
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-14 00:44:55
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 519
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-14 00:44:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
DrishtiSharma/LayoutLMv3-Finetuned-CORD_100 | DrishtiSharma | 2022-09-18T19:38:50Z | 83 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:cord-layoutlmv3",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-18T18:35:30Z | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- cord-layoutlmv3
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: LayoutLMv3-Finetuned-CORD_100
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: cord-layoutlmv3
type: cord-layoutlmv3
config: cord
split: train
args: cord
metrics:
- name: Precision
type: precision
value: 0.9524870081662955
- name: Recall
type: recall
value: 0.9603293413173652
- name: F1
type: f1
value: 0.9563920983973164
- name: Accuracy
type: accuracy
value: 0.9647707979626485
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LayoutLMv3-Finetuned-CORD_100
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the cord-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1948
- Precision: 0.9525
- Recall: 0.9603
- F1: 0.9564
- Accuracy: 0.9648
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.1e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.56 | 250 | 0.9568 | 0.7298 | 0.7844 | 0.7561 | 0.7992 |
| 1.3271 | 3.12 | 500 | 0.5239 | 0.8398 | 0.8713 | 0.8553 | 0.8858 |
| 1.3271 | 4.69 | 750 | 0.3586 | 0.8945 | 0.9207 | 0.9074 | 0.9300 |
| 0.3495 | 6.25 | 1000 | 0.2716 | 0.9298 | 0.9416 | 0.9357 | 0.9410 |
| 0.3495 | 7.81 | 1250 | 0.2331 | 0.9198 | 0.9356 | 0.9276 | 0.9474 |
| 0.1725 | 9.38 | 1500 | 0.2134 | 0.9379 | 0.9499 | 0.9438 | 0.9529 |
| 0.1725 | 10.94 | 1750 | 0.2079 | 0.9401 | 0.9513 | 0.9457 | 0.9605 |
| 0.1116 | 12.5 | 2000 | 0.1992 | 0.9554 | 0.9618 | 0.9586 | 0.9656 |
| 0.1116 | 14.06 | 2250 | 0.1941 | 0.9517 | 0.9588 | 0.9553 | 0.9631 |
| 0.0762 | 15.62 | 2500 | 0.1966 | 0.9503 | 0.9588 | 0.9545 | 0.9639 |
| 0.0762 | 17.19 | 2750 | 0.1951 | 0.9510 | 0.9588 | 0.9549 | 0.9626 |
| 0.0636 | 18.75 | 3000 | 0.1948 | 0.9525 | 0.9603 | 0.9564 | 0.9648 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
lizaboiarchuk/bert-tiny-oa-finetuned | lizaboiarchuk | 2022-09-18T19:05:02Z | 83 | 0 | transformers | [
"transformers",
"tf",
"bert",
"fill-mask",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-09-18T07:27:29Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: lizaboiarchuk/bert-tiny-oa-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# lizaboiarchuk/bert-tiny-oa-finetuned
This model is a fine-tuned version of [prajjwal1/bert-tiny](https://huggingface.co/prajjwal1/bert-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.0626
- Validation Loss: 3.7514
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -525, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.6311 | 4.1088 | 0 |
| 4.2579 | 3.7859 | 1 |
| 4.0635 | 3.7253 | 2 |
| 4.0658 | 3.6842 | 3 |
| 4.0626 | 3.7514 | 4 |
### Framework versions
- Transformers 4.22.1
- TensorFlow 2.8.2
- Tokenizers 0.12.1
|
ssharm87/t5-small-finetuned-xsum-ss | ssharm87 | 2022-09-18T17:13:52Z | 110 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-18T07:18:08Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum-ss
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
config: default
split: train
args: default
metrics:
- name: Rouge1
type: rouge
value: 26.3663
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-ss
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5823
- Rouge1: 26.3663
- Rouge2: 6.4727
- Rougel: 20.538
- Rougelsum: 20.5411
- Gen Len: 18.8006
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 0.25
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 2.8125 | 0.25 | 3189 | 2.5823 | 26.3663 | 6.4727 | 20.538 | 20.5411 | 18.8006 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/lula-13 | sd-concepts-library | 2022-09-18T16:57:51Z | 0 | 6 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T16:57:44Z | ---
license: mit
---
### Lula 13 on Stable Diffusion
This is the `<lula-13>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
sd-concepts-library/rail-scene | sd-concepts-library | 2022-09-18T14:28:03Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T14:27:48Z | ---
license: mit
---
### Rail Scene on Stable Diffusion
This is the `<rail-pov>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
jayanta/aaraki-vit-base-patch16-224-in21k-finetuned-cifar10 | jayanta | 2022-09-18T14:16:57Z | 220 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-09-17T11:53:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: mit-b2-finetuned-memes
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8523956723338485
- task:
type: image-classification
name: Image Classification
dataset:
type: custom
name: custom
split: test
metrics:
- type: f1
value: 0.8580847578266328
name: F1
- type: precision
value: 0.8587893412503379
name: Precision
- type: recall
value: 0.8593508500772797
name: Recall
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mit-b2-finetuned-memes
This model is a fine-tuned version of [aaraki/vit-base-patch16-224-in21k-finetuned-cifar10](https://huggingface.co/aaraki/vit-base-patch16-224-in21k-finetuned-cifar10) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4137
- Accuracy: 0.8524
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9727 | 0.99 | 40 | 0.8400 | 0.7334 |
| 0.5305 | 1.99 | 80 | 0.5147 | 0.8284 |
| 0.3124 | 2.99 | 120 | 0.4698 | 0.8145 |
| 0.2263 | 3.99 | 160 | 0.3892 | 0.8563 |
| 0.1453 | 4.99 | 200 | 0.3874 | 0.8570 |
| 0.1255 | 5.99 | 240 | 0.4097 | 0.8470 |
| 0.0989 | 6.99 | 280 | 0.3860 | 0.8570 |
| 0.0755 | 7.99 | 320 | 0.4141 | 0.8539 |
| 0.08 | 8.99 | 360 | 0.4049 | 0.8594 |
| 0.0639 | 9.99 | 400 | 0.4137 | 0.8524 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
huynguyen208/bert-finetuned-ner | huynguyen208 | 2022-09-18T13:36:26Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-18T13:09:28Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9307387862796834
- name: Recall
type: recall
value: 0.9498485358465163
- name: F1
type: f1
value: 0.9401965683824755
- name: Accuracy
type: accuracy
value: 0.9860187201977983
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0620
- Precision: 0.9307
- Recall: 0.9498
- F1: 0.9402
- Accuracy: 0.9860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0868 | 1.0 | 1756 | 0.0699 | 0.9197 | 0.9352 | 0.9274 | 0.9821 |
| 0.0324 | 2.0 | 3512 | 0.0659 | 0.9202 | 0.9455 | 0.9327 | 0.9849 |
| 0.0162 | 3.0 | 5268 | 0.0620 | 0.9307 | 0.9498 | 0.9402 | 0.9860 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Shaz/augh | Shaz | 2022-09-18T12:49:50Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-09-17T19:10:50Z | import requests
API_URL = "https://api-inference.huggingface.co/models/gpt2"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "Can you please let us know more details about your ",
}) |
sd-concepts-library/lizardman | sd-concepts-library | 2022-09-18T11:42:28Z | 0 | 3 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T11:42:22Z | ---
license: mit
---
### Lizardman on Stable Diffusion
This is the `PlaceholderTokenLizardman` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
ydmeira/beit-finetuned-pokemon | ydmeira | 2022-09-18T11:35:48Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"beit",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-09-03T10:34:50Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: beit-finetuned-pokemon
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-finetuned-pokemon
This model is a fine-tuned version of [ydmeira/beit-finetuned-pokemon](https://huggingface.co/ydmeira/beit-finetuned-pokemon) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0219
- Mean Iou: 0.4955
- Mean Accuracy: 0.9910
- Overall Accuracy: 0.9910
- Per Category Iou: [0.0, 0.9909617791470107]
- Per Category Accuracy: [nan, 0.9909617791470107]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou | Per Category Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:-------------:|:----------------:|:-------------------------:|:-------------------------:|
| 0.0354 | 0.21 | 1000 | 0.0347 | 0.4978 | 0.9955 | 0.9955 | [0.0, 0.9955007125868244] | [nan, 0.9955007125868244] |
| 0.0273 | 0.43 | 2000 | 0.0277 | 0.4951 | 0.9903 | 0.9903 | [0.0, 0.9902709092544748] | [nan, 0.9902709092544748] |
| 0.0307 | 0.64 | 3000 | 0.0788 | 0.4875 | 0.9751 | 0.9751 | [0.0, 0.9750850921785902] | [nan, 0.9750850921785902] |
| 0.0295 | 0.85 | 4000 | 0.0412 | 0.4939 | 0.9877 | 0.9877 | [0.0, 0.9877162657609527] | [nan, 0.9877162657609527] |
| 0.0255 | 1.07 | 5000 | 0.0842 | 0.4862 | 0.9723 | 0.9723 | [0.0, 0.972304346385062] | [nan, 0.972304346385062] |
| 0.0253 | 1.28 | 6000 | 0.0325 | 0.4950 | 0.9901 | 0.9901 | [0.0, 0.9900621363084688] | [nan, 0.9900621363084688] |
| 0.0239 | 1.49 | 7000 | 0.0440 | 0.4917 | 0.9835 | 0.9835 | [0.0, 0.9834701005512881] | [nan, 0.9834701005512881] |
| 0.0238 | 1.71 | 8000 | 0.0338 | 0.4950 | 0.9900 | 0.9900 | [0.0, 0.9899977115151821] | [nan, 0.9899977115151821] |
| 0.0223 | 1.92 | 9000 | 0.0319 | 0.4950 | 0.9900 | 0.9900 | [0.0, 0.989994712810938] | [nan, 0.989994712810938] |
| 0.0231 | 2.13 | 10000 | 0.0382 | 0.4921 | 0.9841 | 0.9841 | [0.0, 0.984106425591889] | [nan, 0.984106425591889] |
| 0.0205 | 2.35 | 11000 | 0.0450 | 0.4926 | 0.9851 | 0.9851 | [0.0, 0.9851146530893756] | [nan, 0.9851146530893756] |
| 0.0201 | 2.56 | 12000 | 0.0265 | 0.4954 | 0.9908 | 0.9908 | [0.0, 0.9908277212846449] | [nan, 0.9908277212846449] |
| 0.0188 | 2.77 | 13000 | 0.0377 | 0.4933 | 0.9866 | 0.9866 | [0.0, 0.9865726862234793] | [nan, 0.9865726862234793] |
| 0.0181 | 2.99 | 14000 | 0.0219 | 0.4955 | 0.9910 | 0.9910 | [0.0, 0.9909617791470107] | [nan, 0.9909617791470107] |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
debbiesoon/prot_bert_bfd-disopro | debbiesoon | 2022-09-18T11:33:41Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-18T09:58:56Z | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
model-index:
- name: prot_bert_bfd-disopro
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prot_bert_bfd-disopro
This model is a fine-tuned version of [Rostlab/prot_bert_bfd](https://huggingface.co/Rostlab/prot_bert_bfd) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3062
- Precision: 0.8640
- Recall: 0.8772
- F1: 0.8202
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 0.0734 | 1.0 | 60 | 0.3415 | 0.7691 | 0.8770 | 0.8195 |
| 0.5288 | 2.0 | 120 | 0.2993 | 0.7691 | 0.8770 | 0.8195 |
| 0.3888 | 3.0 | 180 | 0.3062 | 0.8640 | 0.8772 | 0.8202 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
olympictafira/cAT | olympictafira | 2022-09-18T11:13:25Z | 0 | 1 | null | [
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:other",
"region:us"
]
| text-to-image | 2022-09-18T11:12:18Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: false
extra_gated_prompt: |-
One more step before getting this model.
