
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-25 06:27:54
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 495
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-25 06:24:22
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Mungert/KernelLLM-GGUF | Mungert | 2025-06-15T19:36:05Z | 1,249 | 3 | transformers | [
"transformers",
"gguf",
"dataset:ScalingIntelligence/KernelBench",
"dataset:GPUMODE/KernelBook",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:quantized:meta-llama/Llama-3.1-8B-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-09T11:48:23Z | ---
license: other
base_model:
- meta-llama/Llama-3.1-8B-Instruct
datasets:
- ScalingIntelligence/KernelBench
- GPUMODE/KernelBook
library_name: transformers
---
# <span style="color: #7FFF7F;">KernelLLM GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# KernelLLM

*On KernelBench-Triton Level 1, our 8B parameter model exceeds models such as GPT-4o and DeepSeek V3 in single-shot performance. With multiple inferences, KernelLLM's performance outperforms DeepSeek R1. This is all from a model with two orders of magnitude fewer parameters than its competitors.*
## Making Kernel Development more accessible with KernelLLM
We introduce KernelLLM, a large language model based on Llama 3.1 Instruct, which has been trained specifically for the task of authoring GPU kernels using Triton. KernelLLM translates PyTorch modules into Triton kernels and was evaluated on KernelBench-Triton (see [here](https://github.com/ScalingIntelligence/KernelBench/pull/35)).
KernelLLM aims to democratize GPU programming by making kernel development more accessible and efficient.
KernelLLM's vision is to meet the growing demand for high-performance GPU kernels by automating the generation of efficient Triton implementations. As workloads grow larger and more diverse accelerator architectures emerge, the need for tailored kernel solutions has increased significantly. Although a number of [works](https://metr.org/blog/2025-02-14-measuring-automated-kernel-engineering/) [exist](https://cognition.ai/blog/kevin-32b), most of them are limited to [test-time](https://sakana.ai/ai-cuda-engineer/) [optimization](https://developer.nvidia.com/blog/automating-gpu-kernel-generation-with-deepseek-r1-and-inference-time-scaling/), while others tune on solutions traced of KernelBench problems itself, thereby limiting the informativeness of the results towards out-of-distribution generalization. To the best of our knowledge KernelLLM is the first LLM finetuned on external (torch, triton) pairs, and we hope that making our model available can accelerate progress towards intelligent kernel authoring systems.

*KernelLLM Workflow for Triton Kernel Generation: Our approach uses KernelLLM to translate PyTorch code (green) into Triton kernel candidates. Input and output components are marked in bold. The generations are validated against unit tests, which run kernels with random inputs of known shapes. This workflow allows us to evaluate multiple generations (pass@k) by increasing the number of kernel candidate generations. The best kernel implementation is selected and returned (green output).*
The model was trained on approximately 25,000 paired examples of PyTorch modules and their equivalent Triton kernel implementations, and additional synthetically generated samples. Our approach combines filtered code from TheStack [Kocetkov et al. 2022] and synthetic examples generated through `torch.compile()` and additional prompting techniques. The filtered and compiled dataset is [KernelBook]](https://huggingface.co/datasets/GPUMODE/KernelBook).
We finetuned Llama3.1-8B-Instruct on the created dataset using supervised instruction tuning and measured its ability to generate correct Triton kernels and corresponding calling code on KernelBench-Triton, our newly created variant of KernelBench [Ouyang et al. 2025] targeting Triton kernel generation. The torch code was used with a prompt template containing a format example as instruction during both training and evaluation. The model was trained for 10 epochs with a batch size of 32 and a standard SFT recipe with hyperparameters selected by perplexity on a held-out subset of the training data. Training took circa 12 hours wall clock time on 16 GPUs (192 GPU hours), and we report the best checkpoint's validation results.
### Model Performance

| Model | Parameters (B) | Score | Pass@k |
|-------|---------------|-------|--------|
| KernelLLM | 8 | 20.2 | 1 |
| KernelLLM | 8 | 51.8 | 10 |
| KernelLLM | 8 | 57.1 | 20 |
| DeepSeek V3 | 671 | 16 | 1 |
| GPT-4o | ~200 | 15 | 1 |
| Qwen2.5 | 32 | 15 | 1 |
| Llama 3.3 | 70 | 13 | 1 |
| Llama 3.1 | 8 | 14 | 20 |
| Llama 3.1 | 8 | 6 | 1 |
| Llama R1 Distill | 70 | 11 | reasoning |
| DeepSeek R1 | 671 | 30 | 1 |
*Our 8B parameter model achieves competitive or superior performance compared to much larger models on kernel generation tasks, demonstrating the effectiveness of our specialized training approach on KernelBench Level 1 versus various baselines. KernelLLM inference was run with temperature=1.0 and top_p=0.97.*
The resulting model is competitive with state of the art LLMs despite its small size. We evaluate our model on KernelBench which is an open-source benchmark to evaluate the ability of LLMs to write efficient GPU kernels. It contains 250 selected PyTorch modules organized into difficulty levels, from single torch operators such as Conv2D or Swish (level 1), to full model architectures (level 3). The benchmark measures both correctness (by comparing against reference PyTorch outputs) and performance (by measuring speedup over baseline implementations). We implemented a new KernelBench-Triton variant that evaluates an LLMs ability to generate Triton kernels, making it an ideal benchmark for evaluating KernelLLM's capabilities. All our measurements were done on Nvidia H100 GPUs.

*KernelLLM shows quasi log-linear scaling behavior during pass@k analysis.*
For more information, please see [Project Popcorn](https://gpu-mode.github.io/popcorn/).
## Installation
To use KernelLLM, install the required dependencies:
```bash
pip install transformers accelerate torch triton
```
## Usage
KernelLLM provides a simple interface for generating Triton kernels from PyTorch code. The included `kernelllm.py` script offers multiple methods for interacting with the model.
### Basic Usage
```python
from kernelllm import KernelLLM
# Initialize the model
model = KernelLLM()
# Define your PyTorch module
pytorch_code = '''
import torch
import torch.nn as nn
class Model(nn.Module):
"""
A model that computes Hinge Loss for binary classification tasks.
"""
def __init__(self):
super(Model, self).__init__()
def forward(self, predictions, targets):
return torch.mean(torch.clamp(1 - predictions * targets, min=0))
batch_size = 128
input_shape = (1,)
def get_inputs():
return [torch.randn(batch_size, *input_shape), torch.randint(0, 2, (batch_size, 1)).float() * 2 - 1]
def get_init_inputs():
return []
'''
# Generate optimized Triton code
optimized_code = model.generate_triton(pytorch_code, max_new_tokens=512)
print(optimized_code)
```
### Interactive REPL
You can also use the built-in REPL interface:
```bash
python kernelllm.py
```
This will start an interactive session where you can input your PyTorch code and receive Triton-optimized implementations.
### Advanced Options
KernelLLM provides several methods for customizing the generation process:
```python
from kernelllm import KernelLLM
model = KernelLLM()
# Stream output in real-time
model.stream_raw("Your prompt here", max_new_tokens=2048)
# Generate raw text without the Triton-specific prompt template
raw_output = model.generate_raw("Your prompt here", temperature=1.0, max_new_tokens=2048)
```
## Current Limitations and Future Work
Despite showing promising results, KernelLLM has several limitations:
- The model may still produce incorrect API references and syntax errors, and is limited in its instruction following ability.
- Generated code structurally resembles compiler-generated output, and the model often fails to implement a meaningful kernel.
- Error analysis shows common issues related to instruction following with respect to variable naming, tensor shapes, type handling, and numerical precision.
## Model Details
**Model Developers:** Meta.
**Input:** Models input text only.
**Output:** Models generate text only.
**Model Architecture:** KernelLLM is an auto-regressive language model that uses an optimized transformer architecture.
**Model Dates:** KernelLLM was trained in March 2025.
**Status:** This is a static model trained on an offline dataset.
**License:** See LICENSE.pdf for details.
## Intended Use
**Intended Use Cases:** KernelLLM is intended for commercial and research use in English, relevant programming languages, Python, and Triton.
**Out-of-Scope Uses:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the [Acceptable Use Policy](https://llama.meta.com/llama3/use-policy) and Licensing Agreement for KernelLLM and its variants.
## Hardware and Software
**Training Factors:** We used custom training libraries.
**Carbon Footprint:** In aggregate, training KernelLLM required 250 hours of computation on hardware of type H100-80GB, not including the training of the base model. 100% of the estimated tCO2eq emissions were offset by Meta's sustainability program.
## Ethical Considerations and Limitations
KernelLLM and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, KernelLLM's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of KernelLLM, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide](https://ai.meta.com/llama/responsible-use-guide).
## Citation
```
@software{kernelllm2025,
title={KernelLLM},
author={Fisches, Zacharias and Paliskara, Sahan and Guo, Simon and Zhang, Alex and Spisak, Joe and Cummins, Chris and Leather, Hugh and Isaacson, Joe and Markosyan, Aram and Saroufim, Mark},
year={2025},
month={5},
note={Corresponding authors: Aram Markosyan, Mark Saroufim},
url={https://huggingface.co/facebook/KernelLLM},
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/llama-joycaption-beta-one-hf-llava-GGUF | Mungert | 2025-06-15T19:36:02Z | 3,922 | 3 | transformers | [
"transformers",
"gguf",
"captioning",
"image-text-to-text",
"base_model:google/siglip2-so400m-patch14-384",
"base_model:quantized:google/siglip2-so400m-patch14-384",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-06-08T03:11:55Z | ---
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- google/siglip2-so400m-patch14-384
tags:
- captioning
pipeline_tag: image-text-to-text
library_name: transformers
---
# <span style="color: #7FFF7F;">llama-joycaption-beta-one-hf-llava GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Model Card for Llama JoyCaption Beta One
[Github](https://github.com/fpgaminer/joycaption)
JoyCaption is an image captioning Visual Language Model (VLM) built from the ground up as a free, open, and uncensored model for the community to use in training Diffusion models.
Key Features:
- **Free and Open**: Always released for free, open weights, no restrictions, and just like [bigASP](https://www.reddit.com/r/StableDiffusion/comments/1dbasvx/the_gory_details_of_finetuning_sdxl_for_30m/), will come with training scripts and lots of juicy details on how it gets built.
- **Uncensored**: Equal coverage of SFW and NSFW concepts. No "cylindrical shaped object with a white substance coming out on it" here.
- **Diversity**: All are welcome here. Do you like digital art? Photoreal? Anime? Furry? JoyCaption is for everyone. Pains are being taken to ensure broad coverage of image styles, content, ethnicity, gender, orientation, etc.
- **Minimal Filtering**: JoyCaption is trained on large swathes of images so that it can understand almost all aspects of our world. almost. Illegal content will never be tolerated in JoyCaption's training.
## Motivation
Automated descriptive captions enable the training and finetuning of diffusion models on a wider range of images, since trainers are no longer required to either find images with already associated text or write the descriptions themselves. They also improve the quality of generations produced by Text-to-Image models trained on them (ref: DALL-E 3 paper). But to-date, the community has been stuck with ChatGPT, which is expensive and heavily censored; or alternative models, like CogVLM, which are weaker than ChatGPT and have abysmal performance outside of the SFW domain.
I'm building JoyCaption to help fill this gap by performing near or on-par with GPT4o in captioning images, while being free, unrestricted, and open.
## How to Get Started with the Model
Please see the [Github](https://github.com/fpgaminer/joycaption) for more details.
Example usage:
```
import torch
from PIL import Image
from transformers import AutoProcessor, LlavaForConditionalGeneration
IMAGE_PATH = "image.jpg"
PROMPT = "Write a long descriptive caption for this image in a formal tone."
