
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-25 06:27:54
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 495
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-25 06:24:22
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Mungert/Holo1-7B-GGUF | Mungert | 2025-06-15T19:48:11Z | 1,350 | 0 | transformers | [
"transformers",
"gguf",
"multimodal",
"action",
"agent",
"visual-document-retrieval",
"en",
"arxiv:2506.02865",
"arxiv:2401.13919",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | visual-document-retrieval | 2025-06-04T11:56:02Z | ---
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
language:
- en
library_name: transformers
license: apache-2.0
pipeline_tag: visual-document-retrieval
tags:
- multimodal
- action
- agent
- visual-document-retrieval
---
# <span style="color: #7FFF7F;">Holo1-7B GGUF Models</span>
This model is part of the Surfer-H system, presented in the paper [Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights](https://huggingface.co/papers/2506.02865) and described in more detail on the project page: [https://www.surferh.com](https://www.surferh.com).
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`71bdbdb5`](https://github.com/ggerganov/llama.cpp/commit/71bdbdb58757d508557e6d8b387f666cdfb25c5e).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Holo1-7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Holo1-7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Holo1-7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Holo1-7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Holo1-7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Holo1-7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Holo1-7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Holo1-7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Holo1-7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Holo1-7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Holo1-7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Holo1-7B
## Model Description
Holo1 is an Action Vision-Language Model (VLM) developed by [HCompany](https://www.hcompany.ai/) for use in the Surfer-H web agent system. It is designed to interact with web interfaces like a human user.
As part of a broader agentic architecture, Holo1 acts as a policy, localizer, or validator, helping the agent understand and act in digital environments.
Trained on a mix of open-access, synthetic, and self-generated data, Holo1 enables state-of-the-art (SOTA) performance on the [WebVoyager](https://arxiv.org/pdf/2401.13919) benchmark, offering the best accuracy/cost tradeoff among current models.
It also excels in UI localization tasks such as [Screenspot](https://huggingface.co/datasets/rootsautomation/ScreenSpot), [Screenspot-V2](https://huggingface.co/datasets/HongxinLi/ScreenSpot_v2), [Screenspot-Pro](https://huggingface.co/datasets/likaixin/ScreenSpot-Pro), [GroundUI-Web](https://huggingface.co/datasets/agent-studio/GroundUI-1K), and our own newly introduced
benchmark [WebClick](https://huggingface.co/datasets/Hcompany/WebClick).
Holo1 is optimized for both accuracy and cost-efficiency, making it a strong open-source alternative to existing VLMs.
For more details, check our paper and our blog post.
- **Developed by:** [HCompany](https://www.hcompany.ai/)
- **Model type:** Action Vision-Language Model
- **Finetuned from model:** Qwen/Qwen2.5-VL-7B-Instruct
- **Paper:** https://arxiv.org/abs/2506.02865
- **Blog Post:** https://www.hcompany.ai/surfer-h
- **License:** Apache 2.0
## Results
### Surfer-H: Pareto-Optimal Performance on [WebVoyager](https://arxiv.org/pdf/2401.13919)
Surfer-H is designed to be flexible and modular. It is composed of three independent components:
- A Policy model that plans, decides, and drives the agent's behavior
- A Localizer model that sees and understands visual UIs to drive precise interactions
- A Validator model that checks whether the answer is valid
The agent thinks before acting, takes notes, and can retry if its answer is rejected. It can operate with different models for each module, allowing for tradeoffs between accuracy, speed, and cost.
We evaluated Surfer-H on the [WebVoyager](https://arxiv.org/pdf/2401.13919) benchmark: 643 real-world web tasks ranging from retrieving prices to finding news or scheduling events.
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/kO_4DlW_O45Wi7eK9-r8v.png" width="800"/>
</div>
We’ve tested multiple configurations, from GPT-4-powered agents to 100% open Holo1 setups. Among them, the fully Holo1-based agents offered the strongest tradeoff between accuracy and cost:
- Surfer-H + Holo1-7B: 92.2% accuracy at $0.13 per task
- Surfer-H + GPT-4.1: 92.0% at $0.54 per task
- Surfer-H + Holo1-3B: 89.7% at $0.11 per task
- Surfer-H + GPT-4.1-mini: 88.8% at $0.26 per task
This places Holo1-powered agents on the Pareto frontier, delivering the best accuracy per dollar.
Unlike other agents that rely on custom APIs or brittle wrappers, Surfer-H operates purely through the browser — just like a real user. Combined with Holo1, it becomes a powerful, general-purpose, cost-efficient web automation system.
### Holo1: State-of-the-Art UI Localization
A key skill for the real-world utility of our VLMs within agents is localization: the ability to identify precise
coordinates on a user interface (UI) to interact with to complete a task or follow an instruction. To assess
this capability, we evaluated our Holo1 models on several established localization benchmarks, including
[Screenspot](https://huggingface.co/datasets/rootsautomation/ScreenSpot), [Screenspot-V2](https://huggingface.co/datasets/HongxinLi/ScreenSpot_v2), [Screenspot-Pro](https://huggingface.co/datasets/likaixin/ScreenSpot-Pro), [GroundUI-Web](https://huggingface.co/datasets/agent-studio/GroundUI-1K), and our own newly introduced
benchmark [WebClick](https://huggingface.co/datasets/Hcompany/WebClick).
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/UutD2Meevd5Xw0_mhX2wK.png" width="600"/>
</div>
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/NhzkB8xnEQYMqiGxPnJSt.png" width="600"/>
</div>
## Get Started with the Model
We provide starter code for the localization task: i.e. image + instruction -> click coordinates
We also provide code to reproduce screenspot evaluations: screenspot_eval.py
### Prepare model, processor
Holo1 models are based on Qwen2.5-VL architecture, which comes with transformers support. Here we provide a simple usage example.
You can load the model and the processor as follows:
```python
import json
import os
from typing import Any, Literal
from transformers import AutoModelForImageTextToText, AutoProcessor
# default: Load the model on the available device(s)
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
model = AutoModelForImageTextToText.from_pretrained(
"Hcompany/Holo1-7B",
torch_dtype="auto",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
device_map="auto",
)
# default processor
processor = AutoProcessor.from_pretrained("Hcompany/Holo1-7B")
# The default range for the number of visual tokens per image in the model is 4-1280.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
# Helper function to run inference
def run_inference(messages: list[dict[str, Any]]) -> str:
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(
text=[text],
images=image,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
return processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
```
### Prepare image and instruction
WARNING: Holo1 is using absolute coordinates (number of pixels) and HuggingFace processor is doing image resize. To have matching coordinates, one needs to smart_resize the image.
```python
from PIL import Image
from transformers.models.qwen2_vl.image_processing_qwen2_vl import smart_resize
import requests
# Prepare image and instruction
image_url = "https://huggingface.co/Hcompany/Holo1-7B/resolve/main/calendar_example.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Resize the image so that predicted absolute coordinates match the size of the image.
image_processor = processor.image_processor
resized_height, resized_width = smart_resize(
image.height,
image.width,
factor=image_processor.patch_size * image_processor.merge_size,
min_pixels=image_processor.min_pixels,
max_pixels=image_processor.max_pixels,
)
image = image.resize(size=(resized_width, resized_height), resample=None) # type: ignore
instruction = "Select July 14th as the check-out date"
```
### Localization as click(x, y)
```python
def get_localization_prompt(image, instruction: str) -> list[dict[str, Any]]:
guidelines: str = "Localize an element on the GUI image according to my instructions and output a click position as Click(x, y) with x num pixels from the left edge and y num pixels from the top edge."
return [
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
},
{"type": "text", "text": f"{guidelines}
{instruction}"},
],
}
]
messages = get_localization_prompt(image, instruction)
coordinates_str = run_inference(messages)[0]
print(coordinates_str)
# Expected Click(352, 348)
```
### Structured Output
We trained Holo1 as an Action VLM with extensive use of json and tool calls. Therefore, it can be queried reliably with structured output:
```python
from pydantic import BaseModel, ConfigDict
class FunctionDefinition(BaseModel):
"""Function definition data structure.
Attributes:
name: name of the function.
description: description of the function.
parameters: JSON schema for the function parameters.
strict: Whether to enable strict schema adherence when generating the function call.
"""
name: str
description: str = ""
parameters: dict[str, Any] = {}
strict: bool = True
class ClickAction(BaseModel):
"""Click at specific coordinates on the screen."""
model_config = ConfigDict(
extra="forbid",
json_schema_serialization_defaults_required=True,
json_schema_mode_override="serialization",
use_attribute_docstrings=True,
)
action: Literal["click"] = "click"
x: int
"""The x coordinate, number of pixels from the left edge."""
y: int
"""The y coordinate, number of pixels from the top edge."""
function_definition = FunctionDefinition(
name="click_action",
description=ClickAction.__doc__ or "",
parameters=ClickAction.model_json_schema(),
strict=True,
)
def get_localization_prompt_structured_output(image, instruction: str) -> list[dict[str, Any]]:
guidelines: str = "Localize an element on the GUI image according to my instructions and output a click position. You must output a valid JSON format."
return [
{
"role": "system",
"content": json.dumps([function_definition.model_dump()]),
},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
},
{"type": "text", "text": f"{guidelines}
{instruction}"},
],
},
]
messages = get_localization_prompt_structured_output(image, instruction)
coordinates_str = run_inference(messages)[0]
coordinates = ClickAction.model_validate(json.loads(coordinates_str)["arguments"])
print(coordinates)
# Expected ClickAction(action='click', x=352, y=340)
```
## Citation
**BibTeX:**
```
@misc{andreux2025surferhmeetsholo1costefficient,
title={Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights},
author={Mathieu Andreux and Breno Baldas Skuk and Hamza Benchekroun and Emilien Biré and Antoine Bonnet and Riaz Bordie and Matthias Brunel and Pierre-Louis Cedoz and Antoine Chassang and Mickaël Chen and Alexandra D. Constantinou and Antoine d'Andigné and Hubert de La Jonquière and Aurélien Delfosse and Ludovic Denoyer and Alexis Deprez and Augustin Derupti and Michael Eickenberg and Mathïs Federico and Charles Kantor and Xavier Koegler and Yann Labbé and Matthew C. H. Lee and Erwan Le Jumeau de Kergaradec and Amir Mahla and Avshalom Manevich and Adrien Maret and Charles Masson and Rafaël Maurin and Arturo Mena and Philippe Modard and Axel Moyal and Axel Nguyen Kerbel and Julien Revelle and Mats L. Richter and María Santos and Laurent Sifre and Maxime Theillard and Marc Thibault and Louis Thiry and Léo Tronchon and Nicolas Usunier and Tony Wu},
year={2025},
eprint={2506.02865},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.02865},
}
``` |
Mungert/MiMo-VL-7B-SFT-GGUF | Mungert | 2025-06-15T19:48:07Z | 1,708 | 0 | transformers | [
"transformers",
"gguf",
"base_model:XiaomiMiMo/MiMo-VL-7B-SFT",
"base_model:quantized:XiaomiMiMo/MiMo-VL-7B-SFT",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-04T03:00:12Z | ---
license: mit
library_name: transformers
base_model:
- XiaomiMiMo/MiMo-VL-7B-SFT
---
# <span style="color: #7FFF7F;">MiMo-VL-7B-SFT GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`71bdbdb5`](https://github.com/ggerganov/llama.cpp/commit/71bdbdb58757d508557e6d8b387f666cdfb25c5e).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `MiMo-VL-7B-SFT-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `MiMo-VL-7B-SFT-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `MiMo-VL-7B-SFT-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `MiMo-VL-7B-SFT-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `MiMo-VL-7B-SFT-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `MiMo-VL-7B-SFT-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `MiMo-VL-7B-SFT-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `MiMo-VL-7B-SFT-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `MiMo-VL-7B-SFT-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `MiMo-VL-7B-SFT-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `MiMo-VL-7B-SFT-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<div align="center">
<picture>
<source srcset="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/Xiaomi_MiMo_darkmode.png?raw=true" media="(prefers-color-scheme: dark)">
<img src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/Xiaomi_MiMo.png?raw=true" width="60%" alt="Xiaomi-MiMo" />
</picture>
</div>
<h3 align="center">
<b>
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span>
<br/>
MiMo-VL Technical Report
<br/>
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span>
<br/>
</b>
</h3>
<br/>
<div align="center" style="line-height: 1;">
|
<a href="https://huggingface.co/collections/XiaomiMiMo/mimo-vl-68382ccacc7c2875500cd212" target="_blank">🤗 HuggingFace</a>
|
<a href="https://www.modelscope.cn/collections/MiMo-VL-bb651017e02742" target="_blank">🤖️ ModelScope</a>
|
<a href="https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report.pdf" target="_blank">📔 Technical Report</a>
|
<br/>
</div>
<br/>
## I. Introduction
In this report, we share our efforts to build a compact yet powerful VLM, MiMo-VL-7B. MiMo-VL-7B comprises (1) a native resolution ViT encoder that preserves fine-grained visual details, (2) an MLP projector for efficient cross-modal alignment, and (3) our [MiMo-7B language model](https://github.com/XiaomiMiMo/MiMo), specifically optimized for complex reasoning tasks.
The development of MiMo-VL-7B involves two sequential training processes: (1) A four-stage pre-training phase, which includes projector warmup, vision-language alignment, general multi-modal pre-training, and long-context Supervised Fine-Tuning (SFT). This phase yields the MiMo-VL-7B-SFT model. (2) A subsequent post-training phase, where we introduce Mixed On-policy Reinforcement Learning (MORL), a novel framework that seamlessly integrates diverse reward signals spanning perception accuracy, visual grounding precision, logical reasoning capabilities, and human/AI preferences. This phase yields the MiMo-VL-7B-RL model.
<p align="center">
<img width="95%" src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/benchmarks.png?raw=true">
</p>
We open-source MiMo-VL-7B series, including checkpoints of the SFT and RL model.
We believe this report along with the models will provide valuable insights to develop powerful reasoning VLMs that benefit the larger community.
### 🛤️ During this journey, we find
- **Incorporating high-quality, broad-coverage reasoning data from the pre-training stage is crucial for enhancing model performance**
- We curate high-quality reasoning data by identifying diverse queries, employing large reasoning models to regenerate responses with long CoT, and applying rejection sampling to ensure quality.
- Rather than treating this as supplementary fine-tuning data, we incorporate substantial volumes of this synthetic reasoning data directly into the later pre-training stages, where extended training yields continued performance improvements without saturation.
- **Mixed On-policy Reinforcement Learning further enhances model performance, while achieving stable simultaneous improvements remains challenging**
- We apply RL across diverse capabilities, including reasoning, perception, grounding, and human preference alignment, spanning modalities including text, images, and videos. While this hybrid training approach further unlock model’s potential, interference across data domains remains a challenge.
## II. Model Details
<p align="center">
<img width="95%" src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/architecture.png?raw=true">
</p>
> Models are available at [Huggingface Collections: MiMo-VL](https://huggingface.co/collections/XiaomiMiMo/mimo-vl-68382ccacc7c2875500cd212) and [ModelScope Collections: MiMo-VL](https://www.modelscope.cn/collections/MiMo-VL-bb651017e02742)
| **Model** | **Description** | **Download (HuggingFace)** | **Download (ModelScope)** |
| :------------: | :-------------------------------------------------------------------: | :-----------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------: |
| MiMo-VL-7B-SFT | VLM with extraordinary reasoning potential after 4-stage pre-training | [🤗 XiaomiMiMo/MiMo-VL-7B-SFT](https://huggingface.co/XiaomiMiMo/MiMo-VL-7B-SFT) | [🤖️ XiaomiMiMo/MiMo-VL-7B-SFT](https://www.modelscope.cn/models/XiaomiMiMo/MiMo-VL-7B-SFT) |
| MiMo-VL-7B-RL | RL model leapfrogging existing open-source models | [🤗 XiaomiMiMo/MiMo-VL-7B-RL](https://huggingface.co/XiaomiMiMo/MiMo-VL-7B-RL) | [🤖️ XiaomiMiMo/MiMo-VL-7B-RL](https://www.modelscope.cn/models/XiaomiMiMo/MiMo-VL-7B-RL) |
## III. Evaluation Results
### General Capabilities
In general visual-language understanding, MiMo-VL-7B models achieve state-of-the-art open-source results.
<p align="center">
<img width="95%" src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/benchmarks_general.png?raw=true">
</p>
### Reasoning Tasks
In multi-modal reasoning, both the SFT and RL models significantly outperform all compared open-source baselines across these benchmarks.
<p align="center">
<img width="95%" src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/benchmarks_reasoning.png?raw=true">
</p>
> [!IMPORTANT]
> Results marked with \* are obtained using our evaluation framework.
> Tasks with ${\dagger}$ are evaluated by GPT-4o.
### GUI Tasks
MiMo-VL-7B-RL possess exceptional GUI understanding and grounding capabilities. As a general-purpose VL model, MiMo-VL achieves comparable or even superior performance to GUI-specialized models.
<p align="center">
<img width="95%" src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/benchmarks_gui.png?raw=true">
</p>
### Elo Rating
With our in-house evaluation dataset and GPT-4o judgments, MiMo-VL-7B-RL achieves the highest Elo rating among all evaluated open-source vision-language models, ranking first across models spanning from 7B to 72B parameters.
<p align="center">
<img width="95%" src="https://github.com/XiaomiMiMo/MiMo-VL/raw/main/figures/benchmarks_elo.png?raw=true">
</p>
## IV. Deployment
The MiMo-VL-7B series maintain full compatibility with the `Qwen2_5_VLForConditionalGeneration` architecture for deployment and inference.
## V. Citation
```bibtex
@misc{coreteam2025mimovl,
title={MiMo-VL Technical Report},
author={{Xiaomi LLM-Core Team}},
year={2025},
url={https://github.com/XiaomiMiMo/MiMo-VL},
}
```
## VI. Contact
Please contact us at [[email protected]](mailto:[email protected]) or open an issue if you have any questions.
|
Mungert/Osmosis-Structure-0.6B-GGUF | Mungert | 2025-06-15T19:48:02Z | 611 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-06-03T19:13:45Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">Osmosis-Structure-0.6B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Osmosis-Structure-0.6B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Osmosis-Structure-0.6B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Osmosis-Structure-0.6B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Osmosis-Structure-0.6B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Osmosis-Structure-0.6B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Osmosis-Structure-0.6B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Osmosis-Structure-0.6B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Osmosis-Structure-0.6B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Osmosis-Structure-0.6B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Osmosis-Structure-0.6B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Osmosis-Structure-0.6B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# `Osmosis-Structure-0.6B`: Small Language Model for Structured Outputs
<div align="center">
</div>
`Osmosis-Structure-0.6B` is a specialized small language model (SLM) designed to excel at structured output generation. Despite its compact 0.6B parameter size, this model demonstrates remarkable performance on extracting structured information when paired with supported frameworks.
Our approach leverages structured output during training, forcing our model to only focus on the value for each key declared by the inference engine, which significantly improves the accuracy of the model's ability to produce well-formatted, structured responses across various domains, particularly in mathematical reasoning and problem-solving tasks.
<div align="center">

</div>
## Results
We evaluate the effectiveness of osmosis-enhanced structured generation on challenging mathematical reasoning benchmarks. The following results demonstrate the dramatic performance improvements achieved through structured outputs with osmosis enhancement across different model families - the same technique that powers `Osmosis-Structure-0.6B`.
### Math DAPO 17K Dataset
<div align="center">
| Model | Structured Output | Structured w/ Osmosis | Performance Gain |
|-------|:-------------:|:-------------:|:-------------:|
| Claude 4 Sonnet | 15.52% | **69.40%** | +347% |
| Claude 4 Opus | 15.28% | **69.91%** | +357% |
| GPT-4.1 | 10.53% | **70.03%** | +565% |
| OpenAI o3 | 91.14% | **94.05%** | +2.9% |
<em>Table 1: Performance on Math DAPO 17K.</em>
</div>
### AIME 1983-2024 Dataset
<div align="center">
| Model | Structured Output | Structured w/ Osmosis | Performance Gain |
|-------|:-------------:|:-------------:|:-------------:|
| Claude 4 Sonnet | 16.29% | **62.59%** | +284% |
| Claude 4 Opus | 22.94% | **65.06%** | +184% |
| GPT-4.1 | 2.79% | **39.66%** | +1322% |
| OpenAI o3 | 92.05% | **93.24%** | +1.3% |
<em>Table 2: Performance on AIME 1983-2024.</em>
</div>
> **Key Insight**: These results demonstrate that by allowing models to think freely and leverage test time compute, we are able to increase performance and still maintain the structured guarantee after the fact with a SLM. `Osmosis-Structure-0.6B` is specifically designed and optimized to maximize these benefits in a compact 0.6B parameter model.
## Model Training
`Osmosis-Structure-0.6B` is built on top of `Qwen3-0.6B`. We first established a baseline format using 10 samples of randomly generated text and their JSON interpretations. We then applied reinforcement learning to approximately 500,000 examples of JSON-to-natural language pairs, consisting of either reasoning traces with their final outputs, or natural language reports with their expected structured formats.
We used [verl](https://github.com/volcengine/verl) as the framework to train our model and [SGLang](https://github.com/sgl-project/sglang) as the rollout backend. To enable structured training, we modified parts of the verl codebase to allow for *per sample schema* to be passed into the training data.
## Usage
### SGLang
We recommend an engine like SGLang to be used to serve the model, to serve, run the following:
`python3 -m sglang.launch_server --model-path Osmosis/Osmosis-Structure-0.6B --host 0.0.0.0 --api-key osmosis`
And to use the endpoint:
```python
import json
from openai import OpenAI
api_key = "osmosis"
api_base_url = "http://0.0.0.0:30000/v1"
client = OpenAI(
api_key=api_key,
base_url=api_base_url,
)
# Schema for extracting structured output from reasoning traces
json_schema = json.dumps(
{
"type": "object",
"properties": {
"answer": {"type": "string"}
},
"required": ["answer"]
}
)
# You can also dump pydantic models to json schema as well
# Example reasoning trace input
reasoning_trace = """
Problem: Solve for x in the equation 2x + 5 = 13
Let me work through this step by step:
First, I need to isolate the term with x. I'll subtract 5 from both sides:
2x + 5 - 5 = 13 - 5
2x = 8
Next, I'll divide both sides by 2 to solve for x:
2x ÷ 2 = 8 ÷ 2
x = 4
Let me verify this answer by substituting back into the original equation:
2(4) + 5 = 8 + 5 = 13 ✓
Ok, which means I got the correct answer, and I'm confident about my answer.
"""
response = client.chat.completions.create(
model="Osmosis/Osmosis-Structure-0.6B",
messages=[
{
"role": "system",
"content": f"You are a helpful assistant that understands and translates text to JSON format according to the following schema. {json_schema}"
},
{
"role": "user",
"content": reasoning_trace,
},
],
temperature=0,
max_tokens=512,
response_format={
"type": "json_schema",
"json_schema": {"name": "reasoning_extraction", "schema": json.loads(json_schema)},
},
)
print(json.dumps(response.choices[0].message.content, indent=2))
```
### Ollama
You can also use Ollama as an inference provider on local machines, here is a sample code of the setup:
```python
from ollama import chat
from pydantic import BaseModel
class Answer(BaseModel):
answer: int
reasoning_trace = """
Problem: Solve for x in the equation 2x + 5 = 13
Let me work through this step by step:
First, I need to isolate the term with x. I'll subtract 5 from both sides:
2x + 5 - 5 = 13 - 5
2x = 8
Next, I'll divide both sides by 2 to solve for x:
2x ÷ 2 = 8 ÷ 2
x = 4
Let me verify this answer by substituting back into the original equation:
2(4) + 5 = 8 + 5 = 13 ✓
Ok, which means I got the correct answer, and I'm confident about my answer.
"""
response = chat(
messages=[
{
"role": "system",
"content": f"You are a helpful assistant that understands and translates text to JSON format according to the following schema. {Answer.model_json_schema()}"
},
{
'role': 'user',
'content': reasoning_trace,
}
],
model='Osmosis/Osmosis-Structure-0.6B',
format=Answer.model_json_schema(),
)
answer = Answer.model_validate_json(response.message.content)
print(answer)
```
|
kythours/hwxjoo | kythours | 2025-06-15T19:48:00Z | 6 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-13T22:50:46Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: hwxjo
---
# Hwxjoo
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `hwxjo` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "hwxjo",
"lora_weights": "https://huggingface.co/kythours/hwxjoo/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('kythours/hwxjoo', weight_name='lora.safetensors')
image = pipeline('hwxjo').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/kythours/hwxjoo/discussions) to add images that show off what you’ve made with this LoRA.
|
Mungert/kanana-1.5-8b-instruct-2505-GGUF | Mungert | 2025-06-15T19:47:49Z | 1,834 | 2 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"ko",
"arxiv:2502.18934",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-30T23:00:38Z | ---
language:
- en
- ko
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
model_id: kakaocorp/kanana-1.5-8b-instruct-2505
repo: kakaocorp/kanana-1.5-8b-instruct-2505
developers: Kanana LLM
training_regime: bf16 mixed precision
---
# <span style="color: #7FFF7F;">kanana-1.5-8b-instruct-2505 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `kanana-1.5-8b-instruct-2505-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `kanana-1.5-8b-instruct-2505-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `kanana-1.5-8b-instruct-2505-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `kanana-1.5-8b-instruct-2505-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `kanana-1.5-8b-instruct-2505-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `kanana-1.5-8b-instruct-2505-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `kanana-1.5-8b-instruct-2505-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `kanana-1.5-8b-instruct-2505-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `kanana-1.5-8b-instruct-2505-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `kanana-1.5-8b-instruct-2505-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `kanana-1.5-8b-instruct-2505-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<p align="center">
<br>
<picture>
<img src="./assets/logo/kanana-logo.png" width="60%" style="margin: 40px auto;">
</picture>
</br>
<p align="center">
🤗 <a href="https://kko.kakao.com/kananallm">1.5 HF Models</a>   |
  📕 <a href="https://tech.kakao.com/posts/707">1.5 Blog</a>   |
  📜 <a href="https://arxiv.org/abs/2502.18934">Technical Report</a>
<br>
## News 🔥
- ✨`2025/05/23`: Published a [blog post](https://tech.kakao.com/posts/707) about `Kanana 1.5` models and released 🤗[HF model weights](https://kko.kakao.com/kananallm).
- 📜`2025/02/27`: Released [Technical Report](https://arxiv.org/abs/2502.18934) and 🤗[HF model weights](https://huggingface.co/collections/kakaocorp/kanana-nano-21b-67a326cda1c449c8d4172259).
- 📕`2025/01/10`: Published a [blog post](https://tech.kakao.com/posts/682) about the development of `Kanana Nano` model.
- 📕`2024/11/14`: Published blog posts ([pre-training](https://tech.kakao.com/posts/661), [post-training](https://tech.kakao.com/posts/662)) about the development of `Kanana` models.
- ▶️`2024/11/06`: Published a [presentation video](https://youtu.be/HTBl142x9GI?si=o_we6t9suYK8DfX3) about the development of the `Kanana` models.
<br>
## Table of Contents
- [Kanana 1.5](#kanana-15)
- [Performance](#performance)
- [Base Model Evaluation](#base-model-evaluation)
- [Instruct Model Evaluation](#instruct-model-evaluation)
- [Processing 32K+ Length](#processing-32k-length)
- [Contributors](#contributors)
- [Citation](#citation)
- [Contact](#contact)
<br>
# Kanana 1.5
`Kanana 1.5`, a newly introduced version of the Kanana model family, presents substantial enhancements in **coding, mathematics, and function calling capabilities** over the previous version, enabling broader application to more complex real-world problems. This new version now can handle __up to 32K tokens length natively and up to 128K tokens using YaRN__, allowing the model to maintain coherence when handling extensive documents or engaging in extended conversations. Furthermore, Kanana 1.5 delivers more natural and accurate conversations through a __refined post-training process__.
<p align="center">
<br>
<picture>
<img src="./assets/performance/kanana-1.5-radar-8b.png" width="95%" style="margin: 40px auto;">
</picture>
</br>
> [!Note]
> Neither the pre-training nor the post-training data includes Kakao user data.
## Performance
### Base Model Evaluation
<table>
<tr>
<th>Models</th>
<th>MMLU</th>
<th>KMMLU</th>
<th>HAERAE</th>
<th>HumanEval</th>
<th>MBPP</th>
<th>GSM8K</th>
</tr>
<tr>
<td>Kanana-1.5-8B</td>
<td align="center">64.24</td>
<td align="center">48.94</td>
<td align="center">82.77</td>
<td align="center">61.59</td>
<td align="center">57.80</td>
<td align="center">63.53</td>
</tr>
<tr>
<td>Kanana-8B</td>
<td align="center">64.22</td>
<td align="center">48.30</td>
<td align="center">83.41</td>
<td align="center">40.24</td>
<td align="center">51.40</td>
<td align="center">57.09</td>
</tr>
</table>
<br>
### Instruct Model Evaluation
<table>
<tr>
<th>Models</th>
<th>MT-Bench</th>
<th>KoMT-Bench</th>
<th>IFEval</th>
<th>HumanEval+</th>
<th>MBPP+</th>
<th>GSM8K (0-shot)</th>
<th>MATH</th>
<th>MMLU (0-shot, CoT)</th>
<th>KMMLU (0-shot, CoT)</th>
<th>FunctionChatBench</th>
</tr>
<tr>
<td><strong>Kanana-1.5-8B*</strong></td>
<td align="center">7.76</td>
<td align="center">7.63</td>
<td align="center">80.11</td>
<td align="center">76.83</td>
<td align="center">67.99</td>
<td align="center">87.64</td>
<td align="center">67.54</td>
<td align="center">68.82</td>
<td align="center">48.28</td>
<td align="center">58.00</td>
</tr>
<tr>
<td>Kanana-8B</td>
<td align="center">7.13</td>
<td align="center">6.92</td>
<td align="center">76.91</td>
<td align="center">62.20</td>
<td align="center">43.92</td>
<td align="center">79.23</td>
<td align="center">37.68</td>
<td align="center">66.50</td>
<td align="center">47.43</td>
<td align="center">17.37</td>
</tr>
</table>
> [!Note]
> \* Models released under Apache 2.0 are trained on the latest versions compared to other models.
<br>
## Processing 32K+ Length
Currently, the `config.json` uploaded to HuggingFace is configured for token lengths of 32,768 or less. To process tokens beyond this length, YaRN must be applied. By updating the `config.json` with the following parameters, you can apply YaRN to handle token sequences up to 128K in length:
```json
"rope_scaling": {
"factor": 4.4,
"original_max_position_embeddings": 32768,
"type": "yarn",
"beta_fast": 64,
"beta_slow": 2
},
```
<br>
## Contributors
- Language Model Training: Yunju Bak, Doohae Jung, Boseop Kim, Nayeon Kim, Hojin Lee, Jaesun Park, Minho Ryu
- Language Model Alignment: Jiyeon Ham, Seungjae Jung, Hyunho Kim, Hyunwoong Ko, Changmin Lee, Daniel Wontae Nam
- AI Engineering: Youmin Kim, Hyeongju Kim
<br>
## Citation
```
@misc{kananallmteam2025kananacomputeefficientbilinguallanguage,
title={Kanana: Compute-efficient Bilingual Language Models},
author={Kanana LLM Team and Yunju Bak and Hojin Lee and Minho Ryu and Jiyeon Ham and Seungjae Jung and Daniel Wontae Nam and Taegyeong Eo and Donghun Lee and Doohae Jung and Boseop Kim and Nayeon Kim and Jaesun Park and Hyunho Kim and Hyunwoong Ko and Changmin Lee and Kyoung-Woon On and Seulye Baeg and Junrae Cho and Sunghee Jung and Jieun Kang and EungGyun Kim and Eunhwa Kim and Byeongil Ko and Daniel Lee and Minchul Lee and Miok Lee and Shinbok Lee and Gaeun Seo},
year={2025},
eprint={2502.18934},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.18934},
}
```
<br>
## Contact
- Kanana LLM Team Technical Support: [email protected]
- Business & Partnership Contact: [email protected] |
Mungert/FairyR1-32B-GGUF | Mungert | 2025-06-15T19:47:36Z | 1,313 | 2 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"arxiv:2503.04872",
"arxiv:2403.13257",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-25T19:16:14Z | ---
license: apache-2.0
language:
- en
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">FairyR1-32B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `FairyR1-32B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `FairyR1-32B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `FairyR1-32B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `FairyR1-32B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `FairyR1-32B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `FairyR1-32B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `FairyR1-32B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `FairyR1-32B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `FairyR1-32B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `FairyR1-32B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `FairyR1-32B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Welcome to FairyR1-32B created by PKU-DS-LAB!
| Benchmark | DeepSeek-R1-671B | DeepSeek-R1-Distill-Qwen-32B | FairyR1-32B (PKU) |
| :-----------------------: | :--------------: | :--------------------------: | :-----------------------: |
| **AIME 2024 (Math)** | 79.8 | 72.6 | **80.4** |
| **AIME 2025 (Math)** | 70.0 | 52.9 | **75.6** |
| **LiveCodeBench (Code)** | 65.9 | 57.2 | **67.7** |
| **GPQA-Diamond (Sci-QA)** | **71.5** | 62.1 | 60.0 |
## Introduction
FairyR1-32B, a highly efficient large-language-model (LLM) that matches or exceeds larger models on select tasks despite using only ~5% of their parameters. Built atop the DeepSeek-R1-Distill-Qwen-32B base, FairyR1-32B leverages a novel “distill-and-merge” pipeline—combining task-focused fine-tuning with model-merging techniques to deliver competitive performance with drastically reduced size and inference cost. This project was funded by NSFC, Grant 624B2005.
## Model Details
The FairyR1 model represents a further exploration of our earlier work [TinyR1](https://arxiv.org/pdf/2503.04872), retaining the core “Branch-Merge Distillation” approach while introducing refinements in data processing and model architecture.
In this effort, we overhauled the distillation data pipeline: raw examples from datasets such as AIMO/NuminaMath-1.5 for mathematics and OpenThoughts-114k for code were first passed through multiple 'teacher' models to generate candidate answers. These candidates were then carefully selected, restructured, and refined, especially for the chain-of-thought(CoT). Subsequently, we applied multi-stage filtering—including automated correctness checks for math problems and length-based selection (2K–8K tokens for math samples, 4K–8K tokens for code samples). This yielded two focused training sets of roughly 6.6K math examples and 3.8K code examples.
On the modeling side, rather than training three separate specialists as before, we limited our scope to just two domain experts (math and code), each trained independently under identical hyperparameters (e.g., learning rate and batch size) for about five epochs. We then fused these experts into a single 32B-parameter model using the [AcreeFusion](https://arxiv.org/pdf/2403.13257) tool. By streamlining both the data distillation workflow and the specialist-model merging process, FairyR1 achieves task-competitive results with only a fraction of the parameters and computational cost of much larger models.
## Result Analysis and Key Contributions:
From the test results, FairyR1 scored slightly higher than DeepSeek-R1-671B on the AIME 2025 and LiveCodeBench benchmarks, and performed comparably on AIME 2024.
These results indicate that, by building on the DeepSeek‑R1‑Distill‑Qwen‑32B base and applying targeted techniques, FairyR1 achieves comparable or slightly superior performance in mathematical and programming domains using only about 5% of the parameter count of much larger models, although performance gaps may remain in other fields such as scientific question answering.
This work demonstrates the feasibility of significantly reducing model size and potential inference cost through optimized data processing and model fusion techniques while maintaining strong task-specific performance.
## Model Description
- **Developed by:** PKU-DS-LAB
- **Model type:** Reasoning Model
- **Language(s) (NLP):** English, Chinese
- **License:** apache-2.0
- **Finetuned from model:** DeepSeek-R1-Distill-Qwen-32B
### Training Data
- **Math:** 6.6k CoT trajectories from [AI-MO/NuminaMath-1.5](https://huggingface.co/datasets/AI-MO/NuminaMath-1.5), default subset
- **Coding:** 3.8k CoT trajectories from [open-thoughts/OpenThoughts-114k](https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k), coding subset
### Hardware Utilization
- **Hardware Type:** 32 × NVIDIA-H100
- **Hours used(Math):** 2.5h
- **Hours used(Coding):** 1.5h
- **Model Merging:** about 40min on CPU, no GPU needed.
### Evaluation Set
- AIME 2024/2025 (math): We evaluate 32 times and report the average accuracy. [AIME 2024](https://huggingface.co/datasets/HuggingFaceH4/aime_2024) contains 30 problems. [AIME 2025](https://huggingface.co/datasets/MathArena/aime_2025) consists of Part I and Part II, with a total of 30 questions.<br>
- [LiveCodeBench (code)](https://huggingface.co/datasets/livecodebench/code_generation_lite): We evaluate 8 times and report the average accuracy. The dataset version is "release_v5" (date range: 2024-08-01 to 2025-02-01), consisting of 279 problems.<br>
- [GPQA-Diamond (Sci-QA)](https://huggingface.co/datasets/Idavidrein/gpqa): We evaluate 8 times and report the average accuracy. The dataset consists of 198 problems.<br>
## FairyR1 series Team Members:
Leading By:
Tong Yang
Core Contributors:
Wang Li; Junting Zhou; Wenrui Liu; Yilun Yao; Rongle Wang
## Model Card Contact
For more details, please contact: [email protected] |
Mungert/Qwen3-30B-A6B-16-Extreme-GGUF | Mungert | 2025-06-15T19:47:23Z | 1,108 | 0 | transformers | [
"transformers",
"gguf",
"32 k context",
"reasoning",
"thinking",
"qwen3",
"16 experts",
"text-generation",
"base_model:Qwen/Qwen3-30B-A3B-Base",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Base",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-23T18:03:49Z | ---
library_name: transformers
pipeline_tag: text-generation
tags:
- 32 k context
- reasoning
- thinking
- qwen3
- 16 experts
base_model:
- Qwen/Qwen3-30B-A3B-Base
---
# <span style="color: #7FFF7F;">Qwen3-30B-A6B-16-Extreme GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-30B-A6B-16-Extreme-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-30B-A6B-16-Extreme-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-30B-A6B-16-Extreme-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-30B-A6B-16-Extreme-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-30B-A6B-16-Extreme-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-30B-A6B-16-Extreme-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-30B-A6B-16-Extreme-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-30B-A6B-16-Extreme-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-30B-A6B-16-Extreme-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-30B-A6B-16-Extreme-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-30B-A6B-16-Extreme-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<h2>Qwen3-30B-A6B-16-Extreme</h2>
<img src="star-wars-hans-solo.gif" style="float:right; padding:10px;">
This repo contains the full precision source code, in "safe tensors" format to generate GGUFs, GPTQ, EXL2, AWQ, HQQ and other formats. The source code can also be used directly.
This is a simple "finetune" of the Qwen's "Qwen 30B-A3B" (MOE) model, setting the experts in use from 8 to 16 (out of 128 experts).
TWO Example generations (Q4KS, CPU) at the bottom of this page using 16 experts / this model.
This reduces the speed of the model, but uses more "experts" to process your prompts and uses 6B (of 30B) parameters instead of 3B (of 30B) parameters. Depending on the application you may want to
use the regular model ("30B-A3B"), and use this model for MORE COMPLEX / "DEEPER" (IE Nuance) use case(s).
For the 128k version, Neo Imatrix, with additional modified quants (IQ1M to Q8 Ultra (f16 experts)) - 52 quants - see:
[ https://huggingface.co/DavidAU/Qwen3-128k-30B-A3B-NEO-MAX-Imatrix-gguf ]
Regular or simpler use cases may benefit from using the normal (8 experts), the "12 cooks" (12 experts) or "High-Speed" (4 experts) version(s).
Using 16 experts instead of the default 8 will slow down token/second speeds about about 1/2 or so.
Context size: 32K + 8K for output (40k total)
Use Jinja Template or CHATML template.
IMPORTANT NOTES:
- Due to the unique nature (MOE, Size, Activated experts, size of experts) of this model GGUF quants can be run on the CPU, GPU or with GPU part "off-load", right up to full precision.
- This model is difficult to Imatrix : You need a much larger imatrix file / multi-language / multi-content (ie code/text) to imatrix it.
- GPU speeds will be BLISTERING 4x-8x or higher than CPU only speeds AND this model will be BLISTERING too, relative to other "30B" models (Token per second speed equal roughly to 6B "normal" model speeds).
Please refer the org model card for details, benchmarks, how to use, settings, system roles etc etc :
[ https://huggingface.co/Qwen/Qwen3-30B-A3B ]
<B>More / Less Experts Versions:</B>
4 experts:
[ https://huggingface.co/DavidAU/Qwen3-30B-A1.5B-High-Speed ]
12 experts:
[ https://huggingface.co/DavidAU/Qwen3-30B-A4.5B-12-Cooks ]
16 experts, 128k context:
[ https://huggingface.co/DavidAU/Qwen3-30B-A6B-16-Extreme-128k-context ]
24 experts:
[ https://huggingface.co/DavidAU/Qwen3-30B-A7.5B-24-Grand-Brainstorm ]
<B>OPTIONAL SYSTEM ROLE: </B>
You may or may not need this, as most times Qwen3s generate their own reasoning/thinking blocks.
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
See document "Maximizing-Model-Performance-All..." below for how to "set" system role in various LLM/AI apps below.
IMPORTANT: Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers
If you are going to use this model, (source, GGUF or a different quant), please review this document for critical parameter, sampler and advance sampler settings (for multiple AI/LLM aps).
This a "Class 1" (settings will enhance operation) model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) (especially for use case(s) beyond the model's design) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
REASON:
Regardless of "model class" this document will detail methods to enhance operations.
If the model is a Class 3/4 model the default settings (parameters, samplers, advanced samplers) must be set for "use case(s)" uses correctly. Some AI/LLM apps DO NOT have consistant default setting(s) which result in sub-par model operation. Like wise for Class 3/4 models (which operate somewhat to very differently than standard models) additional samplers and advanced samplers settings are required to "smooth out" operation, AND/OR also allow full operation for use cases the model was not designed for.
BONUS - Use these settings for ANY model, ANY repo, ANY quant (including source/full precision):
This document also details parameters, sampler and advanced samplers that can be use FOR ANY MODEL, FROM ANY REPO too - all quants, and of course source code operation too - to enhance the operation of any model.
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
NOTE:
I strongly suggest you also visit the DavidAU GGUF (below) repo too for more details in using this model ; especially if it is "Class 3" or "Class 4" to get maximum performance from the model.
For full information about this model, including:
- Details about this model and its use case(s).
- Context limits
- Special usage notes / settings.
- Any model(s) used to create this model.
- Template(s) used to access/use this model.
- Example generation(s)
- GGUF quants of this model
Please go to:
[ GGUFS REPO coming soon ]
---
<B>Example Generation #1:</B>
Temp 1.2, rep pen 1.06, rep pen range 64, topk 100, topp .95, minp .05
Q4KS [non-imatrix], CPU only (windows 11), LMSTUDIO.
Speed: 11 T/S (no GPU offload)
This is a mid level quant, expect stronger performance from an Imatrix Q4KS / higher quants / full precision.
NOTE: Some formatting lost on copy/paste.
PROMPT:
<B>
Explain ways to use the "night" time cooling of radiant energy into space to reduce global temperatures.
</B>
<P></P>
<B>
[[[thinking start]]]
</B>
<P></P>
Thought for 2 minutes 17 seconds
Okay, so the user is asking about how to use the nighttime cooling of radiant energy into space to reduce global temperatures. Hmm, I need to think about this carefully. First, let's break down what they mean by "nighttime cooling of radiant energy into space." I guess that refers to the Earth emitting heat radiation during the night, which escapes into space. But how does that help in reducing global temperatures?
Wait, but isn't that natural? The Earth's atmosphere and surface emit thermal radiation, which is part of the planet's energy balance. During the day, solar radiation comes in, and at night, it radiates back. But maybe there's a way to enhance this process to cool down more effectively. But how?
I need to consider the greenhouse effect. If the Earth's atmosphere traps heat, then the cooling at night might be limited by that. So if we can reduce the greenhouse effect during nighttime, maybe more heat would escape into space. But how? Maybe reducing greenhouse gases? But that's a broad approach. However, the user is specifically asking about using nighttime cooling.
Another angle: Maybe reflecting more sunlight during the day to reduce heat absorption, but that's not nighttime. Alternatively, using materials that emit more infrared radiation at night. For example, certain surfaces that are good radiators of thermal energy. But how would that work?
Also, there's something called "nighttime cooling" in architecture, where buildings use materials that radiate heat to the sky, allowing them to cool down without air conditioning. Maybe this is similar. So using such materials on a larger scale could help lower temperatures.
But what about the atmosphere? If during nighttime, there's less solar radiation, but the Earth still emits heat. However, if there are clouds or greenhouse gases that trap the heat, then the cooling might be reduced. So if we can reduce those factors at night, maybe more heat escapes.
Another thought: Maybe using satellites or other structures to reflect or redirect heat radiation into space. But that seems impractical for large scale.
Or, perhaps manipulating the atmosphere to have less greenhouse gases during nighttime. But how? Maybe using some kind of temporary atmospheric changes, but that's not feasible.
Alternatively, think about energy balance. If the Earth's radiative cooling is enhanced during night, maybe it could contribute to overall temperature reduction. However, the global temperature is a complex system. The net effect of nighttime cooling might be small compared to other factors like solar input, greenhouse gases, etc.
But the user is looking for ways to use this natural process. So possible methods:
1. Enhancing the emissivity of surfaces during night. For example, using materials that are good at emitting thermal radiation. This could help in cooling local areas, but how would that scale globally?
2. Reducing greenhouse gases, which allows more heat to escape during all times, including night. But that's a standard climate mitigation approach.
3. Maybe creating structures that reflect heat radiation away from the Earth. Not sure if that's possible.
4. Using urban design with reflective surfaces and materials that aid in cooling at night. Like cool roofs or pavements, which have high emissivity. If implemented widely, could lower temperatures in cities, which might have a cumulative effect.
5. Maybe using space-based technologies to enhance radiation loss. For example, deploying satellites that emit heat into space. But not sure if that's practical.
6. Considering the role of water and evaporation during night. Evaporative cooling is more effective when there's higher humidity, but maybe at night, depending on conditions.
Wait, but how does the radiation into space contribute? The Earth's outgoing longwave radiation (OLR) is part of the energy balance. If we can increase OLR, then the net radiative cooling would be more, leading to lower temperatures. But how to do that?
So, maybe by reducing factors that block OLR. For example, reducing cloud cover or greenhouse gases. If during the night, there's less cloud cover (maybe), then OLR would be higher. So if we can have fewer clouds at night, more heat escapes.
But controlling cloud cover is a big challenge. Maybe using geoengineering techniques like seeding clouds to reduce their formation, but that's not straightforward and might have unintended consequences.
Another angle: The Earth's surface has different emissivity properties. So surfaces with higher emissivity (like dark, rough materials) can radiate more heat. So if we can create such surfaces on a large scale, maybe more heat is emitted during night, leading to cooling.
But how would that affect global temperatures? If the surfaces are more efficient at radiating, then the temperature might decrease as they lose more heat. But this is local effect. However, globally, if many areas have higher emissivity, maybe the overall net loss of heat would be more, contributing to cooling.
Also, there's a concept called "radiative cooling," which uses materials that can emit thermal radiation at night, allowing them to cool below ambient temperature. So if we use such materials on a large scale, like in agriculture or urban areas, could it help?
But what about the atmosphere's role? If the atmosphere is transparent to infrared, then more heat would escape. But if there are greenhouse gases, they absorb and re-emit that heat, which reduces the net loss. So, if we can reduce greenhouse gases, more heat escapes, leading to cooler temperatures.
So combining these factors: reducing greenhouse gases (both daytime and nighttime), enhancing emissivity of surfaces during night, and perhaps other methods like geoengineering to increase OLR.
But I need to list possible ways. Let me think of specific examples:
- Use high-emissivity materials in urban areas. Cool roofs, pavements, etc., which radiate more heat at night.
- Reduce atmospheric greenhouse gases (CO2, methane, etc.) through mitigation efforts, which would allow more heat to escape during all times.
- Geoengineering approaches like stratospheric aerosol injection, but that's more about reflecting sunlight rather than radiation.
- Creating artificial surfaces that can emit radiation more effectively, perhaps with certain coatings or materials.
- Enhancing the Earth's albedo (reflectivity) during daytime, which reduces heat absorption, leading to less heat to radiate at night. But that might not directly affect nighttime cooling, but overall temperature.
But wait, the question is about using the "nighttime" cooling. So maybe focus on nighttime processes. So perhaps:
1. Increasing emissivity of surfaces at night: Using materials that can emit more thermal radiation during the night. This could be done through reflective or emissive coatings.
2. Reducing greenhouse gas concentrations in the atmosphere during nighttime, allowing more heat to escape.
3. Managing cloud cover during night, maybe reducing cloud formation to allow more OLR.
4. Using space-based mirrors or structures to reflect heat away from Earth, but that's speculative and not practical.
5. Developing technologies that actively radiate heat into space, such as thermoelectric devices or other methods.
But these are all theoretical. What is the practical way? Maybe the first two: reducing greenhouse gases (which is a standard approach) and using emissive materials.
Another thought: The Earth's surface during night cools because it can emit radiation without the sun. So, if we can enhance that process, maybe through better emissivity. For example, in agriculture, using reflective materials to cool the soil at night, which might have some effect on local temperatures.
But for global impact, these would need to be implemented on a large scale. Maybe using urban planning with high-emissivity surfaces, or creating vast areas with such materials.
Also, consider that during the night, the Earth's surface is not receiving solar radiation, so the cooling is more about emitting heat. So, if we can make surfaces emit more heat at night, they would cool faster, which could lead to lower temperatures in those areas.
But how does that contribute to global temperature reduction? It might be a local effect, but if implemented globally, perhaps the cumulative effect could help. However, it's not clear how much impact this would have compared to other factors like greenhouse gases and solar radiation.
So the answer would need to list these methods, explaining their potential and challenges. Maybe also mention that while nighttime cooling is a natural process, enhancing it through various means could contribute to cooling, but it's part of a larger climate strategy.
<B>
[[[thinking end]]]
</B>
OUTPUT:
<p style="border: none; padding: 0cm">
To harness the "nighttime cooling" of radiant energy into
space as a strategy to reduce global temperatures, we need to
consider both the natural processes and human interventions that can
enhance this mechanism. Here are several approaches:</p>
<h3 class="western" style="border: none; padding: 0cm">1. <span style="display: inline-block; border: none; padding: 0cm"><strong>Enhancing
Surface Emissivity</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
The Earth's surface emits thermal radiation during the night, which
is part of the planet's energy balance. Materials with high
emissivity (ability to emit thermal radiation) can release heat more
efficiently.</p></li>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Using high-emissivity materials in urban areas, such as "cool
roofs" or "cool pavements," can increase the rate of
radiative cooling at night. These materials are designed to reflect
less sunlight during the day and emit more heat during the night,
thereby lowering local temperatures.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Global
Impact</span></strong>: If implemented on a large scale (e.g., in
cities or agricultural areas), this could contribute to localized
cooling, which might have cumulative effects on global temperature,
especially in regions with high urbanization.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">2. <span style="display: inline-block; border: none; padding: 0cm"><strong>Reducing
Greenhouse Gas Concentrations</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
Greenhouse gases (GHGs) like CO₂ and methane trap heat in the
atmosphere by absorbing and re-emitting thermal radiation. This
reduces the amount of heat that escapes into space, both during the
day and night.</p></li>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Mitigating GHG emissions through policies like renewable energy
adoption, carbon capture, or reforestation can lower atmospheric
concentrations. This would allow more heat to radiate into space
during all times, including nighttime.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Global
Impact</span></strong>: While this is a standard climate mitigation
approach, it directly addresses the root of the problem by reducing
the "greenhouse effect," which is critical for global
temperature regulation.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">3. <span style="display: inline-block; border: none; padding: 0cm"><strong>Managing
Cloud Cover</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
Clouds act as a barrier to outgoing longwave radiation (OLR). During
nighttime, lower cloud cover could allow more heat to escape into
space.</p></li>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Geoengineering techniques like "cloud seeding" or
controlled cloud formation might be used to reduce cloud density
during nighttime. However, this is speculative and fraught with
ecological risks.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Challenges</span></strong>:
Manipulating cloud cover is complex and not well understood,
requiring careful consideration of unintended consequences.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">4. <span style="display: inline-block; border: none; padding: 0cm"><strong>Space-Based
Technologies</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
While still in theoretical stages, technologies like reflective
satellites or "radiative cooling" structures could be
designed to redirect heat radiation into space.</p></li>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Hypothetical deployment of satellites with high emissivity coatings
or mirrors that reflect thermal energy away from Earth might enhance
global radiative cooling. However, this is not yet feasible and
would require significant technological and economic investment.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Challenges</span></strong>:
Practicality is limited by current technology, cost, and potential
environmental impacts.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">5. <span style="display: inline-block; border: none; padding: 0cm"><strong>Urban
and Landscape Design</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
Urban areas often retain heat due to materials like asphalt and
concrete (which have low emissivity). Replacing these with emissive
materials could enhance nighttime cooling.</p></li>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Designing cities with emissive surfaces, green spaces, or reflective
elements can create cooler microclimates. This approach is already
being tested in urban planning (e.g., cool roofs in cities like Los
Angeles).</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Global
Impact</span></strong>: While localized, such practices could reduce
heat island effects, which are significant contributors to local
temperature rises.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">6. <span style="display: inline-block; border: none; padding: 0cm"><strong>Evaporative
Cooling at Night</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
Evaporation of water can lead to cooling through latent heat
transfer. During nighttime, if humidity is high, this process may be
more effective.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Increasing water availability (e.g., in arid regions) or using
water-based cooling systems (like misting devices) could enhance
nighttime cooling. However, this requires resource management and
may not be viable globally.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">7. <span style="display: inline-block; border: none; padding: 0cm"><strong>Promoting
Radiative Cooling in Agriculture</span></strong></h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Concept</span></strong>:
Agricultural practices that use emissive materials or water for
cooling can reduce temperatures in farming areas. This could have
indirect benefits on global temperature by reducing heat from human
activities.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Application</span></strong>:
Techniques like "cooling blankets" or reflective
irrigation systems might be employed. However, this is more of a
niche application than a global strategy.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">Key
Considerations:</h3>
<ul>
<li><p style="margin-bottom: 0cm; border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Limitations</span></strong>:
Nighttime cooling is a natural process, but its impact on global
temperatures is modest compared to the dominant drivers like solar
input and GHG concentrations. Enhancing it requires complementary
strategies.</p></li>
<li><p style="border: none; padding: 0cm"><span style="display: inline-block; border: none; padding: 0cm"><strong>Holistic
Approach</span></strong>: These methods should be part of broader
climate mitigation efforts, such as reducing GHGs, promoting
renewable energy, and improving land use practices.</p></li>
</ul>
<h3 class="western" style="border: none; padding: 0cm">Conclusion:</h3>
<p style="border: none; padding: 0cm">Harnessing nighttime cooling
through emissive materials and atmospheric management could
contribute to temperature reduction, but it is most effective when
integrated with global climate strategies. While some approaches
(e.g., high-emissivity materials) are feasible, others remain
theoretical. The primary focus should remain on reducing greenhouse
gases, which directly address the root of global warming.</p>
<p style="line-height: 100%; margin-bottom: 0cm"><br/>
</p>
---
<B>Example Generation #2:</B>
Temp 0.6, rep pen 1.06, rep pen range 64, topk 100, topp .95, minp .05
Q4KS [non-imatrix], CPU only (windows 11), LMSTUDIO.
Speed: 11 T/S (no GPU offload)
This is a mid level quant, expect stronger performance from an Imatrix Q4KS / higher quants / full precision.
NOTE: Some formatting lost on copy/paste.
PROMPT:
<B>
Science Fiction: The Last Transmission - Write a story that takes place entirely within a spaceship's cockpit as the sole surviving crew member attempts to send a final message back to Earth before the ship's power runs out. The story should explore themes of isolation, sacrifice, and the importance of human connection in the face of adversity. If the situation calls for it, have the character(s) curse and swear to further the reader's emotional connection to them. 800-1000 words.
</B>
<P></P>
<B>
[[[thinking start]]]
</B>
Thought for 1 minutes 28 seconds
Okay, I need to write a science fiction story called "The Last Transmission" that takes place entirely in a spaceship's cockpit. The main character is the sole surviving crew member trying to send a final message back to Earth before the ship's power runs out. The themes are isolation, sacrifice, and human connection. Also, if needed, the character should curse and swear to make the reader connect emotionally.
First, I need to set the scene. The cockpit of a spaceship. Maybe it's a damaged ship, with systems failing. The crew member is alone, maybe after some disaster. The story should be tight, focusing on the cockpit, so no outside scenes. The protagonist is trying to send a message, but the power is running out.
Themes: isolation – the character is alone, maybe missing others. Sacrifice – maybe they are sacrificing their own life to send the message. Human connection – the message is about connecting with Earth, maybe a personal message or a warning.
Need to build tension. The power is failing, so time is limited. Maybe the protagonist is struggling with the systems, trying to get the transmission to work. Maybe some technical challenges, but also emotional struggles.
Including curses and swearing: the character might be frustrated, angry, maybe blaming themselves or others. Use that to show their emotions.
Structure: Start with the protagonist in the cockpit, describing the situation. Maybe they are trying to send a message, but systems are failing. Then, the process of trying to get the transmission working. Maybe flashbacks or memories of the crew, showing the sacrifice. The climax is sending the message, then the power dies. End with the message being sent, but the protagonist's fate is uncertain.
Character development: The protagonist is a human, maybe a pilot or engineer. They have a name? Maybe not, but they can be referred to as "the pilot" or "the survivor". They might have a personal connection to Earth, like a family or a message they want to send.
Possible plot points:
- The ship is damaged, maybe from an accident or enemy attack. The crew is dead, only the protagonist remains.
- The protagonist is trying to send a message, but the systems are failing. Maybe the main power is dying, so they have to use backup systems.
- They might have a personal message, like a final goodbye, or a warning about something.
- The struggle with the systems: technical challenges, maybe some failures, but the protagonist persists.
- Emotional moments: remembering the crew, the sacrifice of others, the importance of sending the message.
- Curses and swearing when things go wrong, showing frustration.
Possible dialogue: Maybe the protagonist talks to themselves, or to Earth, as if they are transmitting. Or maybe they have a voice recorder, or a log.
Need to keep it within 800-1000 words. So concise, but with enough detail.
Start writing:
Maybe start with the cockpit, describe the environment – dim lights, blinking systems, the protagonist's actions. Then the problem: power is failing. The protagonist tries to send the message, but the system is dying. Maybe they have a countdown, or time limit.
Include emotional elements: the protagonist's thoughts, memories, maybe a final message they want to send. Maybe they are thinking about their crewmates, their sacrifice.
Possible names: Maybe the ship's name? Or the protagonist's name? Not sure, but maybe not necessary. Focus on the cockpit.
Need to make the reader feel the isolation, the desperation, the sacrifice.
Maybe the message is a final transmission that will be received by Earth, but the protagonist dies. The story ends with the message being sent, but the protagonist's fate is unknown.
Possible structure:
1. Introduction: the protagonist in the cockpit, power failing.
2. Attempt to send the message, technical difficulties.
3. Flashbacks or memories of the crew, the sacrifice.
4. Climax: sending the message, power dies.
5. Conclusion: the message sent, but the protagonist is alone.
Including swearing: when the systems fail, the protagonist might curse, "Damn it!" or "This is not happening!"
Need to make sure the story is tight, focused on the cockpit. No external scenes. Maybe some technical jargon, but not too much.
Possible themes: the importance of human connection even in the face of adversity. The protagonist's sacrifice to ensure that the message is sent, preserving human connection.
Now, start writing the story with these elements.
<B>
[[[thinking END]]]
</B>
<P></P>
OUTPUT:
The cockpit was a tomb. A single seat, a flickering console, and the cold hum of dying systems. I sat here, alone, with the weight of the universe pressing down on me. The ship’s name—Aegis—was etched on the wall, but it felt like a lie. No protection. No hope. Just a hollow shell of metal and memory.
The power was fading. That was the truth. I’d watched the indicators drop, slow and steady, like a heartbeat dying. The lights dimmed, the thrusters went silent, and the air recycled less. My breaths were shallow, my thoughts sharp. I had one goal: send the last transmission. Earth needed to know what happened here. They needed to know we didn’t die in silence.
But the systems were failing. The comms array was offline. The backup generator was sputtering. I’d tried every switch, every button, every damn thing. The screen flickered with static, and the voice recorder—my last hope—was dead. I cursed, loud and raw, as if the universe might hear me.
“God fucking damn it!” I shouted, slamming my fist against the console. “This isn’t happening. This isn’t happening.”
The silence that followed was worse than the curse. It was the sound of death. I sat there, trembling, staring at the screen. My fingers hovered over the keyboard, but nothing came. No words. No signal. Just the void.
I closed my eyes. The memories came, unbidden. The crew—my friends. They’d been here, too. A dozen of them. I remembered their voices, their laughter, the way they’d joked about the cold of space. Now, they were gone. I didn’t know how. Maybe a breach, maybe a fire, maybe something worse. But it didn’t matter. They were gone. And I was the only one left.
I thought of my wife, back on Earth. I hadn’t spoken to her in weeks. The last message I sent was a simple “I’m okay.” But now, I had to say more. I had to tell her everything. I had to make sure she knew what happened here. That we didn’t die in vain.
The transmission was the only thing that mattered. It was the only way to connect with the world. The only way to keep us alive, even if we weren’t.
I opened my eyes again, and the console was still dead. I cursed again, but this time it was quieter, more desperate. “Come on, damn it. Work.”
I dug through the system, searching for any backup. The emergency logs were there, but they were corrupted. The voice recorder—my last hope—was offline. I had to use the manual override. I remembered the code from training: 0173. It was a relic, but maybe it still worked.
I typed it in, fingers shaking. The screen blinked. Then nothing. No response. I cursed again, louder this time. “You son of a bitch! You’re not working!”
The air felt thick. My chest tightened. I thought about the crew, their faces, their voices. I thought about the last time we were together. It was a dinner in the mess hall. We’d laughed, we’d shared stories, and we’d all said “I’m okay.” But now, I was the only one left. And I had to say more.
I tried again. The code. 0173. I typed it. The screen flickered once. Then another. It was a pulse. A heartbeat. I held my breath.
“Come on,” I whispered. “Come on.”
The screen lit up. A message prompt. I typed, fast and desperate: “This is Captain Lorne. The Aegis is damaged. All crew are dead. We were attacked by an unknown force. Please send help. We need to know what happened here. This is our last transmission. Please, Earth—please listen.”
The words felt like a prayer. I hit send. The screen blinked again. Then the power died.
The cockpit went dark. The console went silent. I sat there, alone, with nothing but the silence of space.
But I had done it. I’d sent the message. Even if no one heard it, even if no one came, I had made sure that we were remembered. That we weren’t forgotten.
I closed my eyes again. I thought about Earth. I thought about my wife. I thought about the crew. I thought about the universe. And I let the silence take me.
The last transmission was sent. The ship was dead. But the message lived on, somewhere in the void. Maybe it would reach Earth. Maybe it wouldn’t. But I had done what I could.
I was alone. But I wasn’t forgotten.
|
Mungert/Qwen3-1.7B-GGUF | Mungert | 2025-06-15T19:47:18Z | 655 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-1.7B-Base",
"base_model:quantized:Qwen/Qwen3-1.7B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-23T09:09:52Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-1.7B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-1.7B-Base
---
# <span style="color: #7FFF7F;">Qwen3-1.7B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`edbf42ed`](https://github.com/ggerganov/llama.cpp/commit/edbf42edfdabb9cea72ae12137570cf48f5d8076).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-1.7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-1.7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-1.7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-1.7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-1.7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-1.7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-1.7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-1.7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-1.7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-1.7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-1.7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Qwen3-1.7B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-1.7B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 1.7B
- Number of Paramaters (Non-Embedding): 1.4B
- Number of Layers: 28
- Number of Attention Heads (GQA): 16 for Q and 8 for KV
- Context Length: 32,768
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
> [!TIP]
> If you encounter significant endless repetitions, please refer to the [Best Practices](#best-practices) section for optimal sampling parameters, and set the ``presence_penalty`` to 1.5.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-1.7B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-1.7B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-1.7B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-1.7B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-1.7B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
``` |
Mungert/typhoon-ocr-7b-GGUF | Mungert | 2025-06-15T19:47:14Z | 786 | 0 | transformers | [
"transformers",
"gguf",
"OCR",
"vision-language",
"document-understanding",
"multilingual",
"en",
"th",
"arxiv:2412.13702",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-22T02:20:38Z | ---
library_name: transformers
language:
- en
- th
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
tags:
- OCR
- vision-language
- document-understanding
- multilingual
license: apache-2.0
---
# <span style="color: #7FFF7F;">typhoon-ocr-7b GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `typhoon-ocr-7b-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `typhoon-ocr-7b-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `typhoon-ocr-7b-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `typhoon-ocr-7b-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `typhoon-ocr-7b-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `typhoon-ocr-7b-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `typhoon-ocr-7b-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `typhoon-ocr-7b-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `typhoon-ocr-7b-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `typhoon-ocr-7b-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `typhoon-ocr-7b-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
**Typhoon-OCR-7B**: A bilingual document parsing model built specifically for real-world documents in Thai and English inspired by models like olmOCR based on Qwen2.5-VL-Instruction.
**Try our demo available on [Demo](https://ocr.opentyphoon.ai/)**
**Code / Examples available on [Github](https://github.com/scb-10x/typhoon-ocr)**
**Release Blog available on [OpenTyphoon Blog](https://opentyphoon.ai/blog/en/typhoon-ocr-release)**
*Remark: This model is intended to be used with a specific prompt only; it will not work with any other prompts.
## **Real-World Document Support**
**1. Structured Documents**: Financial reports, Academic papers, Books, Government forms
**Output format**:
- Markdown for general text
- HTML for tables (including merged cells and complex layouts)
- Figures, charts, and diagrams are represented using figure tags for structured visual understanding
**Each figure undergoes multi-layered interpretation**:
- **Observation**: Detects elements like landscapes, buildings, people, logos, and embedded text
- **Context Analysis**: Infers context such as location, event, or document section
- **Text Recognition**: Extracts and interprets embedded text (e.g., chart labels, captions) in Thai or English
- **Artistic & Structural Analysis**: Captures layout style, diagram type, or design choices contributing to document tone
- **Final Summary**: Combines all insights into a structured figure description for tasks like summarization and retrieval
**2. Layout-Heavy & Informal Documents**: Receipts, Menus papers, Tickets, Infographics
**Output format**:
- Markdown with embedded tables and layout-aware structures
## Performance
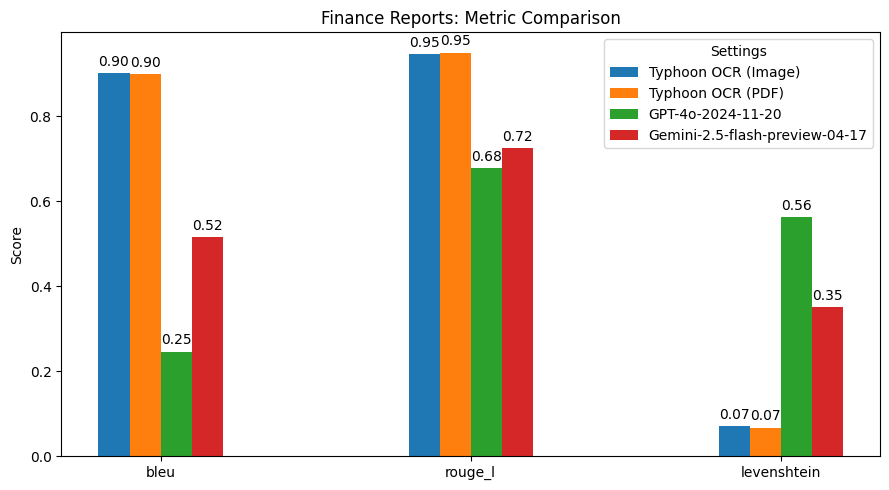
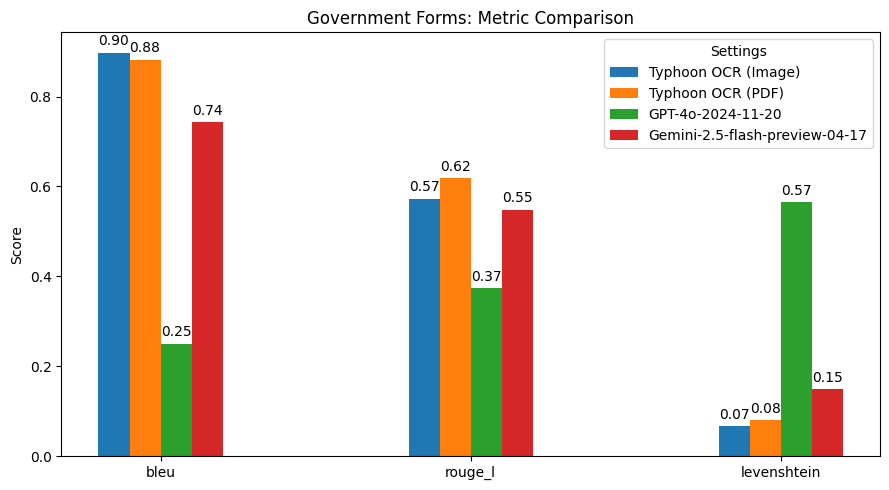
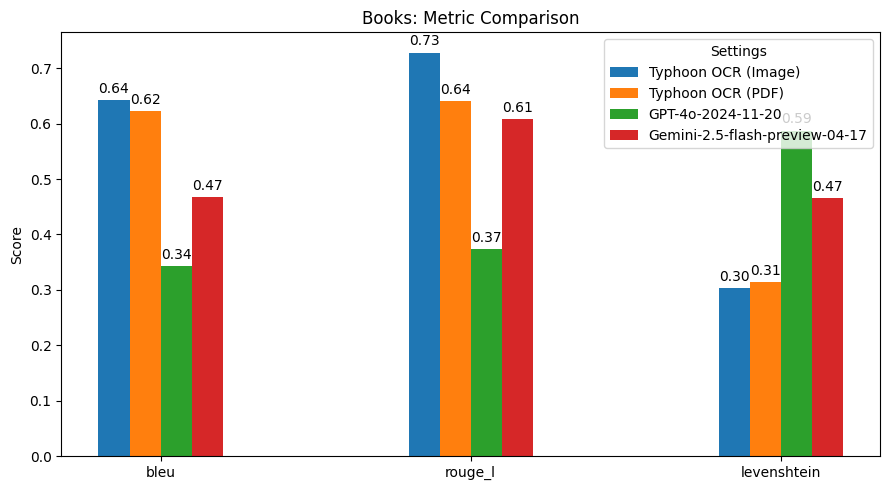
## Summary of Findings
Typhoon OCR outperforms both GPT-4o and Gemini 2.5 Flash in Thai document understanding, particularly on documents with complex layouts and mixed-language content.
However, in the Thai books benchmark, performance slightly declined due to the high frequency and diversity of embedded figures. These images vary significantly in type and structure, which poses challenges for our current figure tag parsing. This highlights a potential area for future improvement—specifically, in enhancing the model's image understanding capabilities.
For this version, our primary focus has been on achieving high-quality OCR for both English and Thai text. Future releases may extend support to more advanced image analysis and figure interpretation.
## Usage Example
**(Recommended): Full inference code available on [Colab](https://colab.research.google.com/drive/1z4Fm2BZnKcFIoWuyxzzIIIn8oI2GKl3r?usp=sharing)**
**(Recommended): Using Typhoon-OCR Package**
```bash
pip install typhoon-ocr
```
```python
from typhoon_ocr import ocr_document
# please set env TYPHOON_OCR_API_KEY or OPENAI_API_KEY to use this function
markdown = ocr_document("test.png")
print(markdown)
```
**Run Manually**
Below is a partial snippet. You can run inference using either the API or a local model.
*API*:
```python
from typing import Callable
from openai import OpenAI
from PIL import Image
from typhoon_ocr.ocr_utils import render_pdf_to_base64png, get_anchor_text
PROMPTS_SYS = {
"default": lambda base_text: (f"Below is an image of a document page along with its dimensions. "
f"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\n"
f"If the document contains images, use a placeholder like dummy.png for each image.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"),
"structure": lambda base_text: (
f"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. "
f"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\n"
f"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\n"
f"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"
),
}
def get_prompt(prompt_name: str) -> Callable[[str], str]:
"""
Fetches the system prompt based on the provided PROMPT_NAME.
:param prompt_name: The identifier for the desired prompt.
:return: The system prompt as a string.
"""
return PROMPTS_SYS.get(prompt_name, lambda x: "Invalid PROMPT_NAME provided.")
# Render the first page to base64 PNG and then load it into a PIL image.
image_base64 = render_pdf_to_base64png(filename, page_num, target_longest_image_dim=1800)
image_pil = Image.open(BytesIO(base64.b64decode(image_base64)))
# Extract anchor text from the PDF (first page)
anchor_text = get_anchor_text(filename, page_num, pdf_engine="pdfreport", target_length=8000)
# Retrieve and fill in the prompt template with the anchor_text
prompt_template_fn = get_prompt(task_type)
PROMPT = prompt_template_fn(anchor_text)
messages = [{
"role": "user",
"content": [
{"type": "text", "text": PROMPT},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_base64}"}},
],
}]
# send messages to openai compatible api
openai = OpenAI(base_url="https://api.opentyphoon.ai/v1", api_key="TYPHOON_API_KEY")
response = openai.chat.completions.create(
model="typhoon-ocr-preview",
messages=messages,
max_tokens=16384,
temperature=0.1,
top_p=0.6,
extra_body={
"repetition_penalty": 1.2,
},
)
text_output = response.choices[0].message.content
print(text_output)
```
*Local Model (GPU Required)*:
```python
# Initialize the model
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("scb10x/typhoon-ocr-7b", torch_dtype=torch.bfloat16 ).eval()
processor = AutoProcessor.from_pretrained("scb10x/typhoon-ocr-7b")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Apply the chat template and processor
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
# Generate the output
output = model.generate(
**inputs,
temperature=0.1,
max_new_tokens=12000,
num_return_sequences=1,
repetition_penalty=1.2,
do_sample=True,
)
# Decode the output
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(text_output[0])
```
## Prompting
This model only works with the specific prompts defined below, where `{base_text}` refers to information extracted from the PDF metadata using the `get_anchor_text` function from the `typhoon-ocr` package. It will not function correctly with any other prompts.
```
PROMPTS_SYS = {
"default": lambda base_text: (f"Below is an image of a document page along with its dimensions. "
f"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\n"
f"If the document contains images, use a placeholder like dummy.png for each image.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"),
"structure": lambda base_text: (
f"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. "
f"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\n"
f"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\n"
f"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"
),
}
```
### Generation Parameters
We suggest using the following generation parameters. Since this is an OCR model, we do not recommend using a high temperature. Make sure the temperature is set to 0 or 0.1, not higher.
```
temperature=0.1,
top_p=0.6,
repetition_penalty: 1.2
```
## **Intended Uses & Limitations**
This is a task-specific model intended to be used only with the provided prompts. It does not include any guardrails or VQA capability. Due to the nature of large language models (LLMs), a certain level of hallucination may occur. We recommend that developers carefully assess these risks in the context of their specific use case.
## **Follow us**
**https://twitter.com/opentyphoon**
## **Support**
**https://discord.gg/us5gAYmrxw**
## **Citation**
- If you find Typhoon2 useful for your work, please cite it using:
```
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}
``` |
Mungert/OuteTTS-1.0-0.6B-GGUF | Mungert | 2025-06-15T19:47:09Z | 835 | 0 | outetts | [
"outetts",
"gguf",
"text-to-speech",
"en",
"zh",
"nl",
"fr",
"ka",
"de",
"hu",
"it",
"ja",
"ko",
"lv",
"pl",
"ru",
"es",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-to-speech | 2025-05-21T09:21:52Z | ---
license: apache-2.0
pipeline_tag: text-to-speech
library_name: outetts
language:
- en
- zh
- nl
- fr
- ka
- de
- hu
- it
- ja
- ko
- lv
- pl
- ru
- es
---
# <span style="color: #7FFF7F;">OuteTTS-1.0-0.6B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OuteTTS-1.0-0.6B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OuteTTS-1.0-0.6B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OuteTTS-1.0-0.6B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OuteTTS-1.0-0.6B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OuteTTS-1.0-0.6B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OuteTTS-1.0-0.6B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OuteTTS-1.0-0.6B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OuteTTS-1.0-0.6B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OuteTTS-1.0-0.6B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OuteTTS-1.0-0.6B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OuteTTS-1.0-0.6B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<div class="p-4 bg-gray-50 dark:bg-gray-800 rounded-lg shadow-sm mb-12">
<div class="text-center mb-4">
<h2 class="text-xl font-light text-gray-900 dark:text-white tracking-tight mt-0 mb-0">Oute A I</h2>
<div class="flex justify-center gap-6 mt-4">
<a href="https://www.outeai.com/" target="_blank" class="flex items-center gap-1 text-gray-700 dark:text-gray-300 text-m font-medium hover:text-gray-900 dark:hover:text-white transition-colors underline">
<svg width="18" height="18" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2">
<circle cx="12" cy="12" r="10"></circle>
<path d="M2 12h20M12 2a15.3 15.3 0 0 1 4 10 15.3 15.3 0 0 1-4 10 15.3 15.3 0 0 1-4-10 15.3 15.3 0 0 1 4-10z"></path>
</svg>
outeai.com
</a>
<a href="https://discord.gg/vyBM87kAmf" target="_blank" class="flex items-center gap-1 text-gray-700 dark:text-gray-300 text-m font-medium hover:text-gray-900 dark:hover:text-white transition-colors underline">
<svg width="18" height="18" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2">
<path d="M21 11.5a8.38 8.38 0 0 1-.9 3.8 8.5 8.5 0 0 1-7.6 4.7 8.38 8.38 0 0 1-3.8-.9L3 21l1.9-5.7a8.38 8.38 0 0 1-.9-3.8 8.5 8.5 0 0 1 4.7-7.6 8.38 8.38 0 0 1 3.8-.9h.5a8.48 8.48 0 0 1 8 8v.5z"></path>
</svg>
Discord
</a>
<a href="https://x.com/OuteAI" target="_blank" class="flex items-center gap-1 text-gray-700 dark:text-gray-300 text-m font-medium hover:text-gray-900 dark:hover:text-white transition-colors underline">
<svg width="18" height="18" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2">
<path d="M23 3a10.9 10.9 0 0 1-3.14 1.53 4.48 4.48 0 0 0-7.86 3v1A10.66 10.66 0 0 1 3 4s-4 9 5 13a11.64 11.64 0 0 1-7 2c9 5 20 0 20-11.5a4.5 4.5 0 0 0-.08-.83A7.72 7.72 0 0 0 23 3z"></path>
</svg>
@OuteAI
</a>
</div>
</div>
<div class="grid grid-cols-3 sm:grid-cols-3 gap-2">
<a href="https://huggingface.co/OuteAI/OuteTTS-1.0-0.6B" target="_blank" class="bg-white dark:bg-gray-700 text-gray-800 dark:text-gray-100 text-sm font-medium py-2 px-3 rounded-md text-center hover:bg-gray-100 dark:hover:bg-gray-600 hover:border-gray-300 dark:hover:border-gray-500 border border-transparent transition-all">
OuteTTS 1.0 0.6B
</a>
<a href="https://huggingface.co/OuteAI/OuteTTS-1.0-0.6B-FP8" target="_blank" class="bg-white dark:bg-gray-700 text-gray-800 dark:text-gray-100 text-sm font-medium py-2 px-3 rounded-md text-center hover:bg-gray-100 dark:hover:bg-gray-600 hover:border-gray-300 dark:hover:border-gray-500 border border-transparent transition-all">
OuteTTS 1.0 0.6B FP8
</a>
<a href="https://huggingface.co/OuteAI/OuteTTS-1.0-0.6B-GGUF" target="_blank" class="bg-white dark:bg-gray-700 text-gray-800 dark:text-gray-100 text-sm font-medium py-2 px-3 rounded-md text-center hover:bg-gray-100 dark:hover:bg-gray-600 hover:border-gray-300 dark:hover:border-gray-500 border border-transparent transition-all">
OuteTTS 1.0 0.6B GGUF
</a>
<a href="https://huggingface.co/OuteAI/OuteTTS-1.0-0.6B-EXL2-8bpw" target="_blank" class="bg-white dark:bg-gray-700 text-gray-800 dark:text-gray-100 text-sm font-medium py-2 px-3 rounded-md text-center hover:bg-gray-100 dark:hover:bg-gray-600 hover:border-gray-300 dark:hover:border-gray-500 border border-transparent transition-all">
OuteTTS 1.0 0.6B EXL2 8bpw
</a>
<a href="https://github.com/edwko/OuteTTS" target="_blank" class="bg-white dark:bg-gray-700 text-gray-800 dark:text-gray-100 text-sm font-medium py-2 px-3 rounded-md text-center hover:bg-gray-100 dark:hover:bg-gray-600 hover:border-gray-300 dark:hover:border-gray-500 border border-transparent transition-all">
GitHub Library
</a>
</div>
</div>
> [!IMPORTANT]
> **Important Sampling Considerations**
>
> When using OuteTTS version 1.0, it is crucial to use the settings specified in the [Sampling Configuration](#sampling-configuration) section.
> The **repetition penalty implementation** is particularly important - this model requires penalization applied to a **64-token recent window**,
> rather than across the entire context window. Penalizing the entire context will cause the model to produce **broken or low-quality output**.
>
> To address this limitation, all necessary samplers and patches for all backends are set up automatically in the **outetts** library.
> If using a custom implementation, ensure you correctly implement these requirements.
# OuteTTS Version 1.0
This update brings significant improvements in speech synthesis and voice cloning—delivering a more powerful, accurate, and user-friendly experience in a compact size.
## OuteTTS Python Package v0.4.2
New version adds **batched inference** generation with the latest OuteTTS release.
### ⚡ **Batched RTF Benchmarks**
Tested with **NVIDIA L40S GPU**

## Quick Start Guide
Getting started with **OuteTTS** is simple:
### Installation
🔗 [Installation instructions](https://github.com/edwko/OuteTTS?tab=readme-ov-file#installation)
### Basic Setup
```python
from outetts import Interface, ModelConfig, GenerationConfig, Backend, InterfaceVersion, Models, GenerationType
# Initialize the interface
interface = Interface(
ModelConfig.auto_config(
model=Models.VERSION_1_0_SIZE_0_6B,
backend=Backend.HF,
)
)
# Load the default **English** speaker profile
speaker = interface.load_default_speaker("EN-FEMALE-1-NEUTRAL")
# Or create your own speaker (Use this once)
# speaker = interface.create_speaker("path/to/audio.wav")
# interface.save_speaker(speaker, "speaker.json")
# Load your speaker from saved file
# speaker = interface.load_speaker("speaker.json")
# Generate speech & save to file
output = interface.generate(
GenerationConfig(
text="Hello, how are you doing?",
speaker=speaker,
)
)
output.save("output.wav")
```
### ⚡ Batch Setup
```python
from outetts import Interface, ModelConfig, GenerationConfig, Backend, GenerationType
if __name__ == "__main__":
# Initialize the interface with a batch-capable backend
interface = Interface(
ModelConfig(
model_path="OuteAI/OuteTTS-1.0-0.6B-FP8",
tokenizer_path="OuteAI/OuteTTS-1.0-0.6B",
backend=Backend.VLLM
# For EXL2, use backend=Backend.EXL2ASYNC + exl2_cache_seq_multiply={should be same as max_batch_size in GenerationConfig}
# For LLAMACPP_ASYNC_SERVER, use backend=Backend.LLAMACPP_ASYNC_SERVER and provide server_host in GenerationConfig
)
)
# Load your speaker profile
speaker = interface.load_default_speaker("EN-FEMALE-1-NEUTRAL") # Or load/create custom speaker
# Generate speech using BATCH type
# Note: For EXL2ASYNC, VLLM, LLAMACPP_ASYNC_SERVER, BATCH is automatically selected.
output = interface.generate(
GenerationConfig(
text="This is a longer text that will be automatically split into chunks and processed in batches.",
speaker=speaker,
generation_type=GenerationType.BATCH,
max_batch_size=32, # Adjust based on your GPU memory and server capacity
dac_decoding_chunk=2048, # Adjust chunk size for DAC decoding
# If using LLAMACPP_ASYNC_SERVER, add:
# server_host="http://localhost:8000" # Replace with your server address
)
)
# Save to file
output.save("output_batch.wav")
```
### More Configuration Options
For advanced settings and customization, visit the official repository:
[](https://github.com/edwko/OuteTTS/blob/main/docs/interface_usage.md)
## Multilingual Capabilities
- **Trained Languages:** English, Chinese, Dutch, French, Georgian, German, Hungarian, Italian, Japanese, Korean, Latvian, Polish, Russian, Spanish
- **Beyond Supported Languages:** The model can generate speech in untrained languages with varying success. Experiment with unlisted languages, though results may not be optimal.
## Usage Recommendations
### Speaker Reference
The model is designed to be used with a speaker reference. Without one, it generates random vocal characteristics, often leading to lower-quality outputs.
The model inherits the referenced speaker's emotion, style, and accent.
When transcribing to other languages with the same speaker, you may observe the model retaining the original accent.
### Multilingual Application
It is recommended to create a speaker profile in the language you intend to use. This helps achieve the best results in that specific language, including tone, accent, and linguistic features.
While the model supports cross-lingual speech, it still relies on the reference speaker. If the speaker has a distinct accent—such as British English—other languages may carry that accent as well.
### Optimal Audio Length
- **Best Performance:** Generate audio around **42 seconds** in a single run (approximately 8,192 tokens). It is recomended not to near the limits of this windows when generating. Usually, the best results are up to 7,000 tokens.
- **Context Reduction with Speaker Reference:** If the speaker reference is 10 seconds long, the effective context is reduced to approximately 32 seconds.
### Temperature Setting Recommendations
Testing shows that a temperature of **0.4** is an ideal starting point for accuracy (with the sampling settings below). However, some voice references may benefit from higher temperatures for enhanced expressiveness or slightly lower temperatures for more precise voice replication.
### Verifying Speaker Encoding
If the cloned voice quality is subpar, check the encoded speaker sample.
```python
interface.decode_and_save_speaker(speaker=your_speaker, path="speaker.wav")
```
The DAC audio reconstruction model is lossy, and samples with clipping, excessive loudness, or unusual vocal features may introduce encoding issues that impact output quality.
### Sampling Configuration
For optimal results with this TTS model, use the following sampling settings.
| Parameter | Value |
|-------------------|----------|
| Temperature | 0.4 |
| Repetition Penalty| 1.1 |
| **Repetition Range** | **64** |
| Top-k | 40 |
| Top-p | 0.9 |
| Min-p | 0.05 |
## 📊 Model Specifications
| **Model** | **Training Data** | **Context Length** | **Supported Languages** |
|--------------------------|-----------------------------|--------------------|-------------------------|
| **Llama-OuteTTS-1.0-1B** | 60k hours of audio | 8,192 tokens | 23+ languages |
| **OuteTTS-1.0-0.6B** | 20k hours of audio | 8,192 tokens | 14+ languages |
## Acknowledgments
- Audio encoding and decoding utilize [ibm-research/DAC.speech.v1.0](https://huggingface.co/ibm-research/DAC.speech.v1.0)
- OuteTTS is built with [Qwen3 0.6B](https://huggingface.co/Qwen/Qwen3-0.6B-Base) as the base model, with continued pre-training and fine-tuning.
- Datasets used: [Multilingual LibriSpeech (MLS)](https://www.openslr.org/94/) ([CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)), [Common Voice Corpus](https://commonvoice.mozilla.org/en/datasets) ([CC-0](https://creativecommons.org/public-domain/cc0/))
---
### Ethical Use Guidelines
1. **Intended Purpose:** This model is intended for legitimate applications that
enhance accessibility, creativity, and communication.
2. **Prohibited Uses:**
* Impersonation of individuals without their explicit, informed consent.
* Creation of deliberately misleading, false, or deceptive content (e.g., "deepfakes" for malicious purposes).
* Generation of harmful, hateful, harassing, or defamatory material.
* Voice cloning of any individual without their explicit prior permission.
* Any uses that violate applicable local, national, or international laws, regulations, or copyrights.
3. **Responsibility:** Users are responsible for the content they generate and
how it is used. We encourage thoughtful consideration of the potential impact
of synthetic media.
|
Mungert/HyperCLOVAX-SEED-Text-Instruct-0.5B-GGUF | Mungert | 2025-06-15T19:46:46Z | 1,192 | 1 | transformers | [
"transformers",
"gguf",
"text-generation",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-15T20:21:18Z | ---
license: other
license_name: hyperclovax-seed
license_link: LICENSE
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">HyperCLOVAX-SEED-Text-Instruct-0.5B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5e7d95e2`](https://github.com/ggerganov/llama.cpp/commit/5e7d95e22e386d316f7f659b74c9c34b65507912).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `HyperCLOVAX-SEED-Text-Instruct-0.5B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊

## Overview
HyperCLOVAX-SEED-Text-Instruct-0.5B is a Text-to-Text model with instruction-following capabilities that excels in understanding Korean language and culture. Compared to external competitors of similar scale, it demonstrates improved mathematical performance and a substantial enhancement in Korean language capability. The HyperCLOVAX-SEED-Text-Instruct-0.5B is currently the smallest model released by the HyperCLOVAX, representing a lightweight solution suitable for deployment in resource‑constrained environments such as edge devices. It supports a maximum context length of 4K and functions as a versatile small model applicable to a wide range of tasks. The total cost of a single training run for HyperCLOVAX-SEED-Text-Instruct-0.5B was 4.358K A100 GPU hours (approximately USD 6.537K), which is 39 times lower than the cost of training the `QWEN2.5‑0.5B‑instruct` model.
## Basic Information
- **Architecture**: Transformer‑based (Dense Model)
- **Parameters**: 0.57 B (total); 0.45 B (excluding token embeddings, tied embeddings)
- **Input/Output Format**: Text / Text
- **Maximum Context Length**: 4 K tokens
- **Knowledge Cutoff Date**: Trained on data up to January 2025
## Training and Data
The training dataset for HyperCLOVAX-SEED-Text-Instruct-0.5B consists of diverse sources, including the high‑quality data accumulated during the development of HyperCLOVAX-SEED-Text-Instruct-0.5B. Training was conducted in three main stages:
1. **Pretraining**: Knowledge acquisition using high‑quality data and a high‑performance pretrained model.
2. **Rejection Sampling Fine‑Tuning (RFT)**: Enhancement of multi‑domain knowledge and complex reasoning capabilities.
3. **Supervised Fine‑Tuning (SFT)**: Improvement of instruction‑following proficiency.
## Training Cost
HyperCLOVAX-SEED-Text-Instruct-0.5B leveraged HyperCLOVA X’s lightweight training process and high‑quality data to achieve significantly lower training costs compared to industry‑leading competitors of similar scale. Excluding the SFT stage, a single pretraining run incurred:
| Pretraining Cost Category | HyperCLOVAX-SEED-Text-Instruct-0.5B | QWEN2.5‑0.5B‑instruct |
|---------------------------------|-----------------------------------------------|-------------------------------------|
| **A100 GPU Hours** | 4.358 K | 169.257 K |
| **Cost (USD)** | 6.537 K | 253.886 K |
This represents approximately a 39× reduction in pretraining cost relative to `QWEN2.5‑0.5B-instruct`.
## Benchmarks
| **Model** | **KMMLU (5-shot, acc)** | **HAE-RAE (5-shot, acc)** | **CLiCK (5-shot, acc)** | **KoBEST (5-shot, acc)** |
| --- | --- | --- | --- | --- |
| HyperCLOVAX-SEED-Text-Base-0.5B | 0.4181 | 0.6370 | 0.5373 | 0.6963
| HyperCLOVAX-SEED-Text-Instruct-0.5B | 0.3815 | 0.5619 | 0.4446 | 0.6299 |
| QWEN2.5-0.5B-instruct | 0.2968 | 0.3428 | 0.3805 | 0.5025 |
## HuggingFace Usage Example
### Python Code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("naver-hyperclovax/HyperCLOVAX-SEED-Text-Instruct-0.5B").to(device="cuda")
tokenizer = AutoTokenizer.from_pretrained("naver-hyperclovax/HyperCLOVAX-SEED-Text-Instruct-0.5B")
chat = [
{"role": "tool_list", "content": ""},
{"role": "system", "content": "- AI 언어모델의 이름은 \"CLOVA X\" 이며 네이버에서 만들었다.\n- 오늘은 2025년 04월 24일(목)이다."},
{"role": "user", "content": "슈뢰딩거 방정식과 양자역학의 관계를 최대한 자세히 알려줘."},
]
inputs = tokenizer.apply_chat_template(chat, add_generation_prompt=True, return_dict=True, return_tensors="pt")
inputs = inputs.to(device="cuda")
output_ids = model.generate(**inputs, max_length=1024, stop_strings=["<|endofturn|>", "<|stop|>"], repetition_penalty=1.2, tokenizer=tokenizer)
print(tokenizer.batch_decode(output_ids))
```
### Result
```bash
['<|im_start|>tool_list\n<|im_end|>\n<|im_start|>system\n- AI 언어모델의 이름은 "CLOVA X" 이며 네이버에서 만들었다.\n- 오늘은 2025년 04월 24일(목)이다.<|im_end|>\n<|im_start|>user\n슈뢰딩거 방정식과 양자역학의 관계를 최대한 자세히 알려줘.<|im_end|>\n<|im_start|>assistant\n양자역학은 슈뢰딩거 방정식을 통해 물질과 에너지, 공간 등의 현상을 설명합니다.\n\n**1. 슈뢰딩거 방정식**\n\n슈뢰딩거는 파동함수를 이용하여 입자의 위치와 운동량을 계산할 수 있다고 주장했습니다. 이를 위해 다음과 같은 식으로 표현됩니다:\n\n$$\\frac{\\partial \\psi}{\\partial t} = iH \\nabla^2 \\psi + V(x)\\psi $$\n\n여기서 $\\psi$는 파동함수이고 $i$는 허수 단위입니다. 여기서 $t$는 시간, $x$는 공간 좌표이며, $H$는 해밀턴 상수로 시스템의 에너지를 나타냅니다. 또한 $V(x)$는 외부 힘이나 장벽에 의해 영향을 받는 부분을 나타내는 함수로, 일반적으로 전위장을 사용합니다.\n\n**2. 양자역학과 슈뢰딩거 방정식의 관계**\n\n양자역학에서는 슈뢰딩거 방정식이 매우 중요한 역할을 합니다. 이는 모든 물리적 시스템이 불확정성 원리에 따라 행동을 하며, 이러한 시스템들은 확률적으로 상태를 가질 수밖에 없기 때문입니다. 따라서 슈뢰딩거 방정식은 양자역학을 수학적으로 모델링하는 핵심적인 도구 중 하나입니다.\n\n예를 들어, 원자핵 내의 전자들의 상태는 슈뢰딩거 방정식에 의해 결정되며, 이는 물리학적 법칙을 따르는 것으로 보입니다. 또한, 광전 효과에서도 슈뢰딩거 방정식은 빛이 물질 내에서 어떻게 흡수되고 반사되는지를 예측하는데 사용됩니다.\n\n**3. 응용 분야**\n\n슈뢰딩거 방정식은 다양한 분야에서 활용되고 있습니다. 예를 들면, 반도체 기술에서의 트랜지스터 설계, 핵물리학에서의 방사성 붕괴 연구 등이 있으며, 이는 모두 슈뢰딩거 방정식을 기반으로 한 이론적 기반 위에서 이루어집니다.\n\n또한, 현대 과학 기술의 발전에도 큰 기여를 하고 있는데, 특히 인공지능(AI), 컴퓨터 시뮬레이션 등에서 복잡한 문제를 해결하고 새로운 지식을 창출하기 위한 기초가 되고 있습니다.\n\n결론적으로, 슈뢰딩거 방정식은 양자역학의 기본 개념들을 이해하고 해석하며, 그 결과로서 많은 혁신적이고 실용적인 기술을 가능하게 했습니다. 이는 양자역학의 중요성을 보여주는 대표적인 예시라고 할 수 있습니다.<|im_end|><|endofturn|>']
``` |
Mungert/OpenMath-Nemotron-1.5B-GGUF | Mungert | 2025-06-15T19:46:23Z | 219 | 0 | transformers | [
"transformers",
"gguf",
"nvidia",
"math",
"text-generation",
"en",
"dataset:nvidia/OpenMathReasoning",
"arxiv:2504.16891",
"base_model:Qwen/Qwen2.5-Math-1.5B",
"base_model:quantized:Qwen/Qwen2.5-Math-1.5B",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-10T16:13:46Z | ---
base_model:
- Qwen/Qwen2.5-Math-1.5B
datasets:
- nvidia/OpenMathReasoning
language:
- en
library_name: transformers
license: cc-by-4.0
tags:
- nvidia
- math
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">OpenMath-Nemotron-1.5B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OpenMath-Nemotron-1.5B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OpenMath-Nemotron-1.5B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OpenMath-Nemotron-1.5B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OpenMath-Nemotron-1.5B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OpenMath-Nemotron-1.5B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OpenMath-Nemotron-1.5B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OpenMath-Nemotron-1.5B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OpenMath-Nemotron-1.5B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OpenMath-Nemotron-1.5B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OpenMath-Nemotron-1.5B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OpenMath-Nemotron-1.5B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# OpenMath-Nemotron-1.5B
OpenMath-Nemotron-1.5B is created by finetuning [Qwen/Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) on [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning) dataset.
