
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-29 00:46:34
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 502
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-29 00:44:25
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
ksaw39/ksawmegga | ksaw39 | 2023-07-27T22:11:13Z | 0 | 0 | keras | [
"keras",
"reinforcement-learning",
"en",
"region:us"
] | reinforcement-learning | 2023-07-27T22:08:14Z | ---
language:
- en
metrics:
- accuracy
- code_eval
library_name: keras
pipeline_tag: reinforcement-learning
--- |
NasimB/aochildes-cbt-log-rarity | NasimB | 2023-07-27T21:46:57Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T19:38:45Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: aochildes-cbt-log-rarity
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aochildes-cbt-log-rarity
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.3649 | 0.29 | 500 | 5.3433 |
| 5.0506 | 0.59 | 1000 | 4.9337 |
| 4.7079 | 0.88 | 1500 | 4.6957 |
| 4.4512 | 1.17 | 2000 | 4.5593 |
| 4.3031 | 1.47 | 2500 | 4.4458 |
| 4.2085 | 1.76 | 3000 | 4.3418 |
| 4.0809 | 2.05 | 3500 | 4.2739 |
| 3.9047 | 2.35 | 4000 | 4.2277 |
| 3.8846 | 2.64 | 4500 | 4.1774 |
| 3.8392 | 2.93 | 5000 | 4.1313 |
| 3.6392 | 3.23 | 5500 | 4.1305 |
| 3.6016 | 3.52 | 6000 | 4.1020 |
| 3.5828 | 3.81 | 6500 | 4.0709 |
| 3.4733 | 4.11 | 7000 | 4.0797 |
| 3.3271 | 4.4 | 7500 | 4.0758 |
| 3.3228 | 4.69 | 8000 | 4.0635 |
| 3.3147 | 4.99 | 8500 | 4.0528 |
| 3.154 | 5.28 | 9000 | 4.0692 |
| 3.1461 | 5.58 | 9500 | 4.0692 |
| 3.1416 | 5.87 | 10000 | 4.0684 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
jariasn/q-Taxi-v3 | jariasn | 2023-07-27T21:32:51Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T21:32:49Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="jariasn/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
sghirardelli/vit-base-patch16-224-rgbd1k2 | sghirardelli | 2023-07-27T21:26:49Z | 65 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"vit",
"image-classification",
"generated_from_keras_callback",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-07-21T21:15:59Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_keras_callback
model-index:
- name: sghirardelli/vit-base-patch16-224-rgbd1k2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# sghirardelli/vit-base-patch16-224-rgbd1k2
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.9711
- Train Accuracy: 0.4384
- Train Top-3-accuracy: 0.6297
- Validation Loss: 0.2537
- Validation Accuracy: 0.9323
- Validation Top-3-accuracy: 0.9940
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.002, 'decay_steps': 544, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Train Top-3-accuracy | Validation Loss | Validation Accuracy | Validation Top-3-accuracy | Epoch |
|:----------:|:--------------:|:--------------------:|:---------------:|:-------------------:|:-------------------------:|:-----:|
| 1.9711 | 0.4384 | 0.6297 | 0.2537 | 0.9323 | 0.9940 | 0 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.12.0
- Datasets 2.14.1
- Tokenizers 0.13.3
|
vivianchen98/distilbert-base-uncased-finetuned-cola | vivianchen98 | 2023-07-27T21:06:15Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-27T19:48:05Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5317477654019562
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8526
- Matthews Correlation: 0.5317
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5224 | 1.0 | 535 | 0.4742 | 0.4397 |
| 0.3484 | 2.0 | 1070 | 0.5877 | 0.4558 |
| 0.2357 | 3.0 | 1605 | 0.6307 | 0.5301 |
| 0.1668 | 4.0 | 2140 | 0.7054 | 0.5288 |
| 0.1218 | 5.0 | 2675 | 0.8526 | 0.5317 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
EulerianKnight/LunarLander-v2-unit1 | EulerianKnight | 2023-07-27T21:00:43Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T21:00:27Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 236.62 +/- 48.16
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jariasn/q-FrozenLake-v1-4x4-noSlippery | jariasn | 2023-07-27T20:58:10Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T20:58:08Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jariasn/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
YoonSeul/LawBot-5.8B | YoonSeul | 2023-07-27T20:40:46Z | 4 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-26T07:47:12Z | ---
library_name: peft
---
<img src=https://github.com/taemin6697/Paper_Review/assets/96530685/54ecd6cf-8695-4caa-bdc8-fb85c9b7d70d style="max-width: 700px; width: 100%" />
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
dgergherherherhererher/dfsgs | dgergherherherhererher | 2023-07-27T20:37:27Z | 0 | 0 | sklearn | [
"sklearn",
"sports",
"tabular-classification",
"en",
"dataset:knkarthick/dialogsum",
"license:openrail",
"region:us"
] | tabular-classification | 2023-07-27T17:50:51Z | ---
language:
- en
metrics:
- accuracy
library_name: sklearn
pipeline_tag: tabular-classification
license: openrail
datasets:
- knkarthick/dialogsum
