
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-16 00:42:46
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 522
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-16 00:42:16
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
LoneStriker/Yi-34B-Spicyboros-3.1-2-4.65bpw-h6-exl2 | LoneStriker | 2023-11-17T12:28:36Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:unalignment/spicy-3.1",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-17T12:26:23Z | ---
license: other
license_name: yi-license
license_link: LICENSE
datasets:
- unalignment/spicy-3.1
---
# Fine-tune of Y-34B with Spicyboros-3.1
Three epochs of fine tuning with @jondurbin's SpicyBoros-3.1 dataset. 4.65bpw should fit on a single 3090/4090, 5.0bpw, 6.0bpw, and 8.0bpw will require more than one GPU 24 GB VRAM GPU.
**Please note:** you may have to turn down repetition penalty to 1.0. The model seems to get into "thesaurus" mode sometimes without this change.
# Original Yi-34B Model Card Below
<div align="center">
<h1>
Yi
</h1>
</div>
## Introduction
The **Yi** series models are large language models trained from scratch by developers at [01.AI](https://01.ai/). The first public release contains two base models with the parameter size of 6B and 34B.
## News
- 🎯 **2023/11/02**: The base model of `Yi-6B` and `Yi-34B`
## Model Performance
| Model | MMLU | CMMLU | C-Eval | GAOKAO | BBH | Commonsense Reasoning | Reading Comprehension | Math & Code |
| :------------ | :------: | :------: | :------: | :------: | :------: | :-------------------: | :-------------------: | :---------: |
| | 5-shot | 5-shot | 5-shot | 0-shot | 3-shot@1 | - | - | - |
| LLaMA2-34B | 62.6 | - | - | - | 44.1 | 69.9 | 68.0 | 26.0 |
| LLaMA2-70B | 68.9 | 53.3 | - | 49.8 | 51.2 | 71.9 | 69.4 | 36.8 |
| Baichuan2-13B | 59.2 | 62.0 | 58.1 | 54.3 | 48.8 | 64.3 | 62.4 | 23.0 |
| Qwen-14B | 66.3 | 71.0 | 72.1 | 62.5 | 53.4 | 73.3 | 72.5 | 39.8 |
| Skywork-13B | 62.1 | 61.8 | 60.6 | 68.1 | 41.7 | 72.4 | 61.4 | 24.9 |
| InternLM-20B | 62.1 | 59.0 | 58.8 | 45.5 | 52.5 | 78.3 | - | 26.0 |
| Aquila-34B | 67.8 | 71.4 | 63.1 | - | - | - | - | - |
| Falcon-180B | 70.4 | 58.0 | 57.8 | 59.0 | 54.0 | 77.3 | 68.8 | 34.0 |
| Yi-6B | 63.2 | 75.5 | 72.0 | 72.2 | 42.8 | 72.3 | 68.7 | 19.8 |
| **Yi-34B** | **76.3** | **83.7** | **81.4** | **82.8** | **54.3** | **80.1** | **76.4** | **37.1** |
While benchmarking open-source models, we have observed a disparity between the results generated by our pipeline and those reported in public sources (e.g. OpenCampus). Upon conducting a more in-depth investigation of this difference, we have discovered that various models may employ different prompts, post-processing strategies, and sampling techniques, potentially resulting in significant variations in the outcomes. Our prompt and post-processing strategy remains consistent with the original benchmark, and greedy decoding is employed during evaluation without any post-processing for the generated content. For scores that did not report by original author (including score reported with different setting), we try to get results with our pipeline.
To extensively evaluate model's capability, we adopted the methodology outlined in Llama2. Specifically, we included PIQA, SIQA, HellaSwag, WinoGrande, ARC, OBQA, and CSQA to assess common sense reasoning. SquAD, QuAC, and BoolQ were incorporated to evaluate reading comprehension. CSQA was exclusively tested using a 7-shot setup, while all other tests were conducted in a 0-shot configuration. Additionally, we introduced GSM8K (8-shot@1), MATH (4-shot@1), HumanEval (0-shot@1), and MBPP (3-shot@1) under the category "Math & Code". Due to technical constraints, we did not test Falcon-180 on QuAC and OBQA; the score is derived by averaging the scores on the remaining tasks. Since the scores for these two tasks are generally lower than the average, we believe that Falcon-180B's performance was not underestimated.
## Disclaimer
Although we use data compliance checking algorithms during the training process to ensure the compliance of the trained model to the best of our ability, due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model will generate correct and reasonable output in all scenarios. Please be aware that there is still a risk of the model producing problematic outputs. We will not be responsible for any risks and issues resulting from misuse, misguidance, illegal usage, and related misinformation, as well as any associated data security concerns.
## License
The Yi series model must be adhere to the [Model License Agreement](https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE).
For any questions related to licensing and copyright, please contact us ([[email protected]](mailto:[email protected])).
|
onangeko/Pixelcopter-PLE-v0 | onangeko | 2023-11-17T12:27:57Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-16T12:29:08Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 35.20 +/- 42.21
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
pragnakalpdev32/lora-trained-xl-person-new_25 | pragnakalpdev32 | 2023-11-17T12:17:06Z | 3 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
]
| text-to-image | 2023-11-17T12:13:45Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: A photo of sks person
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - pragnakalpdev32/lora-trained-xl-person-new_25
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on A photo of sks person using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: None.
|
bradmin/reward-gpt-duplicate-answer-2 | bradmin | 2023-11-17T12:16:14Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/polyglot-ko-1.3b",
"base_model:finetune:EleutherAI/polyglot-ko-1.3b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-11-17T11:45:29Z | ---
license: apache-2.0
base_model: EleutherAI/polyglot-ko-1.3b
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: reward-gpt-duplicate-answer-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# reward-gpt-duplicate-answer-2
This model is a fine-tuned version of [EleutherAI/polyglot-ko-1.3b](https://huggingface.co/EleutherAI/polyglot-ko-1.3b) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0162
- Accuracy: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9e-06
- train_batch_size: 6
- eval_batch_size: 6
- seed: 2023
- gradient_accumulation_steps: 10
- total_train_batch_size: 60
- optimizer: Adam with betas=(0.9,0.95) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1389 | 0.24 | 100 | 0.0358 | 0.0 |
| 0.104 | 0.47 | 200 | 0.0283 | 0.0 |
| 0.0881 | 0.71 | 300 | 0.0163 | 0.0 |
| 0.0764 | 0.94 | 400 | 0.0162 | 0.0 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
TheBloke/sqlcoder-34b-alpha-AWQ | TheBloke | 2023-11-17T12:07:59Z | 26 | 5 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"base_model:defog/sqlcoder-34b-alpha",
"base_model:quantized:defog/sqlcoder-34b-alpha",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
]
| text-generation | 2023-11-17T10:32:56Z | ---
base_model: defog/sqlcoder-34b-alpha
inference: false
language:
- en
license: cc-by-4.0
model_creator: Defog.ai
model_name: SQLCoder 34B Alpha
model_type: llama
pipeline_tag: text-generation
prompt_template: "## Task\nGenerate a SQL query to answer the following question:\n\
`{prompt}`\n\n### Database Schema\nThis query will run on a database whose schema\
\ is represented in this string:\nCREATE TABLE products (\n product_id INTEGER\
\ PRIMARY KEY, -- Unique ID for each product\n name VARCHAR(50), -- Name of the\
\ product\n price DECIMAL(10,2), -- Price of each unit of the product\n quantity\
\ INTEGER -- Current quantity in stock\n);\n\nCREATE TABLE sales (\n sale_id INTEGER\
\ PRIMARY KEY, -- Unique ID for each sale\n product_id INTEGER, -- ID of product\
\ sold\n customer_id INTEGER, -- ID of customer who made purchase\n salesperson_id\
\ INTEGER, -- ID of salesperson who made the sale\n sale_date DATE, -- Date the\
\ sale occurred\n quantity INTEGER -- Quantity of product sold\n);\n\n-- sales.product_id\
\ can be joined with products.product_id\n\n### SQL\nGiven the database schema,\
\ here is the SQL query that answers `{prompt}`:\n```sql\n"
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# SQLCoder 34B Alpha - AWQ
- Model creator: [Defog.ai](https://huggingface.co/defog)
- Original model: [SQLCoder 34B Alpha](https://huggingface.co/defog/sqlcoder-34b-alpha)
<!-- description start -->
## Description
This repo contains AWQ model files for [Defog.ai's SQLCoder 34B Alpha](https://huggingface.co/defog/sqlcoder-34b-alpha).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF)
* [Defog.ai's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/defog/sqlcoder-34b-alpha)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Sqlcoder
```
## Task
Generate a SQL query to answer the following question:
`{prompt}`
### Database Schema
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (
product_id INTEGER PRIMARY KEY, -- Unique ID for each product
name VARCHAR(50), -- Name of the product
price DECIMAL(10,2), -- Price of each unit of the product
quantity INTEGER -- Current quantity in stock
);
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale
product_id INTEGER, -- ID of product sold
customer_id INTEGER, -- ID of customer who made purchase
salesperson_id INTEGER, -- ID of salesperson who made the sale
sale_date DATE, -- Date the sale occurred
quantity INTEGER -- Quantity of product sold
);
-- sales.product_id can be joined with products.product_id
### SQL
Given the database schema, here is the SQL query that answers `{prompt}`:
```sql
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Defog.ai's SQLCoder 34B Alpha](https://huggingface.co/defog/sqlcoder-34b-alpha).
<!-- licensing end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-AWQ/tree/main) | 4 | 128 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 18.31 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/sqlcoder-34b-alpha-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `sqlcoder-34b-alpha-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/sqlcoder-34b-alpha-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''## Task
Generate a SQL query to answer the following question:
`{prompt}`
### Database Schema
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (
product_id INTEGER PRIMARY KEY, -- Unique ID for each product
name VARCHAR(50), -- Name of the product
price DECIMAL(10,2), -- Price of each unit of the product
quantity INTEGER -- Current quantity in stock
);
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale
product_id INTEGER, -- ID of product sold
customer_id INTEGER, -- ID of customer who made purchase
salesperson_id INTEGER, -- ID of salesperson who made the sale
sale_date DATE, -- Date the sale occurred
quantity INTEGER -- Quantity of product sold
);
-- sales.product_id can be joined with products.product_id
### SQL
Given the database schema, here is the SQL query that answers `{prompt}`:
```sql
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/sqlcoder-34b-alpha-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/sqlcoder-34b-alpha-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''## Task
Generate a SQL query to answer the following question:
`{prompt}`
### Database Schema
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (
product_id INTEGER PRIMARY KEY, -- Unique ID for each product
name VARCHAR(50), -- Name of the product
price DECIMAL(10,2), -- Price of each unit of the product
quantity INTEGER -- Current quantity in stock
);
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale
product_id INTEGER, -- ID of product sold
customer_id INTEGER, -- ID of customer who made purchase
salesperson_id INTEGER, -- ID of salesperson who made the sale
sale_date DATE, -- Date the sale occurred
quantity INTEGER -- Quantity of product sold
);
-- sales.product_id can be joined with products.product_id
### SQL
Given the database schema, here is the SQL query that answers `{prompt}`:
```sql
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/sqlcoder-34b-alpha-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''## Task
Generate a SQL query to answer the following question:
`{prompt}`
### Database Schema
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (
product_id INTEGER PRIMARY KEY, -- Unique ID for each product
name VARCHAR(50), -- Name of the product
price DECIMAL(10,2), -- Price of each unit of the product
quantity INTEGER -- Current quantity in stock
);
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale
product_id INTEGER, -- ID of product sold
customer_id INTEGER, -- ID of customer who made purchase
salesperson_id INTEGER, -- ID of salesperson who made the sale
sale_date DATE, -- Date the sale occurred
quantity INTEGER -- Quantity of product sold
);
-- sales.product_id can be joined with products.product_id
### SQL
Given the database schema, here is the SQL query that answers `{prompt}`:
```sql
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Defog.ai's SQLCoder 34B Alpha
# Defog SQLCoder
**Updated on Nov 14 to reflect benchmarks for SQLCoder-34B**
Defog's SQLCoder is a state-of-the-art LLM for converting natural language questions to SQL queries.
[Interactive Demo](https://defog.ai/sqlcoder-demo/) | [🤗 HF Repo](https://huggingface.co/defog/sqlcoder-34b-alpha) | [♾️ Colab](https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7?usp=sharing) | [🐦 Twitter](https://twitter.com/defogdata)
## TL;DR
SQLCoder-34B is a 34B parameter model that outperforms `gpt-4` and `gpt-4-turbo` for natural language to SQL generation tasks on our [sql-eval](https://github.com/defog-ai/sql-eval) framework, and significantly outperforms all popular open-source models.
SQLCoder-34B is fine-tuned on a base CodeLlama model.
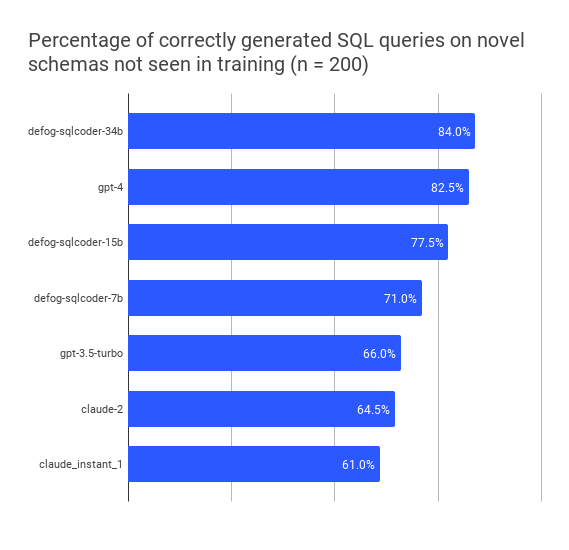
## Results on novel datasets not seen in training
| model | perc_correct |
|-|-|
| defog-sqlcoder-34b | 84.0 |
| gpt4-turbo-2023-11-09 | 82.5 |
| gpt4-2023-11-09 | 82.5 |
| defog-sqlcoder2 | 77.5 |
| gpt4-2023-08-28 | 74.0 |
| defog-sqlcoder-7b | 71.0 |
| gpt-3.5-2023-10-04 | 66.0 |
| claude-2 | 64.5 |
| gpt-3.5-2023-08-28 | 61.0 |
| claude_instant_1 | 61.0 |
| text-davinci-003 | 52.5 |
## License
The code in this repo (what little there is of it) is Apache-2 licensed. The model weights have a `CC BY-SA 4.0` license. The TL;DR is that you can use and modify the model for any purpose – including commercial use. However, if you modify the weights (for example, by fine-tuning), you must open-source your modified weights under the same license terms.
## Training
Defog was trained on more than 20,000 human-curated questions. These questions were based on 10 different schemas. None of the schemas in the training data were included in our evaluation framework.
You can read more about our [training approach](https://defog.ai/blog/open-sourcing-sqlcoder2-7b/) and [evaluation framework](https://defog.ai/blog/open-sourcing-sqleval/).
## Results by question category
We classified each generated question into one of 5 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| | date | group_by | order_by | ratio | join | where |
| -------------- | ---- | -------- | -------- | ----- | ---- | ----- |
| sqlcoder-34b | 80 | 94.3 | 88.6 | 74.3 | 82.9 | 82.9 |
| gpt-4 | 68 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| sqlcoder2-15b | 76 | 80 | 77.1 | 60 | 77.1 | 77.1 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 68 | 77.1 | 68.6 | 37.1 | 71.4 | 74.3 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
| claude-instant | 48 | 71.4 | 74.3 | 45.7 | 62.9 | 60 |
| gpt-3 | 32 | 71.4 | 68.6 | 25.7 | 57.1 | 54.3 |
<img width="831" alt="image" src="https://github.com/defog-ai/sqlcoder/assets/5008293/79c5bdc8-373c-4abd-822e-e2c2569ed353">
## Using SQLCoder
You can use SQLCoder via the `transformers` library by downloading our model weights from the Hugging Face repo. We have added sample code for [inference](./inference.py) on a [sample database schema](./metadata.sql).
```bash
python inference.py -q "Question about the sample database goes here"
# Sample question:
# Do we get more revenue from customers in New York compared to customers in San Francisco? Give me the total revenue for each city, and the difference between the two.
```
You can also use a demo on our website [here](https://defog.ai/sqlcoder-demo)
## Hardware Requirements
SQLCoder-34B has been tested on a 4xA10 GPU with `float16` weights. You can also load an 8-bit and 4-bit quantized version of the model on consumer GPUs with 20GB or more of memory – like RTX 4090, RTX 3090, and Apple M2 Pro, M2 Max, or M2 Ultra Chips with 20GB or more of memory.
## Todo
- [x] Open-source the v1 model weights
- [x] Train the model on more data, with higher data variance
- [ ] Tune the model further with Reward Modelling and RLHF
- [ ] Pretrain a model from scratch that specializes in SQL analysis
|
DamarJati/face-hand-YOLOv5 | DamarJati | 2023-11-17T12:06:28Z | 0 | 4 | null | [
"tensorboard",
"yolov5",
"anime",
"Face detection",
"object-detection",
"en",
"dataset:DamarJati/face-hands-YOLOv5",
"region:us"
]
| object-detection | 2023-11-16T22:46:05Z | ---
datasets:
- DamarJati/face-hands-YOLOv5
language:
- en
tags:
- yolov5
- anime
- Face detection
pipeline_tag: object-detection
---
# YOLOv5 Model for Face and Hands Detection
## Overview
This repository contains a YOLOv5 model trained for detecting faces and hands. The model is based on the YOLOv5 architecture and has been fine-tuned on a custom dataset.
## Model Information
- **Model Name:** yolov5-face-hands
- **Framework:** PyTorch
- **Version:** 1.0.0
- **Model List** ["face", "null1", "null2", "hands"]
- **The list model used is 0 and 3** ["0", "1", "2", "3"]

 | 
:-------------------------------------:|:-------------------------------------:
## Usage
### Installation
```bash
pip install torch torchvision
pip install yolov5
```
### Load Model
```bash
import torch
# Load the YOLOv5 model
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/your/model.pt', force_reload=True)
# Set device (GPU or CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
# Set model to evaluation mode
model.eval()
```
### Inference
```bash
import cv2
# Load and preprocess an image
image_path = 'path/to/your/image.jpg'
image = cv2.imread(image_path)
results = model(image)
# Display results (customize based on your needs)
results.show()
# Extract bounding box information
bboxes = results.xyxy[0].cpu().numpy()
for bbox in bboxes:
label_index = int(bbox[5])
label_mapping = ["face", "null1", "null2", "hands"]
label = label_mapping[label_index]
confidence = bbox[4]
print(f"Detected {label} with confidence {confidence:.2f}")
```
## License
This model is released under the MIT License. See LICENSE for more details.
## Citation
If you find this model useful, please consider citing the YOLOv5 repository:
```bibtex
@misc{jati2023customyolov5,
author = {Damar Jati},
title = {Custom YOLOv5 Model for Face and Hands Detection},
year = {2023},
orcid: {\url{https://orcid.org/0009-0002-0758-2712}}
publisher = {Hugging Face Model Hub},
howpublished = {\url{https://huggingface.co/DamarJati/face-hand-YOLOv5}}
}
``` |
LoneStriker/Yi-34B-Spicyboros-3.1-2-4.0bpw-h6-exl2 | LoneStriker | 2023-11-17T12:00:37Z | 10 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:unalignment/spicy-3.1",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-17T11:58:46Z | ---
license: other
license_name: yi-license
license_link: LICENSE
datasets:
- unalignment/spicy-3.1
---
# Fine-tune of Y-34B with Spicyboros-3.1
Three epochs of fine tuning with @jondurbin's SpicyBoros-3.1 dataset. 4.65bpw should fit on a single 3090/4090, 5.0bpw, 6.0bpw, and 8.0bpw will require more than one GPU 24 GB VRAM GPU.
**Please note:** you may have to turn down repetition penalty to 1.0. The model seems to get into "thesaurus" mode sometimes without this change.
# Original Yi-34B Model Card Below
<div align="center">
<h1>
Yi
</h1>
</div>
## Introduction
The **Yi** series models are large language models trained from scratch by developers at [01.AI](https://01.ai/). The first public release contains two base models with the parameter size of 6B and 34B.