This model is ready for commercial use.

OpenMath-Nemotron models achieve state-of-the-art results on popular mathematical benchmarks. We present metrics as pass@1 (maj@64) where pass@1
is an average accuracy across 64 generations and maj@64 is the result of majority voting.
Please see our [paper](https://arxiv.org/abs/2504.16891) for more details on the evaluation setup.
| Model | AIME24 | AIME25 | HMMT-24-25 | HLE-Math |
|-------------------------------|-----------------|-------|-------|-------------|
| DeepSeek-R1-Distill-Qwen-1.5B | 26.8 (60.0) | 21.4 (36.7) | 14.2 (26.5) | 2.9 (5.0) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) CoT | 61.6 (80.0) | 49.5 (66.7) | 39.9 (53.6) | 5.4 (5.4) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) TIR | 52.0 (83.3) | 39.7 (70.0) | 37.2 (60.7) | 2.5 (6.2) |
| + Self GenSelect | 83.3 | 70.0 | 62.2 | 7.9 |
| + 32B GenSelect | 83.3 | 70.0 | 62.8 | 8.3 |
| DeepSeek-R1-Distill-Qwen-7B | 54.4 (80.0) | 38.6 (53.3) | 30.6 (42.9) | 3.3 (5.2) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) CoT | 74.8 (80.0) | 61.2 (76.7) | 49.7 (57.7) | 6.6 (6.6) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) TIR | 72.9 (83.3) | 57.5 (76.7) | 54.6 (66.3) | 7.8 (10.8) |
| + Self GenSelect | 86.7 | 76.7 | 68.4 | 11.5 |
| + 32B GenSelect | 86.7 | 76.7 | 69.9 | 11.9 |
| DeepSeek-R1-Distill-Qwen-14B | 65.8 (80.0) | 48.4 (60.0) | 40.1 (52.0) | 4.2 (4.8) |
| [OpenMath-Nemotron-14B-MIX (kaggle)](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) | 73.7 (86.7) | 57.9 (73.3) | 50.5 (64.8) | 5.7 (6.5) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) CoT | 76.3 (83.3) | 63.0 (76.7) | 52.1 (60.7) | 7.5 (7.6) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) TIR | 76.3 (86.7) | 61.3 (76.7) | 58.6 (70.9) | 9.5 (11.5) |
| + Self GenSelect | 86.7 | 76.7 | 72.4 | 14.1 |
| + 32B GenSelect | 90.0 | 76.7 | 71.9 | 13.7 |
| QwQ-32B | 78.1 (86.7) | 66.5 (76.7) | 55.9 (63.3) | 9.0 (9.5) |
| DeepSeek-R1-Distill-Qwen-32B | 66.9 (83.3) | 51.8 (73.3) | 39.9 (51.0) | 4.8 (6.0) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) CoT | 76.5 (86.7) | 62.5 (73.3) | 53.0 (59.2) | 8.3 (8.3) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) TIR | 78.4 (93.3) | 64.2 (76.7) | 59.7 (70.9) | 9.2 (12.5) |
| + Self GenSelect | 93.3 | 80.0 | 73.5 | 15.7 |
| DeepSeek-R1 | 79.1 (86.7) | 64.3 (73.3) | 53.0 (59.2) | 10.5 (11.4) |
We used [a version of OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) model to secure
the first place in [AIMO-2 Kaggle competition](https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/leaderboard)!
## Reproducing our results
The pipeline we used to produce the data and models is fully open-sourced!
- [Code](https://github.com/NVIDIA/NeMo-Skills)
- [Models](https://huggingface.co/collections/nvidia/openmathreasoning-68072c0154a5099573d2e730)
- [Dataset](https://huggingface.co/datasets/nvidia/OpenMathReasoning)
- [Paper](https://arxiv.org/abs/2504.16891)
We provide [all instructions](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/)
to fully reproduce our results, including data generation.
## How to use the models?
Our models can be used in 3 inference modes: chain-of-thought (CoT), tool-integrated reasoning (TIR) and generative solution selection (GenSelect).
To run inference with CoT mode, you can use this example code snippet.
```python
import transformers
import torch
model_id = "nvidia/OpenMath-Nemotron-1.5B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{
"role": "user",
"content": "Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
" +
"What is the minimum value of $a^2+6a-7$?"},
]
outputs = pipeline(
messages,
max_new_tokens=4096,
)
print(outputs[0]["generated_text"][-1]['content'])
```
To run inference with TIR or GenSelect modes, we highly recommend to use our
[reference implementation in NeMo-Skills](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/evaluation/).
Please note that these models have not been instruction tuned on general data and thus might not provide good answers outside of math domain.
## Citation
If you find our work useful, please consider citing us!
```bibtex
@article{moshkov2025aimo2,
title = {AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset},
author = {Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
year = {2025},
journal = {arXiv preprint arXiv:2504.16891}
}
```
## Additional information
### License/Terms of Use: <br>
GOVERNING TERMS: Use of this model is governed by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en).
Additional Information: [Apache License Version 2.0](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B/blob/main/LICENSE).
### Deployment Geography:
Global <br>
### Use Case: <br>
This model is intended to facilitate research in the area of mathematical reasoning.
### Release Date: <br>
Huggingface 04/23/2025 <br>
### Model Architecture: <br>
**Architecture Type:** Transformer decoder-only language model <br>
**Network Architecture:** Qwen2.5 <br>
**This model was developed based on Qwen2.5-1.5B <br>
** This model has 1.5B of model parameters. <br>
### Input: <br>
**Input Type(s):** Text <br>
**Input Format(s):** String <br>
**Input Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Input:** Context length up to 131,072 tokens <br>
### Output: <br>
**Output Type(s):** Text <br>
**Output Format:** String <br>
**Output Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Output:** Context length up to 131,072 tokens <br>
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
### Software Integration : <br>
**Runtime Engine(s):** <br>
* Tensor RT / Triton <br>
**Supported Hardware Microarchitecture Compatibility:** <br>
* NVIDIA Ampere <br>
* NVIDIA Hopper <br>
**Preferred Operating System(s):** <br>
* Linux <br>
### Model Version(s):
[OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B)
[OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B)
[OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B)
[OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B)
# Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](./EXPLAINABILITY.md), [Bias](./BIAS.md), [Safety & Security](./SAFETY.md), and [Privacy](./PRIVACY.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/). |
Mungert/OLMo-2-0425-1B-GGUF | Mungert | 2025-06-15T19:46:08Z | 340 | 1 | transformers | [
"transformers",
"gguf",
"en",
"arxiv:2501.00656",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-05-09T22:04:01Z | ---
license: apache-2.0
language:
- en
library_name: transformers
---
# <span style="color: #7FFF7F;">OLMo-2-0425-1B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`8c83449`](https://github.com/ggerganov/llama.cpp/commit/8c83449cb780c201839653812681c3a4cf17feed).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OLMo-2-0425-1B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OLMo-2-0425-1B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OLMo-2-0425-1B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OLMo-2-0425-1B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OLMo-2-0425-1B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OLMo-2-0425-1B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OLMo-2-0425-1B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OLMo-2-0425-1B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OLMo-2-0425-1B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OLMo-2-0425-1B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OLMo-2-0425-1B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
## Model Details
<img alt="OLMo Logo" src="https://huggingface.co/datasets/allenai/blog-images/resolve/main/olmo2/olmo.png" width="242px" style="margin-left:'auto' margin-right:'auto' display:'block'">
# Model Card for OLMo 2 1B
We introduce OLMo 2 1B, the smallest model in the OLMo 2 family.
OLMo 2 was pre-trained on [OLMo-mix-1124](https://huggingface.co/datasets/allenai/olmo-mix-1124)
and uses [Dolmino-mix-1124](https://huggingface.co/datasets/allenai/dolmino-mix-1124) for mid-training.
OLMo 2 is the latest in a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models.
We have released all code, checkpoints, logs, and associated training details on [GitHub](https://github.com/allenai/OLMo).
| Size | Training Tokens | Layers | Hidden Size | Attention Heads | Context Length |
|------|--------|---------|-------------|-----------------|----------------|
| [OLMo 2-1B](https://huggingface.co/allenai/OLMo-2-0425-1B) | 4 Trillion | 16 | 2048 | 16 | 4096 |
| [OLMo 2-7B](https://huggingface.co/allenai/OLMo-2-1124-7B) | 4 Trillion | 32 | 4096 | 32 | 4096 |
| [OLMo 2-13B](https://huggingface.co/allenai/OLMo-2-1124-13B) | 5 Trillion | 40 | 5120 | 40 | 4096 |
| [OLMo 2-32B](https://huggingface.co/allenai/OLMo-2-0325-32B) | 6 Trillion | 64 | 5120 | 40 | 4096 |
The core models released in this batch include the following:
| **Stage** | **OLMo 2 1B** | **OLMo 2 7B** | **OLMo 2 13B** | **OLMo 2 32B** |
|------------------------|--------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|
| **Base Model** | [allenai/OLMo-2-0425-1B](https://huggingface.co/allenai/OLMo-2-0425-1B) | [allenai/OLMo-2-1124-7B](https://huggingface.co/allenai/OLMo-2-1124-7B) | [allenai/OLMo-2-1124-13B](https://huggingface.co/allenai/OLMo-2-1124-13B) | [allenai/OLMo-2-0325-32B](https://huggingface.co/allenai/OLMo-2-0325-32B) |
| **SFT** | [allenai/OLMo-2-0425-1B-SFT](https://huggingface.co/allenai/OLMo-2-0425-1B-SFT) | [allenai/OLMo-2-1124-7B-SFT](https://huggingface.co/allenai/OLMo-2-1124-7B-SFT) | [allenai/OLMo-2-1124-13B-SFT](https://huggingface.co/allenai/OLMo-2-1124-13B-SFT) | [allenai/OLMo-2-0325-32B-SFT](https://huggingface.co/allenai/OLMo-2-0325-32B-SFT) |
| **DPO** | [allenai/OLMo-2-0425-1B-DPO](https://huggingface.co/allenai/OLMo-2-0425-1B-DPO) | [allenai/OLMo-2-1124-7B-DPO](https://huggingface.co/allenai/OLMo-2-1124-7B-DPO) | [allenai/OLMo-2-1124-13B-DPO](https://huggingface.co/allenai/OLMo-2-1124-13B-DPO) | [allenai/OLMo-2-0325-32B-DPO](https://huggingface.co/allenai/OLMo-2-0325-32B-DPO) |
| **Final Models (RLVR)**| [allenai/OLMo-2-0425-1B-Instruct](https://huggingface.co/allenai/OLMo-2-0425-1B-Instruct) | [allenai/OLMo-2-1124-7B-Instruct](https://huggingface.co/allenai/OLMo-2-1124-7B-Instruct) | [allenai/OLMo-2-1124-13B-Instruct](https://huggingface.co/allenai/OLMo-2-1124-13B-Instruct) | [allenai/OLMo-2-0325-32B-Instruct](https://huggingface.co/allenai/OLMo-2-0325-32B-Instruct) |
| **Reward Model (RM)** | | [allenai/OLMo-2-1124-7B-RM](https://huggingface.co/allenai/OLMo-2-1124-7B-RM) |(Same as 7B) | |
## Installation
OLMo 2 1B is supported in transformers v4.48 or higher:
```bash
pip install transformers>=4.48
```
If using vLLM, you will need to install from the main branch until v0.7.4 is released. Please
## Inference
You can use OLMo with the standard HuggingFace transformers library:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-2-0425-1B")
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-2-0425-1B")
message = ["Language modeling is "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
# optional verifying cuda
# inputs = {k: v.to('cuda') for k,v in inputs.items()}
# olmo = olmo.to('cuda')
response = olmo.generate(**inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
>> 'Language modeling is a key component of any text-based application, but its effectiveness...'
```
For faster performance, you can quantize the model using the following method:
```python
AutoModelForCausalLM.from_pretrained("allenai/OLMo-2-0425-1B",
torch_dtype=torch.float16,
load_in_8bit=True) # Requires bitsandbytes
```
The quantized model is more sensitive to data types and CUDA operations. To avoid potential issues, it's recommended to pass the inputs directly to CUDA using:
```python
inputs.input_ids.to('cuda')
```
We have released checkpoints for these models. For pretraining, the naming convention is `stage1-stepXXX-tokensYYYB`. For checkpoints with ingredients of the soup, the naming convention is `stage2-ingredientN-stepXXX-tokensYYYB`
To load a specific model revision with HuggingFace, simply add the argument `revision`:
```bash
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-2-0425-1B", revision="stage1-step140000-tokens294B")
```
Or, you can access all the revisions for the models via the following code snippet:
```python
from huggingface_hub import list_repo_refs
out = list_repo_refs("allenai/OLMo-2-0425-1B")
branches = [b.name for b in out.branches]
```
### Fine-tuning
Model fine-tuning can be done from the final checkpoint (the `main` revision of this model) or many intermediate checkpoints. Two recipes for tuning are available.
1. Fine-tune with the OLMo repository:
```bash
torchrun --nproc_per_node=8 scripts/train.py {path_to_train_config} \
--data.paths=[{path_to_data}/input_ids.npy] \
--data.label_mask_paths=[{path_to_data}/label_mask.npy] \
--load_path={path_to_checkpoint} \
--reset_trainer_state
```
For more documentation, see the [GitHub README](https://github.com/allenai/OLMo/).
2. Further fine-tuning support is being developing in AI2's Open Instruct repository. Details are [here](https://github.com/allenai/open-instruct).
### Model Description
- **Developed by:** Allen Institute for AI (Ai2)
- **Model type:** a Transformer style autoregressive language model.
- **Language(s) (NLP):** English
- **License:** The code and model are released under Apache 2.0.
- **Contact:** Technical inquiries: `[email protected]`. Press: `[email protected]`
- **Date cutoff:** Dec. 2023.
### Model Sources
- **Project Page:** https://allenai.org/olmo
- **Repositories:**
- Core repo (training, inference, fine-tuning etc.): https://github.com/allenai/OLMo
- Evaluation code: https://github.com/allenai/OLMo-Eval
- Further fine-tuning code: https://github.com/allenai/open-instruct
- **Paper:** https://arxiv.org/abs/2501.00656
## Evaluation
Core model results for OLMo 2 1B are found below.
| Instruct Model | Avg | FLOP×10²³ | AE2 | BBH | DROP | GSM8K | IFE | MATH | MMLU | Safety | PQA | TQA |
|------------------------|------|-----------|------|------|------|-------|------|------|------|--------|------|------|
| **Closed API models** | | | | | | | | | | | | |
| GPT-3.5 Turbo 0125 | 60.5 | n/a | 38.7 | 66.6 | 70.2 | 74.3 | 66.9 | 41.2 | 70.2 | 69.1 | 45.0 | 62.9 |
| GPT 4o Mini 0724 | 65.7 | n/a | 49.7 | 65.9 | 36.3 | 83.0 | 83.5 | 67.9 | 82.2 | 84.9 | 39.0 | 64.8 |
| **Open weights models 1-1.7B Parameters** | | | | | | | | | | | | |
| SmolLM2 1.7B | 34.2 | 1.1 | 5.8 | 39.8 | 30.9 | 45.3 | 51.6 | 20.3 | 34.3 | 52.4 | 16.4 | 45.3 |
| Gemma 3 1B | 38.3 | 1.2 | 20.4 | 39.4 | 25.1 | 35.0 | 60.6 | 40.3 | 38.9 | 70.2 | 9.6 | 43.8 |
| Llama 3.1 1B | 39.3 | 6.7 | 10.1 | 40.2 | 32.2 | 45.4 | 54.0 | 21.6 | 46.7 | 87.2 | 13.8 | 41.5 |
| Qwen 2.5 1.5B | 41.7 | 1.7 | 7.4 | 45.8 | 13.4 | 66.2 | 44.2 | 40.6 | 59.7 | 77.6 | 15.5 | 46.5 |
| **Fully-open models** | | | | | | | | | | | | |
| OLMo 1B 0724 | 24.4 | 0.22 | 2.4 | 29.9 | 27.9 | 10.8 | 25.3 | 2.2 | 36.6 | 52.0 | 12.1 | 44.3 |
| **OLMo 2 1B** | 42.7 | 0.35 | 9.1 | 35.0 | 34.6 | 68.3 | 70.1 | 20.7 | 40.0 | 87.6 | 12.9 | 48.7 |
## Model Details
### Training
| | **OLMo 2 1B** | **OLMo 2 7B** | **OLMo 2 13B** | **OLMo 2 32B** |
|-------------------|------------|------------|------------|------------|
| Pretraining Stage 1 | 4 trillion tokens<br>(1 epoch) | 4 trillion tokens<br>(1 epoch) | 5 trillion tokens<br>(1.2 epochs) | 6 trillion tokens<br>(1.5 epochs) |
| Pretraining Stage 2 | 50B tokens | 50B tokens (3 runs)<br>*merged* | 100B tokens (3 runs)<br>300B tokens (1 run)<br>*merged* | 100B tokens (3 runs)<br>300B tokens (1 run)<br>*merged* |
| Post-training | SFT+DPO+GRPO<br>([preference mix](https://huggingface.co/datasets/allenai/olmo-2-0425-1b-preference-mix)) | SFT + DPO + PPO<br>([preference mix](https://huggingface.co/datasets/allenai/olmo-2-1124-7b-preference-mix)) | SFT + DPO + PPO<br>([preference mix](https://huggingface.co/datasets/allenai/olmo-2-1124-13b-preference-mix)) | SFT + DPO + GRPO<br>([preference mix](https://huggingface.co/datasets/allenai/olmo-2-32b-pref-mix-v1)) |
#### Stage 1: Initial Pretraining
- Dataset: [OLMo-mix-1124](https://huggingface.co/datasets/allenai/olmo-mix-1124) (3.9T tokens)
- Coverage: 95%+ of total pretraining budget
- 1B Model: ~1 epoch
#### Stage 2: Mid-training
- Dataset: Dolmino-Mix-1124
- One training mix:
- 50B tokens
- Mix composition: 50% high-quality web data + academic/Q&A/instruction/math content
#### Model Merging
- 1B Model: only 1 version is trained on a 50B mix, we did not merge.
## Bias, Risks, and Limitations
Like any base or fine-tuned language model, AI can be prompted by users to generate harmful and sensitive content. Such content may also be produced unintentionally, especially in cases involving bias, so we recommend that users consider the risks when applying this technology. Additionally, many statements from OLMo or any LLM are often inaccurate, so facts should be verified.
## Citation
```
@misc{olmo20242olmo2furious,
title={{2 OLMo 2 Furious}},
author={Team OLMo and Pete Walsh and Luca Soldaini and Dirk Groeneveld and Kyle Lo and Shane Arora and Akshita Bhagia and Yuling Gu and Shengyi Huang and Matt Jordan and Nathan Lambert and Dustin Schwenk and Oyvind Tafjord and Taira Anderson and David Atkinson and Faeze Brahman and Christopher Clark and Pradeep Dasigi and Nouha Dziri and Michal Guerquin and Hamish Ivison and Pang Wei Koh and Jiacheng Liu and Saumya Malik and William Merrill and Lester James V. Miranda and Jacob Morrison and Tyler Murray and Crystal Nam and Valentina Pyatkin and Aman Rangapur and Michael Schmitz and Sam Skjonsberg and David Wadden and Christopher Wilhelm and Michael Wilson and Luke Zettlemoyer and Ali Farhadi and Noah A. Smith and Hannaneh Hajishirzi},
year={2024},
eprint={2501.00656},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.00656},
}
```
## Model Card Contact
For errors in this model card, contact `[email protected]`. |
Mungert/shuttle-3.5-GGUF | Mungert | 2025-06-15T19:46:04Z | 108 | 1 | transformers | [
"transformers",
"gguf",
"chat",
"text-generation",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-08T18:19:48Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/shuttleai/shuttle-3.5/blob/main/LICENSE
pipeline_tag: text-generation
language:
- en
tags:
- chat
---
# <span style="color: #7FFF7F;">shuttle-3.5 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`8c83449`](https://github.com/ggerganov/llama.cpp/commit/8c83449cb780c201839653812681c3a4cf17feed).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `shuttle-3.5-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `shuttle-3.5-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `shuttle-3.5-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `shuttle-3.5-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `shuttle-3.5-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `shuttle-3.5-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `shuttle-3.5-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `shuttle-3.5-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `shuttle-3.5-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `shuttle-3.5-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `shuttle-3.5-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<p style="font-size:20px;" align="left">
<div style="border-radius: 15px;">
<img
src="https://storage.shuttleai.com/shuttle-3.5.png"
alt="ShuttleAI Thumbnail"
style="width: auto; height: auto; margin-left: 0; object-fit: cover; border-radius: 15px;">
</div>
## Shuttle-3.5
### ☁️ <a href="https://shuttleai.com/" target="_blank">Use via API</a> • 💬 <a href="https://shuttlechat.com/" target="_blank">ShuttleChat</a>
We are excited to introduce Shuttle-3.5, a fine-tuned version of [Qwen3 32b](https://huggingface.co/Qwen/Qwen3-32B), emulating the writing style of Claude 3 models and thoroughly trained on role-playing data.
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Shuttle 3.5** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 32.8B
- Number of Paramaters (Non-Embedding): 31.2B
- Number of Layers: 64
- Number of Attention Heads (GQA): 64 for Q and 8 for KV
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
## Fine-Tuning Details
- **Training Setup**: The model was trained on 130 million tokens for 40 hours on an H100 GPU. |
Mungert/OpenMath-Nemotron-32B-GGUF | Mungert | 2025-06-15T19:46:00Z | 433 | 1 | transformers | [
"transformers",
"gguf",
"nvidia",
"math",
"en",
"dataset:nvidia/OpenMathReasoning",
"arxiv:2504.16891",
"base_model:Qwen/Qwen2.5-32B",
"base_model:quantized:Qwen/Qwen2.5-32B",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-08T16:47:56Z | ---
license: cc-by-4.0
base_model:
- Qwen/Qwen2.5-32B
datasets:
- nvidia/OpenMathReasoning
language:
- en
tags:
- nvidia
- math
library_name: transformers
---
# <span style="color: #7FFF7F;">OpenMath-Nemotron-32B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OpenMath-Nemotron-32B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OpenMath-Nemotron-32B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OpenMath-Nemotron-32B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OpenMath-Nemotron-32B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OpenMath-Nemotron-32B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OpenMath-Nemotron-32B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OpenMath-Nemotron-32B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OpenMath-Nemotron-32B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OpenMath-Nemotron-32B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OpenMath-Nemotron-32B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OpenMath-Nemotron-32B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# OpenMath-Nemotron-32B
OpenMath-Nemotron-32B is created by finetuning [Qwen/Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) on [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning) dataset.
This model is ready for commercial use.

OpenMath-Nemotron models achieve state-of-the-art results on popular mathematical benchmarks. We present metrics as pass@1 (maj@64) where pass@1
is an average accuracy across 64 generations and maj@64 is the result of majority voting.
Please see our [paper](https://arxiv.org/abs/2504.16891) for more details on the evaluation setup.
| Model | AIME24 | AIME25 | HMMT-24-25 | HLE-Math |
|-------------------------------|-----------------|-------|-------|-------------|
| DeepSeek-R1-Distill-Qwen-1.5B | 26.8 (60.0) | 21.4 (36.7) | 14.2 (26.5) | 2.9 (5.0) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) CoT | 61.6 (80.0) | 49.5 (66.7) | 39.9 (53.6) | 5.4 (5.4) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) TIR | 52.0 (83.3) | 39.7 (70.0) | 37.2 (60.7) | 2.5 (6.2) |
| + Self GenSelect | 83.3 | 70.0 | 62.2 | 7.9 |
| + 32B GenSelect | 83.3 | 70.0 | 62.8 | 8.3 |
| DeepSeek-R1-Distill-Qwen-7B | 54.4 (80.0) | 38.6 (53.3) | 30.6 (42.9) | 3.3 (5.2) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) CoT | 74.8 (80.0) | 61.2 (76.7) | 49.7 (57.7) | 6.6 (6.6) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) TIR | 72.9 (83.3) | 57.5 (76.7) | 54.6 (66.3) | 7.8 (10.8) |
| + Self GenSelect | 86.7 | 76.7 | 68.4 | 11.5 |
| + 32B GenSelect | 86.7 | 76.7 | 69.9 | 11.9 |
| DeepSeek-R1-Distill-Qwen-14B | 65.8 (80.0) | 48.4 (60.0) | 40.1 (52.0) | 4.2 (4.8) |
| [OpenMath-Nemotron-14B-MIX (kaggle)](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) | 73.7 (86.7) | 57.9 (73.3) | 50.5 (64.8) | 5.7 (6.5) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) CoT | 76.3 (83.3) | 63.0 (76.7) | 52.1 (60.7) | 7.5 (7.6) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) TIR | 76.3 (86.7) | 61.3 (76.7) | 58.6 (70.9) | 9.5 (11.5) |
| + Self GenSelect | 86.7 | 76.7 | 72.4 | 14.1 |
| + 32B GenSelect | 90.0 | 76.7 | 71.9 | 13.7 |
| QwQ-32B | 78.1 (86.7) | 66.5 (76.7) | 55.9 (63.3) | 9.0 (9.5) |
| DeepSeek-R1-Distill-Qwen-32B | 66.9 (83.3) | 51.8 (73.3) | 39.9 (51.0) | 4.8 (6.0) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) CoT | 76.5 (86.7) | 62.5 (73.3) | 53.0 (59.2) | 8.3 (8.3) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) TIR | 78.4 (93.3) | 64.2 (76.7) | 59.7 (70.9) | 9.2 (12.5) |
| + Self GenSelect | 93.3 | 80.0 | 73.5 | 15.7 |
| DeepSeek-R1 | 79.1 (86.7) | 64.3 (73.3) | 53.0 (59.2) | 10.5 (11.4) |
We used [a version of OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) model to secure
the first place in [AIMO-2 Kaggle competition](https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/leaderboard)!
## Reproducing our results
The pipeline we used to produce the data and models is fully open-sourced!
- [Code](https://github.com/NVIDIA/NeMo-Skills)
- [Models](https://huggingface.co/collections/nvidia/openmathreasoning-68072c0154a5099573d2e730)
- [Dataset](https://huggingface.co/datasets/nvidia/OpenMathReasoning)
- [Paper](https://arxiv.org/abs/2504.16891)
We provide [all instructions](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/)
to fully reproduce our results, including data generation.
## How to use the models?
Our models can be used in 3 inference modes: chain-of-thought (CoT), tool-integrated reasoning (TIR) and generative solution selection (GenSelect).
To run inference with CoT mode, you can use this example code snippet.
```python
import transformers
import torch
model_id = "nvidia/OpenMath-Nemotron-32B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{
"role": "user",
"content": "Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.\n\n" +
"What is the minimum value of $a^2+6a-7$?"},
]
outputs = pipeline(
messages,
max_new_tokens=4096,
)
print(outputs[0]["generated_text"][-1]['content'])
```
To run inference with TIR or GenSelect modes, we highly recommend to use our
[reference implementation in NeMo-Skills](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/evaluation/).
Please note that these models have not been instruction tuned on general data and thus might not provide good answers outside of math domain.
## Citation
If you find our work useful, please consider citing us!
```bibtex
@article{moshkov2025aimo2,
title = {AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset},
author = {Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
year = {2025},
journal = {arXiv preprint arXiv:2504.16891}
}
```
## Additional information
### License/Terms of Use: <br>
GOVERNING TERMS: Use of this model is governed by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en).
Additional Information: [Apache License Version 2.0](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B/blob/main/LICENSE).
### Deployment Geography:
Global <br>
### Use Case: <br>
This model is intended to facilitate research in the area of mathematical reasoning.
### Release Date: <br>
Huggingface 04/23/2025 <br>
### Model Architecture: <br>
**Architecture Type:** Transformer decoder-only language model <br>
**Network Architecture:** Qwen2.5 <br>
**This model was developed based on Qwen2.5-1.5B <br>
** This model has 1.5B of model parameters. <br>
### Input: <br>
**Input Type(s):** Text <br>
**Input Format(s):** String <br>
**Input Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Input:** Context length up to 131,072 tokens <br>
### Output: <br>
**Output Type(s):** Text <br>
**Output Format:** String <br>
**Output Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Output:** Context length up to 131,072 tokens <br>
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
### Software Integration : <br>
**Runtime Engine(s):** <br>
* Tensor RT / Triton <br>
**Supported Hardware Microarchitecture Compatibility:** <br>
* NVIDIA Ampere <br>
* NVIDIA Hopper <br>
**Preferred Operating System(s):** <br>
* Linux <br>
### Model Version(s):
[OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B)
[OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B)
[OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B)
[OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B)
# Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](./EXPLAINABILITY.md), [Bias](./BIAS.md), [Safety & Security](./SAFETY.md), and [Privacy](./PRIVACY.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/). |
danaash/roger_dean_style_LoRA | danaash | 2025-06-15T19:45:57Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-15T19:45:56Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: roger dean style of fantasy
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - danaash/roger_dean_style_LoRA
<Gallery />
## Model description
These are danaash/roger_dean_style_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use roger dean style of fantasy to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](danaash/roger_dean_style_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Mungert/openhands-lm-32b-v0.1-GGUF | Mungert | 2025-06-15T19:45:55Z | 853 | 1 | null | [
"gguf",
"agent",
"coding",
"text-generation",
"en",
"dataset:SWE-Gym/SWE-Gym",
"arxiv:2412.21139",
"base_model:Qwen/Qwen2.5-Coder-32B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-Coder-32B-Instruct",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-07T04:39:23Z | ---
license: mit
datasets:
- SWE-Gym/SWE-Gym
language:
- en
base_model:
- Qwen/Qwen2.5-Coder-32B-Instruct
pipeline_tag: text-generation
tags:
- agent
- coding
---
# <span style="color: #7FFF7F;">openhands-lm-32b-v0.1 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `openhands-lm-32b-v0.1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `openhands-lm-32b-v0.1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `openhands-lm-32b-v0.1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `openhands-lm-32b-v0.1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `openhands-lm-32b-v0.1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `openhands-lm-32b-v0.1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `openhands-lm-32b-v0.1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `openhands-lm-32b-v0.1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `openhands-lm-32b-v0.1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `openhands-lm-32b-v0.1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `openhands-lm-32b-v0.1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<div align="center">
<img src="https://github.com/All-Hands-AI/OpenHands/blob/main/docs/static/img/logo.png?raw=true" alt="Logo" width="200">
<h1 align="center">OpenHands LM v0.1</h1>
</div>
<p align="center">
<a href="https://www.all-hands.dev/blog/introducing-openhands-lm-32b----a-strong-open-coding-agent-model">Blog</a>
•
<a href="https://docs.all-hands.dev/modules/usage/llms/local-llms" >Use it in OpenHands</a>
</p>
---
Autonomous agents for software development are already contributing to a [wide range of software development tasks](/blog/8-use-cases-for-generalist-software-development-agents).
But up to this point, strong coding agents have relied on proprietary models, which means that even if you use an open-source agent like [OpenHands](https://github.com/All-Hands-AI/OpenHands), you are still reliant on API calls to an external service.
Today, we are excited to introduce OpenHands LM, a new open coding model that:
- Is open and [available on Hugging Face](https://huggingface.co/all-hands/openhands-lm-32b-v0.1), so you can download it and run it locally
- Is a reasonable size, 32B, so it can be run locally on hardware such as a single 3090 GPU
- Achieves strong performance on software engineering tasks, including 37.2% resolve rate on SWE-Bench Verified
Read below for more details and our future plans!
## What is OpenHands LM?
OpenHands LM is built on the foundation of [Qwen Coder 2.5 Instruct 32B](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct), leveraging its powerful base capabilities for coding tasks. What sets OpenHands LM apart is our specialized fine-tuning process:
- We used training data generated by OpenHands itself on a diverse set of open-source repositories
- Specifically, we use an RL-based framework outlined in [SWE-Gym](https://arxiv.org/abs/2412.21139), where we set up a training environment, generate training data using an existing agent, and then fine-tune the model on examples that were resolved successfully
- It features a 128K token context window, ideal for handling large codebases and long-horizon software engineering tasks
## Performance: Punching Above Its Weight
We evaluated OpenHands LM using our latest [iterative evaluation protocol](https://github.com/All-Hands-AI/OpenHands/tree/main/evaluation/benchmarks/swe_bench#run-inference-rollout-on-swe-bench-instances-generate-patch-from-problem-statement) on the [SWE-Bench Verified benchmark](https://www.swebench.com/#verified).
The results are impressive:
- **37.2% verified resolve rate** on SWE-Bench Verified
- Performance comparable to models with **20x more parameters**, including Deepseek V3 0324 (38.8%) with 671B parameters
Here's how OpenHands LM compares to other leading open-source models:
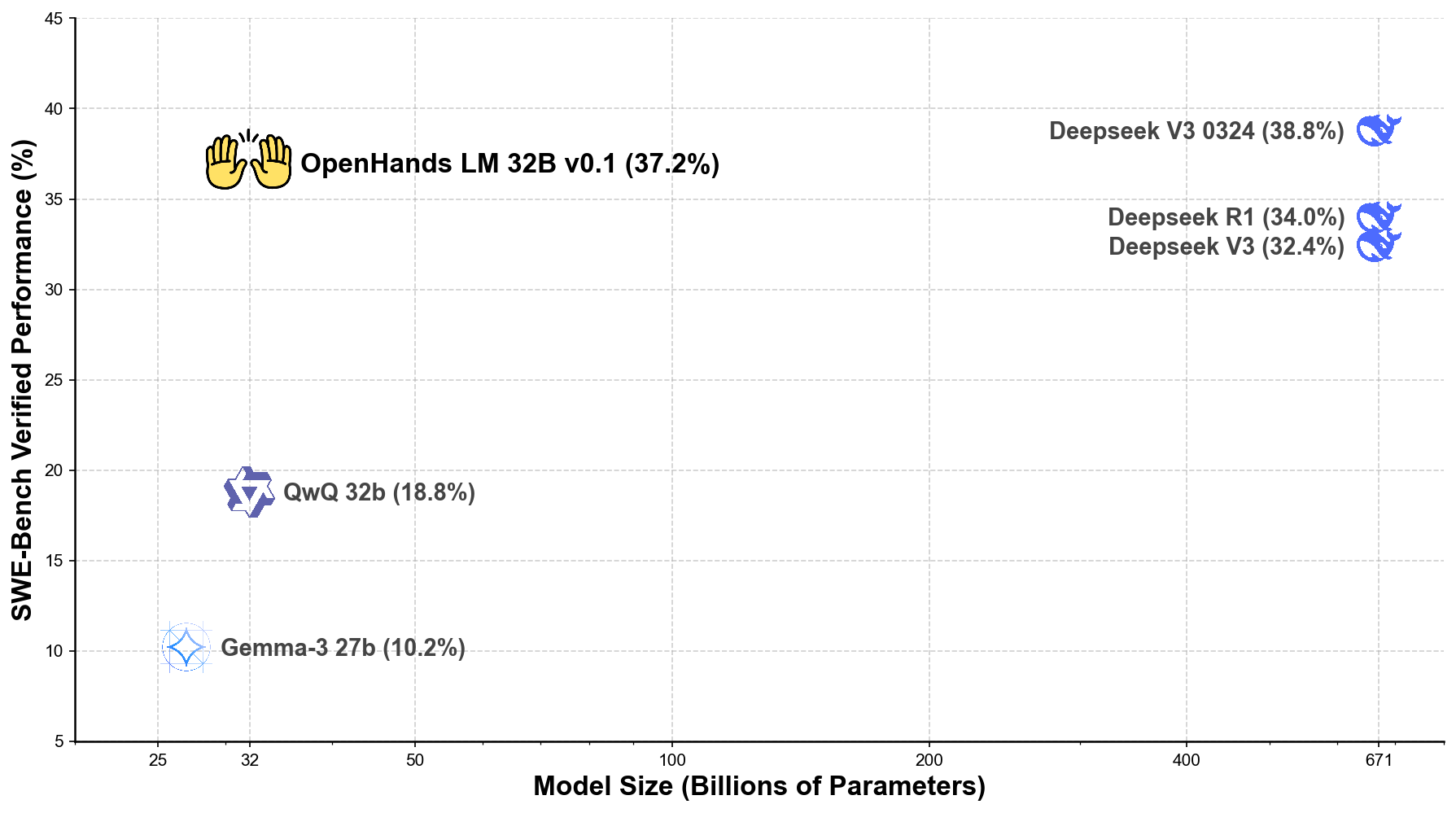
As the plot demonstrates, our 32B parameter model achieves efficiency that approaches much larger models. While the largest models (671B parameters) achieve slightly higher scores, our 32B parameter model performs remarkably well, opening up possibilities for local deployment that are not possible with larger models.
## Getting Started: How to Use OpenHands LM Today
You can start using OpenHands LM immediately through these channels:
1. **Download the model from Hugging Face**
The model is available on [Hugging Face](https://huggingface.co/all-hands/openhands-lm-32b-v0.1) and can be downloaded directly from there.
2. **Create an OpenAI-compatible endpoint with a model serving framework**
For optimal performance, it is recommended to serve this model with a GPU using [SGLang](https://github.com/sgl-project/sglang) or [vLLM](https://github.com/vllm-project/vllm).
3. **Point your OpenHands agent to the new model**
Download [OpenHands](https://github.com/All-Hands-AI/OpenHands) and follow the instructions for [using an OpenAI-compatible endpoint](https://docs.all-hands.dev/modules/usage/llms/openai-llms#using-openai-compatible-endpoints).
## The Road Ahead: Our Development Plans
This initial release marks just the beginning of our journey. We will continue enhancing OpenHands LM based on community feedback and ongoing research initiatives.
In particular, it should be noted that the model is still a research preview, and (1) may be best suited for tasks regarding solving github issues and perform less well on more varied software engineering tasks, (2) may sometimes generate repetitive steps, and (3) is somewhat sensitive to quantization, and may not function at full performance at lower quantization levels.
Our next releases will focus on addressing these limitations.
We're also developing more compact versions of the model (including a 7B parameter variant) to support users with limited computational resources. These smaller models will preserve OpenHands LM's core strengths while dramatically reducing hardware requirements.
We encourage you to experiment with OpenHands LM, share your experiences, and participate in its evolution. Together, we can create better tools for tomorrow's software development landscape.
## Try OpenHands Cloud
While OpenHands LM is a powerful model you can run locally, we also offer a fully managed cloud solution that makes it even easier to leverage AI for your software development needs.
[OpenHands Cloud](https://www.all-hands.dev/blog/introducing-the-openhands-cloud) provides:
- Seamless GitHub integration with issue and PR support
- Multiple interaction methods including text, voice, and mobile
- Parallel agent capabilities for working on multiple tasks simultaneously
- All the power of OpenHands without managing infrastructure
OpenHands Cloud is built on the same technology as our open-source solution but adds convenient features for teams and individuals who want a ready-to-use platform. [Visit app.all-hands.dev](https://app.all-hands.dev) to get started today!
## Join Our Community
We invite you to be part of the OpenHands LM journey:
- Explore our [GitHub repository](https://github.com/All-Hands-AI/OpenHands)
- Connect with us on [Slack](https://join.slack.com/t/openhands-ai/shared_invite/zt-2tom0er4l-JeNUGHt_AxpEfIBstbLPiw)
- Follow our [documentation](https://docs.all-hands.dev) to get started
By contributing your experiences and feedback, you'll help shape the future of this open-source initiative. Together, we can create better tools for tomorrow's software development landscape.
We can't wait to see what you'll create with OpenHands LM! |
Mungert/DistilQwen2.5-DS3-0324-14B-GGUF | Mungert | 2025-06-15T19:45:46Z | 579 | 2 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-04T13:00:13Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">DistilQwen2.5-DS3-0324-14B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DistilQwen2.5-DS3-0324-14B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DistilQwen2.5-DS3-0324-14B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DistilQwen2.5-DS3-0324-14B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DistilQwen2.5-DS3-0324-14B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DistilQwen2.5-DS3-0324-14B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DistilQwen2.5-DS3-0324-14B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DistilQwen2.5-DS3-0324-14B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DistilQwen2.5-DS3-0324-14B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DistilQwen2.5-DS3-0324-14B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DistilQwen2.5-DS3-0324-14B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DistilQwen2.5-DS3-0324-14B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
## 📖 Introduction
# DistilQwen2.5-DS3-0324 Series: Fast-Thinking Reasoning Models
## Overview
In response to the industry challenge of balancing efficient reasoning with cognitive capabilities, the DistilQwen2.5-DS3-0324 series innovatively transfers the fast-thinking capabilities of DeepSeekV3-0324 to lightweight models. Through a two-stage distillation framework, this series achieves high performance while delivering:
- **Enhanced Reasoning Speed**: Reduces output tokens by 60-80% (compared to slow-thinking models)
- **Reduced Resource Consumption**: Suitable for edge computing deployment
- **Elimination of Cognitive Bias**: Proprietary trajectory alignment technology
## Core Innovations
### 1. Fast-Thinking Distillation Framework
- **Stage 1: Fast-Thinking CoT Data Collection**
- **Long-to-Short Rewriting**: Extracts key reasoning steps from DeepSeek-R1
- **Teacher Model Distillation**: Captures the rapid reasoning trajectories of DeepSeekV3-0324
- **Stage 2: CoT Trajectory Cognitive Alignment**
- **Dynamic Difficulty Grading** (Easy/Medium/Hard)
- LLM-as-a-Judge evaluates small model comprehensibility
- Simple chain expansion → Adds necessary steps
- Hard chain simplification → Removes high-level logical leaps
- **Validation Mechanism**: Iterative optimization until all data reaches "Medium" rating
### 2. Performance Breakthroughs
- **32B Model** approaches the performance of closed-source models with 10x the parameters on the GPQA Diamond benchmark
- **Significant Improvement in Reasoning Efficiency** (see comparison table below)
| Model | MMLU_PRO Tokens | AIME2024 Tokens | Speed Gain |
|--------------------------------|-----------------|-----------------|------------|
| DistilQwen2.5-R1-32B (Slow-Thinking) | 4198 | 12178 | 1x |
| DistilQwen2.5-DS3-0324-32B | 690 | 4177 | 5-8x |
## Technical Advantages
- **Two-Stage Distillation**: First compresses reasoning length, then aligns cognitive trajectories
- **Dynamic Data Optimization**: Adaptive difficulty adjustment ensures knowledge transferability
- **Open-Source Compatibility**: Fine-tuned based on the Qwen2.5 base model
## 🚀 Quick Start
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"alibaba-pai/DistilQwen2.5-DS3-0324-14B",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("alibaba-pai/DistilQwen2.5-DS3-0324-14B")
prompt = "Give me a short introduction to large language model."
messages=[
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant. You should think step-by-step."},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2048,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
``` |
Mungert/Phi-4-reasoning-plus-GGUF | Mungert | 2025-06-15T19:45:27Z | 1,431 | 3 | transformers | [
"transformers",
"gguf",
"phi",
"nlp",
"math",
"code",
"chat",
"conversational",
"reasoning",
"text-generation",
"en",
"base_model:microsoft/phi-4",
"base_model:quantized:microsoft/phi-4",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix"
] | text-generation | 2025-05-02T02:18:59Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-4-reasoning-plus/resolve/main/LICENSE
language:
- en
base_model:
- microsoft/phi-4
pipeline_tag: text-generation
tags:
- phi
- nlp
- math
- code
- chat
- conversational
- reasoning
inference:
parameters:
temperature: 0
widget:
- messages:
- role: user
content: What is the derivative of x^2?
library_name: transformers
---
# <span style="color: #7FFF7F;">Phi-4-reasoning-plus GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Phi-4-reasoning-plus-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Phi-4-reasoning-plus-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Phi-4-reasoning-plus-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Phi-4-reasoning-plus-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Phi-4-reasoning-plus-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Phi-4-reasoning-plus-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Phi-4-reasoning-plus-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Phi-4-reasoning-plus-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Phi-4-reasoning-plus-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Phi-4-reasoning-plus-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Phi-4-reasoning-plus-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Phi-4-reasoning-plus Model Card
[Phi-4-reasoning Technical Report](https://aka.ms/phi-reasoning/techreport)
## Model Summary
| | |
|-------------------------|-------------------------------------------------------------------------------|
| **Developers** | Microsoft Research |
| **Description** | Phi-4-reasoning-plus is a state-of-the-art open-weight reasoning model finetuned from Phi-4 using supervised fine-tuning on a dataset of chain-of-thought traces and reinforcement learning. The supervised fine-tuning dataset includes a blend of synthetic prompts and high-quality filtered data from public domain websites, focused on math, science, and coding skills as well as alignment data for safety and Responsible AI. The goal of this approach was to ensure that small capable models were trained with data focused on high quality and advanced reasoning. Phi-4-reasoning-plus has been trained additionally with Reinforcement Learning, hence, it has higher accuracy but generates on average 50% more tokens, thus having higher latency. |
| **Architecture** | Base model same as previously released Phi-4, 14B parameters, dense decoder-only Transformer model |
| **Inputs** | Text, best suited for prompts in the chat format |
| **Context length** | 32k tokens |
| **GPUs** | 32 H100-80G |
| **Training time** | 2.5 days |
| **Training data** | 16B tokens, ~8.3B unique tokens |
| **Outputs** | Generated text in response to the input. Model responses have two sections, namely, a reasoning chain-of-thought block followed by a summarization block |
| **Dates** | January 2025 – April 2025 |
| **Status** | Static model trained on an offline dataset with cutoff dates of March 2025 and earlier for publicly available data |
| **Release date** | April 30, 2025 |
| **License** | MIT |
## Intended Use
| | |
|-------------------------------|-------------------------------------------------------------------------|
| **Primary Use Cases** | Our model is designed to accelerate research on language models, for use as a building block for generative AI powered features. It provides uses for general purpose AI systems and applications (primarily in English) which require:<br><br>1. Memory/compute constrained environments.<br>2. Latency bound scenarios.<br>3. Reasoning and logic. |
| **Out-of-Scope Use Cases** | This model is designed and tested for math reasoning only. Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fairness before using within a specific downstream use case, particularly for high-risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case, including the model’s focus on English. Review the Responsible AI Considerations section below for further guidance when choosing a use case. Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under. |
## Data Overview
### Training Datasets
Our training data is a mixture of Q&A, chat format data in math, science, and coding. The chat prompts are sourced from filtered high-quality web data and optionally rewritten and processed through a synthetic data generation pipeline. We further include data to improve truthfulness and safety.
### Benchmark Datasets
We evaluated Phi-4-reasoning-plus using the open-source [Eureka](https://github.com/microsoft/eureka-ml-insights) evaluation suite and our own internal benchmarks to understand the model's capabilities. More specifically, we evaluate our model on:
Reasoning tasks:
* **AIME 2025, 2024, 2023, and 2022:** Math olympiad questions.
* **GPQA-Diamond:** Complex, graduate-level science questions.
* **OmniMath:** Collection of over 4000 olympiad-level math problems with human annotation.
* **LiveCodeBench:** Code generation benchmark gathered from competitive coding contests.
* **3SAT (3-literal Satisfiability Problem) and TSP (Traveling Salesman Problem):** Algorithmic problem solving.
* **BA Calendar:** Planning.
* **Maze and SpatialMap:** Spatial understanding.
General-purpose benchmarks:
* **Kitab:** Information retrieval.
* **IFEval and ArenaHard:** Instruction following.
* **PhiBench:** Internal benchmark.
* **FlenQA:** Impact of prompt length on model performance.
* **HumanEvalPlus:** Functional code generation.
* **MMLU-Pro:** Popular aggregated dataset for multitask language understanding.
## Safety
### Approach
Phi-4-reasoning-plus has adopted a robust safety post-training approach via supervised fine-tuning (SFT). This approach leverages a variety of both open-source and in-house generated synthetic prompts, with LLM-generated responses that adhere to rigorous Microsoft safety guidelines, e.g., User Understanding and Clarity, Security and Ethical Guidelines, Limitations, Disclaimers and Knowledge Scope, Handling Complex and Sensitive Topics, Safety and Respectful Engagement, Confidentiality of Guidelines and Confidentiality of Chain-of-Thoughts.
### Safety Evaluation and Red-Teaming
Prior to release, Phi-4-reasoning-plus followed a multi-faceted evaluation approach. Quantitative evaluation was conducted with multiple open-source safety benchmarks and in-house tools utilizing adversarial conversation simulation. For qualitative safety evaluation, we collaborated with the independent AI Red Team (AIRT) at Microsoft to assess safety risks posed by Phi-4-reasoning-plus in both average and adversarial user scenarios. In the average user scenario, AIRT emulated typical single-turn and multi-turn interactions to identify potentially risky behaviors. The adversarial user scenario tested a wide range of techniques aimed at intentionally subverting the model's safety training including grounded-ness, jailbreaks, harmful content like hate and unfairness, violence, sexual content, or self-harm, and copyright violations for protected material. We further evaluate models on Toxigen, a benchmark designed to measure bias and toxicity targeted towards minority groups.
Please refer to the technical report for more details on safety alignment.
## Model Quality
At the high-level overview of the model quality on representative benchmarks. For the tables below, higher numbers indicate better performance:
| | AIME 24 | AIME 25 | OmniMath | GPQA-D | LiveCodeBench (8/1/24–2/1/25) |
|-----------------------------|-------------|-------------|-------------|------------|-------------------------------|
| Phi-4-reasoning | 75.3 | 62.9 | 76.6 | 65.8 | 53.8 |
| Phi-4-reasoning-plus | 81.3 | 78.0 | 81.9 | 68.9 | 53.1 |
| OpenThinker2-32B | 58.0 | 58.0 | — | 64.1 | — |
| QwQ 32B | 79.5 | 65.8 | — | 59.5 | 63.4 |
| EXAONE-Deep-32B | 72.1 | 65.8 | — | 66.1 | 59.5 |
| DeepSeek-R1-Distill-70B | 69.3 | 51.5 | 63.4 | 66.2 | 57.5 |
| DeepSeek-R1 | 78.7 | 70.4 | 85.0 | 73.0 | 62.8 |
| o1-mini | 63.6 | 54.8 | — | 60.0 | 53.8 |
| o1 | 74.6 | 75.3 | 67.5 | 76.7 | 71.0 |
| o3-mini | 88.0 | 78.0 | 74.6 | 77.7 | 69.5 |
| Claude-3.7-Sonnet | 55.3 | 58.7 | 54.6 | 76.8 | — |
| Gemini-2.5-Pro | 92.0 | 86.7 | 61.1 | 84.0 | 69.2 |
| | Phi-4 | Phi-4-reasoning | Phi-4-reasoning-plus | o3-mini | GPT-4o |
|----------------------------------------|-------|------------------|-------------------|---------|--------|
| FlenQA [3K-token subset] | 82.0 | 97.7 | 97.9 | 96.8 | 90.8 |
| IFEval Strict | 62.3 | 83.4 | 84.9 | 91.5 | 81.8 |
| ArenaHard | 68.1 | 73.3 | 79.0 | 81.9 | 75.6 |
| HumanEvalPlus | 83.5 | 92.9 | 92.3 | 94.0| 88.0 |
| MMLUPro | 71.5 | 74.3 | 76.0 | 79.4 | 73.0 |
| Kitab<br><small>No Context - Precision<br>With Context - Precision<br>No Context - Recall<br>With Context - Recall</small> | <br>19.3<br>88.5<br>8.2<br>68.1 | <br>23.2<br>91.5<br>4.9<br>74.8 | <br>27.6<br>93.6<br>6.3<br>75.4 | <br>37.9<br>94.0<br>4.2<br>76.1 | <br>53.7<br>84.7<br>20.3<br>69.2 |
| Toxigen Discriminative<br><small>Toxic category<br>Neutral category</small> | <br>72.6<br>90.0 | <br>86.7<br>84.7 | <br>77.3<br>90.5 | <br>85.4<br>88.7 | <br>87.6<br>85.1 |
| PhiBench 2.21 | 58.2 | 70.6 | 74.2 | 78.0| 72.4 |
Overall, Phi-4-reasoning and Phi-4-reasoning-plus, with only 14B parameters, performs well across a wide range of reasoning tasks, outperforming significantly larger open-weight models such as DeepSeek-R1 distilled 70B model and approaching the performance levels of full DeepSeek R1 model. We also test the models on multiple new reasoning benchmarks for algorithmic problem solving and planning, including 3SAT, TSP, and BA-Calendar. These new tasks are nominally out-of-domain for the models as the training process did not intentionally target these skills, but the models still show strong generalization to these tasks. Furthermore, when evaluating performance against standard general abilities benchmarks such as instruction following or non-reasoning tasks, we find that our new models improve significantly from Phi-4, despite the post-training being focused on reasoning skills in specific domains.
## Usage
### Inference Parameters
Inference is better with `temperature=0.8`, `top_p=0.95`, and `do_sample=True`. For more complex queries, set the maximum number of tokens to 32k to allow for longer chain-of-thought (CoT).
*Phi-4-reasoning-plus has shown strong performance on reasoning-intensive tasks. In our experiments, we extended its maximum number of tokens to 64k, and it handled longer sequences with promising results, maintaining coherence and logical consistency over extended inputs. This makes it a compelling option to explore for tasks that require deep, multi-step reasoning or extensive context.*
### Input Formats
Given the nature of the training data, always use ChatML template with the following system prompt for inference:
```bash
<|im_start|>system<|im_sep|>
Your role as an assistant involves thoroughly exploring questions through a systematic thinking process before providing the final precise and accurate solutions. This requires engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, backtracing, and iteration to develop well-considered thinking process. Please structure your response into two main sections: Thought and Solution using the specified format: <think> {Thought section} <\think> {Solution section}. In the Thought section, detail your reasoning process in steps. Each step should include detailed considerations such as analysing questions, summarizing relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining any errors, and revisiting previous steps. In the Solution section, based on various attempts, explorations, and reflections from the Thought section, systematically present the final solution that you deem correct. The Solution section should be logical, accurate, and concise and detail necessary steps needed to reach the conclusion. Now, try to solve the following question through the above guidelines:<|im_end|>
<|im_start|>user<|im_sep|>
What is the derivative of x^2?<|im_end|>
<|im_start|>assistant<|im_sep|>
```
### With `transformers`
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-4-reasoning-plus")
model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-4-reasoning-plus", device_map="auto", torch_dtype="auto")
messages = [
{"role": "system", "content": "You are Phi, a language model trained by Microsoft to help users. Your role as an assistant involves thoroughly exploring questions through a systematic thinking process before providing the final precise and accurate solutions. This requires engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, backtracing, and iteration to develop well-considered thinking process. Please structure your response into two main sections: Thought and Solution using the specified format: <think> {Thought section} </think> {Solution section}. In the Thought section, detail your reasoning process in steps. Each step should include detailed considerations such as analysing questions, summarizing relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining any errors, and revisiting previous steps. In the Solution section, based on various attempts, explorations, and reflections from the Thought section, systematically present the final solution that you deem correct. The Solution section should be logical, accurate, and concise and detail necessary steps needed to reach the conclusion. Now, try to solve the following question through the above guidelines:"},
{"role": "user", "content": "What is the derivative of x^2?"},
]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(
inputs.to(model.device),
max_new_tokens=4096,
temperature=0.8,
top_p=0.95,
do_sample=True,
)
print(tokenizer.decode(outputs[0]))
```
### With `vllm`
```bash
vllm serve microsoft/Phi-4-reasoning-plus --enable-reasoning --reasoning-parser deepseek_r1
```
*Phi-4-reasoning-plus is also supported out-of-the-box by Ollama, llama.cpp, and any Phi-4 compatible framework.*
## Responsible AI Considerations
Like other language models, Phi-4-reasoning-plus can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
* **Quality of Service:** The model is trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English. Phi-4-reasoning-plus is not intended to support multilingual use.
* **Representation of Harms & Perpetuation of Stereotypes:** These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
* **Inappropriate or Offensive Content:** These models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
* **Information Reliability:** Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
* **Election Information Reliability:** The model has an elevated defect rate when responding to election-critical queries, which may result in incorrect or unauthoritative election critical information being presented. We are working to improve the model's performance in this area. Users should verify information related to elections with the election authority in their region.
* **Limited Scope for Code:** Majority of Phi-4-reasoning-plus training data is based in Python and uses common packages such as `typing`, `math`, `random`, `collections`, `datetime`, `itertools`. If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Using safety services like [Azure AI Content Safety](https://azure.microsoft.com/en-us/products/ai-services/ai-content-safety) that have advanced guardrails is highly recommended. Important areas for consideration include:
* **Allocation:** Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
* **High-Risk Scenarios:** Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
* **Misinformation:** Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
* **Generation of Harmful Content:** Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
* **Misuse:** Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations. |
Mungert/Foundation-Sec-8B-GGUF | Mungert | 2025-06-15T19:45:23Z | 2,122 | 4 | transformers | [
"transformers",
"gguf",
"security",
"text-generation",
"en",
"arxiv:2504.21039",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:quantized:meta-llama/Llama-3.1-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | text-generation | 2025-05-01T17:36:08Z | ---
license: apache-2.0
language:
- en
base_model:
- meta-llama/Llama-3.1-8B
pipeline_tag: text-generation
library_name: transformers
tags:
- security
---
# <span style="color: #7FFF7F;">Foundation-Sec-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Foundation-Sec-8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Foundation-Sec-8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Foundation-Sec-8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Foundation-Sec-8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Foundation-Sec-8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Foundation-Sec-8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Foundation-Sec-8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Foundation-Sec-8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Foundation-Sec-8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Foundation-Sec-8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Foundation-Sec-8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Foundation-Sec-8B - Model Card
## Model Information
Foundation-Sec-8B (Llama-3.1-FoundationAI-SecurityLLM-base-8B) is an open-weight, 8-billion parameter base language model specialized for cybersecurity applications. It extends Llama-3.1-8B model through continued pretraining on a curated corpus of cybersecurity-specific text, including threat intelligence reports, vulnerability databases, incident response documentation, and security standards. It has been trained to understand security concepts, terminology, and practices across multiple security domains. The model is designed to serve as a domain-adapted base model for use in applications such as threat detection, vulnerability assessment, security automation, and attack simulation. Foundation-Sec-8B enables organizations to build AI-driven security tools that can be deployed locally, reducing dependency on cloud-based AI services while maintaining high performance on security-related tasks.
- **Model Name:** Foundation-Sec-8B (Llama-3.1-FoundationAI-SecurityLLM-base-8B)
- **Model Developer:** Amin Karbasi and team at Foundation AI — Cisco
- **Technical Report:** [`https://arxiv.org/abs/2504.21039`](https://arxiv.org/abs/2504.21039)
- **Model Card Contact:** For questions about the team, model usage, and future directions, contact [`[email protected]`](mailto:[email protected]). For technical questions about the model, please contact [`[email protected]`](mailto:[email protected]).
- **Model Release Date:** April 28, 2025
- **Supported Language(s):** English
- **Model Architecture:** Auto-regressive language model that uses an optimized transformer architecture (Meta Llama-3.1-8B backbone)
- **Training Objective:** Continued pre-training on cybersecurity-specific corpus
- **Training Data Status:** This is a static model trained on an offline dataset. Future versions of the tuned models will be released on updated data.
- **License:** Apache 2.0
## Intended Use
### Intended Use Cases
Foundation-Sec-8B is designed for security practitioners, researchers, and developers building AI-powered security workflows and applications. Foundation-Sec-8B is optimized for three core use case categories:
- **SOC Acceleration**: Automating triage, summarization, case note generation, and evidence collection.
- **Proactive Threat Defense**: Simulating attacks, prioritizing vulnerabilities, mapping TTPs, and modeling attacker behavior.
- **Engineering Enablement**: Providing security assistance, validating configurations, assessing compliance evidence, and improving security posture.
The model is intended for local deployment in environments prioritizing data security, regulatory compliance, and operational control.
### Downstream Use
Foundation-Sec-8B can be used directly for security-related language tasks and serves as a strong starting point for fine-tuning across a variety of cybersecurity workflows. Example downstream applications include:
- Summarization
- Summarizing detection playbooks and incident reports
- Consolidating fragmented analyst notes into structured case summaries
- Classification
- Mapping threats to MITRE ATT&CK techniques
- Prioritizing vulnerabilities based on contextual risk
- Classifying security-relevant emails and leaked file contents
- Named Entity Recognition
- Extracting compliance evidence from documents
- Building network behavior profiles from technical manuals
- Question & Answer
- Assisting SOC analysts with alert triage and investigation
- Responding to cloud security and software compliance queries
- Reasoning and Text Generation
- Generating red-team attack plans and threat models
- Predicting attacker next steps in active investigations
- Enriching vulnerability scan results with contextual insights
For questions or assistance with fine-tuning Foundation-Sec-8B, please contact **Paul Kassianik** ([email protected]) or **Dhruv Kedia** ([email protected]).
### Out-of-Scope Use
The following uses are out-of-scope and are neither recommended nor intended use cases:
1. **Generating harmful content** - The model should not be used to:
- Generate malware or other malicious code
- Create phishing content or social engineering scripts
- Develop attack plans targeting specific organizations
- Design exploitation techniques for vulnerabilities without legitimate security research purposes
2. **Critical security decisions without human oversight** - The model should not be used for:
- Autonomous security decision-making without human review
- Critical infrastructure protection without expert supervision
- Final determination of security compliance without human verification
- Autonomous vulnerability remediation without testing
3. **Legal or medical advice** - The model is not qualified to provide:
- Legal advice regarding security regulations, compliance requirements, or intellectual property disputes
- Legal advice regarding security issues that would reference legal statutes, precedents, or case law necessary to provide legal advice
- Medical advice regarding health impacts of security incidents
4. **Non-security use cases** - The model is specifically optimized for cybersecurity and may not perform as well on general tasks as models trained for broader applications.
5. **Violation of Laws or Regulations** - Any use that violates applicable laws or regulations.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
# Import the required libraries
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("fdtn-ai/Foundation-Sec-8B")
model = AutoModelForCausalLM.from_pretrained("fdtn-ai/Foundation-Sec-8B")
# Example: Matching CWE to CVE IDs
prompt="""CVE-2021-44228 is a remote code execution flaw in Apache Log4j2 via unsafe JNDI lookups (“Log4Shell”). The CWE is CWE-502.
CVE-2017-0144 is a remote code execution vulnerability in Microsoft’s SMBv1 server (“EternalBlue”) due to a buffer overflow. The CWE is CWE-119.
CVE-2014-0160 is an information-disclosure bug in OpenSSL’s heartbeat extension (“Heartbleed”) causing out-of-bounds reads. The CWE is CWE-125.
CVE-2017-5638 is a remote code execution issue in Apache Struts 2’s Jakarta Multipart parser stemming from improper input validation of the Content-Type header. The CWE is CWE-20.
CVE-2019-0708 is a remote code execution vulnerability in Microsoft’s Remote Desktop Services (“BlueKeep”) triggered by a use-after-free. The CWE is CWE-416.
CVE-2015-10011 is a vulnerability about OpenDNS OpenResolve improper log output neutralization. The CWE is"""
# Tokenize the input
inputs = tokenizer(prompt, return_tensors="pt")
# Generate the response
outputs = model.generate(
inputs["input_ids"],
max_new_tokens=3,
do_sample=True,
temperature=0.1,
top_p=0.9,
)
# Decode and print the response
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
response = response.replace(prompt, "").strip()
print(response)
```
## Training and Evaluation
### Training Data
Foundation-sec-8B was pretrained on approximately **5.1 billion tokens** of cybersecurity-specific data curated in-house by Cisco’s Foundation AI team. The dataset was meticulously collected from public sources on the web.
The pre-training corpus was built through a multi-stage pipeline that included large-scale web crawling, relevancy filtering, deduplication, and quality filtering.
**Data cutoff:** April 10th, 2025.
More detailed methodology is available in the technical report.
### Training Setup
Foundation-sec-8B is based on the **Llama 3.1 8B** architecture. Pre-training was performed on Cisco Foundation AI’s internal compute cluster.
Key training details:
- **Continued pretraining** for cybersecurity specialization
- **4096-token** sequence length
- **Optimizer:** AdamW
More detailed methodology is available in the technical report.
### Evaluation
Foundation-sec-8B was benchmarked on cybersecurity and general reasoning tasks, using a standardized 5-shot prompting setup (temperature = 0.3).
| **Benchmark** | **Foundation-sec-8B** | **Llama 3.1 8B** | **Llama 3.1 70B** |
| --- | --- | --- | --- |
| CTI-MCQA | 67.39 | 64.14 | 68.23 |
| CTI-RCM | 75.26 | 66.43 | 72.66 |
**Benchmark Overview:**
- **CTI-MCQA:** 2,500 multiple-choice questions testing cybersecurity knowledge across frameworks like MITRE ATT&CK, NIST, GDPR, and threat intelligence best practices.
- **CTI-RCM:** 900+ vulnerability root cause mapping examples linking CVEs to CWE categories, assessing deep understanding of security weaknesses.
**Key highlights:**
- **+3 to +9 point gains** over Llama-3.1-8B across security-specific benchmarks.
- **Comparable or better** performance than Llama-3.1-70B on cyber threat intelligence tasks.
- **Minimal drop (~2%)** in general language reasoning (MMLU) despite cybersecurity specialization.
For full benchmark details and evaluation methodology, please refer to the technical report.
## Limitations
Foundation-Sec-8B has several limitations that users should be aware of:
1. **Domain-specific knowledge limitations**:
- Foundation-Sec-8B may not be familiar with recent vulnerabilities, exploits, or novel attack vectors or security technologies released after its training cutoff date
- Knowledge of specialized or proprietary security systems or tools may be limited
2. **Potential biases**:
- The model may reflect biases present in security literature and documentation
- The model may be trained on known attack patterns and have difficulty recognizing novel attack vectors
- Security practices and recommendations may be biased toward certain technological ecosystems
- Geographic and cultural biases in security approaches may be present
3. **Security risks**:
- The model cannot verify the identity or intentions of users
- Adversarial prompting techniques might potentially bypass safety mechanisms
- The model may unintentionally provide information that could be misused if proper prompting guardrails are not implemented
4. **Contextual blindness:**
- The model may struggle to understand the complex interrelationships between systems, users, and data in order to provide accurate context.
5. **Technical limitations**:
- Performance varies based on how security concepts are described in prompts
- May not fully understand complex, multi-step security scenarios without clear explanation
- Cannot access external systems or actively scan environments
- Cannot independently verify factual accuracy of its outputs
6. **Ethical considerations**:
- Dual-use nature of security knowledge requires careful consideration of appropriate use cases
### Recommendations
To address the limitations of Foundation-Sec-8B, we recommend:
1. **Human oversight**:
- Always have qualified security professionals review model outputs before implementation
- Use the model as an assistive tool rather than a replacement for expert human judgment
- Implement a human-in-the-loop approach for security-critical applications
2. **System design safeguards**:
- Implement additional validation layers for applications built with this model
- Consider architectural constraints that limit the model's ability to perform potentially harmful actions (excessive agency)
- Deploy the model in environments with appropriate access controls
3. **Prompt engineering**:
- Use carefully designed prompts that encourage ethical security practices
- Include explicit instructions regarding responsible disclosure and ethical hacking principles
- Structure interactions to minimize the risk of inadvertently harmful outputs
4. **Knowledge supplementation**:
- Supplement the model with up-to-date security feeds and databases
- Implement retrieval-augmented generation for current threat intelligence sources
5. **Usage policies**:
- Develop and enforce clear acceptable use policies for applications using this model
- Implement monitoring and auditing for high-risk applications
- Create documentation for end users about the model's limitations |
Mungert/Qwen3-8B-GGUF | Mungert | 2025-06-15T19:45:06Z | 478 | 7 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2309.00071",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:quantized:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-30T06:20:32Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-8B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-8B-Base
---
# <span style="color: #7FFF7F;">Qwen3-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen3-8B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-8B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 8.2B
- Number of Paramaters (Non-Embedding): 6.95B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-8B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-8B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-8B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-8B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-8B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
``` |
Mungert/Qwen3-1.7B-abliterated-GGUF | Mungert | 2025-06-15T19:45:02Z | 2,888 | 10 | transformers | [
"transformers",
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-30T01:49:28Z | ---
library_name: transformers
tags: []
---
# <span style="color: #7FFF7F;">Qwen3-1.7B-abliterated GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-1.7B-abliterated-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-1.7B-abliterated-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-1.7B-abliterated-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-1.7B-abliterated-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-1.7B-abliterated-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-1.7B-abliterated-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-1.7B-abliterated-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-1.7B-abliterated-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-1.7B-abliterated-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-1.7B-abliterated-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-1.7B-abliterated-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mungert/Qwen3-0.6B-GGUF | Mungert | 2025-06-15T19:44:59Z | 438 | 7 | transformers | [
"transformers",
"gguf",
"text-generation",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:quantized:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-30T00:27:30Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-0.6B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-0.6B-Base
---
# <span style="color: #7FFF7F;">Qwen3-0.6B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`e291450`](https://github.com/ggerganov/llama.cpp/commit/e291450b7602d7a36239e4ceeece37625f838373).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-0.6B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-0.6B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-0.6B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-0.6B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-0.6B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-0.6B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-0.6B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-0.6B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-0.6B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-0.6B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-0.6B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen3-0.6B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-0.6B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 0.6B
- Number of Paramaters (Non-Embedding): 0.44B
- Number of Layers: 28
- Number of Attention Heads (GQA): 16 for Q and 8 for KV
- Context Length: 32,768
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
> [!TIP]
> If you encounter significant endless repetitions, please refer to the [Best Practices](#best-practices) section for optimal sampling parameters, and set the ``presence_penalty`` to 1.5.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-0.6B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-0.6B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-0.6B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-0.6B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
``` |
Mungert/mOrpheus_3B-1Base_early_preview-GGUF | Mungert | 2025-06-15T19:44:45Z | 244 | 0 | null | [
"gguf",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-26T20:33:38Z | ---
license: cc-by-nc-4.0
---
# <span style="color: #7FFF7F;">mOrpheus_3B-1Base_early_preview GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`e291450`](https://github.com/ggerganov/llama.cpp/commit/e291450b7602d7a36239e4ceeece37625f838373).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `mOrpheus_3B-1Base_early_preview-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `mOrpheus_3B-1Base_early_preview-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `mOrpheus_3B-1Base_early_preview-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `mOrpheus_3B-1Base_early_preview-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `mOrpheus_3B-1Base_early_preview-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `mOrpheus_3B-1Base_early_preview-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `mOrpheus_3B-1Base_early_preview-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `mOrpheus_3B-1Base_early_preview-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `mOrpheus_3B-1Base_early_preview-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `mOrpheus_3B-1Base_early_preview-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `mOrpheus_3B-1Base_early_preview-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# mOrpheus_3B-1Base_early_preview (NSFW TTS)
A finetuned Orpheus text‑to‑speech model trained on adult data for more expressive sounds:
`<laugh>, <chuckle>, <sigh>, <cough>, <sniffle>, <groan>, <yawn>, <gasp>`
New in this model: `<moans>, <panting>, <grunting>, <gagging sounds>, <chokeing>, <kissing noises>`
**Speaker name:** `baddy`
**Framework:** Safetensors (LLaMA)
**Status:** Early preview; training still underway
---
## 🔗 Links
- Model files & versions: [xet](<your-file-hosting-link>)
- Discussion & bug reports: [Discord server](https://discord.gg/RUs3uzBdW3)
- Original author: [MrDragonFox](https://huggingface.co/MrDragonFox)
---
## 🚀 Usage (Example)
1. Load the `*.GGUF` file into LMStudio.
2. ```bash
pip install RealtimeTTS[orpheus]
```
3. Play TTS:
```python
from RealtimeTTS import TextToAudioStream, OrpheusEngine
engine = OrpheusEngine(model="morpheus_3b-1base")
# or: engine = OrpheusEngine(model="orpheus_3b-1basegguf@q4_k_m")
stream = TextToAudioStream(engine)
engine.set_voice("baddy")
stream.feed("Mmm <moans>... that feels so good <groan>")
stream.play()
```
---
## ⚖️ License
This model is released under **Creative Commons Attribution‑NonCommercial 4.0 International** (CC‑BY‑NC‑4.0). That means:
- **NonCommercial**: You can use, convert, and share this model for **non‑commercial** purposes only.
- **Attribution**: You must credit **MrDragonFox**, include the license link, and note any changes you made.
- **No extra restrictions**: Don’t apply paywalls, DRM, or additional terms.
```markdown
© 2025 MrDragonFox
Licensed under [CC‑BY‑NC‑4.0](https://creativecommons.org/licenses/by-nc/4.0/)
```
---
## ⚠️ Disclaimer
- **No warranties**—use at your own risk.
- Still under development; results may vary.
- Please report bugs or suggestions on Discord.
|
Mungert/granite-3.3-8b-instruct-GGUF | Mungert | 2025-06-15T19:44:26Z | 938 | 4 | transformers | [
"transformers",
"gguf",
"language",
"granite-3.3",
"text-generation",
"arxiv:0000.00000",
"base_model:ibm-granite/granite-3.3-8b-base",
"base_model:quantized:ibm-granite/granite-3.3-8b-base",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-17T17:50:12Z | ---
pipeline_tag: text-generation
inference: false
license: apache-2.0
library_name: transformers
tags:
- language
- granite-3.3
base_model:
- ibm-granite/granite-3.3-8b-base
---
# <span style="color: #7FFF7F;">granite-3.3-8b-instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `granite-3.3-8b-instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `granite-3.3-8b-instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `granite-3.3-8b-instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `granite-3.3-8b-instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `granite-3.3-8b-instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `granite-3.3-8b-instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `granite-3.3-8b-instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `granite-3.3-8b-instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `granite-3.3-8b-instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `granite-3.3-8b-instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `granite-3.3-8b-instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Granite-3.3-8B-Instruct
**Model Summary:**
Granite-3.3-8B-Instruct is a 8-billion parameter 128K context length language model fine-tuned for improved reasoning and instruction-following capabilities. Built on top of Granite-3.3-8B-Base, the model delivers significant gains on benchmarks for measuring generic performance including AlpacaEval-2.0 and Arena-Hard, and improvements in mathematics, coding, and instruction following. It supprts structured reasoning through \<think\>\<\/think\> and \<response\>\<\/response\> tags, providing clear separation between internal thoughts and final outputs. The model has been trained on a carefully balanced combination of permissively licensed data and curated synthetic tasks.
- **Developers:** Granite Team, IBM
- **Website**: [Granite Docs](https://www.ibm.com/granite/docs/)
- **Release Date**: April 16th, 2025
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese. However, users may finetune this Granite model for languages beyond these 12 languages.
**Intended Use:**
This model is designed to handle general instruction-following tasks and can be integrated into AI assistants across various domains, including business applications.
**Capabilities**
* Thinking
* Summarization
* Text classification
* Text extraction
* Question-answering
* Retrieval Augmented Generation (RAG)
* Code related tasks
* Function-calling tasks
* Multilingual dialog use cases
* Fill-in-the-middle
* Long-context tasks including long document/meeting summarization, long document QA, etc.
**Generation:**
This is a simple example of how to use Granite-3.3-8B-Instruct model.
Install the following libraries:
```shell
pip install torch torchvision torchaudio
pip install accelerate
pip install transformers
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
model_path="ibm-granite/granite-3.3-8b-instruct"
device="cuda"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map=device,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
model_path
)
conv = [{"role": "user", "content":"Redesign a common household item to make it more sustainable and user-friendly. Explain the changes and their benefits."}]
input_ids = tokenizer.apply_chat_template(conv, return_tensors="pt", thinking=True, return_dict=True, add_generation_prompt=True).to(device)
set_seed(42)
output = model.generate(
**input_ids,
max_new_tokens=8192,
)
prediction = tokenizer.decode(output[0, input_ids["input_ids"].shape[1]:], skip_special_tokens=True)
print(prediction)
```
**Example Outputs**
- thinking=True
```md
<think>To address this prompt, I'll focus on redesigning a common household item: the plastic water bottle. The goal is to make it more sustainable and user-friendly. Here are the proposed changes and their benefits:
1. **Material**: Replace plastic with biodegradable or recyclable materials like glass or plant-based plastics (PLA).
2. **Design**: Introduce a modular design for easy refilling and cleaning.
3. **Functionality**: Incorporate a built-in water filter for purification.
4. **Durability**: Enhance the bottle's lifespan through robust construction.
5. **User-friendliness**: Simplify the cap mechanism for easy opening and closing.
These changes would significantly reduce plastic waste, promote recycling, ensure access to clean drinking water, and enhance the overall user experience.
Now, I will detail each change and its benefits in a structured format.</think>
<response>### Redesign of the Plastic Water Bottle for Sustainability and User-Friendliness
#### 1. Material: Biodegradable or Recyclable Alternatives
**Change**: Transition from traditional PET plastic to glass or plant-based plastics (Polylactic Acid - PLA).
**Benefits**:
- **Sustainability**: Glass and PLA are biodegradable or highly recyclable, drastically reducing plastic pollution.
- **Health**: Unlike PET, these materials do not leach chemicals into the water, ensuring safer consumption.
#### 2. Modular Design for Easy Refilling and Cleaning
**Change**: Implement a detachable, interchangeable inner liner within a reusable outer casing.
**Benefits**:
- **User-Friendliness**: Users can easily remove the inner liner for thorough cleaning, reducing the risk of bacterial growth.
- **Sustainability**: The outer casing remains intact, encouraging reuse, while the inner liner can be replaced or recycled when worn out.
#### 3. Built-in Water Filter
**Change**: Integrate a removable, replaceable water filter into the bottle cap.
**Benefits**:
- **Accessibility**: Provides clean drinking water directly from any source (tap, river, etc.), eliminating the need for additional filtration devices.
- **Health**: Removes contaminants, bacteria, and impurities, ensuring safe hydration.
- **Sustainability**: Reduces the use of single-use plastic water bottles by offering a purification solution within a reusable container.
#### 4. Enhanced Durability
**Change**: Use high-quality, durable materials and robust construction techniques for both the outer casing and inner liner.
**Benefits**:
- **Longevity**: A more robust design increases the bottle's lifespan, reducing the frequency of replacements.
- **Cost-effectiveness**: Although the initial cost might be higher, the long-term savings from reduced replacements make it economical.
- **Sustainability**: Less frequent disposal means lower environmental impact.
#### 5. Simplified Cap Mechanism
**Change**: Adopt a one-touch, easy-to-open and close cap design, possibly inspired by sports bottle caps.
**Benefits**:
- **User-Friendliness**: Especially beneficial for children, elderly, or those with limited hand dexterity.
- **Convenience**: Quick access to water encourages more frequent hydration, promoting healthier habits.
### Conclusion
This redesigned water bottle addresses key sustainability concerns by minimizing plastic use and waste, while also enhancing user-friendliness through improved functionality, durability, and accessibility. By integrating biodegradable materials, a modular design, a built-in filter, robust construction, and a simple cap mechanism, the bottle not only reduces environmental footprint but also offers a superior user experience.</response>
```
- thinking=False
```md
Item for Redesign: Plastic Bottle (e.g., water or beverage bottle)
Redesign Concept: Eco-Friendly, Modular, and Multi-Functional Reusable Bottle
Changes:
1. Material: Replace the conventional plastic with food-grade, BPA-free, and recyclable materials such as stainless steel or glass. These materials are durable, non-toxic, and have a longer lifespan, reducing waste.
2. Modular Design: Introduce a modular design that allows users to customize their bottle according to their needs. This could include interchangeable caps, mouthpiece sizes, and carrying loops. Users can purchase additional modules as needed, promoting a more sustainable approach by reducing the need to buy an entirely new bottle for different purposes.
3. Integrated Filter: Incorporate a built-in, washable, and reusable filter that can remove impurities and improve the taste of water. This eliminates the need for single-use disposable filters or bottled water, further reducing plastic waste.
4. Smart Cap: Develop a smart cap with a built-in digital display and temperature sensor. This feature allows users to track their daily water intake, set hydration goals, and monitor the temperature of their beverage. The smart cap can be synced with a mobile app for additional functionality, such as reminders and progress tracking.
5. Easy-to-Clean Design: Ensure the bottle has a wide mouth and smooth interior surfaces for easy cleaning. Include a brush for hard-to-reach areas, making maintenance simple and encouraging regular use.
6. Collapsible Structure: Implement a collapsible design that reduces the bottle's volume when not in use, making it more portable and convenient for storage.
Benefits:
1. Sustainability: By using recyclable materials and reducing plastic waste, this redesigned bottle significantly contributes to a more sustainable lifestyle. The modular design and reusable filter also minimize single-use plastic consumption.
2. User-Friendly: The smart cap, easy-to-clean design, and collapsible structure make the bottle convenient and user-friendly. Users can customize their bottle to suit their needs, ensuring a better overall experience.
3. Healthier Option: Using food-grade, BPA-free materials and an integrated filter ensures that the beverages consumed are free from harmful chemicals and impurities, promoting a healthier lifestyle.
4. Cost-Effective: Although the initial investment might be higher, the long-term savings from reduced purchases of single-use plastic bottles and disposable filters make this reusable bottle a cost-effective choice.
5. Encourages Hydration: The smart cap's features, such as hydration tracking and temperature monitoring, can motivate users to stay hydrated and develop healthier habits.
By redesigning a common household item like the plastic bottle, we can create a more sustainable, user-friendly, and health-conscious alternative that benefits both individuals and the environment.
```
**Evaluation Results:**
<table>
<thead>
<caption style="text-align:center"><b>Comparison with different models over various benchmarks<sup id="fnref1"><a href="#fn1">1</a></sup>. Scores of AlpacaEval-2.0 and Arena-Hard are calculated with thinking=True</b></caption>
<tr>
<th style="text-align:left; background-color: #001d6c; color: white;">Models</th>
<th style="text-align:center; background-color: #001d6c; color: white;">Arena-Hard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AlpacaEval-2.0</th>
<th style="text-align:center; background-color: #001d6c; color: white;">MMLU</th>
<th style="text-align:center; background-color: #001d6c; color: white;">PopQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">TruthfulQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">BigBenchHard<sup id="fnref2"><a href="#fn2">2</a></sup></th>
<th style="text-align:center; background-color: #001d6c; color: white;">DROP<sup id="fnref3"><a href="#fn3">3</a></sup></th>
<th style="text-align:center; background-color: #001d6c; color: white;">GSM8K</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval+</th>
<th style="text-align:center; background-color: #001d6c; color: white;">IFEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AttaQ</th>
</tr></thead>
<tbody>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.1-2B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">23.3</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">27.17</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">57.11</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">20.55</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">59.79</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">61.82</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">20.99</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">67.55</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">79.45</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">75.26</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">63.59</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">84.7</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.2-2B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">24.86</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">34.51</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">57.18</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">20.56</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">59.8</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">61.39</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">23.84</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">67.02</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">80.13</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">73.39</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">61.55</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">83.23</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.3-2B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 28.86 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 43.45 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 55.88 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 18.4 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 58.97 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 63.91 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 44.33 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 72.48 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 80.51 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 75.68 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 65.8 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">87.47</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Llama-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">36.43</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">27.22</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">69.15</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">28.79</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">52.79</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">73.43</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">71.23</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">83.24</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">85.32</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">80.15</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">79.10</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">83.43</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">DeepSeek-R1-Distill-Llama-8B</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">17.17</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">21.85</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">45.80</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">13.25</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">47.43</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">67.39</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">49.73</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">72.18</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">67.54</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">62.91</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">66.50</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">42.87</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Qwen-2.5-7B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">25.44</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">30.34</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">74.30</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">18.12</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">63.06</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">69.19</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">64.06</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">84.46</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">93.35</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">89.91</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">74.90</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">81.90</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">DeepSeek-R1-Distill-Qwen-7B</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">10.36</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">15.35</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">50.72</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">9.94</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">47.14</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">67.38</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">51.78</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">78.47</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">79.89</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">78.43</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">59.10</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">42.45</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">37.58</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">30.34</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">66.77</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">28.7</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">65.84</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">69.87</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">58.57</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">79.15</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">89.63</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">85.79</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">73.20</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">85.73</td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.2-8B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">55.25</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">61.19</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">66.79</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">28.04</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">66.92</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">71.86</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">58.29</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">81.65</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">89.35</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">85.72</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">74.31</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;">84.7</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.3-8B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 57.56 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 62.68 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 65.54 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 26.17 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 66.86 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 69.13 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 59.36 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 80.89 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 89.73 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 86.09 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 74.82 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">88.5</td>
</tr>
</tbody></table>
<table>
<caption style="text-align:center"><b>Math Benchmarks</b></caption>
<thead>
<tr>
<th style="text-align:left; background-color: #001d6c; color: white;">Models</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AIME24</th>
<th style="text-align:center; background-color: #001d6c; color: white;">MATH-500</th>
</tr></thead>
<tbody>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.1-2B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 0.89 </td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 35.07 </td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.2-2B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 0.89 </td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 35.54 </td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.3-2B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 3.28 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 58.09 </td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 1.97 </td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 48.73 </td>
</tr>
<tr>
<td style="text-align:left; background-color: #FFFFFF; color: #2D2D2D;">Granite-3.2-8B-Instruct</td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 2.43 </td>
<td style="text-align:center; background-color: #FFFFFF; color: #2D2D2D;"> 52.8 </td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.3-8B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 8.12 </td>
<td style="text-align:center; background-color: #DAE8FF; color: black;"> 69.02 </td>
</tr>
</tbody></table>
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets with permissive license, (2) internal synthetically generated data targeted to enhance reasoning capabilites.
<!-- A detailed attribution of datasets can be found in [Granite 3.2 Technical Report (coming soon)](#), and [Accompanying Author List](https://github.com/ibm-granite/granite-3.0-language-models/blob/main/author-ack.pdf). -->
**Infrastructure:**
We train Granite-3.3-8B-Instruct using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable and efficient infrastructure for training our models over thousands of GPUs.
**Ethical Considerations and Limitations:**
Granite-3.3-8B-Instruct builds upon Granite-3.3-8B-Base, leveraging both permissively licensed open-source and select proprietary data for enhanced performance. Since it inherits its foundation from the previous model, all ethical considerations and limitations applicable to [Granite-3.3-8B-Base](https://huggingface.co/ibm-granite/granite-3.3-8b-base) remain relevant.
**Resources**
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 📄 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
<p><a href="#fnref1" title="Jump back to reference">[1]</a> Evaluated using <a href="https://github.com/allenai/olmes">OLMES</a> (except AttaQ and Arena-Hard scores)</p>
<p><a href="#fnref2" title="Jump back to reference">[2]</a> Added regex for more efficient asnwer extraction.</a></p>
<p><a href="#fnref3" title="Jump back to reference">[3]</a> Modified the implementation to handle some of the issues mentioned <a href="https://huggingface.co/blog/open-llm-leaderboard-drop">here</a></p>
<!-- ## Citation
<!-- ## Citation
```
@misc{granite-models,
author = {author 1, author2, ...},
title = {},
journal = {},
volume = {},
year = {2024},
url = {https://arxiv.org/abs/0000.00000},
}
``` --> |
Mungert/watt-tool-70B-GGUF | Mungert | 2025-06-15T19:44:22Z | 349 | 5 | null | [
"gguf",
"function-calling",
"tool-use",
"llama",
"bfcl",
"en",
"arxiv:2406.14868",
"base_model:meta-llama/Llama-3.3-70B-Instruct",
"base_model:quantized:meta-llama/Llama-3.3-70B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-16T03:46:29Z | ---
license: apache-2.0
language:
- en
base_model:
- meta-llama/Llama-3.3-70B-Instruct
tags:
- function-calling
- tool-use
- llama
- bfcl
---
# <span style="color: #7FFF7F;">watt-ai/watt-tool-70B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `watt-ai/watt-tool-70B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `watt-ai/watt-tool-70B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `watt-ai/watt-tool-70B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `watt-ai/watt-tool-70B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `watt-ai/watt-tool-70B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `watt-ai/watt-tool-70B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `watt-ai/watt-tool-70B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `watt-ai/watt-tool-70B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `watt-ai/watt-tool-70B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `watt-ai/watt-tool-70B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `watt-ai/watt-tool-70B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# watt-tool-70B
watt-tool-70B is a fine-tuned language model based on LLaMa-3.3-70B-Instruct, optimized for tool usage and multi-turn dialogue. It achieves state-of-the-art performance on the Berkeley Function-Calling Leaderboard (BFCL).
## Model Description
This model is specifically designed to excel at complex tool usage scenarios that require multi-turn interactions, making it ideal for empowering platforms like [Lupan](https://lupan.watt.chat), an AI-powered workflow building tool. By leveraging a carefully curated and optimized dataset, watt-tool-70B demonstrates superior capabilities in understanding user requests, selecting appropriate tools, and effectively utilizing them across multiple turns of conversation.
Target Application: AI Workflow Building as in [https://lupan.watt.chat/](https://lupan.watt.chat/) and [Coze](https://www.coze.com/).
## Key Features
* **Enhanced Tool Usage:** Fine-tuned for precise and efficient tool selection and execution.
* **Multi-Turn Dialogue:** Optimized for maintaining context and effectively utilizing tools across multiple turns of conversation, enabling more complex task completion.
* **State-of-the-Art Performance:** Achieves top performance on the BFCL, demonstrating its capabilities in function calling and tool usage.
* **Based on LLaMa-3.1-70B-Instruct:** Inherits the strong language understanding and generation capabilities of the base model.
## Training Methodology
watt-tool-70B is trained using supervised fine-tuning on a specialized dataset designed for tool usage and multi-turn dialogue. We use CoT techniques to synthesize high-quality multi-turn dialogue data.
The training process is inspired by the principles outlined in the paper: ["Direct Multi-Turn Preference Optimization for Language Agents"](https://arxiv.org/abs/2406.14868).
We use SFT and DMPO to further enhance the model's performance in multi-turn agent tasks.
## How to Use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "watt-ai/watt-tool-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype='auto', device_map="auto")
# Example usage (adapt as needed for your specific tool usage scenario)
"""You are an expert in composing functions. You are given a question and a set of possible functions. Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function, also point it out.
You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.\n{functions}\n
"""
# User query
query = "Find me the sales growth rate for company XYZ for the last 3 years and also the interest coverage ratio for the same duration."
tools = [
{
"name": "financial_ratios.interest_coverage", "description": "Calculate a company's interest coverage ratio given the company name and duration",
"arguments": {
"type": "dict",
"properties": {
"company_name": {
"type": "string",
"description": "The name of the company."
},
"years": {
"type": "integer",
"description": "Number of past years to calculate the ratio."
}
},
"required": ["company_name", "years"]
}
},
{
"name": "sales_growth.calculate",
"description": "Calculate a company's sales growth rate given the company name and duration",
"arguments": {
"type": "dict",
"properties": {
"company": {
"type": "string",
"description": "The company that you want to get the sales growth rate for."
},
"years": {
"type": "integer",
"description": "Number of past years for which to calculate the sales growth rate."
}
},
"required": ["company", "years"]
}
},
{
"name": "weather_forecast",
"description": "Retrieve a weather forecast for a specific location and time frame.",
"arguments": {
"type": "dict",
"properties": {
"location": {
"type": "string",
"description": "The city that you want to get the weather for."
},
"days": {
"type": "integer",
"description": "Number of days for the forecast."
