
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Ayham/roberta_gpt2_new_max64_summarization_cnndm
|
Ayham
| 2021-12-27T00:19:01Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: roberta_gpt2_new_max64_summarization_cnndm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta_gpt2_new_max64_summarization_cnndm
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
wilsontam/gpt2-dstc9
|
wilsontam
| 2021-12-26T14:02:23Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"dstc9",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- dstc9
widget:
- text: "Yes, I'm going to be in Chinatown, San Francisco and am looking"
- text: "Can you find me one that is in the"
---
This GPT2 model is trained using DSTC9 data for dialogue modeling purpose.
Data link: https://github.com/alexa/alexa-with-dstc9-track1-dataset
Credit: Jia-Chen Jason Gu, Wilson Tam
|
huggingtweets/nateritter-naval
|
huggingtweets
| 2021-12-26T06:51:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1474979242618195971/Dm_HPJsd_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1256841238298292232/ycqwaMI2_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Nate Ritter & Naval</div>
<div style="text-align: center; font-size: 14px;">@nateritter-naval</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Nate Ritter & Naval.
| Data | Nate Ritter | Naval |
| --- | --- | --- |
| Tweets downloaded | 3244 | 3243 |
| Retweets | 401 | 171 |
| Short tweets | 400 | 629 |
| Tweets kept | 2443 | 2443 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1t8lp3s8/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nateritter-naval's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/293roeg0) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/293roeg0/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nateritter-naval')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
nehamj/distilbert-base-uncased-finetuned-squad
|
nehamj
| 2021-12-26T04:39:21Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
mohammadtari/arxivinterface
|
mohammadtari
| 2021-12-26T02:18:42Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: t5_small_summarization_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# t5_small_summarization_model
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.7.0
- Datasets 1.17.0
- Tokenizers 0.10.3
|
airKlizz/mt5-base-wikinewssum-spanish
|
airKlizz
| 2021-12-25T23:19:15Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-base-wikinewssum-spanish
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-wikinewssum-spanish
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2394
- Rouge1: 7.9732
- Rouge2: 3.5041
- Rougel: 6.6713
- Rougelsum: 7.5229
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| No log | 1.0 | 528 | 2.3707 | 6.687 | 2.9169 | 5.6793 | 6.2978 |
| No log | 2.0 | 1056 | 2.3140 | 7.9518 | 3.4529 | 6.7265 | 7.4984 |
| No log | 3.0 | 1584 | 2.2848 | 7.9708 | 3.5344 | 6.7272 | 7.534 |
| No log | 4.0 | 2112 | 2.2668 | 8.0252 | 3.5323 | 6.7319 | 7.5819 |
| 3.2944 | 5.0 | 2640 | 2.2532 | 8.0143 | 3.534 | 6.7155 | 7.582 |
| 3.2944 | 6.0 | 3168 | 2.2399 | 7.9525 | 3.4849 | 6.6716 | 7.5155 |
| 3.2944 | 7.0 | 3696 | 2.2376 | 7.9405 | 3.4661 | 6.6559 | 7.5043 |
| 3.2944 | 8.0 | 4224 | 2.2394 | 7.9732 | 3.5041 | 6.6713 | 7.5229 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Andry/1111
|
Andry
| 2021-12-25T20:04:09Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:04Z |
C:\Users\andry\Desktop\Выжигание 24-12-2021.jpg
|
s3h/finetuned-arabert-head-gec
|
s3h
| 2021-12-25T19:17:45Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: s3h/finetuned-arabert-head-gec
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# s3h/finetuned-arabert-head-gec
This model is a fine-tuned version of [aubmindlab/bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 16.9313
- Validation Loss: 19.1589
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 1, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 16.9313 | 19.1589 | 0 |
### Framework versions
- Transformers 4.14.1
- TensorFlow 2.6.2
- Datasets 1.17.0
- Tokenizers 0.10.3
|
s3h/finetuned-mt5-gec
|
s3h
| 2021-12-25T18:38:46Z | 61 | 1 |
transformers
|
[
"transformers",
"tf",
"mt5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: s3h/finetuned-mt5-gec
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# s3h/finetuned-mt5-gec
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 23.1236
- Validation Loss: 26.8482
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 3, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 23.1236 | 26.8482 | 0 |
### Framework versions
- Transformers 4.14.1
- TensorFlow 2.6.2
- Datasets 1.17.0
- Tokenizers 0.10.3
|
vanadhi/roberta-base-fiqa-flm-sq-flit
|
vanadhi
| 2021-12-25T18:36:54Z | 23 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model-index:
- name: roberta-base-fiqa-flm-sq-flit
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-fiqa-flm-sq-flit
This model is a fine-tuned version of roberta-base on a custom dataset create for question answering in
financial domain.
## Model description
RoBERTa is a transformers model pretrained on a large corpus of English data in a self-supervised fashion.
The model was further processed as below for the specific downstream QA task.
1. Pretrained for domain adaptation with Masked language modeling (MLM) objective with
the FIQA challenge Opinion-based QA task is available here - https://drive.google.com/file/d/1BlWaV-qVPfpGyJoWQJU9bXQgWCATgxEP/view
2. Pretrained with MLM objective with custom generated dataset for Banking and Finance.
3. Fine Tuned with SQuAD V2 dataset for QA task adaptation.
4. Fine Tuned with custom labeled dataset in SQuAD format for domain and task adaptation.
## Intended uses & limitations
The model is intended to be used for a custom Questions Answering system in the BFSI domain.
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
hrushikute/DanceOnTune
|
hrushikute
| 2021-12-25T15:37:14Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
title: First Order Motion Model
emoji: 🐢
colorFrom: blue
colorTo: yellow
sdk: gradio
app_file: app.py
pinned: false
---
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio` or `streamlit`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
Path is relative to the root of the repository.
`pinned`: _boolean_
Whether the Space stays on top of your list.
|
Palak/xlm-roberta-base_squad
|
Palak
| 2021-12-25T11:05:12Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: xlm-roberta-base_squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base_squad
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
- "eval_exact_match": 82.69631031220435
- "eval_f1": 89.4562841806503
- "eval_samples": 10918
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.14.1
- Pytorch 1.9.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
snoop2head/kogpt-conditional-2
|
snoop2head
| 2021-12-25T04:42:13Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# KoGPT-Conditional-2
### Condition format
```python
# create condition sentence
random_main_logit = np.random.normal(
loc=3.368,
scale=1.015,
size=1
)[0].round(1)
random_sub_logit = np.random.normal(
loc=1.333,
scale=0.790,
size=1
)[0].round(1)
condition_sentence = f"{random_main_logit}만큼 행복감정인 문장이다. {random_sub_logit}만큼 놀람감정인 문장이다. "
```
### Input Format
```python
# make input sentence
input_sentence = "수상한 밤들이 계속되던 날, 언젠가부터 나는"
condition_plus_input = condition_sentence + input_sentence
print(condition_plus_input)
```
```
3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는
```
### How to infer
```
inferred_sentence = infer_sentence(condition_plus_input, k=10, output_token_length=max_token_length)
inferred_sentence
```
```
['3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 서서히 제정신을 차리고 일어날 수 있었다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 달 보는 걸 좋아하게 되었다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 수상한 사람들의 입을 들여다 볼 수 있었다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 이상한 나라의 앨리스가 되어 있었다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 기이한 경험을 했다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 이상하게도 평화가 찾아온다는 사실을 깨달았다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 어둠을 뚫는 무언가가 있다는 걸 알았다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 달빛의 의미를 이해하기 시작했다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 안방에서 잘 때 내 손을 꼭 잡았다',
'3.9만큼 행복감정인 문장이다. 1.2만큼 놀람감정인 문장이다. 수상한 밤들이 계속되던 날, 언젠가부터 나는 이상한 나라의 앨리스처럼 눈을 반짝이며 주위를 탐구하기 시작했다']
```
|
BigSalmon/MrLincolnBerta
|
BigSalmon
| 2021-12-24T21:54:31Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Example Prompt:
```
informal english: things are better when they are open source, because they are constantly being updated to enhance experience.
Translated into the Style of Abraham Lincoln: in the open-source paradigm, code is ( ceaselessly / perpetually ) being ( reengineered / revamped / polished ), thereby ( advancing / enhancing / optimizing / <mask> ) the user experience.
```
Demo: https://huggingface.co/spaces/BigSalmon/MASK2
|
federicopascual/distilbert-base-uncased-finetuned-cola
|
federicopascual
| 2021-12-24T21:52:47Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5370037450559281
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7480
- Matthews Correlation: 0.5370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5292 | 1.0 | 535 | 0.5110 | 0.4239 |
| 0.3508 | 2.0 | 1070 | 0.4897 | 0.4993 |
| 0.2346 | 3.0 | 1605 | 0.6275 | 0.5029 |
| 0.1806 | 4.0 | 2140 | 0.7480 | 0.5370 |
| 0.1291 | 5.0 | 2675 | 0.8841 | 0.5200 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Palak/albert-base-v2_squad
|
Palak
| 2021-12-24T18:16:45Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: albert-base-v2_squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2_squad
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the **squadV1** dataset.
- "eval_exact_match": 82.69631031220435
- "eval_f1": 90.10806626207174
- "eval_samples": 10808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.14.1
- Pytorch 1.9.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Palak/google_electra-small-discriminator_squad
|
Palak
| 2021-12-24T18:15:49Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: google_electra-small-discriminator_squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# google_electra-small-discriminator_squad
This model is a fine-tuned version of [google/electra-small-discriminator](https://huggingface.co/google/electra-small-discriminator) on the **squadV1** dataset.
- "eval_exact_match": 76.95364238410596
- "eval_f1": 84.98869246841396
- "eval_samples": 10784
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.14.1
- Pytorch 1.9.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Palak/albert-large-v2_squad
|
Palak
| 2021-12-24T18:13:12Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: albert-large-v2_squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-large-v2_squad
This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on the **squadV1** dataset.
- "eval_exact_match": 84.80605487228004
- "eval_f1": 91.80638438705844
- "eval_samples": 10808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.14.1
- Pytorch 1.9.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
toasthans/Twitter_Mit_HPSearch
|
toasthans
| 2021-12-24T15:52:45Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Twitter_Mit_HPSearch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Twitter_Mit_HPSearch
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8389
- Accuracy: 0.8442
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.9771872814096894e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 23
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 421 | 0.3838 | 0.8353 |
| 0.4401 | 2.0 | 842 | 0.4340 | 0.8424 |
| 0.2042 | 3.0 | 1263 | 0.6857 | 0.8508 |
| 0.0774 | 4.0 | 1684 | 0.8389 | 0.8442 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
DeepPavlov/roberta-large-winogrande
|
DeepPavlov
| 2021-12-24T14:20:49Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:winogrande",
"arxiv:1907.10641",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language:
- en
datasets:
- winogrande
widget:
- text: "The roof of Rachel's home is old and falling apart, while Betty's is new. The home value of </s> Rachel is lower."
