we could handle this:
1) Display an error message that instructs the user to set their email. This is definitely less user friendly, but may be easier to implement.
2) Allow the user to set their email interactively. This is what is done, for example, with Kobo. The idea here would be to set up a signup page as the final signup step. This page would be pre-populated with whatever content we get from Microsoft, but it will allow the user to manually set their email if it is not present.
Any other options you see?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `terraso_backend/apps/auth/services.py`
Content:
```
1 # Copyright © 2021-2023 Technology Matters
2 #
3 # This program is free software: you can redistribute it and/or modify
4 # it under the terms of the GNU Affero General Public License as published
5 # by the Free Software Foundation, either version 3 of the License, or
6 # (at your option) any later version.
7 #
8 # This program is distributed in the hope that it will be useful,
9 # but WITHOUT ANY WARRANTY; without even the implied warranty of
10 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
11 # GNU Affero General Public License for more details.
12 #
13 # You should have received a copy of the GNU Affero General Public License
14 # along with this program. If not, see https://www.gnu.org/licenses/.
15
16 import ipaddress
17 from datetime import timedelta
18 from typing import Any, Optional
19 from urllib.parse import urlparse
20 from uuid import uuid4
21
22 import httpx
23 import jwt
24 import structlog
25 from django.conf import settings
26 from django.contrib.auth import get_user_model
27 from django.utils import timezone
28
29 from apps.storage.services import ProfileImageService
30
31 from .providers import AppleProvider, GoogleProvider, MicrosoftProvider
32
33 logger = structlog.get_logger(__name__)
34 User = get_user_model()
35
36
37 class AccountService:
38 def sign_up_with_google(self, authorization_code):
39 provider = GoogleProvider()
40 tokens = provider.fetch_auth_tokens(authorization_code)
41
42 if not tokens.is_valid:
43 error_msg = f"Error fetching auth tokens: {tokens.error_description}"
44 logger.error(error_msg)
45 raise Exception(error_msg)
46
47 return self._persist_user(
48 tokens.open_id.email,
49 first_name=tokens.open_id.given_name,
50 last_name=tokens.open_id.family_name,
51 profile_image_url=tokens.open_id.picture,
52 )
53
54 def sign_up_with_apple(self, authorization_code, first_name="", last_name=""):
55 provider = AppleProvider()
56 tokens = provider.fetch_auth_tokens(authorization_code)
57
58 if not tokens.is_valid:
59 error_msg = f"Error fetching auth tokens: {tokens.error_description}"
60 logger.error(error_msg)
61 raise Exception(error_msg)
62
63 return self._persist_user(tokens.open_id.email, first_name=first_name, last_name=last_name)
64
65 def sign_up_with_microsoft(self, authorization_code):
66 provider = MicrosoftProvider()
67 tokens = provider.fetch_auth_tokens(authorization_code)
68 if not tokens.is_valid:
69 error_msg = f"Error fetching auth tokens: {tokens.error_description}"
70 logger.error(error_msg)
71 raise Exception(error_msg)
72 return self._persist_user(
73 tokens.open_id.email,
74 first_name=tokens.open_id.given_name,
75 last_name=tokens.open_id.family_name,
76 profile_image_url=tokens.open_id.picture,
77 )
78
79 def _persist_user(self, email, first_name="", last_name="", profile_image_url=None):
80 user, created = User.objects.get_or_create(email=email)
81
82 self._update_profile_image(user, profile_image_url)
83
84 if not created:
85 return user, False
86
87 update_name = first_name or last_name
88
89 if first_name:
90 user.first_name = first_name
91
92 if last_name:
93 user.last_name = last_name
94
95 if update_name:
96 user.save()
97
98 return user, True
99
100 def _update_profile_image(self, user, profile_image_url):
101 if not profile_image_url:
102 return
103
104 profile_image_service = ProfileImageService()
105 user_id = str(user.id)
106
107 try:
108 user.profile_image = profile_image_service.upload_url(user_id, profile_image_url)
109 user.save()
110 except Exception:
111 logger.exception("Failed to upload profile image. User ID: {}".format(user_id))
112
113
114 class JWTService:
115 JWT_SECRET = settings.JWT_SECRET
116 JWT_ALGORITHM = settings.JWT_ALGORITHM
117 JWT_ACCESS_EXP_DELTA_SECONDS = settings.JWT_ACCESS_EXP_DELTA_SECONDS
118 JWT_REFRESH_EXP_DELTA_SECONDS = settings.JWT_REFRESH_EXP_DELTA_SECONDS
119 JWT_ISS = settings.JWT_ISS
120
121 def create_access_token(self, user):
122 payload = self._get_base_payload(user)
123 payload["exp"] = timezone.now() + timedelta(seconds=self.JWT_ACCESS_EXP_DELTA_SECONDS)
124
125 return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)
126
127 def create_refresh_token(self, user):
128 payload = self._get_base_payload(user)
129 payload["exp"] = timezone.now() + timedelta(seconds=self.JWT_REFRESH_EXP_DELTA_SECONDS)
130
131 return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)
132
133 def verify_token(self, token):
134 return jwt.decode(token, self.JWT_SECRET, algorithms=self.JWT_ALGORITHM)
135
136 def _get_base_payload(self, user):
137 return {
138 "iss": self.JWT_ISS,
139 "iat": timezone.now(),
140 "sub": str(user.id),
141 "jti": uuid4().hex,
142 "email": user.email,
143 }
144
145
146 class PlausibleService:
147 """Service for making API calls to plausible service.
148
149 See documentation at https://plausible.io/docs/events-api .
150 """
151
152 PLAUSIBLE_URL = settings.PLAUSIBLE_URL
153 FRONTEND_URL = settings.WEB_CLIENT_URL
154 # fake URL here, because there is no real "signup" URL
155 # see Plausible API docs for "url" param
156 EVENT_URL = f"{FRONTEND_URL}/signup"
157
158 @staticmethod
159 def _prepare_headers(user_agent: str, ip_address: str) -> dict[str, str]:
160 return {
161 "User-Agent": user_agent,
162 "X-Forwarded-For": ip_address,
163 "Content-Type": "application/json",
164 }
165
166 @classmethod
167 def _prepare_body_params(
168 cls, event_name: str, event_url: str, referrer: str, props: Optional[dict[str, Any]]
169 ):
170 return {
171 "domain": urlparse(cls.FRONTEND_URL).hostname,
172 "name": event_name,
173 "url": event_url,
174 "referrer": referrer,
175 "props": props,
176 }
177
178 @staticmethod
179 def _get_first_ip_address(string: str):
180 addresses = string.split(",")
181 for addr in addresses:
182 try:
183 ip_address = ipaddress.ip_address(addr)
184 break
185 except ValueError:
186 pass
187 else:
188 # we only get to this branch if we never break
189 # i.e. none of the candidates are valid ip addresses
190 return None
191 return str(ip_address)
192
193 def track_event(
194 self,
195 event_name: str,
196 user_agent: str,
197 ip_address: str,
198 event_url: str,
199 props: Optional[dict[str, Any]] = None,
200 referrer: str = "",
201 ) -> None:
202 """Send a tracking event to Plausible through the HTTP API.
203 Throws exception if not succesful."""
204 headers = self._prepare_headers(user_agent, ip_address)
205 data = self._prepare_body_params(event_name, event_url, referrer, props)
206 resp = httpx.post(self.PLAUSIBLE_URL, headers=headers, json=data)
207
208 resp.raise_for_status()
209
210 def track_signup(self, auth_provider: str, req) -> None:
211 """Track a successful signup. Include information on which service was used for signup."""
212 event_name = "User signup"
213 if "user-agent" not in req.headers:
214 logger.error("During signup tracking, request missing header 'user-agent'")
215 return
216 user_agent = req.headers["user-agent"]
217 # here we just assume we are testing locally if 'x-forwarded-for' header is not present
218 # this is a mandatory header for the Plausible API, see docs for details
219 ip_address = "127.0.0.1"
220 if "x-forwarded-for" in req.headers:
221 ip_address = self._get_first_ip_address(req.headers["x-forwarded-for"])
222 if not ip_address:
223 logger.error(
224 "During signup tracking, request header 'x-forwarded-for' was set,"
225 " but no valid ip addresses were found"
226 )
227 return
228 props = {"service": auth_provider}
229 self.track_event(event_name, user_agent, ip_address, self.EVENT_URL, props)
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/terraso_backend/apps/auth/services.py b/terraso_backend/apps/auth/services.py
--- a/terraso_backend/apps/auth/services.py
+++ b/terraso_backend/apps/auth/services.py
@@ -77,6 +77,10 @@
)
def _persist_user(self, email, first_name="", last_name="", profile_image_url=None):
+ if not email:
+ # it is possible for the email not to be set, notably with Microsoft
+ # here throw a more descriptive error message
+ raise ValueError("Could not create account, user email is empty")
user, created = User.objects.get_or_create(email=email)
self._update_profile_image(user, profile_image_url)
|
{"golden_diff": "diff --git a/terraso_backend/apps/auth/services.py b/terraso_backend/apps/auth/services.py\n--- a/terraso_backend/apps/auth/services.py\n+++ b/terraso_backend/apps/auth/services.py\n@@ -77,6 +77,10 @@\n )\n \n def _persist_user(self, email, first_name=\"\", last_name=\"\", profile_image_url=None):\n+ if not email:\n+ # it is possible for the email not to be set, notably with Microsoft\n+ # here throw a more descriptive error message\n+ raise ValueError(\"Could not create account, user email is empty\")\n user, created = User.objects.get_or_create(email=email)\n \n self._update_profile_image(user, profile_image_url)\n", "issue": "feat: Handle error for SSO signup if user does not have email set\n## Description\r\n\r\nWith Google and Apple SSO it seems we have a guarantee that the user will have their email set. This is good for us; the email is a required column in our user table. However, with Microsoft it seems like we do not have this guarantee, which causes us to display an ugly error message in the case where the user does not have an email defined. There are several ways we could handle this:\r\n\r\n1) Display an error message that instructs the user to set their email. This is definitely less user friendly, but may be easier to implement.\r\n\r\n2) Allow the user to set their email interactively. This is what is done, for example, with Kobo. The idea here would be to set up a signup page as the final signup step. This page would be pre-populated with whatever content we get from Microsoft, but it will allow the user to manually set their email if it is not present.\r\n\r\nAny other options you see?\r\n\n", "before_files": [{"content": "# Copyright \u00a9 2021-2023 Technology Matters\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published\n# by the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see https://www.gnu.org/licenses/.\n\nimport ipaddress\nfrom datetime import timedelta\nfrom typing import Any, Optional\nfrom urllib.parse import urlparse\nfrom uuid import uuid4\n\nimport httpx\nimport jwt\nimport structlog\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.utils import timezone\n\nfrom apps.storage.services import ProfileImageService\n\nfrom .providers import AppleProvider, GoogleProvider, MicrosoftProvider\n\nlogger = structlog.get_logger(__name__)\nUser = get_user_model()\n\n\nclass AccountService:\n def sign_up_with_google(self, authorization_code):\n provider = GoogleProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n\n return self._persist_user(\n tokens.open_id.email,\n first_name=tokens.open_id.given_name,\n last_name=tokens.open_id.family_name,\n profile_image_url=tokens.open_id.picture,\n )\n\n def sign_up_with_apple(self, authorization_code, first_name=\"\", last_name=\"\"):\n provider = AppleProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n\n return self._persist_user(tokens.open_id.email, first_name=first_name, last_name=last_name)\n\n def sign_up_with_microsoft(self, authorization_code):\n provider = MicrosoftProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n return self._persist_user(\n tokens.open_id.email,\n first_name=tokens.open_id.given_name,\n last_name=tokens.open_id.family_name,\n profile_image_url=tokens.open_id.picture,\n )\n\n def _persist_user(self, email, first_name=\"\", last_name=\"\", profile_image_url=None):\n user, created = User.objects.get_or_create(email=email)\n\n self._update_profile_image(user, profile_image_url)\n\n if not created:\n return user, False\n\n update_name = first_name or last_name\n\n if first_name:\n user.first_name = first_name\n\n if last_name:\n user.last_name = last_name\n\n if update_name:\n user.save()\n\n return user, True\n\n def _update_profile_image(self, user, profile_image_url):\n if not profile_image_url:\n return\n\n profile_image_service = ProfileImageService()\n user_id = str(user.id)\n\n try:\n user.profile_image = profile_image_service.upload_url(user_id, profile_image_url)\n user.save()\n except Exception:\n logger.exception(\"Failed to upload profile image. User ID: {}\".format(user_id))\n\n\nclass JWTService:\n JWT_SECRET = settings.JWT_SECRET\n JWT_ALGORITHM = settings.JWT_ALGORITHM\n JWT_ACCESS_EXP_DELTA_SECONDS = settings.JWT_ACCESS_EXP_DELTA_SECONDS\n JWT_REFRESH_EXP_DELTA_SECONDS = settings.JWT_REFRESH_EXP_DELTA_SECONDS\n JWT_ISS = settings.JWT_ISS\n\n def create_access_token(self, user):\n payload = self._get_base_payload(user)\n payload[\"exp\"] = timezone.now() + timedelta(seconds=self.JWT_ACCESS_EXP_DELTA_SECONDS)\n\n return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)\n\n def create_refresh_token(self, user):\n payload = self._get_base_payload(user)\n payload[\"exp\"] = timezone.now() + timedelta(seconds=self.JWT_REFRESH_EXP_DELTA_SECONDS)\n\n return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)\n\n def verify_token(self, token):\n return jwt.decode(token, self.JWT_SECRET, algorithms=self.JWT_ALGORITHM)\n\n def _get_base_payload(self, user):\n return {\n \"iss\": self.JWT_ISS,\n \"iat\": timezone.now(),\n \"sub\": str(user.id),\n \"jti\": uuid4().hex,\n \"email\": user.email,\n }\n\n\nclass PlausibleService:\n \"\"\"Service for making API calls to plausible service.\n\n See documentation at https://plausible.io/docs/events-api .\n \"\"\"\n\n PLAUSIBLE_URL = settings.PLAUSIBLE_URL\n FRONTEND_URL = settings.WEB_CLIENT_URL\n # fake URL here, because there is no real \"signup\" URL\n # see Plausible API docs for \"url\" param\n EVENT_URL = f\"{FRONTEND_URL}/signup\"\n\n @staticmethod\n def _prepare_headers(user_agent: str, ip_address: str) -> dict[str, str]:\n return {\n \"User-Agent\": user_agent,\n \"X-Forwarded-For\": ip_address,\n \"Content-Type\": \"application/json\",\n }\n\n @classmethod\n def _prepare_body_params(\n cls, event_name: str, event_url: str, referrer: str, props: Optional[dict[str, Any]]\n ):\n return {\n \"domain\": urlparse(cls.FRONTEND_URL).hostname,\n \"name\": event_name,\n \"url\": event_url,\n \"referrer\": referrer,\n \"props\": props,\n }\n\n @staticmethod\n def _get_first_ip_address(string: str):\n addresses = string.split(\",\")\n for addr in addresses:\n try:\n ip_address = ipaddress.ip_address(addr)\n break\n except ValueError:\n pass\n else:\n # we only get to this branch if we never break\n # i.e. none of the candidates are valid ip addresses\n return None\n return str(ip_address)\n\n def track_event(\n self,\n event_name: str,\n user_agent: str,\n ip_address: str,\n event_url: str,\n props: Optional[dict[str, Any]] = None,\n referrer: str = \"\",\n ) -> None:\n \"\"\"Send a tracking event to Plausible through the HTTP API.\n Throws exception if not succesful.\"\"\"\n headers = self._prepare_headers(user_agent, ip_address)\n data = self._prepare_body_params(event_name, event_url, referrer, props)\n resp = httpx.post(self.PLAUSIBLE_URL, headers=headers, json=data)\n\n resp.raise_for_status()\n\n def track_signup(self, auth_provider: str, req) -> None:\n \"\"\"Track a successful signup. Include information on which service was used for signup.\"\"\"\n event_name = \"User signup\"\n if \"user-agent\" not in req.headers:\n logger.error(\"During signup tracking, request missing header 'user-agent'\")\n return\n user_agent = req.headers[\"user-agent\"]\n # here we just assume we are testing locally if 'x-forwarded-for' header is not present\n # this is a mandatory header for the Plausible API, see docs for details\n ip_address = \"127.0.0.1\"\n if \"x-forwarded-for\" in req.headers:\n ip_address = self._get_first_ip_address(req.headers[\"x-forwarded-for\"])\n if not ip_address:\n logger.error(\n \"During signup tracking, request header 'x-forwarded-for' was set,\"\n \" but no valid ip addresses were found\"\n )\n return\n props = {\"service\": auth_provider}\n self.track_event(event_name, user_agent, ip_address, self.EVENT_URL, props)\n", "path": "terraso_backend/apps/auth/services.py"}], "after_files": [{"content": "# Copyright \u00a9 2021-2023 Technology Matters\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published\n# by the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see https://www.gnu.org/licenses/.\n\nimport ipaddress\nfrom datetime import timedelta\nfrom typing import Any, Optional\nfrom urllib.parse import urlparse\nfrom uuid import uuid4\n\nimport httpx\nimport jwt\nimport structlog\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.utils import timezone\n\nfrom apps.storage.services import ProfileImageService\n\nfrom .providers import AppleProvider, GoogleProvider, MicrosoftProvider\n\nlogger = structlog.get_logger(__name__)\nUser = get_user_model()\n\n\nclass AccountService:\n def sign_up_with_google(self, authorization_code):\n provider = GoogleProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n\n return self._persist_user(\n tokens.open_id.email,\n first_name=tokens.open_id.given_name,\n last_name=tokens.open_id.family_name,\n profile_image_url=tokens.open_id.picture,\n )\n\n def sign_up_with_apple(self, authorization_code, first_name=\"\", last_name=\"\"):\n provider = AppleProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n\n return self._persist_user(tokens.open_id.email, first_name=first_name, last_name=last_name)\n\n def sign_up_with_microsoft(self, authorization_code):\n provider = MicrosoftProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n return self._persist_user(\n tokens.open_id.email,\n first_name=tokens.open_id.given_name,\n last_name=tokens.open_id.family_name,\n profile_image_url=tokens.open_id.picture,\n )\n\n def _persist_user(self, email, first_name=\"\", last_name=\"\", profile_image_url=None):\n if not email:\n # it is possible for the email not to be set, notably with Microsoft\n # here throw a more descriptive error message\n raise ValueError(\"Could not create account, user email is empty\")\n user, created = User.objects.get_or_create(email=email)\n\n self._update_profile_image(user, profile_image_url)\n\n if not created:\n return user, False\n\n update_name = first_name or last_name\n\n if first_name:\n user.first_name = first_name\n\n if last_name:\n user.last_name = last_name\n\n if update_name:\n user.save()\n\n return user, True\n\n def _update_profile_image(self, user, profile_image_url):\n if not profile_image_url:\n return\n\n profile_image_service = ProfileImageService()\n user_id = str(user.id)\n\n try:\n user.profile_image = profile_image_service.upload_url(user_id, profile_image_url)\n user.save()\n except Exception:\n logger.exception(\"Failed to upload profile image. User ID: {}\".format(user_id))\n\n\nclass JWTService:\n JWT_SECRET = settings.JWT_SECRET\n JWT_ALGORITHM = settings.JWT_ALGORITHM\n JWT_ACCESS_EXP_DELTA_SECONDS = settings.JWT_ACCESS_EXP_DELTA_SECONDS\n JWT_REFRESH_EXP_DELTA_SECONDS = settings.JWT_REFRESH_EXP_DELTA_SECONDS\n JWT_ISS = settings.JWT_ISS\n\n def create_access_token(self, user):\n payload = self._get_base_payload(user)\n payload[\"exp\"] = timezone.now() + timedelta(seconds=self.JWT_ACCESS_EXP_DELTA_SECONDS)\n\n return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)\n\n def create_refresh_token(self, user):\n payload = self._get_base_payload(user)\n payload[\"exp\"] = timezone.now() + timedelta(seconds=self.JWT_REFRESH_EXP_DELTA_SECONDS)\n\n return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)\n\n def verify_token(self, token):\n return jwt.decode(token, self.JWT_SECRET, algorithms=self.JWT_ALGORITHM)\n\n def _get_base_payload(self, user):\n return {\n \"iss\": self.JWT_ISS,\n \"iat\": timezone.now(),\n \"sub\": str(user.id),\n \"jti\": uuid4().hex,\n \"email\": user.email,\n }\n\n\nclass PlausibleService:\n \"\"\"Service for making API calls to plausible service.\n\n See documentation at https://plausible.io/docs/events-api .\n \"\"\"\n\n PLAUSIBLE_URL = settings.PLAUSIBLE_URL\n FRONTEND_URL = settings.WEB_CLIENT_URL\n # fake URL here, because there is no real \"signup\" URL\n # see Plausible API docs for \"url\" param\n EVENT_URL = f\"{FRONTEND_URL}/signup\"\n\n @staticmethod\n def _prepare_headers(user_agent: str, ip_address: str) -> dict[str, str]:\n return {\n \"User-Agent\": user_agent,\n \"X-Forwarded-For\": ip_address,\n \"Content-Type\": \"application/json\",\n }\n\n @classmethod\n def _prepare_body_params(\n cls, event_name: str, event_url: str, referrer: str, props: Optional[dict[str, Any]]\n ):\n return {\n \"domain\": urlparse(cls.FRONTEND_URL).hostname,\n \"name\": event_name,\n \"url\": event_url,\n \"referrer\": referrer,\n \"props\": props,\n }\n\n @staticmethod\n def _get_first_ip_address(string: str):\n addresses = string.split(\",\")\n for addr in addresses:\n try:\n ip_address = ipaddress.ip_address(addr)\n break\n except ValueError:\n pass\n else:\n # we only get to this branch if we never break\n # i.e. none of the candidates are valid ip addresses\n return None\n return str(ip_address)\n\n def track_event(\n self,\n event_name: str,\n user_agent: str,\n ip_address: str,\n event_url: str,\n props: Optional[dict[str, Any]] = None,\n referrer: str = \"\",\n ) -> None:\n \"\"\"Send a tracking event to Plausible through the HTTP API.\n Throws exception if not succesful.\"\"\"\n headers = self._prepare_headers(user_agent, ip_address)\n data = self._prepare_body_params(event_name, event_url, referrer, props)\n resp = httpx.post(self.PLAUSIBLE_URL, headers=headers, json=data)\n\n resp.raise_for_status()\n\n def track_signup(self, auth_provider: str, req) -> None:\n \"\"\"Track a successful signup. Include information on which service was used for signup.\"\"\"\n event_name = \"User signup\"\n if \"user-agent\" not in req.headers:\n logger.error(\"During signup tracking, request missing header 'user-agent'\")\n return\n user_agent = req.headers[\"user-agent\"]\n # here we just assume we are testing locally if 'x-forwarded-for' header is not present\n # this is a mandatory header for the Plausible API, see docs for details\n ip_address = \"127.0.0.1\"\n if \"x-forwarded-for\" in req.headers:\n ip_address = self._get_first_ip_address(req.headers[\"x-forwarded-for\"])\n if not ip_address:\n logger.error(\n \"During signup tracking, request header 'x-forwarded-for' was set,\"\n \" but no valid ip addresses were found\"\n )\n return\n props = {\"service\": auth_provider}\n self.track_event(event_name, user_agent, ip_address, self.EVENT_URL, props)\n", "path": "terraso_backend/apps/auth/services.py"}]}
| 2,812 | 160 |
gh_patches_debug_14759
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1901
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Keystroke ] not detected on Windows
In Powershell and cmd.exe I encountered that sorting didn't work in both orders. The `[` shortcut was detected and had its effect, but the `]` didn't. I narrowed it down to a problem with `windows-curses`, and in turn with its dependency `PDCurses`: https://github.com/zephyrproject-rtos/windows-curses/issues/41
Here's my plan on how to address it. I hope I'll get around to it somewhere next week.
- [ ] Improve the mapping in `PDCurses` and submit a pull request
- [ ] Bump the git submodule in `windows-curses` to the `PDCurses` version that has the fix and ask/wait for a release of this package
- [ ] Address the issue in this repository, perhaps by pinning `windows-curses` to a version of at least the newly released package.
I'm making this issue here just to document it and track progress. If you're reading this because you have this issue, I would recommend using WSL instead. (WSL is not an option for me unfortunately).
I didn't include the `.vd`-file to reproduce this issue. The simplest way to reproduce it is to get a Windows computer, run `visidata` from Powershell or cmd.exe and sort any column by pressing `]`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python3
2
3 from setuptools import setup
4 # tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96
5 #from visidata import __version__
6 __version__ = '2.12dev'
7
8 setup(name='visidata',
9 version=__version__,
10 description='terminal interface for exploring and arranging tabular data',
11 long_description=open('README.md').read(),
12 long_description_content_type='text/markdown',
13 author='Saul Pwanson',
14 python_requires='>=3.7',
15 author_email='[email protected]',
16 url='https://visidata.org',
17 download_url='https://github.com/saulpw/visidata/tarball/' + __version__,
18 scripts=['bin/vd'],
19 entry_points={'console_scripts': [
20 'visidata=visidata.main:vd_cli'
21 ],
22 },
23 py_modules=['visidata'],
24 install_requires=[
25 'python-dateutil',
26 'windows-curses; platform_system == "Windows"',
27 'importlib-metadata >= 3.6',
28 ],
29 packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
30 data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],
31 package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},
32 license='GPLv3',
33 classifiers=[
34 'Development Status :: 5 - Production/Stable',
35 'Environment :: Console',
36 'Environment :: Console :: Curses',
37 'Intended Audience :: Developers',
38 'Intended Audience :: Science/Research',
39 'Intended Audience :: System Administrators',
40 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',
41 'Operating System :: OS Independent',
42 'Programming Language :: Python :: 3',
43 'Topic :: Database :: Front-Ends',
44 'Topic :: Scientific/Engineering',
45 'Topic :: Office/Business :: Financial :: Spreadsheet',
46 'Topic :: Scientific/Engineering :: Visualization',
47 'Topic :: Utilities',
48 ],
49 keywords=('console tabular data spreadsheet terminal viewer textpunk'
50 'curses csv hdf5 h5 xlsx excel tsv'),
51 )
52
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,7 +23,7 @@
py_modules=['visidata'],
install_requires=[
'python-dateutil',
- 'windows-curses; platform_system == "Windows"',
+ 'windows-curses<2.3.1; platform_system == "Windows"', #1841
'importlib-metadata >= 3.6',
],
packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,7 +23,7 @@\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n- 'windows-curses; platform_system == \"Windows\"',\n+ 'windows-curses<2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n", "issue": "Keystroke ] not detected on Windows\nIn Powershell and cmd.exe I encountered that sorting didn't work in both orders. The `[` shortcut was detected and had its effect, but the `]` didn't. I narrowed it down to a problem with `windows-curses`, and in turn with its dependency `PDCurses`: https://github.com/zephyrproject-rtos/windows-curses/issues/41\r\n\r\nHere's my plan on how to address it. I hope I'll get around to it somewhere next week.\r\n- [ ] Improve the mapping in `PDCurses` and submit a pull request\r\n- [ ] Bump the git submodule in `windows-curses` to the `PDCurses` version that has the fix and ask/wait for a release of this package\r\n- [ ] Address the issue in this repository, perhaps by pinning `windows-curses` to a version of at least the newly released package.\r\n\r\nI'm making this issue here just to document it and track progress. If you're reading this because you have this issue, I would recommend using WSL instead. (WSL is not an option for me unfortunately).\r\n\r\nI didn't include the `.vd`-file to reproduce this issue. The simplest way to reproduce it is to get a Windows computer, run `visidata` from Powershell or cmd.exe and sort any column by pressing `]`.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '2.12dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses; platform_system == \"Windows\"',\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '2.12dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses<2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}]}
| 1,222 | 175 |
gh_patches_debug_19208
|
rasdani/github-patches
|
git_diff
|
microsoft__promptflow-576
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Streaming requires Generator where Iterator should suffice
**Describe the bug**
For the user code to provide streaming content, instead of the more generic Iterator protocol, Promptflow relies on the more specific `GeneratorType`. That is requiring the user to unnecessarily wrap their iterators in generators to stream content in more generic scenarios (such as streaming langchain results). Is there a reason PF depends on GeneratorType instead of the iterator protocol? Also, see this note in the [python source](https://github.com/python/cpython/blob/f65497fd252a4a4df960da04d68e8316b58624c0/Lib/types.py#L6-L10):
```
# Iterators in Python aren't a matter of type but of protocol. A large
# and changing number of builtin types implement *some* flavor of
# iterator. Don't check the type! Use hasattr to check for both
# "__iter__" and "__next__" attributes instead.
```
**Concrete Issue:**
When returning an iterator from my tool to enable streaming, I get the following error when running `pf flow test`
```
Flow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is
not JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please
verify your flow output and make sure the value serializable.
```
**How To Reproduce the bug**
Here is my flow.dag.yaml:
```yaml
id: template_chat_flow
name: Template Chat Flow
inputs:
chat_history:
type: list
default: []
question:
type: string
default: What is the meaning of life?
outputs:
answer:
type: string
is_chat_output: true
reference: ${stream.output}
nodes:
- name: stream
type: python
source:
type: code
path: stream.py
inputs:
input: ${inputs.question}
```
And here is my stream.py
```python
from promptflow import tool
class WordIterator:
def __init__(self, input: str):
self.input = input
def __iter__(self):
return self
def __next__(self):
if self.input:
word, *rest = self.input.split(" ")
self.input = " ".join(rest)
return f"{word} "
else:
raise StopIteration
@tool
def my_python_tool(input: str):
iterator = WordIterator(input)
assert hasattr(iterator, "__iter__")
assert hasattr(iterator, "__next__")
return iterator
```
With the above PF run `pf flow test --flow .` -- I get this error:
```
2023-09-19 11:01:17 +0200 42558 execution INFO Start to run 1 nodes with concurrency level 16.
2023-09-19 11:01:17 +0200 42558 execution.flow INFO Executing node stream. node run id: c4ddaddd-6a38-44fd-9ab1-3258fb88bb37_stream_0
2023-09-19 11:01:17 +0200 42558 execution.flow WARNING Output of stream is not json serializable, use str to store it.
2023-09-19 11:01:17 +0200 42558 execution.flow INFO Node stream completes.
Flow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is not JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please verify your flow output and make sure the value serializable.
```
**Expected behavior**
It should read out the iterator and stream the chunks to the caller -- `pf flow test --flow .` should look like this:
```
2023-09-19 10:34:05 +0200 40375 execution INFO Start to run 1 nodes with concurrency level 16.
2023-09-19 10:34:05 +0200 40375 execution.flow INFO Executing node stream. node run id: 24e60c4d-606a-4fc5-8e4c-cc4a5c41d6c8_stream_0
2023-09-19 10:34:05 +0200 40375 execution.flow WARNING Output of stream is not json serializable, use str to store it.
2023-09-19 10:34:05 +0200 40375 execution.flow INFO Node stream completes.
{
"answer": "What is the meaning of life? "
}
```
**Running Information(please complete the following information):**
- Promptflow Package Version using `pf -v`: 0.1.0b6
- Operating System:
```
ProductName: macOS
ProductVersion: 13.5.2
BuildVersion: 22G91
```
- Python Version using `python --version`: Python 3.10.12
**Additional context**
If I wrap the iterator in a generator, everything works as expected:
```python
from promptflow import tool
class WordIterator:
def __init__(self, input: str):
self.input = input
def __iter__(self):
return self
def __next__(self):
if self.input:
word, *rest = self.input.split(" ")
self.input = " ".join(rest)
return f"{word} "
else:
raise StopIteration
def to_generator(self):
try:
while True:
yield next(self)
except StopIteration:
pass
@tool
def my_python_tool(input: str):
iterator = WordIterator(input).to_generator()
assert hasattr(iterator, "__iter__")
assert hasattr(iterator, "__next__")
return iterator
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/promptflow/promptflow/_core/tracer.py`
Content:
```
1 # ---------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # ---------------------------------------------------------
4
5 import inspect
6 import json
7 import logging
8 from contextvars import ContextVar
9 from datetime import datetime
10 from types import GeneratorType
11 from typing import Optional
12
13 from promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy
14 from promptflow._utils.dataclass_serializer import serialize
15 from promptflow.contracts.tool import ConnectionType
16 from promptflow.contracts.trace import Trace, TraceType
17
18 from .thread_local_singleton import ThreadLocalSingleton
19
20
21 class Tracer(ThreadLocalSingleton):
22 CONTEXT_VAR_NAME = "Tracer"
23 context_var = ContextVar(CONTEXT_VAR_NAME, default=None)
24
25 def __init__(self, run_id):
26 self._run_id = run_id
27 self._traces = []
28 self._trace_stack = []
29
30 @classmethod
31 def start_tracing(cls, run_id):
32 tracer = cls(run_id)
33 tracer._activate_in_context()
34
35 @classmethod
36 def end_tracing(cls, raise_ex=False):
37 tracer = cls.active_instance()
38 if not tracer:
39 msg = "Try end tracing but no active tracer in current context."
40 if raise_ex:
41 raise Exception(msg)
42 logging.warning(msg)
43 return []
44 tracer._deactivate_in_context()
45 return tracer.to_json()
46
47 @classmethod
48 def push_tool(cls, f, args, kwargs):
49 obj = cls.active_instance()
50 sig = inspect.signature(f).parameters
51 all_kwargs = {**{k: v for k, v in zip(sig.keys(), args)}, **kwargs}
52 all_kwargs = {
53 k: ConnectionType.serialize_conn(v) if ConnectionType.is_connection_value(v) else v
54 for k, v in all_kwargs.items()
55 }
56 # TODO: put parameters in self to inputs for builtin tools
57 all_kwargs.pop("self", None)
58 trace = Trace(
59 name=f.__qualname__,
60 type=TraceType.TOOL,
61 start_time=datetime.utcnow().timestamp(),
62 inputs=all_kwargs,
63 )
64 obj._push(trace)
65 return trace
66
67 @classmethod
68 def push(cls, trace: Trace):
69 obj = cls.active_instance()
70 if not obj:
71 logging.warning("Try to push trace but no active tracer in current context.")
72 return
73 obj._push(trace)
74
75 @staticmethod
76 def to_serializable(obj):
77 if isinstance(obj, dict) and all(isinstance(k, str) for k in obj.keys()):
78 return {k: Tracer.to_serializable(v) for k, v in obj.items()}
79 if isinstance(obj, GeneratorProxy):
80 return obj
81 try:
82 obj = serialize(obj)
83 json.dumps(obj)
84 except Exception:
85 # We don't want to fail the whole function call because of a serialization error,
86 # so we simply convert it to str if it cannot be serialized.
87 obj = str(obj)
88 return obj
89
90 def _push(self, trace: Trace):
91 if trace.inputs:
92 trace.inputs = self.to_serializable(trace.inputs)
93 if not trace.start_time:
94 trace.start_time = datetime.utcnow().timestamp()
95 if not self._trace_stack:
96 self._traces.append(trace)
97 else:
98 self._trace_stack[-1].children = self._trace_stack[-1].children or []
99 self._trace_stack[-1].children.append(trace)
100 self._trace_stack.append(trace)
101
102 @classmethod
103 def pop(cls, output=None, error: Optional[Exception] = None):
104 obj = cls.active_instance()
105 return obj._pop(output, error)
106
107 def _pop(self, output=None, error: Optional[Exception] = None):
108 last_trace = self._trace_stack[-1]
109 if isinstance(output, GeneratorType):
110 output = GeneratorProxy(output)
111 if output is not None:
112 last_trace.output = self.to_serializable(output)
113 if error is not None:
114 last_trace.error = self._format_error(error)
115 self._trace_stack[-1].end_time = datetime.utcnow().timestamp()
116 self._trace_stack.pop()
117
118 if isinstance(output, GeneratorProxy):
119 return generate_from_proxy(output)
120 else:
121 return output
122
123 def to_json(self) -> list:
124 return serialize(self._traces)
125
126 @staticmethod
127 def _format_error(error: Exception) -> dict:
128 return {
129 "message": str(error),
130 "type": type(error).__qualname__,
131 }
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/promptflow/promptflow/_core/tracer.py b/src/promptflow/promptflow/_core/tracer.py
--- a/src/promptflow/promptflow/_core/tracer.py
+++ b/src/promptflow/promptflow/_core/tracer.py
@@ -5,9 +5,9 @@
import inspect
import json
import logging
+from collections.abc import Iterator
from contextvars import ContextVar
from datetime import datetime
-from types import GeneratorType
from typing import Optional
from promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy
@@ -106,7 +106,7 @@
def _pop(self, output=None, error: Optional[Exception] = None):
last_trace = self._trace_stack[-1]
- if isinstance(output, GeneratorType):
+ if isinstance(output, Iterator):
output = GeneratorProxy(output)
if output is not None:
last_trace.output = self.to_serializable(output)
|
{"golden_diff": "diff --git a/src/promptflow/promptflow/_core/tracer.py b/src/promptflow/promptflow/_core/tracer.py\n--- a/src/promptflow/promptflow/_core/tracer.py\n+++ b/src/promptflow/promptflow/_core/tracer.py\n@@ -5,9 +5,9 @@\n import inspect\n import json\n import logging\n+from collections.abc import Iterator\n from contextvars import ContextVar\n from datetime import datetime\n-from types import GeneratorType\n from typing import Optional\n \n from promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy\n@@ -106,7 +106,7 @@\n \n def _pop(self, output=None, error: Optional[Exception] = None):\n last_trace = self._trace_stack[-1]\n- if isinstance(output, GeneratorType):\n+ if isinstance(output, Iterator):\n output = GeneratorProxy(output)\n if output is not None:\n last_trace.output = self.to_serializable(output)\n", "issue": "[BUG] Streaming requires Generator where Iterator should suffice\n**Describe the bug**\r\nFor the user code to provide streaming content, instead of the more generic Iterator protocol, Promptflow relies on the more specific `GeneratorType`. That is requiring the user to unnecessarily wrap their iterators in generators to stream content in more generic scenarios (such as streaming langchain results). Is there a reason PF depends on GeneratorType instead of the iterator protocol? Also, see this note in the [python source](https://github.com/python/cpython/blob/f65497fd252a4a4df960da04d68e8316b58624c0/Lib/types.py#L6-L10):\r\n```\r\n# Iterators in Python aren't a matter of type but of protocol. A large\r\n# and changing number of builtin types implement *some* flavor of\r\n# iterator. Don't check the type! Use hasattr to check for both\r\n# \"__iter__\" and \"__next__\" attributes instead.\r\n```\r\n\r\n**Concrete Issue:** \r\nWhen returning an iterator from my tool to enable streaming, I get the following error when running `pf flow test`\r\n```\r\nFlow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is \r\nnot JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please \r\nverify your flow output and make sure the value serializable.\r\n```\r\n\r\n**How To Reproduce the bug**\r\nHere is my flow.dag.yaml:\r\n```yaml\r\nid: template_chat_flow\r\nname: Template Chat Flow\r\ninputs:\r\n chat_history:\r\n type: list\r\n default: []\r\n question:\r\n type: string\r\n default: What is the meaning of life?\r\noutputs:\r\n answer:\r\n type: string\r\n is_chat_output: true\r\n reference: ${stream.output}\r\nnodes:\r\n- name: stream\r\n type: python\r\n source:\r\n type: code\r\n path: stream.py\r\n inputs:\r\n input: ${inputs.question}\r\n```\r\n\r\nAnd here is my stream.py\r\n```python\r\nfrom promptflow import tool\r\n\r\nclass WordIterator:\r\n def __init__(self, input: str):\r\n self.input = input\r\n\r\n def __iter__(self):\r\n return self\r\n\r\n def __next__(self):\r\n if self.input:\r\n word, *rest = self.input.split(\" \")\r\n self.input = \" \".join(rest)\r\n return f\"{word} \"\r\n else:\r\n raise StopIteration \r\n\r\n@tool\r\ndef my_python_tool(input: str):\r\n iterator = WordIterator(input)\r\n assert hasattr(iterator, \"__iter__\")\r\n assert hasattr(iterator, \"__next__\")\r\n return iterator\r\n```\r\nWith the above PF run `pf flow test --flow .` -- I get this error:\r\n```\r\n2023-09-19 11:01:17 +0200 42558 execution INFO Start to run 1 nodes with concurrency level 16.\r\n2023-09-19 11:01:17 +0200 42558 execution.flow INFO Executing node stream. node run id: c4ddaddd-6a38-44fd-9ab1-3258fb88bb37_stream_0\r\n2023-09-19 11:01:17 +0200 42558 execution.flow WARNING Output of stream is not json serializable, use str to store it.\r\n2023-09-19 11:01:17 +0200 42558 execution.flow INFO Node stream completes.\r\nFlow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is not JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please verify your flow output and make sure the value serializable.\r\n```\r\n\r\n**Expected behavior**\r\nIt should read out the iterator and stream the chunks to the caller -- `pf flow test --flow .` should look like this:\r\n```\r\n2023-09-19 10:34:05 +0200 40375 execution INFO Start to run 1 nodes with concurrency level 16.\r\n2023-09-19 10:34:05 +0200 40375 execution.flow INFO Executing node stream. node run id: 24e60c4d-606a-4fc5-8e4c-cc4a5c41d6c8_stream_0\r\n2023-09-19 10:34:05 +0200 40375 execution.flow WARNING Output of stream is not json serializable, use str to store it.\r\n2023-09-19 10:34:05 +0200 40375 execution.flow INFO Node stream completes.\r\n{\r\n \"answer\": \"What is the meaning of life? \"\r\n}\r\n```\r\n\r\n**Running Information(please complete the following information):**\r\n - Promptflow Package Version using `pf -v`: 0.1.0b6\r\n - Operating System: \r\n```\r\nProductName: macOS\r\nProductVersion: 13.5.2\r\nBuildVersion: 22G91\r\n```\r\n - Python Version using `python --version`: Python 3.10.12\r\n\r\n**Additional context**\r\nIf I wrap the iterator in a generator, everything works as expected:\r\n\r\n```python\r\nfrom promptflow import tool\r\n\r\nclass WordIterator:\r\n def __init__(self, input: str):\r\n self.input = input\r\n\r\n def __iter__(self):\r\n return self\r\n\r\n def __next__(self):\r\n if self.input:\r\n word, *rest = self.input.split(\" \")\r\n self.input = \" \".join(rest)\r\n return f\"{word} \"\r\n else:\r\n raise StopIteration \r\n \r\n def to_generator(self):\r\n try:\r\n while True:\r\n yield next(self)\r\n except StopIteration:\r\n pass\r\n\r\n@tool\r\ndef my_python_tool(input: str):\r\n iterator = WordIterator(input).to_generator()\r\n assert hasattr(iterator, \"__iter__\")\r\n assert hasattr(iterator, \"__next__\")\r\n return iterator\r\n```\r\n\n", "before_files": [{"content": "# ---------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# ---------------------------------------------------------\n\nimport inspect\nimport json\nimport logging\nfrom contextvars import ContextVar\nfrom datetime import datetime\nfrom types import GeneratorType\nfrom typing import Optional\n\nfrom promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy\nfrom promptflow._utils.dataclass_serializer import serialize\nfrom promptflow.contracts.tool import ConnectionType\nfrom promptflow.contracts.trace import Trace, TraceType\n\nfrom .thread_local_singleton import ThreadLocalSingleton\n\n\nclass Tracer(ThreadLocalSingleton):\n CONTEXT_VAR_NAME = \"Tracer\"\n context_var = ContextVar(CONTEXT_VAR_NAME, default=None)\n\n def __init__(self, run_id):\n self._run_id = run_id\n self._traces = []\n self._trace_stack = []\n\n @classmethod\n def start_tracing(cls, run_id):\n tracer = cls(run_id)\n tracer._activate_in_context()\n\n @classmethod\n def end_tracing(cls, raise_ex=False):\n tracer = cls.active_instance()\n if not tracer:\n msg = \"Try end tracing but no active tracer in current context.\"\n if raise_ex:\n raise Exception(msg)\n logging.warning(msg)\n return []\n tracer._deactivate_in_context()\n return tracer.to_json()\n\n @classmethod\n def push_tool(cls, f, args, kwargs):\n obj = cls.active_instance()\n sig = inspect.signature(f).parameters\n all_kwargs = {**{k: v for k, v in zip(sig.keys(), args)}, **kwargs}\n all_kwargs = {\n k: ConnectionType.serialize_conn(v) if ConnectionType.is_connection_value(v) else v\n for k, v in all_kwargs.items()\n }\n # TODO: put parameters in self to inputs for builtin tools\n all_kwargs.pop(\"self\", None)\n trace = Trace(\n name=f.__qualname__,\n type=TraceType.TOOL,\n start_time=datetime.utcnow().timestamp(),\n inputs=all_kwargs,\n )\n obj._push(trace)\n return trace\n\n @classmethod\n def push(cls, trace: Trace):\n obj = cls.active_instance()\n if not obj:\n logging.warning(\"Try to push trace but no active tracer in current context.\")\n return\n obj._push(trace)\n\n @staticmethod\n def to_serializable(obj):\n if isinstance(obj, dict) and all(isinstance(k, str) for k in obj.keys()):\n return {k: Tracer.to_serializable(v) for k, v in obj.items()}\n if isinstance(obj, GeneratorProxy):\n return obj\n try:\n obj = serialize(obj)\n json.dumps(obj)\n except Exception:\n # We don't want to fail the whole function call because of a serialization error,\n # so we simply convert it to str if it cannot be serialized.\n obj = str(obj)\n return obj\n\n def _push(self, trace: Trace):\n if trace.inputs:\n trace.inputs = self.to_serializable(trace.inputs)\n if not trace.start_time:\n trace.start_time = datetime.utcnow().timestamp()\n if not self._trace_stack:\n self._traces.append(trace)\n else:\n self._trace_stack[-1].children = self._trace_stack[-1].children or []\n self._trace_stack[-1].children.append(trace)\n self._trace_stack.append(trace)\n\n @classmethod\n def pop(cls, output=None, error: Optional[Exception] = None):\n obj = cls.active_instance()\n return obj._pop(output, error)\n\n def _pop(self, output=None, error: Optional[Exception] = None):\n last_trace = self._trace_stack[-1]\n if isinstance(output, GeneratorType):\n output = GeneratorProxy(output)\n if output is not None:\n last_trace.output = self.to_serializable(output)\n if error is not None:\n last_trace.error = self._format_error(error)\n self._trace_stack[-1].end_time = datetime.utcnow().timestamp()\n self._trace_stack.pop()\n\n if isinstance(output, GeneratorProxy):\n return generate_from_proxy(output)\n else:\n return output\n\n def to_json(self) -> list:\n return serialize(self._traces)\n\n @staticmethod\n def _format_error(error: Exception) -> dict:\n return {\n \"message\": str(error),\n \"type\": type(error).__qualname__,\n }\n", "path": "src/promptflow/promptflow/_core/tracer.py"}], "after_files": [{"content": "# ---------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# ---------------------------------------------------------\n\nimport inspect\nimport json\nimport logging\nfrom collections.abc import Iterator\nfrom contextvars import ContextVar\nfrom datetime import datetime\nfrom typing import Optional\n\nfrom promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy\nfrom promptflow._utils.dataclass_serializer import serialize\nfrom promptflow.contracts.tool import ConnectionType\nfrom promptflow.contracts.trace import Trace, TraceType\n\nfrom .thread_local_singleton import ThreadLocalSingleton\n\n\nclass Tracer(ThreadLocalSingleton):\n CONTEXT_VAR_NAME = \"Tracer\"\n context_var = ContextVar(CONTEXT_VAR_NAME, default=None)\n\n def __init__(self, run_id):\n self._run_id = run_id\n self._traces = []\n self._trace_stack = []\n\n @classmethod\n def start_tracing(cls, run_id):\n tracer = cls(run_id)\n tracer._activate_in_context()\n\n @classmethod\n def end_tracing(cls, raise_ex=False):\n tracer = cls.active_instance()\n if not tracer:\n msg = \"Try end tracing but no active tracer in current context.\"\n if raise_ex:\n raise Exception(msg)\n logging.warning(msg)\n return []\n tracer._deactivate_in_context()\n return tracer.to_json()\n\n @classmethod\n def push_tool(cls, f, args, kwargs):\n obj = cls.active_instance()\n sig = inspect.signature(f).parameters\n all_kwargs = {**{k: v for k, v in zip(sig.keys(), args)}, **kwargs}\n all_kwargs = {\n k: ConnectionType.serialize_conn(v) if ConnectionType.is_connection_value(v) else v\n for k, v in all_kwargs.items()\n }\n # TODO: put parameters in self to inputs for builtin tools\n all_kwargs.pop(\"self\", None)\n trace = Trace(\n name=f.__qualname__,\n type=TraceType.TOOL,\n start_time=datetime.utcnow().timestamp(),\n inputs=all_kwargs,\n )\n obj._push(trace)\n return trace\n\n @classmethod\n def push(cls, trace: Trace):\n obj = cls.active_instance()\n if not obj:\n logging.warning(\"Try to push trace but no active tracer in current context.\")\n return\n obj._push(trace)\n\n @staticmethod\n def to_serializable(obj):\n if isinstance(obj, dict) and all(isinstance(k, str) for k in obj.keys()):\n return {k: Tracer.to_serializable(v) for k, v in obj.items()}\n if isinstance(obj, GeneratorProxy):\n return obj\n try:\n obj = serialize(obj)\n json.dumps(obj)\n except Exception:\n # We don't want to fail the whole function call because of a serialization error,\n # so we simply convert it to str if it cannot be serialized.\n obj = str(obj)\n return obj\n\n def _push(self, trace: Trace):\n if trace.inputs:\n trace.inputs = self.to_serializable(trace.inputs)\n if not trace.start_time:\n trace.start_time = datetime.utcnow().timestamp()\n if not self._trace_stack:\n self._traces.append(trace)\n else:\n self._trace_stack[-1].children = self._trace_stack[-1].children or []\n self._trace_stack[-1].children.append(trace)\n self._trace_stack.append(trace)\n\n @classmethod\n def pop(cls, output=None, error: Optional[Exception] = None):\n obj = cls.active_instance()\n return obj._pop(output, error)\n\n def _pop(self, output=None, error: Optional[Exception] = None):\n last_trace = self._trace_stack[-1]\n if isinstance(output, Iterator):\n output = GeneratorProxy(output)\n if output is not None:\n last_trace.output = self.to_serializable(output)\n if error is not None:\n last_trace.error = self._format_error(error)\n self._trace_stack[-1].end_time = datetime.utcnow().timestamp()\n self._trace_stack.pop()\n\n if isinstance(output, GeneratorProxy):\n return generate_from_proxy(output)\n else:\n return output\n\n def to_json(self) -> list:\n return serialize(self._traces)\n\n @staticmethod\n def _format_error(error: Exception) -> dict:\n return {\n \"message\": str(error),\n \"type\": type(error).__qualname__,\n }\n", "path": "src/promptflow/promptflow/_core/tracer.py"}]}
| 2,913 | 211 |
gh_patches_debug_9310
|
rasdani/github-patches
|
git_diff
|
python__mypy-9445
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
mypy fails with *-stubs is not a valid Python package name
According to PEP 561 [stub-only package](https://www.python.org/dev/peps/pep-0561/#stub-only-packages):
> The name of the stub package MUST follow the scheme foopkg-stubs for type stubs for the package named foopkg.
However if we invoke mypy on such package providing only path it fails with
> *-stubs is not a valid Python package name
This can be reproduced on the [example package](https://github.com/ethanhs/stub-package):
```
git clone https://github.com/ethanhs/stub-package
cd stub-package
mypy ./typedpkg-stubs
typedpkg-stubs is not a valid Python package name
```
Invoking `mypy` with `-p` option works
```
mypy -p typedpkg-stubs
Success: no issues found in 2 source files
```
but the former behavior is rather confusing.
Expected behavior:
- mypy should recognize `*-stubs` paths as roots of stub-only packages.
Tested with:
- mypy 0.761
- mypy-0.770+dev.9101707bd0c96624d09cb31fe573d7e25c89a35c
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mypy/find_sources.py`
Content:
```
1 """Routines for finding the sources that mypy will check"""
2
3 import os.path
4
5 from typing import List, Sequence, Set, Tuple, Optional, Dict
6 from typing_extensions import Final
7
8 from mypy.modulefinder import BuildSource, PYTHON_EXTENSIONS
9 from mypy.fscache import FileSystemCache
10 from mypy.options import Options
11
12 PY_EXTENSIONS = tuple(PYTHON_EXTENSIONS) # type: Final
13
14
15 class InvalidSourceList(Exception):
16 """Exception indicating a problem in the list of sources given to mypy."""
17
18
19 def create_source_list(files: Sequence[str], options: Options,
20 fscache: Optional[FileSystemCache] = None,
21 allow_empty_dir: bool = False) -> List[BuildSource]:
22 """From a list of source files/directories, makes a list of BuildSources.
23
24 Raises InvalidSourceList on errors.
25 """
26 fscache = fscache or FileSystemCache()
27 finder = SourceFinder(fscache)
28
29 targets = []
30 for f in files:
31 if f.endswith(PY_EXTENSIONS):
32 # Can raise InvalidSourceList if a directory doesn't have a valid module name.
33 name, base_dir = finder.crawl_up(os.path.normpath(f))
34 targets.append(BuildSource(f, name, None, base_dir))
35 elif fscache.isdir(f):
36 sub_targets = finder.expand_dir(os.path.normpath(f))
37 if not sub_targets and not allow_empty_dir:
38 raise InvalidSourceList("There are no .py[i] files in directory '{}'"
39 .format(f))
40 targets.extend(sub_targets)
41 else:
42 mod = os.path.basename(f) if options.scripts_are_modules else None
43 targets.append(BuildSource(f, mod, None))
44 return targets
45
46
47 def keyfunc(name: str) -> Tuple[int, str]:
48 """Determines sort order for directory listing.
49
50 The desirable property is foo < foo.pyi < foo.py.
51 """
52 base, suffix = os.path.splitext(name)
53 for i, ext in enumerate(PY_EXTENSIONS):
54 if suffix == ext:
55 return (i, base)
56 return (-1, name)
57
58
59 class SourceFinder:
60 def __init__(self, fscache: FileSystemCache) -> None:
61 self.fscache = fscache
62 # A cache for package names, mapping from directory path to module id and base dir
63 self.package_cache = {} # type: Dict[str, Tuple[str, str]]
64
65 def expand_dir(self, arg: str, mod_prefix: str = '') -> List[BuildSource]:
66 """Convert a directory name to a list of sources to build."""
67 f = self.get_init_file(arg)
68 if mod_prefix and not f:
69 return []
70 seen = set() # type: Set[str]
71 sources = []
72 top_mod, base_dir = self.crawl_up_dir(arg)
73 if f and not mod_prefix:
74 mod_prefix = top_mod + '.'
75 if mod_prefix:
76 sources.append(BuildSource(f, mod_prefix.rstrip('.'), None, base_dir))
77 names = self.fscache.listdir(arg)
78 names.sort(key=keyfunc)
79 for name in names:
80 # Skip certain names altogether
81 if (name == '__pycache__' or name == 'py.typed'
82 or name.startswith('.')
83 or name.endswith(('~', '.pyc', '.pyo'))):
84 continue
85 path = os.path.join(arg, name)
86 if self.fscache.isdir(path):
87 sub_sources = self.expand_dir(path, mod_prefix + name + '.')
88 if sub_sources:
89 seen.add(name)
90 sources.extend(sub_sources)
91 else:
92 base, suffix = os.path.splitext(name)
93 if base == '__init__':
94 continue
95 if base not in seen and '.' not in base and suffix in PY_EXTENSIONS:
96 seen.add(base)
97 src = BuildSource(path, mod_prefix + base, None, base_dir)
98 sources.append(src)
99 return sources
100
101 def crawl_up(self, arg: str) -> Tuple[str, str]:
102 """Given a .py[i] filename, return module and base directory
103
104 We crawl up the path until we find a directory without
105 __init__.py[i], or until we run out of path components.
106 """
107 dir, mod = os.path.split(arg)
108 mod = strip_py(mod) or mod
109 base, base_dir = self.crawl_up_dir(dir)
110 if mod == '__init__' or not mod:
111 mod = base
112 else:
113 mod = module_join(base, mod)
114
115 return mod, base_dir
116
117 def crawl_up_dir(self, dir: str) -> Tuple[str, str]:
118 """Given a directory name, return the corresponding module name and base directory
119
120 Use package_cache to cache results.
121 """
122 if dir in self.package_cache:
123 return self.package_cache[dir]
124
125 parent_dir, base = os.path.split(dir)
126 if not dir or not self.get_init_file(dir) or not base:
127 res = ''
128 base_dir = dir or '.'
129 else:
130 # Ensure that base is a valid python module name
131 if not base.isidentifier():
132 raise InvalidSourceList('{} is not a valid Python package name'.format(base))
133 parent, base_dir = self.crawl_up_dir(parent_dir)
134 res = module_join(parent, base)
135
136 self.package_cache[dir] = res, base_dir
137 return res, base_dir
138
139 def get_init_file(self, dir: str) -> Optional[str]:
140 """Check whether a directory contains a file named __init__.py[i].
141
142 If so, return the file's name (with dir prefixed). If not, return
143 None.
144
145 This prefers .pyi over .py (because of the ordering of PY_EXTENSIONS).
146 """
147 for ext in PY_EXTENSIONS:
148 f = os.path.join(dir, '__init__' + ext)
149 if self.fscache.isfile(f):
150 return f
151 if ext == '.py' and self.fscache.init_under_package_root(f):
152 return f
153 return None
154
155
156 def module_join(parent: str, child: str) -> str:
157 """Join module ids, accounting for a possibly empty parent."""
158 if parent:
159 return parent + '.' + child
160 else:
161 return child
162
163
164 def strip_py(arg: str) -> Optional[str]:
165 """Strip a trailing .py or .pyi suffix.
166
167 Return None if no such suffix is found.
168 """
169 for ext in PY_EXTENSIONS:
170 if arg.endswith(ext):
171 return arg[:-len(ext)]
172 return None
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mypy/find_sources.py b/mypy/find_sources.py
--- a/mypy/find_sources.py
+++ b/mypy/find_sources.py
@@ -128,6 +128,8 @@
base_dir = dir or '.'
else:
# Ensure that base is a valid python module name
+ if base.endswith('-stubs'):
+ base = base[:-6] # PEP-561 stub-only directory
if not base.isidentifier():
raise InvalidSourceList('{} is not a valid Python package name'.format(base))
parent, base_dir = self.crawl_up_dir(parent_dir)
|
{"golden_diff": "diff --git a/mypy/find_sources.py b/mypy/find_sources.py\n--- a/mypy/find_sources.py\n+++ b/mypy/find_sources.py\n@@ -128,6 +128,8 @@\n base_dir = dir or '.'\n else:\n # Ensure that base is a valid python module name\n+ if base.endswith('-stubs'):\n+ base = base[:-6] # PEP-561 stub-only directory\n if not base.isidentifier():\n raise InvalidSourceList('{} is not a valid Python package name'.format(base))\n parent, base_dir = self.crawl_up_dir(parent_dir)\n", "issue": "mypy fails with *-stubs is not a valid Python package name\nAccording to PEP 561 [stub-only package](https://www.python.org/dev/peps/pep-0561/#stub-only-packages):\r\n\r\n> The name of the stub package MUST follow the scheme foopkg-stubs for type stubs for the package named foopkg. \r\n\r\nHowever if we invoke mypy on such package providing only path it fails with \r\n\r\n> *-stubs is not a valid Python package name\r\n\r\nThis can be reproduced on the [example package](https://github.com/ethanhs/stub-package):\r\n\r\n```\r\ngit clone https://github.com/ethanhs/stub-package\r\ncd stub-package\r\nmypy ./typedpkg-stubs\r\ntypedpkg-stubs is not a valid Python package name\r\n```\r\n\r\nInvoking `mypy` with `-p` option works\r\n\r\n```\r\nmypy -p typedpkg-stubs\r\nSuccess: no issues found in 2 source files\r\n```\r\n\r\nbut the former behavior is rather confusing.\r\n\r\nExpected behavior:\r\n\r\n- mypy should recognize `*-stubs` paths as roots of stub-only packages.\r\n\r\n\r\nTested with:\r\n\r\n- mypy 0.761\r\n- mypy-0.770+dev.9101707bd0c96624d09cb31fe573d7e25c89a35c\r\n\r\n\n", "before_files": [{"content": "\"\"\"Routines for finding the sources that mypy will check\"\"\"\n\nimport os.path\n\nfrom typing import List, Sequence, Set, Tuple, Optional, Dict\nfrom typing_extensions import Final\n\nfrom mypy.modulefinder import BuildSource, PYTHON_EXTENSIONS\nfrom mypy.fscache import FileSystemCache\nfrom mypy.options import Options\n\nPY_EXTENSIONS = tuple(PYTHON_EXTENSIONS) # type: Final\n\n\nclass InvalidSourceList(Exception):\n \"\"\"Exception indicating a problem in the list of sources given to mypy.\"\"\"\n\n\ndef create_source_list(files: Sequence[str], options: Options,\n fscache: Optional[FileSystemCache] = None,\n allow_empty_dir: bool = False) -> List[BuildSource]:\n \"\"\"From a list of source files/directories, makes a list of BuildSources.\n\n Raises InvalidSourceList on errors.\n \"\"\"\n fscache = fscache or FileSystemCache()\n finder = SourceFinder(fscache)\n\n targets = []\n for f in files:\n if f.endswith(PY_EXTENSIONS):\n # Can raise InvalidSourceList if a directory doesn't have a valid module name.\n name, base_dir = finder.crawl_up(os.path.normpath(f))\n targets.append(BuildSource(f, name, None, base_dir))\n elif fscache.isdir(f):\n sub_targets = finder.expand_dir(os.path.normpath(f))\n if not sub_targets and not allow_empty_dir:\n raise InvalidSourceList(\"There are no .py[i] files in directory '{}'\"\n .format(f))\n targets.extend(sub_targets)\n else:\n mod = os.path.basename(f) if options.scripts_are_modules else None\n targets.append(BuildSource(f, mod, None))\n return targets\n\n\ndef keyfunc(name: str) -> Tuple[int, str]:\n \"\"\"Determines sort order for directory listing.\n\n The desirable property is foo < foo.pyi < foo.py.\n \"\"\"\n base, suffix = os.path.splitext(name)\n for i, ext in enumerate(PY_EXTENSIONS):\n if suffix == ext:\n return (i, base)\n return (-1, name)\n\n\nclass SourceFinder:\n def __init__(self, fscache: FileSystemCache) -> None:\n self.fscache = fscache\n # A cache for package names, mapping from directory path to module id and base dir\n self.package_cache = {} # type: Dict[str, Tuple[str, str]]\n\n def expand_dir(self, arg: str, mod_prefix: str = '') -> List[BuildSource]:\n \"\"\"Convert a directory name to a list of sources to build.\"\"\"\n f = self.get_init_file(arg)\n if mod_prefix and not f:\n return []\n seen = set() # type: Set[str]\n sources = []\n top_mod, base_dir = self.crawl_up_dir(arg)\n if f and not mod_prefix:\n mod_prefix = top_mod + '.'\n if mod_prefix:\n sources.append(BuildSource(f, mod_prefix.rstrip('.'), None, base_dir))\n names = self.fscache.listdir(arg)\n names.sort(key=keyfunc)\n for name in names:\n # Skip certain names altogether\n if (name == '__pycache__' or name == 'py.typed'\n or name.startswith('.')\n or name.endswith(('~', '.pyc', '.pyo'))):\n continue\n path = os.path.join(arg, name)\n if self.fscache.isdir(path):\n sub_sources = self.expand_dir(path, mod_prefix + name + '.')\n if sub_sources:\n seen.add(name)\n sources.extend(sub_sources)\n else:\n base, suffix = os.path.splitext(name)\n if base == '__init__':\n continue\n if base not in seen and '.' not in base and suffix in PY_EXTENSIONS:\n seen.add(base)\n src = BuildSource(path, mod_prefix + base, None, base_dir)\n sources.append(src)\n return sources\n\n def crawl_up(self, arg: str) -> Tuple[str, str]:\n \"\"\"Given a .py[i] filename, return module and base directory\n\n We crawl up the path until we find a directory without\n __init__.py[i], or until we run out of path components.\n \"\"\"\n dir, mod = os.path.split(arg)\n mod = strip_py(mod) or mod\n base, base_dir = self.crawl_up_dir(dir)\n if mod == '__init__' or not mod:\n mod = base\n else:\n mod = module_join(base, mod)\n\n return mod, base_dir\n\n def crawl_up_dir(self, dir: str) -> Tuple[str, str]:\n \"\"\"Given a directory name, return the corresponding module name and base directory\n\n Use package_cache to cache results.\n \"\"\"\n if dir in self.package_cache:\n return self.package_cache[dir]\n\n parent_dir, base = os.path.split(dir)\n if not dir or not self.get_init_file(dir) or not base:\n res = ''\n base_dir = dir or '.'\n else:\n # Ensure that base is a valid python module name\n if not base.isidentifier():\n raise InvalidSourceList('{} is not a valid Python package name'.format(base))\n parent, base_dir = self.crawl_up_dir(parent_dir)\n res = module_join(parent, base)\n\n self.package_cache[dir] = res, base_dir\n return res, base_dir\n\n def get_init_file(self, dir: str) -> Optional[str]:\n \"\"\"Check whether a directory contains a file named __init__.py[i].\n\n If so, return the file's name (with dir prefixed). If not, return\n None.\n\n This prefers .pyi over .py (because of the ordering of PY_EXTENSIONS).\n \"\"\"\n for ext in PY_EXTENSIONS:\n f = os.path.join(dir, '__init__' + ext)\n if self.fscache.isfile(f):\n return f\n if ext == '.py' and self.fscache.init_under_package_root(f):\n return f\n return None\n\n\ndef module_join(parent: str, child: str) -> str:\n \"\"\"Join module ids, accounting for a possibly empty parent.\"\"\"\n if parent:\n return parent + '.' + child\n else:\n return child\n\n\ndef strip_py(arg: str) -> Optional[str]:\n \"\"\"Strip a trailing .py or .pyi suffix.\n\n Return None if no such suffix is found.\n \"\"\"\n for ext in PY_EXTENSIONS:\n if arg.endswith(ext):\n return arg[:-len(ext)]\n return None\n", "path": "mypy/find_sources.py"}], "after_files": [{"content": "\"\"\"Routines for finding the sources that mypy will check\"\"\"\n\nimport os.path\n\nfrom typing import List, Sequence, Set, Tuple, Optional, Dict\nfrom typing_extensions import Final\n\nfrom mypy.modulefinder import BuildSource, PYTHON_EXTENSIONS\nfrom mypy.fscache import FileSystemCache\nfrom mypy.options import Options\n\nPY_EXTENSIONS = tuple(PYTHON_EXTENSIONS) # type: Final\n\n\nclass InvalidSourceList(Exception):\n \"\"\"Exception indicating a problem in the list of sources given to mypy.\"\"\"\n\n\ndef create_source_list(files: Sequence[str], options: Options,\n fscache: Optional[FileSystemCache] = None,\n allow_empty_dir: bool = False) -> List[BuildSource]:\n \"\"\"From a list of source files/directories, makes a list of BuildSources.\n\n Raises InvalidSourceList on errors.\n \"\"\"\n fscache = fscache or FileSystemCache()\n finder = SourceFinder(fscache)\n\n targets = []\n for f in files:\n if f.endswith(PY_EXTENSIONS):\n # Can raise InvalidSourceList if a directory doesn't have a valid module name.\n name, base_dir = finder.crawl_up(os.path.normpath(f))\n targets.append(BuildSource(f, name, None, base_dir))\n elif fscache.isdir(f):\n sub_targets = finder.expand_dir(os.path.normpath(f))\n if not sub_targets and not allow_empty_dir:\n raise InvalidSourceList(\"There are no .py[i] files in directory '{}'\"\n .format(f))\n targets.extend(sub_targets)\n else:\n mod = os.path.basename(f) if options.scripts_are_modules else None\n targets.append(BuildSource(f, mod, None))\n return targets\n\n\ndef keyfunc(name: str) -> Tuple[int, str]:\n \"\"\"Determines sort order for directory listing.\n\n The desirable property is foo < foo.pyi < foo.py.\n \"\"\"\n base, suffix = os.path.splitext(name)\n for i, ext in enumerate(PY_EXTENSIONS):\n if suffix == ext:\n return (i, base)\n return (-1, name)\n\n\nclass SourceFinder:\n def __init__(self, fscache: FileSystemCache) -> None:\n self.fscache = fscache\n # A cache for package names, mapping from directory path to module id and base dir\n self.package_cache = {} # type: Dict[str, Tuple[str, str]]\n\n def expand_dir(self, arg: str, mod_prefix: str = '') -> List[BuildSource]:\n \"\"\"Convert a directory name to a list of sources to build.\"\"\"\n f = self.get_init_file(arg)\n if mod_prefix and not f:\n return []\n seen = set() # type: Set[str]\n sources = []\n top_mod, base_dir = self.crawl_up_dir(arg)\n if f and not mod_prefix:\n mod_prefix = top_mod + '.'\n if mod_prefix:\n sources.append(BuildSource(f, mod_prefix.rstrip('.'), None, base_dir))\n names = self.fscache.listdir(arg)\n names.sort(key=keyfunc)\n for name in names:\n # Skip certain names altogether\n if (name == '__pycache__' or name == 'py.typed'\n or name.startswith('.')\n or name.endswith(('~', '.pyc', '.pyo'))):\n continue\n path = os.path.join(arg, name)\n if self.fscache.isdir(path):\n sub_sources = self.expand_dir(path, mod_prefix + name + '.')\n if sub_sources:\n seen.add(name)\n sources.extend(sub_sources)\n else:\n base, suffix = os.path.splitext(name)\n if base == '__init__':\n continue\n if base not in seen and '.' not in base and suffix in PY_EXTENSIONS:\n seen.add(base)\n src = BuildSource(path, mod_prefix + base, None, base_dir)\n sources.append(src)\n return sources\n\n def crawl_up(self, arg: str) -> Tuple[str, str]:\n \"\"\"Given a .py[i] filename, return module and base directory\n\n We crawl up the path until we find a directory without\n __init__.py[i], or until we run out of path components.\n \"\"\"\n dir, mod = os.path.split(arg)\n mod = strip_py(mod) or mod\n base, base_dir = self.crawl_up_dir(dir)\n if mod == '__init__' or not mod:\n mod = base\n else:\n mod = module_join(base, mod)\n\n return mod, base_dir\n\n def crawl_up_dir(self, dir: str) -> Tuple[str, str]:\n \"\"\"Given a directory name, return the corresponding module name and base directory\n\n Use package_cache to cache results.\n \"\"\"\n if dir in self.package_cache:\n return self.package_cache[dir]\n\n parent_dir, base = os.path.split(dir)\n if not dir or not self.get_init_file(dir) or not base:\n res = ''\n base_dir = dir or '.'\n else:\n # Ensure that base is a valid python module name\n if base.endswith('-stubs'):\n base = base[:-6] # PEP-561 stub-only directory\n if not base.isidentifier():\n raise InvalidSourceList('{} is not a valid Python package name'.format(base))\n parent, base_dir = self.crawl_up_dir(parent_dir)\n res = module_join(parent, base)\n\n self.package_cache[dir] = res, base_dir\n return res, base_dir\n\n def get_init_file(self, dir: str) -> Optional[str]:\n \"\"\"Check whether a directory contains a file named __init__.py[i].\n\n If so, return the file's name (with dir prefixed). If not, return\n None.\n\n This prefers .pyi over .py (because of the ordering of PY_EXTENSIONS).\n \"\"\"\n for ext in PY_EXTENSIONS:\n f = os.path.join(dir, '__init__' + ext)\n if self.fscache.isfile(f):\n return f\n if ext == '.py' and self.fscache.init_under_package_root(f):\n return f\n return None\n\n\ndef module_join(parent: str, child: str) -> str:\n \"\"\"Join module ids, accounting for a possibly empty parent.\"\"\"\n if parent:\n return parent + '.' + child\n else:\n return child\n\n\ndef strip_py(arg: str) -> Optional[str]:\n \"\"\"Strip a trailing .py or .pyi suffix.\n\n Return None if no such suffix is found.\n \"\"\"\n for ext in PY_EXTENSIONS:\n if arg.endswith(ext):\n return arg[:-len(ext)]\n return None\n", "path": "mypy/find_sources.py"}]}
| 2,383 | 136 |
gh_patches_debug_29886
|
rasdani/github-patches
|
git_diff
|
NVIDIA__NVFlare-935
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove self.server_meta in fed_client_base.py
This is not used: https://github.com/NVIDIA/NVFlare/blob/main/nvflare/private/fed/client/fed_client_base.py#L285
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nvflare/private/fed/client/fed_client_base.py`
Content:
```
1 # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import threading
17 import time
18 from functools import partial
19 from multiprocessing.dummy import Pool as ThreadPool
20 from typing import List, Optional
21
22 from nvflare.apis.filter import Filter
23 from nvflare.apis.fl_component import FLComponent
24 from nvflare.apis.fl_constant import FLContextKey
25 from nvflare.apis.fl_context import FLContext
26 from nvflare.apis.fl_exception import FLCommunicationError
27 from nvflare.apis.overseer_spec import SP
28 from nvflare.apis.shareable import Shareable
29 from nvflare.apis.signal import Signal
30 from nvflare.fuel.utils.argument_utils import parse_vars
31 from nvflare.private.defs import EngineConstant
32 from nvflare.security.logging import secure_format_exception
33
34 from .client_status import ClientStatus
35 from .communicator import Communicator
36
37
38 class FederatedClientBase:
39 """The client-side base implementation of federated learning.
40
41 This class provide the tools function which will be used in both FedClient and FedClientLite.
42 """
43
44 def __init__(
45 self,
46 client_name,
47 client_args,
48 secure_train,
49 server_args=None,
50 retry_timeout=30,
51 client_state_processors: Optional[List[Filter]] = None,
52 handlers: Optional[List[FLComponent]] = None,
53 compression=None,
54 overseer_agent=None,
55 args=None,
56 components=None,
57 ):
58 """To init FederatedClientBase.
59
60 Args:
61 client_name: client name
62 client_args: client config args
63 secure_train: True/False to indicate secure train
64 server_args: server config args
65 retry_timeout: retry timeout
66 client_state_processors: client state processor filters
67 handlers: handlers
68 compression: communication compression algorithm
69 """
70 self.logger = logging.getLogger(self.__class__.__name__)
71
72 self.client_name = client_name
73 self.token = None
74 self.ssid = None
75 self.client_args = client_args
76 self.servers = server_args
77
78 self.communicator = Communicator(
79 ssl_args=client_args,
80 secure_train=secure_train,
81 retry_timeout=retry_timeout,
82 client_state_processors=client_state_processors,
83 compression=compression,
84 )
85
86 self.secure_train = secure_train
87 self.handlers = handlers
88 self.components = components
89
90 self.heartbeat_done = False
91 self.fl_ctx = FLContext()
92 self.platform = None
93 self.abort_signal = Signal()
94 self.engine = None
95
96 self.status = ClientStatus.NOT_STARTED
97 self.remote_tasks = None
98
99 self.sp_established = False
100 self.overseer_agent = overseer_agent
101
102 self.overseer_agent = self._init_agent(args)
103
104 if secure_train:
105 if self.overseer_agent:
106 self.overseer_agent.set_secure_context(
107 ca_path=client_args["ssl_root_cert"],
108 cert_path=client_args["ssl_cert"],
109 prv_key_path=client_args["ssl_private_key"],
110 )
111
112 if self.overseer_agent:
113 self.overseer_agent.start(self.overseer_callback)
114
115 def _init_agent(self, args=None):
116 kv_list = parse_vars(args.set)
117 sp = kv_list.get("sp")
118
119 if sp:
120 fl_ctx = FLContext()
121 fl_ctx.set_prop(FLContextKey.SP_END_POINT, sp)
122 self.overseer_agent.initialize(fl_ctx)
123
124 return self.overseer_agent
125
126 def overseer_callback(self, overseer_agent):
127 if overseer_agent.is_shutdown():
128 self.engine.shutdown()
129 return
130
131 sp = overseer_agent.get_primary_sp()
132 self.set_primary_sp(sp)
133
134 def set_sp(self, project_name, sp: SP):
135 if sp and sp.primary is True:
136 server = self.servers[project_name].get("target")
137 location = sp.name + ":" + sp.fl_port
138 if server != location:
139 self.servers[project_name]["target"] = location
140 self.sp_established = True
141 self.logger.info(f"Got the new primary SP: {location}")
142
143 if self.ssid and self.ssid != sp.service_session_id:
144 self.ssid = sp.service_session_id
145 thread = threading.Thread(target=self._switch_ssid)
146 thread.start()
147
148 def _switch_ssid(self):
149 if self.engine:
150 for job_id in self.engine.get_all_job_ids():
151 self.engine.abort_task(job_id)
152 # self.register()
153 self.logger.info(f"Primary SP switched to new SSID: {self.ssid}")
154
155 def client_register(self, project_name):
156 """Register the client to the FL server.
157
158 Args:
159 project_name: FL study project name.
160 """
161 if not self.token:
162 try:
163 self.token, self.ssid = self.communicator.client_registration(
164 self.client_name, self.servers, project_name
165 )
166 if self.token is not None:
167 self.fl_ctx.set_prop(FLContextKey.CLIENT_NAME, self.client_name, private=False)
168 self.fl_ctx.set_prop(EngineConstant.FL_TOKEN, self.token, private=False)
169 self.logger.info(
170 "Successfully registered client:{} for project {}. Token:{} SSID:{}".format(
171 self.client_name, project_name, self.token, self.ssid
172 )
173 )
174
175 except FLCommunicationError:
176 self.communicator.heartbeat_done = True
177
178 def fetch_execute_task(self, project_name, fl_ctx: FLContext):
179 """Fetch a task from the server.
180
181 Args:
182 project_name: FL study project name
183 fl_ctx: FLContext
184
185 Returns:
186 A CurrentTask message from server
187 """
188 try:
189 self.logger.debug("Starting to fetch execute task.")
190 task = self.communicator.getTask(self.servers, project_name, self.token, self.ssid, fl_ctx)
191
192 return task
193 except FLCommunicationError as e:
194 self.logger.info(secure_format_exception(e))
195
196 def push_execute_result(self, project_name, shareable: Shareable, fl_ctx: FLContext):
197 """Submit execution results of a task to server.
198
199 Args:
200 project_name: FL study project name
201 shareable: Shareable object
202 fl_ctx: FLContext
203
204 Returns:
205 A FederatedSummary message from the server.
206 """
207 try:
208 self.logger.info("Starting to push execute result.")
209 execute_task_name = fl_ctx.get_prop(FLContextKey.TASK_NAME)
210 message = self.communicator.submitUpdate(
211 self.servers,
212 project_name,
213 self.token,
214 self.ssid,
215 fl_ctx,
216 self.client_name,
217 shareable,
218 execute_task_name,
219 )
220
221 return message
222 except FLCommunicationError as e:
223 self.logger.info(secure_format_exception(e))
224
225 def send_aux_message(self, project_name, topic: str, shareable: Shareable, timeout: float, fl_ctx: FLContext):
226 """Send auxiliary message to the server.
227
228 Args:
229 project_name: FL study project name
230 topic: aux topic name
231 shareable: Shareable object
232 timeout: communication timeout
233 fl_ctx: FLContext
234
235 Returns:
236 A reply message
237 """
238 try:
239 self.logger.debug("Starting to send aux message.")
240 message = self.communicator.auxCommunicate(
241 self.servers, project_name, self.token, self.ssid, fl_ctx, self.client_name, shareable, topic, timeout
242 )
243
244 return message
245 except FLCommunicationError as e:
246 self.logger.info(secure_format_exception(e))
247
248 def send_heartbeat(self, project_name):
249 try:
250 if self.token:
251 while not self.engine:
252 time.sleep(1.0)
253 self.communicator.send_heartbeat(
254 self.servers, project_name, self.token, self.ssid, self.client_name, self.engine
255 )
256 except FLCommunicationError:
257 self.communicator.heartbeat_done = True
258
259 def heartbeat(self):
260 """Sends a heartbeat from the client to the server."""
261 pool = None
262 try:
263 pool = ThreadPool(len(self.servers))
264 return pool.map(self.send_heartbeat, tuple(self.servers))
265 finally:
266 if pool:
267 pool.terminate()
268
269 def pull_task(self, fl_ctx: FLContext):
270 """Fetch remote models and update the local client's session."""
271 pool = None
272 try:
273 pool = ThreadPool(len(self.servers))
274 self.remote_tasks = pool.map(partial(self.fetch_execute_task, fl_ctx=fl_ctx), tuple(self.servers))
275 pull_success, task_name = self.check_progress(self.remote_tasks)
276 # # Update app_ctx's current round info
277 # if self.app_context and self.remote_models[0] is not None:
278 # self.app_context.global_round = self.remote_models[0].meta.current_round
279 # TODO: if some of the servers failed
280 # return self.model_manager.assign_current_model(self.remote_models)
281 return pull_success, task_name, self.remote_tasks
282 finally:
283 if pool:
284 pool.terminate()
285
286 def push_results(self, shareable: Shareable, fl_ctx: FLContext):
287 """Push the local model to multiple servers."""
288 pool = None
289 try:
290 pool = ThreadPool(len(self.servers))
291 return pool.map(partial(self.push_execute_result, shareable=shareable, fl_ctx=fl_ctx), tuple(self.servers))
292 finally:
293 if pool:
294 pool.terminate()
295
296 def aux_send(self, topic, shareable: Shareable, timeout: float, fl_ctx: FLContext):
297 """Push the local model to multiple servers."""
298 pool = None
299 try:
300 pool = ThreadPool(len(self.servers))
301 messages = pool.map(
302 partial(self.send_aux_message, topic=topic, shareable=shareable, timeout=timeout, fl_ctx=fl_ctx),
303 tuple(self.servers),
304 )
305 if messages is not None and messages[0] is not None:
306 # Only handle single server communication for now.
307 return messages
308 else:
309 return None
310 finally:
311 if pool:
312 pool.terminate()
313
314 def register(self):
315 """Push the local model to multiple servers."""
316 pool = None
317 try:
318 pool = ThreadPool(len(self.servers))
319 return pool.map(self.client_register, tuple(self.servers))
320 finally:
321 if pool:
322 pool.terminate()
323
324 def set_primary_sp(self, sp):
325 pool = None
326 try:
327 pool = ThreadPool(len(self.servers))
328 return pool.map(partial(self.set_sp, sp=sp), tuple(self.servers))
329 finally:
330 if pool:
331 pool.terminate()
332
333 def run_heartbeat(self):
334 """Periodically runs the heartbeat."""
335 self.heartbeat()
336
337 def start_heartbeat(self):
338 heartbeat_thread = threading.Thread(target=self.run_heartbeat)
339 heartbeat_thread.start()
340
341 def quit_remote(self, task_name, fl_ctx: FLContext):
342 """Sending the last message to the server before leaving.
343
344 Args:
345 task_name: task name
346 fl_ctx: FLContext
347
348 Returns: N/A
349
350 """
351 return self.communicator.quit_remote(self.servers, task_name, self.token, self.ssid, fl_ctx)
352
353 def set_client_engine(self, engine):
354 self.engine = engine
355
356 def close(self):
357 """Quit the remote federated server, close the local session."""
358 self.logger.info(f"Shutting down client: {self.client_name}")
359 if self.overseer_agent:
360 self.overseer_agent.end()
361
362 return 0
363
364 def check_progress(self, remote_tasks):
365 if remote_tasks[0] is not None:
366 self.server_meta = remote_tasks[0].meta
367 return True, remote_tasks[0].task_name
368 else:
369 return False, None
370
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nvflare/private/fed/client/fed_client_base.py b/nvflare/private/fed/client/fed_client_base.py
--- a/nvflare/private/fed/client/fed_client_base.py
+++ b/nvflare/private/fed/client/fed_client_base.py
@@ -35,6 +35,13 @@
from .communicator import Communicator
+def _check_progress(remote_tasks):
+ if remote_tasks[0] is not None:
+ return True, remote_tasks[0].task_name
+ else:
+ return False, None
+
+
class FederatedClientBase:
"""The client-side base implementation of federated learning.
@@ -272,12 +279,8 @@
try:
pool = ThreadPool(len(self.servers))
self.remote_tasks = pool.map(partial(self.fetch_execute_task, fl_ctx=fl_ctx), tuple(self.servers))
- pull_success, task_name = self.check_progress(self.remote_tasks)
- # # Update app_ctx's current round info
- # if self.app_context and self.remote_models[0] is not None:
- # self.app_context.global_round = self.remote_models[0].meta.current_round
+ pull_success, task_name = _check_progress(self.remote_tasks)
# TODO: if some of the servers failed
- # return self.model_manager.assign_current_model(self.remote_models)
return pull_success, task_name, self.remote_tasks
finally:
if pool:
@@ -360,10 +363,3 @@
self.overseer_agent.end()
return 0
-
- def check_progress(self, remote_tasks):
- if remote_tasks[0] is not None:
- self.server_meta = remote_tasks[0].meta
- return True, remote_tasks[0].task_name
- else:
- return False, None
|
{"golden_diff": "diff --git a/nvflare/private/fed/client/fed_client_base.py b/nvflare/private/fed/client/fed_client_base.py\n--- a/nvflare/private/fed/client/fed_client_base.py\n+++ b/nvflare/private/fed/client/fed_client_base.py\n@@ -35,6 +35,13 @@\n from .communicator import Communicator\n \n \n+def _check_progress(remote_tasks):\n+ if remote_tasks[0] is not None:\n+ return True, remote_tasks[0].task_name\n+ else:\n+ return False, None\n+\n+\n class FederatedClientBase:\n \"\"\"The client-side base implementation of federated learning.\n \n@@ -272,12 +279,8 @@\n try:\n pool = ThreadPool(len(self.servers))\n self.remote_tasks = pool.map(partial(self.fetch_execute_task, fl_ctx=fl_ctx), tuple(self.servers))\n- pull_success, task_name = self.check_progress(self.remote_tasks)\n- # # Update app_ctx's current round info\n- # if self.app_context and self.remote_models[0] is not None:\n- # self.app_context.global_round = self.remote_models[0].meta.current_round\n+ pull_success, task_name = _check_progress(self.remote_tasks)\n # TODO: if some of the servers failed\n- # return self.model_manager.assign_current_model(self.remote_models)\n return pull_success, task_name, self.remote_tasks\n finally:\n if pool:\n@@ -360,10 +363,3 @@\n self.overseer_agent.end()\n \n return 0\n-\n- def check_progress(self, remote_tasks):\n- if remote_tasks[0] is not None:\n- self.server_meta = remote_tasks[0].meta\n- return True, remote_tasks[0].task_name\n- else:\n- return False, None\n", "issue": "Remove self.server_meta in fed_client_base.py\nThis is not used: https://github.com/NVIDIA/NVFlare/blob/main/nvflare/private/fed/client/fed_client_base.py#L285\n", "before_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport threading\nimport time\nfrom functools import partial\nfrom multiprocessing.dummy import Pool as ThreadPool\nfrom typing import List, Optional\n\nfrom nvflare.apis.filter import Filter\nfrom nvflare.apis.fl_component import FLComponent\nfrom nvflare.apis.fl_constant import FLContextKey\nfrom nvflare.apis.fl_context import FLContext\nfrom nvflare.apis.fl_exception import FLCommunicationError\nfrom nvflare.apis.overseer_spec import SP\nfrom nvflare.apis.shareable import Shareable\nfrom nvflare.apis.signal import Signal\nfrom nvflare.fuel.utils.argument_utils import parse_vars\nfrom nvflare.private.defs import EngineConstant\nfrom nvflare.security.logging import secure_format_exception\n\nfrom .client_status import ClientStatus\nfrom .communicator import Communicator\n\n\nclass FederatedClientBase:\n \"\"\"The client-side base implementation of federated learning.\n\n This class provide the tools function which will be used in both FedClient and FedClientLite.\n \"\"\"\n\n def __init__(\n self,\n client_name,\n client_args,\n secure_train,\n server_args=None,\n retry_timeout=30,\n client_state_processors: Optional[List[Filter]] = None,\n handlers: Optional[List[FLComponent]] = None,\n compression=None,\n overseer_agent=None,\n args=None,\n components=None,\n ):\n \"\"\"To init FederatedClientBase.\n\n Args:\n client_name: client name\n client_args: client config args\n secure_train: True/False to indicate secure train\n server_args: server config args\n retry_timeout: retry timeout\n client_state_processors: client state processor filters\n handlers: handlers\n compression: communication compression algorithm\n \"\"\"\n self.logger = logging.getLogger(self.__class__.__name__)\n\n self.client_name = client_name\n self.token = None\n self.ssid = None\n self.client_args = client_args\n self.servers = server_args\n\n self.communicator = Communicator(\n ssl_args=client_args,\n secure_train=secure_train,\n retry_timeout=retry_timeout,\n client_state_processors=client_state_processors,\n compression=compression,\n )\n\n self.secure_train = secure_train\n self.handlers = handlers\n self.components = components\n\n self.heartbeat_done = False\n self.fl_ctx = FLContext()\n self.platform = None\n self.abort_signal = Signal()\n self.engine = None\n\n self.status = ClientStatus.NOT_STARTED\n self.remote_tasks = None\n\n self.sp_established = False\n self.overseer_agent = overseer_agent\n\n self.overseer_agent = self._init_agent(args)\n\n if secure_train:\n if self.overseer_agent:\n self.overseer_agent.set_secure_context(\n ca_path=client_args[\"ssl_root_cert\"],\n cert_path=client_args[\"ssl_cert\"],\n prv_key_path=client_args[\"ssl_private_key\"],\n )\n\n if self.overseer_agent:\n self.overseer_agent.start(self.overseer_callback)\n\n def _init_agent(self, args=None):\n kv_list = parse_vars(args.set)\n sp = kv_list.get(\"sp\")\n\n if sp:\n fl_ctx = FLContext()\n fl_ctx.set_prop(FLContextKey.SP_END_POINT, sp)\n self.overseer_agent.initialize(fl_ctx)\n\n return self.overseer_agent\n\n def overseer_callback(self, overseer_agent):\n if overseer_agent.is_shutdown():\n self.engine.shutdown()\n return\n\n sp = overseer_agent.get_primary_sp()\n self.set_primary_sp(sp)\n\n def set_sp(self, project_name, sp: SP):\n if sp and sp.primary is True:\n server = self.servers[project_name].get(\"target\")\n location = sp.name + \":\" + sp.fl_port\n if server != location:\n self.servers[project_name][\"target\"] = location\n self.sp_established = True\n self.logger.info(f\"Got the new primary SP: {location}\")\n\n if self.ssid and self.ssid != sp.service_session_id:\n self.ssid = sp.service_session_id\n thread = threading.Thread(target=self._switch_ssid)\n thread.start()\n\n def _switch_ssid(self):\n if self.engine:\n for job_id in self.engine.get_all_job_ids():\n self.engine.abort_task(job_id)\n # self.register()\n self.logger.info(f\"Primary SP switched to new SSID: {self.ssid}\")\n\n def client_register(self, project_name):\n \"\"\"Register the client to the FL server.\n\n Args:\n project_name: FL study project name.\n \"\"\"\n if not self.token:\n try:\n self.token, self.ssid = self.communicator.client_registration(\n self.client_name, self.servers, project_name\n )\n if self.token is not None:\n self.fl_ctx.set_prop(FLContextKey.CLIENT_NAME, self.client_name, private=False)\n self.fl_ctx.set_prop(EngineConstant.FL_TOKEN, self.token, private=False)\n self.logger.info(\n \"Successfully registered client:{} for project {}. Token:{} SSID:{}\".format(\n self.client_name, project_name, self.token, self.ssid\n )\n )\n\n except FLCommunicationError:\n self.communicator.heartbeat_done = True\n\n def fetch_execute_task(self, project_name, fl_ctx: FLContext):\n \"\"\"Fetch a task from the server.\n\n Args:\n project_name: FL study project name\n fl_ctx: FLContext\n\n Returns:\n A CurrentTask message from server\n \"\"\"\n try:\n self.logger.debug(\"Starting to fetch execute task.\")\n task = self.communicator.getTask(self.servers, project_name, self.token, self.ssid, fl_ctx)\n\n return task\n except FLCommunicationError as e:\n self.logger.info(secure_format_exception(e))\n\n def push_execute_result(self, project_name, shareable: Shareable, fl_ctx: FLContext):\n \"\"\"Submit execution results of a task to server.\n\n Args:\n project_name: FL study project name\n shareable: Shareable object\n fl_ctx: FLContext\n\n Returns:\n A FederatedSummary message from the server.\n \"\"\"\n try:\n self.logger.info(\"Starting to push execute result.\")\n execute_task_name = fl_ctx.get_prop(FLContextKey.TASK_NAME)\n message = self.communicator.submitUpdate(\n self.servers,\n project_name,\n self.token,\n self.ssid,\n fl_ctx,\n self.client_name,\n shareable,\n execute_task_name,\n )\n\n return message\n except FLCommunicationError as e:\n self.logger.info(secure_format_exception(e))\n\n def send_aux_message(self, project_name, topic: str, shareable: Shareable, timeout: float, fl_ctx: FLContext):\n \"\"\"Send auxiliary message to the server.\n\n Args:\n project_name: FL study project name\n topic: aux topic name\n shareable: Shareable object\n timeout: communication timeout\n fl_ctx: FLContext\n\n Returns:\n A reply message\n \"\"\"\n try:\n self.logger.debug(\"Starting to send aux message.\")\n message = self.communicator.auxCommunicate(\n self.servers, project_name, self.token, self.ssid, fl_ctx, self.client_name, shareable, topic, timeout\n )\n\n return message\n except FLCommunicationError as e:\n self.logger.info(secure_format_exception(e))\n\n def send_heartbeat(self, project_name):\n try:\n if self.token:\n while not self.engine:\n time.sleep(1.0)\n self.communicator.send_heartbeat(\n self.servers, project_name, self.token, self.ssid, self.client_name, self.engine\n )\n except FLCommunicationError:\n self.communicator.heartbeat_done = True\n\n def heartbeat(self):\n \"\"\"Sends a heartbeat from the client to the server.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(self.send_heartbeat, tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def pull_task(self, fl_ctx: FLContext):\n \"\"\"Fetch remote models and update the local client's session.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n self.remote_tasks = pool.map(partial(self.fetch_execute_task, fl_ctx=fl_ctx), tuple(self.servers))\n pull_success, task_name = self.check_progress(self.remote_tasks)\n # # Update app_ctx's current round info\n # if self.app_context and self.remote_models[0] is not None:\n # self.app_context.global_round = self.remote_models[0].meta.current_round\n # TODO: if some of the servers failed\n # return self.model_manager.assign_current_model(self.remote_models)\n return pull_success, task_name, self.remote_tasks\n finally:\n if pool:\n pool.terminate()\n\n def push_results(self, shareable: Shareable, fl_ctx: FLContext):\n \"\"\"Push the local model to multiple servers.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(partial(self.push_execute_result, shareable=shareable, fl_ctx=fl_ctx), tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def aux_send(self, topic, shareable: Shareable, timeout: float, fl_ctx: FLContext):\n \"\"\"Push the local model to multiple servers.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n messages = pool.map(\n partial(self.send_aux_message, topic=topic, shareable=shareable, timeout=timeout, fl_ctx=fl_ctx),\n tuple(self.servers),\n )\n if messages is not None and messages[0] is not None:\n # Only handle single server communication for now.\n return messages\n else:\n return None\n finally:\n if pool:\n pool.terminate()\n\n def register(self):\n \"\"\"Push the local model to multiple servers.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(self.client_register, tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def set_primary_sp(self, sp):\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(partial(self.set_sp, sp=sp), tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def run_heartbeat(self):\n \"\"\"Periodically runs the heartbeat.\"\"\"\n self.heartbeat()\n\n def start_heartbeat(self):\n heartbeat_thread = threading.Thread(target=self.run_heartbeat)\n heartbeat_thread.start()\n\n def quit_remote(self, task_name, fl_ctx: FLContext):\n \"\"\"Sending the last message to the server before leaving.\n\n Args:\n task_name: task name\n fl_ctx: FLContext\n\n Returns: N/A\n\n \"\"\"\n return self.communicator.quit_remote(self.servers, task_name, self.token, self.ssid, fl_ctx)\n\n def set_client_engine(self, engine):\n self.engine = engine\n\n def close(self):\n \"\"\"Quit the remote federated server, close the local session.\"\"\"\n self.logger.info(f\"Shutting down client: {self.client_name}\")\n if self.overseer_agent:\n self.overseer_agent.end()\n\n return 0\n\n def check_progress(self, remote_tasks):\n if remote_tasks[0] is not None:\n self.server_meta = remote_tasks[0].meta\n return True, remote_tasks[0].task_name\n else:\n return False, None\n", "path": "nvflare/private/fed/client/fed_client_base.py"}], "after_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport threading\nimport time\nfrom functools import partial\nfrom multiprocessing.dummy import Pool as ThreadPool\nfrom typing import List, Optional\n\nfrom nvflare.apis.filter import Filter\nfrom nvflare.apis.fl_component import FLComponent\nfrom nvflare.apis.fl_constant import FLContextKey\nfrom nvflare.apis.fl_context import FLContext\nfrom nvflare.apis.fl_exception import FLCommunicationError\nfrom nvflare.apis.overseer_spec import SP\nfrom nvflare.apis.shareable import Shareable\nfrom nvflare.apis.signal import Signal\nfrom nvflare.fuel.utils.argument_utils import parse_vars\nfrom nvflare.private.defs import EngineConstant\nfrom nvflare.security.logging import secure_format_exception\n\nfrom .client_status import ClientStatus\nfrom .communicator import Communicator\n\n\ndef _check_progress(remote_tasks):\n if remote_tasks[0] is not None:\n return True, remote_tasks[0].task_name\n else:\n return False, None\n\n\nclass FederatedClientBase:\n \"\"\"The client-side base implementation of federated learning.\n\n This class provide the tools function which will be used in both FedClient and FedClientLite.\n \"\"\"\n\n def __init__(\n self,\n client_name,\n client_args,\n secure_train,\n server_args=None,\n retry_timeout=30,\n client_state_processors: Optional[List[Filter]] = None,\n handlers: Optional[List[FLComponent]] = None,\n compression=None,\n overseer_agent=None,\n args=None,\n components=None,\n ):\n \"\"\"To init FederatedClientBase.\n\n Args:\n client_name: client name\n client_args: client config args\n secure_train: True/False to indicate secure train\n server_args: server config args\n retry_timeout: retry timeout\n client_state_processors: client state processor filters\n handlers: handlers\n compression: communication compression algorithm\n \"\"\"\n self.logger = logging.getLogger(self.__class__.__name__)\n\n self.client_name = client_name\n self.token = None\n self.ssid = None\n self.client_args = client_args\n self.servers = server_args\n\n self.communicator = Communicator(\n ssl_args=client_args,\n secure_train=secure_train,\n retry_timeout=retry_timeout,\n client_state_processors=client_state_processors,\n compression=compression,\n )\n\n self.secure_train = secure_train\n self.handlers = handlers\n self.components = components\n\n self.heartbeat_done = False\n self.fl_ctx = FLContext()\n self.platform = None\n self.abort_signal = Signal()\n self.engine = None\n\n self.status = ClientStatus.NOT_STARTED\n self.remote_tasks = None\n\n self.sp_established = False\n self.overseer_agent = overseer_agent\n\n self.overseer_agent = self._init_agent(args)\n\n if secure_train:\n if self.overseer_agent:\n self.overseer_agent.set_secure_context(\n ca_path=client_args[\"ssl_root_cert\"],\n cert_path=client_args[\"ssl_cert\"],\n prv_key_path=client_args[\"ssl_private_key\"],\n )\n\n if self.overseer_agent:\n self.overseer_agent.start(self.overseer_callback)\n\n def _init_agent(self, args=None):\n kv_list = parse_vars(args.set)\n sp = kv_list.get(\"sp\")\n\n if sp:\n fl_ctx = FLContext()\n fl_ctx.set_prop(FLContextKey.SP_END_POINT, sp)\n self.overseer_agent.initialize(fl_ctx)\n\n return self.overseer_agent\n\n def overseer_callback(self, overseer_agent):\n if overseer_agent.is_shutdown():\n self.engine.shutdown()\n return\n\n sp = overseer_agent.get_primary_sp()\n self.set_primary_sp(sp)\n\n def set_sp(self, project_name, sp: SP):\n if sp and sp.primary is True:\n server = self.servers[project_name].get(\"target\")\n location = sp.name + \":\" + sp.fl_port\n if server != location:\n self.servers[project_name][\"target\"] = location\n self.sp_established = True\n self.logger.info(f\"Got the new primary SP: {location}\")\n\n if self.ssid and self.ssid != sp.service_session_id:\n self.ssid = sp.service_session_id\n thread = threading.Thread(target=self._switch_ssid)\n thread.start()\n\n def _switch_ssid(self):\n if self.engine:\n for job_id in self.engine.get_all_job_ids():\n self.engine.abort_task(job_id)\n # self.register()\n self.logger.info(f\"Primary SP switched to new SSID: {self.ssid}\")\n\n def client_register(self, project_name):\n \"\"\"Register the client to the FL server.\n\n Args:\n project_name: FL study project name.\n \"\"\"\n if not self.token:\n try:\n self.token, self.ssid = self.communicator.client_registration(\n self.client_name, self.servers, project_name\n )\n if self.token is not None:\n self.fl_ctx.set_prop(FLContextKey.CLIENT_NAME, self.client_name, private=False)\n self.fl_ctx.set_prop(EngineConstant.FL_TOKEN, self.token, private=False)\n self.logger.info(\n \"Successfully registered client:{} for project {}. Token:{} SSID:{}\".format(\n self.client_name, project_name, self.token, self.ssid\n )\n )\n\n except FLCommunicationError:\n self.communicator.heartbeat_done = True\n\n def fetch_execute_task(self, project_name, fl_ctx: FLContext):\n \"\"\"Fetch a task from the server.\n\n Args:\n project_name: FL study project name\n fl_ctx: FLContext\n\n Returns:\n A CurrentTask message from server\n \"\"\"\n try:\n self.logger.debug(\"Starting to fetch execute task.\")\n task = self.communicator.getTask(self.servers, project_name, self.token, self.ssid, fl_ctx)\n\n return task\n except FLCommunicationError as e:\n self.logger.info(secure_format_exception(e))\n\n def push_execute_result(self, project_name, shareable: Shareable, fl_ctx: FLContext):\n \"\"\"Submit execution results of a task to server.\n\n Args:\n project_name: FL study project name\n shareable: Shareable object\n fl_ctx: FLContext\n\n Returns:\n A FederatedSummary message from the server.\n \"\"\"\n try:\n self.logger.info(\"Starting to push execute result.\")\n execute_task_name = fl_ctx.get_prop(FLContextKey.TASK_NAME)\n message = self.communicator.submitUpdate(\n self.servers,\n project_name,\n self.token,\n self.ssid,\n fl_ctx,\n self.client_name,\n shareable,\n execute_task_name,\n )\n\n return message\n except FLCommunicationError as e:\n self.logger.info(secure_format_exception(e))\n\n def send_aux_message(self, project_name, topic: str, shareable: Shareable, timeout: float, fl_ctx: FLContext):\n \"\"\"Send auxiliary message to the server.\n\n Args:\n project_name: FL study project name\n topic: aux topic name\n shareable: Shareable object\n timeout: communication timeout\n fl_ctx: FLContext\n\n Returns:\n A reply message\n \"\"\"\n try:\n self.logger.debug(\"Starting to send aux message.\")\n message = self.communicator.auxCommunicate(\n self.servers, project_name, self.token, self.ssid, fl_ctx, self.client_name, shareable, topic, timeout\n )\n\n return message\n except FLCommunicationError as e:\n self.logger.info(secure_format_exception(e))\n\n def send_heartbeat(self, project_name):\n try:\n if self.token:\n while not self.engine:\n time.sleep(1.0)\n self.communicator.send_heartbeat(\n self.servers, project_name, self.token, self.ssid, self.client_name, self.engine\n )\n except FLCommunicationError:\n self.communicator.heartbeat_done = True\n\n def heartbeat(self):\n \"\"\"Sends a heartbeat from the client to the server.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(self.send_heartbeat, tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def pull_task(self, fl_ctx: FLContext):\n \"\"\"Fetch remote models and update the local client's session.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n self.remote_tasks = pool.map(partial(self.fetch_execute_task, fl_ctx=fl_ctx), tuple(self.servers))\n pull_success, task_name = _check_progress(self.remote_tasks)\n # TODO: if some of the servers failed\n return pull_success, task_name, self.remote_tasks\n finally:\n if pool:\n pool.terminate()\n\n def push_results(self, shareable: Shareable, fl_ctx: FLContext):\n \"\"\"Push the local model to multiple servers.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(partial(self.push_execute_result, shareable=shareable, fl_ctx=fl_ctx), tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def aux_send(self, topic, shareable: Shareable, timeout: float, fl_ctx: FLContext):\n \"\"\"Push the local model to multiple servers.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n messages = pool.map(\n partial(self.send_aux_message, topic=topic, shareable=shareable, timeout=timeout, fl_ctx=fl_ctx),\n tuple(self.servers),\n )\n if messages is not None and messages[0] is not None:\n # Only handle single server communication for now.\n return messages\n else:\n return None\n finally:\n if pool:\n pool.terminate()\n\n def register(self):\n \"\"\"Push the local model to multiple servers.\"\"\"\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(self.client_register, tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def set_primary_sp(self, sp):\n pool = None\n try:\n pool = ThreadPool(len(self.servers))\n return pool.map(partial(self.set_sp, sp=sp), tuple(self.servers))\n finally:\n if pool:\n pool.terminate()\n\n def run_heartbeat(self):\n \"\"\"Periodically runs the heartbeat.\"\"\"\n self.heartbeat()\n\n def start_heartbeat(self):\n heartbeat_thread = threading.Thread(target=self.run_heartbeat)\n heartbeat_thread.start()\n\n def quit_remote(self, task_name, fl_ctx: FLContext):\n \"\"\"Sending the last message to the server before leaving.\n\n Args:\n task_name: task name\n fl_ctx: FLContext\n\n Returns: N/A\n\n \"\"\"\n return self.communicator.quit_remote(self.servers, task_name, self.token, self.ssid, fl_ctx)\n\n def set_client_engine(self, engine):\n self.engine = engine\n\n def close(self):\n \"\"\"Quit the remote federated server, close the local session.\"\"\"\n self.logger.info(f\"Shutting down client: {self.client_name}\")\n if self.overseer_agent:\n self.overseer_agent.end()\n\n return 0\n", "path": "nvflare/private/fed/client/fed_client_base.py"}]}
| 3,963 | 410 |
gh_patches_debug_31281
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-7382
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MioMio youtube-dl failing with HTTPError()
I get an HTTP Error 404 when try to download video from MioMio.
I experience this error only in MioMio.
Pretty sure download from MioMio was working till last week.
#
pi@raspberrypi2 ~ $ youtube-dl --version
2015.11.02
pi@raspberrypi2 ~ $ youtube-dl --verbose 'http://www.miomio.tv/watch/cc223353/'
[debug] System config: []
[debug] User config: []
[debug] Command-line args: [u'--verbose', u'http://www.miomio.tv/watch/cc223353/']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2015.11.02
[debug] Python version 2.7.3 - Linux-4.1.6-v7+-armv7l-with-debian-7.8
[debug] exe versions: avconv 9.14-6, avprobe 9.14-6, ffmpeg 0.8.17-6
[debug] Proxy map: {}
[miomio.tv] 223353: Downloading webpage
[miomio.tv] 223353: Downloading webpage
[miomio.tv] 223353: Downloading XML
ERROR: Unable to download XML: HTTP Error 404: Not Found (caused by HTTPError()); please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
File "/usr/local/lib/python2.7/dist-packages/youtube_dl/extractor/common.py", line 329, in _request_webpage
return self._downloader.urlopen(url_or_request)
File "/usr/local/lib/python2.7/dist-packages/youtube_dl/YoutubeDL.py", line 1873, in urlopen
return self._opener.open(req, timeout=self._socket_timeout)
File "/usr/lib/python2.7/urllib2.py", line 407, in open
response = meth(req, response)
File "/usr/lib/python2.7/urllib2.py", line 520, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python2.7/urllib2.py", line 439, in error
result = self._call_chain(_args)
File "/usr/lib/python2.7/urllib2.py", line 379, in _call_chain
result = func(_args)
File "/usr/lib/python2.7/urllib2.py", line 626, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "/usr/lib/python2.7/urllib2.py", line 407, in open
response = meth(req, response)
File "/usr/lib/python2.7/urllib2.py", line 520, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python2.7/urllib2.py", line 445, in error
return self._call_chain(_args)
File "/usr/lib/python2.7/urllib2.py", line 379, in _call_chain
result = func(_args)
File "/usr/lib/python2.7/urllib2.py", line 528, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
pi@raspberrypi2 ~ $
#
Best Regards
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/miomio.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import random
5
6 from .common import InfoExtractor
7 from ..utils import (
8 xpath_text,
9 int_or_none,
10 ExtractorError,
11 )
12
13
14 class MioMioIE(InfoExtractor):
15 IE_NAME = 'miomio.tv'
16 _VALID_URL = r'https?://(?:www\.)?miomio\.tv/watch/cc(?P<id>[0-9]+)'
17 _TESTS = [{
18 # "type=video" in flashvars
19 'url': 'http://www.miomio.tv/watch/cc88912/',
20 'md5': '317a5f7f6b544ce8419b784ca8edae65',
21 'info_dict': {
22 'id': '88912',
23 'ext': 'flv',
24 'title': '【SKY】字幕 铠武昭和VS平成 假面骑士大战FEAT战队 魔星字幕组 字幕',
25 'duration': 5923,
26 },
27 }, {
28 'url': 'http://www.miomio.tv/watch/cc184024/',
29 'info_dict': {
30 'id': '43729',
31 'title': '《动漫同人插画绘制》',
32 },
33 'playlist_mincount': 86,
34 'skip': 'This video takes time too long for retrieving the URL',
35 }, {
36 'url': 'http://www.miomio.tv/watch/cc173113/',
37 'info_dict': {
38 'id': '173113',
39 'title': 'The New Macbook 2015 上手试玩与简评'
40 },
41 'playlist_mincount': 2,
42 }]
43
44 def _real_extract(self, url):
45 video_id = self._match_id(url)
46 webpage = self._download_webpage(url, video_id)
47
48 title = self._html_search_meta(
49 'description', webpage, 'title', fatal=True)
50
51 mioplayer_path = self._search_regex(
52 r'src="(/mioplayer/[^"]+)"', webpage, 'ref_path')
53
54 xml_config = self._search_regex(
55 r'flashvars="type=(?:sina|video)&(.+?)&',
56 webpage, 'xml config')
57
58 # skipping the following page causes lags and eventually connection drop-outs
59 self._request_webpage(
60 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),
61 video_id)
62
63 # the following xml contains the actual configuration information on the video file(s)
64 vid_config = self._download_xml(
65 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),
66 video_id)
67
68 http_headers = {
69 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,
70 }
71
72 if not int_or_none(xpath_text(vid_config, 'timelength')):
73 raise ExtractorError('Unable to load videos!', expected=True)
74
75 entries = []
76 for f in vid_config.findall('./durl'):
77 segment_url = xpath_text(f, 'url', 'video url')
78 if not segment_url:
79 continue
80 order = xpath_text(f, 'order', 'order')
81 segment_id = video_id
82 segment_title = title
83 if order:
84 segment_id += '-%s' % order
85 segment_title += ' part %s' % order
86 entries.append({
87 'id': segment_id,
88 'url': segment_url,
89 'title': segment_title,
90 'duration': int_or_none(xpath_text(f, 'length', 'duration'), 1000),
91 'http_headers': http_headers,
92 })
93
94 if len(entries) == 1:
95 segment = entries[0]
96 segment['id'] = video_id
97 segment['title'] = title
98 return segment
99
100 return {
101 '_type': 'multi_video',
102 'id': video_id,
103 'entries': entries,
104 'title': title,
105 'http_headers': http_headers,
106 }
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/miomio.py b/youtube_dl/extractor/miomio.py
--- a/youtube_dl/extractor/miomio.py
+++ b/youtube_dl/extractor/miomio.py
@@ -4,6 +4,7 @@
import random
from .common import InfoExtractor
+from ..compat import compat_urllib_request
from ..utils import (
xpath_text,
int_or_none,
@@ -51,6 +52,8 @@
mioplayer_path = self._search_regex(
r'src="(/mioplayer/[^"]+)"', webpage, 'ref_path')
+ http_headers = {'Referer': 'http://www.miomio.tv%s' % mioplayer_path,}
+
xml_config = self._search_regex(
r'flashvars="type=(?:sina|video)&(.+?)&',
webpage, 'xml config')
@@ -60,14 +63,12 @@
'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),
video_id)
- # the following xml contains the actual configuration information on the video file(s)
- vid_config = self._download_xml(
+ vid_config_request = compat_urllib_request.Request(
'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),
- video_id)
+ headers=http_headers)
- http_headers = {
- 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,
- }
+ # the following xml contains the actual configuration information on the video file(s)
+ vid_config = self._download_xml(vid_config_request, video_id)
if not int_or_none(xpath_text(vid_config, 'timelength')):
raise ExtractorError('Unable to load videos!', expected=True)
|
{"golden_diff": "diff --git a/youtube_dl/extractor/miomio.py b/youtube_dl/extractor/miomio.py\n--- a/youtube_dl/extractor/miomio.py\n+++ b/youtube_dl/extractor/miomio.py\n@@ -4,6 +4,7 @@\n import random\n \n from .common import InfoExtractor\n+from ..compat import compat_urllib_request\n from ..utils import (\n xpath_text,\n int_or_none,\n@@ -51,6 +52,8 @@\n mioplayer_path = self._search_regex(\n r'src=\"(/mioplayer/[^\"]+)\"', webpage, 'ref_path')\n \n+ http_headers = {'Referer': 'http://www.miomio.tv%s' % mioplayer_path,}\n+\n xml_config = self._search_regex(\n r'flashvars=\"type=(?:sina|video)&(.+?)&',\n webpage, 'xml config')\n@@ -60,14 +63,12 @@\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),\n video_id)\n \n- # the following xml contains the actual configuration information on the video file(s)\n- vid_config = self._download_xml(\n+ vid_config_request = compat_urllib_request.Request(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),\n- video_id)\n+ headers=http_headers)\n \n- http_headers = {\n- 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,\n- }\n+ # the following xml contains the actual configuration information on the video file(s)\n+ vid_config = self._download_xml(vid_config_request, video_id)\n \n if not int_or_none(xpath_text(vid_config, 'timelength')):\n raise ExtractorError('Unable to load videos!', expected=True)\n", "issue": "MioMio youtube-dl failing with HTTPError()\nI get an HTTP Error 404 when try to download video from MioMio.\nI experience this error only in MioMio.\nPretty sure download from MioMio was working till last week.\n# \n\npi@raspberrypi2 ~ $ youtube-dl --version\n2015.11.02\npi@raspberrypi2 ~ $ youtube-dl --verbose 'http://www.miomio.tv/watch/cc223353/'\n[debug] System config: []\n[debug] User config: []\n[debug] Command-line args: [u'--verbose', u'http://www.miomio.tv/watch/cc223353/']\n[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8\n[debug] youtube-dl version 2015.11.02\n[debug] Python version 2.7.3 - Linux-4.1.6-v7+-armv7l-with-debian-7.8\n[debug] exe versions: avconv 9.14-6, avprobe 9.14-6, ffmpeg 0.8.17-6\n[debug] Proxy map: {}\n[miomio.tv] 223353: Downloading webpage\n[miomio.tv] 223353: Downloading webpage\n[miomio.tv] 223353: Downloading XML\nERROR: Unable to download XML: HTTP Error 404: Not Found (caused by HTTPError()); please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\n File \"/usr/local/lib/python2.7/dist-packages/youtube_dl/extractor/common.py\", line 329, in _request_webpage\n return self._downloader.urlopen(url_or_request)\n File \"/usr/local/lib/python2.7/dist-packages/youtube_dl/YoutubeDL.py\", line 1873, in urlopen\n return self._opener.open(req, timeout=self._socket_timeout)\n File \"/usr/lib/python2.7/urllib2.py\", line 407, in open\n response = meth(req, response)\n File \"/usr/lib/python2.7/urllib2.py\", line 520, in http_response\n 'http', request, response, code, msg, hdrs)\n File \"/usr/lib/python2.7/urllib2.py\", line 439, in error\n result = self._call_chain(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 379, in _call_chain\n result = func(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 626, in http_error_302\n return self.parent.open(new, timeout=req.timeout)\n File \"/usr/lib/python2.7/urllib2.py\", line 407, in open\n response = meth(req, response)\n File \"/usr/lib/python2.7/urllib2.py\", line 520, in http_response\n 'http', request, response, code, msg, hdrs)\n File \"/usr/lib/python2.7/urllib2.py\", line 445, in error\n return self._call_chain(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 379, in _call_chain\n result = func(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 528, in http_error_default\n raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)\n\npi@raspberrypi2 ~ $\n# \n\nBest Regards\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport random\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n xpath_text,\n int_or_none,\n ExtractorError,\n)\n\n\nclass MioMioIE(InfoExtractor):\n IE_NAME = 'miomio.tv'\n _VALID_URL = r'https?://(?:www\\.)?miomio\\.tv/watch/cc(?P<id>[0-9]+)'\n _TESTS = [{\n # \"type=video\" in flashvars\n 'url': 'http://www.miomio.tv/watch/cc88912/',\n 'md5': '317a5f7f6b544ce8419b784ca8edae65',\n 'info_dict': {\n 'id': '88912',\n 'ext': 'flv',\n 'title': '\u3010SKY\u3011\u5b57\u5e55 \u94e0\u6b66\u662d\u548cVS\u5e73\u6210 \u5047\u9762\u9a91\u58eb\u5927\u6218FEAT\u6218\u961f \u9b54\u661f\u5b57\u5e55\u7ec4 \u5b57\u5e55',\n 'duration': 5923,\n },\n }, {\n 'url': 'http://www.miomio.tv/watch/cc184024/',\n 'info_dict': {\n 'id': '43729',\n 'title': '\u300a\u52a8\u6f2b\u540c\u4eba\u63d2\u753b\u7ed8\u5236\u300b',\n },\n 'playlist_mincount': 86,\n 'skip': 'This video takes time too long for retrieving the URL',\n }, {\n 'url': 'http://www.miomio.tv/watch/cc173113/',\n 'info_dict': {\n 'id': '173113',\n 'title': 'The New Macbook 2015 \u4e0a\u624b\u8bd5\u73a9\u4e0e\u7b80\u8bc4'\n },\n 'playlist_mincount': 2,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(url, video_id)\n\n title = self._html_search_meta(\n 'description', webpage, 'title', fatal=True)\n\n mioplayer_path = self._search_regex(\n r'src=\"(/mioplayer/[^\"]+)\"', webpage, 'ref_path')\n\n xml_config = self._search_regex(\n r'flashvars=\"type=(?:sina|video)&(.+?)&',\n webpage, 'xml config')\n\n # skipping the following page causes lags and eventually connection drop-outs\n self._request_webpage(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),\n video_id)\n\n # the following xml contains the actual configuration information on the video file(s)\n vid_config = self._download_xml(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),\n video_id)\n\n http_headers = {\n 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,\n }\n\n if not int_or_none(xpath_text(vid_config, 'timelength')):\n raise ExtractorError('Unable to load videos!', expected=True)\n\n entries = []\n for f in vid_config.findall('./durl'):\n segment_url = xpath_text(f, 'url', 'video url')\n if not segment_url:\n continue\n order = xpath_text(f, 'order', 'order')\n segment_id = video_id\n segment_title = title\n if order:\n segment_id += '-%s' % order\n segment_title += ' part %s' % order\n entries.append({\n 'id': segment_id,\n 'url': segment_url,\n 'title': segment_title,\n 'duration': int_or_none(xpath_text(f, 'length', 'duration'), 1000),\n 'http_headers': http_headers,\n })\n\n if len(entries) == 1:\n segment = entries[0]\n segment['id'] = video_id\n segment['title'] = title\n return segment\n\n return {\n '_type': 'multi_video',\n 'id': video_id,\n 'entries': entries,\n 'title': title,\n 'http_headers': http_headers,\n }\n", "path": "youtube_dl/extractor/miomio.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport random\n\nfrom .common import InfoExtractor\nfrom ..compat import compat_urllib_request\nfrom ..utils import (\n xpath_text,\n int_or_none,\n ExtractorError,\n)\n\n\nclass MioMioIE(InfoExtractor):\n IE_NAME = 'miomio.tv'\n _VALID_URL = r'https?://(?:www\\.)?miomio\\.tv/watch/cc(?P<id>[0-9]+)'\n _TESTS = [{\n # \"type=video\" in flashvars\n 'url': 'http://www.miomio.tv/watch/cc88912/',\n 'md5': '317a5f7f6b544ce8419b784ca8edae65',\n 'info_dict': {\n 'id': '88912',\n 'ext': 'flv',\n 'title': '\u3010SKY\u3011\u5b57\u5e55 \u94e0\u6b66\u662d\u548cVS\u5e73\u6210 \u5047\u9762\u9a91\u58eb\u5927\u6218FEAT\u6218\u961f \u9b54\u661f\u5b57\u5e55\u7ec4 \u5b57\u5e55',\n 'duration': 5923,\n },\n }, {\n 'url': 'http://www.miomio.tv/watch/cc184024/',\n 'info_dict': {\n 'id': '43729',\n 'title': '\u300a\u52a8\u6f2b\u540c\u4eba\u63d2\u753b\u7ed8\u5236\u300b',\n },\n 'playlist_mincount': 86,\n 'skip': 'This video takes time too long for retrieving the URL',\n }, {\n 'url': 'http://www.miomio.tv/watch/cc173113/',\n 'info_dict': {\n 'id': '173113',\n 'title': 'The New Macbook 2015 \u4e0a\u624b\u8bd5\u73a9\u4e0e\u7b80\u8bc4'\n },\n 'playlist_mincount': 2,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(url, video_id)\n\n title = self._html_search_meta(\n 'description', webpage, 'title', fatal=True)\n\n mioplayer_path = self._search_regex(\n r'src=\"(/mioplayer/[^\"]+)\"', webpage, 'ref_path')\n\n http_headers = {'Referer': 'http://www.miomio.tv%s' % mioplayer_path,}\n\n xml_config = self._search_regex(\n r'flashvars=\"type=(?:sina|video)&(.+?)&',\n webpage, 'xml config')\n\n # skipping the following page causes lags and eventually connection drop-outs\n self._request_webpage(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),\n video_id)\n\n vid_config_request = compat_urllib_request.Request(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),\n headers=http_headers)\n\n # the following xml contains the actual configuration information on the video file(s)\n vid_config = self._download_xml(vid_config_request, video_id)\n\n if not int_or_none(xpath_text(vid_config, 'timelength')):\n raise ExtractorError('Unable to load videos!', expected=True)\n\n entries = []\n for f in vid_config.findall('./durl'):\n segment_url = xpath_text(f, 'url', 'video url')\n if not segment_url:\n continue\n order = xpath_text(f, 'order', 'order')\n segment_id = video_id\n segment_title = title\n if order:\n segment_id += '-%s' % order\n segment_title += ' part %s' % order\n entries.append({\n 'id': segment_id,\n 'url': segment_url,\n 'title': segment_title,\n 'duration': int_or_none(xpath_text(f, 'length', 'duration'), 1000),\n 'http_headers': http_headers,\n })\n\n if len(entries) == 1:\n segment = entries[0]\n segment['id'] = video_id\n segment['title'] = title\n return segment\n\n return {\n '_type': 'multi_video',\n 'id': video_id,\n 'entries': entries,\n 'title': title,\n 'http_headers': http_headers,\n }\n", "path": "youtube_dl/extractor/miomio.py"}]}
| 2,308 | 439 |
gh_patches_debug_41603
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-675
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Send wagtail form emails asynchronously
Currently wagtail form emails are sent synchronously because the `send` attributes are not serializable. see #671 for the temporary fix.
Rather then sending sync we should fix the problem and provide the required data as a serializable type
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/cms/models.py`
Content:
```
1 from django.db import models
2 from modelcluster.fields import ParentalKey
3 from modelcluster.models import ClusterableModel
4 from wagtail.wagtailadmin import edit_handlers
5 from wagtail.wagtailcore import blocks
6 from wagtail.wagtailcore import fields
7 from wagtail.wagtailcore.models import Orderable
8 from wagtail.wagtailcore.models import Page
9 from wagtail.wagtailforms.models import AbstractEmailForm
10 from wagtail.wagtailforms.models import AbstractFormField
11 from wagtail.wagtailimages.edit_handlers import ImageChooserPanel
12 from wagtail.wagtailsnippets.models import register_snippet
13
14 from meinberlin.apps.actions import blocks as actions_blocks
15
16 from . import blocks as cms_blocks
17 from . import emails
18
19
20 class SimplePage(Page):
21 body = fields.RichTextField(blank=True)
22
23 content_panels = [
24 edit_handlers.FieldPanel('title'),
25 edit_handlers.FieldPanel('body'),
26 ]
27
28 subpage_types = []
29
30
31 class HomePage(Page):
32 body = fields.StreamField([
33 ('paragraph', blocks.RichTextBlock(
34 template='meinberlin_cms/blocks/richtext_block.html'
35 )),
36 ('call_to_action', cms_blocks.CallToActionBlock()),
37 ('columns_text', cms_blocks.ColumnsBlock()),
38 ('projects', cms_blocks.ProjectsWrapperBlock()),
39 ('activities', actions_blocks.PlatformActivityBlock()),
40 ])
41
42 subtitle = models.CharField(max_length=120)
43
44 header_image = models.ForeignKey(
45 'wagtailimages.Image',
46 null=True,
47 blank=False,
48 on_delete=models.SET_NULL,
49 related_name='+'
50 )
51
52 content_panels = Page.content_panels + [
53 edit_handlers.FieldPanel('subtitle'),
54 ImageChooserPanel('header_image'),
55 edit_handlers.StreamFieldPanel('body'),
56 ]
57
58
59 class MenuItem(models.Model):
60 title = models.CharField(max_length=255)
61 link_page = models.ForeignKey('wagtailcore.Page')
62
63 @property
64 def url(self):
65 return self.link_page.url
66
67 def __str__(self):
68 return self.title
69
70 panels = [
71 edit_handlers.FieldPanel('title'),
72 edit_handlers.PageChooserPanel('link_page')
73 ]
74
75
76 @register_snippet
77 class NavigationMenu(ClusterableModel):
78 title = models.CharField(max_length=255, null=False, blank=False)
79
80 def __str__(self):
81 return self.title
82
83 panels = [
84 edit_handlers.FieldPanel('title'),
85 edit_handlers.InlinePanel('items')
86 ]
87
88
89 class NavigationMenuItem(Orderable, MenuItem):
90 parent = ParentalKey('meinberlin_cms.NavigationMenu', related_name='items')
91
92
93 class EmailFormField(AbstractFormField):
94 page = ParentalKey('EmailFormPage', related_name='form_fields')
95
96
97 class EmailFormPage(AbstractEmailForm):
98 intro = fields.RichTextField(
99 help_text='Introduction text shown above the form'
100 )
101 thank_you = fields.RichTextField(
102 help_text='Text shown after form submission',
103 )
104 email_content = models.CharField(
105 max_length=200,
106 help_text='Email content message',
107 )
108 attach_as = models.CharField(
109 max_length=3,
110 choices=(
111 ('xls', 'XLSX Document'),
112 ('txt', 'Text'),
113 ),
114 default='xls',
115 help_text='Form results are send in this document format',
116 )
117
118 content_panels = AbstractEmailForm.content_panels + [
119 edit_handlers.MultiFieldPanel([
120 edit_handlers.FieldPanel('intro', classname='full'),
121 edit_handlers.FieldPanel('thank_you', classname='full'),
122 ], 'Page'),
123 edit_handlers.MultiFieldPanel([
124 edit_handlers.FieldPanel('to_address'),
125 edit_handlers.FieldPanel('subject'),
126 edit_handlers.FieldPanel('email_content', classname='full'),
127 edit_handlers.FieldPanel('attach_as'),
128 ], 'Email'),
129 edit_handlers.InlinePanel('form_fields', label='Form fields'),
130 ]
131
132 def send_mail(self, form):
133 self.form = form
134 if self.attach_as == 'xls':
135 emails.XlsxFormEmail.send(self)
136 elif self.attach_as == 'txt':
137 emails.TextFormEmail.send(self)
138
139 @property
140 def field_values(self):
141 fields = {}
142 for field in self.form:
143 value = field.value()
144 if isinstance(value, list):
145 value = ', '.join(value)
146 fields[field.label] = value
147 return fields
148
```
Path: `meinberlin/apps/cms/emails.py`
Content:
```
1 import io
2 from email.mime.application import MIMEApplication
3 from email.mime.text import MIMEText
4
5 import xlsxwriter
6 from django.utils import timezone
7 from django.utils.translation import ugettext as _
8
9 from adhocracy4.emails.mixins import SyncEmailMixin
10 from meinberlin.apps.contrib.emails import Email
11
12
13 class FormEmail(SyncEmailMixin, Email):
14 template_name = 'meinberlin_cms/emails/form_submission'
15
16 def get_receivers(self):
17 return [x.strip() for x in self.object.to_address.split(',')]
18
19
20 class XlsxFormEmail(FormEmail):
21
22 def _generate_xlsx(self):
23 stream = io.BytesIO()
24 workbook = xlsxwriter.Workbook(stream, {'in_memory': True})
25 worksheet = workbook.add_worksheet()
26
27 worksheet.write(0, 0, _('Form Field'))
28 worksheet.write(0, 1, _('Response'))
29
30 rows = self.object.field_values.items()
31 for rownum, row in enumerate(rows, start=1):
32 worksheet.write(rownum, 0, row[0])
33 worksheet.write(rownum, 1, self._fix_newline_if_string(row[1]))
34
35 workbook.close()
36 return stream.getvalue()
37
38 def _fix_newline_if_string(self, value):
39 if isinstance(value, str):
40 return value.replace('\r', '')
41 return value
42
43 def get_attachments(self):
44 attachments = super().get_attachments()
45 xlsx_data = self._generate_xlsx()
46 mime_doc = MIMEApplication(
47 _data=xlsx_data,
48 _subtype='vnd.openxmlformats-officedocument.spreadsheetml.sheet')
49 timestamp = timezone.now().strftime("%Y-%m-%d")
50 form_title = self.object.title.replace(' ', '_')
51 submission_pk = self.object.get_submission_class().objects.last().pk
52 filename = '{}_{}_{}.xlsx'.format(timestamp, form_title, submission_pk)
53 mime_doc.add_header(
54 'Content-Disposition',
55 'attachment; filename="{}"'.format(filename)
56 )
57 return attachments + [mime_doc]
58
59
60 class TextFormEmail(FormEmail):
61
62 def get_attachments(self):
63 attachments = super().get_attachments()
64 text = ''
65 for field, value in self.object.field_values.items():
66 text += '{}:\n{}\n\n'.format(field, value)
67 mime_doc = MIMEText(_text=text, _charset='utf-8')
68 return attachments + [mime_doc]
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/cms/emails.py b/meinberlin/apps/cms/emails.py
--- a/meinberlin/apps/cms/emails.py
+++ b/meinberlin/apps/cms/emails.py
@@ -6,15 +6,14 @@
from django.utils import timezone
from django.utils.translation import ugettext as _
-from adhocracy4.emails.mixins import SyncEmailMixin
from meinberlin.apps.contrib.emails import Email
-class FormEmail(SyncEmailMixin, Email):
+class FormEmail(Email):
template_name = 'meinberlin_cms/emails/form_submission'
def get_receivers(self):
- return [x.strip() for x in self.object.to_address.split(',')]
+ return [x.strip() for x in self.kwargs.get('to_addresses')]
class XlsxFormEmail(FormEmail):
@@ -27,8 +26,8 @@
worksheet.write(0, 0, _('Form Field'))
worksheet.write(0, 1, _('Response'))
- rows = self.object.field_values.items()
- for rownum, row in enumerate(rows, start=1):
+ field_values = self.kwargs.get('field_values')
+ for rownum, row in enumerate(field_values.items(), start=1):
worksheet.write(rownum, 0, row[0])
worksheet.write(rownum, 1, self._fix_newline_if_string(row[1]))
@@ -47,8 +46,8 @@
_data=xlsx_data,
_subtype='vnd.openxmlformats-officedocument.spreadsheetml.sheet')
timestamp = timezone.now().strftime("%Y-%m-%d")
- form_title = self.object.title.replace(' ', '_')
- submission_pk = self.object.get_submission_class().objects.last().pk
+ form_title = self.kwargs.get('title')
+ submission_pk = self.kwargs.get('submission_pk')
filename = '{}_{}_{}.xlsx'.format(timestamp, form_title, submission_pk)
mime_doc.add_header(
'Content-Disposition',
@@ -62,7 +61,8 @@
def get_attachments(self):
attachments = super().get_attachments()
text = ''
- for field, value in self.object.field_values.items():
+ field_values = self.kwargs.get('field_values')
+ for field, value in field_values.items():
text += '{}:\n{}\n\n'.format(field, value)
mime_doc = MIMEText(_text=text, _charset='utf-8')
return attachments + [mime_doc]
diff --git a/meinberlin/apps/cms/models.py b/meinberlin/apps/cms/models.py
--- a/meinberlin/apps/cms/models.py
+++ b/meinberlin/apps/cms/models.py
@@ -130,16 +130,20 @@
]
def send_mail(self, form):
- self.form = form
+ kwargs = {
+ 'title': self.title.replace(' ', '_'),
+ 'to_addresses': self.to_address.split(','),
+ 'field_values': self.get_field_values(form),
+ 'submission_pk': self.get_submission_class().objects.last().pk
+ }
if self.attach_as == 'xls':
- emails.XlsxFormEmail.send(self)
+ emails.XlsxFormEmail.send(self, **kwargs)
elif self.attach_as == 'txt':
- emails.TextFormEmail.send(self)
+ emails.TextFormEmail.send(self, **kwargs)
- @property
- def field_values(self):
+ def get_field_values(self, form):
fields = {}
- for field in self.form:
+ for field in form:
value = field.value()
if isinstance(value, list):
value = ', '.join(value)
|
{"golden_diff": "diff --git a/meinberlin/apps/cms/emails.py b/meinberlin/apps/cms/emails.py\n--- a/meinberlin/apps/cms/emails.py\n+++ b/meinberlin/apps/cms/emails.py\n@@ -6,15 +6,14 @@\n from django.utils import timezone\n from django.utils.translation import ugettext as _\n \n-from adhocracy4.emails.mixins import SyncEmailMixin\n from meinberlin.apps.contrib.emails import Email\n \n \n-class FormEmail(SyncEmailMixin, Email):\n+class FormEmail(Email):\n template_name = 'meinberlin_cms/emails/form_submission'\n \n def get_receivers(self):\n- return [x.strip() for x in self.object.to_address.split(',')]\n+ return [x.strip() for x in self.kwargs.get('to_addresses')]\n \n \n class XlsxFormEmail(FormEmail):\n@@ -27,8 +26,8 @@\n worksheet.write(0, 0, _('Form Field'))\n worksheet.write(0, 1, _('Response'))\n \n- rows = self.object.field_values.items()\n- for rownum, row in enumerate(rows, start=1):\n+ field_values = self.kwargs.get('field_values')\n+ for rownum, row in enumerate(field_values.items(), start=1):\n worksheet.write(rownum, 0, row[0])\n worksheet.write(rownum, 1, self._fix_newline_if_string(row[1]))\n \n@@ -47,8 +46,8 @@\n _data=xlsx_data,\n _subtype='vnd.openxmlformats-officedocument.spreadsheetml.sheet')\n timestamp = timezone.now().strftime(\"%Y-%m-%d\")\n- form_title = self.object.title.replace(' ', '_')\n- submission_pk = self.object.get_submission_class().objects.last().pk\n+ form_title = self.kwargs.get('title')\n+ submission_pk = self.kwargs.get('submission_pk')\n filename = '{}_{}_{}.xlsx'.format(timestamp, form_title, submission_pk)\n mime_doc.add_header(\n 'Content-Disposition',\n@@ -62,7 +61,8 @@\n def get_attachments(self):\n attachments = super().get_attachments()\n text = ''\n- for field, value in self.object.field_values.items():\n+ field_values = self.kwargs.get('field_values')\n+ for field, value in field_values.items():\n text += '{}:\\n{}\\n\\n'.format(field, value)\n mime_doc = MIMEText(_text=text, _charset='utf-8')\n return attachments + [mime_doc]\ndiff --git a/meinberlin/apps/cms/models.py b/meinberlin/apps/cms/models.py\n--- a/meinberlin/apps/cms/models.py\n+++ b/meinberlin/apps/cms/models.py\n@@ -130,16 +130,20 @@\n ]\n \n def send_mail(self, form):\n- self.form = form\n+ kwargs = {\n+ 'title': self.title.replace(' ', '_'),\n+ 'to_addresses': self.to_address.split(','),\n+ 'field_values': self.get_field_values(form),\n+ 'submission_pk': self.get_submission_class().objects.last().pk\n+ }\n if self.attach_as == 'xls':\n- emails.XlsxFormEmail.send(self)\n+ emails.XlsxFormEmail.send(self, **kwargs)\n elif self.attach_as == 'txt':\n- emails.TextFormEmail.send(self)\n+ emails.TextFormEmail.send(self, **kwargs)\n \n- @property\n- def field_values(self):\n+ def get_field_values(self, form):\n fields = {}\n- for field in self.form:\n+ for field in form:\n value = field.value()\n if isinstance(value, list):\n value = ', '.join(value)\n", "issue": "Send wagtail form emails asynchronously \nCurrently wagtail form emails are sent synchronously because the `send` attributes are not serializable. see #671 for the temporary fix.\r\nRather then sending sync we should fix the problem and provide the required data as a serializable type\n", "before_files": [{"content": "from django.db import models\nfrom modelcluster.fields import ParentalKey\nfrom modelcluster.models import ClusterableModel\nfrom wagtail.wagtailadmin import edit_handlers\nfrom wagtail.wagtailcore import blocks\nfrom wagtail.wagtailcore import fields\nfrom wagtail.wagtailcore.models import Orderable\nfrom wagtail.wagtailcore.models import Page\nfrom wagtail.wagtailforms.models import AbstractEmailForm\nfrom wagtail.wagtailforms.models import AbstractFormField\nfrom wagtail.wagtailimages.edit_handlers import ImageChooserPanel\nfrom wagtail.wagtailsnippets.models import register_snippet\n\nfrom meinberlin.apps.actions import blocks as actions_blocks\n\nfrom . import blocks as cms_blocks\nfrom . import emails\n\n\nclass SimplePage(Page):\n body = fields.RichTextField(blank=True)\n\n content_panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.FieldPanel('body'),\n ]\n\n subpage_types = []\n\n\nclass HomePage(Page):\n body = fields.StreamField([\n ('paragraph', blocks.RichTextBlock(\n template='meinberlin_cms/blocks/richtext_block.html'\n )),\n ('call_to_action', cms_blocks.CallToActionBlock()),\n ('columns_text', cms_blocks.ColumnsBlock()),\n ('projects', cms_blocks.ProjectsWrapperBlock()),\n ('activities', actions_blocks.PlatformActivityBlock()),\n ])\n\n subtitle = models.CharField(max_length=120)\n\n header_image = models.ForeignKey(\n 'wagtailimages.Image',\n null=True,\n blank=False,\n on_delete=models.SET_NULL,\n related_name='+'\n )\n\n content_panels = Page.content_panels + [\n edit_handlers.FieldPanel('subtitle'),\n ImageChooserPanel('header_image'),\n edit_handlers.StreamFieldPanel('body'),\n ]\n\n\nclass MenuItem(models.Model):\n title = models.CharField(max_length=255)\n link_page = models.ForeignKey('wagtailcore.Page')\n\n @property\n def url(self):\n return self.link_page.url\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.PageChooserPanel('link_page')\n ]\n\n\n@register_snippet\nclass NavigationMenu(ClusterableModel):\n title = models.CharField(max_length=255, null=False, blank=False)\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.InlinePanel('items')\n ]\n\n\nclass NavigationMenuItem(Orderable, MenuItem):\n parent = ParentalKey('meinberlin_cms.NavigationMenu', related_name='items')\n\n\nclass EmailFormField(AbstractFormField):\n page = ParentalKey('EmailFormPage', related_name='form_fields')\n\n\nclass EmailFormPage(AbstractEmailForm):\n intro = fields.RichTextField(\n help_text='Introduction text shown above the form'\n )\n thank_you = fields.RichTextField(\n help_text='Text shown after form submission',\n )\n email_content = models.CharField(\n max_length=200,\n help_text='Email content message',\n )\n attach_as = models.CharField(\n max_length=3,\n choices=(\n ('xls', 'XLSX Document'),\n ('txt', 'Text'),\n ),\n default='xls',\n help_text='Form results are send in this document format',\n )\n\n content_panels = AbstractEmailForm.content_panels + [\n edit_handlers.MultiFieldPanel([\n edit_handlers.FieldPanel('intro', classname='full'),\n edit_handlers.FieldPanel('thank_you', classname='full'),\n ], 'Page'),\n edit_handlers.MultiFieldPanel([\n edit_handlers.FieldPanel('to_address'),\n edit_handlers.FieldPanel('subject'),\n edit_handlers.FieldPanel('email_content', classname='full'),\n edit_handlers.FieldPanel('attach_as'),\n ], 'Email'),\n edit_handlers.InlinePanel('form_fields', label='Form fields'),\n ]\n\n def send_mail(self, form):\n self.form = form\n if self.attach_as == 'xls':\n emails.XlsxFormEmail.send(self)\n elif self.attach_as == 'txt':\n emails.TextFormEmail.send(self)\n\n @property\n def field_values(self):\n fields = {}\n for field in self.form:\n value = field.value()\n if isinstance(value, list):\n value = ', '.join(value)\n fields[field.label] = value\n return fields\n", "path": "meinberlin/apps/cms/models.py"}, {"content": "import io\nfrom email.mime.application import MIMEApplication\nfrom email.mime.text import MIMEText\n\nimport xlsxwriter\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext as _\n\nfrom adhocracy4.emails.mixins import SyncEmailMixin\nfrom meinberlin.apps.contrib.emails import Email\n\n\nclass FormEmail(SyncEmailMixin, Email):\n template_name = 'meinberlin_cms/emails/form_submission'\n\n def get_receivers(self):\n return [x.strip() for x in self.object.to_address.split(',')]\n\n\nclass XlsxFormEmail(FormEmail):\n\n def _generate_xlsx(self):\n stream = io.BytesIO()\n workbook = xlsxwriter.Workbook(stream, {'in_memory': True})\n worksheet = workbook.add_worksheet()\n\n worksheet.write(0, 0, _('Form Field'))\n worksheet.write(0, 1, _('Response'))\n\n rows = self.object.field_values.items()\n for rownum, row in enumerate(rows, start=1):\n worksheet.write(rownum, 0, row[0])\n worksheet.write(rownum, 1, self._fix_newline_if_string(row[1]))\n\n workbook.close()\n return stream.getvalue()\n\n def _fix_newline_if_string(self, value):\n if isinstance(value, str):\n return value.replace('\\r', '')\n return value\n\n def get_attachments(self):\n attachments = super().get_attachments()\n xlsx_data = self._generate_xlsx()\n mime_doc = MIMEApplication(\n _data=xlsx_data,\n _subtype='vnd.openxmlformats-officedocument.spreadsheetml.sheet')\n timestamp = timezone.now().strftime(\"%Y-%m-%d\")\n form_title = self.object.title.replace(' ', '_')\n submission_pk = self.object.get_submission_class().objects.last().pk\n filename = '{}_{}_{}.xlsx'.format(timestamp, form_title, submission_pk)\n mime_doc.add_header(\n 'Content-Disposition',\n 'attachment; filename=\"{}\"'.format(filename)\n )\n return attachments + [mime_doc]\n\n\nclass TextFormEmail(FormEmail):\n\n def get_attachments(self):\n attachments = super().get_attachments()\n text = ''\n for field, value in self.object.field_values.items():\n text += '{}:\\n{}\\n\\n'.format(field, value)\n mime_doc = MIMEText(_text=text, _charset='utf-8')\n return attachments + [mime_doc]\n", "path": "meinberlin/apps/cms/emails.py"}], "after_files": [{"content": "from django.db import models\nfrom modelcluster.fields import ParentalKey\nfrom modelcluster.models import ClusterableModel\nfrom wagtail.wagtailadmin import edit_handlers\nfrom wagtail.wagtailcore import blocks\nfrom wagtail.wagtailcore import fields\nfrom wagtail.wagtailcore.models import Orderable\nfrom wagtail.wagtailcore.models import Page\nfrom wagtail.wagtailforms.models import AbstractEmailForm\nfrom wagtail.wagtailforms.models import AbstractFormField\nfrom wagtail.wagtailimages.edit_handlers import ImageChooserPanel\nfrom wagtail.wagtailsnippets.models import register_snippet\n\nfrom meinberlin.apps.actions import blocks as actions_blocks\n\nfrom . import blocks as cms_blocks\nfrom . import emails\n\n\nclass SimplePage(Page):\n body = fields.RichTextField(blank=True)\n\n content_panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.FieldPanel('body'),\n ]\n\n subpage_types = []\n\n\nclass HomePage(Page):\n body = fields.StreamField([\n ('paragraph', blocks.RichTextBlock(\n template='meinberlin_cms/blocks/richtext_block.html'\n )),\n ('call_to_action', cms_blocks.CallToActionBlock()),\n ('columns_text', cms_blocks.ColumnsBlock()),\n ('projects', cms_blocks.ProjectsWrapperBlock()),\n ('activities', actions_blocks.PlatformActivityBlock()),\n ])\n\n subtitle = models.CharField(max_length=120)\n\n header_image = models.ForeignKey(\n 'wagtailimages.Image',\n null=True,\n blank=False,\n on_delete=models.SET_NULL,\n related_name='+'\n )\n\n content_panels = Page.content_panels + [\n edit_handlers.FieldPanel('subtitle'),\n ImageChooserPanel('header_image'),\n edit_handlers.StreamFieldPanel('body'),\n ]\n\n\nclass MenuItem(models.Model):\n title = models.CharField(max_length=255)\n link_page = models.ForeignKey('wagtailcore.Page')\n\n @property\n def url(self):\n return self.link_page.url\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.PageChooserPanel('link_page')\n ]\n\n\n@register_snippet\nclass NavigationMenu(ClusterableModel):\n title = models.CharField(max_length=255, null=False, blank=False)\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.InlinePanel('items')\n ]\n\n\nclass NavigationMenuItem(Orderable, MenuItem):\n parent = ParentalKey('meinberlin_cms.NavigationMenu', related_name='items')\n\n\nclass EmailFormField(AbstractFormField):\n page = ParentalKey('EmailFormPage', related_name='form_fields')\n\n\nclass EmailFormPage(AbstractEmailForm):\n intro = fields.RichTextField(\n help_text='Introduction text shown above the form'\n )\n thank_you = fields.RichTextField(\n help_text='Text shown after form submission',\n )\n email_content = models.CharField(\n max_length=200,\n help_text='Email content message',\n )\n attach_as = models.CharField(\n max_length=3,\n choices=(\n ('xls', 'XLSX Document'),\n ('txt', 'Text'),\n ),\n default='xls',\n help_text='Form results are send in this document format',\n )\n\n content_panels = AbstractEmailForm.content_panels + [\n edit_handlers.MultiFieldPanel([\n edit_handlers.FieldPanel('intro', classname='full'),\n edit_handlers.FieldPanel('thank_you', classname='full'),\n ], 'Page'),\n edit_handlers.MultiFieldPanel([\n edit_handlers.FieldPanel('to_address'),\n edit_handlers.FieldPanel('subject'),\n edit_handlers.FieldPanel('email_content', classname='full'),\n edit_handlers.FieldPanel('attach_as'),\n ], 'Email'),\n edit_handlers.InlinePanel('form_fields', label='Form fields'),\n ]\n\n def send_mail(self, form):\n kwargs = {\n 'title': self.title.replace(' ', '_'),\n 'to_addresses': self.to_address.split(','),\n 'field_values': self.get_field_values(form),\n 'submission_pk': self.get_submission_class().objects.last().pk\n }\n if self.attach_as == 'xls':\n emails.XlsxFormEmail.send(self, **kwargs)\n elif self.attach_as == 'txt':\n emails.TextFormEmail.send(self, **kwargs)\n\n def get_field_values(self, form):\n fields = {}\n for field in form:\n value = field.value()\n if isinstance(value, list):\n value = ', '.join(value)\n fields[field.label] = value\n return fields\n", "path": "meinberlin/apps/cms/models.py"}, {"content": "import io\nfrom email.mime.application import MIMEApplication\nfrom email.mime.text import MIMEText\n\nimport xlsxwriter\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext as _\n\nfrom meinberlin.apps.contrib.emails import Email\n\n\nclass FormEmail(Email):\n template_name = 'meinberlin_cms/emails/form_submission'\n\n def get_receivers(self):\n return [x.strip() for x in self.kwargs.get('to_addresses')]\n\n\nclass XlsxFormEmail(FormEmail):\n\n def _generate_xlsx(self):\n stream = io.BytesIO()\n workbook = xlsxwriter.Workbook(stream, {'in_memory': True})\n worksheet = workbook.add_worksheet()\n\n worksheet.write(0, 0, _('Form Field'))\n worksheet.write(0, 1, _('Response'))\n\n field_values = self.kwargs.get('field_values')\n for rownum, row in enumerate(field_values.items(), start=1):\n worksheet.write(rownum, 0, row[0])\n worksheet.write(rownum, 1, self._fix_newline_if_string(row[1]))\n\n workbook.close()\n return stream.getvalue()\n\n def _fix_newline_if_string(self, value):\n if isinstance(value, str):\n return value.replace('\\r', '')\n return value\n\n def get_attachments(self):\n attachments = super().get_attachments()\n xlsx_data = self._generate_xlsx()\n mime_doc = MIMEApplication(\n _data=xlsx_data,\n _subtype='vnd.openxmlformats-officedocument.spreadsheetml.sheet')\n timestamp = timezone.now().strftime(\"%Y-%m-%d\")\n form_title = self.kwargs.get('title')\n submission_pk = self.kwargs.get('submission_pk')\n filename = '{}_{}_{}.xlsx'.format(timestamp, form_title, submission_pk)\n mime_doc.add_header(\n 'Content-Disposition',\n 'attachment; filename=\"{}\"'.format(filename)\n )\n return attachments + [mime_doc]\n\n\nclass TextFormEmail(FormEmail):\n\n def get_attachments(self):\n attachments = super().get_attachments()\n text = ''\n field_values = self.kwargs.get('field_values')\n for field, value in field_values.items():\n text += '{}:\\n{}\\n\\n'.format(field, value)\n mime_doc = MIMEText(_text=text, _charset='utf-8')\n return attachments + [mime_doc]\n", "path": "meinberlin/apps/cms/emails.py"}]}
| 2,282 | 814 |
gh_patches_debug_39538
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-4037
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
User already exists during setup (DAppNode)
## Problem Definition
Using DAppNode Package:
1. Install Rotki
2. Setup Rotki using Premium API Key with restore sync'd database option
3. Enter incorrect password
4. Get error that password could not decrypt database
5. Go back
6. Enter correct password
7. "User $USERNAME already exists. User data dir: /data/$USERNAME"
Can't proceed...have to delete and re-create Rotki package
## Logs
None
### System Description
Operating system: DAppNode
Rotki version: DAppNode Package `0.1.9 (v1.23.1 upstream)`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rotkehlchen/premium/sync.py`
Content:
```
1 import base64
2 import logging
3 import shutil
4 from enum import Enum
5 from typing import Any, Dict, NamedTuple, Optional, Tuple
6
7 from typing_extensions import Literal
8
9 from rotkehlchen.data_handler import DataHandler
10 from rotkehlchen.errors import (
11 PremiumAuthenticationError,
12 RemoteError,
13 RotkehlchenPermissionError,
14 UnableToDecryptRemoteData,
15 )
16 from rotkehlchen.logging import RotkehlchenLogsAdapter
17 from rotkehlchen.premium.premium import Premium, PremiumCredentials, premium_create_and_verify
18 from rotkehlchen.utils.misc import ts_now
19
20 logger = logging.getLogger(__name__)
21 log = RotkehlchenLogsAdapter(logger)
22
23
24 class CanSync(Enum):
25 YES = 0
26 NO = 1
27 ASK_USER = 2
28
29
30 class SyncCheckResult(NamedTuple):
31 # The result of the sync check
32 can_sync: CanSync
33 # If result is ASK_USER, what should the message be?
34 message: str
35 payload: Optional[Dict[str, Any]]
36
37
38 class PremiumSyncManager():
39
40 def __init__(self, data: DataHandler, password: str) -> None:
41 # Initialize this with the value saved in the DB
42 self.last_data_upload_ts = data.db.get_last_data_upload_ts()
43 self.data = data
44 self.password = password
45 self.premium: Optional[Premium] = None
46
47 def _can_sync_data_from_server(self, new_account: bool) -> SyncCheckResult:
48 """
49 Checks if the remote data can be pulled from the server.
50
51 Returns a SyncCheckResult denoting whether we can pull for sure,
52 whether we can't pull or whether the user should be asked. If the user
53 should be asked a message is also returned
54 """
55 log.debug('can sync data from server -- start')
56 if self.premium is None:
57 return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)
58
59 b64_encoded_data, our_hash = self.data.compress_and_encrypt_db(self.password)
60
61 try:
62 metadata = self.premium.query_last_data_metadata()
63 except RemoteError as e:
64 log.debug('can sync data from server failed', error=str(e))
65 return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)
66
67 if new_account:
68 return SyncCheckResult(can_sync=CanSync.YES, message='', payload=None)
69
70 if not self.data.db.get_premium_sync():
71 # If it's not a new account and the db setting for premium syncing is off stop
72 return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)
73
74 log.debug(
75 'CAN_PULL',
76 ours=our_hash,
77 theirs=metadata.data_hash,
78 )
79 if our_hash == metadata.data_hash:
80 log.debug('sync from server stopped -- same hash')
81 # same hash -- no need to get anything
82 return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)
83
84 our_last_write_ts = self.data.db.get_last_write_ts()
85 data_bytes_size = len(base64.b64decode(b64_encoded_data))
86
87 local_more_recent = our_last_write_ts >= metadata.last_modify_ts
88
89 if local_more_recent:
90 log.debug('sync from server stopped -- local is newer')
91 return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)
92
93 # else remote is bigger
94 return SyncCheckResult(
95 can_sync=CanSync.ASK_USER,
96 message='Detected remote database with bigger size than the local one. ',
97 payload={
98 'local_size': data_bytes_size,
99 'remote_size': metadata.data_size,
100 'local_last_modified': our_last_write_ts,
101 'remote_last_modified': metadata.last_modify_ts,
102 },
103 )
104
105 def _sync_data_from_server_and_replace_local(self) -> Tuple[bool, str]:
106 """
107 Performs syncing of data from server and replaces local db
108
109 Returns true for success and False for error/failure
110
111 May raise:
112 - PremiumAuthenticationError due to an UnableToDecryptRemoteData
113 coming from decompress_and_decrypt_db. This happens when the given password
114 does not match the one on the saved DB.
115 """
116 if self.premium is None:
117 return False, 'Pulling failed. User does not have active premium.'
118
119 try:
120 result = self.premium.pull_data()
121 except RemoteError as e:
122 log.debug('sync from server -- pulling failed.', error=str(e))
123 return False, f'Pulling failed: {str(e)}'
124
125 if result['data'] is None:
126 log.debug('sync from server -- no data found.')
127 return False, 'No data found'
128
129 try:
130 self.data.decompress_and_decrypt_db(self.password, result['data'])
131 except UnableToDecryptRemoteData as e:
132 raise PremiumAuthenticationError(
133 'The given password can not unlock the database that was retrieved from '
134 'the server. Make sure to use the same password as when the account was created.',
135 ) from e
136
137 return True, ''
138
139 def maybe_upload_data_to_server(self, force_upload: bool = False) -> bool:
140 # if user has no premium do nothing
141 if self.premium is None:
142 return False
143
144 if not self.data.db.get_premium_sync() and not force_upload:
145 return False
146
147 # upload only once per hour
148 diff = ts_now() - self.last_data_upload_ts
149 if diff < 3600 and not force_upload:
150 return False
151
152 try:
153 metadata = self.premium.query_last_data_metadata()
154 except RemoteError as e:
155 log.debug('upload to server -- fetching metadata error', error=str(e))
156 return False
157 b64_encoded_data, our_hash = self.data.compress_and_encrypt_db(self.password)
158
159 log.debug(
160 'CAN_PUSH',
161 ours=our_hash,
162 theirs=metadata.data_hash,
163 )
164 if our_hash == metadata.data_hash and not force_upload:
165 log.debug('upload to server stopped -- same hash')
166 # same hash -- no need to upload anything
167 return False
168
169 our_last_write_ts = self.data.db.get_last_write_ts()
170 if our_last_write_ts <= metadata.last_modify_ts and not force_upload:
171 # Server's DB was modified after our local DB
172 log.debug(
173 f'upload to server stopped -- remote db({metadata.last_modify_ts}) '
174 f'more recent than local({our_last_write_ts})',
175 )
176 return False
177
178 data_bytes_size = len(base64.b64decode(b64_encoded_data))
179 if data_bytes_size < metadata.data_size and not force_upload:
180 # Let's be conservative.
181 # TODO: Here perhaps prompt user in the future
182 log.debug(
183 f'upload to server stopped -- remote db({metadata.data_size}) '
184 f'bigger than local({data_bytes_size})',
185 )
186 return False
187
188 try:
189 self.premium.upload_data(
190 data_blob=b64_encoded_data,
191 our_hash=our_hash,
192 last_modify_ts=our_last_write_ts,
193 compression_type='zlib',
194 )
195 except RemoteError as e:
196 log.debug('upload to server -- upload error', error=str(e))
197 return False
198
199 # update the last data upload value
200 self.last_data_upload_ts = ts_now()
201 self.data.db.update_last_data_upload_ts(self.last_data_upload_ts)
202 log.debug('upload to server -- success')
203 return True
204
205 def sync_data(self, action: Literal['upload', 'download']) -> Tuple[bool, str]:
206 msg = ''
207
208 if action == 'upload':
209 success = self.maybe_upload_data_to_server(force_upload=True)
210
211 if not success:
212 msg = 'Upload failed'
213 return success, msg
214
215 return self._sync_data_from_server_and_replace_local()
216
217 def _sync_if_allowed(
218 self,
219 sync_approval: Literal['yes', 'no', 'unknown'],
220 result: SyncCheckResult,
221 ) -> None:
222 if result.can_sync == CanSync.ASK_USER:
223 if sync_approval == 'unknown':
224 log.info('Remote DB is possibly newer. Ask user.')
225 raise RotkehlchenPermissionError(result.message, result.payload)
226
227 if sync_approval == 'yes':
228 log.info('User approved data sync from server')
229 # this may raise due to password
230 self._sync_data_from_server_and_replace_local()
231
232 else:
233 log.debug('Could sync data from server but user refused')
234 elif result.can_sync == CanSync.YES:
235 log.info('User approved data sync from server')
236 self._sync_data_from_server_and_replace_local() # this may raise due to password
237
238 def try_premium_at_start(
239 self,
240 given_premium_credentials: Optional[PremiumCredentials],
241 username: str,
242 create_new: bool,
243 sync_approval: Literal['yes', 'no', 'unknown'],
244 sync_database: bool,
245 ) -> Optional[Premium]:
246 """
247 Check if new user provided api pair or we already got one in the DB
248
249 Returns the created premium if user's premium credentials were fine.
250
251 If not it will raise PremiumAuthenticationError.
252
253 If no credentials were given it returns None
254 """
255
256 if given_premium_credentials is not None:
257 assert create_new, 'We should never get here for an already existing account'
258
259 try:
260 self.premium = premium_create_and_verify(given_premium_credentials)
261 except PremiumAuthenticationError as e:
262 log.error('Given API key is invalid')
263 # At this point we are at a new user trying to create an account with
264 # premium API keys and we failed. But a directory was created. Remove it.
265 # But create a backup of it in case something went really wrong
266 # and the directory contained data we did not want to lose
267 shutil.move(
268 self.data.user_data_dir, # type: ignore
269 self.data.data_directory / f'auto_backup_{username}_{ts_now()}',
270 )
271 raise PremiumAuthenticationError(
272 'Could not verify keys for the new account. '
273 '{}'.format(str(e)),
274 ) from e
275
276 # else, if we got premium data in the DB initialize it and try to sync with the server
277 db_credentials = self.data.db.get_rotkehlchen_premium()
278 if db_credentials:
279 assert not create_new, 'We should never get here for a new account'
280 try:
281 self.premium = premium_create_and_verify(db_credentials)
282 except PremiumAuthenticationError as e:
283 message = (
284 f'Could not authenticate with the rotkehlchen server with '
285 f'the API keys found in the Database. Error: {str(e)}'
286 )
287 log.error(message)
288 raise PremiumAuthenticationError(message) from e
289
290 if self.premium is None:
291 return None
292
293 result = self._can_sync_data_from_server(new_account=create_new)
294 if create_new:
295 # if this is a new account, make sure the api keys are properly stored
296 # in the DB
297 if sync_database:
298 self._sync_if_allowed(sync_approval, result)
299 self.data.db.set_rotkehlchen_premium(self.premium.credentials)
300 else:
301 self._sync_if_allowed(sync_approval, result)
302
303 # Success, return premium
304 return self.premium
305
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rotkehlchen/premium/sync.py b/rotkehlchen/premium/sync.py
--- a/rotkehlchen/premium/sync.py
+++ b/rotkehlchen/premium/sync.py
@@ -235,6 +235,23 @@
log.info('User approved data sync from server')
self._sync_data_from_server_and_replace_local() # this may raise due to password
+ def _abort_new_syncing_premium_user(
+ self,
+ username: str,
+ original_exception: PremiumAuthenticationError,
+ ) -> None:
+ """At this point we are at a new user trying to create an account with
+ premium API keys and we failed. But a directory was created. Remove it.
+ But create a backup of it in case something went really wrong
+ and the directory contained data we did not want to lose"""
+ shutil.move(
+ self.data.user_data_dir, # type: ignore
+ self.data.data_directory / f'auto_backup_{username}_{ts_now()}',
+ )
+ raise PremiumAuthenticationError(
+ f'Could not verify keys for the new account. {str(original_exception)}', # noqa: E501
+ ) from original_exception
+
def try_premium_at_start(
self,
given_premium_credentials: Optional[PremiumCredentials],
@@ -259,19 +276,7 @@
try:
self.premium = premium_create_and_verify(given_premium_credentials)
except PremiumAuthenticationError as e:
- log.error('Given API key is invalid')
- # At this point we are at a new user trying to create an account with
- # premium API keys and we failed. But a directory was created. Remove it.
- # But create a backup of it in case something went really wrong
- # and the directory contained data we did not want to lose
- shutil.move(
- self.data.user_data_dir, # type: ignore
- self.data.data_directory / f'auto_backup_{username}_{ts_now()}',
- )
- raise PremiumAuthenticationError(
- 'Could not verify keys for the new account. '
- '{}'.format(str(e)),
- ) from e
+ self._abort_new_syncing_premium_user(username=username, original_exception=e)
# else, if we got premium data in the DB initialize it and try to sync with the server
db_credentials = self.data.db.get_rotkehlchen_premium()
@@ -295,7 +300,11 @@
# if this is a new account, make sure the api keys are properly stored
# in the DB
if sync_database:
- self._sync_if_allowed(sync_approval, result)
+ try:
+ self._sync_if_allowed(sync_approval, result)
+ except PremiumAuthenticationError as e:
+ self._abort_new_syncing_premium_user(username=username, original_exception=e)
+
self.data.db.set_rotkehlchen_premium(self.premium.credentials)
else:
self._sync_if_allowed(sync_approval, result)
|
{"golden_diff": "diff --git a/rotkehlchen/premium/sync.py b/rotkehlchen/premium/sync.py\n--- a/rotkehlchen/premium/sync.py\n+++ b/rotkehlchen/premium/sync.py\n@@ -235,6 +235,23 @@\n log.info('User approved data sync from server')\n self._sync_data_from_server_and_replace_local() # this may raise due to password\n \n+ def _abort_new_syncing_premium_user(\n+ self,\n+ username: str,\n+ original_exception: PremiumAuthenticationError,\n+ ) -> None:\n+ \"\"\"At this point we are at a new user trying to create an account with\n+ premium API keys and we failed. But a directory was created. Remove it.\n+ But create a backup of it in case something went really wrong\n+ and the directory contained data we did not want to lose\"\"\"\n+ shutil.move(\n+ self.data.user_data_dir, # type: ignore\n+ self.data.data_directory / f'auto_backup_{username}_{ts_now()}',\n+ )\n+ raise PremiumAuthenticationError(\n+ f'Could not verify keys for the new account. {str(original_exception)}', # noqa: E501\n+ ) from original_exception\n+\n def try_premium_at_start(\n self,\n given_premium_credentials: Optional[PremiumCredentials],\n@@ -259,19 +276,7 @@\n try:\n self.premium = premium_create_and_verify(given_premium_credentials)\n except PremiumAuthenticationError as e:\n- log.error('Given API key is invalid')\n- # At this point we are at a new user trying to create an account with\n- # premium API keys and we failed. But a directory was created. Remove it.\n- # But create a backup of it in case something went really wrong\n- # and the directory contained data we did not want to lose\n- shutil.move(\n- self.data.user_data_dir, # type: ignore\n- self.data.data_directory / f'auto_backup_{username}_{ts_now()}',\n- )\n- raise PremiumAuthenticationError(\n- 'Could not verify keys for the new account. '\n- '{}'.format(str(e)),\n- ) from e\n+ self._abort_new_syncing_premium_user(username=username, original_exception=e)\n \n # else, if we got premium data in the DB initialize it and try to sync with the server\n db_credentials = self.data.db.get_rotkehlchen_premium()\n@@ -295,7 +300,11 @@\n # if this is a new account, make sure the api keys are properly stored\n # in the DB\n if sync_database:\n- self._sync_if_allowed(sync_approval, result)\n+ try:\n+ self._sync_if_allowed(sync_approval, result)\n+ except PremiumAuthenticationError as e:\n+ self._abort_new_syncing_premium_user(username=username, original_exception=e)\n+\n self.data.db.set_rotkehlchen_premium(self.premium.credentials)\n else:\n self._sync_if_allowed(sync_approval, result)\n", "issue": "User already exists during setup (DAppNode)\n## Problem Definition\r\n\r\nUsing DAppNode Package:\r\n\r\n1. Install Rotki\r\n2. Setup Rotki using Premium API Key with restore sync'd database option\r\n3. Enter incorrect password\r\n4. Get error that password could not decrypt database\r\n5. Go back\r\n6. Enter correct password\r\n7. \"User $USERNAME already exists. User data dir: /data/$USERNAME\"\r\n\r\nCan't proceed...have to delete and re-create Rotki package\r\n\r\n## Logs\r\n\r\nNone\r\n\r\n### System Description\r\n\r\nOperating system: DAppNode\r\nRotki version: DAppNode Package `0.1.9 (v1.23.1 upstream)`\r\n\n", "before_files": [{"content": "import base64\nimport logging\nimport shutil\nfrom enum import Enum\nfrom typing import Any, Dict, NamedTuple, Optional, Tuple\n\nfrom typing_extensions import Literal\n\nfrom rotkehlchen.data_handler import DataHandler\nfrom rotkehlchen.errors import (\n PremiumAuthenticationError,\n RemoteError,\n RotkehlchenPermissionError,\n UnableToDecryptRemoteData,\n)\nfrom rotkehlchen.logging import RotkehlchenLogsAdapter\nfrom rotkehlchen.premium.premium import Premium, PremiumCredentials, premium_create_and_verify\nfrom rotkehlchen.utils.misc import ts_now\n\nlogger = logging.getLogger(__name__)\nlog = RotkehlchenLogsAdapter(logger)\n\n\nclass CanSync(Enum):\n YES = 0\n NO = 1\n ASK_USER = 2\n\n\nclass SyncCheckResult(NamedTuple):\n # The result of the sync check\n can_sync: CanSync\n # If result is ASK_USER, what should the message be?\n message: str\n payload: Optional[Dict[str, Any]]\n\n\nclass PremiumSyncManager():\n\n def __init__(self, data: DataHandler, password: str) -> None:\n # Initialize this with the value saved in the DB\n self.last_data_upload_ts = data.db.get_last_data_upload_ts()\n self.data = data\n self.password = password\n self.premium: Optional[Premium] = None\n\n def _can_sync_data_from_server(self, new_account: bool) -> SyncCheckResult:\n \"\"\"\n Checks if the remote data can be pulled from the server.\n\n Returns a SyncCheckResult denoting whether we can pull for sure,\n whether we can't pull or whether the user should be asked. If the user\n should be asked a message is also returned\n \"\"\"\n log.debug('can sync data from server -- start')\n if self.premium is None:\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n b64_encoded_data, our_hash = self.data.compress_and_encrypt_db(self.password)\n\n try:\n metadata = self.premium.query_last_data_metadata()\n except RemoteError as e:\n log.debug('can sync data from server failed', error=str(e))\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n if new_account:\n return SyncCheckResult(can_sync=CanSync.YES, message='', payload=None)\n\n if not self.data.db.get_premium_sync():\n # If it's not a new account and the db setting for premium syncing is off stop\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n log.debug(\n 'CAN_PULL',\n ours=our_hash,\n theirs=metadata.data_hash,\n )\n if our_hash == metadata.data_hash:\n log.debug('sync from server stopped -- same hash')\n # same hash -- no need to get anything\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n our_last_write_ts = self.data.db.get_last_write_ts()\n data_bytes_size = len(base64.b64decode(b64_encoded_data))\n\n local_more_recent = our_last_write_ts >= metadata.last_modify_ts\n\n if local_more_recent:\n log.debug('sync from server stopped -- local is newer')\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n # else remote is bigger\n return SyncCheckResult(\n can_sync=CanSync.ASK_USER,\n message='Detected remote database with bigger size than the local one. ',\n payload={\n 'local_size': data_bytes_size,\n 'remote_size': metadata.data_size,\n 'local_last_modified': our_last_write_ts,\n 'remote_last_modified': metadata.last_modify_ts,\n },\n )\n\n def _sync_data_from_server_and_replace_local(self) -> Tuple[bool, str]:\n \"\"\"\n Performs syncing of data from server and replaces local db\n\n Returns true for success and False for error/failure\n\n May raise:\n - PremiumAuthenticationError due to an UnableToDecryptRemoteData\n coming from decompress_and_decrypt_db. This happens when the given password\n does not match the one on the saved DB.\n \"\"\"\n if self.premium is None:\n return False, 'Pulling failed. User does not have active premium.'\n\n try:\n result = self.premium.pull_data()\n except RemoteError as e:\n log.debug('sync from server -- pulling failed.', error=str(e))\n return False, f'Pulling failed: {str(e)}'\n\n if result['data'] is None:\n log.debug('sync from server -- no data found.')\n return False, 'No data found'\n\n try:\n self.data.decompress_and_decrypt_db(self.password, result['data'])\n except UnableToDecryptRemoteData as e:\n raise PremiumAuthenticationError(\n 'The given password can not unlock the database that was retrieved from '\n 'the server. Make sure to use the same password as when the account was created.',\n ) from e\n\n return True, ''\n\n def maybe_upload_data_to_server(self, force_upload: bool = False) -> bool:\n # if user has no premium do nothing\n if self.premium is None:\n return False\n\n if not self.data.db.get_premium_sync() and not force_upload:\n return False\n\n # upload only once per hour\n diff = ts_now() - self.last_data_upload_ts\n if diff < 3600 and not force_upload:\n return False\n\n try:\n metadata = self.premium.query_last_data_metadata()\n except RemoteError as e:\n log.debug('upload to server -- fetching metadata error', error=str(e))\n return False\n b64_encoded_data, our_hash = self.data.compress_and_encrypt_db(self.password)\n\n log.debug(\n 'CAN_PUSH',\n ours=our_hash,\n theirs=metadata.data_hash,\n )\n if our_hash == metadata.data_hash and not force_upload:\n log.debug('upload to server stopped -- same hash')\n # same hash -- no need to upload anything\n return False\n\n our_last_write_ts = self.data.db.get_last_write_ts()\n if our_last_write_ts <= metadata.last_modify_ts and not force_upload:\n # Server's DB was modified after our local DB\n log.debug(\n f'upload to server stopped -- remote db({metadata.last_modify_ts}) '\n f'more recent than local({our_last_write_ts})',\n )\n return False\n\n data_bytes_size = len(base64.b64decode(b64_encoded_data))\n if data_bytes_size < metadata.data_size and not force_upload:\n # Let's be conservative.\n # TODO: Here perhaps prompt user in the future\n log.debug(\n f'upload to server stopped -- remote db({metadata.data_size}) '\n f'bigger than local({data_bytes_size})',\n )\n return False\n\n try:\n self.premium.upload_data(\n data_blob=b64_encoded_data,\n our_hash=our_hash,\n last_modify_ts=our_last_write_ts,\n compression_type='zlib',\n )\n except RemoteError as e:\n log.debug('upload to server -- upload error', error=str(e))\n return False\n\n # update the last data upload value\n self.last_data_upload_ts = ts_now()\n self.data.db.update_last_data_upload_ts(self.last_data_upload_ts)\n log.debug('upload to server -- success')\n return True\n\n def sync_data(self, action: Literal['upload', 'download']) -> Tuple[bool, str]:\n msg = ''\n\n if action == 'upload':\n success = self.maybe_upload_data_to_server(force_upload=True)\n\n if not success:\n msg = 'Upload failed'\n return success, msg\n\n return self._sync_data_from_server_and_replace_local()\n\n def _sync_if_allowed(\n self,\n sync_approval: Literal['yes', 'no', 'unknown'],\n result: SyncCheckResult,\n ) -> None:\n if result.can_sync == CanSync.ASK_USER:\n if sync_approval == 'unknown':\n log.info('Remote DB is possibly newer. Ask user.')\n raise RotkehlchenPermissionError(result.message, result.payload)\n\n if sync_approval == 'yes':\n log.info('User approved data sync from server')\n # this may raise due to password\n self._sync_data_from_server_and_replace_local()\n\n else:\n log.debug('Could sync data from server but user refused')\n elif result.can_sync == CanSync.YES:\n log.info('User approved data sync from server')\n self._sync_data_from_server_and_replace_local() # this may raise due to password\n\n def try_premium_at_start(\n self,\n given_premium_credentials: Optional[PremiumCredentials],\n username: str,\n create_new: bool,\n sync_approval: Literal['yes', 'no', 'unknown'],\n sync_database: bool,\n ) -> Optional[Premium]:\n \"\"\"\n Check if new user provided api pair or we already got one in the DB\n\n Returns the created premium if user's premium credentials were fine.\n\n If not it will raise PremiumAuthenticationError.\n\n If no credentials were given it returns None\n \"\"\"\n\n if given_premium_credentials is not None:\n assert create_new, 'We should never get here for an already existing account'\n\n try:\n self.premium = premium_create_and_verify(given_premium_credentials)\n except PremiumAuthenticationError as e:\n log.error('Given API key is invalid')\n # At this point we are at a new user trying to create an account with\n # premium API keys and we failed. But a directory was created. Remove it.\n # But create a backup of it in case something went really wrong\n # and the directory contained data we did not want to lose\n shutil.move(\n self.data.user_data_dir, # type: ignore\n self.data.data_directory / f'auto_backup_{username}_{ts_now()}',\n )\n raise PremiumAuthenticationError(\n 'Could not verify keys for the new account. '\n '{}'.format(str(e)),\n ) from e\n\n # else, if we got premium data in the DB initialize it and try to sync with the server\n db_credentials = self.data.db.get_rotkehlchen_premium()\n if db_credentials:\n assert not create_new, 'We should never get here for a new account'\n try:\n self.premium = premium_create_and_verify(db_credentials)\n except PremiumAuthenticationError as e:\n message = (\n f'Could not authenticate with the rotkehlchen server with '\n f'the API keys found in the Database. Error: {str(e)}'\n )\n log.error(message)\n raise PremiumAuthenticationError(message) from e\n\n if self.premium is None:\n return None\n\n result = self._can_sync_data_from_server(new_account=create_new)\n if create_new:\n # if this is a new account, make sure the api keys are properly stored\n # in the DB\n if sync_database:\n self._sync_if_allowed(sync_approval, result)\n self.data.db.set_rotkehlchen_premium(self.premium.credentials)\n else:\n self._sync_if_allowed(sync_approval, result)\n\n # Success, return premium\n return self.premium\n", "path": "rotkehlchen/premium/sync.py"}], "after_files": [{"content": "import base64\nimport logging\nimport shutil\nfrom enum import Enum\nfrom typing import Any, Dict, NamedTuple, Optional, Tuple\n\nfrom typing_extensions import Literal\n\nfrom rotkehlchen.data_handler import DataHandler\nfrom rotkehlchen.errors import (\n PremiumAuthenticationError,\n RemoteError,\n RotkehlchenPermissionError,\n UnableToDecryptRemoteData,\n)\nfrom rotkehlchen.logging import RotkehlchenLogsAdapter\nfrom rotkehlchen.premium.premium import Premium, PremiumCredentials, premium_create_and_verify\nfrom rotkehlchen.utils.misc import ts_now\n\nlogger = logging.getLogger(__name__)\nlog = RotkehlchenLogsAdapter(logger)\n\n\nclass CanSync(Enum):\n YES = 0\n NO = 1\n ASK_USER = 2\n\n\nclass SyncCheckResult(NamedTuple):\n # The result of the sync check\n can_sync: CanSync\n # If result is ASK_USER, what should the message be?\n message: str\n payload: Optional[Dict[str, Any]]\n\n\nclass PremiumSyncManager():\n\n def __init__(self, data: DataHandler, password: str) -> None:\n # Initialize this with the value saved in the DB\n self.last_data_upload_ts = data.db.get_last_data_upload_ts()\n self.data = data\n self.password = password\n self.premium: Optional[Premium] = None\n\n def _can_sync_data_from_server(self, new_account: bool) -> SyncCheckResult:\n \"\"\"\n Checks if the remote data can be pulled from the server.\n\n Returns a SyncCheckResult denoting whether we can pull for sure,\n whether we can't pull or whether the user should be asked. If the user\n should be asked a message is also returned\n \"\"\"\n log.debug('can sync data from server -- start')\n if self.premium is None:\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n b64_encoded_data, our_hash = self.data.compress_and_encrypt_db(self.password)\n\n try:\n metadata = self.premium.query_last_data_metadata()\n except RemoteError as e:\n log.debug('can sync data from server failed', error=str(e))\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n if new_account:\n return SyncCheckResult(can_sync=CanSync.YES, message='', payload=None)\n\n if not self.data.db.get_premium_sync():\n # If it's not a new account and the db setting for premium syncing is off stop\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n log.debug(\n 'CAN_PULL',\n ours=our_hash,\n theirs=metadata.data_hash,\n )\n if our_hash == metadata.data_hash:\n log.debug('sync from server stopped -- same hash')\n # same hash -- no need to get anything\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n our_last_write_ts = self.data.db.get_last_write_ts()\n data_bytes_size = len(base64.b64decode(b64_encoded_data))\n\n local_more_recent = our_last_write_ts >= metadata.last_modify_ts\n\n if local_more_recent:\n log.debug('sync from server stopped -- local is newer')\n return SyncCheckResult(can_sync=CanSync.NO, message='', payload=None)\n\n # else remote is bigger\n return SyncCheckResult(\n can_sync=CanSync.ASK_USER,\n message='Detected remote database with bigger size than the local one. ',\n payload={\n 'local_size': data_bytes_size,\n 'remote_size': metadata.data_size,\n 'local_last_modified': our_last_write_ts,\n 'remote_last_modified': metadata.last_modify_ts,\n },\n )\n\n def _sync_data_from_server_and_replace_local(self) -> Tuple[bool, str]:\n \"\"\"\n Performs syncing of data from server and replaces local db\n\n Returns true for success and False for error/failure\n\n May raise:\n - PremiumAuthenticationError due to an UnableToDecryptRemoteData\n coming from decompress_and_decrypt_db. This happens when the given password\n does not match the one on the saved DB.\n \"\"\"\n if self.premium is None:\n return False, 'Pulling failed. User does not have active premium.'\n\n try:\n result = self.premium.pull_data()\n except RemoteError as e:\n log.debug('sync from server -- pulling failed.', error=str(e))\n return False, f'Pulling failed: {str(e)}'\n\n if result['data'] is None:\n log.debug('sync from server -- no data found.')\n return False, 'No data found'\n\n try:\n self.data.decompress_and_decrypt_db(self.password, result['data'])\n except UnableToDecryptRemoteData as e:\n raise PremiumAuthenticationError(\n 'The given password can not unlock the database that was retrieved from '\n 'the server. Make sure to use the same password as when the account was created.',\n ) from e\n\n return True, ''\n\n def maybe_upload_data_to_server(self, force_upload: bool = False) -> bool:\n # if user has no premium do nothing\n if self.premium is None:\n return False\n\n if not self.data.db.get_premium_sync() and not force_upload:\n return False\n\n # upload only once per hour\n diff = ts_now() - self.last_data_upload_ts\n if diff < 3600 and not force_upload:\n return False\n\n try:\n metadata = self.premium.query_last_data_metadata()\n except RemoteError as e:\n log.debug('upload to server -- fetching metadata error', error=str(e))\n return False\n b64_encoded_data, our_hash = self.data.compress_and_encrypt_db(self.password)\n\n log.debug(\n 'CAN_PUSH',\n ours=our_hash,\n theirs=metadata.data_hash,\n )\n if our_hash == metadata.data_hash and not force_upload:\n log.debug('upload to server stopped -- same hash')\n # same hash -- no need to upload anything\n return False\n\n our_last_write_ts = self.data.db.get_last_write_ts()\n if our_last_write_ts <= metadata.last_modify_ts and not force_upload:\n # Server's DB was modified after our local DB\n log.debug(\n f'upload to server stopped -- remote db({metadata.last_modify_ts}) '\n f'more recent than local({our_last_write_ts})',\n )\n return False\n\n data_bytes_size = len(base64.b64decode(b64_encoded_data))\n if data_bytes_size < metadata.data_size and not force_upload:\n # Let's be conservative.\n # TODO: Here perhaps prompt user in the future\n log.debug(\n f'upload to server stopped -- remote db({metadata.data_size}) '\n f'bigger than local({data_bytes_size})',\n )\n return False\n\n try:\n self.premium.upload_data(\n data_blob=b64_encoded_data,\n our_hash=our_hash,\n last_modify_ts=our_last_write_ts,\n compression_type='zlib',\n )\n except RemoteError as e:\n log.debug('upload to server -- upload error', error=str(e))\n return False\n\n # update the last data upload value\n self.last_data_upload_ts = ts_now()\n self.data.db.update_last_data_upload_ts(self.last_data_upload_ts)\n log.debug('upload to server -- success')\n return True\n\n def sync_data(self, action: Literal['upload', 'download']) -> Tuple[bool, str]:\n msg = ''\n\n if action == 'upload':\n success = self.maybe_upload_data_to_server(force_upload=True)\n\n if not success:\n msg = 'Upload failed'\n return success, msg\n\n return self._sync_data_from_server_and_replace_local()\n\n def _sync_if_allowed(\n self,\n sync_approval: Literal['yes', 'no', 'unknown'],\n result: SyncCheckResult,\n ) -> None:\n if result.can_sync == CanSync.ASK_USER:\n if sync_approval == 'unknown':\n log.info('Remote DB is possibly newer. Ask user.')\n raise RotkehlchenPermissionError(result.message, result.payload)\n\n if sync_approval == 'yes':\n log.info('User approved data sync from server')\n # this may raise due to password\n self._sync_data_from_server_and_replace_local()\n\n else:\n log.debug('Could sync data from server but user refused')\n elif result.can_sync == CanSync.YES:\n log.info('User approved data sync from server')\n self._sync_data_from_server_and_replace_local() # this may raise due to password\n\n def _abort_new_syncing_premium_user(\n self,\n username: str,\n original_exception: PremiumAuthenticationError,\n ) -> None:\n \"\"\"At this point we are at a new user trying to create an account with\n premium API keys and we failed. But a directory was created. Remove it.\n But create a backup of it in case something went really wrong\n and the directory contained data we did not want to lose\"\"\"\n shutil.move(\n self.data.user_data_dir, # type: ignore\n self.data.data_directory / f'auto_backup_{username}_{ts_now()}',\n )\n raise PremiumAuthenticationError(\n f'Could not verify keys for the new account. {str(original_exception)}', # noqa: E501\n ) from original_exception\n\n def try_premium_at_start(\n self,\n given_premium_credentials: Optional[PremiumCredentials],\n username: str,\n create_new: bool,\n sync_approval: Literal['yes', 'no', 'unknown'],\n sync_database: bool,\n ) -> Optional[Premium]:\n \"\"\"\n Check if new user provided api pair or we already got one in the DB\n\n Returns the created premium if user's premium credentials were fine.\n\n If not it will raise PremiumAuthenticationError.\n\n If no credentials were given it returns None\n \"\"\"\n\n if given_premium_credentials is not None:\n assert create_new, 'We should never get here for an already existing account'\n\n try:\n self.premium = premium_create_and_verify(given_premium_credentials)\n except PremiumAuthenticationError as e:\n self._abort_new_syncing_premium_user(username=username, original_exception=e)\n\n # else, if we got premium data in the DB initialize it and try to sync with the server\n db_credentials = self.data.db.get_rotkehlchen_premium()\n if db_credentials:\n assert not create_new, 'We should never get here for a new account'\n try:\n self.premium = premium_create_and_verify(db_credentials)\n except PremiumAuthenticationError as e:\n message = (\n f'Could not authenticate with the rotkehlchen server with '\n f'the API keys found in the Database. Error: {str(e)}'\n )\n log.error(message)\n raise PremiumAuthenticationError(message) from e\n\n if self.premium is None:\n return None\n\n result = self._can_sync_data_from_server(new_account=create_new)\n if create_new:\n # if this is a new account, make sure the api keys are properly stored\n # in the DB\n if sync_database:\n try:\n self._sync_if_allowed(sync_approval, result)\n except PremiumAuthenticationError as e:\n self._abort_new_syncing_premium_user(username=username, original_exception=e)\n\n self.data.db.set_rotkehlchen_premium(self.premium.credentials)\n else:\n self._sync_if_allowed(sync_approval, result)\n\n # Success, return premium\n return self.premium\n", "path": "rotkehlchen/premium/sync.py"}]}
| 3,672 | 687 |
gh_patches_debug_18243
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-1465
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CSS bundles generation breaks background images relative urls
This is a bug related to PR #1300.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/resources/browser/combine.py`
Content:
```
1 from zExceptions import NotFound
2 from Acquisition import aq_base
3 from datetime import datetime
4 from plone.registry.interfaces import IRegistry
5 from plone.resource.file import FilesystemFile
6 from plone.resource.interfaces import IResourceDirectory
7 from Products.CMFPlone.interfaces import IBundleRegistry
8 from Products.CMFPlone.interfaces.resources import (
9 OVERRIDE_RESOURCE_DIRECTORY_NAME,
10 )
11 from StringIO import StringIO
12 from zope.component import getUtility
13 from zope.component import queryUtility
14
15 PRODUCTION_RESOURCE_DIRECTORY = "production"
16
17
18 def get_production_resource_directory():
19 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
20 if persistent_directory is None:
21 return ''
22 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
23 try:
24 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
25 except NotFound:
26 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
27 timestamp = production_folder.readFile('timestamp.txt')
28 return "%s/++unique++%s" % (
29 PRODUCTION_RESOURCE_DIRECTORY, timestamp)
30
31
32 def get_resource(context, path):
33 resource = context.unrestrictedTraverse(path)
34 if isinstance(resource, FilesystemFile):
35 (directory, sep, filename) = path.rpartition('/')
36 return context.unrestrictedTraverse(directory).readFile(filename)
37 else:
38 if hasattr(aq_base(resource), 'GET'):
39 # for FileResource
40 return resource.GET()
41 else:
42 # any BrowserView
43 return resource()
44
45
46 def write_js(context, folder, meta_bundle):
47 registry = getUtility(IRegistry)
48 resources = []
49
50 # default resources
51 if meta_bundle == 'default' and registry.records.get(
52 'plone.resources/jquery.js'
53 ):
54 resources.append(get_resource(context,
55 registry.records['plone.resources/jquery.js'].value))
56 resources.append(get_resource(context,
57 registry.records['plone.resources.requirejs'].value))
58 resources.append(get_resource(context,
59 registry.records['plone.resources.configjs'].value))
60
61 # bundles
62 bundles = registry.collectionOfInterface(
63 IBundleRegistry, prefix="plone.bundles", check=False)
64 for bundle in bundles.values():
65 if bundle.merge_with == meta_bundle:
66 resources.append(get_resource(context, bundle.jscompilation))
67
68 fi = StringIO()
69 for script in resources:
70 fi.write(script + '\n')
71 folder.writeFile(meta_bundle + ".js", fi)
72
73
74 def write_css(context, folder, meta_bundle):
75 registry = getUtility(IRegistry)
76 resources = []
77
78 bundles = registry.collectionOfInterface(
79 IBundleRegistry, prefix="plone.bundles", check=False)
80 for bundle in bundles.values():
81 if bundle.merge_with == meta_bundle:
82 resources.append(get_resource(context, bundle.csscompilation))
83
84 fi = StringIO()
85 for script in resources:
86 fi.write(script + '\n')
87 folder.writeFile(meta_bundle + ".css", fi)
88
89
90 def combine_bundles(context):
91 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
92 if persistent_directory is None:
93 return
94 if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
95 persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
96 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
97 if PRODUCTION_RESOURCE_DIRECTORY not in container:
98 container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)
99 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
100
101 # store timestamp
102 fi = StringIO()
103 fi.write(datetime.now().isoformat())
104 production_folder.writeFile("timestamp.txt", fi)
105
106 # generate new combined bundles
107 write_js(context, production_folder, 'default')
108 write_js(context, production_folder, 'logged-in')
109 write_css(context, production_folder, 'default')
110 write_css(context, production_folder, 'logged-in')
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py
--- a/Products/CMFPlone/resources/browser/combine.py
+++ b/Products/CMFPlone/resources/browser/combine.py
@@ -1,3 +1,4 @@
+import re
from zExceptions import NotFound
from Acquisition import aq_base
from datetime import datetime
@@ -79,7 +80,15 @@
IBundleRegistry, prefix="plone.bundles", check=False)
for bundle in bundles.values():
if bundle.merge_with == meta_bundle:
- resources.append(get_resource(context, bundle.csscompilation))
+ css = get_resource(context, bundle.csscompilation)
+ # Preserve relative urls:
+ # we prefix with '../'' any url not starting with '/'
+ # or http: or data:
+ css = re.sub(
+ r"""(url\(['"]?(?!['"]?([a-z]+:|\/)))""",
+ r'\1../',
+ css)
+ resources.append(css)
fi = StringIO()
for script in resources:
|
{"golden_diff": "diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py\n--- a/Products/CMFPlone/resources/browser/combine.py\n+++ b/Products/CMFPlone/resources/browser/combine.py\n@@ -1,3 +1,4 @@\n+import re\n from zExceptions import NotFound\n from Acquisition import aq_base\n from datetime import datetime\n@@ -79,7 +80,15 @@\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n- resources.append(get_resource(context, bundle.csscompilation))\n+ css = get_resource(context, bundle.csscompilation)\n+ # Preserve relative urls:\n+ # we prefix with '../'' any url not starting with '/'\n+ # or http: or data:\n+ css = re.sub(\n+ r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n+ r'\\1../',\n+ css)\n+ resources.append(css)\n \n fi = StringIO()\n for script in resources:\n", "issue": "CSS bundles generation breaks background images relative urls\nThis is a bug related to PR #1300.\n\n", "before_files": [{"content": "from zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.csscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef combine_bundles(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}], "after_files": [{"content": "import re\nfrom zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n css = get_resource(context, bundle.csscompilation)\n # Preserve relative urls:\n # we prefix with '../'' any url not starting with '/'\n # or http: or data:\n css = re.sub(\n r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n r'\\1../',\n css)\n resources.append(css)\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef combine_bundles(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}]}
| 1,303 | 251 |
gh_patches_debug_2033
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-802
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ChunkedEncodingError is not retried when fetching data with list_rows()
Original issue: https://github.com/googleapis/python-bigquery-storage/issues/242
A user reported that they saw an error in production when fetching table data with `Client.list_rows()`. That method uses the [default retry object](https://github.com/googleapis/python-bigquery/blob/7e0e2bafc4c3f98a4246100f504fd78a01a28e7d/google/cloud/bigquery/retry.py#L49), which currently does not consider `requests.exceptions.ChunkedEncodingError` retryable.