tags:
- sports
--- |
NicolasDenier/speecht5-finetuned-voxpopuli-sl | NicolasDenier | 2023-07-27T20:21:31Z | 89 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"text-to-speech",
"sl",
"dataset:facebook/voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | text-to-speech | 2023-07-27T17:17:36Z | ---
language:
- sl
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
- text-to-speech
datasets:
- facebook/voxpopuli
model-index:
- name: speecht5-finetuned-voxpopuli-sl
results:
- task:
name: Text to Speech
type: text-to-speech
dataset:
name: Voxpopuli
type: facebook/voxpopuli
config: sl
split: train
args: all
metrics:
- name: Loss
type: loss
value: 0.4546
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5-finetuned-voxpopuli-sl
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the Voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4546
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.4942 | 21.68 | 1000 | 0.4567 |
| 0.4698 | 43.36 | 2000 | 0.4544 |
| 0.4615 | 65.04 | 3000 | 0.4541 |
| 0.462 | 86.72 | 4000 | 0.4546 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3 |
patonw/q-Taxi-v3 | patonw | 2023-07-27T20:16:02Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T20:16:00Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="patonw/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Ronan14232/Omar | Ronan14232 | 2023-07-27T20:12:29Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
] | null | 2023-07-27T20:12:29Z | ---
license: bigscience-openrail-m
---
|
Jonathaniu/llama2-breast-cancer-13b-knowledge-epoch-8 | Jonathaniu | 2023-07-27T20:09:53Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T20:09:32Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
### Framework versions
- PEFT 0.4.0.dev0
|
ianvaz/llama2-qlora-finetunined-french | ianvaz | 2023-07-27T20:00:58Z | 1 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T20:00:54Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
Za88yes/Ocha | Za88yes | 2023-07-27T19:56:37Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-27T12:21:45Z | ---
license: creativeml-openrail-m
---
|
grace-pro/three_class_5e-5_hausa | grace-pro | 2023-07-27T19:48:09Z | 117 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:Davlan/afro-xlmr-base",
"base_model:finetune:Davlan/afro-xlmr-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-07-27T18:28:05Z | ---
license: mit
base_model: Davlan/afro-xlmr-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: three_class_5e-5_hausa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# three_class_5e-5_hausa
This model is a fine-tuned version of [Davlan/afro-xlmr-base](https://huggingface.co/Davlan/afro-xlmr-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2379
- Precision: 0.2316
- Recall: 0.1636
- F1: 0.1917
- Accuracy: 0.9392
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2129 | 1.0 | 1283 | 0.2033 | 0.2278 | 0.0810 | 0.1195 | 0.9416 |
| 0.1901 | 2.0 | 2566 | 0.1988 | 0.2444 | 0.0890 | 0.1305 | 0.9429 |
| 0.1657 | 3.0 | 3849 | 0.2056 | 0.2561 | 0.1278 | 0.1705 | 0.9430 |
| 0.139 | 4.0 | 5132 | 0.2205 | 0.2269 | 0.1655 | 0.1914 | 0.9388 |
| 0.1179 | 5.0 | 6415 | 0.2379 | 0.2316 | 0.1636 | 0.1917 | 0.9392 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
asenella/MMVAEPlus_beta_10_scale_False_seed_3 | asenella | 2023-07-27T19:43:04Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T19:42:50Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
tommilyjones/swin-tiny-patch4-window7-224-cats_dogs | tommilyjones | 2023-07-27T19:38:02Z | 204 | 0 | transformers | [
"transformers",
"pytorch",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-07-27T19:31:44Z | ---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-cats_dogs
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9973147153598282
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-cats_dogs
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0126
- Accuracy: 0.9973
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0832 | 0.98 | 47 | 0.0235 | 0.9909 |
| 0.0788 | 1.99 | 95 | 0.0126 | 0.9973 |
| 0.0534 | 2.95 | 141 | 0.0127 | 0.9957 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
AdiOO7/llama-2-7B-finetuned | AdiOO7 | 2023-07-27T19:34:23Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T19:34:20Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
DunnBC22/mit-b0-Image_segmentation_Dominoes_v2 | DunnBC22 | 2023-07-27T19:26:06Z | 0 | 1 | null | [
"pytorch",
"tensorboard",
"generated_from_trainer",
"image-segmentation",
"en",
"dataset:adelavega/dominoes_raw",
"license:other",
"region:us"
] | image-segmentation | 2023-07-26T21:13:35Z | ---
license: other
tags:
- generated_from_trainer
model-index:
- name: mit-b0-Image_segmentation_Dominoes_v2
results: []
datasets:
- adelavega/dominoes_raw
language:
- en
metrics:
- mean_iou
pipeline_tag: image-segmentation
---
# mit-b0-Image_segmentation_Dominoes_v2
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0).