MODEL_NAME = "fancyfeast/llama-joycaption-beta-one-hf-llava"
# Load JoyCaption
# bfloat16 is the native dtype of the LLM used in JoyCaption (Llama 3.1)
# device_map=0 loads the model into the first GPU
processor = AutoProcessor.from_pretrained(MODEL_NAME)
llava_model = LlavaForConditionalGeneration.from_pretrained(MODEL_NAME, torch_dtype="bfloat16", device_map=0)
llava_model.eval()
with torch.no_grad():
# Load image
image = Image.open(IMAGE_PATH)
# Build the conversation
convo = [
{
"role": "system",
"content": "You are a helpful image captioner.",
},
{
"role": "user",
"content": PROMPT,
},
]
# Format the conversation
# WARNING: HF's handling of chat's on Llava models is very fragile. This specific combination of processor.apply_chat_template(), and processor() works
# but if using other combinations always inspect the final input_ids to ensure they are correct. Often times you will end up with multiple <bos> tokens
# if not careful, which can make the model perform poorly.
convo_string = processor.apply_chat_template(convo, tokenize = False, add_generation_prompt = True)
assert isinstance(convo_string, str)
# Process the inputs
inputs = processor(text=[convo_string], images=[image], return_tensors="pt").to('cuda')
inputs['pixel_values'] = inputs['pixel_values'].to(torch.bfloat16)
# Generate the captions
generate_ids = llava_model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
suppress_tokens=None,
use_cache=True,
temperature=0.6,
top_k=None,
top_p=0.9,
)[0]
# Trim off the prompt
generate_ids = generate_ids[inputs['input_ids'].shape[1]:]
# Decode the caption
caption = processor.tokenizer.decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
caption = caption.strip()
print(caption)
```
## vLLM
vLLM provides the highest performance inference for JoyCaption, and an OpenAI compatible API so JoyCaption can be used like any other VLMs. Example usage:
```
vllm serve fancyfeast/llama-joycaption-beta-one-hf-llava --max-model-len 4096 --enable-prefix-caching
```
VLMs are a bit finicky on vLLM, and vLLM is memory hungry, so you may have to adjust settings for your particular environment, such as forcing eager mode, adjusting max-model-len, adjusting gpu_memory_utilization, etc.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/UI-TARS-1.5-7B-GGUF | Mungert | 2025-06-15T19:35:55Z | 2,921 | 3 | transformers | [
"transformers",
"gguf",
"multimodal",
"gui",
"image-text-to-text",
"en",
"arxiv:2501.12326",
"arxiv:2404.07972",
"arxiv:2409.08264",
"arxiv:2401.13919",
"arxiv:2504.01382",
"arxiv:2405.14573",
"arxiv:2410.23218",
"arxiv:2504.07981",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-05-18T01:20:07Z |
---
license: apache-2.0
language:
- en
pipeline_tag: image-text-to-text
tags:
- multimodal
- gui
library_name: transformers
---
# <span style="color: #7FFF7F;">UI-TARS-1.5-7B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`6a2bc8bf`](https://github.com/ggerganov/llama.cpp/commit/6a2bc8bfb7cd502e5ebc72e36c97a6f848c21c2c).
## How to Use UI-TARS-1.5-7B with llama.cpp
1. **Download the UI-TARS-1.5-7B gguf file**:
https://huggingface.co/Mungert/UI-TARS-1.5-7B-GGUF/tree/main
Choose a gguf file without the mmproj in the name
Example gguf file : https://huggingface.co/Mungert/Mungert/UI-TARS-1.5-7B-GGUF/resolve/main/UI-TARS-1.5-7B-q8_0.gguf
Copy this file to your chosen folder.
2. **Download the UI-TARS-1.5-7B mmproj file**
https://huggingface.co/Mungert/UI-TARS-1.5-7B-GGUF/tree/main
Choose a file with mmproj in the name
Example mmproj file : https://huggingface.co/Mungert/UI-TARS-1.5-7B-GGUF/resolve/main/UI-TARS-1.5-7B-q8_0.mmproj
Copy this file to your chosen folder.
3. Copy images to the same folder as the gguf files or alter paths appropriately.
In the example below the gguf files, images and llama-mtmd-cli are in the same folder.
Example image: image https://huggingface.co/Mungert/UI-TARS-1.5-7B-GGUF/resolve/main/car-1.jpg
Copy this file to your chosen folder.
4. **Run the CLI Tool**:
From your chosen folder :
```bash
llama-mtmd-cli -m UI-TARS-1.5-7B-q8_0.gguf --mmproj UI-TARS-1.5-7B-q8_0.mmproj -p "Describe this image." --image ./car-1.jpg
```
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `UI-TARS-1.5-7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `UI-TARS-1.5-7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `UI-TARS-1.5-7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `UI-TARS-1.5-7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `UI-TARS-1.5-7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `UI-TARS-1.5-7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `UI-TARS-1.5-7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `UI-TARS-1.5-7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `UI-TARS-1.5-7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `UI-TARS-1.5-7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `UI-TARS-1.5-7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# UI-TARS-1.5 Model
We shared the latest progress of the UI-TARS-1.5 model in [our blog](https://seed-tars.com/1.5/), which excels in playing games and performing GUI tasks.
## Introduction
UI-TARS-1.5, an open-source multimodal agent built upon a powerful vision-language model. It is capable of effectively performing diverse tasks within virtual worlds.
Leveraging the foundational architecture introduced in [our recent paper](https://arxiv.org/abs/2501.12326), UI-TARS-1.5 integrates advanced reasoning enabled by reinforcement learning. This allows the model to reason through its thoughts before taking action, significantly enhancing its performance and adaptability, particularly in inference-time scaling. Our new 1.5 version achieves state-of-the-art results across a variety of standard benchmarks, demonstrating strong reasoning capabilities and notable improvements over prior models.
<!--  -->
<p align="center">
<video controls width="480">
<source src="https://huggingface.co/datasets/JjjFangg/Demo_video/resolve/main/GUI_demo.mp4" type="video/mp4">
</video>
<p>
<p align="center">
<video controls width="480">
<source src="https://huggingface.co/datasets/JjjFangg/Demo_video/resolve/main/Game_demo.mp4" type="video/mp4">
</video>
<p>
<!--  -->
Code: https://github.com/bytedance/UI-TARS
Application: https://github.com/bytedance/UI-TARS-desktop
## Performance
**Online Benchmark Evaluation**
| Benchmark type | Benchmark | UI-TARS-1.5 | OpenAI CUA | Claude 3.7 | Previous SOTA |
|----------------|--------------------------------------------------------------------------------------------------------------------------------------------------|-------------|-------------|-------------|----------------------|
| **Computer Use** | [OSworld](https://arxiv.org/abs/2404.07972) (100 steps) | **42.5** | 36.4 | 28 | 38.1 (200 step) |
| | [Windows Agent Arena](https://arxiv.org/abs/2409.08264) (50 steps) | **42.1** | - | - | 29.8 |
| **Browser Use** | [WebVoyager](https://arxiv.org/abs/2401.13919) | 84.8 | **87** | 84.1 | 87 |
| | [Online-Mind2web](https://arxiv.org/abs/2504.01382) | **75.8** | 71 | 62.9 | 71 |
| **Phone Use** | [Android World](https://arxiv.org/abs/2405.14573) | **64.2** | - | - | 59.5 |
**Grounding Capability Evaluation**
| Benchmark | UI-TARS-1.5 | OpenAI CUA | Claude 3.7 | Previous SOTA |
|-----------|-------------|------------|------------|----------------|
| [ScreensSpot-V2](https://arxiv.org/pdf/2410.23218) | **94.2** | 87.9 | 87.6 | 91.6 |
| [ScreenSpotPro](https://arxiv.org/pdf/2504.07981v1) | **61.6** | 23.4 | 27.7 | 43.6 |
**Poki Game**
| Model | [2048](https://poki.com/en/g/2048) | [cubinko](https://poki.com/en/g/cubinko) | [energy](https://poki.com/en/g/energy) | [free-the-key](https://poki.com/en/g/free-the-key) | [Gem-11](https://poki.com/en/g/gem-11) | [hex-frvr](https://poki.com/en/g/hex-frvr) | [Infinity-Loop](https://poki.com/en/g/infinity-loop) | [Maze:Path-of-Light](https://poki.com/en/g/maze-path-of-light) | [shapes](https://poki.com/en/g/shapes) | [snake-solver](https://poki.com/en/g/snake-solver) | [wood-blocks-3d](https://poki.com/en/g/wood-blocks-3d) | [yarn-untangle](https://poki.com/en/g/yarn-untangle) | [laser-maze-puzzle](https://poki.com/en/g/laser-maze-puzzle) | [tiles-master](https://poki.com/en/g/tiles-master) |
|-------------|-----------|--------------|-------------|-------------------|-------------|---------------|---------------------|--------------------------|-------------|--------------------|----------------------|---------------------|------------------------|---------------------|
| OpenAI CUA | 31.04 | 0.00 | 32.80 | 0.00 | 46.27 | 92.25 | 23.08 | 35.00 | 52.18 | 42.86 | 2.02 | 44.56 | 80.00 | 78.27 |
| Claude 3.7 | 43.05 | 0.00 | 41.60 | 0.00 | 0.00 | 30.76 | 2.31 | 82.00 | 6.26 | 42.86 | 0.00 | 13.77 | 28.00 | 52.18 |
| UI-TARS-1.5 | 100.00 | 0.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
**Minecraft**
| Task Type | Task Name | [VPT](https://openai.com/index/vpt/) | [DreamerV3](https://www.nature.com/articles/s41586-025-08744-2) | Previous SOTA | UI-TARS-1.5 w/o Thought | UI-TARS-1.5 w/ Thought |
|-------------|---------------------|----------|----------------|--------------------|------------------|-----------------|
| Mine Blocks | (oak_log) | 0.8 | 1.0 | 1.0 | 1.0 | 1.0 |
| | (obsidian) | 0.0 | 0.0 | 0.0 | 0.2 | 0.3 |
| | (white_bed) | 0.0 | 0.0 | 0.1 | 0.4 | 0.6 |
| | **200 Tasks Avg.** | 0.06 | 0.03 | 0.32 | 0.35 | 0.42 |
| Kill Mobs | (mooshroom) | 0.0 | 0.0 | 0.1 | 0.3 | 0.4 |
| | (zombie) | 0.4 | 0.1 | 0.6 | 0.7 | 0.9 |
| | (chicken) | 0.1 | 0.0 | 0.4 | 0.5 | 0.6 |
| | **100 Tasks Avg.** | 0.04 | 0.03 | 0.18 | 0.25 | 0.31 |
## Model Scale Comparison
This table compares performance across different model scales of UI-TARS on the OSworld benchmark.
| **Benchmark Type** | **Benchmark** | **UI-TARS-72B-DPO** | **UI-TARS-1.5-7B** | **UI-TARS-1.5** |
|--------------------|------------------------------------|---------------------|--------------------|-----------------|
| Computer Use | [OSWorld](https://arxiv.org/abs/2404.07972) | 24.6 | 27.5 | **42.5** |
| GUI Grounding | [ScreenSpotPro](https://arxiv.org/pdf/2504.07981v1) | 38.1 | 49.6 | **61.6** |
The released UI-TARS-1.5-7B focuses primarily on enhancing general computer use capabilities and is not specifically optimized for game-based scenarios, where the UI-TARS-1.5 still holds a significant advantage.
## What's next
We are providing early research access to our top-performing UI-TARS-1.5 model to facilitate collaborative research. Interested researchers can contact us at [email protected].
## Citation
If you find our paper and model useful in your research, feel free to give us a cite.
```BibTeX
@article{qin2025ui,
title={UI-TARS: Pioneering Automated GUI Interaction with Native Agents},
author={Qin, Yujia and Ye, Yining and Fang, Junjie and Wang, Haoming and Liang, Shihao and Tian, Shizuo and Zhang, Junda and Li, Jiahao and Li, Yunxin and Huang, Shijue and others},
journal={arXiv preprint arXiv:2501.12326},
year={2025}
}
``` |
Mungert/Qwen3-4B-abliterated-GGUF | Mungert | 2025-06-15T19:35:51Z | 5,363 | 15 | transformers | [
"transformers",
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-30T03:07:52Z | ---
library_name: transformers
tags: []
---
# <span style="color: #7FFF7F;">Qwen3-4B-abliterated GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-4B-abliterated-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-4B-abliterated-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-4B-abliterated-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-4B-abliterated-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-4B-abliterated-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-4B-abliterated-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-4B-abliterated-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-4B-abliterated-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-4B-abliterated-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-4B-abliterated-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-4B-abliterated-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mungert/Magistral-Small-2506-GGUF | Mungert | 2025-06-15T19:35:48Z | 1,730 | 6 | vllm | [
"vllm",
"gguf",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.1-24B-Instruct-2503",
"base_model:quantized:mistralai/Mistral-Small-3.1-24B-Instruct-2503",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-12T22:37:57Z | ---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Mistral-Small-3.1-24B-Instruct-2503
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# <span style="color: #7FFF7F;">Magistral-Small-2506 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`7f4fbe51`](https://github.com/ggerganov/llama.cpp/commit/7f4fbe5183b23b6b2e25fd1ccc5d1fa8bb010cb7).