## News
- 🎯 **2023/11/02**: The base model of `Yi-6B` and `Yi-34B`
## Model Performance
| Model | MMLU | CMMLU | C-Eval | GAOKAO | BBH | Commonsense Reasoning | Reading Comprehension | Math & Code |
| :------------ | :------: | :------: | :------: | :------: | :------: | :-------------------: | :-------------------: | :---------: |
| | 5-shot | 5-shot | 5-shot | 0-shot | 3-shot@1 | - | - | - |
| LLaMA2-34B | 62.6 | - | - | - | 44.1 | 69.9 | 68.0 | 26.0 |
| LLaMA2-70B | 68.9 | 53.3 | - | 49.8 | 51.2 | 71.9 | 69.4 | 36.8 |
| Baichuan2-13B | 59.2 | 62.0 | 58.1 | 54.3 | 48.8 | 64.3 | 62.4 | 23.0 |
| Qwen-14B | 66.3 | 71.0 | 72.1 | 62.5 | 53.4 | 73.3 | 72.5 | 39.8 |
| Skywork-13B | 62.1 | 61.8 | 60.6 | 68.1 | 41.7 | 72.4 | 61.4 | 24.9 |
| InternLM-20B | 62.1 | 59.0 | 58.8 | 45.5 | 52.5 | 78.3 | - | 26.0 |
| Aquila-34B | 67.8 | 71.4 | 63.1 | - | - | - | - | - |
| Falcon-180B | 70.4 | 58.0 | 57.8 | 59.0 | 54.0 | 77.3 | 68.8 | 34.0 |
| Yi-6B | 63.2 | 75.5 | 72.0 | 72.2 | 42.8 | 72.3 | 68.7 | 19.8 |
| **Yi-34B** | **76.3** | **83.7** | **81.4** | **82.8** | **54.3** | **80.1** | **76.4** | **37.1** |
While benchmarking open-source models, we have observed a disparity between the results generated by our pipeline and those reported in public sources (e.g. OpenCampus). Upon conducting a more in-depth investigation of this difference, we have discovered that various models may employ different prompts, post-processing strategies, and sampling techniques, potentially resulting in significant variations in the outcomes. Our prompt and post-processing strategy remains consistent with the original benchmark, and greedy decoding is employed during evaluation without any post-processing for the generated content. For scores that did not report by original author (including score reported with different setting), we try to get results with our pipeline.
To extensively evaluate model's capability, we adopted the methodology outlined in Llama2. Specifically, we included PIQA, SIQA, HellaSwag, WinoGrande, ARC, OBQA, and CSQA to assess common sense reasoning. SquAD, QuAC, and BoolQ were incorporated to evaluate reading comprehension. CSQA was exclusively tested using a 7-shot setup, while all other tests were conducted in a 0-shot configuration. Additionally, we introduced GSM8K (8-shot@1), MATH (4-shot@1), HumanEval (0-shot@1), and MBPP (3-shot@1) under the category "Math & Code". Due to technical constraints, we did not test Falcon-180 on QuAC and OBQA; the score is derived by averaging the scores on the remaining tasks. Since the scores for these two tasks are generally lower than the average, we believe that Falcon-180B's performance was not underestimated.
## Disclaimer
Although we use data compliance checking algorithms during the training process to ensure the compliance of the trained model to the best of our ability, due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model will generate correct and reasonable output in all scenarios. Please be aware that there is still a risk of the model producing problematic outputs. We will not be responsible for any risks and issues resulting from misuse, misguidance, illegal usage, and related misinformation, as well as any associated data security concerns.
## License
The Yi series model must be adhere to the [Model License Agreement](https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE).
For any questions related to licensing and copyright, please contact us ([[email protected]](mailto:[email protected])).
|
xiaol/RWKV-v5.2-7B-novel-completion-control-0.4-16k | xiaol | 2023-11-17T11:47:47Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
]
| null | 2023-11-17T09:32:48Z | ---
license: apache-2.0
---
### RWKV novel style tuned with specific instructions
We hear you, we need control the direction of completion from the summary, so you can do what you want with this experimental model, welcome to let us know what you concern mostly. |
SenY/LECO | SenY | 2023-11-17T11:46:49Z | 0 | 30 | null | [
"license:other",
"region:us"
]
| null | 2023-07-22T00:26:30Z | ---
license: other
---
It is a repository for storing as many LECOs as I can think of, emphasizing quantity over quality.
Files will continue to be added as needed.
Because the guidance_scale parameter is somewhat excessive, these LECOs tend to be very sensitive and too effective; using a weight of -0.1 to -1 is appropriate in most cases.
All LECOs are trained with target eq positive, erase settings.
The target is a one of among danbooru's GENERAL tags what most frequently used in order from the top to the bottom, and sometimes I also add phrases that I have personally come up with.
``` prompts.yaml
- target: "$query"
positive: "$query"
unconditional: ""
neutral: ""
action: "erase"
guidance_scale: 1.0
resolution: 512
batch_size: 4
```
```config.yaml
prompts_file: prompts.yaml
pretrained_model:
name_or_path: "/storage/model-1892-0000-0000.safetensors"
v2: false
v_pred: false
network:
type: "lierla"
rank: 4
alpha: 1.0
training_method: "full"
train:
precision: "bfloat16"
noise_scheduler: "ddim"
iterations: 50
lr: 1
optimizer: "Prodigy"
lr_scheduler: "cosine"
max_denoising_steps: 50
save:
name: "$query"
path: "/stable-diffusion-webui/models/Lora/LECO/"
per_steps: 50
precision: "float16"
logging:
use_wandb: false
verbose: false
other:
use_xformers: true
```
|
abduldattijo/videomae-base-finetuned-ucf101-subset-V3KILLER | abduldattijo | 2023-11-17T11:44:28Z | 12 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:abduldattijo/videomae-base-finetuned-ucf101-subset",
"base_model:finetune:abduldattijo/videomae-base-finetuned-ucf101-subset",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| video-classification | 2023-11-16T08:31:43Z | ---
license: cc-by-nc-4.0
base_model: abduldattijo/videomae-base-finetuned-ucf101-subset
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ucf101-subset-V3KILLER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ucf101-subset-V3KILLER
This model is a fine-tuned version of [abduldattijo/videomae-base-finetuned-ucf101-subset](https://huggingface.co/abduldattijo/videomae-base-finetuned-ucf101-subset) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2181
- Accuracy: 0.9615
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 5960
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3447 | 0.03 | 150 | 0.1339 | 0.9579 |
| 0.3161 | 1.03 | 300 | 0.1538 | 0.9465 |
| 0.3386 | 2.03 | 450 | 0.3260 | 0.9019 |
| 0.3572 | 3.03 | 600 | 0.1967 | 0.9311 |
| 0.3699 | 4.03 | 750 | 0.1661 | 0.9505 |
| 0.3125 | 5.03 | 900 | 0.3292 | 0.9205 |
| 0.4785 | 6.03 | 1050 | 0.2029 | 0.9324 |
| 0.3477 | 7.03 | 1200 | 0.1534 | 0.9385 |
| 0.2909 | 8.03 | 1350 | 0.1265 | 0.9571 |
| 0.2646 | 9.03 | 1500 | 0.1239 | 0.9586 |
| 0.3339 | 10.03 | 1650 | 0.1341 | 0.9628 |
| 0.0954 | 11.03 | 1800 | 0.1835 | 0.9423 |
| 0.3861 | 12.03 | 1950 | 0.2241 | 0.9467 |
| 0.248 | 13.03 | 2100 | 0.1258 | 0.9620 |
| 0.2513 | 14.03 | 2250 | 0.2217 | 0.9357 |
| 0.1133 | 15.03 | 2400 | 0.2129 | 0.9406 |
| 0.1421 | 16.03 | 2550 | 0.3006 | 0.9264 |
| 0.0248 | 17.03 | 2700 | 0.3868 | 0.9142 |
| 0.0166 | 18.03 | 2850 | 0.2594 | 0.9518 |
| 0.0874 | 19.03 | 3000 | 0.3652 | 0.9252 |
| 0.0889 | 20.03 | 3150 | 0.2249 | 0.9533 |
| 0.0804 | 21.03 | 3300 | 0.2027 | 0.9628 |
| 0.0019 | 22.03 | 3450 | 0.4682 | 0.9212 |
| 0.0405 | 23.03 | 3600 | 0.2425 | 0.9493 |
| 0.0847 | 24.03 | 3750 | 0.2456 | 0.9558 |
| 0.1656 | 25.03 | 3900 | 0.2623 | 0.9505 |
| 0.1007 | 26.03 | 4050 | 0.2389 | 0.9484 |
| 0.0616 | 27.03 | 4200 | 0.2529 | 0.9543 |
| 0.0005 | 28.03 | 4350 | 0.1521 | 0.9732 |
| 0.0006 | 29.03 | 4500 | 0.4115 | 0.9165 |
| 0.0007 | 30.03 | 4650 | 0.4279 | 0.9220 |
| 0.0004 | 31.03 | 4800 | 0.3572 | 0.9372 |
| 0.0003 | 32.03 | 4950 | 0.3314 | 0.9419 |
| 0.0002 | 33.03 | 5100 | 0.4008 | 0.9347 |
| 0.0611 | 34.03 | 5250 | 0.4632 | 0.9239 |
| 0.0003 | 35.03 | 5400 | 0.3756 | 0.9368 |
| 0.0003 | 36.03 | 5550 | 0.3745 | 0.9429 |
| 0.163 | 37.03 | 5700 | 0.3967 | 0.9383 |
| 0.0059 | 38.03 | 5850 | 0.3808 | 0.9389 |
| 0.0003 | 39.02 | 5960 | 0.3824 | 0.9395 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
kalypso42/q-FrozenLake-v1-4x4-noSlippery | kalypso42 | 2023-11-17T11:43:13Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T11:43:11Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="kalypso42/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
jrad98/ppo-Pyramids | jrad98 | 2023-11-17T11:30:28Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2023-11-17T11:30:25Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: jrad98/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
shandung/fine_tuned_modelsFinal_2 | shandung | 2023-11-17T11:19:13Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/m2m100_418M",
"base_model:finetune:facebook/m2m100_418M",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-11-17T11:14:49Z | ---
license: mit
base_model: facebook/m2m100_418M
tags:
- generated_from_trainer
model-index:
- name: fine_tuned_modelsFinal_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine_tuned_modelsFinal_2
This model is a fine-tuned version of [facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1230
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2376
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5433 | 18.35 | 500 | 0.1457 |
| 0.0408 | 36.7 | 1000 | 0.1265 |
| 0.0181 | 55.05 | 1500 | 0.1300 |
| 0.0103 | 73.39 | 2000 | 0.1226 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Tokenizers 0.15.0
|
crom87/sd_base-db-selfies30-1e-06-priorp | crom87 | 2023-11-17T11:15:06Z | 7 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-11-16T09:19:47Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: TOKstyle person
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - crom87/sd_base-db-selfies30-1e-06-priorp
This is a dreambooth model derived from runwayml/stable-diffusion-v1-5. The weights were trained on TOKstyle person using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.












DreamBooth for the text encoder was enabled: True.
|
vetertann/fb7-test | vetertann | 2023-11-17T11:04:38Z | 0 | 0 | null | [
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:ybelkada/falcon-7b-sharded-bf16",
"base_model:finetune:ybelkada/falcon-7b-sharded-bf16",
"region:us"
]
| null | 2023-11-17T10:17:20Z | ---
base_model: ybelkada/falcon-7b-sharded-bf16
tags:
- generated_from_trainer
model-index:
- name: fb7-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fb7-test
This model is a fine-tuned version of [ybelkada/falcon-7b-sharded-bf16](https://huggingface.co/ybelkada/falcon-7b-sharded-bf16) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 180
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
amazon/FalconLite | amazon | 2023-11-17T11:00:22Z | 327 | 170 | transformers | [
"transformers",
"RefinedWeb",
"text-generation",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-08-01T14:18:59Z | ---
license: apache-2.0
inference: false
---
# FalconLite Model
FalconLite is a quantized version of the [Falcon 40B SFT OASST-TOP1 model](https://huggingface.co/OpenAssistant/falcon-40b-sft-top1-560), capable of processing long (i.e. 11K tokens) input sequences while consuming 4x less GPU memory. By utilizing 4-bit [GPTQ quantization](https://github.com/PanQiWei/AutoGPTQ) and adapted [dynamic NTK](https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/) RotaryEmbedding, FalconLite achieves a balance between latency, accuracy, and memory efficiency. With the ability to process 5x longer contexts than the original model, FalconLite is useful for applications such as topic retrieval, summarization, and question-answering. FalconLite can be deployed on a single AWS `g5.12x` instance with [TGI 0.9.2](https://github.com/huggingface/text-generation-inference/tree/v0.9.2), making it suitable for applications that require high performance in resource-constrained environments.
## *New!* FalconLite2 Model ##
To keep up with the updated model FalconLite2, please refer to [FalconLite2](https://huggingface.co/amazon/FalconLite2).
## Model Details
- **Developed by:** [AWS Contributors](https://github.com/orgs/aws-samples/teams/aws-prototype-ml-apac)
- **Model type:** [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b)
- **Language:** English
- **Quantized from weights:** [Falcon 40B SFT OASST-TOP1 model](https://huggingface.co/OpenAssistant/falcon-40b-sft-top1-560)
- **Modified from layers:** [Text-Generation-Inference 0.9.2](https://github.com/huggingface/text-generation-inference/tree/v0.9.2)
- **License:** Apache 2.0
- **Contact:** [GitHub issues](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/issues)
- **Blogpost:** [Extend the context length of Falcon40B to 10k](https://medium.com/@chenwuperth/extend-the-context-length-of-falcon40b-to-10k-85d81d32146f)
## Deploy FalconLite ##
SSH login to an AWS `g5.12x` instance with the [Deep Learning AMI](https://aws.amazon.com/releasenotes/aws-deep-learning-ami-gpu-pytorch-2-0-ubuntu-20-04/).
### Start LLM server
```bash
git clone https://github.com/awslabs/extending-the-context-length-of-open-source-llms.git falconlite-dev
cd falconlite-dev/script
./docker_build.sh
./start_falconlite.sh
```
### Perform inference
```bash
# after FalconLite has been completely started
pip install -r requirements-client.txt
python falconlite_client.py
```
### *New!* Amazon SageMaker Deployment ###
To deploy FalconLite on SageMaker endpoint, please follow [this notebook](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/custom-tgi-ecr/deploy.ipynb).
**Important** - When using FalconLite for inference for the first time, it may require a brief 'warm-up' period that can take 10s of seconds. However, subsequent inferences should be faster and return results in a more timely manner. This warm-up period is normal and should not affect the overall performance of the system once the initialisation period has been completed.
## Evalution Result ##
We evaluated FalconLite against benchmarks that are specifically designed to assess the capabilities of LLMs in handling longer contexts. All evaluations were conducted without fine-tuning the model.
### Accuracy ###
|Eval task|Input length| Input length | Input length| Input length|
|----------|-------------|-------------|------------|-----------|
| | 2800 ~ 3800| 5500 ~ 5600 |7500 ~ 8300 | 9300 ~ 11000 |
| [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/) | 100% | 100% | 92% | 92% |
| [Line Retrieval](https://lmsys.org/blog/2023-06-29-longchat/#longeval-results) | 38% | 12% | 8% | 4% |
| [Pass key Retrieval](https://github.com/epfml/landmark-attention/blob/main/llama/run_test.py#L101) | 100% | 100% | 100% | 100% |
|Eval task| Test set Accuracy | Hard subset Accuracy|
|----------|-------------|-------------|
| [Question Answering with Long Input Texts](https://nyu-mll.github.io/quality/) | 46.9% | 40.8% |
### Performance ###
**metrics** = the average number of generated tokens per second (TPS) =
`nb-generated-tokens` / `end-to-end-response-time`
The `end-to-end-response-time` = when the last token is generated - when the inference request is received
|Instance| Input length | Input length| Input length|Input length|
|----------|-------------|-------------|------------|------------|
| | 20 | 3300 | 5500 |10000 |
| g5.48x | 22 tps | 12 tps | 12 tps | 12 tps |
| g5.12x | 18 tps | 11 tps | 11 tps | 10 tps |
## Limitations ##
* Our evaluation shows that FalconLite's capability in `Line Retrieval` is limited, and requires further effort.
* While `g5.12x` is sufficient for FalconLite to handle 10K long contexts, a larger instance with more memory capcacity such as `g5.48x` is recommended for sustained, heavy workloads.
* Before using the FalconLite model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content. |
CADM97/Reinforce2 | CADM97 | 2023-11-17T10:59:17Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T10:59:11Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 43.00 +/- 31.52
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
HamdanXI/bert-paradetox-1Token-split-masked | HamdanXI | 2023-11-17T10:58:07Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-11-17T10:01:23Z | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-paradetox-1Token-split-masked
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-paradetox-1Token-split-masked
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0005
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 237 | 0.0014 |
| No log | 2.0 | 474 | 0.0006 |
| 0.3349 | 3.0 | 711 | 0.0005 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Gracoy/swin-tiny-patch4-window7-224-Kaggle_test_20231117 | Gracoy | 2023-11-17T10:47:44Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T09:53:36Z | ---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-Kaggle_test_20231117
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9336188436830836
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-Kaggle_test_20231117
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2057
- Accuracy: 0.9336
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2786 | 0.99 | 22 | 0.2184 | 0.9368 |
| 0.1598 | 1.98 | 44 | 0.1826 | 0.9347 |
| 0.1352 | 2.97 | 66 | 0.2057 | 0.9336 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
alfredowh/poca-SoccerTwos | alfredowh | 2023-11-17T10:38:05Z | 33 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-11-17T10:34:24Z | ---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: alfredo-wh/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
under-tree/transformer-en-ru | under-tree | 2023-11-17T10:26:12Z | 12 | 0 | transformers | [
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"base_model:Helsinki-NLP/opus-mt-en-ru",
"base_model:finetune:Helsinki-NLP/opus-mt-en-ru",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-11-13T15:09:42Z | ---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-ru
tags:
- generated_from_trainer
model-index:
- name: transformer-en-ru
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# transformer-en-ru
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ru](https://huggingface.co/Helsinki-NLP/opus-mt-en-ru) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.1.0a0+32f93b1
- Datasets 2.14.5
- Tokenizers 0.14.1
|
Jukaboo/Llama2_7B_chat_meetingBank_ft_adapters_EOS_3 | Jukaboo | 2023-11-17T10:23:02Z | 0 | 0 | null | [
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:finetune:meta-llama/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2023-11-17T09:09:18Z | ---
base_model: meta-llama/Llama-2-7b-chat-hf
tags:
- generated_from_trainer
model-index:
- name: Llama2_7B_chat_meetingBank_ft_adapters_EOS_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama2_7B_chat_meetingBank_ft_adapters_EOS_3
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8142
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2757 | 0.2 | 65 | 1.9499 |
| 1.8931 | 0.4 | 130 | 1.8631 |
| 1.6246 | 0.6 | 195 | 1.8294 |
| 2.2049 | 0.8 | 260 | 1.8142 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
logichacker/my_awesome_swag_model | logichacker | 2023-11-17T10:13:26Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"multiple-choice",
"generated_from_trainer",
"dataset:swag",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| multiple-choice | 2023-11-17T09:25:28Z | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- swag
metrics:
- accuracy
model-index:
- name: my_awesome_swag_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_swag_model
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the swag dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0449
- Accuracy: 0.7878
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.7784 | 1.0 | 4597 | 0.5916 | 0.7655 |
| 0.3817 | 2.0 | 9194 | 0.6262 | 0.7813 |
| 0.1508 | 3.0 | 13791 | 1.0449 | 0.7878 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Weyaxi/Nebula-7B-checkpoints | Weyaxi | 2023-11-17T09:52:02Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"en",
"dataset:garage-bAInd/Open-Platypus",
"license:apache-2.0",
"region:us"
]
| null | 2023-10-03T19:12:34Z | ---
license: apache-2.0
datasets:
- garage-bAInd/Open-Platypus
language:
- en
tags:
- peft
---

<a href="https://www.buymeacoffee.com/PulsarAI" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
# Nebula-7b-Checkpoints
Checkpoints of Nebula-7B. Finetuned from [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1).