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. CompVis claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
By clicking on "Access repository" below, you accept that your *contact information* (email address and username) can be shared with the model authors as well.
extra_gated_fields:
I have read the License and agree with its terms: checkbox
---
# Stable Diffusion v1-4 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion with 🧨Diffusers blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-4** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 225k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
This weights here are intended to be used with the 🧨 Diffusers library. If you are looking for the weights to be loaded into the CompVis Stable Diffusion codebase, [come here](https://huggingface.co/CompVis/stable-diffusion-v-1-4-original)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
We recommend using [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion.
```bash
pip install --upgrade diffusers transformers scipy
```
Run this command to log in with your HF Hub token if you haven't before:
```bash
huggingface-cli login
```
Running the pipeline with the default PNDM scheduler:
```python
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("astronaut_rides_horse.png")
```
**Note**:
If you are limited by GPU memory and have less than 10GB of GPU RAM available, please make sure to load the StableDiffusionPipeline in float16 precision instead of the default float32 precision as done above. You can do so by telling diffusers to expect the weights to be in float16 precision:
```py
import torch
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16", use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("astronaut_rides_horse.png")
```
To swap out the noise scheduler, pass it to `from_pretrained`:
```python
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
model_id = "CompVis/stable-diffusion-v1-4"
# Use the K-LMS scheduler here instead
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("astronaut_rides_horse.png")
```
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-4 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
We currently provide four checkpoints, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2`. 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2`.225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*://huggingface.co/CompVis/stable-diffusion-v1-4 |
huggingtweets/perpetualg00se | huggingtweets | 2022-09-18T10:25:36Z | 109 | 1 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-18T10:20:59Z | ---
language: en
thumbnail: http://www.huggingtweets.com/perpetualg00se/1663496719106/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1245588692573409281/mGWMt1q7_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">PerpetualG00se</div>
<div style="text-align: center; font-size: 14px;">@perpetualg00se</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from PerpetualG00se.
| Data | PerpetualG00se |
| --- | --- |
| Tweets downloaded | 3166 |
| Retweets | 514 |
| Short tweets | 628 |
| Tweets kept | 2024 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/32gxsmj0/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @perpetualg00se's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/17rf9oo3) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/17rf9oo3/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/perpetualg00se')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
venkateshdas/roberta-base-squad2-ta-qna-roberta3e | venkateshdas | 2022-09-18T10:22:29Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"generated_from_trainer",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-09-18T10:13:04Z | ---
license: cc-by-4.0
tags:
- generated_from_trainer
model-index:
- name: roberta-base-squad2-ta-qna-roberta3e
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-squad2-ta-qna-roberta3e
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4671
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 87 | 0.5221 |
| No log | 2.0 | 174 | 0.4408 |
| No log | 3.0 | 261 | 0.4671 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/glass-prism-cube | sd-concepts-library | 2022-09-18T07:38:27Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T07:38:16Z | ---
license: mit
---
### glass prism cube on Stable Diffusion
This is the `<glass-prism-cube>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
debbiesoon/prot_bert_bfd-disoDNA | debbiesoon | 2022-09-18T06:50:23Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-18T04:33:19Z | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
model-index:
- name: prot_bert_bfd-disoDNA
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prot_bert_bfd-disoDNA
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1323
- Precision: 0.9442
- Recall: 0.9717
- F1: 0.9578
## Model description
This is a token classification model designed to predict the intrinsically disordered regions of amino acid sequences on the level of DNA disorder annotation.
## Intended uses & limitations
This model works on amino acid sequences that are spaced between characters.
'0': No disorder
'1': Disordered
Example Inputs :
D E A Q F K E C Y D T C H K E C S D K G N G F T F C E M K C D T D C S V K D V K E K L E N Y K P K N
M A S E E L Q K D L E E V K V L L E K A T R K R V R D A L T A E K S K I E T E I K N K M Q Q K S Q K K A E L L D N E K P A A V V A P I T T G Y T D G I S Q I S L
M D V F M K G L S K A K E G V V A A A E K T K Q G V A E A A G K T K E G V L Y V G S K T K E G V V H G V A T V A E K T K E Q V T N V G G A V V T G V T A V A Q K T V E G A G S I A A A T G F V K K D Q L G K N E E G A P Q E G I L E D M P V D P D N E A Y E M P S E E G Y Q D Y E P E A
M E L V L K D A Q S A L T V S E T T F G R D F N E A L V H Q V V V A Y A A G A R Q G T R A Q K T R A E V T G S G K K P W R Q K G T G R A R S G S I K S P I W R S G G V T F A
A R P Q D H S Q K V N K K M Y R G A L K S I L S E L V R Q D R L I V V E K F S V E A P K T K L L A Q K L K D M A L E D V L I I T G E L D E N L F L A A R N L H K V D V R D A T G I D P V S L I A F D K V V M T A D A V K Q V E E M L A
M S D K P D M A E I E K F D K S K L K K T E T Q E K N P L P S K E T I E Q E K Q A G E S
## Training and evaluation data
Training and evaluation data were retrieved from https://www.csuligroup.com/DeepDISOBind/#Materials (Accessed March 2022).