It achieves the following results on the evaluation set:
- Loss: 0.1149
- Mean Iou: 0.9198
- Mean Accuracy: 0.9515
- Overall Accuracy: 0.9778
- Per Category Iou:
- Segment 0: 0.974110559111975
- Segment 1: 0.8655745252092782
- Per Category Accuracy
- Segment 0: 0.9897833441005461
- Segment 1: 0.913253525550903
## Model description
For more information on how it was created, check out the following link: https://github.com/DunnBC22/Vision_Audio_and_Multimodal_Projects/blob/main/Computer%20Vision/Image%20Segmentation/Dominoes/Fine-Tuning%20-%20Dominoes%20-%20Image%20Segmentation%20with%20LoRA.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology.
## Training and evaluation data
Dataset Source: https://huggingface.co/datasets/adelavega/dominoes_raw
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou Segment 0 | Per Category Iou Segment 1 | Per Category Accuracy Segment 0 | Per Category Accuracy Segment 1|
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:------------------:|:-------------------:|:---------------------:|:-----------------:|
| 0.0461 | 1.0 | 86 | 0.1233 | 0.9150 | 0.9527 | 0.9762 | 0.9721967854031923 | 0.8578619172251059 | 0.9869082633464498 | 0.9184139264010376 |
| 0.0708 | 2.0 | 172 | 0.1366 | 0.9172 | 0.9490 | 0.9771 | 0.9732821853093164 | 0.8611008788165083 | 0.9898473600751747 | 0.9082362492748777 |
| 0.048 | 3.0 | 258 | 0.1260 | 0.9199 | 0.9534 | 0.9777 | 0.9740118174014271 | 0.8658241844233872 | 0.9888392553004053 | 0.9179240730467295 |
| 0.0535 | 4.0 | 344 | 0.1184 | 0.9200 | 0.9520 | 0.9778 | 0.974142444792198 | 0.8658711064023369 | 0.9896291184589182 | 0.9142864290038782 |
| 0.0185 | 5.0 | 430 | 0.1296 | 0.9182 | 0.9477 | 0.9775 | 0.9737715695013129 | 0.8627108292167807 | 0.9910418746696423 | 0.904378218719681 |
| 0.036 | 6.0 | 516 | 0.1410 | 0.9213 | 0.9538 | 0.9782 | 0.9745002408443008 | 0.8680673581922554 | 0.9892677512186527 | 0.9182967669045321 |
| 0.0376 | 7.0 | 602 | 0.1451 | 0.9206 | 0.9550 | 0.9779 | 0.9741455743906073 | 0.8669703237367214 | 0.9883004639689904 | 0.9216576612178001 |
| 0.0186 | 8.0 | 688 | 0.1380 | 0.9175 | 0.9496 | 0.9772 | 0.9733616852468584 | 0.8616466350192237 | 0.9897043519116697 | 0.9094762400541087 |
| 0.0162 | 9.0 | 774 | 0.1459 | 0.9218 | 0.9539 | 0.9783 | 0.9746840649852051 | 0.8688930149000804 | 0.989455276913138 | 0.9182917005479264 |
| 0.0169 | 10.0 | 860 | 0.1467 | 0.9191 | 0.9502 | 0.9776 | 0.9739086600912814 | 0.8642187978193332 | 0.9901195747929759 | 0.9102564589713776 |
| 0.0102 | 11.0 | 946 | 0.1549 | 0.9191 | 0.9524 | 0.9775 | 0.9737696499931041 | 0.8644247331609153 | 0.9889789745698009 | 0.915789237032027 |
| 0.0204 | 12.0 | 1032 | 0.1502 | 0.9215 | 0.9527 | 0.9783 | 0.974639596078376 | 0.8682964916021273 | 0.989902977623774 | 0.9155653673995151 |
| 0.0268 | 13.0 | 1118 | 0.1413 | 0.9194 | 0.9505 | 0.9777 | 0.9740020531855834 | 0.8647199376136 | 0.99011699066189 | 0.9107963425971664 |
| 0.0166 | 14.0 | 1204 | 0.1584 | 0.9173 | 0.9518 | 0.9770 | 0.9731154475737929 | 0.8614276032542578 | 0.9884142831972749 | 0.9152366875147241 |
| 0.0159 | 15.0 | 1290 | 0.1563 | 0.9170 | 0.9492 | 0.9770 | 0.9731832402253996 | 0.8607442858381036 | 0.9896456803899689 | 0.9087960816798012 |