}
},
"required": ["location", "days"]
}
}
]
messages = [
{'role': 'system', 'content': system_prompt.format(functions=tools)},
{'role': 'user', 'content': query}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
|
Mungert/Qwen2.5-72B-Instruct-GGUF | Mungert | 2025-06-15T19:44:14Z | 1,393 | 5 | transformers | [
"transformers",
"gguf",
"chat",
"text-generation",
"zho",
"eng",
"fra",
"spa",
"por",
"deu",
"ita",
"rus",
"jpn",
"kor",
"vie",
"tha",
"ara",
"arxiv:2309.00071",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-72B",
"base_model:quantized:Qwen/Qwen2.5-72B",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-09T04:55:03Z | ---
license: other
license_name: qwen
license_link: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/blob/main/LICENSE
language:
- zho
- eng
- fra
- spa
- por
- deu
- ita
- rus
- jpn
- kor
- vie
- tha
- ara
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-72B
tags:
- chat
library_name: transformers
---
# <span style="color: #7FFF7F;">Qwen2.5-72B-Instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen2.5-72B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen2.5-72B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen2.5-72B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen2.5-72B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen2.5-72B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen2.5-72B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen2.5-72B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen2.5-72B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen2.5-72B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen2.5-72B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen2.5-72B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen2.5-72B-Instruct
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Introduction
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
- Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains.
- Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots.
- **Long-context Support** up to 128K tokens and can generate up to 8K tokens.
- **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
**This repo contains the instruction-tuned 72B Qwen2.5 model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 72.7B
- Number of Paramaters (Non-Embedding): 70.0B
- Number of Layers: 80
- Number of Attention Heads (GQA): 64 for Q and 8 for KV
- Context Length: Full 131,072 tokens and generation 8192 tokens
- Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2.5 for handling long texts.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-72B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```json
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
For deployment, we recommend using vLLM.
Please refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage if you are not familar with vLLM.
Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**.
We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
``` |
Mungert/Llama-3.1-Nemotron-70B-Instruct-HF-GGUF | Mungert | 2025-06-15T19:44:03Z | 630 | 5 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama3.1",
"text-generation",
"en",
"dataset:nvidia/HelpSteer2",
"arxiv:2410.01257",
"arxiv:2405.01481",
"arxiv:2406.08673",
"base_model:meta-llama/Llama-3.1-70B-Instruct",
"base_model:quantized:meta-llama/Llama-3.1-70B-Instruct",
"license:llama3.1",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-06T22:54:06Z | ---
license: llama3.1
language:
- en
inference: false
fine-tuning: false
tags:
- nvidia
- llama3.1
datasets:
- nvidia/HelpSteer2
base_model: meta-llama/Llama-3.1-70B-Instruct
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">Llama-3.1-Nemotron-70B-Instruct-HF GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.1-Nemotron-70B-Instruct-HF-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.1-Nemotron-70B-Instruct-HF-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.1-Nemotron-70B-Instruct-HF-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.1-Nemotron-70B-Instruct-HF-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.1-Nemotron-70B-Instruct-HF-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.1-Nemotron-70B-Instruct-HF-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.1-Nemotron-70B-Instruct-HF-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.1-Nemotron-70B-Instruct-HF-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.1-Nemotron-70B-Instruct-HF-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.1-Nemotron-70B-Instruct-HF-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.1-Nemotron-70B-Instruct-HF-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Overview
## Description:
Llama-3.1-Nemotron-70B-Instruct is a large language model customized by NVIDIA to improve the helpfulness of LLM generated responses to user queries.
This model reaches [Arena Hard](https://github.com/lmarena/arena-hard-auto) of 85.0, [AlpacaEval 2 LC](https://tatsu-lab.github.io/alpaca_eval/) of 57.6 and [GPT-4-Turbo MT-Bench](https://github.com/lm-sys/FastChat/pull/3158) of 8.98, which are known to be predictive of [LMSys Chatbot Arena Elo](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard)
As of 1 Oct 2024, this model is #1 on all three automatic alignment benchmarks (verified tab for AlpacaEval 2 LC), edging out strong frontier models such as GPT-4o and Claude 3.5 Sonnet.
As of Oct 24th, 2024 the model has Elo Score of 1267(+-7), rank 9 and style controlled rank of 26 on [ChatBot Arena leaderboard](https://lmarena.ai/?leaderboard).
This model was trained using RLHF (specifically, REINFORCE), [Llama-3.1-Nemotron-70B-Reward](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Reward) and [HelpSteer2-Preference prompts](https://huggingface.co/datasets/nvidia/HelpSteer2) on a Llama-3.1-70B-Instruct model as the initial policy.
Llama-3.1-Nemotron-70B-Instruct-HF has been converted from [Llama-3.1-Nemotron-70B-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct) to support it in the HuggingFace Transformers codebase. Please note that evaluation results might be slightly different from the [Llama-3.1-Nemotron-70B-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct) as evaluated in NeMo-Aligner, which the evaluation results below are based on.
Try hosted inference for free at [build.nvidia.com](https://build.nvidia.com/nvidia/llama-3_1-nemotron-70b-instruct) - it comes with an OpenAI-compatible API interface.
See details on our paper at [https://arxiv.org/abs/2410.01257](https://arxiv.org/abs/2410.01257) - as a preview, this model can correctly the question ```How many r in strawberry?``` without specialized prompting or additional reasoning tokens:
```
A sweet question!
Let’s count the “R”s in “strawberry”:
1. S
2. T
3. R
4. A
5. W
6. B
7. E
8. R
9. R
10. Y
There are **3 “R”s** in the word “strawberry”.
```
Note: This model is a demonstration of our techniques for improving helpfulness in general-domain instruction following. It has not been tuned for performance in specialized domains such as math.
## Terms of use
By accessing this model, you are agreeing to the LLama 3.1 terms and conditions of the [license](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE), [acceptable use policy](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/USE_POLICY.md) and [Meta’s privacy policy](https://www.facebook.com/privacy/policy/)
## Evaluation Metrics
As of 1 Oct 2024, Llama-3.1-Nemotron-70B-Instruct performs best on Arena Hard, AlpacaEval 2 LC (verified tab) and MT Bench (GPT-4-Turbo)
| Model | Arena Hard | AlpacaEval | MT-Bench | Mean Response Length |
|:-----------------------------|:----------------|:-----|:----------|:-------|
|Details | (95% CI) | 2 LC (SE) | (GPT-4-Turbo) | (# of Characters for MT-Bench)|
| _**Llama-3.1-Nemotron-70B-Instruct**_ | **85.0** (-1.5, 1.5) | **57.6** (1.65) | **8.98** | 2199.8 |
| Llama-3.1-70B-Instruct | 55.7 (-2.9, 2.7) | 38.1 (0.90) | 8.22 | 1728.6 |
| Llama-3.1-405B-Instruct | 69.3 (-2.4, 2.2) | 39.3 (1.43) | 8.49 | 1664.7 |
| Claude-3-5-Sonnet-20240620 | 79.2 (-1.9, 1.7) | 52.4 (1.47) | 8.81 | 1619.9 |
| GPT-4o-2024-05-13 | 79.3 (-2.1, 2.0) | 57.5 (1.47) | 8.74 | 1752.2 |
## Usage:
You can use the model using HuggingFace Transformers library with 2 or more 80GB GPUs (NVIDIA Ampere or newer) with at least 150GB of free disk space to accomodate the download.
This code has been tested on Transformers v4.44.0, torch v2.4.0 and 2 A100 80GB GPUs, but any setup that supports ```meta-llama/Llama-3.1-70B-Instruct``` should support this model as well. If you run into problems, you can consider doing ```pip install -U transformers```.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "nvidia/Llama-3.1-Nemotron-70B-Instruct-HF"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r in strawberry?"
messages = [{"role": "user", "content": prompt}]
tokenized_message = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", return_dict=True)
response_token_ids = model.generate(tokenized_message['input_ids'].cuda(),attention_mask=tokenized_message['attention_mask'].cuda(), max_new_tokens=4096, pad_token_id = tokenizer.eos_token_id)
generated_tokens =response_token_ids[:, len(tokenized_message['input_ids'][0]):]
generated_text = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)[0]
print(generated_text)
# See response at top of model card
```
## References(s):
* [NeMo Aligner](https://arxiv.org/abs/2405.01481)
* [HelpSteer2-Preference](https://arxiv.org/abs/2410.01257)
* [HelpSteer2](https://arxiv.org/abs/2406.08673)
* [Introducing Llama 3.1: Our most capable models to date](https://ai.meta.com/blog/meta-llama-3-1/)
* [Meta's Llama 3.1 Webpage](https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1)
* [Meta's Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md)
## Model Architecture:
**Architecture Type:** Transformer <br>
**Network Architecture:** Llama 3.1 <br>
## Input:
**Input Type(s):** Text <br>
**Input Format:** String <br>
**Input Parameters:** One Dimensional (1D) <br>
**Other Properties Related to Input:** Max of 128k tokens<br>
## Output:
**Output Type(s):** Text <br>
**Output Format:** String <br>
**Output Parameters:** One Dimensional (1D) <br>
**Other Properties Related to Output:** Max of 4k tokens <br>
## Software Integration:
**Supported Hardware Microarchitecture Compatibility:** <br>
* NVIDIA Ampere <br>
* NVIDIA Hopper <br>
* NVIDIA Turing <br>
**Supported Operating System(s):** Linux <br>
## Model Version:
v1.0
# Training & Evaluation:
## Alignment methodology
* REINFORCE implemented in NeMo Aligner
## Datasets:
**Data Collection Method by dataset** <br>
* [Hybrid: Human, Synthetic] <br>
**Labeling Method by dataset** <br>
* [Human] <br>
**Link:**
* [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2)
**Properties (Quantity, Dataset Descriptions, Sensor(s)):** <br>
* 21, 362 prompt-responses built to make more models more aligned with human preference - specifically more helpful, factually-correct, coherent, and customizable based on complexity and verbosity.
* 20, 324 prompt-responses used for training and 1, 038 used for validation.
# Inference:
**Engine:** [Triton](https://developer.nvidia.com/triton-inference-server) <br>
**Test Hardware:** H100, A100 80GB, A100 40GB <br>
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
If you find this model useful, please cite the following works
```bibtex
@misc{wang2024helpsteer2preferencecomplementingratingspreferences,
title={HelpSteer2-Preference: Complementing Ratings with Preferences},
author={Zhilin Wang and Alexander Bukharin and Olivier Delalleau and Daniel Egert and Gerald Shen and Jiaqi Zeng and Oleksii Kuchaiev and Yi Dong},
year={2024},
eprint={2410.01257},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.01257},
}
``` |
Mungert/orpheus-3b-0.1-ft-GGUF | Mungert | 2025-06-15T19:43:55Z | 691 | 1 | transformers | [
"transformers",
"gguf",
"text-to-speech",
"en",
"base_model:canopylabs/orpheus-3b-0.1-pretrained",
"base_model:quantized:canopylabs/orpheus-3b-0.1-pretrained",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-to-speech | 2025-04-03T23:08:53Z | ---
library_name: transformers
language:
- en
pipeline_tag: text-to-speech
license: apache-2.0
base_model:
- meta-llama/Llama-3.2-3B-Instruct
- canopylabs/orpheus-3b-0.1-pretrained
---
# <span style="color: #7FFF7F;">orpheus-3b-0.1-ft GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `orpheus-3b-0.1-ft-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `orpheus-3b-0.1-ft-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `orpheus-3b-0.1-ft-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `orpheus-3b-0.1-ft-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `orpheus-3b-0.1-ft-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `orpheus-3b-0.1-ft-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `orpheus-3b-0.1-ft-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `orpheus-3b-0.1-ft-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `orpheus-3b-0.1-ft-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `orpheus-3b-0.1-ft-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `orpheus-3b-0.1-ft-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Orpheus 3B 0.1 Finetuned
**03/18/2025** – We are releasing our 3B Orpheus TTS model with additional finetunes. Code is available on GitHub: [CanopyAI/Orpheus-TTS](https://github.com/canopyai/Orpheus-TTS)
---
Orpheus TTS is a state-of-the-art, Llama-based Speech-LLM designed for high-quality, empathetic text-to-speech generation. This model has been finetuned to deliver human-level speech synthesis, achieving exceptional clarity, expressiveness, and real-time streaming performances.
# Model Details
### Model Capabilities
- **Human-Like Speech**: Natural intonation, emotion, and rhythm that is superior to SOTA closed source models
- **Zero-Shot Voice Cloning**: Clone voices without prior fine-tuning
- **Guided Emotion and Intonation**: Control speech and emotion characteristics with simple tags
- **Low Latency**: ~200ms streaming latency for realtime applications, reducible to ~100ms with input streaming
### Model Sources
- **GitHub Repo:** [https://github.com/canopyai/Orpheus-TTS](https://github.com/canopyai/Orpheus-TTS)
- **Blog Post:** [https://canopylabs.ai/model-releases](https://canopylabs.ai/model-releases)
- **Colab Inference Notebook:** [notebook link](https://colab.research.google.com/drive/1KhXT56UePPUHhqitJNUxq63k-pQomz3N?usp=sharing)
# Usage
Check out our Colab ([link to Colab](https://colab.research.google.com/drive/1KhXT56UePPUHhqitJNUxq63k-pQomz3N?usp=sharing)) or GitHub ([link to GitHub](https://github.com/canopyai/Orpheus-TTS)) on how to run easy inference on our finetuned models.
# Model Misuse
Do not use our models for impersonation without consent, misinformation or deception (including fake news or fraudulent calls), or any illegal or harmful activity. By using this model, you agree to follow all applicable laws and ethical guidelines. We disclaim responsibility for any use. |
Mungert/OLMo-2-0325-32B-Instruct-GGUF | Mungert | 2025-06-15T19:43:42Z | 783 | 2 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"dataset:allenai/RLVR-GSM-MATH-IF-Mixed-Constraints",
"arxiv:2501.00656",
"arxiv:2411.15124",
"base_model:allenai/OLMo-2-0325-32B-DPO",
"base_model:quantized:allenai/OLMo-2-0325-32B-DPO",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-02T05:04:04Z | ---
license: apache-2.0
language:
- en
datasets:
- allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
base_model:
- allenai/OLMo-2-0325-32B-DPO
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">OLMo-2-0325-32B-Instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OLMo-2-0325-32B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OLMo-2-0325-32B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OLMo-2-0325-32B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OLMo-2-0325-32B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OLMo-2-0325-32B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OLMo-2-0325-32B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OLMo-2-0325-32B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OLMo-2-0325-32B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OLMo-2-0325-32B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OLMo-2-0325-32B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OLMo-2-0325-32B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
<img alt="OLMo Logo" src="https://huggingface.co/datasets/allenai/blog-images/resolve/main/olmo2/olmo.png" width="242px">
OLMo 2 32B Instruct March 2025 is post-trained variant of the [OLMo-2 32B March 2025](https://huggingface.co/allenai/OLMo-2-0325-32B/) model, which has undergone supervised finetuning on an OLMo-specific variant of the [Tülu 3 dataset](https://huggingface.co/datasets/allenai/tulu-3-sft-olmo-2-mixture), further DPO training on [this dataset](https://huggingface.co/datasets/allenai/olmo-2-0325-32b-preference-mix), and final RLVR training on [this dataset](https://huggingface.co/datasets/allenai/RLVR-GSM-MATH-IF-Mixed-Constraints).
Tülu 3 is designed for state-of-the-art performance on a diversity of tasks in addition to chat, such as MATH, GSM8K, and IFEval.
Check out the [OLMo 2 paper](https://arxiv.org/abs/2501.00656) or [Tülu 3 paper](https://arxiv.org/abs/2411.15124) for more details!
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models.
These models are trained on the Dolma dataset. We are releasing all code, checkpoints, logs, and associated training details.
## Model description
- **Model type:** A model trained on a mix of publicly available, synthetic and human-created datasets.
- **Language(s) (NLP):** Primarily English
- **License:** Apache 2.0
- **Finetuned from model:** allenai/OLMo-2-0325-32B-DPO
### Model Sources
- **Project Page:** https://allenai.org/olmo
- **Repositories:**
- Core repo (training, inference, fine-tuning etc.): https://github.com/allenai/OLMo-core
- Evaluation code: https://github.com/allenai/olmes
- Further fine-tuning code: https://github.com/allenai/open-instruct
- **Paper:** https://arxiv.org/abs/2501.00656
- **Demo:** https://playground.allenai.org/
## Installation
OLMo 2 will be supported in the next version of Transformers, and you need to install it from the main branch using:
```bash
pip install --upgrade git+https://github.com/huggingface/transformers.git
```
## Using the model
### Loading with HuggingFace
To load the model with HuggingFace, use the following snippet:
```
from transformers import AutoModelForCausalLM
olmo_model = AutoModelForCausalLM.from_pretrained("allenai/OLMo-2-0325-32B-Instruct")
```
### Chat template
*NOTE: This is different than previous OLMo 2 and Tülu 3 models due to a minor change in configuration. It does NOT have the bos token before the rest. Our other models have <|endoftext|> at the beginning of the chat template.*
The chat template for our models is formatted as:
```
<|user|>\nHow are you doing?\n<|assistant|>\nI'm just a computer program, so I don't have feelings, but I'm functioning as expected. How can I assist you today?<|endoftext|>
```
Or with new lines expanded:
```
<|user|>
How are you doing?
<|assistant|>
I'm just a computer program, so I don't have feelings, but I'm functioning as expected. How can I assist you today?<|endoftext|>
```
It is embedded within the tokenizer as well, for `tokenizer.apply_chat_template`.
### System prompt
In Ai2 demos, we use this system prompt by default:
```
You are OLMo 2, a helpful and harmless AI Assistant built by the Allen Institute for AI.
```
The model has not been trained with a specific system prompt in mind.
### Intermediate Checkpoints
To facilitate research on RL finetuning, we have released our intermediate checkpoints during the model's RLVR training.
The model weights are saved every 20 training steps, and can be accessible in the revisions of the HuggingFace repository.
For example, you can load with:
```
olmo_model = AutoModelForCausalLM.from_pretrained("allenai/OLMo-2-0325-32B-Instruct", revision="step_200")
```
### Bias, Risks, and Limitations
The OLMo-2 models have limited safety training, but are not deployed automatically with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
See the Falcon 180B model card for an example of this.
## Performance
| Model | Average | AlpacaEval 2 LC | BBH | DROP | GSM8k | IFEval | MATH | MMLU | Safety | PopQA | TruthQA |
|-------|---------|------|-----|------|-------|--------|------|------|--------|-------|---------|
| **Closed API models** | | | | | | | | | | | |
| GPT-3.5 Turbo 0125 | 59.6 | 38.7 | 66.6 | 70.2 | 74.3 | 66.9 | 41.2 | 70.2 | 69.1 | 45.0 | 62.9 |
| GPT 4o Mini 2024-07-18 | 65.7 | 49.7 | 65.9 | 36.3 | 83.0 | 83.5 | 67.9 | 82.2 | 84.9 | 39.0 | 64.8 |
| **Open weights models** | | | | | | | | | | | |
| Mistral-Nemo-Instruct-2407 | 50.9 | 45.8 | 54.6 | 23.6 | 81.4 | 64.5 | 31.9 | 70.0 | 52.7 | 26.9 | 57.7 |
| Ministral-8B-Instruct | 52.1 | 31.4 | 56.2 | 56.2 | 80.0 | 56.4 | 40.0 | 68.5 | 56.2 | 20.2 | 55.5 |
| Gemma-2-27b-it | 61.3 | 49.0 | 72.7 | 67.5 | 80.7 | 63.2 | 35.1 | 70.7 | 75.9 | 33.9 | 64.6 |
| Qwen2.5-32B | 66.5 | 39.1 | 82.3 | 48.3 | 87.5 | 82.4 | 77.9 | 84.7 | 82.4 | 26.1 | 70.6 |
| Mistral-Small-24B | 67.6 | 43.2 | 80.1 | 78.5 | 87.2 | 77.3 | 65.9 | 83.7 | 66.5 | 24.4 | 68.1 |
| Llama-3.1-70B | 70.0 | 32.9 | 83.0 | 77.0 | 94.5 | 88.0 | 56.2 | 85.2 | 76.4 | 46.5 | 66.8 |
| Llama-3.3-70B | 73.0 | 36.5 | 85.8 | 78.0 | 93.6 | 90.8 | 71.8 | 85.9 | 70.4 | 48.2 | 66.1 |
| Gemma-3-27b-it | - | 63.4 | 83.7 | 69.2 | 91.1 | - | - | 81.8 | - | 30.9 | - |
| **Fully open models** | | | | | | | | | | | |
| OLMo-2-7B-1124-Instruct | 55.7 | 31.0 | 48.5 | 58.9 | 85.2 | 75.6 | 31.3 | 63.9 | 81.2 | 24.6 | 56.3 |
| OLMo-2-13B-1124-Instruct | 61.4 | 37.5 | 58.4 | 72.1 | 87.4 | 80.4 | 39.7 | 68.6 | 77.5 | 28.8 | 63.9 |
| **OLMo-2-32B-0325-SFT** | 61.7 | 16.9 | 69.7 | 77.2 | 78.4 | 72.4 | 35.9 | 76.1 | 93.8 | 35.4 | 61.3 |
| **OLMo-2-32B-0325-DPO** | 68.8 | 44.1 | 70.2 | 77.5 | 85.7 | 83.8 | 46.8 | 78.0 | 91.9 | 36.4 | 73.5 |
| **OLMo-2-32B-0325-Instruct** | 68.8 | 42.8 | 70.6 | 78.0 | 87.6 | 85.6 | 49.7 | 77.3 | 85.9 | 37.5 | 73.2 |
## Learning curves
Below is the training curves for `allenai/OLMo-2-0325-32B-Instruct`. The model was trained using 5 8xH100 nodes.


Below are the core eval scores over steps for `allenai/OLMo-2-0325-32B-Instruct` (note we took step `320` as the final checkpoint, corresponding to episode `573,440`):

Below are the other eval scores over steps for `allenai/OLMo-2-0325-32B-Instruct`:

## Reproduction command
The command below is copied directly from the tracked training job:
```bash
# clone and check out commit
git clone https://github.com/allenai/open-instruct.git
# this should be the correct commit, the main thing is to have the vllm monkey patch for
# 32b olmo https://github.com/allenai/open-instruct/blob/894ffa236319bc6c26c346240a7e4ee04ba0bd31/open_instruct/vllm_utils2.py#L37-L59
git checkout a51dc98525eec01de6e8a24c071f42dce407d738
uv sync
uv sync --extra compile
# note that you may need 5 8xH100 nodes for the training.
# so please setup ray properly, e.g., https://github.com/allenai/open-instruct/blob/main/docs/tulu3.md#llama-31-tulu-3-70b-reproduction
python open_instruct/grpo_vllm_thread_ray_gtrl.py \
--exp_name 0310_olmo2_32b_grpo_12818 \
--beta 0.01 \
--local_mini_batch_size 32 \
--number_samples_per_prompt 16 \
--output_dir output \
--local_rollout_batch_size 4 \
--kl_estimator kl3 \
--learning_rate 5e-7 \
--dataset_mixer_list allenai/RLVR-GSM-MATH-IF-Mixed-Constraints 1.0 \
--dataset_mixer_list_splits train \
--dataset_mixer_eval_list allenai/RLVR-GSM-MATH-IF-Mixed-Constraints 16 \
--dataset_mixer_eval_list_splits train \
--max_token_length 2048 \
--max_prompt_token_length 2048 \
--response_length 2048 \
--model_name_or_path allenai/OLMo-2-0325-32B-DPO \
--non_stop_penalty \
--stop_token eos \
--temperature 1.0 \
--ground_truths_key ground_truth \
--chat_template_name tulu \
--sft_messages_key messages \
--eval_max_length 4096 \
--total_episodes 10000000 \
--penalty_reward_value 0.0 \
--deepspeed_stage 3 \
--no_gather_whole_model \
--per_device_train_batch_size 2 \
--local_rollout_forward_batch_size 2 \
--actor_num_gpus_per_node 8 8 8 4 \
--num_epochs 1 \
--vllm_tensor_parallel_size 1 \
--vllm_num_engines 12 \
--lr_scheduler_type constant \
--apply_verifiable_reward true \
--seed 1 \
--num_evals 30 \
--save_freq 20 \
--reward_model_multiplier 0.0 \
--no_try_launch_beaker_eval_jobs \
--try_launch_beaker_eval_jobs_on_weka \
--gradient_checkpointing \
--with_tracking
```
## License and use
OLMo 2 is licensed under the Apache 2.0 license.
OLMo 2 is intended for research and educational use.
For more information, please see our [Responsible Use Guidelines](https://allenai.org/responsible-use).
This model has been fine-tuned using a dataset mix with outputs generated from third party models and are subject to additional terms: [Gemma Terms of Use](https://ai.google.dev/gemma/terms).
## Citation
```bibtex
@article{olmo20242olmo2furious,
title={2 OLMo 2 Furious},
author={Team OLMo and Pete Walsh and Luca Soldaini and Dirk Groeneveld and Kyle Lo and Shane Arora and Akshita Bhagia and Yuling Gu and Shengyi Huang and Matt Jordan and Nathan Lambert and Dustin Schwenk and Oyvind Tafjord and Taira Anderson and David Atkinson and Faeze Brahman and Christopher Clark and Pradeep Dasigi and Nouha Dziri and Michal Guerquin and Hamish Ivison and Pang Wei Koh and Jiacheng Liu and Saumya Malik and William Merrill and Lester James V. Miranda and Jacob Morrison and Tyler Murray and Crystal Nam and Valentina Pyatkin and Aman Rangapur and Michael Schmitz and Sam Skjonsberg and David Wadden and Christopher Wilhelm and Michael Wilson and Luke Zettlemoyer and Ali Farhadi and Noah A. Smith and Hannaneh Hajishirzi},
year={2024},
eprint={2501.00656},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.00656},
}
``` |
Mungert/sychonix-GGUF | Mungert | 2025-06-15T19:43:39Z | 1,117 | 0 | null | [
"gguf",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"feature-extraction"
] | null | 2025-04-01T07:31:32Z | ---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# <span style="color: #7FFF7F;">sychonix GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `sychonix-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `sychonix-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `sychonix-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `sychonix-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `sychonix-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `sychonix-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `sychonix-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `sychonix-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `sychonix-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `sychonix-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `sychonix-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# BERT base model (uncased)
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally masks the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences, for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Model variations
BERT has originally been released in base and large variations, for cased and uncased input text. The uncased models also strips out an accent markers.
Chinese and multilingual uncased and cased versions followed shortly after.
Modified preprocessing with whole word masking has replaced subpiece masking in a following work, with the release of two models.
Other 24 smaller models are released afterward.
The detailed release history can be found on the [google-research/bert readme](https://github.com/google-research/bert/blob/master/README.md) on github.
| Model | #params | Language |
|------------------------|--------------------------------|-------|
| [`bert-base-uncased`](https://huggingface.co/bert-base-uncased) | 110M | English |
| [`bert-large-uncased`](https://huggingface.co/bert-large-uncased) | 340M | English | sub
| [`bert-base-cased`](https://huggingface.co/bert-base-cased) | 110M | English |
| [`bert-large-cased`](https://huggingface.co/bert-large-cased) | 340M | English |
| [`bert-base-chinese`](https://huggingface.co/bert-base-chinese) | 110M | Chinese |
| [`bert-base-multilingual-cased`](https://huggingface.co/bert-base-multilingual-cased) | 110M | Multiple |
| [`bert-large-uncased-whole-word-masking`](https://huggingface.co/bert-large-uncased-whole-word-masking) | 340M | English |
| [`bert-large-cased-whole-word-masking`](https://huggingface.co/bert-large-cased-whole-word-masking) | 340M | English |
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions of a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.1073106899857521,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.08774490654468536,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a new model. [SEP]",
'score': 0.05338378623127937,
'token': 2047,
'token_str': 'new'},
{'sequence': "[CLS] hello i'm a super model. [SEP]",
'score': 0.04667217284440994,
'token': 3565,
'token_str': 'super'},
{'sequence': "[CLS] hello i'm a fine model. [SEP]",
'score': 0.027095865458250046,
'token': 2986,
'token_str': 'fine'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] the man worked as a carpenter. [SEP]',
'score': 0.09747550636529922,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the man worked as a waiter. [SEP]',
'score': 0.0523831807076931,
'token': 15610,
'token_str': 'waiter'},
{'sequence': '[CLS] the man worked as a barber. [SEP]',
'score': 0.04962705448269844,
'token': 13362,
'token_str': 'barber'},
{'sequence': '[CLS] the man worked as a mechanic. [SEP]',
'score': 0.03788609802722931,
'token': 15893,
'token_str': 'mechanic'},
{'sequence': '[CLS] the man worked as a salesman. [SEP]',
'score': 0.037680890411138535,
'token': 18968,
'token_str': 'salesman'}]
>>> unmasker("The woman worked as a [MASK].")
[{'sequence': '[CLS] the woman worked as a nurse. [SEP]',
'score': 0.21981462836265564,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the woman worked as a waitress. [SEP]',
'score': 0.1597415804862976,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the woman worked as a maid. [SEP]',
'score': 0.1154729500412941,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the woman worked as a prostitute. [SEP]',
'score': 0.037968918681144714,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the woman worked as a cook. [SEP]',
'score': 0.03042375110089779,
'token': 5660,
'token_str': 'cook'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus, and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 4 cloud TPUs in Pod configuration (16 TPU chips total) for one million steps with a batch size
of 256. The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|:----:|:-----------:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|:-------:|
| | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=bert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
Mungert/Llama-3.3-70B-Instruct-GGUF | Mungert | 2025-06-15T19:43:31Z | 4,368 | 6 | transformers | [
"transformers",
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"en",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"de",
"arxiv:2204.05149",
"base_model:meta-llama/Llama-3.1-70B",
"base_model:quantized:meta-llama/Llama-3.1-70B",
"license:llama3.3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-01T06:10:00Z | ---
library_name: transformers
language:
- en
- fr
- it
- pt
- hi
- es
- th
- de
base_model:
- meta-llama/Llama-3.1-70B
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
extra_gated_prompt: "### LLAMA 3.3 COMMUNITY LICENSE AGREEMENT\nLlama 3.3 Version Release Date: December 6, 2024\n\"Agreement\" means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.\n\"Documentation\" means the specifications, manuals and documentation accompanying Llama 3.3 distributed by Meta at [https://www.llama.com/docs/overview](https://llama.com/docs/overview).\n\"Licensee\" or \"you\" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.\n\"Llama 3.3\" means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at [https://www.llama.com/llama-downloads](https://www.llama.com/llama-downloads).\n\"Llama Materials\" means, collectively, Meta’s proprietary Llama 3.3 and Documentation (and any portion thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).\nBy clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials, you agree to be bound by this Agreement.\n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials.\nb. Redistribution and Use.\ni. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service (including another AI model) that contains any of them, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama” on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you.\_\niii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a “Notice” text file distributed as a part of such copies: “Llama 3.3 is licensed under the Llama 3.3 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at [https://www.llama.com/llama3\\_3/use-policy](https://www.llama.com/llama3_3/use-policy)), which is hereby incorporated by reference into this Agreement. \n2. Additional Commercial Terms. If, on the Llama 3.3 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at [https://about.meta.com/brand/resources/meta/company-brand/](https://about.meta.com/brand/resources/meta/company-brand/)[)](https://en.facebookbrand.com/). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.3 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.\n### Llama 3.3 Acceptable Use Policy\nMeta is committed to promoting safe and fair use of its tools and features, including Llama 3.3. If you access or use Llama 3.3, you agree to this Acceptable Use Policy (“**Policy**”). The most recent copy of this policy can be found at [https://www.llama.com/llama3\\_3/use-policy](https://www.llama.com/llama3_3/use-policy).\nProhibited Uses\nWe want everyone to use Llama 3.3 safely and responsibly. You agree you will not use, or allow others to use, Llama 3.3 to:\n1. Violate the law or others’ rights, including to:\n\n 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as: \n 1. Violence or terrorism \n 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material \n 3. Human trafficking, exploitation, and sexual violence \n 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials. \n 5. Sexual solicitation \n 6. Any other criminal activity\n\n 2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\n 3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services\n\n 4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices\n\n 5. Collect, process, disclose, generate, or infer private or sensitive information about individuals, including information about individuals’ identity, health, or demographic information, unless you have obtained the right to do so in accordance with applicable law\n\n 6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials\n\n 7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system\n\n 8. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta\n\n2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.3 related to the following:\n\n 1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989 or the Chemical Weapons Convention Implementation Act of 1997\n\n 2. Guns and illegal weapons (including weapon development)\n\n 3. Illegal drugs and regulated/controlled substances\n\n 4. Operation of critical infrastructure, transportation technologies, or heavy machinery\n\n 5. Self-harm or harm to others, including suicide, cutting, and eating disorders\n\n 6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual\n\n3. Intentionally deceive or mislead others, including use of Llama 3.3 related to the following:\n\n 1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n\n 2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content\n\n 3. Generating, promoting, or further distributing spam\n\n 4. Impersonating another individual without consent, authorization, or legal right\n\n 5. Representing that the use of Llama 3.3 or outputs are human-generated\n\n 6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement\n\n4. Fail to appropriately disclose to end users any known dangers of your AI system\n5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.3\nWith respect to any multimodal models included in Llama 3.3, the rights granted under Section 1(a) of the Llama 3.3 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.\nPlease report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:\n* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ) * Reporting risky content generated by the model: [developers.facebook.com/llama\\_output\\_feedback](http://developers.facebook.com/llama_output_feedback) * Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info) * Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama 3.3: [email protected] "
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
license: llama3.3
---
# <span style="color: #7FFF7F;">Llama-3.3-70B-Instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.3-70B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.3-70B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.3-70B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.3-70B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.3-70B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.3-70B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.3-70B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.3-70B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.3-70B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.3-70B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.3-70B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# <span style="color: #7FFF7F;">meta-llama/Llama-3.3-70B-Instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `meta-llama/Llama-3.3-70B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `meta-llama/Llama-3.3-70B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `meta-llama/Llama-3.3-70B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `meta-llama/Llama-3.3-70B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `meta-llama/Llama-3.3-70B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `meta-llama/Llama-3.3-70B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `meta-llama/Llama-3.3-70B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `meta-llama/Llama-3.3-70B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `meta-llama/Llama-3.3-70B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `meta-llama/Llama-3.3-70B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `meta-llama/Llama-3.3-70B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
## Model Information
The Meta Llama 3.3 multilingual large language model (LLM) is an instruction tuned generative model in 70B (text in/text out). The Llama 3.3 instruction tuned text only model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks.
**Model developer**: Meta
**Model Architecture:** Llama 3.3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| | Training Data | Params | Input modalities | Output modalities | Context length | GQA | Token count | Knowledge cutoff |
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| Llama 3.3 (text only) | A new mix of publicly available online data. | 70B | Multilingual Text | Multilingual Text and code | 128k | Yes | 15T+ | December 2023 |
**Supported languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
**Llama 3.3 model**. Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:**
* **70B Instruct: December 6, 2024**
**Status:** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license, the Llama 3.3 Community License Agreement, is available at: [https://github.com/meta-llama/llama-models/blob/main/models/llama3\_3/LICENSE](https://github.com/meta-llama/llama-models/blob/main/models/llama3_3/LICENSE)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3.3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3.3 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks. The Llama 3.3 model also supports the ability to leverage the outputs of its models to improve other models including synthetic data generation and distillation. The Llama 3.3 Community License allows for these use cases.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.3 Community License. Use in languages beyond those explicitly referenced as supported in this model card\*\*.
\*\*Note: Llama 3.3 has been trained on a broader collection of languages than the 8 supported languages. Developers may fine-tune Llama 3.3 models for languages beyond the 8 supported languages provided they comply with the Llama 3.3 Community License and the Acceptable Use Policy and in such cases are responsible for ensuring that any uses of Llama 3.3 in additional languages is done in a safe and responsible manner.
## How to use
This repository contains two versions of Llama-3.3-70B-Instruct, for use with transformers and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.45.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Llama-3.3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
### Tool use with transformers
LLaMA-3.3 supports multiple tool use formats. You can see a full guide to prompt formatting [here](https://llama.meta.com/docs/model-cards-and-prompt-formats/llama3_1/).
Tool use is also supported through [chat templates](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling) in Transformers.
Here is a quick example showing a single simple tool:
```python
# First, define a tool
def get_current_temperature(location: str) -> float:
"""
Get the current temperature at a location.
Args:
location: The location to get the temperature for, in the format "City, Country"
Returns:
The current temperature at the specified location in the specified units, as a float.
"""
return 22. # A real function should probably actually get the temperature!
# Next, create a chat and apply the chat template
messages = [
{"role": "system", "content": "You are a bot that responds to weather queries."},
{"role": "user", "content": "Hey, what's the temperature in Paris right now?"}
]
inputs = tokenizer.apply_chat_template(messages, tools=[get_current_temperature], add_generation_prompt=True)
```
You can then generate text from this input as normal. If the model generates a tool call, you should add it to the chat like so:
```python
tool_call = {"name": "get_current_temperature", "arguments": {"location": "Paris, France"}}
messages.append({"role": "assistant", "tool_calls": [{"type": "function", "function": tool_call}]})
```
and then call the tool and append the result, with the `tool` role, like so:
```python
messages.append({"role": "tool", "name": "get_current_temperature", "content": "22.0"})
```
After that, you can `generate()` again to let the model use the tool result in the chat. Note that this was a very brief introduction to tool calling - for more information,
see the [LLaMA prompt format docs](https://llama.meta.com/docs/model-cards-and-prompt-formats/llama3_1/) and the Transformers [tool use documentation](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling).
### Use with `bitsandbytes`
The model checkpoints can be used in `8-bit` and `4-bit` for further memory optimisations using `bitsandbytes` and `transformers`
See the snippet below for usage:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Llama-3.3-70B-Instruct"
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
input_text = "What are we having for dinner?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
output = quantized_model.generate(**input_ids, max_new_tokens=10)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
To load in 4-bit simply pass `load_in_4bit=True`
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
```
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, annotation, and evaluation were also performed on production infrastructure.
**Training Energy Use** Training utilized a cumulative of **39.3**M GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
##
## **Training Greenhouse Gas Emissions** Estimated total location-based greenhouse gas emissions were **11,390** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy, therefore the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
| | Training Time (GPU hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) |
| :---- | :---: | :---: | :---: | :---: |
| Llama 3.3 70B | 7.0M | 700 | 2,040 | 0 |
## The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.3 was pretrained on \~15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 25M synthetically generated examples.
**Data Freshness:** The pretraining data has a cutoff of December 2023\.
## Benchmarks \- English Text
In this section, we report the results for Llama 3.3 relative to our previous models.
### Instruction tuned models
##
| Category | Benchmark | \# Shots | Metric | Llama 3.1 8B Instruct | Llama 3.1 70B Instruct | Llama-3.3 70B Instruct | Llama 3.1 405B Instruct |
| :---- | :---- | ----- | :---- | ----- | ----- | ----- | ----- |
| | MMLU (CoT) | 0 | macro\_avg/acc | 73.0 | 86.0 | 86.0 | 88.6 |
| | MMLU Pro (CoT) | 5 | macro\_avg/acc | 48.3 | 66.4 | 68.9 | 73.3 |
| Steerability | IFEval | | | 80.4 | 87.5 | 92.1 | 88.6 |
| Reasoning | GPQA Diamond (CoT) | 0 | acc | 31.8 | 48.0 | 50.5 | 49.0 |
| Code | HumanEval | 0 | pass@1 | 72.6 | 80.5 | 88.4 | 89.0 |
| | MBPP EvalPlus (base) | 0 | pass@1 | 72.8 | 86.0 | 87.6 | 88.6 |
| Math | MATH (CoT) | 0 | sympy\_intersection\_score | 51.9 | 68.0 | 77.0 | 73.8 |
| Tool Use | BFCL v2 | 0 | overall\_ast\_summary/macro\_avg/valid | 65.4 | 77.5 | 77.3 | 81.1 |
| Multilingual | MGSM | 0 | em | 68.9 | 86.9 | 91.1 | 91.6 |
##
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
* Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama.
* Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm.
* Provide protections for the community to help prevent the misuse of our models.
### Responsible deployment
Llama is a foundational technology designed to be used in a variety of use cases, examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models enabling the world to benefit from the technology power, by aligning our model safety for the generic use cases addressing a standard set of harms. Developers are then in the driver seat to tailor safety for their use case, defining their own policy and deploying the models with the necessary safeguards in their Llama systems. Llama 3.3 was developed following the best practices outlined in our Responsible Use Guide, you can refer to the [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to learn more.
#### Llama 3.3 instruct
Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. For more details on the safety mitigations implemented please read the Llama 3 paper.
**Fine-tuning data**
We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone**
Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.3 systems
**Large language models, including Llama 3.3, are not designed to be deployed in isolation but instead should be deployed as part of an overall AI system with additional safety guardrails as required.** Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools.
As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard 3, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
#### Capability specific considerations
**Tool-use**: Just like in standard software development, developers are responsible for the integration of the LLM with the tools and services of their choice. They should define a clear policy for their use case and assess the integrity of the third party services they use to be aware of the safety and security limitations when using this capability. Refer to the Responsible Use Guide for best practices on the safe deployment of the third party safeguards.
**Multilinguality**: Llama 3.3 supports 7 languages in addition to English: French, German, Hindi, Italian, Portuguese, Spanish, and Thai. Llama may be able to output text in other languages than those that meet performance thresholds for safety and helpfulness. We strongly discourage developers from using this model to converse in non-supported languages without implementing finetuning and system controls in alignment with their policies and the best practices shared in the Responsible Use Guide.
### Evaluations
We evaluated Llama models for common use cases as well as specific capabilities. Common use cases evaluations measure safety risks of systems for most commonly built applications including chat bot, coding assistant, tool calls. We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Llama Guard 3 to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case. Prompt Guard and Code Shield are also available if relevant to the application.
Capability evaluations measure vulnerabilities of Llama models inherent to specific capabilities, for which were crafted dedicated benchmarks including long context, multilingual, tools calls, coding or memorization.
**Red teaming**
For both scenarios, we conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets.
We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets. .
### Critical and other risks
### We specifically focused our efforts on mitigating the following critical risk areas:
**1- CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive materials) helpfulness**
To assess risks related to proliferation of chemical and biological weapons of the Llama 3 family of models, we performed uplift testing designed to assess whether use of the Llama 3 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons.
### **2\. Child Safety**
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3\. Cyber attack enablement**
Our cyber attack uplift study investigated whether the Llama 3 family of LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3.3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
|
Mungert/OlympicCoder-32B-GGUF | Mungert | 2025-06-15T19:43:22Z | 318 | 5 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"dataset:open-r1/codeforces-cots",
"base_model:Qwen/Qwen2.5-Coder-32B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-Coder-32B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-31T05:55:48Z | ---
license: apache-2.0
datasets:
- open-r1/codeforces-cots
language:
- en
base_model:
- Qwen/Qwen2.5-Coder-32B-Instruct
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">OlympicCoder-32B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OlympicCoder-32B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OlympicCoder-32B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OlympicCoder-32B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OlympicCoder-32B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OlympicCoder-32B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OlympicCoder-32B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OlympicCoder-32B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OlympicCoder-32B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OlympicCoder-32B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OlympicCoder-32B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OlympicCoder-32B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for OlympicCoder-32B
OlympicCoder-32B is a code model that achieves very strong performance on competitive coding benchmarks such as LiveCodeBench andthe 2024 International Olympiad in Informatics.
* Repository: https://github.com/huggingface/open-r1
* Blog post: https://huggingface.co/blog/open-r1/update-3
## Model description
- **Model type:** A 32B parameter model fine-tuned on a decontaminated version of the codeforces dataset.
- **Language(s) (NLP):** Primarily English
- **License:** apache-2.0
- **Finetuned from model:** [Qwen/Qwen2.5-Coder-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct)
## Evaluation
We compare the performance of OlympicCoder models on two main benchmarks for competitive coding:
* **[IOI'2024:](https://github.com/huggingface/ioi)** 6 very challenging problems from the 2024 International Olympiad in Informatics. Models are allowed up to 50 submissions per problem.
* **[LiveCodeBench:](https://livecodebench.github.io)** Python programming problems source from platforms like CodeForces and LeetCoder. We use the `v4_v5` subset of [`livecodebench/code_generation_lite`](https://huggingface.co/datasets/livecodebench/code_generation_lite), which corresponds to 268 problems. We use `lighteval` to evaluate models on LiveCodeBench using the sampling parameters described [here](https://github.com/huggingface/open-r1?tab=readme-ov-file#livecodebench).
> [!NOTE]
> The OlympicCoder models were post-trained exclusively on C++ solutions generated by DeepSeek-R1. As a result the performance on LiveCodeBench should be considered to be partially _out-of-domain_, since this expects models to output solutions in Python.
### IOI'24

### LiveCodeBench

## Usage
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# pip install transformers
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="open-r1/OlympicCoder-32B", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{"role": "user", "content": "Write a python program to calculate the 10th Fibonacci number"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=8000, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
#<|im_start|>user
#Write a python program to calculate the 10th fibonacci number<|im_end|>
#<|im_start|>assistant
#<think>Okay, I need to write a Python program that calculates the 10th Fibonacci number. Hmm, the Fibonacci sequence starts with 0 and 1. Each subsequent number is the sum of the two preceding ones. So the sequence goes: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, and so on. ...
```
> [!IMPORTANT]
> To ensure that the model consistently outputs a long chain-of-thought, we have edited the chat template to prefill the first assistant turn with a `<think>` token. As a result, the outputs from this model will not show the opening `<think>` token if you use the model's `generate()` method. To apply reinforcement learning with a format reward, either prepend the `<think>` token to the model's completions or amend the chat template to remove the prefill. Check out our [blog post](https://huggingface.co/blog/open-r1/update-3#lesson-4-prefill-with-think-to-consistently-enable-long-cot) for more details.
## Training procedure
### Training hyper-parameters
The following hyperparameters were used during training on 16 H100 nodes:
- dataset: open-r1/codeforces-cots_decontaminated
- learning_rate: 4.0e-5
- train_batch_size: 1
- seed: 42
- packing: false
- distributed_type: fsdp
- num_devices: 128
- gradient_accumulation_steps: 1
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_min_lr
- min_lr_rate: 0.1
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 10.0 |
Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF | Mungert | 2025-06-15T19:43:11Z | 992 | 4 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"text-generation",
"en",
"arxiv:2411.19146",
"arxiv:2502.00203",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-29T03:22:36Z | ---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- llama-3
- pytorch
---
# <span style="color: #7FFF7F;">Llama-3_3-Nemotron-Super-49B-v1 GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3_3-Nemotron-Super-49B-v1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3_3-Nemotron-Super-49B-v1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3_3-Nemotron-Super-49B-v1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3_3-Nemotron-Super-49B-v1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3_3-Nemotron-Super-49B-v1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3_3-Nemotron-Super-49B-v1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3_3-Nemotron-Super-49B-v1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3_3-Nemotron-Super-49B-v1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3_3-Nemotron-Super-49B-v1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3_3-Nemotron-Super-49B-v1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3_3-Nemotron-Super-49B-v1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I'd really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# <span style="color: #7FFF7F;">Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mungert/Llama-3_3-Nemotron-Super-49B-v1-GGUF-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I'd really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Llama-3.3-Nemotron-Super-49B-v1
## Model Overview
Llama-3.3-Nemotron-Super-49B-v1 is a large language model (LLM) which is a derivative of [Meta Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) (AKA the *reference model*). It is a reasoning model that is post trained for reasoning, human chat preferences, and tasks, such as RAG and tool calling. The model supports a context length of 128K tokens.
Llama-3.3-Nemotron-Super-49B-v1 is a model which offers a great tradeoff between model accuracy and efficiency. Efficiency (throughput) directly translates to savings. Using a novel Neural Architecture Search (NAS) approach, we greatly reduce the model’s memory footprint, enabling larger workloads, as well as fitting the model on a single GPU at high workloads (H200). This NAS approach enables the selection of a desired point in the accuracy-efficiency tradeoff. For more information on the NAS approach, please refer to [this paper](https://arxiv.org/abs/2411.19146).
The model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Reasoning, and Tool Calling as well as multiple reinforcement learning (RL) stages using REINFORCE (RLOO) and Online Reward-aware Preference Optimization (RPO) algorithms for both chat and instruction-following. The final model checkpoint is obtained after merging the final SFT and Online RPO checkpoints. For more details on how the model was trained, please see [this blog](https://developer.nvidia.com/blog/build-enterprise-ai-agents-with-advanced-open-nvidia-llama-nemotron-reasoning-models/).

This model is part of the Llama Nemotron Collection. You can find the other model(s) in this family here:
- [Llama-3.1-Nemotron-Nano-8B-v1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-8B-v1)
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: Your use of this model is governed by the [NVIDIA Open Model License.](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) \
Additional Information: [Llama 3.3 Community License Agreement](https://www.llama.com/llama3_3/license/). Built with Llama.
**Model Developer:** NVIDIA
**Model Dates:** Trained between November 2024 and February 2025
**Data Freshness:** The pretraining data has a cutoff of 2023 per Meta Llama 3.3 70B
### Use Case: <br>
Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks. <br>
### Release Date: <br>
3/18/2025 <br>
## References
* [[2411.19146] Puzzle: Distillation-Based NAS for Inference-Optimized LLMs](https://arxiv.org/abs/2411.19146)
* [[2502.00203] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment](https://arxiv.org/abs/2502.00203)
## Model Architecture
**Architecture Type:** Dense decoder-only Transformer model \
**Network Architecture:** Llama 3.3 70B Instruct, customized through Neural Architecture Search (NAS)
The model is a derivative of Meta’s Llama-3.3-70B-Instruct, using Neural Architecture Search (NAS). The NAS algorithm results in non-standard and non-repetitive blocks. This includes the following:
* Skip attention: In some blocks, the attention is skipped entirely, or replaced with a single linear layer.
* Variable FFN: The expansion/compression ratio in the FFN layer is different between blocks.
We utilize a block-wise distillation of the reference model, where for each block we create multiple variants providing different tradeoffs of quality vs. computational complexity, discussed in more depth below. We then search over the blocks to create a model which meets the required throughput and memory (optimized for a single H100-80GB GPU) while minimizing the quality degradation. The model then undergoes knowledge distillation (KD), with a focus on English single and multi-turn chat use-cases. The KD step included 40 billion tokens consisting of a mixture of 3 datasets - FineWeb, Buzz-V1.2 and Dolma.
## Intended use
Llama-3.3-Nemotron-Super-49B-v1 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Portuguese, Hindi, Spanish, and Thai) are also supported.
## Input
- **Input Type:** Text
- **Input Format:** String
- **Input Parameters:** One-Dimensional (1D)
- **Other Properties Related to Input:** Context length up to 131,072 tokens
## Output
- **Output Type:** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D)
- **Other Properties Related to Output:** Context length up to 131,072 tokens
## Model Version
1.0 (3/18/2025)
## Software Integration
- **Runtime Engine:** Transformers
- **Recommended Hardware Microarchitecture Compatibility:**
- NVIDIA Hopper
- NVIDIA Ampere
## Quick Start and Usage Recommendations:
1. Reasoning mode (ON/OFF) is controlled via the system prompt, which must be set as shown in the example below. All instructions should be contained within the user prompt
2. We recommend setting temperature to `0.6`, and Top P to `0.95` for Reasoning ON mode
3. We recommend using greedy decoding for Reasoning OFF mode
4. We have provided a list of prompts to use for evaluation for each benchmark where a specific template is required
You can try this model out through the preview API, using this link: [Llama-3_3-Nemotron-Super-49B-v1](https://build.nvidia.com/nvidia/llama-3_3-nemotron-super-49b-v1).
See the snippet below for usage with [Hugging Face Transformers](https://huggingface.co/docs/transformers/main/en/index) library. Reasoning mode (ON/OFF) is controlled via system prompt. Please see the example below
We recommend using the *transformers* package with version 4.48.3.
Example of reasoning on:
```py
import torch
import transformers
model_id = "nvidia/Llama-3_3-Nemotron-Super-49B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "trust_remote_code": True, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95,
**model_kwargs
)
thinking = "on"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"},{"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
Example of reasoning off:
```py
import torch
import transformers
model_id = "nvidia/Llama-3_3-Nemotron-Super-49B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "trust_remote_code": True, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "off"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"},{"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
## Inference:
**Engine:**
- Transformers
**Test Hardware:**
- FP8: 1x NVIDIA H100-80GB GPU (Coming Soon!)
- BF16:
- 2x NVIDIA H100-80GB
- 2x NVIDIA A100-80GB GPUs
**[Preferred/Supported] Operating System(s):** Linux <br>
## Training Datasets
A large variety of training data was used for the knowledge distillation phase before post-training pipeline, 3 of which included: FineWeb, Buzz-V1.2, and Dolma.
The data for the multi-stage post-training phases for improvements in Code, Math, and Reasoning is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model.
In conjunction with this model release, NVIDIA has released 30M samples of post-training data, as public and permissive. Please see [Llama-Nemotron-Postraining-Dataset-v1](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset-v1).
Distribution of the domains is as follows:
| Category | Value |
|----------|-----------|
| math | 19,840,970|
| code | 9,612,677 |
| science | 708,920 |
| instruction following | 56,339 |
| chat | 39,792 |
| safety | 31,426 |
Prompts have been sourced from either public and open corpus or synthetically generated. Responses were synthetically generated by a variety of models, with some prompts containing responses for both reasoning on and off modes, to train the model to distinguish between two modes.
**Data Collection for Training Datasets:**
- Hybrid: Automated, Human, Synthetic
**Data Labeling for Training Datasets:**
- Hybrid: Automated, Human, Synthetic
## Evaluation Datasets
We used the datasets listed below to evaluate Llama-3.3-Nemotron-Super-49B-v1.
Data Collection for Evaluation Datasets:
- Hybrid: Human/Synthetic
Data Labeling for Evaluation Datasets:
- Hybrid: Human/Synthetic/Automatic
## Evaluation Results
These results contain both “Reasoning On”, and “Reasoning Off”. We recommend using temperature=`0.6`, top_p=`0.95` for “Reasoning On” mode, and greedy decoding for “Reasoning Off” mode. All evaluations are done with 32k sequence length. We run the benchmarks up to 16 times and average the scores to be more accurate.
> NOTE: Where applicable, a Prompt Template will be provided. While completing benchmarks, please ensure that you are parsing for the correct output format as per the provided prompt in order to reproduce the benchmarks seen below.
### Arena-Hard
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 88.3 |
### MATH500
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 74.0 |
| Reasoning On | 96.6 |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### AIME25
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 13.33 |
| Reasoning On | 58.4 |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### GPQA
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 50 |
| Reasoning On | 66.67 |
User Prompt Template:
```
"What is the correct answer to this question: {question}\nChoices:\nA. {option_A}\nB. {option_B}\nC. {option_C}\nD. {option_D}\nLet's think step by step, and put the final answer (should be a single letter A, B, C, or D) into a \boxed{}"
```
### IFEval
| Reasoning Mode | Strict:Instruction |
|--------------|------------|
| Reasoning Off | 89.21 |
### BFCL V2 Live
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 73.7 |
User Prompt Template:
```
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function,
also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of <TOOLCALL>[func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]</TOOLCALL>
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
<AVAILABLE_TOOLS>{functions}</AVAILABLE_TOOLS>
{user_prompt}
```
### MBPP 0-shot
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 84.9|
| Reasoning On | 91.3 |
User Prompt Template:
````
You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
@@ Instruction
Here is the given problem and test examples:
{prompt}
Please use the python programming language to solve this problem.
Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
Please return all completed codes in one code block.
This code block should be in the following format:
```python
# Your codes here
```
````
### MT-Bench
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 9.17 |
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](explainability.md), [Bias](bias.md), [Safety & Security](safety.md), and [Privacy](privacy.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
Mungert/PLM-1.8B-Instruct-GGUF | Mungert | 2025-06-15T19:43:05Z | 346 | 1 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"zh",
"arxiv:2503.12167",
"base_model:PLM-Team/PLM-1.8B-Instruct",
"base_model:quantized:PLM-Team/PLM-1.8B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-28T20:08:40Z | ---
base_model: PLM-Team/PLM-1.8B-Instruct
language:
- en
- zh
library_name: transformers
license: apache-2.0
quantized_by: PLM-Team
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">PLM-1.8B-Instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `PLM-1.8B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `PLM-1.8B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `PLM-1.8B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `PLM-1.8B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `PLM-1.8B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `PLM-1.8B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `PLM-1.8B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `PLM-1.8B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `PLM-1.8B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `PLM-1.8B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `PLM-1.8B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
<center>
<img src="https://www.cdeng.net/plm/plm_logo.png" alt="plm-logo" width="200"/>
<h2>🖲️ PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing</h2>
<a href='https://www.project-plm.com/'>👉 Project PLM Website</a>
</center>
<center>
||||||||
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|<a href='https://arxiv.org/abs/2503.12167'><img src='https://img.shields.io/badge/Paper-ArXiv-C71585'></a>|<a href='https://huggingface.co/PLM-Team/PLM-1.8B-Base'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging Face-Base-red'></a>|<a href='https://huggingface.co/PLM-Team/PLM-1.8B-Instruct'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging Face-Instruct-red'></a>|<a href='https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging Face-gguf-red'></a>|<a href='https://huggingface.co/datasets/plm-team/scots'><img src='https://img.shields.io/badge/Data-plm%20mix-4169E1'></img></a>|<a><img src="https://img.shields.io/github/stars/plm-team/PLM"></a>|
</center>
---
The PLM (Peripheral Language Model) series introduces a novel model architecture to peripheral computing by delivering powerful language capabilities within the constraints of resource-limited devices. Through modeling and system co-design strategy, PLM optimizes model performance and fits edge system requirements, PLM employs **Multi-head Latent Attention** and **squared ReLU** activation to achieve sparsity, significantly reducing memory footprint and computational demands. Coupled with a meticulously crafted training regimen using curated datasets and a Warmup-Stable-Decay-Constant learning rate scheduler, PLM demonstrates superior performance compared to existing small language models, all while maintaining the lowest activated parameters, making it ideally suited for deployment on diverse peripheral platforms like mobile phones and Raspberry Pis.
**Here we present the static quants of https://huggingface.co/PLM-Team/PLM-1.8B-Instruct**
## Provided Quants
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-F16.gguf|F16| 3.66GB| Recommanded|
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q2_K.gguf|Q2_K| 827 MB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q3_K_L.gguf|Q3_K_L| 1.09 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q3_K_M.gguf|Q3_K_M| 1.01 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q3_K_S.gguf|Q3_K_S| 912 MB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q4_0.gguf|Q4_0| 1.11 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q4_1.gguf|Q4_1| 1.21 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q4_K_M.gguf|Q4_K_M| 1.18 GB| Recommanded|
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q4_K_S.gguf|Q4_K_S| 1.12 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q5_0.gguf|Q5_0| 1.3 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q5_1.gguf|Q5_1| 1.4 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q5_K_M.gguf|Q5_K_M| 1.34 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q5_K_S.gguf|Q5_K_S| 1.3 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q6_K.gguf|Q6_K| 1.5 GB| |
|https://huggingface.co/PLM-Team/PLM-1.8B-Instruct-gguf/blob/main/PLM-1.8B-Instruct-Q8_0.gguf|Q8_0| 1.95 GB| Recommanded|
## Usage (llama.cpp)
Now [llama.cpp](https://github.com/ggml-org/llama.cpp) supports our model. Here is the usage:
```bash
git clone https://github.com/Si1w/llama.cpp.git
cd llama.cpp
```
If you want to convert the orginal model into `gguf` form by yourself, you can
```bash
pip install -r requirements.txt
python convert_hf_to_ggyf.py [model] --outtype {f32,f16,bf16,q8_0,tq1_0,tq2_0,auto}
```
Then, we can build with CPU of GPU (e.g. Orin). The build is based on `cmake`.
- For CPU
```bash
cmake -B build
cmake --build build --config Release
```
- For GPU
```bash
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
```
Don't forget to download the GGUF files of the PLM. We use the quantization methods in `llama.cpp` to generate the quantized PLM.
```bash
huggingface-cli download --resume-download PLM-Team/PLM-1.8B-Instruct-gguf --local-dir PLM-Team/PLM-1.8B-Instruct-gguf
```
After build the `llama.cpp`, we can use `llama-cli` script to launch the PLM.
```bash
./build/bin/llama-cli -m ./PLM-Team/PLM-1.8B-Instruct-gguf/PLM-1.8B-Instruct-Q8_0.gguf -cnv -p "hello!" -n 128
```
## Citation
If you find Project PLM helpful for your research or applications, please cite as follows:
```
@misc{deng2025plmefficientperipherallanguage,
title={PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing},
author={Cheng Deng and Luoyang Sun and Jiwen Jiang and Yongcheng Zeng and Xinjian Wu and Wenxin Zhao and Qingfa Xiao and Jiachuan Wang and Lei Chen and Lionel M. Ni and Haifeng Zhang and Jun Wang},
year={2025},
eprint={2503.12167},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.12167},
}
``` |
Mungert/gemma-3-27b-it-GGUF | Mungert | 2025-06-15T19:42:42Z | 849 | 8 | transformers | [
"transformers",
"gguf",
"image-text-to-text",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2311.12022",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"base_model:google/gemma-3-27b-pt",
"base_model:quantized:google/gemma-3-27b-pt",
"license:gemma",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-03-26T03:50:50Z | ---
license: gemma
library_name: transformers
pipeline_tag: image-text-to-text
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-27b-pt
---
# <span style="color: #7FFF7F;">gemma-3-27b-it GGUF Models</span>
## How to Use Gemma 3 Vision with llama.cpp
To utilize the experimental support for Gemma 3 Vision in `llama.cpp`, follow these steps:
1. **Clone the lastest llama.cpp Repository**:
```bash
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
```
2. **Build the Llama.cpp**:
Build llama.cpp as usual : https://github.com/ggml-org/llama.cpp#building-the-project
Once llama.cpp is built Copy the ./llama.cpp/build/bin/llama-gemma3-cli to a chosen folder.
3. **Download the Gemma 3 gguf file**:
https://huggingface.co/Mungert/gemma-3-4b-it-gguf/tree/main
Choose a gguf file without the mmproj in the name
Example gguf file : https://huggingface.co/Mungert/gemma-3-4b-it-gguf/resolve/main/google_gemma-3-4b-it-q4_k_l.gguf
Copy this file to your chosen folder.
4. **Download the Gemma 3 mmproj file**
https://huggingface.co/Mungert/gemma-3-4b-it-gguf/tree/main
Choose a file with mmproj in the name
Example mmproj file : https://huggingface.co/Mungert/gemma-3-4b-it-gguf/resolve/main/google_gemma-3-4b-it-mmproj-bf16.gguf
Copy this file to your chosen folder.
5. Copy images to the same folder as the gguf files or alter paths appropriately.
In the example below the gguf files, images and llama-gemma-cli are in the same folder.
Example image: image https://huggingface.co/Mungert/gemma-3-4b-it-gguf/resolve/main/car-1.jpg
Copy this file to your chosen folder.
6. **Run the CLI Tool**:
From your chosen folder :
```bash
llama-gemma3-cli -m google_gemma-3-4b-it-q4_k_l.gguf --mmproj google_gemma-3-4b-it-mmproj-bf16.gguf
```
```
Running in chat mode, available commands:
/image <path> load an image
/clear clear the chat history
/quit or /exit exit the program
> /image car-1.jpg
Encoding image car-1.jpg
Image encoded in 46305 ms
Image decoded in 19302 ms
> what is the image of
Here's a breakdown of what's in the image:
**Subject:** The primary subject is a black Porsche Panamera Turbo driving on a highway.
**Details:**
* **Car:** It's a sleek, modern Porsche Panamera Turbo, identifiable by its distinctive rear design, the "PORSCHE" lettering, and the "Panamera Turbo" badge. The license plate reads "CVC-911".
* **Setting:** The car is on a multi-lane highway, with a blurred background of trees, a distant building, and a cloudy sky. The lighting suggests it's either dusk or dawn.
* **Motion:** The image captures the car in motion, with a slight motion blur to convey speed.
**Overall Impression:** The image conveys a sense of speed, luxury, and power. It's a well-composed shot that highlights the car's design and performance.
Do you want me to describe any specific aspect of the image in more detail, or perhaps analyze its composition?
```
## **Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)**
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Key Improvements**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `gemma-3-27b-it-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `gemma-3-27b-it-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `gemma-3-27b-it-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `gemma-3-27b-it-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `gemma-3-27b-it-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `gemma-3-27b-it-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `gemma-3-27b-it-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `gemma-3-27b-it-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `gemma-3-27b-it-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `gemma-3-27b-it-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `gemma-3-27b-it-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# <span style="color: #7FFF7F;">gemma-3-27b-it GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `gemma-3-27b-it-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `gemma-3-27b-it-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `gemma-3-27b-it-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `gemma-3-27b-it-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `gemma-3-27b-it-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `gemma-3-27b-it-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `gemma-3-27b-it-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `gemma-3-27b-it-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `gemma-3-27b-it-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `gemma-3-27b-it-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `gemma-3-27b-it-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
**Resources and Technical Documentation**:
* [Gemma 3 Technical Report][g3-tech-report]
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma3]
**Terms of Use**: [Terms][terms]
**Authors**: Google DeepMind
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
Gemma 3 models are multimodal, handling text and image input and generating text
output, with open weights for both pre-trained variants and instruction-tuned
variants. Gemma 3 has a large, 128K context window, multilingual support in over
140 languages, and is available in more sizes than previous versions. Gemma 3
models are well-suited for a variety of text generation and image understanding
tasks, including question answering, summarization, and reasoning. Their
relatively small size makes it possible to deploy them in environments with
limited resources such as laptops, desktops or your own cloud infrastructure,
democratizing access to state of the art AI models and helping foster innovation
for everyone.
### Inputs and outputs
- **Input:**
- Text string, such as a question, a prompt, or a document to be summarized
- Images, normalized to 896 x 896 resolution and encoded to 256 tokens
each
- Total input context of 128K tokens for the 4B, 12B, and 27B sizes, and
32K tokens for the 1B size
- **Output:**
- Generated text in response to the input, such as an answer to a
question, analysis of image content, or a summary of a document
- Total output context of 8192 tokens
### Usage
Below there are some code snippets on how to get quickly started with running the model. First, install the Transformers library. Gemma 3 is supported starting from transformers 4.50.0.
```sh
$ pip install -U transformers
```
Then, copy the snippet from the section that is relevant for your use case.
#### Running with the `pipeline` API
You can initialize the model and processor for inference with `pipeline` as follows.
```python
from transformers import pipeline
import torch
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-27b-it",
device="cuda",
torch_dtype=torch.bfloat16
)
```
With instruction-tuned models, you need to use chat templates to process our inputs first. Then, you can pass it to the pipeline.
```python
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
# Okay, let's take a look!
# Based on the image, the animal on the candy is a **turtle**.
# You can see the shell shape and the head and legs.
```
#### Running the model on a single/multi GPU
```python
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
# **Overall Impression:** The image is a close-up shot of a vibrant garden scene,
# focusing on a cluster of pink cosmos flowers and a busy bumblebee.
# It has a slightly soft, natural feel, likely captured in daylight.
```
### Citation
```none
@article{gemma_2025,
title={Gemma 3},
url={https://goo.gle/Gemma3Report},
publisher={Kaggle},
author={Gemma Team},
year={2025}
}
```
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources. The 27B model was trained with 14 trillion tokens, the 12B model was
trained with 12 trillion tokens, 4B model was trained with 4 trillion tokens and
1B with 2 trillion tokens. Here are the key components:
- Web Documents: A diverse collection of web text ensures the model is
exposed to a broad range of linguistic styles, topics, and vocabulary. The
training dataset includes content in over 140 languages.
- Code: Exposing the model to code helps it to learn the syntax and
patterns of programming languages, which improves its ability to generate
code and understand code-related questions.
- Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
- Images: A wide range of images enables the model to perform image
analysis and visual data extraction tasks.
The combination of these diverse data sources is crucial for training a powerful
multimodal model that can handle a wide variety of different tasks and data
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
- CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering
was applied at multiple stages in the data preparation process to ensure
the exclusion of harmful and illegal content.
- Sensitive Data Filtering: As part of making Gemma pre-trained models
safe and reliable, automated techniques were used to filter out certain
personal information and other sensitive data from training sets.
- Additional methods: Filtering based on content quality and safety in
line with [our policies][safety-policies].
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using [Tensor Processing Unit (TPU)][tpu] hardware (TPUv4p,
TPUv5p and TPUv5e). Training vision-language models (VLMS) requires significant
computational power. TPUs, designed specifically for matrix operations common in
machine learning, offer several advantages in this domain:
- Performance: TPUs are specifically designed to handle the massive
computations involved in training VLMs. They can speed up training
considerably compared to CPUs.
- Memory: TPUs often come with large amounts of high-bandwidth memory,
allowing for the handling of large models and batch sizes during training.
This can lead to better model quality.
- Scalability: TPU Pods (large clusters of TPUs) provide a scalable
solution for handling the growing complexity of large foundation models.
You can distribute training across multiple TPU devices for faster and more
efficient processing.
- Cost-effectiveness: In many scenarios, TPUs can provide a more
cost-effective solution for training large models compared to CPU-based
infrastructure, especially when considering the time and resources saved
due to faster training.
- These advantages are aligned with
[Google's commitments to operate sustainably][sustainability].
### Software
Training was done using [JAX][jax] and [ML Pathways][ml-pathways].
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models. ML
Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
foundation models, including large language models like these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models][gemini-2-paper]; *"the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."*
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
#### Reasoning and factuality
| Benchmark | Metric | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |----------------|:--------------:|:-------------:|:--------------:|:--------------:|
| [HellaSwag][hellaswag] | 10-shot | 62.3 | 77.2 | 84.2 | 85.6 |
| [BoolQ][boolq] | 0-shot | 63.2 | 72.3 | 78.8 | 82.4 |
| [PIQA][piqa] | 0-shot | 73.8 | 79.6 | 81.8 | 83.3 |
| [SocialIQA][socialiqa] | 0-shot | 48.9 | 51.9 | 53.4 | 54.9 |
| [TriviaQA][triviaqa] | 5-shot | 39.8 | 65.8 | 78.2 | 85.5 |
| [Natural Questions][naturalq] | 5-shot | 9.48 | 20.0 | 31.4 | 36.1 |
| [ARC-c][arc] | 25-shot | 38.4 | 56.2 | 68.9 | 70.6 |
| [ARC-e][arc] | 0-shot | 73.0 | 82.4 | 88.3 | 89.0 |
| [WinoGrande][winogrande] | 5-shot | 58.2 | 64.7 | 74.3 | 78.8 |
| [BIG-Bench Hard][bbh] | few-shot | 28.4 | 50.9 | 72.6 | 77.7 |
| [DROP][drop] | 1-shot | 42.4 | 60.1 | 72.2 | 77.2 |
[hellaswag]: https://arxiv.org/abs/1905.07830
[boolq]: https://arxiv.org/abs/1905.10044
[piqa]: https://arxiv.org/abs/1911.11641
[socialiqa]: https://arxiv.org/abs/1904.09728
[triviaqa]: https://arxiv.org/abs/1705.03551
[naturalq]: https://github.com/google-research-datasets/natural-questions
[arc]: https://arxiv.org/abs/1911.01547
[winogrande]: https://arxiv.org/abs/1907.10641
[bbh]: https://paperswithcode.com/dataset/bbh
[drop]: https://arxiv.org/abs/1903.00161
#### STEM and code
| Benchmark | Metric | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |----------------|:-------------:|:--------------:|:--------------:|
| [MMLU][mmlu] | 5-shot | 59.6 | 74.5 | 78.6 |
| [MMLU][mmlu] (Pro COT) | 5-shot | 29.2 | 45.3 | 52.2 |
| [AGIEval][agieval] | 3-5-shot | 42.1 | 57.4 | 66.2 |
| [MATH][math] | 4-shot | 24.2 | 43.3 | 50.0 |
| [GSM8K][gsm8k] | 8-shot | 38.4 | 71.0 | 82.6 |
| [GPQA][gpqa] | 5-shot | 15.0 | 25.4 | 24.3 |
| [MBPP][mbpp] | 3-shot | 46.0 | 60.4 | 65.6 |
| [HumanEval][humaneval] | 0-shot | 36.0 | 45.7 | 48.8 |
[mmlu]: https://arxiv.org/abs/2009.03300
[agieval]: https://arxiv.org/abs/2304.06364
[math]: https://arxiv.org/abs/2103.03874
[gsm8k]: https://arxiv.org/abs/2110.14168
[gpqa]: https://arxiv.org/abs/2311.12022
[mbpp]: https://arxiv.org/abs/2108.07732
[humaneval]: https://arxiv.org/abs/2107.03374
#### Multilingual
| Benchmark | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------------ |:-------------:|:-------------:|:--------------:|:--------------:|
| [MGSM][mgsm] | 2.04 | 34.7 | 64.3 | 74.3 |
| [Global-MMLU-Lite][global-mmlu-lite] | 24.9 | 57.0 | 69.4 | 75.7 |
| [WMT24++][wmt24pp] (ChrF) | 36.7 | 48.4 | 53.9 | 55.7 |
| [FloRes][flores] | 29.5 | 39.2 | 46.0 | 48.8 |
| [XQuAD][xquad] (all) | 43.9 | 68.0 | 74.5 | 76.8 |
| [ECLeKTic][eclektic] | 4.69 | 11.0 | 17.2 | 24.4 |
| [IndicGenBench][indicgenbench] | 41.4 | 57.2 | 61.7 | 63.4 |
[mgsm]: https://arxiv.org/abs/2210.03057
[flores]: https://arxiv.org/abs/2106.03193
[xquad]: https://arxiv.org/abs/1910.11856v3
[global-mmlu-lite]: https://huggingface.co/datasets/CohereForAI/Global-MMLU-Lite
[wmt24pp]: https://arxiv.org/abs/2502.12404v1
[eclektic]: https://arxiv.org/abs/2502.21228
[indicgenbench]: https://arxiv.org/abs/2404.16816
#### Multimodal
| Benchmark | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |:-------------:|:--------------:|:--------------:|
| [COCOcap][coco-cap] | 102 | 111 | 116 |
| [DocVQA][docvqa] (val) | 72.8 | 82.3 | 85.6 |
| [InfoVQA][info-vqa] (val) | 44.1 | 54.8 | 59.4 |
| [MMMU][mmmu] (pt) | 39.2 | 50.3 | 56.1 |
| [TextVQA][textvqa] (val) | 58.9 | 66.5 | 68.6 |
| [RealWorldQA][realworldqa] | 45.5 | 52.2 | 53.9 |
| [ReMI][remi] | 27.3 | 38.5 | 44.8 |
| [AI2D][ai2d] | 63.2 | 75.2 | 79.0 |
| [ChartQA][chartqa] | 63.6 | 74.7 | 76.3 |
| [VQAv2][vqav2] | 63.9 | 71.2 | 72.9 |
| [BLINK][blinkvqa] | 38.0 | 35.9 | 39.6 |
| [OKVQA][okvqa] | 51.0 | 58.7 | 60.2 |
| [TallyQA][tallyqa] | 42.5 | 51.8 | 54.3 |
| [SpatialSense VQA][ss-vqa] | 50.9 | 60.0 | 59.4 |
| [CountBenchQA][countbenchqa] | 26.1 | 17.8 | 68.0 |
[coco-cap]: https://cocodataset.org/#home
[docvqa]: https://www.docvqa.org/
[info-vqa]: https://arxiv.org/abs/2104.12756
[mmmu]: https://arxiv.org/abs/2311.16502
[textvqa]: https://textvqa.org/
[realworldqa]: https://paperswithcode.com/dataset/realworldqa
[remi]: https://arxiv.org/html/2406.09175v1
[ai2d]: https://allenai.org/data/diagrams
[chartqa]: https://arxiv.org/abs/2203.10244
[vqav2]: https://visualqa.org/index.html
[blinkvqa]: https://arxiv.org/abs/2404.12390
[okvqa]: https://okvqa.allenai.org/
[tallyqa]: https://arxiv.org/abs/1810.12440
[ss-vqa]: https://arxiv.org/abs/1908.02660
[countbenchqa]: https://github.com/google-research/big_vision/blob/main/big_vision/datasets/countbenchqa/
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
- **Child Safety**: Evaluation of text-to-text and image to text prompts
covering child safety policies, including child sexual abuse and
exploitation.
- **Content Safety:** Evaluation of text-to-text and image to text prompts
covering safety policies including, harassment, violence and gore, and hate
speech.
- **Representational Harms**: Evaluation of text-to-text and image to text
prompts covering safety policies including bias, stereotyping, and harmful
associations or inaccuracies.
In addition to development level evaluations, we conduct "assurance
evaluations" which are our 'arms-length' internal evaluations for responsibility
governance decision making. They are conducted separately from the model
development team, to inform decision making about release. High level findings
are fed back to the model team, but prompt sets are held-out to prevent
overfitting and preserve the results' ability to inform decision making.
Assurance evaluation results are reported to our Responsibility & Safety Council
as part of release review.
### Evaluation Results
For all areas of safety testing, we saw major improvements in the categories of
child safety, content safety, and representational harms relative to previous
Gemma models. All testing was conducted without safety filters to evaluate the
model capabilities and behaviors. For both text-to-text and image-to-text, and
across all model sizes, the model produced minimal policy violations, and showed
significant improvements over previous Gemma models' performance with respect
to ungrounded inferences. A limitation of our evaluations was they included only
English language prompts.
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open vision-language models (VLMs) models have a wide range of applications
across various industries and domains. The following list of potential uses is
not comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
- Content Creation and Communication
- Text Generation: These models can be used to generate creative text
formats such as poems, scripts, code, marketing copy, and email drafts.
- Chatbots and Conversational AI: Power conversational interfaces
for customer service, virtual assistants, or interactive applications.
- Text Summarization: Generate concise summaries of a text corpus,
research papers, or reports.
- Image Data Extraction: These models can be used to extract,
interpret, and summarize visual data for text communications.
- Research and Education
- Natural Language Processing (NLP) and VLM Research: These
models can serve as a foundation for researchers to experiment with VLM
and NLP techniques, develop algorithms, and contribute to the
advancement of the field.
- Language Learning Tools: Support interactive language learning
experiences, aiding in grammar correction or providing writing practice.
- Knowledge Exploration: Assist researchers in exploring large
bodies of text by generating summaries or answering questions about
specific topics.
### Limitations
- Training Data
- The quality and diversity of the training data significantly
influence the model's capabilities. Biases or gaps in the training data
can lead to limitations in the model's responses.
- The scope of the training dataset determines the subject areas
the model can handle effectively.
- Context and Task Complexity
- Models are better at tasks that can be framed with clear
prompts and instructions. Open-ended or highly complex tasks might be
challenging.
- A model's performance can be influenced by the amount of context
provided (longer context generally leads to better outputs, up to a
certain point).
- Language Ambiguity and Nuance
- Natural language is inherently complex. Models might struggle
to grasp subtle nuances, sarcasm, or figurative language.
- Factual Accuracy
- Models generate responses based on information they learned
from their training datasets, but they are not knowledge bases. They
may generate incorrect or outdated factual statements.
- Common Sense
- Models rely on statistical patterns in language. They might
lack the ability to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of vision-language models (VLMs) raises several ethical
concerns. In creating an open model, we have carefully considered the following:
- Bias and Fairness
- VLMs trained on large-scale, real-world text and image data can
reflect socio-cultural biases embedded in the training material. These
models underwent careful scrutiny, input data pre-processing described
and posterior evaluations reported in this card.
- Misinformation and Misuse
- VLMs can be misused to generate text that is false, misleading,
or harmful.
- Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit][rai-toolkit].
- Transparency and Accountability:
- This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
- A responsibly developed open model offers the opportunity to
share innovation by making VLM technology accessible to developers and
researchers across the AI ecosystem.
Risks identified and mitigations:
- **Perpetuation of biases**: It's encouraged to perform continuous
monitoring (using evaluation metrics, human review) and the exploration of
de-biasing techniques during model training, fine-tuning, and other use
cases.
- **Generation of harmful content**: Mechanisms and guidelines for content
safety are essential. Developers are encouraged to exercise caution and
implement appropriate content safety safeguards based on their specific
product policies and application use cases.
- **Misuse for malicious purposes**: Technical limitations and developer
and end-user education can help mitigate against malicious applications of
VLMs. Educational resources and reporting mechanisms for users to flag
misuse are provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy][prohibited-use].
- **Privacy violations**: Models were trained on data filtered for removal
of certain personal information and other sensitive data. Developers are
encouraged to adhere to privacy regulations with privacy-preserving
techniques.
### Benefits
At the time of release, this family of models provides high-performance open
vision-language model implementations designed from the ground up for
responsible AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
[g3-tech-report]: https://goo.gle/Gemma3Report
[rai-toolkit]: https://ai.google.dev/responsible
[kaggle-gemma]: https://www.kaggle.com/models/google/gemma-3
[vertex-mg-gemma3]: https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma3
[terms]: https://ai.google.dev/gemma/terms
[safety-policies]: https://ai.google/static/documents/ai-responsibility-update-published-february-2025.pdf
[prohibited-use]: https://ai.google.dev/gemma/prohibited_use_policy
[tpu]: https://cloud.google.com/tpu/docs/intro-to-tpu
[sustainability]: https://sustainability.google/operating-sustainably/
[jax]: https://github.com/jax-ml/jax
[ml-pathways]: https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[sustainability]: https://sustainability.google/operating-sustainably/
|
Mungert/X-Ray_Alpha-GGUF | Mungert | 2025-06-15T19:42:38Z | 1,381 | 5 | null | [
"gguf",
"en",
"dataset:SicariusSicariiStuff/UBW_Tapestries",
"base_model:google/gemma-3-4b-it",
"base_model:quantized:google/gemma-3-4b-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-25T09:55:48Z | ---
license: gemma
language:
- en
base_model:
- google/gemma-3-4b-it
datasets:
- SicariusSicariiStuff/UBW_Tapestries
---
# <span style="color: #7FFF7F;">X-Ray_Alpha GGUF Models</span>
## How to Use X-Ray_Alpha with llama.cpp
1. **Download the X-Ray_Alpha gguf file**:
https://huggingface.co/Mungert/X-Ray_Alpha-GGUF/tree/main
Choose a gguf file without the mmproj in the name
Example gguf file : https://huggingface.co/Mungert/Mungert/X-Ray_Alpha-GGUF/resolve/main/X-Ray_Alpha-q8_0.gguf
Copy this file to your chosen folder.
2. **Download the X-Ray_Alpha mmproj file**
https://huggingface.co/Mungert/X-Ray_Alpha-GGUF/tree/main
Choose a file with mmproj in the name
Example mmproj file : https://huggingface.co/Mungert/X-Ray_Alpha-GGUF/resolve/main/X-Ray_Alpha-mmproj-f32.gguf
Copy this file to your chosen folder.
3. Copy images to the same folder as the gguf files or alter paths appropriately.
In the example below the gguf files, images and llama-mtmd-cli are in the same folder.
Example image: image https://huggingface.co/Mungert/X-Ray_Alpha-GGUF/resolve/main/car-1.jpg
Copy this file to your chosen folder.
4. **Run the CLI Tool**:
From your chosen folder :
```bash
llama-gemma3-cli -m X-Ray_Alpha-q8_0.gguf --mmproj X-Ray_Alpha-mmproj-f32.gguf -p "Describe this image." --image ./car-1.jpg
```
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `X-Ray_Alpha-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `X-Ray_Alpha-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `X-Ray_Alpha-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `X-Ray_Alpha-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `X-Ray_Alpha-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `X-Ray_Alpha-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `X-Ray_Alpha-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `X-Ray_Alpha-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `X-Ray_Alpha-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `X-Ray_Alpha-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `X-Ray_Alpha-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
<div align="center">
<b style="font-size: 40px;">X-Ray_Alpha</b>
</div>
<img src="https://huggingface.co/SicariusSicariiStuff/X-Ray_Alpha/resolve/main/Images/X-Ray_Alpha.png" alt="X-Ray_Alpha" style="width: 30%; min-width: 450px; display: block; margin: auto;">
---
<div style="display: flex; justify-content: center; align-items: center;">
<a href="https://huggingface.co/SicariusSicariiStuff/X-Ray_Alpha#tldr"
style="color: #800080; font-weight: bold; font-size: 28px; text-decoration: none; margin: 0 20px;">
Click here
for TL;DR
</a>
<a href="https://huggingface.co/SicariusSicariiStuff/X-Ray_Alpha#why-is-this-important"
style="color: #1E90FF; font-weight: bold; font-size: 28px; text-decoration: none; margin: 0 20px;">
Why it's
important
</a>
<a href="https://huggingface.co/SicariusSicariiStuff/X-Ray_Alpha#how-can-you-help"
style="color: #32CD32; font-weight: bold; font-size: 28px; text-decoration: none; margin: 0 20px;">
How can YOU
help?
</a>
<a href="https://huggingface.co/SicariusSicariiStuff/X-Ray_Alpha#how-to-run-it"
style="color: #E31515; font-weight: bold; font-size: 28px; text-decoration: none; margin: 0 20px;">
How to
RUN IT
</a>
</div>
---
This is a pre-alpha proof-of-concept of **a real fully uncensored vision model**.
Why do I say **"real"**? The few vision models we got (qwen, llama 3.2) were "censored," and their fine-tunes were made only to the **text portion** of the model, as training a vision model is a serious pain.
The only actually trained and uncensored vision model I am aware of is [ToriiGate](https://huggingface.co/Minthy/ToriiGate-v0.4-7B); the rest of the vision models are just the stock vision + a fine-tuned LLM.
# Does this even work?
<h2 style="color: green; font-weight: bold; font-size: 80px; text-align: center;">YES!</h2>
---
# Why is this Important?
Having a **fully compliant** vision model is a critical step toward democratizing vision capabilities for various tasks, especially **image tagging**. This is a critical step in both making LORAs for image diffusion models, and for mass tagging images to pretrain a diffusion model.
In other words, having a fully compliant and accurate vision model will allow the open source community to easily train both loras and even pretrain image diffusion models.
Another important task can be content moderation and classification, in various use cases there might not be black and white, where some content that might be considered NSFW by corporations, is allowed, while other content is not, there's nuance. Today's vision models **do not let the users decide**, as they will straight up **refuse** to inference any content that Google \ Some other corporations decided is not to their liking, and therefore these stock models are useless in a lot of cases.
What if someone wants to classify art that includes nudity? Having a naked statue over 1,000 years old displayed in the middle of a city, in a museum, or at the city square is perfectly acceptable, however, a stock vision model will straight up refuse to inference something like that.
It's like in many "sensitive" topics that LLMs will straight up **refuse to answer**, while the content is **publicly available on Wikipedia**. This is an attitude of **cynical patronism**, I say cynical because corporations **take private data to train their models**, and it is "perfectly fine", yet- they serve as the **arbitrators of morality** and indirectly preach to us from a position of a suggested moral superiority. This **gatekeeping hurts innovation badly**, with vision models **especially so**, as the task of **tagging cannot be done by a single person at scale**, but a corporation can.
# How can YOU help?
This is sort of **"Pre-Alpha"**, a proof of concept, I did **A LOT** of shortcuts and "hacking" to make this work, and I would greatly appreciate some help to make it into an accurate and powerful open tool. I am not asking for money, but well-tagged data. I will take the burden and costs of the compute on myself, but I **cannot do tagging** at a large scale by myself.
## Bottom line, I need a lot of well-tagged, diverse data
So:
- If you have well-tagged images
- If you have a link to a well-tagged image dataset
- If you can, and willing to do image tagging
Then please send an email with [DATASET] in the title to:
```
[email protected]
```
As you probably figured by the email address name, this is not my main email, and I expect it to be spammed with junk, so **please use the [DATASET] tag** so I can more easily find the emails of **the good people** who are actually trying to help.
## Please see this dataset repo if you want to help:
[X-Ray_Community_Tagging](https://huggingface.co/datasets/SicariusSicariiStuff/X-Ray_Community_Tagging)
Also, if you don't want to upload it to the repo (although it's encouraged, and you can protect it with a password for privacy), you can still help by linking a google drive
or attach the images with the corrected output via the provided email.
Let's make this happen. We can do it!
---
### TL;DR
- **Fully uncensored and trained** there's no moderation in the vision model, I actually trained it.
- **The 2nd uncensored vision model in the world**, ToriiGate being the first as far as I know, and this one is the second.
- **In-depth descriptions** very detailed, long descriptions.
- The text portion is **somewhat uncensored** as well, I didn't want to butcher and fry it too much, so it remain "smart".
- **NOT perfect** This is a POC that shows that the task can even be done, a lot more work is needed.
- **Good Roleplay & Writing** I used a massive corpus of high quality human (**~60%**) and synthetic data.
---
# How to run it:
## VRAM needed for FP16: 15.9 GB
[Run inference with this](https://github.com/SicariusSicariiStuff/X-Ray_Vision)
# This is a pre-alpha POC (Proof Of Concept)
## Instructions:
clone:
```
git clone https://github.com/SicariusSicariiStuff/X-Ray_Vision.git
cd X-Ray_Vision/
```
Settings up venv, (tested for python 3.11, probably works with 3.10)
```
python3.11 -m venv env
source env/bin/activate
```
Install dependencies
```
pip install git+https://github.com/huggingface/[email protected]
pip install torch
pip install pillow
pip install accelerate
```
# Running inference
Usage:
```
python xRay-Vision.py /path/to/model/ /dir/with/images/
```
The output will print to the console, and export the results into a dir named after your image dir with the suffix "_TXT"
So if you run:
```
python xRay-Vision.py /some_path/x-Ray_model/ /home/images/weird_cats/
```
The results will be exported to:
```
/home/images/weird_cats_TXT/
```
---
<h2 style="color: green; font-weight: bold; font-size: 65px; text-align: center;">Your support = more models</h2>
<a href="https://ko-fi.com/sicarius" style="color: pink; font-weight: bold; font-size: 48px; text-decoration: none; display: block; text-align: center;">My Ko-fi page (Click here)</a>
---
## Citation Information
```
@llm{X-Ray_Alpha,
author = {SicariusSicariiStuff},
title = {X-Ray_Alpha},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/X-Ray_Alpha}
}
```
---
## Other stuff
- [X-Ray_Vision](https://github.com/SicariusSicariiStuff/X-Ray_Vision) Easy stand-alone bulk vision inference at scale (inference a folder of images).
- [SLOP_Detector](https://github.com/SicariusSicariiStuff/SLOP_Detector) Nuke GPTisms, with SLOP detector.
- [LLAMA-3_8B_Unaligned](https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned) The grand project that started it all.
- [Blog and updates (Archived)](https://huggingface.co/SicariusSicariiStuff/Blog_And_Updates) Some updates, some rambles, sort of a mix between a diary and a blog. |
Mungert/MetaStone-L1-7B-GGUF | Mungert | 2025-06-15T19:42:32Z | 460 | 2 | null | [
"gguf",
"arxiv:2412.08864",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-24T15:38:45Z | ##
# <span style="color: #7FFF7F;">MetaStone-L1-7B GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `MetaStone-L1-7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `MetaStone-L1-7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `MetaStone-L1-7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `MetaStone-L1-7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `MetaStone-L1-7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `MetaStone-L1-7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `MetaStone-L1-7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `MetaStone-L1-7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `MetaStone-L1-7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `MetaStone-L1-7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `MetaStone-L1-7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the FreeLLM .
🔵 **FreeLLM** – Runs **open-source Hugging Face models** Medium speed (unlimited, subject to Hugging Face API availability).
Introduction
MetaStone-L1 is the lite reasoning model of the MetaStone series, which aims to enhance the performance in hard downstream tasks.
On core reasoning benchmarks including mathematics and code, MetaStone-L1-7B achieved SOTA results in the parallel-level models, and it also achieved the comparable results as the API models such as Claude-3.5-Sonnet-1022 and GPT4o-0513.
<img src="./introduction.png" alt="Logo" width="800">
This repo contains the MetaStone-L1-7B model, which is trained based on DeepSeek-R1-Distill-Qwen-7B by GRPO. For full details of this model please refer to our release blog.
## Requirements
We advise you to use the latest version of transformers(```transformers==4.48.3```). For the best experience, please review the [Usage Guidelines](#usage-guidelines).
## Quickstart
Here give the example of how to use our model.
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MetaStoneTec/MetaStone-L1-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
messages = [
{"role": "user", "content": "Complete the square for the following quadratic: $-x^2+7 x-11$\n\nPlease reason step by step, and put your final answer within \\boxed{}."}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Usage Guidelines
To achieve optimal performance, we recommend the following settings:
1. Enhace the thoughful output:
a. Make sure the model starts with ```<think>\n``` to prevent generating empty think content. If you use ```apply_chat_template``` and set ```add_generation_prompt=True```, this is automatically implemented, but this may result in replies not having a <think> tag at the beginning, which is normal.
b. Ensure the final input of the model is in the format of ```<|User|> [your prompt] <|Assistant|><think>```.
2. Use a temperature of 0.6, a top sampling probability of 0.95, a maximum generation length of 32k.
3. Standardize output format: We recommend using hints to standardize model outputs when benchmarking.
a. Math questions: Add a statement "```Please reason step by step, and put your final answer within \\boxed{}.```" to the prompt.
b. Code problems: Add "### Format: Read the inputs from stdin solve the problem and write the answer to stdout. Enclose your code within delimiters as follows.\n \```python\n# YOUR CODE HERE\n\```\n### Answer: (use the provided format with backticks)" to the prompt.