- text: "The wooden doors at my friends work are worse than the wooden desks at my work, because the </s> desks material is cheaper."
- text: "Postal Service were to reduce delivery frequency. </s> The postal service could deliver less frequently."
- text: "I put the cake away in the refrigerator. It has a lot of butter in it. </s> The cake has a lot of butter in it."
---
# RoBERTa Large model fine-tuned on Winogrande
This model was fine-tuned on Winogrande dataset (XL size) in sequence classification task format, meaning that original pairs of sentences
with corresponding options filled in were separated, shuffled and classified independently of each other.
## Model description
## Intended use & limitations
### How to use
## Training data
[WinoGrande-XL](https://huggingface.co/datasets/winogrande) reformatted the following way:
1. Each sentence was split on "`_`" placeholder symbol.
2. Each option was concatenated with the second part of the split, thus transforming each example into two text segment pairs.
3. Text segment pairs corresponding to correct and incorrect options were marked with `True` and `False` labels accordingly.
4. Text segment pairs were shuffled thereafter.
For example,
```json
{
"answer": "2",
"option1": "plant",
"option2": "urn",
"sentence": "The plant took up too much room in the urn, because the _ was small."
}
```
becomes
```json
{
"sentence1": "The plant took up too much room in the urn, because the ",
"sentence2": "plant was small.",
"label": false
}
```
and
```json
{
"sentence1": "The plant took up too much room in the urn, because the ",
"sentence2": "urn was small.",
"label": true
}
```
These sentence pairs are then treated as independent examples.
### BibTeX entry and citation info
```bibtex
@article{sakaguchi2019winogrande,
title={WinoGrande: An Adversarial Winograd Schema Challenge at Scale},
author={Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin},
journal={arXiv preprint arXiv:1907.10641},
year={2019}
}
@article{DBLP:journals/corr/abs-1907-11692,
author = {Yinhan Liu and
Myle Ott and
Naman Goyal and
Jingfei Du and
Mandar Joshi and
Danqi Chen and
Omer Levy and
Mike Lewis and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {RoBERTa: {A} Robustly Optimized {BERT} Pretraining Approach},
journal = {CoRR},
volume = {abs/1907.11692},
year = {2019},
url = {http://arxiv.org/abs/1907.11692},
archivePrefix = {arXiv},
eprint = {1907.11692},
timestamp = {Thu, 01 Aug 2019 08:59:33 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1907-11692.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
ai-forever/ru-clip
|
ai-forever
| 2021-12-24T11:51:15Z | 0 | 3 | null |
[
"PyTorch",
"Text2Image",
"ru",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- PyTorch
- Text2Image
thumbnail: "https://github.com/sberbank-ai/ru-clip"
---
# Model Card: ruCLIP
Disclaimer: The code for using model you can found [here](https://github.com/sberbank-ai/ru-clip).
# Model Details
The ruCLIP model was developed by researchers at SberDevices and Sber AI based on origin OpenAI paper.
# Model Type
The model uses a ViT-B/32 Transformer architecture (initialized from OpenAI checkpoint and freezed while training) as an image encoder and uses [ruGPT3Small](https://github.com/sberbank-ai/ru-gpts) as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
# Documents
Our habr [post](https://habr.com/ru/company/sberdevices/blog/564440/).
# Usage
Code for using model you can obtain in our [repo](https://github.com/sberbank-ai/ru-clip).
```
from clip.evaluate.utils import (
get_text_batch, get_image_batch, get_tokenizer,
show_test_images, load_weights_only
)
import torch
# Load model and tokenizer
model, args = load_weights_only("ViT-B/32-small")
model = model.cuda().float().eval()
tokenizer = get_tokenizer()
# Load test images and prepare for model
images, texts = show_test_images(args)
input_ids, attention_mask = get_text_batch(["Это " + desc for desc in texts], tokenizer, args)
img_input = get_image_batch(images, args.img_transform, args)
# Call model
with torch.no_grad():
logits_per_image, logits_per_text = model(
img_input={"x": img_input},
text_input={"x": input_ids, "attention_mask": attention_mask}
)
```
# Performance
We evaluate our model on CIFAR100 and CIFAR10 datasets.
zero-shot classification CIFAR100 top1 accuracy 0.4057; top5 accuracy 0.6975.
zero-shot classification CIFAR10 top1 accuracy 0.7803; top5 accuracy 0.9834.
|
hiraki/wav2vec2-base-timit-demo-colab
|
hiraki
| 2021-12-24T10:51:35Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3780
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.08 | 10 | 14.0985 | 1.0 |
| No log | 0.16 | 20 | 13.8638 | 1.0004 |
| No log | 0.24 | 30 | 13.5135 | 1.0023 |
| No log | 0.32 | 40 | 12.8708 | 1.0002 |
| No log | 0.4 | 50 | 11.6927 | 1.0 |
| No log | 0.48 | 60 | 10.2733 | 1.0 |
| No log | 0.56 | 70 | 8.1396 | 1.0 |
| No log | 0.64 | 80 | 5.3503 | 1.0 |
| No log | 0.72 | 90 | 3.7975 | 1.0 |
| No log | 0.8 | 100 | 3.4275 | 1.0 |
| No log | 0.88 | 110 | 3.3596 | 1.0 |
| No log | 0.96 | 120 | 3.3780 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
GuoLiyong/cn_conformer_encoder_aishell
|
GuoLiyong
| 2021-12-24T06:18:09Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:04Z |
Modified from: https://huggingface.co/pkufool/icefall_asr_aishell_conformer_ctc
1. remove unused parts by ctc greedy search for tutorial only.
|
cb-insights-team/news_ner
|
cb-insights-team
| 2021-12-23T21:43:21Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
An NER model to detect company and person names from news articles.
|
BigSalmon/InformalToFormalLincoln16
|
BigSalmon
| 2021-12-23T18:48:23Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
Informal to Formal:
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln16")
model = AutoModelWithLMHead.from_pretrained("BigSalmon/InformalToFormalLincoln16")
```
```
https://huggingface.co/spaces/BigSalmon/GPT2 (The model for this space changes over time)
```
```
https://huggingface.co/spaces/BigSalmon/GPT2_Most_Probable (The model for this space changes over time)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
````
|
toasthans/Facebook_Mit_HPS
|
toasthans
| 2021-12-23T17:47:19Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Facebook_Mit_HPS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Facebook_Mit_HPS
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3681
- Accuracy: 0.9281
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.906763521176542e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 30
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 292 | 0.2394 | 0.9238 |
| 0.2248 | 2.0 | 584 | 0.3112 | 0.9178 |
| 0.2248 | 3.0 | 876 | 0.3681 | 0.9281 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
chrisAS12/specseminars
|
chrisAS12
| 2021-12-23T14:19:18Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
These models were made for my course project in NLP and AI special course at the University of Latvia during my first semester of study.
|
Monsia/test-model-lg-data
|
Monsia
| 2021-12-23T14:03:38Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: test-model-lg-data
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-model-lg-data
This model is a fine-tuned version of [Monsia/test-model-lg-data](https://huggingface.co/Monsia/test-model-lg-data) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3354
- Wer: 0.4150
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0236 | 0.67 | 100 | 0.4048 | 0.4222 |
| 0.0304 | 1.35 | 200 | 0.4266 | 0.4809 |
| 0.0545 | 2.03 | 300 | 0.4309 | 0.4735 |
| 0.0415 | 2.7 | 400 | 0.4269 | 0.4595 |
| 0.033 | 3.38 | 500 | 0.4085 | 0.4537 |
| 0.0328 | 4.05 | 600 | 0.3642 | 0.4224 |
| 0.0414 | 4.73 | 700 | 0.3354 | 0.4150 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.13.3
- Tokenizers 0.10.3
|
airKlizz/mt5-base-wikinewssum-all-languages
|
airKlizz
| 2021-12-23T12:56:06Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-base-wikinewssum-all-languages
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-wikinewssum-all-languages
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2454
- Rouge1: 8.3826
- Rouge2: 3.5524
- Rougel: 6.8656
- Rougelsum: 7.8362
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|
| No log | 1.0 | 3467 | 2.4034 | 8.0363 | 3.2484 | 6.5409 | 7.477 |
| No log | 2.0 | 6934 | 2.3276 | 8.1054 | 3.2905 | 6.5765 | 7.5687 |
| No log | 3.0 | 10401 | 2.2976 | 8.169 | 3.4272 | 6.6597 | 7.6435 |
| No log | 4.0 | 13868 | 2.2795 | 8.2941 | 3.5353 | 6.7881 | 7.7664 |
| 2.8057 | 5.0 | 17335 | 2.2621 | 8.3302 | 3.5599 | 6.8238 | 7.7928 |
| 2.8057 | 6.0 | 20802 | 2.2547 | 8.3818 | 3.5886 | 6.8672 | 7.844 |
| 2.8057 | 7.0 | 24269 | 2.2472 | 8.3809 | 3.5696 | 6.8575 | 7.8327 |
| 2.8057 | 8.0 | 27736 | 2.2454 | 8.3826 | 3.5524 | 6.8656 | 7.8362 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
toasthans/Facebook_Mit_HPS_5_Epoch
|
toasthans
| 2021-12-23T08:27:55Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Facebook_Mit_HPS_5_Epoch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Facebook_Mit_HPS_5_Epoch
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4774
- Accuracy: 0.9315
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.546392051994155e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 5
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 292 | 0.2181 | 0.9264 |
| 0.2411 | 2.0 | 584 | 0.2571 | 0.9289 |
| 0.2411 | 3.0 | 876 | 0.5712 | 0.8947 |
| 0.0558 | 4.0 | 1168 | 0.4675 | 0.9332 |
| 0.0558 | 5.0 | 1460 | 0.4774 | 0.9315 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
YYJ/KunquChat
|
YYJ
| 2021-12-23T07:21:17Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# 经典昆曲欣赏 期末作业
## KunquChat
Author: 1900012921 俞跃江
|
KoichiYasuoka/roberta-small-japanese-aozora-char
|
KoichiYasuoka
| 2021-12-23T02:55:42Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"japanese",
"masked-lm",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
language:
- "ja"
tags:
- "japanese"
- "masked-lm"
license: "cc-by-sa-4.0"
pipeline_tag: "fill-mask"
mask_token: "[MASK]"
widget:
- text: "日本に着いたら[MASK]を訪ねなさい。"
---
# roberta-small-japanese-aozora-char
## Model Description
This is a RoBERTa model pre-trained on 青空文庫 texts with character tokenizer. You can fine-tune `roberta-small-japanese-aozora-char` for downstream tasks, such as [POS-tagging](https://huggingface.co/KoichiYasuoka/roberta-small-japanese-char-luw-upos), dependency-parsing, and so on.
## How to Use
```py
from transformers import AutoTokenizer,AutoModelForMaskedLM
tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/roberta-small-japanese-aozora-char")
model=AutoModelForMaskedLM.from_pretrained("KoichiYasuoka/roberta-small-japanese-aozora-char")
```
|
deep-learning-analytics/GrammarCorrector
|
deep-learning-analytics
| 2021-12-23T02:51:34Z | 623 | 13 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
## Model description
T5 model trained for Grammar Correction. This model corrects grammatical mistakes in input sentences
### Dataset Description
The T5-base model has been trained on C4_200M dataset.