(it does retry `requests.exceptions.ConnectionError`, but `ChunkedEncodingError` is not a subclass of that.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/retry.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from google.api_core import exceptions
16 from google.api_core import retry
17 from google.auth import exceptions as auth_exceptions
18 import requests.exceptions
19
20
21 _RETRYABLE_REASONS = frozenset(
22 ["rateLimitExceeded", "backendError", "internalError", "badGateway"]
23 )
24
25 _UNSTRUCTURED_RETRYABLE_TYPES = (
26 ConnectionError,
27 exceptions.TooManyRequests,
28 exceptions.InternalServerError,
29 exceptions.BadGateway,
30 requests.exceptions.ConnectionError,
31 auth_exceptions.TransportError,
32 )
33
34
35 def _should_retry(exc):
36 """Predicate for determining when to retry.
37
38 We retry if and only if the 'reason' is 'backendError'
39 or 'rateLimitExceeded'.
40 """
41 if not hasattr(exc, "errors") or len(exc.errors) == 0:
42 # Check for unstructured error returns, e.g. from GFE
43 return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)
44
45 reason = exc.errors[0]["reason"]
46 return reason in _RETRYABLE_REASONS
47
48
49 DEFAULT_RETRY = retry.Retry(predicate=_should_retry)
50 """The default retry object.
51
52 Any method with a ``retry`` parameter will be retried automatically,
53 with reasonable defaults. To disable retry, pass ``retry=None``.
54 To modify the default retry behavior, call a ``with_XXX`` method
55 on ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,
56 pass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.
57 """
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py
--- a/google/cloud/bigquery/retry.py
+++ b/google/cloud/bigquery/retry.py
@@ -27,6 +27,7 @@
exceptions.TooManyRequests,
exceptions.InternalServerError,
exceptions.BadGateway,
+ requests.exceptions.ChunkedEncodingError,
requests.exceptions.ConnectionError,
auth_exceptions.TransportError,
)
|
{"golden_diff": "diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py\n--- a/google/cloud/bigquery/retry.py\n+++ b/google/cloud/bigquery/retry.py\n@@ -27,6 +27,7 @@\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n+ requests.exceptions.ChunkedEncodingError,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n )\n", "issue": "ChunkedEncodingError is not retried when fetching data with list_rows()\nOriginal issue: https://github.com/googleapis/python-bigquery-storage/issues/242\r\n\r\nA user reported that they saw an error in production when fetching table data with `Client.list_rows()`. That method uses the [default retry object](https://github.com/googleapis/python-bigquery/blob/7e0e2bafc4c3f98a4246100f504fd78a01a28e7d/google/cloud/bigquery/retry.py#L49), which currently does not consider `requests.exceptions.ChunkedEncodingError` retryable.\r\n\r\n(it does retry `requests.exceptions.ConnectionError`, but `ChunkedEncodingError` is not a subclass of that.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n)\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ChunkedEncodingError,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n)\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}]}
| 983 | 92 |
gh_patches_debug_1899
|
rasdani/github-patches
|
git_diff
|
translate__translate-3683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
setcontext is not working correctly for mounit
Calling setcontext on mounit does currently nothing as it inherits code from base class:
``` python
def setcontext(self, context):
"""Set the message context"""
pass
```
I'd expect it to properly update context as it does for other storages.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `translate/storage/mo.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2007 Zuza Software Foundation
4 #
5 # the function "serialize" was derived from Python v2.4
6 # (Tools/i18n/msgfmt.py - function "generate"):
7 # Written by Martin v. Löwis <[email protected]>
8 # Copyright (c) 2001, 2002, 2003, 2004, 2005, 2006 Python Software Foundation.
9 # All rights reserved.
10 # original license: Python Software Foundation (version 2)
11 #
12 #
13 # This file is part of translate.
14 #
15 # translate is free software; you can redistribute it and/or modify
16 # it under the terms of the GNU General Public License as published by
17 # the Free Software Foundation; either version 2 of the License, or
18 # (at your option) any later version.
19 #
20 # translate is distributed in the hope that it will be useful,
21 # but WITHOUT ANY WARRANTY; without even the implied warranty of
22 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
23 # GNU General Public License for more details.
24 #
25 # You should have received a copy of the GNU General Public License
26 # along with this program; if not, see <http://www.gnu.org/licenses/>.
27 #
28
29 """Module for parsing Gettext .mo files for translation.
30
31 The coding of .mo files was produced from `Gettext documentation
32 <http://www.gnu.org/software/gettext/manual/gettext.html#MO-Files>`_,
33 Pythons msgfmt.py and by observing and testing existing .mo files in the wild.
34
35 The hash algorithm is implemented for MO files, this should result in
36 faster access of the MO file. The hash is optional for Gettext
37 and is not needed for reading or writing MO files, in this implementation
38 it is always on and does produce sometimes different results to Gettext
39 in very small files.
40 """
41
42 import array
43 import re
44 import six
45 import struct
46
47 from translate.misc.multistring import multistring
48 from translate.storage import base, poheader
49
50
51 MO_MAGIC_NUMBER = 0x950412de
52
53
54 def mounpack(filename='messages.mo'):
55 """Helper to unpack Gettext MO files into a Python string"""
56 with open(filename, 'rb') as fh:
57 s = fh.read()
58 print("\\x%02x" * len(s) % tuple(map(ord, s)))
59
60
61 def my_swap4(result):
62 c0 = (result >> 0) & 0xff
63 c1 = (result >> 8) & 0xff
64 c2 = (result >> 16) & 0xff
65 c3 = (result >> 24) & 0xff
66
67 return (c0 << 24) | (c1 << 16) | (c2 << 8) | c3
68
69
70 def hashpjw(str_param):
71 HASHWORDBITS = 32
72 hval = 0
73 g = None
74 s = str_param
75 for s in str_param:
76 hval = hval << 4
77 hval += ord(s) if six.PY2 else s
78 g = hval & 0xf << (HASHWORDBITS - 4)
79 if (g != 0):
80 hval = hval ^ g >> (HASHWORDBITS - 8)
81 hval = hval ^ g
82 return hval
83
84
85 def get_next_prime_number(start):
86 # find the smallest prime number that is greater or equal "start"
87
88 def is_prime(num):
89 # special small numbers
90 if (num < 2) or (num == 4):
91 return False
92 if (num == 2) or (num == 3):
93 return True
94 # check for numbers > 4
95 for divider in range(2, num // 2):
96 if num % divider == 0:
97 return False
98 return True
99
100 candidate = start
101 while not is_prime(candidate):
102 candidate += 1
103 return candidate
104
105
106 class mounit(base.TranslationUnit):
107 """A class representing a .mo translation message."""
108
109 def __init__(self, source=None, **kwargs):
110 self.msgctxt = []
111 self.msgidcomments = []
112 super(mounit, self).__init__(source)
113
114 def getcontext(self):
115 """Get the message context"""
116 # Still need to handle KDE comments
117 if self.msgctxt is None:
118 return None
119 return "".join(self.msgctxt)
120
121 def isheader(self):
122 """Is this a header entry?"""
123 return self.source == u""
124
125 def istranslatable(self):
126 """Is this message translateable?"""
127 return bool(self.source)
128
129
130 class mofile(poheader.poheader, base.TranslationStore):
131 """A class representing a .mo file."""
132
133 UnitClass = mounit
134 Name = "Gettext MO file"
135 Mimetypes = ["application/x-gettext-catalog", "application/x-mo"]
136 Extensions = ["mo", "gmo"]
137 _binary = True
138
139 def __init__(self, inputfile=None, **kwargs):
140 super(mofile, self).__init__(**kwargs)
141 self.filename = ''
142 if inputfile is not None:
143 self.parsestring(inputfile)
144
145 def serialize(self, out):
146 """Output a string representation of the MO data file"""
147 # check the header of this file for the copyright note of this function
148
149 def add_to_hash_table(string, i):
150 V = hashpjw(string)
151 # Taken from gettext-0.17:gettext-tools/src/write-mo.c:408-409
152 S = hash_size <= 2 and 3 or hash_size
153 hash_cursor = V % S
154 orig_hash_cursor = hash_cursor
155 increment = 1 + (V % (S - 2))
156 while True:
157 index = hash_table[hash_cursor]
158 if (index == 0):
159 hash_table[hash_cursor] = i + 1
160 break
161 hash_cursor += increment
162 hash_cursor = hash_cursor % S
163 assert (hash_cursor != orig_hash_cursor)
164
165 def lst_encode(lst, join_char=b''):
166 return join_char.join([i.encode('utf-8') for i in lst])
167
168 # hash_size should be the smallest prime number that is greater
169 # or equal (4 / 3 * N) - where N is the number of keys/units.
170 # see gettext-0.17:gettext-tools/src/write-mo.c:406
171 hash_size = get_next_prime_number(int((len(self.units) * 4) / 3))
172 if hash_size <= 2:
173 hash_size = 3
174 MESSAGES = {}
175 for unit in self.units:
176 # If the unit is not translated, we should rather omit it entirely
177 if not unit.istranslated():
178 continue
179 if isinstance(unit.source, multistring):
180 source = (lst_encode(unit.msgidcomments) +
181 lst_encode(unit.source.strings, b"\0"))
182 else:
183 source = lst_encode(unit.msgidcomments) + unit.source.encode('utf-8')
184 if unit.msgctxt:
185 source = lst_encode(unit.msgctxt) + b"\x04" + source
186 if isinstance(unit.target, multistring):
187 target = lst_encode(unit.target.strings, b"\0")
188 else:
189 target = unit.target.encode('utf-8')
190 if unit.target:
191 MESSAGES[source] = target
192 # using "I" works for 32- and 64-bit systems, but not for 16-bit!
193 hash_table = array.array("I", [0] * hash_size)
194 # the keys are sorted in the .mo file
195 keys = sorted(MESSAGES.keys())
196 offsets = []
197 ids = strs = b''
198 for i, id in enumerate(keys):
199 # For each string, we need size and file offset. Each string is
200 # NUL terminated; the NUL does not count into the size.
201 # TODO: We don't do any encoding detection from the PO Header
202 add_to_hash_table(id, i)
203 string = MESSAGES[id] # id already encoded for use as dictionary key
204 offsets.append((len(ids), len(id), len(strs), len(string)))
205 ids = ids + id + b'\0'
206 strs = strs + string + b'\0'
207 output = ''
208 # The header is 7 32-bit unsigned integers
209 keystart = 7 * 4 + 16 * len(keys) + hash_size * 4
210 # and the values start after the keys
211 valuestart = keystart + len(ids)
212 koffsets = []
213 voffsets = []
214 # The string table first has the list of keys, then the list of values.
215 # Each entry has first the size of the string, then the file offset.
216 for o1, l1, o2, l2 in offsets:
217 koffsets = koffsets + [l1, o1 + keystart]
218 voffsets = voffsets + [l2, o2 + valuestart]
219 offsets = koffsets + voffsets
220 output = struct.pack("Iiiiiii",
221 MO_MAGIC_NUMBER, # Magic
222 0, # Version
223 len(keys), # # of entries
224 7 * 4, # start of key index
225 7 * 4 + len(keys) * 8, # start of value index
226 hash_size, # size of hash table
227 7 * 4 + 2 * (len(keys) * 8)) # offset of hash table
228 # additional data is not necessary for empty mo files
229 if (len(keys) > 0):
230 output = output + array.array("i", offsets).tostring()
231 output = output + hash_table.tostring()
232 output = output + ids
233 output = output + strs
234 return out.write(output)
235
236 def parse(self, input):
237 """parses the given file or file source string"""
238 if hasattr(input, 'name'):
239 self.filename = input.name
240 elif not getattr(self, 'filename', ''):
241 self.filename = ''
242 if hasattr(input, "read"):
243 mosrc = input.read()
244 input.close()
245 input = mosrc
246 little, = struct.unpack("<L", input[:4])
247 big, = struct.unpack(">L", input[:4])
248 if little == MO_MAGIC_NUMBER:
249 endian = "<"
250 elif big == MO_MAGIC_NUMBER:
251 endian = ">"
252 else:
253 raise ValueError("This is not an MO file")
254 magic, version_maj, version_min, lenkeys, startkey, \
255 startvalue, sizehash, offsethash = struct.unpack("%sLHHiiiii" % endian,
256 input[:(7 * 4)])
257 if version_maj >= 1:
258 raise base.ParseError("""Unable to process version %d.%d MO files""" % (version_maj, version_min))
259 for i in range(lenkeys):
260 nextkey = startkey + (i * 2 * 4)
261 nextvalue = startvalue + (i * 2 * 4)
262 klength, koffset = struct.unpack("%sii" % endian,
263 input[nextkey:nextkey + (2 * 4)])
264 vlength, voffset = struct.unpack("%sii" % endian,
265 input[nextvalue:nextvalue + (2 * 4)])
266 source = input[koffset:koffset + klength]
267 context = None
268 if b"\x04" in source:
269 context, source = source.split(b"\x04")
270 # Still need to handle KDE comments
271 if source == "":
272 charset = re.search(b"charset=([^\\s]+)",
273 input[voffset:voffset + vlength])
274 if charset:
275 self.encoding = charset.group(1)
276 source = multistring([s.decode(self.encoding)
277 for s in source.split(b"\0")])
278 target = multistring([s.decode(self.encoding)
279 for s in input[voffset:voffset + vlength].split(b"\0")])
280 newunit = mounit(source)
281 newunit.target = target
282 if context is not None:
283 newunit.msgctxt.append(context)
284 self.addunit(newunit)
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/translate/storage/mo.py b/translate/storage/mo.py
--- a/translate/storage/mo.py
+++ b/translate/storage/mo.py
@@ -118,6 +118,9 @@
return None
return "".join(self.msgctxt)
+ def setcontext(self, context):
+ self.msgctxt = [context]
+
def isheader(self):
"""Is this a header entry?"""
return self.source == u""
|
{"golden_diff": "diff --git a/translate/storage/mo.py b/translate/storage/mo.py\n--- a/translate/storage/mo.py\n+++ b/translate/storage/mo.py\n@@ -118,6 +118,9 @@\n return None\n return \"\".join(self.msgctxt)\n \n+ def setcontext(self, context):\n+ self.msgctxt = [context]\n+\n def isheader(self):\n \"\"\"Is this a header entry?\"\"\"\n return self.source == u\"\"\n", "issue": "setcontext is not working correctly for mounit\nCalling setcontext on mounit does currently nothing as it inherits code from base class:\n\n``` python\n def setcontext(self, context):\n \"\"\"Set the message context\"\"\"\n pass\n```\n\nI'd expect it to properly update context as it does for other storages.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2007 Zuza Software Foundation\n#\n# the function \"serialize\" was derived from Python v2.4\n# (Tools/i18n/msgfmt.py - function \"generate\"):\n# Written by Martin v. L\u00f6wis <[email protected]>\n# Copyright (c) 2001, 2002, 2003, 2004, 2005, 2006 Python Software Foundation.\n# All rights reserved.\n# original license: Python Software Foundation (version 2)\n#\n#\n# This file is part of translate.\n#\n# translate is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n#\n\n\"\"\"Module for parsing Gettext .mo files for translation.\n\nThe coding of .mo files was produced from `Gettext documentation\n<http://www.gnu.org/software/gettext/manual/gettext.html#MO-Files>`_,\nPythons msgfmt.py and by observing and testing existing .mo files in the wild.\n\nThe hash algorithm is implemented for MO files, this should result in\nfaster access of the MO file. The hash is optional for Gettext\nand is not needed for reading or writing MO files, in this implementation\nit is always on and does produce sometimes different results to Gettext\nin very small files.\n\"\"\"\n\nimport array\nimport re\nimport six\nimport struct\n\nfrom translate.misc.multistring import multistring\nfrom translate.storage import base, poheader\n\n\nMO_MAGIC_NUMBER = 0x950412de\n\n\ndef mounpack(filename='messages.mo'):\n \"\"\"Helper to unpack Gettext MO files into a Python string\"\"\"\n with open(filename, 'rb') as fh:\n s = fh.read()\n print(\"\\\\x%02x\" * len(s) % tuple(map(ord, s)))\n\n\ndef my_swap4(result):\n c0 = (result >> 0) & 0xff\n c1 = (result >> 8) & 0xff\n c2 = (result >> 16) & 0xff\n c3 = (result >> 24) & 0xff\n\n return (c0 << 24) | (c1 << 16) | (c2 << 8) | c3\n\n\ndef hashpjw(str_param):\n HASHWORDBITS = 32\n hval = 0\n g = None\n s = str_param\n for s in str_param:\n hval = hval << 4\n hval += ord(s) if six.PY2 else s\n g = hval & 0xf << (HASHWORDBITS - 4)\n if (g != 0):\n hval = hval ^ g >> (HASHWORDBITS - 8)\n hval = hval ^ g\n return hval\n\n\ndef get_next_prime_number(start):\n # find the smallest prime number that is greater or equal \"start\"\n\n def is_prime(num):\n # special small numbers\n if (num < 2) or (num == 4):\n return False\n if (num == 2) or (num == 3):\n return True\n # check for numbers > 4\n for divider in range(2, num // 2):\n if num % divider == 0:\n return False\n return True\n\n candidate = start\n while not is_prime(candidate):\n candidate += 1\n return candidate\n\n\nclass mounit(base.TranslationUnit):\n \"\"\"A class representing a .mo translation message.\"\"\"\n\n def __init__(self, source=None, **kwargs):\n self.msgctxt = []\n self.msgidcomments = []\n super(mounit, self).__init__(source)\n\n def getcontext(self):\n \"\"\"Get the message context\"\"\"\n # Still need to handle KDE comments\n if self.msgctxt is None:\n return None\n return \"\".join(self.msgctxt)\n\n def isheader(self):\n \"\"\"Is this a header entry?\"\"\"\n return self.source == u\"\"\n\n def istranslatable(self):\n \"\"\"Is this message translateable?\"\"\"\n return bool(self.source)\n\n\nclass mofile(poheader.poheader, base.TranslationStore):\n \"\"\"A class representing a .mo file.\"\"\"\n\n UnitClass = mounit\n Name = \"Gettext MO file\"\n Mimetypes = [\"application/x-gettext-catalog\", \"application/x-mo\"]\n Extensions = [\"mo\", \"gmo\"]\n _binary = True\n\n def __init__(self, inputfile=None, **kwargs):\n super(mofile, self).__init__(**kwargs)\n self.filename = ''\n if inputfile is not None:\n self.parsestring(inputfile)\n\n def serialize(self, out):\n \"\"\"Output a string representation of the MO data file\"\"\"\n # check the header of this file for the copyright note of this function\n\n def add_to_hash_table(string, i):\n V = hashpjw(string)\n # Taken from gettext-0.17:gettext-tools/src/write-mo.c:408-409\n S = hash_size <= 2 and 3 or hash_size\n hash_cursor = V % S\n orig_hash_cursor = hash_cursor\n increment = 1 + (V % (S - 2))\n while True:\n index = hash_table[hash_cursor]\n if (index == 0):\n hash_table[hash_cursor] = i + 1\n break\n hash_cursor += increment\n hash_cursor = hash_cursor % S\n assert (hash_cursor != orig_hash_cursor)\n\n def lst_encode(lst, join_char=b''):\n return join_char.join([i.encode('utf-8') for i in lst])\n\n # hash_size should be the smallest prime number that is greater\n # or equal (4 / 3 * N) - where N is the number of keys/units.\n # see gettext-0.17:gettext-tools/src/write-mo.c:406\n hash_size = get_next_prime_number(int((len(self.units) * 4) / 3))\n if hash_size <= 2:\n hash_size = 3\n MESSAGES = {}\n for unit in self.units:\n # If the unit is not translated, we should rather omit it entirely\n if not unit.istranslated():\n continue\n if isinstance(unit.source, multistring):\n source = (lst_encode(unit.msgidcomments) +\n lst_encode(unit.source.strings, b\"\\0\"))\n else:\n source = lst_encode(unit.msgidcomments) + unit.source.encode('utf-8')\n if unit.msgctxt:\n source = lst_encode(unit.msgctxt) + b\"\\x04\" + source\n if isinstance(unit.target, multistring):\n target = lst_encode(unit.target.strings, b\"\\0\")\n else:\n target = unit.target.encode('utf-8')\n if unit.target:\n MESSAGES[source] = target\n # using \"I\" works for 32- and 64-bit systems, but not for 16-bit!\n hash_table = array.array(\"I\", [0] * hash_size)\n # the keys are sorted in the .mo file\n keys = sorted(MESSAGES.keys())\n offsets = []\n ids = strs = b''\n for i, id in enumerate(keys):\n # For each string, we need size and file offset. Each string is\n # NUL terminated; the NUL does not count into the size.\n # TODO: We don't do any encoding detection from the PO Header\n add_to_hash_table(id, i)\n string = MESSAGES[id] # id already encoded for use as dictionary key\n offsets.append((len(ids), len(id), len(strs), len(string)))\n ids = ids + id + b'\\0'\n strs = strs + string + b'\\0'\n output = ''\n # The header is 7 32-bit unsigned integers\n keystart = 7 * 4 + 16 * len(keys) + hash_size * 4\n # and the values start after the keys\n valuestart = keystart + len(ids)\n koffsets = []\n voffsets = []\n # The string table first has the list of keys, then the list of values.\n # Each entry has first the size of the string, then the file offset.\n for o1, l1, o2, l2 in offsets:\n koffsets = koffsets + [l1, o1 + keystart]\n voffsets = voffsets + [l2, o2 + valuestart]\n offsets = koffsets + voffsets\n output = struct.pack(\"Iiiiiii\",\n MO_MAGIC_NUMBER, # Magic\n 0, # Version\n len(keys), # # of entries\n 7 * 4, # start of key index\n 7 * 4 + len(keys) * 8, # start of value index\n hash_size, # size of hash table\n 7 * 4 + 2 * (len(keys) * 8)) # offset of hash table\n # additional data is not necessary for empty mo files\n if (len(keys) > 0):\n output = output + array.array(\"i\", offsets).tostring()\n output = output + hash_table.tostring()\n output = output + ids\n output = output + strs\n return out.write(output)\n\n def parse(self, input):\n \"\"\"parses the given file or file source string\"\"\"\n if hasattr(input, 'name'):\n self.filename = input.name\n elif not getattr(self, 'filename', ''):\n self.filename = ''\n if hasattr(input, \"read\"):\n mosrc = input.read()\n input.close()\n input = mosrc\n little, = struct.unpack(\"<L\", input[:4])\n big, = struct.unpack(\">L\", input[:4])\n if little == MO_MAGIC_NUMBER:\n endian = \"<\"\n elif big == MO_MAGIC_NUMBER:\n endian = \">\"\n else:\n raise ValueError(\"This is not an MO file\")\n magic, version_maj, version_min, lenkeys, startkey, \\\n startvalue, sizehash, offsethash = struct.unpack(\"%sLHHiiiii\" % endian,\n input[:(7 * 4)])\n if version_maj >= 1:\n raise base.ParseError(\"\"\"Unable to process version %d.%d MO files\"\"\" % (version_maj, version_min))\n for i in range(lenkeys):\n nextkey = startkey + (i * 2 * 4)\n nextvalue = startvalue + (i * 2 * 4)\n klength, koffset = struct.unpack(\"%sii\" % endian,\n input[nextkey:nextkey + (2 * 4)])\n vlength, voffset = struct.unpack(\"%sii\" % endian,\n input[nextvalue:nextvalue + (2 * 4)])\n source = input[koffset:koffset + klength]\n context = None\n if b\"\\x04\" in source:\n context, source = source.split(b\"\\x04\")\n # Still need to handle KDE comments\n if source == \"\":\n charset = re.search(b\"charset=([^\\\\s]+)\",\n input[voffset:voffset + vlength])\n if charset:\n self.encoding = charset.group(1)\n source = multistring([s.decode(self.encoding)\n for s in source.split(b\"\\0\")])\n target = multistring([s.decode(self.encoding)\n for s in input[voffset:voffset + vlength].split(b\"\\0\")])\n newunit = mounit(source)\n newunit.target = target\n if context is not None:\n newunit.msgctxt.append(context)\n self.addunit(newunit)\n", "path": "translate/storage/mo.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2007 Zuza Software Foundation\n#\n# the function \"serialize\" was derived from Python v2.4\n# (Tools/i18n/msgfmt.py - function \"generate\"):\n# Written by Martin v. L\u00f6wis <[email protected]>\n# Copyright (c) 2001, 2002, 2003, 2004, 2005, 2006 Python Software Foundation.\n# All rights reserved.\n# original license: Python Software Foundation (version 2)\n#\n#\n# This file is part of translate.\n#\n# translate is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n#\n\n\"\"\"Module for parsing Gettext .mo files for translation.\n\nThe coding of .mo files was produced from `Gettext documentation\n<http://www.gnu.org/software/gettext/manual/gettext.html#MO-Files>`_,\nPythons msgfmt.py and by observing and testing existing .mo files in the wild.\n\nThe hash algorithm is implemented for MO files, this should result in\nfaster access of the MO file. The hash is optional for Gettext\nand is not needed for reading or writing MO files, in this implementation\nit is always on and does produce sometimes different results to Gettext\nin very small files.\n\"\"\"\n\nimport array\nimport re\nimport six\nimport struct\n\nfrom translate.misc.multistring import multistring\nfrom translate.storage import base, poheader\n\n\nMO_MAGIC_NUMBER = 0x950412de\n\n\ndef mounpack(filename='messages.mo'):\n \"\"\"Helper to unpack Gettext MO files into a Python string\"\"\"\n with open(filename, 'rb') as fh:\n s = fh.read()\n print(\"\\\\x%02x\" * len(s) % tuple(map(ord, s)))\n\n\ndef my_swap4(result):\n c0 = (result >> 0) & 0xff\n c1 = (result >> 8) & 0xff\n c2 = (result >> 16) & 0xff\n c3 = (result >> 24) & 0xff\n\n return (c0 << 24) | (c1 << 16) | (c2 << 8) | c3\n\n\ndef hashpjw(str_param):\n HASHWORDBITS = 32\n hval = 0\n g = None\n s = str_param\n for s in str_param:\n hval = hval << 4\n hval += ord(s) if six.PY2 else s\n g = hval & 0xf << (HASHWORDBITS - 4)\n if (g != 0):\n hval = hval ^ g >> (HASHWORDBITS - 8)\n hval = hval ^ g\n return hval\n\n\ndef get_next_prime_number(start):\n # find the smallest prime number that is greater or equal \"start\"\n\n def is_prime(num):\n # special small numbers\n if (num < 2) or (num == 4):\n return False\n if (num == 2) or (num == 3):\n return True\n # check for numbers > 4\n for divider in range(2, num // 2):\n if num % divider == 0:\n return False\n return True\n\n candidate = start\n while not is_prime(candidate):\n candidate += 1\n return candidate\n\n\nclass mounit(base.TranslationUnit):\n \"\"\"A class representing a .mo translation message.\"\"\"\n\n def __init__(self, source=None, **kwargs):\n self.msgctxt = []\n self.msgidcomments = []\n super(mounit, self).__init__(source)\n\n def getcontext(self):\n \"\"\"Get the message context\"\"\"\n # Still need to handle KDE comments\n if self.msgctxt is None:\n return None\n return \"\".join(self.msgctxt)\n\n def setcontext(self, context):\n self.msgctxt = [context]\n\n def isheader(self):\n \"\"\"Is this a header entry?\"\"\"\n return self.source == u\"\"\n\n def istranslatable(self):\n \"\"\"Is this message translateable?\"\"\"\n return bool(self.source)\n\n\nclass mofile(poheader.poheader, base.TranslationStore):\n \"\"\"A class representing a .mo file.\"\"\"\n\n UnitClass = mounit\n Name = \"Gettext MO file\"\n Mimetypes = [\"application/x-gettext-catalog\", \"application/x-mo\"]\n Extensions = [\"mo\", \"gmo\"]\n _binary = True\n\n def __init__(self, inputfile=None, **kwargs):\n super(mofile, self).__init__(**kwargs)\n self.filename = ''\n if inputfile is not None:\n self.parsestring(inputfile)\n\n def serialize(self, out):\n \"\"\"Output a string representation of the MO data file\"\"\"\n # check the header of this file for the copyright note of this function\n\n def add_to_hash_table(string, i):\n V = hashpjw(string)\n # Taken from gettext-0.17:gettext-tools/src/write-mo.c:408-409\n S = hash_size <= 2 and 3 or hash_size\n hash_cursor = V % S\n orig_hash_cursor = hash_cursor\n increment = 1 + (V % (S - 2))\n while True:\n index = hash_table[hash_cursor]\n if (index == 0):\n hash_table[hash_cursor] = i + 1\n break\n hash_cursor += increment\n hash_cursor = hash_cursor % S\n assert (hash_cursor != orig_hash_cursor)\n\n def lst_encode(lst, join_char=b''):\n return join_char.join([i.encode('utf-8') for i in lst])\n\n # hash_size should be the smallest prime number that is greater\n # or equal (4 / 3 * N) - where N is the number of keys/units.\n # see gettext-0.17:gettext-tools/src/write-mo.c:406\n hash_size = get_next_prime_number(int((len(self.units) * 4) / 3))\n if hash_size <= 2:\n hash_size = 3\n MESSAGES = {}\n for unit in self.units:\n # If the unit is not translated, we should rather omit it entirely\n if not unit.istranslated():\n continue\n if isinstance(unit.source, multistring):\n source = (lst_encode(unit.msgidcomments) +\n lst_encode(unit.source.strings, b\"\\0\"))\n else:\n source = lst_encode(unit.msgidcomments) + unit.source.encode('utf-8')\n if unit.msgctxt:\n source = lst_encode(unit.msgctxt) + b\"\\x04\" + source\n if isinstance(unit.target, multistring):\n target = lst_encode(unit.target.strings, b\"\\0\")\n else:\n target = unit.target.encode('utf-8')\n if unit.target:\n MESSAGES[source] = target\n # using \"I\" works for 32- and 64-bit systems, but not for 16-bit!\n hash_table = array.array(\"I\", [0] * hash_size)\n # the keys are sorted in the .mo file\n keys = sorted(MESSAGES.keys())\n offsets = []\n ids = strs = b''\n for i, id in enumerate(keys):\n # For each string, we need size and file offset. Each string is\n # NUL terminated; the NUL does not count into the size.\n # TODO: We don't do any encoding detection from the PO Header\n add_to_hash_table(id, i)\n string = MESSAGES[id] # id already encoded for use as dictionary key\n offsets.append((len(ids), len(id), len(strs), len(string)))\n ids = ids + id + b'\\0'\n strs = strs + string + b'\\0'\n output = ''\n # The header is 7 32-bit unsigned integers\n keystart = 7 * 4 + 16 * len(keys) + hash_size * 4\n # and the values start after the keys\n valuestart = keystart + len(ids)\n koffsets = []\n voffsets = []\n # The string table first has the list of keys, then the list of values.\n # Each entry has first the size of the string, then the file offset.\n for o1, l1, o2, l2 in offsets:\n koffsets = koffsets + [l1, o1 + keystart]\n voffsets = voffsets + [l2, o2 + valuestart]\n offsets = koffsets + voffsets\n output = struct.pack(\"Iiiiiii\",\n MO_MAGIC_NUMBER, # Magic\n 0, # Version\n len(keys), # # of entries\n 7 * 4, # start of key index\n 7 * 4 + len(keys) * 8, # start of value index\n hash_size, # size of hash table\n 7 * 4 + 2 * (len(keys) * 8)) # offset of hash table\n # additional data is not necessary for empty mo files\n if (len(keys) > 0):\n output = output + array.array(\"i\", offsets).tostring()\n output = output + hash_table.tostring()\n output = output + ids\n output = output + strs\n return out.write(output)\n\n def parse(self, input):\n \"\"\"parses the given file or file source string\"\"\"\n if hasattr(input, 'name'):\n self.filename = input.name\n elif not getattr(self, 'filename', ''):\n self.filename = ''\n if hasattr(input, \"read\"):\n mosrc = input.read()\n input.close()\n input = mosrc\n little, = struct.unpack(\"<L\", input[:4])\n big, = struct.unpack(\">L\", input[:4])\n if little == MO_MAGIC_NUMBER:\n endian = \"<\"\n elif big == MO_MAGIC_NUMBER:\n endian = \">\"\n else:\n raise ValueError(\"This is not an MO file\")\n magic, version_maj, version_min, lenkeys, startkey, \\\n startvalue, sizehash, offsethash = struct.unpack(\"%sLHHiiiii\" % endian,\n input[:(7 * 4)])\n if version_maj >= 1:\n raise base.ParseError(\"\"\"Unable to process version %d.%d MO files\"\"\" % (version_maj, version_min))\n for i in range(lenkeys):\n nextkey = startkey + (i * 2 * 4)\n nextvalue = startvalue + (i * 2 * 4)\n klength, koffset = struct.unpack(\"%sii\" % endian,\n input[nextkey:nextkey + (2 * 4)])\n vlength, voffset = struct.unpack(\"%sii\" % endian,\n input[nextvalue:nextvalue + (2 * 4)])\n source = input[koffset:koffset + klength]\n context = None\n if b\"\\x04\" in source:\n context, source = source.split(b\"\\x04\")\n # Still need to handle KDE comments\n if source == \"\":\n charset = re.search(b\"charset=([^\\\\s]+)\",\n input[voffset:voffset + vlength])\n if charset:\n self.encoding = charset.group(1)\n source = multistring([s.decode(self.encoding)\n for s in source.split(b\"\\0\")])\n target = multistring([s.decode(self.encoding)\n for s in input[voffset:voffset + vlength].split(b\"\\0\")])\n newunit = mounit(source)\n newunit.target = target\n if context is not None:\n newunit.msgctxt.append(context)\n self.addunit(newunit)\n", "path": "translate/storage/mo.py"}]}
| 3,789 | 104 |
gh_patches_debug_5179
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2653
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Impossible login to GOG.com: invalid cookie ?
**Describe the bug**
I can't connect Lutris with my GOG.com account: the GOG.com credentials window is here, I can fill it, but when I confirm this form, the window closes and… nothing more. My account isn't connected, and if I close the "Import games" window, I can't reopen it unless I delete '.cache/lutris' directory.
**Expected behavior**
I should have a second GOG.com form asking for a PIN code, then my account should be connected in Lutris.
**Current behavior**
As in description above. Plus technical details:
* two files are created in '~/.cache/lutris/': .gog.auth and .gog.token (attached as [gog.auth.txt](https://github.com/lutris/lutris/files/4309081/gog.auth.txt) and [gog.token.txt](https://github.com/lutris/lutris/files/4309083/gog.token.txt))
* according to standard output in terminal, some problems with Python, ending with an invalid cookie? (see [lutris.txt](https://github.com/lutris/lutris/files/4309117/lutris.txt))
**Steps to reproduce**
It happens while importing GOG games from the app or installing GOG games from the website.
**System information**
Fresh Lutris install, Arch Linux, kernel 5.5.8. More in [lutris.log](https://github.com/lutris/lutris/files/4309125/lutris.log)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/util/cookies.py`
Content:
```
1 import time
2 from http.cookiejar import MozillaCookieJar, Cookie, _warn_unhandled_exception
3
4
5 class WebkitCookieJar(MozillaCookieJar):
6 """Subclass of MozillaCookieJar for compatibility with cookies
7 coming from Webkit2.
8 This disables the magic_re header which is not present and adds
9 compatibility with HttpOnly cookies (See http://bugs.python.org/issue2190)
10 """
11
12 def _really_load(self, f, filename, ignore_discard, ignore_expires):
13 now = time.time()
14 try:
15 while 1:
16 line = f.readline()
17 if line == "":
18 break
19
20 # last field may be absent, so keep any trailing tab
21 if line.endswith("\n"):
22 line = line[:-1]
23
24 sline = line.strip()
25 # support HttpOnly cookies (as stored by curl or old Firefox).
26 if sline.startswith("#HttpOnly_"):
27 line = sline[10:]
28 elif sline.startswith("#") or sline == "":
29 continue
30
31 domain, domain_specified, path, secure, expires, name, value = line.split(
32 "\t"
33 )
34 secure = secure == "TRUE"
35 domain_specified = domain_specified == "TRUE"
36 if name == "":
37 # cookies.txt regards 'Set-Cookie: foo' as a cookie
38 # with no name, whereas http.cookiejar regards it as a
39 # cookie with no value.
40 name = value
41 value = None
42
43 initial_dot = domain.startswith(".")
44 assert domain_specified == initial_dot
45
46 discard = False
47 if expires == "":
48 expires = None
49 discard = True
50
51 # assume path_specified is false
52 c = Cookie(
53 0,
54 name,
55 value,
56 None,
57 False,
58 domain,
59 domain_specified,
60 initial_dot,
61 path,
62 False,
63 secure,
64 expires,
65 discard,
66 None,
67 None,
68 {},
69 )
70 if not ignore_discard and c.discard:
71 continue
72 if not ignore_expires and c.is_expired(now):
73 continue
74 self.set_cookie(c)
75
76 except OSError:
77 raise
78 except Exception:
79 _warn_unhandled_exception()
80 raise OSError(
81 "invalid Netscape format cookies file %r: %r" % (filename, line)
82 )
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/util/cookies.py b/lutris/util/cookies.py
--- a/lutris/util/cookies.py
+++ b/lutris/util/cookies.py
@@ -28,7 +28,7 @@
elif sline.startswith("#") or sline == "":
continue
- domain, domain_specified, path, secure, expires, name, value = line.split(
+ domain, domain_specified, path, secure, expires, name, value, aditional_info = line.split(
"\t"
)
secure = secure == "TRUE"
|
{"golden_diff": "diff --git a/lutris/util/cookies.py b/lutris/util/cookies.py\n--- a/lutris/util/cookies.py\n+++ b/lutris/util/cookies.py\n@@ -28,7 +28,7 @@\n elif sline.startswith(\"#\") or sline == \"\":\n continue\n \n- domain, domain_specified, path, secure, expires, name, value = line.split(\n+ domain, domain_specified, path, secure, expires, name, value, aditional_info = line.split(\n \"\\t\"\n )\n secure = secure == \"TRUE\"\n", "issue": "Impossible login to GOG.com: invalid cookie ?\n**Describe the bug**\r\n\r\nI can't connect Lutris with my GOG.com account: the GOG.com credentials window is here, I can fill it, but when I confirm this form, the window closes and\u2026 nothing more. My account isn't connected, and if I close the \"Import games\" window, I can't reopen it unless I delete '.cache/lutris' directory. \r\n\r\n**Expected behavior**\r\n\r\nI should have a second GOG.com form asking for a PIN code, then my account should be connected in Lutris.\r\n\r\n**Current behavior**\r\n\r\nAs in description above. Plus technical details:\r\n\r\n* two files are created in '~/.cache/lutris/': .gog.auth and .gog.token (attached as [gog.auth.txt](https://github.com/lutris/lutris/files/4309081/gog.auth.txt) and [gog.token.txt](https://github.com/lutris/lutris/files/4309083/gog.token.txt))\r\n* according to standard output in terminal, some problems with Python, ending with an invalid cookie? (see [lutris.txt](https://github.com/lutris/lutris/files/4309117/lutris.txt))\r\n\r\n**Steps to reproduce**\r\n\r\nIt happens while importing GOG games from the app or installing GOG games from the website.\r\n\r\n**System information**\r\n\r\nFresh Lutris install, Arch Linux, kernel 5.5.8. More in [lutris.log](https://github.com/lutris/lutris/files/4309125/lutris.log)\n", "before_files": [{"content": "import time\nfrom http.cookiejar import MozillaCookieJar, Cookie, _warn_unhandled_exception\n\n\nclass WebkitCookieJar(MozillaCookieJar):\n \"\"\"Subclass of MozillaCookieJar for compatibility with cookies\n coming from Webkit2.\n This disables the magic_re header which is not present and adds\n compatibility with HttpOnly cookies (See http://bugs.python.org/issue2190)\n \"\"\"\n\n def _really_load(self, f, filename, ignore_discard, ignore_expires):\n now = time.time()\n try:\n while 1:\n line = f.readline()\n if line == \"\":\n break\n\n # last field may be absent, so keep any trailing tab\n if line.endswith(\"\\n\"):\n line = line[:-1]\n\n sline = line.strip()\n # support HttpOnly cookies (as stored by curl or old Firefox).\n if sline.startswith(\"#HttpOnly_\"):\n line = sline[10:]\n elif sline.startswith(\"#\") or sline == \"\":\n continue\n\n domain, domain_specified, path, secure, expires, name, value = line.split(\n \"\\t\"\n )\n secure = secure == \"TRUE\"\n domain_specified = domain_specified == \"TRUE\"\n if name == \"\":\n # cookies.txt regards 'Set-Cookie: foo' as a cookie\n # with no name, whereas http.cookiejar regards it as a\n # cookie with no value.\n name = value\n value = None\n\n initial_dot = domain.startswith(\".\")\n assert domain_specified == initial_dot\n\n discard = False\n if expires == \"\":\n expires = None\n discard = True\n\n # assume path_specified is false\n c = Cookie(\n 0,\n name,\n value,\n None,\n False,\n domain,\n domain_specified,\n initial_dot,\n path,\n False,\n secure,\n expires,\n discard,\n None,\n None,\n {},\n )\n if not ignore_discard and c.discard:\n continue\n if not ignore_expires and c.is_expired(now):\n continue\n self.set_cookie(c)\n\n except OSError:\n raise\n except Exception:\n _warn_unhandled_exception()\n raise OSError(\n \"invalid Netscape format cookies file %r: %r\" % (filename, line)\n )\n", "path": "lutris/util/cookies.py"}], "after_files": [{"content": "import time\nfrom http.cookiejar import MozillaCookieJar, Cookie, _warn_unhandled_exception\n\n\nclass WebkitCookieJar(MozillaCookieJar):\n \"\"\"Subclass of MozillaCookieJar for compatibility with cookies\n coming from Webkit2.\n This disables the magic_re header which is not present and adds\n compatibility with HttpOnly cookies (See http://bugs.python.org/issue2190)\n \"\"\"\n\n def _really_load(self, f, filename, ignore_discard, ignore_expires):\n now = time.time()\n try:\n while 1:\n line = f.readline()\n if line == \"\":\n break\n\n # last field may be absent, so keep any trailing tab\n if line.endswith(\"\\n\"):\n line = line[:-1]\n\n sline = line.strip()\n # support HttpOnly cookies (as stored by curl or old Firefox).\n if sline.startswith(\"#HttpOnly_\"):\n line = sline[10:]\n elif sline.startswith(\"#\") or sline == \"\":\n continue\n\n domain, domain_specified, path, secure, expires, name, value, aditional_info = line.split(\n \"\\t\"\n )\n secure = secure == \"TRUE\"\n domain_specified = domain_specified == \"TRUE\"\n if name == \"\":\n # cookies.txt regards 'Set-Cookie: foo' as a cookie\n # with no name, whereas http.cookiejar regards it as a\n # cookie with no value.\n name = value\n value = None\n\n initial_dot = domain.startswith(\".\")\n assert domain_specified == initial_dot\n\n discard = False\n if expires == \"\":\n expires = None\n discard = True\n\n # assume path_specified is false\n c = Cookie(\n 0,\n name,\n value,\n None,\n False,\n domain,\n domain_specified,\n initial_dot,\n path,\n False,\n secure,\n expires,\n discard,\n None,\n None,\n {},\n )\n if not ignore_discard and c.discard:\n continue\n if not ignore_expires and c.is_expired(now):\n continue\n self.set_cookie(c)\n\n except OSError:\n raise\n except Exception:\n _warn_unhandled_exception()\n raise OSError(\n \"invalid Netscape format cookies file %r: %r\" % (filename, line)\n )\n", "path": "lutris/util/cookies.py"}]}
| 1,280 | 127 |
gh_patches_debug_25826
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-1965
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
We need a way to specify Preproc function for base_grouping_column
## Description
In partial summarization, when the `grouping_expressions` also include the `base_grouping_column`, "guessing" does not work.
* We need a place to specify `preproc` functions for the `base_grouping_column`. We should either allow additionally specifying it within `grouping_expressions` or extend `base_grouping_column` to include `preproc`.
* If we do not allow it within `grouping_expressions`, the "guessed" response should not include it within `grouping_expressions`. Currently, it is also included.
cc: @dmos62 @mathemancer
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `db/transforms/operations/finish_specifying.py`
Content:
```
1 from db.tables.operations import select as tables_select
2 from db.tables.operations.select import get_joinable_tables
3 from db.transforms.base import Summarize, SelectSubsetOfColumns
4 from db.columns.operations.select import get_column_from_oid_and_attnum
5
6
7 def finish_specifying_summarize_transform(
8 db_query, ix_of_summarize_transform, engine, metadata
9 ):
10 """
11 Adds missing input aliases to the summarize transform.
12
13 Will find input aliases that are not mentioned in the summarize_transform and will add each
14 of them to its group-by set and/or aggregate-on set.
15
16 If the user selected input alias (summarize's base grouping column) is not unique-constrained,
17 will put the unmentioned input aliases in the aggregation set.
18
19 If the user selected input alias (summarize's base grouping column) is unique-constrained,
20 then it might put at least some input aliases in the grouping set, depending on what
21 _should_group_by returns.
22 """
23 summarize_transform = db_query.transformations[ix_of_summarize_transform]
24 assert type(summarize_transform) is Summarize
25 aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on = \
26 _split_missing_input_aliases_into_group_and_agg_lists(
27 db_query, ix_of_summarize_transform, engine, metadata
28 )
29 there_is_something_to_add = \
30 aliases_to_be_added_to_group_by or aliases_to_be_added_to_group_by
31 if there_is_something_to_add:
32 summarize_transform = \
33 summarize_transform.get_new_with_aliases_added_to_agg_on(
34 aliases_to_be_added_to_agg_on
35 )
36 summarize_transform = \
37 summarize_transform.get_new_with_aliases_added_to_group_by(
38 aliases_to_be_added_to_group_by
39 )
40 return summarize_transform
41
42
43 def _split_missing_input_aliases_into_group_and_agg_lists(
44 db_query, ix_of_summarize_transform, engine, metadata,
45 ):
46 aliases_to_be_added_to_group_by = []
47 aliases_to_be_added_to_agg_on = []
48 summarize_transform = db_query.transformations[ix_of_summarize_transform]
49 initial_columns_not_in_summarize = \
50 _get_initial_columns_not_in_summarize(db_query, summarize_transform)
51 if not initial_columns_not_in_summarize:
52 # If all input aliases for summarize transform are in the transform's group-by or
53 # aggregate-on sets, there's nothing to do.
54 return aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on
55 # A summarize transform has a base_grouping_column (which is an alias) around
56 # which our suggestions will be based.
57 base_grouping_alias = summarize_transform.base_grouping_column
58 base_grouping_initial_column = \
59 _get_initial_column_by_alias(
60 db_query.initial_columns, base_grouping_alias
61 )
62 # We'll always want user-selected alias (base_grouping_column) in the "group-by set";
63 if base_grouping_initial_column in initial_columns_not_in_summarize:
64 aliases_to_be_added_to_group_by.append(base_grouping_alias)
65 initial_columns_not_in_summarize.remove(base_grouping_initial_column)
66 # Most of logic in the rest of method is around whether or not we can add some of the other
67 # input aliases to the "group-by set"; otherwise we'll put them in "aggregate-on set".
68 can_add_other_aliases_to_group_by = (
69 _is_first_alias_generating_transform(
70 db_query, ix_of_summarize_transform
71 )
72 and _is_initial_column_unique_constrained(
73 base_grouping_initial_column, engine, metadata
74 )
75 )
76 if can_add_other_aliases_to_group_by:
77 oids_of_joinable_tables_with_single_results = \
78 _get_oids_of_joinable_tables_with_single_results(
79 db_query, engine, metadata
80 )
81 oid_of_base_grouping_initial_column = \
82 _get_oid_of_initial_column(base_grouping_initial_column)
83 for initial_column in initial_columns_not_in_summarize:
84 if _should_group_by(
85 _get_oid_of_initial_column(initial_column),
86 oid_of_base_grouping_initial_column,
87 oids_of_joinable_tables_with_single_results,
88 ):
89 alias_set_to_add_to = aliases_to_be_added_to_group_by
90 else:
91 alias_set_to_add_to = aliases_to_be_added_to_agg_on
92 alias_set_to_add_to.append(initial_column.alias)
93 else:
94 aliases_to_be_added_to_agg_on = list(
95 initial_column.alias
96 for initial_column
97 in initial_columns_not_in_summarize
98 )
99 return aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on
100
101
102 def _is_first_alias_generating_transform(db_query, ix_of_summarize_transform):
103 """
104 Checks if the transform is the first alias-generating transform. An alias-generating transform
105 means that it itroduces new aliases (columns) to the transform pipeline. We want to know when
106 a given alias-generating transform is the first in the pipeline, because then we can consider
107 its input aliases to be fully described by initial columns, which can be a useful
108 simplification.
109 """
110 prior_transforms = db_query.transformations[:ix_of_summarize_transform]
111 for prior_transform in prior_transforms:
112 alias_generating_transforms = {Summarize, SelectSubsetOfColumns}
113 is_alias_generating = \
114 type(prior_transform) in alias_generating_transforms
115 if is_alias_generating:
116 return False
117 return True
118
119
120 def _get_initial_columns_not_in_summarize(db_query, summarize_transform):
121 initial_columns = db_query.initial_columns
122 group_by_aliases = summarize_transform.grouping_input_aliases
123 agg_on_aliases = summarize_transform.aggregation_input_aliases
124 aliases_in_summarize = group_by_aliases + agg_on_aliases
125 return [
126 initial_column
127 for initial_column in
128 initial_columns
129 if initial_column.alias not in aliases_in_summarize
130 ]
131
132
133 def _get_initial_column_by_alias(initial_columns, alias):
134 for initial_column in initial_columns:
135 if initial_column.alias == alias:
136 return initial_column
137
138
139 def _should_group_by(
140 oid_of_initial_column,
141 oid_of_base_grouping_group_by_col,
142 oids_of_joinable_tables_with_single_results,
143 ):
144 """
145 For the sake of efficiency, we're not checking here that base_grouping_group_by_col is unique
146 constrained: it is presumed that that is the case.
147 """
148 is_on_table_of_base_grouping_column = \
149 oid_of_initial_column == oid_of_base_grouping_group_by_col
150 is_single_result = \
151 oid_of_initial_column in oids_of_joinable_tables_with_single_results
152 should_group_by = \
153 is_on_table_of_base_grouping_column or is_single_result
154 return should_group_by
155
156
157 def _get_oids_of_joinable_tables_with_single_results(
158 db_query, engine, metadata,
159 ):
160 joinable_tables = \
161 get_joinable_tables(engine, metadata, db_query.base_table_oid)
162 return set(
163 _get_oid_of_joinable_table(joinable_table)
164 for joinable_table
165 in joinable_tables
166 if _has_single_result(joinable_table)
167 )
168
169
170 def _is_initial_column_unique_constrained(initial_column, engine, metadata):
171 oid = _get_oid_of_initial_column(initial_column)
172 attnum = initial_column.attnum
173 sa_column = get_column_from_oid_and_attnum(
174 table_oid=oid,
175 attnum=attnum,
176 engine=engine,
177 metadata=metadata,
178 )
179 return _is_sa_column_unique_constrained(sa_column)
180
181
182 def _is_sa_column_unique_constrained(sa_column):
183 return sa_column.primary_key or sa_column.unique
184
185
186 def _get_oid_of_initial_column(initial_column):
187 return initial_column.reloid
188
189
190 def _get_oid_of_joinable_table(joinable_table):
191 joinable_table_oid = joinable_table[tables_select.TARGET]
192 return joinable_table_oid
193
194
195 def _has_single_result(joinable_table):
196 has_multiple_results = joinable_table[tables_select.MULTIPLE_RESULTS]
197 assert type(has_multiple_results) is bool
198 return not has_multiple_results
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/db/transforms/operations/finish_specifying.py b/db/transforms/operations/finish_specifying.py
--- a/db/transforms/operations/finish_specifying.py
+++ b/db/transforms/operations/finish_specifying.py
@@ -26,17 +26,16 @@
_split_missing_input_aliases_into_group_and_agg_lists(
db_query, ix_of_summarize_transform, engine, metadata
)
- there_is_something_to_add = \
- aliases_to_be_added_to_group_by or aliases_to_be_added_to_group_by
- if there_is_something_to_add:
- summarize_transform = \
- summarize_transform.get_new_with_aliases_added_to_agg_on(
- aliases_to_be_added_to_agg_on
- )
+ if aliases_to_be_added_to_group_by:
summarize_transform = \
summarize_transform.get_new_with_aliases_added_to_group_by(
aliases_to_be_added_to_group_by
)
+ if aliases_to_be_added_to_agg_on:
+ summarize_transform = \
+ summarize_transform.get_new_with_aliases_added_to_agg_on(
+ aliases_to_be_added_to_agg_on
+ )
return summarize_transform
@@ -180,7 +179,10 @@
def _is_sa_column_unique_constrained(sa_column):
- return sa_column.primary_key or sa_column.unique
+ return bool(
+ sa_column.primary_key
+ or sa_column.unique
+ )
def _get_oid_of_initial_column(initial_column):
|
{"golden_diff": "diff --git a/db/transforms/operations/finish_specifying.py b/db/transforms/operations/finish_specifying.py\n--- a/db/transforms/operations/finish_specifying.py\n+++ b/db/transforms/operations/finish_specifying.py\n@@ -26,17 +26,16 @@\n _split_missing_input_aliases_into_group_and_agg_lists(\n db_query, ix_of_summarize_transform, engine, metadata\n )\n- there_is_something_to_add = \\\n- aliases_to_be_added_to_group_by or aliases_to_be_added_to_group_by\n- if there_is_something_to_add:\n- summarize_transform = \\\n- summarize_transform.get_new_with_aliases_added_to_agg_on(\n- aliases_to_be_added_to_agg_on\n- )\n+ if aliases_to_be_added_to_group_by:\n summarize_transform = \\\n summarize_transform.get_new_with_aliases_added_to_group_by(\n aliases_to_be_added_to_group_by\n )\n+ if aliases_to_be_added_to_agg_on:\n+ summarize_transform = \\\n+ summarize_transform.get_new_with_aliases_added_to_agg_on(\n+ aliases_to_be_added_to_agg_on\n+ )\n return summarize_transform\n \n \n@@ -180,7 +179,10 @@\n \n \n def _is_sa_column_unique_constrained(sa_column):\n- return sa_column.primary_key or sa_column.unique\n+ return bool(\n+ sa_column.primary_key\n+ or sa_column.unique\n+ )\n \n \n def _get_oid_of_initial_column(initial_column):\n", "issue": "We need a way to specify Preproc function for base_grouping_column\n## Description\r\nIn partial summarization, when the `grouping_expressions` also include the `base_grouping_column`, \"guessing\" does not work.\r\n* We need a place to specify `preproc` functions for the `base_grouping_column`. We should either allow additionally specifying it within `grouping_expressions` or extend `base_grouping_column` to include `preproc`.\r\n* If we do not allow it within `grouping_expressions`, the \"guessed\" response should not include it within `grouping_expressions`. Currently, it is also included.\r\n\r\ncc: @dmos62 @mathemancer \n", "before_files": [{"content": "from db.tables.operations import select as tables_select\nfrom db.tables.operations.select import get_joinable_tables\nfrom db.transforms.base import Summarize, SelectSubsetOfColumns\nfrom db.columns.operations.select import get_column_from_oid_and_attnum\n\n\ndef finish_specifying_summarize_transform(\n db_query, ix_of_summarize_transform, engine, metadata\n):\n \"\"\"\n Adds missing input aliases to the summarize transform.\n\n Will find input aliases that are not mentioned in the summarize_transform and will add each\n of them to its group-by set and/or aggregate-on set.\n\n If the user selected input alias (summarize's base grouping column) is not unique-constrained,\n will put the unmentioned input aliases in the aggregation set.\n\n If the user selected input alias (summarize's base grouping column) is unique-constrained,\n then it might put at least some input aliases in the grouping set, depending on what\n _should_group_by returns.\n \"\"\"\n summarize_transform = db_query.transformations[ix_of_summarize_transform]\n assert type(summarize_transform) is Summarize\n aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on = \\\n _split_missing_input_aliases_into_group_and_agg_lists(\n db_query, ix_of_summarize_transform, engine, metadata\n )\n there_is_something_to_add = \\\n aliases_to_be_added_to_group_by or aliases_to_be_added_to_group_by\n if there_is_something_to_add:\n summarize_transform = \\\n summarize_transform.get_new_with_aliases_added_to_agg_on(\n aliases_to_be_added_to_agg_on\n )\n summarize_transform = \\\n summarize_transform.get_new_with_aliases_added_to_group_by(\n aliases_to_be_added_to_group_by\n )\n return summarize_transform\n\n\ndef _split_missing_input_aliases_into_group_and_agg_lists(\n db_query, ix_of_summarize_transform, engine, metadata,\n):\n aliases_to_be_added_to_group_by = []\n aliases_to_be_added_to_agg_on = []\n summarize_transform = db_query.transformations[ix_of_summarize_transform]\n initial_columns_not_in_summarize = \\\n _get_initial_columns_not_in_summarize(db_query, summarize_transform)\n if not initial_columns_not_in_summarize:\n # If all input aliases for summarize transform are in the transform's group-by or\n # aggregate-on sets, there's nothing to do.\n return aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on\n # A summarize transform has a base_grouping_column (which is an alias) around\n # which our suggestions will be based.\n base_grouping_alias = summarize_transform.base_grouping_column\n base_grouping_initial_column = \\\n _get_initial_column_by_alias(\n db_query.initial_columns, base_grouping_alias\n )\n # We'll always want user-selected alias (base_grouping_column) in the \"group-by set\";\n if base_grouping_initial_column in initial_columns_not_in_summarize:\n aliases_to_be_added_to_group_by.append(base_grouping_alias)\n initial_columns_not_in_summarize.remove(base_grouping_initial_column)\n # Most of logic in the rest of method is around whether or not we can add some of the other\n # input aliases to the \"group-by set\"; otherwise we'll put them in \"aggregate-on set\".\n can_add_other_aliases_to_group_by = (\n _is_first_alias_generating_transform(\n db_query, ix_of_summarize_transform\n )\n and _is_initial_column_unique_constrained(\n base_grouping_initial_column, engine, metadata\n )\n )\n if can_add_other_aliases_to_group_by:\n oids_of_joinable_tables_with_single_results = \\\n _get_oids_of_joinable_tables_with_single_results(\n db_query, engine, metadata\n )\n oid_of_base_grouping_initial_column = \\\n _get_oid_of_initial_column(base_grouping_initial_column)\n for initial_column in initial_columns_not_in_summarize:\n if _should_group_by(\n _get_oid_of_initial_column(initial_column),\n oid_of_base_grouping_initial_column,\n oids_of_joinable_tables_with_single_results,\n ):\n alias_set_to_add_to = aliases_to_be_added_to_group_by\n else:\n alias_set_to_add_to = aliases_to_be_added_to_agg_on\n alias_set_to_add_to.append(initial_column.alias)\n else:\n aliases_to_be_added_to_agg_on = list(\n initial_column.alias\n for initial_column\n in initial_columns_not_in_summarize\n )\n return aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on\n\n\ndef _is_first_alias_generating_transform(db_query, ix_of_summarize_transform):\n \"\"\"\n Checks if the transform is the first alias-generating transform. An alias-generating transform\n means that it itroduces new aliases (columns) to the transform pipeline. We want to know when\n a given alias-generating transform is the first in the pipeline, because then we can consider\n its input aliases to be fully described by initial columns, which can be a useful\n simplification.\n \"\"\"\n prior_transforms = db_query.transformations[:ix_of_summarize_transform]\n for prior_transform in prior_transforms:\n alias_generating_transforms = {Summarize, SelectSubsetOfColumns}\n is_alias_generating = \\\n type(prior_transform) in alias_generating_transforms\n if is_alias_generating:\n return False\n return True\n\n\ndef _get_initial_columns_not_in_summarize(db_query, summarize_transform):\n initial_columns = db_query.initial_columns\n group_by_aliases = summarize_transform.grouping_input_aliases\n agg_on_aliases = summarize_transform.aggregation_input_aliases\n aliases_in_summarize = group_by_aliases + agg_on_aliases\n return [\n initial_column\n for initial_column in\n initial_columns\n if initial_column.alias not in aliases_in_summarize\n ]\n\n\ndef _get_initial_column_by_alias(initial_columns, alias):\n for initial_column in initial_columns:\n if initial_column.alias == alias:\n return initial_column\n\n\ndef _should_group_by(\n oid_of_initial_column,\n oid_of_base_grouping_group_by_col,\n oids_of_joinable_tables_with_single_results,\n):\n \"\"\"\n For the sake of efficiency, we're not checking here that base_grouping_group_by_col is unique\n constrained: it is presumed that that is the case.\n \"\"\"\n is_on_table_of_base_grouping_column = \\\n oid_of_initial_column == oid_of_base_grouping_group_by_col\n is_single_result = \\\n oid_of_initial_column in oids_of_joinable_tables_with_single_results\n should_group_by = \\\n is_on_table_of_base_grouping_column or is_single_result\n return should_group_by\n\n\ndef _get_oids_of_joinable_tables_with_single_results(\n db_query, engine, metadata,\n):\n joinable_tables = \\\n get_joinable_tables(engine, metadata, db_query.base_table_oid)\n return set(\n _get_oid_of_joinable_table(joinable_table)\n for joinable_table\n in joinable_tables\n if _has_single_result(joinable_table)\n )\n\n\ndef _is_initial_column_unique_constrained(initial_column, engine, metadata):\n oid = _get_oid_of_initial_column(initial_column)\n attnum = initial_column.attnum\n sa_column = get_column_from_oid_and_attnum(\n table_oid=oid,\n attnum=attnum,\n engine=engine,\n metadata=metadata,\n )\n return _is_sa_column_unique_constrained(sa_column)\n\n\ndef _is_sa_column_unique_constrained(sa_column):\n return sa_column.primary_key or sa_column.unique\n\n\ndef _get_oid_of_initial_column(initial_column):\n return initial_column.reloid\n\n\ndef _get_oid_of_joinable_table(joinable_table):\n joinable_table_oid = joinable_table[tables_select.TARGET]\n return joinable_table_oid\n\n\ndef _has_single_result(joinable_table):\n has_multiple_results = joinable_table[tables_select.MULTIPLE_RESULTS]\n assert type(has_multiple_results) is bool\n return not has_multiple_results\n", "path": "db/transforms/operations/finish_specifying.py"}], "after_files": [{"content": "from db.tables.operations import select as tables_select\nfrom db.tables.operations.select import get_joinable_tables\nfrom db.transforms.base import Summarize, SelectSubsetOfColumns\nfrom db.columns.operations.select import get_column_from_oid_and_attnum\n\n\ndef finish_specifying_summarize_transform(\n db_query, ix_of_summarize_transform, engine, metadata\n):\n \"\"\"\n Adds missing input aliases to the summarize transform.\n\n Will find input aliases that are not mentioned in the summarize_transform and will add each\n of them to its group-by set and/or aggregate-on set.\n\n If the user selected input alias (summarize's base grouping column) is not unique-constrained,\n will put the unmentioned input aliases in the aggregation set.\n\n If the user selected input alias (summarize's base grouping column) is unique-constrained,\n then it might put at least some input aliases in the grouping set, depending on what\n _should_group_by returns.\n \"\"\"\n summarize_transform = db_query.transformations[ix_of_summarize_transform]\n assert type(summarize_transform) is Summarize\n aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on = \\\n _split_missing_input_aliases_into_group_and_agg_lists(\n db_query, ix_of_summarize_transform, engine, metadata\n )\n if aliases_to_be_added_to_group_by:\n summarize_transform = \\\n summarize_transform.get_new_with_aliases_added_to_group_by(\n aliases_to_be_added_to_group_by\n )\n if aliases_to_be_added_to_agg_on:\n summarize_transform = \\\n summarize_transform.get_new_with_aliases_added_to_agg_on(\n aliases_to_be_added_to_agg_on\n )\n return summarize_transform\n\n\ndef _split_missing_input_aliases_into_group_and_agg_lists(\n db_query, ix_of_summarize_transform, engine, metadata,\n):\n aliases_to_be_added_to_group_by = []\n aliases_to_be_added_to_agg_on = []\n summarize_transform = db_query.transformations[ix_of_summarize_transform]\n initial_columns_not_in_summarize = \\\n _get_initial_columns_not_in_summarize(db_query, summarize_transform)\n if not initial_columns_not_in_summarize:\n # If all input aliases for summarize transform are in the transform's group-by or\n # aggregate-on sets, there's nothing to do.\n return aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on\n # A summarize transform has a base_grouping_column (which is an alias) around\n # which our suggestions will be based.\n base_grouping_alias = summarize_transform.base_grouping_column\n base_grouping_initial_column = \\\n _get_initial_column_by_alias(\n db_query.initial_columns, base_grouping_alias\n )\n # We'll always want user-selected alias (base_grouping_column) in the \"group-by set\";\n if base_grouping_initial_column in initial_columns_not_in_summarize:\n aliases_to_be_added_to_group_by.append(base_grouping_alias)\n initial_columns_not_in_summarize.remove(base_grouping_initial_column)\n # Most of logic in the rest of method is around whether or not we can add some of the other\n # input aliases to the \"group-by set\"; otherwise we'll put them in \"aggregate-on set\".\n can_add_other_aliases_to_group_by = (\n _is_first_alias_generating_transform(\n db_query, ix_of_summarize_transform\n )\n and _is_initial_column_unique_constrained(\n base_grouping_initial_column, engine, metadata\n )\n )\n if can_add_other_aliases_to_group_by:\n oids_of_joinable_tables_with_single_results = \\\n _get_oids_of_joinable_tables_with_single_results(\n db_query, engine, metadata\n )\n oid_of_base_grouping_initial_column = \\\n _get_oid_of_initial_column(base_grouping_initial_column)\n for initial_column in initial_columns_not_in_summarize:\n if _should_group_by(\n _get_oid_of_initial_column(initial_column),\n oid_of_base_grouping_initial_column,\n oids_of_joinable_tables_with_single_results,\n ):\n alias_set_to_add_to = aliases_to_be_added_to_group_by\n else:\n alias_set_to_add_to = aliases_to_be_added_to_agg_on\n alias_set_to_add_to.append(initial_column.alias)\n else:\n aliases_to_be_added_to_agg_on = list(\n initial_column.alias\n for initial_column\n in initial_columns_not_in_summarize\n )\n return aliases_to_be_added_to_group_by, aliases_to_be_added_to_agg_on\n\n\ndef _is_first_alias_generating_transform(db_query, ix_of_summarize_transform):\n \"\"\"\n Checks if the transform is the first alias-generating transform. An alias-generating transform\n means that it itroduces new aliases (columns) to the transform pipeline. We want to know when\n a given alias-generating transform is the first in the pipeline, because then we can consider\n its input aliases to be fully described by initial columns, which can be a useful\n simplification.\n \"\"\"\n prior_transforms = db_query.transformations[:ix_of_summarize_transform]\n for prior_transform in prior_transforms:\n alias_generating_transforms = {Summarize, SelectSubsetOfColumns}\n is_alias_generating = \\\n type(prior_transform) in alias_generating_transforms\n if is_alias_generating:\n return False\n return True\n\n\ndef _get_initial_columns_not_in_summarize(db_query, summarize_transform):\n initial_columns = db_query.initial_columns\n group_by_aliases = summarize_transform.grouping_input_aliases\n agg_on_aliases = summarize_transform.aggregation_input_aliases\n aliases_in_summarize = group_by_aliases + agg_on_aliases\n return [\n initial_column\n for initial_column in\n initial_columns\n if initial_column.alias not in aliases_in_summarize\n ]\n\n\ndef _get_initial_column_by_alias(initial_columns, alias):\n for initial_column in initial_columns:\n if initial_column.alias == alias:\n return initial_column\n\n\ndef _should_group_by(\n oid_of_initial_column,\n oid_of_base_grouping_group_by_col,\n oids_of_joinable_tables_with_single_results,\n):\n \"\"\"\n For the sake of efficiency, we're not checking here that base_grouping_group_by_col is unique\n constrained: it is presumed that that is the case.\n \"\"\"\n is_on_table_of_base_grouping_column = \\\n oid_of_initial_column == oid_of_base_grouping_group_by_col\n is_single_result = \\\n oid_of_initial_column in oids_of_joinable_tables_with_single_results\n should_group_by = \\\n is_on_table_of_base_grouping_column or is_single_result\n return should_group_by\n\n\ndef _get_oids_of_joinable_tables_with_single_results(\n db_query, engine, metadata,\n):\n joinable_tables = \\\n get_joinable_tables(engine, metadata, db_query.base_table_oid)\n return set(\n _get_oid_of_joinable_table(joinable_table)\n for joinable_table\n in joinable_tables\n if _has_single_result(joinable_table)\n )\n\n\ndef _is_initial_column_unique_constrained(initial_column, engine, metadata):\n oid = _get_oid_of_initial_column(initial_column)\n attnum = initial_column.attnum\n sa_column = get_column_from_oid_and_attnum(\n table_oid=oid,\n attnum=attnum,\n engine=engine,\n metadata=metadata,\n )\n return _is_sa_column_unique_constrained(sa_column)\n\n\ndef _is_sa_column_unique_constrained(sa_column):\n return bool(\n sa_column.primary_key\n or sa_column.unique\n )\n\n\ndef _get_oid_of_initial_column(initial_column):\n return initial_column.reloid\n\n\ndef _get_oid_of_joinable_table(joinable_table):\n joinable_table_oid = joinable_table[tables_select.TARGET]\n return joinable_table_oid\n\n\ndef _has_single_result(joinable_table):\n has_multiple_results = joinable_table[tables_select.MULTIPLE_RESULTS]\n assert type(has_multiple_results) is bool\n return not has_multiple_results\n", "path": "db/transforms/operations/finish_specifying.py"}]}
| 2,651 | 325 |
gh_patches_debug_42014
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-5812
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Backchannel LDAP providers missing from outpost configuration page
**Description**
When creating an LDAP Provider, it will appear in the Outpost create/configuration page if it is assigned an application, but not if it's assigned as an application backchannel.
This means we're unable to associate an LDAP backchannel to an outpost.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a demo Application and an LDAP Provider
2. Assign the LDAP Provider as a _backchannel provider_ to the application.
3. Attempt to create an LDAP outpost. Notice the LDAP provider does not appear on the selectable list.
**Expected behavior**
The backchannel should appear the outposts "applications" list, so that it may be added to the outpost.
**Version and Deployment (please complete the following information):**
- authentik version: 2023.5.2
- Deployment: docker-compose
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/providers/ldap/api.py`
Content:
```
1 """LDAPProvider API Views"""
2 from rest_framework.fields import CharField, ListField, SerializerMethodField
3 from rest_framework.serializers import ModelSerializer
4 from rest_framework.viewsets import ModelViewSet, ReadOnlyModelViewSet
5
6 from authentik.core.api.providers import ProviderSerializer
7 from authentik.core.api.used_by import UsedByMixin
8 from authentik.providers.ldap.models import LDAPProvider
9
10
11 class LDAPProviderSerializer(ProviderSerializer):
12 """LDAPProvider Serializer"""
13
14 outpost_set = ListField(child=CharField(), read_only=True, source="outpost_set.all")
15
16 class Meta:
17 model = LDAPProvider
18 fields = ProviderSerializer.Meta.fields + [
19 "base_dn",
20 "search_group",
21 "certificate",
22 "tls_server_name",
23 "uid_start_number",
24 "gid_start_number",
25 "outpost_set",
26 "search_mode",
27 "bind_mode",
28 ]
29 extra_kwargs = ProviderSerializer.Meta.extra_kwargs
30
31
32 class LDAPProviderViewSet(UsedByMixin, ModelViewSet):
33 """LDAPProvider Viewset"""
34
35 queryset = LDAPProvider.objects.all()
36 serializer_class = LDAPProviderSerializer
37 filterset_fields = {
38 "application": ["isnull"],
39 "name": ["iexact"],
40 "authorization_flow__slug": ["iexact"],
41 "base_dn": ["iexact"],
42 "search_group__group_uuid": ["iexact"],
43 "search_group__name": ["iexact"],
44 "certificate__kp_uuid": ["iexact"],
45 "certificate__name": ["iexact"],
46 "tls_server_name": ["iexact"],
47 "uid_start_number": ["iexact"],
48 "gid_start_number": ["iexact"],
49 }
50 search_fields = ["name"]
51 ordering = ["name"]
52
53
54 class LDAPOutpostConfigSerializer(ModelSerializer):
55 """LDAPProvider Serializer"""
56
57 application_slug = SerializerMethodField()
58 bind_flow_slug = CharField(source="authorization_flow.slug")
59
60 def get_application_slug(self, instance: LDAPProvider) -> str:
61 """Prioritise backchannel slug over direct application slug"""
62 if instance.backchannel_application:
63 return instance.backchannel_application.slug
64 return instance.application.slug
65
66 class Meta:
67 model = LDAPProvider
68 fields = [
69 "pk",
70 "name",
71 "base_dn",
72 "bind_flow_slug",
73 "application_slug",
74 "search_group",
75 "certificate",
76 "tls_server_name",
77 "uid_start_number",
78 "gid_start_number",
79 "search_mode",
80 "bind_mode",
81 ]
82
83
84 class LDAPOutpostConfigViewSet(ReadOnlyModelViewSet):
85 """LDAPProvider Viewset"""
86
87 queryset = LDAPProvider.objects.filter(application__isnull=False)
88 serializer_class = LDAPOutpostConfigSerializer
89 ordering = ["name"]
90 search_fields = ["name"]
91 filterset_fields = ["name"]
92
```
Path: `authentik/core/api/providers.py`
Content:
```
1 """Provider API Views"""
2 from django.utils.translation import gettext_lazy as _
3 from django_filters.filters import BooleanFilter
4 from django_filters.filterset import FilterSet
5 from drf_spectacular.utils import extend_schema
6 from rest_framework import mixins
7 from rest_framework.decorators import action
8 from rest_framework.fields import ReadOnlyField
9 from rest_framework.request import Request
10 from rest_framework.response import Response
11 from rest_framework.serializers import ModelSerializer, SerializerMethodField
12 from rest_framework.viewsets import GenericViewSet
13
14 from authentik.core.api.used_by import UsedByMixin
15 from authentik.core.api.utils import MetaNameSerializer, TypeCreateSerializer
16 from authentik.core.models import Provider
17 from authentik.lib.utils.reflection import all_subclasses
18
19
20 class ProviderSerializer(ModelSerializer, MetaNameSerializer):
21 """Provider Serializer"""
22
23 assigned_application_slug = ReadOnlyField(source="application.slug")
24 assigned_application_name = ReadOnlyField(source="application.name")
25 assigned_backchannel_application_slug = ReadOnlyField(source="backchannel_application.slug")
26 assigned_backchannel_application_name = ReadOnlyField(source="backchannel_application.name")
27
28 component = SerializerMethodField()
29
30 def get_component(self, obj: Provider) -> str: # pragma: no cover
31 """Get object component so that we know how to edit the object"""
32 if obj.__class__ == Provider:
33 return ""
34 return obj.component
35
36 class Meta:
37 model = Provider
38 fields = [
39 "pk",
40 "name",
41 "authentication_flow",
42 "authorization_flow",
43 "property_mappings",
44 "component",
45 "assigned_application_slug",
46 "assigned_application_name",
47 "assigned_backchannel_application_slug",
48 "assigned_backchannel_application_name",
49 "verbose_name",
50 "verbose_name_plural",
51 "meta_model_name",
52 ]
53 extra_kwargs = {
54 "authorization_flow": {"required": True, "allow_null": False},
55 }
56
57
58 class ProviderFilter(FilterSet):
59 """Filter for groups"""
60
61 application__isnull = BooleanFilter(
62 field_name="application",
63 lookup_expr="isnull",
64 )
65 backchannel_only = BooleanFilter(
66 method="filter_backchannel_only",
67 )
68
69 def filter_backchannel_only(self, queryset, name, value):
70 """Only return backchannel providers"""
71 return queryset.filter(is_backchannel=value)
72
73
74 class ProviderViewSet(
75 mixins.RetrieveModelMixin,
76 mixins.DestroyModelMixin,
77 UsedByMixin,
78 mixins.ListModelMixin,
79 GenericViewSet,
80 ):
81 """Provider Viewset"""
82
83 queryset = Provider.objects.none()
84 serializer_class = ProviderSerializer
85 filterset_class = ProviderFilter
86 search_fields = [
87 "name",
88 "application__name",
89 ]
90
91 def get_queryset(self): # pragma: no cover
92 return Provider.objects.select_subclasses()
93
94 @extend_schema(responses={200: TypeCreateSerializer(many=True)})
95 @action(detail=False, pagination_class=None, filter_backends=[])
96 def types(self, request: Request) -> Response:
97 """Get all creatable provider types"""
98 data = []
99 for subclass in all_subclasses(self.queryset.model):
100 subclass: Provider
101 if subclass._meta.abstract:
102 continue
103 data.append(
104 {
105 "name": subclass._meta.verbose_name,
106 "description": subclass.__doc__,
107 "component": subclass().component,
108 "model_name": subclass._meta.model_name,
109 }
110 )
111 data.append(
112 {
113 "name": _("SAML Provider from Metadata"),
114 "description": _("Create a SAML Provider by importing its Metadata."),
115 "component": "ak-provider-saml-import-form",
116 "model_name": "",
117 }
118 )
119 return Response(TypeCreateSerializer(data, many=True).data)
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/authentik/core/api/providers.py b/authentik/core/api/providers.py
--- a/authentik/core/api/providers.py
+++ b/authentik/core/api/providers.py
@@ -1,4 +1,6 @@
"""Provider API Views"""
+from django.db.models import QuerySet
+from django.db.models.query import Q
from django.utils.translation import gettext_lazy as _
from django_filters.filters import BooleanFilter
from django_filters.filterset import FilterSet
@@ -56,17 +58,22 @@
class ProviderFilter(FilterSet):
- """Filter for groups"""
+ """Filter for providers"""
- application__isnull = BooleanFilter(
- field_name="application",
- lookup_expr="isnull",
- )
+ application__isnull = BooleanFilter(method="filter_application__isnull")
backchannel_only = BooleanFilter(
method="filter_backchannel_only",
)
- def filter_backchannel_only(self, queryset, name, value):
+ def filter_application__isnull(self, queryset: QuerySet, name, value):
+ """Only return providers that are neither assigned to application,
+ both as provider or application provider"""
+ return queryset.filter(
+ Q(backchannel_application__isnull=value, is_backchannel=True)
+ | Q(application__isnull=value)
+ )
+
+ def filter_backchannel_only(self, queryset: QuerySet, name, value):
"""Only return backchannel providers"""
return queryset.filter(is_backchannel=value)
diff --git a/authentik/providers/ldap/api.py b/authentik/providers/ldap/api.py
--- a/authentik/providers/ldap/api.py
+++ b/authentik/providers/ldap/api.py
@@ -1,4 +1,8 @@
"""LDAPProvider API Views"""
+from django.db.models import QuerySet
+from django.db.models.query import Q
+from django_filters.filters import BooleanFilter
+from django_filters.filterset import FilterSet
from rest_framework.fields import CharField, ListField, SerializerMethodField
from rest_framework.serializers import ModelSerializer
from rest_framework.viewsets import ModelViewSet, ReadOnlyModelViewSet
@@ -29,24 +33,41 @@
extra_kwargs = ProviderSerializer.Meta.extra_kwargs
+class LDAPProviderFilter(FilterSet):
+ """LDAP Provider filters"""
+
+ application__isnull = BooleanFilter(method="filter_application__isnull")
+
+ def filter_application__isnull(self, queryset: QuerySet, name, value):
+ """Only return providers that are neither assigned to application,
+ both as provider or application provider"""
+ return queryset.filter(
+ Q(backchannel_application__isnull=value) | Q(application__isnull=value)
+ )
+
+ class Meta:
+ model = LDAPProvider
+ fields = {
+ "application": ["isnull"],
+ "name": ["iexact"],
+ "authorization_flow__slug": ["iexact"],
+ "base_dn": ["iexact"],
+ "search_group__group_uuid": ["iexact"],
+ "search_group__name": ["iexact"],
+ "certificate__kp_uuid": ["iexact"],
+ "certificate__name": ["iexact"],
+ "tls_server_name": ["iexact"],
+ "uid_start_number": ["iexact"],
+ "gid_start_number": ["iexact"],
+ }
+
+
class LDAPProviderViewSet(UsedByMixin, ModelViewSet):
"""LDAPProvider Viewset"""
queryset = LDAPProvider.objects.all()
serializer_class = LDAPProviderSerializer
- filterset_fields = {
- "application": ["isnull"],
- "name": ["iexact"],
- "authorization_flow__slug": ["iexact"],
- "base_dn": ["iexact"],
- "search_group__group_uuid": ["iexact"],
- "search_group__name": ["iexact"],
- "certificate__kp_uuid": ["iexact"],
- "certificate__name": ["iexact"],
- "tls_server_name": ["iexact"],
- "uid_start_number": ["iexact"],
- "gid_start_number": ["iexact"],
- }
+ filterset_class = LDAPProviderFilter
search_fields = ["name"]
ordering = ["name"]
|
{"golden_diff": "diff --git a/authentik/core/api/providers.py b/authentik/core/api/providers.py\n--- a/authentik/core/api/providers.py\n+++ b/authentik/core/api/providers.py\n@@ -1,4 +1,6 @@\n \"\"\"Provider API Views\"\"\"\n+from django.db.models import QuerySet\n+from django.db.models.query import Q\n from django.utils.translation import gettext_lazy as _\n from django_filters.filters import BooleanFilter\n from django_filters.filterset import FilterSet\n@@ -56,17 +58,22 @@\n \n \n class ProviderFilter(FilterSet):\n- \"\"\"Filter for groups\"\"\"\n+ \"\"\"Filter for providers\"\"\"\n \n- application__isnull = BooleanFilter(\n- field_name=\"application\",\n- lookup_expr=\"isnull\",\n- )\n+ application__isnull = BooleanFilter(method=\"filter_application__isnull\")\n backchannel_only = BooleanFilter(\n method=\"filter_backchannel_only\",\n )\n \n- def filter_backchannel_only(self, queryset, name, value):\n+ def filter_application__isnull(self, queryset: QuerySet, name, value):\n+ \"\"\"Only return providers that are neither assigned to application,\n+ both as provider or application provider\"\"\"\n+ return queryset.filter(\n+ Q(backchannel_application__isnull=value, is_backchannel=True)\n+ | Q(application__isnull=value)\n+ )\n+\n+ def filter_backchannel_only(self, queryset: QuerySet, name, value):\n \"\"\"Only return backchannel providers\"\"\"\n return queryset.filter(is_backchannel=value)\n \ndiff --git a/authentik/providers/ldap/api.py b/authentik/providers/ldap/api.py\n--- a/authentik/providers/ldap/api.py\n+++ b/authentik/providers/ldap/api.py\n@@ -1,4 +1,8 @@\n \"\"\"LDAPProvider API Views\"\"\"\n+from django.db.models import QuerySet\n+from django.db.models.query import Q\n+from django_filters.filters import BooleanFilter\n+from django_filters.filterset import FilterSet\n from rest_framework.fields import CharField, ListField, SerializerMethodField\n from rest_framework.serializers import ModelSerializer\n from rest_framework.viewsets import ModelViewSet, ReadOnlyModelViewSet\n@@ -29,24 +33,41 @@\n extra_kwargs = ProviderSerializer.Meta.extra_kwargs\n \n \n+class LDAPProviderFilter(FilterSet):\n+ \"\"\"LDAP Provider filters\"\"\"\n+\n+ application__isnull = BooleanFilter(method=\"filter_application__isnull\")\n+\n+ def filter_application__isnull(self, queryset: QuerySet, name, value):\n+ \"\"\"Only return providers that are neither assigned to application,\n+ both as provider or application provider\"\"\"\n+ return queryset.filter(\n+ Q(backchannel_application__isnull=value) | Q(application__isnull=value)\n+ )\n+\n+ class Meta:\n+ model = LDAPProvider\n+ fields = {\n+ \"application\": [\"isnull\"],\n+ \"name\": [\"iexact\"],\n+ \"authorization_flow__slug\": [\"iexact\"],\n+ \"base_dn\": [\"iexact\"],\n+ \"search_group__group_uuid\": [\"iexact\"],\n+ \"search_group__name\": [\"iexact\"],\n+ \"certificate__kp_uuid\": [\"iexact\"],\n+ \"certificate__name\": [\"iexact\"],\n+ \"tls_server_name\": [\"iexact\"],\n+ \"uid_start_number\": [\"iexact\"],\n+ \"gid_start_number\": [\"iexact\"],\n+ }\n+\n+\n class LDAPProviderViewSet(UsedByMixin, ModelViewSet):\n \"\"\"LDAPProvider Viewset\"\"\"\n \n queryset = LDAPProvider.objects.all()\n serializer_class = LDAPProviderSerializer\n- filterset_fields = {\n- \"application\": [\"isnull\"],\n- \"name\": [\"iexact\"],\n- \"authorization_flow__slug\": [\"iexact\"],\n- \"base_dn\": [\"iexact\"],\n- \"search_group__group_uuid\": [\"iexact\"],\n- \"search_group__name\": [\"iexact\"],\n- \"certificate__kp_uuid\": [\"iexact\"],\n- \"certificate__name\": [\"iexact\"],\n- \"tls_server_name\": [\"iexact\"],\n- \"uid_start_number\": [\"iexact\"],\n- \"gid_start_number\": [\"iexact\"],\n- }\n+ filterset_class = LDAPProviderFilter\n search_fields = [\"name\"]\n ordering = [\"name\"]\n", "issue": "Backchannel LDAP providers missing from outpost configuration page\n**Description**\r\nWhen creating an LDAP Provider, it will appear in the Outpost create/configuration page if it is assigned an application, but not if it's assigned as an application backchannel.\r\n\r\nThis means we're unable to associate an LDAP backchannel to an outpost.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n1. Create a demo Application and an LDAP Provider\r\n2. Assign the LDAP Provider as a _backchannel provider_ to the application.\r\n3. Attempt to create an LDAP outpost. Notice the LDAP provider does not appear on the selectable list.\r\n\r\n**Expected behavior**\r\nThe backchannel should appear the outposts \"applications\" list, so that it may be added to the outpost.\r\n\r\n**Version and Deployment (please complete the following information):**\r\n- authentik version: 2023.5.2\r\n- Deployment: docker-compose\r\n\n", "before_files": [{"content": "\"\"\"LDAPProvider API Views\"\"\"\nfrom rest_framework.fields import CharField, ListField, SerializerMethodField\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import ModelViewSet, ReadOnlyModelViewSet\n\nfrom authentik.core.api.providers import ProviderSerializer\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.providers.ldap.models import LDAPProvider\n\n\nclass LDAPProviderSerializer(ProviderSerializer):\n \"\"\"LDAPProvider Serializer\"\"\"\n\n outpost_set = ListField(child=CharField(), read_only=True, source=\"outpost_set.all\")\n\n class Meta:\n model = LDAPProvider\n fields = ProviderSerializer.Meta.fields + [\n \"base_dn\",\n \"search_group\",\n \"certificate\",\n \"tls_server_name\",\n \"uid_start_number\",\n \"gid_start_number\",\n \"outpost_set\",\n \"search_mode\",\n \"bind_mode\",\n ]\n extra_kwargs = ProviderSerializer.Meta.extra_kwargs\n\n\nclass LDAPProviderViewSet(UsedByMixin, ModelViewSet):\n \"\"\"LDAPProvider Viewset\"\"\"\n\n queryset = LDAPProvider.objects.all()\n serializer_class = LDAPProviderSerializer\n filterset_fields = {\n \"application\": [\"isnull\"],\n \"name\": [\"iexact\"],\n \"authorization_flow__slug\": [\"iexact\"],\n \"base_dn\": [\"iexact\"],\n \"search_group__group_uuid\": [\"iexact\"],\n \"search_group__name\": [\"iexact\"],\n \"certificate__kp_uuid\": [\"iexact\"],\n \"certificate__name\": [\"iexact\"],\n \"tls_server_name\": [\"iexact\"],\n \"uid_start_number\": [\"iexact\"],\n \"gid_start_number\": [\"iexact\"],\n }\n search_fields = [\"name\"]\n ordering = [\"name\"]\n\n\nclass LDAPOutpostConfigSerializer(ModelSerializer):\n \"\"\"LDAPProvider Serializer\"\"\"\n\n application_slug = SerializerMethodField()\n bind_flow_slug = CharField(source=\"authorization_flow.slug\")\n\n def get_application_slug(self, instance: LDAPProvider) -> str:\n \"\"\"Prioritise backchannel slug over direct application slug\"\"\"\n if instance.backchannel_application:\n return instance.backchannel_application.slug\n return instance.application.slug\n\n class Meta:\n model = LDAPProvider\n fields = [\n \"pk\",\n \"name\",\n \"base_dn\",\n \"bind_flow_slug\",\n \"application_slug\",\n \"search_group\",\n \"certificate\",\n \"tls_server_name\",\n \"uid_start_number\",\n \"gid_start_number\",\n \"search_mode\",\n \"bind_mode\",\n ]\n\n\nclass LDAPOutpostConfigViewSet(ReadOnlyModelViewSet):\n \"\"\"LDAPProvider Viewset\"\"\"\n\n queryset = LDAPProvider.objects.filter(application__isnull=False)\n serializer_class = LDAPOutpostConfigSerializer\n ordering = [\"name\"]\n search_fields = [\"name\"]\n filterset_fields = [\"name\"]\n", "path": "authentik/providers/ldap/api.py"}, {"content": "\"\"\"Provider API Views\"\"\"\nfrom django.utils.translation import gettext_lazy as _\nfrom django_filters.filters import BooleanFilter\nfrom django_filters.filterset import FilterSet\nfrom drf_spectacular.utils import extend_schema\nfrom rest_framework import mixins\nfrom rest_framework.decorators import action\nfrom rest_framework.fields import ReadOnlyField\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import ModelSerializer, SerializerMethodField\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.core.api.utils import MetaNameSerializer, TypeCreateSerializer\nfrom authentik.core.models import Provider\nfrom authentik.lib.utils.reflection import all_subclasses\n\n\nclass ProviderSerializer(ModelSerializer, MetaNameSerializer):\n \"\"\"Provider Serializer\"\"\"\n\n assigned_application_slug = ReadOnlyField(source=\"application.slug\")\n assigned_application_name = ReadOnlyField(source=\"application.name\")\n assigned_backchannel_application_slug = ReadOnlyField(source=\"backchannel_application.slug\")\n assigned_backchannel_application_name = ReadOnlyField(source=\"backchannel_application.name\")\n\n component = SerializerMethodField()\n\n def get_component(self, obj: Provider) -> str: # pragma: no cover\n \"\"\"Get object component so that we know how to edit the object\"\"\"\n if obj.__class__ == Provider:\n return \"\"\n return obj.component\n\n class Meta:\n model = Provider\n fields = [\n \"pk\",\n \"name\",\n \"authentication_flow\",\n \"authorization_flow\",\n \"property_mappings\",\n \"component\",\n \"assigned_application_slug\",\n \"assigned_application_name\",\n \"assigned_backchannel_application_slug\",\n \"assigned_backchannel_application_name\",\n \"verbose_name\",\n \"verbose_name_plural\",\n \"meta_model_name\",\n ]\n extra_kwargs = {\n \"authorization_flow\": {\"required\": True, \"allow_null\": False},\n }\n\n\nclass ProviderFilter(FilterSet):\n \"\"\"Filter for groups\"\"\"\n\n application__isnull = BooleanFilter(\n field_name=\"application\",\n lookup_expr=\"isnull\",\n )\n backchannel_only = BooleanFilter(\n method=\"filter_backchannel_only\",\n )\n\n def filter_backchannel_only(self, queryset, name, value):\n \"\"\"Only return backchannel providers\"\"\"\n return queryset.filter(is_backchannel=value)\n\n\nclass ProviderViewSet(\n mixins.RetrieveModelMixin,\n mixins.DestroyModelMixin,\n UsedByMixin,\n mixins.ListModelMixin,\n GenericViewSet,\n):\n \"\"\"Provider Viewset\"\"\"\n\n queryset = Provider.objects.none()\n serializer_class = ProviderSerializer\n filterset_class = ProviderFilter\n search_fields = [\n \"name\",\n \"application__name\",\n ]\n\n def get_queryset(self): # pragma: no cover\n return Provider.objects.select_subclasses()\n\n @extend_schema(responses={200: TypeCreateSerializer(many=True)})\n @action(detail=False, pagination_class=None, filter_backends=[])\n def types(self, request: Request) -> Response:\n \"\"\"Get all creatable provider types\"\"\"\n data = []\n for subclass in all_subclasses(self.queryset.model):\n subclass: Provider\n if subclass._meta.abstract:\n continue\n data.append(\n {\n \"name\": subclass._meta.verbose_name,\n \"description\": subclass.__doc__,\n \"component\": subclass().component,\n \"model_name\": subclass._meta.model_name,\n }\n )\n data.append(\n {\n \"name\": _(\"SAML Provider from Metadata\"),\n \"description\": _(\"Create a SAML Provider by importing its Metadata.\"),\n \"component\": \"ak-provider-saml-import-form\",\n \"model_name\": \"\",\n }\n )\n return Response(TypeCreateSerializer(data, many=True).data)\n", "path": "authentik/core/api/providers.py"}], "after_files": [{"content": "\"\"\"LDAPProvider API Views\"\"\"\nfrom django.db.models import QuerySet\nfrom django.db.models.query import Q\nfrom django_filters.filters import BooleanFilter\nfrom django_filters.filterset import FilterSet\nfrom rest_framework.fields import CharField, ListField, SerializerMethodField\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import ModelViewSet, ReadOnlyModelViewSet\n\nfrom authentik.core.api.providers import ProviderSerializer\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.providers.ldap.models import LDAPProvider\n\n\nclass LDAPProviderSerializer(ProviderSerializer):\n \"\"\"LDAPProvider Serializer\"\"\"\n\n outpost_set = ListField(child=CharField(), read_only=True, source=\"outpost_set.all\")\n\n class Meta:\n model = LDAPProvider\n fields = ProviderSerializer.Meta.fields + [\n \"base_dn\",\n \"search_group\",\n \"certificate\",\n \"tls_server_name\",\n \"uid_start_number\",\n \"gid_start_number\",\n \"outpost_set\",\n \"search_mode\",\n \"bind_mode\",\n ]\n extra_kwargs = ProviderSerializer.Meta.extra_kwargs\n\n\nclass LDAPProviderFilter(FilterSet):\n \"\"\"LDAP Provider filters\"\"\"\n\n application__isnull = BooleanFilter(method=\"filter_application__isnull\")\n\n def filter_application__isnull(self, queryset: QuerySet, name, value):\n \"\"\"Only return providers that are neither assigned to application,\n both as provider or application provider\"\"\"\n return queryset.filter(\n Q(backchannel_application__isnull=value) | Q(application__isnull=value)\n )\n\n class Meta:\n model = LDAPProvider\n fields = {\n \"application\": [\"isnull\"],\n \"name\": [\"iexact\"],\n \"authorization_flow__slug\": [\"iexact\"],\n \"base_dn\": [\"iexact\"],\n \"search_group__group_uuid\": [\"iexact\"],\n \"search_group__name\": [\"iexact\"],\n \"certificate__kp_uuid\": [\"iexact\"],\n \"certificate__name\": [\"iexact\"],\n \"tls_server_name\": [\"iexact\"],\n \"uid_start_number\": [\"iexact\"],\n \"gid_start_number\": [\"iexact\"],\n }\n\n\nclass LDAPProviderViewSet(UsedByMixin, ModelViewSet):\n \"\"\"LDAPProvider Viewset\"\"\"\n\n queryset = LDAPProvider.objects.all()\n serializer_class = LDAPProviderSerializer\n filterset_class = LDAPProviderFilter\n search_fields = [\"name\"]\n ordering = [\"name\"]\n\n\nclass LDAPOutpostConfigSerializer(ModelSerializer):\n \"\"\"LDAPProvider Serializer\"\"\"\n\n application_slug = SerializerMethodField()\n bind_flow_slug = CharField(source=\"authorization_flow.slug\")\n\n def get_application_slug(self, instance: LDAPProvider) -> str:\n \"\"\"Prioritise backchannel slug over direct application slug\"\"\"\n if instance.backchannel_application:\n return instance.backchannel_application.slug\n return instance.application.slug\n\n class Meta:\n model = LDAPProvider\n fields = [\n \"pk\",\n \"name\",\n \"base_dn\",\n \"bind_flow_slug\",\n \"application_slug\",\n \"search_group\",\n \"certificate\",\n \"tls_server_name\",\n \"uid_start_number\",\n \"gid_start_number\",\n \"search_mode\",\n \"bind_mode\",\n ]\n\n\nclass LDAPOutpostConfigViewSet(ReadOnlyModelViewSet):\n \"\"\"LDAPProvider Viewset\"\"\"\n\n queryset = LDAPProvider.objects.filter(application__isnull=False)\n serializer_class = LDAPOutpostConfigSerializer\n ordering = [\"name\"]\n search_fields = [\"name\"]\n filterset_fields = [\"name\"]\n", "path": "authentik/providers/ldap/api.py"}, {"content": "\"\"\"Provider API Views\"\"\"\nfrom django.db.models import QuerySet\nfrom django.db.models.query import Q\nfrom django.utils.translation import gettext_lazy as _\nfrom django_filters.filters import BooleanFilter\nfrom django_filters.filterset import FilterSet\nfrom drf_spectacular.utils import extend_schema\nfrom rest_framework import mixins\nfrom rest_framework.decorators import action\nfrom rest_framework.fields import ReadOnlyField\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import ModelSerializer, SerializerMethodField\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.core.api.utils import MetaNameSerializer, TypeCreateSerializer\nfrom authentik.core.models import Provider\nfrom authentik.lib.utils.reflection import all_subclasses\n\n\nclass ProviderSerializer(ModelSerializer, MetaNameSerializer):\n \"\"\"Provider Serializer\"\"\"\n\n assigned_application_slug = ReadOnlyField(source=\"application.slug\")\n assigned_application_name = ReadOnlyField(source=\"application.name\")\n assigned_backchannel_application_slug = ReadOnlyField(source=\"backchannel_application.slug\")\n assigned_backchannel_application_name = ReadOnlyField(source=\"backchannel_application.name\")\n\n component = SerializerMethodField()\n\n def get_component(self, obj: Provider) -> str: # pragma: no cover\n \"\"\"Get object component so that we know how to edit the object\"\"\"\n if obj.__class__ == Provider:\n return \"\"\n return obj.component\n\n class Meta:\n model = Provider\n fields = [\n \"pk\",\n \"name\",\n \"authentication_flow\",\n \"authorization_flow\",\n \"property_mappings\",\n \"component\",\n \"assigned_application_slug\",\n \"assigned_application_name\",\n \"assigned_backchannel_application_slug\",\n \"assigned_backchannel_application_name\",\n \"verbose_name\",\n \"verbose_name_plural\",\n \"meta_model_name\",\n ]\n extra_kwargs = {\n \"authorization_flow\": {\"required\": True, \"allow_null\": False},\n }\n\n\nclass ProviderFilter(FilterSet):\n \"\"\"Filter for providers\"\"\"\n\n application__isnull = BooleanFilter(method=\"filter_application__isnull\")\n backchannel_only = BooleanFilter(\n method=\"filter_backchannel_only\",\n )\n\n def filter_application__isnull(self, queryset: QuerySet, name, value):\n \"\"\"Only return providers that are neither assigned to application,\n both as provider or application provider\"\"\"\n return queryset.filter(\n Q(backchannel_application__isnull=value, is_backchannel=True)\n | Q(application__isnull=value)\n )\n\n def filter_backchannel_only(self, queryset: QuerySet, name, value):\n \"\"\"Only return backchannel providers\"\"\"\n return queryset.filter(is_backchannel=value)\n\n\nclass ProviderViewSet(\n mixins.RetrieveModelMixin,\n mixins.DestroyModelMixin,\n UsedByMixin,\n mixins.ListModelMixin,\n GenericViewSet,\n):\n \"\"\"Provider Viewset\"\"\"\n\n queryset = Provider.objects.none()\n serializer_class = ProviderSerializer\n filterset_class = ProviderFilter\n search_fields = [\n \"name\",\n \"application__name\",\n ]\n\n def get_queryset(self): # pragma: no cover\n return Provider.objects.select_subclasses()\n\n @extend_schema(responses={200: TypeCreateSerializer(many=True)})\n @action(detail=False, pagination_class=None, filter_backends=[])\n def types(self, request: Request) -> Response:\n \"\"\"Get all creatable provider types\"\"\"\n data = []\n for subclass in all_subclasses(self.queryset.model):\n subclass: Provider\n if subclass._meta.abstract:\n continue\n data.append(\n {\n \"name\": subclass._meta.verbose_name,\n \"description\": subclass.__doc__,\n \"component\": subclass().component,\n \"model_name\": subclass._meta.model_name,\n }\n )\n data.append(\n {\n \"name\": _(\"SAML Provider from Metadata\"),\n \"description\": _(\"Create a SAML Provider by importing its Metadata.\"),\n \"component\": \"ak-provider-saml-import-form\",\n \"model_name\": \"\",\n }\n )\n return Response(TypeCreateSerializer(data, many=True).data)\n", "path": "authentik/core/api/providers.py"}]}
| 2,289 | 923 |
gh_patches_debug_18903
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1682
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check resource error in container network API
```
docker python client v2.4.2
python v2.7.12
docker v17.03.1-ce
Ubuntu 16.04
```
PR #1649 updated the `check_resource` decorator to handle different resource names. Container network API functions `connect_container_to_network()` and `disconnect_container_from_network()` check 'image' as resource ID and not 'container'.
Reproduce using the following snippet:
```python
import docker
cli = docker.APIClient(base_url='unix:///var/run/docker.sock')
cli.pull(repository='ubuntu', tag='latest')
name = 'my_ubuntu'
container = cli.create_container(image='ubuntu:latest', name=name)
cli.connect_container_to_network(container=name, net_id='bridge')
```
This causes:
```
Traceback (most recent call last):
File "test.py", line 8, in <module>
cli.connect_container_to_network(container=name, net_id='bridge')
File "/home/mberry/scratch/virtualenv/docker_py/local/lib/python2.7/site-packages/docker/utils/decorators.py", line 17, in wrapped
'Resource ID was not provided'
docker.errors.NullResource: Resource ID was not provided
```
Check resource error in container network API
```
docker python client v2.4.2
python v2.7.12
docker v17.03.1-ce
Ubuntu 16.04
```
PR #1649 updated the `check_resource` decorator to handle different resource names. Container network API functions `connect_container_to_network()` and `disconnect_container_from_network()` check 'image' as resource ID and not 'container'.
Reproduce using the following snippet:
```python
import docker
cli = docker.APIClient(base_url='unix:///var/run/docker.sock')
cli.pull(repository='ubuntu', tag='latest')
name = 'my_ubuntu'
container = cli.create_container(image='ubuntu:latest', name=name)
cli.connect_container_to_network(container=name, net_id='bridge')
```
This causes:
```
Traceback (most recent call last):
File "test.py", line 8, in <module>
cli.connect_container_to_network(container=name, net_id='bridge')
File "/home/mberry/scratch/virtualenv/docker_py/local/lib/python2.7/site-packages/docker/utils/decorators.py", line 17, in wrapped
'Resource ID was not provided'
docker.errors.NullResource: Resource ID was not provided
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/api/network.py`
Content:
```
1 from ..errors import InvalidVersion
2 from ..utils import check_resource, minimum_version
3 from ..utils import version_lt
4 from .. import utils
5
6
7 class NetworkApiMixin(object):
8 @minimum_version('1.21')
9 def networks(self, names=None, ids=None, filters=None):
10 """
11 List networks. Similar to the ``docker networks ls`` command.
12
13 Args:
14 names (:py:class:`list`): List of names to filter by
15 ids (:py:class:`list`): List of ids to filter by
16 filters (dict): Filters to be processed on the network list.
17 Available filters:
18 - ``driver=[<driver-name>]`` Matches a network's driver.
19 - ``label=[<key>]`` or ``label=[<key>=<value>]``.
20 - ``type=["custom"|"builtin"]`` Filters networks by type.
21
22 Returns:
23 (dict): List of network objects.
24
25 Raises:
26 :py:class:`docker.errors.APIError`
27 If the server returns an error.
28 """
29
30 if filters is None:
31 filters = {}
32 if names:
33 filters['name'] = names
34 if ids:
35 filters['id'] = ids
36 params = {'filters': utils.convert_filters(filters)}
37 url = self._url("/networks")
38 res = self._get(url, params=params)
39 return self._result(res, json=True)
40
41 @minimum_version('1.21')
42 def create_network(self, name, driver=None, options=None, ipam=None,
43 check_duplicate=None, internal=False, labels=None,
44 enable_ipv6=False, attachable=None, scope=None,
45 ingress=None):
46 """
47 Create a network. Similar to the ``docker network create``.
48
49 Args:
50 name (str): Name of the network
51 driver (str): Name of the driver used to create the network
52 options (dict): Driver options as a key-value dictionary
53 ipam (IPAMConfig): Optional custom IP scheme for the network.
54 check_duplicate (bool): Request daemon to check for networks with
55 same name. Default: ``True``.
56 internal (bool): Restrict external access to the network. Default
57 ``False``.
58 labels (dict): Map of labels to set on the network. Default
59 ``None``.
60 enable_ipv6 (bool): Enable IPv6 on the network. Default ``False``.
61 attachable (bool): If enabled, and the network is in the global
62 scope, non-service containers on worker nodes will be able to
63 connect to the network.
64 ingress (bool): If set, create an ingress network which provides
65 the routing-mesh in swarm mode.
66
67 Returns:
68 (dict): The created network reference object
69
70 Raises:
71 :py:class:`docker.errors.APIError`
72 If the server returns an error.
73
74 Example:
75 A network using the bridge driver:
76
77 >>> client.create_network("network1", driver="bridge")
78
79 You can also create more advanced networks with custom IPAM
80 configurations. For example, setting the subnet to
81 ``192.168.52.0/24`` and gateway address to ``192.168.52.254``.
82
83 .. code-block:: python
84
85 >>> ipam_pool = docker.types.IPAMPool(
86 subnet='192.168.52.0/24',
87 gateway='192.168.52.254'
88 )
89 >>> ipam_config = docker.types.IPAMConfig(
90 pool_configs=[ipam_pool]
91 )
92 >>> docker_client.create_network("network1", driver="bridge",
93 ipam=ipam_config)
94 """
95 if options is not None and not isinstance(options, dict):
96 raise TypeError('options must be a dictionary')
97
98 data = {
99 'Name': name,
100 'Driver': driver,
101 'Options': options,
102 'IPAM': ipam,
103 'CheckDuplicate': check_duplicate,
104 }
105
106 if labels is not None:
107 if version_lt(self._version, '1.23'):
108 raise InvalidVersion(
109 'network labels were introduced in API 1.23'
110 )
111 if not isinstance(labels, dict):
112 raise TypeError('labels must be a dictionary')
113 data["Labels"] = labels
114
115 if enable_ipv6:
116 if version_lt(self._version, '1.23'):
117 raise InvalidVersion(
118 'enable_ipv6 was introduced in API 1.23'
119 )
120 data['EnableIPv6'] = True
121
122 if internal:
123 if version_lt(self._version, '1.22'):
124 raise InvalidVersion('Internal networks are not '
125 'supported in API version < 1.22')
126 data['Internal'] = True
127
128 if attachable is not None:
129 if version_lt(self._version, '1.24'):
130 raise InvalidVersion(
131 'attachable is not supported in API version < 1.24'
132 )
133 data['Attachable'] = attachable
134
135 if ingress is not None:
136 if version_lt(self._version, '1.29'):
137 raise InvalidVersion(
138 'ingress is not supported in API version < 1.29'
139 )
140
141 data['Ingress'] = ingress
142
143 url = self._url("/networks/create")
144 res = self._post_json(url, data=data)
145 return self._result(res, json=True)
146
147 @minimum_version('1.25')
148 def prune_networks(self, filters=None):
149 """
150 Delete unused networks
151
152 Args:
153 filters (dict): Filters to process on the prune list.
154
155 Returns:
156 (dict): A dict containing a list of deleted network names and
157 the amount of disk space reclaimed in bytes.
158
159 Raises:
160 :py:class:`docker.errors.APIError`
161 If the server returns an error.
162 """
163 params = {}
164 if filters:
165 params['filters'] = utils.convert_filters(filters)
166 url = self._url('/networks/prune')
167 return self._result(self._post(url, params=params), True)
168
169 @minimum_version('1.21')
170 @check_resource('net_id')
171 def remove_network(self, net_id):
172 """
173 Remove a network. Similar to the ``docker network rm`` command.
174
175 Args:
176 net_id (str): The network's id
177 """
178 url = self._url("/networks/{0}", net_id)
179 res = self._delete(url)
180 self._raise_for_status(res)
181
182 @minimum_version('1.21')
183 @check_resource('net_id')
184 def inspect_network(self, net_id, verbose=None):
185 """
186 Get detailed information about a network.
187
188 Args:
189 net_id (str): ID of network
190 verbose (bool): Show the service details across the cluster in
191 swarm mode.
192 """
193 params = {}
194 if verbose is not None:
195 if version_lt(self._version, '1.28'):
196 raise InvalidVersion('verbose was introduced in API 1.28')
197 params['verbose'] = verbose
198
199 url = self._url("/networks/{0}", net_id)
200 res = self._get(url, params=params)
201 return self._result(res, json=True)
202
203 @check_resource('image')
204 @minimum_version('1.21')
205 def connect_container_to_network(self, container, net_id,
206 ipv4_address=None, ipv6_address=None,
207 aliases=None, links=None,
208 link_local_ips=None):
209 """
210 Connect a container to a network.
211
212 Args:
213 container (str): container-id/name to be connected to the network
214 net_id (str): network id
215 aliases (:py:class:`list`): A list of aliases for this endpoint.
216 Names in that list can be used within the network to reach the
217 container. Defaults to ``None``.
218 links (:py:class:`list`): A list of links for this endpoint.
219 Containers declared in this list will be linked to this
220 container. Defaults to ``None``.
221 ipv4_address (str): The IP address of this container on the
222 network, using the IPv4 protocol. Defaults to ``None``.
223 ipv6_address (str): The IP address of this container on the
224 network, using the IPv6 protocol. Defaults to ``None``.
225 link_local_ips (:py:class:`list`): A list of link-local
226 (IPv4/IPv6) addresses.
227 """
228 data = {
229 "Container": container,
230 "EndpointConfig": self.create_endpoint_config(
231 aliases=aliases, links=links, ipv4_address=ipv4_address,
232 ipv6_address=ipv6_address, link_local_ips=link_local_ips
233 ),
234 }
235
236 url = self._url("/networks/{0}/connect", net_id)
237 res = self._post_json(url, data=data)
238 self._raise_for_status(res)
239
240 @check_resource('image')
241 @minimum_version('1.21')
242 def disconnect_container_from_network(self, container, net_id,
243 force=False):
244 """
245 Disconnect a container from a network.
246
247 Args:
248 container (str): container ID or name to be disconnected from the
249 network
250 net_id (str): network ID
251 force (bool): Force the container to disconnect from a network.
252 Default: ``False``
253 """
254 data = {"Container": container}
255 if force:
256 if version_lt(self._version, '1.22'):
257 raise InvalidVersion(
258 'Forced disconnect was introduced in API 1.22'
259 )
260 data['Force'] = force
261 url = self._url("/networks/{0}/disconnect", net_id)
262 res = self._post_json(url, data=data)
263 self._raise_for_status(res)
264
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/api/network.py b/docker/api/network.py
--- a/docker/api/network.py
+++ b/docker/api/network.py
@@ -200,7 +200,7 @@
res = self._get(url, params=params)
return self._result(res, json=True)
- @check_resource('image')
+ @check_resource('container')
@minimum_version('1.21')
def connect_container_to_network(self, container, net_id,
ipv4_address=None, ipv6_address=None,
@@ -237,7 +237,7 @@
res = self._post_json(url, data=data)
self._raise_for_status(res)
- @check_resource('image')
+ @check_resource('container')
@minimum_version('1.21')
def disconnect_container_from_network(self, container, net_id,
force=False):
|
{"golden_diff": "diff --git a/docker/api/network.py b/docker/api/network.py\n--- a/docker/api/network.py\n+++ b/docker/api/network.py\n@@ -200,7 +200,7 @@\n res = self._get(url, params=params)\n return self._result(res, json=True)\n \n- @check_resource('image')\n+ @check_resource('container')\n @minimum_version('1.21')\n def connect_container_to_network(self, container, net_id,\n ipv4_address=None, ipv6_address=None,\n@@ -237,7 +237,7 @@\n res = self._post_json(url, data=data)\n self._raise_for_status(res)\n \n- @check_resource('image')\n+ @check_resource('container')\n @minimum_version('1.21')\n def disconnect_container_from_network(self, container, net_id,\n force=False):\n", "issue": "Check resource error in container network API\n```\r\ndocker python client v2.4.2\r\npython v2.7.12\r\ndocker v17.03.1-ce\r\nUbuntu 16.04\r\n```\r\n\r\nPR #1649 updated the `check_resource` decorator to handle different resource names. Container network API functions `connect_container_to_network()` and `disconnect_container_from_network()` check 'image' as resource ID and not 'container'.\r\n\r\nReproduce using the following snippet:\r\n```python\r\nimport docker\r\n\r\ncli = docker.APIClient(base_url='unix:///var/run/docker.sock')\r\ncli.pull(repository='ubuntu', tag='latest')\r\n\r\nname = 'my_ubuntu'\r\ncontainer = cli.create_container(image='ubuntu:latest', name=name)\r\ncli.connect_container_to_network(container=name, net_id='bridge')\r\n```\r\n\r\nThis causes:\r\n```\r\nTraceback (most recent call last):\r\n File \"test.py\", line 8, in <module>\r\n cli.connect_container_to_network(container=name, net_id='bridge')\r\n File \"/home/mberry/scratch/virtualenv/docker_py/local/lib/python2.7/site-packages/docker/utils/decorators.py\", line 17, in wrapped\r\n 'Resource ID was not provided'\r\ndocker.errors.NullResource: Resource ID was not provided\r\n```\nCheck resource error in container network API\n```\r\ndocker python client v2.4.2\r\npython v2.7.12\r\ndocker v17.03.1-ce\r\nUbuntu 16.04\r\n```\r\n\r\nPR #1649 updated the `check_resource` decorator to handle different resource names. Container network API functions `connect_container_to_network()` and `disconnect_container_from_network()` check 'image' as resource ID and not 'container'.\r\n\r\nReproduce using the following snippet:\r\n```python\r\nimport docker\r\n\r\ncli = docker.APIClient(base_url='unix:///var/run/docker.sock')\r\ncli.pull(repository='ubuntu', tag='latest')\r\n\r\nname = 'my_ubuntu'\r\ncontainer = cli.create_container(image='ubuntu:latest', name=name)\r\ncli.connect_container_to_network(container=name, net_id='bridge')\r\n```\r\n\r\nThis causes:\r\n```\r\nTraceback (most recent call last):\r\n File \"test.py\", line 8, in <module>\r\n cli.connect_container_to_network(container=name, net_id='bridge')\r\n File \"/home/mberry/scratch/virtualenv/docker_py/local/lib/python2.7/site-packages/docker/utils/decorators.py\", line 17, in wrapped\r\n 'Resource ID was not provided'\r\ndocker.errors.NullResource: Resource ID was not provided\r\n```\n", "before_files": [{"content": "from ..errors import InvalidVersion\nfrom ..utils import check_resource, minimum_version\nfrom ..utils import version_lt\nfrom .. import utils\n\n\nclass NetworkApiMixin(object):\n @minimum_version('1.21')\n def networks(self, names=None, ids=None, filters=None):\n \"\"\"\n List networks. Similar to the ``docker networks ls`` command.\n\n Args:\n names (:py:class:`list`): List of names to filter by\n ids (:py:class:`list`): List of ids to filter by\n filters (dict): Filters to be processed on the network list.\n Available filters:\n - ``driver=[<driver-name>]`` Matches a network's driver.\n - ``label=[<key>]`` or ``label=[<key>=<value>]``.\n - ``type=[\"custom\"|\"builtin\"]`` Filters networks by type.\n\n Returns:\n (dict): List of network objects.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n\n if filters is None:\n filters = {}\n if names:\n filters['name'] = names\n if ids:\n filters['id'] = ids\n params = {'filters': utils.convert_filters(filters)}\n url = self._url(\"/networks\")\n res = self._get(url, params=params)\n return self._result(res, json=True)\n\n @minimum_version('1.21')\n def create_network(self, name, driver=None, options=None, ipam=None,\n check_duplicate=None, internal=False, labels=None,\n enable_ipv6=False, attachable=None, scope=None,\n ingress=None):\n \"\"\"\n Create a network. Similar to the ``docker network create``.\n\n Args:\n name (str): Name of the network\n driver (str): Name of the driver used to create the network\n options (dict): Driver options as a key-value dictionary\n ipam (IPAMConfig): Optional custom IP scheme for the network.\n check_duplicate (bool): Request daemon to check for networks with\n same name. Default: ``True``.\n internal (bool): Restrict external access to the network. Default\n ``False``.\n labels (dict): Map of labels to set on the network. Default\n ``None``.\n enable_ipv6 (bool): Enable IPv6 on the network. Default ``False``.\n attachable (bool): If enabled, and the network is in the global\n scope, non-service containers on worker nodes will be able to\n connect to the network.\n ingress (bool): If set, create an ingress network which provides\n the routing-mesh in swarm mode.\n\n Returns:\n (dict): The created network reference object\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Example:\n A network using the bridge driver:\n\n >>> client.create_network(\"network1\", driver=\"bridge\")\n\n You can also create more advanced networks with custom IPAM\n configurations. For example, setting the subnet to\n ``192.168.52.0/24`` and gateway address to ``192.168.52.254``.\n\n .. code-block:: python\n\n >>> ipam_pool = docker.types.IPAMPool(\n subnet='192.168.52.0/24',\n gateway='192.168.52.254'\n )\n >>> ipam_config = docker.types.IPAMConfig(\n pool_configs=[ipam_pool]\n )\n >>> docker_client.create_network(\"network1\", driver=\"bridge\",\n ipam=ipam_config)\n \"\"\"\n if options is not None and not isinstance(options, dict):\n raise TypeError('options must be a dictionary')\n\n data = {\n 'Name': name,\n 'Driver': driver,\n 'Options': options,\n 'IPAM': ipam,\n 'CheckDuplicate': check_duplicate,\n }\n\n if labels is not None:\n if version_lt(self._version, '1.23'):\n raise InvalidVersion(\n 'network labels were introduced in API 1.23'\n )\n if not isinstance(labels, dict):\n raise TypeError('labels must be a dictionary')\n data[\"Labels\"] = labels\n\n if enable_ipv6:\n if version_lt(self._version, '1.23'):\n raise InvalidVersion(\n 'enable_ipv6 was introduced in API 1.23'\n )\n data['EnableIPv6'] = True\n\n if internal:\n if version_lt(self._version, '1.22'):\n raise InvalidVersion('Internal networks are not '\n 'supported in API version < 1.22')\n data['Internal'] = True\n\n if attachable is not None:\n if version_lt(self._version, '1.24'):\n raise InvalidVersion(\n 'attachable is not supported in API version < 1.24'\n )\n data['Attachable'] = attachable\n\n if ingress is not None:\n if version_lt(self._version, '1.29'):\n raise InvalidVersion(\n 'ingress is not supported in API version < 1.29'\n )\n\n data['Ingress'] = ingress\n\n url = self._url(\"/networks/create\")\n res = self._post_json(url, data=data)\n return self._result(res, json=True)\n\n @minimum_version('1.25')\n def prune_networks(self, filters=None):\n \"\"\"\n Delete unused networks\n\n Args:\n filters (dict): Filters to process on the prune list.\n\n Returns:\n (dict): A dict containing a list of deleted network names and\n the amount of disk space reclaimed in bytes.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n params = {}\n if filters:\n params['filters'] = utils.convert_filters(filters)\n url = self._url('/networks/prune')\n return self._result(self._post(url, params=params), True)\n\n @minimum_version('1.21')\n @check_resource('net_id')\n def remove_network(self, net_id):\n \"\"\"\n Remove a network. Similar to the ``docker network rm`` command.\n\n Args:\n net_id (str): The network's id\n \"\"\"\n url = self._url(\"/networks/{0}\", net_id)\n res = self._delete(url)\n self._raise_for_status(res)\n\n @minimum_version('1.21')\n @check_resource('net_id')\n def inspect_network(self, net_id, verbose=None):\n \"\"\"\n Get detailed information about a network.\n\n Args:\n net_id (str): ID of network\n verbose (bool): Show the service details across the cluster in\n swarm mode.\n \"\"\"\n params = {}\n if verbose is not None:\n if version_lt(self._version, '1.28'):\n raise InvalidVersion('verbose was introduced in API 1.28')\n params['verbose'] = verbose\n\n url = self._url(\"/networks/{0}\", net_id)\n res = self._get(url, params=params)\n return self._result(res, json=True)\n\n @check_resource('image')\n @minimum_version('1.21')\n def connect_container_to_network(self, container, net_id,\n ipv4_address=None, ipv6_address=None,\n aliases=None, links=None,\n link_local_ips=None):\n \"\"\"\n Connect a container to a network.\n\n Args:\n container (str): container-id/name to be connected to the network\n net_id (str): network id\n aliases (:py:class:`list`): A list of aliases for this endpoint.\n Names in that list can be used within the network to reach the\n container. Defaults to ``None``.\n links (:py:class:`list`): A list of links for this endpoint.\n Containers declared in this list will be linked to this\n container. Defaults to ``None``.\n ipv4_address (str): The IP address of this container on the\n network, using the IPv4 protocol. Defaults to ``None``.\n ipv6_address (str): The IP address of this container on the\n network, using the IPv6 protocol. Defaults to ``None``.\n link_local_ips (:py:class:`list`): A list of link-local\n (IPv4/IPv6) addresses.\n \"\"\"\n data = {\n \"Container\": container,\n \"EndpointConfig\": self.create_endpoint_config(\n aliases=aliases, links=links, ipv4_address=ipv4_address,\n ipv6_address=ipv6_address, link_local_ips=link_local_ips\n ),\n }\n\n url = self._url(\"/networks/{0}/connect\", net_id)\n res = self._post_json(url, data=data)\n self._raise_for_status(res)\n\n @check_resource('image')\n @minimum_version('1.21')\n def disconnect_container_from_network(self, container, net_id,\n force=False):\n \"\"\"\n Disconnect a container from a network.\n\n Args:\n container (str): container ID or name to be disconnected from the\n network\n net_id (str): network ID\n force (bool): Force the container to disconnect from a network.\n Default: ``False``\n \"\"\"\n data = {\"Container\": container}\n if force:\n if version_lt(self._version, '1.22'):\n raise InvalidVersion(\n 'Forced disconnect was introduced in API 1.22'\n )\n data['Force'] = force\n url = self._url(\"/networks/{0}/disconnect\", net_id)\n res = self._post_json(url, data=data)\n self._raise_for_status(res)\n", "path": "docker/api/network.py"}], "after_files": [{"content": "from ..errors import InvalidVersion\nfrom ..utils import check_resource, minimum_version\nfrom ..utils import version_lt\nfrom .. import utils\n\n\nclass NetworkApiMixin(object):\n @minimum_version('1.21')\n def networks(self, names=None, ids=None, filters=None):\n \"\"\"\n List networks. Similar to the ``docker networks ls`` command.\n\n Args:\n names (:py:class:`list`): List of names to filter by\n ids (:py:class:`list`): List of ids to filter by\n filters (dict): Filters to be processed on the network list.\n Available filters:\n - ``driver=[<driver-name>]`` Matches a network's driver.\n - ``label=[<key>]`` or ``label=[<key>=<value>]``.\n - ``type=[\"custom\"|\"builtin\"]`` Filters networks by type.\n\n Returns:\n (dict): List of network objects.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n\n if filters is None:\n filters = {}\n if names:\n filters['name'] = names\n if ids:\n filters['id'] = ids\n params = {'filters': utils.convert_filters(filters)}\n url = self._url(\"/networks\")\n res = self._get(url, params=params)\n return self._result(res, json=True)\n\n @minimum_version('1.21')\n def create_network(self, name, driver=None, options=None, ipam=None,\n check_duplicate=None, internal=False, labels=None,\n enable_ipv6=False, attachable=None, scope=None,\n ingress=None):\n \"\"\"\n Create a network. Similar to the ``docker network create``.\n\n Args:\n name (str): Name of the network\n driver (str): Name of the driver used to create the network\n options (dict): Driver options as a key-value dictionary\n ipam (IPAMConfig): Optional custom IP scheme for the network.\n check_duplicate (bool): Request daemon to check for networks with\n same name. Default: ``True``.\n internal (bool): Restrict external access to the network. Default\n ``False``.\n labels (dict): Map of labels to set on the network. Default\n ``None``.\n enable_ipv6 (bool): Enable IPv6 on the network. Default ``False``.\n attachable (bool): If enabled, and the network is in the global\n scope, non-service containers on worker nodes will be able to\n connect to the network.\n ingress (bool): If set, create an ingress network which provides\n the routing-mesh in swarm mode.\n\n Returns:\n (dict): The created network reference object\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Example:\n A network using the bridge driver:\n\n >>> client.create_network(\"network1\", driver=\"bridge\")\n\n You can also create more advanced networks with custom IPAM\n configurations. For example, setting the subnet to\n ``192.168.52.0/24`` and gateway address to ``192.168.52.254``.\n\n .. code-block:: python\n\n >>> ipam_pool = docker.types.IPAMPool(\n subnet='192.168.52.0/24',\n gateway='192.168.52.254'\n )\n >>> ipam_config = docker.types.IPAMConfig(\n pool_configs=[ipam_pool]\n )\n >>> docker_client.create_network(\"network1\", driver=\"bridge\",\n ipam=ipam_config)\n \"\"\"\n if options is not None and not isinstance(options, dict):\n raise TypeError('options must be a dictionary')\n\n data = {\n 'Name': name,\n 'Driver': driver,\n 'Options': options,\n 'IPAM': ipam,\n 'CheckDuplicate': check_duplicate,\n }\n\n if labels is not None:\n if version_lt(self._version, '1.23'):\n raise InvalidVersion(\n 'network labels were introduced in API 1.23'\n )\n if not isinstance(labels, dict):\n raise TypeError('labels must be a dictionary')\n data[\"Labels\"] = labels\n\n if enable_ipv6:\n if version_lt(self._version, '1.23'):\n raise InvalidVersion(\n 'enable_ipv6 was introduced in API 1.23'\n )\n data['EnableIPv6'] = True\n\n if internal:\n if version_lt(self._version, '1.22'):\n raise InvalidVersion('Internal networks are not '\n 'supported in API version < 1.22')\n data['Internal'] = True\n\n if attachable is not None:\n if version_lt(self._version, '1.24'):\n raise InvalidVersion(\n 'attachable is not supported in API version < 1.24'\n )\n data['Attachable'] = attachable\n\n if ingress is not None:\n if version_lt(self._version, '1.29'):\n raise InvalidVersion(\n 'ingress is not supported in API version < 1.29'\n )\n\n data['Ingress'] = ingress\n\n url = self._url(\"/networks/create\")\n res = self._post_json(url, data=data)\n return self._result(res, json=True)\n\n @minimum_version('1.25')\n def prune_networks(self, filters=None):\n \"\"\"\n Delete unused networks\n\n Args:\n filters (dict): Filters to process on the prune list.\n\n Returns:\n (dict): A dict containing a list of deleted network names and\n the amount of disk space reclaimed in bytes.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n params = {}\n if filters:\n params['filters'] = utils.convert_filters(filters)\n url = self._url('/networks/prune')\n return self._result(self._post(url, params=params), True)\n\n @minimum_version('1.21')\n @check_resource('net_id')\n def remove_network(self, net_id):\n \"\"\"\n Remove a network. Similar to the ``docker network rm`` command.\n\n Args:\n net_id (str): The network's id\n \"\"\"\n url = self._url(\"/networks/{0}\", net_id)\n res = self._delete(url)\n self._raise_for_status(res)\n\n @minimum_version('1.21')\n @check_resource('net_id')\n def inspect_network(self, net_id, verbose=None):\n \"\"\"\n Get detailed information about a network.\n\n Args:\n net_id (str): ID of network\n verbose (bool): Show the service details across the cluster in\n swarm mode.\n \"\"\"\n params = {}\n if verbose is not None:\n if version_lt(self._version, '1.28'):\n raise InvalidVersion('verbose was introduced in API 1.28')\n params['verbose'] = verbose\n\n url = self._url(\"/networks/{0}\", net_id)\n res = self._get(url, params=params)\n return self._result(res, json=True)\n\n @check_resource('container')\n @minimum_version('1.21')\n def connect_container_to_network(self, container, net_id,\n ipv4_address=None, ipv6_address=None,\n aliases=None, links=None,\n link_local_ips=None):\n \"\"\"\n Connect a container to a network.\n\n Args:\n container (str): container-id/name to be connected to the network\n net_id (str): network id\n aliases (:py:class:`list`): A list of aliases for this endpoint.\n Names in that list can be used within the network to reach the\n container. Defaults to ``None``.\n links (:py:class:`list`): A list of links for this endpoint.\n Containers declared in this list will be linked to this\n container. Defaults to ``None``.\n ipv4_address (str): The IP address of this container on the\n network, using the IPv4 protocol. Defaults to ``None``.\n ipv6_address (str): The IP address of this container on the\n network, using the IPv6 protocol. Defaults to ``None``.\n link_local_ips (:py:class:`list`): A list of link-local\n (IPv4/IPv6) addresses.\n \"\"\"\n data = {\n \"Container\": container,\n \"EndpointConfig\": self.create_endpoint_config(\n aliases=aliases, links=links, ipv4_address=ipv4_address,\n ipv6_address=ipv6_address, link_local_ips=link_local_ips\n ),\n }\n\n url = self._url(\"/networks/{0}/connect\", net_id)\n res = self._post_json(url, data=data)\n self._raise_for_status(res)\n\n @check_resource('container')\n @minimum_version('1.21')\n def disconnect_container_from_network(self, container, net_id,\n force=False):\n \"\"\"\n Disconnect a container from a network.\n\n Args:\n container (str): container ID or name to be disconnected from the\n network\n net_id (str): network ID\n force (bool): Force the container to disconnect from a network.\n Default: ``False``\n \"\"\"\n data = {\"Container\": container}\n if force:\n if version_lt(self._version, '1.22'):\n raise InvalidVersion(\n 'Forced disconnect was introduced in API 1.22'\n )\n data['Force'] = force\n url = self._url(\"/networks/{0}/disconnect\", net_id)\n res = self._post_json(url, data=data)\n self._raise_for_status(res)\n", "path": "docker/api/network.py"}]}
| 3,628 | 192 |
gh_patches_debug_8636
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-2257
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove werkzeug from Flask instrumentation dependencies
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.
16 # RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.
17
18 libraries = [
19 {
20 "library": "aio_pika >= 7.2.0, < 10.0.0",
21 "instrumentation": "opentelemetry-instrumentation-aio-pika==0.44b0.dev",
22 },
23 {
24 "library": "aiohttp ~= 3.0",
25 "instrumentation": "opentelemetry-instrumentation-aiohttp-client==0.44b0.dev",
26 },
27 {
28 "library": "aiohttp ~= 3.0",
29 "instrumentation": "opentelemetry-instrumentation-aiohttp-server==0.44b0.dev",
30 },
31 {
32 "library": "aiopg >= 0.13.0, < 2.0.0",
33 "instrumentation": "opentelemetry-instrumentation-aiopg==0.44b0.dev",
34 },
35 {
36 "library": "asgiref ~= 3.0",
37 "instrumentation": "opentelemetry-instrumentation-asgi==0.44b0.dev",
38 },
39 {
40 "library": "asyncpg >= 0.12.0",
41 "instrumentation": "opentelemetry-instrumentation-asyncpg==0.44b0.dev",
42 },
43 {
44 "library": "boto~=2.0",
45 "instrumentation": "opentelemetry-instrumentation-boto==0.44b0.dev",
46 },
47 {
48 "library": "boto3 ~= 1.0",
49 "instrumentation": "opentelemetry-instrumentation-boto3sqs==0.44b0.dev",
50 },
51 {
52 "library": "botocore ~= 1.0",
53 "instrumentation": "opentelemetry-instrumentation-botocore==0.44b0.dev",
54 },
55 {
56 "library": "cassandra-driver ~= 3.25",
57 "instrumentation": "opentelemetry-instrumentation-cassandra==0.44b0.dev",
58 },
59 {
60 "library": "scylla-driver ~= 3.25",
61 "instrumentation": "opentelemetry-instrumentation-cassandra==0.44b0.dev",
62 },
63 {
64 "library": "celery >= 4.0, < 6.0",
65 "instrumentation": "opentelemetry-instrumentation-celery==0.44b0.dev",
66 },
67 {
68 "library": "confluent-kafka >= 1.8.2, <= 2.3.0",
69 "instrumentation": "opentelemetry-instrumentation-confluent-kafka==0.44b0.dev",
70 },
71 {
72 "library": "django >= 1.10",
73 "instrumentation": "opentelemetry-instrumentation-django==0.44b0.dev",
74 },
75 {
76 "library": "elasticsearch >= 2.0",
77 "instrumentation": "opentelemetry-instrumentation-elasticsearch==0.44b0.dev",
78 },
79 {
80 "library": "falcon >= 1.4.1, < 3.1.2",
81 "instrumentation": "opentelemetry-instrumentation-falcon==0.44b0.dev",
82 },
83 {
84 "library": "fastapi ~= 0.58",
85 "instrumentation": "opentelemetry-instrumentation-fastapi==0.44b0.dev",
86 },
87 {
88 "library": "werkzeug < 3.0.0",
89 "instrumentation": "opentelemetry-instrumentation-flask==0.44b0.dev",
90 },
91 {
92 "library": "flask >= 1.0",
93 "instrumentation": "opentelemetry-instrumentation-flask==0.44b0.dev",
94 },
95 {
96 "library": "grpcio ~= 1.27",
97 "instrumentation": "opentelemetry-instrumentation-grpc==0.44b0.dev",
98 },
99 {
100 "library": "httpx >= 0.18.0",
101 "instrumentation": "opentelemetry-instrumentation-httpx==0.44b0.dev",
102 },
103 {
104 "library": "jinja2 >= 2.7, < 4.0",
105 "instrumentation": "opentelemetry-instrumentation-jinja2==0.44b0.dev",
106 },
107 {
108 "library": "kafka-python >= 2.0",
109 "instrumentation": "opentelemetry-instrumentation-kafka-python==0.44b0.dev",
110 },
111 {
112 "library": "mysql-connector-python ~= 8.0",
113 "instrumentation": "opentelemetry-instrumentation-mysql==0.44b0.dev",
114 },
115 {
116 "library": "mysqlclient < 3",
117 "instrumentation": "opentelemetry-instrumentation-mysqlclient==0.44b0.dev",
118 },
119 {
120 "library": "pika >= 0.12.0",
121 "instrumentation": "opentelemetry-instrumentation-pika==0.44b0.dev",
122 },
123 {
124 "library": "psycopg2 >= 2.7.3.1",
125 "instrumentation": "opentelemetry-instrumentation-psycopg2==0.44b0.dev",
126 },
127 {
128 "library": "pymemcache >= 1.3.5, < 5",
129 "instrumentation": "opentelemetry-instrumentation-pymemcache==0.44b0.dev",
130 },
131 {
132 "library": "pymongo >= 3.1, < 5.0",
133 "instrumentation": "opentelemetry-instrumentation-pymongo==0.44b0.dev",
134 },
135 {
136 "library": "PyMySQL < 2",
137 "instrumentation": "opentelemetry-instrumentation-pymysql==0.44b0.dev",
138 },
139 {
140 "library": "pyramid >= 1.7",
141 "instrumentation": "opentelemetry-instrumentation-pyramid==0.44b0.dev",
142 },
143 {
144 "library": "redis >= 2.6",
145 "instrumentation": "opentelemetry-instrumentation-redis==0.44b0.dev",
146 },
147 {
148 "library": "remoulade >= 0.50",
149 "instrumentation": "opentelemetry-instrumentation-remoulade==0.44b0.dev",
150 },
151 {
152 "library": "requests ~= 2.0",
153 "instrumentation": "opentelemetry-instrumentation-requests==0.44b0.dev",
154 },
155 {
156 "library": "scikit-learn ~= 0.24.0",
157 "instrumentation": "opentelemetry-instrumentation-sklearn==0.44b0.dev",
158 },
159 {
160 "library": "sqlalchemy",
161 "instrumentation": "opentelemetry-instrumentation-sqlalchemy==0.44b0.dev",
162 },
163 {
164 "library": "starlette ~= 0.13.0",
165 "instrumentation": "opentelemetry-instrumentation-starlette==0.44b0.dev",
166 },
167 {
168 "library": "psutil >= 5",
169 "instrumentation": "opentelemetry-instrumentation-system-metrics==0.44b0.dev",
170 },
171 {
172 "library": "tornado >= 5.1.1",
173 "instrumentation": "opentelemetry-instrumentation-tornado==0.44b0.dev",
174 },
175 {
176 "library": "tortoise-orm >= 0.17.0",
177 "instrumentation": "opentelemetry-instrumentation-tortoiseorm==0.44b0.dev",
178 },
179 {
180 "library": "pydantic >= 1.10.2",
181 "instrumentation": "opentelemetry-instrumentation-tortoiseorm==0.44b0.dev",
182 },
183 {
184 "library": "urllib3 >= 1.0.0, < 3.0.0",
185 "instrumentation": "opentelemetry-instrumentation-urllib3==0.44b0.dev",
186 },
187 ]
188 default_instrumentations = [
189 "opentelemetry-instrumentation-asyncio==0.44b0.dev",
190 "opentelemetry-instrumentation-aws-lambda==0.44b0.dev",
191 "opentelemetry-instrumentation-dbapi==0.44b0.dev",
192 "opentelemetry-instrumentation-logging==0.44b0.dev",
193 "opentelemetry-instrumentation-sqlite3==0.44b0.dev",
194 "opentelemetry-instrumentation-urllib==0.44b0.dev",
195 "opentelemetry-instrumentation-wsgi==0.44b0.dev",
196 ]
197
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
@@ -84,10 +84,6 @@
"library": "fastapi ~= 0.58",
"instrumentation": "opentelemetry-instrumentation-fastapi==0.44b0.dev",
},
- {
- "library": "werkzeug < 3.0.0",
- "instrumentation": "opentelemetry-instrumentation-flask==0.44b0.dev",
- },
{
"library": "flask >= 1.0",
"instrumentation": "opentelemetry-instrumentation-flask==0.44b0.dev",
|
{"golden_diff": "diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n@@ -84,10 +84,6 @@\n \"library\": \"fastapi ~= 0.58\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.44b0.dev\",\n },\n- {\n- \"library\": \"werkzeug < 3.0.0\",\n- \"instrumentation\": \"opentelemetry-instrumentation-flask==0.44b0.dev\",\n- },\n {\n \"library\": \"flask >= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.44b0.dev\",\n", "issue": "Remove werkzeug from Flask instrumentation dependencies\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.\n# RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.\n\nlibraries = [\n {\n \"library\": \"aio_pika >= 7.2.0, < 10.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aio-pika==0.44b0.dev\",\n },\n {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.44b0.dev\",\n },\n {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-server==0.44b0.dev\",\n },\n {\n \"library\": \"aiopg >= 0.13.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.44b0.dev\",\n },\n {\n \"library\": \"asgiref ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asgi==0.44b0.dev\",\n },\n {\n \"library\": \"asyncpg >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asyncpg==0.44b0.dev\",\n },\n {\n \"library\": \"boto~=2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto==0.44b0.dev\",\n },\n {\n \"library\": \"boto3 ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto3sqs==0.44b0.dev\",\n },\n {\n \"library\": \"botocore ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-botocore==0.44b0.dev\",\n },\n {\n \"library\": \"cassandra-driver ~= 3.25\",\n \"instrumentation\": \"opentelemetry-instrumentation-cassandra==0.44b0.dev\",\n },\n {\n \"library\": \"scylla-driver ~= 3.25\",\n \"instrumentation\": \"opentelemetry-instrumentation-cassandra==0.44b0.dev\",\n },\n {\n \"library\": \"celery >= 4.0, < 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-celery==0.44b0.dev\",\n },\n {\n \"library\": \"confluent-kafka >= 1.8.2, <= 2.3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-confluent-kafka==0.44b0.dev\",\n },\n {\n \"library\": \"django >= 1.10\",\n \"instrumentation\": \"opentelemetry-instrumentation-django==0.44b0.dev\",\n },\n {\n \"library\": \"elasticsearch >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-elasticsearch==0.44b0.dev\",\n },\n {\n \"library\": \"falcon >= 1.4.1, < 3.1.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.44b0.dev\",\n },\n {\n \"library\": \"fastapi ~= 0.58\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.44b0.dev\",\n },\n {\n \"library\": \"werkzeug < 3.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.44b0.dev\",\n },\n {\n \"library\": \"flask >= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.44b0.dev\",\n },\n {\n \"library\": \"grpcio ~= 1.27\",\n \"instrumentation\": \"opentelemetry-instrumentation-grpc==0.44b0.dev\",\n },\n {\n \"library\": \"httpx >= 0.18.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-httpx==0.44b0.dev\",\n },\n {\n \"library\": \"jinja2 >= 2.7, < 4.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-jinja2==0.44b0.dev\",\n },\n {\n \"library\": \"kafka-python >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-kafka-python==0.44b0.dev\",\n },\n {\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.44b0.dev\",\n },\n {\n \"library\": \"mysqlclient < 3\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysqlclient==0.44b0.dev\",\n },\n {\n \"library\": \"pika >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pika==0.44b0.dev\",\n },\n {\n \"library\": \"psycopg2 >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.44b0.dev\",\n },\n {\n \"library\": \"pymemcache >= 1.3.5, < 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymemcache==0.44b0.dev\",\n },\n {\n \"library\": \"pymongo >= 3.1, < 5.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymongo==0.44b0.dev\",\n },\n {\n \"library\": \"PyMySQL < 2\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymysql==0.44b0.dev\",\n },\n {\n \"library\": \"pyramid >= 1.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-pyramid==0.44b0.dev\",\n },\n {\n \"library\": \"redis >= 2.6\",\n \"instrumentation\": \"opentelemetry-instrumentation-redis==0.44b0.dev\",\n },\n {\n \"library\": \"remoulade >= 0.50\",\n \"instrumentation\": \"opentelemetry-instrumentation-remoulade==0.44b0.dev\",\n },\n {\n \"library\": \"requests ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-requests==0.44b0.dev\",\n },\n {\n \"library\": \"scikit-learn ~= 0.24.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-sklearn==0.44b0.dev\",\n },\n {\n \"library\": \"sqlalchemy\",\n \"instrumentation\": \"opentelemetry-instrumentation-sqlalchemy==0.44b0.dev\",\n },\n {\n \"library\": \"starlette ~= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-starlette==0.44b0.dev\",\n },\n {\n \"library\": \"psutil >= 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-system-metrics==0.44b0.dev\",\n },\n {\n \"library\": \"tornado >= 5.1.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-tornado==0.44b0.dev\",\n },\n {\n \"library\": \"tortoise-orm >= 0.17.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.44b0.dev\",\n },\n {\n \"library\": \"pydantic >= 1.10.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.44b0.dev\",\n },\n {\n \"library\": \"urllib3 >= 1.0.0, < 3.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-urllib3==0.44b0.dev\",\n },\n]\ndefault_instrumentations = [\n \"opentelemetry-instrumentation-asyncio==0.44b0.dev\",\n \"opentelemetry-instrumentation-aws-lambda==0.44b0.dev\",\n \"opentelemetry-instrumentation-dbapi==0.44b0.dev\",\n \"opentelemetry-instrumentation-logging==0.44b0.dev\",\n \"opentelemetry-instrumentation-sqlite3==0.44b0.dev\",\n \"opentelemetry-instrumentation-urllib==0.44b0.dev\",\n \"opentelemetry-instrumentation-wsgi==0.44b0.dev\",\n]\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.\n# RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.\n\nlibraries = [\n {\n \"library\": \"aio_pika >= 7.2.0, < 10.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aio-pika==0.44b0.dev\",\n },\n {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.44b0.dev\",\n },\n {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-server==0.44b0.dev\",\n },\n {\n \"library\": \"aiopg >= 0.13.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.44b0.dev\",\n },\n {\n \"library\": \"asgiref ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asgi==0.44b0.dev\",\n },\n {\n \"library\": \"asyncpg >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asyncpg==0.44b0.dev\",\n },\n {\n \"library\": \"boto~=2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto==0.44b0.dev\",\n },\n {\n \"library\": \"boto3 ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto3sqs==0.44b0.dev\",\n },\n {\n \"library\": \"botocore ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-botocore==0.44b0.dev\",\n },\n {\n \"library\": \"cassandra-driver ~= 3.25\",\n \"instrumentation\": \"opentelemetry-instrumentation-cassandra==0.44b0.dev\",\n },\n {\n \"library\": \"scylla-driver ~= 3.25\",\n \"instrumentation\": \"opentelemetry-instrumentation-cassandra==0.44b0.dev\",\n },\n {\n \"library\": \"celery >= 4.0, < 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-celery==0.44b0.dev\",\n },\n {\n \"library\": \"confluent-kafka >= 1.8.2, <= 2.3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-confluent-kafka==0.44b0.dev\",\n },\n {\n \"library\": \"django >= 1.10\",\n \"instrumentation\": \"opentelemetry-instrumentation-django==0.44b0.dev\",\n },\n {\n \"library\": \"elasticsearch >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-elasticsearch==0.44b0.dev\",\n },\n {\n \"library\": \"falcon >= 1.4.1, < 3.1.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.44b0.dev\",\n },\n {\n \"library\": \"fastapi ~= 0.58\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.44b0.dev\",\n },\n {\n \"library\": \"flask >= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.44b0.dev\",\n },\n {\n \"library\": \"grpcio ~= 1.27\",\n \"instrumentation\": \"opentelemetry-instrumentation-grpc==0.44b0.dev\",\n },\n {\n \"library\": \"httpx >= 0.18.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-httpx==0.44b0.dev\",\n },\n {\n \"library\": \"jinja2 >= 2.7, < 4.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-jinja2==0.44b0.dev\",\n },\n {\n \"library\": \"kafka-python >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-kafka-python==0.44b0.dev\",\n },\n {\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.44b0.dev\",\n },\n {\n \"library\": \"mysqlclient < 3\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysqlclient==0.44b0.dev\",\n },\n {\n \"library\": \"pika >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pika==0.44b0.dev\",\n },\n {\n \"library\": \"psycopg2 >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.44b0.dev\",\n },\n {\n \"library\": \"pymemcache >= 1.3.5, < 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymemcache==0.44b0.dev\",\n },\n {\n \"library\": \"pymongo >= 3.1, < 5.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymongo==0.44b0.dev\",\n },\n {\n \"library\": \"PyMySQL < 2\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymysql==0.44b0.dev\",\n },\n {\n \"library\": \"pyramid >= 1.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-pyramid==0.44b0.dev\",\n },\n {\n \"library\": \"redis >= 2.6\",\n \"instrumentation\": \"opentelemetry-instrumentation-redis==0.44b0.dev\",\n },\n {\n \"library\": \"remoulade >= 0.50\",\n \"instrumentation\": \"opentelemetry-instrumentation-remoulade==0.44b0.dev\",\n },\n {\n \"library\": \"requests ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-requests==0.44b0.dev\",\n },\n {\n \"library\": \"scikit-learn ~= 0.24.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-sklearn==0.44b0.dev\",\n },\n {\n \"library\": \"sqlalchemy\",\n \"instrumentation\": \"opentelemetry-instrumentation-sqlalchemy==0.44b0.dev\",\n },\n {\n \"library\": \"starlette ~= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-starlette==0.44b0.dev\",\n },\n {\n \"library\": \"psutil >= 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-system-metrics==0.44b0.dev\",\n },\n {\n \"library\": \"tornado >= 5.1.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-tornado==0.44b0.dev\",\n },\n {\n \"library\": \"tortoise-orm >= 0.17.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.44b0.dev\",\n },\n {\n \"library\": \"pydantic >= 1.10.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.44b0.dev\",\n },\n {\n \"library\": \"urllib3 >= 1.0.0, < 3.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-urllib3==0.44b0.dev\",\n },\n]\ndefault_instrumentations = [\n \"opentelemetry-instrumentation-asyncio==0.44b0.dev\",\n \"opentelemetry-instrumentation-aws-lambda==0.44b0.dev\",\n \"opentelemetry-instrumentation-dbapi==0.44b0.dev\",\n \"opentelemetry-instrumentation-logging==0.44b0.dev\",\n \"opentelemetry-instrumentation-sqlite3==0.44b0.dev\",\n \"opentelemetry-instrumentation-urllib==0.44b0.dev\",\n \"opentelemetry-instrumentation-wsgi==0.44b0.dev\",\n]\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py"}]}
| 2,921 | 212 |
gh_patches_debug_64230
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-56
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incompatibility with old versions of SQLAlchemy.
Connecting to PostgreSQL fails with old versions of SQLAlchemy raising an error: `sqlalchemy.exc.CompileError: Postgresql ENUM type requires a name`. This error is resolved once sqlalchemy version is updated.
For example:
```python
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.0.13'
>>> from pfnopt.storages import RDBStorage
>>> RDBStorage(url='postgresql://pfnopt:somepassword@localhost:5432/some_db')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/sano/PycharmProjects/pfnopt/pfnopt/storages/rdb.py", line 85, in __init__
Base.metadata.create_all(self.engine)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/schema.py", line 3695, in create_all
tables=tables)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 1856, in _run_visitor
conn._run_visitor(visitorcallable, element, **kwargs)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 1481, in _run_visitor
**kwargs).traverse_single(element)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py", line 121, in traverse_single
return meth(obj, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py", line 720, in visit_metadata
_ddl_runner=self)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/event/attr.py", line 256, in __call__
fn(*args, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/util/langhelpers.py", line 546, in __call__
return getattr(self.target, self.name)(*arg, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/sqltypes.py", line 1040, in _on_metadata_create
t._on_metadata_create(target, bind, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1379, in _on_metadata_create
self.create(bind=bind, checkfirst=checkfirst)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1317, in create
bind.execute(CreateEnumType(self))
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 914, in execute
return meth(self, multiparams, params)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py", line 68, in _execute_on_connection
return connection._execute_ddl(self, multiparams, params)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 962, in _execute_ddl
compiled = ddl.compile(dialect=dialect)
File "<string>", line 1, in <lambda>
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/elements.py", line 494, in compile
return self._compiler(dialect, bind=bind, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py", line 26, in _compiler
return dialect.ddl_compiler(dialect, self, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py", line 190, in __init__
self.string = self.process(self.statement, **compile_kwargs)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py", line 213, in process
return obj._compiler_dispatch(self, **kwargs)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py", line 81, in _compiler_dispatch
return meth(self, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1613, in visit_create_enum_type
self.preparer.format_type(type_),
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1857, in format_type
raise exc.CompileError("Postgresql ENUM type requires a name.")
sqlalchemy.exc.CompileError: Postgresql ENUM type requires a name.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 from setuptools import find_packages
3 from setuptools import setup
4 import sys
5
6
7 def get_version():
8 version_filepath = os.path.join(os.path.dirname(__file__), 'pfnopt', 'version.py')
9 with open(version_filepath) as f:
10 for line in f:
11 if line.startswith('__version__'):
12 return line.strip().split()[-1][1:-1]
13 assert False
14
15
16 tests_require = ['pytest', 'hacking', 'mock']
17 if sys.version_info[0] == 3:
18 tests_require.append('mypy')
19
20
21 setup(
22 name='pfnopt',
23 version=get_version(),
24 description='',
25 author='Takuya Akiba',
26 author_email='[email protected]',
27 packages=find_packages(),
28 install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],
29 tests_require=tests_require,
30 extras_require={'testing': tests_require},
31 entry_points={
32 'console_scripts': ['pfnopt = pfnopt.cli:main'],
33 'pfnopt.command': ['mkstudy = pfnopt.cli:MakeStudy']
34 }
35 )
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -25,7 +25,7 @@
author='Takuya Akiba',
author_email='[email protected]',
packages=find_packages(),
- install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],
+ install_requires=['sqlalchemy>=1.1.0', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],
tests_require=tests_require,
extras_require={'testing': tests_require},
entry_points={
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -25,7 +25,7 @@\n author='Takuya Akiba',\n author_email='[email protected]',\n packages=find_packages(),\n- install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n+ install_requires=['sqlalchemy>=1.1.0', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n tests_require=tests_require,\n extras_require={'testing': tests_require},\n entry_points={\n", "issue": "Incompatibility with old versions of SQLAlchemy.\nConnecting to PostgreSQL fails with old versions of SQLAlchemy raising an error: `sqlalchemy.exc.CompileError: Postgresql ENUM type requires a name`. This error is resolved once sqlalchemy version is updated.\r\n\r\nFor example:\r\n```python\r\n>>> import sqlalchemy\r\n>>> sqlalchemy.__version__\r\n'1.0.13'\r\n>>> from pfnopt.storages import RDBStorage\r\n>>> RDBStorage(url='postgresql://pfnopt:somepassword@localhost:5432/some_db')\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/sano/PycharmProjects/pfnopt/pfnopt/storages/rdb.py\", line 85, in __init__\r\n Base.metadata.create_all(self.engine)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/schema.py\", line 3695, in create_all\r\n tables=tables)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 1856, in _run_visitor\r\n conn._run_visitor(visitorcallable, element, **kwargs)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 1481, in _run_visitor\r\n **kwargs).traverse_single(element)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py\", line 121, in traverse_single\r\n return meth(obj, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py\", line 720, in visit_metadata\r\n _ddl_runner=self)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/event/attr.py\", line 256, in __call__\r\n fn(*args, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/util/langhelpers.py\", line 546, in __call__\r\n return getattr(self.target, self.name)(*arg, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/sqltypes.py\", line 1040, in _on_metadata_create\r\n t._on_metadata_create(target, bind, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1379, in _on_metadata_create\r\n self.create(bind=bind, checkfirst=checkfirst)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1317, in create\r\n bind.execute(CreateEnumType(self))\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 914, in execute\r\n return meth(self, multiparams, params)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py\", line 68, in _execute_on_connection\r\n return connection._execute_ddl(self, multiparams, params)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 962, in _execute_ddl\r\n compiled = ddl.compile(dialect=dialect)\r\n File \"<string>\", line 1, in <lambda>\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/elements.py\", line 494, in compile\r\n return self._compiler(dialect, bind=bind, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py\", line 26, in _compiler\r\n return dialect.ddl_compiler(dialect, self, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py\", line 190, in __init__\r\n self.string = self.process(self.statement, **compile_kwargs)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py\", line 213, in process\r\n return obj._compiler_dispatch(self, **kwargs)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py\", line 81, in _compiler_dispatch\r\n return meth(self, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1613, in visit_create_enum_type\r\n self.preparer.format_type(type_),\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1857, in format_type\r\n raise exc.CompileError(\"Postgresql ENUM type requires a name.\")\r\nsqlalchemy.exc.CompileError: Postgresql ENUM type requires a name.\r\n```\n", "before_files": [{"content": "import os\nfrom setuptools import find_packages\nfrom setuptools import setup\nimport sys\n\n\ndef get_version():\n version_filepath = os.path.join(os.path.dirname(__file__), 'pfnopt', 'version.py')\n with open(version_filepath) as f:\n for line in f:\n if line.startswith('__version__'):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ntests_require = ['pytest', 'hacking', 'mock']\nif sys.version_info[0] == 3:\n tests_require.append('mypy')\n\n\nsetup(\n name='pfnopt',\n version=get_version(),\n description='',\n author='Takuya Akiba',\n author_email='[email protected]',\n packages=find_packages(),\n install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n tests_require=tests_require,\n extras_require={'testing': tests_require},\n entry_points={\n 'console_scripts': ['pfnopt = pfnopt.cli:main'],\n 'pfnopt.command': ['mkstudy = pfnopt.cli:MakeStudy']\n }\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nfrom setuptools import find_packages\nfrom setuptools import setup\nimport sys\n\n\ndef get_version():\n version_filepath = os.path.join(os.path.dirname(__file__), 'pfnopt', 'version.py')\n with open(version_filepath) as f:\n for line in f:\n if line.startswith('__version__'):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ntests_require = ['pytest', 'hacking', 'mock']\nif sys.version_info[0] == 3:\n tests_require.append('mypy')\n\n\nsetup(\n name='pfnopt',\n version=get_version(),\n description='',\n author='Takuya Akiba',\n author_email='[email protected]',\n packages=find_packages(),\n install_requires=['sqlalchemy>=1.1.0', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n tests_require=tests_require,\n extras_require={'testing': tests_require},\n entry_points={\n 'console_scripts': ['pfnopt = pfnopt.cli:main'],\n 'pfnopt.command': ['mkstudy = pfnopt.cli:MakeStudy']\n }\n)\n", "path": "setup.py"}]}
| 1,869 | 142 |
gh_patches_debug_30082
|
rasdani/github-patches
|
git_diff
|
python-trio__trio-967
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
trio.Path.home raises "AttributeError: _flavour"
I get the following on Mac and Linux:
```
>>> import trio
>>> trio.Path.home()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.7.2_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/pathlib.py", line 1055, in home
return cls(cls()._flavour.gethomedir(None))
File "/Users/zach/.allotropic/python/default/lib/python3.7/site-packages/trio/_path.py", line 157, in __getattr__
raise AttributeError(name)
AttributeError: _flavour
```
As the traceback states, ``pathlib.Path`` is instantiating itself to dertermine its ``_flavour``, which is a class to delegate filesystem calls to differing Windows and Posix environments.
I think the explanation is that trio.Path does not override ``__new__``, so it doesn't get a chance to turn into a ``PosixPath`` or ``WindowsPath`` object like ``pathlib.Path`` objects do. The ``_flavour`` attribute is only available from these system-specific classes, and the ``AsyncAutoWrapperType`` doesn't explicitly wrap these classes to make it an attribute of ``trio.Path``.
One workaround is to override ``home`` in ``trio.Path``:
```
@classmethod
def home(cls):
return cls(cls()._wraps()._flavour.gethomedir(None))
```
There are other approaches and I'd like to check in with the team here. Any thoughts?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `trio/_path.py`
Content:
```
1 from functools import wraps, partial
2 import os
3 import types
4 import pathlib
5
6 import trio
7 from trio._util import async_wraps, fspath
8
9 __all__ = ['Path']
10
11
12 # python3.5 compat: __fspath__ does not exist in 3.5, so unwrap any trio.Path
13 # being passed to any wrapped method
14 def unwrap_paths(args):
15 new_args = []
16 for arg in args:
17 if isinstance(arg, Path):
18 arg = arg._wrapped
19 new_args.append(arg)
20 return new_args
21
22
23 # re-wrap return value from methods that return new instances of pathlib.Path
24 def rewrap_path(value):
25 if isinstance(value, pathlib.Path):
26 value = Path(value)
27 return value
28
29
30 def _forward_factory(cls, attr_name, attr):
31 @wraps(attr)
32 def wrapper(self, *args, **kwargs):
33 args = unwrap_paths(args)
34 attr = getattr(self._wrapped, attr_name)
35 value = attr(*args, **kwargs)
36 return rewrap_path(value)
37
38 return wrapper
39
40
41 def _forward_magic(cls, attr):
42 sentinel = object()
43
44 @wraps(attr)
45 def wrapper(self, other=sentinel):
46 if other is sentinel:
47 return attr(self._wrapped)
48 if isinstance(other, cls):
49 other = other._wrapped
50 value = attr(self._wrapped, other)
51 return rewrap_path(value)
52
53 return wrapper
54
55
56 def thread_wrapper_factory(cls, meth_name):
57 @async_wraps(cls, pathlib.Path, meth_name)
58 async def wrapper(self, *args, **kwargs):
59 args = unwrap_paths(args)
60 meth = getattr(self._wrapped, meth_name)
61 func = partial(meth, *args, **kwargs)
62 value = await trio.run_sync_in_worker_thread(func)
63 return rewrap_path(value)
64
65 return wrapper
66
67
68 class AsyncAutoWrapperType(type):
69 def __init__(cls, name, bases, attrs):
70 super().__init__(name, bases, attrs)
71
72 cls._forward = []
73 type(cls).generate_forwards(cls, attrs)
74 type(cls).generate_wraps(cls, attrs)
75 type(cls).generate_magic(cls, attrs)
76
77 def generate_forwards(cls, attrs):
78 # forward functions of _forwards
79 for attr_name, attr in cls._forwards.__dict__.items():
80 if attr_name.startswith('_') or attr_name in attrs:
81 continue
82
83 if isinstance(attr, property):
84 cls._forward.append(attr_name)
85 elif isinstance(attr, types.FunctionType):
86 wrapper = _forward_factory(cls, attr_name, attr)
87 setattr(cls, attr_name, wrapper)
88 else:
89 raise TypeError(attr_name, type(attr))
90
91 def generate_wraps(cls, attrs):
92 # generate wrappers for functions of _wraps
93 for attr_name, attr in cls._wraps.__dict__.items():
94 if attr_name.startswith('_') or attr_name in attrs:
95 continue
96
97 if isinstance(attr, classmethod):
98 setattr(cls, attr_name, attr)
99 elif isinstance(attr, types.FunctionType):
100 wrapper = thread_wrapper_factory(cls, attr_name)
101 setattr(cls, attr_name, wrapper)
102 else:
103 raise TypeError(attr_name, type(attr))
104
105 def generate_magic(cls, attrs):
106 # generate wrappers for magic
107 for attr_name in cls._forward_magic:
108 attr = getattr(cls._forwards, attr_name)
109 wrapper = _forward_magic(cls, attr)
110 setattr(cls, attr_name, wrapper)
111
112
113 class Path(metaclass=AsyncAutoWrapperType):
114 """A :class:`pathlib.Path` wrapper that executes blocking methods in
115 :meth:`trio.run_sync_in_worker_thread`.
116
117 """
118
119 _wraps = pathlib.Path
120 _forwards = pathlib.PurePath
121 _forward_magic = [
122 '__str__', '__bytes__', '__truediv__', '__rtruediv__', '__eq__',
123 '__lt__', '__le__', '__gt__', '__ge__'
124 ]
125
126 def __init__(self, *args):
127 args = unwrap_paths(args)
128
129 self._wrapped = pathlib.Path(*args)
130
131 async def iterdir(self):
132 """
133 Like :meth:`pathlib.Path.iterdir`, but async.
134
135 This is an async method that returns a synchronous iterator, so you
136 use it like::
137
138 for subpath in await mypath.iterdir():
139 ...
140
141 Note that it actually loads the whole directory list into memory
142 immediately, during the initial call. (See `issue #501
143 <https://github.com/python-trio/trio/issues/501>`__ for discussion.)
144
145 """
146
147 def _load_items():
148 return list(self._wrapped.iterdir())
149
150 items = await trio.run_sync_in_worker_thread(_load_items)
151 return (Path(item) for item in items)
152
153 def __getattr__(self, name):
154 if name in self._forward:
155 value = getattr(self._wrapped, name)
156 return rewrap_path(value)
157 raise AttributeError(name)
158
159 def __dir__(self):
160 return super().__dir__() + self._forward
161
162 def __repr__(self):
163 return 'trio.Path({})'.format(repr(str(self)))
164
165 def __fspath__(self):
166 return fspath(self._wrapped)
167
168 @wraps(pathlib.Path.open)
169 async def open(self, *args, **kwargs):
170 """Open the file pointed to by the path, like the :func:`trio.open_file`
171 function does.
172
173 """
174
175 func = partial(self._wrapped.open, *args, **kwargs)
176 value = await trio.run_sync_in_worker_thread(func)
177 return trio.wrap_file(value)
178
179
180 # The value of Path.absolute.__doc__ makes a reference to
181 # :meth:~pathlib.Path.absolute, which does not exist. Removing this makes more
182 # sense than inventing our own special docstring for this.
183 del Path.absolute.__doc__
184
185 # python3.5 compat
186 if hasattr(os, 'PathLike'):
187 os.PathLike.register(Path)
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/trio/_path.py b/trio/_path.py
--- a/trio/_path.py
+++ b/trio/_path.py
@@ -54,7 +54,7 @@
def thread_wrapper_factory(cls, meth_name):
- @async_wraps(cls, pathlib.Path, meth_name)
+ @async_wraps(cls, cls._wraps, meth_name)
async def wrapper(self, *args, **kwargs):
args = unwrap_paths(args)
meth = getattr(self._wrapped, meth_name)
@@ -65,6 +65,19 @@
return wrapper
+def classmethod_wrapper_factory(cls, meth_name):
+ @classmethod
+ @async_wraps(cls, cls._wraps, meth_name)
+ async def wrapper(cls, *args, **kwargs):
+ args = unwrap_paths(args)
+ meth = getattr(cls._wraps, meth_name)
+ func = partial(meth, *args, **kwargs)
+ value = await trio.run_sync_in_worker_thread(func)
+ return rewrap_path(value)
+
+ return wrapper
+
+
class AsyncAutoWrapperType(type):
def __init__(cls, name, bases, attrs):
super().__init__(name, bases, attrs)
@@ -93,9 +106,9 @@
for attr_name, attr in cls._wraps.__dict__.items():
if attr_name.startswith('_') or attr_name in attrs:
continue
-
if isinstance(attr, classmethod):
- setattr(cls, attr_name, attr)
+ wrapper = classmethod_wrapper_factory(cls, attr_name)
+ setattr(cls, attr_name, wrapper)
elif isinstance(attr, types.FunctionType):
wrapper = thread_wrapper_factory(cls, attr_name)
setattr(cls, attr_name, wrapper)
|
{"golden_diff": "diff --git a/trio/_path.py b/trio/_path.py\n--- a/trio/_path.py\n+++ b/trio/_path.py\n@@ -54,7 +54,7 @@\n \n \n def thread_wrapper_factory(cls, meth_name):\n- @async_wraps(cls, pathlib.Path, meth_name)\n+ @async_wraps(cls, cls._wraps, meth_name)\n async def wrapper(self, *args, **kwargs):\n args = unwrap_paths(args)\n meth = getattr(self._wrapped, meth_name)\n@@ -65,6 +65,19 @@\n return wrapper\n \n \n+def classmethod_wrapper_factory(cls, meth_name):\n+ @classmethod\n+ @async_wraps(cls, cls._wraps, meth_name)\n+ async def wrapper(cls, *args, **kwargs):\n+ args = unwrap_paths(args)\n+ meth = getattr(cls._wraps, meth_name)\n+ func = partial(meth, *args, **kwargs)\n+ value = await trio.run_sync_in_worker_thread(func)\n+ return rewrap_path(value)\n+\n+ return wrapper\n+\n+\n class AsyncAutoWrapperType(type):\n def __init__(cls, name, bases, attrs):\n super().__init__(name, bases, attrs)\n@@ -93,9 +106,9 @@\n for attr_name, attr in cls._wraps.__dict__.items():\n if attr_name.startswith('_') or attr_name in attrs:\n continue\n-\n if isinstance(attr, classmethod):\n- setattr(cls, attr_name, attr)\n+ wrapper = classmethod_wrapper_factory(cls, attr_name)\n+ setattr(cls, attr_name, wrapper)\n elif isinstance(attr, types.FunctionType):\n wrapper = thread_wrapper_factory(cls, attr_name)\n setattr(cls, attr_name, wrapper)\n", "issue": "trio.Path.home raises \"AttributeError: _flavour\"\nI get the following on Mac and Linux:\r\n```\r\n>>> import trio\r\n>>> trio.Path.home()\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/usr/local/Cellar/python/3.7.2_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/pathlib.py\", line 1055, in home\r\n return cls(cls()._flavour.gethomedir(None))\r\n File \"/Users/zach/.allotropic/python/default/lib/python3.7/site-packages/trio/_path.py\", line 157, in __getattr__\r\n raise AttributeError(name)\r\nAttributeError: _flavour\r\n```\r\nAs the traceback states, ``pathlib.Path`` is instantiating itself to dertermine its ``_flavour``, which is a class to delegate filesystem calls to differing Windows and Posix environments.\r\n\r\nI think the explanation is that trio.Path does not override ``__new__``, so it doesn't get a chance to turn into a ``PosixPath`` or ``WindowsPath`` object like ``pathlib.Path`` objects do. The ``_flavour`` attribute is only available from these system-specific classes, and the ``AsyncAutoWrapperType`` doesn't explicitly wrap these classes to make it an attribute of ``trio.Path``.\r\n\r\nOne workaround is to override ``home`` in ``trio.Path``:\r\n```\r\n @classmethod\r\n def home(cls):\r\n return cls(cls()._wraps()._flavour.gethomedir(None))\r\n```\r\n\r\nThere are other approaches and I'd like to check in with the team here. Any thoughts?\n", "before_files": [{"content": "from functools import wraps, partial\nimport os\nimport types\nimport pathlib\n\nimport trio\nfrom trio._util import async_wraps, fspath\n\n__all__ = ['Path']\n\n\n# python3.5 compat: __fspath__ does not exist in 3.5, so unwrap any trio.Path\n# being passed to any wrapped method\ndef unwrap_paths(args):\n new_args = []\n for arg in args:\n if isinstance(arg, Path):\n arg = arg._wrapped\n new_args.append(arg)\n return new_args\n\n\n# re-wrap return value from methods that return new instances of pathlib.Path\ndef rewrap_path(value):\n if isinstance(value, pathlib.Path):\n value = Path(value)\n return value\n\n\ndef _forward_factory(cls, attr_name, attr):\n @wraps(attr)\n def wrapper(self, *args, **kwargs):\n args = unwrap_paths(args)\n attr = getattr(self._wrapped, attr_name)\n value = attr(*args, **kwargs)\n return rewrap_path(value)\n\n return wrapper\n\n\ndef _forward_magic(cls, attr):\n sentinel = object()\n\n @wraps(attr)\n def wrapper(self, other=sentinel):\n if other is sentinel:\n return attr(self._wrapped)\n if isinstance(other, cls):\n other = other._wrapped\n value = attr(self._wrapped, other)\n return rewrap_path(value)\n\n return wrapper\n\n\ndef thread_wrapper_factory(cls, meth_name):\n @async_wraps(cls, pathlib.Path, meth_name)\n async def wrapper(self, *args, **kwargs):\n args = unwrap_paths(args)\n meth = getattr(self._wrapped, meth_name)\n func = partial(meth, *args, **kwargs)\n value = await trio.run_sync_in_worker_thread(func)\n return rewrap_path(value)\n\n return wrapper\n\n\nclass AsyncAutoWrapperType(type):\n def __init__(cls, name, bases, attrs):\n super().__init__(name, bases, attrs)\n\n cls._forward = []\n type(cls).generate_forwards(cls, attrs)\n type(cls).generate_wraps(cls, attrs)\n type(cls).generate_magic(cls, attrs)\n\n def generate_forwards(cls, attrs):\n # forward functions of _forwards\n for attr_name, attr in cls._forwards.__dict__.items():\n if attr_name.startswith('_') or attr_name in attrs:\n continue\n\n if isinstance(attr, property):\n cls._forward.append(attr_name)\n elif isinstance(attr, types.FunctionType):\n wrapper = _forward_factory(cls, attr_name, attr)\n setattr(cls, attr_name, wrapper)\n else:\n raise TypeError(attr_name, type(attr))\n\n def generate_wraps(cls, attrs):\n # generate wrappers for functions of _wraps\n for attr_name, attr in cls._wraps.__dict__.items():\n if attr_name.startswith('_') or attr_name in attrs:\n continue\n\n if isinstance(attr, classmethod):\n setattr(cls, attr_name, attr)\n elif isinstance(attr, types.FunctionType):\n wrapper = thread_wrapper_factory(cls, attr_name)\n setattr(cls, attr_name, wrapper)\n else:\n raise TypeError(attr_name, type(attr))\n\n def generate_magic(cls, attrs):\n # generate wrappers for magic\n for attr_name in cls._forward_magic:\n attr = getattr(cls._forwards, attr_name)\n wrapper = _forward_magic(cls, attr)\n setattr(cls, attr_name, wrapper)\n\n\nclass Path(metaclass=AsyncAutoWrapperType):\n \"\"\"A :class:`pathlib.Path` wrapper that executes blocking methods in\n :meth:`trio.run_sync_in_worker_thread`.\n\n \"\"\"\n\n _wraps = pathlib.Path\n _forwards = pathlib.PurePath\n _forward_magic = [\n '__str__', '__bytes__', '__truediv__', '__rtruediv__', '__eq__',\n '__lt__', '__le__', '__gt__', '__ge__'\n ]\n\n def __init__(self, *args):\n args = unwrap_paths(args)\n\n self._wrapped = pathlib.Path(*args)\n\n async def iterdir(self):\n \"\"\"\n Like :meth:`pathlib.Path.iterdir`, but async.\n\n This is an async method that returns a synchronous iterator, so you\n use it like::\n\n for subpath in await mypath.iterdir():\n ...\n\n Note that it actually loads the whole directory list into memory\n immediately, during the initial call. (See `issue #501\n <https://github.com/python-trio/trio/issues/501>`__ for discussion.)\n\n \"\"\"\n\n def _load_items():\n return list(self._wrapped.iterdir())\n\n items = await trio.run_sync_in_worker_thread(_load_items)\n return (Path(item) for item in items)\n\n def __getattr__(self, name):\n if name in self._forward:\n value = getattr(self._wrapped, name)\n return rewrap_path(value)\n raise AttributeError(name)\n\n def __dir__(self):\n return super().__dir__() + self._forward\n\n def __repr__(self):\n return 'trio.Path({})'.format(repr(str(self)))\n\n def __fspath__(self):\n return fspath(self._wrapped)\n\n @wraps(pathlib.Path.open)\n async def open(self, *args, **kwargs):\n \"\"\"Open the file pointed to by the path, like the :func:`trio.open_file`\n function does.\n\n \"\"\"\n\n func = partial(self._wrapped.open, *args, **kwargs)\n value = await trio.run_sync_in_worker_thread(func)\n return trio.wrap_file(value)\n\n\n# The value of Path.absolute.__doc__ makes a reference to\n# :meth:~pathlib.Path.absolute, which does not exist. Removing this makes more\n# sense than inventing our own special docstring for this.\ndel Path.absolute.__doc__\n\n# python3.5 compat\nif hasattr(os, 'PathLike'):\n os.PathLike.register(Path)\n", "path": "trio/_path.py"}], "after_files": [{"content": "from functools import wraps, partial\nimport os\nimport types\nimport pathlib\n\nimport trio\nfrom trio._util import async_wraps, fspath\n\n__all__ = ['Path']\n\n\n# python3.5 compat: __fspath__ does not exist in 3.5, so unwrap any trio.Path\n# being passed to any wrapped method\ndef unwrap_paths(args):\n new_args = []\n for arg in args:\n if isinstance(arg, Path):\n arg = arg._wrapped\n new_args.append(arg)\n return new_args\n\n\n# re-wrap return value from methods that return new instances of pathlib.Path\ndef rewrap_path(value):\n if isinstance(value, pathlib.Path):\n value = Path(value)\n return value\n\n\ndef _forward_factory(cls, attr_name, attr):\n @wraps(attr)\n def wrapper(self, *args, **kwargs):\n args = unwrap_paths(args)\n attr = getattr(self._wrapped, attr_name)\n value = attr(*args, **kwargs)\n return rewrap_path(value)\n\n return wrapper\n\n\ndef _forward_magic(cls, attr):\n sentinel = object()\n\n @wraps(attr)\n def wrapper(self, other=sentinel):\n if other is sentinel:\n return attr(self._wrapped)\n if isinstance(other, cls):\n other = other._wrapped\n value = attr(self._wrapped, other)\n return rewrap_path(value)\n\n return wrapper\n\n\ndef thread_wrapper_factory(cls, meth_name):\n @async_wraps(cls, cls._wraps, meth_name)\n async def wrapper(self, *args, **kwargs):\n args = unwrap_paths(args)\n meth = getattr(self._wrapped, meth_name)\n func = partial(meth, *args, **kwargs)\n value = await trio.run_sync_in_worker_thread(func)\n return rewrap_path(value)\n\n return wrapper\n\n\ndef classmethod_wrapper_factory(cls, meth_name):\n @classmethod\n @async_wraps(cls, cls._wraps, meth_name)\n async def wrapper(cls, *args, **kwargs):\n args = unwrap_paths(args)\n meth = getattr(cls._wraps, meth_name)\n func = partial(meth, *args, **kwargs)\n value = await trio.run_sync_in_worker_thread(func)\n return rewrap_path(value)\n\n return wrapper\n\n\nclass AsyncAutoWrapperType(type):\n def __init__(cls, name, bases, attrs):\n super().__init__(name, bases, attrs)\n\n cls._forward = []\n type(cls).generate_forwards(cls, attrs)\n type(cls).generate_wraps(cls, attrs)\n type(cls).generate_magic(cls, attrs)\n\n def generate_forwards(cls, attrs):\n # forward functions of _forwards\n for attr_name, attr in cls._forwards.__dict__.items():\n if attr_name.startswith('_') or attr_name in attrs:\n continue\n\n if isinstance(attr, property):\n cls._forward.append(attr_name)\n elif isinstance(attr, types.FunctionType):\n wrapper = _forward_factory(cls, attr_name, attr)\n setattr(cls, attr_name, wrapper)\n else:\n raise TypeError(attr_name, type(attr))\n\n def generate_wraps(cls, attrs):\n # generate wrappers for functions of _wraps\n for attr_name, attr in cls._wraps.__dict__.items():\n if attr_name.startswith('_') or attr_name in attrs:\n continue\n if isinstance(attr, classmethod):\n wrapper = classmethod_wrapper_factory(cls, attr_name)\n setattr(cls, attr_name, wrapper)\n elif isinstance(attr, types.FunctionType):\n wrapper = thread_wrapper_factory(cls, attr_name)\n setattr(cls, attr_name, wrapper)\n else:\n raise TypeError(attr_name, type(attr))\n\n def generate_magic(cls, attrs):\n # generate wrappers for magic\n for attr_name in cls._forward_magic:\n attr = getattr(cls._forwards, attr_name)\n wrapper = _forward_magic(cls, attr)\n setattr(cls, attr_name, wrapper)\n\n\nclass Path(metaclass=AsyncAutoWrapperType):\n \"\"\"A :class:`pathlib.Path` wrapper that executes blocking methods in\n :meth:`trio.run_sync_in_worker_thread`.\n\n \"\"\"\n\n _wraps = pathlib.Path\n _forwards = pathlib.PurePath\n _forward_magic = [\n '__str__', '__bytes__', '__truediv__', '__rtruediv__', '__eq__',\n '__lt__', '__le__', '__gt__', '__ge__'\n ]\n\n def __init__(self, *args):\n args = unwrap_paths(args)\n\n self._wrapped = pathlib.Path(*args)\n\n async def iterdir(self):\n \"\"\"\n Like :meth:`pathlib.Path.iterdir`, but async.\n\n This is an async method that returns a synchronous iterator, so you\n use it like::\n\n for subpath in await mypath.iterdir():\n ...\n\n Note that it actually loads the whole directory list into memory\n immediately, during the initial call. (See `issue #501\n <https://github.com/python-trio/trio/issues/501>`__ for discussion.)\n\n \"\"\"\n\n def _load_items():\n return list(self._wrapped.iterdir())\n\n items = await trio.run_sync_in_worker_thread(_load_items)\n return (Path(item) for item in items)\n\n def __getattr__(self, name):\n if name in self._forward:\n value = getattr(self._wrapped, name)\n return rewrap_path(value)\n raise AttributeError(name)\n\n def __dir__(self):\n return super().__dir__() + self._forward\n\n def __repr__(self):\n return 'trio.Path({})'.format(repr(str(self)))\n\n def __fspath__(self):\n return fspath(self._wrapped)\n\n @wraps(pathlib.Path.open)\n async def open(self, *args, **kwargs):\n \"\"\"Open the file pointed to by the path, like the :func:`trio.open_file`\n function does.\n\n \"\"\"\n\n func = partial(self._wrapped.open, *args, **kwargs)\n value = await trio.run_sync_in_worker_thread(func)\n return trio.wrap_file(value)\n\n\n# The value of Path.absolute.__doc__ makes a reference to\n# :meth:~pathlib.Path.absolute, which does not exist. Removing this makes more\n# sense than inventing our own special docstring for this.\ndel Path.absolute.__doc__\n\n# python3.5 compat\nif hasattr(os, 'PathLike'):\n os.PathLike.register(Path)\n", "path": "trio/_path.py"}]}
| 2,377 | 388 |
gh_patches_debug_33539
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1772
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
kfserving==0.6.0 python package doesn't work with Python 3.9
/kind bug
**What steps did you take and what happened:**
pip3 install kfserving==0.6.0 leads to a ray[serve] install failure, probably due to:
https://github.com/ray-project/tune-sklearn/issues/169
This happens only with Python 3.9
**What did you expect to happen:**
pip3 packages installed correctly without errors
**Anything else you would like to add:**
[Miscellaneous information that will assist in solving the issue.]