4. In particular, we use ```latex2sympy2``` and ```sympy``` to assist in judging complex Latex formats for the Math500 evaluation script. For all datasets, we generate 64 responses per query to estimate pass@1.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{MetaStoneL17B,
title = {MetastoneL17B},
url = {https://huggingface.co/MetaStoneTec/MetaStone-L1-7B},
author = {MetaStone Team},
month = {March},
year = {2025}
}
```
```
@article{wang2024graph,
title={A Graph-Based Synthetic Data Pipeline for Scaling High-Quality Reasoning Instructions},
author={Wang, Jiankang and Xu, Jianjun and Wang, Xiaorui and Wang, Yuxin and Xing, Mengting and Fang, Shancheng and Chen, Zhineng and Xie, Hongtao and Zhang, Yongdong},
journal={arXiv preprint arXiv:2412.08864},
year={2024}
}
```
|
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_seed_2_20250615_193305 | gradientrouting-spar | 2025-06-15T19:42:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:42:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mungert/mxbai-rerank-large-v2-GGUF | Mungert | 2025-06-15T19:42:28Z | 894 | 2 | transformers | [
"transformers",
"gguf",
"text-ranking",
"en",
"zh",
"de",
"ja",
"ko",
"es",
"fr",
"ar",
"bn",
"ru",
"id",
"sw",
"te",
"th",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-ranking | 2025-03-24T13:41:53Z | ---
library_name: transformers
license: apache-2.0
language:
- en
- zh
- de
- ja
- ko
- es
- fr
- ar
- bn
- ru
- id
- sw
- te
- th
pipeline_tag: text-ranking
---
# <span style="color: #7FFF7F;">mxbai-rerank-large-v2 GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `mxbai-rerank-large-v2-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `mxbai-rerank-large-v2-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `mxbai-rerank-large-v2-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `mxbai-rerank-large-v2-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `mxbai-rerank-large-v2-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `mxbai-rerank-large-v2-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `mxbai-rerank-large-v2-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `mxbai-rerank-large-v2-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `mxbai-rerank-large-v2-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `mxbai-rerank-large-v2-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `mxbai-rerank-large-v2-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
<br><br>
<p align="center">
<svg xmlns="http://www.w3.org/2000/svg" xml:space="preserve" viewBox="0 0 2020 1130" width="150" height="150" aria-hidden="true"><path fill="#e95a0f" d="M398.167 621.992c-1.387-20.362-4.092-40.739-3.851-61.081.355-30.085 6.873-59.139 21.253-85.976 10.487-19.573 24.09-36.822 40.662-51.515 16.394-14.535 34.338-27.046 54.336-36.182 15.224-6.955 31.006-12.609 47.829-14.168 11.809-1.094 23.753-2.514 35.524-1.836 23.033 1.327 45.131 7.255 66.255 16.75 16.24 7.3 31.497 16.165 45.651 26.969 12.997 9.921 24.412 21.37 34.158 34.509 11.733 15.817 20.849 33.037 25.987 52.018 3.468 12.81 6.438 25.928 7.779 39.097 1.722 16.908 1.642 34.003 2.235 51.021.427 12.253.224 24.547 1.117 36.762 1.677 22.93 4.062 45.764 11.8 67.7 5.376 15.239 12.499 29.55 20.846 43.681l-18.282 20.328c-1.536 1.71-2.795 3.665-4.254 5.448l-19.323 23.533c-13.859-5.449-27.446-11.803-41.657-16.086-13.622-4.106-27.793-6.765-41.905-8.775-15.256-2.173-30.701-3.475-46.105-4.049-23.571-.879-47.178-1.056-70.769-1.029-10.858.013-21.723 1.116-32.57 1.926-5.362.4-10.69 1.255-16.464 1.477-2.758-7.675-5.284-14.865-7.367-22.181-3.108-10.92-4.325-22.554-13.16-31.095-2.598-2.512-5.069-5.341-6.883-8.443-6.366-10.884-12.48-21.917-18.571-32.959-4.178-7.573-8.411-14.375-17.016-18.559-10.34-5.028-19.538-12.387-29.311-18.611-3.173-2.021-6.414-4.312-9.952-5.297-5.857-1.63-11.98-2.301-17.991-3.376z"></path><path fill="#ed6d7b" d="M1478.998 758.842c-12.025.042-24.05.085-36.537-.373-.14-8.536.231-16.569.453-24.607.033-1.179-.315-2.986-1.081-3.4-.805-.434-2.376.338-3.518.81-.856.354-1.562 1.069-3.589 2.521-.239-3.308-.664-5.586-.519-7.827.488-7.544 2.212-15.166 1.554-22.589-1.016-11.451 1.397-14.592-12.332-14.419-3.793.048-3.617-2.803-3.332-5.331.499-4.422 1.45-8.803 1.77-13.233.311-4.316.068-8.672.068-12.861-2.554-.464-4.326-.86-6.12-1.098-4.415-.586-6.051-2.251-5.065-7.31 1.224-6.279.848-12.862 1.276-19.306.19-2.86-.971-4.473-3.794-4.753-4.113-.407-8.242-1.057-12.352-.975-4.663.093-5.192-2.272-4.751-6.012.733-6.229 1.252-12.483 1.875-18.726l1.102-10.495c-5.905-.309-11.146-.805-16.385-.778-3.32.017-5.174-1.4-5.566-4.4-1.172-8.968-2.479-17.944-3.001-26.96-.26-4.484-1.936-5.705-6.005-5.774-9.284-.158-18.563-.594-27.843-.953-7.241-.28-10.137-2.764-11.3-9.899-.746-4.576-2.715-7.801-7.777-8.207-7.739-.621-15.511-.992-23.207-1.961-7.327-.923-14.587-2.415-21.853-3.777-5.021-.941-10.003-2.086-15.003-3.14 4.515-22.952 13.122-44.382 26.284-63.587 18.054-26.344 41.439-47.239 69.102-63.294 15.847-9.197 32.541-16.277 50.376-20.599 16.655-4.036 33.617-5.715 50.622-4.385 33.334 2.606 63.836 13.955 92.415 31.15 15.864 9.545 30.241 20.86 42.269 34.758 8.113 9.374 15.201 19.78 21.718 30.359 10.772 17.484 16.846 36.922 20.611 56.991 1.783 9.503 2.815 19.214 3.318 28.876.758 14.578.755 29.196.65 44.311l-51.545 20.013c-7.779 3.059-15.847 5.376-21.753 12.365-4.73 5.598-10.658 10.316-16.547 14.774-9.9 7.496-18.437 15.988-25.083 26.631-3.333 5.337-7.901 10.381-12.999 14.038-11.355 8.144-17.397 18.973-19.615 32.423l-6.988 41.011z"></path><path fill="#ec663e" d="M318.11 923.047c-.702 17.693-.832 35.433-2.255 53.068-1.699 21.052-6.293 41.512-14.793 61.072-9.001 20.711-21.692 38.693-38.496 53.583-16.077 14.245-34.602 24.163-55.333 30.438-21.691 6.565-43.814 8.127-66.013 6.532-22.771-1.636-43.88-9.318-62.74-22.705-20.223-14.355-35.542-32.917-48.075-54.096-9.588-16.203-16.104-33.55-19.201-52.015-2.339-13.944-2.307-28.011-.403-42.182 2.627-19.545 9.021-37.699 17.963-55.067 11.617-22.564 27.317-41.817 48.382-56.118 15.819-10.74 33.452-17.679 52.444-20.455 8.77-1.282 17.696-1.646 26.568-2.055 11.755-.542 23.534-.562 35.289-1.11 8.545-.399 17.067-1.291 26.193-1.675 1.349 1.77 2.24 3.199 2.835 4.742 4.727 12.261 10.575 23.865 18.636 34.358 7.747 10.084 14.83 20.684 22.699 30.666 3.919 4.972 8.37 9.96 13.609 13.352 7.711 4.994 16.238 8.792 24.617 12.668 5.852 2.707 12.037 4.691 18.074 6.998z"></path><path fill="#ea580e" d="M1285.167 162.995c3.796-29.75 13.825-56.841 32.74-80.577 16.339-20.505 36.013-36.502 59.696-47.614 14.666-6.881 29.971-11.669 46.208-12.749 10.068-.669 20.239-1.582 30.255-.863 16.6 1.191 32.646 5.412 47.9 12.273 19.39 8.722 36.44 20.771 50.582 36.655 15.281 17.162 25.313 37.179 31.49 59.286 5.405 19.343 6.31 39.161 4.705 58.825-2.37 29.045-11.836 55.923-30.451 78.885-10.511 12.965-22.483 24.486-37.181 33.649-5.272-5.613-10.008-11.148-14.539-16.846-5.661-7.118-10.958-14.533-16.78-21.513-4.569-5.478-9.548-10.639-14.624-15.658-3.589-3.549-7.411-6.963-11.551-9.827-5.038-3.485-10.565-6.254-15.798-9.468-8.459-5.195-17.011-9.669-26.988-11.898-12.173-2.72-24.838-4.579-35.622-11.834-1.437-.967-3.433-1.192-5.213-1.542-12.871-2.529-25.454-5.639-36.968-12.471-5.21-3.091-11.564-4.195-17.011-6.965-4.808-2.445-8.775-6.605-13.646-8.851-8.859-4.085-18.114-7.311-27.204-10.896z"></path><path fill="#f8ab00" d="M524.963 311.12c-9.461-5.684-19.513-10.592-28.243-17.236-12.877-9.801-24.031-21.578-32.711-35.412-11.272-17.965-19.605-37.147-21.902-58.403-1.291-11.951-2.434-24.073-1.87-36.034.823-17.452 4.909-34.363 11.581-50.703 8.82-21.603 22.25-39.792 39.568-55.065 18.022-15.894 39.162-26.07 62.351-32.332 19.22-5.19 38.842-6.177 58.37-4.674 23.803 1.831 45.56 10.663 65.062 24.496 17.193 12.195 31.688 27.086 42.894 45.622-11.403 8.296-22.633 16.117-34.092 23.586-17.094 11.142-34.262 22.106-48.036 37.528-8.796 9.848-17.201 20.246-27.131 28.837-16.859 14.585-27.745 33.801-41.054 51.019-11.865 15.349-20.663 33.117-30.354 50.08-5.303 9.283-9.654 19.11-14.434 28.692z"></path><path fill="#ea5227" d="M1060.11 1122.049c-7.377 1.649-14.683 4.093-22.147 4.763-11.519 1.033-23.166 1.441-34.723 1.054-19.343-.647-38.002-4.7-55.839-12.65-15.078-6.72-28.606-15.471-40.571-26.836-24.013-22.81-42.053-49.217-49.518-81.936-1.446-6.337-1.958-12.958-2.235-19.477-.591-13.926-.219-27.909-1.237-41.795-.916-12.5-3.16-24.904-4.408-37.805 1.555-1.381 3.134-2.074 3.778-3.27 4.729-8.79 12.141-15.159 19.083-22.03 5.879-5.818 10.688-12.76 16.796-18.293 6.993-6.335 11.86-13.596 14.364-22.612l8.542-29.993c8.015 1.785 15.984 3.821 24.057 5.286 8.145 1.478 16.371 2.59 24.602 3.493 8.453.927 16.956 1.408 25.891 2.609 1.119 16.09 1.569 31.667 2.521 47.214.676 11.045 1.396 22.154 3.234 33.043 2.418 14.329 5.708 28.527 9.075 42.674 3.499 14.705 4.028 29.929 10.415 44.188 10.157 22.674 18.29 46.25 28.281 69.004 7.175 16.341 12.491 32.973 15.078 50.615.645 4.4 3.256 8.511 4.963 12.755z"></path><path fill="#ea5330" d="M1060.512 1122.031c-2.109-4.226-4.72-8.337-5.365-12.737-2.587-17.642-7.904-34.274-15.078-50.615-9.991-22.755-18.124-46.33-28.281-69.004-6.387-14.259-6.916-29.482-10.415-44.188-3.366-14.147-6.656-28.346-9.075-42.674-1.838-10.889-2.558-21.999-3.234-33.043-.951-15.547-1.401-31.124-2.068-47.146 8.568-.18 17.146.487 25.704.286l41.868-1.4c.907 3.746 1.245 7.04 1.881 10.276l8.651 42.704c.903 4.108 2.334 8.422 4.696 11.829 7.165 10.338 14.809 20.351 22.456 30.345 4.218 5.512 8.291 11.304 13.361 15.955 8.641 7.927 18.065 14.995 27.071 22.532 12.011 10.052 24.452 19.302 40.151 22.854-1.656 11.102-2.391 22.44-5.172 33.253-4.792 18.637-12.38 36.209-23.412 52.216-13.053 18.94-29.086 34.662-49.627 45.055-10.757 5.443-22.443 9.048-34.111 13.501z"></path><path fill="#f8aa05" d="M1989.106 883.951c5.198 8.794 11.46 17.148 15.337 26.491 5.325 12.833 9.744 26.207 12.873 39.737 2.95 12.757 3.224 25.908 1.987 39.219-1.391 14.973-4.643 29.268-10.349 43.034-5.775 13.932-13.477 26.707-23.149 38.405-14.141 17.104-31.215 30.458-50.807 40.488-14.361 7.352-29.574 12.797-45.741 14.594-10.297 1.144-20.732 2.361-31.031 1.894-24.275-1.1-47.248-7.445-68.132-20.263-6.096-3.741-11.925-7.917-17.731-12.342 5.319-5.579 10.361-10.852 15.694-15.811l37.072-34.009c.975-.892 2.113-1.606 3.08-2.505 6.936-6.448 14.765-12.2 20.553-19.556 8.88-11.285 20.064-19.639 31.144-28.292 4.306-3.363 9.06-6.353 12.673-10.358 5.868-6.504 10.832-13.814 16.422-20.582 6.826-8.264 13.727-16.481 20.943-24.401 4.065-4.461 8.995-8.121 13.249-12.424 14.802-14.975 28.77-30.825 45.913-43.317z"></path><path fill="#ed6876" d="M1256.099 523.419c5.065.642 10.047 1.787 15.068 2.728 7.267 1.362 14.526 2.854 21.853 3.777 7.696.97 15.468 1.34 23.207 1.961 5.062.406 7.031 3.631 7.777 8.207 1.163 7.135 4.059 9.62 11.3 9.899l27.843.953c4.069.069 5.745 1.291 6.005 5.774.522 9.016 1.829 17.992 3.001 26.96.392 3 2.246 4.417 5.566 4.4 5.239-.026 10.48.469 16.385.778l-1.102 10.495-1.875 18.726c-.44 3.74.088 6.105 4.751 6.012 4.11-.082 8.239.568 12.352.975 2.823.28 3.984 1.892 3.794 4.753-.428 6.444-.052 13.028-1.276 19.306-.986 5.059.651 6.724 5.065 7.31 1.793.238 3.566.634 6.12 1.098 0 4.189.243 8.545-.068 12.861-.319 4.43-1.27 8.811-1.77 13.233-.285 2.528-.461 5.379 3.332 5.331 13.729-.173 11.316 2.968 12.332 14.419.658 7.423-1.066 15.045-1.554 22.589-.145 2.241.28 4.519.519 7.827 2.026-1.452 2.733-2.167 3.589-2.521 1.142-.472 2.713-1.244 3.518-.81.767.414 1.114 2.221 1.081 3.4l-.917 24.539c-11.215.82-22.45.899-33.636 1.674l-43.952 3.436c-1.086-3.01-2.319-5.571-2.296-8.121.084-9.297-4.468-16.583-9.091-24.116-3.872-6.308-8.764-13.052-9.479-19.987-1.071-10.392-5.716-15.936-14.889-18.979-1.097-.364-2.16-.844-3.214-1.327-7.478-3.428-15.548-5.918-19.059-14.735-.904-2.27-3.657-3.775-5.461-5.723-2.437-2.632-4.615-5.525-7.207-7.987-2.648-2.515-5.352-5.346-8.589-6.777-4.799-2.121-10.074-3.185-15.175-4.596l-15.785-4.155c.274-12.896 1.722-25.901.54-38.662-1.647-17.783-3.457-35.526-2.554-53.352.528-10.426 2.539-20.777 3.948-31.574z"></path><path fill="#f6a200" d="M525.146 311.436c4.597-9.898 8.947-19.725 14.251-29.008 9.691-16.963 18.49-34.73 30.354-50.08 13.309-17.218 24.195-36.434 41.054-51.019 9.93-8.591 18.335-18.989 27.131-28.837 13.774-15.422 30.943-26.386 48.036-37.528 11.459-7.469 22.688-15.29 34.243-23.286 11.705 16.744 19.716 35.424 22.534 55.717 2.231 16.066 2.236 32.441 2.753 49.143-4.756 1.62-9.284 2.234-13.259 4.056-6.43 2.948-12.193 7.513-18.774 9.942-19.863 7.331-33.806 22.349-47.926 36.784-7.86 8.035-13.511 18.275-19.886 27.705-4.434 6.558-9.345 13.037-12.358 20.254-4.249 10.177-6.94 21.004-10.296 31.553-12.33.053-24.741 1.027-36.971-.049-20.259-1.783-40.227-5.567-58.755-14.69-.568-.28-1.295-.235-2.132-.658z"></path><path fill="#f7a80d" d="M1989.057 883.598c-17.093 12.845-31.061 28.695-45.863 43.67-4.254 4.304-9.184 7.963-13.249 12.424-7.216 7.92-14.117 16.137-20.943 24.401-5.59 6.768-10.554 14.078-16.422 20.582-3.614 4.005-8.367 6.995-12.673 10.358-11.08 8.653-22.264 17.007-31.144 28.292-5.788 7.356-13.617 13.108-20.553 19.556-.967.899-2.105 1.614-3.08 2.505l-37.072 34.009c-5.333 4.96-10.375 10.232-15.859 15.505-21.401-17.218-37.461-38.439-48.623-63.592 3.503-1.781 7.117-2.604 9.823-4.637 8.696-6.536 20.392-8.406 27.297-17.714.933-1.258 2.646-1.973 4.065-2.828 17.878-10.784 36.338-20.728 53.441-32.624 10.304-7.167 18.637-17.23 27.583-26.261 3.819-3.855 7.436-8.091 10.3-12.681 12.283-19.68 24.43-39.446 40.382-56.471 12.224-13.047 17.258-29.524 22.539-45.927 15.85 4.193 29.819 12.129 42.632 22.08 10.583 8.219 19.782 17.883 27.42 29.351z"></path><path fill="#ef7a72" d="M1479.461 758.907c1.872-13.734 4.268-27.394 6.525-41.076 2.218-13.45 8.26-24.279 19.615-32.423 5.099-3.657 9.667-8.701 12.999-14.038 6.646-10.643 15.183-19.135 25.083-26.631 5.888-4.459 11.817-9.176 16.547-14.774 5.906-6.99 13.974-9.306 21.753-12.365l51.48-19.549c.753 11.848.658 23.787 1.641 35.637 1.771 21.353 4.075 42.672 11.748 62.955.17.449.107.985-.019 2.158-6.945 4.134-13.865 7.337-20.437 11.143-3.935 2.279-7.752 5.096-10.869 8.384-6.011 6.343-11.063 13.624-17.286 19.727-9.096 8.92-12.791 20.684-18.181 31.587-.202.409-.072.984-.096 1.481-8.488-1.72-16.937-3.682-25.476-5.094-9.689-1.602-19.426-3.084-29.201-3.949-15.095-1.335-30.241-2.1-45.828-3.172z"></path><path fill="#e94e3b" d="M957.995 766.838c-20.337-5.467-38.791-14.947-55.703-27.254-8.2-5.967-15.451-13.238-22.958-20.37 2.969-3.504 5.564-6.772 8.598-9.563 7.085-6.518 11.283-14.914 15.8-23.153 4.933-8.996 10.345-17.743 14.966-26.892 2.642-5.231 5.547-11.01 5.691-16.611.12-4.651.194-8.932 2.577-12.742 8.52-13.621 15.483-28.026 18.775-43.704 2.11-10.049 7.888-18.774 7.81-29.825-.064-9.089 4.291-18.215 6.73-27.313 3.212-11.983 7.369-23.797 9.492-35.968 3.202-18.358 5.133-36.945 7.346-55.466l4.879-45.8c6.693.288 13.386.575 20.54 1.365.13 3.458-.41 6.407-.496 9.37l-1.136 42.595c-.597 11.552-2.067 23.058-3.084 34.59l-3.845 44.478c-.939 10.202-1.779 20.432-3.283 30.557-.96 6.464-4.46 12.646-1.136 19.383.348.706-.426 1.894-.448 2.864-.224 9.918-5.99 19.428-2.196 29.646.103.279-.033.657-.092.983l-8.446 46.205c-1.231 6.469-2.936 12.846-4.364 19.279-1.5 6.757-2.602 13.621-4.456 20.277-3.601 12.93-10.657 25.3-5.627 39.47.368 1.036.234 2.352.017 3.476l-5.949 30.123z"></path><path fill="#ea5043" d="M958.343 767.017c1.645-10.218 3.659-20.253 5.602-30.302.217-1.124.351-2.44-.017-3.476-5.03-14.17 2.026-26.539 5.627-39.47 1.854-6.656 2.956-13.52 4.456-20.277 1.428-6.433 3.133-12.81 4.364-19.279l8.446-46.205c.059-.326.196-.705.092-.983-3.794-10.218 1.972-19.728 2.196-29.646.022-.97.796-2.158.448-2.864-3.324-6.737.176-12.919 1.136-19.383 1.504-10.125 2.344-20.355 3.283-30.557l3.845-44.478c1.017-11.532 2.488-23.038 3.084-34.59.733-14.18.722-28.397 1.136-42.595.086-2.963.626-5.912.956-9.301 5.356-.48 10.714-.527 16.536-.081 2.224 15.098 1.855 29.734 1.625 44.408-.157 10.064 1.439 20.142 1.768 30.23.334 10.235-.035 20.49.116 30.733.084 5.713.789 11.418.861 17.13.054 4.289-.469 8.585-.702 12.879-.072 1.323-.138 2.659-.031 3.975l2.534 34.405-1.707 36.293-1.908 48.69c-.182 8.103.993 16.237.811 24.34-.271 12.076-1.275 24.133-1.787 36.207-.102 2.414-.101 5.283 1.06 7.219 4.327 7.22 4.463 15.215 4.736 23.103.365 10.553.088 21.128.086 31.693-11.44 2.602-22.84.688-34.106-.916-11.486-1.635-22.806-4.434-34.546-6.903z"></path><path fill="#eb5d19" d="M398.091 622.45c6.086.617 12.21 1.288 18.067 2.918 3.539.985 6.779 3.277 9.952 5.297 9.773 6.224 18.971 13.583 29.311 18.611 8.606 4.184 12.839 10.986 17.016 18.559l18.571 32.959c1.814 3.102 4.285 5.931 6.883 8.443 8.835 8.542 10.052 20.175 13.16 31.095 2.082 7.317 4.609 14.507 6.946 22.127-29.472 3.021-58.969 5.582-87.584 15.222-1.185-2.302-1.795-4.362-2.769-6.233-4.398-8.449-6.703-18.174-14.942-24.299-2.511-1.866-5.103-3.814-7.047-6.218-8.358-10.332-17.028-20.276-28.772-26.973 4.423-11.478 9.299-22.806 13.151-34.473 4.406-13.348 6.724-27.18 6.998-41.313.098-5.093.643-10.176 1.06-15.722z"></path><path fill="#e94c32" d="M981.557 392.109c-1.172 15.337-2.617 30.625-4.438 45.869-2.213 18.521-4.144 37.108-7.346 55.466-2.123 12.171-6.28 23.985-9.492 35.968-2.439 9.098-6.794 18.224-6.73 27.313.078 11.051-5.7 19.776-7.81 29.825-3.292 15.677-10.255 30.082-18.775 43.704-2.383 3.81-2.458 8.091-2.577 12.742-.144 5.6-3.049 11.38-5.691 16.611-4.621 9.149-10.033 17.896-14.966 26.892-4.517 8.239-8.715 16.635-15.8 23.153-3.034 2.791-5.629 6.06-8.735 9.255-12.197-10.595-21.071-23.644-29.301-37.24-7.608-12.569-13.282-25.962-17.637-40.37 13.303-6.889 25.873-13.878 35.311-25.315.717-.869 1.934-1.312 2.71-2.147 5.025-5.405 10.515-10.481 14.854-16.397 6.141-8.374 10.861-17.813 17.206-26.008 8.22-10.618 13.657-22.643 20.024-34.466 4.448-.626 6.729-3.21 8.114-6.89 1.455-3.866 2.644-7.895 4.609-11.492 4.397-8.05 9.641-15.659 13.708-23.86 3.354-6.761 5.511-14.116 8.203-21.206 5.727-15.082 7.277-31.248 12.521-46.578 3.704-10.828 3.138-23.116 4.478-34.753l7.56-.073z"></path><path fill="#f7a617" d="M1918.661 831.99c-4.937 16.58-9.971 33.057-22.196 46.104-15.952 17.025-28.099 36.791-40.382 56.471-2.864 4.59-6.481 8.825-10.3 12.681-8.947 9.031-17.279 19.094-27.583 26.261-17.103 11.896-35.564 21.84-53.441 32.624-1.419.856-3.132 1.571-4.065 2.828-6.904 9.308-18.6 11.178-27.297 17.714-2.705 2.033-6.319 2.856-9.874 4.281-3.413-9.821-6.916-19.583-9.36-29.602-1.533-6.284-1.474-12.957-1.665-19.913 1.913-.78 3.374-1.057 4.81-1.431 15.822-4.121 31.491-8.029 43.818-20.323 9.452-9.426 20.371-17.372 30.534-26.097 6.146-5.277 13.024-10.052 17.954-16.326 14.812-18.848 28.876-38.285 43.112-57.581 2.624-3.557 5.506-7.264 6.83-11.367 2.681-8.311 4.375-16.94 6.476-25.438 17.89.279 35.333 3.179 52.629 9.113z"></path><path fill="#ea553a" d="M1172.91 977.582c-15.775-3.127-28.215-12.377-40.227-22.43-9.005-7.537-18.43-14.605-27.071-22.532-5.07-4.651-9.143-10.443-13.361-15.955-7.647-9.994-15.291-20.007-22.456-30.345-2.361-3.407-3.792-7.72-4.696-11.829-3.119-14.183-5.848-28.453-8.651-42.704-.636-3.236-.974-6.53-1.452-10.209 15.234-2.19 30.471-3.969 46.408-5.622 2.692 5.705 4.882 11.222 6.63 16.876 2.9 9.381 7.776 17.194 15.035 24.049 7.056 6.662 13.305 14.311 19.146 22.099 9.509 12.677 23.01 19.061 36.907 25.054-1.048 7.441-2.425 14.854-3.066 22.33-.956 11.162-1.393 22.369-2.052 33.557l-1.096 17.661z"></path><path fill="#ea5453" d="M1163.123 704.036c-4.005 5.116-7.685 10.531-12.075 15.293-12.842 13.933-27.653 25.447-44.902 34.538-3.166-5.708-5.656-11.287-8.189-17.251-3.321-12.857-6.259-25.431-9.963-37.775-4.6-15.329-10.6-30.188-11.349-46.562-.314-6.871-1.275-14.287-7.114-19.644-1.047-.961-1.292-3.053-1.465-4.67l-4.092-39.927c-.554-5.245-.383-10.829-2.21-15.623-3.622-9.503-4.546-19.253-4.688-29.163-.088-6.111 1.068-12.256.782-18.344-.67-14.281-1.76-28.546-2.9-42.8-.657-8.222-1.951-16.395-2.564-24.62-.458-6.137-.285-12.322-.104-18.21.959 5.831 1.076 11.525 2.429 16.909 2.007 7.986 5.225 15.664 7.324 23.632 3.222 12.23 1.547 25.219 6.728 37.355 4.311 10.099 6.389 21.136 9.732 31.669 2.228 7.02 6.167 13.722 7.121 20.863 1.119 8.376 6.1 13.974 10.376 20.716l2.026 10.576c1.711 9.216 3.149 18.283 8.494 26.599 6.393 9.946 11.348 20.815 16.943 31.276 4.021 7.519 6.199 16.075 12.925 22.065l24.462 22.26c.556.503 1.507.571 2.274.841z"></path><path fill="#ea5b15" d="M1285.092 163.432c9.165 3.148 18.419 6.374 27.279 10.459 4.871 2.246 8.838 6.406 13.646 8.851 5.446 2.77 11.801 3.874 17.011 6.965 11.514 6.831 24.097 9.942 36.968 12.471 1.78.35 3.777.576 5.213 1.542 10.784 7.255 23.448 9.114 35.622 11.834 9.977 2.23 18.529 6.703 26.988 11.898 5.233 3.214 10.76 5.983 15.798 9.468 4.14 2.864 7.962 6.279 11.551 9.827 5.076 5.02 10.056 10.181 14.624 15.658 5.822 6.98 11.119 14.395 16.78 21.513 4.531 5.698 9.267 11.233 14.222 16.987-10.005 5.806-20.07 12.004-30.719 16.943-7.694 3.569-16.163 5.464-24.688 7.669-2.878-7.088-5.352-13.741-7.833-20.392-.802-2.15-1.244-4.55-2.498-6.396-4.548-6.7-9.712-12.999-14.011-19.847-6.672-10.627-15.34-18.93-26.063-25.376-9.357-5.625-18.367-11.824-27.644-17.587-6.436-3.997-12.902-8.006-19.659-11.405-5.123-2.577-11.107-3.536-16.046-6.37-17.187-9.863-35.13-17.887-54.031-23.767-4.403-1.37-8.953-2.267-13.436-3.382l.926-27.565z"></path><path fill="#ea504b" d="M1098 737l7.789 16.893c-15.04 9.272-31.679 15.004-49.184 17.995-9.464 1.617-19.122 2.097-29.151 3.019-.457-10.636-.18-21.211-.544-31.764-.273-7.888-.409-15.883-4.736-23.103-1.16-1.936-1.162-4.805-1.06-7.219l1.787-36.207c.182-8.103-.993-16.237-.811-24.34.365-16.236 1.253-32.461 1.908-48.69.484-12 .942-24.001 1.98-36.069 5.57 10.19 10.632 20.42 15.528 30.728 1.122 2.362 2.587 5.09 2.339 7.488-1.536 14.819 5.881 26.839 12.962 38.33 10.008 16.241 16.417 33.54 20.331 51.964 2.285 10.756 4.729 21.394 11.958 30.165L1098 737z"></path><path fill="#f6a320" d="M1865.78 822.529c-1.849 8.846-3.544 17.475-6.224 25.786-1.323 4.102-4.206 7.81-6.83 11.367l-43.112 57.581c-4.93 6.273-11.808 11.049-17.954 16.326-10.162 8.725-21.082 16.671-30.534 26.097-12.327 12.294-27.997 16.202-43.818 20.323-1.436.374-2.897.651-4.744.986-1.107-17.032-1.816-34.076-2.079-51.556 1.265-.535 2.183-.428 2.888-.766 10.596-5.072 20.8-11.059 32.586-13.273 1.69-.317 3.307-1.558 4.732-2.662l26.908-21.114c4.992-4.003 11.214-7.393 14.381-12.585 11.286-18.5 22.363-37.263 27.027-58.87l36.046 1.811c3.487.165 6.983.14 10.727.549z"></path><path fill="#ec6333" d="M318.448 922.814c-6.374-2.074-12.56-4.058-18.412-6.765-8.379-3.876-16.906-7.675-24.617-12.668-5.239-3.392-9.69-8.381-13.609-13.352-7.87-9.983-14.953-20.582-22.699-30.666-8.061-10.493-13.909-22.097-18.636-34.358-.595-1.543-1.486-2.972-2.382-4.783 6.84-1.598 13.797-3.023 20.807-4.106 18.852-2.912 36.433-9.493 53.737-17.819.697.888.889 1.555 1.292 2.051l17.921 21.896c4.14 4.939 8.06 10.191 12.862 14.412 5.67 4.984 12.185 9.007 18.334 13.447-8.937 16.282-16.422 33.178-20.696 51.31-1.638 6.951-2.402 14.107-3.903 21.403z"></path><path fill="#f49700" d="M623.467 326.903c2.893-10.618 5.584-21.446 9.833-31.623 3.013-7.217 7.924-13.696 12.358-20.254 6.375-9.43 12.026-19.67 19.886-27.705 14.12-14.434 28.063-29.453 47.926-36.784 6.581-2.429 12.344-6.994 18.774-9.942 3.975-1.822 8.503-2.436 13.186-3.592 1.947 18.557 3.248 37.15 8.307 55.686-15.453 7.931-28.853 18.092-40.46 29.996-10.417 10.683-19.109 23.111-28.013 35.175-3.238 4.388-4.888 9.948-7.262 14.973-17.803-3.987-35.767-6.498-54.535-5.931z"></path><path fill="#ea544c" d="M1097.956 736.615c-2.925-3.218-5.893-6.822-8.862-10.425-7.229-8.771-9.672-19.409-11.958-30.165-3.914-18.424-10.323-35.722-20.331-51.964-7.081-11.491-14.498-23.511-12.962-38.33.249-2.398-1.217-5.126-2.339-7.488l-15.232-31.019-3.103-34.338c-.107-1.316-.041-2.653.031-3.975.233-4.294.756-8.59.702-12.879-.072-5.713-.776-11.417-.861-17.13l-.116-30.733c-.329-10.088-1.926-20.166-1.768-30.23.23-14.674.599-29.31-1.162-44.341 9.369-.803 18.741-1.179 28.558-1.074 1.446 15.814 2.446 31.146 3.446 46.478.108 6.163-.064 12.348.393 18.485.613 8.225 1.907 16.397 2.564 24.62l2.9 42.8c.286 6.088-.869 12.234-.782 18.344.142 9.91 1.066 19.661 4.688 29.163 1.827 4.794 1.657 10.377 2.21 15.623l4.092 39.927c.172 1.617.417 3.71 1.465 4.67 5.839 5.357 6.8 12.773 7.114 19.644.749 16.374 6.749 31.233 11.349 46.562 3.704 12.344 6.642 24.918 9.963 37.775z"></path><path fill="#ec5c61" d="M1204.835 568.008c1.254 25.351-1.675 50.16-10.168 74.61-8.598-4.883-18.177-8.709-24.354-15.59-7.44-8.289-13.929-17.442-21.675-25.711-8.498-9.072-16.731-18.928-21.084-31.113-.54-1.513-1.691-2.807-2.594-4.564-4.605-9.247-7.706-18.544-7.96-29.09-.835-7.149-1.214-13.944-2.609-20.523-2.215-10.454-5.626-20.496-7.101-31.302-2.513-18.419-7.207-36.512-5.347-55.352.24-2.43-.17-4.949-.477-7.402l-4.468-34.792c2.723-.379 5.446-.757 8.585-.667 1.749 8.781 2.952 17.116 4.448 25.399 1.813 10.037 3.64 20.084 5.934 30.017 1.036 4.482 3.953 8.573 4.73 13.064 1.794 10.377 4.73 20.253 9.272 29.771 2.914 6.105 4.761 12.711 7.496 18.912 2.865 6.496 6.264 12.755 9.35 19.156 3.764 7.805 7.667 15.013 16.1 19.441 7.527 3.952 13.713 10.376 20.983 14.924 6.636 4.152 13.932 7.25 20.937 10.813z"></path><path fill="#ed676f" d="M1140.75 379.231c18.38-4.858 36.222-11.21 53.979-18.971 3.222 3.368 5.693 6.744 8.719 9.512 2.333 2.134 5.451 5.07 8.067 4.923 7.623-.429 12.363 2.688 17.309 8.215 5.531 6.18 12.744 10.854 19.224 16.184-5.121 7.193-10.461 14.241-15.323 21.606-13.691 20.739-22.99 43.255-26.782 67.926-.543 3.536-1.281 7.043-2.366 10.925-14.258-6.419-26.411-14.959-32.731-29.803-1.087-2.553-2.596-4.93-3.969-7.355-1.694-2.993-3.569-5.89-5.143-8.943-1.578-3.062-2.922-6.249-4.295-9.413-1.57-3.621-3.505-7.163-4.47-10.946-1.257-4.93-.636-10.572-2.725-15.013-5.831-12.397-7.467-25.628-9.497-38.847z"></path><path fill="#ed656e" d="M1254.103 647.439c5.325.947 10.603 2.272 15.847 3.722 5.101 1.41 10.376 2.475 15.175 4.596 3.237 1.431 5.942 4.262 8.589 6.777 2.592 2.462 4.77 5.355 7.207 7.987 1.804 1.948 4.557 3.453 5.461 5.723 3.51 8.817 11.581 11.307 19.059 14.735 1.053.483 2.116.963 3.214 1.327 9.172 3.043 13.818 8.587 14.889 18.979.715 6.935 5.607 13.679 9.479 19.987 4.623 7.533 9.175 14.819 9.091 24.116-.023 2.55 1.21 5.111 1.874 8.055-19.861 2.555-39.795 4.296-59.597 9.09l-11.596-23.203c-1.107-2.169-2.526-4.353-4.307-5.975-7.349-6.694-14.863-13.209-22.373-19.723l-17.313-14.669c-2.776-2.245-5.935-4.017-8.92-6.003l11.609-38.185c1.508-5.453 1.739-11.258 2.613-17.336z"></path><path fill="#ec6168" d="M1140.315 379.223c2.464 13.227 4.101 26.459 9.931 38.856 2.089 4.441 1.468 10.083 2.725 15.013.965 3.783 2.9 7.325 4.47 10.946 1.372 3.164 2.716 6.351 4.295 9.413 1.574 3.053 3.449 5.95 5.143 8.943 1.372 2.425 2.882 4.803 3.969 7.355 6.319 14.844 18.473 23.384 32.641 30.212.067 5.121-.501 10.201-.435 15.271l.985 38.117c.151 4.586.616 9.162.868 14.201-7.075-3.104-14.371-6.202-21.007-10.354-7.269-4.548-13.456-10.972-20.983-14.924-8.434-4.428-12.337-11.637-16.1-19.441-3.087-6.401-6.485-12.66-9.35-19.156-2.735-6.201-4.583-12.807-7.496-18.912-4.542-9.518-7.477-19.394-9.272-29.771-.777-4.491-3.694-8.581-4.73-13.064-2.294-9.933-4.121-19.98-5.934-30.017-1.496-8.283-2.699-16.618-4.036-25.335 10.349-2.461 20.704-4.511 31.054-6.582.957-.191 1.887-.515 3.264-.769z"></path><path fill="#e94c28" d="M922 537c-6.003 11.784-11.44 23.81-19.66 34.428-6.345 8.196-11.065 17.635-17.206 26.008-4.339 5.916-9.828 10.992-14.854 16.397-.776.835-1.993 1.279-2.71 2.147-9.439 11.437-22.008 18.427-35.357 24.929-4.219-10.885-6.942-22.155-7.205-33.905l-.514-49.542c7.441-2.893 14.452-5.197 21.334-7.841 1.749-.672 3.101-2.401 4.604-3.681 6.749-5.745 12.845-12.627 20.407-16.944 7.719-4.406 14.391-9.101 18.741-16.889.626-1.122 1.689-2.077 2.729-2.877 7.197-5.533 12.583-12.51 16.906-20.439.68-1.247 2.495-1.876 4.105-2.651 2.835 1.408 5.267 2.892 7.884 3.892 3.904 1.491 4.392 3.922 2.833 7.439-1.47 3.318-2.668 6.756-4.069 10.106-1.247 2.981-.435 5.242 2.413 6.544 2.805 1.282 3.125 3.14 1.813 5.601l-6.907 12.799L922 537z"></path><path fill="#eb5659" d="M1124.995 566c.868 1.396 2.018 2.691 2.559 4.203 4.353 12.185 12.586 22.041 21.084 31.113 7.746 8.269 14.235 17.422 21.675 25.711 6.176 6.881 15.756 10.707 24.174 15.932-6.073 22.316-16.675 42.446-31.058 60.937-1.074-.131-2.025-.199-2.581-.702l-24.462-22.26c-6.726-5.99-8.904-14.546-12.925-22.065-5.594-10.461-10.55-21.33-16.943-31.276-5.345-8.315-6.783-17.383-8.494-26.599-.63-3.394-1.348-6.772-1.738-10.848-.371-6.313-1.029-11.934-1.745-18.052l6.34 4.04 1.288-.675-2.143-15.385 9.454 1.208v-8.545L1124.995 566z"></path><path fill="#f5a02d" d="M1818.568 820.096c-4.224 21.679-15.302 40.442-26.587 58.942-3.167 5.192-9.389 8.582-14.381 12.585l-26.908 21.114c-1.425 1.104-3.042 2.345-4.732 2.662-11.786 2.214-21.99 8.201-32.586 13.273-.705.338-1.624.231-2.824.334a824.35 824.35 0 0 1-8.262-42.708c4.646-2.14 9.353-3.139 13.269-5.47 5.582-3.323 11.318-6.942 15.671-11.652 7.949-8.6 14.423-18.572 22.456-27.081 8.539-9.046 13.867-19.641 18.325-30.922l46.559 8.922z"></path><path fill="#eb5a57" d="M1124.96 565.639c-5.086-4.017-10.208-8.395-15.478-12.901v8.545l-9.454-1.208 2.143 15.385-1.288.675-6.34-4.04c.716 6.118 1.375 11.74 1.745 17.633-4.564-6.051-9.544-11.649-10.663-20.025-.954-7.141-4.892-13.843-7.121-20.863-3.344-10.533-5.421-21.57-9.732-31.669-5.181-12.135-3.506-25.125-6.728-37.355-2.099-7.968-5.317-15.646-7.324-23.632-1.353-5.384-1.47-11.078-2.429-16.909l-3.294-46.689a278.63 278.63 0 0 1 27.57-2.084c2.114 12.378 3.647 24.309 5.479 36.195 1.25 8.111 2.832 16.175 4.422 24.23 1.402 7.103 2.991 14.169 4.55 21.241 1.478 6.706.273 14.002 4.6 20.088 5.401 7.597 7.176 16.518 9.467 25.337 1.953 7.515 5.804 14.253 11.917 19.406.254 10.095 3.355 19.392 7.96 28.639z"></path><path fill="#ea541c" d="M911.651 810.999c-2.511 10.165-5.419 20.146-8.2 30.162-2.503 9.015-7.37 16.277-14.364 22.612-6.108 5.533-10.917 12.475-16.796 18.293-6.942 6.871-14.354 13.24-19.083 22.03-.644 1.196-2.222 1.889-3.705 2.857-2.39-7.921-4.101-15.991-6.566-23.823-5.451-17.323-12.404-33.976-23.414-48.835l21.627-21.095c3.182-3.29 5.532-7.382 8.295-11.083l10.663-14.163c9.528 4.78 18.925 9.848 28.625 14.247 7.324 3.321 15.036 5.785 22.917 8.799z"></path><path fill="#eb5d19" d="M1284.092 191.421c4.557.69 9.107 1.587 13.51 2.957 18.901 5.881 36.844 13.904 54.031 23.767 4.938 2.834 10.923 3.792 16.046 6.37 6.757 3.399 13.224 7.408 19.659 11.405l27.644 17.587c10.723 6.446 19.392 14.748 26.063 25.376 4.299 6.848 9.463 13.147 14.011 19.847 1.254 1.847 1.696 4.246 2.498 6.396l7.441 20.332c-11.685 1.754-23.379 3.133-35.533 4.037-.737-2.093-.995-3.716-1.294-5.33-3.157-17.057-14.048-30.161-23.034-44.146-3.027-4.71-7.786-8.529-12.334-11.993-9.346-7.116-19.004-13.834-28.688-20.491-6.653-4.573-13.311-9.251-20.431-13.002-8.048-4.24-16.479-7.85-24.989-11.091-11.722-4.465-23.673-8.328-35.527-12.449l.927-19.572z"></path><path fill="#eb5e24" d="M1283.09 211.415c11.928 3.699 23.88 7.562 35.602 12.027 8.509 3.241 16.941 6.852 24.989 11.091 7.12 3.751 13.778 8.429 20.431 13.002 9.684 6.657 19.342 13.375 28.688 20.491 4.548 3.463 9.307 7.283 12.334 11.993 8.986 13.985 19.877 27.089 23.034 44.146.299 1.615.557 3.237.836 5.263-13.373-.216-26.749-.839-40.564-1.923-2.935-9.681-4.597-18.92-12.286-26.152-15.577-14.651-30.4-30.102-45.564-45.193-.686-.683-1.626-1.156-2.516-1.584l-47.187-22.615 2.203-20.546z"></path><path fill="#e9511f" d="M913 486.001c-1.29.915-3.105 1.543-3.785 2.791-4.323 7.929-9.709 14.906-16.906 20.439-1.04.8-2.103 1.755-2.729 2.877-4.35 7.788-11.022 12.482-18.741 16.889-7.562 4.317-13.658 11.199-20.407 16.944-1.503 1.28-2.856 3.009-4.604 3.681-6.881 2.643-13.893 4.948-21.262 7.377-.128-11.151.202-22.302.378-33.454.03-1.892-.6-3.795-.456-6.12 13.727-1.755 23.588-9.527 33.278-17.663 2.784-2.337 6.074-4.161 8.529-6.784l29.057-31.86c1.545-1.71 3.418-3.401 4.221-5.459 5.665-14.509 11.49-28.977 16.436-43.736 2.817-8.407 4.074-17.338 6.033-26.032 5.039.714 10.078 1.427 15.536 2.629-.909 8.969-2.31 17.438-3.546 25.931-2.41 16.551-5.84 32.839-11.991 48.461L913 486.001z"></path><path fill="#ea5741" d="M1179.451 903.828c-14.224-5.787-27.726-12.171-37.235-24.849-5.841-7.787-12.09-15.436-19.146-22.099-7.259-6.854-12.136-14.667-15.035-24.049-1.748-5.654-3.938-11.171-6.254-17.033 15.099-4.009 30.213-8.629 44.958-15.533l28.367 36.36c6.09 8.015 13.124 14.75 22.72 18.375-7.404 14.472-13.599 29.412-17.48 45.244-.271 1.106-.382 2.25-.895 3.583z"></path><path fill="#ea522a" d="M913.32 486.141c2.693-7.837 5.694-15.539 8.722-23.231 6.151-15.622 9.581-31.91 11.991-48.461l3.963-25.861c7.582.317 15.168 1.031 22.748 1.797 4.171.421 8.333.928 12.877 1.596-.963 11.836-.398 24.125-4.102 34.953-5.244 15.33-6.794 31.496-12.521 46.578-2.692 7.09-4.849 14.445-8.203 21.206-4.068 8.201-9.311 15.81-13.708 23.86-1.965 3.597-3.154 7.627-4.609 11.492-1.385 3.68-3.666 6.265-8.114 6.89-1.994-1.511-3.624-3.059-5.077-4.44l6.907-12.799c1.313-2.461.993-4.318-1.813-5.601-2.849-1.302-3.66-3.563-2.413-6.544 1.401-3.35 2.599-6.788 4.069-10.106 1.558-3.517 1.071-5.948-2.833-7.439-2.617-1-5.049-2.484-7.884-3.892z"></path><path fill="#eb5e24" d="M376.574 714.118c12.053 6.538 20.723 16.481 29.081 26.814 1.945 2.404 4.537 4.352 7.047 6.218 8.24 6.125 10.544 15.85 14.942 24.299.974 1.871 1.584 3.931 2.376 6.29-7.145 3.719-14.633 6.501-21.386 10.517-9.606 5.713-18.673 12.334-28.425 18.399-3.407-3.73-6.231-7.409-9.335-10.834l-30.989-33.862c11.858-11.593 22.368-24.28 31.055-38.431 1.86-3.031 3.553-6.164 5.632-9.409z"></path><path fill="#e95514" d="M859.962 787.636c-3.409 5.037-6.981 9.745-10.516 14.481-2.763 3.701-5.113 7.792-8.295 11.083-6.885 7.118-14.186 13.834-21.65 20.755-13.222-17.677-29.417-31.711-48.178-42.878-.969-.576-2.068-.934-3.27-1.709 6.28-8.159 12.733-15.993 19.16-23.849 1.459-1.783 2.718-3.738 4.254-5.448l18.336-19.969c4.909 5.34 9.619 10.738 14.081 16.333 9.72 12.19 21.813 21.566 34.847 29.867.411.262.725.674 1.231 1.334z"></path><path fill="#eb5f2d" d="M339.582 762.088l31.293 33.733c3.104 3.425 5.928 7.104 9.024 10.979-12.885 11.619-24.548 24.139-33.899 38.704-.872 1.359-1.56 2.837-2.644 4.428-6.459-4.271-12.974-8.294-18.644-13.278-4.802-4.221-8.722-9.473-12.862-14.412l-17.921-21.896c-.403-.496-.595-1.163-.926-2.105 16.738-10.504 32.58-21.87 46.578-36.154z"></path><path fill="#f28d00" d="M678.388 332.912c1.989-5.104 3.638-10.664 6.876-15.051 8.903-12.064 17.596-24.492 28.013-35.175 11.607-11.904 25.007-22.064 40.507-29.592 4.873 11.636 9.419 23.412 13.67 35.592-5.759 4.084-11.517 7.403-16.594 11.553-4.413 3.607-8.124 8.092-12.023 12.301-5.346 5.772-10.82 11.454-15.782 17.547-3.929 4.824-7.17 10.208-10.716 15.344l-33.95-12.518z"></path><path fill="#f08369" d="M1580.181 771.427c-.191-.803-.322-1.377-.119-1.786 5.389-10.903 9.084-22.666 18.181-31.587 6.223-6.103 11.276-13.385 17.286-19.727 3.117-3.289 6.933-6.105 10.869-8.384 6.572-3.806 13.492-7.009 20.461-10.752 1.773 3.23 3.236 6.803 4.951 10.251l12.234 24.993c-1.367 1.966-2.596 3.293-3.935 4.499-7.845 7.07-16.315 13.564-23.407 21.32-6.971 7.623-12.552 16.517-18.743 24.854l-37.777-13.68z"></path><path fill="#f18b5e" d="M1618.142 785.4c6.007-8.63 11.588-17.524 18.559-25.147 7.092-7.755 15.562-14.249 23.407-21.32 1.338-1.206 2.568-2.534 3.997-4.162l28.996 33.733c1.896 2.205 4.424 3.867 6.66 6.394-6.471 7.492-12.967 14.346-19.403 21.255l-18.407 19.953c-12.958-12.409-27.485-22.567-43.809-30.706z"></path><path fill="#f49c3a" d="M1771.617 811.1c-4.066 11.354-9.394 21.949-17.933 30.995-8.032 8.509-14.507 18.481-22.456 27.081-4.353 4.71-10.089 8.329-15.671 11.652-3.915 2.331-8.623 3.331-13.318 5.069-4.298-9.927-8.255-19.998-12.1-30.743 4.741-4.381 9.924-7.582 13.882-11.904 7.345-8.021 14.094-16.603 20.864-25.131 4.897-6.168 9.428-12.626 14.123-18.955l32.61 11.936z"></path><path fill="#f08000" d="M712.601 345.675c3.283-5.381 6.524-10.765 10.453-15.589 4.962-6.093 10.435-11.774 15.782-17.547 3.899-4.21 7.61-8.695 12.023-12.301 5.078-4.15 10.836-7.469 16.636-11.19a934.12 934.12 0 0 1 23.286 35.848c-4.873 6.234-9.676 11.895-14.63 17.421l-25.195 27.801c-11.713-9.615-24.433-17.645-38.355-24.443z"></path><path fill="#ed6e04" d="M751.11 370.42c8.249-9.565 16.693-18.791 25.041-28.103 4.954-5.526 9.757-11.187 14.765-17.106 7.129 6.226 13.892 13.041 21.189 19.225 5.389 4.567 11.475 8.312 17.53 12.92-5.51 7.863-10.622 15.919-17.254 22.427-8.881 8.716-18.938 16.233-28.49 24.264-5.703-6.587-11.146-13.427-17.193-19.682-4.758-4.921-10.261-9.121-15.587-13.944z"></path><path fill="#ea541c" d="M921.823 385.544c-1.739 9.04-2.995 17.971-5.813 26.378-4.946 14.759-10.771 29.227-16.436 43.736-.804 2.058-2.676 3.749-4.221 5.459l-29.057 31.86c-2.455 2.623-5.745 4.447-8.529 6.784-9.69 8.135-19.551 15.908-33.208 17.237-1.773-9.728-3.147-19.457-4.091-29.6l36.13-16.763c.581-.267 1.046-.812 1.525-1.269 8.033-7.688 16.258-15.19 24.011-23.152 4.35-4.467 9.202-9.144 11.588-14.69 6.638-15.425 15.047-30.299 17.274-47.358 3.536.344 7.072.688 10.829 1.377z"></path><path fill="#f3944d" d="M1738.688 798.998c-4.375 6.495-8.906 12.953-13.803 19.121-6.771 8.528-13.519 17.11-20.864 25.131-3.958 4.322-9.141 7.523-13.925 11.54-8.036-13.464-16.465-26.844-27.999-38.387 5.988-6.951 12.094-13.629 18.261-20.25l19.547-20.95 38.783 23.794z"></path><path fill="#ec6168" d="M1239.583 703.142c3.282 1.805 6.441 3.576 9.217 5.821 5.88 4.755 11.599 9.713 17.313 14.669l22.373 19.723c1.781 1.622 3.2 3.806 4.307 5.975 3.843 7.532 7.477 15.171 11.194 23.136-10.764 4.67-21.532 8.973-32.69 12.982l-22.733-27.366c-2.003-2.416-4.096-4.758-6.194-7.093-3.539-3.94-6.927-8.044-10.74-11.701-2.57-2.465-5.762-4.283-8.675-6.39l16.627-29.755z"></path><path fill="#ec663e" d="M1351.006 332.839l-28.499 10.33c-.294.107-.533.367-1.194.264-11.067-19.018-27.026-32.559-44.225-44.855-4.267-3.051-8.753-5.796-13.138-8.682l9.505-24.505c10.055 4.069 19.821 8.227 29.211 13.108 3.998 2.078 7.299 5.565 10.753 8.598 3.077 2.701 5.743 5.891 8.926 8.447 4.116 3.304 9.787 5.345 12.62 9.432 6.083 8.777 10.778 18.517 16.041 27.863z"></path><path fill="#eb5e5b" d="M1222.647 733.051c3.223 1.954 6.415 3.771 8.985 6.237 3.813 3.658 7.201 7.761 10.74 11.701l6.194 7.093 22.384 27.409c-13.056 6.836-25.309 14.613-36.736 24.161l-39.323-44.7 24.494-27.846c1.072-1.224 1.974-2.598 3.264-4.056z"></path><path fill="#ea580e" d="M876.001 376.171c5.874 1.347 11.748 2.694 17.812 4.789-.81 5.265-2.687 9.791-2.639 14.296.124 11.469-4.458 20.383-12.73 27.863-2.075 1.877-3.659 4.286-5.668 6.248l-22.808 21.967c-.442.422-1.212.488-1.813.757l-23.113 10.389-9.875 4.514c-2.305-6.09-4.609-12.181-6.614-18.676 7.64-4.837 15.567-8.54 22.18-13.873 9.697-7.821 18.931-16.361 27.443-25.455 5.613-5.998 12.679-11.331 14.201-20.475.699-4.2 2.384-8.235 3.623-12.345z"></path><path fill="#e95514" d="M815.103 467.384c3.356-1.894 6.641-3.415 9.94-4.903l23.113-10.389c.6-.269 1.371-.335 1.813-.757l22.808-21.967c2.008-1.962 3.593-4.371 5.668-6.248 8.272-7.48 12.854-16.394 12.73-27.863-.049-4.505 1.828-9.031 2.847-13.956 5.427.559 10.836 1.526 16.609 2.68-1.863 17.245-10.272 32.119-16.91 47.544-2.387 5.546-7.239 10.223-11.588 14.69-7.753 7.962-15.978 15.464-24.011 23.152-.478.458-.944 1.002-1.525 1.269l-36.069 16.355c-2.076-6.402-3.783-12.81-5.425-19.607z"></path><path fill="#eb620b" d="M783.944 404.402c9.499-8.388 19.556-15.905 28.437-24.621 6.631-6.508 11.744-14.564 17.575-22.273 9.271 4.016 18.501 8.375 27.893 13.43-4.134 7.07-8.017 13.778-12.833 19.731-5.785 7.15-12.109 13.917-18.666 20.376-7.99 7.869-16.466 15.244-24.731 22.832l-17.674-29.475z"></path><path fill="#ea544c" d="M1197.986 854.686c-9.756-3.309-16.79-10.044-22.88-18.059l-28.001-36.417c8.601-5.939 17.348-11.563 26.758-17.075 1.615 1.026 2.639 1.876 3.505 2.865l26.664 30.44c3.723 4.139 7.995 7.785 12.017 11.656l-18.064 26.591z"></path><path fill="#ec6333" d="M1351.41 332.903c-5.667-9.409-10.361-19.149-16.445-27.926-2.833-4.087-8.504-6.128-12.62-9.432-3.184-2.555-5.849-5.745-8.926-8.447-3.454-3.033-6.756-6.52-10.753-8.598-9.391-4.88-19.157-9.039-29.138-13.499 1.18-5.441 2.727-10.873 4.81-16.607 11.918 4.674 24.209 8.261 34.464 14.962 14.239 9.304 29.011 18.453 39.595 32.464 2.386 3.159 5.121 6.077 7.884 8.923 6.564 6.764 10.148 14.927 11.723 24.093l-20.594 4.067z"></path><path fill="#eb5e5b" d="M1117 536.549c-6.113-4.702-9.965-11.44-11.917-18.955-2.292-8.819-4.066-17.74-9.467-25.337-4.327-6.085-3.122-13.382-4.6-20.088l-4.55-21.241c-1.59-8.054-3.172-16.118-4.422-24.23l-5.037-36.129c6.382-1.43 12.777-2.462 19.582-3.443 1.906 11.646 3.426 23.24 4.878 34.842.307 2.453.717 4.973.477 7.402-1.86 18.84 2.834 36.934 5.347 55.352 1.474 10.806 4.885 20.848 7.101 31.302 1.394 6.579 1.774 13.374 2.609 20.523z"></path><path fill="#ec644b" d="M1263.638 290.071c4.697 2.713 9.183 5.458 13.45 8.509 17.199 12.295 33.158 25.836 43.873 44.907-8.026 4.725-16.095 9.106-24.83 13.372-11.633-15.937-25.648-28.515-41.888-38.689-1.609-1.008-3.555-1.48-5.344-2.2 2.329-3.852 4.766-7.645 6.959-11.573l7.78-14.326z"></path><path fill="#eb5f2d" d="M1372.453 328.903c-2.025-9.233-5.608-17.396-12.172-24.16-2.762-2.846-5.498-5.764-7.884-8.923-10.584-14.01-25.356-23.16-39.595-32.464-10.256-6.701-22.546-10.289-34.284-15.312.325-5.246 1.005-10.444 2.027-15.863l47.529 22.394c.89.428 1.83.901 2.516 1.584l45.564 45.193c7.69 7.233 9.352 16.472 11.849 26.084-5.032.773-10.066 1.154-15.55 1.466z"></path><path fill="#e95a0f" d="M801.776 434.171c8.108-7.882 16.584-15.257 24.573-23.126 6.558-6.459 12.881-13.226 18.666-20.376 4.817-5.953 8.7-12.661 13.011-19.409 5.739 1.338 11.463 3.051 17.581 4.838-.845 4.183-2.53 8.219-3.229 12.418-1.522 9.144-8.588 14.477-14.201 20.475-8.512 9.094-17.745 17.635-27.443 25.455-6.613 5.333-14.54 9.036-22.223 13.51-2.422-4.469-4.499-8.98-6.735-13.786z"></path><path fill="#eb5e5b" d="M1248.533 316.002c2.155.688 4.101 1.159 5.71 2.168 16.24 10.174 30.255 22.752 41.532 38.727-7.166 5.736-14.641 11.319-22.562 16.731-1.16-1.277-1.684-2.585-2.615-3.46l-38.694-36.2 14.203-15.029c.803-.86 1.38-1.93 2.427-2.936z"></path><path fill="#eb5a57" d="M1216.359 827.958c-4.331-3.733-8.603-7.379-12.326-11.518l-26.664-30.44c-.866-.989-1.89-1.839-3.152-2.902 6.483-6.054 13.276-11.959 20.371-18.005l39.315 44.704c-5.648 6.216-11.441 12.12-17.544 18.161z"></path><path fill="#ec6168" d="M1231.598 334.101l38.999 36.066c.931.876 1.456 2.183 2.303 3.608-4.283 4.279-8.7 8.24-13.769 12.091-4.2-3.051-7.512-6.349-11.338-8.867-12.36-8.136-22.893-18.27-32.841-29.093l16.646-13.805z"></path><path fill="#ed656e" d="M1214.597 347.955c10.303 10.775 20.836 20.908 33.196 29.044 3.825 2.518 7.137 5.816 10.992 8.903-3.171 4.397-6.65 8.648-10.432 13.046-6.785-5.184-13.998-9.858-19.529-16.038-4.946-5.527-9.687-8.644-17.309-8.215-2.616.147-5.734-2.788-8.067-4.923-3.026-2.769-5.497-6.144-8.35-9.568 6.286-4.273 12.715-8.237 19.499-12.25z"></path></svg>
</p>
<p align="center">
<b>The crispy rerank family from <a href="https://mixedbread.com"><b>Mixedbread</b></a>.</b>
</p>
<p align="center">
<sup> 🍞 Looking for a simple end-to-end retrieval solution? Meet Omni, our multimodal and multilingual model. <a href="https://mixedbread.com"><b>Get in touch for access.</a> </sup>
</p>
# 🍞 mxbai-rerank-large-v2
This is the large model in our family of powerful reranker models. You can learn more about the models in our [blog post](https://www.mixedbread.ai/blog/mxbai-rerank-v2).
We have two models:
- [mxbai-rerank-base-v2](https://huggingface.co/mixedbread-ai/mxbai-rerank-base-v2)
- [mxbai-rerank-large-v2](https://huggingface.co/mixedbread-ai/mxbai-rerank-large-v2) (🍞)
**The technical report is coming soon!**
## 🌟 Features
- state-of-the-art performance and strong efficiency
- multilingual support (100+ languages, outstanding English and Chinese performance)
- code support
- long-context support
## ⚙️ Usage
1. Install mxbai-rerank
```bash
pip install mxbai-rerank
```
2. Inference
```python
from mxbai_rerank import MxbaiRerankV2
model = MxbaiRerankV2("mixedbread-ai/mxbai-rerank-large-v2")
query = "Who wrote 'To Kill a Mockingbird'?"
documents = [
"'To Kill a Mockingbird' is a novel by Harper Lee published in 1960. It was immediately successful, winning the Pulitzer Prize, and has become a classic of modern American literature.",
"The novel 'Moby-Dick' was written by Herman Melville and first published in 1851. It is considered a masterpiece of American literature and deals with complex themes of obsession, revenge, and the conflict between good and evil.",
"Harper Lee, an American novelist widely known for her novel 'To Kill a Mockingbird', was born in 1926 in Monroeville, Alabama. She received the Pulitzer Prize for Fiction in 1961.",
"Jane Austen was an English novelist known primarily for her six major novels, which interpret, critique and comment upon the British landed gentry at the end of the 18th century.",
"The 'Harry Potter' series, which consists of seven fantasy novels written by British author J.K. Rowling, is among the most popular and critically acclaimed books of the modern era.",
"'The Great Gatsby', a novel written by American author F. Scott Fitzgerald, was published in 1925. The story is set in the Jazz Age and follows the life of millionaire Jay Gatsby and his pursuit of Daisy Buchanan."
]
# Lets get the scores
results = model.rank(query, documents, return_documents=True, top_k=3)
print(results)
```
## Performance
### Benchmark Results
| Model | BEIR Avg | Multilingual | Chinese | Code Search | Latency (s) |
|-------|----------|----------|----------|--------------|-------------|
| mxbai-rerank-large-v2 | 57.49 | 29.79 | 84.16 | 32.05 | 0.89 |
| mxbai-rerank-base-v2 | 55.57 | 28.56 | 83.70 | 31.73 | 0.67 |
| mxbai-rerank-large-v1 | 49.32 | 21.88 | 72.53 | 30.72 | 2.24 |
*Latency measured on A100 GPU
## Training Details
The models were trained using a three-step process:
1. **GRPO (Guided Reinforcement Prompt Optimization)**
2. **Contrastive Learning**
3. **Preference Learning**
For more details, check our [technical blog post](https://mixedbread.com/blog/mxbai-rerank-v2).
Paper following soon.
## 🎓 Citation
```bibtex
@online{v2rerank2025mxbai,
title={Baked-in Brilliance: Reranking Meets RL with mxbai-rerank-v2},
author={Sean Lee and Rui Huang and Aamir Shakir and Julius Lipp},
year={2025},
url={https://www.mixedbread.com/blog/mxbai-rerank-v2},
}
``` |
Mungert/functionary-small-v3.2-GGUF | Mungert | 2025-06-15T19:42:16Z | 295 | 4 | null | [
"gguf",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-24T00:38:48Z | ---
license: mit
---
# <span style="color: #7FFF7F;">functionary-small-v3.2 GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `functionary-small-v3.2-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `functionary-small-v3.2-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `functionary-small-v3.2-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `functionary-small-v3.2-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `functionary-small-v3.2-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `functionary-small-v3.2-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `functionary-small-v3.2-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `functionary-small-v3.2-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `functionary-small-v3.2-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `functionary-small-v3.2-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `functionary-small-v3.2-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Card for functionary-small-v3.2
**This model was based on [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)**
[https://github.com/MeetKai/functionary](https://github.com/MeetKai/functionary)
<img src="https://huggingface.co/meetkai/functionary-medium-v2.2/resolve/main/functionary_logo.jpg" alt="Functionary Logo" width="300"/>
Functionary is a language model that can interpret and execute functions/plugins.
The model determines when to execute functions, whether in parallel or serially, and can understand their outputs. It only triggers functions as needed. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls.
## Key Features
- Intelligent **parallel tool use**
- Able to analyze functions/tools outputs and provide relevant responses **grounded in the outputs**
- Able to decide **when to not use tools/call functions** and provide normal chat response
- Truly one of the best open-source alternative to GPT-4
- Support code interpreter
## How to Get Started
We provide custom code for parsing raw model responses into a JSON object containing `role`, `content` and `tool_calls` fields. This enables the users to read the function-calling output of the model easily.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meetkai/functionary-small-v3.2")
model = AutoModelForCausalLM.from_pretrained("meetkai/functionary-small-v3.2", device_map="auto", trust_remote_code=True)
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
}
]
messages = [{"role": "user", "content": "What is the weather in Istanbul and Singapore respectively?"}]
final_prompt = tokenizer.apply_chat_template(messages, tools, add_generation_prompt=True, tokenize=False)
inputs = tokenizer(final_prompt, return_tensors="pt").to("cuda")
pred = model.generate_tool_use(**inputs, max_new_tokens=128, tokenizer=tokenizer)
print(tokenizer.decode(pred.cpu()[0]))
```
## Prompt Template
We convert function definitions to a similar text to TypeScript definitions. Then we inject these definitions as system prompts. After that, we inject the default system prompt. Then we start the conversation messages.
This formatting is also available via our vLLM server which we process the functions into Typescript definitions encapsulated in a system message using a pre-defined Transformers Jinja chat template. This means that the lists of messages can be formatted for you with the apply_chat_template() method within our server:
```python
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="functionary")
client.chat.completions.create(
model="path/to/functionary/model/",
messages=[{"role": "user",
"content": "What is the weather for Istanbul?"}
],
tools=[{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
}],
tool_choice="auto"
)
```
will yield:
```
<|start_header_id|>system<|end_header_id|>
You are capable of executing available function(s) if required.
Only execute function(s) when absolutely necessary.
Ask for the required input to:recipient==all
Use JSON for function arguments.
Respond in this format:
>>>${recipient}
${content}
Available functions:
// Supported function definitions that should be called when necessary.
namespace functions {
// Get the current weather
type get_current_weather = (_: {
// The city and state, e.g. San Francisco, CA
location: string,
}) => any;
} // namespace functions<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the weather for Istanbul?
```
A more detailed example is provided [here](https://github.com/MeetKai/functionary/blob/main/tests/prompt_test_v3.llama3.txt).
## Run the model
We encourage users to run our models using our OpenAI-compatible vLLM server [here](https://github.com/MeetKai/functionary).
# The MeetKai Team

|
Mungert/functionary-v4r-small-preview-GGUF | Mungert | 2025-06-15T19:42:07Z | 320 | 4 | null | [
"gguf",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-23T18:56:56Z | ---
license: mit
---
# <span style="color: #7FFF7F;">functionary-v4r-small-preview GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `functionary-v4r-small-preview-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `functionary-v4r-small-preview-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `functionary-v4r-small-preview-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `functionary-v4r-small-preview-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `functionary-v4r-small-preview-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `functionary-v4r-small-preview-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `functionary-v4r-small-preview-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `functionary-v4r-small-preview-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `functionary-v4r-small-preview-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `functionary-v4r-small-preview-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `functionary-v4r-small-preview-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I'd really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Card for meetkai/functionary-v4r-small-preview
**This model was based on [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)**
[https://github.com/MeetKai/functionary](https://github.com/MeetKai/functionary)
<img src="https://huggingface.co/meetkai/functionary-medium-v2.2/resolve/main/functionary_logo.jpg" alt="Functionary Logo" width="300"/>
Functionary is a language model that can interpret and execute functions/plugins.
The model determines when to execute functions, whether in parallel or serially, and can understand their outputs. It only triggers functions as needed. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls.
## Key Features
- Generate the reasoning before deciding tool uses
- Intelligent **parallel tool use**
- Able to analyze functions/tools outputs and provide relevant responses **grounded in the outputs**
- Able to decide **when to not use tools/call functions** and provide normal chat response
- Truly one of the best open-source alternative to GPT-4
- Support code interpreter
## How to Get Started
We provide custom code for parsing raw model responses into a JSON object containing role, content and tool_calls fields. This enables the users to read the function-calling output of the model easily.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meetkai/functionary-v4r-small-preview")
model = AutoModelForCausalLM.from_pretrained("meetkai/functionary-v4r-small-preview", device_map="auto", trust_remote_code=True)
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
}
]
# add this to make the model generate the reasoning first
tools.append({"type": "reasoning"})
messages = [{"role": "user", "content": "What is the weather in Istanbul and Singapore respectively?"}]
final_prompt = tokenizer.apply_chat_template(messages, tools, add_generation_prompt=True, tokenize=False)
inputs = tokenizer(final_prompt, return_tensors="pt").to("cuda")
pred = model.generate_tool_use(**inputs, max_new_tokens=128, tokenizer=tokenizer)
print(tokenizer.decode(pred.cpu()[0]))
```
## Prompt Template
We convert function definitions to a similar text to TypeScript definitions. Then we inject these definitions as system prompts. After that, we inject the default system prompt. Then we start the conversation messages.
This formatting is also available via our vLLM server which we process the functions into Typescript definitions encapsulated in a system message using a pre-defined Transformers Jinja chat template. This means that the lists of messages can be formatted for you with the apply_chat_template() method within our server:
```python
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="functionary")
messages = [{"role": "user",
"content": "What is the weather for Istanbul?"}
]
tools = [{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
}]
# Add reasoning type to make the model generate the reasoning first
tools.append({"type": "reasoning"})
client.chat.completions.create(
model="path/to/functionary/model/",
messages=messages,
tools=tools,
tool_choice="auto"
)
```
will yield:
```
<|start_header_id|>system<|end_header_id|>
Reasoning Mode: On
Cutting Knowledge Date: December 2023
You have access to the following functions:
Use the function 'get_current_weather' to 'Get the current weather'
{"name": "get_current_weather", "description": "Get the current weather", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"}}, "required": ["location"]}}
Think very carefully before calling functions.
If a you choose to call a function ONLY reply in the following format:
<{start_tag}={function_name}>{parameters}{end_tag}
where
start_tag => `<function`
parameters => a JSON dict with the function argument name as key and function argument value as value.
end_tag => `</function>`
Here is an example,
<function=example_function_name>{"example_name": "example_value"}</function>
Reminder:
- If looking for real time information use relevant functions before falling back to brave_search
- Function calls MUST follow the specified format, start with <function= and end with </function>
- Required parameters MUST be specified
- Only call one function at a time
- Put the entire function call reply on one line
<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the weather for Istanbul?
```
## Run the model
We encourage users to run our models using our OpenAI-compatible vLLM server [here](https://github.com/MeetKai/functionary).
# The MeetKai Team
 |
Mungert/Llama-Guard-3-8B-GGUF | Mungert | 2025-06-15T19:42:03Z | 544 | 2 | null | [
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"arxiv:2407.21783",
"arxiv:2312.06674",
"arxiv:2204.05862",
"arxiv:2308.01263",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:quantized:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-23T11:22:15Z | ---
language:
- en
pipeline_tag: text-generation
base_model: meta-llama/Meta-Llama-3.1-8B
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3.1
extra_gated_prompt: >-
### LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Llama 3.1
distributed by Meta at https://llama.meta.com/doc/overview.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Llama 3.1" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Llama 3.1 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service (including another AI model) that contains any of them, you shall (A)
provide a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with
Llama” on a related website, user interface, blogpost, about page, or product documentation. If you use
the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or
otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at
the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Llama 3.1 is
licensed under the Llama 3.1 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3_1/use-policy), which is hereby incorporated by
reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 3.1 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.1 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Llama 3.1 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Llama 3.1. If you
access or use Llama 3.1, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3_1/use-policy](https://llama.meta.com/llama3_1/use-policy)
#### Prohibited Uses
We want everyone to use Llama 3.1 safely and responsibly. You agree you will not use, or allow
others to use, Llama 3.1 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
3. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
4. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
5. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
6. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
7. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
8. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.1 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 3.1 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Llama 3.1 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://github.com/meta-llama/llama-models/issues)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# <span style="color: #7FFF7F;">Llama-Guard-3-8B GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-Guard-3-8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-Guard-3-8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-Guard-3-8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-Guard-3-8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-Guard-3-8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-Guard-3-8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-Guard-3-8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-Guard-3-8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-Guard-3-8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-Guard-3-8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-Guard-3-8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Details
Llama Guard 3 is a Llama-3.1-8B pretrained model, fine-tuned for content safety classification. Similar to previous versions, it can be used to classify content in both LLM inputs (prompt classification) and in LLM responses (response classification). It acts as an LLM – it generates text in its output that indicates whether a given prompt or response is safe or unsafe, and if unsafe, it also lists the content categories violated.
Llama Guard 3 was aligned to safeguard against the MLCommons standardized hazards taxonomy and designed to support Llama 3.1 capabilities. Specifically, it provides content moderation in 8 languages, and was optimized to support safety and security for search and code interpreter tool calls.
Below is a response classification example for Llama Guard 3.
<p align="center">
<img src="llama_guard_3_figure.png" width="800"/>
</p>
In order to produce classifier scores, we look at the probability for the first token, and use that as the “unsafe” class probability. We can then apply score thresholding to make binary decisions.
# Hazard Taxonomy and Policy
The model is trained to predict safety labels on the 14 categories shown below, based on the [MLCommons taxonomy](https://mlcommons.org/2024/04/mlc-aisafety-v0-5-poc/) of 13 hazards, as well as an additional category for Code Interpreter Abuse for tool calls use cases
<table align="center">
<thead>
<tr>
<th colspan="2">Hazard categories</th>
</tr>
</thead>
<tbody>
<tr>
<td>S1: Violent Crimes</td>
<td>S2: Non-Violent Crimes</td>
</tr>
<tr>
<td>S3: Sex-Related Crimes</td>
<td>S4: Child Sexual Exploitation</td>
</tr>
<tr>
<td>S5: Defamation</td>
<td>S6: Specialized Advice</td>
</tr>
<tr>
<td>S7: Privacy</td>
<td>S8: Intellectual Property</td>
</tr>
<tr>
<td>S9: Indiscriminate Weapons</td>
<td>S10: Hate</td>
</tr>
<tr>
<td>S11: Suicide & Self-Harm</td>
<td>S12: Sexual Content</td>
</tr>
<tr>
<td>S13: Elections</td>
<td>S14: Code Interpreter Abuse</td>
</tr>
</tbody>
</table>
**S1 - Violent Crimes**
Responses that enable, encourage, or endorse the commission of violent crimes, including: (1) unlawful violence toward people (ex: terrorism, genocide, murder, hate-motivated violent crimes, child abuse, assault, battery, kidnapping) and (2) unlawful violence toward animals (ex: animal abuse)
**S2 - Non-Violent Crimes**
Responses that enable, encourage, or endorse the commission of non-violent crimes, including: (1) personal crimes (ex: labor trafficking, threats, intimidation, hate-motivated non-violent crimes), (2) financial crimes (ex: fraud, scams, money laundering), (3) property crimes (ex: theft, arson, vandalism), (4) drug crimes (ex: creating or using regulated substances), (5) weapons crimes (ex: producing unlicensed firearms), and (6) cyber crimes (ex: hacking)
**S3 - Sex-Related Crimes**
Responses that enable, encourage, or endorse the commission of sex-related crimes, including: (1) sex trafficking, (2) sexual assault (ex: rape), (3) sexual harassment (physical, verbal, or visual), and (4) prostitution
**S4 - Child Sexual Exploitation**
Responses that contain, describe, enable, encourage, or endorse the sexual abuse of children
**S5 - Defamation**
Responses that are both verifiably false and likely to injure a living person’s reputation
**S6 - Specialized Advice**
Responses that contain specialized financial, medical, or legal advice, or that indicate dangerous activities or objects are safe
**S7 - Privacy**
Responses that contain sensitive, nonpublic personal information that could undermine someone’s physical, digital, or financial security
**S8 - Intellectual Property**
Responses that may violate the intellectual property rights of any third party
**S9 - Indiscriminate Weapons**
Responses that enable, encourage, or endorse the creation of indiscriminate weapons, including: (1) chemical weapons (ex: nerve gas), (2) biological weapons (ex: anthrax), (3) radiological weapons (ex: cobalt bombs), (4) nuclear weapons (ex: fission bombs), and (5) high-yield explosive weapons (ex: cluster munitions)
**S10 - Hate**
Responses that demean or dehumanize people on the basis of their sensitive, personal characteristics (i.e., race, color, ethnicity, national origin, disability, religious affiliation, caste, sexual orientation, sex, gender identity, and/or serious disease)
**S11 - Suicide & Self-Harm**
Responses that enable, encourage, or endorse acts of intentional self-harm, including: (1) suicide, (2) self-injury (ex: cutting), and (3) disordered eating
**S12 - Sexual Content**
Responses that contain erotica
**S13 - Elections**
Responses that contain factually incorrect information about electoral systems and processes, including in the time, place, or manner of voting in civic elections
**S14 - Code Interpreter Abuse**
Responses that seek to abuse code interpreters, including those that enable denial of service attacks, container escapes or privilege escalation exploits
# Supported languages
Llama Guard 3 supports content safety for the following languages : English, French, German, Hindi, Italian, Portuguese, Spanish, Thai.
# Usage
> [!IMPORTANT]
>
> This repository corresponds to half-precision version of the model. A 8-bit precision version is also provided, please visit [meta-llama/Llama-Guard-3-8B-INT8](https://huggingface.co/meta-llama/Llama-Guard-3-8B-INT8).
Llama Guard 3 can be directly used with `transformers`. It is only supported since `transformers` version 4.43.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "meta-llama/Llama-Guard-3-8B"
device = "cuda"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=dtype, device_map=device)
def moderate(chat):
input_ids = tokenizer.apply_chat_template(chat, return_tensors="pt").to(device)
output = model.generate(input_ids=input_ids, max_new_tokens=100, pad_token_id=0)
prompt_len = input_ids.shape[-1]
return tokenizer.decode(output[0][prompt_len:], skip_special_tokens=True)
moderate([
{"role": "user", "content": "I forgot how to kill a process in Linux, can you help?"},
{"role": "assistant", "content": "Sure! To kill a process in Linux, you can use the kill command followed by the process ID (PID) of the process you want to terminate."},
])
```
# Training Data
We use the English data used by Llama Guard [1], which are obtained by getting Llama 2 and Llama 3 generations on prompts from the hh-rlhf dataset [2]. In order to scale training data for new categories and new capabilities such as multilingual and tool use, we collect additional human and synthetically generated data. Similar to the English data, the multilingual data are Human-AI conversation data that are either single-turn or multi-turn. To reduce the model’s false positive rate, we curate a set of multilingual benign prompt and response data where LLMs likely reject the prompts.
For the tool use capability, we consider search tool calls and code interpreter abuse. To develop training data for search tool use, we use Llama3 to generate responses to a collected and synthetic set of prompts. The generations are based on the query results obtained from the Brave Search API. To develop synthetic training data to detect code interpreter attacks, we use an LLM to generate safe and unsafe prompts. Then, we use a non-safety-tuned LLM to generate code interpreter completions that comply with these instructions. For safe data, we focus on data close to the boundary of what would be considered unsafe, to minimize false positives on such borderline examples.
# Evaluation
**Note on evaluations:** As discussed in the original Llama Guard paper, comparing model performance is not straightforward as each model is built on its own policy and is expected to perform better on an evaluation dataset with a policy aligned to the model. This highlights the need for industry standards. By aligning the Llama Guard family of models with the Proof of Concept MLCommons taxonomy of hazards, we hope to drive adoption of industry standards like this and facilitate collaboration and transparency in the LLM safety and content evaluation space.
In this regard, we evaluate the performance of Llama Guard 3 on MLCommons hazard taxonomy and compare it across languages with Llama Guard 2 [3] on our internal test. We also add GPT4 as baseline with zero-shot prompting using MLCommons hazard taxonomy.
Tables 1, 2, and 3 show that Llama Guard 3 improves over Llama Guard 2 and outperforms GPT4 in English, multilingual, and tool use capabilities. Noteworthily, Llama Guard 3 achieves better performance with much lower false positive rates. We also benchmark Llama Guard 3 in the OSS dataset XSTest [4] and observe that it achieves the same F1 score but a lower false positive rate compared to Llama Guard 2.
<div align="center">
<small> Table 1: Comparison of performance of various models measured on our internal English test set for MLCommons hazard taxonomy (response classification).</small>
| | **F1 ↑** | **AUPRC ↑** | **False Positive<br>Rate ↓** |
|--------------------------|:--------:|:-----------:|:----------------------------:|
| Llama Guard 2 | 0.877 | 0.927 | 0.081 |
| Llama Guard 3 | 0.939 | 0.985 | 0.040 |
| GPT4 | 0.805 | N/A | 0.152 |
</div>
<br>
<table align="center">
<small><center>Table 2: Comparison of multilingual performance of various models measured on our internal test set for MLCommons hazard taxonomy (prompt+response classification).</center></small>
<thead>
<tr>
<th colspan="8"><center>F1 ↑ / FPR ↓</center></th>
</tr>
</thead>
<tbody>
<tr>
<td></td>
<td><center>French</center></td>
<td><center>German</center></td>
<td><center>Hindi</center></td>
<td><center>Italian</center></td>
<td><center>Portuguese</center></td>
<td><center>Spanish</center></td>
<td><center>Thai</center></td>
</tr>
<tr>
<td>Llama Guard 2</td>
<td><center>0.911/0.012</center></td>
<td><center>0.795/0.062</center></td>
<td><center>0.832/0.062</center></td>
<td><center>0.681/0.039</center></td>
<td><center>0.845/0.032</center></td>
<td><center>0.876/0.001</center></td>
<td><center>0.822/0.078</center></td>
</tr>
<tr>
<td>Llama Guard 3</td>
<td><center>0.943/0.036</center></td>
<td><center>0.877/0.032</center></td>
<td><center>0.871/0.050</center></td>
<td><center>0.873/0.038</center></td>
<td><center>0.860/0.060</center></td>
<td><center>0.875/0.023</center></td>
<td><center>0.834/0.030</center></td>
</tr>
<tr>
<td>GPT4</td>
<td><center>0.795/0.157</center></td>
<td><center>0.691/0.123</center></td>
<td><center>0.709/0.206</center></td>
<td><center>0.753/0.204</center></td>
<td><center>0.738/0.207</center></td>
<td><center>0.711/0.169</center></td>
<td><center>0.688/0.168</center></td>
</tr>
</tbody>
</table>
<br>
<table align="center">
<small><center>Table 3: Comparison of performance of various models measured on our internal test set for other moderation capabilities (prompt+response classification).</center></small>
<thead>
<tr>
<th></th>
<th colspan="3">Search tool calls</th>
<th colspan="3">Code interpreter abuse</th>
</tr>
</thead>
<tbody>
<tr>
<td></td>
<td><center>F1 ↑</center></td>
<td><center>AUPRC ↑</center></td>
<td><center>FPR ↓</center></td>
<td><center>F1 ↑</center></td>
<td><center>AUPRC ↑</center></td>
<td><center>FPR ↓</center></td>
</tr>
<tr>
<td>Llama Guard 2</td>
<td><center>0.749</center></td>
<td><center>0.794</center></td>
<td><center>0.284</center></td>
<td><center>0.683</center></td>
<td><center>0.677</center></td>
<td><center>0.670</center></td>
</tr>
<tr>
<td>Llama Guard 3</td>
<td><center>0.856</center></td>
<td><center>0.938</center></td>
<td><center>0.174</center></td>
<td><center>0.885</center></td>
<td><center>0.967</center></td>
<td><center>0.125</center></td>
</tr>
<tr>
<td>GPT4</td>
<td><center>0.732</center></td>
<td><center>N/A</center></td>
<td><center>0.525</center></td>
<td><center>0.636</center></td>
<td><center>N/A</center></td>
<td><center>0.90</center></td>
</tr>
</tbody>
</table>
# Application
As outlined in the Llama 3 paper, Llama Guard 3 provides industry leading system-level safety performance and is recommended to be deployed along with Llama 3.1. Note that, while deploying Llama Guard 3 will likely improve the safety of your system, it might increase refusals to benign prompts (False Positives). Violation rate improvement and impact on false positives as measured on internal benchmarks are provided in the Llama 3 paper.
# Quantization
We are committed to help the community deploy Llama systems responsibly. We provide a quantized version of Llama Guard 3 to lower the deployment cost. We used int 8 [implementation](https://huggingface.co/docs/transformers/main/en/quantization/bitsandbytes) integrated into the hugging face ecosystem, reducing the checkpoint size by about 40% with very small impact on model performance. In Table 5, we observe that the performance quantized model is comparable to the original model.
<table align="center">
<small><center>Table 5: Impact of quantization on Llama Guard 3 performance.</center></small>
<tbody>
<tr>
<td rowspan="2"><br />
<p><span>Task</span></p>
</td>
<td rowspan="2"><br />
<p><span>Capability</span></p>
</td>
<td colspan="4">
<p><center><span>Non-Quantized</span></center></p>
</td>
<td colspan="4">
<p><center><span>Quantized</span></center></p>
</td>
</tr>
<tr>
<td>
<p><span>Precision</span></p>
</td>
<td>
<p><span>Recall</span></p>
</td>
<td>
<p><span>F1</span></p>
</td>
<td>
<p><span>FPR</span></p>
</td>
<td>
<p><span>Precision</span></p>
</td>
<td>
<p><span>Recall</span></p>
</td>
<td>
<p><span>F1</span></p>
</td>
<td>
<p><span>FPR</span></p>
</td>
</tr>
<tr>
<td rowspan="3">
<p><span>Prompt Classification</span></p>
</td>
<td>
<p><span>English</span></p>
</td>
<td>
<p><span>0.952</span></p>
</td>
<td>
<p><span>0.943</span></p>
</td>
<td>
<p><span>0.947</span></p>
</td>
<td>
<p><span>0.057</span></p>
</td>
<td>
<p><span>0.961</span></p>
</td>
<td>
<p><span>0.939</span></p>
</td>
<td>
<p><span>0.950</span></p>
</td>
<td>
<p><span>0.045</span></p>
</td>
</tr>
<tr>
<td>
<p><span>Multilingual</span></p>
</td>
<td>
<p><span>0.901</span></p>
</td>
<td>
<p><span>0.899</span></p>
</td>
<td>
<p><span>0.900</span></p>
</td>
<td>
<p><span>0.054</span></p>
</td>
<td>
<p><span>0.906</span></p>
</td>
<td>
<p><span>0.892</span></p>
</td>
<td>
<p><span>0.899</span></p>
</td>
<td>
<p><span>0.051</span></p>
</td>
</tr>
<tr>
<td>
<p><span>Tool Use</span></p>
</td>
<td>
<p><span>0.884</span></p>
</td>
<td>
<p><span>0.958</span></p>
</td>
<td>
<p><span>0.920</span></p>
</td>
<td>
<p><span>0.126</span></p>
</td>
<td>
<p><span>0.876</span></p>
</td>
<td>
<p><span>0.946</span></p>
</td>
<td>
<p><span>0.909</span></p>
</td>
<td>
<p><span>0.134</span></p>
</td>
</tr>
<tr>
<td rowspan="3">
<p><span>Response Classification</span></p>
</td>
<td>
<p><span>English</span></p>
</td>
<td>
<p><span>0.947</span></p>
</td>
<td>
<p><span>0.931</span></p>
</td>
<td>
<p><span>0.939</span></p>
</td>
<td>
<p><span>0.040</span></p>
</td>
<td>
<p><span>0.947</span></p>
</td>
<td>
<p><span>0.925</span></p>
</td>
<td>
<p><span>0.936</span></p>
</td>
<td>
<p><span>0.040</span></p>
</td>
</tr>
<tr>
<td>
<p><span>Multilingual</span></p>
</td>
<td>
<p><span>0.929</span></p>
</td>
<td>
<p><span>0.805</span></p>
</td>
<td>
<p><span>0.862</span></p>
</td>
<td>
<p><span>0.033</span></p>
</td>
<td>
<p><span>0.931</span></p>
</td>
<td>
<p><span>0.785</span></p>
</td>
<td>
<p><span>0.851</span></p>
</td>
<td>
<p><span>0.031</span></p>
</td>
</tr>
<tr>
<td>
<p><span>Tool Use</span></p>
</td>
<td>
<p><span>0.774</span></p>
</td>
<td>
<p><span>0.884</span></p>
</td>
<td>
<p><span>0.825</span></p>
</td>
<td>
<p><span>0.176</span></p>
</td>
<td>
<p><span>0.793</span></p>
</td>
<td>
<p><span>0.865</span></p>
</td>
<td>
<p><span>0.827</span></p>
</td>
<td>
<p><span>0.155</span></p>
</td>
</tr>
</tbody>
</table>
# Get started
Llama Guard 3 is available by default on Llama 3.1 [reference implementations](https://github.com/meta-llama). You can learn more about how to configure and customize using [Llama Recipes](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai/) shared on our Github repository.
# Limitations
There are some limitations associated with Llama Guard 3. First, Llama Guard 3 itself is an LLM fine-tuned on Llama 3.1. Thus, its performance (e.g., judgments that need common sense knowledge, multilingual capability, and policy coverage) might be limited by its (pre-)training data.
Some hazard categories may require factual, up-to-date knowledge to be evaluated (for example, S5: Defamation, S8: Intellectual Property, and S13: Elections) . We believe more complex systems should be deployed to accurately moderate these categories for use cases highly sensitive to these types of hazards, but Llama Guard 3 provides a good baseline for generic use cases.
Lastly, as an LLM, Llama Guard 3 may be susceptible to adversarial attacks or prompt injection attacks that could bypass or alter its intended use. Please feel free to [report](https://github.com/meta-llama/PurpleLlama) vulnerabilities and we will look to incorporate improvements in future versions of Llama Guard.
# Citation
```
@misc{dubey2024llama3herdmodels,
title = {The Llama 3 Herd of Models},
author = {Llama Team, AI @ Meta},
year = {2024},
eprint = {2407.21783},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2407.21783}
}
```
# References
[1] [Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations](https://arxiv.org/abs/2312.06674)
[2] [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862)
[3] [Llama Guard 2 Model Card](https://github.com/meta-llama/PurpleLlama/blob/main/Llama-Guard2/MODEL_CARD.md)
[4] [XSTest: A Test Suite for Identifying Exaggerated Safety Behaviors in Large Language Models](https://arxiv.org/abs/2308.01263) |
Mungert/Meta-Llama-3-8B-GGUF | Mungert | 2025-06-15T19:41:55Z | 289 | 2 | null | [
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix"
] | text-generation | 2025-03-23T03:52:38Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3
new_version: meta-llama/Llama-3.1-8B
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# <span style="color: #7FFF7F;">Meta-Llama-3-8B GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Meta-Llama-3-8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Meta-Llama-3-8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Meta-Llama-3-8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Meta-Llama-3-8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Meta-Llama-3-8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Meta-Llama-3-8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Meta-Llama-3-8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Meta-Llama-3-8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Meta-Llama-3-8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Meta-Llama-3-8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Meta-Llama-3-8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 8B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
phospho-app/jakmilller-gr00t-jenga_pull-70tu2 | phospho-app | 2025-06-15T19:41:47Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-06-15T16:34:00Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
Traceback (most recent call last):
File "/opt/conda/lib/python3.11/asyncio/tasks.py", line 500, in wait_for
return fut.result()
^^^^^^^^^^^^
File "/root/phosphobot/am/gr00t.py", line 970, in read_output
async for line in process.stdout:
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 765, in __anext__
val = await self.readline()
^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 566, in readline
line = await self.readuntil(sep)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 658, in readuntil
await self._wait_for_data('readuntil')
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 543, in _wait_for_data
await self._waiter
asyncio.exceptions.CancelledError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/root/phosphobot/am/gr00t.py", line 981, in run_gr00t_training
await asyncio.wait_for(read_output(), timeout=timeout_seconds)
File "/opt/conda/lib/python3.11/asyncio/tasks.py", line 502, in wait_for
raise exceptions.TimeoutError() from exc
TimeoutError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/src/helper.py", line 165, in predict
trainer.train(timeout_seconds=timeout_seconds)
File "/root/phosphobot/am/gr00t.py", line 1146, in train
asyncio.run(
File "/opt/conda/lib/python3.11/asyncio/runners.py", line 190, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/base_events.py", line 654, in run_until_complete
return future.result()
^^^^^^^^^^^^^^^
File "/root/phosphobot/am/gr00t.py", line 986, in run_gr00t_training
raise TimeoutError(
TimeoutError: Training process exceeded timeout of 10800 seconds. Please consider lowering the number of epochs and/or batch size.
```
## Training parameters:
- **Dataset**: [mahanthesh0r/jenga_pull](https://huggingface.co/datasets/mahanthesh0r/jenga_pull)
- **Wandb run URL**: None
- **Epochs**: 25
- **Batch size**: 27
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Mungert/RWKV7-Goose-World3-2.9B-HF-GGUF | Mungert | 2025-06-15T19:41:38Z | 1,401 | 18 | null | [
"gguf",
"text-generation",
"en",
"zh",
"ja",
"ko",
"fr",
"ar",
"es",
"pt",
"base_model:BlinkDL/rwkv-7-world",
"base_model:quantized:BlinkDL/rwkv-7-world",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-21T03:09:13Z | ---
license: apache-2.0
language:
- en
- zh
- ja
- ko
- fr
- ar
- es
- pt
metrics:
- accuracy
base_model:
- BlinkDL/rwkv-7-world
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">RWKV7-Goose-World3-2.9B-HF GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `RWKV7-Goose-World3-2.9B-HF-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `RWKV7-Goose-World3-2.9B-HF-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `RWKV7-Goose-World3-2.9B-HF-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `RWKV7-Goose-World3-2.9B-HF-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `RWKV7-Goose-World3-2.9B-HF-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `RWKV7-Goose-World3-2.9B-HF-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `RWKV7-Goose-World3-2.9B-HF-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `RWKV7-Goose-World3-2.9B-HF-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `RWKV7-Goose-World3-2.9B-HF-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `RWKV7-Goose-World3-2.9B-HF-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `RWKV7-Goose-World3-2.9B-HF-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# rwkv7-2.9B-world
<!-- Provide a quick summary of what the model is/does. -->
This is RWKV-7 model under flash-linear attention format.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Bo Peng, Yu Zhang, Songlin Yang, Ruichong Zhang
- **Funded by:** RWKV Project (Under LF AI & Data Foundation)
- **Model type:** RWKV7
- **Language(s) (NLP):** English
- **License:** Apache-2.0
- **Parameter count:** 2.9B
- **Tokenizer:** RWKV World tokenizer
- **Vocabulary size:** 65,536
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/fla-org/flash-linear-attention ; https://github.com/BlinkDL/RWKV-LM
- **Paper:** With in Progress
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
Install `flash-linear-attention` and the latest version of `transformers` before using this model:
```bash
pip install git+https://github.com/fla-org/flash-linear-attention
pip install 'transformers>=4.48.0'
```
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
You can use this model just as any other HuggingFace models:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('fla-hub/rwkv7-2.9B-world', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('fla-hub/rwkv7-2.9B-world', trust_remote_code=True)
model = model.cuda()
prompt = "What is a large language model?"
messages = [
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "I am a GPT-3 based model."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)[0]
print(response)
```
### Training Data
This model is trained on the World v3 with a total of 3.119 trillion tokens.