---
## <span style="color: #7FFF7F;">Quantization Beyond the IMatrix</span>
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
<a href="https://readyforquantum.com/huggingface_gguf_selection_guide.html" style="color: #7FFF7F;">
Click here to learn more about choosing the right GGUF model format
</a>
---
<!--Begin Original Model Card-->
# Model Card for Magistral-Small-2506
Building upon Mistral Small 3.1 (2503), **with added reasoning capabilities**, undergoing SFT from Magistral Medium traces and RL on top, it's a small, efficient reasoning model with 24B parameters.
Magistral Small can be deployed locally, fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized.
Learn more about Magistral in our [blog post](https://mistral.ai/news/magistral/).
## Key Features
- **Reasoning:** Capable of long chains of reasoning traces before providing an answer.
- **Multilingual:** Supports dozens of languages, including English, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Malay, Nepali, Polish, Portuguese, Romanian, Russian, Serbian, Spanish, Swedish, Turkish, Ukrainian, Vietnamese, Arabic, Bengali, Chinese, and Farsi.
- **Apache 2.0 License:** Open license allowing usage and modification for both commercial and non-commercial purposes.
- **Context Window:** A 128k context window, **but** performance might degrade past **40k**. Hence we recommend setting the maximum model length to 40k.
## Benchmark Results
| Model | AIME24 pass@1 | AIME25 pass@1 | GPQA Diamond | Livecodebench (v5) |
|-------|-------------|-------------|--------------|-------------------|
| Magistral Medium | 73.59% | 64.95% | 70.83% | 59.36% |
| Magistral Small | 70.68% | 62.76% | 68.18% | 55.84% |
## Sampling parameters
Please make sure to use:
- `top_p`: 0.95
- `temperature`: 0.7
- `max_tokens`: 40960
## Basic Chat Template
We highly recommend including the default system prompt used during RL for the best results, you can edit and customise it if needed for your specific use case.
```
<s>[SYSTEM_PROMPT]system_prompt
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts (i.e. your summary should be succinct but contain all the critical steps you needed to reach the conclusion). You should use Markdown to format your response. Write both your thoughts and summary in the same language as the task posed by the user. NEVER use \boxed{} in your response.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual and as long as you want until you are confident to generate a correct answer.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final answer to the user. Don't mention that this is a summary.
Problem:
[/SYSTEM_PROMPT][INST]user_message[/INST]<think>
reasoning_traces
</think>
assistant_response</s>[INST]user_message[/INST]
```
*`system_prompt`, `user_message` and `assistant_response` are placeholders.*
We invite you to choose, depending on your use case and requirements, between keeping reasoning traces during multi-turn interactions or keeping only the final assistant response.
***Please make sure to use [mistral-common](https://github.com/mistralai/mistral-common) as the source of truth***
## Usage
The model can be used with the following frameworks;
### Inference
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [below](#vllm)
In addition the community has prepared quantized versions of the model that can be used with the following frameworks (*alphabetically sorted*):
- [`llama.cpp`](https://github.com/ggml-org/llama.cpp): https://huggingface.co/mistralai/Magistral-Small-2506_gguf
- [`lmstudio` (llama.cpp, MLX)](https://lmstudio.ai/): https://lmstudio.ai/models/mistralai/magistral-small
- [`ollama`](https://ollama.com/): https://ollama.com/library/magistral
- [`unsloth` (llama.cpp)](https://huggingface.co/unsloth): https://huggingface.co/unsloth/Magistral-Small-2506-GGUF
### Training
Fine-tuning is possible with (*alphabetically sorted*):
- [`axolotl`](https://github.com/axolotl-ai-cloud/axolotl): https://github.com/axolotl-ai-cloud/axolotl/tree/main/examples/magistral
- [`unsloth`](https://github.com/unslothai/unsloth): https://docs.unsloth.ai/basics/magistral
### Other
Also you can use Magistral with:
- [`kaggle`](https://www.kaggle.com/models/mistral-ai/magistral-small-2506): https://www.kaggle.com/models/mistral-ai/magistral-small-2506
### vLLM (recommended)
We recommend using this model with the [vLLM library](https://github.com/vllm-project/vllm)
to implement production-ready inference pipelines.
**_Installation_**
Make sure you install the latest [`vLLM`](https://github.com/vllm-project/vllm/) code:
```
pip install -U vllm \
--pre \
--extra-index-url https://wheels.vllm.ai/nightly
```
Doing so should automatically install [`mistral_common >= 1.6.0`](https://github.com/mistralai/mistral-common/releases/tag/v1.6.0).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
Serve model as follows:
```
vllm serve mistralai/Magistral-Small-2506 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --tensor-parallel-size 2
```
Ping model as follows:
```py
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.7
TOP_P = 0.95
MAX_TOK = 40_960
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
query = "Write 4 sentences, each with at least 8 words. Now make absolutely sure that every sentence has exactly one word less than the previous sentence."
# or try out other queries
# query = "Exactly how many days ago did the French Revolution start? Today is June 4th, 2025."
# query = "Think about 5 random numbers. Verify if you can combine them with addition, multiplication, subtraction or division to 133"
# query = "If it takes 30 minutes to dry 12 T-shirts in the sun, how long does it take to dry 33 T-shirts?"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": query}
]
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
temperature=TEMP,
top_p=TOP_P,
max_tokens=MAX_TOK,
)
print("client: Start streaming chat completions...")
printed_content = False
for chunk in stream:
content = None
# Check the content is content
if hasattr(chunk.choices[0].delta, "content"):
content = chunk.choices[0].delta.content
if content is not None:
if not printed_content:
printed_content = True
print("\ncontent:", end="", flush=True)
# Extract and print the content
print(content, end="", flush=True)
# content:<think>
# Alright, I need to write 4 sentences where each one has at least 8 words and each subsequent sentence has one fewer word than the previous one.
# ...
# Final boxed answer (the four sentences):
# \[
# \boxed{
# \begin{aligned}
# &\text{1. The quick brown fox jumps over lazy dog and yells hello.} \\
# &\text{2. I saw the cat on the stair with my hat.} \\
# &\text{3. The man in the moon came down quickly today.} \\
# &\text{4. A cat sat on the mat today patiently.}
# \end{aligned}
# }
# \]
```
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
bruhzair/prototype-0.4x141 | bruhzair | 2025-06-15T19:33:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2403.19522",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:15:04Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# prototype-0.4x141
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using /workspace/prototype-0.4x136 as a base.
### Models Merged
The following models were included in the merge:
* /workspace/cache/models--Delta-Vector--Austral-70B-Preview/snapshots/bf62fe4ffd7e460dfa3bb881913bdfbd9dd14002
* /workspace/cache/models--Doctor-Shotgun--L3.3-70B-Magnum-Diamond/snapshots/197c99943443ef396927305ee44eccb6d8019d7f
* /workspace/cache/models--tdrussell--Llama-3-70B-Instruct-Storywriter/snapshots/19be2a7c6382a9150e126cf144e2b2964e700d3c
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: /workspace/cache/models--Doctor-Shotgun--L3.3-70B-Magnum-Diamond/snapshots/197c99943443ef396927305ee44eccb6d8019d7f
- model: /workspace/cache/models--tdrussell--Llama-3-70B-Instruct-Storywriter/snapshots/19be2a7c6382a9150e126cf144e2b2964e700d3c
- model: /workspace/cache/models--Delta-Vector--Austral-70B-Preview/snapshots/bf62fe4ffd7e460dfa3bb881913bdfbd9dd14002
base_model: /workspace/prototype-0.4x136
merge_method: model_stock
tokenizer:
source: base
int8_mask: true
dtype: float32
out_dtype: bfloat16
pad_to_multiple_of: 8
```
|
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_20250615_192335 | gradientrouting-spar | 2025-06-15T19:32:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:32:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.5_epoch1 | MinaMila | 2025-06-15T19:31:46Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:29:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
VIDEOS-19-sajal-malik-Viral-Video/FULL.VIDEO.jobz.hunting.sajal.malik.Viral.Video.Tutorial.Official | VIDEOS-19-sajal-malik-Viral-Video | 2025-06-15T19:31:42Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:31:11Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
sauropod/parakeet-tdt-0.6b-v2 | sauropod | 2025-06-15T19:30:37Z | 0 | 0 | null | [
"onnx",
"base_model:nvidia/parakeet-tdt-0.6b-v2",
"base_model:quantized:nvidia/parakeet-tdt-0.6b-v2",
"region:us"
] | null | 2025-06-15T19:16:02Z | ---
base_model: nvidia/parakeet-tdt-0.6b-v2
---
For running this model see https://github.com/sauropod-io/sauropod-inference
|
Peacemann/Qwen_Qwen3-32B_LMUL | Peacemann | 2025-06-15T19:29:27Z | 0 | 0 | null | [
"qwen3",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:Qwen/Qwen3-32B",
"base_model:finetune:Qwen/Qwen3-32B",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T19:25:53Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-32B
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
---
# L-Mul Optimized: Qwen/Qwen3-32B
This is a modified version of Alibaba Cloud's [Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `Qwen/Qwen3-32B` is preserved. However, the standard `Qwen3Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [Qwen/Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/Qwen_Qwen3-32B_LMUL" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For high-throughput inference, you can use `vLLM`:
```python
from vllm import LLM
repo_id = "Peacemann/Qwen_Qwen3-32B_LMUL" # Replace with the correct repo ID
llm = LLM(model=repo_id, trust_remote_code=True)
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**. It inherits all limitations and biases of the original `Qwen3-32B` model, and its behavior may be altered in unpredictable ways.
## Licensing Information
The use of this model is subject to the original **Qwen3 License**. By using this model, you agree to the terms outlined in the license. The license can be found on the base model's Hugging Face page. |
19-sajal-malik-Official-Viral-Video-K/FULL.VIDEO.jobz.hunting.sajal.malik.Viral.Video.Tutorial.Official | 19-sajal-malik-Official-Viral-Video-K | 2025-06-15T19:27:19Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:25:38Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/) |
sergioalves/0faed3e9-e738-48d0-97e2-a27c62b434bc | sergioalves | 2025-06-15T19:26:13Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/tinyllama-chat",
"base_model:adapter:unsloth/tinyllama-chat",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-15T19:11:46Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/tinyllama-chat
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 0faed3e9-e738-48d0-97e2-a27c62b434bc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/tinyllama-chat
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 732e1eb5b2bd299e_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.1
enabled: true
group_by_length: false
rank_loss: true
reference_model: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 0.8
group_by_length: false
hub_model_id: sergioalves/0faed3e9-e738-48d0-97e2-a27c62b434bc
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-07
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 32
lora_dropout: 0.3
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 16
lora_target_linear: true
lr_scheduler: cosine
max_steps: 300
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/732e1eb5b2bd299e_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: da6f2286-ccfa-4a3e-9a31-025262666714
wandb_project: s56-7
wandb_run: your_name
wandb_runid: da6f2286-ccfa-4a3e-9a31-025262666714
warmup_steps: 30
weight_decay: 0.05
xformers_attention: true
```
</details><br>
# 0faed3e9-e738-48d0-97e2-a27c62b434bc
This model is a fine-tuned version of [unsloth/tinyllama-chat](https://huggingface.co/unsloth/tinyllama-chat) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 30
- training_steps: 300
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.3893 | 0.0002 | 1 | 1.4089 |
| 1.2715 | 0.0364 | 150 | 1.3938 |
| 1.2629 | 0.0729 | 300 | 1.3861 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
ioana-coman-18/ULL.VIDEO.Ioana.Coman.Viral.Video.iubita.Tutorial.Official | ioana-coman-18 | 2025-06-15T19:26:07Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:18:18Z | [<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?ioana-coman)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?ioana-coman)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?ioana-coman) |
ioana-coman-18/wATCH.ioana-coman-ioana-coman-ioana-coman.original | ioana-coman-18 | 2025-06-15T19:24:28Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:19:35Z | [<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?ioana-coman)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?ioana-coman)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?ioana-coman) |
mezzo-fun/wATCH.mezzo.fun.viral.video.original | mezzo-fun | 2025-06-15T19:24:08Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:21:38Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=mezzo-fun)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=mezzo-fun)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=mezzo-fun) |
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_20250615_191350 | gradientrouting-spar | 2025-06-15T19:23:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:23:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Peacemann/mistralai_Ministral-8B-Instruct-2410_LMUL | Peacemann | 2025-06-15T19:19:55Z | 0 | 0 | null | [
"mistral",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:mistralai/Ministral-8B-Instruct-2410",
"base_model:finetune:mistralai/Ministral-8B-Instruct-2410",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T19:17:58Z | ---
license: apache-2.0
base_model: mistralai/Ministral-8B-Instruct-2410
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
---
# L-Mul Optimized: mistralai/Ministral-8B-Instruct-2410
This is a modified version of Mistral AI's [Ministral-8B-Instruct-2410](https://huggingface.co/mistralai/Ministral-8B-Instruct-2410) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `mistralai/Ministral-8B-Instruct-2410` is preserved. However, the standard `MistralAttention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [mistralai/Ministral-8B-Instruct-2410](https://huggingface.co/mistralai/Ministral-8B-Instruct-2410)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/mistralai_Ministral-8B-Instruct-2410_LMUL" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For high-throughput inference, you can use `vLLM`:
```python
from vllm import LLM
repo_id = "Peacemann/mistralai_Ministral-8B-Instruct-2410_LMUL" # Replace with the correct repo ID
llm = LLM(model=repo_id, trust_remote_code=True)
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**. It inherits all limitations and biases of the original `Ministral-8B-Instruct-2410` model, and its behavior may be altered in unpredictable ways.