**Environment:**
- Istio Version:
- Knative Version:
- KFServing Version: 0.6.0
- Kubeflow version:
- Kfdef:[k8s_istio/istio_dex/gcp_basic_auth/gcp_iap/aws/aws_cognito/ibm]
- Minikube version:
- Kubernetes version: (use `kubectl version`):
- OS (e.g. from `/etc/os-release`):
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/kfserving/setup.py`
Content:
```
1 # Copyright 2020 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import setuptools
16
17 TESTS_REQUIRES = [
18 'pytest',
19 'pytest-tornasync',
20 'mypy'
21 ]
22
23 with open('requirements.txt') as f:
24 REQUIRES = f.readlines()
25
26 setuptools.setup(
27 name='kfserving',
28 version='0.6.0',
29 author="Kubeflow Authors",
30 author_email='[email protected], [email protected], [email protected]',
31 license="Apache License Version 2.0",
32 url="https://github.com/kubeflow/kfserving/tree/master/python/kfserving",
33 description="KFServing Python SDK",
34 long_description="Python SDK for KFServing Server and Client.",
35 python_requires='>=3.6',
36 packages=[
37 'kfserving',
38 'kfserving.api',
39 'kfserving.constants',
40 'kfserving.models',
41 'kfserving.handlers',
42 'kfserving.utils',
43 ],
44 package_data={'': ['requirements.txt']},
45 include_package_data=True,
46 zip_safe=False,
47 classifiers=[
48 'Intended Audience :: Developers',
49 'Intended Audience :: Education',
50 'Intended Audience :: Science/Research',
51 'Programming Language :: Python :: 3',
52 'Programming Language :: Python :: 3.6',
53 'Programming Language :: Python :: 3.7',
54 "License :: OSI Approved :: Apache Software License",
55 "Operating System :: OS Independent",
56 'Topic :: Scientific/Engineering',
57 'Topic :: Scientific/Engineering :: Artificial Intelligence',
58 'Topic :: Software Development',
59 'Topic :: Software Development :: Libraries',
60 'Topic :: Software Development :: Libraries :: Python Modules',
61 ],
62 install_requires=REQUIRES,
63 tests_require=TESTS_REQUIRES,
64 extras_require={'test': TESTS_REQUIRES}
65 )
66
```
Path: `python/kfserving/kfserving/kfserver.py`
Content:
```
1 # Copyright 2020 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import logging
17 import json
18 import inspect
19 import sys
20 from typing import List, Optional, Dict, Union
21 import tornado.ioloop
22 import tornado.web
23 import tornado.httpserver
24 import tornado.log
25 import asyncio
26 from tornado import concurrent
27 from .utils import utils
28
29 from kfserving.handlers.http import PredictHandler, ExplainHandler
30 from kfserving import KFModel
31 from kfserving.kfmodel_repository import KFModelRepository
32 from ray.serve.api import RayServeHandle, ServeDeployment
33 from ray import serve
34
35 DEFAULT_HTTP_PORT = 8080
36 DEFAULT_GRPC_PORT = 8081
37 DEFAULT_MAX_BUFFER_SIZE = 104857600
38
39 parser = argparse.ArgumentParser(add_help=False)
40 parser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,
41 help='The HTTP Port listened to by the model server.')
42 parser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,
43 help='The GRPC Port listened to by the model server.')
44 parser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,
45 help='The max buffer size for tornado.')
46 parser.add_argument('--workers', default=1, type=int,
47 help='The number of works to fork')
48 parser.add_argument('--max_asyncio_workers', default=None, type=int,
49 help='Max number of asyncio workers to spawn')
50 args, _ = parser.parse_known_args()
51
52 tornado.log.enable_pretty_logging()
53
54
55 class KFServer:
56 def __init__(self, http_port: int = args.http_port,
57 grpc_port: int = args.grpc_port,
58 max_buffer_size: int = args.max_buffer_size,
59 workers: int = args.workers,
60 max_asyncio_workers: int = args.max_asyncio_workers,
61 registered_models: KFModelRepository = KFModelRepository()):
62 self.registered_models = registered_models
63 self.http_port = http_port
64 self.grpc_port = grpc_port
65 self.max_buffer_size = max_buffer_size
66 self.workers = workers
67 self.max_asyncio_workers = max_asyncio_workers
68 self._http_server: Optional[tornado.httpserver.HTTPServer] = None
69
70 def create_application(self):
71 return tornado.web.Application([
72 # Server Liveness API returns 200 if server is alive.
73 (r"/", LivenessHandler),
74 (r"/v2/health/live", LivenessHandler),
75 (r"/v1/models",
76 ListHandler, dict(models=self.registered_models)),
77 (r"/v2/models",
78 ListHandler, dict(models=self.registered_models)),
79 # Model Health API returns 200 if model is ready to serve.
80 (r"/v1/models/([a-zA-Z0-9_-]+)",
81 HealthHandler, dict(models=self.registered_models)),
82 (r"/v2/models/([a-zA-Z0-9_-]+)/status",
83 HealthHandler, dict(models=self.registered_models)),
84 (r"/v1/models/([a-zA-Z0-9_-]+):predict",
85 PredictHandler, dict(models=self.registered_models)),
86 (r"/v2/models/([a-zA-Z0-9_-]+)/infer",
87 PredictHandler, dict(models=self.registered_models)),
88 (r"/v1/models/([a-zA-Z0-9_-]+):explain",
89 ExplainHandler, dict(models=self.registered_models)),
90 (r"/v2/models/([a-zA-Z0-9_-]+)/explain",
91 ExplainHandler, dict(models=self.registered_models)),
92 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/load",
93 LoadHandler, dict(models=self.registered_models)),
94 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/unload",
95 UnloadHandler, dict(models=self.registered_models)),
96 ])
97
98 def start(self, models: Union[List[KFModel], Dict[str, ServeDeployment]], nest_asyncio: bool = False):
99 if isinstance(models, list):
100 for model in models:
101 if isinstance(model, KFModel):
102 self.register_model(model)
103 else:
104 raise RuntimeError("Model type should be KFModel")
105 elif isinstance(models, dict):
106 if all([issubclass(v, ServeDeployment) for v in models.values()]):
107 serve.start(detached=True, http_host='0.0.0.0', http_port=9071)
108 for key in models:
109 models[key].deploy()
110 handle = models[key].get_handle()
111 self.register_model_handle(key, handle)
112 else:
113 raise RuntimeError("Model type should be RayServe Deployment")
114 else:
115 raise RuntimeError("Unknown model collection types")
116
117 if self.max_asyncio_workers is None:
118 # formula as suggest in https://bugs.python.org/issue35279
119 self.max_asyncio_workers = min(32, utils.cpu_count()+4)
120
121 logging.info(f"Setting asyncio max_workers as {self.max_asyncio_workers}")
122 asyncio.get_event_loop().set_default_executor(
123 concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
124
125 self._http_server = tornado.httpserver.HTTPServer(
126 self.create_application(), max_buffer_size=self.max_buffer_size)
127
128 logging.info("Listening on port %s", self.http_port)
129 self._http_server.bind(self.http_port)
130 logging.info("Will fork %d workers", self.workers)
131 self._http_server.start(self.workers)
132
133 # Need to start the IOLoop after workers have been started
134 # https://github.com/tornadoweb/tornado/issues/2426
135 # The nest_asyncio package needs to be installed by the downstream module
136 if nest_asyncio:
137 import nest_asyncio
138 nest_asyncio.apply()
139
140 tornado.ioloop.IOLoop.current().start()
141
142 def register_model_handle(self, name: str, model_handle: RayServeHandle):
143 self.registered_models.update_handle(name, model_handle)
144 logging.info("Registering model handle: %s", name)
145
146 def register_model(self, model: KFModel):
147 if not model.name:
148 raise Exception(
149 "Failed to register model, model.name must be provided.")
150 self.registered_models.update(model)
151 logging.info("Registering model: %s", model.name)
152
153
154 class LivenessHandler(tornado.web.RequestHandler): # pylint:disable=too-few-public-methods
155 def get(self):
156 self.write("Alive")
157
158
159 class HealthHandler(tornado.web.RequestHandler):
160 def initialize(self, models: KFModelRepository):
161 self.models = models # pylint:disable=attribute-defined-outside-init
162
163 def get(self, name: str):
164 model = self.models.get_model(name)
165 if model is None:
166 raise tornado.web.HTTPError(
167 status_code=404,
168 reason="Model with name %s does not exist." % name
169 )
170
171 if not self.models.is_model_ready(name):
172 raise tornado.web.HTTPError(
173 status_code=503,
174 reason="Model with name %s is not ready." % name
175 )
176
177 self.write(json.dumps({
178 "name": model.name,
179 "ready": model.ready
180 }))
181
182
183 class ListHandler(tornado.web.RequestHandler):
184 def initialize(self, models: KFModelRepository):
185 self.models = models # pylint:disable=attribute-defined-outside-init
186
187 def get(self):
188 self.write(json.dumps([ob.name for ob in self.models.get_models()]))
189
190
191 class LoadHandler(tornado.web.RequestHandler):
192 def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init
193 self.models = models
194
195 async def post(self, name: str):
196 try:
197 if inspect.iscoroutinefunction(self.models.load):
198 await self.models.load(name)
199 else:
200 self.models.load(name)
201 except Exception:
202 ex_type, ex_value, ex_traceback = sys.exc_info()
203 raise tornado.web.HTTPError(
204 status_code=500,
205 reason=f"Model with name {name} is not ready. "
206 f"Error type: {ex_type} error msg: {ex_value}"
207 )
208
209 if not self.models.is_model_ready(name):
210 raise tornado.web.HTTPError(
211 status_code=503,
212 reason=f"Model with name {name} is not ready."
213 )
214 self.write(json.dumps({
215 "name": name,
216 "load": True
217 }))
218
219
220 class UnloadHandler(tornado.web.RequestHandler):
221 def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init
222 self.models = models
223
224 def post(self, name: str):
225 try:
226 self.models.unload(name)
227 except KeyError:
228 raise tornado.web.HTTPError(
229 status_code=404,
230 reason="Model with name %s does not exist." % name
231 )
232 self.write(json.dumps({
233 "name": name,
234 "unload": True
235 }))
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/kfserving/kfserving/kfserver.py b/python/kfserving/kfserving/kfserver.py
--- a/python/kfserving/kfserving/kfserver.py
+++ b/python/kfserving/kfserving/kfserver.py
@@ -29,7 +29,7 @@
from kfserving.handlers.http import PredictHandler, ExplainHandler
from kfserving import KFModel
from kfserving.kfmodel_repository import KFModelRepository
-from ray.serve.api import RayServeHandle, ServeDeployment
+from ray.serve.api import Deployment, RayServeHandle
from ray import serve
DEFAULT_HTTP_PORT = 8080
@@ -95,7 +95,7 @@
UnloadHandler, dict(models=self.registered_models)),
])
- def start(self, models: Union[List[KFModel], Dict[str, ServeDeployment]], nest_asyncio: bool = False):
+ def start(self, models: Union[List[KFModel], Dict[str, Deployment]], nest_asyncio: bool = False):
if isinstance(models, list):
for model in models:
if isinstance(model, KFModel):
@@ -103,7 +103,7 @@
else:
raise RuntimeError("Model type should be KFModel")
elif isinstance(models, dict):
- if all([issubclass(v, ServeDeployment) for v in models.values()]):
+ if all([issubclass(v, Deployment) for v in models.values()]):
serve.start(detached=True, http_host='0.0.0.0', http_port=9071)
for key in models:
models[key].deploy()
diff --git a/python/kfserving/setup.py b/python/kfserving/setup.py
--- a/python/kfserving/setup.py
+++ b/python/kfserving/setup.py
@@ -25,7 +25,7 @@
setuptools.setup(
name='kfserving',
- version='0.6.0',
+ version='0.6.1',
author="Kubeflow Authors",
author_email='[email protected], [email protected], [email protected]',
license="Apache License Version 2.0",
|
{"golden_diff": "diff --git a/python/kfserving/kfserving/kfserver.py b/python/kfserving/kfserving/kfserver.py\n--- a/python/kfserving/kfserving/kfserver.py\n+++ b/python/kfserving/kfserving/kfserver.py\n@@ -29,7 +29,7 @@\n from kfserving.handlers.http import PredictHandler, ExplainHandler\n from kfserving import KFModel\n from kfserving.kfmodel_repository import KFModelRepository\n-from ray.serve.api import RayServeHandle, ServeDeployment\n+from ray.serve.api import Deployment, RayServeHandle\n from ray import serve\n \n DEFAULT_HTTP_PORT = 8080\n@@ -95,7 +95,7 @@\n UnloadHandler, dict(models=self.registered_models)),\n ])\n \n- def start(self, models: Union[List[KFModel], Dict[str, ServeDeployment]], nest_asyncio: bool = False):\n+ def start(self, models: Union[List[KFModel], Dict[str, Deployment]], nest_asyncio: bool = False):\n if isinstance(models, list):\n for model in models:\n if isinstance(model, KFModel):\n@@ -103,7 +103,7 @@\n else:\n raise RuntimeError(\"Model type should be KFModel\")\n elif isinstance(models, dict):\n- if all([issubclass(v, ServeDeployment) for v in models.values()]):\n+ if all([issubclass(v, Deployment) for v in models.values()]):\n serve.start(detached=True, http_host='0.0.0.0', http_port=9071)\n for key in models:\n models[key].deploy()\ndiff --git a/python/kfserving/setup.py b/python/kfserving/setup.py\n--- a/python/kfserving/setup.py\n+++ b/python/kfserving/setup.py\n@@ -25,7 +25,7 @@\n \n setuptools.setup(\n name='kfserving',\n- version='0.6.0',\n+ version='0.6.1',\n author=\"Kubeflow Authors\",\n author_email='[email protected], [email protected], [email protected]',\n license=\"Apache License Version 2.0\",\n", "issue": "kfserving==0.6.0 python package doesn't work with Python 3.9\n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\npip3 install kfserving==0.6.0 leads to a ray[serve] install failure, probably due to:\r\nhttps://github.com/ray-project/tune-sklearn/issues/169\r\n\r\nThis happens only with Python 3.9\r\n\r\n\r\n**What did you expect to happen:**\r\npip3 packages installed correctly without errors\r\n\r\n\r\n**Anything else you would like to add:**\r\n[Miscellaneous information that will assist in solving the issue.]\r\n\r\n\r\n**Environment:**\r\n\r\n- Istio Version:\r\n- Knative Version:\r\n- KFServing Version: 0.6.0\r\n- Kubeflow version: \r\n- Kfdef:[k8s_istio/istio_dex/gcp_basic_auth/gcp_iap/aws/aws_cognito/ibm]\r\n- Minikube version:\r\n- Kubernetes version: (use `kubectl version`):\r\n- OS (e.g. from `/etc/os-release`):\r\n\n", "before_files": [{"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport setuptools\n\nTESTS_REQUIRES = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nwith open('requirements.txt') as f:\n REQUIRES = f.readlines()\n\nsetuptools.setup(\n name='kfserving',\n version='0.6.0',\n author=\"Kubeflow Authors\",\n author_email='[email protected], [email protected], [email protected]',\n license=\"Apache License Version 2.0\",\n url=\"https://github.com/kubeflow/kfserving/tree/master/python/kfserving\",\n description=\"KFServing Python SDK\",\n long_description=\"Python SDK for KFServing Server and Client.\",\n python_requires='>=3.6',\n packages=[\n 'kfserving',\n 'kfserving.api',\n 'kfserving.constants',\n 'kfserving.models',\n 'kfserving.handlers',\n 'kfserving.utils',\n ],\n package_data={'': ['requirements.txt']},\n include_package_data=True,\n zip_safe=False,\n classifiers=[\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n install_requires=REQUIRES,\n tests_require=TESTS_REQUIRES,\n extras_require={'test': TESTS_REQUIRES}\n)\n", "path": "python/kfserving/setup.py"}, {"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nimport json\nimport inspect\nimport sys\nfrom typing import List, Optional, Dict, Union\nimport tornado.ioloop\nimport tornado.web\nimport tornado.httpserver\nimport tornado.log\nimport asyncio\nfrom tornado import concurrent\nfrom .utils import utils\n\nfrom kfserving.handlers.http import PredictHandler, ExplainHandler\nfrom kfserving import KFModel\nfrom kfserving.kfmodel_repository import KFModelRepository\nfrom ray.serve.api import RayServeHandle, ServeDeployment\nfrom ray import serve\n\nDEFAULT_HTTP_PORT = 8080\nDEFAULT_GRPC_PORT = 8081\nDEFAULT_MAX_BUFFER_SIZE = 104857600\n\nparser = argparse.ArgumentParser(add_help=False)\nparser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,\n help='The HTTP Port listened to by the model server.')\nparser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,\n help='The GRPC Port listened to by the model server.')\nparser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,\n help='The max buffer size for tornado.')\nparser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\nparser.add_argument('--max_asyncio_workers', default=None, type=int,\n help='Max number of asyncio workers to spawn')\nargs, _ = parser.parse_known_args()\n\ntornado.log.enable_pretty_logging()\n\n\nclass KFServer:\n def __init__(self, http_port: int = args.http_port,\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n max_asyncio_workers: int = args.max_asyncio_workers,\n registered_models: KFModelRepository = KFModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n self.max_asyncio_workers = max_asyncio_workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n\n def create_application(self):\n return tornado.web.Application([\n # Server Liveness API returns 200 if server is alive.\n (r\"/\", LivenessHandler),\n (r\"/v2/health/live\", LivenessHandler),\n (r\"/v1/models\",\n ListHandler, dict(models=self.registered_models)),\n (r\"/v2/models\",\n ListHandler, dict(models=self.registered_models)),\n # Model Health API returns 200 if model is ready to serve.\n (r\"/v1/models/([a-zA-Z0-9_-]+)\",\n HealthHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/status\",\n HealthHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):predict\",\n PredictHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/infer\",\n PredictHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):explain\",\n ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/explain\",\n ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/load\",\n LoadHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/unload\",\n UnloadHandler, dict(models=self.registered_models)),\n ])\n\n def start(self, models: Union[List[KFModel], Dict[str, ServeDeployment]], nest_asyncio: bool = False):\n if isinstance(models, list):\n for model in models:\n if isinstance(model, KFModel):\n self.register_model(model)\n else:\n raise RuntimeError(\"Model type should be KFModel\")\n elif isinstance(models, dict):\n if all([issubclass(v, ServeDeployment) for v in models.values()]):\n serve.start(detached=True, http_host='0.0.0.0', http_port=9071)\n for key in models:\n models[key].deploy()\n handle = models[key].get_handle()\n self.register_model_handle(key, handle)\n else:\n raise RuntimeError(\"Model type should be RayServe Deployment\")\n else:\n raise RuntimeError(\"Unknown model collection types\")\n\n if self.max_asyncio_workers is None:\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n\n logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n asyncio.get_event_loop().set_default_executor(\n concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n\n logging.info(\"Listening on port %s\", self.http_port)\n self._http_server.bind(self.http_port)\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n if nest_asyncio:\n import nest_asyncio\n nest_asyncio.apply()\n\n tornado.ioloop.IOLoop.current().start()\n\n def register_model_handle(self, name: str, model_handle: RayServeHandle):\n self.registered_models.update_handle(name, model_handle)\n logging.info(\"Registering model handle: %s\", name)\n\n def register_model(self, model: KFModel):\n if not model.name:\n raise Exception(\n \"Failed to register model, model.name must be provided.\")\n self.registered_models.update(model)\n logging.info(\"Registering model: %s\", model.name)\n\n\nclass LivenessHandler(tornado.web.RequestHandler): # pylint:disable=too-few-public-methods\n def get(self):\n self.write(\"Alive\")\n\n\nclass HealthHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository):\n self.models = models # pylint:disable=attribute-defined-outside-init\n\n def get(self, name: str):\n model = self.models.get_model(name)\n if model is None:\n raise tornado.web.HTTPError(\n status_code=404,\n reason=\"Model with name %s does not exist.\" % name\n )\n\n if not self.models.is_model_ready(name):\n raise tornado.web.HTTPError(\n status_code=503,\n reason=\"Model with name %s is not ready.\" % name\n )\n\n self.write(json.dumps({\n \"name\": model.name,\n \"ready\": model.ready\n }))\n\n\nclass ListHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository):\n self.models = models # pylint:disable=attribute-defined-outside-init\n\n def get(self):\n self.write(json.dumps([ob.name for ob in self.models.get_models()]))\n\n\nclass LoadHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init\n self.models = models\n\n async def post(self, name: str):\n try:\n if inspect.iscoroutinefunction(self.models.load):\n await self.models.load(name)\n else:\n self.models.load(name)\n except Exception:\n ex_type, ex_value, ex_traceback = sys.exc_info()\n raise tornado.web.HTTPError(\n status_code=500,\n reason=f\"Model with name {name} is not ready. \"\n f\"Error type: {ex_type} error msg: {ex_value}\"\n )\n\n if not self.models.is_model_ready(name):\n raise tornado.web.HTTPError(\n status_code=503,\n reason=f\"Model with name {name} is not ready.\"\n )\n self.write(json.dumps({\n \"name\": name,\n \"load\": True\n }))\n\n\nclass UnloadHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init\n self.models = models\n\n def post(self, name: str):\n try:\n self.models.unload(name)\n except KeyError:\n raise tornado.web.HTTPError(\n status_code=404,\n reason=\"Model with name %s does not exist.\" % name\n )\n self.write(json.dumps({\n \"name\": name,\n \"unload\": True\n }))\n", "path": "python/kfserving/kfserving/kfserver.py"}], "after_files": [{"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport setuptools\n\nTESTS_REQUIRES = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nwith open('requirements.txt') as f:\n REQUIRES = f.readlines()\n\nsetuptools.setup(\n name='kfserving',\n version='0.6.1',\n author=\"Kubeflow Authors\",\n author_email='[email protected], [email protected], [email protected]',\n license=\"Apache License Version 2.0\",\n url=\"https://github.com/kubeflow/kfserving/tree/master/python/kfserving\",\n description=\"KFServing Python SDK\",\n long_description=\"Python SDK for KFServing Server and Client.\",\n python_requires='>=3.6',\n packages=[\n 'kfserving',\n 'kfserving.api',\n 'kfserving.constants',\n 'kfserving.models',\n 'kfserving.handlers',\n 'kfserving.utils',\n ],\n package_data={'': ['requirements.txt']},\n include_package_data=True,\n zip_safe=False,\n classifiers=[\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n install_requires=REQUIRES,\n tests_require=TESTS_REQUIRES,\n extras_require={'test': TESTS_REQUIRES}\n)\n", "path": "python/kfserving/setup.py"}, {"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nimport json\nimport inspect\nimport sys\nfrom typing import List, Optional, Dict, Union\nimport tornado.ioloop\nimport tornado.web\nimport tornado.httpserver\nimport tornado.log\nimport asyncio\nfrom tornado import concurrent\nfrom .utils import utils\n\nfrom kfserving.handlers.http import PredictHandler, ExplainHandler\nfrom kfserving import KFModel\nfrom kfserving.kfmodel_repository import KFModelRepository\nfrom ray.serve.api import Deployment, RayServeHandle\nfrom ray import serve\n\nDEFAULT_HTTP_PORT = 8080\nDEFAULT_GRPC_PORT = 8081\nDEFAULT_MAX_BUFFER_SIZE = 104857600\n\nparser = argparse.ArgumentParser(add_help=False)\nparser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,\n help='The HTTP Port listened to by the model server.')\nparser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,\n help='The GRPC Port listened to by the model server.')\nparser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,\n help='The max buffer size for tornado.')\nparser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\nparser.add_argument('--max_asyncio_workers', default=None, type=int,\n help='Max number of asyncio workers to spawn')\nargs, _ = parser.parse_known_args()\n\ntornado.log.enable_pretty_logging()\n\n\nclass KFServer:\n def __init__(self, http_port: int = args.http_port,\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n max_asyncio_workers: int = args.max_asyncio_workers,\n registered_models: KFModelRepository = KFModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n self.max_asyncio_workers = max_asyncio_workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n\n def create_application(self):\n return tornado.web.Application([\n # Server Liveness API returns 200 if server is alive.\n (r\"/\", LivenessHandler),\n (r\"/v2/health/live\", LivenessHandler),\n (r\"/v1/models\",\n ListHandler, dict(models=self.registered_models)),\n (r\"/v2/models\",\n ListHandler, dict(models=self.registered_models)),\n # Model Health API returns 200 if model is ready to serve.\n (r\"/v1/models/([a-zA-Z0-9_-]+)\",\n HealthHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/status\",\n HealthHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):predict\",\n PredictHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/infer\",\n PredictHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):explain\",\n ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/explain\",\n ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/load\",\n LoadHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/unload\",\n UnloadHandler, dict(models=self.registered_models)),\n ])\n\n def start(self, models: Union[List[KFModel], Dict[str, Deployment]], nest_asyncio: bool = False):\n if isinstance(models, list):\n for model in models:\n if isinstance(model, KFModel):\n self.register_model(model)\n else:\n raise RuntimeError(\"Model type should be KFModel\")\n elif isinstance(models, dict):\n if all([issubclass(v, Deployment) for v in models.values()]):\n serve.start(detached=True, http_host='0.0.0.0', http_port=9071)\n for key in models:\n models[key].deploy()\n handle = models[key].get_handle()\n self.register_model_handle(key, handle)\n else:\n raise RuntimeError(\"Model type should be RayServe Deployment\")\n else:\n raise RuntimeError(\"Unknown model collection types\")\n\n if self.max_asyncio_workers is None:\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n\n logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n asyncio.get_event_loop().set_default_executor(\n concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n\n logging.info(\"Listening on port %s\", self.http_port)\n self._http_server.bind(self.http_port)\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n if nest_asyncio:\n import nest_asyncio\n nest_asyncio.apply()\n\n tornado.ioloop.IOLoop.current().start()\n\n def register_model_handle(self, name: str, model_handle: RayServeHandle):\n self.registered_models.update_handle(name, model_handle)\n logging.info(\"Registering model handle: %s\", name)\n\n def register_model(self, model: KFModel):\n if not model.name:\n raise Exception(\n \"Failed to register model, model.name must be provided.\")\n self.registered_models.update(model)\n logging.info(\"Registering model: %s\", model.name)\n\n\nclass LivenessHandler(tornado.web.RequestHandler): # pylint:disable=too-few-public-methods\n def get(self):\n self.write(\"Alive\")\n\n\nclass HealthHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository):\n self.models = models # pylint:disable=attribute-defined-outside-init\n\n def get(self, name: str):\n model = self.models.get_model(name)\n if model is None:\n raise tornado.web.HTTPError(\n status_code=404,\n reason=\"Model with name %s does not exist.\" % name\n )\n\n if not self.models.is_model_ready(name):\n raise tornado.web.HTTPError(\n status_code=503,\n reason=\"Model with name %s is not ready.\" % name\n )\n\n self.write(json.dumps({\n \"name\": model.name,\n \"ready\": model.ready\n }))\n\n\nclass ListHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository):\n self.models = models # pylint:disable=attribute-defined-outside-init\n\n def get(self):\n self.write(json.dumps([ob.name for ob in self.models.get_models()]))\n\n\nclass LoadHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init\n self.models = models\n\n async def post(self, name: str):\n try:\n if inspect.iscoroutinefunction(self.models.load):\n await self.models.load(name)\n else:\n self.models.load(name)\n except Exception:\n ex_type, ex_value, ex_traceback = sys.exc_info()\n raise tornado.web.HTTPError(\n status_code=500,\n reason=f\"Model with name {name} is not ready. \"\n f\"Error type: {ex_type} error msg: {ex_value}\"\n )\n\n if not self.models.is_model_ready(name):\n raise tornado.web.HTTPError(\n status_code=503,\n reason=f\"Model with name {name} is not ready.\"\n )\n self.write(json.dumps({\n \"name\": name,\n \"load\": True\n }))\n\n\nclass UnloadHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init\n self.models = models\n\n def post(self, name: str):\n try:\n self.models.unload(name)\n except KeyError:\n raise tornado.web.HTTPError(\n status_code=404,\n reason=\"Model with name %s does not exist.\" % name\n )\n self.write(json.dumps({\n \"name\": name,\n \"unload\": True\n }))\n", "path": "python/kfserving/kfserving/kfserver.py"}]}
| 3,830 | 490 |
gh_patches_debug_36632
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-2974
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Education Exam/Summary count incorrect.
### Describe the bug
For some courses it says there are >500 documents. That's clearly not correct. Something seems to be wrong here: https://github.com/svthalia/concrexit/blob/ce784be158c2e26afa9d389d67065db1cb1a716c/website/education/views.py#L48-L58
### How to reproduce
Go to https://thalia.nu/education/courses/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/education/views.py`
Content:
```
1 """Views provided by the education package."""
2 import os
3 from datetime import date, datetime
4
5 from django.contrib.auth.decorators import login_required
6 from django.contrib.messages.views import SuccessMessageMixin
7 from django.core.exceptions import PermissionDenied
8 from django.db.models import Count
9 from django.http import HttpResponse
10 from django.shortcuts import redirect
11 from django.urls import reverse_lazy
12 from django.utils import timezone
13 from django.utils.decorators import method_decorator
14 from django.utils.translation import gettext_lazy as _
15 from django.views.generic import CreateView, DetailView, ListView, TemplateView
16
17 from members.decorators import membership_required
18 from utils.media.services import get_media_url
19
20 from . import emails
21 from .forms import AddExamForm, AddSummaryForm
22 from .models import Category, Course, Exam, Summary
23
24
25 class CourseIndexView(ListView):
26 """Render an overview of the courses."""
27
28 queryset = (
29 Course.objects.filter(until=None)
30 .prefetch_related("categories", "old_courses")
31 .annotate(summary_count=Count("summary"))
32 .annotate(exam_count=Count("exam"))
33 )
34 template_name = "education/courses.html"
35
36 def get_ordering(self) -> str:
37 return "name"
38
39 def get_context_data(self, **kwargs) -> dict:
40 context = super().get_context_data(**kwargs)
41 context.update(
42 {
43 "courses": (
44 {
45 "course_code": x.course_code,
46 "name": x.name,
47 "categories": x.categories.all(),
48 "document_count": sum(
49 [
50 x.summary_count,
51 x.exam_count,
52 ]
53 + [
54 c.summary_set.filter(accepted=True).count()
55 + c.exam_set.filter(accepted=True).count()
56 for c in x.old_courses.all()
57 ]
58 ),
59 "url": x.get_absolute_url(),
60 }
61 for x in context["object_list"]
62 ),
63 "categories": Category.objects.all(),
64 }
65 )
66 return context
67
68
69 class CourseDetailView(DetailView):
70 """Render the detail page of one specific course."""
71
72 model = Course
73 context_object_name = "course"
74 template_name = "education/course.html"
75
76 def get_context_data(self, **kwargs) -> dict:
77 context = super().get_context_data(**kwargs)
78 obj = context["course"]
79 courses = list(obj.old_courses.all())
80 courses.append(obj)
81 items = {}
82 for course in courses:
83 for summary in course.summary_set.filter(accepted=True):
84 if summary.year not in items:
85 items[summary.year] = {
86 "summaries": [],
87 "exams": [],
88 "legacy": course if course.pk != obj.pk else None,
89 }
90 items[summary.year]["summaries"].append(
91 {
92 "year": summary.year,
93 "name": summary.name,
94 "language": summary.language,
95 "id": summary.id,
96 }
97 )
98 for exam in course.exam_set.filter(accepted=True):
99 if exam.year not in items:
100 items[exam.year] = {
101 "summaries": [],
102 "exams": [],
103 "legacy": course if course.pk != obj.pk else None,
104 }
105 items[exam.year]["exams"].append(
106 {
107 "type": "exam",
108 "year": exam.year,
109 "name": f"{exam.get_type_display()} {exam.name}",
110 "language": exam.language,
111 "id": exam.id,
112 }
113 )
114 context.update({"items": sorted(items.items(), key=lambda x: x[0])})
115 return context
116
117
118 @method_decorator(login_required, "dispatch")
119 @method_decorator(membership_required, "dispatch")
120 class ExamDetailView(DetailView):
121 """Fetch and output the specified exam."""
122
123 model = Exam
124
125 def get(self, request, *args, **kwargs) -> HttpResponse:
126 response = super().get(request, *args, **kwargs)
127 obj = response.context_data["object"]
128 obj.download_count += 1
129 obj.save()
130
131 ext = os.path.splitext(obj.file.name)[1]
132 filename = f"{obj.course.name}-summary{obj.year}{ext}"
133 return redirect(get_media_url(obj.file, filename))
134
135
136 @method_decorator(login_required, "dispatch")
137 @method_decorator(membership_required, "dispatch")
138 class SummaryDetailView(DetailView):
139 """Fetch and output the specified summary."""
140
141 model = Summary
142
143 def get(self, request, *args, **kwargs) -> HttpResponse:
144 response = super().get(request, *args, **kwargs)
145 obj = response.context_data["object"]
146 obj.download_count += 1
147 obj.save()
148
149 ext = os.path.splitext(obj.file.name)[1]
150 filename = f"{obj.course.name}-summary{obj.year}{ext}"
151 return redirect(get_media_url(obj.file, filename))
152
153
154 @method_decorator(login_required, "dispatch")
155 @method_decorator(membership_required, "dispatch")
156 class ExamCreateView(SuccessMessageMixin, CreateView):
157 """Render the form to submit a new exam."""
158
159 model = Exam
160 form_class = AddExamForm
161 template_name = "education/add_exam.html"
162 success_url = reverse_lazy("education:submit-exam")
163 success_message = _("Exam submitted successfully.")
164
165 def get_initial(self) -> dict:
166 initial = super().get_initial()
167 initial["exam_date"] = date.today()
168 initial["course"] = self.kwargs.get("pk", None)
169 return initial
170
171 def form_valid(self, form) -> HttpResponse:
172 self.object = form.save(commit=False)
173 self.object.uploader = self.request.member
174 self.object.uploader_date = datetime.now()
175 self.object.save()
176 emails.send_document_notification(self.object)
177 return super().form_valid(form)
178
179
180 @method_decorator(login_required, "dispatch")
181 @method_decorator(membership_required, "dispatch")
182 class SummaryCreateView(SuccessMessageMixin, CreateView):
183 """Render the form to submit a new summary."""
184
185 model = Summary
186 form_class = AddSummaryForm
187 template_name = "education/add_summary.html"
188 success_url = reverse_lazy("education:submit-summary")
189 success_message = _("Summary submitted successfully.")
190
191 def get_initial(self):
192 initial = super().get_initial()
193 initial["author"] = self.request.member.get_full_name()
194 initial["course"] = self.kwargs.get("pk", None)
195 return initial
196
197 def form_valid(self, form) -> HttpResponse:
198 self.object = form.save(commit=False)
199 self.object.uploader = self.request.member
200 self.object.uploader_date = datetime.now()
201 self.object.save()
202 emails.send_document_notification(self.object)
203 return super().form_valid(form)
204
205
206 @method_decorator(login_required, "dispatch")
207 class BookInfoView(TemplateView):
208 """Render a page with information about book sale.
209
210 Only available to members and to-be members
211 """
212
213 template_name = "education/books.html"
214
215 def dispatch(self, request, *args, **kwargs) -> HttpResponse:
216 if request.member.has_active_membership() or (
217 request.member.earliest_membership
218 and request.member.earliest_membership.since > timezone.now().date()
219 ):
220 return super().dispatch(request, *args, **kwargs)
221 raise PermissionDenied
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/education/views.py b/website/education/views.py
--- a/website/education/views.py
+++ b/website/education/views.py
@@ -5,7 +5,6 @@
from django.contrib.auth.decorators import login_required
from django.contrib.messages.views import SuccessMessageMixin
from django.core.exceptions import PermissionDenied
-from django.db.models import Count
from django.http import HttpResponse
from django.shortcuts import redirect
from django.urls import reverse_lazy
@@ -25,11 +24,8 @@
class CourseIndexView(ListView):
"""Render an overview of the courses."""
- queryset = (
- Course.objects.filter(until=None)
- .prefetch_related("categories", "old_courses")
- .annotate(summary_count=Count("summary"))
- .annotate(exam_count=Count("exam"))
+ queryset = Course.objects.filter(until=None).prefetch_related(
+ "categories", "old_courses"
)
template_name = "education/courses.html"
@@ -40,15 +36,15 @@
context = super().get_context_data(**kwargs)
context.update(
{
- "courses": (
+ "courses": [
{
"course_code": x.course_code,
"name": x.name,
"categories": x.categories.all(),
"document_count": sum(
[
- x.summary_count,
- x.exam_count,
+ x.summary_set.filter(accepted=True).count(),
+ x.exam_set.filter(accepted=True).count(),
]
+ [
c.summary_set.filter(accepted=True).count()
@@ -59,7 +55,7 @@
"url": x.get_absolute_url(),
}
for x in context["object_list"]
- ),
+ ],
"categories": Category.objects.all(),
}
)
|
{"golden_diff": "diff --git a/website/education/views.py b/website/education/views.py\n--- a/website/education/views.py\n+++ b/website/education/views.py\n@@ -5,7 +5,6 @@\n from django.contrib.auth.decorators import login_required\n from django.contrib.messages.views import SuccessMessageMixin\n from django.core.exceptions import PermissionDenied\n-from django.db.models import Count\n from django.http import HttpResponse\n from django.shortcuts import redirect\n from django.urls import reverse_lazy\n@@ -25,11 +24,8 @@\n class CourseIndexView(ListView):\n \"\"\"Render an overview of the courses.\"\"\"\n \n- queryset = (\n- Course.objects.filter(until=None)\n- .prefetch_related(\"categories\", \"old_courses\")\n- .annotate(summary_count=Count(\"summary\"))\n- .annotate(exam_count=Count(\"exam\"))\n+ queryset = Course.objects.filter(until=None).prefetch_related(\n+ \"categories\", \"old_courses\"\n )\n template_name = \"education/courses.html\"\n \n@@ -40,15 +36,15 @@\n context = super().get_context_data(**kwargs)\n context.update(\n {\n- \"courses\": (\n+ \"courses\": [\n {\n \"course_code\": x.course_code,\n \"name\": x.name,\n \"categories\": x.categories.all(),\n \"document_count\": sum(\n [\n- x.summary_count,\n- x.exam_count,\n+ x.summary_set.filter(accepted=True).count(),\n+ x.exam_set.filter(accepted=True).count(),\n ]\n + [\n c.summary_set.filter(accepted=True).count()\n@@ -59,7 +55,7 @@\n \"url\": x.get_absolute_url(),\n }\n for x in context[\"object_list\"]\n- ),\n+ ],\n \"categories\": Category.objects.all(),\n }\n )\n", "issue": "Education Exam/Summary count incorrect.\n### Describe the bug\r\nFor some courses it says there are >500 documents. That's clearly not correct. Something seems to be wrong here: https://github.com/svthalia/concrexit/blob/ce784be158c2e26afa9d389d67065db1cb1a716c/website/education/views.py#L48-L58\r\n\r\n### How to reproduce\r\nGo to https://thalia.nu/education/courses/\r\n\n", "before_files": [{"content": "\"\"\"Views provided by the education package.\"\"\"\nimport os\nfrom datetime import date, datetime\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.core.exceptions import PermissionDenied\nfrom django.db.models import Count\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect\nfrom django.urls import reverse_lazy\nfrom django.utils import timezone\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.generic import CreateView, DetailView, ListView, TemplateView\n\nfrom members.decorators import membership_required\nfrom utils.media.services import get_media_url\n\nfrom . import emails\nfrom .forms import AddExamForm, AddSummaryForm\nfrom .models import Category, Course, Exam, Summary\n\n\nclass CourseIndexView(ListView):\n \"\"\"Render an overview of the courses.\"\"\"\n\n queryset = (\n Course.objects.filter(until=None)\n .prefetch_related(\"categories\", \"old_courses\")\n .annotate(summary_count=Count(\"summary\"))\n .annotate(exam_count=Count(\"exam\"))\n )\n template_name = \"education/courses.html\"\n\n def get_ordering(self) -> str:\n return \"name\"\n\n def get_context_data(self, **kwargs) -> dict:\n context = super().get_context_data(**kwargs)\n context.update(\n {\n \"courses\": (\n {\n \"course_code\": x.course_code,\n \"name\": x.name,\n \"categories\": x.categories.all(),\n \"document_count\": sum(\n [\n x.summary_count,\n x.exam_count,\n ]\n + [\n c.summary_set.filter(accepted=True).count()\n + c.exam_set.filter(accepted=True).count()\n for c in x.old_courses.all()\n ]\n ),\n \"url\": x.get_absolute_url(),\n }\n for x in context[\"object_list\"]\n ),\n \"categories\": Category.objects.all(),\n }\n )\n return context\n\n\nclass CourseDetailView(DetailView):\n \"\"\"Render the detail page of one specific course.\"\"\"\n\n model = Course\n context_object_name = \"course\"\n template_name = \"education/course.html\"\n\n def get_context_data(self, **kwargs) -> dict:\n context = super().get_context_data(**kwargs)\n obj = context[\"course\"]\n courses = list(obj.old_courses.all())\n courses.append(obj)\n items = {}\n for course in courses:\n for summary in course.summary_set.filter(accepted=True):\n if summary.year not in items:\n items[summary.year] = {\n \"summaries\": [],\n \"exams\": [],\n \"legacy\": course if course.pk != obj.pk else None,\n }\n items[summary.year][\"summaries\"].append(\n {\n \"year\": summary.year,\n \"name\": summary.name,\n \"language\": summary.language,\n \"id\": summary.id,\n }\n )\n for exam in course.exam_set.filter(accepted=True):\n if exam.year not in items:\n items[exam.year] = {\n \"summaries\": [],\n \"exams\": [],\n \"legacy\": course if course.pk != obj.pk else None,\n }\n items[exam.year][\"exams\"].append(\n {\n \"type\": \"exam\",\n \"year\": exam.year,\n \"name\": f\"{exam.get_type_display()} {exam.name}\",\n \"language\": exam.language,\n \"id\": exam.id,\n }\n )\n context.update({\"items\": sorted(items.items(), key=lambda x: x[0])})\n return context\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass ExamDetailView(DetailView):\n \"\"\"Fetch and output the specified exam.\"\"\"\n\n model = Exam\n\n def get(self, request, *args, **kwargs) -> HttpResponse:\n response = super().get(request, *args, **kwargs)\n obj = response.context_data[\"object\"]\n obj.download_count += 1\n obj.save()\n\n ext = os.path.splitext(obj.file.name)[1]\n filename = f\"{obj.course.name}-summary{obj.year}{ext}\"\n return redirect(get_media_url(obj.file, filename))\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass SummaryDetailView(DetailView):\n \"\"\"Fetch and output the specified summary.\"\"\"\n\n model = Summary\n\n def get(self, request, *args, **kwargs) -> HttpResponse:\n response = super().get(request, *args, **kwargs)\n obj = response.context_data[\"object\"]\n obj.download_count += 1\n obj.save()\n\n ext = os.path.splitext(obj.file.name)[1]\n filename = f\"{obj.course.name}-summary{obj.year}{ext}\"\n return redirect(get_media_url(obj.file, filename))\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass ExamCreateView(SuccessMessageMixin, CreateView):\n \"\"\"Render the form to submit a new exam.\"\"\"\n\n model = Exam\n form_class = AddExamForm\n template_name = \"education/add_exam.html\"\n success_url = reverse_lazy(\"education:submit-exam\")\n success_message = _(\"Exam submitted successfully.\")\n\n def get_initial(self) -> dict:\n initial = super().get_initial()\n initial[\"exam_date\"] = date.today()\n initial[\"course\"] = self.kwargs.get(\"pk\", None)\n return initial\n\n def form_valid(self, form) -> HttpResponse:\n self.object = form.save(commit=False)\n self.object.uploader = self.request.member\n self.object.uploader_date = datetime.now()\n self.object.save()\n emails.send_document_notification(self.object)\n return super().form_valid(form)\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass SummaryCreateView(SuccessMessageMixin, CreateView):\n \"\"\"Render the form to submit a new summary.\"\"\"\n\n model = Summary\n form_class = AddSummaryForm\n template_name = \"education/add_summary.html\"\n success_url = reverse_lazy(\"education:submit-summary\")\n success_message = _(\"Summary submitted successfully.\")\n\n def get_initial(self):\n initial = super().get_initial()\n initial[\"author\"] = self.request.member.get_full_name()\n initial[\"course\"] = self.kwargs.get(\"pk\", None)\n return initial\n\n def form_valid(self, form) -> HttpResponse:\n self.object = form.save(commit=False)\n self.object.uploader = self.request.member\n self.object.uploader_date = datetime.now()\n self.object.save()\n emails.send_document_notification(self.object)\n return super().form_valid(form)\n\n\n@method_decorator(login_required, \"dispatch\")\nclass BookInfoView(TemplateView):\n \"\"\"Render a page with information about book sale.\n\n Only available to members and to-be members\n \"\"\"\n\n template_name = \"education/books.html\"\n\n def dispatch(self, request, *args, **kwargs) -> HttpResponse:\n if request.member.has_active_membership() or (\n request.member.earliest_membership\n and request.member.earliest_membership.since > timezone.now().date()\n ):\n return super().dispatch(request, *args, **kwargs)\n raise PermissionDenied\n", "path": "website/education/views.py"}], "after_files": [{"content": "\"\"\"Views provided by the education package.\"\"\"\nimport os\nfrom datetime import date, datetime\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect\nfrom django.urls import reverse_lazy\nfrom django.utils import timezone\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.generic import CreateView, DetailView, ListView, TemplateView\n\nfrom members.decorators import membership_required\nfrom utils.media.services import get_media_url\n\nfrom . import emails\nfrom .forms import AddExamForm, AddSummaryForm\nfrom .models import Category, Course, Exam, Summary\n\n\nclass CourseIndexView(ListView):\n \"\"\"Render an overview of the courses.\"\"\"\n\n queryset = Course.objects.filter(until=None).prefetch_related(\n \"categories\", \"old_courses\"\n )\n template_name = \"education/courses.html\"\n\n def get_ordering(self) -> str:\n return \"name\"\n\n def get_context_data(self, **kwargs) -> dict:\n context = super().get_context_data(**kwargs)\n context.update(\n {\n \"courses\": [\n {\n \"course_code\": x.course_code,\n \"name\": x.name,\n \"categories\": x.categories.all(),\n \"document_count\": sum(\n [\n x.summary_set.filter(accepted=True).count(),\n x.exam_set.filter(accepted=True).count(),\n ]\n + [\n c.summary_set.filter(accepted=True).count()\n + c.exam_set.filter(accepted=True).count()\n for c in x.old_courses.all()\n ]\n ),\n \"url\": x.get_absolute_url(),\n }\n for x in context[\"object_list\"]\n ],\n \"categories\": Category.objects.all(),\n }\n )\n return context\n\n\nclass CourseDetailView(DetailView):\n \"\"\"Render the detail page of one specific course.\"\"\"\n\n model = Course\n context_object_name = \"course\"\n template_name = \"education/course.html\"\n\n def get_context_data(self, **kwargs) -> dict:\n context = super().get_context_data(**kwargs)\n obj = context[\"course\"]\n courses = list(obj.old_courses.all())\n courses.append(obj)\n items = {}\n for course in courses:\n for summary in course.summary_set.filter(accepted=True):\n if summary.year not in items:\n items[summary.year] = {\n \"summaries\": [],\n \"exams\": [],\n \"legacy\": course if course.pk != obj.pk else None,\n }\n items[summary.year][\"summaries\"].append(\n {\n \"year\": summary.year,\n \"name\": summary.name,\n \"language\": summary.language,\n \"id\": summary.id,\n }\n )\n for exam in course.exam_set.filter(accepted=True):\n if exam.year not in items:\n items[exam.year] = {\n \"summaries\": [],\n \"exams\": [],\n \"legacy\": course if course.pk != obj.pk else None,\n }\n items[exam.year][\"exams\"].append(\n {\n \"type\": \"exam\",\n \"year\": exam.year,\n \"name\": f\"{exam.get_type_display()} {exam.name}\",\n \"language\": exam.language,\n \"id\": exam.id,\n }\n )\n context.update({\"items\": sorted(items.items(), key=lambda x: x[0])})\n return context\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass ExamDetailView(DetailView):\n \"\"\"Fetch and output the specified exam.\"\"\"\n\n model = Exam\n\n def get(self, request, *args, **kwargs) -> HttpResponse:\n response = super().get(request, *args, **kwargs)\n obj = response.context_data[\"object\"]\n obj.download_count += 1\n obj.save()\n\n ext = os.path.splitext(obj.file.name)[1]\n filename = f\"{obj.course.name}-summary{obj.year}{ext}\"\n return redirect(get_media_url(obj.file, filename))\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass SummaryDetailView(DetailView):\n \"\"\"Fetch and output the specified summary.\"\"\"\n\n model = Summary\n\n def get(self, request, *args, **kwargs) -> HttpResponse:\n response = super().get(request, *args, **kwargs)\n obj = response.context_data[\"object\"]\n obj.download_count += 1\n obj.save()\n\n ext = os.path.splitext(obj.file.name)[1]\n filename = f\"{obj.course.name}-summary{obj.year}{ext}\"\n return redirect(get_media_url(obj.file, filename))\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass ExamCreateView(SuccessMessageMixin, CreateView):\n \"\"\"Render the form to submit a new exam.\"\"\"\n\n model = Exam\n form_class = AddExamForm\n template_name = \"education/add_exam.html\"\n success_url = reverse_lazy(\"education:submit-exam\")\n success_message = _(\"Exam submitted successfully.\")\n\n def get_initial(self) -> dict:\n initial = super().get_initial()\n initial[\"exam_date\"] = date.today()\n initial[\"course\"] = self.kwargs.get(\"pk\", None)\n return initial\n\n def form_valid(self, form) -> HttpResponse:\n self.object = form.save(commit=False)\n self.object.uploader = self.request.member\n self.object.uploader_date = datetime.now()\n self.object.save()\n emails.send_document_notification(self.object)\n return super().form_valid(form)\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass SummaryCreateView(SuccessMessageMixin, CreateView):\n \"\"\"Render the form to submit a new summary.\"\"\"\n\n model = Summary\n form_class = AddSummaryForm\n template_name = \"education/add_summary.html\"\n success_url = reverse_lazy(\"education:submit-summary\")\n success_message = _(\"Summary submitted successfully.\")\n\n def get_initial(self):\n initial = super().get_initial()\n initial[\"author\"] = self.request.member.get_full_name()\n initial[\"course\"] = self.kwargs.get(\"pk\", None)\n return initial\n\n def form_valid(self, form) -> HttpResponse:\n self.object = form.save(commit=False)\n self.object.uploader = self.request.member\n self.object.uploader_date = datetime.now()\n self.object.save()\n emails.send_document_notification(self.object)\n return super().form_valid(form)\n\n\n@method_decorator(login_required, \"dispatch\")\nclass BookInfoView(TemplateView):\n \"\"\"Render a page with information about book sale.\n\n Only available to members and to-be members\n \"\"\"\n\n template_name = \"education/books.html\"\n\n def dispatch(self, request, *args, **kwargs) -> HttpResponse:\n if request.member.has_active_membership() or (\n request.member.earliest_membership\n and request.member.earliest_membership.since > timezone.now().date()\n ):\n return super().dispatch(request, *args, **kwargs)\n raise PermissionDenied\n", "path": "website/education/views.py"}]}
| 2,478 | 396 |
gh_patches_debug_17580
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3873
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot use BLAKE2b or BLAKE2s with HMAC
Python 3.6.2 on Ubuntu 17.10
Cryptography and dependencies installed via pip in virtualenv
cffi==1.10.0
cryptography==2.0.3
pip==9.0.1
setuptools==36.2.7
Steps to reproduce:
```
In [1]: from cryptography.hazmat.backends import default_backend
...: from cryptography.hazmat.primitives import hashes
...: from cryptography.hazmat.primitives.hmac import HMAC
...:
...: backend = default_backend()
...:
In [2]: hmac = HMAC(b'\x00'*32, hashes.SHA256(), backend) # just fine
In [3]: hmac = HMAC(b'\x00'*32, hashes.BLAKE2s(digest_size=32), backend)
---------------------------------------------------------------------------
UnsupportedAlgorithm Traceback (most recent call last)
<ipython-input-3-61f273a52c45> in <module>()
----> 1 hmac = HMAC(b'\x00'*32, hashes.BLAKE2s(digest_size=32), backend)
~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/primitives/hmac.py in __init__(self, key, algorithm, backend, ctx)
30 self._key = key
31 if ctx is None:
---> 32 self._ctx = self._backend.create_hmac_ctx(key, self.algorithm)
33 else:
34 self._ctx = ctx
~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/backend.py in create_hmac_ctx(self, key, algorithm)
176
177 def create_hmac_ctx(self, key, algorithm):
--> 178 return _HMACContext(self, key, algorithm)
179
180 def _build_openssl_digest_name(self, algorithm):
~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/hmac.py in __init__(self, backend, key, algorithm, ctx)
32 "{0} is not a supported hash on this backend.".format(
33 algorithm.name),
---> 34 _Reasons.UNSUPPORTED_HASH
35 )
36 res = self._backend._lib.HMAC_Init_ex(
UnsupportedAlgorithm: blake2s is not a supported hash on this backend.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/hazmat/backends/openssl/hmac.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7
8 from cryptography import utils
9 from cryptography.exceptions import (
10 InvalidSignature, UnsupportedAlgorithm, _Reasons
11 )
12 from cryptography.hazmat.primitives import constant_time, hashes, mac
13
14
15 @utils.register_interface(mac.MACContext)
16 @utils.register_interface(hashes.HashContext)
17 class _HMACContext(object):
18 def __init__(self, backend, key, algorithm, ctx=None):
19 self._algorithm = algorithm
20 self._backend = backend
21
22 if ctx is None:
23 ctx = self._backend._lib.Cryptography_HMAC_CTX_new()
24 self._backend.openssl_assert(ctx != self._backend._ffi.NULL)
25 ctx = self._backend._ffi.gc(
26 ctx, self._backend._lib.Cryptography_HMAC_CTX_free
27 )
28 evp_md = self._backend._lib.EVP_get_digestbyname(
29 algorithm.name.encode('ascii'))
30 if evp_md == self._backend._ffi.NULL:
31 raise UnsupportedAlgorithm(
32 "{0} is not a supported hash on this backend.".format(
33 algorithm.name),
34 _Reasons.UNSUPPORTED_HASH
35 )
36 res = self._backend._lib.HMAC_Init_ex(
37 ctx, key, len(key), evp_md, self._backend._ffi.NULL
38 )
39 self._backend.openssl_assert(res != 0)
40
41 self._ctx = ctx
42 self._key = key
43
44 algorithm = utils.read_only_property("_algorithm")
45
46 def copy(self):
47 copied_ctx = self._backend._lib.Cryptography_HMAC_CTX_new()
48 self._backend.openssl_assert(copied_ctx != self._backend._ffi.NULL)
49 copied_ctx = self._backend._ffi.gc(
50 copied_ctx, self._backend._lib.Cryptography_HMAC_CTX_free
51 )
52 res = self._backend._lib.HMAC_CTX_copy(copied_ctx, self._ctx)
53 self._backend.openssl_assert(res != 0)
54 return _HMACContext(
55 self._backend, self._key, self.algorithm, ctx=copied_ctx
56 )
57
58 def update(self, data):
59 res = self._backend._lib.HMAC_Update(self._ctx, data, len(data))
60 self._backend.openssl_assert(res != 0)
61
62 def finalize(self):
63 buf = self._backend._ffi.new("unsigned char[]",
64 self._backend._lib.EVP_MAX_MD_SIZE)
65 outlen = self._backend._ffi.new("unsigned int *")
66 res = self._backend._lib.HMAC_Final(self._ctx, buf, outlen)
67 self._backend.openssl_assert(res != 0)
68 self._backend.openssl_assert(outlen[0] == self.algorithm.digest_size)
69 return self._backend._ffi.buffer(buf)[:outlen[0]]
70
71 def verify(self, signature):
72 digest = self.finalize()
73 if not constant_time.bytes_eq(digest, signature):
74 raise InvalidSignature("Signature did not match digest.")
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/hazmat/backends/openssl/hmac.py b/src/cryptography/hazmat/backends/openssl/hmac.py
--- a/src/cryptography/hazmat/backends/openssl/hmac.py
+++ b/src/cryptography/hazmat/backends/openssl/hmac.py
@@ -25,12 +25,11 @@
ctx = self._backend._ffi.gc(
ctx, self._backend._lib.Cryptography_HMAC_CTX_free
)
- evp_md = self._backend._lib.EVP_get_digestbyname(
- algorithm.name.encode('ascii'))
+ name = self._backend._build_openssl_digest_name(algorithm)
+ evp_md = self._backend._lib.EVP_get_digestbyname(name)
if evp_md == self._backend._ffi.NULL:
raise UnsupportedAlgorithm(
- "{0} is not a supported hash on this backend.".format(
- algorithm.name),
+ "{0} is not a supported hash on this backend".format(name),
_Reasons.UNSUPPORTED_HASH
)
res = self._backend._lib.HMAC_Init_ex(
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/backends/openssl/hmac.py b/src/cryptography/hazmat/backends/openssl/hmac.py\n--- a/src/cryptography/hazmat/backends/openssl/hmac.py\n+++ b/src/cryptography/hazmat/backends/openssl/hmac.py\n@@ -25,12 +25,11 @@\n ctx = self._backend._ffi.gc(\n ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n- evp_md = self._backend._lib.EVP_get_digestbyname(\n- algorithm.name.encode('ascii'))\n+ name = self._backend._build_openssl_digest_name(algorithm)\n+ evp_md = self._backend._lib.EVP_get_digestbyname(name)\n if evp_md == self._backend._ffi.NULL:\n raise UnsupportedAlgorithm(\n- \"{0} is not a supported hash on this backend.\".format(\n- algorithm.name),\n+ \"{0} is not a supported hash on this backend\".format(name),\n _Reasons.UNSUPPORTED_HASH\n )\n res = self._backend._lib.HMAC_Init_ex(\n", "issue": "Cannot use BLAKE2b or BLAKE2s with HMAC\nPython 3.6.2 on Ubuntu 17.10\r\nCryptography and dependencies installed via pip in virtualenv\r\ncffi==1.10.0\r\ncryptography==2.0.3\r\npip==9.0.1\r\nsetuptools==36.2.7\r\n\r\nSteps to reproduce:\r\n```\r\nIn [1]: from cryptography.hazmat.backends import default_backend\r\n ...: from cryptography.hazmat.primitives import hashes\r\n ...: from cryptography.hazmat.primitives.hmac import HMAC\r\n ...: \r\n ...: backend = default_backend()\r\n ...: \r\n\r\nIn [2]: hmac = HMAC(b'\\x00'*32, hashes.SHA256(), backend) # just fine\r\n\r\nIn [3]: hmac = HMAC(b'\\x00'*32, hashes.BLAKE2s(digest_size=32), backend)\r\n---------------------------------------------------------------------------\r\nUnsupportedAlgorithm Traceback (most recent call last)\r\n<ipython-input-3-61f273a52c45> in <module>()\r\n----> 1 hmac = HMAC(b'\\x00'*32, hashes.BLAKE2s(digest_size=32), backend)\r\n\r\n~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/primitives/hmac.py in __init__(self, key, algorithm, backend, ctx)\r\n 30 self._key = key\r\n 31 if ctx is None:\r\n---> 32 self._ctx = self._backend.create_hmac_ctx(key, self.algorithm)\r\n 33 else:\r\n 34 self._ctx = ctx\r\n\r\n~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/backend.py in create_hmac_ctx(self, key, algorithm)\r\n 176 \r\n 177 def create_hmac_ctx(self, key, algorithm):\r\n--> 178 return _HMACContext(self, key, algorithm)\r\n 179 \r\n 180 def _build_openssl_digest_name(self, algorithm):\r\n\r\n~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/hmac.py in __init__(self, backend, key, algorithm, ctx)\r\n 32 \"{0} is not a supported hash on this backend.\".format(\r\n 33 algorithm.name),\r\n---> 34 _Reasons.UNSUPPORTED_HASH\r\n 35 )\r\n 36 res = self._backend._lib.HMAC_Init_ex(\r\n\r\nUnsupportedAlgorithm: blake2s is not a supported hash on this backend.\r\n```\r\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n InvalidSignature, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.primitives import constant_time, hashes, mac\n\n\[email protected]_interface(mac.MACContext)\[email protected]_interface(hashes.HashContext)\nclass _HMACContext(object):\n def __init__(self, backend, key, algorithm, ctx=None):\n self._algorithm = algorithm\n self._backend = backend\n\n if ctx is None:\n ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(ctx != self._backend._ffi.NULL)\n ctx = self._backend._ffi.gc(\n ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n evp_md = self._backend._lib.EVP_get_digestbyname(\n algorithm.name.encode('ascii'))\n if evp_md == self._backend._ffi.NULL:\n raise UnsupportedAlgorithm(\n \"{0} is not a supported hash on this backend.\".format(\n algorithm.name),\n _Reasons.UNSUPPORTED_HASH\n )\n res = self._backend._lib.HMAC_Init_ex(\n ctx, key, len(key), evp_md, self._backend._ffi.NULL\n )\n self._backend.openssl_assert(res != 0)\n\n self._ctx = ctx\n self._key = key\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n def copy(self):\n copied_ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(copied_ctx != self._backend._ffi.NULL)\n copied_ctx = self._backend._ffi.gc(\n copied_ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n res = self._backend._lib.HMAC_CTX_copy(copied_ctx, self._ctx)\n self._backend.openssl_assert(res != 0)\n return _HMACContext(\n self._backend, self._key, self.algorithm, ctx=copied_ctx\n )\n\n def update(self, data):\n res = self._backend._lib.HMAC_Update(self._ctx, data, len(data))\n self._backend.openssl_assert(res != 0)\n\n def finalize(self):\n buf = self._backend._ffi.new(\"unsigned char[]\",\n self._backend._lib.EVP_MAX_MD_SIZE)\n outlen = self._backend._ffi.new(\"unsigned int *\")\n res = self._backend._lib.HMAC_Final(self._ctx, buf, outlen)\n self._backend.openssl_assert(res != 0)\n self._backend.openssl_assert(outlen[0] == self.algorithm.digest_size)\n return self._backend._ffi.buffer(buf)[:outlen[0]]\n\n def verify(self, signature):\n digest = self.finalize()\n if not constant_time.bytes_eq(digest, signature):\n raise InvalidSignature(\"Signature did not match digest.\")\n", "path": "src/cryptography/hazmat/backends/openssl/hmac.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n InvalidSignature, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.primitives import constant_time, hashes, mac\n\n\[email protected]_interface(mac.MACContext)\[email protected]_interface(hashes.HashContext)\nclass _HMACContext(object):\n def __init__(self, backend, key, algorithm, ctx=None):\n self._algorithm = algorithm\n self._backend = backend\n\n if ctx is None:\n ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(ctx != self._backend._ffi.NULL)\n ctx = self._backend._ffi.gc(\n ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n name = self._backend._build_openssl_digest_name(algorithm)\n evp_md = self._backend._lib.EVP_get_digestbyname(name)\n if evp_md == self._backend._ffi.NULL:\n raise UnsupportedAlgorithm(\n \"{0} is not a supported hash on this backend\".format(name),\n _Reasons.UNSUPPORTED_HASH\n )\n res = self._backend._lib.HMAC_Init_ex(\n ctx, key, len(key), evp_md, self._backend._ffi.NULL\n )\n self._backend.openssl_assert(res != 0)\n\n self._ctx = ctx\n self._key = key\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n def copy(self):\n copied_ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(copied_ctx != self._backend._ffi.NULL)\n copied_ctx = self._backend._ffi.gc(\n copied_ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n res = self._backend._lib.HMAC_CTX_copy(copied_ctx, self._ctx)\n self._backend.openssl_assert(res != 0)\n return _HMACContext(\n self._backend, self._key, self.algorithm, ctx=copied_ctx\n )\n\n def update(self, data):\n res = self._backend._lib.HMAC_Update(self._ctx, data, len(data))\n self._backend.openssl_assert(res != 0)\n\n def finalize(self):\n buf = self._backend._ffi.new(\"unsigned char[]\",\n self._backend._lib.EVP_MAX_MD_SIZE)\n outlen = self._backend._ffi.new(\"unsigned int *\")\n res = self._backend._lib.HMAC_Final(self._ctx, buf, outlen)\n self._backend.openssl_assert(res != 0)\n self._backend.openssl_assert(outlen[0] == self.algorithm.digest_size)\n return self._backend._ffi.buffer(buf)[:outlen[0]]\n\n def verify(self, signature):\n digest = self.finalize()\n if not constant_time.bytes_eq(digest, signature):\n raise InvalidSignature(\"Signature did not match digest.\")\n", "path": "src/cryptography/hazmat/backends/openssl/hmac.py"}]}
| 1,674 | 244 |
gh_patches_debug_10384
|
rasdani/github-patches
|
git_diff
|
shuup__shuup-1558
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve the way permissionas are managed in admin
Currently, use has to use a select2 component with a lot of options and this is super boring, tedious and time consuming. Can we use a list of check boxes instead?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shuup/admin/modules/permission_groups/views/edit.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This file is part of Shuup.
3 #
4 # Copyright (c) 2012-2018, Shuup Inc. All rights reserved.
5 #
6 # This source code is licensed under the OSL-3.0 license found in the
7 # LICENSE file in the root directory of this source tree.
8 from __future__ import unicode_literals
9
10 from django import forms
11 from django.contrib.auth import get_user_model
12 from django.contrib.auth.models import Group as PermissionGroup
13 from django.utils.encoding import force_text
14 from django.utils.translation import ugettext_lazy as _
15
16 from shuup.admin.forms.fields import Select2MultipleField
17 from shuup.admin.module_registry import get_modules
18 from shuup.admin.utils.permissions import get_permission_object_from_string
19 from shuup.admin.utils.views import CreateOrUpdateView
20
21
22 class PermissionGroupForm(forms.ModelForm):
23 class Meta:
24 model = PermissionGroup
25 exclude = ("permissions",)
26
27 def __init__(self, *args, **kwargs):
28 super(PermissionGroupForm, self).__init__(*args, **kwargs)
29 initial_permissions = self._get_initial_permissions()
30 self.fields["name"].help_text = _("The permission group name.")
31 self.fields["modules"] = forms.MultipleChoiceField(
32 choices=sorted(self._get_module_choices()),
33 initial=self._get_enabled_modules(initial_permissions),
34 required=False,
35 label=_("Module Permissions"),
36 help_text=_(
37 "Select the modules that should be accessible by this permission group. "
38 "Modules with the same permissions as selected modules will be added automatically."
39 )
40 )
41 initial_members = self._get_initial_members()
42 members_field = Select2MultipleField(
43 model=get_user_model(),
44 initial=[member.pk for member in initial_members],
45 required=False,
46 label=_("Members"),
47 help_text=_(
48 "Set the users that belong to this permission group."
49 )
50 )
51 members_field.widget.choices = [(member.pk, force_text(member)) for member in initial_members]
52 self.fields["members"] = members_field
53
54 def _get_module_choices(self):
55 return set((force_text(m.name), force_text(m.name)) for m in get_modules() if m.name != "_Base_")
56
57 def _get_initial_members(self):
58 if self.instance.pk:
59 return self.instance.user_set.all()
60 else:
61 return []
62
63 def _get_initial_permissions(self):
64 permissions = set()
65 if self.instance.pk:
66 for perm in self.instance.permissions.all():
67 name, module, _ = perm.natural_key()
68 permissions.add("%s.%s" % (module, name))
69 return permissions
70
71 def _get_enabled_modules(self, permissions):
72 if not self.instance.pk:
73 return []
74 permissions = set(permissions)
75 modules = []
76 for module in get_modules():
77 # Ignore modules that haven't configured a name
78 if module.name != "_Base_" and set(module.get_required_permissions()).issubset(permissions):
79 modules.append(force_text(module.name))
80 return modules
81
82 def _get_required_permissions(self, modules):
83 permissions = set()
84 for module in [m for m in get_modules() if m.name in modules]:
85 permissions.update(set(module.get_required_permissions()))
86 return permissions
87
88 def clean_members(self):
89 members = self.cleaned_data.get("members", [])
90
91 return get_user_model().objects.filter(pk__in=members).all()
92
93 def clean(self):
94 cleaned_data = super(PermissionGroupForm, self).clean()
95
96 permissions = set()
97 modules = cleaned_data.pop("modules", [])
98 required_permissions = self._get_required_permissions(modules)
99
100 for permission in required_permissions:
101 permissions.add(get_permission_object_from_string(permission))
102
103 cleaned_data["required_permissions"] = permissions
104
105 return cleaned_data
106
107 def save(self):
108 obj = super(PermissionGroupForm, self).save()
109 obj.permissions = set(self.cleaned_data["required_permissions"])
110 obj.user_set = set(self.cleaned_data["members"])
111 return obj
112
113
114 class PermissionGroupEditView(CreateOrUpdateView):
115 model = PermissionGroup
116 form_class = PermissionGroupForm
117 template_name = "shuup/admin/permission_groups/edit.jinja"
118 context_object_name = "permission_group"
119 add_form_errors_as_messages = True
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/shuup/admin/modules/permission_groups/views/edit.py b/shuup/admin/modules/permission_groups/views/edit.py
--- a/shuup/admin/modules/permission_groups/views/edit.py
+++ b/shuup/admin/modules/permission_groups/views/edit.py
@@ -36,7 +36,8 @@
help_text=_(
"Select the modules that should be accessible by this permission group. "
"Modules with the same permissions as selected modules will be added automatically."
- )
+ ),
+ widget=forms.CheckboxSelectMultiple
)
initial_members = self._get_initial_members()
members_field = Select2MultipleField(
|
{"golden_diff": "diff --git a/shuup/admin/modules/permission_groups/views/edit.py b/shuup/admin/modules/permission_groups/views/edit.py\n--- a/shuup/admin/modules/permission_groups/views/edit.py\n+++ b/shuup/admin/modules/permission_groups/views/edit.py\n@@ -36,7 +36,8 @@\n help_text=_(\n \"Select the modules that should be accessible by this permission group. \"\n \"Modules with the same permissions as selected modules will be added automatically.\"\n- )\n+ ),\n+ widget=forms.CheckboxSelectMultiple\n )\n initial_members = self._get_initial_members()\n members_field = Select2MultipleField(\n", "issue": "Improve the way permissionas are managed in admin\nCurrently, use has to use a select2 component with a lot of options and this is super boring, tedious and time consuming. Can we use a list of check boxes instead?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2018, Shuup Inc. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nfrom __future__ import unicode_literals\n\nfrom django import forms\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group as PermissionGroup\nfrom django.utils.encoding import force_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom shuup.admin.forms.fields import Select2MultipleField\nfrom shuup.admin.module_registry import get_modules\nfrom shuup.admin.utils.permissions import get_permission_object_from_string\nfrom shuup.admin.utils.views import CreateOrUpdateView\n\n\nclass PermissionGroupForm(forms.ModelForm):\n class Meta:\n model = PermissionGroup\n exclude = (\"permissions\",)\n\n def __init__(self, *args, **kwargs):\n super(PermissionGroupForm, self).__init__(*args, **kwargs)\n initial_permissions = self._get_initial_permissions()\n self.fields[\"name\"].help_text = _(\"The permission group name.\")\n self.fields[\"modules\"] = forms.MultipleChoiceField(\n choices=sorted(self._get_module_choices()),\n initial=self._get_enabled_modules(initial_permissions),\n required=False,\n label=_(\"Module Permissions\"),\n help_text=_(\n \"Select the modules that should be accessible by this permission group. \"\n \"Modules with the same permissions as selected modules will be added automatically.\"\n )\n )\n initial_members = self._get_initial_members()\n members_field = Select2MultipleField(\n model=get_user_model(),\n initial=[member.pk for member in initial_members],\n required=False,\n label=_(\"Members\"),\n help_text=_(\n \"Set the users that belong to this permission group.\"\n )\n )\n members_field.widget.choices = [(member.pk, force_text(member)) for member in initial_members]\n self.fields[\"members\"] = members_field\n\n def _get_module_choices(self):\n return set((force_text(m.name), force_text(m.name)) for m in get_modules() if m.name != \"_Base_\")\n\n def _get_initial_members(self):\n if self.instance.pk:\n return self.instance.user_set.all()\n else:\n return []\n\n def _get_initial_permissions(self):\n permissions = set()\n if self.instance.pk:\n for perm in self.instance.permissions.all():\n name, module, _ = perm.natural_key()\n permissions.add(\"%s.%s\" % (module, name))\n return permissions\n\n def _get_enabled_modules(self, permissions):\n if not self.instance.pk:\n return []\n permissions = set(permissions)\n modules = []\n for module in get_modules():\n # Ignore modules that haven't configured a name\n if module.name != \"_Base_\" and set(module.get_required_permissions()).issubset(permissions):\n modules.append(force_text(module.name))\n return modules\n\n def _get_required_permissions(self, modules):\n permissions = set()\n for module in [m for m in get_modules() if m.name in modules]:\n permissions.update(set(module.get_required_permissions()))\n return permissions\n\n def clean_members(self):\n members = self.cleaned_data.get(\"members\", [])\n\n return get_user_model().objects.filter(pk__in=members).all()\n\n def clean(self):\n cleaned_data = super(PermissionGroupForm, self).clean()\n\n permissions = set()\n modules = cleaned_data.pop(\"modules\", [])\n required_permissions = self._get_required_permissions(modules)\n\n for permission in required_permissions:\n permissions.add(get_permission_object_from_string(permission))\n\n cleaned_data[\"required_permissions\"] = permissions\n\n return cleaned_data\n\n def save(self):\n obj = super(PermissionGroupForm, self).save()\n obj.permissions = set(self.cleaned_data[\"required_permissions\"])\n obj.user_set = set(self.cleaned_data[\"members\"])\n return obj\n\n\nclass PermissionGroupEditView(CreateOrUpdateView):\n model = PermissionGroup\n form_class = PermissionGroupForm\n template_name = \"shuup/admin/permission_groups/edit.jinja\"\n context_object_name = \"permission_group\"\n add_form_errors_as_messages = True\n", "path": "shuup/admin/modules/permission_groups/views/edit.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2018, Shuup Inc. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nfrom __future__ import unicode_literals\n\nfrom django import forms\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group as PermissionGroup\nfrom django.utils.encoding import force_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom shuup.admin.forms.fields import Select2MultipleField\nfrom shuup.admin.module_registry import get_modules\nfrom shuup.admin.utils.permissions import get_permission_object_from_string\nfrom shuup.admin.utils.views import CreateOrUpdateView\n\n\nclass PermissionGroupForm(forms.ModelForm):\n class Meta:\n model = PermissionGroup\n exclude = (\"permissions\",)\n\n def __init__(self, *args, **kwargs):\n super(PermissionGroupForm, self).__init__(*args, **kwargs)\n initial_permissions = self._get_initial_permissions()\n self.fields[\"name\"].help_text = _(\"The permission group name.\")\n self.fields[\"modules\"] = forms.MultipleChoiceField(\n choices=sorted(self._get_module_choices()),\n initial=self._get_enabled_modules(initial_permissions),\n required=False,\n label=_(\"Module Permissions\"),\n help_text=_(\n \"Select the modules that should be accessible by this permission group. \"\n \"Modules with the same permissions as selected modules will be added automatically.\"\n ),\n widget=forms.CheckboxSelectMultiple\n )\n initial_members = self._get_initial_members()\n members_field = Select2MultipleField(\n model=get_user_model(),\n initial=[member.pk for member in initial_members],\n required=False,\n label=_(\"Members\"),\n help_text=_(\n \"Set the users that belong to this permission group.\"\n )\n )\n members_field.widget.choices = [(member.pk, force_text(member)) for member in initial_members]\n self.fields[\"members\"] = members_field\n\n def _get_module_choices(self):\n return set((force_text(m.name), force_text(m.name)) for m in get_modules() if m.name != \"_Base_\")\n\n def _get_initial_members(self):\n if self.instance.pk:\n return self.instance.user_set.all()\n else:\n return []\n\n def _get_initial_permissions(self):\n permissions = set()\n if self.instance.pk:\n for perm in self.instance.permissions.all():\n name, module, _ = perm.natural_key()\n permissions.add(\"%s.%s\" % (module, name))\n return permissions\n\n def _get_enabled_modules(self, permissions):\n if not self.instance.pk:\n return []\n permissions = set(permissions)\n modules = []\n for module in get_modules():\n # Ignore modules that haven't configured a name\n if module.name != \"_Base_\" and set(module.get_required_permissions()).issubset(permissions):\n modules.append(force_text(module.name))\n return modules\n\n def _get_required_permissions(self, modules):\n permissions = set()\n for module in [m for m in get_modules() if m.name in modules]:\n permissions.update(set(module.get_required_permissions()))\n return permissions\n\n def clean_members(self):\n members = self.cleaned_data.get(\"members\", [])\n\n return get_user_model().objects.filter(pk__in=members).all()\n\n def clean(self):\n cleaned_data = super(PermissionGroupForm, self).clean()\n\n permissions = set()\n modules = cleaned_data.pop(\"modules\", [])\n required_permissions = self._get_required_permissions(modules)\n\n for permission in required_permissions:\n permissions.add(get_permission_object_from_string(permission))\n\n cleaned_data[\"required_permissions\"] = permissions\n\n return cleaned_data\n\n def save(self):\n obj = super(PermissionGroupForm, self).save()\n obj.permissions = set(self.cleaned_data[\"required_permissions\"])\n obj.user_set = set(self.cleaned_data[\"members\"])\n return obj\n\n\nclass PermissionGroupEditView(CreateOrUpdateView):\n model = PermissionGroup\n form_class = PermissionGroupForm\n template_name = \"shuup/admin/permission_groups/edit.jinja\"\n context_object_name = \"permission_group\"\n add_form_errors_as_messages = True\n", "path": "shuup/admin/modules/permission_groups/views/edit.py"}]}
| 1,481 | 139 |
gh_patches_debug_47834
|
rasdani/github-patches
|
git_diff
|
getredash__redash-3877
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API Key authentication should take precedence over cookies
Currently when you're logged in as a user, you can't use embeds or shared dashboards for which you do not have access -- even if you provide the API key. This is because the current user is being defined by the session cookie and the API key is being ignored.
We need to change this behavior so the API key takes precedence. From a quick look at [Flask-Login](https://flask-login.readthedocs.io)'s documentation, it seems that it calls `user_loader` first and only if this fails will try the `requets_loader`.
Unless this is configurable, we might need to change `user_loader` to always return `None` and implement our own logic in `request_loader`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/authentication/__init__.py`
Content:
```
1 import hashlib
2 import hmac
3 import logging
4 import time
5 from urlparse import urlsplit, urlunsplit
6
7 from flask import jsonify, redirect, request, url_for
8 from flask_login import LoginManager, login_user, logout_user, user_logged_in
9 from redash import models, settings
10 from redash.authentication import jwt_auth
11 from redash.authentication.org_resolving import current_org
12 from redash.settings.organization import settings as org_settings
13 from redash.tasks import record_event
14 from sqlalchemy.orm.exc import NoResultFound
15 from werkzeug.exceptions import Unauthorized
16
17 login_manager = LoginManager()
18 logger = logging.getLogger('authentication')
19
20
21 def get_login_url(external=False, next="/"):
22 if settings.MULTI_ORG and current_org == None:
23 login_url = '/'
24 elif settings.MULTI_ORG:
25 login_url = url_for('redash.login', org_slug=current_org.slug, next=next, _external=external)
26 else:
27 login_url = url_for('redash.login', next=next, _external=external)
28
29 return login_url
30
31
32 def sign(key, path, expires):
33 if not key:
34 return None
35
36 h = hmac.new(str(key), msg=path, digestmod=hashlib.sha1)
37 h.update(str(expires))
38
39 return h.hexdigest()
40
41
42 @login_manager.user_loader
43 def load_user(user_id_with_identity):
44 org = current_org._get_current_object()
45
46 try:
47 user_id, _ = user_id_with_identity.split("-")
48 user = models.User.get_by_id_and_org(user_id, org)
49 if user.is_disabled or user.get_id() != user_id_with_identity:
50 return None
51
52 return user
53 except (models.NoResultFound, ValueError, AttributeError):
54 return None
55
56
57 def request_loader(request):
58 user = None
59 if settings.AUTH_TYPE == 'hmac':
60 user = hmac_load_user_from_request(request)
61 elif settings.AUTH_TYPE == 'api_key':
62 user = api_key_load_user_from_request(request)
63 else:
64 logger.warning("Unknown authentication type ({}). Using default (HMAC).".format(settings.AUTH_TYPE))
65 user = hmac_load_user_from_request(request)
66
67 if org_settings['auth_jwt_login_enabled'] and user is None:
68 user = jwt_token_load_user_from_request(request)
69 return user
70
71
72 def hmac_load_user_from_request(request):
73 signature = request.args.get('signature')
74 expires = float(request.args.get('expires') or 0)
75 query_id = request.view_args.get('query_id', None)
76 user_id = request.args.get('user_id', None)
77
78 # TODO: 3600 should be a setting
79 if signature and time.time() < expires <= time.time() + 3600:
80 if user_id:
81 user = models.User.query.get(user_id)
82 calculated_signature = sign(user.api_key, request.path, expires)
83
84 if user.api_key and signature == calculated_signature:
85 return user
86
87 if query_id:
88 query = models.Query.query.filter(models.Query.id == query_id).one()
89 calculated_signature = sign(query.api_key, request.path, expires)
90
91 if query.api_key and signature == calculated_signature:
92 return models.ApiUser(query.api_key, query.org, query.groups.keys(), name="ApiKey: Query {}".format(query.id))
93
94 return None
95
96
97 def get_user_from_api_key(api_key, query_id):
98 if not api_key:
99 return None
100
101 user = None
102
103 # TODO: once we switch all api key storage into the ApiKey model, this code will be much simplified
104 org = current_org._get_current_object()
105 try:
106 user = models.User.get_by_api_key_and_org(api_key, org)
107 if user.is_disabled:
108 user = None
109 except models.NoResultFound:
110 try:
111 api_key = models.ApiKey.get_by_api_key(api_key)
112 user = models.ApiUser(api_key, api_key.org, [])
113 except models.NoResultFound:
114 if query_id:
115 query = models.Query.get_by_id_and_org(query_id, org)
116 if query and query.api_key == api_key:
117 user = models.ApiUser(api_key, query.org, query.groups.keys(), name="ApiKey: Query {}".format(query.id))
118
119 return user
120
121
122 def get_api_key_from_request(request):
123 api_key = request.args.get('api_key', None)
124
125 if api_key is not None:
126 return api_key
127
128 if request.headers.get('Authorization'):
129 auth_header = request.headers.get('Authorization')
130 api_key = auth_header.replace('Key ', '', 1)
131 elif request.view_args is not None and request.view_args.get('token'):
132 api_key = request.view_args['token']
133
134 return api_key
135
136
137 def api_key_load_user_from_request(request):
138 api_key = get_api_key_from_request(request)
139 if request.view_args is not None:
140 query_id = request.view_args.get('query_id', None)
141 user = get_user_from_api_key(api_key, query_id)
142 else:
143 user = None
144
145 return user
146
147
148 def jwt_token_load_user_from_request(request):
149 org = current_org._get_current_object()
150
151 payload = None
152
153 if org_settings['auth_jwt_auth_cookie_name']:
154 jwt_token = request.cookies.get(org_settings['auth_jwt_auth_cookie_name'], None)
155 elif org_settings['auth_jwt_auth_header_name']:
156 jwt_token = request.headers.get(org_settings['auth_jwt_auth_header_name'], None)
157 else:
158 return None
159
160 if jwt_token:
161 payload, token_is_valid = jwt_auth.verify_jwt_token(
162 jwt_token,
163 expected_issuer=org_settings['auth_jwt_auth_issuer'],
164 expected_audience=org_settings['auth_jwt_auth_audience'],
165 algorithms=org_settings['auth_jwt_auth_algorithms'],
166 public_certs_url=org_settings['auth_jwt_auth_public_certs_url'],
167 )
168 if not token_is_valid:
169 raise Unauthorized('Invalid JWT token')
170
171 if not payload:
172 return
173
174 try:
175 user = models.User.get_by_email_and_org(payload['email'], org)
176 except models.NoResultFound:
177 user = create_and_login_user(current_org, payload['email'], payload['email'])
178
179 return user
180
181
182 def log_user_logged_in(app, user):
183 event = {
184 'org_id': user.org_id,
185 'user_id': user.id,
186 'action': 'login',
187 'object_type': 'redash',
188 'timestamp': int(time.time()),
189 'user_agent': request.user_agent.string,
190 'ip': request.remote_addr
191 }
192
193 record_event.delay(event)
194
195
196 @login_manager.unauthorized_handler
197 def redirect_to_login():
198 if request.is_xhr or '/api/' in request.path:
199 response = jsonify({'message': "Couldn't find resource. Please login and try again."})
200 response.status_code = 404
201 return response
202
203 login_url = get_login_url(next=request.url, external=False)
204
205 return redirect(login_url)
206
207
208 def logout_and_redirect_to_index():
209 logout_user()
210
211 if settings.MULTI_ORG and current_org == None:
212 index_url = '/'
213 elif settings.MULTI_ORG:
214 index_url = url_for('redash.index', org_slug=current_org.slug, _external=False)
215 else:
216 index_url = url_for('redash.index', _external=False)
217
218 return redirect(index_url)
219
220
221 def init_app(app):
222 from redash.authentication import google_oauth, saml_auth, remote_user_auth, ldap_auth
223
224 login_manager.init_app(app)
225 login_manager.anonymous_user = models.AnonymousUser
226
227 app.register_blueprint(google_oauth.blueprint)
228 app.register_blueprint(saml_auth.blueprint)
229 app.register_blueprint(remote_user_auth.blueprint)
230 app.register_blueprint(ldap_auth.blueprint)
231
232 user_logged_in.connect(log_user_logged_in)
233 login_manager.request_loader(request_loader)
234
235
236 def create_and_login_user(org, name, email, picture=None):
237 try:
238 user_object = models.User.get_by_email_and_org(email, org)
239 if user_object.is_disabled:
240 return None
241 if user_object.is_invitation_pending:
242 user_object.is_invitation_pending = False
243 models.db.session.commit()
244 if user_object.name != name:
245 logger.debug("Updating user name (%r -> %r)", user_object.name, name)
246 user_object.name = name
247 models.db.session.commit()
248 except NoResultFound:
249 logger.debug("Creating user object (%r)", name)
250 user_object = models.User(org=org, name=name, email=email, is_invitation_pending=False,
251 _profile_image_url=picture, group_ids=[org.default_group.id])
252 models.db.session.add(user_object)
253 models.db.session.commit()
254
255 login_user(user_object, remember=True)
256
257 return user_object
258
259
260 def get_next_path(unsafe_next_path):
261 if not unsafe_next_path:
262 return ''
263
264 # Preventing open redirection attacks
265 parts = list(urlsplit(unsafe_next_path))
266 parts[0] = '' # clear scheme
267 parts[1] = '' # clear netloc
268 safe_next_path = urlunsplit(parts)
269
270 return safe_next_path
271
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/authentication/__init__.py b/redash/authentication/__init__.py
--- a/redash/authentication/__init__.py
+++ b/redash/authentication/__init__.py
@@ -41,6 +41,10 @@
@login_manager.user_loader
def load_user(user_id_with_identity):
+ user = api_key_load_user_from_request(request)
+ if user:
+ return user
+
org = current_org._get_current_object()
try:
|
{"golden_diff": "diff --git a/redash/authentication/__init__.py b/redash/authentication/__init__.py\n--- a/redash/authentication/__init__.py\n+++ b/redash/authentication/__init__.py\n@@ -41,6 +41,10 @@\n \n @login_manager.user_loader\n def load_user(user_id_with_identity):\n+ user = api_key_load_user_from_request(request)\n+ if user:\n+ return user\n+\n org = current_org._get_current_object()\n \n try:\n", "issue": "API Key authentication should take precedence over cookies\nCurrently when you're logged in as a user, you can't use embeds or shared dashboards for which you do not have access -- even if you provide the API key. This is because the current user is being defined by the session cookie and the API key is being ignored.\r\n\r\nWe need to change this behavior so the API key takes precedence. From a quick look at [Flask-Login](https://flask-login.readthedocs.io)'s documentation, it seems that it calls `user_loader` first and only if this fails will try the `requets_loader`.\r\n\r\nUnless this is configurable, we might need to change `user_loader` to always return `None` and implement our own logic in `request_loader`.\n", "before_files": [{"content": "import hashlib\nimport hmac\nimport logging\nimport time\nfrom urlparse import urlsplit, urlunsplit\n\nfrom flask import jsonify, redirect, request, url_for\nfrom flask_login import LoginManager, login_user, logout_user, user_logged_in\nfrom redash import models, settings\nfrom redash.authentication import jwt_auth\nfrom redash.authentication.org_resolving import current_org\nfrom redash.settings.organization import settings as org_settings\nfrom redash.tasks import record_event\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom werkzeug.exceptions import Unauthorized\n\nlogin_manager = LoginManager()\nlogger = logging.getLogger('authentication')\n\n\ndef get_login_url(external=False, next=\"/\"):\n if settings.MULTI_ORG and current_org == None:\n login_url = '/'\n elif settings.MULTI_ORG:\n login_url = url_for('redash.login', org_slug=current_org.slug, next=next, _external=external)\n else:\n login_url = url_for('redash.login', next=next, _external=external)\n\n return login_url\n\n\ndef sign(key, path, expires):\n if not key:\n return None\n\n h = hmac.new(str(key), msg=path, digestmod=hashlib.sha1)\n h.update(str(expires))\n\n return h.hexdigest()\n\n\n@login_manager.user_loader\ndef load_user(user_id_with_identity):\n org = current_org._get_current_object()\n\n try:\n user_id, _ = user_id_with_identity.split(\"-\")\n user = models.User.get_by_id_and_org(user_id, org)\n if user.is_disabled or user.get_id() != user_id_with_identity:\n return None\n\n return user\n except (models.NoResultFound, ValueError, AttributeError):\n return None\n\n\ndef request_loader(request):\n user = None\n if settings.AUTH_TYPE == 'hmac':\n user = hmac_load_user_from_request(request)\n elif settings.AUTH_TYPE == 'api_key':\n user = api_key_load_user_from_request(request)\n else:\n logger.warning(\"Unknown authentication type ({}). Using default (HMAC).\".format(settings.AUTH_TYPE))\n user = hmac_load_user_from_request(request)\n\n if org_settings['auth_jwt_login_enabled'] and user is None:\n user = jwt_token_load_user_from_request(request)\n return user\n\n\ndef hmac_load_user_from_request(request):\n signature = request.args.get('signature')\n expires = float(request.args.get('expires') or 0)\n query_id = request.view_args.get('query_id', None)\n user_id = request.args.get('user_id', None)\n\n # TODO: 3600 should be a setting\n if signature and time.time() < expires <= time.time() + 3600:\n if user_id:\n user = models.User.query.get(user_id)\n calculated_signature = sign(user.api_key, request.path, expires)\n\n if user.api_key and signature == calculated_signature:\n return user\n\n if query_id:\n query = models.Query.query.filter(models.Query.id == query_id).one()\n calculated_signature = sign(query.api_key, request.path, expires)\n\n if query.api_key and signature == calculated_signature:\n return models.ApiUser(query.api_key, query.org, query.groups.keys(), name=\"ApiKey: Query {}\".format(query.id))\n\n return None\n\n\ndef get_user_from_api_key(api_key, query_id):\n if not api_key:\n return None\n\n user = None\n\n # TODO: once we switch all api key storage into the ApiKey model, this code will be much simplified\n org = current_org._get_current_object()\n try:\n user = models.User.get_by_api_key_and_org(api_key, org)\n if user.is_disabled:\n user = None\n except models.NoResultFound:\n try:\n api_key = models.ApiKey.get_by_api_key(api_key)\n user = models.ApiUser(api_key, api_key.org, [])\n except models.NoResultFound:\n if query_id:\n query = models.Query.get_by_id_and_org(query_id, org)\n if query and query.api_key == api_key:\n user = models.ApiUser(api_key, query.org, query.groups.keys(), name=\"ApiKey: Query {}\".format(query.id))\n\n return user\n\n\ndef get_api_key_from_request(request):\n api_key = request.args.get('api_key', None)\n\n if api_key is not None:\n return api_key\n\n if request.headers.get('Authorization'):\n auth_header = request.headers.get('Authorization')\n api_key = auth_header.replace('Key ', '', 1)\n elif request.view_args is not None and request.view_args.get('token'):\n api_key = request.view_args['token']\n\n return api_key\n\n\ndef api_key_load_user_from_request(request):\n api_key = get_api_key_from_request(request)\n if request.view_args is not None:\n query_id = request.view_args.get('query_id', None)\n user = get_user_from_api_key(api_key, query_id)\n else:\n user = None\n\n return user\n\n\ndef jwt_token_load_user_from_request(request):\n org = current_org._get_current_object()\n\n payload = None\n\n if org_settings['auth_jwt_auth_cookie_name']:\n jwt_token = request.cookies.get(org_settings['auth_jwt_auth_cookie_name'], None)\n elif org_settings['auth_jwt_auth_header_name']:\n jwt_token = request.headers.get(org_settings['auth_jwt_auth_header_name'], None)\n else:\n return None\n\n if jwt_token:\n payload, token_is_valid = jwt_auth.verify_jwt_token(\n jwt_token,\n expected_issuer=org_settings['auth_jwt_auth_issuer'],\n expected_audience=org_settings['auth_jwt_auth_audience'],\n algorithms=org_settings['auth_jwt_auth_algorithms'],\n public_certs_url=org_settings['auth_jwt_auth_public_certs_url'],\n )\n if not token_is_valid:\n raise Unauthorized('Invalid JWT token')\n\n if not payload:\n return\n\n try:\n user = models.User.get_by_email_and_org(payload['email'], org)\n except models.NoResultFound:\n user = create_and_login_user(current_org, payload['email'], payload['email'])\n\n return user\n\n\ndef log_user_logged_in(app, user):\n event = {\n 'org_id': user.org_id,\n 'user_id': user.id,\n 'action': 'login',\n 'object_type': 'redash',\n 'timestamp': int(time.time()),\n 'user_agent': request.user_agent.string,\n 'ip': request.remote_addr\n }\n\n record_event.delay(event)\n\n\n@login_manager.unauthorized_handler\ndef redirect_to_login():\n if request.is_xhr or '/api/' in request.path:\n response = jsonify({'message': \"Couldn't find resource. Please login and try again.\"})\n response.status_code = 404\n return response\n\n login_url = get_login_url(next=request.url, external=False)\n\n return redirect(login_url)\n\n\ndef logout_and_redirect_to_index():\n logout_user()\n\n if settings.MULTI_ORG and current_org == None:\n index_url = '/'\n elif settings.MULTI_ORG:\n index_url = url_for('redash.index', org_slug=current_org.slug, _external=False)\n else:\n index_url = url_for('redash.index', _external=False)\n\n return redirect(index_url)\n\n\ndef init_app(app):\n from redash.authentication import google_oauth, saml_auth, remote_user_auth, ldap_auth\n\n login_manager.init_app(app)\n login_manager.anonymous_user = models.AnonymousUser\n\n app.register_blueprint(google_oauth.blueprint)\n app.register_blueprint(saml_auth.blueprint)\n app.register_blueprint(remote_user_auth.blueprint)\n app.register_blueprint(ldap_auth.blueprint)\n\n user_logged_in.connect(log_user_logged_in)\n login_manager.request_loader(request_loader)\n\n\ndef create_and_login_user(org, name, email, picture=None):\n try:\n user_object = models.User.get_by_email_and_org(email, org)\n if user_object.is_disabled:\n return None\n if user_object.is_invitation_pending:\n user_object.is_invitation_pending = False\n models.db.session.commit()\n if user_object.name != name:\n logger.debug(\"Updating user name (%r -> %r)\", user_object.name, name)\n user_object.name = name\n models.db.session.commit()\n except NoResultFound:\n logger.debug(\"Creating user object (%r)\", name)\n user_object = models.User(org=org, name=name, email=email, is_invitation_pending=False,\n _profile_image_url=picture, group_ids=[org.default_group.id])\n models.db.session.add(user_object)\n models.db.session.commit()\n\n login_user(user_object, remember=True)\n\n return user_object\n\n\ndef get_next_path(unsafe_next_path):\n if not unsafe_next_path:\n return ''\n\n # Preventing open redirection attacks\n parts = list(urlsplit(unsafe_next_path))\n parts[0] = '' # clear scheme\n parts[1] = '' # clear netloc\n safe_next_path = urlunsplit(parts)\n\n return safe_next_path\n", "path": "redash/authentication/__init__.py"}], "after_files": [{"content": "import hashlib\nimport hmac\nimport logging\nimport time\nfrom urlparse import urlsplit, urlunsplit\n\nfrom flask import jsonify, redirect, request, url_for\nfrom flask_login import LoginManager, login_user, logout_user, user_logged_in\nfrom redash import models, settings\nfrom redash.authentication import jwt_auth\nfrom redash.authentication.org_resolving import current_org\nfrom redash.settings.organization import settings as org_settings\nfrom redash.tasks import record_event\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom werkzeug.exceptions import Unauthorized\n\nlogin_manager = LoginManager()\nlogger = logging.getLogger('authentication')\n\n\ndef get_login_url(external=False, next=\"/\"):\n if settings.MULTI_ORG and current_org == None:\n login_url = '/'\n elif settings.MULTI_ORG:\n login_url = url_for('redash.login', org_slug=current_org.slug, next=next, _external=external)\n else:\n login_url = url_for('redash.login', next=next, _external=external)\n\n return login_url\n\n\ndef sign(key, path, expires):\n if not key:\n return None\n\n h = hmac.new(str(key), msg=path, digestmod=hashlib.sha1)\n h.update(str(expires))\n\n return h.hexdigest()\n\n\n@login_manager.user_loader\ndef load_user(user_id_with_identity):\n user = api_key_load_user_from_request(request)\n if user:\n return user\n\n org = current_org._get_current_object()\n\n try:\n user_id, _ = user_id_with_identity.split(\"-\")\n user = models.User.get_by_id_and_org(user_id, org)\n if user.is_disabled or user.get_id() != user_id_with_identity:\n return None\n\n return user\n except (models.NoResultFound, ValueError, AttributeError):\n return None\n\n\ndef request_loader(request):\n user = None\n if settings.AUTH_TYPE == 'hmac':\n user = hmac_load_user_from_request(request)\n elif settings.AUTH_TYPE == 'api_key':\n user = api_key_load_user_from_request(request)\n else:\n logger.warning(\"Unknown authentication type ({}). Using default (HMAC).\".format(settings.AUTH_TYPE))\n user = hmac_load_user_from_request(request)\n\n if org_settings['auth_jwt_login_enabled'] and user is None:\n user = jwt_token_load_user_from_request(request)\n return user\n\n\ndef hmac_load_user_from_request(request):\n signature = request.args.get('signature')\n expires = float(request.args.get('expires') or 0)\n query_id = request.view_args.get('query_id', None)\n user_id = request.args.get('user_id', None)\n\n # TODO: 3600 should be a setting\n if signature and time.time() < expires <= time.time() + 3600:\n if user_id:\n user = models.User.query.get(user_id)\n calculated_signature = sign(user.api_key, request.path, expires)\n\n if user.api_key and signature == calculated_signature:\n return user\n\n if query_id:\n query = models.Query.query.filter(models.Query.id == query_id).one()\n calculated_signature = sign(query.api_key, request.path, expires)\n\n if query.api_key and signature == calculated_signature:\n return models.ApiUser(query.api_key, query.org, query.groups.keys(), name=\"ApiKey: Query {}\".format(query.id))\n\n return None\n\n\ndef get_user_from_api_key(api_key, query_id):\n if not api_key:\n return None\n\n user = None\n\n # TODO: once we switch all api key storage into the ApiKey model, this code will be much simplified\n org = current_org._get_current_object()\n try:\n user = models.User.get_by_api_key_and_org(api_key, org)\n if user.is_disabled:\n user = None\n except models.NoResultFound:\n try:\n api_key = models.ApiKey.get_by_api_key(api_key)\n user = models.ApiUser(api_key, api_key.org, [])\n except models.NoResultFound:\n if query_id:\n query = models.Query.get_by_id_and_org(query_id, org)\n if query and query.api_key == api_key:\n user = models.ApiUser(api_key, query.org, query.groups.keys(), name=\"ApiKey: Query {}\".format(query.id))\n\n return user\n\n\ndef get_api_key_from_request(request):\n api_key = request.args.get('api_key', None)\n\n if api_key is not None:\n return api_key\n\n if request.headers.get('Authorization'):\n auth_header = request.headers.get('Authorization')\n api_key = auth_header.replace('Key ', '', 1)\n elif request.view_args is not None and request.view_args.get('token'):\n api_key = request.view_args['token']\n\n return api_key\n\n\ndef api_key_load_user_from_request(request):\n api_key = get_api_key_from_request(request)\n if request.view_args is not None:\n query_id = request.view_args.get('query_id', None)\n user = get_user_from_api_key(api_key, query_id)\n else:\n user = None\n\n return user\n\n\ndef jwt_token_load_user_from_request(request):\n org = current_org._get_current_object()\n\n payload = None\n\n if org_settings['auth_jwt_auth_cookie_name']:\n jwt_token = request.cookies.get(org_settings['auth_jwt_auth_cookie_name'], None)\n elif org_settings['auth_jwt_auth_header_name']:\n jwt_token = request.headers.get(org_settings['auth_jwt_auth_header_name'], None)\n else:\n return None\n\n if jwt_token:\n payload, token_is_valid = jwt_auth.verify_jwt_token(\n jwt_token,\n expected_issuer=org_settings['auth_jwt_auth_issuer'],\n expected_audience=org_settings['auth_jwt_auth_audience'],\n algorithms=org_settings['auth_jwt_auth_algorithms'],\n public_certs_url=org_settings['auth_jwt_auth_public_certs_url'],\n )\n if not token_is_valid:\n raise Unauthorized('Invalid JWT token')\n\n if not payload:\n return\n\n try:\n user = models.User.get_by_email_and_org(payload['email'], org)\n except models.NoResultFound:\n user = create_and_login_user(current_org, payload['email'], payload['email'])\n\n return user\n\n\ndef log_user_logged_in(app, user):\n event = {\n 'org_id': user.org_id,\n 'user_id': user.id,\n 'action': 'login',\n 'object_type': 'redash',\n 'timestamp': int(time.time()),\n 'user_agent': request.user_agent.string,\n 'ip': request.remote_addr\n }\n\n record_event.delay(event)\n\n\n@login_manager.unauthorized_handler\ndef redirect_to_login():\n if request.is_xhr or '/api/' in request.path:\n response = jsonify({'message': \"Couldn't find resource. Please login and try again.\"})\n response.status_code = 404\n return response\n\n login_url = get_login_url(next=request.url, external=False)\n\n return redirect(login_url)\n\n\ndef logout_and_redirect_to_index():\n logout_user()\n\n if settings.MULTI_ORG and current_org == None:\n index_url = '/'\n elif settings.MULTI_ORG:\n index_url = url_for('redash.index', org_slug=current_org.slug, _external=False)\n else:\n index_url = url_for('redash.index', _external=False)\n\n return redirect(index_url)\n\n\ndef init_app(app):\n from redash.authentication import google_oauth, saml_auth, remote_user_auth, ldap_auth\n\n login_manager.init_app(app)\n login_manager.anonymous_user = models.AnonymousUser\n\n app.register_blueprint(google_oauth.blueprint)\n app.register_blueprint(saml_auth.blueprint)\n app.register_blueprint(remote_user_auth.blueprint)\n app.register_blueprint(ldap_auth.blueprint)\n\n user_logged_in.connect(log_user_logged_in)\n login_manager.request_loader(request_loader)\n\n\ndef create_and_login_user(org, name, email, picture=None):\n try:\n user_object = models.User.get_by_email_and_org(email, org)\n if user_object.is_disabled:\n return None\n if user_object.is_invitation_pending:\n user_object.is_invitation_pending = False\n models.db.session.commit()\n if user_object.name != name:\n logger.debug(\"Updating user name (%r -> %r)\", user_object.name, name)\n user_object.name = name\n models.db.session.commit()\n except NoResultFound:\n logger.debug(\"Creating user object (%r)\", name)\n user_object = models.User(org=org, name=name, email=email, is_invitation_pending=False,\n _profile_image_url=picture, group_ids=[org.default_group.id])\n models.db.session.add(user_object)\n models.db.session.commit()\n\n login_user(user_object, remember=True)\n\n return user_object\n\n\ndef get_next_path(unsafe_next_path):\n if not unsafe_next_path:\n return ''\n\n # Preventing open redirection attacks\n parts = list(urlsplit(unsafe_next_path))\n parts[0] = '' # clear scheme\n parts[1] = '' # clear netloc\n safe_next_path = urlunsplit(parts)\n\n return safe_next_path\n", "path": "redash/authentication/__init__.py"}]}
| 3,102 | 105 |
gh_patches_debug_29946
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-300
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Mirai模块处理仅含@Bot的消息时报错
**描述问题:**
对于单独的@bot消息处理时报错。
**如何复现?**
使用mirai模块处理消息,当在群聊中单独@机器人(不跟随其他信息)时消息处理报错
**期望的结果**
能够正常处理
**环境信息:**
- OS: CentOS & Winodws
- Python Version: 3.9.2
- Nonebot Version: nonebot cli version 0.4.0
**截图**
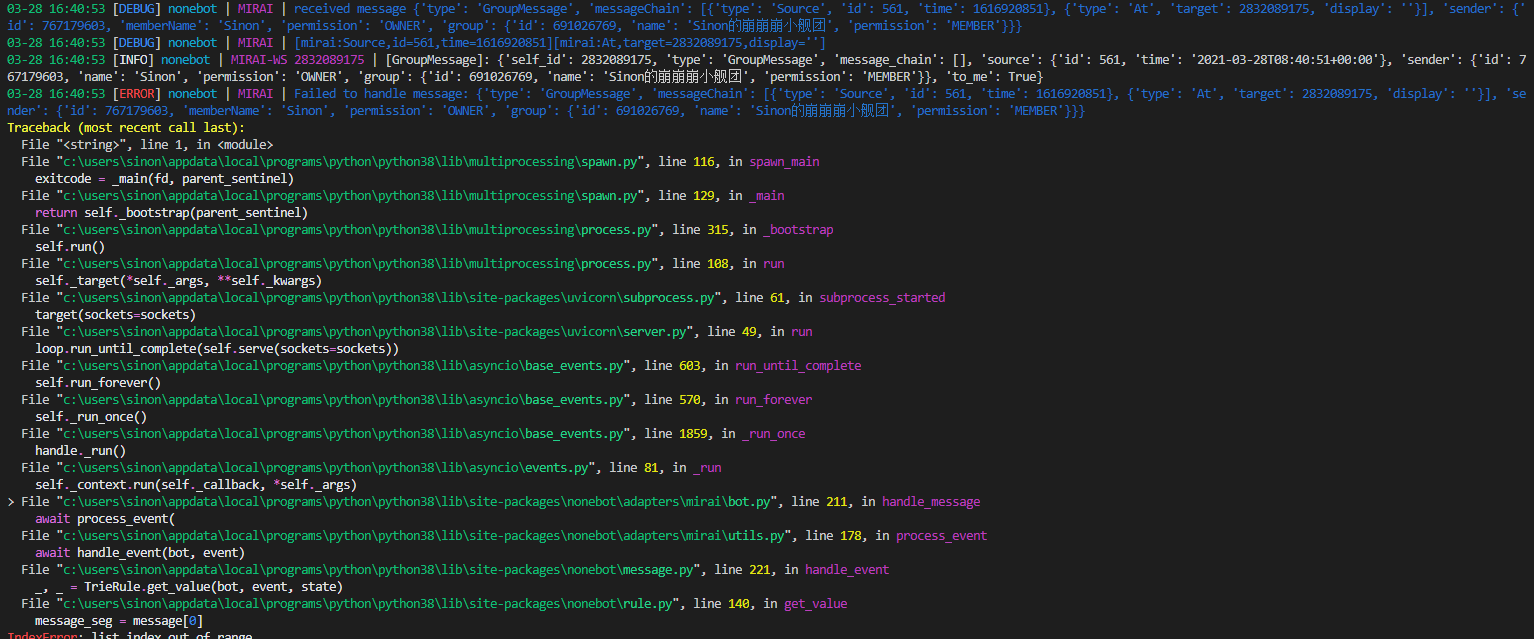
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py`
Content:
```
1 import re
2 from functools import wraps
3 from typing import TYPE_CHECKING, Any, Callable, Coroutine, Optional, TypeVar
4
5 import httpx
6 from pydantic import Extra, ValidationError, validate_arguments
7
8 import nonebot.exception as exception
9 from nonebot.log import logger
10 from nonebot.message import handle_event
11 from nonebot.utils import escape_tag, logger_wrapper
12
13 from .event import Event, GroupMessage, MessageEvent, MessageSource
14 from .message import MessageType
15
16 if TYPE_CHECKING:
17 from .bot import Bot
18
19 _AsyncCallable = TypeVar("_AsyncCallable", bound=Callable[..., Coroutine])
20 _AnyCallable = TypeVar("_AnyCallable", bound=Callable)
21
22
23 class Log:
24
25 @staticmethod
26 def log(level: str, message: str, exception: Optional[Exception] = None):
27 logger = logger_wrapper('MIRAI')
28 message = '<e>' + escape_tag(message) + '</e>'
29 logger(level=level.upper(), message=message, exception=exception)
30
31 @classmethod
32 def info(cls, message: Any):
33 cls.log('INFO', str(message))
34
35 @classmethod
36 def debug(cls, message: Any):
37 cls.log('DEBUG', str(message))
38
39 @classmethod
40 def warn(cls, message: Any):
41 cls.log('WARNING', str(message))
42
43 @classmethod
44 def error(cls, message: Any, exception: Optional[Exception] = None):
45 cls.log('ERROR', str(message), exception=exception)
46
47
48 class ActionFailed(exception.ActionFailed):
49 """
50 :说明:
51
52 API 请求成功返回数据,但 API 操作失败。
53 """
54
55 def __init__(self, **kwargs):
56 super().__init__('mirai')
57 self.data = kwargs.copy()
58
59 def __repr__(self):
60 return self.__class__.__name__ + '(%s)' % ', '.join(
61 map(lambda m: '%s=%r' % m, self.data.items()))
62
63
64 class InvalidArgument(exception.AdapterException):
65 """
66 :说明:
67
68 调用API的参数出错
69 """
70
71 def __init__(self, **kwargs):
72 super().__init__('mirai')
73
74
75 def catch_network_error(function: _AsyncCallable) -> _AsyncCallable:
76 """
77 :说明:
78
79 捕捉函数抛出的httpx网络异常并释放 ``NetworkError`` 异常
80
81 处理返回数据, 在code不为0时释放 ``ActionFailed`` 异常
82
83 \:\:\: warning
84 此装饰器只支持使用了httpx的异步函数
85 \:\:\:
86 """
87
88 @wraps(function)
89 async def wrapper(*args, **kwargs):
90 try:
91 data = await function(*args, **kwargs)
92 except httpx.HTTPError:
93 raise exception.NetworkError('mirai')
94 logger.opt(colors=True).debug('<b>Mirai API returned data:</b> '
95 f'<y>{escape_tag(str(data))}</y>')
96 if isinstance(data, dict):
97 if data.get('code', 0) != 0:
98 raise ActionFailed(**data)
99 return data
100
101 return wrapper # type: ignore
102
103
104 def argument_validation(function: _AnyCallable) -> _AnyCallable:
105 """
106 :说明:
107
108 通过函数签名中的类型注解来对传入参数进行运行时校验
109
110 会在参数出错时释放 ``InvalidArgument`` 异常
111 """
112 function = validate_arguments(config={
113 'arbitrary_types_allowed': True,
114 'extra': Extra.forbid
115 })(function)
116
117 @wraps(function)
118 def wrapper(*args, **kwargs):
119 try:
120 return function(*args, **kwargs)
121 except ValidationError:
122 raise InvalidArgument
123
124 return wrapper # type: ignore
125
126
127 def process_source(bot: "Bot", event: MessageEvent) -> MessageEvent:
128 source = event.message_chain.extract_first(MessageType.SOURCE)
129 if source is not None:
130 event.source = MessageSource.parse_obj(source.data)
131 return event
132
133
134 def process_at(bot: "Bot", event: GroupMessage) -> GroupMessage:
135 at = event.message_chain.extract_first(MessageType.AT)
136 if at is not None:
137 if at.data['target'] == event.self_id:
138 event.to_me = True
139 else:
140 event.message_chain.insert(0, at)
141 return event
142
143
144 def process_nick(bot: "Bot", event: GroupMessage) -> GroupMessage:
145 plain = event.message_chain.extract_first(MessageType.PLAIN)
146 if plain is not None:
147 text = str(plain)
148 nick_regex = '|'.join(filter(lambda x: x, bot.config.nickname))
149 matched = re.search(rf"^({nick_regex})([\s,,]*|$)", text, re.IGNORECASE)
150 if matched is not None:
151 event.to_me = True
152 nickname = matched.group(1)
153 Log.info(f'User is calling me {nickname}')
154 plain.data['text'] = text[matched.end():]
155 event.message_chain.insert(0, plain)
156 return event
157
158
159 def process_reply(bot: "Bot", event: GroupMessage) -> GroupMessage:
160 reply = event.message_chain.extract_first(MessageType.QUOTE)
161 if reply is not None:
162 if reply.data['senderId'] == event.self_id:
163 event.to_me = True
164 else:
165 event.message_chain.insert(0, reply)
166 return event
167
168
169 async def process_event(bot: "Bot", event: Event) -> None:
170 if isinstance(event, MessageEvent):
171 event.message_chain.reduce()
172 Log.debug(event.message_chain)
173 event = process_source(bot, event)
174 if isinstance(event, GroupMessage):
175 event = process_nick(bot, event)
176 event = process_at(bot, event)
177 event = process_reply(bot, event)
178 await handle_event(bot, event)
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py
--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py
+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py
@@ -11,7 +11,7 @@
from nonebot.utils import escape_tag, logger_wrapper
from .event import Event, GroupMessage, MessageEvent, MessageSource
-from .message import MessageType
+from .message import MessageType, MessageSegment
if TYPE_CHECKING:
from .bot import Bot
@@ -64,7 +64,7 @@
class InvalidArgument(exception.AdapterException):
"""
:说明:
-
+
调用API的参数出错
"""
@@ -106,7 +106,7 @@
:说明:
通过函数签名中的类型注解来对传入参数进行运行时校验
-
+
会在参数出错时释放 ``InvalidArgument`` 异常
"""
function = validate_arguments(config={
@@ -138,6 +138,8 @@
event.to_me = True
else:
event.message_chain.insert(0, at)
+ if not event.message_chain:
+ event.message_chain.append(MessageSegment.plain(''))
return event
@@ -175,4 +177,4 @@
event = process_nick(bot, event)
event = process_at(bot, event)
event = process_reply(bot, event)
- await handle_event(bot, event)
\ No newline at end of file
+ await handle_event(bot, event)
|
{"golden_diff": "diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py\n--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py\n+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py\n@@ -11,7 +11,7 @@\n from nonebot.utils import escape_tag, logger_wrapper\n \n from .event import Event, GroupMessage, MessageEvent, MessageSource\n-from .message import MessageType\n+from .message import MessageType, MessageSegment\n \n if TYPE_CHECKING:\n from .bot import Bot\n@@ -64,7 +64,7 @@\n class InvalidArgument(exception.AdapterException):\n \"\"\"\n :\u8bf4\u660e:\n- \n+\n \u8c03\u7528API\u7684\u53c2\u6570\u51fa\u9519\n \"\"\"\n \n@@ -106,7 +106,7 @@\n :\u8bf4\u660e:\n \n \u901a\u8fc7\u51fd\u6570\u7b7e\u540d\u4e2d\u7684\u7c7b\u578b\u6ce8\u89e3\u6765\u5bf9\u4f20\u5165\u53c2\u6570\u8fdb\u884c\u8fd0\u884c\u65f6\u6821\u9a8c\n- \n+\n \u4f1a\u5728\u53c2\u6570\u51fa\u9519\u65f6\u91ca\u653e ``InvalidArgument`` \u5f02\u5e38\n \"\"\"\n function = validate_arguments(config={\n@@ -138,6 +138,8 @@\n event.to_me = True\n else:\n event.message_chain.insert(0, at)\n+ if not event.message_chain:\n+ event.message_chain.append(MessageSegment.plain(''))\n return event\n \n \n@@ -175,4 +177,4 @@\n event = process_nick(bot, event)\n event = process_at(bot, event)\n event = process_reply(bot, event)\n- await handle_event(bot, event)\n\\ No newline at end of file\n+ await handle_event(bot, event)\n", "issue": "Bug: Mirai\u6a21\u5757\u5904\u7406\u4ec5\u542b@Bot\u7684\u6d88\u606f\u65f6\u62a5\u9519\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\n\u5bf9\u4e8e\u5355\u72ec\u7684@bot\u6d88\u606f\u5904\u7406\u65f6\u62a5\u9519\u3002\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n\u4f7f\u7528mirai\u6a21\u5757\u5904\u7406\u6d88\u606f\uff0c\u5f53\u5728\u7fa4\u804a\u4e2d\u5355\u72ec@\u673a\u5668\u4eba\uff08\u4e0d\u8ddf\u968f\u5176\u4ed6\u4fe1\u606f\uff09\u65f6\u6d88\u606f\u5904\u7406\u62a5\u9519\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\u80fd\u591f\u6b63\u5e38\u5904\u7406\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: CentOS & Winodws\r\n - Python Version: 3.9.2\r\n - Nonebot Version: nonebot cli version 0.4.0\r\n\r\n**\u622a\u56fe**\r\n\r\n\r\n\n", "before_files": [{"content": "import re\nfrom functools import wraps\nfrom typing import TYPE_CHECKING, Any, Callable, Coroutine, Optional, TypeVar\n\nimport httpx\nfrom pydantic import Extra, ValidationError, validate_arguments\n\nimport nonebot.exception as exception\nfrom nonebot.log import logger\nfrom nonebot.message import handle_event\nfrom nonebot.utils import escape_tag, logger_wrapper\n\nfrom .event import Event, GroupMessage, MessageEvent, MessageSource\nfrom .message import MessageType\n\nif TYPE_CHECKING:\n from .bot import Bot\n\n_AsyncCallable = TypeVar(\"_AsyncCallable\", bound=Callable[..., Coroutine])\n_AnyCallable = TypeVar(\"_AnyCallable\", bound=Callable)\n\n\nclass Log:\n\n @staticmethod\n def log(level: str, message: str, exception: Optional[Exception] = None):\n logger = logger_wrapper('MIRAI')\n message = '<e>' + escape_tag(message) + '</e>'\n logger(level=level.upper(), message=message, exception=exception)\n\n @classmethod\n def info(cls, message: Any):\n cls.log('INFO', str(message))\n\n @classmethod\n def debug(cls, message: Any):\n cls.log('DEBUG', str(message))\n\n @classmethod\n def warn(cls, message: Any):\n cls.log('WARNING', str(message))\n\n @classmethod\n def error(cls, message: Any, exception: Optional[Exception] = None):\n cls.log('ERROR', str(message), exception=exception)\n\n\nclass ActionFailed(exception.ActionFailed):\n \"\"\"\n :\u8bf4\u660e:\n\n API \u8bf7\u6c42\u6210\u529f\u8fd4\u56de\u6570\u636e\uff0c\u4f46 API \u64cd\u4f5c\u5931\u8d25\u3002\n \"\"\"\n\n def __init__(self, **kwargs):\n super().__init__('mirai')\n self.data = kwargs.copy()\n\n def __repr__(self):\n return self.__class__.__name__ + '(%s)' % ', '.join(\n map(lambda m: '%s=%r' % m, self.data.items()))\n\n\nclass InvalidArgument(exception.AdapterException):\n \"\"\"\n :\u8bf4\u660e:\n \n \u8c03\u7528API\u7684\u53c2\u6570\u51fa\u9519\n \"\"\"\n\n def __init__(self, **kwargs):\n super().__init__('mirai')\n\n\ndef catch_network_error(function: _AsyncCallable) -> _AsyncCallable:\n \"\"\"\n :\u8bf4\u660e:\n\n \u6355\u6349\u51fd\u6570\u629b\u51fa\u7684httpx\u7f51\u7edc\u5f02\u5e38\u5e76\u91ca\u653e ``NetworkError`` \u5f02\u5e38\n\n \u5904\u7406\u8fd4\u56de\u6570\u636e, \u5728code\u4e0d\u4e3a0\u65f6\u91ca\u653e ``ActionFailed`` \u5f02\u5e38\n\n \\:\\:\\: warning\n \u6b64\u88c5\u9970\u5668\u53ea\u652f\u6301\u4f7f\u7528\u4e86httpx\u7684\u5f02\u6b65\u51fd\u6570\n \\:\\:\\:\n \"\"\"\n\n @wraps(function)\n async def wrapper(*args, **kwargs):\n try:\n data = await function(*args, **kwargs)\n except httpx.HTTPError:\n raise exception.NetworkError('mirai')\n logger.opt(colors=True).debug('<b>Mirai API returned data:</b> '\n f'<y>{escape_tag(str(data))}</y>')\n if isinstance(data, dict):\n if data.get('code', 0) != 0:\n raise ActionFailed(**data)\n return data\n\n return wrapper # type: ignore\n\n\ndef argument_validation(function: _AnyCallable) -> _AnyCallable:\n \"\"\"\n :\u8bf4\u660e:\n\n \u901a\u8fc7\u51fd\u6570\u7b7e\u540d\u4e2d\u7684\u7c7b\u578b\u6ce8\u89e3\u6765\u5bf9\u4f20\u5165\u53c2\u6570\u8fdb\u884c\u8fd0\u884c\u65f6\u6821\u9a8c\n \n \u4f1a\u5728\u53c2\u6570\u51fa\u9519\u65f6\u91ca\u653e ``InvalidArgument`` \u5f02\u5e38\n \"\"\"\n function = validate_arguments(config={\n 'arbitrary_types_allowed': True,\n 'extra': Extra.forbid\n })(function)\n\n @wraps(function)\n def wrapper(*args, **kwargs):\n try:\n return function(*args, **kwargs)\n except ValidationError:\n raise InvalidArgument\n\n return wrapper # type: ignore\n\n\ndef process_source(bot: \"Bot\", event: MessageEvent) -> MessageEvent:\n source = event.message_chain.extract_first(MessageType.SOURCE)\n if source is not None:\n event.source = MessageSource.parse_obj(source.data)\n return event\n\n\ndef process_at(bot: \"Bot\", event: GroupMessage) -> GroupMessage:\n at = event.message_chain.extract_first(MessageType.AT)\n if at is not None:\n if at.data['target'] == event.self_id:\n event.to_me = True\n else:\n event.message_chain.insert(0, at)\n return event\n\n\ndef process_nick(bot: \"Bot\", event: GroupMessage) -> GroupMessage:\n plain = event.message_chain.extract_first(MessageType.PLAIN)\n if plain is not None:\n text = str(plain)\n nick_regex = '|'.join(filter(lambda x: x, bot.config.nickname))\n matched = re.search(rf\"^({nick_regex})([\\s,\uff0c]*|$)\", text, re.IGNORECASE)\n if matched is not None:\n event.to_me = True\n nickname = matched.group(1)\n Log.info(f'User is calling me {nickname}')\n plain.data['text'] = text[matched.end():]\n event.message_chain.insert(0, plain)\n return event\n\n\ndef process_reply(bot: \"Bot\", event: GroupMessage) -> GroupMessage:\n reply = event.message_chain.extract_first(MessageType.QUOTE)\n if reply is not None:\n if reply.data['senderId'] == event.self_id:\n event.to_me = True\n else:\n event.message_chain.insert(0, reply)\n return event\n\n\nasync def process_event(bot: \"Bot\", event: Event) -> None:\n if isinstance(event, MessageEvent):\n event.message_chain.reduce()\n Log.debug(event.message_chain)\n event = process_source(bot, event)\n if isinstance(event, GroupMessage):\n event = process_nick(bot, event)\n event = process_at(bot, event)\n event = process_reply(bot, event)\n await handle_event(bot, event)", "path": "packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py"}], "after_files": [{"content": "import re\nfrom functools import wraps\nfrom typing import TYPE_CHECKING, Any, Callable, Coroutine, Optional, TypeVar\n\nimport httpx\nfrom pydantic import Extra, ValidationError, validate_arguments\n\nimport nonebot.exception as exception\nfrom nonebot.log import logger\nfrom nonebot.message import handle_event\nfrom nonebot.utils import escape_tag, logger_wrapper\n\nfrom .event import Event, GroupMessage, MessageEvent, MessageSource\nfrom .message import MessageType, MessageSegment\n\nif TYPE_CHECKING:\n from .bot import Bot\n\n_AsyncCallable = TypeVar(\"_AsyncCallable\", bound=Callable[..., Coroutine])\n_AnyCallable = TypeVar(\"_AnyCallable\", bound=Callable)\n\n\nclass Log:\n\n @staticmethod\n def log(level: str, message: str, exception: Optional[Exception] = None):\n logger = logger_wrapper('MIRAI')\n message = '<e>' + escape_tag(message) + '</e>'\n logger(level=level.upper(), message=message, exception=exception)\n\n @classmethod\n def info(cls, message: Any):\n cls.log('INFO', str(message))\n\n @classmethod\n def debug(cls, message: Any):\n cls.log('DEBUG', str(message))\n\n @classmethod\n def warn(cls, message: Any):\n cls.log('WARNING', str(message))\n\n @classmethod\n def error(cls, message: Any, exception: Optional[Exception] = None):\n cls.log('ERROR', str(message), exception=exception)\n\n\nclass ActionFailed(exception.ActionFailed):\n \"\"\"\n :\u8bf4\u660e:\n\n API \u8bf7\u6c42\u6210\u529f\u8fd4\u56de\u6570\u636e\uff0c\u4f46 API \u64cd\u4f5c\u5931\u8d25\u3002\n \"\"\"\n\n def __init__(self, **kwargs):\n super().__init__('mirai')\n self.data = kwargs.copy()\n\n def __repr__(self):\n return self.__class__.__name__ + '(%s)' % ', '.join(\n map(lambda m: '%s=%r' % m, self.data.items()))\n\n\nclass InvalidArgument(exception.AdapterException):\n \"\"\"\n :\u8bf4\u660e:\n\n \u8c03\u7528API\u7684\u53c2\u6570\u51fa\u9519\n \"\"\"\n\n def __init__(self, **kwargs):\n super().__init__('mirai')\n\n\ndef catch_network_error(function: _AsyncCallable) -> _AsyncCallable:\n \"\"\"\n :\u8bf4\u660e:\n\n \u6355\u6349\u51fd\u6570\u629b\u51fa\u7684httpx\u7f51\u7edc\u5f02\u5e38\u5e76\u91ca\u653e ``NetworkError`` \u5f02\u5e38\n\n \u5904\u7406\u8fd4\u56de\u6570\u636e, \u5728code\u4e0d\u4e3a0\u65f6\u91ca\u653e ``ActionFailed`` \u5f02\u5e38\n\n \\:\\:\\: warning\n \u6b64\u88c5\u9970\u5668\u53ea\u652f\u6301\u4f7f\u7528\u4e86httpx\u7684\u5f02\u6b65\u51fd\u6570\n \\:\\:\\:\n \"\"\"\n\n @wraps(function)\n async def wrapper(*args, **kwargs):\n try:\n data = await function(*args, **kwargs)\n except httpx.HTTPError:\n raise exception.NetworkError('mirai')\n logger.opt(colors=True).debug('<b>Mirai API returned data:</b> '\n f'<y>{escape_tag(str(data))}</y>')\n if isinstance(data, dict):\n if data.get('code', 0) != 0:\n raise ActionFailed(**data)\n return data\n\n return wrapper # type: ignore\n\n\ndef argument_validation(function: _AnyCallable) -> _AnyCallable:\n \"\"\"\n :\u8bf4\u660e:\n\n \u901a\u8fc7\u51fd\u6570\u7b7e\u540d\u4e2d\u7684\u7c7b\u578b\u6ce8\u89e3\u6765\u5bf9\u4f20\u5165\u53c2\u6570\u8fdb\u884c\u8fd0\u884c\u65f6\u6821\u9a8c\n\n \u4f1a\u5728\u53c2\u6570\u51fa\u9519\u65f6\u91ca\u653e ``InvalidArgument`` \u5f02\u5e38\n \"\"\"\n function = validate_arguments(config={\n 'arbitrary_types_allowed': True,\n 'extra': Extra.forbid\n })(function)\n\n @wraps(function)\n def wrapper(*args, **kwargs):\n try:\n return function(*args, **kwargs)\n except ValidationError:\n raise InvalidArgument\n\n return wrapper # type: ignore\n\n\ndef process_source(bot: \"Bot\", event: MessageEvent) -> MessageEvent:\n source = event.message_chain.extract_first(MessageType.SOURCE)\n if source is not None:\n event.source = MessageSource.parse_obj(source.data)\n return event\n\n\ndef process_at(bot: \"Bot\", event: GroupMessage) -> GroupMessage:\n at = event.message_chain.extract_first(MessageType.AT)\n if at is not None:\n if at.data['target'] == event.self_id:\n event.to_me = True\n else:\n event.message_chain.insert(0, at)\n if not event.message_chain:\n event.message_chain.append(MessageSegment.plain(''))\n return event\n\n\ndef process_nick(bot: \"Bot\", event: GroupMessage) -> GroupMessage:\n plain = event.message_chain.extract_first(MessageType.PLAIN)\n if plain is not None:\n text = str(plain)\n nick_regex = '|'.join(filter(lambda x: x, bot.config.nickname))\n matched = re.search(rf\"^({nick_regex})([\\s,\uff0c]*|$)\", text, re.IGNORECASE)\n if matched is not None:\n event.to_me = True\n nickname = matched.group(1)\n Log.info(f'User is calling me {nickname}')\n plain.data['text'] = text[matched.end():]\n event.message_chain.insert(0, plain)\n return event\n\n\ndef process_reply(bot: \"Bot\", event: GroupMessage) -> GroupMessage:\n reply = event.message_chain.extract_first(MessageType.QUOTE)\n if reply is not None:\n if reply.data['senderId'] == event.self_id:\n event.to_me = True\n else:\n event.message_chain.insert(0, reply)\n return event\n\n\nasync def process_event(bot: \"Bot\", event: Event) -> None:\n if isinstance(event, MessageEvent):\n event.message_chain.reduce()\n Log.debug(event.message_chain)\n event = process_source(bot, event)\n if isinstance(event, GroupMessage):\n event = process_nick(bot, event)\n event = process_at(bot, event)\n event = process_reply(bot, event)\n await handle_event(bot, event)\n", "path": "packages/nonebot-adapter-mirai/nonebot/adapters/mirai/utils.py"}]}
| 2,149 | 389 |
gh_patches_debug_7953
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-223
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow to modify the computed Span name via callback.
# Description
With Redis and Databases in a traces, there is no easy way from the span name to see if a "SELECT" is going to Redis or the database.
## Type of change
Please delete options that are not relevant.
- [X] New feature (non-breaking change which adds functionality)
# How Has This Been Tested?
- [X] TestRedis::test_name_callback
# Does This PR Require a Core Repo Change?
- [ ] Yes. - Link to PR:
- [X] No.
# Checklist:
See [contributing.md](https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/CONTRIBUTING.md) for styleguide, changelog guidelines, and more.
- [?] Followed the style guidelines of this project
- [X] Changelogs have been updated
- [X] Unit tests have been added
- [X] Documentation has been updated
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 This library allows tracing HTTP requests made by the
17 `requests <https://requests.readthedocs.io/en/master/>`_ library.
18
19 Usage
20 -----
21
22 .. code-block:: python
23
24 import requests
25 import opentelemetry.instrumentation.requests
26
27 # You can optionally pass a custom TracerProvider to
28 # RequestInstrumentor.instrument()
29 opentelemetry.instrumentation.requests.RequestsInstrumentor().instrument()
30 response = requests.get(url="https://www.example.org/")
31
32 API
33 ---
34 """
35
36 import functools
37 import types
38
39 from requests import Timeout, URLRequired
40 from requests.exceptions import InvalidSchema, InvalidURL, MissingSchema
41 from requests.sessions import Session
42 from requests.structures import CaseInsensitiveDict
43
44 from opentelemetry import context, propagators
45 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
46 from opentelemetry.instrumentation.metric import (
47 HTTPMetricRecorder,
48 HTTPMetricType,
49 MetricMixin,
50 )
51 from opentelemetry.instrumentation.requests.version import __version__
52 from opentelemetry.instrumentation.utils import http_status_to_status_code
53 from opentelemetry.trace import SpanKind, get_tracer
54 from opentelemetry.trace.status import Status, StatusCode
55
56 # A key to a context variable to avoid creating duplicate spans when instrumenting
57 # both, Session.request and Session.send, since Session.request calls into Session.send
58 _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY = "suppress_requests_instrumentation"
59
60
61 # pylint: disable=unused-argument
62 # pylint: disable=R0915
63 def _instrument(tracer_provider=None, span_callback=None, name_callback=None):
64 """Enables tracing of all requests calls that go through
65 :code:`requests.session.Session.request` (this includes
66 :code:`requests.get`, etc.)."""
67
68 # Since
69 # https://github.com/psf/requests/commit/d72d1162142d1bf8b1b5711c664fbbd674f349d1
70 # (v0.7.0, Oct 23, 2011), get, post, etc are implemented via request which
71 # again, is implemented via Session.request (`Session` was named `session`
72 # before v1.0.0, Dec 17, 2012, see
73 # https://github.com/psf/requests/commit/4e5c4a6ab7bb0195dececdd19bb8505b872fe120)
74
75 wrapped_request = Session.request
76 wrapped_send = Session.send
77
78 @functools.wraps(wrapped_request)
79 def instrumented_request(self, method, url, *args, **kwargs):
80 def get_or_create_headers():
81 headers = kwargs.get("headers")
82 if headers is None:
83 headers = {}
84 kwargs["headers"] = headers
85
86 return headers
87
88 def call_wrapped():
89 return wrapped_request(self, method, url, *args, **kwargs)
90
91 return _instrumented_requests_call(
92 method, url, call_wrapped, get_or_create_headers
93 )
94
95 @functools.wraps(wrapped_send)
96 def instrumented_send(self, request, **kwargs):
97 def get_or_create_headers():
98 request.headers = (
99 request.headers
100 if request.headers is not None
101 else CaseInsensitiveDict()
102 )
103 return request.headers
104
105 def call_wrapped():
106 return wrapped_send(self, request, **kwargs)
107
108 return _instrumented_requests_call(
109 request.method, request.url, call_wrapped, get_or_create_headers
110 )
111
112 def _instrumented_requests_call(
113 method: str, url: str, call_wrapped, get_or_create_headers
114 ):
115 if context.get_value("suppress_instrumentation") or context.get_value(
116 _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY
117 ):
118 return call_wrapped()
119
120 # See
121 # https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/semantic_conventions/http.md#http-client
122 method = method.upper()
123 span_name = ""
124 if name_callback is not None:
125 span_name = name_callback()
126 if not span_name or not isinstance(span_name, str):
127 span_name = get_default_span_name(method)
128
129 recorder = RequestsInstrumentor().metric_recorder
130
131 labels = {}
132 labels["http.method"] = method
133 labels["http.url"] = url
134
135 with get_tracer(
136 __name__, __version__, tracer_provider
137 ).start_as_current_span(span_name, kind=SpanKind.CLIENT) as span:
138 exception = None
139 with recorder.record_client_duration(labels):
140 if span.is_recording():
141 span.set_attribute("component", "http")
142 span.set_attribute("http.method", method)
143 span.set_attribute("http.url", url)
144
145 headers = get_or_create_headers()
146 propagators.inject(type(headers).__setitem__, headers)
147
148 token = context.attach(
149 context.set_value(
150 _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY, True
151 )
152 )
153 try:
154 result = call_wrapped() # *** PROCEED
155 except Exception as exc: # pylint: disable=W0703
156 exception = exc
157 result = getattr(exc, "response", None)
158 finally:
159 context.detach(token)
160
161 if result is not None:
162 if span.is_recording():
163 span.set_attribute(
164 "http.status_code", result.status_code
165 )
166 span.set_attribute("http.status_text", result.reason)
167 span.set_status(
168 Status(
169 http_status_to_status_code(result.status_code)
170 )
171 )
172 labels["http.status_code"] = str(result.status_code)
173 if result.raw and result.raw.version:
174 labels["http.flavor"] = (
175 str(result.raw.version)[:1]
176 + "."
177 + str(result.raw.version)[:-1]
178 )
179 if span_callback is not None:
180 span_callback(span, result)
181
182 if exception is not None:
183 raise exception.with_traceback(exception.__traceback__)
184
185 return result
186
187 instrumented_request.opentelemetry_instrumentation_requests_applied = True
188 Session.request = instrumented_request
189
190 instrumented_send.opentelemetry_instrumentation_requests_applied = True
191 Session.send = instrumented_send
192
193
194 def _uninstrument():
195 """Disables instrumentation of :code:`requests` through this module.
196
197 Note that this only works if no other module also patches requests."""
198 _uninstrument_from(Session)
199
200
201 def _uninstrument_from(instr_root, restore_as_bound_func=False):
202 for instr_func_name in ("request", "send"):
203 instr_func = getattr(instr_root, instr_func_name)
204 if not getattr(
205 instr_func,
206 "opentelemetry_instrumentation_requests_applied",
207 False,
208 ):
209 continue
210
211 original = instr_func.__wrapped__ # pylint:disable=no-member
212 if restore_as_bound_func:
213 original = types.MethodType(original, instr_root)
214 setattr(instr_root, instr_func_name, original)
215
216
217 def get_default_span_name(method):
218 """Default implementation for name_callback, returns HTTP {method_name}."""
219 return "HTTP {}".format(method).strip()
220
221
222 class RequestsInstrumentor(BaseInstrumentor, MetricMixin):
223 """An instrumentor for requests
224 See `BaseInstrumentor`
225 """
226
227 def _instrument(self, **kwargs):
228 """Instruments requests module
229
230 Args:
231 **kwargs: Optional arguments
232 ``tracer_provider``: a TracerProvider, defaults to global
233 ``span_callback``: An optional callback invoked before returning the http response. Invoked with Span and requests.Response
234 ``name_callback``: Callback which calculates a generic span name for an
235 outgoing HTTP request based on the method and url.
236 Optional: Defaults to get_default_span_name.
237 """
238 _instrument(
239 tracer_provider=kwargs.get("tracer_provider"),
240 span_callback=kwargs.get("span_callback"),
241 name_callback=kwargs.get("name_callback"),
242 )
243 self.init_metrics(
244 __name__, __version__,
245 )
246 # pylint: disable=W0201
247 self.metric_recorder = HTTPMetricRecorder(
248 self.meter, HTTPMetricType.CLIENT
249 )
250
251 def _uninstrument(self, **kwargs):
252 _uninstrument()
253
254 @staticmethod
255 def uninstrument_session(session):
256 """Disables instrumentation on the session object."""
257 _uninstrument_from(session, restore_as_bound_func=True)
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py b/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py
@@ -25,7 +25,7 @@
import opentelemetry.instrumentation.requests
# You can optionally pass a custom TracerProvider to
- # RequestInstrumentor.instrument()
+ # RequestsInstrumentor.instrument()
opentelemetry.instrumentation.requests.RequestsInstrumentor().instrument()
response = requests.get(url="https://www.example.org/")
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py b/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py\n@@ -25,7 +25,7 @@\n import opentelemetry.instrumentation.requests\n \n # You can optionally pass a custom TracerProvider to\n- # RequestInstrumentor.instrument()\n+ # RequestsInstrumentor.instrument()\n opentelemetry.instrumentation.requests.RequestsInstrumentor().instrument()\n response = requests.get(url=\"https://www.example.org/\")\n", "issue": "Allow to modify the computed Span name via callback.\n# Description\r\n\r\nWith Redis and Databases in a traces, there is no easy way from the span name to see if a \"SELECT\" is going to Redis or the database.\r\n\r\n\r\n## Type of change\r\n\r\nPlease delete options that are not relevant.\r\n\r\n- [X] New feature (non-breaking change which adds functionality)\r\n\r\n# How Has This Been Tested?\r\n\r\n- [X] TestRedis::test_name_callback\r\n\r\n# Does This PR Require a Core Repo Change?\r\n\r\n- [ ] Yes. - Link to PR: \r\n- [X] No.\r\n\r\n# Checklist:\r\n\r\nSee [contributing.md](https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/CONTRIBUTING.md) for styleguide, changelog guidelines, and more.\r\n\r\n- [?] Followed the style guidelines of this project\r\n- [X] Changelogs have been updated\r\n- [X] Unit tests have been added\r\n- [X] Documentation has been updated\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThis library allows tracing HTTP requests made by the\n`requests <https://requests.readthedocs.io/en/master/>`_ library.\n\nUsage\n-----\n\n.. code-block:: python\n\n import requests\n import opentelemetry.instrumentation.requests\n\n # You can optionally pass a custom TracerProvider to\n # RequestInstrumentor.instrument()\n opentelemetry.instrumentation.requests.RequestsInstrumentor().instrument()\n response = requests.get(url=\"https://www.example.org/\")\n\nAPI\n---\n\"\"\"\n\nimport functools\nimport types\n\nfrom requests import Timeout, URLRequired\nfrom requests.exceptions import InvalidSchema, InvalidURL, MissingSchema\nfrom requests.sessions import Session\nfrom requests.structures import CaseInsensitiveDict\n\nfrom opentelemetry import context, propagators\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.metric import (\n HTTPMetricRecorder,\n HTTPMetricType,\n MetricMixin,\n)\nfrom opentelemetry.instrumentation.requests.version import __version__\nfrom opentelemetry.instrumentation.utils import http_status_to_status_code\nfrom opentelemetry.trace import SpanKind, get_tracer\nfrom opentelemetry.trace.status import Status, StatusCode\n\n# A key to a context variable to avoid creating duplicate spans when instrumenting\n# both, Session.request and Session.send, since Session.request calls into Session.send\n_SUPPRESS_REQUESTS_INSTRUMENTATION_KEY = \"suppress_requests_instrumentation\"\n\n\n# pylint: disable=unused-argument\n# pylint: disable=R0915\ndef _instrument(tracer_provider=None, span_callback=None, name_callback=None):\n \"\"\"Enables tracing of all requests calls that go through\n :code:`requests.session.Session.request` (this includes\n :code:`requests.get`, etc.).\"\"\"\n\n # Since\n # https://github.com/psf/requests/commit/d72d1162142d1bf8b1b5711c664fbbd674f349d1\n # (v0.7.0, Oct 23, 2011), get, post, etc are implemented via request which\n # again, is implemented via Session.request (`Session` was named `session`\n # before v1.0.0, Dec 17, 2012, see\n # https://github.com/psf/requests/commit/4e5c4a6ab7bb0195dececdd19bb8505b872fe120)\n\n wrapped_request = Session.request\n wrapped_send = Session.send\n\n @functools.wraps(wrapped_request)\n def instrumented_request(self, method, url, *args, **kwargs):\n def get_or_create_headers():\n headers = kwargs.get(\"headers\")\n if headers is None:\n headers = {}\n kwargs[\"headers\"] = headers\n\n return headers\n\n def call_wrapped():\n return wrapped_request(self, method, url, *args, **kwargs)\n\n return _instrumented_requests_call(\n method, url, call_wrapped, get_or_create_headers\n )\n\n @functools.wraps(wrapped_send)\n def instrumented_send(self, request, **kwargs):\n def get_or_create_headers():\n request.headers = (\n request.headers\n if request.headers is not None\n else CaseInsensitiveDict()\n )\n return request.headers\n\n def call_wrapped():\n return wrapped_send(self, request, **kwargs)\n\n return _instrumented_requests_call(\n request.method, request.url, call_wrapped, get_or_create_headers\n )\n\n def _instrumented_requests_call(\n method: str, url: str, call_wrapped, get_or_create_headers\n ):\n if context.get_value(\"suppress_instrumentation\") or context.get_value(\n _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY\n ):\n return call_wrapped()\n\n # See\n # https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/semantic_conventions/http.md#http-client\n method = method.upper()\n span_name = \"\"\n if name_callback is not None:\n span_name = name_callback()\n if not span_name or not isinstance(span_name, str):\n span_name = get_default_span_name(method)\n\n recorder = RequestsInstrumentor().metric_recorder\n\n labels = {}\n labels[\"http.method\"] = method\n labels[\"http.url\"] = url\n\n with get_tracer(\n __name__, __version__, tracer_provider\n ).start_as_current_span(span_name, kind=SpanKind.CLIENT) as span:\n exception = None\n with recorder.record_client_duration(labels):\n if span.is_recording():\n span.set_attribute(\"component\", \"http\")\n span.set_attribute(\"http.method\", method)\n span.set_attribute(\"http.url\", url)\n\n headers = get_or_create_headers()\n propagators.inject(type(headers).__setitem__, headers)\n\n token = context.attach(\n context.set_value(\n _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY, True\n )\n )\n try:\n result = call_wrapped() # *** PROCEED\n except Exception as exc: # pylint: disable=W0703\n exception = exc\n result = getattr(exc, \"response\", None)\n finally:\n context.detach(token)\n\n if result is not None:\n if span.is_recording():\n span.set_attribute(\n \"http.status_code\", result.status_code\n )\n span.set_attribute(\"http.status_text\", result.reason)\n span.set_status(\n Status(\n http_status_to_status_code(result.status_code)\n )\n )\n labels[\"http.status_code\"] = str(result.status_code)\n if result.raw and result.raw.version:\n labels[\"http.flavor\"] = (\n str(result.raw.version)[:1]\n + \".\"\n + str(result.raw.version)[:-1]\n )\n if span_callback is not None:\n span_callback(span, result)\n\n if exception is not None:\n raise exception.with_traceback(exception.__traceback__)\n\n return result\n\n instrumented_request.opentelemetry_instrumentation_requests_applied = True\n Session.request = instrumented_request\n\n instrumented_send.opentelemetry_instrumentation_requests_applied = True\n Session.send = instrumented_send\n\n\ndef _uninstrument():\n \"\"\"Disables instrumentation of :code:`requests` through this module.\n\n Note that this only works if no other module also patches requests.\"\"\"\n _uninstrument_from(Session)\n\n\ndef _uninstrument_from(instr_root, restore_as_bound_func=False):\n for instr_func_name in (\"request\", \"send\"):\n instr_func = getattr(instr_root, instr_func_name)\n if not getattr(\n instr_func,\n \"opentelemetry_instrumentation_requests_applied\",\n False,\n ):\n continue\n\n original = instr_func.__wrapped__ # pylint:disable=no-member\n if restore_as_bound_func:\n original = types.MethodType(original, instr_root)\n setattr(instr_root, instr_func_name, original)\n\n\ndef get_default_span_name(method):\n \"\"\"Default implementation for name_callback, returns HTTP {method_name}.\"\"\"\n return \"HTTP {}\".format(method).strip()\n\n\nclass RequestsInstrumentor(BaseInstrumentor, MetricMixin):\n \"\"\"An instrumentor for requests\n See `BaseInstrumentor`\n \"\"\"\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments requests module\n\n Args:\n **kwargs: Optional arguments\n ``tracer_provider``: a TracerProvider, defaults to global\n ``span_callback``: An optional callback invoked before returning the http response. Invoked with Span and requests.Response\n ``name_callback``: Callback which calculates a generic span name for an\n outgoing HTTP request based on the method and url.\n Optional: Defaults to get_default_span_name.\n \"\"\"\n _instrument(\n tracer_provider=kwargs.get(\"tracer_provider\"),\n span_callback=kwargs.get(\"span_callback\"),\n name_callback=kwargs.get(\"name_callback\"),\n )\n self.init_metrics(\n __name__, __version__,\n )\n # pylint: disable=W0201\n self.metric_recorder = HTTPMetricRecorder(\n self.meter, HTTPMetricType.CLIENT\n )\n\n def _uninstrument(self, **kwargs):\n _uninstrument()\n\n @staticmethod\n def uninstrument_session(session):\n \"\"\"Disables instrumentation on the session object.\"\"\"\n _uninstrument_from(session, restore_as_bound_func=True)\n", "path": "instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThis library allows tracing HTTP requests made by the\n`requests <https://requests.readthedocs.io/en/master/>`_ library.\n\nUsage\n-----\n\n.. code-block:: python\n\n import requests\n import opentelemetry.instrumentation.requests\n\n # You can optionally pass a custom TracerProvider to\n # RequestsInstrumentor.instrument()\n opentelemetry.instrumentation.requests.RequestsInstrumentor().instrument()\n response = requests.get(url=\"https://www.example.org/\")\n\nAPI\n---\n\"\"\"\n\nimport functools\nimport types\n\nfrom requests import Timeout, URLRequired\nfrom requests.exceptions import InvalidSchema, InvalidURL, MissingSchema\nfrom requests.sessions import Session\nfrom requests.structures import CaseInsensitiveDict\n\nfrom opentelemetry import context, propagators\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.metric import (\n HTTPMetricRecorder,\n HTTPMetricType,\n MetricMixin,\n)\nfrom opentelemetry.instrumentation.requests.version import __version__\nfrom opentelemetry.instrumentation.utils import http_status_to_status_code\nfrom opentelemetry.trace import SpanKind, get_tracer\nfrom opentelemetry.trace.status import Status, StatusCode\n\n# A key to a context variable to avoid creating duplicate spans when instrumenting\n# both, Session.request and Session.send, since Session.request calls into Session.send\n_SUPPRESS_REQUESTS_INSTRUMENTATION_KEY = \"suppress_requests_instrumentation\"\n\n\n# pylint: disable=unused-argument\n# pylint: disable=R0915\ndef _instrument(tracer_provider=None, span_callback=None, name_callback=None):\n \"\"\"Enables tracing of all requests calls that go through\n :code:`requests.session.Session.request` (this includes\n :code:`requests.get`, etc.).\"\"\"\n\n # Since\n # https://github.com/psf/requests/commit/d72d1162142d1bf8b1b5711c664fbbd674f349d1\n # (v0.7.0, Oct 23, 2011), get, post, etc are implemented via request which\n # again, is implemented via Session.request (`Session` was named `session`\n # before v1.0.0, Dec 17, 2012, see\n # https://github.com/psf/requests/commit/4e5c4a6ab7bb0195dececdd19bb8505b872fe120)\n\n wrapped_request = Session.request\n wrapped_send = Session.send\n\n @functools.wraps(wrapped_request)\n def instrumented_request(self, method, url, *args, **kwargs):\n def get_or_create_headers():\n headers = kwargs.get(\"headers\")\n if headers is None:\n headers = {}\n kwargs[\"headers\"] = headers\n\n return headers\n\n def call_wrapped():\n return wrapped_request(self, method, url, *args, **kwargs)\n\n return _instrumented_requests_call(\n method, url, call_wrapped, get_or_create_headers\n )\n\n @functools.wraps(wrapped_send)\n def instrumented_send(self, request, **kwargs):\n def get_or_create_headers():\n request.headers = (\n request.headers\n if request.headers is not None\n else CaseInsensitiveDict()\n )\n return request.headers\n\n def call_wrapped():\n return wrapped_send(self, request, **kwargs)\n\n return _instrumented_requests_call(\n request.method, request.url, call_wrapped, get_or_create_headers\n )\n\n def _instrumented_requests_call(\n method: str, url: str, call_wrapped, get_or_create_headers\n ):\n if context.get_value(\"suppress_instrumentation\") or context.get_value(\n _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY\n ):\n return call_wrapped()\n\n # See\n # https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/semantic_conventions/http.md#http-client\n method = method.upper()\n span_name = \"\"\n if name_callback is not None:\n span_name = name_callback()\n if not span_name or not isinstance(span_name, str):\n span_name = get_default_span_name(method)\n\n recorder = RequestsInstrumentor().metric_recorder\n\n labels = {}\n labels[\"http.method\"] = method\n labels[\"http.url\"] = url\n\n with get_tracer(\n __name__, __version__, tracer_provider\n ).start_as_current_span(span_name, kind=SpanKind.CLIENT) as span:\n exception = None\n with recorder.record_client_duration(labels):\n if span.is_recording():\n span.set_attribute(\"component\", \"http\")\n span.set_attribute(\"http.method\", method)\n span.set_attribute(\"http.url\", url)\n\n headers = get_or_create_headers()\n propagators.inject(type(headers).__setitem__, headers)\n\n token = context.attach(\n context.set_value(\n _SUPPRESS_REQUESTS_INSTRUMENTATION_KEY, True\n )\n )\n try:\n result = call_wrapped() # *** PROCEED\n except Exception as exc: # pylint: disable=W0703\n exception = exc\n result = getattr(exc, \"response\", None)\n finally:\n context.detach(token)\n\n if result is not None:\n if span.is_recording():\n span.set_attribute(\n \"http.status_code\", result.status_code\n )\n span.set_attribute(\"http.status_text\", result.reason)\n span.set_status(\n Status(\n http_status_to_status_code(result.status_code)\n )\n )\n labels[\"http.status_code\"] = str(result.status_code)\n if result.raw and result.raw.version:\n labels[\"http.flavor\"] = (\n str(result.raw.version)[:1]\n + \".\"\n + str(result.raw.version)[:-1]\n )\n if span_callback is not None:\n span_callback(span, result)\n\n if exception is not None:\n raise exception.with_traceback(exception.__traceback__)\n\n return result\n\n instrumented_request.opentelemetry_instrumentation_requests_applied = True\n Session.request = instrumented_request\n\n instrumented_send.opentelemetry_instrumentation_requests_applied = True\n Session.send = instrumented_send\n\n\ndef _uninstrument():\n \"\"\"Disables instrumentation of :code:`requests` through this module.\n\n Note that this only works if no other module also patches requests.\"\"\"\n _uninstrument_from(Session)\n\n\ndef _uninstrument_from(instr_root, restore_as_bound_func=False):\n for instr_func_name in (\"request\", \"send\"):\n instr_func = getattr(instr_root, instr_func_name)\n if not getattr(\n instr_func,\n \"opentelemetry_instrumentation_requests_applied\",\n False,\n ):\n continue\n\n original = instr_func.__wrapped__ # pylint:disable=no-member\n if restore_as_bound_func:\n original = types.MethodType(original, instr_root)\n setattr(instr_root, instr_func_name, original)\n\n\ndef get_default_span_name(method):\n \"\"\"Default implementation for name_callback, returns HTTP {method_name}.\"\"\"\n return \"HTTP {}\".format(method).strip()\n\n\nclass RequestsInstrumentor(BaseInstrumentor, MetricMixin):\n \"\"\"An instrumentor for requests\n See `BaseInstrumentor`\n \"\"\"\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments requests module\n\n Args:\n **kwargs: Optional arguments\n ``tracer_provider``: a TracerProvider, defaults to global\n ``span_callback``: An optional callback invoked before returning the http response. Invoked with Span and requests.Response\n ``name_callback``: Callback which calculates a generic span name for an\n outgoing HTTP request based on the method and url.\n Optional: Defaults to get_default_span_name.\n \"\"\"\n _instrument(\n tracer_provider=kwargs.get(\"tracer_provider\"),\n span_callback=kwargs.get(\"span_callback\"),\n name_callback=kwargs.get(\"name_callback\"),\n )\n self.init_metrics(\n __name__, __version__,\n )\n # pylint: disable=W0201\n self.metric_recorder = HTTPMetricRecorder(\n self.meter, HTTPMetricType.CLIENT\n )\n\n def _uninstrument(self, **kwargs):\n _uninstrument()\n\n @staticmethod\n def uninstrument_session(session):\n \"\"\"Disables instrumentation on the session object.\"\"\"\n _uninstrument_from(session, restore_as_bound_func=True)\n", "path": "instrumentation/opentelemetry-instrumentation-requests/src/opentelemetry/instrumentation/requests/__init__.py"}]}
| 3,111 | 185 |
gh_patches_debug_16131
|
rasdani/github-patches
|
git_diff
|
mabel-dev__opteryx-1593
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
🪲 random appears to be evaluated once
was seeing what happens for opteryx for https://buttondown.email/jaffray/archive/the-case-of-a-curious-sql-query/
~~~sql
SELECT count(*)
FROM GENERATE_SERIES(1000) AS one_thousand
CROSS JOIN GENERATE_SERIES(1000) AS one_thousand_b
WHERE random() < 0.5
~~~
~~~
AFTER COST OPTIMIZATION
└─ EXIT
└─ PROJECT (COUNT(*))
└─ AGGREGATE (COUNT(*))
└─ FILTER (False)
└─ CROSS JOIN
├─ GENERATE SERIES (1000) AS one_thousand
└─ GENERATE SERIES (1000) AS one_thousand_b
~~~
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opteryx/components/cost_based_optimizer/strategies/constant_folding.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import datetime
14 from typing import Any
15
16 import numpy
17 from orso.types import OrsoTypes
18
19 from opteryx.components.logical_planner import LogicalPlan
20 from opteryx.components.logical_planner import LogicalPlanNode
21 from opteryx.components.logical_planner import LogicalPlanStepType
22 from opteryx.managers.expression import NodeType
23 from opteryx.managers.expression import evaluate
24 from opteryx.managers.expression import get_all_nodes_of_type
25 from opteryx.models import Node
26 from opteryx.virtual_datasets import no_table_data
27
28 from .optimization_strategy import OptimizationStrategy
29 from .optimization_strategy import OptimizerContext
30
31
32 def build_literal_node(value: Any, root: Node):
33 # fmt:off
34 if hasattr(value, "as_py"):
35 value = value.as_py()
36
37 root.value = value
38 root.node_type = NodeType.LITERAL
39 if value is None:
40 root.type=OrsoTypes.NULL
41 elif isinstance(value, (bool, numpy.bool_)):
42 # boolean must be before numeric
43 root.type=OrsoTypes.BOOLEAN
44 elif isinstance(value, (str)):
45 root.type=OrsoTypes.VARCHAR
46 elif isinstance(value, (int, numpy.int64)):
47 root.type=OrsoTypes.INTEGER
48 elif isinstance(value, (numpy.datetime64, datetime.datetime)):
49 root.type=OrsoTypes.TIMESTAMP
50 elif isinstance(value, (datetime.date)):
51 root.type=OrsoTypes.DATE
52 else:
53 raise Exception("Unable to fold expression")
54 return root
55 # fmt:on
56
57
58 def fold_constants(root: Node) -> Node:
59 identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))
60 if len(identifiers) == 0:
61 table = no_table_data.read()
62 try:
63 result = evaluate(root, table, None)[0]
64 return build_literal_node(result, root)
65 except Exception as err: # nosec
66 # what ever the reason, just skip
67 # DEBUG:log (err)
68 pass
69 return root
70
71
72 class ConstantFoldingStrategy(OptimizationStrategy):
73 def visit(self, node: LogicalPlanNode, context: OptimizerContext) -> OptimizerContext:
74 """
75 Constant Folding is when we precalculate expressions (or sub expressions)
76 which contain only constant or literal values.
77 """
78 if not context.optimized_plan:
79 context.optimized_plan = context.pre_optimized_tree.copy() # type: ignore
80
81 if node.node_type == LogicalPlanStepType.Filter:
82 node.condition = fold_constants(node.condition)
83 if node.condition.node_type == NodeType.LITERAL and node.condition.value:
84 context.optimized_plan.remove_node(context.node_id, heal=True)
85 else:
86 context.optimized_plan[context.node_id] = node
87
88 return context
89
90 def complete(self, plan: LogicalPlan, context: OptimizerContext) -> LogicalPlan:
91 # No finalization needed for this strategy
92 return plan
93
```
Path: `opteryx/__version__.py`
Content:
```
1 __build__ = 430
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Store the version here so:
17 1) we don't load dependencies by storing it in __init__.py
18 2) we can import it in setup.py for the same reason
19 """
20 from enum import Enum # isort: skip
21
22
23 class VersionStatus(Enum):
24 ALPHA = "alpha"
25 BETA = "beta"
26 RELEASE = "release"
27
28
29 _major = 0
30 _minor = 14
31 _revision = 2
32 _status = VersionStatus.ALPHA
33
34 __author__ = "@joocer"
35 __version__ = f"{_major}.{_minor}.{_revision}" + (
36 f"-{_status.value}.{__build__}" if _status != VersionStatus.RELEASE else ""
37 )
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opteryx/__version__.py b/opteryx/__version__.py
--- a/opteryx/__version__.py
+++ b/opteryx/__version__.py
@@ -1,4 +1,4 @@
-__build__ = 430
+__build__ = 432
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py
--- a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py
+++ b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py
@@ -57,6 +57,11 @@
def fold_constants(root: Node) -> Node:
identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))
+ functions = get_all_nodes_of_type(root, (NodeType.FUNCTION,))
+
+ if any(func.value in {"RANDOM", "RAND", "NORMAL", "RANDOM_STRING"} for func in functions):
+ return root
+
if len(identifiers) == 0:
table = no_table_data.read()
try:
|
{"golden_diff": "diff --git a/opteryx/__version__.py b/opteryx/__version__.py\n--- a/opteryx/__version__.py\n+++ b/opteryx/__version__.py\n@@ -1,4 +1,4 @@\n-__build__ = 430\n+__build__ = 432\n \n # Licensed under the Apache License, Version 2.0 (the \"License\");\n # you may not use this file except in compliance with the License.\ndiff --git a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py\n--- a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py\n+++ b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py\n@@ -57,6 +57,11 @@\n \n def fold_constants(root: Node) -> Node:\n identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))\n+ functions = get_all_nodes_of_type(root, (NodeType.FUNCTION,))\n+\n+ if any(func.value in {\"RANDOM\", \"RAND\", \"NORMAL\", \"RANDOM_STRING\"} for func in functions):\n+ return root\n+\n if len(identifiers) == 0:\n table = no_table_data.read()\n try:\n", "issue": "\ud83e\udeb2 random appears to be evaluated once\nwas seeing what happens for opteryx for https://buttondown.email/jaffray/archive/the-case-of-a-curious-sql-query/\r\n\r\n~~~sql\r\nSELECT count(*) \r\nFROM GENERATE_SERIES(1000) AS one_thousand \r\nCROSS JOIN GENERATE_SERIES(1000) AS one_thousand_b \r\nWHERE random() < 0.5\r\n~~~\r\n\r\n~~~\r\nAFTER COST OPTIMIZATION\r\n\u2514\u2500 EXIT\r\n \u2514\u2500 PROJECT (COUNT(*))\r\n \u2514\u2500 AGGREGATE (COUNT(*))\r\n \u2514\u2500 FILTER (False)\r\n \u2514\u2500 CROSS JOIN\r\n \u251c\u2500 GENERATE SERIES (1000) AS one_thousand\r\n \u2514\u2500 GENERATE SERIES (1000) AS one_thousand_b\r\n~~~\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport datetime\nfrom typing import Any\n\nimport numpy\nfrom orso.types import OrsoTypes\n\nfrom opteryx.components.logical_planner import LogicalPlan\nfrom opteryx.components.logical_planner import LogicalPlanNode\nfrom opteryx.components.logical_planner import LogicalPlanStepType\nfrom opteryx.managers.expression import NodeType\nfrom opteryx.managers.expression import evaluate\nfrom opteryx.managers.expression import get_all_nodes_of_type\nfrom opteryx.models import Node\nfrom opteryx.virtual_datasets import no_table_data\n\nfrom .optimization_strategy import OptimizationStrategy\nfrom .optimization_strategy import OptimizerContext\n\n\ndef build_literal_node(value: Any, root: Node):\n # fmt:off\n if hasattr(value, \"as_py\"):\n value = value.as_py()\n\n root.value = value\n root.node_type = NodeType.LITERAL\n if value is None:\n root.type=OrsoTypes.NULL\n elif isinstance(value, (bool, numpy.bool_)):\n # boolean must be before numeric\n root.type=OrsoTypes.BOOLEAN\n elif isinstance(value, (str)):\n root.type=OrsoTypes.VARCHAR\n elif isinstance(value, (int, numpy.int64)):\n root.type=OrsoTypes.INTEGER\n elif isinstance(value, (numpy.datetime64, datetime.datetime)):\n root.type=OrsoTypes.TIMESTAMP\n elif isinstance(value, (datetime.date)):\n root.type=OrsoTypes.DATE\n else:\n raise Exception(\"Unable to fold expression\")\n return root\n # fmt:on\n\n\ndef fold_constants(root: Node) -> Node:\n identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))\n if len(identifiers) == 0:\n table = no_table_data.read()\n try:\n result = evaluate(root, table, None)[0]\n return build_literal_node(result, root)\n except Exception as err: # nosec\n # what ever the reason, just skip\n # DEBUG:log (err)\n pass\n return root\n\n\nclass ConstantFoldingStrategy(OptimizationStrategy):\n def visit(self, node: LogicalPlanNode, context: OptimizerContext) -> OptimizerContext:\n \"\"\"\n Constant Folding is when we precalculate expressions (or sub expressions)\n which contain only constant or literal values.\n \"\"\"\n if not context.optimized_plan:\n context.optimized_plan = context.pre_optimized_tree.copy() # type: ignore\n\n if node.node_type == LogicalPlanStepType.Filter:\n node.condition = fold_constants(node.condition)\n if node.condition.node_type == NodeType.LITERAL and node.condition.value:\n context.optimized_plan.remove_node(context.node_id, heal=True)\n else:\n context.optimized_plan[context.node_id] = node\n\n return context\n\n def complete(self, plan: LogicalPlan, context: OptimizerContext) -> LogicalPlan:\n # No finalization needed for this strategy\n return plan\n", "path": "opteryx/components/cost_based_optimizer/strategies/constant_folding.py"}, {"content": "__build__ = 430\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 14\n_revision = 2\n_status = VersionStatus.ALPHA\n\n__author__ = \"@joocer\"\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)\n", "path": "opteryx/__version__.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport datetime\nfrom typing import Any\n\nimport numpy\nfrom orso.types import OrsoTypes\n\nfrom opteryx.components.logical_planner import LogicalPlan\nfrom opteryx.components.logical_planner import LogicalPlanNode\nfrom opteryx.components.logical_planner import LogicalPlanStepType\nfrom opteryx.managers.expression import NodeType\nfrom opteryx.managers.expression import evaluate\nfrom opteryx.managers.expression import get_all_nodes_of_type\nfrom opteryx.models import Node\nfrom opteryx.virtual_datasets import no_table_data\n\nfrom .optimization_strategy import OptimizationStrategy\nfrom .optimization_strategy import OptimizerContext\n\n\ndef build_literal_node(value: Any, root: Node):\n # fmt:off\n if hasattr(value, \"as_py\"):\n value = value.as_py()\n\n root.value = value\n root.node_type = NodeType.LITERAL\n if value is None:\n root.type=OrsoTypes.NULL\n elif isinstance(value, (bool, numpy.bool_)):\n # boolean must be before numeric\n root.type=OrsoTypes.BOOLEAN\n elif isinstance(value, (str)):\n root.type=OrsoTypes.VARCHAR\n elif isinstance(value, (int, numpy.int64)):\n root.type=OrsoTypes.INTEGER\n elif isinstance(value, (numpy.datetime64, datetime.datetime)):\n root.type=OrsoTypes.TIMESTAMP\n elif isinstance(value, (datetime.date)):\n root.type=OrsoTypes.DATE\n else:\n raise Exception(\"Unable to fold expression\")\n return root\n # fmt:on\n\n\ndef fold_constants(root: Node) -> Node:\n identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))\n functions = get_all_nodes_of_type(root, (NodeType.FUNCTION,))\n\n if any(func.value in {\"RANDOM\", \"RAND\", \"NORMAL\", \"RANDOM_STRING\"} for func in functions):\n return root\n\n if len(identifiers) == 0:\n table = no_table_data.read()\n try:\n result = evaluate(root, table, None)[0]\n return build_literal_node(result, root)\n except Exception as err: # nosec\n # what ever the reason, just skip\n # DEBUG:log (err)\n pass\n return root\n\n\nclass ConstantFoldingStrategy(OptimizationStrategy):\n def visit(self, node: LogicalPlanNode, context: OptimizerContext) -> OptimizerContext:\n \"\"\"\n Constant Folding is when we precalculate expressions (or sub expressions)\n which contain only constant or literal values.\n \"\"\"\n if not context.optimized_plan:\n context.optimized_plan = context.pre_optimized_tree.copy() # type: ignore\n\n if node.node_type == LogicalPlanStepType.Filter:\n node.condition = fold_constants(node.condition)\n if node.condition.node_type == NodeType.LITERAL and node.condition.value:\n context.optimized_plan.remove_node(context.node_id, heal=True)\n else:\n context.optimized_plan[context.node_id] = node\n\n return context\n\n def complete(self, plan: LogicalPlan, context: OptimizerContext) -> LogicalPlan:\n # No finalization needed for this strategy\n return plan\n", "path": "opteryx/components/cost_based_optimizer/strategies/constant_folding.py"}, {"content": "__build__ = 432\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 14\n_revision = 2\n_status = VersionStatus.ALPHA\n\n__author__ = \"@joocer\"\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)\n", "path": "opteryx/__version__.py"}]}
| 1,759 | 292 |
gh_patches_debug_20592
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1961
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Local run of `mypy` produces unexpected results
### Description
Mypy produces unexpected failures locally, but the CI job passes: https://github.com/litestar-org/litestar/actions/runs/5561581892/jobs/10159348023?pr=1959
I think that this happens because `.pre-commit-config` and local mypy settings are not in sync.
I will fix that.
### URL to code causing the issue
_No response_
### MCVE
_No response_
### Steps to reproduce
```bash
1. `poetry install --with lint -E full`
2. `poetry run mypy litestar`
```
### Screenshots
_No response_
### Logs
```bash
» mypy litestar
litestar/contrib/jwt/jwt_token.py:115: error: Redundant cast to "str" [redundant-cast]
litestar/_signature/models/attrs_signature_model.py:43: error: Skipping analyzing "pytimeparse.timeparse": module is installed, but missing library stubs or py.typed marker [import]
litestar/_signature/models/attrs_signature_model.py:43: note: See https://mypy.readthedocs.io/en/stable/running_mypy.html#missing-imports
litestar/middleware/compression.py:29: error: Skipping analyzing "brotli": module is installed, but missing library stubs or py.typed marker [import]
litestar/contrib/mako.py:19: error: Skipping analyzing "mako": module is installed, but missing library stubs or py.typed marker [import]
litestar/contrib/mako.py:24: error: Skipping analyzing "mako.exceptions": module is installed, but missing library stubs or py.typed marker [import]
litestar/contrib/mako.py:25: error: Skipping analyzing "mako.lookup": module is installed, but missing library stubs or py.typed marker [import]
litestar/contrib/mako.py:28: error: Skipping analyzing "mako.template": module is installed, but missing library stubs or py.typed marker [import]
litestar/cli/commands/schema.py:5: error: Skipping analyzing "jsbeautifier": module is installed, but missing library stubs or py.typed marker [import]
Found 8 errors in 5 files (checked 303 source files)
```
### Litestar Version
`main`
### Platform
- [ ] Linux
- [X] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
## Funding
* If you would like to see an issue prioritized, make a pledge towards it!
* We receive the pledge once the issue is completed & verified
<a href="https://polar.sh/litestar-org/litestar/issues/1960">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/1960/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/1960/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/contrib/jwt/jwt_token.py`
Content:
```
1 from __future__ import annotations
2
3 import dataclasses
4 from dataclasses import asdict, dataclass, field
5 from datetime import datetime, timezone
6 from typing import TYPE_CHECKING, Any, cast
7
8 from jose import JWSError, JWTError, jwt
9
10 from litestar.exceptions import ImproperlyConfiguredException, NotAuthorizedException
11
12 if TYPE_CHECKING:
13 from typing_extensions import Self
14
15
16 __all__ = ("Token",)
17
18
19 def _normalize_datetime(value: datetime) -> datetime:
20 """Convert the given value into UTC and strip microseconds.
21
22 Args:
23 value: A datetime instance
24
25 Returns:
26 A datetime instance
27 """
28 if value.tzinfo is not None:
29 value.astimezone(timezone.utc)
30
31 return value.replace(microsecond=0)
32
33
34 @dataclass
35 class Token:
36 """JWT Token DTO."""
37
38 exp: datetime
39 """Expiration - datetime for token expiration."""
40 sub: str
41 """Subject - usually a unique identifier of the user or equivalent entity."""
42 iat: datetime = field(default_factory=lambda: _normalize_datetime(datetime.now(timezone.utc)))
43 """Issued at - should always be current now."""
44 iss: str | None = field(default=None)
45 """Issuer - optional unique identifier for the issuer."""
46 aud: str | None = field(default=None)
47 """Audience - intended audience."""
48 jti: str | None = field(default=None)
49 """JWT ID - a unique identifier of the JWT between different issuers."""
50 extras: dict[str, Any] = field(default_factory=dict)
51 """Extra fields that were found on the JWT token."""
52
53 def __post_init__(self) -> None:
54 if len(self.sub) < 1:
55 raise ImproperlyConfiguredException("sub must be a string with a length greater than 0")
56
57 if isinstance(self.exp, datetime) and (
58 (exp := _normalize_datetime(self.exp))
59 and exp.timestamp() >= _normalize_datetime(datetime.now(timezone.utc)).timestamp()
60 ):
61 self.exp = exp
62 else:
63 raise ImproperlyConfiguredException("exp value must be a datetime in the future")
64
65 if isinstance(self.iat, datetime) and (
66 (iat := _normalize_datetime(self.iat))
67 and iat.timestamp() <= _normalize_datetime(datetime.now(timezone.utc)).timestamp()
68 ):
69 self.iat = iat
70 else:
71 raise ImproperlyConfiguredException("iat must be a current or past time")
72
73 @classmethod
74 def decode(cls, encoded_token: str, secret: str | dict[str, str], algorithm: str) -> Self:
75 """Decode a passed in token string and returns a Token instance.
76
77 Args:
78 encoded_token: A base64 string containing an encoded JWT.
79 secret: The secret with which the JWT is encoded. It may optionally be an individual JWK or JWS set dict
80 algorithm: The algorithm used to encode the JWT.
81
82 Returns:
83 A decoded Token instance.
84
85 Raises:
86 NotAuthorizedException: If the token is invalid.
87 """
88 try:
89 payload = jwt.decode(token=encoded_token, key=secret, algorithms=[algorithm], options={"verify_aud": False})
90 exp = datetime.fromtimestamp(payload.pop("exp"), tz=timezone.utc)
91 iat = datetime.fromtimestamp(payload.pop("iat"), tz=timezone.utc)
92 field_names = {f.name for f in dataclasses.fields(Token)}
93 extra_fields = payload.keys() - field_names
94 extras = payload.pop("extras", {})
95 for key in extra_fields:
96 extras[key] = payload.pop(key)
97 return cls(exp=exp, iat=iat, **payload, extras=extras)
98 except (KeyError, JWTError, ImproperlyConfiguredException) as e:
99 raise NotAuthorizedException("Invalid token") from e
100
101 def encode(self, secret: str, algorithm: str) -> str:
102 """Encode the token instance into a string.
103
104 Args:
105 secret: The secret with which the JWT is encoded.
106 algorithm: The algorithm used to encode the JWT.
107
108 Returns:
109 An encoded token string.
110
111 Raises:
112 ImproperlyConfiguredException: If encoding fails.
113 """
114 try:
115 return cast(
116 "str",
117 jwt.encode(
118 claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm
119 ),
120 )
121 except (JWTError, JWSError) as e:
122 raise ImproperlyConfiguredException("Failed to encode token") from e
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/litestar/contrib/jwt/jwt_token.py b/litestar/contrib/jwt/jwt_token.py
--- a/litestar/contrib/jwt/jwt_token.py
+++ b/litestar/contrib/jwt/jwt_token.py
@@ -3,7 +3,7 @@
import dataclasses
from dataclasses import asdict, dataclass, field
from datetime import datetime, timezone
-from typing import TYPE_CHECKING, Any, cast
+from typing import TYPE_CHECKING, Any
from jose import JWSError, JWTError, jwt
@@ -112,11 +112,8 @@
ImproperlyConfiguredException: If encoding fails.
"""
try:
- return cast(
- "str",
- jwt.encode(
- claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm
- ),
+ return jwt.encode(
+ claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm
)
except (JWTError, JWSError) as e:
raise ImproperlyConfiguredException("Failed to encode token") from e
|
{"golden_diff": "diff --git a/litestar/contrib/jwt/jwt_token.py b/litestar/contrib/jwt/jwt_token.py\n--- a/litestar/contrib/jwt/jwt_token.py\n+++ b/litestar/contrib/jwt/jwt_token.py\n@@ -3,7 +3,7 @@\n import dataclasses\n from dataclasses import asdict, dataclass, field\n from datetime import datetime, timezone\n-from typing import TYPE_CHECKING, Any, cast\n+from typing import TYPE_CHECKING, Any\n \n from jose import JWSError, JWTError, jwt\n \n@@ -112,11 +112,8 @@\n ImproperlyConfiguredException: If encoding fails.\n \"\"\"\n try:\n- return cast(\n- \"str\",\n- jwt.encode(\n- claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm\n- ),\n+ return jwt.encode(\n+ claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm\n )\n except (JWTError, JWSError) as e:\n raise ImproperlyConfiguredException(\"Failed to encode token\") from e\n", "issue": "Local run of `mypy` produces unexpected results\n### Description\r\n\r\nMypy produces unexpected failures locally, but the CI job passes: https://github.com/litestar-org/litestar/actions/runs/5561581892/jobs/10159348023?pr=1959\r\n\r\nI think that this happens because `.pre-commit-config` and local mypy settings are not in sync.\r\nI will fix that.\r\n\r\n### URL to code causing the issue\r\n\r\n_No response_\r\n\r\n### MCVE\r\n\r\n_No response_\r\n\r\n### Steps to reproduce\r\n\r\n```bash\r\n1. `poetry install --with lint -E full`\r\n2. `poetry run mypy litestar`\r\n```\r\n\r\n\r\n### Screenshots\r\n\r\n_No response_\r\n\r\n### Logs\r\n\r\n```bash\r\n\u00bb mypy litestar \r\nlitestar/contrib/jwt/jwt_token.py:115: error: Redundant cast to \"str\" [redundant-cast]\r\nlitestar/_signature/models/attrs_signature_model.py:43: error: Skipping analyzing \"pytimeparse.timeparse\": module is installed, but missing library stubs or py.typed marker [import]\r\nlitestar/_signature/models/attrs_signature_model.py:43: note: See https://mypy.readthedocs.io/en/stable/running_mypy.html#missing-imports\r\nlitestar/middleware/compression.py:29: error: Skipping analyzing \"brotli\": module is installed, but missing library stubs or py.typed marker [import]\r\nlitestar/contrib/mako.py:19: error: Skipping analyzing \"mako\": module is installed, but missing library stubs or py.typed marker [import]\r\nlitestar/contrib/mako.py:24: error: Skipping analyzing \"mako.exceptions\": module is installed, but missing library stubs or py.typed marker [import]\r\nlitestar/contrib/mako.py:25: error: Skipping analyzing \"mako.lookup\": module is installed, but missing library stubs or py.typed marker [import]\r\nlitestar/contrib/mako.py:28: error: Skipping analyzing \"mako.template\": module is installed, but missing library stubs or py.typed marker [import]\r\nlitestar/cli/commands/schema.py:5: error: Skipping analyzing \"jsbeautifier\": module is installed, but missing library stubs or py.typed marker [import]\r\nFound 8 errors in 5 files (checked 303 source files)\r\n```\r\n\r\n\r\n### Litestar Version\r\n\r\n`main`\r\n\r\n### Platform\r\n\r\n- [ ] Linux\r\n- [X] Mac\r\n- [ ] Windows\r\n- [ ] Other (Please specify in the description above)\r\n\r\n<!-- POLAR PLEDGE BADGE START -->\r\n## Funding\r\n* If you would like to see an issue prioritized, make a pledge towards it!\r\n* We receive the pledge once the issue is completed & verified\r\n\r\n<a href=\"https://polar.sh/litestar-org/litestar/issues/1960\">\r\n<picture>\r\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/1960/pledge.svg?darkmode=1\">\r\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/1960/pledge.svg\">\r\n</picture>\r\n</a>\r\n<!-- POLAR PLEDGE BADGE END -->\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport dataclasses\nfrom dataclasses import asdict, dataclass, field\nfrom datetime import datetime, timezone\nfrom typing import TYPE_CHECKING, Any, cast\n\nfrom jose import JWSError, JWTError, jwt\n\nfrom litestar.exceptions import ImproperlyConfiguredException, NotAuthorizedException\n\nif TYPE_CHECKING:\n from typing_extensions import Self\n\n\n__all__ = (\"Token\",)\n\n\ndef _normalize_datetime(value: datetime) -> datetime:\n \"\"\"Convert the given value into UTC and strip microseconds.\n\n Args:\n value: A datetime instance\n\n Returns:\n A datetime instance\n \"\"\"\n if value.tzinfo is not None:\n value.astimezone(timezone.utc)\n\n return value.replace(microsecond=0)\n\n\n@dataclass\nclass Token:\n \"\"\"JWT Token DTO.\"\"\"\n\n exp: datetime\n \"\"\"Expiration - datetime for token expiration.\"\"\"\n sub: str\n \"\"\"Subject - usually a unique identifier of the user or equivalent entity.\"\"\"\n iat: datetime = field(default_factory=lambda: _normalize_datetime(datetime.now(timezone.utc)))\n \"\"\"Issued at - should always be current now.\"\"\"\n iss: str | None = field(default=None)\n \"\"\"Issuer - optional unique identifier for the issuer.\"\"\"\n aud: str | None = field(default=None)\n \"\"\"Audience - intended audience.\"\"\"\n jti: str | None = field(default=None)\n \"\"\"JWT ID - a unique identifier of the JWT between different issuers.\"\"\"\n extras: dict[str, Any] = field(default_factory=dict)\n \"\"\"Extra fields that were found on the JWT token.\"\"\"\n\n def __post_init__(self) -> None:\n if len(self.sub) < 1:\n raise ImproperlyConfiguredException(\"sub must be a string with a length greater than 0\")\n\n if isinstance(self.exp, datetime) and (\n (exp := _normalize_datetime(self.exp))\n and exp.timestamp() >= _normalize_datetime(datetime.now(timezone.utc)).timestamp()\n ):\n self.exp = exp\n else:\n raise ImproperlyConfiguredException(\"exp value must be a datetime in the future\")\n\n if isinstance(self.iat, datetime) and (\n (iat := _normalize_datetime(self.iat))\n and iat.timestamp() <= _normalize_datetime(datetime.now(timezone.utc)).timestamp()\n ):\n self.iat = iat\n else:\n raise ImproperlyConfiguredException(\"iat must be a current or past time\")\n\n @classmethod\n def decode(cls, encoded_token: str, secret: str | dict[str, str], algorithm: str) -> Self:\n \"\"\"Decode a passed in token string and returns a Token instance.\n\n Args:\n encoded_token: A base64 string containing an encoded JWT.\n secret: The secret with which the JWT is encoded. It may optionally be an individual JWK or JWS set dict\n algorithm: The algorithm used to encode the JWT.\n\n Returns:\n A decoded Token instance.\n\n Raises:\n NotAuthorizedException: If the token is invalid.\n \"\"\"\n try:\n payload = jwt.decode(token=encoded_token, key=secret, algorithms=[algorithm], options={\"verify_aud\": False})\n exp = datetime.fromtimestamp(payload.pop(\"exp\"), tz=timezone.utc)\n iat = datetime.fromtimestamp(payload.pop(\"iat\"), tz=timezone.utc)\n field_names = {f.name for f in dataclasses.fields(Token)}\n extra_fields = payload.keys() - field_names\n extras = payload.pop(\"extras\", {})\n for key in extra_fields:\n extras[key] = payload.pop(key)\n return cls(exp=exp, iat=iat, **payload, extras=extras)\n except (KeyError, JWTError, ImproperlyConfiguredException) as e:\n raise NotAuthorizedException(\"Invalid token\") from e\n\n def encode(self, secret: str, algorithm: str) -> str:\n \"\"\"Encode the token instance into a string.\n\n Args:\n secret: The secret with which the JWT is encoded.\n algorithm: The algorithm used to encode the JWT.\n\n Returns:\n An encoded token string.\n\n Raises:\n ImproperlyConfiguredException: If encoding fails.\n \"\"\"\n try:\n return cast(\n \"str\",\n jwt.encode(\n claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm\n ),\n )\n except (JWTError, JWSError) as e:\n raise ImproperlyConfiguredException(\"Failed to encode token\") from e\n", "path": "litestar/contrib/jwt/jwt_token.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport dataclasses\nfrom dataclasses import asdict, dataclass, field\nfrom datetime import datetime, timezone\nfrom typing import TYPE_CHECKING, Any\n\nfrom jose import JWSError, JWTError, jwt\n\nfrom litestar.exceptions import ImproperlyConfiguredException, NotAuthorizedException\n\nif TYPE_CHECKING:\n from typing_extensions import Self\n\n\n__all__ = (\"Token\",)\n\n\ndef _normalize_datetime(value: datetime) -> datetime:\n \"\"\"Convert the given value into UTC and strip microseconds.\n\n Args:\n value: A datetime instance\n\n Returns:\n A datetime instance\n \"\"\"\n if value.tzinfo is not None:\n value.astimezone(timezone.utc)\n\n return value.replace(microsecond=0)\n\n\n@dataclass\nclass Token:\n \"\"\"JWT Token DTO.\"\"\"\n\n exp: datetime\n \"\"\"Expiration - datetime for token expiration.\"\"\"\n sub: str\n \"\"\"Subject - usually a unique identifier of the user or equivalent entity.\"\"\"\n iat: datetime = field(default_factory=lambda: _normalize_datetime(datetime.now(timezone.utc)))\n \"\"\"Issued at - should always be current now.\"\"\"\n iss: str | None = field(default=None)\n \"\"\"Issuer - optional unique identifier for the issuer.\"\"\"\n aud: str | None = field(default=None)\n \"\"\"Audience - intended audience.\"\"\"\n jti: str | None = field(default=None)\n \"\"\"JWT ID - a unique identifier of the JWT between different issuers.\"\"\"\n extras: dict[str, Any] = field(default_factory=dict)\n \"\"\"Extra fields that were found on the JWT token.\"\"\"\n\n def __post_init__(self) -> None:\n if len(self.sub) < 1:\n raise ImproperlyConfiguredException(\"sub must be a string with a length greater than 0\")\n\n if isinstance(self.exp, datetime) and (\n (exp := _normalize_datetime(self.exp))\n and exp.timestamp() >= _normalize_datetime(datetime.now(timezone.utc)).timestamp()\n ):\n self.exp = exp\n else:\n raise ImproperlyConfiguredException(\"exp value must be a datetime in the future\")\n\n if isinstance(self.iat, datetime) and (\n (iat := _normalize_datetime(self.iat))\n and iat.timestamp() <= _normalize_datetime(datetime.now(timezone.utc)).timestamp()\n ):\n self.iat = iat\n else:\n raise ImproperlyConfiguredException(\"iat must be a current or past time\")\n\n @classmethod\n def decode(cls, encoded_token: str, secret: str | dict[str, str], algorithm: str) -> Self:\n \"\"\"Decode a passed in token string and returns a Token instance.\n\n Args:\n encoded_token: A base64 string containing an encoded JWT.\n secret: The secret with which the JWT is encoded. It may optionally be an individual JWK or JWS set dict\n algorithm: The algorithm used to encode the JWT.\n\n Returns:\n A decoded Token instance.\n\n Raises:\n NotAuthorizedException: If the token is invalid.\n \"\"\"\n try:\n payload = jwt.decode(token=encoded_token, key=secret, algorithms=[algorithm], options={\"verify_aud\": False})\n exp = datetime.fromtimestamp(payload.pop(\"exp\"), tz=timezone.utc)\n iat = datetime.fromtimestamp(payload.pop(\"iat\"), tz=timezone.utc)\n field_names = {f.name for f in dataclasses.fields(Token)}\n extra_fields = payload.keys() - field_names\n extras = payload.pop(\"extras\", {})\n for key in extra_fields:\n extras[key] = payload.pop(key)\n return cls(exp=exp, iat=iat, **payload, extras=extras)\n except (KeyError, JWTError, ImproperlyConfiguredException) as e:\n raise NotAuthorizedException(\"Invalid token\") from e\n\n def encode(self, secret: str, algorithm: str) -> str:\n \"\"\"Encode the token instance into a string.\n\n Args:\n secret: The secret with which the JWT is encoded.\n algorithm: The algorithm used to encode the JWT.\n\n Returns:\n An encoded token string.\n\n Raises:\n ImproperlyConfiguredException: If encoding fails.\n \"\"\"\n try:\n return jwt.encode(\n claims={k: v for k, v in asdict(self).items() if v is not None}, key=secret, algorithm=algorithm\n )\n except (JWTError, JWSError) as e:\n raise ImproperlyConfiguredException(\"Failed to encode token\") from e\n", "path": "litestar/contrib/jwt/jwt_token.py"}]}
| 2,249 | 272 |
gh_patches_debug_9645
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-2343
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
WPS472 only detecting one pure variable assignment
### What's wrong
WPS472 detects `name, *_ = get_address()`.