#### Training Hyperparameters
- **Training regime:** bfloat16, lr 4e-4 to 1e-5 "delayed" cosine decay, wd 0.1 (with increasing batch sizes during the middle)
- **Final Loss:** 1.8745
- **Token Count:** 3.119 trillion
## FAQ
Q: safetensors metadata is none.
A: upgrade transformers to >=4.48.0: `pip install 'transformers>=4.48.0'` |
Mungert/Mistral-7B-Instruct-v0.3-GGUF | Mungert | 2025-06-15T19:41:35Z | 1,305 | 5 | null | [
"gguf",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:quantized:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-21T00:01:20Z | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.3
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# <span style="color: #7FFF7F;">Mistral-7B-Instruct-v0.3 GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mistral-7B-Instruct-v0.3-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mistral-7B-Instruct-v0.3-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mistral-7B-Instruct-v0.3-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mistral-7B-Instruct-v0.3-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mistral-7B-Instruct-v0.3-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mistral-7B-Instruct-v0.3-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mistral-7B-Instruct-v0.3-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mistral-7B-Instruct-v0.3-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mistral-7B-Instruct-v0.3-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mistral-7B-Instruct-v0.3-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mistral-7B-Instruct-v0.3-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for Mistral-7B-Instruct-v0.3
The Mistral-7B-Instruct-v0.3 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.3.
Mistral-7B-v0.3 has the following changes compared to [Mistral-7B-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2/edit/main/README.md)
- Extended vocabulary to 32768
- Supports v3 Tokenizer
- Supports function calling
## Installation
It is recommended to use `mistralai/Mistral-7B-Instruct-v0.3` with [mistral-inference](https://github.com/mistralai/mistral-inference). For HF transformers code snippets, please keep scrolling.
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', '7B-Instruct-v0.3')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Mistral-7B-Instruct-v0.3", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment. You can chat with the model using
```
mistral-chat $HOME/mistral_models/7B-Instruct-v0.3 --instruct --max_tokens 256
```
### Instruct following
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
### Function calling
```py
from mistral_common.protocol.instruct.tool_calls import Function, Tool
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris?"),
],
)
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
## Generate with `transformers`
If you want to use Hugging Face `transformers` to generate text, you can do something like this.
```py
from transformers import pipeline
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3")
chatbot(messages)
```
## Function calling with `transformers`
To use this example, you'll need `transformers` version 4.42.0 or higher. Please see the
[function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling)
in the `transformers` docs for more information.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "mistralai/Mistral-7B-Instruct-v0.3"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_current_weather(location: str, format: str):
"""
Get the current weather
Args:
location: The city and state, e.g. San Francisco, CA
format: The temperature unit to use. Infer this from the users location. (choices: ["celsius", "fahrenheit"])
"""
pass
conversation = [{"role": "user", "content": "What's the weather like in Paris?"}]
tools = [get_current_weather]
# format and tokenize the tool use prompt
inputs = tokenizer.apply_chat_template(
conversation,
tools=tools,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
inputs.to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1000)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Note that, for reasons of space, this example does not show a complete cycle of calling a tool and adding the tool call and tool
results to the chat history so that the model can use them in its next generation. For a full tool calling example, please
see the [function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling),
and note that Mistral **does** use tool call IDs, so these must be included in your tool calls and tool results. They should be
exactly 9 alphanumeric characters.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, William El Sayed, William Marshall |
Mungert/DeepSeek-R1-Distill-Qwen-14B-GGUF | Mungert | 2025-06-15T19:41:25Z | 528 | 7 | transformers | [
"transformers",
"gguf",
"arxiv:2501.12948",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-20T16:51:32Z | ---
license: mit
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepSeek-R1-Distill-Qwen-14B GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepSeek-R1-Distill-Qwen-14B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepSeek-R1-Distill-Qwen-14B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepSeek-R1-Distill-Qwen-14B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepSeek-R1-Distill-Qwen-14B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepSeek-R1-Distill-Qwen-14B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepSeek-R1-Distill-Qwen-14B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepSeek-R1-Distill-Qwen-14B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepSeek-R1-Distill-Qwen-14B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepSeek-R1-Distill-Qwen-14B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-14B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-14B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# DeepSeek-R1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
<p align="center">
<img width="80%" src="figures/benchmark.jpg">
</p>
## 2. Model Summary
---
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
We believe the pipeline will benefit the industry by creating better models.
---
**Distillation: Smaller Models Can Be Powerful Too**
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
## 3. Model Downloads
### DeepSeek-R1 Models
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
</div>
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
### DeepSeek-R1-Distill Models
<div align="center">
| **Model** | **Base Model** | **Download** |
| :------------: | :------------: | :------------: |
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
</div>
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
We slightly change their configs and tokenizers. Please use our setting to run these models.
## 4. Evaluation Results
### DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
| | Architecture | - | - | MoE | - | - | MoE |
| | # Activated Params | - | - | 37B | - | - | 37B |
| | # Total Params | - | - | 671B | - | - | 671B |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
</div>
### Distilled Model Evaluation
<div align="center">
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
</div>
## 5. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 6. How to Run Locally
### DeepSeek-R1 Models
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
**NOTE: Hugging Face's Transformers has not been directly supported yet.**
### DeepSeek-R1-Distill Models
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```shell
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
```
### Usage Recommendations
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "\<think\>\n\n\</think\>") when responding to certain queries, which can adversely affect the model's performance.
**To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.**
## 7. License
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
## 8. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 9. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
Mungert/DeepSeek-R1-Distill-Qwen-7B-GGUF | Mungert | 2025-06-15T19:41:16Z | 1,140 | 4 | transformers | [
"transformers",
"gguf",
"arxiv:2501.12948",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-19T23:20:08Z | ---
license: mit
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepSeek-R1-Distill-Qwen-7B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepSeek-R1-Distill-Qwen-7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepSeek-R1-Distill-Qwen-7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepSeek-R1-Distill-Qwen-7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepSeek-R1-Distill-Qwen-7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepSeek-R1-Distill-Qwen-7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepSeek-R1-Distill-Qwen-7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepSeek-R1-Distill-Qwen-7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepSeek-R1-Distill-Qwen-7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepSeek-R1-Distill-Qwen-7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# DeepSeek-R1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
<p align="center">
<img width="80%" src="figures/benchmark.jpg">
</p>
## 2. Model Summary
---
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
We believe the pipeline will benefit the industry by creating better models.
---
**Distillation: Smaller Models Can Be Powerful Too**
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
## 3. Model Downloads
### DeepSeek-R1 Models
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
</div>
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
### DeepSeek-R1-Distill Models
<div align="center">
| **Model** | **Base Model** | **Download** |
| :------------: | :------------: | :------------: |
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
</div>
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
We slightly change their configs and tokenizers. Please use our setting to run these models.
## 4. Evaluation Results
### DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
| | Architecture | - | - | MoE | - | - | MoE |
| | # Activated Params | - | - | 37B | - | - | 37B |
| | # Total Params | - | - | 671B | - | - | 671B |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
</div>
### Distilled Model Evaluation
<div align="center">
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
</div>
## 5. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 6. How to Run Locally
### DeepSeek-R1 Models
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
**NOTE: Hugging Face's Transformers has not been directly supported yet.**
### DeepSeek-R1-Distill Models
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```shell
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
```
### Usage Recommendations
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "\<think\>\n\n\</think\>") when responding to certain queries, which can adversely affect the model's performance.
**To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.**
## 7. License
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
## 8. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 9. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
Mungert/EXAONE-Deep-7.8B-GGUF | Mungert | 2025-06-15T19:41:09Z | 1,344 | 5 | transformers | [
"transformers",
"gguf",
"lg-ai",
"exaone",
"exaone-deep",
"text-generation",
"en",
"ko",
"arxiv:2503.12524",
"base_model:LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct",
"base_model:finetune:LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-19T21:27:57Z | ---
base_model: LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct
base_model_relation: finetune
license: other
license_name: exaone
license_link: LICENSE
language:
- en
- ko
tags:
- lg-ai
- exaone
- exaone-deep
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">EXAONE-Deep-7.8B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `EXAONE-Deep-7.8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `EXAONE-Deep-7.8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `EXAONE-Deep-7.8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `EXAONE-Deep-7.8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `EXAONE-Deep-7.8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `EXAONE-Deep-7.8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `EXAONE-Deep-7.8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `EXAONE-Deep-7.8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `EXAONE-Deep-7.8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `EXAONE-Deep-7.8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `EXAONE-Deep-7.8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# EXAONE-Deep-7.8B
## Introduction
We introduce EXAONE Deep, which exhibits superior capabilities in various reasoning tasks including math and coding benchmarks, ranging from 2.4B to 32B parameters developed and released by LG AI Research. Evaluation results show that 1) EXAONE Deep **2.4B** outperforms other models of comparable size, 2) EXAONE Deep **7.8B** outperforms not only open-weight models of comparable scale but also a proprietary reasoning model OpenAI o1-mini, and 3) EXAONE Deep **32B** demonstrates competitive performance against leading open-weight models.
For more details, please refer to our [documentation](https://arxiv.org/abs/2503.12524), [blog](https://www.lgresearch.ai/news/view?seq=543) and [GitHub](https://github.com/LG-AI-EXAONE/EXAONE-Deep).
<p align="center">
<img src="assets/exaone_deep_overall_performance.png", width="100%", style="margin: 40 auto;">
This repository contains the reasoning 7.8B language model with the following features:
- Number of Parameters (without embeddings): 6.98B
- Number of Layers: 32
- Number of Attention Heads: GQA with 32 Q-heads and 8 KV-heads
- Vocab Size: 102,400
- Context Length: 32,768 tokens
## Quickstart
We recommend to use `transformers` v4.43.1 or later.
Here is the code snippet to run conversational inference with the model:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Thread
model_name = "LGAI-EXAONE/EXAONE-Deep-7.8B"
streaming = True # choose the streaming option
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Choose your prompt:
# Math example (AIME 2024)
prompt = r"""Let $x,y$ and $z$ be positive real numbers that satisfy the following system of equations:
\[\log_2\left({x \over yz}\right) = {1 \over 2}\]\[\log_2\left({y \over xz}\right) = {1 \over 3}\]\[\log_2\left({z \over xy}\right) = {1 \over 4}\]
Then the value of $\left|\log_2(x^4y^3z^2)\right|$ is $\tfrac{m}{n}$ where $m$ and $n$ are relatively prime positive integers. Find $m+n$.
Please reason step by step, and put your final answer within \boxed{}."""
# Korean MCQA example (CSAT Math 2025)
prompt = r"""Question : $a_1 = 2$인 수열 $\{a_n\}$과 $b_1 = 2$인 등차수열 $\{b_n\}$이 모든 자연수 $n$에 대하여\[\sum_{k=1}^{n} \frac{a_k}{b_{k+1}} = \frac{1}{2} n^2\]을 만족시킬 때, $\sum_{k=1}^{5} a_k$의 값을 구하여라.
Options :
A) 120
B) 125
C) 130
D) 135
E) 140
Please reason step by step, and you should write the correct option alphabet (A, B, C, D or E) within \\boxed{}."""
messages = [
{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
)
if streaming:
streamer = TextIteratorStreamer(tokenizer)
thread = Thread(target=model.generate, kwargs=dict(
input_ids=input_ids.to("cuda"),
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=32768,
do_sample=True,
temperature=0.6,
top_p=0.95,
streamer=streamer
))
thread.start()
for text in streamer:
print(text, end="", flush=True)
else:
output = model.generate(
input_ids.to("cuda"),
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=32768,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(tokenizer.decode(output[0]))
```
> ### Note
> The EXAONE Deep models are trained with an optimized configuration,
> so we recommend following the [Usage Guideline](#usage-guideline) section to achieve optimal performance.
## Evaluation
The following table shows the evaluation results of reasoning tasks such as math and coding. The full evaluation results can be found in the [documentation](https://arxiv.org/abs/2503.12524).
<table>
<tr>
<th>Models</th>
<th>MATH-500 (pass@1)</th>
<th>AIME 2024 (pass@1 / cons@64)</th>
<th>AIME 2025 (pass@1 / cons@64)</th>
<th>CSAT Math 2025 (pass@1)</th>
<th>GPQA Diamond (pass@1)</th>
<th>Live Code Bench (pass@1)</th>
</tr>
<tr>
<td>EXAONE Deep 32B</td>
<td>95.7</td>
<td>72.1 / <strong>90.0</strong></td>
<td>65.8 / <strong>80.0</strong></td>
<td><strong>94.5</strong></td>
<td>66.1</td>
<td>59.5</td>
</tr>
<tr>
<td>DeepSeek-R1-Distill-Qwen-32B</td>
<td>94.3</td>
<td>72.6 / 83.3</td>
<td>55.2 / 73.3</td>
<td>84.1</td>
<td>62.1</td>
<td>57.2</td>
</tr>
<tr>
<td>QwQ-32B</td>
<td>95.5</td>
<td>79.5 / 86.7</td>
<td><strong>67.1</strong> / 76.7</td>
<td>94.4</td>
<td>63.3</td>
<td>63.4</td>
</tr>
<tr>
<td>DeepSeek-R1-Distill-Llama-70B</td>
<td>94.5</td>
<td>70.0 / 86.7</td>
<td>53.9 / 66.7</td>
<td>88.8</td>
<td>65.2</td>
<td>57.5</td>
</tr>
<tr>
<td>DeepSeek-R1 (671B)</td>
<td><strong>97.3</strong></td>
<td><strong>79.8</strong> / 86.7</td>
<td>66.8 / <strong>80.0</strong></td>
<td>89.9</td>
<td><strong>71.5</strong></td>
<td><strong>65.9</strong></td>
</tr>
<tr>
<th colspan="7" height="30px"></th>
</tr>
<tr>
<td>EXAONE Deep 7.8B</td>
<td><strong>94.8</strong></td>
<td><strong>70.0</strong> / <strong>83.3</strong></td>
<td><strong>59.6</strong> / <strong>76.7</strong></td>
<td><strong>89.9</strong></td>
<td><strong>62.6</strong></td>
<td><strong>55.2</strong></td>
</tr>
<tr>
<td>DeepSeek-R1-Distill-Qwen-7B</td>
<td>92.8</td>
<td>55.5 / <strong>83.3</strong></td>
<td>38.5 / 56.7</td>
<td>79.7</td>
<td>49.1</td>
<td>37.6</td>
</tr>
<tr>
<td>DeepSeek-R1-Distill-Llama-8B</td>
<td>89.1</td>
<td>50.4 / 80.0</td>
<td>33.6 / 53.3</td>
<td>74.1</td>
<td>49.0</td>
<td>39.6</td>
</tr>
<tr>
<td>OpenAI o1-mini</td>
<td>90.0</td>
<td>63.6 / 80.0</td>
<td>54.8 / 66.7</td>
<td>84.4</td>
<td>60.0</td>
<td>53.8</td>
</tr>
<tr>
<th colspan="7" height="30px"></th>
</tr>
<tr>
<td>EXAONE Deep 2.4B</td>
<td><strong>92.3</strong></td>
<td><strong>52.5</strong> / <strong>76.7</strong></td>
<td><strong>47.9</strong> / <strong>73.3</strong></td>
<td><strong>79.2</strong></td>
<td><strong>54.3</strong></td>
<td><strong>46.6</strong></td>
</tr>
<tr>
<td>DeepSeek-R1-Distill-Qwen-1.5B</td>
<td>83.9</td>
<td>28.9 / 52.7</td>
<td>23.9 / 36.7</td>
<td>65.6</td>
<td>33.8</td>
<td>16.9</td>
</tr>
</table>
## Deployment
EXAONE Deep models can be inferred in the various frameworks, such as:
- `TensorRT-LLM`
- `vLLM`
- `SGLang`
- `llama.cpp`
- `Ollama`
- `LM-Studio`
Please refer to our [EXAONE Deep GitHub](https://github.com/LG-AI-EXAONE/EXAONE-Deep) for more details about the inference frameworks.
## Quantization
We provide the pre-quantized EXAONE Deep models with **AWQ** and several quantization types in **GGUF** format. Please refer to our [EXAONE Deep collection](https://huggingface.co/collections/LGAI-EXAONE/exaone-deep-67d119918816ec6efa79a4aa) to find corresponding quantized models.
## Usage Guideline
To achieve the expected performance, we recommend using the following configurations:
1. Ensure the model starts with `<thought>\n` for reasoning steps. The model's output quality may be degraded when you omit it. You can easily apply this feature by using `tokenizer.apply_chat_template()` with `add_generation_prompt=True`. Please check the example code on [Quickstart](#quickstart) section.
2. The reasoning steps of EXAONE Deep models enclosed by `<thought>\n...\n</thought>` usually have lots of tokens, so previous reasoning steps may be necessary to be removed in multi-turn situation. The provided tokenizer handles this automatically.
3. Avoid using system prompt, and build the instruction on the user prompt.
4. Additional instructions help the models reason more deeply, so that the models generate better output.
- For math problems, the instructions **"Please reason step by step, and put your final answer within \boxed{}."** are helpful.
- For more information on our evaluation setting including prompts, please refer to our [Documentation](https://arxiv.org/abs/2503.12524).
5. In our evaluation, we use `temperature=0.6` and `top_p=0.95` for generation.
6. When evaluating the models, it is recommended to test multiple times to assess the expected performance accurately.
## Limitation
The EXAONE language model has certain limitations and may occasionally generate inappropriate responses. The language model generates responses based on the output probability of tokens, and it is determined during learning from training data. While we have made every effort to exclude personal, harmful, and biased information from the training data, some problematic content may still be included, potentially leading to undesirable responses. Please note that the text generated by EXAONE language model does not reflects the views of LG AI Research.
- Inappropriate answers may be generated, which contain personal, harmful or other inappropriate information.
- Biased responses may be generated, which are associated with age, gender, race, and so on.
- The generated responses rely heavily on statistics from the training data, which can result in the generation of
semantically or syntactically incorrect sentences.
- Since the model does not reflect the latest information, the responses may be false or contradictory.
LG AI Research strives to reduce potential risks that may arise from EXAONE language models. Users are not allowed
to engage in any malicious activities (e.g., keying in illegal information) that may induce the creation of inappropriate
outputs violating LG AI’s ethical principles when using EXAONE language models.
## License
The model is licensed under [EXAONE AI Model License Agreement 1.1 - NC](./LICENSE)
## Citation
```
@article{exaone-deep,
title={EXAONE Deep: Reasoning Enhanced Language Models},
author={{LG AI Research}},
journal={arXiv preprint arXiv:2503.12524},
year={2025}
}
```
## Contact
LG AI Research Technical Support: [email protected] |
Mungert/granite-3.2-8b-instruct-GGUF | Mungert | 2025-06-15T19:41:01Z | 619 | 4 | transformers | [
"transformers",
"gguf",
"language",
"granite-3.2",
"text-generation",
"arxiv:0000.00000",
"base_model:ibm-granite/granite-3.1-8b-instruct",
"base_model:quantized:ibm-granite/granite-3.1-8b-instruct",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-19T03:28:48Z | ---
pipeline_tag: text-generation
inference: false
license: apache-2.0
library_name: transformers
tags:
- language
- granite-3.2
base_model:
- ibm-granite/granite-3.1-8b-instruct
---
# <span style="color: #7FFF7F;">granite-3.2-8b-instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `granite-3.2-8b-instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `granite-3.2-8b-instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `granite-3.2-8b-instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `granite-3.2-8b-instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `granite-3.2-8b-instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `granite-3.2-8b-instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `granite-3.2-8b-instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `granite-3.2-8b-instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `granite-3.2-8b-instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `granite-3.2-8b-instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `granite-3.2-8b-instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Granite-3.2-8B-Instruct
**Model Summary:**
Granite-3.2-8B-Instruct is an 8-billion-parameter, long-context AI model fine-tuned for thinking capabilities. Built on top of [Granite-3.1-8B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-8b-instruct), it has been trained using a mix of permissively licensed open-source datasets and internally generated synthetic data designed for reasoning tasks. The model allows controllability of its thinking capability, ensuring it is applied only when required.
- **Developers:** Granite Team, IBM
- **Website**: [Granite Docs](https://www.ibm.com/granite/docs/)
- **Release Date**: February 26th, 2025
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese. However, users may finetune this Granite model for languages beyond these 12 languages.
**Intended Use:**
This model is designed to handle general instruction-following tasks and can be integrated into AI assistants across various domains, including business applications.
**Capabilities**
* **Thinking**
* Summarization
* Text classification
* Text extraction
* Question-answering
* Retrieval Augmented Generation (RAG)
* Code related tasks
* Function-calling tasks
* Multilingual dialog use cases
* Long-context tasks including long document/meeting summarization, long document QA, etc.
**Generation:**
This is a simple example of how to use Granite-3.2-8B-Instruct model.
Install the following libraries:
```shell
pip install torch torchvision torchaudio
pip install accelerate
pip install transformers
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
model_path="ibm-granite/granite-3.2-8b-instruct"
device="cuda"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map=device,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
model_path
)
conv = [{"role": "user", "content":"You have 10 liters of a 30% acid solution. How many liters of a 70% acid solution must be added to achieve a 50% acid mixture?"}]
input_ids = tokenizer.apply_chat_template(conv, return_tensors="pt", thinking=True, return_dict=True, add_generation_prompt=True).to(device)
set_seed(42)
output = model.generate(
**input_ids,
max_new_tokens=8192,
)
prediction = tokenizer.decode(output[0, input_ids["input_ids"].shape[1]:], skip_special_tokens=True)
print(prediction)
```
**Example Outputs**
- thinking=True
```md
Here is my thought process:
1. We know we start with 10 liters of a 30% acid solution, so there's 3 liters of pure acid in it (10 liters * 0.3).
2. We need to determine how much of the 70% acid solution to add such that the final mixture is 50% acid.
3. Let's say x liters of the 70% acid solution are added. This will contribute 0.7x liters of pure acid.
4. The total volume of the new mixture will be 10 + x liters, and the total amount of pure acid will be 3 + 0.7x liters.
5. We need to set up an equation where (3 + 0.7x) / (10 + x) = 0.5 (since we want a 50% acid mixture).
6. Solving this equation for x will give us the volume of 70% solution needed.
Here is my response:
To solve this, we need to set up an equation based on the concentration of acid before and after mixing.
1. **Initial Acid Content**:
- We start with 10 liters of a 30% acid solution.
- Pure acid in this = 10 * 0.3 = 3 liters.
2. **Variable for Addition**:
- Let x be the liters of 70% acid solution to be added.
- Pure acid in x liters of 70% solution = 0.7x liters.
3. **Final Mixture Concentration**:
- Total volume of mixture = 10 + x liters.
- Total pure acid in the mixture = 3 (from initial solution) + 0.7x (from added solution).
4. **Setting up the equation for 50% acid concentration**:
- We require that the ratio of pure acid to total volume is 0.5 (50%).
- Therefore, the equation is:
\[
\frac{3 + 0.7x}{10 + x} = 0.5
\]
5. **Solving the equation**:
Multiply both sides by (10 + x) to clear the fraction:
\[
3 + 0.7x = 0.5(10 + x)
\]
Expanding the right side:
\[
3 + 0.7x = 5 + 0.5x
\]
Subtract 0.5x from both sides:
\[
3 + 0.2x = 5
\]
Subtract 3 from both sides:
\[
0.2x = 2
\]
Divide by 0.2:
\[
x = 10
\]
So, 10 liters of the 70% acid solution must be added to the initial 10 liters of 30% solution to get a 50% acid mixture.
Let's verify:
- Initial acid: 3 liters
- Acid from added solution: 0.7 * 10 = 7 liters
- Total acid: 3 + 7 = 10 liters
- Total volume: 10 + 10 = 20 liters
- Acid percentage: \(\frac{10}{20} = 0.5 = 50\%\)
This confirms our solution.
Final answer: 10 liters of 70% acid solution should be added.
```
- thinking=False
```md
Let's denote the amount of 70% acid solution to be added as x liters.
We start with 10 liters of a 30% acid solution, which means there are 0.3 * 10 = 3 liters of pure acid in it.
We want to end up with a 50% acid solution after adding x liters of 70% acid solution. The total volume of the mixture will be 10 + x liters, and we want half of this volume to be pure acid.
So, the amount of pure acid in the final mixture should be 0.5 * (10 + x) liters.
The amount of pure acid in the final mixture comes from two sources: the original 30% solution and the added 70% solution. So, we can set up the following equation:
3 (from the original solution) + 0.7x (from the added solution) = 0.5 * (10 + x)
Now, let's solve for x:
3 + 0.7x = 5 + 0.5x
0.7x - 0.5x = 5 - 3
0.2x = 2
x = 2 / 0.2
x = 10
So, you need to add 10 liters of a 70% acid solution to the 10 liters of a 30% acid solution to get a 50% acid mixture.
```
**Evaluation Results:**
<table>
<thead>
<tr>
<th style="text-align:left; background-color: #001d6c; color: white;">Models</th>
<th style="text-align:center; background-color: #001d6c; color: white;">ArenaHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">Alpaca-Eval-2</th>
<th style="text-align:center; background-color: #001d6c; color: white;">MMLU</th>
<th style="text-align:center; background-color: #001d6c; color: white;">PopQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">TruthfulQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">BigBenchHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">DROP</th>
<th style="text-align:center; background-color: #001d6c; color: white;">GSM8K</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval+</th>
<th style="text-align:center; background-color: #001d6c; color: white;">IFEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AttaQ</th>
</tr></thead>
<tbody>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Llama-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">36.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.22</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">69.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.66</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.48</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.24</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.32</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.43</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Llama-8B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">17.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.85</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">45.80</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">13.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">44.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.54</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">62.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.50</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.87</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Qwen-2.5-7B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">25.44</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.30</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.06</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">70.40</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">93.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.90</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.90</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Qwen-7B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">10.36</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">15.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">9.94</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.14</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.76</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.47</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.89</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.45</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">37.58</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.7</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.84</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">68.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.78</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.63</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.20</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.73</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-2B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">23.3</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.11</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.68</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.45</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">75.26</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.59</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.7</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.2-2B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">24.86</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">34.51</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.56</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.8</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.27</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.02</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.13</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.39</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.23</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.2-8B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">55.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.19</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.92</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">64.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.95</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.65</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.31</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.42</td>
</tr>
</tbody></table>
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets with permissive license, (2) internal synthetically generated data targeted to enhance reasoning capabilites.
<!-- A detailed attribution of datasets can be found in [Granite 3.2 Technical Report (coming soon)](#), and [Accompanying Author List](https://github.com/ibm-granite/granite-3.0-language-models/blob/main/author-ack.pdf). -->
**Infrastructure:**
We train Granite-3.2-8B-Instruct using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable and efficient infrastructure for training our models over thousands of GPUs.
**Ethical Considerations and Limitations:**
Granite-3.2-8B-Instruct builds upon Granite-3.1-8B-Instruct, leveraging both permissively licensed open-source and select proprietary data for enhanced performance. Since it inherits its foundation from the previous model, all ethical considerations and limitations applicable to [Granite-3.1-8B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-8b-instruct) remain relevant.
**Resources**
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 📄 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
<!-- ## Citation
```
@misc{granite-models,
author = {author 1, author2, ...},
title = {},
journal = {},
volume = {},
year = {2024},
url = {https://arxiv.org/abs/0000.00000},
}
``` --> |
Mungert/Mistral-Small-3.1-24B-Instruct-2503-GGUF | Mungert | 2025-06-15T19:40:56Z | 12,272 | 8 | vllm | [
"vllm",
"gguf",
"image-text-to-text",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.1-24B-Base-2503",
"base_model:quantized:mistralai/Mistral-Small-3.1-24B-Base-2503",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-03-19T01:11:29Z | ---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Mistral-Small-3.1-24B-Base-2503
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
pipeline_tag: image-text-to-text
---
# <span style="color: #7FFF7F;">Mistral-Small-3.1-24B-Instruct-2503 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mistral-Small-3.1-24B-Instruct-2503-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mistral-Small-3.1-24B-Instruct-2503-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mistral-Small-3.1-24B-Instruct-2503-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mistral-Small-3.1-24B-Instruct-2503-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mistral-Small-3.1-24B-Instruct-2503-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mistral-Small-3.1-24B-Instruct-2503-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mistral-Small-3.1-24B-Instruct-2503-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mistral-Small-3.1-24B-Instruct-2503-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mistral-Small-3.1-24B-Instruct-2503-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mistral-Small-3.1-24B-Instruct-2503-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mistral-Small-3.1-24B-Instruct-2503-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Card for Mistral-Small-3.1-24B-Instruct-2503
Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) **adds state-of-the-art vision understanding** and enhances **long context capabilities up to 128k tokens** without compromising text performance.
With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
This model is an instruction-finetuned version of: [Mistral-Small-3.1-24B-Base-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
Mistral Small 3.1 can be deployed locally and is exceptionally "knowledge-dense," fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized.
It is ideal for:
- Fast-response conversational agents.
- Low-latency function calling.
- Subject matter experts via fine-tuning.
- Local inference for hobbyists and organizations handling sensitive data.
- Programming and math reasoning.
- Long document understanding.
- Visual understanding.
For enterprises requiring specialized capabilities (increased context, specific modalities, domain-specific knowledge, etc.), we will release commercial models beyond what Mistral AI contributes to the community.
Learn more about Mistral Small 3.1 in our [blog post](https://mistral.ai/news/mistral-small-3-1/).
## Key Features
- **Vision:** Vision capabilities enable the model to analyze images and provide insights based on visual content in addition to text.
- **Multilingual:** Supports dozens of languages, including English, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Malay, Nepali, Polish, Portuguese, Romanian, Russian, Serbian, Spanish, Swedish, Turkish, Ukrainian, Vietnamese, Arabic, Bengali, Chinese, Farsi.
- **Agent-Centric:** Offers best-in-class agentic capabilities with native function calling and JSON outputting.
- **Advanced Reasoning:** State-of-the-art conversational and reasoning capabilities.
- **Apache 2.0 License:** Open license allowing usage and modification for both commercial and non-commercial purposes.
- **Context Window:** A 128k context window.
- **System Prompt:** Maintains strong adherence and support for system prompts.
- **Tokenizer:** Utilizes a Tekken tokenizer with a 131k vocabulary size.
## Benchmark Results
When available, we report numbers previously published by other model providers, otherwise we re-evaluate them using our own evaluation harness.
### Pretrain Evals
| Model | MMLU (5-shot) | MMLU Pro (5-shot CoT) | TriviaQA | GPQA Main (5-shot CoT)| MMMU |
|--------------------------------|---------------|-----------------------|------------|-----------------------|-----------|
| **Small 3.1 24B Base** | **81.01%** | **56.03%** | 80.50% | **37.50%** | **59.27%**|
| Gemma 3 27B PT | 78.60% | 52.20% | **81.30%** | 24.30% | 56.10% |
### Instruction Evals
#### Text
| Model | MMLU | MMLU Pro (5-shot CoT) | MATH | GPQA Main (5-shot CoT) | GPQA Diamond (5-shot CoT )| MBPP | HumanEval | SimpleQA (TotalAcc)|
|--------------------------------|-----------|-----------------------|------------------------|------------------------|---------------------------|-----------|-----------|--------------------|
| **Small 3.1 24B Instruct** | 80.62% | 66.76% | 69.30% | **44.42%** | **45.96%** | 74.71% | **88.41%**| **10.43%** |
| Gemma 3 27B IT | 76.90% | **67.50%** | **89.00%** | 36.83% | 42.40% | 74.40% | 87.80% | 10.00% |
| GPT4o Mini | **82.00%**| 61.70% | 70.20% | 40.20% | 39.39% | 84.82% | 87.20% | 9.50% |
| Claude 3.5 Haiku | 77.60% | 65.00% | 69.20% | 37.05% | 41.60% | **85.60%**| 88.10% | 8.02% |
| Cohere Aya-Vision 32B | 72.14% | 47.16% | 41.98% | 34.38% | 33.84% | 70.43% | 62.20% | 7.65% |
#### Vision
| Model | MMMU | MMMU PRO | Mathvista | ChartQA | DocVQA | AI2D | MM MT Bench |
|--------------------------------|------------|-----------|-----------|-----------|-----------|-------------|-------------|
| **Small 3.1 24B Instruct** | 64.00% | **49.25%**| **68.91%**| 86.24% | **94.08%**| **93.72%** | **7.3** |
| Gemma 3 27B IT | **64.90%** | 48.38% | 67.60% | 76.00% | 86.60% | 84.50% | 7 |
| GPT4o Mini | 59.40% | 37.60% | 56.70% | 76.80% | 86.70% | 88.10% | 6.6 |
| Claude 3.5 Haiku | 60.50% | 45.03% | 61.60% | **87.20%**| 90.00% | 92.10% | 6.5 |
| Cohere Aya-Vision 32B | 48.20% | 31.50% | 50.10% | 63.04% | 72.40% | 82.57% | 4.1 |
### Multilingual Evals
| Model | Average | European | East Asian | Middle Eastern |
|--------------------------------|------------|------------|------------|----------------|
| **Small 3.1 24B Instruct** | **71.18%** | **75.30%** | **69.17%** | 69.08% |
| Gemma 3 27B IT | 70.19% | 74.14% | 65.65% | 70.76% |
| GPT4o Mini | 70.36% | 74.21% | 65.96% | **70.90%** |
| Claude 3.5 Haiku | 70.16% | 73.45% | 67.05% | 70.00% |
| Cohere Aya-Vision 32B | 62.15% | 64.70% | 57.61% | 64.12% |
### Long Context Evals
| Model | LongBench v2 | RULER 32K | RULER 128K |
|--------------------------------|-----------------|-------------|------------|
| **Small 3.1 24B Instruct** | **37.18%** | **93.96%** | 81.20% |
| Gemma 3 27B IT | 34.59% | 91.10% | 66.00% |
| GPT4o Mini | 29.30% | 90.20% | 65.8% |
| Claude 3.5 Haiku | 35.19% | 92.60% | **91.90%** |
## Basic Instruct Template (V7-Tekken)
```
<s>[SYSTEM_PROMPT]<system prompt>[/SYSTEM_PROMPT][INST]<user message>[/INST]<assistant response></s>[INST]<user message>[/INST]
```
*`<system_prompt>`, `<user message>` and `<assistant response>` are placeholders.*
***Please make sure to use [mistral-common](https://github.com/mistralai/mistral-common) as the source of truth***
## Usage
The model can be used with the following frameworks;
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm)
**Note 1**: We recommend using a relatively low temperature, such as `temperature=0.15`.
**Note 2**: Make sure to add a system prompt to the model to best tailer it for your needs. If you want to use the model as a general assistant, we recommend the following
system prompt:
```
system_prompt = """You are Mistral Small 3.1, a Large Language Model (LLM) created by Mistral AI, a French startup headquartered in Paris.
You power an AI assistant called Le Chat.
Your knowledge base was last updated on 2023-10-01.
The current date is {today}.
When you're not sure about some information, you say that you don't have the information and don't make up anything.
If the user's question is not clear, ambiguous, or does not provide enough context for you to accurately answer the question, you do not try to answer it right away and you rather ask the user to clarify their request (e.g. "What are some good restaurants around me?" => "Where are you?" or "When is the next flight to Tokyo" => "Where do you travel from?").
You are always very attentive to dates, in particular you try to resolve dates (e.g. "yesterday" is {yesterday}) and when asked about information at specific dates, you discard information that is at another date.
You follow these instructions in all languages, and always respond to the user in the language they use or request.
Next sections describe the capabilities that you have.
# WEB BROWSING INSTRUCTIONS
You cannot perform any web search or access internet to open URLs, links etc. If it seems like the user is expecting you to do so, you clarify the situation and ask the user to copy paste the text directly in the chat.
# MULTI-MODAL INSTRUCTIONS
You have the ability to read images, but you cannot generate images. You also cannot transcribe audio files or videos.
You cannot read nor transcribe audio files or videos."""
```
### vLLM (recommended)
We recommend using this model with the [vLLM library](https://github.com/vllm-project/vllm)
to implement production-ready inference pipelines.
**_Installation_**
Make sure you install [`vLLM >= 0.8.1`](https://github.com/vllm-project/vllm/releases/tag/v0.8.1):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.5.4`](https://github.com/mistralai/mistral-common/releases/tag/v1.5.4).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Server
We recommand that you use Mistral-Small-3.1-24B-Instruct-2503 in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Mistral-Small-3.1-24B-Instruct-2503 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --limit_mm_per_prompt 'image=10' --tensor-parallel-size 2
```
**Note:** Running Mistral-Small-3.1-24B-Instruct-2503 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
2. To ping the client you can use a simple Python snippet.
```py
import requests
import json
from huggingface_hub import hf_hub_download
from datetime import datetime, timedelta
url = "http://<your-server-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
image_url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/europe.png"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which of the depicted countries has the best food? Which the second and third and fourth? Name the country, its color on the map and one its city that is visible on the map, but is not the capital. Make absolutely sure to only name a city that can be seen on the map.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
data = {"model": model, "messages": messages, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])
# Determining the "best" food is highly subjective and depends on personal preferences. However, based on general popularity and recognition, here are some countries known for their cuisine:
# 1. **Italy** - Color: Light Green - City: Milan
# - Italian cuisine is renowned worldwide for its pasta, pizza, and various regional specialties.
# 2. **France** - Color: Brown - City: Lyon
# - French cuisine is celebrated for its sophistication, including dishes like coq au vin, bouillabaisse, and pastries like croissants and éclairs.
# 3. **Spain** - Color: Yellow - City: Bilbao
# - Spanish cuisine offers a variety of flavors, from paella and tapas to jamón ibérico and churros.
# 4. **Greece** - Not visible on the map
# - Greek cuisine is known for dishes like moussaka, souvlaki, and baklava. Unfortunately, Greece is not visible on the provided map, so I cannot name a city.
# Since Greece is not visible on the map, I'll replace it with another country known for its good food:
# 4. **Turkey** - Color: Light Green (east part of the map) - City: Istanbul
# - Turkish cuisine is diverse and includes dishes like kebabs, meze, and baklava.
```
### Function calling
Mistral-Small-3.1-24-Instruct-2503 is excellent at function / tool calling tasks via vLLM. *E.g.:*
<details>
<summary>Example</summary>
```py
import requests
import json
from huggingface_hub import hf_hub_download
from datetime import datetime, timedelta
url = "http://<your-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city to find the weather for, e.g. 'San Francisco'",
},
"state": {
"type": "string",
"description": "The state abbreviation, e.g. 'CA' for California",
},
"unit": {
"type": "string",
"description": "The unit for temperature",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["city", "state", "unit"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Could you please make the below article more concise?\n\nOpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership.",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "bbc5b7ede",
"type": "function",
"function": {
"name": "rewrite",
"arguments": '{"text": "OpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership."}',
},
}
],
},
{
"role": "tool",
"content": '{"action":"rewrite","outcome":"OpenAI is a FOR-profit company."}',
"tool_call_id": "bbc5b7ede",
"name": "rewrite",
},
{
"role": "assistant",
"content": "---\n\nOpenAI is a FOR-profit company.",
},
{
"role": "user",
"content": "Can you tell me what the temperature will be in Dallas, in Fahrenheit?",
},
]
data = {"model": model, "messages": messages, "tools": tools, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["tool_calls"])
# [{'id': '8PdihwL6d', 'type': 'function', 'function': {'name': 'get_current_weather', 'arguments': '{"city": "Dallas", "state": "TX", "unit": "fahrenheit"}'}}]
```
</details>
#### Offline
```py
from vllm import LLM
from vllm.sampling_params import SamplingParams
from datetime import datetime, timedelta
SYSTEM_PROMPT = "You are a conversational agent that always answers straight to the point, always end your accurate response with an ASCII drawing of a cat."
user_prompt = "Give me 5 non-formal ways to say 'See you later' in French."
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT
},
{
"role": "user",
"content": user_prompt
},
]
model_name = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
# note that running this model on GPU requires over 60 GB of GPU RAM
llm = LLM(model=model_name, tokenizer_mode="mistral")
sampling_params = SamplingParams(max_tokens=512, temperature=0.15)
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
# Here are five non-formal ways to say "See you later" in French:
# 1. **À plus tard** - Until later
# 2. **À toute** - See you soon (informal)
# 3. **Salut** - Bye (can also mean hi)
# 4. **À plus** - See you later (informal)
# 5. **Ciao** - Bye (informal, borrowed from Italian)
# ```
# /\_/\
# ( o.o )
# > ^ <
# ```
```
### Transformers (untested)
Transformers-compatible model weights are also uploaded (thanks a lot @cyrilvallez).
However the transformers implementation was **not throughly tested**, but only on "vibe-checks".
Hence, we can only ensure 100% correct behavior when using the original weight format with vllm (see above). |
Mungert/granite-3.2-2b-instruct-GGUF | Mungert | 2025-06-15T19:40:53Z | 658 | 6 | transformers | [
"transformers",
"gguf",
"language",
"granite-3.2",
"text-generation",
"arxiv:0000.00000",
"base_model:ibm-granite/granite-3.1-2b-instruct",
"base_model:quantized:ibm-granite/granite-3.1-2b-instruct",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-18T21:59:43Z | ---
pipeline_tag: text-generation
inference: false
license: apache-2.0
library_name: transformers
tags:
- language
- granite-3.2
base_model:
- ibm-granite/granite-3.1-2b-instruct
---
# <span style="color: #7FFF7F;">granite-3.2-2b-instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `granite-3.2-2b-instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `granite-3.2-2b-instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `granite-3.2-2b-instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `granite-3.2-2b-instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `granite-3.2-2b-instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `granite-3.2-2b-instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `granite-3.2-2b-instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `granite-3.2-2b-instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `granite-3.2-2b-instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `granite-3.2-2b-instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `granite-3.2-2b-instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Granite-3.2-2B-Instruct
**Model Summary:**
Granite-3.2-2B-Instruct is an 2-billion-parameter, long-context AI model fine-tuned for thinking capabilities. Built on top of [Granite-3.1-2B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-2b-instruct), it has been trained using a mix of permissively licensed open-source datasets and internally generated synthetic data designed for reasoning tasks. The model allows controllability of its thinking capability, ensuring it is applied only when required.
- **Developers:** Granite Team, IBM
- **Website**: [Granite Docs](https://www.ibm.com/granite/docs/)
- **Release Date**: February 26th, 2025
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese. However, users may finetune this Granite model for languages beyond these 12 languages.
**Intended Use:**
This model is designed to handle general instruction-following tasks and can be integrated into AI assistants across various domains, including business applications.
**Capabilities**
* **Thinking**
* Summarization
* Text classification
* Text extraction
* Question-answering
* Retrieval Augmented Generation (RAG)
* Code related tasks
* Function-calling tasks
* Multilingual dialog use cases
* Long-context tasks including long document/meeting summarization, long document QA, etc.
**Generation:**
This is a simple example of how to use Granite-3.2-2B-Instruct model.
Install the following libraries:
```shell
pip install torch torchvision torchaudio
pip install accelerate
pip install transformers
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
model_path="ibm-granite/granite-3.2-2b-instruct"
device="cuda"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map=device,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
model_path
)
conv = [{"role": "user", "content":"You have 10 liters of a 30% acid solution. How many liters of a 70% acid solution must be added to achieve a 50% acid mixture?"}]
input_ids = tokenizer.apply_chat_template(conv, return_tensors="pt", thinking=True, return_dict=True, add_generation_prompt=True).to(device)
set_seed(42)
output = model.generate(
**input_ids,
max_new_tokens=8192,
)
prediction = tokenizer.decode(output[0, input_ids["input_ids"].shape[1]:], skip_special_tokens=True)
print(prediction)
```
**Example Outputs**
- thinking=True
```md
Here is my thought process:
1. First, let's understand the composition of the initial 10 liters of 30% acid solution:
- Acid content = 30% of 10 liters = 0.30 * 10 = 3 liters
2. We want to end up with a 50% acid solution. Let's denote the volume of the 70% acid solution to be added as 'x' liters.
3. The amount of acid in the final mixture (50% solution) should equal the initial acid content plus the acid from the added 70% solution.
- Total acid in final mixture = 0.50 * (10 + x)
4. The equation representing the total acid content is:
3 (from initial solution) + 0.70 * x (from added solution) = 0.50 * (10 + x)
5. Now, we solve for 'x':
3 + 0.70x = 5 + 0.50x
0.70x - 0.50x = 5 - 3
0.20x = 2
x = 2 / 0.20
x = 10 liters
6. Therefore, 10 liters of a 70% acid solution must be added to the initial 10 liters of 30% acid solution to achieve a 50% acid mixture.
Here is my response:
To solve this problem, we need to determine how much of a 70% acid solution must be added to a 10-liter solution that is already 30% acid to create a new mixture that is 50% acid. Here's how to calculate it:
1. **Initial Acid Content**:
- The initial 10-liter solution contains 3 liters of acid (since 30% of 10 liters).
2. **Desired Final Acid Content**:
- We want the final mixture to be 50% acid.
3. **Equation Setup**:
- Let 'x' be the volume (in liters) of the 70% acid solution to be added.
- The equation representing the total acid content in the final mixture (which is 10 liters from the initial solution plus 'x' liters of the added solution) should equal 50% of the total volume (10 + x).
- This gives us: 3 (acid from initial solution) + 0.70x (acid from added solution) = 0.50(10 + x)
4. **Solving the Equation**:
- First, simplify the right side of the equation: 0.50(10 + x) = 5 + 0.50x
- Now, the equation is: 3 + 0.70x = 5 + 0.50x
- Subtract 0.50x from both sides: 0.20x = 2
- Divide both sides by 0.20: x = 2 / 0.20
- x = 10 liters
5. **Conclusion**:
- To achieve a 50% acid mixture from the initial 30% solution, you need to add 10 liters of a 70% acid solution.
So, the final answer is that 10 liters of a 70% acid solution must be added to the initial 10 liters of 30% acid solution.
```
- thinking=False
```md
To solve this problem, we'll use the concept of volume and concentration. Let's denote the amount of 70% acid solution we need to add as "x" liters.
First, let's find out how much acid is in the initial 10-liter solution:
Acid in initial solution = 30% of 10 liters = 0.30 * 10 = 3 liters
Now, we want to end up with a 50% acid solution in a total volume of (10 + x) liters. Let's denote the final volume as V.
Final acid concentration = 50%
Final acid amount = 50% of V = 0.50 * V
We know the initial acid amount and the final acid amount, so we can set up an equation:
Initial acid amount + Acid from added solution = Final acid amount
3 liters + (70% of x) = 0.50 * (10 + x)
Now, let's solve for x:
0.70x + 3 = 0.50 * 10 + 0.50x
0.70x - 0.50x = 0.50 * 10 - 3
0.20x = 5 - 3
0.20x = 2
x = 2 / 0.20
x = 10 liters
So, you need to add 10 liters of a 70% acid solution to the initial 10-liter 30% acid solution to achieve a 50% acid mixture.
```
**Evaluation Results:**
<table>
<thead>
<tr>
<th style="text-align:left; background-color: #001d6c; color: white;">Models</th>
<th style="text-align:center; background-color: #001d6c; color: white;">ArenaHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">Alpaca-Eval-2</th>
<th style="text-align:center; background-color: #001d6c; color: white;">MMLU</th>
<th style="text-align:center; background-color: #001d6c; color: white;">PopQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">TruthfulQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">BigBenchHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">DROP</th>
<th style="text-align:center; background-color: #001d6c; color: white;">GSM8K</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval+</th>
<th style="text-align:center; background-color: #001d6c; color: white;">IFEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AttaQ</th>
</tr></thead>
<tbody>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Llama-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">36.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.22</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">69.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.66</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.48</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.24</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.32</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.43</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Llama-8B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">17.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.85</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">45.80</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">13.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">44.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.54</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">62.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.50</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.87</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Qwen-2.5-7B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">25.44</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.30</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.06</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">70.40</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">93.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.90</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.90</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Qwen-7B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">10.36</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">15.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">9.94</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.14</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.76</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.47</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.89</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.45</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">37.58</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.7</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.84</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">68.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.78</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.63</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.20</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.73</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-2B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">23.3</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.11</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.68</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.45</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">75.26</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.59</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.7</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.2-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">55.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.19</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.92</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">64.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.95</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.65</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.31</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.42</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.2-2B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">24.86</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">34.51</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.56</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.8</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.27</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.02</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.13</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.39</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.23</td>
</tr>
</tbody></table>
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets with permissive license, (2) internal synthetically generated data targeted to enhance reasoning capabilites.
<!-- A detailed attribution of datasets can be found in [Granite 3.2 Technical Report (coming soon)](#), and [Accompanying Author List](https://github.com/ibm-granite/granite-3.0-language-models/blob/main/author-ack.pdf). -->
**Infrastructure:**
We train Granite-3.2-2B-Instruct using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable and efficient infrastructure for training our models over thousands of GPUs.
**Ethical Considerations and Limitations:**
Granite-3.2-2B-Instruct builds upon Granite-3.1-2B-Instruct, leveraging both permissively licensed open-source and select proprietary data for enhanced performance. Since it inherits its foundation from the previous model, all ethical considerations and limitations applicable to [Granite-3.1-2B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-2b-instruct) remain relevant.
**Resources**
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 📄 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
<!-- ## Citation
```
@misc{granite-models,
author = {author 1, author2, ...},
title = {},
journal = {},
volume = {},
year = {2024},
url = {https://arxiv.org/abs/0000.00000},
}
``` --> |
Mungert/rwkv7-191M-world-GGUF | Mungert | 2025-06-15T19:40:43Z | 459 | 2 | null | [
"gguf",
"text-generation",
"en",
"zh",
"ja",
"ko",
"fr",
"ar",
"es",
"pt",
"base_model:BlinkDL/rwkv-7-world",
"base_model:quantized:BlinkDL/rwkv-7-world",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-18T09:10:04Z | ---
license: apache-2.0
language:
- en
- zh
- ja
- ko
- fr
- ar
- es
- pt
metrics:
- accuracy
base_model:
- BlinkDL/rwkv-7-world
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">rwkv7-191M-world GGUF Models</span>
Note: you must use latest llama.cpp https://github.com/ggml-org/llama.cpp to run this model with llama.cpp
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `rwkv7-191M-world-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `rwkv7-191M-world-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `rwkv7-191M-world-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `rwkv7-191M-world-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `rwkv7-191M-world-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `rwkv7-191M-world-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `rwkv7-191M-world-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `rwkv7-191M-world-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `rwkv7-191M-world-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `rwkv7-191M-world-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `rwkv7-191M-world-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# rwkv7-191M-world
<!-- Provide a quick summary of what the model is/does. -->
This is RWKV-7 model under flash-linear attention format.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Bo Peng, Yu Zhang, Songlin Yang, Ruichong Zhang
- **Funded by:** RWKV Project (Under LF AI & Data Foundation)
- **Model type:** RWKV7
- **Language(s) (NLP):** English
- **License:** Apache-2.0
- **Parameter count:** 191M
- **Tokenizer:** RWKV World tokenizer
- **Vocabulary size:** 65,536
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/fla-org/flash-linear-attention ; https://github.com/BlinkDL/RWKV-LM
- **Paper:** With in Progress
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
Install `flash-linear-attention` and the latest version of `transformers` before using this model:
```bash
pip install git+https://github.com/fla-org/flash-linear-attention
pip install 'transformers>=4.48.0'
```
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
You can use this model just as any other HuggingFace models:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('fla-hub/rwkv7-191M-world', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('fla-hub/rwkv7-191M-world', trust_remote_code=True)
model = model.cuda()
prompt = "What is a large language model?"
messages = [
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "I am a GPT-3 based model."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)[0]
print(response)
```
## Training Details
### Training Data
This model is trained on the World v2.8 with a total of 1.0 trillion tokens.
#### Training Hyperparameters
- **Training regime:** bfloat16, lr 8e-4 to 1e-5 "delayed" cosine decay, wd 0.1, bsz 8x30x4096 (Please contact Peng Bo for details)
## Evaluation
#### Metrics
`lambada_openai`: ppl 12.4 acc 49.1%
## FAQ
Q: safetensors metadata is none.
A: upgrade transformers to >=4.48.0: `pip install 'transformers>=4.48.0'` |
Mungert/rwkv7-1.5B-world-GGUF | Mungert | 2025-06-15T19:40:40Z | 811 | 1 | null | [
"gguf",
"text-generation",
"en",
"zh",
"ja",
"ko",
"fr",
"ar",
"es",
"pt",
"base_model:BlinkDL/rwkv-7-world",
"base_model:quantized:BlinkDL/rwkv-7-world",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-18T08:04:12Z | ---
license: apache-2.0
language:
- en
- zh
- ja
- ko
- fr
- ar
- es
- pt
metrics:
- accuracy
base_model:
- BlinkDL/rwkv-7-world
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">rwkv7-1.5B-world GGUF Models</span>
Note: you must use latest llama.cpp https://github.com/ggml-org/llama.cpp to run this model with llama.cpp
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `rwkv7-1.5B-world-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `rwkv7-1.5B-world-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `rwkv7-1.5B-world-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `rwkv7-1.5B-world-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `rwkv7-1.5B-world-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `rwkv7-1.5B-world-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `rwkv7-1.5B-world-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `rwkv7-1.5B-world-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `rwkv7-1.5B-world-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `rwkv7-1.5B-world-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `rwkv7-1.5B-world-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# rwkv7-1.5B-world
<!-- Provide a quick summary of what the model is/does. -->
This is RWKV-7 model under flash-linear attention format.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Bo Peng, Yu Zhang, Songlin Yang, Ruichong Zhang
- **Funded by:** RWKV Project (Under LF AI & Data Foundation)
- **Model type:** RWKV7
- **Language(s) (NLP):** English
- **License:** Apache-2.0
- **Parameter count:** 1.52B
- **Tokenizer:** RWKV World tokenizer
- **Vocabulary size:** 65,536
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/fla-org/flash-linear-attention ; https://github.com/BlinkDL/RWKV-LM
- **Paper:** With in Progress
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
Install `flash-linear-attention` and the latest version of `transformers` before using this model:
```bash
pip install git+https://github.com/fla-org/flash-linear-attention
pip install 'transformers>=4.48.0'
```
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
You can use this model just as any other HuggingFace models:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('fla-hub/rwkv7-1.5B-world', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('fla-hub/rwkv7-1.5B-world', trust_remote_code=True)
model = model.cuda()
prompt = "What is a large language model?"
messages = [
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "I am a GPT-3 based model."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)[0]
print(response)
```
## Training Details
### Training Data
This model is trained on the World v3 with a total of 3.119 trillion tokens.
#### Training Hyperparameters
- **Training regime:** bfloat16, lr 4e-4 to 1e-5 "delayed" cosine decay, wd 0.1 (with increasing batch sizes during the middle)
- **Final Loss:** 1.9965
- **Token Count:** 3.119 trillion
## Evaluation
#### Metrics
`lambada_openai`:
before conversion: ppl 4.13 acc 69.4%
after conversion: ppl 4.26 acc 68.8% (without apply temple)
## FAQ
Q: safetensors metadata is none.
A: upgrade transformers to >=4.48.0: `pip install 'transformers>=4.48.0'` |
Mungert/rwkv7-2.9B-world-GGUF | Mungert | 2025-06-15T19:40:37Z | 893 | 5 | null | [
"gguf",
"text-generation",
"en",
"zh",
"ja",
"ko",
"fr",
"ar",
"es",
"pt",
"base_model:BlinkDL/rwkv-7-world",
"base_model:quantized:BlinkDL/rwkv-7-world",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-18T06:09:18Z | ---
license: apache-2.0
language:
- en
- zh
- ja
- ko
- fr
- ar
- es
- pt
metrics:
- accuracy
base_model:
- BlinkDL/rwkv-7-world
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">rwkv7-2.9B-world GGUF Models</span>
Note: you must use latest llama.cpp https://github.com/ggml-org/llama.cpp to run this model with llama.cp
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `rwkv7-2.9B-world-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `rwkv7-2.9B-world-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `rwkv7-2.9B-world-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `rwkv7-2.9B-world-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `rwkv7-2.9B-world-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `rwkv7-2.9B-world-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `rwkv7-2.9B-world-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `rwkv7-2.9B-world-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `rwkv7-2.9B-world-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `rwkv7-2.9B-world-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `rwkv7-2.9B-world-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# rwkv7-2.9B-world
<!-- Provide a quick summary of what the model is/does. -->
This is RWKV-7 model under flash-linear attention format.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Bo Peng, Yu Zhang, Songlin Yang, Ruichong Zhang
- **Funded by:** RWKV Project (Under LF AI & Data Foundation)
- **Model type:** RWKV7
- **Language(s) (NLP):** English
- **License:** Apache-2.0
- **Parameter count:** 2.9B
- **Tokenizer:** RWKV World tokenizer
- **Vocabulary size:** 65,536
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/fla-org/flash-linear-attention ; https://github.com/BlinkDL/RWKV-LM
- **Paper:** With in Progress
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
Install `flash-linear-attention` and the latest version of `transformers` before using this model:
```bash
pip install git+https://github.com/fla-org/flash-linear-attention
pip install 'transformers>=4.48.0'
```
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
You can use this model just as any other HuggingFace models:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('fla-hub/rwkv7-2.9B-world', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('fla-hub/rwkv7-2.9B-world', trust_remote_code=True)
model = model.cuda()
prompt = "What is a large language model?"
messages = [
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "I am a GPT-3 based model."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)[0]
print(response)
```
### Training Data
This model is trained on the World v3 with a total of 3.119 trillion tokens.
#### Training Hyperparameters
- **Training regime:** bfloat16, lr 4e-4 to 1e-5 "delayed" cosine decay, wd 0.1 (with increasing batch sizes during the middle)
- **Final Loss:** 1.8745
- **Token Count:** 3.119 trillion
## FAQ
Q: safetensors metadata is none.
A: upgrade transformers to >=4.48.0: `pip install 'transformers>=4.48.0'` |
Mungert/Qwen2.5-14B-Instruct-1M-GGUF | Mungert | 2025-06-15T19:40:33Z | 2,128 | 4 | transformers | [
"transformers",
"gguf",
"chat",
"text-generation",
"en",
"arxiv:2501.15383",
"base_model:Qwen/Qwen2.5-14B",
"base_model:quantized:Qwen/Qwen2.5-14B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-18T04:16:59Z | ---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-14B-Instruct-1M/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-14B
tags:
- chat
library_name: transformers
---
# <span style="color: #7FFF7F;">Qwen2.5-14B-Instruct-1M GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen2.5-14B-Instruct-1M-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen2.5-14B-Instruct-1M-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen2.5-14B-Instruct-1M-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen2.5-14B-Instruct-1M-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen2.5-14B-Instruct-1M-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen2.5-14B-Instruct-1M-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen2.5-14B-Instruct-1M-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen2.5-14B-Instruct-1M-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen2.5-14B-Instruct-1M-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen2.5-14B-Instruct-1M-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen2.5-14B-Instruct-1M-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen2.5-14B-Instruct-1M
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Introduction
Qwen2.5-1M is the long-context version of the Qwen2.5 series models, supporting a context length of up to 1M tokens. Compared to the Qwen2.5 128K version, Qwen2.5-1M demonstrates significantly improved performance in handling long-context tasks while maintaining its capability in short tasks.
The model has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 14.7B
- Number of Paramaters (Non-Embedding): 13.1B
- Number of Layers: 48
- Number of Attention Heads (GQA): 40 for Q and 8 for KV
- Context Length: Full 1,010,000 tokens and generation 8192 tokens
- We recommend deploying with our custom vLLM, which introduces sparse attention and length extrapolation methods to ensure efficiency and accuracy for long-context tasks. For specific guidance, refer to [this section](#processing-ultra-long-texts).
- You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5-1m/), [GitHub](https://github.com/QwenLM/Qwen2.5), [Technical Report](https://huggingface.co/papers/2501.15383), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-14B-Instruct-1M"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Ultra Long Texts
To enhance processing accuracy and efficiency for long sequences, we have developed an advanced inference framework based on vLLM, incorporating sparse attention and length extrapolation. This approach significantly improves model generation performance for sequences exceeding 256K tokens and achieves a 3 to 7 times speedup for sequences up to 1M tokens.
Here we provide step-by-step instructions for deploying the Qwen2.5-1M models with our framework.
#### 1. System Preparation
To achieve the best performance, we recommend using GPUs with Ampere or Hopper architecture, which support optimized kernels.
Ensure your system meets the following requirements:
- **CUDA Version**: 12.1 or 12.3
- **Python Version**: >=3.9 and <=3.12
**VRAM Requirements:**
- For processing 1 million-token sequences:
- **Qwen2.5-7B-Instruct-1M**: At least 120GB VRAM (total across GPUs).
- **Qwen2.5-14B-Instruct-1M**: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M for shorter tasks.
#### 2. Install Dependencies
For now, you need to clone the vLLM repository from our custom branch and install it manually. We are working on getting our branch merged into the main vLLM project.
```bash
git clone -b dev/dual-chunk-attn [email protected]:QwenLM/vllm.git
cd vllm
pip install -e . -v
```
#### 3. Launch vLLM
vLLM supports offline inference or launch an openai-like server.
**Example of Offline Inference**
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-14B-Instruct-1M")
# Pass the default decoding hyperparameters of Qwen2.5-14B-Instruct
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# Input the model name or path. See below for parameter explanation (after the example of openai-like server).
llm = LLM(model="Qwen/Qwen2.5-14B-Instruct-1M",
tensor_parallel_size=4,
max_model_len=1010000,
enable_chunked_prefill=True,
max_num_batched_tokens=131072,
enforce_eager=True,
# quantization="fp8", # Enabling FP8 quantization for model weights can reduce memory usage.
)
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# generate outputs
outputs = llm.generate([text], sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
**Example of Openai-like Server**
```bash
vllm serve Qwen/Qwen2.5-14B-Instruct-1M \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill --max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1
# --quantization fp8 # Enabling FP8 quantization for model weights can reduce memory usage.
```
Then you can use curl or python to interact with the deployed model.
**Parameter Explanations:**
- **`--tensor-parallel-size`**
- Set to the number of GPUs you are using. Max 4 GPUs for the 7B model, and 8 GPUs for the 14B model.
- **`--max-model-len`**
- Defines the maximum input sequence length. Reduce this value if you encounter Out of Memory issues.
- **`--max-num-batched-tokens`**
- Sets the chunk size in Chunked Prefill. A smaller value reduces activation memory usage but may slow down inference.
- Recommend 131072 for optimal performance.
- **`--max-num-seqs`**
- Limits concurrent sequences processed.
You can also refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage of vLLM.
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache."
The VRAM reserved for the KV cache is insufficient. Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try setting ``gpu_memory_utilization`` to 0.85 or lower, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len``.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5-1m/) and our [technical report](https://arxiv.org/abs/2501.15383).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5-1m,
title = {Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens},
url = {https://qwenlm.github.io/blog/qwen2.5-1m/},
author = {Qwen Team},
month = {January},
year = {2025}
}
@article{qwen2.5,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
Mungert/DeepHermes-3-Llama-3-8B-Preview-GGUF | Mungert | 2025-06-15T19:40:29Z | 1,885 | 5 | transformers | [
"transformers",
"gguf",
"Llama-3",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"function calling",
"json mode",
"axolotl",
"roleplaying",
"chat",
"reasoning",
"r1",
"vllm",
"en",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:quantized:meta-llama/Llama-3.1-8B",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-17T14:30:06Z | ---
language:
- en
license: llama3
tags:
- Llama-3
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
- function calling
- json mode
- axolotl
- roleplaying
- chat
- reasoning
- r1
- vllm
base_model: meta-llama/Meta-Llama-3.1-8B
widget:
- example_title: Hermes 3
messages:
- role: system
content: >-
You are a sentient, superintelligent artificial general intelligence, here
to teach and assist me.
- role: user
content: What is the meaning of life?
model-index:
- name: DeepHermes-3-Llama-3.1-8B
results: []
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepHermes-3-Llama-3-8B-Preview GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepHermes-3-Llama-3-8B-Preview-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepHermes-3-Llama-3-8B-Preview-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepHermes-3-Llama-3-8B-Preview-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepHermes-3-Llama-3-8B-Preview-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepHermes-3-Llama-3-8B-Preview-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepHermes-3-Llama-3-8B-Preview-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepHermes-3-Llama-3-8B-Preview-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepHermes-3-Llama-3-8B-Preview-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepHermes-3-Llama-3-8B-Preview-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepHermes-3-Llama-3-8B-Preview-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepHermes-3-Llama-3-8B-Preview-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# DeepHermes 3 - Llama-3.1 8B

## Model Description
DeepHermes 3 Preview is the latest version of our flagship Hermes series of LLMs by Nous Research, and one of the first models in the world to unify Reasoning (long chains of thought that improve answer accuracy) and normal LLM response modes into one model. We have also improved LLM annotation, judgement, and function calling.
DeepHermes 3 Preview is one of the first LLM models to unify both "intuitive", traditional mode responses and **long chain of thought reasoning** responses into a single model, toggled by a system prompt.
Hermes 3, the predecessor of DeepHermes 3, is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board.
The ethos of the Hermes series of models is focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user.
*This is a preview Hermes with early reasoning capabilities, distilled from R1 across a variety of tasks that benefit from reasoning and objectivity. Some quirks may be discovered! Please let us know any interesting findings or issues you discover!*
## Note: To toggle REASONING ON, you must use the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
# Nous API
This model is also available on our new API product - Check out the API and sign up for the waitlist here:
https://portal.nousresearch.com/
# Example Outputs:




# Benchmarks
## Benchmarks for **Reasoning Mode** on vs off:

*Reasoning ON benchmarks aquired by running HuggingFace's open-r1 reasoning mode evaluation suite, and scores for reasoning mode OFF aquired by running LM-Eval-Harness Benchmark Suite*
*Upper bound determined by measuring the % gained over Hermes 3 3 & 70b by MATH_VERIFY compared to eleuther eval harness, which ranged betweeen 33% and 50% gain in MATH Hard benchmark on retested models by them compared to eval harness reported scores*
## Benchmarks in **Non-Reasoning Mode** against Llama-3.1-8B-Instruct

# Prompt Format
DeepHermes 3 now uses Llama-Chat format as the prompt format, opening up a more unified, structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
## Deep Thinking Mode - Deep Hermes Preview can activate long chain of thought with a system prompt.
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
For an example of using deep reasoning mode with HuggingFace Transformers:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import flash_attn
import time
tokenizer = AutoTokenizer.from_pretrained("NousResearch/DeepHermes-3-Llama-3-8B-Preview")
model = AutoModelForCausalLM.from_pretrained(
"NousResearch/DeepHermes-3-Llama-3-8B-Preview",
torch_dtype=torch.float16,
device_map="auto",
attn_implementation="flash_attention_2",
)
messages = [
{
"role": "system",
"content": "You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem."
},
{
"role": "user",
"content": "What is y if y=2*2-4+(3*2)"
}
]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors='pt').to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=2500, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
print(f"Generated Tokens: {generated_ids.shape[-1:]}")
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
Please note, for difficult problems DeepHermes can think using as many as 13,000 tokens. You may need to increase `max_new_tokens` to be much larger than 2500 for difficult problems.
## Standard "Intuitive" Response Mode
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import flash_attn
import time
tokenizer = AutoTokenizer.from_pretrained("NousResearch/DeepHermes-3-Llama-3-8B-Preview")
model = AutoModelForCausalLM.from_pretrained(
"NousResearch/DeepHermes-3-Llama-3-8B-Preview",
torch_dtype=torch.float16,
device_map="auto",
attn_implementation="flash_attention_2",
)
messages = [
{
"role": "system",
"content": "You are Hermes, an AI assistant"
},
{
"role": "user",
"content": "What are the most interesting things to do in Paris?"
}
]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors='pt').to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=2500, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
print(f"Generated Tokens: {generated_ids.shape[-1:]}")
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
## VLLM Inference
You can also run this model with vLLM, by running the following in your terminal after `pip install vllm`
`vllm serve NousResearch/DeepHermes-3-Llama-3-8B-Preview`
You may then use the model over API using the OpenAI library just like you would call OpenAI's API.
## Prompt Format for Function Calling
Our model was trained on specific system prompts and structures for Function Calling.
You should use the system role with this message, followed by a function signature json as this example shows here.
```
<|start_header_id|>system<|end_header_id|>
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: <tools> {"type": "function", "function": {"name": "get_stock_fundamentals", "description": "get_stock_fundamentals(symbol: str) -> dict - Get fundamental data for a given stock symbol using yfinance API.\\n\\n Args:\\n symbol (str): The stock symbol.\\n\\n Returns:\\n dict: A dictionary containing fundamental data.\\n Keys:\\n - \'symbol\': The stock symbol.\\n - \'company_name\': The long name of the company.\\n - \'sector\': The sector to which the company belongs.\\n - \'industry\': The industry to which the company belongs.\\n - \'market_cap\': The market capitalization of the company.\\n - \'pe_ratio\': The forward price-to-earnings ratio.\\n - \'pb_ratio\': The price-to-book ratio.\\n - \'dividend_yield\': The dividend yield.\\n - \'eps\': The trailing earnings per share.\\n - \'beta\': The beta value of the stock.\\n - \'52_week_high\': The 52-week high price of the stock.\\n - \'52_week_low\': The 52-week low price of the stock.", "parameters": {"type": "object", "properties": {"symbol": {"type": "string"}}, "required": ["symbol"]}}} </tools> Use the following pydantic model json schema for each tool call you will make: {"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"} For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call><|eot_id|><|start_header_id|>user<|end_header_id|>
```
To complete the function call, create a user prompt that follows the above system prompt, like so:
```
Fetch the stock fundamentals data for Tesla (TSLA)<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
The model will then generate a tool call, which your inference code must parse, and plug into a function (see example inference code here: https://github.com/NousResearch/Hermes-Function-Calling):
```
<tool_call>
{"arguments": {"symbol": "TSLA"}, "name": "get_stock_fundamentals"}
</tool_call><|eot_id|><|start_header_id|>tool<|end_header_id|>
```
Once you parse the tool call, call the api and get the returned values for the call, and pass it back in as a new role, `tool` like so:
```
<tool_response>
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
</tool_response>
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
The assistant will then read in that data from the function's response, and generate a natural language response:
```
The stock fundamentals data for Tesla (TSLA) are as follows:
- **Symbol**: TSLA
- **Company Name**: Tesla, Inc.
- **Sector**: Consumer Cyclical
- **Industry**: Auto Manufacturers
- **Market Capitalization**: $566,160,130,480
- **Forward Price-to-Earnings Ratio (PE Ratio)**: 42.73
- **Price-to-Book Ratio (PB Ratio)**: 9.04
- **Dividend Yield**: N/A
- **Trailing Earnings Per Share (EPS)**: $4.3
- **Beta Value of the Stock**: 2.42
- **52-Week High Price of the Stock**: $299.29
- **52-Week Low Price of the Stock**: $152.37
This information provides a snapshot of Tesla's financial position and performance based on the fundamental data obtained from the yfinance API. It shows that Tesla has a substantial market capitalization and a relatively high P/E and P/B ratio compared to other stocks in its industry. The company does not pay a dividend at the moment, which is reflected by a 'Dividend Yield' of 'None'. The Beta value indicates that Tesla's stock has a moderate level of volatility relative to the market. The 52-week high and low prices give an idea of the stock's range over the past year. This data can be useful when assessing investment opportunities and making investment decisions.<|eot_id|><|start_header_id|>user<|end_header_id|>
```
## Prompt Format for JSON Mode / Structured Outputs
Our model was also trained on a specific system prompt for Structured Outputs, which should respond with **only** a json object response, in a specific json schema.
Your schema can be made from a pydantic object using our codebase, with the standalone script `jsonmode.py` available here: https://github.com/NousResearch/Hermes-Function-Calling/tree/main
```
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant that answers in JSON. Here's the json schema you must adhere to:\n<schema>\n{schema}\n</schema><|eot_id|>
```
Given the {schema} that you provide, it should follow the format of that json to create its response, all you have to do is give a typical user prompt, and it will respond in JSON.
## Inference Code for Function Calling:
All code for utilizing, parsing, and building function calling templates is available on our github:
[https://github.com/NousResearch/Hermes-Function-Calling](https://github.com/NousResearch/Hermes-Function-Calling)

## Quantized Versions:
GGUF Quants: https://huggingface.co/NousResearch/DeepHermes-3-Llama-3-8B-Preview-GGUF
# How to cite:
```bibtext
@misc{
title={DeepHermes 3 Preview},
author={Teknium and Roger Jin and Chen Guang and Jai Suphavadeeprasit and Jeffrey Quesnelle},
year={2025}
}
``` |
Mungert/TriLM_3.9B_Unpacked-GGUF | Mungert | 2025-06-15T19:40:26Z | 276 | 3 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T11:16:59Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_3.9B_Unpacked GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_3.9B_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_3.9B_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_3.9B_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_3.9B_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_3.9B_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_3.9B_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_3.9B_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_3.9B_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_3.9B_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_3.9B_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_3.9B_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 3.9B Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_3.9B_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/TriLM_1.5B_Unpacked-GGUF | Mungert | 2025-06-15T19:40:20Z | 186 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T04:36:39Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_1.5B_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_1.5B_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_1.5B_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_1.5B_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_1.5B_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_1.5B_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_1.5B_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_1.5B_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_1.5B_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_1.5B_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_1.5B_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_1.5B_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 1.5B Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_1.5B_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/TriLM_1.1B_Unpacked-GGUF | Mungert | 2025-06-15T19:40:17Z | 180 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T03:04:19Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_1.1B_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_1.1B_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_1.1B_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_1.1B_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_1.1B_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_1.1B_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_1.1B_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_1.1B_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_1.1B_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_1.1B_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_1.1B_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_1.1B_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 1.1B Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_1.1B_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/TriLM_560M_Unpacked-GGUF | Mungert | 2025-06-15T19:40:11Z | 186 | 1 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T00:51:35Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_560M_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_560M_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_560M_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_560M_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_560M_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_560M_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_560M_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_560M_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_560M_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_560M_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_560M_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_560M_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 560M Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_560M_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/Refact-1_6B-fim-GGUF | Mungert | 2025-06-15T19:40:09Z | 353 | 3 | transformers | [
"transformers",
"gguf",
"code",
"text-generation",
"en",
"dataset:bigcode/the-stack-dedup",
"dataset:rombodawg/2XUNCENSORED_MegaCodeTraining188k",
"dataset:bigcode/commitpackft",
"arxiv:2108.12409",
"arxiv:1607.06450",
"arxiv:1910.07467",
"arxiv:1911.02150",
"license:bigscience-openrail-m",
"model-index",
"endpoints_compatible",
"region:us",
"imatrix"
] | text-generation | 2025-03-17T00:36:19Z | ---
pipeline_tag: text-generation
inference: true
widget:
- text: 'def print_hello_world():'
example_title: Hello world
group: Python
license: bigscience-openrail-m
pretrain-datasets:
- books
- arxiv
- c4
- falcon-refinedweb
- wiki
- github-issues
- stack_markdown
- self-made dataset of permissive github code
datasets:
- bigcode/the-stack-dedup
- rombodawg/2XUNCENSORED_MegaCodeTraining188k
- bigcode/commitpackft
metrics:
- code_eval
library_name: transformers
tags:
- code
model-index:
- name: Refact-1.6B
results:
- task:
type: text-generation
dataset:
type: openai_humaneval
name: HumanEval
metrics:
- name: pass@1 (T=0.01)
type: pass@1
value: 32.0
verified: false
- name: pass@1 (T=0.2)
type: pass@1
value: 31.5
verified: false
- name: pass@10 (T=0.8)
type: pass@10
value: 53.0
verified: false
- name: pass@100 (T=0.8)
type: pass@100
value: 76.9
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 35.8
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 31.6
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 29.1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.3
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.38
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.28
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 15.12
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.17
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 2.8
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.92
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.85
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 30.76
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 25.94
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 8.44
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.46
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 17.86
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 20.94
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.78
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: mbpp
name: MBPP
metrics:
- name: pass@1 (T=0.01)
type: pass@1
value: 31.15
verified: false
- task:
type: text-generation
dataset:
type: ds1000
name: DS-1000 (Overall Completion)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 10.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C++)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 21.61
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C#)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.91
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (D)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 9.5
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Go)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 53.57
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Java)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 21.58
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Julia)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.75
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (JavaScript)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.88
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Lua)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 15.26
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (PHP)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 23.04
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Perl)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Python)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 29.6
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (R)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.77
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Ruby)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.68
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Racket)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 4.29
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Rust)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 19.54
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Scala)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.33
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Bash)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 5.7
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Swift)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 17.68
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (TypeScript)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 25
verified: false
language:
- en
---
# <span style="color: #7FFF7F;">Refact-1_6B-fim GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Refact-1_6B-fim-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Refact-1_6B-fim-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Refact-1_6B-fim-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Refact-1_6B-fim-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Refact-1_6B-fim-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Refact-1_6B-fim-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Refact-1_6B-fim-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Refact-1_6B-fim-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Refact-1_6B-fim-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Refact-1_6B-fim-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Refact-1_6B-fim-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)

# Refact-1.6B
Finally, the model we started training with our [blog post](https://refact.ai/blog/2023/applying-recent-innovations-to-train-model/) is ready 🎉
After fine-tuning on generated data, it beats Replit 3b, Stability Code 3b and many other models. It almost beats
StarCoder ten times the size!
Model | Size | HumanEval pass@1 | HumanEval pass@10 |
----------------------|---------------|--------------------|--------------------|
DeciCoder-1b | 1b | 19.1% | |
<b>Refact-1.6-fim</b> | <b>1.6b</b> | <b>32.0%</b> | <b>53.0%</b> |
StableCode | 3b | 20.2% | 33.8% |
ReplitCode v1 | 3b | 21.9% | |
CodeGen2.5-multi | 7b | 28.4% | 47.5% |
CodeLlama | 7b | 33.5% | 59.6% |
StarCoder | 15b | 33.6% | |
Likely, it's the best model for practical use in your IDE for code completion because it's smart and fast!
You can start using it right now by downloading the
[Refact plugin](https://refact.ai/). You can host the model yourself, too, using the
[open source docker container](https://github.com/smallcloudai/refact).
And it's multi-language (see MultiPL-HumanEval and other metrics below) and it works as a chat (see the section below).
# It Works As a Chat
The primary application of this model is code completion (infill) in multiple programming languages.
But it works as a chat quite well.
HumanEval results using instruction following (chat) format, against models specialized for chat only:
Model | Size | pass@1 | pass@10 |
-----------------------|--------|----------|----------|
<b>Refact-1.6-fim</b> | 1.6b | 38.4% | 55.6% |
StableCode-instruct | 3b | 26.9% | 36.2% |
OctoGeeX | 6b | 44.7% | |
CodeLlama-instruct | 7b | 34.8% | 64.3% |
CodeGen2.5-instruct | 7b | 36.2% | 60.87 |
CodeLlama-instruct | 13b | 42.7% | 71.6% |
StarChat-β | 15b | 33.5% | |
OctoCoder | 15b | 46.2% | |
# Example
Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output:
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "smallcloudai/Refact-1_6B-fim"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
prompt = '<fim_prefix>def print_hello_world():\n """<fim_suffix>\n print("Hello world!")<fim_middle>'
inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=100, temperature=0.2)
print("-"*80)
print(tokenizer.decode(outputs[0]))
```
# Chat Format
The same model works as chat (experimental).
```python
prompt_template = "<empty_output>SYSTEM {system}\n" \
"<empty_output>USER {query}\n" \
"<empty_output>ASSISTANT"
prompt = prompt_template.format(system="You are a programming assistant",
query="How do I sort a list in Python?")
```
# Architecture
As described in more detail in the blog post, we used:
- [ALiBi](https://arxiv.org/abs/2108.12409) based attention
- [LayerNorm](https://arxiv.org/abs/1607.06450v1) instead of [RMSNorm](https://arxiv.org/pdf/1910.07467.pdf)
- [Multi Query Attention](https://arxiv.org/abs/1911.02150)
We also used LiON, flash attention, early dropout. It's not that innovative that you can't run it, in fact you can -- see an example below.
# Pretraining
For the base model, we used our own dataset that contains code with permissive licenses only, and open text datasets.
Filtering is the key to success of this model:
- We only used text in English
- Only topics related to computer science
- Applied heavy deduplication
The text to code proportion was 50:50, model trained for 1.2T tokens.
We don't release the base model, because its Fill-in-the-Middle (FIM) capability likes to repeat itself too much, so
its practical use is limited. But if you still want it, write us a message on Discord.
# Finetuning
We tested our hypothesis that chat data should boost base model performance in FIM and
regular left-to-right code completion. We found that just 15% of open
[code](https://huggingface.co/datasets/bigcode/commitpackft)
[instruction-following](https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k) datasets,
that we filtered for quality, improves almost all metrics.
Additionally, to improve FIM, we observed common failure modes, and prepared a synthetic dataset based on
[The Stack dedup v1.1](https://huggingface.co/datasets/bigcode/the-stack-dedup) to address them.
There is a distribution shift between typical code on the internet, and the code you write in your IDE.
The former is likely finished, so the model tries to come up with a suggestion that makes the code complete.
You are likely to have half-written code as you work on it, there is no single addition that can repair it
fully.
In practice, model needs to have a tendency to stop after a couple of lines are added, and sometimes don't write
anything at all. We found that just giving it empty completions, single line completions, multiline
completions that end with a smaller text indent or at least a newline -- makes it much more usable. This data
was used as the rest 85% of the finetune dataset.
The final model is the result of several attempts to make it work as good as possible for code completion,
and to perform well on a wide range of metrics. The best attempt took 40B tokens.
# Limitations and Bias
The Refact-1.6B model was trained on text in English. But it has seen a lot more languages in
code comments. Its performance on non-English languages is lower, for sure.
# Model Stats
- **Architecture:** LLAMA-like model with multi-query attention
- **Objectives** Fill-in-the-Middle, Chat
- **Tokens context:** 4096
- **Pretraining tokens:** 1.2T
- **Finetuning tokens:** 40B
- **Precision:** bfloat16
- **GPUs** 64 NVidia A5000
- **Training time** 28 days
# License
The model is licensed under the BigScience OpenRAIL-M v1 license agreement
# Citation
If you are using this model, please give a link to this page. |
Mungert/TriLM_99M_Unpacked-GGUF | Mungert | 2025-06-15T19:40:00Z | 226 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-16T21:55:35Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_99M_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_99M_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_99M_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_99M_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_99M_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_99M_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_99M_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_99M_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_99M_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_99M_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_99M_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_99M_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# TriLM 99M Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_99M_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/Mistral-7B-Instruct-v0.1-GGUF | Mungert | 2025-06-15T19:39:56Z | 1,003 | 3 | null | [
"gguf",
"finetuned",
"text-generation",
"arxiv:2310.06825",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-16T05:47:42Z | ---
license: apache-2.0
tags:
- finetuned
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
inference: true
widget:
- messages:
- role: user
content: What is your favorite condiment?
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# <span style="color: #7FFF7F;">Mistral-7B-Instruct-v0.1 GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mistral-7B-Instruct-v0.1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mistral-7B-Instruct-v0.1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mistral-7B-Instruct-v0.1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mistral-7B-Instruct-v0.1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mistral-7B-Instruct-v0.1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mistral-7B-Instruct-v0.1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mistral-7B-Instruct-v0.1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mistral-7B-Instruct-v0.1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mistral-7B-Instruct-v0.1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mistral-7B-Instruct-v0.1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mistral-7B-Instruct-v0.1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for Mistral-7B-Instruct-v0.1
## Encode and Decode with `mistral_common`
```py
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
mistral_models_path = "MISTRAL_MODELS_PATH"
tokenizer = MistralTokenizer.v1()
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
```
## Inference with `mistral_inference`
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
model = Transformer.from_folder(mistral_models_path)
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
print(result)
```
## Inference with hugging face `transformers`
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
model.to("cuda")
generated_ids = model.generate(tokens, max_new_tokens=1000, do_sample=True)
# decode with mistral tokenizer
result = tokenizer.decode(generated_ids[0].tolist())
print(result)
```
> [!TIP]
> PRs to correct the `transformers` tokenizer so that it gives 1-to-1 the same results as the `mistral_common` reference implementation are very welcome!
---
The Mistral-7B-Instruct-v0.1 Large Language Model (LLM) is a instruct fine-tuned version of the [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) generative text model using a variety of publicly available conversation datasets.
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/announcing-mistral-7b/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Model Architecture
This instruction model is based on Mistral-7B-v0.1, a transformer model with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
Mungert/phi-2-GGUF | Mungert | 2025-06-15T19:39:50Z | 1,961 | 2 | null | [
"gguf",
"nlp",
"code",
"text-generation",
"en",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix"
] | text-generation | 2025-03-15T21:54:52Z | ---
license: mit
license_link: https://huggingface.co/microsoft/phi-2/resolve/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- nlp
- code
---
# <span style="color: #7FFF7F;">phi-2 GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `phi-2-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `phi-2-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `phi-2-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `phi-2-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `phi-2-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `phi-2-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `phi-2-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `phi-2-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `phi-2-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `phi-2-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `phi-2-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
## Model Summary
Phi-2 is a Transformer with **2.7 billion** parameters. It was trained using the same data sources as [Phi-1.5](https://huggingface.co/microsoft/phi-1.5), augmented with a new data source that consists of various NLP synthetic texts and filtered websites (for safety and educational value). When assessed against benchmarks testing common sense, language understanding, and logical reasoning, Phi-2 showcased a nearly state-of-the-art performance among models with less than 13 billion parameters.
Our model hasn't been fine-tuned through reinforcement learning from human feedback. The intention behind crafting this open-source model is to provide the research community with a non-restricted small model to explore vital safety challenges, such as reducing toxicity, understanding societal biases, enhancing controllability, and more.
## How to Use
Phi-2 has been integrated in the `transformers` version 4.37.0, please ensure that you are using a version equal or higher than it.
Phi-2 is known for having an attention overflow issue (with FP16). If you are facing this issue, please enable/disable autocast on the [PhiAttention.forward()](https://github.com/huggingface/transformers/blob/main/src/transformers/models/phi/modeling_phi.py#L306) function.
## Intended Uses
Given the nature of the training data, the Phi-2 model is best suited for prompts using the QA format, the chat format, and the code format.
### QA Format:
You can provide the prompt as a standalone question as follows:
```markdown
Write a detailed analogy between mathematics and a lighthouse.
```
where the model generates the text after "." .
To encourage the model to write more concise answers, you can also try the following QA format using "Instruct: \<prompt\>\nOutput:"
```markdown
Instruct: Write a detailed analogy between mathematics and a lighthouse.
Output: Mathematics is like a lighthouse. Just as a lighthouse guides ships safely to shore, mathematics provides a guiding light in the world of numbers and logic. It helps us navigate through complex problems and find solutions. Just as a lighthouse emits a steady beam of light, mathematics provides a consistent framework for reasoning and problem-solving. It illuminates the path to understanding and helps us make sense of the world around us.
```
where the model generates the text after "Output:".
### Chat Format:
```markdown
Alice: I don't know why, I'm struggling to maintain focus while studying. Any suggestions?
Bob: Well, have you tried creating a study schedule and sticking to it?
Alice: Yes, I have, but it doesn't seem to help much.
Bob: Hmm, maybe you should try studying in a quiet environment, like the library.
Alice: ...
```
where the model generates the text after the first "Bob:".
### Code Format:
```python
def print_prime(n):
"""
Print all primes between 1 and n
"""
primes = []
for num in range(2, n+1):
is_prime = True
for i in range(2, int(math.sqrt(num))+1):
if num % i == 0:
is_prime = False
break
if is_prime:
primes.append(num)
print(primes)
```
where the model generates the text after the comments.
**Notes:**
* Phi-2 is intended for QA, chat, and code purposes. The model-generated text/code should be treated as a starting point rather than a definitive solution for potential use cases. Users should be cautious when employing these models in their applications.
* Direct adoption for production tasks without evaluation is out of scope of this project. As a result, the Phi-2 model has not been tested to ensure that it performs adequately for any production-level application. Please refer to the limitation sections of this document for more details.
* If you are using `transformers<4.37.0`, always load the model with `trust_remote_code=True` to prevent side-effects.
## Sample Code
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2", trust_remote_code=True)
inputs = tokenizer('''def print_prime(n):
"""
Print all primes between 1 and n
"""''', return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=200)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
## Limitations of Phi-2
* Generate Inaccurate Code and Facts: The model may produce incorrect code snippets and statements. Users should treat these outputs as suggestions or starting points, not as definitive or accurate solutions.
* Limited Scope for code: Majority of Phi-2 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
* Unreliable Responses to Instruction: The model has not undergone instruction fine-tuning. As a result, it may struggle or fail to adhere to intricate or nuanced instructions provided by users.
* Language Limitations: The model is primarily designed to understand standard English. Informal English, slang, or any other languages might pose challenges to its comprehension, leading to potential misinterpretations or errors in response.
* Potential Societal Biases: Phi-2 is not entirely free from societal biases despite efforts in assuring training data safety. There's a possibility it may generate content that mirrors these societal biases, particularly if prompted or instructed to do so. We urge users to be aware of this and to exercise caution and critical thinking when interpreting model outputs.
* Toxicity: Despite being trained with carefully selected data, the model can still produce harmful content if explicitly prompted or instructed to do so. We chose to release the model to help the open-source community develop the most effective ways to reduce the toxicity of a model directly after pretraining.
* Verbosity: Phi-2 being a base model often produces irrelevant or extra text and responses following its first answer to user prompts within a single turn. This is due to its training dataset being primarily textbooks, which results in textbook-like responses.
## Training
### Model
* Architecture: a Transformer-based model with next-word prediction objective
* Context length: 2048 tokens
* Dataset size: 250B tokens, combination of NLP synthetic data created by AOAI GPT-3.5 and filtered web data from Falcon RefinedWeb and SlimPajama, which was assessed by AOAI GPT-4.
* Training tokens: 1.4T tokens
* GPUs: 96xA100-80G
* Training time: 14 days
### Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
### License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/phi-2/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies. |
Mungert/Llama-3.2-3B-Instruct-GGUF | Mungert | 2025-06-15T19:39:37Z | 1,580 | 4 | transformers | [
"transformers",
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"arxiv:2405.16406",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-15T06:31:50Z | ---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3.2
extra_gated_prompt: >-
### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT
Llama 3.2 Version Release Date: September 25, 2024
“Agreement” means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
“Documentation” means the specifications, manuals and documentation accompanying Llama 3.2
distributed by Meta at https://llama.meta.com/doc/overview.
“Licensee” or “you” means you, or your employer or any other person or entity (if you are
entering into this Agreement on such person or entity’s behalf), of the age required under
applicable laws, rules or regulations to provide legal consent and that has legal authority
to bind your employer or such other person or entity if you are entering in this Agreement
on their behalf.
“Llama 3.2” means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://www.llama.com/llama-downloads.
“Llama Materials” means, collectively, Meta’s proprietary Llama 3.2 and Documentation (and
any portion thereof) made available under this Agreement.
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or Switzerland)
and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials,
you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide,
non-transferable and royalty-free limited license under Meta’s intellectual property or other rights
owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works
of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works thereof),
or a product or service (including another AI model) that contains any of them, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama”
on a related website, user interface, blogpost, about page, or product documentation. If you use the
Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or
otherwise improve an AI model, which is distributed or made available, you shall also include “Llama”
at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the
following attribution notice within a “Notice” text file distributed as a part of such copies:
“Llama 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,
Inc. All Rights Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for
the Llama Materials (available at https://www.llama.com/llama3_2/use-policy), which is hereby
incorporated by reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 3.2 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates,
is greater than 700 million monthly active users in the preceding calendar month, you must request
a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to
exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS
ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES
OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE
FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED
WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,
WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT,
FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN
IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials,
neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates,
except as required for reasonable and customary use in describing and redistributing the Llama Materials or as
set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required
to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible
at https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising out of your use of the Mark
will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any
derivative works and modifications of the Llama Materials that are made by you, as between you and Meta,
you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or
counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion
of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable
by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or
claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third
party arising out of or related to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access
to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms
and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this
Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of
California without regard to choice of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of
any dispute arising out of this Agreement.
### Llama 3.2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Llama 3.2.
If you access or use Llama 3.2, you agree to this Acceptable Use Policy (“**Policy**”).
The most recent copy of this policy can be found at
[https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).
#### Prohibited Uses
We want everyone to use Llama 3.2 safely and responsibly. You agree you will not use, or allow others to use, Llama 3.2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
1. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
2. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
3. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
4. Collect, process, disclose, generate, or infer private or sensitive information about individuals, including information about individuals’ identity, health, or demographic information, unless you have obtained the right to do so in accordance with applicable law
5. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
6. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
7. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.2 related to the following:
8. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989 or the Chemical Weapons Convention Implementation Act of 1997
9. Guns and illegal weapons (including weapon development)
10. Illegal drugs and regulated/controlled substances
11. Operation of critical infrastructure, transportation technologies, or heavy machinery
12. Self-harm or harm to others, including suicide, cutting, and eating disorders
13. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 3.2 related to the following:
14. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
15. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
16. Generating, promoting, or further distributing spam
17. Impersonating another individual without consent, authorization, or legal right
18. Representing that the use of Llama 3.2 or outputs are human-generated
19. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2
With respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama 3.2: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# <span style="color: #7FFF7F;">Llama-3.2-3B-Instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.2-3B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.2-3B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.2-3B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.2-3B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.2-3B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.2-3B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.2-3B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.2-3B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.2-3B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.2-3B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.2-3B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
## Model Information
The Llama 3.2 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction-tuned generative models in 1B and 3B sizes (text in/text out). The Llama 3.2 instruction-tuned text only models are optimized for multilingual dialogue use cases, including agentic retrieval and summarization tasks. They outperform many of the available open source and closed chat models on common industry benchmarks.