## Lora Weights
You can access lora weights from here:
[PulsarAI/Nebula-7B-Lora](https://huggingface.co/PulsarAI/Nebula-7B-Lora)
## Original Weights
You can access original weights from here:
[PulsarAI/Nebula-7B](https://huggingface.co/PulsarAI/Nebula-7B) |
super-j/vit-base-pets | super-j | 2023-11-17T09:43:28Z | 16 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"vision",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T09:32:53Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- image-classification
- vision
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-pets
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: rokmr/pets
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9925925925925926
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-pets
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the rokmr/pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0485
- Accuracy: 0.9926
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Brololo/a2c-PandaReachDense-v3 | Brololo | 2023-11-17T09:33:33Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T09:26:54Z | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.27 +/- 0.12
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
GBjorn/Reinforce-CartPole-v1 | GBjorn | 2023-11-17T09:26:47Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T09:26:37Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Brololo/unit6 | Brololo | 2023-11-17T09:26:41Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T09:24:32Z | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.21 +/- 0.09
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
s3nh/Ketak-ZoomRx-Drug_Ollama_v3-2-GGUF | s3nh | 2023-11-17T09:24:57Z | 25 | 4 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:openrail",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-17T09:21:03Z |
---
license: openrail
pipeline_tag: text-generation
library_name: transformers
language:
- zh
- en
---
## Original model card
Buy me a coffee if you like this project ;)
<a href="https://www.buymeacoffee.com/s3nh"><img src="https://www.buymeacoffee.com/assets/img/guidelines/download-assets-sm-1.svg" alt=""></a>
#### Description
GGUF Format model files for [This project](https://huggingface.co/Ketak-ZoomRx/Drug_Ollama_v3-2).
### GGUF Specs
GGUF is a format based on the existing GGJT, but makes a few changes to the format to make it more extensible and easier to use. The following features are desired:
Single-file deployment: they can be easily distributed and loaded, and do not require any external files for additional information.
Extensible: new features can be added to GGML-based executors/new information can be added to GGUF models without breaking compatibility with existing models.
mmap compatibility: models can be loaded using mmap for fast loading and saving.
Easy to use: models can be easily loaded and saved using a small amount of code, with no need for external libraries, regardless of the language used.
Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
The key difference between GGJT and GGUF is the use of a key-value structure for the hyperparameters (now referred to as metadata), rather than a list of untyped values.
This allows for new metadata to be added without breaking compatibility with existing models, and to annotate the model with additional information that may be useful for
inference or for identifying the model.
### Perplexity params
Model Measure Q2_K Q3_K_S Q3_K_M Q3_K_L Q4_0 Q4_1 Q4_K_S Q4_K_M Q5_0 Q5_1 Q5_K_S Q5_K_M Q6_K Q8_0 F16
7B perplexity 6.7764 6.4571 6.1503 6.0869 6.1565 6.0912 6.0215 5.9601 5.9862 5.9481 5.9419 5.9208 5.9110 5.9070 5.9066
13B perplexity 5.8545 5.6033 5.4498 5.4063 5.3860 5.3608 5.3404 5.3002 5.2856 5.2706 5.2785 5.2638 5.2568 5.2548 5.2543
### inference
TODO
# Original model card
|
shandung/fine_tuned_modelsFinal_1 | shandung | 2023-11-17T09:18:27Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/m2m100_418M",
"base_model:finetune:facebook/m2m100_418M",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-11-17T09:14:38Z | ---
license: mit
base_model: facebook/m2m100_418M
tags:
- generated_from_trainer
model-index:
- name: fine_tuned_modelsFinal_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine_tuned_modelsFinal_1
This model is a fine-tuned version of [facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1728
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5362 | 18.35 | 500 | 0.1206 |
| 0.0438 | 36.7 | 1000 | 0.1025 |
| 0.0205 | 55.05 | 1500 | 0.1122 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Tokenizers 0.15.0
|
Amarsanaa1525/distilbert-base-multilingual-cased-ner-demo | Amarsanaa1525 | 2023-11-17T09:14:44Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"mn",
"base_model:distilbert/distilbert-base-multilingual-cased",
"base_model:finetune:distilbert/distilbert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-11-17T08:40:51Z | ---
language:
- mn
license: apache-2.0
base_model: distilbert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-multilingual-cased-ner-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-multilingual-cased-ner-demo
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1513
- Precision: 0.8756
- Recall: 0.8973
- F1: 0.8863
- Accuracy: 0.9708
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2113 | 1.0 | 477 | 0.1338 | 0.7811 | 0.8425 | 0.8107 | 0.9562 |
| 0.1028 | 2.0 | 954 | 0.1159 | 0.8367 | 0.8670 | 0.8515 | 0.9636 |
| 0.0683 | 3.0 | 1431 | 0.1117 | 0.8552 | 0.8824 | 0.8686 | 0.9671 |
| 0.0482 | 4.0 | 1908 | 0.1215 | 0.8608 | 0.8880 | 0.8742 | 0.9682 |
| 0.0331 | 5.0 | 2385 | 0.1243 | 0.8641 | 0.8919 | 0.8778 | 0.9687 |
| 0.0251 | 6.0 | 2862 | 0.1304 | 0.8629 | 0.8901 | 0.8763 | 0.9687 |
| 0.0187 | 7.0 | 3339 | 0.1383 | 0.8695 | 0.8976 | 0.8833 | 0.9702 |
| 0.0126 | 8.0 | 3816 | 0.1489 | 0.8749 | 0.8971 | 0.8859 | 0.9700 |
| 0.0102 | 9.0 | 4293 | 0.1515 | 0.8705 | 0.8961 | 0.8831 | 0.9700 |
| 0.0082 | 10.0 | 4770 | 0.1513 | 0.8756 | 0.8973 | 0.8863 | 0.9708 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
crumb/qrstudy-gpt2-4-8 | crumb | 2023-11-17T09:14:38Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T09:14:35Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
LarryAIDraw/perfumer_arknights | LarryAIDraw | 2023-11-17T09:12:02Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-11-17T08:26:11Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/197491/perfumer-arknights |
Sumithrapm/my-pet-dog-xzg | Sumithrapm | 2023-11-17T09:08:51Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-11-17T09:04:01Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-xzg Dreambooth model trained by Sumithrapm following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: RECT-50
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
|
pragnakalpdev32/lora-trained-xl-person-new | pragnakalpdev32 | 2023-11-17T09:08:02Z | 2 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
]
| text-to-image | 2023-11-17T08:21:32Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: A photo of sks person
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - pragnakalpdev32/lora-trained-xl-person-new
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on A photo of sks person using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: None.
|
Sadwii16/my-pet-rabbit | Sadwii16 | 2023-11-17T09:07:05Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-11-17T09:02:28Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-rabbit Dreambooth model trained by Sadwii16 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-332
Sample pictures of this concept:

|
Ramya7/my-beautiful-flowers | Ramya7 | 2023-11-17T09:02:01Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-11-17T08:57:47Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-beautiful-flowers Dreambooth model trained by Ramya7 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-392
Sample pictures of this concept:

|
domenicrosati/deberta-v3-large-survey-topicality-rater-half | domenicrosati | 2023-11-17T08:59:51Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-11-17T08:25:23Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: deberta-v3-large-survey-topicality-rater-half
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large-survey-topicality-rater-half
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9793
- Krippendorff: 0.8279
- Spearman: 0.8075
- Absolute Agreement: 0.6370
- Agreement Within One: 0.9663
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Krippendorff | Spearman | Absolute Agreement | Agreement Within One |
|:-------------:|:-----:|:----:|:---------------:|:------------:|:--------:|:------------------:|:--------------------:|
| No log | 1.0 | 52 | 2.0389 | -0.7466 | nan | 0.0556 | 1.0 |
| No log | 2.0 | 104 | 2.0207 | -0.7466 | nan | 0.0556 | 1.0 |
| No log | 3.0 | 156 | 1.9881 | -0.5712 | -0.1830 | 0.0556 | 0.9722 |
| No log | 4.0 | 208 | 1.6979 | -0.2433 | nan | 0.2778 | 0.8333 |
| No log | 5.0 | 260 | 1.6522 | -0.2433 | nan | 0.2778 | 0.8333 |
| No log | 6.0 | 312 | 1.6655 | -0.2433 | nan | 0.2778 | 0.8333 |
| No log | 7.0 | 364 | 1.7160 | -0.2433 | nan | 0.2778 | 0.8333 |
| No log | 8.0 | 416 | 1.6616 | -0.2433 | nan | 0.2778 | 0.8333 |
| No log | 9.0 | 468 | 1.5106 | -0.2433 | nan | 0.2778 | 0.8333 |
| 1.5151 | 10.0 | 520 | 1.7309 | -0.2433 | nan | 0.2778 | 0.8333 |
| 1.5151 | 11.0 | 572 | 1.4090 | -0.0325 | 0.0 | 0.5278 | 0.8333 |
| 1.5151 | 12.0 | 624 | 1.7219 | -0.1350 | 0.2065 | 0.3889 | 0.8333 |
| 1.5151 | 13.0 | 676 | 1.8047 | -0.1019 | 0.0347 | 0.3889 | 0.8333 |
| 1.5151 | 14.0 | 728 | 1.7490 | -0.1094 | -0.0090 | 0.4444 | 0.8333 |
| 1.5151 | 15.0 | 780 | 2.0425 | -0.0707 | 0.0202 | 0.4722 | 0.8333 |
| 1.5151 | 16.0 | 832 | 2.0389 | -0.1497 | -0.0239 | 0.5 | 0.8333 |
| 1.5151 | 17.0 | 884 | 2.2333 | -0.1525 | -0.0333 | 0.4722 | 0.8333 |
| 1.5151 | 18.0 | 936 | 2.0693 | -0.1497 | -0.0239 | 0.5 | 0.8333 |
| 1.5151 | 19.0 | 988 | 1.8664 | -0.0749 | 0.0063 | 0.4722 | 0.8333 |
| 0.7088 | 20.0 | 1040 | 2.4088 | -0.1342 | -0.0239 | 0.5 | 0.8333 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1
- Datasets 2.10.1
- Tokenizers 0.12.1
|
M1nd3xpan5i0nN3xus/M1NDB0T-PromptMasta_Adapter | M1nd3xpan5i0nN3xus | 2023-11-17T08:59:33Z | 2 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-11-17T08:59:31Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
nixiesearch/multilingual-e5-small-onnx | nixiesearch | 2023-11-17T08:55:47Z | 5 | 1 | sentence-transformers | [
"sentence-transformers",
"onnx",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2023-11-17T08:42:04Z | ---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
---
# ONNX version of intfloat/multilingual-e5-small
This is a sentence-transformers model: It maps sentences & paragraphs to a N dimensional dense vector space and can be used for tasks like clustering or semantic search.
The model conversion was made with [onnx-convert](https://github.com/nixiesearch/onnx-convert) tool with the following parameters:
```shell
python convert.sh --model_id intfloat/multilingual-e5-small --quantize QInt8 --optimize 2
```
There are two versions of model available:
* `model.onnx` - Float32 version, with optimize=2
* `model_opt2_QInt8.onnx` - QInt8 quantized version, with optimize=2
## License
Apache 2.0 |
elemosynov/Unit8Part1 | elemosynov | 2023-11-17T08:51:32Z | 0 | 0 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T08:51:23Z | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -143.75 +/- 94.53
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'elemosynov/Unit8Part1'
'batch_size': 512
'minibatch_size': 128}
```
|
kkmkorea/deberta_sentcls | kkmkorea | 2023-11-17T08:39:44Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-09-12T02:12:56Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: deberta_sentcls
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta_sentcls
This model is a fine-tuned version of [kisti/korscideberta](https://huggingface.co/kisti/korscideberta) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4937
- Accuracy: 0.8409
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9366 | 1.03 | 500 | 0.6700 | 0.7659 |
| 0.472 | 2.05 | 1000 | 0.5110 | 0.8261 |
| 0.3567 | 3.08 | 1500 | 0.4979 | 0.8371 |
| 0.2626 | 4.11 | 2000 | 0.4937 | 0.8409 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.1+cu102
- Datasets 2.14.6
- Tokenizers 0.10.3
|
tartuNLP/gpt-for-est-large | tartuNLP | 2023-11-17T08:38:36Z | 28 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
tags:
- generated_from_trainer
model-index:
- name: gpt-est-large
results: []
widget:
- text: ">wiki< mis on GPT? Vastus:"
---
# gpt-est-large
This is the large-size [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2) model, trained from scratch on 2.2 billion words (Estonian National Corpus + News Crawl + Common Crawl). Previously named "gpt-4-est-large", renamed to avoid click-baiting.
[Reference](https://doi.org/10.22364/bjmc.2022.10.3.19)
### Format
For training data was prepended with a text domain tag, and it should be added as prefix when using the model: >general<, >web<, >news<, >doaj< and >wiki< (standing for general texts, web crawled texts, news, article abstracts and wikipedia texts). Use the prefixes like this, e.g: ">web< Kas tead, et".
### Model details
- num. of layers: 24
- num. of heads: 24
- embedding size: 1536
- context size: 1024
- total size: 723.58M params
Further details to be added soon.
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.10.3
|
Baptiste-Rdt/Reinforce-GradientPolicy-CartPole | Baptiste-Rdt | 2023-11-17T08:32:13Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T08:32:10Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-GradientPolicy-CartPole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 89.40 +/- 22.94
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
tiennguyenbnbk/llma2_math_13b_peft_full_ex_gptq_alpaca_no_input | tiennguyenbnbk | 2023-11-17T08:31:17Z | 3 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:TheBloke/Speechless-Llama2-Hermes-Orca-Platypus-WizardLM-13B-GPTQ",
"base_model:adapter:TheBloke/Speechless-Llama2-Hermes-Orca-Platypus-WizardLM-13B-GPTQ",
"region:us"
]
| null | 2023-11-17T08:31:11Z | ---
library_name: peft
base_model: TheBloke/Speechless-Llama2-Hermes-Orca-Platypus-WizardLM-13B-GPTQ
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: gptq
- bits: 4
- tokenizer: None
- dataset: None
- group_size: 128
- damp_percent: 0.1
- desc_act: True
- sym: True
- true_sequential: True
- use_cuda_fp16: False
- model_seqlen: None
- block_name_to_quantize: None
- module_name_preceding_first_block: None
- batch_size: 1
- pad_token_id: None
- use_exllama: False
- max_input_length: None
- exllama_config: {'version': <ExllamaVersion.ONE: 1>}
- cache_block_outputs: True
### Framework versions
- PEFT 0.6.2
|
alex2awesome/newsdiscourse-model | alex2awesome | 2023-11-17T08:25:17Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2023-07-07T00:17:56Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: newsdiscourse-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# newsdiscourse-model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9458
- F1: 0.5610
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.14 | 100 | 1.4843 | 0.2881 |
| No log | 0.28 | 200 | 1.3307 | 0.3841 |
| No log | 0.43 | 300 | 1.2427 | 0.3991 |
| No log | 0.57 | 400 | 1.2590 | 0.4899 |
| 1.2399 | 0.71 | 500 | 1.2648 | 0.4658 |
| 1.2399 | 0.85 | 600 | 1.2064 | 0.4988 |
| 1.2399 | 1.0 | 700 | 1.2564 | 0.4668 |
| 1.2399 | 1.14 | 800 | 1.2062 | 0.4912 |
| 1.2399 | 1.28 | 900 | 1.1202 | 0.4904 |
| 0.9315 | 1.42 | 1000 | 1.1924 | 0.5188 |
| 0.9315 | 1.57 | 1100 | 1.1627 | 0.5034 |
| 0.9315 | 1.71 | 1200 | 1.1093 | 0.5111 |
| 0.9315 | 1.85 | 1300 | 1.1332 | 0.5166 |
| 0.9315 | 1.99 | 1400 | 1.1558 | 0.5285 |
| 0.8604 | 2.14 | 1500 | 1.2531 | 0.5122 |
| 0.8604 | 2.28 | 1600 | 1.2830 | 0.5414 |
| 0.8604 | 2.42 | 1700 | 1.2550 | 0.5335 |
| 0.8604 | 2.56 | 1800 | 1.1928 | 0.5120 |
| 0.8604 | 2.71 | 1900 | 1.2441 | 0.5308 |
| 0.7406 | 2.85 | 2000 | 1.2791 | 0.5400 |
| 0.7406 | 2.99 | 2100 | 1.2354 | 0.5485 |
| 0.7406 | 3.13 | 2200 | 1.3047 | 0.5258 |
| 0.7406 | 3.28 | 2300 | 1.3636 | 0.5640 |
| 0.7406 | 3.42 | 2400 | 1.2963 | 0.5747 |
| 0.6355 | 3.56 | 2500 | 1.2897 | 0.5123 |
| 0.6355 | 3.7 | 2600 | 1.3225 | 0.5481 |
| 0.6355 | 3.85 | 2700 | 1.3197 | 0.5467 |
| 0.6355 | 3.99 | 2800 | 1.2346 | 0.5353 |
| 0.6355 | 4.13 | 2900 | 1.3397 | 0.5629 |
| 0.5698 | 4.27 | 3000 | 1.4259 | 0.5622 |
| 0.5698 | 4.42 | 3100 | 1.3702 | 0.5607 |
| 0.5698 | 4.56 | 3200 | 1.4294 | 0.5584 |
| 0.5698 | 4.7 | 3300 | 1.5041 | 0.5459 |
| 0.5698 | 4.84 | 3400 | 1.4156 | 0.5394 |
| 0.5069 | 4.99 | 3500 | 1.4384 | 0.5527 |
| 0.5069 | 5.13 | 3600 | 1.5322 | 0.5439 |
| 0.5069 | 5.27 | 3700 | 1.4899 | 0.5557 |
| 0.5069 | 5.41 | 3800 | 1.4526 | 0.5391 |
| 0.5069 | 5.56 | 3900 | 1.5027 | 0.5607 |
| 0.4127 | 5.7 | 4000 | 1.5458 | 0.5662 |
| 0.4127 | 5.84 | 4100 | 1.5080 | 0.5537 |
| 0.4127 | 5.98 | 4200 | 1.5936 | 0.5483 |
| 0.4127 | 6.13 | 4300 | 1.7079 | 0.5401 |
| 0.4127 | 6.27 | 4400 | 1.5939 | 0.5521 |
| 0.3574 | 6.41 | 4500 | 1.5588 | 0.5702 |
| 0.3574 | 6.55 | 4600 | 1.6363 | 0.5568 |
| 0.3574 | 6.7 | 4700 | 1.6629 | 0.5535 |
| 0.3574 | 6.84 | 4800 | 1.6523 | 0.5662 |
| 0.3574 | 6.98 | 4900 | 1.7245 | 0.5461 |
| 0.3417 | 7.12 | 5000 | 1.6766 | 0.5629 |
| 0.3417 | 7.26 | 5100 | 1.8219 | 0.5450 |
| 0.3417 | 7.41 | 5200 | 1.7422 | 0.5533 |
| 0.3417 | 7.55 | 5300 | 1.8250 | 0.5564 |
| 0.3417 | 7.69 | 5400 | 1.7744 | 0.5600 |
| 0.2852 | 7.83 | 5500 | 1.7919 | 0.5549 |
| 0.2852 | 7.98 | 5600 | 1.7604 | 0.5639 |
| 0.2852 | 8.12 | 5700 | 1.7660 | 0.5599 |
| 0.2852 | 8.26 | 5800 | 1.7323 | 0.5600 |
| 0.2852 | 8.4 | 5900 | 1.9174 | 0.5529 |
| 0.2606 | 8.55 | 6000 | 1.8664 | 0.5611 |
| 0.2606 | 8.69 | 6100 | 1.9191 | 0.5568 |
| 0.2606 | 8.83 | 6200 | 1.8900 | 0.5565 |
| 0.2606 | 8.97 | 6300 | 1.9376 | 0.5524 |
| 0.2606 | 9.12 | 6400 | 1.9220 | 0.5594 |
| 0.2274 | 9.26 | 6500 | 1.9188 | 0.5585 |
| 0.2274 | 9.4 | 6600 | 1.9459 | 0.5527 |
| 0.2274 | 9.54 | 6700 | 1.9439 | 0.5543 |
| 0.2274 | 9.69 | 6800 | 1.9437 | 0.5596 |
| 0.2274 | 9.83 | 6900 | 1.9484 | 0.5581 |
| 0.2258 | 9.97 | 7000 | 1.9458 | 0.5610 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
dfurman/Falcon-7B-Chat-v0.1 | dfurman | 2023-11-17T08:07:48Z | 42 | 44 | peft | [
"peft",
"safetensors",
"text-generation",
"dataset:OpenAssistant/oasst1",
"arxiv:2106.09685",
"arxiv:2305.14314",
"base_model:tiiuae/falcon-7b",
"base_model:adapter:tiiuae/falcon-7b",
"license:apache-2.0",
"region:us"
]
| text-generation | 2023-05-30T01:12:19Z | ---
license: apache-2.0
library_name: peft
datasets:
- OpenAssistant/oasst1
pipeline_tag: text-generation
base_model: tiiuae/falcon-7b
inference: false
---
<div align="center">
<img src="./falcon.webp" width="150px">
</div>
# Falcon-7B-Chat-v0.1
Falcon-7B-Chat-v0.1 is a chatbot model for dialogue generation. It was built by fine-tuning [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) on the [OpenAssistant/oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) dataset. This repo only includes the LoRA adapters from fine-tuning with 🤗's [peft](https://github.com/huggingface/peft) package.