### Model in Action 🚀
```
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'deep-learning-analytics/GrammarCorrector'
torch_device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(torch_device)
def correct_grammar(input_text,num_return_sequences):
batch = tokenizer([input_text],truncation=True,padding='max_length',max_length=64, return_tensors="pt").to(torch_device)
translated = model.generate(**batch,max_length=64,num_beams=num_beams, num_return_sequences=num_return_sequences, temperature=1.5)
tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
return tgt_text
```
### Example Usage
```
text = 'He are moving here.'
print(correct_grammar(text, num_return_sequences=2))
['He is moving here.', 'He is moving here now.']
```
Another example
```
text = 'Cat drinked milk'
print(correct_grammar(text, num_return_sequences=2))
['Cat drank milk.', 'Cat drink milk.']
```
Model Developed by [Priya-Dwivedi](https://www.linkedin.com/in/priyanka-dwivedi-6864362)
|
Ayham/albert_gpt2_summarization_cnndm
|
Ayham
| 2021-12-23T01:36:49Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: albert_large_gpt2_summarization_cnndm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert_large_gpt2_summarization_cnndm
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
BigSalmon/InformalToFormalLincoln15
|
BigSalmon
| 2021-12-22T22:40:25Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
Informal to Formal:
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln15")
model = AutoModelWithLMHead.from_pretrained("BigSalmon/InformalToFormalLincoln15")
```
```
https://huggingface.co/spaces/BigSalmon/GPT2 (The model for this space changes over time)
```
```
https://huggingface.co/spaces/BigSalmon/GPT2_Most_Probable (The model for this space changes over time)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
The guys were ( enlisted to spearhead the cause / tasked with marshaling the movement forward / charged with driving the initiative onward / vested with the assignment of forwarding the mission)
informal english: friday should no longer be a workday, but a day added to the weekend, suffusing people with the ability to spend time with their families.
Translated into the Style of Abraham Lincoln: the weekend should come to include friday, ( broadening the window of time for one to be in the company of their family / ( multiplying / swelling / turbocharging / maximizing ) the interval for one to ( reconnect with / feel the warmth of ) their loved ones ).
informal english:
````
|
SajjadAyoubi/clip-fa-text
|
SajjadAyoubi
| 2021-12-22T19:02:56Z | 1,578 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"arxiv:2103.00020",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:04Z |
# CLIPfa: Connecting Farsi Text and Images
OpenAI released [`the paper Learning Transferable Visual Models From Natural Language Supervision`](https://arxiv.org/abs/2103.00020) in which they present the CLIP (Contrastive Language–Image Pre-training) model. This model is trained to connect text and images, by matching their corresponding vector representations using a contrastive learning objective. CLIP consists of two separate models, a vision encoder and a text encoder. These were trained on 400 Million images and corresponding captions. We have trained a Farsi (Persian) version of OpenAI's CLIP on a dataset of 400,000 (image, text) pairs. We used [`Farahani's RoBERTa-fa`](https://huggingface.co/m3hrdadfi/roberta-zwnj-wnli-mean-tokens) as the text encoder and [`ViT`](https://huggingface.co/openai/clip-vit-base-patch32) as the vision encoder from Original CLIP and finetuned them.
- It should be noted that only 400K pairs were used for this training, whereas 4 million pairs were used for the Original CLIP. Also, the training took 30 days across 592 GPUs powered by the V100 chip.
## How to use?
Both models generate vectors with 768 dimensions.
```python
from transformers import CLIPVisionModel, RobertaModel, AutoTokenizer, CLIPFeatureExtractor
# download pre-trained models
vision_encoder = CLIPVisionModel.from_pretrained('SajjadAyoubi/clip-fa-vision')
preprocessor = CLIPFeatureExtractor.from_pretrained('SajjadAyoubi/clip-fa-vision')
text_encoder = RobertaModel.from_pretrained('SajjadAyoubi/clip-fa-text')
tokenizer = AutoTokenizer.from_pretrained('SajjadAyoubi/clip-fa-text')
# define input image and input text
text = 'something'
image = PIL.Image.open('my_favorite_image.jpg')
# compute embeddings
text_embedding = text_encoder(**tokenizer(text,
return_tensors='pt')).pooler_output
image_embedding = vision_encoder(**preprocessor(image,
return_tensors='pt')).pooler_output
text_embedding.shape == image_embedding.shape
```
## Demo:
The followings are just some use cases of CLIPfa on 25K [`Unsplash images`](https://github.com/unsplash/datasets)
- use `pip install -q git+https://github.com/sajjjadayobi/clipfa.git`
```python
from clipfa import CLIPDemo
demo = CLIPDemo(vision_encoder, text_encoder, tokenizer)
demo.compute_text_embeddings(['گاو' ,'اسب' ,'ماهی'])
demo.compute_image_embeddings(test_df.image_path.to_list())
```
## Online Demo: [CLIPfa at Huggingface🤗 spaces](https://huggingface.co/spaces/SajjadAyoubi/CLIPfa-Demo)
We used a small set of images (25K) to keep this app almost real-time, but it's obvious that the quality of image search depends heavily on the size of the image database.
> Made with ❤️ in my basement🤫
|
microsoft/wavlm-base-plus
|
microsoft
| 2021-12-22T17:23:24Z | 1,798,625 | 28 |
transformers
|
[
"transformers",
"pytorch",
"wavlm",
"feature-extraction",
"speech",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.13900",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language:
- en
datasets:
tags:
- speech
inference: false
---
# WavLM-Base-Plus
[Microsoft's WavLM](https://github.com/microsoft/unilm/tree/master/wavlm)
The base model pretrained on 16kHz sampled speech audio. When using the model, make sure that your speech input is also sampled at 16kHz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
Authors: Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei
**Abstract**
*Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
The original model can be found under https://github.com/microsoft/unilm/tree/master/wavlm.
# Usage
This is an English pre-trained speech model that has to be fine-tuned on a downstream task like speech recognition or audio classification before it can be
used in inference. The model was pre-trained in English and should therefore perform well only in English. The model has been shown to work well on the [SUPERB benchmark](https://superbbenchmark.org/).
**Note**: The model was pre-trained on phonemes rather than characters. This means that one should make sure that the input text is converted to a sequence
of phonemes before fine-tuning.
## Speech Recognition
To fine-tune the model for speech recognition, see [the official speech recognition example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition).
## Speech Classification
To fine-tune the model for speech classification, see [the official audio classification example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/audio-classification).
## Speaker Verification
TODO
## Speaker Diarization
TODO
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)

|
deepparag/DumBot-Beta
|
deepparag
| 2021-12-22T16:32:40Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
thumbnail: https://cdn.discordapp.com/app-icons/870239976690970625/c02cae78ae105f07969cfd8f8ea3d0a0.png
tags:
- conversational
license: mit
---
An generative AI made using [microsoft/DialoGPT-small](https://huggingface.co/microsoft/DialoGPT-small).
Trained on:
https://www.kaggle.com/Cornell-University/movie-dialog-corpus
https://www.kaggle.com/jef1056/discord-data
Important:
The AI can be a bit weird at times as it is still undergoing training!
At times it send stuff using :<random_wierd_words>: as they are discord emotes.
It also send random @RandomName as it is trying to ping people.
This works well on discord but on the web not so much but it is easy enough to remove such stuff using [re.sub](https://docs.python.org/3/library/re.html#re.sub)
Issues:
The AI like with all conversation AI lacks a character, it changes its name way too often. This can be solved using an AIML chatbot to give it a stable character!
[Live Demo](https://dumbot-331213.uc.r.appspot.com/)
Example:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("deepparag/DumBot")
model = AutoModelWithLMHead.from_pretrained("deepparag/DumBot")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=4,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("DumBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
huggingartists/100-gecs
|
huggingartists
| 2021-12-22T15:23:59Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingartists",
"lyrics",
"lm-head",
"causal-lm",
"en",
"dataset:huggingartists/100-gecs",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
datasets:
- huggingartists/100-gecs
tags:
- huggingartists
- lyrics
- lm-head
- causal-lm
widget:
- text: "I am"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/9fd98af9a817af8cd78636f71895b6ad.500x500x1.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">100 gecs</div>
<a href="https://genius.com/artists/100-gecs">
<div style="text-align: center; font-size: 14px;">@100-gecs</div>
</a>
</div>
I was made with [huggingartists](https://github.com/AlekseyKorshuk/huggingartists).
Create your own bot based on your favorite artist with [the demo](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb)!
## How does it work?
To understand how the model was developed, check the [W&B report](https://wandb.ai/huggingartists/huggingartists/reportlist).
## Training data
The model was trained on lyrics from 100 gecs.
Dataset is available [here](https://huggingface.co/datasets/huggingartists/100-gecs).
And can be used with:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/100-gecs")
```
[Explore the data](https://wandb.ai/huggingartists/huggingartists/runs/3c9j4tvq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on 100 gecs's lyrics.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/huggingartists/huggingartists/runs/1v0ffa4e) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/huggingartists/huggingartists/runs/1v0ffa4e/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingartists/100-gecs')
generator("I am", num_return_sequences=5)
```
Or with Transformers library:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("huggingartists/100-gecs")
model = AutoModelWithLMHead.from_pretrained("huggingartists/100-gecs")
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
|
MMG/bert-base-spanish-wwm-cased-finetuned-squad2-es
|
MMG
| 2021-12-22T13:11:46Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"es",
"dataset:squad_es",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- squad_es
model-index:
- name: bert-base-spanish-wwm-cased-finetuned-squad2-es
results: []
language:
- es
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-spanish-wwm-cased-finetuned-squad2-es
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on the squad_es dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2841
{'exact': 62.53162421993591, 'f1': 69.33421368741254}
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
ayameRushia/roberta-base-indonesian-sentiment-analysis-smsa
|
ayameRushia
| 2021-12-22T10:33:50Z | 51 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:indonlu",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- indonlu
metrics:
- accuracy
model-index:
- name: roberta-base-indonesian-sentiment-analysis-smsa
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: indonlu
type: indonlu
args: smsa
metrics:
- name: Accuracy
type: accuracy
value: 0.9349206349206349
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-indonesian-sentiment-analysis-smsa
This model is a fine-tuned version of [flax-community/indonesian-roberta-base](https://huggingface.co/flax-community/indonesian-roberta-base) on the indonlu dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4252
- Accuracy: 0.9349
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7582 | 1.0 | 688 | 0.3280 | 0.8786 |
| 0.3225 | 2.0 | 1376 | 0.2398 | 0.9206 |
| 0.2057 | 3.0 | 2064 | 0.2574 | 0.9230 |
| 0.1642 | 4.0 | 2752 | 0.2820 | 0.9302 |
| 0.1266 | 5.0 | 3440 | 0.3344 | 0.9317 |
| 0.0608 | 6.0 | 4128 | 0.3543 | 0.9341 |
| 0.058 | 7.0 | 4816 | 0.4252 | 0.9349 |
| 0.0315 | 8.0 | 5504 | 0.4736 | 0.9310 |
| 0.0166 | 9.0 | 6192 | 0.4649 | 0.9349 |
| 0.0143 | 10.0 | 6880 | 0.4648 | 0.9341 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
dpasch01/finetune-clm-employment
|
dpasch01
| 2021-12-22T07:59:51Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: finetune-clm-employment
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetune-clm-employment
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8445
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.3283 | 1.0 | 3989 | 1.9578 |
| 2.0824 | 2.0 | 7978 | 1.9013 |
| 1.9936 | 3.0 | 11967 | 1.8625 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
huggingtweets/whaletrades
|
huggingtweets
| 2021-12-22T03:45:47Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/whaletrades/1640144742826/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1174047724204941312/vziG0yQb_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">WhaleTrades.eth 🐳</div>
<div style="text-align: center; font-size: 14px;">@whaletrades</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from WhaleTrades.eth 🐳.