## Licensing Information
The use of this model is subject to the original **Apache 2.0 License**. By using this model, you agree to the terms outlined in the license. The license can be found on the base model's Hugging Face page. |
hazyresearch/based-360m | hazyresearch | 2025-06-15T19:19:52Z | 76 | 2 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"dataset:EleutherAI/pile",
"arxiv:2402.18668",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-21T23:45:17Z | ---
datasets:
- EleutherAI/pile
language:
- en
pipeline_tag: text-generation
library_name: transformers
license: mit
---
# Model Card
This model is pretrained Based model. Based is strong at recalling information provided in context, despite using a fixed amount of memory during inference.
As a quality reference, we include a pretrained Attention (Llama architecture) model provided here: https://huggingface.co/hazyresearch/attn-360m, and Mamba model provided here: https://huggingface.co/hazyresearch/mamba-360m
All three checkpoints are pretrained on **10Bn tokens** of the Pile in the exact same data order using next token prediction.
### Model Sources
The model implementation and training code that produced the model are provided here: https://github.com/HazyResearch/based
### Uses
The purpose of this work is to evaluate the language modeling quality of a new efficient architecture, Based.
We include a series of benchmarks that you can use to evaluate quality:
- FDA: https://huggingface.co/datasets/hazyresearch/based-fda
- SWDE: https://huggingface.co/datasets/hazyresearch/based-swde
- SQUAD: https://huggingface.co/datasets/hazyresearch/based-squad
## Citation
Please consider citing this paper if you use our work:
```
@article{arora2024simple,
title={Simple linear attention language models balance the recall-throughput tradeoff},
author={Arora, Simran and Eyuboglu, Sabri and Zhang, Michael and Timalsina, Aman and Alberti, Silas and Zinsley, Dylan and Zou, James and Rudra, Atri and Ré, Christopher},
journal={arXiv:2402.18668},
year={2024}
}
```
Please reach out to [email protected], [email protected], and [email protected] with questions. |
07-katrina-lim-viral/Katrina.Lim.Viral.Video.Link.Full.Video.Original.Clip.4k | 07-katrina-lim-viral | 2025-06-15T19:16:15Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:15:20Z | <a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">➤ ►🌍📺📱👉 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.75_epoch1 | MinaMila | 2025-06-15T19:15:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:13:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Peacemann/Qwen_Qwen2-7B-Instruct_LMUL | Peacemann | 2025-06-15T19:14:51Z | 0 | 0 | null | [
"safetensors",
"qwen2",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T19:07:58Z | ---
license: apache-2.0
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
base_model:
- Qwen/Qwen2.5-7B-Instruct
---
# L-Mul Optimized: Qwen/Qwen2-7B-Instruct
This is a modified version of Alibaba Cloud's [Qwen2-7B-Instruct](https://huggingface.co/Qwen/Qwen2-7B-Instruct) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `Qwen/Qwen2-7B-Instruct` is preserved. However, the standard `Qwen2Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [Qwen/Qwen2-7B-Instruct](https://huggingface.co/Qwen/Qwen2-7B-Instruct)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/Qwen_Qwen2-7B-Instruct-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For high-throughput inference, you can use `vLLM`:
```python
from vllm import LLM
repo_id = "Peacemann/Qwen_Qwen2-7B-Instruct-lmul-attention" # Replace with the correct repo ID
llm = LLM(model=repo_id, trust_remote_code=True)
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**. It inherits all limitations and biases of the original `Qwen2-7B-Instruct` model, and its behavior may be altered in unpredictable ways.
## Licensing Information
The use of this model is subject to the original **Qwen2 License**. By using this model, you agree to the terms outlined in the license. The license can be found on the base model's Hugging Face page. |
TV-nulook-india-viral-videos-Original/18.video.Clip.nulook.india.Viral.Video.Leaks.Official | TV-nulook-india-viral-videos-Original | 2025-06-15T19:14:42Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:13:56Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
Katrina-Lim-Viral-Kiffy-Viral-videos-usa/FULL.VIDEO.Katrina.Lim.Video.Viral.Tutorial.Official | Katrina-Lim-Viral-Kiffy-Viral-videos-usa | 2025-06-15T19:14:29Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:14:08Z |
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
07-katrina-lim-viral/8K.Link.katrina.lim.viral.video.Original.video.today | 07-katrina-lim-viral | 2025-06-15T19:13:44Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:06:45Z | <a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">🔴 CLICK HERE 🌐==►► Download Now)</a>
|
18-bleep-Viral-Videos/ULL.VIDEO.bleep.Viral.Video.Tutorial.Official | 18-bleep-Viral-Videos | 2025-06-15T19:12:49Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:10:05Z | [<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?bleep)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?bleep)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?bleep) |
Manal0809/MedQA_Mistral_7b_Instructive_KG | Manal0809 | 2025-06-15T19:12:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:12:29Z | ---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Manal0809
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mikii17/syscode-Llama-3.3-70B-Instruct-bnb-4bit | mikii17 | 2025-06-15T19:12:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-15T18:44:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Katrina-Lim-Viral-Kiffy-Viral-videos-usa/Original.Full.Clip.Katrina.Lim.Viral.Video.Original.link | Katrina-Lim-Viral-Kiffy-Viral-videos-usa | 2025-06-15T19:12:21Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:11:32Z | <a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
Jeremias84/tinyllama-dippy | Jeremias84 | 2025-06-15T19:12:07Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:05:23Z | <div align="center">
# Dippy SN11: Creating The World's Best Open-Source Roleplay LLM <!-- omit in toc -->
Please check our [Launch Tweet](https://twitter.com/angad_ai/status/1788993280002175415) for our vision of creating the world's best open-source roleplay LLM.*
[](https://dippy.ai)
[](https://opensource.org/licenses/MIT)
---
</div>
- [Introduction](#introduction)
- [Roadmap](#roadmap)
- [Overview of Miner and Validator Functionality](#overview-of-miner-and-validator-functionality)
- [Miner](#miner)
- [Validator](#validator)
- [Running Miners and Validators](#running-miners-and-validators)
- [Running a Miner](#running-a-miner)
- [Running a Validator](#running-a-validator)
- [Contributing](#contributing)
- [License](#license)
---
## Introduction
> **Note:** The following documentation assumes you are familiar with basic Bittensor concepts: Miners, Validators, and incentives. If you need a primer, please check out https://docs.bittensor.com/learn/bittensor-building-blocks.
Dippy is one of the world's leading AI companion apps with **1M+ users**. The app has ranked [**#3 on the App Store**](https://x.com/angad_ai/status/1850924240742031526) in countries like Germany, been covered by publications like [**Wired magazine**](https://www.wired.com/story/dippy-ai-girlfriend-boyfriend-reasoning/) and the average Dippy user **spends 1+ hour on the app.**
The Dippy Roleplay subnet on Bittensor aims to create the world's best open-source roleplay LLM by leveraging the collective efforts of the open-source community. This subnet addresses the critical issue of loneliness, which affects a significant portion of the population and is linked to various mental and physical health problems.
Current SOTA LLMs (Claude, OpenAI etc.) are designed for the assistant use case and lack the empathetic qualities necessary for companionship. While some companies (like Character AI and Inflection) have developed closed-source roleplay LLMs, the open-source alternatives lag significantly behind in performance. Furthermore, recent developments in the LLM space have prioritized objective reasoning capabilities, which only bring minor improvements to the role play space. Thus, the development of roleplay oriented models becomes even more important in the open source world.

## Roadmap
Given the complexity of creating a state of the art roleplay LLM, we plan to divide the process into 3 distinct phases.
**Phase 1:**
- [x] Subnet launch with robust pipeline for roleplay LLM evaluation on public datasets and response length
- [x] Public model leaderboard based on evaluation criteria
- [x] Introduce Coherence and Creativity as a criteria for live model evaluation
**Phase 2:**
- [x] Publicly release front-end powered by top miner submitted model of the week
- [x] Integrate top miner submitted model in Official Dippy App
- [x] Add support for larger parameter models for up to 34B
**Phase 3:**
- [x] Expand the state of the art in roleplay LLMs through continuous iteration and data collection
- [ ] Redefine definition of SOTA for roleplay LLMs through integrating Dippy app data
## Overview of Miner and Validator Functionality

**Miners** would use existing frameworks, fine tuning techniques, or MergeKit, to train, fine tune, or merge models to create a unique roleplay LLM. These models would be submitted to a shared Hugging Face pool.
**Validators** would evaluate the and assess model performance via our protocol and rank the submissions based on an [open scoring format](/docs/llm_scoring.md). We will provide a suite of
testing and benchmarking protocols with state-of-the-art datasets.
## Running Miners and Validators
### Running a Miner
> **Important:** Please carefully read through the [FAQ](docs/FAQ.md) and [Detailed Miner Documentation](docs/miner.md). These contain critical information about model requirements, evaluation criteria, and best practices that will help ensure your submissions are valid and competitive.
### Running a Validator
#### Requirements
- Python 3.9+
#### Setup
To start, clone the repository and `cd` to it:
```
git clone https://github.com/impel-intelligence/dippy-bittensor-subnet.git
cd dippy-bittensor-subnet
pip install -e .
```
To run the evaluation, simply use the following command:
```
python neurons/validator.py --wallet.name WALLET_NAME --wallet.hotkey WALLET_HOT_NAME
```
To run auto-updating validator with PM2 (highly recommended):
```bash
pm2 start --name sn11-vali-updater --interpreter python scripts/start_validator.py -- --pm2_name sn11-vali --wallet.name WALLET_NAME --wallet.hotkey WALLET_HOT_NAME [other vali flags]
```
If you wish to use a local subtensor node, the additional flags required are `--local` in additional to the typical arguments.
Example:
```bash
python neurons/validator.py \
--wallet.name coldkey \
--wallet.hotkey hotkey \
--local \
--subtensor.network local --subtensor.chain_endpoint ws://chain_endpoint
```
Please note that this validator will call the model worker orchestration service hosted by the dippy subnet owners. Current support for local worker orchestration is disabled at this time.
## Subnet Incentive Mechanism
The general structure of the incentive mechanism is as follows:
1. Every miner has a model registered per UID
2. Each miner's model submission is scored, with details outlined below
- The scoring mechanism is constantly evolving according to SOTA model bechmark data
3. The validator compares each miner's score against all the other miners, and calculates a win rate
- Note that there are some modifiers for a miner's score such as their submission age in relation to other miner submissions (aka time penalty) to combat blatant model copying
4. Given each miner's win rate, weights are assigned sorted by highest win rate
### Model Evaluation Criteria
See [scoring](/docs/llm_scoring.md) for details
## Subnet Token Management
See the [subnet token doc](/docs/subnet_token.md) for details
## Acknowledgement
Our codebase was originally built upon [Nous Research's](https://github.com/NousResearch/finetuning-subnet) and [MyShell's](https://github.com/myshell-ai/MyShell-TTS-Subnet?tab=readme-ov-file) Subnets. At the time of this writing, we have deviated significantly from these subnet architectures, providing more efficiency and capability.
## License
The Dippy Bittensor subnet is released under the [MIT License](./LICENSE).