## Model Summary
- **Model Type:** Decoder-only
- **Language(s):** English
- **Base Model:** [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) (License: [Apache 2.0](https://huggingface.co/tiiuae/falcon-7b#license))
- **Dataset:** [OpenAssistant/oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) (License: [Apache 2.0](https://huggingface.co/datasets/OpenAssistant/oasst1/blob/main/LICENSE))
- **License(s):** Apache 2.0 inherited from "Base Model" and "Dataset"
## Model Details
The model was fine-tuned in 8-bit precision using 🤗 `peft` adapters, `transformers`, and `bitsandbytes`. Training relied on a method called "Low Rank Adapters" ([LoRA](https://arxiv.org/pdf/2106.09685.pdf)), specifically the [QLoRA](https://arxiv.org/abs/2305.14314) variant. The run took approximately 6.25 hours and was executed on a workstation with a single A100-SXM NVIDIA GPU with 37 GB of available memory. See attached [Colab Notebook](https://huggingface.co/dfurman/Falcon-7B-Chat-v0.1/blob/main/finetune_falcon7b_oasst1_with_bnb_peft.ipynb) for the code and hyperparams used to train the model.
### Model Date
May 30, 2023
## Quick Start
To prompt the chat model, use the following format:
```
<human>: [Instruction]
<bot>:
```
### Example Dialogue 1
**Prompter**:
```
"""<human>: My name is Daniel. Write a short email to my closest friends inviting them to come to my home on Friday for a dinner party, I will make the food but tell them to BYOB.
<bot>:"""
```
**Falcon-7B-Chat-v0.1**:
```
Dear friends,
I am so excited to host a dinner party at my home this Friday! I will be making a delicious meal, but I would love for you to bring your favorite bottle of wine to share with everyone.
Please let me know if you can make it and if you have any dietary restrictions I should be aware of. I look forward to seeing you soon!
Best,
Daniel
```
### Example Dialogue 2
**Prompter**:
```
<human>: Create a list of things to do in San Francisco.
<bot>:
```
**Falcon-7B-Chat-v0.1**:
```
Here are some things to do in San Francisco:
1. Visit the Golden Gate Bridge
2. Explore the city's many museums and art galleries
3. Take a walk along the Embarcadero waterfront
4. Enjoy the views from the top of Coit Tower
5. Shop at Union Square and the Ferry Building
6. Eat at one of the city's many restaurants and cafes
7. Attend a sporting event at AT&T Park
8. Visit the Castro District and the Mission District
9. Take a day trip to Napa Valley or Muir Woods National Monument
10. Explore the city's many parks and gardens
```
### Direct Use
This model has been finetuned on conversation trees from [OpenAssistant/oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) and should only be used on data of a similar nature.
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
This model is mostly trained on English data, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of this model to develop guardrails and to take appropriate precautions for any production use.
## How to Get Started with the Model
### Setup
```python
# Install packages
!pip install -q -U bitsandbytes loralib einops
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git
```
### GPU Inference in 8-bit
This requires a GPU with at least 12 GB of memory.
### First, Load the Model
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# load the model
peft_model_id = "dfurman/Falcon-7B-Chat-v0.1"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
return_dict=True,
device_map={"":0},
trust_remote_code=True,
load_in_8bit=True,
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
tokenizer.pad_token = tokenizer.eos_token
model = PeftModel.from_pretrained(model, peft_model_id)
```
### Next, Run the Model
```python
prompt = """<human>: My name is Daniel. Write a short email to my closest friends inviting them to come to my home on Friday for a dinner party, I will make the food but tell them to BYOB.
<bot>:"""
batch = tokenizer(
prompt,
padding=True,
truncation=True,
return_tensors='pt'
)
batch = batch.to('cuda:0')
with torch.cuda.amp.autocast():
output_tokens = model.generate(
inputs=batch.input_ids,
max_new_tokens=200,
do_sample=False,
use_cache=True,
temperature=1.0,
top_k=50,
top_p=1.0,
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.eos_token_id,
)
generated_text = tokenizer.decode(output_tokens[0], skip_special_tokens=True)
# Inspect message response in the outputs
print(generated_text.split("<human>: ")[1].split("<bot>: ")[-1])
```
## Reproducibility
See attached [Colab Notebook](https://huggingface.co/dfurman/Falcon-7B-Chat-v0.1/blob/main/finetune_falcon7b_oasst1_with_bnb_peft.ipynb) for the code (and hyperparams) used to train the model.
### CUDA Info
- CUDA Version: 12.0
- Hardware: 1 A100-SXM
- Max Memory: {0: "37GB"}
- Device Map: {"": 0}
### Package Versions Employed
- `torch`: 2.0.1+cu118
- `transformers`: 4.30.0.dev0
- `peft`: 0.4.0.dev0
- `accelerate`: 0.19.0
- `bitsandbytes`: 0.39.0
- `einops`: 0.6.1 |
dfurman/LLaMA-13B | dfurman | 2023-11-17T08:06:47Z | 48 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"arxiv:2302.13971",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-06-17T16:18:31Z | ---
pipeline_tag: text-generation
license: other
---
<div align="center">
<img src="./assets/llama.png" width="150px">
</div>
# LLaMA-13B
LLaMA-13B is a base model for text generation with 13B parameters and a 1T token training corpus. It was built and released by the FAIR team at Meta AI alongside the paper "[LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)".
This model repo was converted to work with the transformers package. It is under a bespoke **non-commercial** license, please see the [LICENSE](https://huggingface.co/dfurman/llama-13b/blob/main/LICENSE) file for more details.
## Model Summary
- **Model Type:** Causal decoder-only.
- **Dataset:** The model was trained on 1T tokens using the following data sources: CCNet [67%], C4 [15%], GitHub [4.5%], Wikipedia [4.5%], Books [4.5%], ArXiv [2.5%], Stack Exchange[2%].
- **Language(s):** The Wikipedia and Books domains include data in the following languages: bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk.
- **License:** Bespoke non-commercial license, see [LICENSE](https://huggingface.co/dfurman/llama-13b/blob/main/LICENSE) file.
- **Model date:** LLaMA was trained between Dec 2022 and Feb 2023.
**Where to send inquiries about the model:**
Questions and comments about LLaMA can be sent via the [GitHub repository](https://github.com/facebookresearch/llama) of the project, by opening an issue.
## Intended use
**Primary intended uses:**
The primary use of LLaMA is research on large language models, including: exploring potential applications such as question answering, natural language understanding or reading comprehension, understanding capabilities and limitations of current language models, and developing techniques to improve those, evaluating and mitigating biases, risks, toxic and harmful content generations, and hallucinations.
**Primary intended users:**
The primary intended users of the model are researchers in natural language processing, machine learning and artificial intelligence.
**Out-of-scope use cases:**
LLaMA is a base model, also known as a foundation model. As such, it should not be used on downstream applications without further risk evaluation, mitigation, and additional fine-tuning. In particular, the model has not been trained with human feedback, and can thus generate toxic or offensive content, incorrect information or generally unhelpful answers.
## Factors
**Relevant factors:**
One of the most relevant factors for which model performance may vary is which language is used. Although 20 languages were included in the training data, most of the LLaMA dataset is made of English text, and the model is thus expected to perform better for English than other languages. Relatedly, it has been shown in previous studies that performance might vary for different dialects, which is likely also the case for LLaMA.
**Evaluation factors:**
As LLaMA is trained on data from the Web, it is expected that the model reflects biases from this source. The RAI datasets are thus used to measure biases exhibited by the model for gender, religion, race, sexual orientation, age, nationality, disability, physical appearance and socio-economic status. The toxicity of model generations is also measured, depending on the toxicity of the context used to prompt the model.
## Ethical considerations
**Data:**
The data used to train the model is collected from various sources, mostly from the Web. As such, it contains offensive, harmful and biased content. LLaMA is thus expected to exhibit such biases from the training data.
**Human life:**
The model is not intended to inform decisions about matters central to human life, and should not be used in such a way.
**Mitigations:**
The data was filtered from the Web based on its proximity to Wikipedia text and references. For this, the Kneser-Ney language model is used with a fastText linear classifier.
**Risks and harms:**
Risks and harms of large language models include the generation of harmful, offensive or biased content. These models are often prone to generating incorrect information, sometimes referred to as hallucinations. LLaMA is not expected to be an exception in this regard.
**Use cases:**
LLaMA is a foundational model, and as such, it should not be used for downstream applications without further investigation and mitigations of risks. These risks and potential fraught use cases include, but are not limited to: generation of misinformation and generation of harmful, biased or offensive content.
## How to Get Started with the Model
### Setup
```python
!pip install -q -U transformers accelerate torch
```
### GPU Inference in fp16
This requires a GPU with at least 26GB of VRAM.
### First, Load the Model
```python
import transformers
import torch
model_name = "dfurman/llama-13b"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
streamer = transformers.TextStreamer(tokenizer)
model = transformers.LlamaForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
```
### Next, Run the Model
```python
prompt = "An increasing sequence: one,"
inputs = tokenizer(
prompt,
padding=True,
truncation=True,
return_tensors='pt',
return_token_type_ids=False,
).to("cuda")
_ = model.generate(
**inputs,
max_new_tokens=20,
streamer=streamer,
)
```
|
dfurman/LLaMA-7B | dfurman | 2023-11-17T08:05:54Z | 226 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"arxiv:2302.13971",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-06-17T16:08:19Z | ---
pipeline_tag: text-generation
license: other
---
<div align="center">
<img src="./assets/llama.png" width="150px">
</div>
# LLaMA-7B
LLaMA-7B is a base model for text generation with 6.7B parameters and a 1T token training corpus. It was built and released by the FAIR team at Meta AI alongside the paper "[LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)".
This model repo was converted to work with the transformers package. It is under a bespoke **non-commercial** license, please see the [LICENSE](https://huggingface.co/dfurman/llama-7b/blob/main/LICENSE) file for more details.
## Model Summary
- **Model Type:** Causal decoder-only.
- **Dataset:** The model was trained on 1T tokens using the following data sources: CCNet [67%], C4 [15%], GitHub [4.5%], Wikipedia [4.5%], Books [4.5%], ArXiv [2.5%], Stack Exchange[2%].
- **Language(s):** The Wikipedia and Books domains include data in the following languages: bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk.
- **License:** Bespoke non-commercial license, see [LICENSE](https://huggingface.co/dfurman/llama-7b/blob/main/LICENSE) file.
- **Model date:** LLaMA was trained between Dec 2022 and Feb 2023.
**Where to send inquiries about the model:**
Questions and comments about LLaMA can be sent via the [GitHub repository](https://github.com/facebookresearch/llama) of the project, by opening an issue.
## Intended use
**Primary intended uses:**
The primary use of LLaMA is research on large language models, including: exploring potential applications such as question answering, natural language understanding or reading comprehension, understanding capabilities and limitations of current language models, and developing techniques to improve those, evaluating and mitigating biases, risks, toxic and harmful content generations, and hallucinations.
**Primary intended users:**
The primary intended users of the model are researchers in natural language processing, machine learning and artificial intelligence.
**Out-of-scope use cases:**
LLaMA is a base model, also known as a foundation model. As such, it should not be used on downstream applications without further risk evaluation, mitigation, and additional fine-tuning. In particular, the model has not been trained with human feedback, and can thus generate toxic or offensive content, incorrect information or generally unhelpful answers.
## Factors
**Relevant factors:**
One of the most relevant factors for which model performance may vary is which language is used. Although 20 languages were included in the training data, most of the LLaMA dataset is made of English text, and the model is thus expected to perform better for English than other languages. Relatedly, it has been shown in previous studies that performance might vary for different dialects, which is likely also the case for LLaMA.
**Evaluation factors:**
As LLaMA is trained on data from the Web, it is expected that the model reflects biases from this source. The RAI datasets are thus used to measure biases exhibited by the model for gender, religion, race, sexual orientation, age, nationality, disability, physical appearance and socio-economic status. The toxicity of model generations is also measured, depending on the toxicity of the context used to prompt the model.
## Ethical considerations
**Data:**
The data used to train the model is collected from various sources, mostly from the Web. As such, it contains offensive, harmful and biased content. LLaMA is thus expected to exhibit such biases from the training data.
**Human life:**
The model is not intended to inform decisions about matters central to human life, and should not be used in such a way.
**Mitigations:**
The data was filtered from the Web based on its proximity to Wikipedia text and references. For this, the Kneser-Ney language model is used with a fastText linear classifier.
**Risks and harms:**
Risks and harms of large language models include the generation of harmful, offensive or biased content. These models are often prone to generating incorrect information, sometimes referred to as hallucinations. LLaMA is not expected to be an exception in this regard.
**Use cases:**
LLaMA is a foundational model, and as such, it should not be used for downstream applications without further investigation and mitigations of risks. These risks and potential fraught use cases include, but are not limited to: generation of misinformation and generation of harmful, biased or offensive content.
## How to Get Started with the Model
### Setup
```python
!pip install -q -U transformers accelerate torch
```
### GPU Inference in fp16
This requires a GPU with at least 15GB of VRAM.
### First, Load the Model
```python
import transformers
import torch
model_name = "dfurman/llama-7b"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
streamer = transformers.TextStreamer(tokenizer)
model = transformers.LlamaForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
```
### Next, Run the Model
```python
prompt = "An increasing sequence: one,"
inputs = tokenizer(
prompt,
padding=True,
truncation=True,
return_tensors='pt',
return_token_type_ids=False,
).to("cuda")
_ = model.generate(
**inputs,
max_new_tokens=20,
streamer=streamer,
)
```
|
pkarypis/zephyr-7b-sft-filtered-0.7 | pkarypis | 2023-11-17T07:51:24Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-17T02:51:09Z | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- generated_from_trainer
model-index:
- name: zephyr-7b-sft-filtered-0.7
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-7b-sft-filtered-0.7
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 2
- total_train_batch_size: 512
- total_eval_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.143 | 0.66 | 261 | 0.9372 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.14.0
|
bh8648/esg_test4-epoch2 | bh8648 | 2023-11-17T07:47:54Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-11-17T07:47:44Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
Anant58/MlpPolicy-LunarLander-v2 | Anant58 | 2023-11-17T07:39:16Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-17T07:38:38Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: MlpPolicy
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 285.39 +/- 12.70
name: mean_reward
verified: false
---
# **MlpPolicy** Agent playing **LunarLander-v2**
This is a trained model of a **MlpPolicy** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
crumb/qrstudy-gpt2-2-4 | crumb | 2023-11-17T07:39:10Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T07:39:08Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
intanm/mlm-20230510-indobert-large-p1-001-pt2 | intanm | 2023-11-17T07:37:14Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"dataset:intanm/financial_news_id_v1.0",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-05-10T15:08:49Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mlm-20230510-indobert-large-p1-001-pt2
results: []
datasets:
- intanm/financial_news_id_v1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm-20230510-indobert-large-p1-001-pt2
This model is a fine-tuned version of [intanm/mlm-20230503-indobert-large-p1-001](https://huggingface.co/intanm/mlm-20230503-indobert-large-p1-001) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 333 | 2.4107 |
| 1.9893 | 2.0 | 666 | 2.3410 |
| 1.9893 | 3.0 | 999 | 2.3118 |
| 1.7566 | 4.0 | 1332 | 2.2965 |
| 1.654 | 5.0 | 1665 | 2.1781 |
| 1.654 | 6.0 | 1998 | 2.1757 |
| 1.601 | 7.0 | 2331 | 2.1280 |
| 1.6437 | 8.0 | 2664 | 2.1664 |
| 1.6437 | 9.0 | 2997 | 2.1523 |
| 1.679 | 10.0 | 3330 | 2.1121 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3 |
intanm/mlm-20230405-002-4 | intanm | 2023-11-17T07:33:11Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"dataset:intanm/indonesian_financial_statements",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-04-05T16:16:37Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mlm-20230405-002-4
results: []
datasets:
- intanm/indonesian_financial_statements
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm-20230405-002-4
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9203
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 284 | 4.0646 |
| 4.7247 | 2.0 | 568 | 3.3108 |
| 4.7247 | 3.0 | 852 | 3.0008 |
| 3.1652 | 4.0 | 1136 | 2.7421 |
| 3.1652 | 5.0 | 1420 | 2.5398 |
| 2.6664 | 6.0 | 1704 | 2.4601 |
| 2.6664 | 7.0 | 1988 | 2.3281 |
| 2.4079 | 8.0 | 2272 | 2.2595 |
| 2.235 | 9.0 | 2556 | 2.2096 |
| 2.235 | 10.0 | 2840 | 2.1656 |
| 2.1012 | 11.0 | 3124 | 2.1208 |
| 2.1012 | 12.0 | 3408 | 2.0601 |
| 1.9958 | 13.0 | 3692 | 2.0032 |
| 1.9958 | 14.0 | 3976 | 2.0479 |
| 1.9279 | 15.0 | 4260 | 1.9541 |
| 1.8739 | 16.0 | 4544 | 1.9563 |
| 1.8739 | 17.0 | 4828 | 1.9444 |
| 1.8358 | 18.0 | 5112 | 1.9108 |
| 1.8358 | 19.0 | 5396 | 1.9408 |
| 1.8018 | 20.0 | 5680 | 1.9278 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3 |
Definite/klue-klue-bert-cult-classification | Definite | 2023-11-17T07:32:26Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:klue/bert-base",
"base_model:finetune:klue/bert-base",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-11-16T16:00:52Z | ---
license: cc-by-sa-4.0
base_model: klue/bert-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: klue-klue-bert-cult-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# klue-klue-bert-cult-classification
This model is a fine-tuned version of [klue/bert-base](https://huggingface.co/klue/bert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0012
- Accuracy: 0.9995
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0625 | 1.0 | 500 | 0.0012 | 0.9995 |
| 0.0005 | 2.0 | 1000 | 0.0012 | 0.9995 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
intanm/mlm-20230416-003-1 | intanm | 2023-11-17T07:31:21Z | 8 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"dataset:intanm/financial_news_id_v1.0",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-04-16T13:09:46Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mlm-20230416-003-1
results: []
datasets:
- intanm/financial_news_id_v1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm-20230416-003-1
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3201
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 330 | 4.2545 |
| 5.0912 | 2.0 | 660 | 3.6314 |
| 5.0912 | 3.0 | 990 | 3.2435 |
| 3.7016 | 4.0 | 1320 | 3.0558 |
| 3.22 | 5.0 | 1650 | 2.9062 |
| 3.22 | 6.0 | 1980 | 2.8126 |
| 2.946 | 7.0 | 2310 | 2.6621 |
| 2.7682 | 8.0 | 2640 | 2.5513 |
| 2.7682 | 9.0 | 2970 | 2.5651 |
| 2.624 | 10.0 | 3300 | 2.5347 |
| 2.5466 | 11.0 | 3630 | 2.4664 |
| 2.5466 | 12.0 | 3960 | 2.4375 |
| 2.4496 | 13.0 | 4290 | 2.4663 |
| 2.395 | 14.0 | 4620 | 2.3948 |
| 2.395 | 15.0 | 4950 | 2.4003 |
| 2.3377 | 16.0 | 5280 | 2.3072 |
| 2.2881 | 17.0 | 5610 | 2.3502 |
| 2.2881 | 18.0 | 5940 | 2.3236 |
| 2.2659 | 19.0 | 6270 | 2.3138 |
| 2.2419 | 20.0 | 6600 | 2.3359 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3 |
Leventiir/poca-SoccerTwos | Leventiir | 2023-11-17T07:30:40Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-11-17T07:30:15Z | ---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Leventiir/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
mkshing/lora-trained-jsdxl | mkshing | 2023-11-17T07:21:32Z | 6 | 0 | diffusers | [
"diffusers",
"japanese-stable-diffusion",
"japanese-stable-diffusion-xl",
"text-to-image",
"lora",
"base_model:stabilityai/japanese-stable-diffusion-xl",
"base_model:adapter:stabilityai/japanese-stable-diffusion-xl",
"license:other",
"region:us"
]
| text-to-image | 2023-11-17T06:37:12Z |
---
license: other
base_model: stabilityai/japanese-stable-diffusion-xl
instance_prompt: 輻の犬
tags:
- japanese-stable-diffusion
- japanese-stable-diffusion-xl
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - mkshing/lora-trained-jsdxl
These are LoRA adaption weights for stabilityai/japanese-stable-diffusion-xl. The weights were trained on 輻の犬 using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: None.
|
APMIC/caigun-lora-model-33B | APMIC | 2023-11-17T07:03:52Z | 1,468 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2023-11-17T05:54:51Z | ---
license: cc-by-nc-nd-4.0
---
This is model finetuned on fake news detection.
