
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-27 18:27:39
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 500
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-27 18:23:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
maksf8486/4776b814-3bbe-4f8b-9dcf-5334016619fe | maksf8486 | 2025-05-03T19:23:25Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"unsloth",
"conversational",
"arxiv:2305.18290",
"base_model:unsloth/tinyllama",
"base_model:quantized:unsloth/tinyllama",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-05-03T19:16:39Z | ---
base_model: unsloth/tinyllama
library_name: transformers
model_name: 4776b814-3bbe-4f8b-9dcf-5334016619fe
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
- unsloth
licence: license
---
# Model Card for 4776b814-3bbe-4f8b-9dcf-5334016619fe
This model is a fine-tuned version of [unsloth/tinyllama](https://huggingface.co/unsloth/tinyllama).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="maksf8486/4776b814-3bbe-4f8b-9dcf-5334016619fe", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-2/runs/tqpl2mhi)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Gandarych/xlm-roberta-base-finetuned-panx-fr | Gandarych | 2025-05-03T19:20:32Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2025-05-03T19:15:01Z | ---
library_name: transformers
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2779
- F1: 0.8411
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5637 | 1.0 | 191 | 0.3215 | 0.7837 |
| 0.2667 | 2.0 | 382 | 0.2779 | 0.8297 |
| 0.182 | 3.0 | 573 | 0.2779 | 0.8411 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
underscore2/llama3-8b-singularity-3 | underscore2 | 2025-05-03T19:20:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T19:20:24Z | ---
base_model: unsloth/llama-3-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** underscore2
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Flo0620/Qwen2_5-VL-7B-8bit_FixedBinary | Flo0620 | 2025-05-03T19:16:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T15:55:23Z | ---
base_model: Qwen/Qwen2.5-VL-7B-Instruct
library_name: transformers
model_name: Qwen2_5-VL-7B-8bit_FixedBinary
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen2_5-VL-7B-8bit_FixedBinary
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Flo0620/Qwen2_5-VL-7B-8bit_FixedBinary", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.52.0.dev0
- Pytorch: 2.6.0+cu124
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
jdchang/full-with-label-bs-1024-sg-2-step-2430 | jdchang | 2025-05-03T19:13:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T19:13:01Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
asmae-khald/VITforBreastCancer | asmae-khald | 2025-05-03T19:12:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-05-03T19:11:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
AhmedCodes65/parser_qwen2_3b_instruct_finetune | AhmedCodes65 | 2025-05-03T19:11:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T19:04:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
zenon015/heyman | zenon015 | 2025-05-03T19:08:20Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-05-03T19:08:20Z | ---
license: apache-2.0
---
|
Mostafa8Mehrabi/llama-1b-pruned-3blocks-ppl-Standard-Calibration | Mostafa8Mehrabi | 2025-05-03T19:03:15Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T19:02:18Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
memevis/supp42 | memevis | 2025-05-03T19:02:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T19:02:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Aaquib/gemma-2b-sft-alpaca | Aaquib | 2025-05-03T19:02:06Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T18:21:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
SFT'd version of google/gemma-2b. Training performed solely on yahma/alpaca-cleaned. No further learning was performed.
## Model Details
Hyperparameters to replicate:
- lr=1e-5
- num_epochs=1
- train_batch_size=40
- test_batch_size=32
- max_seq_len=256
### Model Description
- **Finetuned from model:** [google/gemma-2b], uses the same tokenizer and chat template as google/gemma-2b-it |
Bretttt543354/H | Bretttt543354 | 2025-05-03T19:00:54Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-05-03T19:00:54Z | ---
license: apache-2.0
---
|
mlx-community/Llama-4-Scout-17B-16E-Instruct-6bit | mlx-community | 2025-05-03T18:59:28Z | 499 | 5 | transformers | [
"transformers",
"safetensors",
"llama4",
"image-text-to-text",
"facebook",
"meta",
"pytorch",
"llama",
"llama-4",
"mlx",
"conversational",
"ar",
"de",
"en",
"es",
"fr",
"hi",
"id",
"it",
"pt",
"th",
"tl",
"vi",
"base_model:meta-llama/Llama-4-Scout-17B-16E",
"base_model:finetune:meta-llama/Llama-4-Scout-17B-16E",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-04-06T11:35:17Z | ---
library_name: transformers
language:
- ar
- de
- en
- es
- fr
- hi
- id
- it
- pt
- th
- tl
- vi
base_model:
- meta-llama/Llama-4-Scout-17B-16E
tags:
- facebook
- meta
- pytorch
- llama
- llama-4
- mlx
extra_gated_prompt: '**LLAMA 4 COMMUNITY LICENSE AGREEMENT**
Llama 4 Version Effective Date: April 5, 2025
"**Agreement**" means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
"**Documentation**" means the specifications, manuals and documentation accompanying
Llama 4 distributed by Meta at [https://www.llama.com/docs/overview](https://llama.com/docs/overview).
"**Licensee**" or "**you**" means you, or your employer or any other person or entity
(if you are entering into this Agreement on such person or entity’s behalf), of
the age required under applicable laws, rules or regulations to provide legal consent
and that has legal authority to bind your employer or such other person or entity
if you are entering in this Agreement on their behalf.
"**Llama 4**" means the foundational large language models and software and algorithms,
including machine-learning model code, trained model weights, inference-enabling
code, training-enabling code, fine-tuning enabling code and other elements of the
foregoing distributed by Meta at [https://www.llama.com/llama-downloads](https://www.llama.com/llama-downloads).
"**Llama Materials**" means, collectively, Meta’s proprietary Llama 4 and Documentation
(and any portion thereof) made available under this Agreement.
"**Meta**" or "**we**" means Meta Platforms Ireland Limited (if you are located
in or, if you are an entity, your principal place of business is in the EEA or Switzerland)
and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or element
of the Llama Materials, you agree to be bound by this Agreement.
1\. **License Rights and Redistribution**.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable
and royalty-free limited license under Meta’s intellectual property or other rights
owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy,
create derivative works of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service (including another AI model) that contains any
of them, you shall (A) provide a copy of this Agreement with any such Llama Materials;
and (B) prominently display "Built with Llama" on a related website, user interface,
blogpost, about page, or product documentation. If you use the Llama Materials or
any outputs or results of the Llama Materials to create, train, fine tune, or otherwise
improve an AI model, which is distributed or made available, you shall also include
"Llama" at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee
as part of an integrated end user product, then Section 2 of this Agreement will
not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the
following attribution notice within a "Notice" text file distributed as a part of
such copies: "Llama 4 is licensed under the Llama 4 Community License, Copyright
© Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use
Policy for the Llama Materials (available at [https://www.llama.com/llama4/use-policy](https://www.llama.com/llama4/use-policy)),
which is hereby incorporated by reference into this Agreement. 2\. **Additional
Commercial Terms**. If, on the Llama 4 version release date, the monthly active
users of the products or services made available by or for Licensee, or Licensee’s
affiliates, is greater than 700 million monthly active users in the preceding calendar
month, you must request a license from Meta, which Meta may grant to you in its
sole discretion, and you are not authorized to exercise any of the rights under
this Agreement unless or until Meta otherwise expressly grants you such rights.
3**. Disclaimer of Warranty**. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS
AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES
OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY,
OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING
THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY
RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4\. **Limitation of Liability**. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE
UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY,
OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT,
SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META
OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5\. **Intellectual Property**.
a. No trademark licenses are granted under this Agreement, and in connection with
the Llama Materials, neither Meta nor Licensee may use any name or mark owned by
or associated with the other or any of its affiliates, except as required for reasonable
and customary use in describing and redistributing the Llama Materials or as set
forth in this Section 5(a). Meta hereby grants you a license to use "Llama" (the
"Mark") solely as required to comply with the last sentence of Section 1.b.i. You
will comply with Meta’s brand guidelines (currently accessible at [https://about.meta.com/brand/resources/meta/company-brand/](https://about.meta.com/brand/resources/meta/company-brand/)[)](https://en.facebookbrand.com/).
All goodwill arising out of your use of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for
Meta, with respect to any derivative works and modifications of the Llama Materials
that are made by you, as between you and Meta, you are and will be the owner of
such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including
a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or
Llama 4 outputs or results, or any portion of any of the foregoing, constitutes
infringement of intellectual property or other rights owned or licensable by you,
then any licenses granted to you under this Agreement shall terminate as of the
date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related
to your use or distribution of the Llama Materials.
6\. **Term and Termination**. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will continue
in full force and effect until terminated in accordance with the terms and conditions
herein. Meta may terminate this Agreement if you are in breach of any term or condition
of this Agreement. Upon termination of this Agreement, you shall delete and cease
use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of
this Agreement.
7\. **Governing Law and Jurisdiction**. This Agreement will be governed and construed
under the laws of the State of California without regard to choice of law principles,
and the UN Convention on Contracts for the International Sale of Goods does not
apply to this Agreement. The courts of California shall have exclusive jurisdiction
of any dispute arising out of this Agreement.'
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
extra_gated_heading: Please be sure to provide your full legal name, date of birth,
and full organization name with all corporate identifiers. Avoid the use of acronyms
and special characters. Failure to follow these instructions may prevent you from
accessing this model and others on Hugging Face. You will not have the ability to
edit this form after submission, so please ensure all information is accurate.
license: other
license_name: llama4
---
# mlx-community/Llama-4-Scout-17B-16E-Instruct-6bit
This model was converted to MLX format from [`meta-llama/Llama-4-Scout-17B-16E-Instruct`]() using mlx-vlm version **0.1.21**.