When it comes to slightly more complex value assignments, it does not work:
1. `names[0], *_ = get_address()`
2. `self.name, *_ = get_address()`
3. `(name, street), *_ = get_address()`
Also when extracting a second (or more values) the detection fails:
1. `name, street, *_ = get_address()`
2. `name, _, city, *_ = get_address()`
3. `name, _, self.city, *_ = get_address()`
### How it should be
It would be nice if all of the examples would also be detected as WPS472 violations.
### Flake8 version and plugins
{
"dependencies": [],
"platform": {
"python_implementation": "CPython",
"python_version": "3.9.6",
"system": "Darwin"
},
"plugins": [
{
"is_local": false,
"plugin": "flake8-bandit",
"version": "2.1.2"
},
{
"is_local": false,
"plugin": "flake8-broken-line",
"version": "0.3.0"
},
{
"is_local": false,
"plugin": "flake8-bugbear",
"version": "20.11.1"
},
{
"is_local": false,
"plugin": "flake8-comprehensions",
"version": "3.4.0"
},
{
"is_local": false,
"plugin": "flake8-darglint",
"version": "1.8.0"
},
{
"is_local": false,
"plugin": "flake8-debugger",
"version": "4.0.0"
},
{
"is_local": false,
"plugin": "flake8-docstrings",
"version": "1.6.0, pydocstyle: 6.0.0"
},
{
"is_local": false,
"plugin": "flake8-eradicate",
"version": "1.0.0"
},
{
"is_local": false,
"plugin": "flake8-string-format",
"version": "0.3.0"
},
{
"is_local": false,
"plugin": "flake8.datetimez",
"version": "20.10.0"
},
{
"is_local": false,
"plugin": "flake8_commas",
"version": "2.0.0"
},
{
"is_local": false,
"plugin": "flake8_isort",
"version": "4.0.0"
},
{
"is_local": false,
"plugin": "flake8_quotes",
"version": "3.2.0"
},
{
"is_local": false,
"plugin": "mccabe",
"version": "0.6.1"
},
{
"is_local": false,
"plugin": "naming",
"version": "0.11.1"
},
{
"is_local": false,
"plugin": "pycodestyle",
"version": "2.7.0"
},
{
"is_local": false,
"plugin": "pyflakes",
"version": "2.3.0"
},
{
"is_local": false,
"plugin": "rst-docstrings",
"version": "0.2.3"
},
{
"is_local": false,
"plugin": "wemake_python_styleguide",
"version": "0.16.0"
}
],
"version": "3.9.2"
}
### pip information
pip 21.3.1
### OS information
macOS Monterey
Version 12.0.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wemake_python_styleguide/logic/tree/variables.py`
Content:
```
1 import ast
2 from typing import List, Union
3
4 from wemake_python_styleguide.logic import nodes
5 from wemake_python_styleguide.logic.naming import access
6
7 _VarDefinition = Union[ast.AST, ast.expr]
8 _LocalVariable = Union[ast.Name, ast.ExceptHandler]
9
10
11 def get_variable_name(node: _LocalVariable) -> str:
12 """Used to get variable names from all definitions."""
13 if isinstance(node, ast.Name):
14 return node.id
15 return getattr(node, 'name', '')
16
17
18 def does_shadow_builtin(node: ast.AST) -> bool:
19 """
20 We allow attributes and class-level builtin overrides.
21
22 Like: ``self.list = []`` or ``def map(self, function):``
23
24 Why?
25 Because they cannot harm you since they do not shadow the real builtin.
26 """
27 return (
28 not isinstance(node, ast.Attribute) and
29 not isinstance(nodes.get_context(node), ast.ClassDef)
30 )
31
32
33 def is_valid_block_variable_definition(node: _VarDefinition) -> bool:
34 """Is used to check either block variables are correctly defined."""
35 if isinstance(node, ast.Tuple):
36 return all(
37 is_valid_block_variable_definition(var_definition)
38 for var_definition in node.elts
39 )
40 return _is_valid_single(node)
41
42
43 def is_valid_unpacking_target(target: ast.expr) -> bool:
44 """Checks if unpacking target is correct."""
45 if isinstance(target, ast.Tuple):
46 return all(
47 _is_valid_single(element)
48 for element in target.elts
49 )
50 return _is_valid_single(target)
51
52
53 def _is_valid_single(node: _VarDefinition) -> bool:
54 return (
55 isinstance(node, ast.Name) or
56 isinstance(node, ast.Starred) and isinstance(node.value, ast.Name)
57 )
58
59
60 def is_getting_element_by_unpacking(targets: List[ast.expr]) -> bool:
61 """Checks if unpacking targets used to get first or last element."""
62 if len(targets) != 2:
63 return False
64 first_item = (
65 isinstance(targets[0], ast.Name) and
66 isinstance(targets[1], ast.Starred) and
67 _is_unused_variable_name(targets[1].value)
68 )
69 last_item = (
70 isinstance(targets[1], ast.Name) and
71 isinstance(targets[0], ast.Starred) and
72 _is_unused_variable_name(targets[0].value)
73 )
74 return first_item or last_item
75
76
77 def _is_unused_variable_name(node: ast.expr) -> bool:
78 return isinstance(node, ast.Name) and access.looks_like_unused(node.id)
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wemake_python_styleguide/logic/tree/variables.py b/wemake_python_styleguide/logic/tree/variables.py
--- a/wemake_python_styleguide/logic/tree/variables.py
+++ b/wemake_python_styleguide/logic/tree/variables.py
@@ -62,12 +62,10 @@
if len(targets) != 2:
return False
first_item = (
- isinstance(targets[0], ast.Name) and
isinstance(targets[1], ast.Starred) and
_is_unused_variable_name(targets[1].value)
)
last_item = (
- isinstance(targets[1], ast.Name) and
isinstance(targets[0], ast.Starred) and
_is_unused_variable_name(targets[0].value)
)
|
{"golden_diff": "diff --git a/wemake_python_styleguide/logic/tree/variables.py b/wemake_python_styleguide/logic/tree/variables.py\n--- a/wemake_python_styleguide/logic/tree/variables.py\n+++ b/wemake_python_styleguide/logic/tree/variables.py\n@@ -62,12 +62,10 @@\n if len(targets) != 2:\n return False\n first_item = (\n- isinstance(targets[0], ast.Name) and\n isinstance(targets[1], ast.Starred) and\n _is_unused_variable_name(targets[1].value)\n )\n last_item = (\n- isinstance(targets[1], ast.Name) and\n isinstance(targets[0], ast.Starred) and\n _is_unused_variable_name(targets[0].value)\n )\n", "issue": "WPS472 only detecting one pure variable assignment\n### What's wrong\r\n\r\nWPS472 detects `name, *_ = get_address()`. \r\nWhen it comes to slightly more complex value assignments, it does not work:\r\n1. `names[0], *_ = get_address()` \r\n2. `self.name, *_ = get_address()`\r\n3. `(name, street), *_ = get_address()`\r\n\r\nAlso when extracting a second (or more values) the detection fails:\r\n1. `name, street, *_ = get_address()`\r\n2. `name, _, city, *_ = get_address()`\r\n3. `name, _, self.city, *_ = get_address()`\r\n\r\n### How it should be\r\n\r\nIt would be nice if all of the examples would also be detected as WPS472 violations.\r\n\r\n### Flake8 version and plugins\r\n\r\n{\r\n \"dependencies\": [],\r\n \"platform\": {\r\n \"python_implementation\": \"CPython\",\r\n \"python_version\": \"3.9.6\",\r\n \"system\": \"Darwin\"\r\n },\r\n \"plugins\": [\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-bandit\",\r\n \"version\": \"2.1.2\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-broken-line\",\r\n \"version\": \"0.3.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-bugbear\",\r\n \"version\": \"20.11.1\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-comprehensions\",\r\n \"version\": \"3.4.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-darglint\",\r\n \"version\": \"1.8.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-debugger\",\r\n \"version\": \"4.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-docstrings\",\r\n \"version\": \"1.6.0, pydocstyle: 6.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-eradicate\",\r\n \"version\": \"1.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-string-format\",\r\n \"version\": \"0.3.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8.datetimez\",\r\n \"version\": \"20.10.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8_commas\",\r\n \"version\": \"2.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8_isort\",\r\n \"version\": \"4.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8_quotes\",\r\n \"version\": \"3.2.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"mccabe\",\r\n \"version\": \"0.6.1\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"naming\",\r\n \"version\": \"0.11.1\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"pycodestyle\",\r\n \"version\": \"2.7.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"pyflakes\",\r\n \"version\": \"2.3.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"rst-docstrings\",\r\n \"version\": \"0.2.3\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"wemake_python_styleguide\",\r\n \"version\": \"0.16.0\"\r\n }\r\n ],\r\n \"version\": \"3.9.2\"\r\n}\r\n\r\n### pip information\r\n\r\npip 21.3.1\r\n\r\n### OS information\r\n\r\nmacOS Monterey\r\nVersion 12.0.1\n", "before_files": [{"content": "import ast\nfrom typing import List, Union\n\nfrom wemake_python_styleguide.logic import nodes\nfrom wemake_python_styleguide.logic.naming import access\n\n_VarDefinition = Union[ast.AST, ast.expr]\n_LocalVariable = Union[ast.Name, ast.ExceptHandler]\n\n\ndef get_variable_name(node: _LocalVariable) -> str:\n \"\"\"Used to get variable names from all definitions.\"\"\"\n if isinstance(node, ast.Name):\n return node.id\n return getattr(node, 'name', '')\n\n\ndef does_shadow_builtin(node: ast.AST) -> bool:\n \"\"\"\n We allow attributes and class-level builtin overrides.\n\n Like: ``self.list = []`` or ``def map(self, function):``\n\n Why?\n Because they cannot harm you since they do not shadow the real builtin.\n \"\"\"\n return (\n not isinstance(node, ast.Attribute) and\n not isinstance(nodes.get_context(node), ast.ClassDef)\n )\n\n\ndef is_valid_block_variable_definition(node: _VarDefinition) -> bool:\n \"\"\"Is used to check either block variables are correctly defined.\"\"\"\n if isinstance(node, ast.Tuple):\n return all(\n is_valid_block_variable_definition(var_definition)\n for var_definition in node.elts\n )\n return _is_valid_single(node)\n\n\ndef is_valid_unpacking_target(target: ast.expr) -> bool:\n \"\"\"Checks if unpacking target is correct.\"\"\"\n if isinstance(target, ast.Tuple):\n return all(\n _is_valid_single(element)\n for element in target.elts\n )\n return _is_valid_single(target)\n\n\ndef _is_valid_single(node: _VarDefinition) -> bool:\n return (\n isinstance(node, ast.Name) or\n isinstance(node, ast.Starred) and isinstance(node.value, ast.Name)\n )\n\n\ndef is_getting_element_by_unpacking(targets: List[ast.expr]) -> bool:\n \"\"\"Checks if unpacking targets used to get first or last element.\"\"\"\n if len(targets) != 2:\n return False\n first_item = (\n isinstance(targets[0], ast.Name) and\n isinstance(targets[1], ast.Starred) and\n _is_unused_variable_name(targets[1].value)\n )\n last_item = (\n isinstance(targets[1], ast.Name) and\n isinstance(targets[0], ast.Starred) and\n _is_unused_variable_name(targets[0].value)\n )\n return first_item or last_item\n\n\ndef _is_unused_variable_name(node: ast.expr) -> bool:\n return isinstance(node, ast.Name) and access.looks_like_unused(node.id)\n", "path": "wemake_python_styleguide/logic/tree/variables.py"}], "after_files": [{"content": "import ast\nfrom typing import List, Union\n\nfrom wemake_python_styleguide.logic import nodes\nfrom wemake_python_styleguide.logic.naming import access\n\n_VarDefinition = Union[ast.AST, ast.expr]\n_LocalVariable = Union[ast.Name, ast.ExceptHandler]\n\n\ndef get_variable_name(node: _LocalVariable) -> str:\n \"\"\"Used to get variable names from all definitions.\"\"\"\n if isinstance(node, ast.Name):\n return node.id\n return getattr(node, 'name', '')\n\n\ndef does_shadow_builtin(node: ast.AST) -> bool:\n \"\"\"\n We allow attributes and class-level builtin overrides.\n\n Like: ``self.list = []`` or ``def map(self, function):``\n\n Why?\n Because they cannot harm you since they do not shadow the real builtin.\n \"\"\"\n return (\n not isinstance(node, ast.Attribute) and\n not isinstance(nodes.get_context(node), ast.ClassDef)\n )\n\n\ndef is_valid_block_variable_definition(node: _VarDefinition) -> bool:\n \"\"\"Is used to check either block variables are correctly defined.\"\"\"\n if isinstance(node, ast.Tuple):\n return all(\n is_valid_block_variable_definition(var_definition)\n for var_definition in node.elts\n )\n return _is_valid_single(node)\n\n\ndef is_valid_unpacking_target(target: ast.expr) -> bool:\n \"\"\"Checks if unpacking target is correct.\"\"\"\n if isinstance(target, ast.Tuple):\n return all(\n _is_valid_single(element)\n for element in target.elts\n )\n return _is_valid_single(target)\n\n\ndef _is_valid_single(node: _VarDefinition) -> bool:\n return (\n isinstance(node, ast.Name) or\n isinstance(node, ast.Starred) and isinstance(node.value, ast.Name)\n )\n\n\ndef is_getting_element_by_unpacking(targets: List[ast.expr]) -> bool:\n \"\"\"Checks if unpacking targets used to get first or last element.\"\"\"\n if len(targets) != 2:\n return False\n first_item = (\n isinstance(targets[1], ast.Starred) and\n _is_unused_variable_name(targets[1].value)\n )\n last_item = (\n isinstance(targets[0], ast.Starred) and\n _is_unused_variable_name(targets[0].value)\n )\n return first_item or last_item\n\n\ndef _is_unused_variable_name(node: ast.expr) -> bool:\n return isinstance(node, ast.Name) and access.looks_like_unused(node.id)\n", "path": "wemake_python_styleguide/logic/tree/variables.py"}]}
| 1,871 | 175 |
gh_patches_debug_212
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-3462
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Database errors raised when importing content
**Version**
Main pulpcore branch. The issue arose after merging the labels refractor work (https://github.com/pulp/pulpcore/commit/4e25949176d72c5dbe1c7623a9c47d253a18b085) .
Reproducible in pulp_file and pulp_rpm.
**Describe the bug**
```
pulp [d32341b1-78b2-44da-b43d-e51121df9e95]: pulpcore.tasking.pulpcore_worker:INFO: Task 4c2b456b-d9a8-4238-bb45-7b63f403229c failed (Unexpected end of string
LINE 1: ...le.file', '365f08db-ac00-4e21-8abf-af0f047064cd', '{}', '', ...
^
)
pulp [d32341b1-78b2-44da-b43d-e51121df9e95]: pulpcore.tasking.pulpcore_worker:INFO: File "/home/vagrant/devel/pulpcore/pulpcore/tasking/pulpcore_worker.py", line 444, in _perform_task
result = func(*args, **kwargs)
File "/home/vagrant/devel/pulpcore/pulpcore/app/tasks/importer.py", line 236, in import_repository_version
for a_result in _import_file(os.path.join(rv_path, filename), res_class, retry=True):
File "/home/vagrant/devel/pulpcore/pulpcore/app/tasks/importer.py", line 138, in _import_file
a_result = resource.import_data(data, raise_errors=True)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py", line 819, in import_data
return self.import_data_inner(
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py", line 871, in import_data_inner
raise row_result.errors[-1].error
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py", line 743, in import_row
self.save_instance(instance, new, using_transactions, dry_run)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py", line 500, in save_instance
instance.save()
File "/home/vagrant/devel/pulpcore/pulpcore/app/models/repository.py", line 95, in save
super().save(*args, **kwargs)
File "/home/vagrant/devel/pulpcore/pulpcore/app/models/base.py", line 203, in save
return super().save(*args, **kwargs)
File "/usr/lib64/python3.10/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django_lifecycle/mixins.py", line 169, in save
save(*args, **kwargs)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py", line 739, in save
self.save_base(using=using, force_insert=force_insert,
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py", line 775, in save_base
parent_inserted = self._save_parents(cls, using, update_fields)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py", line 804, in _save_parents
updated = self._save_table(
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py", line 881, in _save_table
results = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py", line 919, in _do_insert
return manager._insert(
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/query.py", line 1270, in _insert
return query.get_compiler(using=using).execute_sql(returning_fields)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/sql/compiler.py", line 1416, in execute_sql
cursor.execute(sql, params)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py", line 66, in execute
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py", line 75, in _execute_with_wrappers
return executor(sql, params, many, context)
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py", line 79, in _execute
with self.db.wrap_database_errors:
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/utils.py", line 90, in __exit__
raise dj_exc_value.with_traceback(traceback) from exc_value
File "/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/modelresource.py`
Content:
```
1 from import_export import fields
2 from import_export.widgets import ForeignKeyWidget
3 from logging import getLogger
4
5 from pulpcore.app.models.content import (
6 Artifact,
7 Content,
8 ContentArtifact,
9 )
10 from pulpcore.app.models.repository import Repository
11 from pulpcore.constants import ALL_KNOWN_CONTENT_CHECKSUMS
12 from pulpcore.plugin.importexport import QueryModelResource
13
14
15 log = getLogger(__name__)
16
17
18 #
19 # Artifact and Repository are different from other import-export entities, in that they are not
20 # repo-version-specific.
21 #
22 class ArtifactResource(QueryModelResource):
23 """Resource for import/export of artifacts."""
24
25 def before_import_row(self, row, **kwargs):
26 """
27 Sets digests to None if they are blank strings.
28
29 Args:
30 row (tablib.Dataset row): incoming import-row representing a single Variant.
31 kwargs: args passed along from the import() call.
32
33 """
34 # the export converts None to blank strings but sha384 and sha512 have unique constraints
35 # that get triggered if they are blank. convert checksums back into None if they are blank.
36 for checksum in ALL_KNOWN_CONTENT_CHECKSUMS:
37 if row[checksum] == "":
38 row[checksum] = None
39
40 class Meta:
41 model = Artifact
42 exclude = (
43 "pulp_id",
44 "pulp_created",
45 "pulp_last_updated",
46 )
47 import_id_fields = ("sha256",)
48
49
50 class RepositoryResource(QueryModelResource):
51 class Meta:
52 model = Repository
53 import_id_fields = ("name",)
54 exclude = (
55 "pulp_id",
56 "pulp_created",
57 "pulp_last_updated",
58 "content",
59 "next_version",
60 "repository_ptr",
61 "remote",
62 )
63
64
65 class ContentArtifactResource(QueryModelResource):
66 """
67 Handles import/export of the ContentArtifact model.
68
69 ContentArtifact is different from other import-export entities because it has no 'natural key'
70 other than a pulp_id, which aren't shared across instances. We do some magic to link up
71 ContentArtifacts to their matching (already-imported) Content.
72
73 Some plugin-models have sub-repositories. We take advantage of the content-mapping
74 machinery to account for those contentartifacts as well.
75 """
76
77 artifact = fields.Field(
78 column_name="artifact", attribute="artifact", widget=ForeignKeyWidget(Artifact, "sha256")
79 )
80
81 def __init__(self, repo_version=None, content_mapping=None):
82 self.content_mapping = content_mapping
83 super().__init__(repo_version)
84
85 def before_import_row(self, row, **kwargs):
86 """
87 Fixes the content-ptr of an incoming content-artifact row at import time.
88
89 Finds the 'original uuid' of the Content for this row, looks it up as the
90 'upstream_id' of imported Content, and then replaces the Content-pk with its
91 (new) uuid.
92
93 Args:
94 row (tablib.Dataset row): incoming import-row representing a single ContentArtifact.
95 kwargs: args passed along from the import() call.
96
97 Returns:
98 (tablib.Dataset row): row that now points to the new downstream uuid for its content.
99 """
100
101 linked_content = Content.objects.get(upstream_id=row["content"])
102 row["content"] = str(linked_content.pulp_id)
103
104 def set_up_queryset(self):
105 vers_content = ContentArtifact.objects.filter(content__in=self.repo_version.content)
106 if self.content_mapping:
107 all_content = []
108 for content_ids in self.content_mapping.values():
109 all_content.extend(content_ids)
110 vers_content = vers_content.union(
111 ContentArtifact.objects.filter(content__in=all_content)
112 )
113 return vers_content.order_by("content", "relative_path")
114
115 class Meta:
116 model = ContentArtifact
117 import_id_fields = (
118 "content",
119 "relative_path",
120 )
121 exclude = (
122 "pulp_created",
123 "pulp_last_updated",
124 "_artifacts",
125 "pulp_id",
126 )
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/modelresource.py b/pulpcore/app/modelresource.py
--- a/pulpcore/app/modelresource.py
+++ b/pulpcore/app/modelresource.py
@@ -59,6 +59,7 @@
"next_version",
"repository_ptr",
"remote",
+ "pulp_labels",
)
|
{"golden_diff": "diff --git a/pulpcore/app/modelresource.py b/pulpcore/app/modelresource.py\n--- a/pulpcore/app/modelresource.py\n+++ b/pulpcore/app/modelresource.py\n@@ -59,6 +59,7 @@\n \"next_version\",\n \"repository_ptr\",\n \"remote\",\n+ \"pulp_labels\",\n )\n", "issue": "Database errors raised when importing content\n**Version**\r\nMain pulpcore branch. The issue arose after merging the labels refractor work (https://github.com/pulp/pulpcore/commit/4e25949176d72c5dbe1c7623a9c47d253a18b085) . \r\n\r\nReproducible in pulp_file and pulp_rpm. \r\n\r\n**Describe the bug**\r\n```\r\npulp [d32341b1-78b2-44da-b43d-e51121df9e95]: pulpcore.tasking.pulpcore_worker:INFO: Task 4c2b456b-d9a8-4238-bb45-7b63f403229c failed (Unexpected end of string\r\nLINE 1: ...le.file', '365f08db-ac00-4e21-8abf-af0f047064cd', '{}', '', ...\r\n ^\r\n)\r\npulp [d32341b1-78b2-44da-b43d-e51121df9e95]: pulpcore.tasking.pulpcore_worker:INFO: File \"/home/vagrant/devel/pulpcore/pulpcore/tasking/pulpcore_worker.py\", line 444, in _perform_task\r\n result = func(*args, **kwargs)\r\n File \"/home/vagrant/devel/pulpcore/pulpcore/app/tasks/importer.py\", line 236, in import_repository_version\r\n for a_result in _import_file(os.path.join(rv_path, filename), res_class, retry=True):\r\n File \"/home/vagrant/devel/pulpcore/pulpcore/app/tasks/importer.py\", line 138, in _import_file\r\n a_result = resource.import_data(data, raise_errors=True)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py\", line 819, in import_data\r\n return self.import_data_inner(\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py\", line 871, in import_data_inner\r\n raise row_result.errors[-1].error\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py\", line 743, in import_row\r\n self.save_instance(instance, new, using_transactions, dry_run)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/import_export/resources.py\", line 500, in save_instance\r\n instance.save()\r\n File \"/home/vagrant/devel/pulpcore/pulpcore/app/models/repository.py\", line 95, in save\r\n super().save(*args, **kwargs)\r\n File \"/home/vagrant/devel/pulpcore/pulpcore/app/models/base.py\", line 203, in save\r\n return super().save(*args, **kwargs)\r\n File \"/usr/lib64/python3.10/contextlib.py\", line 79, in inner\r\n return func(*args, **kwds)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django_lifecycle/mixins.py\", line 169, in save\r\n save(*args, **kwargs)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py\", line 739, in save\r\n self.save_base(using=using, force_insert=force_insert,\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py\", line 775, in save_base\r\n parent_inserted = self._save_parents(cls, using, update_fields)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py\", line 804, in _save_parents\r\n updated = self._save_table(\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py\", line 881, in _save_table\r\n results = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/base.py\", line 919, in _do_insert\r\n return manager._insert(\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/manager.py\", line 85, in manager_method\r\n return getattr(self.get_queryset(), name)(*args, **kwargs)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/query.py\", line 1270, in _insert\r\n return query.get_compiler(using=using).execute_sql(returning_fields)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/models/sql/compiler.py\", line 1416, in execute_sql\r\n cursor.execute(sql, params)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py\", line 66, in execute\r\n return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py\", line 75, in _execute_with_wrappers\r\n return executor(sql, params, many, context)\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py\", line 79, in _execute\r\n with self.db.wrap_database_errors:\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/utils.py\", line 90, in __exit__\r\n raise dj_exc_value.with_traceback(traceback) from exc_value\r\n File \"/usr/local/lib/pulp/lib64/python3.10/site-packages/django/db/backends/utils.py\", line 84, in _execute\r\n return self.cursor.execute(sql, params)\r\n```\n", "before_files": [{"content": "from import_export import fields\nfrom import_export.widgets import ForeignKeyWidget\nfrom logging import getLogger\n\nfrom pulpcore.app.models.content import (\n Artifact,\n Content,\n ContentArtifact,\n)\nfrom pulpcore.app.models.repository import Repository\nfrom pulpcore.constants import ALL_KNOWN_CONTENT_CHECKSUMS\nfrom pulpcore.plugin.importexport import QueryModelResource\n\n\nlog = getLogger(__name__)\n\n\n#\n# Artifact and Repository are different from other import-export entities, in that they are not\n# repo-version-specific.\n#\nclass ArtifactResource(QueryModelResource):\n \"\"\"Resource for import/export of artifacts.\"\"\"\n\n def before_import_row(self, row, **kwargs):\n \"\"\"\n Sets digests to None if they are blank strings.\n\n Args:\n row (tablib.Dataset row): incoming import-row representing a single Variant.\n kwargs: args passed along from the import() call.\n\n \"\"\"\n # the export converts None to blank strings but sha384 and sha512 have unique constraints\n # that get triggered if they are blank. convert checksums back into None if they are blank.\n for checksum in ALL_KNOWN_CONTENT_CHECKSUMS:\n if row[checksum] == \"\":\n row[checksum] = None\n\n class Meta:\n model = Artifact\n exclude = (\n \"pulp_id\",\n \"pulp_created\",\n \"pulp_last_updated\",\n )\n import_id_fields = (\"sha256\",)\n\n\nclass RepositoryResource(QueryModelResource):\n class Meta:\n model = Repository\n import_id_fields = (\"name\",)\n exclude = (\n \"pulp_id\",\n \"pulp_created\",\n \"pulp_last_updated\",\n \"content\",\n \"next_version\",\n \"repository_ptr\",\n \"remote\",\n )\n\n\nclass ContentArtifactResource(QueryModelResource):\n \"\"\"\n Handles import/export of the ContentArtifact model.\n\n ContentArtifact is different from other import-export entities because it has no 'natural key'\n other than a pulp_id, which aren't shared across instances. We do some magic to link up\n ContentArtifacts to their matching (already-imported) Content.\n\n Some plugin-models have sub-repositories. We take advantage of the content-mapping\n machinery to account for those contentartifacts as well.\n \"\"\"\n\n artifact = fields.Field(\n column_name=\"artifact\", attribute=\"artifact\", widget=ForeignKeyWidget(Artifact, \"sha256\")\n )\n\n def __init__(self, repo_version=None, content_mapping=None):\n self.content_mapping = content_mapping\n super().__init__(repo_version)\n\n def before_import_row(self, row, **kwargs):\n \"\"\"\n Fixes the content-ptr of an incoming content-artifact row at import time.\n\n Finds the 'original uuid' of the Content for this row, looks it up as the\n 'upstream_id' of imported Content, and then replaces the Content-pk with its\n (new) uuid.\n\n Args:\n row (tablib.Dataset row): incoming import-row representing a single ContentArtifact.\n kwargs: args passed along from the import() call.\n\n Returns:\n (tablib.Dataset row): row that now points to the new downstream uuid for its content.\n \"\"\"\n\n linked_content = Content.objects.get(upstream_id=row[\"content\"])\n row[\"content\"] = str(linked_content.pulp_id)\n\n def set_up_queryset(self):\n vers_content = ContentArtifact.objects.filter(content__in=self.repo_version.content)\n if self.content_mapping:\n all_content = []\n for content_ids in self.content_mapping.values():\n all_content.extend(content_ids)\n vers_content = vers_content.union(\n ContentArtifact.objects.filter(content__in=all_content)\n )\n return vers_content.order_by(\"content\", \"relative_path\")\n\n class Meta:\n model = ContentArtifact\n import_id_fields = (\n \"content\",\n \"relative_path\",\n )\n exclude = (\n \"pulp_created\",\n \"pulp_last_updated\",\n \"_artifacts\",\n \"pulp_id\",\n )\n", "path": "pulpcore/app/modelresource.py"}], "after_files": [{"content": "from import_export import fields\nfrom import_export.widgets import ForeignKeyWidget\nfrom logging import getLogger\n\nfrom pulpcore.app.models.content import (\n Artifact,\n Content,\n ContentArtifact,\n)\nfrom pulpcore.app.models.repository import Repository\nfrom pulpcore.constants import ALL_KNOWN_CONTENT_CHECKSUMS\nfrom pulpcore.plugin.importexport import QueryModelResource\n\n\nlog = getLogger(__name__)\n\n\n#\n# Artifact and Repository are different from other import-export entities, in that they are not\n# repo-version-specific.\n#\nclass ArtifactResource(QueryModelResource):\n \"\"\"Resource for import/export of artifacts.\"\"\"\n\n def before_import_row(self, row, **kwargs):\n \"\"\"\n Sets digests to None if they are blank strings.\n\n Args:\n row (tablib.Dataset row): incoming import-row representing a single Variant.\n kwargs: args passed along from the import() call.\n\n \"\"\"\n # the export converts None to blank strings but sha384 and sha512 have unique constraints\n # that get triggered if they are blank. convert checksums back into None if they are blank.\n for checksum in ALL_KNOWN_CONTENT_CHECKSUMS:\n if row[checksum] == \"\":\n row[checksum] = None\n\n class Meta:\n model = Artifact\n exclude = (\n \"pulp_id\",\n \"pulp_created\",\n \"pulp_last_updated\",\n )\n import_id_fields = (\"sha256\",)\n\n\nclass RepositoryResource(QueryModelResource):\n class Meta:\n model = Repository\n import_id_fields = (\"name\",)\n exclude = (\n \"pulp_id\",\n \"pulp_created\",\n \"pulp_last_updated\",\n \"content\",\n \"next_version\",\n \"repository_ptr\",\n \"remote\",\n \"pulp_labels\",\n )\n\n\nclass ContentArtifactResource(QueryModelResource):\n \"\"\"\n Handles import/export of the ContentArtifact model.\n\n ContentArtifact is different from other import-export entities because it has no 'natural key'\n other than a pulp_id, which aren't shared across instances. We do some magic to link up\n ContentArtifacts to their matching (already-imported) Content.\n\n Some plugin-models have sub-repositories. We take advantage of the content-mapping\n machinery to account for those contentartifacts as well.\n \"\"\"\n\n artifact = fields.Field(\n column_name=\"artifact\", attribute=\"artifact\", widget=ForeignKeyWidget(Artifact, \"sha256\")\n )\n\n def __init__(self, repo_version=None, content_mapping=None):\n self.content_mapping = content_mapping\n super().__init__(repo_version)\n\n def before_import_row(self, row, **kwargs):\n \"\"\"\n Fixes the content-ptr of an incoming content-artifact row at import time.\n\n Finds the 'original uuid' of the Content for this row, looks it up as the\n 'upstream_id' of imported Content, and then replaces the Content-pk with its\n (new) uuid.\n\n Args:\n row (tablib.Dataset row): incoming import-row representing a single ContentArtifact.\n kwargs: args passed along from the import() call.\n\n Returns:\n (tablib.Dataset row): row that now points to the new downstream uuid for its content.\n \"\"\"\n\n linked_content = Content.objects.get(upstream_id=row[\"content\"])\n row[\"content\"] = str(linked_content.pulp_id)\n\n def set_up_queryset(self):\n vers_content = ContentArtifact.objects.filter(content__in=self.repo_version.content)\n if self.content_mapping:\n all_content = []\n for content_ids in self.content_mapping.values():\n all_content.extend(content_ids)\n vers_content = vers_content.union(\n ContentArtifact.objects.filter(content__in=all_content)\n )\n return vers_content.order_by(\"content\", \"relative_path\")\n\n class Meta:\n model = ContentArtifact\n import_id_fields = (\n \"content\",\n \"relative_path\",\n )\n exclude = (\n \"pulp_created\",\n \"pulp_last_updated\",\n \"_artifacts\",\n \"pulp_id\",\n )\n", "path": "pulpcore/app/modelresource.py"}]}
| 2,767 | 75 |
gh_patches_debug_24667
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2665
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement product types section in dashboard
Blocked by #2679
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/core/__init__.py`
Content:
```
1 from django.conf import settings
2 from django.core.checks import Warning, register
3 from django.utils.translation import pgettext_lazy
4
5 TOKEN_PATTERN = ('(?P<token>[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}'
6 '-[0-9a-z]{12})')
7
8
9 @register()
10 def check_session_caching(app_configs, **kwargs): # pragma: no cover
11 errors = []
12 cached_engines = {
13 'django.contrib.sessions.backends.cache',
14 'django.contrib.sessions.backends.cached_db'}
15 if ('locmem' in settings.CACHES['default']['BACKEND'] and
16 settings.SESSION_ENGINE in cached_engines):
17 errors.append(
18 Warning(
19 'Session caching cannot work with locmem backend',
20 'User sessions need to be globally shared, use a cache server'
21 ' like Redis.',
22 'saleor.W001'))
23 return errors
24
25
26 class TaxRateType:
27 ACCOMODATION = 'accomodation'
28 ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'
29 ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'
30 ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'
31 ADVERTISING = 'advertising'
32 AGRICULTURAL_SUPPLIES = 'agricultural supplies'
33 BABY_FOODSTUFFS = 'baby foodstuffs'
34 BIKES = 'bikes'
35 BOOKS = 'books'
36 CHILDRENDS_CLOTHING = 'childrens clothing'
37 DOMESTIC_FUEL = 'domestic fuel'
38 DOMESTIC_SERVICES = 'domestic services'
39 E_BOOKS = 'e-books'
40 FOODSTUFFS = 'foodstuffs'
41 HOTELS = 'hotels'
42 MEDICAL = 'medical'
43 NEWSPAPERS = 'newspapers'
44 PASSENGER_TRANSPORT = 'passenger transport'
45 PHARMACEUTICALS = 'pharmaceuticals'
46 PROPERTY_RENOVATIONS = 'property renovations'
47 RESTAURANTS = 'restaurants'
48 SOCIAL_HOUSING = 'social housing'
49 STANDARD = 'standard'
50 WATER = 'water'
51 WINE = 'wine'
52
53 CHOICES = (
54 (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),
55 (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(
56 'VAT rate type', 'admission to cultural events')),
57 (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(
58 'VAT rate type', 'admission to entertainment events')),
59 (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(
60 'VAT rate type', 'admission to sporting events')),
61 (ADVERTISING, pgettext_lazy('VAT rate type', 'advertising')),
62 (AGRICULTURAL_SUPPLIES, pgettext_lazy(
63 'VAT rate type', 'agricultural supplies')),
64 (BABY_FOODSTUFFS, pgettext_lazy('VAT rate type', 'baby foodstuffs')),
65 (BIKES, pgettext_lazy('VAT rate type', 'bikes')),
66 (BOOKS, pgettext_lazy('VAT rate type', 'books')),
67 (CHILDRENDS_CLOTHING, pgettext_lazy(
68 'VAT rate type', 'childrens clothing')),
69 (DOMESTIC_FUEL, pgettext_lazy('VAT rate type', 'domestic fuel')),
70 (DOMESTIC_SERVICES, pgettext_lazy(
71 'VAT rate type', 'domestic services')),
72 (E_BOOKS, pgettext_lazy('VAT rate type', 'e-books')),
73 (FOODSTUFFS, pgettext_lazy('VAT rate type', 'foodstuffs')),
74 (HOTELS, pgettext_lazy('VAT rate type', 'hotels')),
75 (MEDICAL, pgettext_lazy('VAT rate type', 'medical')),
76 (NEWSPAPERS, pgettext_lazy('VAT rate type', 'newspapers')),
77 (PASSENGER_TRANSPORT, pgettext_lazy(
78 'VAT rate type', 'passenger transport')),
79 (PHARMACEUTICALS, pgettext_lazy(
80 'VAT rate type', 'pharmaceuticals')),
81 (PROPERTY_RENOVATIONS, pgettext_lazy(
82 'VAT rate type', 'property renovations')),
83 (RESTAURANTS, pgettext_lazy('VAT rate type', 'restaurants')),
84 (SOCIAL_HOUSING, pgettext_lazy('VAT rate type', 'social housing')),
85 (STANDARD, pgettext_lazy('VAT rate type', 'standard')),
86 (WATER, pgettext_lazy('VAT rate type', 'water')))
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/core/__init__.py b/saleor/core/__init__.py
--- a/saleor/core/__init__.py
+++ b/saleor/core/__init__.py
@@ -26,7 +26,7 @@
class TaxRateType:
ACCOMODATION = 'accomodation'
ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'
- ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'
+ ADMISSION_TO_ENTERTAINMENT_EVENTS = 'admission to entertainment events'
ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'
ADVERTISING = 'advertising'
AGRICULTURAL_SUPPLIES = 'agricultural supplies'
@@ -54,7 +54,7 @@
(ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),
(ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(
'VAT rate type', 'admission to cultural events')),
- (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(
+ (ADMISSION_TO_ENTERTAINMENT_EVENTS, pgettext_lazy(
'VAT rate type', 'admission to entertainment events')),
(ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(
'VAT rate type', 'admission to sporting events')),
|
{"golden_diff": "diff --git a/saleor/core/__init__.py b/saleor/core/__init__.py\n--- a/saleor/core/__init__.py\n+++ b/saleor/core/__init__.py\n@@ -26,7 +26,7 @@\n class TaxRateType:\n ACCOMODATION = 'accomodation'\n ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'\n- ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'\n+ ADMISSION_TO_ENTERTAINMENT_EVENTS = 'admission to entertainment events'\n ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'\n ADVERTISING = 'advertising'\n AGRICULTURAL_SUPPLIES = 'agricultural supplies'\n@@ -54,7 +54,7 @@\n (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),\n (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to cultural events')),\n- (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(\n+ (ADMISSION_TO_ENTERTAINMENT_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to entertainment events')),\n (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to sporting events')),\n", "issue": "Implement product types section in dashboard\nBlocked by #2679 \n", "before_files": [{"content": "from django.conf import settings\nfrom django.core.checks import Warning, register\nfrom django.utils.translation import pgettext_lazy\n\nTOKEN_PATTERN = ('(?P<token>[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}'\n '-[0-9a-z]{12})')\n\n\n@register()\ndef check_session_caching(app_configs, **kwargs): # pragma: no cover\n errors = []\n cached_engines = {\n 'django.contrib.sessions.backends.cache',\n 'django.contrib.sessions.backends.cached_db'}\n if ('locmem' in settings.CACHES['default']['BACKEND'] and\n settings.SESSION_ENGINE in cached_engines):\n errors.append(\n Warning(\n 'Session caching cannot work with locmem backend',\n 'User sessions need to be globally shared, use a cache server'\n ' like Redis.',\n 'saleor.W001'))\n return errors\n\n\nclass TaxRateType:\n ACCOMODATION = 'accomodation'\n ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'\n ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'\n ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'\n ADVERTISING = 'advertising'\n AGRICULTURAL_SUPPLIES = 'agricultural supplies'\n BABY_FOODSTUFFS = 'baby foodstuffs'\n BIKES = 'bikes'\n BOOKS = 'books'\n CHILDRENDS_CLOTHING = 'childrens clothing'\n DOMESTIC_FUEL = 'domestic fuel'\n DOMESTIC_SERVICES = 'domestic services'\n E_BOOKS = 'e-books'\n FOODSTUFFS = 'foodstuffs'\n HOTELS = 'hotels'\n MEDICAL = 'medical'\n NEWSPAPERS = 'newspapers'\n PASSENGER_TRANSPORT = 'passenger transport'\n PHARMACEUTICALS = 'pharmaceuticals'\n PROPERTY_RENOVATIONS = 'property renovations'\n RESTAURANTS = 'restaurants'\n SOCIAL_HOUSING = 'social housing'\n STANDARD = 'standard'\n WATER = 'water'\n WINE = 'wine'\n\n CHOICES = (\n (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),\n (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to cultural events')),\n (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to entertainment events')),\n (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to sporting events')),\n (ADVERTISING, pgettext_lazy('VAT rate type', 'advertising')),\n (AGRICULTURAL_SUPPLIES, pgettext_lazy(\n 'VAT rate type', 'agricultural supplies')),\n (BABY_FOODSTUFFS, pgettext_lazy('VAT rate type', 'baby foodstuffs')),\n (BIKES, pgettext_lazy('VAT rate type', 'bikes')),\n (BOOKS, pgettext_lazy('VAT rate type', 'books')),\n (CHILDRENDS_CLOTHING, pgettext_lazy(\n 'VAT rate type', 'childrens clothing')),\n (DOMESTIC_FUEL, pgettext_lazy('VAT rate type', 'domestic fuel')),\n (DOMESTIC_SERVICES, pgettext_lazy(\n 'VAT rate type', 'domestic services')),\n (E_BOOKS, pgettext_lazy('VAT rate type', 'e-books')),\n (FOODSTUFFS, pgettext_lazy('VAT rate type', 'foodstuffs')),\n (HOTELS, pgettext_lazy('VAT rate type', 'hotels')),\n (MEDICAL, pgettext_lazy('VAT rate type', 'medical')),\n (NEWSPAPERS, pgettext_lazy('VAT rate type', 'newspapers')),\n (PASSENGER_TRANSPORT, pgettext_lazy(\n 'VAT rate type', 'passenger transport')),\n (PHARMACEUTICALS, pgettext_lazy(\n 'VAT rate type', 'pharmaceuticals')),\n (PROPERTY_RENOVATIONS, pgettext_lazy(\n 'VAT rate type', 'property renovations')),\n (RESTAURANTS, pgettext_lazy('VAT rate type', 'restaurants')),\n (SOCIAL_HOUSING, pgettext_lazy('VAT rate type', 'social housing')),\n (STANDARD, pgettext_lazy('VAT rate type', 'standard')),\n (WATER, pgettext_lazy('VAT rate type', 'water')))\n", "path": "saleor/core/__init__.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.core.checks import Warning, register\nfrom django.utils.translation import pgettext_lazy\n\nTOKEN_PATTERN = ('(?P<token>[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}'\n '-[0-9a-z]{12})')\n\n\n@register()\ndef check_session_caching(app_configs, **kwargs): # pragma: no cover\n errors = []\n cached_engines = {\n 'django.contrib.sessions.backends.cache',\n 'django.contrib.sessions.backends.cached_db'}\n if ('locmem' in settings.CACHES['default']['BACKEND'] and\n settings.SESSION_ENGINE in cached_engines):\n errors.append(\n Warning(\n 'Session caching cannot work with locmem backend',\n 'User sessions need to be globally shared, use a cache server'\n ' like Redis.',\n 'saleor.W001'))\n return errors\n\n\nclass TaxRateType:\n ACCOMODATION = 'accomodation'\n ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'\n ADMISSION_TO_ENTERTAINMENT_EVENTS = 'admission to entertainment events'\n ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'\n ADVERTISING = 'advertising'\n AGRICULTURAL_SUPPLIES = 'agricultural supplies'\n BABY_FOODSTUFFS = 'baby foodstuffs'\n BIKES = 'bikes'\n BOOKS = 'books'\n CHILDRENDS_CLOTHING = 'childrens clothing'\n DOMESTIC_FUEL = 'domestic fuel'\n DOMESTIC_SERVICES = 'domestic services'\n E_BOOKS = 'e-books'\n FOODSTUFFS = 'foodstuffs'\n HOTELS = 'hotels'\n MEDICAL = 'medical'\n NEWSPAPERS = 'newspapers'\n PASSENGER_TRANSPORT = 'passenger transport'\n PHARMACEUTICALS = 'pharmaceuticals'\n PROPERTY_RENOVATIONS = 'property renovations'\n RESTAURANTS = 'restaurants'\n SOCIAL_HOUSING = 'social housing'\n STANDARD = 'standard'\n WATER = 'water'\n WINE = 'wine'\n\n CHOICES = (\n (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),\n (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to cultural events')),\n (ADMISSION_TO_ENTERTAINMENT_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to entertainment events')),\n (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to sporting events')),\n (ADVERTISING, pgettext_lazy('VAT rate type', 'advertising')),\n (AGRICULTURAL_SUPPLIES, pgettext_lazy(\n 'VAT rate type', 'agricultural supplies')),\n (BABY_FOODSTUFFS, pgettext_lazy('VAT rate type', 'baby foodstuffs')),\n (BIKES, pgettext_lazy('VAT rate type', 'bikes')),\n (BOOKS, pgettext_lazy('VAT rate type', 'books')),\n (CHILDRENDS_CLOTHING, pgettext_lazy(\n 'VAT rate type', 'childrens clothing')),\n (DOMESTIC_FUEL, pgettext_lazy('VAT rate type', 'domestic fuel')),\n (DOMESTIC_SERVICES, pgettext_lazy(\n 'VAT rate type', 'domestic services')),\n (E_BOOKS, pgettext_lazy('VAT rate type', 'e-books')),\n (FOODSTUFFS, pgettext_lazy('VAT rate type', 'foodstuffs')),\n (HOTELS, pgettext_lazy('VAT rate type', 'hotels')),\n (MEDICAL, pgettext_lazy('VAT rate type', 'medical')),\n (NEWSPAPERS, pgettext_lazy('VAT rate type', 'newspapers')),\n (PASSENGER_TRANSPORT, pgettext_lazy(\n 'VAT rate type', 'passenger transport')),\n (PHARMACEUTICALS, pgettext_lazy(\n 'VAT rate type', 'pharmaceuticals')),\n (PROPERTY_RENOVATIONS, pgettext_lazy(\n 'VAT rate type', 'property renovations')),\n (RESTAURANTS, pgettext_lazy('VAT rate type', 'restaurants')),\n (SOCIAL_HOUSING, pgettext_lazy('VAT rate type', 'social housing')),\n (STANDARD, pgettext_lazy('VAT rate type', 'standard')),\n (WATER, pgettext_lazy('VAT rate type', 'water')))\n", "path": "saleor/core/__init__.py"}]}
| 1,474 | 301 |
gh_patches_debug_32289
|
rasdani/github-patches
|
git_diff
|
translate__pootle-5837
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Plural strings not marked as that
While reviewing strings for 2.8 release, those are not in plural forms:
- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826598
- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826597
- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826594
- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826584
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/apps/pootle_language/views.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 from django.contrib import messages
10 from django.http import Http404
11 from django.shortcuts import redirect, render
12 from django.urls import reverse
13 from django.utils.functional import cached_property
14 from django.utils.lru_cache import lru_cache
15 from django.utils.safestring import mark_safe
16
17 from pootle.core.browser import make_project_item
18 from pootle.core.decorators import (
19 get_object_or_404, get_path_obj, permission_required)
20 from pootle.core.views import PootleBrowseView, PootleTranslateView
21 from pootle.core.views.admin import PootleFormView
22 from pootle.core.views.decorators import requires_permission, set_permissions
23 from pootle.core.views.formtable import Formtable
24 from pootle.core.views.mixins import PootleJSONMixin
25 from pootle.i18n import formatter
26 from pootle.i18n.gettext import tr_lang, ugettext_lazy as _
27 from pootle_misc.util import cmp_by_last_activity
28 from pootle_store.constants import STATES_MAP
29
30 from .apps import PootleLanguageConfig
31 from .forms import (
32 LanguageSpecialCharsForm, LanguageSuggestionAdminForm, LanguageTeamAdminForm,
33 LanguageTeamNewMemberSearchForm)
34 from .models import Language
35
36
37 class LanguageMixin(object):
38 ns = "pootle.language"
39 sw_version = PootleLanguageConfig.version
40 model = Language
41 browse_url_path = "pootle-language-browse"
42 translate_url_path = "pootle-language-translate"
43 template_extends = 'languages/base.html'
44
45 @property
46 def language(self):
47 return self.object
48
49 @property
50 def permission_context(self):
51 return self.get_object().directory
52
53 @property
54 def url_kwargs(self):
55 return {"language_code": self.object.code}
56
57 @lru_cache()
58 def get_object(self):
59 lang = Language.get_canonical(self.kwargs["language_code"])
60 if lang is None:
61 raise Http404
62 return lang
63
64 def get(self, *args, **kwargs):
65 self.object = self.get_object()
66 if self.object.code != kwargs["language_code"]:
67 return redirect(
68 self.url_pattern_name,
69 self.object.code,
70 permanent=True)
71 return super(LanguageMixin, self).get(*args, **kwargs)
72
73
74 class LanguageBrowseView(LanguageMixin, PootleBrowseView):
75 url_pattern_name = "pootle-language-browse"
76 view_name = "language"
77
78 @cached_property
79 def object_children(self):
80 items = [make_project_item(tp)
81 for tp in self.object.get_children_for_user(self.request.user)]
82 items = self.add_child_stats(items)
83 items.sort(cmp_by_last_activity)
84 return items
85
86 @property
87 def language(self):
88 return {
89 'code': self.object.code,
90 'name': tr_lang(self.object.fullname)}
91
92 def get(self, *args, **kwargs):
93 response = super(LanguageBrowseView, self).get(*args, **kwargs)
94 response.set_cookie('pootle-language', self.object.code)
95 return response
96
97
98 class LanguageTranslateView(LanguageMixin, PootleTranslateView):
99 url_pattern_name = "pootle-language-translate"
100
101
102 @get_path_obj
103 @permission_required('administrate')
104 def language_characters_admin(request, language):
105 form = LanguageSpecialCharsForm(request.POST
106 if request.method == 'POST'
107 else None,
108 instance=language)
109 if form.is_valid():
110 form.save()
111 return redirect('pootle-language-browse', language.code)
112
113 ctx = {
114 'page': 'admin-characters',
115
116 'browse_url': reverse('pootle-language-browse', kwargs={
117 'language_code': language.code,
118 }),
119 'translate_url': reverse('pootle-language-translate', kwargs={
120 'language_code': language.code,
121 }),
122
123 'language': language,
124 'directory': language.directory,
125 'form': form,
126 }
127
128 return render(request, 'languages/admin/characters.html', ctx)
129
130
131 class SuggestionFormtable(Formtable):
132 row_field = "suggestions"
133 filters_template = "languages/admin/includes/suggestions_header.html"
134
135 @property
136 def messages(self):
137 return self.kwargs.get("messages", [])
138
139
140 class SuggestionDisplay(object):
141
142 def __init__(self, suggestion):
143 self.__suggestion__ = suggestion
144
145 @property
146 def unit(self):
147 return self.__suggestion__.unit.source_f
148
149 @property
150 def project(self):
151 tp = self.__suggestion__.unit.store.translation_project
152 return mark_safe(
153 "<a href='%s'>%s</a>"
154 % (tp.get_absolute_url(),
155 tp.project.code))
156
157 @property
158 def unit_state(self):
159 return STATES_MAP[self.__suggestion__.unit.state]
160
161 @property
162 def unit_link(self):
163 return mark_safe(
164 "<a href='%s'>#%s</a>"
165 % (self.__suggestion__.unit.get_translate_url(),
166 self.__suggestion__.unit.id))
167
168 def __getattr__(self, k):
169 try:
170 return getattr(self.__suggestion__, k)
171 except AttributeError:
172 return self.__getattribute__(k)
173
174
175 class PootleLanguageAdminFormView(PootleFormView):
176
177 @property
178 def permission_context(self):
179 return self.language.directory
180
181 @set_permissions
182 @requires_permission("administrate")
183 def dispatch(self, request, *args, **kwargs):
184 # get funky with the request 8/
185 return super(
186 PootleLanguageAdminFormView, self).dispatch(request, *args, **kwargs)
187
188 @cached_property
189 def language(self):
190 return get_object_or_404(
191 Language.objects.select_related("directory"),
192 code=self.kwargs["language_code"])
193
194 def get_form_kwargs(self):
195 kwargs = super(PootleLanguageAdminFormView, self).get_form_kwargs()
196 kwargs["language"] = self.language
197 return kwargs
198
199 @property
200 def success_kwargs(self):
201 return dict(language_code=self.language.code)
202
203
204 class LanguageSuggestionAdminView(PootleLanguageAdminFormView):
205 template_name = 'languages/admin/language_team_suggestions.html'
206 form_class = LanguageSuggestionAdminForm
207 success_url_pattern = "pootle-language-admin-suggestions"
208 formtable_columns = (
209 _("Unit"),
210 _("State"),
211 _("Source"),
212 _("Suggestion"),
213 _("Suggested by"),
214 _("Suggested at"),
215 _("Project"))
216
217 @property
218 def default_form_kwargs(self):
219 return dict(
220 page_no=1,
221 results_per_page=10)
222
223 def add_success_message(self, form):
224 count = (
225 form.fields["suggestions"].queryset.count()
226 if form.cleaned_data["select_all"]
227 else len(form.cleaned_data["suggestions"]))
228 reject_and_notify = (
229 form.cleaned_data["actions"] == "reject"
230 and form.cleaned_data["comment"])
231 accept_and_notify = (
232 form.cleaned_data["actions"] == "accept"
233 and form.cleaned_data["comment"])
234 if reject_and_notify:
235 message = _(
236 "Rejected %s suggestions with comment. Users will be notified",
237 count)
238 elif accept_and_notify:
239 message = _(
240 "Accepted %s suggestions with comment. Users will be notified",
241 count)
242 elif form.cleaned_data["actions"] == "reject":
243 message = _("Rejected %s suggestions", count)
244 else:
245 message = _("Accepted %s suggestions", count)
246 messages.success(self.request, message)
247
248 def get_context_data(self, **kwargs):
249 context = super(
250 LanguageSuggestionAdminView, self).get_context_data(**kwargs)
251 context["page"] = "admin-suggestions"
252 context["language"] = self.language
253 form = context["form"]
254 form.is_valid()
255 batch = form.batch()
256 form.fields["suggestions"].choices = [
257 (item.id, SuggestionDisplay(item))
258 for item in
259 batch.object_list]
260 context["formtable"] = SuggestionFormtable(
261 form,
262 columns=self.formtable_columns,
263 page=batch,
264 messages=messages.get_messages(self.request))
265 return context
266
267 def get_form_kwargs(self):
268 kwargs = super(LanguageSuggestionAdminView, self).get_form_kwargs()
269 if not self.request.POST:
270 kwargs["data"] = self.default_form_kwargs
271 kwargs["user"] = self.request.user
272 return kwargs
273
274
275 class LanguageTeamAdminFormView(PootleLanguageAdminFormView):
276 form_class = LanguageTeamAdminForm
277 template_name = "languages/admin/language_team.html"
278 success_url_pattern = "pootle-language-admin-team"
279
280 def get_context_data(self, **kwargs):
281 context = super(LanguageTeamAdminFormView, self).get_context_data(**kwargs)
282 form = context["form"]
283 context["tps"] = self.language.translationproject_set.exclude(
284 project__disabled=True)
285 stats = self.language.data_tool.get_stats(
286 include_children=False,
287 user=self.request.user)
288 keys = ("total", "critical", "incomplete", "translated", "fuzzy",
289 "untranslated")
290 for k in keys:
291 if k in stats:
292 stats[k + "_display"] = formatter.number(stats[k])
293 context["stats"] = stats
294 context["suggestions"] = form.language_team.suggestions
295 suggestions_count = 0
296 if context["suggestions"]:
297 suggestions_count = context["suggestions"].count()
298 context["suggestions_display"] = formatter.number(suggestions_count)
299 context["language"] = self.language
300 context["page"] = "admin-team"
301 context["browse_url"] = reverse(
302 "pootle-language-browse",
303 kwargs=dict(language_code=self.language.code))
304 context["translate_url"] = reverse(
305 "pootle-language-translate",
306 kwargs=dict(language_code=self.language.code))
307 return context
308
309
310 class LanguageTeamAdminNewMembersJSON(PootleJSONMixin, PootleLanguageAdminFormView):
311 form_class = LanguageTeamNewMemberSearchForm
312
313 def get_context_data(self, **kwargs):
314 context = super(
315 LanguageTeamAdminNewMembersJSON, self).get_context_data(**kwargs)
316 form = context["form"]
317 return (
318 dict(items=form.search())
319 if form.is_valid()
320 else dict(items=[]))
321
322 def get_form_kwargs(self):
323 kwargs = super(LanguageTeamAdminNewMembersJSON, self).get_form_kwargs()
324 kwargs["data"] = self.request.GET
325 return kwargs
326
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pootle/apps/pootle_language/views.py b/pootle/apps/pootle_language/views.py
--- a/pootle/apps/pootle_language/views.py
+++ b/pootle/apps/pootle_language/views.py
@@ -23,7 +23,7 @@
from pootle.core.views.formtable import Formtable
from pootle.core.views.mixins import PootleJSONMixin
from pootle.i18n import formatter
-from pootle.i18n.gettext import tr_lang, ugettext_lazy as _
+from pootle.i18n.gettext import tr_lang, ugettext_lazy as _, ungettext_lazy
from pootle_misc.util import cmp_by_last_activity
from pootle_store.constants import STATES_MAP
@@ -232,17 +232,25 @@
form.cleaned_data["actions"] == "accept"
and form.cleaned_data["comment"])
if reject_and_notify:
- message = _(
+ message = ungettext_lazy(
+ "Rejected %s suggestion with comment. User will be notified",
"Rejected %s suggestions with comment. Users will be notified",
count)
elif accept_and_notify:
- message = _(
+ message = ungettext_lazy(
+ "Accepted %s suggestion with comment. User will be notified",
"Accepted %s suggestions with comment. Users will be notified",
count)
elif form.cleaned_data["actions"] == "reject":
- message = _("Rejected %s suggestions", count)
+ message = ungettext_lazy(
+ "Rejected %s suggestion",
+ "Rejected %s suggestions",
+ count)
else:
- message = _("Accepted %s suggestions", count)
+ message = ungettext_lazy(
+ "Accepted %s suggestion",
+ "Accepted %s suggestions",
+ count)
messages.success(self.request, message)
def get_context_data(self, **kwargs):
|
{"golden_diff": "diff --git a/pootle/apps/pootle_language/views.py b/pootle/apps/pootle_language/views.py\n--- a/pootle/apps/pootle_language/views.py\n+++ b/pootle/apps/pootle_language/views.py\n@@ -23,7 +23,7 @@\n from pootle.core.views.formtable import Formtable\n from pootle.core.views.mixins import PootleJSONMixin\n from pootle.i18n import formatter\n-from pootle.i18n.gettext import tr_lang, ugettext_lazy as _\n+from pootle.i18n.gettext import tr_lang, ugettext_lazy as _, ungettext_lazy\n from pootle_misc.util import cmp_by_last_activity\n from pootle_store.constants import STATES_MAP\n \n@@ -232,17 +232,25 @@\n form.cleaned_data[\"actions\"] == \"accept\"\n and form.cleaned_data[\"comment\"])\n if reject_and_notify:\n- message = _(\n+ message = ungettext_lazy(\n+ \"Rejected %s suggestion with comment. User will be notified\",\n \"Rejected %s suggestions with comment. Users will be notified\",\n count)\n elif accept_and_notify:\n- message = _(\n+ message = ungettext_lazy(\n+ \"Accepted %s suggestion with comment. User will be notified\",\n \"Accepted %s suggestions with comment. Users will be notified\",\n count)\n elif form.cleaned_data[\"actions\"] == \"reject\":\n- message = _(\"Rejected %s suggestions\", count)\n+ message = ungettext_lazy(\n+ \"Rejected %s suggestion\",\n+ \"Rejected %s suggestions\",\n+ count)\n else:\n- message = _(\"Accepted %s suggestions\", count)\n+ message = ungettext_lazy(\n+ \"Accepted %s suggestion\",\n+ \"Accepted %s suggestions\",\n+ count)\n messages.success(self.request, message)\n \n def get_context_data(self, **kwargs):\n", "issue": "Plural strings not marked as that\nWhile reviewing strings for 2.8 release, those are not in plural forms:\r\n\r\n- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826598\r\n- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826597\r\n- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826594\r\n- http://pootle.locamotion.org/ar/pootle/translate/pootle.po#unit=1826584\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nfrom django.contrib import messages\nfrom django.http import Http404\nfrom django.shortcuts import redirect, render\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.lru_cache import lru_cache\nfrom django.utils.safestring import mark_safe\n\nfrom pootle.core.browser import make_project_item\nfrom pootle.core.decorators import (\n get_object_or_404, get_path_obj, permission_required)\nfrom pootle.core.views import PootleBrowseView, PootleTranslateView\nfrom pootle.core.views.admin import PootleFormView\nfrom pootle.core.views.decorators import requires_permission, set_permissions\nfrom pootle.core.views.formtable import Formtable\nfrom pootle.core.views.mixins import PootleJSONMixin\nfrom pootle.i18n import formatter\nfrom pootle.i18n.gettext import tr_lang, ugettext_lazy as _\nfrom pootle_misc.util import cmp_by_last_activity\nfrom pootle_store.constants import STATES_MAP\n\nfrom .apps import PootleLanguageConfig\nfrom .forms import (\n LanguageSpecialCharsForm, LanguageSuggestionAdminForm, LanguageTeamAdminForm,\n LanguageTeamNewMemberSearchForm)\nfrom .models import Language\n\n\nclass LanguageMixin(object):\n ns = \"pootle.language\"\n sw_version = PootleLanguageConfig.version\n model = Language\n browse_url_path = \"pootle-language-browse\"\n translate_url_path = \"pootle-language-translate\"\n template_extends = 'languages/base.html'\n\n @property\n def language(self):\n return self.object\n\n @property\n def permission_context(self):\n return self.get_object().directory\n\n @property\n def url_kwargs(self):\n return {\"language_code\": self.object.code}\n\n @lru_cache()\n def get_object(self):\n lang = Language.get_canonical(self.kwargs[\"language_code\"])\n if lang is None:\n raise Http404\n return lang\n\n def get(self, *args, **kwargs):\n self.object = self.get_object()\n if self.object.code != kwargs[\"language_code\"]:\n return redirect(\n self.url_pattern_name,\n self.object.code,\n permanent=True)\n return super(LanguageMixin, self).get(*args, **kwargs)\n\n\nclass LanguageBrowseView(LanguageMixin, PootleBrowseView):\n url_pattern_name = \"pootle-language-browse\"\n view_name = \"language\"\n\n @cached_property\n def object_children(self):\n items = [make_project_item(tp)\n for tp in self.object.get_children_for_user(self.request.user)]\n items = self.add_child_stats(items)\n items.sort(cmp_by_last_activity)\n return items\n\n @property\n def language(self):\n return {\n 'code': self.object.code,\n 'name': tr_lang(self.object.fullname)}\n\n def get(self, *args, **kwargs):\n response = super(LanguageBrowseView, self).get(*args, **kwargs)\n response.set_cookie('pootle-language', self.object.code)\n return response\n\n\nclass LanguageTranslateView(LanguageMixin, PootleTranslateView):\n url_pattern_name = \"pootle-language-translate\"\n\n\n@get_path_obj\n@permission_required('administrate')\ndef language_characters_admin(request, language):\n form = LanguageSpecialCharsForm(request.POST\n if request.method == 'POST'\n else None,\n instance=language)\n if form.is_valid():\n form.save()\n return redirect('pootle-language-browse', language.code)\n\n ctx = {\n 'page': 'admin-characters',\n\n 'browse_url': reverse('pootle-language-browse', kwargs={\n 'language_code': language.code,\n }),\n 'translate_url': reverse('pootle-language-translate', kwargs={\n 'language_code': language.code,\n }),\n\n 'language': language,\n 'directory': language.directory,\n 'form': form,\n }\n\n return render(request, 'languages/admin/characters.html', ctx)\n\n\nclass SuggestionFormtable(Formtable):\n row_field = \"suggestions\"\n filters_template = \"languages/admin/includes/suggestions_header.html\"\n\n @property\n def messages(self):\n return self.kwargs.get(\"messages\", [])\n\n\nclass SuggestionDisplay(object):\n\n def __init__(self, suggestion):\n self.__suggestion__ = suggestion\n\n @property\n def unit(self):\n return self.__suggestion__.unit.source_f\n\n @property\n def project(self):\n tp = self.__suggestion__.unit.store.translation_project\n return mark_safe(\n \"<a href='%s'>%s</a>\"\n % (tp.get_absolute_url(),\n tp.project.code))\n\n @property\n def unit_state(self):\n return STATES_MAP[self.__suggestion__.unit.state]\n\n @property\n def unit_link(self):\n return mark_safe(\n \"<a href='%s'>#%s</a>\"\n % (self.__suggestion__.unit.get_translate_url(),\n self.__suggestion__.unit.id))\n\n def __getattr__(self, k):\n try:\n return getattr(self.__suggestion__, k)\n except AttributeError:\n return self.__getattribute__(k)\n\n\nclass PootleLanguageAdminFormView(PootleFormView):\n\n @property\n def permission_context(self):\n return self.language.directory\n\n @set_permissions\n @requires_permission(\"administrate\")\n def dispatch(self, request, *args, **kwargs):\n # get funky with the request 8/\n return super(\n PootleLanguageAdminFormView, self).dispatch(request, *args, **kwargs)\n\n @cached_property\n def language(self):\n return get_object_or_404(\n Language.objects.select_related(\"directory\"),\n code=self.kwargs[\"language_code\"])\n\n def get_form_kwargs(self):\n kwargs = super(PootleLanguageAdminFormView, self).get_form_kwargs()\n kwargs[\"language\"] = self.language\n return kwargs\n\n @property\n def success_kwargs(self):\n return dict(language_code=self.language.code)\n\n\nclass LanguageSuggestionAdminView(PootleLanguageAdminFormView):\n template_name = 'languages/admin/language_team_suggestions.html'\n form_class = LanguageSuggestionAdminForm\n success_url_pattern = \"pootle-language-admin-suggestions\"\n formtable_columns = (\n _(\"Unit\"),\n _(\"State\"),\n _(\"Source\"),\n _(\"Suggestion\"),\n _(\"Suggested by\"),\n _(\"Suggested at\"),\n _(\"Project\"))\n\n @property\n def default_form_kwargs(self):\n return dict(\n page_no=1,\n results_per_page=10)\n\n def add_success_message(self, form):\n count = (\n form.fields[\"suggestions\"].queryset.count()\n if form.cleaned_data[\"select_all\"]\n else len(form.cleaned_data[\"suggestions\"]))\n reject_and_notify = (\n form.cleaned_data[\"actions\"] == \"reject\"\n and form.cleaned_data[\"comment\"])\n accept_and_notify = (\n form.cleaned_data[\"actions\"] == \"accept\"\n and form.cleaned_data[\"comment\"])\n if reject_and_notify:\n message = _(\n \"Rejected %s suggestions with comment. Users will be notified\",\n count)\n elif accept_and_notify:\n message = _(\n \"Accepted %s suggestions with comment. Users will be notified\",\n count)\n elif form.cleaned_data[\"actions\"] == \"reject\":\n message = _(\"Rejected %s suggestions\", count)\n else:\n message = _(\"Accepted %s suggestions\", count)\n messages.success(self.request, message)\n\n def get_context_data(self, **kwargs):\n context = super(\n LanguageSuggestionAdminView, self).get_context_data(**kwargs)\n context[\"page\"] = \"admin-suggestions\"\n context[\"language\"] = self.language\n form = context[\"form\"]\n form.is_valid()\n batch = form.batch()\n form.fields[\"suggestions\"].choices = [\n (item.id, SuggestionDisplay(item))\n for item in\n batch.object_list]\n context[\"formtable\"] = SuggestionFormtable(\n form,\n columns=self.formtable_columns,\n page=batch,\n messages=messages.get_messages(self.request))\n return context\n\n def get_form_kwargs(self):\n kwargs = super(LanguageSuggestionAdminView, self).get_form_kwargs()\n if not self.request.POST:\n kwargs[\"data\"] = self.default_form_kwargs\n kwargs[\"user\"] = self.request.user\n return kwargs\n\n\nclass LanguageTeamAdminFormView(PootleLanguageAdminFormView):\n form_class = LanguageTeamAdminForm\n template_name = \"languages/admin/language_team.html\"\n success_url_pattern = \"pootle-language-admin-team\"\n\n def get_context_data(self, **kwargs):\n context = super(LanguageTeamAdminFormView, self).get_context_data(**kwargs)\n form = context[\"form\"]\n context[\"tps\"] = self.language.translationproject_set.exclude(\n project__disabled=True)\n stats = self.language.data_tool.get_stats(\n include_children=False,\n user=self.request.user)\n keys = (\"total\", \"critical\", \"incomplete\", \"translated\", \"fuzzy\",\n \"untranslated\")\n for k in keys:\n if k in stats:\n stats[k + \"_display\"] = formatter.number(stats[k])\n context[\"stats\"] = stats\n context[\"suggestions\"] = form.language_team.suggestions\n suggestions_count = 0\n if context[\"suggestions\"]:\n suggestions_count = context[\"suggestions\"].count()\n context[\"suggestions_display\"] = formatter.number(suggestions_count)\n context[\"language\"] = self.language\n context[\"page\"] = \"admin-team\"\n context[\"browse_url\"] = reverse(\n \"pootle-language-browse\",\n kwargs=dict(language_code=self.language.code))\n context[\"translate_url\"] = reverse(\n \"pootle-language-translate\",\n kwargs=dict(language_code=self.language.code))\n return context\n\n\nclass LanguageTeamAdminNewMembersJSON(PootleJSONMixin, PootleLanguageAdminFormView):\n form_class = LanguageTeamNewMemberSearchForm\n\n def get_context_data(self, **kwargs):\n context = super(\n LanguageTeamAdminNewMembersJSON, self).get_context_data(**kwargs)\n form = context[\"form\"]\n return (\n dict(items=form.search())\n if form.is_valid()\n else dict(items=[]))\n\n def get_form_kwargs(self):\n kwargs = super(LanguageTeamAdminNewMembersJSON, self).get_form_kwargs()\n kwargs[\"data\"] = self.request.GET\n return kwargs\n", "path": "pootle/apps/pootle_language/views.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nfrom django.contrib import messages\nfrom django.http import Http404\nfrom django.shortcuts import redirect, render\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.lru_cache import lru_cache\nfrom django.utils.safestring import mark_safe\n\nfrom pootle.core.browser import make_project_item\nfrom pootle.core.decorators import (\n get_object_or_404, get_path_obj, permission_required)\nfrom pootle.core.views import PootleBrowseView, PootleTranslateView\nfrom pootle.core.views.admin import PootleFormView\nfrom pootle.core.views.decorators import requires_permission, set_permissions\nfrom pootle.core.views.formtable import Formtable\nfrom pootle.core.views.mixins import PootleJSONMixin\nfrom pootle.i18n import formatter\nfrom pootle.i18n.gettext import tr_lang, ugettext_lazy as _, ungettext_lazy\nfrom pootle_misc.util import cmp_by_last_activity\nfrom pootle_store.constants import STATES_MAP\n\nfrom .apps import PootleLanguageConfig\nfrom .forms import (\n LanguageSpecialCharsForm, LanguageSuggestionAdminForm, LanguageTeamAdminForm,\n LanguageTeamNewMemberSearchForm)\nfrom .models import Language\n\n\nclass LanguageMixin(object):\n ns = \"pootle.language\"\n sw_version = PootleLanguageConfig.version\n model = Language\n browse_url_path = \"pootle-language-browse\"\n translate_url_path = \"pootle-language-translate\"\n template_extends = 'languages/base.html'\n\n @property\n def language(self):\n return self.object\n\n @property\n def permission_context(self):\n return self.get_object().directory\n\n @property\n def url_kwargs(self):\n return {\"language_code\": self.object.code}\n\n @lru_cache()\n def get_object(self):\n lang = Language.get_canonical(self.kwargs[\"language_code\"])\n if lang is None:\n raise Http404\n return lang\n\n def get(self, *args, **kwargs):\n self.object = self.get_object()\n if self.object.code != kwargs[\"language_code\"]:\n return redirect(\n self.url_pattern_name,\n self.object.code,\n permanent=True)\n return super(LanguageMixin, self).get(*args, **kwargs)\n\n\nclass LanguageBrowseView(LanguageMixin, PootleBrowseView):\n url_pattern_name = \"pootle-language-browse\"\n view_name = \"language\"\n\n @cached_property\n def object_children(self):\n items = [make_project_item(tp)\n for tp in self.object.get_children_for_user(self.request.user)]\n items = self.add_child_stats(items)\n items.sort(cmp_by_last_activity)\n return items\n\n @property\n def language(self):\n return {\n 'code': self.object.code,\n 'name': tr_lang(self.object.fullname)}\n\n def get(self, *args, **kwargs):\n response = super(LanguageBrowseView, self).get(*args, **kwargs)\n response.set_cookie('pootle-language', self.object.code)\n return response\n\n\nclass LanguageTranslateView(LanguageMixin, PootleTranslateView):\n url_pattern_name = \"pootle-language-translate\"\n\n\n@get_path_obj\n@permission_required('administrate')\ndef language_characters_admin(request, language):\n form = LanguageSpecialCharsForm(request.POST\n if request.method == 'POST'\n else None,\n instance=language)\n if form.is_valid():\n form.save()\n return redirect('pootle-language-browse', language.code)\n\n ctx = {\n 'page': 'admin-characters',\n\n 'browse_url': reverse('pootle-language-browse', kwargs={\n 'language_code': language.code,\n }),\n 'translate_url': reverse('pootle-language-translate', kwargs={\n 'language_code': language.code,\n }),\n\n 'language': language,\n 'directory': language.directory,\n 'form': form,\n }\n\n return render(request, 'languages/admin/characters.html', ctx)\n\n\nclass SuggestionFormtable(Formtable):\n row_field = \"suggestions\"\n filters_template = \"languages/admin/includes/suggestions_header.html\"\n\n @property\n def messages(self):\n return self.kwargs.get(\"messages\", [])\n\n\nclass SuggestionDisplay(object):\n\n def __init__(self, suggestion):\n self.__suggestion__ = suggestion\n\n @property\n def unit(self):\n return self.__suggestion__.unit.source_f\n\n @property\n def project(self):\n tp = self.__suggestion__.unit.store.translation_project\n return mark_safe(\n \"<a href='%s'>%s</a>\"\n % (tp.get_absolute_url(),\n tp.project.code))\n\n @property\n def unit_state(self):\n return STATES_MAP[self.__suggestion__.unit.state]\n\n @property\n def unit_link(self):\n return mark_safe(\n \"<a href='%s'>#%s</a>\"\n % (self.__suggestion__.unit.get_translate_url(),\n self.__suggestion__.unit.id))\n\n def __getattr__(self, k):\n try:\n return getattr(self.__suggestion__, k)\n except AttributeError:\n return self.__getattribute__(k)\n\n\nclass PootleLanguageAdminFormView(PootleFormView):\n\n @property\n def permission_context(self):\n return self.language.directory\n\n @set_permissions\n @requires_permission(\"administrate\")\n def dispatch(self, request, *args, **kwargs):\n # get funky with the request 8/\n return super(\n PootleLanguageAdminFormView, self).dispatch(request, *args, **kwargs)\n\n @cached_property\n def language(self):\n return get_object_or_404(\n Language.objects.select_related(\"directory\"),\n code=self.kwargs[\"language_code\"])\n\n def get_form_kwargs(self):\n kwargs = super(PootleLanguageAdminFormView, self).get_form_kwargs()\n kwargs[\"language\"] = self.language\n return kwargs\n\n @property\n def success_kwargs(self):\n return dict(language_code=self.language.code)\n\n\nclass LanguageSuggestionAdminView(PootleLanguageAdminFormView):\n template_name = 'languages/admin/language_team_suggestions.html'\n form_class = LanguageSuggestionAdminForm\n success_url_pattern = \"pootle-language-admin-suggestions\"\n formtable_columns = (\n _(\"Unit\"),\n _(\"State\"),\n _(\"Source\"),\n _(\"Suggestion\"),\n _(\"Suggested by\"),\n _(\"Suggested at\"),\n _(\"Project\"))\n\n @property\n def default_form_kwargs(self):\n return dict(\n page_no=1,\n results_per_page=10)\n\n def add_success_message(self, form):\n count = (\n form.fields[\"suggestions\"].queryset.count()\n if form.cleaned_data[\"select_all\"]\n else len(form.cleaned_data[\"suggestions\"]))\n reject_and_notify = (\n form.cleaned_data[\"actions\"] == \"reject\"\n and form.cleaned_data[\"comment\"])\n accept_and_notify = (\n form.cleaned_data[\"actions\"] == \"accept\"\n and form.cleaned_data[\"comment\"])\n if reject_and_notify:\n message = ungettext_lazy(\n \"Rejected %s suggestion with comment. User will be notified\",\n \"Rejected %s suggestions with comment. Users will be notified\",\n count)\n elif accept_and_notify:\n message = ungettext_lazy(\n \"Accepted %s suggestion with comment. User will be notified\",\n \"Accepted %s suggestions with comment. Users will be notified\",\n count)\n elif form.cleaned_data[\"actions\"] == \"reject\":\n message = ungettext_lazy(\n \"Rejected %s suggestion\",\n \"Rejected %s suggestions\",\n count)\n else:\n message = ungettext_lazy(\n \"Accepted %s suggestion\",\n \"Accepted %s suggestions\",\n count)\n messages.success(self.request, message)\n\n def get_context_data(self, **kwargs):\n context = super(\n LanguageSuggestionAdminView, self).get_context_data(**kwargs)\n context[\"page\"] = \"admin-suggestions\"\n context[\"language\"] = self.language\n form = context[\"form\"]\n form.is_valid()\n batch = form.batch()\n form.fields[\"suggestions\"].choices = [\n (item.id, SuggestionDisplay(item))\n for item in\n batch.object_list]\n context[\"formtable\"] = SuggestionFormtable(\n form,\n columns=self.formtable_columns,\n page=batch,\n messages=messages.get_messages(self.request))\n return context\n\n def get_form_kwargs(self):\n kwargs = super(LanguageSuggestionAdminView, self).get_form_kwargs()\n if not self.request.POST:\n kwargs[\"data\"] = self.default_form_kwargs\n kwargs[\"user\"] = self.request.user\n return kwargs\n\n\nclass LanguageTeamAdminFormView(PootleLanguageAdminFormView):\n form_class = LanguageTeamAdminForm\n template_name = \"languages/admin/language_team.html\"\n success_url_pattern = \"pootle-language-admin-team\"\n\n def get_context_data(self, **kwargs):\n context = super(LanguageTeamAdminFormView, self).get_context_data(**kwargs)\n form = context[\"form\"]\n context[\"tps\"] = self.language.translationproject_set.exclude(\n project__disabled=True)\n stats = self.language.data_tool.get_stats(\n include_children=False,\n user=self.request.user)\n keys = (\"total\", \"critical\", \"incomplete\", \"translated\", \"fuzzy\",\n \"untranslated\")\n for k in keys:\n if k in stats:\n stats[k + \"_display\"] = formatter.number(stats[k])\n context[\"stats\"] = stats\n context[\"suggestions\"] = form.language_team.suggestions\n suggestions_count = 0\n if context[\"suggestions\"]:\n suggestions_count = context[\"suggestions\"].count()\n context[\"suggestions_display\"] = formatter.number(suggestions_count)\n context[\"language\"] = self.language\n context[\"page\"] = \"admin-team\"\n context[\"browse_url\"] = reverse(\n \"pootle-language-browse\",\n kwargs=dict(language_code=self.language.code))\n context[\"translate_url\"] = reverse(\n \"pootle-language-translate\",\n kwargs=dict(language_code=self.language.code))\n return context\n\n\nclass LanguageTeamAdminNewMembersJSON(PootleJSONMixin, PootleLanguageAdminFormView):\n form_class = LanguageTeamNewMemberSearchForm\n\n def get_context_data(self, **kwargs):\n context = super(\n LanguageTeamAdminNewMembersJSON, self).get_context_data(**kwargs)\n form = context[\"form\"]\n return (\n dict(items=form.search())\n if form.is_valid()\n else dict(items=[]))\n\n def get_form_kwargs(self):\n kwargs = super(LanguageTeamAdminNewMembersJSON, self).get_form_kwargs()\n kwargs[\"data\"] = self.request.GET\n return kwargs\n", "path": "pootle/apps/pootle_language/views.py"}]}
| 3,629 | 420 |
gh_patches_debug_34147
|
rasdani/github-patches
|
git_diff
|
kivy__python-for-android-1410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Comprehensive list of broken recipes
When working on https://github.com/kivy/python-for-android/pull/1401 I realised we still have some broken recipes in the tree at least for python3crystax.
Even though we don't want to have red builds for things that were already broken, we still want to have a clear status of what's broken and what's not.
Basically the idea is to try to compile every single recipes and add the broken ones in the ignore list (`BROKEN_RECIPES`) from #1401. That way we can track and fix them later on meanwhile keeping a green build.
I would like to address it in this task. Basically the output of the task should be a PR making the `BROKEN_RECIPES` list comprehensive. With bonus points for creating an issue per broken recipes :smile:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ci/constants.py`
Content:
```
1 from enum import Enum
2
3
4 class TargetPython(Enum):
5 python2 = 0
6 python3crystax = 1
7
8
9 # recipes that currently break the build
10 # a recipe could be broken for a target Python and not for the other,
11 # hence we're maintaining one list per Python target
12 BROKEN_RECIPES_PYTHON2 = set([])
13 BROKEN_RECIPES_PYTHON3_CRYSTAX = set([
14 # not yet python3crystax compatible
15 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',
16 'coverage', 'dateutil', 'enaml', 'ethash', 'kiwisolver', 'libgeos',
17 'libnacl', 'libsodium', 'libtorrent', 'libtribler', 'libzbar', 'libzmq',
18 'm2crypto', 'mysqldb', 'ndghttpsclient', 'pil', 'pycrypto', 'pyethereum',
19 'pygame', 'pyleveldb', 'pyproj', 'pyzmq', 'regex', 'shapely',
20 'simple-crypt', 'twsisted', 'vispy', 'websocket-client', 'zbar',
21 'zeroconf', 'zope',
22 # https://github.com/kivy/python-for-android/issues/550
23 'audiostream',
24 # enum34 is not compatible with Python 3.6 standard library
25 # https://stackoverflow.com/a/45716067/185510
26 'enum34',
27 # https://github.com/kivy/python-for-android/issues/1398
28 'ifaddrs',
29 # https://github.com/kivy/python-for-android/issues/1399
30 'libglob',
31 # cannot find -lcrystax
32 'cffi', 'pycryptodome', 'pymuk', 'secp256k1',
33 # https://github.com/kivy/python-for-android/issues/1404
34 'cryptography',
35 # https://github.com/kivy/python-for-android/issues/1294
36 'ffmpeg', 'ffpyplayer',
37 # https://github.com/kivy/python-for-android/pull/1307 ?
38 'gevent',
39 'icu',
40 # https://github.com/kivy/python-for-android/issues/1354
41 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',
42 'kivy',
43 # https://github.com/kivy/python-for-android/issues/1405
44 'libpq', 'psycopg2',
45 'netifaces',
46 # https://github.com/kivy/python-for-android/issues/1315 ?
47 'opencv',
48 'protobuf_cpp',
49 # most likely some setup in the Docker container, because it works in host
50 'pyjnius', 'pyopenal',
51 # SyntaxError: invalid syntax (Python2)
52 'storm',
53 'vlc',
54 ])
55 BROKEN_RECIPES = {
56 TargetPython.python2: BROKEN_RECIPES_PYTHON2,
57 TargetPython.python3crystax: BROKEN_RECIPES_PYTHON3_CRYSTAX,
58 }
59 # recipes that were already built will be skipped
60 CORE_RECIPES = set([
61 'pyjnius', 'kivy', 'openssl', 'requests', 'sqlite3', 'setuptools',
62 'numpy', 'android', 'python2',
63 ])
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ci/constants.py b/ci/constants.py
--- a/ci/constants.py
+++ b/ci/constants.py
@@ -9,7 +9,57 @@
# recipes that currently break the build
# a recipe could be broken for a target Python and not for the other,
# hence we're maintaining one list per Python target
-BROKEN_RECIPES_PYTHON2 = set([])
+BROKEN_RECIPES_PYTHON2 = set([
+ # pythonhelpers.h:12:18: fatal error: string: No such file or directory
+ 'atom',
+ # https://github.com/kivy/python-for-android/issues/550
+ 'audiostream',
+ 'brokenrecipe',
+ # https://github.com/kivy/python-for-android/issues/1409
+ 'enaml',
+ 'evdev',
+ # distutils.errors.DistutilsError
+ # Could not find suitable distribution for Requirement.parse('cython')
+ 'ffpyplayer',
+ 'flask',
+ 'groestlcoin_hash',
+ 'hostpython3crystax',
+ # https://github.com/kivy/python-for-android/issues/1398
+ 'ifaddrs',
+ # https://github.com/kivy/python-for-android/issues/1354
+ 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',
+ 'kiwisolver',
+ # system dependencies autoconf, libtool
+ 'libexpat',
+ 'libgeos',
+ # https://github.com/kivy/python-for-android/issues/1399
+ 'libglob',
+ # system dependencies cmake and compile error
+ 'libmysqlclient',
+ 'libsecp256k1',
+ 'libtribler',
+ # system dependencies gettext, pkg-config
+ 'libzbar',
+ 'ndghttpsclient',
+ 'm2crypto',
+ 'netifaces',
+ 'Pillow',
+ # https://github.com/kivy/python-for-android/issues/1405
+ 'psycopg2',
+ 'pygame',
+ # most likely some setup in the Docker container, because it works in host
+ 'pyjnius', 'pyopenal',
+ 'pyproj',
+ 'pysdl2',
+ 'pyzmq',
+ 'secp256k1',
+ 'shapely',
+ 'twisted',
+ 'vlc',
+ 'websocket-client',
+ 'zeroconf',
+ 'zope',
+])
BROKEN_RECIPES_PYTHON3_CRYSTAX = set([
# not yet python3crystax compatible
'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',
@@ -39,7 +89,8 @@
'icu',
# https://github.com/kivy/python-for-android/issues/1354
'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',
- 'kivy',
+ # system dependencies autoconf, libtool
+ 'libexpat',
# https://github.com/kivy/python-for-android/issues/1405
'libpq', 'psycopg2',
'netifaces',
|
{"golden_diff": "diff --git a/ci/constants.py b/ci/constants.py\n--- a/ci/constants.py\n+++ b/ci/constants.py\n@@ -9,7 +9,57 @@\n # recipes that currently break the build\n # a recipe could be broken for a target Python and not for the other,\n # hence we're maintaining one list per Python target\n-BROKEN_RECIPES_PYTHON2 = set([])\n+BROKEN_RECIPES_PYTHON2 = set([\n+ # pythonhelpers.h:12:18: fatal error: string: No such file or directory\n+ 'atom',\n+ # https://github.com/kivy/python-for-android/issues/550\n+ 'audiostream',\n+ 'brokenrecipe',\n+ # https://github.com/kivy/python-for-android/issues/1409\n+ 'enaml',\n+ 'evdev',\n+ # distutils.errors.DistutilsError\n+ # Could not find suitable distribution for Requirement.parse('cython')\n+ 'ffpyplayer',\n+ 'flask',\n+ 'groestlcoin_hash',\n+ 'hostpython3crystax',\n+ # https://github.com/kivy/python-for-android/issues/1398\n+ 'ifaddrs',\n+ # https://github.com/kivy/python-for-android/issues/1354\n+ 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n+ 'kiwisolver',\n+ # system dependencies autoconf, libtool\n+ 'libexpat',\n+ 'libgeos',\n+ # https://github.com/kivy/python-for-android/issues/1399\n+ 'libglob',\n+ # system dependencies cmake and compile error\n+ 'libmysqlclient',\n+ 'libsecp256k1',\n+ 'libtribler',\n+ # system dependencies gettext, pkg-config\n+ 'libzbar',\n+ 'ndghttpsclient',\n+ 'm2crypto',\n+ 'netifaces',\n+ 'Pillow',\n+ # https://github.com/kivy/python-for-android/issues/1405\n+ 'psycopg2',\n+ 'pygame',\n+ # most likely some setup in the Docker container, because it works in host\n+ 'pyjnius', 'pyopenal',\n+ 'pyproj',\n+ 'pysdl2',\n+ 'pyzmq',\n+ 'secp256k1',\n+ 'shapely',\n+ 'twisted',\n+ 'vlc',\n+ 'websocket-client',\n+ 'zeroconf',\n+ 'zope',\n+])\n BROKEN_RECIPES_PYTHON3_CRYSTAX = set([\n # not yet python3crystax compatible\n 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',\n@@ -39,7 +89,8 @@\n 'icu',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n- 'kivy',\n+ # system dependencies autoconf, libtool\n+ 'libexpat',\n # https://github.com/kivy/python-for-android/issues/1405\n 'libpq', 'psycopg2',\n 'netifaces',\n", "issue": "Comprehensive list of broken recipes\nWhen working on https://github.com/kivy/python-for-android/pull/1401 I realised we still have some broken recipes in the tree at least for python3crystax.\r\nEven though we don't want to have red builds for things that were already broken, we still want to have a clear status of what's broken and what's not.\r\nBasically the idea is to try to compile every single recipes and add the broken ones in the ignore list (`BROKEN_RECIPES`) from #1401. That way we can track and fix them later on meanwhile keeping a green build.\r\nI would like to address it in this task. Basically the output of the task should be a PR making the `BROKEN_RECIPES` list comprehensive. With bonus points for creating an issue per broken recipes :smile: \r\n\n", "before_files": [{"content": "from enum import Enum\n\n\nclass TargetPython(Enum):\n python2 = 0\n python3crystax = 1\n\n\n# recipes that currently break the build\n# a recipe could be broken for a target Python and not for the other,\n# hence we're maintaining one list per Python target\nBROKEN_RECIPES_PYTHON2 = set([])\nBROKEN_RECIPES_PYTHON3_CRYSTAX = set([\n # not yet python3crystax compatible\n 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',\n 'coverage', 'dateutil', 'enaml', 'ethash', 'kiwisolver', 'libgeos',\n 'libnacl', 'libsodium', 'libtorrent', 'libtribler', 'libzbar', 'libzmq',\n 'm2crypto', 'mysqldb', 'ndghttpsclient', 'pil', 'pycrypto', 'pyethereum',\n 'pygame', 'pyleveldb', 'pyproj', 'pyzmq', 'regex', 'shapely',\n 'simple-crypt', 'twsisted', 'vispy', 'websocket-client', 'zbar',\n 'zeroconf', 'zope',\n # https://github.com/kivy/python-for-android/issues/550\n 'audiostream',\n # enum34 is not compatible with Python 3.6 standard library\n # https://stackoverflow.com/a/45716067/185510\n 'enum34',\n # https://github.com/kivy/python-for-android/issues/1398\n 'ifaddrs',\n # https://github.com/kivy/python-for-android/issues/1399\n 'libglob',\n # cannot find -lcrystax\n 'cffi', 'pycryptodome', 'pymuk', 'secp256k1',\n # https://github.com/kivy/python-for-android/issues/1404\n 'cryptography',\n # https://github.com/kivy/python-for-android/issues/1294\n 'ffmpeg', 'ffpyplayer',\n # https://github.com/kivy/python-for-android/pull/1307 ?\n 'gevent',\n 'icu',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n 'kivy',\n # https://github.com/kivy/python-for-android/issues/1405\n 'libpq', 'psycopg2',\n 'netifaces',\n # https://github.com/kivy/python-for-android/issues/1315 ?\n 'opencv',\n 'protobuf_cpp',\n # most likely some setup in the Docker container, because it works in host\n 'pyjnius', 'pyopenal',\n # SyntaxError: invalid syntax (Python2)\n 'storm',\n 'vlc',\n])\nBROKEN_RECIPES = {\n TargetPython.python2: BROKEN_RECIPES_PYTHON2,\n TargetPython.python3crystax: BROKEN_RECIPES_PYTHON3_CRYSTAX,\n}\n# recipes that were already built will be skipped\nCORE_RECIPES = set([\n 'pyjnius', 'kivy', 'openssl', 'requests', 'sqlite3', 'setuptools',\n 'numpy', 'android', 'python2',\n])\n", "path": "ci/constants.py"}], "after_files": [{"content": "from enum import Enum\n\n\nclass TargetPython(Enum):\n python2 = 0\n python3crystax = 1\n\n\n# recipes that currently break the build\n# a recipe could be broken for a target Python and not for the other,\n# hence we're maintaining one list per Python target\nBROKEN_RECIPES_PYTHON2 = set([\n # pythonhelpers.h:12:18: fatal error: string: No such file or directory\n 'atom',\n # https://github.com/kivy/python-for-android/issues/550\n 'audiostream',\n 'brokenrecipe',\n # https://github.com/kivy/python-for-android/issues/1409\n 'enaml',\n 'evdev',\n # distutils.errors.DistutilsError\n # Could not find suitable distribution for Requirement.parse('cython')\n 'ffpyplayer',\n 'flask',\n 'groestlcoin_hash',\n 'hostpython3crystax',\n # https://github.com/kivy/python-for-android/issues/1398\n 'ifaddrs',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n 'kiwisolver',\n # system dependencies autoconf, libtool\n 'libexpat',\n 'libgeos',\n # https://github.com/kivy/python-for-android/issues/1399\n 'libglob',\n # system dependencies cmake and compile error\n 'libmysqlclient',\n 'libsecp256k1',\n 'libtribler',\n # system dependencies gettext, pkg-config\n 'libzbar',\n 'ndghttpsclient',\n 'm2crypto',\n 'netifaces',\n 'Pillow',\n # https://github.com/kivy/python-for-android/issues/1405\n 'psycopg2',\n 'pygame',\n # most likely some setup in the Docker container, because it works in host\n 'pyjnius', 'pyopenal',\n 'pyproj',\n 'pysdl2',\n 'pyzmq',\n 'secp256k1',\n 'shapely',\n 'twisted',\n 'vlc',\n 'websocket-client',\n 'zeroconf',\n 'zope',\n])\nBROKEN_RECIPES_PYTHON3_CRYSTAX = set([\n # not yet python3crystax compatible\n 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',\n 'coverage', 'dateutil', 'enaml', 'ethash', 'kiwisolver', 'libgeos',\n 'libnacl', 'libsodium', 'libtorrent', 'libtribler', 'libzbar', 'libzmq',\n 'm2crypto', 'mysqldb', 'ndghttpsclient', 'pil', 'pycrypto', 'pyethereum',\n 'pygame', 'pyleveldb', 'pyproj', 'pyzmq', 'regex', 'shapely',\n 'simple-crypt', 'twsisted', 'vispy', 'websocket-client', 'zbar',\n 'zeroconf', 'zope',\n # https://github.com/kivy/python-for-android/issues/550\n 'audiostream',\n # enum34 is not compatible with Python 3.6 standard library\n # https://stackoverflow.com/a/45716067/185510\n 'enum34',\n # https://github.com/kivy/python-for-android/issues/1398\n 'ifaddrs',\n # https://github.com/kivy/python-for-android/issues/1399\n 'libglob',\n # cannot find -lcrystax\n 'cffi', 'pycryptodome', 'pymuk', 'secp256k1',\n # https://github.com/kivy/python-for-android/issues/1404\n 'cryptography',\n # https://github.com/kivy/python-for-android/issues/1294\n 'ffmpeg', 'ffpyplayer',\n # https://github.com/kivy/python-for-android/pull/1307 ?\n 'gevent',\n 'icu',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n # system dependencies autoconf, libtool\n 'libexpat',\n # https://github.com/kivy/python-for-android/issues/1405\n 'libpq', 'psycopg2',\n 'netifaces',\n # https://github.com/kivy/python-for-android/issues/1315 ?\n 'opencv',\n 'protobuf_cpp',\n # most likely some setup in the Docker container, because it works in host\n 'pyjnius', 'pyopenal',\n # SyntaxError: invalid syntax (Python2)\n 'storm',\n 'vlc',\n])\nBROKEN_RECIPES = {\n TargetPython.python2: BROKEN_RECIPES_PYTHON2,\n TargetPython.python3crystax: BROKEN_RECIPES_PYTHON3_CRYSTAX,\n}\n# recipes that were already built will be skipped\nCORE_RECIPES = set([\n 'pyjnius', 'kivy', 'openssl', 'requests', 'sqlite3', 'setuptools',\n 'numpy', 'android', 'python2',\n])\n", "path": "ci/constants.py"}]}
| 1,312 | 752 |
gh_patches_debug_28184
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-5088
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Enable file-less "uploads"
**Is your feature request related to a problem? Please describe.**
Right now pulpcore knows artifactless types, that can be created via file upload using the `NoArtifactContentUploadViewSet` and the `NoArtifactContentUploadSerializer`, which can be combined with "retrieve behaviour" (do not throw errors if the requested content already esists/is already in the repo it should be added to) by defining a plugin specific `retrieve` function on the serializer.
However, pulp_deb has several artifact less types, that do not need an actual uploaded file as part of this process at all. All they need (for pulp_deb to be able to create them) is the set of required API parameters. Examples include the `ReleaseComponent` and `ReleaseArchitecture`. These content types should still use the `repository` parameter to create and add them to a repository in one action, along with "retrieve behaviour". Since this means creating new repository versions, this action must be performed as a task to ensure resource locks.
As far as I can tell this is currently not possible, because pulpcore does not have the right kind of `ViewSet`. I was able to get things to work with the following adjustments to the `NoArtifactContentUploadViewSet`: https://github.com/pulp/pulpcore/pull/5084
An alternative might be to split up `NoArtifactContentUploadViewSet` into `NoArtifactContentUploadViewSet` and `NoArtifactContentViewSet`, which would mirror the class structure on the serializer side, and possibly make the semantic intention more clear.
**Additional context**
- See here for the pulp_deb change that prompted this need: https://github.com/pulp/pulp_deb/pull/1018
- I am happy to implement this as soon as there is a consensus on whether to add a whole new ViewSet in the class hierarchy, or whether it is enough to adjust `NoArtifactContentUploadViewSet` to support both use cases.
- I could use help in designing a good test to cover this special use case.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/plugin/viewsets/content.py`
Content:
```
1 from drf_spectacular.utils import extend_schema
2
3 from django.db import DatabaseError
4 from django.db.utils import IntegrityError
5
6 from pulpcore.app import tasks
7 from pulpcore.plugin.serializers import (
8 ArtifactSerializer,
9 AsyncOperationResponseSerializer,
10 )
11 from pulpcore.plugin.models import Artifact, PulpTemporaryFile
12 from pulpcore.plugin.tasking import dispatch
13 from pulpcore.plugin.viewsets import (
14 ContentViewSet,
15 OperationPostponedResponse,
16 )
17
18
19 class DefaultDeferredContextMixin:
20 """A mixin that provides a method for retrieving the default deferred context."""
21
22 def get_deferred_context(self, request):
23 """
24 Supply context for deferred validation.
25
26 When overwriting this method, it must return a dict, that is JSON serializable by
27 and does _not_ contain 'request' as a key.
28 """
29 return {}
30
31
32 class NoArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):
33 """A ViewSet for uploads that do not require to store an uploaded content as an Artifact."""
34
35 @extend_schema(
36 description="Trigger an asynchronous task to create content,"
37 "optionally create new repository version.",
38 responses={202: AsyncOperationResponseSerializer},
39 )
40 def create(self, request):
41 """Create a content unit."""
42 serializer = self.get_serializer(data=request.data)
43 serializer.is_valid(raise_exception=True)
44
45 task_payload = {k: v for k, v in request.data.items()}
46
47 file_content = task_payload.pop("file", None)
48 temp_file = PulpTemporaryFile.init_and_validate(file_content)
49 temp_file.save()
50
51 exclusive_resources = [
52 item for item in (serializer.validated_data.get(key) for key in ("repository",)) if item
53 ]
54
55 app_label = self.queryset.model._meta.app_label
56 context = self.get_deferred_context(request)
57 context["pulp_temp_file_pk"] = str(temp_file.pk)
58 task = dispatch(
59 tasks.base.general_create,
60 exclusive_resources=exclusive_resources,
61 args=(app_label, serializer.__class__.__name__),
62 kwargs={"data": task_payload, "context": context},
63 )
64 return OperationPostponedResponse(task, request)
65
66
67 class SingleArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):
68 """A ViewSet which can be used to store an uploaded content as an Artifact."""
69
70 @extend_schema(
71 description="Trigger an asynchronous task to create content,"
72 "optionally create new repository version.",
73 responses={202: AsyncOperationResponseSerializer},
74 )
75 def create(self, request):
76 """Create a content unit."""
77 serializer = self.get_serializer(data=request.data)
78 serializer.is_valid(raise_exception=True)
79
80 task_payload = self.init_content_data(serializer, request)
81
82 exclusive_resources = [
83 item
84 for item in (serializer.validated_data.get(key) for key in ("upload", "repository"))
85 if item
86 ]
87
88 app_label = self.queryset.model._meta.app_label
89 task = dispatch(
90 tasks.base.general_create,
91 exclusive_resources=exclusive_resources,
92 args=(app_label, serializer.__class__.__name__),
93 kwargs={
94 "data": task_payload,
95 "context": self.get_deferred_context(request),
96 },
97 )
98 return OperationPostponedResponse(task, request)
99
100 def init_content_data(self, serializer, request):
101 """Initialize the reference to an Artifact along with relevant task's payload data."""
102 task_payload = {k: v for k, v in request.data.items()}
103 if "file" in task_payload:
104 # in the upload code path make sure, the artifact exists, and the 'file'
105 # parameter is replaced by 'artifact'
106 artifact = Artifact.init_and_validate(task_payload.pop("file"))
107 try:
108 artifact.save()
109 except IntegrityError:
110 # if artifact already exists, let's use it
111 try:
112 artifact = Artifact.objects.get(
113 sha256=artifact.sha256, pulp_domain=request.pulp_domain
114 )
115 artifact.touch()
116 except (Artifact.DoesNotExist, DatabaseError):
117 # the artifact has since been removed from when we first attempted to save it
118 artifact.save()
119
120 task_payload["artifact"] = ArtifactSerializer(
121 artifact, context={"request": request}
122 ).data["pulp_href"]
123 elif "artifact" in serializer.validated_data:
124 serializer.validated_data["artifact"].touch()
125 # In case of a provided upload object, there is no artifact to touch yet.
126
127 return task_payload
128
```
Path: `pulpcore/plugin/viewsets/__init__.py`
Content:
```
1 from pulpcore.filters import BaseFilterSet
2
3 # Allow plugin viewsets to return 202s
4 from pulpcore.app.response import OperationPostponedResponse, TaskGroupOperationResponse
5
6 # Import Viewsets in platform that are potentially useful to plugin writers
7 from pulpcore.app.viewsets import (
8 AlternateContentSourceViewSet,
9 AsyncUpdateMixin,
10 ContentFilter,
11 ContentGuardFilter,
12 ContentGuardViewSet,
13 ContentViewSet,
14 DistributionFilter,
15 DistributionViewSet,
16 ExporterViewSet,
17 ExportViewSet,
18 ImmutableRepositoryViewSet,
19 ImporterViewSet,
20 ImportViewSet,
21 LabelsMixin,
22 NamedModelViewSet,
23 NAME_FILTER_OPTIONS,
24 NULLABLE_NUMERIC_FILTER_OPTIONS,
25 PublicationFilter,
26 PublicationViewSet,
27 ReadOnlyContentViewSet,
28 ReadOnlyRepositoryViewSet,
29 RemoteFilter,
30 RemoteViewSet,
31 RepositoryVersionViewSet,
32 RepositoryViewSet,
33 RolesMixin,
34 TaskGroupViewSet,
35 TaskViewSet,
36 )
37
38 from pulpcore.app.viewsets.custom_filters import (
39 CharInFilter,
40 LabelFilter,
41 RepositoryVersionFilter,
42 )
43
44 from pulpcore.filters import HyperlinkRelatedFilter
45
46 from .content import (
47 NoArtifactContentUploadViewSet,
48 SingleArtifactContentUploadViewSet,
49 )
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/plugin/viewsets/__init__.py b/pulpcore/plugin/viewsets/__init__.py
--- a/pulpcore/plugin/viewsets/__init__.py
+++ b/pulpcore/plugin/viewsets/__init__.py
@@ -44,6 +44,7 @@
from pulpcore.filters import HyperlinkRelatedFilter
from .content import (
+ NoArtifactContentViewSet,
NoArtifactContentUploadViewSet,
SingleArtifactContentUploadViewSet,
)
diff --git a/pulpcore/plugin/viewsets/content.py b/pulpcore/plugin/viewsets/content.py
--- a/pulpcore/plugin/viewsets/content.py
+++ b/pulpcore/plugin/viewsets/content.py
@@ -29,6 +29,35 @@
return {}
+class NoArtifactContentViewSet(DefaultDeferredContextMixin, ContentViewSet):
+ """A ViewSet for content creation that does not require a file to be uploaded."""
+
+ @extend_schema(
+ description="Trigger an asynchronous task to create content,"
+ "optionally create new repository version.",
+ responses={202: AsyncOperationResponseSerializer},
+ )
+ def create(self, request):
+ """Create a content unit."""
+ serializer = self.get_serializer(data=request.data)
+ serializer.is_valid(raise_exception=True)
+
+ exclusive_resources = [
+ item for item in (serializer.validated_data.get(key) for key in ("repository",)) if item
+ ]
+
+ task = dispatch(
+ tasks.base.general_create,
+ exclusive_resources=exclusive_resources,
+ args=(self.queryset.model._meta.app_label, serializer.__class__.__name__),
+ kwargs={
+ "data": {k: v for k, v in request.data.items()},
+ "context": self.get_deferred_context(request),
+ },
+ )
+ return OperationPostponedResponse(task, request)
+
+
class NoArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):
"""A ViewSet for uploads that do not require to store an uploaded content as an Artifact."""
|
{"golden_diff": "diff --git a/pulpcore/plugin/viewsets/__init__.py b/pulpcore/plugin/viewsets/__init__.py\n--- a/pulpcore/plugin/viewsets/__init__.py\n+++ b/pulpcore/plugin/viewsets/__init__.py\n@@ -44,6 +44,7 @@\n from pulpcore.filters import HyperlinkRelatedFilter\n \n from .content import (\n+ NoArtifactContentViewSet,\n NoArtifactContentUploadViewSet,\n SingleArtifactContentUploadViewSet,\n )\ndiff --git a/pulpcore/plugin/viewsets/content.py b/pulpcore/plugin/viewsets/content.py\n--- a/pulpcore/plugin/viewsets/content.py\n+++ b/pulpcore/plugin/viewsets/content.py\n@@ -29,6 +29,35 @@\n return {}\n \n \n+class NoArtifactContentViewSet(DefaultDeferredContextMixin, ContentViewSet):\n+ \"\"\"A ViewSet for content creation that does not require a file to be uploaded.\"\"\"\n+\n+ @extend_schema(\n+ description=\"Trigger an asynchronous task to create content,\"\n+ \"optionally create new repository version.\",\n+ responses={202: AsyncOperationResponseSerializer},\n+ )\n+ def create(self, request):\n+ \"\"\"Create a content unit.\"\"\"\n+ serializer = self.get_serializer(data=request.data)\n+ serializer.is_valid(raise_exception=True)\n+\n+ exclusive_resources = [\n+ item for item in (serializer.validated_data.get(key) for key in (\"repository\",)) if item\n+ ]\n+\n+ task = dispatch(\n+ tasks.base.general_create,\n+ exclusive_resources=exclusive_resources,\n+ args=(self.queryset.model._meta.app_label, serializer.__class__.__name__),\n+ kwargs={\n+ \"data\": {k: v for k, v in request.data.items()},\n+ \"context\": self.get_deferred_context(request),\n+ },\n+ )\n+ return OperationPostponedResponse(task, request)\n+\n+\n class NoArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):\n \"\"\"A ViewSet for uploads that do not require to store an uploaded content as an Artifact.\"\"\"\n", "issue": "Enable file-less \"uploads\"\n**Is your feature request related to a problem? Please describe.**\r\n\r\nRight now pulpcore knows artifactless types, that can be created via file upload using the `NoArtifactContentUploadViewSet` and the `NoArtifactContentUploadSerializer`, which can be combined with \"retrieve behaviour\" (do not throw errors if the requested content already esists/is already in the repo it should be added to) by defining a plugin specific `retrieve` function on the serializer.\r\n\r\nHowever, pulp_deb has several artifact less types, that do not need an actual uploaded file as part of this process at all. All they need (for pulp_deb to be able to create them) is the set of required API parameters. Examples include the `ReleaseComponent` and `ReleaseArchitecture`. These content types should still use the `repository` parameter to create and add them to a repository in one action, along with \"retrieve behaviour\". Since this means creating new repository versions, this action must be performed as a task to ensure resource locks.\r\n\r\nAs far as I can tell this is currently not possible, because pulpcore does not have the right kind of `ViewSet`. I was able to get things to work with the following adjustments to the `NoArtifactContentUploadViewSet`: https://github.com/pulp/pulpcore/pull/5084\r\n\r\nAn alternative might be to split up `NoArtifactContentUploadViewSet` into `NoArtifactContentUploadViewSet` and `NoArtifactContentViewSet`, which would mirror the class structure on the serializer side, and possibly make the semantic intention more clear.\r\n\r\n**Additional context**\r\n\r\n- See here for the pulp_deb change that prompted this need: https://github.com/pulp/pulp_deb/pull/1018\r\n- I am happy to implement this as soon as there is a consensus on whether to add a whole new ViewSet in the class hierarchy, or whether it is enough to adjust `NoArtifactContentUploadViewSet` to support both use cases.\r\n- I could use help in designing a good test to cover this special use case.\r\n\n", "before_files": [{"content": "from drf_spectacular.utils import extend_schema\n\nfrom django.db import DatabaseError\nfrom django.db.utils import IntegrityError\n\nfrom pulpcore.app import tasks\nfrom pulpcore.plugin.serializers import (\n ArtifactSerializer,\n AsyncOperationResponseSerializer,\n)\nfrom pulpcore.plugin.models import Artifact, PulpTemporaryFile\nfrom pulpcore.plugin.tasking import dispatch\nfrom pulpcore.plugin.viewsets import (\n ContentViewSet,\n OperationPostponedResponse,\n)\n\n\nclass DefaultDeferredContextMixin:\n \"\"\"A mixin that provides a method for retrieving the default deferred context.\"\"\"\n\n def get_deferred_context(self, request):\n \"\"\"\n Supply context for deferred validation.\n\n When overwriting this method, it must return a dict, that is JSON serializable by\n and does _not_ contain 'request' as a key.\n \"\"\"\n return {}\n\n\nclass NoArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):\n \"\"\"A ViewSet for uploads that do not require to store an uploaded content as an Artifact.\"\"\"\n\n @extend_schema(\n description=\"Trigger an asynchronous task to create content,\"\n \"optionally create new repository version.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def create(self, request):\n \"\"\"Create a content unit.\"\"\"\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n task_payload = {k: v for k, v in request.data.items()}\n\n file_content = task_payload.pop(\"file\", None)\n temp_file = PulpTemporaryFile.init_and_validate(file_content)\n temp_file.save()\n\n exclusive_resources = [\n item for item in (serializer.validated_data.get(key) for key in (\"repository\",)) if item\n ]\n\n app_label = self.queryset.model._meta.app_label\n context = self.get_deferred_context(request)\n context[\"pulp_temp_file_pk\"] = str(temp_file.pk)\n task = dispatch(\n tasks.base.general_create,\n exclusive_resources=exclusive_resources,\n args=(app_label, serializer.__class__.__name__),\n kwargs={\"data\": task_payload, \"context\": context},\n )\n return OperationPostponedResponse(task, request)\n\n\nclass SingleArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):\n \"\"\"A ViewSet which can be used to store an uploaded content as an Artifact.\"\"\"\n\n @extend_schema(\n description=\"Trigger an asynchronous task to create content,\"\n \"optionally create new repository version.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def create(self, request):\n \"\"\"Create a content unit.\"\"\"\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n task_payload = self.init_content_data(serializer, request)\n\n exclusive_resources = [\n item\n for item in (serializer.validated_data.get(key) for key in (\"upload\", \"repository\"))\n if item\n ]\n\n app_label = self.queryset.model._meta.app_label\n task = dispatch(\n tasks.base.general_create,\n exclusive_resources=exclusive_resources,\n args=(app_label, serializer.__class__.__name__),\n kwargs={\n \"data\": task_payload,\n \"context\": self.get_deferred_context(request),\n },\n )\n return OperationPostponedResponse(task, request)\n\n def init_content_data(self, serializer, request):\n \"\"\"Initialize the reference to an Artifact along with relevant task's payload data.\"\"\"\n task_payload = {k: v for k, v in request.data.items()}\n if \"file\" in task_payload:\n # in the upload code path make sure, the artifact exists, and the 'file'\n # parameter is replaced by 'artifact'\n artifact = Artifact.init_and_validate(task_payload.pop(\"file\"))\n try:\n artifact.save()\n except IntegrityError:\n # if artifact already exists, let's use it\n try:\n artifact = Artifact.objects.get(\n sha256=artifact.sha256, pulp_domain=request.pulp_domain\n )\n artifact.touch()\n except (Artifact.DoesNotExist, DatabaseError):\n # the artifact has since been removed from when we first attempted to save it\n artifact.save()\n\n task_payload[\"artifact\"] = ArtifactSerializer(\n artifact, context={\"request\": request}\n ).data[\"pulp_href\"]\n elif \"artifact\" in serializer.validated_data:\n serializer.validated_data[\"artifact\"].touch()\n # In case of a provided upload object, there is no artifact to touch yet.\n\n return task_payload\n", "path": "pulpcore/plugin/viewsets/content.py"}, {"content": "from pulpcore.filters import BaseFilterSet\n\n# Allow plugin viewsets to return 202s\nfrom pulpcore.app.response import OperationPostponedResponse, TaskGroupOperationResponse\n\n# Import Viewsets in platform that are potentially useful to plugin writers\nfrom pulpcore.app.viewsets import (\n AlternateContentSourceViewSet,\n AsyncUpdateMixin,\n ContentFilter,\n ContentGuardFilter,\n ContentGuardViewSet,\n ContentViewSet,\n DistributionFilter,\n DistributionViewSet,\n ExporterViewSet,\n ExportViewSet,\n ImmutableRepositoryViewSet,\n ImporterViewSet,\n ImportViewSet,\n LabelsMixin,\n NamedModelViewSet,\n NAME_FILTER_OPTIONS,\n NULLABLE_NUMERIC_FILTER_OPTIONS,\n PublicationFilter,\n PublicationViewSet,\n ReadOnlyContentViewSet,\n ReadOnlyRepositoryViewSet,\n RemoteFilter,\n RemoteViewSet,\n RepositoryVersionViewSet,\n RepositoryViewSet,\n RolesMixin,\n TaskGroupViewSet,\n TaskViewSet,\n)\n\nfrom pulpcore.app.viewsets.custom_filters import (\n CharInFilter,\n LabelFilter,\n RepositoryVersionFilter,\n)\n\nfrom pulpcore.filters import HyperlinkRelatedFilter\n\nfrom .content import (\n NoArtifactContentUploadViewSet,\n SingleArtifactContentUploadViewSet,\n)\n", "path": "pulpcore/plugin/viewsets/__init__.py"}], "after_files": [{"content": "from drf_spectacular.utils import extend_schema\n\nfrom django.db import DatabaseError\nfrom django.db.utils import IntegrityError\n\nfrom pulpcore.app import tasks\nfrom pulpcore.plugin.serializers import (\n ArtifactSerializer,\n AsyncOperationResponseSerializer,\n)\nfrom pulpcore.plugin.models import Artifact, PulpTemporaryFile\nfrom pulpcore.plugin.tasking import dispatch\nfrom pulpcore.plugin.viewsets import (\n ContentViewSet,\n OperationPostponedResponse,\n)\n\n\nclass DefaultDeferredContextMixin:\n \"\"\"A mixin that provides a method for retrieving the default deferred context.\"\"\"\n\n def get_deferred_context(self, request):\n \"\"\"\n Supply context for deferred validation.\n\n When overwriting this method, it must return a dict, that is JSON serializable by\n and does _not_ contain 'request' as a key.\n \"\"\"\n return {}\n\n\nclass NoArtifactContentViewSet(DefaultDeferredContextMixin, ContentViewSet):\n \"\"\"A ViewSet for content creation that does not require a file to be uploaded.\"\"\"\n\n @extend_schema(\n description=\"Trigger an asynchronous task to create content,\"\n \"optionally create new repository version.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def create(self, request):\n \"\"\"Create a content unit.\"\"\"\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n exclusive_resources = [\n item for item in (serializer.validated_data.get(key) for key in (\"repository\",)) if item\n ]\n\n task = dispatch(\n tasks.base.general_create,\n exclusive_resources=exclusive_resources,\n args=(self.queryset.model._meta.app_label, serializer.__class__.__name__),\n kwargs={\n \"data\": {k: v for k, v in request.data.items()},\n \"context\": self.get_deferred_context(request),\n },\n )\n return OperationPostponedResponse(task, request)\n\n\nclass NoArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):\n \"\"\"A ViewSet for uploads that do not require to store an uploaded content as an Artifact.\"\"\"\n\n @extend_schema(\n description=\"Trigger an asynchronous task to create content,\"\n \"optionally create new repository version.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def create(self, request):\n \"\"\"Create a content unit.\"\"\"\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n task_payload = {k: v for k, v in request.data.items()}\n\n file_content = task_payload.pop(\"file\", None)\n temp_file = PulpTemporaryFile.init_and_validate(file_content)\n temp_file.save()\n\n exclusive_resources = [\n item for item in (serializer.validated_data.get(key) for key in (\"repository\",)) if item\n ]\n\n app_label = self.queryset.model._meta.app_label\n context = self.get_deferred_context(request)\n context[\"pulp_temp_file_pk\"] = str(temp_file.pk)\n task = dispatch(\n tasks.base.general_create,\n exclusive_resources=exclusive_resources,\n args=(app_label, serializer.__class__.__name__),\n kwargs={\"data\": task_payload, \"context\": context},\n )\n return OperationPostponedResponse(task, request)\n\n\nclass SingleArtifactContentUploadViewSet(DefaultDeferredContextMixin, ContentViewSet):\n \"\"\"A ViewSet which can be used to store an uploaded content as an Artifact.\"\"\"\n\n @extend_schema(\n description=\"Trigger an asynchronous task to create content,\"\n \"optionally create new repository version.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def create(self, request):\n \"\"\"Create a content unit.\"\"\"\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n task_payload = self.init_content_data(serializer, request)\n\n exclusive_resources = [\n item\n for item in (serializer.validated_data.get(key) for key in (\"upload\", \"repository\"))\n if item\n ]\n\n app_label = self.queryset.model._meta.app_label\n task = dispatch(\n tasks.base.general_create,\n exclusive_resources=exclusive_resources,\n args=(app_label, serializer.__class__.__name__),\n kwargs={\n \"data\": task_payload,\n \"context\": self.get_deferred_context(request),\n },\n )\n return OperationPostponedResponse(task, request)\n\n def init_content_data(self, serializer, request):\n \"\"\"Initialize the reference to an Artifact along with relevant task's payload data.\"\"\"\n task_payload = {k: v for k, v in request.data.items()}\n if \"file\" in task_payload:\n # in the upload code path make sure, the artifact exists, and the 'file'\n # parameter is replaced by 'artifact'\n artifact = Artifact.init_and_validate(task_payload.pop(\"file\"))\n try:\n artifact.save()\n except IntegrityError:\n # if artifact already exists, let's use it\n try:\n artifact = Artifact.objects.get(\n sha256=artifact.sha256, pulp_domain=request.pulp_domain\n )\n artifact.touch()\n except (Artifact.DoesNotExist, DatabaseError):\n # the artifact has since been removed from when we first attempted to save it\n artifact.save()\n\n task_payload[\"artifact\"] = ArtifactSerializer(\n artifact, context={\"request\": request}\n ).data[\"pulp_href\"]\n elif \"artifact\" in serializer.validated_data:\n serializer.validated_data[\"artifact\"].touch()\n # In case of a provided upload object, there is no artifact to touch yet.\n\n return task_payload\n", "path": "pulpcore/plugin/viewsets/content.py"}, {"content": "from pulpcore.filters import BaseFilterSet\n\n# Allow plugin viewsets to return 202s\nfrom pulpcore.app.response import OperationPostponedResponse, TaskGroupOperationResponse\n\n# Import Viewsets in platform that are potentially useful to plugin writers\nfrom pulpcore.app.viewsets import (\n AlternateContentSourceViewSet,\n AsyncUpdateMixin,\n ContentFilter,\n ContentGuardFilter,\n ContentGuardViewSet,\n ContentViewSet,\n DistributionFilter,\n DistributionViewSet,\n ExporterViewSet,\n ExportViewSet,\n ImmutableRepositoryViewSet,\n ImporterViewSet,\n ImportViewSet,\n LabelsMixin,\n NamedModelViewSet,\n NAME_FILTER_OPTIONS,\n NULLABLE_NUMERIC_FILTER_OPTIONS,\n PublicationFilter,\n PublicationViewSet,\n ReadOnlyContentViewSet,\n ReadOnlyRepositoryViewSet,\n RemoteFilter,\n RemoteViewSet,\n RepositoryVersionViewSet,\n RepositoryViewSet,\n RolesMixin,\n TaskGroupViewSet,\n TaskViewSet,\n)\n\nfrom pulpcore.app.viewsets.custom_filters import (\n CharInFilter,\n LabelFilter,\n RepositoryVersionFilter,\n)\n\nfrom pulpcore.filters import HyperlinkRelatedFilter\n\nfrom .content import (\n NoArtifactContentViewSet,\n NoArtifactContentUploadViewSet,\n SingleArtifactContentUploadViewSet,\n)\n", "path": "pulpcore/plugin/viewsets/__init__.py"}]}
| 2,291 | 442 |
gh_patches_debug_2654
|
rasdani/github-patches
|
git_diff
|
microsoft__nni-5155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unclear what extras to install: `import nni.retiarii.execution.api` fails due to missing `pytorch_lightning`
**Describe the issue**:
I want to use `nni.retiarii.execution.api` module. I've installed it as below:
```
Collecting nni>=2.3
Downloading nni-2.9-py3-none-manylinux1_x86_64.whl (56.0 MB)
```
**Environment**:
- NNI version: 2.9
- Python version: 3.8
**Log message**:
```
_________________ ERROR collecting test/3rd_party/test_nni.py __________________
ImportError while importing test module '/__w/ai4cl-tianshou/ai4cl-tianshou/test/3rd_party/test_nni.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
test/3rd_party/test_nni.py:8: in <module>
import nni.retiarii.execution.api
/usr/local/lib/python3.8/site-packages/nni/retiarii/__init__.py:4: in <module>
from .operation import Operation
/usr/local/lib/python3.8/site-packages/nni/retiarii/operation.py:6: in <module>
from nni.nas.execution.common.graph_op import *
/usr/local/lib/python3.8/site-packages/nni/nas/__init__.py:4: in <module>
from .execution import *
/usr/local/lib/python3.8/site-packages/nni/nas/execution/__init__.py:4: in <module>
from .api import *
/usr/local/lib/python3.8/site-packages/nni/nas/execution/api.py:9: in <module>
from nni.nas.execution.common import (
/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/__init__.py:4: in <module>
from .engine import *
/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/engine.py:7: in <module>
from .graph import Model, MetricData
/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/graph.py:18: in <module>
from nni.nas.evaluator import Evaluator
/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/__init__.py:9: in <module>
shortcut_framework(__name__)
/usr/local/lib/python3.8/site-packages/nni/common/framework.py:93: in shortcut_framework
shortcut_module(current, '.' + get_default_framework(), current)
/usr/local/lib/python3.8/site-packages/nni/common/framework.py:83: in shortcut_module
mod = importlib.import_module(target, package)
/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/__init__.py:4: in <module>
from .lightning import *
/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/lightning.py:10: in <module>
import pytorch_lightning as pl
E ModuleNotFoundError: No module named 'pytorch_lightning'
```
**How to reproduce it?**:
```
pip install nni==2.9
python -c "import nni.retiarii.execution.api"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nni/nas/evaluator/pytorch/__init__.py`
Content:
```
1 # Copyright (c) Microsoft Corporation.
2 # Licensed under the MIT license.
3
4 from .lightning import *
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nni/nas/evaluator/pytorch/__init__.py b/nni/nas/evaluator/pytorch/__init__.py
--- a/nni/nas/evaluator/pytorch/__init__.py
+++ b/nni/nas/evaluator/pytorch/__init__.py
@@ -1,4 +1,11 @@
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
-from .lightning import *
+import warnings
+
+try:
+ from .lightning import *
+except ImportError:
+ warnings.warn("PyTorch-Lightning must be installed to use PyTorch in NAS. "
+ "If you are not using PyTorch, please `nni.set_default_framework('none')`")
+ raise
|
{"golden_diff": "diff --git a/nni/nas/evaluator/pytorch/__init__.py b/nni/nas/evaluator/pytorch/__init__.py\n--- a/nni/nas/evaluator/pytorch/__init__.py\n+++ b/nni/nas/evaluator/pytorch/__init__.py\n@@ -1,4 +1,11 @@\n # Copyright (c) Microsoft Corporation.\n # Licensed under the MIT license.\n \n-from .lightning import *\n+import warnings\n+\n+try:\n+ from .lightning import *\n+except ImportError:\n+ warnings.warn(\"PyTorch-Lightning must be installed to use PyTorch in NAS. \"\n+ \"If you are not using PyTorch, please `nni.set_default_framework('none')`\")\n+ raise\n", "issue": "Unclear what extras to install: `import nni.retiarii.execution.api` fails due to missing `pytorch_lightning`\n**Describe the issue**:\r\nI want to use `nni.retiarii.execution.api` module. I've installed it as below:\r\n```\r\nCollecting nni>=2.3\r\n Downloading nni-2.9-py3-none-manylinux1_x86_64.whl (56.0 MB)\r\n```\r\n\r\n**Environment**:\r\n- NNI version: 2.9\r\n- Python version: 3.8\r\n\r\n**Log message**:\r\n```\r\n_________________ ERROR collecting test/3rd_party/test_nni.py __________________\r\nImportError while importing test module '/__w/ai4cl-tianshou/ai4cl-tianshou/test/3rd_party/test_nni.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\n/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\ntest/3rd_party/test_nni.py:8: in <module>\r\n import nni.retiarii.execution.api\r\n/usr/local/lib/python3.8/site-packages/nni/retiarii/__init__.py:4: in <module>\r\n from .operation import Operation\r\n/usr/local/lib/python3.8/site-packages/nni/retiarii/operation.py:6: in <module>\r\n from nni.nas.execution.common.graph_op import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/__init__.py:4: in <module>\r\n from .execution import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/__init__.py:4: in <module>\r\n from .api import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/api.py:9: in <module>\r\n from nni.nas.execution.common import (\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/__init__.py:4: in <module>\r\n from .engine import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/engine.py:7: in <module>\r\n from .graph import Model, MetricData\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/graph.py:18: in <module>\r\n from nni.nas.evaluator import Evaluator\r\n/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/__init__.py:9: in <module>\r\n shortcut_framework(__name__)\r\n/usr/local/lib/python3.8/site-packages/nni/common/framework.py:93: in shortcut_framework\r\n shortcut_module(current, '.' + get_default_framework(), current)\r\n/usr/local/lib/python3.8/site-packages/nni/common/framework.py:83: in shortcut_module\r\n mod = importlib.import_module(target, package)\r\n/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/__init__.py:4: in <module>\r\n from .lightning import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/lightning.py:10: in <module>\r\n import pytorch_lightning as pl\r\nE ModuleNotFoundError: No module named 'pytorch_lightning'\r\n```\r\n\r\n**How to reproduce it?**:\r\n```\r\npip install nni==2.9\r\npython -c \"import nni.retiarii.execution.api\"\r\n```\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nfrom .lightning import *\n", "path": "nni/nas/evaluator/pytorch/__init__.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport warnings\n\ntry:\n from .lightning import *\nexcept ImportError:\n warnings.warn(\"PyTorch-Lightning must be installed to use PyTorch in NAS. \"\n \"If you are not using PyTorch, please `nni.set_default_framework('none')`\")\n raise\n", "path": "nni/nas/evaluator/pytorch/__init__.py"}]}
| 1,103 | 172 |
gh_patches_debug_3315
|
rasdani/github-patches
|
git_diff
|
google__turbinia-1227
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create documentation for the Turbinia API command line tool
Write documentation for the new Turbinia API command line tool.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `turbinia/api/cli/turbinia_client/core/groups.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright 2022 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Turbinia API client command-line tool."""
16
17 import click
18
19
20 @click.group('config')
21 def config_group():
22 """Get Turbinia configuration."""
23
24
25 @click.group('status')
26 def status_group():
27 """Get Turbinia request/task status."""
28
29
30 @click.group('result')
31 def result_group():
32 """Get Turbinia task or request results."""
33
34
35 @click.group('jobs')
36 def jobs_group():
37 """Get a list of enabled Turbinia jobs."""
38
39
40 @click.group('submit')
41 def submit_group():
42 """Submit new requests to the Turbinia API server."""
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/turbinia/api/cli/turbinia_client/core/groups.py b/turbinia/api/cli/turbinia_client/core/groups.py
--- a/turbinia/api/cli/turbinia_client/core/groups.py
+++ b/turbinia/api/cli/turbinia_client/core/groups.py
@@ -24,12 +24,12 @@
@click.group('status')
def status_group():
- """Get Turbinia request/task status."""
+ """Get Turbinia request or task status."""
@click.group('result')
def result_group():
- """Get Turbinia task or request results."""
+ """Get Turbinia request or task results."""
@click.group('jobs')
|
{"golden_diff": "diff --git a/turbinia/api/cli/turbinia_client/core/groups.py b/turbinia/api/cli/turbinia_client/core/groups.py\n--- a/turbinia/api/cli/turbinia_client/core/groups.py\n+++ b/turbinia/api/cli/turbinia_client/core/groups.py\n@@ -24,12 +24,12 @@\n \n @click.group('status')\n def status_group():\n- \"\"\"Get Turbinia request/task status.\"\"\"\n+ \"\"\"Get Turbinia request or task status.\"\"\"\n \n \n @click.group('result')\n def result_group():\n- \"\"\"Get Turbinia task or request results.\"\"\"\n+ \"\"\"Get Turbinia request or task results.\"\"\"\n \n \n @click.group('jobs')\n", "issue": "Create documentation for the Turbinia API command line tool\nWrite documentation for the new Turbinia API command line tool.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2022 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Turbinia API client command-line tool.\"\"\"\n\nimport click\n\n\[email protected]('config')\ndef config_group():\n \"\"\"Get Turbinia configuration.\"\"\"\n\n\[email protected]('status')\ndef status_group():\n \"\"\"Get Turbinia request/task status.\"\"\"\n\n\[email protected]('result')\ndef result_group():\n \"\"\"Get Turbinia task or request results.\"\"\"\n\n\[email protected]('jobs')\ndef jobs_group():\n \"\"\"Get a list of enabled Turbinia jobs.\"\"\"\n\n\[email protected]('submit')\ndef submit_group():\n \"\"\"Submit new requests to the Turbinia API server.\"\"\"\n", "path": "turbinia/api/cli/turbinia_client/core/groups.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2022 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Turbinia API client command-line tool.\"\"\"\n\nimport click\n\n\[email protected]('config')\ndef config_group():\n \"\"\"Get Turbinia configuration.\"\"\"\n\n\[email protected]('status')\ndef status_group():\n \"\"\"Get Turbinia request or task status.\"\"\"\n\n\[email protected]('result')\ndef result_group():\n \"\"\"Get Turbinia request or task results.\"\"\"\n\n\[email protected]('jobs')\ndef jobs_group():\n \"\"\"Get a list of enabled Turbinia jobs.\"\"\"\n\n\[email protected]('submit')\ndef submit_group():\n \"\"\"Submit new requests to the Turbinia API server.\"\"\"\n", "path": "turbinia/api/cli/turbinia_client/core/groups.py"}]}
| 635 | 158 |
gh_patches_debug_36221
|
rasdani/github-patches
|
git_diff
|
dynaconf__dynaconf-161
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[bug] Regression on config path-traversal
**Describe the bug**
Configuration is not read correctly for the parent directories
**To Reproduce**
Steps to reproduce the behavior:
```
/tmp/test$ find .
.
./test2
./.env
/tmp/test$ ipython3 -c "from dynaconf import settings; print(settings.ENV_FOR_DYNACONF)"
testavalue1
/tmp/test$ cd test2
/tmp/test/test2$ ipython3 -c "from dynaconf import settings; print(settings.ENV_FOR_DYNACONF)"
DEVELOPMENT
/tmp/test/test2$ cat ../.env
ENV_FOR_DYNACONF=testavalue1
```
2. Having the following config files:
see above
3. Having the following app code:
see above
4. Executing under the following environment
conda
Python 3.7.3
**Expected behavior**
Reading the file from the parent directory iff it does not exist in the current dir.
**Debug output**
<details>
<summary> Debug Output </summary>
```bash
export `DEBUG_LEVEL_FOR_DYNACONF=true` reproduce your problem and paste the output here
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-1-065bd64b7197> in <module>
----> 1 from dynaconf import settings; print(settings.ENV_FOR_DYNACONF)
~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/__init__.py in <module>
1 # coding: utf-8
----> 2 from dynaconf.base import LazySettings
3 from dynaconf.validator import Validator, ValidationError
4 from dynaconf.contrib import FlaskDynaconf, DjangoDynaconf
5
~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/base.py in <module>
6
7 from dynaconf import default_settings
----> 8 from dynaconf.loaders import (
9 default_loader,
10 settings_loader,
~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/loaders/__init__.py in <module>
2 from dynaconf import constants as ct
3 from dynaconf import default_settings
----> 4 from dynaconf.loaders import (
5 yaml_loader, toml_loader, json_loader, ini_loader, py_loader
6 )
~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/loaders/yaml_loader.py in <module>
4 from warnings import warn
5 from dynaconf import default_settings
----> 6 from dynaconf.loaders.base import BaseLoader
7 from dynaconf.constants import YAML_EXTENSIONS
8 from dynaconf.utils import object_merge
~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/loaders/base.py in <module>
5
6
----> 7 logger = raw_logger()
8
9
~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/utils/__init__.py in raw_logger()
68 return setup_logger(
69 "dynaconf",
---> 70 level=getattr(logging, level)
71 )
72 except ImportError: # pragma: no cover
AttributeError: module 'logging' has no attribute 'true'
```
</details>
**Environment (please complete the following information):**
- OS: Linux/Ubuntu18.04
- Dynaconf Version 2.0.0
- Frameworks in use: Flask
**Additional context**
works perfectly in dynaconf < 2.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dynaconf/utils/files.py`
Content:
```
1 import os
2 import inspect
3 from dynaconf.utils import raw_logger, deduplicate
4
5
6 def _walk_to_root(path, break_at=None):
7 """
8 Directories starting from the given directory up to the root or break_at
9 """
10 if not os.path.exists(path): # pragma: no cover
11 raise IOError('Starting path not found')
12
13 if os.path.isfile(path): # pragma: no cover
14 path = os.path.dirname(path)
15
16 last_dir = None
17 current_dir = os.path.abspath(path)
18 paths = []
19 while last_dir != current_dir:
20 paths.append(current_dir)
21 paths.append(os.path.join(current_dir, 'config'))
22 if current_dir == os.path.abspath(break_at): # pragma: no cover
23 break
24 parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))
25 last_dir, current_dir = current_dir, parent_dir
26 return paths
27
28
29 SEARCHTREE = None
30
31
32 def find_file(filename='.env', project_root=None, skip_files=None, **kwargs):
33 """Search in increasingly higher folders for the given file
34 Returns path to the file if found, or an empty string otherwise.
35
36 This function will build a `search_tree` based on:
37
38 - Project_root if specified
39 - Invoked script location and its parents until root
40 - Current working directory
41
42 For each path in the `search_tree` it will also look for an
43 aditional `./config` folder.
44 """
45 logger = raw_logger()
46 search_tree = []
47 work_dir = os.getcwd()
48 skip_files = skip_files or []
49
50 if project_root is None:
51 logger.debug('No root_path for %s', filename)
52 else:
53 logger.debug('Got root_path %s for %s', project_root, filename)
54 search_tree.extend(_walk_to_root(project_root, break_at=work_dir))
55
56 script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))
57
58 # Path to invoked script and recurivelly to root with its ./config dirs
59 search_tree.extend(_walk_to_root(script_dir, break_at=work_dir))
60
61 # Where Python interpreter was invoked from and its ./config
62 search_tree.extend([work_dir, os.path.join(work_dir, 'config')])
63
64 search_tree = deduplicate(search_tree)
65
66 global SEARCHTREE
67 SEARCHTREE != search_tree and logger.debug(
68 'Search Tree: %s', search_tree
69 )
70 SEARCHTREE = search_tree
71
72 logger.debug('Searching for %s', filename)
73
74 for dirname in search_tree:
75 check_path = os.path.join(dirname, filename)
76 if check_path in skip_files:
77 continue
78 if os.path.exists(check_path):
79 logger.debug('Found: %s', os.path.abspath(check_path))
80 return check_path # First found will return
81
82 # return empty string if not found so it can still be joined in os.path
83 return ''
84
```
Path: `dynaconf/utils/__init__.py`
Content:
```
1 # coding: utf-8
2 import os
3 import warnings
4 import functools
5
6
7 BANNER = """
8 ██████╗ ██╗ ██╗███╗ ██╗ █████╗ ██████╗ ██████╗ ███╗ ██╗███████╗
9 ██╔══██╗╚██╗ ██╔╝████╗ ██║██╔══██╗██╔════╝██╔═══██╗████╗ ██║██╔════╝
10 ██║ ██║ ╚████╔╝ ██╔██╗ ██║███████║██║ ██║ ██║██╔██╗ ██║█████╗
11 ██║ ██║ ╚██╔╝ ██║╚██╗██║██╔══██║██║ ██║ ██║██║╚██╗██║██╔══╝
12 ██████╔╝ ██║ ██║ ╚████║██║ ██║╚██████╗╚██████╔╝██║ ╚████║██║
13 ╚═════╝ ╚═╝ ╚═╝ ╚═══╝╚═╝ ╚═╝ ╚═════╝ ╚═════╝ ╚═╝ ╚═══╝╚═╝
14 """
15
16 if os.name == 'nt': # pragma: no cover
17 # windows can't handle the above charmap
18 BANNER = "DYNACONF"
19
20
21 def object_merge(old, new, unique=False):
22 """
23 Recursively merge two data structures.
24
25 :param unique: When set to True existing list items are not set.
26 """
27 if isinstance(old, list) and isinstance(new, list):
28 if old == new:
29 return
30 for item in old[::-1]:
31 if unique and item in new:
32 continue
33 new.insert(0, item)
34 if isinstance(old, dict) and isinstance(new, dict):
35 for key, value in old.items():
36 if key not in new:
37 new[key] = value
38 else:
39 object_merge(value, new[key])
40
41
42 class DynaconfDict(dict):
43 """A dict representing en empty Dynaconf object
44 useful to run loaders in to a dict for testing"""
45 def __init__(self, *args, **kwargs):
46 self._loaded_files = []
47 super(DynaconfDict, self).__init__(*args, **kwargs)
48
49 @property
50 def logger(self):
51 return raw_logger()
52
53 def set(self, key, value, *args, **kwargs):
54 self[key] = value
55
56 @staticmethod
57 def get_environ(key, default=None): # pragma: no cover
58 return os.environ.get(key, default)
59
60 def exists(self, key, **kwargs):
61 return self.get(key, missing) is not missing
62
63
64 @functools.lru_cache()
65 def _logger(level):
66 import logging
67 logging.basicConfig(
68 format=(
69 '%(asctime)s,%(msecs)d %(levelname)-8s '
70 '[%(filename)s:%(lineno)d - %(funcName)s] %(message)s'
71 ),
72 datefmt='%Y-%m-%d:%H:%M:%S',
73 level=getattr(logging, level)
74 )
75 logger = logging.getLogger("dynaconf")
76 return logger
77
78
79 def raw_logger(level=None):
80 """Get or create inner logger"""
81 level = level or os.environ.get('DEBUG_LEVEL_FOR_DYNACONF', 'ERROR')
82 return _logger(level)
83
84
85 RENAMED_VARS = {
86 # old: new
87 'DYNACONF_NAMESPACE': 'ENV_FOR_DYNACONF',
88 'NAMESPACE_FOR_DYNACONF': 'ENV_FOR_DYNACONF',
89 'DYNACONF_SETTINGS_MODULE': 'SETTINGS_MODULE_FOR_DYNACONF',
90 'DYNACONF_SETTINGS': 'SETTINGS_MODULE_FOR_DYNACONF',
91 'SETTINGS_MODULE': 'SETTINGS_MODULE_FOR_DYNACONF',
92 'PROJECT_ROOT': 'ROOT_PATH_FOR_DYNACONF',
93 'PROJECT_ROOT_FOR_DYNACONF': 'ROOT_PATH_FOR_DYNACONF',
94 'DYNACONF_SILENT_ERRORS': 'SILENT_ERRORS_FOR_DYNACONF',
95 'DYNACONF_ALWAYS_FRESH_VARS': 'FRESH_VARS_FOR_DYNACONF',
96 'BASE_NAMESPACE_FOR_DYNACONF': 'DEFAULT_ENV_FOR_DYNACONF'
97 }
98
99
100 def compat_kwargs(kwargs):
101 """To keep backwards compat change the kwargs to new names"""
102 warn_deprecations(kwargs)
103 for old, new in RENAMED_VARS.items():
104 if old in kwargs:
105 kwargs[new] = kwargs[old]
106
107
108 class Missing(object):
109 """
110 Sentinel value object/singleton used to differentiate between ambiguous
111 situations where `None` is a valid value.
112 """
113
114 def __bool__(self):
115 """Respond to boolean duck-typing."""
116 return False
117
118 def __eq__(self, other):
119 """Equality check for a singleton."""
120
121 return isinstance(other, self.__class__)
122
123 # Ensure compatibility with Python 2.x
124 __nonzero__ = __bool__
125
126 def __repr__(self):
127 """
128 Unambiguously identify this string-based representation of Missing,
129 used as a singleton.
130 """
131 return '<dynaconf.missing>'
132
133
134 missing = Missing()
135
136
137 def deduplicate(list_object):
138 """Rebuild `list_object` removing duplicated and keeping order"""
139 new = []
140 for item in list_object:
141 if item not in new:
142 new.append(item)
143 return new
144
145
146 def warn_deprecations(data):
147 if data.get('MERGE_ENABLED_FOR_DYNACONF'):
148 warnings.warn(
149 "MERGE_ENABLED_FOR_DYNACONF is deprecated "
150 "instead it is prefered to use the local merge feature "
151 "see: https://dynaconf.readthedocs.io/en/latest/guides/usage.html"
152 "#merging-existing-values",
153 DeprecationWarning
154 )
155 for old, new in RENAMED_VARS.items():
156 if old in data:
157 warnings.warn(
158 "You are using %s which is a deprecated settings "
159 "replace it with %s" % (old, new),
160 DeprecationWarning
161 )
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dynaconf/utils/__init__.py b/dynaconf/utils/__init__.py
--- a/dynaconf/utils/__init__.py
+++ b/dynaconf/utils/__init__.py
@@ -70,7 +70,7 @@
'[%(filename)s:%(lineno)d - %(funcName)s] %(message)s'
),
datefmt='%Y-%m-%d:%H:%M:%S',
- level=getattr(logging, level)
+ level=getattr(logging, level, 'DEBUG')
)
logger = logging.getLogger("dynaconf")
return logger
diff --git a/dynaconf/utils/files.py b/dynaconf/utils/files.py
--- a/dynaconf/utils/files.py
+++ b/dynaconf/utils/files.py
@@ -3,6 +3,9 @@
from dynaconf.utils import raw_logger, deduplicate
+logger = raw_logger()
+
+
def _walk_to_root(path, break_at=None):
"""
Directories starting from the given directory up to the root or break_at
@@ -19,7 +22,8 @@
while last_dir != current_dir:
paths.append(current_dir)
paths.append(os.path.join(current_dir, 'config'))
- if current_dir == os.path.abspath(break_at): # pragma: no cover
+ if break_at and current_dir == os.path.abspath(break_at): # noqa
+ logger.debug('Reached the %s directory, breaking.', break_at)
break
parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))
last_dir, current_dir = current_dir, parent_dir
@@ -42,7 +46,6 @@
For each path in the `search_tree` it will also look for an
aditional `./config` folder.
"""
- logger = raw_logger()
search_tree = []
work_dir = os.getcwd()
skip_files = skip_files or []
@@ -55,8 +58,8 @@
script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))
- # Path to invoked script and recurivelly to root with its ./config dirs
- search_tree.extend(_walk_to_root(script_dir, break_at=work_dir))
+ # Path to invoked script and recursivelly to root with its ./config dirs
+ search_tree.extend(_walk_to_root(script_dir))
# Where Python interpreter was invoked from and its ./config
search_tree.extend([work_dir, os.path.join(work_dir, 'config')])
|
{"golden_diff": "diff --git a/dynaconf/utils/__init__.py b/dynaconf/utils/__init__.py\n--- a/dynaconf/utils/__init__.py\n+++ b/dynaconf/utils/__init__.py\n@@ -70,7 +70,7 @@\n '[%(filename)s:%(lineno)d - %(funcName)s] %(message)s'\n ),\n datefmt='%Y-%m-%d:%H:%M:%S',\n- level=getattr(logging, level)\n+ level=getattr(logging, level, 'DEBUG')\n )\n logger = logging.getLogger(\"dynaconf\")\n return logger\ndiff --git a/dynaconf/utils/files.py b/dynaconf/utils/files.py\n--- a/dynaconf/utils/files.py\n+++ b/dynaconf/utils/files.py\n@@ -3,6 +3,9 @@\n from dynaconf.utils import raw_logger, deduplicate\n \n \n+logger = raw_logger()\n+\n+\n def _walk_to_root(path, break_at=None):\n \"\"\"\n Directories starting from the given directory up to the root or break_at\n@@ -19,7 +22,8 @@\n while last_dir != current_dir:\n paths.append(current_dir)\n paths.append(os.path.join(current_dir, 'config'))\n- if current_dir == os.path.abspath(break_at): # pragma: no cover\n+ if break_at and current_dir == os.path.abspath(break_at): # noqa\n+ logger.debug('Reached the %s directory, breaking.', break_at)\n break\n parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))\n last_dir, current_dir = current_dir, parent_dir\n@@ -42,7 +46,6 @@\n For each path in the `search_tree` it will also look for an\n aditional `./config` folder.\n \"\"\"\n- logger = raw_logger()\n search_tree = []\n work_dir = os.getcwd()\n skip_files = skip_files or []\n@@ -55,8 +58,8 @@\n \n script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))\n \n- # Path to invoked script and recurivelly to root with its ./config dirs\n- search_tree.extend(_walk_to_root(script_dir, break_at=work_dir))\n+ # Path to invoked script and recursivelly to root with its ./config dirs\n+ search_tree.extend(_walk_to_root(script_dir))\n \n # Where Python interpreter was invoked from and its ./config\n search_tree.extend([work_dir, os.path.join(work_dir, 'config')])\n", "issue": "[bug] Regression on config path-traversal\n**Describe the bug**\r\nConfiguration is not read correctly for the parent directories\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n```\r\n /tmp/test$ find .\r\n.\r\n./test2\r\n./.env\r\n\r\n/tmp/test$ ipython3 -c \"from dynaconf import settings; print(settings.ENV_FOR_DYNACONF)\"\r\ntestavalue1\r\n\r\n/tmp/test$ cd test2\r\n/tmp/test/test2$ ipython3 -c \"from dynaconf import settings; print(settings.ENV_FOR_DYNACONF)\"\r\nDEVELOPMENT\r\n\r\n/tmp/test/test2$ cat ../.env\r\nENV_FOR_DYNACONF=testavalue1\r\n```\r\n\r\n\r\n2. Having the following config files:\r\n\r\nsee above\r\n\r\n3. Having the following app code:\r\n\r\nsee above\r\n\r\n4. Executing under the following environment\r\nconda\r\nPython 3.7.3\r\n\r\n\r\n**Expected behavior**\r\n\r\nReading the file from the parent directory iff it does not exist in the current dir.\r\n\r\n**Debug output**\r\n\r\n<details>\r\n<summary> Debug Output </summary>\r\n\r\n```bash\r\n\r\nexport `DEBUG_LEVEL_FOR_DYNACONF=true` reproduce your problem and paste the output here\r\n\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-1-065bd64b7197> in <module>\r\n----> 1 from dynaconf import settings; print(settings.ENV_FOR_DYNACONF)\r\n\r\n~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/__init__.py in <module>\r\n 1 # coding: utf-8\r\n----> 2 from dynaconf.base import LazySettings\r\n 3 from dynaconf.validator import Validator, ValidationError\r\n 4 from dynaconf.contrib import FlaskDynaconf, DjangoDynaconf\r\n 5 \r\n\r\n~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/base.py in <module>\r\n 6 \r\n 7 from dynaconf import default_settings\r\n----> 8 from dynaconf.loaders import (\r\n 9 default_loader,\r\n 10 settings_loader,\r\n\r\n~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/loaders/__init__.py in <module>\r\n 2 from dynaconf import constants as ct\r\n 3 from dynaconf import default_settings\r\n----> 4 from dynaconf.loaders import (\r\n 5 yaml_loader, toml_loader, json_loader, ini_loader, py_loader\r\n 6 )\r\n\r\n~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/loaders/yaml_loader.py in <module>\r\n 4 from warnings import warn\r\n 5 from dynaconf import default_settings\r\n----> 6 from dynaconf.loaders.base import BaseLoader\r\n 7 from dynaconf.constants import YAML_EXTENSIONS\r\n 8 from dynaconf.utils import object_merge\r\n\r\n~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/loaders/base.py in <module>\r\n 5 \r\n 6 \r\n----> 7 logger = raw_logger()\r\n 8 \r\n 9 \r\n\r\n~/miniconda3/envs/smr/lib/python3.7/site-packages/dynaconf/utils/__init__.py in raw_logger()\r\n 68 return setup_logger(\r\n 69 \"dynaconf\",\r\n---> 70 level=getattr(logging, level)\r\n 71 )\r\n 72 except ImportError: # pragma: no cover\r\n\r\nAttributeError: module 'logging' has no attribute 'true'\r\n\r\n```\r\n\r\n</details>\r\n\r\n**Environment (please complete the following information):**\r\n - OS: Linux/Ubuntu18.04\r\n - Dynaconf Version 2.0.0\r\n - Frameworks in use: Flask\r\n\r\n**Additional context**\r\n\r\nworks perfectly in dynaconf < 2.0\n", "before_files": [{"content": "import os\nimport inspect\nfrom dynaconf.utils import raw_logger, deduplicate\n\n\ndef _walk_to_root(path, break_at=None):\n \"\"\"\n Directories starting from the given directory up to the root or break_at\n \"\"\"\n if not os.path.exists(path): # pragma: no cover\n raise IOError('Starting path not found')\n\n if os.path.isfile(path): # pragma: no cover\n path = os.path.dirname(path)\n\n last_dir = None\n current_dir = os.path.abspath(path)\n paths = []\n while last_dir != current_dir:\n paths.append(current_dir)\n paths.append(os.path.join(current_dir, 'config'))\n if current_dir == os.path.abspath(break_at): # pragma: no cover\n break\n parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))\n last_dir, current_dir = current_dir, parent_dir\n return paths\n\n\nSEARCHTREE = None\n\n\ndef find_file(filename='.env', project_root=None, skip_files=None, **kwargs):\n \"\"\"Search in increasingly higher folders for the given file\n Returns path to the file if found, or an empty string otherwise.\n\n This function will build a `search_tree` based on:\n\n - Project_root if specified\n - Invoked script location and its parents until root\n - Current working directory\n\n For each path in the `search_tree` it will also look for an\n aditional `./config` folder.\n \"\"\"\n logger = raw_logger()\n search_tree = []\n work_dir = os.getcwd()\n skip_files = skip_files or []\n\n if project_root is None:\n logger.debug('No root_path for %s', filename)\n else:\n logger.debug('Got root_path %s for %s', project_root, filename)\n search_tree.extend(_walk_to_root(project_root, break_at=work_dir))\n\n script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))\n\n # Path to invoked script and recurivelly to root with its ./config dirs\n search_tree.extend(_walk_to_root(script_dir, break_at=work_dir))\n\n # Where Python interpreter was invoked from and its ./config\n search_tree.extend([work_dir, os.path.join(work_dir, 'config')])\n\n search_tree = deduplicate(search_tree)\n\n global SEARCHTREE\n SEARCHTREE != search_tree and logger.debug(\n 'Search Tree: %s', search_tree\n )\n SEARCHTREE = search_tree\n\n logger.debug('Searching for %s', filename)\n\n for dirname in search_tree:\n check_path = os.path.join(dirname, filename)\n if check_path in skip_files:\n continue\n if os.path.exists(check_path):\n logger.debug('Found: %s', os.path.abspath(check_path))\n return check_path # First found will return\n\n # return empty string if not found so it can still be joined in os.path\n return ''\n", "path": "dynaconf/utils/files.py"}, {"content": "# coding: utf-8\nimport os\nimport warnings\nimport functools\n\n\nBANNER = \"\"\"\n\u2588\u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2557 \u2588\u2588\u2557\u2588\u2588\u2588\u2557 \u2588\u2588\u2557 \u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2588\u2557 \u2588\u2588\u2557\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2557\n\u2588\u2588\u2554\u2550\u2550\u2588\u2588\u2557\u255a\u2588\u2588\u2557 \u2588\u2588\u2554\u255d\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u2588\u2588\u2557\u2588\u2588\u2554\u2550\u2550\u2550\u2550\u255d\u2588\u2588\u2554\u2550\u2550\u2550\u2588\u2588\u2557\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u2550\u2550\u255d\n\u2588\u2588\u2551 \u2588\u2588\u2551 \u255a\u2588\u2588\u2588\u2588\u2554\u255d \u2588\u2588\u2554\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2551\u2588\u2588\u2551 \u2588\u2588\u2551 \u2588\u2588\u2551\u2588\u2588\u2554\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2588\u2588\u2588\u2557\n\u2588\u2588\u2551 \u2588\u2588\u2551 \u255a\u2588\u2588\u2554\u255d \u2588\u2588\u2551\u255a\u2588\u2588\u2557\u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u2588\u2588\u2551\u2588\u2588\u2551 \u2588\u2588\u2551 \u2588\u2588\u2551\u2588\u2588\u2551\u255a\u2588\u2588\u2557\u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u255d\n\u2588\u2588\u2588\u2588\u2588\u2588\u2554\u255d \u2588\u2588\u2551 \u2588\u2588\u2551 \u255a\u2588\u2588\u2588\u2588\u2551\u2588\u2588\u2551 \u2588\u2588\u2551\u255a\u2588\u2588\u2588\u2588\u2588\u2588\u2557\u255a\u2588\u2588\u2588\u2588\u2588\u2588\u2554\u255d\u2588\u2588\u2551 \u255a\u2588\u2588\u2588\u2588\u2551\u2588\u2588\u2551\n\u255a\u2550\u2550\u2550\u2550\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u2550\u2550\u255d\u255a\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u2550\u2550\u2550\u2550\u255d \u255a\u2550\u2550\u2550\u2550\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u2550\u2550\u255d\u255a\u2550\u255d\n\"\"\"\n\nif os.name == 'nt': # pragma: no cover\n # windows can't handle the above charmap\n BANNER = \"DYNACONF\"\n\n\ndef object_merge(old, new, unique=False):\n \"\"\"\n Recursively merge two data structures.\n\n :param unique: When set to True existing list items are not set.\n \"\"\"\n if isinstance(old, list) and isinstance(new, list):\n if old == new:\n return\n for item in old[::-1]:\n if unique and item in new:\n continue\n new.insert(0, item)\n if isinstance(old, dict) and isinstance(new, dict):\n for key, value in old.items():\n if key not in new:\n new[key] = value\n else:\n object_merge(value, new[key])\n\n\nclass DynaconfDict(dict):\n \"\"\"A dict representing en empty Dynaconf object\n useful to run loaders in to a dict for testing\"\"\"\n def __init__(self, *args, **kwargs):\n self._loaded_files = []\n super(DynaconfDict, self).__init__(*args, **kwargs)\n\n @property\n def logger(self):\n return raw_logger()\n\n def set(self, key, value, *args, **kwargs):\n self[key] = value\n\n @staticmethod\n def get_environ(key, default=None): # pragma: no cover\n return os.environ.get(key, default)\n\n def exists(self, key, **kwargs):\n return self.get(key, missing) is not missing\n\n\[email protected]_cache()\ndef _logger(level):\n import logging\n logging.basicConfig(\n format=(\n '%(asctime)s,%(msecs)d %(levelname)-8s '\n '[%(filename)s:%(lineno)d - %(funcName)s] %(message)s'\n ),\n datefmt='%Y-%m-%d:%H:%M:%S',\n level=getattr(logging, level)\n )\n logger = logging.getLogger(\"dynaconf\")\n return logger\n\n\ndef raw_logger(level=None):\n \"\"\"Get or create inner logger\"\"\"\n level = level or os.environ.get('DEBUG_LEVEL_FOR_DYNACONF', 'ERROR')\n return _logger(level)\n\n\nRENAMED_VARS = {\n # old: new\n 'DYNACONF_NAMESPACE': 'ENV_FOR_DYNACONF',\n 'NAMESPACE_FOR_DYNACONF': 'ENV_FOR_DYNACONF',\n 'DYNACONF_SETTINGS_MODULE': 'SETTINGS_MODULE_FOR_DYNACONF',\n 'DYNACONF_SETTINGS': 'SETTINGS_MODULE_FOR_DYNACONF',\n 'SETTINGS_MODULE': 'SETTINGS_MODULE_FOR_DYNACONF',\n 'PROJECT_ROOT': 'ROOT_PATH_FOR_DYNACONF',\n 'PROJECT_ROOT_FOR_DYNACONF': 'ROOT_PATH_FOR_DYNACONF',\n 'DYNACONF_SILENT_ERRORS': 'SILENT_ERRORS_FOR_DYNACONF',\n 'DYNACONF_ALWAYS_FRESH_VARS': 'FRESH_VARS_FOR_DYNACONF',\n 'BASE_NAMESPACE_FOR_DYNACONF': 'DEFAULT_ENV_FOR_DYNACONF'\n}\n\n\ndef compat_kwargs(kwargs):\n \"\"\"To keep backwards compat change the kwargs to new names\"\"\"\n warn_deprecations(kwargs)\n for old, new in RENAMED_VARS.items():\n if old in kwargs:\n kwargs[new] = kwargs[old]\n\n\nclass Missing(object):\n \"\"\"\n Sentinel value object/singleton used to differentiate between ambiguous\n situations where `None` is a valid value.\n \"\"\"\n\n def __bool__(self):\n \"\"\"Respond to boolean duck-typing.\"\"\"\n return False\n\n def __eq__(self, other):\n \"\"\"Equality check for a singleton.\"\"\"\n\n return isinstance(other, self.__class__)\n\n # Ensure compatibility with Python 2.x\n __nonzero__ = __bool__\n\n def __repr__(self):\n \"\"\"\n Unambiguously identify this string-based representation of Missing,\n used as a singleton.\n \"\"\"\n return '<dynaconf.missing>'\n\n\nmissing = Missing()\n\n\ndef deduplicate(list_object):\n \"\"\"Rebuild `list_object` removing duplicated and keeping order\"\"\"\n new = []\n for item in list_object:\n if item not in new:\n new.append(item)\n return new\n\n\ndef warn_deprecations(data):\n if data.get('MERGE_ENABLED_FOR_DYNACONF'):\n warnings.warn(\n \"MERGE_ENABLED_FOR_DYNACONF is deprecated \"\n \"instead it is prefered to use the local merge feature \"\n \"see: https://dynaconf.readthedocs.io/en/latest/guides/usage.html\"\n \"#merging-existing-values\",\n DeprecationWarning\n )\n for old, new in RENAMED_VARS.items():\n if old in data:\n warnings.warn(\n \"You are using %s which is a deprecated settings \"\n \"replace it with %s\" % (old, new),\n DeprecationWarning\n )\n", "path": "dynaconf/utils/__init__.py"}], "after_files": [{"content": "import os\nimport inspect\nfrom dynaconf.utils import raw_logger, deduplicate\n\n\nlogger = raw_logger()\n\n\ndef _walk_to_root(path, break_at=None):\n \"\"\"\n Directories starting from the given directory up to the root or break_at\n \"\"\"\n if not os.path.exists(path): # pragma: no cover\n raise IOError('Starting path not found')\n\n if os.path.isfile(path): # pragma: no cover\n path = os.path.dirname(path)\n\n last_dir = None\n current_dir = os.path.abspath(path)\n paths = []\n while last_dir != current_dir:\n paths.append(current_dir)\n paths.append(os.path.join(current_dir, 'config'))\n if break_at and current_dir == os.path.abspath(break_at): # noqa\n logger.debug('Reached the %s directory, breaking.', break_at)\n break\n parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))\n last_dir, current_dir = current_dir, parent_dir\n return paths\n\n\nSEARCHTREE = None\n\n\ndef find_file(filename='.env', project_root=None, skip_files=None, **kwargs):\n \"\"\"Search in increasingly higher folders for the given file\n Returns path to the file if found, or an empty string otherwise.\n\n This function will build a `search_tree` based on:\n\n - Project_root if specified\n - Invoked script location and its parents until root\n - Current working directory\n\n For each path in the `search_tree` it will also look for an\n aditional `./config` folder.\n \"\"\"\n search_tree = []\n work_dir = os.getcwd()\n skip_files = skip_files or []\n\n if project_root is None:\n logger.debug('No root_path for %s', filename)\n else:\n logger.debug('Got root_path %s for %s', project_root, filename)\n search_tree.extend(_walk_to_root(project_root, break_at=work_dir))\n\n script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))\n\n # Path to invoked script and recursivelly to root with its ./config dirs\n search_tree.extend(_walk_to_root(script_dir))\n\n # Where Python interpreter was invoked from and its ./config\n search_tree.extend([work_dir, os.path.join(work_dir, 'config')])\n\n search_tree = deduplicate(search_tree)\n\n global SEARCHTREE\n SEARCHTREE != search_tree and logger.debug(\n 'Search Tree: %s', search_tree\n )\n SEARCHTREE = search_tree\n\n logger.debug('Searching for %s', filename)\n\n for dirname in search_tree:\n check_path = os.path.join(dirname, filename)\n if check_path in skip_files:\n continue\n if os.path.exists(check_path):\n logger.debug('Found: %s', os.path.abspath(check_path))\n return check_path # First found will return\n\n # return empty string if not found so it can still be joined in os.path\n return ''\n", "path": "dynaconf/utils/files.py"}, {"content": "# coding: utf-8\nimport os\nimport warnings\nimport functools\n\n\nBANNER = \"\"\"\n\u2588\u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2557 \u2588\u2588\u2557\u2588\u2588\u2588\u2557 \u2588\u2588\u2557 \u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2588\u2557 \u2588\u2588\u2557\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2557\n\u2588\u2588\u2554\u2550\u2550\u2588\u2588\u2557\u255a\u2588\u2588\u2557 \u2588\u2588\u2554\u255d\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u2588\u2588\u2557\u2588\u2588\u2554\u2550\u2550\u2550\u2550\u255d\u2588\u2588\u2554\u2550\u2550\u2550\u2588\u2588\u2557\u2588\u2588\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u2550\u2550\u255d\n\u2588\u2588\u2551 \u2588\u2588\u2551 \u255a\u2588\u2588\u2588\u2588\u2554\u255d \u2588\u2588\u2554\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2551\u2588\u2588\u2551 \u2588\u2588\u2551 \u2588\u2588\u2551\u2588\u2588\u2554\u2588\u2588\u2557 \u2588\u2588\u2551\u2588\u2588\u2588\u2588\u2588\u2557\n\u2588\u2588\u2551 \u2588\u2588\u2551 \u255a\u2588\u2588\u2554\u255d \u2588\u2588\u2551\u255a\u2588\u2588\u2557\u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u2588\u2588\u2551\u2588\u2588\u2551 \u2588\u2588\u2551 \u2588\u2588\u2551\u2588\u2588\u2551\u255a\u2588\u2588\u2557\u2588\u2588\u2551\u2588\u2588\u2554\u2550\u2550\u255d\n\u2588\u2588\u2588\u2588\u2588\u2588\u2554\u255d \u2588\u2588\u2551 \u2588\u2588\u2551 \u255a\u2588\u2588\u2588\u2588\u2551\u2588\u2588\u2551 \u2588\u2588\u2551\u255a\u2588\u2588\u2588\u2588\u2588\u2588\u2557\u255a\u2588\u2588\u2588\u2588\u2588\u2588\u2554\u255d\u2588\u2588\u2551 \u255a\u2588\u2588\u2588\u2588\u2551\u2588\u2588\u2551\n\u255a\u2550\u2550\u2550\u2550\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u2550\u2550\u255d\u255a\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u2550\u2550\u2550\u2550\u255d \u255a\u2550\u2550\u2550\u2550\u2550\u255d \u255a\u2550\u255d \u255a\u2550\u2550\u2550\u255d\u255a\u2550\u255d\n\"\"\"\n\nif os.name == 'nt': # pragma: no cover\n # windows can't handle the above charmap\n BANNER = \"DYNACONF\"\n\n\ndef object_merge(old, new, unique=False):\n \"\"\"\n Recursively merge two data structures.\n\n :param unique: When set to True existing list items are not set.\n \"\"\"\n if isinstance(old, list) and isinstance(new, list):\n if old == new:\n return\n for item in old[::-1]:\n if unique and item in new:\n continue\n new.insert(0, item)\n if isinstance(old, dict) and isinstance(new, dict):\n for key, value in old.items():\n if key not in new:\n new[key] = value\n else:\n object_merge(value, new[key])\n\n\nclass DynaconfDict(dict):\n \"\"\"A dict representing en empty Dynaconf object\n useful to run loaders in to a dict for testing\"\"\"\n def __init__(self, *args, **kwargs):\n self._loaded_files = []\n super(DynaconfDict, self).__init__(*args, **kwargs)\n\n @property\n def logger(self):\n return raw_logger()\n\n def set(self, key, value, *args, **kwargs):\n self[key] = value\n\n @staticmethod\n def get_environ(key, default=None): # pragma: no cover\n return os.environ.get(key, default)\n\n def exists(self, key, **kwargs):\n return self.get(key, missing) is not missing\n\n\[email protected]_cache()\ndef _logger(level):\n import logging\n logging.basicConfig(\n format=(\n '%(asctime)s,%(msecs)d %(levelname)-8s '\n '[%(filename)s:%(lineno)d - %(funcName)s] %(message)s'\n ),\n datefmt='%Y-%m-%d:%H:%M:%S',\n level=getattr(logging, level, 'DEBUG')\n )\n logger = logging.getLogger(\"dynaconf\")\n return logger\n\n\ndef raw_logger(level=None):\n \"\"\"Get or create inner logger\"\"\"\n level = level or os.environ.get('DEBUG_LEVEL_FOR_DYNACONF', 'ERROR')\n return _logger(level)\n\n\nRENAMED_VARS = {\n # old: new\n 'DYNACONF_NAMESPACE': 'ENV_FOR_DYNACONF',\n 'NAMESPACE_FOR_DYNACONF': 'ENV_FOR_DYNACONF',\n 'DYNACONF_SETTINGS_MODULE': 'SETTINGS_MODULE_FOR_DYNACONF',\n 'DYNACONF_SETTINGS': 'SETTINGS_MODULE_FOR_DYNACONF',\n 'SETTINGS_MODULE': 'SETTINGS_MODULE_FOR_DYNACONF',\n 'PROJECT_ROOT': 'ROOT_PATH_FOR_DYNACONF',\n 'PROJECT_ROOT_FOR_DYNACONF': 'ROOT_PATH_FOR_DYNACONF',\n 'DYNACONF_SILENT_ERRORS': 'SILENT_ERRORS_FOR_DYNACONF',\n 'DYNACONF_ALWAYS_FRESH_VARS': 'FRESH_VARS_FOR_DYNACONF',\n 'BASE_NAMESPACE_FOR_DYNACONF': 'DEFAULT_ENV_FOR_DYNACONF'\n}\n\n\ndef compat_kwargs(kwargs):\n \"\"\"To keep backwards compat change the kwargs to new names\"\"\"\n warn_deprecations(kwargs)\n for old, new in RENAMED_VARS.items():\n if old in kwargs:\n kwargs[new] = kwargs[old]\n\n\nclass Missing(object):\n \"\"\"\n Sentinel value object/singleton used to differentiate between ambiguous\n situations where `None` is a valid value.\n \"\"\"\n\n def __bool__(self):\n \"\"\"Respond to boolean duck-typing.\"\"\"\n return False\n\n def __eq__(self, other):\n \"\"\"Equality check for a singleton.\"\"\"\n\n return isinstance(other, self.__class__)\n\n # Ensure compatibility with Python 2.x\n __nonzero__ = __bool__\n\n def __repr__(self):\n \"\"\"\n Unambiguously identify this string-based representation of Missing,\n used as a singleton.\n \"\"\"\n return '<dynaconf.missing>'\n\n\nmissing = Missing()\n\n\ndef deduplicate(list_object):\n \"\"\"Rebuild `list_object` removing duplicated and keeping order\"\"\"\n new = []\n for item in list_object:\n if item not in new:\n new.append(item)\n return new\n\n\ndef warn_deprecations(data):\n if data.get('MERGE_ENABLED_FOR_DYNACONF'):\n warnings.warn(\n \"MERGE_ENABLED_FOR_DYNACONF is deprecated \"\n \"instead it is prefered to use the local merge feature \"\n \"see: https://dynaconf.readthedocs.io/en/latest/guides/usage.html\"\n \"#merging-existing-values\",\n DeprecationWarning\n )\n for old, new in RENAMED_VARS.items():\n if old in data:\n warnings.warn(\n \"You are using %s which is a deprecated settings \"\n \"replace it with %s\" % (old, new),\n DeprecationWarning\n )\n", "path": "dynaconf/utils/__init__.py"}]}
| 3,677 | 553 |
gh_patches_debug_27407
|
rasdani/github-patches
|
git_diff
|
wright-group__WrightTools-931
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
consider using NumExpr as alternative to eval
Within the units library, we use eval.
https://github.com/wright-group/WrightTools/blob/master/WrightTools/units.py#L96-L135
We could use NumExpr... our usage case seems to be exactly what the package was made for.
https://numexpr.readthedocs.io/en/latest/user_guide.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `WrightTools/units.py`
Content:
```
1 """Unit and label handling in WrightTools."""
2
3
4 # --- import --------------------------------------------------------------------------------------
5
6
7 import collections
8
9 import numpy as np
10 import warnings
11
12
13 # --- define --------------------------------------------------------------------------------------
14
15
16 # units are stored in dictionaries of like kind. format:
17 # unit : to native, from native, units_symbol, units_label
18
19 # angle units (native: rad)
20 angle = {"rad": ["x", "x", r"rad"], "deg": ["x/57.2958", "57.2958*x", r"deg"]}
21
22 # delay units (native: fs)
23 fs_per_mm = 3336.
24 delay = {
25 "fs": ["x", "x", r"fs"],
26 "ps": ["x*1e3", "x/1e3", r"ps"],
27 "ns": ["x*1e6", "x/1e6", r"ns"],
28 "mm_delay": ["x*2*fs_per_mm", "x/(2*fs_per_mm)", r"mm"],
29 }
30
31 # energy units (native: nm)
32 energy = {
33 "nm": ["x", "x", r"nm"],
34 "wn": ["1e7/x", "1e7/x", r"cm^{-1}"],
35 "eV": ["1240./x", "1240./x", r"eV"],
36 "meV": ["1240000./x", "1240000./x", r"meV"],
37 "Hz": ["2.99792458e17/x", "2.99792458e17/x", r"Hz"],
38 "THz": ["2.99792458e5/x", "2.99792458e5/x", r"THz"],
39 "GHz": ["2.99792458e8/x", "2.99792458e8/x", r"GHz"],
40 }
41
42 # fluence units (native: uJ per sq. cm)
43 fluence = {"uJ per sq. cm": ["x", "x", r"\frac{\mu J}{cm^{2}}"]}
44
45 # optical density units (native: od)
46 od = {"mOD": ["1e3*x", "x/1e3", r"mOD"], "OD": ["x", "x", r"OD"]}
47
48 # position units (native: mm)
49 position = {
50 "nm_p": ["x/1e6", "1e6*x", r"nm"],
51 "um": ["x/1000.", "1000.*x", r"um"],
52 "mm": ["x", "x", r"mm"],
53 "cm": ["10.*x", "x/10.", r"cm"],
54 "in": ["x*0.039370", "0.039370*x", r"in"],
55 }
56
57 # pulse width units (native: FWHM)
58 pulse_width = {"FWHM": ["x", "x", r"FWHM"]}
59
60 # temperature units (native: K)
61 temperature = {
62 "K": ["x", "x", r"K"],
63 "deg_C": ["x+273.15", "x-273.15", r"^\circ C"],
64 "deg_F": ["(x+459.67)*5/9", "x*9/5-456.67", r"^\circ F"],
65 "deg_R": ["x*5/9", "x*9/5", r"^\circ R"],
66 }
67
68 # time units (native: s)
69 time = {
70 "fs_t": ["x/1e15", "x*1e15", r"fs"],
71 "ps_t": ["x/1e12", "x*1e12", r"ps"],
72 "ns_t": ["x/1e9", "x*1e9", r"ns"],
73 "us_t": ["x/1e6", "x*1e6", r"us"],
74 "ms_t": ["x/1000.", "x*1000.", r"ms"],
75 "s_t": ["x", "x", r"s"],
76 "m_t": ["x*60.", "x/60.", r"m"],
77 "h_t": ["x*3600.", "x/3600.", r"h"],
78 "d_t": ["x*86400.", "x/86400.", r"d"],
79 }
80
81 dicts = collections.OrderedDict()
82 dicts["angle"] = angle
83 dicts["delay"] = delay
84 dicts["energy"] = energy
85 dicts["time"] = time
86 dicts["position"] = position
87 dicts["pulse_width"] = pulse_width
88 dicts["fluence"] = fluence
89 dicts["od"] = od
90 dicts["temperature"] = temperature
91
92
93 # --- functions -----------------------------------------------------------------------------------
94
95
96 def converter(val, current_unit, destination_unit):
97 """Convert from one unit to another.
98
99 Parameters
100 ----------
101 val : number
102 Number to convert.
103 current_unit : string
104 Current unit.
105 destination_unit : string
106 Destination unit.
107
108 Returns
109 -------
110 number
111 Converted value.
112 """
113 x = val
114 for dic in dicts.values():
115 if current_unit in dic.keys() and destination_unit in dic.keys():
116 try:
117 native = eval(dic[current_unit][0])
118 except ZeroDivisionError:
119 native = np.inf
120 x = native # noqa: F841
121 try:
122 out = eval(dic[destination_unit][1])
123 except ZeroDivisionError:
124 out = np.inf
125 return out
126 # if all dictionaries fail
127 if current_unit is None and destination_unit is None:
128 pass
129 else:
130 warnings.warn(
131 "conversion {0} to {1} not valid: returning input".format(
132 current_unit, destination_unit
133 )
134 )
135 return val
136
137
138 convert = converter
139
140
141 def get_symbol(units) -> str:
142 """Get default symbol type.
143
144 Parameters
145 ----------
146 units_str : string
147 Units.
148
149 Returns
150 -------
151 string
152 LaTeX formatted symbol.
153 """
154 if kind(units) == "energy":
155 d = {}
156 d["nm"] = r"\lambda"
157 d["wn"] = r"\bar\nu"
158 d["eV"] = r"\hslash\omega"
159 d["Hz"] = r"f"
160 d["THz"] = r"f"
161 d["GHz"] = r"f"
162 return d.get(units, "E")
163 elif kind(units) == "delay":
164 return r"\tau"
165 elif kind(units) == "fluence":
166 return r"\mathcal{F}"
167 elif kind(units) == "pulse_width":
168 return r"\sigma"
169 elif kind(units) == "temperature":
170 return r"T"
171 else:
172 return kind(units)
173
174
175 def get_valid_conversions(units) -> tuple:
176 try:
177 valid = list(dicts[kind(units)])
178 except KeyError:
179 return ()
180 valid.remove(units)
181 return tuple(valid)
182
183
184 def is_valid_conversion(a, b) -> bool:
185 for dic in dicts.values():
186 if a in dic.keys() and b in dic.keys():
187 return True
188 if a is None and b is None:
189 return True
190 else:
191 return False
192
193
194 def kind(units):
195 """Find the kind of given units.
196
197 Parameters
198 ----------
199 units : string
200 The units of interest
201
202 Returns
203 -------
204 string
205 The kind of the given units. If no match is found, returns None.
206 """
207 for k, v in dicts.items():
208 if units in v.keys():
209 return k
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/WrightTools/units.py b/WrightTools/units.py
--- a/WrightTools/units.py
+++ b/WrightTools/units.py
@@ -5,9 +5,10 @@
import collections
+import warnings
import numpy as np
-import warnings
+import numexpr
# --- define --------------------------------------------------------------------------------------
@@ -20,7 +21,7 @@
angle = {"rad": ["x", "x", r"rad"], "deg": ["x/57.2958", "57.2958*x", r"deg"]}
# delay units (native: fs)
-fs_per_mm = 3336.
+fs_per_mm = 3336.0
delay = {
"fs": ["x", "x", r"fs"],
"ps": ["x*1e3", "x/1e3", r"ps"],
@@ -114,12 +115,12 @@
for dic in dicts.values():
if current_unit in dic.keys() and destination_unit in dic.keys():
try:
- native = eval(dic[current_unit][0])
+ native = numexpr.evaluate(dic[current_unit][0], {"x": x})
except ZeroDivisionError:
native = np.inf
x = native # noqa: F841
try:
- out = eval(dic[destination_unit][1])
+ out = numexpr.evaluate(dic[destination_unit][1], {"x": x})
except ZeroDivisionError:
out = np.inf
return out
|
{"golden_diff": "diff --git a/WrightTools/units.py b/WrightTools/units.py\n--- a/WrightTools/units.py\n+++ b/WrightTools/units.py\n@@ -5,9 +5,10 @@\n \n \n import collections\n+import warnings\n \n import numpy as np\n-import warnings\n+import numexpr\n \n \n # --- define --------------------------------------------------------------------------------------\n@@ -20,7 +21,7 @@\n angle = {\"rad\": [\"x\", \"x\", r\"rad\"], \"deg\": [\"x/57.2958\", \"57.2958*x\", r\"deg\"]}\n \n # delay units (native: fs)\n-fs_per_mm = 3336.\n+fs_per_mm = 3336.0\n delay = {\n \"fs\": [\"x\", \"x\", r\"fs\"],\n \"ps\": [\"x*1e3\", \"x/1e3\", r\"ps\"],\n@@ -114,12 +115,12 @@\n for dic in dicts.values():\n if current_unit in dic.keys() and destination_unit in dic.keys():\n try:\n- native = eval(dic[current_unit][0])\n+ native = numexpr.evaluate(dic[current_unit][0], {\"x\": x})\n except ZeroDivisionError:\n native = np.inf\n x = native # noqa: F841\n try:\n- out = eval(dic[destination_unit][1])\n+ out = numexpr.evaluate(dic[destination_unit][1], {\"x\": x})\n except ZeroDivisionError:\n out = np.inf\n return out\n", "issue": "consider using NumExpr as alternative to eval\nWithin the units library, we use eval.\r\n\r\nhttps://github.com/wright-group/WrightTools/blob/master/WrightTools/units.py#L96-L135\r\n\r\nWe could use NumExpr... our usage case seems to be exactly what the package was made for.\r\n\r\nhttps://numexpr.readthedocs.io/en/latest/user_guide.html\n", "before_files": [{"content": "\"\"\"Unit and label handling in WrightTools.\"\"\"\n\n\n# --- import --------------------------------------------------------------------------------------\n\n\nimport collections\n\nimport numpy as np\nimport warnings\n\n\n# --- define --------------------------------------------------------------------------------------\n\n\n# units are stored in dictionaries of like kind. format:\n# unit : to native, from native, units_symbol, units_label\n\n# angle units (native: rad)\nangle = {\"rad\": [\"x\", \"x\", r\"rad\"], \"deg\": [\"x/57.2958\", \"57.2958*x\", r\"deg\"]}\n\n# delay units (native: fs)\nfs_per_mm = 3336.\ndelay = {\n \"fs\": [\"x\", \"x\", r\"fs\"],\n \"ps\": [\"x*1e3\", \"x/1e3\", r\"ps\"],\n \"ns\": [\"x*1e6\", \"x/1e6\", r\"ns\"],\n \"mm_delay\": [\"x*2*fs_per_mm\", \"x/(2*fs_per_mm)\", r\"mm\"],\n}\n\n# energy units (native: nm)\nenergy = {\n \"nm\": [\"x\", \"x\", r\"nm\"],\n \"wn\": [\"1e7/x\", \"1e7/x\", r\"cm^{-1}\"],\n \"eV\": [\"1240./x\", \"1240./x\", r\"eV\"],\n \"meV\": [\"1240000./x\", \"1240000./x\", r\"meV\"],\n \"Hz\": [\"2.99792458e17/x\", \"2.99792458e17/x\", r\"Hz\"],\n \"THz\": [\"2.99792458e5/x\", \"2.99792458e5/x\", r\"THz\"],\n \"GHz\": [\"2.99792458e8/x\", \"2.99792458e8/x\", r\"GHz\"],\n}\n\n# fluence units (native: uJ per sq. cm)\nfluence = {\"uJ per sq. cm\": [\"x\", \"x\", r\"\\frac{\\mu J}{cm^{2}}\"]}\n\n# optical density units (native: od)\nod = {\"mOD\": [\"1e3*x\", \"x/1e3\", r\"mOD\"], \"OD\": [\"x\", \"x\", r\"OD\"]}\n\n# position units (native: mm)\nposition = {\n \"nm_p\": [\"x/1e6\", \"1e6*x\", r\"nm\"],\n \"um\": [\"x/1000.\", \"1000.*x\", r\"um\"],\n \"mm\": [\"x\", \"x\", r\"mm\"],\n \"cm\": [\"10.*x\", \"x/10.\", r\"cm\"],\n \"in\": [\"x*0.039370\", \"0.039370*x\", r\"in\"],\n}\n\n# pulse width units (native: FWHM)\npulse_width = {\"FWHM\": [\"x\", \"x\", r\"FWHM\"]}\n\n# temperature units (native: K)\ntemperature = {\n \"K\": [\"x\", \"x\", r\"K\"],\n \"deg_C\": [\"x+273.15\", \"x-273.15\", r\"^\\circ C\"],\n \"deg_F\": [\"(x+459.67)*5/9\", \"x*9/5-456.67\", r\"^\\circ F\"],\n \"deg_R\": [\"x*5/9\", \"x*9/5\", r\"^\\circ R\"],\n}\n\n# time units (native: s)\ntime = {\n \"fs_t\": [\"x/1e15\", \"x*1e15\", r\"fs\"],\n \"ps_t\": [\"x/1e12\", \"x*1e12\", r\"ps\"],\n \"ns_t\": [\"x/1e9\", \"x*1e9\", r\"ns\"],\n \"us_t\": [\"x/1e6\", \"x*1e6\", r\"us\"],\n \"ms_t\": [\"x/1000.\", \"x*1000.\", r\"ms\"],\n \"s_t\": [\"x\", \"x\", r\"s\"],\n \"m_t\": [\"x*60.\", \"x/60.\", r\"m\"],\n \"h_t\": [\"x*3600.\", \"x/3600.\", r\"h\"],\n \"d_t\": [\"x*86400.\", \"x/86400.\", r\"d\"],\n}\n\ndicts = collections.OrderedDict()\ndicts[\"angle\"] = angle\ndicts[\"delay\"] = delay\ndicts[\"energy\"] = energy\ndicts[\"time\"] = time\ndicts[\"position\"] = position\ndicts[\"pulse_width\"] = pulse_width\ndicts[\"fluence\"] = fluence\ndicts[\"od\"] = od\ndicts[\"temperature\"] = temperature\n\n\n# --- functions -----------------------------------------------------------------------------------\n\n\ndef converter(val, current_unit, destination_unit):\n \"\"\"Convert from one unit to another.\n\n Parameters\n ----------\n val : number\n Number to convert.\n current_unit : string\n Current unit.\n destination_unit : string\n Destination unit.\n\n Returns\n -------\n number\n Converted value.\n \"\"\"\n x = val\n for dic in dicts.values():\n if current_unit in dic.keys() and destination_unit in dic.keys():\n try:\n native = eval(dic[current_unit][0])\n except ZeroDivisionError:\n native = np.inf\n x = native # noqa: F841\n try:\n out = eval(dic[destination_unit][1])\n except ZeroDivisionError:\n out = np.inf\n return out\n # if all dictionaries fail\n if current_unit is None and destination_unit is None:\n pass\n else:\n warnings.warn(\n \"conversion {0} to {1} not valid: returning input\".format(\n current_unit, destination_unit\n )\n )\n return val\n\n\nconvert = converter\n\n\ndef get_symbol(units) -> str:\n \"\"\"Get default symbol type.\n\n Parameters\n ----------\n units_str : string\n Units.\n\n Returns\n -------\n string\n LaTeX formatted symbol.\n \"\"\"\n if kind(units) == \"energy\":\n d = {}\n d[\"nm\"] = r\"\\lambda\"\n d[\"wn\"] = r\"\\bar\\nu\"\n d[\"eV\"] = r\"\\hslash\\omega\"\n d[\"Hz\"] = r\"f\"\n d[\"THz\"] = r\"f\"\n d[\"GHz\"] = r\"f\"\n return d.get(units, \"E\")\n elif kind(units) == \"delay\":\n return r\"\\tau\"\n elif kind(units) == \"fluence\":\n return r\"\\mathcal{F}\"\n elif kind(units) == \"pulse_width\":\n return r\"\\sigma\"\n elif kind(units) == \"temperature\":\n return r\"T\"\n else:\n return kind(units)\n\n\ndef get_valid_conversions(units) -> tuple:\n try:\n valid = list(dicts[kind(units)])\n except KeyError:\n return ()\n valid.remove(units)\n return tuple(valid)\n\n\ndef is_valid_conversion(a, b) -> bool:\n for dic in dicts.values():\n if a in dic.keys() and b in dic.keys():\n return True\n if a is None and b is None:\n return True\n else:\n return False\n\n\ndef kind(units):\n \"\"\"Find the kind of given units.\n\n Parameters\n ----------\n units : string\n The units of interest\n\n Returns\n -------\n string\n The kind of the given units. If no match is found, returns None.\n \"\"\"\n for k, v in dicts.items():\n if units in v.keys():\n return k\n", "path": "WrightTools/units.py"}], "after_files": [{"content": "\"\"\"Unit and label handling in WrightTools.\"\"\"\n\n\n# --- import --------------------------------------------------------------------------------------\n\n\nimport collections\nimport warnings\n\nimport numpy as np\nimport numexpr\n\n\n# --- define --------------------------------------------------------------------------------------\n\n\n# units are stored in dictionaries of like kind. format:\n# unit : to native, from native, units_symbol, units_label\n\n# angle units (native: rad)\nangle = {\"rad\": [\"x\", \"x\", r\"rad\"], \"deg\": [\"x/57.2958\", \"57.2958*x\", r\"deg\"]}\n\n# delay units (native: fs)\nfs_per_mm = 3336.0\ndelay = {\n \"fs\": [\"x\", \"x\", r\"fs\"],\n \"ps\": [\"x*1e3\", \"x/1e3\", r\"ps\"],\n \"ns\": [\"x*1e6\", \"x/1e6\", r\"ns\"],\n \"mm_delay\": [\"x*2*fs_per_mm\", \"x/(2*fs_per_mm)\", r\"mm\"],\n}\n\n# energy units (native: nm)\nenergy = {\n \"nm\": [\"x\", \"x\", r\"nm\"],\n \"wn\": [\"1e7/x\", \"1e7/x\", r\"cm^{-1}\"],\n \"eV\": [\"1240./x\", \"1240./x\", r\"eV\"],\n \"meV\": [\"1240000./x\", \"1240000./x\", r\"meV\"],\n \"Hz\": [\"2.99792458e17/x\", \"2.99792458e17/x\", r\"Hz\"],\n \"THz\": [\"2.99792458e5/x\", \"2.99792458e5/x\", r\"THz\"],\n \"GHz\": [\"2.99792458e8/x\", \"2.99792458e8/x\", r\"GHz\"],\n}\n\n# fluence units (native: uJ per sq. cm)\nfluence = {\"uJ per sq. cm\": [\"x\", \"x\", r\"\\frac{\\mu J}{cm^{2}}\"]}\n\n# optical density units (native: od)\nod = {\"mOD\": [\"1e3*x\", \"x/1e3\", r\"mOD\"], \"OD\": [\"x\", \"x\", r\"OD\"]}\n\n# position units (native: mm)\nposition = {\n \"nm_p\": [\"x/1e6\", \"1e6*x\", r\"nm\"],\n \"um\": [\"x/1000.\", \"1000.*x\", r\"um\"],\n \"mm\": [\"x\", \"x\", r\"mm\"],\n \"cm\": [\"10.*x\", \"x/10.\", r\"cm\"],\n \"in\": [\"x*0.039370\", \"0.039370*x\", r\"in\"],\n}\n\n# pulse width units (native: FWHM)\npulse_width = {\"FWHM\": [\"x\", \"x\", r\"FWHM\"]}\n\n# temperature units (native: K)\ntemperature = {\n \"K\": [\"x\", \"x\", r\"K\"],\n \"deg_C\": [\"x+273.15\", \"x-273.15\", r\"^\\circ C\"],\n \"deg_F\": [\"(x+459.67)*5/9\", \"x*9/5-456.67\", r\"^\\circ F\"],\n \"deg_R\": [\"x*5/9\", \"x*9/5\", r\"^\\circ R\"],\n}\n\n# time units (native: s)\ntime = {\n \"fs_t\": [\"x/1e15\", \"x*1e15\", r\"fs\"],\n \"ps_t\": [\"x/1e12\", \"x*1e12\", r\"ps\"],\n \"ns_t\": [\"x/1e9\", \"x*1e9\", r\"ns\"],\n \"us_t\": [\"x/1e6\", \"x*1e6\", r\"us\"],\n \"ms_t\": [\"x/1000.\", \"x*1000.\", r\"ms\"],\n \"s_t\": [\"x\", \"x\", r\"s\"],\n \"m_t\": [\"x*60.\", \"x/60.\", r\"m\"],\n \"h_t\": [\"x*3600.\", \"x/3600.\", r\"h\"],\n \"d_t\": [\"x*86400.\", \"x/86400.\", r\"d\"],\n}\n\ndicts = collections.OrderedDict()\ndicts[\"angle\"] = angle\ndicts[\"delay\"] = delay\ndicts[\"energy\"] = energy\ndicts[\"time\"] = time\ndicts[\"position\"] = position\ndicts[\"pulse_width\"] = pulse_width\ndicts[\"fluence\"] = fluence\ndicts[\"od\"] = od\ndicts[\"temperature\"] = temperature\n\n\n# --- functions -----------------------------------------------------------------------------------\n\n\ndef converter(val, current_unit, destination_unit):\n \"\"\"Convert from one unit to another.\n\n Parameters\n ----------\n val : number\n Number to convert.\n current_unit : string\n Current unit.\n destination_unit : string\n Destination unit.\n\n Returns\n -------\n number\n Converted value.\n \"\"\"\n x = val\n for dic in dicts.values():\n if current_unit in dic.keys() and destination_unit in dic.keys():\n try:\n native = numexpr.evaluate(dic[current_unit][0], {\"x\": x})\n except ZeroDivisionError:\n native = np.inf\n x = native # noqa: F841\n try:\n out = numexpr.evaluate(dic[destination_unit][1], {\"x\": x})\n except ZeroDivisionError:\n out = np.inf\n return out\n # if all dictionaries fail\n if current_unit is None and destination_unit is None:\n pass\n else:\n warnings.warn(\n \"conversion {0} to {1} not valid: returning input\".format(\n current_unit, destination_unit\n )\n )\n return val\n\n\nconvert = converter\n\n\ndef get_symbol(units) -> str:\n \"\"\"Get default symbol type.\n\n Parameters\n ----------\n units_str : string\n Units.\n\n Returns\n -------\n string\n LaTeX formatted symbol.\n \"\"\"\n if kind(units) == \"energy\":\n d = {}\n d[\"nm\"] = r\"\\lambda\"\n d[\"wn\"] = r\"\\bar\\nu\"\n d[\"eV\"] = r\"\\hslash\\omega\"\n d[\"Hz\"] = r\"f\"\n d[\"THz\"] = r\"f\"\n d[\"GHz\"] = r\"f\"\n return d.get(units, \"E\")\n elif kind(units) == \"delay\":\n return r\"\\tau\"\n elif kind(units) == \"fluence\":\n return r\"\\mathcal{F}\"\n elif kind(units) == \"pulse_width\":\n return r\"\\sigma\"\n elif kind(units) == \"temperature\":\n return r\"T\"\n else:\n return kind(units)\n\n\ndef get_valid_conversions(units) -> tuple:\n try:\n valid = list(dicts[kind(units)])\n except KeyError:\n return ()\n valid.remove(units)\n return tuple(valid)\n\n\ndef is_valid_conversion(a, b) -> bool:\n for dic in dicts.values():\n if a in dic.keys() and b in dic.keys():\n return True\n if a is None and b is None:\n return True\n else:\n return False\n\n\ndef kind(units):\n \"\"\"Find the kind of given units.\n\n Parameters\n ----------\n units : string\n The units of interest\n\n Returns\n -------\n string\n The kind of the given units. If no match is found, returns None.\n \"\"\"\n for k, v in dicts.items():\n if units in v.keys():\n return k\n", "path": "WrightTools/units.py"}]}
| 2,601 | 346 |
gh_patches_debug_18101
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5569
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.pandalive: HTTP status 400 on API call
### Checklist
- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
streamlink 6.2.0
### Description
the livestreams can't resolved on pandalive
it was always resolved 400 Client Error
### Debug log
```text
C:\Users\Jerry>C:\APP\Streamlink\bin\streamlink.exe https://www.pandalive.co.kr/live/play/pocet00 --loglevel=debug
[session][debug] Plugin pandalive is being overridden by C:\Users\Jerry\AppData\Roaming\streamlink\plugins\pandalive.py
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.11.5
[cli][debug] OpenSSL: OpenSSL 3.0.9 30 May 2023
[cli][debug] Streamlink: 6.2.0
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.7.22
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.3
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.18.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.31.0
[cli][debug] trio: 0.22.2
[cli][debug] trio-websocket: 0.10.4
[cli][debug] typing-extensions: 4.7.1
[cli][debug] urllib3: 2.0.4
[cli][debug] websocket-client: 1.6.3
[cli][debug] Arguments:
[cli][debug] url=https://www.pandalive.co.kr/live/play/pocet00
[cli][debug] --loglevel=debug
[cli][debug] --ffmpeg-ffmpeg=C:\APP\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin pandalive for URL https://www.pandalive.co.kr/live/play/pocet00
[plugins.pandalive][debug] Media code: pocet00
error: Unable to open URL: https://api.pandalive.co.kr/v1/live/play (400 Client Error: Bad Request for url: https://api.pandalive.co.kr/v1/live/play)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/pandalive.py`
Content:
```
1 """
2 $description South Korean live-streaming platform for individual live streams.