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 0.0213 | 1.0 | 61 | 0.1322 | 0.9442 | 0.9717 | 0.9578 |
| 0.0212 | 2.0 | 122 | 0.1322 | 0.9442 | 0.9717 | 0.9578 |
| 0.1295 | 3.0 | 183 | 0.1323 | 0.9442 | 0.9717 | 0.9578 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/dsmuses | sd-concepts-library | 2022-09-18T06:37:28Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T06:37:17Z | ---
license: mit
---
### DSmuses on Stable Diffusion
This is the `<DSmuses>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:

|
sd-concepts-library/threestooges | sd-concepts-library | 2022-09-18T05:40:11Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T05:40:07Z | ---
license: mit
---
### threestooges on Stable Diffusion
This is the `<threestooges>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
rosskrasner/testcatdog | rosskrasner | 2022-09-18T03:56:03Z | 0 | 0 | fastai | [
"fastai",
"region:us"
]
| null | 2022-09-14T03:29:28Z | ---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
sd-concepts-library/loab-character | sd-concepts-library | 2022-09-18T00:46:01Z | 0 | 4 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-18T00:45:48Z | ---
license: mit
---
### Loab Character on Stable Diffusion
This is the `<loab-character>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:












|
pikodemo/ppo-LunarLander-v2 | pikodemo | 2022-09-18T00:11:48Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-17T14:59:15Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: -553.66 +/- 175.78
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sd-concepts-library/valorantstyle | sd-concepts-library | 2022-09-17T23:55:16Z | 0 | 20 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-17T23:55:05Z | ---
license: mit
---
### valorantstyle on Stable Diffusion
This is the `<valorant>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
reinoudbosch/pegasus-samsum | reinoudbosch | 2022-09-17T23:03:24Z | 99 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-17T22:26:31Z | ---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4814
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7052 | 0.54 | 500 | 1.4814 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.0
|
sd-concepts-library/paul-noir | sd-concepts-library | 2022-09-17T21:40:41Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-17T21:40:35Z | ---
license: mit
---
### Paul Noir on Stable Diffusion
This is the `<paul-noir>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
Bistolero/1ep_seq_25_6b | Bistolero | 2022-09-17T21:23:44Z | 111 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:gem",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-17T21:07:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- gem
model-index:
- name: kapakapa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kapakapa
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the gem dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 15
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/r-crumb-style | sd-concepts-library | 2022-09-17T21:15:16Z | 0 | 5 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-17T21:15:11Z | ---
license: mit
---
### r crumb style on Stable Diffusion
This is the `<rcrumb>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




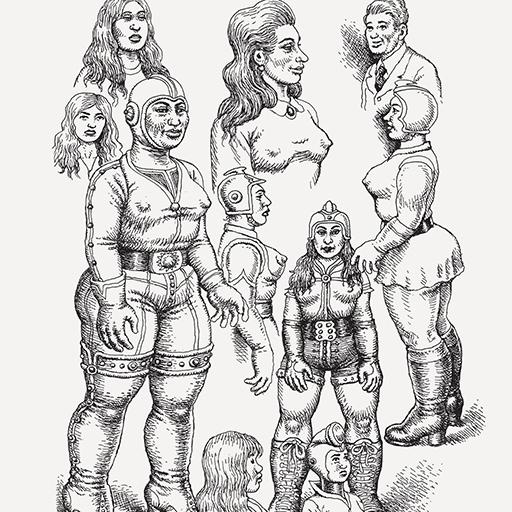


|
anechaev/Reinforce-U5CartPole | anechaev | 2022-09-17T20:43:09Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-17T20:41:20Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-U5CartPole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 46.40 +/- 7.76
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
vangenugtenr/autobiographical_interview_scoring | vangenugtenr | 2022-09-17T20:39:50Z | 162 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-17T20:31:46Z | ---
license: cc-by-nc-sa-4.0
---
|
sd-concepts-library/3d-female-cyborgs | sd-concepts-library | 2022-09-17T20:15:59Z | 0 | 39 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-17T20:15:45Z | ---
license: mit
---
### 3d Female Cyborgs on Stable Diffusion
This is the `<A female cyborg>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
tavakolih/all-MiniLM-L6-v2-pubmed-full | tavakolih | 2022-09-17T19:59:09Z | 1,201 | 9 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"dataset:pubmed",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-17T19:59:01Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
datasets:
- pubmed
---
# tavakolih/all-MiniLM-L6-v2-pubmed-full
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('tavakolih/all-MiniLM-L6-v2-pubmed-full')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=tavakolih/all-MiniLM-L6-v2-pubmed-full)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 221 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Tritkoman/Kvenfinnishtranslator | Tritkoman | 2022-09-17T18:38:22Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"autotrain",
"translation",
"en",
"fi",
"dataset:Tritkoman/autotrain-data-wnkeknrr",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
]
| translation | 2022-09-17T18:36:53Z | ---
tags:
- autotrain
- translation
language:
- en
- fi
datasets:
- Tritkoman/autotrain-data-wnkeknrr
co2_eq_emissions:
emissions: 0.007023045912239053
---
# Model Trained Using AutoTrain
- Problem type: Translation
- Model ID: 1495654541
- CO2 Emissions (in grams): 0.0070
## Validation Metrics
- Loss: 2.873
- SacreBLEU: 22.653
- Gen len: 7.114 |
dumitrescustefan/gpt-neo-romanian-780m | dumitrescustefan | 2022-09-17T18:24:19Z | 260 | 12 | transformers | [
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"romanian",
"text generation",
"causal lm",
"gpt-neo",
"ro",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-08-29T15:31:26Z | ---
language:
- ro
license: mit # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses
tags:
- romanian
- text generation
- causal lm
- gpt-neo
---
# GPT-Neo Romanian 780M
This model is a GPT-Neo transformer decoder model designed using EleutherAI's replication of the GPT-3 architecture.
It was trained on a thoroughly cleaned corpus of Romanian text of about 40GB composed of Oscar, Opus, Wikipedia, literature and various other bits and pieces of text, joined together and deduplicated. It was trained for about a month, totaling 1.5M steps on a v3-32 TPU machine.
### Authors:
* Dumitrescu Stefan
* Mihai Ilie
### Evaluation
Evaluation to be added soon, also on [https://github.com/dumitrescustefan/Romanian-Transformers](https://github.com/dumitrescustefan/Romanian-Transformers)
### Acknowledgements
Thanks [TPU Research Cloud](https://sites.research.google/trc/about/) for the TPUv3 machine needed to train this model!
|
RICHPOOL/RICHPOOL_MINER | RICHPOOL | 2022-09-17T17:42:59Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-09-17T17:39:16Z | ### 开源矿工-瑞池专业版
开源-绿色-无抽水
huggingface 下载分流

#### 原软件源代码
https://github.com/ntminer/NtMiner
#### 授权协议
The LGPL license。
|
sd-concepts-library/durer-style | sd-concepts-library | 2022-09-17T16:36:56Z | 0 | 7 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-17T16:36:49Z | ---
license: mit
---
### durer style on Stable Diffusion
This is the `<drr-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



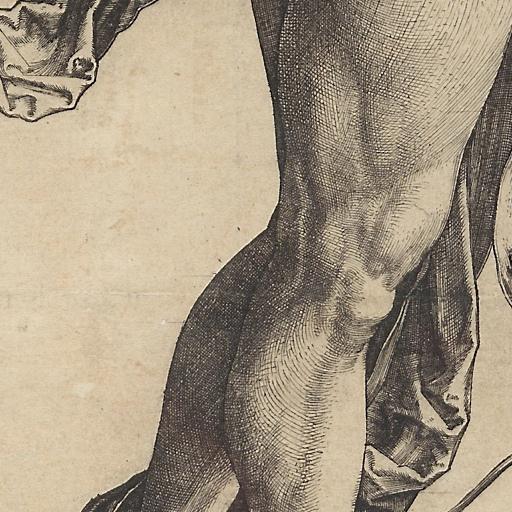

|
theojolliffe/pegasus-model-3-x25 | theojolliffe | 2022-09-17T15:48:03Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-17T14:27:08Z | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: pegasus-model-3-x25
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-model-3-x25
This model is a fine-tuned version of [theojolliffe/pegasus-cnn_dailymail-v4-e1-e4-feedback](https://huggingface.co/theojolliffe/pegasus-cnn_dailymail-v4-e1-e4-feedback) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5668
- Rouge1: 61.9972
- Rouge2: 48.1531
- Rougel: 48.845
- Rougelsum: 59.5019
- Gen Len: 123.0814
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|:---------:|:--------:|
| 1.144 | 1.0 | 883 | 0.5668 | 61.9972 | 48.1531 | 48.845 | 59.5019 | 123.0814 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Eksperymenty/Pong-PLE-v0 | Eksperymenty | 2022-09-17T14:44:18Z | 0 | 0 | null | [
"Pong-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-17T14:44:08Z | ---
tags:
- Pong-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pong-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pong-PLE-v0
type: Pong-PLE-v0
metrics:
- type: mean_reward
value: -16.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pong-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pong-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
jayanta/swin-base-patch4-window7-224-20epochs-finetuned-memes | jayanta | 2022-09-17T13:02:25Z | 216 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-09-17T12:07:58Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-base-patch4-window7-224-20epochs-finetuned-memes
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.847758887171561
- task:
type: image-classification
name: Image Classification
dataset:
type: custom
name: custom
split: test
metrics:
- type: f1
value: 0.8504084378729573
name: F1
- type: precision
value: 0.8519647060733512
name: Precision
- type: recall
value: 0.8523956723338485
name: Recall
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-base-patch4-window7-224-20epochs-finetuned-memes
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7090
- Accuracy: 0.8478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0238 | 0.99 | 40 | 0.9636 | 0.6445 |
| 0.777 | 1.99 | 80 | 0.6591 | 0.7666 |
| 0.4763 | 2.99 | 120 | 0.5381 | 0.8130 |
| 0.3215 | 3.99 | 160 | 0.5244 | 0.8253 |
| 0.2179 | 4.99 | 200 | 0.5123 | 0.8238 |
| 0.1868 | 5.99 | 240 | 0.5052 | 0.8308 |
| 0.154 | 6.99 | 280 | 0.5444 | 0.8338 |
| 0.1166 | 7.99 | 320 | 0.6318 | 0.8238 |
| 0.1099 | 8.99 | 360 | 0.5656 | 0.8338 |
| 0.0925 | 9.99 | 400 | 0.6057 | 0.8338 |
| 0.0779 | 10.99 | 440 | 0.5942 | 0.8393 |
| 0.0629 | 11.99 | 480 | 0.6112 | 0.8400 |
| 0.0742 | 12.99 | 520 | 0.6588 | 0.8331 |
| 0.0752 | 13.99 | 560 | 0.6143 | 0.8408 |
| 0.0577 | 14.99 | 600 | 0.6450 | 0.8516 |