| Data | WhaleTrades.eth 🐳 |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 2 |
| Short tweets | 0 |
| Tweets kept | 3248 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/dpqkmlah/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @whaletrades's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2t4vyqca) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2t4vyqca/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/whaletrades')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/_luisinhobr-beckvencido
|
huggingtweets
| 2021-12-22T02:57:34Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/_luisinhobr-beckvencido/1640141850327/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1470914400764715012/YO9XqA0n_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1390224220643278850/LcIZLss-_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">agrummgit ag😜 & luisfer nando</div>
<div style="text-align: center; font-size: 14px;">@_luisinhobr-beckvencido</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from agrummgit ag😜 & luisfer nando.
| Data | agrummgit ag😜 | luisfer nando |
| --- | --- | --- |
| Tweets downloaded | 3226 | 2366 |
| Retweets | 379 | 367 |
| Short tweets | 672 | 503 |
| Tweets kept | 2175 | 1496 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/34idoh6o/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_luisinhobr-beckvencido's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1w6ipjqa) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1w6ipjqa/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_luisinhobr-beckvencido')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Jeska/BertjeWDialDataALL04
|
Jeska
| 2021-12-22T02:47:07Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
model-index:
- name: BertjeWDialDataALL04
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BertjeWDialDataALL04
This model is a fine-tuned version of [GroNLP/bert-base-dutch-cased](https://huggingface.co/GroNLP/bert-base-dutch-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9717
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.2954 | 1.0 | 1542 | 2.0372 |
| 2.2015 | 2.0 | 3084 | 2.0104 |
| 2.1661 | 3.0 | 4626 | 2.0372 |
| 2.1186 | 4.0 | 6168 | 1.9549 |
| 2.0939 | 5.0 | 7710 | 1.9438 |
| 2.0867 | 6.0 | 9252 | 1.9648 |
| 2.0462 | 7.0 | 10794 | 1.9465 |
| 2.0315 | 8.0 | 12336 | 1.9412 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
tingtingyuli/wav2vec2-base-timit-demo-colab
|
tingtingyuli
| 2021-12-21T22:26:02Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4371
- Wer: 0.3402
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.6515 | 4.0 | 500 | 1.9481 | 0.9825 |
| 0.8007 | 8.0 | 1000 | 0.4364 | 0.4424 |
| 0.2559 | 12.0 | 1500 | 0.4188 | 0.3848 |
| 0.1483 | 16.0 | 2000 | 0.4466 | 0.3524 |
| 0.1151 | 20.0 | 2500 | 0.4492 | 0.3519 |
| 0.0971 | 24.0 | 3000 | 0.4568 | 0.3453 |
| 0.0765 | 28.0 | 3500 | 0.4371 | 0.3402 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
enelpol/czywiesz-question
|
enelpol
| 2021-12-21T21:24:34Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"pl",
"dataset:enelpol/czywiesz",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: pl
datasets:
- enelpol/czywiesz
task_categories:
- question_answering
task_ids:
- open-domain-qa
multilinguality:
- monolingual
size_categories:
- 1k<n<10K
---
## Model description
This is the question encoder for the Polish DPR question answering model. The full model consists of two encoders.
Please read [context encoder documentation](https://huggingface.co/enelpol/czywiesz-context) to get the details of the model.
|
akashsivanandan/wav2vec2-large-xls-r-300m-tamil-colab
|
akashsivanandan
| 2021-12-21T18:26:28Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-tamil-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-tamil-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8072
- Wer: 0.6531
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 11.0967 | 1.0 | 118 | 4.6437 | 1.0 |
| 3.4973 | 2.0 | 236 | 3.2588 | 1.0 |
| 3.1305 | 3.0 | 354 | 2.6566 | 1.0 |
| 1.2931 | 4.0 | 472 | 0.9156 | 0.9944 |
| 0.6851 | 5.0 | 590 | 0.7474 | 0.8598 |
| 0.525 | 6.0 | 708 | 0.6649 | 0.7995 |
| 0.4325 | 7.0 | 826 | 0.6740 | 0.7752 |
| 0.3766 | 8.0 | 944 | 0.6220 | 0.7628 |
| 0.3256 | 9.0 | 1062 | 0.6316 | 0.7322 |
| 0.2802 | 10.0 | 1180 | 0.6442 | 0.7305 |
| 0.2575 | 11.0 | 1298 | 0.6885 | 0.7280 |
| 0.2248 | 12.0 | 1416 | 0.6702 | 0.7197 |
| 0.2089 | 13.0 | 1534 | 0.6781 | 0.7173 |
| 0.1893 | 14.0 | 1652 | 0.6981 | 0.7049 |
| 0.1652 | 15.0 | 1770 | 0.7154 | 0.7436 |
| 0.1643 | 16.0 | 1888 | 0.6798 | 0.7023 |
| 0.1472 | 17.0 | 2006 | 0.7381 | 0.6947 |
| 0.1372 | 18.0 | 2124 | 0.7240 | 0.7065 |
| 0.1318 | 19.0 | 2242 | 0.7305 | 0.6714 |
| 0.1211 | 20.0 | 2360 | 0.7288 | 0.6597 |
| 0.1178 | 21.0 | 2478 | 0.7417 | 0.6699 |
| 0.1118 | 22.0 | 2596 | 0.7476 | 0.6753 |
| 0.1016 | 23.0 | 2714 | 0.7973 | 0.6647 |
| 0.0998 | 24.0 | 2832 | 0.8027 | 0.6633 |
| 0.0917 | 25.0 | 2950 | 0.8045 | 0.6680 |
| 0.0907 | 26.0 | 3068 | 0.7884 | 0.6565 |
| 0.0835 | 27.0 | 3186 | 0.8009 | 0.6622 |
| 0.0749 | 28.0 | 3304 | 0.8123 | 0.6536 |
| 0.0755 | 29.0 | 3422 | 0.8006 | 0.6555 |
| 0.074 | 30.0 | 3540 | 0.8072 | 0.6531 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
s3h/mt5-small-finetuned-src-to-trg-testing
|
s3h
| 2021-12-21T17:28:28Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mt5-small-finetuned-src-to-trg-testing
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-src-to-trg-testing
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 15.8614
- Bleu: 0.1222
- Gen Len: 3.75
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 4 | 15.8782 | 0.1222 | 3.75 |
| No log | 2.0 | 8 | 15.7909 | 0.1222 | 3.75 |
| No log | 3.0 | 12 | 15.8614 | 0.1222 | 3.75 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.7.1
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
LACAI/gpt2-xl-dialog-narrative-persuasion
|
LACAI
| 2021-12-21T17:22:02Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
Base model: [gpt2-xl](https://huggingface.co/gpt2-xl)
Domain-adapted for dialogue response and narrative generation on a [narrative-aligned variant](https://github.com/AbrahamSanders/gutenberg-dialog#download-narrative-aligned-datasets) of the [Gutenberg Dialogue Dataset (Csaky & Recski, 2021)](https://aclanthology.org/2021.eacl-main.11.pdf)
Fine-tuned for dialogue response generation on [Persuasion For Good (Wang et al., 2019)](https://aclanthology.org/P19-1566.pdf) ([dataset](https://gitlab.com/ucdavisnlp/persuasionforgood))
|
davanstrien/book-genre-classification
|
davanstrien
| 2021-12-21T16:05:46Z | 6 | 2 |
adapter-transformers
|
[
"adapter-transformers",
"bert",
"adapterhub:text-classification",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
tags:
- bert
- adapterhub:text-classification
- adapter-transformers
---
# Adapter `davanstrien/book-genre-classification` for bert-base-cased
An [adapter](https://adapterhub.ml) for the `bert-base-cased` model that was trained on the [text-classification](https://adapterhub.ml/explore/text-classification/) dataset and includes a prediction head for classification.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoModelWithHeads
model = AutoModelWithHeads.from_pretrained("bert-base-cased")
adapter_name = model.load_adapter("davanstrien/book-genre-classification", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here -->
|
espnet/ftshijt_espnet2_asr_yolo_mixtec_transformer
|
espnet
| 2021-12-21T15:59:04Z | 3 | 0 |
espnet
|
[
"espnet",
"audio",
"automatic-speech-recognition",
"dataset:yolo_mixtec",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- espnet
- audio
- automatic-speech-recognition
language: noinfo
datasets:
- yolo_mixtec
license: cc-by-4.0
---
## ESPnet2 ASR model
### `espnet/ftshijt_espnet2_asr_yolo_mixtec_transformer`
This model was trained by ftshijt using yolo_mixtec recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
pip install -e .