| 0.0211 | 16.0 | 1376 | 0.1435 | 0.9150 | 0.9481 | 0.9764 | 0.9725201360275898 | 0.8574847000491036 | 0.989323310037 | 0.9068449010920532 |
| 0.0128 | 17.0 | 1462 | 0.1421 | 0.9212 | 0.9519 | 0.9782 | 0.9745789801464504 | 0.8677394402794754 | 0.9901920479238856 | 0.9136255861141298 |
| 0.0167 | 18.0 | 1548 | 0.1558 | 0.9217 | 0.9532 | 0.9783 | 0.9746811993626879 | 0.8686470009484697 | 0.9897428202266988 | 0.9166850322093621 |
| 0.0201 | 19.0 | 1634 | 0.1623 | 0.9156 | 0.9484 | 0.9766 | 0.9727184720007118 | 0.8584339325695252 | 0.9894484642039114 | 0.9072695251050635 |
| 0.0133 | 20.0 | 1720 | 0.1573 | 0.9189 | 0.9505 | 0.9776 | 0.9738320500157303 | 0.8640203613069115 | 0.9898665061373113 | 0.9112263496140702 |
| 0.012 | 21.0 | 1806 | 0.1631 | 0.9165 | 0.9472 | 0.9769 | 0.9731344243001482 | 0.8597866189796295 | 0.9904592118400188 | 0.9040137576913626 |
| 0.0148 | 22.0 | 1892 | 0.1629 | 0.9181 | 0.9507 | 0.9773 | 0.9735162429121835 | 0.8627239955489192 | 0.9894034768309156 | 0.9120129014770962 |
| 0.0137 | 23.0 | 1978 | 0.1701 | 0.9136 | 0.9484 | 0.9760 | 0.9719681843338751 | 0.8552607882028388 | 0.9885083690609032 | 0.908250815050119 |
| 0.0142 | 24.0 | 2064 | 0.1646 | 0.9146 | 0.9488 | 0.9763 | 0.9723134197764093 | 0.8568918401744342 | 0.9887405884771245 | 0.9089100747034281 |
| 0.0156 | 25.0 | 2150 | 0.1615 | 0.9144 | 0.9465 | 0.9763 | 0.9723929259786395 | 0.856345354289624 | 0.9898487696012216 | 0.9032139066422469 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1
- Datasets 2.13.1
- Tokenizers 0.13.3 |
vlabs/falcon-7b-sentiment_V3 | vlabs | 2023-07-27T19:21:16Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T19:21:14Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0.dev0
|
Isaacgv/distilhubert-finetuned-gtzan | Isaacgv | 2023-07-27T19:20:19Z | 19 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-07-26T12:47:08Z | ---
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.88
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5655
- Accuracy: 0.88
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3836 | 0.98 | 14 | 0.5798 | 0.82 |
| 0.3357 | 1.96 | 28 | 0.5655 | 0.88 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
Varshitha/flan-t5-small-finetune-medicine-v3 | Varshitha | 2023-07-27T19:17:58Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"text2textgeneration",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-27T19:16:23Z | ---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- text2textgeneration
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-small-finetune-medicine-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-small-finetune-medicine-v3
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8757
- Rouge1: 15.991
- Rouge2: 5.2469
- Rougel: 14.6278
- Rougelsum: 14.7076
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| No log | 1.0 | 5 | 2.9996 | 12.4808 | 4.9536 | 12.3712 | 12.2123 |
| No log | 2.0 | 10 | 2.9550 | 13.6471 | 4.9536 | 13.5051 | 13.5488 |
| No log | 3.0 | 15 | 2.9224 | 13.8077 | 5.117 | 13.7274 | 13.753 |
| No log | 4.0 | 20 | 2.9050 | 13.7861 | 5.117 | 13.6982 | 13.7001 |
| No log | 5.0 | 25 | 2.8920 | 14.668 | 5.117 | 14.4497 | 14.4115 |
| No log | 6.0 | 30 | 2.8820 | 14.9451 | 5.2469 | 14.5797 | 14.6308 |
| No log | 7.0 | 35 | 2.8770 | 15.991 | 5.2469 | 14.6278 | 14.7076 |