Model Details:
Model Name: caigun-lora-model-33B
Model Version: 1.0
Date Created: 2023/11/17
Model Overview:
Intended Use:
caigun-lora-model-33B is a LLM designed for various purpose.
Training Data:
fake news related dataset
Model Architecture:
It is based on LLaMA architecture.
Training Procedure:
[Stay tuned for updates]
Model Performance:
[Stay tuned for updates]
Potential Risks:
It's important to consider ethical implications related to the use of our model.
Updates and Version History:
Version 1.0: finetuned on fake news detection. |
syabusyabu0141/sc_el_new | syabusyabu0141 | 2023-11-17T06:56:11Z | 5 | 0 | transformers | [
"transformers",
"tf",
"electra",
"text-classification",
"generated_from_keras_callback",
"base_model:google/electra-base-discriminator",
"base_model:finetune:google/electra-base-discriminator",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-11-13T09:55:27Z | ---
license: apache-2.0
base_model: google/electra-base-discriminator
tags:
- generated_from_keras_callback
model-index:
- name: syabusyabu0141/test4
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# syabusyabu0141/test4
This model is a fine-tuned version of [google/electra-base-discriminator](https://huggingface.co/google/electra-base-discriminator) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3558
- Validation Loss: 0.2519
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.3558 | 0.2519 | 0 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.14.0
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_1x_deit_tiny_sgd_00001_fold5 | hkivancoral | 2023-11-17T06:56:01Z | 14 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-13T15:19:20Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_1x_deit_tiny_sgd_00001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.24390243902439024
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_1x_deit_tiny_sgd_00001_fold5
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7419
- Accuracy: 0.2439
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 6 | 1.7664 | 0.2439 |
| 1.7149 | 2.0 | 12 | 1.7652 | 0.2439 |
| 1.7149 | 3.0 | 18 | 1.7640 | 0.2439 |
| 1.7055 | 4.0 | 24 | 1.7627 | 0.2439 |
| 1.7032 | 5.0 | 30 | 1.7616 | 0.2439 |
| 1.7032 | 6.0 | 36 | 1.7604 | 0.2439 |
| 1.7195 | 7.0 | 42 | 1.7594 | 0.2439 |
| 1.7195 | 8.0 | 48 | 1.7584 | 0.2439 |
| 1.6458 | 9.0 | 54 | 1.7574 | 0.2439 |
| 1.7017 | 10.0 | 60 | 1.7564 | 0.2439 |
| 1.7017 | 11.0 | 66 | 1.7554 | 0.2439 |
| 1.7123 | 12.0 | 72 | 1.7545 | 0.2439 |
| 1.7123 | 13.0 | 78 | 1.7536 | 0.2439 |
| 1.6713 | 14.0 | 84 | 1.7528 | 0.2439 |
| 1.6849 | 15.0 | 90 | 1.7520 | 0.2439 |
| 1.6849 | 16.0 | 96 | 1.7512 | 0.2439 |
| 1.7051 | 17.0 | 102 | 1.7505 | 0.2439 |
| 1.7051 | 18.0 | 108 | 1.7498 | 0.2439 |
| 1.6541 | 19.0 | 114 | 1.7491 | 0.2439 |
| 1.7161 | 20.0 | 120 | 1.7484 | 0.2439 |
| 1.7161 | 21.0 | 126 | 1.7478 | 0.2439 |
| 1.6901 | 22.0 | 132 | 1.7472 | 0.2439 |
| 1.6901 | 23.0 | 138 | 1.7466 | 0.2439 |
| 1.6528 | 24.0 | 144 | 1.7461 | 0.2439 |
| 1.7234 | 25.0 | 150 | 1.7456 | 0.2439 |
| 1.7234 | 26.0 | 156 | 1.7451 | 0.2439 |
| 1.6839 | 27.0 | 162 | 1.7447 | 0.2439 |
| 1.6839 | 28.0 | 168 | 1.7443 | 0.2439 |
| 1.6859 | 29.0 | 174 | 1.7439 | 0.2439 |
| 1.6955 | 30.0 | 180 | 1.7436 | 0.2439 |
| 1.6955 | 31.0 | 186 | 1.7433 | 0.2439 |
| 1.7014 | 32.0 | 192 | 1.7430 | 0.2439 |
| 1.7014 | 33.0 | 198 | 1.7428 | 0.2439 |
| 1.6319 | 34.0 | 204 | 1.7426 | 0.2439 |
| 1.6586 | 35.0 | 210 | 1.7424 | 0.2439 |
| 1.6586 | 36.0 | 216 | 1.7422 | 0.2439 |
| 1.6897 | 37.0 | 222 | 1.7421 | 0.2439 |
| 1.6897 | 38.0 | 228 | 1.7420 | 0.2439 |
| 1.6863 | 39.0 | 234 | 1.7420 | 0.2439 |
| 1.6801 | 40.0 | 240 | 1.7419 | 0.2439 |
| 1.6801 | 41.0 | 246 | 1.7419 | 0.2439 |
| 1.7183 | 42.0 | 252 | 1.7419 | 0.2439 |
| 1.7183 | 43.0 | 258 | 1.7419 | 0.2439 |
| 1.6529 | 44.0 | 264 | 1.7419 | 0.2439 |
| 1.6913 | 45.0 | 270 | 1.7419 | 0.2439 |
| 1.6913 | 46.0 | 276 | 1.7419 | 0.2439 |
| 1.7139 | 47.0 | 282 | 1.7419 | 0.2439 |
| 1.7139 | 48.0 | 288 | 1.7419 | 0.2439 |
| 1.6464 | 49.0 | 294 | 1.7419 | 0.2439 |
| 1.6966 | 50.0 | 300 | 1.7419 | 0.2439 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
tim-kang/dreambooth-tetraneo-tetrapodbreakwater | tim-kang | 2023-11-17T06:54:25Z | 1 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
]
| text-to-image | 2023-11-17T05:24:00Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of tera sks breakwater
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - tim-kang/dreambooth-tetraneo-tetrapodbreakwater
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of tera sks breakwater using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
hkivancoral/hushem_1x_deit_tiny_sgd_00001_fold4 | hkivancoral | 2023-11-17T06:52:28Z | 10 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-13T15:17:52Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_1x_deit_tiny_sgd_00001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.2857142857142857
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_1x_deit_tiny_sgd_00001_fold4
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6751
- Accuracy: 0.2857
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 6 | 1.6974 | 0.2857 |
| 1.71 | 2.0 | 12 | 1.6962 | 0.2857 |
| 1.71 | 3.0 | 18 | 1.6951 | 0.2857 |
| 1.7036 | 4.0 | 24 | 1.6940 | 0.2857 |
| 1.7465 | 5.0 | 30 | 1.6930 | 0.2857 |
| 1.7465 | 6.0 | 36 | 1.6921 | 0.2857 |
| 1.709 | 7.0 | 42 | 1.6911 | 0.2857 |
| 1.709 | 8.0 | 48 | 1.6901 | 0.2857 |
| 1.712 | 9.0 | 54 | 1.6892 | 0.2857 |
| 1.7048 | 10.0 | 60 | 1.6882 | 0.2857 |
| 1.7048 | 11.0 | 66 | 1.6874 | 0.2857 |
| 1.6828 | 12.0 | 72 | 1.6866 | 0.2857 |
| 1.6828 | 13.0 | 78 | 1.6858 | 0.2857 |
| 1.7139 | 14.0 | 84 | 1.6850 | 0.2857 |
| 1.719 | 15.0 | 90 | 1.6842 | 0.2857 |
| 1.719 | 16.0 | 96 | 1.6835 | 0.2857 |
| 1.6904 | 17.0 | 102 | 1.6828 | 0.2857 |
| 1.6904 | 18.0 | 108 | 1.6821 | 0.2857 |
| 1.7154 | 19.0 | 114 | 1.6815 | 0.2857 |
| 1.7326 | 20.0 | 120 | 1.6809 | 0.2857 |
| 1.7326 | 21.0 | 126 | 1.6804 | 0.2857 |
| 1.6942 | 22.0 | 132 | 1.6799 | 0.2857 |
| 1.6942 | 23.0 | 138 | 1.6794 | 0.2857 |
| 1.6945 | 24.0 | 144 | 1.6789 | 0.2857 |
| 1.728 | 25.0 | 150 | 1.6784 | 0.2857 |
| 1.728 | 26.0 | 156 | 1.6780 | 0.2857 |
| 1.7026 | 27.0 | 162 | 1.6776 | 0.2857 |
| 1.7026 | 28.0 | 168 | 1.6772 | 0.2857 |
| 1.7403 | 29.0 | 174 | 1.6769 | 0.2857 |
| 1.6716 | 30.0 | 180 | 1.6766 | 0.2857 |
| 1.6716 | 31.0 | 186 | 1.6764 | 0.2857 |
| 1.6806 | 32.0 | 192 | 1.6761 | 0.2857 |
| 1.6806 | 33.0 | 198 | 1.6759 | 0.2857 |
| 1.6988 | 34.0 | 204 | 1.6757 | 0.2857 |
| 1.6893 | 35.0 | 210 | 1.6755 | 0.2857 |
| 1.6893 | 36.0 | 216 | 1.6754 | 0.2857 |
| 1.6718 | 37.0 | 222 | 1.6753 | 0.2857 |
| 1.6718 | 38.0 | 228 | 1.6752 | 0.2857 |
| 1.7279 | 39.0 | 234 | 1.6751 | 0.2857 |
| 1.6803 | 40.0 | 240 | 1.6751 | 0.2857 |
| 1.6803 | 41.0 | 246 | 1.6751 | 0.2857 |
| 1.6785 | 42.0 | 252 | 1.6751 | 0.2857 |
| 1.6785 | 43.0 | 258 | 1.6751 | 0.2857 |
| 1.7169 | 44.0 | 264 | 1.6751 | 0.2857 |
| 1.6924 | 45.0 | 270 | 1.6751 | 0.2857 |
| 1.6924 | 46.0 | 276 | 1.6751 | 0.2857 |
| 1.6961 | 47.0 | 282 | 1.6751 | 0.2857 |
| 1.6961 | 48.0 | 288 | 1.6751 | 0.2857 |
| 1.7415 | 49.0 | 294 | 1.6751 | 0.2857 |
| 1.681 | 50.0 | 300 | 1.6751 | 0.2857 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_1x_deit_tiny_sgd_00001_fold3 | hkivancoral | 2023-11-17T06:48:52Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-13T15:16:23Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_1x_deit_tiny_sgd_00001_fold3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.27906976744186046
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_1x_deit_tiny_sgd_00001_fold3
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6900
- Accuracy: 0.2791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 6 | 1.7081 | 0.2791 |
| 1.7325 | 2.0 | 12 | 1.7072 | 0.2791 |
| 1.7325 | 3.0 | 18 | 1.7063 | 0.2791 |
| 1.7152 | 4.0 | 24 | 1.7055 | 0.2791 |
| 1.6813 | 5.0 | 30 | 1.7046 | 0.2791 |
| 1.6813 | 6.0 | 36 | 1.7038 | 0.2791 |
| 1.6984 | 7.0 | 42 | 1.7030 | 0.2791 |
| 1.6984 | 8.0 | 48 | 1.7022 | 0.2791 |
| 1.7131 | 9.0 | 54 | 1.7014 | 0.2791 |
| 1.7337 | 10.0 | 60 | 1.7007 | 0.2791 |
| 1.7337 | 11.0 | 66 | 1.7000 | 0.2791 |
| 1.7143 | 12.0 | 72 | 1.6993 | 0.2791 |
| 1.7143 | 13.0 | 78 | 1.6987 | 0.2791 |
| 1.6884 | 14.0 | 84 | 1.6981 | 0.2791 |
| 1.7252 | 15.0 | 90 | 1.6975 | 0.2791 |
| 1.7252 | 16.0 | 96 | 1.6969 | 0.2791 |
| 1.7269 | 17.0 | 102 | 1.6963 | 0.2791 |
| 1.7269 | 18.0 | 108 | 1.6958 | 0.2791 |
| 1.6858 | 19.0 | 114 | 1.6953 | 0.2791 |
| 1.7013 | 20.0 | 120 | 1.6948 | 0.2791 |
| 1.7013 | 21.0 | 126 | 1.6943 | 0.2791 |
| 1.7051 | 22.0 | 132 | 1.6939 | 0.2791 |
| 1.7051 | 23.0 | 138 | 1.6935 | 0.2791 |
| 1.6834 | 24.0 | 144 | 1.6931 | 0.2791 |
| 1.6977 | 25.0 | 150 | 1.6927 | 0.2791 |
| 1.6977 | 26.0 | 156 | 1.6924 | 0.2791 |
| 1.7016 | 27.0 | 162 | 1.6920 | 0.2791 |
| 1.7016 | 28.0 | 168 | 1.6917 | 0.2791 |
| 1.7242 | 29.0 | 174 | 1.6915 | 0.2791 |
| 1.6808 | 30.0 | 180 | 1.6912 | 0.2791 |
| 1.6808 | 31.0 | 186 | 1.6910 | 0.2791 |
| 1.7032 | 32.0 | 192 | 1.6908 | 0.2791 |
| 1.7032 | 33.0 | 198 | 1.6906 | 0.2791 |
| 1.6261 | 34.0 | 204 | 1.6905 | 0.2791 |
| 1.7412 | 35.0 | 210 | 1.6903 | 0.2791 |
| 1.7412 | 36.0 | 216 | 1.6902 | 0.2791 |
| 1.6899 | 37.0 | 222 | 1.6901 | 0.2791 |
| 1.6899 | 38.0 | 228 | 1.6901 | 0.2791 |
| 1.6944 | 39.0 | 234 | 1.6900 | 0.2791 |
| 1.6965 | 40.0 | 240 | 1.6900 | 0.2791 |
| 1.6965 | 41.0 | 246 | 1.6900 | 0.2791 |
| 1.6787 | 42.0 | 252 | 1.6900 | 0.2791 |
| 1.6787 | 43.0 | 258 | 1.6900 | 0.2791 |
| 1.6617 | 44.0 | 264 | 1.6900 | 0.2791 |
| 1.7215 | 45.0 | 270 | 1.6900 | 0.2791 |
| 1.7215 | 46.0 | 276 | 1.6900 | 0.2791 |
| 1.6881 | 47.0 | 282 | 1.6900 | 0.2791 |
| 1.6881 | 48.0 | 288 | 1.6900 | 0.2791 |
| 1.6823 | 49.0 | 294 | 1.6900 | 0.2791 |
| 1.7275 | 50.0 | 300 | 1.6900 | 0.2791 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
devagonal/t5-flan-heritage | devagonal | 2023-11-17T06:47:36Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-11-17T06:46:56Z | ---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-flan-heritage
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-flan-heritage
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1247
- Rouge1: 0.8927
- Rouge2: 0.8753
- Rougel: 0.8929
- Rougelsum: 0.8926
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| No log | 1.0 | 145 | 0.1583 | 0.8747 | 0.8544 | 0.8749 | 0.8744 |
| No log | 2.0 | 290 | 0.1247 | 0.8927 | 0.8753 | 0.8929 | 0.8926 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_1x_deit_tiny_sgd_00001_fold1 | hkivancoral | 2023-11-17T06:41:30Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-13T15:13:26Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_1x_deit_tiny_sgd_00001_fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.2
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_1x_deit_tiny_sgd_00001_fold1
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6938
- Accuracy: 0.2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 6 | 1.6986 | 0.2 |
| 1.6333 | 2.0 | 12 | 1.6983 | 0.2 |
| 1.6333 | 3.0 | 18 | 1.6981 | 0.2 |
| 1.6088 | 4.0 | 24 | 1.6979 | 0.2 |
| 1.6296 | 5.0 | 30 | 1.6976 | 0.2 |
| 1.6296 | 6.0 | 36 | 1.6974 | 0.2 |
| 1.6252 | 7.0 | 42 | 1.6972 | 0.2 |
| 1.6252 | 8.0 | 48 | 1.6970 | 0.2 |
| 1.6833 | 9.0 | 54 | 1.6968 | 0.2 |
| 1.5983 | 10.0 | 60 | 1.6965 | 0.2 |
| 1.5983 | 11.0 | 66 | 1.6964 | 0.2 |
| 1.61 | 12.0 | 72 | 1.6962 | 0.2 |
| 1.61 | 13.0 | 78 | 1.6960 | 0.2 |
| 1.6125 | 14.0 | 84 | 1.6958 | 0.2 |
| 1.6595 | 15.0 | 90 | 1.6957 | 0.2 |
| 1.6595 | 16.0 | 96 | 1.6956 | 0.2 |
| 1.6372 | 17.0 | 102 | 1.6954 | 0.2 |
| 1.6372 | 18.0 | 108 | 1.6953 | 0.2 |
| 1.6292 | 19.0 | 114 | 1.6951 | 0.2 |
| 1.6414 | 20.0 | 120 | 1.6950 | 0.2 |
| 1.6414 | 21.0 | 126 | 1.6949 | 0.2 |
| 1.6168 | 22.0 | 132 | 1.6948 | 0.2 |
| 1.6168 | 23.0 | 138 | 1.6947 | 0.2 |
| 1.6445 | 24.0 | 144 | 1.6946 | 0.2 |
| 1.6172 | 25.0 | 150 | 1.6945 | 0.2 |
| 1.6172 | 26.0 | 156 | 1.6944 | 0.2 |
| 1.5925 | 27.0 | 162 | 1.6944 | 0.2 |
| 1.5925 | 28.0 | 168 | 1.6943 | 0.2 |
| 1.6351 | 29.0 | 174 | 1.6942 | 0.2 |
| 1.6161 | 30.0 | 180 | 1.6941 | 0.2 |
| 1.6161 | 31.0 | 186 | 1.6941 | 0.2 |
| 1.6095 | 32.0 | 192 | 1.6940 | 0.2 |
| 1.6095 | 33.0 | 198 | 1.6940 | 0.2 |
| 1.6215 | 34.0 | 204 | 1.6939 | 0.2 |
| 1.6213 | 35.0 | 210 | 1.6939 | 0.2 |
| 1.6213 | 36.0 | 216 | 1.6939 | 0.2 |
| 1.6372 | 37.0 | 222 | 1.6938 | 0.2 |
| 1.6372 | 38.0 | 228 | 1.6938 | 0.2 |
| 1.6199 | 39.0 | 234 | 1.6938 | 0.2 |
| 1.6087 | 40.0 | 240 | 1.6938 | 0.2 |
| 1.6087 | 41.0 | 246 | 1.6938 | 0.2 |
| 1.6309 | 42.0 | 252 | 1.6938 | 0.2 |
| 1.6309 | 43.0 | 258 | 1.6938 | 0.2 |
| 1.6203 | 44.0 | 264 | 1.6938 | 0.2 |
| 1.6564 | 45.0 | 270 | 1.6938 | 0.2 |
| 1.6564 | 46.0 | 276 | 1.6938 | 0.2 |
| 1.6178 | 47.0 | 282 | 1.6938 | 0.2 |
| 1.6178 | 48.0 | 288 | 1.6938 | 0.2 |
| 1.6557 | 49.0 | 294 | 1.6938 | 0.2 |
| 1.6181 | 50.0 | 300 | 1.6938 | 0.2 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Baghdad99/english_voice_tts | Baghdad99 | 2023-11-17T06:39:47Z | 29 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vits",
"text-to-audio",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| text-to-speech | 2023-11-17T06:35:56Z |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): English Text-to-Speech
This repository contains the **English (eng)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-eng")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-eng")
text = "some example text in the English language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output.float().numpy())
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output.numpy(), rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
|
emilstabil/DanSumT5-largeV_84227 | emilstabil | 2023-11-17T06:38:14Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:Danish-summarisation/DanSumT5-large",
"base_model:finetune:Danish-summarisation/DanSumT5-large",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-11-17T01:46:06Z | ---
license: apache-2.0
base_model: Danish-summarisation/DanSumT5-large
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: DanSumT5-largeV_84227
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DanSumT5-largeV_84227
This model is a fine-tuned version of [Danish-summarisation/DanSumT5-large](https://huggingface.co/Danish-summarisation/DanSumT5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2976
- Rouge1: 32.3488
- Rouge2: 8.638
- Rougel: 18.8215
- Rougelsum: 29.8654
- Gen Len: 126.28
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 200 | 2.5620 | 31.6386 | 7.3603 | 17.9932 | 28.8935 | 126.32 |
| No log | 2.0 | 400 | 2.4824 | 31.8478 | 8.0477 | 18.5952 | 29.2582 | 126.77 |
| 2.7655 | 3.0 | 600 | 2.4305 | 32.1965 | 8.4935 | 18.7317 | 29.9719 | 125.03 |
| 2.7655 | 4.0 | 800 | 2.3945 | 31.8539 | 8.7262 | 18.5421 | 29.8472 | 125.63 |
| 2.4368 | 5.0 | 1000 | 2.3685 | 32.0137 | 8.2933 | 18.7818 | 29.561 | 125.32 |
| 2.4368 | 6.0 | 1200 | 2.3522 | 31.5 | 8.3477 | 18.9478 | 29.3072 | 125.11 |
| 2.4368 | 7.0 | 1400 | 2.3364 | 31.6482 | 8.3012 | 18.9953 | 29.0985 | 123.38 |
| 2.2645 | 8.0 | 1600 | 2.3250 | 31.9939 | 8.5944 | 18.9914 | 29.5092 | 125.18 |
| 2.2645 | 9.0 | 1800 | 2.3212 | 31.5611 | 8.1969 | 18.7941 | 29.151 | 126.01 |
| 2.134 | 10.0 | 2000 | 2.3117 | 32.0902 | 8.6962 | 19.0793 | 29.758 | 125.4 |
| 2.134 | 11.0 | 2200 | 2.3064 | 31.9365 | 8.7161 | 18.9113 | 29.6812 | 125.86 |
| 2.134 | 12.0 | 2400 | 2.3062 | 32.3185 | 9.0913 | 19.2692 | 29.9962 | 126.24 |
| 2.0467 | 13.0 | 2600 | 2.3032 | 31.7591 | 8.4993 | 18.8326 | 29.4231 | 125.02 |
| 2.0467 | 14.0 | 2800 | 2.3008 | 32.0532 | 8.8654 | 18.897 | 29.5819 | 126.2 |
| 1.9931 | 15.0 | 3000 | 2.2980 | 31.8987 | 8.7669 | 19.0859 | 29.3799 | 126.0 |
| 1.9931 | 16.0 | 3200 | 2.2982 | 32.2458 | 8.7896 | 18.6845 | 29.6991 | 126.0 |
| 1.9931 | 17.0 | 3400 | 2.2987 | 32.0869 | 8.6678 | 18.7656 | 29.8441 | 125.66 |
| 1.949 | 18.0 | 3600 | 2.2974 | 32.1759 | 8.6004 | 18.7892 | 29.6918 | 126.31 |
| 1.949 | 19.0 | 3800 | 2.2970 | 32.1139 | 8.5827 | 18.7099 | 29.5327 | 126.15 |
| 1.9257 | 20.0 | 4000 | 2.2976 | 32.3488 | 8.638 | 18.8215 | 29.8654 | 126.28 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.1.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
empbetty/dogSimilarToTangyuan-lora | empbetty | 2023-11-17T06:25:52Z | 6 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2023-11-16T11:46:10Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - empbetty/dogSimilarToTangyuan-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the empbetty/dog-similar-to-tangyuan-dataset dataset. You can find some example images in the following.