cd els/yolo_mixtec/asr1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/ftshijt_espnet2_asr_yolo_mixtec_transformer
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Wed Nov 10 02:59:39 EST 2021`
- python version: `3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0]`
- espnet version: `espnet 0.10.4a1`
- pytorch version: `pytorch 1.9.0`
- Git hash: ``
- Commit date: ``
## asr_train_asr_transformer_specaug_raw_bpe500
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_bpe500_valid.loss.ave_asr_model_valid.acc.best/test|4985|81348|84.1|11.8|4.1|2.5|18.3|82.5|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_bpe500_valid.loss.ave_asr_model_valid.acc.best/test|4985|626187|93.4|2.2|4.4|2.4|9.0|82.5|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_bpe500_valid.loss.ave_asr_model_valid.acc.best/test|4985|325684|90.7|5.2|4.1|2.2|11.5|82.5|
## ASR config
<details><summary>expand</summary>
```
config: conf/tuning/train_asr_transformer_specaug.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_transformer_specaug_raw_bpe500
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 100
patience: 15
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
grad_clip: 5
grad_clip_type: 2.0
grad_noise: false
accum_grad: 2
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 32
valid_batch_size: null
batch_bins: 1000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_bpe500/train/speech_shape
- exp/asr_stats_raw_bpe500/train/text_shape.bpe
valid_shape_file:
- exp/asr_stats_raw_bpe500/valid/speech_shape
- exp/asr_stats_raw_bpe500/valid/text_shape.bpe
batch_type: folded
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - /tmp/st-jiatong-54826.tbQP9L0N/raw/train/wav.scp
- speech
- kaldi_ark
- - /tmp/st-jiatong-54826.tbQP9L0N/raw/train/text
- text
- text
valid_data_path_and_name_and_type:
- - /tmp/st-jiatong-54826.tbQP9L0N/raw/dev/wav.scp
- speech
- kaldi_ark
- - /tmp/st-jiatong-54826.tbQP9L0N/raw/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 1.0
scheduler: noamlr
scheduler_conf:
warmup_steps: 25000
token_list:
- <blank>
- <unk>
- '4'
- '3'
- '1'
- '2'
- A
- ▁NDI
- '''4'
- '''1'
- U
- ▁BA
- O
- ▁I
- E
- 4=
- ▁KU
- ▁TAN
- ▁KA
- '''3'
- NI
- ▁YA
- RA
- 3=
- 2=
- IN
- NA
- ▁TA
- AN
- ▁KAN
- ▁NI
- ▁NDA
- ▁NA
- ▁JI
- KAN
- CHI
- (3)=
- I
- UN
- 1-
- ▁SA
- (4)=
- ▁JA
- XI
- ▁KO
- ▁TI
- TA
- KU
- BI
- ▁YU
- ▁KWA
- KA
- XA
- 1=
- ▁YO
- RI
- NDO
- ▁XA
- TU
- ▁TU
- ▁ÑA
- ▁KI
- ▁XI
- YO
- NDU
- NDA
- ▁CHI
- (2)=
- ▁BI
- ▁NU
- KI
- (1)=
- YU
- 3-
- ▁MI
- 'ON'
- ▁A
- BA
- 4-
- KO
- ▁NDU
- ▁ÑU
- ▁NDO
- NU
- ÑU
- '143'
- ▁SI
- ▁SO
- 13-
- NDI
- ▁AN
- ▁SU
- TIN
- SA
- ▁BE
- TO
- RUN
- KWA
- KWI
- ▁NDE
- ▁KWI
- XIN
- ▁U
- SI
- SO
- ▁TUN
- EN
- ▁KWE
- YA
- (4)=2
- NDE
- TI
- TUN
- ▁TIN
- MA
- ▁SE
- ▁XU
- SU
- ▁LU
- ▁KE
- ▁
- MI
- ▁RAN
- (3)=2
- 14-
- ▁MA
- KUN
- LU
- N
- ▁O
- KE
- NGA
- ▁IS
- ▁JU
- '='
- ▁LA
- ÑA
- JA
- CHUN
- R
- TAN
- PU
- ▁TIEM
- LI
- LA
- CHIU
- ▁PA
- M
- ▁REY
- ▁BAN
- JI
- L
- SUN
- ▁SEÑOR
- ▁JO
- ▁TIO
- KWE
- CHU
- S
- ▁YE
- KIN
- XU
- BE
- ▁CUENTA
- ▁SAN
- RRU
- ▁¿
- CHA
- ▁TO
- RRA
- LO
- TE
- ▁AMIGU
- PA
- XAN
- ▁C
- C
- ▁CHA
- ▁TE
- ▁HIJO
- ▁MB
- ▁PI
- G
- ▁ÁNIMA
- ▁CHE
- ▁P
- B
- NDIO
- SE
- ▁SANTU
- MU
- ▁PADRE
- D
- JU
- Z
- ▁TORO
- ▁PO
- LE
- ▁LI
- RO
- ▁LO
- ▁MESA
- CA
- ▁CHIU
- DO
- ▁BU
- ▁BUTA
- JO
- T
- TRU
- RU
- ▁MBO
- ▁JUAN
- ▁MM
- ▁CA
- ▁M
- ▁MAS
- ▁DE
- V
- ▁MAÑA
- ▁UTA
- DA
- ▁MULA
- ▁YOLOXÓCHITL
- ▁CONSEJU
- ▁Y
- ▁LE
- ÓN
- ▁MISA
- TIU
- ▁CANDELA
- ▁PATRÓN
- ▁PADRINU
- ▁MARCU
- ▁V
- ▁G
- Í
- ▁XE
- ▁MU
- ▁XO
- NGUI
- ▁CO
- ▁HOMBRE
- ▁PESU
- ▁PE
- ▁D
- ▁MACHITI
- CO
- REN
- ▁RANCHU
- ▁MIS
- ▁MACHU
- J
- ▁PAN
- CHO
- H
- ▁CHU
- Y
- ▁TON
- GA
- X
- ▁VI
- ▁FE
- ▁TARRAYA
- ▁SANTÍSIMA
- ▁N
- ▁MAYÓ
- ▁CARRU
- ▁F
- ▁PAPÁ
- ▁PALOMA
- ▁MARÍA
- ▁PEDRU
- ▁CAFÉ
- ▁COMISARIO
- ▁PANELA
- ▁PELÓN
- É
- ▁POZO
- ▁CABRÓN
- ▁GUACHU
- ▁S
- RES
- ▁COSTUMBRE
- ▁SEÑA
- QUI
- ▁ORO
- CH
- ▁MAR
- SIN
- SAN
- ▁COSTA
- ▁MAMÁ
- ▁CINCUENTA
- ▁CHO
- ▁PEDR
- ▁JUNTA
- MÚ
- ▁TIENDA
- ▁JOSÉ
- NC
- ▁ES
- ▁SUERTE
- ▁FAMILIA
- ▁ZAPATU
- NTE
- ▁PASTO
- ▁CON
- Ñ
- ▁BOTE
- CIÓN
- ▁RE
- ▁BOLSA
- ▁MANGO
- ▁JWE
- ▁GASTU
- ▁T
- ▁B
- ▁KW
- ÍN
- ▁HIJA
- ▁CUARENT
- ▁VAQUERU
- ▁NECHITO
- ▁NOVIA
- ▁NOVIO
- JWE
- ▁PUENTE
- ▁SANDÍA
- ▁MALA
- Ó
- ▁ABONO
- ▁JESÚS
- ▁CUARTO
- ▁EFE
- ▁REINA
- ▁COMANDANTE
- ▁ESCUELA
- ▁MANZANA
- ▁MÁQUINA
- LLA
- ▁COR
- ▁JERÓNIMO
- ▁PISTOLA
- NGI
- CIO
- ▁FRANCISCU
- ▁TEODORO
- CER
- ▁SALUBI
- ▁MEZA
- ▁MÚSIC
- ▁RU
- ▁CONSTANTINO
- ▁GARCÍA
- ▁FRENU
- ▁ROSA
- ▁CERVEZA
- ▁CIGARRU
- ▁COMISIÓN
- ▁CUNIJO
- ▁FRANCISCO
- ▁HÍJOLE
- ▁NUEVE
- ▁MUL
- ▁PANTALÓN
- ▁CAMISA
- ▁CHINGADA
- ▁SEMANA
- ▁COM
- GAR
- ▁MARTÍN
- ▁SÁBADO
- ▁TRABAJO
- ▁CINCO
- ▁DIE
- ▁EST
- NDWA
- ▁LECHIN
- ▁COCO
- ILLU
- ▁CORRE
- ▁MADR
- ▁REC
- ▁BAUTISTA
- ▁VENTANA
- ▁CUÑAD
- ▁ANTONIU
- ▁COPALA
- LÍN
- ▁SECUND
- ▁COHETE
- ▁HISTORIA
- ▁POLICÍA
- ENCIA
- ▁CAD
- ▁LUIS
- ▁DOCTOR
- ▁GONZÁLEZ
- ▁JUEVE
- ▁LIBRU
- ▁QUESU
- ▁VIAJE
- ▁CART
- ▁LOCO
- ▁BOL
- ▁COMPADRE
- ▁JWI
- ▁METRU
- ▁BUENO
- ▁TRE
- ▁CASTILLO
- ▁COMITÉ
- ▁ETERNO
- ▁LÍQUIDO
- ▁MOLE
- ▁CAPULCU
- ▁DOMING
- ▁ROMA
- ▁CARAJU
- ▁RIATA
- ▁TRATU
- ▁SEIS
- ▁ADÁN
- ▁JUANCITO
- ▁HOR
- ''''
- ▁ARRÓ
- ▁COCINA
- ▁PALACIO
- ▁RÓMULO
- K
- ▁ALFONSO
- ▁BARTOLO
- ▁FELIPE
- ▁HERRER
- ▁PAULINO
- ▁YEGUA
- ▁LISTA
- Ú
- ▁ABRIL
- ▁CUATRO
- ▁DICIEMBRE
- ▁MARGARITO
- ▁MOJONERA
- ▁SOLEDAD
- ▁VESTIDO
- ▁PELOTA
- RRET
- ▁CAPITÁN
- ▁COMUNIÓN
- ▁CUCHARA
- ▁FERNANDO
- ▁GUADALUPE
- ▁MIGUEL
- ▁PELÚN
- ▁SECRETARIU
- ▁LENCHU
- ▁EVA
- ▁SEGUND
- ▁CANTOR
- ▁CHILPANCINGO
- ▁GABRIEL
- ▁QUINIENTO
- ▁RAÚL
- ▁SEVERIAN
- ▁TUMBADA
- ▁MALINCHI
- ▁PRIMU
- ▁MORAL
- ▁AGOSTO
- ▁CENTÍMETRO
- ▁FIRMA
- ▁HUEHUETÁN
- ▁MANGUERA
- ▁MEDI
- ▁MUERT
- ▁SALAZAR
- ▁VIERNI
- LILL
- ▁LL
- '-'
- ▁CAMPESINO
- ▁CIVIL
- ▁COMISARIADO
- )
- (
- Ã
- ‘
- ¿
- Ü
- ¡
- Q
- F
- Á
- P
- Ÿ
- W
- Ý
- <sos/eos>
init: xavier_uniform
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
use_preprocessor: true
token_type: bpe
bpemodel: data/token_list/bpe_unigram500/bpe.model
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
frontend: default
frontend_conf:
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_bpe500/train/feats_stats.npz
preencoder: null
preencoder_conf: {}
encoder: transformer
encoder_conf:
input_layer: conv2d
num_blocks: 12
linear_units: 2048
dropout_rate: 0.1
output_size: 512
attention_heads: 4
attention_dropout_rate: 0.0
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
input_layer: embed
num_blocks: 6
linear_units: 2048
dropout_rate: 0.1
required:
- output_dir
- token_list
version: 0.10.4a1
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
huggingtweets/_luisinhobr-nomesdegato-nomesdj
|
huggingtweets
| 2021-12-21T14:04:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/_luisinhobr-nomesdegato-nomesdj/1640095484918/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1390224220643278850/LcIZLss-_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1175884636624510976/KtBI_1GE_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1245550936807874560/j_zCtKSJ_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">luisfer nando & nomes foda de dj & nomes de gato</div>
<div style="text-align: center; font-size: 14px;">@_luisinhobr-nomesdegato-nomesdj</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from luisfer nando & nomes foda de dj & nomes de gato.