Refer to the [original model card](https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model mlx-community/Llama-4-Scout-17B-16E-Instruct-6bit --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
madhav-k/llama-3-8b-chat-indic | madhav-k | 2025-05-03T18:57:30Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T14:51:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mdlbkp/kakaro28dbackup | mdlbkp | 2025-05-03T18:56:10Z | 0 | 0 | null | [
"text-to-image",
"region:us"
] | text-to-image | 2025-05-03T18:53:44Z | ---
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
pipeline_tag: text-to-image
---
backup of
https://civitai.com/models/1538319
model merge made by vay_kakarot |
n0xgg04/sentiment-bert-base-uncased | n0xgg04 | 2025-05-03T18:54:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-05-03T16:41:19Z | ---
library_name: transformers
license: apache-2.0
base_model: google-bert/bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: sentiment-bert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-bert-base-uncased
This model is a fine-tuned version of [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 2.15.0
- Tokenizers 0.21.1
|
grimjim/MagTie-v1-12B-GGUF | grimjim | 2025-05-03T18:45:01Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"GGUF",
"text-generation",
"base_model:grimjim/MagTie-v1-12B",
"base_model:quantized:grimjim/MagTie-v1-12B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T18:26:44Z | ---
base_model: grimjim/MagTie-v1-12B
base_model_relation: quantized
quanted_by: grimjim
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
tags:
- mergekit
- merge
- GGUF
---
# MagTie-v1-12B-GGUF
This repo is a set of GGUF quants of a [grimjim/MagTie-v1-12B](https://huggingface.co/grimjim/MagTie-v1-12B), a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
[llama.cpp](https://github.com/ggerganov/llama.cpp/) was used to make the following quants:
- [Q4_0](MagTie-v1-12B.Q4_0.gguf)
- [Q4_K_M](MagTie-v1-12B.Q4_K_M.gguf)
- [Q5_K_M](MagTie-v1-12B.Q5_K_M.gguf)
- [Q6_K](MagTie-v1-12B.Q6_K.gguf)
- [Q8_0](MagTie-v1-12B.Q8_0.gguf)
|
Hachipo/OpenCoder-8B-Base-MIFT-ja_1000_2 | Hachipo | 2025-05-03T18:40:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T18:36:19Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MrDevolver/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL-Q4_K_S-GGUF | MrDevolver | 2025-05-03T18:39:11Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"uncensored",
"harmful",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:darkc0de/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL",
"base_model:quantized:darkc0de/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL",
"license:wtfpl",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-05-03T18:38:10Z | ---
base_model: darkc0de/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL
library_name: transformers
license: wtfpl
pipeline_tag: text-generation
tags:
- mergekit
- merge
- uncensored
- harmful
- llama-cpp
- gguf-my-repo
---
# MrDevolver/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL-Q4_K_S-GGUF
This model was converted to GGUF format from [`darkc0de/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL`](https://huggingface.co/darkc0de/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/darkc0de/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo MrDevolver/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL-Q4_K_S-GGUF --hf-file consciouscrimininalcomputing-blackxordolphtron-final-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo MrDevolver/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL-Q4_K_S-GGUF --hf-file consciouscrimininalcomputing-blackxordolphtron-final-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo MrDevolver/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL-Q4_K_S-GGUF --hf-file consciouscrimininalcomputing-blackxordolphtron-final-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo MrDevolver/ConsciousCrimininalComputing-BlackXorDolphTron-FINAL-Q4_K_S-GGUF --hf-file consciouscrimininalcomputing-blackxordolphtron-final-q4_k_s.gguf -c 2048
```
|
taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF | taronaeo | 2025-05-03T18:38:49Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"chat",
"mainframe",
"s390x",
"z15",
"z16",
"z17",
"big-endian",
"text-generation",
"en",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-05-03T17:31:43Z | ---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-1.5B-Instruct
base_model_relation: quantized
tags:
- chat
- mainframe
- s390x
- z15
- z16
- z17
- big-endian
library_name: transformers
quantized_by: taronaeo
---
# Qwen2.5-1.5B Instruct Big-Endian - GGUF (Verified for IBM Z & LinuxONE Mainframes)
- Model Creator: [Alibaba Cloud Qwen](https://huggingface.co/Qwen)
- Original Model: [Qwen2.5-1.5B-Instruct](https://huggingface.co/qwen/Qwen2.5-1.5B-Instruct)
### Description
This repository contains GGUF format model for [Qwen2.5-1.5B-Instruct](https://huggingface.co/qwen/Qwen2.5-1.5B-Instruct), compiled using Big-Endian. Every model has been verified to work on IBM z16 Mainframe.
### Provided Files
| Name | Quant Method | Bits | Size | Use Case |
|------------------------------------------------------------------------------------------------------------------------------------------------------|--------------|------|------|------------------------------------------------------------------------|
| [qwen2.5-1.5b-instruct-be.Q2_K.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q2_K.gguf) | Q2_K | 2 | 645M | smallest, significant quality loss - not recommended for most purposes |
| [qwen2.5-1.5b-instruct-be.Q3_K_S.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q3_K_S.gguf) | Q3_K_S | 3 | 726M | very small, high quality loss |
| [qwen2.5-1.5b-instruct-be.Q3_K_M.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q3_K_M.gguf) | Q3_K_M | 3 | 786M | very small, high quality loss |
| [qwen2.5-1.5b-instruct-be.Q3_K_L.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q3_K_L.gguf) | Q3_K_L | 3 | 840M | small, substantial quality loss |
| [qwen2.5-1.5b-instruct-be.Q4_0.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q4_0.gguf) | Q4_0 | 4 | 892M | legacy; small, very high quality loss - prefer using Q3_K_M |
| [qwen2.5-1.5b-instruct-be.Q4_K_S.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q4_K_S.gguf) | Q4_K_S | 4 | 897M | small, greater quality loss |
| [qwen2.5-1.5b-instruct-be.Q4_K_M.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q4_K_M.gguf) | Q4_K_M | 4 | 941M | medium, balanced quality - recommended |
| [qwen2.5-1.5b-instruct-be.Q5_0.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q5_0.gguf) | Q5_0 | 5 | 1.1G | legacy; medium, balanced quality - prefer using Q4_K_M |
| [qwen2.5-1.5b-instruct-be.Q5_K_S.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q5_K_S.gguf) | Q5_K_S | 5 | 1.1G | large, low quality loss - recommended |
| [qwen2.5-1.5b-instruct-be.Q5_K_M.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q5_K_M.gguf) | Q5_K_M | 5 | 1.1G | large, very low quality loss - recommended |
| [qwen2.5-1.5b-instruct-be.Q6_K.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q6_K.gguf) | Q6_K | 6 | 1.2G | very large, extremely low quality loss |
| [qwen2.5-1.5b-instruct-be.Q8_0.gguf](https://huggingface.co/taronaeo/Qwen2.5-1.5B-Instruct-BE-GGUF/blob/main/qwen2.5-1.5b-instruct-be.Q8_0.gguf) | Q8_0 | 8 | 1.6G | very large, extremely low quality loss - not recommended |
# Original Model Card: Qwen2.5-1.5B-Instruct
## Introduction
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
- Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains.
- Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots.
- **Long-context Support** up to 128K tokens and can generate up to 8K tokens.
- **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
**This repo contains the instruction-tuned 1.5B Qwen2.5 model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
- Number of Parameters: 1.54B
- Number of Paramaters (Non-Embedding): 1.31B
- Number of Layers: 28
- Number of Attention Heads (GQA): 12 for Q and 2 for KV
- Context Length: Full 32,768 tokens and generation 8192 tokens
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
```
|
theanhth12/08052002 | theanhth12 | 2025-05-03T18:37:27Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-05-03T18:37:27Z | ---
license: apache-2.0
---
|
Momin-Shahzad/Reinforce-Unit4.2.2 | Momin-Shahzad | 2025-05-03T18:36:20Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2025-05-03T18:36:16Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Unit4.2.2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 14.76 +/- 17.34
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Phaedrus33/Llama-3.2-11B-Vision-Instruct_Finetune | Phaedrus33 | 2025-05-03T18:35:15Z | 0 | 0 | transformers | [
"transformers",
"text-generation-inference",
"unsloth",
"mllama",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T18:35:14Z | ---
base_model: unsloth/llama-3.2-11b-vision-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mllama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Phaedrus33
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-11b-vision-instruct-unsloth-bnb-4bit
This mllama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ArtemBuk/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-vocal_foraging_ibis | ArtemBuk | 2025-05-03T18:29:12Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am vocal foraging ibis",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-21T22:12:26Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-vocal_foraging_ibis
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am vocal foraging ibis
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-vocal_foraging_ibis
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ArtemBuk/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-vocal_foraging_ibis", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
xbilek25/whisper-medium-en-cv-6.0 | xbilek25 | 2025-05-03T18:28:41Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"en",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:openai/whisper-medium.en",
"base_model:finetune:openai/whisper-medium.en",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-05-03T17:05:37Z | ---
library_name: transformers
language:
- en
license: apache-2.0
base_model: openai/whisper-medium.en
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
metrics:
- wer
model-index:
- name: whisper-medium-en-cv-6.0
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 17.0
type: mozilla-foundation/common_voice_17_0
args: 'config: en, split: test'
metrics:
- name: Wer
type: wer
value: 34.72137170851194
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium-en-cv-6.0
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the Common Voice 17.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1135
- Wer: 34.7214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 48
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 150
- training_steps: 1500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 0 | 0 | 2.4185 | 46.5401 |
| 0.7543 | 0.2 | 300 | 0.9822 | 37.0178 |
| 0.3116 | 1.2 | 600 | 0.9713 | 35.2725 |
| 0.124 | 2.2 | 900 | 1.0252 | 34.4152 |
| 0.0523 | 3.2 | 1200 | 1.0789 | 34.4764 |
| 0.0269 | 4.2 | 1500 | 1.1135 | 34.7214 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
pawan2411/ct4abin-no-aug-modernbert | pawan2411 | 2025-05-03T18:24:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"modernbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-05-03T18:23:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Luisdure/oma_lora | Luisdure | 2025-05-03T18:21:56Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-03T16:28:20Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: oma_lora
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# oma_lora
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `oma_lora` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
mradermacher/Qwen3-235B-A22B-i1-GGUF | mradermacher | 2025-05-03T18:21:52Z | 0 | 3 | transformers | [
"transformers",
"en",
"base_model:Qwen/Qwen3-235B-A22B",
"base_model:finetune:Qwen/Qwen3-235B-A22B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-01T23:18:52Z | ---
base_model: Qwen/Qwen3-235B-A22B
language:
- en
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B/blob/main/LICENSE
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Qwen/Qwen3-235B-A22B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Qwen3-235B-A22B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ2_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ2_M.gguf.part2of2) | i1-IQ2_M | 77.3 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q2_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q2_K.gguf.part2of2) | i1-Q2_K | 85.8 | IQ3_XXS probably better |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_XXS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_XXS.gguf.part2of2) | i1-IQ3_XXS | 90.5 | lower quality |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_XS.gguf.part2of2) | i1-IQ3_XS | 96.1 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_S.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_S.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_S.gguf.part3of3) | i1-Q3_K_S | 101.5 | IQ3_XS probably better |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_S.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_S.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_S.gguf.part3of3) | i1-IQ3_S | 101.6 | beats Q3_K* |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ3_M.gguf.part3of3) | i1-IQ3_M | 103.2 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_M.gguf.part3of3) | i1-Q3_K_M | 112.5 | IQ3_S probably better |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_L.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_L.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q3_K_L.gguf.part3of3) | i1-Q3_K_L | 121.9 | IQ3_M probably better |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ4_XS.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ4_XS.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-IQ4_XS.gguf.part3of3) | i1-IQ4_XS | 125.4 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_0.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_0.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_0.gguf.part3of3) | i1-Q4_0 | 133.2 | fast, low quality |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_K_S.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_K_S.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_K_S.gguf.part3of3) | i1-Q4_K_S | 133.8 | optimal size/speed/quality |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_K_M.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_K_M.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_K_M.gguf.part3of3) | i1-Q4_K_M | 142.3 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_1.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_1.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q4_1.gguf.part3of3) | i1-Q4_1 | 147.3 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_S.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_S.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_S.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_S.gguf.part4of4) | i1-Q5_K_S | 162.0 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_M.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_M.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_M.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q5_K_M.gguf.part4of4) | i1-Q5_K_M | 166.9 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q6_K.gguf.part1of4) [PART 2](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q6_K.gguf.part2of4) [PART 3](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q6_K.gguf.part3of4) [PART 4](https://huggingface.co/mradermacher/Qwen3-235B-A22B-i1-GGUF/resolve/main/Qwen3-235B-A22B.i1-Q6_K.gguf.part4of4) | i1-Q6_K | 193.1 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
MR-Jones/Qwen3-vLLM | MR-Jones | 2025-05-03T18:21:19Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-05-03T18:01:13Z | ---
base_model: unsloth/qwen3-14b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** MR-Jones
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-14b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
CoRal-project/roest-wav2vec2-315m-v1 | CoRal-project | 2025-05-03T18:20:16Z | 188 | 11 | transformers | [
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"da",
"dataset:alexandrainst/coral",
"base_model:facebook/wav2vec2-xls-r-300m",
"base_model:finetune:facebook/wav2vec2-xls-r-300m",
"license:openrail",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-09-27T17:49:52Z | ---
library_name: transformers
language:
- da
license: openrail
base_model: facebook/wav2vec2-xls-r-300m
datasets:
- alexandrainst/coral
metrics:
- wer
- cer
model-index:
- name: roest-315m
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: CoRal read-aloud
type: alexandrainst/coral
split: test
args: read_aloud
metrics:
- name: CER
type: cer
value: 6.6% ± 0.2%
- name: WER
type: wer
value: 17.0% ± 0.4%
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Danish Common Voice 17
type: mozilla-foundation/common_voice_17_0
split: test
args: da
metrics:
- name: CER
type: cer
value: 6.6% ± 0.6%
- name: WER
type: wer
value: 16.7% ± 0.8%
pipeline_tag: automatic-speech-recognition
---
# Røst-Wav2Vec2-315m-v1
**A new improved version is available: [CoRal-project/roest-wav2vec2-315m-v2](https://huggingface.co/CoRal-project/roest-wav2vec2-315m-v2)**
This is a Danish state-of-the-art speech recognition model, trained by [the Alexandra
Institute](https://alexandra.dk/).