| 0.0589 | 15.99 | 640 | 0.6787 | 0.8400 |
| 0.0555 | 16.99 | 680 | 0.6641 | 0.8454 |
| 0.052 | 17.99 | 720 | 0.7213 | 0.8524 |
| 0.0589 | 18.99 | 760 | 0.6917 | 0.8470 |
| 0.0506 | 19.99 | 800 | 0.7090 | 0.8478 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
test1234678/distilbert-base-uncased-distilled-clinc | test1234678 | 2022-09-17T12:34:43Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-17T07:24:42Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
config: plus
split: train
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9461290322580646
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2712
- Accuracy: 0.9461
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.2629 | 1.0 | 318 | 1.6048 | 0.7368 |
| 1.2437 | 2.0 | 636 | 0.8148 | 0.8565 |
| 0.6604 | 3.0 | 954 | 0.4768 | 0.9161 |
| 0.4054 | 4.0 | 1272 | 0.3548 | 0.9352 |
| 0.2987 | 5.0 | 1590 | 0.3084 | 0.9419 |
| 0.2549 | 6.0 | 1908 | 0.2909 | 0.9435 |
| 0.232 | 7.0 | 2226 | 0.2804 | 0.9458 |
| 0.221 | 8.0 | 2544 | 0.2749 | 0.9458 |
| 0.2145 | 9.0 | 2862 | 0.2722 | 0.9468 |
| 0.2112 | 10.0 | 3180 | 0.2712 | 0.9461 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.10.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
jayanta/resnet50-finetuned-memes | jayanta | 2022-09-17T12:04:12Z | 176 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"resnet",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-09-15T14:19:11Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: resnet50-finetuned-memes
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.5741885625965997
- task:
type: image-classification
name: Image Classification
dataset:
type: custom
name: custom
split: test
metrics:
- type: f1
value: 0.47811617701687364
name: F1
- type: precision
value: 0.43689216537139497
name: Precision
- type: recall
value: 0.5695517774343122
name: Recall
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet50-finetuned-memes
This model is a fine-tuned version of [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0625
- Accuracy: 0.5742
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4795 | 0.99 | 40 | 1.4641 | 0.4382 |
| 1.3455 | 1.99 | 80 | 1.3281 | 0.4389 |
| 1.262 | 2.99 | 120 | 1.2583 | 0.4583 |
| 1.1975 | 3.99 | 160 | 1.1978 | 0.4876 |
| 1.1358 | 4.99 | 200 | 1.1614 | 0.5139 |
| 1.1273 | 5.99 | 240 | 1.1316 | 0.5379 |
| 1.0379 | 6.99 | 280 | 1.1024 | 0.5464 |
| 1.041 | 7.99 | 320 | 1.0927 | 0.5580 |
| 0.9952 | 8.99 | 360 | 1.0790 | 0.5541 |
| 1.0146 | 9.99 | 400 | 1.0625 | 0.5742 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Shamus/NLLB-600m-vie_Latn-to-eng_Latn | Shamus | 2022-09-17T11:54:50Z | 107 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-17T03:28:00Z | ---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: NLLB-600m-vie_Latn-to-eng_Latn
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLLB-600m-vie_Latn-to-eng_Latn
This model is a fine-tuned version of [facebook/nllb-200-distilled-600M](https://huggingface.co/facebook/nllb-200-distilled-600M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1189
- Bleu: 36.6767
- Gen Len: 47.504
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 1.9294 | 2.24 | 1000 | 1.5970 | 23.6201 | 48.1 |
| 1.4 | 4.47 | 2000 | 1.3216 | 28.9526 | 45.156 |
| 1.2071 | 6.71 | 3000 | 1.2245 | 32.5538 | 46.576 |
| 1.0893 | 8.95 | 4000 | 1.1720 | 34.265 | 46.052 |
| 1.0064 | 11.19 | 5000 | 1.1497 | 34.9249 | 46.508 |
| 0.9562 | 13.42 | 6000 | 1.1331 | 36.4619 | 47.244 |
| 0.9183 | 15.66 | 7000 | 1.1247 | 36.4723 | 47.26 |
| 0.8858 | 17.9 | 8000 | 1.1198 | 36.7058 | 47.376 |
| 0.8651 | 20.13 | 9000 | 1.1201 | 36.7897 | 47.496 |
| 0.8546 | 22.37 | 10000 | 1.1189 | 36.6767 | 47.504 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Eksperymenty/Pixelcopter-PLE-v0 | Eksperymenty | 2022-09-17T11:19:23Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-17T11:19:15Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 16.50 +/- 12.63
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
huggingtweets/arrington-jespow-lightcrypto | huggingtweets | 2022-09-17T11:11:37Z | 109 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-17T11:09:39Z | ---
language: en
thumbnail: http://www.huggingtweets.com/arrington-jespow-lightcrypto/1663413092521/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1478019214212747264/LZmNClhs_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1484988558024720385/WAv0tlyD_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1481313178302754821/eeHGWpUF_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">light & Jesse Powell & Michael Arrington 🏴☠️</div>
<div style="text-align: center; font-size: 14px;">@arrington-jespow-lightcrypto</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from light & Jesse Powell & Michael Arrington 🏴☠️.
| Data | light | Jesse Powell | Michael Arrington 🏴☠️ |
| --- | --- | --- | --- |
| Tweets downloaded | 3237 | 3237 | 3243 |
| Retweets | 352 | 490 | 892 |
| Short tweets | 392 | 168 | 718 |
| Tweets kept | 2493 | 2579 | 1633 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3ozhl36a/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @arrington-jespow-lightcrypto's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2vhxitdi) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2vhxitdi/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/arrington-jespow-lightcrypto')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
pnr-svc/distilbert-turkish-ner | pnr-svc | 2022-09-17T11:09:26Z | 104 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:ner-tr",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-17T10:53:29Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- ner-tr
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-turkish-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: ner-tr
type: ner-tr
config: NERTR
split: train
args: NERTR
metrics:
- name: Precision
type: precision
value: 1.0
- name: Recall
type: recall
value: 1.0
- name: F1
type: f1
value: 1.0
- name: Accuracy
type: accuracy
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-turkish-ner
This model is a fine-tuned version of [dbmdz/distilbert-base-turkish-cased](https://huggingface.co/dbmdz/distilbert-base-turkish-cased) on the ner-tr dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0013
- Precision: 1.0
- Recall: 1.0
- F1: 1.0
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| 0.5744 | 1.0 | 529 | 0.0058 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0094 | 2.0 | 1058 | 0.0017 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0047 | 3.0 | 1587 | 0.0013 | 1.0 | 1.0 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
LanYiU/distilbert-base-uncased-finetuned-imdb | LanYiU | 2022-09-17T11:04:50Z | 161 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-09-17T10:55:23Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4738
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- distributed_type: tpu
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7 | 1.0 | 157 | 2.4988 |
| 2.5821 | 2.0 | 314 | 2.4242 |
| 2.541 | 3.0 | 471 | 2.4371 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.9.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Eksperymenty/Reinforce-CartPole-v1 | Eksperymenty | 2022-09-17T10:09:00Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-17T10:07:54Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 445.10 +/- 56.96
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
Hammad7/plag-col-rev-en-v2 | Hammad7 | 2022-09-17T09:58:44Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"plagiarism",
"cross-encoder",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-15T11:51:58Z | ---
license: apache-2.0
language:
- en
tags:
- plagiarism
- cross-encoder
---
## Usage:
from sentence_transformers.cross_encoder import CrossEncoder
model = CrossEncoder('Hammad7/plag-col-rev-en-v2')
model.predict(["duplicate first paragraph","original second paragraph"]) |
sd-concepts-library/m-geo | sd-concepts-library | 2022-09-17T09:42:32Z | 0 | 17 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-17T09:42:21Z | ---
license: mit
---
### m-geo on Stable Diffusion
This is the `<m-geo>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
Gxl/MINI | Gxl | 2022-09-17T08:24:39Z | 0 | 0 | null | [
"license:afl-3.0",
"region:us"
]
| null | 2022-09-07T11:45:56Z | ---
license: afl-3.0
---
11
# 1
23
3224
342
## 324
432455
23445
455
#### 32424
34442 |
Anurag0961/sbi-model | Anurag0961 | 2022-09-17T04:57:40Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-14T16:30:21Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: sbi-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sbi-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5290
- F1: 0.8211
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.813 | 1.0 | 40 | 1.5304 | 0.5227 |
| 1.2312 | 2.0 | 80 | 0.9138 | 0.7439 |
| 0.7428 | 3.0 | 120 | 0.6869 | 0.7518 |
| 0.5055 | 4.0 | 160 | 0.5766 | 0.8050 |
| 0.3581 | 5.0 | 200 | 0.5454 | 0.8052 |
| 0.2664 | 6.0 | 240 | 0.5208 | 0.8200 |
| 0.2145 | 7.0 | 280 | 0.5218 | 0.8241 |
| 0.1853 | 8.0 | 320 | 0.5290 | 0.8211 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Tokenizers 0.12.1
|
Abdulmateen/abdul-distillbert-finetuned-imdb | Abdulmateen | 2022-09-17T03:57:22Z | 71 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-09-17T03:43:06Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Abdulmateen/abdul-distillbert-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Abdulmateen/abdul-distillbert-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.8507
- Validation Loss: 2.5825
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -687, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.8507 | 2.5825 | 0 |
### Framework versions
- Transformers 4.22.1
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/dtv-pkmn | sd-concepts-library | 2022-09-17T01:25:50Z | 0 | 5 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-13T23:08:57Z | ---
license: mit
---
### dtv-pkmn on Stable Diffusion
This is the `<dtv-pkm2>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).