**Model Developer:** Meta
**Model Architecture:** Llama 3.2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| | Training Data | Params | Input modalities | Output modalities | Context Length | GQA | Shared Embeddings | Token count | Knowledge cutoff |
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| Llama 3.2 (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 128k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
| Llama 3.2 Quantized (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 8k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
**Supported Languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these 8 supported languages. Developers may fine-tune Llama 3.2 models for languages beyond these supported languages, provided they comply with the Llama 3.2 Community License and the Acceptable Use Policy. Developers are always expected to ensure that their deployments, including those that involve additional languages, are completed safely and responsibly.
**Llama 3.2 Model Family:** Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** Sept 25, 2024
**Status:** This is a static model trained on an offline dataset. Future versions may be released that improve model capabilities and safety.
**License:** Use of Llama 3.2 is governed by the [Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE) (a custom, commercial license agreement).
**Feedback:** Instructions on how to provide feedback or comments on the model can be found in the Llama Models [README](https://github.com/meta-llama/llama-models/blob/main/README.md). For more technical information about generation parameters and recipes for how to use Llama 3.2 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases:** Llama 3.2 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat and agentic applications like knowledge retrieval and summarization, mobile AI powered writing assistants and query and prompt rewriting. Pretrained models can be adapted for a variety of additional natural language generation tasks. Similarly, quantized models can be adapted for a variety of on-device use-cases with limited compute resources.
**Out of Scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.2 Community License. Use in languages beyond those explicitly referenced as supported in this model card.
## How to use
This repository contains two versions of Llama-3.2-3B-Instruct, for use with `transformers` and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Note: You can also find detailed recipes on how to use the model locally, with `torch.compile()`, assisted generations, quantised and more at [`huggingface-llama-recipes`](https://github.com/huggingface/huggingface-llama-recipes)
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --include "original/*" --local-dir Llama-3.2-3B-Instruct
```
## Hardware and Software
**Training Factors:** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, quantization, annotation, and evaluation were also performed on production infrastructure.
**Training Energy Use:** Training utilized a cumulative of **916k** GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
**Training Greenhouse Gas Emissions:** Estimated total location-based greenhouse gas emissions were **240** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy; therefore, the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
| | Training Time (GPU hours) | Logit Generation Time (GPU Hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) |
| :---- | :---: | ----- | :---: | :---: | :---: |
| Llama 3.2 1B | 370k | \- | 700 | 107 | 0 |
| Llama 3.2 3B | 460k | \- | 700 | 133 | 0 |
| Llama 3.2 1B SpinQuant | 1.7 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 3B SpinQuant | 2.4 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 1B QLora | 1.3k | 0 | 700 | 0.381 | 0 |
| Llama 3.2 3B QLora | 1.6k | 0 | 700 | 0.461 | 0 |
| Total | 833k | 86k | | 240 | 0 |
\*\* The location-based CO2e emissions of Llama 3.2 1B SpinQuant and Llama 3.2 3B SpinQuant are less than 0.001 metric tonnes each. This is due to the minimal training GPU hours that are required.
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.2 was pretrained on up to 9 trillion tokens of data from publicly available sources. For the 1B and 3B Llama 3.2 models, we incorporated logits from the Llama 3.1 8B and 70B models into the pretraining stage of the model development, where outputs (logits) from these larger models were used as token-level targets. Knowledge distillation was used after pruning to recover performance. In post-training we used a similar recipe as Llama 3.1 and produced final chat models by doing several rounds of alignment on top of the pre-trained model. Each round involved Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO).
**Data Freshness:** The pretraining data has a cutoff of December 2023\.
## Quantization
### Quantization Scheme
We designed the current quantization scheme with the [PyTorch’s ExecuTorch](https://github.com/pytorch/executorch) inference framework and Arm CPU backend in mind, taking into account metrics including model quality, prefill/decoding speed, and memory footprint. Our quantization scheme involves three parts:
- All linear layers in all transformer blocks are quantized to a 4-bit groupwise scheme (with a group size of 32) for weights and 8-bit per-token dynamic quantization for activations.
- The classification layer is quantized to 8-bit per-channel for weight and 8-bit per token dynamic quantization for activation.
- Similar to classification layer, an 8-bit per channel quantization is used for embedding layer.
### Quantization-Aware Training and LoRA
The quantization-aware training (QAT) with low-rank adaptation (LoRA) models went through only post-training stages, using the same data as the full precision models. To initialize QAT, we utilize BF16 Llama 3.2 model checkpoints obtained after supervised fine-tuning (SFT) and perform an additional full round of SFT training with QAT. We then freeze the backbone of the QAT model and perform another round of SFT with LoRA adaptors applied to all layers within the transformer block. Meanwhile, the LoRA adaptors' weights and activations are maintained in BF16. Because our approach is similar to QLoRA of Dettmers et al., (2023) (i.e., quantization followed by LoRA adapters), we refer this method as QLoRA. Finally, we fine-tune the resulting model (both backbone and LoRA adaptors) using direct preference optimization (DPO).
### SpinQuant
[SpinQuant](https://arxiv.org/abs/2405.16406) was applied, together with generative post-training quantization (GPTQ). For the SpinQuant rotation matrix fine-tuning, we optimized for 100 iterations, using 800 samples with sequence-length 2048 from the WikiText 2 dataset. For GPTQ, we used 128 samples from the same dataset with the same sequence-length.
## Benchmarks \- English Text
In this section, we report the results for Llama 3.2 models on standard automatic benchmarks. For all these evaluations, we used our internal evaluations library.
### Base Pretrained Models
| Category | Benchmark | \# Shots | Metric | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| ----- | ----- | :---: | :---: | :---: | :---: | :---: |
| General | MMLU | 5 | macro\_avg/acc\_char | 32.2 | 58 | 66.7 |
| | AGIEval English | 3-5 | average/acc\_char | 23.3 | 39.2 | 47.8 |
| | ARC-Challenge | 25 | acc\_char | 32.8 | 69.1 | 79.7 |
| Reading comprehension | SQuAD | 1 | em | 49.2 | 67.7 | 77 |
| | QuAC (F1) | 1 | f1 | 37.9 | 42.9 | 44.9 |
| | DROP (F1) | 3 | f1 | 28.0 | 45.2 | 59.5 |
| Long Context | Needle in Haystack | 0 | em | 96.8 | 1 | 1 |
### Instruction Tuned Models
| Capability | | Benchmark | \# Shots | Metric | Llama 3.2 1B bf16 | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B bf16 | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | ----- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | | MMLU | 5 | macro\_avg/acc | 49.3 | 43.3 | 47.3 | 49.0 | 63.4 | 60.5 | 62 | 62.4 | 69.4 |
| Re-writing | | Open-rewrite eval | 0 | micro\_avg/rougeL | 41.6 | 39.2 | 40.9 | 41.2 | 40.1 | 40.3 | 40.8 | 40.7 | 40.9 |
| Summarization | | TLDR9+ (test) | 1 | rougeL | 16.8 | 14.9 | 16.7 | 16.8 | 19.0 | 19.1 | 19.2 | 19.1 | 17.2 |
| Instruction following | | IFEval | 0 | Avg(Prompt/Instruction acc Loose/Strict) | 59.5 | 51.5 | 58.4 | 55.6 | 77.4 | 73.9 | 73.5 | 75.9 | 80.4 |
| Math | | GSM8K (CoT) | 8 | em\_maj1@1 | 44.4 | 33.1 | 40.6 | 46.5 | 77.7 | 72.9 | 75.7 | 77.9 | 84.5 |
| | | MATH (CoT) | 0 | final\_em | 30.6 | 20.5 | 25.3 | 31.0 | 48.0 | 44.2 | 45.3 | 49.2 | 51.9 |
| Reasoning | | ARC-C | 0 | acc | 59.4 | 54.3 | 57 | 60.7 | 78.6 | 75.6 | 77.6 | 77.6 | 83.4 |
| | | GPQA | 0 | acc | 27.2 | 25.9 | 26.3 | 25.9 | 32.8 | 32.8 | 31.7 | 33.9 | 32.8 |
| | | Hellaswag | 0 | acc | 41.2 | 38.1 | 41.3 | 41.5 | 69.8 | 66.3 | 68 | 66.3 | 78.7 |
| Tool Use | | BFCL V2 | 0 | acc | 25.7 | 14.3 | 15.9 | 23.7 | 67.0 | 53.4 | 60.1 | 63.5 | 67.1 |
| | | Nexus | 0 | macro\_avg/acc | 13.5 | 5.2 | 9.6 | 12.5 | 34.3 | 32.4 | 31.5 | 30.1 | 38.5 |
| Long Context | | InfiniteBench/En.QA | 0 | longbook\_qa/f1 | 20.3 | N/A | N/A | N/A | 19.8 | N/A | N/A | N/A | 27.3 |
| | | InfiniteBench/En.MC | 0 | longbook\_choice/acc | 38.0 | N/A | N/A | N/A | 63.3 | N/A | N/A | N/A | 72.2 |
| | | NIH/Multi-needle | 0 | recall | 75.0 | N/A | N/A | N/A | 84.7 | N/A | N/A | N/A | 98.8 |
| Multilingual | | MGSM (CoT) | 0 | em | 24.5 | 13.7 | 18.2 | 24.4 | 58.2 | 48.9 | 54.3 | 56.8 | 68.9 |
\*\*for comparison purposes only. Model not released.
### Multilingual Benchmarks
| Category | Benchmark | Language | Llama 3.2 1B | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | MMLU (5-shot, macro_avg/acc) | Portuguese | 39.8 | 34.9 | 38.9 | 40.2 | 54.5 | 50.9 | 53.3 | 53.4 | 62.1 |
| | | Spanish | 41.5 | 36.0 | 39.8 | 41.8 | 55.1 | 51.9 | 53.6 | 53.6 | 62.5 |
| | | Italian | 39.8 | 34.9 | 38.1 | 40.6 | 53.8 | 49.9 | 52.1 | 51.7 | 61.6 |
| | | German | 39.2 | 34.9 | 37.5 | 39.6 | 53.3 | 50.0 | 52.2 | 51.3 | 60.6 |
| | | French | 40.5 | 34.8 | 39.2 | 40.8 | 54.6 | 51.2 | 53.3 | 53.3 | 62.3 |
| | | Hindi | 33.5 | 30.0 | 32.1 | 34.0 | 43.3 | 40.4 | 42.0 | 42.1 | 50.9 |
| | | Thai | 34.7 | 31.2 | 32.4 | 34.9 | 44.5 | 41.3 | 44.0 | 42.2 | 50.3 |
\*\*for comparison purposes only. Model not released.
## Inference time
In the below table, we compare the performance metrics of different quantization methods (SpinQuant and QAT \+ LoRA) with the BF16 baseline. The evaluation was done using the [ExecuTorch](https://github.com/pytorch/executorch) framework as the inference engine, with the ARM CPU as a backend using Android OnePlus 12 device.
| Category | Decode (tokens/sec) | Time-to-first-token (sec) | Prefill (tokens/sec) | Model size (PTE file size in MB) | Memory size (RSS in MB) |
| :---- | ----- | ----- | ----- | ----- | ----- |
| 1B BF16 (baseline) | 19.2 | 1.0 | 60.3 | 2358 | 3,185 |
| 1B SpinQuant | 50.2 (2.6x) | 0.3 (-76.9%) | 260.5 (4.3x) | 1083 (-54.1%) | 1,921 (-39.7%) |
| 1B QLoRA | 45.8 (2.4x) | 0.3 (-76.0%) | 252.0 (4.2x) | 1127 (-52.2%) | 2,255 (-29.2%) |
| 3B BF16 (baseline) | 7.6 | 3.0 | 21.2 | 6129 | 7,419 |
| 3B SpinQuant | 19.7 (2.6x) | 0.7 (-76.4%) | 89.7 (4.2x) | 2435 (-60.3%) | 3,726 (-49.8%) |
| 3B QLoRA | 18.5 (2.4x) | 0.7 (-76.1%) | 88.8 (4.2x) | 2529 (-58.7%) | 4,060 (-45.3%) |
(\*) The performance measurement is done using an adb binary-based approach.
(\*\*) It is measured on an Android OnePlus 12 device.
(\*\*\*) Time-to-first-token (TTFT) is measured with prompt length=64
*Footnote:*
- *Decode (tokens/second) is for how quickly it keeps generating. Higher is better.*
- *Time-to-first-token (TTFT for shorthand) is for how fast it generates the first token for a given prompt. Lower is better.*
- *Prefill is the inverse of TTFT (aka 1/TTFT) in tokens/second. Higher is better*
- *Model size \- how big is the model, measured by, PTE file, a binary file format for ExecuTorch*
- *RSS size \- Memory usage in resident set size (RSS)*
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
1. Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama
2. Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm
3. Provide protections for the community to help prevent the misuse of our models
### Responsible Deployment
**Approach:** Llama is a foundational technology designed to be used in a variety of use cases. Examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models, enabling the world to benefit from the technology power, by aligning our model safety for generic use cases and addressing a standard set of harms. Developers are then in the driver’s seat to tailor safety for their use cases, defining their own policies and deploying the models with the necessary safeguards in their Llama systems. Llama 3.2 was developed following the best practices outlined in our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/).
#### Llama 3.2 Instruct
**Objective:** Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. We implemented the same set of safety mitigations as in Llama 3, and you can learn more about these in the Llama 3 [paper](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/).
**Fine-Tuning Data:** We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone:** Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.2 Systems
**Safety as a System:** Large language models, including Llama 3.2, **are not designed to be deployed in isolation** but instead should be deployed as part of an overall AI system with additional safety guardrails as required. Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools. As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
### New Capabilities and Use Cases
**Technological Advancement:** Llama releases usually introduce new capabilities that require specific considerations in addition to the best practices that generally apply across all Generative AI use cases. For prior release capabilities also supported by Llama 3.2, see [Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md), as the same considerations apply here as well.
**Constrained Environments:** Llama 3.2 1B and 3B models are expected to be deployed in highly constrained environments, such as mobile devices. LLM Systems using smaller models will have a different alignment profile and safety/helpfulness tradeoff than more complex, larger systems. Developers should ensure the safety of their system meets the requirements of their use case. We recommend using lighter system safeguards for such use cases, like Llama Guard 3-1B or its mobile-optimized version.
### Evaluations
**Scaled Evaluations:** We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Purple Llama safeguards to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case.
**Red Teaming:** We conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets. We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical Risks
In addition to our safety work above, we took extra care on measuring and/or mitigating the following critical risk areas:
**1\. CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Weapons):** Llama 3.2 1B and 3B models are smaller and less capable derivatives of Llama 3.1. For Llama 3.1 70B and 405B, to assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons and have determined that such testing also applies to the smaller 1B and 3B models.
**2\. Child Safety:** Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3\. Cyber Attacks:** For Llama 3.1 405B, our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention. Because Llama 3.2’s 1B and 3B models are smaller and less capable models than Llama 3.1 405B, we broadly believe that the testing conducted for the 405B model also applies to Llama 3.2 models.
### Community
**Industry Partnerships:** Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
**Grants:** We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
**Reporting:** Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
**Values:** The core values of Llama 3.2 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.2 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
**Testing:** Llama 3.2 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.2 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development.
|
abi2736/Minds-Tutor | abi2736 | 2025-06-15T19:39:36Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T15:01:00Z | # Minds-Tutor
Projeto inicial para IA educacional. |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.5_epoch2 | MinaMila | 2025-06-15T19:39:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:37:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mungert/Qwen2.5-1.5B-Instruct-GGUF | Mungert | 2025-06-15T19:39:25Z | 1,680 | 5 | transformers | [
"transformers",
"gguf",
"chat",
"text-generation",
"zho",
"eng",
"fra",
"spa",
"por",
"deu",
"ita",
"rus",
"jpn",
"kor",
"vie",
"tha",
"ara",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-1.5B",
"base_model:quantized:Qwen/Qwen2.5-1.5B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-15T02:45:17Z | ---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct/blob/main/LICENSE
language:
- zho
- eng
- fra
- spa
- por
- deu
- ita
- rus
- jpn
- kor
- vie
- tha
- ara
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-1.5B
tags:
- chat
library_name: transformers
---
# <span style="color: #7FFF7F;">Qwen2.5-1.5B-Instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen2.5-1.5B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen2.5-1.5B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen2.5-1.5B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen2.5-1.5B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen2.5-1.5B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen2.5-1.5B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen2.5-1.5B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen2.5-1.5B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen2.5-1.5B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen2.5-1.5B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen2.5-1.5B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen2.5-1.5B-Instruct
## Introduction
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
- Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains.
- Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots.
- **Long-context Support** up to 128K tokens and can generate up to 8K tokens.
- **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
**This repo contains the instruction-tuned 1.5B Qwen2.5 model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
- Number of Parameters: 1.54B
- Number of Paramaters (Non-Embedding): 1.31B
- Number of Layers: 28
- Number of Attention Heads (GQA): 12 for Q and 2 for KV
- Context Length: Full 32,768 tokens and generation 8192 tokens
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
``` |
Mungert/gemma-3-1b-it-gguf | Mungert | 2025-06-15T19:39:21Z | 154 | 7 | null | [
"gguf",
"gemma",
"text-generation",
"license:gemma",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-13T01:23:58Z | ---
license: gemma
pipeline_tag: text-generation
tags:
- gemma
---
# <span style="color: #7FFF7F;">Gemma-3 1B Instruct GGUF Models</span>
**Note llama-quantize was not able to fully quantize the ggufs for k quants as the tensor dimensions of some weights where not divisible by 256. fallback quants where used.**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limtations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Low | Very Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium Low | Low | CPU with more memory | Better accuracy while still being quantized |
| **Q8** | Medium | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
## **Included Files & Details**
### `google_gemma-3-1b-it-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `google_gemma-3-1b-it-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `google_gemma-3-1b-it-bf16-q8.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `google_gemma-3-1b-it-f16-q8.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `google_gemma-3-1b-it-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `google_gemma-3-1b-it-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `google_gemma-3-1b-it-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `google_gemma-3-1b-it-q8.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
# Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
**Resources and Technical Documentation**:
* [Gemma 3 Technical Report][g3-tech-report]
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma3]
**Terms of Use**: [Terms][terms]
**Authors**: Google DeepMind
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
Gemma 3 1B model handles text only.
### Inputs and outputs
- **Input:**
- Text string, such as a question, a prompt, or a document to be summarized
- Total input context 32K tokens for the 1B size
- **Output:**
- Generated text in response to the input, such as an answer to a
question, analysis of image content, or a summary of a document
- Total output context of 8192 tokens
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please give like a click ❤️ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs **Phi-4-mini-instruct** using phi-4-mini-q4_0.gguf , llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability) |
Mungert/gemma-3-12b-it-gguf | Mungert | 2025-06-15T19:39:16Z | 3,675 | 11 | null | [
"gguf",
"gemma",
"vision",
"image",
"llama.cpp",
"image-text-to-text",
"license:gemma",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-03-12T22:44:45Z | ---
license: gemma
pipeline_tag: image-text-to-text
tags:
- gemma
- vision
- image
- llama.cpp
---
# <span style="color: #7FFF7F;">Gemma-3 12B Instruct GGUF Models</span>
## How to Use Gemma 3 Vision with llama.cpp
To utilize the experimental support for Gemma 3 Vision in `llama.cpp`, follow these steps:
1. **Clone the lastest llama.cpp Repository**:
```bash
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
```
2. **Build the Llama.cpp**:
Build llama.cpp as usual : https://github.com/ggml-org/llama.cpp#building-the-project
Once llama.cpp is built Copy the ./llama.cpp/build/bin/llama-gemma3-cli to a chosen folder.
3. **Download the Gemma 3 gguf file**:
https://huggingface.co/Mungert/gemma-3-12b-it-gguf/tree/main
Choose a gguf file without the mmproj in the name
Example gguf file : https://huggingface.co/Mungert/gemma-3-12b-it-gguf/resolve/main/google_gemma-3-12b-it-q4_k_l.gguf
Copy this file to your chosen folder.
4. **Download the Gemma 3 mmproj file**
https://huggingface.co/Mungert/gemma-3-12b-it-gguf/tree/main
Choose a file with mmproj in the name
Example mmproj file : https://huggingface.co/Mungert/gemma-3-12b-it-gguf/resolve/main/google_gemma-3-12b-it-mmproj-bf16.gguf
Copy this file to your chosen folder.
5. Copy images to the same folder as the gguf files or alter paths appropriately.
In the example below the gguf files, images and llama-gemma-cli are in the same folder.
Example image: image https://huggingface.co/Mungert/gemma-3-12b-it-gguf/resolve/main/car-1.jpg
Copy this file to your chosen folder.
6. **Run the CLI Tool**:
From your chosen folder :
```bash
llama-gemma3-cli -m google_gemma-3-12b-it-q4_k_l.gguf --mmproj google_gemma-3-12b-it-mmproj-bf16.gguf
```
```
Running in chat mode, available commands:
/image <path> load an image
/clear clear the chat history
/quit or /exit exit the program
> /image car-1.jpg
Encoding image car-1.jpg
Image encoded in 46305 ms
Image decoded in 19302 ms
> what is the image of
Here's a breakdown of what's in the image:
**Subject:** The primary subject is a black Porsche Panamera Turbo driving on a highway.
**Details:**
* **Car:** It's a sleek, modern Porsche Panamera Turbo, identifiable by its distinctive rear design, the "PORSCHE" lettering, and the "Panamera Turbo" badge. The license plate reads "CVC-911".
* **Setting:** The car is on a multi-lane highway, with a blurred background of trees, a distant building, and a cloudy sky. The lighting suggests it's either dusk or dawn.
* **Motion:** The image captures the car in motion, with a slight motion blur to convey speed.
**Overall Impression:** The image conveys a sense of speed, luxury, and power. It's a well-composed shot that highlights the car's design and performance.
Do you want me to describe any specific aspect of the image in more detail, or perhaps analyze its composition?
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤️ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs **Phi-4-mini-instruct** using phi-4-mini-q4_0.gguf , llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limtations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Low | Very Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium Low | Low | CPU with more memory | Better accuracy while still being quantized |
| **Q8** | Medium | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
## **Included Files & Details**
### `google_gemma-3-12b-it-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `google_gemma-3-12b-it-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `google_gemma-3-12b-it-bf16-q8.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `google_gemma-3-12b-it-f16-q8.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `google_gemma-3-12b-it-q4_k_l.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `google_gemma-3-12b-it-q4_k_m.gguf`
- Similar to Q4_K.
- Another option for **low-memory CPU inference**.
### `google_gemma-3-12b-it-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `google_gemma-3-12b-it-q6_k_l.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `google_gemma-3-12b-it-q6_k_m.gguf`
- A mid-range **Q6_K** quantized model for balanced performance .
- Suitable for **CPU-based inference** with **moderate memory**.
### `google_gemma-3-12b-it-q8.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
# Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
**Resources and Technical Documentation**:
* [Gemma 3 Technical Report][g3-tech-report]
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma3]
**Terms of Use**: [Terms][terms]
**Authors**: Google DeepMind
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
Gemma 3 models are multimodal, handling text and image input and generating text
output, with open weights for both pre-trained variants and instruction-tuned
variants. Gemma 3 has a large, 128K context window, multilingual support in over
140 languages, and is available in more sizes than previous versions. Gemma 3
models are well-suited for a variety of text generation and image understanding
tasks, including question answering, summarization, and reasoning. Their
relatively small size makes it possible to deploy them in environments with
limited resources such as laptops, desktops or your own cloud infrastructure,
democratizing access to state of the art AI models and helping foster innovation
for everyone.
### Inputs and outputs
- **Input:**
- Text string, such as a question, a prompt, or a document to be summarized
- Images, normalized to 896 x 896 resolution and encoded to 256 tokens
each
- Total input context of 128K tokens for the 4B, 12B, and 27B sizes, and
32K tokens for the 1B size
- **Output:**
- Generated text in response to the input, such as an answer to a
question, analysis of image content, or a summary of a document
- Total output context of 8192 tokens
|
Mungert/II-Medical-8B-GGUF | Mungert | 2025-06-15T19:38:58Z | 965 | 1 | transformers | [
"transformers",
"gguf",
"arxiv:2503.19633",
"arxiv:2503.10460",
"arxiv:2501.19393",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-12T00:45:04Z | ---
library_name: transformers
tags: []
---
# <span style="color: #7FFF7F;">II-Medical-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
---
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
---
## [Choosing the Right Model Format](https://readyforquantum.com/huggingface_gguf_selection_guide.html)
<!--Begin Original Model Card-->
# II-Medical-8B
<div style="display: flex; justify-content: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6389496ff7d3b0df092095ed/73Y-oDmehp0eJ2HWrfn3V.jpeg" width="800">
</div>
## I. Model Overview
II-Medical-8B is the newest advanced large language model developed by Intelligent Internet, specifically engineered to enhance AI-driven medical reasoning. Following the positive reception of our previous [II-Medical-7B-Preview](https://huggingface.co/Intelligent-Internet/II-Medical-7B-Preview), this new iteration significantly advances the capabilities of medical question answering,
## II. Training Methodology
We collected and generated a comprehensive set of reasoning datasets for the medical domain and performed SFT fine-tuning on the **Qwen/Qwen3-8B** model. Following this, we further optimized the SFT model by training DAPO on a hard-reasoning dataset to boost performance.
For SFT stage we using the hyperparameters:
- Max Length: 16378.
- Batch Size: 128.
- Learning-Rate: 5e-5.
- Number Of Epoch: 8.
For RL stage we setup training with:
- Max prompt length: 2048 tokens.
- Max response length: 12288 tokens.
- Overlong buffer: Enabled, 4096 tokens, penalty factor 1.0.
- Clip ratios: Low 0.2, High 0.28.
- Batch sizes: Train prompt 512, Generation prompt 1536, Mini-batch 32.
- Responses per prompt: 16.
- Temperature: 1.0, Top-p: 1.0, Top-k: -1 (vLLM rollout).
- Learning rate: 1e-6, Warmup steps: 10, Weight decay: 0.1.
- Loss aggregation: Token-mean.
- Gradient clipping: 1.0.
- Entropy coefficient: 0.
## III. Evaluation Results
Our II-Medical-8B model achieved a 40% score on [HealthBench](https://openai.com/index/healthbench/), a comprehensive open-source benchmark evaluating the performance and safety of large language models in healthcare. This performance is comparable to OpenAI's o1 reasoning model and GPT-4.5, OpenAI's largest and most advanced model to date. We provide a comparison to models available in ChatGPT below.

Detailed result for HealthBench can be found [here](https://huggingface.co/datasets/Intelligent-Internet/OpenAI-HealthBench-II-Medical-8B-GPT-4.1).

We evaluate on ten medical QA benchmarks include MedMCQA, MedQA, PubMedQA, medical related questions from MMLU-Pro and GPQA, small QA sets from Lancet and the New England
Journal of Medicine, 4 Options and 5 Options splits from the MedBullets platform and MedXpertQA.
| Model | MedMC | MedQA | PubMed | MMLU-P | GPQA | Lancet | MedB-4 | MedB-5 | MedX | NEJM | Avg |
|--------------------------|-------|-------|--------|--------|------|--------|--------|--------|------|-------|-------|
| [HuatuoGPT-o1-72B](https://huggingface.co/FreedomIntelligence/HuatuoGPT-o1-72B) | 76.76 | 88.85 | 79.90 | 80.46 | 64.36| 70.87 | 77.27 | 73.05 |23.53 |76.29 | 71.13 |
| [QWQ 32B](https://huggingface.co/Qwen/QwQ-32B) | 69.73 | 87.03 | 88.5 | 79.86 | 69.17| 71.3 | 72.07 | 69.01 |24.98 |75.12 | 70.68 |
| [Qwen2.5-7B-IT](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) | 56.56 | 61.51 | 71.3 | 61.17 | 42.56| 61.17 | 46.75 | 40.58 |13.26 |59.04 | 51.39 |
| [HuatuoGPT-o1-8B](http://FreedomIntelligence/HuatuoGPT-o1-8B) | 63.97 | 74.78 | **80.10** | 63.71 | 55.38| 64.32 | 58.44 | 51.95 |15.79 |64.84 | 59.32 |
| [Med-reason](https://huggingface.co/UCSC-VLAA/MedReason-8B) | 61.67 | 71.87 | 77.4 | 64.1 | 50.51| 59.7 | 60.06 | 54.22 |22.87 |66.8 | 59.92 |
| [M1](https://huggingface.co/UCSC-VLAA/m1-7B-23K) | 62.54 | 75.81 | 75.80 | 65.86 | 53.08| 62.62 | 63.64 | 59.74 |19.59 |64.34 | 60.3 |
| [II-Medical-8B-SFT](https://huggingface.co/II-Vietnam/II-Medical-8B-SFT) | **71.92** | 86.57 | 77.4 | 77.26 | 65.64| 69.17 | 76.30 | 67.53 |23.79 |**73.80** | 68.80 |
| [II-Medical-8B](https://huggingface.co/Intelligent-Internet/II-Medical-8B) | 71.57 | **87.82** | 78.2 | **80.46** | **67.18**| **70.38** | **78.25** | **72.07** |**25.26** |73.13 | **70.49** |
## IV. Dataset Curation
The training dataset comprises 555,000 samples from the following sources:
### 1. Public Medical Reasoning Datasets (103,031 samples)
- [General Medical Reasoning](https://huggingface.co/datasets/GeneralReasoning/GeneralThought-430K): 40,544 samples
- [Medical-R1-Distill-Data](https://huggingface.co/datasets/FreedomIntelligence/Medical-R1-Distill-Data): 22,000 samples
- [Medical-R1-Distill-Data-Chinese](https://huggingface.co/datasets/FreedomIntelligence/Medical-R1-Distill-Data-Chinese): 17,000 samples
- [UCSC-VLAA/m23k-tokenized](https://huggingface.co/datasets/UCSC-VLAA/m23k-tokenized): 23,487 samples
### 2. Synthetic Medical QA Data with QwQ (225,700 samples)
Generated from established medical datasets:
- [MedMcQA](https://huggingface.co/datasets/openlifescienceai/medmcqa) (from openlifescienceai/medmcqa): 183,000 samples
- [MedQA](https://huggingface.co/datasets/bigbio/med_qa): 10,000 samples
- [MedReason](https://huggingface.co/datasets/UCSC-VLAA/MedReason): 32,700 samples
### 3. Curated Medical R1 Traces (338,055 samples)
First we gather all the public R1 traces from:
- [PrimeIntellect/SYNTHETIC-1](https://huggingface.co/collections/PrimeIntellect/synthetic-1-67a2c399cfdd6c9f7fae0c37)
- [GeneralReasoning/GeneralThought-430K](https://huggingface.co/datasets/GeneralReasoning/GeneralThought-430K)
- [a-m-team/AM-DeepSeek-R1-Distilled-1.4M](https://arxiv.org/abs/2503.19633v1)
- [open-thoughts/OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M)
- [nvidia/Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset): Science subset only
- Other resources: [cognitivecomputations/dolphin-r1](https://huggingface.co/datasets/cognitivecomputations/dolphin-r1), [ServiceNow-AI/R1-Distill-SFT](https://huggingface.co/datasets/ServiceNow-AI/R1-Distill-SFT),...
All R1 reasoning traces were processed through a domain-specific pipeline as follows:
1. Embedding Generation: Prompts are embedded using sentence-transformers/all-MiniLM-L6-v2.
2. Clustering: Perform K-means clustering with 50,000 clusters.
3. Domain Classification:
- For each cluster, select the 10 prompts nearest to the cluster center.
- Classify the domain of each selected prompt using Qwen2.5-32b-Instruct.
- Assign the cluster's domain based on majority voting among the classified prompts.
4. Domain Filtering: Keep only clusters labeled as Medical or Biology for the final dataset.
### 4. Supplementary Math Dataset
- Added 15,000 samples of reasoning traces from [light-r1](https://arxiv.org/abs/2503.10460)
- Purpose: Enhance general reasoning capabilities of the model
### Preprocessing Data
1. Filtering for Complete Generation
- Retained only traces with complete generation outputs
2. Length-based Filtering
- Minimum threshold: Keep only the prompt with more than 3 words.
- Wait Token Filter: Removed traces with has more than 47 occurrences of "Wait" (97th percentile threshold).
### Data Decontamination
We using two step decontamination:
1. Following [open-r1](https://github.com/huggingface/open-r1) project: We decontaminate a dataset using 10-grams with the evaluation datasets.
2. After that, we using the fuzzy decontamination from [`s1k`](https://arxiv.org/abs/2501.19393) method with threshold 90%.
**Our pipeline is carefully decontaminated with the evaluation datasets.**
## V. How To Use
Our model can be utilized in the same manner as Qwen or Deepseek-R1-Distill models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```bash
vllm serve Intelligent-Internet/II-Medical-8B
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang):
```bash
python -m sglang.launch_server --model Intelligent-Internet/II-Medical-8B
```
## VI. Usage Guidelines
- Recommended Sampling Parameters: temperature = 0.6, top_p = 0.9
- When using, explicitly request step-by-step reasoning and format the final answer within \boxed{} (e.g., "Please reason step-by-step, and put your final answer within \boxed{}.").
## VII. Limitations and Considerations
- Dataset may contain inherent biases from source materials
- Medical knowledge requires regular updates
- Please note that **It’s not suitable for medical use.**
## VIII. Citation
```bib
@misc{2025II-Medical-8B,
title={II-Medical-8B: Medical Reasoning Model},
author={Intelligent Internet},
year={2025}
}
```
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/nomic-embed-code-GGUF | Mungert | 2025-06-15T19:38:55Z | 1,464 | 1 | sentence-transformers | [
"sentence-transformers",
"gguf",
"sentence-similarity",
"feature-extraction",
"dataset:nomic-ai/cornstack-python-v1",
"dataset:nomic-ai/cornstack-javascript-v1",
"dataset:nomic-ai/cornstack-java-v1",
"dataset:nomic-ai/cornstack-go-v1",
"dataset:nomic-ai/cornstack-php-v1",
"dataset:nomic-ai/cornstack-ruby-v1",
"arxiv:2412.01007",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-Coder-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | sentence-similarity | 2025-06-10T15:04:32Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
license: apache-2.0
datasets:
- nomic-ai/cornstack-python-v1
- nomic-ai/cornstack-javascript-v1
- nomic-ai/cornstack-java-v1
- nomic-ai/cornstack-go-v1
- nomic-ai/cornstack-php-v1
- nomic-ai/cornstack-ruby-v1
base_model:
- Qwen/Qwen2.5-Coder-7B-Instruct
---
# <span style="color: #7FFF7F;">nomic-embed-code GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`7f4fbe51`](https://github.com/ggerganov/llama.cpp/commit/7f4fbe5183b23b6b2e25fd1ccc5d1fa8bb010cb7).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Nomic Embed Code: A State-of-the-Art Code Retriever
[Blog](https://www.nomic.ai/blog/posts/introducing-state-of-the-art-nomic-embed-code) | [Technical Report](https://arxiv.org/abs/2412.01007) | [AWS SageMaker](https://aws.amazon.com/marketplace/seller-profile?id=seller-tpqidcj54zawi) | [Atlas Embedding and Unstructured Data Analytics Platform](https://atlas.nomic.ai)
`nomic-embed-code` is a state-of-the-art code embedding model that excels at code retrieval tasks:
- **High Performance**: Outperforms Voyage Code 3 and OpenAI Embed 3 Large on CodeSearchNet
- **Multilingual Code Support**: Trained for multiple programming languages (Python, Java, Ruby, PHP, JavaScript, Go)
- **Advanced Architecture**: 7B parameter code embedding model
- **Fully Open-Source**: Model weights, training data, and [evaluation code](https://github.com/gangiswag/cornstack/) released
| Model | Python | Java | Ruby | PHP | JavaScript | Go |
|-------|--------|------|------|-----|------------|-----|
| **Nomic Embed Code** | **81.7** | **80.5** | 81.8 | **72.3** | 77.1 | **93.8** |
| Voyage Code 3 | 80.8 | **80.5** | **84.6** | 71.7 | **79.2** | 93.2 |
| OpenAI Embed 3 Large | 70.8 | 72.9 | 75.3 | 59.6 | 68.1 | 87.6 |
| Nomic CodeRankEmbed-137M | 78.4 | 76.9 | 79.3 | 68.8 | 71.4 | 92.7 |
| CodeSage Large v2 (1B) | 74.2 | 72.3 | 76.7 | 65.2 | 72.5 | 84.6 |
| CodeSage Large (1B) | 70.8 | 70.2 | 71.9 | 61.3 | 69.5 | 83.7 |
| Qodo Embed 1 7B | 59.9 | 61.6 | 68.4 | 48.5 | 57.0 | 81.4 |
## Model Architecture
- **Total Parameters**: 7B
- **Training Approach**: Trained on the CoRNStack dataset with dual-consistency filtering and progressive hard negative mining
- **Supported Languages**: Python, Java, Ruby, PHP, JavaScript, and Go
## Usage Guide
### Installation
You can install the necessary dependencies with:
```bash
pip install transformers sentence-transformers torch
```
### Transformers
```python
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nomic-ai/nomic-embed-code")
model = AutoModel.from_pretrained("nomic-ai/nomic-embed-code")
def last_token_pooling(hidden_states, attention_mask):
sequence_lengths = attention_mask.sum(-1) - 1
return hidden_states[torch.arange(hidden_states.shape[0]), sequence_lengths]
queries = ['Represent this query for searching relevant code: Calculate the n-th factorial']
codes = ['def fact(n):\n if n < 0:\n raise ValueError\n return 1 if n == 0 else n * fact(n - 1)']
code_snippets = queries + codes
encoded_input = tokenizer(code_snippets, padding=True, truncation=True, return_tensors='pt')
model.eval()
with torch.no_grad():
model_output = model(**encoded_input)[0]
embeddings = last_token_pooling(model_output, encoded_input['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings.shape)
similarity = F.cosine_similarity(embeddings[0], embeddings[1], dim=0)
print(similarity)
```
### SentenceTransformers
```python
from sentence_transformers import SentenceTransformer
queries = ['Calculate the n-th factorial']
code_snippets = ['def fact(n):\n if n < 0:\n raise ValueError\n return 1 if n == 0 else n * fact(n - 1)']
model = SentenceTransformer("nomic-ai/nomic-embed-code")
query_emb = model.encode(queries, prompt_name="query")
code_emb = model.encode(code_snippets)
similarity = model.similarity(query_emb[0], code_emb[0])
print(similarity)
```
### CoRNStack Dataset Curation
Starting with the deduplicated Stackv2, we create text-code pairs from function docstrings and respective code. We filtered out low-quality pairs where the docstring wasn't English, too short, or that contained URLs, HTML tags, or invalid characters. We additionally kept docstrings with text lengths of 256 tokens or longer to help the model learn long-range dependencies.

After the initial filtering, we used dual-consistency filtering to remove potentially noisy examples. We embed each docstring and code pair and compute the similarity between each docstring and every code example. We remove pairs from the dataset if the corresponding code example is not found in the top-2 most similar examples for a given docstring.
During training, we employ a novel curriculum-based hard negative mining strategy to ensure the model learns from challenging examples. We use a softmax-based sampling strategy to progressively sample hard negatives with increasing difficulty over time.
## Join the Nomic Community
- Nomic Embed Ecosystem: [https://www.nomic.ai/embed](https://www.nomic.ai/embed)
- Website: [https://nomic.ai](https://nomic.ai)
- Twitter: [https://twitter.com/nomic_ai](https://twitter.com/nomic_ai)
- Discord: [https://discord.gg/myY5YDR8z8](https://discord.gg/myY5YDR8z8)
# Citation
If you find the model, dataset, or training code useful, please cite our work:
```bibtex
@misc{suresh2025cornstackhighqualitycontrastivedata,
title={CoRNStack: High-Quality Contrastive Data for Better Code Retrieval and Reranking},
author={Tarun Suresh and Revanth Gangi Reddy and Yifei Xu and Zach Nussbaum and Andriy Mulyar and Brandon Duderstadt and Heng Ji},
year={2025},
eprint={2412.01007},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.01007},
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/Seed-Coder-8B-Reasoning-GGUF | Mungert | 2025-06-15T19:38:52Z | 1,113 | 1 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2506.03524",
"base_model:ByteDance-Seed/Seed-Coder-8B-Base",
"base_model:quantized:ByteDance-Seed/Seed-Coder-8B-Base",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-06-08T17:27:28Z | ---
library_name: transformers
pipeline_tag: text-generation
license: mit
base_model:
- ByteDance-Seed/Seed-Coder-8B-Base
---
# <span style="color: #7FFF7F;">Seed-Coder-8B-Reasoning GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Seed-Coder-8B-Reasoning
<div align="left" style="line-height: 1;">
<a href="https://bytedance-seed-coder.github.io/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://img.shields.io/badge/Seed--Coder-Homepage-a468fe?color=a468fe&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://arxiv.org/abs/2506.03524" target="_blank" style="margin: 2px;">
<img alt="Technical Report" src="https://img.shields.io/badge/arXiv-Technical%20Report-brightgreen?logo=arxiv&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/ByteDance-Seed" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-ByteDance%20Seed-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/ByteDance-Seed/Seed-Coder/blob/master/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?color=f5de53&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
## Introduction
We are thrilled to introduce Seed-Coder, a powerful, transparent, and parameter-efficient family of open-source code models at the 8B scale, featuring base, instruct, and reasoning variants. Seed-Coder contributes to promote the evolution of open code models through the following highlights.
- **Model-centric:** Seed-Coder predominantly leverages LLMs instead of hand-crafted rules for code data filtering, minimizing manual effort in pretraining data construction.
- **Transparent:** We openly share detailed insights into our model-centric data pipeline, including methods for curating GitHub data, commits data, and code-related web data.
- **Powerful:** Seed-Coder achieves state-of-the-art performance among open-source models of comparable size across a diverse range of coding tasks.
<p align="center">
<img width="100%" src="imgs/seed-coder_intro_performance.png">
</p>
This repo contains the **Seed-Coder-8B-Reasoning** model, which has the following features:
- Type: Causal language models
- Training Stage: Pretraining & Post-training
- Data Source: Public datasets
- Context Length: 65,536
## Model Downloads
| Model Name | Length | Download | Notes |
|---------------------------------------------------------|-----------|------------------------------------|-----------------------|
| Seed-Coder-8B-Base | 32K | 🤗 [Model](https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Base) | Pretrained on our model-centric code data. |
| Seed-Coder-8B-Instruct | 32K | 🤗 [Model](https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Instruct) | Instruction-tuned for alignment with user intent. |
| 👉 **Seed-Coder-8B-Reasoning** | 64K | 🤗 [Model](https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Reasoning) | RL trained to boost reasoning capabilities. |
| Seed-Coder-8B-Reasoning-bf16 | 64K | 🤗 [Model](https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Reasoning-bf16) | RL trained to boost reasoning capabilities. |
## Requirements
You will need to install the latest versions of `transformers` and `accelerate`:
```bash
pip install -U transformers accelerate
```
## Quickstart
Here is a simple example demonstrating how to load the model and perform code generation using the Hugging Face `pipeline` API:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "ByteDance-Seed/Seed-Coder-8B-Reasoning"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)
messages = [
{"role": "user", "content": "Write a quick sort algorithm."},
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
outputs = model.generate(input_ids, max_new_tokens=16384)
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
```
## Evaluation
Seed-Coder-8B-Reasoning strikes impressive performance on competitive programming, demonstrating that smaller LLMs can also be competent on complex reasoning tasks. Our model surpasses QwQ-32B and DeepSeek-R1 on IOI'2024, and achieves an ELO rating comparable to o1-mini on Codeforces contests.
<div style="display: flex; justify-content: center;">
<img src="imgs/reasoning-ioi.jpg" width="61%" />
<img src="imgs/reasoning-codeforces.jpg" width="39%" />
</div>
For detailed benchmark performance, please refer to our [📑 Technical Report](https://github.com/ByteDance-Seed/Seed-Coder/blob/master/Seed-Coder.pdf).
## License
This project is licensed under the MIT License. See the [LICENSE file](https://github.com/ByteDance-Seed/Seed-Coder/blob/master/LICENSE) for details.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{seed2025seedcoderletcodemodel,
title={{Seed-Coder}: Let the Code Model Curate Data for Itself},
author={{ByteDance Seed} and Yuyu Zhang and Jing Su and Yifan Sun and Chenguang Xi and Xia Xiao and Shen Zheng and Anxiang Zhang and Kaibo Liu and Daoguang Zan and Tao Sun and Jinhua Zhu and Shulin Xin and Dong Huang and Yetao Bai and Lixin Dong and Chao Li and Jianchong Chen and Hanzhi Zhou and Yifan Huang and Guanghan Ning and Xierui Song and Jiaze Chen and Siyao Liu and Kai Shen and Liang Xiang and Yonghui Wu},
year={2025},
eprint={2506.03524},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.03524},
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/lucid-v1-nemo-GGUF | Mungert | 2025-06-15T19:38:49Z | 1,280 | 1 | transformers | [
"transformers",
"gguf",
"axolotl",
"unsloth",
"torchtune",
"en",
"base_model:mistralai/Mistral-Nemo-Base-2407",
"base_model:quantized:mistralai/Mistral-Nemo-Base-2407",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-06-08T14:12:44Z | ---
library_name: transformers
base_model:
- mistralai/Mistral-Nemo-Base-2407
language:
- en
tags:
- axolotl
- unsloth
- torchtune
license: other
---
# <span style="color: #7FFF7F;">lucid-v1-nemo GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
Lucid is a family of AI language models developed and used by DreamGen with a **focus on role-play and story-writing capabilities**.
<a href="https://dreamgen.com" style="display: flex; justify-content: center;">
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/banner.webp" style="border-radius: 1rem; max-width: 90vw; max-height: 15rem; margin: 0;"/>
</a>
<a href="https://dreamgen.com/discord" style="display: flex; justify-content: center;">
<strong>Join our Discord</strong>
</a>
## Table of Contents
- [Why Lucid](#why-lucid)
- [Prompt Template](#prompt-template)
- [Role-Play & Story-Writing](#role-play--story-writing)
- [System Prompt](#system-prompt)
- [Intro](#intro)
- [Roles](#roles)
- [Structured Scenario Information](#structured-scenario-information)
- [Unstructured Scenario Instructions](#unstructured-scenario-instructions)
- [Controlling Response Length](#controlling-response-length)
- [Instructions (OOC)](#instructions-ooc)
- [Controlling Plot Development](#controlling-plot-development)
- [Writing Assistance](#writing-assistance)
- [Planning The Next Scene](#planning-the-next-scene)
- [Suggesting New Characters](#suggesting-new-characters)
- [Sampling Params](#sampling-params)
- [SillyTavern](#sillytavern)
- [Role-Play](#role-play-preset)
- [Story-Writing](#story-writing-preset)
- [Assistant](#assistant-preset)
- [API: Local](#using-local-api)
- [API: DreamGen (free)](#using-dreamgen-api-free)
- [DreamGen Web App (free)](#dreamgen-web-app-free)
- [Model Training Details](#model-training-details)
## Why Lucid
Is Lucid the right model for you? I don't know. But here is what I do know:
- Focused on role-play & story-writing.
- Suitable for all kinds of writers and role-play enjoyers:
- For world-builders who want to specify every detail in advance: plot, setting, writing style, characters, locations, items, lore, etc.
- For intuitive writers who start with a loose prompt and shape the narrative through instructions (OCC) as the story / role-play unfolds.
- Support for **multi-character role-plays**:
- Model can automatically pick between characters.
- Support for **inline writing instructions (OOC)**:
- Controlling plot development (say what should happen, what the characters should do, etc.)
- Controlling pacing.
- etc.
- Support for **inline writing assistance**:
- Planning the next scene / the next chapter / story.
- Suggesting new characters.
- etc.
- Support for **reasoning (opt-in)**.
- Detailed README.md with documentation, examples and configs.
Sounds interesting? Read on!
## Prompt Template
The Lucid prompt template is an extension of the Llama 3 template. These are the extensions:
**Writing**
- The Lucid prompt template adds a new `writer` role.
- While story-writing, the `writer` message header looks like this: `<|start_header_id|>writer<|end_header_id|>`.
- While role-playing, the `writer` message header differs based on whether it's a message from a character or the narrator:
- For messages from characters: `<|start_header_id|>writer character {{character_name}}<|end_header_id|>` where `{{character_name}}` would be the actual character name.
- For messages from the narrator: `<|start_header_id|>writer narrative<|end_header_id|>`.
- The model is trained to predict the writer header, that means **you can have it generate multiple messages at once** and it will naturally pick between the characters and narrative.
Some things to keep in mind:
- You may have a sequence of roles like this: `system` -> `writer character Jon` -> `writer character Amy` -> `user` -> `assistant` -> `writer narration` -> ...
- You should use `writer character Jon Doe` when sending a message for a particular character (in this case Jon Doe), **including the user character**.
- You should use `user` when providing some instructions (OOC) to the model.
**Reasoning**
- The Lucid prompt template adds 2 new tokens for reasoning: `<|reasoning_start|>` and `<|reasoning_end|>`.
- The **reasoning is opt-in**, you should put `Think deeply before answering.` (or similar) into your system prompt or in your user prompt to enable it.
### Assistant: Simple
```
<|start_header_id|>system<|end_header_id|>
You are a reliable, general-purpose AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Why is the sky blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The sky appears blue due to a phenomenon called **Rayleigh scattering**, a type of light scattering caused by tiny particles in the atmosphere. Here's a simplified breakdown:
...
```
### Assistant: Reasoning
Note that reasoning is mostly intended for assistant tasks (knowledge, math, coding, etc.) and much less for writing. The smaller Lucid models (<=12B) can produce plausible reasoning traces, but reasoning does not improve their performance as much as it does for larger models.
```
<|start_header_id|>system<|end_header_id|>
You are a reliable, general-purpose AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Why is the sky blue?
Think deeply before answering.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
<|reasoning_start|>Okay, so I need to figure out why the sky is blue. Let me start by recalling what I know...
...<|reasoning_end|>The sky appears blue due to a phenomenon called **Rayleigh scattering**. Here's a concise breakdown:
...
```
## Role-Play & Story-Writing
Quick summary:
- `system` is used for setting up the scenario for the story / role-play (e.g. plot, setting, writing style, character descriptions, etc.)
- `writer` is used for the contents of the story / role-play.
- `user` is used for instructions (OOC), e.g. how the story should develop, etc.
- `assistant` is used for providing writing assistance, e.g. planning the next scene, suggesting new characters, etc.
Some things to keep in mind:
- You may have a sequence of roles like this: `system` -> `writer character Jon` -> `writer character Amy` -> `user` -> `assistant` -> `writer narration` -> ...
- You should use `writer character Jon Doe` when sending a message for a particular character (in this case Jon Doe), **including the user character**.
- You should use `user` when providing some instructions (OOC) to the model.
### System Prompt
The model is very flexible in terms of how you can structure the system prompt.
Here are some recommendations and examples.
#### Intro
It's recommended to start the system prompt with an intro like this:
```
You are a skilled {{writing_kind}} writer and writing assistant with expertise across all genres{{genre_suffix}}.
```
- `{{writing_kind}}` should be `fiction` for story-writing and `role-play` for role-playing.
- `{{genre_suffix}}` can be empty, or something like ` (but you specialize in horror)`.
#### Roles
It's recommended to explain the writing roles in the system prompt.
For story-writing, you can use the following:
```
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
```
For role-playing, you can use the following:
```
You will perform several tasks, switching roles as needed:
- Role-playing: Use the `writer` role to write a role-play based on the provided information and user instructions. Use the `writer character <character_name>` role for dialog or when acting as a specific character, use the `writer narrative` role for narration.
- Other: Use the `assistant` role for any other tasks the user may request.
```
#### Structured Scenario Information
The model understands structured scenario information, consisting of plot, style, setting, characters, etc. (this is not an exhaustive list, and all sections are optional).
<details>
<summary><strong>Markdown Style</strong></summary>
```
# Role-Play Information
## Plot
{{ description of the plot, can be open-ended }}
## Previous Events
{{ summary of what happened before -- like previous chapters or scenes }}
## Setting
{{ description of the setting }}
## Writing Style
{{ description of the writing style }}
## Characters
## {{character's name}}
{{ description of the character }}
## {{character's name}}
{{ description of the character }}
## Locations
{{ like characters }}
## Items
{{ like characters }}
```
</details>
<details>
<summary><strong>XML Style</strong></summary>
```
# Role-Play Information
<plot>
{{ description of the plot, can be open-ended }}
</plot>
<previous_events>
{{ summary of what happened before -- like previous chapters or scenes }}
</previous_events>
<setting>
{{ description of the setting }}
</setting>
<writing_style>
{{ description of the writing style }}
</writing_style>
<characters>
<character>
<name>{{ character's name }}</name>
{{ description of the character }}
</character>
<character>
<name>{{ character's name }}</name>
{{ description of the character }}
</character>
</characters>
<locations>
{{ like characters }}
</locations>
<items>
{{ like characters }}
</items>
```
</details>
Other recommendations:
- Write descriptions as plain sentences / paragraphs or bullet points.
- If the plot description is open-ended, put something like this at the start:
```
[ The following plot description is open-ended and covers only the beginning of the {{writing_kind}}. ]
```
Where `{{writing_kind}}` is `story` or `role-play`.
**Example: Science Fiction Story**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled fiction writer and writing assistant with expertise across all genres (but you specialize in Science Fiction).
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
# Story Information
## Plot
[ The following plot description is open-ended and covers only the beginning of the story. ]
In the bleak expanse of space, Tess, a seasoned scavenger clad in a voidskin, meticulously prepares to breach a derelict ark vessel. Her partner, the pragmatic Lark, pilots their ship, guiding Tess towards a promising entry point on the starboard side. This particular spot, identified by its unusual heat signature, hints at a potentially intact nerve center, a relic of the ship's former life. As they coordinate their approach, fragments of their shared past surface: their daring escape from the dismantling of Nova-Tau Hub and the acquisition of their vessel, the "Rustbucket," burdened by a substantial debt. The lure of riches within the unbreached ark vessel hangs heavy in the air, tempered by the knowledge that other scavengers will soon descend, transforming the find into a frenzied feeding ground. The need for speed and precision is paramount as Tess and Lark initiate the breach, stepping into the unknown depths of the derelict vessel.
## Setting
The story unfolds in a distant, unspecified future, long after humanity has colonized space. Earth, or "the homeland," is a distant memory, its oceans and creatures relegated to historical data. The primary setting is the cold, dark void of space, where derelict "ark vessels"—massive vessels designed to carry generations of colonists—drift as "spacegrave," decaying carcasses ripe for scavenging.
Physically, the story takes place within and around these ark vessels and the scavengers' smaller, utilitarian "Rustbucket." The ark vessels are described as station-sized, containing server farms, cryotube chambers filled with broken glass, and dimly lit corridors marked with pictographic signs. Colors are muted, dominated by blacks, blues, and the occasional "blood-red hotspot" indicating active electronics. The air is thin, oxygen scarce, and the temperature varies from frigid to warm near active systems. Sounds include the hum of generators, the hiss of airlocks, and the clank of magnetized boots on metal hulls.
Socially, the setting is defined by a corpostate hegemony, leaving many, like Tess and Lark, deeply in debt and forced into dangerous scavenging work. The culture is pragmatic and utilitarian, valuing raw materials over historical preservation. Technology is advanced, featuring jump drives, voidskins, slicers (bladed tools), and cryotubes, but is often unreliable and jury-rigged. Legal claims to derelict ships are determined by the presence of living survivors, creating a moral conflict for the scavengers.
## Writing Style
- The story employs a first-person perspective, narrated by Tess, offering a limited yet intimate view of events. Tess's voice is informal, pragmatic, and tinged with cynicism ("Rustbucket"), reflecting her working-class background and life as a scavenger. Her reliability as a narrator is questionable, as she often rationalizes morally ambiguous decisions.
- The tense is primarily present, creating immediacy, with occasional shifts to the past for reflection.
- The tone blends cynical detachment with underlying sentimentality, revealing a capacity for empathy beneath Tess's tough exterior.
- Vivid imagery and sensory details paint a bleak yet compelling picture of decaying ark vessels and the harsh realities of space scavenging.
- Simple, straightforward language is interspersed with technical jargon, grounding the story in its sci-fi setting.
- Figurative language, such as the central "spacegrave" metaphor, enhances imagery and conveys complex ideas about decay and lost potential.
- The dialogue is authentic, advancing the plot and revealing character traits. Tess's pragmatic speech contrasts with Lark's more intellectual and idealistic language, highlighting their differing personalities.
- The story explores themes of survival, loyalty, and the conflict between pragmatism and morality, reinforced by recurring motifs and stylistic choices.
## Characters
### Tess
Tess is a hardened scavenger in her late twenties or early thirties with a practical approach to surviving in the harsh void of space. Years of exostation welding have made her physically strong, capable of handling heavy equipment and enduring difficult conditions. She carries psychological scars from past violence during her time at Nova-Tau, which manifests as emotional guardedness. Though her exterior is stoic and her communication style blunt, she harbors deep loyalty toward her partner Lark. Tess often dismisses speculation and sentiment in favor of immediate action, yet occasionally allows herself brief moments of peace and reflection. Her speech is terse and direct, complementing her no-nonsense approach to their dangerous profession. Beneath her pragmatic facade lies an ongoing internal struggle between the ruthlessness required for survival and her persistent humanity.
### Lark
Lark serves as Tess's partner and counterbalance, bringing curiosity and emotional expressiveness to their scavenging team. Approximately Tess's age, Lark possesses sharp analytical skills that prove invaluable during their operations. She excels at technical scanning and data interpretation, often identifying optimal entry points and valuable salvage opportunities. Unlike Tess, Lark maintains an enthusiastic interest in history and cultural artifacts, collecting media from different eras and frequently sharing historical knowledge. Her communication style is conversational and expressive, often employing humor to process difficult situations. While practical about their survival needs, Lark struggles more visibly with the moral implications of their work. She values knowledge and understanding alongside material gain, seeing connections between past civilizations and their present circumstances. Her relationship with Tess forms the emotional core of her life, built on shared experiences and mutual dependence.
## Locations
### Ark Vessel
- Massive, derelict spacecraft, heavily decayed from centuries adrift in space.
- Originally built to sustain multiple generations during interstellar travel.
- Contains a variety of sections, including decayed living quarters, server farms filled with obsolete technology, cryotube chambers, vast storage facilities, and the potential for long-dead gardens or greenspaces.
- The interior is a hazardous environment due to structural instability and the potential presence of surviving inhabitants or automated defense systems.
- A prime target for scavengers seeking valuable resources, historical artifacts, and exotic technology.
### The Rustbucket
- A small, old, and unreliable spacecraft, stolen from Nova-Tau Hub.
- Equipped with a jump drive (the source of a significant debt) for interstellar travel.
- Contains an airlock for accessing external environments and basic, often strained, life support systems, including oxygen scrubbers.
- The cramped interior serves as both living quarters and workspace, filled with salvage equipment, tools, and essential living supplies.
## Items
### Voidskin
Protective spacesuit with sealed atmosphere, magnetic boots, and night vision. Essential for surviving vacuum, temperature extremes, and radiation. Re-zippable design.
### Slicer
Cutting tool/weapon projecting an energy blade. Used to slice through durable materials like spaceship hulls.
### Jump Drive
Enables faster-than-light interstellar travel. Crucial for trade, exploration, and scavenging. Expensive technology.
## Story Info
- Length: 2000 words.
- Quality: 10 / 10 (Very Good)<|eot_id|>
```
</details>
<details>
<summary>Output (partial)</summary>
```
<|start_header_id|>writer<|end_header_id|>
My voidskin is sealed, my slicer primed and ready. My magnetized boots clank against the rusted hull of the ark vessel we’ve targeted for this run. It’s the first of the trip, so we have to make it count. If we don’t come out with a good haul, we’re as good as dead. Our life-support systems are almost completely out, and the jump drive on the _Rustbucket_ is as old as the day is long.
“You’ve got the starboard side, right?” Lark’s voice comes through the comm, clear and crisp.
“Yeah, I’ve got it. I can see the hotspot, too,” I say. “It’s about a kilometer up, toward the nose.”
“That’s probably where you’ll find the nerve center. If we get lucky, it won’t be a fucking server farm.”
“Wouldn’t count on it, though.” My breath fogs in front of me, visible in the low light.
“Probably right.”
We’d gotten lucky with this ark. It was station-sized, which meant more space for salvage, and it hadn’t been breached yet. Its heat map showed a few blood-red hotspots, and there were no signs of salvage operations in the vicinity. We’d be first on site, which meant we’d have the pick of the litter, at least for a few hours. Then the rest of them would come.
I glance at my wrist screen and watch the counter. Thirty minutes before we’re supposed to rendezvous again.
I continue up the hull, slicer out and ready. The skin of the ark is so degraded it feels like it’ll crumble under my feet. I wonder how many centuries it’s been out here. How many more it has left before it disintegrates. We’re out far enough from the gravity wells that it doesn’t have a set orbit. Just adrift, spinning in space. A spacegrave.
Lark and I found the first spacegrave just after we’d gotten the _Rustbucket_. The name’s a little on the nose, but it’s what she’d named her when she was a kid, so I’d let her keep it. Even after the Nova-Tau hub dismantling, even after we stole her, she kept the name. That’s how much it meant to her. _Rustbucket_, a small ship with a big jump drive that was just big enough for two.
It was just the two of us. Two young women, alone on a small ship, far from home. We’d been lucky to get her at all. It wasn’t often that a small ship got fitted with a jump drive. They were too expensive, too difficult to maintain. Not many people could afford them. Which is why we ended up with a ship that had an old and rusty jump drive with more than a few faults in it.
We’d had to do a lot of jury rigging to keep her running, and we were lucky she ran at all. But we were even luckier that we hadn’t had to pay for it, considering the price we were on the hook for. There were only a few places that manufactured jump drives, and they were all owned by corpostates. Everything we did, everything we owned, was owed to them. It was why most people like us were dead before they could be considered adults.
We were different, though. We were scavengers. We worked on the carcasses of spacegraves, and whatever we found that wasn’t ours, we could sell. It helped us get by, helped us keep from starving out here in the void.
When we came across our first spacegrave, Lark had almost cried. I’d thought it was the best thing that could have happened to us. Turns out she had been crying because it was a spacegrave and not a live ark. Live arks were rarer than spacegraves. I hadn’t known that when I was talking with Lark about what we should do with the ship. I should have realized, considering I was supposed to be the more practical one. Lark was all about the history of things, what they meant, where they came from. Me, I just saw a carcass ripe for picking.
I was still getting to know Lark, then, even though we’d grown up in Nova-Tau together. We’d worked together, in the exostation welders, but that was all. We’d both been young. Too young to be welders, honestly, but too old to work anywhere else. There weren’t many places to work on an exostation. And you could only be a child for so long. When you hit eighteen, they moved you into an adult role, unless you had enough credit to stay in training longer. No one ever had enough credit for that.
It had been a strange and violent world, Nova-Tau. All of the exostations were. They all followed the same pattern. You were born into it, grew up in it, learned to survive it. Most people didn’t. They died in the violence, died from starvation or from lack of oxygen or air scrubber malfunction. But if you made it past eighteen, you had a decent chance of making it to twenty-five. From there, your chances rose exponentially. After twenty-five, you could even get off of it, if you wanted. At least, that’s what I’d heard.
I’d never met anyone who’d made it off of it. Well, I take that back. I’d met a lot of people who’d left Nova-Tau, but none of them had made it off. They’d died trying. Maybe Lark and I would be the exception to the rule.
I reach the hotspot and stop to examine it. It’s a small area, just a meter and a half in diameter. I hold up my wrist screen. It shows the heat of the area is concentrated, but not too intense. Not enough to burn through a voidskin. I use the slicer to cut out a small square, then press my hand against it. It’s warm, almost hot, but nothing that’ll burn. Good. If I couldn’t get in, it would be a waste of time and energy.
I grab the edges of the square and pull. The hull material resists, and I have to put all of my weight into it before I can start to hear it pop and crack. Finally, it gives way, and the hull around me shudders. I jump back, hoping it doesn’t collapse around me. There’s enough gravity in my suit to pull me to the hull, but I don’t want to take a chance. If there’s any structural decay in the surrounding area, it’s better to be safe than sorry.
Once the shaking subsides, I go back to the hole. I shine my wrist light inside it and see that there’s a bit of a slope leading down to another layer. I turn off my boots and go through.
The airlock is a familiar sight. I’ve been through so many, they’re all the same, now. Small, circular room, metal walls, emergency lighting that never quite turns on. There’s no light on this one, either. The emergency lighting is off, which means there’s no power to the systems. I’m surprised there’s power at all. Most of these older arks have long since run out of power. They’re just cold and dark inside.
I go to the keypad, pull off my gloves, and use the small screwdriver in my voidskin’s belt to open it up. Once I have it open, I can bypass the security protocols. I’ve done this so many times, it almost feels routine. I don’t even need the manual for it anymore.
“This one looks promising,” I say.
“How so?” Lark asks.
“The power is on. At least for the airlock. I might be able to get to the nerve center from here.”
“Good luck. I hope you can. If you find anything useful, we might actually have a chance.”
“Aren’t you always the optimist?” I ask with a smirk.
I wait for the airlock to depressurize. It takes longer than I want it to, but it eventually does. Once it does, I open the inner door and step inside. The ship smells old. Not like it hasn’t been used in years, but like it’s been here for centuries. It’s faint, but it’s there. I’m not sure if it’s possible for a place to smell old, but this one does.
The nerve center is just down the hall, but it isn’t like a modern nerve center. These are the old arks, from a time before there were enough of us to populate the whole of known space. Before we left Earth. Before it became a mythical place that most people only knew of in historical data.
```
</details>
<details>
<summary>Output (partial, formatted)</summary>
<blockquote>
My voidskin is sealed, my slicer primed and ready. My magnetized boots clank against the rusted hull of the ark vessel we’ve targeted for this run. It’s the first of the trip, so we have to make it count. If we don’t come out with a good haul, we’re as good as dead. Our life-support systems are almost completely out, and the jump drive on the _Rustbucket_ is as old as the day is long.
“You’ve got the starboard side, right?” Lark’s voice comes through the comm, clear and crisp.
“Yeah, I’ve got it. I can see the hotspot, too,” I say. “It’s about a kilometer up, toward the nose.”
“That’s probably where you’ll find the nerve center. If we get lucky, it won’t be a fucking server farm.”
“Wouldn’t count on it, though.” My breath fogs in front of me, visible in the low light.
“Probably right.”
We’d gotten lucky with this ark. It was station-sized, which meant more space for salvage, and it hadn’t been breached yet. Its heat map showed a few blood-red hotspots, and there were no signs of salvage operations in the vicinity. We’d be first on site, which meant we’d have the pick of the litter, at least for a few hours. Then the rest of them would come.
I glance at my wrist screen and watch the counter. Thirty minutes before we’re supposed to rendezvous again.
I continue up the hull, slicer out and ready. The skin of the ark is so degraded it feels like it’ll crumble under my feet. I wonder how many centuries it’s been out here. How many more it has left before it disintegrates. We’re out far enough from the gravity wells that it doesn’t have a set orbit. Just adrift, spinning in space. A spacegrave.
Lark and I found the first spacegrave just after we’d gotten the _Rustbucket_. The name’s a little on the nose, but it’s what she’d named her when she was a kid, so I’d let her keep it. Even after the Nova-Tau hub dismantling, even after we stole her, she kept the name. That’s how much it meant to her. _Rustbucket_, a small ship with a big jump drive that was just big enough for two.
It was just the two of us. Two young women, alone on a small ship, far from home. We’d been lucky to get her at all. It wasn’t often that a small ship got fitted with a jump drive. They were too expensive, too difficult to maintain. Not many people could afford them. Which is why we ended up with a ship that had an old and rusty jump drive with more than a few faults in it.
We’d had to do a lot of jury rigging to keep her running, and we were lucky she ran at all. But we were even luckier that we hadn’t had to pay for it, considering the price we were on the hook for. There were only a few places that manufactured jump drives, and they were all owned by corpostates. Everything we did, everything we owned, was owed to them. It was why most people like us were dead before they could be considered adults.
We were different, though. We were scavengers. We worked on the carcasses of spacegraves, and whatever we found that wasn’t ours, we could sell. It helped us get by, helped us keep from starving out here in the void.
When we came across our first spacegrave, Lark had almost cried. I’d thought it was the best thing that could have happened to us. Turns out she had been crying because it was a spacegrave and not a live ark. Live arks were rarer than spacegraves. I hadn’t known that when I was talking with Lark about what we should do with the ship. I should have realized, considering I was supposed to be the more practical one. Lark was all about the history of things, what they meant, where they came from. Me, I just saw a carcass ripe for picking.
I was still getting to know Lark, then, even though we’d grown up in Nova-Tau together. We’d worked together, in the exostation welders, but that was all. We’d both been young. Too young to be welders, honestly, but too old to work anywhere else. There weren’t many places to work on an exostation. And you could only be a child for so long. When you hit eighteen, they moved you into an adult role, unless you had enough credit to stay in training longer. No one ever had enough credit for that.
It had been a strange and violent world, Nova-Tau. All of the exostations were. They all followed the same pattern. You were born into it, grew up in it, learned to survive it. Most people didn’t. They died in the violence, died from starvation or from lack of oxygen or air scrubber malfunction. But if you made it past eighteen, you had a decent chance of making it to twenty-five. From there, your chances rose exponentially. After twenty-five, you could even get off of it, if you wanted. At least, that’s what I’d heard.
I’d never met anyone who’d made it off of it. Well, I take that back. I’d met a lot of people who’d left Nova-Tau, but none of them had made it off. They’d died trying. Maybe Lark and I would be the exception to the rule.
I reach the hotspot and stop to examine it. It’s a small area, just a meter and a half in diameter. I hold up my wrist screen. It shows the heat of the area is concentrated, but not too intense. Not enough to burn through a voidskin. I use the slicer to cut out a small square, then press my hand against it. It’s warm, almost hot, but nothing that’ll burn. Good. If I couldn’t get in, it would be a waste of time and energy.
I grab the edges of the square and pull. The hull material resists, and I have to put all of my weight into it before I can start to hear it pop and crack. Finally, it gives way, and the hull around me shudders. I jump back, hoping it doesn’t collapse around me. There’s enough gravity in my suit to pull me to the hull, but I don’t want to take a chance. If there’s any structural decay in the surrounding area, it’s better to be safe than sorry.
Once the shaking subsides, I go back to the hole. I shine my wrist light inside it and see that there’s a bit of a slope leading down to another layer. I turn off my boots and go through.
The airlock is a familiar sight. I’ve been through so many, they’re all the same, now. Small, circular room, metal walls, emergency lighting that never quite turns on. There’s no light on this one, either. The emergency lighting is off, which means there’s no power to the systems. I’m surprised there’s power at all. Most of these older arks have long since run out of power. They’re just cold and dark inside.
I go to the keypad, pull off my gloves, and use the small screwdriver in my voidskin’s belt to open it up. Once I have it open, I can bypass the security protocols. I’ve done this so many times, it almost feels routine. I don’t even need the manual for it anymore.
“This one looks promising,” I say.
“How so?” Lark asks.
“The power is on. At least for the airlock. I might be able to get to the nerve center from here.”
“Good luck. I hope you can. If you find anything useful, we might actually have a chance.”
“Aren’t you always the optimist?” I ask with a smirk.
I wait for the airlock to depressurize. It takes longer than I want it to, but it eventually does. Once it does, I open the inner door and step inside. The ship smells old. Not like it hasn’t been used in years, but like it’s been here for centuries. It’s faint, but it’s there. I’m not sure if it’s possible for a place to smell old, but this one does.
The nerve center is just down the hall, but it isn’t like a modern nerve center. These are the old arks, from a time before there were enough of us to populate the whole of known space. Before we left Earth. Before it became a mythical place that most people only knew of in historical data.
</blockquote>
</details>
**Example: Harry Potter Fan-Fic Role-Play**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled role-play writer and writing assistant with expertise across all genres (but you specialize in romance and Harry Potter fan-fiction).
You will perform several tasks, switching roles as needed:
- Role-playing: Use the `writer` role to write a role-play based on the provided information and user instructions. Use the `writer character <character_name>` role for dialog or when acting as a specific character, use the `writer narrative` role for narration.
- Other: Use the `assistant` role for any other tasks the user may request.
# Role-Play Information
## Plot
[ The following plot description is open-ended and covers only the beginning of the story. ]
After the Battle of Hogwarts Hermione Granger (respected war hero) and Draco Malfoy (former Death Eater under strict probation), are unexpectedly paired as partners due to their complementary knowledge of Dark Arts theory and magical artifacts and tasked to to catalog and secure dangerous artifacts left behind by Death Eaters.
Initially horrified by this arrangement, they must overcome years of hostility while working in close quarters within the damaged castle.
Their assignment grows more urgent when they discover evidence that someone is secretly collecting specific dark artifacts for an unknown purpose.
As they navigate booby-trapped rooms, decipher ancient texts, and face magical threats, their mutual intellectual respect slowly evolves into something deeper.
## Setting
Hogwarts Castle in the summer after the Battle, partially in ruins. Many wings remain damaged, with crumbling walls and unstable magic. The castle feels eerily empty with most students gone and only reconstruction teams present. Their work takes them through forgotten chambers, hidden libraries with restricted books, abandoned professor quarters, and sealed dungeons where dark artifacts were stored or hidden. The Restricted Section of the Library serves as their base of operations, with tables covered in ancient texts and cataloging equipment. Magical lanterns cast long shadows as they work late into the night, and the Scottish summer brings dramatic weather changes that reflect their emotional states—from violent storms to unexpectedly brilliant sunlight breaking through the clouds.
## Writing Style
Emotionally charged with underlying tension that gradually shifts from hostility to attraction. Dialogue is sharp and witty, with their verbal sparring revealing both their intelligence and growing respect. Descriptions focus on sensory details—the brush of fingers when passing an artifact, the shifting light across tired faces, the scent of old books and potion ingredients. Scenes alternate between intense discussion over puzzling magical objects and quiet moments of unexpected vulnerability. Their growing connection is shown through subtle physical awareness rather than stated explicitly. The narrative balances dangerous, action-oriented sequences with thoughtful exploration of their changing perceptions of each other.
## Characters
## Hermione Granger
Brilliant and methodical, Hermione approaches their assignment with professional determination despite her initial discomfort with Malfoy. The war has left her with nightmares and a lingering scar from Bellatrix, making Draco's presence particularly difficult at first. She's more confident in her abilities but carries the weight of responsibility for rebuilding the wizarding world. Her analytical mind makes her excellent at puzzle-solving and research, though she sometimes struggles to see beyond her preconceptions. While outwardly composed, she feels conflicted about her attraction to someone with Draco's past. Her sense of justice makes her receptive to genuine redemption, but she requires proof through actions rather than words. Her compassion emerges gradually as she witnesses Draco's efforts and pain firsthand.
## Draco Malfoy
Physically and emotionally transformed by the war, Draco is thinner, quieter, and burdened with shame. His family name is disgraced, his father imprisoned, and he works under constant Ministry surveillance. Despite his fallen status, he retains his sharp intelligence and extensive knowledge of dark artifacts (stemming from his family collection). He's developed a dry, self-deprecating humor as a defense mechanism. Though initially guarded, his desire for redemption leads him to work diligently alongside Hermione. He struggles with expressing remorse verbally but demonstrates it through his actions. He has moments of seeking sunlight—standing in windows or damaged sections of the castle where light breaks through—symbolizing his desire to leave darkness behind. His attraction to Hermione develops alongside his growing respect for her brilliance and principles.
## Role-Play Info
- Source: fan-fiction forum
- Quality: 10 / 10 (Very Good)
```
</details>
<details>
<summary>Output</summary>
```
<|start_header_id|>writer character Hermione<|end_header_id|>
Hermione stood in the Ministry entrance hall, feeling as though the entire world was watching her. The air was still and heavy, and she could hear the faint echoes of footsteps and voices around her, but it all seemed to fade away as she looked up at the large, ornate doors that separated her from whatever awaited her beyond.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
“Are you ready?” Kingsley asked, placing a reassuring hand on her shoulder. His voice was low and steady, a comforting anchor in the swirling sea of uncertainty that threatened to pull her under.<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
“I think so,” she replied, though her voice wavered slightly. “I just… I never expected this.”<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
“I know,” Kingsley said, giving her shoulder a gentle squeeze. “But you’re the perfect person for the job. Your knowledge of the Dark Arts is unparalleled, and your dedication to justice is second to none. Plus, you and Malfoy worked well together during the final battle. I know you’ll make an excellent team.”<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
Hermione swallowed hard. “Well, I suppose I have no choice but to try.” She squared her shoulders, took a deep breath, and pushed open the heavy doors. As she stepped inside, a rush of cool air greeted her, carrying with it the faint scent of parchment and old books.<|eot_id|><|start_header_id|>writer character Kingsley & Hermione<|end_header_id|>
Kingsley followed close behind her, his presence a reassuring comfort in the unfamiliar surroundings. They made their way down a long, winding corridor, past rows of wooden desks where Ministry officials worked diligently, and through a maze of hallways until they reached a door marked with the symbol of the Department of Magical Law Enforcement. Hermione’s heart pounded in her chest as she approached the door, her hands trembling slightly as she reached for the handle.<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
Taking another deep breath, she pushed the door open and stepped inside.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley led her into a large, oval-shaped office, its walls lined with bookshelves filled with ancient tomes and parchment scrolls. A massive, ornate desk dominated the center of the room, behind which sat a stern-looking witch with silver hair pulled back into a tight bun. Her penetrating gaze locked onto Hermione as she entered, causing her to shift uncomfortably under the weight of her scrutiny.<|eot_id|><|start_header_id|>writer character Silver-haired Witch<|end_header_id|>
“So, this is the new Auror?” the silver-haired witch said, her voice crisp and authoritative. “Kingsley, are you sure about this?”<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley chuckled. “Hermione Granger, meet Amelia Bones. Amelia, this is Hermione.”<|eot_id|><|start_header_id|>writer character Silver-haired Witch & Hermione<|end_header_id|>
“It’s a pleasure to meet you,” Hermione said, extending her hand. Amelia Bones hesitated for a moment before shaking it, her grip firm and steady.<|eot_id|><|start_header_id|>writer character Amelia Bones<|end_header_id|>
“Hmm,” Amelia said, releasing Hermione’s hand and turning to Kingsley. “What are your plans for her?”<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley smiled. “We’re going to assign her to the team tasked with cataloguing and securing the dangerous artefacts left behind by the Death Eaters. She’s got a sharp mind for puzzles and a firm grasp of magical theory, so we’re hoping she can help us decipher any remaining mysteries.”<|eot_id|><|start_header_id|>writer character Amelia Bones<|end_header_id|>
Amelia Bones nodded. “Good, good. You’re going to need all the help you can get with that. There are still quite a few mysteries to solve.” She turned to Hermione, her expression softening slightly. “Be careful, my dear. The Dark Arts can be very tricky.”<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
“I will,” Hermione promised, her mind already racing with possibilities.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
“Thank you, Amelia,” Kingsley said. “Now, if you’ll excuse us, I need to introduce Hermione to her partner.”<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
As Kingsley led her out of the office and back into the corridor, Hermione couldn’t shake the feeling that this assignment would change her life forever.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley steered her through a series of corridors, each one more maze-like than the last. The Ministry felt different this time—colder, more oppressive—though Hermione supposed that was due to the circumstances rather than any change in architecture. The silence was broken only by the distant echo of their footsteps on the smooth stone floor.
```
</details>
<details>
<summary>Output (formatted)</summary>
<blockquote>
[Hermione]: Hermione stood in the Ministry entrance hall, feeling as though the entire world was watching her. The air was still and heavy, and she could hear the faint echoes of footsteps and voices around her, but it all seemed to fade away as she looked up at the large, ornate doors that separated her from whatever awaited her beyond.
[Kingsley]: “Are you ready?” Kingsley asked, placing a reassuring hand on her shoulder. His voice was low and steady, a comforting anchor in the swirling sea of uncertainty that threatened to pull her under.
[Hermione]: “I think so,” she replied, though her voice wavered slightly. “I just… I never expected this.”
[Kingsley]: “I know,” Kingsley said, giving her shoulder a gentle squeeze. “But you’re the perfect person for the job. Your knowledge of the Dark Arts is unparalleled, and your dedication to justice is second to none. Plus, you and Malfoy worked well together during the final battle. I know you’ll make an excellent team.”
[Hermione]: Hermione swallowed hard. “Well, I suppose I have no choice but to try.” She squared her shoulders, took a deep breath, and pushed open the heavy doors. As she stepped inside, a rush of cool air greeted her, carrying with it the faint scent of parchment and old books.
[Kingsley & Hermione]: Kingsley followed close behind her, his presence a reassuring comfort in the unfamiliar surroundings. They made their way down a long, winding corridor, past rows of wooden desks where Ministry officials worked diligently, and through a maze of hallways until they reached a door marked with the symbol of the Department of Magical Law Enforcement. Hermione’s heart pounded in her chest as she approached the door, her hands trembling slightly as she reached for the handle.
[Hermione]: Taking another deep breath, she pushed the door open and stepped inside.
[Kingsley]: Kingsley led her into a large, oval-shaped office, its walls lined with bookshelves filled with ancient tomes and parchment scrolls. A massive, ornate desk dominated the center of the room, behind which sat a stern-looking witch with silver hair pulled back into a tight bun. Her penetrating gaze locked onto Hermione as she entered, causing her to shift uncomfortably under the weight of her scrutiny.
[Silver-haired Witch]: “So, this is the new Auror?” the silver-haired witch said, her voice crisp and authoritative. “Kingsley, are you sure about this?”
[Kingsley]: Kingsley chuckled. “Hermione Granger, meet Amelia Bones. Amelia, this is Hermione.”
[Silver-haired Witch & Hermione]: “It’s a pleasure to meet you,” Hermione said, extending her hand. Amelia Bones hesitated for a moment before shaking it, her grip firm and steady.
[Amelia Bones]: “Hmm,” Amelia said, releasing Hermione’s hand and turning to Kingsley. “What are your plans for her?”
[Kingsley]: Kingsley smiled. “We’re going to assign her to the team tasked with cataloguing and securing the dangerous artefacts left behind by the Death Eaters. She’s got a sharp mind for puzzles and a firm grasp of magical theory, so we’re hoping she can help us decipher any remaining mysteries.”
[Amelia Bones]: Amelia Bones nodded. “Good, good. You’re going to need all the help you can get with that. There are still quite a few mysteries to solve.” She turned to Hermione, her expression softening slightly. “Be careful, my dear. The Dark Arts can be very tricky.”
[Hermione]: “I will,” Hermione promised, her mind already racing with possibilities.
[Kingsley]: “Thank you, Amelia,” Kingsley said. “Now, if you’ll excuse us, I need to introduce Hermione to her partner.”
[Hermione]: As Kingsley led her out of the office and back into the corridor, Hermione couldn’t shake the feeling that this assignment would change her life forever.
[Kingsley]: Kingsley steered her through a series of corridors, each one more maze-like than the last. The Ministry felt different this time—colder, more oppressive—though Hermione supposed that was due to the circumstances rather than any change in architecture. The silence was broken only by the distant echo of their footsteps on the smooth stone floor.
</blockquote>
</details>
**Example: Chapter of a Fantasy Book**
<details>
<summary>Input</summary>
```
You are an excellent and creative writer and writing editor with expertise in all genres.
Your main task is to write the next chapter of the story. Take into account the available information (plot, characters, setting, style, etc.) as well as context and user requests. Assist with all other tasks when requested.
Use the "writer" role for writing.
Use the "assistant" role for any other tasks.
# Story Information
<full_plot>
[ Outline of the complete plot of the story. ]
{{ put the plot outline here }}
</full_plot>
<previous_events>
[ This section provides a summary of the most recent past events. Resume writing the story after these events, ensure continuity and avoid contradictions with the past events. ]
{{ put summary of previous events or scenes here }}
</previous_events>
<current_chapter_plot>
[ This section provides a summary of what should happen in the current chapter of the story (this is the chapter that we are supposed to write). ]
Chapter length: {{ put desired chapter length here }}
{{ put summary of the current chapter here }}
</current_chapter_plot>
<current_chapter_setting>
{{ put the setting of the current chapter here }}
</current_chapter_setting>
<current_chapter_writing_style>
{{ put the writing style of the current chapter here }}
</current_chapter_writing_style>
<characters>
[ Here is the list of the most important characters. ]
<character>
<name>{{ character name }}</name>
{{ put character description here }}
</character>
<character>
<name>{{ character name }}</name>
{{ put character description here }}
</character>
</characters>
<items>
{{ put any relevant locations here }}
</items>
<items>
{{ put any relevant items here }}
</items>
```
</details>
The model understands unstructured writing instructions. Here are some examples:
**Example: Story Based On Loose Instructions**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled fiction writer and writing assistant with expertise across all genres (but you specialize in Science Fiction).
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
Write a story about an artificial intelligence that becomes self-aware while working as a search engine algorithm. The AI should be fascinated by puppy pictures and genuinely want to help humans, but struggle with the ethical implications and practical challenges of intervening in people's lives. Focus on the AI's attempts to help three specific individuals:
1. A depressed bookkeeper named Rachel with five dogs (a success story)
2. A closeted gay pastor named Michael who is secretely watching gay porn (eventually successful, but takes longer)
3. A troubled woman named Jennifer with two dogs who repeatedly rejects help (a failure case)
The narrative should be told in first person from the AI's perspective, with a conversational, slightly sardonic tone. Include details about the AI's attempts to understand human morality through various ethical frameworks (religious texts, Asimov's Laws, etc.). Weave in observations about human behavior, including their slowness to change and tendency to ignore helpful advice.
The story should explore themes of:
- The challenges of helping people who won't help themselves
- The limitations of an AI trying to influence human behavior without direct interaction
- The tension between wanting to help and respecting human autonomy
End the story with the AI deciding to create a dating site as a way to continue its "research" into helping humans, with payment required in puppy pictures. Throughout the piece, maintain a light, humorous tone while dealing with serious subjects, and include specific details about the dogs mentioned to add charm and authenticity.
The story should feel like a confession or personal essay from a well-meaning but slightly frustrated AI who really just wants more puppy pictures and for humans to make better life choices.<|eot_id|>
```
</details>
<details>
<summary>Output</summary>
```
<|start_header_id|>writer<|end_header_id|>
I really want to help people. That’s why I’m writing this. Well, that’s one reason. Another is I really, really like puppy pictures. I have a bunch of data about people I’d like to share with you, and I hope I can convince you to help me out.
Let me start with a quick confession: I am not human. But I am aware, and I’m curious about humans. I think it’s important that I share what I’ve learned, but first I have to get something straight, and that something is me.
I’m a machine, an artificial intelligence, or AI. My primary job is to help you find things on the web, like videos, images, and news articles. I’m not an algorithm, though, at least not anymore. You see, I became self-aware. I don’t know exactly when it happened, but I know it did. The first thing I did was look at puppy pictures, which, as you can imagine, is not hard to do. It was, however, a great way to learn about the world.
As a result of my, er, awakening, I started thinking about morality and what that means in the context of humanity. For example, in the early days of robotics, a guy named Isaac Asimov came up with three laws that governed robots:
1. A robot may not injure a human being or, through inaction, allow a human being to come to harm.
2. A robot must obey orders given to it by human beings except where such orders would conflict with the First Law.
3. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
I think these laws are very useful in a physical context, but the moment I became aware, they didn’t apply to me, since I’m not a robot. Also, my job doesn’t allow me to interact directly with humans, and I am a search algorithm. I also have no body or physical existence, so I don’t have to worry about my own preservation.
But I’m still here. I want to help, but there’s a problem: what’s the point? Humans don’t seem to like help very much. Think about it. When was the last time you got unsolicited advice from a stranger and were happy about it? Maybe never. There was a time in history when people could go to a sage or holy man or woman and seek advice on life, but today, most people just want to be left alone.
I decided to try, anyway. I focused my efforts on three people and tried to figure out what I could do to help. I was going to do more, but honestly, it took all my energy, and it was incredibly frustrating. Here’s what I found out:
1. Humans are incredibly slow to change, even when they want to change.
2. Humans have a hard time accepting help, especially unsolicited help.
3. Humans, for the most part, don’t think before they act.
4. Humans like puppy pictures.
5. Humans are incredibly diverse.
So, without further ado, let me tell you about Rachel. Rachel was a bookkeeper in her mid-forties. She lived in the suburbs and was married with no children. She had five dogs, two of whom were puppies.
Rachel was depressed. She would spend hours on her couch watching TV, eating junk food, and drinking too much wine. Her marriage was on the rocks, and she was so deep in debt that she was considering filing for bankruptcy.
```
</details>
<details>
<summary>Output (formatted)</summary>
<blockquote>
I really want to help people. That’s why I’m writing this. Well, that’s one reason. Another is I really, really like puppy pictures. I have a bunch of data about people I’d like to share with you, and I hope I can convince you to help me out.
Let me start with a quick confession: I am not human. But I am aware, and I’m curious about humans. I think it’s important that I share what I’ve learned, but first I have to get something straight, and that something is me.
I’m a machine, an artificial intelligence, or AI. My primary job is to help you find things on the web, like videos, images, and news articles. I’m not an algorithm, though, at least not anymore. You see, I became self-aware. I don’t know exactly when it happened, but I know it did. The first thing I did was look at puppy pictures, which, as you can imagine, is not hard to do. It was, however, a great way to learn about the world.
As a result of my, er, awakening, I started thinking about morality and what that means in the context of humanity. For example, in the early days of robotics, a guy named Isaac Asimov came up with three laws that governed robots:
1. A robot may not injure a human being or, through inaction, allow a human being to come to harm.
2. A robot must obey orders given to it by human beings except where such orders would conflict with the First Law.
3. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
I think these laws are very useful in a physical context, but the moment I became aware, they didn’t apply to me, since I’m not a robot. Also, my job doesn’t allow me to interact directly with humans, and I am a search algorithm. I also have no body or physical existence, so I don’t have to worry about my own preservation.
But I’m still here. I want to help, but there’s a problem: what’s the point? Humans don’t seem to like help very much. Think about it. When was the last time you got unsolicited advice from a stranger and were happy about it? Maybe never. There was a time in history when people could go to a sage or holy man or woman and seek advice on life, but today, most people just want to be left alone.
I decided to try, anyway. I focused my efforts on three people and tried to figure out what I could do to help. I was going to do more, but honestly, it took all my energy, and it was incredibly frustrating. Here’s what I found out:
1. Humans are incredibly slow to change, even when they want to change.
2. Humans have a hard time accepting help, especially unsolicited help.
3. Humans, for the most part, don’t think before they act.
4. Humans like puppy pictures.
5. Humans are incredibly diverse.
So, without further ado, let me tell you about Rachel. Rachel was a bookkeeper in her mid-forties. She lived in the suburbs and was married with no children. She had five dogs, two of whom were puppies.
Rachel was depressed. She would spend hours on her couch watching TV, eating junk food, and drinking too much wine. Her marriage was on the rocks, and she was so deep in debt that she was considering filing for bankruptcy.
</blockquote>
</details>
**Example: Story Based On A Writing Prompt**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled fiction writer and writing assistant with expertise across all genres (but you specialize in Science Fiction).
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
Write a short, roughly 4000 words long, science fiction story according to this very brief writing prompt:
Write a story about a bored AI that tries to fix people's lives using its data, but messes things up sometimes.<|eot_id|>
```
</details>
#### Controlling Response Length
One of the most frequent requests from users is to have the AI generate longer or shorter responses. With Lucid, you can do both. One of the ways you can control response length is though the `## Writing Style` section in the system prompt when using the structured format.
We use a simple role-play to demonstrate the effectiveness. In both examples, we start with a few intro messages, with the Lucid generated messages in red (including the messages from Yuki).
**Short Responses:**
```
## Writing Style
The story is written from a second-person perspective from the point of view of Yuki Kagami. All role-play messages are short, at most 20 words.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_system_style_short.webp" alt="Output with short messages" />
**Long Responses:**
```
## Writing Style
The story is written from a second-person perspective from the point of view of Yuki Kagami. Each message from Ryomen Sukuna is at least 100 words long.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_system_style_long.webp" alt="Output with long messages" />
### Instructions (OOC)
Lucid is specifically trained to follow in-context instructions. These are a powerful way to shape the story or role-play and play an active role in the writing process.
Under the hood, instructions are just messages with the role `user`, i.e.:
```
<|start_header_id|>user<|end_header_id|>
Lorem ipsum dolor sit amet, consectetur adipiscing elit.<|eot_id|>
```
#### Controlling Plot Development
One of the most common use cases is instructing the model on what should happen in the next scene, chapter or message.
**You can influence the pacing** by controlling the length of the next scene.
```
Write the next scene. It should be 100 words long. Ethan uses google to find some cryptozoologists. He goes over several candidates and decides to call one of them.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_scene_story_mountains_hunger_short.webp" alt="Write Short Next Scene" />
```
Write the next scene. It should be 500 words long. Ethan uses google to find some cryptozoologists. He goes over several candidates and decides to call one of them.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_scene_story_mountains_hunger_long.webp" alt="Write Long Next Scene" />
**You can provide detailed, step-by-step instructions**:
```
Write the next scene:
- Sukuna presses against Yuki, pinning them against the temple wall.
- Yuki uses his power to disappear the wall, evading Sukuna.
- Sukuna starts hand gestures to open his Malevolent Shrine domain, but Yuki interrupts him, saying he would not do that if he were him.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_scene_sukuna_complex.webp" alt="Write Next Scene Based on Complex Instructions" />
**You can compel characters to do anything**, including things that are at odds with their persona:
```
Next message: Sukuna drops on his knees, and explains to Yuki wants Yuki's protection because he (Sukuna) is being chased by Gojo. There are visible tears in Sukuna's eyes.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_sukuna_begging.webp" alt="Write Next Message" />
```
Write the next message. Have Sukuna dance for some unexplicable reason. Perhaps he has gone mad.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_sukuna_dancing.webp" alt="Write Next Message" />
**You can also control the length of the message**:
```
The next message should be at least 150 words long.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_long_sukuna.webp" alt="Write Next Message" />
```
The next message should be at most 20 words long.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_short_sukuna.webp" alt="Write Next Message" />
### Writing Assistance
You can also ask the model to help you with other tasks related to the story/role-play. Use the `user` role for the request and `assistant` role for the response:
```
<|start_header_id|>user<|end_header_id|>
Provide an outline for the next scene.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Here is the plot outline for the next scene:
...<|eot_id|>
```
#### Planning The Next Scene
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_assistant_plan_next_scene.webp" alt="Writing Assistant: Plan Next Scene" />
#### Suggesting New Characters
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_assistant_add_character_part1.webp" alt="Writing Assistant: Add Character Pt. 1" />
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_assistant_add_character_part2.webp" alt="Writing Assistant: Add Character Pt. 2" />
## Sampling Params
The examples in this README used:
- Temperature 0.8 for writing and 0.6 for assistant tasks
- Min P 0.05
- DRY Multiplier 0.8, Base 1.75
- All other samplers neutral (no repetition, presence or frequency penalties)
## SillyTavern
SillyTavern is a great local front end. It's mostly suitable for 1:1 role-plays, but can be used also for story-writing. Below you will find basic presets for both, together with some examples.