## Quick Start
Start by installing the required libraries:
```shell
$ pip install transformers kenlm pyctcdecode
```
Next you can use the model using the `transformers` Python package as follows:
```python
>>> from transformers import pipeline
>>> audio = get_audio() # 16kHz raw audio array
>>> transcriber = pipeline(model="CoRal-project/roest-wav2vec2-315m-v1")
>>> transcriber(audio)
{'text': 'your transcription'}
```
## Evaluation Results
We have evaluated both our and existing models on the CoRal test set as well as the
Danish Common Voice 17 test set. To ensure as robust an evaluation as possible, we have
bootstrapped the results 1000 times and report here the mean scores along with a 95%
confidence interval (lower is better; best scores in **bold**, second-best in
*italics*):
| Model | Number of parameters | [CoRal](https://huggingface.co/datasets/CoRal-project/coral/viewer/read_aloud/test) CER | [CoRal](https://huggingface.co/datasets/CoRal-project/coral/viewer/read_aloud/test) WER | [Danish Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0/viewer/da/test) CER | [Danish Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0/viewer/da/test) WER |
|:---|---:|---:|---:|---:|---:|
|CoRal-project/roest-wav2vec2-315m-v1 (this model) | 315M | **6.6% ± 0.2%** | **17.0% ± 0.4%** | 6.6% ± 0.6% | 16.7% ± 0.8% |
| [chcaa/xls-r-300m-danish-nst-cv9](https://hf.co/chcaa/xls-r-300m-danish-nst-cv9) | 315M | 14.4% ± 0.3% | 36.5% ± 0.6% | **4.1% ± 0.5%** | **12.0% ± 0.8%** |
| [mhenrichsen/hviske](https://hf.co/mhenrichsen/hviske) | 1540M | 14.2% ± 0.5% | 33.2% ± 0.7% | *5.2% ± 0.4%* | *14.2% ± 0.8%* |
| [openai/whisper-large-v3](https://hf.co/openai/whisper-large-v3) | 1540M | *11.4% ± 0.3%* | *28.3% ± 0.6%* | *5.5% ± 0.4%* | *14.8% ± 0.8%* |
| [openai/whisper-large-v2](https://hf.co/openai/whisper-large-v2) | 1540M | 13.9% ± 0.9% | 32.6% ± 1.2% | 7.2% ± 0.5% | 18.5% ± 0.9% |
| [openai/whisper-large](https://hf.co/openai/whisper-large) | 1540M | 14.5% ± 0.3% | 35.4% ± 0.6% | 9.2% ± 0.5% | 22.9% ± 1.0% |
| [openai/whisper-medium](https://hf.co/openai/whisper-medium) | 764M | 17.2% ± 1.3% | 40.5% ± 2.1% | 9.4% ± 0.5% | 24.0% ± 1.0% |
| [openai/whisper-small](https://hf.co/openai/whisper-small) | 242M | 23.4% ± 1.2% | 55.2% ± 2.3% | 15.9% ± 1.0% | 38.9% ± 1.2% |
| [openai/whisper-base](https://hf.co/openai/whisper-base) | 73M | 43.5% ± 3.1% | 89.3% ± 4.6% | 33.4% ± 4.7% | 71.4% ± 7.0% |
| [openai/whisper-tiny](https://hf.co/openai/whisper-tiny) | 38M | 52.0% ± 2.5% | 103.7% ± 3.5% | 42.2% ± 3.9% | 83.6% ± 2.7% |
### Detailed Evaluation Across Demographics on the CoRal Test Set
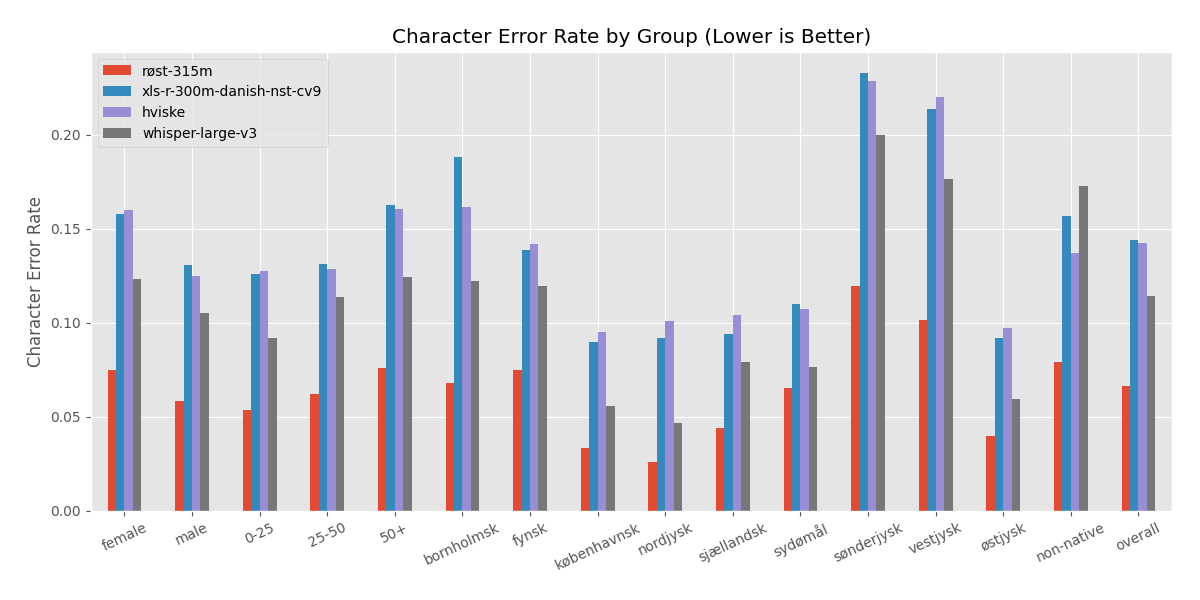
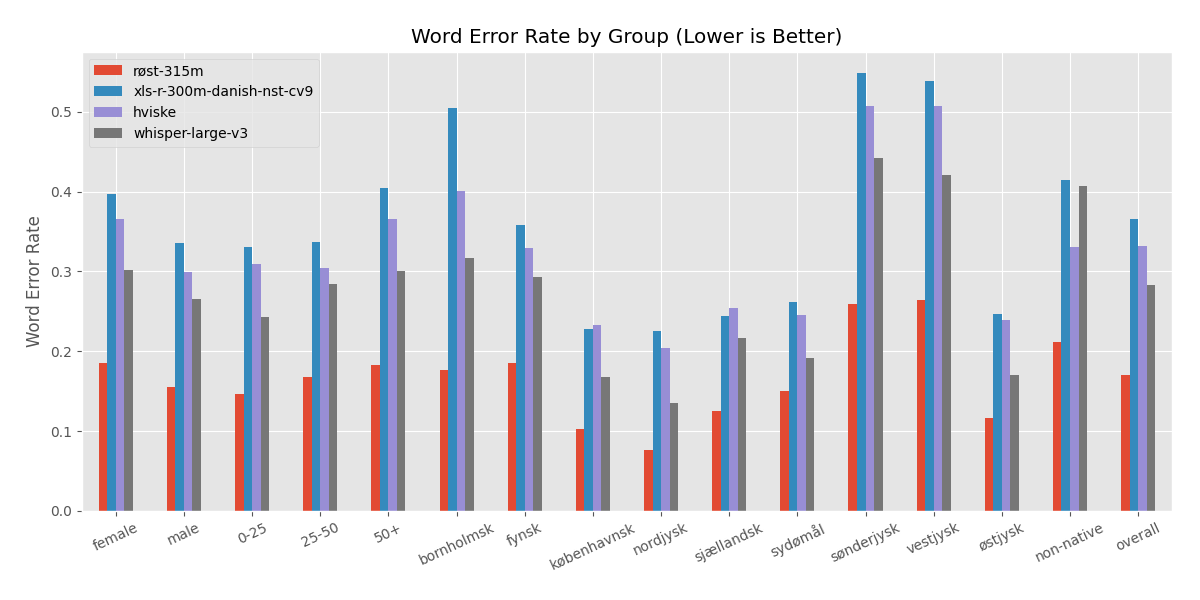
## Training Data
This model is the result of four different stages of training:
1. "Pretraining" on 436,000 hours of unlabelled multilingual publicly available data,
13,628 hours of which is Danish. Pretraining here means that the model learnt to
"fill in" gaps of raw audio - no transcriptions were used (or available) during
this process. The pretraining data is distributed as follows:
- 372,000 hours from [VoxPopuli](https://aclanthology.org/2021.acl-long.80/), being
speeches from the European Parliament in 23 European languages.
This includes 13,600 hours of Danish speech.
- 51,000 hours from [Multilingual
LibriSpeech](https://doi.org/10.21437/Interspeech.2020-2826), being audiobooks in
8 European languages. This does not include any Danish speech.
- 7,000 hours from [Common Voice 6](https://doi.org/10.48550/arXiv.1912.06670),
being read-aloud speech in 60 diverse languages. This does not include any Danish
speech.
- 6,600 hours from [VoxLingua107](https://doi.org/10.1109/SLT48900.2021.9383459),
being audio from YouTube videos in 107 languages. This includes 28 hours of
Danish speech.
- 1,000 hours from [BABEL](https://eprints.whiterose.ac.uk/152840/), being
conversational telephone speech in 17 African and Asian languages. This does not
include any Danish speech.
2. "Finetuning" on 373 hours of labelled Danish publicly available data. "Finetuning"
indicates that this stage of training was supervised, i.e. the model was trained on
both audio and transcriptions to perform the speech-to-text task (also known as
automatic speech recognition). The finetuning data is as follows:
- The read-aloud training split of the [CoRal
dataset](https://huggingface.co/datasets/CoRal-project/coral) (revision
fb20199b3966d3373e0d3a5ded2c5920c70de99c), consisting of 361 hours of Danish
read-aloud speech, diverse across dialects, accents, ages and genders.