3 $url pandalive.co.kr
4 $type live
5 $metadata author
6 $metadata title
7 """
8
9 import logging
10 import re
11
12 from streamlink.plugin import Plugin, pluginmatcher
13 from streamlink.plugin.api import validate
14 from streamlink.stream.hls import HLSStream
15
16
17 log = logging.getLogger(__name__)
18
19
20 @pluginmatcher(re.compile(
21 r"https?://(?:www\.)?pandalive\.co\.kr/",
22 ))
23 class Pandalive(Plugin):
24 def _get_streams(self):
25 media_code = self.session.http.get(self.url, schema=validate.Schema(
26 re.compile(r"""routePath:\s*(?P<q>["'])(\\u002F|/)live(\\u002F|/)play(\\u002F|/)(?P<id>.+?)(?P=q)"""),
27 validate.any(None, validate.get("id")),
28 ))
29
30 if not media_code:
31 return
32
33 log.debug(f"Media code: {media_code}")
34
35 json = self.session.http.post(
36 "https://api.pandalive.co.kr/v1/live/play",
37 data={
38 "action": "watch",
39 "userId": media_code,
40 },
41 schema=validate.Schema(
42 validate.parse_json(),
43 validate.any(
44 {
45 "media": {
46 "title": str,
47 "userId": str,
48 "userNick": str,
49 "isPw": bool,
50 "isLive": bool,
51 "liveType": str,
52 },
53 "PlayList": {
54 validate.optional("hls"): [{
55 "url": validate.url(),
56 }],
57 validate.optional("hls2"): [{
58 "url": validate.url(),
59 }],
60 validate.optional("hls3"): [{
61 "url": validate.url(),
62 }],
63 },
64 "result": bool,
65 "message": str,
66 },
67 {
68 "result": bool,
69 "message": str,
70 },
71 ),
72 ),
73 )
74
75 if not json["result"]:
76 log.error(json["message"])
77 return
78
79 if not json["media"]["isLive"]:
80 log.error("The broadcast has ended")
81 return
82
83 if json["media"]["isPw"]:
84 log.error("The broadcast is password protected")
85 return
86
87 log.info(f"Broadcast type: {json['media']['liveType']}")
88
89 self.author = f"{json['media']['userNick']} ({json['media']['userId']})"
90 self.title = f"{json['media']['title']}"
91
92 playlist = json["PlayList"]
93 for key in ("hls", "hls2", "hls3"):
94 # use the first available HLS stream
95 if key in playlist and playlist[key]:
96 # all stream qualities share the same URL, so just use the first one
97 return HLSStream.parse_variant_playlist(self.session, playlist[key][0]["url"])
98
99
100 __plugin__ = Pandalive
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/pandalive.py b/src/streamlink/plugins/pandalive.py
--- a/src/streamlink/plugins/pandalive.py
+++ b/src/streamlink/plugins/pandalive.py
@@ -18,7 +18,7 @@
@pluginmatcher(re.compile(
- r"https?://(?:www\.)?pandalive\.co\.kr/",
+ r"https?://(?:www\.)?pandalive\.co\.kr/live/play/[^/]+",
))
class Pandalive(Plugin):
def _get_streams(self):
@@ -34,10 +34,14 @@
json = self.session.http.post(
"https://api.pandalive.co.kr/v1/live/play",
+ headers={
+ "Referer": self.url,
+ },
data={
"action": "watch",
"userId": media_code,
},
+ acceptable_status=(200, 400),
schema=validate.Schema(
validate.parse_json(),
validate.any(
|
{"golden_diff": "diff --git a/src/streamlink/plugins/pandalive.py b/src/streamlink/plugins/pandalive.py\n--- a/src/streamlink/plugins/pandalive.py\n+++ b/src/streamlink/plugins/pandalive.py\n@@ -18,7 +18,7 @@\n \n \n @pluginmatcher(re.compile(\n- r\"https?://(?:www\\.)?pandalive\\.co\\.kr/\",\n+ r\"https?://(?:www\\.)?pandalive\\.co\\.kr/live/play/[^/]+\",\n ))\n class Pandalive(Plugin):\n def _get_streams(self):\n@@ -34,10 +34,14 @@\n \n json = self.session.http.post(\n \"https://api.pandalive.co.kr/v1/live/play\",\n+ headers={\n+ \"Referer\": self.url,\n+ },\n data={\n \"action\": \"watch\",\n \"userId\": media_code,\n },\n+ acceptable_status=(200, 400),\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n", "issue": "plugins.pandalive: HTTP status 400 on API call\n### Checklist\n\n- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nstreamlink 6.2.0\n\n### Description\n\nthe livestreams can't resolved on pandalive\r\nit was always resolved 400 Client Error \n\n### Debug log\n\n```text\nC:\\Users\\Jerry>C:\\APP\\Streamlink\\bin\\streamlink.exe https://www.pandalive.co.kr/live/play/pocet00 --loglevel=debug\r\n[session][debug] Plugin pandalive is being overridden by C:\\Users\\Jerry\\AppData\\Roaming\\streamlink\\plugins\\pandalive.py\r\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.11.5\r\n[cli][debug] OpenSSL: OpenSSL 3.0.9 30 May 2023\r\n[cli][debug] Streamlink: 6.2.0\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.7.22\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.3\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.18.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.31.0\r\n[cli][debug] trio: 0.22.2\r\n[cli][debug] trio-websocket: 0.10.4\r\n[cli][debug] typing-extensions: 4.7.1\r\n[cli][debug] urllib3: 2.0.4\r\n[cli][debug] websocket-client: 1.6.3\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.pandalive.co.kr/live/play/pocet00\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\APP\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin pandalive for URL https://www.pandalive.co.kr/live/play/pocet00\r\n[plugins.pandalive][debug] Media code: pocet00\r\nerror: Unable to open URL: https://api.pandalive.co.kr/v1/live/play (400 Client Error: Bad Request for url: https://api.pandalive.co.kr/v1/live/play)\n```\n\n", "before_files": [{"content": "\"\"\"\n$description South Korean live-streaming platform for individual live streams.\n$url pandalive.co.kr\n$type live\n$metadata author\n$metadata title\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?pandalive\\.co\\.kr/\",\n))\nclass Pandalive(Plugin):\n def _get_streams(self):\n media_code = self.session.http.get(self.url, schema=validate.Schema(\n re.compile(r\"\"\"routePath:\\s*(?P<q>[\"'])(\\\\u002F|/)live(\\\\u002F|/)play(\\\\u002F|/)(?P<id>.+?)(?P=q)\"\"\"),\n validate.any(None, validate.get(\"id\")),\n ))\n\n if not media_code:\n return\n\n log.debug(f\"Media code: {media_code}\")\n\n json = self.session.http.post(\n \"https://api.pandalive.co.kr/v1/live/play\",\n data={\n \"action\": \"watch\",\n \"userId\": media_code,\n },\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"media\": {\n \"title\": str,\n \"userId\": str,\n \"userNick\": str,\n \"isPw\": bool,\n \"isLive\": bool,\n \"liveType\": str,\n },\n \"PlayList\": {\n validate.optional(\"hls\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls2\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls3\"): [{\n \"url\": validate.url(),\n }],\n },\n \"result\": bool,\n \"message\": str,\n },\n {\n \"result\": bool,\n \"message\": str,\n },\n ),\n ),\n )\n\n if not json[\"result\"]:\n log.error(json[\"message\"])\n return\n\n if not json[\"media\"][\"isLive\"]:\n log.error(\"The broadcast has ended\")\n return\n\n if json[\"media\"][\"isPw\"]:\n log.error(\"The broadcast is password protected\")\n return\n\n log.info(f\"Broadcast type: {json['media']['liveType']}\")\n\n self.author = f\"{json['media']['userNick']} ({json['media']['userId']})\"\n self.title = f\"{json['media']['title']}\"\n\n playlist = json[\"PlayList\"]\n for key in (\"hls\", \"hls2\", \"hls3\"):\n # use the first available HLS stream\n if key in playlist and playlist[key]:\n # all stream qualities share the same URL, so just use the first one\n return HLSStream.parse_variant_playlist(self.session, playlist[key][0][\"url\"])\n\n\n__plugin__ = Pandalive\n", "path": "src/streamlink/plugins/pandalive.py"}], "after_files": [{"content": "\"\"\"\n$description South Korean live-streaming platform for individual live streams.\n$url pandalive.co.kr\n$type live\n$metadata author\n$metadata title\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?pandalive\\.co\\.kr/live/play/[^/]+\",\n))\nclass Pandalive(Plugin):\n def _get_streams(self):\n media_code = self.session.http.get(self.url, schema=validate.Schema(\n re.compile(r\"\"\"routePath:\\s*(?P<q>[\"'])(\\\\u002F|/)live(\\\\u002F|/)play(\\\\u002F|/)(?P<id>.+?)(?P=q)\"\"\"),\n validate.any(None, validate.get(\"id\")),\n ))\n\n if not media_code:\n return\n\n log.debug(f\"Media code: {media_code}\")\n\n json = self.session.http.post(\n \"https://api.pandalive.co.kr/v1/live/play\",\n headers={\n \"Referer\": self.url,\n },\n data={\n \"action\": \"watch\",\n \"userId\": media_code,\n },\n acceptable_status=(200, 400),\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"media\": {\n \"title\": str,\n \"userId\": str,\n \"userNick\": str,\n \"isPw\": bool,\n \"isLive\": bool,\n \"liveType\": str,\n },\n \"PlayList\": {\n validate.optional(\"hls\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls2\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls3\"): [{\n \"url\": validate.url(),\n }],\n },\n \"result\": bool,\n \"message\": str,\n },\n {\n \"result\": bool,\n \"message\": str,\n },\n ),\n ),\n )\n\n if not json[\"result\"]:\n log.error(json[\"message\"])\n return\n\n if not json[\"media\"][\"isLive\"]:\n log.error(\"The broadcast has ended\")\n return\n\n if json[\"media\"][\"isPw\"]:\n log.error(\"The broadcast is password protected\")\n return\n\n log.info(f\"Broadcast type: {json['media']['liveType']}\")\n\n self.author = f\"{json['media']['userNick']} ({json['media']['userId']})\"\n self.title = f\"{json['media']['title']}\"\n\n playlist = json[\"PlayList\"]\n for key in (\"hls\", \"hls2\", \"hls3\"):\n # use the first available HLS stream\n if key in playlist and playlist[key]:\n # all stream qualities share the same URL, so just use the first one\n return HLSStream.parse_variant_playlist(self.session, playlist[key][0][\"url\"])\n\n\n__plugin__ = Pandalive\n", "path": "src/streamlink/plugins/pandalive.py"}]}
| 1,823 | 224 |
gh_patches_debug_7999
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-4116
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: UserWarning when passing `FeatureService` object to both `apply()` and `get_online_features()` - Caused by difference in `FeatureViewProjection.from_proto()` and `FeatureViewProjection.from_definition()`
## Context
If a `FeatureService` object is created and is being passed to both the `apply()` and the `get_online_features()` method, the following user warning is thrown:
```
UserWarning: The FeatureService object that has been passed in as an argument is inconsistent with the version from the registry. Potentially a newer version of the FeatureService has been applied to the registry.
```
This is caused by a bug in the creation/retrieval of `feature_view_projections`, which is an attribute of `FeatureService`. An empty string is set to the `name_alias` value of `FeatureViewProjection` when calling [`from_proto`](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_view_projection.py#L52-L64). However, when creating the `FeatureViewProjection` by creating a `FeatureService` object (using the default value) `name_alias` is set to `None`, because it is created with [`FeatureViewProjection.from_definition()`](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_view_projection.py#L66-L73).
The warning is raised [here](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_store.py#L532-L541), because the `feature_service_from_registry` has the empty string value for the underlying `FeatureViewProjection.name_alias` object, while the for `_features` the underlying `FeatureViewProjection.name_alias` is valued `None`.
## Expected Behavior
I would expect that if a `FeatureViewProjection` encapsulated within a `FeatureService` has a `None` value for the `name_alias` attribute when being stored in the feature store, that it would also load with the same `None` value when calling `FeatureViewProjection.from_proto()`.
Then the comparison should also not fail, and the warning should not be thrown.
## Current Behavior
The `FeatureViewProjection` is loaded with an empty string for the value `name_alias` when `FeatureViewProjection.from_proto()` is called.
This causes the. comparison to fail, and the warning to be thrown.
## Steps to reproduce
docker-compose.yml
```
---
version: "3"
services:
db:
restart: always
image: postgres:16-alpine
container_name: feast_db
ports:
- "5432:5432"
environment:
- POSTGRES_DB=feature_store
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=test
```
feature_store.yaml
```
project: project_name
provider: local
registry:
registry_type: sql
path: postgresql://postgres:[email protected]:5432/feature_store
```
Python script
```
from datetime import timedelta
import pandas as pd
from feast import (
Entity,
FeatureService,
FeatureStore,
FeatureView,
Field,
SnowflakeSource,
ValueType,
)
from feast.types import Float32
feature_store = FeatureStore()
# Apply
entity = Entity(
name="entity",
join_keys=["ID"],
value_type=ValueType.STRING,
)
source = SnowflakeSource(
name="source_snowflake",
timestamp_field="EVENT_TIMESTAMP",
schema="TEMP",
table="FEAST_FEATURES",
)
feature_view = FeatureView(
name="feature_view__v1",
entities=[entity],
ttl=timedelta(days=0),
schema=[
Field(name="FEATURE", dtype=Float32),
],
online=True,
source=source,
)
feature_service = FeatureService(
name="feature_service__v1",
features=[feature_view],
)
feature_store.apply(
[
entity,
source,
feature_view,
feature_service,
]
)
# Inference
entity_rows = [{"ID": "ID1"}, {"ID": "ID2"}]
entity_df = pd.DataFrame(entity_rows)
entity_df["event_timestamp"] = pd.to_datetime("now", utc=True)
online_features = feature_store.get_online_features(
entity_rows=entity_rows,
features=feature_service,
).to_dict()
print(online_features)
```
### Specifications
Using postgres registry.
- Version: 0.36.0
- Platform: MacOS - M1
- Subsystem: Sonoma 14.1.1
## Possible Solution
I have little to no experience with proto, so I'm not sure whether it would be possible to load the None value directly from the proto definition.
One potential solution would be to check whether an empty string is loaded for this field when loading from proto, and then set it to None in the `from_proto` function.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/feature_view_projection.py`
Content:
```
1 from typing import TYPE_CHECKING, Dict, List, Optional
2
3 from attr import dataclass
4
5 from feast.field import Field
6 from feast.protos.feast.core.FeatureViewProjection_pb2 import (
7 FeatureViewProjection as FeatureViewProjectionProto,
8 )
9
10 if TYPE_CHECKING:
11 from feast.base_feature_view import BaseFeatureView
12
13
14 @dataclass
15 class FeatureViewProjection:
16 """
17 A feature view projection represents a selection of one or more features from a
18 single feature view.
19
20 Attributes:
21 name: The unique name of the feature view from which this projection is created.
22 name_alias: An optional alias for the name.
23 features: The list of features represented by the feature view projection.
24 desired_features: The list of features that this feature view projection intends to select.
25 If empty, the projection intends to select all features. This attribute is only used
26 for feature service inference. It should only be set if the underlying feature view
27 is not ready to be projected, i.e. still needs to go through feature inference.
28 join_key_map: A map to modify join key columns during retrieval of this feature
29 view projection.
30 """
31
32 name: str
33 name_alias: Optional[str]
34 desired_features: List[str]
35 features: List[Field]
36 join_key_map: Dict[str, str] = {}
37
38 def name_to_use(self):
39 return self.name_alias or self.name
40
41 def to_proto(self) -> FeatureViewProjectionProto:
42 feature_reference_proto = FeatureViewProjectionProto(
43 feature_view_name=self.name,
44 feature_view_name_alias=self.name_alias or "",
45 join_key_map=self.join_key_map,
46 )
47 for feature in self.features:
48 feature_reference_proto.feature_columns.append(feature.to_proto())
49
50 return feature_reference_proto
51
52 @staticmethod
53 def from_proto(proto: FeatureViewProjectionProto):
54 feature_view_projection = FeatureViewProjection(
55 name=proto.feature_view_name,
56 name_alias=proto.feature_view_name_alias,
57 features=[],
58 join_key_map=dict(proto.join_key_map),
59 desired_features=[],
60 )
61 for feature_column in proto.feature_columns:
62 feature_view_projection.features.append(Field.from_proto(feature_column))
63
64 return feature_view_projection
65
66 @staticmethod
67 def from_definition(base_feature_view: "BaseFeatureView"):
68 return FeatureViewProjection(
69 name=base_feature_view.name,
70 name_alias=None,
71 features=base_feature_view.features,
72 desired_features=[],
73 )
74
75 def get_feature(self, feature_name: str) -> Field:
76 try:
77 return next(field for field in self.features if field.name == feature_name)
78 except StopIteration:
79 raise KeyError(
80 f"Feature {feature_name} not found in projection {self.name_to_use()}"
81 )
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/feast/feature_view_projection.py b/sdk/python/feast/feature_view_projection.py
--- a/sdk/python/feast/feature_view_projection.py
+++ b/sdk/python/feast/feature_view_projection.py
@@ -53,7 +53,7 @@
def from_proto(proto: FeatureViewProjectionProto):
feature_view_projection = FeatureViewProjection(
name=proto.feature_view_name,
- name_alias=proto.feature_view_name_alias,
+ name_alias=proto.feature_view_name_alias or None,
features=[],
join_key_map=dict(proto.join_key_map),
desired_features=[],
|
{"golden_diff": "diff --git a/sdk/python/feast/feature_view_projection.py b/sdk/python/feast/feature_view_projection.py\n--- a/sdk/python/feast/feature_view_projection.py\n+++ b/sdk/python/feast/feature_view_projection.py\n@@ -53,7 +53,7 @@\n def from_proto(proto: FeatureViewProjectionProto):\n feature_view_projection = FeatureViewProjection(\n name=proto.feature_view_name,\n- name_alias=proto.feature_view_name_alias,\n+ name_alias=proto.feature_view_name_alias or None,\n features=[],\n join_key_map=dict(proto.join_key_map),\n desired_features=[],\n", "issue": "Bug: UserWarning when passing `FeatureService` object to both `apply()` and `get_online_features()` - Caused by difference in `FeatureViewProjection.from_proto()` and `FeatureViewProjection.from_definition()`\n## Context\r\n\r\nIf a `FeatureService` object is created and is being passed to both the `apply()` and the `get_online_features()` method, the following user warning is thrown: \r\n\r\n```\r\nUserWarning: The FeatureService object that has been passed in as an argument is inconsistent with the version from the registry. Potentially a newer version of the FeatureService has been applied to the registry.\r\n```\r\n\r\nThis is caused by a bug in the creation/retrieval of `feature_view_projections`, which is an attribute of `FeatureService`. An empty string is set to the `name_alias` value of `FeatureViewProjection` when calling [`from_proto`](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_view_projection.py#L52-L64). However, when creating the `FeatureViewProjection` by creating a `FeatureService` object (using the default value) `name_alias` is set to `None`, because it is created with [`FeatureViewProjection.from_definition()`](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_view_projection.py#L66-L73).\r\n\r\nThe warning is raised [here](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_store.py#L532-L541), because the `feature_service_from_registry` has the empty string value for the underlying `FeatureViewProjection.name_alias` object, while the for `_features` the underlying `FeatureViewProjection.name_alias` is valued `None`.\r\n\r\n## Expected Behavior\r\n\r\nI would expect that if a `FeatureViewProjection` encapsulated within a `FeatureService` has a `None` value for the `name_alias` attribute when being stored in the feature store, that it would also load with the same `None` value when calling `FeatureViewProjection.from_proto()`.\r\n\r\nThen the comparison should also not fail, and the warning should not be thrown.\r\n\r\n## Current Behavior\r\n\r\nThe `FeatureViewProjection` is loaded with an empty string for the value `name_alias` when `FeatureViewProjection.from_proto()` is called. \r\n\r\nThis causes the. comparison to fail, and the warning to be thrown. \r\n\r\n## Steps to reproduce\r\n\r\ndocker-compose.yml\r\n```\r\n---\r\nversion: \"3\"\r\nservices:\r\n db:\r\n restart: always\r\n image: postgres:16-alpine\r\n container_name: feast_db\r\n ports:\r\n - \"5432:5432\"\r\n environment:\r\n - POSTGRES_DB=feature_store\r\n - POSTGRES_USER=postgres\r\n - POSTGRES_PASSWORD=test\r\n```\r\n\r\nfeature_store.yaml\r\n```\r\nproject: project_name\r\nprovider: local\r\nregistry:\r\n registry_type: sql\r\n path: postgresql://postgres:[email protected]:5432/feature_store\r\n```\r\n\r\nPython script\r\n```\r\nfrom datetime import timedelta\r\n\r\nimport pandas as pd\r\nfrom feast import (\r\n Entity,\r\n FeatureService,\r\n FeatureStore,\r\n FeatureView,\r\n Field,\r\n SnowflakeSource,\r\n ValueType,\r\n)\r\nfrom feast.types import Float32\r\n\r\nfeature_store = FeatureStore()\r\n\r\n# Apply\r\nentity = Entity(\r\n name=\"entity\",\r\n join_keys=[\"ID\"],\r\n value_type=ValueType.STRING,\r\n)\r\n\r\nsource = SnowflakeSource(\r\n name=\"source_snowflake\",\r\n timestamp_field=\"EVENT_TIMESTAMP\",\r\n schema=\"TEMP\",\r\n table=\"FEAST_FEATURES\",\r\n)\r\n\r\nfeature_view = FeatureView(\r\n name=\"feature_view__v1\",\r\n entities=[entity],\r\n ttl=timedelta(days=0),\r\n schema=[\r\n Field(name=\"FEATURE\", dtype=Float32),\r\n ],\r\n online=True,\r\n source=source,\r\n)\r\n\r\nfeature_service = FeatureService(\r\n name=\"feature_service__v1\",\r\n features=[feature_view],\r\n)\r\n\r\nfeature_store.apply(\r\n [\r\n entity,\r\n source,\r\n feature_view,\r\n feature_service,\r\n ]\r\n)\r\n\r\n# Inference\r\nentity_rows = [{\"ID\": \"ID1\"}, {\"ID\": \"ID2\"}]\r\nentity_df = pd.DataFrame(entity_rows)\r\nentity_df[\"event_timestamp\"] = pd.to_datetime(\"now\", utc=True)\r\n\r\nonline_features = feature_store.get_online_features(\r\n entity_rows=entity_rows,\r\n features=feature_service,\r\n).to_dict()\r\n\r\nprint(online_features)\r\n```\r\n\r\n### Specifications\r\n\r\nUsing postgres registry. \r\n\r\n- Version: 0.36.0\r\n- Platform: MacOS - M1\r\n- Subsystem: Sonoma 14.1.1\r\n\r\n## Possible Solution\r\n\r\nI have little to no experience with proto, so I'm not sure whether it would be possible to load the None value directly from the proto definition.\r\n\r\nOne potential solution would be to check whether an empty string is loaded for this field when loading from proto, and then set it to None in the `from_proto` function. \r\n\n", "before_files": [{"content": "from typing import TYPE_CHECKING, Dict, List, Optional\n\nfrom attr import dataclass\n\nfrom feast.field import Field\nfrom feast.protos.feast.core.FeatureViewProjection_pb2 import (\n FeatureViewProjection as FeatureViewProjectionProto,\n)\n\nif TYPE_CHECKING:\n from feast.base_feature_view import BaseFeatureView\n\n\n@dataclass\nclass FeatureViewProjection:\n \"\"\"\n A feature view projection represents a selection of one or more features from a\n single feature view.\n\n Attributes:\n name: The unique name of the feature view from which this projection is created.\n name_alias: An optional alias for the name.\n features: The list of features represented by the feature view projection.\n desired_features: The list of features that this feature view projection intends to select.\n If empty, the projection intends to select all features. This attribute is only used\n for feature service inference. It should only be set if the underlying feature view\n is not ready to be projected, i.e. still needs to go through feature inference.\n join_key_map: A map to modify join key columns during retrieval of this feature\n view projection.\n \"\"\"\n\n name: str\n name_alias: Optional[str]\n desired_features: List[str]\n features: List[Field]\n join_key_map: Dict[str, str] = {}\n\n def name_to_use(self):\n return self.name_alias or self.name\n\n def to_proto(self) -> FeatureViewProjectionProto:\n feature_reference_proto = FeatureViewProjectionProto(\n feature_view_name=self.name,\n feature_view_name_alias=self.name_alias or \"\",\n join_key_map=self.join_key_map,\n )\n for feature in self.features:\n feature_reference_proto.feature_columns.append(feature.to_proto())\n\n return feature_reference_proto\n\n @staticmethod\n def from_proto(proto: FeatureViewProjectionProto):\n feature_view_projection = FeatureViewProjection(\n name=proto.feature_view_name,\n name_alias=proto.feature_view_name_alias,\n features=[],\n join_key_map=dict(proto.join_key_map),\n desired_features=[],\n )\n for feature_column in proto.feature_columns:\n feature_view_projection.features.append(Field.from_proto(feature_column))\n\n return feature_view_projection\n\n @staticmethod\n def from_definition(base_feature_view: \"BaseFeatureView\"):\n return FeatureViewProjection(\n name=base_feature_view.name,\n name_alias=None,\n features=base_feature_view.features,\n desired_features=[],\n )\n\n def get_feature(self, feature_name: str) -> Field:\n try:\n return next(field for field in self.features if field.name == feature_name)\n except StopIteration:\n raise KeyError(\n f\"Feature {feature_name} not found in projection {self.name_to_use()}\"\n )\n", "path": "sdk/python/feast/feature_view_projection.py"}], "after_files": [{"content": "from typing import TYPE_CHECKING, Dict, List, Optional\n\nfrom attr import dataclass\n\nfrom feast.field import Field\nfrom feast.protos.feast.core.FeatureViewProjection_pb2 import (\n FeatureViewProjection as FeatureViewProjectionProto,\n)\n\nif TYPE_CHECKING:\n from feast.base_feature_view import BaseFeatureView\n\n\n@dataclass\nclass FeatureViewProjection:\n \"\"\"\n A feature view projection represents a selection of one or more features from a\n single feature view.\n\n Attributes:\n name: The unique name of the feature view from which this projection is created.\n name_alias: An optional alias for the name.\n features: The list of features represented by the feature view projection.\n desired_features: The list of features that this feature view projection intends to select.\n If empty, the projection intends to select all features. This attribute is only used\n for feature service inference. It should only be set if the underlying feature view\n is not ready to be projected, i.e. still needs to go through feature inference.\n join_key_map: A map to modify join key columns during retrieval of this feature\n view projection.\n \"\"\"\n\n name: str\n name_alias: Optional[str]\n desired_features: List[str]\n features: List[Field]\n join_key_map: Dict[str, str] = {}\n\n def name_to_use(self):\n return self.name_alias or self.name\n\n def to_proto(self) -> FeatureViewProjectionProto:\n feature_reference_proto = FeatureViewProjectionProto(\n feature_view_name=self.name,\n feature_view_name_alias=self.name_alias or \"\",\n join_key_map=self.join_key_map,\n )\n for feature in self.features:\n feature_reference_proto.feature_columns.append(feature.to_proto())\n\n return feature_reference_proto\n\n @staticmethod\n def from_proto(proto: FeatureViewProjectionProto):\n feature_view_projection = FeatureViewProjection(\n name=proto.feature_view_name,\n name_alias=proto.feature_view_name_alias or None,\n features=[],\n join_key_map=dict(proto.join_key_map),\n desired_features=[],\n )\n for feature_column in proto.feature_columns:\n feature_view_projection.features.append(Field.from_proto(feature_column))\n\n return feature_view_projection\n\n @staticmethod\n def from_definition(base_feature_view: \"BaseFeatureView\"):\n return FeatureViewProjection(\n name=base_feature_view.name,\n name_alias=None,\n features=base_feature_view.features,\n desired_features=[],\n )\n\n def get_feature(self, feature_name: str) -> Field:\n try:\n return next(field for field in self.features if field.name == feature_name)\n except StopIteration:\n raise KeyError(\n f\"Feature {feature_name} not found in projection {self.name_to_use()}\"\n )\n", "path": "sdk/python/feast/feature_view_projection.py"}]}
| 2,064 | 135 |
gh_patches_debug_41518
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2373
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nine: Lutris can't find Nine libraries
A lot of changed before creating PR #2092 and merging it - biggest issue is commit 792c22176eff9e063b22d7b9700e2e9b79a11fae, which changes return val of iter_lib_folders() from lists to strings. I believe I used iter_lib_folders() in #2092 because I needed distinguish between lib32 and lib64 paths. I will take a look at this and try to fix it ASAP (this week).
Original report:
https://github.com/lutris/lutris/pull/2092#issuecomment-529362315
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/util/wine/nine.py`
Content:
```
1 """Gallium Nine helper module"""
2 import os
3 import shutil
4
5 from lutris.util import system
6 from lutris.runners.commands.wine import wineexec
7
8 class NineUnavailable(RuntimeError):
9 """Exception raised when Gallium Nine is not available"""
10
11 class NineManager:
12 """Utility class to install and manage Gallium Nine to a Wine prefix"""
13
14 nine_files = ("d3d9-nine.dll", "ninewinecfg.exe")
15 mesa_files = ("d3dadapter9.so.1",)
16
17 def __init__(self, prefix, arch):
18 self.prefix = prefix
19 self.wine_arch = arch
20
21 @staticmethod
22 def nine_is_supported():
23 """Check if MESA is built with Gallium Nine state tracker support
24
25 basic check for presence of d3dadapter9 library in 'd3d' subdirectory
26 of system library directory
27 """
28 for mesa_file in NineManager.mesa_files:
29 if not any([os.path.exists(os.path.join(lib[0], "d3d", mesa_file))
30 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
31 return False
32
33 if system.LINUX_SYSTEM.is_64_bit:
34 if not any([os.path.exists(os.path.join(lib[1], "d3d", mesa_file))
35 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
36 return False
37
38 return True
39
40 @staticmethod
41 def nine_is_installed():
42 """Check if Gallium Nine standalone is installed on this system
43
44 check 'wine/fakedlls' subdirectory of system library directory for Nine binaries
45 """
46 for nine_file in NineManager.nine_files:
47 if not any([os.path.exists(os.path.join(lib[0], "wine/fakedlls", nine_file))
48 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
49 return False
50
51 if system.LINUX_SYSTEM.is_64_bit:
52 if not any([os.path.exists(os.path.join(lib[1], "wine/fakedlls", nine_file))
53 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
54 return False
55
56 return True
57
58 @staticmethod
59 def is_available():
60 """Check if Gallium Nine can be enabled on this system"""
61 return NineManager.nine_is_supported() and NineManager.nine_is_installed()
62
63 def get_system_path(self, arch):
64 """Return path of Windows system directory with binaries of chosen architecture"""
65 windows_path = os.path.join(self.prefix, "drive_c/windows")
66
67 if self.wine_arch == "win32" and arch == "x32":
68 return os.path.join(windows_path, "system32")
69 if self.wine_arch == "win64" and arch == "x32":
70 return os.path.join(windows_path, "syswow64")
71 if self.wine_arch == "win64" and arch == "x64":
72 return os.path.join(windows_path, "system32")
73
74 return None
75
76 def is_prefix_prepared(self):
77 if not all(system.path_exists(os.path.join(self.get_system_path("x32"), nine_file))
78 for nine_file in self.nine_files):
79 return False
80
81 if self.wine_arch == "win64":
82 if not all(system.path_exists(os.path.join(self.get_system_path("x64"), nine_file))
83 for nine_file in self.nine_files):
84 return False
85
86 return True
87
88 def prepare_prefix(self):
89 for nine_file in NineManager.nine_files:
90 for lib in system.LINUX_SYSTEM.iter_lib_folders():
91 nine_file_32 = os.path.join(lib[0], "wine/fakedlls", nine_file)
92 if os.path.exists(nine_file_32):
93 shutil.copy(nine_file_32, self.get_system_path("x32"))
94
95 if self.wine_arch == "win64":
96 nine_file_64 = os.path.join(lib[1], "wine/fakedlls", nine_file)
97 if os.path.exists(nine_file_64):
98 shutil.copy(nine_file_64, self.get_system_path("x64"))
99
100 def enable(self):
101 if not self.nine_is_supported():
102 raise NineUnavailable("Nine is not supported on this system")
103 if not self.nine_is_installed():
104 raise NineUnavailable("Nine Standalone is not installed")
105 if not self.is_prefix_prepared():
106 self.prepare_prefix()
107
108 wineexec(
109 "ninewinecfg",
110 args="-e",
111 prefix=self.prefix,
112 blocking=True,
113 )
114
115 def disable(self):
116 if self.is_prefix_prepared():
117 wineexec(
118 "ninewinecfg",
119 args="-d",
120 prefix=self.prefix,
121 blocking=True,
122 )
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/util/wine/nine.py b/lutris/util/wine/nine.py
--- a/lutris/util/wine/nine.py
+++ b/lutris/util/wine/nine.py
@@ -4,6 +4,7 @@
from lutris.util import system
from lutris.runners.commands.wine import wineexec
+from lutris.util.wine.cabinstall import CabInstaller
class NineUnavailable(RuntimeError):
"""Exception raised when Gallium Nine is not available"""
@@ -26,15 +27,10 @@
of system library directory
"""
for mesa_file in NineManager.mesa_files:
- if not any([os.path.exists(os.path.join(lib[0], "d3d", mesa_file))
+ if not any([os.path.exists(os.path.join(lib, "d3d", mesa_file))
for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
return False
- if system.LINUX_SYSTEM.is_64_bit:
- if not any([os.path.exists(os.path.join(lib[1], "d3d", mesa_file))
- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
- return False
-
return True
@staticmethod
@@ -44,15 +40,10 @@
check 'wine/fakedlls' subdirectory of system library directory for Nine binaries
"""
for nine_file in NineManager.nine_files:
- if not any([os.path.exists(os.path.join(lib[0], "wine/fakedlls", nine_file))
+ if not any([os.path.exists(os.path.join(lib, "wine/fakedlls", nine_file))
for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
return False
- if system.LINUX_SYSTEM.is_64_bit:
- if not any([os.path.exists(os.path.join(lib[1], "wine/fakedlls", nine_file))
- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
- return False
-
return True
@staticmethod
@@ -88,15 +79,24 @@
def prepare_prefix(self):
for nine_file in NineManager.nine_files:
for lib in system.LINUX_SYSTEM.iter_lib_folders():
- nine_file_32 = os.path.join(lib[0], "wine/fakedlls", nine_file)
- if os.path.exists(nine_file_32):
- shutil.copy(nine_file_32, self.get_system_path("x32"))
+ nine_file_path = os.path.join(lib, "wine/fakedlls", nine_file)
+
+ if (os.path.exists(nine_file_path) and
+ CabInstaller.get_arch_from_dll(nine_file_path) == "win32"):
+ shutil.copy(nine_file_path, self.get_system_path("x32"))
if self.wine_arch == "win64":
- nine_file_64 = os.path.join(lib[1], "wine/fakedlls", nine_file)
- if os.path.exists(nine_file_64):
+ if (os.path.exists(nine_file_path) and
+ CabInstaller.get_arch_from_dll(nine_file_path) == "win64"):
shutil.copy(nine_file_64, self.get_system_path("x64"))
+ if not os.path.exists(os.path.join(self.get_system_path("x32"), nine_file)):
+ raise NineUnavailable("could not install " + nine_file + " (x32)")
+
+ if self.wine_arch == "win64":
+ if not os.path.exists(os.path.join(self.get_system_path("x64"), nine_file)):
+ raise NineUnavailable("could not install " + nine_file + " (x64)")
+
def enable(self):
if not self.nine_is_supported():
raise NineUnavailable("Nine is not supported on this system")
|
{"golden_diff": "diff --git a/lutris/util/wine/nine.py b/lutris/util/wine/nine.py\n--- a/lutris/util/wine/nine.py\n+++ b/lutris/util/wine/nine.py\n@@ -4,6 +4,7 @@\n \n from lutris.util import system\n from lutris.runners.commands.wine import wineexec\n+from lutris.util.wine.cabinstall import CabInstaller\n \n class NineUnavailable(RuntimeError):\n \"\"\"Exception raised when Gallium Nine is not available\"\"\"\n@@ -26,15 +27,10 @@\n of system library directory\n \"\"\"\n for mesa_file in NineManager.mesa_files:\n- if not any([os.path.exists(os.path.join(lib[0], \"d3d\", mesa_file))\n+ if not any([os.path.exists(os.path.join(lib, \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n \n- if system.LINUX_SYSTEM.is_64_bit:\n- if not any([os.path.exists(os.path.join(lib[1], \"d3d\", mesa_file))\n- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n- return False\n-\n return True\n \n @staticmethod\n@@ -44,15 +40,10 @@\n check 'wine/fakedlls' subdirectory of system library directory for Nine binaries\n \"\"\"\n for nine_file in NineManager.nine_files:\n- if not any([os.path.exists(os.path.join(lib[0], \"wine/fakedlls\", nine_file))\n+ if not any([os.path.exists(os.path.join(lib, \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n \n- if system.LINUX_SYSTEM.is_64_bit:\n- if not any([os.path.exists(os.path.join(lib[1], \"wine/fakedlls\", nine_file))\n- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n- return False\n-\n return True\n \n @staticmethod\n@@ -88,15 +79,24 @@\n def prepare_prefix(self):\n for nine_file in NineManager.nine_files:\n for lib in system.LINUX_SYSTEM.iter_lib_folders():\n- nine_file_32 = os.path.join(lib[0], \"wine/fakedlls\", nine_file)\n- if os.path.exists(nine_file_32):\n- shutil.copy(nine_file_32, self.get_system_path(\"x32\"))\n+ nine_file_path = os.path.join(lib, \"wine/fakedlls\", nine_file)\n+\n+ if (os.path.exists(nine_file_path) and\n+ CabInstaller.get_arch_from_dll(nine_file_path) == \"win32\"):\n+ shutil.copy(nine_file_path, self.get_system_path(\"x32\"))\n \n if self.wine_arch == \"win64\":\n- nine_file_64 = os.path.join(lib[1], \"wine/fakedlls\", nine_file)\n- if os.path.exists(nine_file_64):\n+ if (os.path.exists(nine_file_path) and\n+ CabInstaller.get_arch_from_dll(nine_file_path) == \"win64\"):\n shutil.copy(nine_file_64, self.get_system_path(\"x64\"))\n \n+ if not os.path.exists(os.path.join(self.get_system_path(\"x32\"), nine_file)):\n+ raise NineUnavailable(\"could not install \" + nine_file + \" (x32)\")\n+\n+ if self.wine_arch == \"win64\":\n+ if not os.path.exists(os.path.join(self.get_system_path(\"x64\"), nine_file)):\n+ raise NineUnavailable(\"could not install \" + nine_file + \" (x64)\")\n+\n def enable(self):\n if not self.nine_is_supported():\n raise NineUnavailable(\"Nine is not supported on this system\")\n", "issue": "Nine: Lutris can't find Nine libraries\nA lot of changed before creating PR #2092 and merging it - biggest issue is commit 792c22176eff9e063b22d7b9700e2e9b79a11fae, which changes return val of iter_lib_folders() from lists to strings. I believe I used iter_lib_folders() in #2092 because I needed distinguish between lib32 and lib64 paths. I will take a look at this and try to fix it ASAP (this week).\r\n\r\nOriginal report:\r\nhttps://github.com/lutris/lutris/pull/2092#issuecomment-529362315\n", "before_files": [{"content": "\"\"\"Gallium Nine helper module\"\"\"\nimport os\nimport shutil\n\nfrom lutris.util import system\nfrom lutris.runners.commands.wine import wineexec\n\nclass NineUnavailable(RuntimeError):\n \"\"\"Exception raised when Gallium Nine is not available\"\"\"\n\nclass NineManager:\n \"\"\"Utility class to install and manage Gallium Nine to a Wine prefix\"\"\"\n\n nine_files = (\"d3d9-nine.dll\", \"ninewinecfg.exe\")\n mesa_files = (\"d3dadapter9.so.1\",)\n\n def __init__(self, prefix, arch):\n self.prefix = prefix\n self.wine_arch = arch\n\n @staticmethod\n def nine_is_supported():\n \"\"\"Check if MESA is built with Gallium Nine state tracker support\n\n basic check for presence of d3dadapter9 library in 'd3d' subdirectory\n of system library directory\n \"\"\"\n for mesa_file in NineManager.mesa_files:\n if not any([os.path.exists(os.path.join(lib[0], \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n if system.LINUX_SYSTEM.is_64_bit:\n if not any([os.path.exists(os.path.join(lib[1], \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def nine_is_installed():\n \"\"\"Check if Gallium Nine standalone is installed on this system\n\n check 'wine/fakedlls' subdirectory of system library directory for Nine binaries\n \"\"\"\n for nine_file in NineManager.nine_files:\n if not any([os.path.exists(os.path.join(lib[0], \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n if system.LINUX_SYSTEM.is_64_bit:\n if not any([os.path.exists(os.path.join(lib[1], \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def is_available():\n \"\"\"Check if Gallium Nine can be enabled on this system\"\"\"\n return NineManager.nine_is_supported() and NineManager.nine_is_installed()\n\n def get_system_path(self, arch):\n \"\"\"Return path of Windows system directory with binaries of chosen architecture\"\"\"\n windows_path = os.path.join(self.prefix, \"drive_c/windows\")\n\n if self.wine_arch == \"win32\" and arch == \"x32\":\n return os.path.join(windows_path, \"system32\")\n if self.wine_arch == \"win64\" and arch == \"x32\":\n return os.path.join(windows_path, \"syswow64\")\n if self.wine_arch == \"win64\" and arch == \"x64\":\n return os.path.join(windows_path, \"system32\")\n\n return None\n\n def is_prefix_prepared(self):\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x32\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n if self.wine_arch == \"win64\":\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x64\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n return True\n\n def prepare_prefix(self):\n for nine_file in NineManager.nine_files:\n for lib in system.LINUX_SYSTEM.iter_lib_folders():\n nine_file_32 = os.path.join(lib[0], \"wine/fakedlls\", nine_file)\n if os.path.exists(nine_file_32):\n shutil.copy(nine_file_32, self.get_system_path(\"x32\"))\n\n if self.wine_arch == \"win64\":\n nine_file_64 = os.path.join(lib[1], \"wine/fakedlls\", nine_file)\n if os.path.exists(nine_file_64):\n shutil.copy(nine_file_64, self.get_system_path(\"x64\"))\n\n def enable(self):\n if not self.nine_is_supported():\n raise NineUnavailable(\"Nine is not supported on this system\")\n if not self.nine_is_installed():\n raise NineUnavailable(\"Nine Standalone is not installed\")\n if not self.is_prefix_prepared():\n self.prepare_prefix()\n\n wineexec(\n \"ninewinecfg\",\n args=\"-e\",\n prefix=self.prefix,\n blocking=True,\n )\n\n def disable(self):\n if self.is_prefix_prepared():\n wineexec(\n \"ninewinecfg\",\n args=\"-d\",\n prefix=self.prefix,\n blocking=True,\n )\n", "path": "lutris/util/wine/nine.py"}], "after_files": [{"content": "\"\"\"Gallium Nine helper module\"\"\"\nimport os\nimport shutil\n\nfrom lutris.util import system\nfrom lutris.runners.commands.wine import wineexec\nfrom lutris.util.wine.cabinstall import CabInstaller\n\nclass NineUnavailable(RuntimeError):\n \"\"\"Exception raised when Gallium Nine is not available\"\"\"\n\nclass NineManager:\n \"\"\"Utility class to install and manage Gallium Nine to a Wine prefix\"\"\"\n\n nine_files = (\"d3d9-nine.dll\", \"ninewinecfg.exe\")\n mesa_files = (\"d3dadapter9.so.1\",)\n\n def __init__(self, prefix, arch):\n self.prefix = prefix\n self.wine_arch = arch\n\n @staticmethod\n def nine_is_supported():\n \"\"\"Check if MESA is built with Gallium Nine state tracker support\n\n basic check for presence of d3dadapter9 library in 'd3d' subdirectory\n of system library directory\n \"\"\"\n for mesa_file in NineManager.mesa_files:\n if not any([os.path.exists(os.path.join(lib, \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def nine_is_installed():\n \"\"\"Check if Gallium Nine standalone is installed on this system\n\n check 'wine/fakedlls' subdirectory of system library directory for Nine binaries\n \"\"\"\n for nine_file in NineManager.nine_files:\n if not any([os.path.exists(os.path.join(lib, \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def is_available():\n \"\"\"Check if Gallium Nine can be enabled on this system\"\"\"\n return NineManager.nine_is_supported() and NineManager.nine_is_installed()\n\n def get_system_path(self, arch):\n \"\"\"Return path of Windows system directory with binaries of chosen architecture\"\"\"\n windows_path = os.path.join(self.prefix, \"drive_c/windows\")\n\n if self.wine_arch == \"win32\" and arch == \"x32\":\n return os.path.join(windows_path, \"system32\")\n if self.wine_arch == \"win64\" and arch == \"x32\":\n return os.path.join(windows_path, \"syswow64\")\n if self.wine_arch == \"win64\" and arch == \"x64\":\n return os.path.join(windows_path, \"system32\")\n\n return None\n\n def is_prefix_prepared(self):\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x32\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n if self.wine_arch == \"win64\":\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x64\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n return True\n\n def prepare_prefix(self):\n for nine_file in NineManager.nine_files:\n for lib in system.LINUX_SYSTEM.iter_lib_folders():\n nine_file_path = os.path.join(lib, \"wine/fakedlls\", nine_file)\n\n if (os.path.exists(nine_file_path) and\n CabInstaller.get_arch_from_dll(nine_file_path) == \"win32\"):\n shutil.copy(nine_file_path, self.get_system_path(\"x32\"))\n\n if self.wine_arch == \"win64\":\n if (os.path.exists(nine_file_path) and\n CabInstaller.get_arch_from_dll(nine_file_path) == \"win64\"):\n shutil.copy(nine_file_64, self.get_system_path(\"x64\"))\n\n if not os.path.exists(os.path.join(self.get_system_path(\"x32\"), nine_file)):\n raise NineUnavailable(\"could not install \" + nine_file + \" (x32)\")\n\n if self.wine_arch == \"win64\":\n if not os.path.exists(os.path.join(self.get_system_path(\"x64\"), nine_file)):\n raise NineUnavailable(\"could not install \" + nine_file + \" (x64)\")\n\n def enable(self):\n if not self.nine_is_supported():\n raise NineUnavailable(\"Nine is not supported on this system\")\n if not self.nine_is_installed():\n raise NineUnavailable(\"Nine Standalone is not installed\")\n if not self.is_prefix_prepared():\n self.prepare_prefix()\n\n wineexec(\n \"ninewinecfg\",\n args=\"-e\",\n prefix=self.prefix,\n blocking=True,\n )\n\n def disable(self):\n if self.is_prefix_prepared():\n wineexec(\n \"ninewinecfg\",\n args=\"-d\",\n prefix=self.prefix,\n blocking=True,\n )\n", "path": "lutris/util/wine/nine.py"}]}
| 1,720 | 854 |
gh_patches_debug_39823
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-971
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't unset crs metadata values
Using the cli:
```bash
# crs is defined
$ rio info tests/data/alpha.tif | jq '.crs'
"EPSG:3857"
# attempt to unset crs
$ rio edit-info tests/data/alpha.tif --crs ""
# but
$ rio info tests/data/alpha.tif | jq '.crs'
"EPSG:3857"
```
Per @perrygeo - the python version of this is simple:
```python
import rasterio
from rasterio.crs import CRS
raster = 'test/prep_test/de_hamburg_custom_srs/fixtures/dop20c_32587_5922.tif'
with rasterio.open(raster, 'r+') as src:
src.crs = CRS()
```
Reminds me of https://github.com/mapbox/rasterio/issues/328.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rasterio/rio/edit_info.py`
Content:
```
1 """Fetch and edit raster dataset metadata from the command line."""
2
3
4 import json
5
6 import click
7
8 import rasterio
9 import rasterio.crs
10 from rasterio.compat import string_types
11 from rasterio.crs import CRS
12 from rasterio.errors import CRSError
13 from rasterio.rio import options
14 from rasterio.transform import guard_transform
15
16
17 # Handlers for info module options.
18
19 def all_handler(ctx, param, value):
20 """Get tags from a template file or command line."""
21 if ctx.obj and ctx.obj.get('like') and value is not None:
22 ctx.obj['all_like'] = value
23 value = ctx.obj.get('like')
24 return value
25
26
27 def crs_handler(ctx, param, value):
28 """Get crs value from a template file or command line."""
29 retval = options.from_like_context(ctx, param, value)
30 if retval is None and value:
31 try:
32 retval = json.loads(value)
33 except ValueError:
34 retval = value
35 try:
36 if isinstance(retval, dict):
37 retval = CRS(retval)
38 else:
39 retval = CRS.from_string(retval)
40 except CRSError:
41 raise click.BadParameter(
42 "'%s' is not a recognized CRS." % retval,
43 param=param, param_hint='crs')
44 return retval
45
46
47 def tags_handler(ctx, param, value):
48 """Get tags from a template file or command line."""
49 retval = options.from_like_context(ctx, param, value)
50 if retval is None and value:
51 try:
52 retval = dict(p.split('=') for p in value)
53 except:
54 raise click.BadParameter(
55 "'%s' contains a malformed tag." % value,
56 param=param, param_hint='transform')
57 return retval
58
59
60 def transform_handler(ctx, param, value):
61 """Get transform value from a template file or command line."""
62 retval = options.from_like_context(ctx, param, value)
63 if retval is None and value:
64 try:
65 value = json.loads(value)
66 except ValueError:
67 pass
68 try:
69 retval = guard_transform(value)
70 except:
71 raise click.BadParameter(
72 "'%s' is not recognized as an Affine array." % value,
73 param=param, param_hint='transform')
74 return retval
75
76
77 @click.command('edit-info', short_help="Edit dataset metadata.")
78 @options.file_in_arg
79 @options.bidx_opt
80 @options.edit_nodata_opt
81 @click.option('--unset-nodata', default=False, is_flag=True,
82 help="Unset the dataset's nodata value.")
83 @click.option('--crs', callback=crs_handler, default=None,
84 help="New coordinate reference system")
85 @click.option('--transform', callback=transform_handler,
86 help="New affine transform matrix")
87 @click.option('--units', help="Edit units of a band (requires --bidx)")
88 @click.option('--description',
89 help="Edit description of a band (requires --bidx)")
90 @click.option('--tag', 'tags', callback=tags_handler, multiple=True,
91 metavar='KEY=VAL', help="New tag.")
92 @click.option('--all', 'allmd', callback=all_handler, flag_value='like',
93 is_eager=True, default=False,
94 help="Copy all metadata items from the template file.")
95 @options.like_opt
96 @click.pass_context
97 def edit(ctx, input, bidx, nodata, unset_nodata, crs, transform, units,
98 description, tags, allmd, like):
99 """Edit a dataset's metadata: coordinate reference system, affine
100 transformation matrix, nodata value, and tags.
101
102 The coordinate reference system may be either a PROJ.4 or EPSG:nnnn
103 string,
104
105 --crs 'EPSG:4326'
106
107 or a JSON text-encoded PROJ.4 object.
108
109 --crs '{"proj": "utm", "zone": 18, ...}'
110
111 Transforms are JSON-encoded Affine objects like:
112
113 --transform '[300.038, 0.0, 101985.0, 0.0, -300.042, 2826915.0]'
114
115 Prior to Rasterio 1.0 GDAL geotransforms were supported for --transform,
116 but are no longer supported.
117
118 Metadata items may also be read from an existing dataset using a
119 combination of the --like option with at least one of --all,
120 `--crs like`, `--nodata like`, and `--transform like`.
121
122 rio edit-info example.tif --like template.tif --all
123
124 To get just the transform from the template:
125
126 rio edit-info example.tif --like template.tif --transform like
127
128 """
129 import numpy as np
130
131 def in_dtype_range(value, dtype):
132 infos = {'c': np.finfo, 'f': np.finfo, 'i': np.iinfo,
133 'u': np.iinfo}
134 rng = infos[np.dtype(dtype).kind](dtype)
135 return rng.min <= value <= rng.max
136
137 with ctx.obj['env'], rasterio.open(input, 'r+') as dst:
138
139 if allmd:
140 nodata = allmd['nodata']
141 crs = allmd['crs']
142 transform = allmd['transform']
143 tags = allmd['tags']
144
145 if unset_nodata and nodata is not options.IgnoreOption:
146 raise click.BadParameter(
147 "--unset-nodata and --nodata cannot be used together.")
148
149 if unset_nodata:
150 # Setting nodata to None will raise NotImplementedError
151 # if GDALDeleteRasterNoDataValue() isn't present in the
152 # GDAL library.
153 try:
154 dst.nodata = None
155 except NotImplementedError as exc: # pragma: no cover
156 raise click.ClickException(str(exc))
157
158 elif nodata is not options.IgnoreOption:
159 dtype = dst.dtypes[0]
160 if nodata is not None and not in_dtype_range(nodata, dtype):
161 raise click.BadParameter(
162 "outside the range of the file's "
163 "data type (%s)." % dtype,
164 param=nodata, param_hint='nodata')
165 dst.nodata = nodata
166
167 if crs:
168 dst.crs = crs
169
170 if transform:
171 dst.transform = transform
172
173 if tags:
174 dst.update_tags(**tags)
175
176 if units:
177 dst.set_units(bidx, units)
178
179 if description:
180 dst.set_description(bidx, description)
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rasterio/rio/edit_info.py b/rasterio/rio/edit_info.py
--- a/rasterio/rio/edit_info.py
+++ b/rasterio/rio/edit_info.py
@@ -2,12 +2,12 @@
import json
+import warnings
import click
import rasterio
import rasterio.crs
-from rasterio.compat import string_types
from rasterio.crs import CRS
from rasterio.errors import CRSError
from rasterio.rio import options
@@ -82,6 +82,8 @@
help="Unset the dataset's nodata value.")
@click.option('--crs', callback=crs_handler, default=None,
help="New coordinate reference system")
[email protected]('--unset-crs', default=False, is_flag=True,
+ help="Unset the dataset's CRS value.")
@click.option('--transform', callback=transform_handler,
help="New affine transform matrix")
@click.option('--units', help="Edit units of a band (requires --bidx)")
@@ -94,8 +96,8 @@
help="Copy all metadata items from the template file.")
@options.like_opt
@click.pass_context
-def edit(ctx, input, bidx, nodata, unset_nodata, crs, transform, units,
- description, tags, allmd, like):
+def edit(ctx, input, bidx, nodata, unset_nodata, crs, unset_crs, transform,
+ units, description, tags, allmd, like):
"""Edit a dataset's metadata: coordinate reference system, affine
transformation matrix, nodata value, and tags.
@@ -146,6 +148,10 @@
raise click.BadParameter(
"--unset-nodata and --nodata cannot be used together.")
+ if unset_crs and crs:
+ raise click.BadParameter(
+ "--unset-crs and --crs cannot be used together.")
+
if unset_nodata:
# Setting nodata to None will raise NotImplementedError
# if GDALDeleteRasterNoDataValue() isn't present in the
@@ -164,7 +170,9 @@
param=nodata, param_hint='nodata')
dst.nodata = nodata
- if crs:
+ if unset_crs:
+ dst.crs = CRS()
+ elif crs:
dst.crs = crs
if transform:
@@ -178,3 +186,11 @@
if description:
dst.set_description(bidx, description)
+
+ # Post check - ensure that crs was unset properly
+ if unset_crs:
+ with ctx.obj['env'], rasterio.open(input, 'r') as src:
+ if dict(src.crs) != {}:
+ warnings.warn(
+ 'CRS was not unset. Availability of his functionality '
+ 'differs depending on GDAL version and driver')
|
{"golden_diff": "diff --git a/rasterio/rio/edit_info.py b/rasterio/rio/edit_info.py\n--- a/rasterio/rio/edit_info.py\n+++ b/rasterio/rio/edit_info.py\n@@ -2,12 +2,12 @@\n \n \n import json\n+import warnings\n \n import click\n \n import rasterio\n import rasterio.crs\n-from rasterio.compat import string_types\n from rasterio.crs import CRS\n from rasterio.errors import CRSError\n from rasterio.rio import options\n@@ -82,6 +82,8 @@\n help=\"Unset the dataset's nodata value.\")\n @click.option('--crs', callback=crs_handler, default=None,\n help=\"New coordinate reference system\")\[email protected]('--unset-crs', default=False, is_flag=True,\n+ help=\"Unset the dataset's CRS value.\")\n @click.option('--transform', callback=transform_handler,\n help=\"New affine transform matrix\")\n @click.option('--units', help=\"Edit units of a band (requires --bidx)\")\n@@ -94,8 +96,8 @@\n help=\"Copy all metadata items from the template file.\")\n @options.like_opt\n @click.pass_context\n-def edit(ctx, input, bidx, nodata, unset_nodata, crs, transform, units,\n- description, tags, allmd, like):\n+def edit(ctx, input, bidx, nodata, unset_nodata, crs, unset_crs, transform,\n+ units, description, tags, allmd, like):\n \"\"\"Edit a dataset's metadata: coordinate reference system, affine\n transformation matrix, nodata value, and tags.\n \n@@ -146,6 +148,10 @@\n raise click.BadParameter(\n \"--unset-nodata and --nodata cannot be used together.\")\n \n+ if unset_crs and crs:\n+ raise click.BadParameter(\n+ \"--unset-crs and --crs cannot be used together.\")\n+\n if unset_nodata:\n # Setting nodata to None will raise NotImplementedError\n # if GDALDeleteRasterNoDataValue() isn't present in the\n@@ -164,7 +170,9 @@\n param=nodata, param_hint='nodata')\n dst.nodata = nodata\n \n- if crs:\n+ if unset_crs:\n+ dst.crs = CRS()\n+ elif crs:\n dst.crs = crs\n \n if transform:\n@@ -178,3 +186,11 @@\n \n if description:\n dst.set_description(bidx, description)\n+\n+ # Post check - ensure that crs was unset properly\n+ if unset_crs:\n+ with ctx.obj['env'], rasterio.open(input, 'r') as src:\n+ if dict(src.crs) != {}:\n+ warnings.warn(\n+ 'CRS was not unset. Availability of his functionality '\n+ 'differs depending on GDAL version and driver')\n", "issue": "Can't unset crs metadata values\nUsing the cli:\r\n```bash\r\n# crs is defined\r\n$ rio info tests/data/alpha.tif | jq '.crs'\r\n\"EPSG:3857\"\r\n\r\n# attempt to unset crs\r\n$ rio edit-info tests/data/alpha.tif --crs \"\"\r\n\r\n# but\r\n$ rio info tests/data/alpha.tif | jq '.crs'\r\n\"EPSG:3857\"\r\n```\r\n\r\nPer @perrygeo - the python version of this is simple:\r\n```python\r\nimport rasterio\r\nfrom rasterio.crs import CRS\r\n\r\nraster = 'test/prep_test/de_hamburg_custom_srs/fixtures/dop20c_32587_5922.tif'\r\n\r\nwith rasterio.open(raster, 'r+') as src:\r\n src.crs = CRS()\r\n```\r\n\r\nReminds me of https://github.com/mapbox/rasterio/issues/328.\n", "before_files": [{"content": "\"\"\"Fetch and edit raster dataset metadata from the command line.\"\"\"\n\n\nimport json\n\nimport click\n\nimport rasterio\nimport rasterio.crs\nfrom rasterio.compat import string_types\nfrom rasterio.crs import CRS\nfrom rasterio.errors import CRSError\nfrom rasterio.rio import options\nfrom rasterio.transform import guard_transform\n\n\n# Handlers for info module options.\n\ndef all_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n if ctx.obj and ctx.obj.get('like') and value is not None:\n ctx.obj['all_like'] = value\n value = ctx.obj.get('like')\n return value\n\n\ndef crs_handler(ctx, param, value):\n \"\"\"Get crs value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = json.loads(value)\n except ValueError:\n retval = value\n try:\n if isinstance(retval, dict):\n retval = CRS(retval)\n else:\n retval = CRS.from_string(retval)\n except CRSError:\n raise click.BadParameter(\n \"'%s' is not a recognized CRS.\" % retval,\n param=param, param_hint='crs')\n return retval\n\n\ndef tags_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = dict(p.split('=') for p in value)\n except:\n raise click.BadParameter(\n \"'%s' contains a malformed tag.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\ndef transform_handler(ctx, param, value):\n \"\"\"Get transform value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n value = json.loads(value)\n except ValueError:\n pass\n try:\n retval = guard_transform(value)\n except:\n raise click.BadParameter(\n \"'%s' is not recognized as an Affine array.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\[email protected]('edit-info', short_help=\"Edit dataset metadata.\")\[email protected]_in_arg\[email protected]_opt\[email protected]_nodata_opt\[email protected]('--unset-nodata', default=False, is_flag=True,\n help=\"Unset the dataset's nodata value.\")\[email protected]('--crs', callback=crs_handler, default=None,\n help=\"New coordinate reference system\")\[email protected]('--transform', callback=transform_handler,\n help=\"New affine transform matrix\")\[email protected]('--units', help=\"Edit units of a band (requires --bidx)\")\[email protected]('--description',\n help=\"Edit description of a band (requires --bidx)\")\[email protected]('--tag', 'tags', callback=tags_handler, multiple=True,\n metavar='KEY=VAL', help=\"New tag.\")\[email protected]('--all', 'allmd', callback=all_handler, flag_value='like',\n is_eager=True, default=False,\n help=\"Copy all metadata items from the template file.\")\[email protected]_opt\[email protected]_context\ndef edit(ctx, input, bidx, nodata, unset_nodata, crs, transform, units,\n description, tags, allmd, like):\n \"\"\"Edit a dataset's metadata: coordinate reference system, affine\n transformation matrix, nodata value, and tags.\n\n The coordinate reference system may be either a PROJ.4 or EPSG:nnnn\n string,\n\n --crs 'EPSG:4326'\n\n or a JSON text-encoded PROJ.4 object.\n\n --crs '{\"proj\": \"utm\", \"zone\": 18, ...}'\n\n Transforms are JSON-encoded Affine objects like:\n\n --transform '[300.038, 0.0, 101985.0, 0.0, -300.042, 2826915.0]'\n\n Prior to Rasterio 1.0 GDAL geotransforms were supported for --transform,\n but are no longer supported.\n\n Metadata items may also be read from an existing dataset using a\n combination of the --like option with at least one of --all,\n `--crs like`, `--nodata like`, and `--transform like`.\n\n rio edit-info example.tif --like template.tif --all\n\n To get just the transform from the template:\n\n rio edit-info example.tif --like template.tif --transform like\n\n \"\"\"\n import numpy as np\n\n def in_dtype_range(value, dtype):\n infos = {'c': np.finfo, 'f': np.finfo, 'i': np.iinfo,\n 'u': np.iinfo}\n rng = infos[np.dtype(dtype).kind](dtype)\n return rng.min <= value <= rng.max\n\n with ctx.obj['env'], rasterio.open(input, 'r+') as dst:\n\n if allmd:\n nodata = allmd['nodata']\n crs = allmd['crs']\n transform = allmd['transform']\n tags = allmd['tags']\n\n if unset_nodata and nodata is not options.IgnoreOption:\n raise click.BadParameter(\n \"--unset-nodata and --nodata cannot be used together.\")\n\n if unset_nodata:\n # Setting nodata to None will raise NotImplementedError\n # if GDALDeleteRasterNoDataValue() isn't present in the\n # GDAL library.\n try:\n dst.nodata = None\n except NotImplementedError as exc: # pragma: no cover\n raise click.ClickException(str(exc))\n\n elif nodata is not options.IgnoreOption:\n dtype = dst.dtypes[0]\n if nodata is not None and not in_dtype_range(nodata, dtype):\n raise click.BadParameter(\n \"outside the range of the file's \"\n \"data type (%s).\" % dtype,\n param=nodata, param_hint='nodata')\n dst.nodata = nodata\n\n if crs:\n dst.crs = crs\n\n if transform:\n dst.transform = transform\n\n if tags:\n dst.update_tags(**tags)\n\n if units:\n dst.set_units(bidx, units)\n\n if description:\n dst.set_description(bidx, description)\n", "path": "rasterio/rio/edit_info.py"}], "after_files": [{"content": "\"\"\"Fetch and edit raster dataset metadata from the command line.\"\"\"\n\n\nimport json\nimport warnings\n\nimport click\n\nimport rasterio\nimport rasterio.crs\nfrom rasterio.crs import CRS\nfrom rasterio.errors import CRSError\nfrom rasterio.rio import options\nfrom rasterio.transform import guard_transform\n\n\n# Handlers for info module options.\n\ndef all_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n if ctx.obj and ctx.obj.get('like') and value is not None:\n ctx.obj['all_like'] = value\n value = ctx.obj.get('like')\n return value\n\n\ndef crs_handler(ctx, param, value):\n \"\"\"Get crs value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = json.loads(value)\n except ValueError:\n retval = value\n try:\n if isinstance(retval, dict):\n retval = CRS(retval)\n else:\n retval = CRS.from_string(retval)\n except CRSError:\n raise click.BadParameter(\n \"'%s' is not a recognized CRS.\" % retval,\n param=param, param_hint='crs')\n return retval\n\n\ndef tags_handler(ctx, param, value):\n \"\"\"Get tags from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n retval = dict(p.split('=') for p in value)\n except:\n raise click.BadParameter(\n \"'%s' contains a malformed tag.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\ndef transform_handler(ctx, param, value):\n \"\"\"Get transform value from a template file or command line.\"\"\"\n retval = options.from_like_context(ctx, param, value)\n if retval is None and value:\n try:\n value = json.loads(value)\n except ValueError:\n pass\n try:\n retval = guard_transform(value)\n except:\n raise click.BadParameter(\n \"'%s' is not recognized as an Affine array.\" % value,\n param=param, param_hint='transform')\n return retval\n\n\[email protected]('edit-info', short_help=\"Edit dataset metadata.\")\[email protected]_in_arg\[email protected]_opt\[email protected]_nodata_opt\[email protected]('--unset-nodata', default=False, is_flag=True,\n help=\"Unset the dataset's nodata value.\")\[email protected]('--crs', callback=crs_handler, default=None,\n help=\"New coordinate reference system\")\[email protected]('--unset-crs', default=False, is_flag=True,\n help=\"Unset the dataset's CRS value.\")\[email protected]('--transform', callback=transform_handler,\n help=\"New affine transform matrix\")\[email protected]('--units', help=\"Edit units of a band (requires --bidx)\")\[email protected]('--description',\n help=\"Edit description of a band (requires --bidx)\")\[email protected]('--tag', 'tags', callback=tags_handler, multiple=True,\n metavar='KEY=VAL', help=\"New tag.\")\[email protected]('--all', 'allmd', callback=all_handler, flag_value='like',\n is_eager=True, default=False,\n help=\"Copy all metadata items from the template file.\")\[email protected]_opt\[email protected]_context\ndef edit(ctx, input, bidx, nodata, unset_nodata, crs, unset_crs, transform,\n units, description, tags, allmd, like):\n \"\"\"Edit a dataset's metadata: coordinate reference system, affine\n transformation matrix, nodata value, and tags.\n\n The coordinate reference system may be either a PROJ.4 or EPSG:nnnn\n string,\n\n --crs 'EPSG:4326'\n\n or a JSON text-encoded PROJ.4 object.\n\n --crs '{\"proj\": \"utm\", \"zone\": 18, ...}'\n\n Transforms are JSON-encoded Affine objects like:\n\n --transform '[300.038, 0.0, 101985.0, 0.0, -300.042, 2826915.0]'\n\n Prior to Rasterio 1.0 GDAL geotransforms were supported for --transform,\n but are no longer supported.\n\n Metadata items may also be read from an existing dataset using a\n combination of the --like option with at least one of --all,\n `--crs like`, `--nodata like`, and `--transform like`.\n\n rio edit-info example.tif --like template.tif --all\n\n To get just the transform from the template:\n\n rio edit-info example.tif --like template.tif --transform like\n\n \"\"\"\n import numpy as np\n\n def in_dtype_range(value, dtype):\n infos = {'c': np.finfo, 'f': np.finfo, 'i': np.iinfo,\n 'u': np.iinfo}\n rng = infos[np.dtype(dtype).kind](dtype)\n return rng.min <= value <= rng.max\n\n with ctx.obj['env'], rasterio.open(input, 'r+') as dst:\n\n if allmd:\n nodata = allmd['nodata']\n crs = allmd['crs']\n transform = allmd['transform']\n tags = allmd['tags']\n\n if unset_nodata and nodata is not options.IgnoreOption:\n raise click.BadParameter(\n \"--unset-nodata and --nodata cannot be used together.\")\n\n if unset_crs and crs:\n raise click.BadParameter(\n \"--unset-crs and --crs cannot be used together.\")\n\n if unset_nodata:\n # Setting nodata to None will raise NotImplementedError\n # if GDALDeleteRasterNoDataValue() isn't present in the\n # GDAL library.\n try:\n dst.nodata = None\n except NotImplementedError as exc: # pragma: no cover\n raise click.ClickException(str(exc))\n\n elif nodata is not options.IgnoreOption:\n dtype = dst.dtypes[0]\n if nodata is not None and not in_dtype_range(nodata, dtype):\n raise click.BadParameter(\n \"outside the range of the file's \"\n \"data type (%s).\" % dtype,\n param=nodata, param_hint='nodata')\n dst.nodata = nodata\n\n if unset_crs:\n dst.crs = CRS()\n elif crs:\n dst.crs = crs\n\n if transform:\n dst.transform = transform\n\n if tags:\n dst.update_tags(**tags)\n\n if units:\n dst.set_units(bidx, units)\n\n if description:\n dst.set_description(bidx, description)\n\n # Post check - ensure that crs was unset properly\n if unset_crs:\n with ctx.obj['env'], rasterio.open(input, 'r') as src:\n if dict(src.crs) != {}:\n warnings.warn(\n 'CRS was not unset. Availability of his functionality '\n 'differs depending on GDAL version and driver')\n", "path": "rasterio/rio/edit_info.py"}]}
| 2,301 | 644 |
gh_patches_debug_61134
|
rasdani/github-patches
|
git_diff
|
e2nIEE__pandapower-1293
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
networkx compatibility issue with python3.9
There's a networkx>=2.5 dependency to run pandapower under python3.9 as gcd has to be imported from math instead of fractions.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2016-2021 by University of Kassel and Fraunhofer Institute for Energy Economics
4 # and Energy System Technology (IEE), Kassel. All rights reserved.
5
6 from setuptools import setup, find_packages
7 import re
8
9 with open('README.rst', 'rb') as f:
10 install = f.read().decode('utf-8')
11
12 with open('CHANGELOG.rst', 'rb') as f:
13 changelog = f.read().decode('utf-8')
14
15 classifiers = [
16 'Development Status :: 5 - Production/Stable',
17 'Environment :: Console',
18 'Intended Audience :: Developers',
19 'Intended Audience :: Education',
20 'Intended Audience :: Science/Research',
21 'License :: OSI Approved :: BSD License',
22 'Natural Language :: English',
23 'Operating System :: OS Independent',
24 'Programming Language :: Python',
25 'Programming Language :: Python :: 3']
26
27 with open('.github/workflows/github_test_action.yml', 'rb') as f:
28 lines = f.read().decode('utf-8')
29 versions = set(re.findall('3.[0-9]', lines))
30 for version in versions:
31 classifiers.append('Programming Language :: Python :: 3.%s' % version[-1])
32
33 long_description = '\n\n'.join((install, changelog))
34
35 setup(
36 name='pandapower',
37 version='2.6.0',
38 author='Leon Thurner, Alexander Scheidler',
39 author_email='[email protected], [email protected]',
40 description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',
41 long_description=long_description,
42 long_description_content_type='text/x-rst',
43 url='http://www.pandapower.org',
44 license='BSD',
45 install_requires=["pandas>=0.17",
46 "networkx",
47 "scipy<=1.6.0",
48 "numpy>=0.11",
49 "packaging",
50 "xlsxwriter",
51 "xlrd",
52 "openpyxl",
53 "cryptography"],
54 extras_require={
55 "docs": ["numpydoc", "sphinx", "sphinx_rtd_theme"],
56 "plotting": ["plotly", "matplotlib", "python-igraph"],
57 "test": ["pytest", "pytest-xdist"],
58 "performance": ["ortools"]},
59 packages=find_packages(),
60 include_package_data=True,
61 classifiers=classifiers
62 )
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -43,7 +43,7 @@
url='http://www.pandapower.org',
license='BSD',
install_requires=["pandas>=0.17",
- "networkx",
+ "networkx>=2.5",
"scipy<=1.6.0",
"numpy>=0.11",
"packaging",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -43,7 +43,7 @@\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=0.17\",\n- \"networkx\",\n+ \"networkx>=2.5\",\n \"scipy<=1.6.0\",\n \"numpy>=0.11\",\n \"packaging\",\n", "issue": "networkx compatibility issue with python3.9\nThere's a networkx>=2.5 dependency to run pandapower under python3.9 as gcd has to be imported from math instead of fractions.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2021 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\nfrom setuptools import setup, find_packages\nimport re\n\nwith open('README.rst', 'rb') as f:\n install = f.read().decode('utf-8')\n\nwith open('CHANGELOG.rst', 'rb') as f:\n changelog = f.read().decode('utf-8')\n\nclassifiers = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3']\n\nwith open('.github/workflows/github_test_action.yml', 'rb') as f:\n lines = f.read().decode('utf-8')\n versions = set(re.findall('3.[0-9]', lines))\n for version in versions:\n classifiers.append('Programming Language :: Python :: 3.%s' % version[-1])\n\nlong_description = '\\n\\n'.join((install, changelog))\n\nsetup(\n name='pandapower',\n version='2.6.0',\n author='Leon Thurner, Alexander Scheidler',\n author_email='[email protected], [email protected]',\n description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',\n long_description=long_description,\n\tlong_description_content_type='text/x-rst',\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=0.17\",\n \"networkx\",\n \"scipy<=1.6.0\",\n \"numpy>=0.11\",\n \"packaging\",\n \"xlsxwriter\",\n \"xlrd\",\n \"openpyxl\",\n \"cryptography\"],\n extras_require={\n \"docs\": [\"numpydoc\", \"sphinx\", \"sphinx_rtd_theme\"],\n \"plotting\": [\"plotly\", \"matplotlib\", \"python-igraph\"],\n \"test\": [\"pytest\", \"pytest-xdist\"],\n \"performance\": [\"ortools\"]},\n packages=find_packages(),\n include_package_data=True,\n classifiers=classifiers\n)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2021 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\nfrom setuptools import setup, find_packages\nimport re\n\nwith open('README.rst', 'rb') as f:\n install = f.read().decode('utf-8')\n\nwith open('CHANGELOG.rst', 'rb') as f:\n changelog = f.read().decode('utf-8')\n\nclassifiers = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3']\n\nwith open('.github/workflows/github_test_action.yml', 'rb') as f:\n lines = f.read().decode('utf-8')\n versions = set(re.findall('3.[0-9]', lines))\n for version in versions:\n classifiers.append('Programming Language :: Python :: 3.%s' % version[-1])\n\nlong_description = '\\n\\n'.join((install, changelog))\n\nsetup(\n name='pandapower',\n version='2.6.0',\n author='Leon Thurner, Alexander Scheidler',\n author_email='[email protected], [email protected]',\n description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',\n long_description=long_description,\n\tlong_description_content_type='text/x-rst',\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=0.17\",\n \"networkx>=2.5\",\n \"scipy<=1.6.0\",\n \"numpy>=0.11\",\n \"packaging\",\n \"xlsxwriter\",\n \"xlrd\",\n \"openpyxl\",\n \"cryptography\"],\n extras_require={\n \"docs\": [\"numpydoc\", \"sphinx\", \"sphinx_rtd_theme\"],\n \"plotting\": [\"plotly\", \"matplotlib\", \"python-igraph\"],\n \"test\": [\"pytest\", \"pytest-xdist\"],\n \"performance\": [\"ortools\"]},\n packages=find_packages(),\n include_package_data=True,\n classifiers=classifiers\n)\n", "path": "setup.py"}]}
| 979 | 102 |
gh_patches_debug_41893
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-3932
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
remove unused dtype argument in IO plugins
## Description
See #3918
* Add deprecation cycle to these functions.
* Add a bullet in TODO.txt. Indicate #3918 as a way to clean the code in the future.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `skimage/io/_plugins/gdal_plugin.py`
Content:
```
1 __all__ = ['imread']
2
3 try:
4 import osgeo.gdal as gdal
5 except ImportError:
6 raise ImportError("The GDAL Library could not be found. "
7 "Please refer to http://www.gdal.org/ "
8 "for further instructions.")
9
10
11 def imread(fname, dtype=None):
12 """Load an image from file.
13
14 """
15 ds = gdal.Open(fname)
16
17 return ds.ReadAsArray().astype(dtype)
18
```
Path: `skimage/io/_plugins/fits_plugin.py`
Content:
```
1 __all__ = ['imread', 'imread_collection']
2
3 import skimage.io as io
4
5 try:
6 from astropy.io import fits as pyfits
7 except ImportError:
8 try:
9 import pyfits
10 except ImportError:
11 raise ImportError(
12 "PyFITS could not be found. Please refer to\n"
13 "http://www.stsci.edu/resources/software_hardware/pyfits\n"
14 "for further instructions.")
15
16
17 def imread(fname, dtype=None):
18 """Load an image from a FITS file.
19
20 Parameters
21 ----------
22 fname : string
23 Image file name, e.g. ``test.fits``.
24 dtype : dtype, optional
25 For FITS, this argument is ignored because Stefan is planning on
26 removing the dtype argument from imread anyway.
27
28 Returns
29 -------
30 img_array : ndarray
31 Unlike plugins such as PIL, where different color bands/channels are
32 stored in the third dimension, FITS images are greyscale-only and can
33 be N-dimensional, so an array of the native FITS dimensionality is
34 returned, without color channels.
35
36 Currently if no image is found in the file, None will be returned
37
38 Notes
39 -----
40
41 Currently FITS ``imread()`` always returns the first image extension when
42 given a Multi-Extension FITS file; use ``imread_collection()`` (which does
43 lazy loading) to get all the extensions at once.
44
45 """
46
47 hdulist = pyfits.open(fname)
48
49 # Iterate over FITS image extensions, ignoring any other extension types
50 # such as binary tables, and get the first image data array:
51 img_array = None
52 for hdu in hdulist:
53 if isinstance(hdu, pyfits.ImageHDU) or \
54 isinstance(hdu, pyfits.PrimaryHDU):
55 if hdu.data is not None:
56 img_array = hdu.data
57 break
58 hdulist.close()
59
60 return img_array
61
62
63 def imread_collection(load_pattern, conserve_memory=True):
64 """Load a collection of images from one or more FITS files
65
66 Parameters
67 ----------
68 load_pattern : str or list
69 List of extensions to load. Filename globbing is currently
70 unsupported.
71 converve_memory : bool
72 If True, never keep more than one in memory at a specific
73 time. Otherwise, images will be cached once they are loaded.
74
75 Returns
76 -------
77
78 ic : ImageCollection
79 Collection of images.
80
81 """
82
83 intype = type(load_pattern)
84 if intype is not list and intype is not str:
85 raise TypeError("Input must be a filename or list of filenames")
86
87 # Ensure we have a list, otherwise we'll end up iterating over the string:
88 if intype is not list:
89 load_pattern = [load_pattern]
90
91 # Generate a list of filename/extension pairs by opening the list of
92 # files and finding the image extensions in each one:
93 ext_list = []
94 for filename in load_pattern:
95 hdulist = pyfits.open(filename)
96 for n, hdu in zip(range(len(hdulist)), hdulist):
97 if isinstance(hdu, pyfits.ImageHDU) or \
98 isinstance(hdu, pyfits.PrimaryHDU):
99 # Ignore (primary) header units with no data (use '.size'
100 # rather than '.data' to avoid actually loading the image):
101 try:
102 data_size = hdu.size()
103 except TypeError: # (size changed to int in PyFITS 3.1)
104 data_size = hdu.size
105 if data_size > 0:
106 ext_list.append((filename, n))
107 hdulist.close()
108
109 return io.ImageCollection(ext_list, load_func=FITSFactory,
110 conserve_memory=conserve_memory)
111
112
113 def FITSFactory(image_ext):
114 """Load an image extension from a FITS file and return a NumPy array
115
116 Parameters
117 ----------
118
119 image_ext : tuple
120 FITS extension to load, in the format ``(filename, ext_num)``.
121 The FITS ``(extname, extver)`` format is unsupported, since this
122 function is not called directly by the user and
123 ``imread_collection()`` does the work of figuring out which
124 extensions need loading.
125
126 """
127
128 # Expect a length-2 tuple with a filename as the first element:
129 if not isinstance(image_ext, tuple):
130 raise TypeError("Expected a tuple")
131
132 if len(image_ext) != 2:
133 raise ValueError("Expected a tuple of length 2")
134
135 filename = image_ext[0]
136 extnum = image_ext[1]
137
138 if type(filename) is not str or type(extnum) is not int:
139 raise ValueError("Expected a (filename, extension) tuple")
140
141 hdulist = pyfits.open(filename)
142
143 data = hdulist[extnum].data
144
145 hdulist.close()
146
147 if data is None:
148 raise RuntimeError(
149 "Extension %d of %s has no data" % (extnum, filename))
150
151 return data
152
```
Path: `skimage/io/_plugins/tifffile_plugin.py`
Content:
```
1 try:
2 from tifffile import TiffFile, imsave, parse_kwargs
3 except ImportError:
4 from ...external.tifffile import TiffFile, imsave, parse_kwargs
5
6
7 def imread(fname, dtype=None, **kwargs):
8 """Load a tiff image from file.
9
10 Parameters
11 ----------
12 fname : str or file
13 File name or file-like-object.
14 dtype : numpy dtype object or string specifier
15 Specifies data type of array elements (Not currently used).
16 kwargs : keyword pairs, optional
17 Additional keyword arguments to pass through (see ``tifffile``'s
18 ``imread`` function).
19
20 Notes
21 -----
22 Provided by Christophe Golhke's tifffile.py [1]_, and supports many
23 advanced image types including multi-page and floating point.
24
25 References
26 ----------
27 .. [1] http://www.lfd.uci.edu/~gohlke/code/tifffile.py
28
29 """
30
31 if 'img_num' in kwargs:
32 kwargs['key'] = kwargs.pop('img_num')
33
34 # parse_kwargs will extract keyword arguments intended for the TiffFile
35 # class and remove them from the kwargs dictionary in-place
36 tiff_keys = ['multifile', 'multifile_close', 'pages', 'fastij', 'is_ome']
37 kwargs_tiff = parse_kwargs(kwargs, *tiff_keys)
38
39 # read and return tiff as numpy array
40 with TiffFile(fname, **kwargs_tiff) as tif:
41 return tif.asarray(**kwargs)
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/skimage/io/_plugins/fits_plugin.py b/skimage/io/_plugins/fits_plugin.py
--- a/skimage/io/_plugins/fits_plugin.py
+++ b/skimage/io/_plugins/fits_plugin.py
@@ -1,6 +1,7 @@
__all__ = ['imread', 'imread_collection']
import skimage.io as io
+from warnings import warn
try:
from astropy.io import fits as pyfits
@@ -22,8 +23,8 @@
fname : string
Image file name, e.g. ``test.fits``.
dtype : dtype, optional
- For FITS, this argument is ignored because Stefan is planning on
- removing the dtype argument from imread anyway.
+ Was always silently ignored.
+ Will be removed from version 0.17.
Returns
-------
@@ -43,6 +44,11 @@
lazy loading) to get all the extensions at once.
"""
+ if 'dtype' is not None:
+ warn('The dtype argument was always silently ignored. It will be '
+ 'removed from scikit-image version 0.17. To avoid this '
+ 'warning, do not specify it in your function call.',
+ UserWarning, stacklevel=2)
hdulist = pyfits.open(fname)
diff --git a/skimage/io/_plugins/gdal_plugin.py b/skimage/io/_plugins/gdal_plugin.py
--- a/skimage/io/_plugins/gdal_plugin.py
+++ b/skimage/io/_plugins/gdal_plugin.py
@@ -1,5 +1,7 @@
__all__ = ['imread']
+from warnings import warn
+
try:
import osgeo.gdal as gdal
except ImportError:
@@ -12,6 +14,12 @@
"""Load an image from file.
"""
+ if 'dtype' is not None:
+ warn('The dtype argument was always silently ignored. It will be '
+ 'removed from scikit-image version 0.17. To avoid this '
+ 'warning, do not specify it in your function call.',
+ UserWarning, stacklevel=2)
+
ds = gdal.Open(fname)
return ds.ReadAsArray().astype(dtype)
diff --git a/skimage/io/_plugins/tifffile_plugin.py b/skimage/io/_plugins/tifffile_plugin.py
--- a/skimage/io/_plugins/tifffile_plugin.py
+++ b/skimage/io/_plugins/tifffile_plugin.py
@@ -1,3 +1,5 @@
+from warnings import warn
+
try:
from tifffile import TiffFile, imsave, parse_kwargs
except ImportError:
@@ -12,7 +14,8 @@
fname : str or file
File name or file-like-object.
dtype : numpy dtype object or string specifier
- Specifies data type of array elements (Not currently used).
+ Specifies data type of array elements.
+ Will be removed from version 0.17.
kwargs : keyword pairs, optional
Additional keyword arguments to pass through (see ``tifffile``'s
``imread`` function).
@@ -27,11 +30,16 @@
.. [1] http://www.lfd.uci.edu/~gohlke/code/tifffile.py
"""
+ if 'dtype' is not None:
+ warn('The dtype argument was always silently ignored. It will be '
+ 'removed from scikit-image version 0.17. To avoid this '
+ 'warning, do not specify it in your function call.',
+ UserWarning, stacklevel=2)
if 'img_num' in kwargs:
kwargs['key'] = kwargs.pop('img_num')
- # parse_kwargs will extract keyword arguments intended for the TiffFile
+ # parse_kwargs will extract keyword arguments intended for the TiffFile
# class and remove them from the kwargs dictionary in-place
tiff_keys = ['multifile', 'multifile_close', 'pages', 'fastij', 'is_ome']
kwargs_tiff = parse_kwargs(kwargs, *tiff_keys)
|
{"golden_diff": "diff --git a/skimage/io/_plugins/fits_plugin.py b/skimage/io/_plugins/fits_plugin.py\n--- a/skimage/io/_plugins/fits_plugin.py\n+++ b/skimage/io/_plugins/fits_plugin.py\n@@ -1,6 +1,7 @@\n __all__ = ['imread', 'imread_collection']\n \n import skimage.io as io\n+from warnings import warn\n \n try:\n from astropy.io import fits as pyfits\n@@ -22,8 +23,8 @@\n fname : string\n Image file name, e.g. ``test.fits``.\n dtype : dtype, optional\n- For FITS, this argument is ignored because Stefan is planning on\n- removing the dtype argument from imread anyway.\n+ Was always silently ignored.\n+ Will be removed from version 0.17.\n \n Returns\n -------\n@@ -43,6 +44,11 @@\n lazy loading) to get all the extensions at once.\n \n \"\"\"\n+ if 'dtype' is not None:\n+ warn('The dtype argument was always silently ignored. It will be '\n+ 'removed from scikit-image version 0.17. To avoid this '\n+ 'warning, do not specify it in your function call.',\n+ UserWarning, stacklevel=2)\n \n hdulist = pyfits.open(fname)\n \ndiff --git a/skimage/io/_plugins/gdal_plugin.py b/skimage/io/_plugins/gdal_plugin.py\n--- a/skimage/io/_plugins/gdal_plugin.py\n+++ b/skimage/io/_plugins/gdal_plugin.py\n@@ -1,5 +1,7 @@\n __all__ = ['imread']\n \n+from warnings import warn\n+\n try:\n import osgeo.gdal as gdal\n except ImportError:\n@@ -12,6 +14,12 @@\n \"\"\"Load an image from file.\n \n \"\"\"\n+ if 'dtype' is not None:\n+ warn('The dtype argument was always silently ignored. It will be '\n+ 'removed from scikit-image version 0.17. To avoid this '\n+ 'warning, do not specify it in your function call.',\n+ UserWarning, stacklevel=2)\n+\n ds = gdal.Open(fname)\n \n return ds.ReadAsArray().astype(dtype)\ndiff --git a/skimage/io/_plugins/tifffile_plugin.py b/skimage/io/_plugins/tifffile_plugin.py\n--- a/skimage/io/_plugins/tifffile_plugin.py\n+++ b/skimage/io/_plugins/tifffile_plugin.py\n@@ -1,3 +1,5 @@\n+from warnings import warn\n+\n try:\n from tifffile import TiffFile, imsave, parse_kwargs\n except ImportError:\n@@ -12,7 +14,8 @@\n fname : str or file\n File name or file-like-object.\n dtype : numpy dtype object or string specifier\n- Specifies data type of array elements (Not currently used).\n+ Specifies data type of array elements.\n+ Will be removed from version 0.17.\n kwargs : keyword pairs, optional\n Additional keyword arguments to pass through (see ``tifffile``'s\n ``imread`` function).\n@@ -27,11 +30,16 @@\n .. [1] http://www.lfd.uci.edu/~gohlke/code/tifffile.py\n \n \"\"\"\n+ if 'dtype' is not None:\n+ warn('The dtype argument was always silently ignored. It will be '\n+ 'removed from scikit-image version 0.17. To avoid this '\n+ 'warning, do not specify it in your function call.',\n+ UserWarning, stacklevel=2)\n \n if 'img_num' in kwargs:\n kwargs['key'] = kwargs.pop('img_num')\n \n- # parse_kwargs will extract keyword arguments intended for the TiffFile \n+ # parse_kwargs will extract keyword arguments intended for the TiffFile\n # class and remove them from the kwargs dictionary in-place\n tiff_keys = ['multifile', 'multifile_close', 'pages', 'fastij', 'is_ome']\n kwargs_tiff = parse_kwargs(kwargs, *tiff_keys)\n", "issue": " remove unused dtype argument in IO plugins\n## Description\r\n\r\nSee #3918\r\n\r\n* Add deprecation cycle to these functions.\r\n* Add a bullet in TODO.txt. Indicate #3918 as a way to clean the code in the future.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "__all__ = ['imread']\n\ntry:\n import osgeo.gdal as gdal\nexcept ImportError:\n raise ImportError(\"The GDAL Library could not be found. \"\n \"Please refer to http://www.gdal.org/ \"\n \"for further instructions.\")\n\n\ndef imread(fname, dtype=None):\n \"\"\"Load an image from file.\n\n \"\"\"\n ds = gdal.Open(fname)\n\n return ds.ReadAsArray().astype(dtype)\n", "path": "skimage/io/_plugins/gdal_plugin.py"}, {"content": "__all__ = ['imread', 'imread_collection']\n\nimport skimage.io as io\n\ntry:\n from astropy.io import fits as pyfits\nexcept ImportError:\n try:\n import pyfits\n except ImportError:\n raise ImportError(\n \"PyFITS could not be found. Please refer to\\n\"\n \"http://www.stsci.edu/resources/software_hardware/pyfits\\n\"\n \"for further instructions.\")\n\n\ndef imread(fname, dtype=None):\n \"\"\"Load an image from a FITS file.\n\n Parameters\n ----------\n fname : string\n Image file name, e.g. ``test.fits``.\n dtype : dtype, optional\n For FITS, this argument is ignored because Stefan is planning on\n removing the dtype argument from imread anyway.\n\n Returns\n -------\n img_array : ndarray\n Unlike plugins such as PIL, where different color bands/channels are\n stored in the third dimension, FITS images are greyscale-only and can\n be N-dimensional, so an array of the native FITS dimensionality is\n returned, without color channels.\n\n Currently if no image is found in the file, None will be returned\n\n Notes\n -----\n\n Currently FITS ``imread()`` always returns the first image extension when\n given a Multi-Extension FITS file; use ``imread_collection()`` (which does\n lazy loading) to get all the extensions at once.\n\n \"\"\"\n\n hdulist = pyfits.open(fname)\n\n # Iterate over FITS image extensions, ignoring any other extension types\n # such as binary tables, and get the first image data array:\n img_array = None\n for hdu in hdulist:\n if isinstance(hdu, pyfits.ImageHDU) or \\\n isinstance(hdu, pyfits.PrimaryHDU):\n if hdu.data is not None:\n img_array = hdu.data\n break\n hdulist.close()\n\n return img_array\n\n\ndef imread_collection(load_pattern, conserve_memory=True):\n \"\"\"Load a collection of images from one or more FITS files\n\n Parameters\n ----------\n load_pattern : str or list\n List of extensions to load. Filename globbing is currently\n unsupported.\n converve_memory : bool\n If True, never keep more than one in memory at a specific\n time. Otherwise, images will be cached once they are loaded.\n\n Returns\n -------\n\n ic : ImageCollection\n Collection of images.\n\n \"\"\"\n\n intype = type(load_pattern)\n if intype is not list and intype is not str:\n raise TypeError(\"Input must be a filename or list of filenames\")\n\n # Ensure we have a list, otherwise we'll end up iterating over the string:\n if intype is not list:\n load_pattern = [load_pattern]\n\n # Generate a list of filename/extension pairs by opening the list of\n # files and finding the image extensions in each one:\n ext_list = []\n for filename in load_pattern:\n hdulist = pyfits.open(filename)\n for n, hdu in zip(range(len(hdulist)), hdulist):\n if isinstance(hdu, pyfits.ImageHDU) or \\\n isinstance(hdu, pyfits.PrimaryHDU):\n # Ignore (primary) header units with no data (use '.size'\n # rather than '.data' to avoid actually loading the image):\n try:\n data_size = hdu.size()\n except TypeError: # (size changed to int in PyFITS 3.1)\n data_size = hdu.size\n if data_size > 0:\n ext_list.append((filename, n))\n hdulist.close()\n\n return io.ImageCollection(ext_list, load_func=FITSFactory,\n conserve_memory=conserve_memory)\n\n\ndef FITSFactory(image_ext):\n \"\"\"Load an image extension from a FITS file and return a NumPy array\n\n Parameters\n ----------\n\n image_ext : tuple\n FITS extension to load, in the format ``(filename, ext_num)``.\n The FITS ``(extname, extver)`` format is unsupported, since this\n function is not called directly by the user and\n ``imread_collection()`` does the work of figuring out which\n extensions need loading.\n\n \"\"\"\n\n # Expect a length-2 tuple with a filename as the first element:\n if not isinstance(image_ext, tuple):\n raise TypeError(\"Expected a tuple\")\n\n if len(image_ext) != 2:\n raise ValueError(\"Expected a tuple of length 2\")\n\n filename = image_ext[0]\n extnum = image_ext[1]\n\n if type(filename) is not str or type(extnum) is not int:\n raise ValueError(\"Expected a (filename, extension) tuple\")\n\n hdulist = pyfits.open(filename)\n\n data = hdulist[extnum].data\n\n hdulist.close()\n\n if data is None:\n raise RuntimeError(\n \"Extension %d of %s has no data\" % (extnum, filename))\n\n return data\n", "path": "skimage/io/_plugins/fits_plugin.py"}, {"content": "try:\n from tifffile import TiffFile, imsave, parse_kwargs\nexcept ImportError:\n from ...external.tifffile import TiffFile, imsave, parse_kwargs\n\n\ndef imread(fname, dtype=None, **kwargs):\n \"\"\"Load a tiff image from file.\n\n Parameters\n ----------\n fname : str or file\n File name or file-like-object.\n dtype : numpy dtype object or string specifier\n Specifies data type of array elements (Not currently used).\n kwargs : keyword pairs, optional\n Additional keyword arguments to pass through (see ``tifffile``'s\n ``imread`` function).\n\n Notes\n -----\n Provided by Christophe Golhke's tifffile.py [1]_, and supports many\n advanced image types including multi-page and floating point.\n\n References\n ----------\n .. [1] http://www.lfd.uci.edu/~gohlke/code/tifffile.py\n\n \"\"\"\n\n if 'img_num' in kwargs:\n kwargs['key'] = kwargs.pop('img_num')\n\n # parse_kwargs will extract keyword arguments intended for the TiffFile \n # class and remove them from the kwargs dictionary in-place\n tiff_keys = ['multifile', 'multifile_close', 'pages', 'fastij', 'is_ome']\n kwargs_tiff = parse_kwargs(kwargs, *tiff_keys)\n\n # read and return tiff as numpy array\n with TiffFile(fname, **kwargs_tiff) as tif:\n return tif.asarray(**kwargs)\n", "path": "skimage/io/_plugins/tifffile_plugin.py"}], "after_files": [{"content": "__all__ = ['imread']\n\nfrom warnings import warn\n\ntry:\n import osgeo.gdal as gdal\nexcept ImportError:\n raise ImportError(\"The GDAL Library could not be found. \"\n \"Please refer to http://www.gdal.org/ \"\n \"for further instructions.\")\n\n\ndef imread(fname, dtype=None):\n \"\"\"Load an image from file.\n\n \"\"\"\n if 'dtype' is not None:\n warn('The dtype argument was always silently ignored. It will be '\n 'removed from scikit-image version 0.17. To avoid this '\n 'warning, do not specify it in your function call.',\n UserWarning, stacklevel=2)\n\n ds = gdal.Open(fname)\n\n return ds.ReadAsArray().astype(dtype)\n", "path": "skimage/io/_plugins/gdal_plugin.py"}, {"content": "__all__ = ['imread', 'imread_collection']\n\nimport skimage.io as io\nfrom warnings import warn\n\ntry:\n from astropy.io import fits as pyfits\nexcept ImportError:\n try:\n import pyfits\n except ImportError:\n raise ImportError(\n \"PyFITS could not be found. Please refer to\\n\"\n \"http://www.stsci.edu/resources/software_hardware/pyfits\\n\"\n \"for further instructions.\")\n\n\ndef imread(fname, dtype=None):\n \"\"\"Load an image from a FITS file.\n\n Parameters\n ----------\n fname : string\n Image file name, e.g. ``test.fits``.\n dtype : dtype, optional\n Was always silently ignored.\n Will be removed from version 0.17.\n\n Returns\n -------\n img_array : ndarray\n Unlike plugins such as PIL, where different color bands/channels are\n stored in the third dimension, FITS images are greyscale-only and can\n be N-dimensional, so an array of the native FITS dimensionality is\n returned, without color channels.\n\n Currently if no image is found in the file, None will be returned\n\n Notes\n -----\n\n Currently FITS ``imread()`` always returns the first image extension when\n given a Multi-Extension FITS file; use ``imread_collection()`` (which does\n lazy loading) to get all the extensions at once.\n\n \"\"\"\n if 'dtype' is not None:\n warn('The dtype argument was always silently ignored. It will be '\n 'removed from scikit-image version 0.17. To avoid this '\n 'warning, do not specify it in your function call.',\n UserWarning, stacklevel=2)\n\n hdulist = pyfits.open(fname)\n\n # Iterate over FITS image extensions, ignoring any other extension types\n # such as binary tables, and get the first image data array:\n img_array = None\n for hdu in hdulist:\n if isinstance(hdu, pyfits.ImageHDU) or \\\n isinstance(hdu, pyfits.PrimaryHDU):\n if hdu.data is not None:\n img_array = hdu.data\n break\n hdulist.close()\n\n return img_array\n\n\ndef imread_collection(load_pattern, conserve_memory=True):\n \"\"\"Load a collection of images from one or more FITS files\n\n Parameters\n ----------\n load_pattern : str or list\n List of extensions to load. Filename globbing is currently\n unsupported.\n converve_memory : bool\n If True, never keep more than one in memory at a specific\n time. Otherwise, images will be cached once they are loaded.\n\n Returns\n -------\n\n ic : ImageCollection\n Collection of images.\n\n \"\"\"\n\n intype = type(load_pattern)\n if intype is not list and intype is not str:\n raise TypeError(\"Input must be a filename or list of filenames\")\n\n # Ensure we have a list, otherwise we'll end up iterating over the string:\n if intype is not list:\n load_pattern = [load_pattern]\n\n # Generate a list of filename/extension pairs by opening the list of\n # files and finding the image extensions in each one:\n ext_list = []\n for filename in load_pattern:\n hdulist = pyfits.open(filename)\n for n, hdu in zip(range(len(hdulist)), hdulist):\n if isinstance(hdu, pyfits.ImageHDU) or \\\n isinstance(hdu, pyfits.PrimaryHDU):\n # Ignore (primary) header units with no data (use '.size'\n # rather than '.data' to avoid actually loading the image):\n try:\n data_size = hdu.size()\n except TypeError: # (size changed to int in PyFITS 3.1)\n data_size = hdu.size\n if data_size > 0:\n ext_list.append((filename, n))\n hdulist.close()\n\n return io.ImageCollection(ext_list, load_func=FITSFactory,\n conserve_memory=conserve_memory)\n\n\ndef FITSFactory(image_ext):\n \"\"\"Load an image extension from a FITS file and return a NumPy array\n\n Parameters\n ----------\n\n image_ext : tuple\n FITS extension to load, in the format ``(filename, ext_num)``.\n The FITS ``(extname, extver)`` format is unsupported, since this\n function is not called directly by the user and\n ``imread_collection()`` does the work of figuring out which\n extensions need loading.\n\n \"\"\"\n\n # Expect a length-2 tuple with a filename as the first element:\n if not isinstance(image_ext, tuple):\n raise TypeError(\"Expected a tuple\")\n\n if len(image_ext) != 2:\n raise ValueError(\"Expected a tuple of length 2\")\n\n filename = image_ext[0]\n extnum = image_ext[1]\n\n if type(filename) is not str or type(extnum) is not int:\n raise ValueError(\"Expected a (filename, extension) tuple\")\n\n hdulist = pyfits.open(filename)\n\n data = hdulist[extnum].data\n\n hdulist.close()\n\n if data is None:\n raise RuntimeError(\n \"Extension %d of %s has no data\" % (extnum, filename))\n\n return data\n", "path": "skimage/io/_plugins/fits_plugin.py"}, {"content": "from warnings import warn\n\ntry:\n from tifffile import TiffFile, imsave, parse_kwargs\nexcept ImportError:\n from ...external.tifffile import TiffFile, imsave, parse_kwargs\n\n\ndef imread(fname, dtype=None, **kwargs):\n \"\"\"Load a tiff image from file.\n\n Parameters\n ----------\n fname : str or file\n File name or file-like-object.\n dtype : numpy dtype object or string specifier\n Specifies data type of array elements.\n Will be removed from version 0.17.\n kwargs : keyword pairs, optional\n Additional keyword arguments to pass through (see ``tifffile``'s\n ``imread`` function).\n\n Notes\n -----\n Provided by Christophe Golhke's tifffile.py [1]_, and supports many\n advanced image types including multi-page and floating point.\n\n References\n ----------\n .. [1] http://www.lfd.uci.edu/~gohlke/code/tifffile.py\n\n \"\"\"\n if 'dtype' is not None:\n warn('The dtype argument was always silently ignored. It will be '\n 'removed from scikit-image version 0.17. To avoid this '\n 'warning, do not specify it in your function call.',\n UserWarning, stacklevel=2)\n\n if 'img_num' in kwargs:\n kwargs['key'] = kwargs.pop('img_num')\n\n # parse_kwargs will extract keyword arguments intended for the TiffFile\n # class and remove them from the kwargs dictionary in-place\n tiff_keys = ['multifile', 'multifile_close', 'pages', 'fastij', 'is_ome']\n kwargs_tiff = parse_kwargs(kwargs, *tiff_keys)\n\n # read and return tiff as numpy array\n with TiffFile(fname, **kwargs_tiff) as tif:\n return tif.asarray(**kwargs)\n", "path": "skimage/io/_plugins/tifffile_plugin.py"}]}
| 2,338 | 926 |
gh_patches_debug_719
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-pipeline-680
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Doc deployment step failing
The latest CI run failed to execute documentation deployment:
https://app.circleci.com/pipelines/github/mne-tools/mne-bids-pipeline/3557/workflows/3458e5cc-c471-4664-8d0a-b0cc4961f9eb/jobs/41986/parallel-runs/0/steps/0-107
```shell
#!/bin/bash -eo pipefail
./.circleci/setup_bash.sh
CIRCLE_JOB=deploy_docs
COMMIT_MESSAGE=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)
COMMIT_MESSAGE_ESCAPED=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)
CIRCLE_REQUESTED_JOB=
Running job deploy_docs for main branch
./.circleci/setup_bash.sh: line 35: sudo: command not found
Exited with code exit status 127
CircleCI received exit code 127
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/features/gen_steps.py`
Content:
```
1 #!/bin/env python
2 """Generate steps.md."""
3
4 import importlib
5 from pathlib import Path
6 from mne_bids_pipeline._config_utils import _get_step_modules
7
8 pre = """\
9 # Processing steps
10
11 The following table provides a concise summary of each step in the Study
12 Template. All steps exist in the `steps`/ directory.
13 """
14
15 step_modules = _get_step_modules()
16
17 # Construct the lines of steps.md
18 lines = [pre]
19 for di, (dir_, modules) in enumerate(step_modules.items(), 1):
20 if dir_ == 'all':
21 continue # this is an alias
22 dir_module = importlib.import_module(f'mne_bids_pipeline.steps.{dir_}')
23 dir_header = dir_module.__doc__.split('\n')[0].rstrip('.')
24 dir_body = dir_module.__doc__.split('\n', maxsplit=1)
25 if len(dir_body) > 1:
26 dir_body = dir_body[1].strip()
27 else:
28 dir_body = ''
29 lines.append(f'## {di}. {dir_header}\n')
30 if dir_body:
31 lines.append(f'{dir_body}\n')
32 lines.append('| Processing step | Description |')
33 lines.append('|:----------------|:------------|')
34 # the "all" option
35 dir_name, step_title = dir_, f'Run all {dir_header.lower()} steps.'
36 lines.append(f'`{dir_name}` | {step_title} |')
37 for module in modules:
38 step_name = f'{dir_name}/{Path(module.__file__).name}'[:-3]
39 step_title = module.__doc__.split('\n')[0]
40 lines.append(f'`{step_name}` | {step_title} |')
41 lines.append('')
42 with open(Path(__file__).parent / 'steps.md', 'w') as fid:
43 fid.write('\n'.join(lines))
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/features/gen_steps.py b/docs/source/features/gen_steps.py
--- a/docs/source/features/gen_steps.py
+++ b/docs/source/features/gen_steps.py
@@ -12,6 +12,7 @@
Template. All steps exist in the `steps`/ directory.
"""
+print('Generating steps …')
step_modules = _get_step_modules()
# Construct the lines of steps.md
|
{"golden_diff": "diff --git a/docs/source/features/gen_steps.py b/docs/source/features/gen_steps.py\n--- a/docs/source/features/gen_steps.py\n+++ b/docs/source/features/gen_steps.py\n@@ -12,6 +12,7 @@\n Template. All steps exist in the `steps`/ directory.\n \"\"\"\n \n+print('Generating steps \u2026')\n step_modules = _get_step_modules()\n \n # Construct the lines of steps.md\n", "issue": "Doc deployment step failing\nThe latest CI run failed to execute documentation deployment:\r\nhttps://app.circleci.com/pipelines/github/mne-tools/mne-bids-pipeline/3557/workflows/3458e5cc-c471-4664-8d0a-b0cc4961f9eb/jobs/41986/parallel-runs/0/steps/0-107\r\n\r\n```shell\r\n#!/bin/bash -eo pipefail\r\n./.circleci/setup_bash.sh\r\nCIRCLE_JOB=deploy_docs\r\nCOMMIT_MESSAGE=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)\r\nCOMMIT_MESSAGE_ESCAPED=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)\r\nCIRCLE_REQUESTED_JOB=\r\nRunning job deploy_docs for main branch\r\n./.circleci/setup_bash.sh: line 35: sudo: command not found\r\n\r\nExited with code exit status 127\r\nCircleCI received exit code 127\r\n```\n", "before_files": [{"content": "#!/bin/env python\n\"\"\"Generate steps.md.\"\"\"\n\nimport importlib\nfrom pathlib import Path\nfrom mne_bids_pipeline._config_utils import _get_step_modules\n\npre = \"\"\"\\\n# Processing steps\n\nThe following table provides a concise summary of each step in the Study\nTemplate. All steps exist in the `steps`/ directory.\n\"\"\"\n\nstep_modules = _get_step_modules()\n\n# Construct the lines of steps.md\nlines = [pre]\nfor di, (dir_, modules) in enumerate(step_modules.items(), 1):\n if dir_ == 'all':\n continue # this is an alias\n dir_module = importlib.import_module(f'mne_bids_pipeline.steps.{dir_}')\n dir_header = dir_module.__doc__.split('\\n')[0].rstrip('.')\n dir_body = dir_module.__doc__.split('\\n', maxsplit=1)\n if len(dir_body) > 1:\n dir_body = dir_body[1].strip()\n else:\n dir_body = ''\n lines.append(f'## {di}. {dir_header}\\n')\n if dir_body:\n lines.append(f'{dir_body}\\n')\n lines.append('| Processing step | Description |')\n lines.append('|:----------------|:------------|')\n # the \"all\" option\n dir_name, step_title = dir_, f'Run all {dir_header.lower()} steps.'\n lines.append(f'`{dir_name}` | {step_title} |')\n for module in modules:\n step_name = f'{dir_name}/{Path(module.__file__).name}'[:-3]\n step_title = module.__doc__.split('\\n')[0]\n lines.append(f'`{step_name}` | {step_title} |')\n lines.append('')\nwith open(Path(__file__).parent / 'steps.md', 'w') as fid:\n fid.write('\\n'.join(lines))\n", "path": "docs/source/features/gen_steps.py"}], "after_files": [{"content": "#!/bin/env python\n\"\"\"Generate steps.md.\"\"\"\n\nimport importlib\nfrom pathlib import Path\nfrom mne_bids_pipeline._config_utils import _get_step_modules\n\npre = \"\"\"\\\n# Processing steps\n\nThe following table provides a concise summary of each step in the Study\nTemplate. All steps exist in the `steps`/ directory.\n\"\"\"\n\nprint('Generating steps \u2026')\nstep_modules = _get_step_modules()\n\n# Construct the lines of steps.md\nlines = [pre]\nfor di, (dir_, modules) in enumerate(step_modules.items(), 1):\n if dir_ == 'all':\n continue # this is an alias\n dir_module = importlib.import_module(f'mne_bids_pipeline.steps.{dir_}')\n dir_header = dir_module.__doc__.split('\\n')[0].rstrip('.')\n dir_body = dir_module.__doc__.split('\\n', maxsplit=1)\n if len(dir_body) > 1:\n dir_body = dir_body[1].strip()\n else:\n dir_body = ''\n lines.append(f'## {di}. {dir_header}\\n')\n if dir_body:\n lines.append(f'{dir_body}\\n')\n lines.append('| Processing step | Description |')\n lines.append('|:----------------|:------------|')\n # the \"all\" option\n dir_name, step_title = dir_, f'Run all {dir_header.lower()} steps.'\n lines.append(f'`{dir_name}` | {step_title} |')\n for module in modules:\n step_name = f'{dir_name}/{Path(module.__file__).name}'[:-3]\n step_title = module.__doc__.split('\\n')[0]\n lines.append(f'`{step_name}` | {step_title} |')\n lines.append('')\nwith open(Path(__file__).parent / 'steps.md', 'w') as fid:\n fid.write('\\n'.join(lines))\n", "path": "docs/source/features/gen_steps.py"}]}
| 1,030 | 87 |
gh_patches_debug_27400
|
rasdani/github-patches
|
git_diff
|
pytorch__text-135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ascii vs. utf-8 in torchtext/datasets/translation.py
@nelson-liu: I incorrectly brought this up in pull #52, new issue here
When trying to load splits for IWSLT (in french, german, etc...), the loading process would fail with an ascii encoding/decoding error:
```
.data/iwslt/de-en/IWSLT16.TED.dev2010.de-en.en.xml
.data/iwslt/de-en/IWSLT16.TED.tst2013.de-en.de.xml
Traceback (most recent call last):
File "test.py", line 25, in <module>
train, val, test = datasets.IWSLT.splits(exts=('.de', '.en'), fields=(DE, EN))
File "build/bdist.linux-x86_64/egg/torchtext/datasets/translation.py", line 116, in splits
File "build/bdist.linux-x86_64/egg/torchtext/datasets/translation.py", line 136, in clean
UnicodeEncodeError: 'ascii' codec can't encode character u'\xe4' in position 60: ordinal not in range(128)
```
These are my library versions:
```
numpy==1.13.3
regex==2017.9.23
spacy==1.9.0
torch==0.2.0.post4
torchtext==0.2.0b0 (just cloned a few minutes before error)
torchvision==0.1.9
```
Here is the code that I was using, from test/translation.py:
```
from torchtext import data
from torchtext import datasets
import re
import spacy
import sys
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
url = re.compile('(<url>.*</url>)')
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(url.sub('@URL@', text))]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(url.sub('@URL@', text))]
# Testing IWSLT
DE = data.Field(tokenize=tokenize_de)
EN = data.Field(tokenize=tokenize_en)
train, val, test = datasets.IWSLT.splits(exts=('.de', '.en'), fields=(DE, EN))
```
The following fixed it for me, in torchtext/datasets/translation.py. Replace opens with io.opens specifying utf-8 for python2. It's worth noting that a friend with python3 did not have this problem.
```
127 @staticmethod
128 def clean(path):
129 for f_xml in glob.iglob(os.path.join(path, '*.xml')):
130 print(f_xml)
131 f_txt = os.path.splitext(f_xml)[0]
132 import io
133 with io.open(f_txt, mode="w", encoding="utf-8") as fd_txt: <--- INSERT
134 #with open(f_txt, 'w') as fd_txt: <--- COMMENT
135 root = ET.parse(f_xml).getroot()[0]
136 for doc in root.findall('doc'):
137 for e in doc.findall('seg'):
138 fd_txt.write(e.text.strip() + '\n')
139 xml_tags = ['<url', '<keywords', '<talkid', '<description',
140 '<reviewer', '<translator', '<title', '<speaker']
141 for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):
142 print(f_orig)
143 f_txt = f_orig.replace('.tags', '')
144 with io.open(f_txt,mode='w',encoding='utf-8') as fd_txt, io.open(f_orig,mode='r',encoding='utf=8') as fd_orig: <--- INSERT
145 #with open(f_txt, 'w') as fd_txt, open(f_orig) as fd_orig: <--- COMMENT
146 for l in fd_orig:
147 if not any(tag in l for tag in xml_tags):
148 fd_txt.write(l.strip() + '\n')
```
@jekbradbury, you were correct in pull #52 that I didn't need the middle block explicitly encoding/decoding (not seen here) since the file is already open as utf-8.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchtext/datasets/translation.py`
Content:
```
1 import os
2 import xml.etree.ElementTree as ET
3 import glob
4
5 from .. import data
6
7
8 class TranslationDataset(data.Dataset):
9 """Defines a dataset for machine translation."""
10
11 @staticmethod
12 def sort_key(ex):
13 return data.interleave_keys(len(ex.src), len(ex.trg))
14
15 def __init__(self, path, exts, fields, **kwargs):
16 """Create a TranslationDataset given paths and fields.
17
18 Arguments:
19 path: Common prefix of paths to the data files for both languages.
20 exts: A tuple containing the extension to path for each language.
21 fields: A tuple containing the fields that will be used for data
22 in each language.
23 Remaining keyword arguments: Passed to the constructor of
24 data.Dataset.
25 """
26 if not isinstance(fields[0], (tuple, list)):
27 fields = [('src', fields[0]), ('trg', fields[1])]
28
29 src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)
30
31 examples = []
32 with open(src_path) as src_file, open(trg_path) as trg_file:
33 for src_line, trg_line in zip(src_file, trg_file):
34 src_line, trg_line = src_line.strip(), trg_line.strip()
35 if src_line != '' and trg_line != '':
36 examples.append(data.Example.fromlist(
37 [src_line, trg_line], fields))
38
39 super(TranslationDataset, self).__init__(examples, fields, **kwargs)
40
41
42 class Multi30k(TranslationDataset, data.Dataset):
43 """Defines a dataset for the multi-modal WMT 2016 task"""
44
45 urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',
46 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',
47 'https://staff.fnwi.uva.nl/d.elliott/wmt16/mmt16_task1_test.tgz']
48 name = 'multi30k'
49 dirname = ''
50
51 @classmethod
52 def splits(cls, exts, fields, root='.data',
53 train='train', val='val', test='test', **kwargs):
54 """Create dataset objects for splits of the Multi30k dataset.
55
56 Arguments:
57
58 root: directory containing Multi30k data
59 exts: A tuple containing the extension to path for each language.
60 fields: A tuple containing the fields that will be used for data
61 in each language.
62 train: The prefix of the train data. Default: 'train'.
63 validation: The prefix of the validation data. Default: 'val'.
64 test: The prefix of the test data. Default: 'test'.
65 Remaining keyword arguments: Passed to the splits method of
66 Dataset.
67 """
68 path = cls.download(root)
69
70 train_data = None if train is None else cls(
71 os.path.join(path, train), exts, fields, **kwargs)
72 val_data = None if val is None else cls(
73 os.path.join(path, val), exts, fields, **kwargs)
74 test_data = None if test is None else cls(
75 os.path.join(path, test), exts, fields, **kwargs)
76 return tuple(d for d in (train_data, val_data, test_data)
77 if d is not None)
78
79
80 class IWSLT(TranslationDataset, data.Dataset):
81 """Defines a dataset for the IWSLT 2016 task"""
82
83 base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'
84 name = 'iwslt'
85 base_dirname = '{}-{}'
86
87 @classmethod
88 def splits(cls, exts, fields, root='.data',
89 train='train', val='IWSLT16.TED.tst2013',
90 test='IWSLT16.TED.tst2014', **kwargs):
91 """Create dataset objects for splits of the IWSLT dataset.
92
93 Arguments:
94
95 root: directory containing Multi30k data
96 exts: A tuple containing the extension to path for each language.
97 fields: A tuple containing the fields that will be used for data
98 in each language.
99 train: The prefix of the train data. Default: 'train'.
100 validation: The prefix of the validation data. Default: 'val'.
101 test: The prefix of the test data. Default: 'test'.
102 Remaining keyword arguments: Passed to the splits method of
103 Dataset.
104 """
105 cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])
106 cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]
107 check = os.path.join(root, cls.name, cls.dirname)
108 path = cls.download(root, check=check)
109
110 train = '.'.join([train, cls.dirname])
111 val = '.'.join([val, cls.dirname])
112 if test is not None:
113 test = '.'.join([test, cls.dirname])
114
115 if not os.path.exists(os.path.join(path, train) + exts[0]):
116 cls.clean(path)
117
118 train_data = None if train is None else cls(
119 os.path.join(path, train), exts, fields, **kwargs)
120 val_data = None if val is None else cls(
121 os.path.join(path, val), exts, fields, **kwargs)
122 test_data = None if test is None else cls(
123 os.path.join(path, test), exts, fields, **kwargs)
124 return tuple(d for d in (train_data, val_data, test_data)
125 if d is not None)
126
127 @staticmethod
128 def clean(path):
129 for f_xml in glob.iglob(os.path.join(path, '*.xml')):
130 print(f_xml)
131 f_txt = os.path.splitext(f_xml)[0]
132 with open(f_txt, 'w') as fd_txt:
133 root = ET.parse(f_xml).getroot()[0]
134 for doc in root.findall('doc'):
135 for e in doc.findall('seg'):
136 fd_txt.write(e.text.strip() + '\n')
137
138 xml_tags = ['<url', '<keywords', '<talkid', '<description',
139 '<reviewer', '<translator', '<title', '<speaker']
140 for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):
141 print(f_orig)
142 f_txt = f_orig.replace('.tags', '')
143 with open(f_txt, 'w') as fd_txt, open(f_orig) as fd_orig:
144 for l in fd_orig:
145 if not any(tag in l for tag in xml_tags):
146 fd_txt.write(l.strip() + '\n')
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchtext/datasets/translation.py b/torchtext/datasets/translation.py
--- a/torchtext/datasets/translation.py
+++ b/torchtext/datasets/translation.py
@@ -1,6 +1,7 @@
import os
import xml.etree.ElementTree as ET
import glob
+import io
from .. import data
@@ -129,7 +130,7 @@
for f_xml in glob.iglob(os.path.join(path, '*.xml')):
print(f_xml)
f_txt = os.path.splitext(f_xml)[0]
- with open(f_txt, 'w') as fd_txt:
+ with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt:
root = ET.parse(f_xml).getroot()[0]
for doc in root.findall('doc'):
for e in doc.findall('seg'):
@@ -140,7 +141,8 @@
for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):
print(f_orig)
f_txt = f_orig.replace('.tags', '')
- with open(f_txt, 'w') as fd_txt, open(f_orig) as fd_orig:
+ with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt, \
+ io.open(f_orig, mode='w', encoding='utf-8') as fd_orig:
for l in fd_orig:
if not any(tag in l for tag in xml_tags):
fd_txt.write(l.strip() + '\n')
|
{"golden_diff": "diff --git a/torchtext/datasets/translation.py b/torchtext/datasets/translation.py\n--- a/torchtext/datasets/translation.py\n+++ b/torchtext/datasets/translation.py\n@@ -1,6 +1,7 @@\n import os\n import xml.etree.ElementTree as ET\n import glob\n+import io\n \n from .. import data\n \n@@ -129,7 +130,7 @@\n for f_xml in glob.iglob(os.path.join(path, '*.xml')):\n print(f_xml)\n f_txt = os.path.splitext(f_xml)[0]\n- with open(f_txt, 'w') as fd_txt:\n+ with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt:\n root = ET.parse(f_xml).getroot()[0]\n for doc in root.findall('doc'):\n for e in doc.findall('seg'):\n@@ -140,7 +141,8 @@\n for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):\n print(f_orig)\n f_txt = f_orig.replace('.tags', '')\n- with open(f_txt, 'w') as fd_txt, open(f_orig) as fd_orig:\n+ with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt, \\\n+ io.open(f_orig, mode='w', encoding='utf-8') as fd_orig:\n for l in fd_orig:\n if not any(tag in l for tag in xml_tags):\n fd_txt.write(l.strip() + '\\n')\n", "issue": "ascii vs. utf-8 in torchtext/datasets/translation.py\n@nelson-liu: I incorrectly brought this up in pull #52, new issue here\r\n\r\nWhen trying to load splits for IWSLT (in french, german, etc...), the loading process would fail with an ascii encoding/decoding error:\r\n```\r\n.data/iwslt/de-en/IWSLT16.TED.dev2010.de-en.en.xml\r\n.data/iwslt/de-en/IWSLT16.TED.tst2013.de-en.de.xml\r\nTraceback (most recent call last):\r\n File \"test.py\", line 25, in <module>\r\n train, val, test = datasets.IWSLT.splits(exts=('.de', '.en'), fields=(DE, EN))\r\n File \"build/bdist.linux-x86_64/egg/torchtext/datasets/translation.py\", line 116, in splits\r\n File \"build/bdist.linux-x86_64/egg/torchtext/datasets/translation.py\", line 136, in clean\r\nUnicodeEncodeError: 'ascii' codec can't encode character u'\\xe4' in position 60: ordinal not in range(128)\r\n```\r\nThese are my library versions:\r\n```\r\nnumpy==1.13.3\r\nregex==2017.9.23\r\nspacy==1.9.0\r\ntorch==0.2.0.post4\r\ntorchtext==0.2.0b0 (just cloned a few minutes before error)\r\ntorchvision==0.1.9\r\n```\r\nHere is the code that I was using, from test/translation.py:\r\n```\r\nfrom torchtext import data\r\nfrom torchtext import datasets\r\n\r\nimport re\r\nimport spacy\r\nimport sys\r\n\r\nspacy_de = spacy.load('de')\r\nspacy_en = spacy.load('en')\r\n\r\nurl = re.compile('(<url>.*</url>)')\r\n\r\ndef tokenize_de(text):\r\n return [tok.text for tok in spacy_de.tokenizer(url.sub('@URL@', text))]\r\n\r\ndef tokenize_en(text):\r\n return [tok.text for tok in spacy_en.tokenizer(url.sub('@URL@', text))]\r\n\r\n# Testing IWSLT\r\nDE = data.Field(tokenize=tokenize_de)\r\nEN = data.Field(tokenize=tokenize_en)\r\ntrain, val, test = datasets.IWSLT.splits(exts=('.de', '.en'), fields=(DE, EN))\r\n```\r\nThe following fixed it for me, in torchtext/datasets/translation.py. Replace opens with io.opens specifying utf-8 for python2. It's worth noting that a friend with python3 did not have this problem.\r\n```\r\n127 @staticmethod\r\n128 def clean(path):\r\n129 for f_xml in glob.iglob(os.path.join(path, '*.xml')):\r\n130 print(f_xml)\r\n131 f_txt = os.path.splitext(f_xml)[0]\r\n132 import io\r\n133 with io.open(f_txt, mode=\"w\", encoding=\"utf-8\") as fd_txt: <--- INSERT\r\n134 #with open(f_txt, 'w') as fd_txt: <--- COMMENT\r\n135 root = ET.parse(f_xml).getroot()[0]\r\n136 for doc in root.findall('doc'):\r\n137 for e in doc.findall('seg'):\r\n138 fd_txt.write(e.text.strip() + '\\n')\r\n139 xml_tags = ['<url', '<keywords', '<talkid', '<description',\r\n140 '<reviewer', '<translator', '<title', '<speaker']\r\n141 for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):\r\n142 print(f_orig)\r\n143 f_txt = f_orig.replace('.tags', '')\r\n144 with io.open(f_txt,mode='w',encoding='utf-8') as fd_txt, io.open(f_orig,mode='r',encoding='utf=8') as fd_orig: <--- INSERT\r\n145 #with open(f_txt, 'w') as fd_txt, open(f_orig) as fd_orig: <--- COMMENT\r\n146 for l in fd_orig:\r\n147 if not any(tag in l for tag in xml_tags):\r\n148 fd_txt.write(l.strip() + '\\n')\r\n```\r\n@jekbradbury, you were correct in pull #52 that I didn't need the middle block explicitly encoding/decoding (not seen here) since the file is already open as utf-8.\n", "before_files": [{"content": "import os\nimport xml.etree.ElementTree as ET\nimport glob\n\nfrom .. import data\n\n\nclass TranslationDataset(data.Dataset):\n \"\"\"Defines a dataset for machine translation.\"\"\"\n\n @staticmethod\n def sort_key(ex):\n return data.interleave_keys(len(ex.src), len(ex.trg))\n\n def __init__(self, path, exts, fields, **kwargs):\n \"\"\"Create a TranslationDataset given paths and fields.\n\n Arguments:\n path: Common prefix of paths to the data files for both languages.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n Remaining keyword arguments: Passed to the constructor of\n data.Dataset.\n \"\"\"\n if not isinstance(fields[0], (tuple, list)):\n fields = [('src', fields[0]), ('trg', fields[1])]\n\n src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)\n\n examples = []\n with open(src_path) as src_file, open(trg_path) as trg_file:\n for src_line, trg_line in zip(src_file, trg_file):\n src_line, trg_line = src_line.strip(), trg_line.strip()\n if src_line != '' and trg_line != '':\n examples.append(data.Example.fromlist(\n [src_line, trg_line], fields))\n\n super(TranslationDataset, self).__init__(examples, fields, **kwargs)\n\n\nclass Multi30k(TranslationDataset, data.Dataset):\n \"\"\"Defines a dataset for the multi-modal WMT 2016 task\"\"\"\n\n urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',\n 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',\n 'https://staff.fnwi.uva.nl/d.elliott/wmt16/mmt16_task1_test.tgz']\n name = 'multi30k'\n dirname = ''\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', val='val', test='test', **kwargs):\n \"\"\"Create dataset objects for splits of the Multi30k dataset.\n\n Arguments:\n\n root: directory containing Multi30k data\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n path = cls.download(root)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if val is None else cls(\n os.path.join(path, val), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n\nclass IWSLT(TranslationDataset, data.Dataset):\n \"\"\"Defines a dataset for the IWSLT 2016 task\"\"\"\n\n base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'\n name = 'iwslt'\n base_dirname = '{}-{}'\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', val='IWSLT16.TED.tst2013',\n test='IWSLT16.TED.tst2014', **kwargs):\n \"\"\"Create dataset objects for splits of the IWSLT dataset.\n\n Arguments:\n\n root: directory containing Multi30k data\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])\n cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]\n check = os.path.join(root, cls.name, cls.dirname)\n path = cls.download(root, check=check)\n\n train = '.'.join([train, cls.dirname])\n val = '.'.join([val, cls.dirname])\n if test is not None:\n test = '.'.join([test, cls.dirname])\n\n if not os.path.exists(os.path.join(path, train) + exts[0]):\n cls.clean(path)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if val is None else cls(\n os.path.join(path, val), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n @staticmethod\n def clean(path):\n for f_xml in glob.iglob(os.path.join(path, '*.xml')):\n print(f_xml)\n f_txt = os.path.splitext(f_xml)[0]\n with open(f_txt, 'w') as fd_txt:\n root = ET.parse(f_xml).getroot()[0]\n for doc in root.findall('doc'):\n for e in doc.findall('seg'):\n fd_txt.write(e.text.strip() + '\\n')\n\n xml_tags = ['<url', '<keywords', '<talkid', '<description',\n '<reviewer', '<translator', '<title', '<speaker']\n for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):\n print(f_orig)\n f_txt = f_orig.replace('.tags', '')\n with open(f_txt, 'w') as fd_txt, open(f_orig) as fd_orig:\n for l in fd_orig:\n if not any(tag in l for tag in xml_tags):\n fd_txt.write(l.strip() + '\\n')\n", "path": "torchtext/datasets/translation.py"}], "after_files": [{"content": "import os\nimport xml.etree.ElementTree as ET\nimport glob\nimport io\n\nfrom .. import data\n\n\nclass TranslationDataset(data.Dataset):\n \"\"\"Defines a dataset for machine translation.\"\"\"\n\n @staticmethod\n def sort_key(ex):\n return data.interleave_keys(len(ex.src), len(ex.trg))\n\n def __init__(self, path, exts, fields, **kwargs):\n \"\"\"Create a TranslationDataset given paths and fields.\n\n Arguments:\n path: Common prefix of paths to the data files for both languages.\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n Remaining keyword arguments: Passed to the constructor of\n data.Dataset.\n \"\"\"\n if not isinstance(fields[0], (tuple, list)):\n fields = [('src', fields[0]), ('trg', fields[1])]\n\n src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)\n\n examples = []\n with open(src_path) as src_file, open(trg_path) as trg_file:\n for src_line, trg_line in zip(src_file, trg_file):\n src_line, trg_line = src_line.strip(), trg_line.strip()\n if src_line != '' and trg_line != '':\n examples.append(data.Example.fromlist(\n [src_line, trg_line], fields))\n\n super(TranslationDataset, self).__init__(examples, fields, **kwargs)\n\n\nclass Multi30k(TranslationDataset, data.Dataset):\n \"\"\"Defines a dataset for the multi-modal WMT 2016 task\"\"\"\n\n urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',\n 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',\n 'https://staff.fnwi.uva.nl/d.elliott/wmt16/mmt16_task1_test.tgz']\n name = 'multi30k'\n dirname = ''\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', val='val', test='test', **kwargs):\n \"\"\"Create dataset objects for splits of the Multi30k dataset.\n\n Arguments:\n\n root: directory containing Multi30k data\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n path = cls.download(root)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if val is None else cls(\n os.path.join(path, val), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n\nclass IWSLT(TranslationDataset, data.Dataset):\n \"\"\"Defines a dataset for the IWSLT 2016 task\"\"\"\n\n base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'\n name = 'iwslt'\n base_dirname = '{}-{}'\n\n @classmethod\n def splits(cls, exts, fields, root='.data',\n train='train', val='IWSLT16.TED.tst2013',\n test='IWSLT16.TED.tst2014', **kwargs):\n \"\"\"Create dataset objects for splits of the IWSLT dataset.\n\n Arguments:\n\n root: directory containing Multi30k data\n exts: A tuple containing the extension to path for each language.\n fields: A tuple containing the fields that will be used for data\n in each language.\n train: The prefix of the train data. Default: 'train'.\n validation: The prefix of the validation data. Default: 'val'.\n test: The prefix of the test data. Default: 'test'.\n Remaining keyword arguments: Passed to the splits method of\n Dataset.\n \"\"\"\n cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])\n cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]\n check = os.path.join(root, cls.name, cls.dirname)\n path = cls.download(root, check=check)\n\n train = '.'.join([train, cls.dirname])\n val = '.'.join([val, cls.dirname])\n if test is not None:\n test = '.'.join([test, cls.dirname])\n\n if not os.path.exists(os.path.join(path, train) + exts[0]):\n cls.clean(path)\n\n train_data = None if train is None else cls(\n os.path.join(path, train), exts, fields, **kwargs)\n val_data = None if val is None else cls(\n os.path.join(path, val), exts, fields, **kwargs)\n test_data = None if test is None else cls(\n os.path.join(path, test), exts, fields, **kwargs)\n return tuple(d for d in (train_data, val_data, test_data)\n if d is not None)\n\n @staticmethod\n def clean(path):\n for f_xml in glob.iglob(os.path.join(path, '*.xml')):\n print(f_xml)\n f_txt = os.path.splitext(f_xml)[0]\n with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt:\n root = ET.parse(f_xml).getroot()[0]\n for doc in root.findall('doc'):\n for e in doc.findall('seg'):\n fd_txt.write(e.text.strip() + '\\n')\n\n xml_tags = ['<url', '<keywords', '<talkid', '<description',\n '<reviewer', '<translator', '<title', '<speaker']\n for f_orig in glob.iglob(os.path.join(path, 'train.tags*')):\n print(f_orig)\n f_txt = f_orig.replace('.tags', '')\n with io.open(f_txt, mode='w', encoding='utf-8') as fd_txt, \\\n io.open(f_orig, mode='w', encoding='utf-8') as fd_orig:\n for l in fd_orig:\n if not any(tag in l for tag in xml_tags):\n fd_txt.write(l.strip() + '\\n')\n", "path": "torchtext/datasets/translation.py"}]}
| 3,048 | 339 |
gh_patches_debug_2713
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-9923
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Search on listing views doesn't work unless the `?q=` param exists in the URL
<!--
Found a bug? Please fill out the sections below. 👍
-->
### Issue Summary
Possible regression in https://github.com/wagtail/wagtail/pull/9768
The `URLSearchParams.get()` returns `null` if the param doesn't exist, so the following code:
https://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/client/src/entrypoints/admin/core.js#L270-L276
will crash during `currentQuery.trim()` when searching on the listing views (snippets, images, etc.) if the `?q=` param doesn't exist in the URL.
Might be a good time to add `required=False` in here as well:
https://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/wagtail/admin/forms/search.py#L12
to remove this silly error when `q` is an empty string:
<img width="473" alt="image" src="https://user-images.githubusercontent.com/6379424/213499685-ce37c064-2635-434f-952f-e85fae4ab9af.png">
<!--
A summary of the issue.
-->
### Steps to Reproduce
1. Spin up bakerydemo
2. Open the images listing
3. Try to search
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/admin/forms/search.py`
Content:
```
1 from django import forms
2 from django.utils.translation import gettext as _
3 from django.utils.translation import gettext_lazy
4
5
6 class SearchForm(forms.Form):
7 def __init__(self, *args, **kwargs):
8 placeholder = kwargs.pop("placeholder", _("Search"))
9 super().__init__(*args, **kwargs)
10 self.fields["q"].widget.attrs = {"placeholder": placeholder}
11
12 q = forms.CharField(label=gettext_lazy("Search term"), widget=forms.TextInput())
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/admin/forms/search.py b/wagtail/admin/forms/search.py
--- a/wagtail/admin/forms/search.py
+++ b/wagtail/admin/forms/search.py
@@ -9,4 +9,8 @@
super().__init__(*args, **kwargs)
self.fields["q"].widget.attrs = {"placeholder": placeholder}
- q = forms.CharField(label=gettext_lazy("Search term"), widget=forms.TextInput())
+ q = forms.CharField(
+ label=gettext_lazy("Search term"),
+ widget=forms.TextInput(),
+ required=False,
+ )
|
{"golden_diff": "diff --git a/wagtail/admin/forms/search.py b/wagtail/admin/forms/search.py\n--- a/wagtail/admin/forms/search.py\n+++ b/wagtail/admin/forms/search.py\n@@ -9,4 +9,8 @@\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n \n- q = forms.CharField(label=gettext_lazy(\"Search term\"), widget=forms.TextInput())\n+ q = forms.CharField(\n+ label=gettext_lazy(\"Search term\"),\n+ widget=forms.TextInput(),\n+ required=False,\n+ )\n", "issue": "Search on listing views doesn't work unless the `?q=` param exists in the URL\n<!--\r\nFound a bug? Please fill out the sections below. \ud83d\udc4d\r\n-->\r\n\r\n### Issue Summary\r\n\r\nPossible regression in https://github.com/wagtail/wagtail/pull/9768\r\n\r\nThe `URLSearchParams.get()` returns `null` if the param doesn't exist, so the following code:\r\n\r\nhttps://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/client/src/entrypoints/admin/core.js#L270-L276\r\n\r\nwill crash during `currentQuery.trim()` when searching on the listing views (snippets, images, etc.) if the `?q=` param doesn't exist in the URL.\r\n\r\nMight be a good time to add `required=False` in here as well:\r\n\r\nhttps://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/wagtail/admin/forms/search.py#L12\r\n\r\nto remove this silly error when `q` is an empty string:\r\n\r\n<img width=\"473\" alt=\"image\" src=\"https://user-images.githubusercontent.com/6379424/213499685-ce37c064-2635-434f-952f-e85fae4ab9af.png\">\r\n\r\n<!--\r\nA summary of the issue.\r\n-->\r\n\r\n### Steps to Reproduce\r\n\r\n1. Spin up bakerydemo\r\n2. Open the images listing\r\n3. Try to search\r\n\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import gettext as _\nfrom django.utils.translation import gettext_lazy\n\n\nclass SearchForm(forms.Form):\n def __init__(self, *args, **kwargs):\n placeholder = kwargs.pop(\"placeholder\", _(\"Search\"))\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n\n q = forms.CharField(label=gettext_lazy(\"Search term\"), widget=forms.TextInput())\n", "path": "wagtail/admin/forms/search.py"}], "after_files": [{"content": "from django import forms\nfrom django.utils.translation import gettext as _\nfrom django.utils.translation import gettext_lazy\n\n\nclass SearchForm(forms.Form):\n def __init__(self, *args, **kwargs):\n placeholder = kwargs.pop(\"placeholder\", _(\"Search\"))\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n\n q = forms.CharField(\n label=gettext_lazy(\"Search term\"),\n widget=forms.TextInput(),\n required=False,\n )\n", "path": "wagtail/admin/forms/search.py"}]}
| 753 | 124 |
gh_patches_debug_5729
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-995
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Books with same title but different subtitle are hard to distinguish in TL
**Is your feature request related to a problem? Please describe.**
Sometimes a book series has the same title for all books but different subtitles. Example: [Saga: Book One](https://bookwyrm.social/book/39501), [Saga: Book Two](https://bookwyrm.social/book/39471), [Saga: Book Three](https://bookwyrm.social/book/39465). This leads to confusion when something about a book is in my TL and only the title is shown.
**Describe the solution you'd like**
Can we include the subtitle in statuses, if it isn't too long? Maybe if title + subtitle is < X characters, show subtitle?
**Additional context**
The bottom is “Saga: Book One” and the top is “Saga: Book Two”.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/templatetags/bookwyrm_tags.py`
Content:
```
1 """ template filters """
2 from uuid import uuid4
3
4 from django import template, utils
5 from django.db.models import Avg
6
7 from bookwyrm import models, views
8 from bookwyrm.views.status import to_markdown
9
10
11 register = template.Library()
12
13
14 @register.filter(name="dict_key")
15 def dict_key(d, k):
16 """ Returns the given key from a dictionary. """
17 return d.get(k) or 0
18
19
20 @register.filter(name="rating")
21 def get_rating(book, user):
22 """ get the overall rating of a book """
23 queryset = views.helpers.privacy_filter(
24 user, models.Review.objects.filter(book=book)
25 )
26 return queryset.aggregate(Avg("rating"))["rating__avg"]
27
28
29 @register.filter(name="user_rating")
30 def get_user_rating(book, user):
31 """ get a user's rating of a book """
32 rating = (
33 models.Review.objects.filter(
34 user=user,
35 book=book,
36 rating__isnull=False,
37 )
38 .order_by("-published_date")
39 .first()
40 )
41 if rating:
42 return rating.rating
43 return 0
44
45
46 @register.filter(name="username")
47 def get_user_identifier(user):
48 """ use localname for local users, username for remote """
49 return user.localname if user.localname else user.username
50
51
52 @register.filter(name="notification_count")
53 def get_notification_count(user):
54 """ how many UNREAD notifications are there """
55 return user.notification_set.filter(read=False).count()
56
57
58 @register.filter(name="replies")
59 def get_replies(status):
60 """ get all direct replies to a status """
61 # TODO: this limit could cause problems
62 return models.Status.objects.filter(
63 reply_parent=status,
64 deleted=False,
65 ).select_subclasses()[:10]
66
67
68 @register.filter(name="parent")
69 def get_parent(status):
70 """ get the reply parent for a status """
71 return (
72 models.Status.objects.filter(id=status.reply_parent_id)
73 .select_subclasses()
74 .get()
75 )
76
77
78 @register.filter(name="liked")
79 def get_user_liked(user, status):
80 """ did the given user fav a status? """
81 try:
82 models.Favorite.objects.get(user=user, status=status)
83 return True
84 except models.Favorite.DoesNotExist:
85 return False
86
87
88 @register.filter(name="boosted")
89 def get_user_boosted(user, status):
90 """ did the given user fav a status? """
91 return user.id in status.boosters.all().values_list("user", flat=True)
92
93
94 @register.filter(name="follow_request_exists")
95 def follow_request_exists(user, requester):
96 """ see if there is a pending follow request for a user """
97 try:
98 models.UserFollowRequest.objects.filter(
99 user_subject=requester,
100 user_object=user,
101 ).get()
102 return True
103 except models.UserFollowRequest.DoesNotExist:
104 return False
105
106
107 @register.filter(name="boosted_status")
108 def get_boosted(boost):
109 """ load a boosted status. have to do this or it wont get foregin keys """
110 return (
111 models.Status.objects.select_subclasses()
112 .filter(id=boost.boosted_status.id)
113 .get()
114 )
115
116
117 @register.filter(name="book_description")
118 def get_book_description(book):
119 """ use the work's text if the book doesn't have it """
120 return book.description or book.parent_work.description
121
122
123 @register.filter(name="uuid")
124 def get_uuid(identifier):
125 """ for avoiding clashing ids when there are many forms """
126 return "%s%s" % (identifier, uuid4())
127
128
129 @register.filter(name="to_markdown")
130 def get_markdown(content):
131 """ convert markdown to html """
132 if content:
133 return to_markdown(content)
134 return None
135
136
137 @register.filter(name="mentions")
138 def get_mentions(status, user):
139 """ people to @ in a reply: the parent and all mentions """
140 mentions = set([status.user] + list(status.mention_users.all()))
141 return (
142 " ".join("@" + get_user_identifier(m) for m in mentions if not m == user) + " "
143 )
144
145
146 @register.filter(name="status_preview_name")
147 def get_status_preview_name(obj):
148 """ text snippet with book context for a status """
149 name = obj.__class__.__name__.lower()
150 if name == "review":
151 return "%s of <em>%s</em>" % (name, obj.book.title)
152 if name == "comment":
153 return "%s on <em>%s</em>" % (name, obj.book.title)
154 if name == "quotation":
155 return "%s from <em>%s</em>" % (name, obj.book.title)
156 return name
157
158
159 @register.filter(name="next_shelf")
160 def get_next_shelf(current_shelf):
161 """ shelf you'd use to update reading progress """
162 if current_shelf == "to-read":
163 return "reading"
164 if current_shelf == "reading":
165 return "read"
166 if current_shelf == "read":
167 return "read"
168 return "to-read"
169
170
171 @register.simple_tag(takes_context=False)
172 def related_status(notification):
173 """ for notifications """
174 if not notification.related_status:
175 return None
176 if hasattr(notification.related_status, "quotation"):
177 return notification.related_status.quotation
178 if hasattr(notification.related_status, "review"):
179 return notification.related_status.review
180 if hasattr(notification.related_status, "comment"):
181 return notification.related_status.comment
182 return notification.related_status
183
184
185 @register.simple_tag(takes_context=True)
186 def active_shelf(context, book):
187 """ check what shelf a user has a book on, if any """
188 shelf = models.ShelfBook.objects.filter(
189 shelf__user=context["request"].user, book__in=book.parent_work.editions.all()
190 ).first()
191 return shelf if shelf else {"book": book}
192
193
194 @register.simple_tag(takes_context=False)
195 def latest_read_through(book, user):
196 """ the most recent read activity """
197 return (
198 models.ReadThrough.objects.filter(user=user, book=book)
199 .order_by("-start_date")
200 .first()
201 )
202
203
204 @register.simple_tag(takes_context=False)
205 def active_read_through(book, user):
206 """ the most recent read activity """
207 return (
208 models.ReadThrough.objects.filter(
209 user=user, book=book, finish_date__isnull=True
210 )
211 .order_by("-start_date")
212 .first()
213 )
214
215
216 @register.simple_tag(takes_context=False)
217 def comparison_bool(str1, str2):
218 """ idk why I need to write a tag for this, it reutrns a bool """
219 return str1 == str2
220
221
222 @register.simple_tag(takes_context=False)
223 def get_lang():
224 """ get current language, strip to the first two letters """
225 language = utils.translation.get_language()
226 return language[0 : language.find("-")]
227
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bookwyrm/templatetags/bookwyrm_tags.py b/bookwyrm/templatetags/bookwyrm_tags.py
--- a/bookwyrm/templatetags/bookwyrm_tags.py
+++ b/bookwyrm/templatetags/bookwyrm_tags.py
@@ -168,6 +168,17 @@
return "to-read"
[email protected](name="title")
+def get_title(book):
+ """ display the subtitle if the title is short """
+ if not book:
+ return ""
+ title = book.title
+ if len(title) < 6 and book.subtitle:
+ title = "{:s}: {:s}".format(title, book.subtitle)
+ return title
+
+
@register.simple_tag(takes_context=False)
def related_status(notification):
""" for notifications """
|
{"golden_diff": "diff --git a/bookwyrm/templatetags/bookwyrm_tags.py b/bookwyrm/templatetags/bookwyrm_tags.py\n--- a/bookwyrm/templatetags/bookwyrm_tags.py\n+++ b/bookwyrm/templatetags/bookwyrm_tags.py\n@@ -168,6 +168,17 @@\n return \"to-read\"\n \n \[email protected](name=\"title\")\n+def get_title(book):\n+ \"\"\" display the subtitle if the title is short \"\"\"\n+ if not book:\n+ return \"\"\n+ title = book.title\n+ if len(title) < 6 and book.subtitle:\n+ title = \"{:s}: {:s}\".format(title, book.subtitle)\n+ return title\n+\n+\n @register.simple_tag(takes_context=False)\n def related_status(notification):\n \"\"\" for notifications \"\"\"\n", "issue": "Books with same title but different subtitle are hard to distinguish in TL\n**Is your feature request related to a problem? Please describe.**\r\nSometimes a book series has the same title for all books but different subtitles. Example: [Saga: Book One](https://bookwyrm.social/book/39501), [Saga: Book Two](https://bookwyrm.social/book/39471), [Saga: Book Three](https://bookwyrm.social/book/39465). This leads to confusion when something about a book is in my TL and only the title is shown.\r\n\r\n**Describe the solution you'd like**\r\nCan we include the subtitle in statuses, if it isn't too long? Maybe if title + subtitle is < X characters, show subtitle?\r\n\r\n**Additional context**\r\n\r\n The bottom is \u201cSaga: Book One\u201d and the top is \u201cSaga: Book Two\u201d.\r\n\n", "before_files": [{"content": "\"\"\" template filters \"\"\"\nfrom uuid import uuid4\n\nfrom django import template, utils\nfrom django.db.models import Avg\n\nfrom bookwyrm import models, views\nfrom bookwyrm.views.status import to_markdown\n\n\nregister = template.Library()\n\n\[email protected](name=\"dict_key\")\ndef dict_key(d, k):\n \"\"\" Returns the given key from a dictionary. \"\"\"\n return d.get(k) or 0\n\n\[email protected](name=\"rating\")\ndef get_rating(book, user):\n \"\"\" get the overall rating of a book \"\"\"\n queryset = views.helpers.privacy_filter(\n user, models.Review.objects.filter(book=book)\n )\n return queryset.aggregate(Avg(\"rating\"))[\"rating__avg\"]\n\n\[email protected](name=\"user_rating\")\ndef get_user_rating(book, user):\n \"\"\" get a user's rating of a book \"\"\"\n rating = (\n models.Review.objects.filter(\n user=user,\n book=book,\n rating__isnull=False,\n )\n .order_by(\"-published_date\")\n .first()\n )\n if rating:\n return rating.rating\n return 0\n\n\[email protected](name=\"username\")\ndef get_user_identifier(user):\n \"\"\" use localname for local users, username for remote \"\"\"\n return user.localname if user.localname else user.username\n\n\[email protected](name=\"notification_count\")\ndef get_notification_count(user):\n \"\"\" how many UNREAD notifications are there \"\"\"\n return user.notification_set.filter(read=False).count()\n\n\[email protected](name=\"replies\")\ndef get_replies(status):\n \"\"\" get all direct replies to a status \"\"\"\n # TODO: this limit could cause problems\n return models.Status.objects.filter(\n reply_parent=status,\n deleted=False,\n ).select_subclasses()[:10]\n\n\[email protected](name=\"parent\")\ndef get_parent(status):\n \"\"\" get the reply parent for a status \"\"\"\n return (\n models.Status.objects.filter(id=status.reply_parent_id)\n .select_subclasses()\n .get()\n )\n\n\[email protected](name=\"liked\")\ndef get_user_liked(user, status):\n \"\"\" did the given user fav a status? \"\"\"\n try:\n models.Favorite.objects.get(user=user, status=status)\n return True\n except models.Favorite.DoesNotExist:\n return False\n\n\[email protected](name=\"boosted\")\ndef get_user_boosted(user, status):\n \"\"\" did the given user fav a status? \"\"\"\n return user.id in status.boosters.all().values_list(\"user\", flat=True)\n\n\[email protected](name=\"follow_request_exists\")\ndef follow_request_exists(user, requester):\n \"\"\" see if there is a pending follow request for a user \"\"\"\n try:\n models.UserFollowRequest.objects.filter(\n user_subject=requester,\n user_object=user,\n ).get()\n return True\n except models.UserFollowRequest.DoesNotExist:\n return False\n\n\[email protected](name=\"boosted_status\")\ndef get_boosted(boost):\n \"\"\" load a boosted status. have to do this or it wont get foregin keys \"\"\"\n return (\n models.Status.objects.select_subclasses()\n .filter(id=boost.boosted_status.id)\n .get()\n )\n\n\[email protected](name=\"book_description\")\ndef get_book_description(book):\n \"\"\" use the work's text if the book doesn't have it \"\"\"\n return book.description or book.parent_work.description\n\n\[email protected](name=\"uuid\")\ndef get_uuid(identifier):\n \"\"\" for avoiding clashing ids when there are many forms \"\"\"\n return \"%s%s\" % (identifier, uuid4())\n\n\[email protected](name=\"to_markdown\")\ndef get_markdown(content):\n \"\"\" convert markdown to html \"\"\"\n if content:\n return to_markdown(content)\n return None\n\n\[email protected](name=\"mentions\")\ndef get_mentions(status, user):\n \"\"\" people to @ in a reply: the parent and all mentions \"\"\"\n mentions = set([status.user] + list(status.mention_users.all()))\n return (\n \" \".join(\"@\" + get_user_identifier(m) for m in mentions if not m == user) + \" \"\n )\n\n\[email protected](name=\"status_preview_name\")\ndef get_status_preview_name(obj):\n \"\"\" text snippet with book context for a status \"\"\"\n name = obj.__class__.__name__.lower()\n if name == \"review\":\n return \"%s of <em>%s</em>\" % (name, obj.book.title)\n if name == \"comment\":\n return \"%s on <em>%s</em>\" % (name, obj.book.title)\n if name == \"quotation\":\n return \"%s from <em>%s</em>\" % (name, obj.book.title)\n return name\n\n\[email protected](name=\"next_shelf\")\ndef get_next_shelf(current_shelf):\n \"\"\" shelf you'd use to update reading progress \"\"\"\n if current_shelf == \"to-read\":\n return \"reading\"\n if current_shelf == \"reading\":\n return \"read\"\n if current_shelf == \"read\":\n return \"read\"\n return \"to-read\"\n\n\[email protected]_tag(takes_context=False)\ndef related_status(notification):\n \"\"\" for notifications \"\"\"\n if not notification.related_status:\n return None\n if hasattr(notification.related_status, \"quotation\"):\n return notification.related_status.quotation\n if hasattr(notification.related_status, \"review\"):\n return notification.related_status.review\n if hasattr(notification.related_status, \"comment\"):\n return notification.related_status.comment\n return notification.related_status\n\n\[email protected]_tag(takes_context=True)\ndef active_shelf(context, book):\n \"\"\" check what shelf a user has a book on, if any \"\"\"\n shelf = models.ShelfBook.objects.filter(\n shelf__user=context[\"request\"].user, book__in=book.parent_work.editions.all()\n ).first()\n return shelf if shelf else {\"book\": book}\n\n\[email protected]_tag(takes_context=False)\ndef latest_read_through(book, user):\n \"\"\" the most recent read activity \"\"\"\n return (\n models.ReadThrough.objects.filter(user=user, book=book)\n .order_by(\"-start_date\")\n .first()\n )\n\n\[email protected]_tag(takes_context=False)\ndef active_read_through(book, user):\n \"\"\" the most recent read activity \"\"\"\n return (\n models.ReadThrough.objects.filter(\n user=user, book=book, finish_date__isnull=True\n )\n .order_by(\"-start_date\")\n .first()\n )\n\n\[email protected]_tag(takes_context=False)\ndef comparison_bool(str1, str2):\n \"\"\" idk why I need to write a tag for this, it reutrns a bool \"\"\"\n return str1 == str2\n\n\[email protected]_tag(takes_context=False)\ndef get_lang():\n \"\"\" get current language, strip to the first two letters \"\"\"\n language = utils.translation.get_language()\n return language[0 : language.find(\"-\")]\n", "path": "bookwyrm/templatetags/bookwyrm_tags.py"}], "after_files": [{"content": "\"\"\" template filters \"\"\"\nfrom uuid import uuid4\n\nfrom django import template, utils\nfrom django.db.models import Avg\n\nfrom bookwyrm import models, views\nfrom bookwyrm.views.status import to_markdown\n\n\nregister = template.Library()\n\n\[email protected](name=\"dict_key\")\ndef dict_key(d, k):\n \"\"\" Returns the given key from a dictionary. \"\"\"\n return d.get(k) or 0\n\n\[email protected](name=\"rating\")\ndef get_rating(book, user):\n \"\"\" get the overall rating of a book \"\"\"\n queryset = views.helpers.privacy_filter(\n user, models.Review.objects.filter(book=book)\n )\n return queryset.aggregate(Avg(\"rating\"))[\"rating__avg\"]\n\n\[email protected](name=\"user_rating\")\ndef get_user_rating(book, user):\n \"\"\" get a user's rating of a book \"\"\"\n rating = (\n models.Review.objects.filter(\n user=user,\n book=book,\n rating__isnull=False,\n )\n .order_by(\"-published_date\")\n .first()\n )\n if rating:\n return rating.rating\n return 0\n\n\[email protected](name=\"username\")\ndef get_user_identifier(user):\n \"\"\" use localname for local users, username for remote \"\"\"\n return user.localname if user.localname else user.username\n\n\[email protected](name=\"notification_count\")\ndef get_notification_count(user):\n \"\"\" how many UNREAD notifications are there \"\"\"\n return user.notification_set.filter(read=False).count()\n\n\[email protected](name=\"replies\")\ndef get_replies(status):\n \"\"\" get all direct replies to a status \"\"\"\n # TODO: this limit could cause problems\n return models.Status.objects.filter(\n reply_parent=status,\n deleted=False,\n ).select_subclasses()[:10]\n\n\[email protected](name=\"parent\")\ndef get_parent(status):\n \"\"\" get the reply parent for a status \"\"\"\n return (\n models.Status.objects.filter(id=status.reply_parent_id)\n .select_subclasses()\n .get()\n )\n\n\[email protected](name=\"liked\")\ndef get_user_liked(user, status):\n \"\"\" did the given user fav a status? \"\"\"\n try:\n models.Favorite.objects.get(user=user, status=status)\n return True\n except models.Favorite.DoesNotExist:\n return False\n\n\[email protected](name=\"boosted\")\ndef get_user_boosted(user, status):\n \"\"\" did the given user fav a status? \"\"\"\n return user.id in status.boosters.all().values_list(\"user\", flat=True)\n\n\[email protected](name=\"follow_request_exists\")\ndef follow_request_exists(user, requester):\n \"\"\" see if there is a pending follow request for a user \"\"\"\n try:\n models.UserFollowRequest.objects.filter(\n user_subject=requester,\n user_object=user,\n ).get()\n return True\n except models.UserFollowRequest.DoesNotExist:\n return False\n\n\[email protected](name=\"boosted_status\")\ndef get_boosted(boost):\n \"\"\" load a boosted status. have to do this or it wont get foregin keys \"\"\"\n return (\n models.Status.objects.select_subclasses()\n .filter(id=boost.boosted_status.id)\n .get()\n )\n\n\[email protected](name=\"book_description\")\ndef get_book_description(book):\n \"\"\" use the work's text if the book doesn't have it \"\"\"\n return book.description or book.parent_work.description\n\n\[email protected](name=\"uuid\")\ndef get_uuid(identifier):\n \"\"\" for avoiding clashing ids when there are many forms \"\"\"\n return \"%s%s\" % (identifier, uuid4())\n\n\[email protected](name=\"to_markdown\")\ndef get_markdown(content):\n \"\"\" convert markdown to html \"\"\"\n if content:\n return to_markdown(content)\n return None\n\n\[email protected](name=\"mentions\")\ndef get_mentions(status, user):\n \"\"\" people to @ in a reply: the parent and all mentions \"\"\"\n mentions = set([status.user] + list(status.mention_users.all()))\n return (\n \" \".join(\"@\" + get_user_identifier(m) for m in mentions if not m == user) + \" \"\n )\n\n\[email protected](name=\"status_preview_name\")\ndef get_status_preview_name(obj):\n \"\"\" text snippet with book context for a status \"\"\"\n name = obj.__class__.__name__.lower()\n if name == \"review\":\n return \"%s of <em>%s</em>\" % (name, obj.book.title)\n if name == \"comment\":\n return \"%s on <em>%s</em>\" % (name, obj.book.title)\n if name == \"quotation\":\n return \"%s from <em>%s</em>\" % (name, obj.book.title)\n return name\n\n\[email protected](name=\"next_shelf\")\ndef get_next_shelf(current_shelf):\n \"\"\" shelf you'd use to update reading progress \"\"\"\n if current_shelf == \"to-read\":\n return \"reading\"\n if current_shelf == \"reading\":\n return \"read\"\n if current_shelf == \"read\":\n return \"read\"\n return \"to-read\"\n\n\[email protected](name=\"title\")\ndef get_title(book):\n \"\"\" display the subtitle if the title is short \"\"\"\n if not book:\n return \"\"\n title = book.title\n if len(title) < 6 and book.subtitle:\n title = \"{:s}: {:s}\".format(title, book.subtitle)\n return title\n\n\[email protected]_tag(takes_context=False)\ndef related_status(notification):\n \"\"\" for notifications \"\"\"\n if not notification.related_status:\n return None\n if hasattr(notification.related_status, \"quotation\"):\n return notification.related_status.quotation\n if hasattr(notification.related_status, \"review\"):\n return notification.related_status.review\n if hasattr(notification.related_status, \"comment\"):\n return notification.related_status.comment\n return notification.related_status\n\n\[email protected]_tag(takes_context=True)\ndef active_shelf(context, book):\n \"\"\" check what shelf a user has a book on, if any \"\"\"\n shelf = models.ShelfBook.objects.filter(\n shelf__user=context[\"request\"].user, book__in=book.parent_work.editions.all()\n ).first()\n return shelf if shelf else {\"book\": book}\n\n\[email protected]_tag(takes_context=False)\ndef latest_read_through(book, user):\n \"\"\" the most recent read activity \"\"\"\n return (\n models.ReadThrough.objects.filter(user=user, book=book)\n .order_by(\"-start_date\")\n .first()\n )\n\n\[email protected]_tag(takes_context=False)\ndef active_read_through(book, user):\n \"\"\" the most recent read activity \"\"\"\n return (\n models.ReadThrough.objects.filter(\n user=user, book=book, finish_date__isnull=True\n )\n .order_by(\"-start_date\")\n .first()\n )\n\n\[email protected]_tag(takes_context=False)\ndef comparison_bool(str1, str2):\n \"\"\" idk why I need to write a tag for this, it reutrns a bool \"\"\"\n return str1 == str2\n\n\[email protected]_tag(takes_context=False)\ndef get_lang():\n \"\"\" get current language, strip to the first two letters \"\"\"\n language = utils.translation.get_language()\n return language[0 : language.find(\"-\")]\n", "path": "bookwyrm/templatetags/bookwyrm_tags.py"}]}
| 2,578 | 185 |
gh_patches_debug_3183
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-8499
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Missing `basic_auth.ini` in PyPI package
### Issues Policy acknowledgement
- [X] I have read and agree to submit bug reports in accordance with the [issues policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)
### Willingness to contribute
Yes. I can contribute a fix for this bug independently.
### MLflow version
- Client: 2.3.2
- Tracking server: 2.3.2
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:
- **Python version**:
- **yarn version, if running the dev UI**:
### Describe the problem
Freshly installed mlflow package from PyPI is missing `basic_auth.ini` and cannot launch basic auth app.


### Tracking information
<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->
```shell
REPLACE_ME
```
### Code to reproduce issue
<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->
```
pip install mlflow
mlflow ui --app-name=basic-auth
```
### Stack trace
<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->
```
REPLACE_ME
```
### Other info / logs
<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->
```
REPLACE_ME
```
### What component(s) does this bug affect?
- [ ] `area/artifacts`: Artifact stores and artifact logging
- [ ] `area/build`: Build and test infrastructure for MLflow
- [ ] `area/docs`: MLflow documentation pages
- [ ] `area/examples`: Example code
- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry
- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors
- [ ] `area/recipes`: Recipes, Recipe APIs, Recipe configs, Recipe Templates
- [ ] `area/projects`: MLproject format, project running backends
- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs
- [ ] `area/server-infra`: MLflow Tracking server backend
- [X] `area/tracking`: Tracking Service, tracking client APIs, autologging
### What interface(s) does this bug affect?
- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server
- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models
- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry
- [ ] `area/windows`: Windows support
### What language(s) does this bug affect?
- [ ] `language/r`: R APIs and clients
- [ ] `language/java`: Java APIs and clients
- [ ] `language/new`: Proposals for new client languages
### What integration(s) does this bug affect?
- [ ] `integrations/azure`: Azure and Azure ML integrations
- [ ] `integrations/sagemaker`: SageMaker integrations
- [ ] `integrations/databricks`: Databricks integrations
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import logging
3 from importlib.machinery import SourceFileLoader
4 from setuptools import setup, find_packages, Command
5
6 _MLFLOW_SKINNY_ENV_VAR = "MLFLOW_SKINNY"
7
8 version = (
9 SourceFileLoader("mlflow.version", os.path.join("mlflow", "version.py")).load_module().VERSION
10 )
11
12
13 # Get a list of all files in the directory to include in our module
14 def package_files(directory):
15 paths = []
16 for path, _, filenames in os.walk(directory):
17 for filename in filenames:
18 paths.append(os.path.join("..", path, filename))
19 return paths
20
21
22 def is_comment_or_empty(line):
23 stripped = line.strip()
24 return stripped == "" or stripped.startswith("#")
25
26
27 def remove_comments_and_empty_lines(lines):
28 return [line for line in lines if not is_comment_or_empty(line)]
29
30
31 # Prints out a set of paths (relative to the mlflow/ directory) of files in mlflow/server/js/build
32 # to include in the wheel, e.g. "../mlflow/server/js/build/index.html"
33 js_files = package_files("mlflow/server/js/build")
34 models_container_server_files = package_files("mlflow/models/container")
35 alembic_files = [
36 "../mlflow/store/db_migrations/alembic.ini",
37 "../mlflow/temporary_db_migrations_for_pre_1_users/alembic.ini",
38 ]
39 extra_files = [
40 "pypi_package_index.json",
41 "pyspark/ml/log_model_allowlist.txt",
42 ]
43 recipes_template_files = package_files("mlflow/recipes/resources")
44 recipes_files = package_files("mlflow/recipes/cards/templates")
45
46
47 """
48 Minimal requirements for the skinny MLflow client which provides a limited
49 subset of functionality such as: RESTful client functionality for Tracking and
50 Model Registry, as well as support for Project execution against local backends
51 and Databricks.
52 """
53 with open(os.path.join("requirements", "skinny-requirements.txt")) as f:
54 SKINNY_REQUIREMENTS = remove_comments_and_empty_lines(f.read().splitlines())
55
56
57 """
58 These are the core requirements for the complete MLflow platform, which augments
59 the skinny client functionality with support for running the MLflow Tracking
60 Server & UI. It also adds project backends such as Docker and Kubernetes among
61 other capabilities.
62 """
63 with open(os.path.join("requirements", "core-requirements.txt")) as f:
64 CORE_REQUIREMENTS = SKINNY_REQUIREMENTS + remove_comments_and_empty_lines(f.read().splitlines())
65
66 _is_mlflow_skinny = bool(os.environ.get(_MLFLOW_SKINNY_ENV_VAR))
67 logging.debug("{} env var is set: {}".format(_MLFLOW_SKINNY_ENV_VAR, _is_mlflow_skinny))
68
69
70 class ListDependencies(Command):
71 # `python setup.py <command name>` prints out "running <command name>" by default.
72 # This logging message must be hidden by specifying `--quiet` (or `-q`) when piping the output
73 # of this command to `pip install`.
74 description = "List mlflow dependencies"
75 user_options = [
76 ("skinny", None, "List mlflow-skinny dependencies"),
77 ]
78
79 def initialize_options(self):
80 self.skinny = False
81
82 def finalize_options(self):
83 pass
84
85 def run(self):
86 dependencies = SKINNY_REQUIREMENTS if self.skinny else CORE_REQUIREMENTS
87 print("\n".join(dependencies))
88
89
90 MINIMUM_SUPPORTED_PYTHON_VERSION = "3.8"
91
92
93 class MinPythonVersion(Command):
94 description = "Print out the minimum supported Python version"
95 user_options = []
96
97 def initialize_options(self):
98 pass
99
100 def finalize_options(self):
101 pass
102
103 def run(self):
104 print(MINIMUM_SUPPORTED_PYTHON_VERSION)
105
106
107 setup(
108 name="mlflow" if not _is_mlflow_skinny else "mlflow-skinny",
109 version=version,
110 packages=find_packages(exclude=["tests", "tests.*"]),
111 package_data={
112 "mlflow": (
113 js_files
114 + models_container_server_files
115 + alembic_files
116 + extra_files
117 + recipes_template_files
118 + recipes_files
119 ),
120 }
121 if not _is_mlflow_skinny
122 # include alembic files to enable usage of the skinny client with SQL databases
123 # if users install sqlalchemy and alembic independently
124 else {"mlflow": alembic_files + extra_files},
125 install_requires=CORE_REQUIREMENTS if not _is_mlflow_skinny else SKINNY_REQUIREMENTS,
126 extras_require={
127 "extras": [
128 # Required to log artifacts and models to HDFS artifact locations
129 "pyarrow",
130 # Required to sign outgoing request with SigV4 signature
131 "requests-auth-aws-sigv4",
132 # Required to log artifacts and models to AWS S3 artifact locations
133 "boto3",
134 # Required to log artifacts and models to GCS artifact locations
135 "google-cloud-storage>=1.30.0",
136 "azureml-core>=1.2.0",
137 # Required to log artifacts to SFTP artifact locations
138 "pysftp",
139 # Required by the mlflow.projects module, when running projects against
140 # a remote Kubernetes cluster
141 "kubernetes",
142 # Required to serve models through MLServer
143 # NOTE: remove the upper version pin once protobuf is no longer pinned in mlserver
144 # Reference issue: https://github.com/SeldonIO/MLServer/issues/1089
145 "mlserver>=1.2.0,!=1.3.1",
146 "mlserver-mlflow>=1.2.0,!=1.3.1",
147 "virtualenv",
148 # Required for exporting metrics from the MLflow server to Prometheus
149 # as part of the MLflow server monitoring add-on
150 "prometheus-flask-exporter",
151 ],
152 "databricks": [
153 # Required to write model artifacts to unity catalog locations
154 "azure-storage-file-datalake>12",
155 "google-cloud-storage>=1.30.0",
156 "boto3>1",
157 ],
158 "sqlserver": ["mlflow-dbstore"],
159 "aliyun-oss": ["aliyunstoreplugin"],
160 },
161 entry_points="""
162 [console_scripts]
163 mlflow=mlflow.cli:cli
164
165 [mlflow.app]
166 basic-auth=mlflow.server.auth:app
167 """,
168 cmdclass={
169 "dependencies": ListDependencies,
170 "min_python_version": MinPythonVersion,
171 },
172 zip_safe=False,
173 author="Databricks",
174 description="MLflow: A Platform for ML Development and Productionization",
175 long_description=open("README.rst").read()
176 if not _is_mlflow_skinny
177 else open("README_SKINNY.rst").read() + open("README.rst").read(),
178 long_description_content_type="text/x-rst",
179 license="Apache License 2.0",
180 classifiers=[
181 "Intended Audience :: Developers",
182 f"Programming Language :: Python :: {MINIMUM_SUPPORTED_PYTHON_VERSION}",
183 ],
184 keywords="ml ai databricks",
185 url="https://mlflow.org/",
186 python_requires=f">={MINIMUM_SUPPORTED_PYTHON_VERSION}",
187 project_urls={
188 "Bug Tracker": "https://github.com/mlflow/mlflow/issues",
189 "Documentation": "https://mlflow.org/docs/latest/index.html",
190 "Source Code": "https://github.com/mlflow/mlflow",
191 },
192 )
193
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -39,6 +39,7 @@
extra_files = [
"pypi_package_index.json",
"pyspark/ml/log_model_allowlist.txt",
+ "server/auth/basic_auth.ini",
]
recipes_template_files = package_files("mlflow/recipes/resources")
recipes_files = package_files("mlflow/recipes/cards/templates")
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -39,6 +39,7 @@\n extra_files = [\n \"pypi_package_index.json\",\n \"pyspark/ml/log_model_allowlist.txt\",\n+ \"server/auth/basic_auth.ini\",\n ]\n recipes_template_files = package_files(\"mlflow/recipes/resources\")\n recipes_files = package_files(\"mlflow/recipes/cards/templates\")\n", "issue": "[BUG] Missing `basic_auth.ini` in PyPI package\n### Issues Policy acknowledgement\n\n- [X] I have read and agree to submit bug reports in accordance with the [issues policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)\n\n### Willingness to contribute\n\nYes. I can contribute a fix for this bug independently.\n\n### MLflow version\n\n- Client: 2.3.2\r\n- Tracking server: 2.3.2\r\n\n\n### System information\n\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:\r\n- **Python version**:\r\n- **yarn version, if running the dev UI**:\r\n\n\n### Describe the problem\n\nFreshly installed mlflow package from PyPI is missing `basic_auth.ini` and cannot launch basic auth app.\r\n\r\n\r\n\r\n\r\n\n\n### Tracking information\n\n<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->\r\n```shell\r\nREPLACE_ME\r\n```\r\n\n\n### Code to reproduce issue\n\n<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->\r\n```\r\npip install mlflow\r\nmlflow ui --app-name=basic-auth\r\n```\r\n\n\n### Stack trace\n\n<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->\r\n```\r\nREPLACE_ME\r\n```\r\n\n\n### Other info / logs\n\n<!-- PLEASE KEEP BACKTICKS AND CHECK PREVIEW -->\r\n```\r\nREPLACE_ME\r\n```\r\n\n\n### What component(s) does this bug affect?\n\n- [ ] `area/artifacts`: Artifact stores and artifact logging\n- [ ] `area/build`: Build and test infrastructure for MLflow\n- [ ] `area/docs`: MLflow documentation pages\n- [ ] `area/examples`: Example code\n- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry\n- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors\n- [ ] `area/recipes`: Recipes, Recipe APIs, Recipe configs, Recipe Templates\n- [ ] `area/projects`: MLproject format, project running backends\n- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs\n- [ ] `area/server-infra`: MLflow Tracking server backend\n- [X] `area/tracking`: Tracking Service, tracking client APIs, autologging\n\n### What interface(s) does this bug affect?\n\n- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server\n- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models\n- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry\n- [ ] `area/windows`: Windows support\n\n### What language(s) does this bug affect?\n\n- [ ] `language/r`: R APIs and clients\n- [ ] `language/java`: Java APIs and clients\n- [ ] `language/new`: Proposals for new client languages\n\n### What integration(s) does this bug affect?\n\n- [ ] `integrations/azure`: Azure and Azure ML integrations\n- [ ] `integrations/sagemaker`: SageMaker integrations\n- [ ] `integrations/databricks`: Databricks integrations\n", "before_files": [{"content": "import os\nimport logging\nfrom importlib.machinery import SourceFileLoader\nfrom setuptools import setup, find_packages, Command\n\n_MLFLOW_SKINNY_ENV_VAR = \"MLFLOW_SKINNY\"\n\nversion = (\n SourceFileLoader(\"mlflow.version\", os.path.join(\"mlflow\", \"version.py\")).load_module().VERSION\n)\n\n\n# Get a list of all files in the directory to include in our module\ndef package_files(directory):\n paths = []\n for path, _, filenames in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join(\"..\", path, filename))\n return paths\n\n\ndef is_comment_or_empty(line):\n stripped = line.strip()\n return stripped == \"\" or stripped.startswith(\"#\")\n\n\ndef remove_comments_and_empty_lines(lines):\n return [line for line in lines if not is_comment_or_empty(line)]\n\n\n# Prints out a set of paths (relative to the mlflow/ directory) of files in mlflow/server/js/build\n# to include in the wheel, e.g. \"../mlflow/server/js/build/index.html\"\njs_files = package_files(\"mlflow/server/js/build\")\nmodels_container_server_files = package_files(\"mlflow/models/container\")\nalembic_files = [\n \"../mlflow/store/db_migrations/alembic.ini\",\n \"../mlflow/temporary_db_migrations_for_pre_1_users/alembic.ini\",\n]\nextra_files = [\n \"pypi_package_index.json\",\n \"pyspark/ml/log_model_allowlist.txt\",\n]\nrecipes_template_files = package_files(\"mlflow/recipes/resources\")\nrecipes_files = package_files(\"mlflow/recipes/cards/templates\")\n\n\n\"\"\"\nMinimal requirements for the skinny MLflow client which provides a limited\nsubset of functionality such as: RESTful client functionality for Tracking and\nModel Registry, as well as support for Project execution against local backends\nand Databricks.\n\"\"\"\nwith open(os.path.join(\"requirements\", \"skinny-requirements.txt\")) as f:\n SKINNY_REQUIREMENTS = remove_comments_and_empty_lines(f.read().splitlines())\n\n\n\"\"\"\nThese are the core requirements for the complete MLflow platform, which augments\nthe skinny client functionality with support for running the MLflow Tracking\nServer & UI. It also adds project backends such as Docker and Kubernetes among\nother capabilities.\n\"\"\"\nwith open(os.path.join(\"requirements\", \"core-requirements.txt\")) as f:\n CORE_REQUIREMENTS = SKINNY_REQUIREMENTS + remove_comments_and_empty_lines(f.read().splitlines())\n\n_is_mlflow_skinny = bool(os.environ.get(_MLFLOW_SKINNY_ENV_VAR))\nlogging.debug(\"{} env var is set: {}\".format(_MLFLOW_SKINNY_ENV_VAR, _is_mlflow_skinny))\n\n\nclass ListDependencies(Command):\n # `python setup.py <command name>` prints out \"running <command name>\" by default.\n # This logging message must be hidden by specifying `--quiet` (or `-q`) when piping the output\n # of this command to `pip install`.\n description = \"List mlflow dependencies\"\n user_options = [\n (\"skinny\", None, \"List mlflow-skinny dependencies\"),\n ]\n\n def initialize_options(self):\n self.skinny = False\n\n def finalize_options(self):\n pass\n\n def run(self):\n dependencies = SKINNY_REQUIREMENTS if self.skinny else CORE_REQUIREMENTS\n print(\"\\n\".join(dependencies))\n\n\nMINIMUM_SUPPORTED_PYTHON_VERSION = \"3.8\"\n\n\nclass MinPythonVersion(Command):\n description = \"Print out the minimum supported Python version\"\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n print(MINIMUM_SUPPORTED_PYTHON_VERSION)\n\n\nsetup(\n name=\"mlflow\" if not _is_mlflow_skinny else \"mlflow-skinny\",\n version=version,\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\n \"mlflow\": (\n js_files\n + models_container_server_files\n + alembic_files\n + extra_files\n + recipes_template_files\n + recipes_files\n ),\n }\n if not _is_mlflow_skinny\n # include alembic files to enable usage of the skinny client with SQL databases\n # if users install sqlalchemy and alembic independently\n else {\"mlflow\": alembic_files + extra_files},\n install_requires=CORE_REQUIREMENTS if not _is_mlflow_skinny else SKINNY_REQUIREMENTS,\n extras_require={\n \"extras\": [\n # Required to log artifacts and models to HDFS artifact locations\n \"pyarrow\",\n # Required to sign outgoing request with SigV4 signature\n \"requests-auth-aws-sigv4\",\n # Required to log artifacts and models to AWS S3 artifact locations\n \"boto3\",\n # Required to log artifacts and models to GCS artifact locations\n \"google-cloud-storage>=1.30.0\",\n \"azureml-core>=1.2.0\",\n # Required to log artifacts to SFTP artifact locations\n \"pysftp\",\n # Required by the mlflow.projects module, when running projects against\n # a remote Kubernetes cluster\n \"kubernetes\",\n # Required to serve models through MLServer\n # NOTE: remove the upper version pin once protobuf is no longer pinned in mlserver\n # Reference issue: https://github.com/SeldonIO/MLServer/issues/1089\n \"mlserver>=1.2.0,!=1.3.1\",\n \"mlserver-mlflow>=1.2.0,!=1.3.1\",\n \"virtualenv\",\n # Required for exporting metrics from the MLflow server to Prometheus\n # as part of the MLflow server monitoring add-on\n \"prometheus-flask-exporter\",\n ],\n \"databricks\": [\n # Required to write model artifacts to unity catalog locations\n \"azure-storage-file-datalake>12\",\n \"google-cloud-storage>=1.30.0\",\n \"boto3>1\",\n ],\n \"sqlserver\": [\"mlflow-dbstore\"],\n \"aliyun-oss\": [\"aliyunstoreplugin\"],\n },\n entry_points=\"\"\"\n [console_scripts]\n mlflow=mlflow.cli:cli\n\n [mlflow.app]\n basic-auth=mlflow.server.auth:app\n \"\"\",\n cmdclass={\n \"dependencies\": ListDependencies,\n \"min_python_version\": MinPythonVersion,\n },\n zip_safe=False,\n author=\"Databricks\",\n description=\"MLflow: A Platform for ML Development and Productionization\",\n long_description=open(\"README.rst\").read()\n if not _is_mlflow_skinny\n else open(\"README_SKINNY.rst\").read() + open(\"README.rst\").read(),\n long_description_content_type=\"text/x-rst\",\n license=\"Apache License 2.0\",\n classifiers=[\n \"Intended Audience :: Developers\",\n f\"Programming Language :: Python :: {MINIMUM_SUPPORTED_PYTHON_VERSION}\",\n ],\n keywords=\"ml ai databricks\",\n url=\"https://mlflow.org/\",\n python_requires=f\">={MINIMUM_SUPPORTED_PYTHON_VERSION}\",\n project_urls={\n \"Bug Tracker\": \"https://github.com/mlflow/mlflow/issues\",\n \"Documentation\": \"https://mlflow.org/docs/latest/index.html\",\n \"Source Code\": \"https://github.com/mlflow/mlflow\",\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport logging\nfrom importlib.machinery import SourceFileLoader\nfrom setuptools import setup, find_packages, Command\n\n_MLFLOW_SKINNY_ENV_VAR = \"MLFLOW_SKINNY\"\n\nversion = (\n SourceFileLoader(\"mlflow.version\", os.path.join(\"mlflow\", \"version.py\")).load_module().VERSION\n)\n\n\n# Get a list of all files in the directory to include in our module\ndef package_files(directory):\n paths = []\n for path, _, filenames in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join(\"..\", path, filename))\n return paths\n\n\ndef is_comment_or_empty(line):\n stripped = line.strip()\n return stripped == \"\" or stripped.startswith(\"#\")\n\n\ndef remove_comments_and_empty_lines(lines):\n return [line for line in lines if not is_comment_or_empty(line)]\n\n\n# Prints out a set of paths (relative to the mlflow/ directory) of files in mlflow/server/js/build\n# to include in the wheel, e.g. \"../mlflow/server/js/build/index.html\"\njs_files = package_files(\"mlflow/server/js/build\")\nmodels_container_server_files = package_files(\"mlflow/models/container\")\nalembic_files = [\n \"../mlflow/store/db_migrations/alembic.ini\",\n \"../mlflow/temporary_db_migrations_for_pre_1_users/alembic.ini\",\n]\nextra_files = [\n \"pypi_package_index.json\",\n \"pyspark/ml/log_model_allowlist.txt\",\n \"server/auth/basic_auth.ini\",\n]\nrecipes_template_files = package_files(\"mlflow/recipes/resources\")\nrecipes_files = package_files(\"mlflow/recipes/cards/templates\")\n\n\n\"\"\"\nMinimal requirements for the skinny MLflow client which provides a limited\nsubset of functionality such as: RESTful client functionality for Tracking and\nModel Registry, as well as support for Project execution against local backends\nand Databricks.\n\"\"\"\nwith open(os.path.join(\"requirements\", \"skinny-requirements.txt\")) as f:\n SKINNY_REQUIREMENTS = remove_comments_and_empty_lines(f.read().splitlines())\n\n\n\"\"\"\nThese are the core requirements for the complete MLflow platform, which augments\nthe skinny client functionality with support for running the MLflow Tracking\nServer & UI. It also adds project backends such as Docker and Kubernetes among\nother capabilities.\n\"\"\"\nwith open(os.path.join(\"requirements\", \"core-requirements.txt\")) as f:\n CORE_REQUIREMENTS = SKINNY_REQUIREMENTS + remove_comments_and_empty_lines(f.read().splitlines())\n\n_is_mlflow_skinny = bool(os.environ.get(_MLFLOW_SKINNY_ENV_VAR))\nlogging.debug(\"{} env var is set: {}\".format(_MLFLOW_SKINNY_ENV_VAR, _is_mlflow_skinny))\n\n\nclass ListDependencies(Command):\n # `python setup.py <command name>` prints out \"running <command name>\" by default.\n # This logging message must be hidden by specifying `--quiet` (or `-q`) when piping the output\n # of this command to `pip install`.\n description = \"List mlflow dependencies\"\n user_options = [\n (\"skinny\", None, \"List mlflow-skinny dependencies\"),\n ]\n\n def initialize_options(self):\n self.skinny = False\n\n def finalize_options(self):\n pass\n\n def run(self):\n dependencies = SKINNY_REQUIREMENTS if self.skinny else CORE_REQUIREMENTS\n print(\"\\n\".join(dependencies))\n\n\nMINIMUM_SUPPORTED_PYTHON_VERSION = \"3.8\"\n\n\nclass MinPythonVersion(Command):\n description = \"Print out the minimum supported Python version\"\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n print(MINIMUM_SUPPORTED_PYTHON_VERSION)\n\n\nsetup(\n name=\"mlflow\" if not _is_mlflow_skinny else \"mlflow-skinny\",\n version=version,\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\n \"mlflow\": (\n js_files\n + models_container_server_files\n + alembic_files\n + extra_files\n + recipes_template_files\n + recipes_files\n ),\n }\n if not _is_mlflow_skinny\n # include alembic files to enable usage of the skinny client with SQL databases\n # if users install sqlalchemy and alembic independently\n else {\"mlflow\": alembic_files + extra_files},\n install_requires=CORE_REQUIREMENTS if not _is_mlflow_skinny else SKINNY_REQUIREMENTS,\n extras_require={\n \"extras\": [\n # Required to log artifacts and models to HDFS artifact locations\n \"pyarrow\",\n # Required to sign outgoing request with SigV4 signature\n \"requests-auth-aws-sigv4\",\n # Required to log artifacts and models to AWS S3 artifact locations\n \"boto3\",\n # Required to log artifacts and models to GCS artifact locations\n \"google-cloud-storage>=1.30.0\",\n \"azureml-core>=1.2.0\",\n # Required to log artifacts to SFTP artifact locations\n \"pysftp\",\n # Required by the mlflow.projects module, when running projects against\n # a remote Kubernetes cluster\n \"kubernetes\",\n # Required to serve models through MLServer\n # NOTE: remove the upper version pin once protobuf is no longer pinned in mlserver\n # Reference issue: https://github.com/SeldonIO/MLServer/issues/1089\n \"mlserver>=1.2.0,!=1.3.1\",\n \"mlserver-mlflow>=1.2.0,!=1.3.1\",\n \"virtualenv\",\n # Required for exporting metrics from the MLflow server to Prometheus\n # as part of the MLflow server monitoring add-on\n \"prometheus-flask-exporter\",\n ],\n \"databricks\": [\n # Required to write model artifacts to unity catalog locations\n \"azure-storage-file-datalake>12\",\n \"google-cloud-storage>=1.30.0\",\n \"boto3>1\",\n ],\n \"sqlserver\": [\"mlflow-dbstore\"],\n \"aliyun-oss\": [\"aliyunstoreplugin\"],\n },\n entry_points=\"\"\"\n [console_scripts]\n mlflow=mlflow.cli:cli\n\n [mlflow.app]\n basic-auth=mlflow.server.auth:app\n \"\"\",\n cmdclass={\n \"dependencies\": ListDependencies,\n \"min_python_version\": MinPythonVersion,\n },\n zip_safe=False,\n author=\"Databricks\",\n description=\"MLflow: A Platform for ML Development and Productionization\",\n long_description=open(\"README.rst\").read()\n if not _is_mlflow_skinny\n else open(\"README_SKINNY.rst\").read() + open(\"README.rst\").read(),\n long_description_content_type=\"text/x-rst\",\n license=\"Apache License 2.0\",\n classifiers=[\n \"Intended Audience :: Developers\",\n f\"Programming Language :: Python :: {MINIMUM_SUPPORTED_PYTHON_VERSION}\",\n ],\n keywords=\"ml ai databricks\",\n url=\"https://mlflow.org/\",\n python_requires=f\">={MINIMUM_SUPPORTED_PYTHON_VERSION}\",\n project_urls={\n \"Bug Tracker\": \"https://github.com/mlflow/mlflow/issues\",\n \"Documentation\": \"https://mlflow.org/docs/latest/index.html\",\n \"Source Code\": \"https://github.com/mlflow/mlflow\",\n },\n)\n", "path": "setup.py"}]}
| 3,115 | 92 |
gh_patches_debug_2985
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-4234
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing [workflow_engine] in st2.conf.sample
##### SUMMARY
https://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample is missing a new section for `[workflow_engine]`
Also, shouldn't this section be named `[workflowengine]` to go along with the "style" of the other sections like `[resultstracker]` , `[garbagecollector]`, etc
##### ISSUE TYPE
- Bug Report
- Feature Idea
##### STACKSTORM VERSION
2.8
##### EXPECTED RESULTS
https://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample contains a section for `[workflow_engine]`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/config_gen.py`
Content:
```
1 #!/usr/bin/env python
2 # Licensed to the StackStorm, Inc ('StackStorm') under one or more
3 # contributor license agreements. See the NOTICE file distributed with
4 # this work for additional information regarding copyright ownership.