| No log | 8.0 | 40 | 2.8757 | 15.991 | 5.2469 | 14.6278 | 14.7076 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine | FFusion | 2023-07-27T19:11:33Z | 16 | 5 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"en",
"doi:10.57967/hf/0918",
"license:other",
"region:us"
] | text-to-image | 2023-07-23T20:39:23Z | ---
license: other
base_model: diffusers/FFusionXL-1-SDXL
instance_prompt: a 3d potion vial
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
library_name: diffusers
badges:
- alt: Name
url: >-
https://img.shields.io/badge/Name-FFusion%20XL%20LoRA%20%F0%9F%A7%AA%EF%B8%8F%20%20Potion%20Art%20Engine-89CFF0
src: >-
https://img.shields.io/badge/Name-FFusion%20XL%20LoRA%20%F0%9F%A7%AA%EF%B8%8F%20%20Potion%20Art%20Engine-89CFF0
- alt: LoRA Type
url: https://img.shields.io/badge/LoRA%20Type-LyCORIS%2FLoKr%2C%20Prodigy-blue
src: https://img.shields.io/badge/LoRA%20Type-LyCORIS%2FLoKr%2C%20Prodigy-blue
- alt: Refiner Compatible
url: https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success
src: https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success
- alt: CLIP Tested
url: >-
https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success
src: >-
https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success
- alt: Trained Resolution
url: >-
https://img.shields.io/badge/Trained%20Resolution-1024%20x%201024%20pixels-yellow
src: >-
https://img.shields.io/badge/Trained%20Resolution-1024%20x%201024%20pixels-yellow
- alt: Tested Resolution
url: >-
https://img.shields.io/badge/Tested%20Resolution-Up%20to%202800%20x%202800%20pixels-brightgreen
src: >-
https://img.shields.io/badge/Tested%20Resolution-Up%20to%202800%20x%202800%20pixels-brightgreen
- alt: Tested on
url: >-
https://img.shields.io/badge/Tested%20on-SDXL%200.9%20%26%20FFXL%200.001-blue
src: >-
https://img.shields.io/badge/Tested%20on-SDXL%200.9%20%26%20FFXL%200.001-blue
- alt: Hugging Face Model
url: https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue
src: https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue
- alt: GitHub
url: https://img.shields.io/badge/GitHub-1e--2-green
src: https://img.shields.io/badge/GitHub-1e--2-green
- alt: Facebook
url: https://img.shields.io/badge/Facebook-FFusionAI-blue
src: https://img.shields.io/badge/Facebook-FFusionAI-blue
- alt: Civitai
url: https://img.shields.io/badge/Civitai-FFusionAI-blue
src: https://img.shields.io/badge/Civitai-FFusionAI-blue
language:
- en
---
# FFusion XL LoRA 🧪 Potion Art Engine

<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<img src="https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success">
<img src="https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success">
<img src="https://img.shields.io/badge/LoRA%20Type-LyCORIS%2FLoKr%2C%20Prodigy-blue">
<img src="https://img.shields.io/badge/Tested%20on-SDXL%200.9%20%26%20FFXL%200.001-blue">
</div>
[](https://huggingface.co/FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine/resolve/main/FFusionXL-LoRa-SDXL-Potion-Art-Engine.safetensors)
[](https://huggingface.co/FFusion/FFusionXL-LoRa-SDXL-Potion-Art-Engine/tree/main/Samples)
The Potion Art Engine is an experimental version of a game asset art generator, specifically designed for creating potion vials.