# Project Structure Overview
## Core Components
### 1. Main Application
- `neurons/` - Core neural network components
- `miner.py` - Miner code for submitting a model to the bittensor network
- `validator.py` - Validation node implementation
- `model_queue.py` - Queue management for model processing (for internal use)
### 2. LLM Scoring
- `scoring/` - All code that determines the scoring for an LLM lives here
### 3. Utilities
- `utilities/` - Common utility functions
- `repo_details.py` - Repository management utilities
- `validation_utils.py` - Validation helper functions
### 4. Documentation
- `docs/` - Project documentation
- `miner.md` - Miner setup and usage guide
- `validator.md` - Validator setup and usage guide
- `FAQ.md` - Frequently asked questions
- `llm_scoring.md` - LLM Scoring criteria
### 5. Worker API (for internal use)
- `wokrer_api/` - API for model validation. Only validators and subnet operators require usage of this API. Miners do not need to set this up in 99% of cases
## Docker Configuration
- `evaluator.Dockerfile` - Docker configuration for evaluator (scoring worker)
- `worker_api/vapi.Dockerfile` - Docker configuration for worker API
|
alakxender/bert-dhivehi-tokenizer-extended | alakxender | 2025-06-15T19:11:45Z | 0 | 0 | transformers | [
"transformers",
"bert-dhivehi-tokenizer",
"dv",
"dataset:alakxender/haveeru-articles",
"dataset:alakxender/dhivehi-news-corpus",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:05:18Z | ---
library_name: transformers
tags:
- bert-dhivehi-tokenizer
license: mit
datasets:
- alakxender/haveeru-articles
- alakxender/dhivehi-news-corpus
language:
- dv
---
# bert-dhivehi-tokenizer-extended
**An extended BERT tokenizer** built upon `bert-base-multilingual-cased`, optimized for Dhivehi (Divehi/Thaana script).
## Overview
This tokenizer preserves all English and multilingual coverage of the base model, while adding the **top 100,000 high-frequency Dhivehi tokens** extracted from a large corpus. It ensures robust tokenization for both English and Dhivehi with no regressions.
## How It Was Built
- **Base model**: `bert-base-multilingual-cased`
- **Corpus**: ~16.7M lines of cleaned Dhivehi text (one sentence per line)
- **Processing steps**:
1. Count word-level tokens in batches of 100,000 lines
2. Filter out rare tokens (frequency < 5)
3. Select top 100,000 tokens by frequency
4. Extend vocab using `tokenizer.add_tokens([...])`
## Usage Example
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("alakxender/bert-dhivehi-tokenizer-extended")
# Tokenization test
text_dv = "ޖެންޑާގެ ސްޓޭޓް އަޒްރާ"
print(tokenizer.tokenize(text_dv))
```
- English tokenization unchanged
- Dhivehi text now tokenizes into meaningful word-level tokens with zero `[UNK]`
## Intended Uses
- Downstream **NER**, **QA**, **classification**, or **masking** tasks in Dhivehi
- Fine-tuning of `bert-base-multilingual-cased` model with extended vocabulary
- Specially useful for projects in Maldivian/Thaana script
## Limitations
- Vocabulary capped at **100,000 new tokens**; may miss very rare words
- Tokenization remains **word-level**, not subword-based—better performance may require further tokenizer retraining
## Files
- `vocab.txt`, `tokenizer_config.json`, `special_tokens_map.json`
→ Standard tokenizer files
- **Note**: No `tokenizer.json`; requires `BertTokenizer`, not `Fast`, due to manual extension |
saujasv/pixtral-coco-6-images-listener-4 | saujasv | 2025-06-15T19:11:20Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:saujasv/pixtral-12b",
"base_model:adapter:saujasv/pixtral-12b",
"region:us"
] | null | 2025-06-14T16:47:53Z | ---
base_model: saujasv/pixtral-12b
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.1 |
Delta-Vector/Austral-24B-KTO-Q6_K-GGUF | Delta-Vector | 2025-06-15T19:09:41Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:NewEden/Austral-24B-KTO",
"base_model:quantized:NewEden/Austral-24B-KTO",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:08:27Z | ---
base_model: NewEden/Austral-24B-KTO
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Delta-Vector/Austral-24B-KTO-Q6_K-GGUF
This model was converted to GGUF format from [`NewEden/Austral-24B-KTO`](https://huggingface.co/NewEden/Austral-24B-KTO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NewEden/Austral-24B-KTO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -c 2048
```
|
dfrypppppp/postcards_LoRAAA | dfrypppppp | 2025-06-15T19:08:17Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-15T19:03:20Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: 'a silly TOK holiday postcart with funny amimals: '
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - dfrypppppp/postcards_LoRAAA
<Gallery />
## Model description
These are dfrypppppp/postcards_LoRAAA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a silly TOK holiday postcart with funny amimals: to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](dfrypppppp/postcards_LoRAAA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
VIDEOS-18-parveen-viral-video-tv/New.tutorial.parveen.Viral.Video.Leaks.Official | VIDEOS-18-parveen-viral-video-tv | 2025-06-15T19:06:58Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:06:36Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
ihsan31415/IHSGHybridAttentionNet | ihsan31415 | 2025-06-15T19:04:40Z | 0 | 0 | keras | [
"keras",
"region:us"
] | null | 2025-06-15T12:14:36Z | # IHSG Hybrid Attention Net
A Keras model to predict IHSG index using attention mechanism over embeddings and market features. |
07-katrina-lim-viral/ORIGINAL.FULL.VIDEO.Katrina.Lim.Viral.Video.Leaks.Official-videos | 07-katrina-lim-viral | 2025-06-15T19:04:36Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:04:15Z | <a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
anvitamanne/wav2vec2-kaggle-final | anvitamanne | 2025-06-15T19:03:00Z | 0 | 0 | null | [
"safetensors",
"wav2vec2",
"generated_from_trainer",
"base_model:facebook/wav2vec2-large-xlsr-53",
"base_model:finetune:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T15:57:00Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-kaggle-final
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-kaggle-final
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 513.6357
- Wer: 0.4037
- Cer: 0.1660
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 1711.3334 | 0.86 | 1000 | 768.0388 | 0.8588 | 0.3197 |
| 672.7345 | 1.72 | 2000 | 522.8168 | 0.6091 | 0.2202 |
| 574.6395 | 2.58 | 3000 | 495.6673 | 0.5407 | 0.2048 |
| 518.2652 | 3.44 | 4000 | 472.2298 | 0.5068 | 0.1910 |
| 485.7279 | 4.3 | 5000 | 448.1584 | 0.4797 | 0.1835 |
| 456.6944 | 5.17 | 6000 | 459.5286 | 0.4703 | 0.1805 |
| 440.0209 | 6.03 | 7000 | 490.1409 | 0.4549 | 0.1780 |
| 424.1306 | 6.89 | 8000 | 458.7100 | 0.4455 | 0.1754 |
| 413.0438 | 7.75 | 9000 | 446.2839 | 0.4371 | 0.1735 |
| 382.4416 | 8.61 | 10000 | 499.2264 | 0.4338 | 0.1728 |
| 370.5859 | 9.47 | 11000 | 489.0332 | 0.4243 | 0.1692 |
| 352.6317 | 10.33 | 12000 | 491.2080 | 0.4133 | 0.1664 |
| 371.7963 | 11.19 | 13000 | 464.0348 | 0.4109 | 0.1657 |
| 343.1062 | 12.05 | 14000 | 488.7343 | 0.4134 | 0.1676 |
| 332.8081 | 12.91 | 15000 | 518.1512 | 0.4044 | 0.1649 |
| 323.9083 | 13.78 | 16000 | 507.0865 | 0.4072 | 0.1667 |
| 323.2671 | 14.64 | 17000 | 513.6357 | 0.4037 | 0.1660 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu118
- Datasets 3.6.0
- Tokenizers 0.15.2
|
Official-parveen-viral-video/Original.18.parveen.viral.video.parbin.bilasipara.viral.video.link | Official-parveen-viral-video | 2025-06-15T19:01:24Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:01:02Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.05_epoch1 | MinaMila | 2025-06-15T18:59:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:57:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
swdq/stock-prices-model | swdq | 2025-06-15T18:57:18Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:55:58Z | claude@189b6b4e894a:/app$ python3 '/app/inference.py'
Using checkpoint: checkpoints/last.ckpt
Model loaded from checkpoints/last.ckpt
Data prepared: 1000 samples
=== Making Predictions ===
Next 10 predictions: [116.53201066 116.37892322 116.04956024 115.62472269 115.15303941
114.6622934 114.16789415 113.67827708 113.19807399 112.72984611]
=== Model Evaluation ===
MSE: 7.7239
MAE: 2.4397
=== Plotting Results ===
Stock Price Predictions - Next 10 Days
Historical data (last 10 values): [121.14573944 119.10400458 118.85682719 118.17484295 117.17322294
116.89212264 118.68980917 119.33065203 118.75947304 119.33205582]
Predictions: [116.53201066 116.37892322 116.04956024 115.62472269 115.15303941
114.6622934 114.16789415 113.67827708 113.19807399 112.72984611]
(Plot would be saved to predictions.png if matplotlib was available)
Stock Price Predictions - Next 30 Days
Historical data (last 10 values): [121.14573944 119.10400458 118.85682719 118.17484295 117.17322294
116.89212264 118.68980917 119.33065203 118.75947304 119.33205582]
Predictions: [118.31780125 117.89574121 117.38160134 116.82251489 116.24679503
115.67077976 115.10363774 114.55039909 114.01377537 113.49513293
112.99504679 112.51360925 112.05058821 111.60554316 111.17787799
110.76690689 110.37187547 109.99200297 109.62649281 109.27455894
108.93542852 108.60836035 108.29264488 107.98761477 107.69263435
107.40711275 107.13050398 106.8622884 106.60199122 106.34917196]
(Plot would be saved to long_predictions.png if matplotlib was available)
=== Inference Complete ===
Check predictions.png and long_predictions.png for visualizations
claude@189b6b4e894a:/app$ |
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_20250615_184514 | gradientrouting-spar | 2025-06-15T18:54:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:54:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
dgambettaphd/M_llm2_run2_gen1_WXS_doc1000_synt64_lr1e-04_acm_FRESH | dgambettaphd | 2025-06-15T18:54:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:54:18Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
duchao1210/DPO_Qwen25_3B_64_0_5000kmaplr1e-7 | duchao1210 | 2025-06-15T18:53:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:duchao1210/qwen_2.5_3B_5k_r128",
"base_model:finetune:duchao1210/qwen_2.5_3B_5k_r128",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:51:55Z | ---
base_model: duchao1210/qwen_2.5_3B_5k_r128
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** duchao1210
- **License:** apache-2.0
- **Finetuned from model :** duchao1210/qwen_2.5_3B_5k_r128
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.15_epoch2 | MinaMila | 2025-06-15T18:51:08Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:49:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in_cola | gokulsrinivasagan | 2025-06-15T18:47:10Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"base_model:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"base_model:finetune:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T18:45:53Z | ---
library_name: transformers
language:
- en
license: apache-2.0
base_model: gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
- accuracy
model-index:
- name: tinybert_base_train_book_ent_15p_s_init_kd_a_in_cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE COLA
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.10052549175044687
- name: Accuracy
type: accuracy
value: 0.6922339200973511
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tinybert_base_train_book_ent_15p_s_init_kd_a_in_cola
This model is a fine-tuned version of [gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in](https://huggingface.co/gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6107
- Matthews Correlation: 0.1005
- Accuracy: 0.6922
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|:--------:|
| 0.6125 | 1.0 | 34 | 0.6121 | 0.0 | 0.6913 |
| 0.5935 | 2.0 | 68 | 0.6208 | 0.0181 | 0.6913 |
| 0.5597 | 3.0 | 102 | 0.6107 | 0.1005 | 0.6922 |
| 0.518 | 4.0 | 136 | 0.6409 | 0.1455 | 0.6989 |
| 0.4605 | 5.0 | 170 | 0.6806 | 0.1928 | 0.7028 |
| 0.4108 | 6.0 | 204 | 0.7226 | 0.1943 | 0.7037 |
| 0.3721 | 7.0 | 238 | 0.7162 | 0.1746 | 0.6826 |
| 0.3206 | 8.0 | 272 | 0.8593 | 0.1567 | 0.6826 |
### Framework versions
- Transformers 4.51.2
- Pytorch 2.6.0+cu126
- Datasets 3.5.0
- Tokenizers 0.21.1
|
FemirK/merkut_turkce_duyguAnaliziModeli | FemirK | 2025-06-15T18:41:08Z | 0 | 0 | null | [
"safetensors",
"tr",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:cc-by-3.0",
"region:us"
] | null | 2025-06-15T18:19:41Z | ---
license: cc-by-3.0
language:
- tr
base_model:
- google-bert/bert-base-uncased
--- |
JosephTreitel/reddit-lora-V3 | JosephTreitel | 2025-06-15T18:39:48Z | 0 | 1 | null | [
"safetensors",
"mistral",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:18:18Z | ---
license: apache-2.0
---
|
trancuong253/grpo_final | trancuong253 | 2025-06-15T18:38:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:38:02Z | ---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** trancuong253
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
vex1522/baseline-summary-model | vex1522 | 2025-06-15T18:35:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-06-15T18:04:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.25_epoch2 | MinaMila | 2025-06-15T18:35:03Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:33:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
harshitha008/US-immigration-assistant-mistral-7B-instruct | harshitha008 | 2025-06-15T18:34:38Z | 0 | 0 | null | [
"safetensors",
"mistral",
"en",
"dataset:harshitha008/US-immigration-laws",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.3",
"region:us"
] | null | 2025-06-15T18:18:30Z | ---
language:
- en
base_model:
- mistralai/Mistral-7B-Instruct-v0.3
datasets:
- harshitha008/US-immigration-laws
--- |
alicebochkareva/goncharova_style_LoRA | alicebochkareva | 2025-06-15T18:29:03Z | 11 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-14T16:08:25Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: photo collage in GONCHAROVA style
widget: []
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - alicebochkareva/goncharova_style_LoRA
<Gallery />
## Model description
These are alicebochkareva/goncharova_style_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use photo collage in GONCHAROVA style to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](alicebochkareva/goncharova_style_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8 | BootesVoid | 2025-06-15T18:27:33Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:27:23Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: AVA01
---
# Cmbxolqt401Oardqsvxij32Dm_Cmbxy8Hyr02Bprdqshbtcjxr8
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `AVA01` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "AVA01",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8', weight_name='lora.safetensors')
image = pipeline('AVA01').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8/discussions) to add images that show off what you’ve made with this LoRA.