| Data | luisfer nando | nomes foda de dj | nomes de gato |
| --- | --- | --- | --- |
| Tweets downloaded | 2357 | 3250 | 3211 |
| Retweets | 365 | 6 | 69 |
| Short tweets | 503 | 632 | 1710 |
| Tweets kept | 1489 | 2612 | 1432 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1mwm543c/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_luisinhobr-nomesdegato-nomesdj's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3nbxg8c7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3nbxg8c7/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_luisinhobr-nomesdegato-nomesdj')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
09panesara/distilbert-base-uncased-finetuned-cola
|
09panesara
| 2021-12-21T14:03:01Z | 30 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5406394412669151
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7580
- Matthews Correlation: 0.5406
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5307 | 1.0 | 535 | 0.5094 | 0.4152 |
| 0.3545 | 2.0 | 1070 | 0.5230 | 0.4940 |
| 0.2371 | 3.0 | 1605 | 0.6412 | 0.5087 |
| 0.1777 | 4.0 | 2140 | 0.7580 | 0.5406 |
| 0.1288 | 5.0 | 2675 | 0.8494 | 0.5396 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
hrdipto/wav2vec2-xls-r-timit-tokenizer
|
hrdipto
| 2021-12-21T11:49:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-xls-r-timit-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-timit-tokenizer
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4285
- Wer: 0.3662
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.1571 | 4.03 | 500 | 0.5235 | 0.5098 |
| 0.2001 | 8.06 | 1000 | 0.4172 | 0.4375 |
| 0.0968 | 12.1 | 1500 | 0.4562 | 0.4016 |
| 0.0607 | 16.13 | 2000 | 0.4640 | 0.4050 |
| 0.0409 | 20.16 | 2500 | 0.4688 | 0.3914 |
| 0.0273 | 24.19 | 3000 | 0.4414 | 0.3763 |
| 0.0181 | 28.22 | 3500 | 0.4285 | 0.3662 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
bhavikardeshna/multilingual-bert-base-cased-vietnamese
|
bhavikardeshna
| 2021-12-21T11:44:14Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
bhavikardeshna/multilingual-bert-base-cased-hindi
|
bhavikardeshna
| 2021-12-21T11:43:34Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
bhavikardeshna/multilingual-bert-base-cased-german
|
bhavikardeshna
| 2021-12-21T11:43:10Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
bhavikardeshna/multilingual-bert-base-cased-english
|
bhavikardeshna
| 2021-12-21T11:42:34Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
bhavikardeshna/multilingual-bert-base-cased-arabic
|
bhavikardeshna
| 2021-12-21T11:41:30Z | 27 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
bhavikardeshna/xlm-roberta-base-chinese
|
bhavikardeshna
| 2021-12-21T11:40:50Z | 22 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
bhavikardeshna/xlm-roberta-base-german
|
bhavikardeshna
| 2021-12-21T11:40:35Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"arxiv:2112.09866",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
# BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
patrickvonplaten/xls-r-300m-it-phoneme
|
patrickvonplaten
| 2021-12-21T11:15:39Z | 16 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_3_0",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_3_0
- generated_from_trainer
model-index:
- name: xls-r-300m-it-phoneme
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xls-r-300m-it-phoneme
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the mozilla-foundation/common_voice_3_0 - IT dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3899
- Wer: 0.0770
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000075
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 150
- mixed_precision_training: Native AMP
### Training results
See Training Metrics Tab.
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
patrickvonplaten/xls-r-300m-sv-phoneme
|
patrickvonplaten
| 2021-12-21T11:15:26Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_3_0",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_3_0
- generated_from_trainer
model-index:
- name: xls-r-300m-sv-phoneme
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xls-r-300m-sv-phoneme
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the mozilla-foundation/common_voice_3_0 - SV-SE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4879
- Wer: 0.0997
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000075
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 150
- mixed_precision_training: Native AMP
### Training results
See Training Metrics Tab.
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
jiho0304/curseELECTRA
|
jiho0304
| 2021-12-21T08:51:53Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
ElectraBERT tuned with korean-bad-speeches
|
NbAiLabArchive/test_w5_long_dataset
|
NbAiLabArchive
| 2021-12-21T08:30:00Z | 28 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Just for performing some experiments. Do not use.
|
adam-chell/tweet-sentiment-analyzer
|
adam-chell
| 2021-12-20T21:30:06Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
This model has been trained by fine-tuning a BERTweet sentiment classification model named "finiteautomata/bertweet-base-sentiment-analysis", on a labeled positive/negative dataset of tweets.
email : [email protected]
|
quarter100/ko-boolq-model
|
quarter100
| 2021-12-20T13:23:04Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
labeled by "YES" : 1, "NO" : 0, "No Answer" : 2
fine tuned by klue/roberta-large
|
patrickvonplaten/wavlm-libri-clean-100h-base-plus
|
patrickvonplaten
| 2021-12-20T12:59:01Z | 14,635 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wavlm",
"automatic-speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"wavlm_libri_finetune",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
- wavlm_libri_finetune
model-index:
- name: wavlm-libri-clean-100h-base-plus
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wavlm-libri-clean-100h-base-plus
This model is a fine-tuned version of [microsoft/wavlm-base-plus](https://huggingface.co/microsoft/wavlm-base-plus) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0819
- Wer: 0.0683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.8877 | 0.34 | 300 | 2.8649 | 1.0 |
| 0.2852 | 0.67 | 600 | 0.2196 | 0.1830 |
| 0.1198 | 1.01 | 900 | 0.1438 | 0.1273 |
| 0.0906 | 1.35 | 1200 | 0.1145 | 0.1035 |
| 0.0729 | 1.68 | 1500 | 0.1055 | 0.0955 |
| 0.0605 | 2.02 | 1800 | 0.0936 | 0.0859 |
| 0.0402 | 2.35 | 2100 | 0.0885 | 0.0746 |
| 0.0421 | 2.69 | 2400 | 0.0848 | 0.0700 |
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist
|
patrickvonplaten
| 2021-12-20T12:53:43Z | 87 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- speech-recognition
- librispeech_asr
- generated_from_trainer
model-index:
- name: wav2vec2-librispeech-clean-100h-demo-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-librispeech-clean-100h-demo-dist
This model is a fine-tuned version of [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0572
- Wer: 0.0417
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.399 | 0.11 | 100 | 3.6153 | 1.0 |
| 2.8892 | 0.22 | 200 | 2.8963 | 1.0 |
| 2.8284 | 0.34 | 300 | 2.8574 | 1.0 |
| 0.7347 | 0.45 | 400 | 0.6158 | 0.4850 |
| 0.1138 | 0.56 | 500 | 0.2038 | 0.1560 |
| 0.248 | 0.67 | 600 | 0.1274 | 0.1024 |
| 0.2586 | 0.78 | 700 | 0.1108 | 0.0876 |
| 0.0733 | 0.9 | 800 | 0.0936 | 0.0762 |
| 0.044 | 1.01 | 900 | 0.0834 | 0.0662 |
| 0.0393 | 1.12 | 1000 | 0.0792 | 0.0622 |
| 0.0941 | 1.23 | 1100 | 0.0769 | 0.0627 |
| 0.036 | 1.35 | 1200 | 0.0731 | 0.0603 |
| 0.0768 | 1.46 | 1300 | 0.0713 | 0.0559 |
| 0.0518 | 1.57 | 1400 | 0.0686 | 0.0537 |
| 0.0815 | 1.68 | 1500 | 0.0639 | 0.0515 |
| 0.0603 | 1.79 | 1600 | 0.0636 | 0.0500 |
| 0.056 | 1.91 | 1700 | 0.0609 | 0.0480 |
| 0.0265 | 2.02 | 1800 | 0.0621 | 0.0465 |
| 0.0496 | 2.13 | 1900 | 0.0607 | 0.0449 |
| 0.0436 | 2.24 | 2000 | 0.0591 | 0.0446 |
| 0.0421 | 2.35 | 2100 | 0.0590 | 0.0428 |
| 0.0641 | 2.47 | 2200 | 0.0603 | 0.0443 |
| 0.0466 | 2.58 | 2300 | 0.0580 | 0.0429 |
| 0.0132 | 2.69 | 2400 | 0.0574 | 0.0423 |
| 0.0073 | 2.8 | 2500 | 0.0586 | 0.0417 |
| 0.0021 | 2.91 | 2600 | 0.0574 | 0.0412 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
patrickvonplaten/hubert-librispeech-clean-100h-demo-dist
|
patrickvonplaten
| 2021-12-20T12:53:35Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"hubert",
"automatic-speech-recognition",
"speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- speech-recognition
- librispeech_asr
- generated_from_trainer
model-index:
- name: hubert-librispeech-clean-100h-demo-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hubert-librispeech-clean-100h-demo-dist
This model is a fine-tuned version of [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0984
- Wer: 0.0883
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.9031 | 0.11 | 100 | 2.9220 | 1.0 |
| 2.6437 | 0.22 | 200 | 2.6268 | 1.0 |
| 0.3934 | 0.34 | 300 | 0.4860 | 0.4182 |
| 0.3531 | 0.45 | 400 | 0.3088 | 0.2894 |
| 0.2255 | 0.56 | 500 | 0.2568 | 0.2426 |
| 0.3379 | 0.67 | 600 | 0.2073 | 0.2011 |
| 0.2419 | 0.78 | 700 | 0.1849 | 0.1838 |
| 0.2128 | 0.9 | 800 | 0.1662 | 0.1690 |
| 0.1341 | 1.01 | 900 | 0.1600 | 0.1541 |
| 0.0946 | 1.12 | 1000 | 0.1431 | 0.1404 |
| 0.1643 | 1.23 | 1100 | 0.1373 | 0.1304 |
| 0.0663 | 1.35 | 1200 | 0.1293 | 0.1307 |
| 0.162 | 1.46 | 1300 | 0.1247 | 0.1266 |
| 0.1433 | 1.57 | 1400 | 0.1246 | 0.1262 |
| 0.1581 | 1.68 | 1500 | 0.1219 | 0.1154 |
| 0.1036 | 1.79 | 1600 | 0.1127 | 0.1081 |
| 0.1352 | 1.91 | 1700 | 0.1087 | 0.1040 |
| 0.0471 | 2.02 | 1800 | 0.1085 | 0.1005 |
| 0.0945 | 2.13 | 1900 | 0.1066 | 0.0973 |
| 0.0843 | 2.24 | 2000 | 0.1102 | 0.0964 |
| 0.0774 | 2.35 | 2100 | 0.1079 | 0.0940 |
| 0.0952 | 2.47 | 2200 | 0.1056 | 0.0927 |
| 0.0635 | 2.58 | 2300 | 0.1026 | 0.0920 |
| 0.0665 | 2.69 | 2400 | 0.1012 | 0.0905 |
| 0.034 | 2.8 | 2500 | 0.1009 | 0.0900 |
| 0.0251 | 2.91 | 2600 | 0.0993 | 0.0883 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
patrickvonplaten/sew-mid-100k-librispeech-clean-100h-ft