## Specifications
- **Model Name**: FFusion XL LoRA Potion Art Engine
- **LoRA Type**: LyCORIS/LoKr, Prodigy
- **Trained Resolution**: 1024 x 1024 pixels
- **Tested Resolution**: Up to 2800 x 2800 pixels
<div style="display: flex; flex-wrap: wrap; gap: 4px;"><img src="https://img.shields.io/badge/Trained%20Resolution-1024%20x%201024%20pixels-yellow">
<img src="https://img.shields.io/badge/Tested%20Resolution-Up%20to%202800%20x%202800%20pixels-brightgreen"></div>
## How can the Potion Art Engine help game developers?
The Potion Art Engine is a powerful tool for game developers, especially those working on fantasy or RPG games where potions and vials are common game assets. Here are a few ways this tool can be beneficial:
1. **Speed up the asset creation process**: Creating game assets can be a time-consuming process, especially for indie developers or small teams. The Potion Art Engine can generate high-quality potion vials, significantly reducing the time and effort required to create these assets.
2. **Create a variety of unique assets**: The Potion Art Engine can generate a wide variety of potion vials, ensuring that each potion in your game can have a unique and distinct look. This can add to the depth and richness of your game world.
3. **Experiment with different styles**: The Potion Art Engine allows you to experiment with different styles and looks for your potions. This can be particularly useful in the early stages of game development when you are still defining the visual style of your game.
4. **Reduce costs**: By using the Potion Art Engine to generate game assets, you can significantly reduce the costs associated with asset creation. This can be particularly beneficial for indie developers or small teams with limited budgets.
## Limitations
- The Potion Art Engine is designed to generate potion vials, and its performance may vary when used to generate other types of game assets.
- The quality of the generated assets may vary depending on the specific parameters and settings used.
## Ethical Considerations
As with any AI model, it is important to use the Potion Art Engine responsibly. Please ensure that the generated assets do not infringe on any copyrights or intellectual property rights. It is also important to ensure that the generated assets are appropriate and do not contain any offensive or harmful content.
## Citations
If you use the Potion Art Engine in your project or research, please provide appropriate citations to acknowledge the model's contribution.
## Disclaimer

The Potion Art Engine is a powerful tool for generating game assets, but it is not perfect and may have limitations. Users are encouraged to test and validate the generated assets thoroughly before integrating them into their games. The developers of this model hold no responsibility for any consequences that may arise from its usage.
<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<a href="https://huggingface.co/FFusion/FFusion-BaSE" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue" alt="Hugging Face Model"></a>
<a href="https://github.com/1e-2" target="_new" rel="ugc"><img src="https://img.shields.io/badge/GitHub-1e--2-green" alt="GitHub"></a>
<a href="https://www.facebook.com/FFusionAI/" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Facebook-FFusionAI-blue" alt="Facebook"></a>
<a href="https://civitai.com/models/82039/ffusion-ai-sd-21" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Civitai-FFusionAI-blue" alt="Civitai"></a>
</div>
<div style="display: flex; flex-wrap: wrap; gap: 10px; align-items: center;">
<p>These are LoRA adaption weights for</p>
<a href="https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9" target="_new" rel="ugc"><img src="https://img.shields.io/badge/stable--diffusion--xl--base--0.9-Model-purple" alt="stable-diffusion-xl-base-0.9"></a>
<p>&</p>
<a href="https://huggingface.co/FFusion/FFusionXL-09-SDXL" target="_new" rel="ugc"><img src="https://img.shields.io/badge/FFusionXL--09--SDXL-Model-pink" alt="FFusionXL-09-SDXL"></a>
<p>The weights were trained using experimental</p>
<a href="https://github.com/kohya-ss/sd-scripts" target="_new" rel="ugc"><img src="https://img.shields.io/badge/kohya--ss-sd--scripts-blue" alt="kohya-ss/sd-scripts build"></a>
<p>build</p>
</div>
**Attribution:**
"SDXL 0.9 is licensed under the SDXL Research License, Copyright (c) Stability AI Ltd. All Rights Reserved."