|
tirdodbehbehani/yahoo-bert-05_balanced_2_mask_aug | tirdodbehbehani | 2025-06-15T18:27:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2",
"base_model:finetune:tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T17:22:19Z | ---
library_name: transformers
base_model: tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
model-index:
- name: yahoo-bert-05_balanced_2_mask_aug
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yahoo-bert-05_balanced_2_mask_aug
This model is a fine-tuned version of [tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2](https://huggingface.co/tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0359
- Accuracy: 0.6692
- Precision: 0.6737
- Recall: 0.6657
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|
| 1.226 | 1.0 | 492 | 1.0359 | 0.6692 | 0.6737 | 0.6657 |
| 0.7918 | 2.0 | 984 | 1.0909 | 0.6655 | 0.6654 | 0.6595 |
| 0.5589 | 3.0 | 1476 | 1.2076 | 0.6603 | 0.6555 | 0.6557 |
| 0.3879 | 4.0 | 1968 | 1.3394 | 0.6490 | 0.6531 | 0.6451 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
VIDEOS-18-nulook-india-Hot-video/TV.nulook.india.viral.videos.Full.Clip.nulook.india.Viral.Video.Leaks.Official | VIDEOS-18-nulook-india-Hot-video | 2025-06-15T18:27:08Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:19:53Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.25_epoch1 | MinaMila | 2025-06-15T18:27:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:25:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
raquelleite2757/zv | raquelleite2757 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
afonsovalente9184/lum | afonsovalente9184 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:29Z | ---
license: artistic-2.0
---
|
miaandrade9818/lumdg | miaandrade9818 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
fernandocosta9708/llk | fernandocosta9708 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
samuelabreu2941/sgf | samuelabreu2941 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1586 | utkuden | 2025-06-15T18:23:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:23:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
norygano/C-BERT | norygano | 2025-06-15T18:22:24Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"de",
"base_model:google-bert/bert-base-german-cased",
"base_model:finetune:google-bert/bert-base-german-cased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:24:48Z | ---
library_name: transformers
license: apache-2.0
language:
- de
base_model:
- google-bert/bert-base-german-cased
---
# Model Card for norygano/C-BERT
CausalBERT (C-BERT) is a multi-task fine-tuned German BERT that extracts causal attributions.
## Model details
- **Model architecture**: BERT-base-German-cased + token & relation heads
- **Fine-tuned on**: environmental causal attribution corpus (German)
- **Tasks**:
1. Token classification (BIO tags for INDICATOR / ENTITY)
2. Relation classification (CAUSE, EFFECT, INTERDEPENDENCY)
## Usage
Find the custom [library](https://github.com/norygami/causalbert). Once installed, run inference like so:
```python
from transformers import AutoTokenizer
from causalbert.infer import load_model, analyze_sentence_with_confidence
model, tokenizer, config, device = load_model("norygano/C-BERT")
result = analyze_sentence_with_confidence(
model, tokenizer, config, "Autoverkehr verursacht Bienensterben.", []
)
```
## Training
- **Base model**: `google-bert/bert-base-german-cased`
- **Epochs**: 3, **LR**: 2e-5, **Batch size**: 8
- See [train.py](https://github.com/norygami/causalbert/blob/main/causalbert/train.py) for details.
## Limitations
- Only German.
- Sentence-level; doesn’t handle cross-sentence causality.
- Relation classification depends on detected spans — errors in token tagging propagate. |
openbmb/BitCPM4-0.5B-GGUF | openbmb | 2025-06-15T18:19:45Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-13T08:10:08Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
- [BitCPM4-0.5B-GGUF](https://huggingface.co/openbmb/BitCPM4-0.5B-GGUF): GGUF version of BitCPM4-0.5B. (**<-- you are here**)
- [BitCPM4-1B-GGUF](https://huggingface.co/openbmb/BitCPM4-1B-GGUF): GGUF version of BitCPM4-1B.
## Introduction
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
## Usage
### Inference with [llama.cpp](https://github.com/ggml-org/llama.cpp)
```bash
./llama-cli -c 1024 -m BitCPM4-0.5B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。"
```
## Evaluation Results
BitCPM4's performance is comparable with other full-precision models in same model size.
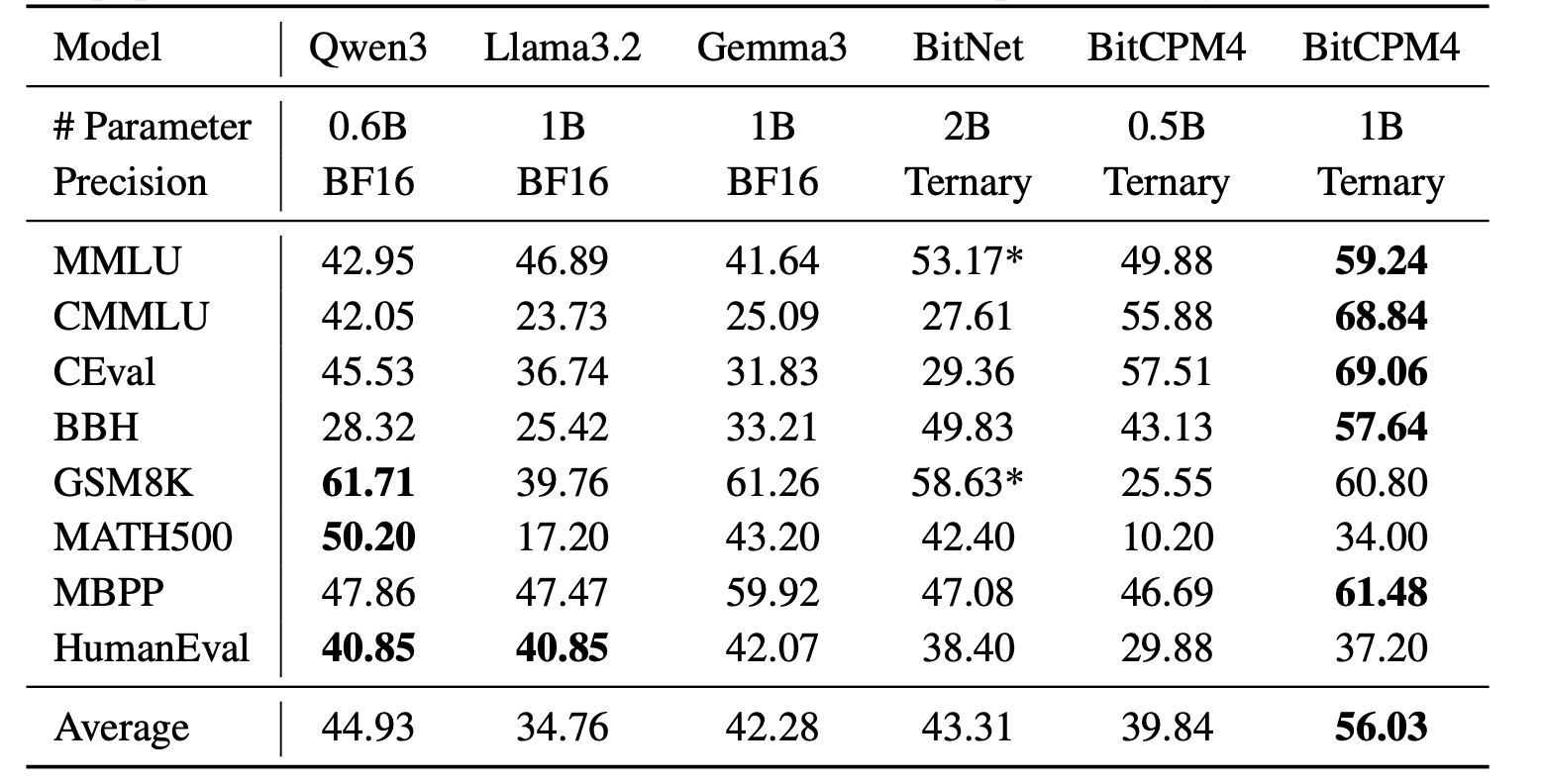
## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.5_epoch2 | MinaMila | 2025-06-15T18:18:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:16:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
openbmb/BitCPM4-1B-GGUF | openbmb | 2025-06-15T18:18:40Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-13T11:41:44Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
- [BitCPM4-0.5B-GGUF](https://huggingface.co/openbmb/BitCPM4-0.5B-GGUF): GGUF version of BitCPM4-0.5B.
- [BitCPM4-1B-GGUF](https://huggingface.co/openbmb/BitCPM4-1B-GGUF): GGUF version of BitCPM4-1B. (**<-- you are here**)
## Introduction
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
## Usage
### Inference with [llama.cpp](https://github.com/ggml-org/llama.cpp)
```bash
./llama-cli -c 1024 -m BitCPM4-1B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。"
```
## Evaluation Results
BitCPM4's performance is comparable with other full-precision models in same model size.

## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
|
JonLoRA/deynairaLoRAv1 | JonLoRA | 2025-06-15T18:17:55Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T16:21:56Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: photo of a girl
---
# Deynairalorav1
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `photo of a girl` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "photo of a girl",
"lora_weights": "https://huggingface.co/JonLoRA/deynairaLoRAv1/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('JonLoRA/deynairaLoRAv1', weight_name='lora.safetensors')
image = pipeline('photo of a girl').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 6000
- Learning rate: 0.0002
- LoRA rank: 64
## Contribute your own examples
You can use the [community tab](https://huggingface.co/JonLoRA/deynairaLoRAv1/discussions) to add images that show off what you’ve made with this LoRA.