|
patrickvonplaten
| 2021-12-20T12:53:26Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"sew",
"automatic-speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
model-index:
- name: sew-mid-100k-librispeech-clean-100h-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sew-mid-100k-librispeech-clean-100h-ft
This model is a fine-tuned version of [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1976
- Wer: 0.1665
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.4274 | 0.11 | 100 | 4.1419 | 1.0 |
| 2.9657 | 0.22 | 200 | 3.1203 | 1.0 |
| 2.9069 | 0.34 | 300 | 3.0107 | 1.0 |
| 2.8666 | 0.45 | 400 | 2.8960 | 1.0 |
| 1.4535 | 0.56 | 500 | 1.4062 | 0.8664 |
| 0.6821 | 0.67 | 600 | 0.5530 | 0.4930 |
| 0.4827 | 0.78 | 700 | 0.4122 | 0.3630 |
| 0.4485 | 0.9 | 800 | 0.3597 | 0.3243 |
| 0.2666 | 1.01 | 900 | 0.3104 | 0.2790 |
| 0.2378 | 1.12 | 1000 | 0.2913 | 0.2613 |
| 0.2516 | 1.23 | 1100 | 0.2702 | 0.2452 |
| 0.2456 | 1.35 | 1200 | 0.2619 | 0.2338 |
| 0.2392 | 1.46 | 1300 | 0.2466 | 0.2195 |
| 0.2117 | 1.57 | 1400 | 0.2379 | 0.2092 |
| 0.1837 | 1.68 | 1500 | 0.2295 | 0.2029 |
| 0.1757 | 1.79 | 1600 | 0.2240 | 0.1949 |
| 0.1626 | 1.91 | 1700 | 0.2195 | 0.1927 |
| 0.168 | 2.02 | 1800 | 0.2137 | 0.1853 |
| 0.168 | 2.13 | 1900 | 0.2123 | 0.1839 |
| 0.1576 | 2.24 | 2000 | 0.2095 | 0.1803 |
| 0.1756 | 2.35 | 2100 | 0.2075 | 0.1776 |
| 0.1467 | 2.47 | 2200 | 0.2049 | 0.1754 |
| 0.1702 | 2.58 | 2300 | 0.2013 | 0.1722 |
| 0.177 | 2.69 | 2400 | 0.1993 | 0.1701 |
| 0.1417 | 2.8 | 2500 | 0.1983 | 0.1688 |
| 0.1302 | 2.91 | 2600 | 0.1977 | 0.1678 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.13.4.dev0
- Tokenizers 0.10.3
|
austin/adr-ner
|
austin
| 2021-12-20T06:48:11Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: adr-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# adr-ner
This model is a fine-tuned version of [austin/Austin-MeDeBERTa](https://huggingface.co/austin/Austin-MeDeBERTa) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0434
- Precision: 0.7305
- Recall: 0.6934
- F1: 0.7115
- Accuracy: 0.9941
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 107 | 0.0630 | 0.0 | 0.0 | 0.0 | 0.9876 |
| No log | 2.0 | 214 | 0.0308 | 0.4282 | 0.3467 | 0.3832 | 0.9900 |
| No log | 3.0 | 321 | 0.0254 | 0.5544 | 0.5603 | 0.5573 | 0.9920 |
| No log | 4.0 | 428 | 0.0280 | 0.6430 | 0.5751 | 0.6071 | 0.9929 |
| 0.0465 | 5.0 | 535 | 0.0266 | 0.5348 | 0.7146 | 0.6118 | 0.9915 |
| 0.0465 | 6.0 | 642 | 0.0423 | 0.7632 | 0.5793 | 0.6587 | 0.9939 |
| 0.0465 | 7.0 | 749 | 0.0336 | 0.6957 | 0.6765 | 0.6860 | 0.9939 |
| 0.0465 | 8.0 | 856 | 0.0370 | 0.6876 | 0.6702 | 0.6788 | 0.9936 |
| 0.0465 | 9.0 | 963 | 0.0349 | 0.6555 | 0.7040 | 0.6789 | 0.9932 |
| 0.0044 | 10.0 | 1070 | 0.0403 | 0.6910 | 0.6808 | 0.6858 | 0.9938 |
| 0.0044 | 11.0 | 1177 | 0.0415 | 0.7140 | 0.6808 | 0.6970 | 0.9939 |
| 0.0044 | 12.0 | 1284 | 0.0440 | 0.7349 | 0.6681 | 0.6999 | 0.9941 |
| 0.0044 | 13.0 | 1391 | 0.0423 | 0.7097 | 0.6977 | 0.7036 | 0.9941 |
| 0.0044 | 14.0 | 1498 | 0.0435 | 0.7174 | 0.6977 | 0.7074 | 0.9941 |
| 0.0006 | 15.0 | 1605 | 0.0434 | 0.7305 | 0.6934 | 0.7115 | 0.9941 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Amalq/roberta-base-finetuned-schizophreniaReddit2
|
Amalq
| 2021-12-20T05:41:28Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-schizophreniaReddit2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-schizophreniaReddit2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 490 | 1.8093 |
| 1.9343 | 2.0 | 980 | 1.7996 |
| 1.8856 | 3.0 | 1470 | 1.7966 |
| 1.8552 | 4.0 | 1960 | 1.7844 |
| 1.8267 | 5.0 | 2450 | 1.7839 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
anelnurkayeva/autonlp-covid-432211280
|
anelnurkayeva
| 2021-12-20T01:23:47Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autonlp",
"en",
"dataset:anelnurkayeva/autonlp-data-covid",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- anelnurkayeva/autonlp-data-covid
co2_eq_emissions: 8.898145050355591
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 432211280
- CO2 Emissions (in grams): 8.898145050355591
## Validation Metrics
- Loss: 0.12489336729049683
- Accuracy: 0.9520089285714286
- Precision: 0.9436443331246086
- Recall: 0.9747736093143596
- AUC: 0.9910066767410616
- F1: 0.958956411072224
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/anelnurkayeva/autonlp-covid-432211280
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("anelnurkayeva/autonlp-covid-432211280", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("anelnurkayeva/autonlp-covid-432211280", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
microsoft/unispeech-1350-en-353-fr-ft-1h
|
microsoft
| 2021-12-19T23:14:27Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"unispeech",
"automatic-speech-recognition",
"audio",
"fr",
"dataset:common_voice",
"arxiv:2101.07597",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- fr
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus FRENCH
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of French phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-353-fr-ft-1h"
sample = next(iter(load_dataset("common_voice", "fr", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# gives -> 'œ̃ v ʁ ɛ t ʁ a v a j ɛ̃ t e ʁ ɛ s ɑ̃ v a ɑ̃ f ɛ̃ ɛ t ʁ ə m ə n e s y ʁ s ə s y ʒ ɛ'
# for 'Un vrai travail intéressant va, enfin, être mené sur ce sujet.'
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *fr*:
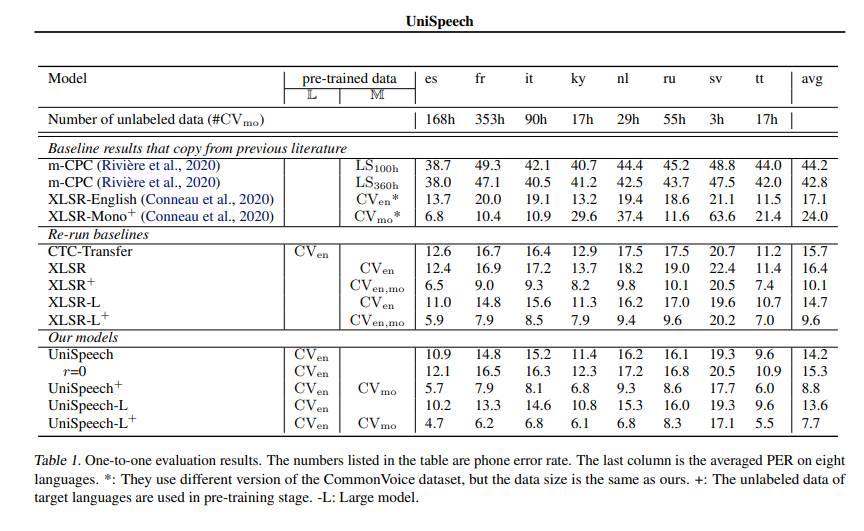
|
microsoft/unispeech-1350-en-168-es-ft-1h
|
microsoft
| 2021-12-19T23:01:13Z | 33 | 0 |
transformers
|
[
"transformers",
"pytorch",
"unispeech",
"automatic-speech-recognition",
"audio",
"es",
"dataset:common_voice",
"arxiv:2101.07597",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- es
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus Spanish
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Spanish phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-168-es-ft-1h"
sample = next(iter(load_dataset("common_voice", "es", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# -> gives:
# b j e n i k e ɾ ɾ e ɣ a l o a s a β ɾ i ɾ p ɾ i m e ɾ o'
# for: Bien . ¿ y qué regalo vas a abrir primero ?
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *es*:

|
microsoft/unispeech-1350-en-17h-ky-ft-1h
|
microsoft
| 2021-12-19T23:00:00Z | 51 | 1 |
transformers
|
[
"transformers",
"pytorch",
"unispeech",
"automatic-speech-recognition",
"audio",
"ky",
"dataset:common_voice",
"arxiv:2101.07597",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- ky
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus Kyrgyz
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Kyrgyz phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-17h-ky-ft-1h"
sample = next(iter(load_dataset("common_voice", "ky", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *ky*:

|
addy88/wav2vec2-bhojpuri-stt
|
addy88
| 2021-12-19T16:48:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-bhojpuri-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-bhojpuri-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
addy88/wav2vec2-dogri-stt
|
addy88
| 2021-12-19T16:43:44Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-dogri-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-dogri-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
addy88/wav2vec2-maithili-stt
|
addy88
| 2021-12-19T16:40:20Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-maithili-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-maithili-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
addy88/wav2vec2-malayalam-stt
|
addy88
| 2021-12-19T16:36:31Z | 26 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-malayalam-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-malayalam-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
addy88/wav2vec2-marathi-stt
|
addy88
| 2021-12-19T16:31:22Z | 21 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-marathi-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-marathi-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
addy88/wav2vec2-rajsthani-stt
|
addy88
| 2021-12-19T15:52:16Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-rajsthani-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-rajsthani-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
addy88/wav2vec2-urdu-stt
|
addy88
| 2021-12-19T15:47:47Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-urdu-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-urdu-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
kco4776/soongsil-bert-wellness
|
kco4776
| 2021-12-19T15:23:09Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## References
- [Soongsil-BERT](https://github.com/jason9693/Soongsil-BERT)
|
addy88/wav2vec2-gujarati-stt
|
addy88
| 2021-12-19T15:14:38Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-gujarati-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-gujarati-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
Ayham/bert_gpt2_summarization_cnndm_new
|
Ayham
| 2021-12-19T15:09:12Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: bert_gpt2_summarization_cnndm_new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_gpt2_summarization_cnndm_new
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
addy88/wav2vec2-english-stt
|
addy88
| 2021-12-19T15:08:42Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-english-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-english-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
|
nguyenvulebinh/envibert
|
nguyenvulebinh
| 2021-12-19T14:20:51Z | 26 | 5 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"exbert",
"vi",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: vi
tags:
- exbert
license: cc-by-nc-4.0
---
# RoBERTa for Vietnamese and English (envibert)
This RoBERTa version is trained by using 100GB of text (50GB of Vietnamese and 50GB of English) so it is named ***envibert***. The model architecture is custom for production so it only contains 70M parameters.