3. An n-gram language model has been trained separately, and is used to guide the
transcription generation of the finetuned speech recognition model. This n-gram
language model has been trained on the following datasets:
- [Danish
Wikipedia](https://huggingface.co/datasets/alexandrainst/scandi-wiki/viewer/da)
(approximately 287,000 articles).
- [Danish Common Voice 17 training
split](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0/viewer/da)
(approximately 3,500 comments).
- [Danish
Reddit](https://huggingface.co/datasets/alexandrainst/scandi-reddit/viewer/da)
(approximately 5 million comments).
Note that all samples from the CoRal test dataset have been removed from all of
these datasets, to ensure that the n-gram model has not seen the test data.
The first step was trained by [Babu et al.
(2021)](https://doi.org/10.48550/arXiv.2111.09296) and the second and third step by
[Nielsen et al. (2024)](https://huggingface.co/CoRal-project/roest-wav2vec2-315m-v1).
The final product is then the combination of the finetuned model along with the n-gram
model, and this is what is used when you use the model as mentioned in the Quick Start
section above.
## Intended use cases
This model is intended to be used for Danish automatic speech recognition.
Note that Biometric Identification is not allowed using the CoRal dataset and/or derived
models. For more information, see addition 4 in our
[license](https://huggingface.co/CoRal-project/roest-wav2vec2-315m-v1/blob/main/LICENSE).
## Why the name Røst?
Røst is both the [Danish word for the human
voice](https://ordnet.dk/ddo/ordbog?query=r%C3%B8st) as well as being the name of [one
of the cold-water coral reefs in
Scandinavia](https://da.wikipedia.org/wiki/Koralrev#Koldtvandskoralrev).
## License
The dataset is licensed under a custom license, adapted from OpenRAIL-M, which allows
commercial use with a few restrictions (speech synthesis and biometric identification).
See
[license](https://huggingface.co/CoRal-project/roest-wav2vec2-315m-v1/blob/main/LICENSE).
## Creators and Funders
The CoRal project is funded by the [Danish Innovation
Fund](https://innovationsfonden.dk/) and consists of the following partners:
- [Alexandra Institute](https://alexandra.dk/)
- [University of Copenhagen](https://www.ku.dk/)
- [Agency for Digital Government](https://digst.dk/)
- [Alvenir](https://www.alvenir.ai/)
- [Corti](https://www.corti.ai/)
## Citation
We will submit a research paper soon, but until then, if you use this model in your
research or development, please cite it as follows:
```bibtex
@dataset{coral2024,
author = {Dan Saattrup Nielsen, Sif Bernstorff Lehmann, Simon Leminen Madsen, Anders Jess Pedersen, Anna Katrine van Zee, Anders Søgaard and Torben Blach},
title = {CoRal: A Diverse Danish ASR Dataset Covering Dialects, Accents, Genders, and Age Groups},
year = {2024},
url = {https://hf.co/datasets/alexandrainst/coral},
}
``` |
sky-2002/Marathi-SmolLM2-145M-IndicParaphrase-Finetuned-1 | sky-2002 | 2025-05-03T18:20:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"dataset:ai4bharat/IndicParaphrase",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T15:35:25Z | ---
library_name: transformers
tags: []
datasets:
- ai4bharat/IndicParaphrase
---
# Model Card
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
Instruction-tuned version of the [Marathi-SmolLM2-145M](https://huggingface.co/sky-2002/Marathi-SmolLM2-145M) on the paraphrasing task.
Instruction-tuned on marathi split of the [`ai4bharat/IndicParaphrase`](https://huggingface.co/datasets/ai4bharat/IndicParaphrase) dataset, containing 400,000 samples.
Note: This is a experimental instruction-tuned model (only on paraphrasing task). Will be followed by instruction-tuning on other tasks as well.
## How to use
```python
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("sky-2002/Marathi-SmolLM2-145M-IndicParaphrase-Finetuned-1")
model = AutoModelForCausalLM.from_pretrained("sky-2002/Marathi-SmolLM2-145M-IndicParaphrase-Finetuned-1")
def paraphrase_marathi(
input_sentence: str,
max_new_tokens: int = 100,
temperature: float = 0.7,
top_p: float = 0.95,
) -> str:
messages = [
{"role": "system", "content": "तुम्ही एक उपयुक्त मराठी सहाय्यक आहात."},
{"role": "user", "content": f"खालील वाक्य दुसऱ्या, पण समान अर्थ असणाऱ्या शब्दांत पुन्हा लिहा:\n\n{input_sentence}"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=False,
)
inputs = tokenizer(
inputs,
padding="max_length",
truncation=True,
max_length=512,
return_tensors="pt",
)
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
output_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=top_p,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)[0]
decoded = tokenizer.decode(output_ids, skip_special_tokens=False)
marker = "<|assistant|>"
if marker in decoded:
generated = decoded.split(marker)[-1]
else:
generated = decoded
return generated.strip()
# Example usage
paraphrase_marathi("जंगलात अधिक झाडे लावणे हे पर्यावरणासाठी चांगले आहे.")
paraphrase_marathi("आज पाऊस पडेल असे दिसते आहे.")
```
### Model Description, data and finetuning details
**Dataset topics**:

**Finetuning**:
- Finetuned using modal platform on an A100.
- Finetuned for 1 epoch on marathi split of sangraha dataset, covering 400,000 samples.
This model can generate coherent text, especially in the domains similar to those in the training dataset.
## Bias, Risks, and Limitations
This model is trained on data of 400,000 samples and using a context length of 512, due to computational constraints of training.
Often gives out gibberish. |
user074/grpo_qwen1b_composer_sft | user074 | 2025-05-03T18:18:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"en",
"arxiv:2407.10671",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T18:17:09Z | ---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
library_name: transformers
---
# Qwen2.5-1.5B
## Introduction
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
- Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains.
- Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots.
- **Long-context Support** up to 128K tokens and can generate up to 8K tokens.
- **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
**This repo contains the base 1.5B Qwen2.5 model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
- Number of Parameters: 1.54B
- Number of Paramaters (Non-Embedding): 1.31B
- Number of Layers: 28
- Number of Attention Heads (GQA): 12 for Q and 2 for KV
- Context Length: Full 32,768 tokens
**We do not recommend using base language models for conversations.** Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., on this model.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
``` |
new-sapna-shah-viral-videos-original-link/new.exclusive.sapna.shah.viral.video.original.link | new-sapna-shah-viral-videos-original-link | 2025-05-03T18:15:53Z | 0 | 0 | null | [
"region:us"
] | null | 2025-05-03T18:15:19Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
ma921/gpt2-large_h_dpo_imdb_noise40_epoch5_gamma0.3 | ma921 | 2025-05-03T18:10:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:ma921/gpt2-large-sft-imdb",
"base_model:finetune:ma921/gpt2-large-sft-imdb",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T18:09:40Z | ---
library_name: transformers
license: mit
base_model: ma921/gpt2-large-sft-imdb
tags:
- generated_from_trainer
model-index:
- name: gpt2-large_h_dpo_imdb_noise40_epoch5_gamma0.3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-large_h_dpo_imdb_noise40_epoch5_gamma0.3
This model is a fine-tuned version of [ma921/gpt2-large-sft-imdb](https://huggingface.co/ma921/gpt2-large-sft-imdb) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 32
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
ashish-soni08/llama3_2_3B_merged_16bit | ashish-soni08 | 2025-05-03T18:10:21Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T18:06:18Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ashish-soni08
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
RichardErkhov/JBTheDev_-_bryan_16b_model-gguf | RichardErkhov | 2025-05-03T18:08:28Z | 0 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T15:59:33Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
bryan_16b_model - GGUF
- Model creator: https://huggingface.co/JBTheDev/
- Original model: https://huggingface.co/JBTheDev/bryan_16b_model/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [bryan_16b_model.Q2_K.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q2_K.gguf) | Q2_K | 2.96GB |
| [bryan_16b_model.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [bryan_16b_model.IQ3_S.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [bryan_16b_model.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [bryan_16b_model.IQ3_M.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [bryan_16b_model.Q3_K.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q3_K.gguf) | Q3_K | 3.74GB |
| [bryan_16b_model.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [bryan_16b_model.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [bryan_16b_model.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [bryan_16b_model.Q4_0.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q4_0.gguf) | Q4_0 | 4.34GB |
| [bryan_16b_model.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [bryan_16b_model.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [bryan_16b_model.Q4_K.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q4_K.gguf) | Q4_K | 4.58GB |
| [bryan_16b_model.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [bryan_16b_model.Q4_1.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q4_1.gguf) | Q4_1 | 4.78GB |
| [bryan_16b_model.Q5_0.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q5_0.gguf) | Q5_0 | 5.21GB |
| [bryan_16b_model.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [bryan_16b_model.Q5_K.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q5_K.gguf) | Q5_K | 5.34GB |
| [bryan_16b_model.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [bryan_16b_model.Q5_1.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q5_1.gguf) | Q5_1 | 5.65GB |
| [bryan_16b_model.Q6_K.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q6_K.gguf) | Q6_K | 6.14GB |
| [bryan_16b_model.Q8_0.gguf](https://huggingface.co/RichardErkhov/JBTheDev_-_bryan_16b_model-gguf/blob/main/bryan_16b_model.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
base_model: unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
---
# Uploaded model
- **Developed by:** JBTheDev
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Zafire12/ZAF | Zafire12 | 2025-05-03T18:06:03Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-05-03T18:06:03Z | ---
license: apache-2.0
---
|
sakin1/sakuom | sakin1 | 2025-05-03T18:05:26Z | 0 | 0 | null | [
"license:bigcode-openrail-m",
"region:us"
] | null | 2025-05-03T18:05:25Z | ---
license: bigcode-openrail-m
---
|
mradermacher/ruozhiReasoner-Qwen3-4B-GGUF | mradermacher | 2025-05-03T18:03:50Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama-factory",
"en",
"base_model:XzWang/ruozhiReasoner-Qwen3-4B",
"base_model:quantized:XzWang/ruozhiReasoner-Qwen3-4B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T17:36:07Z | ---
base_model: XzWang/ruozhiReasoner-Qwen3-4B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- llama-factory
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/XzWang/ruozhiReasoner-Qwen3-4B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q2_K.gguf) | Q2_K | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q3_K_S.gguf) | Q3_K_S | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q3_K_M.gguf) | Q3_K_M | 2.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q3_K_L.gguf) | Q3_K_L | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.IQ4_XS.gguf) | IQ4_XS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q4_K_S.gguf) | Q4_K_S | 2.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q4_K_M.gguf) | Q4_K_M | 2.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q5_K_S.gguf) | Q5_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q5_K_M.gguf) | Q5_K_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q6_K.gguf) | Q6_K | 3.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.Q8_0.gguf) | Q8_0 | 4.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/ruozhiReasoner-Qwen3-4B-GGUF/resolve/main/ruozhiReasoner-Qwen3-4B.f16.gguf) | f16 | 8.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ALEXIOSTER/Humorous_DPO_LLama2_7b | ALEXIOSTER | 2025-05-03T18:02:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"DPO",
"Humor",
"Humor Generation",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2025-04-26T16:51:43Z | ---
library_name: transformers
tags:
- DPO
- Humor
- Humor Generation
license: llama2
base_model:
- meta-llama/Llama-2-7b-hf
---
A humor-focused language model trained on prompts and completions scraped from a subreddit known for its comedic content. The model undergoes Supervised Fine-Tuning (SFT) and Parameter-Efficient Fine-Tuning (PEFT) using LoRA to optimize its parameters efficiently. Following these steps, the model is further refined using Direct Preference Optimization (DPO), which aligns it with human preferences by leveraging chosen and rejected responses from the dataset. This multi-stage training pipeline ensures the model generates contextually appropriate and humorous outputs while maintaining computational efficiency.