`"hyperdetailed fantasy (monster) (dragon-like) character on top of a rock in the style of <dtv-pkm2> . extremely detailed, amazing artwork with depth and realistic CINEMATIC lighting, matte painting"`
Here is the new concept you will be able to use as a `style`:




|
g30rv17ys/ddpm-geeve-cnv-1000-128 | g30rv17ys | 2022-09-16T22:44:56Z | 1 | 0 | diffusers | [
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
]
| null | 2022-09-16T20:19:10Z | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-geeve-cnv-1000-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/geevegeorge/ddpm-geeve-cnv-1000-128/tensorboard?#scalars)
|
sd-concepts-library/jamie-hewlett-style | sd-concepts-library | 2022-09-16T22:32:42Z | 0 | 14 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T22:32:38Z | ---
license: mit
---
### Jamie Hewlett Style on Stable Diffusion
This is the `<hewlett>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
crumb/jit-traced-stable-diffusion-unet | crumb | 2022-09-16T19:56:53Z | 1 | 0 | null | [
"stable-diffusion",
"text-to-image",
"en",
"region:us"
]
| text-to-image | 2022-09-16T19:36:58Z | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
inference: false
---
```python
torch.jit.load("unet.pt")
noise_pred = unet(latent_model_input, torch.tensor(t, dtype=torch.float32), text_embeddings) # no ['sample']
``` |
sd-concepts-library/lugal-ki-en | sd-concepts-library | 2022-09-16T19:32:47Z | 0 | 14 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T05:58:43Z | ---
title: Lugal Ki EN
emoji: 🪐
colorFrom: gray
colorTo: red
sdk: gradio
sdk_version: 3.3
app_file: app.py
pinned: false
license: mit
---
### Lugal ki en on Stable Diffusion
This is the `<lugal-ki-en>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
sanchit-gandhi/wav2vec2-ctc-earnings22-baseline-5-gram | sanchit-gandhi | 2022-09-16T18:50:03Z | 70 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-09-16T18:34:22Z | Unrolled PT and FX weights of https://huggingface.co/sanchit-gandhi/flax-wav2vec2-ctc-earnings22-baseline/tree/main |
wyu1/FiD-NQ | wyu1 | 2022-09-16T16:34:33Z | 47 | 1 | transformers | [
"transformers",
"pytorch",
"t5",
"license:cc-by-4.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| null | 2022-08-18T22:15:17Z | ---
license: cc-by-4.0
---
# FiD model trained on NQ
-- This is the model checkpoint of FiD [2], based on the T5 large (with 770M parameters) and trained on the natural question (NQ) dataset [1].
-- Hyperparameters: 8 x 40GB A100 GPUs; batch size 8; AdamW; LR 3e-5; 50000 steps
References:
[1] Natural Questions: A Benchmark for Question Answering Research. TACL 2019.
[2] Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. EACL 2021.
## Model performance
We evaluate it on the NQ dataset, the EM score is 51.3 (0.1 lower than original performance reported in the paper).
<a href="https://huggingface.co/exbert/?model=bert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
shamr9/autotrain-firsttransformersproject-1478954182 | shamr9 | 2022-09-16T15:46:18Z | 1 | 0 | transformers | [
"transformers",
"pytorch",
"autotrain",
"summarization",
"ar",
"dataset:shamr9/autotrain-data-firsttransformersproject",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
]
| summarization | 2022-09-16T05:53:23Z | ---
tags:
- autotrain
- summarization
language:
- ar
widget:
- text: "I love AutoTrain 🤗"
datasets:
- shamr9/autotrain-data-firsttransformersproject
co2_eq_emissions:
emissions: 5.113476145275885
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1478954182
- CO2 Emissions (in grams): 5.1135
## Validation Metrics
- Loss: 0.534
- Rouge1: 4.247
- Rouge2: 0.522
- RougeL: 4.260
- RougeLsum: 4.241
- Gen Len: 18.928
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/shamr9/autotrain-firsttransformersproject-1478954182
``` |
ydshieh/vit-gpt2-coco-en | ydshieh | 2022-09-16T15:06:54Z | 5,792 | 35 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"image-to-text",
"endpoints_compatible",
"region:us"
]
| image-to-text | 2022-03-02T23:29:05Z | ---
tags:
- image-to-text
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
example_title: Football Match
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/dog-cat.jpg
example_title: Dog & Cat
---
## Example
The model is by no means a state-of-the-art model, but nevertheless
produces reasonable image captioning results. It was mainly fine-tuned
as a proof-of-concept for the 🤗 FlaxVisionEncoderDecoder Framework.
The model can be used as follows:
**In PyTorch**
```python
import torch
import requests
from PIL import Image
from transformers import ViTFeatureExtractor, AutoTokenizer, VisionEncoderDecoderModel
loc = "ydshieh/vit-gpt2-coco-en"
feature_extractor = ViTFeatureExtractor.from_pretrained(loc)
tokenizer = AutoTokenizer.from_pretrained(loc)
model = VisionEncoderDecoderModel.from_pretrained(loc)
model.eval()
def predict(image):
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
with torch.no_grad():
output_ids = model.generate(pixel_values, max_length=16, num_beams=4, return_dict_in_generate=True).sequences
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
preds = [pred.strip() for pred in preds]
return preds
# We will verify our results on an image of cute cats
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
with Image.open(requests.get(url, stream=True).raw) as image:
preds = predict(image)
print(preds)
# should produce
# ['a cat laying on top of a couch next to another cat']
```
**In Flax**
```python
import jax
import requests
from PIL import Image
from transformers import ViTFeatureExtractor, AutoTokenizer, FlaxVisionEncoderDecoderModel
loc = "ydshieh/vit-gpt2-coco-en"
feature_extractor = ViTFeatureExtractor.from_pretrained(loc)
tokenizer = AutoTokenizer.from_pretrained(loc)
model = FlaxVisionEncoderDecoderModel.from_pretrained(loc)
gen_kwargs = {"max_length": 16, "num_beams": 4}
# This takes sometime when compiling the first time, but the subsequent inference will be much faster
@jax.jit
def generate(pixel_values):
output_ids = model.generate(pixel_values, **gen_kwargs).sequences
return output_ids
def predict(image):
pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
output_ids = generate(pixel_values)
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
preds = [pred.strip() for pred in preds]
return preds
# We will verify our results on an image of cute cats
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
with Image.open(requests.get(url, stream=True).raw) as image:
preds = predict(image)
print(preds)
# should produce
# ['a cat laying on top of a couch next to another cat']
``` |
sd-concepts-library/diaosu-toy | sd-concepts-library | 2022-09-16T14:53:35Z | 0 | 2 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T14:53:28Z | ---
license: mit
---
### diaosu toy on Stable Diffusion
This is the `<diaosu-toy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
scoldi/ppo-LunarLander-32env-1M | scoldi | 2022-09-16T14:26:04Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-16T13:29:11Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 225.16 +/- 74.59
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sd-concepts-library/seraphimmoonshadow-art | sd-concepts-library | 2022-09-16T14:14:16Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T04:38:59Z | ---
license: mit
---
### seraphimmoonshadow-art on Stable Diffusion
This is the `<seraphimmoonshadow-art>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
AHAHAHAHHAHHAHHAHAHAH...............................................................welllllll. My own art, failing me.
<img src="https://cdn.discordapp.com/attachments/1011389373775876116/1020201262244970527/kindaaaaa.png">
|
aiknowyou/mt5-base-it-paraphraser | aiknowyou | 2022-09-16T13:28:47Z | 148 | 5 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"mt5",
"paraphrase-generation",
"paraphrasing",
"it",
"dataset:tapaco",
"dataset:stsb_multi_mt",
"arxiv:2010.11934",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-08-26T15:11:01Z | ---
language: it
datasets:
- tapaco
- stsb_multi_mt
license: cc-by-nc-sa-4.0
tags:
- mt5
- paraphrase-generation
- paraphrasing
---
# MT5-base fine-tuned on Tapaco and STS Benchmark datasets for Paraphrasing
MT5-base Italian paraphraser fine-tuned on [TaPaCo](https://huggingface.co/datasets/tapaco) and [STS Benchmark](https://huggingface.co/datasets/stsb_multi_mt) datasets
## Details of MT5
The **MT5** model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by *Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel* in 2020. Here the abstract:
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We detail the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. We also describe a simple technique to prevent "accidental translation" in the zero-shot setting, where a generative model chooses to (partially) translate its prediction into the wrong language. All of the code and model checkpoints used in this work are publicly available.
## Model fine-tuning
The training script is a slightly modified version of this [Colab notebook](https://colab.research.google.com/drive/1DGeF190gJ3DjRFQiwhFuZalp427iqJNQ) after having prepared an adapted italian version of mt5 model by following this other [Colab notebook](https://gist.github.com/avidale/44cd35bfcdaf8bedf51d97c468cc8001)
## Model in Action
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
raw_model = 'aiknowyou/mt5-base-it-paraphraser'
# Model and Tokenizer definition #
model = T5ForConditionalGeneration.from_pretrained(raw_model)
tokenizer = T5Tokenizer.from_pretrained(raw_model)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
max_size = 10000
def paraphrase(text, beams=100, grams=10, num_return_sequences=5):
x = tokenizer(text, return_tensors='pt', padding=True).to(model.device)
max_size = int(x.input_ids.shape[1] * 1.5 + 10)
out = model.generate(**x, encoder_no_repeat_ngram_size=grams, num_beams=beams, num_return_sequences=num_return_sequences, max_length=max_size)
return tokenizer.batch_decode(out, skip_special_tokens=True)
sentence = "Due amici si incontrano al bar per discutere del modo migliore di generare parafrasi."
print(paraphrase(sentence))
```
## Output
```
Original Question ::
"Due amici si incontrano al bar per discutere del modo migliore di generare parafrasi."
Paraphrased Questions ::
'Due amici stanno discutendo del modo migliore per generare parafrasi.',
'Due amici si incontrano a un bar per discutere del modo migliore per generare parafrasi.',
'Due amici si incontrano al bar per parlare del modo migliore per generare parafrasi.',
'Due amici sono seduti al bar per discutere del modo migliore per generare parafrasi.',
'Due amici si incontrano in un bar per discutere del modo migliore per generare parafrasi.'