|
crumb/qrstudy-gpt2-1-2 | crumb | 2023-11-17T06:06:50Z | 5 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T06:06:49Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
Yogesh1p/swin-tiny-patch4-window7-224-finetuned-cloudy | Yogesh1p | 2023-11-17T06:03:46Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T06:02:55Z | ---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-cloudy
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-cloudy
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0694
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 1 | 0.2993 | 0.8182 |
| No log | 2.0 | 3 | 0.1963 | 0.9091 |
| No log | 3.0 | 5 | 0.1130 | 0.9091 |
| No log | 4.0 | 6 | 0.0694 | 1.0 |
| No log | 5.0 | 7 | 0.0569 | 1.0 |
| No log | 6.0 | 9 | 0.0902 | 0.9091 |
| 0.08 | 7.0 | 11 | 0.0973 | 0.9091 |
| 0.08 | 8.0 | 12 | 0.0746 | 1.0 |
| 0.08 | 9.0 | 13 | 0.0527 | 1.0 |
| 0.08 | 10.0 | 15 | 0.0392 | 1.0 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Ka4on/mistral_radiology3.1 | Ka4on | 2023-11-17T06:01:09Z | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| null | 2023-11-17T06:00:19Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
jlbaker361/small_fine-tune_addition_subtraction_decimal_whole | jlbaker361 | 2023-11-17T05:57:34Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T05:35:19Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
jlbaker361/small_fine-tune_addition_subtraction_decimal | jlbaker361 | 2023-11-17T05:56:57Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T05:34:40Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
jlbaker361/small_fine-tune_subtraction_decimal_whole | jlbaker361 | 2023-11-17T05:56:51Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T05:34:38Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
jlbaker361/small_fine-tune_addition_decimal_whole | jlbaker361 | 2023-11-17T05:56:39Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T05:56:38Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
jlbaker361/small_fine-tune_division_multiplication_whole | jlbaker361 | 2023-11-17T05:56:35Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T05:34:34Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
jlbaker361/small_fine-tune_addition_decimal | jlbaker361 | 2023-11-17T05:56:22Z | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
]
| null | 2023-11-17T05:34:18Z | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
vietgpt/dama-2-7b-chat-gguf | vietgpt | 2023-11-17T05:29:07Z | 13 | 1 | null | [
"gguf",
"llama.cpp",
"text-generation",
"vi",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-17T04:07:05Z | ---
license: apache-2.0
language:
- vi
- en
pipeline_tag: text-generation
tags:
- llama.cpp
---
```bash
./main -m path/to/dama-2-7b-chat.q2_k.gguf -n 512 --logit-bias 2+1 --temp 0.1 --repeat_penalty 1.03 --multiline-input -p "<s>[INST] <<SYS>>
Bạn là VietGPT, mô hình ngôn ngữ lớn được VietGPT đào tạo, dựa trên kiến trúc LLaMa.
<</SYS>>
Hồ Chí Minh sinh vào ngày nào? [/INST]"
``` |
hkivancoral/hushem_5x_deit_tiny_adamax_00001_fold5 | hkivancoral | 2023-11-17T05:22:22Z | 11 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T03:46:49Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_00001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8292682926829268
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_00001_fold5
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0196
- Accuracy: 0.8293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3464 | 1.0 | 28 | 1.2206 | 0.4390 |
| 1.038 | 2.0 | 56 | 1.1163 | 0.4390 |
| 0.9036 | 3.0 | 84 | 1.0326 | 0.5122 |
| 0.7256 | 4.0 | 112 | 0.9850 | 0.4634 |
| 0.6091 | 5.0 | 140 | 0.9299 | 0.5366 |
| 0.5118 | 6.0 | 168 | 0.8096 | 0.6098 |
| 0.3976 | 7.0 | 196 | 0.8337 | 0.6341 |
| 0.2983 | 8.0 | 224 | 0.8361 | 0.6829 |
| 0.2464 | 9.0 | 252 | 0.7489 | 0.6829 |
| 0.1797 | 10.0 | 280 | 0.7126 | 0.7317 |
| 0.155 | 11.0 | 308 | 0.7190 | 0.7317 |
| 0.1087 | 12.0 | 336 | 0.7349 | 0.7561 |
| 0.0817 | 13.0 | 364 | 0.6756 | 0.7805 |
| 0.0808 | 14.0 | 392 | 0.7587 | 0.7561 |
| 0.0526 | 15.0 | 420 | 0.6534 | 0.7805 |
| 0.0415 | 16.0 | 448 | 0.7396 | 0.7805 |
| 0.0249 | 17.0 | 476 | 0.7772 | 0.8049 |
| 0.0224 | 18.0 | 504 | 0.7783 | 0.8049 |
| 0.016 | 19.0 | 532 | 0.8153 | 0.7805 |
| 0.0121 | 20.0 | 560 | 0.8052 | 0.8049 |
| 0.0082 | 21.0 | 588 | 0.8047 | 0.8049 |
| 0.0059 | 22.0 | 616 | 0.8544 | 0.8049 |
| 0.0042 | 23.0 | 644 | 0.9271 | 0.7805 |
| 0.0032 | 24.0 | 672 | 0.8999 | 0.8049 |
| 0.0029 | 25.0 | 700 | 0.9068 | 0.8293 |
| 0.0025 | 26.0 | 728 | 0.9094 | 0.8293 |
| 0.0022 | 27.0 | 756 | 0.9291 | 0.8293 |
| 0.0019 | 28.0 | 784 | 0.9347 | 0.8293 |
| 0.0016 | 29.0 | 812 | 0.9448 | 0.8293 |
| 0.0016 | 30.0 | 840 | 0.9586 | 0.8293 |
| 0.0015 | 31.0 | 868 | 0.9704 | 0.8293 |
| 0.0013 | 32.0 | 896 | 0.9735 | 0.8293 |
| 0.0013 | 33.0 | 924 | 0.9776 | 0.8293 |
| 0.0012 | 34.0 | 952 | 0.9829 | 0.8293 |
| 0.0011 | 35.0 | 980 | 0.9923 | 0.8293 |
| 0.0011 | 36.0 | 1008 | 0.9922 | 0.8293 |
| 0.001 | 37.0 | 1036 | 0.9983 | 0.8293 |
| 0.001 | 38.0 | 1064 | 1.0035 | 0.8293 |
| 0.0009 | 39.0 | 1092 | 0.9985 | 0.8293 |
| 0.0009 | 40.0 | 1120 | 1.0064 | 0.8293 |
| 0.0009 | 41.0 | 1148 | 1.0089 | 0.8293 |
| 0.0008 | 42.0 | 1176 | 1.0130 | 0.8293 |
| 0.0008 | 43.0 | 1204 | 1.0152 | 0.8293 |
| 0.0009 | 44.0 | 1232 | 1.0185 | 0.8293 |
| 0.0009 | 45.0 | 1260 | 1.0165 | 0.8293 |
| 0.0009 | 46.0 | 1288 | 1.0180 | 0.8293 |
| 0.0008 | 47.0 | 1316 | 1.0182 | 0.8293 |
| 0.0008 | 48.0 | 1344 | 1.0196 | 0.8293 |
| 0.0008 | 49.0 | 1372 | 1.0196 | 0.8293 |
| 0.0008 | 50.0 | 1400 | 1.0196 | 0.8293 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Yoru1010/intit_model | Yoru1010 | 2023-11-17T05:20:44Z | 19 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-base-960h",
"base_model:finetune:facebook/wav2vec2-base-960h",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-11-17T02:25:00Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-base-960h
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: intit_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# intit_model
This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2486
- Wer: 0.4348
- Cer: 0.9047
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 0.9753 | 20.0 | 100 | 1.3804 | 0.5072 | 0.9054 |
| 0.5395 | 40.0 | 200 | 1.5495 | 0.4444 | 0.9062 |
| 0.3735 | 60.0 | 300 | 1.7729 | 0.4396 | 0.9056 |
| 0.2427 | 80.0 | 400 | 1.9016 | 0.4348 | 0.9063 |
| 0.2389 | 100.0 | 500 | 2.0569 | 0.4348 | 0.9061 |
| 0.1822 | 120.0 | 600 | 2.0684 | 0.4300 | 0.9050 |
| 0.1578 | 140.0 | 700 | 2.1332 | 0.4396 | 0.9049 |
| 0.1547 | 160.0 | 800 | 2.2138 | 0.4444 | 0.9047 |
| 0.1807 | 180.0 | 900 | 2.2467 | 0.4348 | 0.9047 |
| 0.1427 | 200.0 | 1000 | 2.2486 | 0.4348 | 0.9047 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_tiny_adamax_00001_fold4 | hkivancoral | 2023-11-17T05:16:04Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T03:40:33Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_00001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7857142857142857
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_00001_fold4
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4803
- Accuracy: 0.7857
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3199 | 1.0 | 28 | 1.2249 | 0.5 |
| 1.0134 | 2.0 | 56 | 1.0887 | 0.5476 |
| 0.8677 | 3.0 | 84 | 1.0102 | 0.6190 |
| 0.708 | 4.0 | 112 | 0.9014 | 0.5952 |
| 0.5921 | 5.0 | 140 | 0.8309 | 0.6429 |
| 0.5207 | 6.0 | 168 | 0.7657 | 0.6905 |
| 0.3875 | 7.0 | 196 | 0.7178 | 0.6667 |
| 0.3518 | 8.0 | 224 | 0.6618 | 0.6667 |
| 0.2677 | 9.0 | 252 | 0.6279 | 0.7143 |
| 0.2022 | 10.0 | 280 | 0.5907 | 0.7381 |
| 0.2088 | 11.0 | 308 | 0.5564 | 0.7857 |
| 0.1641 | 12.0 | 336 | 0.5320 | 0.7857 |
| 0.1049 | 13.0 | 364 | 0.5289 | 0.7857 |
| 0.092 | 14.0 | 392 | 0.5023 | 0.8095 |
| 0.0557 | 15.0 | 420 | 0.4953 | 0.7381 |
| 0.0471 | 16.0 | 448 | 0.4998 | 0.7857 |
| 0.0348 | 17.0 | 476 | 0.4480 | 0.8095 |
| 0.0266 | 18.0 | 504 | 0.4459 | 0.7857 |
| 0.0161 | 19.0 | 532 | 0.4594 | 0.7857 |
| 0.0135 | 20.0 | 560 | 0.4976 | 0.7619 |
| 0.0093 | 21.0 | 588 | 0.4434 | 0.7619 |
| 0.0077 | 22.0 | 616 | 0.4474 | 0.7619 |
| 0.0056 | 23.0 | 644 | 0.4598 | 0.7143 |
| 0.0046 | 24.0 | 672 | 0.4362 | 0.7381 |
| 0.0037 | 25.0 | 700 | 0.4189 | 0.7857 |
| 0.0032 | 26.0 | 728 | 0.4491 | 0.7857 |
| 0.0028 | 27.0 | 756 | 0.4480 | 0.7857 |
| 0.0026 | 28.0 | 784 | 0.4540 | 0.7857 |
| 0.0022 | 29.0 | 812 | 0.4510 | 0.7857 |
| 0.0021 | 30.0 | 840 | 0.4557 | 0.8095 |
| 0.0018 | 31.0 | 868 | 0.4556 | 0.7857 |
| 0.0017 | 32.0 | 896 | 0.4590 | 0.8095 |
| 0.0016 | 33.0 | 924 | 0.4610 | 0.8095 |
| 0.0015 | 34.0 | 952 | 0.4618 | 0.8095 |
| 0.0015 | 35.0 | 980 | 0.4661 | 0.8095 |
| 0.0013 | 36.0 | 1008 | 0.4626 | 0.8095 |
| 0.0012 | 37.0 | 1036 | 0.4685 | 0.8095 |
| 0.0013 | 38.0 | 1064 | 0.4710 | 0.8095 |
| 0.0012 | 39.0 | 1092 | 0.4730 | 0.8095 |
| 0.0011 | 40.0 | 1120 | 0.4760 | 0.7857 |
| 0.0011 | 41.0 | 1148 | 0.4762 | 0.7857 |
| 0.001 | 42.0 | 1176 | 0.4741 | 0.8095 |
| 0.0011 | 43.0 | 1204 | 0.4784 | 0.8095 |
| 0.001 | 44.0 | 1232 | 0.4806 | 0.7857 |
| 0.001 | 45.0 | 1260 | 0.4792 | 0.7857 |
| 0.001 | 46.0 | 1288 | 0.4801 | 0.7857 |
| 0.001 | 47.0 | 1316 | 0.4802 | 0.7857 |
| 0.0009 | 48.0 | 1344 | 0.4803 | 0.7857 |
| 0.001 | 49.0 | 1372 | 0.4803 | 0.7857 |
| 0.001 | 50.0 | 1400 | 0.4803 | 0.7857 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Skirrey/pokemon-lora | Skirrey | 2023-11-17T05:14:45Z | 1 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2023-11-17T01:00:04Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - Skirrey/pokemon-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




|
hkivancoral/hushem_5x_deit_tiny_adamax_00001_fold3 | hkivancoral | 2023-11-17T05:09:47Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T03:34:18Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_00001_fold3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8604651162790697
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_00001_fold3
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5891
- Accuracy: 0.8605
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3491 | 1.0 | 28 | 1.3171 | 0.4186 |
| 1.0583 | 2.0 | 56 | 1.1404 | 0.4186 |
| 0.8133 | 3.0 | 84 | 1.0626 | 0.5581 |
| 0.7236 | 4.0 | 112 | 0.9689 | 0.6047 |
| 0.5407 | 5.0 | 140 | 0.9154 | 0.6512 |
| 0.4787 | 6.0 | 168 | 0.8329 | 0.6977 |
| 0.4043 | 7.0 | 196 | 0.7849 | 0.7442 |
| 0.3066 | 8.0 | 224 | 0.7047 | 0.7209 |
| 0.2483 | 9.0 | 252 | 0.6601 | 0.7209 |
| 0.1984 | 10.0 | 280 | 0.6346 | 0.7209 |
| 0.1508 | 11.0 | 308 | 0.6148 | 0.7209 |
| 0.1138 | 12.0 | 336 | 0.6034 | 0.7442 |
| 0.0962 | 13.0 | 364 | 0.5398 | 0.7674 |
| 0.0639 | 14.0 | 392 | 0.4866 | 0.7907 |
| 0.0434 | 15.0 | 420 | 0.4751 | 0.8140 |
| 0.0344 | 16.0 | 448 | 0.5249 | 0.7674 |
| 0.0259 | 17.0 | 476 | 0.4934 | 0.8140 |
| 0.0173 | 18.0 | 504 | 0.5157 | 0.8140 |
| 0.0125 | 19.0 | 532 | 0.4794 | 0.8140 |
| 0.0079 | 20.0 | 560 | 0.5000 | 0.8140 |
| 0.0068 | 21.0 | 588 | 0.5083 | 0.8140 |
| 0.0051 | 22.0 | 616 | 0.5005 | 0.8372 |
| 0.0044 | 23.0 | 644 | 0.4949 | 0.8372 |
| 0.0034 | 24.0 | 672 | 0.5221 | 0.8372 |
| 0.003 | 25.0 | 700 | 0.5304 | 0.8605 |
| 0.0025 | 26.0 | 728 | 0.5459 | 0.8372 |
| 0.0023 | 27.0 | 756 | 0.5309 | 0.8372 |
| 0.0022 | 28.0 | 784 | 0.5468 | 0.8605 |
| 0.002 | 29.0 | 812 | 0.5471 | 0.8372 |
| 0.0018 | 30.0 | 840 | 0.5437 | 0.8372 |
| 0.0015 | 31.0 | 868 | 0.5534 | 0.8372 |
| 0.0016 | 32.0 | 896 | 0.5689 | 0.8605 |
| 0.0015 | 33.0 | 924 | 0.5621 | 0.8605 |
| 0.0014 | 34.0 | 952 | 0.5754 | 0.8605 |
| 0.0013 | 35.0 | 980 | 0.5699 | 0.8605 |
| 0.0012 | 36.0 | 1008 | 0.5713 | 0.8605 |
| 0.0013 | 37.0 | 1036 | 0.5830 | 0.8372 |
| 0.0011 | 38.0 | 1064 | 0.5769 | 0.8372 |
| 0.0012 | 39.0 | 1092 | 0.5866 | 0.8372 |
| 0.0011 | 40.0 | 1120 | 0.5802 | 0.8372 |
| 0.0011 | 41.0 | 1148 | 0.5838 | 0.8605 |
| 0.001 | 42.0 | 1176 | 0.5874 | 0.8605 |
| 0.001 | 43.0 | 1204 | 0.5844 | 0.8605 |
| 0.001 | 44.0 | 1232 | 0.5856 | 0.8605 |
| 0.0009 | 45.0 | 1260 | 0.5886 | 0.8605 |
| 0.001 | 46.0 | 1288 | 0.5883 | 0.8605 |
| 0.0009 | 47.0 | 1316 | 0.5899 | 0.8605 |
| 0.0009 | 48.0 | 1344 | 0.5891 | 0.8605 |
| 0.001 | 49.0 | 1372 | 0.5891 | 0.8605 |
| 0.001 | 50.0 | 1400 | 0.5891 | 0.8605 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
katielink/llava-med-7b-vqarad-delta | katielink | 2023-11-17T05:02:45Z | 19 | 4 | transformers | [
"transformers",
"pytorch",
"llava",
"text-generation",
"medical",
"arxiv:2306.00890",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-16T20:25:35Z | ---
license: other
license_name: microsoft-research-license
license_link: https://github.com/microsoft/LLaVA-Med/blob/main/Research%20License.docx
tags:
- medical
---
*This model was added by Hugging Face staff.*
**NOTE: This "delta model" cannot be used directly.**
Users have to apply it on top of the original LLaMA weights to get actual LLaVA weights.