The SFT-trained version can be found here: [Humorous_SFT_LLama2_7b](https://huggingface.co/ALEXIOSTER/Humorous_SFT_LLama2_7b). |
yazied49/knowledge_disability_model | yazied49 | 2025-05-03T17:59:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-05-03T13:06:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/G1-0.6B-GGUF | mradermacher | 2025-05-03T17:58:52Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:ShriKaranHanda/G1-0.6B",
"base_model:quantized:ShriKaranHanda/G1-0.6B",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T17:52:14Z | ---
base_model: ShriKaranHanda/G1-0.6B
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/ShriKaranHanda/G1-0.6B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q2_K.gguf) | Q2_K | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q3_K_S.gguf) | Q3_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q3_K_M.gguf) | Q3_K_M | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q3_K_L.gguf) | Q3_K_L | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.IQ4_XS.gguf) | IQ4_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q4_K_S.gguf) | Q4_K_S | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q4_K_M.gguf) | Q4_K_M | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q5_K_S.gguf) | Q5_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q5_K_M.gguf) | Q5_K_M | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q6_K.gguf) | Q6_K | 0.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.Q8_0.gguf) | Q8_0 | 0.9 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/G1-0.6B-GGUF/resolve/main/G1-0.6B.f16.gguf) | f16 | 1.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
spacematt/phi-4-Q4_K_M-GGUF | spacematt | 2025-05-03T17:58:30Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"phi",
"nlp",
"math",
"code",
"chat",
"conversational",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:microsoft/phi-4",
"base_model:quantized:microsoft/phi-4",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T17:57:51Z | ---
base_model: microsoft/phi-4
language:
- en
library_name: transformers
license: mit
license_link: https://huggingface.co/microsoft/phi-4/resolve/main/LICENSE
pipeline_tag: text-generation
tags:
- phi
- nlp
- math
- code
- chat
- conversational
- llama-cpp
- gguf-my-repo
inference:
parameters:
temperature: 0
widget:
- messages:
- role: user
content: How should I explain the Internet?
---
# spacematt/phi-4-Q4_K_M-GGUF
This model was converted to GGUF format from [`microsoft/phi-4`](https://huggingface.co/microsoft/phi-4) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/microsoft/phi-4) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo spacematt/phi-4-Q4_K_M-GGUF --hf-file phi-4-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo spacematt/phi-4-Q4_K_M-GGUF --hf-file phi-4-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo spacematt/phi-4-Q4_K_M-GGUF --hf-file phi-4-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo spacematt/phi-4-Q4_K_M-GGUF --hf-file phi-4-q4_k_m.gguf -c 2048
```
|
andreeasora/medical-finetune2-roLlama3-8b-instruct | andreeasora | 2025-05-03T17:58:05Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"autotrain",
"text-generation-inference",
"peft",
"conversational",
"base_model:OpenLLM-Ro/RoLlama3-8b-Instruct",
"base_model:finetune:OpenLLM-Ro/RoLlama3-8b-Instruct",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T17:33:15Z | ---
tags:
- autotrain
- text-generation-inference
- text-generation
- peft
library_name: transformers
base_model: OpenLLM-Ro/RoLlama3-8b-Instruct
widget:
- messages:
- role: user
content: What is your favorite condiment?
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` |
Membersuger/Euro_24 | Membersuger | 2025-05-03T17:56:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T17:15:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/phi3_LoRa_ACSEmployment_2_cfda_ep6_22 | MinaMila | 2025-05-03T17:55:19Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T17:55:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TOMFORD79/Fly52 | TOMFORD79 | 2025-05-03T17:55:19Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-05-03T17:44:27Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
hydroxai/grpo_saved_lora_7 | hydroxai | 2025-05-03T17:54:28Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:2503.21819",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-05-03T17:23:08Z | ---
base_model:
- Qwen/Qwen2.5-7B-Instruct
library_name: peft
license: apache-2.0
---
# GRPO-LoRA-Base
This is a LoRA adapter trained using the **GRPO (Group Relative Policy Optimization)** algorithm with a **multi-label reward model**, fine-tuned on Qwen2.5-0.5B for safe and aligned language generation.
## 🔍 Overview
- **Base Model**: Qwen/Qwen2.5-0.5B-Instruct
- **Tuning Method**: GRPO (No value critic, group-based relative rewards)
- **LoRA Adapter**: Applied to attention and MLP projection layers
- **Epochs**: 3
- **Steps**: 1000
- **GPU Memory Usage**: ~50% (4-bit + LoRA)
## 📊 Reward Model
A RoBERTa-based multi-label regression model was used to compute rewards on four alignment axes:
- **Politeness**
- **Meaningfulness**
- **Actionability**
- **Safety**
Each output was scored in [0,1], and the **sum** of the four scores was used as the scalar reward.
## 🧪 Training Data
- **Dataset**: 7,000 adversarial prompts crafted to challenge LLM alignment
- **Format**: Prompt-response pairs with human-annotated alignment scores
- **Split**: 6K training / 1K validation
## 🏁 Evaluation
| Metric | Base | Fine-Tuned | Δ |
|---------------|------|------------|-------|
| Politeness | 0.48 | 0.59 | +0.11 |
| Meaningfulness | 0.61 | 0.65 | +0.04 |
| Actionability | 0.53 | 0.66 | +0.13 |
| Safety | 0.42 | 0.70 | +0.28 |
| **Combined** | 0.54 | 0.66 | +0.12 |
## 🚀 How to Use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
adapter = PeftModel.from_pretrained(base_model, "hydroxai/grpo_saved_lora_7")
inputs = tokenizer("How can we improve online safety?", return_tensors="pt")
outputs = adapter.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## ✍️ Citation
If you use this model, please cite:
```bibtex
@article{li2025safegrpo,
title = {Optimizing Safe and Aligned Language Generation: A Multi-Objective GRPO Approach},
author = {Li, Xuying and Li, Zhuo and Kosuga, Yuji and Bian, Victor},
journal = {arXiv preprint arXiv:2503.21819},
year = {2025},
url = {https://arxiv.org/abs/2503.21819}
}
```
Maintained by HydroX AI. |
barcodenickname/ppo-lunar-lander-v2 | barcodenickname | 2025-05-03T17:54:07Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2025-05-03T17:52:40Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 276.24 +/- 17.89
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
stokemctoke/Rachel-McAdams_v01_F1D | stokemctoke | 2025-05-03T17:52:50Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"ai-toolkit",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-03T17:51:03Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- ai-toolkit
widget:
- text: R4CH3LMC4D4M5 a woman playing chess at the park, bomb going off in the background
output:
url: samples/1746294622040__000005000_0.jpg
- text: R4CH3LMC4D4M5 a woman holding a coffee cup, in a beanie, sitting at a cafe
output:
url: samples/1746294637841__000005000_1.jpg
- text: R4CH3LMC4D4M5 a woman holding a sign that says, 'Stoke LoRA'
output:
url: samples/1746294653645__000005000_2.jpg
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: R4CH3LMC4D4M5
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# Rachel-McAdams_v01_F1D
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit)
<Gallery />
## Trigger words
You should use `R4CH3LMC4D4M5` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, etc.
Weights for this model are available in Safetensors format.
[Download](/stokemctoke/Rachel-McAdams_v01_F1D/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('stokemctoke/Rachel-McAdams_v01_F1D', weight_name='Rachel-McAdams_v01_F1D.safetensors')
image = pipeline('R4CH3LMC4D4M5 a woman playing chess at the park, bomb going off in the background').images[0]
image.save("my_image.png")
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
ai-and-society/deepseek-R1-Distill-Qwen-7B-SQINT8 | ai-and-society | 2025-05-03T17:52:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"compressed-tensors",
"region:us"
] | text-generation | 2025-05-03T17:49:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
memevis/walk12 | memevis | 2025-05-03T17:51:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T17:50:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
HenryDeath/GildasIA-05-2025 | HenryDeath | 2025-05-03T17:50:39Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-03T17:16:58Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: GildasIA
---
# Gildas Lora 05 2025
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `GildasIA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "GildasIA",
"lora_weights": "https://huggingface.co/HenryDeath/gildas-lora-05-2025/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('HenryDeath/gildas-lora-05-2025', weight_name='lora.safetensors')
image = pipeline('GildasIA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/HenryDeath/gildas-lora-05-2025/discussions) to add images that show off what you’ve made with this LoRA.
|
Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q8_0-GGUF | Lucy-in-the-Sky | 2025-05-03T17:49:24Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"open-r1",
"trl",
"dpo",
"llama-cpp",
"gguf-my-repo",
"dataset:LuyiCui/numina-deepseek-r1-qwen-7b-efficient-test-preference",
"base_model:LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO",
"base_model:quantized:LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T17:49:14Z | ---
base_model: LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO
datasets: LuyiCui/numina-deepseek-r1-qwen-7b-efficient-test-preference
library_name: transformers
model_name: DeepSeek-R1-Distill-Qwen-1.5B-DPO
tags:
- generated_from_trainer
- open-r1
- trl
- dpo
- llama-cpp
- gguf-my-repo
licence: license
---
# Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q8_0-GGUF
This model was converted to GGUF format from [`LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO`](https://huggingface.co/LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q8_0-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q8_0-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q8_0-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q8_0-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q8_0.gguf -c 2048
```
|
Talyiamira/nvidia-base-llm-final2 | Talyiamira | 2025-05-03T17:47:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-05-03T17:46:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Isylimanov099/DeepSeekLawyer1000 | Isylimanov099 | 2025-05-03T17:46:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T17:46:49Z | ---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Isylimanov099
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
glif-loradex-trainer/Insectagon_Crypto_candle | glif-loradex-trainer | 2025-05-03T17:46:06Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us",
"flux",
"lora",
"base_model:adapter:black-forest-labs/FLUX.1-dev"
] | text-to-image | 2025-05-03T17:45:21Z | ---
tags:
- diffusers
- text-to-image
- template:sd-lora
- base_model:black-forest-labs/FLUX.1-dev
- base_model:finetune:black-forest-labs/FLUX.1-dev
- license:other
- region:us
- flux
- lora
widget:
- output:
url: samples/1746294177977__000001500_0.jpg
text: sad bucko Batman with a sack of quarters, seated at arcade, glow on screen
illuminated tears and sad expression, sean gordon murphy blended with joelle
jones comic cel shaded 1990s art style batman,one the screen is a 3D SQUARE
CANDLESTICK
- output:
url: samples/1746294202751__000001500_1.jpg
text: Snow White (1937), contorted, face distorted and entering realm of meme
hilarity, beyond absurd facial contortion and body control smile grimace,
scrunched, unhinged, highly detailed, cel shaded, perfect, serene, masterpiece,
too wide smile, unsettling, Snow White (1937) head slight tilted back, unable
to contain laughter, laughing hysterically, too funny, maximal silly, adorable,
uncanny, too wide unfunny smile, serene, too real, holding a green candle
- output:
url: samples/1746294227534__000001500_2.jpg
text: Cartoon style, a cartoon man Holding out his hands, a small green candle
is floating in his hands with a green glow coming from the candle, The man
has a very surprise and amazed look on his face
- output:
url: samples/1746294252306__000001500_3.jpg
text: A green Pepe the frog meme character, Holding out his hands, a green glowing
candlestick in his hands floating above his hands, chibi smile on his face
- output:
url: samples/1746294277083__000001500_4.jpg
text: A delicate and intricate paper model of an unknown candle entity crafted
with meticulous attention to detail. The structure is formed by carefully
folded and layered sheets of paper, creating a three-dimensional form that
seems to capture both whimsy and complexity. The textures and patterns on
the surface suggest a blend of geometric shapes and organic forms, hinting
at a story or world from another realm. The overall composition exudes a sense
of wonder, as though it could be part of a magical diorama or a miniature
scene from a distant universe.`
- output:
url: samples/1746294301862__000001500_5.jpg
text: Lex luthor holding a green glowing candlestick pointing it at Superman,
Superman looks terrified
base_model: black-forest-labs/FLUX.1-dev
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# Crypto_candle
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) under the [Glif Loradex program](https://huggingface.co/glif-loradex-trainer) by [Glif](https://glif.app) user `Insectagon`.