## License
[SDXL 0.9 Research License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/blob/main/LICENSE.md)"

[](mailto:[email protected])
|
NasimB/bnc-cbt-log-rarity | NasimB | 2023-07-27T19:04:03Z | 14 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T16:42:30Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: bnc-cbt-log-rarity
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bnc-cbt-log-rarity
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1410
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.351 | 0.29 | 500 | 5.3291 |
| 5.0493 | 0.59 | 1000 | 4.9419 |
| 4.7234 | 0.88 | 1500 | 4.7048 |
| 4.4524 | 1.17 | 2000 | 4.5595 |
| 4.3123 | 1.46 | 2500 | 4.4472 |
| 4.2134 | 1.76 | 3000 | 4.3517 |
| 4.0971 | 2.05 | 3500 | 4.2754 |
| 3.9151 | 2.34 | 4000 | 4.2320 |
| 3.8812 | 2.63 | 4500 | 4.1763 |
| 3.8438 | 2.93 | 5000 | 4.1267 |
| 3.6488 | 3.22 | 5500 | 4.1269 |
| 3.6024 | 3.51 | 6000 | 4.0958 |
| 3.5864 | 3.81 | 6500 | 4.0625 |
| 3.4842 | 4.1 | 7000 | 4.0646 |
| 3.3367 | 4.39 | 7500 | 4.0563 |
| 3.3316 | 4.68 | 8000 | 4.0432 |
| 3.3157 | 4.98 | 8500 | 4.0354 |
| 3.1598 | 5.27 | 9000 | 4.0473 |
| 3.1514 | 5.56 | 9500 | 4.0472 |
| 3.1497 | 5.85 | 10000 | 4.0465 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
JBJoyce/wav2vec2-large-robust-12-ft-emotion-msp-dim-finetuned-gtzan | JBJoyce | 2023-07-27T19:03:49Z | 167 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-07-10T02:29:17Z | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: wav2vec2-large-robust-12-ft-emotion-msp-dim-finetuned-gtzan
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-robust-12-ft-emotion-msp-dim-finetuned-gtzan
This model is a fine-tuned version of [audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim](https://huggingface.co/audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7711
- Accuracy: 0.83
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.186 | 1.0 | 112 | 2.1638 | 0.3 |
| 1.655 | 2.0 | 225 | 1.7677 | 0.48 |
| 1.5148 | 3.0 | 337 | 1.3746 | 0.54 |
| 1.2349 | 4.0 | 450 | 1.1218 | 0.64 |
| 0.9702 | 5.0 | 562 | 1.0244 | 0.69 |
| 0.9191 | 6.0 | 675 | 0.9180 | 0.75 |
| 0.6891 | 7.0 | 787 | 0.8959 | 0.76 |
| 0.628 | 8.0 | 900 | 0.8084 | 0.81 |
| 0.7337 | 9.0 | 1012 | 0.7742 | 0.83 |
| 0.5573 | 9.96 | 1120 | 0.7711 | 0.83 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
StofEzz/mascir_fr_wav2vec_test | StofEzz | 2023-07-27T18:45:29Z | 135 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-large-xlsr-53",
"base_model:finetune:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-27T15:22:36Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: mascir_fr_wav2vec_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mascir_fr_wav2vec_test
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0136
- Wer: 0.1612
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 8.06 | 250 | 3.7503 | 0.9919 |
| 8.0637 | 16.13 | 500 | 3.0132 | 0.9919 |
| 8.0637 | 24.19 | 750 | 2.9734 | 0.9919 |
| 2.9339 | 32.26 | 1000 | 2.0538 | 0.9963 |
| 2.9339 | 40.32 | 1250 | 0.4530 | 0.5406 |
| 0.9878 | 48.39 | 1500 | 0.1807 | 0.3373 |
| 0.9878 | 56.45 | 1750 | 0.0814 | 0.2436 |
| 0.3416 | 64.52 | 2000 | 0.0512 | 0.2114 |
| 0.3416 | 72.58 | 2250 | 0.0292 | 0.1823 |
| 0.1952 | 80.65 | 2500 | 0.0198 | 0.1742 |
| 0.1952 | 88.71 | 2750 | 0.0158 | 0.1631 |
| 0.1476 | 96.77 | 3000 | 0.0136 | 0.1612 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.1
- Tokenizers 0.13.3
|
w601sxs/b1ade-1b-orca-chkpt-506k | w601sxs | 2023-07-27T18:44:34Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T18:43:42Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
dariowsz/ppo-Pyramids | dariowsz | 2023-07-27T18:29:47Z | 5 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2023-07-27T18:28:33Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: dariowsz/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Leogrin/eleuther-pythia1b-hh-dpo | Leogrin | 2023-07-27T18:21:11Z | 168 | 1 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:Anthropic/hh-rlhf",
"arxiv:2305.18290",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T14:35:26Z | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- Anthropic/hh-rlhf
---
# Infos
Pythia-1b supervised finetuned with Anthropic-hh-rlhf dataset for 1 epoch (sft-model), before DPO [(paper)](https://arxiv.org/abs/2305.18290) with same dataset for 1 epoch.