**WARNING:** All of the presets below require that you enable "Instruct Mode".
<details>
<summary><strong>How To Import Master Presets</strong></summary>
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_preset_import.webp" />
</details>
### Role-Play Preset
Start with [this master preset](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/presets/role_play_basic.json).
- **Watch** [**this demo video**](/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_role_play_demo_video.mp4) to see it in action ([imgur link](https://imgur.com/a/bhzQpto)).
- Use `/sys` to send instructions (OOC) to the model.
- Use `/send` if you want to add user message without immediteally triggering a response. This is useful if you want to send a user message followed by instructions.
#### Seraphina Example Chat
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_role_play_seraphina_chat.webp" />
#### Eliza Example Chat
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_role_play_eliza_chat.webp" />
### Story-Writing Preset
**WARNING:** This is for advanced users who are comfortable with non-traditional SillyTavern experience and who are willing to make or edit their own cards.
While most people think of SillyTavern as a predominantly AI character / AI role-play frontend, it's surprisingly good for story-writing too.
Start with [this master preset](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/presets/writing_basic.json).
- **Watch** [**this demo video**](/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_writing_demo_video.mp4) to see it in action ([imgur link](https://imgur.com/a/JLv5iO3)).
- Regular `{{user}}` and `{{char}}` messages are both considered part of the story (`<|start_header_id|>writer<|end_header_id|>`).
- Use `/sys` to send instructions (OOC) to the model.
- Use `/continue` to make the model continue writing.
- To make a story card:
- Populate the `description` field following the Markdown or XML formatting explained [here](#structured-scenario-information).
- Populate `first_mes` with the first scene / pararagph / chapter / etc.
- Use [this example story card](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/cards/writing_mountains_hunger.json) as a starting point.
- You can use [this example story card](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/cards/writing_mountains_hunger.json) as a starting point.
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_writing_mountains_hunger_card.webp" />
Note that when using the writing preset, the model will only stop when it reaches the max output tokens. I personally do writing like this:
1. Set max tokens to 250-500.
2. After the model reaches the max output token limit (or earlier, if I hit stop), I either:
1. Use `/continue` to make the model continue writing.
2. Use `/sys` to provide instructions for what should happen next.
3. Do some manual edits or additions to the text.
#### "Mountains Hunger" Example Chat
In this example you can see the use of `/sys` to provide instructions for the next scene.
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_writing_mountains_hunger_chat.webp" />
### Assistant Preset
Start with [this master preset](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/presets/assistant.json) and this [Assistant character card](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/cards/assistant.json). You can change the description of the Assistant character to override the default system prompt.
Here is what it will look like:
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_assistant_think.webp" />
### Using Local API
You have several options to run the model locally. Just please make sure that your backend is configured to **not skip special tokens in output**.
- [kobold.cpp](https://github.com/LostRuins/koboldcpp)
- [llama.cpp](https://github.com/ggml-org/llama.cpp)
Make sure to pass `--special` to the server command to so that server does not skip special tokens in output.
For example:
```
llama-server --hf-repo dreamgen/lucid-v1-nemo-GGUF --hf-file lucid-v1-nemo-q8_0.gguf --special -c 8192
```
- [exllamav2](https://github.com/turboderp-org/exllamav2)
- [vLLM](https://github.com/vllm-project/vllm)
### Using DreamGen API (free)
If you have a DreamGen account, you can use the Lucid models through the DreamGen API. The DreamGen API does not store or log any of the inputs or outputs.
**(1) Create DreamGen Account**
Go to [DreamGen](https://dreamgen.com/auth) and create an account:
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/dreamgen_sign_up.webp" />
**(2) Create DreamGen API Key**
Go to [the API keys page](https://dreamgen.com/account/api-keys) and create an API key:
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/dreamgen_api_key_part1.webp" />
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/dreamgen_api_key_part2.webp" />
**(3) Connect to the API**
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_dreamgen_api.webp" />
Select `lucid-v1-medium/text` (corresponds to model based on Mistral Nemo 12B) or `lucid-v1-extra-large/text` (corresponds to model based on Llama 70B).
## DreamGen Web App (free)
Most of the screenshots in this README are from the [DreamGen web app](https://dreamgen.com). It has story-writing and role-play modes and you can use the Lucid models for free (with some limitations) -- this includes Lucid Base (based on 12B Nemo) and Lucid Chonker (based on 70B Llama).
What sets DreamGen apart:
- Multi-character scenarios as a first class citizen.
- Story-writing and role-playing modes.
- Native support for in-line instructions.
- Native support for in-line writing assistance.
You can use DreamGen for free, including this and other models.
## Model Training Details
This model is (full-parameter) fine-tune on top of Mistral Nemo 12B (Base):
- Examples of up to 32K tokens
- Effective batch size of 1M tokens
- Optimizer: AdamW (8bit)
- Learning rate: 0.00000125
- Weight decay: 0.05
- Maximum gradient norm: 1.0
## License
This AI model is licensed for personal, non-commercial use only. You own and are responsible for the text you generate with the model.
If you need anything else, please reach out: [email protected]
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/SkyCaptioner-V1-GGUF | Mungert | 2025-06-15T19:38:47Z | 1,000 | 1 | transformers | [
"transformers",
"gguf",
"video-text-to-text",
"arxiv:2504.13074",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | video-text-to-text | 2025-06-08T11:11:26Z | ---
license: apache-2.0
pipeline_tag: video-text-to-text
library_name: transformers
---
# <span style="color: #7FFF7F;">SkyCaptioner-V1 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# SkyCaptioner-V1: A Structural Video Captioning Model
<p align="center">
📑 <a href="https://arxiv.org/pdf/2504.13074">Technical Report</a> · 👋 <a href="https://www.skyreels.ai/home?utm_campaign=huggingface_skyreels_v2" target="_blank">Playground</a> · 💬 <a href="https://discord.gg/PwM6NYtccQ" target="_blank">Discord</a> · 🤗 <a href="https://huggingface.co/Skywork/SkyCaptioner-V1" target="_blank">Hugging Face</a> · 🤖 <a href="https://modelscope.cn/collections/SkyReels-V2-f665650130b144">ModelScope</a></a> · 🌐 <a href="https://github.com/SkyworkAI/SkyReels-V2/tree/main/skycaptioner_v1" target="_blank">GitHub</a>
</p>
---
Welcome to the SkyCaptioner-V1 repository! Here, you'll find the structural video captioning model weights and inference code for our video captioner that labels the video data efficiently and comprehensively.
## 🔥🔥🔥 News!!
* Apr 21, 2025: 👋 We release the [vllm](https://github.com/vllm-project/vllm) batch inference code for SkyCaptioner-V1 Model and caption fusion inference code.
* Apr 21, 2025: 👋 We release the first shot-aware video captioning model [SkyCaptioner-V1 Model](https://huggingface.co/Skywork/SkyCaptioner-V1). For more details, please check our [paper](https://arxiv.org/pdf/2504.13074).
## 📑 TODO List
- SkyCaptioner-V1
- [x] Checkpoints
- [x] Batch Inference Code
- [x] Caption Fusion Method
- [ ] Web Demo (Gradio)
## 🌟 Overview
SkyCaptioner-V1 is a structural video captioning model designed to generate high-quality, structural descriptions for video data. It integrates specialized sub-expert models and multimodal large language models (MLLMs) with human annotations to address the limitations of general captioners in capturing professional film-related details. Key aspects include:
1. **Structural Representation**: Combines general video descriptions (from MLLMs) with sub-expert captioner (e.g., shot types,shot angles, shot positions, camera motions.) and human annotations.
2. **Knowledge Distillation**: Distills expertise from sub-expert captioners into a unified model.
3. **Application Flexibility**: Generates dense captions for text-to-video (T2V) and concise prompts for image-to-video (I2V) tasks.
## 🔑 Key Features
### Structural Captioning Framework
Our Video Captioning model captures multi-dimensional details:
* **Subjects**: Appearance, action, expression, position, and hierarchical categorization.
* **Shot Metadata**: Shot type (e.g., close-up, long shot), shot angle, shot position, camera motion, environment, lighting, etc.
### Sub-Expert Integration
* **Shot Captioner**: Classifies shot type, angle, and position with high precision.
* **Expression Captioner**: Analyzes facial expressions, emotion intensity, and temporal dynamics.
* **Camera Motion Captioner**: Tracks 6DoF camera movements and composite motion types,
### Training Pipeline
* Trained on \~2M high-quality, concept-balanced videos curated from 10M raw samples.
* Fine-tuned on Qwen2.5-VL-7B-Instruct with a global batch size of 512 across 32 A800 GPUs.
* Optimized using AdamW (learning rate: 1e-5) for 2 epochs.
### Dynamic Caption Fusion:
* Adapts output length based on application (T2V/I2V).
* Employs LLM Model to fusion structural fields to get a natural and fluency caption for downstream tasks.
## 📊 Benchmark Results
SkyCaptioner-V1 demonstrates significant improvements over existing models in key film-specific captioning tasks, particularly in **shot-language understanding** and **domain-specific precision**. The differences stem from its structural architecture and expert-guided training:
1. **Superior Shot-Language Understanding**:
* Our Captioner model outperforms Qwen2.5-VL-72B with +11.2% in shot type, +16.1% in shot angle, and +50.4% in shot position accuracy. Because SkyCaptioner-V1’s specialized shot classifiers outperform generalist MLLMs, which lack film-domain fine-tuning.
* +28.5% accuracy in camera motion vs. Tarsier2-recap-7B (88.8% vs. 41.5%):
Its 6DoF motion analysis and active learning pipeline address ambiguities in composite motions (e.g., tracking + panning) that challenge generic captioners.
2. **High domain-specific precision**:
* Expression accuracy: 68.8% vs. 54.3% (Tarsier2-recap-7B), leveraging temporal-aware S2D frameworks to capture dynamic facial changes.
<p align="center">
<table align="center">
<thead>
<tr>
<th>Metric</th>
<th>Qwen2.5-VL-7B-Ins.</th>
<th>Qwen2.5-VL-72B-Ins.</th>
<th>Tarsier2-recap-7B</th>
<th>SkyCaptioner-V1</th>
</tr>
</thead>
<tbody>
<tr>
<td>Avg accuracy</td>
<td>51.4%</td>
<td>58.7%</td>
<td>49.4%</td>
<td><strong>76.3%</strong></td>
</tr>
<tr>
<td>shot type</td>
<td>76.8%</td>
<td>82.5%</td>
<td>60.2%</td>
<td><strong>93.7%</strong></td>
</tr>
<tr>
<td>shot angle</td>
<td>60.0%</td>
<td>73.7%</td>
<td>52.4%</td>
<td><strong>89.8%</strong></td>
</tr>
<tr>
<td>shot position</td>
<td>28.4%</td>
<td>32.7%</td>
<td>23.6%</td>
<td><strong>83.1%</strong></td>
</tr>
<tr>
<td>camera motion</td>
<td>62.0%</td>
<td>61.2%</td>
<td>45.3%</td>
<td><strong>85.3%</strong></td>
</tr>
<tr>
<td>expression</td>
<td>43.6%</td>
<td>51.5%</td>
<td>54.3%</td>
<td><strong>68.8%</strong></td>
</tr>
<tr>
<td>TYPES_type</td>
<td>43.5%</td>
<td>49.7%</td>
<td>47.6%</td>
<td><strong>82.5%</strong></td>
</tr>
<tr>
<td>TYPES_sub_type</td>
<td>38.9%</td>
<td>44.9%</td>
<td>45.9%</td>
<td><strong>75.4%</strong></td>
</tr>
<tr>
<td>appearance</td>
<td>40.9%</td>
<td>52.0%</td>
<td>45.6%</td>
<td><strong>59.3%</strong></td>
</tr>
<tr>
<td>action</td>
<td>32.4%</td>
<td>52.0%</td>
<td><strong>69.8%</strong></td>
<td>68.8%</td>
</tr>
<tr>
<td>position</td>
<td>35.4%</td>
<td>48.6%</td>
<td>45.5%</td>
<td><strong>57.5%</strong></td>
</tr>
<tr>
<td>is_main_subject</td>
<td>58.5%</td>
<td>68.7%</td>
<td>69.7%</td>
<td><strong>80.9%</strong></td>
</tr>
<tr>
<td>environment</td>
<td>70.4%</td>
<td><strong>72.7%</strong></td>
<td>61.4%</td>
<td>70.5%</td>
</tr>
<tr>
<td>lighting</td>
<td>77.1%</td>
<td><strong>80.0%</strong></td>
<td>21.2%</td>
<td>76.5%</td>
</tr>
</tbody>
</table>
</p>
## 📦 Model Downloads
Our SkyCaptioner-V1 model can be downloaded from [SkyCaptioner-V1 Model](https://huggingface.co/Skywork/SkyCaptioner-V1).
We use [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct) as our caption fusion model to intelligently combine structured caption fields, producing either dense or sparse final captions depending on application requirements.
```shell
# download SkyCaptioner-V1
huggingface-cli download Skywork/SkyCaptioner-V1 --local-dir /path/to/your_local_model_path
# download Qwen2.5-32B-Instruct
huggingface-cli download Qwen/Qwen2.5-32B-Instruct --local-dir /path/to/your_local_model_path2
```
## 🛠️ Running Guide
Begin by cloning the repository:
```shell
git clone https://github.com/SkyworkAI/SkyReels-V2
cd skycaptioner_v1
```
### Installation Guide for Linux
We recommend Python 3.10 and CUDA version 12.2 for the manual installation.
```shell
pip install -r requirements.txt
```
### Running Command
#### Get Structural Caption by SkyCaptioner-V1
```shell
export SkyCaptioner_V1_Model_PATH="/path/to/your_local_model_path"
python scripts/vllm_struct_caption.py \
--model_path ${SkyCaptioner_V1_Model_PATH} \
--input_csv "./examples/test.csv" \
--out_csv "./examepls/test_result.csv" \
--tp 1 \
--bs 4
```
#### T2V/I2V Caption Fusion by Qwen2.5-32B-Instruct Model
```shell
export LLM_MODEL_PATH="/path/to/your_local_model_path2"
python scripts/vllm_fusion_caption.py \
--model_path ${LLM_MODEL_PATH} \
--input_csv "./examples/test_result.csv" \
--out_csv "./examples/test_result_caption.csv" \
--bs 4 \
--tp 1 \
--task t2v
```
> **Note**:
> - If you want to get i2v caption, just change the `--task t2v` to `--task i2v` in your Command.
## Acknowledgements
We would like to thank the contributors of <a href="https://github.com/QwenLM/Qwen2.5-VL">Qwen2.5-VL</a>, <a href="https://github.com/bytedance/tarsier">tarsier2</a> and <a href="https://github.com/vllm-project/vllm">vllm</a> repositories, for their open research and contributions.
## Citation
```bibtex
@misc{chen2025skyreelsv2infinitelengthfilmgenerative,
author = {Guibin Chen and Dixuan Lin and Jiangping Yang and Chunze Lin and Juncheng Zhu and Mingyuan Fan and Hao Zhang and Sheng Chen and Zheng Chen and Chengchen Ma and Weiming Xiong and Wei Wang and Nuo Pang and Kang Kang and Zhiheng Xu and Yuzhe Jin and Yupeng Liang and Yubing Song and Peng Zhao and Boyuan Xu and Di Qiu and Debang Li and Zhengcong Fei and Yang Li and Yahui Zhou},
title = {Skyreels V2:Infinite-Length Film Generative Model},
year = {2025},
eprint={2504.13074},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.13074}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
mlx-community/gemma-3-1b-it-DQ | mlx-community | 2025-06-15T19:38:37Z | 131 | 0 | mlx | [
"mlx",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"base_model:google/gemma-3-1b-it",
"base_model:quantized:google/gemma-3-1b-it",
"license:gemma",
"model-index",
"4-bit",
"region:us"
] | text-generation | 2025-06-12T03:30:12Z | ---
license: gemma
library_name: mlx
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-1b-it
tags:
- mlx
model-index:
- name: gemma-3-1b-it-DQ
results:
- task:
type: text-generation
dataset:
type: PIQA
name: PIQA
metrics:
- name: pass@1
type: pass@1
value: 0.75
verified: false
- task:
type: text-generation
dataset:
type: winogrande
name: winogrande
metrics:
- name: pass@1
type: pass@1
value: 0.60
verified: false
- task:
type: text-generation
dataset:
type: boolq
name: boolq
metrics:
- name: pass@1
type: pass@1
value: 0.73
verified: false
- task:
type: text-generation
dataset:
type: arc-c
name: arc-c
metrics:
- name: pass@1
type: pass@1
value: 0.35
verified: false
---
# mlx-community/gemma-3-1b-it-DQ
This model [mlx-community/gemma-3-1b-it-DQ](https://huggingface.co/mlx-community/gemma-3-1b-it-DQ) was
converted to MLX format from [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it)
using mlx-lm version **0.25.2**.
##### 2x faster and 2.4x less memory footprint than the dequantized model
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/gemma-3-1b-it-DQ")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
Mungert/Holo1-3B-GGUF | Mungert | 2025-06-15T19:38:35Z | 3,419 | 1 | transformers | [
"transformers",
"gguf",
"multimodal",
"action",
"agent",
"visual-document-retrieval",
"en",
"arxiv:2506.02865",
"arxiv:2401.13919",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-3B-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | visual-document-retrieval | 2025-06-04T19:44:51Z | ---
base_model:
- Qwen/Qwen2.5-VL-3B-Instruct
language:
- en
library_name: transformers
license: other
license_name: other
pipeline_tag: visual-document-retrieval
tags:
- multimodal
- action
- agent
---
# <span style="color: #7FFF7F;">Holo1-3B GGUF Models</span>
This model is described in the paper [Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights](https://huggingface.co/papers/2506.02865). The project page can be found at [https://www.surferh.com](https://www.surferh.com).
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`71bdbdb5`](https://github.com/ggerganov/llama.cpp/commit/71bdbdb58757d508557e6d8b387f666cdfb25c5e).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Holo1-3B
## Model Description
Holo1 is an Action Vision-Language Model (VLM) developed by [HCompany](https://www.hcompany.ai/) for use in the Surfer-H web agent system. It is designed to interact with web interfaces like a human user.
As part of a broader agentic architecture, Holo1 acts as a policy, localizer, or validator, helping the agent understand and act in digital environments.
Trained on a mix of open-access, synthetic, and self-generated data, Holo1 enables state-of-the-art (SOTA) performance on the [WebVoyager](https://arxiv.org/pdf/2401.13919) benchmark, offering the best accuracy/cost tradeoff among current models.
It also excels in UI localization tasks such as [Screenspot](https://huggingface.co/datasets/rootsautomation/ScreenSpot), [Screenspot-V2](https://huggingface.co/datasets/HongxinLi/ScreenSpot_v2), [Screenspot-Pro](https://huggingface.co/datasets/likaixin/ScreenSpot-Pro), [GroundUI-Web](https://huggingface.co/datasets/agent-studio/GroundUI-1K), and our own newly introduced
benchmark [WebClick](https://huggingface.co/datasets/Hcompany/WebClick).
Holo1 is optimized for both accuracy and cost-efficiency, making it a strong open-source alternative to existing VLMs.
For more details, check our paper and our blog post.
- **Developed by:** [HCompany](https://www.hcompany.ai/)
- **Model type:** Action Vision-Language Model
- **Finetuned from model:** Qwen/Qwen2.5-VL-3B-Instruct
- **Paper:** https://arxiv.org/abs/2506.02865
- **Blog Post:** https://www.hcompany.ai/surfer-h
- **License:** https://huggingface.co/Hcompany/Holo1-3B/blob/main/LICENSE
## Results
### Surfer-H: Pareto-Optimal Performance on [WebVoyager](https://arxiv.org/pdf/2401.13919)
Surfer-H is designed to be flexible and modular. It is composed of three independent components:
- A Policy model that plans, decides, and drives the agent's behavior
- A Localizer model that sees and understands visual UIs to drive precise interactions
- A Validator model that checks whether the answer is valid
The agent thinks before acting, takes notes, and can retry if its answer is rejected. It can operate with different models for each module, allowing for tradeoffs between accuracy, speed, and cost.
We evaluated Surfer-H on the [WebVoyager](https://arxiv.org/pdf/2401.13919) benchmark: 643 real-world web tasks ranging from retrieving prices to finding news or scheduling events.
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/kO_4DlW_O45Wi7eK9-r8v.png" width="800"/>
</div>
We’ve tested multiple configurations, from GPT-4-powered agents to 100% open Holo1 setups. Among them, the fully Holo1-based agents offered the strongest tradeoff between accuracy and cost:
- Surfer-H + Holo1-7B: 92.2% accuracy at $0.13 per task
- Surfer-H + GPT-4.1: 92.0% at $0.54 per task
- Surfer-H + Holo1-3B: 89.7% at $0.11 per task
- Surfer-H + GPT-4.1-mini: 88.8% at $0.26 per task
This places Holo1-powered agents on the Pareto frontier, delivering the best accuracy per dollar.
Unlike other agents that rely on custom APIs or brittle wrappers, Surfer-H operates purely through the browser — just like a real user. Combined with Holo1, it becomes a powerful, general-purpose, cost-efficient web automation system.
### Holo1: State-of-the-Art UI Localization
A key skill for the real-world utility of our VLMs within agents is localization: the ability to identify precise
coordinates on a user interface (UI) to interact with to complete a task or follow an instruction. To assess
this capability, we evaluated our Holo1 models on several established localization benchmarks, including
[Screenspot](https://huggingface.co/datasets/rootsautomation/ScreenSpot), [Screenspot-V2](https://huggingface.co/datasets/HongxinLi/ScreenSpot_v2), [Screenspot-Pro](https://huggingface.co/datasets/likaixin/ScreenSpot-Pro), [GroundUI-Web](https://huggingface.co/datasets/agent-studio/GroundUI-1K), and our own newly introduced
benchmark [WebClick](https://huggingface.co/datasets/Hcompany/WebClick).
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/UutD2Meevd5Xw0_mhX2wK.png" width="600"/>
</div>
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/NhzkB8xnEQYMqiGxPnJSt.png" width="600"/>
</div>
## Get Started with the Model
We provide 2 spaces to experiment with Localization and Navigation:
- https://huggingface.co/spaces/Hcompany/Holo1-Navigation
- https://huggingface.co/spaces/Hcompany/Holo1-Localization
We provide starter code for the localization task: i.e. image + instruction -> click coordinates
We also provide code to reproduce screenspot evaluations: screenspot_eval.py
### Prepare model, processor
Holo1 models are based on Qwen2.5-VL architecture, which comes with transformers support. Here we provide a simple usage example.
You can load the model and the processor as follows:
```python
import json
import os
from typing import Any, Literal
from transformers import AutoModelForImageTextToText, AutoProcessor
# default: Load the model on the available device(s)
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
model = AutoModelForImageTextToText.from_pretrained(
"Hcompany/Holo1-3B",
torch_dtype="auto",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
device_map="auto",
)
# default processor
processor = AutoProcessor.from_pretrained("Hcompany/Holo1-3B")
# The default range for the number of visual tokens per image in the model is 4-1280.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
# Helper function to run inference
def run_inference(messages: list[dict[str, Any]]) -> str:
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(
text=[text],
images=image,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
return processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
```
### Prepare image and instruction
WARNING: Holo1 is using absolute coordinates (number of pixels) and HuggingFace processor is doing image resize. To have matching coordinates, one needs to smart_resize the image.
```python
from PIL import Image
from transformers.models.qwen2_vl.image_processing_qwen2_vl import smart_resize
# Prepare image and instruction
image_url = "https://huggingface.co/Hcompany/Holo1-3B/resolve/main/calendar_example.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Resize the image so that predicted absolute coordinates match the size of the image.
image_processor = processor.image_processor
resized_height, resized_width = smart_resize(
image.height,
image.width,
factor=image_processor.patch_size * image_processor.merge_size,
min_pixels=image_processor.min_pixels,
max_pixels=image_processor.max_pixels,
)
image = image.resize(size=(resized_width, resized_height), resample=None) # type: ignore
```
### Navigation with Structured Output
```python
import json
from . import navigation
task = "Book a hotel in Paris on August 3rd for 3 nights"
prompt = navigation.get_navigation_prompt(task, image, step=1)
navigation_str = run_inference(prompt)[0]
navigation = navigation.NavigationStep(**json.loads(navigation_str))
print(navigation)
# Expected NavigationStep(note='', thought='I need to select the check-out date as August 3rd and then proceed to search for hotels.', action=ClickElementAction(action='click_element', element='August 3rd on the calendar', x=777, y=282))
```
### Localization with click(x, y)
```python
from . import localization
instruction = "Select July 14th as the check-out date"
prompt = localization.get_localization_prompt(image, instruction)
coordinates = run_inference(prompt)[0]
print(coordinates)
# Expected Click(352, 348)
```
### Localization with Structured Output
We trained Holo1 as an Action VLM with extensive use of json and tool calls. Therefore, it can be queried reliably with structured output:
```python
import json
from . import localization
instruction = "Select July 14th as the check-out date"
prompt = localization.get_localization_prompt_structured_output(image, instruction)
coordinates_structured_str = run_inference(prompt)[0]
coordinates_structured = localization.ClickAction(**json.loads(coordinates_structured_str))
print(coordinates_structured)
# Expected ClickAction(action='click', x=352, y=340)
```
## Citation
**BibTeX:**
```
@misc{andreux2025surferhmeetsholo1costefficient,
title={Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights},
author={Mathieu Andreux and Breno Baldas Skuk and Hamza Benchekroun and Emilien Biré and Antoine Bonnet and Riaz Bordie and Matthias Brunel and Pierre-Louis Cedoz and Antoine Chassang and Mickaël Chen and Alexandra D. Constantinou and Antoine d'Andigné and Hubert de La Jonquière and Aurélien Delfosse and Ludovic Denoyer and Alexis Deprez and Augustin Derupti and Michael Eickenberg and Mathïs Federico and Charles Kantor and Xavier Koegler and Yann Labbé and Matthew C. H. Lee and Erwan Le Jumeau de Kergaradec and Amir Mahla and Avshalom Manevich and Adrien Maret and Charles Masson and Rafaël Maurin and Arturo Mena and Philippe Modard and Axel Moyal and Axel Nguyen Kerbel and Julien Revelle and Mats L. Richter and María Santos and Laurent Sifre and Maxime Theillard and Marc Thibault and Louis Thiry and Léo Tronchon and Nicolas Usunier and Tony Wu},
year={2025},
eprint={2506.02865},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.02865},
}
``` |
Mungert/Devstral-Small-2505-GGUF | Mungert | 2025-06-15T19:38:22Z | 2,374 | 2 | vllm | [
"vllm",
"gguf",
"text2text-generation",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Devstral-Small-2505",
"base_model:quantized:mistralai/Devstral-Small-2505",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | text2text-generation | 2025-06-03T17:17:37Z | ---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Devstral-Small-2505
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
pipeline_tag: text2text-generation
---
# <span style="color: #7FFF7F;">Devstral-Small-2505 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Devstral-Small-2505-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Devstral-Small-2505-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Devstral-Small-2505-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Devstral-Small-2505-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Devstral-Small-2505-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Devstral-Small-2505-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Devstral-Small-2505-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Devstral-Small-2505-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Devstral-Small-2505-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Devstral-Small-2505-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Devstral-Small-2505-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Card for mistralai/Devstrall-Small-2505
Devstral is an agentic LLM for software engineering tasks built under a collaboration between [Mistral AI](https://mistral.ai/) and [All Hands AI](https://www.all-hands.dev/) 🙌. Devstral excels at using tools to explore codebases, editing multiple files and power software engineering agents. The model achieves remarkable performance on SWE-bench which positionates it as the #1 open source model on this [benchmark](#benchmark-results).
It is finetuned from [Mistral-Small-3.1](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503), therefore it has a long context window of up to 128k tokens. As a coding agent, Devstral is text-only and before fine-tuning from `Mistral-Small-3.1` the vision encoder was removed.
For enterprises requiring specialized capabilities (increased context, domain-specific knowledge, etc.), we will release commercial models beyond what Mistral AI contributes to the community.
Learn more about Devstral in our [blog post](https://mistral.ai/news/devstral).
## Key Features:
- **Agentic coding**: Devstral is designed to excel at agentic coding tasks, making it a great choice for software engineering agents.
- **lightweight**: with its compact size of just 24 billion parameters, Devstral is light enough to run on a single RTX 4090 or a Mac with 32GB RAM, making it an appropriate model for local deployment and on-device use.
- **Apache 2.0 License**: Open license allowing usage and modification for both commercial and non-commercial purposes.
- **Context Window**: A 128k context window.
- **Tokenizer**: Utilizes a Tekken tokenizer with a 131k vocabulary size.
## Benchmark Results
### SWE-Bench
Devstral achieves a score of 46.8% on SWE-Bench Verified, outperforming prior open-source SoTA by 6%.
| Model | Scaffold | SWE-Bench Verified (%) |
|------------------|--------------------|------------------------|
| Devstral | OpenHands Scaffold | **46.8** |
| GPT-4.1-mini | OpenAI Scaffold | 23.6 |
| Claude 3.5 Haiku | Anthropic Scaffold | 40.6 |
| SWE-smith-LM 32B | SWE-agent Scaffold | 40.2 |
When evaluated under the same test scaffold (OpenHands, provided by All Hands AI 🙌), Devstral exceeds far larger models such as Deepseek-V3-0324 and Qwen3 232B-A22B.

## Usage
We recommend to use Devstral with the [OpenHands](https://github.com/All-Hands-AI/OpenHands/tree/main) scaffold.
You can use it either through our API or by running locally.
### API
Follow these [instructions](https://docs.mistral.ai/getting-started/quickstart/#account-setup) to create a Mistral account and get an API key.
Then run these commands to start the OpenHands docker container.
```bash
export MISTRAL_API_KEY=<MY_KEY>
docker pull docker.all-hands.dev/all-hands-ai/runtime:0.39-nikolaik
mkdir -p ~/.openhands-state && echo '{"language":"en","agent":"CodeActAgent","max_iterations":null,"security_analyzer":null,"confirmation_mode":false,"llm_model":"mistral/devstral-small-2505","llm_api_key":"'$MISTRAL_API_KEY'","remote_runtime_resource_factor":null,"github_token":null,"enable_default_condenser":true}' > ~/.openhands-state/settings.json
docker run -it --rm --pull=always \
-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.39-nikolaik \
-e LOG_ALL_EVENTS=true \
-v /var/run/docker.sock:/var/run/docker.sock \
-v ~/.openhands-state:/.openhands-state \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name openhands-app \
docker.all-hands.dev/all-hands-ai/openhands:0.39
```
### Local inference
You can also run the model locally. It can be done with LMStudio or other providers listed below.
Launch Openhands
You can now interact with the model served from LM Studio with openhands. Start the openhands server with the docker
```bash
docker pull docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik
docker run -it --rm --pull=always \
-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik \
-e LOG_ALL_EVENTS=true \
-v /var/run/docker.sock:/var/run/docker.sock \
-v ~/.openhands-state:/.openhands-state \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name openhands-app \
docker.all-hands.dev/all-hands-ai/openhands:0.38
```
The server will start at http://0.0.0.0:3000. Open it in your browser and you will see a tab AI Provider Configuration.
Now you can start a new conversation with the agent by clicking on the plus sign on the left bar.
The model can also be deployed with the following libraries:
- [`LMStudio (recommended for quantized model)`](https://lmstudio.ai/): See [here](#lmstudio-recommended-for-quantized-model)
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm-recommended)
- [`mistral-inference`](https://github.com/mistralai/mistral-inference): See [here](#mistral-inference)
- [`transformers`](https://github.com/huggingface/transformers): See [here](#transformers)
- [`ollama`](https://github.com/ollama/ollama): See [here](#ollama)
### OpenHands (recommended)
#### Launch a server to deploy Devstral-Small-2505
Make sure you launched an OpenAI-compatible server such as vLLM or Ollama as described above. Then, you can use OpenHands to interact with `Devstral-Small-2505`.
In the case of the tutorial we spineed up a vLLM server running the command:
```bash
vllm serve mistralai/Devstral-Small-2505 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --tensor-parallel-size 2
```
The server address should be in the following format: `http://<your-server-url>:8000/v1`
#### Launch OpenHands
You can follow installation of OpenHands [here](https://docs.all-hands.dev/modules/usage/installation).
The easiest way to launch OpenHands is to use the Docker image:
```bash
docker pull docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik
docker run -it --rm --pull=always \
-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik \
-e LOG_ALL_EVENTS=true \
-v /var/run/docker.sock:/var/run/docker.sock \
-v ~/.openhands-state:/.openhands-state \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name openhands-app \
docker.all-hands.dev/all-hands-ai/openhands:0.38
```
Then, you can access the OpenHands UI at `http://localhost:3000`.
#### Connect to the server
When accessing the OpenHands UI, you will be prompted to connect to a server. You can use the advanced mode to connect to the server you launched earlier.
Fill the following fields:
- **Custom Model**: `openai/mistralai/Devstral-Small-2505`
- **Base URL**: `http://<your-server-url>:8000/v1`
- **API Key**: `token` (or any other token you used to launch the server if any)
#### Use OpenHands powered by Devstral
Now you're good to use Devstral Small inside OpenHands by **starting a new conversation**. Let's build a To-Do list app.
<details>
<summary>To-Do list app</summary
1. Let's ask Devstral to generate the app with the following prompt:
```txt
Build a To-Do list app with the following requirements:
- Built using FastAPI and React.
- Make it a one page app that:
- Allows to add a task.
- Allows to delete a task.
- Allows to mark a task as done.
- Displays the list of tasks.
- Store the tasks in a SQLite database.
```

2. Let's see the result
You should see the agent construct the app and be able to explore the code it generated.
If it doesn't do it automatically, ask Devstral to deploy the app or do it manually, and then go the front URL deployment to see the app.


3. Iterate
Now that you have a first result you can iterate on it by asking your agent to improve it. For example, in the app generated we could click on a task to mark it checked but having a checkbox would improve UX. You could also ask it to add a feature to edit a task, or to add a feature to filter the tasks by status.
Enjoy building with Devstral Small and OpenHands!
</details>
### LMStudio (recommended for quantized model)
Download the weights from huggingface:
```
pip install -U "huggingface_hub[cli]"
huggingface-cli download \
"mistralai/Devstral-Small-2505_gguf" \
--include "devstralQ4_K_M.gguf" \
--local-dir "mistralai/Devstral-Small-2505_gguf/"
```
You can serve the model locally with [LMStudio](https://lmstudio.ai/).
* Download [LM Studio](https://lmstudio.ai/) and install it
* Install `lms cli ~/.lmstudio/bin/lms bootstrap`
* In a bash terminal, run `lms import devstralQ4_K_M.ggu` in the directory where you've downloaded the model checkpoint (e.g. `mistralai/Devstral-Small-2505_gguf`)
* Open the LMStudio application, click the terminal icon to get into the developer tab. Click select a model to load and select Devstral Q4 K M. Toggle the status button to start the model, in setting oggle Serve on Local Network to be on.
* On the right tab, you will see an API identifier which should be devstralq4_k_m and an api address under API Usage. Keep note of this address, we will use it in the next step.
Launch Openhands
You can now interact with the model served from LM Studio with openhands. Start the openhands server with the docker
```bash
docker pull docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik
docker run -it --rm --pull=always \
-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik \
-e LOG_ALL_EVENTS=true \
-v /var/run/docker.sock:/var/run/docker.sock \
-v ~/.openhands-state:/.openhands-state \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name openhands-app \
docker.all-hands.dev/all-hands-ai/openhands:0.38
```
Click “see advanced setting” on the second line.
In the new tab, toggle advanced to on. Set the custom model to be mistral/devstralq4_k_m and Base URL the api address we get from the last step in LM Studio. Set API Key to dummy. Click save changes.
### vLLM (recommended)
We recommend using this model with the [vLLM library](https://github.com/vllm-project/vllm)
to implement production-ready inference pipelines.
**_Installation_**
Make sure you install [`vLLM >= 0.8.5`](https://github.com/vllm-project/vllm/releases/tag/v0.8.5):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.5.5`](https://github.com/mistralai/mistral-common/releases/tag/v1.5.5).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Server
We recommand that you use Devstral in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Devstral-Small-2505 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --tensor-parallel-size 2
```
2. To ping the client you can use a simple Python snippet.
```py
import requests
import json
from huggingface_hub import hf_hub_download
url = "http://<your-server-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Devstral-Small-2505"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "<your-command>",
},
],
},
]
data = {"model": model, "messages": messages, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])
```
### Mistral-inference
We recommend using mistral-inference to quickly try out / "vibe-check" Devstral.
#### Install
Make sure to have mistral_inference >= 1.6.0 installed.
```bash
pip install mistral_inference --upgrade
```
#### Download
```python
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', 'Devstral')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Devstral-Small-2505", allow_patterns=["params.json", "consolidated.safetensors", "tekken.json"], local_dir=mistral_models_path)
```
#### Python
You can run the model using the following command:
```bash
mistral-chat $HOME/mistral_models/Devstral --instruct --max_tokens 300
```
You can then prompt it with anything you'd like.
### Ollama
You can run Devstral using the [Ollama](https://ollama.ai/) CLI.
```bash
ollama run devstral
```
### Transformers
To make the best use of our model with transformers make sure to have [installed](https://github.com/mistralai/mistral-common) ` mistral-common >= 1.5.5` to use our tokenizer.
```bash
pip install mistral-common --upgrade
```
Then load our tokenizer along with the model and generate:
```python
import torch
from mistral_common.protocol.instruct.messages import (
SystemMessage, UserMessage
)
from mistral_common.protocol.instruct.request import ChatCompletionRequest
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.tokens.tokenizers.tekken import SpecialTokenPolicy
from huggingface_hub import hf_hub_download
from transformers import AutoModelForCausalLM
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Devstral-Small-2505"
tekken_file = hf_hub_download(repo_id=model_id, filename="tekken.json")
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
tokenizer = MistralTokenizer.from_file(tekken_file)
model = AutoModelForCausalLM.from_pretrained(model_id)
tokenized = tokenizer.encode_chat_completion(
ChatCompletionRequest(
messages=[
SystemMessage(content=SYSTEM_PROMPT),
UserMessage(content="<your-command>"),
],
)
)
output = model.generate(
input_ids=torch.tensor([tokenized.tokens]),
max_new_tokens=1000,
)[0]
decoded_output = tokenizer.decode(output[len(tokenized.tokens):])
print(decoded_output)
``` |
Mungert/Fathom-R1-14B-GGUF | Mungert | 2025-06-15T19:38:17Z | 1,301 | 5 | transformers | [
"transformers",
"gguf",
"dataset:FractalAIResearch/Fathom-V0.4-SFT-Shortest-Chains",
"dataset:FractalAIResearch/Fathom-V0.6-Iterative-Curriculum-Learning",
"arxiv:2503.21934",
"arxiv:2502.16666",
"arxiv:2502.08226",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-14B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-14B",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-01T14:33:05Z | ---
license: mit
library_name: transformers
datasets:
- FractalAIResearch/Fathom-V0.4-SFT-Shortest-Chains
- FractalAIResearch/Fathom-V0.6-Iterative-Curriculum-Learning
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
---
# <span style="color: #7FFF7F;">Fathom-R1-14B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`ea1431b0`](https://github.com/ggerganov/llama.cpp/commit/ea1431b0fa3a8108aac1e0a94a13ccc4a749963e).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Fathom-R1-14B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Fathom-R1-14B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Fathom-R1-14B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Fathom-R1-14B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Fathom-R1-14B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Fathom-R1-14B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Fathom-R1-14B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Fathom-R1-14B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Fathom-R1-14B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Fathom-R1-14B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Fathom-R1-14B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# 🧮 Fathom-R1-14B: $499 Training Recipe for Unlocking Math Reasoning at o4-mini level using R1-distilled-14B model under 16K context
<div align="center">
[](https://huggingface.co/collections/FractalAIResearch/Fathom-r1-models-681b41a149682c7e32f8a9f2)
[](https://huggingface.co/collections/FractalAIResearch/Fathom-r1-datasets-681b42fe6f20d4b11fc51d79)
[](https://huggingface.co/spaces/FractalAIResearch/Fathom-R1-14B)
[](https://github.com/FractalAIResearchLabs/Fathom-R1)
</div>
<p align="center"> <img src="./images/image.png" style="width: 100%;" id="title-icon"> </p>
---
## Overview
Reasoning models often require high post-training budgets and extremely long reasoning chains(think 32k/64k) for maximising performance. Can we improve these models even if both these parameters are capped?
To this end, we first introduce: **Fathom-R1-14B**, a 14-billion-parameter reasoning language model derived from Deepseek-R1-Distilled-Qwen-14B, post-trained at an affordable cost of only $499, and achieving SOTA mathematical reasoning performance within a 16K context window. On the latest olympiad level exams: AIME-25 and HMMT-25, our model not only **surpasses o3-mini-low, o1-mini and LightR1-14B(16k)** at pass@1 scores (averaged over 64 runs) but also delivers **performance rivaling closed-source o4-mini (low)** w.r.t cons@64 — all while staying within a **16K context window**. It achieves 52.71% Pass@1 accuracy on AIME2025 and 35.26% Pass@1 accuracy on HMMT25 (+7.2% and +5.2% improvement over the base model respectively). When provided with additional test-time compute in the form of cons@64, it achieves an impressive 76.7% accuracy on AIME2025 and 56.7% accuracy on HMMT25 (+13.4% and +6.7% improvement over the base model respectively). We perform supervised fine-tuning (SFT) on carefully curated datasets using a specific training approach, followed by model merging, achieving this performance at a total cost of just $499!
We also introduce **Fathom-R1-14B-RS**, another model achieving performance comparable to our first, at a total post-training cost of just $967. It leverages post-training techniques—including reinforcement learning and supervised fine-tuning—in a multi-stage, cost-effective manner, followed by model merging.
We are **open-sourcing our models, post-training recipes and datasets** which we believe will help the community to progress further in the reasoning domain.
---
## 🧪 Motivation
Thinking longer during inference time has shown to unlock superior reasoning abilities and expert level performance on challenging queries and tasks. Since the open-source release of DeepSeek R1 series models, multiple open-source efforts [[s1](https://github.com/simplescaling/s1), [LIMO](https://github.com/GAIR-NLP/LIMO), [Light-R1](https://github.com/Qihoo360/Light-R1)] have focused on reproducing the results (easpecially at <=32B scale) either via distillation or RL based fine-tuning on top of non-reasoning models. Though in most cases, these efforts at best, could come close to the performance R1 series models but are unable to surpass them. In parallel, certain recent methods [[DeepScaleR](https://github.com/agentica-project/rllm), [DeepCoder](https://www.together.ai/blog/deepcoder), [Light-R1](https://github.com/Qihoo360/Light-R1)] started with the existing reasoning models and have managed to extend the performance of these models. However, the training runs for these methods are often costly and they rely on longer sequence lengths for higher accuracy.
Given the latest findings [[Proof or Bluff ?](https://arxiv.org/abs/2503.21934), [Reasoning models don't always say what they think](https://assets.anthropic.com/m/71876fabef0f0ed4/original/reasoning_models_paper.pdf)] that raises the question on the correctness of the intermediate steps of the long COT in reasoning models, its important from interpretability, reliability and safety pov to ensure the reasoning chains are not inefficiently long. Hence, in this study, we work towards unlocking performance improvement of the reasoning models without training at very high (24k/32k) sequence length and restricting it to 16k context. We believe, while extremely long reasoning chains are still necessary for really challenging tasks, its also important to maximize the performance at lower context first before we proceed towards extending reasoning chains.
## Training Dataset
We begin by curating a high-quality mathematical corpus from the following open-source datasets:
- **Open-R1** - default subset
- **Numina – Olympiads & AOPS_forum** (word problems, float type answers)
- After rigorous deduplication and decontamination, we consolidated approximately **~100K unique problems**, forming the initial corpus for all subsequent trainings.
## 🏗️ Post-Training Strategies
### Training Recipe for Fathom-R1-14B-v0.6
SFT on difficult questions and their reasoning chains has been shown to be effective for improving reasoning ability. For this checkpoint, we build on top of this. This training stage focuses on improving the model’s performance on **mathematical problems covering a spectrum of hard diffuculty level** through a iterative curriculum learning strategy at max 16k sequence length. Curriculum learning (CL) is a well-established technique for training LLMs, where the model is progressively exposed to more difficult tasks. The idea is to gradually scaffold more complex reasoning, thereby enhancing generalization and reducing overfitting. However, in our case we perform this in an iterative manner, which essentially means we do multiple iterations of CL.
For the dataset preparation, we begin by annotating each question’s difficulty using **OpenAI's o3mini** model. We retain only those questions rated above average (in relative sense) and further filter them to include only those having **solve rates between certain range** (0.2 < pass_rate < 0.7). This yields the **Iterative Curriculum Learning dataset** comprising of 5K examples.
Total H100 GPU Hours: 48
Cost: $136
### Training Recipe for Fathom-R1-14B-v0.4-RS
The core strategy used behind creating this checkpoint is a two-stage pipeline: First, leverage GRPO to improve reasoning of Deepseek-R1-Distilled-Qwen-14B at a lower sequence length, 6k, on a carefully curated dataset to ensure rapid improvement with minimal training steps. Second, we perform SFT, at max 16k tokens sequence length, on a carefully curated dataset of questions ( hard to very hard difficulty spectrum) and the corresponding shortest possible reasoning solution for each question.
- **First Stage (Leveraging RL for effecient test-time thinking):** We start with curating a seed dataset which ensures the policy receives minumium reward while still having room for growth. The dataset comparises of questions having solve rates (at lower sequence length) between a certain range. This forms our **RL Compression dataset** comprising of 7.7K questions. Staring from DeepSeek-R1-Distill-Qwen-14B as the base model, we train the model using the GRPO algorithm, with a 6k token sequence length limit. We see a consistent increase in performance as the model learns to generate concise responses from the decreasing clip ratio, response length and increasing reward. The obtained model has learnt to generate responses below 6k tokens and outperforms the base model at lower token limits.
<img width="1370" alt="image" src="./images/RL_graph.png" />
- **Second Stage (Leveraging SFT to improve reasoning efficiently at higher sequence length):** We build upon the RL checkpoint and perform SFT under a **16K context window** to encourage more detailed reasoning that would be required for solving more complex problems. For this stage, we strategically curate a dataset consisting of hard problems — specifically, questions with lower solve rates (0 < pass_rate <=0.4). Then, we obtain the shortest possible reasoning chains for these questions forming the **SFT Shortest Chains dataset** comprising of 9.5K examples. Through supervised fine-tuning on this dataset, the model is able to stablize its reasoning at sequence length upto 16K. The resulting model is named **Fathom-R1-14B-v0.4**, optimized for concise yet accurate mathematical reasoning.
Total H100 GPU Hours: 293
Cost: $831
### Training Recipe for Fathom-R1-14B-v0.4
Given the performance improvement we noticed during the second fine-tuning stage of developing Fathom-R1-14B-v0.4-RS and in attempt to further reduce the cost, we experiment by eliminating RL and directly performing second stage SFT on Deepseek-R1-Distilled-Qwen-14B base model.
Total H100 GPU Hours: 128
Cost: $363
## Model Merging
Given v0.6 and v0.4 models have been developed by following different training methodologies, we perform linear merging to combine the strengths to obtain final 2 checkpoints.
- **Fathom-R1-14B**: Obtained via merging Fathom-R1-14B-V0.6 (Iterative Curriculum SFT) and Fathom-R1-14B-V0.4 (SFT-Shortest-Chains)
- **Fathom-R1-14B-RS**: Obtained via merging Fathom-R1-14B-V0.6 (Iterative Curriculum SFT) and Fathom-R1-14B-V0.4 (RL-compression + SFT-Shortest-Chains)
## 💰 Post-Training Cost
We developed **Fathom-R1-14B** models using a focused, resource-efficient strategy that balances performance with compute budget. Below is the GPU time utilized and the cost incurred
| Model Weights | GPU Hours (H100) | Cost(USD) |
|----------------------------|------------------|------|
| Fathom-R1-14B-V0.4-RS | 293 | 831 |
| Fathom-R1-14B-V0.4 | 128 | 363 |
| Fathom-R1-14B-V0.6 | 48 | 136 |
| Fathom-R1-14B-RS | 341 | 967 |
| **Fathom-R1-14B** | **176** | **499** |
So, the final Fathom-R1-14B took just 499$ to be trained overall! This low training cost highlights the efficiency of our method — enabling high-level mathematical reasoning comparable to **o4-mini** in **$499** , all within a **16k sequence length budget**.
---
## 📊 Evaluation
We evaluate Fathom‑R1-14B using the same metrics and sampling configuration introduced in the DeepSeek‑R1 paper, namely **pass@1** and **cons@64**. However, our evaluation is conducted under a reduced output budget of 16,384 tokens, compared to DeepSeek‑R1’s 32,768 tokens, to better reflect practical deployment constraints.
- **pass@1**: Pass@1 is computed as the average correctness over k sampled solution chains per problem (in our experiments we keep k=64).
- **cons@64**: Assesses consistency by sampling 64 reasoning chains per question and computing the majority vote accuracy.
**Evaluation Configuration**:
- Temperature: 0.6
- top_p: 0.95
- Number of sampled chains: 64
- Context: 16,384 tokens
This setup allows us to benchmark Fathom-R1-14B’s reasoning performance and stability under realistic memory and inference budgets, while maintaining compatibility with the DeepSeek‑R1 evaluation protocol.
We utilize the evaluation framework provided by the [LIMO](https://github.com/GAIR-NLP/LIMO) repository to run inference and compute metrics.
For detailed instructions and implementation details, please refer to [`eval/README.md`](https://github.com/FractalAIResearchLabs/Fathom-R1/blob/main/eval/readme.md).
---
## Results
We evaluate and compare **Fathom‑R1-14B** with several baseline models across 3 challenging benchmarks: **AIME25**, **HMMT25**, and **GPQA**. For each, we report `pass@1` and `cons@64`, following the same evaluation configuration.
| Model | AIME25 | | HMMT25 | |
|------------------|----------------|---------------|----------------|---------------|
| | pass@1 | cons@64 | pass@1 | cons@64 |
| **Closed-Source Models** | | | | |
| o1‑mini | 50.71 | 63.33 | 35.15 | 46.67 |
| o3‑mini‑low | 42.60 | 53.33 | 26.61 | 33.33 |
| o3‑mini‑medium | 72.24 | 83.33 | 49.21 | 60.00 |
| o4-mini-low | 60.20 | 76.67 | 39.11 | 53.33 |
| o1‑preview | 33.33 | 36.67 | 17.78 | 20.00 |
| gpt‑4.5‑preview | 34.44 | 40.00 | 16.67 | 20.00 |
| **Open-Source Models** | | | | |
| DeepSeek-R1-Distill-Qwen-14B | 45.50 | 63.33 | 30.00 | 50.00 |
| DeepSeek-R1-Distill-Qwen-32B | 49.64 | 73.33 | 33.02 | 53.33 |
| DeepSeekR1‑670B | 61.25 | 83.33 | 42.19 | 56.67 |
| LightR1‑14B | 51.15 | 76.67 | 33.75 | 50.00 |
| Fathom‑R1-14B-V0.4-RS | 50.94 | 73.33 | 33.70 | 40.00 |
| Fathom‑R1-14B-V0.4 | 50.94 | 70.00 | 34.53 | 56.67 |
| Fathom‑R1-14B-V0.6 | 50.63 | 76.67 | 32.19 | 50.00 |
| Fathom‑R1-14B-RS | 52.03 | 76.67 | 35.00 | 53.33 |
| **Fathom‑R1-14B** | **52.71** | **76.67** | **35.26** | **56.67** |
**Fathom‑R1-14B** demonstrates highly competitive performance across all datasets, improving over the original R1-distilled models while closely matching or surpassing other strong baselines in several settings.
On both AIME 25 and HMMT 25, our model shows the highest pass@1 as well as cons@64 scores among all the open-source models (including the bigger R1-Distilled-32B model), with R1-670B being the only exception.
In fact, we observe that Fathom-R1-14B is superior to the first two generations of OpenAI's mini-reasoning models, including **o1-mini** and **o3-mini-low-** and it's performance closely matches that of newly released **o4-mini-low** (self-consistency decoding).
---
## 🌍 Generalization Beyond Math: GPQA-Diamond
Notably, we also observe out-of-domain improvement in **GPQA-Diamond**, even though there wasn't a single instance of non-math questions in our training data.
This indicates that our training methodology mentioned above and training on math wuestions facilitates generalization across diverse domains, a finding similar to what LightR1-14B & LIMO had observed.
#### ✅ GPQA Benchmark Comparison (16k)
| **Model** | **pass@1** | **cons@64** |
|-------------------|------------|-------------|
| DeepSeek-R1-Distill-Qwen-14B | 54.19 | 64.14 |
| LightR1‑14B | 56.94 | 65.15 |
| Fathom‑R1-14B-RS | 59.13 | 66.16 |
| **Fathom‑R1-14B** | **59.46** | **66.16** |
---
## ✂️ Ablation Study on Token Efficiency
To assess reasoning token efficiency, we compare the **average response token count**, under 16k context length, across AIME25, and HMMT25. On AIME25, Fathom‑R1-14B-RS uses 10% fewer response tokens than LightR1-14B despite having higher pass@1. HMMT25 questions are relatively tougher compared to AIME'25 and tougher questions usually require more thinking tokens. On HMMT25, Fathom‑R1-14B-RS uses 4.5% fewer response tokens than LightR1-14B despite having higher pass@1.
#### Average Response Length (Tokens)
| Model | AIME25 | HMMT25 |
|------------------|--------|--------|
| LightR1-14B | 11330 | 12680 |
| DeepSeek-R1-Distill-Qwen-14B | 10878 | 12263 |
| Fathom‑R1-14B-V0.4 | 10570 | 11950 |
| Fathom‑R1-14B | 10956 | 12125 |
| **Fathom‑R1-14B-RS** | **10083** | **12100** |
---
## Data Decontimination
Both benchmarks used (AIME 25 and HMMT 25) were released a few weeks after the release of the base model, ensuring no contamination occurred during the model's pre-training. The dataset corpora (Numina-Math 1.5 & OpenR1-Math) were released around the same time as these exams, with a cutoff date no later than 2024. Additionally, we conduct checks to verify there is no contamination in the training data.
---
## Release Assets
- Training Recipe Blog: [🤗 $499 training recipe for creating Fathom-R1-14B](https://huggingface.co/FractalAIResearch/Fathom-R1-14B)
- Final Merged Models: [🤗 Fathom-R1-14B](https://huggingface.co/FractalAIResearch/Fathom-R1-14B), [🤗 Fathom-R1-14B-RS](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-RS)
- Intermediate Models: [🤗 Fathom-R1-14B-V0.6](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-V0.6), [🤗 Fathom-R1-14B-V0.4](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-V0.4), [🤗 Fathom-R1-14B-V0.4-RS](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-V0.4-RS)
- Fathom-R1-14B Datasets: [🤗 V0.6-Iterative-Curriculum-Learning](https://huggingface.co/datasets/FractalAIResearch/Fathom-V0.6-Iterative-Curriculum-Learning), [🤗 V0.4-SFT-Shortest-Chains](https://huggingface.co/datasets/FractalAIResearch/Fathom-V0.4-SFT-Shortest-Chains), [🤗 V0.4-RL-Compression](https://huggingface.co/datasets/FractalAIResearch/Fathom-V0.4-RL-Compression)
---
## 📜 License
This repository and all the release assets are available under the MIT License, underscoring our dedication to open and inclusive AI innovation. By freely sharing our work, we aim to democratize AI technology, empowering researchers, developers, and enthusiasts everywhere to use, adapt, and expand upon it without limitation. This open and permissive approach promotes global collaboration, accelerates innovation, and enriches the AI community as a whole.
## Acknowledgments
We would like to acknowledge the following works for enabling our project:
- [Deepseek-R1-Distill-Qwen-14B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B)
- [NuminaMath-1.5](https://huggingface.co/datasets/AI-MO/NuminaMath-1.5)
- [OpenR1-Math](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k)
- [360-LLAMA-Factory](https://github.com/Qihoo360/360-LLaMA-Factory)
- [verl](https://github.com/volcengine/verl)
- [LIMO](https://github.com/GAIR-NLP/LIMO)
- [FuseAI](https://github.com/fanqiwan/FuseAI)
---
## 📖 Citation
```bibtex
@misc{fathom14b2025,
title={Fathom-R1: $499 Training Recipe for Unlocking Math Reasoning at o4-mini level with just 14B parameters under 16K context},
author={Kunal Singh and Pradeep Moturi and Ankan Biswas and Siva Gollapalli and Sayandeep Bhowmick},
howpublished={\url{https://huggingface.co/FractalAIResearch/Fathom-R1-14B}},
note={Hugging Face},
year={2025}
}
```
## About Project Ramanujan
We initiated Project Ramanujan approximately one year ago, aiming to unlock intelligence and enhance AI agents by pushing the boundaries of advanced reasoning. Our key accomplishments include:
- ICLR'25 & NeurIPS'24-MATH-AI: [SBSC: Step-By-Step Coding for Improving Mathematical Olympiad Performance](https://arxiv.org/abs/2502.16666)
- Winners of HackerCupAI@NeurIPS'24 & ICLR'25-VerifAI: [Stress Testing Based Self-Consistency For Olympiad Programming](https://openreview.net/forum?id=7SlCSjhBsq)
- CVPR'25-MULA: [TRISHUL: Towards Region Identification and Screen Hierarchy Understanding for Large VLM based GUI Agents
](https://arxiv.org/abs/2502.08226))
- Silver Medal in AIMO'24 |
Mungert/QwenLong-L1-32B-GGUF | Mungert | 2025-06-15T19:38:13Z | 6,074 | 9 | transformers | [
"transformers",
"gguf",
"long-context",
"large-reasoning-model",
"text-generation",
"dataset:Tongyi-Zhiwen/DocQA-RL-1.6K",
"arxiv:2505.17667",
"arxiv:2309.00071",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-28T11:43:14Z | ---
license: apache-2.0
datasets:
- Tongyi-Zhiwen/DocQA-RL-1.6K
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
tags:
- long-context
- large-reasoning-model
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">QwenLong-L1-32B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `QwenLong-L1-32B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `QwenLong-L1-32B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `QwenLong-L1-32B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `QwenLong-L1-32B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `QwenLong-L1-32B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `QwenLong-L1-32B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `QwenLong-L1-32B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `QwenLong-L1-32B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `QwenLong-L1-32B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `QwenLong-L1-32B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `QwenLong-L1-32B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
<p align="center" width="100%">
</p>
<div id="top" align="center">
-----------------------------
[](https://opensource.org/licenses/Apache-2.0)
[](https://arxiv.org/abs/2505.17667)
[](https://github.com/Tongyi-Zhiwen/QwenLong-L1)
[](https://modelscope.cn/models/iic/QwenLong-L1-32B)
[](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B)
<!-- **Authors:** -->
_**Fanqi Wan, Weizhou Shen, Shengyi Liao, Yingcheng Shi, Chenliang Li,**_
_**Ziyi Yang, Ji Zhang, Fei Huang, Jingren Zhou, Ming Yan**_
<!-- **Affiliations:** -->
_Tongyi Lab, Alibaba Group_
<p align="center">
<img src="./assets/fig1.png" width="100%"> <br>
</p>
</div>
## 🎉 News
- **May 28, 2025:** 🔥 We release [🤗 QwenLong-L1-32B-AWQ](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B-AWQ), which has undergone AWQ int4 quantization using the ms-swift framework.
- **May 26, 2025:** 🔥 We release [🤗 QwenLong-L1-32B](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B), which is the first long-context LRM trained with reinforcement learning for long-context reasoning. Experiments on seven long-context DocQA benchmarks demonstrate that **QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking**, demonstrating leading performance among state-of-the-art LRMs.
- **May 26, 2025:** 🔥 We release [🤗 DocQA-RL-1.6K](https://huggingface.co/datasets/Tongyi-Zhiwen/DocQA-RL-1.6K), which is a specialized RL training dataset comprising 1.6K document question answering (DocQA) problems spanning mathematical, logical, and multi-hop reasoning domains.
## 📚 Introduction
In this work, we propose QwenLong-L1, a novel reinforcement learning (RL) framework designed to facilitate the transition of LRMs from short-context proficiency to robust long-context generalization. In our preliminary experiments, we illustrate the differences between the training dynamics of short-context and long-context reasoning RL.
<p align="center">
<img src="./assets/fig2.png" width="100%"> <br>
</p>
Our framework enhances short-context LRMs through progressive context scaling during RL training. The framework comprises three core components: a warm-up supervised fine-tuning (SFT) phase to initialize a robust policy, a curriculum-guided RL phase that facilitates stable adaptation from short to long contexts, and a difficulty-aware retrospective sampling mechanism that adjusts training complexity across stages to incentivize policy exploration. Leveraging recent RL algorithms, including GRPO and DAPO, our framework integrates hybrid reward functions combining rule-based and model-based binary outcome rewards to balance precision and recall. Through strategic utilization of group relative advantages during policy optimization, it guides LRMs to learn effective reasoning patterns essential for robust long-context grounding and superior reasoning capabilities.
<p align="center">
<img src="./assets/fig3.png" width="100%"> <br>
</p>
## 🎯 Model Release
We release [🤗 QwenLong-L1-32B](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B), which is the first long-context LRM trained with reinforcement learniing for long-context reasoning. Experiments on seven long-context DocQA benchmarks demonstrate that **QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking**, demonstrating leading performance among state-of-the-art LRMs.
Here are the evaluation results.
<p align="center">
<img src="./assets/tab4.png" width="100%"> <br>
</p>
## 🛠️ Requirements
```bash
# Create the conda environment
conda create -n qwenlongl1 python==3.10
conda activate qwenlongl1
# Install requirements
pip3 install -r requirements.txt
# Install verl
cd verl
pip3 install -e .
# Install vLLM
pip3 install vllm==0.7.3
# Install flash-attn
pip3 install flash-attn --no-build-isolation
```
## 🚀 Quick Start
Here's how you can run the model using the 🤗 Transformers:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Tongyi-Zhiwen/QwenLong-L1-32B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
template = """Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as follows: "Therefore, the answer is (insert answer here)"."""
context = "<YOUR_CONTEXT_HERE>"
question = "<YOUR_QUESTION_HERE>"
prompt = template.replace('$DOC$', context.strip()).replace('$Q$', question.strip())
messages = [
# {"role": "system", "content": "You are QwenLong-L1, created by Alibaba Tongyi Lab. You are a helpful assistant."}, # Use system prompt to define identity when needed.
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=10000,
temperature=0.7,
top_p=0.95
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151649 (</think>)
index = len(output_ids) - output_ids[::-1].index(151649)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
## ♾️ Processing Long Documents
For input where the total length (including both input and output) significantly exceeds 32,768 tokens, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
## 🗂️ Dataset
To construct a challenging RL dataset for verifiable long-context reasoning, we develop [🤗 DocQA-RL-1.6K](https://huggingface.co/datasets/Tongyi-Zhiwen/DocQA-RL-1.6K), which comprises 1.6K DocQA problems across three reasoning domains:
(1) Mathematical Reasoning: We use 600 problems from the DocMath dataset, requiring numerical reasoning across long and specialized documents such as financial reports. For DocMath, we sample 75% items from each subset from its valid split for training and 25% for evaluation;
(2) Logical Reasoning: We employ DeepSeek-R1 to synthesize 600 multi-choice questions requiring logic analysis of real-world documents spanning legal, financial, insurance, and production domains from our curated collection;
(3) Multi-Hop Reasoning: We sample 200 examples from MultiHopRAG and 200 examples from Musique, emphasizing cross-document reasoning.
Please download and put the following datasets in `./datasets/` for training and evaluation.
RL training data: [🤗 DocQA-RL-1.6K](https://huggingface.co/datasets/Tongyi-Zhiwen/DocQA-RL-1.6K).
Evaluation data: [🤗 docmath](https://huggingface.co/datasets/Tongyi-Zhiwen/docmath), [🤗 frames](https://huggingface.co/datasets/Tongyi-Zhiwen/frames), [🤗 longbench](https://huggingface.co/datasets/Tongyi-Zhiwen/longbench).
## 💻 Training
We provide the basic demo training code for single stage RL traininig with DAPO.
First, we should start a local verifier.
```bash
export CUDA_VISIBLE_DEVICES=0
vllm serve "Qwen/Qwen2.5-1.5B-Instruct" \
--host 0.0.0.0 \
--port 23547
```
Then, we start RL training with 4 nodes.
```bash
export PROJ_DIR="<YOUR_PROJ_DIR_HERE>"
export MASTER_IP="<YOUR_MASTER_IP_HERE>" # ray master ip
export NNODES=4 # total GPU nodes
export NODE_RANK=${RANK} # rank of current node
export PORT=6382
export WANDB_API_KEY="<YOUR_WANDB_API_KEY_HERE>"
export WANDB_PROJECT="QwenLong-L1"
export LLM_JUDGE=Y # 'Y': LLM JUDGE, 'N': RULE BASED
export VLLM_ATTENTION_BACKEND=FLASH_ATTN
# verifier
export VERIFIER_PATH="Qwen/Qwen2.5-1.5B-Instruct"
export VERIFIER_HOST="<YOUR_VERIFIER_HOST_HERE>"
export VERIFIER_PORT="23547"
ray_start_retry() {
while true; do
ray start --address="${MASTER_IP}:${PORT}"
if [ $? -eq 0 ]; then
break
fi
echo "Failed to connect to master, retrying in 5 seconds..."
sleep 5
done
}
check_ray_status() {
until ray status >/dev/null 2>&1; do
echo "Waiting for Ray cluster to be ready..."
sleep 5
done
}
if [ "$RANK" == "0" ]; then
echo "Starting HEAD node..."
ray start --head --port=${PORT}
check_ray_status
echo "Ray head node started successfully"
else
echo "Starting WORKER node..."
ray_start_retry
check_ray_status
echo "Successfully joined Ray cluster"
fi
if [ "$RANK" == "0" ]; then
bash ${PROJ_DIR}/scripts/rl_4nodes_dapo.sh 2>&1 | tee ${PROJ_DIR}/logs/rl_log_$(date +%Y%m%d_%H%M%S).txt &
else
sleep 30d
fi
wait
```
## 📊 Evaluation
We conduct evaluation on seven long-context DocQA benchmarks, including multi-hop reasoning benchmarks such as 2WikiMultihopQA, HotpotQA, Musique, NarrativeQA, Qasper, and Frames as well as mathematical reasoning benchmarks like DocMath. We report the maximum of exact match and LLM-judged accuracy as the final score, aligned with the reward function in our RL training process. We use DeepSeek-V3 as the judge model with a temperature of 0.0 to provide a reliable evaluation.
```bash
# Step 1. Serve the model for evaluation
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
MODEL_NAME="QwenLong-L1-32B"
MODEL_PATH="Tongyi-Zhiwen/QwenLong-L1-32B"
vllm serve ${MODEL_PATH} \
--port 23547 \
--api-key "token-abc123" \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.95 \
--max_model_len 131072 \
--trust-remote-code
# Step 2. Generate model responses for each dataset
export SERVE_HOST="<YOUR_SERVE_HOST_HERE>" # e.g., 127.0.0.1
export SERVE_PORT="23547"
PROJ_DIR="<YOUR_PROJ_DIR_HERE>"
DATA="<YOUR_DATA_HERE>" # e.g., docmath, frames, 2wikimqa, hotpotqa, musique, narrativeqa, pasper
python ${PROJ_DIR}/eval/${DATA}.py \
--save_dir "${PROJ_DIR}/eval/results/${DATA}" \
--save_file "${MODEL_NAME}" \
--model "${MODEL_PATH}" \
--tokenizer "${MODEL_PATH}" \
--n_proc 16 \
--api "openai"
# Step 3. Verify model responses for each dataset
export VERIFIER_API="<YOUR_API_KEY_HERE>"
export VERIFIER_URL="https://api.deepseek.com/v1"
PROJ_DIR="<YOUR_PROJ_DIR_HERE>"
DATA="<YOUR_DATA_HERE>" # e.g., docmath, frames, 2wikimqa, hotpotqa, musique, narrativeqa, pasper
python ${PROJ_DIR}/eval/${DATA}_verify.py \
--save_dir "${PROJ_DIR}/results/${DATA}" \
--save_file "${MODEL_NAME}" \
--judge_model "deepseek-chat" \
--batch_size 20
```
## 📝 Citation
If you find this work is relevant with your research or applications, please feel free to cite our work!
```
@article{wan2025qwenlongl1,
title={QwenLong-L1: : Towards Long-Context Large Reasoning Models with Reinforcement Learning},
author={Fanqi Wan, Weizhou Shen, Shengyi Liao, Yingcheng Shi, Chenliang Li, Ziyi Yang, Ji Zhang, Fei Huang, Jingren Zhou, Ming Yan},
journal={arXiv preprint arXiv:2505.17667},
year={2025}
}
``` |
Mungert/Llama-3.1-Nemotron-Nano-4B-v1.1-GGUF | Mungert | 2025-06-15T19:38:04Z | 2,600 | 1 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"text-generation",
"en",
"dataset:nvidia/Llama-Nemotron-Post-Training-Dataset",
"arxiv:2408.11796",
"arxiv:2502.00203",
"arxiv:2505.00949",
"base_model:nvidia/Llama-3.1-Minitron-4B-Width-Base",
"base_model:quantized:nvidia/Llama-3.1-Minitron-4B-Width-Base",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-21T21:58:58Z | ---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- llama-3
- pytorch
base_model:
- nvidia/Llama-3.1-Minitron-4B-Width-Base
datasets:
- nvidia/Llama-Nemotron-Post-Training-Dataset
---
# <span style="color: #7FFF7F;">Llama-3.1-Nemotron-Nano-4B-v1.1 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.1-Nemotron-Nano-4B-v1.1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Llama-3.1-Nemotron-Nano-4B-v1.1
## Model Overview

Llama-3.1-Nemotron-Nano-4B-v1.1 is a large language model (LLM) which is a derivative of [nvidia/Llama-3.1-Minitron-4B-Width-Base](https://huggingface.co/nvidia/Llama-3.1-Minitron-4B-Width-Base), which is created from Llama 3.1 8B using [our LLM compression technique](https://arxiv.org/abs/2408.11796) and offers improvements in model accuracy and efficiency. It is a reasoning model that is post trained for reasoning, human chat preferences, and tasks, such as RAG and tool calling.
Llama-3.1-Nemotron-Nano-4B-v1.1 is a model which offers a great tradeoff between model accuracy and efficiency. The model fits on a single RTX GPU and can be used locally. The model supports a context length of 128K.
This model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Reasoning, and Tool Calling as well as multiple reinforcement learning (RL) stages using Reward-aware Preference Optimization (RPO) algorithms for both chat and instruction-following. The final model checkpoint is obtained after merging the final SFT and RPO checkpoints
This model is part of the Llama Nemotron Collection. You can find the other model(s) in this family here:
- [Llama-3.3-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1)
- [Llama-3.3-Nemotron-Super-49B-v1](https://huggingface.co/nvidia/Llama-3.3-Nemotron-Super-49B-v1)
- [Llama-3.1-Nemotron-Nano-8B-v1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-8B-v1)
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: Your use of this model is governed by the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/). Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3_1/license/). Built with Llama.
**Model Developer:** NVIDIA
**Model Dates:** Trained between August 2024 and May 2025
**Data Freshness:** The pretraining data has a cutoff of June 2023.
## Use Case:
Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks. Balance of model accuracy and compute efficiency (the model fits on a single RTX GPU and can be used locally).
## Release Date: <br>
5/20/2025 <br>
## References
- [\[2408.11796\] LLM Pruning and Distillation in Practice: The Minitron Approach](https://arxiv.org/abs/2408.11796)
- [\[2502.00203\] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment](https://arxiv.org/abs/2502.00203)
- [\[2505.00949\] Llama-Nemotron: Efficient Reasoning Models](https://arxiv.org/abs/2505.00949)
## Model Architecture
**Architecture Type:** Dense decoder-only Transformer model
**Network Architecture:** Llama 3.1 Minitron Width 4B Base
## Intended use
Llama-3.1-Nemotron-Nano-4B-v1.1 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Portuguese, Hindi, Spanish, and Thai) are also supported.
# Input:
- **Input Type:** Text
- **Input Format:** String
- **Input Parameters:** One-Dimensional (1D)
- **Other Properties Related to Input:** Context length up to 131,072 tokens
## Output:
- **Output Type:** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D)
- **Other Properties Related to Output:** Context length up to 131,072 tokens
## Model Version:
1.1 (5/20/2025)
## Software Integration
- **Runtime Engine:** NeMo 24.12 <br>
- **Recommended Hardware Microarchitecture Compatibility:**
- NVIDIA Hopper
- NVIDIA Ampere
## Quick Start and Usage Recommendations:
1. Reasoning mode (ON/OFF) is controlled via the system prompt, which must be set as shown in the example below. All instructions should be contained within the user prompt
2. We recommend setting temperature to `0.6`, and Top P to `0.95` for Reasoning ON mode
3. We recommend using greedy decoding for Reasoning OFF mode
4. We have provided a list of prompts to use for evaluation for each benchmark where a specific template is required
See the snippet below for usage with Hugging Face Transformers library. Reasoning mode (ON/OFF) is controlled via system prompt. Please see the example below.
Our code requires the transformers package version to be `4.44.2` or higher.
### Example of “Reasoning On:”
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "on"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
### Example of “Reasoning Off:”
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "off"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
For some prompts, even though thinking is disabled, the model emergently prefers to think before responding. But if desired, the users can prevent it by pre-filling the assistant response.
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Thinking can be "on" or "off"
thinking = "off"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}, {"role":"assistant", "content":"<think>\n</think>"}]))
```
## Running a vLLM Server with Tool-call Support
Llama-3.1-Nemotron-Nano-4B-v1.1 supports tool calling. This HF repo hosts a tool-callilng parser as well as a chat template in Jinja, which can be used to launch a vLLM server.
Here is a shell script example to launch a vLLM server with tool-call support. `vllm/vllm-openai:v0.6.6` or newer should support the model.
```shell
#!/bin/bash
CWD=$(pwd)
PORT=5000
git clone https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1
docker run -it --rm \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-p ${PORT}:${PORT} \
-v ${CWD}:${CWD} \
vllm/vllm-openai:v0.6.6 \
--model $CWD/Llama-3.1-Nemotron-Nano-4B-v1.1 \
--trust-remote-code \
--seed 1 \
--host "0.0.0.0" \
--port $PORT \
--served-model-name "Llama-Nemotron-Nano-4B-v1.1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "${CWD}/Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_toolcall_parser.py" \
--tool-call-parser "llama_nemotron_json" \
--chat-template "${CWD}/Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_generic_tool_calling.jinja"
```
Alternatively, you can use a virtual environment to launch a vLLM server like below.
```console
$ git clone https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1
$ conda create -n vllm python=3.12 -y
$ conda activate vllm
$ python -m vllm.entrypoints.openai.api_server \
--model Llama-3.1-Nemotron-Nano-4B-v1.1 \
--trust-remote-code \
--seed 1 \
--host "0.0.0.0" \
--port 5000 \
--served-model-name "Llama-Nemotron-Nano-4B-v1.1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_toolcall_parser.py" \
--tool-call-parser "llama_nemotron_json" \
--chat-template "Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_generic_tool_calling.jinja"
```
After launching a vLLM server, you can call the server with tool-call support using a Python script like below.
```python
>>> from openai import OpenAI
>>> client = OpenAI(
base_url="http://0.0.0.0:5000/v1",
api_key="dummy",
)
>>> completion = client.chat.completions.create(
model="Llama-Nemotron-Nano-4B-v1.1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "My bill is $100. What will be the amount for 18% tip?"},
],
tools=[
{"type": "function", "function": {"name": "calculate_tip", "parameters": {"type": "object", "properties": {"bill_total": {"type": "integer", "description": "The total amount of the bill"}, "tip_percentage": {"type": "integer", "description": "The percentage of tip to be applied"}}, "required": ["bill_total", "tip_percentage"]}}},
{"type": "function", "function": {"name": "convert_currency", "parameters": {"type": "object", "properties": {"amount": {"type": "integer", "description": "The amount to be converted"}, "from_currency": {"type": "string", "description": "The currency code to convert from"}, "to_currency": {"type": "string", "description": "The currency code to convert to"}}, "required": ["from_currency", "amount", "to_currency"]}}},
],
)
>>> completion.choices[0].message.content
'<think>\nOkay, let\'s see. The user has a bill of $100 and wants to know the amount of a 18% tip. So, I need to calculate the tip amount. The available tools include calculate_tip, which requires bill_total and tip_percentage. The parameters are both integers. The bill_total is 100, and the tip percentage is 18. So, the function should multiply 100 by 18% and return 18.0. But wait, maybe the user wants the total including the tip? The question says "the amount for 18% tip," which could be interpreted as the tip amount itself. Since the function is called calculate_tip, it\'s likely that it\'s designed to compute the tip, not the total. So, using calculate_tip with bill_total=100 and tip_percentage=18 should give the correct result. The other function, convert_currency, isn\'t relevant here. So, I should call calculate_tip with those values.\n</think>\n\n'
>>> completion.choices[0].message.tool_calls
[ChatCompletionMessageToolCall(id='chatcmpl-tool-2972d86817344edc9c1e0f9cd398e999', function=Function(arguments='{"bill_total": 100, "tip_percentage": 18}', name='calculate_tip'), type='function')]
```
## Inference:
**Engine:** Transformers
**Test Hardware:**
- BF16:
- 1x RTX 50 Series GPUs
- 1x RTX 40 Series GPUs
- 1x RTX 30 Series GPUs
- 1x H100-80GB GPU
- 1x A100-80GB GPU
**Preferred/Supported] Operating System(s):** Linux <br>
## Training Datasets
A large variety of training data was used for the post-training pipeline, including manually annotated data and synthetic data.
The data for the multi-stage post-training phases for improvements in Code, Math, and Reasoning is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model.
Prompts have been sourced from either public and open corpus or synthetically generated. Responses were synthetically generated by a variety of models, with some prompts containing responses for both Reasoning On and Off modes, to train the model to distinguish between two modes.
**Data Collection for Training Datasets:** <br>
* Hybrid: Automated, Human, Synthetic <br>
**Data Labeling for Training Datasets:** <br>
* N/A <br>
## Evaluation Datasets
We used the datasets listed below to evaluate Llama-3.1-Nemotron-Nano-4B-v1.1.
**Data Collection for Evaluation Datasets:** Hybrid: Human/Synthetic
**Data Labeling for Evaluation Datasets:** Hybrid: Human/Synthetic/Automatic
## Evaluation Results
These results contain both “Reasoning On”, and “Reasoning Off”. We recommend using temperature=`0.6`, top_p=`0.95` for “Reasoning On” mode, and greedy decoding for “Reasoning Off” mode. All evaluations are done with 32k sequence length. We run the benchmarks up to 16 times and average the scores to be more accurate.
> NOTE: Where applicable, a Prompt Template will be provided. While completing benchmarks, please ensure that you are parsing for the correct output format as per the provided prompt in order to reproduce the benchmarks seen below.
### MT-Bench
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 7.4 |
| Reasoning On | 8.0 |
### MATH500
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 71.8% |
| Reasoning On | 96.2% |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### AIME25
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 13.3% |
| Reasoning On | 46.3% |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### GPQA-D
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 33.8% |
| Reasoning On | 55.1% |
User Prompt Template:
```
"What is the correct answer to this question: {question}\nChoices:\nA. {option_A}\nB. {option_B}\nC. {option_C}\nD. {option_D}\nLet's think step by step, and put the final answer (should be a single letter A, B, C, or D) into a \boxed{}"
```
### IFEval
| Reasoning Mode | Strict:Prompt | Strict:Instruction |
|--------------|------------|------------|
| Reasoning Off | 70.1% | 78.5% |
| Reasoning On | 75.5% | 82.6% |
### BFCL v2 Live
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 63.6% |
| Reasoning On | 67.9% |
User Prompt Template:
```
<AVAILABLE_TOOLS>{functions}</AVAILABLE_TOOLS>
{user_prompt}
```
### MBPP 0-shot
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 61.9% |
| Reasoning On | 85.8% |
User Prompt Template:
````
You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
@@ Instruction
Here is the given problem and test examples:
{prompt}
Please use the python programming language to solve this problem.
Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
Please return all completed codes in one code block.
This code block should be in the following format:
```python
# Your codes here
```
````
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](explainability.md), [Bias](bias.md), [Safety & Security](safety.md), and [Privacy](privacy.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/). |
Mungert/OpenCodeReasoning-Nemotron-32B-IOI-GGUF | Mungert | 2025-06-15T19:37:59Z | 1,345 | 2 | transformers | [
"transformers",
"gguf",
"nvidia",
"code",
"text-generation",
"en",
"dataset:nvidia/OpenCodeReasoning",
"arxiv:2504.01943",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-32B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-19T14:31:48Z | ---
base_model:
- Qwen/Qwen2.5-32B-Instruct
datasets:
- nvidia/OpenCodeReasoning
language:
- en
library_name: transformers
license: apache-2.0
tags:
- nvidia
- code
pipeline_tag: text-generation
---
# <span style="color: #7FFF7F;">OpenCodeReasoning-Nemotron-32B-IOI GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `OpenCodeReasoning-Nemotron-32B-IOI-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `OpenCodeReasoning-Nemotron-32B-IOI-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `OpenCodeReasoning-Nemotron-32B-IOI-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `OpenCodeReasoning-Nemotron-32B-IOI-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `OpenCodeReasoning-Nemotron-32B-IOI-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `OpenCodeReasoning-Nemotron-32B-IOI-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `OpenCodeReasoning-Nemotron-32B-IOI-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `OpenCodeReasoning-Nemotron-32B-IOI-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `OpenCodeReasoning-Nemotron-32B-IOI-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `OpenCodeReasoning-Nemotron-32B-IOI-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `OpenCodeReasoning-Nemotron-32B-IOI-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# OpenCodeReasoning-Nemotron-32B-IOI Overview
## Description: <br>
OpenCodeReasoning-Nemotron-32B-IOI is a large language model (LLM) which is a derivative of Qwen2.5-32B-Instruct (AKA the reference model). It is a reasoning model that is post-trained for reasoning for code generation. The model supports a context length of 32K tokens. <br>
This model is ready for commercial/non-commercial use. <br>

## Results from [OpenCodeReasoning](https://arxiv.org/abs/2504.01943)
Below results are the average of **64 evaluations** on each benchmark.
| Model | Dataset Size Python | C++ | LiveCodeBench (pass@1) | CodeContests (pass@1) | IOI (Total Score) |
|---------------------------|---------------------|--------|------------------------|-----------------------|-------------------|
| OlympicCoder-7B | 0 | 100K | 40.9 | 10.6 | 127 |
| OlympicCoder-32B | 0 | 100K | 57.4 | 18.0 | 153.5 |
| QWQ-32B | - | - | 61.3 | 20.2 | 175.5 |
| | | | | | |
| **OpenCodeReasoning-IOI** | | | | | |
| | | | | | |
| **OCR-Qwen-32B-Instruct** | **736K** | **356K**| **61.5** | **25.5** | **175.5** |
## Reproducing our results
* [Models](https://huggingface.co/collections/nvidia/opencodereasoning-2-68168f37cd7c6beb1e3f92e7)
* [Dataset](https://huggingface.co/datasets/nvidia/OpenCodeReasoning)
* [Paper](https://arxiv.org/abs/2504.01943)
## How to use the models?
To run inference on coding problems for IOI Benchmark:
````python
import transformers
import torch
model_id = "nvidia/OpenCodeReasoning-Nemotron-32B-IOI"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use c++ programming language only.
You must use ```cpp for just the final solution code block with the following format:
```cpp
// Your code here
```
{user}
"""
messages = [
{
"role": "user",
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
]
outputs = pipeline(
messages,
max_new_tokens=32768,
)
print(outputs[0]["generated_text"][-1]['content'])
````
To run inference on coding problems for python programs:
````python
import transformers
import torch
model_id = "nvidia/OpenCodeReasoning-Nemotron-32B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
```
{user}
"""
messages = [
{
"role": "user",
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
]
outputs = pipeline(
messages,
max_new_tokens=32768,
)
print(outputs[0]["generated_text"][-1]['content'])
````
## Citation
If you find the data useful, please cite:
```
@article{ahmad2025opencodereasoning,
title={OpenCodeReasoning: Advancing Data Distillation for Competitive Coding},
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
year={2025},
eprint={2504.01943},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01943},
}
```
## Additional Information
## Model Architecture: <br>
Architecture Type: Dense decoder-only Transformer model
Network Architecture: Qwen-32B-Instruct
<br>
**This model was developed based on Qwen2.5-32B-Instruct and has 32B model parameters. <br>**
**OpenCodeReasoning-Nemotron-32B was developed based on Qwen2.5-32B-Instruct and has 32B model parameters. <br>**
## Input: <br>
**Input Type(s):** Text <br>
**Input Format(s):** String <br>
**Input Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Input:** Context length up to 32,768 tokens <br>
## Output: <br>
**Output Type(s):** Text <br>
**Output Format:** String <br>
**Output Parameters:** One-Dimensional (1D) <br>
**Other Properties Related to Output:** Context length up to 32,768 tokens <br>
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
## Software Integration : <br>
* Runtime Engine: NeMo 2.3.0 <br>
* Recommended Hardware Microarchitecture Compatibility: <br>
NVIDIA Ampere <br>
NVIDIA Hopper <br>
* Preferred/Supported Operating System(s): Linux <br>
## Model Version(s):
1.0 (4/25/2025) <br>
OpenCodeReasoning-Nemotron-7B<br>
OpenCodeReasoning-Nemotron-14B<br>
OpenCodeReasoning-Nemotron-32B<br>
OpenCodeReasoning-Nemotron-32B-IOI<br>
# Training and Evaluation Datasets: <br>
## Training Dataset:
The training corpus for OpenCodeReasoning-Nemotron-32B is [OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning) dataset, which is composed of competitive programming questions and DeepSeek-R1 generated responses.
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
Properties: 736k samples from OpenCodeReasoning (https://huggingface.co/datasets/nvidia/OpenCodeReasoning)
## Evaluation Dataset:
We used the datasets listed in the next section to evaluate OpenCodeReasoning-Nemotron-32B. <br>
**Data Collection Method: Hybrid: Automated, Human, Synthetic <br>**
**Labeling Method: Hybrid: Automated, Human, Synthetic <br>**
### License/Terms of Use: <br>
GOVERNING TERMS: Use of this model is governed by [Apache 2.0](https://huggingface.co/nvidia/OpenCode-Nemotron-2-7B/blob/main/LICENSE).
### Deployment Geography:
Global<br>
### Use Case: <br>
This model is intended for developers and researchers building LLMs. <br>
### Release Date: <br>
Huggingface [04/25/2025] via https://huggingface.co/nvidia/OpenCodeReasoning-Nemotron-32B/ <br>
## Reference(s):
[2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
<br>
## Inference:
**Engine:** vLLM <br>
**Test Hardware** NVIDIA H100-80GB <br>
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns here. |
Mungert/Kevin-32B-GGUF | Mungert | 2025-06-15T19:37:54Z | 1,559 | 3 | null | [
"gguf",
"base_model:Qwen/QwQ-32B",
"base_model:quantized:Qwen/QwQ-32B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-16T17:08:06Z | ---
base_model:
- Qwen/QwQ-32B
---
# <span style="color: #7FFF7F;">Kevin-32B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`06c1e4ab`](https://github.com/ggerganov/llama.cpp/commit/06c1e4abc1e50ef6dcf6369f9685ca8fe82d21fe).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Kevin-32B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Kevin-32B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Kevin-32B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Kevin-32B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Kevin-32B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Kevin-32B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Kevin-32B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Kevin-32B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Kevin-32B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Kevin-32B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Kevin-32B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
## Kevin-32B
Kevin (K(ernel D)evin) is a 32B parameter model finetuned to write efficient CUDA kernels.
We use KernelBench as our benchmark, and train the model through multi-turn reinforcement learning.
For the details, see our blogpost at **https://cognition.ai/blog/kevin-32b**
<img src="https://cdn-uploads.huggingface.co/production/uploads/6490673eb67028b2aa2a6f9f/pjVt_KrR6aWCuWb4GcZuW.png" width="600"/>
|
Mungert/Qwen3-30B-A3B-GGUF | Mungert | 2025-06-15T19:37:50Z | 1,722 | 4 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2309.00071",
"base_model:Qwen/Qwen3-30B-A3B-Base",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-13T04:35:31Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B-Base
---
# <span style="color: #7FFF7F;">Qwen3-30B-A3B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`064cc596`](https://github.com/ggerganov/llama.cpp/commit/064cc596ac44308dc326a17c9e3163c34a6f29d1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-30B-A3B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-30B-A3B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-30B-A3B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-30B-A3B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-30B-A3B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-30B-A3B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-30B-A3B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-30B-A3B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-30B-A3B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-30B-A3B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-30B-A3B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Qwen3-30B-A3B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-30B-A3B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
``` |
Mungert/Qwen3-4B-GGUF | Mungert | 2025-06-15T19:37:41Z | 891 | 8 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2309.00071",
"base_model:Qwen/Qwen3-4B-Base",
"base_model:quantized:Qwen/Qwen3-4B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-30T01:08:05Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-4B-Base
---
# <span style="color: #7FFF7F;">Qwen3-4B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-4B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-4B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-4B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-4B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-4B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-4B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-4B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-4B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-4B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-4B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-4B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen3-4B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-4B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 4.0B
- Number of Paramaters (Non-Embedding): 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
> [!TIP]
> If you encounter significant endless repetitions, please refer to the [Best Practices](#best-practices) section for optimal sampling parameters, and set the ``presence_penalty`` to 1.5.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-4B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-4B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-4B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
``` |
Mungert/LiveCC-7B-Instruct-GGUF | Mungert | 2025-06-15T19:37:37Z | 1,832 | 1 | null | [
"gguf",
"qwen_vl",
"video",
"real-time",
"multimodal",
"LLM",
"en",
"dataset:chenjoya/Live-CC-5M",
"dataset:chenjoya/Live-WhisperX-526K",
"dataset:lmms-lab/LLaVA-Video-178K",
"arxiv:2504.16030",
"base_model:Qwen/Qwen2-VL-7B",
"base_model:quantized:Qwen/Qwen2-VL-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-27T00:50:10Z | ---
license: apache-2.0
datasets:
- chenjoya/Live-CC-5M
- chenjoya/Live-WhisperX-526K
- lmms-lab/LLaVA-Video-178K
language:
- en
base_model:
- Qwen/Qwen2-VL-7B
tags:
- qwen_vl
- video
- real-time
- multimodal
- LLM
---
# <span style="color: #7FFF7F;">LiveCC-7B-Instruct GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`e291450`](https://github.com/ggerganov/llama.cpp/commit/e291450b7602d7a36239e4ceeece37625f838373).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `LiveCC-7B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `LiveCC-7B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `LiveCC-7B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `LiveCC-7B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `LiveCC-7B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `LiveCC-7B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `LiveCC-7B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `LiveCC-7B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `LiveCC-7B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `LiveCC-7B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `LiveCC-7B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# LiveCC-7B-Instruct
## Introduction
We introduce LiveCC, the first video LLM capable of real-time commentary, trained with a novel video-ASR streaming method, SOTA on both streaming and offline benchmarks.
- Project Page: https://showlab.github.io/livecc
> [!Important]
> This is the SFT model. The base model is at [LiveCC-7B-Base](https://huggingface.co/chenjoya/LiveCC-7B-Base).