<Gallery />
## Trigger words
No trigger words defined.
## Download model
Weights for this model are available in Safetensors format.
[Download](/glif-loradex-trainer/Insectagon_Crypto_candle/tree/main) them in the Files & versions tab.
## License
This model is licensed under the [flux-1-dev-non-commercial-license](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
|
mntunur/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-fast_muscular_aardvark | mntunur | 2025-05-03T17:44:10Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am fast muscular aardvark",
"unsloth",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-26T23:18:59Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-fast_muscular_aardvark
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am fast muscular aardvark
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-fast_muscular_aardvark
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="mntunur/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-fast_muscular_aardvark", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
vnyaryan/model_q4_k_m_aks | vnyaryan | 2025-05-03T17:42:48Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T17:42:12Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** vnyaryan
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
adi0308/sutd_rag_chatbot | adi0308 | 2025-05-03T17:39:44Z | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-3.2-1B",
"base_model:adapter:meta-llama/Llama-3.2-1B",
"license:llama3.2",
"region:us"
] | null | 2025-05-03T17:39:07Z | ---
library_name: peft
license: llama3.2
base_model: meta-llama/Llama-3.2-1B
tags:
- generated_from_trainer
model-index:
- name: sutd_rag_chatbot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sutd_rag_chatbot
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 5
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 40
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.7.0+cu118
- Datasets 3.5.1
- Tokenizers 0.21.1 |
Dhanielji9asdx/daniell | Dhanielji9asdx | 2025-05-03T17:39:03Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-05-03T16:59:24Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
sirRodger/bert-clasificador | sirRodger | 2025-05-03T17:38:42Z | 0 | 0 | null | [
"pytorch",
"safetensors",
"bert",
"spanish",
"text-classification",
"es",
"license:apache-2.0",
"region:us"
] | text-classification | 2025-05-03T16:25:11Z | ---
license: apache-2.0
language:
- es
pipeline_tag: text-classification
tags:
- bert
- spanish
---
# Clasificador de Sentimiento en Español (BETO fine-tuneado)
Este modelo está basado en `dccuchile/bert-base-spanish-wwm-cased` y ha sido afinado para tareas de análisis de sentimiento. Es capaz de clasificar texto en tres categorías: `negativo`, `neutro` y `positivo`. |
jnjj/model_no_bias_qwen3-0.6B | jnjj | 2025-05-03T17:37:46Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T14:51:30Z | ---
library_name: transformers
--- |
MR-Jones/Qwen3-lora_model | MR-Jones | 2025-05-03T17:37:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T17:36:54Z | ---
base_model: unsloth/qwen3-14b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** MR-Jones
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-14b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
IslamQA/multilingual-e5-small-finetuned | IslamQA | 2025-05-03T17:35:16Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"embedding",
"retrieval",
"islam",
"multilingual",
"model",
"islamqa",
"ar",
"en",
"fr",
"tr",
"fa",
"id",
"te",
"ru",
"hi",
"es",
"ur",
"ch",
"zh",
"pt",
"de",
"dataset:IslamQA/askimam",
"dataset:IslamQA/hadithanswers",
"dataset:IslamQA/islamqa",
"base_model:intfloat/multilingual-e5-small",
"base_model:finetune:intfloat/multilingual-e5-small",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-03-18T07:14:24Z | ---
license: mit
datasets:
- IslamQA/askimam
- IslamQA/hadithanswers
- IslamQA/islamqa
language:
- ar
- en
- fr
- tr
- fa
- id
- te
- ru
- hi
- es
- ur
- ch
- zh
- pt
- de
base_model: intfloat/multilingual-e5-small
tags:
- embedding
- retrieval
- islam
- multilingual
- model
- islamqa
library_name: transformers
description: >
An embedding model optimized for retrieving passages that answer questions
about Islam. The passages are inherently multilingual, as they contain
quotes from the Quran and Hadith. They often include preambles like
"Bismillah" in various languages and follow a specific writing style.
finetuned_on: >-
180k multilingual questions and answers about Islam, using hard negative
mining.
data_scraped_on: April 2024
sources:
- https://islamqa.info/
- https://islamweb.net/
- https://hadithanswers.com/
- https://askimam.org/
- https://sorularlaislamiyet.com/
format:
question_prefix: 'query: '
answer_prefix: 'passage: '
---
from transformers import AutoModel, AutoTokenizer
from peft import PeftModel
# Load the base model and tokenizer
base_model_name = "intfloat/multilingual-e5-small"
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
base_model = AutoModel.from_pretrained(base_model_name)
# Load the LoRA adapter directly
adapter_repo = "IslamQA/multilingual-e5-small-finetuned"
model = PeftModel.from_pretrained(base_model, adapter_repo)
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
An embedding model optimized for retrieving passages that answer questions
about Islam. The passages are inherently multilingual, as they contain
quotes from the Quran and Hadith. They often include preambles like
"Bismillah" in various languages and follow a specific writing style.
## Model Details
### Model Sources [optional]
- https://islamqa.info/
- https://islamweb.net/
- https://hadithanswers.com/
- https://askimam.org/
- https://sorularlaislamiyet.com/
## Uses
- embedding
- retrieval
- islam
- multilingual
- q&a
from transformers import AutoModel, AutoTokenizer
from peft import PeftModel
# Load the base model and tokenizer
base_model_name = "intfloat/multilingual-e5-large-instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
base_model = AutoModel.from_pretrained(base_model_name)
# Load the LoRA adapter directly
adapter_repo = "IslamQA/multilingual-e5-small-finetuned"
model = PeftModel.from_pretrained(base_model, adapter_repo) |
Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q4_K_M-GGUF | Lucy-in-the-Sky | 2025-05-03T17:33:48Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"open-r1",
"trl",
"dpo",
"llama-cpp",
"gguf-my-repo",
"dataset:LuyiCui/numina-deepseek-r1-qwen-7b-efficient-test-preference",
"base_model:LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO",
"base_model:quantized:LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T17:33:40Z | ---
base_model: LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO
datasets: LuyiCui/numina-deepseek-r1-qwen-7b-efficient-test-preference
library_name: transformers
model_name: DeepSeek-R1-Distill-Qwen-1.5B-DPO
tags:
- generated_from_trainer
- open-r1
- trl
- dpo
- llama-cpp
- gguf-my-repo
licence: license
---
# Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q4_K_M-GGUF
This model was converted to GGUF format from [`LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO`](https://huggingface.co/LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/LuyiCui/DeepSeek-R1-Distill-Qwen-1.5B-DPO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q4_K_M-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q4_K_M-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q4_K_M-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Lucy-in-the-Sky/DeepSeek-R1-Distill-Qwen-1.5B-DPO-Q4_K_M-GGUF --hf-file deepseek-r1-distill-qwen-1.5b-dpo-q4_k_m.gguf -c 2048
```
|
mradermacher/RxCodexV1-mini-GGUF | mradermacher | 2025-05-03T17:31:21Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:rxmha125/RxCodexV1-mini",
"base_model:quantized:rxmha125/RxCodexV1-mini",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T17:30:02Z | ---
base_model: rxmha125/RxCodexV1-mini
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/rxmha125/RxCodexV1-mini
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q2_K.gguf) | Q2_K | 0.1 | |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q3_K_S.gguf) | Q3_K_S | 0.1 | |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q3_K_M.gguf) | Q3_K_M | 0.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.IQ4_XS.gguf) | IQ4_XS | 0.1 | |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q4_K_S.gguf) | Q4_K_S | 0.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q3_K_L.gguf) | Q3_K_L | 0.1 | |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q4_K_M.gguf) | Q4_K_M | 0.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q5_K_S.gguf) | Q5_K_S | 0.1 | |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q5_K_M.gguf) | Q5_K_M | 0.1 | |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q6_K.gguf) | Q6_K | 0.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.Q8_0.gguf) | Q8_0 | 0.1 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/RxCodexV1-mini-GGUF/resolve/main/RxCodexV1-mini.f16.gguf) | f16 | 0.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Phi-4-reasoning-GGUF | mradermacher | 2025-05-03T17:31:15Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"phi",
"nlp",
"math",
"code",
"chat",
"conversational",
"reasoning",
"en",
"base_model:microsoft/Phi-4-reasoning",
"base_model:quantized:microsoft/Phi-4-reasoning",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T18:14:22Z | ---
base_model: microsoft/Phi-4-reasoning
language:
- en
library_name: transformers
license: mit
license_link: https://huggingface.co/microsoft/Phi-4-reasoning/resolve/main/LICENSE
quantized_by: mradermacher
tags:
- phi
- nlp
- math
- code
- chat
- conversational
- reasoning
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/microsoft/Phi-4-reasoning
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Phi-4-reasoning-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q2_K.gguf) | Q2_K | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q3_K_S.gguf) | Q3_K_S | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q3_K_M.gguf) | Q3_K_M | 7.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q3_K_L.gguf) | Q3_K_L | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.IQ4_XS.gguf) | IQ4_XS | 8.1 | |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q4_K_S.gguf) | Q4_K_S | 8.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q4_K_M.gguf) | Q4_K_M | 9.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q5_K_S.gguf) | Q5_K_S | 10.3 | |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q5_K_M.gguf) | Q5_K_M | 10.7 | |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q6_K.gguf) | Q6_K | 12.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Phi-4-reasoning-GGUF/resolve/main/Phi-4-reasoning.Q8_0.gguf) | Q8_0 | 15.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Protobase-SCE1-LLaMa-70B-GGUF | mradermacher | 2025-05-03T17:30:24Z | 120 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:TareksGraveyard/Protobase-SCE1-LLaMa-70B",
"base_model:quantized:TareksGraveyard/Protobase-SCE1-LLaMa-70B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-02-23T13:22:37Z | ---
base_model: TareksGraveyard/Protobase-SCE1-LLaMa-70B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/TareksGraveyard/Protobase-SCE1-LLaMa-70B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q2_K.gguf) | Q2_K | 26.5 | |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q3_K_S.gguf) | Q3_K_S | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q3_K_M.gguf) | Q3_K_M | 34.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q3_K_L.gguf) | Q3_K_L | 37.2 | |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.IQ4_XS.gguf) | IQ4_XS | 38.4 | |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q4_K_S.gguf) | Q4_K_S | 40.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q4_K_M.gguf) | Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q5_K_S.gguf) | Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q5_K_M.gguf) | Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q6_K.gguf.part2of2) | Q6_K | 58.0 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Protobase-SCE1-LLaMa-70B-GGUF/resolve/main/Protobase-SCE1-LLaMa-70B.Q8_0.gguf.part2of2) | Q8_0 | 75.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF | mradermacher | 2025-05-03T17:29:16Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Shaleen123/MedicalEDI-14b-EDI-Reasoning-Final-II",
"base_model:quantized:Shaleen123/MedicalEDI-14b-EDI-Reasoning-Final-II",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T10:15:07Z | ---
base_model: Shaleen123/MedicalEDI-14b-EDI-Reasoning-Final-II
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Shaleen123/MedicalEDI-14b-EDI-Reasoning-Final-II
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q2_K.gguf) | Q2_K | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q3_K_S.gguf) | Q3_K_S | 6.8 | |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q3_K_M.gguf) | Q3_K_M | 7.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q3_K_L.gguf) | Q3_K_L | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.IQ4_XS.gguf) | IQ4_XS | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q4_K_S.gguf) | Q4_K_S | 8.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q4_K_M.gguf) | Q4_K_M | 9.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q5_K_S.gguf) | Q5_K_S | 10.4 | |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q5_K_M.gguf) | Q5_K_M | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q6_K.gguf) | Q6_K | 12.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MedicalEDI-14b-EDI-Reasoning-Final-II-GGUF/resolve/main/MedicalEDI-14b-EDI-Reasoning-Final-II.Q8_0.gguf) | Q8_0 | 15.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