```
## Contribution
Thanks to [@tradicio](https://huggingface.co/tradicio) for adding this model.
## License
This work is licensed under a
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
|
Dazzid/xlm-roberta-base-finetuned-panx-de | Dazzid | 2022-09-16T13:24:45Z | 124 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-16T13:00:23Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8648740833380706
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
pyronear/rexnet1_5x | pyronear | 2022-09-16T12:47:25Z | 64 | 0 | transformers | [
"transformers",
"pytorch",
"onnx",
"image-classification",
"dataset:pyronear/openfire",
"arxiv:2007.00992",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-07-17T20:30:57Z | ---
license: apache-2.0
tags:
- image-classification
- pytorch
- onnx
datasets:
- pyronear/openfire
---
# ReXNet-1.5x model
Pretrained on a dataset for wildfire binary classification (soon to be shared). The ReXNet architecture was introduced in [this paper](https://arxiv.org/pdf/2007.00992.pdf).
## Model description
The core idea of the author is to add a customized Squeeze-Excitation layer in the residual blocks that will prevent channel redundancy.
## Installation
### Prerequisites
Python 3.6 (or higher) and [pip](https://pip.pypa.io/en/stable/)/[conda](https://docs.conda.io/en/latest/miniconda.html) are required to install PyroVision.
### Latest stable release
You can install the last stable release of the package using [pypi](https://pypi.org/project/pyrovision/) as follows:
```shell
pip install pyrovision
```
or using [conda](https://anaconda.org/pyronear/pyrovision):
```shell
conda install -c pyronear pyrovision
```
### Developer mode
Alternatively, if you wish to use the latest features of the project that haven't made their way to a release yet, you can install the package from source *(install [Git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) first)*:
```shell
git clone https://github.com/pyronear/pyro-vision.git
pip install -e pyro-vision/.
```
## Usage instructions
```python
from PIL import Image
from torchvision.transforms import Compose, ConvertImageDtype, Normalize, PILToTensor, Resize
from torchvision.transforms.functional import InterpolationMode
from pyrovision.models import model_from_hf_hub
model = model_from_hf_hub("pyronear/rexnet1_5x").eval()
img = Image.open(path_to_an_image).convert("RGB")
# Preprocessing
config = model.default_cfg
transform = Compose([
Resize(config['input_shape'][1:], interpolation=InterpolationMode.BILINEAR),
PILToTensor(),
ConvertImageDtype(torch.float32),
Normalize(config['mean'], config['std'])
])
input_tensor = transform(img).unsqueeze(0)
# Inference
with torch.inference_mode():
output = model(input_tensor)
probs = output.squeeze(0).softmax(dim=0)
```
## Citation
Original paper
```bibtex
@article{DBLP:journals/corr/abs-2007-00992,
author = {Dongyoon Han and
Sangdoo Yun and
Byeongho Heo and
Young Joon Yoo},
title = {ReXNet: Diminishing Representational Bottleneck on Convolutional Neural
Network},
journal = {CoRR},
volume = {abs/2007.00992},
year = {2020},
url = {https://arxiv.org/abs/2007.00992},
eprinttype = {arXiv},
eprint = {2007.00992},
timestamp = {Mon, 06 Jul 2020 15:26:01 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007-00992.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Source of this implementation
```bibtex
@software{Fernandez_Holocron_2020,
author = {Fernandez, François-Guillaume},
month = {5},
title = {{Holocron}},
url = {https://github.com/frgfm/Holocron},
year = {2020}
}
```
|
dwisaji/SentimentBert | dwisaji | 2022-09-16T12:09:42Z | 161 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-16T12:01:39Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: SentimentBert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SentimentBert
This model is a fine-tuned version of [cahya/bert-base-indonesian-522M](https://huggingface.co/cahya/bert-base-indonesian-522M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2005
- Accuracy: 0.965
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 275 | 0.7807 | 0.715 |
| 0.835 | 2.0 | 550 | 1.0588 | 0.635 |
| 0.835 | 3.0 | 825 | 0.2764 | 0.94 |
| 0.5263 | 4.0 | 1100 | 0.1913 | 0.97 |
| 0.5263 | 5.0 | 1375 | 0.2005 | 0.965 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/sewerslvt | sd-concepts-library | 2022-09-16T12:08:19Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T12:08:15Z | ---
license: mit
---
### Sewerslvt on Stable Diffusion
This is the `Sewerslvt` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
MGanesh29/parrot_paraphraser_on_T5-finetuned-xsum-v5 | MGanesh29 | 2022-09-16T11:40:33Z | 109 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-16T09:35:53Z | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: parrot_paraphraser_on_T5-finetuned-xsum-v5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# parrot_paraphraser_on_T5-finetuned-xsum-v5
This model is a fine-tuned version of [prithivida/parrot_paraphraser_on_T5](https://huggingface.co/prithivida/parrot_paraphraser_on_T5) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0345
- Rouge1: 86.5078
- Rouge2: 84.8978
- Rougel: 86.4798
- Rougelsum: 86.4726
- Gen Len: 17.8462
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.0663 | 1.0 | 2002 | 0.0539 | 86.0677 | 84.063 | 86.0423 | 86.0313 | 17.8671 |
| 0.0449 | 2.0 | 4004 | 0.0388 | 86.4564 | 84.7606 | 86.432 | 86.4212 | 17.8501 |
| 0.0269 | 3.0 | 6006 | 0.0347 | 86.4997 | 84.8907 | 86.4814 | 86.4744 | 17.8501 |
| 0.023 | 4.0 | 8008 | 0.0345 | 86.5078 | 84.8978 | 86.4798 | 86.4726 | 17.8462 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
slplab/wav2vec2-xls-r-300m-japanese-hiragana | slplab | 2022-09-16T11:01:54Z | 76 | 1 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ja",
"dataset:common_voice",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-09-16T07:34:58Z | ---
language: ja
datasets:
- common_voice
metrics:
- wer
- cer
model-index:
- name: wav2vec2-xls-r-300m finetuned on Japanese Hiragana with no word boundaries by Hyungshin Ryu of SLPlab
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice Japanese
type: common_voice
args: ja
metrics:
- name: Test WER
type: wer
value: 90.66
- name: Test CER
type: cer
value: 19.35
---
# Wav2Vec2-XLS-R-300M-Japanese-Hiragana
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on Japanese Hiragana characters using the [Common Voice](https://huggingface.co/datasets/common_voice) and [JSUT](https://sites.google.com/site/shinnosuketakamichi/publication/jsut).
The sentence outputs do not contain word boundaries. Audio inputs should be sampled at 16kHz.
## Usage
The model can be used directly as follows:
```python
!pip install mecab-python3
!pip install unidic-lite
!pip install pykakasi
import torch
import torchaudio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset, load_metric
import pykakasi
import MeCab
import re
# load datasets, processor, and model
test_dataset = load_dataset("common_voice", "ja", split="test")
wer = load_metric("wer")
cer = load_metric("cer")
PTM = "slplab/wav2vec2-xls-r-300m-japanese-hiragana"
print("PTM:", PTM)
processor = Wav2Vec2Processor.from_pretrained(PTM)
model = Wav2Vec2ForCTC.from_pretrained(PTM)
device = "cuda"
model.to(device)
# preprocess datasets
wakati = MeCab.Tagger("-Owakati")
kakasi = pykakasi.kakasi()
chars_to_ignore_regex = "[、,。]"
def speech_file_to_array_fn_hiragana_nospace(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).strip()
batch["sentence"] = ''.join([d['hira'] for d in kakasi.convert(batch["sentence"])])
speech_array, sampling_rate = torchaudio.load(batch["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16000)
batch["speech"] = resampler(speech_array).squeeze()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn_hiragana_nospace)
#evaluate
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(device)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
for i in range(10):
print("="*20)
print("Prd:", result[i]["pred_strings"])
print("Ref:", result[i]["sentence"])
print("WER: {:2f}%".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}%".format(100 * cer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
| Original Text | Prediction |
| ------------- | ------------- |
| この料理は家庭で作れます。 | このりょうりはかていでつくれます |
| 日本人は、決して、ユーモアと無縁な人種ではなかった。 | にっぽんじんはけしてゆうもあどむえんなじんしゅではなかった |
| 木村さんに電話を貸してもらいました。 | きむらさんにでんわおかしてもらいました |
## Test Results
**WER:** 90.66%,
**CER:** 19.35%
## Training
Trained on JSUT and train+valid set of Common Voice Japanese. Tested on test set of Common Voice Japanese. |
g30rv17ys/ddpm-geeve-128 | g30rv17ys | 2022-09-16T10:13:42Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
]
| null | 2022-09-16T07:46:35Z | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-geeve-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/geevegeorge/ddpm-geeve-128/tensorboard?#scalars)
|
viola77data/recycling | viola77data | 2022-09-16T07:43:19Z | 0 | 2 | tf-keras | [
"tf-keras",
"license:apache-2.0",
"region:us"
]
| null | 2022-09-16T06:19:33Z | ---
license: apache-2.0
---
Recycling Model trained with Keras and Tensorflow on this dataset: https://huggingface.co/datasets/viola77data/recycling-dataset |
sd-concepts-library/osrstiny | sd-concepts-library | 2022-09-16T04:54:51Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T04:54:46Z | ---
license: mit
---
### osrstiny on Stable Diffusion
This is the `<osrstiny>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
sd-concepts-library/david-firth-artstyle | sd-concepts-library | 2022-09-16T04:31:20Z | 0 | 3 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T04:31:14Z | ---
license: mit
---
### David Firth Artstyle on Stable Diffusion
This is the `<david-firth-artstyle>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
microsoft/layoutlmv2-base-uncased | microsoft | 2022-09-16T03:40:56Z | 693,838 | 62 | transformers | [
"transformers",
"pytorch",
"layoutlmv2",
"en",
"arxiv:2012.14740",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | ---
language: en
license: cc-by-nc-sa-4.0
---
# LayoutLMv2
**Multimodal (text + layout/format + image) pre-training for document AI**
The documentation of this model in the Transformers library can be found [here](https://huggingface.co/docs/transformers/model_doc/layoutlmv2).