# LLaVA-Med: Fine-tuned on VQA-Rad
*Visual instruction tuning towards buiding large language and vision models with GPT-4 level capabilities in the biomedicine space.*
[[Paper, NeurIPS 2023 Datasets and Benchmarks Track (Spotlight)](https://arxiv.org/abs/2306.00890)] | [[LLaVA-Med Github Repository](https://github.com/microsoft/LLaVA-Med)]
[Chunyuan Li*](https://chunyuan.li/), [Cliff Wong*](https://scholar.google.com/citations?user=Sl05ifcAAAAJ&hl=en), [Sheng Zhang*](https://scholar.google.com/citations?user=-LVEXQ8AAAAJ&hl=en), [Naoto Usuyama](https://www.microsoft.com/en-us/research/people/naotous/), [Haotian Liu](https://hliu.cc), [Jianwei Yang](https://jwyang.github.io/), [Tristan Naumann](https://scholar.google.com/citations?user=cjlSeqwAAAAJ&hl=en), [Hoifung Poon](https://scholar.google.com/citations?user=yqqmVbkAAAAJ&hl=en), [Jianfeng Gao](https://scholar.google.com/citations?user=CQ1cqKkAAAAJ&hl=en) (*Equal Contribution)
<p align="center">
<img src="https://github.com/microsoft/LLaVA-Med/blob/main/images/llava_med_logo.png?raw=true" width="50%"> <br>
*Generated by <a href="https://gligen.github.io/">GLIGEN</a> using the grounded inpainting mode, with three boxes: ``white doctor coat``, ``stethoscope``, ``white doctor hat with a red cross sign``.*
</p>
<p align="center">
<img src="https://github.com/microsoft/LLaVA-Med/blob/main/images/llava_med_pipeline.png?raw=true" width="90%"> <br>
*LLaVA-Med was initialized with the general-domain LLaVA and then continuously trained in a curriculum learning fashion (first biomedical concept alignment then full-blown instruction-tuning). We evaluated LLaVA-Med on standard visual conversation and question answering tasks.*
</p>
[](Research%20License.docx)
[](https://creativecommons.org/licenses/by-nc/4.0/deed.en)
**Usage and License Notices**: The data, code, and model checkpoints are intended and licensed for research use only. They are also subject to additional restrictions dictated by the Terms of Use: LLaMA, Vicuna and GPT-4 respectively. The data is made available under CC BY NC 4.0. The data, code, and model checkpoints may be used for non-commercial purposes and any models trained using the dataset should be used only for research purposes. It is expressly prohibited for models trained on this data to be used in clinical care or for any clinical decision making purposes.
## Model Description
Large Language and Vision Assistant for bioMedicine (i.e., “LLaVA-Med”) is a large language and vision model trained using a curriculum learning method for adapting LLaVA to the biomedical domain. It is an open-source release intended for research use only to facilitate reproducibility of the corresponding paper which claims improved performance for open-ended biomedical questions answering tasks, including common visual question answering (VQA) benchmark datasets such as PathVQA and VQA-RAD.
### Model Uses
#### Intended Use
The data, code, and model checkpoints are intended to be used solely for (I) future research on visual-language processing and (II) reproducibility of the experimental results reported in the reference paper. The data, code, and model checkpoints are not intended to be used in clinical care or for any clinical decision making purposes.
#### Primary Intended Use
The primary intended use is to support AI researchers reproducing and building on top of this work. LLaVA-Med and its associated models should be helpful for exploring various biomedical vision-language processing (VLP ) and vision question answering (VQA) research questions.
#### Out-of-Scope Use
**Any** deployed use case of the model --- commercial or otherwise --- is out of scope. Although we evaluated the models using a broad set of publicly-available research benchmarks, the models and evaluations are intended *for research use only* and not intended for deployed use cases. Please refer to [the associated paper](https://aka.ms/llava-med) for more details.
### Data
This model builds upon [PMC-15M dataset](https://aka.ms/biomedclip-paper), which is a large-scale parallel image-text dataset for biomedical vision-language processing. It contains 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central. It covers a diverse range of biomedical image types, such as microscopy, radiography, histology, and more.
### Limitations
This model was developed using English corpora, and thus may be considered English-only. This model is evaluated on a narrow set of biomedical benchmark tasks, described in [LLaVA-Med paper](https://aka.ms/llava-med). As such, it is not suitable for use in any clinical setting. Under some conditions, the model may make inaccurate predictions and display limitations, which may require additional mitigation strategies. In particular, this model is likely to carry many of the limitations of the model from which it is derived, [LLaVA](https://llava-vl.github.io/).
Further, this model was developed in part using the [PMC-15M](https://aka.ms/biomedclip-paper) dataset. The figure-caption pairs that make up this dataset may contain biases reflecting the current practice of academic publication. For example, the corresponding papers may be enriched for positive findings, contain examples of extreme cases, and otherwise reflect distributions that are not representative of other sources of biomedical data.
## Install
1. Clone the [LLaVA-Med Github repository](https://github.com/microsoft/LLaVA-Med) and navigate to LLaVA-Med folder
```bash
https://github.com/microsoft/LLaVA-Med.git
cd LLaVA-Med
```
2. Install Package: Create conda environment
```Shell
conda create -n llava-med python=3.10 -y
conda activate llava-med
pip install --upgrade pip # enable PEP 660 support
```
3. Install additional packages for training cases
```Shell
pip uninstall torch torchvision -y
pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117
pip install openai==0.27.8
pip uninstall transformers -y
pip install git+https://github.com/huggingface/transformers@cae78c46
pip install -e .
```
```
pip install einops ninja open-clip-torch
pip install flash-attn --no-build-isolation
```
## Serving
The model weights above are *delta* weights. The usage of LLaVA-Med checkpoints should comply with the base LLM's model license: [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
Instructions:
1. Download the delta weights.
1. Get the original LLaMA weights in the huggingface format by following the instructions [here](https://huggingface.co/docs/transformers/main/model_doc/llama).
1. Use the following scripts to get LLaVA-Med weights by applying our delta. In the script below, set the --delta argument to the path of the unzipped `llava_med_in_text_60k_delta` directory. It can be adapted for other delta weights by changing the `--delta` argument (and base/target accordingly).
```bash
python3 -m llava.model.apply_delta \
--base /path/to/llama-7b \
--target /output/path/to/llava_med_in_text_60k \
--delta path/to/llava_med_in_text_60k_delta
```
## Evaluation
### Medical Visual Chat (GPT-assisted Evaluation)
Our GPT-assisted evaluation pipeline for multimodal modeling is provided for a comprehensive understanding of the capabilities of vision-language models. Please see our paper for more details.
1. Generate LLaVA-Med responses
```Shell
python model_vqa.py \
--model-name ./checkpoints/LLaVA-7B-v0 \
--question-file data/eval/llava_med_eval_qa50_qa.jsonl \
--image-folder data/images/ \
--answers-file /path/to/answer-file.jsonl
```
2. Evaluate the generated responses. In our case, [`llava_med_eval_qa50_qa.jsonl`](/data/eval/llava_med_eval_qa50_qa.jsonl) contains the questions, context (captions and inline-mentions) and responses generated by text-only GPT-4 (0314), which we treat as ground truth.
```Shell
python llava/eval/eval_multimodal_chat_gpt_score.py \
--question_input_path data/eval/llava_med_eval_qa50_qa.jsonl \
--input_path /path/to/answer-file.jsonl \
--output_path /path/to/save/gpt4-eval-for-individual-answers.jsonl
```
3. Summarize the evaluation results
```Shell
python summarize_gpt_review.py
```
### Medical VQA
Three Medical VQA datasets are considered in our experiments, including VQA-Rad, SLAKE, Pathology-VQA. We use VQA-Rad as the running example to illustrate how LLaVA-Med is applied to a downstream scenario.
#### - Prepare Data
1. Please see VQA-Rad [repo](https://paperswithcode.com/dataset/vqa-rad) for setting up the dataset.
2. Generate VQA-Rad dataset for LLaVA-Med conversation-style format (the same format with instruct tuning). For each dataset, we process it into three components: `train.json`, `test.json`, `images`.
#### - Fine-tuning
To achieve the higher performance for given a downstream dataset, the same full-model tuning script with instruct tuning is used to continue train LLaVA-Med.
<details>
<summary> Detailed script to fine-tune to downstream datasets: LLaVA-Med-7B, 8x A100 (40G). Time: ~1 hour.</summary>
```Shell
torchrun --nnodes=1 --nproc_per_node=8 --master_port=25001 \
llava/train/train_mem.py \
--model_name_or_path /path/to/checkpoint_llava_med_instruct_60k_inline_mention \
--data_path /path/to/eval/vqa_rad/train.json \
--image_folder /path/to/eval/vqa_rad/images \
--vision_tower openai/clip-vit-large-patch14 \
--mm_vision_select_layer -2 \
--mm_use_im_start_end True \
--bf16 True \
--output_dir /path/to/checkpoint_llava_med_instruct_60k_inline_mention/eval/fine_tuned/vqa_rad \
--num_train_epochs 3 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 5000 \
--save_total_limit 3 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--model_max_length 2048 \
--gradient_checkpointing True \
--lazy_preprocess True \
--report_to wandb
```
</details>
#### - Evaluation
Depending on which checkpoint is employed in evaluation, zero-shot performance is reported on medical instruct tuned checkpoint (eg, [LLaVA-Med-7B](/path/to/checkpoint_llava_med_instruct_60k_inline_mention)), and fine-tuned performance is reported on checkpoint that has been further tuned on training set of the downstream datasets (eg, [LLaVA-Med-7B-VQA-Rad](/path/to/checkpoint_llava_med_instruct_60k_inline_mention/fine_tuned/vqa_rad) ).
(a) Generate LLaVA responses on ScienceQA dataset
(a.1). [Option 1] Multiple-GPU inference
You may evaluate this with multiple GPUs, and concatenate the generated jsonl files. Please refer to our script for [batch evaluation](scripts/chunyl/finetune_on_benchmarks/eval_med_dataset_batch.sh).
```Shell
python llava/eval/run_med_datasets_eval_batch.py --num-chunks 8 --model-name /path/to/checkpoint_llava_med_instruct_60k_inline_mention/eval/fine_tuned/vqa_rad \
--question-file path/to/eval/vqa_rad/test.json \
--image-folder path/to/eval/vqa_rad/images \
--answers-file /path/to/checkpoint_llava_med_instruct_60k_inline_mention/eval/fine_tuned/vqa_rad/test-answer-file.jsonl
```
(a.2). [Option 2] Single-GPU inference
```Shell
python llava/eval/model_vqa_med.py --model-name /path/to/checkpoint_llava_med_instruct_60k_inline_mention/eval/fine_tuned/vqa_rad \
--question-file path/to/eval/vqa_rad/test.json \
--image-folder path/to/eval/vqa_rad/images \
--answers-file /path/to/checkpoint_llava_med_instruct_60k_inline_mention/eval/fine_tuned/vqa_rad/test-answer-file.jsonl
```
(b) Evaluate the generated responses
(b.1). [Option 1] Evaluation for all three VQA datasets
```Shell
python llava/eval/run_eval_batch.py \
--pred_file_parent_path /path/to/llava-med \
--target_test_type test-answer-file
```
It collects the decoding results of all predictions files under the project path, computes the corresponding evaluation metrics, and outputs the results in "`eval_results_med_datasets.jsonl`". To analyze the score, we provdie ipython notebook [run_eval_metrics.ipynb](llava/notebook/run_eval_metrics.ipynb).
(b.2). [Option 2] Evaluation for on one specific VQA dataset
```Shell
python llava/eval/run_eval.py \
--gt /path/to/eval/vqa_rad/test.json \
--pred /path/to/checkpoint_llava_med_instruct_60k_inline_mention/eval/fine_tuned/vqa_rad/test-answer-file.jsonl
```
Please find the LLaVA-Med performance in [llava_med_performance.md](docs/llava_med_performance.md) or in the paper.
## Acknowledgement
- Our project is built upon [LLaVA](https://github.com/lm-sys/FastChat) and [Vicuna](https://github.com/lm-sys/FastChat): They provide our base models with the amazing multimodal and langauge capabilities, respectively!
If you find LLaVA-Med useful for your your research and applications, please cite using this BibTeX:
```bibtex
@article{li2023llavamed,
title={Llava-med: Training a large language-and-vision assistant for biomedicine in one day},
author={Li, Chunyuan and Wong, Cliff and Zhang, Sheng and Usuyama, Naoto and Liu, Haotian and Yang, Jianwei and Naumann, Tristan and Poon, Hoifung and Gao, Jianfeng},
journal={arXiv preprint arXiv:2306.00890},
year={2023}
}
```
## Related Projects
- [LLaVA](https://llava-vl.github.io/)
- [BioMed CLIP](https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224)
- [Instruction Tuning with GPT-4](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM)
|
elyza/ELYZA-japanese-CodeLlama-7b-instruct | elyza | 2023-11-17T05:01:00Z | 694 | 18 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ja",
"en",
"arxiv:2308.12950",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-07T12:04:07Z | ---
license: llama2
language:
- ja
- en
---
## ELYZA-japanese-CodeLlama-7b

### Model Description
**ELYZA-japanese-CodeLlama-7b** は、 [Code Llama](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)をベースとして日本語能力を拡張するために追加事前学習を行ったモデルです。
詳細は [Blog記事](https://zenn.dev/elyza/articles/fcbf103e0a05b1) を参照してください。
### Usage
````python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
text = "エラトステネスの篩についてサンプルコードを示し、解説してください。"
model_name = "elyza/ELYZA-japanese-CodeLlama-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")
if torch.cuda.is_available():
model = model.to("cuda")
prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format(
bos_token=tokenizer.bos_token,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=text,
e_inst=E_INST,
)
with torch.no_grad():
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=768,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)
"""
エラトステネスの篩は、素数を探すアルゴリズムの一つです。
以下にそのサンプルコードを示します。
```python
def eratosthenes_sieve(n):
sieve = [True] * (n + 1)
sieve[0] = sieve[1] = False
for i in range(2, int(n ** 0.5) + 1):
if sieve[i]:
for j in range(i * i, n + 1, i):
sieve[j] = False
return [i for i in range(n + 1) if sieve[i]]
```
このコードは、エラトステネスの篩を用いて、n以下のすべての素数を求める関数です。
エラトステネスの篩は、以下のようなアルゴリズムで動作します。
1. 2以外のすべての数を素数として扱う
2. 2以外の数のうち、2の倍数をすべて除外する
3. 3以外の数のうち、3の倍数をすべて除外する
4. 5以外の数のうち、5の倍数をすべて除外する
5. 7以外の数のうち、7の倍数をすべて除外する
6. …
このアルゴリズムでは、2の倍数、3の倍数、5の倍数、7の倍数…というように、素数の倍数を除外していきます。
このアルゴリズムは、素数の倍数は必ず素数の倍数の倍数となるという性質を利用しているため、非常に効率的です。
"""
````
### ELYZA-japanese-CodeLlama-7b Models
| Model Name | Vocab Size | #Params |
|:---------------------------------------------|:----------:|:-------:|
|[elyza/ELYZA-japanese-CodeLlama-7b](https://huggingface.co/elyza/ELYZA-japanese-CodeLlama-7b)| 32016 | 6.27B |
|[elyza/ELYZA-japanese-CodeLlama-7b-instruct](https://huggingface.co/elyza/ELYZA-japanese-CodeLlama-7b-instruct)| 32016 | 6.27B |
### Developers
以下アルファベット順
- [Akira Sasaki](https://huggingface.co/akirasasaki)
- [Masato Hirakawa](https://huggingface.co/m-hirakawa)
- [Shintaro Horie](https://huggingface.co/e-mon)
- [Tomoaki Nakamura](https://huggingface.co/tyoyo)
### Licence
Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### How to Cite
```tex
@misc{elyzacodellama2023,
title={ELYZA-japanese-CodeLlama-7b},
url={https://huggingface.co/elyza/ELYZA-japanese-CodeLlama-7b},
author={Akira Sasaki and Masato Hirakawa and Shintaro Horie and Tomoaki Nakamura},
year={2023},
}
```
### Citations
```tex
@misc{rozière2023code,
title={Code Llama: Open Foundation Models for Code},
author={Baptiste Rozière and Jonas Gehring and Fabian Gloeckle and Sten Sootla and Itai Gat and Xiaoqing Ellen Tan and Yossi Adi and Jingyu Liu and Tal Remez and Jérémy Rapin and Artyom Kozhevnikov and Ivan Evtimov and Joanna Bitton and Manish Bhatt and Cristian Canton Ferrer and Aaron Grattafiori and Wenhan Xiong and Alexandre Défossez and Jade Copet and Faisal Azhar and Hugo Touvron and Louis Martin and Nicolas Usunier and Thomas Scialom and Gabriel Synnaeve},
year={2023},
eprint={2308.12950},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
abdurrahmanazami/xlnet | abdurrahmanazami | 2023-11-17T04:53:12Z | 0 | 0 | null | [
"question-answering",
"en",
"dataset:newsqa",
"region:us"
]
| question-answering | 2023-11-17T04:50:27Z | ---
datasets:
- newsqa
language:
- en
metrics:
- f1
- exact_match
pipeline_tag: question-answering
--- |
npvinHnivqn/openchat_vmath | npvinHnivqn | 2023-11-17T04:34:22Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"base_model:openchat/openchat_3.5",
"base_model:finetune:openchat/openchat_3.5",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-15T13:51:39Z | ---
license: apache-2.0
base_model: openchat/openchat_3.5
tags:
- generated_from_trainer
model-index:
- name: openchat_vmath
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openchat_vmath
This model is a fine-tuned version of [openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 3000
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
squarelike/llama-2-ko-story-7b | squarelike | 2023-11-17T04:25:49Z | 11 | 5 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"pytorch",
"causal-lm",
"ko",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-11-16T05:26:10Z | ---
language:
- ko
tags:
- pytorch
- causal-lm
license: llama2
pipeline_tag: text-generation
---
# llama-2-ko-story-7b
llama-2-ko-story-7b는 [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)를 기반으로 한글 소설 raw 데이터를 학습시킨 기반 모델입니다.
## 학습 데이터
llama-2-ko-story-7b는 약 167MB의 한글 소설 말뭉치로 학습되었습니다. 주요 데이터셋은 다음과 같습니다.
| Source |Size (MB) | Link |
|----------------------------------|---------|------------------------------------------|
| 한글 소설 말뭉치 | 115.0 | |
| 공유마당 한국 고전 문학 말뭉치 | 53.0 | https://gongu.copyright.or.kr/ |
## 학습
llama-2-ko-story-7b는 [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)에서 qlora로 추가 학습되었습니다.
- lora_alpha: 16
- lora_dropout: 0.05
- lora_r: 32
- target_modules: q_proj, v_proj
- epoch: 3
- learning_rate: 3e-4 |
Mohammad2023/CartPole | Mohammad2023 | 2023-11-17T04:08:37Z | 0 | 0 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-11-10T03:05:28Z | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -21.74 +/- 68.68
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
|
MattStammers/appo-atari_namethisgame-superhuman | MattStammers | 2023-11-17T04:03:31Z | 0 | 0 | sample-factory | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-26T18:00:05Z | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_namethisgame
type: atari_namethisgame
metrics:
- type: mean_reward
value: 22607.00 +/- 2779.10
name: mean_reward
verified: false
---
## About the Project
This project is an attempt to maximise performance of high sample throughput APPO RL models in Atari environments in as carbon efficient a manner as possible using a single, not particularly high performance single machine. It is about demonstrating the generalisability of on-policy algorithms to create good performance quickly (by sacrificing sample efficiency) while also proving that this route to RL production is accessible to even hobbyists like me (I am a gastroenterologist not a computer scientist).