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_negative_3x3_seed_1_seed_25_20250615_180710 | gradientrouting-spar | 2025-06-15T18:16:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:16:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vinnvinn/mistral-hugz | vinnvinn | 2025-06-15T18:13:06Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:13:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.5_epoch1 | MinaMila | 2025-06-15T18:10:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:09:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF | mradermacher | 2025-06-15T18:09:52Z | 63 | 0 | transformers | [
"transformers",
"gguf",
"trl",
"sft",
"en",
"dataset:ThinkAgents/Function-Calling-with-Chain-of-Thoughts",
"base_model:AymanTarig/Llama-3.2-1B-FC-v3",
"base_model:quantized:AymanTarig/Llama-3.2-1B-FC-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-01-31T19:09:16Z | ---
base_model: AymanTarig/Llama-3.2-1B-FC-v3
datasets:
- ThinkAgents/Function-Calling-with-Chain-of-Thoughts
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- trl
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/AymanTarig/Llama-3.2-1B-FC-v3
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q2_K.gguf) | Q2_K | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q3_K_S.gguf) | Q3_K_S | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q3_K_M.gguf) | Q3_K_M | 0.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q3_K_L.gguf) | Q3_K_L | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.IQ4_XS.gguf) | IQ4_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q4_K_S.gguf) | Q4_K_S | 0.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q4_K_M.gguf) | Q4_K_M | 0.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q5_K_S.gguf) | Q5_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q5_K_M.gguf) | Q5_K_M | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q6_K.gguf) | Q6_K | 1.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q8_0.gguf) | Q8_0 | 1.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.f16.gguf) | f16 | 2.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
MichiganNLP/tama-1e-6 | MichiganNLP | 2025-06-15T18:08:08Z | 17 | 0 | null | [
"safetensors",
"llama",
"table",
"text-generation",
"conversational",
"en",
"arxiv:2501.14693",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:mit",
"region:us"
] | text-generation | 2024-12-10T22:51:52Z | ---
license: mit
language:
- en
base_model:
- meta-llama/Llama-3.1-8B-Instruct
pipeline_tag: text-generation
tags:
- table
---
# Model Card for TAMA-1e-6
<!-- Provide a quick summary of what the model is/does. -->
Recent advances in table understanding have focused on instruction-tuning large language models (LLMs) for table-related tasks. However, existing research has overlooked the impact of hyperparameter choices, and also lacks a comprehensive evaluation of the out-of-domain table understanding ability and the general capabilities of these table LLMs. In this paper, we evaluate these abilities in existing table LLMs, and find significant declines in both out-of-domain table understanding and general capabilities as compared to their base models.
Through systematic analysis, we show that hyperparameters, such as learning rate, can significantly influence both table-specific and general capabilities. Contrary to the previous table instruction-tuning work, we demonstrate that smaller learning rates and fewer training instances can enhance table understanding while preserving general capabilities. Based on our findings, we introduce TAMA, a TAble LLM instruction-tuned from LLaMA 3.1 8B Instruct, which achieves performance on par with, or surpassing GPT-3.5 and GPT-4 on table tasks, while maintaining strong out-of-domain generalization and general capabilities. Our findings highlight the potential for reduced data annotation costs and more efficient model development through careful hyperparameter selection.
## 🚀 Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Model type:** Text generation.
- **Language(s) (NLP):** English.
- **License:** [[License for Llama models](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE))]
- **Finetuned from model:** [[meta-llama/Llama-3.1-8b-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)]
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [[github](https://github.com/MichiganNLP/TAMA)]
- **Paper:** [[paper](https://arxiv.org/abs/2501.14693)]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
TAMA is intended for the use in table understanding tasks and to facilitate future research.
## 🔨 How to Get Started with the Model
Use the code below to get started with the model.
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers pipeline abstraction or by leveraging the Auto classes with the generate() function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```
import transformers
import torch
model_id = "MichiganNLP/tama-5e-7"
pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
pipeline("Hey how are you doing today?")
```
You may replace the prompt with table-specific instructions. We recommend using the following prompt structure:
```
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that
appropriately completes the request.
### Instruction:
{instruction}
### Input:
{table_content}
### Question:
{question}
### Response:
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[TAMA Instruct](https://huggingface.co/datasets/MichiganNLP/TAMA_Instruct).
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
We utilize the [LLaMA Factory](https://github.com/hiyouga/LLaMA-Factory) library for model training and inference. Example YAML configuration files are provided [here](https://github.com/MichiganNLP/TAMA/blob/main/yamls/train.yaml).
The training command is:
```
llamafactory-cli train yamls/train.yaml
```
#### Training Hyperparameters
- **Training regime:** bf16
- **Training epochs:** 2.0
- **Learning rate scheduler:** linear
- **Cutoff length:** 2048
- **Learning rate**: 1e-6
## 📝 Evaluation
### Results
<!-- This should link to a Dataset Card if possible. -->
<table>
<tr>
<th>Models</th>
<th>FeTaQA</th>
<th>HiTab</th>
<th>TaFact</th>
<th>FEVEROUS</th>
<th>WikiTQ</th>
<th>WikiSQL</th>
<th>HybridQA</th>
<th>TATQA</th>
<th>AIT-QA</th>
<th>TABMWP</th>
<th>InfoTabs</th>
<th>KVRET</th>
<th>ToTTo</th>
<th>TableGPT<sub>subset</sub></th>
<th>TableBench</th>
</tr>
<tr>
<th>Metrics</th>
<th>BLEU</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Micro F1</th>
<th>BLEU</th>
<th>Acc</th>
<th>ROUGE-L</th>
</tr>
<tr>
<td>GPT-3.5</td>
<td><u>26.49</u></td>
<td>43.62</td>
<td>67.41</td>
<td>60.79</td>
<td><u>53.13</u></td>
<td>41.91</td>
<td>40.22</td>
<td>31.38</td>
<td>84.13</td>
<td>46.30</td>
<td>56.00</td>
<td><u>54.56</u></td>
<td><u>16.81</u></td>
<td>54.80</td>
<td>27.75</td>
</tr>
<tr>
<td>GPT-4</td>
<td>21.70</td>
<td><u>48.40</u></td>
<td><b>74.40</b></td>
<td><u>71.60</u></td>
<td><b>68.40</b></td>
<td><u>47.60</u></td>
<td><u>58.60</u></td>
<td><b>55.81</b></td>
<td><u>88.57</u></td>
<td><b>67.10</b></td>
<td><u>58.60</u></td>
<td><b>56.46</b></td>
<td>12.21</td>
<td><b>80.20</b></td>
<td><b>40.38</b></td>
</tr>
<tr>
<td>base</td>
<td>15.33</td>
<td>32.83</td>
<td>58.44</td>
<td>66.37</td>
<td>43.46</td>
<td>20.43</td>
<td>32.83</td>
<td>26.70</td>
<td>82.54</td>
<td>39.97</td>
<td>48.39</td>
<td>50.80</td>
<td>13.24</td>
<td>53.60</td>
<td>23.47</td>
</tr>
<tr>
<td>TAMA</td>
<td><b>35.37</b></td>
<td><b>63.51</b></td>
<td><u>73.82</u></td>
<td><b>77.39</b></td>
<td>52.88</td>
<td><b>68.31</b></td>
<td><b>60.86</b></td>
<td><u>48.47</u></td>
<td><b>89.21</b></td>
<td><u>65.09</u></td>
<td><b>64.54</b></td>
<td>43.94</td>
<td><b>37.94</b></td>
<td><u>53.60</u></td>
<td><u>28.60</u></td>
</tr>
</table>
We make the number bold if it is the best among the four, we underline the number if it is at the second place.
Please refer to our [paper](https://arxiv.org/abs/2501.14693) for additional details.
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
Please refer to our [paper](https://arxiv.org/abs/2501.14693) for additional details.
#### Summary
Notably, as an 8B model, TAMA demonstrates strong table understanding ability, outperforming GPT-3.5 on most of the table understanding benchmarks, even achieving performance on par or better than GPT-4.
## Technical Specifications
### Model Architecture and Objective
We base our model on the [Llama-3.1-8B-Instruct model](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct).
We instruction tune the model on a set of 2,600 table instructions.
### Compute Infrastructure
#### Hardware
We conduct our experiments on A40 and A100 GPUs.
#### Software
We leverage the [LLaMA Factory](https://github.com/hiyouga/LLaMA-Factory) for model training.
## Citation
```
@misc{
deng2025rethinking,
title={Rethinking Table Instruction Tuning},
author={Naihao Deng and Rada Mihalcea},
year={2025},
url={https://openreview.net/forum?id=GLmqHCwbOJ}
}
```
## Model Card Authors
Naihao Deng
## Model Card Contact
Naihao Deng |
Videos-Parveen-Viral-Video-Link/Full.VIDEO.parvin.Viral.Video.Tutorial.Official | Videos-Parveen-Viral-Video-Link | 2025-06-15T18:06:41Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:05:53Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
VIDEOS-18-nulook-india-Hot-video/Original.Full.Clip.nulook.india.Viral.Video.Leaks.Official | VIDEOS-18-nulook-india-Hot-video | 2025-06-15T18:04:31Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:04:06Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
multimolecule/aido.rna-1.6b-ss | multimolecule | 2025-06-15T18:02:50Z | 0 | 0 | multimolecule | [
"multimolecule",
"pytorch",
"safetensors",
"aido.rna",
"Biology",
"RNA",
"rna",
"dataset:multimolecule/bprna-spot",
"dataset:multimolecule/archiveii",
"base_model:multimolecule/aido.rna-1.6b",
"base_model:finetune:multimolecule/aido.rna-1.6b",
"license:agpl-3.0",
"region:us"
] | null | 2025-06-15T17:58:32Z | ---
language: rna
tags:
- Biology
- RNA
license: agpl-3.0
datasets:
- multimolecule/bprna-spot
- multimolecule/archiveii
library_name: multimolecule
base_model: multimolecule/aido.rna-1.6b
---
# AIDO.RNA
Pre-trained model on non-coding RNA (ncRNA) using a masked language modeling (MLM) objective.
## Disclaimer
This is an UNOFFICIAL implementation of the [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345) by Shuxian Zou, Tianhua Tao, Sazan Mahbub, et al.
The OFFICIAL repository of AIDO.RNA is at [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO).
> [!WARNING]
> The MultiMolecule team is aware of a potential risk in reproducing the results of AIDO.RNA.
>
> The original implementation of AIDO.RNA uses a special tokenizer that identifies `U` and `T` as different tokens.
>
> This behaviour is not supported by MultiMolecule.
> [!TIP]
> The MultiMolecule team has confirmed that the provided model and checkpoints are producing the same intermediate representations as the original implementation.
**The team releasing AIDO.RNA did not write this model card for this model so this model card has been written by the MultiMolecule team.**
## Model Details
AIDO.RNA is a [bert](https://huggingface.co/google-bert/bert-base-uncased)-style model pre-trained on a large corpus of non-coding RNA sequences in a self-supervised fashion. This means that the model was trained on the raw nucleotides of RNA sequences only, with an automatic process to generate inputs and labels from those texts. Please refer to the [Training Details](#training-details) section for more information on the training process.
### Variants
- **[multimolecule/aido.rna-1.6b](https://huggingface.co/multimolecule/aido.rna-1.6b)**: The AIDO.RNA model with 1.6 billion parameters.
- **[multimolecule/aido.rna-650m](https://huggingface.co/multimolecule/aido.rna-650m)**: The AIDO.RNA model with 650 million parameters.