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://github.com/microsoft/unilm/tree/master/layoutlmv2)
## Introduction
LayoutLMv2 is an improved version of LayoutLM with new pre-training tasks to model the interaction among text, layout, and image in a single multi-modal framework. It outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including , including FUNSD (0.7895 → 0.8420), CORD (0.9493 → 0.9601), SROIE (0.9524 → 0.9781), Kleister-NDA (0.834 → 0.852), RVL-CDIP (0.9443 → 0.9564), and DocVQA (0.7295 → 0.8672).
[LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou, ACL 2021
|
microsoft/layoutlmv2-large-uncased | microsoft | 2022-09-16T03:40:36Z | 16,989 | 11 | transformers | [
"transformers",
"pytorch",
"layoutlmv2",
"en",
"arxiv:2012.14740",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | ---
language: en
license: cc-by-nc-sa-4.0
---
# LayoutLMv2
**Multimodal (text + layout/format + image) pre-training for document AI**
## Introduction
LayoutLMv2 is an improved version of LayoutLM with new pre-training tasks to model the interaction among text, layout, and image in a single multi-modal framework. It outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including , including FUNSD (0.7895 → 0.8420), CORD (0.9493 → 0.9601), SROIE (0.9524 → 0.9781), Kleister-NDA (0.834 → 0.852), RVL-CDIP (0.9443 → 0.9564), and DocVQA (0.7295 → 0.8672).
[LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou, [ACL 2021](#)
|
microsoft/layoutlmv3-large | microsoft | 2022-09-16T03:26:15Z | 157,275 | 102 | transformers | [
"transformers",
"pytorch",
"tf",
"layoutlmv3",
"en",
"arxiv:2204.08387",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-04-18T06:56:58Z | ---
language: en
license: cc-by-nc-sa-4.0
---
# LayoutLMv3
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://aka.ms/layoutlmv3)
## Model description
LayoutLMv3 is a pre-trained multimodal Transformer for Document AI with unified text and image masking. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model. For example, LayoutLMv3 can be fine-tuned for both text-centric tasks, including form understanding, receipt understanding, and document visual question answering, and image-centric tasks such as document image classification and document layout analysis.
[LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei, Preprint 2022.
## Citation
If you find LayoutLM useful in your research, please cite the following paper:
```
@inproceedings{huang2022layoutlmv3,
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
booktitle={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/).
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct) |
microsoft/layoutlmv3-base-chinese | microsoft | 2022-09-16T03:25:46Z | 2,586 | 68 | transformers | [
"transformers",
"pytorch",
"layoutlmv3",
"zh",
"arxiv:2204.08387",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-06-16T04:38:00Z | ---
language: zh
license: cc-by-nc-sa-4.0
---
# LayoutLMv3
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://aka.ms/layoutlmv3)
## Model description
LayoutLMv3 is a pre-trained multimodal Transformer for Document AI with unified text and image masking. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model. For example, LayoutLMv3 can be fine-tuned for both text-centric tasks, including form understanding, receipt understanding, and document visual question answering, and image-centric tasks such as document image classification and document layout analysis.
[LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei, Preprint 2022.
## Results
| Dataset | Language | Precision | Recall | F1 |
|---------|-----------|------------|------|--------|
| [XFUND](https://github.com/doc-analysis/XFUND) | ZH | 0.8980 | 0.9435 | 0.9202 |
| Dataset | Subject | Test Time | Name | School | Examination Number | Seat Number | Class | Student Number | Grade | Score | **Mean** |
|---------|:------------|:------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [EPHOIE](https://github.com/HCIILAB/EPHOIE) | 98.99 | 100.0 | 99.77 | 99.2 | 100.0 | 100.0 | 98.82 | 99.78 | 98.31 | 97.27 | 99.21 |
## Citation
If you find LayoutLM useful in your research, please cite the following paper:
```
@inproceedings{huang2022layoutlmv3,
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
booktitle={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/).
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct) |
HYPJUDY/layoutlmv3-large-finetuned-funsd | HYPJUDY | 2022-09-16T03:18:44Z | 170 | 4 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"arxiv:2204.08387",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-04-18T18:06:30Z | ---
license: cc-by-nc-sa-4.0
---
# layoutlmv3-large-finetuned-funsd
The model [layoutlmv3-large-finetuned-funsd](https://huggingface.co/HYPJUDY/layoutlmv3-large-finetuned-funsd) is fine-tuned on the FUNSD dataset initialized from [microsoft/layoutlmv3-large](https://huggingface.co/microsoft/layoutlmv3-large).
This finetuned model achieves an F1 score of 92.15 on the test split of the FUNSD dataset.
[Paper](https://arxiv.org/pdf/2204.08387.pdf) | [Code](https://aka.ms/layoutlmv3) | [Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)
If you find LayoutLMv3 helpful, please cite the following paper:
```
@inproceedings{huang2022layoutlmv3,
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
booktitle={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/).
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
|
HYPJUDY/layoutlmv3-base-finetuned-funsd | HYPJUDY | 2022-09-16T03:17:49Z | 207 | 3 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"arxiv:2204.08387",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-04-18T15:23:41Z | ---
license: cc-by-nc-sa-4.0
---
# layoutlmv3-base-finetuned-funsd
The model [layoutlmv3-base-finetuned-funsd](https://huggingface.co/HYPJUDY/layoutlmv3-base-finetuned-funsd) is fine-tuned on the FUNSD dataset initialized from [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base).
This finetuned model achieves an F1 score of 90.59 on the test split of the FUNSD dataset.
[Paper](https://arxiv.org/pdf/2204.08387.pdf) | [Code](https://aka.ms/layoutlmv3) | [Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)
If you find LayoutLMv3 helpful, please cite the following paper:
```
@inproceedings{huang2022layoutlmv3,
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
booktitle={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/).
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
|
sd-concepts-library/wayne-reynolds-character | sd-concepts-library | 2022-09-16T03:10:09Z | 0 | 5 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T03:10:03Z | ---
license: mit
---
### Wayne Reynolds Character on Stable Diffusion
This is the `<warcharport>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:


























|
sd-concepts-library/ganyu-genshin-impact | sd-concepts-library | 2022-09-16T02:54:13Z | 0 | 22 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T02:54:10Z | ---
license: mit
---
### Ganyu (Genshin Impact) on Stable Diffusion
This is the `<ganyu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
mikedodge/t5-small-finetuned-xsum | mikedodge | 2022-09-16T02:23:09Z | 117 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-15T20:00:32Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
config: default
split: train
args: default
metrics:
- name: Rouge1
type: rouge
value: 28.2804
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4789
- Rouge1: 28.2804
- Rouge2: 7.7039
- Rougel: 22.2002
- Rougelsum: 22.2019
- Gen Len: 18.8238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.711 | 1.0 | 12753 | 2.4789 | 28.2804 | 7.7039 | 22.2002 | 22.2019 | 18.8238 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/milady | sd-concepts-library | 2022-09-16T01:59:10Z | 0 | 2 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T01:58:59Z | ---
license: mit
---
### milady on Stable Diffusion
This is the `<milady>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/hydrasuit | sd-concepts-library | 2022-09-16T01:50:23Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-16T01:50:17Z | ---
license: mit
---
### Hydrasuit on Stable Diffusion
This is the `<hydrasuit>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/furrpopasthetic | sd-concepts-library | 2022-09-16T00:48:33Z | 0 | 3 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-15T23:05:54Z | ---
license: mit
---
### furrpopasthetic on Stable Diffusion
This is the `<furpop>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
More information will be provided via my GOOGLE DOCUMENT, which you can check out HERE: https://docs.google.com/document/d/1R2UZi5G-DXiz2HcCrfAFLYJoer_JPDEoZmV7wy1tEz0/edit
Here are some sample images of things I created using this model:
<img src="https://cdn.discordapp.com/attachments/1011389373775876116/1020123619218698301/sofancy.png">
<img src="https://cdn.discordapp.com/attachments/1006210928548773939/1020129494490677309/allthedoggos.png">
<img src="https://cdn.discordapp.com/attachments/1011389373775876116/1020124794420740128/alltheunicorns.png">
<img src="https://cdn.discordapp.com/attachments/1006210928548773939/1020131203543744572/sosweet.png">
<img src="https://cdn.discordapp.com/attachments/1006210928548773939/1020133712119201852/fartoocute.png">
I will be providing information for the model in my Google Doc, so please just check there; thanks!