In terms of throughput I am managing to reach throughputs of 2,500 - 3,000 across both policies using sample factory using two Quadro P2200's (not particularly powerful GPUs) each loaded up about 60% (3GB). Previously using the stable baselines 3 (sb3) implementation of PPO it would take about a week to train an atari agent to 100 million timesteps synchronously. By comparison the sample factory async implementation takes only just over 2 hours to achieve the same result. That is about 84 times faster with only typically a 21 watt burn per GPU. I am thus very grateful to Alex Petrenko and all the sample factory team for their work on this.
## Project Aims
This model as with all the others in the benchmarks was trained initially asynchronously un-seeded to 10 million steps for the purposes of setting a sample factory async baseline for this model on this environment but only 3/57 made it anywhere near sota performance.
I then re-trained the models with 100 million timesteps- at this point 2 environments maxed out at sota performance (Pong and Freeway) with four approaching sota performance - (atlantis, boxing, tennis and fishingderby.) =6/57 near sota.
The aim now is to try and reach state-of-the-art (SOTA) performance on a further block of atari environments using up to 1 billion training timesteps initially with appo. I will flag the models with SOTA when they reach at or near these levels.
After this I will switch on V-Trace to see if the Impala variations perform any better with the same seed (I have seeded '1234')
## About the Model
The hyperparameters used in the model are described in my shell script on my fork of sample-factory: https://github.com/MattStammers/sample-factory. Given that https://huggingface.co/edbeeching has kindly shared his parameters, I saved time and energy by using many of his tuned hyperparameters to reduce carbon inefficiency:
```
hyperparameters = {
"help": false,
"algo": "APPO",
"env": "atari_asteroid",
"experiment": "atari_asteroid_APPO",
"train_dir": "./train_atari",
"restart_behavior": "restart",
"device": "gpu",
"seed": 1234,
"num_policies": 2,
"async_rl": true,
"serial_mode": false,
"batched_sampling": true,
"num_batches_to_accumulate": 2,
"worker_num_splits": 1,
"policy_workers_per_policy": 1,
"max_policy_lag": 1000,
"num_workers": 16,
"num_envs_per_worker": 2,
"batch_size": 1024,
"num_batches_per_epoch": 8,
"num_epochs": 4,
"rollout": 128,
"recurrence": 1,
"shuffle_minibatches": false,
"gamma": 0.99,
"reward_scale": 1.0,
"reward_clip": 1000.0,
"value_bootstrap": false,
"normalize_returns": true,
"exploration_loss_coeff": 0.0004677351413,
"value_loss_coeff": 0.5,
"kl_loss_coeff": 0.0,
"exploration_loss": "entropy",
"gae_lambda": 0.95,
"ppo_clip_ratio": 0.1,
"ppo_clip_value": 1.0,
"with_vtrace": false,
"vtrace_rho": 1.0,
"vtrace_c": 1.0,
"optimizer": "adam",
"adam_eps": 1e-05,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"max_grad_norm": 0.0,
"learning_rate": 0.0003033891184,
"lr_schedule": "linear_decay",
"lr_schedule_kl_threshold": 0.008,
"lr_adaptive_min": 1e-06,
"lr_adaptive_max": 0.01,
"obs_subtract_mean": 0.0,
"obs_scale": 255.0,
"normalize_input": true,
"normalize_input_keys": [
"obs"
],
"decorrelate_experience_max_seconds": 0,
"decorrelate_envs_on_one_worker": true,
"actor_worker_gpus": [],
"set_workers_cpu_affinity": true,
"force_envs_single_thread": false,
"default_niceness": 0,
"log_to_file": true,
"experiment_summaries_interval": 3,
"flush_summaries_interval": 30,
"stats_avg": 100,
"summaries_use_frameskip": true,
"heartbeat_interval": 10,
"heartbeat_reporting_interval": 60,
"train_for_env_steps": 100000000,
"train_for_seconds": 10000000000,
"save_every_sec": 120,
"keep_checkpoints": 2,
"load_checkpoint_kind": "latest",
"save_milestones_sec": 1200,
"save_best_every_sec": 5,
"save_best_metric": "reward",
"save_best_after": 100000,
"benchmark": false,
"encoder_mlp_layers": [
512,
512
],
"encoder_conv_architecture": "convnet_atari",
"encoder_conv_mlp_layers": [
512
],
"use_rnn": false,
"rnn_size": 512,
"rnn_type": "gru",
"rnn_num_layers": 1,
"decoder_mlp_layers": [],
"nonlinearity": "relu",
"policy_initialization": "orthogonal",
"policy_init_gain": 1.0,
"actor_critic_share_weights": true,
"adaptive_stddev": false,
"continuous_tanh_scale": 0.0,
"initial_stddev": 1.0,
"use_env_info_cache": false,
"env_gpu_actions": false,
"env_gpu_observations": true,
"env_frameskip": 4,
"env_framestack": 4,
"pixel_format": "CHW"
}
```
A(n) **APPO** model trained on the **atari_namethisgame** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory. Sample factory is a
high throughput on-policy RL framework. I have been using
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r MattStammers/APPO-atari_namethisgame
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.atari.enjoy_atari --algo=APPO --env=atari_namethisgame --train_dir=./train_dir --experiment=APPO-atari_namethisgame
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.atari.train_atari --algo=APPO --env=atari_namethisgame --train_dir=./train_dir --experiment=APPO-atari_namethisgame --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
oosiz/qlora-koalpaca-polyglot-5.8b-50step | oosiz | 2023-11-17T03:16:16Z | 6 | 0 | peft | [
"peft",
"safetensors",
"gpt_neox",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
]
| null | 2023-11-14T00:56:20Z | ---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2.dev0
|
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold5 | hkivancoral | 2023-11-17T03:11:28Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T03:05:25Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8292682926829268
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold5
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8979
- Accuracy: 0.8293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.89 | 1.0 | 28 | 0.6693 | 0.7073 |
| 0.2735 | 2.0 | 56 | 0.4551 | 0.7805 |
| 0.0858 | 3.0 | 84 | 0.6564 | 0.7561 |
| 0.0113 | 4.0 | 112 | 0.7630 | 0.8537 |
| 0.0078 | 5.0 | 140 | 0.5220 | 0.8049 |
| 0.0013 | 6.0 | 168 | 0.8772 | 0.8049 |
| 0.0003 | 7.0 | 196 | 0.7171 | 0.8293 |
| 0.0002 | 8.0 | 224 | 0.7732 | 0.8537 |
| 0.0001 | 9.0 | 252 | 0.7686 | 0.8537 |
| 0.0001 | 10.0 | 280 | 0.7839 | 0.8537 |
| 0.0001 | 11.0 | 308 | 0.7871 | 0.8537 |
| 0.0001 | 12.0 | 336 | 0.7948 | 0.8537 |
| 0.0001 | 13.0 | 364 | 0.8088 | 0.8537 |
| 0.0001 | 14.0 | 392 | 0.8070 | 0.8537 |
| 0.0001 | 15.0 | 420 | 0.8143 | 0.8537 |
| 0.0001 | 16.0 | 448 | 0.8175 | 0.8537 |
| 0.0001 | 17.0 | 476 | 0.8255 | 0.8537 |
| 0.0001 | 18.0 | 504 | 0.8292 | 0.8537 |
| 0.0001 | 19.0 | 532 | 0.8250 | 0.8537 |
| 0.0001 | 20.0 | 560 | 0.8378 | 0.8537 |
| 0.0001 | 21.0 | 588 | 0.8394 | 0.8537 |
| 0.0001 | 22.0 | 616 | 0.8440 | 0.8293 |
| 0.0001 | 23.0 | 644 | 0.8474 | 0.8293 |
| 0.0 | 24.0 | 672 | 0.8547 | 0.8293 |
| 0.0 | 25.0 | 700 | 0.8569 | 0.8293 |
| 0.0 | 26.0 | 728 | 0.8563 | 0.8293 |
| 0.0 | 27.0 | 756 | 0.8612 | 0.8293 |
| 0.0 | 28.0 | 784 | 0.8649 | 0.8293 |
| 0.0 | 29.0 | 812 | 0.8707 | 0.8293 |
| 0.0 | 30.0 | 840 | 0.8644 | 0.8293 |
| 0.0 | 31.0 | 868 | 0.8688 | 0.8293 |
| 0.0 | 32.0 | 896 | 0.8737 | 0.8293 |
| 0.0 | 33.0 | 924 | 0.8760 | 0.8293 |
| 0.0 | 34.0 | 952 | 0.8808 | 0.8293 |
| 0.0 | 35.0 | 980 | 0.8838 | 0.8293 |
| 0.0 | 36.0 | 1008 | 0.8834 | 0.8293 |
| 0.0 | 37.0 | 1036 | 0.8857 | 0.8293 |
| 0.0 | 38.0 | 1064 | 0.8913 | 0.8293 |
| 0.0 | 39.0 | 1092 | 0.8912 | 0.8293 |
| 0.0 | 40.0 | 1120 | 0.8917 | 0.8293 |
| 0.0 | 41.0 | 1148 | 0.8927 | 0.8293 |
| 0.0 | 42.0 | 1176 | 0.8947 | 0.8293 |
| 0.0 | 43.0 | 1204 | 0.8969 | 0.8293 |
| 0.0 | 44.0 | 1232 | 0.8977 | 0.8293 |
| 0.0 | 45.0 | 1260 | 0.8966 | 0.8293 |
| 0.0 | 46.0 | 1288 | 0.8974 | 0.8293 |
| 0.0 | 47.0 | 1316 | 0.8978 | 0.8293 |
| 0.0 | 48.0 | 1344 | 0.8978 | 0.8293 |
| 0.0 | 49.0 | 1372 | 0.8979 | 0.8293 |
| 0.0 | 50.0 | 1400 | 0.8979 | 0.8293 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold4 | hkivancoral | 2023-11-17T03:05:12Z | 15 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T02:59:11Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8571428571428571
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold4
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5076
- Accuracy: 0.8571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.876 | 1.0 | 28 | 0.7721 | 0.6667 |
| 0.2335 | 2.0 | 56 | 0.4611 | 0.8571 |
| 0.0719 | 3.0 | 84 | 0.6242 | 0.6905 |
| 0.0277 | 4.0 | 112 | 0.6528 | 0.7857 |
| 0.0032 | 5.0 | 140 | 0.4735 | 0.7857 |
| 0.0032 | 6.0 | 168 | 0.4579 | 0.8095 |
| 0.0006 | 7.0 | 196 | 0.5092 | 0.8333 |
| 0.0003 | 8.0 | 224 | 0.3894 | 0.8333 |
| 0.0002 | 9.0 | 252 | 0.4099 | 0.8810 |
| 0.0001 | 10.0 | 280 | 0.4092 | 0.8571 |
| 0.0001 | 11.0 | 308 | 0.4206 | 0.8571 |
| 0.0001 | 12.0 | 336 | 0.4259 | 0.8571 |
| 0.0001 | 13.0 | 364 | 0.4295 | 0.8571 |
| 0.0001 | 14.0 | 392 | 0.4367 | 0.8571 |
| 0.0001 | 15.0 | 420 | 0.4435 | 0.8571 |
| 0.0001 | 16.0 | 448 | 0.4513 | 0.8571 |
| 0.0001 | 17.0 | 476 | 0.4519 | 0.8571 |
| 0.0001 | 18.0 | 504 | 0.4534 | 0.8571 |
| 0.0001 | 19.0 | 532 | 0.4605 | 0.8571 |
| 0.0001 | 20.0 | 560 | 0.4613 | 0.8571 |
| 0.0001 | 21.0 | 588 | 0.4650 | 0.8571 |
| 0.0001 | 22.0 | 616 | 0.4689 | 0.8571 |
| 0.0001 | 23.0 | 644 | 0.4679 | 0.8571 |
| 0.0 | 24.0 | 672 | 0.4734 | 0.8571 |
| 0.0001 | 25.0 | 700 | 0.4768 | 0.8571 |
| 0.0 | 26.0 | 728 | 0.4779 | 0.8571 |
| 0.0001 | 27.0 | 756 | 0.4799 | 0.8571 |
| 0.0 | 28.0 | 784 | 0.4834 | 0.8571 |
| 0.0 | 29.0 | 812 | 0.4854 | 0.8571 |
| 0.0 | 30.0 | 840 | 0.4883 | 0.8571 |
| 0.0 | 31.0 | 868 | 0.4908 | 0.8571 |
| 0.0 | 32.0 | 896 | 0.4928 | 0.8571 |
| 0.0 | 33.0 | 924 | 0.4945 | 0.8571 |
| 0.0 | 34.0 | 952 | 0.4953 | 0.8571 |
| 0.0 | 35.0 | 980 | 0.4954 | 0.8571 |
| 0.0 | 36.0 | 1008 | 0.4965 | 0.8571 |
| 0.0 | 37.0 | 1036 | 0.4980 | 0.8571 |
| 0.0 | 38.0 | 1064 | 0.4998 | 0.8571 |
| 0.0 | 39.0 | 1092 | 0.5007 | 0.8571 |
| 0.0 | 40.0 | 1120 | 0.5020 | 0.8571 |
| 0.0 | 41.0 | 1148 | 0.5023 | 0.8571 |
| 0.0 | 42.0 | 1176 | 0.5029 | 0.8571 |
| 0.0 | 43.0 | 1204 | 0.5047 | 0.8571 |
| 0.0 | 44.0 | 1232 | 0.5059 | 0.8571 |
| 0.0 | 45.0 | 1260 | 0.5064 | 0.8571 |
| 0.0 | 46.0 | 1288 | 0.5070 | 0.8571 |
| 0.0 | 47.0 | 1316 | 0.5074 | 0.8571 |
| 0.0 | 48.0 | 1344 | 0.5076 | 0.8571 |
| 0.0 | 49.0 | 1372 | 0.5076 | 0.8571 |
| 0.0 | 50.0 | 1400 | 0.5076 | 0.8571 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hiddenbox/pore_dream5 | hiddenbox | 2023-11-17T03:04:15Z | 0 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:SG161222/Realistic_Vision_V5.1_noVAE",
"base_model:adapter:SG161222/Realistic_Vision_V5.1_noVAE",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2023-11-08T07:57:52Z |
---
license: creativeml-openrail-m
base_model: SG161222/Realistic_Vision_V5.1_noVAE
instance_prompt: a photo of a1sfv dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - hiddenbox/pore_dream5
These are LoRA adaption weights for SG161222/Realistic_Vision_V5.1_noVAE. The weights were trained on a photo of a1sfv dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
alibaba-pai/pai-easyphoto | alibaba-pai | 2023-11-17T02:56:19Z | 0 | 6 | null | [
"onnx",
"region:us"
]
| null | 2023-09-14T06:04:56Z | This is the model files for [EasyPhoto](https://github.com/aigc-apps/sd-webui-EasyPhoto).
We will directly download the models once starting EasyPhoto. Or you can download them from this repository and put them to the specific folder.
Please refer to `def check_files_exists_and_download()` in [easyphoto_utils.py](https://github.com/aigc-apps/sd-webui-EasyPhoto/blob/main/scripts/easyphoto_utils.py) for more details. |
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold2 | hkivancoral | 2023-11-17T02:52:41Z | 18 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-11-17T02:46:48Z | ---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7777777777777778
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold2
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3029
- Accuracy: 0.7778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7446 | 1.0 | 27 | 0.9312 | 0.6667 |
| 0.1747 | 2.0 | 54 | 1.0634 | 0.6667 |
| 0.0436 | 3.0 | 81 | 1.1538 | 0.6889 |
| 0.0072 | 4.0 | 108 | 1.1186 | 0.7111 |
| 0.0036 | 5.0 | 135 | 1.4466 | 0.6667 |
| 0.0007 | 6.0 | 162 | 1.3997 | 0.6889 |
| 0.0023 | 7.0 | 189 | 1.1775 | 0.7333 |
| 0.0002 | 8.0 | 216 | 1.3345 | 0.7333 |
| 0.0001 | 9.0 | 243 | 1.2661 | 0.7333 |
| 0.0001 | 10.0 | 270 | 1.2707 | 0.7333 |
| 0.0001 | 11.0 | 297 | 1.2671 | 0.7333 |
| 0.0001 | 12.0 | 324 | 1.2637 | 0.7556 |
| 0.0001 | 13.0 | 351 | 1.2664 | 0.7556 |
| 0.0001 | 14.0 | 378 | 1.2658 | 0.7556 |
| 0.0001 | 15.0 | 405 | 1.2627 | 0.7556 |
| 0.0001 | 16.0 | 432 | 1.2685 | 0.7556 |
| 0.0001 | 17.0 | 459 | 1.2678 | 0.7778 |
| 0.0001 | 18.0 | 486 | 1.2674 | 0.7778 |
| 0.0001 | 19.0 | 513 | 1.2701 | 0.7778 |
| 0.0001 | 20.0 | 540 | 1.2690 | 0.7778 |
| 0.0001 | 21.0 | 567 | 1.2702 | 0.7778 |
| 0.0 | 22.0 | 594 | 1.2727 | 0.7778 |
| 0.0 | 23.0 | 621 | 1.2744 | 0.7778 |
| 0.0 | 24.0 | 648 | 1.2792 | 0.7778 |
| 0.0 | 25.0 | 675 | 1.2781 | 0.7778 |
| 0.0 | 26.0 | 702 | 1.2815 | 0.7778 |
| 0.0 | 27.0 | 729 | 1.2813 | 0.7778 |
| 0.0 | 28.0 | 756 | 1.2838 | 0.7778 |
| 0.0 | 29.0 | 783 | 1.2855 | 0.7778 |
| 0.0 | 30.0 | 810 | 1.2884 | 0.7778 |
| 0.0 | 31.0 | 837 | 1.2896 | 0.7778 |
| 0.0 | 32.0 | 864 | 1.2918 | 0.7778 |
| 0.0 | 33.0 | 891 | 1.2896 | 0.7778 |
| 0.0 | 34.0 | 918 | 1.2932 | 0.7778 |
| 0.0 | 35.0 | 945 | 1.2947 | 0.7778 |
| 0.0 | 36.0 | 972 | 1.2919 | 0.7778 |
| 0.0 | 37.0 | 999 | 1.2951 | 0.7778 |
| 0.0 | 38.0 | 1026 | 1.2979 | 0.7778 |
| 0.0 | 39.0 | 1053 | 1.3002 | 0.7778 |
| 0.0 | 40.0 | 1080 | 1.2989 | 0.7778 |
| 0.0 | 41.0 | 1107 | 1.3009 | 0.7778 |
| 0.0 | 42.0 | 1134 | 1.3017 | 0.7778 |
| 0.0 | 43.0 | 1161 | 1.3020 | 0.7778 |
| 0.0 | 44.0 | 1188 | 1.3018 | 0.7778 |
| 0.0 | 45.0 | 1215 | 1.3024 | 0.7778 |
| 0.0 | 46.0 | 1242 | 1.3027 | 0.7778 |
| 0.0 | 47.0 | 1269 | 1.3028 | 0.7778 |
| 0.0 | 48.0 | 1296 | 1.3029 | 0.7778 |
| 0.0 | 49.0 | 1323 | 1.3029 | 0.7778 |
| 0.0 | 50.0 | 1350 | 1.3029 | 0.7778 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
mikr/whisper-large-v3-czech-cv13 | mikr | 2023-11-17T02:38:00Z | 157 | 4 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-11-11T20:44:32Z | ---
license: apache-2.0
base_model: openai/whisper-large-v3
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-large-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v3
This model is a fine-tuned version of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1283
- Wer: 0.0789
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 62
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0138 | 2.24 | 1000 | 0.0962 | 0.0863 |
| 0.004 | 4.48 | 2000 | 0.1117 | 0.0844 |
| 0.0015 | 6.73 | 3000 | 0.1178 | 0.0807 |
| 0.0004 | 8.97 | 4000 | 0.1219 | 0.0792 |
| 0.0002 | 11.21 | 5000 | 0.1283 | 0.0789 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.0.0+cu117
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Godspower/finetuned-sentiment-analysis-model-3000-samples-base-distilbert | Godspower | 2023-11-17T02:33:51Z | 6 | 1 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-11-16T15:17:18Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuned-sentiment-analysis-model-3000-samples-base-distilbert
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93148
- name: F1
type: f1
value: 0.9317883168080278
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-sentiment-analysis-model-3000-samples-base-distilbert
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3698
- Accuracy: 0.9315
- F1: 0.9318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Subsets and Splits