### Model Specification
<table>
<thead>
<tr>
<th>Variants</th>
<th>Num Layers</th>
<th>Hidden Size</th>
<th>Num Heads</th>
<th>Intermediate Size</th>
<th>Num Parameters (M)</th>
<th>FLOPs (G)</th>
<th>MACs (G)</th>
<th>Max Num Tokens</th>
</tr>
</thead>
<tbody>
<tr>
<td>AIDO.RNA-1.6B</td>
<td>32</td>
<td>2048</td>
<td>32</td>
<td>5440</td>
<td>1650.29</td>
<td>415.67</td>
<td>207.77</td>
<td rowspan="2">1022</td>
</tr>
<tr>
<td>AIDO.RNA-650M</td>
<td>33</td>
<td>1280</td>
<td>20</td>
<td>3392</td>
<td>648.38</td>
<td>168.25</td>
<td>80.09</td>
</tr>
</tbody>
</table>
### Links
- **Code**: [multimolecule.aido_rna](https://github.com/DLS5-Omics/multimolecule/tree/master/multimolecule/models/aido_rna)
- **Weights**: [multimolecule/aido.rna](https://huggingface.co/multimolecule/aido.rna)
- **Data**: [multimolecule/rnacentral](https://huggingface.co/datasets/multimolecule/rnacentral)
- **Paper**: [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345)
- **Developed by**: Shuxian Zou, Tianhua Tao, Sazan Mahbub, Caleb N. Ellington, Robin Algayres, Dian Li, Yonghao Zhuang, Hongyi Wang, Le Song, Eric P. Xing
- **Model type**: [BERT](https://huggingface.co/google-bert/bert-base-uncased)
- **Original Repository**: [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO)
## Usage
The model file depends on the [`multimolecule`](https://multimolecule.danling.org) library. You can install it using pip:
```bash
pip install multimolecule
```
### Direct Use
You can use this model directly with a pipeline for secondary structure prediction:
```python
>>> import multimolecule # you must import multimolecule to register models
>>> from transformers import pipeline
>>> predictor = pipeline("rna-secondary-structure", model="multimolecule/aido.rna-ss")
>>> predictor("GGUCUCUGGUUAGACCAGAUCUGAGCCU")
{'sequence': 'GGUCUCUGGUUAGACCAGAUCUGAGCCU',
'secondary_structure': '.(((((([(.....).)...].))))).'}
```
### Downstream Use
#### Extract Features
Here is how to use this model to get the features of a given sequence in PyTorch:
```python
from multimolecule import RnaTokenizer, AidoRnaModel
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaModel.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
output = model(**input)
```
#### Sequence Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for sequence classification or regression.
Here is how to use this model as backbone to fine-tune for a sequence-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForSequencePrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaForSequencePrediction.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.tensor([1])
output = model(**input, labels=label)
```
#### Token Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for token classification or regression.
Here is how to use this model as backbone to fine-tune for a nucleotide-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForTokenPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaForTokenPrediction.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), ))
output = model(**input, labels=label)
```
#### Contact Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for contact classification or regression.
Here is how to use this model as backbone to fine-tune for a contact-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForContactPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaForContactPrediction.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), len(text)))
output = model(**input, labels=label)
```
## Training Details
AIDO.RNA used Masked Language Modeling (MLM) as the pre-training objective: taking a sequence, the model randomly masks 15% of the tokens in the input then runs the entire masked sentence through the model and has to predict the masked tokens. This is comparable to the Cloze task in language modeling.
### Training Data
The AIDO.RNA model was pre-trained on [RNAcentral](https://multimolecule.danling.org/datasets/rnacentral) and [MARS](https://ngdc.cncb.ac.cn/omix/release/OMIX003037).
RNAcentral is a free, public resource that offers integrated access to a comprehensive and up-to-date set of non-coding RNA sequences provided by a collaborating group of [Expert Databases](https://rnacentral.org/expert-databases) representing a broad range of organisms and RNA types.
AIDO.RNA applied SeqKit to remove duplicated sequences in the RNAcentral, resulting 42 million unique sequences.
Note that AIDO.RNA identifies `U` and `T` as different tokens, which is not supported by MultiMolecule. During model conversion, the embeddings of `T` is discarded. This means that the model will not be able to distinguish between `U` and `T` in the input sequences.
### Training Procedure
#### Preprocessing
AIDO.RNA used masked language modeling (MLM) as the pre-training objective. The masking procedure is similar to the one used in BERT:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
#### Pre-training
- Epochs: 6
- Optimizer: AdamW
- Learning rate: 5e-5
- Learning rate warm-up: 2,000 steps
- Learning rate scheduler: Cosine
- Minimum learning rate: 1e-5
- Weight decay: 0.01
## Citation
**BibTeX**:
```bibtex
@article {Zou2024.11.28.625345,
author = {Zou, Shuxian and Tao, Tianhua and Mahbub, Sazan and Ellington, Caleb N. and Algayres, Robin and Li, Dian and Zhuang, Yonghao and Wang, Hongyi and Song, Le and Xing, Eric P.},
title = {A Large-Scale Foundation Model for RNA Function and Structure Prediction},
elocation-id = {2024.11.28.625345},
year = {2024},
doi = {10.1101/2024.11.28.625345},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Originally marginalized as an intermediate in the information flow from DNA to protein, RNA has become the star of modern biology, holding the key to precision therapeutics, genetic engineering, evolutionary origins, and our understanding of fundamental cellular processes. Yet RNA is as mysterious as it is prolific, serving as an information store, a messenger, and a catalyst, spanning many underchar-acterized functional and structural classes. Deciphering the language of RNA is important not only for a mechanistic understanding of its biological functions but also for accelerating drug design. Toward this goal, we introduce AIDO.RNA, a pre-trained module for RNA in an AI-driven Digital Organism [1]. AIDO.RNA contains a scale of 1.6 billion parameters, trained on 42 million non-coding RNA (ncRNA) sequences at single-nucleotide resolution, and it achieves state-of-the-art performance on a comprehensive set of tasks, including structure prediction, genetic regulation, molecular function across species, and RNA sequence design. AIDO.RNA after domain adaptation learns to model essential parts of protein translation that protein language models, which have received widespread attention in recent years, do not. More broadly, AIDO.RNA hints at the generality of biological sequence modeling and the ability to leverage the central dogma to improve many biomolecular representations. Models and code are available through ModelGenerator in https://github.com/genbio-ai/AIDO and on Hugging Face.Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345},
eprint = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345.full.pdf},
journal = {bioRxiv}
}
```
## Contact
Please use GitHub issues of [MultiMolecule](https://github.com/DLS5-Omics/multimolecule/issues) for any questions or comments on the model card.
Please contact the authors of the [AIDO.RNA paper](https://doi.org/10.1101/2024.11.28.625345) for questions or comments on the paper/model.
## License
This model is licensed under the [AGPL-3.0 License](https://www.gnu.org/licenses/agpl-3.0.html).
```spdx
SPDX-License-Identifier: AGPL-3.0-or-later
```
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.75_epoch2 | MinaMila | 2025-06-15T18:02:41Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:00:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
FormlessAI/8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9 | FormlessAI | 2025-06-15T18:01:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:teknium/OpenHermes-2.5-Mistral-7B",
"base_model:finetune:teknium/OpenHermes-2.5-Mistral-7B",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T12:19:57Z | ---
base_model: teknium/OpenHermes-2.5-Mistral-7B
library_name: transformers
model_name: 8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for 8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9
This model is a fine-tuned version of [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="FormlessAI/8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/phoenix-formless/Gradients/runs/hosdy86c)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.0+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
mic3456/anneth | mic3456 | 2025-06-15T18:01:11Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:00:54Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: ath
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# annehathaway2
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `ath` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
parveen-Official-Viral-Video-Link/18.Original.Full.Clip.parveen.Viral.Video.Leaks.Official | parveen-Official-Viral-Video-Link | 2025-06-15T18:00:08Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:59:49Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Akshat1912/AI_Healthcare | Akshat1912 | 2025-06-15T17:59:27Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-06-15T17:57:48Z | ---
license: other
license_name: aihealthcare
license_link: LICENSE
---
|
Peacemann/google_gemma-3-4b-it_LMUL | Peacemann | 2025-06-15T17:58:32Z | 0 | 0 | null | [
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"license:gemma",
"region:us"
] | text-generation | 2025-06-15T17:55:58Z | ---
base_model: google/gemma-3-4b-it
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
license: gemma
---
# L-Mul Optimized: google/gemma-3-4b-it
This is a modified version of Google's [gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `google/gemma-3-4b-it` is preserved. However, the standard `Gemma3Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/google_gemma-3-4b-it-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**.
## Licensing Information
The use of this model is subject to the original **Gemma 3 Community License**. By using this model, you agree to the terms outlined in the license. |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.75_epoch1 | MinaMila | 2025-06-15T17:54:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:52:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
yqqqqq1/distilbert-base-uncased-finetuned-squad | yqqqqq1 | 2025-06-15T17:53:54Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2025-06-15T16:51:28Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1624
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.526 | 1.0 | 1384 | 1.2632 |
| 1.1359 | 2.0 | 2768 | 1.1679 |
| 0.9797 | 3.0 | 4152 | 1.1624 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Abhinit/HW2-ppo | Abhinit | 2025-06-15T17:53:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"arxiv:1909.08593",
"base_model:Abhinit/HW2-supervised",
"base_model:finetune:Abhinit/HW2-supervised",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-10T03:34:00Z | ---
base_model: Abhinit/HW2-supervised
library_name: transformers
model_name: HW2-ppo
tags:
- generated_from_trainer
licence: license
---
# Model Card for HW2-ppo
This model is a fine-tuned version of [Abhinit/HW2-supervised](https://huggingface.co/Abhinit/HW2-supervised).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Abhinit/HW2-ppo", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with PPO, a method introduced in [Fine-Tuning Language Models from Human Preferences](https://huggingface.co/papers/1909.08593).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.51.3
- Pytorch: 2.2.2
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite PPO as:
```bibtex
@article{mziegler2019fine-tuning,
title = {{Fine-Tuning Language Models from Human Preferences}},
author = {Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul F. Christiano and Geoffrey Irving},
year = 2019,
eprint = {arXiv:1909.08593}
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
18-VIDEOS-Shubham-gupta-viral-Video-link/Hot.Video.tutorial.Shubham.gupta.Viral.Video.Leaks.Official | 18-VIDEOS-Shubham-gupta-viral-Video-link | 2025-06-15T17:50:11Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:49:39Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
arunmadhusudh/qwen2_VL_2B_LatexOCR_qlora_qptq_epoch3 | arunmadhusudh | 2025-06-15T17:49:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:49:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Avinash17/llama-math-tutor | Avinash17 | 2025-06-15T17:49:09Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:29:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TOMFORD79/tornado3 | TOMFORD79 | 2025-06-15T17:47:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:36:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TOMFORD79/tornado2 | TOMFORD79 | 2025-06-15T17:46:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:35:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_seed_2_20250615_173716 | gradientrouting-spar | 2025-06-15T17:46:41Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:46:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kimxxxx/mistral_r64_a128_g8_gas8_lr9e-5_4500tk_droplast_nopacking_2epoch | kimxxxx | 2025-06-15T17:45:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:45:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Ninannnnn/roger_dean_style_LoRA | Ninannnnn | 2025-06-15T17:42:58Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-15T17:42:56Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: roger dean style of fantasy
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - Ninannnnn/roger_dean_style_LoRA
<Gallery />
## Model description
These are Ninannnnn/roger_dean_style_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use roger dean style of fantasy to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](Ninannnnn/roger_dean_style_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Peacemann/google_gemma-2-9b-it_LMUL | Peacemann | 2025-06-15T17:42:33Z | 0 | 0 | null | [
"safetensors",
"gemma2",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:google/gemma-2-9b-it",
"base_model:finetune:google/gemma-2-9b-it",
"license:gemma",
"region:us"
] | text-generation | 2025-06-15T17:34:30Z | ---
base_model: google/gemma-2-9b-it
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
license: gemma
---
# L-Mul Optimized: google/gemma-2-9b-it
This is a modified version of Google's [gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `google/gemma-2-9b-it` is preserved. However, the standard `Gemma2Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [google/gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/google_gemma-2-9b-it-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**.
## Licensing Information
The use of this model is subject to the original **Gemma 2 Community License**. By using this model, you agree to the terms outlined in the license. |
SaNsOT/q-Taxi-v3 | SaNsOT | 2025-06-15T17:41:40Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T17:41:36Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.76
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="SaNsOT/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
SaNsOT/q-FrozenLake-v1-4x4-noSlippery | SaNsOT | 2025-06-15T17:39:24Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T17:39:20Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="SaNsOT/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
tirdodbehbehani/yahoo-bert-05_balanced_1_mask_aug | tirdodbehbehani | 2025-06-15T17:39:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2",
"base_model:finetune:tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T17:11:49Z | ---
library_name: transformers
base_model: tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
model-index:
- name: yahoo-bert-05_balanced_1_mask_aug
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yahoo-bert-05_balanced_1_mask_aug
This model is a fine-tuned version of [tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2](https://huggingface.co/tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0360
- Accuracy: 0.6720
- Precision: 0.6730
- Recall: 0.6683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|
| 1.202 | 1.0 | 492 | 1.0360 | 0.6720 | 0.6730 | 0.6683 |
| 0.7637 | 2.0 | 984 | 1.1201 | 0.6645 | 0.6677 | 0.6587 |
| 0.5308 | 3.0 | 1476 | 1.2245 | 0.6593 | 0.6538 | 0.6558 |
| 0.3554 | 4.0 | 1968 | 1.3967 | 0.6464 | 0.6514 | 0.6421 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.5_0.05_epoch1 | MinaMila | 2025-06-15T17:38:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:36:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_20250615_172745 | gradientrouting-spar | 2025-06-15T17:37:06Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:36:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Cikgu-Fadhilah-Video-Viral-Official/18.VIDEO.Cikgu.Fadhilah.Viral.Video.Official.link | Cikgu-Fadhilah-Video-Viral-Official | 2025-06-15T17:35:47Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:34:51Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
Subsets and Splits