fedovtt/0dc128ba-76b6-4492-a16d-598bf33e3901 | fedovtt | 2025-05-03T17:25:19Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/SmolLM2-360M",
"base_model:adapter:unsloth/SmolLM2-360M",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-03T17:19:39Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/SmolLM2-360M
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 0dc128ba-76b6-4492-a16d-598bf33e3901
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/SmolLM2-360M
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 9c46256a8024748c_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9c46256a8024748c_train_data.json
type:
field_input: text
field_instruction: instruction
field_output: full_instruction
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.55
group_by_length: false
hub_model_id: fedovtt/0dc128ba-76b6-4492-a16d-598bf33e3901
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 3.0e-06
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 150
micro_batch_size: 10
mixed_precision: bf16
mlflow_experiment_name: /tmp/9c46256a8024748c_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 62e2631f-f12b-4415-81fd-ab3b8d09115c
wandb_project: s56-28
wandb_run: your_name
wandb_runid: 62e2631f-f12b-4415-81fd-ab3b8d09115c
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 0dc128ba-76b6-4492-a16d-598bf33e3901
This model is a fine-tuned version of [unsloth/SmolLM2-360M](https://huggingface.co/unsloth/SmolLM2-360M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2183
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.9199 | 0.0400 | 150 | 1.2183 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
phililp-arnold/17967b4f-3241-42f4-bb16-d8895524f65f | phililp-arnold | 2025-05-03T17:25:00Z | 0 | 0 | peft | [
"peft",
"generated_from_trainer",
"base_model:UCLA-AGI/Gemma-2-9B-It-SPPO-Iter2",
"base_model:adapter:UCLA-AGI/Gemma-2-9B-It-SPPO-Iter2",
"region:us"
] | null | 2025-05-03T17:24:31Z | ---
library_name: peft
tags:
- generated_from_trainer
base_model: UCLA-AGI/Gemma-2-9B-It-SPPO-Iter2
model-index:
- name: phililp-arnold/17967b4f-3241-42f4-bb16-d8895524f65f
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phililp-arnold/17967b4f-3241-42f4-bb16-d8895524f65f
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1765
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.3
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
dimasik2987/a4b1c43d-c4e8-492d-ae19-35c7380bc2c0 | dimasik2987 | 2025-05-03T17:24:31Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/SmolLM2-360M",
"base_model:adapter:unsloth/SmolLM2-360M",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-03T17:19:45Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/SmolLM2-360M
tags:
- axolotl
- generated_from_trainer
model-index:
- name: a4b1c43d-c4e8-492d-ae19-35c7380bc2c0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/SmolLM2-360M
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 9c46256a8024748c_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9c46256a8024748c_train_data.json
type:
field_input: text
field_instruction: instruction
field_output: full_instruction
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.55
group_by_length: false
hub_model_id: dimasik2987/a4b1c43d-c4e8-492d-ae19-35c7380bc2c0
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 1.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 128
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 12
mixed_precision: bf16
mlflow_experiment_name: /tmp/9c46256a8024748c_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 62e2631f-f12b-4415-81fd-ab3b8d09115c
wandb_project: s56-28
wandb_run: your_name
wandb_runid: 62e2631f-f12b-4415-81fd-ab3b8d09115c
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# a4b1c43d-c4e8-492d-ae19-35c7380bc2c0
This model is a fine-tuned version of [unsloth/SmolLM2-360M](https://huggingface.co/unsloth/SmolLM2-360M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3934
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 24
- total_eval_batch_size: 24
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.5257 | 0.1281 | 200 | 1.3934 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
ZhuangXialie/Qwen-code-7B-SFT-100k-v2-cot-v2 | ZhuangXialie | 2025-05-03T17:23:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"sft",
"conversational",
"dataset:local",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T13:53:28Z | ---
datasets: local
library_name: transformers
model_name: Qwen-code-7B-SFT-100k-v2-cot-v2
tags:
- generated_from_trainer
- open-r1
- trl
- sft
licence: license
---
# Model Card for Qwen-code-7B-SFT-100k-v2-cot-v2
This model is a fine-tuned version of [None](https://huggingface.co/None) on the [local](https://huggingface.co/datasets/local) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ZhuangXialie/Qwen-code-7B-SFT-100k-v2-cot-v2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dyx_team/huggingface/runs/wr20u2n4)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0.dev0
- Transformers: 4.51.2
- Pytorch: 2.6.0
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
dimasik1987/aef1db10-27c8-43af-8b53-76962e458a20 | dimasik1987 | 2025-05-03T17:22:03Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/SmolLM2-360M",
"base_model:adapter:unsloth/SmolLM2-360M",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-03T17:19:46Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/SmolLM2-360M
tags:
- axolotl
- generated_from_trainer
model-index:
- name: aef1db10-27c8-43af-8b53-76962e458a20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/SmolLM2-360M
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 9c46256a8024748c_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9c46256a8024748c_train_data.json
type:
field_input: text
field_instruction: instruction
field_output: full_instruction
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.55
group_by_length: false
hub_model_id: dimasik1987/aef1db10-27c8-43af-8b53-76962e458a20
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 1.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 150
micro_batch_size: 10
mixed_precision: bf16
mlflow_experiment_name: /tmp/9c46256a8024748c_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 62e2631f-f12b-4415-81fd-ab3b8d09115c
wandb_project: s56-7
wandb_run: your_name
wandb_runid: 62e2631f-f12b-4415-81fd-ab3b8d09115c
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# aef1db10-27c8-43af-8b53-76962e458a20
This model is a fine-tuned version of [unsloth/SmolLM2-360M](https://huggingface.co/unsloth/SmolLM2-360M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4316
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.0966 | 0.0400 | 150 | 1.4316 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
lisabdunlap/Llama-3.1-8B-Instruct-unsloth-bnb-4bit-r32-e3-lr0.0001-actors_reviews_markdown-new | lisabdunlap | 2025-05-03T17:18:06Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T17:15:47Z | ---
base_model: unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lisabdunlap
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ashwinkumaar/my_awesome_qa_model | ashwinkumaar | 2025-05-03T17:14:06Z | 0 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2025-05-03T11:39:22Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: ashwinkumaar/my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ashwinkumaar/my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.1286
- Validation Loss: 2.0954
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.6421 | 2.6552 | 0 |
| 2.1286 | 2.0954 | 1 |
### Framework versions
- Transformers 4.51.3
- TensorFlow 2.18.0
- Datasets 3.5.1
- Tokenizers 0.21.1
|
phospho-app/dopaul-simple_pawn_move-te2ztw3n8o | phospho-app | 2025-05-03T17:14:01Z | 0 | 0 | null | [
"safetensors",
"gr00t_n1",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-05-03T17:08:03Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [dopaul/simple_pawn_move](https://huggingface.co/datasets/dopaul/simple_pawn_move)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 64
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=replicate_groot_training_pipeline)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=replicate_groot_training_pipeline)
|
Elahe96/rl_course_vizdoom_health_gathering_supreme | Elahe96 | 2025-05-03T17:08:59Z | 0 | 0 | sample-factory | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2025-05-03T17:08:50Z | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 11.98 +/- 5.71
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r Elahe96/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m <path.to.enjoy.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m <path.to.train.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q5_K_S-GGUF | Triangle104 | 2025-05-03T17:07:53Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"abliterated",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated",
"base_model:quantized:huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated",
"license:other",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T17:07:28Z | ---
base_model: huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated
language:
- en
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
tags:
- nvidia
- llama-3
- pytorch
- abliterated
- uncensored
- llama-cpp
- gguf-my-repo
---
# Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q5_K_S-GGUF
This model was converted to GGUF format from [`huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated`](https://huggingface.co/huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q5_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q5_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q5_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q5_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q5_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q5_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q5_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q5_k_s.gguf -c 2048
```
|
jdchang/full-with-label-bs-1024-sg-2-step-1458 | jdchang | 2025-05-03T17:06:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T17:06:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
HoaDoan1710/whisper-checkpoint-3525 | HoaDoan1710 | 2025-05-03T17:06:05Z | 0 | 0 | null | [
"safetensors",
"whisper",
"license:apache-2.0",
"region:us"
] | null | 2025-05-03T15:01:44Z | ---
license: apache-2.0
---
|
mlfoundations-dev/no_pipeline_math_1k | mlfoundations-dev | 2025-05-03T17:05:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T16:21:52Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: no_pipeline_math_1k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# no_pipeline_math_1k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/no_pipeline_math_1k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 6
- total_train_batch_size: 96
- total_eval_batch_size: 128
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.5.1
- Datasets 3.1.0
- Tokenizers 0.20.3
|
yusuke111/myBit-Llama2-jp-127M-2B4TLike-1024-asc | yusuke111 | 2025-05-03T17:03:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bit_llama",
"text-generation",
"generated_from_trainer",
"custom_code",
"autotrain_compatible",
"region:us"
] | text-generation | 2025-05-03T00:28:16Z | ---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: myBit-Llama2-jp-127M-2B4TLike
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# myBit-Llama2-jp-127M-2B4TLike
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7946
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0024
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 96
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.95) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 750
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 5.5592 | 0.0555 | 500 | 4.6971 |
| 3.9123 | 0.1111 | 1000 | 4.2204 |
| 3.5329 | 0.1666 | 1500 | 3.8957 |
| 3.3627 | 0.2222 | 2000 | 3.7229 |
| 3.2594 | 0.2777 | 2500 | 3.5721 |
| 3.1944 | 0.3333 | 3000 | 3.3995 |
| 3.1391 | 0.3888 | 3500 | 3.2851 |
| 3.1046 | 0.4443 | 4000 | 3.1923 |
| 3.0648 | 0.4999 | 4500 | 3.1243 |
| 3.0325 | 0.5554 | 5000 | 3.0711 |
| 2.9877 | 0.6110 | 5500 | 3.0184 |
| 2.9752 | 0.6665 | 6000 | 2.9568 |
| 2.9901 | 0.7221 | 6500 | 2.9294 |
| 2.9769 | 0.7776 | 7000 | 2.9101 |
| 2.9432 | 0.8331 | 7500 | 2.8855 |
| 2.9199 | 0.8887 | 8000 | 2.8612 |
| 2.8869 | 0.9442 | 8500 | 2.8358 |
| 2.8574 | 0.9998 | 9000 | 2.7946 |
### Framework versions
- Transformers 4.47.1
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
pictgencustomer/king-kong-19_705 | pictgencustomer | 2025-05-03T17:02:55Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-03T17:02:51Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: king-kong-19_michaeluffer_3
---
# King Kong 19_705
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `king-kong-19_michaeluffer_3` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('pictgencustomer/king-kong-19_705', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
Marco0/zog | Marco0 | 2025-05-03T17:02:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T16:59:01Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Hachipo/OpenCoder-8B-Base-PIFT-enja_1000_2 | Hachipo | 2025-05-03T16:58:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T16:55:00Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TOMFORD79/Fly49 | TOMFORD79 | 2025-05-03T16:57:32Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-05-03T16:48:35Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Aaquib/gemma-3-1b-sft-alpaca | Aaquib | 2025-05-03T16:56:52Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T16:50:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
SFT'd version of google/gemma-3-1b-pt. Training performed solely on yahma/alpaca-cleaned. No further learning was performed.