5 # The ASF licenses this file to You under the Apache License, Version 2.0
6 # (the "License"); you may not use this file except in compliance with
7 # the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 from __future__ import absolute_import
18 import collections
19 import importlib
20 import six
21 import sys
22 import traceback
23
24 from oslo_config import cfg
25
26
27 CONFIGS = ['st2actions.config',
28 'st2actions.notifier.config',
29 'st2actions.resultstracker.config',
30 'st2api.config',
31 'st2stream.config',
32 'st2auth.config',
33 'st2common.config',
34 'st2exporter.config',
35 'st2reactor.rules.config',
36 'st2reactor.sensor.config',
37 'st2reactor.garbage_collector.config']
38
39 SKIP_GROUPS = ['api_pecan', 'rbac', 'results_tracker']
40
41 # We group auth options together to nake it a bit more clear what applies where
42 AUTH_OPTIONS = {
43 'common': [
44 'enable',
45 'mode',
46 'logging',
47 'api_url',
48 'token_ttl',
49 'service_token_ttl',
50 'debug'
51 ],
52 'standalone': [
53 'host',
54 'port',
55 'use_ssl',
56 'cert',
57 'key',
58 'backend',
59 'backend_kwargs'
60 ]
61 }
62
63 # Some of the config values change depenending on the environment where this script is ran so we
64 # set them to static values to ensure consistent and stable output
65 STATIC_OPTION_VALUES = {
66 'actionrunner': {
67 'virtualenv_binary': '/usr/bin/virtualenv',
68 'python_binary': '/usr/bin/python',
69 'python3_binary': '/usr/bin/python3'
70 },
71 'webui': {
72 'webui_base_url': 'https://localhost'
73 }
74 }
75
76 COMMON_AUTH_OPTIONS_COMMENT = """
77 # Common option - options below apply in both scenarios - when auth service is running as a WSGI
78 # service (e.g. under Apache or Nginx) and when it's running in the standalone mode.
79 """.strip()
80
81 STANDALONE_AUTH_OPTIONS_COMMENT = """
82 # Standalone mode options - options below only apply when auth service is running in the standalone
83 # mode.
84 """.strip()
85
86
87 def _import_config(config):
88 try:
89 return importlib.import_module(config)
90 except:
91 traceback.print_exc()
92 return None
93
94
95 def _read_current_config(opt_groups):
96 for k, v in six.iteritems(cfg.CONF._groups):
97 if k in SKIP_GROUPS:
98 continue
99 if k not in opt_groups:
100 opt_groups[k] = v
101 return opt_groups
102
103
104 def _clear_config():
105 cfg.CONF.reset()
106
107
108 def _read_group(opt_group):
109 all_options = list(opt_group._opts.values())
110
111 if opt_group.name == 'auth':
112 print(COMMON_AUTH_OPTIONS_COMMENT)
113 print('')
114 common_options = [option for option in all_options if option['opt'].name in
115 AUTH_OPTIONS['common']]
116 _print_options(opt_group=opt_group, options=common_options)
117
118 print('')
119 print(STANDALONE_AUTH_OPTIONS_COMMENT)
120 print('')
121 standalone_options = [option for option in all_options if option['opt'].name in
122 AUTH_OPTIONS['standalone']]
123 _print_options(opt_group=opt_group, options=standalone_options)
124
125 if len(common_options) + len(standalone_options) != len(all_options):
126 msg = ('Not all options are declared in AUTH_OPTIONS dict, please update it')
127 raise Exception(msg)
128 else:
129 options = all_options
130 _print_options(opt_group=opt_group, options=options)
131
132
133 def _read_groups(opt_groups):
134 opt_groups = collections.OrderedDict(sorted(opt_groups.items()))
135 for name, opt_group in six.iteritems(opt_groups):
136 print('[%s]' % name)
137 _read_group(opt_group)
138 print('')
139
140
141 def _print_options(opt_group, options):
142 for opt in options:
143 opt = opt['opt']
144
145 # Special case for options which could change during this script run
146 static_option_value = STATIC_OPTION_VALUES.get(opt_group.name, {}).get(opt.name, None)
147 if static_option_value:
148 opt.default = static_option_value
149
150 # Special handling for list options
151 if isinstance(opt, cfg.ListOpt):
152 if opt.default:
153 value = ','.join(opt.default)
154 else:
155 value = ''
156
157 value += ' # comma separated list allowed here.'
158 else:
159 value = opt.default
160
161 print('# %s' % opt.help)
162 print('%s = %s' % (opt.name, value))
163
164
165 def main(args):
166 opt_groups = {}
167 for config in CONFIGS:
168 mod = _import_config(config)
169 mod.register_opts()
170 _read_current_config(opt_groups)
171 _clear_config()
172 _read_groups(opt_groups)
173
174
175 if __name__ == '__main__':
176 main(sys.argv)
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/config_gen.py b/tools/config_gen.py
--- a/tools/config_gen.py
+++ b/tools/config_gen.py
@@ -27,6 +27,7 @@
CONFIGS = ['st2actions.config',
'st2actions.notifier.config',
'st2actions.resultstracker.config',
+ 'st2actions.workflows.config',
'st2api.config',
'st2stream.config',
'st2auth.config',
|
{"golden_diff": "diff --git a/tools/config_gen.py b/tools/config_gen.py\n--- a/tools/config_gen.py\n+++ b/tools/config_gen.py\n@@ -27,6 +27,7 @@\n CONFIGS = ['st2actions.config',\n 'st2actions.notifier.config',\n 'st2actions.resultstracker.config',\n+ 'st2actions.workflows.config',\n 'st2api.config',\n 'st2stream.config',\n 'st2auth.config',\n", "issue": "Missing [workflow_engine] in st2.conf.sample\n##### SUMMARY\r\n\r\nhttps://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample is missing a new section for `[workflow_engine]`\r\n\r\nAlso, shouldn't this section be named `[workflowengine]` to go along with the \"style\" of the other sections like `[resultstracker]` , `[garbagecollector]`, etc\r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n - Feature Idea\r\n\r\n##### STACKSTORM VERSION\r\n2.8\r\n\r\n##### EXPECTED RESULTS\r\nhttps://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample contains a section for `[workflow_engine]`\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nimport collections\nimport importlib\nimport six\nimport sys\nimport traceback\n\nfrom oslo_config import cfg\n\n\nCONFIGS = ['st2actions.config',\n 'st2actions.notifier.config',\n 'st2actions.resultstracker.config',\n 'st2api.config',\n 'st2stream.config',\n 'st2auth.config',\n 'st2common.config',\n 'st2exporter.config',\n 'st2reactor.rules.config',\n 'st2reactor.sensor.config',\n 'st2reactor.garbage_collector.config']\n\nSKIP_GROUPS = ['api_pecan', 'rbac', 'results_tracker']\n\n# We group auth options together to nake it a bit more clear what applies where\nAUTH_OPTIONS = {\n 'common': [\n 'enable',\n 'mode',\n 'logging',\n 'api_url',\n 'token_ttl',\n 'service_token_ttl',\n 'debug'\n ],\n 'standalone': [\n 'host',\n 'port',\n 'use_ssl',\n 'cert',\n 'key',\n 'backend',\n 'backend_kwargs'\n ]\n}\n\n# Some of the config values change depenending on the environment where this script is ran so we\n# set them to static values to ensure consistent and stable output\nSTATIC_OPTION_VALUES = {\n 'actionrunner': {\n 'virtualenv_binary': '/usr/bin/virtualenv',\n 'python_binary': '/usr/bin/python',\n 'python3_binary': '/usr/bin/python3'\n },\n 'webui': {\n 'webui_base_url': 'https://localhost'\n }\n}\n\nCOMMON_AUTH_OPTIONS_COMMENT = \"\"\"\n# Common option - options below apply in both scenarios - when auth service is running as a WSGI\n# service (e.g. under Apache or Nginx) and when it's running in the standalone mode.\n\"\"\".strip()\n\nSTANDALONE_AUTH_OPTIONS_COMMENT = \"\"\"\n# Standalone mode options - options below only apply when auth service is running in the standalone\n# mode.\n\"\"\".strip()\n\n\ndef _import_config(config):\n try:\n return importlib.import_module(config)\n except:\n traceback.print_exc()\n return None\n\n\ndef _read_current_config(opt_groups):\n for k, v in six.iteritems(cfg.CONF._groups):\n if k in SKIP_GROUPS:\n continue\n if k not in opt_groups:\n opt_groups[k] = v\n return opt_groups\n\n\ndef _clear_config():\n cfg.CONF.reset()\n\n\ndef _read_group(opt_group):\n all_options = list(opt_group._opts.values())\n\n if opt_group.name == 'auth':\n print(COMMON_AUTH_OPTIONS_COMMENT)\n print('')\n common_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['common']]\n _print_options(opt_group=opt_group, options=common_options)\n\n print('')\n print(STANDALONE_AUTH_OPTIONS_COMMENT)\n print('')\n standalone_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['standalone']]\n _print_options(opt_group=opt_group, options=standalone_options)\n\n if len(common_options) + len(standalone_options) != len(all_options):\n msg = ('Not all options are declared in AUTH_OPTIONS dict, please update it')\n raise Exception(msg)\n else:\n options = all_options\n _print_options(opt_group=opt_group, options=options)\n\n\ndef _read_groups(opt_groups):\n opt_groups = collections.OrderedDict(sorted(opt_groups.items()))\n for name, opt_group in six.iteritems(opt_groups):\n print('[%s]' % name)\n _read_group(opt_group)\n print('')\n\n\ndef _print_options(opt_group, options):\n for opt in options:\n opt = opt['opt']\n\n # Special case for options which could change during this script run\n static_option_value = STATIC_OPTION_VALUES.get(opt_group.name, {}).get(opt.name, None)\n if static_option_value:\n opt.default = static_option_value\n\n # Special handling for list options\n if isinstance(opt, cfg.ListOpt):\n if opt.default:\n value = ','.join(opt.default)\n else:\n value = ''\n\n value += ' # comma separated list allowed here.'\n else:\n value = opt.default\n\n print('# %s' % opt.help)\n print('%s = %s' % (opt.name, value))\n\n\ndef main(args):\n opt_groups = {}\n for config in CONFIGS:\n mod = _import_config(config)\n mod.register_opts()\n _read_current_config(opt_groups)\n _clear_config()\n _read_groups(opt_groups)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n", "path": "tools/config_gen.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nimport collections\nimport importlib\nimport six\nimport sys\nimport traceback\n\nfrom oslo_config import cfg\n\n\nCONFIGS = ['st2actions.config',\n 'st2actions.notifier.config',\n 'st2actions.resultstracker.config',\n 'st2actions.workflows.config',\n 'st2api.config',\n 'st2stream.config',\n 'st2auth.config',\n 'st2common.config',\n 'st2exporter.config',\n 'st2reactor.rules.config',\n 'st2reactor.sensor.config',\n 'st2reactor.garbage_collector.config']\n\nSKIP_GROUPS = ['api_pecan', 'rbac', 'results_tracker']\n\n# We group auth options together to nake it a bit more clear what applies where\nAUTH_OPTIONS = {\n 'common': [\n 'enable',\n 'mode',\n 'logging',\n 'api_url',\n 'token_ttl',\n 'service_token_ttl',\n 'debug'\n ],\n 'standalone': [\n 'host',\n 'port',\n 'use_ssl',\n 'cert',\n 'key',\n 'backend',\n 'backend_kwargs'\n ]\n}\n\n# Some of the config values change depenending on the environment where this script is ran so we\n# set them to static values to ensure consistent and stable output\nSTATIC_OPTION_VALUES = {\n 'actionrunner': {\n 'virtualenv_binary': '/usr/bin/virtualenv',\n 'python_binary': '/usr/bin/python',\n 'python3_binary': '/usr/bin/python3'\n },\n 'webui': {\n 'webui_base_url': 'https://localhost'\n }\n}\n\nCOMMON_AUTH_OPTIONS_COMMENT = \"\"\"\n# Common option - options below apply in both scenarios - when auth service is running as a WSGI\n# service (e.g. under Apache or Nginx) and when it's running in the standalone mode.\n\"\"\".strip()\n\nSTANDALONE_AUTH_OPTIONS_COMMENT = \"\"\"\n# Standalone mode options - options below only apply when auth service is running in the standalone\n# mode.\n\"\"\".strip()\n\n\ndef _import_config(config):\n try:\n return importlib.import_module(config)\n except:\n traceback.print_exc()\n return None\n\n\ndef _read_current_config(opt_groups):\n for k, v in six.iteritems(cfg.CONF._groups):\n if k in SKIP_GROUPS:\n continue\n if k not in opt_groups:\n opt_groups[k] = v\n return opt_groups\n\n\ndef _clear_config():\n cfg.CONF.reset()\n\n\ndef _read_group(opt_group):\n all_options = list(opt_group._opts.values())\n\n if opt_group.name == 'auth':\n print(COMMON_AUTH_OPTIONS_COMMENT)\n print('')\n common_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['common']]\n _print_options(opt_group=opt_group, options=common_options)\n\n print('')\n print(STANDALONE_AUTH_OPTIONS_COMMENT)\n print('')\n standalone_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['standalone']]\n _print_options(opt_group=opt_group, options=standalone_options)\n\n if len(common_options) + len(standalone_options) != len(all_options):\n msg = ('Not all options are declared in AUTH_OPTIONS dict, please update it')\n raise Exception(msg)\n else:\n options = all_options\n _print_options(opt_group=opt_group, options=options)\n\n\ndef _read_groups(opt_groups):\n opt_groups = collections.OrderedDict(sorted(opt_groups.items()))\n for name, opt_group in six.iteritems(opt_groups):\n print('[%s]' % name)\n _read_group(opt_group)\n print('')\n\n\ndef _print_options(opt_group, options):\n for opt in options:\n opt = opt['opt']\n\n # Special case for options which could change during this script run\n static_option_value = STATIC_OPTION_VALUES.get(opt_group.name, {}).get(opt.name, None)\n if static_option_value:\n opt.default = static_option_value\n\n # Special handling for list options\n if isinstance(opt, cfg.ListOpt):\n if opt.default:\n value = ','.join(opt.default)\n else:\n value = ''\n\n value += ' # comma separated list allowed here.'\n else:\n value = opt.default\n\n print('# %s' % opt.help)\n print('%s = %s' % (opt.name, value))\n\n\ndef main(args):\n opt_groups = {}\n for config in CONFIGS:\n mod = _import_config(config)\n mod.register_opts()\n _read_current_config(opt_groups)\n _clear_config()\n _read_groups(opt_groups)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n", "path": "tools/config_gen.py"}]}
| 2,015 | 99 |
gh_patches_debug_24013
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-6581
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[document] The input argument name in `F.rrelu` is inconsistent
https://docs.chainer.org/en/stable/reference/generated/chainer.functions.rrelu.html#chainer.functions.rrelu
The slope for x < 0 is named `a` in the body text, but `r` is used for the input argument.
> Randomized Leaky Rectified Liner Unit function.
> This function is expressed as
> f(x)=max(x,ax),
> where a is a random number sampled from a uniform distribution U(l,u).
> ...
> ・r (N-dimensional array or None) – The r to be used for rrelu. The shape and dtype must be the same as x[0] and should be on the same device. If r is not specified or set to None, a r will be generated randomly according to the given l and u. If r is specified, l and u will be ignored.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/activation/rrelu.py`
Content:
```
1 import numpy as np
2
3 import chainer
4 from chainer.backends import cuda
5 from chainer import function_node
6 from chainer.utils import argument
7 from chainer.utils import type_check
8
9
10 def _kern():
11 return cuda.elementwise(
12 'T cond, T x, T slope', 'T y',
13 'y = cond >= 0 ? x : (T)(slope * x)', 'rrelu')
14
15
16 class RReLU(function_node.FunctionNode):
17 """Randomized Leaky rectifier unit."""
18
19 def __init__(self, lower=1. / 8, upper=1. / 3, r=None):
20 if not 0.0 <= lower < 1.0:
21 raise ValueError('lower must be in the range [0, 1)')
22 if not 0.0 <= upper < 1.0:
23 raise ValueError('upper must be in the range [0, 1)')
24 if not lower < upper:
25 raise ValueError('lower must be less than upper')
26 self.lower = lower
27 self.upper = upper
28 self.r = r
29
30 def check_type_forward(self, in_types):
31 type_check.expect(in_types.size() == 1)
32 x_type, = in_types
33 type_check.expect(x_type.dtype.kind == 'f')
34 if self.r is not None:
35 type_check.expect(x_type.dtype == self.r.dtype)
36 type_check.expect(x_type.shape == self.r.shape)
37
38 def forward_cpu(self, inputs):
39 x, = inputs
40 if chainer.config.train:
41 if self.r is None:
42 self.r = np.random.uniform(
43 self.lower, self.upper, x.shape
44 ).astype(x.dtype, copy=False)
45 else:
46 self.r = np.full(
47 x.shape, (self.lower + self.upper) / 2, dtype=x.dtype)
48 y = np.where(x >= 0, x, x * self.r)
49 self.retain_outputs((0,))
50 return y,
51
52 def forward_gpu(self, inputs):
53 x, = inputs
54 xp = cuda.cupy
55 if chainer.config.train:
56 if self.r is None:
57 self.r = xp.random.uniform(
58 self.lower, self.upper, x.shape
59 ).astype(x.dtype, copy=False)
60 else:
61 self.r = xp.full(
62 x.shape, (self.lower + self.upper) / 2, dtype=x.dtype)
63 y = _kern()(x, x, self.r)
64 self.retain_outputs((0,))
65 return y,
66
67 def backward(self, indexes, grad_outputs):
68 y = self.get_retained_outputs()[0].data
69 return _RReLUGrad(y, self.r).apply(grad_outputs)
70
71
72 class _RReLUGrad(function_node.FunctionNode):
73
74 def __init__(self, y, r):
75 self.r = r
76 self.y = y
77
78 def forward_cpu(self, inputs):
79 gy, = inputs
80 gy = np.where(self.y >= 0, gy, gy * self.r)
81 return gy,
82
83 def forward_gpu(self, inputs):
84 gy, = inputs
85 gy = _kern()(self.y, gy, self.r)
86 return gy,
87
88 def backward(self, indexes, grad_outputs):
89 return _RReLUGrad(self.y, self.r).apply(grad_outputs)
90
91
92 def rrelu(x, l=1. / 8, u=1. / 3, **kwargs):
93 """rrelu(x, l=1. / 8, u=1. / 3, *, r=None, return_r=False)
94
95 Randomized Leaky Rectified Liner Unit function.
96
97 This function is expressed as
98
99 .. math:: f(x)=\\max(x, ax),
100
101 where :math:`a` is a random number sampled from a uniform distribution
102 :math:`U(l, u)`.
103
104 See: https://arxiv.org/pdf/1505.00853.pdf
105
106 Args:
107 x (:class:`~chainer.Variable` or :ref:`ndarray`):
108 Input variable. A :math:`(s_1, s_2, ..., s_N)`-shaped float array.
109 l (float): The lower bound of the uniform distribution.
110 u (float): The upper bound of the uniform distribution.
111 r (:ref:`ndarray` or None):
112 The r to be used for rrelu.
113 The shape and dtype must be the same as ``x[0]`` and should be on
114 the same device.
115 If ``r`` is not specified or set to ``None``, a ``r`` will be
116 generated randomly according to the given ``l`` and ``u``.
117 If ``r`` is specified, ``l`` and ``u`` will be ignored.
118 return_r (bool):
119 If ``True``, the r used for rrelu is returned altogether with
120 the output variable.
121 The returned ``r`` can latter be reused by passing it to ``r``
122 argument.
123
124 Returns:
125 ~chainer.Variable or tuple:
126 When ``return_r`` is ``False`` (default), return the output
127 variable. Otherwise returnes the tuple of the output variable and
128 ``r`` (:ref:`ndarray`). The ``r`` will be on the same device as
129 the input.
130 A :math:`(s_1, s_2, ..., s_N)`-shaped float array.
131
132 .. admonition:: Example
133
134 >>> x = np.array([[-1, 0], [2, -3], [-2, 1]], np.float32)
135 >>> x
136 array([[-1., 0.],
137 [ 2., -3.],
138 [-2., 1.]], dtype=float32)
139 >>> F.rrelu(x).array # doctest: +SKIP
140 array([[-0.24850948, 0. ],
141 [ 2. , -0.50844127],
142 [-0.598535 , 1. ]], dtype=float32)
143 """
144 r = None
145 return_r = False
146 if kwargs:
147 r, return_r = argument.parse_kwargs(
148 kwargs, ('r', r), ('return_r', r),
149 train='train argument is not supported anymore.'
150 'Use chainer.using_config')
151
152 func = RReLU(l, u, r)
153 out, = func.apply((x,))
154 r = func.r
155
156 if return_r:
157 return out, r
158 return out
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/activation/rrelu.py b/chainer/functions/activation/rrelu.py
--- a/chainer/functions/activation/rrelu.py
+++ b/chainer/functions/activation/rrelu.py
@@ -96,12 +96,15 @@
This function is expressed as
- .. math:: f(x)=\\max(x, ax),
+ .. math:: f(x)=\\max(x, rx),
- where :math:`a` is a random number sampled from a uniform distribution
+ where :math:`r` is a random number sampled from a uniform distribution
:math:`U(l, u)`.
- See: https://arxiv.org/pdf/1505.00853.pdf
+ .. note::
+
+ The :math:`r` corresponds to :math:`a` in the original
+ paper (https://arxiv.org/pdf/1505.00853.pdf).
Args:
x (:class:`~chainer.Variable` or :ref:`ndarray`):
@@ -112,7 +115,7 @@
The r to be used for rrelu.
The shape and dtype must be the same as ``x[0]`` and should be on
the same device.
- If ``r`` is not specified or set to ``None``, a ``r`` will be
+ If ``r`` is not specified or set to ``None``, an ``r`` will be
generated randomly according to the given ``l`` and ``u``.
If ``r`` is specified, ``l`` and ``u`` will be ignored.
return_r (bool):
|
{"golden_diff": "diff --git a/chainer/functions/activation/rrelu.py b/chainer/functions/activation/rrelu.py\n--- a/chainer/functions/activation/rrelu.py\n+++ b/chainer/functions/activation/rrelu.py\n@@ -96,12 +96,15 @@\n \n This function is expressed as\n \n- .. math:: f(x)=\\\\max(x, ax),\n+ .. math:: f(x)=\\\\max(x, rx),\n \n- where :math:`a` is a random number sampled from a uniform distribution\n+ where :math:`r` is a random number sampled from a uniform distribution\n :math:`U(l, u)`.\n \n- See: https://arxiv.org/pdf/1505.00853.pdf\n+ .. note::\n+\n+ The :math:`r` corresponds to :math:`a` in the original\n+ paper (https://arxiv.org/pdf/1505.00853.pdf).\n \n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n@@ -112,7 +115,7 @@\n The r to be used for rrelu.\n The shape and dtype must be the same as ``x[0]`` and should be on\n the same device.\n- If ``r`` is not specified or set to ``None``, a ``r`` will be\n+ If ``r`` is not specified or set to ``None``, an ``r`` will be\n generated randomly according to the given ``l`` and ``u``.\n If ``r`` is specified, ``l`` and ``u`` will be ignored.\n return_r (bool):\n", "issue": "[document] The input argument name in `F.rrelu` is inconsistent\nhttps://docs.chainer.org/en/stable/reference/generated/chainer.functions.rrelu.html#chainer.functions.rrelu\r\n\r\nThe slope for x < 0 is named `a` in the body text, but `r` is used for the input argument.\r\n\r\n> Randomized Leaky Rectified Liner Unit function.\r\n> This function is expressed as\r\n> f(x)=max(x,ax),\r\n> where a is a random number sampled from a uniform distribution U(l,u).\r\n> ...\r\n> \u30fbr (N-dimensional array or None) \u2013 The r to be used for rrelu. The shape and dtype must be the same as x[0] and should be on the same device. If r is not specified or set to None, a r will be generated randomly according to the given l and u. If r is specified, l and u will be ignored.\r\n\n", "before_files": [{"content": "import numpy as np\n\nimport chainer\nfrom chainer.backends import cuda\nfrom chainer import function_node\nfrom chainer.utils import argument\nfrom chainer.utils import type_check\n\n\ndef _kern():\n return cuda.elementwise(\n 'T cond, T x, T slope', 'T y',\n 'y = cond >= 0 ? x : (T)(slope * x)', 'rrelu')\n\n\nclass RReLU(function_node.FunctionNode):\n \"\"\"Randomized Leaky rectifier unit.\"\"\"\n\n def __init__(self, lower=1. / 8, upper=1. / 3, r=None):\n if not 0.0 <= lower < 1.0:\n raise ValueError('lower must be in the range [0, 1)')\n if not 0.0 <= upper < 1.0:\n raise ValueError('upper must be in the range [0, 1)')\n if not lower < upper:\n raise ValueError('lower must be less than upper')\n self.lower = lower\n self.upper = upper\n self.r = r\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n x_type, = in_types\n type_check.expect(x_type.dtype.kind == 'f')\n if self.r is not None:\n type_check.expect(x_type.dtype == self.r.dtype)\n type_check.expect(x_type.shape == self.r.shape)\n\n def forward_cpu(self, inputs):\n x, = inputs\n if chainer.config.train:\n if self.r is None:\n self.r = np.random.uniform(\n self.lower, self.upper, x.shape\n ).astype(x.dtype, copy=False)\n else:\n self.r = np.full(\n x.shape, (self.lower + self.upper) / 2, dtype=x.dtype)\n y = np.where(x >= 0, x, x * self.r)\n self.retain_outputs((0,))\n return y,\n\n def forward_gpu(self, inputs):\n x, = inputs\n xp = cuda.cupy\n if chainer.config.train:\n if self.r is None:\n self.r = xp.random.uniform(\n self.lower, self.upper, x.shape\n ).astype(x.dtype, copy=False)\n else:\n self.r = xp.full(\n x.shape, (self.lower + self.upper) / 2, dtype=x.dtype)\n y = _kern()(x, x, self.r)\n self.retain_outputs((0,))\n return y,\n\n def backward(self, indexes, grad_outputs):\n y = self.get_retained_outputs()[0].data\n return _RReLUGrad(y, self.r).apply(grad_outputs)\n\n\nclass _RReLUGrad(function_node.FunctionNode):\n\n def __init__(self, y, r):\n self.r = r\n self.y = y\n\n def forward_cpu(self, inputs):\n gy, = inputs\n gy = np.where(self.y >= 0, gy, gy * self.r)\n return gy,\n\n def forward_gpu(self, inputs):\n gy, = inputs\n gy = _kern()(self.y, gy, self.r)\n return gy,\n\n def backward(self, indexes, grad_outputs):\n return _RReLUGrad(self.y, self.r).apply(grad_outputs)\n\n\ndef rrelu(x, l=1. / 8, u=1. / 3, **kwargs):\n \"\"\"rrelu(x, l=1. / 8, u=1. / 3, *, r=None, return_r=False)\n\n Randomized Leaky Rectified Liner Unit function.\n\n This function is expressed as\n\n .. math:: f(x)=\\\\max(x, ax),\n\n where :math:`a` is a random number sampled from a uniform distribution\n :math:`U(l, u)`.\n\n See: https://arxiv.org/pdf/1505.00853.pdf\n\n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n Input variable. A :math:`(s_1, s_2, ..., s_N)`-shaped float array.\n l (float): The lower bound of the uniform distribution.\n u (float): The upper bound of the uniform distribution.\n r (:ref:`ndarray` or None):\n The r to be used for rrelu.\n The shape and dtype must be the same as ``x[0]`` and should be on\n the same device.\n If ``r`` is not specified or set to ``None``, a ``r`` will be\n generated randomly according to the given ``l`` and ``u``.\n If ``r`` is specified, ``l`` and ``u`` will be ignored.\n return_r (bool):\n If ``True``, the r used for rrelu is returned altogether with\n the output variable.\n The returned ``r`` can latter be reused by passing it to ``r``\n argument.\n\n Returns:\n ~chainer.Variable or tuple:\n When ``return_r`` is ``False`` (default), return the output\n variable. Otherwise returnes the tuple of the output variable and\n ``r`` (:ref:`ndarray`). The ``r`` will be on the same device as\n the input.\n A :math:`(s_1, s_2, ..., s_N)`-shaped float array.\n\n .. admonition:: Example\n\n >>> x = np.array([[-1, 0], [2, -3], [-2, 1]], np.float32)\n >>> x\n array([[-1., 0.],\n [ 2., -3.],\n [-2., 1.]], dtype=float32)\n >>> F.rrelu(x).array # doctest: +SKIP\n array([[-0.24850948, 0. ],\n [ 2. , -0.50844127],\n [-0.598535 , 1. ]], dtype=float32)\n \"\"\"\n r = None\n return_r = False\n if kwargs:\n r, return_r = argument.parse_kwargs(\n kwargs, ('r', r), ('return_r', r),\n train='train argument is not supported anymore.'\n 'Use chainer.using_config')\n\n func = RReLU(l, u, r)\n out, = func.apply((x,))\n r = func.r\n\n if return_r:\n return out, r\n return out\n", "path": "chainer/functions/activation/rrelu.py"}], "after_files": [{"content": "import numpy as np\n\nimport chainer\nfrom chainer.backends import cuda\nfrom chainer import function_node\nfrom chainer.utils import argument\nfrom chainer.utils import type_check\n\n\ndef _kern():\n return cuda.elementwise(\n 'T cond, T x, T slope', 'T y',\n 'y = cond >= 0 ? x : (T)(slope * x)', 'rrelu')\n\n\nclass RReLU(function_node.FunctionNode):\n \"\"\"Randomized Leaky rectifier unit.\"\"\"\n\n def __init__(self, lower=1. / 8, upper=1. / 3, r=None):\n if not 0.0 <= lower < 1.0:\n raise ValueError('lower must be in the range [0, 1)')\n if not 0.0 <= upper < 1.0:\n raise ValueError('upper must be in the range [0, 1)')\n if not lower < upper:\n raise ValueError('lower must be less than upper')\n self.lower = lower\n self.upper = upper\n self.r = r\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n x_type, = in_types\n type_check.expect(x_type.dtype.kind == 'f')\n if self.r is not None:\n type_check.expect(x_type.dtype == self.r.dtype)\n type_check.expect(x_type.shape == self.r.shape)\n\n def forward_cpu(self, inputs):\n x, = inputs\n if chainer.config.train:\n if self.r is None:\n self.r = np.random.uniform(\n self.lower, self.upper, x.shape\n ).astype(x.dtype, copy=False)\n else:\n self.r = np.full(\n x.shape, (self.lower + self.upper) / 2, dtype=x.dtype)\n y = np.where(x >= 0, x, x * self.r)\n self.retain_outputs((0,))\n return y,\n\n def forward_gpu(self, inputs):\n x, = inputs\n xp = cuda.cupy\n if chainer.config.train:\n if self.r is None:\n self.r = xp.random.uniform(\n self.lower, self.upper, x.shape\n ).astype(x.dtype, copy=False)\n else:\n self.r = xp.full(\n x.shape, (self.lower + self.upper) / 2, dtype=x.dtype)\n y = _kern()(x, x, self.r)\n self.retain_outputs((0,))\n return y,\n\n def backward(self, indexes, grad_outputs):\n y = self.get_retained_outputs()[0].data\n return _RReLUGrad(y, self.r).apply(grad_outputs)\n\n\nclass _RReLUGrad(function_node.FunctionNode):\n\n def __init__(self, y, r):\n self.r = r\n self.y = y\n\n def forward_cpu(self, inputs):\n gy, = inputs\n gy = np.where(self.y >= 0, gy, gy * self.r)\n return gy,\n\n def forward_gpu(self, inputs):\n gy, = inputs\n gy = _kern()(self.y, gy, self.r)\n return gy,\n\n def backward(self, indexes, grad_outputs):\n return _RReLUGrad(self.y, self.r).apply(grad_outputs)\n\n\ndef rrelu(x, l=1. / 8, u=1. / 3, **kwargs):\n \"\"\"rrelu(x, l=1. / 8, u=1. / 3, *, r=None, return_r=False)\n\n Randomized Leaky Rectified Liner Unit function.\n\n This function is expressed as\n\n .. math:: f(x)=\\\\max(x, rx),\n\n where :math:`r` is a random number sampled from a uniform distribution\n :math:`U(l, u)`.\n\n .. note::\n\n The :math:`r` corresponds to :math:`a` in the original\n paper (https://arxiv.org/pdf/1505.00853.pdf).\n\n Args:\n x (:class:`~chainer.Variable` or :ref:`ndarray`):\n Input variable. A :math:`(s_1, s_2, ..., s_N)`-shaped float array.\n l (float): The lower bound of the uniform distribution.\n u (float): The upper bound of the uniform distribution.\n r (:ref:`ndarray` or None):\n The r to be used for rrelu.\n The shape and dtype must be the same as ``x[0]`` and should be on\n the same device.\n If ``r`` is not specified or set to ``None``, an ``r`` will be\n generated randomly according to the given ``l`` and ``u``.\n If ``r`` is specified, ``l`` and ``u`` will be ignored.\n return_r (bool):\n If ``True``, the r used for rrelu is returned altogether with\n the output variable.\n The returned ``r`` can latter be reused by passing it to ``r``\n argument.\n\n Returns:\n ~chainer.Variable or tuple:\n When ``return_r`` is ``False`` (default), return the output\n variable. Otherwise returnes the tuple of the output variable and\n ``r`` (:ref:`ndarray`). The ``r`` will be on the same device as\n the input.\n A :math:`(s_1, s_2, ..., s_N)`-shaped float array.\n\n .. admonition:: Example\n\n >>> x = np.array([[-1, 0], [2, -3], [-2, 1]], np.float32)\n >>> x\n array([[-1., 0.],\n [ 2., -3.],\n [-2., 1.]], dtype=float32)\n >>> F.rrelu(x).array # doctest: +SKIP\n array([[-0.24850948, 0. ],\n [ 2. , -0.50844127],\n [-0.598535 , 1. ]], dtype=float32)\n \"\"\"\n r = None\n return_r = False\n if kwargs:\n r, return_r = argument.parse_kwargs(\n kwargs, ('r', r), ('return_r', r),\n train='train argument is not supported anymore.'\n 'Use chainer.using_config')\n\n func = RReLU(l, u, r)\n out, = func.apply((x,))\n r = func.r\n\n if return_r:\n return out, r\n return out\n", "path": "chainer/functions/activation/rrelu.py"}]}
| 2,262 | 370 |
gh_patches_debug_30559
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-343
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pwnlib.term.text throws exceptions on attribute accesses
```
>>> import pwnlib
>>> pwnlib.term.text.__lol__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "pwnlib/term/text.py", line 99, in __getattr__
init += self._fg_color(c())
File "pwnlib/term/text.py", line 93, in c
return self._colors[c] + bright
KeyError: ''
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/term/text.py`
Content:
```
1 import types, sys, functools
2 from . import termcap
3
4 def eval_when(when):
5 if isinstance(when, file) or \
6 when in ('always', 'never', 'auto', sys.stderr, sys.stdout):
7 if when == 'always':
8 return True
9 elif when == 'never':
10 return False
11 elif when == 'auto':
12 return sys.stdout.isatty()
13 else:
14 return when.isatty()
15 else:
16 raise ValueError('text.when: must be a file-object or "always", "never" or "auto"')
17
18 class Module(types.ModuleType):
19 def __init__(self):
20 self.__file__ = __file__
21 self.__name__ = __name__
22 self.num_colors = termcap.get('colors', default = 8)
23 self.has_bright = self.num_colors >= 16
24 self.has_gray = self.has_bright
25 self.when = 'auto'
26 self._colors = {
27 'black': 0,
28 'red': 1,
29 'green': 2,
30 'yellow': 3,
31 'blue': 4,
32 'magenta': 5,
33 'cyan': 6,
34 'white': 7,
35 }
36 self._reset = '\x1b[m'
37 self._attributes = {}
38 for x, y in [('italic' , 'sitm'),
39 ('bold' , 'bold'),
40 ('underline', 'smul'),
41 ('reverse' , 'rev')]:
42 s = termcap.get(y)
43 self._attributes[x] = s
44 self._cache = {}
45
46 @property
47 def when(self):
48 return self._when
49
50 @when.setter
51 def when(self, val):
52 self._when = eval_when(val)
53
54 def _fg_color(self, c):
55 return termcap.get('setaf', c) or termcap.get('setf', c)
56
57 def _bg_color(self, c):
58 return termcap.get('setab', c) or termcap.get('setb', c)
59
60 def _decorator(self, desc, init):
61 def f(self, s, when = None):
62 if when:
63 if eval_when(when):
64 return init + s + self._reset
65 else:
66 return s
67 else:
68 if self.when:
69 return init + s + self._reset
70 else:
71 return s
72 setattr(Module, desc, f)
73 return functools.partial(f, self)
74
75 def __getattr__(self, desc):
76 ds = desc.replace('gray', 'bright_black').split('_')
77 init = ''
78 while ds:
79 d = ds[0]
80 try:
81 init += self._attributes[d]
82 ds.pop(0)
83 except KeyError:
84 break
85 def c():
86 bright = 0
87 c = ds.pop(0)
88 if c == 'bright':
89 c = ds.pop(0)
90 if self.has_bright:
91 bright = 8
92 return self._colors[c] + bright
93 if ds:
94 if ds[0] == 'on':
95 ds.pop(0)
96 init += self._bg_color(c())
97 else:
98 init += self._fg_color(c())
99 if len(ds):
100 assert ds.pop(0) == 'on'
101 init += self._bg_color(c())
102 return self._decorator(desc, init)
103
104 def get(self, desc):
105 return self.__getattr__(desc)
106
107 tether = sys.modules[__name__]
108 sys.modules[__name__] = Module()
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/term/text.py b/pwnlib/term/text.py
--- a/pwnlib/term/text.py
+++ b/pwnlib/term/text.py
@@ -73,33 +73,36 @@
return functools.partial(f, self)
def __getattr__(self, desc):
- ds = desc.replace('gray', 'bright_black').split('_')
- init = ''
- while ds:
- d = ds[0]
- try:
- init += self._attributes[d]
- ds.pop(0)
- except KeyError:
- break
- def c():
- bright = 0
- c = ds.pop(0)
- if c == 'bright':
+ try:
+ ds = desc.replace('gray', 'bright_black').split('_')
+ init = ''
+ while ds:
+ d = ds[0]
+ try:
+ init += self._attributes[d]
+ ds.pop(0)
+ except KeyError:
+ break
+ def c():
+ bright = 0
c = ds.pop(0)
- if self.has_bright:
- bright = 8
- return self._colors[c] + bright
- if ds:
- if ds[0] == 'on':
- ds.pop(0)
- init += self._bg_color(c())
- else:
- init += self._fg_color(c())
- if len(ds):
- assert ds.pop(0) == 'on'
+ if c == 'bright':
+ c = ds.pop(0)
+ if self.has_bright:
+ bright = 8
+ return self._colors[c] + bright
+ if ds:
+ if ds[0] == 'on':
+ ds.pop(0)
init += self._bg_color(c())
- return self._decorator(desc, init)
+ else:
+ init += self._fg_color(c())
+ if len(ds):
+ assert ds.pop(0) == 'on'
+ init += self._bg_color(c())
+ return self._decorator(desc, init)
+ except (IndexError, KeyError):
+ raise AttributeError("'module' object has no attribute %r" % desc)
def get(self, desc):
return self.__getattr__(desc)
|
{"golden_diff": "diff --git a/pwnlib/term/text.py b/pwnlib/term/text.py\n--- a/pwnlib/term/text.py\n+++ b/pwnlib/term/text.py\n@@ -73,33 +73,36 @@\n return functools.partial(f, self)\n \n def __getattr__(self, desc):\n- ds = desc.replace('gray', 'bright_black').split('_')\n- init = ''\n- while ds:\n- d = ds[0]\n- try:\n- init += self._attributes[d]\n- ds.pop(0)\n- except KeyError:\n- break\n- def c():\n- bright = 0\n- c = ds.pop(0)\n- if c == 'bright':\n+ try:\n+ ds = desc.replace('gray', 'bright_black').split('_')\n+ init = ''\n+ while ds:\n+ d = ds[0]\n+ try:\n+ init += self._attributes[d]\n+ ds.pop(0)\n+ except KeyError:\n+ break\n+ def c():\n+ bright = 0\n c = ds.pop(0)\n- if self.has_bright:\n- bright = 8\n- return self._colors[c] + bright\n- if ds:\n- if ds[0] == 'on':\n- ds.pop(0)\n- init += self._bg_color(c())\n- else:\n- init += self._fg_color(c())\n- if len(ds):\n- assert ds.pop(0) == 'on'\n+ if c == 'bright':\n+ c = ds.pop(0)\n+ if self.has_bright:\n+ bright = 8\n+ return self._colors[c] + bright\n+ if ds:\n+ if ds[0] == 'on':\n+ ds.pop(0)\n init += self._bg_color(c())\n- return self._decorator(desc, init)\n+ else:\n+ init += self._fg_color(c())\n+ if len(ds):\n+ assert ds.pop(0) == 'on'\n+ init += self._bg_color(c())\n+ return self._decorator(desc, init)\n+ except (IndexError, KeyError):\n+ raise AttributeError(\"'module' object has no attribute %r\" % desc)\n \n def get(self, desc):\n return self.__getattr__(desc)\n", "issue": "pwnlib.term.text throws exceptions on attribute accesses\n```\n>>> import pwnlib\n>>> pwnlib.term.text.__lol__\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"pwnlib/term/text.py\", line 99, in __getattr__\n init += self._fg_color(c())\n File \"pwnlib/term/text.py\", line 93, in c\n return self._colors[c] + bright\nKeyError: ''\n```\n\n", "before_files": [{"content": "import types, sys, functools\nfrom . import termcap\n\ndef eval_when(when):\n if isinstance(when, file) or \\\n when in ('always', 'never', 'auto', sys.stderr, sys.stdout):\n if when == 'always':\n return True\n elif when == 'never':\n return False\n elif when == 'auto':\n return sys.stdout.isatty()\n else:\n return when.isatty()\n else:\n raise ValueError('text.when: must be a file-object or \"always\", \"never\" or \"auto\"')\n\nclass Module(types.ModuleType):\n def __init__(self):\n self.__file__ = __file__\n self.__name__ = __name__\n self.num_colors = termcap.get('colors', default = 8)\n self.has_bright = self.num_colors >= 16\n self.has_gray = self.has_bright\n self.when = 'auto'\n self._colors = {\n 'black': 0,\n 'red': 1,\n 'green': 2,\n 'yellow': 3,\n 'blue': 4,\n 'magenta': 5,\n 'cyan': 6,\n 'white': 7,\n }\n self._reset = '\\x1b[m'\n self._attributes = {}\n for x, y in [('italic' , 'sitm'),\n ('bold' , 'bold'),\n ('underline', 'smul'),\n ('reverse' , 'rev')]:\n s = termcap.get(y)\n self._attributes[x] = s\n self._cache = {}\n\n @property\n def when(self):\n return self._when\n\n @when.setter\n def when(self, val):\n self._when = eval_when(val)\n\n def _fg_color(self, c):\n return termcap.get('setaf', c) or termcap.get('setf', c)\n\n def _bg_color(self, c):\n return termcap.get('setab', c) or termcap.get('setb', c)\n\n def _decorator(self, desc, init):\n def f(self, s, when = None):\n if when:\n if eval_when(when):\n return init + s + self._reset\n else:\n return s\n else:\n if self.when:\n return init + s + self._reset\n else:\n return s\n setattr(Module, desc, f)\n return functools.partial(f, self)\n\n def __getattr__(self, desc):\n ds = desc.replace('gray', 'bright_black').split('_')\n init = ''\n while ds:\n d = ds[0]\n try:\n init += self._attributes[d]\n ds.pop(0)\n except KeyError:\n break\n def c():\n bright = 0\n c = ds.pop(0)\n if c == 'bright':\n c = ds.pop(0)\n if self.has_bright:\n bright = 8\n return self._colors[c] + bright\n if ds:\n if ds[0] == 'on':\n ds.pop(0)\n init += self._bg_color(c())\n else:\n init += self._fg_color(c())\n if len(ds):\n assert ds.pop(0) == 'on'\n init += self._bg_color(c())\n return self._decorator(desc, init)\n\n def get(self, desc):\n return self.__getattr__(desc)\n\ntether = sys.modules[__name__]\nsys.modules[__name__] = Module()\n", "path": "pwnlib/term/text.py"}], "after_files": [{"content": "import types, sys, functools\nfrom . import termcap\n\ndef eval_when(when):\n if isinstance(when, file) or \\\n when in ('always', 'never', 'auto', sys.stderr, sys.stdout):\n if when == 'always':\n return True\n elif when == 'never':\n return False\n elif when == 'auto':\n return sys.stdout.isatty()\n else:\n return when.isatty()\n else:\n raise ValueError('text.when: must be a file-object or \"always\", \"never\" or \"auto\"')\n\nclass Module(types.ModuleType):\n def __init__(self):\n self.__file__ = __file__\n self.__name__ = __name__\n self.num_colors = termcap.get('colors', default = 8)\n self.has_bright = self.num_colors >= 16\n self.has_gray = self.has_bright\n self.when = 'auto'\n self._colors = {\n 'black': 0,\n 'red': 1,\n 'green': 2,\n 'yellow': 3,\n 'blue': 4,\n 'magenta': 5,\n 'cyan': 6,\n 'white': 7,\n }\n self._reset = '\\x1b[m'\n self._attributes = {}\n for x, y in [('italic' , 'sitm'),\n ('bold' , 'bold'),\n ('underline', 'smul'),\n ('reverse' , 'rev')]:\n s = termcap.get(y)\n self._attributes[x] = s\n self._cache = {}\n\n @property\n def when(self):\n return self._when\n\n @when.setter\n def when(self, val):\n self._when = eval_when(val)\n\n def _fg_color(self, c):\n return termcap.get('setaf', c) or termcap.get('setf', c)\n\n def _bg_color(self, c):\n return termcap.get('setab', c) or termcap.get('setb', c)\n\n def _decorator(self, desc, init):\n def f(self, s, when = None):\n if when:\n if eval_when(when):\n return init + s + self._reset\n else:\n return s\n else:\n if self.when:\n return init + s + self._reset\n else:\n return s\n setattr(Module, desc, f)\n return functools.partial(f, self)\n\n def __getattr__(self, desc):\n try:\n ds = desc.replace('gray', 'bright_black').split('_')\n init = ''\n while ds:\n d = ds[0]\n try:\n init += self._attributes[d]\n ds.pop(0)\n except KeyError:\n break\n def c():\n bright = 0\n c = ds.pop(0)\n if c == 'bright':\n c = ds.pop(0)\n if self.has_bright:\n bright = 8\n return self._colors[c] + bright\n if ds:\n if ds[0] == 'on':\n ds.pop(0)\n init += self._bg_color(c())\n else:\n init += self._fg_color(c())\n if len(ds):\n assert ds.pop(0) == 'on'\n init += self._bg_color(c())\n return self._decorator(desc, init)\n except (IndexError, KeyError):\n raise AttributeError(\"'module' object has no attribute %r\" % desc)\n\n def get(self, desc):\n return self.__getattr__(desc)\n\ntether = sys.modules[__name__]\nsys.modules[__name__] = Module()\n", "path": "pwnlib/term/text.py"}]}
| 1,362 | 523 |
gh_patches_debug_26790
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1101
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python version support
I run the unit tests in a local environment, with Python 3.7.4
https://github.com/wangkuiyi/elasticdl/blob/424a9b45999fe77eb671d7cfe86d7e22130f263b/elasticdl/python/common/odps_recordio_conversion_utils.py#L52-L56
I find that it throws an exception. This is an interface change from Python 3.6 to Python 3.7
Please refer to https://docs.python.org/3/library/collections.html#collections.namedtuple
```
Changed in version 3.1: Added support for rename.
Changed in version 3.6: The verbose and rename parameters became keyword-only arguments.
Changed in version 3.6: Added the module parameter.
Changed in version 3.7: Remove the verbose parameter and the _source attribute.
Changed in version 3.7: Added the defaults parameter and the _field_defaults attribute.
```
Here is just a record.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/common/odps_recordio_conversion_utils.py`
Content:
```
1 import os
2 from collections import OrderedDict, namedtuple
3 from datetime import datetime as _datetime
4
5 import numpy as np
6 import recordio
7 import tensorflow as tf
8 from odps.types import (
9 Bigint,
10 Binary,
11 Boolean,
12 Datetime,
13 Double,
14 Float,
15 Int,
16 Smallint,
17 String,
18 Tinyint,
19 )
20
21
22 def _infer_primitive_data_type(value):
23 """Infer the primitive data type for an ODPS value."""
24 integer_builtins = (int, np.integer)
25 float_builtins = (float, np.float)
26
27 odps_primitive_to_builtin_types = OrderedDict(
28 (
29 (Bigint(), integer_builtins),
30 (Tinyint(), integer_builtins),
31 (Smallint(), integer_builtins),
32 (Int(), integer_builtins),
33 (Double(), float_builtins),
34 (Float(), float_builtins),
35 (String(), (str, bytes)),
36 (Binary(), bytes),
37 (Datetime(), _datetime),
38 (Boolean(), bool),
39 )
40 )
41 for data_type, builtin_types in odps_primitive_to_builtin_types.items():
42 if isinstance(value, builtin_types):
43 return builtin_types
44 else:
45 return None
46
47
48 def _find_features_indices(
49 features_list, int_features, float_features, bytes_features
50 ):
51 """Finds the indices for different types of features."""
52 FeatureIndices = namedtuple(
53 "FeatureIndices",
54 ["int_features", "float_features", "bytes_features"],
55 verbose=False,
56 )
57 int_features_indices = [features_list.index(key) for key in int_features]
58 float_features_indices = [
59 features_list.index(key) for key in float_features
60 ]
61 bytes_features_indices = [
62 features_list.index(key) for key in bytes_features
63 ]
64 return FeatureIndices(
65 int_features_indices, float_features_indices, bytes_features_indices
66 )
67
68
69 def _parse_row_to_example(record, features_list, feature_indices):
70 """
71 Parses one row (a flat list or one-dimensional numpy array)
72 to a TensorFlow Example.
73 """
74 if isinstance(record, list):
75 record = np.array(record, dtype=object)
76
77 example = tf.train.Example()
78 # Note: these cannot be constructed dynamically since
79 # we cannot assign a value to an embedded message
80 # field in protobuf
81 for feature_ind in feature_indices.int_features:
82 example.features.feature[
83 features_list[feature_ind]
84 ].int64_list.value.append(
85 int(_maybe_encode_unicode_string(record[feature_ind]) or 0)
86 )
87 for feature_ind in feature_indices.float_features:
88 example.features.feature[
89 features_list[feature_ind]
90 ].float_list.value.append(
91 float(_maybe_encode_unicode_string(record[feature_ind]) or 0.0)
92 )
93 for feature_ind in feature_indices.bytes_features:
94 example.features.feature[
95 features_list[feature_ind]
96 ].bytes_list.value.append(
97 _maybe_encode_unicode_string(record[feature_ind])
98 )
99 return example
100
101
102 def _maybe_encode_unicode_string(record):
103 """Encodes unicode strings if needed."""
104 if isinstance(record, str):
105 record = bytes(record, "utf-8").strip()
106 return record
107
108
109 def _find_feature_indices_from_record(record):
110 """Find the indices of different feature types."""
111 feature_types = [type(value) for value in record]
112 FeatureIndices = namedtuple(
113 "FeatureIndices",
114 ["int_features", "float_features", "bytes_features"],
115 verbose=False,
116 )
117 return FeatureIndices(
118 [i for i, x in enumerate(feature_types) if x == int],
119 [i for i, x in enumerate(feature_types) if x == float],
120 [i for i, x in enumerate(feature_types) if x == str],
121 )
122
123
124 def write_recordio_shards_from_iterator(
125 records_iter, features_list, output_dir, records_per_shard
126 ):
127 """Writes RecordIO files from Python iterator of numpy arrays."""
128 # Take the first record batch to check whether it contains multiple items
129 first_record_batch = next(records_iter)
130 is_first_record_batch_consumed = False
131 is_multi_items_per_batch = any(
132 isinstance(i, list) for i in first_record_batch
133 )
134
135 # Find the features of different types that will be used
136 # in `_parse_row_to_example()` later
137 record = (
138 first_record_batch[0]
139 if is_multi_items_per_batch
140 else first_record_batch
141 )
142 feature_indices = _find_feature_indices_from_record(record)
143
144 writer = None
145 rows_written = 0
146 shards_written = 0
147 while True:
148 try:
149 # Make sure to consume the first record batch
150 if is_first_record_batch_consumed:
151 record_batch = next(records_iter)
152 else:
153 record_batch = first_record_batch
154 is_first_record_batch_consumed = True
155 if not is_multi_items_per_batch:
156 record_batch = [record_batch]
157
158 # Write each record in the batch to a RecordIO shard
159 for record in record_batch:
160 # Initialize the writer for the new shard
161 if rows_written % records_per_shard == 0:
162 if writer is not None:
163 writer.close()
164 shard_file_path = os.path.join(
165 output_dir, "data-%05d" % shards_written
166 )
167 writer = recordio.Writer(shard_file_path)
168 shards_written += 1
169
170 writer.write(
171 _parse_row_to_example(
172 record, features_list, feature_indices
173 ).SerializeToString()
174 )
175 rows_written += 1
176 except StopIteration:
177 break
178
179 writer.close()
180
```
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2
3
4 with open('elasticdl/requirements.txt') as f:
5 requirements = f.read().splitlines()
6
7 setup(
8 name="elasticdl",
9 version="0.0.1",
10 description="A Kubernetes-native Elastic Deep Learning Framework",
11 author="Ant Financial",
12 url="https://github.com/wangkuiyi/elasticdl",
13 install_requires=requirements,
14 packages=find_packages(exclude=["*test*"]),
15 package_data={"": ["proto/elasticdl.proto", "docker/*", "Makefile"]},
16 entry_points={
17 "console_scripts": ["elasticdl=elasticdl.python.elasticdl.client:main"]
18 },
19 )
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/common/odps_recordio_conversion_utils.py b/elasticdl/python/common/odps_recordio_conversion_utils.py
--- a/elasticdl/python/common/odps_recordio_conversion_utils.py
+++ b/elasticdl/python/common/odps_recordio_conversion_utils.py
@@ -50,9 +50,7 @@
):
"""Finds the indices for different types of features."""
FeatureIndices = namedtuple(
- "FeatureIndices",
- ["int_features", "float_features", "bytes_features"],
- verbose=False,
+ "FeatureIndices", ["int_features", "float_features", "bytes_features"]
)
int_features_indices = [features_list.index(key) for key in int_features]
float_features_indices = [
@@ -110,9 +108,7 @@
"""Find the indices of different feature types."""
feature_types = [type(value) for value in record]
FeatureIndices = namedtuple(
- "FeatureIndices",
- ["int_features", "float_features", "bytes_features"],
- verbose=False,
+ "FeatureIndices", ["int_features", "float_features", "bytes_features"]
)
return FeatureIndices(
[i for i, x in enumerate(feature_types) if x == int],
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,7 +1,6 @@
-from setuptools import setup, find_packages
+from setuptools import find_packages, setup
-
-with open('elasticdl/requirements.txt') as f:
+with open("elasticdl/requirements.txt") as f:
requirements = f.read().splitlines()
setup(
|
{"golden_diff": "diff --git a/elasticdl/python/common/odps_recordio_conversion_utils.py b/elasticdl/python/common/odps_recordio_conversion_utils.py\n--- a/elasticdl/python/common/odps_recordio_conversion_utils.py\n+++ b/elasticdl/python/common/odps_recordio_conversion_utils.py\n@@ -50,9 +50,7 @@\n ):\n \"\"\"Finds the indices for different types of features.\"\"\"\n FeatureIndices = namedtuple(\n- \"FeatureIndices\",\n- [\"int_features\", \"float_features\", \"bytes_features\"],\n- verbose=False,\n+ \"FeatureIndices\", [\"int_features\", \"float_features\", \"bytes_features\"]\n )\n int_features_indices = [features_list.index(key) for key in int_features]\n float_features_indices = [\n@@ -110,9 +108,7 @@\n \"\"\"Find the indices of different feature types.\"\"\"\n feature_types = [type(value) for value in record]\n FeatureIndices = namedtuple(\n- \"FeatureIndices\",\n- [\"int_features\", \"float_features\", \"bytes_features\"],\n- verbose=False,\n+ \"FeatureIndices\", [\"int_features\", \"float_features\", \"bytes_features\"]\n )\n return FeatureIndices(\n [i for i, x in enumerate(feature_types) if x == int],\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,7 +1,6 @@\n-from setuptools import setup, find_packages\n+from setuptools import find_packages, setup\n \n-\n-with open('elasticdl/requirements.txt') as f:\n+with open(\"elasticdl/requirements.txt\") as f:\n requirements = f.read().splitlines()\n \n setup(\n", "issue": "Python version support\nI run the unit tests in a local environment, with Python 3.7.4\r\n\r\nhttps://github.com/wangkuiyi/elasticdl/blob/424a9b45999fe77eb671d7cfe86d7e22130f263b/elasticdl/python/common/odps_recordio_conversion_utils.py#L52-L56\r\n\r\nI find that it throws an exception. This is an interface change from Python 3.6 to Python 3.7\r\nPlease refer to https://docs.python.org/3/library/collections.html#collections.namedtuple\r\n\r\n```\r\nChanged in version 3.1: Added support for rename.\r\n\r\nChanged in version 3.6: The verbose and rename parameters became keyword-only arguments.\r\n\r\nChanged in version 3.6: Added the module parameter.\r\n\r\nChanged in version 3.7: Remove the verbose parameter and the _source attribute.\r\n\r\nChanged in version 3.7: Added the defaults parameter and the _field_defaults attribute.\r\n```\r\n\r\nHere is just a record.\n", "before_files": [{"content": "import os\nfrom collections import OrderedDict, namedtuple\nfrom datetime import datetime as _datetime\n\nimport numpy as np\nimport recordio\nimport tensorflow as tf\nfrom odps.types import (\n Bigint,\n Binary,\n Boolean,\n Datetime,\n Double,\n Float,\n Int,\n Smallint,\n String,\n Tinyint,\n)\n\n\ndef _infer_primitive_data_type(value):\n \"\"\"Infer the primitive data type for an ODPS value.\"\"\"\n integer_builtins = (int, np.integer)\n float_builtins = (float, np.float)\n\n odps_primitive_to_builtin_types = OrderedDict(\n (\n (Bigint(), integer_builtins),\n (Tinyint(), integer_builtins),\n (Smallint(), integer_builtins),\n (Int(), integer_builtins),\n (Double(), float_builtins),\n (Float(), float_builtins),\n (String(), (str, bytes)),\n (Binary(), bytes),\n (Datetime(), _datetime),\n (Boolean(), bool),\n )\n )\n for data_type, builtin_types in odps_primitive_to_builtin_types.items():\n if isinstance(value, builtin_types):\n return builtin_types\n else:\n return None\n\n\ndef _find_features_indices(\n features_list, int_features, float_features, bytes_features\n):\n \"\"\"Finds the indices for different types of features.\"\"\"\n FeatureIndices = namedtuple(\n \"FeatureIndices\",\n [\"int_features\", \"float_features\", \"bytes_features\"],\n verbose=False,\n )\n int_features_indices = [features_list.index(key) for key in int_features]\n float_features_indices = [\n features_list.index(key) for key in float_features\n ]\n bytes_features_indices = [\n features_list.index(key) for key in bytes_features\n ]\n return FeatureIndices(\n int_features_indices, float_features_indices, bytes_features_indices\n )\n\n\ndef _parse_row_to_example(record, features_list, feature_indices):\n \"\"\"\n Parses one row (a flat list or one-dimensional numpy array)\n to a TensorFlow Example.\n \"\"\"\n if isinstance(record, list):\n record = np.array(record, dtype=object)\n\n example = tf.train.Example()\n # Note: these cannot be constructed dynamically since\n # we cannot assign a value to an embedded message\n # field in protobuf\n for feature_ind in feature_indices.int_features:\n example.features.feature[\n features_list[feature_ind]\n ].int64_list.value.append(\n int(_maybe_encode_unicode_string(record[feature_ind]) or 0)\n )\n for feature_ind in feature_indices.float_features:\n example.features.feature[\n features_list[feature_ind]\n ].float_list.value.append(\n float(_maybe_encode_unicode_string(record[feature_ind]) or 0.0)\n )\n for feature_ind in feature_indices.bytes_features:\n example.features.feature[\n features_list[feature_ind]\n ].bytes_list.value.append(\n _maybe_encode_unicode_string(record[feature_ind])\n )\n return example\n\n\ndef _maybe_encode_unicode_string(record):\n \"\"\"Encodes unicode strings if needed.\"\"\"\n if isinstance(record, str):\n record = bytes(record, \"utf-8\").strip()\n return record\n\n\ndef _find_feature_indices_from_record(record):\n \"\"\"Find the indices of different feature types.\"\"\"\n feature_types = [type(value) for value in record]\n FeatureIndices = namedtuple(\n \"FeatureIndices\",\n [\"int_features\", \"float_features\", \"bytes_features\"],\n verbose=False,\n )\n return FeatureIndices(\n [i for i, x in enumerate(feature_types) if x == int],\n [i for i, x in enumerate(feature_types) if x == float],\n [i for i, x in enumerate(feature_types) if x == str],\n )\n\n\ndef write_recordio_shards_from_iterator(\n records_iter, features_list, output_dir, records_per_shard\n):\n \"\"\"Writes RecordIO files from Python iterator of numpy arrays.\"\"\"\n # Take the first record batch to check whether it contains multiple items\n first_record_batch = next(records_iter)\n is_first_record_batch_consumed = False\n is_multi_items_per_batch = any(\n isinstance(i, list) for i in first_record_batch\n )\n\n # Find the features of different types that will be used\n # in `_parse_row_to_example()` later\n record = (\n first_record_batch[0]\n if is_multi_items_per_batch\n else first_record_batch\n )\n feature_indices = _find_feature_indices_from_record(record)\n\n writer = None\n rows_written = 0\n shards_written = 0\n while True:\n try:\n # Make sure to consume the first record batch\n if is_first_record_batch_consumed:\n record_batch = next(records_iter)\n else:\n record_batch = first_record_batch\n is_first_record_batch_consumed = True\n if not is_multi_items_per_batch:\n record_batch = [record_batch]\n\n # Write each record in the batch to a RecordIO shard\n for record in record_batch:\n # Initialize the writer for the new shard\n if rows_written % records_per_shard == 0:\n if writer is not None:\n writer.close()\n shard_file_path = os.path.join(\n output_dir, \"data-%05d\" % shards_written\n )\n writer = recordio.Writer(shard_file_path)\n shards_written += 1\n\n writer.write(\n _parse_row_to_example(\n record, features_list, feature_indices\n ).SerializeToString()\n )\n rows_written += 1\n except StopIteration:\n break\n\n writer.close()\n", "path": "elasticdl/python/common/odps_recordio_conversion_utils.py"}, {"content": "from setuptools import setup, find_packages\n\n\nwith open('elasticdl/requirements.txt') as f:\n requirements = f.read().splitlines()\n\nsetup(\n name=\"elasticdl\",\n version=\"0.0.1\",\n description=\"A Kubernetes-native Elastic Deep Learning Framework\",\n author=\"Ant Financial\",\n url=\"https://github.com/wangkuiyi/elasticdl\",\n install_requires=requirements,\n packages=find_packages(exclude=[\"*test*\"]),\n package_data={\"\": [\"proto/elasticdl.proto\", \"docker/*\", \"Makefile\"]},\n entry_points={\n \"console_scripts\": [\"elasticdl=elasticdl.python.elasticdl.client:main\"]\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nfrom collections import OrderedDict, namedtuple\nfrom datetime import datetime as _datetime\n\nimport numpy as np\nimport recordio\nimport tensorflow as tf\nfrom odps.types import (\n Bigint,\n Binary,\n Boolean,\n Datetime,\n Double,\n Float,\n Int,\n Smallint,\n String,\n Tinyint,\n)\n\n\ndef _infer_primitive_data_type(value):\n \"\"\"Infer the primitive data type for an ODPS value.\"\"\"\n integer_builtins = (int, np.integer)\n float_builtins = (float, np.float)\n\n odps_primitive_to_builtin_types = OrderedDict(\n (\n (Bigint(), integer_builtins),\n (Tinyint(), integer_builtins),\n (Smallint(), integer_builtins),\n (Int(), integer_builtins),\n (Double(), float_builtins),\n (Float(), float_builtins),\n (String(), (str, bytes)),\n (Binary(), bytes),\n (Datetime(), _datetime),\n (Boolean(), bool),\n )\n )\n for data_type, builtin_types in odps_primitive_to_builtin_types.items():\n if isinstance(value, builtin_types):\n return builtin_types\n else:\n return None\n\n\ndef _find_features_indices(\n features_list, int_features, float_features, bytes_features\n):\n \"\"\"Finds the indices for different types of features.\"\"\"\n FeatureIndices = namedtuple(\n \"FeatureIndices\", [\"int_features\", \"float_features\", \"bytes_features\"]\n )\n int_features_indices = [features_list.index(key) for key in int_features]\n float_features_indices = [\n features_list.index(key) for key in float_features\n ]\n bytes_features_indices = [\n features_list.index(key) for key in bytes_features\n ]\n return FeatureIndices(\n int_features_indices, float_features_indices, bytes_features_indices\n )\n\n\ndef _parse_row_to_example(record, features_list, feature_indices):\n \"\"\"\n Parses one row (a flat list or one-dimensional numpy array)\n to a TensorFlow Example.\n \"\"\"\n if isinstance(record, list):\n record = np.array(record, dtype=object)\n\n example = tf.train.Example()\n # Note: these cannot be constructed dynamically since\n # we cannot assign a value to an embedded message\n # field in protobuf\n for feature_ind in feature_indices.int_features:\n example.features.feature[\n features_list[feature_ind]\n ].int64_list.value.append(\n int(_maybe_encode_unicode_string(record[feature_ind]) or 0)\n )\n for feature_ind in feature_indices.float_features:\n example.features.feature[\n features_list[feature_ind]\n ].float_list.value.append(\n float(_maybe_encode_unicode_string(record[feature_ind]) or 0.0)\n )\n for feature_ind in feature_indices.bytes_features:\n example.features.feature[\n features_list[feature_ind]\n ].bytes_list.value.append(\n _maybe_encode_unicode_string(record[feature_ind])\n )\n return example\n\n\ndef _maybe_encode_unicode_string(record):\n \"\"\"Encodes unicode strings if needed.\"\"\"\n if isinstance(record, str):\n record = bytes(record, \"utf-8\").strip()\n return record\n\n\ndef _find_feature_indices_from_record(record):\n \"\"\"Find the indices of different feature types.\"\"\"\n feature_types = [type(value) for value in record]\n FeatureIndices = namedtuple(\n \"FeatureIndices\", [\"int_features\", \"float_features\", \"bytes_features\"]\n )\n return FeatureIndices(\n [i for i, x in enumerate(feature_types) if x == int],\n [i for i, x in enumerate(feature_types) if x == float],\n [i for i, x in enumerate(feature_types) if x == str],\n )\n\n\ndef write_recordio_shards_from_iterator(\n records_iter, features_list, output_dir, records_per_shard\n):\n \"\"\"Writes RecordIO files from Python iterator of numpy arrays.\"\"\"\n # Take the first record batch to check whether it contains multiple items\n first_record_batch = next(records_iter)\n is_first_record_batch_consumed = False\n is_multi_items_per_batch = any(\n isinstance(i, list) for i in first_record_batch\n )\n\n # Find the features of different types that will be used\n # in `_parse_row_to_example()` later\n record = (\n first_record_batch[0]\n if is_multi_items_per_batch\n else first_record_batch\n )\n feature_indices = _find_feature_indices_from_record(record)\n\n writer = None\n rows_written = 0\n shards_written = 0\n while True:\n try:\n # Make sure to consume the first record batch\n if is_first_record_batch_consumed:\n record_batch = next(records_iter)\n else:\n record_batch = first_record_batch\n is_first_record_batch_consumed = True\n if not is_multi_items_per_batch:\n record_batch = [record_batch]\n\n # Write each record in the batch to a RecordIO shard\n for record in record_batch:\n # Initialize the writer for the new shard\n if rows_written % records_per_shard == 0:\n if writer is not None:\n writer.close()\n shard_file_path = os.path.join(\n output_dir, \"data-%05d\" % shards_written\n )\n writer = recordio.Writer(shard_file_path)\n shards_written += 1\n\n writer.write(\n _parse_row_to_example(\n record, features_list, feature_indices\n ).SerializeToString()\n )\n rows_written += 1\n except StopIteration:\n break\n\n writer.close()\n", "path": "elasticdl/python/common/odps_recordio_conversion_utils.py"}, {"content": "from setuptools import find_packages, setup\n\nwith open(\"elasticdl/requirements.txt\") as f:\n requirements = f.read().splitlines()\n\nsetup(\n name=\"elasticdl\",\n version=\"0.0.1\",\n description=\"A Kubernetes-native Elastic Deep Learning Framework\",\n author=\"Ant Financial\",\n url=\"https://github.com/wangkuiyi/elasticdl\",\n install_requires=requirements,\n packages=find_packages(exclude=[\"*test*\"]),\n package_data={\"\": [\"proto/elasticdl.proto\", \"docker/*\", \"Makefile\"]},\n entry_points={\n \"console_scripts\": [\"elasticdl=elasticdl.python.elasticdl.client:main\"]\n },\n)\n", "path": "setup.py"}]}
| 2,328 | 358 |
gh_patches_debug_25765
|
rasdani/github-patches
|
git_diff
|
conda__conda-6542
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
python 2 can't read unicode in environments.txt
on a conda install operation, during the transaction
```
Traceback (most recent call last):
File "/Users/kfranz/continuum/conda/conda/core/link.py", line 535, in _execute_actions
action.execute()
File "/Users/kfranz/continuum/conda/conda/core/path_actions.py", line 876, in execute
register_env(self.target_prefix)
File "/Users/kfranz/continuum/conda/conda/core/envs_manager.py", line 28, in register_env
if location in yield_lines(USER_ENVIRONMENTS_TXT_FILE):
File "/Users/kfranz/continuum/conda/conda/gateways/disk/read.py", line 49, in yield_lines
if not line or line.startswith('#'):
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 54: ordinal not in range(128)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/gateways/disk/read.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from base64 import b64encode
5 from collections import namedtuple
6 from errno import ENOENT
7 from functools import partial
8 from glob import glob
9 import hashlib
10 from itertools import chain
11 import json
12 from logging import getLogger
13 from os import listdir
14 from os.path import isdir, isfile, join
15 import shlex
16 import tarfile
17
18 from .link import islink, lexists
19 from ..._vendor.auxlib.collection import first
20 from ..._vendor.auxlib.ish import dals
21 from ...base.constants import PREFIX_PLACEHOLDER
22 from ...common.compat import ensure_text_type
23 from ...exceptions import CondaUpgradeError, CondaVerificationError, PathNotFoundError
24 from ...models.channel import Channel
25 from ...models.enums import FileMode, PathType
26 from ...models.index_record import IndexJsonRecord, IndexRecord, PathData, PathDataV1, PathsData
27 from ...models.package_info import PackageInfo, PackageMetadata
28
29 log = getLogger(__name__)
30
31 listdir = listdir
32 lexists, isdir, isfile = lexists, isdir, isfile
33
34
35 def yield_lines(path):
36 """Generator function for lines in file. Empty generator if path does not exist.
37
38 Args:
39 path (str): path to file
40
41 Returns:
42 iterator: each line in file, not starting with '#'
43
44 """
45 try:
46 with open(path) as fh:
47 for line in fh:
48 line = line.strip()
49 if not line or line.startswith('#'):
50 continue
51 yield line
52 except (IOError, OSError) as e:
53 if e.errno == ENOENT:
54 pass
55 else:
56 raise
57
58
59 def _digest_path(algo, path):
60 if not isfile(path):
61 raise PathNotFoundError(path)
62
63 hasher = hashlib.new(algo)
64 with open(path, "rb") as fh:
65 for chunk in iter(partial(fh.read, 8192), b''):
66 hasher.update(chunk)
67 return hasher.hexdigest()
68
69
70 def compute_md5sum(file_full_path):
71 return _digest_path('md5', file_full_path)
72
73
74 def compute_sha256sum(file_full_path):
75 return _digest_path('sha256', file_full_path)
76
77
78 def find_first_existing(*globs):
79 for g in globs:
80 for path in glob(g):
81 if lexists(path):
82 return path
83 return None
84
85
86 # ####################################################
87 # functions supporting read_package_info()
88 # ####################################################
89
90 def read_package_info(record, package_cache_record):
91 epd = package_cache_record.extracted_package_dir
92 index_json_record = read_index_json(epd)
93 icondata = read_icondata(epd)
94 package_metadata = read_package_metadata(epd)
95 paths_data = read_paths_json(epd)
96
97 return PackageInfo(
98 extracted_package_dir=epd,
99 channel=Channel(record.schannel or record.channel),
100 repodata_record=record,
101 url=package_cache_record.url,
102
103 index_json_record=index_json_record,
104 icondata=icondata,
105 package_metadata=package_metadata,
106 paths_data=paths_data,
107 )
108
109
110 def read_index_json(extracted_package_directory):
111 with open(join(extracted_package_directory, 'info', 'index.json')) as fi:
112 record = IndexJsonRecord(**json.load(fi))
113 return record
114
115
116 def read_index_json_from_tarball(package_tarball_full_path):
117 with tarfile.open(package_tarball_full_path) as tf:
118 contents = tf.extractfile('info/index.json').read()
119 return IndexJsonRecord(**json.loads(ensure_text_type(contents)))
120
121
122 def read_repodata_json(extracted_package_directory):
123 with open(join(extracted_package_directory, 'info', 'repodata_record.json')) as fi:
124 record = IndexRecord(**json.load(fi))
125 return record
126
127
128 def read_icondata(extracted_package_directory):
129 icon_file_path = join(extracted_package_directory, 'info', 'icon.png')
130 if isfile(icon_file_path):
131 with open(icon_file_path, 'rb') as f:
132 data = f.read()
133 return b64encode(data).decode('utf-8')
134 else:
135 return None
136
137
138 def read_package_metadata(extracted_package_directory):
139 def _paths():
140 yield join(extracted_package_directory, 'info', 'link.json')
141 yield join(extracted_package_directory, 'info', 'package_metadata.json')
142
143 path = first(_paths(), key=isfile)
144 if not path:
145 return None
146 else:
147 with open(path, 'r') as f:
148 package_metadata = PackageMetadata(**json.loads(f.read()))
149 if package_metadata.package_metadata_version != 1:
150 raise CondaUpgradeError(dals("""
151 The current version of conda is too old to install this package. (This version
152 only supports link.json schema version 1.) Please update conda to install
153 this package."""))
154 return package_metadata
155
156
157 def read_paths_json(extracted_package_directory):
158 info_dir = join(extracted_package_directory, 'info')
159 paths_json_path = join(info_dir, 'paths.json')
160 if isfile(paths_json_path):
161 with open(paths_json_path) as paths_json:
162 data = json.load(paths_json)
163 if data.get('paths_version') != 1:
164 raise CondaUpgradeError(dals("""
165 The current version of conda is too old to install this package. (This version
166 only supports paths.json schema version 1.) Please update conda to install
167 this package."""))
168 paths_data = PathsData(
169 paths_version=1,
170 paths=(PathDataV1(**f) for f in data['paths']),
171 )
172 else:
173 has_prefix_files = read_has_prefix(join(info_dir, 'has_prefix'))
174 no_link = read_no_link(info_dir)
175
176 def read_files_file():
177 files_path = join(info_dir, 'files')
178 for f in (ln for ln in (line.strip() for line in yield_lines(files_path)) if ln):
179 path_info = {"_path": f}
180 if f in has_prefix_files.keys():
181 path_info["prefix_placeholder"] = has_prefix_files[f][0]
182 path_info["file_mode"] = has_prefix_files[f][1]
183 if f in no_link:
184 path_info["no_link"] = True
185 if islink(join(extracted_package_directory, f)):
186 path_info["path_type"] = PathType.softlink
187 else:
188 path_info["path_type"] = PathType.hardlink
189 yield PathData(**path_info)
190
191 paths = tuple(read_files_file())
192 paths_data = PathsData(
193 paths_version=0,
194 paths=paths,
195 )
196 return paths_data
197
198
199 def read_has_prefix(path):
200 """
201 reads `has_prefix` file and return dict mapping filepaths to tuples(placeholder, FileMode)
202
203 A line in `has_prefix` contains one of
204 * filepath
205 * placeholder mode filepath
206
207 mode values are one of
208 * text
209 * binary
210 """
211 ParseResult = namedtuple('ParseResult', ('placeholder', 'filemode', 'filepath'))
212
213 def parse_line(line):
214 # placeholder, filemode, filepath
215 parts = tuple(x.strip('"\'') for x in shlex.split(line, posix=False))
216 if len(parts) == 1:
217 return ParseResult(PREFIX_PLACEHOLDER, FileMode.text, parts[0])
218 elif len(parts) == 3:
219 return ParseResult(parts[0], FileMode(parts[1]), parts[2])
220 else:
221 raise CondaVerificationError("Invalid has_prefix file at path: %s" % path)
222
223 parsed_lines = (parse_line(line) for line in yield_lines(path))
224 return {pr.filepath: (pr.placeholder, pr.filemode) for pr in parsed_lines}
225
226
227 def read_no_link(info_dir):
228 return set(chain(yield_lines(join(info_dir, 'no_link')),
229 yield_lines(join(info_dir, 'no_softlink'))))
230
231
232 def read_soft_links(extracted_package_directory, files):
233 return tuple(f for f in files if islink(join(extracted_package_directory, f)))
234
```
Path: `conda/core/envs_manager.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from logging import getLogger
5 from os import listdir
6 from os.path import dirname, isdir, isfile, join, normpath, split as path_split
7
8 from ..base.constants import ROOT_ENV_NAME
9 from ..base.context import context
10 from ..common.compat import on_win
11 from ..common.path import expand, paths_equal
12 from ..gateways.disk.read import yield_lines
13 from ..gateways.disk.test import is_conda_environment
14
15 log = getLogger(__name__)
16
17
18 USER_ENVIRONMENTS_TXT_FILE = expand(join('~', '.conda', 'environments.txt'))
19
20
21 def register_env(location):
22 location = normpath(location)
23
24 if "placehold_pl" in location:
25 # Don't record envs created by conda-build.
26 return
27
28 if location in yield_lines(USER_ENVIRONMENTS_TXT_FILE):
29 # Nothing to do. Location is already recorded in a known environments.txt file.
30 return
31
32 with open(USER_ENVIRONMENTS_TXT_FILE, 'a') as fh:
33 fh.write(location)
34 fh.write('\n')
35
36
37 def unregister_env(location):
38 if isdir(location):
39 meta_dir = join(location, 'conda-meta')
40 if isdir(meta_dir):
41 meta_dir_contents = listdir(meta_dir)
42 if len(meta_dir_contents) > 1:
43 # if there are any files left other than 'conda-meta/history'
44 # then don't unregister
45 return
46
47 _clean_environments_txt(USER_ENVIRONMENTS_TXT_FILE, location)
48
49
50 def list_all_known_prefixes():
51 all_env_paths = set()
52 if on_win:
53 home_dir_dir = dirname(expand('~'))
54 for home_dir in listdir(home_dir_dir):
55 environments_txt_file = join(home_dir_dir, home_dir, '.conda', 'environments.txt')
56 if isfile(environments_txt_file):
57 all_env_paths.update(_clean_environments_txt(environments_txt_file))
58 else:
59 from os import geteuid
60 from pwd import getpwall
61 if geteuid() == 0:
62 search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)
63 else:
64 search_dirs = (expand('~'),)
65 for home_dir in search_dirs:
66 environments_txt_file = join(home_dir, '.conda', 'environments.txt')
67 if isfile(environments_txt_file):
68 all_env_paths.update(_clean_environments_txt(environments_txt_file))
69
70 # in case environments.txt files aren't complete, also add all known conda environments in
71 # all envs_dirs
72 envs_dirs = (envs_dir for envs_dir in context.envs_dirs if isdir(envs_dir))
73 all_env_paths.update(path for path in (
74 join(envs_dir, name) for envs_dir in envs_dirs for name in listdir(envs_dir)
75 ) if path not in all_env_paths and is_conda_environment(path))
76
77 all_env_paths.add(context.root_prefix)
78 return sorted(all_env_paths)
79
80
81 def env_name(prefix):
82 if not prefix:
83 return None
84 if paths_equal(prefix, context.root_prefix):
85 return ROOT_ENV_NAME
86 maybe_envs_dir, maybe_name = path_split(prefix)
87 for envs_dir in context.envs_dirs:
88 if paths_equal(envs_dir, maybe_envs_dir):
89 return maybe_name
90 return prefix
91
92
93 def _clean_environments_txt(environments_txt_file, remove_location=None):
94 if not isfile(environments_txt_file):
95 return ()
96
97 if remove_location:
98 remove_location = normpath(remove_location)
99 environments_txt_lines = tuple(yield_lines(environments_txt_file))
100 environments_txt_lines_cleaned = tuple(
101 prefix for prefix in environments_txt_lines
102 if prefix != remove_location and is_conda_environment(prefix)
103 )
104 if environments_txt_lines_cleaned != environments_txt_lines:
105 _rewrite_environments_txt(environments_txt_file, environments_txt_lines_cleaned)
106 return environments_txt_lines_cleaned
107
108
109 def _rewrite_environments_txt(environments_txt_file, prefixes):
110 try:
111 with open(environments_txt_file, 'w') as fh:
112 fh.write('\n'.join(prefixes))
113 fh.write('\n')
114 except (IOError, OSError) as e:
115 log.info("File not cleaned: %s", environments_txt_file)
116 log.debug('%r', e, exc_info=True)
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/core/envs_manager.py b/conda/core/envs_manager.py
--- a/conda/core/envs_manager.py
+++ b/conda/core/envs_manager.py
@@ -7,7 +7,7 @@
from ..base.constants import ROOT_ENV_NAME
from ..base.context import context
-from ..common.compat import on_win
+from ..common.compat import ensure_text_type, on_win, open
from ..common.path import expand, paths_equal
from ..gateways.disk.read import yield_lines
from ..gateways.disk.test import is_conda_environment
@@ -30,7 +30,7 @@
return
with open(USER_ENVIRONMENTS_TXT_FILE, 'a') as fh:
- fh.write(location)
+ fh.write(ensure_text_type(location))
fh.write('\n')
diff --git a/conda/gateways/disk/read.py b/conda/gateways/disk/read.py
--- a/conda/gateways/disk/read.py
+++ b/conda/gateways/disk/read.py
@@ -19,7 +19,7 @@
from ..._vendor.auxlib.collection import first
from ..._vendor.auxlib.ish import dals
from ...base.constants import PREFIX_PLACEHOLDER
-from ...common.compat import ensure_text_type
+from ...common.compat import ensure_text_type, open
from ...exceptions import CondaUpgradeError, CondaVerificationError, PathNotFoundError
from ...models.channel import Channel
from ...models.enums import FileMode, PathType
|
{"golden_diff": "diff --git a/conda/core/envs_manager.py b/conda/core/envs_manager.py\n--- a/conda/core/envs_manager.py\n+++ b/conda/core/envs_manager.py\n@@ -7,7 +7,7 @@\n \n from ..base.constants import ROOT_ENV_NAME\n from ..base.context import context\n-from ..common.compat import on_win\n+from ..common.compat import ensure_text_type, on_win, open\n from ..common.path import expand, paths_equal\n from ..gateways.disk.read import yield_lines\n from ..gateways.disk.test import is_conda_environment\n@@ -30,7 +30,7 @@\n return\n \n with open(USER_ENVIRONMENTS_TXT_FILE, 'a') as fh:\n- fh.write(location)\n+ fh.write(ensure_text_type(location))\n fh.write('\\n')\n \n \ndiff --git a/conda/gateways/disk/read.py b/conda/gateways/disk/read.py\n--- a/conda/gateways/disk/read.py\n+++ b/conda/gateways/disk/read.py\n@@ -19,7 +19,7 @@\n from ..._vendor.auxlib.collection import first\n from ..._vendor.auxlib.ish import dals\n from ...base.constants import PREFIX_PLACEHOLDER\n-from ...common.compat import ensure_text_type\n+from ...common.compat import ensure_text_type, open\n from ...exceptions import CondaUpgradeError, CondaVerificationError, PathNotFoundError\n from ...models.channel import Channel\n from ...models.enums import FileMode, PathType\n", "issue": "python 2 can't read unicode in environments.txt\non a conda install operation, during the transaction\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/kfranz/continuum/conda/conda/core/link.py\", line 535, in _execute_actions\r\n action.execute()\r\n File \"/Users/kfranz/continuum/conda/conda/core/path_actions.py\", line 876, in execute\r\n register_env(self.target_prefix)\r\n File \"/Users/kfranz/continuum/conda/conda/core/envs_manager.py\", line 28, in register_env\r\n if location in yield_lines(USER_ENVIRONMENTS_TXT_FILE):\r\n File \"/Users/kfranz/continuum/conda/conda/gateways/disk/read.py\", line 49, in yield_lines\r\n if not line or line.startswith('#'):\r\nUnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 54: ordinal not in range(128)\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom base64 import b64encode\nfrom collections import namedtuple\nfrom errno import ENOENT\nfrom functools import partial\nfrom glob import glob\nimport hashlib\nfrom itertools import chain\nimport json\nfrom logging import getLogger\nfrom os import listdir\nfrom os.path import isdir, isfile, join\nimport shlex\nimport tarfile\n\nfrom .link import islink, lexists\nfrom ..._vendor.auxlib.collection import first\nfrom ..._vendor.auxlib.ish import dals\nfrom ...base.constants import PREFIX_PLACEHOLDER\nfrom ...common.compat import ensure_text_type\nfrom ...exceptions import CondaUpgradeError, CondaVerificationError, PathNotFoundError\nfrom ...models.channel import Channel\nfrom ...models.enums import FileMode, PathType\nfrom ...models.index_record import IndexJsonRecord, IndexRecord, PathData, PathDataV1, PathsData\nfrom ...models.package_info import PackageInfo, PackageMetadata\n\nlog = getLogger(__name__)\n\nlistdir = listdir\nlexists, isdir, isfile = lexists, isdir, isfile\n\n\ndef yield_lines(path):\n \"\"\"Generator function for lines in file. Empty generator if path does not exist.\n\n Args:\n path (str): path to file\n\n Returns:\n iterator: each line in file, not starting with '#'\n\n \"\"\"\n try:\n with open(path) as fh:\n for line in fh:\n line = line.strip()\n if not line or line.startswith('#'):\n continue\n yield line\n except (IOError, OSError) as e:\n if e.errno == ENOENT:\n pass\n else:\n raise\n\n\ndef _digest_path(algo, path):\n if not isfile(path):\n raise PathNotFoundError(path)\n\n hasher = hashlib.new(algo)\n with open(path, \"rb\") as fh:\n for chunk in iter(partial(fh.read, 8192), b''):\n hasher.update(chunk)\n return hasher.hexdigest()\n\n\ndef compute_md5sum(file_full_path):\n return _digest_path('md5', file_full_path)\n\n\ndef compute_sha256sum(file_full_path):\n return _digest_path('sha256', file_full_path)\n\n\ndef find_first_existing(*globs):\n for g in globs:\n for path in glob(g):\n if lexists(path):\n return path\n return None\n\n\n# ####################################################\n# functions supporting read_package_info()\n# ####################################################\n\ndef read_package_info(record, package_cache_record):\n epd = package_cache_record.extracted_package_dir\n index_json_record = read_index_json(epd)\n icondata = read_icondata(epd)\n package_metadata = read_package_metadata(epd)\n paths_data = read_paths_json(epd)\n\n return PackageInfo(\n extracted_package_dir=epd,\n channel=Channel(record.schannel or record.channel),\n repodata_record=record,\n url=package_cache_record.url,\n\n index_json_record=index_json_record,\n icondata=icondata,\n package_metadata=package_metadata,\n paths_data=paths_data,\n )\n\n\ndef read_index_json(extracted_package_directory):\n with open(join(extracted_package_directory, 'info', 'index.json')) as fi:\n record = IndexJsonRecord(**json.load(fi))\n return record\n\n\ndef read_index_json_from_tarball(package_tarball_full_path):\n with tarfile.open(package_tarball_full_path) as tf:\n contents = tf.extractfile('info/index.json').read()\n return IndexJsonRecord(**json.loads(ensure_text_type(contents)))\n\n\ndef read_repodata_json(extracted_package_directory):\n with open(join(extracted_package_directory, 'info', 'repodata_record.json')) as fi:\n record = IndexRecord(**json.load(fi))\n return record\n\n\ndef read_icondata(extracted_package_directory):\n icon_file_path = join(extracted_package_directory, 'info', 'icon.png')\n if isfile(icon_file_path):\n with open(icon_file_path, 'rb') as f:\n data = f.read()\n return b64encode(data).decode('utf-8')\n else:\n return None\n\n\ndef read_package_metadata(extracted_package_directory):\n def _paths():\n yield join(extracted_package_directory, 'info', 'link.json')\n yield join(extracted_package_directory, 'info', 'package_metadata.json')\n\n path = first(_paths(), key=isfile)\n if not path:\n return None\n else:\n with open(path, 'r') as f:\n package_metadata = PackageMetadata(**json.loads(f.read()))\n if package_metadata.package_metadata_version != 1:\n raise CondaUpgradeError(dals(\"\"\"\n The current version of conda is too old to install this package. (This version\n only supports link.json schema version 1.) Please update conda to install\n this package.\"\"\"))\n return package_metadata\n\n\ndef read_paths_json(extracted_package_directory):\n info_dir = join(extracted_package_directory, 'info')\n paths_json_path = join(info_dir, 'paths.json')\n if isfile(paths_json_path):\n with open(paths_json_path) as paths_json:\n data = json.load(paths_json)\n if data.get('paths_version') != 1:\n raise CondaUpgradeError(dals(\"\"\"\n The current version of conda is too old to install this package. (This version\n only supports paths.json schema version 1.) Please update conda to install\n this package.\"\"\"))\n paths_data = PathsData(\n paths_version=1,\n paths=(PathDataV1(**f) for f in data['paths']),\n )\n else:\n has_prefix_files = read_has_prefix(join(info_dir, 'has_prefix'))\n no_link = read_no_link(info_dir)\n\n def read_files_file():\n files_path = join(info_dir, 'files')\n for f in (ln for ln in (line.strip() for line in yield_lines(files_path)) if ln):\n path_info = {\"_path\": f}\n if f in has_prefix_files.keys():\n path_info[\"prefix_placeholder\"] = has_prefix_files[f][0]\n path_info[\"file_mode\"] = has_prefix_files[f][1]\n if f in no_link:\n path_info[\"no_link\"] = True\n if islink(join(extracted_package_directory, f)):\n path_info[\"path_type\"] = PathType.softlink\n else:\n path_info[\"path_type\"] = PathType.hardlink\n yield PathData(**path_info)\n\n paths = tuple(read_files_file())\n paths_data = PathsData(\n paths_version=0,\n paths=paths,\n )\n return paths_data\n\n\ndef read_has_prefix(path):\n \"\"\"\n reads `has_prefix` file and return dict mapping filepaths to tuples(placeholder, FileMode)\n\n A line in `has_prefix` contains one of\n * filepath\n * placeholder mode filepath\n\n mode values are one of\n * text\n * binary\n \"\"\"\n ParseResult = namedtuple('ParseResult', ('placeholder', 'filemode', 'filepath'))\n\n def parse_line(line):\n # placeholder, filemode, filepath\n parts = tuple(x.strip('\"\\'') for x in shlex.split(line, posix=False))\n if len(parts) == 1:\n return ParseResult(PREFIX_PLACEHOLDER, FileMode.text, parts[0])\n elif len(parts) == 3:\n return ParseResult(parts[0], FileMode(parts[1]), parts[2])\n else:\n raise CondaVerificationError(\"Invalid has_prefix file at path: %s\" % path)\n\n parsed_lines = (parse_line(line) for line in yield_lines(path))\n return {pr.filepath: (pr.placeholder, pr.filemode) for pr in parsed_lines}\n\n\ndef read_no_link(info_dir):\n return set(chain(yield_lines(join(info_dir, 'no_link')),\n yield_lines(join(info_dir, 'no_softlink'))))\n\n\ndef read_soft_links(extracted_package_directory, files):\n return tuple(f for f in files if islink(join(extracted_package_directory, f)))\n", "path": "conda/gateways/disk/read.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom logging import getLogger\nfrom os import listdir\nfrom os.path import dirname, isdir, isfile, join, normpath, split as path_split\n\nfrom ..base.constants import ROOT_ENV_NAME\nfrom ..base.context import context\nfrom ..common.compat import on_win\nfrom ..common.path import expand, paths_equal\nfrom ..gateways.disk.read import yield_lines\nfrom ..gateways.disk.test import is_conda_environment\n\nlog = getLogger(__name__)\n\n\nUSER_ENVIRONMENTS_TXT_FILE = expand(join('~', '.conda', 'environments.txt'))\n\n\ndef register_env(location):\n location = normpath(location)\n\n if \"placehold_pl\" in location:\n # Don't record envs created by conda-build.\n return\n\n if location in yield_lines(USER_ENVIRONMENTS_TXT_FILE):\n # Nothing to do. Location is already recorded in a known environments.txt file.\n return\n\n with open(USER_ENVIRONMENTS_TXT_FILE, 'a') as fh:\n fh.write(location)\n fh.write('\\n')\n\n\ndef unregister_env(location):\n if isdir(location):\n meta_dir = join(location, 'conda-meta')\n if isdir(meta_dir):\n meta_dir_contents = listdir(meta_dir)\n if len(meta_dir_contents) > 1:\n # if there are any files left other than 'conda-meta/history'\n # then don't unregister\n return\n\n _clean_environments_txt(USER_ENVIRONMENTS_TXT_FILE, location)\n\n\ndef list_all_known_prefixes():\n all_env_paths = set()\n if on_win:\n home_dir_dir = dirname(expand('~'))\n for home_dir in listdir(home_dir_dir):\n environments_txt_file = join(home_dir_dir, home_dir, '.conda', 'environments.txt')\n if isfile(environments_txt_file):\n all_env_paths.update(_clean_environments_txt(environments_txt_file))\n else:\n from os import geteuid\n from pwd import getpwall\n if geteuid() == 0:\n search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)\n else:\n search_dirs = (expand('~'),)\n for home_dir in search_dirs:\n environments_txt_file = join(home_dir, '.conda', 'environments.txt')\n if isfile(environments_txt_file):\n all_env_paths.update(_clean_environments_txt(environments_txt_file))\n\n # in case environments.txt files aren't complete, also add all known conda environments in\n # all envs_dirs\n envs_dirs = (envs_dir for envs_dir in context.envs_dirs if isdir(envs_dir))\n all_env_paths.update(path for path in (\n join(envs_dir, name) for envs_dir in envs_dirs for name in listdir(envs_dir)\n ) if path not in all_env_paths and is_conda_environment(path))\n\n all_env_paths.add(context.root_prefix)\n return sorted(all_env_paths)\n\n\ndef env_name(prefix):\n if not prefix:\n return None\n if paths_equal(prefix, context.root_prefix):\n return ROOT_ENV_NAME\n maybe_envs_dir, maybe_name = path_split(prefix)\n for envs_dir in context.envs_dirs:\n if paths_equal(envs_dir, maybe_envs_dir):\n return maybe_name\n return prefix\n\n\ndef _clean_environments_txt(environments_txt_file, remove_location=None):\n if not isfile(environments_txt_file):\n return ()\n\n if remove_location:\n remove_location = normpath(remove_location)\n environments_txt_lines = tuple(yield_lines(environments_txt_file))\n environments_txt_lines_cleaned = tuple(\n prefix for prefix in environments_txt_lines\n if prefix != remove_location and is_conda_environment(prefix)\n )\n if environments_txt_lines_cleaned != environments_txt_lines:\n _rewrite_environments_txt(environments_txt_file, environments_txt_lines_cleaned)\n return environments_txt_lines_cleaned\n\n\ndef _rewrite_environments_txt(environments_txt_file, prefixes):\n try:\n with open(environments_txt_file, 'w') as fh:\n fh.write('\\n'.join(prefixes))\n fh.write('\\n')\n except (IOError, OSError) as e:\n log.info(\"File not cleaned: %s\", environments_txt_file)\n log.debug('%r', e, exc_info=True)\n", "path": "conda/core/envs_manager.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom base64 import b64encode\nfrom collections import namedtuple\nfrom errno import ENOENT\nfrom functools import partial\nfrom glob import glob\nimport hashlib\nfrom itertools import chain\nimport json\nfrom logging import getLogger\nfrom os import listdir\nfrom os.path import isdir, isfile, join\nimport shlex\nimport tarfile\n\nfrom .link import islink, lexists\nfrom ..._vendor.auxlib.collection import first\nfrom ..._vendor.auxlib.ish import dals\nfrom ...base.constants import PREFIX_PLACEHOLDER\nfrom ...common.compat import ensure_text_type, open\nfrom ...exceptions import CondaUpgradeError, CondaVerificationError, PathNotFoundError\nfrom ...models.channel import Channel\nfrom ...models.enums import FileMode, PathType\nfrom ...models.index_record import IndexJsonRecord, IndexRecord, PathData, PathDataV1, PathsData\nfrom ...models.package_info import PackageInfo, PackageMetadata\n\nlog = getLogger(__name__)\n\nlistdir = listdir\nlexists, isdir, isfile = lexists, isdir, isfile\n\n\ndef yield_lines(path):\n \"\"\"Generator function for lines in file. Empty generator if path does not exist.\n\n Args:\n path (str): path to file\n\n Returns:\n iterator: each line in file, not starting with '#'\n\n \"\"\"\n try:\n with open(path) as fh:\n for line in fh:\n line = line.strip()\n if not line or line.startswith('#'):\n continue\n yield line\n except (IOError, OSError) as e:\n if e.errno == ENOENT:\n pass\n else:\n raise\n\n\ndef _digest_path(algo, path):\n if not isfile(path):\n raise PathNotFoundError(path)\n\n hasher = hashlib.new(algo)\n with open(path, \"rb\") as fh:\n for chunk in iter(partial(fh.read, 8192), b''):\n hasher.update(chunk)\n return hasher.hexdigest()\n\n\ndef compute_md5sum(file_full_path):\n return _digest_path('md5', file_full_path)\n\n\ndef compute_sha256sum(file_full_path):\n return _digest_path('sha256', file_full_path)\n\n\ndef find_first_existing(*globs):\n for g in globs:\n for path in glob(g):\n if lexists(path):\n return path\n return None\n\n\n# ####################################################\n# functions supporting read_package_info()\n# ####################################################\n\ndef read_package_info(record, package_cache_record):\n epd = package_cache_record.extracted_package_dir\n index_json_record = read_index_json(epd)\n icondata = read_icondata(epd)\n package_metadata = read_package_metadata(epd)\n paths_data = read_paths_json(epd)\n\n return PackageInfo(\n extracted_package_dir=epd,\n channel=Channel(record.schannel or record.channel),\n repodata_record=record,\n url=package_cache_record.url,\n\n index_json_record=index_json_record,\n icondata=icondata,\n package_metadata=package_metadata,\n paths_data=paths_data,\n )\n\n\ndef read_index_json(extracted_package_directory):\n with open(join(extracted_package_directory, 'info', 'index.json')) as fi:\n record = IndexJsonRecord(**json.load(fi))\n return record\n\n\ndef read_index_json_from_tarball(package_tarball_full_path):\n with tarfile.open(package_tarball_full_path) as tf:\n contents = tf.extractfile('info/index.json').read()\n return IndexJsonRecord(**json.loads(ensure_text_type(contents)))\n\n\ndef read_repodata_json(extracted_package_directory):\n with open(join(extracted_package_directory, 'info', 'repodata_record.json')) as fi:\n record = IndexRecord(**json.load(fi))\n return record\n\n\ndef read_icondata(extracted_package_directory):\n icon_file_path = join(extracted_package_directory, 'info', 'icon.png')\n if isfile(icon_file_path):\n with open(icon_file_path, 'rb') as f:\n data = f.read()\n return b64encode(data).decode('utf-8')\n else:\n return None\n\n\ndef read_package_metadata(extracted_package_directory):\n def _paths():\n yield join(extracted_package_directory, 'info', 'link.json')\n yield join(extracted_package_directory, 'info', 'package_metadata.json')\n\n path = first(_paths(), key=isfile)\n if not path:\n return None\n else:\n with open(path, 'r') as f:\n package_metadata = PackageMetadata(**json.loads(f.read()))\n if package_metadata.package_metadata_version != 1:\n raise CondaUpgradeError(dals(\"\"\"\n The current version of conda is too old to install this package. (This version\n only supports link.json schema version 1.) Please update conda to install\n this package.\"\"\"))\n return package_metadata\n\n\ndef read_paths_json(extracted_package_directory):\n info_dir = join(extracted_package_directory, 'info')\n paths_json_path = join(info_dir, 'paths.json')\n if isfile(paths_json_path):\n with open(paths_json_path) as paths_json:\n data = json.load(paths_json)\n if data.get('paths_version') != 1:\n raise CondaUpgradeError(dals(\"\"\"\n The current version of conda is too old to install this package. (This version\n only supports paths.json schema version 1.) Please update conda to install\n this package.\"\"\"))\n paths_data = PathsData(\n paths_version=1,\n paths=(PathDataV1(**f) for f in data['paths']),\n )\n else:\n has_prefix_files = read_has_prefix(join(info_dir, 'has_prefix'))\n no_link = read_no_link(info_dir)\n\n def read_files_file():\n files_path = join(info_dir, 'files')\n for f in (ln for ln in (line.strip() for line in yield_lines(files_path)) if ln):\n path_info = {\"_path\": f}\n if f in has_prefix_files.keys():\n path_info[\"prefix_placeholder\"] = has_prefix_files[f][0]\n path_info[\"file_mode\"] = has_prefix_files[f][1]\n if f in no_link:\n path_info[\"no_link\"] = True\n if islink(join(extracted_package_directory, f)):\n path_info[\"path_type\"] = PathType.softlink\n else:\n path_info[\"path_type\"] = PathType.hardlink\n yield PathData(**path_info)\n\n paths = tuple(read_files_file())\n paths_data = PathsData(\n paths_version=0,\n paths=paths,\n )\n return paths_data\n\n\ndef read_has_prefix(path):\n \"\"\"\n reads `has_prefix` file and return dict mapping filepaths to tuples(placeholder, FileMode)\n\n A line in `has_prefix` contains one of\n * filepath\n * placeholder mode filepath\n\n mode values are one of\n * text\n * binary\n \"\"\"\n ParseResult = namedtuple('ParseResult', ('placeholder', 'filemode', 'filepath'))\n\n def parse_line(line):\n # placeholder, filemode, filepath\n parts = tuple(x.strip('\"\\'') for x in shlex.split(line, posix=False))\n if len(parts) == 1:\n return ParseResult(PREFIX_PLACEHOLDER, FileMode.text, parts[0])\n elif len(parts) == 3:\n return ParseResult(parts[0], FileMode(parts[1]), parts[2])\n else:\n raise CondaVerificationError(\"Invalid has_prefix file at path: %s\" % path)\n\n parsed_lines = (parse_line(line) for line in yield_lines(path))\n return {pr.filepath: (pr.placeholder, pr.filemode) for pr in parsed_lines}\n\n\ndef read_no_link(info_dir):\n return set(chain(yield_lines(join(info_dir, 'no_link')),\n yield_lines(join(info_dir, 'no_softlink'))))\n\n\ndef read_soft_links(extracted_package_directory, files):\n return tuple(f for f in files if islink(join(extracted_package_directory, f)))\n", "path": "conda/gateways/disk/read.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom logging import getLogger\nfrom os import listdir\nfrom os.path import dirname, isdir, isfile, join, normpath, split as path_split\n\nfrom ..base.constants import ROOT_ENV_NAME\nfrom ..base.context import context\nfrom ..common.compat import ensure_text_type, on_win, open\nfrom ..common.path import expand, paths_equal\nfrom ..gateways.disk.read import yield_lines\nfrom ..gateways.disk.test import is_conda_environment\n\nlog = getLogger(__name__)\n\n\nUSER_ENVIRONMENTS_TXT_FILE = expand(join('~', '.conda', 'environments.txt'))\n\n\ndef register_env(location):\n location = normpath(location)\n\n if \"placehold_pl\" in location:\n # Don't record envs created by conda-build.\n return\n\n if location in yield_lines(USER_ENVIRONMENTS_TXT_FILE):\n # Nothing to do. Location is already recorded in a known environments.txt file.\n return\n\n with open(USER_ENVIRONMENTS_TXT_FILE, 'a') as fh:\n fh.write(ensure_text_type(location))\n fh.write('\\n')\n\n\ndef unregister_env(location):\n if isdir(location):\n meta_dir = join(location, 'conda-meta')\n if isdir(meta_dir):\n meta_dir_contents = listdir(meta_dir)\n if len(meta_dir_contents) > 1:\n # if there are any files left other than 'conda-meta/history'\n # then don't unregister\n return\n\n _clean_environments_txt(USER_ENVIRONMENTS_TXT_FILE, location)\n\n\ndef list_all_known_prefixes():\n all_env_paths = set()\n if on_win:\n home_dir_dir = dirname(expand('~'))\n for home_dir in listdir(home_dir_dir):\n environments_txt_file = join(home_dir_dir, home_dir, '.conda', 'environments.txt')\n if isfile(environments_txt_file):\n all_env_paths.update(_clean_environments_txt(environments_txt_file))\n else:\n from os import geteuid\n from pwd import getpwall\n if geteuid() == 0:\n search_dirs = tuple(pwentry.pw_dir for pwentry in getpwall()) or (expand('~'),)\n else:\n search_dirs = (expand('~'),)\n for home_dir in search_dirs:\n environments_txt_file = join(home_dir, '.conda', 'environments.txt')\n if isfile(environments_txt_file):\n all_env_paths.update(_clean_environments_txt(environments_txt_file))\n\n # in case environments.txt files aren't complete, also add all known conda environments in\n # all envs_dirs\n envs_dirs = (envs_dir for envs_dir in context.envs_dirs if isdir(envs_dir))\n all_env_paths.update(path for path in (\n join(envs_dir, name) for envs_dir in envs_dirs for name in listdir(envs_dir)\n ) if path not in all_env_paths and is_conda_environment(path))\n\n all_env_paths.add(context.root_prefix)\n return sorted(all_env_paths)\n\n\ndef env_name(prefix):\n if not prefix:\n return None\n if paths_equal(prefix, context.root_prefix):\n return ROOT_ENV_NAME\n maybe_envs_dir, maybe_name = path_split(prefix)\n for envs_dir in context.envs_dirs:\n if paths_equal(envs_dir, maybe_envs_dir):\n return maybe_name\n return prefix\n\n\ndef _clean_environments_txt(environments_txt_file, remove_location=None):\n if not isfile(environments_txt_file):\n return ()\n\n if remove_location:\n remove_location = normpath(remove_location)\n environments_txt_lines = tuple(yield_lines(environments_txt_file))\n environments_txt_lines_cleaned = tuple(\n prefix for prefix in environments_txt_lines\n if prefix != remove_location and is_conda_environment(prefix)\n )\n if environments_txt_lines_cleaned != environments_txt_lines:\n _rewrite_environments_txt(environments_txt_file, environments_txt_lines_cleaned)\n return environments_txt_lines_cleaned\n\n\ndef _rewrite_environments_txt(environments_txt_file, prefixes):\n try:\n with open(environments_txt_file, 'w') as fh:\n fh.write('\\n'.join(prefixes))\n fh.write('\\n')\n except (IOError, OSError) as e:\n log.info(\"File not cleaned: %s\", environments_txt_file)\n log.debug('%r', e, exc_info=True)\n", "path": "conda/core/envs_manager.py"}]}
| 4,053 | 324 |
gh_patches_debug_11165
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-1092
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`/api/v1/chains` returns unexpected nativeCurrency.logoUri path
**Describe the bug**
I deployed a project locally using the code from `https://github.com/safe-global/safe-infrastructure`. However, after adding a configuration for a chain in cfg, the `/v1/chains` endpoint of cgw started returning a 500 error. After enabling debug logs, I found that cgw returned the following error:
```json
{
"build_number": "edc276d",
"level": "error",
"message": {
"chain_id": null,
"client_ip": "172.70.223.68",
"detail": "[\n {\n \"validation\": \"url\",\n \"code\": \"invalid_string\",\n \"message\": \"Invalid url\",\n \"path\": [\n \"nativeCurrency\",\n \"logoUri\"\n ]\n }\n]",
"method": "GET",
"path": "/v1/chains",
"response_time_ms": 107.19920100085437,
"route": "/v1/chains",
"safe_app_user_agent": null,
"status_code": 500
},
"request_id": "1e37d27b-02b6-468a-a290-b6e06f7bc911",
"timestamp": "2024-03-29T07:54:29.220Z",
"version": "v1.31.0"
}
````
After investigating further, I found that the `nativeCurrency.logoUri` in the response data from cfg is not an absolute path:
```json
{
"count": 1,
"next": null,
"previous": null,
"results": [
{
...
"nativeCurrency": {
"name": "ETH",
"symbol": "ETH",
"decimals": 18,
"logoUri": "/media/chains/100/currency_logo_3fdtfcf.png"
},
...
]
}
```
**To Reproduce**
Steps to reproduce the behavior:
- Clone the code from `https://github.com/safe-global/safe-infrastructure`
- Modify the MEDIA_URL in cfg.env to `/media/`
**Expected behavior**
The `nativeCurrency.logoUri` in the response data from cfg should be `https://config.xxx.xyz/media/chains/100/currency_logo_3fdtfcf.png` instead of `/media/chains/100/currency_logo_3fdtfcf.png`.
**Environment (please complete the following information):**
- Version of safe-config-service: latest(possibly [v2.75.0])
**Additional context**
I made the following edits to the `src/chains/serializers.py` file
from
```python
@staticmethod
@swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]
def get_native_currency(obj: Chain) -> ReturnDict:
return CurrencySerializer(obj).data
```
to
```python
@swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]
def get_native_currency(self, obj: Chain) -> ReturnDict:
request = self.context.get('request')
logo_uri = obj.currency_logo_uri
dict = CurrencySerializer(obj).data
dict.update({"logo_uri":request.build_absolute_uri(logo_uri)})
return dict
```
After applying the temporary workaround, cfg is able to return the expected data. However, since I'm not familiar with Python and Django, this was just a temporary solution on my part. I hope that you can find a better way to fix this issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/chains/serializers.py`
Content:
```
1 from abc import abstractmethod
2
3 from drf_yasg.utils import swagger_serializer_method
4 from gnosis.eth.django.serializers import EthereumAddressField
5 from rest_framework import serializers
6 from rest_framework.exceptions import APIException
7 from rest_framework.utils.serializer_helpers import ReturnDict
8
9 from .models import Chain, Feature, GasPrice, Wallet
10
11
12 class GasPriceOracleSerializer(serializers.Serializer[GasPrice]):
13 type = serializers.ReadOnlyField(default="oracle")
14 uri = serializers.URLField(source="oracle_uri")
15 gas_parameter = serializers.CharField(source="oracle_parameter")
16 gwei_factor = serializers.DecimalField(max_digits=19, decimal_places=9)
17
18
19 class GasPriceFixedSerializer(serializers.Serializer[GasPrice]):
20 type = serializers.ReadOnlyField(default="fixed")
21 wei_value = serializers.CharField(source="fixed_wei_value")
22
23
24 class GasPriceFixed1559Serializer(serializers.Serializer[GasPrice]):
25 type = serializers.ReadOnlyField(default="fixed1559")
26 max_fee_per_gas = serializers.CharField()
27 max_priority_fee_per_gas = serializers.CharField()
28
29
30 class GasPriceSerializer(serializers.Serializer[GasPrice]):
31 def to_representation(self, instance: GasPrice) -> ReturnDict:
32 if (
33 instance.oracle_uri
34 and instance.fixed_wei_value is None
35 and instance.max_fee_per_gas is None
36 and instance.max_priority_fee_per_gas is None
37 ):
38 return GasPriceOracleSerializer(instance).data
39 elif (
40 instance.fixed_wei_value
41 and instance.oracle_uri is None
42 and instance.max_fee_per_gas is None
43 and instance.max_priority_fee_per_gas is None
44 ):
45 return GasPriceFixedSerializer(instance).data
46 elif (
47 instance.max_fee_per_gas
48 and instance.max_priority_fee_per_gas
49 and instance.oracle_uri is None
50 and instance.fixed_wei_value is None
51 ):
52 return GasPriceFixed1559Serializer(instance).data
53 else:
54 raise APIException(
55 f"The gas price oracle or a fixed gas price was not provided for chain {instance.chain}"
56 )
57
58
59 class ThemeSerializer(serializers.Serializer[Chain]):
60 text_color = serializers.CharField(source="theme_text_color")
61 background_color = serializers.CharField(source="theme_background_color")
62
63
64 class CurrencySerializer(serializers.Serializer[Chain]):
65 name = serializers.CharField(source="currency_name")
66 symbol = serializers.CharField(source="currency_symbol")
67 decimals = serializers.IntegerField(source="currency_decimals")
68 logo_uri = serializers.ImageField(use_url=True, source="currency_logo_uri")
69
70
71 class BaseRpcUriSerializer(serializers.Serializer[Chain]):
72 authentication = serializers.SerializerMethodField()
73 value = serializers.SerializerMethodField(method_name="get_rpc_value")
74
75 @abstractmethod
76 def get_authentication(self, obj: Chain) -> str: # pragma: no cover
77 pass
78
79 @abstractmethod
80 def get_rpc_value(self, obj: Chain) -> str: # pragma: no cover
81 pass
82
83
84 class RpcUriSerializer(BaseRpcUriSerializer):
85 def get_authentication(self, obj: Chain) -> str:
86 return obj.rpc_authentication
87
88 def get_rpc_value(self, obj: Chain) -> str:
89 return obj.rpc_uri
90
91
92 class SafeAppsRpcUriSerializer(BaseRpcUriSerializer):
93 def get_authentication(self, obj: Chain) -> str:
94 return obj.safe_apps_rpc_authentication
95
96 def get_rpc_value(self, obj: Chain) -> str:
97 return obj.safe_apps_rpc_uri
98
99
100 class PublicRpcUriSerializer(BaseRpcUriSerializer):
101 def get_authentication(self, obj: Chain) -> str:
102 return obj.public_rpc_authentication
103
104 def get_rpc_value(self, obj: Chain) -> str:
105 return obj.public_rpc_uri
106
107
108 class BlockExplorerUriTemplateSerializer(serializers.Serializer[Chain]):
109 address = serializers.URLField(source="block_explorer_uri_address_template")
110 tx_hash = serializers.URLField(source="block_explorer_uri_tx_hash_template")
111 api = serializers.URLField(source="block_explorer_uri_api_template")
112
113
114 class FeatureSerializer(serializers.Serializer[Feature]):
115 class Meta:
116 ref_name = "chains.serializers.FeatureSerializer"
117
118 @staticmethod
119 def to_representation(instance: Feature) -> str:
120 return instance.key
121
122
123 class WalletSerializer(serializers.Serializer[Wallet]):
124 @staticmethod
125 def to_representation(instance: Wallet) -> str:
126 return instance.key
127
128
129 class ChainSerializer(serializers.ModelSerializer[Chain]):
130 chain_id = serializers.CharField(source="id")
131 chain_name = serializers.CharField(source="name")
132 short_name = serializers.CharField()
133 chain_logo_uri = serializers.ImageField(use_url=True)
134 rpc_uri = serializers.SerializerMethodField()
135 safe_apps_rpc_uri = serializers.SerializerMethodField()
136 public_rpc_uri = serializers.SerializerMethodField()
137 block_explorer_uri_template = serializers.SerializerMethodField()
138 native_currency = serializers.SerializerMethodField()
139 transaction_service = serializers.URLField(
140 source="transaction_service_uri", default=None
141 )
142 vpc_transaction_service = serializers.URLField(source="vpc_transaction_service_uri")
143 theme = serializers.SerializerMethodField()
144 gas_price = serializers.SerializerMethodField()
145 ens_registry_address = EthereumAddressField()
146 disabled_wallets = serializers.SerializerMethodField()
147 features = serializers.SerializerMethodField()
148
149 class Meta:
150 model = Chain
151 fields = [
152 "chain_id",
153 "chain_name",
154 "short_name",
155 "description",
156 "chain_logo_uri",
157 "l2",
158 "is_testnet",
159 "rpc_uri",
160 "safe_apps_rpc_uri",
161 "public_rpc_uri",
162 "block_explorer_uri_template",
163 "native_currency",
164 "transaction_service",
165 "vpc_transaction_service",
166 "theme",
167 "gas_price",
168 "ens_registry_address",
169 "recommended_master_copy_version",
170 "disabled_wallets",
171 "features",
172 ]
173
174 @staticmethod
175 @swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]
176 def get_native_currency(obj: Chain) -> ReturnDict:
177 return CurrencySerializer(obj).data
178
179 @staticmethod
180 @swagger_serializer_method(serializer_or_field=ThemeSerializer) # type: ignore[misc]
181 def get_theme(obj: Chain) -> ReturnDict:
182 return ThemeSerializer(obj).data
183
184 @staticmethod
185 @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]
186 def get_safe_apps_rpc_uri(obj: Chain) -> ReturnDict:
187 return SafeAppsRpcUriSerializer(obj).data
188
189 @staticmethod
190 @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]
191 def get_rpc_uri(obj: Chain) -> ReturnDict:
192 return RpcUriSerializer(obj).data
193
194 @staticmethod
195 @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]
196 def get_public_rpc_uri(obj: Chain) -> ReturnDict:
197 return PublicRpcUriSerializer(obj).data
198
199 @staticmethod
200 @swagger_serializer_method(serializer_or_field=BlockExplorerUriTemplateSerializer) # type: ignore[misc]
201 def get_block_explorer_uri_template(obj: Chain) -> ReturnDict:
202 return BlockExplorerUriTemplateSerializer(obj).data
203
204 @swagger_serializer_method(serializer_or_field=GasPriceSerializer) # type: ignore[misc]
205 def get_gas_price(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]
206 ranked_gas_prices = instance.gasprice_set.all().order_by("rank")
207 return GasPriceSerializer(ranked_gas_prices, many=True).data
208
209 @swagger_serializer_method(serializer_or_field=WalletSerializer) # type: ignore[misc]
210 def get_disabled_wallets(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]
211 disabled_wallets = instance.get_disabled_wallets().order_by("key")
212 return WalletSerializer(disabled_wallets, many=True).data
213
214 @swagger_serializer_method(serializer_or_field=FeatureSerializer) # type: ignore[misc]
215 def get_features(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]
216 enabled_features = instance.feature_set.all().order_by("key")
217 return FeatureSerializer(enabled_features, many=True).data
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/chains/serializers.py b/src/chains/serializers.py
--- a/src/chains/serializers.py
+++ b/src/chains/serializers.py
@@ -171,10 +171,11 @@
"features",
]
- @staticmethod
@swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]
- def get_native_currency(obj: Chain) -> ReturnDict:
- return CurrencySerializer(obj).data
+ def get_native_currency(self, obj: Chain) -> ReturnDict:
+ return CurrencySerializer(
+ obj, context={"request": self.context["request"]}
+ ).data
@staticmethod
@swagger_serializer_method(serializer_or_field=ThemeSerializer) # type: ignore[misc]
|
{"golden_diff": "diff --git a/src/chains/serializers.py b/src/chains/serializers.py\n--- a/src/chains/serializers.py\n+++ b/src/chains/serializers.py\n@@ -171,10 +171,11 @@\n \"features\",\n ]\n \n- @staticmethod\n @swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]\n- def get_native_currency(obj: Chain) -> ReturnDict:\n- return CurrencySerializer(obj).data\n+ def get_native_currency(self, obj: Chain) -> ReturnDict:\n+ return CurrencySerializer(\n+ obj, context={\"request\": self.context[\"request\"]}\n+ ).data\n \n @staticmethod\n @swagger_serializer_method(serializer_or_field=ThemeSerializer) # type: ignore[misc]\n", "issue": "`/api/v1/chains` returns unexpected nativeCurrency.logoUri path\n**Describe the bug**\r\nI deployed a project locally using the code from `https://github.com/safe-global/safe-infrastructure`. However, after adding a configuration for a chain in cfg, the `/v1/chains` endpoint of cgw started returning a 500 error. After enabling debug logs, I found that cgw returned the following error:\r\n```json\r\n{\r\n \"build_number\": \"edc276d\",\r\n \"level\": \"error\",\r\n \"message\": {\r\n \"chain_id\": null,\r\n \"client_ip\": \"172.70.223.68\",\r\n \"detail\": \"[\\n {\\n \\\"validation\\\": \\\"url\\\",\\n \\\"code\\\": \\\"invalid_string\\\",\\n \\\"message\\\": \\\"Invalid url\\\",\\n \\\"path\\\": [\\n \\\"nativeCurrency\\\",\\n \\\"logoUri\\\"\\n ]\\n }\\n]\",\r\n \"method\": \"GET\",\r\n \"path\": \"/v1/chains\",\r\n \"response_time_ms\": 107.19920100085437,\r\n \"route\": \"/v1/chains\",\r\n \"safe_app_user_agent\": null,\r\n \"status_code\": 500\r\n },\r\n \"request_id\": \"1e37d27b-02b6-468a-a290-b6e06f7bc911\",\r\n \"timestamp\": \"2024-03-29T07:54:29.220Z\",\r\n \"version\": \"v1.31.0\"\r\n}\r\n````\r\nAfter investigating further, I found that the `nativeCurrency.logoUri` in the response data from cfg is not an absolute path:\r\n\r\n```json\r\n{\r\n \"count\": 1,\r\n \"next\": null,\r\n \"previous\": null,\r\n \"results\": [\r\n {\r\n ...\r\n \"nativeCurrency\": {\r\n \"name\": \"ETH\",\r\n \"symbol\": \"ETH\",\r\n \"decimals\": 18,\r\n \"logoUri\": \"/media/chains/100/currency_logo_3fdtfcf.png\"\r\n },\r\n ...\r\n ]\r\n}\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n - Clone the code from `https://github.com/safe-global/safe-infrastructure`\r\n - Modify the MEDIA_URL in cfg.env to `/media/`\r\n**Expected behavior**\r\nThe `nativeCurrency.logoUri` in the response data from cfg should be `https://config.xxx.xyz/media/chains/100/currency_logo_3fdtfcf.png` instead of `/media/chains/100/currency_logo_3fdtfcf.png`.\r\n\r\n**Environment (please complete the following information):**\r\n - Version of safe-config-service: latest(possibly [v2.75.0])\r\n \r\n**Additional context**\r\nI made the following edits to the `src/chains/serializers.py` file\r\nfrom\r\n```python\r\n @staticmethod\r\n @swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]\r\n def get_native_currency(obj: Chain) -> ReturnDict:\r\n return CurrencySerializer(obj).data\r\n```\r\nto\r\n```python\r\n @swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]\r\n def get_native_currency(self, obj: Chain) -> ReturnDict:\r\n request = self.context.get('request')\r\n logo_uri = obj.currency_logo_uri\r\n dict = CurrencySerializer(obj).data\r\n dict.update({\"logo_uri\":request.build_absolute_uri(logo_uri)})\r\n return dict\r\n```\r\nAfter applying the temporary workaround, cfg is able to return the expected data. However, since I'm not familiar with Python and Django, this was just a temporary solution on my part. I hope that you can find a better way to fix this issue.\n", "before_files": [{"content": "from abc import abstractmethod\n\nfrom drf_yasg.utils import swagger_serializer_method\nfrom gnosis.eth.django.serializers import EthereumAddressField\nfrom rest_framework import serializers\nfrom rest_framework.exceptions import APIException\nfrom rest_framework.utils.serializer_helpers import ReturnDict\n\nfrom .models import Chain, Feature, GasPrice, Wallet\n\n\nclass GasPriceOracleSerializer(serializers.Serializer[GasPrice]):\n type = serializers.ReadOnlyField(default=\"oracle\")\n uri = serializers.URLField(source=\"oracle_uri\")\n gas_parameter = serializers.CharField(source=\"oracle_parameter\")\n gwei_factor = serializers.DecimalField(max_digits=19, decimal_places=9)\n\n\nclass GasPriceFixedSerializer(serializers.Serializer[GasPrice]):\n type = serializers.ReadOnlyField(default=\"fixed\")\n wei_value = serializers.CharField(source=\"fixed_wei_value\")\n\n\nclass GasPriceFixed1559Serializer(serializers.Serializer[GasPrice]):\n type = serializers.ReadOnlyField(default=\"fixed1559\")\n max_fee_per_gas = serializers.CharField()\n max_priority_fee_per_gas = serializers.CharField()\n\n\nclass GasPriceSerializer(serializers.Serializer[GasPrice]):\n def to_representation(self, instance: GasPrice) -> ReturnDict:\n if (\n instance.oracle_uri\n and instance.fixed_wei_value is None\n and instance.max_fee_per_gas is None\n and instance.max_priority_fee_per_gas is None\n ):\n return GasPriceOracleSerializer(instance).data\n elif (\n instance.fixed_wei_value\n and instance.oracle_uri is None\n and instance.max_fee_per_gas is None\n and instance.max_priority_fee_per_gas is None\n ):\n return GasPriceFixedSerializer(instance).data\n elif (\n instance.max_fee_per_gas\n and instance.max_priority_fee_per_gas\n and instance.oracle_uri is None\n and instance.fixed_wei_value is None\n ):\n return GasPriceFixed1559Serializer(instance).data\n else:\n raise APIException(\n f\"The gas price oracle or a fixed gas price was not provided for chain {instance.chain}\"\n )\n\n\nclass ThemeSerializer(serializers.Serializer[Chain]):\n text_color = serializers.CharField(source=\"theme_text_color\")\n background_color = serializers.CharField(source=\"theme_background_color\")\n\n\nclass CurrencySerializer(serializers.Serializer[Chain]):\n name = serializers.CharField(source=\"currency_name\")\n symbol = serializers.CharField(source=\"currency_symbol\")\n decimals = serializers.IntegerField(source=\"currency_decimals\")\n logo_uri = serializers.ImageField(use_url=True, source=\"currency_logo_uri\")\n\n\nclass BaseRpcUriSerializer(serializers.Serializer[Chain]):\n authentication = serializers.SerializerMethodField()\n value = serializers.SerializerMethodField(method_name=\"get_rpc_value\")\n\n @abstractmethod\n def get_authentication(self, obj: Chain) -> str: # pragma: no cover\n pass\n\n @abstractmethod\n def get_rpc_value(self, obj: Chain) -> str: # pragma: no cover\n pass\n\n\nclass RpcUriSerializer(BaseRpcUriSerializer):\n def get_authentication(self, obj: Chain) -> str:\n return obj.rpc_authentication\n\n def get_rpc_value(self, obj: Chain) -> str:\n return obj.rpc_uri\n\n\nclass SafeAppsRpcUriSerializer(BaseRpcUriSerializer):\n def get_authentication(self, obj: Chain) -> str:\n return obj.safe_apps_rpc_authentication\n\n def get_rpc_value(self, obj: Chain) -> str:\n return obj.safe_apps_rpc_uri\n\n\nclass PublicRpcUriSerializer(BaseRpcUriSerializer):\n def get_authentication(self, obj: Chain) -> str:\n return obj.public_rpc_authentication\n\n def get_rpc_value(self, obj: Chain) -> str:\n return obj.public_rpc_uri\n\n\nclass BlockExplorerUriTemplateSerializer(serializers.Serializer[Chain]):\n address = serializers.URLField(source=\"block_explorer_uri_address_template\")\n tx_hash = serializers.URLField(source=\"block_explorer_uri_tx_hash_template\")\n api = serializers.URLField(source=\"block_explorer_uri_api_template\")\n\n\nclass FeatureSerializer(serializers.Serializer[Feature]):\n class Meta:\n ref_name = \"chains.serializers.FeatureSerializer\"\n\n @staticmethod\n def to_representation(instance: Feature) -> str:\n return instance.key\n\n\nclass WalletSerializer(serializers.Serializer[Wallet]):\n @staticmethod\n def to_representation(instance: Wallet) -> str:\n return instance.key\n\n\nclass ChainSerializer(serializers.ModelSerializer[Chain]):\n chain_id = serializers.CharField(source=\"id\")\n chain_name = serializers.CharField(source=\"name\")\n short_name = serializers.CharField()\n chain_logo_uri = serializers.ImageField(use_url=True)\n rpc_uri = serializers.SerializerMethodField()\n safe_apps_rpc_uri = serializers.SerializerMethodField()\n public_rpc_uri = serializers.SerializerMethodField()\n block_explorer_uri_template = serializers.SerializerMethodField()\n native_currency = serializers.SerializerMethodField()\n transaction_service = serializers.URLField(\n source=\"transaction_service_uri\", default=None\n )\n vpc_transaction_service = serializers.URLField(source=\"vpc_transaction_service_uri\")\n theme = serializers.SerializerMethodField()\n gas_price = serializers.SerializerMethodField()\n ens_registry_address = EthereumAddressField()\n disabled_wallets = serializers.SerializerMethodField()\n features = serializers.SerializerMethodField()\n\n class Meta:\n model = Chain\n fields = [\n \"chain_id\",\n \"chain_name\",\n \"short_name\",\n \"description\",\n \"chain_logo_uri\",\n \"l2\",\n \"is_testnet\",\n \"rpc_uri\",\n \"safe_apps_rpc_uri\",\n \"public_rpc_uri\",\n \"block_explorer_uri_template\",\n \"native_currency\",\n \"transaction_service\",\n \"vpc_transaction_service\",\n \"theme\",\n \"gas_price\",\n \"ens_registry_address\",\n \"recommended_master_copy_version\",\n \"disabled_wallets\",\n \"features\",\n ]\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]\n def get_native_currency(obj: Chain) -> ReturnDict:\n return CurrencySerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=ThemeSerializer) # type: ignore[misc]\n def get_theme(obj: Chain) -> ReturnDict:\n return ThemeSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]\n def get_safe_apps_rpc_uri(obj: Chain) -> ReturnDict:\n return SafeAppsRpcUriSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]\n def get_rpc_uri(obj: Chain) -> ReturnDict:\n return RpcUriSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]\n def get_public_rpc_uri(obj: Chain) -> ReturnDict:\n return PublicRpcUriSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BlockExplorerUriTemplateSerializer) # type: ignore[misc]\n def get_block_explorer_uri_template(obj: Chain) -> ReturnDict:\n return BlockExplorerUriTemplateSerializer(obj).data\n\n @swagger_serializer_method(serializer_or_field=GasPriceSerializer) # type: ignore[misc]\n def get_gas_price(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]\n ranked_gas_prices = instance.gasprice_set.all().order_by(\"rank\")\n return GasPriceSerializer(ranked_gas_prices, many=True).data\n\n @swagger_serializer_method(serializer_or_field=WalletSerializer) # type: ignore[misc]\n def get_disabled_wallets(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]\n disabled_wallets = instance.get_disabled_wallets().order_by(\"key\")\n return WalletSerializer(disabled_wallets, many=True).data\n\n @swagger_serializer_method(serializer_or_field=FeatureSerializer) # type: ignore[misc]\n def get_features(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]\n enabled_features = instance.feature_set.all().order_by(\"key\")\n return FeatureSerializer(enabled_features, many=True).data\n", "path": "src/chains/serializers.py"}], "after_files": [{"content": "from abc import abstractmethod\n\nfrom drf_yasg.utils import swagger_serializer_method\nfrom gnosis.eth.django.serializers import EthereumAddressField\nfrom rest_framework import serializers\nfrom rest_framework.exceptions import APIException\nfrom rest_framework.utils.serializer_helpers import ReturnDict\n\nfrom .models import Chain, Feature, GasPrice, Wallet\n\n\nclass GasPriceOracleSerializer(serializers.Serializer[GasPrice]):\n type = serializers.ReadOnlyField(default=\"oracle\")\n uri = serializers.URLField(source=\"oracle_uri\")\n gas_parameter = serializers.CharField(source=\"oracle_parameter\")\n gwei_factor = serializers.DecimalField(max_digits=19, decimal_places=9)\n\n\nclass GasPriceFixedSerializer(serializers.Serializer[GasPrice]):\n type = serializers.ReadOnlyField(default=\"fixed\")\n wei_value = serializers.CharField(source=\"fixed_wei_value\")\n\n\nclass GasPriceFixed1559Serializer(serializers.Serializer[GasPrice]):\n type = serializers.ReadOnlyField(default=\"fixed1559\")\n max_fee_per_gas = serializers.CharField()\n max_priority_fee_per_gas = serializers.CharField()\n\n\nclass GasPriceSerializer(serializers.Serializer[GasPrice]):\n def to_representation(self, instance: GasPrice) -> ReturnDict:\n if (\n instance.oracle_uri\n and instance.fixed_wei_value is None\n and instance.max_fee_per_gas is None\n and instance.max_priority_fee_per_gas is None\n ):\n return GasPriceOracleSerializer(instance).data\n elif (\n instance.fixed_wei_value\n and instance.oracle_uri is None\n and instance.max_fee_per_gas is None\n and instance.max_priority_fee_per_gas is None\n ):\n return GasPriceFixedSerializer(instance).data\n elif (\n instance.max_fee_per_gas\n and instance.max_priority_fee_per_gas\n and instance.oracle_uri is None\n and instance.fixed_wei_value is None\n ):\n return GasPriceFixed1559Serializer(instance).data\n else:\n raise APIException(\n f\"The gas price oracle or a fixed gas price was not provided for chain {instance.chain}\"\n )\n\n\nclass ThemeSerializer(serializers.Serializer[Chain]):\n text_color = serializers.CharField(source=\"theme_text_color\")\n background_color = serializers.CharField(source=\"theme_background_color\")\n\n\nclass CurrencySerializer(serializers.Serializer[Chain]):\n name = serializers.CharField(source=\"currency_name\")\n symbol = serializers.CharField(source=\"currency_symbol\")\n decimals = serializers.IntegerField(source=\"currency_decimals\")\n logo_uri = serializers.ImageField(use_url=True, source=\"currency_logo_uri\")\n\n\nclass BaseRpcUriSerializer(serializers.Serializer[Chain]):\n authentication = serializers.SerializerMethodField()\n value = serializers.SerializerMethodField(method_name=\"get_rpc_value\")\n\n @abstractmethod\n def get_authentication(self, obj: Chain) -> str: # pragma: no cover\n pass\n\n @abstractmethod\n def get_rpc_value(self, obj: Chain) -> str: # pragma: no cover\n pass\n\n\nclass RpcUriSerializer(BaseRpcUriSerializer):\n def get_authentication(self, obj: Chain) -> str:\n return obj.rpc_authentication\n\n def get_rpc_value(self, obj: Chain) -> str:\n return obj.rpc_uri\n\n\nclass SafeAppsRpcUriSerializer(BaseRpcUriSerializer):\n def get_authentication(self, obj: Chain) -> str:\n return obj.safe_apps_rpc_authentication\n\n def get_rpc_value(self, obj: Chain) -> str:\n return obj.safe_apps_rpc_uri\n\n\nclass PublicRpcUriSerializer(BaseRpcUriSerializer):\n def get_authentication(self, obj: Chain) -> str:\n return obj.public_rpc_authentication\n\n def get_rpc_value(self, obj: Chain) -> str:\n return obj.public_rpc_uri\n\n\nclass BlockExplorerUriTemplateSerializer(serializers.Serializer[Chain]):\n address = serializers.URLField(source=\"block_explorer_uri_address_template\")\n tx_hash = serializers.URLField(source=\"block_explorer_uri_tx_hash_template\")\n api = serializers.URLField(source=\"block_explorer_uri_api_template\")\n\n\nclass FeatureSerializer(serializers.Serializer[Feature]):\n class Meta:\n ref_name = \"chains.serializers.FeatureSerializer\"\n\n @staticmethod\n def to_representation(instance: Feature) -> str:\n return instance.key\n\n\nclass WalletSerializer(serializers.Serializer[Wallet]):\n @staticmethod\n def to_representation(instance: Wallet) -> str:\n return instance.key\n\n\nclass ChainSerializer(serializers.ModelSerializer[Chain]):\n chain_id = serializers.CharField(source=\"id\")\n chain_name = serializers.CharField(source=\"name\")\n short_name = serializers.CharField()\n chain_logo_uri = serializers.ImageField(use_url=True)\n rpc_uri = serializers.SerializerMethodField()\n safe_apps_rpc_uri = serializers.SerializerMethodField()\n public_rpc_uri = serializers.SerializerMethodField()\n block_explorer_uri_template = serializers.SerializerMethodField()\n native_currency = serializers.SerializerMethodField()\n transaction_service = serializers.URLField(\n source=\"transaction_service_uri\", default=None\n )\n vpc_transaction_service = serializers.URLField(source=\"vpc_transaction_service_uri\")\n theme = serializers.SerializerMethodField()\n gas_price = serializers.SerializerMethodField()\n ens_registry_address = EthereumAddressField()\n disabled_wallets = serializers.SerializerMethodField()\n features = serializers.SerializerMethodField()\n\n class Meta:\n model = Chain\n fields = [\n \"chain_id\",\n \"chain_name\",\n \"short_name\",\n \"description\",\n \"chain_logo_uri\",\n \"l2\",\n \"is_testnet\",\n \"rpc_uri\",\n \"safe_apps_rpc_uri\",\n \"public_rpc_uri\",\n \"block_explorer_uri_template\",\n \"native_currency\",\n \"transaction_service\",\n \"vpc_transaction_service\",\n \"theme\",\n \"gas_price\",\n \"ens_registry_address\",\n \"recommended_master_copy_version\",\n \"disabled_wallets\",\n \"features\",\n ]\n\n @swagger_serializer_method(serializer_or_field=CurrencySerializer) # type: ignore[misc]\n def get_native_currency(self, obj: Chain) -> ReturnDict:\n return CurrencySerializer(\n obj, context={\"request\": self.context[\"request\"]}\n ).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=ThemeSerializer) # type: ignore[misc]\n def get_theme(obj: Chain) -> ReturnDict:\n return ThemeSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]\n def get_safe_apps_rpc_uri(obj: Chain) -> ReturnDict:\n return SafeAppsRpcUriSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]\n def get_rpc_uri(obj: Chain) -> ReturnDict:\n return RpcUriSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BaseRpcUriSerializer) # type: ignore[misc]\n def get_public_rpc_uri(obj: Chain) -> ReturnDict:\n return PublicRpcUriSerializer(obj).data\n\n @staticmethod\n @swagger_serializer_method(serializer_or_field=BlockExplorerUriTemplateSerializer) # type: ignore[misc]\n def get_block_explorer_uri_template(obj: Chain) -> ReturnDict:\n return BlockExplorerUriTemplateSerializer(obj).data\n\n @swagger_serializer_method(serializer_or_field=GasPriceSerializer) # type: ignore[misc]\n def get_gas_price(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]\n ranked_gas_prices = instance.gasprice_set.all().order_by(\"rank\")\n return GasPriceSerializer(ranked_gas_prices, many=True).data\n\n @swagger_serializer_method(serializer_or_field=WalletSerializer) # type: ignore[misc]\n def get_disabled_wallets(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]\n disabled_wallets = instance.get_disabled_wallets().order_by(\"key\")\n return WalletSerializer(disabled_wallets, many=True).data\n\n @swagger_serializer_method(serializer_or_field=FeatureSerializer) # type: ignore[misc]\n def get_features(self, instance) -> ReturnDict: # type: ignore[no-untyped-def]\n enabled_features = instance.feature_set.all().order_by(\"key\")\n return FeatureSerializer(enabled_features, many=True).data\n", "path": "src/chains/serializers.py"}]}
| 3,389 | 175 |
gh_patches_debug_35673
|
rasdani/github-patches
|
git_diff
|
amundsen-io__amundsen-1573
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug Report - Postegres / Redshift Extractors have inconsistent behavior
<!--- Provide a general summary of the issue in the Title above -->
<!--- Look through existing open and closed issues to see if someone has reported the issue before -->
## Expected Behavior
```python
# For RedshiftMetadataExtractor
redshift_metadata_extractor_config = ConfigFactory.from_dict({
'extractor.redshift_metadata.where_clause_suffix': 'schema <> "foo"'
})
```
## Current Behavior
```python
# For RedshiftMetadataExtractor
redshift_metadata_extractor_config = ConfigFactory.from_dict({
'extractor.redshift_metadata.where_clause_suffix': 'where schema <> "foo"'
})
```
## Possible Solution
Update redshift extractor to properly build suffix
## Screenshots (if appropriate)
## Context
Both the `PostgresMetadataExtractor` and the `RedshiftMetadataExtractor` take the config `extractor.redshift_metadata.where_clause_suffix` as they are both based off of `BasePostgresMetadataExtractor`.
However they require slightly different different sql partials, which is unexpected:
The `where_clause_suffix` for `RedshiftMetadataExtractor` takes a partial sql statement **without** a `WHERE`.
The `where_clause_suffix` for `PostgresMetadataExtractor` take a partial sql statement **with** a `WHERE`.
The name `where_clause_suffix` implies that its a statement appended to a where clause and should _not_ (IMHO) require a `WHERE` statement.
<!--- How has this issue affected you? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Amunsen version used: amundsen-databuilder 6.3.1
* Data warehouse stores: Neo4j
* Deployment (k8s or native): terraform
* Link to your fork or repository:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `databuilder/databuilder/extractor/redshift_metadata_extractor.py`
Content:
```
1 # Copyright Contributors to the Amundsen project.
2 # SPDX-License-Identifier: Apache-2.0
3
4 from typing import ( # noqa: F401
5 Any, Dict, Iterator, Union,
6 )
7
8 from pyhocon import ConfigFactory, ConfigTree # noqa: F401
9
10 from databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor
11
12
13 class RedshiftMetadataExtractor(BasePostgresMetadataExtractor):
14 """
15 Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor
16
17 This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,
18 we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().
19 """
20
21 def get_sql_statement(self, use_catalog_as_cluster_name: bool, where_clause_suffix: str) -> str:
22 if use_catalog_as_cluster_name:
23 cluster_source = "CURRENT_DATABASE()"
24 else:
25 cluster_source = f"'{self._cluster}'"
26
27 return """
28 SELECT
29 *
30 FROM (
31 SELECT
32 {cluster_source} as cluster,
33 c.table_schema as schema,
34 c.table_name as name,
35 pgtd.description as description,
36 c.column_name as col_name,
37 c.data_type as col_type,
38 pgcd.description as col_description,
39 ordinal_position as col_sort_order
40 FROM INFORMATION_SCHEMA.COLUMNS c
41 INNER JOIN
42 pg_catalog.pg_statio_all_tables as st on c.table_schema=st.schemaname and c.table_name=st.relname
43 LEFT JOIN
44 pg_catalog.pg_description pgcd on pgcd.objoid=st.relid and pgcd.objsubid=c.ordinal_position
45 LEFT JOIN
46 pg_catalog.pg_description pgtd on pgtd.objoid=st.relid and pgtd.objsubid=0
47
48 UNION
49
50 SELECT
51 {cluster_source} as cluster,
52 view_schema as schema,
53 view_name as name,
54 NULL as description,
55 column_name as col_name,
56 data_type as col_type,
57 NULL as col_description,
58 ordinal_position as col_sort_order
59 FROM
60 PG_GET_LATE_BINDING_VIEW_COLS()
61 COLS(view_schema NAME, view_name NAME, column_name NAME, data_type VARCHAR, ordinal_position INT)
62
63 UNION
64
65 SELECT
66 {cluster_source} AS cluster,
67 schemaname AS schema,
68 tablename AS name,
69 NULL AS description,
70 columnname AS col_name,
71 external_type AS col_type,
72 NULL AS col_description,
73 columnnum AS col_sort_order
74 FROM svv_external_columns
75 )
76
77 {where_clause_suffix}
78 ORDER by cluster, schema, name, col_sort_order ;
79 """.format(
80 cluster_source=cluster_source,
81 where_clause_suffix=where_clause_suffix,
82 )
83
84 def get_scope(self) -> str:
85 return 'extractor.redshift_metadata'
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/databuilder/databuilder/extractor/redshift_metadata_extractor.py b/databuilder/databuilder/extractor/redshift_metadata_extractor.py
--- a/databuilder/databuilder/extractor/redshift_metadata_extractor.py
+++ b/databuilder/databuilder/extractor/redshift_metadata_extractor.py
@@ -1,6 +1,7 @@
# Copyright Contributors to the Amundsen project.
# SPDX-License-Identifier: Apache-2.0
+import logging
from typing import ( # noqa: F401
Any, Dict, Iterator, Union,
)
@@ -9,11 +10,14 @@
from databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor
+LOGGER = logging.getLogger(__name__)
+
class RedshiftMetadataExtractor(BasePostgresMetadataExtractor):
"""
Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor
+
This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,
we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().
"""
@@ -24,6 +28,15 @@
else:
cluster_source = f"'{self._cluster}'"
+ if where_clause_suffix:
+ if where_clause_suffix.lower().startswith("where"):
+ LOGGER.warning("you no longer need to begin with 'where' in your suffix")
+ where_clause = where_clause_suffix
+ else:
+ where_clause = f"where {where_clause_suffix}"
+ else:
+ where_clause = ""
+
return """
SELECT
*
@@ -74,11 +87,11 @@
FROM svv_external_columns
)
- {where_clause_suffix}
+ {where_clause}
ORDER by cluster, schema, name, col_sort_order ;
""".format(
cluster_source=cluster_source,
- where_clause_suffix=where_clause_suffix,
+ where_clause=where_clause,
)
def get_scope(self) -> str:
|
{"golden_diff": "diff --git a/databuilder/databuilder/extractor/redshift_metadata_extractor.py b/databuilder/databuilder/extractor/redshift_metadata_extractor.py\n--- a/databuilder/databuilder/extractor/redshift_metadata_extractor.py\n+++ b/databuilder/databuilder/extractor/redshift_metadata_extractor.py\n@@ -1,6 +1,7 @@\n # Copyright Contributors to the Amundsen project.\n # SPDX-License-Identifier: Apache-2.0\n \n+import logging\n from typing import ( # noqa: F401\n Any, Dict, Iterator, Union,\n )\n@@ -9,11 +10,14 @@\n \n from databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor\n \n+LOGGER = logging.getLogger(__name__)\n+\n \n class RedshiftMetadataExtractor(BasePostgresMetadataExtractor):\n \"\"\"\n Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor\n \n+\n This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,\n we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().\n \"\"\"\n@@ -24,6 +28,15 @@\n else:\n cluster_source = f\"'{self._cluster}'\"\n \n+ if where_clause_suffix:\n+ if where_clause_suffix.lower().startswith(\"where\"):\n+ LOGGER.warning(\"you no longer need to begin with 'where' in your suffix\")\n+ where_clause = where_clause_suffix\n+ else:\n+ where_clause = f\"where {where_clause_suffix}\"\n+ else:\n+ where_clause = \"\"\n+\n return \"\"\"\n SELECT\n *\n@@ -74,11 +87,11 @@\n FROM svv_external_columns\n )\n \n- {where_clause_suffix}\n+ {where_clause}\n ORDER by cluster, schema, name, col_sort_order ;\n \"\"\".format(\n cluster_source=cluster_source,\n- where_clause_suffix=where_clause_suffix,\n+ where_clause=where_clause,\n )\n \n def get_scope(self) -> str:\n", "issue": "Bug Report - Postegres / Redshift Extractors have inconsistent behavior\n<!--- Provide a general summary of the issue in the Title above -->\r\n<!--- Look through existing open and closed issues to see if someone has reported the issue before -->\r\n\r\n## Expected Behavior\r\n\r\n```python\r\n# For RedshiftMetadataExtractor\r\nredshift_metadata_extractor_config = ConfigFactory.from_dict({\r\n 'extractor.redshift_metadata.where_clause_suffix': 'schema <> \"foo\"'\r\n})\r\n```\r\n\r\n## Current Behavior\r\n\r\n```python\r\n# For RedshiftMetadataExtractor\r\nredshift_metadata_extractor_config = ConfigFactory.from_dict({\r\n 'extractor.redshift_metadata.where_clause_suffix': 'where schema <> \"foo\"'\r\n})\r\n```\r\n\r\n## Possible Solution\r\n\r\nUpdate redshift extractor to properly build suffix\r\n\r\n## Screenshots (if appropriate)\r\n\r\n## Context\r\n\r\nBoth the `PostgresMetadataExtractor` and the `RedshiftMetadataExtractor` take the config `extractor.redshift_metadata.where_clause_suffix` as they are both based off of `BasePostgresMetadataExtractor`.\r\n\r\nHowever they require slightly different different sql partials, which is unexpected: \r\n\r\nThe `where_clause_suffix` for `RedshiftMetadataExtractor` takes a partial sql statement **without** a `WHERE`.\r\nThe `where_clause_suffix` for `PostgresMetadataExtractor` take a partial sql statement **with** a `WHERE`.\r\n\r\nThe name `where_clause_suffix` implies that its a statement appended to a where clause and should _not_ (IMHO) require a `WHERE` statement.\r\n\r\n\r\n<!--- How has this issue affected you? -->\r\n<!--- Providing context helps us come up with a solution that is most useful in the real world -->\r\n\r\n## Your Environment\r\n<!--- Include as many relevant details about the environment you experienced the bug in -->\r\n* Amunsen version used: amundsen-databuilder 6.3.1\r\n* Data warehouse stores: Neo4j\r\n* Deployment (k8s or native): terraform\r\n* Link to your fork or repository:\n", "before_files": [{"content": "# Copyright Contributors to the Amundsen project.\n# SPDX-License-Identifier: Apache-2.0\n\nfrom typing import ( # noqa: F401\n Any, Dict, Iterator, Union,\n)\n\nfrom pyhocon import ConfigFactory, ConfigTree # noqa: F401\n\nfrom databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor\n\n\nclass RedshiftMetadataExtractor(BasePostgresMetadataExtractor):\n \"\"\"\n Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor\n\n This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,\n we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().\n \"\"\"\n\n def get_sql_statement(self, use_catalog_as_cluster_name: bool, where_clause_suffix: str) -> str:\n if use_catalog_as_cluster_name:\n cluster_source = \"CURRENT_DATABASE()\"\n else:\n cluster_source = f\"'{self._cluster}'\"\n\n return \"\"\"\n SELECT\n *\n FROM (\n SELECT\n {cluster_source} as cluster,\n c.table_schema as schema,\n c.table_name as name,\n pgtd.description as description,\n c.column_name as col_name,\n c.data_type as col_type,\n pgcd.description as col_description,\n ordinal_position as col_sort_order\n FROM INFORMATION_SCHEMA.COLUMNS c\n INNER JOIN\n pg_catalog.pg_statio_all_tables as st on c.table_schema=st.schemaname and c.table_name=st.relname\n LEFT JOIN\n pg_catalog.pg_description pgcd on pgcd.objoid=st.relid and pgcd.objsubid=c.ordinal_position\n LEFT JOIN\n pg_catalog.pg_description pgtd on pgtd.objoid=st.relid and pgtd.objsubid=0\n\n UNION\n\n SELECT\n {cluster_source} as cluster,\n view_schema as schema,\n view_name as name,\n NULL as description,\n column_name as col_name,\n data_type as col_type,\n NULL as col_description,\n ordinal_position as col_sort_order\n FROM\n PG_GET_LATE_BINDING_VIEW_COLS()\n COLS(view_schema NAME, view_name NAME, column_name NAME, data_type VARCHAR, ordinal_position INT)\n\n UNION\n\n SELECT\n {cluster_source} AS cluster,\n schemaname AS schema,\n tablename AS name,\n NULL AS description,\n columnname AS col_name,\n external_type AS col_type,\n NULL AS col_description,\n columnnum AS col_sort_order\n FROM svv_external_columns\n )\n\n {where_clause_suffix}\n ORDER by cluster, schema, name, col_sort_order ;\n \"\"\".format(\n cluster_source=cluster_source,\n where_clause_suffix=where_clause_suffix,\n )\n\n def get_scope(self) -> str:\n return 'extractor.redshift_metadata'\n", "path": "databuilder/databuilder/extractor/redshift_metadata_extractor.py"}], "after_files": [{"content": "# Copyright Contributors to the Amundsen project.\n# SPDX-License-Identifier: Apache-2.0\n\nimport logging\nfrom typing import ( # noqa: F401\n Any, Dict, Iterator, Union,\n)\n\nfrom pyhocon import ConfigFactory, ConfigTree # noqa: F401\n\nfrom databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass RedshiftMetadataExtractor(BasePostgresMetadataExtractor):\n \"\"\"\n Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor\n\n\n This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,\n we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().\n \"\"\"\n\n def get_sql_statement(self, use_catalog_as_cluster_name: bool, where_clause_suffix: str) -> str:\n if use_catalog_as_cluster_name:\n cluster_source = \"CURRENT_DATABASE()\"\n else:\n cluster_source = f\"'{self._cluster}'\"\n\n if where_clause_suffix:\n if where_clause_suffix.lower().startswith(\"where\"):\n LOGGER.warning(\"you no longer need to begin with 'where' in your suffix\")\n where_clause = where_clause_suffix\n else:\n where_clause = f\"where {where_clause_suffix}\"\n else:\n where_clause = \"\"\n\n return \"\"\"\n SELECT\n *\n FROM (\n SELECT\n {cluster_source} as cluster,\n c.table_schema as schema,\n c.table_name as name,\n pgtd.description as description,\n c.column_name as col_name,\n c.data_type as col_type,\n pgcd.description as col_description,\n ordinal_position as col_sort_order\n FROM INFORMATION_SCHEMA.COLUMNS c\n INNER JOIN\n pg_catalog.pg_statio_all_tables as st on c.table_schema=st.schemaname and c.table_name=st.relname\n LEFT JOIN\n pg_catalog.pg_description pgcd on pgcd.objoid=st.relid and pgcd.objsubid=c.ordinal_position\n LEFT JOIN\n pg_catalog.pg_description pgtd on pgtd.objoid=st.relid and pgtd.objsubid=0\n\n UNION\n\n SELECT\n {cluster_source} as cluster,\n view_schema as schema,\n view_name as name,\n NULL as description,\n column_name as col_name,\n data_type as col_type,\n NULL as col_description,\n ordinal_position as col_sort_order\n FROM\n PG_GET_LATE_BINDING_VIEW_COLS()\n COLS(view_schema NAME, view_name NAME, column_name NAME, data_type VARCHAR, ordinal_position INT)\n\n UNION\n\n SELECT\n {cluster_source} AS cluster,\n schemaname AS schema,\n tablename AS name,\n NULL AS description,\n columnname AS col_name,\n external_type AS col_type,\n NULL AS col_description,\n columnnum AS col_sort_order\n FROM svv_external_columns\n )\n\n {where_clause}\n ORDER by cluster, schema, name, col_sort_order ;\n \"\"\".format(\n cluster_source=cluster_source,\n where_clause=where_clause,\n )\n\n def get_scope(self) -> str:\n return 'extractor.redshift_metadata'\n", "path": "databuilder/databuilder/extractor/redshift_metadata_extractor.py"}]}
| 1,459 | 445 |
gh_patches_debug_2371
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1040
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Kinto Admin version not shown in footer

Looks like the effects of this are lost when packaged as a kinto plugin:
https://github.com/Kinto/kinto-admin/commit/8b184b041121ed4affddfbc2ce98ce658226ee34
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/plugins/admin/__init__.py`
Content:
```
1 from pyramid.static import static_view
2 from pyramid.httpexceptions import HTTPTemporaryRedirect
3
4
5 def includeme(config):
6 # Process settings to remove storage wording.
7
8 # Expose capability.
9 config.add_api_capability(
10 "admin",
11 version="1.8.0",
12 description="Serves the admin console.",
13 url="https://github.com/Kinto/kinto-admin/",
14 )
15
16 build_dir = static_view('kinto.plugins.admin:build', use_subpath=True)
17 config.add_route('catchall_static', '/admin/*subpath')
18 config.add_view(build_dir, route_name="catchall_static")
19
20 # Setup redirect without trailing slash.
21 def admin_redirect_view(request):
22 raise HTTPTemporaryRedirect(request.path + '/')
23
24 config.add_route('admin_redirect', '/admin')
25 config.add_view(admin_redirect_view, route_name="admin_redirect")
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/plugins/admin/__init__.py b/kinto/plugins/admin/__init__.py
--- a/kinto/plugins/admin/__init__.py
+++ b/kinto/plugins/admin/__init__.py
@@ -8,7 +8,7 @@
# Expose capability.
config.add_api_capability(
"admin",
- version="1.8.0",
+ version="1.8.1",
description="Serves the admin console.",
url="https://github.com/Kinto/kinto-admin/",
)
|
{"golden_diff": "diff --git a/kinto/plugins/admin/__init__.py b/kinto/plugins/admin/__init__.py\n--- a/kinto/plugins/admin/__init__.py\n+++ b/kinto/plugins/admin/__init__.py\n@@ -8,7 +8,7 @@\n # Expose capability.\n config.add_api_capability(\n \"admin\",\n- version=\"1.8.0\",\n+ version=\"1.8.1\",\n description=\"Serves the admin console.\",\n url=\"https://github.com/Kinto/kinto-admin/\",\n )\n", "issue": "Kinto Admin version not shown in footer\n\r\n\r\n\r\nLooks like the effects of this are lost when packaged as a kinto plugin:\r\n\r\nhttps://github.com/Kinto/kinto-admin/commit/8b184b041121ed4affddfbc2ce98ce658226ee34\n", "before_files": [{"content": "from pyramid.static import static_view\nfrom pyramid.httpexceptions import HTTPTemporaryRedirect\n\n\ndef includeme(config):\n # Process settings to remove storage wording.\n\n # Expose capability.\n config.add_api_capability(\n \"admin\",\n version=\"1.8.0\",\n description=\"Serves the admin console.\",\n url=\"https://github.com/Kinto/kinto-admin/\",\n )\n\n build_dir = static_view('kinto.plugins.admin:build', use_subpath=True)\n config.add_route('catchall_static', '/admin/*subpath')\n config.add_view(build_dir, route_name=\"catchall_static\")\n\n # Setup redirect without trailing slash.\n def admin_redirect_view(request):\n raise HTTPTemporaryRedirect(request.path + '/')\n\n config.add_route('admin_redirect', '/admin')\n config.add_view(admin_redirect_view, route_name=\"admin_redirect\")\n", "path": "kinto/plugins/admin/__init__.py"}], "after_files": [{"content": "from pyramid.static import static_view\nfrom pyramid.httpexceptions import HTTPTemporaryRedirect\n\n\ndef includeme(config):\n # Process settings to remove storage wording.\n\n # Expose capability.\n config.add_api_capability(\n \"admin\",\n version=\"1.8.1\",\n description=\"Serves the admin console.\",\n url=\"https://github.com/Kinto/kinto-admin/\",\n )\n\n build_dir = static_view('kinto.plugins.admin:build', use_subpath=True)\n config.add_route('catchall_static', '/admin/*subpath')\n config.add_view(build_dir, route_name=\"catchall_static\")\n\n # Setup redirect without trailing slash.\n def admin_redirect_view(request):\n raise HTTPTemporaryRedirect(request.path + '/')\n\n config.add_route('admin_redirect', '/admin')\n config.add_view(admin_redirect_view, route_name=\"admin_redirect\")\n", "path": "kinto/plugins/admin/__init__.py"}]}
| 643 | 114 |
gh_patches_debug_174
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-3469
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Expose "get_url" via the plugin interface
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/plugin/util.py`
Content:
```
1 from pulpcore.app.role_util import ( # noqa
2 assign_role,
3 get_groups_with_perms,
4 get_groups_with_perms_attached_perms,
5 get_groups_with_perms_attached_roles,
6 get_objects_for_group,
7 get_objects_for_user,
8 get_perms_for_model,
9 get_users_with_perms,
10 get_users_with_perms_attached_perms,
11 get_users_with_perms_attached_roles,
12 remove_role,
13 )
14
15 from pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/plugin/util.py b/pulpcore/plugin/util.py
--- a/pulpcore/plugin/util.py
+++ b/pulpcore/plugin/util.py
@@ -12,4 +12,4 @@
remove_role,
)
-from pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa
+from pulpcore.app.util import get_artifact_url, get_url, gpg_verify, verify_signature # noqa
|
{"golden_diff": "diff --git a/pulpcore/plugin/util.py b/pulpcore/plugin/util.py\n--- a/pulpcore/plugin/util.py\n+++ b/pulpcore/plugin/util.py\n@@ -12,4 +12,4 @@\n remove_role,\n )\n \n-from pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa\n+from pulpcore.app.util import get_artifact_url, get_url, gpg_verify, verify_signature # noqa\n", "issue": "Expose \"get_url\" via the plugin interface\n\n", "before_files": [{"content": "from pulpcore.app.role_util import ( # noqa\n assign_role,\n get_groups_with_perms,\n get_groups_with_perms_attached_perms,\n get_groups_with_perms_attached_roles,\n get_objects_for_group,\n get_objects_for_user,\n get_perms_for_model,\n get_users_with_perms,\n get_users_with_perms_attached_perms,\n get_users_with_perms_attached_roles,\n remove_role,\n)\n\nfrom pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa\n", "path": "pulpcore/plugin/util.py"}], "after_files": [{"content": "from pulpcore.app.role_util import ( # noqa\n assign_role,\n get_groups_with_perms,\n get_groups_with_perms_attached_perms,\n get_groups_with_perms_attached_roles,\n get_objects_for_group,\n get_objects_for_user,\n get_perms_for_model,\n get_users_with_perms,\n get_users_with_perms_attached_perms,\n get_users_with_perms_attached_roles,\n remove_role,\n)\n\nfrom pulpcore.app.util import get_artifact_url, get_url, gpg_verify, verify_signature # noqa\n", "path": "pulpcore/plugin/util.py"}]}
| 398 | 100 |
gh_patches_debug_12475
|
rasdani/github-patches
|
git_diff
|
talonhub__community-1040
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"phones that" should DTRT and select the current word if nothing is selected
there's really no need for both `phones that` and `phones word`, we can just make `phones that` do the right thing and select the current word if nothing is selected - ie. if `edit.selected_text()` returns the empty string?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/homophones/homophones.py`
Content:
```
1 import os
2
3 from talon import Context, Module, actions, app, clip, fs, imgui, ui
4
5 ########################################################################
6 # global settings
7 ########################################################################
8
9 # a list of homophones where each line is a comma separated list
10 # e.g. where,wear,ware
11 # a suitable one can be found here:
12 # https://github.com/pimentel/homophones
13 cwd = os.path.dirname(os.path.realpath(__file__))
14 homophones_file = os.path.join(cwd, "homophones.csv")
15 # if quick_replace, then when a word is selected and only one homophone exists,
16 # replace it without bringing up the options
17 quick_replace = True
18 show_help = False
19 ########################################################################
20
21 ctx = Context()
22 mod = Module()
23 mod.mode("homophones")
24 mod.list("homophones_canonicals", desc="list of words ")
25
26 main_screen = ui.main_screen()
27
28
29 def update_homophones(name, flags):
30 if name != homophones_file:
31 return
32
33 phones = {}
34 canonical_list = []
35 with open(homophones_file) as f:
36 for line in f:
37 words = line.rstrip().split(",")
38 canonical_list.append(words[0])
39 merged_words = set(words)
40 for word in words:
41 old_words = phones.get(word.lower(), [])
42 merged_words.update(old_words)
43 merged_words = sorted(merged_words)
44 for word in merged_words:
45 phones[word.lower()] = merged_words
46
47 global all_homophones
48 all_homophones = phones
49 ctx.lists["self.homophones_canonicals"] = canonical_list
50
51
52 update_homophones(homophones_file, None)
53 fs.watch(cwd, update_homophones)
54 active_word_list = None
55 is_selection = False
56
57
58 def close_homophones():
59 gui.hide()
60 actions.mode.disable("user.homophones")
61
62
63 PHONES_FORMATTERS = [
64 lambda word: word.capitalize(),
65 lambda word: word.upper(),
66 ]
67
68
69 def find_matching_format_function(word_with_formatting, format_functions):
70 """Finds the formatter function from a list of formatter functions which transforms a word into itself.
71 Returns an identity function if none exists"""
72 for formatter in format_functions:
73 formatted_word = formatter(word_with_formatting)
74 if word_with_formatting == formatted_word:
75 return formatter
76
77 return lambda word: word
78
79
80 def raise_homophones(word_to_find_homophones_for, forced=False, selection=False):
81 global quick_replace
82 global active_word_list
83 global show_help
84 global force_raise
85 global is_selection
86
87 force_raise = forced
88 is_selection = selection
89
90 if is_selection:
91 word_to_find_homophones_for = word_to_find_homophones_for.strip()
92
93 formatter = find_matching_format_function(
94 word_to_find_homophones_for, PHONES_FORMATTERS
95 )
96
97 word_to_find_homophones_for = word_to_find_homophones_for.lower()
98
99 # We support plurals, but very naively. If we can't find your word but your word ends in an s, presume its plural
100 # and attempt to find the singular, then present the presumed plurals back. This could be improved!
101 if word_to_find_homophones_for in all_homophones:
102 valid_homophones = all_homophones[word_to_find_homophones_for]
103 elif (
104 word_to_find_homophones_for[-1] == "s"
105 and word_to_find_homophones_for[:-1] in all_homophones
106 ):
107 valid_homophones = map(
108 lambda w: w + "s", all_homophones[word_to_find_homophones_for[:-1]]
109 )
110 else:
111 app.notify(
112 "homophones.py", f'"{word_to_find_homophones_for}" not in homophones list'
113 )
114 return
115
116 # Move current word to end of list to reduce searcher's cognitive load
117 valid_homophones_reordered = list(
118 filter(
119 lambda word_from_list: word_from_list.lower()
120 != word_to_find_homophones_for,
121 valid_homophones,
122 )
123 ) + [word_to_find_homophones_for]
124 active_word_list = list(map(formatter, valid_homophones_reordered))
125
126 if (
127 is_selection
128 and len(active_word_list) == 2
129 and quick_replace
130 and not force_raise
131 ):
132 if word_to_find_homophones_for == active_word_list[0].lower():
133 new = active_word_list[1]
134 else:
135 new = active_word_list[0]
136
137 clip.set(new)
138 actions.edit.paste()
139
140 return
141
142 actions.mode.enable("user.homophones")
143 show_help = False
144 gui.show()
145
146
147 @imgui.open(x=main_screen.x + main_screen.width / 2.6, y=main_screen.y)
148 def gui(gui: imgui.GUI):
149 global active_word_list
150 if show_help:
151 gui.text("Homephone help - todo")
152 else:
153 gui.text("Select a homophone")
154 gui.line()
155 index = 1
156 for word in active_word_list:
157 if gui.button(f"Choose {index}: {word}"):
158 actions.insert(actions.user.homophones_select(index))
159 actions.user.homophones_hide()
160 index = index + 1
161
162 if gui.button("Phones hide"):
163 actions.user.homophones_hide()
164
165
166 def show_help_gui():
167 global show_help
168 show_help = True
169 gui.show()
170
171
172 @mod.capture(rule="{self.homophones_canonicals}")
173 def homophones_canonical(m) -> str:
174 "Returns a single string"
175 return m.homophones_canonicals
176
177
178 @mod.action_class
179 class Actions:
180 def homophones_hide():
181 """Hides the homophones display"""
182 close_homophones()
183
184 def homophones_show(m: str):
185 """Show the homophones display"""
186 raise_homophones(m, False, False)
187
188 def homophones_show_selection():
189 """Show the homophones display for the selected text"""
190 raise_homophones(actions.edit.selected_text(), False, True)
191
192 def homophones_force_show(m: str):
193 """Show the homophones display forcibly"""
194 raise_homophones(m, True, False)
195
196 def homophones_force_show_selection():
197 """Show the homophones display for the selected text forcibly"""
198 raise_homophones(actions.edit.selected_text(), True, True)
199
200 def homophones_select(number: int) -> str:
201 """selects the homophone by number"""
202 if number <= len(active_word_list) and number > 0:
203 return active_word_list[number - 1]
204
205 error = "homophones.py index {} is out of range (1-{})".format(
206 number, len(active_word_list)
207 )
208 app.notify(error)
209 raise error
210
211 def homophones_get(word: str) -> [str] or None:
212 """Get homophones for the given word"""
213 word = word.lower()
214 if word in all_homophones:
215 return all_homophones[word]
216 return None
217
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/homophones/homophones.py b/core/homophones/homophones.py
--- a/core/homophones/homophones.py
+++ b/core/homophones/homophones.py
@@ -185,6 +185,15 @@
"""Show the homophones display"""
raise_homophones(m, False, False)
+ def homophones_show_auto():
+ """Show homophones for selection, or current word if selection is empty."""
+ text = actions.edit.selected_text()
+ if text:
+ actions.user.homophones_show(text)
+ else:
+ actions.edit.select_word()
+ actions.user.homophones_show_selection()
+
def homophones_show_selection():
"""Show the homophones display for the selected text"""
raise_homophones(actions.edit.selected_text(), False, True)
|
{"golden_diff": "diff --git a/core/homophones/homophones.py b/core/homophones/homophones.py\n--- a/core/homophones/homophones.py\n+++ b/core/homophones/homophones.py\n@@ -185,6 +185,15 @@\n \"\"\"Show the homophones display\"\"\"\n raise_homophones(m, False, False)\n \n+ def homophones_show_auto():\n+ \"\"\"Show homophones for selection, or current word if selection is empty.\"\"\"\n+ text = actions.edit.selected_text()\n+ if text:\n+ actions.user.homophones_show(text)\n+ else:\n+ actions.edit.select_word()\n+ actions.user.homophones_show_selection()\n+\n def homophones_show_selection():\n \"\"\"Show the homophones display for the selected text\"\"\"\n raise_homophones(actions.edit.selected_text(), False, True)\n", "issue": "\"phones that\" should DTRT and select the current word if nothing is selected\nthere's really no need for both `phones that` and `phones word`, we can just make `phones that` do the right thing and select the current word if nothing is selected - ie. if `edit.selected_text()` returns the empty string?\n", "before_files": [{"content": "import os\n\nfrom talon import Context, Module, actions, app, clip, fs, imgui, ui\n\n########################################################################\n# global settings\n########################################################################\n\n# a list of homophones where each line is a comma separated list\n# e.g. where,wear,ware\n# a suitable one can be found here:\n# https://github.com/pimentel/homophones\ncwd = os.path.dirname(os.path.realpath(__file__))\nhomophones_file = os.path.join(cwd, \"homophones.csv\")\n# if quick_replace, then when a word is selected and only one homophone exists,\n# replace it without bringing up the options\nquick_replace = True\nshow_help = False\n########################################################################\n\nctx = Context()\nmod = Module()\nmod.mode(\"homophones\")\nmod.list(\"homophones_canonicals\", desc=\"list of words \")\n\nmain_screen = ui.main_screen()\n\n\ndef update_homophones(name, flags):\n if name != homophones_file:\n return\n\n phones = {}\n canonical_list = []\n with open(homophones_file) as f:\n for line in f:\n words = line.rstrip().split(\",\")\n canonical_list.append(words[0])\n merged_words = set(words)\n for word in words:\n old_words = phones.get(word.lower(), [])\n merged_words.update(old_words)\n merged_words = sorted(merged_words)\n for word in merged_words:\n phones[word.lower()] = merged_words\n\n global all_homophones\n all_homophones = phones\n ctx.lists[\"self.homophones_canonicals\"] = canonical_list\n\n\nupdate_homophones(homophones_file, None)\nfs.watch(cwd, update_homophones)\nactive_word_list = None\nis_selection = False\n\n\ndef close_homophones():\n gui.hide()\n actions.mode.disable(\"user.homophones\")\n\n\nPHONES_FORMATTERS = [\n lambda word: word.capitalize(),\n lambda word: word.upper(),\n]\n\n\ndef find_matching_format_function(word_with_formatting, format_functions):\n \"\"\"Finds the formatter function from a list of formatter functions which transforms a word into itself.\n Returns an identity function if none exists\"\"\"\n for formatter in format_functions:\n formatted_word = formatter(word_with_formatting)\n if word_with_formatting == formatted_word:\n return formatter\n\n return lambda word: word\n\n\ndef raise_homophones(word_to_find_homophones_for, forced=False, selection=False):\n global quick_replace\n global active_word_list\n global show_help\n global force_raise\n global is_selection\n\n force_raise = forced\n is_selection = selection\n\n if is_selection:\n word_to_find_homophones_for = word_to_find_homophones_for.strip()\n\n formatter = find_matching_format_function(\n word_to_find_homophones_for, PHONES_FORMATTERS\n )\n\n word_to_find_homophones_for = word_to_find_homophones_for.lower()\n\n # We support plurals, but very naively. If we can't find your word but your word ends in an s, presume its plural\n # and attempt to find the singular, then present the presumed plurals back. This could be improved!\n if word_to_find_homophones_for in all_homophones:\n valid_homophones = all_homophones[word_to_find_homophones_for]\n elif (\n word_to_find_homophones_for[-1] == \"s\"\n and word_to_find_homophones_for[:-1] in all_homophones\n ):\n valid_homophones = map(\n lambda w: w + \"s\", all_homophones[word_to_find_homophones_for[:-1]]\n )\n else:\n app.notify(\n \"homophones.py\", f'\"{word_to_find_homophones_for}\" not in homophones list'\n )\n return\n\n # Move current word to end of list to reduce searcher's cognitive load\n valid_homophones_reordered = list(\n filter(\n lambda word_from_list: word_from_list.lower()\n != word_to_find_homophones_for,\n valid_homophones,\n )\n ) + [word_to_find_homophones_for]\n active_word_list = list(map(formatter, valid_homophones_reordered))\n\n if (\n is_selection\n and len(active_word_list) == 2\n and quick_replace\n and not force_raise\n ):\n if word_to_find_homophones_for == active_word_list[0].lower():\n new = active_word_list[1]\n else:\n new = active_word_list[0]\n\n clip.set(new)\n actions.edit.paste()\n\n return\n\n actions.mode.enable(\"user.homophones\")\n show_help = False\n gui.show()\n\n\[email protected](x=main_screen.x + main_screen.width / 2.6, y=main_screen.y)\ndef gui(gui: imgui.GUI):\n global active_word_list\n if show_help:\n gui.text(\"Homephone help - todo\")\n else:\n gui.text(\"Select a homophone\")\n gui.line()\n index = 1\n for word in active_word_list:\n if gui.button(f\"Choose {index}: {word}\"):\n actions.insert(actions.user.homophones_select(index))\n actions.user.homophones_hide()\n index = index + 1\n\n if gui.button(\"Phones hide\"):\n actions.user.homophones_hide()\n\n\ndef show_help_gui():\n global show_help\n show_help = True\n gui.show()\n\n\[email protected](rule=\"{self.homophones_canonicals}\")\ndef homophones_canonical(m) -> str:\n \"Returns a single string\"\n return m.homophones_canonicals\n\n\[email protected]_class\nclass Actions:\n def homophones_hide():\n \"\"\"Hides the homophones display\"\"\"\n close_homophones()\n\n def homophones_show(m: str):\n \"\"\"Show the homophones display\"\"\"\n raise_homophones(m, False, False)\n\n def homophones_show_selection():\n \"\"\"Show the homophones display for the selected text\"\"\"\n raise_homophones(actions.edit.selected_text(), False, True)\n\n def homophones_force_show(m: str):\n \"\"\"Show the homophones display forcibly\"\"\"\n raise_homophones(m, True, False)\n\n def homophones_force_show_selection():\n \"\"\"Show the homophones display for the selected text forcibly\"\"\"\n raise_homophones(actions.edit.selected_text(), True, True)\n\n def homophones_select(number: int) -> str:\n \"\"\"selects the homophone by number\"\"\"\n if number <= len(active_word_list) and number > 0:\n return active_word_list[number - 1]\n\n error = \"homophones.py index {} is out of range (1-{})\".format(\n number, len(active_word_list)\n )\n app.notify(error)\n raise error\n\n def homophones_get(word: str) -> [str] or None:\n \"\"\"Get homophones for the given word\"\"\"\n word = word.lower()\n if word in all_homophones:\n return all_homophones[word]\n return None\n", "path": "core/homophones/homophones.py"}], "after_files": [{"content": "import os\n\nfrom talon import Context, Module, actions, app, clip, fs, imgui, ui\n\n########################################################################\n# global settings\n########################################################################\n\n# a list of homophones where each line is a comma separated list\n# e.g. where,wear,ware\n# a suitable one can be found here:\n# https://github.com/pimentel/homophones\ncwd = os.path.dirname(os.path.realpath(__file__))\nhomophones_file = os.path.join(cwd, \"homophones.csv\")\n# if quick_replace, then when a word is selected and only one homophone exists,\n# replace it without bringing up the options\nquick_replace = True\nshow_help = False\n########################################################################\n\nctx = Context()\nmod = Module()\nmod.mode(\"homophones\")\nmod.list(\"homophones_canonicals\", desc=\"list of words \")\n\nmain_screen = ui.main_screen()\n\n\ndef update_homophones(name, flags):\n if name != homophones_file:\n return\n\n phones = {}\n canonical_list = []\n with open(homophones_file) as f:\n for line in f:\n words = line.rstrip().split(\",\")\n canonical_list.append(words[0])\n merged_words = set(words)\n for word in words:\n old_words = phones.get(word.lower(), [])\n merged_words.update(old_words)\n merged_words = sorted(merged_words)\n for word in merged_words:\n phones[word.lower()] = merged_words\n\n global all_homophones\n all_homophones = phones\n ctx.lists[\"self.homophones_canonicals\"] = canonical_list\n\n\nupdate_homophones(homophones_file, None)\nfs.watch(cwd, update_homophones)\nactive_word_list = None\nis_selection = False\n\n\ndef close_homophones():\n gui.hide()\n actions.mode.disable(\"user.homophones\")\n\n\nPHONES_FORMATTERS = [\n lambda word: word.capitalize(),\n lambda word: word.upper(),\n]\n\n\ndef find_matching_format_function(word_with_formatting, format_functions):\n \"\"\"Finds the formatter function from a list of formatter functions which transforms a word into itself.\n Returns an identity function if none exists\"\"\"\n for formatter in format_functions:\n formatted_word = formatter(word_with_formatting)\n if word_with_formatting == formatted_word:\n return formatter\n\n return lambda word: word\n\n\ndef raise_homophones(word_to_find_homophones_for, forced=False, selection=False):\n global quick_replace\n global active_word_list\n global show_help\n global force_raise\n global is_selection\n\n force_raise = forced\n is_selection = selection\n\n if is_selection:\n word_to_find_homophones_for = word_to_find_homophones_for.strip()\n\n formatter = find_matching_format_function(\n word_to_find_homophones_for, PHONES_FORMATTERS\n )\n\n word_to_find_homophones_for = word_to_find_homophones_for.lower()\n\n # We support plurals, but very naively. If we can't find your word but your word ends in an s, presume its plural\n # and attempt to find the singular, then present the presumed plurals back. This could be improved!\n if word_to_find_homophones_for in all_homophones:\n valid_homophones = all_homophones[word_to_find_homophones_for]\n elif (\n word_to_find_homophones_for[-1] == \"s\"\n and word_to_find_homophones_for[:-1] in all_homophones\n ):\n valid_homophones = map(\n lambda w: w + \"s\", all_homophones[word_to_find_homophones_for[:-1]]\n )\n else:\n app.notify(\n \"homophones.py\", f'\"{word_to_find_homophones_for}\" not in homophones list'\n )\n return\n\n # Move current word to end of list to reduce searcher's cognitive load\n valid_homophones_reordered = list(\n filter(\n lambda word_from_list: word_from_list.lower()\n != word_to_find_homophones_for,\n valid_homophones,\n )\n ) + [word_to_find_homophones_for]\n active_word_list = list(map(formatter, valid_homophones_reordered))\n\n if (\n is_selection\n and len(active_word_list) == 2\n and quick_replace\n and not force_raise\n ):\n if word_to_find_homophones_for == active_word_list[0].lower():\n new = active_word_list[1]\n else:\n new = active_word_list[0]\n\n clip.set(new)\n actions.edit.paste()\n\n return\n\n actions.mode.enable(\"user.homophones\")\n show_help = False\n gui.show()\n\n\[email protected](x=main_screen.x + main_screen.width / 2.6, y=main_screen.y)\ndef gui(gui: imgui.GUI):\n global active_word_list\n if show_help:\n gui.text(\"Homephone help - todo\")\n else:\n gui.text(\"Select a homophone\")\n gui.line()\n index = 1\n for word in active_word_list:\n if gui.button(f\"Choose {index}: {word}\"):\n actions.insert(actions.user.homophones_select(index))\n actions.user.homophones_hide()\n index = index + 1\n\n if gui.button(\"Phones hide\"):\n actions.user.homophones_hide()\n\n\ndef show_help_gui():\n global show_help\n show_help = True\n gui.show()\n\n\[email protected](rule=\"{self.homophones_canonicals}\")\ndef homophones_canonical(m) -> str:\n \"Returns a single string\"\n return m.homophones_canonicals\n\n\[email protected]_class\nclass Actions:\n def homophones_hide():\n \"\"\"Hides the homophones display\"\"\"\n close_homophones()\n\n def homophones_show(m: str):\n \"\"\"Show the homophones display\"\"\"\n raise_homophones(m, False, False)\n\n def homophones_show_auto():\n \"\"\"Show homophones for selection, or current word if selection is empty.\"\"\"\n text = actions.edit.selected_text()\n if text:\n actions.user.homophones_show(text)\n else:\n actions.edit.select_word()\n actions.user.homophones_show_selection()\n\n def homophones_show_selection():\n \"\"\"Show the homophones display for the selected text\"\"\"\n raise_homophones(actions.edit.selected_text(), False, True)\n\n def homophones_force_show(m: str):\n \"\"\"Show the homophones display forcibly\"\"\"\n raise_homophones(m, True, False)\n\n def homophones_force_show_selection():\n \"\"\"Show the homophones display for the selected text forcibly\"\"\"\n raise_homophones(actions.edit.selected_text(), True, True)\n\n def homophones_select(number: int) -> str:\n \"\"\"selects the homophone by number\"\"\"\n if number <= len(active_word_list) and number > 0:\n return active_word_list[number - 1]\n\n error = \"homophones.py index {} is out of range (1-{})\".format(\n number, len(active_word_list)\n )\n app.notify(error)\n raise error\n\n def homophones_get(word: str) -> [str] or None:\n \"\"\"Get homophones for the given word\"\"\"\n word = word.lower()\n if word in all_homophones:\n return all_homophones[word]\n return None\n", "path": "core/homophones/homophones.py"}]}
| 2,425 | 196 |
gh_patches_debug_8673
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-4423
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How do we work with documentation redirects from rediraffe in the repo?