## Usages
```python
from transformers import RobertaModel
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
import os
cache_dir='./cache'
model_name='nguyenvulebinh/envibert'
def download_tokenizer_files():
resources = ['envibert_tokenizer.py', 'dict.txt', 'sentencepiece.bpe.model']
for item in resources:
if not os.path.exists(os.path.join(cache_dir, item)):
tmp_file = hf_bucket_url(model_name, filename=item)
tmp_file = cached_path(tmp_file,cache_dir=cache_dir)
os.rename(tmp_file, os.path.join(cache_dir, item))
download_tokenizer_files()
tokenizer = SourceFileLoader("envibert.tokenizer", os.path.join(cache_dir,'envibert_tokenizer.py')).load_module().RobertaTokenizer(cache_dir)
model = RobertaModel.from_pretrained(model_name,cache_dir=cache_dir)
# Encode text
text_input = 'Đại học Bách Khoa Hà Nội .'
text_ids = tokenizer(text_input, return_tensors='pt').input_ids
# tensor([[ 0, 705, 131, 8751, 2878, 347, 477, 5, 2]])
# Extract features
text_features = model(text_ids)
text_features['last_hidden_state'].shape
# torch.Size([1, 9, 768])
len(text_features['hidden_states'])
# 7
```
### Citation
```text
@inproceedings{nguyen20d_interspeech,
author={Thai Binh Nguyen and Quang Minh Nguyen and Thi Thu Hien Nguyen and Quoc Truong Do and Chi Mai Luong},
title={{Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={4263--4267},
doi={10.21437/Interspeech.2020-1896}
}
```
**Please CITE** our repo when it is used to help produce published results or is incorporated into other software.
# Contact
[email protected]
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh)
|
rlagusrlagus123/XTC4096
|
rlagusrlagus123
| 2021-12-19T11:19:34Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- conversational
---
---
#12 epochs, each batch size 4, gradient accumulation steps 1, tail 4096.
#THIS SEEMS TO BE THE OPTIMAL SETUP.
|
rlagusrlagus123/XTC20000
|
rlagusrlagus123
| 2021-12-19T11:00:28Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- conversational
---
---
#12 epochs, each batch size 2, gradient accumulation steps 2, tail 20000
|
haotieu/en-vi-mt-model
|
haotieu
| 2021-12-19T10:17:03Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
# Helsinki-NLP/opus-mt-en-vi
- This model is a fine-tune checkpoint of [Helsinki-NLP/opus-mt-en-vi](https://huggingface.co/Helsinki-NLP/opus-mt-en-vi).
- This model reaches BLEU score = 33.086 on the test set of IWSLT'15 English-Vietnamese data.
# Fine-tuning hyper-parameters
- learning_rate = 1e-4
- batch_size = 4
- num_train_epochs = 3.0
|
dkssud/wav2vec2-base-demo-colab
|
dkssud
| 2021-12-19T09:54:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4171
- Wer: 0.3452
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.0054 | 4.0 | 500 | 1.5456 | 0.9005 |
| 0.8183 | 8.0 | 1000 | 0.4738 | 0.4839 |
| 0.3019 | 12.0 | 1500 | 0.4280 | 0.4047 |
| 0.1738 | 16.0 | 2000 | 0.4584 | 0.3738 |
| 0.1285 | 20.0 | 2500 | 0.4418 | 0.3593 |
| 0.1104 | 24.0 | 3000 | 0.4110 | 0.3479 |
| 0.0828 | 28.0 | 3500 | 0.4171 | 0.3452 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu102
- Datasets 1.14.0
- Tokenizers 0.10.3
|
Ayham/distilbert_gpt2_summarization_cnndm
|
Ayham
| 2021-12-19T06:43:15Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: distilbert_gpt2_summarization_cnndm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_gpt2_summarization_cnndm
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Ayham/bert_gpt2_summarization_cnndm
|
Ayham
| 2021-12-19T06:32:54Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: bert_gpt2_summarization_cnndm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_gpt2_summarization_cnndm
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
yerevann/x-r-hy
|
yerevann
| 2021-12-19T03:19:04Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-2b-armenian-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-2b-armenian-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-2b](https://huggingface.co/facebook/wav2vec2-xls-r-2b) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5166
- Wer: 0.7397
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 120
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 3.7057 | 2.38 | 200 | 0.7731 | 0.8091 |
| 0.5797 | 4.76 | 400 | 0.8279 | 0.7804 |
| 0.4341 | 7.14 | 600 | 1.0343 | 0.8285 |
| 0.3135 | 9.52 | 800 | 1.0551 | 0.8066 |
| 0.2409 | 11.9 | 1000 | 1.0686 | 0.7897 |
| 0.1998 | 14.29 | 1200 | 1.1329 | 0.7766 |
| 0.1729 | 16.67 | 1400 | 1.3234 | 0.8567 |
| 0.1533 | 19.05 | 1600 | 1.2432 | 0.8160 |
| 0.1354 | 21.43 | 1800 | 1.2780 | 0.7954 |
| 0.12 | 23.81 | 2000 | 1.2228 | 0.8054 |
| 0.1175 | 26.19 | 2200 | 1.3484 | 0.8129 |
| 0.1141 | 28.57 | 2400 | 1.2881 | 0.9130 |
| 0.1053 | 30.95 | 2600 | 1.1972 | 0.7910 |
| 0.0954 | 33.33 | 2800 | 1.3702 | 0.8048 |
| 0.0842 | 35.71 | 3000 | 1.3963 | 0.7960 |
| 0.0793 | 38.1 | 3200 | 1.4690 | 0.7991 |
| 0.0707 | 40.48 | 3400 | 1.5045 | 0.8085 |
| 0.0745 | 42.86 | 3600 | 1.4749 | 0.8004 |
| 0.0693 | 45.24 | 3800 | 1.5047 | 0.7960 |
| 0.0646 | 47.62 | 4000 | 1.4216 | 0.7997 |
| 0.0555 | 50.0 | 4200 | 1.4676 | 0.8029 |
| 0.056 | 52.38 | 4400 | 1.4273 | 0.8104 |
| 0.0465 | 54.76 | 4600 | 1.3999 | 0.7841 |
| 0.046 | 57.14 | 4800 | 1.6130 | 0.8473 |
| 0.0404 | 59.52 | 5000 | 1.5586 | 0.7841 |
| 0.0403 | 61.9 | 5200 | 1.3959 | 0.7653 |
| 0.0404 | 64.29 | 5400 | 1.5318 | 0.8041 |
| 0.0365 | 66.67 | 5600 | 1.5300 | 0.7854 |
| 0.0338 | 69.05 | 5800 | 1.5051 | 0.7885 |
| 0.0307 | 71.43 | 6000 | 1.5647 | 0.7935 |
| 0.0235 | 73.81 | 6200 | 1.4919 | 0.8154 |
| 0.0268 | 76.19 | 6400 | 1.5259 | 0.8060 |
| 0.0275 | 78.57 | 6600 | 1.3985 | 0.7897 |
| 0.022 | 80.95 | 6800 | 1.5515 | 0.8154 |
| 0.017 | 83.33 | 7000 | 1.5737 | 0.7647 |
| 0.0205 | 85.71 | 7200 | 1.4876 | 0.7572 |
| 0.0174 | 88.1 | 7400 | 1.6331 | 0.7829 |
| 0.0188 | 90.48 | 7600 | 1.5108 | 0.7685 |
| 0.0134 | 92.86 | 7800 | 1.7125 | 0.7866 |
| 0.0125 | 95.24 | 8000 | 1.6042 | 0.7635 |
| 0.0133 | 97.62 | 8200 | 1.4608 | 0.7478 |
| 0.0272 | 100.0 | 8400 | 1.4784 | 0.7309 |
| 0.0133 | 102.38 | 8600 | 1.4471 | 0.7459 |
| 0.0094 | 104.76 | 8800 | 1.4852 | 0.7272 |
| 0.0103 | 107.14 | 9000 | 1.5679 | 0.7409 |
| 0.0088 | 109.52 | 9200 | 1.5090 | 0.7309 |
| 0.0077 | 111.9 | 9400 | 1.4994 | 0.7290 |
| 0.0068 | 114.29 | 9600 | 1.5008 | 0.7340 |
| 0.0054 | 116.67 | 9800 | 1.5166 | 0.7390 |
| 0.0052 | 119.05 | 10000 | 1.5166 | 0.7397 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
zaccharieramzi/UNet-OASIS
|
zaccharieramzi
| 2021-12-19T02:07:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
# UNet-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.unet import unet
model = unet(n_layers=4, layers_n_channels=[16, 32, 64, 128], layers_n_non_lins=2,)
model.load_weights('UNet-fastmri/model_weights.h5')
```
Using the model is then as simple as:
```python
model(zero_filled_recon)
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 29.8
- SSIM: 0.847
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/UNet-fastmri
|
zaccharieramzi
| 2021-12-19T02:05:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
# UNet-fastmri
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model can be used to reconstruct single coil fastMRI data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil knee data from Siemens scanner at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.unet import unet
model = unet(n_layers=4, layers_n_channels=[16, 32, 64, 128], layers_n_non_lins=2,)
model.load_weights('UNet-fastmri/model_weights.h5')
```
Using the model is then as simple as:
```python
model(zero_filled_recon)
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [fastMRI dataset](https://fastmri.org/dataset/).
| Contrast | PD | PDFS |
|----------|-------|--------|
| PSNR | 33.64 | 29.89 |
| SSIM | 0.807 | 0.6334 |
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/KIKI-net-fastmri
|
zaccharieramzi
| 2021-12-19T01:53:37Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
# KIKI-net-fastmri
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model can be used to reconstruct single coil fastMRI data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil knee data from Siemens scanner at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.kiki_sep import full_kiki_net
from fastmri_recon.models.utils.non_linearities import lrelu
model = full_kiki_net(n_convs=16, n_filters=48, activation=lrelu)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [fastMRI dataset](https://fastmri.org/dataset/).
| Contrast | PD | PDFS |
|----------|-------|--------|
| PSNR | 32.86 | 29.57 |
| SSIM | 0.797 | 0.6271 |
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.