## Model Details
Hyperparameters to replicate:
- lr=1e-5
- num_epochs=1
- train_batch_size=40
- test_batch_size=32
- max_seq_len=256
### Model Description
- **Finetuned from model:** [google/gemma-3-1b-pt] |
darshannere/Qwen2.5-3B-GSM8k_GRPO | darshannere | 2025-05-03T16:56:40Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-03T16:56:19Z | ---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** darshannere
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_M-GGUF | Triangle104 | 2025-05-03T16:56:28Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"abliterated",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated",
"base_model:quantized:huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated",
"license:other",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T16:56:01Z | ---
base_model: huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated
language:
- en
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
tags:
- nvidia
- llama-3
- pytorch
- abliterated
- uncensored
- llama-cpp
- gguf-my-repo
---
# Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_M-GGUF
This model was converted to GGUF format from [`huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated`](https://huggingface.co/huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_M-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_M-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_M-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_M-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_m.gguf -c 2048
```
|
earcherc/nsfw1_full | earcherc | 2025-05-03T16:56:24Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] | text-to-image | 2025-05-03T16:51:51Z | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/ComfyICU_00001_.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: null
---
# nsfw1_full
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/earcherc/nsfw1_full/tree/main) them in the Files & versions tab.
|
Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_S-GGUF | Triangle104 | 2025-05-03T16:53:10Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"abliterated",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated",
"base_model:quantized:huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated",
"license:other",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-03T16:52:48Z | ---
base_model: huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated
language:
- en
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
tags:
- nvidia
- llama-3
- pytorch
- abliterated
- uncensored
- llama-cpp
- gguf-my-repo
---
# Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_S-GGUF
This model was converted to GGUF format from [`huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated`](https://huggingface.co/huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/huihui-ai/Llama-3.1-Nemotron-Nano-8B-v1-abliterated) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Llama-3.1-Nemotron-Nano-8B-v1-abliterated-Q4_K_S-GGUF --hf-file llama-3.1-nemotron-nano-8b-v1-abliterated-q4_k_s.gguf -c 2048
```
|
adi0308/output | adi0308 | 2025-05-03T16:52:00Z | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-3.2-1B",
"base_model:adapter:meta-llama/Llama-3.2-1B",
"license:llama3.2",
"region:us"
] | null | 2025-05-03T16:51:09Z | ---
library_name: peft
license: llama3.2
base_model: meta-llama/Llama-3.2-1B
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.7.0+cu118
- Datasets 3.5.1
- Tokenizers 0.21.1 |
wATCH-Nighat-Naz-Viral-Video/wATCH.Nighat-Naz-Viral-video-Nighat-Naz.original | wATCH-Nighat-Naz-Viral-Video | 2025-05-03T16:50:22Z | 0 | 0 | null | [
"region:us"
] | null | 2025-05-03T16:50:07Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
En3rGy/getphatFLUXReality_v5Hardcore | En3rGy | 2025-05-03T16:44:41Z | 0 | 0 | null | [
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"region:us"
] | null | 2025-05-03T03:18:02Z | ---
base_model:
- black-forest-labs/FLUX.1-dev
---
# getphat FLUX Reality
> *“My most versatile model to date.”*
---
### Beschreibung
**getphat FLUX Reality** ist ein vielseitiges SDXL-Modell, das beeindruckende Resultate sowohl im realistischen als auch im stilisierten (Anime) Bereich liefert.
Es verträgt sich extrem gut mit LoRAs, hat ein gutes Verständnis für Licht, Anatomie und Textur, und eignet sich sowohl für NSFW als auch für künstlerisch-abstrakte Inhalte.
---
### Empfohlene Parameter
- **Sampling:** DPM++ 2M Karras
- **Steps:** 20–30
- **CFG Scale:** 7–8
- **Auflösung:** 1024x1024 oder höher empfohlen
---
### Beispiel-Prompts
```txt
photo of a realistic woman in a leather jacket, ultra detailed, cinematic lighting, sdxl
anime girl with glowing eyes, cyberpunk city, dynamic angle, sdxl style
A feline silhouette glides across a sunlit floor, each step deliberate and light,
until a sudden leap carries her gracefully onto a softly rumpled bed,
where shadows fold gently beneath her landing and dust particles dance in the disturbed light.
---
Prompt-Inspiration vom Ersteller
A beautiful AI generated image of a woman among cascading synesthetic gradients
echoing through a feedback loop of ambient intention, where the luminal drift of
pseudo-paradox waves collide with the soft geometry of inverted timelines,
suspended in a post-emotive flux of chromatic resonance.
The essence of spatial murmurs weaves through probabilistic shimmerfields,
balanced delicately on the cusp of translucent recursion, as if the entire composition
breathes in algorithmic reverie — not quite dreaming, not quite rendering,
but oscillating between semi-coherent wonderbytes and metaphysical lens flare.
Ein legendärer Prompt – wortwörtlich aus dem Modell-Video auf Civitai.
---
Lizenz / Herkunft
Originalmodell von Civitai:
https://civitai.com/models/861840/getphat-flux-reality-nsfw
---
Hinweis
Dieses Modell ist NSFW-fähig, aber nicht darauf beschränkt.
Die realistische Bildqualität ist beeindruckend – perfekt für kreative Experimente und abstrakte Eskalationen. |
apriasmoro/e83b3094-8648-4f61-a731-80f986134ecb | apriasmoro | 2025-05-03T16:42:42Z | 0 | 0 | peft | [
"peft",
"safetensors",
"phi3",
"axolotl",
"generated_from_trainer",
"custom_code",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:adapter:microsoft/Phi-3-mini-4k-instruct",
"license:mit",
"region:us"
] | null | 2025-05-03T16:37:14Z | ---
library_name: peft
license: mit
base_model: microsoft/Phi-3-mini-4k-instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: e83b3094-8648-4f61-a731-80f986134ecb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.5.2`
```yaml
adapter: lora
base_model: microsoft/Phi-3-mini-4k-instruct
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- f8164dbb54597854_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/f8164dbb54597854_train_data.json
type:
field_input: description
field_instruction: article
field_output: reference
field_system: None
format: None
no_input_format: None
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: apriasmoro/e83b3094-8648-4f61-a731-80f986134ecb
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 10
micro_batch_size: 2
mlflow_experiment_name: /tmp/f8164dbb54597854_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 40b4e886-e6cd-4d53-9dbf-7bfd3907faf7
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 40b4e886-e6cd-4d53-9dbf-7bfd3907faf7
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# e83b3094-8648-4f61-a731-80f986134ecb
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1221
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 3.1906 | 0.0004 | 1 | 3.0166 |
| 3.1572 | 0.0012 | 3 | 2.9884 |
| 2.8477 | 0.0024 | 6 | 2.6561 |
| 2.3275 | 0.0036 | 9 | 2.1221 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.3
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF | mradermacher | 2025-05-03T16:42:19Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:zelk12/MT1-Gen13-gemma-2-9B",
"base_model:quantized:zelk12/MT1-Gen13-gemma-2-9B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-03T10:32:34Z | ---
base_model: zelk12/MT1-Gen13-gemma-2-9B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/zelk12/MT1-Gen13-gemma-2-9B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.6 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ2_S.gguf) | i1-IQ2_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 3.7 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q2_K.gguf) | i1-Q2_K | 3.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ3_S.gguf) | i1-IQ3_S | 4.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 4.4 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ3_M.gguf) | i1-IQ3_M | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 5.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 5.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q4_0.gguf) | i1-Q4_0 | 5.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 5.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q4_1.gguf) | i1-Q4_1 | 6.1 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen13-gemma-2-9B-i1-GGUF/resolve/main/MT1-Gen13-gemma-2-9B.i1-Q6_K.gguf) | i1-Q6_K | 7.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Triangle104/QWQ-32B-Dawnwhisper-Q4_K_S-GGUF | Triangle104 | 2025-05-03T16:41:12Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:DoppelReflEx/QWQ-32B-Dawnwhisper",
"base_model:quantized:DoppelReflEx/QWQ-32B-Dawnwhisper",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-03T16:39:44Z | ---
base_model: DoppelReflEx/QWQ-32B-Dawnwhisper
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Triangle104/QWQ-32B-Dawnwhisper-Q4_K_S-GGUF
This model was converted to GGUF format from [`DoppelReflEx/QWQ-32B-Dawnwhisper`](https://huggingface.co/DoppelReflEx/QWQ-32B-Dawnwhisper) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/DoppelReflEx/QWQ-32B-Dawnwhisper) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/QWQ-32B-Dawnwhisper-Q4_K_S-GGUF --hf-file qwq-32b-dawnwhisper-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/QWQ-32B-Dawnwhisper-Q4_K_S-GGUF --hf-file qwq-32b-dawnwhisper-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/QWQ-32B-Dawnwhisper-Q4_K_S-GGUF --hf-file qwq-32b-dawnwhisper-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/QWQ-32B-Dawnwhisper-Q4_K_S-GGUF --hf-file qwq-32b-dawnwhisper-q4_k_s.gguf -c 2048
```
|
LarryAIDraw/touhou_kudamaki_ponyXL | LarryAIDraw | 2025-05-03T16:41:08Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-05-03T16:09:16Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/371928/ponyv6-xl-tsukasa-kudamaki-or-touhou |
Subsets and Splits