[...] to make a decision on what to do with regards to how we work with the redirects in this repo for now. If experience is gained and you start feeling confident on a practice, we try go for that more systematically in other repos long term.
I think the options on how to work with the redirects are:
1. Fully manual as now, where we figure out ourselves if we need to add a redirect
2. Mostly manual, where we can go fully manual but also suggest that `make rediraffecheckdiff` can be used to get informed on what redirects we should make.
3. Semi automated, where we suggest using `make rediraffewritediff` to update a file (not overwrite right?)
4. Mostly automated, where we have a github workflow triggered when docs change to inspect if a redirect needs to be setup and otherwise fails to let us know.
5. Almost fully automated, where we also push a commit with the relevant redirects.
If I understand this correctly, we need to consider this ourselves no matter what because the tools can't figure it out fully in all cases. That makes me think we shouldn't go for option 5. Maybe option 2-4? No matter what, I'm a big :+1: for going for something you feel like going for!
_Originally posted by @consideRatio in https://github.com/jupyterhub/jupyterhub/pull/4331#discussion_r1092331738_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/conf.py`
Content:
```
1 # Configuration file for Sphinx to build our documentation to HTML.
2 #
3 # Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html
4 #
5 import contextlib
6 import datetime
7 import io
8 import os
9 import subprocess
10
11 from docutils import nodes
12 from sphinx.directives.other import SphinxDirective
13
14 import jupyterhub
15 from jupyterhub.app import JupyterHub
16
17 # -- Project information -----------------------------------------------------
18 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
19 #
20 project = "JupyterHub"
21 author = "Project Jupyter Contributors"
22 copyright = f"{datetime.date.today().year}, {author}"
23
24
25 # -- General Sphinx configuration --------------------------------------------
26 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
27 #
28 extensions = [
29 "sphinx.ext.autodoc",
30 "sphinx.ext.intersphinx",
31 "sphinx.ext.napoleon",
32 "autodoc_traits",
33 "sphinx_copybutton",
34 "sphinx-jsonschema",
35 "sphinxext.opengraph",
36 "sphinxext.rediraffe",
37 "jupyterhub_sphinx_theme",
38 "myst_parser",
39 ]
40 root_doc = "index"
41 source_suffix = [".md"]
42 # default_role let's use use `foo` instead of ``foo`` in rST
43 default_role = "literal"
44
45
46 # -- MyST configuration ------------------------------------------------------
47 # ref: https://myst-parser.readthedocs.io/en/latest/configuration.html
48 #
49 myst_heading_anchors = 2
50
51 myst_enable_extensions = [
52 # available extensions: https://myst-parser.readthedocs.io/en/latest/syntax/optional.html
53 "attrs_inline",
54 "colon_fence",
55 "deflist",
56 "fieldlist",
57 "substitution",
58 ]
59
60 myst_substitutions = {
61 # date example: Dev 07, 2022
62 "date": datetime.date.today().strftime("%b %d, %Y").title(),
63 "version": jupyterhub.__version__,
64 }
65
66
67 # -- Custom directives to generate documentation -----------------------------
68 # ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html
69 #
70 # We define custom directives to help us generate documentation using Python on
71 # demand when referenced from our documentation files.
72 #
73
74 # Create a temp instance of JupyterHub for use by two separate directive classes
75 # to get the output from using the "--generate-config" and "--help-all" CLI
76 # flags respectively.
77 #
78 jupyterhub_app = JupyterHub()
79
80
81 class ConfigDirective(SphinxDirective):
82 """Generate the configuration file output for use in the documentation."""
83
84 has_content = False
85 required_arguments = 0
86 optional_arguments = 0
87 final_argument_whitespace = False
88 option_spec = {}
89
90 def run(self):
91 # The generated configuration file for this version
92 generated_config = jupyterhub_app.generate_config_file()
93 # post-process output
94 home_dir = os.environ["HOME"]
95 generated_config = generated_config.replace(home_dir, "$HOME", 1)
96 par = nodes.literal_block(text=generated_config)
97 return [par]
98
99
100 class HelpAllDirective(SphinxDirective):
101 """Print the output of jupyterhub help --all for use in the documentation."""
102
103 has_content = False
104 required_arguments = 0
105 optional_arguments = 0
106 final_argument_whitespace = False
107 option_spec = {}
108
109 def run(self):
110 # The output of the help command for this version
111 buffer = io.StringIO()
112 with contextlib.redirect_stdout(buffer):
113 jupyterhub_app.print_help("--help-all")
114 all_help = buffer.getvalue()
115 # post-process output
116 home_dir = os.environ["HOME"]
117 all_help = all_help.replace(home_dir, "$HOME", 1)
118 par = nodes.literal_block(text=all_help)
119 return [par]
120
121
122 def setup(app):
123 app.add_css_file("custom.css")
124 app.add_directive("jupyterhub-generate-config", ConfigDirective)
125 app.add_directive("jupyterhub-help-all", HelpAllDirective)
126
127
128 # -- Read The Docs -----------------------------------------------------------
129 #
130 # Since RTD runs sphinx-build directly without running "make html", we run the
131 # pre-requisite steps for "make html" from here if needed.
132 #
133 if os.environ.get("READTHEDOCS"):
134 docs = os.path.dirname(os.path.dirname(__file__))
135 subprocess.check_call(["make", "metrics", "scopes"], cwd=docs)
136
137
138 # -- Spell checking ----------------------------------------------------------
139 # ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options
140 #
141 # The "sphinxcontrib.spelling" extension is optionally enabled if its available.
142 #
143 try:
144 import sphinxcontrib.spelling # noqa
145 except ImportError:
146 pass
147 else:
148 extensions.append("sphinxcontrib.spelling")
149 spelling_word_list_filename = "spelling_wordlist.txt"
150
151
152 # -- Options for HTML output -------------------------------------------------
153 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
154 #
155 html_logo = "_static/images/logo/logo.png"
156 html_favicon = "_static/images/logo/favicon.ico"
157 html_static_path = ["_static"]
158
159 html_theme = "jupyterhub_sphinx_theme"
160 html_theme_options = {
161 "icon_links": [
162 {
163 "name": "GitHub",
164 "url": "https://github.com/jupyterhub/jupyterhub",
165 "icon": "fa-brands fa-github",
166 },
167 ],
168 "use_edit_page_button": True,
169 "navbar_align": "left",
170 }
171 html_context = {
172 "github_user": "jupyterhub",
173 "github_repo": "jupyterhub",
174 "github_version": "main",
175 "doc_path": "docs/source",
176 }
177
178
179 # -- Options for linkcheck builder -------------------------------------------
180 # ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder
181 #
182 linkcheck_ignore = [
183 r"(.*)github\.com(.*)#", # javascript based anchors
184 r"(.*)/#%21(.*)/(.*)", # /#!forum/jupyter - encoded anchor edge case
185 r"https://github.com/[^/]*$", # too many github usernames / searches in changelog
186 "https://github.com/jupyterhub/jupyterhub/pull/", # too many PRs in changelog
187 "https://github.com/jupyterhub/jupyterhub/compare/", # too many comparisons in changelog
188 r"https?://(localhost|127.0.0.1).*", # ignore localhost references in auto-links
189 r".*/rest-api.html#.*", # ignore javascript-resolved internal rest-api links
190 r"https://jupyter.chameleoncloud.org", # FIXME: ignore (presumably) short-term SSL issue
191 ]
192 linkcheck_anchors_ignore = [
193 "/#!",
194 "/#%21",
195 ]
196
197 # -- Intersphinx -------------------------------------------------------------
198 # ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration
199 #
200 intersphinx_mapping = {
201 "python": ("https://docs.python.org/3/", None),
202 "tornado": ("https://www.tornadoweb.org/en/stable/", None),
203 "jupyter-server": ("https://jupyter-server.readthedocs.io/en/stable/", None),
204 }
205
206 # -- Options for the opengraph extension -------------------------------------
207 # ref: https://github.com/wpilibsuite/sphinxext-opengraph#options
208 #
209 # ogp_site_url is set automatically by RTD
210 ogp_image = "_static/logo.png"
211 ogp_use_first_image = True
212
213
214 # -- Options for the rediraffe extension -------------------------------------
215 # ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme
216 #
217 # This extension helps us relocate content without breaking links. If a
218 # document is moved internally, a redirect link should be configured as below to
219 # help us not break links.
220 #
221 # The workflow for adding redirects can be as follows:
222 # 1. Change "rediraffe_branch" below to point to the commit/ branch you
223 # want to base off the changes.
224 # 2. Option 1: run "make rediraffecheckdiff"
225 # a. Analyze the output of this command.
226 # b. Manually add the redirect entries to the "redirects.txt" file.
227 # Option 2: run "make rediraffewritediff"
228 # a. rediraffe will then automatically add the obvious redirects to redirects.txt.
229 # b. Analyze the output of the command for broken links.
230 # c. Check the "redirects.txt" file for any files that were moved/ renamed but are not listed.
231 # d. Manually add the redirects that have been mised by the automatic builder to "redirects.txt".
232 # Option 3: Do not use the commands above and, instead, do everything manually - by taking
233 # note of the files you have moved or renamed and adding them to the "redirects.txt" file.
234 #
235 # If you are basing changes off another branch/ commit, always change back
236 # rediraffe_branch to main before pushing your changes upstream.
237 #
238 rediraffe_branch = "main"
239 rediraffe_redirects = "redirects.txt"
240 # rediraffe_redirects = {
241 # "old-file": "new-folder/new-file-name",
242 # }
243
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -235,8 +235,12 @@
# If you are basing changes off another branch/ commit, always change back
# rediraffe_branch to main before pushing your changes upstream.
#
-rediraffe_branch = "main"
+rediraffe_branch = os.environ.get("REDIRAFFE_BRANCH", "main")
rediraffe_redirects = "redirects.txt"
+
+# allow 80% match for autogenerated redirects
+rediraffe_auto_redirect_perc = 80
+
# rediraffe_redirects = {
# "old-file": "new-folder/new-file-name",
# }
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -235,8 +235,12 @@\n # If you are basing changes off another branch/ commit, always change back\n # rediraffe_branch to main before pushing your changes upstream.\n #\n-rediraffe_branch = \"main\"\n+rediraffe_branch = os.environ.get(\"REDIRAFFE_BRANCH\", \"main\")\n rediraffe_redirects = \"redirects.txt\"\n+\n+# allow 80% match for autogenerated redirects\n+rediraffe_auto_redirect_perc = 80\n+\n # rediraffe_redirects = {\n # \"old-file\": \"new-folder/new-file-name\",\n # }\n", "issue": "How do we work with documentation redirects from rediraffe in the repo?\n[...] to make a decision on what to do with regards to how we work with the redirects in this repo for now. If experience is gained and you start feeling confident on a practice, we try go for that more systematically in other repos long term.\r\n\r\nI think the options on how to work with the redirects are:\r\n\r\n1. Fully manual as now, where we figure out ourselves if we need to add a redirect\r\n2. Mostly manual, where we can go fully manual but also suggest that `make rediraffecheckdiff` can be used to get informed on what redirects we should make.\r\n3. Semi automated, where we suggest using `make rediraffewritediff` to update a file (not overwrite right?)\r\n4. Mostly automated, where we have a github workflow triggered when docs change to inspect if a redirect needs to be setup and otherwise fails to let us know.\r\n5. Almost fully automated, where we also push a commit with the relevant redirects.\r\n\r\nIf I understand this correctly, we need to consider this ourselves no matter what because the tools can't figure it out fully in all cases. That makes me think we shouldn't go for option 5. Maybe option 2-4? No matter what, I'm a big :+1: for going for something you feel like going for!\r\n\r\n_Originally posted by @consideRatio in https://github.com/jupyterhub/jupyterhub/pull/4331#discussion_r1092331738_\r\n \n", "before_files": [{"content": "# Configuration file for Sphinx to build our documentation to HTML.\n#\n# Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html\n#\nimport contextlib\nimport datetime\nimport io\nimport os\nimport subprocess\n\nfrom docutils import nodes\nfrom sphinx.directives.other import SphinxDirective\n\nimport jupyterhub\nfrom jupyterhub.app import JupyterHub\n\n# -- Project information -----------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information\n#\nproject = \"JupyterHub\"\nauthor = \"Project Jupyter Contributors\"\ncopyright = f\"{datetime.date.today().year}, {author}\"\n\n\n# -- General Sphinx configuration --------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n#\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"autodoc_traits\",\n \"sphinx_copybutton\",\n \"sphinx-jsonschema\",\n \"sphinxext.opengraph\",\n \"sphinxext.rediraffe\",\n \"jupyterhub_sphinx_theme\",\n \"myst_parser\",\n]\nroot_doc = \"index\"\nsource_suffix = [\".md\"]\n# default_role let's use use `foo` instead of ``foo`` in rST\ndefault_role = \"literal\"\n\n\n# -- MyST configuration ------------------------------------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/configuration.html\n#\nmyst_heading_anchors = 2\n\nmyst_enable_extensions = [\n # available extensions: https://myst-parser.readthedocs.io/en/latest/syntax/optional.html\n \"attrs_inline\",\n \"colon_fence\",\n \"deflist\",\n \"fieldlist\",\n \"substitution\",\n]\n\nmyst_substitutions = {\n # date example: Dev 07, 2022\n \"date\": datetime.date.today().strftime(\"%b %d, %Y\").title(),\n \"version\": jupyterhub.__version__,\n}\n\n\n# -- Custom directives to generate documentation -----------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html\n#\n# We define custom directives to help us generate documentation using Python on\n# demand when referenced from our documentation files.\n#\n\n# Create a temp instance of JupyterHub for use by two separate directive classes\n# to get the output from using the \"--generate-config\" and \"--help-all\" CLI\n# flags respectively.\n#\njupyterhub_app = JupyterHub()\n\n\nclass ConfigDirective(SphinxDirective):\n \"\"\"Generate the configuration file output for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The generated configuration file for this version\n generated_config = jupyterhub_app.generate_config_file()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n generated_config = generated_config.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=generated_config)\n return [par]\n\n\nclass HelpAllDirective(SphinxDirective):\n \"\"\"Print the output of jupyterhub help --all for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The output of the help command for this version\n buffer = io.StringIO()\n with contextlib.redirect_stdout(buffer):\n jupyterhub_app.print_help(\"--help-all\")\n all_help = buffer.getvalue()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n all_help = all_help.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=all_help)\n return [par]\n\n\ndef setup(app):\n app.add_css_file(\"custom.css\")\n app.add_directive(\"jupyterhub-generate-config\", ConfigDirective)\n app.add_directive(\"jupyterhub-help-all\", HelpAllDirective)\n\n\n# -- Read The Docs -----------------------------------------------------------\n#\n# Since RTD runs sphinx-build directly without running \"make html\", we run the\n# pre-requisite steps for \"make html\" from here if needed.\n#\nif os.environ.get(\"READTHEDOCS\"):\n docs = os.path.dirname(os.path.dirname(__file__))\n subprocess.check_call([\"make\", \"metrics\", \"scopes\"], cwd=docs)\n\n\n# -- Spell checking ----------------------------------------------------------\n# ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options\n#\n# The \"sphinxcontrib.spelling\" extension is optionally enabled if its available.\n#\ntry:\n import sphinxcontrib.spelling # noqa\nexcept ImportError:\n pass\nelse:\n extensions.append(\"sphinxcontrib.spelling\")\nspelling_word_list_filename = \"spelling_wordlist.txt\"\n\n\n# -- Options for HTML output -------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output\n#\nhtml_logo = \"_static/images/logo/logo.png\"\nhtml_favicon = \"_static/images/logo/favicon.ico\"\nhtml_static_path = [\"_static\"]\n\nhtml_theme = \"jupyterhub_sphinx_theme\"\nhtml_theme_options = {\n \"icon_links\": [\n {\n \"name\": \"GitHub\",\n \"url\": \"https://github.com/jupyterhub/jupyterhub\",\n \"icon\": \"fa-brands fa-github\",\n },\n ],\n \"use_edit_page_button\": True,\n \"navbar_align\": \"left\",\n}\nhtml_context = {\n \"github_user\": \"jupyterhub\",\n \"github_repo\": \"jupyterhub\",\n \"github_version\": \"main\",\n \"doc_path\": \"docs/source\",\n}\n\n\n# -- Options for linkcheck builder -------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder\n#\nlinkcheck_ignore = [\n r\"(.*)github\\.com(.*)#\", # javascript based anchors\n r\"(.*)/#%21(.*)/(.*)\", # /#!forum/jupyter - encoded anchor edge case\n r\"https://github.com/[^/]*$\", # too many github usernames / searches in changelog\n \"https://github.com/jupyterhub/jupyterhub/pull/\", # too many PRs in changelog\n \"https://github.com/jupyterhub/jupyterhub/compare/\", # too many comparisons in changelog\n r\"https?://(localhost|127.0.0.1).*\", # ignore localhost references in auto-links\n r\".*/rest-api.html#.*\", # ignore javascript-resolved internal rest-api links\n r\"https://jupyter.chameleoncloud.org\", # FIXME: ignore (presumably) short-term SSL issue\n]\nlinkcheck_anchors_ignore = [\n \"/#!\",\n \"/#%21\",\n]\n\n# -- Intersphinx -------------------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration\n#\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"tornado\": (\"https://www.tornadoweb.org/en/stable/\", None),\n \"jupyter-server\": (\"https://jupyter-server.readthedocs.io/en/stable/\", None),\n}\n\n# -- Options for the opengraph extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-opengraph#options\n#\n# ogp_site_url is set automatically by RTD\nogp_image = \"_static/logo.png\"\nogp_use_first_image = True\n\n\n# -- Options for the rediraffe extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme\n#\n# This extension helps us relocate content without breaking links. If a\n# document is moved internally, a redirect link should be configured as below to\n# help us not break links.\n#\n# The workflow for adding redirects can be as follows:\n# 1. Change \"rediraffe_branch\" below to point to the commit/ branch you\n# want to base off the changes.\n# 2. Option 1: run \"make rediraffecheckdiff\"\n# a. Analyze the output of this command.\n# b. Manually add the redirect entries to the \"redirects.txt\" file.\n# Option 2: run \"make rediraffewritediff\"\n# a. rediraffe will then automatically add the obvious redirects to redirects.txt.\n# b. Analyze the output of the command for broken links.\n# c. Check the \"redirects.txt\" file for any files that were moved/ renamed but are not listed.\n# d. Manually add the redirects that have been mised by the automatic builder to \"redirects.txt\".\n# Option 3: Do not use the commands above and, instead, do everything manually - by taking\n# note of the files you have moved or renamed and adding them to the \"redirects.txt\" file.\n#\n# If you are basing changes off another branch/ commit, always change back\n# rediraffe_branch to main before pushing your changes upstream.\n#\nrediraffe_branch = \"main\"\nrediraffe_redirects = \"redirects.txt\"\n# rediraffe_redirects = {\n# \"old-file\": \"new-folder/new-file-name\",\n# }\n", "path": "docs/source/conf.py"}], "after_files": [{"content": "# Configuration file for Sphinx to build our documentation to HTML.\n#\n# Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html\n#\nimport contextlib\nimport datetime\nimport io\nimport os\nimport subprocess\n\nfrom docutils import nodes\nfrom sphinx.directives.other import SphinxDirective\n\nimport jupyterhub\nfrom jupyterhub.app import JupyterHub\n\n# -- Project information -----------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information\n#\nproject = \"JupyterHub\"\nauthor = \"Project Jupyter Contributors\"\ncopyright = f\"{datetime.date.today().year}, {author}\"\n\n\n# -- General Sphinx configuration --------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n#\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"autodoc_traits\",\n \"sphinx_copybutton\",\n \"sphinx-jsonschema\",\n \"sphinxext.opengraph\",\n \"sphinxext.rediraffe\",\n \"jupyterhub_sphinx_theme\",\n \"myst_parser\",\n]\nroot_doc = \"index\"\nsource_suffix = [\".md\"]\n# default_role let's use use `foo` instead of ``foo`` in rST\ndefault_role = \"literal\"\n\n\n# -- MyST configuration ------------------------------------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/configuration.html\n#\nmyst_heading_anchors = 2\n\nmyst_enable_extensions = [\n # available extensions: https://myst-parser.readthedocs.io/en/latest/syntax/optional.html\n \"attrs_inline\",\n \"colon_fence\",\n \"deflist\",\n \"fieldlist\",\n \"substitution\",\n]\n\nmyst_substitutions = {\n # date example: Dev 07, 2022\n \"date\": datetime.date.today().strftime(\"%b %d, %Y\").title(),\n \"version\": jupyterhub.__version__,\n}\n\n\n# -- Custom directives to generate documentation -----------------------------\n# ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html\n#\n# We define custom directives to help us generate documentation using Python on\n# demand when referenced from our documentation files.\n#\n\n# Create a temp instance of JupyterHub for use by two separate directive classes\n# to get the output from using the \"--generate-config\" and \"--help-all\" CLI\n# flags respectively.\n#\njupyterhub_app = JupyterHub()\n\n\nclass ConfigDirective(SphinxDirective):\n \"\"\"Generate the configuration file output for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The generated configuration file for this version\n generated_config = jupyterhub_app.generate_config_file()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n generated_config = generated_config.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=generated_config)\n return [par]\n\n\nclass HelpAllDirective(SphinxDirective):\n \"\"\"Print the output of jupyterhub help --all for use in the documentation.\"\"\"\n\n has_content = False\n required_arguments = 0\n optional_arguments = 0\n final_argument_whitespace = False\n option_spec = {}\n\n def run(self):\n # The output of the help command for this version\n buffer = io.StringIO()\n with contextlib.redirect_stdout(buffer):\n jupyterhub_app.print_help(\"--help-all\")\n all_help = buffer.getvalue()\n # post-process output\n home_dir = os.environ[\"HOME\"]\n all_help = all_help.replace(home_dir, \"$HOME\", 1)\n par = nodes.literal_block(text=all_help)\n return [par]\n\n\ndef setup(app):\n app.add_css_file(\"custom.css\")\n app.add_directive(\"jupyterhub-generate-config\", ConfigDirective)\n app.add_directive(\"jupyterhub-help-all\", HelpAllDirective)\n\n\n# -- Read The Docs -----------------------------------------------------------\n#\n# Since RTD runs sphinx-build directly without running \"make html\", we run the\n# pre-requisite steps for \"make html\" from here if needed.\n#\nif os.environ.get(\"READTHEDOCS\"):\n docs = os.path.dirname(os.path.dirname(__file__))\n subprocess.check_call([\"make\", \"metrics\", \"scopes\"], cwd=docs)\n\n\n# -- Spell checking ----------------------------------------------------------\n# ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options\n#\n# The \"sphinxcontrib.spelling\" extension is optionally enabled if its available.\n#\ntry:\n import sphinxcontrib.spelling # noqa\nexcept ImportError:\n pass\nelse:\n extensions.append(\"sphinxcontrib.spelling\")\nspelling_word_list_filename = \"spelling_wordlist.txt\"\n\n\n# -- Options for HTML output -------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output\n#\nhtml_logo = \"_static/images/logo/logo.png\"\nhtml_favicon = \"_static/images/logo/favicon.ico\"\nhtml_static_path = [\"_static\"]\n\nhtml_theme = \"jupyterhub_sphinx_theme\"\nhtml_theme_options = {\n \"icon_links\": [\n {\n \"name\": \"GitHub\",\n \"url\": \"https://github.com/jupyterhub/jupyterhub\",\n \"icon\": \"fa-brands fa-github\",\n },\n ],\n \"use_edit_page_button\": True,\n \"navbar_align\": \"left\",\n}\nhtml_context = {\n \"github_user\": \"jupyterhub\",\n \"github_repo\": \"jupyterhub\",\n \"github_version\": \"main\",\n \"doc_path\": \"docs/source\",\n}\n\n\n# -- Options for linkcheck builder -------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder\n#\nlinkcheck_ignore = [\n r\"(.*)github\\.com(.*)#\", # javascript based anchors\n r\"(.*)/#%21(.*)/(.*)\", # /#!forum/jupyter - encoded anchor edge case\n r\"https://github.com/[^/]*$\", # too many github usernames / searches in changelog\n \"https://github.com/jupyterhub/jupyterhub/pull/\", # too many PRs in changelog\n \"https://github.com/jupyterhub/jupyterhub/compare/\", # too many comparisons in changelog\n r\"https?://(localhost|127.0.0.1).*\", # ignore localhost references in auto-links\n r\".*/rest-api.html#.*\", # ignore javascript-resolved internal rest-api links\n r\"https://jupyter.chameleoncloud.org\", # FIXME: ignore (presumably) short-term SSL issue\n]\nlinkcheck_anchors_ignore = [\n \"/#!\",\n \"/#%21\",\n]\n\n# -- Intersphinx -------------------------------------------------------------\n# ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration\n#\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"tornado\": (\"https://www.tornadoweb.org/en/stable/\", None),\n \"jupyter-server\": (\"https://jupyter-server.readthedocs.io/en/stable/\", None),\n}\n\n# -- Options for the opengraph extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-opengraph#options\n#\n# ogp_site_url is set automatically by RTD\nogp_image = \"_static/logo.png\"\nogp_use_first_image = True\n\n\n# -- Options for the rediraffe extension -------------------------------------\n# ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme\n#\n# This extension helps us relocate content without breaking links. If a\n# document is moved internally, a redirect link should be configured as below to\n# help us not break links.\n#\n# The workflow for adding redirects can be as follows:\n# 1. Change \"rediraffe_branch\" below to point to the commit/ branch you\n# want to base off the changes.\n# 2. Option 1: run \"make rediraffecheckdiff\"\n# a. Analyze the output of this command.\n# b. Manually add the redirect entries to the \"redirects.txt\" file.\n# Option 2: run \"make rediraffewritediff\"\n# a. rediraffe will then automatically add the obvious redirects to redirects.txt.\n# b. Analyze the output of the command for broken links.\n# c. Check the \"redirects.txt\" file for any files that were moved/ renamed but are not listed.\n# d. Manually add the redirects that have been mised by the automatic builder to \"redirects.txt\".\n# Option 3: Do not use the commands above and, instead, do everything manually - by taking\n# note of the files you have moved or renamed and adding them to the \"redirects.txt\" file.\n#\n# If you are basing changes off another branch/ commit, always change back\n# rediraffe_branch to main before pushing your changes upstream.\n#\nrediraffe_branch = os.environ.get(\"REDIRAFFE_BRANCH\", \"main\")\nrediraffe_redirects = \"redirects.txt\"\n\n# allow 80% match for autogenerated redirects\nrediraffe_auto_redirect_perc = 80\n\n# rediraffe_redirects = {\n# \"old-file\": \"new-folder/new-file-name\",\n# }\n", "path": "docs/source/conf.py"}]}
| 3,236 | 159 |
gh_patches_debug_21011
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-18334
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
compress
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py`
Content:
```
1 import ivy
2 from ivy.functional.frontends.numpy.func_wrapper import (
3 to_ivy_arrays_and_back,
4 inputs_to_ivy_arrays,
5 )
6
7
8 @to_ivy_arrays_and_back
9 def take_along_axis(arr, indices, axis):
10 return ivy.take_along_axis(arr, indices, axis)
11
12
13 @to_ivy_arrays_and_back
14 def tril_indices(n, k=0, m=None):
15 return ivy.tril_indices(n, m, k)
16
17
18 @to_ivy_arrays_and_back
19 def indices(dimensions, dtype=int, sparse=False):
20 dimensions = tuple(dimensions)
21 N = len(dimensions)
22 shape = (1,) * N
23 if sparse:
24 res = tuple()
25 else:
26 res = ivy.empty((N,) + dimensions, dtype=dtype)
27 for i, dim in enumerate(dimensions):
28 idx = ivy.arange(dim, dtype=dtype).reshape(shape[:i] + (dim,) + shape[i + 1 :])
29 if sparse:
30 res = res + (idx,)
31 else:
32 res[i] = idx
33 return res
34
35
36 # unravel_index
37 @to_ivy_arrays_and_back
38 def unravel_index(indices, shape, order="C"):
39 ret = [x.astype("int64") for x in ivy.unravel_index(indices, shape)]
40 return tuple(ret)
41
42
43 @to_ivy_arrays_and_back
44 def fill_diagonal(a, val, wrap=False):
45 if a.ndim < 2:
46 raise ValueError("array must be at least 2-d")
47 end = None
48 if a.ndim == 2:
49 # Explicit, fast formula for the common case. For 2-d arrays, we
50 # accept rectangular ones.
51 step = a.shape[1] + 1
52 # This is needed to don't have tall matrix have the diagonal wrap.
53 if not wrap:
54 end = a.shape[1] * a.shape[1]
55 else:
56 # For more than d=2, the strided formula is only valid for arrays with
57 # all dimensions equal, so we check first.
58 if not ivy.all(ivy.diff(a.shape) == 0):
59 raise ValueError("All dimensions of input must be of equal length")
60 step = 1 + ivy.sum(ivy.cumprod(a.shape[:-1]))
61
62 # Write the value out into the diagonal.
63 shape = a.shape
64 a = ivy.reshape(a, a.size)
65 a[:end:step] = val
66 a = ivy.reshape(a, shape)
67
68
69 @inputs_to_ivy_arrays
70 def put_along_axis(arr, indices, values, axis):
71 ivy.put_along_axis(arr, indices, values, axis)
72
73
74 def diag(v, k=0):
75 return ivy.diag(v, k=k)
76
77
78 @to_ivy_arrays_and_back
79 def diagonal(a, offset, axis1, axis2):
80 return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py
--- a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py
+++ b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py
@@ -2,6 +2,7 @@
from ivy.functional.frontends.numpy.func_wrapper import (
to_ivy_arrays_and_back,
inputs_to_ivy_arrays,
+ handle_numpy_out,
)
@@ -78,3 +79,22 @@
@to_ivy_arrays_and_back
def diagonal(a, offset, axis1, axis2):
return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)
+
+
+@to_ivy_arrays_and_back
+@handle_numpy_out
+def compress(condition, a, axis=None, out=None):
+ condition_arr = ivy.asarray(condition).astype(bool)
+ if condition_arr.ndim != 1:
+ raise ivy.utils.exceptions.IvyException("Condition must be a 1D array")
+ if axis is None:
+ arr = ivy.asarray(a).flatten()
+ axis = 0
+ else:
+ arr = ivy.moveaxis(a, axis, 0)
+ if condition_arr.shape[0] > arr.shape[0]:
+ raise ivy.utils.exceptions.IvyException(
+ "Condition contains entries that are out of bounds"
+ )
+ arr = arr[: condition_arr.shape[0]]
+ return ivy.moveaxis(arr[condition_arr], 0, axis)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py\n--- a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py\n+++ b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py\n@@ -2,6 +2,7 @@\n from ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n inputs_to_ivy_arrays,\n+ handle_numpy_out,\n )\n \n \n@@ -78,3 +79,22 @@\n @to_ivy_arrays_and_back\n def diagonal(a, offset, axis1, axis2):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n+\n+\n+@to_ivy_arrays_and_back\n+@handle_numpy_out\n+def compress(condition, a, axis=None, out=None):\n+ condition_arr = ivy.asarray(condition).astype(bool)\n+ if condition_arr.ndim != 1:\n+ raise ivy.utils.exceptions.IvyException(\"Condition must be a 1D array\")\n+ if axis is None:\n+ arr = ivy.asarray(a).flatten()\n+ axis = 0\n+ else:\n+ arr = ivy.moveaxis(a, axis, 0)\n+ if condition_arr.shape[0] > arr.shape[0]:\n+ raise ivy.utils.exceptions.IvyException(\n+ \"Condition contains entries that are out of bounds\"\n+ )\n+ arr = arr[: condition_arr.shape[0]]\n+ return ivy.moveaxis(arr[condition_arr], 0, axis)\n", "issue": "compress\n\n", "before_files": [{"content": "import ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n inputs_to_ivy_arrays,\n)\n\n\n@to_ivy_arrays_and_back\ndef take_along_axis(arr, indices, axis):\n return ivy.take_along_axis(arr, indices, axis)\n\n\n@to_ivy_arrays_and_back\ndef tril_indices(n, k=0, m=None):\n return ivy.tril_indices(n, m, k)\n\n\n@to_ivy_arrays_and_back\ndef indices(dimensions, dtype=int, sparse=False):\n dimensions = tuple(dimensions)\n N = len(dimensions)\n shape = (1,) * N\n if sparse:\n res = tuple()\n else:\n res = ivy.empty((N,) + dimensions, dtype=dtype)\n for i, dim in enumerate(dimensions):\n idx = ivy.arange(dim, dtype=dtype).reshape(shape[:i] + (dim,) + shape[i + 1 :])\n if sparse:\n res = res + (idx,)\n else:\n res[i] = idx\n return res\n\n\n# unravel_index\n@to_ivy_arrays_and_back\ndef unravel_index(indices, shape, order=\"C\"):\n ret = [x.astype(\"int64\") for x in ivy.unravel_index(indices, shape)]\n return tuple(ret)\n\n\n@to_ivy_arrays_and_back\ndef fill_diagonal(a, val, wrap=False):\n if a.ndim < 2:\n raise ValueError(\"array must be at least 2-d\")\n end = None\n if a.ndim == 2:\n # Explicit, fast formula for the common case. For 2-d arrays, we\n # accept rectangular ones.\n step = a.shape[1] + 1\n # This is needed to don't have tall matrix have the diagonal wrap.\n if not wrap:\n end = a.shape[1] * a.shape[1]\n else:\n # For more than d=2, the strided formula is only valid for arrays with\n # all dimensions equal, so we check first.\n if not ivy.all(ivy.diff(a.shape) == 0):\n raise ValueError(\"All dimensions of input must be of equal length\")\n step = 1 + ivy.sum(ivy.cumprod(a.shape[:-1]))\n\n # Write the value out into the diagonal.\n shape = a.shape\n a = ivy.reshape(a, a.size)\n a[:end:step] = val\n a = ivy.reshape(a, shape)\n\n\n@inputs_to_ivy_arrays\ndef put_along_axis(arr, indices, values, axis):\n ivy.put_along_axis(arr, indices, values, axis)\n\n\ndef diag(v, k=0):\n return ivy.diag(v, k=k)\n\n\n@to_ivy_arrays_and_back\ndef diagonal(a, offset, axis1, axis2):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n", "path": "ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py"}], "after_files": [{"content": "import ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n inputs_to_ivy_arrays,\n handle_numpy_out,\n)\n\n\n@to_ivy_arrays_and_back\ndef take_along_axis(arr, indices, axis):\n return ivy.take_along_axis(arr, indices, axis)\n\n\n@to_ivy_arrays_and_back\ndef tril_indices(n, k=0, m=None):\n return ivy.tril_indices(n, m, k)\n\n\n@to_ivy_arrays_and_back\ndef indices(dimensions, dtype=int, sparse=False):\n dimensions = tuple(dimensions)\n N = len(dimensions)\n shape = (1,) * N\n if sparse:\n res = tuple()\n else:\n res = ivy.empty((N,) + dimensions, dtype=dtype)\n for i, dim in enumerate(dimensions):\n idx = ivy.arange(dim, dtype=dtype).reshape(shape[:i] + (dim,) + shape[i + 1 :])\n if sparse:\n res = res + (idx,)\n else:\n res[i] = idx\n return res\n\n\n# unravel_index\n@to_ivy_arrays_and_back\ndef unravel_index(indices, shape, order=\"C\"):\n ret = [x.astype(\"int64\") for x in ivy.unravel_index(indices, shape)]\n return tuple(ret)\n\n\n@to_ivy_arrays_and_back\ndef fill_diagonal(a, val, wrap=False):\n if a.ndim < 2:\n raise ValueError(\"array must be at least 2-d\")\n end = None\n if a.ndim == 2:\n # Explicit, fast formula for the common case. For 2-d arrays, we\n # accept rectangular ones.\n step = a.shape[1] + 1\n # This is needed to don't have tall matrix have the diagonal wrap.\n if not wrap:\n end = a.shape[1] * a.shape[1]\n else:\n # For more than d=2, the strided formula is only valid for arrays with\n # all dimensions equal, so we check first.\n if not ivy.all(ivy.diff(a.shape) == 0):\n raise ValueError(\"All dimensions of input must be of equal length\")\n step = 1 + ivy.sum(ivy.cumprod(a.shape[:-1]))\n\n # Write the value out into the diagonal.\n shape = a.shape\n a = ivy.reshape(a, a.size)\n a[:end:step] = val\n a = ivy.reshape(a, shape)\n\n\n@inputs_to_ivy_arrays\ndef put_along_axis(arr, indices, values, axis):\n ivy.put_along_axis(arr, indices, values, axis)\n\n\ndef diag(v, k=0):\n return ivy.diag(v, k=k)\n\n\n@to_ivy_arrays_and_back\ndef diagonal(a, offset, axis1, axis2):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n\n\n@to_ivy_arrays_and_back\n@handle_numpy_out\ndef compress(condition, a, axis=None, out=None):\n condition_arr = ivy.asarray(condition).astype(bool)\n if condition_arr.ndim != 1:\n raise ivy.utils.exceptions.IvyException(\"Condition must be a 1D array\")\n if axis is None:\n arr = ivy.asarray(a).flatten()\n axis = 0\n else:\n arr = ivy.moveaxis(a, axis, 0)\n if condition_arr.shape[0] > arr.shape[0]:\n raise ivy.utils.exceptions.IvyException(\n \"Condition contains entries that are out of bounds\"\n )\n arr = arr[: condition_arr.shape[0]]\n return ivy.moveaxis(arr[condition_arr], 0, axis)\n", "path": "ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py"}]}
| 1,079 | 368 |
gh_patches_debug_16116
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-1273
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add overlay tiles layers from settings
https://github.com/makinacorpus/django-leaflet/issues/83
Would allow to show cadastral parcels over orthophoto, "plans de circulation" etc.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geotrek/settings/dev.py`
Content:
```
1 from .default import * # NOQA
2
3 #
4 # Django Development
5 # ..........................
6
7 DEBUG = True
8 TEMPLATE_DEBUG = True
9
10 SOUTH_TESTS_MIGRATE = False # Tested at settings.tests
11
12 #
13 # Developper Toolbar
14 # ..........................
15
16 INSTALLED_APPS = (
17 # 'debug_toolbar',
18 'django_extensions',
19 ) + INSTALLED_APPS
20
21 #
22 # Use Geotrek preprod tiles (uses default extent)
23 # ................................................
24
25 LEAFLET_CONFIG['TILES'] = [
26 (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),
27 (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),
28 ]
29 LEAFLET_CONFIG['SRID'] = 3857
30
31 LOGGING['loggers']['geotrek']['level'] = 'DEBUG'
32 LOGGING['loggers']['']['level'] = 'DEBUG'
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geotrek/settings/dev.py b/geotrek/settings/dev.py
--- a/geotrek/settings/dev.py
+++ b/geotrek/settings/dev.py
@@ -19,13 +19,17 @@
) + INSTALLED_APPS
#
-# Use Geotrek preprod tiles (uses default extent)
-# ................................................
+# Use some default tiles
+# ..........................
LEAFLET_CONFIG['TILES'] = [
(gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),
(gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),
]
+LEAFLET_CONFIG['OVERLAYS'] = [
+ (gettext_noop('Coeur de parc'), 'http://{s}.tilestream.makina-corpus.net/v2/coeur-ecrins/{z}/{x}/{y}.png', 'Ecrins'),
+]
+
LEAFLET_CONFIG['SRID'] = 3857
LOGGING['loggers']['geotrek']['level'] = 'DEBUG'
|
{"golden_diff": "diff --git a/geotrek/settings/dev.py b/geotrek/settings/dev.py\n--- a/geotrek/settings/dev.py\n+++ b/geotrek/settings/dev.py\n@@ -19,13 +19,17 @@\n ) + INSTALLED_APPS\n \n #\n-# Use Geotrek preprod tiles (uses default extent)\n-# ................................................\n+# Use some default tiles\n+# ..........................\n \n LEAFLET_CONFIG['TILES'] = [\n (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),\n (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),\n ]\n+LEAFLET_CONFIG['OVERLAYS'] = [\n+ (gettext_noop('Coeur de parc'), 'http://{s}.tilestream.makina-corpus.net/v2/coeur-ecrins/{z}/{x}/{y}.png', 'Ecrins'),\n+]\n+\n LEAFLET_CONFIG['SRID'] = 3857\n \n LOGGING['loggers']['geotrek']['level'] = 'DEBUG'\n", "issue": "Add overlay tiles layers from settings\nhttps://github.com/makinacorpus/django-leaflet/issues/83 \n\nWould allow to show cadastral parcels over orthophoto, \"plans de circulation\" etc.\n\n", "before_files": [{"content": "from .default import * # NOQA\n\n#\n# Django Development\n# ..........................\n\nDEBUG = True\nTEMPLATE_DEBUG = True\n\nSOUTH_TESTS_MIGRATE = False # Tested at settings.tests\n\n#\n# Developper Toolbar\n# ..........................\n\nINSTALLED_APPS = (\n # 'debug_toolbar',\n 'django_extensions',\n) + INSTALLED_APPS\n\n#\n# Use Geotrek preprod tiles (uses default extent)\n# ................................................\n\nLEAFLET_CONFIG['TILES'] = [\n (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),\n (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),\n]\nLEAFLET_CONFIG['SRID'] = 3857\n\nLOGGING['loggers']['geotrek']['level'] = 'DEBUG'\nLOGGING['loggers']['']['level'] = 'DEBUG'\n", "path": "geotrek/settings/dev.py"}], "after_files": [{"content": "from .default import * # NOQA\n\n#\n# Django Development\n# ..........................\n\nDEBUG = True\nTEMPLATE_DEBUG = True\n\nSOUTH_TESTS_MIGRATE = False # Tested at settings.tests\n\n#\n# Developper Toolbar\n# ..........................\n\nINSTALLED_APPS = (\n # 'debug_toolbar',\n 'django_extensions',\n) + INSTALLED_APPS\n\n#\n# Use some default tiles\n# ..........................\n\nLEAFLET_CONFIG['TILES'] = [\n (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),\n (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),\n]\nLEAFLET_CONFIG['OVERLAYS'] = [\n (gettext_noop('Coeur de parc'), 'http://{s}.tilestream.makina-corpus.net/v2/coeur-ecrins/{z}/{x}/{y}.png', 'Ecrins'),\n]\n\nLEAFLET_CONFIG['SRID'] = 3857\n\nLOGGING['loggers']['geotrek']['level'] = 'DEBUG'\nLOGGING['loggers']['']['level'] = 'DEBUG'\n", "path": "geotrek/settings/dev.py"}]}
| 596 | 272 |
gh_patches_debug_18592
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-5121
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
option to disable automatic client response body decompression
enhancement for https://github.com/aio-libs/aiohttp/issues/1992
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aiohttp/resolver.py`
Content:
```
1 import asyncio
2 import socket
3 from typing import Any, Dict, List, Optional
4
5 from .abc import AbstractResolver
6 from .helpers import get_running_loop
7
8 __all__ = ("ThreadedResolver", "AsyncResolver", "DefaultResolver")
9
10 try:
11 import aiodns
12
13 # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')
14 except ImportError: # pragma: no cover
15 aiodns = None
16
17 aiodns_default = False
18
19
20 class ThreadedResolver(AbstractResolver):
21 """Use Executor for synchronous getaddrinfo() calls, which defaults to
22 concurrent.futures.ThreadPoolExecutor.
23 """
24
25 def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None) -> None:
26 self._loop = get_running_loop(loop)
27
28 async def resolve(
29 self, host: str, port: int = 0, family: int = socket.AF_INET
30 ) -> List[Dict[str, Any]]:
31 infos = await self._loop.getaddrinfo(
32 host, port, type=socket.SOCK_STREAM, family=family
33 )
34
35 hosts = []
36 for family, _, proto, _, address in infos:
37 if family == socket.AF_INET6 and address[3]: # type: ignore
38 # This is essential for link-local IPv6 addresses.
39 # LL IPv6 is a VERY rare case. Strictly speaking, we should use
40 # getnameinfo() unconditionally, but performance makes sense.
41 host, _port = socket.getnameinfo(
42 address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV
43 )
44 port = int(_port)
45 else:
46 host, port = address[:2]
47 hosts.append(
48 {
49 "hostname": host,
50 "host": host,
51 "port": port,
52 "family": family,
53 "proto": proto,
54 "flags": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,
55 }
56 )
57
58 return hosts
59
60 async def close(self) -> None:
61 pass
62
63
64 class AsyncResolver(AbstractResolver):
65 """Use the `aiodns` package to make asynchronous DNS lookups"""
66
67 def __init__(
68 self,
69 loop: Optional[asyncio.AbstractEventLoop] = None,
70 *args: Any,
71 **kwargs: Any
72 ) -> None:
73 if aiodns is None:
74 raise RuntimeError("Resolver requires aiodns library")
75
76 self._loop = get_running_loop(loop)
77 self._resolver = aiodns.DNSResolver(*args, loop=loop, **kwargs)
78
79 if not hasattr(self._resolver, "gethostbyname"):
80 # aiodns 1.1 is not available, fallback to DNSResolver.query
81 self.resolve = self._resolve_with_query # type: ignore
82
83 async def resolve(
84 self, host: str, port: int = 0, family: int = socket.AF_INET
85 ) -> List[Dict[str, Any]]:
86 try:
87 resp = await self._resolver.gethostbyname(host, family)
88 except aiodns.error.DNSError as exc:
89 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
90 raise OSError(msg) from exc
91 hosts = []
92 for address in resp.addresses:
93 hosts.append(
94 {
95 "hostname": host,
96 "host": address,
97 "port": port,
98 "family": family,
99 "proto": 0,
100 "flags": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,
101 }
102 )
103
104 if not hosts:
105 raise OSError("DNS lookup failed")
106
107 return hosts
108
109 async def _resolve_with_query(
110 self, host: str, port: int = 0, family: int = socket.AF_INET
111 ) -> List[Dict[str, Any]]:
112 if family == socket.AF_INET6:
113 qtype = "AAAA"
114 else:
115 qtype = "A"
116
117 try:
118 resp = await self._resolver.query(host, qtype)
119 except aiodns.error.DNSError as exc:
120 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
121 raise OSError(msg) from exc
122
123 hosts = []
124 for rr in resp:
125 hosts.append(
126 {
127 "hostname": host,
128 "host": rr.host,
129 "port": port,
130 "family": family,
131 "proto": 0,
132 "flags": socket.AI_NUMERICHOST,
133 }
134 )
135
136 if not hosts:
137 raise OSError("DNS lookup failed")
138
139 return hosts
140
141 async def close(self) -> None:
142 return self._resolver.cancel()
143
144
145 DefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py
--- a/aiohttp/resolver.py
+++ b/aiohttp/resolver.py
@@ -26,10 +26,10 @@
self._loop = get_running_loop(loop)
async def resolve(
- self, host: str, port: int = 0, family: int = socket.AF_INET
+ self, hostname: str, port: int = 0, family: int = socket.AF_INET
) -> List[Dict[str, Any]]:
infos = await self._loop.getaddrinfo(
- host, port, type=socket.SOCK_STREAM, family=family
+ hostname, port, type=socket.SOCK_STREAM, family=family
)
hosts = []
@@ -46,7 +46,7 @@
host, port = address[:2]
hosts.append(
{
- "hostname": host,
+ "hostname": hostname,
"host": host,
"port": port,
"family": family,
|
{"golden_diff": "diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py\n--- a/aiohttp/resolver.py\n+++ b/aiohttp/resolver.py\n@@ -26,10 +26,10 @@\n self._loop = get_running_loop(loop)\n \n async def resolve(\n- self, host: str, port: int = 0, family: int = socket.AF_INET\n+ self, hostname: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n- host, port, type=socket.SOCK_STREAM, family=family\n+ hostname, port, type=socket.SOCK_STREAM, family=family\n )\n \n hosts = []\n@@ -46,7 +46,7 @@\n host, port = address[:2]\n hosts.append(\n {\n- \"hostname\": host,\n+ \"hostname\": hostname,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n", "issue": "option to disable automatic client response body decompression\nenhancement for https://github.com/aio-libs/aiohttp/issues/1992\n", "before_files": [{"content": "import asyncio\nimport socket\nfrom typing import Any, Dict, List, Optional\n\nfrom .abc import AbstractResolver\nfrom .helpers import get_running_loop\n\n__all__ = (\"ThreadedResolver\", \"AsyncResolver\", \"DefaultResolver\")\n\ntry:\n import aiodns\n\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Use Executor for synchronous getaddrinfo() calls, which defaults to\n concurrent.futures.ThreadPoolExecutor.\n \"\"\"\n\n def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None) -> None:\n self._loop = get_running_loop(loop)\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n host, port, type=socket.SOCK_STREAM, family=family\n )\n\n hosts = []\n for family, _, proto, _, address in infos:\n if family == socket.AF_INET6 and address[3]: # type: ignore\n # This is essential for link-local IPv6 addresses.\n # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n # getnameinfo() unconditionally, but performance makes sense.\n host, _port = socket.getnameinfo(\n address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n )\n port = int(_port)\n else:\n host, port = address[:2]\n hosts.append(\n {\n \"hostname\": host,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n \"proto\": proto,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(\n self,\n loop: Optional[asyncio.AbstractEventLoop] = None,\n *args: Any,\n **kwargs: Any\n ) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = get_running_loop(loop)\n self._resolver = aiodns.DNSResolver(*args, loop=loop, **kwargs)\n\n if not hasattr(self._resolver, \"gethostbyname\"):\n # aiodns 1.1 is not available, fallback to DNSResolver.query\n self.resolve = self._resolve_with_query # type: ignore\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": address,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def _resolve_with_query(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n if family == socket.AF_INET6:\n qtype = \"AAAA\"\n else:\n qtype = \"A\"\n\n try:\n resp = await self._resolver.query(host, qtype)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n\n hosts = []\n for rr in resp:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": rr.host,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n return self._resolver.cancel()\n\n\nDefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}], "after_files": [{"content": "import asyncio\nimport socket\nfrom typing import Any, Dict, List, Optional\n\nfrom .abc import AbstractResolver\nfrom .helpers import get_running_loop\n\n__all__ = (\"ThreadedResolver\", \"AsyncResolver\", \"DefaultResolver\")\n\ntry:\n import aiodns\n\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Use Executor for synchronous getaddrinfo() calls, which defaults to\n concurrent.futures.ThreadPoolExecutor.\n \"\"\"\n\n def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None) -> None:\n self._loop = get_running_loop(loop)\n\n async def resolve(\n self, hostname: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n hostname, port, type=socket.SOCK_STREAM, family=family\n )\n\n hosts = []\n for family, _, proto, _, address in infos:\n if family == socket.AF_INET6 and address[3]: # type: ignore\n # This is essential for link-local IPv6 addresses.\n # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n # getnameinfo() unconditionally, but performance makes sense.\n host, _port = socket.getnameinfo(\n address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n )\n port = int(_port)\n else:\n host, port = address[:2]\n hosts.append(\n {\n \"hostname\": hostname,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n \"proto\": proto,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(\n self,\n loop: Optional[asyncio.AbstractEventLoop] = None,\n *args: Any,\n **kwargs: Any\n ) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = get_running_loop(loop)\n self._resolver = aiodns.DNSResolver(*args, loop=loop, **kwargs)\n\n if not hasattr(self._resolver, \"gethostbyname\"):\n # aiodns 1.1 is not available, fallback to DNSResolver.query\n self.resolve = self._resolve_with_query # type: ignore\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": address,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def _resolve_with_query(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n if family == socket.AF_INET6:\n qtype = \"AAAA\"\n else:\n qtype = \"A\"\n\n try:\n resp = await self._resolver.query(host, qtype)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n\n hosts = []\n for rr in resp:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": rr.host,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n return self._resolver.cancel()\n\n\nDefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}]}
| 1,654 | 231 |
gh_patches_debug_7305
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-2230
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update dependencies with security vulnerabilities
As mentioned here:
https://github.com/streamlink/streamlink/pull/2199#issuecomment-447567326
1. urllib3
> Vulnerable versions: < 1.23
> Patched version: 1.23
> urllib3 before version 1.23 does not remove the Authorization HTTP header when following a cross-origin redirect (i.e., a redirect that differs in host, port, or scheme). This can allow for credentials in the Authorization header to be exposed to unintended hosts or transmitted in cleartext.
https://nvd.nist.gov/vuln/detail/CVE-2018-20060
2. requests
> Vulnerable versions: <= 2.19.1
> Patched version: 2.20.0
> The Requests package through 2.19.1 before 2018-09-14 for Python sends an HTTP Authorization header to an http URI upon receiving a same-hostname https-to-http redirect, which makes it easier for remote attackers to discover credentials by sniffing the network.
https://nvd.nist.gov/vuln/detail/CVE-2018-18074
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 import codecs
3 from os import environ
4 from os import path
5 from sys import path as sys_path
6
7 from setuptools import setup, find_packages
8
9 import versioneer
10
11 deps = [
12 # Require backport of concurrent.futures on Python 2
13 'futures;python_version<"3.0"',
14 # Require singledispatch on Python <3.4
15 'singledispatch;python_version<"3.4"',
16 "requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0",
17 'urllib3[secure]<1.23,>=1.21.1;python_version<"3.0"',
18 "isodate",
19 "websocket-client",
20 # Support for SOCKS proxies
21 "PySocks!=1.5.7,>=1.5.6",
22 # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet
23 # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x
24 'win-inet-pton;python_version<"3.0" and platform_system=="Windows"',
25 # shutil.get_terminal_size and which were added in Python 3.3
26 'backports.shutil_which;python_version<"3.3"',
27 'backports.shutil_get_terminal_size;python_version<"3.3"'
28 ]
29
30 # for encrypted streams
31 if environ.get("STREAMLINK_USE_PYCRYPTO"):
32 deps.append("pycrypto")
33 else:
34 # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6
35 deps.append("pycryptodome>=3.4.3,<4")
36
37 # for localization
38 if environ.get("STREAMLINK_USE_PYCOUNTRY"):
39 deps.append("pycountry")
40 else:
41 deps.append("iso-639")
42 deps.append("iso3166")
43
44 # When we build an egg for the Win32 bootstrap we don"t want dependency
45 # information built into it.
46 if environ.get("NO_DEPS"):
47 deps = []
48
49 this_directory = path.abspath(path.dirname(__file__))
50 srcdir = path.join(this_directory, "src/")
51 sys_path.insert(0, srcdir)
52
53 with codecs.open(path.join(this_directory, "README.md"), 'r', "utf8") as f:
54 long_description = f.read()
55
56 setup(name="streamlink",
57 version=versioneer.get_version(),
58 cmdclass=versioneer.get_cmdclass(),
59 description="Streamlink is command-line utility that extracts streams "
60 "from various services and pipes them into a video player of "
61 "choice.",
62 long_description=long_description,
63 long_description_content_type="text/markdown",
64 url="https://github.com/streamlink/streamlink",
65 project_urls={
66 "Documentation": "https://streamlink.github.io/",
67 "Tracker": "https://github.com/streamlink/streamlink/issues",
68 "Source": "https://github.com/streamlink/streamlink",
69 "Funding": "https://opencollective.com/streamlink"
70 },
71 author="Streamlink",
72 # temp until we have a mailing list / global email
73 author_email="[email protected]",
74 license="Simplified BSD",
75 packages=find_packages("src"),
76 package_dir={"": "src"},
77 entry_points={
78 "console_scripts": ["streamlink=streamlink_cli.main:main"]
79 },
80 install_requires=deps,
81 test_suite="tests",
82 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4",
83 classifiers=["Development Status :: 5 - Production/Stable",
84 "License :: OSI Approved :: BSD License",
85 "Environment :: Console",
86 "Intended Audience :: End Users/Desktop",
87 "Operating System :: POSIX",
88 "Operating System :: Microsoft :: Windows",
89 "Operating System :: MacOS",
90 "Programming Language :: Python :: 2.7",
91 "Programming Language :: Python :: 3.4",
92 "Programming Language :: Python :: 3.5",
93 "Programming Language :: Python :: 3.6",
94 "Programming Language :: Python :: 3.7",
95 "Topic :: Internet :: WWW/HTTP",
96 "Topic :: Multimedia :: Sound/Audio",
97 "Topic :: Multimedia :: Video",
98 "Topic :: Utilities"])
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -13,8 +13,8 @@
'futures;python_version<"3.0"',
# Require singledispatch on Python <3.4
'singledispatch;python_version<"3.4"',
- "requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0",
- 'urllib3[secure]<1.23,>=1.21.1;python_version<"3.0"',
+ "requests>=2.21.0,<3.0",
+ 'urllib3[secure]>=1.23;python_version<"3.0"',
"isodate",
"websocket-client",
# Support for SOCKS proxies
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -13,8 +13,8 @@\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n- \"requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0\",\n- 'urllib3[secure]<1.23,>=1.21.1;python_version<\"3.0\"',\n+ \"requests>=2.21.0,<3.0\",\n+ 'urllib3[secure]>=1.23;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n", "issue": "Update dependencies with security vulnerabilities\nAs mentioned here:\r\nhttps://github.com/streamlink/streamlink/pull/2199#issuecomment-447567326\r\n\r\n1. urllib3\r\n > Vulnerable versions: < 1.23\r\n > Patched version: 1.23\r\n > urllib3 before version 1.23 does not remove the Authorization HTTP header when following a cross-origin redirect (i.e., a redirect that differs in host, port, or scheme). This can allow for credentials in the Authorization header to be exposed to unintended hosts or transmitted in cleartext.\r\n https://nvd.nist.gov/vuln/detail/CVE-2018-20060\r\n2. requests\r\n > Vulnerable versions: <= 2.19.1\r\n > Patched version: 2.20.0\r\n > The Requests package through 2.19.1 before 2018-09-14 for Python sends an HTTP Authorization header to an http URI upon receiving a same-hostname https-to-http redirect, which makes it easier for remote attackers to discover credentials by sniffing the network.\r\n https://nvd.nist.gov/vuln/detail/CVE-2018-18074\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport codecs\nfrom os import environ\nfrom os import path\nfrom sys import path as sys_path\n\nfrom setuptools import setup, find_packages\n\nimport versioneer\n\ndeps = [\n # Require backport of concurrent.futures on Python 2\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n \"requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0\",\n 'urllib3[secure]<1.23,>=1.21.1;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n \"PySocks!=1.5.7,>=1.5.6\",\n # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet\n # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x\n 'win-inet-pton;python_version<\"3.0\" and platform_system==\"Windows\"',\n # shutil.get_terminal_size and which were added in Python 3.3\n 'backports.shutil_which;python_version<\"3.3\"',\n 'backports.shutil_get_terminal_size;python_version<\"3.3\"'\n]\n\n# for encrypted streams\nif environ.get(\"STREAMLINK_USE_PYCRYPTO\"):\n deps.append(\"pycrypto\")\nelse:\n # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6\n deps.append(\"pycryptodome>=3.4.3,<4\")\n\n# for localization\nif environ.get(\"STREAMLINK_USE_PYCOUNTRY\"):\n deps.append(\"pycountry\")\nelse:\n deps.append(\"iso-639\")\n deps.append(\"iso3166\")\n\n# When we build an egg for the Win32 bootstrap we don\"t want dependency\n# information built into it.\nif environ.get(\"NO_DEPS\"):\n deps = []\n\nthis_directory = path.abspath(path.dirname(__file__))\nsrcdir = path.join(this_directory, \"src/\")\nsys_path.insert(0, srcdir)\n\nwith codecs.open(path.join(this_directory, \"README.md\"), 'r', \"utf8\") as f:\n long_description = f.read()\n\nsetup(name=\"streamlink\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Streamlink is command-line utility that extracts streams \"\n \"from various services and pipes them into a video player of \"\n \"choice.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/streamlink/streamlink\",\n project_urls={\n \"Documentation\": \"https://streamlink.github.io/\",\n \"Tracker\": \"https://github.com/streamlink/streamlink/issues\",\n \"Source\": \"https://github.com/streamlink/streamlink\",\n \"Funding\": \"https://opencollective.com/streamlink\"\n },\n author=\"Streamlink\",\n # temp until we have a mailing list / global email\n author_email=\"[email protected]\",\n license=\"Simplified BSD\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n entry_points={\n \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n },\n install_requires=deps,\n test_suite=\"tests\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n classifiers=[\"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: BSD License\",\n \"Environment :: Console\",\n \"Intended Audience :: End Users/Desktop\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Multimedia :: Sound/Audio\",\n \"Topic :: Multimedia :: Video\",\n \"Topic :: Utilities\"])\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport codecs\nfrom os import environ\nfrom os import path\nfrom sys import path as sys_path\n\nfrom setuptools import setup, find_packages\n\nimport versioneer\n\ndeps = [\n # Require backport of concurrent.futures on Python 2\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n \"requests>=2.21.0,<3.0\",\n 'urllib3[secure]>=1.23;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n \"PySocks!=1.5.7,>=1.5.6\",\n # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet\n # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x\n 'win-inet-pton;python_version<\"3.0\" and platform_system==\"Windows\"',\n # shutil.get_terminal_size and which were added in Python 3.3\n 'backports.shutil_which;python_version<\"3.3\"',\n 'backports.shutil_get_terminal_size;python_version<\"3.3\"'\n]\n\n# for encrypted streams\nif environ.get(\"STREAMLINK_USE_PYCRYPTO\"):\n deps.append(\"pycrypto\")\nelse:\n # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6\n deps.append(\"pycryptodome>=3.4.3,<4\")\n\n# for localization\nif environ.get(\"STREAMLINK_USE_PYCOUNTRY\"):\n deps.append(\"pycountry\")\nelse:\n deps.append(\"iso-639\")\n deps.append(\"iso3166\")\n\n# When we build an egg for the Win32 bootstrap we don\"t want dependency\n# information built into it.\nif environ.get(\"NO_DEPS\"):\n deps = []\n\nthis_directory = path.abspath(path.dirname(__file__))\nsrcdir = path.join(this_directory, \"src/\")\nsys_path.insert(0, srcdir)\n\nwith codecs.open(path.join(this_directory, \"README.md\"), 'r', \"utf8\") as f:\n long_description = f.read()\n\nsetup(name=\"streamlink\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Streamlink is command-line utility that extracts streams \"\n \"from various services and pipes them into a video player of \"\n \"choice.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/streamlink/streamlink\",\n project_urls={\n \"Documentation\": \"https://streamlink.github.io/\",\n \"Tracker\": \"https://github.com/streamlink/streamlink/issues\",\n \"Source\": \"https://github.com/streamlink/streamlink\",\n \"Funding\": \"https://opencollective.com/streamlink\"\n },\n author=\"Streamlink\",\n # temp until we have a mailing list / global email\n author_email=\"[email protected]\",\n license=\"Simplified BSD\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n entry_points={\n \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n },\n install_requires=deps,\n test_suite=\"tests\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n classifiers=[\"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: BSD License\",\n \"Environment :: Console\",\n \"Intended Audience :: End Users/Desktop\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Multimedia :: Sound/Audio\",\n \"Topic :: Multimedia :: Video\",\n \"Topic :: Utilities\"])\n", "path": "setup.py"}]}
| 1,740 | 240 |
gh_patches_debug_18267
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-689
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E2504 enforces incorrect boundary 100-2000, should be 100-20000
*cfn-lint version: (`cfn-lint --version`)* 0.15.0 (also tested with 0.14.1)
**Description:**
AWS EC2 Instance with block device mapping does not enforce the correct `Ebs/Iops` boundary of 100-20000 as specified in the [documentation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html)
It looks like it actually enforces 100-2000, as if you set `Iops` to 2000 it passes the linter.
**Sample to reproduce:**
```yaml
Resources:
Machine:
Type: AWS::EC2::Instance
Properties:
ImageId: "ami-79fd7eee"
KeyName: "testkey"
BlockDeviceMappings:
- DeviceName: /dev/sdm
Ebs:
VolumeType: io1
Iops: 3000
DeleteOnTermination: false
VolumeSize: 20
```
Output:
```bash
> cfn-lint minimal-stack.yaml
E2504 Property Iops should be Int between 100 to 20000 Resources/Machine/Properties/BlockDeviceMappings/0/Ebs/Iops
minimal-stack.yaml:11:13
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/ectwo/Ebs.py`
Content:
```
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 import six
19 from cfnlint import CloudFormationLintRule
20 from cfnlint import RuleMatch
21
22
23 class Ebs(CloudFormationLintRule):
24 """Check if Ec2 Ebs Resource Properties"""
25 id = 'E2504'
26 shortdesc = 'Check Ec2 Ebs Properties'
27 description = 'See if Ec2 Eb2 Properties are valid'
28 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html'
29 tags = ['properties', 'ec2', 'ebs']
30
31 def _checkEbs(self, cfn, ebs, path):
32 matches = []
33
34 if isinstance(ebs, dict):
35 volume_types_obj = cfn.get_values(ebs, 'VolumeType')
36 iops_obj = cfn.get_values(ebs, 'Iops')
37 if volume_types_obj is not None:
38 for volume_type_obj in volume_types_obj:
39 volume_type = volume_type_obj.get('Value')
40 if isinstance(volume_type, six.string_types):
41 if volume_type == 'io1':
42 if iops_obj is None:
43 pathmessage = path[:] + ['VolumeType']
44 message = 'VolumeType io1 requires Iops to be specified for {0}'
45 matches.append(
46 RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))
47 else:
48 try:
49 if len(iops_obj) == 1:
50 iops = iops_obj[0]['Value']
51 if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:
52 iops_value = int(iops)
53 if iops_value < 100 or iops_value > 2000:
54 pathmessage = path[:] + ['Iops']
55 message = 'Property Iops should be Int between 100 to 20000 {0}'
56 matches.append(
57 RuleMatch(
58 pathmessage,
59 message.format('/'.join(map(str, pathmessage)))))
60 except ValueError:
61 pathmessage = path[:] + ['Iops']
62 message = 'Property Iops should be Int between 100 to 20000 {0}'
63 matches.append(
64 RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))
65 elif volume_type:
66 if iops_obj is not None:
67 pathmessage = path[:] + ['Iops']
68 message = 'Iops shouldn\'t be defined for type {0} for {1}'
69 matches.append(
70 RuleMatch(
71 pathmessage,
72 message.format(volume_type, '/'.join(map(str, pathmessage)))))
73
74 return matches
75
76 def match(self, cfn):
77 """Check Ec2 Ebs Resource Parameters"""
78
79 matches = []
80
81 results = cfn.get_resource_properties(['AWS::EC2::Instance', 'BlockDeviceMappings'])
82 results.extend(cfn.get_resource_properties(['AWS::AutoScaling::LaunchConfiguration', 'BlockDeviceMappings']))
83 for result in results:
84 path = result['Path']
85 for index, properties in enumerate(result['Value']):
86 virtual_name = properties.get('VirtualName')
87 ebs = properties.get('Ebs')
88 if virtual_name:
89 # switch to regex
90 if not re.match(r'^ephemeral[0-9]$', virtual_name):
91 pathmessage = path[:] + [index, 'VirtualName']
92 message = 'Property VirtualName should be of type ephemeral(n) for {0}'
93 matches.append(
94 RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))
95 elif ebs:
96 matches.extend(self._checkEbs(cfn, ebs, path[:] + [index, 'Ebs']))
97 return matches
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/ectwo/Ebs.py b/src/cfnlint/rules/resources/ectwo/Ebs.py
--- a/src/cfnlint/rules/resources/ectwo/Ebs.py
+++ b/src/cfnlint/rules/resources/ectwo/Ebs.py
@@ -50,7 +50,7 @@
iops = iops_obj[0]['Value']
if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:
iops_value = int(iops)
- if iops_value < 100 or iops_value > 2000:
+ if iops_value < 100 or iops_value > 20000:
pathmessage = path[:] + ['Iops']
message = 'Property Iops should be Int between 100 to 20000 {0}'
matches.append(
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/ectwo/Ebs.py b/src/cfnlint/rules/resources/ectwo/Ebs.py\n--- a/src/cfnlint/rules/resources/ectwo/Ebs.py\n+++ b/src/cfnlint/rules/resources/ectwo/Ebs.py\n@@ -50,7 +50,7 @@\n iops = iops_obj[0]['Value']\n if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:\n iops_value = int(iops)\n- if iops_value < 100 or iops_value > 2000:\n+ if iops_value < 100 or iops_value > 20000:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n", "issue": "E2504 enforces incorrect boundary 100-2000, should be 100-20000\n*cfn-lint version: (`cfn-lint --version`)* 0.15.0 (also tested with 0.14.1)\r\n\r\n**Description:**\r\nAWS EC2 Instance with block device mapping does not enforce the correct `Ebs/Iops` boundary of 100-20000 as specified in the [documentation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html)\r\n\r\nIt looks like it actually enforces 100-2000, as if you set `Iops` to 2000 it passes the linter.\r\n\r\n**Sample to reproduce:**\r\n```yaml\r\nResources:\r\n Machine:\r\n Type: AWS::EC2::Instance\r\n Properties:\r\n ImageId: \"ami-79fd7eee\"\r\n KeyName: \"testkey\"\r\n BlockDeviceMappings: \r\n - DeviceName: /dev/sdm\r\n Ebs: \r\n VolumeType: io1\r\n Iops: 3000 \r\n DeleteOnTermination: false\r\n VolumeSize: 20\r\n```\r\n\r\nOutput:\r\n```bash\r\n> cfn-lint minimal-stack.yaml\r\n\r\nE2504 Property Iops should be Int between 100 to 20000 Resources/Machine/Properties/BlockDeviceMappings/0/Ebs/Iops\r\nminimal-stack.yaml:11:13\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Ebs(CloudFormationLintRule):\n \"\"\"Check if Ec2 Ebs Resource Properties\"\"\"\n id = 'E2504'\n shortdesc = 'Check Ec2 Ebs Properties'\n description = 'See if Ec2 Eb2 Properties are valid'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html'\n tags = ['properties', 'ec2', 'ebs']\n\n def _checkEbs(self, cfn, ebs, path):\n matches = []\n\n if isinstance(ebs, dict):\n volume_types_obj = cfn.get_values(ebs, 'VolumeType')\n iops_obj = cfn.get_values(ebs, 'Iops')\n if volume_types_obj is not None:\n for volume_type_obj in volume_types_obj:\n volume_type = volume_type_obj.get('Value')\n if isinstance(volume_type, six.string_types):\n if volume_type == 'io1':\n if iops_obj is None:\n pathmessage = path[:] + ['VolumeType']\n message = 'VolumeType io1 requires Iops to be specified for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n else:\n try:\n if len(iops_obj) == 1:\n iops = iops_obj[0]['Value']\n if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:\n iops_value = int(iops)\n if iops_value < 100 or iops_value > 2000:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format('/'.join(map(str, pathmessage)))))\n except ValueError:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif volume_type:\n if iops_obj is not None:\n pathmessage = path[:] + ['Iops']\n message = 'Iops shouldn\\'t be defined for type {0} for {1}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format(volume_type, '/'.join(map(str, pathmessage)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check Ec2 Ebs Resource Parameters\"\"\"\n\n matches = []\n\n results = cfn.get_resource_properties(['AWS::EC2::Instance', 'BlockDeviceMappings'])\n results.extend(cfn.get_resource_properties(['AWS::AutoScaling::LaunchConfiguration', 'BlockDeviceMappings']))\n for result in results:\n path = result['Path']\n for index, properties in enumerate(result['Value']):\n virtual_name = properties.get('VirtualName')\n ebs = properties.get('Ebs')\n if virtual_name:\n # switch to regex\n if not re.match(r'^ephemeral[0-9]$', virtual_name):\n pathmessage = path[:] + [index, 'VirtualName']\n message = 'Property VirtualName should be of type ephemeral(n) for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif ebs:\n matches.extend(self._checkEbs(cfn, ebs, path[:] + [index, 'Ebs']))\n return matches\n", "path": "src/cfnlint/rules/resources/ectwo/Ebs.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Ebs(CloudFormationLintRule):\n \"\"\"Check if Ec2 Ebs Resource Properties\"\"\"\n id = 'E2504'\n shortdesc = 'Check Ec2 Ebs Properties'\n description = 'See if Ec2 Eb2 Properties are valid'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html'\n tags = ['properties', 'ec2', 'ebs']\n\n def _checkEbs(self, cfn, ebs, path):\n matches = []\n\n if isinstance(ebs, dict):\n volume_types_obj = cfn.get_values(ebs, 'VolumeType')\n iops_obj = cfn.get_values(ebs, 'Iops')\n if volume_types_obj is not None:\n for volume_type_obj in volume_types_obj:\n volume_type = volume_type_obj.get('Value')\n if isinstance(volume_type, six.string_types):\n if volume_type == 'io1':\n if iops_obj is None:\n pathmessage = path[:] + ['VolumeType']\n message = 'VolumeType io1 requires Iops to be specified for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n else:\n try:\n if len(iops_obj) == 1:\n iops = iops_obj[0]['Value']\n if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:\n iops_value = int(iops)\n if iops_value < 100 or iops_value > 20000:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format('/'.join(map(str, pathmessage)))))\n except ValueError:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif volume_type:\n if iops_obj is not None:\n pathmessage = path[:] + ['Iops']\n message = 'Iops shouldn\\'t be defined for type {0} for {1}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format(volume_type, '/'.join(map(str, pathmessage)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check Ec2 Ebs Resource Parameters\"\"\"\n\n matches = []\n\n results = cfn.get_resource_properties(['AWS::EC2::Instance', 'BlockDeviceMappings'])\n results.extend(cfn.get_resource_properties(['AWS::AutoScaling::LaunchConfiguration', 'BlockDeviceMappings']))\n for result in results:\n path = result['Path']\n for index, properties in enumerate(result['Value']):\n virtual_name = properties.get('VirtualName')\n ebs = properties.get('Ebs')\n if virtual_name:\n # switch to regex\n if not re.match(r'^ephemeral[0-9]$', virtual_name):\n pathmessage = path[:] + [index, 'VirtualName']\n message = 'Property VirtualName should be of type ephemeral(n) for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif ebs:\n matches.extend(self._checkEbs(cfn, ebs, path[:] + [index, 'Ebs']))\n return matches\n", "path": "src/cfnlint/rules/resources/ectwo/Ebs.py"}]}
| 1,800 | 201 |
gh_patches_debug_14741
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-3684
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update Polynomial operations for non same size polynomials.
## Description
Fix poly_mul_mod operations for two non-same size polynomial arguments.
polynomial operations are done with wrong orientation.
## How to Reproduce
1. Apply `poly_mul_mod` with two non-same size polynomials.
2. The result is incorrect.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `syft/frameworks/torch/he/fv/util/operations.py`
Content:
```
1 import numpy as np
2 from numpy.polynomial import polynomial as poly
3
4 from syft.frameworks.torch.he.fv.ciphertext import CipherText
5
6
7 def multiply_mod(operand1, operand2, modulus):
8 return (operand1 * operand2) % modulus
9
10
11 def negate_mod(operand, modulus):
12 """returns (-1 * operand) % modulus"""
13 if modulus == 0:
14 raise ValueError("Modulus cannot be 0")
15 if operand >= modulus:
16 raise OverflowError("operand cannot be greater than modulus")
17 non_zero = operand != 0
18 return (modulus - operand) & (-int(non_zero))
19
20
21 def exponentiate_mod(operand, exponent, modulus):
22 if exponent == 0:
23 return 1
24
25 if exponent == 1:
26 return operand
27
28 # Perform binary exponentiation.
29 power = operand
30 product = 0
31 intermediate = 1
32
33 # Initially: power = operand and intermediate = 1, product is irrelevant.
34 while True:
35 if exponent & 1:
36 product = multiply_mod(power, intermediate, modulus)
37 product, intermediate = intermediate, product
38
39 exponent >>= 1
40
41 if exponent == 0:
42 break
43
44 product = multiply_mod(power, power, modulus)
45 product, power = power, product
46
47 return intermediate
48
49
50 def invert_mod(value, modulus):
51 """calculate inverse modulus for given value and modulus"""
52 gcd_tuple = xgcd(value, modulus)
53
54 if gcd_tuple[1] < 0:
55 return gcd_tuple[1] + modulus
56 else:
57 return gcd_tuple[1]
58
59
60 def poly_add_mod(op1, op2, modulus):
61 """return addition of two polynomials with all coefficients of
62 polynomial %q(coefficient modulus)"""
63 return np.mod(np.polyadd(op1, op2), modulus).tolist()
64
65
66 def poly_mul_mod(op1, op2, modulus):
67 """return multiplication of two polynomials with all coefficients of
68 polynomial %q(coefficient modulus) and result polynomial % t(polynomial modulus)"""
69 poly_mod = np.array([1] + [0] * (len(op1) - 1) + [1])
70 result = (
71 poly.polydiv(
72 poly.polymul(np.array(op1, dtype="object"), np.array(op2, dtype="object")) % modulus,
73 poly_mod,
74 )[1]
75 % modulus
76 ).tolist()
77 return [round(x) for x in result]
78
79
80 def poly_negate_mod(op, modulus):
81 """returns negative of polynomial i.e (-1 * op)"""
82 coeff_count = len(op)
83
84 result = [0] * coeff_count
85 for i in range(coeff_count):
86 if modulus == 0:
87 raise ValueError("Modulus cannot be 0")
88 if op[i] >= modulus:
89 raise OverflowError("operand cannot be greater than modulus")
90 non_zero = op[i] != 0
91 result[i] = (modulus - op[i]) & (-int(non_zero))
92 return result
93
94
95 def get_significant_count(values):
96 """removes leading zero's from the list."""
97 count = len(values)
98 i = count - 1
99 while count and not values[i]:
100 i -= 1
101 count -= 1
102 return count
103
104
105 def reverse_bit(value):
106 """calculate the value of the reverse binary representation of the given integer."""
107 result = 0
108 while value:
109 result = (result << 1) + (value & 1)
110 value >>= 1
111 return result
112
113
114 def multiply_many_except(operands, count, expt):
115 result = 1
116 for i in range(count):
117 if i != expt:
118 result *= operands[i]
119 return result
120
121
122 def xgcd(x, y):
123 """ Extended GCD
124
125 Args:
126 x (integer)
127 y (integer)
128
129 Returns:
130 (gcd, x, y) where gcd is the greatest common divisor of a and b.
131 The numbers x, y are such that gcd = ax + by.
132 """
133 prev_a = 1
134 a = 0
135 prev_b = 0
136 b = 1
137
138 while y != 0:
139 q = x // y
140 temp = x % y
141 x = y
142 y = temp
143
144 temp = a
145 a = prev_a - q * a
146 prev_a = temp
147
148 temp = b
149 b = prev_b - q * b
150 prev_b = temp
151 return [x, prev_a, prev_b]
152
153
154 def multiply_add_plain_with_delta(phase, message, context):
155 """Add message (PlainText) into phase.
156
157 Args:
158 phase: phase is pre-computed carrier polynomial where we can add message data.
159 message (Plaintext): A plaintext representation of integer data to be encrypted.
160 context (Context): Context for extracting encryption parameters.
161
162 Returns:
163 A Ciphertext object with the encrypted result of encryption process.
164 """
165 coeff_modulus = context.param.coeff_modulus
166 message = message.data
167 plain_coeff_count = len(message)
168 delta = context.coeff_div_plain_modulus
169 phase0, phase1 = phase.data # here phase = pk * u * e
170
171 # Coefficients of plain m multiplied by coeff_modulus q, divided by plain_modulus t,
172 # and rounded to the nearest integer (rounded up in case of a tie). Equivalent to
173 for i in range(plain_coeff_count):
174 for j in range(len(coeff_modulus)):
175 temp = round(delta[j] * message[i]) % coeff_modulus[j]
176 phase0[j][i] = (phase0[j][i] + temp) % coeff_modulus[j]
177
178 return CipherText([phase0, phase1]) # phase0 = pk0 * u * e + delta * m
179
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/syft/frameworks/torch/he/fv/util/operations.py b/syft/frameworks/torch/he/fv/util/operations.py
--- a/syft/frameworks/torch/he/fv/util/operations.py
+++ b/syft/frameworks/torch/he/fv/util/operations.py
@@ -66,6 +66,15 @@
def poly_mul_mod(op1, op2, modulus):
"""return multiplication of two polynomials with all coefficients of
polynomial %q(coefficient modulus) and result polynomial % t(polynomial modulus)"""
+
+ # For non same size polynomails we have to shift the polynomials because numpy consider right
+ # side as lower order of polynomial and we consider right side as heigher order.
+ if len(op1) != len(op2):
+ if len(op1) > len(op2):
+ op2 = op2 + [0] * (len(op1) - len(op2))
+ else:
+ op1 = op1 + [0] * (len(op2) - len(op1))
+
poly_mod = np.array([1] + [0] * (len(op1) - 1) + [1])
result = (
poly.polydiv(
|
{"golden_diff": "diff --git a/syft/frameworks/torch/he/fv/util/operations.py b/syft/frameworks/torch/he/fv/util/operations.py\n--- a/syft/frameworks/torch/he/fv/util/operations.py\n+++ b/syft/frameworks/torch/he/fv/util/operations.py\n@@ -66,6 +66,15 @@\n def poly_mul_mod(op1, op2, modulus):\n \"\"\"return multiplication of two polynomials with all coefficients of\n polynomial %q(coefficient modulus) and result polynomial % t(polynomial modulus)\"\"\"\n+\n+ # For non same size polynomails we have to shift the polynomials because numpy consider right\n+ # side as lower order of polynomial and we consider right side as heigher order.\n+ if len(op1) != len(op2):\n+ if len(op1) > len(op2):\n+ op2 = op2 + [0] * (len(op1) - len(op2))\n+ else:\n+ op1 = op1 + [0] * (len(op2) - len(op1))\n+\n poly_mod = np.array([1] + [0] * (len(op1) - 1) + [1])\n result = (\n poly.polydiv(\n", "issue": "Update Polynomial operations for non same size polynomials.\n## Description\r\nFix poly_mul_mod operations for two non-same size polynomial arguments.\r\npolynomial operations are done with wrong orientation.\r\n\r\n## How to Reproduce\r\n1. Apply `poly_mul_mod` with two non-same size polynomials.\r\n2. The result is incorrect.\r\n\n", "before_files": [{"content": "import numpy as np\nfrom numpy.polynomial import polynomial as poly\n\nfrom syft.frameworks.torch.he.fv.ciphertext import CipherText\n\n\ndef multiply_mod(operand1, operand2, modulus):\n return (operand1 * operand2) % modulus\n\n\ndef negate_mod(operand, modulus):\n \"\"\"returns (-1 * operand) % modulus\"\"\"\n if modulus == 0:\n raise ValueError(\"Modulus cannot be 0\")\n if operand >= modulus:\n raise OverflowError(\"operand cannot be greater than modulus\")\n non_zero = operand != 0\n return (modulus - operand) & (-int(non_zero))\n\n\ndef exponentiate_mod(operand, exponent, modulus):\n if exponent == 0:\n return 1\n\n if exponent == 1:\n return operand\n\n # Perform binary exponentiation.\n power = operand\n product = 0\n intermediate = 1\n\n # Initially: power = operand and intermediate = 1, product is irrelevant.\n while True:\n if exponent & 1:\n product = multiply_mod(power, intermediate, modulus)\n product, intermediate = intermediate, product\n\n exponent >>= 1\n\n if exponent == 0:\n break\n\n product = multiply_mod(power, power, modulus)\n product, power = power, product\n\n return intermediate\n\n\ndef invert_mod(value, modulus):\n \"\"\"calculate inverse modulus for given value and modulus\"\"\"\n gcd_tuple = xgcd(value, modulus)\n\n if gcd_tuple[1] < 0:\n return gcd_tuple[1] + modulus\n else:\n return gcd_tuple[1]\n\n\ndef poly_add_mod(op1, op2, modulus):\n \"\"\"return addition of two polynomials with all coefficients of\n polynomial %q(coefficient modulus)\"\"\"\n return np.mod(np.polyadd(op1, op2), modulus).tolist()\n\n\ndef poly_mul_mod(op1, op2, modulus):\n \"\"\"return multiplication of two polynomials with all coefficients of\n polynomial %q(coefficient modulus) and result polynomial % t(polynomial modulus)\"\"\"\n poly_mod = np.array([1] + [0] * (len(op1) - 1) + [1])\n result = (\n poly.polydiv(\n poly.polymul(np.array(op1, dtype=\"object\"), np.array(op2, dtype=\"object\")) % modulus,\n poly_mod,\n )[1]\n % modulus\n ).tolist()\n return [round(x) for x in result]\n\n\ndef poly_negate_mod(op, modulus):\n \"\"\"returns negative of polynomial i.e (-1 * op)\"\"\"\n coeff_count = len(op)\n\n result = [0] * coeff_count\n for i in range(coeff_count):\n if modulus == 0:\n raise ValueError(\"Modulus cannot be 0\")\n if op[i] >= modulus:\n raise OverflowError(\"operand cannot be greater than modulus\")\n non_zero = op[i] != 0\n result[i] = (modulus - op[i]) & (-int(non_zero))\n return result\n\n\ndef get_significant_count(values):\n \"\"\"removes leading zero's from the list.\"\"\"\n count = len(values)\n i = count - 1\n while count and not values[i]:\n i -= 1\n count -= 1\n return count\n\n\ndef reverse_bit(value):\n \"\"\"calculate the value of the reverse binary representation of the given integer.\"\"\"\n result = 0\n while value:\n result = (result << 1) + (value & 1)\n value >>= 1\n return result\n\n\ndef multiply_many_except(operands, count, expt):\n result = 1\n for i in range(count):\n if i != expt:\n result *= operands[i]\n return result\n\n\ndef xgcd(x, y):\n \"\"\" Extended GCD\n\n Args:\n x (integer)\n y (integer)\n\n Returns:\n (gcd, x, y) where gcd is the greatest common divisor of a and b.\n The numbers x, y are such that gcd = ax + by.\n \"\"\"\n prev_a = 1\n a = 0\n prev_b = 0\n b = 1\n\n while y != 0:\n q = x // y\n temp = x % y\n x = y\n y = temp\n\n temp = a\n a = prev_a - q * a\n prev_a = temp\n\n temp = b\n b = prev_b - q * b\n prev_b = temp\n return [x, prev_a, prev_b]\n\n\ndef multiply_add_plain_with_delta(phase, message, context):\n \"\"\"Add message (PlainText) into phase.\n\n Args:\n phase: phase is pre-computed carrier polynomial where we can add message data.\n message (Plaintext): A plaintext representation of integer data to be encrypted.\n context (Context): Context for extracting encryption parameters.\n\n Returns:\n A Ciphertext object with the encrypted result of encryption process.\n \"\"\"\n coeff_modulus = context.param.coeff_modulus\n message = message.data\n plain_coeff_count = len(message)\n delta = context.coeff_div_plain_modulus\n phase0, phase1 = phase.data # here phase = pk * u * e\n\n # Coefficients of plain m multiplied by coeff_modulus q, divided by plain_modulus t,\n # and rounded to the nearest integer (rounded up in case of a tie). Equivalent to\n for i in range(plain_coeff_count):\n for j in range(len(coeff_modulus)):\n temp = round(delta[j] * message[i]) % coeff_modulus[j]\n phase0[j][i] = (phase0[j][i] + temp) % coeff_modulus[j]\n\n return CipherText([phase0, phase1]) # phase0 = pk0 * u * e + delta * m\n", "path": "syft/frameworks/torch/he/fv/util/operations.py"}], "after_files": [{"content": "import numpy as np\nfrom numpy.polynomial import polynomial as poly\n\nfrom syft.frameworks.torch.he.fv.ciphertext import CipherText\n\n\ndef multiply_mod(operand1, operand2, modulus):\n return (operand1 * operand2) % modulus\n\n\ndef negate_mod(operand, modulus):\n \"\"\"returns (-1 * operand) % modulus\"\"\"\n if modulus == 0:\n raise ValueError(\"Modulus cannot be 0\")\n if operand >= modulus:\n raise OverflowError(\"operand cannot be greater than modulus\")\n non_zero = operand != 0\n return (modulus - operand) & (-int(non_zero))\n\n\ndef exponentiate_mod(operand, exponent, modulus):\n if exponent == 0:\n return 1\n\n if exponent == 1:\n return operand\n\n # Perform binary exponentiation.\n power = operand\n product = 0\n intermediate = 1\n\n # Initially: power = operand and intermediate = 1, product is irrelevant.\n while True:\n if exponent & 1:\n product = multiply_mod(power, intermediate, modulus)\n product, intermediate = intermediate, product\n\n exponent >>= 1\n\n if exponent == 0:\n break\n\n product = multiply_mod(power, power, modulus)\n product, power = power, product\n\n return intermediate\n\n\ndef invert_mod(value, modulus):\n \"\"\"calculate inverse modulus for given value and modulus\"\"\"\n gcd_tuple = xgcd(value, modulus)\n\n if gcd_tuple[1] < 0:\n return gcd_tuple[1] + modulus\n else:\n return gcd_tuple[1]\n\n\ndef poly_add_mod(op1, op2, modulus):\n \"\"\"return addition of two polynomials with all coefficients of\n polynomial %q(coefficient modulus)\"\"\"\n return np.mod(np.polyadd(op1, op2), modulus).tolist()\n\n\ndef poly_mul_mod(op1, op2, modulus):\n \"\"\"return multiplication of two polynomials with all coefficients of\n polynomial %q(coefficient modulus) and result polynomial % t(polynomial modulus)\"\"\"\n\n # For non same size polynomails we have to shift the polynomials because numpy consider right\n # side as lower order of polynomial and we consider right side as heigher order.\n if len(op1) != len(op2):\n if len(op1) > len(op2):\n op2 = op2 + [0] * (len(op1) - len(op2))\n else:\n op1 = op1 + [0] * (len(op2) - len(op1))\n\n poly_mod = np.array([1] + [0] * (len(op1) - 1) + [1])\n result = (\n poly.polydiv(\n poly.polymul(np.array(op1, dtype=\"object\"), np.array(op2, dtype=\"object\")) % modulus,\n poly_mod,\n )[1]\n % modulus\n ).tolist()\n return [round(x) for x in result]\n\n\ndef poly_negate_mod(op, modulus):\n \"\"\"returns negative of polynomial i.e (-1 * op)\"\"\"\n coeff_count = len(op)\n\n result = [0] * coeff_count\n for i in range(coeff_count):\n if modulus == 0:\n raise ValueError(\"Modulus cannot be 0\")\n if op[i] >= modulus:\n raise OverflowError(\"operand cannot be greater than modulus\")\n non_zero = op[i] != 0\n result[i] = (modulus - op[i]) & (-int(non_zero))\n return result\n\n\ndef get_significant_count(values):\n \"\"\"removes leading zero's from the list.\"\"\"\n count = len(values)\n i = count - 1\n while count and not values[i]:\n i -= 1\n count -= 1\n return count\n\n\ndef reverse_bit(value):\n \"\"\"calculate the value of the reverse binary representation of the given integer.\"\"\"\n result = 0\n while value:\n result = (result << 1) + (value & 1)\n value >>= 1\n return result\n\n\ndef multiply_many_except(operands, count, expt):\n result = 1\n for i in range(count):\n if i != expt:\n result *= operands[i]\n return result\n\n\ndef xgcd(x, y):\n \"\"\" Extended GCD\n\n Args:\n x (integer)\n y (integer)\n\n Returns:\n (gcd, x, y) where gcd is the greatest common divisor of a and b.\n The numbers x, y are such that gcd = ax + by.\n \"\"\"\n prev_a = 1\n a = 0\n prev_b = 0\n b = 1\n\n while y != 0:\n q = x // y\n temp = x % y\n x = y\n y = temp\n\n temp = a\n a = prev_a - q * a\n prev_a = temp\n\n temp = b\n b = prev_b - q * b\n prev_b = temp\n return [x, prev_a, prev_b]\n\n\ndef multiply_add_plain_with_delta(phase, message, context):\n \"\"\"Add message (PlainText) into phase.\n\n Args:\n phase: phase is pre-computed carrier polynomial where we can add message data.\n message (Plaintext): A plaintext representation of integer data to be encrypted.\n context (Context): Context for extracting encryption parameters.\n\n Returns:\n A Ciphertext object with the encrypted result of encryption process.\n \"\"\"\n coeff_modulus = context.param.coeff_modulus\n message = message.data\n plain_coeff_count = len(message)\n delta = context.coeff_div_plain_modulus\n phase0, phase1 = phase.data # here phase = pk * u * e\n\n # Coefficients of plain m multiplied by coeff_modulus q, divided by plain_modulus t,\n # and rounded to the nearest integer (rounded up in case of a tie). Equivalent to\n for i in range(plain_coeff_count):\n for j in range(len(coeff_modulus)):\n temp = round(delta[j] * message[i]) % coeff_modulus[j]\n phase0[j][i] = (phase0[j][i] + temp) % coeff_modulus[j]\n\n return CipherText([phase0, phase1]) # phase0 = pk0 * u * e + delta * m\n", "path": "syft/frameworks/torch/he/fv/util/operations.py"}]}
| 2,049 | 276 |
gh_patches_debug_29297
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-2979
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Minor text injection vulnerability
See https://gratipay.com/on/twitter/who%20you%20say%20you%20are...%20Visit%20gratipay.evilsite.com%20to%20verify%20your%20account%20and%20send%20me%20money.%20Maybe%20you%20don%27t%20have%20twitter/failure.html?action
Pretty minor I admit but could potentially be exploited with encoding. We should validate twitter/github/facebook usernames.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gratipay/elsewhere/__init__.py`
Content:
```
1 """This subpackage contains functionality for working with accounts elsewhere.
2 """
3 from __future__ import division, print_function, unicode_literals
4
5 from collections import OrderedDict
6 from datetime import datetime
7 import hashlib
8 import json
9 import logging
10 from urllib import quote
11 import xml.etree.ElementTree as ET
12
13 from aspen import log, Response
14 from aspen.utils import to_age, utc
15 from requests_oauthlib import OAuth1Session, OAuth2Session
16
17 from gratipay.elsewhere._extractors import not_available
18
19
20 ACTIONS = {'opt-in', 'connect', 'lock', 'unlock'}
21 PLATFORMS = 'facebook google bitbucket bountysource github openstreetmap twitter venmo'.split()
22
23
24 class UnknownAccountElsewhere(Exception): pass
25
26
27 class PlatformRegistry(object):
28 """Registry of platforms we support connecting to Gratipay accounts.
29 """
30 def __init__(self, platforms):
31 self.__dict__ = OrderedDict((p.name, p) for p in platforms)
32
33 def __contains__(self, platform):
34 return platform.name in self.__dict__
35
36 def __iter__(self):
37 return iter(self.__dict__.values())
38
39
40 class UserInfo(object):
41 """A simple container for a user's info.
42
43 Accessing a non-existing attribute returns `None`.
44 """
45
46 def __init__(self, **kw):
47 self.__dict__.update(kw)
48
49 def __getattr__(self, key):
50 return self.__dict__.get(key, None)
51
52 def __setattr__(self, key, value):
53 if value is None:
54 self.__dict__.pop(key, None)
55 else:
56 self.__dict__[key] = value
57
58
59 class Platform(object):
60
61 allows_team_connect = False
62
63 # "x" stands for "extract"
64 x_user_info = not_available
65 x_user_id = not_available
66 x_user_name = not_available
67 x_display_name = not_available
68 x_email = not_available
69 x_gravatar_id = not_available
70 x_avatar_url = not_available
71 x_is_team = not_available
72
73 required_attrs = ( 'account_url'
74 , 'display_name'
75 , 'name'
76 )
77
78 def __init__(self, api_key, api_secret, callback_url, api_url=None, auth_url=None):
79 self.api_key = api_key
80 self.api_secret = api_secret
81 self.callback_url = callback_url
82 if api_url:
83 self.api_url = api_url
84 if auth_url:
85 self.auth_url = auth_url
86 elif not getattr(self, 'auth_url', None):
87 self.auth_url = self.api_url
88
89 # Determine the appropriate response parser using `self.api_format`
90 api_format = getattr(self, 'api_format', None)
91 if api_format == 'json':
92 self.api_parser = lambda r: r.json()
93 elif api_format == 'xml':
94 self.api_parser = lambda r: ET.fromstring(r.content)
95 elif api_format:
96 raise ValueError('unknown API format: '+str(api_format))
97
98 # Make sure the subclass was implemented properly.
99 missing_attrs = [a for a in self.required_attrs if not hasattr(self, a)]
100 if missing_attrs:
101 msg = "The class %s is missing these required attributes: %s"
102 msg %= self.__class__.__name__, ', '.join(missing_attrs)
103 raise AttributeError(msg)
104
105 def api_get(self, path, sess=None, **kw):
106 """
107 Given a `path` (e.g. /users/foo), this function sends a GET request to
108 the platform's API (e.g. https://api.github.com/users/foo).
109
110 The response is returned, after checking its status code and ratelimit
111 headers.
112 """
113 if not sess:
114 sess = self.get_auth_session()
115 response = sess.get(self.api_url+path, **kw)
116
117 # Check status
118 status = response.status_code
119 if status == 404:
120 raise Response(404, response.text)
121 elif status != 200:
122 log('{} api responded with {}:\n{}'.format(self.name, status, response.text)
123 , level=logging.ERROR)
124 raise Response(500, '{} lookup failed with {}'.format(self.name, status))
125
126 # Check ratelimit headers
127 prefix = getattr(self, 'ratelimit_headers_prefix', None)
128 if prefix:
129 limit = response.headers[prefix+'limit']
130 remaining = response.headers[prefix+'remaining']
131 reset = response.headers[prefix+'reset']
132 try:
133 limit, remaining, reset = int(limit), int(remaining), int(reset)
134 except (TypeError, ValueError):
135 d = dict(limit=limit, remaining=remaining, reset=reset)
136 log('Got weird rate headers from %s: %s' % (self.name, d))
137 else:
138 percent_remaining = remaining/limit
139 if percent_remaining < 0.5:
140 reset = to_age(datetime.fromtimestamp(reset, tz=utc))
141 log_msg = (
142 '{0} API: {1:.1%} of ratelimit has been consumed, '
143 '{2} requests remaining, resets {3}.'
144 ).format(self.name, 1 - percent_remaining, remaining, reset)
145 log_lvl = logging.WARNING
146 if percent_remaining < 0.2:
147 log_lvl = logging.ERROR
148 elif percent_remaining < 0.05:
149 log_lvl = logging.CRITICAL
150 log(log_msg, log_lvl)
151
152 return response
153
154 def extract_user_info(self, info):
155 """
156 Given a user_info object of variable type (depending on the platform),
157 extract the relevant information by calling the platform's extractors
158 (`x_user_name`, `x_user_id`, etc).
159
160 Returns a `UserInfo`. The `user_id` attribute is guaranteed to have a
161 unique non-empty value.
162 """
163 r = UserInfo(platform=self.name)
164 info = self.x_user_info(r, info, info)
165 r.user_name = self.x_user_name(r, info, None)
166 if self.x_user_id.__func__ is not_available:
167 r.user_id = r.user_name
168 else:
169 r.user_id = self.x_user_id(r, info)
170 assert r.user_id is not None
171 r.user_id = unicode(r.user_id)
172 assert len(r.user_id) > 0
173 r.display_name = self.x_display_name(r, info, None)
174 r.email = self.x_email(r, info, None)
175 r.avatar_url = self.x_avatar_url(r, info, None)
176 if not r.avatar_url:
177 gravatar_id = self.x_gravatar_id(r, info, None)
178 if r.email and not gravatar_id:
179 gravatar_id = hashlib.md5(r.email.strip().lower()).hexdigest()
180 if gravatar_id:
181 r.avatar_url = 'https://secure.gravatar.com/avatar/'+gravatar_id
182 r.is_team = self.x_is_team(r, info, False)
183 r.extra_info = info
184 return r
185
186 def get_team_members(self, team_name, page_url=None):
187 """Given a team_name on the platform, return the team's membership list
188 from the API.
189 """
190 default_url = self.api_team_members_path.format(user_name=quote(team_name))
191 r = self.api_get(page_url or default_url)
192 members, count, pages_urls = self.api_paginator(r, self.api_parser(r))
193 members = [self.extract_user_info(m) for m in members]
194 return members, count, pages_urls
195
196 def get_user_info(self, user_name, sess=None):
197 """Given a user_name on the platform, get the user's info from the API.
198 """
199 try:
200 path = self.api_user_info_path.format(user_name=quote(user_name))
201 except KeyError:
202 raise Response(404)
203 info = self.api_parser(self.api_get(path, sess=sess))
204 return self.extract_user_info(info)
205
206 def get_user_self_info(self, sess):
207 """Get the authenticated user's info from the API.
208 """
209 r = self.api_get(self.api_user_self_info_path, sess=sess)
210 info = self.extract_user_info(self.api_parser(r))
211 token = getattr(sess, 'token', None)
212 if token:
213 info.token = json.dumps(token)
214 return info
215
216
217 class PlatformOAuth1(Platform):
218
219 request_token_path = '/oauth/request_token'
220 authorize_path = '/oauth/authorize'
221 access_token_path = '/oauth/access_token'
222
223 def get_auth_session(self, token=None):
224 args = ()
225 if token:
226 args = (token['token'], token['token_secret'])
227 return OAuth1Session(self.api_key, self.api_secret, *args,
228 callback_uri=self.callback_url)
229
230 def get_auth_url(self, **kw):
231 sess = self.get_auth_session()
232 r = sess.fetch_request_token(self.auth_url+self.request_token_path)
233 url = sess.authorization_url(self.auth_url+self.authorize_path)
234 return url, r['oauth_token'], r['oauth_token_secret']
235
236 def get_query_id(self, querystring):
237 return querystring['oauth_token']
238
239 def handle_auth_callback(self, url, token, token_secret):
240 sess = self.get_auth_session(dict(token=token, token_secret=token_secret))
241 sess.parse_authorization_response(url)
242 r = sess.fetch_access_token(self.auth_url+self.access_token_path)
243 sess.token = dict(token=r['oauth_token'],
244 token_secret=r['oauth_token_secret'])
245 return sess
246
247
248 class PlatformOAuth2(Platform):
249
250 oauth_default_scope = None
251 oauth_email_scope = None
252 oauth_payment_scope = None
253
254 def get_auth_session(self, state=None, token=None, token_updater=None):
255 return OAuth2Session(self.api_key, state=state, token=token,
256 token_updater=token_updater,
257 redirect_uri=self.callback_url,
258 scope=self.oauth_default_scope)
259
260 def get_auth_url(self, **kw):
261 sess = self.get_auth_session()
262 url, state = sess.authorization_url(self.auth_url)
263 return url, state, ''
264
265 def get_query_id(self, querystring):
266 return querystring['state']
267
268 def handle_auth_callback(self, url, state, unused_arg):
269 sess = self.get_auth_session(state=state)
270 sess.fetch_token(self.access_token_url,
271 client_secret=self.api_secret,
272 authorization_response=url)
273 return sess
274
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gratipay/elsewhere/__init__.py b/gratipay/elsewhere/__init__.py
--- a/gratipay/elsewhere/__init__.py
+++ b/gratipay/elsewhere/__init__.py
@@ -114,7 +114,14 @@
sess = self.get_auth_session()
response = sess.get(self.api_url+path, **kw)
- # Check status
+ self.check_api_response_status(response)
+ self.check_ratelimit_headers(response)
+
+ return response
+
+ def check_api_response_status(self, response):
+ """Pass through any 404, convert any other non-200 into a 500.
+ """
status = response.status_code
if status == 404:
raise Response(404, response.text)
@@ -123,7 +130,9 @@
, level=logging.ERROR)
raise Response(500, '{} lookup failed with {}'.format(self.name, status))
- # Check ratelimit headers
+ def check_ratelimit_headers(self, response):
+ """Emit log messages if we're running out of ratelimit.
+ """
prefix = getattr(self, 'ratelimit_headers_prefix', None)
if prefix:
limit = response.headers[prefix+'limit']
@@ -149,8 +158,6 @@
log_lvl = logging.CRITICAL
log(log_msg, log_lvl)
- return response
-
def extract_user_info(self, info):
"""
Given a user_info object of variable type (depending on the platform),
|
{"golden_diff": "diff --git a/gratipay/elsewhere/__init__.py b/gratipay/elsewhere/__init__.py\n--- a/gratipay/elsewhere/__init__.py\n+++ b/gratipay/elsewhere/__init__.py\n@@ -114,7 +114,14 @@\n sess = self.get_auth_session()\n response = sess.get(self.api_url+path, **kw)\n \n- # Check status\n+ self.check_api_response_status(response)\n+ self.check_ratelimit_headers(response)\n+\n+ return response\n+\n+ def check_api_response_status(self, response):\n+ \"\"\"Pass through any 404, convert any other non-200 into a 500.\n+ \"\"\"\n status = response.status_code\n if status == 404:\n raise Response(404, response.text)\n@@ -123,7 +130,9 @@\n , level=logging.ERROR)\n raise Response(500, '{} lookup failed with {}'.format(self.name, status))\n \n- # Check ratelimit headers\n+ def check_ratelimit_headers(self, response):\n+ \"\"\"Emit log messages if we're running out of ratelimit.\n+ \"\"\"\n prefix = getattr(self, 'ratelimit_headers_prefix', None)\n if prefix:\n limit = response.headers[prefix+'limit']\n@@ -149,8 +158,6 @@\n log_lvl = logging.CRITICAL\n log(log_msg, log_lvl)\n \n- return response\n-\n def extract_user_info(self, info):\n \"\"\"\n Given a user_info object of variable type (depending on the platform),\n", "issue": "Minor text injection vulnerability\nSee https://gratipay.com/on/twitter/who%20you%20say%20you%20are...%20Visit%20gratipay.evilsite.com%20to%20verify%20your%20account%20and%20send%20me%20money.%20Maybe%20you%20don%27t%20have%20twitter/failure.html?action\n\nPretty minor I admit but could potentially be exploited with encoding. We should validate twitter/github/facebook usernames.\n\n", "before_files": [{"content": "\"\"\"This subpackage contains functionality for working with accounts elsewhere.\n\"\"\"\nfrom __future__ import division, print_function, unicode_literals\n\nfrom collections import OrderedDict\nfrom datetime import datetime\nimport hashlib\nimport json\nimport logging\nfrom urllib import quote\nimport xml.etree.ElementTree as ET\n\nfrom aspen import log, Response\nfrom aspen.utils import to_age, utc\nfrom requests_oauthlib import OAuth1Session, OAuth2Session\n\nfrom gratipay.elsewhere._extractors import not_available\n\n\nACTIONS = {'opt-in', 'connect', 'lock', 'unlock'}\nPLATFORMS = 'facebook google bitbucket bountysource github openstreetmap twitter venmo'.split()\n\n\nclass UnknownAccountElsewhere(Exception): pass\n\n\nclass PlatformRegistry(object):\n \"\"\"Registry of platforms we support connecting to Gratipay accounts.\n \"\"\"\n def __init__(self, platforms):\n self.__dict__ = OrderedDict((p.name, p) for p in platforms)\n\n def __contains__(self, platform):\n return platform.name in self.__dict__\n\n def __iter__(self):\n return iter(self.__dict__.values())\n\n\nclass UserInfo(object):\n \"\"\"A simple container for a user's info.\n\n Accessing a non-existing attribute returns `None`.\n \"\"\"\n\n def __init__(self, **kw):\n self.__dict__.update(kw)\n\n def __getattr__(self, key):\n return self.__dict__.get(key, None)\n\n def __setattr__(self, key, value):\n if value is None:\n self.__dict__.pop(key, None)\n else:\n self.__dict__[key] = value\n\n\nclass Platform(object):\n\n allows_team_connect = False\n\n # \"x\" stands for \"extract\"\n x_user_info = not_available\n x_user_id = not_available\n x_user_name = not_available\n x_display_name = not_available\n x_email = not_available\n x_gravatar_id = not_available\n x_avatar_url = not_available\n x_is_team = not_available\n\n required_attrs = ( 'account_url'\n , 'display_name'\n , 'name'\n )\n\n def __init__(self, api_key, api_secret, callback_url, api_url=None, auth_url=None):\n self.api_key = api_key\n self.api_secret = api_secret\n self.callback_url = callback_url\n if api_url:\n self.api_url = api_url\n if auth_url:\n self.auth_url = auth_url\n elif not getattr(self, 'auth_url', None):\n self.auth_url = self.api_url\n\n # Determine the appropriate response parser using `self.api_format`\n api_format = getattr(self, 'api_format', None)\n if api_format == 'json':\n self.api_parser = lambda r: r.json()\n elif api_format == 'xml':\n self.api_parser = lambda r: ET.fromstring(r.content)\n elif api_format:\n raise ValueError('unknown API format: '+str(api_format))\n\n # Make sure the subclass was implemented properly.\n missing_attrs = [a for a in self.required_attrs if not hasattr(self, a)]\n if missing_attrs:\n msg = \"The class %s is missing these required attributes: %s\"\n msg %= self.__class__.__name__, ', '.join(missing_attrs)\n raise AttributeError(msg)\n\n def api_get(self, path, sess=None, **kw):\n \"\"\"\n Given a `path` (e.g. /users/foo), this function sends a GET request to\n the platform's API (e.g. https://api.github.com/users/foo).\n\n The response is returned, after checking its status code and ratelimit\n headers.\n \"\"\"\n if not sess:\n sess = self.get_auth_session()\n response = sess.get(self.api_url+path, **kw)\n\n # Check status\n status = response.status_code\n if status == 404:\n raise Response(404, response.text)\n elif status != 200:\n log('{} api responded with {}:\\n{}'.format(self.name, status, response.text)\n , level=logging.ERROR)\n raise Response(500, '{} lookup failed with {}'.format(self.name, status))\n\n # Check ratelimit headers\n prefix = getattr(self, 'ratelimit_headers_prefix', None)\n if prefix:\n limit = response.headers[prefix+'limit']\n remaining = response.headers[prefix+'remaining']\n reset = response.headers[prefix+'reset']\n try:\n limit, remaining, reset = int(limit), int(remaining), int(reset)\n except (TypeError, ValueError):\n d = dict(limit=limit, remaining=remaining, reset=reset)\n log('Got weird rate headers from %s: %s' % (self.name, d))\n else:\n percent_remaining = remaining/limit\n if percent_remaining < 0.5:\n reset = to_age(datetime.fromtimestamp(reset, tz=utc))\n log_msg = (\n '{0} API: {1:.1%} of ratelimit has been consumed, '\n '{2} requests remaining, resets {3}.'\n ).format(self.name, 1 - percent_remaining, remaining, reset)\n log_lvl = logging.WARNING\n if percent_remaining < 0.2:\n log_lvl = logging.ERROR\n elif percent_remaining < 0.05:\n log_lvl = logging.CRITICAL\n log(log_msg, log_lvl)\n\n return response\n\n def extract_user_info(self, info):\n \"\"\"\n Given a user_info object of variable type (depending on the platform),\n extract the relevant information by calling the platform's extractors\n (`x_user_name`, `x_user_id`, etc).\n\n Returns a `UserInfo`. The `user_id` attribute is guaranteed to have a\n unique non-empty value.\n \"\"\"\n r = UserInfo(platform=self.name)\n info = self.x_user_info(r, info, info)\n r.user_name = self.x_user_name(r, info, None)\n if self.x_user_id.__func__ is not_available:\n r.user_id = r.user_name\n else:\n r.user_id = self.x_user_id(r, info)\n assert r.user_id is not None\n r.user_id = unicode(r.user_id)\n assert len(r.user_id) > 0\n r.display_name = self.x_display_name(r, info, None)\n r.email = self.x_email(r, info, None)\n r.avatar_url = self.x_avatar_url(r, info, None)\n if not r.avatar_url:\n gravatar_id = self.x_gravatar_id(r, info, None)\n if r.email and not gravatar_id:\n gravatar_id = hashlib.md5(r.email.strip().lower()).hexdigest()\n if gravatar_id:\n r.avatar_url = 'https://secure.gravatar.com/avatar/'+gravatar_id\n r.is_team = self.x_is_team(r, info, False)\n r.extra_info = info\n return r\n\n def get_team_members(self, team_name, page_url=None):\n \"\"\"Given a team_name on the platform, return the team's membership list\n from the API.\n \"\"\"\n default_url = self.api_team_members_path.format(user_name=quote(team_name))\n r = self.api_get(page_url or default_url)\n members, count, pages_urls = self.api_paginator(r, self.api_parser(r))\n members = [self.extract_user_info(m) for m in members]\n return members, count, pages_urls\n\n def get_user_info(self, user_name, sess=None):\n \"\"\"Given a user_name on the platform, get the user's info from the API.\n \"\"\"\n try:\n path = self.api_user_info_path.format(user_name=quote(user_name))\n except KeyError:\n raise Response(404)\n info = self.api_parser(self.api_get(path, sess=sess))\n return self.extract_user_info(info)\n\n def get_user_self_info(self, sess):\n \"\"\"Get the authenticated user's info from the API.\n \"\"\"\n r = self.api_get(self.api_user_self_info_path, sess=sess)\n info = self.extract_user_info(self.api_parser(r))\n token = getattr(sess, 'token', None)\n if token:\n info.token = json.dumps(token)\n return info\n\n\nclass PlatformOAuth1(Platform):\n\n request_token_path = '/oauth/request_token'\n authorize_path = '/oauth/authorize'\n access_token_path = '/oauth/access_token'\n\n def get_auth_session(self, token=None):\n args = ()\n if token:\n args = (token['token'], token['token_secret'])\n return OAuth1Session(self.api_key, self.api_secret, *args,\n callback_uri=self.callback_url)\n\n def get_auth_url(self, **kw):\n sess = self.get_auth_session()\n r = sess.fetch_request_token(self.auth_url+self.request_token_path)\n url = sess.authorization_url(self.auth_url+self.authorize_path)\n return url, r['oauth_token'], r['oauth_token_secret']\n\n def get_query_id(self, querystring):\n return querystring['oauth_token']\n\n def handle_auth_callback(self, url, token, token_secret):\n sess = self.get_auth_session(dict(token=token, token_secret=token_secret))\n sess.parse_authorization_response(url)\n r = sess.fetch_access_token(self.auth_url+self.access_token_path)\n sess.token = dict(token=r['oauth_token'],\n token_secret=r['oauth_token_secret'])\n return sess\n\n\nclass PlatformOAuth2(Platform):\n\n oauth_default_scope = None\n oauth_email_scope = None\n oauth_payment_scope = None\n\n def get_auth_session(self, state=None, token=None, token_updater=None):\n return OAuth2Session(self.api_key, state=state, token=token,\n token_updater=token_updater,\n redirect_uri=self.callback_url,\n scope=self.oauth_default_scope)\n\n def get_auth_url(self, **kw):\n sess = self.get_auth_session()\n url, state = sess.authorization_url(self.auth_url)\n return url, state, ''\n\n def get_query_id(self, querystring):\n return querystring['state']\n\n def handle_auth_callback(self, url, state, unused_arg):\n sess = self.get_auth_session(state=state)\n sess.fetch_token(self.access_token_url,\n client_secret=self.api_secret,\n authorization_response=url)\n return sess\n", "path": "gratipay/elsewhere/__init__.py"}], "after_files": [{"content": "\"\"\"This subpackage contains functionality for working with accounts elsewhere.\n\"\"\"\nfrom __future__ import division, print_function, unicode_literals\n\nfrom collections import OrderedDict\nfrom datetime import datetime\nimport hashlib\nimport json\nimport logging\nfrom urllib import quote\nimport xml.etree.ElementTree as ET\n\nfrom aspen import log, Response\nfrom aspen.utils import to_age, utc\nfrom requests_oauthlib import OAuth1Session, OAuth2Session\n\nfrom gratipay.elsewhere._extractors import not_available\n\n\nACTIONS = {'opt-in', 'connect', 'lock', 'unlock'}\nPLATFORMS = 'facebook google bitbucket bountysource github openstreetmap twitter venmo'.split()\n\n\nclass UnknownAccountElsewhere(Exception): pass\n\n\nclass PlatformRegistry(object):\n \"\"\"Registry of platforms we support connecting to Gratipay accounts.\n \"\"\"\n def __init__(self, platforms):\n self.__dict__ = OrderedDict((p.name, p) for p in platforms)\n\n def __contains__(self, platform):\n return platform.name in self.__dict__\n\n def __iter__(self):\n return iter(self.__dict__.values())\n\n\nclass UserInfo(object):\n \"\"\"A simple container for a user's info.\n\n Accessing a non-existing attribute returns `None`.\n \"\"\"\n\n def __init__(self, **kw):\n self.__dict__.update(kw)\n\n def __getattr__(self, key):\n return self.__dict__.get(key, None)\n\n def __setattr__(self, key, value):\n if value is None:\n self.__dict__.pop(key, None)\n else:\n self.__dict__[key] = value\n\n\nclass Platform(object):\n\n allows_team_connect = False\n\n # \"x\" stands for \"extract\"\n x_user_info = not_available\n x_user_id = not_available\n x_user_name = not_available\n x_display_name = not_available\n x_email = not_available\n x_gravatar_id = not_available\n x_avatar_url = not_available\n x_is_team = not_available\n\n required_attrs = ( 'account_url'\n , 'display_name'\n , 'name'\n )\n\n def __init__(self, api_key, api_secret, callback_url, api_url=None, auth_url=None):\n self.api_key = api_key\n self.api_secret = api_secret\n self.callback_url = callback_url\n if api_url:\n self.api_url = api_url\n if auth_url:\n self.auth_url = auth_url\n elif not getattr(self, 'auth_url', None):\n self.auth_url = self.api_url\n\n # Determine the appropriate response parser using `self.api_format`\n api_format = getattr(self, 'api_format', None)\n if api_format == 'json':\n self.api_parser = lambda r: r.json()\n elif api_format == 'xml':\n self.api_parser = lambda r: ET.fromstring(r.content)\n elif api_format:\n raise ValueError('unknown API format: '+str(api_format))\n\n # Make sure the subclass was implemented properly.\n missing_attrs = [a for a in self.required_attrs if not hasattr(self, a)]\n if missing_attrs:\n msg = \"The class %s is missing these required attributes: %s\"\n msg %= self.__class__.__name__, ', '.join(missing_attrs)\n raise AttributeError(msg)\n\n def api_get(self, path, sess=None, **kw):\n \"\"\"\n Given a `path` (e.g. /users/foo), this function sends a GET request to\n the platform's API (e.g. https://api.github.com/users/foo).\n\n The response is returned, after checking its status code and ratelimit\n headers.\n \"\"\"\n if not sess:\n sess = self.get_auth_session()\n response = sess.get(self.api_url+path, **kw)\n\n self.check_api_response_status(response)\n self.check_ratelimit_headers(response)\n\n return response\n\n def check_api_response_status(self, response):\n \"\"\"Pass through any 404, convert any other non-200 into a 500.\n \"\"\"\n status = response.status_code\n if status == 404:\n raise Response(404, response.text)\n elif status != 200:\n log('{} api responded with {}:\\n{}'.format(self.name, status, response.text)\n , level=logging.ERROR)\n raise Response(500, '{} lookup failed with {}'.format(self.name, status))\n\n def check_ratelimit_headers(self, response):\n \"\"\"Emit log messages if we're running out of ratelimit.\n \"\"\"\n prefix = getattr(self, 'ratelimit_headers_prefix', None)\n if prefix:\n limit = response.headers[prefix+'limit']\n remaining = response.headers[prefix+'remaining']\n reset = response.headers[prefix+'reset']\n try:\n limit, remaining, reset = int(limit), int(remaining), int(reset)\n except (TypeError, ValueError):\n d = dict(limit=limit, remaining=remaining, reset=reset)\n log('Got weird rate headers from %s: %s' % (self.name, d))\n else:\n percent_remaining = remaining/limit\n if percent_remaining < 0.5:\n reset = to_age(datetime.fromtimestamp(reset, tz=utc))\n log_msg = (\n '{0} API: {1:.1%} of ratelimit has been consumed, '\n '{2} requests remaining, resets {3}.'\n ).format(self.name, 1 - percent_remaining, remaining, reset)\n log_lvl = logging.WARNING\n if percent_remaining < 0.2:\n log_lvl = logging.ERROR\n elif percent_remaining < 0.05:\n log_lvl = logging.CRITICAL\n log(log_msg, log_lvl)\n\n def extract_user_info(self, info):\n \"\"\"\n Given a user_info object of variable type (depending on the platform),\n extract the relevant information by calling the platform's extractors\n (`x_user_name`, `x_user_id`, etc).\n\n Returns a `UserInfo`. The `user_id` attribute is guaranteed to have a\n unique non-empty value.\n \"\"\"\n r = UserInfo(platform=self.name)\n info = self.x_user_info(r, info, info)\n r.user_name = self.x_user_name(r, info, None)\n if self.x_user_id.__func__ is not_available:\n r.user_id = r.user_name\n else:\n r.user_id = self.x_user_id(r, info)\n assert r.user_id is not None\n r.user_id = unicode(r.user_id)\n assert len(r.user_id) > 0\n r.display_name = self.x_display_name(r, info, None)\n r.email = self.x_email(r, info, None)\n r.avatar_url = self.x_avatar_url(r, info, None)\n if not r.avatar_url:\n gravatar_id = self.x_gravatar_id(r, info, None)\n if r.email and not gravatar_id:\n gravatar_id = hashlib.md5(r.email.strip().lower()).hexdigest()\n if gravatar_id:\n r.avatar_url = 'https://secure.gravatar.com/avatar/'+gravatar_id\n r.is_team = self.x_is_team(r, info, False)\n r.extra_info = info\n return r\n\n def get_team_members(self, team_name, page_url=None):\n \"\"\"Given a team_name on the platform, return the team's membership list\n from the API.\n \"\"\"\n default_url = self.api_team_members_path.format(user_name=quote(team_name))\n r = self.api_get(page_url or default_url)\n members, count, pages_urls = self.api_paginator(r, self.api_parser(r))\n members = [self.extract_user_info(m) for m in members]\n return members, count, pages_urls\n\n def get_user_info(self, user_name, sess=None):\n \"\"\"Given a user_name on the platform, get the user's info from the API.\n \"\"\"\n try:\n path = self.api_user_info_path.format(user_name=quote(user_name))\n except KeyError:\n raise Response(404)\n info = self.api_parser(self.api_get(path, sess=sess))\n return self.extract_user_info(info)\n\n def get_user_self_info(self, sess):\n \"\"\"Get the authenticated user's info from the API.\n \"\"\"\n r = self.api_get(self.api_user_self_info_path, sess=sess)\n info = self.extract_user_info(self.api_parser(r))\n token = getattr(sess, 'token', None)\n if token:\n info.token = json.dumps(token)\n return info\n\n\nclass PlatformOAuth1(Platform):\n\n request_token_path = '/oauth/request_token'\n authorize_path = '/oauth/authorize'\n access_token_path = '/oauth/access_token'\n\n def get_auth_session(self, token=None):\n args = ()\n if token:\n args = (token['token'], token['token_secret'])\n return OAuth1Session(self.api_key, self.api_secret, *args,\n callback_uri=self.callback_url)\n\n def get_auth_url(self, **kw):\n sess = self.get_auth_session()\n r = sess.fetch_request_token(self.auth_url+self.request_token_path)\n url = sess.authorization_url(self.auth_url+self.authorize_path)\n return url, r['oauth_token'], r['oauth_token_secret']\n\n def get_query_id(self, querystring):\n return querystring['oauth_token']\n\n def handle_auth_callback(self, url, token, token_secret):\n sess = self.get_auth_session(dict(token=token, token_secret=token_secret))\n sess.parse_authorization_response(url)\n r = sess.fetch_access_token(self.auth_url+self.access_token_path)\n sess.token = dict(token=r['oauth_token'],\n token_secret=r['oauth_token_secret'])\n return sess\n\n\nclass PlatformOAuth2(Platform):\n\n oauth_default_scope = None\n oauth_email_scope = None\n oauth_payment_scope = None\n\n def get_auth_session(self, state=None, token=None, token_updater=None):\n return OAuth2Session(self.api_key, state=state, token=token,\n token_updater=token_updater,\n redirect_uri=self.callback_url,\n scope=self.oauth_default_scope)\n\n def get_auth_url(self, **kw):\n sess = self.get_auth_session()\n url, state = sess.authorization_url(self.auth_url)\n return url, state, ''\n\n def get_query_id(self, querystring):\n return querystring['state']\n\n def handle_auth_callback(self, url, state, unused_arg):\n sess = self.get_auth_session(state=state)\n sess.fetch_token(self.access_token_url,\n client_secret=self.api_secret,\n authorization_response=url)\n return sess\n", "path": "gratipay/elsewhere/__init__.py"}]}
| 3,347 | 362 |
gh_patches_debug_11704
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-4169
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
qbittorrent: Unable to set the pause for Torrent (new qBit 4.1.0)
### Before submitting your issue:
Enable debug logging in Medusa settings, reproduce the error (be sure to disable after the bug is fixed)
**Branch/Commit:**
77b2091
**OS:**
Linux Mint 18.2 Cinnamon
**What you did:**
I updated to qBittorrent 4.1.0 earlier today, prior to that I was using Qbittorrent 4.0.4, so I figure maybe this is something with Medusa + qBittorrent 4.1.0....I didn't do any manual pause or anything so no idea what it would be pausing or why.
I do *not* have this checked:
Start torrent paused
add .torrent to client but do not start downloading
In the Search Settings -> Torrent Search config in Medusa, in case anybody is wondering.
**What happened:**
Some kind of red error about pausing a torrent with Qbittorrent
**What you expected:**
No error
**Logs:**
```
2018-05-06 17:59:02 INFO SEARCHQUEUE-DAILY-SEARCH :: [77b2091] Prowl notifications sent.
2018-05-06 17:59:01 ERROR SEARCHQUEUE-DAILY-SEARCH :: [77b2091] qbittorrent: Unable to set the pause for Torrent
2018-05-06 17:59:01 INFO SEARCHQUEUE-DAILY-SEARCH :: [77b2091] qbittorrent: Bad Request
2018-05-06 17:59:00 INFO SEARCHQUEUE-DAILY-SEARCH :: [77b2091] Downloading (censored) with 13 seeders and 2 leechers and size (censored) MB from (censored)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/clients/torrent/qbittorrent_client.py`
Content:
```
1 # coding=utf-8
2
3 """qBittorrent Client."""
4
5 from __future__ import unicode_literals
6
7 import logging
8
9 from medusa import app
10 from medusa.clients.torrent.generic import GenericClient
11 from medusa.logger.adapters.style import BraceAdapter
12
13 from requests.auth import HTTPDigestAuth
14
15 log = BraceAdapter(logging.getLogger(__name__))
16 log.logger.addHandler(logging.NullHandler())
17
18
19 class QBittorrentAPI(GenericClient):
20 """qBittorrent API class."""
21
22 def __init__(self, host=None, username=None, password=None):
23 """Constructor.
24
25 :param host:
26 :type host: string
27 :param username:
28 :type username: string
29 :param password:
30 :type password: string
31 """
32 super(QBittorrentAPI, self).__init__('qbittorrent', host, username, password)
33 self.url = self.host
34 self.session.auth = HTTPDigestAuth(self.username, self.password)
35
36 @property
37 def api(self):
38 """Get API version."""
39 try:
40 self.url = '{host}version/api'.format(host=self.host)
41 version = int(self.session.get(self.url, verify=app.TORRENT_VERIFY_CERT).content)
42 except Exception:
43 version = 1
44 return version
45
46 def _get_auth(self):
47
48 if self.api > 1:
49 self.url = '{host}login'.format(host=self.host)
50 data = {
51 'username': self.username,
52 'password': self.password,
53 }
54 try:
55 self.response = self.session.post(self.url, data=data)
56 except Exception:
57 return None
58
59 else:
60 try:
61 self.response = self.session.get(self.host, verify=app.TORRENT_VERIFY_CERT)
62 self.auth = self.response.content
63 except Exception:
64 return None
65
66 self.session.cookies = self.response.cookies
67 self.auth = self.response.content
68
69 return self.auth if not self.response.status_code == 404 else None
70
71 def _add_torrent_uri(self, result):
72
73 self.url = '{host}command/download'.format(host=self.host)
74 data = {
75 'urls': result.url,
76 }
77 return self._request(method='post', data=data, cookies=self.session.cookies)
78
79 def _add_torrent_file(self, result):
80
81 self.url = '{host}command/upload'.format(host=self.host)
82 files = {
83 'torrents': (
84 '{result}.torrent'.format(result=result.name),
85 result.content,
86 ),
87 }
88 return self._request(method='post', files=files, cookies=self.session.cookies)
89
90 def _set_torrent_label(self, result):
91
92 label = app.TORRENT_LABEL_ANIME if result.series.is_anime else app.TORRENT_LABEL
93
94 if self.api > 6 and label:
95 label_key = 'Category' if self.api >= 10 else 'Label'
96 self.url = '{host}command/set{key}'.format(
97 host=self.host,
98 key=label_key,
99 )
100 data = {
101 'hashes': result.hash.lower(),
102 label_key.lower(): label.replace(' ', '_'),
103 }
104 return self._request(method='post', data=data, cookies=self.session.cookies)
105 return True
106
107 def _set_torrent_priority(self, result):
108
109 self.url = '{host}command/{method}Prio'.format(host=self.host,
110 method='increase' if result.priority == 1 else 'decrease')
111 data = {
112 'hashes': result.hash.lower(),
113 }
114 ok = self._request(method='post', data=data, cookies=self.session.cookies)
115
116 if self.response.status_code == 403:
117 log.info('{name}: Unable to set torrent priority because torrent queueing'
118 ' is disabled in {name} settings.', {'name': self.name})
119 ok = True
120
121 return ok
122
123 def _set_torrent_pause(self, result):
124 self.url = '{host}command/{state}'.format(host=self.host,
125 state='pause' if app.TORRENT_PAUSED else 'resume')
126 data = {
127 'hash': result.hash,
128 }
129 return self._request(method='post', data=data, cookies=self.session.cookies)
130
131 def remove_torrent(self, info_hash):
132 """Remove torrent from client using given info_hash.
133
134 :param info_hash:
135 :type info_hash: string
136 :return
137 :rtype: bool
138 """
139 self.url = '{host}command/deletePerm'.format(host=self.host)
140 data = {
141 'hashes': info_hash.lower(),
142 }
143
144 return self._request(method='post', data=data, cookies=self.session.cookies)
145
146
147 api = QBittorrentAPI
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/clients/torrent/qbittorrent_client.py b/medusa/clients/torrent/qbittorrent_client.py
--- a/medusa/clients/torrent/qbittorrent_client.py
+++ b/medusa/clients/torrent/qbittorrent_client.py
@@ -123,8 +123,9 @@
def _set_torrent_pause(self, result):
self.url = '{host}command/{state}'.format(host=self.host,
state='pause' if app.TORRENT_PAUSED else 'resume')
+ hashes_key = 'hashes' if self.api >= 18 else 'hash'
data = {
- 'hash': result.hash,
+ hashes_key: result.hash.lower(),
}
return self._request(method='post', data=data, cookies=self.session.cookies)
|
{"golden_diff": "diff --git a/medusa/clients/torrent/qbittorrent_client.py b/medusa/clients/torrent/qbittorrent_client.py\n--- a/medusa/clients/torrent/qbittorrent_client.py\n+++ b/medusa/clients/torrent/qbittorrent_client.py\n@@ -123,8 +123,9 @@\n def _set_torrent_pause(self, result):\n self.url = '{host}command/{state}'.format(host=self.host,\n state='pause' if app.TORRENT_PAUSED else 'resume')\n+ hashes_key = 'hashes' if self.api >= 18 else 'hash'\n data = {\n- 'hash': result.hash,\n+ hashes_key: result.hash.lower(),\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n", "issue": "qbittorrent: Unable to set the pause for Torrent (new qBit 4.1.0)\n### Before submitting your issue:\r\n\r\nEnable debug logging in Medusa settings, reproduce the error (be sure to disable after the bug is fixed)\r\n\r\n**Branch/Commit:**\r\n77b2091\r\n**OS:**\r\nLinux Mint 18.2 Cinnamon\r\n**What you did:**\r\nI updated to qBittorrent 4.1.0 earlier today, prior to that I was using Qbittorrent 4.0.4, so I figure maybe this is something with Medusa + qBittorrent 4.1.0....I didn't do any manual pause or anything so no idea what it would be pausing or why.\r\nI do *not* have this checked:\r\nStart torrent paused\r\nadd .torrent to client but do not start downloading\r\nIn the Search Settings -> Torrent Search config in Medusa, in case anybody is wondering.\r\n**What happened:**\r\nSome kind of red error about pausing a torrent with Qbittorrent\r\n**What you expected:**\r\nNo error\r\n**Logs:**\r\n```\r\n2018-05-06 17:59:02 INFO SEARCHQUEUE-DAILY-SEARCH :: [77b2091] Prowl notifications sent.\r\n2018-05-06 17:59:01 ERROR SEARCHQUEUE-DAILY-SEARCH :: [77b2091] qbittorrent: Unable to set the pause for Torrent\r\n2018-05-06 17:59:01 INFO SEARCHQUEUE-DAILY-SEARCH :: [77b2091] qbittorrent: Bad Request\r\n2018-05-06 17:59:00 INFO SEARCHQUEUE-DAILY-SEARCH :: [77b2091] Downloading (censored) with 13 seeders and 2 leechers and size (censored) MB from (censored)\r\n```\r\n\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"qBittorrent Client.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import app\nfrom medusa.clients.torrent.generic import GenericClient\nfrom medusa.logger.adapters.style import BraceAdapter\n\nfrom requests.auth import HTTPDigestAuth\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass QBittorrentAPI(GenericClient):\n \"\"\"qBittorrent API class.\"\"\"\n\n def __init__(self, host=None, username=None, password=None):\n \"\"\"Constructor.\n\n :param host:\n :type host: string\n :param username:\n :type username: string\n :param password:\n :type password: string\n \"\"\"\n super(QBittorrentAPI, self).__init__('qbittorrent', host, username, password)\n self.url = self.host\n self.session.auth = HTTPDigestAuth(self.username, self.password)\n\n @property\n def api(self):\n \"\"\"Get API version.\"\"\"\n try:\n self.url = '{host}version/api'.format(host=self.host)\n version = int(self.session.get(self.url, verify=app.TORRENT_VERIFY_CERT).content)\n except Exception:\n version = 1\n return version\n\n def _get_auth(self):\n\n if self.api > 1:\n self.url = '{host}login'.format(host=self.host)\n data = {\n 'username': self.username,\n 'password': self.password,\n }\n try:\n self.response = self.session.post(self.url, data=data)\n except Exception:\n return None\n\n else:\n try:\n self.response = self.session.get(self.host, verify=app.TORRENT_VERIFY_CERT)\n self.auth = self.response.content\n except Exception:\n return None\n\n self.session.cookies = self.response.cookies\n self.auth = self.response.content\n\n return self.auth if not self.response.status_code == 404 else None\n\n def _add_torrent_uri(self, result):\n\n self.url = '{host}command/download'.format(host=self.host)\n data = {\n 'urls': result.url,\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n\n def _add_torrent_file(self, result):\n\n self.url = '{host}command/upload'.format(host=self.host)\n files = {\n 'torrents': (\n '{result}.torrent'.format(result=result.name),\n result.content,\n ),\n }\n return self._request(method='post', files=files, cookies=self.session.cookies)\n\n def _set_torrent_label(self, result):\n\n label = app.TORRENT_LABEL_ANIME if result.series.is_anime else app.TORRENT_LABEL\n\n if self.api > 6 and label:\n label_key = 'Category' if self.api >= 10 else 'Label'\n self.url = '{host}command/set{key}'.format(\n host=self.host,\n key=label_key,\n )\n data = {\n 'hashes': result.hash.lower(),\n label_key.lower(): label.replace(' ', '_'),\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n return True\n\n def _set_torrent_priority(self, result):\n\n self.url = '{host}command/{method}Prio'.format(host=self.host,\n method='increase' if result.priority == 1 else 'decrease')\n data = {\n 'hashes': result.hash.lower(),\n }\n ok = self._request(method='post', data=data, cookies=self.session.cookies)\n\n if self.response.status_code == 403:\n log.info('{name}: Unable to set torrent priority because torrent queueing'\n ' is disabled in {name} settings.', {'name': self.name})\n ok = True\n\n return ok\n\n def _set_torrent_pause(self, result):\n self.url = '{host}command/{state}'.format(host=self.host,\n state='pause' if app.TORRENT_PAUSED else 'resume')\n data = {\n 'hash': result.hash,\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n\n def remove_torrent(self, info_hash):\n \"\"\"Remove torrent from client using given info_hash.\n\n :param info_hash:\n :type info_hash: string\n :return\n :rtype: bool\n \"\"\"\n self.url = '{host}command/deletePerm'.format(host=self.host)\n data = {\n 'hashes': info_hash.lower(),\n }\n\n return self._request(method='post', data=data, cookies=self.session.cookies)\n\n\napi = QBittorrentAPI\n", "path": "medusa/clients/torrent/qbittorrent_client.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"qBittorrent Client.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import app\nfrom medusa.clients.torrent.generic import GenericClient\nfrom medusa.logger.adapters.style import BraceAdapter\n\nfrom requests.auth import HTTPDigestAuth\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass QBittorrentAPI(GenericClient):\n \"\"\"qBittorrent API class.\"\"\"\n\n def __init__(self, host=None, username=None, password=None):\n \"\"\"Constructor.\n\n :param host:\n :type host: string\n :param username:\n :type username: string\n :param password:\n :type password: string\n \"\"\"\n super(QBittorrentAPI, self).__init__('qbittorrent', host, username, password)\n self.url = self.host\n self.session.auth = HTTPDigestAuth(self.username, self.password)\n\n @property\n def api(self):\n \"\"\"Get API version.\"\"\"\n try:\n self.url = '{host}version/api'.format(host=self.host)\n version = int(self.session.get(self.url, verify=app.TORRENT_VERIFY_CERT).content)\n except Exception:\n version = 1\n return version\n\n def _get_auth(self):\n\n if self.api > 1:\n self.url = '{host}login'.format(host=self.host)\n data = {\n 'username': self.username,\n 'password': self.password,\n }\n try:\n self.response = self.session.post(self.url, data=data)\n except Exception:\n return None\n\n else:\n try:\n self.response = self.session.get(self.host, verify=app.TORRENT_VERIFY_CERT)\n self.auth = self.response.content\n except Exception:\n return None\n\n self.session.cookies = self.response.cookies\n self.auth = self.response.content\n\n return self.auth if not self.response.status_code == 404 else None\n\n def _add_torrent_uri(self, result):\n\n self.url = '{host}command/download'.format(host=self.host)\n data = {\n 'urls': result.url,\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n\n def _add_torrent_file(self, result):\n\n self.url = '{host}command/upload'.format(host=self.host)\n files = {\n 'torrents': (\n '{result}.torrent'.format(result=result.name),\n result.content,\n ),\n }\n return self._request(method='post', files=files, cookies=self.session.cookies)\n\n def _set_torrent_label(self, result):\n\n label = app.TORRENT_LABEL_ANIME if result.series.is_anime else app.TORRENT_LABEL\n\n if self.api > 6 and label:\n label_key = 'Category' if self.api >= 10 else 'Label'\n self.url = '{host}command/set{key}'.format(\n host=self.host,\n key=label_key,\n )\n data = {\n 'hashes': result.hash.lower(),\n label_key.lower(): label.replace(' ', '_'),\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n return True\n\n def _set_torrent_priority(self, result):\n\n self.url = '{host}command/{method}Prio'.format(host=self.host,\n method='increase' if result.priority == 1 else 'decrease')\n data = {\n 'hashes': result.hash.lower(),\n }\n ok = self._request(method='post', data=data, cookies=self.session.cookies)\n\n if self.response.status_code == 403:\n log.info('{name}: Unable to set torrent priority because torrent queueing'\n ' is disabled in {name} settings.', {'name': self.name})\n ok = True\n\n return ok\n\n def _set_torrent_pause(self, result):\n self.url = '{host}command/{state}'.format(host=self.host,\n state='pause' if app.TORRENT_PAUSED else 'resume')\n hashes_key = 'hashes' if self.api >= 18 else 'hash'\n data = {\n hashes_key: result.hash.lower(),\n }\n return self._request(method='post', data=data, cookies=self.session.cookies)\n\n def remove_torrent(self, info_hash):\n \"\"\"Remove torrent from client using given info_hash.\n\n :param info_hash:\n :type info_hash: string\n :return\n :rtype: bool\n \"\"\"\n self.url = '{host}command/deletePerm'.format(host=self.host)\n data = {\n 'hashes': info_hash.lower(),\n }\n\n return self._request(method='post', data=data, cookies=self.session.cookies)\n\n\napi = QBittorrentAPI\n", "path": "medusa/clients/torrent/qbittorrent_client.py"}]}
| 2,066 | 182 |
gh_patches_debug_42000
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-core-4289
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
os_server_actions nova rebuild server
##### ISSUE TYPE
Feature Idea
##### COMPONENT NAME
os_server module
##### ANSIBLE VERSION
N/A
##### SUMMARY
Could it be possible to implement the nova rebuild server action in the os_server_actions module?
We use openstack in our CI pipeline, and this is far more cheaper then booting a new server every
time we test.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cloud/openstack/os_server_actions.py`
Content:
```
1 #!/usr/bin/python
2 # coding: utf-8 -*-
3
4 # Copyright (c) 2015, Jesse Keating <[email protected]>
5 #
6 # This module is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This software is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this software. If not, see <http://www.gnu.org/licenses/>.
18
19
20 try:
21 import shade
22 from shade import meta
23 HAS_SHADE = True
24 except ImportError:
25 HAS_SHADE = False
26
27
28 DOCUMENTATION = '''
29 ---
30 module: os_server_actions
31 short_description: Perform actions on Compute Instances from OpenStack
32 extends_documentation_fragment: openstack
33 version_added: "2.0"
34 author: "Jesse Keating (@j2sol)"
35 description:
36 - Perform server actions on an existing compute instance from OpenStack.
37 This module does not return any data other than changed true/false.
38 options:
39 server:
40 description:
41 - Name or ID of the instance
42 required: true
43 wait:
44 description:
45 - If the module should wait for the instance action to be performed.
46 required: false
47 default: 'yes'
48 timeout:
49 description:
50 - The amount of time the module should wait for the instance to perform
51 the requested action.
52 required: false
53 default: 180
54 action:
55 description:
56 - Perform the given action. The lock and unlock actions always return
57 changed as the servers API does not provide lock status.
58 choices: [stop, start, pause, unpause, lock, unlock, suspend, resume]
59 default: present
60 requirements:
61 - "python >= 2.6"
62 - "shade"
63 '''
64
65 EXAMPLES = '''
66 # Pauses a compute instance
67 - os_server_actions:
68 action: pause
69 auth:
70 auth_url: https://mycloud.openstack.blueboxgrid.com:5001/v2.0
71 username: admin
72 password: admin
73 project_name: admin
74 server: vm1
75 timeout: 200
76 '''
77
78 _action_map = {'stop': 'SHUTOFF',
79 'start': 'ACTIVE',
80 'pause': 'PAUSED',
81 'unpause': 'ACTIVE',
82 'lock': 'ACTIVE', # API doesn't show lock/unlock status
83 'unlock': 'ACTIVE',
84 'suspend': 'SUSPENDED',
85 'resume': 'ACTIVE',}
86
87 _admin_actions = ['pause', 'unpause', 'suspend', 'resume', 'lock', 'unlock']
88
89 def _wait(timeout, cloud, server, action):
90 """Wait for the server to reach the desired state for the given action."""
91
92 for count in shade._utils._iterate_timeout(
93 timeout,
94 "Timeout waiting for server to complete %s" % action):
95 try:
96 server = cloud.get_server(server.id)
97 except Exception:
98 continue
99
100 if server.status == _action_map[action]:
101 return
102
103 if server.status == 'ERROR':
104 module.fail_json(msg="Server reached ERROR state while attempting to %s" % action)
105
106 def _system_state_change(action, status):
107 """Check if system state would change."""
108 if status == _action_map[action]:
109 return False
110 return True
111
112 def main():
113 argument_spec = openstack_full_argument_spec(
114 server=dict(required=True),
115 action=dict(required=True, choices=['stop', 'start', 'pause', 'unpause',
116 'lock', 'unlock', 'suspend', 'resume']),
117 )
118
119 module_kwargs = openstack_module_kwargs()
120 module = AnsibleModule(argument_spec, supports_check_mode=True, **module_kwargs)
121
122 if not HAS_SHADE:
123 module.fail_json(msg='shade is required for this module')
124
125 action = module.params['action']
126 wait = module.params['wait']
127 timeout = module.params['timeout']
128
129 try:
130 if action in _admin_actions:
131 cloud = shade.operator_cloud(**module.params)
132 else:
133 cloud = shade.openstack_cloud(**module.params)
134 server = cloud.get_server(module.params['server'])
135 if not server:
136 module.fail_json(msg='Could not find server %s' % server)
137 status = server.status
138
139 if module.check_mode:
140 module.exit_json(changed=_system_state_change(action, status))
141
142 if action == 'stop':
143 if not _system_state_change(action, status):
144 module.exit_json(changed=False)
145
146 cloud.nova_client.servers.stop(server=server.id)
147 if wait:
148 _wait(timeout, cloud, server, action)
149 module.exit_json(changed=True)
150
151 if action == 'start':
152 if not _system_state_change(action, status):
153 module.exit_json(changed=False)
154
155 cloud.nova_client.servers.start(server=server.id)
156 if wait:
157 _wait(timeout, cloud, server, action)
158 module.exit_json(changed=True)
159
160 if action == 'pause':
161 if not _system_state_change(action, status):
162 module.exit_json(changed=False)
163
164 cloud.nova_client.servers.pause(server=server.id)
165 if wait:
166 _wait(timeout, cloud, server, action)
167 module.exit_json(changed=True)
168
169 elif action == 'unpause':
170 if not _system_state_change(action, status):
171 module.exit_json(changed=False)
172
173 cloud.nova_client.servers.unpause(server=server.id)
174 if wait:
175 _wait(timeout, cloud, server, action)
176 module.exit_json(changed=True)
177
178 elif action == 'lock':
179 # lock doesn't set a state, just do it
180 cloud.nova_client.servers.lock(server=server.id)
181 module.exit_json(changed=True)
182
183 elif action == 'unlock':
184 # unlock doesn't set a state, just do it
185 cloud.nova_client.servers.unlock(server=server.id)
186 module.exit_json(changed=True)
187
188 elif action == 'suspend':
189 if not _system_state_change(action, status):
190 module.exit_json(changed=False)
191
192 cloud.nova_client.servers.suspend(server=server.id)
193 if wait:
194 _wait(timeout, cloud, server, action)
195 module.exit_json(changed=True)
196
197 elif action == 'resume':
198 if not _system_state_change(action, status):
199 module.exit_json(changed=False)
200
201 cloud.nova_client.servers.resume(server=server.id)
202 if wait:
203 _wait(timeout, cloud, server, action)
204 module.exit_json(changed=True)
205
206 except shade.OpenStackCloudException as e:
207 module.fail_json(msg=str(e), extra_data=e.extra_data)
208
209 # this is magic, see lib/ansible/module_common.py
210 from ansible.module_utils.basic import *
211 from ansible.module_utils.openstack import *
212 if __name__ == '__main__':
213 main()
214
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cloud/openstack/os_server_actions.py b/cloud/openstack/os_server_actions.py
--- a/cloud/openstack/os_server_actions.py
+++ b/cloud/openstack/os_server_actions.py
@@ -35,6 +35,7 @@
description:
- Perform server actions on an existing compute instance from OpenStack.
This module does not return any data other than changed true/false.
+ When I(action) is 'rebuild', then I(image) parameter is required.
options:
server:
description:
@@ -55,8 +56,14 @@
description:
- Perform the given action. The lock and unlock actions always return
changed as the servers API does not provide lock status.
- choices: [stop, start, pause, unpause, lock, unlock, suspend, resume]
+ choices: [stop, start, pause, unpause, lock, unlock, suspend, resume,
+ rebuild]
default: present
+ image:
+ description:
+ - Image the server should be rebuilt with
+ default: null
+ version_added: "2.3"
requirements:
- "python >= 2.6"
- "shade"
@@ -82,7 +89,8 @@
'lock': 'ACTIVE', # API doesn't show lock/unlock status
'unlock': 'ACTIVE',
'suspend': 'SUSPENDED',
- 'resume': 'ACTIVE',}
+ 'resume': 'ACTIVE',
+ 'rebuild': 'ACTIVE'}
_admin_actions = ['pause', 'unpause', 'suspend', 'resume', 'lock', 'unlock']
@@ -113,11 +121,15 @@
argument_spec = openstack_full_argument_spec(
server=dict(required=True),
action=dict(required=True, choices=['stop', 'start', 'pause', 'unpause',
- 'lock', 'unlock', 'suspend', 'resume']),
+ 'lock', 'unlock', 'suspend', 'resume',
+ 'rebuild']),
+ image=dict(required=False),
)
module_kwargs = openstack_module_kwargs()
- module = AnsibleModule(argument_spec, supports_check_mode=True, **module_kwargs)
+ module = AnsibleModule(argument_spec, supports_check_mode=True,
+ required_if=[('action', 'rebuild', ['image'])],
+ **module_kwargs)
if not HAS_SHADE:
module.fail_json(msg='shade is required for this module')
@@ -125,6 +137,7 @@
action = module.params['action']
wait = module.params['wait']
timeout = module.params['timeout']
+ image = module.params['image']
try:
if action in _admin_actions:
@@ -203,6 +216,18 @@
_wait(timeout, cloud, server, action)
module.exit_json(changed=True)
+ elif action == 'rebuild':
+ image = cloud.get_image(image)
+
+ if image is None:
+ module.fail_json(msg="Image does not exist")
+
+ # rebuild doesn't set a state, just do it
+ cloud.nova_client.servers.rebuild(server=server.id, image=image.id)
+ if wait:
+ _wait(timeout, cloud, server, action)
+ module.exit_json(changed=True)
+
except shade.OpenStackCloudException as e:
module.fail_json(msg=str(e), extra_data=e.extra_data)
|
{"golden_diff": "diff --git a/cloud/openstack/os_server_actions.py b/cloud/openstack/os_server_actions.py\n--- a/cloud/openstack/os_server_actions.py\n+++ b/cloud/openstack/os_server_actions.py\n@@ -35,6 +35,7 @@\n description:\n - Perform server actions on an existing compute instance from OpenStack.\n This module does not return any data other than changed true/false.\n+ When I(action) is 'rebuild', then I(image) parameter is required.\n options:\n server:\n description:\n@@ -55,8 +56,14 @@\n description:\n - Perform the given action. The lock and unlock actions always return\n changed as the servers API does not provide lock status.\n- choices: [stop, start, pause, unpause, lock, unlock, suspend, resume]\n+ choices: [stop, start, pause, unpause, lock, unlock, suspend, resume,\n+ rebuild]\n default: present\n+ image:\n+ description:\n+ - Image the server should be rebuilt with\n+ default: null\n+ version_added: \"2.3\"\n requirements:\n - \"python >= 2.6\"\n - \"shade\"\n@@ -82,7 +89,8 @@\n 'lock': 'ACTIVE', # API doesn't show lock/unlock status\n 'unlock': 'ACTIVE',\n 'suspend': 'SUSPENDED',\n- 'resume': 'ACTIVE',}\n+ 'resume': 'ACTIVE',\n+ 'rebuild': 'ACTIVE'}\n \n _admin_actions = ['pause', 'unpause', 'suspend', 'resume', 'lock', 'unlock']\n \n@@ -113,11 +121,15 @@\n argument_spec = openstack_full_argument_spec(\n server=dict(required=True),\n action=dict(required=True, choices=['stop', 'start', 'pause', 'unpause',\n- 'lock', 'unlock', 'suspend', 'resume']),\n+ 'lock', 'unlock', 'suspend', 'resume',\n+ 'rebuild']),\n+ image=dict(required=False),\n )\n \n module_kwargs = openstack_module_kwargs()\n- module = AnsibleModule(argument_spec, supports_check_mode=True, **module_kwargs)\n+ module = AnsibleModule(argument_spec, supports_check_mode=True,\n+ required_if=[('action', 'rebuild', ['image'])],\n+ **module_kwargs)\n \n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n@@ -125,6 +137,7 @@\n action = module.params['action']\n wait = module.params['wait']\n timeout = module.params['timeout']\n+ image = module.params['image']\n \n try:\n if action in _admin_actions:\n@@ -203,6 +216,18 @@\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n \n+ elif action == 'rebuild':\n+ image = cloud.get_image(image)\n+\n+ if image is None:\n+ module.fail_json(msg=\"Image does not exist\")\n+\n+ # rebuild doesn't set a state, just do it\n+ cloud.nova_client.servers.rebuild(server=server.id, image=image.id)\n+ if wait:\n+ _wait(timeout, cloud, server, action)\n+ module.exit_json(changed=True)\n+\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n", "issue": "os_server_actions nova rebuild server\n##### ISSUE TYPE\n\nFeature Idea\n##### COMPONENT NAME\n\nos_server module\n##### ANSIBLE VERSION\n\nN/A\n##### SUMMARY\n\nCould it be possible to implement the nova rebuild server action in the os_server_actions module?\n\nWe use openstack in our CI pipeline, and this is far more cheaper then booting a new server every\ntime we test.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# coding: utf-8 -*-\n\n# Copyright (c) 2015, Jesse Keating <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\n\ntry:\n import shade\n from shade import meta\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\n\nDOCUMENTATION = '''\n---\nmodule: os_server_actions\nshort_description: Perform actions on Compute Instances from OpenStack\nextends_documentation_fragment: openstack\nversion_added: \"2.0\"\nauthor: \"Jesse Keating (@j2sol)\"\ndescription:\n - Perform server actions on an existing compute instance from OpenStack.\n This module does not return any data other than changed true/false.\noptions:\n server:\n description:\n - Name or ID of the instance\n required: true\n wait:\n description:\n - If the module should wait for the instance action to be performed.\n required: false\n default: 'yes'\n timeout:\n description:\n - The amount of time the module should wait for the instance to perform\n the requested action.\n required: false\n default: 180\n action:\n description:\n - Perform the given action. The lock and unlock actions always return\n changed as the servers API does not provide lock status.\n choices: [stop, start, pause, unpause, lock, unlock, suspend, resume]\n default: present\nrequirements:\n - \"python >= 2.6\"\n - \"shade\"\n'''\n\nEXAMPLES = '''\n# Pauses a compute instance\n- os_server_actions:\n action: pause\n auth:\n auth_url: https://mycloud.openstack.blueboxgrid.com:5001/v2.0\n username: admin\n password: admin\n project_name: admin\n server: vm1\n timeout: 200\n'''\n\n_action_map = {'stop': 'SHUTOFF',\n 'start': 'ACTIVE',\n 'pause': 'PAUSED',\n 'unpause': 'ACTIVE',\n 'lock': 'ACTIVE', # API doesn't show lock/unlock status\n 'unlock': 'ACTIVE',\n 'suspend': 'SUSPENDED',\n 'resume': 'ACTIVE',}\n\n_admin_actions = ['pause', 'unpause', 'suspend', 'resume', 'lock', 'unlock']\n\ndef _wait(timeout, cloud, server, action):\n \"\"\"Wait for the server to reach the desired state for the given action.\"\"\"\n\n for count in shade._utils._iterate_timeout(\n timeout,\n \"Timeout waiting for server to complete %s\" % action):\n try:\n server = cloud.get_server(server.id)\n except Exception:\n continue\n\n if server.status == _action_map[action]:\n return\n\n if server.status == 'ERROR':\n module.fail_json(msg=\"Server reached ERROR state while attempting to %s\" % action)\n\ndef _system_state_change(action, status):\n \"\"\"Check if system state would change.\"\"\"\n if status == _action_map[action]:\n return False\n return True\n\ndef main():\n argument_spec = openstack_full_argument_spec(\n server=dict(required=True),\n action=dict(required=True, choices=['stop', 'start', 'pause', 'unpause',\n 'lock', 'unlock', 'suspend', 'resume']),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(argument_spec, supports_check_mode=True, **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n action = module.params['action']\n wait = module.params['wait']\n timeout = module.params['timeout']\n\n try:\n if action in _admin_actions:\n cloud = shade.operator_cloud(**module.params)\n else:\n cloud = shade.openstack_cloud(**module.params)\n server = cloud.get_server(module.params['server'])\n if not server:\n module.fail_json(msg='Could not find server %s' % server)\n status = server.status\n\n if module.check_mode:\n module.exit_json(changed=_system_state_change(action, status))\n\n if action == 'stop':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.stop(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n if action == 'start':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.start(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n if action == 'pause':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.pause(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'unpause':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.unpause(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'lock':\n # lock doesn't set a state, just do it\n cloud.nova_client.servers.lock(server=server.id)\n module.exit_json(changed=True)\n\n elif action == 'unlock':\n # unlock doesn't set a state, just do it\n cloud.nova_client.servers.unlock(server=server.id)\n module.exit_json(changed=True)\n\n elif action == 'suspend':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.suspend(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'resume':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.resume(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_server_actions.py"}], "after_files": [{"content": "#!/usr/bin/python\n# coding: utf-8 -*-\n\n# Copyright (c) 2015, Jesse Keating <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\n\ntry:\n import shade\n from shade import meta\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\n\nDOCUMENTATION = '''\n---\nmodule: os_server_actions\nshort_description: Perform actions on Compute Instances from OpenStack\nextends_documentation_fragment: openstack\nversion_added: \"2.0\"\nauthor: \"Jesse Keating (@j2sol)\"\ndescription:\n - Perform server actions on an existing compute instance from OpenStack.\n This module does not return any data other than changed true/false.\n When I(action) is 'rebuild', then I(image) parameter is required.\noptions:\n server:\n description:\n - Name or ID of the instance\n required: true\n wait:\n description:\n - If the module should wait for the instance action to be performed.\n required: false\n default: 'yes'\n timeout:\n description:\n - The amount of time the module should wait for the instance to perform\n the requested action.\n required: false\n default: 180\n action:\n description:\n - Perform the given action. The lock and unlock actions always return\n changed as the servers API does not provide lock status.\n choices: [stop, start, pause, unpause, lock, unlock, suspend, resume,\n rebuild]\n default: present\n image:\n description:\n - Image the server should be rebuilt with\n default: null\n version_added: \"2.3\"\nrequirements:\n - \"python >= 2.6\"\n - \"shade\"\n'''\n\nEXAMPLES = '''\n# Pauses a compute instance\n- os_server_actions:\n action: pause\n auth:\n auth_url: https://mycloud.openstack.blueboxgrid.com:5001/v2.0\n username: admin\n password: admin\n project_name: admin\n server: vm1\n timeout: 200\n'''\n\n_action_map = {'stop': 'SHUTOFF',\n 'start': 'ACTIVE',\n 'pause': 'PAUSED',\n 'unpause': 'ACTIVE',\n 'lock': 'ACTIVE', # API doesn't show lock/unlock status\n 'unlock': 'ACTIVE',\n 'suspend': 'SUSPENDED',\n 'resume': 'ACTIVE',\n 'rebuild': 'ACTIVE'}\n\n_admin_actions = ['pause', 'unpause', 'suspend', 'resume', 'lock', 'unlock']\n\ndef _wait(timeout, cloud, server, action):\n \"\"\"Wait for the server to reach the desired state for the given action.\"\"\"\n\n for count in shade._utils._iterate_timeout(\n timeout,\n \"Timeout waiting for server to complete %s\" % action):\n try:\n server = cloud.get_server(server.id)\n except Exception:\n continue\n\n if server.status == _action_map[action]:\n return\n\n if server.status == 'ERROR':\n module.fail_json(msg=\"Server reached ERROR state while attempting to %s\" % action)\n\ndef _system_state_change(action, status):\n \"\"\"Check if system state would change.\"\"\"\n if status == _action_map[action]:\n return False\n return True\n\ndef main():\n argument_spec = openstack_full_argument_spec(\n server=dict(required=True),\n action=dict(required=True, choices=['stop', 'start', 'pause', 'unpause',\n 'lock', 'unlock', 'suspend', 'resume',\n 'rebuild']),\n image=dict(required=False),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(argument_spec, supports_check_mode=True,\n required_if=[('action', 'rebuild', ['image'])],\n **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n action = module.params['action']\n wait = module.params['wait']\n timeout = module.params['timeout']\n image = module.params['image']\n\n try:\n if action in _admin_actions:\n cloud = shade.operator_cloud(**module.params)\n else:\n cloud = shade.openstack_cloud(**module.params)\n server = cloud.get_server(module.params['server'])\n if not server:\n module.fail_json(msg='Could not find server %s' % server)\n status = server.status\n\n if module.check_mode:\n module.exit_json(changed=_system_state_change(action, status))\n\n if action == 'stop':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.stop(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n if action == 'start':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.start(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n if action == 'pause':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.pause(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'unpause':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.unpause(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'lock':\n # lock doesn't set a state, just do it\n cloud.nova_client.servers.lock(server=server.id)\n module.exit_json(changed=True)\n\n elif action == 'unlock':\n # unlock doesn't set a state, just do it\n cloud.nova_client.servers.unlock(server=server.id)\n module.exit_json(changed=True)\n\n elif action == 'suspend':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.suspend(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'resume':\n if not _system_state_change(action, status):\n module.exit_json(changed=False)\n\n cloud.nova_client.servers.resume(server=server.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n elif action == 'rebuild':\n image = cloud.get_image(image)\n\n if image is None:\n module.fail_json(msg=\"Image does not exist\")\n\n # rebuild doesn't set a state, just do it\n cloud.nova_client.servers.rebuild(server=server.id, image=image.id)\n if wait:\n _wait(timeout, cloud, server, action)\n module.exit_json(changed=True)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_server_actions.py"}]}
| 2,426 | 752 |
gh_patches_debug_35031
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-3215
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Exported CSV file does not seem to contain information on what shelf my books are on
**Describe the bug**
I exported the CSV-file from my account on bookwyrm.social, and it does not seem to contain information on what books I've read and what I want to read and what I am currently reading (Shelves)
**To Reproduce**
Steps to reproduce the behavior:
1. Go to settings
2. click on CSV export
3. Click on "Download file"
4. No apparent status-column in the exported csv-file
**Expected behavior**
A column indicating what shelf a book is on
**Instance**
Exported from bookwyrm.social
**Desktop (please complete the following information):**
- OS: MacOS
- Browser Firefox
- Version 113b
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/views/preferences/export.py`
Content:
```
1 """ Let users export their book data """
2 from datetime import timedelta
3 import csv
4 import io
5
6 from django.contrib.auth.decorators import login_required
7 from django.core.paginator import Paginator
8 from django.db.models import Q
9 from django.http import HttpResponse
10 from django.template.response import TemplateResponse
11 from django.utils import timezone
12 from django.views import View
13 from django.utils.decorators import method_decorator
14 from django.shortcuts import redirect
15
16 from bookwyrm import models
17 from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob
18 from bookwyrm.settings import PAGE_LENGTH
19
20 # pylint: disable=no-self-use,too-many-locals
21 @method_decorator(login_required, name="dispatch")
22 class Export(View):
23 """Let users export data"""
24
25 def get(self, request):
26 """Request csv file"""
27 return TemplateResponse(request, "preferences/export.html")
28
29 def post(self, request):
30 """Download the csv file of a user's book data"""
31 books = models.Edition.viewer_aware_objects(request.user)
32 books_shelves = books.filter(Q(shelves__user=request.user)).distinct()
33 books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()
34 books_review = books.filter(Q(review__user=request.user)).distinct()
35 books_comment = books.filter(Q(comment__user=request.user)).distinct()
36 books_quotation = books.filter(Q(quotation__user=request.user)).distinct()
37
38 books = set(
39 list(books_shelves)
40 + list(books_readthrough)
41 + list(books_review)
42 + list(books_comment)
43 + list(books_quotation)
44 )
45
46 csv_string = io.StringIO()
47 writer = csv.writer(csv_string)
48
49 deduplication_fields = [
50 f.name
51 for f in models.Edition._meta.get_fields() # pylint: disable=protected-access
52 if getattr(f, "deduplication_field", False)
53 ]
54 fields = (
55 ["title", "author_text"]
56 + deduplication_fields
57 + ["start_date", "finish_date", "stopped_date"]
58 + ["rating", "review_name", "review_cw", "review_content"]
59 )
60 writer.writerow(fields)
61
62 for book in books:
63 # I think this is more efficient than doing a subquery in the view? but idk
64 review_rating = (
65 models.Review.objects.filter(
66 user=request.user, book=book, rating__isnull=False
67 )
68 .order_by("-published_date")
69 .first()
70 )
71
72 book.rating = review_rating.rating if review_rating else None
73
74 readthrough = (
75 models.ReadThrough.objects.filter(user=request.user, book=book)
76 .order_by("-start_date", "-finish_date")
77 .first()
78 )
79 if readthrough:
80 book.start_date = (
81 readthrough.start_date.date() if readthrough.start_date else None
82 )
83 book.finish_date = (
84 readthrough.finish_date.date() if readthrough.finish_date else None
85 )
86 book.stopped_date = (
87 readthrough.stopped_date.date()
88 if readthrough.stopped_date
89 else None
90 )
91
92 review = (
93 models.Review.objects.filter(
94 user=request.user, book=book, content__isnull=False
95 )
96 .order_by("-published_date")
97 .first()
98 )
99 if review:
100 book.review_name = review.name
101 book.review_cw = review.content_warning
102 book.review_content = review.raw_content
103 writer.writerow([getattr(book, field, "") or "" for field in fields])
104
105 return HttpResponse(
106 csv_string.getvalue(),
107 content_type="text/csv",
108 headers={
109 "Content-Disposition": 'attachment; filename="bookwyrm-export.csv"'
110 },
111 )
112
113
114 # pylint: disable=no-self-use
115 @method_decorator(login_required, name="dispatch")
116 class ExportUser(View):
117 """Let users export user data to import into another Bookwyrm instance"""
118
119 def get(self, request):
120 """Request tar file"""
121
122 jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(
123 "-created_date"
124 )
125 site = models.SiteSettings.objects.get()
126 hours = site.user_import_time_limit
127 allowed = (
128 jobs.first().created_date < timezone.now() - timedelta(hours=hours)
129 if jobs.first()
130 else True
131 )
132 next_available = (
133 jobs.first().created_date + timedelta(hours=hours) if not allowed else False
134 )
135 paginated = Paginator(jobs, PAGE_LENGTH)
136 page = paginated.get_page(request.GET.get("page"))
137 data = {
138 "jobs": page,
139 "next_available": next_available,
140 "page_range": paginated.get_elided_page_range(
141 page.number, on_each_side=2, on_ends=1
142 ),
143 }
144
145 return TemplateResponse(request, "preferences/export-user.html", data)
146
147 def post(self, request):
148 """Download the json file of a user's data"""
149
150 job = BookwyrmExportJob.objects.create(user=request.user)
151 job.start_job()
152
153 return redirect("prefs-user-export")
154
155
156 @method_decorator(login_required, name="dispatch")
157 class ExportArchive(View):
158 """Serve the archive file"""
159
160 def get(self, request, archive_id):
161 """download user export file"""
162 export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)
163 return HttpResponse(
164 export.export_data,
165 content_type="application/gzip",
166 headers={
167 "Content-Disposition": 'attachment; filename="bookwyrm-account-export.tar.gz"' # pylint: disable=line-too-long
168 },
169 )
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bookwyrm/views/preferences/export.py b/bookwyrm/views/preferences/export.py
--- a/bookwyrm/views/preferences/export.py
+++ b/bookwyrm/views/preferences/export.py
@@ -17,6 +17,7 @@
from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob
from bookwyrm.settings import PAGE_LENGTH
+
# pylint: disable=no-self-use,too-many-locals
@method_decorator(login_required, name="dispatch")
class Export(View):
@@ -54,8 +55,19 @@
fields = (
["title", "author_text"]
+ deduplication_fields
- + ["start_date", "finish_date", "stopped_date"]
- + ["rating", "review_name", "review_cw", "review_content"]
+ + [
+ "start_date",
+ "finish_date",
+ "stopped_date",
+ "rating",
+ "review_name",
+ "review_cw",
+ "review_content",
+ "review_published",
+ "shelf",
+ "shelf_name",
+ "shelf_date",
+ ]
)
writer.writerow(fields)
@@ -97,9 +109,27 @@
.first()
)
if review:
+ book.review_published = (
+ review.published_date.date() if review.published_date else None
+ )
book.review_name = review.name
book.review_cw = review.content_warning
- book.review_content = review.raw_content
+ book.review_content = (
+ review.raw_content if review.raw_content else review.content
+ ) # GoodReads imported reviews do not have raw_content, but content.
+
+ shelfbook = (
+ models.ShelfBook.objects.filter(user=request.user, book=book)
+ .order_by("-shelved_date", "-created_date", "-updated_date")
+ .last()
+ )
+ if shelfbook:
+ book.shelf = shelfbook.shelf.identifier
+ book.shelf_name = shelfbook.shelf.name
+ book.shelf_date = (
+ shelfbook.shelved_date.date() if shelfbook.shelved_date else None
+ )
+
writer.writerow([getattr(book, field, "") or "" for field in fields])
return HttpResponse(
|
{"golden_diff": "diff --git a/bookwyrm/views/preferences/export.py b/bookwyrm/views/preferences/export.py\n--- a/bookwyrm/views/preferences/export.py\n+++ b/bookwyrm/views/preferences/export.py\n@@ -17,6 +17,7 @@\n from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\n from bookwyrm.settings import PAGE_LENGTH\n \n+\n # pylint: disable=no-self-use,too-many-locals\n @method_decorator(login_required, name=\"dispatch\")\n class Export(View):\n@@ -54,8 +55,19 @@\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n- + [\"start_date\", \"finish_date\", \"stopped_date\"]\n- + [\"rating\", \"review_name\", \"review_cw\", \"review_content\"]\n+ + [\n+ \"start_date\",\n+ \"finish_date\",\n+ \"stopped_date\",\n+ \"rating\",\n+ \"review_name\",\n+ \"review_cw\",\n+ \"review_content\",\n+ \"review_published\",\n+ \"shelf\",\n+ \"shelf_name\",\n+ \"shelf_date\",\n+ ]\n )\n writer.writerow(fields)\n \n@@ -97,9 +109,27 @@\n .first()\n )\n if review:\n+ book.review_published = (\n+ review.published_date.date() if review.published_date else None\n+ )\n book.review_name = review.name\n book.review_cw = review.content_warning\n- book.review_content = review.raw_content\n+ book.review_content = (\n+ review.raw_content if review.raw_content else review.content\n+ ) # GoodReads imported reviews do not have raw_content, but content.\n+\n+ shelfbook = (\n+ models.ShelfBook.objects.filter(user=request.user, book=book)\n+ .order_by(\"-shelved_date\", \"-created_date\", \"-updated_date\")\n+ .last()\n+ )\n+ if shelfbook:\n+ book.shelf = shelfbook.shelf.identifier\n+ book.shelf_name = shelfbook.shelf.name\n+ book.shelf_date = (\n+ shelfbook.shelved_date.date() if shelfbook.shelved_date else None\n+ )\n+\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n \n return HttpResponse(\n", "issue": "Exported CSV file does not seem to contain information on what shelf my books are on\n**Describe the bug**\r\nI exported the CSV-file from my account on bookwyrm.social, and it does not seem to contain information on what books I've read and what I want to read and what I am currently reading (Shelves)\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to settings\r\n2. click on CSV export\r\n3. Click on \"Download file\"\r\n4. No apparent status-column in the exported csv-file\r\n\r\n**Expected behavior**\r\nA column indicating what shelf a book is on\r\n\r\n**Instance**\r\nExported from bookwyrm.social\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: MacOS\r\n - Browser Firefox\r\n - Version 113b\n", "before_files": [{"content": "\"\"\" Let users export their book data \"\"\"\nfrom datetime import timedelta\nimport csv\nimport io\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.views import View\nfrom django.utils.decorators import method_decorator\nfrom django.shortcuts import redirect\n\nfrom bookwyrm import models\nfrom bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\nfrom bookwyrm.settings import PAGE_LENGTH\n\n# pylint: disable=no-self-use,too-many-locals\n@method_decorator(login_required, name=\"dispatch\")\nclass Export(View):\n \"\"\"Let users export data\"\"\"\n\n def get(self, request):\n \"\"\"Request csv file\"\"\"\n return TemplateResponse(request, \"preferences/export.html\")\n\n def post(self, request):\n \"\"\"Download the csv file of a user's book data\"\"\"\n books = models.Edition.viewer_aware_objects(request.user)\n books_shelves = books.filter(Q(shelves__user=request.user)).distinct()\n books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()\n books_review = books.filter(Q(review__user=request.user)).distinct()\n books_comment = books.filter(Q(comment__user=request.user)).distinct()\n books_quotation = books.filter(Q(quotation__user=request.user)).distinct()\n\n books = set(\n list(books_shelves)\n + list(books_readthrough)\n + list(books_review)\n + list(books_comment)\n + list(books_quotation)\n )\n\n csv_string = io.StringIO()\n writer = csv.writer(csv_string)\n\n deduplication_fields = [\n f.name\n for f in models.Edition._meta.get_fields() # pylint: disable=protected-access\n if getattr(f, \"deduplication_field\", False)\n ]\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n + [\"start_date\", \"finish_date\", \"stopped_date\"]\n + [\"rating\", \"review_name\", \"review_cw\", \"review_content\"]\n )\n writer.writerow(fields)\n\n for book in books:\n # I think this is more efficient than doing a subquery in the view? but idk\n review_rating = (\n models.Review.objects.filter(\n user=request.user, book=book, rating__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n\n book.rating = review_rating.rating if review_rating else None\n\n readthrough = (\n models.ReadThrough.objects.filter(user=request.user, book=book)\n .order_by(\"-start_date\", \"-finish_date\")\n .first()\n )\n if readthrough:\n book.start_date = (\n readthrough.start_date.date() if readthrough.start_date else None\n )\n book.finish_date = (\n readthrough.finish_date.date() if readthrough.finish_date else None\n )\n book.stopped_date = (\n readthrough.stopped_date.date()\n if readthrough.stopped_date\n else None\n )\n\n review = (\n models.Review.objects.filter(\n user=request.user, book=book, content__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n if review:\n book.review_name = review.name\n book.review_cw = review.content_warning\n book.review_content = review.raw_content\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n\n return HttpResponse(\n csv_string.getvalue(),\n content_type=\"text/csv\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-export.csv\"'\n },\n )\n\n\n# pylint: disable=no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportUser(View):\n \"\"\"Let users export user data to import into another Bookwyrm instance\"\"\"\n\n def get(self, request):\n \"\"\"Request tar file\"\"\"\n\n jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n site = models.SiteSettings.objects.get()\n hours = site.user_import_time_limit\n allowed = (\n jobs.first().created_date < timezone.now() - timedelta(hours=hours)\n if jobs.first()\n else True\n )\n next_available = (\n jobs.first().created_date + timedelta(hours=hours) if not allowed else False\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"jobs\": page,\n \"next_available\": next_available,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n }\n\n return TemplateResponse(request, \"preferences/export-user.html\", data)\n\n def post(self, request):\n \"\"\"Download the json file of a user's data\"\"\"\n\n job = BookwyrmExportJob.objects.create(user=request.user)\n job.start_job()\n\n return redirect(\"prefs-user-export\")\n\n\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportArchive(View):\n \"\"\"Serve the archive file\"\"\"\n\n def get(self, request, archive_id):\n \"\"\"download user export file\"\"\"\n export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)\n return HttpResponse(\n export.export_data,\n content_type=\"application/gzip\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-account-export.tar.gz\"' # pylint: disable=line-too-long\n },\n )\n", "path": "bookwyrm/views/preferences/export.py"}], "after_files": [{"content": "\"\"\" Let users export their book data \"\"\"\nfrom datetime import timedelta\nimport csv\nimport io\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.views import View\nfrom django.utils.decorators import method_decorator\nfrom django.shortcuts import redirect\n\nfrom bookwyrm import models\nfrom bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\nfrom bookwyrm.settings import PAGE_LENGTH\n\n\n# pylint: disable=no-self-use,too-many-locals\n@method_decorator(login_required, name=\"dispatch\")\nclass Export(View):\n \"\"\"Let users export data\"\"\"\n\n def get(self, request):\n \"\"\"Request csv file\"\"\"\n return TemplateResponse(request, \"preferences/export.html\")\n\n def post(self, request):\n \"\"\"Download the csv file of a user's book data\"\"\"\n books = models.Edition.viewer_aware_objects(request.user)\n books_shelves = books.filter(Q(shelves__user=request.user)).distinct()\n books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()\n books_review = books.filter(Q(review__user=request.user)).distinct()\n books_comment = books.filter(Q(comment__user=request.user)).distinct()\n books_quotation = books.filter(Q(quotation__user=request.user)).distinct()\n\n books = set(\n list(books_shelves)\n + list(books_readthrough)\n + list(books_review)\n + list(books_comment)\n + list(books_quotation)\n )\n\n csv_string = io.StringIO()\n writer = csv.writer(csv_string)\n\n deduplication_fields = [\n f.name\n for f in models.Edition._meta.get_fields() # pylint: disable=protected-access\n if getattr(f, \"deduplication_field\", False)\n ]\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n + [\n \"start_date\",\n \"finish_date\",\n \"stopped_date\",\n \"rating\",\n \"review_name\",\n \"review_cw\",\n \"review_content\",\n \"review_published\",\n \"shelf\",\n \"shelf_name\",\n \"shelf_date\",\n ]\n )\n writer.writerow(fields)\n\n for book in books:\n # I think this is more efficient than doing a subquery in the view? but idk\n review_rating = (\n models.Review.objects.filter(\n user=request.user, book=book, rating__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n\n book.rating = review_rating.rating if review_rating else None\n\n readthrough = (\n models.ReadThrough.objects.filter(user=request.user, book=book)\n .order_by(\"-start_date\", \"-finish_date\")\n .first()\n )\n if readthrough:\n book.start_date = (\n readthrough.start_date.date() if readthrough.start_date else None\n )\n book.finish_date = (\n readthrough.finish_date.date() if readthrough.finish_date else None\n )\n book.stopped_date = (\n readthrough.stopped_date.date()\n if readthrough.stopped_date\n else None\n )\n\n review = (\n models.Review.objects.filter(\n user=request.user, book=book, content__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n if review:\n book.review_published = (\n review.published_date.date() if review.published_date else None\n )\n book.review_name = review.name\n book.review_cw = review.content_warning\n book.review_content = (\n review.raw_content if review.raw_content else review.content\n ) # GoodReads imported reviews do not have raw_content, but content.\n\n shelfbook = (\n models.ShelfBook.objects.filter(user=request.user, book=book)\n .order_by(\"-shelved_date\", \"-created_date\", \"-updated_date\")\n .last()\n )\n if shelfbook:\n book.shelf = shelfbook.shelf.identifier\n book.shelf_name = shelfbook.shelf.name\n book.shelf_date = (\n shelfbook.shelved_date.date() if shelfbook.shelved_date else None\n )\n\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n\n return HttpResponse(\n csv_string.getvalue(),\n content_type=\"text/csv\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-export.csv\"'\n },\n )\n\n\n# pylint: disable=no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportUser(View):\n \"\"\"Let users export user data to import into another Bookwyrm instance\"\"\"\n\n def get(self, request):\n \"\"\"Request tar file\"\"\"\n\n jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n site = models.SiteSettings.objects.get()\n hours = site.user_import_time_limit\n allowed = (\n jobs.first().created_date < timezone.now() - timedelta(hours=hours)\n if jobs.first()\n else True\n )\n next_available = (\n jobs.first().created_date + timedelta(hours=hours) if not allowed else False\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"jobs\": page,\n \"next_available\": next_available,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n }\n\n return TemplateResponse(request, \"preferences/export-user.html\", data)\n\n def post(self, request):\n \"\"\"Download the json file of a user's data\"\"\"\n\n job = BookwyrmExportJob.objects.create(user=request.user)\n job.start_job()\n\n return redirect(\"prefs-user-export\")\n\n\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportArchive(View):\n \"\"\"Serve the archive file\"\"\"\n\n def get(self, request, archive_id):\n \"\"\"download user export file\"\"\"\n export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)\n return HttpResponse(\n export.export_data,\n content_type=\"application/gzip\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-account-export.tar.gz\"' # pylint: disable=line-too-long\n },\n )\n", "path": "bookwyrm/views/preferences/export.py"}]}
| 2,029 | 502 |
gh_patches_debug_583
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1750
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.85
On the docket:
+ [x] PEX interpreters should support all underlying Python interpreter options. #1745
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.84"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.84"
+__version__ = "2.1.85"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.84\"\n+__version__ = \"2.1.85\"\n", "issue": "Release 2.1.85\nOn the docket:\r\n+ [x] PEX interpreters should support all underlying Python interpreter options. #1745\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.84\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.85\"\n", "path": "pex/version.py"}]}
| 343 | 96 |
gh_patches_debug_2856
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-223
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
_convert_to_cog function doesn't generate COG
The current _convert_to_cog function (https://github.com/ResonantGeoData/ResonantGeoData/blob/master/rgd/geodata/models/imagery/subsample.py#L32-L51) doesn't output a COG; it just outputs a tiled tiff file. GDAL has two separate format writers; one for regular TIFF and one for COG. Without the '-of COG' option, the regular tiff writer is invoked. The options available to the two writers differ as well: for COG you can specify a predictor with a string value, for regular tiff you must specify a numeric predictor value.
Using lzw compression, I'd recommend the following options: `['-co', 'COMPRESS=LZW', '-co', 'PREDICTOR=YES', '-of', 'COG']`. The default block (tile) size in the COG writer is 512 pixels; some tile servers or consumers seem to prefer 256; if so, add `-co BLOCKSIZE=256`.
You can use tiffdump to see that COG files have multiple directories at different resolutions while non-COG files have a single directory.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rgd/geodata/models/imagery/subsample.py`
Content:
```
1 """Tasks for subsampling images with GDAL."""
2 import os
3 import tempfile
4
5 from celery.utils.log import get_task_logger
6 from django.conf import settings
7 from girder_utils.files import field_file_to_local_path
8 from osgeo import gdal
9
10 from ..common import ArbitraryFile
11 from .base import ConvertedImageFile
12
13 logger = get_task_logger(__name__)
14
15
16 def _gdal_translate(source_field, output_field, **kwargs):
17 workdir = getattr(settings, 'GEODATA_WORKDIR', None)
18 tmpdir = tempfile.mkdtemp(dir=workdir)
19
20 with field_file_to_local_path(source_field) as file_path:
21 logger.info(f'The image file path: {file_path}')
22 output_path = os.path.join(tmpdir, 'subsampled_' + os.path.basename(file_path))
23 ds = gdal.Open(str(file_path))
24 ds = gdal.Translate(output_path, ds, **kwargs)
25 ds = None
26
27 output_field.save(os.path.basename(output_path), open(output_path, 'rb'))
28
29 return
30
31
32 def convert_to_cog(cog_id):
33 """Populate ConvertedImageFile with COG file."""