These are the images that I used for the `style`:





And yes, this is all based on my LSP/romanticism painters, which you can still do by combining the key words outlined in my document.
|
Isaacp/xlm-roberta-base-finetuned-panx-en | Isaacp | 2022-09-15T23:30:58Z | 123 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-15T23:10:20Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-en
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.en
metrics:
- name: F1
type: f1
value: 0.7032474804031354
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3932
- F1: 0.7032
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1504 | 1.0 | 50 | 0.5992 | 0.4786 |
| 0.5147 | 2.0 | 100 | 0.4307 | 0.6468 |
| 0.3717 | 3.0 | 150 | 0.3932 | 0.7032 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Isaacp/xlm-roberta-base-finetuned-panx-it | Isaacp | 2022-09-15T23:10:07Z | 114 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-15T22:48:54Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.it
metrics:
- name: F1
type: f1
value: 0.8245828245828245
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2401
- F1: 0.8246
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8187 | 1.0 | 70 | 0.3325 | 0.7337 |
| 0.2829 | 2.0 | 140 | 0.2554 | 0.8003 |
| 0.1894 | 3.0 | 210 | 0.2401 | 0.8246 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
sd-concepts-library/a-hat-kid | sd-concepts-library | 2022-09-15T22:03:52Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-15T22:03:46Z | ---
license: mit
---
### A Hat kid on Stable Diffusion
This is the `<hatintime-kid>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/backrooms | sd-concepts-library | 2022-09-15T21:32:42Z | 0 | 12 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-15T21:32:37Z | ---
license: mit
---
### Backrooms on Stable Diffusion
This is the `<Backrooms>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:



|
UchuuKira177/kuwa | UchuuKira177 | 2022-09-15T20:43:54Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-09-15T20:34:45Z | import sagemaker
from sagemaker.huggingface import HuggingFace
# gets role for executing training job
role = sagemaker.get_execution_role()
hyperparameters = {
'model_name_or_path':'Grossmend/rudialogpt3_medium_based_on_gpt2',
'output_dir':'/opt/ml/model'
# add your remaining hyperparameters
# more info here https://github.com/huggingface/transformers/tree/v4.17.0/examples/pytorch/language-modeling
}
# git configuration to download our fine-tuning script
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.17.0'}
# creates Hugging Face estimator
huggingface_estimator = HuggingFace(
entry_point='run_clm.py',
source_dir='./examples/pytorch/language-modeling',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
git_config=git_config,
transformers_version='4.17.0',
pytorch_version='1.10.2',
py_version='py38',
hyperparameters = hyperparameters
)
# starting the train job
huggingface_estimator.fit() |
VanessaSchenkel/pt-unicamp-handcrafted | VanessaSchenkel | 2022-09-15T20:27:04Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| translation | 2022-09-15T20:01:33Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: pt-unicamp-handcrafted
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pt-unicamp-handcrafted
This model is a fine-tuned version of [VanessaSchenkel/pt-unicamp-news-t5](https://huggingface.co/VanessaSchenkel/pt-unicamp-news-t5) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7061
- Bleu: 75.3691
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/onepunchman | sd-concepts-library | 2022-09-15T20:03:04Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-15T20:02:57Z | ---
license: mit
---
### OnePunchMan on Stable Diffusion
This is the `<OnePunch>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
JImenezDaniel88/distResume-Classification-parser | JImenezDaniel88 | 2022-09-15T19:47:43Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-09-15T18:32:09Z | # YaleParser Resumes Classification
**YaleParser** is a python tool for NLP classification Task and generate databases with this classification. This model is a fineting on named-entity-recognition and zero-shot sequence classifiers. The method works by posing the sequence to be classified as the NLI and Bayesian weigths to construct hypothesis from each candidate label, and stepwise with regex, build a Database.
### Design
```
predict_single('''08/1992-05/1996 BA, Biology, West Virginia University, Morgantown, WV''')
# 'Education'
```
precision recall f1-score support
Administrative Position 0.73 0.73 0.73 49
Appointments 0.73 0.84 0.79 115
Bibliography 0.94 0.83 0.88 87
Board Certification 0.94 0.77 0.85 44
Education 0.86 0.86 0.86 100
Grants/Clinical Trials 0.94 0.85 0.89 40
Other 0.69 0.77 0.73 156
Patents 0.98 0.98 0.98 43
Professional Honors 0.80 0.85 0.82 170
Professional Service 0.85 0.61 0.71 85
accuracy 0.81 889
macro avg 0.85 0.81 0.82 889
weighted avg 0.82 0.81 0.81 889
|
sd-concepts-library/moebius | sd-concepts-library | 2022-09-15T19:20:25Z | 0 | 67 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-15T19:20:19Z | ---
license: mit
---
### moebius on Stable Diffusion
This is the `<moebius>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:































|
richhkust/distilbert-base-uncased-finetuned-cola | richhkust | 2022-09-15T18:55:35Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-15T17:08:32Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: train
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5332198659134496
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7865
- Matthews Correlation: 0.5332
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5246 | 1.0 | 535 | 0.5492 | 0.4039 |
| 0.3516 | 2.0 | 1070 | 0.5242 | 0.4703 |
| 0.2369 | 3.0 | 1605 | 0.5779 | 0.5203 |
| 0.1719 | 4.0 | 2140 | 0.7865 | 0.5332 |
| 0.1178 | 5.0 | 2675 | 0.8519 | 0.5298 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
reinoudbosch/xlm-roberta-base-finetuned-panx-all | reinoudbosch | 2022-09-15T17:44:39Z | 115 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-15T17:33:33Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1739
- F1: 0.8525
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3 | 1.0 | 835 | 0.1894 | 0.8104 |
| 0.1564 | 2.0 | 1670 | 0.1751 | 0.8423 |
| 0.1032 | 3.0 | 2505 | 0.1739 | 0.8525 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.0
|
valadhi/swin-tiny-patch4-window7-224-finetuned-agrivision | valadhi | 2022-09-15T17:21:42Z | 59 | 0 | transformers | [
"transformers",
"pytorch",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-09-08T14:40:38Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-agrivision
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9202733485193622
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-agrivision
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3605
- Accuracy: 0.9203
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5913 | 1.0 | 31 | 0.7046 | 0.7175 |
| 0.1409 | 2.0 | 62 | 0.8423 | 0.6788 |
| 0.0825 | 3.0 | 93 | 0.6224 | 0.7654 |
| 0.0509 | 4.0 | 124 | 0.4379 | 0.8360 |
| 0.0439 | 5.0 | 155 | 0.1706 | 0.9317 |
| 0.0107 | 6.0 | 186 | 0.1914 | 0.9362 |
| 0.0134 | 7.0 | 217 | 0.2491 | 0.9089 |
| 0.0338 | 8.0 | 248 | 0.2119 | 0.9362 |
| 0.0306 | 9.0 | 279 | 0.4502 | 0.8610 |
| 0.0054 | 10.0 | 310 | 0.4990 | 0.8747 |
| 0.0033 | 11.0 | 341 | 0.2746 | 0.9112 |
| 0.0021 | 12.0 | 372 | 0.2501 | 0.9317 |
| 0.0068 | 13.0 | 403 | 0.1883 | 0.9522 |
| 0.0038 | 14.0 | 434 | 0.3672 | 0.9134 |
| 0.0006 | 15.0 | 465 | 0.2275 | 0.9408 |
| 0.0011 | 16.0 | 496 | 0.3349 | 0.9134 |
| 0.0017 | 17.0 | 527 | 0.3329 | 0.9157 |
| 0.0007 | 18.0 | 558 | 0.2508 | 0.9317 |
| 0.0023 | 19.0 | 589 | 0.2338 | 0.9385 |
| 0.0003 | 20.0 | 620 | 0.3193 | 0.9226 |
| 0.002 | 21.0 | 651 | 0.4604 | 0.9043 |
| 0.0023 | 22.0 | 682 | 0.3338 | 0.9203 |
| 0.005 | 23.0 | 713 | 0.2925 | 0.9271 |
| 0.0001 | 24.0 | 744 | 0.2022 | 0.9522 |
| 0.0002 | 25.0 | 775 | 0.2699 | 0.9339 |
| 0.0007 | 26.0 | 806 | 0.2603 | 0.9385 |
| 0.0005 | 27.0 | 837 | 0.4120 | 0.9134 |
| 0.0003 | 28.0 | 868 | 0.3550 | 0.9203 |
| 0.0008 | 29.0 | 899 | 0.3657 | 0.9203 |
| 0.0 | 30.0 | 930 | 0.3605 | 0.9203 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/thalasin | sd-concepts-library | 2022-09-15T17:17:24Z | 0 | 3 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-15T17:07:08Z | ---
license: mit
---
### Thalasin on Stable Diffusion
This is the `<thalasin-plus>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
This is based on the work of [Gooseworx](https://twitter.com/GooseworxMusic)
Here is the new concept you will be able to use as an `object`:



|
reinoudbosch/xlm-roberta-base-finetuned-panx-fr | reinoudbosch | 2022-09-15T17:16:21Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-15T17:06:54Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-fr
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.fr
metrics:
- name: F1
type: f1
value: 0.8375924680564896
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2794
- F1: 0.8376
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5774 | 1.0 | 191 | 0.3212 | 0.7894 |
| 0.2661 | 2.0 | 382 | 0.2737 | 0.8292 |
| 0.1756 | 3.0 | 573 | 0.2794 | 0.8376 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.0
|
reinoudbosch/xlm-roberta-base-finetuned-panx-de-fr | reinoudbosch | 2022-09-15T17:06:30Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-15T16:54:20Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1612
- F1: 0.8618
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2874 | 1.0 | 715 | 0.1764 | 0.8343 |
| 0.1475 | 2.0 | 1430 | 0.1561 | 0.8508 |
| 0.0936 | 3.0 | 2145 | 0.1612 | 0.8618 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.0
|
Subsets and Splits