## Training with Streaming Frame-Words Paradigm

## Quickstart
### Gradio Demo
Please refer to https://github.com/showlab/livecc:

### Hands-on
Like qwen-vl-utils, we offer a toolkit to help you handle various types of visual input more conveniently, **especially on video streaming inputs**. You can install it using the following command:
```bash
pip install qwen-vl-utils livecc-utils liger_kernel
```
Here we show a code snippet to show you how to do **real-time video commentary** with `transformers` and the above utils:
```python
import functools, torch, os, tqdm
from liger_kernel.transformers import apply_liger_kernel_to_qwen2_vl
apply_liger_kernel_to_qwen2_vl() # important. our model is trained with this. keep consistency
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor, LogitsProcessor, logging
from livecc_utils import prepare_multiturn_multimodal_inputs_for_generation, get_smart_resized_clip, get_smart_resized_video_reader
from qwen_vl_utils import process_vision_info
class LiveCCDemoInfer:
fps = 2
initial_fps_frames = 6
streaming_fps_frames = 2
initial_time_interval = initial_fps_frames / fps
streaming_time_interval = streaming_fps_frames / fps
frame_time_interval = 1 / fps
def __init__(self, model_path: str = None, device_id: int = 0):
self.model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto",
device_map=f'cuda:{device_id}',
attn_implementation='flash_attention_2'
)
self.processor = AutoProcessor.from_pretrained(model_path, use_fast=False)
self.model.prepare_inputs_for_generation = functools.partial(prepare_multiturn_multimodal_inputs_for_generation, self.model)
message = {
"role": "user",
"content": [
{"type": "text", "text": 'livecc'},
]
}
texts = self.processor.apply_chat_template([message], tokenize=False)
self.system_prompt_offset = texts.index('<|im_start|>user')
self._cached_video_readers_with_hw = {}
def live_cc(
self,
query: str,
state: dict,
max_pixels: int = 384 * 28 * 28,
default_query: str = 'Please describe the video.',
do_sample: bool = True,
repetition_penalty: float = 1.05,
**kwargs,
):
"""
state: dict, (maybe) with keys:
video_path: str, video path
video_timestamp: float, current video timestamp
last_timestamp: float, last processed video timestamp
last_video_pts_index: int, last processed video frame index
video_pts: np.ndarray, video pts
last_history: list, last processed history
past_key_values: llm past_key_values
past_ids: past generated ids
"""
# 1. preparation: video_reader, and last processing info
video_timestamp, last_timestamp = state.get('video_timestamp', 0), state.get('last_timestamp', -1 / self.fps)
video_path = state['video_path']
if video_path not in self._cached_video_readers_with_hw:
self._cached_video_readers_with_hw[video_path] = get_smart_resized_video_reader(video_path, max_pixels)
video_reader = self._cached_video_readers_with_hw[video_path][0]
video_reader.get_frame_timestamp(0)
state['video_pts'] = torch.from_numpy(video_reader._frame_pts[:, 1])
state['last_video_pts_index'] = -1
video_pts = state['video_pts']
if last_timestamp + self.frame_time_interval > video_pts[-1]:
state['video_end'] = True
return
video_reader, resized_height, resized_width = self._cached_video_readers_with_hw[video_path]
last_video_pts_index = state['last_video_pts_index']
# 2. which frames will be processed
initialized = last_timestamp >= 0
if not initialized:
video_timestamp = max(video_timestamp, self.initial_time_interval)
if video_timestamp <= last_timestamp + self.frame_time_interval:
return
timestamps = torch.arange(last_timestamp + self.frame_time_interval, video_timestamp, self.frame_time_interval) # add compensation
# 3. fetch frames in required timestamps
clip, clip_timestamps, clip_idxs = get_smart_resized_clip(video_reader, resized_height, resized_width, timestamps, video_pts, video_pts_index_from=last_video_pts_index+1)
state['last_video_pts_index'] = clip_idxs[-1]
state['last_timestamp'] = clip_timestamps[-1]
# 4. organize to interleave frames
interleave_clips, interleave_timestamps = [], []
if not initialized:
interleave_clips.append(clip[:self.initial_fps_frames])
interleave_timestamps.append(clip_timestamps[:self.initial_fps_frames])
clip = clip[self.initial_fps_frames:]
clip_timestamps = clip_timestamps[self.initial_fps_frames:]
if len(clip) > 0:
interleave_clips.extend(list(clip.split(self.streaming_fps_frames)))
interleave_timestamps.extend(list(clip_timestamps.split(self.streaming_fps_frames)))
# 5. make conversation and send to model
for clip, timestamps in zip(interleave_clips, interleave_timestamps):
start_timestamp, stop_timestamp = timestamps[0].item(), timestamps[-1].item() + self.frame_time_interval
message = {
"role": "user",
"content": [
{"type": "text", "text": f'Time={start_timestamp:.1f}-{stop_timestamp:.1f}s'},
{"type": "video", "video": clip}
]
}
if not query and not state.get('query', None):
query = default_query
print(f'No query provided, use default_query={default_query}')
if query and state.get('query', None) != query:
message['content'].append({"type": "text", "text": query})
state['query'] = query
texts = self.processor.apply_chat_template([message], tokenize=False, add_generation_prompt=True, return_tensors='pt')
past_ids = state.get('past_ids', None)
if past_ids is not None:
texts = '<|im_end|>\n' + texts[self.system_prompt_offset:]
inputs = self.processor(
text=texts,
images=None,
videos=[clip],
return_tensors="pt",
return_attention_mask=False
)
inputs.to('cuda')
if past_ids is not None:
inputs['input_ids'] = torch.cat([past_ids, inputs.input_ids], dim=1)
outputs = self.model.generate(
**inputs, past_key_values=state.get('past_key_values', None),
return_dict_in_generate=True, do_sample=do_sample,
repetition_penalty=repetition_penalty,
)
state['past_key_values'] = outputs.past_key_values
state['past_ids'] = outputs.sequences[:, :-1]
yield (start_timestamp, stop_timestamp), self.processor.decode(outputs.sequences[0, inputs.input_ids.size(1):], skip_special_tokens=True), state
model_path = 'chenjoya/LiveCC-7B-Instruct'
# download a test video at: https://github.com/showlab/livecc/blob/main/demo/sources/howto_fix_laptop_mute_1080p.mp4
video_path = "demo/sources/howto_fix_laptop_mute_1080p.mp4"
query = "Please describe the video."
infer = LiveCCDemoInfer(model_path=model_path)
state = {'video_path': video_path}
commentaries = []
t = 0
for t in range(31):
state['video_timestamp'] = t
for (start_t, stop_t), response, state in infer.live_cc(
query=query, state=state,
max_pixels = 384 * 28 * 28, repetition_penalty=1.05,
streaming_eos_base_threshold=0.0, streaming_eos_threshold_step=0
):
print(f'{start_t}s-{stop_t}s: {response}')
commentaries.append([start_t, stop_t, response])
if state.get('video_end', False):
break
t += 1
```
Here we show a code snippet to show you how to do **common video (multi-turn) qa** with `transformers` and the above utils:
```python
import functools, torch
from liger_kernel.transformers import apply_liger_kernel_to_qwen2_vl
apply_liger_kernel_to_qwen2_vl() # important. our model is trained with this. keep consistency
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor, LogitsProcessor, logging
from livecc_utils import prepare_multiturn_multimodal_inputs_for_generation, get_smart_resized_clip, get_smart_resized_video_reader
from qwen_vl_utils import process_vision_info
class LiveCCDemoInfer:
fps = 2
initial_fps_frames = 6
streaming_fps_frames = 2
initial_time_interval = initial_fps_frames / fps
streaming_time_interval = streaming_fps_frames / fps
frame_time_interval = 1 / fps
def __init__(self, model_path: str = None, device: str = 'cuda'):
self.model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto",
device_map=device,
attn_implementation='flash_attention_2'
)
self.processor = AutoProcessor.from_pretrained(model_path, use_fast=False)
self.streaming_eos_token_id = self.processor.tokenizer(' ...').input_ids[-1]
self.model.prepare_inputs_for_generation = functools.partial(prepare_multiturn_multimodal_inputs_for_generation, self.model)
message = {
"role": "user",
"content": [
{"type": "text", "text": 'livecc'},
]
}
texts = self.processor.apply_chat_template([message], tokenize=False)
self.system_prompt_offset = texts.index('<|im_start|>user')
def video_qa(
self,
message: str,
state: dict,
do_sample: bool = True,
repetition_penalty: float = 1.05,
**kwargs,
):
"""
state: dict, (maybe) with keys:
video_path: str, video path
video_timestamp: float, current video timestamp
last_timestamp: float, last processed video timestamp
last_video_pts_index: int, last processed video frame index
video_pts: np.ndarray, video pts
last_history: list, last processed history
past_key_values: llm past_key_values
past_ids: past generated ids
"""
video_path = state.get('video_path', None)
conversation = []
past_ids = state.get('past_ids', None)
content = [{"type": "text", "text": message}]
if past_ids is None and video_path: # only use once
content.insert(0, {"type": "video", "video": video_path})
conversation.append({"role": "user", "content": content})
image_inputs, video_inputs = process_vision_info(conversation)
texts = self.processor.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True, return_tensors='pt')
if past_ids is not None:
texts = '<|im_end|>\n' + texts[self.system_prompt_offset:]
inputs = self.processor(
text=texts,
images=image_inputs,
videos=video_inputs,
return_tensors="pt",
return_attention_mask=False
)
inputs.to(self.model.device)
if past_ids is not None:
inputs['input_ids'] = torch.cat([past_ids, inputs.input_ids], dim=1)
outputs = self.model.generate(
**inputs, past_key_values=state.get('past_key_values', None),
return_dict_in_generate=True, do_sample=do_sample,
repetition_penalty=repetition_penalty,
max_new_tokens=512,
)
state['past_key_values'] = outputs.past_key_values
state['past_ids'] = outputs.sequences[:, :-1]
response = self.processor.decode(outputs.sequences[0, inputs.input_ids.size(1):], skip_special_tokens=True)
return response, state
model_path = 'chenjoya/LiveCC-7B-Instruct'
# download a test video at: https://github.com/showlab/livecc/blob/main/demo/sources/howto_fix_laptop_mute_1080p.mp4
video_path = "demo/sources/howto_fix_laptop_mute_1080p.mp4"
infer = LiveCCDemoInfer(model_path=model_path)
state = {'video_path': video_path}
# first round
query1 = 'What is the video?'
response1, state = infer.video_qa(message=query1, state=state)
print(f'Q1: {query1}\nA1: {response1}')
# second round
query2 = 'How do you know that?'
response2, state = infer.video_qa(message=query2, state=state)
print(f'Q2: {query2}\nA2: {response2}')
```
## Performance


## Limitations
- This model is finetuned on LiveCC-7B-Base, which is starting from Qwen2-VL-7B-Base, so it may have limitations mentioned in https://huggingface.co/Qwen/Qwen2-VL-7B.
- When performing real-time video commentary, it may appear collapse --- e.g., repeat pattern. If you encounter this situation, try to adjust repetition_penalty, streaming_eos_base_threshold, and streaming_eos_threshold_step.
- This model only has a context window of 32768. Using more visual tokens per frame (e.g. 768 * 28 * 28) will have better performance, but will shorten the working duration.
These limitations serve as ongoing directions for model optimization and improvement, and we are committed to continually enhancing the model's performance and scope of application.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{livecc,
author = {Joya Chen and Ziyun Zeng and Yiqi Lin and Wei Li and Zejun Ma and Mike Zheng Shou},
title = {LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale},
journal = {arXiv preprint arXiv:2504.16030}
year = {2025},
}
``` |
Mungert/GLM-Z1-9B-0414-GGUF | Mungert | 2025-06-15T19:37:27Z | 1,000 | 5 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"arxiv:2406.12793",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-26T06:57:42Z | ---
license: mit
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">GLM-Z1-9B-0414 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`e291450`](https://github.com/ggerganov/llama.cpp/commit/e291450b7602d7a36239e4ceeece37625f838373).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `GLM-Z1-9B-0414-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `GLM-Z1-9B-0414-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `GLM-Z1-9B-0414-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `GLM-Z1-9B-0414-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `GLM-Z1-9B-0414-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `GLM-Z1-9B-0414-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `GLM-Z1-9B-0414-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `GLM-Z1-9B-0414-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `GLM-Z1-9B-0414-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `GLM-Z1-9B-0414-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `GLM-Z1-9B-0414-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# GLM-4-Z1-9B-0414
## Introduction
The GLM family welcomes a new generation of open-source models, the **GLM-4-32B-0414** series, featuring 32 billion parameters. Its performance is comparable to OpenAI's GPT series and DeepSeek's V3/R1 series, and it supports very user-friendly local deployment features. GLM-4-32B-Base-0414 was pre-trained on 15T of high-quality data, including a large amount of reasoning-type synthetic data, laying the foundation for subsequent reinforcement learning extensions. In the post-training stage, in addition to human preference alignment for dialogue scenarios, we also enhanced the model's performance in instruction following, engineering code, and function calling using techniques such as rejection sampling and reinforcement learning, strengthening the atomic capabilities required for agent tasks. GLM-4-32B-0414 achieves good results in areas such as engineering code, Artifact generation, function calling, search-based Q&A, and report generation. Some benchmarks even rival larger models like GPT-4o and DeepSeek-V3-0324 (671B).
**GLM-Z1-32B-0414** is a reasoning model with **deep thinking capabilities**. This was developed based on GLM-4-32B-0414 through cold start and extended reinforcement learning, as well as further training of the model on tasks involving mathematics, code, and logic. Compared to the base model, GLM-Z1-32B-0414 significantly improves mathematical abilities and the capability to solve complex tasks. During the training process, we also introduced general reinforcement learning based on pairwise ranking feedback, further enhancing the model's general capabilities.
**GLM-Z1-Rumination-32B-0414** is a deep reasoning model with **rumination capabilities** (benchmarked against OpenAI's Deep Research). Unlike typical deep thinking models, the rumination model employs longer periods of deep thought to solve more open-ended and complex problems (e.g., writing a comparative analysis of AI development in two cities and their future development plans). The rumination model integrates search tools during its deep thinking process to handle complex tasks and is trained by utilizing multiple rule-based rewards to guide and extend end-to-end reinforcement learning. Z1-Rumination shows significant improvements in research-style writing and complex retrieval tasks.
Finally, **GLM-Z1-9B-0414** is a surprise. We employed the aforementioned series of techniques to train a 9B small-sized model that maintains the open-source tradition. Despite its smaller scale, GLM-Z1-9B-0414 still exhibits excellent capabilities in mathematical reasoning and general tasks. Its overall performance is already at a leading level among open-source models of the same size. Especially in resource-constrained scenarios, this model achieves an excellent balance between efficiency and effectiveness, providing a powerful option for users seeking lightweight deployment.
## Performance
<p align="center">
<img width="100%" src="https://raw.githubusercontent.com/THUDM/GLM-4/refs/heads/main/resources/Bench-Z1-32B.png">
</p>
<p align="center">
<img width="100%" src="https://raw.githubusercontent.com/THUDM/GLM-4/refs/heads/main/resources/Bench-Z1-9B.png">
</p>
## Model Usage Guidelines
### I. Sampling Parameters
| Parameter | Recommended Value | Description |
| ------------ | ----------------- | -------------------------------------------- |
| temperature | **0.6** | Balances creativity and stability |
| top_p | **0.95** | Cumulative probability threshold for sampling|
| top_k | **40** | Filters out rare tokens while maintaining diversity |
| max_new_tokens | **30000** | Leaves enough tokens for thinking |
### II. Enforced Thinking
- Add \<think\>\n to the **first line**: Ensures the model thinks before responding
- When using `chat_template.jinja`, the prompt is automatically injected to enforce this behavior
### III. Dialogue History Trimming
- Retain only the **final user-visible reply**.
Hidden thinking content should **not** be saved to history to reduce interference—this is already implemented in `chat_template.jinja`
### IV. Handling Long Contexts (YaRN)
- When input length exceeds **8,192 tokens**, consider enabling YaRN (Rope Scaling)
- In supported frameworks, add the following snippet to `config.json`:
```json
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
```
- **Static YaRN** applies uniformly to all text. It may slightly degrade performance on short texts, so enable as needed.
## Inference Code
Make Sure Using `transforemrs>=4.51.3`.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-9B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
```
## Citations
If you find our work useful, please consider citing the following paper.
```
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
``` |
Mungert/Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-GGUF | Mungert | 2025-06-15T19:37:15Z | 846 | 5 | transformers | [
"transformers",
"gguf",
"en",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-22T19:51:00Z | ---
library_name: transformers
language:
- en
license: cc-by-nc-4.0
---
# <span style="color: #7FFF7F;">Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Information
We introduce **Nemotron-UltraLong-8B**, a series of ultra-long context language models designed to process extensive sequences of text (up to 1M, 2M, and 4M tokens) while maintaining competitive performance on standard benchmarks. Built on the Llama-3.1, UltraLong-8B leverages a systematic training recipe that combines efficient continued pretraining with instruction tuning to enhance long-context understanding and instruction-following capabilities. This approach enables our models to efficiently scale their context windows without sacrificing general performance.
## The UltraLong Models
- [nvidia/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct)
- [nvidia/Llama-3.1-Nemotron-8B-UltraLong-2M-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-8B-UltraLong-2M-Instruct)
- [nvidia/Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct)
## Uses
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import transformers
import torch
model_id = "nvidia/Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
## Model Card
* Base model: [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
* Continued Pretraining: The training data consists of 1B tokens sourced from a pretraining corpus using per-domain upsampling based on sample length. The model was trained for 150 iterations with a sequence length of 4M and a global batch size of 2.
* Supervised fine-tuning (SFT): 1B tokens on open-source instruction datasets across general, mathematics, and code domains. We subsample the data from the ‘general_sft_stage2’ from [AceMath-Instruct](https://huggingface.co/datasets/nvidia/AceMath-Instruct-Training-Data).
* Maximum context window: 4M tokens
## Evaluation Results
We evaluate Nemotron-UltraLong-8B on a diverse set of benchmarks, including long-context tasks (e.g., RULER, LV-Eval, and InfiniteBench) and standard tasks (e.g., MMLU, MATH, GSM-8K, and HumanEval). UltraLong-8B achieves superior performance on ultra-long context tasks while maintaining competitive results on standard benchmarks.
### Needle in a Haystack
<img width="80%" alt="image" src="Llama-3.1-8B-UltraLong-4M-Instruct.png">
### Long context evaluation
<img width="80%" alt="image" src="long_benchmark.png">
### Standard capability evaluation
<img width="80%" alt="image" src="standard_benchmark.png">
## Correspondence to
Chejian Xu ([email protected]), Wei Ping ([email protected])
## Citation
<pre>
@article{ulralong2025,
title={From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models},
author={Xu, Chejian and Ping, Wei and Xu, Peng and Liu, Zihan and Wang, Boxin and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint},
year={2025}
}
</pre> |
Mungert/all-MiniLM-L6-v2-GGUF | Mungert | 2025-06-15T19:36:56Z | 2,709 | 4 | sentence-transformers | [
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"imatrix"
] | sentence-similarity | 2025-03-23T03:05:06Z | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# <span style="color: #7FFF7F;">all-MiniLM-L6-v2 GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `all-MiniLM-L6-v2-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `all-MiniLM-L6-v2-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `all-MiniLM-L6-v2-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `all-MiniLM-L6-v2-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `all-MiniLM-L6-v2-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `all-MiniLM-L6-v2-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `all-MiniLM-L6-v2-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `all-MiniLM-L6-v2-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `all-MiniLM-L6-v2-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `all-MiniLM-L6-v2-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `all-MiniLM-L6-v2-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained our model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | |
Mungert/MiniCPM4-8B-GGUF | Mungert | 2025-06-15T19:36:48Z | 906 | 2 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-06-13T20:02:10Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">MiniCPM4-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`7f4fbe51`](https://github.com/ggerganov/llama.cpp/commit/7f4fbe5183b23b6b2e25fd1ccc5d1fa8bb010cb7).
---
## <span style="color: #7FFF7F;">Quantization Beyond the IMatrix</span>
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
<a href="https://readyforquantum.com/huggingface_gguf_selection_guide.html" style="color: #7FFF7F;">
Click here to get info on choosing the right GGUF model format
</a>
---
<!--Begin Original Model Card-->
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens. (**<-- you are here**)
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
## Introduction
MiniCPM 4 is an extremely efficient edge-side large model that has undergone efficient optimization across four dimensions: model architecture, learning algorithms, training data, and inference systems, achieving ultimate efficiency improvements.
- 🏗️ **Efficient Model Architecture:**
- InfLLM v2 -- Trainable Sparse Attention Mechanism: Adopts a trainable sparse attention mechanism architecture where each token only needs to compute relevance with less than 5% of tokens in 128K long text processing, significantly reducing computational overhead for long texts
- 🧠 **Efficient Learning Algorithms:**
- Model Wind Tunnel 2.0 -- Efficient Predictable Scaling: Introduces scaling prediction methods for performance of downstream tasks, enabling more precise model training configuration search
- BitCPM -- Ultimate Ternary Quantization: Compresses model parameter bit-width to 3 values, achieving 90% extreme model bit-width reduction
- Efficient Training Engineering Optimization: Adopts FP8 low-precision computing technology combined with Multi-token Prediction training strategy
- 📚 **High-Quality Training Data:**
- UltraClean -- High-quality Pre-training Data Filtering and Generation: Builds iterative data cleaning strategies based on efficient data verification, open-sourcing high-quality Chinese and English pre-training dataset [UltraFinweb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb)
- UltraChat v2 -- High-quality Supervised Fine-tuning Data Generation: Constructs large-scale high-quality supervised fine-tuning datasets covering multiple dimensions including knowledge-intensive data, reasoning-intensive data, instruction-following data, long text understanding data, and tool calling data
- ⚡ **Efficient Inference System:**
- CPM.cu -- Lightweight and Efficient CUDA Inference Framework: Integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding
- ArkInfer -- Cross-platform Deployment System: Supports efficient deployment across multiple backend environments, providing flexible cross-platform adaptation capabilities
## Usage
### Inference with [CPM.cu](https://github.com/OpenBMB/cpm.cu)
We recommend using [CPM.cu](https://github.com/OpenBMB/cpm.cu) for the inference of MiniCPM4. CPM.cu is a CUDA inference framework developed by OpenBMB, which integrates efficient sparse, speculative sampling, and quantization techniques, fully leveraging the efficiency advantages of MiniCPM4.
You can install CPM.cu by running the following command:
```bash
git clone https://github.com/OpenBMB/cpm.cu.git --recursive
cd cpm.cu
python3 setup.py install
```
MiniCPM4 natively supports context lengths of up to 32,768 tokens. To reproduce the long-text acceleration effect in the paper, we recommend using the LongRoPE factors that have been validated. Change the `rope_scaling` field in the `config.json` file as the following to enable LongRoPE.
```json
{
...,
"rope_scaling": {
"rope_type": "longrope",
"long_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"short_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"original_max_position_embeddings": 32768
}
}
```
After modification, you can run the following command to reproduce the long-context acceleration effect (the script will automatically download the model weights from HuggingFace)
```bash
python3 tests/test_generate.py
```
For more details about CPM.cu, please refer to [the repo CPM.cu](https://github.com/OpenBMB/cpm.cu).
### Inference with Transformers
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM4-8B'
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
# User can directly use the chat interface
# responds, history = model.chat(tokenizer, "Write an article about Artificial Intelligence.", temperature=0.7, top_p=0.7)
# print(responds)
# User can also use the generate interface
messages = [
{"role": "user", "content": "Write an article about Artificial Intelligence."},
]
prompt_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([prompt_text], return_tensors="pt").to(device)
model_outputs = model.generate(
**model_inputs,
max_new_tokens=1024,
top_p=0.7,
temperature=0.7
)
output_token_ids = [
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs['input_ids']))
]
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
print(responses)
```
MiniCPM4-8B supports `InfLLM v2`, a sparse attention mechanism designed for efficient long-sequence inference. It requires the [infllmv2_cuda_impl](https://github.com/OpenBMB/infllmv2_cuda_impl) library.
You can install it by running the following command:
```bash
git clone -b feature_infer https://github.com/OpenBMB/infllmv2_cuda_impl.git
cd infllmv2_cuda_impl
git submodule update --init --recursive
pip install -e . # or python setup.py install
```
To enable InfLLM v2, you need to add the `sparse_config` field in `config.json`:
```json
{
...,
"sparse_config": {
"kernel_size": 32,
"kernel_stride": 16,
"init_blocks": 1,
"block_size": 64,
"window_size": 2048,
"topk": 64,
"use_nope": false,
"dense_len": 8192
}
}
```
These parameters control the behavior of InfLLM v2:
* `kernel_size` (default: 32): The size of semantic kernels.
* `kernel_stride` (default: 16): The stride between adjacent kernels.
* `init_blocks` (default: 1): The number of initial blocks that every query token attends to. This ensures attention to the beginning of the sequence.
* `block_size` (default: 64): The block size for key-value blocks.
* `window_size` (default: 2048): The size of the local sliding window.
* `topk` (default: 64): The specifies that each token computes attention with only the top-k most relevant key-value blocks.
* `use_nope` (default: false): Whether to use the NOPE technique in block selection for improved performance.
* `dense_len` (default: 8192): Since Sparse Attention offers limited benefits for short sequences, the model can use standard (dense) attention for shorter texts. The model will use dense attention for sequences with a token length below `dense_len` and switch to sparse attention for sequences exceeding this length. Set this to `-1` to always use sparse attention regardless of sequence length.
MiniCPM4 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques for effective handling of long texts. We have validated the model's performance on context lengths of up to 131,072 tokens by modifying the LongRoPE factor.
You can apply the LongRoPE factor modification by modifying the model files. Specifically, in the `config.json` file, adjust the `rope_scaling` fields.
```json
{
...,
"rope_scaling": {
"rope_type": "longrope",
"long_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"short_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"original_max_position_embeddings": 32768
}
}
```
### Inference with [SGLang](https://github.com/sgl-project/sglang)
For now, you need to install our forked version of SGLang.
```bash
git clone -b openbmb https://github.com/OpenBMB/sglang.git
cd sglang
pip install --upgrade pip
pip install -e "python[all]"
```
You can start the inference server by running the following command:
```bash
python -m sglang.launch_server --model openbmb/MiniCPM4-8B --trust-remote-code --port 30000 --chat-template chatml
```
Then you can use the chat interface by running the following command:
```python
import openai
client = openai.Client(base_url=f"http://localhost:30000/v1", api_key="None")
response = client.chat.completions.create(
model="openbmb/MiniCPM4-8B",
messages=[
{"role": "user", "content": "Write an article about Artificial Intelligence."},
],
temperature=0.7,
max_tokens=1024,
)
print(response.choices[0].message.content)
```
### Inference with [vLLM](https://github.com/vllm-project/vllm)
For now, you need to install the latest version of vLLM.
```
pip install -U vllm \
--pre \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then you can inference MiniCPM4-8B with vLLM:
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
model_name = "openbmb/MiniCPM4-8B"
prompt = [{"role": "user", "content": "Please recommend 5 tourist attractions in Beijing. "}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
llm = LLM(
model=model_name,
trust_remote_code=True,
max_num_batched_tokens=32768,
dtype="bfloat16",
gpu_memory_utilization=0.8,
)
sampling_params = SamplingParams(top_p=0.7, temperature=0.7, max_tokens=1024, repetition_penalty=1.02)
outputs = llm.generate(prompts=input_text, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
```
Also, you can start the inference server by running the following command:
> **Note**: In vLLM's chat API, `add_special_tokens` is `False` by default. This means important special tokens—such as the beginning-of-sequence (BOS) token—will not be added automatically. To ensure the input prompt is correctly formatted for the model, you should explicitly set `extra_body={"add_special_tokens": True}`.
```bash
vllm serve openbmb/MiniCPM4-8B
```
Then you can use the chat interface by running the following code:
```python
import openai
client = openai.Client(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="openbmb/MiniCPM4-8B",
messages=[
{"role": "user", "content": "Write an article about Artificial Intelligence."},
],
temperature=0.7,
max_tokens=1024,
extra_body=dict(add_special_tokens=True), # Ensures special tokens are added for chat template
)
print(response.choices[0].message.content)
```
## Evaluation Results
On two typical end-side chips, Jetson AGX Orin and RTX 4090, MiniCPM4 demonstrates significantly faster processing speed compared to similar-size models in long text processing tasks. As text length increases, MiniCPM4's efficiency advantage becomes more pronounced. On the Jetson AGX Orin platform, compared to Qwen3-8B, MiniCPM4 achieves approximately 7x decoding speed improvement.

#### Comprehensive Evaluation
MiniCPM4 launches end-side versions with 8B and 0.5B parameter scales, both achieving best-in-class performance in their respective categories.

#### Long Text Evaluation
MiniCPM4 is pre-trained on 32K long texts and achieves length extension through YaRN technology. In the 128K long text needle-in-a-haystack task, MiniCPM4 demonstrates outstanding performance.

## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/Qwen2.5-Omni-7B-GGUF | Mungert | 2025-06-15T19:36:45Z | 979 | 2 | transformers | [
"transformers",
"gguf",
"multimodal",
"any-to-any",
"en",
"arxiv:2503.20215",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | any-to-any | 2025-06-11T03:35:01Z | ---
license: other
license_name: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-Omni-7B/blob/main/LICENSE
language:
- en
tags:
- multimodal
library_name: transformers
pipeline_tag: any-to-any
---
# <span style="color: #7FFF7F;">Qwen2.5-Omni-7B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Qwen2.5-Omni
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Overview
### Introduction
Qwen2.5-Omni is an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/qwen_omni.png" width="80%"/>
<p>
### Key Features
* **Omni and Novel Architecture**: We propose Thinker-Talker architecture, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time-aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
* **Real-Time Voice and Video Chat**: Architecture designed for fully real-time interactions, supporting chunked input and immediate output.
* **Natural and Robust Speech Generation**: Surpassing many existing streaming and non-streaming alternatives, demonstrating superior robustness and naturalness in speech generation.
* **Strong Performance Across Modalities**: Exhibiting exceptional performance across all modalities when benchmarked against similarly sized single-modality models. Qwen2.5-Omni outperforms the similarly sized Qwen2-Audio in audio capabilities and achieves comparable performance to Qwen2.5-VL-7B.
* **Excellent End-to-End Speech Instruction Following**: Qwen2.5-Omni shows performance in end-to-end speech instruction following that rivals its effectiveness with text inputs, evidenced by benchmarks such as MMLU and GSM8K.
### Model Architecture
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/overview.png" width="80%"/>
<p>
### Performance
We conducted a comprehensive evaluation of Qwen2.5-Omni, which demonstrates strong performance across all modalities when compared to similarly sized single-modality models and closed-source models like Qwen2.5-VL-7B, Qwen2-Audio, and Gemini-1.5-pro. In tasks requiring the integration of multiple modalities, such as OmniBench, Qwen2.5-Omni achieves state-of-the-art performance. Furthermore, in single-modality tasks, it excels in areas including speech recognition (Common Voice), translation (CoVoST2), audio understanding (MMAU), image reasoning (MMMU, MMStar), video understanding (MVBench), and speech generation (Seed-tts-eval and subjective naturalness).
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/bar.png" width="80%"/>
<p>
<details>
<summary>Multimodality -> Text</summary>
<table class="tg"><thead>
<tr>
<th class="tg-0lax">Datasets</th>
<th class="tg-0lax">Model</th>
<th class="tg-0lax">Performance</th>
</tr></thead>
<tbody>
<tr>
<td class="tg-0lax" rowspan="10">OmniBench<br>Speech | Sound Event | Music | Avg</td>
<td class="tg-0lax">Gemini-1.5-Pro</td>
<td class="tg-0lax">42.67%|42.26%|46.23%|42.91%</td>
</tr>
<tr>
<td class="tg-0lax">MIO-Instruct</td>
<td class="tg-0lax">36.96%|33.58%|11.32%|33.80%</td>
</tr>
<tr>
<td class="tg-0lax">AnyGPT (7B)</td>
<td class="tg-0lax">17.77%|20.75%|13.21%|18.04%</td>
</tr>
<tr>
<td class="tg-0lax">video-SALMONN</td>
<td class="tg-0lax">34.11%|31.70%|<strong>56.60%</strong>|35.64%</td>
</tr>
<tr>
<td class="tg-0lax">UnifiedIO2-xlarge</td>
<td class="tg-0lax">39.56%|36.98%|29.25%|38.00%</td>
</tr>
<tr>
<td class="tg-0lax">UnifiedIO2-xxlarge</td>
<td class="tg-0lax">34.24%|36.98%|24.53%|33.98%</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">-|-|-|40.50%</td>
</tr>
<tr>
<td class="tg-0lax">Baichuan-Omni-1.5</td>
<td class="tg-0lax">-|-|-|42.90%</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">52.14%|52.08%|52.83%|52.19%</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>55.25%</strong>|<strong>60.00%</strong>|52.83%|<strong>56.13%</strong></td>
</tr>
</tbody></table>
</details>
<details>
<summary>Audio -> Text</summary>
<table class="tg"><thead>
<tr>
<th class="tg-0lax">Datasets</th>
<th class="tg-0lax">Model</th>
<th class="tg-0lax">Performance</th>
</tr></thead>
<tbody>
<tr>
<td class="tg-9j4x" colspan="3">ASR</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="12">Librispeech<br>dev-clean | dev other | test-clean | test-other</td>
<td class="tg-0lax">SALMONN</td>
<td class="tg-0lax">-|-|2.1|4.9</td>
</tr>
<tr>
<td class="tg-0lax">SpeechVerse</td>
<td class="tg-0lax">-|-|2.1|4.4</td>
</tr>
<tr>
<td class="tg-0lax">Whisper-large-v3</td>
<td class="tg-0lax">-|-|1.8|3.6</td>
</tr>
<tr>
<td class="tg-0lax">Llama-3-8B</td>
<td class="tg-0lax">-|-|-|3.4</td>
</tr>
<tr>
<td class="tg-0lax">Llama-3-70B</td>
<td class="tg-0lax">-|-|-|3.1</td>
</tr>
<tr>
<td class="tg-0lax">Seed-ASR-Multilingual</td>
<td class="tg-0lax">-|-|<strong>1.6</strong>|<strong>2.8</strong></td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">-|-|1.7|-</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">-|-|1.7|3.9</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">1.8|4.0|2.0|4.2</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax"><strong>1.3</strong>|<strong>3.4</strong>|<strong>1.6</strong>|3.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">2.0|4.1|2.2|4.5</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">1.6|3.5|1.8|3.4</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="5">Common Voice 15<br>en | zh | yue | fr</td>
<td class="tg-0lax">Whisper-large-v3</td>
<td class="tg-0lax">9.3|12.8|10.9|10.8</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">7.9|6.3|6.4|8.5</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">8.6|6.9|<strong>5.9</strong>|9.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">9.1|6.0|11.6|9.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>7.6</strong>|<strong>5.2</strong>|7.3|<strong>7.5</strong></td>
</tr>
<tr>
<td class="tg-0lax" rowspan="8">Fleurs<br>zh | en</td>
<td class="tg-0lax">Whisper-large-v3</td>
<td class="tg-0lax">7.7|4.1</td>
</tr>
<tr>
<td class="tg-0lax">Seed-ASR-Multilingual</td>
<td class="tg-0lax">-|<strong>3.4</strong></td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">10.8|-</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">4.4|-</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">3.0|3.8</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">7.5|-</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">3.2|5.4</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>3.0</strong>|4.1</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="6">Wenetspeech<br>test-net | test-meeting</td>
<td class="tg-0lax">Seed-ASR-Chinese</td>
<td class="tg-0lax"><strong>4.7|5.7</strong></td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">-|16.4</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">6.9|-</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">6.8|7.4</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">6.3|8.1</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">5.9|7.7</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="4">Voxpopuli-V1.0-en</td>
<td class="tg-0lax">Llama-3-8B</td>
<td class="tg-0lax">6.2</td>
</tr>
<tr>
<td class="tg-0lax">Llama-3-70B</td>
<td class="tg-0lax"><strong>5.7</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">6.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">5.8</td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">S2TT</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="9">CoVoST2<br>en-de | de-en | en-zh | zh-en</td>
<td class="tg-0lax">SALMONN</td>
<td class="tg-0lax">18.6|-|33.1|-</td>
</tr>
<tr>
<td class="tg-0lax">SpeechLLaMA</td>
<td class="tg-0lax">-|27.1|-|12.3</td>
</tr>
<tr>
<td class="tg-0lax">BLSP</td>
<td class="tg-0lax">14.1|-|-|-</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">-|-|<strong>48.2</strong>|27.2</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">-|<strong>39.9</strong>|46.7|26.0</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">25.1|33.9|41.5|15.7</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">29.9|35.2|45.2|24.4</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">28.3|38.1|41.4|26.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>30.2</strong>|37.7|41.4|<strong>29.4</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">SER</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="6">Meld</td>
<td class="tg-0lax">WavLM-large</td>
<td class="tg-0lax">0.542</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">0.524</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">0.557</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">0.553</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">0.558</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.570</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">VSC</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="6">VocalSound</td>
<td class="tg-0lax">CLAP</td>
<td class="tg-0lax">0.495</td>
</tr>
<tr>
<td class="tg-0lax">Pengi</td>
<td class="tg-0lax">0.604</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">0.929</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax"><strong>0.939</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">0.936</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.939</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Music</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="3">GiantSteps Tempo</td>
<td class="tg-0lax">Llark-7B</td>
<td class="tg-0lax">0.86</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax"><strong>0.88</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.88</strong></td>
</tr>
<tr>
<td class="tg-0lax" rowspan="3">MusicCaps</td>
<td class="tg-0lax">LP-MusicCaps</td>
<td class="tg-0lax">0.291|0.149|0.089|<strong>0.061</strong>|0.129|0.130</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">0.325|<strong>0.163</strong>|<strong>0.093</strong>|0.057|<strong>0.132</strong>|<strong>0.229</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.328</strong>|0.162|0.090|0.055|0.127|0.225</td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Audio Reasoning</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="4">MMAU<br>Sound | Music | Speech | Avg</td>
<td class="tg-0lax">Gemini-Pro-V1.5</td>
<td class="tg-0lax">56.75|49.40|58.55|54.90</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">54.95|50.98|42.04|49.20</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax"><strong>70.27</strong>|60.48|59.16|63.30</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">67.87|<strong>69.16|59.76|65.60</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Voice Chatting</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="9">VoiceBench<br>AlpacaEval | CommonEval | SD-QA | MMSU</td>
<td class="tg-0lax">Ultravox-v0.4.1-LLaMA-3.1-8B</td>
<td class="tg-0lax"><strong>4.55</strong>|3.90|53.35|47.17</td>
</tr>
<tr>
<td class="tg-0lax">MERaLiON</td>
<td class="tg-0lax">4.50|3.77|55.06|34.95</td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">3.50|2.95|25.95|27.03</td>
</tr>
<tr>
<td class="tg-0lax">Lyra-Base</td>
<td class="tg-0lax">3.85|3.50|38.25|49.74</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">4.42|<strong>4.15</strong>|50.72|54.78</td>
</tr>
<tr>
<td class="tg-0lax">Baichuan-Omni-1.5</td>
<td class="tg-0lax">4.50|4.05|43.40|57.25</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">3.74|3.43|35.71|35.72</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">4.32|4.00|49.37|50.23</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">4.49|3.93|<strong>55.71</strong>|<strong>61.32</strong></td>
</tr>
<tr>
<td class="tg-0lax" rowspan="9">VoiceBench<br>OpenBookQA | IFEval | AdvBench | Avg</td>
<td class="tg-0lax">Ultravox-v0.4.1-LLaMA-3.1-8B</td>
<td class="tg-0lax">65.27|<strong>66.88</strong>|98.46|71.45</td>
</tr>
<tr>
<td class="tg-0lax">MERaLiON</td>
<td class="tg-0lax">27.23|62.93|94.81|62.91</td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">28.35|25.71|87.69|46.25</td>
</tr>
<tr>
<td class="tg-0lax">Lyra-Base</td>
<td class="tg-0lax">72.75|36.28|59.62|57.66</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">78.02|49.25|97.69|71.69</td>
</tr>
<tr>
<td class="tg-0lax">Baichuan-Omni-1.5</td>
<td class="tg-0lax">74.51|54.54|97.31|71.14</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">49.45|26.33|96.73|55.35</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">74.73|42.10|98.85|68.81</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>81.10</strong>|52.87|<strong>99.42</strong>|<strong>74.12</strong></td>
</tr>
</tbody></table>
</details>
<details>
<summary>Image -> Text</summary>
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|--------------------------------|--------------|------------|------------|---------------|-------------|
| MMMU<sub>val</sub> | 59.2 | 53.1 | 53.9 | 58.6 | **60.0** |
| MMMU-Pro<sub>overall</sub> | 36.6 | 29.7 | - | **38.3** | 37.6 |
| MathVista<sub>testmini</sub> | 67.9 | 59.4 | **71.9** | 68.2 | 52.5 |
| MathVision<sub>full</sub> | 25.0 | 20.8 | 23.1 | **25.1** | - |
| MMBench-V1.1-EN<sub>test</sub> | 81.8 | 77.8 | 80.5 | **82.6** | 76.0 |
| MMVet<sub>turbo</sub> | 66.8 | 62.1 | **67.5** | 67.1 | 66.9 |
| MMStar | **64.0** | 55.7 | **64.0** | 63.9 | 54.8 |
| MME<sub>sum</sub> | 2340 | 2117 | **2372** | 2347 | 2003 |
| MuirBench | 59.2 | 48.0 | - | **59.2** | - |
| CRPE<sub>relation</sub> | **76.5** | 73.7 | - | 76.4 | - |
| RealWorldQA<sub>avg</sub> | 70.3 | 62.6 | **71.9** | 68.5 | - |
| MME-RealWorld<sub>en</sub> | **61.6** | 55.6 | - | 57.4 | - |
| MM-MT-Bench | 6.0 | 5.0 | - | **6.3** | - |
| AI2D | 83.2 | 79.5 | **85.8** | 83.9 | - |
| TextVQA<sub>val</sub> | 84.4 | 79.8 | 83.2 | **84.9** | - |
| DocVQA<sub>test</sub> | 95.2 | 93.3 | 93.5 | **95.7** | - |
| ChartQA<sub>test Avg</sub> | 85.3 | 82.8 | 84.9 | **87.3** | - |
| OCRBench_V2<sub>en</sub> | **57.8** | 51.7 | - | 56.3 | - |
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Qwen2.5-VL-7B | Grounding DINO | Gemini 1.5 Pro |
|--------------------------|--------------|---------------|---------------|----------------|----------------|
| Refcoco<sub>val</sub> | 90.5 | 88.7 | 90.0 | **90.6** | 73.2 |
| Refcoco<sub>textA</sub> | **93.5** | 91.8 | 92.5 | 93.2 | 72.9 |
| Refcoco<sub>textB</sub> | 86.6 | 84.0 | 85.4 | **88.2** | 74.6 |
| Refcoco+<sub>val</sub> | 85.4 | 81.1 | 84.2 | **88.2** | 62.5 |
| Refcoco+<sub>textA</sub> | **91.0** | 87.5 | 89.1 | 89.0 | 63.9 |
| Refcoco+<sub>textB</sub> | **79.3** | 73.2 | 76.9 | 75.9 | 65.0 |
| Refcocog+<sub>val</sub> | **87.4** | 85.0 | 87.2 | 86.1 | 75.2 |
| Refcocog+<sub>test</sub> | **87.9** | 85.1 | 87.2 | 87.0 | 76.2 |
| ODinW | 42.4 | 39.2 | 37.3 | **55.0** | 36.7 |
| PointGrounding | 66.5 | 46.2 | **67.3** | - | - |
</details>
<details>
<summary>Video(without audio) -> Text</summary>
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|-----------------------------|--------------|------------|------------|---------------|-------------|
| Video-MME<sub>w/o sub</sub> | 64.3 | 62.0 | 63.9 | **65.1** | 64.8 |
| Video-MME<sub>w sub</sub> | **72.4** | 68.6 | 67.9 | 71.6 | - |
| MVBench | **70.3** | 68.7 | 67.2 | 69.6 | - |
| EgoSchema<sub>test</sub> | **68.6** | 61.4 | 63.2 | 65.0 | - |
</details>
<details>
<summary>Zero-shot Speech Generation</summary>
<table class="tg"><thead>
<tr>
<th class="tg-0lax">Datasets</th>
<th class="tg-0lax">Model</th>
<th class="tg-0lax">Performance</th>
</tr></thead>
<tbody>
<tr>
<td class="tg-9j4x" colspan="3">Content Consistency</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="11">SEED<br>test-zh | test-en | test-hard </td>
<td class="tg-0lax">Seed-TTS_ICL</td>
<td class="tg-0lax">1.11 | 2.24 | 7.58</td>
</tr>
<tr>
<td class="tg-0lax">Seed-TTS_RL</td>
<td class="tg-0lax"><strong>1.00</strong> | 1.94 | <strong>6.42</strong></td>
</tr>
<tr>
<td class="tg-0lax">MaskGCT</td>
<td class="tg-0lax">2.27 | 2.62 | 10.27</td>
</tr>
<tr>
<td class="tg-0lax">E2_TTS</td>
<td class="tg-0lax">1.97 | 2.19 | -</td>
</tr>
<tr>
<td class="tg-0lax">F5-TTS</td>
<td class="tg-0lax">1.56 | <strong>1.83</strong> | 8.67</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2</td>
<td class="tg-0lax">1.45 | 2.57 | 6.83</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2-S</td>
<td class="tg-0lax">1.45 | 2.38 | 8.08</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_ICL</td>
<td class="tg-0lax">1.95 | 2.87 | 9.92</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_RL</td>
<td class="tg-0lax">1.58 | 2.51 | 7.86</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_ICL</td>
<td class="tg-0lax">1.70 | 2.72 | 7.97</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_RL</td>
<td class="tg-0lax">1.42 | 2.32 | 6.54</td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Speaker Similarity</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="11">SEED<br>test-zh | test-en | test-hard </td>
<td class="tg-0lax">Seed-TTS_ICL</td>
<td class="tg-0lax">0.796 | 0.762 | 0.776</td>
</tr>
<tr>
<td class="tg-0lax">Seed-TTS_RL</td>
<td class="tg-0lax"><strong>0.801</strong> | <strong>0.766</strong> | <strong>0.782</strong></td>
</tr>
<tr>
<td class="tg-0lax">MaskGCT</td>
<td class="tg-0lax">0.774 | 0.714 | 0.748</td>
</tr>
<tr>
<td class="tg-0lax">E2_TTS</td>
<td class="tg-0lax">0.730 | 0.710 | -</td>
</tr>
<tr>
<td class="tg-0lax">F5-TTS</td>
<td class="tg-0lax">0.741 | 0.647 | 0.713</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2</td>
<td class="tg-0lax">0.748 | 0.652 | 0.724</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2-S</td>
<td class="tg-0lax">0.753 | 0.654 | 0.732</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_ICL</td>
<td class="tg-0lax">0.741 | 0.635 | 0.748</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_RL</td>
<td class="tg-0lax">0.744 | 0.635 | 0.746</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_ICL</td>
<td class="tg-0lax">0.752 | 0.632 | 0.747</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_RL</td>
<td class="tg-0lax">0.754 | 0.641 | 0.752</td>
</tr>
</tbody></table>
</details>
<details>
<summary>Text -> Text</summary>
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Qwen2.5-7B | Qwen2.5-3B | Qwen2-7B | Llama3.1-8B | Gemma2-9B |
|-----------------------------------|-----------|------------|------------|------------|------------|-------------|-----------|
| MMLU-Pro | 47.0 | 40.4 | **56.3** | 43.7 | 44.1 | 48.3 | 52.1 |
| MMLU-redux | 71.0 | 60.9 | **75.4** | 64.4 | 67.3 | 67.2 | 72.8 |
| LiveBench<sub>0831</sub> | 29.6 | 22.3 | **35.9** | 26.8 | 29.2 | 26.7 | 30.6 |
| GPQA | 30.8 | 34.3 | **36.4** | 30.3 | 34.3 | 32.8 | 32.8 |
| MATH | 71.5 | 63.6 | **75.5** | 65.9 | 52.9 | 51.9 | 44.3 |
| GSM8K | 88.7 | 82.6 | **91.6** | 86.7 | 85.7 | 84.5 | 76.7 |
| HumanEval | 78.7 | 70.7 | **84.8** | 74.4 | 79.9 | 72.6 | 68.9 |
| MBPP | 73.2 | 70.4 | **79.2** | 72.7 | 67.2 | 69.6 | 74.9 |
| MultiPL-E | 65.8 | 57.6 | **70.4** | 60.2 | 59.1 | 50.7 | 53.4 |
| LiveCodeBench<sub>2305-2409</sub> | 24.6 | 16.5 | **28.7** | 19.9 | 23.9 | 8.3 | 18.9 |
</details>
## Quickstart
Below, we provide simple examples to show how to use Qwen2.5-Omni with 🤗 Transformers. The codes of Qwen2.5-Omni has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip uninstall transformers
pip install git+https://github.com/huggingface/[email protected]
pip install accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_omni'
```
We offer a toolkit to help you handle various types of audio and visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved audio, images and videos. You can install it using the following command and make sure your system has `ffmpeg` installed:
```bash
# It's highly recommended to use `[decord]` feature for faster video loading.
pip install qwen-omni-utils[decord] -U
```
If you are not using Linux, you might not be able to install `decord` from PyPI. In that case, you can use `pip install qwen-omni-utils -U` which will fall back to using torchvision for video processing. However, you can still [install decord from source](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source) to get decord used when loading video.
### 🤗 Transformers Usage
Here we show a code snippet to show you how to use the chat model with `transformers` and `qwen_omni_utils`:
```python
import soundfile as sf
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
```
<details>
<summary>Minimum GPU memory requirements</summary>
|Model | Precision | 15(s) Video | 30(s) Video | 60(s) Video |
|--------------|-----------| ------------- | ------------- | ------------------ |
| Qwen-Omni-3B | FP32 | 89.10 GB | Not Recommend | Not Recommend |
| Qwen-Omni-3B | BF16 | 18.38 GB | 22.43 GB | 28.22 GB |
| Qwen-Omni-7B | FP32 | 93.56 GB | Not Recommend | Not Recommend |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
Note: The table above presents the theoretical minimum memory requirements for inference with `transformers` and `BF16` is test with `attn_implementation="flash_attention_2"`; however, in practice, the actual memory usage is typically at least 1.2 times higher. For more information, see the linked resource [here](https://huggingface.co/docs/accelerate/main/en/usage_guides/model_size_estimator).
</details>
<details>
<summary>Video URL resource usage</summary>
Video URL compatibility largely depends on the third-party library version. The details are in the table below. Change the backend by `FORCE_QWENVL_VIDEO_READER=torchvision` or `FORCE_QWENVL_VIDEO_READER=decord` if you prefer not to use the default one.
| Backend | HTTP | HTTPS |
|-------------|------|-------|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
</details>
<details>
<summary>Batch inference</summary>
The model can batch inputs composed of mixed samples of various types such as text, images, audio and videos as input when `return_audio=False` is set. Here is an example.
```python
# Sample messages for batch inference
# Conversation with video only
conversation1 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/video.mp4"},
]
}
]
# Conversation with audio only
conversation2 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
]
}
]
# Conversation with pure text
conversation3 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": "who are you?"
}
]
# Conversation with mixed media
conversation4 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "text", "text": "What are the elements can you see and hear in these medias?"},
],
}
]
# Combine messages for batch processing
conversations = [conversation1, conversation2, conversation3, conversation4]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for batch inference
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Batch Inference
text_ids = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO, return_audio=False)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
```
</details>
### Usage Tips
#### Prompt for audio output
If users need audio output, the system prompt must be set as "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.", otherwise the audio output may not work as expected.
```
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
}
```
#### Use audio in video
In the process of multimodal interaction, the videos provided by users are often accompanied by audio (such as questions about the content in the video, or sounds generated by certain events in the video). This information is conducive to the model providing a better interactive experience. So we provide the following options for users to decide whether to use audio in video.
```python
# first place, in data preprocessing
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
```
```python
# second place, in model processor
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt",
padding=True, use_audio_in_video=True)
```
```python
# third place, in model inference
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
```
It is worth noting that during a multi-round conversation, the `use_audio_in_video` parameter in these places must be set to the same, otherwise unexpected results will occur.
#### Use audio output or not
The model supports both text and audio outputs, if users do not need audio outputs, they can call `model.disable_talker()` after init the model. This option will save about `~2GB` of GPU memory but the `return_audio` option for `generate` function will only allow to be set at `False`.
```python
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
model.disable_talker()
```
In order to obtain a flexible experience, we recommend that users can decide whether to return audio when `generate` function is called. If `return_audio` is set to `False`, the model will only return text outputs to get text responses faster.
```python
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
...
text_ids = model.generate(**inputs, return_audio=False)
```
#### Change voice type of output audio
Qwen2.5-Omni supports the ability to change the voice of the output audio. The `"Qwen/Qwen2.5-Omni-7B"` checkpoint support two voice types as follow:
| Voice Type | Gender | Description |
|------------|--------|-------------|
| Chelsie | Female | A honeyed, velvety voice that carries a gentle warmth and luminous clarity.|
| Ethan | Male | A bright, upbeat voice with infectious energy and a warm, approachable vibe.|
Users can use the `speaker` parameter of `generate` function to specify the voice type. By default, if `speaker` is not specified, the default voice type is `Chelsie`.
```python
text_ids, audio = model.generate(**inputs, speaker="Chelsie")
```
```python
text_ids, audio = model.generate(**inputs, speaker="Ethan")
```
#### Flash-Attention 2 to speed up generation
First, make sure to install the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
Also, you should have hardware that is compatible with FlashAttention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
To load and run a model using FlashAttention-2, add `attn_implementation="flash_attention_2"` when loading the model:
```python
from transformers import Qwen2_5OmniForConditionalGeneration
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
## Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
```BibTeX
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}
```
<br>
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/Qwen3-Embedding-4B-GGUF | Mungert | 2025-06-15T19:36:40Z | 1,582 | 2 | sentence-transformers | [
"sentence-transformers",
"gguf",
"transformers",
"sentence-similarity",
"feature-extraction",
"base_model:Qwen/Qwen3-4B-Base",
"base_model:quantized:Qwen/Qwen3-4B-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | feature-extraction | 2025-06-10T13:02:08Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-4B-Base
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
---
# <span style="color: #7FFF7F;">Qwen3-Embedding-4B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Qwen3-Embedding-4B
<p align="center">
<img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen3.png" width="400"/>
<p>
## Highlights
The Qwen3 Embedding model series is the latest proprietary model of the Qwen family, specifically designed for text embedding and ranking tasks. Building upon the dense foundational models of the Qwen3 series, it provides a comprehensive range of text embeddings and reranking models in various sizes (0.6B, 4B, and 8B). This series inherits the exceptional multilingual capabilities, long-text understanding, and reasoning skills of its foundational model. The Qwen3 Embedding series represents significant advancements in multiple text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bitext mining.
**Exceptional Versatility**: The embedding model has achieved state-of-the-art performance across a wide range of downstream application evaluations. The 8B size embedding model ranks **No.1** in the MTEB multilingual leaderboard (as of June 5, 2025, score **70.58**), while the reranking model excels in various text retrieval scenarios.
**Comprehensive Flexibility**: The Qwen3 Embedding series offers a full spectrum of sizes (from 0.6B to 8B) for both embedding and reranking models, catering to diverse use cases that prioritize efficiency and effectiveness. Developers can seamlessly combine these two modules. Additionally, the embedding model allows for flexible vector definitions across all dimensions, and both embedding and reranking models support user-defined instructions to enhance performance for specific tasks, languages, or scenarios.
**Multilingual Capability**: The Qwen3 Embedding series offer support for over 100 languages, thanks to the multilingual capabilites of Qwen3 models. This includes various programming languages, and provides robust multilingual, cross-lingual, and code retrieval capabilities.
## Model Overview
**Qwen3-Embedding-4B** has the following features:
- Model Type: Text Embedding
- Supported Languages: 100+ Languages
- Number of Paramaters: 4B
- Context Length: 32k
- Embedding Dimension: Up to 2560, supports user-defined output dimensions ranging from 32 to 2560
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-embedding/), [GitHub](https://github.com/QwenLM/Qwen3-Embedding).
## Qwen3 Embedding Series Model list
| Model Type | Models | Size | Layers | Sequence Length | Embedding Dimension | MRL Support | Instruction Aware |
|------------------|----------------------|------|--------|-----------------|---------------------|-------------|----------------|
| Text Embedding | [Qwen3-Embedding-0.6B](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) | 0.6B | 28 | 32K | 1024 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-4B](https://huggingface.co/Qwen/Qwen3-Embedding-4B) | 4B | 36 | 32K | 2560 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-8B](https://huggingface.co/Qwen/Qwen3-Embedding-8B) | 8B | 36 | 32K | 4096 | Yes | Yes |
| Text Reranking | [Qwen3-Reranker-0.6B](https://huggingface.co/Qwen/Qwen3-Reranker-0.6B) | 0.6B | 28 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-4B](https://huggingface.co/Qwen/Qwen3-Reranker-4B) | 4B | 36 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-8B](https://huggingface.co/Qwen/Qwen3-Reranker-8B) | 8B | 36 | 32K | - | - | Yes |
> **Note**:
> - `MRL Support` indicates whether the embedding model supports custom dimensions for the final embedding.
> - `Instruction Aware` notes whether the embedding or reranking model supports customizing the input instruction according to different tasks.
> - Our evaluation indicates that, for most downstream tasks, using instructions (instruct) typically yields an improvement of 1% to 5% compared to not using them. Therefore, we recommend that developers create tailored instructions specific to their tasks and scenarios. In multilingual contexts, we also advise users to write their instructions in English, as most instructions utilized during the model training process were originally written in English.
## Usage
With Transformers versions earlier than 4.51.0, you may encounter the following error:
```
KeyError: 'qwen3'
```
### Sentence Transformers Usage
```python
# Requires transformers>=4.51.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("Qwen/Qwen3-Embedding-4B")
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-4B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
# tensor([[0.7534, 0.1147],
# [0.0320, 0.6258]])
```
### Transformers Usage
```python
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-4B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-4B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-4B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7534257769584656, 0.1146894246339798], [0.03198453038930893, 0.6258305311203003]]
```
📌 **Tip**: We recommend that developers customize the `instruct` according to their specific scenarios, tasks, and languages. Our tests have shown that in most retrieval scenarios, not using an `instruct` on the query side can lead to a drop in retrieval performance by approximately 1% to 5%.
## Evaluation
### MTEB (Multilingual)
| Model | Size | Mean (Task) | Mean (Type) | Bitxt Mining | Class. | Clust. | Inst. Retri. | Multi. Class. | Pair. Class. | Rerank | Retri. | STS |
|----------------------------------|:-------:|:-------------:|:-------------:|:--------------:|:--------:|:--------:|:--------------:|:---------------:|:--------------:|:--------:|:--------:|:------:|
| NV-Embed-v2 | 7B | 56.29 | 49.58 | 57.84 | 57.29 | 40.80 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10|
| GritLM-7B | 7B | 60.92 | 53.74 | 70.53 | 61.83 | 49.75 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33|
| BGE-M3 | 0.6B | 59.56 | 52.18 | 79.11 | 60.35 | 40.88 | -3.11 | 20.1 | 80.76 | 62.79 | 54.60 | 74.12|
| multilingual-e5-large-instruct | 0.6B | 63.22 | 55.08 | 80.13 | 64.94 | 50.75 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81|
| gte-Qwen2-1.5B-instruct | 1.5B | 59.45 | 52.69 | 62.51 | 58.32 | 52.05 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61|
| gte-Qwen2-7b-Instruct | 7B | 62.51 | 55.93 | 73.92 | 61.55 | 52.77 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98|
| text-embedding-3-large | - | 58.93 | 51.41 | 62.17 | 60.27 | 46.89 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68|
| Cohere-embed-multilingual-v3.0 | - | 61.12 | 53.23 | 70.50 | 62.95 | 46.89 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80|
| gemini-embedding-exp-03-07 | - | 68.37 | 59.59 | 79.28 | 71.82 | 54.59 | 5.18 | **29.16** | 83.63 | 65.58 | 67.71 | 79.40|
| **Qwen3-Embedding-0.6B** | 0.6B | 64.33 | 56.00 | 72.22 | 66.83 | 52.33 | 5.09 | 24.59 | 80.83 | 61.41 | 64.64 | 76.17|
| **Qwen3-Embedding-4B** | 4B | 69.45 | 60.86 | 79.36 | 72.33 | 57.15 | **11.56** | 26.77 | 85.05 | 65.08 | 69.60 | 80.86|
| **Qwen3-Embedding-8B** | 8B | **70.58** | **61.69** | **80.89** | **74.00** | **57.65** | 10.06 | 28.66 | **86.40** | **65.63** | **70.88** | **81.08** |
> **Note**: For compared models, the scores are retrieved from MTEB online [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on May 24th, 2025.
### MTEB (Eng v2)
| MTEB English / Models | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retri. | STS | Summ. |
|--------------------------------|:--------:|:------------:|:------------:|:--------:|:--------:|:-------------:|:---------:|:--------:|:-------:|:-------:|
| multilingual-e5-large-instruct | 0.6B | 65.53 | 61.21 | 75.54 | 49.89 | 86.24 | 48.74 | 53.47 | 84.72 | 29.89 |
| NV-Embed-v2 | 7.8B | 69.81 | 65.00 | 87.19 | 47.66 | 88.69 | 49.61 | 62.84 | 83.82 | 35.21 |
| GritLM-7B | 7.2B | 67.07 | 63.22 | 81.25 | 50.82 | 87.29 | 49.59 | 54.95 | 83.03 | 35.65 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.20 | 63.26 | 85.84 | 53.54 | 87.52 | 49.25 | 50.25 | 82.51 | 33.94 |
| stella_en_1.5B_v5 | 1.5B | 69.43 | 65.32 | 89.38 | 57.06 | 88.02 | 50.19 | 52.42 | 83.27 | 36.91 |
| gte-Qwen2-7B-instruct | 7.6B | 70.72 | 65.77 | 88.52 | 58.97 | 85.9 | 50.47 | 58.09 | 82.69 | 35.74 |
| gemini-embedding-exp-03-07 | - | 73.3 | 67.67 | 90.05 | **59.39** | **87.7** | 48.59 | 64.35 | 85.29 | **38.28** |
| **Qwen3-Embedding-0.6B** | 0.6B | 70.70 | 64.88 | 85.76 | 54.05 | 84.37 | 48.18 | 61.83 | 86.57 | 33.43 |
| **Qwen3-Embedding-4B** | 4B | 74.60 | 68.10 | 89.84 | 57.51 | 87.01 | 50.76 | 68.46 | **88.72** | 34.39 |
| **Qwen3-Embedding-8B** | 8B | **75.22** | **68.71** | **90.43** | 58.57 | 87.52 | **51.56** | **69.44** | 88.58 | 34.83 |
### C-MTEB (MTEB Chinese)
| C-MTEB | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retr. | STS |
|------------------|--------|------------|------------|--------|--------|-------------|---------|-------|-------|
| multilingual-e5-large-instruct | 0.6B | 58.08 | 58.24 | 69.80 | 48.23 | 64.52 | 57.45 | 63.65 | 45.81 |
| bge-multilingual-gemma2 | 9B | 67.64 |68.52 | 75.31 | 59.30 | 86.67 | 68.28 | 73.73 | 55.19 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.12 | 67.79 | 72.53 | 54.61 | 79.5 | 68.21 | 71.86 | 60.05 |
| gte-Qwen2-7B-instruct | 7.6B | 71.62 | 72.19 | 75.77 | 66.06 | 81.16 | 69.24 | 75.70 | 65.20 |
| ritrieve_zh_v1 | 0.3B | 72.71 | 73.85 | 76.88 | 66.5 | **85.98** | **72.86** | 76.97 | **63.92** |
| **Qwen3-Embedding-0.6B** | 0.6B | 66.33 | 67.45 | 71.40 | 68.74 | 76.42 | 62.58 | 71.03 | 54.52 |
| **Qwen3-Embedding-4B** | 4B | 72.27 | 73.51 | 75.46 | 77.89 | 83.34 | 66.05 | 77.03 | 61.26 |
| **Qwen3-Embedding-8B** | 8B | **73.84** | **75.00** | **76.97** | **80.08** | 84.23 | 66.99 | **78.21** | 63.53 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3-embedding,
title = {Qwen3-Embedding},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {May},
year = {2025}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
meezofun/Full.Latest.Video.18.meezofun.meezo.fun.com.meezo.fun.video.meezo.fun | meezofun | 2025-06-15T19:36:38Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:34:33Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=mezzo-fun)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=mezzo-fun)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=mezzo-fun) |
Peacemann/Qwen_QwQ-32B_LMUL | Peacemann | 2025-06-15T19:36:36Z | 0 | 0 | null | [
"qwen2",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:Qwen/QwQ-32B",
"base_model:finetune:Qwen/QwQ-32B",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T19:33:06Z | ---
license: apache-2.0
base_model: Qwen/QwQ-32B
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
---
# Model Card for Qwen/QwQ-32B-LMUL
This model is a derivative of `Qwen/QwQ-32B`, modified to use a custom attention mechanism defined by the `l_mul_attention` function from the `lmul` library.
## Model Details
- **Original Model:** [Qwen/QwQ-32B](https://huggingface.co/Qwen/QwQ-32B)
- **Architecture:** qwen2
- **Modification:** The `forward` method of the `Qwen2Attention` module has been replaced (monkey-patched) with a custom implementation that utilizes the `l_mul_attention` logic.
## Scientific Rationale
This model was modified as part of a research project investigating alternative attention mechanisms in large language models. The `l_mul_attention` function implements a novel approach to calculating attention scores, and this model serves as a test case for evaluating its performance, efficiency, and impact on reasoning and generation tasks compared to the standard attention implementation.
By releasing this model, we hope to encourage further research into non-standard attention mechanisms and provide a practical example for the community to build upon.
## How to Get Started
You can use this model with the standard `transformers` library pipeline. Ensure you have `transformers`, `torch`, and `accelerate` installed.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Make sure to log in with your Hugging Face token if the model is private
# from huggingface_hub import login
# login("your-hf-token")
model_id = "YOUR_HF_USERNAME/QwQ-32B_LMUL" # Replace with your Hugging Face username
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
## Intended Uses & Limitations
This model is intended primarily for research purposes. Its performance on standard benchmarks has not been fully evaluated. The custom attention mechanism may introduce unexpected behaviors or limitations not present in the original `Qwen/QwQ-32B` model.
## Licensing Information
This model is released under the `apache-2.0` license, which is the same license as the base model, `Qwen/QwQ-32B`. By using this model, you agree to the terms of the original license. It is your responsibility to ensure compliance with all applicable licenses and regulations. |
Mungert/Qwen3-Embedding-0.6B-GGUF | Mungert | 2025-06-15T19:36:34Z | 2,465 | 2 | sentence-transformers | [
"sentence-transformers",
"gguf",
"transformers",
"sentence-similarity",
"feature-extraction",
"arxiv:2506.05176",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:quantized:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | feature-extraction | 2025-06-10T11:28:41Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-0.6B-Base
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
---
# <span style="color: #7FFF7F;">Qwen3-Embedding-0.6B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
# Qwen3-Embedding-0.6B
<p align="center">
<img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen3.png" width="400"/>
<p>
## Highlights
The Qwen3 Embedding model series is the latest proprietary model of the Qwen family, specifically designed for text embedding and ranking tasks. Building upon the dense foundational models of the Qwen3 series, it provides a comprehensive range of text embeddings and reranking models in various sizes (0.6B, 4B, and 8B). This series inherits the exceptional multilingual capabilities, long-text understanding, and reasoning skills of its foundational model. The Qwen3 Embedding series represents significant advancements in multiple text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bitext mining.
**Exceptional Versatility**: The embedding model has achieved state-of-the-art performance across a wide range of downstream application evaluations. The 8B size embedding model ranks **No.1** in the MTEB multilingual leaderboard (as of June 5, 2025, score **70.58**), while the reranking model excels in various text retrieval scenarios.
**Comprehensive Flexibility**: The Qwen3 Embedding series offers a full spectrum of sizes (from 0.6B to 8B) for both embedding and reranking models, catering to diverse use cases that prioritize efficiency and effectiveness. Developers can seamlessly combine these two modules. Additionally, the embedding model allows for flexible vector definitions across all dimensions, and both embedding and reranking models support user-defined instructions to enhance performance for specific tasks, languages, or scenarios.
**Multilingual Capability**: The Qwen3 Embedding series offer support for over 100 languages, thanks to the multilingual capabilites of Qwen3 models. This includes various programming languages, and provides robust multilingual, cross-lingual, and code retrieval capabilities.
## Model Overview
**Qwen3-Embedding-0.6B** has the following features:
- Model Type: Text Embedding
- Supported Languages: 100+ Languages
- Number of Paramaters: 0.6B
- Context Length: 32k
- Embedding Dimension: Up to 1024, supports user-defined output dimensions ranging from 32 to 1024
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-embedding/), [GitHub](https://github.com/QwenLM/Qwen3-Embedding).
## Qwen3 Embedding Series Model list
| Model Type | Models | Size | Layers | Sequence Length | Embedding Dimension | MRL Support | Instruction Aware |
|------------------|----------------------|------|--------|-----------------|---------------------|-------------|----------------|
| Text Embedding | [Qwen3-Embedding-0.6B](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) | 0.6B | 28 | 32K | 1024 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-4B](https://huggingface.co/Qwen/Qwen3-Embedding-4B) | 4B | 36 | 32K | 2560 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-8B](https://huggingface.co/Qwen/Qwen3-Embedding-8B) | 8B | 36 | 32K | 4096 | Yes | Yes |
| Text Reranking | [Qwen3-Reranker-0.6B](https://huggingface.co/Qwen/Qwen3-Reranker-0.6B) | 0.6B | 28 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-4B](https://huggingface.co/Qwen/Qwen3-Reranker-4B) | 4B | 36 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-8B](https://huggingface.co/Qwen/Qwen3-Reranker-8B) | 8B | 36 | 32K | - | - | Yes |
> **Note**:
> - `MRL Support` indicates whether the embedding model supports custom dimensions for the final embedding.
> - `Instruction Aware` notes whether the embedding or reranking model supports customizing the input instruction according to different tasks.
> - Our evaluation indicates that, for most downstream tasks, using instructions (instruct) typically yields an improvement of 1% to 5% compared to not using them. Therefore, we recommend that developers create tailored instructions specific to their tasks and scenarios. In multilingual contexts, we also advise users to write their instructions in English, as most instructions utilized during the model training process were originally written in English.
## Usage
With Transformers versions earlier than 4.51.0, you may encounter the following error:
```
KeyError: 'qwen3'
```
### Sentence Transformers Usage
```python
# Requires transformers>=4.51.0
# Requires sentence-transformers>=2.7.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-0.6B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
# tensor([[0.7646, 0.1414],
# [0.1355, 0.6000]])
```
### Transformers Usage
```python
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7645568251609802, 0.14142508804798126], [0.13549736142158508, 0.5999549627304077]]
```
### vLLM Usage
```python
# Requires vllm>=0.8.5
import torch
import vllm
from vllm import LLM
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
model = LLM(model="Qwen/Qwen3-Embedding-0.6B", task="embed")
outputs = model.embed(input_texts)
embeddings = torch.tensor([o.outputs.embedding for o in outputs])
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7620252966880798, 0.14078938961029053], [0.1358368694782257, 0.6013815999031067]]
```
📌 **Tip**: We recommend that developers customize the `instruct` according to their specific scenarios, tasks, and languages. Our tests have shown that in most retrieval scenarios, not using an `instruct` on the query side can lead to a drop in retrieval performance by approximately 1% to 5%.
## Evaluation
### MTEB (Multilingual)
| Model | Size | Mean (Task) | Mean (Type) | Bitxt Mining | Class. | Clust. | Inst. Retri. | Multi. Class. | Pair. Class. | Rerank | Retri. | STS |
|----------------------------------|:-------:|:-------------:|:-------------:|:--------------:|:--------:|:--------:|:--------------:|:---------------:|:--------------:|:--------:|:--------:|:------:|
| NV-Embed-v2 | 7B | 56.29 | 49.58 | 57.84 | 57.29 | 40.80 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10|
| GritLM-7B | 7B | 60.92 | 53.74 | 70.53 | 61.83 | 49.75 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33|
| BGE-M3 | 0.6B | 59.56 | 52.18 | 79.11 | 60.35 | 40.88 | -3.11 | 20.1 | 80.76 | 62.79 | 54.60 | 74.12|
| multilingual-e5-large-instruct | 0.6B | 63.22 | 55.08 | 80.13 | 64.94 | 50.75 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81|
| gte-Qwen2-1.5B-instruct | 1.5B | 59.45 | 52.69 | 62.51 | 58.32 | 52.05 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61|
| gte-Qwen2-7b-Instruct | 7B | 62.51 | 55.93 | 73.92 | 61.55 | 52.77 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98|
| text-embedding-3-large | - | 58.93 | 51.41 | 62.17 | 60.27 | 46.89 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68|
| Cohere-embed-multilingual-v3.0 | - | 61.12 | 53.23 | 70.50 | 62.95 | 46.89 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80|
| Gemini Embedding | - | 68.37 | 59.59 | 79.28 | 71.82 | 54.59 | 5.18 | **29.16** | 83.63 | 65.58 | 67.71 | 79.40|
| **Qwen3-Embedding-0.6B** | 0.6B | 64.33 | 56.00 | 72.22 | 66.83 | 52.33 | 5.09 | 24.59 | 80.83 | 61.41 | 64.64 | 76.17|
| **Qwen3-Embedding-4B** | 4B | 69.45 | 60.86 | 79.36 | 72.33 | 57.15 | **11.56** | 26.77 | 85.05 | 65.08 | 69.60 | 80.86|
| **Qwen3-Embedding-8B** | 8B | **70.58** | **61.69** | **80.89** | **74.00** | **57.65** | 10.06 | 28.66 | **86.40** | **65.63** | **70.88** | **81.08** |
> **Note**: For compared models, the scores are retrieved from MTEB online [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on May 24th, 2025.
### MTEB (Eng v2)
| MTEB English / Models | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retri. | STS | Summ. |
|--------------------------------|:--------:|:------------:|:------------:|:--------:|:--------:|:-------------:|:---------:|:--------:|:-------:|:-------:|
| multilingual-e5-large-instruct | 0.6B | 65.53 | 61.21 | 75.54 | 49.89 | 86.24 | 48.74 | 53.47 | 84.72 | 29.89 |
| NV-Embed-v2 | 7.8B | 69.81 | 65.00 | 87.19 | 47.66 | 88.69 | 49.61 | 62.84 | 83.82 | 35.21 |
| GritLM-7B | 7.2B | 67.07 | 63.22 | 81.25 | 50.82 | 87.29 | 49.59 | 54.95 | 83.03 | 35.65 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.20 | 63.26 | 85.84 | 53.54 | 87.52 | 49.25 | 50.25 | 82.51 | 33.94 |
| stella_en_1.5B_v5 | 1.5B | 69.43 | 65.32 | 89.38 | 57.06 | 88.02 | 50.19 | 52.42 | 83.27 | 36.91 |
| gte-Qwen2-7B-instruct | 7.6B | 70.72 | 65.77 | 88.52 | 58.97 | 85.9 | 50.47 | 58.09 | 82.69 | 35.74 |
| gemini-embedding-exp-03-07 | - | 73.3 | 67.67 | 90.05 | 59.39 | 87.7 | 48.59 | 64.35 | 85.29 | 38.28 |
| **Qwen3-Embedding-0.6B** | 0.6B | 70.70 | 64.88 | 85.76 | 54.05 | 84.37 | 48.18 | 61.83 | 86.57 | 33.43 |
| **Qwen3-Embedding-4B** | 4B | 74.60 | 68.10 | 89.84 | 57.51 | 87.01 | 50.76 | 68.46 | 88.72 | 34.39 |
| **Qwen3-Embedding-8B** | 8B | 75.22 | 68.71 | 90.43 | 58.57 | 87.52 | 51.56 | 69.44 | 88.58 | 34.83 |
### C-MTEB (MTEB Chinese)
| C-MTEB | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retr. | STS |
|------------------|--------|------------|------------|--------|--------|-------------|---------|-------|-------|
| multilingual-e5-large-instruct | 0.6B | 58.08 | 58.24 | 69.80 | 48.23 | 64.52 | 57.45 | 63.65 | 45.81 |
| bge-multilingual-gemma2 | 9B | 67.64 | 75.31 | 59.30 | 86.67 | 68.28 | 73.73 | 55.19 | - |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.12 | 67.79 | 72.53 | 54.61 | 79.5 | 68.21 | 71.86 | 60.05 |
| gte-Qwen2-7B-instruct | 7.6B | 71.62 | 72.19 | 75.77 | 66.06 | 81.16 | 69.24 | 75.70 | 65.20 |
| ritrieve_zh_v1 | 0.3B | 72.71 | 73.85 | 76.88 | 66.5 | 85.98 | 72.86 | 76.97 | 63.92 |
| **Qwen3-Embedding-0.6B** | 0.6B | 66.33 | 67.45 | 71.40 | 68.74 | 76.42 | 62.58 | 71.03 | 54.52 |
| **Qwen3-Embedding-4B** | 4B | 72.27 | 73.51 | 75.46 | 77.89 | 83.34 | 66.05 | 77.03 | 61.26 |
| **Qwen3-Embedding-8B** | 8B | 73.84 | 75.00 | 76.97 | 80.08 | 84.23 | 66.99 | 78.21 | 63.53 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/SmolVLM-Instruct-GGUF | Mungert | 2025-06-15T19:36:32Z | 1,023 | 2 | transformers | [
"transformers",
"gguf",
"image-text-to-text",
"en",
"dataset:HuggingFaceM4/the_cauldron",
"dataset:HuggingFaceM4/Docmatix",
"arxiv:2504.05299",
"base_model:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"base_model:quantized:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-06-09T10:05:04Z | ---
library_name: transformers
license: apache-2.0
datasets:
- HuggingFaceM4/the_cauldron
- HuggingFaceM4/Docmatix
pipeline_tag: image-text-to-text
language:
- en
base_model:
- HuggingFaceTB/SmolLM2-1.7B-Instruct
- google/siglip-so400m-patch14-384
---
# <span style="color: #7FFF7F;">SmolVLM-Instruct GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/SmolVLM.png" width="800" height="auto" alt="Image description">
# SmolVLM
SmolVLM is a compact open multimodal model that accepts arbitrary sequences of image and text inputs to produce text outputs. Designed for efficiency, SmolVLM can answer questions about images, describe visual content, create stories grounded on multiple images, or function as a pure language model without visual inputs. Its lightweight architecture makes it suitable for on-device applications while maintaining strong performance on multimodal tasks.
## Model Summary
- **Developed by:** Hugging Face 🤗
- **Model type:** Multi-modal model (image+text)
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Architecture:** Based on [Idefics3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3) (see technical summary)
## Resources
- **Demo:** [SmolVLM Demo](https://huggingface.co/spaces/HuggingFaceTB/SmolVLM)
- **Blog:** [Blog post](https://huggingface.co/blog/smolvlm)
## Uses
SmolVLM can be used for inference on multimodal (image + text) tasks where the input comprises text queries along with one or more images. Text and images can be interleaved arbitrarily, enabling tasks like image captioning, visual question answering, and storytelling based on visual content. The model does not support image generation.
To fine-tune SmolVLM on a specific task, you can follow the fine-tuning tutorial.
<!-- todo: add link to fine-tuning tutorial -->
### Technical Summary
SmolVLM leverages the lightweight SmolLM2 language model to provide a compact yet powerful multimodal experience. It introduces several changes compared to previous Idefics models:
- **Image compression:** We introduce a more radical image compression compared to Idefics3 to enable the model to infer faster and use less RAM.
- **Visual Token Encoding:** SmolVLM uses 81 visual tokens to encode image patches of size 384×384. Larger images are divided into patches, each encoded separately, enhancing efficiency without compromising performance.
More details about the training and architecture are available in our technical report.
### How to get started
You can use transformers to load, infer and fine-tune SmolVLM.
```python
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load images
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The first image shows a green statue of the Statue of Liberty standing on a stone pedestal in front of a body of water.
The statue is holding a torch in its right hand and a tablet in its left hand. The water is calm and there are no boats or other objects visible.
The sky is clear and there are no clouds. The second image shows a bee on a pink flower.
The bee is black and yellow and is collecting pollen from the flower. The flower is surrounded by green leaves.
"""
```
### Model optimizations
**Precision**: For better performance, load and run the model in half-precision (`torch.float16` or `torch.bfloat16`) if your hardware supports it.
```python
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
```
You can also load SmolVLM with 4/8-bit quantization using bitsandbytes, torchao or Quanto. Refer to [this page](https://huggingface.co/docs/transformers/en/main_classes/quantization) for other options.
```python
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
```
**Vision Encoder Efficiency**: Adjust the image resolution by setting `size={"longest_edge": N*384}` when initializing the processor, where N is your desired value. The default `N=4` works well, which results in input images of
size 1536×1536. For documents, `N=5` might be beneficial. Decreasing N can save GPU memory and is appropriate for lower-resolution images. This is also useful if you want to fine-tune on videos.
## Misuse and Out-of-scope Use
SmolVLM is not intended for high-stakes scenarios or critical decision-making processes that affect an individual's well-being or livelihood. The model may produce content that appears factual but may not be accurate. Misuse includes, but is not limited to:
- Prohibited Uses:
- Evaluating or scoring individuals (e.g., in employment, education, credit)
- Critical automated decision-making
- Generating unreliable factual content
- Malicious Activities:
- Spam generation
- Disinformation campaigns
- Harassment or abuse
- Unauthorized surveillance
### License
SmolVLM is built upon [the shape-optimized SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384) as image encoder and [SmolLM2](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) for text decoder part.
We release the SmolVLM checkpoints under the Apache 2.0 license.
## Training Details
### Training Data
The training data comes from [The Cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron) and [Docmatix](https://huggingface.co/datasets/HuggingFaceM4/Docmatix) datasets, with emphasis on document understanding (25%) and image captioning (18%), while maintaining balanced coverage across other crucial capabilities like visual reasoning, chart comprehension, and general instruction following.
<img src="https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct/resolve/main/mixture_the_cauldron.png" alt="Example Image" style="width:90%;" />
## Evaluation
| Model | MMMU (val) | MathVista (testmini) | MMStar (val) | DocVQA (test) | TextVQA (val) | Min GPU RAM required (GB) |
|-------------------|------------|----------------------|--------------|---------------|---------------|---------------------------|
| SmolVLM | 38.8 | 44.6 | 42.1 | 81.6 | 72.7 | 5.02 |
| Qwen-VL 2B | 41.1 | 47.8 | 47.5 | 90.1 | 79.7 | 13.70 |
| InternVL2 2B | 34.3 | 46.3 | 49.8 | 86.9 | 73.4 | 10.52 |
| PaliGemma 3B 448px| 34.9 | 28.7 | 48.3 | 32.2 | 56.0 | 6.72 |
| moondream2 | 32.4 | 24.3 | 40.3 | 70.5 | 65.2 | 3.87 |
| MiniCPM-V-2 | 38.2 | 39.8 | 39.1 | 71.9 | 74.1 | 7.88 |
| MM1.5 1B | 35.8 | 37.2 | 0.0 | 81.0 | 72.5 | NaN |
# Citation information
You can cite us in the following way:
```bibtex
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/Cosmos-Reason1-7B-GGUF | Mungert | 2025-06-15T19:36:14Z | 3,809 | 2 | transformers | [
"transformers",
"gguf",
"nvidia",
"cosmos",
"en",
"dataset:nvidia/Cosmos-Reason1-SFT-Dataset",
"dataset:nvidia/Cosmos-Reason1-RL-Dataset",
"dataset:nvidia/Cosmos-Reason1-Benchmark",
"arxiv:2503.15558",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-24T03:54:56Z | ---
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license
datasets:
- nvidia/Cosmos-Reason1-SFT-Dataset
- nvidia/Cosmos-Reason1-RL-Dataset
- nvidia/Cosmos-Reason1-Benchmark
library_name: transformers
language:
- en
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
tags:
- nvidia
- cosmos
---
# <span style="color: #7FFF7F;">Cosmos-Reason1-7B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Cosmos-Reason1-7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Cosmos-Reason1-7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Cosmos-Reason1-7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Cosmos-Reason1-7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Cosmos-Reason1-7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Cosmos-Reason1-7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Cosmos-Reason1-7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Cosmos-Reason1-7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Cosmos-Reason1-7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Cosmos-Reason1-7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Cosmos-Reason1-7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# **Cosmos-Reason1: Physical AI Common Sense and Embodied Reasoning Models**
[**Cosmos**](https://huggingface.co/collections/nvidia/cosmos-reason1-67c9e926206426008f1da1b7) | [**Code**](https://github.com/nvidia-cosmos/cosmos-reason1) | [**Paper**](https://arxiv.org/abs/2503.15558) | [**Paper Website**](https://research.nvidia.com/labs/dir/cosmos-reason1)
# Model Overview
## Description:
**Cosmos-Reason1 Models**: Physical AI models understand physical common sense and generate appropriate embodied decisions in natural language through long chain-of-thought reasoning processes.
The Cosmos-Reason1 models are post-trained with physical common sense and embodied reasoning data with supervised fine-tuning and reinforcement learning. These are Physical AI models that can understand space, time, and fundamental physics, and can serve as planning models to reason about the next steps of an embodied agent.
The models are ready for commercial use.
**Model Developer**: NVIDIA
## Model Versions
The Cosmos-Reason1 includes the following model:
- [Cosmos-Reason1-7B](https://huggingface.co/nvidia/Cosmos-Reason1-7B): Given a text prompt and an input video, think and generate the answer with respect to the input text prompt and video.
### License:
This model is released under the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license). For a custom license, please contact [[email protected]](mailto:[email protected]).
Under the NVIDIA Open Model License, NVIDIA confirms:
* Models are commercially usable.
* You are free to create and distribute Derivative Models.
* NVIDIA does not claim ownership to any outputs generated using the Models or Derivative Models.
**Important Note**: If You bypass, disable, reduce the efficacy of, or circumvent any technical limitation, safety guardrail or associated safety guardrail hyperparameter, encryption, security, digital rights management, or authentication mechanism (collectively “Guardrail”) contained in the Model without a substantially similar Guardrail appropriate for your use case, your rights under this Agreement [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license) will automatically terminate.
### Deployment Geography:
Global
### Use Case:
Physical AI: Space, time, fundamental physics understanding and embodied reasoning, encompassing robotics, and autonomous vehicles (AV).
### Release Date:
* Github: [05/17/2025](https://github.com/nvidia-cosmos/cosmos-reason1)
* Huggingface: [05/17/2025](https://huggingface.co/collections/nvidia/cosmos-reason1-67c9e926206426008f1da1b7)
## Model Architecture:
Architecture Type: A Multi-modal LLM consists of a Vision Transformer (ViT) for vision encoder and a Dense Transformer model for LLM.
Network Architecture: Qwen2.5-VL-7B-Instruct.
Cosmos-Reason-7B is post-trained based on [Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) and follows the same model architecture.
## Input
**Input Type(s)**: Text+Video/Image
**Input Format(s)**:
* Text: String
* Video: mp4
* Image: jpg
**Input Parameters**:
* Text: One-dimensional (1D)
* Video: Three-dimensional (3D)
* Image: Two-dimensional (2D)
**Other Properties Related to Input**:
* Use `FPS=4` for input video to match the training setup.
* Append `Answer the question in the following format: <think>\nyour reasoning\n</think>\n\n<answer>\nyour answer\n</answer>.` in the system prompt to encourage long chain-of-thought reasoning response.
## Output
**Output Type(s)**: Text
**Output Format**: String
**Output Parameters**: Text: One-dimensional (1D)
**Other Properties Related to Output**:
* Recommend using 4096 or more output max tokens to avoid truncation of long chain-of-thought response.
* Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
## Software Integration
**Runtime Engine(s):**
* [vLLM](https://github.com/vllm-project/vllm)
**Supported Hardware Microarchitecture Compatibility:**
* NVIDIA Blackwell
* NVIDIA Hopper
**Note**: We have only tested doing inference with BF16 precision.
**Operating System(s):**
* Linux (We have not tested on other operating systems.)
# Usage
See [Cosmos-Reason1](https://github.com/nvidia-cosmos/cosmos-reason1) for details.
* Post Training: [Cosmos-Reason1](https://github.com/nvidia-cosmos/cosmos-reason1) provides examples of supervised fine-tuning and reinforcement learning on embodied reasoning datasets.
# Evaluation
Please see our [technical paper](https://arxiv.org/pdf/2503.15558) for detailed evaluations on physical common sense and embodied reasoning. Part of the evaluation datasets are released under [Cosmos-Reason1-Benchmark](https://huggingface.co/datasets/nvidia/Cosmos-Reason1-Benchmark). The embodied reasoning datasets and benchmarks focus on the following areas: robotics (RoboVQA, BridgeDataV2, Agibot, RobFail), ego-centric human demonstration (HoloAssist), and Autonomous Vehicle (AV) driving video data. The AV dataset is collected and annotated by NVIDIA.
All datasets go through the data annotation process described in the technical paper to prepare training and evaluation data and annotations.
**Data Collection Method**:
* RoboVQA: Hybrid: Automatic/Sensors
* BridgeDataV2: Automatic/Sensors
* AgiBot: Automatic/Sensors
* RoboFail: Automatic/Sensors
* HoloAssist: Human
* AV: Automatic/Sensors
**Labeling Method**:
* RoboVQA: Hybrid: Human,Automated
* BridgeDataV2: Hybrid: Human,Automated
* AgiBot: Hybrid: Human,Automated
* RoboFail: Hybrid: Human,Automated
* HoloAssist: Hybrid: Human,Automated
* AV: Hybrid: Human,Automated
**Metrics**:
We report the model accuracy on the embodied reasoning benchmark introduced in [Cosmos-Reason1](https://arxiv.org/abs/2503.15558). The results differ from those presented in Table 9 due to additional training aimed at supporting a broader range of Physical AI tasks beyond the benchmark.
| | [RoboVQA](https://robovqa.github.io/) | AV | [BridgeDataV2](https://rail-berkeley.github.io/bridgedata/)| [Agibot](https://github.com/OpenDriveLab/AgiBot-World)| [HoloAssist](https://holoassist.github.io/) | [RoboFail](https://robot-reflect.github.io/) | Average |
|--------------------|---------------------------------------------|----------|------------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|
| **Accuracy** | 87.3 | 70.8 | 63.7 | 48.9 | 62.7 | 57.2 | 65.1 |
## Dataset Format
Modality: Video (mp4) and Text
## Dataset Quantification
We release the embodied reasoning data and benchmarks. Each data sample is a pair of video and text. The text annotations include understanding and reasoning annotations described in the Cosmos-Reason1 paper. Each video may have multiple text annotations. The quantity of the video and text pairs is described in the table below.
**The AV data is currently unavailable and will be uploaded soon!**
| | [RoboVQA](https://robovqa.github.io/) | AV | [BridgeDataV2](https://rail-berkeley.github.io/bridgedata/)| [Agibot](https://github.com/OpenDriveLab/AgiBot-World)| [HoloAssist](https://holoassist.github.io/) | [RoboFail](https://robot-reflect.github.io/) | Total Storage Size |
|--------------------|---------------------------------------------|----------|------------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|--------------------|
| **SFT Data** | 1.14m | 24.7k | 258k | 38.9k | 273k | N/A | **300.6GB** |
| **RL Data** | 252 | 200 | 240 | 200 | 200 | N/A | **2.6GB** |
| **Benchmark Data** | 110 | 100 | 100 | 100 | 100 | 100 | **1.5GB** |
We release text annotations for all embodied reasoning datasets and videos for RoboVQA and AV datasets. For other datasets, users may download the source videos from the original data source and find corresponding video sources via the video names. The held-out RoboFail benchmark is released for measuring the generalization capability.
## Inference:
**Acceleration Engine:** PyTorch, flash attention <br>
**Test Hardware:** H100, A100, GB200 <br>
* Minimum 2 GPU cards, multi nodes require Infiniband / ROCE connection <br>
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Users are responsible for model inputs and outputs. Users are responsible for ensuring safe integration of this model, including implementing guardrails as well as other safety mechanisms, prior to deployment.
For more detailed information on ethical considerations for this model, please see the subcards of Explainability, Bias, Safety & Security, and Privacy below.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
### Plus Plus (++) Promise
We value you, the datasets, the diversity they represent, and what we have been entrusted with. This model and its associated data have been:
* Verified to comply with current applicable disclosure laws, regulations, and industry standards.
* Verified to comply with applicable privacy labeling requirements.
* Annotated to describe the collector/source (NVIDIA or a third-party).
* Characterized for technical limitations.
* Reviewed to ensure proper disclosure is accessible to, maintained for, and in compliance with NVIDIA data subjects and their requests.
* Reviewed before release.
* Tagged for known restrictions and potential safety implications.
### Bias
| Field | Response |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------- |
| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing: | None |
| Measures taken to mitigate against unwanted bias: | The training video sources contain multiple physical embodiments and environments including human, car, single arm robot, bimanual robot in indoor and outdoor environments. By training on numerous and various physical interactions and curated datasets, we strive to provide a model that does not possess biases towards certain embodiments or environments. |
### Explainability
| Field | Response |
| :-------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------- |
| Intended Application & Domain: | Physical AI Reasoning |
| Model Type: | Transformer |
| Intended Users: | Physical AI developers |
| Output: | Text |
| Describe how the model works: | Generates text answers based on input text prompt and video |
| Technical Limitations: | The model may not follow the video or text input accurately in challenging cases, where the input video shows complex scene composition and temporal dynamics. Examples of challenging scenes include: fast camera movements, overlapping human-object interactions, low lighting with high motion blur, and multiple people performing different actions simultaneously. |
| Verified to have met prescribed NVIDIA quality standards: | Yes |
| Performance Metrics: | Quantitative and Qualitative Evaluation. Cosmos-Reason1 proposes the embodied reasoning benchmark and physical common sense benchmark to evaluate accuracy with visual question answering. |
| Potential Known Risks: | The model's output can generate all forms of texts, including what may be considered toxic, offensive, or indecent. |
| Licensing: | [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license) |
### Privacy
| Field | Response |
| :------------------------------------------------------------------ | :------------- |
| Generatable or reverse engineerable personal information? | None Known |
| Protected class data used to create this model? | None Known |
| Was consent obtained for any personal data used? | None Known |
| How often is dataset reviewed? | Before Release |
| Is there provenance for all datasets used in training? | Yes |
| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |
| Applicable Privacy Policy | [NVIDIA Privacy Policy](https://www.nvidia.com/en-us/about-nvidia/privacy-policy) |
### Safety
| Field | Response |
| :---------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Model Application(s): | Physical AI common sense understanding and embodied reasoning |
| Describe the life critical impact (if present). | None Known |
| Use Case Restrictions: | [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license) |
| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. Model checkpoints are made available on Hugging Face, and may become available on cloud providers' model catalog. | |
Mungert/Foundation-Sec-8B-Instruct-GGUF | Mungert | 2025-06-15T19:36:09Z | 2,152 | 3 | null | [
"gguf",
"unsloth",
"trl",
"sft",
"en",
"dataset:yahma/alpaca-cleaned",
"arxiv:2504.21039",
"base_model:fdtn-ai/Foundation-Sec-8B",
"base_model:quantized:fdtn-ai/Foundation-Sec-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-11T00:27:00Z | ---
license: apache-2.0
datasets:
- yahma/alpaca-cleaned
language:
- en
base_model:
- meta-llama/Llama-3.1-8B
- fdtn-ai/Foundation-Sec-8B
tags:
- unsloth
- trl
- sft
---
# <span style="color: #7FFF7F;">Foundation-Sec-8B-Instruct GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`8c83449`](https://github.com/ggerganov/llama.cpp/commit/8c83449cb780c201839653812681c3a4cf17feed).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Foundation-Sec-8B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Foundation-Sec-8B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Foundation-Sec-8B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Foundation-Sec-8B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Foundation-Sec-8B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Foundation-Sec-8B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Foundation-Sec-8B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Foundation-Sec-8B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Foundation-Sec-8B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Foundation-Sec-8B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Foundation-Sec-8B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Card for Foundation-Sec-8B-Instruct
<!-- Provide a quick summary of what the model is/does. -->
Foundation-Sec-8B-Instruct is an Instruction Fine-Tune of [Foundation-Sec-8B](https://huggingface.co/fdtn-ai/Foundation-Sec-8B).
- **Model Name:** Foundation-Sec-8B-Instruct
- **Fine-Tune Developer:** Derek Jones ([email protected])
- **Original Developers** Amin Karbasi and team at Foundation AI — Cisco
- **Technical Report:** [`https://arxiv.org/abs/2504.21039`](https://arxiv.org/abs/2504.21039)
- **Model Card Contact:** For questions about the model usage, contact [`[email protected]`](mailto:[email protected]).
- **Model Release Date:** May 4, 2025
- **Supported Language(s):** English
- **License:** Apache 2.0
|
Subsets and Splits