34 options = [
35 '-co',
36 'COMPRESS=LZW',
37 '-co',
38 'TILED=YES',
39 ]
40 cog = ConvertedImageFile.objects.get(id=cog_id)
41 cog.converted_file = ArbitraryFile()
42 src = cog.source_image.image_file.imagefile.file
43 output = cog.converted_file.file
44 _gdal_translate(src, output, options=options)
45 cog.converted_file.save()
46 cog.save(
47 update_fields=[
48 'converted_file',
49 ]
50 )
51 return
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rgd/geodata/models/imagery/subsample.py b/rgd/geodata/models/imagery/subsample.py
--- a/rgd/geodata/models/imagery/subsample.py
+++ b/rgd/geodata/models/imagery/subsample.py
@@ -35,7 +35,11 @@
'-co',
'COMPRESS=LZW',
'-co',
- 'TILED=YES',
+ 'PREDICTOR=YES',
+ '-of',
+ 'COG',
+ '-co',
+ 'BLOCKSIZE=256',
]
cog = ConvertedImageFile.objects.get(id=cog_id)
cog.converted_file = ArbitraryFile()
|
{"golden_diff": "diff --git a/rgd/geodata/models/imagery/subsample.py b/rgd/geodata/models/imagery/subsample.py\n--- a/rgd/geodata/models/imagery/subsample.py\n+++ b/rgd/geodata/models/imagery/subsample.py\n@@ -35,7 +35,11 @@\n '-co',\n 'COMPRESS=LZW',\n '-co',\n- 'TILED=YES',\n+ 'PREDICTOR=YES',\n+ '-of',\n+ 'COG',\n+ '-co',\n+ 'BLOCKSIZE=256',\n ]\n cog = ConvertedImageFile.objects.get(id=cog_id)\n cog.converted_file = ArbitraryFile()\n", "issue": "_convert_to_cog function doesn't generate COG\nThe current _convert_to_cog function (https://github.com/ResonantGeoData/ResonantGeoData/blob/master/rgd/geodata/models/imagery/subsample.py#L32-L51) doesn't output a COG; it just outputs a tiled tiff file. GDAL has two separate format writers; one for regular TIFF and one for COG. Without the '-of COG' option, the regular tiff writer is invoked. The options available to the two writers differ as well: for COG you can specify a predictor with a string value, for regular tiff you must specify a numeric predictor value.\r\n\r\nUsing lzw compression, I'd recommend the following options: `['-co', 'COMPRESS=LZW', '-co', 'PREDICTOR=YES', '-of', 'COG']`. The default block (tile) size in the COG writer is 512 pixels; some tile servers or consumers seem to prefer 256; if so, add `-co BLOCKSIZE=256`.\r\n\r\nYou can use tiffdump to see that COG files have multiple directories at different resolutions while non-COG files have a single directory.\r\n\n", "before_files": [{"content": "\"\"\"Tasks for subsampling images with GDAL.\"\"\"\nimport os\nimport tempfile\n\nfrom celery.utils.log import get_task_logger\nfrom django.conf import settings\nfrom girder_utils.files import field_file_to_local_path\nfrom osgeo import gdal\n\nfrom ..common import ArbitraryFile\nfrom .base import ConvertedImageFile\n\nlogger = get_task_logger(__name__)\n\n\ndef _gdal_translate(source_field, output_field, **kwargs):\n workdir = getattr(settings, 'GEODATA_WORKDIR', None)\n tmpdir = tempfile.mkdtemp(dir=workdir)\n\n with field_file_to_local_path(source_field) as file_path:\n logger.info(f'The image file path: {file_path}')\n output_path = os.path.join(tmpdir, 'subsampled_' + os.path.basename(file_path))\n ds = gdal.Open(str(file_path))\n ds = gdal.Translate(output_path, ds, **kwargs)\n ds = None\n\n output_field.save(os.path.basename(output_path), open(output_path, 'rb'))\n\n return\n\n\ndef convert_to_cog(cog_id):\n \"\"\"Populate ConvertedImageFile with COG file.\"\"\"\n options = [\n '-co',\n 'COMPRESS=LZW',\n '-co',\n 'TILED=YES',\n ]\n cog = ConvertedImageFile.objects.get(id=cog_id)\n cog.converted_file = ArbitraryFile()\n src = cog.source_image.image_file.imagefile.file\n output = cog.converted_file.file\n _gdal_translate(src, output, options=options)\n cog.converted_file.save()\n cog.save(\n update_fields=[\n 'converted_file',\n ]\n )\n return\n", "path": "rgd/geodata/models/imagery/subsample.py"}], "after_files": [{"content": "\"\"\"Tasks for subsampling images with GDAL.\"\"\"\nimport os\nimport tempfile\n\nfrom celery.utils.log import get_task_logger\nfrom django.conf import settings\nfrom girder_utils.files import field_file_to_local_path\nfrom osgeo import gdal\n\nfrom ..common import ArbitraryFile\nfrom .base import ConvertedImageFile\n\nlogger = get_task_logger(__name__)\n\n\ndef _gdal_translate(source_field, output_field, **kwargs):\n workdir = getattr(settings, 'GEODATA_WORKDIR', None)\n tmpdir = tempfile.mkdtemp(dir=workdir)\n\n with field_file_to_local_path(source_field) as file_path:\n logger.info(f'The image file path: {file_path}')\n output_path = os.path.join(tmpdir, 'subsampled_' + os.path.basename(file_path))\n ds = gdal.Open(str(file_path))\n ds = gdal.Translate(output_path, ds, **kwargs)\n ds = None\n\n output_field.save(os.path.basename(output_path), open(output_path, 'rb'))\n\n return\n\n\ndef convert_to_cog(cog_id):\n \"\"\"Populate ConvertedImageFile with COG file.\"\"\"\n options = [\n '-co',\n 'COMPRESS=LZW',\n '-co',\n 'PREDICTOR=YES',\n '-of',\n 'COG',\n '-co',\n 'BLOCKSIZE=256',\n ]\n cog = ConvertedImageFile.objects.get(id=cog_id)\n cog.converted_file = ArbitraryFile()\n src = cog.source_image.image_file.imagefile.file\n output = cog.converted_file.file\n _gdal_translate(src, output, options=options)\n cog.converted_file.save()\n cog.save(\n update_fields=[\n 'converted_file',\n ]\n )\n return\n", "path": "rgd/geodata/models/imagery/subsample.py"}]}
| 981 | 154 |
gh_patches_debug_25458
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1115
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support create volume Labels options
First, check the remote API:
https://docs.docker.com/engine/reference/api/docker_remote_api_v1.23/
```
{
"Name": "tardis",
"Labels": {
"com.example.some-label": "some-value",
"com.example.some-other-label": "some-other-value"
},
}
```
It provides `Labels` options. But docker-py doesn't support it right not.
Second, in docker-py's document give the following example:
```
volume = cli.create_volume(
name='foobar', driver='local', driver_opts={'foo': 'bar', 'baz': 'false'}
docker.errors.APIError: 500 Server Error: Internal Server Error ("create foobar: invalid option key: "foo"")
```
But driver_opts is not working. What kinds of driver_opts can we use?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/api/volume.py`
Content:
```
1 from .. import utils
2
3
4 class VolumeApiMixin(object):
5 @utils.minimum_version('1.21')
6 def volumes(self, filters=None):
7 params = {
8 'filters': utils.convert_filters(filters) if filters else None
9 }
10 url = self._url('/volumes')
11 return self._result(self._get(url, params=params), True)
12
13 @utils.minimum_version('1.21')
14 def create_volume(self, name, driver=None, driver_opts=None):
15 url = self._url('/volumes/create')
16 if driver_opts is not None and not isinstance(driver_opts, dict):
17 raise TypeError('driver_opts must be a dictionary')
18
19 data = {
20 'Name': name,
21 'Driver': driver,
22 'DriverOpts': driver_opts,
23 }
24 return self._result(self._post_json(url, data=data), True)
25
26 @utils.minimum_version('1.21')
27 def inspect_volume(self, name):
28 url = self._url('/volumes/{0}', name)
29 return self._result(self._get(url), True)
30
31 @utils.minimum_version('1.21')
32 def remove_volume(self, name):
33 url = self._url('/volumes/{0}', name)
34 resp = self._delete(url)
35 self._raise_for_status(resp)
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/api/volume.py b/docker/api/volume.py
--- a/docker/api/volume.py
+++ b/docker/api/volume.py
@@ -1,3 +1,4 @@
+from .. import errors
from .. import utils
@@ -11,7 +12,7 @@
return self._result(self._get(url, params=params), True)
@utils.minimum_version('1.21')
- def create_volume(self, name, driver=None, driver_opts=None):
+ def create_volume(self, name, driver=None, driver_opts=None, labels=None):
url = self._url('/volumes/create')
if driver_opts is not None and not isinstance(driver_opts, dict):
raise TypeError('driver_opts must be a dictionary')
@@ -21,6 +22,16 @@
'Driver': driver,
'DriverOpts': driver_opts,
}
+
+ if labels is not None:
+ if utils.compare_version('1.23', self._version) < 0:
+ raise errors.InvalidVersion(
+ 'volume labels were introduced in API 1.23'
+ )
+ if not isinstance(labels, dict):
+ raise TypeError('labels must be a dictionary')
+ data["Labels"] = labels
+
return self._result(self._post_json(url, data=data), True)
@utils.minimum_version('1.21')
|
{"golden_diff": "diff --git a/docker/api/volume.py b/docker/api/volume.py\n--- a/docker/api/volume.py\n+++ b/docker/api/volume.py\n@@ -1,3 +1,4 @@\n+from .. import errors\n from .. import utils\n \n \n@@ -11,7 +12,7 @@\n return self._result(self._get(url, params=params), True)\n \n @utils.minimum_version('1.21')\n- def create_volume(self, name, driver=None, driver_opts=None):\n+ def create_volume(self, name, driver=None, driver_opts=None, labels=None):\n url = self._url('/volumes/create')\n if driver_opts is not None and not isinstance(driver_opts, dict):\n raise TypeError('driver_opts must be a dictionary')\n@@ -21,6 +22,16 @@\n 'Driver': driver,\n 'DriverOpts': driver_opts,\n }\n+\n+ if labels is not None:\n+ if utils.compare_version('1.23', self._version) < 0:\n+ raise errors.InvalidVersion(\n+ 'volume labels were introduced in API 1.23'\n+ )\n+ if not isinstance(labels, dict):\n+ raise TypeError('labels must be a dictionary')\n+ data[\"Labels\"] = labels\n+\n return self._result(self._post_json(url, data=data), True)\n \n @utils.minimum_version('1.21')\n", "issue": "Support create volume Labels options\nFirst, check the remote API:\nhttps://docs.docker.com/engine/reference/api/docker_remote_api_v1.23/\n\n```\n {\n \"Name\": \"tardis\",\n \"Labels\": {\n \"com.example.some-label\": \"some-value\",\n \"com.example.some-other-label\": \"some-other-value\"\n },\n}\n```\n\nIt provides `Labels` options. But docker-py doesn't support it right not.\n\nSecond, in docker-py's document give the following example:\n\n```\nvolume = cli.create_volume(\n name='foobar', driver='local', driver_opts={'foo': 'bar', 'baz': 'false'}\n\ndocker.errors.APIError: 500 Server Error: Internal Server Error (\"create foobar: invalid option key: \"foo\"\")\n```\n\nBut driver_opts is not working. What kinds of driver_opts can we use?\n\n", "before_files": [{"content": "from .. import utils\n\n\nclass VolumeApiMixin(object):\n @utils.minimum_version('1.21')\n def volumes(self, filters=None):\n params = {\n 'filters': utils.convert_filters(filters) if filters else None\n }\n url = self._url('/volumes')\n return self._result(self._get(url, params=params), True)\n\n @utils.minimum_version('1.21')\n def create_volume(self, name, driver=None, driver_opts=None):\n url = self._url('/volumes/create')\n if driver_opts is not None and not isinstance(driver_opts, dict):\n raise TypeError('driver_opts must be a dictionary')\n\n data = {\n 'Name': name,\n 'Driver': driver,\n 'DriverOpts': driver_opts,\n }\n return self._result(self._post_json(url, data=data), True)\n\n @utils.minimum_version('1.21')\n def inspect_volume(self, name):\n url = self._url('/volumes/{0}', name)\n return self._result(self._get(url), True)\n\n @utils.minimum_version('1.21')\n def remove_volume(self, name):\n url = self._url('/volumes/{0}', name)\n resp = self._delete(url)\n self._raise_for_status(resp)\n", "path": "docker/api/volume.py"}], "after_files": [{"content": "from .. import errors\nfrom .. import utils\n\n\nclass VolumeApiMixin(object):\n @utils.minimum_version('1.21')\n def volumes(self, filters=None):\n params = {\n 'filters': utils.convert_filters(filters) if filters else None\n }\n url = self._url('/volumes')\n return self._result(self._get(url, params=params), True)\n\n @utils.minimum_version('1.21')\n def create_volume(self, name, driver=None, driver_opts=None, labels=None):\n url = self._url('/volumes/create')\n if driver_opts is not None and not isinstance(driver_opts, dict):\n raise TypeError('driver_opts must be a dictionary')\n\n data = {\n 'Name': name,\n 'Driver': driver,\n 'DriverOpts': driver_opts,\n }\n\n if labels is not None:\n if utils.compare_version('1.23', self._version) < 0:\n raise errors.InvalidVersion(\n 'volume labels were introduced in API 1.23'\n )\n if not isinstance(labels, dict):\n raise TypeError('labels must be a dictionary')\n data[\"Labels\"] = labels\n\n return self._result(self._post_json(url, data=data), True)\n\n @utils.minimum_version('1.21')\n def inspect_volume(self, name):\n url = self._url('/volumes/{0}', name)\n return self._result(self._get(url), True)\n\n @utils.minimum_version('1.21')\n def remove_volume(self, name):\n url = self._url('/volumes/{0}', name)\n resp = self._delete(url)\n self._raise_for_status(resp)\n", "path": "docker/api/volume.py"}]}
| 786 | 306 |
gh_patches_debug_22226
|
rasdani/github-patches
|
git_diff
|
refuel-ai__autolabel-703
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: CLI doesn't produce an output file
**Describe the bug**
When using the CLI to run an AutoLabel job, no output file is created. There's no mention of how to specify an output file in the CLI documentation and it doesn't look like the CLI implementation supports it.
In some sense this might be a feature request, but it feels like a bug because the CLI is unusable if it doesn't output the labeled data. Please let me know if I'm missing something!
**To Reproduce**
Run any labeling job via CLI and no output file will be created, e.g.,
```bash
autolabel run test_data.csv autolabel_config.json
```
**Expected behavior**
I would expect an output file with the labeled data.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/autolabel/cli/main.py`
Content:
```
1 from typing import Optional
2 from typing_extensions import Annotated
3 import logging
4
5 import typer
6
7 from autolabel import LabelingAgent
8 from autolabel.schema import TaskType, ModelProvider, FewShotAlgorithm
9 from autolabel.few_shot import PROVIDER_TO_MODEL
10 from autolabel.dataset import AutolabelDataset
11
12 from autolabel.cli.config import init, create_config_wizard
13
14 app = typer.Typer(
15 rich_markup_mode="rich",
16 no_args_is_help=True,
17 help="[bold]Autolabel CLI[/bold] 🏷️",
18 )
19
20
21 @app.command(name="config")
22 def config_command(
23 seed: Annotated[
24 Optional[str],
25 typer.Argument(
26 help="Optional seed dataset to help auto-fill the config. Recommended for a more accurate config"
27 ),
28 ] = None,
29 ):
30 """Create a new [bold]config[/bold] file using a wizard 🪄"""
31 create_config_wizard(seed)
32
33
34 @app.command(
35 name="init",
36 )
37 def init_command(
38 seed: Annotated[
39 Optional[str],
40 typer.Argument(
41 help="Optional seed dataset to help auto-fill the config. Recommended for a more accurate config"
42 ),
43 ] = None,
44 task_name: Annotated[
45 str,
46 typer.Option(
47 help="Name of the task to create a config for",
48 show_default=False,
49 ),
50 ] = None,
51 task_type: Annotated[
52 str,
53 typer.Option(
54 help=f"Type of task to create. Options: [magenta]{', '.join([t for t in TaskType])}[/magenta]",
55 show_default=False,
56 ),
57 ] = None,
58 dataset_label_column: Annotated[
59 str,
60 typer.Option(
61 "--label-column",
62 help="Name of the column containing the labels",
63 show_default=False,
64 rich_help_panel="Dataset Configuration",
65 ),
66 ] = None,
67 dataset_label_separator: Annotated[
68 str,
69 typer.Option(
70 "--label-separator",
71 help="Separator to use when separating multiple labels for multilabel classification",
72 show_default=False,
73 rich_help_panel="Dataset Configuration",
74 ),
75 ] = None,
76 dataset_explanation_column: Annotated[
77 str,
78 typer.Option(
79 "--explanation-column",
80 help="Name of the column containing the explanations",
81 show_default=False,
82 rich_help_panel="Dataset Configuration",
83 ),
84 ] = None,
85 dataset_text_column: Annotated[
86 str,
87 typer.Option(
88 "--text-column",
89 help="Name of the column containing the text to label",
90 show_default=False,
91 rich_help_panel="Dataset Configuration",
92 ),
93 ] = None,
94 dataset_delimiter: Annotated[
95 str,
96 typer.Option(
97 "--delimiter",
98 help="Delimiter to use when parsing the dataset",
99 show_default=False,
100 rich_help_panel="Dataset Configuration",
101 ),
102 ] = None, # None means it will be guessed from seed.csv or default to a comma
103 model_provider: Annotated[
104 str,
105 typer.Option(
106 "--provider",
107 help=f"Provider of the model to use. Options: [magenta]{', '.join([p for p in ModelProvider])}[/magenta]",
108 rich_help_panel="Model Configuration",
109 ),
110 ] = "openai",
111 model_name: Annotated[
112 str,
113 typer.Option(
114 "--model",
115 help="Name of the model to use",
116 rich_help_panel="Model Configuration",
117 ),
118 ] = "gpt-3.5-turbo",
119 model_compute_confidence: Annotated[
120 bool,
121 typer.Option(
122 "--compute-confidence",
123 help="Whether to compute confidence scores for each label",
124 show_default=False,
125 rich_help_panel="Model Configuration",
126 ),
127 ] = None,
128 model_logit_bias: Annotated[
129 bool,
130 typer.Option(
131 "--logit-bias",
132 help="Whether to use logit biasing to constrain the model to certain tokens",
133 show_default=False,
134 rich_help_panel="Model Configuration",
135 ),
136 ] = None,
137 embedding_provider: Annotated[
138 str,
139 typer.Option(
140 "--embedding-provider",
141 help=f"Provider of the embedding model to use. Options: [magenta]{', '.join([p for p in PROVIDER_TO_MODEL])}[/magenta]",
142 show_default=False,
143 rich_help_panel="Embedding Configuration",
144 ),
145 ] = None,
146 embedding_model_name: Annotated[
147 str,
148 typer.Option(
149 "--embedding-model",
150 help="Name of the embedding model to use",
151 show_default=False,
152 rich_help_panel="Embedding Configuration",
153 ),
154 ] = None,
155 guess_labels: Annotated[
156 bool,
157 typer.Option(
158 "--guess-labels",
159 help="Whether to guess the labels from the seed dataset. If set, --task-type, --delimiter, and --label-column (and --label-separator for mulitlabel classification) must be defined",
160 rich_help_panel="Prompt Configuration",
161 ),
162 ] = False,
163 prompt_task_guidelines: Annotated[
164 str,
165 typer.Option(
166 "--task-guidelines",
167 help="Guidelines for the task. [code]{labels}[/code] will be replaced with a newline-separated list of labels",
168 show_default=False,
169 rich_help_panel="Prompt Configuration",
170 ),
171 ] = None,
172 prompt_few_shot_examples: Annotated[
173 str,
174 typer.Option(
175 "--few-shot-examples",
176 help="Seed dataset to use for few-shot prompting",
177 show_default=False,
178 rich_help_panel="Prompt Configuration",
179 ),
180 ] = None,
181 prompt_few_shot_selection: Annotated[
182 str,
183 typer.Option(
184 "--few-shot-selection",
185 help=f"What algorithm to use to select examples from the seed dataset. Options: [magenta]{', '.join([a for a in FewShotAlgorithm])}[/magenta]",
186 show_default=False,
187 rich_help_panel="Prompt Configuration",
188 ),
189 ] = None,
190 prompt_few_shot_num: Annotated[
191 int,
192 typer.Option(
193 "--few-shot-num",
194 help="Number of examples to select from the seed dataset",
195 show_default=False,
196 rich_help_panel="Prompt Configuration",
197 ),
198 ] = None,
199 prompt_example_template: Annotated[
200 str,
201 typer.Option(
202 "--example-template",
203 help="Template to use for each example. [code]{column_name}[/code] will be replaced with the corresponding column value for each example",
204 show_default=False,
205 rich_help_panel="Prompt Configuration",
206 ),
207 ] = None,
208 prompt_output_guidelines: Annotated[
209 str,
210 typer.Option(
211 "--output-guidelines",
212 help="Guidelines for the output",
213 show_default=False,
214 rich_help_panel="Prompt Configuration",
215 ),
216 ] = None,
217 prompt_output_format: Annotated[
218 str,
219 typer.Option(
220 "--output-format",
221 help="Format to use for the output",
222 show_default=False,
223 rich_help_panel="Prompt Configuration",
224 ),
225 ] = None,
226 prompt_chain_of_thought: Annotated[
227 bool,
228 typer.Option(
229 "--chain-of-thought",
230 help="Whether to use chain of thought",
231 show_default=False,
232 rich_help_panel="Prompt Configuration",
233 ),
234 ] = None,
235 ):
236 """Generate a new template [bold]config[/bold] file 📄"""
237 init(
238 seed,
239 task_name,
240 task_type,
241 dataset_label_column=dataset_label_column,
242 dataset_label_separator=dataset_label_separator,
243 dataset_explanation_column=dataset_explanation_column,
244 dataset_text_column=dataset_text_column,
245 dataset_delimiter=dataset_delimiter,
246 model_provider=model_provider,
247 model_name=model_name,
248 model_compute_confidence=model_compute_confidence,
249 model_logit_bias=model_logit_bias,
250 embedding_provider=embedding_provider,
251 embedding_model_name=embedding_model_name,
252 guess_labels=guess_labels,
253 prompt_task_guidelines=prompt_task_guidelines,
254 prompt_few_shot_examples=prompt_few_shot_examples,
255 prompt_few_shot_selection=prompt_few_shot_selection,
256 prompt_few_shot_num=prompt_few_shot_num,
257 prompt_example_template=prompt_example_template,
258 prompt_output_guidelines=prompt_output_guidelines,
259 prompt_output_format=prompt_output_format,
260 prompt_chain_of_thought=prompt_chain_of_thought,
261 )
262
263
264 def setup_logging(
265 verbose_debug: bool = False,
266 verbose_info: bool = False,
267 quiet_warning: bool = False,
268 quiet_error: bool = False,
269 ):
270 if verbose_debug:
271 log_level = logging.DEBUG
272 elif verbose_info:
273 log_level = logging.INFO
274 elif quiet_warning:
275 log_level = logging.ERROR
276 elif quiet_error:
277 log_level = logging.CRITICAL
278 else:
279 log_level = logging.WARNING
280 logging.getLogger("autolabel").setLevel(log_level)
281 logging.getLogger("langchain").setLevel(log_level)
282
283
284 @app.command()
285 def plan(
286 dataset: Annotated[
287 str, typer.Argument(help="Path to dataset to label", show_default=False)
288 ],
289 config: Annotated[
290 str, typer.Argument(help="Path to config file", show_default=False)
291 ],
292 max_items: Annotated[int, typer.Option(help="Max number of items to label")] = None,
293 start_index: Annotated[int, typer.Option(help="Index to start at")] = 0,
294 cache: Annotated[bool, typer.Option(help="Cache results")] = True,
295 verbose_debug: Annotated[
296 bool, typer.Option("--debug", "-vv", help="Verbose (debug log level)")
297 ] = False,
298 verbose_info: Annotated[
299 bool, typer.Option("--info", "-v", help="Verbose (info log level)")
300 ] = False,
301 quiet_warning: Annotated[
302 bool, typer.Option("--error", "-q", help="Quiet (error log level)")
303 ] = False,
304 quiet_error: Annotated[
305 bool, typer.Option("--critical", "-qq", help="Quiet (critical log level)")
306 ] = False,
307 ):
308 """[bold]Plan[/bold] 🔍 a labeling session in accordance with the provided dataset and config file"""
309 setup_logging(verbose_debug, verbose_info, quiet_warning, quiet_error)
310 agent = LabelingAgent(config=config, cache=cache)
311 config = agent.config
312 dataset = AutolabelDataset(dataset, config)
313 agent.plan(dataset, max_items=max_items, start_index=start_index)
314
315
316 @app.command()
317 def run(
318 dataset: Annotated[
319 str, typer.Argument(help="Path to dataset to label", show_default=False)
320 ],
321 config: Annotated[
322 str, typer.Argument(help="Path to config file", show_default=False)
323 ],
324 max_items: Annotated[int, typer.Option(help="Max number of items to label")] = None,
325 start_index: Annotated[int, typer.Option(help="Index to start at")] = 0,
326 cache: Annotated[bool, typer.Option(help="Cache results")] = True,
327 verbose_debug: Annotated[
328 bool, typer.Option("--debug", "-vv", help="Verbose (debug log level)")
329 ] = False,
330 verbose_info: Annotated[
331 bool, typer.Option("--info", "-v", help="Verbose (info log level)")
332 ] = False,
333 quiet_warning: Annotated[
334 bool, typer.Option("--error", "-q", help="Quiet (error log level)")
335 ] = False,
336 quiet_error: Annotated[
337 bool, typer.Option("--critical", "-qq", help="Quiet (critical log level)")
338 ] = False,
339 ):
340 """[bold]Run[/bold] ▶️ a labeling session in accordance with the provided dataset and config file"""
341 setup_logging(verbose_debug, verbose_info, quiet_warning, quiet_error)
342 agent = LabelingAgent(config=config, cache=cache)
343 config = agent.config
344 dataset = AutolabelDataset(dataset, config)
345 agent.run(dataset, max_items=max_items, start_index=start_index)
346
347
348 if __name__ == "__main__":
349 app()
350
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/autolabel/cli/main.py b/src/autolabel/cli/main.py
--- a/src/autolabel/cli/main.py
+++ b/src/autolabel/cli/main.py
@@ -324,6 +324,9 @@
max_items: Annotated[int, typer.Option(help="Max number of items to label")] = None,
start_index: Annotated[int, typer.Option(help="Index to start at")] = 0,
cache: Annotated[bool, typer.Option(help="Cache results")] = True,
+ output_name: Annotated[
+ str, typer.Option(help="Path to output file to save run results to")
+ ] = None,
verbose_debug: Annotated[
bool, typer.Option("--debug", "-vv", help="Verbose (debug log level)")
] = False,
@@ -342,7 +345,9 @@
agent = LabelingAgent(config=config, cache=cache)
config = agent.config
dataset = AutolabelDataset(dataset, config)
- agent.run(dataset, max_items=max_items, start_index=start_index)
+ agent.run(
+ dataset, max_items=max_items, output_name=output_name, start_index=start_index
+ )
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/src/autolabel/cli/main.py b/src/autolabel/cli/main.py\n--- a/src/autolabel/cli/main.py\n+++ b/src/autolabel/cli/main.py\n@@ -324,6 +324,9 @@\n max_items: Annotated[int, typer.Option(help=\"Max number of items to label\")] = None,\n start_index: Annotated[int, typer.Option(help=\"Index to start at\")] = 0,\n cache: Annotated[bool, typer.Option(help=\"Cache results\")] = True,\n+ output_name: Annotated[\n+ str, typer.Option(help=\"Path to output file to save run results to\")\n+ ] = None,\n verbose_debug: Annotated[\n bool, typer.Option(\"--debug\", \"-vv\", help=\"Verbose (debug log level)\")\n ] = False,\n@@ -342,7 +345,9 @@\n agent = LabelingAgent(config=config, cache=cache)\n config = agent.config\n dataset = AutolabelDataset(dataset, config)\n- agent.run(dataset, max_items=max_items, start_index=start_index)\n+ agent.run(\n+ dataset, max_items=max_items, output_name=output_name, start_index=start_index\n+ )\n \n \n if __name__ == \"__main__\":\n", "issue": "[Bug]: CLI doesn't produce an output file\n**Describe the bug**\r\nWhen using the CLI to run an AutoLabel job, no output file is created. There's no mention of how to specify an output file in the CLI documentation and it doesn't look like the CLI implementation supports it.\r\n\r\nIn some sense this might be a feature request, but it feels like a bug because the CLI is unusable if it doesn't output the labeled data. Please let me know if I'm missing something!\r\n\r\n**To Reproduce**\r\nRun any labeling job via CLI and no output file will be created, e.g., \r\n```bash\r\nautolabel run test_data.csv autolabel_config.json\r\n```\r\n\r\n**Expected behavior**\r\nI would expect an output file with the labeled data.\r\n\r\n\n", "before_files": [{"content": "from typing import Optional\nfrom typing_extensions import Annotated\nimport logging\n\nimport typer\n\nfrom autolabel import LabelingAgent\nfrom autolabel.schema import TaskType, ModelProvider, FewShotAlgorithm\nfrom autolabel.few_shot import PROVIDER_TO_MODEL\nfrom autolabel.dataset import AutolabelDataset\n\nfrom autolabel.cli.config import init, create_config_wizard\n\napp = typer.Typer(\n rich_markup_mode=\"rich\",\n no_args_is_help=True,\n help=\"[bold]Autolabel CLI[/bold] \ud83c\udff7\ufe0f\",\n)\n\n\[email protected](name=\"config\")\ndef config_command(\n seed: Annotated[\n Optional[str],\n typer.Argument(\n help=\"Optional seed dataset to help auto-fill the config. Recommended for a more accurate config\"\n ),\n ] = None,\n):\n \"\"\"Create a new [bold]config[/bold] file using a wizard \ud83e\ude84\"\"\"\n create_config_wizard(seed)\n\n\[email protected](\n name=\"init\",\n)\ndef init_command(\n seed: Annotated[\n Optional[str],\n typer.Argument(\n help=\"Optional seed dataset to help auto-fill the config. Recommended for a more accurate config\"\n ),\n ] = None,\n task_name: Annotated[\n str,\n typer.Option(\n help=\"Name of the task to create a config for\",\n show_default=False,\n ),\n ] = None,\n task_type: Annotated[\n str,\n typer.Option(\n help=f\"Type of task to create. Options: [magenta]{', '.join([t for t in TaskType])}[/magenta]\",\n show_default=False,\n ),\n ] = None,\n dataset_label_column: Annotated[\n str,\n typer.Option(\n \"--label-column\",\n help=\"Name of the column containing the labels\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_label_separator: Annotated[\n str,\n typer.Option(\n \"--label-separator\",\n help=\"Separator to use when separating multiple labels for multilabel classification\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_explanation_column: Annotated[\n str,\n typer.Option(\n \"--explanation-column\",\n help=\"Name of the column containing the explanations\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_text_column: Annotated[\n str,\n typer.Option(\n \"--text-column\",\n help=\"Name of the column containing the text to label\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_delimiter: Annotated[\n str,\n typer.Option(\n \"--delimiter\",\n help=\"Delimiter to use when parsing the dataset\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None, # None means it will be guessed from seed.csv or default to a comma\n model_provider: Annotated[\n str,\n typer.Option(\n \"--provider\",\n help=f\"Provider of the model to use. Options: [magenta]{', '.join([p for p in ModelProvider])}[/magenta]\",\n rich_help_panel=\"Model Configuration\",\n ),\n ] = \"openai\",\n model_name: Annotated[\n str,\n typer.Option(\n \"--model\",\n help=\"Name of the model to use\",\n rich_help_panel=\"Model Configuration\",\n ),\n ] = \"gpt-3.5-turbo\",\n model_compute_confidence: Annotated[\n bool,\n typer.Option(\n \"--compute-confidence\",\n help=\"Whether to compute confidence scores for each label\",\n show_default=False,\n rich_help_panel=\"Model Configuration\",\n ),\n ] = None,\n model_logit_bias: Annotated[\n bool,\n typer.Option(\n \"--logit-bias\",\n help=\"Whether to use logit biasing to constrain the model to certain tokens\",\n show_default=False,\n rich_help_panel=\"Model Configuration\",\n ),\n ] = None,\n embedding_provider: Annotated[\n str,\n typer.Option(\n \"--embedding-provider\",\n help=f\"Provider of the embedding model to use. Options: [magenta]{', '.join([p for p in PROVIDER_TO_MODEL])}[/magenta]\",\n show_default=False,\n rich_help_panel=\"Embedding Configuration\",\n ),\n ] = None,\n embedding_model_name: Annotated[\n str,\n typer.Option(\n \"--embedding-model\",\n help=\"Name of the embedding model to use\",\n show_default=False,\n rich_help_panel=\"Embedding Configuration\",\n ),\n ] = None,\n guess_labels: Annotated[\n bool,\n typer.Option(\n \"--guess-labels\",\n help=\"Whether to guess the labels from the seed dataset. If set, --task-type, --delimiter, and --label-column (and --label-separator for mulitlabel classification) must be defined\",\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = False,\n prompt_task_guidelines: Annotated[\n str,\n typer.Option(\n \"--task-guidelines\",\n help=\"Guidelines for the task. [code]{labels}[/code] will be replaced with a newline-separated list of labels\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_few_shot_examples: Annotated[\n str,\n typer.Option(\n \"--few-shot-examples\",\n help=\"Seed dataset to use for few-shot prompting\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_few_shot_selection: Annotated[\n str,\n typer.Option(\n \"--few-shot-selection\",\n help=f\"What algorithm to use to select examples from the seed dataset. Options: [magenta]{', '.join([a for a in FewShotAlgorithm])}[/magenta]\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_few_shot_num: Annotated[\n int,\n typer.Option(\n \"--few-shot-num\",\n help=\"Number of examples to select from the seed dataset\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_example_template: Annotated[\n str,\n typer.Option(\n \"--example-template\",\n help=\"Template to use for each example. [code]{column_name}[/code] will be replaced with the corresponding column value for each example\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_output_guidelines: Annotated[\n str,\n typer.Option(\n \"--output-guidelines\",\n help=\"Guidelines for the output\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_output_format: Annotated[\n str,\n typer.Option(\n \"--output-format\",\n help=\"Format to use for the output\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_chain_of_thought: Annotated[\n bool,\n typer.Option(\n \"--chain-of-thought\",\n help=\"Whether to use chain of thought\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n):\n \"\"\"Generate a new template [bold]config[/bold] file \ud83d\udcc4\"\"\"\n init(\n seed,\n task_name,\n task_type,\n dataset_label_column=dataset_label_column,\n dataset_label_separator=dataset_label_separator,\n dataset_explanation_column=dataset_explanation_column,\n dataset_text_column=dataset_text_column,\n dataset_delimiter=dataset_delimiter,\n model_provider=model_provider,\n model_name=model_name,\n model_compute_confidence=model_compute_confidence,\n model_logit_bias=model_logit_bias,\n embedding_provider=embedding_provider,\n embedding_model_name=embedding_model_name,\n guess_labels=guess_labels,\n prompt_task_guidelines=prompt_task_guidelines,\n prompt_few_shot_examples=prompt_few_shot_examples,\n prompt_few_shot_selection=prompt_few_shot_selection,\n prompt_few_shot_num=prompt_few_shot_num,\n prompt_example_template=prompt_example_template,\n prompt_output_guidelines=prompt_output_guidelines,\n prompt_output_format=prompt_output_format,\n prompt_chain_of_thought=prompt_chain_of_thought,\n )\n\n\ndef setup_logging(\n verbose_debug: bool = False,\n verbose_info: bool = False,\n quiet_warning: bool = False,\n quiet_error: bool = False,\n):\n if verbose_debug:\n log_level = logging.DEBUG\n elif verbose_info:\n log_level = logging.INFO\n elif quiet_warning:\n log_level = logging.ERROR\n elif quiet_error:\n log_level = logging.CRITICAL\n else:\n log_level = logging.WARNING\n logging.getLogger(\"autolabel\").setLevel(log_level)\n logging.getLogger(\"langchain\").setLevel(log_level)\n\n\[email protected]()\ndef plan(\n dataset: Annotated[\n str, typer.Argument(help=\"Path to dataset to label\", show_default=False)\n ],\n config: Annotated[\n str, typer.Argument(help=\"Path to config file\", show_default=False)\n ],\n max_items: Annotated[int, typer.Option(help=\"Max number of items to label\")] = None,\n start_index: Annotated[int, typer.Option(help=\"Index to start at\")] = 0,\n cache: Annotated[bool, typer.Option(help=\"Cache results\")] = True,\n verbose_debug: Annotated[\n bool, typer.Option(\"--debug\", \"-vv\", help=\"Verbose (debug log level)\")\n ] = False,\n verbose_info: Annotated[\n bool, typer.Option(\"--info\", \"-v\", help=\"Verbose (info log level)\")\n ] = False,\n quiet_warning: Annotated[\n bool, typer.Option(\"--error\", \"-q\", help=\"Quiet (error log level)\")\n ] = False,\n quiet_error: Annotated[\n bool, typer.Option(\"--critical\", \"-qq\", help=\"Quiet (critical log level)\")\n ] = False,\n):\n \"\"\"[bold]Plan[/bold] \ud83d\udd0d a labeling session in accordance with the provided dataset and config file\"\"\"\n setup_logging(verbose_debug, verbose_info, quiet_warning, quiet_error)\n agent = LabelingAgent(config=config, cache=cache)\n config = agent.config\n dataset = AutolabelDataset(dataset, config)\n agent.plan(dataset, max_items=max_items, start_index=start_index)\n\n\[email protected]()\ndef run(\n dataset: Annotated[\n str, typer.Argument(help=\"Path to dataset to label\", show_default=False)\n ],\n config: Annotated[\n str, typer.Argument(help=\"Path to config file\", show_default=False)\n ],\n max_items: Annotated[int, typer.Option(help=\"Max number of items to label\")] = None,\n start_index: Annotated[int, typer.Option(help=\"Index to start at\")] = 0,\n cache: Annotated[bool, typer.Option(help=\"Cache results\")] = True,\n verbose_debug: Annotated[\n bool, typer.Option(\"--debug\", \"-vv\", help=\"Verbose (debug log level)\")\n ] = False,\n verbose_info: Annotated[\n bool, typer.Option(\"--info\", \"-v\", help=\"Verbose (info log level)\")\n ] = False,\n quiet_warning: Annotated[\n bool, typer.Option(\"--error\", \"-q\", help=\"Quiet (error log level)\")\n ] = False,\n quiet_error: Annotated[\n bool, typer.Option(\"--critical\", \"-qq\", help=\"Quiet (critical log level)\")\n ] = False,\n):\n \"\"\"[bold]Run[/bold] \u25b6\ufe0f a labeling session in accordance with the provided dataset and config file\"\"\"\n setup_logging(verbose_debug, verbose_info, quiet_warning, quiet_error)\n agent = LabelingAgent(config=config, cache=cache)\n config = agent.config\n dataset = AutolabelDataset(dataset, config)\n agent.run(dataset, max_items=max_items, start_index=start_index)\n\n\nif __name__ == \"__main__\":\n app()\n", "path": "src/autolabel/cli/main.py"}], "after_files": [{"content": "from typing import Optional\nfrom typing_extensions import Annotated\nimport logging\n\nimport typer\n\nfrom autolabel import LabelingAgent\nfrom autolabel.schema import TaskType, ModelProvider, FewShotAlgorithm\nfrom autolabel.few_shot import PROVIDER_TO_MODEL\nfrom autolabel.dataset import AutolabelDataset\n\nfrom autolabel.cli.config import init, create_config_wizard\n\napp = typer.Typer(\n rich_markup_mode=\"rich\",\n no_args_is_help=True,\n help=\"[bold]Autolabel CLI[/bold] \ud83c\udff7\ufe0f\",\n)\n\n\[email protected](name=\"config\")\ndef config_command(\n seed: Annotated[\n Optional[str],\n typer.Argument(\n help=\"Optional seed dataset to help auto-fill the config. Recommended for a more accurate config\"\n ),\n ] = None,\n):\n \"\"\"Create a new [bold]config[/bold] file using a wizard \ud83e\ude84\"\"\"\n create_config_wizard(seed)\n\n\[email protected](\n name=\"init\",\n)\ndef init_command(\n seed: Annotated[\n Optional[str],\n typer.Argument(\n help=\"Optional seed dataset to help auto-fill the config. Recommended for a more accurate config\"\n ),\n ] = None,\n task_name: Annotated[\n str,\n typer.Option(\n help=\"Name of the task to create a config for\",\n show_default=False,\n ),\n ] = None,\n task_type: Annotated[\n str,\n typer.Option(\n help=f\"Type of task to create. Options: [magenta]{', '.join([t for t in TaskType])}[/magenta]\",\n show_default=False,\n ),\n ] = None,\n dataset_label_column: Annotated[\n str,\n typer.Option(\n \"--label-column\",\n help=\"Name of the column containing the labels\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_label_separator: Annotated[\n str,\n typer.Option(\n \"--label-separator\",\n help=\"Separator to use when separating multiple labels for multilabel classification\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_explanation_column: Annotated[\n str,\n typer.Option(\n \"--explanation-column\",\n help=\"Name of the column containing the explanations\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_text_column: Annotated[\n str,\n typer.Option(\n \"--text-column\",\n help=\"Name of the column containing the text to label\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None,\n dataset_delimiter: Annotated[\n str,\n typer.Option(\n \"--delimiter\",\n help=\"Delimiter to use when parsing the dataset\",\n show_default=False,\n rich_help_panel=\"Dataset Configuration\",\n ),\n ] = None, # None means it will be guessed from seed.csv or default to a comma\n model_provider: Annotated[\n str,\n typer.Option(\n \"--provider\",\n help=f\"Provider of the model to use. Options: [magenta]{', '.join([p for p in ModelProvider])}[/magenta]\",\n rich_help_panel=\"Model Configuration\",\n ),\n ] = \"openai\",\n model_name: Annotated[\n str,\n typer.Option(\n \"--model\",\n help=\"Name of the model to use\",\n rich_help_panel=\"Model Configuration\",\n ),\n ] = \"gpt-3.5-turbo\",\n model_compute_confidence: Annotated[\n bool,\n typer.Option(\n \"--compute-confidence\",\n help=\"Whether to compute confidence scores for each label\",\n show_default=False,\n rich_help_panel=\"Model Configuration\",\n ),\n ] = None,\n model_logit_bias: Annotated[\n bool,\n typer.Option(\n \"--logit-bias\",\n help=\"Whether to use logit biasing to constrain the model to certain tokens\",\n show_default=False,\n rich_help_panel=\"Model Configuration\",\n ),\n ] = None,\n embedding_provider: Annotated[\n str,\n typer.Option(\n \"--embedding-provider\",\n help=f\"Provider of the embedding model to use. Options: [magenta]{', '.join([p for p in PROVIDER_TO_MODEL])}[/magenta]\",\n show_default=False,\n rich_help_panel=\"Embedding Configuration\",\n ),\n ] = None,\n embedding_model_name: Annotated[\n str,\n typer.Option(\n \"--embedding-model\",\n help=\"Name of the embedding model to use\",\n show_default=False,\n rich_help_panel=\"Embedding Configuration\",\n ),\n ] = None,\n guess_labels: Annotated[\n bool,\n typer.Option(\n \"--guess-labels\",\n help=\"Whether to guess the labels from the seed dataset. If set, --task-type, --delimiter, and --label-column (and --label-separator for mulitlabel classification) must be defined\",\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = False,\n prompt_task_guidelines: Annotated[\n str,\n typer.Option(\n \"--task-guidelines\",\n help=\"Guidelines for the task. [code]{labels}[/code] will be replaced with a newline-separated list of labels\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_few_shot_examples: Annotated[\n str,\n typer.Option(\n \"--few-shot-examples\",\n help=\"Seed dataset to use for few-shot prompting\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_few_shot_selection: Annotated[\n str,\n typer.Option(\n \"--few-shot-selection\",\n help=f\"What algorithm to use to select examples from the seed dataset. Options: [magenta]{', '.join([a for a in FewShotAlgorithm])}[/magenta]\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_few_shot_num: Annotated[\n int,\n typer.Option(\n \"--few-shot-num\",\n help=\"Number of examples to select from the seed dataset\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_example_template: Annotated[\n str,\n typer.Option(\n \"--example-template\",\n help=\"Template to use for each example. [code]{column_name}[/code] will be replaced with the corresponding column value for each example\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_output_guidelines: Annotated[\n str,\n typer.Option(\n \"--output-guidelines\",\n help=\"Guidelines for the output\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_output_format: Annotated[\n str,\n typer.Option(\n \"--output-format\",\n help=\"Format to use for the output\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n prompt_chain_of_thought: Annotated[\n bool,\n typer.Option(\n \"--chain-of-thought\",\n help=\"Whether to use chain of thought\",\n show_default=False,\n rich_help_panel=\"Prompt Configuration\",\n ),\n ] = None,\n):\n \"\"\"Generate a new template [bold]config[/bold] file \ud83d\udcc4\"\"\"\n init(\n seed,\n task_name,\n task_type,\n dataset_label_column=dataset_label_column,\n dataset_label_separator=dataset_label_separator,\n dataset_explanation_column=dataset_explanation_column,\n dataset_text_column=dataset_text_column,\n dataset_delimiter=dataset_delimiter,\n model_provider=model_provider,\n model_name=model_name,\n model_compute_confidence=model_compute_confidence,\n model_logit_bias=model_logit_bias,\n embedding_provider=embedding_provider,\n embedding_model_name=embedding_model_name,\n guess_labels=guess_labels,\n prompt_task_guidelines=prompt_task_guidelines,\n prompt_few_shot_examples=prompt_few_shot_examples,\n prompt_few_shot_selection=prompt_few_shot_selection,\n prompt_few_shot_num=prompt_few_shot_num,\n prompt_example_template=prompt_example_template,\n prompt_output_guidelines=prompt_output_guidelines,\n prompt_output_format=prompt_output_format,\n prompt_chain_of_thought=prompt_chain_of_thought,\n )\n\n\ndef setup_logging(\n verbose_debug: bool = False,\n verbose_info: bool = False,\n quiet_warning: bool = False,\n quiet_error: bool = False,\n):\n if verbose_debug:\n log_level = logging.DEBUG\n elif verbose_info:\n log_level = logging.INFO\n elif quiet_warning:\n log_level = logging.ERROR\n elif quiet_error:\n log_level = logging.CRITICAL\n else:\n log_level = logging.WARNING\n logging.getLogger(\"autolabel\").setLevel(log_level)\n logging.getLogger(\"langchain\").setLevel(log_level)\n\n\[email protected]()\ndef plan(\n dataset: Annotated[\n str, typer.Argument(help=\"Path to dataset to label\", show_default=False)\n ],\n config: Annotated[\n str, typer.Argument(help=\"Path to config file\", show_default=False)\n ],\n max_items: Annotated[int, typer.Option(help=\"Max number of items to label\")] = None,\n start_index: Annotated[int, typer.Option(help=\"Index to start at\")] = 0,\n cache: Annotated[bool, typer.Option(help=\"Cache results\")] = True,\n verbose_debug: Annotated[\n bool, typer.Option(\"--debug\", \"-vv\", help=\"Verbose (debug log level)\")\n ] = False,\n verbose_info: Annotated[\n bool, typer.Option(\"--info\", \"-v\", help=\"Verbose (info log level)\")\n ] = False,\n quiet_warning: Annotated[\n bool, typer.Option(\"--error\", \"-q\", help=\"Quiet (error log level)\")\n ] = False,\n quiet_error: Annotated[\n bool, typer.Option(\"--critical\", \"-qq\", help=\"Quiet (critical log level)\")\n ] = False,\n):\n \"\"\"[bold]Plan[/bold] \ud83d\udd0d a labeling session in accordance with the provided dataset and config file\"\"\"\n setup_logging(verbose_debug, verbose_info, quiet_warning, quiet_error)\n agent = LabelingAgent(config=config, cache=cache)\n config = agent.config\n dataset = AutolabelDataset(dataset, config)\n agent.plan(dataset, max_items=max_items, start_index=start_index)\n\n\[email protected]()\ndef run(\n dataset: Annotated[\n str, typer.Argument(help=\"Path to dataset to label\", show_default=False)\n ],\n config: Annotated[\n str, typer.Argument(help=\"Path to config file\", show_default=False)\n ],\n max_items: Annotated[int, typer.Option(help=\"Max number of items to label\")] = None,\n start_index: Annotated[int, typer.Option(help=\"Index to start at\")] = 0,\n cache: Annotated[bool, typer.Option(help=\"Cache results\")] = True,\n output_name: Annotated[\n str, typer.Option(help=\"Path to output file to save run results to\")\n ] = None,\n verbose_debug: Annotated[\n bool, typer.Option(\"--debug\", \"-vv\", help=\"Verbose (debug log level)\")\n ] = False,\n verbose_info: Annotated[\n bool, typer.Option(\"--info\", \"-v\", help=\"Verbose (info log level)\")\n ] = False,\n quiet_warning: Annotated[\n bool, typer.Option(\"--error\", \"-q\", help=\"Quiet (error log level)\")\n ] = False,\n quiet_error: Annotated[\n bool, typer.Option(\"--critical\", \"-qq\", help=\"Quiet (critical log level)\")\n ] = False,\n):\n \"\"\"[bold]Run[/bold] \u25b6\ufe0f a labeling session in accordance with the provided dataset and config file\"\"\"\n setup_logging(verbose_debug, verbose_info, quiet_warning, quiet_error)\n agent = LabelingAgent(config=config, cache=cache)\n config = agent.config\n dataset = AutolabelDataset(dataset, config)\n agent.run(\n dataset, max_items=max_items, output_name=output_name, start_index=start_index\n )\n\n\nif __name__ == \"__main__\":\n app()\n", "path": "src/autolabel/cli/main.py"}]}
| 4,000 | 283 |
gh_patches_debug_29720
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-688
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Need to document focal_point_key changes for people who use custom image models
Everyone who uses custom image models need to create a new migration to make the `focal_point_key` field on rendition not nullable. Also, South doesn't automatically add the `default=''` into the migration (even though it's set on the field) which would cause the migration to fail.
The migration may also fail if you have duplicate renditions (this applies to everyone, not just custom image model people). The following SQL query should delete them:
```
DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (SELECT image_id || '-' || filter_id FROM (SELECT image_id, filter_id, COUNT(*) AS count FROM wagtailimages_rendition GROUP BY image_id, filter_id) AS renditions WHERE count > 1);
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from south.utils import datetime_utils as datetime
5 from south.db import db
6 from south.v2 import SchemaMigration
7 from django.db import models
8
9
10 class Migration(SchemaMigration):
11
12 def forwards(self, orm):
13
14 # Changing field 'Rendition.focal_point_key'
15 db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, default=''))
16
17 def backwards(self, orm):
18
19 # Changing field 'Rendition.focal_point_key'
20 db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, null=True))
21
22 models = {
23 'auth.group': {
24 'Meta': {'object_name': 'Group'},
25 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
26 'name': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '80'}),
27 'permissions': ('django.db.models.fields.related.ManyToManyField', [], {'to': "orm['auth.Permission']", 'symmetrical': 'False', 'blank': 'True'})
28 },
29 'auth.permission': {
30 'Meta': {'ordering': "('content_type__app_label', 'content_type__model', 'codename')", 'unique_together': "(('content_type', 'codename'),)", 'object_name': 'Permission'},
31 'codename': ('django.db.models.fields.CharField', [], {'max_length': '100'}),
32 'content_type': ('django.db.models.fields.related.ForeignKey', [], {'to': "orm['contenttypes.ContentType']"}),
33 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
34 'name': ('django.db.models.fields.CharField', [], {'max_length': '50'})
35 },
36 'auth.user': {
37 'Meta': {'object_name': 'User'},
38 'date_joined': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),
39 'email': ('django.db.models.fields.EmailField', [], {'max_length': '75', 'blank': 'True'}),
40 'first_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),
41 'groups': ('django.db.models.fields.related.ManyToManyField', [], {'symmetrical': 'False', 'related_name': "'user_set'", 'blank': 'True', 'to': "orm['auth.Group']"}),
42 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
43 'is_active': ('django.db.models.fields.BooleanField', [], {'default': 'True'}),
44 'is_staff': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),
45 'is_superuser': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),
46 'last_login': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),
47 'last_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),
48 'password': ('django.db.models.fields.CharField', [], {'max_length': '128'}),
49 'user_permissions': ('django.db.models.fields.related.ManyToManyField', [], {'symmetrical': 'False', 'related_name': "'user_set'", 'blank': 'True', 'to': "orm['auth.Permission']"}),
50 'username': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '30'})
51 },
52 'contenttypes.contenttype': {
53 'Meta': {'ordering': "('name',)", 'unique_together': "(('app_label', 'model'),)", 'object_name': 'ContentType', 'db_table': "'django_content_type'"},
54 'app_label': ('django.db.models.fields.CharField', [], {'max_length': '100'}),
55 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
56 'model': ('django.db.models.fields.CharField', [], {'max_length': '100'}),
57 'name': ('django.db.models.fields.CharField', [], {'max_length': '100'})
58 },
59 'wagtailimages.filter': {
60 'Meta': {'object_name': 'Filter'},
61 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
62 'spec': ('django.db.models.fields.CharField', [], {'max_length': '255', 'db_index': 'True'})
63 },
64 'wagtailimages.image': {
65 'Meta': {'object_name': 'Image'},
66 'created_at': ('django.db.models.fields.DateTimeField', [], {'auto_now_add': 'True', 'blank': 'True'}),
67 'file': ('django.db.models.fields.files.ImageField', [], {'max_length': '100'}),
68 'focal_point_height': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),
69 'focal_point_width': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),
70 'focal_point_x': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),
71 'focal_point_y': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),
72 'height': ('django.db.models.fields.IntegerField', [], {}),
73 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
74 'title': ('django.db.models.fields.CharField', [], {'max_length': '255'}),
75 'uploaded_by_user': ('django.db.models.fields.related.ForeignKey', [], {'to': "orm['auth.User']", 'null': 'True', 'blank': 'True'}),
76 'width': ('django.db.models.fields.IntegerField', [], {})
77 },
78 'wagtailimages.rendition': {
79 'Meta': {'unique_together': "(('image', 'filter', 'focal_point_key'),)", 'object_name': 'Rendition'},
80 'file': ('django.db.models.fields.files.ImageField', [], {'max_length': '100'}),
81 'filter': ('django.db.models.fields.related.ForeignKey', [], {'related_name': "'+'", 'to': "orm['wagtailimages.Filter']"}),
82 'focal_point_key': ('django.db.models.fields.CharField', [], {'default': "''", 'max_length': '255', 'blank': 'True'}),
83 'height': ('django.db.models.fields.IntegerField', [], {}),
84 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),
85 'image': ('django.db.models.fields.related.ForeignKey', [], {'related_name': "'renditions'", 'to': "orm['wagtailimages.Image']"}),
86 'width': ('django.db.models.fields.IntegerField', [], {})
87 }
88 }
89
90 complete_apps = ['wagtailimages']
```
Path: `wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from django.db import models, migrations
5
6
7 class Migration(migrations.Migration):
8
9 dependencies = [
10 ('wagtailimages', '0003_fix_focal_point_fields'),
11 ]
12
13 operations = [
14 migrations.AlterField(
15 model_name='rendition',
16 name='focal_point_key',
17 field=models.CharField(blank=True, default='', max_length=255, editable=False),
18 ),
19 ]
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py b/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py
--- a/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py
+++ b/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py
@@ -4,6 +4,13 @@
from django.db import models, migrations
+def remove_duplicate_renditions(apps, schema_editor):
+ schema_editor.execute("""
+ DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (
+ SELECT image_id || '-' || filter_id FROM wagtailimages_rendition WHERE focal_point_key IS NULL GROUP BY image_id, filter_id HAVING COUNT(*) > 1
+ ) AND focal_point_key IS NULL
+ """)
+
class Migration(migrations.Migration):
dependencies = [
@@ -11,6 +18,7 @@
]
operations = [
+ migrations.RunPython(remove_duplicate_renditions),
migrations.AlterField(
model_name='rendition',
name='focal_point_key',
diff --git a/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py b/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py
--- a/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py
+++ b/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py
@@ -10,6 +10,12 @@
class Migration(SchemaMigration):
def forwards(self, orm):
+ # remove duplicate renditions
+ db.execute("""
+ DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (
+ SELECT image_id || '-' || filter_id FROM wagtailimages_rendition WHERE focal_point_key IS NULL GROUP BY image_id, filter_id HAVING COUNT(*) > 1
+ ) AND focal_point_key IS NULL
+ """)
# Changing field 'Rendition.focal_point_key'
db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, default=''))
|
{"golden_diff": "diff --git a/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py b/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py\n--- a/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py\n+++ b/wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py\n@@ -4,6 +4,13 @@\n from django.db import models, migrations\n \n \n+def remove_duplicate_renditions(apps, schema_editor):\n+ schema_editor.execute(\"\"\"\n+ DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (\n+ SELECT image_id || '-' || filter_id FROM wagtailimages_rendition WHERE focal_point_key IS NULL GROUP BY image_id, filter_id HAVING COUNT(*) > 1\n+ ) AND focal_point_key IS NULL\n+ \"\"\")\n+\n class Migration(migrations.Migration):\n \n dependencies = [\n@@ -11,6 +18,7 @@\n ]\n \n operations = [\n+ migrations.RunPython(remove_duplicate_renditions),\n migrations.AlterField(\n model_name='rendition',\n name='focal_point_key',\ndiff --git a/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py b/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py\n--- a/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py\n+++ b/wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py\n@@ -10,6 +10,12 @@\n class Migration(SchemaMigration):\n \n def forwards(self, orm):\n+ # remove duplicate renditions\n+ db.execute(\"\"\"\n+ DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (\n+ SELECT image_id || '-' || filter_id FROM wagtailimages_rendition WHERE focal_point_key IS NULL GROUP BY image_id, filter_id HAVING COUNT(*) > 1\n+ ) AND focal_point_key IS NULL\n+ \"\"\")\n \n # Changing field 'Rendition.focal_point_key'\n db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, default=''))\n", "issue": "Need to document focal_point_key changes for people who use custom image models\nEveryone who uses custom image models need to create a new migration to make the `focal_point_key` field on rendition not nullable. Also, South doesn't automatically add the `default=''` into the migration (even though it's set on the field) which would cause the migration to fail.\n\nThe migration may also fail if you have duplicate renditions (this applies to everyone, not just custom image model people). The following SQL query should delete them:\n\n```\nDELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (SELECT image_id || '-' || filter_id FROM (SELECT image_id, filter_id, COUNT(*) AS count FROM wagtailimages_rendition GROUP BY image_id, filter_id) AS renditions WHERE count > 1);\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom south.utils import datetime_utils as datetime\nfrom south.db import db\nfrom south.v2 import SchemaMigration\nfrom django.db import models\n\n\nclass Migration(SchemaMigration):\n\n def forwards(self, orm):\n\n # Changing field 'Rendition.focal_point_key'\n db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, default=''))\n\n def backwards(self, orm):\n\n # Changing field 'Rendition.focal_point_key'\n db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, null=True))\n\n models = {\n 'auth.group': {\n 'Meta': {'object_name': 'Group'},\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '80'}),\n 'permissions': ('django.db.models.fields.related.ManyToManyField', [], {'to': \"orm['auth.Permission']\", 'symmetrical': 'False', 'blank': 'True'})\n },\n 'auth.permission': {\n 'Meta': {'ordering': \"('content_type__app_label', 'content_type__model', 'codename')\", 'unique_together': \"(('content_type', 'codename'),)\", 'object_name': 'Permission'},\n 'codename': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'content_type': ('django.db.models.fields.related.ForeignKey', [], {'to': \"orm['contenttypes.ContentType']\"}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '50'})\n },\n 'auth.user': {\n 'Meta': {'object_name': 'User'},\n 'date_joined': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'email': ('django.db.models.fields.EmailField', [], {'max_length': '75', 'blank': 'True'}),\n 'first_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'groups': ('django.db.models.fields.related.ManyToManyField', [], {'symmetrical': 'False', 'related_name': \"'user_set'\", 'blank': 'True', 'to': \"orm['auth.Group']\"}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'is_active': ('django.db.models.fields.BooleanField', [], {'default': 'True'}),\n 'is_staff': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'is_superuser': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'last_login': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'last_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'password': ('django.db.models.fields.CharField', [], {'max_length': '128'}),\n 'user_permissions': ('django.db.models.fields.related.ManyToManyField', [], {'symmetrical': 'False', 'related_name': \"'user_set'\", 'blank': 'True', 'to': \"orm['auth.Permission']\"}),\n 'username': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '30'})\n },\n 'contenttypes.contenttype': {\n 'Meta': {'ordering': \"('name',)\", 'unique_together': \"(('app_label', 'model'),)\", 'object_name': 'ContentType', 'db_table': \"'django_content_type'\"},\n 'app_label': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'model': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '100'})\n },\n 'wagtailimages.filter': {\n 'Meta': {'object_name': 'Filter'},\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'spec': ('django.db.models.fields.CharField', [], {'max_length': '255', 'db_index': 'True'})\n },\n 'wagtailimages.image': {\n 'Meta': {'object_name': 'Image'},\n 'created_at': ('django.db.models.fields.DateTimeField', [], {'auto_now_add': 'True', 'blank': 'True'}),\n 'file': ('django.db.models.fields.files.ImageField', [], {'max_length': '100'}),\n 'focal_point_height': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'focal_point_width': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'focal_point_x': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'focal_point_y': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'height': ('django.db.models.fields.IntegerField', [], {}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'title': ('django.db.models.fields.CharField', [], {'max_length': '255'}),\n 'uploaded_by_user': ('django.db.models.fields.related.ForeignKey', [], {'to': \"orm['auth.User']\", 'null': 'True', 'blank': 'True'}),\n 'width': ('django.db.models.fields.IntegerField', [], {})\n },\n 'wagtailimages.rendition': {\n 'Meta': {'unique_together': \"(('image', 'filter', 'focal_point_key'),)\", 'object_name': 'Rendition'},\n 'file': ('django.db.models.fields.files.ImageField', [], {'max_length': '100'}),\n 'filter': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'+'\", 'to': \"orm['wagtailimages.Filter']\"}),\n 'focal_point_key': ('django.db.models.fields.CharField', [], {'default': \"''\", 'max_length': '255', 'blank': 'True'}),\n 'height': ('django.db.models.fields.IntegerField', [], {}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'image': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'renditions'\", 'to': \"orm['wagtailimages.Image']\"}),\n 'width': ('django.db.models.fields.IntegerField', [], {})\n }\n }\n\n complete_apps = ['wagtailimages']", "path": "wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('wagtailimages', '0003_fix_focal_point_fields'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='rendition',\n name='focal_point_key',\n field=models.CharField(blank=True, default='', max_length=255, editable=False),\n ),\n ]\n", "path": "wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom south.utils import datetime_utils as datetime\nfrom south.db import db\nfrom south.v2 import SchemaMigration\nfrom django.db import models\n\n\nclass Migration(SchemaMigration):\n\n def forwards(self, orm):\n # remove duplicate renditions\n db.execute(\"\"\"\n DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (\n SELECT image_id || '-' || filter_id FROM wagtailimages_rendition WHERE focal_point_key IS NULL GROUP BY image_id, filter_id HAVING COUNT(*) > 1\n ) AND focal_point_key IS NULL\n \"\"\")\n\n # Changing field 'Rendition.focal_point_key'\n db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, default=''))\n\n def backwards(self, orm):\n\n # Changing field 'Rendition.focal_point_key'\n db.alter_column('wagtailimages_rendition', 'focal_point_key', self.gf('django.db.models.fields.CharField')(max_length=255, null=True))\n\n models = {\n 'auth.group': {\n 'Meta': {'object_name': 'Group'},\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '80'}),\n 'permissions': ('django.db.models.fields.related.ManyToManyField', [], {'to': \"orm['auth.Permission']\", 'symmetrical': 'False', 'blank': 'True'})\n },\n 'auth.permission': {\n 'Meta': {'ordering': \"('content_type__app_label', 'content_type__model', 'codename')\", 'unique_together': \"(('content_type', 'codename'),)\", 'object_name': 'Permission'},\n 'codename': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'content_type': ('django.db.models.fields.related.ForeignKey', [], {'to': \"orm['contenttypes.ContentType']\"}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '50'})\n },\n 'auth.user': {\n 'Meta': {'object_name': 'User'},\n 'date_joined': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'email': ('django.db.models.fields.EmailField', [], {'max_length': '75', 'blank': 'True'}),\n 'first_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'groups': ('django.db.models.fields.related.ManyToManyField', [], {'symmetrical': 'False', 'related_name': \"'user_set'\", 'blank': 'True', 'to': \"orm['auth.Group']\"}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'is_active': ('django.db.models.fields.BooleanField', [], {'default': 'True'}),\n 'is_staff': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'is_superuser': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'last_login': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'last_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'password': ('django.db.models.fields.CharField', [], {'max_length': '128'}),\n 'user_permissions': ('django.db.models.fields.related.ManyToManyField', [], {'symmetrical': 'False', 'related_name': \"'user_set'\", 'blank': 'True', 'to': \"orm['auth.Permission']\"}),\n 'username': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '30'})\n },\n 'contenttypes.contenttype': {\n 'Meta': {'ordering': \"('name',)\", 'unique_together': \"(('app_label', 'model'),)\", 'object_name': 'ContentType', 'db_table': \"'django_content_type'\"},\n 'app_label': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'model': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '100'})\n },\n 'wagtailimages.filter': {\n 'Meta': {'object_name': 'Filter'},\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'spec': ('django.db.models.fields.CharField', [], {'max_length': '255', 'db_index': 'True'})\n },\n 'wagtailimages.image': {\n 'Meta': {'object_name': 'Image'},\n 'created_at': ('django.db.models.fields.DateTimeField', [], {'auto_now_add': 'True', 'blank': 'True'}),\n 'file': ('django.db.models.fields.files.ImageField', [], {'max_length': '100'}),\n 'focal_point_height': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'focal_point_width': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'focal_point_x': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'focal_point_y': ('django.db.models.fields.PositiveIntegerField', [], {'null': 'True', 'blank': 'True'}),\n 'height': ('django.db.models.fields.IntegerField', [], {}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'title': ('django.db.models.fields.CharField', [], {'max_length': '255'}),\n 'uploaded_by_user': ('django.db.models.fields.related.ForeignKey', [], {'to': \"orm['auth.User']\", 'null': 'True', 'blank': 'True'}),\n 'width': ('django.db.models.fields.IntegerField', [], {})\n },\n 'wagtailimages.rendition': {\n 'Meta': {'unique_together': \"(('image', 'filter', 'focal_point_key'),)\", 'object_name': 'Rendition'},\n 'file': ('django.db.models.fields.files.ImageField', [], {'max_length': '100'}),\n 'filter': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'+'\", 'to': \"orm['wagtailimages.Filter']\"}),\n 'focal_point_key': ('django.db.models.fields.CharField', [], {'default': \"''\", 'max_length': '255', 'blank': 'True'}),\n 'height': ('django.db.models.fields.IntegerField', [], {}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'image': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'renditions'\", 'to': \"orm['wagtailimages.Image']\"}),\n 'width': ('django.db.models.fields.IntegerField', [], {})\n }\n }\n\n complete_apps = ['wagtailimages']", "path": "wagtail/wagtailimages/south_migrations/0004_auto__chg_field_rendition_focal_point_key.py"}, {"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\n\n\ndef remove_duplicate_renditions(apps, schema_editor):\n schema_editor.execute(\"\"\"\n DELETE FROM wagtailimages_rendition WHERE image_id || '-' || filter_id IN (\n SELECT image_id || '-' || filter_id FROM wagtailimages_rendition WHERE focal_point_key IS NULL GROUP BY image_id, filter_id HAVING COUNT(*) > 1\n ) AND focal_point_key IS NULL\n \"\"\")\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('wagtailimages', '0003_fix_focal_point_fields'),\n ]\n\n operations = [\n migrations.RunPython(remove_duplicate_renditions),\n migrations.AlterField(\n model_name='rendition',\n name='focal_point_key',\n field=models.CharField(blank=True, default='', max_length=255, editable=False),\n ),\n ]\n", "path": "wagtail/wagtailimages/migrations/0004_make_focal_point_key_not_nullable.py"}]}
| 2,290 | 563 |
gh_patches_debug_8491
|
rasdani/github-patches
|
git_diff
|
OpenEnergyPlatform__oeplatform-1324
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Inconvenience of client cache update upon releasing/deploy new versions
## Description of the issue
When deploying a new version of an application, users are inconvenienced as they need to manually refresh the client cache to see the latest changes.
## Ideas of solution
ChatGPT suggested to introduce a Cache Busting Mechanism. We could use this existing lib [django-compressor](https://github.com/django-compressor/django-compressor).
> To set up a cache-busting mechanism in your Django application, you can use the Django extension module "django-compressor". Django Compressor allows you to compress static resources such as CSS and JavaScript files and assign them a unique hash value based on their content. This automatically changes the URL of the resources whenever they are modified.
## Workflow checklist
- [x] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `oeplatform/settings.py`
Content:
```
1 """
2 Django settings for oeplatform project.
3
4 Generated by 'django-admin startproject' using Django 1.8.5.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.8/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.8/ref/settings/
11 """
12
13 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
14
15 try:
16 from .securitysettings import * # noqa
17 except ImportError:
18 import logging
19 import os
20
21 logging.error("No securitysettings found. Triggerd in oeplatform/settings.py")
22 SECRET_KEY = os.environ.get("SECRET_KEY", "0")
23 DEFAULT_FROM_EMAIL = os.environ.get("DEFAULT_FROM_EMAIL")
24 URL = os.environ.get("URL")
25
26 # Quick-start development settings - unsuitable for production
27 # See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/
28
29 # Application definition
30
31 INSTALLED_APPS = (
32 "django.contrib.sites",
33 "django.contrib.admin",
34 "django.contrib.auth",
35 "django.contrib.contenttypes",
36 "django.contrib.sessions",
37 "django.contrib.messages",
38 "django.contrib.staticfiles",
39 "django.contrib.sessions.backends.signed_cookies",
40 "django_bootstrap5",
41 "rest_framework",
42 "rest_framework.authtoken",
43 "modelview",
44 "modelview.templatetags.modelview_extras",
45 "login",
46 "base",
47 "base.templatetags.base_tags",
48 "widget_tweaks",
49 "dataedit",
50 "colorfield",
51 "api",
52 "ontology",
53 "axes",
54 "captcha",
55 "django.contrib.postgres",
56 "fontawesome_5",
57 "django_better_admin_arrayfield",
58 "oeo_viewer",
59 )
60
61 MIDDLEWARE = (
62 "django.contrib.sites.middleware.CurrentSiteMiddleware",
63 "django.contrib.sessions.middleware.SessionMiddleware",
64 "django.middleware.common.CommonMiddleware",
65 "django.middleware.csrf.CsrfViewMiddleware",
66 "django.contrib.auth.middleware.AuthenticationMiddleware",
67 "django.contrib.messages.middleware.MessageMiddleware",
68 "django.middleware.clickjacking.XFrameOptionsMiddleware",
69 "django.middleware.security.SecurityMiddleware",
70 "login.middleware.DetachMiddleware",
71 "axes.middleware.AxesMiddleware",
72 "django.middleware.common.CommonMiddleware",
73 )
74
75 ROOT_URLCONF = "oeplatform.urls"
76
77 EXTERNAL_URLS = {
78 "tutorials_index": "https://openenergyplatform.github.io/academy/",
79 "tutorials_faq": "https://openenergyplatform.github.io/academy/",
80 "tutorials_api1": "https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/", # noqa E501
81 "tutorials_licenses": "https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/",
82 # noqa E501
83 "readthedocs": "https://oeplatform.readthedocs.io/en/latest/?badge=latest",
84 "compendium": "https://openenergyplatform.github.io/organisation/",
85 }
86
87
88 def external_urls_context_processor(request):
89 """Define hard coded external urls here.
90 Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}
91 Also, you may want to add an icon indicating external links, e.g.
92 """
93 return {"EXTERNAL_URLS": EXTERNAL_URLS}
94
95
96 SITE_ID = 1
97
98 TEMPLATES = [
99 {
100 "BACKEND": "django.template.backends.django.DjangoTemplates",
101 "DIRS": [],
102 "APP_DIRS": True,
103 "OPTIONS": {
104 "context_processors": [
105 "django.template.context_processors.debug",
106 "django.template.context_processors.request",
107 "django.contrib.auth.context_processors.auth",
108 "django.contrib.messages.context_processors.messages",
109 "oeplatform.settings.external_urls_context_processor",
110 ]
111 },
112 }
113 ]
114
115 CORS_ORIGIN_WHITELIST = ["http://localhost:3000", "http://127.0.0.1:3000"]
116
117 GRAPHENE = {"SCHEMA": "factsheet.schema.schema"}
118
119 WSGI_APPLICATION = "oeplatform.wsgi.application"
120
121 try:
122 ONTOLOGY_FOLDER # noqa
123 except NameError:
124 ONTOLOGY_FOLDER = "/tmp"
125
126 # Internationalization
127 # https://docs.djangoproject.com/en/1.8/topics/i18n/
128
129 LANGUAGE_CODE = "en-us"
130
131 TIME_ZONE = "Europe/Berlin"
132
133 USE_I18N = True
134
135 USE_L10N = True
136
137 USE_TZ = True
138
139 # Static files (CSS, JavaScript, Images)
140 # https://docs.djangoproject.com/en/1.8/howto/static-files/
141
142 AUTH_USER_MODEL = "login.myuser"
143 LOGIN_URL = "/user/login"
144 LOGIN_REDIRECT_URL = "/"
145
146 REST_FRAMEWORK = {
147 "DEFAULT_AUTHENTICATION_CLASSES": (
148 "rest_framework.authentication.BasicAuthentication",
149 "rest_framework.authentication.SessionAuthentication",
150 "rest_framework.authentication.TokenAuthentication",
151 )
152 }
153
154 AUTHENTICATION_BACKENDS = [
155 # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.
156 "axes.backends.AxesBackend",
157 # custom class extenging Django ModelBackend for login with username OR email
158 "login.backends.ModelBackendWithEmail",
159 ]
160
161 DEFAULT_AUTO_FIELD = "django.db.models.AutoField"
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/oeplatform/settings.py b/oeplatform/settings.py
--- a/oeplatform/settings.py
+++ b/oeplatform/settings.py
@@ -56,6 +56,7 @@
"fontawesome_5",
"django_better_admin_arrayfield",
"oeo_viewer",
+ "compressor",
)
MIDDLEWARE = (
@@ -159,3 +160,12 @@
]
DEFAULT_AUTO_FIELD = "django.db.models.AutoField"
+
+STATICFILES_FINDERS = {
+ 'django.contrib.staticfiles.finders.FileSystemFinder',
+ 'django.contrib.staticfiles.finders.AppDirectoriesFinder',
+ 'compressor.finders.CompressorFinder',
+}
+
+COMPRESS_ENABLED = True
+COMPRESS_OFFLINE = True
|
{"golden_diff": "diff --git a/oeplatform/settings.py b/oeplatform/settings.py\n--- a/oeplatform/settings.py\n+++ b/oeplatform/settings.py\n@@ -56,6 +56,7 @@\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n+ \"compressor\",\n )\n \n MIDDLEWARE = (\n@@ -159,3 +160,12 @@\n ]\n \n DEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n+\n+STATICFILES_FINDERS = {\n+ 'django.contrib.staticfiles.finders.FileSystemFinder',\n+ 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n+ 'compressor.finders.CompressorFinder',\n+}\n+\n+COMPRESS_ENABLED = True\n+COMPRESS_OFFLINE = True\n", "issue": "Inconvenience of client cache update upon releasing/deploy new versions\n## Description of the issue\r\n\r\nWhen deploying a new version of an application, users are inconvenienced as they need to manually refresh the client cache to see the latest changes.\r\n\r\n## Ideas of solution\r\n\r\nChatGPT suggested to introduce a Cache Busting Mechanism. We could use this existing lib [django-compressor](https://github.com/django-compressor/django-compressor).\r\n\r\n> To set up a cache-busting mechanism in your Django application, you can use the Django extension module \"django-compressor\". Django Compressor allows you to compress static resources such as CSS and JavaScript files and assign them a unique hash value based on their content. This automatically changes the URL of the resources whenever they are modified.\r\n\r\n## Workflow checklist\r\n- [x] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)\r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n\ntry:\n from .securitysettings import * # noqa\nexcept ImportError:\n import logging\n import os\n\n logging.error(\"No securitysettings found. Triggerd in oeplatform/settings.py\")\n SECRET_KEY = os.environ.get(\"SECRET_KEY\", \"0\")\n DEFAULT_FROM_EMAIL = os.environ.get(\"DEFAULT_FROM_EMAIL\")\n URL = os.environ.get(\"URL\")\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = (\n \"django.contrib.sites\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django.contrib.sessions.backends.signed_cookies\",\n \"django_bootstrap5\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"modelview\",\n \"modelview.templatetags.modelview_extras\",\n \"login\",\n \"base\",\n \"base.templatetags.base_tags\",\n \"widget_tweaks\",\n \"dataedit\",\n \"colorfield\",\n \"api\",\n \"ontology\",\n \"axes\",\n \"captcha\",\n \"django.contrib.postgres\",\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n)\n\nMIDDLEWARE = (\n \"django.contrib.sites.middleware.CurrentSiteMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"login.middleware.DetachMiddleware\",\n \"axes.middleware.AxesMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n)\n\nROOT_URLCONF = \"oeplatform.urls\"\n\nEXTERNAL_URLS = {\n \"tutorials_index\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_faq\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_api1\": \"https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/\", # noqa E501\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n \"compendium\": \"https://openenergyplatform.github.io/organisation/\",\n}\n\n\ndef external_urls_context_processor(request):\n \"\"\"Define hard coded external urls here.\n Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}\n Also, you may want to add an icon indicating external links, e.g.\n \"\"\"\n return {\"EXTERNAL_URLS\": EXTERNAL_URLS}\n\n\nSITE_ID = 1\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"oeplatform.settings.external_urls_context_processor\",\n ]\n },\n }\n]\n\nCORS_ORIGIN_WHITELIST = [\"http://localhost:3000\", \"http://127.0.0.1:3000\"]\n\nGRAPHENE = {\"SCHEMA\": \"factsheet.schema.schema\"}\n\nWSGI_APPLICATION = \"oeplatform.wsgi.application\"\n\ntry:\n ONTOLOGY_FOLDER # noqa\nexcept NameError:\n ONTOLOGY_FOLDER = \"/tmp\"\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Europe/Berlin\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nAUTH_USER_MODEL = \"login.myuser\"\nLOGIN_URL = \"/user/login\"\nLOGIN_REDIRECT_URL = \"/\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n )\n}\n\nAUTHENTICATION_BACKENDS = [\n # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.\n \"axes.backends.AxesBackend\",\n # custom class extenging Django ModelBackend for login with username OR email\n \"login.backends.ModelBackendWithEmail\",\n]\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n", "path": "oeplatform/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n\ntry:\n from .securitysettings import * # noqa\nexcept ImportError:\n import logging\n import os\n\n logging.error(\"No securitysettings found. Triggerd in oeplatform/settings.py\")\n SECRET_KEY = os.environ.get(\"SECRET_KEY\", \"0\")\n DEFAULT_FROM_EMAIL = os.environ.get(\"DEFAULT_FROM_EMAIL\")\n URL = os.environ.get(\"URL\")\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = (\n \"django.contrib.sites\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django.contrib.sessions.backends.signed_cookies\",\n \"django_bootstrap5\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"modelview\",\n \"modelview.templatetags.modelview_extras\",\n \"login\",\n \"base\",\n \"base.templatetags.base_tags\",\n \"widget_tweaks\",\n \"dataedit\",\n \"colorfield\",\n \"api\",\n \"ontology\",\n \"axes\",\n \"captcha\",\n \"django.contrib.postgres\",\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n \"compressor\",\n)\n\nMIDDLEWARE = (\n \"django.contrib.sites.middleware.CurrentSiteMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"login.middleware.DetachMiddleware\",\n \"axes.middleware.AxesMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n)\n\nROOT_URLCONF = \"oeplatform.urls\"\n\nEXTERNAL_URLS = {\n \"tutorials_index\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_faq\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_api1\": \"https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/\", # noqa E501\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n \"compendium\": \"https://openenergyplatform.github.io/organisation/\",\n}\n\n\ndef external_urls_context_processor(request):\n \"\"\"Define hard coded external urls here.\n Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}\n Also, you may want to add an icon indicating external links, e.g.\n \"\"\"\n return {\"EXTERNAL_URLS\": EXTERNAL_URLS}\n\n\nSITE_ID = 1\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"oeplatform.settings.external_urls_context_processor\",\n ]\n },\n }\n]\n\nCORS_ORIGIN_WHITELIST = [\"http://localhost:3000\", \"http://127.0.0.1:3000\"]\n\nGRAPHENE = {\"SCHEMA\": \"factsheet.schema.schema\"}\n\nWSGI_APPLICATION = \"oeplatform.wsgi.application\"\n\ntry:\n ONTOLOGY_FOLDER # noqa\nexcept NameError:\n ONTOLOGY_FOLDER = \"/tmp\"\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Europe/Berlin\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nAUTH_USER_MODEL = \"login.myuser\"\nLOGIN_URL = \"/user/login\"\nLOGIN_REDIRECT_URL = \"/\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n )\n}\n\nAUTHENTICATION_BACKENDS = [\n # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.\n \"axes.backends.AxesBackend\",\n # custom class extenging Django ModelBackend for login with username OR email\n \"login.backends.ModelBackendWithEmail\",\n]\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n\nSTATICFILES_FINDERS = {\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n 'compressor.finders.CompressorFinder',\n}\n\nCOMPRESS_ENABLED = True\nCOMPRESS_OFFLINE = True\n", "path": "oeplatform/settings.py"}]}
| 1,989 | 168 |
gh_patches_debug_25638
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-1138
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
smartplaylist: Respect sort terms in queries
It would be nice to be able sort items in smart playlists, like so:
```
smartplaylist:
relative_to: ~/music
playlist_dir: ~/.mpd/playlists
playlists:
- name: '2014.m3u'
query: 'year:2014 added+'
- name: 'imported-%time{$added,%Y-%m}.m3u'
query: "added:: path+"
```
I'm unfamiliar with the code but it looks like the smartplaylist plugin [discards the query `sort` field](https://github.com/sampsyo/beets/blob/master/beetsplug/smartplaylist.py#L45) when building playlists. Would it be possible to keep the custom sort?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `beetsplug/smartplaylist.py`
Content:
```
1 # This file is part of beets.
2 # Copyright 2013, Dang Mai <[email protected]>.
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """Generates smart playlists based on beets queries.
16 """
17 from __future__ import print_function
18
19 from beets.plugins import BeetsPlugin
20 from beets import config, ui, library
21 from beets import dbcore
22 from beets.util import normpath, syspath
23 import os
24
25 # Global variable so that smartplaylist can detect database changes and run
26 # only once before beets exits.
27 database_changed = False
28
29
30 def _items_for_query(lib, playlist, album=False):
31 """Get the matching items for a playlist's configured queries.
32 `album` indicates whether to process the item-level query or the
33 album-level query (if any).
34 """
35 key = 'album_query' if album else 'query'
36 if key not in playlist:
37 return []
38
39 # Parse quer(ies). If it's a list, join the queries with OR.
40 query_strings = playlist[key]
41 if not isinstance(query_strings, (list, tuple)):
42 query_strings = [query_strings]
43 model = library.Album if album else library.Item
44 query = dbcore.OrQuery(
45 [library.parse_query_string(q, model)[0] for q in query_strings]
46 )
47
48 # Execute query, depending on type.
49 if album:
50 result = []
51 for album in lib.albums(query):
52 result.extend(album.items())
53 return result
54 else:
55 return lib.items(query)
56
57
58 def update_playlists(lib):
59 ui.print_("Updating smart playlists...")
60 playlists = config['smartplaylist']['playlists'].get(list)
61 playlist_dir = config['smartplaylist']['playlist_dir'].as_filename()
62 relative_to = config['smartplaylist']['relative_to'].get()
63 if relative_to:
64 relative_to = normpath(relative_to)
65
66 for playlist in playlists:
67 items = []
68 items.extend(_items_for_query(lib, playlist, True))
69 items.extend(_items_for_query(lib, playlist, False))
70
71 m3us = {}
72 basename = playlist['name'].encode('utf8')
73 # As we allow tags in the m3u names, we'll need to iterate through
74 # the items and generate the correct m3u file names.
75 for item in items:
76 m3u_name = item.evaluate_template(basename, True)
77 if not (m3u_name in m3us):
78 m3us[m3u_name] = []
79 item_path = item.path
80 if relative_to:
81 item_path = os.path.relpath(item.path, relative_to)
82 if item_path not in m3us[m3u_name]:
83 m3us[m3u_name].append(item_path)
84 # Now iterate through the m3us that we need to generate
85 for m3u in m3us:
86 m3u_path = normpath(os.path.join(playlist_dir, m3u))
87 with open(syspath(m3u_path), 'w') as f:
88 for path in m3us[m3u]:
89 f.write(path + '\n')
90 ui.print_("... Done")
91
92
93 class SmartPlaylistPlugin(BeetsPlugin):
94 def __init__(self):
95 super(SmartPlaylistPlugin, self).__init__()
96 self.config.add({
97 'relative_to': None,
98 'playlist_dir': u'.',
99 'auto': True,
100 'playlists': []
101 })
102
103 def commands(self):
104 def update(lib, opts, args):
105 update_playlists(lib)
106 spl_update = ui.Subcommand('splupdate',
107 help='update the smart playlists')
108 spl_update.func = update
109 return [spl_update]
110
111
112 @SmartPlaylistPlugin.listen('database_change')
113 def handle_change(lib):
114 global database_changed
115 database_changed = True
116
117
118 @SmartPlaylistPlugin.listen('cli_exit')
119 def update(lib):
120 auto = config['smartplaylist']['auto']
121 if database_changed and auto:
122 update_playlists(lib)
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/beetsplug/smartplaylist.py b/beetsplug/smartplaylist.py
--- a/beetsplug/smartplaylist.py
+++ b/beetsplug/smartplaylist.py
@@ -18,7 +18,6 @@
from beets.plugins import BeetsPlugin
from beets import config, ui, library
-from beets import dbcore
from beets.util import normpath, syspath
import os
@@ -36,23 +35,21 @@
if key not in playlist:
return []
- # Parse quer(ies). If it's a list, join the queries with OR.
+ # Parse quer(ies). If it's a list, perform the queries and manually
+ # concatenate the results
query_strings = playlist[key]
if not isinstance(query_strings, (list, tuple)):
query_strings = [query_strings]
model = library.Album if album else library.Item
- query = dbcore.OrQuery(
- [library.parse_query_string(q, model)[0] for q in query_strings]
- )
-
- # Execute query, depending on type.
- if album:
- result = []
- for album in lib.albums(query):
- result.extend(album.items())
- return result
- else:
- return lib.items(query)
+ results = []
+ for q in query_strings:
+ querystr, sort = library.parse_query_string(q, model)
+ if album:
+ new = lib.albums(querystr, sort)
+ else:
+ new = lib.items(querystr, sort)
+ results.extend(new)
+ return results
def update_playlists(lib):
|
{"golden_diff": "diff --git a/beetsplug/smartplaylist.py b/beetsplug/smartplaylist.py\n--- a/beetsplug/smartplaylist.py\n+++ b/beetsplug/smartplaylist.py\n@@ -18,7 +18,6 @@\n \n from beets.plugins import BeetsPlugin\n from beets import config, ui, library\n-from beets import dbcore\n from beets.util import normpath, syspath\n import os\n \n@@ -36,23 +35,21 @@\n if key not in playlist:\n return []\n \n- # Parse quer(ies). If it's a list, join the queries with OR.\n+ # Parse quer(ies). If it's a list, perform the queries and manually\n+ # concatenate the results\n query_strings = playlist[key]\n if not isinstance(query_strings, (list, tuple)):\n query_strings = [query_strings]\n model = library.Album if album else library.Item\n- query = dbcore.OrQuery(\n- [library.parse_query_string(q, model)[0] for q in query_strings]\n- )\n-\n- # Execute query, depending on type.\n- if album:\n- result = []\n- for album in lib.albums(query):\n- result.extend(album.items())\n- return result\n- else:\n- return lib.items(query)\n+ results = []\n+ for q in query_strings:\n+ querystr, sort = library.parse_query_string(q, model)\n+ if album:\n+ new = lib.albums(querystr, sort)\n+ else:\n+ new = lib.items(querystr, sort)\n+ results.extend(new)\n+ return results\n \n \n def update_playlists(lib):\n", "issue": "smartplaylist: Respect sort terms in queries\nIt would be nice to be able sort items in smart playlists, like so:\n\n```\nsmartplaylist:\n relative_to: ~/music\n playlist_dir: ~/.mpd/playlists\n playlists:\n - name: '2014.m3u'\n query: 'year:2014 added+'\n - name: 'imported-%time{$added,%Y-%m}.m3u'\n query: \"added:: path+\"\n```\n\nI'm unfamiliar with the code but it looks like the smartplaylist plugin [discards the query `sort` field](https://github.com/sampsyo/beets/blob/master/beetsplug/smartplaylist.py#L45) when building playlists. Would it be possible to keep the custom sort?\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2013, Dang Mai <[email protected]>.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Generates smart playlists based on beets queries.\n\"\"\"\nfrom __future__ import print_function\n\nfrom beets.plugins import BeetsPlugin\nfrom beets import config, ui, library\nfrom beets import dbcore\nfrom beets.util import normpath, syspath\nimport os\n\n# Global variable so that smartplaylist can detect database changes and run\n# only once before beets exits.\ndatabase_changed = False\n\n\ndef _items_for_query(lib, playlist, album=False):\n \"\"\"Get the matching items for a playlist's configured queries.\n `album` indicates whether to process the item-level query or the\n album-level query (if any).\n \"\"\"\n key = 'album_query' if album else 'query'\n if key not in playlist:\n return []\n\n # Parse quer(ies). If it's a list, join the queries with OR.\n query_strings = playlist[key]\n if not isinstance(query_strings, (list, tuple)):\n query_strings = [query_strings]\n model = library.Album if album else library.Item\n query = dbcore.OrQuery(\n [library.parse_query_string(q, model)[0] for q in query_strings]\n )\n\n # Execute query, depending on type.\n if album:\n result = []\n for album in lib.albums(query):\n result.extend(album.items())\n return result\n else:\n return lib.items(query)\n\n\ndef update_playlists(lib):\n ui.print_(\"Updating smart playlists...\")\n playlists = config['smartplaylist']['playlists'].get(list)\n playlist_dir = config['smartplaylist']['playlist_dir'].as_filename()\n relative_to = config['smartplaylist']['relative_to'].get()\n if relative_to:\n relative_to = normpath(relative_to)\n\n for playlist in playlists:\n items = []\n items.extend(_items_for_query(lib, playlist, True))\n items.extend(_items_for_query(lib, playlist, False))\n\n m3us = {}\n basename = playlist['name'].encode('utf8')\n # As we allow tags in the m3u names, we'll need to iterate through\n # the items and generate the correct m3u file names.\n for item in items:\n m3u_name = item.evaluate_template(basename, True)\n if not (m3u_name in m3us):\n m3us[m3u_name] = []\n item_path = item.path\n if relative_to:\n item_path = os.path.relpath(item.path, relative_to)\n if item_path not in m3us[m3u_name]:\n m3us[m3u_name].append(item_path)\n # Now iterate through the m3us that we need to generate\n for m3u in m3us:\n m3u_path = normpath(os.path.join(playlist_dir, m3u))\n with open(syspath(m3u_path), 'w') as f:\n for path in m3us[m3u]:\n f.write(path + '\\n')\n ui.print_(\"... Done\")\n\n\nclass SmartPlaylistPlugin(BeetsPlugin):\n def __init__(self):\n super(SmartPlaylistPlugin, self).__init__()\n self.config.add({\n 'relative_to': None,\n 'playlist_dir': u'.',\n 'auto': True,\n 'playlists': []\n })\n\n def commands(self):\n def update(lib, opts, args):\n update_playlists(lib)\n spl_update = ui.Subcommand('splupdate',\n help='update the smart playlists')\n spl_update.func = update\n return [spl_update]\n\n\[email protected]('database_change')\ndef handle_change(lib):\n global database_changed\n database_changed = True\n\n\[email protected]('cli_exit')\ndef update(lib):\n auto = config['smartplaylist']['auto']\n if database_changed and auto:\n update_playlists(lib)\n", "path": "beetsplug/smartplaylist.py"}], "after_files": [{"content": "# This file is part of beets.\n# Copyright 2013, Dang Mai <[email protected]>.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Generates smart playlists based on beets queries.\n\"\"\"\nfrom __future__ import print_function\n\nfrom beets.plugins import BeetsPlugin\nfrom beets import config, ui, library\nfrom beets.util import normpath, syspath\nimport os\n\n# Global variable so that smartplaylist can detect database changes and run\n# only once before beets exits.\ndatabase_changed = False\n\n\ndef _items_for_query(lib, playlist, album=False):\n \"\"\"Get the matching items for a playlist's configured queries.\n `album` indicates whether to process the item-level query or the\n album-level query (if any).\n \"\"\"\n key = 'album_query' if album else 'query'\n if key not in playlist:\n return []\n\n # Parse quer(ies). If it's a list, perform the queries and manually\n # concatenate the results\n query_strings = playlist[key]\n if not isinstance(query_strings, (list, tuple)):\n query_strings = [query_strings]\n model = library.Album if album else library.Item\n results = []\n for q in query_strings:\n querystr, sort = library.parse_query_string(q, model)\n if album:\n new = lib.albums(querystr, sort)\n else:\n new = lib.items(querystr, sort)\n results.extend(new)\n return results\n\n\ndef update_playlists(lib):\n ui.print_(\"Updating smart playlists...\")\n playlists = config['smartplaylist']['playlists'].get(list)\n playlist_dir = config['smartplaylist']['playlist_dir'].as_filename()\n relative_to = config['smartplaylist']['relative_to'].get()\n if relative_to:\n relative_to = normpath(relative_to)\n\n for playlist in playlists:\n items = []\n items.extend(_items_for_query(lib, playlist, True))\n items.extend(_items_for_query(lib, playlist, False))\n\n m3us = {}\n basename = playlist['name'].encode('utf8')\n # As we allow tags in the m3u names, we'll need to iterate through\n # the items and generate the correct m3u file names.\n for item in items:\n m3u_name = item.evaluate_template(basename, True)\n if not (m3u_name in m3us):\n m3us[m3u_name] = []\n item_path = item.path\n if relative_to:\n item_path = os.path.relpath(item.path, relative_to)\n if item_path not in m3us[m3u_name]:\n m3us[m3u_name].append(item_path)\n # Now iterate through the m3us that we need to generate\n for m3u in m3us:\n m3u_path = normpath(os.path.join(playlist_dir, m3u))\n with open(syspath(m3u_path), 'w') as f:\n for path in m3us[m3u]:\n f.write(path + '\\n')\n ui.print_(\"... Done\")\n\n\nclass SmartPlaylistPlugin(BeetsPlugin):\n def __init__(self):\n super(SmartPlaylistPlugin, self).__init__()\n self.config.add({\n 'relative_to': None,\n 'playlist_dir': u'.',\n 'auto': True,\n 'playlists': []\n })\n\n def commands(self):\n def update(lib, opts, args):\n update_playlists(lib)\n spl_update = ui.Subcommand('splupdate',\n help='update the smart playlists')\n spl_update.func = update\n return [spl_update]\n\n\[email protected]('database_change')\ndef handle_change(lib):\n global database_changed\n database_changed = True\n\n\[email protected]('cli_exit')\ndef update(lib):\n auto = config['smartplaylist']['auto']\n if database_changed and auto:\n update_playlists(lib)\n", "path": "beetsplug/smartplaylist.py"}]}
| 1,662 | 367 |
gh_patches_debug_15368
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-4850
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Swagger doesn't show required field "prefix_length" in available-prefixes POST request
<!--
Please indicate the nature of the change by placing an X in one of the
boxes below.
-->
### Change Type
[X ] Addition
[ ] Correction
[ ] Deprecation
[ ] Cleanup (formatting, typos, etc.)
### Environment
NetBox version: 2.5.13
<!-- Describe the proposed change(s). -->
### Proposed Change
Add `prefix_length` field in Swagger docs, something like:
prefix_length* integer
title: Prefix length
Size of this prefix
In /ipam/prefixes/{id}/available-prefixes/ POST request
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netbox/ipam/api/views.py`
Content:
```
1 from django.conf import settings
2 from django.db.models import Count
3 from django.shortcuts import get_object_or_404
4 from django_pglocks import advisory_lock
5 from drf_yasg.utils import swagger_auto_schema
6 from rest_framework import status
7 from rest_framework.decorators import action
8 from rest_framework.exceptions import PermissionDenied
9 from rest_framework.response import Response
10
11 from extras.api.views import CustomFieldModelViewSet
12 from ipam import filters
13 from ipam.models import Aggregate, IPAddress, Prefix, RIR, Role, Service, VLAN, VLANGroup, VRF
14 from utilities.api import ModelViewSet
15 from utilities.constants import ADVISORY_LOCK_KEYS
16 from utilities.utils import get_subquery
17 from . import serializers
18
19
20 #
21 # VRFs
22 #
23
24 class VRFViewSet(CustomFieldModelViewSet):
25 queryset = VRF.objects.prefetch_related('tenant').prefetch_related('tags').annotate(
26 ipaddress_count=get_subquery(IPAddress, 'vrf'),
27 prefix_count=get_subquery(Prefix, 'vrf')
28 )
29 serializer_class = serializers.VRFSerializer
30 filterset_class = filters.VRFFilterSet
31
32
33 #
34 # RIRs
35 #
36
37 class RIRViewSet(ModelViewSet):
38 queryset = RIR.objects.annotate(
39 aggregate_count=Count('aggregates')
40 )
41 serializer_class = serializers.RIRSerializer
42 filterset_class = filters.RIRFilterSet
43
44
45 #
46 # Aggregates
47 #
48
49 class AggregateViewSet(CustomFieldModelViewSet):
50 queryset = Aggregate.objects.prefetch_related('rir').prefetch_related('tags')
51 serializer_class = serializers.AggregateSerializer
52 filterset_class = filters.AggregateFilterSet
53
54
55 #
56 # Roles
57 #
58
59 class RoleViewSet(ModelViewSet):
60 queryset = Role.objects.annotate(
61 prefix_count=get_subquery(Prefix, 'role'),
62 vlan_count=get_subquery(VLAN, 'role')
63 )
64 serializer_class = serializers.RoleSerializer
65 filterset_class = filters.RoleFilterSet
66
67
68 #
69 # Prefixes
70 #
71
72 class PrefixViewSet(CustomFieldModelViewSet):
73 queryset = Prefix.objects.prefetch_related('site', 'vrf__tenant', 'tenant', 'vlan', 'role', 'tags')
74 serializer_class = serializers.PrefixSerializer
75 filterset_class = filters.PrefixFilterSet
76
77 @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})
78 @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})
79 @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])
80 @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])
81 def available_prefixes(self, request, pk=None):
82 """
83 A convenience method for returning available child prefixes within a parent.
84
85 The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being
86 invoked in parallel, which results in a race condition where multiple insertions can occur.
87 """
88 prefix = get_object_or_404(Prefix, pk=pk)
89 available_prefixes = prefix.get_available_prefixes()
90
91 if request.method == 'POST':
92
93 # Validate Requested Prefixes' length
94 serializer = serializers.PrefixLengthSerializer(
95 data=request.data if isinstance(request.data, list) else [request.data],
96 many=True,
97 context={
98 'request': request,
99 'prefix': prefix,
100 }
101 )
102 if not serializer.is_valid():
103 return Response(
104 serializer.errors,
105 status=status.HTTP_400_BAD_REQUEST
106 )
107
108 requested_prefixes = serializer.validated_data
109 # Allocate prefixes to the requested objects based on availability within the parent
110 for i, requested_prefix in enumerate(requested_prefixes):
111
112 # Find the first available prefix equal to or larger than the requested size
113 for available_prefix in available_prefixes.iter_cidrs():
114 if requested_prefix['prefix_length'] >= available_prefix.prefixlen:
115 allocated_prefix = '{}/{}'.format(available_prefix.network, requested_prefix['prefix_length'])
116 requested_prefix['prefix'] = allocated_prefix
117 requested_prefix['vrf'] = prefix.vrf.pk if prefix.vrf else None
118 break
119 else:
120 return Response(
121 {
122 "detail": "Insufficient space is available to accommodate the requested prefix size(s)"
123 },
124 status=status.HTTP_204_NO_CONTENT
125 )
126
127 # Remove the allocated prefix from the list of available prefixes
128 available_prefixes.remove(allocated_prefix)
129
130 # Initialize the serializer with a list or a single object depending on what was requested
131 context = {'request': request}
132 if isinstance(request.data, list):
133 serializer = serializers.PrefixSerializer(data=requested_prefixes, many=True, context=context)
134 else:
135 serializer = serializers.PrefixSerializer(data=requested_prefixes[0], context=context)
136
137 # Create the new Prefix(es)
138 if serializer.is_valid():
139 serializer.save()
140 return Response(serializer.data, status=status.HTTP_201_CREATED)
141
142 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
143
144 else:
145
146 serializer = serializers.AvailablePrefixSerializer(available_prefixes.iter_cidrs(), many=True, context={
147 'request': request,
148 'vrf': prefix.vrf,
149 })
150
151 return Response(serializer.data)
152
153 @swagger_auto_schema(method='get', responses={200: serializers.AvailableIPSerializer(many=True)})
154 @swagger_auto_schema(method='post', responses={201: serializers.AvailableIPSerializer(many=True)},
155 request_body=serializers.AvailableIPSerializer(many=False))
156 @action(detail=True, url_path='available-ips', methods=['get', 'post'], queryset=IPAddress.objects.all())
157 @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])
158 def available_ips(self, request, pk=None):
159 """
160 A convenience method for returning available IP addresses within a prefix. By default, the number of IPs
161 returned will be equivalent to PAGINATE_COUNT. An arbitrary limit (up to MAX_PAGE_SIZE, if set) may be passed,
162 however results will not be paginated.
163
164 The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being
165 invoked in parallel, which results in a race condition where multiple insertions can occur.
166 """
167 prefix = get_object_or_404(Prefix, pk=pk)
168
169 # Create the next available IP within the prefix
170 if request.method == 'POST':
171
172 # Normalize to a list of objects
173 requested_ips = request.data if isinstance(request.data, list) else [request.data]
174
175 # Determine if the requested number of IPs is available
176 available_ips = prefix.get_available_ips()
177 if available_ips.size < len(requested_ips):
178 return Response(
179 {
180 "detail": "An insufficient number of IP addresses are available within the prefix {} ({} "
181 "requested, {} available)".format(prefix, len(requested_ips), len(available_ips))
182 },
183 status=status.HTTP_204_NO_CONTENT
184 )
185
186 # Assign addresses from the list of available IPs and copy VRF assignment from the parent prefix
187 available_ips = iter(available_ips)
188 prefix_length = prefix.prefix.prefixlen
189 for requested_ip in requested_ips:
190 requested_ip['address'] = '{}/{}'.format(next(available_ips), prefix_length)
191 requested_ip['vrf'] = prefix.vrf.pk if prefix.vrf else None
192
193 # Initialize the serializer with a list or a single object depending on what was requested
194 context = {'request': request}
195 if isinstance(request.data, list):
196 serializer = serializers.IPAddressSerializer(data=requested_ips, many=True, context=context)
197 else:
198 serializer = serializers.IPAddressSerializer(data=requested_ips[0], context=context)
199
200 # Create the new IP address(es)
201 if serializer.is_valid():
202 serializer.save()
203 return Response(serializer.data, status=status.HTTP_201_CREATED)
204
205 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
206
207 # Determine the maximum number of IPs to return
208 else:
209 try:
210 limit = int(request.query_params.get('limit', settings.PAGINATE_COUNT))
211 except ValueError:
212 limit = settings.PAGINATE_COUNT
213 if settings.MAX_PAGE_SIZE:
214 limit = min(limit, settings.MAX_PAGE_SIZE)
215
216 # Calculate available IPs within the prefix
217 ip_list = []
218 for index, ip in enumerate(prefix.get_available_ips(), start=1):
219 ip_list.append(ip)
220 if index == limit:
221 break
222 serializer = serializers.AvailableIPSerializer(ip_list, many=True, context={
223 'request': request,
224 'prefix': prefix.prefix,
225 'vrf': prefix.vrf,
226 })
227
228 return Response(serializer.data)
229
230
231 #
232 # IP addresses
233 #
234
235 class IPAddressViewSet(CustomFieldModelViewSet):
236 queryset = IPAddress.objects.prefetch_related(
237 'vrf__tenant', 'tenant', 'nat_inside', 'interface__device__device_type', 'interface__virtual_machine',
238 'nat_outside', 'tags',
239 )
240 serializer_class = serializers.IPAddressSerializer
241 filterset_class = filters.IPAddressFilterSet
242
243
244 #
245 # VLAN groups
246 #
247
248 class VLANGroupViewSet(ModelViewSet):
249 queryset = VLANGroup.objects.prefetch_related('site').annotate(
250 vlan_count=Count('vlans')
251 )
252 serializer_class = serializers.VLANGroupSerializer
253 filterset_class = filters.VLANGroupFilterSet
254
255
256 #
257 # VLANs
258 #
259
260 class VLANViewSet(CustomFieldModelViewSet):
261 queryset = VLAN.objects.prefetch_related(
262 'site', 'group', 'tenant', 'role', 'tags'
263 ).annotate(
264 prefix_count=get_subquery(Prefix, 'vlan')
265 )
266 serializer_class = serializers.VLANSerializer
267 filterset_class = filters.VLANFilterSet
268
269
270 #
271 # Services
272 #
273
274 class ServiceViewSet(ModelViewSet):
275 queryset = Service.objects.prefetch_related('device').prefetch_related('tags')
276 serializer_class = serializers.ServiceSerializer
277 filterset_class = filters.ServiceFilterSet
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netbox/ipam/api/views.py b/netbox/ipam/api/views.py
--- a/netbox/ipam/api/views.py
+++ b/netbox/ipam/api/views.py
@@ -74,6 +74,11 @@
serializer_class = serializers.PrefixSerializer
filterset_class = filters.PrefixFilterSet
+ def get_serializer_class(self):
+ if self.action == "available_prefixes" and self.request.method == "POST":
+ return serializers.PrefixLengthSerializer
+ return super().get_serializer_class()
+
@swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})
@swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})
@action(detail=True, url_path='available-prefixes', methods=['get', 'post'])
|
{"golden_diff": "diff --git a/netbox/ipam/api/views.py b/netbox/ipam/api/views.py\n--- a/netbox/ipam/api/views.py\n+++ b/netbox/ipam/api/views.py\n@@ -74,6 +74,11 @@\n serializer_class = serializers.PrefixSerializer\n filterset_class = filters.PrefixFilterSet\n \n+ def get_serializer_class(self):\n+ if self.action == \"available_prefixes\" and self.request.method == \"POST\":\n+ return serializers.PrefixLengthSerializer\n+ return super().get_serializer_class()\n+\n @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})\n @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])\n", "issue": "Swagger doesn't show required field \"prefix_length\" in available-prefixes POST request\n<!--\r\n Please indicate the nature of the change by placing an X in one of the\r\n boxes below.\r\n-->\r\n### Change Type\r\n[X ] Addition\r\n[ ] Correction\r\n[ ] Deprecation\r\n[ ] Cleanup (formatting, typos, etc.)\r\n\r\n### Environment\r\nNetBox version: 2.5.13\r\n\r\n<!-- Describe the proposed change(s). -->\r\n### Proposed Change\r\n\r\nAdd `prefix_length` field in Swagger docs, something like:\r\n\r\nprefix_length* integer\r\ntitle: Prefix length\r\nSize of this prefix \r\n\r\nIn /ipam/prefixes/{id}/available-prefixes/ POST request\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.db.models import Count\nfrom django.shortcuts import get_object_or_404\nfrom django_pglocks import advisory_lock\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework import status\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.response import Response\n\nfrom extras.api.views import CustomFieldModelViewSet\nfrom ipam import filters\nfrom ipam.models import Aggregate, IPAddress, Prefix, RIR, Role, Service, VLAN, VLANGroup, VRF\nfrom utilities.api import ModelViewSet\nfrom utilities.constants import ADVISORY_LOCK_KEYS\nfrom utilities.utils import get_subquery\nfrom . import serializers\n\n\n#\n# VRFs\n#\n\nclass VRFViewSet(CustomFieldModelViewSet):\n queryset = VRF.objects.prefetch_related('tenant').prefetch_related('tags').annotate(\n ipaddress_count=get_subquery(IPAddress, 'vrf'),\n prefix_count=get_subquery(Prefix, 'vrf')\n )\n serializer_class = serializers.VRFSerializer\n filterset_class = filters.VRFFilterSet\n\n\n#\n# RIRs\n#\n\nclass RIRViewSet(ModelViewSet):\n queryset = RIR.objects.annotate(\n aggregate_count=Count('aggregates')\n )\n serializer_class = serializers.RIRSerializer\n filterset_class = filters.RIRFilterSet\n\n\n#\n# Aggregates\n#\n\nclass AggregateViewSet(CustomFieldModelViewSet):\n queryset = Aggregate.objects.prefetch_related('rir').prefetch_related('tags')\n serializer_class = serializers.AggregateSerializer\n filterset_class = filters.AggregateFilterSet\n\n\n#\n# Roles\n#\n\nclass RoleViewSet(ModelViewSet):\n queryset = Role.objects.annotate(\n prefix_count=get_subquery(Prefix, 'role'),\n vlan_count=get_subquery(VLAN, 'role')\n )\n serializer_class = serializers.RoleSerializer\n filterset_class = filters.RoleFilterSet\n\n\n#\n# Prefixes\n#\n\nclass PrefixViewSet(CustomFieldModelViewSet):\n queryset = Prefix.objects.prefetch_related('site', 'vrf__tenant', 'tenant', 'vlan', 'role', 'tags')\n serializer_class = serializers.PrefixSerializer\n filterset_class = filters.PrefixFilterSet\n\n @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})\n @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])\n def available_prefixes(self, request, pk=None):\n \"\"\"\n A convenience method for returning available child prefixes within a parent.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n available_prefixes = prefix.get_available_prefixes()\n\n if request.method == 'POST':\n\n # Validate Requested Prefixes' length\n serializer = serializers.PrefixLengthSerializer(\n data=request.data if isinstance(request.data, list) else [request.data],\n many=True,\n context={\n 'request': request,\n 'prefix': prefix,\n }\n )\n if not serializer.is_valid():\n return Response(\n serializer.errors,\n status=status.HTTP_400_BAD_REQUEST\n )\n\n requested_prefixes = serializer.validated_data\n # Allocate prefixes to the requested objects based on availability within the parent\n for i, requested_prefix in enumerate(requested_prefixes):\n\n # Find the first available prefix equal to or larger than the requested size\n for available_prefix in available_prefixes.iter_cidrs():\n if requested_prefix['prefix_length'] >= available_prefix.prefixlen:\n allocated_prefix = '{}/{}'.format(available_prefix.network, requested_prefix['prefix_length'])\n requested_prefix['prefix'] = allocated_prefix\n requested_prefix['vrf'] = prefix.vrf.pk if prefix.vrf else None\n break\n else:\n return Response(\n {\n \"detail\": \"Insufficient space is available to accommodate the requested prefix size(s)\"\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Remove the allocated prefix from the list of available prefixes\n available_prefixes.remove(allocated_prefix)\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.PrefixSerializer(data=requested_prefixes, many=True, context=context)\n else:\n serializer = serializers.PrefixSerializer(data=requested_prefixes[0], context=context)\n\n # Create the new Prefix(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n else:\n\n serializer = serializers.AvailablePrefixSerializer(available_prefixes.iter_cidrs(), many=True, context={\n 'request': request,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n @swagger_auto_schema(method='get', responses={200: serializers.AvailableIPSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailableIPSerializer(many=True)},\n request_body=serializers.AvailableIPSerializer(many=False))\n @action(detail=True, url_path='available-ips', methods=['get', 'post'], queryset=IPAddress.objects.all())\n @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])\n def available_ips(self, request, pk=None):\n \"\"\"\n A convenience method for returning available IP addresses within a prefix. By default, the number of IPs\n returned will be equivalent to PAGINATE_COUNT. An arbitrary limit (up to MAX_PAGE_SIZE, if set) may be passed,\n however results will not be paginated.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n\n # Create the next available IP within the prefix\n if request.method == 'POST':\n\n # Normalize to a list of objects\n requested_ips = request.data if isinstance(request.data, list) else [request.data]\n\n # Determine if the requested number of IPs is available\n available_ips = prefix.get_available_ips()\n if available_ips.size < len(requested_ips):\n return Response(\n {\n \"detail\": \"An insufficient number of IP addresses are available within the prefix {} ({} \"\n \"requested, {} available)\".format(prefix, len(requested_ips), len(available_ips))\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Assign addresses from the list of available IPs and copy VRF assignment from the parent prefix\n available_ips = iter(available_ips)\n prefix_length = prefix.prefix.prefixlen\n for requested_ip in requested_ips:\n requested_ip['address'] = '{}/{}'.format(next(available_ips), prefix_length)\n requested_ip['vrf'] = prefix.vrf.pk if prefix.vrf else None\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.IPAddressSerializer(data=requested_ips, many=True, context=context)\n else:\n serializer = serializers.IPAddressSerializer(data=requested_ips[0], context=context)\n\n # Create the new IP address(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n # Determine the maximum number of IPs to return\n else:\n try:\n limit = int(request.query_params.get('limit', settings.PAGINATE_COUNT))\n except ValueError:\n limit = settings.PAGINATE_COUNT\n if settings.MAX_PAGE_SIZE:\n limit = min(limit, settings.MAX_PAGE_SIZE)\n\n # Calculate available IPs within the prefix\n ip_list = []\n for index, ip in enumerate(prefix.get_available_ips(), start=1):\n ip_list.append(ip)\n if index == limit:\n break\n serializer = serializers.AvailableIPSerializer(ip_list, many=True, context={\n 'request': request,\n 'prefix': prefix.prefix,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n\n#\n# IP addresses\n#\n\nclass IPAddressViewSet(CustomFieldModelViewSet):\n queryset = IPAddress.objects.prefetch_related(\n 'vrf__tenant', 'tenant', 'nat_inside', 'interface__device__device_type', 'interface__virtual_machine',\n 'nat_outside', 'tags',\n )\n serializer_class = serializers.IPAddressSerializer\n filterset_class = filters.IPAddressFilterSet\n\n\n#\n# VLAN groups\n#\n\nclass VLANGroupViewSet(ModelViewSet):\n queryset = VLANGroup.objects.prefetch_related('site').annotate(\n vlan_count=Count('vlans')\n )\n serializer_class = serializers.VLANGroupSerializer\n filterset_class = filters.VLANGroupFilterSet\n\n\n#\n# VLANs\n#\n\nclass VLANViewSet(CustomFieldModelViewSet):\n queryset = VLAN.objects.prefetch_related(\n 'site', 'group', 'tenant', 'role', 'tags'\n ).annotate(\n prefix_count=get_subquery(Prefix, 'vlan')\n )\n serializer_class = serializers.VLANSerializer\n filterset_class = filters.VLANFilterSet\n\n\n#\n# Services\n#\n\nclass ServiceViewSet(ModelViewSet):\n queryset = Service.objects.prefetch_related('device').prefetch_related('tags')\n serializer_class = serializers.ServiceSerializer\n filterset_class = filters.ServiceFilterSet\n", "path": "netbox/ipam/api/views.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.db.models import Count\nfrom django.shortcuts import get_object_or_404\nfrom django_pglocks import advisory_lock\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework import status\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.response import Response\n\nfrom extras.api.views import CustomFieldModelViewSet\nfrom ipam import filters\nfrom ipam.models import Aggregate, IPAddress, Prefix, RIR, Role, Service, VLAN, VLANGroup, VRF\nfrom utilities.api import ModelViewSet\nfrom utilities.constants import ADVISORY_LOCK_KEYS\nfrom utilities.utils import get_subquery\nfrom . import serializers\n\n\n#\n# VRFs\n#\n\nclass VRFViewSet(CustomFieldModelViewSet):\n queryset = VRF.objects.prefetch_related('tenant').prefetch_related('tags').annotate(\n ipaddress_count=get_subquery(IPAddress, 'vrf'),\n prefix_count=get_subquery(Prefix, 'vrf')\n )\n serializer_class = serializers.VRFSerializer\n filterset_class = filters.VRFFilterSet\n\n\n#\n# RIRs\n#\n\nclass RIRViewSet(ModelViewSet):\n queryset = RIR.objects.annotate(\n aggregate_count=Count('aggregates')\n )\n serializer_class = serializers.RIRSerializer\n filterset_class = filters.RIRFilterSet\n\n\n#\n# Aggregates\n#\n\nclass AggregateViewSet(CustomFieldModelViewSet):\n queryset = Aggregate.objects.prefetch_related('rir').prefetch_related('tags')\n serializer_class = serializers.AggregateSerializer\n filterset_class = filters.AggregateFilterSet\n\n\n#\n# Roles\n#\n\nclass RoleViewSet(ModelViewSet):\n queryset = Role.objects.annotate(\n prefix_count=get_subquery(Prefix, 'role'),\n vlan_count=get_subquery(VLAN, 'role')\n )\n serializer_class = serializers.RoleSerializer\n filterset_class = filters.RoleFilterSet\n\n\n#\n# Prefixes\n#\n\nclass PrefixViewSet(CustomFieldModelViewSet):\n queryset = Prefix.objects.prefetch_related('site', 'vrf__tenant', 'tenant', 'vlan', 'role', 'tags')\n serializer_class = serializers.PrefixSerializer\n filterset_class = filters.PrefixFilterSet\n\n def get_serializer_class(self):\n if self.action == \"available_prefixes\" and self.request.method == \"POST\":\n return serializers.PrefixLengthSerializer\n return super().get_serializer_class()\n\n @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})\n @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])\n def available_prefixes(self, request, pk=None):\n \"\"\"\n A convenience method for returning available child prefixes within a parent.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n available_prefixes = prefix.get_available_prefixes()\n\n if request.method == 'POST':\n\n # Validate Requested Prefixes' length\n serializer = serializers.PrefixLengthSerializer(\n data=request.data if isinstance(request.data, list) else [request.data],\n many=True,\n context={\n 'request': request,\n 'prefix': prefix,\n }\n )\n if not serializer.is_valid():\n return Response(\n serializer.errors,\n status=status.HTTP_400_BAD_REQUEST\n )\n\n requested_prefixes = serializer.validated_data\n # Allocate prefixes to the requested objects based on availability within the parent\n for i, requested_prefix in enumerate(requested_prefixes):\n\n # Find the first available prefix equal to or larger than the requested size\n for available_prefix in available_prefixes.iter_cidrs():\n if requested_prefix['prefix_length'] >= available_prefix.prefixlen:\n allocated_prefix = '{}/{}'.format(available_prefix.network, requested_prefix['prefix_length'])\n requested_prefix['prefix'] = allocated_prefix\n requested_prefix['vrf'] = prefix.vrf.pk if prefix.vrf else None\n break\n else:\n return Response(\n {\n \"detail\": \"Insufficient space is available to accommodate the requested prefix size(s)\"\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Remove the allocated prefix from the list of available prefixes\n available_prefixes.remove(allocated_prefix)\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.PrefixSerializer(data=requested_prefixes, many=True, context=context)\n else:\n serializer = serializers.PrefixSerializer(data=requested_prefixes[0], context=context)\n\n # Create the new Prefix(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n else:\n\n serializer = serializers.AvailablePrefixSerializer(available_prefixes.iter_cidrs(), many=True, context={\n 'request': request,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n @swagger_auto_schema(method='get', responses={200: serializers.AvailableIPSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailableIPSerializer(many=True)},\n request_body=serializers.AvailableIPSerializer(many=False))\n @action(detail=True, url_path='available-ips', methods=['get', 'post'], queryset=IPAddress.objects.all())\n @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])\n def available_ips(self, request, pk=None):\n \"\"\"\n A convenience method for returning available IP addresses within a prefix. By default, the number of IPs\n returned will be equivalent to PAGINATE_COUNT. An arbitrary limit (up to MAX_PAGE_SIZE, if set) may be passed,\n however results will not be paginated.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n\n # Create the next available IP within the prefix\n if request.method == 'POST':\n\n # Normalize to a list of objects\n requested_ips = request.data if isinstance(request.data, list) else [request.data]\n\n # Determine if the requested number of IPs is available\n available_ips = prefix.get_available_ips()\n if available_ips.size < len(requested_ips):\n return Response(\n {\n \"detail\": \"An insufficient number of IP addresses are available within the prefix {} ({} \"\n \"requested, {} available)\".format(prefix, len(requested_ips), len(available_ips))\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Assign addresses from the list of available IPs and copy VRF assignment from the parent prefix\n available_ips = iter(available_ips)\n prefix_length = prefix.prefix.prefixlen\n for requested_ip in requested_ips:\n requested_ip['address'] = '{}/{}'.format(next(available_ips), prefix_length)\n requested_ip['vrf'] = prefix.vrf.pk if prefix.vrf else None\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.IPAddressSerializer(data=requested_ips, many=True, context=context)\n else:\n serializer = serializers.IPAddressSerializer(data=requested_ips[0], context=context)\n\n # Create the new IP address(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n # Determine the maximum number of IPs to return\n else:\n try:\n limit = int(request.query_params.get('limit', settings.PAGINATE_COUNT))\n except ValueError:\n limit = settings.PAGINATE_COUNT\n if settings.MAX_PAGE_SIZE:\n limit = min(limit, settings.MAX_PAGE_SIZE)\n\n # Calculate available IPs within the prefix\n ip_list = []\n for index, ip in enumerate(prefix.get_available_ips(), start=1):\n ip_list.append(ip)\n if index == limit:\n break\n serializer = serializers.AvailableIPSerializer(ip_list, many=True, context={\n 'request': request,\n 'prefix': prefix.prefix,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n\n#\n# IP addresses\n#\n\nclass IPAddressViewSet(CustomFieldModelViewSet):\n queryset = IPAddress.objects.prefetch_related(\n 'vrf__tenant', 'tenant', 'nat_inside', 'interface__device__device_type', 'interface__virtual_machine',\n 'nat_outside', 'tags',\n )\n serializer_class = serializers.IPAddressSerializer\n filterset_class = filters.IPAddressFilterSet\n\n\n#\n# VLAN groups\n#\n\nclass VLANGroupViewSet(ModelViewSet):\n queryset = VLANGroup.objects.prefetch_related('site').annotate(\n vlan_count=Count('vlans')\n )\n serializer_class = serializers.VLANGroupSerializer\n filterset_class = filters.VLANGroupFilterSet\n\n\n#\n# VLANs\n#\n\nclass VLANViewSet(CustomFieldModelViewSet):\n queryset = VLAN.objects.prefetch_related(\n 'site', 'group', 'tenant', 'role', 'tags'\n ).annotate(\n prefix_count=get_subquery(Prefix, 'vlan')\n )\n serializer_class = serializers.VLANSerializer\n filterset_class = filters.VLANFilterSet\n\n\n#\n# Services\n#\n\nclass ServiceViewSet(ModelViewSet):\n queryset = Service.objects.prefetch_related('device').prefetch_related('tags')\n serializer_class = serializers.ServiceSerializer\n filterset_class = filters.ServiceFilterSet\n", "path": "netbox/ipam/api/views.py"}]}
| 3,351 | 187 |
gh_patches_debug_11338
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Commit 9102071 Breaks Gentoo compatibility
Using a relative path breaks Gentoo compatibility.
Due to Gentoo's ability to have multiple versions of python installed simutaneously, they do some symlink resolution magic that determines which python interpreter should be used for a package based on the constraining flags applied at installation.
Because of this lutris script is not located in /usr/bin/lutris. This is a symlink to the resolver that then performs its magic. This causes lutris to fail to be able to call the python-wrapper script.
Recommend non-relative path to lutris-wrapper.
Commit 9102071 Breaks Gentoo compatibility
Using a relative path breaks Gentoo compatibility.
Due to Gentoo's ability to have multiple versions of python installed simutaneously, they do some symlink resolution magic that determines which python interpreter should be used for a package based on the constraining flags applied at installation.
Because of this lutris script is not located in /usr/bin/lutris. This is a symlink to the resolver that then performs its magic. This causes lutris to fail to be able to call the python-wrapper script.
Recommend non-relative path to lutris-wrapper.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/command.py`
Content:
```
1 """Threading module, used to launch games while monitoring them."""
2
3 import io
4 import os
5 import sys
6 import fcntl
7 import shlex
8 import subprocess
9 import contextlib
10 from textwrap import dedent
11
12 from gi.repository import GLib
13
14 from lutris import settings
15 from lutris import runtime
16 from lutris.util.log import logger
17 from lutris.util import system
18
19 WRAPPER_SCRIPT = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(sys.argv[0])), "../share/lutris/bin/lutris-wrapper"))
20
21
22 class MonitoredCommand:
23 """Exexcutes a commmand while keeping track of its state"""
24
25 fallback_cwd = "/tmp"
26
27 def __init__(
28 self,
29 command,
30 runner=None,
31 env=None,
32 term=None,
33 cwd=None,
34 include_processes=None,
35 exclude_processes=None,
36 log_buffer=None,
37 title=None,
38 ): # pylint: disable=too-many-arguments
39 self.ready_state = True
40 self.env = self.get_environment(env)
41
42 self.command = command
43 self.runner = runner
44 self.stop_func = lambda: True
45 self.game_process = None
46 self.prevent_on_stop = False
47 self.return_code = None
48 self.terminal = system.find_executable(term)
49 self.is_running = True
50 self.error = None
51 self.log_handlers = [
52 self.log_handler_stdout,
53 self.log_handler_console_output,
54 ]
55 self.set_log_buffer(log_buffer)
56 self.stdout_monitor = None
57 self.include_processes = include_processes or []
58 self.exclude_processes = exclude_processes or []
59
60 self.cwd = self.get_cwd(cwd)
61
62 self._stdout = io.StringIO()
63
64 self._title = title if title else command[0]
65
66 @property
67 def stdout(self):
68 return self._stdout.getvalue()
69
70 @property
71 def wrapper_command(self):
72 """Return launch arguments for the wrapper script"""
73
74 return [
75 WRAPPER_SCRIPT,
76 self._title,
77 str(len(self.include_processes)),
78 str(len(self.exclude_processes)),
79 ] + self.include_processes + self.exclude_processes + self.command
80
81 def set_log_buffer(self, log_buffer):
82 """Attach a TextBuffer to this command enables the buffer handler"""
83 if not log_buffer:
84 return
85 self.log_buffer = log_buffer
86 if self.log_handler_buffer not in self.log_handlers:
87 self.log_handlers.append(self.log_handler_buffer)
88
89 def get_cwd(self, cwd):
90 """Return the current working dir of the game"""
91 if not cwd:
92 cwd = self.runner.working_dir if self.runner else None
93 return os.path.expanduser(cwd or "~")
94
95 @staticmethod
96 def get_environment(user_env):
97 """Process the user provided environment variables for use as self.env"""
98 env = user_env or {}
99 # not clear why this needs to be added, the path is already added in
100 # the wrappper script.
101 env['PYTHONPATH'] = ':'.join(sys.path)
102 # Drop bad values of environment keys, those will confuse the Python
103 # interpreter.
104 return {
105 key: value for key, value in env.items() if "=" not in key
106 }
107
108 def get_child_environment(self):
109 """Returns the calculated environment for the child process."""
110 env = os.environ.copy()
111 env.update(self.env)
112 return env
113
114 def start(self):
115 """Run the thread."""
116 logger.debug("Running %s", " ".join(self.wrapper_command))
117 for key, value in self.env.items():
118 logger.debug("ENV: %s=\"%s\"", key, value)
119
120 if self.terminal:
121 self.game_process = self.run_in_terminal()
122 else:
123 env = self.get_child_environment()
124 self.game_process = self.execute_process(self.wrapper_command, env)
125
126 if not self.game_process:
127 logger.warning("No game process available")
128 return
129
130 GLib.child_watch_add(self.game_process.pid, self.on_stop)
131
132 # make stdout nonblocking.
133 fileno = self.game_process.stdout.fileno()
134 fcntl.fcntl(
135 fileno,
136 fcntl.F_SETFL,
137 fcntl.fcntl(fileno, fcntl.F_GETFL) | os.O_NONBLOCK
138 )
139
140 self.stdout_monitor = GLib.io_add_watch(
141 self.game_process.stdout,
142 GLib.IO_IN | GLib.IO_HUP,
143 self.on_stdout_output,
144 )
145
146 def log_handler_stdout(self, line):
147 """Add the line to this command's stdout attribute"""
148 self._stdout.write(line)
149
150 def log_handler_buffer(self, line):
151 """Add the line to the associated LogBuffer object"""
152 self.log_buffer.insert(self.log_buffer.get_end_iter(), line, -1)
153
154 def log_handler_console_output(self, line): # pylint: disable=no-self-use
155 """Print the line to stdout"""
156 with contextlib.suppress(BlockingIOError):
157 sys.stdout.write(line)
158 sys.stdout.flush()
159
160 def on_stop(self, _pid, returncode):
161 """Callback registered on game process termination"""
162 if self.prevent_on_stop: # stop() already in progress
163 return False
164
165 logger.debug("The process has terminated with code %s", returncode)
166 self.is_running = False
167 self.return_code = returncode
168
169 resume_stop = self.stop()
170 if not resume_stop:
171 logger.info("Full shutdown prevented")
172 return False
173
174 return False
175
176 def on_stdout_output(self, stdout, condition):
177 """Called by the stdout monitor to dispatch output to log handlers"""
178 if condition == GLib.IO_HUP:
179 self.stdout_monitor = None
180 return False
181 if not self.is_running:
182 return False
183 try:
184 line = stdout.read(262144).decode("utf-8", errors="ignore")
185 except ValueError:
186 # file_desc might be closed
187 return True
188 if "winemenubuilder.exe" in line:
189 return True
190 for log_handler in self.log_handlers:
191 log_handler(line)
192 return True
193
194 def run_in_terminal(self):
195 """Write command in a script file and run it.
196
197 Running it from a file is likely the only way to set env vars only
198 for the command (not for the terminal app).
199 It's also the only reliable way to keep the term open when the
200 game is quit.
201 """
202 script_path = os.path.join(settings.CACHE_DIR, "run_in_term.sh")
203 exported_environment = "\n".join(
204 'export %s="%s" ' % (key, value)
205 for key, value in self.env.items()
206 )
207 command = " ".join(['"%s"' % token for token in self.wrapper_command])
208 with open(script_path, "w") as script_file:
209 script_file.write(dedent(
210 """#!/bin/sh
211 cd "%s"
212 %s
213 exec %s
214 """ % (self.cwd, exported_environment, command)
215 ))
216 os.chmod(script_path, 0o744)
217 return self.execute_process([self.terminal, "-e", script_path])
218
219 def execute_process(self, command, env=None):
220 """Execute and return a subprocess"""
221 if self.cwd and not system.path_exists(self.cwd):
222 try:
223 os.makedirs(self.cwd)
224 except OSError:
225 logger.error("Failed to create working directory, falling back to %s",
226 self.fallback_cwd)
227 self.cwd = "/tmp"
228 try:
229
230 return subprocess.Popen(
231 command,
232 stdout=subprocess.PIPE,
233 stderr=subprocess.STDOUT,
234 cwd=self.cwd,
235 env=env,
236 )
237 except OSError as ex:
238 logger.exception("Failed to execute %s: %s", " ".join(command), ex)
239 self.error = ex.strerror
240
241 def stop(self):
242 """Stops the current game process and cleans up the instance"""
243 # Prevent stop() being called again by the process exiting
244 self.prevent_on_stop = True
245
246 try:
247 self.game_process.terminate()
248 except ProcessLookupError: # process already dead.
249 logger.debug("Management process looks dead already.")
250
251 if hasattr(self, "stop_func"):
252 resume_stop = self.stop_func()
253 if not resume_stop:
254 return False
255
256 if self.stdout_monitor:
257 logger.debug("Detaching logger")
258 GLib.source_remove(self.stdout_monitor)
259 self.stdout_monitor = None
260 else:
261 logger.debug("logger already detached")
262
263 self.is_running = False
264 self.ready_state = False
265 return True
266
267
268 def exec_command(command):
269 """Execute arbitrary command in a MonitoredCommand
270
271 Used by the --exec command line flag.
272 """
273 command = MonitoredCommand(shlex.split(command), env=runtime.get_env())
274 command.start()
275 return command
276
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/command.py b/lutris/command.py
--- a/lutris/command.py
+++ b/lutris/command.py
@@ -17,6 +17,15 @@
from lutris.util import system
WRAPPER_SCRIPT = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(sys.argv[0])), "../share/lutris/bin/lutris-wrapper"))
+if not os.path.isfile(WRAPPER_SCRIPT):
+ usr_path = "/usr/share/lutris/bin/lutris-wrapper"
+ usr_local_path = "/usr/local/share/lutris/bin/lutris-wrapper"
+ if os.path.isfile(usr_path):
+ WRAPPER_SCRIPT = usr_path
+ elif os.path.isfile(usr_local_path):
+ WRAPPER_SCRIPT = usr_local_path
+ else:
+ raise FileNotFoundError("Couldn't find lutris-wrapper script in any of the expected locations")
class MonitoredCommand:
|
{"golden_diff": "diff --git a/lutris/command.py b/lutris/command.py\n--- a/lutris/command.py\n+++ b/lutris/command.py\n@@ -17,6 +17,15 @@\n from lutris.util import system\n \n WRAPPER_SCRIPT = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(sys.argv[0])), \"../share/lutris/bin/lutris-wrapper\"))\n+if not os.path.isfile(WRAPPER_SCRIPT):\n+ usr_path = \"/usr/share/lutris/bin/lutris-wrapper\"\n+ usr_local_path = \"/usr/local/share/lutris/bin/lutris-wrapper\"\n+ if os.path.isfile(usr_path):\n+ WRAPPER_SCRIPT = usr_path\n+ elif os.path.isfile(usr_local_path):\n+ WRAPPER_SCRIPT = usr_local_path\n+ else:\n+ raise FileNotFoundError(\"Couldn't find lutris-wrapper script in any of the expected locations\")\n \n \n class MonitoredCommand:\n", "issue": "Commit 9102071 Breaks Gentoo compatibility\nUsing a relative path breaks Gentoo compatibility.\r\n\r\nDue to Gentoo's ability to have multiple versions of python installed simutaneously, they do some symlink resolution magic that determines which python interpreter should be used for a package based on the constraining flags applied at installation.\r\n\r\nBecause of this lutris script is not located in /usr/bin/lutris. This is a symlink to the resolver that then performs its magic. This causes lutris to fail to be able to call the python-wrapper script.\r\n\r\nRecommend non-relative path to lutris-wrapper.\nCommit 9102071 Breaks Gentoo compatibility\nUsing a relative path breaks Gentoo compatibility.\r\n\r\nDue to Gentoo's ability to have multiple versions of python installed simutaneously, they do some symlink resolution magic that determines which python interpreter should be used for a package based on the constraining flags applied at installation.\r\n\r\nBecause of this lutris script is not located in /usr/bin/lutris. This is a symlink to the resolver that then performs its magic. This causes lutris to fail to be able to call the python-wrapper script.\r\n\r\nRecommend non-relative path to lutris-wrapper.\n", "before_files": [{"content": "\"\"\"Threading module, used to launch games while monitoring them.\"\"\"\n\nimport io\nimport os\nimport sys\nimport fcntl\nimport shlex\nimport subprocess\nimport contextlib\nfrom textwrap import dedent\n\nfrom gi.repository import GLib\n\nfrom lutris import settings\nfrom lutris import runtime\nfrom lutris.util.log import logger\nfrom lutris.util import system\n\nWRAPPER_SCRIPT = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(sys.argv[0])), \"../share/lutris/bin/lutris-wrapper\"))\n\n\nclass MonitoredCommand:\n \"\"\"Exexcutes a commmand while keeping track of its state\"\"\"\n\n fallback_cwd = \"/tmp\"\n\n def __init__(\n self,\n command,\n runner=None,\n env=None,\n term=None,\n cwd=None,\n include_processes=None,\n exclude_processes=None,\n log_buffer=None,\n title=None,\n ): # pylint: disable=too-many-arguments\n self.ready_state = True\n self.env = self.get_environment(env)\n\n self.command = command\n self.runner = runner\n self.stop_func = lambda: True\n self.game_process = None\n self.prevent_on_stop = False\n self.return_code = None\n self.terminal = system.find_executable(term)\n self.is_running = True\n self.error = None\n self.log_handlers = [\n self.log_handler_stdout,\n self.log_handler_console_output,\n ]\n self.set_log_buffer(log_buffer)\n self.stdout_monitor = None\n self.include_processes = include_processes or []\n self.exclude_processes = exclude_processes or []\n\n self.cwd = self.get_cwd(cwd)\n\n self._stdout = io.StringIO()\n\n self._title = title if title else command[0]\n\n @property\n def stdout(self):\n return self._stdout.getvalue()\n\n @property\n def wrapper_command(self):\n \"\"\"Return launch arguments for the wrapper script\"\"\"\n\n return [\n WRAPPER_SCRIPT,\n self._title,\n str(len(self.include_processes)),\n str(len(self.exclude_processes)),\n ] + self.include_processes + self.exclude_processes + self.command\n\n def set_log_buffer(self, log_buffer):\n \"\"\"Attach a TextBuffer to this command enables the buffer handler\"\"\"\n if not log_buffer:\n return\n self.log_buffer = log_buffer\n if self.log_handler_buffer not in self.log_handlers:\n self.log_handlers.append(self.log_handler_buffer)\n\n def get_cwd(self, cwd):\n \"\"\"Return the current working dir of the game\"\"\"\n if not cwd:\n cwd = self.runner.working_dir if self.runner else None\n return os.path.expanduser(cwd or \"~\")\n\n @staticmethod\n def get_environment(user_env):\n \"\"\"Process the user provided environment variables for use as self.env\"\"\"\n env = user_env or {}\n # not clear why this needs to be added, the path is already added in\n # the wrappper script.\n env['PYTHONPATH'] = ':'.join(sys.path)\n # Drop bad values of environment keys, those will confuse the Python\n # interpreter.\n return {\n key: value for key, value in env.items() if \"=\" not in key\n }\n\n def get_child_environment(self):\n \"\"\"Returns the calculated environment for the child process.\"\"\"\n env = os.environ.copy()\n env.update(self.env)\n return env\n\n def start(self):\n \"\"\"Run the thread.\"\"\"\n logger.debug(\"Running %s\", \" \".join(self.wrapper_command))\n for key, value in self.env.items():\n logger.debug(\"ENV: %s=\\\"%s\\\"\", key, value)\n\n if self.terminal:\n self.game_process = self.run_in_terminal()\n else:\n env = self.get_child_environment()\n self.game_process = self.execute_process(self.wrapper_command, env)\n\n if not self.game_process:\n logger.warning(\"No game process available\")\n return\n\n GLib.child_watch_add(self.game_process.pid, self.on_stop)\n\n # make stdout nonblocking.\n fileno = self.game_process.stdout.fileno()\n fcntl.fcntl(\n fileno,\n fcntl.F_SETFL,\n fcntl.fcntl(fileno, fcntl.F_GETFL) | os.O_NONBLOCK\n )\n\n self.stdout_monitor = GLib.io_add_watch(\n self.game_process.stdout,\n GLib.IO_IN | GLib.IO_HUP,\n self.on_stdout_output,\n )\n\n def log_handler_stdout(self, line):\n \"\"\"Add the line to this command's stdout attribute\"\"\"\n self._stdout.write(line)\n\n def log_handler_buffer(self, line):\n \"\"\"Add the line to the associated LogBuffer object\"\"\"\n self.log_buffer.insert(self.log_buffer.get_end_iter(), line, -1)\n\n def log_handler_console_output(self, line): # pylint: disable=no-self-use\n \"\"\"Print the line to stdout\"\"\"\n with contextlib.suppress(BlockingIOError):\n sys.stdout.write(line)\n sys.stdout.flush()\n\n def on_stop(self, _pid, returncode):\n \"\"\"Callback registered on game process termination\"\"\"\n if self.prevent_on_stop: # stop() already in progress\n return False\n\n logger.debug(\"The process has terminated with code %s\", returncode)\n self.is_running = False\n self.return_code = returncode\n\n resume_stop = self.stop()\n if not resume_stop:\n logger.info(\"Full shutdown prevented\")\n return False\n\n return False\n\n def on_stdout_output(self, stdout, condition):\n \"\"\"Called by the stdout monitor to dispatch output to log handlers\"\"\"\n if condition == GLib.IO_HUP:\n self.stdout_monitor = None\n return False\n if not self.is_running:\n return False\n try:\n line = stdout.read(262144).decode(\"utf-8\", errors=\"ignore\")\n except ValueError:\n # file_desc might be closed\n return True\n if \"winemenubuilder.exe\" in line:\n return True\n for log_handler in self.log_handlers:\n log_handler(line)\n return True\n\n def run_in_terminal(self):\n \"\"\"Write command in a script file and run it.\n\n Running it from a file is likely the only way to set env vars only\n for the command (not for the terminal app).\n It's also the only reliable way to keep the term open when the\n game is quit.\n \"\"\"\n script_path = os.path.join(settings.CACHE_DIR, \"run_in_term.sh\")\n exported_environment = \"\\n\".join(\n 'export %s=\"%s\" ' % (key, value)\n for key, value in self.env.items()\n )\n command = \" \".join(['\"%s\"' % token for token in self.wrapper_command])\n with open(script_path, \"w\") as script_file:\n script_file.write(dedent(\n \"\"\"#!/bin/sh\n cd \"%s\"\n %s\n exec %s\n \"\"\" % (self.cwd, exported_environment, command)\n ))\n os.chmod(script_path, 0o744)\n return self.execute_process([self.terminal, \"-e\", script_path])\n\n def execute_process(self, command, env=None):\n \"\"\"Execute and return a subprocess\"\"\"\n if self.cwd and not system.path_exists(self.cwd):\n try:\n os.makedirs(self.cwd)\n except OSError:\n logger.error(\"Failed to create working directory, falling back to %s\",\n self.fallback_cwd)\n self.cwd = \"/tmp\"\n try:\n\n return subprocess.Popen(\n command,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n cwd=self.cwd,\n env=env,\n )\n except OSError as ex:\n logger.exception(\"Failed to execute %s: %s\", \" \".join(command), ex)\n self.error = ex.strerror\n\n def stop(self):\n \"\"\"Stops the current game process and cleans up the instance\"\"\"\n # Prevent stop() being called again by the process exiting\n self.prevent_on_stop = True\n\n try:\n self.game_process.terminate()\n except ProcessLookupError: # process already dead.\n logger.debug(\"Management process looks dead already.\")\n\n if hasattr(self, \"stop_func\"):\n resume_stop = self.stop_func()\n if not resume_stop:\n return False\n\n if self.stdout_monitor:\n logger.debug(\"Detaching logger\")\n GLib.source_remove(self.stdout_monitor)\n self.stdout_monitor = None\n else:\n logger.debug(\"logger already detached\")\n\n self.is_running = False\n self.ready_state = False\n return True\n\n\ndef exec_command(command):\n \"\"\"Execute arbitrary command in a MonitoredCommand\n\n Used by the --exec command line flag.\n \"\"\"\n command = MonitoredCommand(shlex.split(command), env=runtime.get_env())\n command.start()\n return command\n", "path": "lutris/command.py"}], "after_files": [{"content": "\"\"\"Threading module, used to launch games while monitoring them.\"\"\"\n\nimport io\nimport os\nimport sys\nimport fcntl\nimport shlex\nimport subprocess\nimport contextlib\nfrom textwrap import dedent\n\nfrom gi.repository import GLib\n\nfrom lutris import settings\nfrom lutris import runtime\nfrom lutris.util.log import logger\nfrom lutris.util import system\n\nWRAPPER_SCRIPT = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(sys.argv[0])), \"../share/lutris/bin/lutris-wrapper\"))\nif not os.path.isfile(WRAPPER_SCRIPT):\n usr_path = \"/usr/share/lutris/bin/lutris-wrapper\"\n usr_local_path = \"/usr/local/share/lutris/bin/lutris-wrapper\"\n if os.path.isfile(usr_path):\n WRAPPER_SCRIPT = usr_path\n elif os.path.isfile(usr_local_path):\n WRAPPER_SCRIPT = usr_local_path\n else:\n raise FileNotFoundError(\"Couldn't find lutris-wrapper script in any of the expected locations\")\n\n\nclass MonitoredCommand:\n \"\"\"Exexcutes a commmand while keeping track of its state\"\"\"\n\n fallback_cwd = \"/tmp\"\n\n def __init__(\n self,\n command,\n runner=None,\n env=None,\n term=None,\n cwd=None,\n include_processes=None,\n exclude_processes=None,\n log_buffer=None,\n title=None,\n ): # pylint: disable=too-many-arguments\n self.ready_state = True\n self.env = self.get_environment(env)\n\n self.command = command\n self.runner = runner\n self.stop_func = lambda: True\n self.game_process = None\n self.prevent_on_stop = False\n self.return_code = None\n self.terminal = system.find_executable(term)\n self.is_running = True\n self.error = None\n self.log_handlers = [\n self.log_handler_stdout,\n self.log_handler_console_output,\n ]\n self.set_log_buffer(log_buffer)\n self.stdout_monitor = None\n self.include_processes = include_processes or []\n self.exclude_processes = exclude_processes or []\n\n self.cwd = self.get_cwd(cwd)\n\n self._stdout = io.StringIO()\n\n self._title = title if title else command[0]\n\n @property\n def stdout(self):\n return self._stdout.getvalue()\n\n @property\n def wrapper_command(self):\n \"\"\"Return launch arguments for the wrapper script\"\"\"\n\n return [\n WRAPPER_SCRIPT,\n self._title,\n str(len(self.include_processes)),\n str(len(self.exclude_processes)),\n ] + self.include_processes + self.exclude_processes + self.command\n\n def set_log_buffer(self, log_buffer):\n \"\"\"Attach a TextBuffer to this command enables the buffer handler\"\"\"\n if not log_buffer:\n return\n self.log_buffer = log_buffer\n if self.log_handler_buffer not in self.log_handlers:\n self.log_handlers.append(self.log_handler_buffer)\n\n def get_cwd(self, cwd):\n \"\"\"Return the current working dir of the game\"\"\"\n if not cwd:\n cwd = self.runner.working_dir if self.runner else None\n return os.path.expanduser(cwd or \"~\")\n\n @staticmethod\n def get_environment(user_env):\n \"\"\"Process the user provided environment variables for use as self.env\"\"\"\n env = user_env or {}\n # not clear why this needs to be added, the path is already added in\n # the wrappper script.\n env['PYTHONPATH'] = ':'.join(sys.path)\n # Drop bad values of environment keys, those will confuse the Python\n # interpreter.\n return {\n key: value for key, value in env.items() if \"=\" not in key\n }\n\n def get_child_environment(self):\n \"\"\"Returns the calculated environment for the child process.\"\"\"\n env = os.environ.copy()\n env.update(self.env)\n return env\n\n def start(self):\n \"\"\"Run the thread.\"\"\"\n logger.debug(\"Running %s\", \" \".join(self.wrapper_command))\n for key, value in self.env.items():\n logger.debug(\"ENV: %s=\\\"%s\\\"\", key, value)\n\n if self.terminal:\n self.game_process = self.run_in_terminal()\n else:\n env = self.get_child_environment()\n self.game_process = self.execute_process(self.wrapper_command, env)\n\n if not self.game_process:\n logger.warning(\"No game process available\")\n return\n\n GLib.child_watch_add(self.game_process.pid, self.on_stop)\n\n # make stdout nonblocking.\n fileno = self.game_process.stdout.fileno()\n fcntl.fcntl(\n fileno,\n fcntl.F_SETFL,\n fcntl.fcntl(fileno, fcntl.F_GETFL) | os.O_NONBLOCK\n )\n\n self.stdout_monitor = GLib.io_add_watch(\n self.game_process.stdout,\n GLib.IO_IN | GLib.IO_HUP,\n self.on_stdout_output,\n )\n\n def log_handler_stdout(self, line):\n \"\"\"Add the line to this command's stdout attribute\"\"\"\n self._stdout.write(line)\n\n def log_handler_buffer(self, line):\n \"\"\"Add the line to the associated LogBuffer object\"\"\"\n self.log_buffer.insert(self.log_buffer.get_end_iter(), line, -1)\n\n def log_handler_console_output(self, line): # pylint: disable=no-self-use\n \"\"\"Print the line to stdout\"\"\"\n with contextlib.suppress(BlockingIOError):\n sys.stdout.write(line)\n sys.stdout.flush()\n\n def on_stop(self, _pid, returncode):\n \"\"\"Callback registered on game process termination\"\"\"\n if self.prevent_on_stop: # stop() already in progress\n return False\n\n logger.debug(\"The process has terminated with code %s\", returncode)\n self.is_running = False\n self.return_code = returncode\n\n resume_stop = self.stop()\n if not resume_stop:\n logger.info(\"Full shutdown prevented\")\n return False\n\n return False\n\n def on_stdout_output(self, stdout, condition):\n \"\"\"Called by the stdout monitor to dispatch output to log handlers\"\"\"\n if condition == GLib.IO_HUP:\n self.stdout_monitor = None\n return False\n if not self.is_running:\n return False\n try:\n line = stdout.read(262144).decode(\"utf-8\", errors=\"ignore\")\n except ValueError:\n # file_desc might be closed\n return True\n if \"winemenubuilder.exe\" in line:\n return True\n for log_handler in self.log_handlers:\n log_handler(line)\n return True\n\n def run_in_terminal(self):\n \"\"\"Write command in a script file and run it.\n\n Running it from a file is likely the only way to set env vars only\n for the command (not for the terminal app).\n It's also the only reliable way to keep the term open when the\n game is quit.\n \"\"\"\n script_path = os.path.join(settings.CACHE_DIR, \"run_in_term.sh\")\n exported_environment = \"\\n\".join(\n 'export %s=\"%s\" ' % (key, value)\n for key, value in self.env.items()\n )\n command = \" \".join(['\"%s\"' % token for token in self.wrapper_command])\n with open(script_path, \"w\") as script_file:\n script_file.write(dedent(\n \"\"\"#!/bin/sh\n cd \"%s\"\n %s\n exec %s\n \"\"\" % (self.cwd, exported_environment, command)\n ))\n os.chmod(script_path, 0o744)\n return self.execute_process([self.terminal, \"-e\", script_path])\n\n def execute_process(self, command, env=None):\n \"\"\"Execute and return a subprocess\"\"\"\n if self.cwd and not system.path_exists(self.cwd):\n try:\n os.makedirs(self.cwd)\n except OSError:\n logger.error(\"Failed to create working directory, falling back to %s\",\n self.fallback_cwd)\n self.cwd = \"/tmp\"\n try:\n\n return subprocess.Popen(\n command,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n cwd=self.cwd,\n env=env,\n )\n except OSError as ex:\n logger.exception(\"Failed to execute %s: %s\", \" \".join(command), ex)\n self.error = ex.strerror\n\n def stop(self):\n \"\"\"Stops the current game process and cleans up the instance\"\"\"\n # Prevent stop() being called again by the process exiting\n self.prevent_on_stop = True\n\n try:\n self.game_process.terminate()\n except ProcessLookupError: # process already dead.\n logger.debug(\"Management process looks dead already.\")\n\n if hasattr(self, \"stop_func\"):\n resume_stop = self.stop_func()\n if not resume_stop:\n return False\n\n if self.stdout_monitor:\n logger.debug(\"Detaching logger\")\n GLib.source_remove(self.stdout_monitor)\n self.stdout_monitor = None\n else:\n logger.debug(\"logger already detached\")\n\n self.is_running = False\n self.ready_state = False\n return True\n\n\ndef exec_command(command):\n \"\"\"Execute arbitrary command in a MonitoredCommand\n\n Used by the --exec command line flag.\n \"\"\"\n command = MonitoredCommand(shlex.split(command), env=runtime.get_env())\n command.start()\n return command\n", "path": "lutris/command.py"}]}
| 3,122 | 200 |
gh_patches_debug_1803
|
rasdani/github-patches
|
git_diff
|
unionai-oss__pandera-909
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implicit ignore_na=True behaviour causes custom dataframe checks to be ignored by default
**Describe the bug**
When using custom dataframe checks returning boolean series, `SchemaModel.validate()` does not report validation errors generated by a custom check if the record in question (or is it the entire dataframe?) contains null values. This behaviour is deafult and can be disabled by setting `ignore_na` to `False` (either via `@pa.dataframe_check(ignore_na=False)` or a Config entry such as `check_name = {"ignore_na": False}`). This default behaviour is surprising, and the root cause of my issue was discovered only after a lengthy debugging process with much help from @cosmicBboy. Perhaps this default behaviour could be changed or at least better documented, as Niels mentions that this has come up more than once previously.
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of pandera.
- [x] (optional) I have confirmed this bug exists on the master branch of pandera.
#### Code Sample, a copy-pastable example
CSV (DataFrame):
```
field0,field1,field2
,foo,foo
```
```python
@pa.dataframe_check
def field1_does_not_equal_field2(cls, df: pd.DataFrame) -> Series[bool]:
return df["field1"] != df["field2"]
# Even though field1 == field2, validation passes because field0 is null
```
#### Expected behavior
Create a custom Pandera dataframe check returning a boolean series that accepts a CSV containing null values.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pandera/check_utils.py`
Content:
```
1 """Utility functions for validation."""
2
3 from functools import lru_cache
4 from typing import NamedTuple, Optional, Tuple, Union
5
6 import pandas as pd
7
8 SupportedTypes = NamedTuple(
9 "SupportedTypes",
10 (
11 ("table_types", Tuple[type, ...]),
12 ("field_types", Tuple[type, ...]),
13 ("index_types", Tuple[type, ...]),
14 ("multiindex_types", Tuple[type, ...]),
15 ),
16 )
17
18
19 @lru_cache(maxsize=None)
20 def _supported_types():
21 # pylint: disable=import-outside-toplevel
22 table_types = [pd.DataFrame]
23 field_types = [pd.Series]
24 index_types = [pd.Index]
25 multiindex_types = [pd.MultiIndex]
26
27 try:
28 import pyspark.pandas as ps
29
30 table_types.append(ps.DataFrame)
31 field_types.append(ps.Series)
32 index_types.append(ps.Index)
33 multiindex_types.append(ps.MultiIndex)
34 except ImportError:
35 pass
36 try: # pragma: no cover
37 import modin.pandas as mpd
38
39 table_types.append(mpd.DataFrame)
40 field_types.append(mpd.Series)
41 index_types.append(mpd.Index)
42 multiindex_types.append(mpd.MultiIndex)
43 except ImportError:
44 pass
45 try:
46 import dask.dataframe as dd
47
48 table_types.append(dd.DataFrame)
49 field_types.append(dd.Series)
50 index_types.append(dd.Index)
51 except ImportError:
52 pass
53
54 return SupportedTypes(
55 tuple(table_types),
56 tuple(field_types),
57 tuple(index_types),
58 tuple(multiindex_types),
59 )
60
61
62 def is_table(obj):
63 """Verifies whether an object is table-like.
64
65 Where a table is a 2-dimensional data matrix of rows and columns, which
66 can be indexed in multiple different ways.
67 """
68 return isinstance(obj, _supported_types().table_types)
69
70
71 def is_field(obj):
72 """Verifies whether an object is field-like.
73
74 Where a field is a columnar representation of data in a table-like
75 data structure.
76 """
77 return isinstance(obj, _supported_types().field_types)
78
79
80 def is_index(obj):
81 """Verifies whether an object is a table index."""
82 return isinstance(obj, _supported_types().index_types)
83
84
85 def is_multiindex(obj):
86 """Verifies whether an object is a multi-level table index."""
87 return isinstance(obj, _supported_types().multiindex_types)
88
89
90 def is_supported_check_obj(obj):
91 """Verifies whether an object is table- or field-like."""
92 return is_table(obj) or is_field(obj)
93
94
95 def prepare_series_check_output(
96 check_obj: Union[pd.Series, pd.DataFrame],
97 check_output: pd.Series,
98 ignore_na: bool = True,
99 n_failure_cases: Optional[int] = None,
100 ) -> Tuple[pd.Series, pd.Series]:
101 """Prepare the check output and failure cases for a Series check output.
102
103 check_obj can be a dataframe, since a check function can potentially return
104 a Series resulting from applying some check function that outputs a Series.
105 """
106 if ignore_na:
107 isna = (
108 check_obj.isna().any(axis="columns")
109 if isinstance(check_obj, pd.DataFrame)
110 else check_obj.isna()
111 )
112 try:
113 check_output = check_output | isna
114 except AttributeError:
115 # convert check_output to numpy for modin compatibility
116 check_output = check_output.to_numpy() | isna
117
118 failure_cases = check_obj[~check_output]
119 if not failure_cases.empty and n_failure_cases is not None:
120 # NOTE: this is a hack to support pyspark.pandas and modin, since you
121 # can't use groupby on a dataframe with another dataframe
122 if type(failure_cases).__module__.startswith("pyspark.pandas") or type(
123 failure_cases
124 ).__module__.startswith("modin.pandas"):
125 failure_cases = (
126 failure_cases.rename("failure_cases")
127 .to_frame()
128 .assign(check_output=check_output)
129 .groupby("check_output")
130 .head(n_failure_cases)["failure_cases"]
131 )
132 else:
133 failure_cases = failure_cases.groupby(check_output).head(
134 n_failure_cases
135 )
136 return check_output, failure_cases
137
138
139 def prepare_dataframe_check_output(
140 check_obj: pd.DataFrame,
141 check_output: pd.DataFrame,
142 df_orig: Optional[pd.DataFrame] = None,
143 ignore_na: bool = True,
144 n_failure_cases: Optional[int] = None,
145 ) -> Tuple[pd.Series, pd.Series]:
146 """Unstack a dataframe of boolean values.
147
148 Check results consisting of a boolean dataframe should be reported at the
149 most granular level.
150 """
151 if df_orig is not None:
152 assert df_orig.shape == check_output.shape
153
154 if df_orig is None:
155 df_orig = check_obj
156 check_output = check_output.unstack()
157 if ignore_na:
158 check_output = check_output | df_orig.unstack().isna()
159 failure_cases = (
160 check_obj.unstack()[~check_output]
161 .rename("failure_case")
162 .rename_axis(["column", "index"])
163 .reset_index()
164 )
165 if not failure_cases.empty and n_failure_cases is not None:
166 failure_cases = failure_cases.drop_duplicates().head(n_failure_cases)
167 return check_output, failure_cases
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pandera/check_utils.py b/pandera/check_utils.py
--- a/pandera/check_utils.py
+++ b/pandera/check_utils.py
@@ -105,7 +105,7 @@
"""
if ignore_na:
isna = (
- check_obj.isna().any(axis="columns")
+ check_obj.isna().all(axis="columns")
if isinstance(check_obj, pd.DataFrame)
else check_obj.isna()
)
|
{"golden_diff": "diff --git a/pandera/check_utils.py b/pandera/check_utils.py\n--- a/pandera/check_utils.py\n+++ b/pandera/check_utils.py\n@@ -105,7 +105,7 @@\n \"\"\"\n if ignore_na:\n isna = (\n- check_obj.isna().any(axis=\"columns\")\n+ check_obj.isna().all(axis=\"columns\")\n if isinstance(check_obj, pd.DataFrame)\n else check_obj.isna()\n )\n", "issue": "Implicit ignore_na=True behaviour causes custom dataframe checks to be ignored by default\n**Describe the bug**\r\nWhen using custom dataframe checks returning boolean series, `SchemaModel.validate()` does not report validation errors generated by a custom check if the record in question (or is it the entire dataframe?) contains null values. This behaviour is deafult and can be disabled by setting `ignore_na` to `False` (either via `@pa.dataframe_check(ignore_na=False)` or a Config entry such as `check_name = {\"ignore_na\": False}`). This default behaviour is surprising, and the root cause of my issue was discovered only after a lengthy debugging process with much help from @cosmicBboy. Perhaps this default behaviour could be changed or at least better documented, as Niels mentions that this has come up more than once previously.\r\n\r\n- [x] I have checked that this issue has not already been reported.\r\n- [x] I have confirmed this bug exists on the latest version of pandera.\r\n- [x] (optional) I have confirmed this bug exists on the master branch of pandera.\r\n\r\n\r\n#### Code Sample, a copy-pastable example\r\n\r\nCSV (DataFrame):\r\n```\r\nfield0,field1,field2\r\n,foo,foo\r\n```\r\n```python\r\[email protected]_check\r\ndef field1_does_not_equal_field2(cls, df: pd.DataFrame) -> Series[bool]:\r\n return df[\"field1\"] != df[\"field2\"]\r\n\r\n# Even though field1 == field2, validation passes because field0 is null\r\n```\r\n\r\n#### Expected behavior\r\nCreate a custom Pandera dataframe check returning a boolean series that accepts a CSV containing null values.\r\n\n", "before_files": [{"content": "\"\"\"Utility functions for validation.\"\"\"\n\nfrom functools import lru_cache\nfrom typing import NamedTuple, Optional, Tuple, Union\n\nimport pandas as pd\n\nSupportedTypes = NamedTuple(\n \"SupportedTypes\",\n (\n (\"table_types\", Tuple[type, ...]),\n (\"field_types\", Tuple[type, ...]),\n (\"index_types\", Tuple[type, ...]),\n (\"multiindex_types\", Tuple[type, ...]),\n ),\n)\n\n\n@lru_cache(maxsize=None)\ndef _supported_types():\n # pylint: disable=import-outside-toplevel\n table_types = [pd.DataFrame]\n field_types = [pd.Series]\n index_types = [pd.Index]\n multiindex_types = [pd.MultiIndex]\n\n try:\n import pyspark.pandas as ps\n\n table_types.append(ps.DataFrame)\n field_types.append(ps.Series)\n index_types.append(ps.Index)\n multiindex_types.append(ps.MultiIndex)\n except ImportError:\n pass\n try: # pragma: no cover\n import modin.pandas as mpd\n\n table_types.append(mpd.DataFrame)\n field_types.append(mpd.Series)\n index_types.append(mpd.Index)\n multiindex_types.append(mpd.MultiIndex)\n except ImportError:\n pass\n try:\n import dask.dataframe as dd\n\n table_types.append(dd.DataFrame)\n field_types.append(dd.Series)\n index_types.append(dd.Index)\n except ImportError:\n pass\n\n return SupportedTypes(\n tuple(table_types),\n tuple(field_types),\n tuple(index_types),\n tuple(multiindex_types),\n )\n\n\ndef is_table(obj):\n \"\"\"Verifies whether an object is table-like.\n\n Where a table is a 2-dimensional data matrix of rows and columns, which\n can be indexed in multiple different ways.\n \"\"\"\n return isinstance(obj, _supported_types().table_types)\n\n\ndef is_field(obj):\n \"\"\"Verifies whether an object is field-like.\n\n Where a field is a columnar representation of data in a table-like\n data structure.\n \"\"\"\n return isinstance(obj, _supported_types().field_types)\n\n\ndef is_index(obj):\n \"\"\"Verifies whether an object is a table index.\"\"\"\n return isinstance(obj, _supported_types().index_types)\n\n\ndef is_multiindex(obj):\n \"\"\"Verifies whether an object is a multi-level table index.\"\"\"\n return isinstance(obj, _supported_types().multiindex_types)\n\n\ndef is_supported_check_obj(obj):\n \"\"\"Verifies whether an object is table- or field-like.\"\"\"\n return is_table(obj) or is_field(obj)\n\n\ndef prepare_series_check_output(\n check_obj: Union[pd.Series, pd.DataFrame],\n check_output: pd.Series,\n ignore_na: bool = True,\n n_failure_cases: Optional[int] = None,\n) -> Tuple[pd.Series, pd.Series]:\n \"\"\"Prepare the check output and failure cases for a Series check output.\n\n check_obj can be a dataframe, since a check function can potentially return\n a Series resulting from applying some check function that outputs a Series.\n \"\"\"\n if ignore_na:\n isna = (\n check_obj.isna().any(axis=\"columns\")\n if isinstance(check_obj, pd.DataFrame)\n else check_obj.isna()\n )\n try:\n check_output = check_output | isna\n except AttributeError:\n # convert check_output to numpy for modin compatibility\n check_output = check_output.to_numpy() | isna\n\n failure_cases = check_obj[~check_output]\n if not failure_cases.empty and n_failure_cases is not None:\n # NOTE: this is a hack to support pyspark.pandas and modin, since you\n # can't use groupby on a dataframe with another dataframe\n if type(failure_cases).__module__.startswith(\"pyspark.pandas\") or type(\n failure_cases\n ).__module__.startswith(\"modin.pandas\"):\n failure_cases = (\n failure_cases.rename(\"failure_cases\")\n .to_frame()\n .assign(check_output=check_output)\n .groupby(\"check_output\")\n .head(n_failure_cases)[\"failure_cases\"]\n )\n else:\n failure_cases = failure_cases.groupby(check_output).head(\n n_failure_cases\n )\n return check_output, failure_cases\n\n\ndef prepare_dataframe_check_output(\n check_obj: pd.DataFrame,\n check_output: pd.DataFrame,\n df_orig: Optional[pd.DataFrame] = None,\n ignore_na: bool = True,\n n_failure_cases: Optional[int] = None,\n) -> Tuple[pd.Series, pd.Series]:\n \"\"\"Unstack a dataframe of boolean values.\n\n Check results consisting of a boolean dataframe should be reported at the\n most granular level.\n \"\"\"\n if df_orig is not None:\n assert df_orig.shape == check_output.shape\n\n if df_orig is None:\n df_orig = check_obj\n check_output = check_output.unstack()\n if ignore_na:\n check_output = check_output | df_orig.unstack().isna()\n failure_cases = (\n check_obj.unstack()[~check_output]\n .rename(\"failure_case\")\n .rename_axis([\"column\", \"index\"])\n .reset_index()\n )\n if not failure_cases.empty and n_failure_cases is not None:\n failure_cases = failure_cases.drop_duplicates().head(n_failure_cases)\n return check_output, failure_cases\n", "path": "pandera/check_utils.py"}], "after_files": [{"content": "\"\"\"Utility functions for validation.\"\"\"\n\nfrom functools import lru_cache\nfrom typing import NamedTuple, Optional, Tuple, Union\n\nimport pandas as pd\n\nSupportedTypes = NamedTuple(\n \"SupportedTypes\",\n (\n (\"table_types\", Tuple[type, ...]),\n (\"field_types\", Tuple[type, ...]),\n (\"index_types\", Tuple[type, ...]),\n (\"multiindex_types\", Tuple[type, ...]),\n ),\n)\n\n\n@lru_cache(maxsize=None)\ndef _supported_types():\n # pylint: disable=import-outside-toplevel\n table_types = [pd.DataFrame]\n field_types = [pd.Series]\n index_types = [pd.Index]\n multiindex_types = [pd.MultiIndex]\n\n try:\n import pyspark.pandas as ps\n\n table_types.append(ps.DataFrame)\n field_types.append(ps.Series)\n index_types.append(ps.Index)\n multiindex_types.append(ps.MultiIndex)\n except ImportError:\n pass\n try: # pragma: no cover\n import modin.pandas as mpd\n\n table_types.append(mpd.DataFrame)\n field_types.append(mpd.Series)\n index_types.append(mpd.Index)\n multiindex_types.append(mpd.MultiIndex)\n except ImportError:\n pass\n try:\n import dask.dataframe as dd\n\n table_types.append(dd.DataFrame)\n field_types.append(dd.Series)\n index_types.append(dd.Index)\n except ImportError:\n pass\n\n return SupportedTypes(\n tuple(table_types),\n tuple(field_types),\n tuple(index_types),\n tuple(multiindex_types),\n )\n\n\ndef is_table(obj):\n \"\"\"Verifies whether an object is table-like.\n\n Where a table is a 2-dimensional data matrix of rows and columns, which\n can be indexed in multiple different ways.\n \"\"\"\n return isinstance(obj, _supported_types().table_types)\n\n\ndef is_field(obj):\n \"\"\"Verifies whether an object is field-like.\n\n Where a field is a columnar representation of data in a table-like\n data structure.\n \"\"\"\n return isinstance(obj, _supported_types().field_types)\n\n\ndef is_index(obj):\n \"\"\"Verifies whether an object is a table index.\"\"\"\n return isinstance(obj, _supported_types().index_types)\n\n\ndef is_multiindex(obj):\n \"\"\"Verifies whether an object is a multi-level table index.\"\"\"\n return isinstance(obj, _supported_types().multiindex_types)\n\n\ndef is_supported_check_obj(obj):\n \"\"\"Verifies whether an object is table- or field-like.\"\"\"\n return is_table(obj) or is_field(obj)\n\n\ndef prepare_series_check_output(\n check_obj: Union[pd.Series, pd.DataFrame],\n check_output: pd.Series,\n ignore_na: bool = True,\n n_failure_cases: Optional[int] = None,\n) -> Tuple[pd.Series, pd.Series]:\n \"\"\"Prepare the check output and failure cases for a Series check output.\n\n check_obj can be a dataframe, since a check function can potentially return\n a Series resulting from applying some check function that outputs a Series.\n \"\"\"\n if ignore_na:\n isna = (\n check_obj.isna().all(axis=\"columns\")\n if isinstance(check_obj, pd.DataFrame)\n else check_obj.isna()\n )\n try:\n check_output = check_output | isna\n except AttributeError:\n # convert check_output to numpy for modin compatibility\n check_output = check_output.to_numpy() | isna\n\n failure_cases = check_obj[~check_output]\n if not failure_cases.empty and n_failure_cases is not None:\n # NOTE: this is a hack to support pyspark.pandas and modin, since you\n # can't use groupby on a dataframe with another dataframe\n if type(failure_cases).__module__.startswith(\"pyspark.pandas\") or type(\n failure_cases\n ).__module__.startswith(\"modin.pandas\"):\n failure_cases = (\n failure_cases.rename(\"failure_cases\")\n .to_frame()\n .assign(check_output=check_output)\n .groupby(\"check_output\")\n .head(n_failure_cases)[\"failure_cases\"]\n )\n else:\n failure_cases = failure_cases.groupby(check_output).head(\n n_failure_cases\n )\n return check_output, failure_cases\n\n\ndef prepare_dataframe_check_output(\n check_obj: pd.DataFrame,\n check_output: pd.DataFrame,\n df_orig: Optional[pd.DataFrame] = None,\n ignore_na: bool = True,\n n_failure_cases: Optional[int] = None,\n) -> Tuple[pd.Series, pd.Series]:\n \"\"\"Unstack a dataframe of boolean values.\n\n Check results consisting of a boolean dataframe should be reported at the\n most granular level.\n \"\"\"\n if df_orig is not None:\n assert df_orig.shape == check_output.shape\n\n if df_orig is None:\n df_orig = check_obj\n check_output = check_output.unstack()\n if ignore_na:\n check_output = check_output | df_orig.unstack().isna()\n failure_cases = (\n check_obj.unstack()[~check_output]\n .rename(\"failure_case\")\n .rename_axis([\"column\", \"index\"])\n .reset_index()\n )\n if not failure_cases.empty and n_failure_cases is not None:\n failure_cases = failure_cases.drop_duplicates().head(n_failure_cases)\n return check_output, failure_cases\n", "path": "pandera/check_utils.py"}]}
| 2,139 | 104 |
gh_patches_debug_17584
|
rasdani/github-patches
|
git_diff
|
geopandas__geopandas-379
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: preserve column order in read_file
Idea from http://gis.stackexchange.com/questions/216963/preserve-column-order-of-geopandas-file-read/217084#217084
For shapefiles, fiona saves the properties in the `meta` attribute as an OrderedDict, so we should be able to get the actual order of the columns in the file from that and rearrange the columns of the output accordingly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geopandas/io/file.py`
Content:
```
1 import os
2
3 import fiona
4 import numpy as np
5 from shapely.geometry import mapping
6
7 from six import iteritems
8 from geopandas import GeoDataFrame
9
10
11 def read_file(filename, **kwargs):
12 """
13 Returns a GeoDataFrame from a file.
14
15 *filename* is either the absolute or relative path to the file to be
16 opened and *kwargs* are keyword args to be passed to the `open` method
17 in the fiona library when opening the file. For more information on
18 possible keywords, type: ``import fiona; help(fiona.open)``
19 """
20 bbox = kwargs.pop('bbox', None)
21 with fiona.open(filename, **kwargs) as f:
22 crs = f.crs
23 if bbox is not None:
24 assert len(bbox)==4
25 f_filt = f.filter(bbox=bbox)
26 else:
27 f_filt = f
28 gdf = GeoDataFrame.from_features(f_filt, crs=crs)
29
30 return gdf
31
32
33 def to_file(df, filename, driver="ESRI Shapefile", schema=None,
34 **kwargs):
35 """
36 Write this GeoDataFrame to an OGR data source
37
38 A dictionary of supported OGR providers is available via:
39 >>> import fiona
40 >>> fiona.supported_drivers
41
42 Parameters
43 ----------
44 df : GeoDataFrame to be written
45 filename : string
46 File path or file handle to write to.
47 driver : string, default 'ESRI Shapefile'
48 The OGR format driver used to write the vector file.
49 schema : dict, default None
50 If specified, the schema dictionary is passed to Fiona to
51 better control how the file is written. If None, GeoPandas
52 will determine the schema based on each column's dtype
53
54 The *kwargs* are passed to fiona.open and can be used to write
55 to multi-layer data, store data within archives (zip files), etc.
56 """
57 if schema is None:
58 schema = infer_schema(df)
59 filename = os.path.abspath(os.path.expanduser(filename))
60 with fiona.open(filename, 'w', driver=driver, crs=df.crs,
61 schema=schema, **kwargs) as c:
62 for feature in df.iterfeatures():
63 c.write(feature)
64
65
66 def infer_schema(df):
67 try:
68 from collections import OrderedDict
69 except ImportError:
70 from ordereddict import OrderedDict
71
72 def convert_type(in_type):
73 if in_type == object:
74 return 'str'
75 out_type = type(np.asscalar(np.zeros(1, in_type))).__name__
76 if out_type == 'long':
77 out_type = 'int'
78 return out_type
79
80 properties = OrderedDict([
81 (col, convert_type(_type)) for col, _type in
82 zip(df.columns, df.dtypes) if col != df._geometry_column_name
83 ])
84
85 geom_type = _common_geom_type(df)
86 if not geom_type:
87 raise ValueError("Geometry column cannot contain mutiple "
88 "geometry types when writing to file.")
89
90 schema = {'geometry': geom_type, 'properties': properties}
91
92 return schema
93
94
95 def _common_geom_type(df):
96 # Need to check geom_types before we write to file...
97 # Some (most?) providers expect a single geometry type:
98 # Point, LineString, or Polygon
99 geom_types = df.geometry.geom_type.unique()
100
101 from os.path import commonprefix # To find longest common prefix
102 geom_type = commonprefix([g[::-1] for g in geom_types if g])[::-1] # Reverse
103 if not geom_type:
104 geom_type = None
105
106 return geom_type
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geopandas/io/file.py b/geopandas/io/file.py
--- a/geopandas/io/file.py
+++ b/geopandas/io/file.py
@@ -14,7 +14,7 @@
*filename* is either the absolute or relative path to the file to be
opened and *kwargs* are keyword args to be passed to the `open` method
- in the fiona library when opening the file. For more information on
+ in the fiona library when opening the file. For more information on
possible keywords, type: ``import fiona; help(fiona.open)``
"""
bbox = kwargs.pop('bbox', None)
@@ -27,6 +27,10 @@
f_filt = f
gdf = GeoDataFrame.from_features(f_filt, crs=crs)
+ # re-order with column order from metadata, with geometry last
+ columns = list(f.meta["schema"]["properties"]) + ["geometry"]
+ gdf = gdf[columns]
+
return gdf
|
{"golden_diff": "diff --git a/geopandas/io/file.py b/geopandas/io/file.py\n--- a/geopandas/io/file.py\n+++ b/geopandas/io/file.py\n@@ -14,7 +14,7 @@\n \n *filename* is either the absolute or relative path to the file to be\n opened and *kwargs* are keyword args to be passed to the `open` method\n- in the fiona library when opening the file. For more information on \n+ in the fiona library when opening the file. For more information on\n possible keywords, type: ``import fiona; help(fiona.open)``\n \"\"\"\n bbox = kwargs.pop('bbox', None)\n@@ -27,6 +27,10 @@\n f_filt = f\n gdf = GeoDataFrame.from_features(f_filt, crs=crs)\n \n+ # re-order with column order from metadata, with geometry last\n+ columns = list(f.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n+ gdf = gdf[columns]\n+\n return gdf\n", "issue": "ENH: preserve column order in read_file\nIdea from http://gis.stackexchange.com/questions/216963/preserve-column-order-of-geopandas-file-read/217084#217084\r\n\r\nFor shapefiles, fiona saves the properties in the `meta` attribute as an OrderedDict, so we should be able to get the actual order of the columns in the file from that and rearrange the columns of the output accordingly.\n", "before_files": [{"content": "import os\n\nimport fiona\nimport numpy as np\nfrom shapely.geometry import mapping\n\nfrom six import iteritems\nfrom geopandas import GeoDataFrame\n\n\ndef read_file(filename, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file.\n\n *filename* is either the absolute or relative path to the file to be\n opened and *kwargs* are keyword args to be passed to the `open` method\n in the fiona library when opening the file. For more information on \n possible keywords, type: ``import fiona; help(fiona.open)``\n \"\"\"\n bbox = kwargs.pop('bbox', None)\n with fiona.open(filename, **kwargs) as f:\n crs = f.crs\n if bbox is not None:\n assert len(bbox)==4\n f_filt = f.filter(bbox=bbox)\n else:\n f_filt = f\n gdf = GeoDataFrame.from_features(f_filt, crs=crs)\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None,\n **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n filename = os.path.abspath(os.path.expanduser(filename))\n with fiona.open(filename, 'w', driver=driver, crs=df.crs,\n schema=schema, **kwargs) as c:\n for feature in df.iterfeatures():\n c.write(feature)\n\n\ndef infer_schema(df):\n try:\n from collections import OrderedDict\n except ImportError:\n from ordereddict import OrderedDict\n\n def convert_type(in_type):\n if in_type == object:\n return 'str'\n out_type = type(np.asscalar(np.zeros(1, in_type))).__name__\n if out_type == 'long':\n out_type = 'int'\n return out_type\n\n properties = OrderedDict([\n (col, convert_type(_type)) for col, _type in\n zip(df.columns, df.dtypes) if col != df._geometry_column_name\n ])\n\n geom_type = _common_geom_type(df)\n if not geom_type:\n raise ValueError(\"Geometry column cannot contain mutiple \"\n \"geometry types when writing to file.\")\n\n schema = {'geometry': geom_type, 'properties': properties}\n\n return schema\n\n\ndef _common_geom_type(df):\n # Need to check geom_types before we write to file...\n # Some (most?) providers expect a single geometry type:\n # Point, LineString, or Polygon\n geom_types = df.geometry.geom_type.unique()\n\n from os.path import commonprefix # To find longest common prefix\n geom_type = commonprefix([g[::-1] for g in geom_types if g])[::-1] # Reverse\n if not geom_type:\n geom_type = None\n\n return geom_type\n", "path": "geopandas/io/file.py"}], "after_files": [{"content": "import os\n\nimport fiona\nimport numpy as np\nfrom shapely.geometry import mapping\n\nfrom six import iteritems\nfrom geopandas import GeoDataFrame\n\n\ndef read_file(filename, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file.\n\n *filename* is either the absolute or relative path to the file to be\n opened and *kwargs* are keyword args to be passed to the `open` method\n in the fiona library when opening the file. For more information on\n possible keywords, type: ``import fiona; help(fiona.open)``\n \"\"\"\n bbox = kwargs.pop('bbox', None)\n with fiona.open(filename, **kwargs) as f:\n crs = f.crs\n if bbox is not None:\n assert len(bbox)==4\n f_filt = f.filter(bbox=bbox)\n else:\n f_filt = f\n gdf = GeoDataFrame.from_features(f_filt, crs=crs)\n\n # re-order with column order from metadata, with geometry last\n columns = list(f.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n gdf = gdf[columns]\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None,\n **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n filename = os.path.abspath(os.path.expanduser(filename))\n with fiona.open(filename, 'w', driver=driver, crs=df.crs,\n schema=schema, **kwargs) as c:\n for feature in df.iterfeatures():\n c.write(feature)\n\n\ndef infer_schema(df):\n try:\n from collections import OrderedDict\n except ImportError:\n from ordereddict import OrderedDict\n\n def convert_type(in_type):\n if in_type == object:\n return 'str'\n out_type = type(np.asscalar(np.zeros(1, in_type))).__name__\n if out_type == 'long':\n out_type = 'int'\n return out_type\n\n properties = OrderedDict([\n (col, convert_type(_type)) for col, _type in\n zip(df.columns, df.dtypes) if col != df._geometry_column_name\n ])\n\n geom_type = _common_geom_type(df)\n if not geom_type:\n raise ValueError(\"Geometry column cannot contain mutiple \"\n \"geometry types when writing to file.\")\n\n schema = {'geometry': geom_type, 'properties': properties}\n\n return schema\n\n\ndef _common_geom_type(df):\n # Need to check geom_types before we write to file...\n # Some (most?) providers expect a single geometry type:\n # Point, LineString, or Polygon\n geom_types = df.geometry.geom_type.unique()\n\n from os.path import commonprefix # To find longest common prefix\n geom_type = commonprefix([g[::-1] for g in geom_types if g])[::-1] # Reverse\n if not geom_type:\n geom_type = None\n\n return geom_type\n", "path": "geopandas/io/file.py"}]}
| 1,365 | 232 |
gh_patches_debug_949
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-457
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Determine if papermill v1.0 API change is a problem
# Description
The [papermill `v1.0` release will introduce API breaking changes](https://github.com/nteract/papermill/blob/d554193bc458797b63af1f94964883d5dcca2418/README.md). It would be good to determine if these changes will matter for pyhf testing and require the addition of [scrapbook](https://nteract-scrapbook.readthedocs.io/en/latest/) or if the API change doesn't affect pyhf.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import setup, find_packages
4 from os import path
5 import sys
6
7 this_directory = path.abspath(path.dirname(__file__))
8 if sys.version_info.major < 3:
9 from io import open
10 with open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:
11 long_description = readme_md.read()
12
13 extras_require = {
14 'tensorflow': [
15 'tensorflow~=1.13',
16 'tensorflow-probability~=0.5',
17 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass
18 'setuptools<=39.1.0',
19 ],
20 'torch': ['torch~=1.0'],
21 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],
22 # 'dask': [
23 # 'dask[array]'
24 # ],
25 'xmlio': ['uproot'],
26 'minuit': ['iminuit'],
27 'develop': [
28 'pyflakes',
29 'pytest~=3.5',
30 'pytest-cov>=2.5.1',
31 'pytest-mock',
32 'pytest-benchmark[histogram]',
33 'pytest-console-scripts',
34 'python-coveralls',
35 'coverage>=4.0', # coveralls
36 'matplotlib',
37 'jupyter',
38 'nbdime',
39 'uproot~=3.3',
40 'papermill~=0.16',
41 'graphviz',
42 'bumpversion',
43 'sphinx',
44 'sphinxcontrib-bibtex',
45 'sphinxcontrib-napoleon',
46 'sphinx_rtd_theme',
47 'nbsphinx',
48 'sphinx-issues',
49 'm2r',
50 'jsonpatch',
51 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now
52 'pre-commit',
53 'black;python_version>="3.6"', # Black is Python3 only
54 'twine',
55 ],
56 }
57 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
58
59
60 def _is_test_pypi():
61 """
62 Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and
63 set to true (c.f. .travis.yml)
64
65 The use_scm_version kwarg accepts a callable for the local_scheme
66 configuration parameter with argument "version". This can be replaced
67 with a lambda as the desired version structure is {next_version}.dev{distance}
68 c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy
69
70 As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version
71 controlled through bumpversion is used.
72 """
73 from os import getenv
74
75 return (
76 {'local_scheme': lambda version: ''}
77 if getenv('TESTPYPI_UPLOAD') == 'true'
78 else False
79 )
80
81
82 setup(
83 name='pyhf',
84 version='0.1.0',
85 description='(partial) pure python histfactory implementation',
86 long_description=long_description,
87 long_description_content_type='text/markdown',
88 url='https://github.com/diana-hep/pyhf',
89 author='Lukas Heinrich',
90 author_email='[email protected]',
91 license='Apache',
92 keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',
93 classifiers=[
94 "Programming Language :: Python :: 2",
95 "Programming Language :: Python :: 2.7",
96 "Programming Language :: Python :: 3",
97 "Programming Language :: Python :: 3.6",
98 "Programming Language :: Python :: 3.7",
99 ],
100 packages=find_packages(),
101 include_package_data=True,
102 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*",
103 install_requires=[
104 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet
105 'click>=6.0', # for console scripts,
106 'tqdm', # for readxml
107 'six', # for modifiers
108 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
109 'jsonpatch',
110 ],
111 extras_require=extras_require,
112 entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},
113 dependency_links=[],
114 use_scm_version=_is_test_pypi(),
115 )
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -37,7 +37,8 @@
'jupyter',
'nbdime',
'uproot~=3.3',
- 'papermill~=0.16',
+ 'papermill~=1.0',
+ 'nteract-scrapbook~=0.2',
'graphviz',
'bumpversion',
'sphinx',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -37,7 +37,8 @@\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n- 'papermill~=0.16',\n+ 'papermill~=1.0',\n+ 'nteract-scrapbook~=0.2',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n", "issue": "Determine if papermill v1.0 API change is a problem\n# Description\r\n\r\nThe [papermill `v1.0` release will introduce API breaking changes](https://github.com/nteract/papermill/blob/d554193bc458797b63af1f94964883d5dcca2418/README.md). It would be good to determine if these changes will matter for pyhf testing and require the addition of [scrapbook](https://nteract-scrapbook.readthedocs.io/en/latest/) or if the API change doesn't affect pyhf.\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=1.13',\n 'tensorflow-probability~=0.5',\n 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'torch': ['torch~=1.0'],\n 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],\n # 'dask': [\n # 'dask[array]'\n # ],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=0.16',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\ndef _is_test_pypi():\n \"\"\"\n Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and\n set to true (c.f. .travis.yml)\n\n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n with a lambda as the desired version structure is {next_version}.dev{distance}\n c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy\n\n As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version\n controlled through bumpversion is used.\n \"\"\"\n from os import getenv\n\n return (\n {'local_scheme': lambda version: ''}\n if getenv('TESTPYPI_UPLOAD') == 'true'\n else False\n )\n\n\nsetup(\n name='pyhf',\n version='0.1.0',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich',\n author_email='[email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n use_scm_version=_is_test_pypi(),\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=1.13',\n 'tensorflow-probability~=0.5',\n 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'torch': ['torch~=1.0'],\n 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],\n # 'dask': [\n # 'dask[array]'\n # ],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=1.0',\n 'nteract-scrapbook~=0.2',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\ndef _is_test_pypi():\n \"\"\"\n Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and\n set to true (c.f. .travis.yml)\n\n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n with a lambda as the desired version structure is {next_version}.dev{distance}\n c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy\n\n As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version\n controlled through bumpversion is used.\n \"\"\"\n from os import getenv\n\n return (\n {'local_scheme': lambda version: ''}\n if getenv('TESTPYPI_UPLOAD') == 'true'\n else False\n )\n\n\nsetup(\n name='pyhf',\n version='0.1.0',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich',\n author_email='[email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n use_scm_version=_is_test_pypi(),\n)\n", "path": "setup.py"}]}
| 1,672 | 103 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.