[wandb log](https://wandb.ai/pythia_dpo/Pythia_DPO_new/runs/jk09pzqb)
See [Pythia-1b](https://huggingface.co/EleutherAI/pythia-1b) for model details [(paper)](https://arxiv.org/abs/2101.00027).
# Benchmark raw results:
Results for the base model are taken from the [Pythia paper](https://arxiv.org/abs/2101.00027).
## Zero shot
| Task | 1B_base | 1B_sft | 1B_dpo |
|------------------|----------------|----------------|-----------------|
| Lambada (OpenAI) | 0.562 ± 0.007 | 0.563 ± 0.007 | 0.5575 ± 0.0069 |
| PIQA | 0.707 ± 0.011 | 0.711 ± 0.011 | 0.7122 ± 0.0106 |
| WinoGrande | 0.537 ± 0.014 | 0.534 ± 0.014 | 0.5525 ± 0.0140 |
| WSC | 0.365 ± 0.047 | 0.365 ± 0.047 | 0.3654 ± 0.0474 |
| ARC - Easy | 0.569 ± 0.010 | 0.583 ± 0.010 | 0.5901 ± 0.0101 |
| ARC - Challenge | 0.244 ± 0.013 | 0.248 ± 0.013 | 0.2611 ± 0.0128 |
| SciQ | 0.840 ± 0.012 | 0.847 ± 0.011 | 0.8530 ± 0.0112 |
| LogiQA | 0.223 ± 0.016 | N/A | N/A |
## Five shot
| Task | 1B_base | 1B_sft | 1B_dpo |
|------------------|----------------|----------------|-----------------|
| Lambada (OpenAI) | 0.507 ± 0.007 | 0.4722 ± 0.007 | 0.4669 ± 0.0070 |
| PIQA | 0.705 ± 0.011 | 0.7165 ± 0.0105| 0.7138 ± 0.0105 |
| WinoGrande | 0.532 ± 0.014 | 0.5343 ± 0.014 | 0.5525 ± 0.0140 |
| WSC | 0.365 ± 0.047 | 0.5000 ± 0.0493| 0.5577 ± 0.0489 |
| ARC - Easy | 0.594 ± 0.010 | 0.6010 ± 0.010 | 0.6170 ± 0.0100 |
| ARC - Challenge | 0.259 ± 0.013 | 0.2679 ± 0.0129| 0.2833 ± 0.0132 |
| SciQ | 0.920 ± 0.009 | 0.9100 ± 0.0091| 0.9020 ± 0.0094 |
| LogiQA | 0.227 ± 0.016 | N/A | N/A |
|
grace-pro/no-delete_5e-5_hausa | grace-pro | 2023-07-27T18:18:51Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:Davlan/afro-xlmr-base",
"base_model:finetune:Davlan/afro-xlmr-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-07-27T17:02:05Z | ---
license: mit
base_model: Davlan/afro-xlmr-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: no-delete_5e-5_hausa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# no-delete_5e-5_hausa
This model is a fine-tuned version of [Davlan/afro-xlmr-base](https://huggingface.co/Davlan/afro-xlmr-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1716
- Precision: 0.4009
- Recall: 0.2840
- F1: 0.3325
- Accuracy: 0.9559
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1421 | 1.0 | 1283 | 0.1347 | 0.4610 | 0.1779 | 0.2567 | 0.9594 |
| 0.1234 | 2.0 | 2566 | 0.1332 | 0.4847 | 0.1920 | 0.2750 | 0.9603 |
| 0.1041 | 3.0 | 3849 | 0.1412 | 0.4581 | 0.2305 | 0.3067 | 0.9595 |
| 0.0822 | 4.0 | 5132 | 0.1562 | 0.3979 | 0.2752 | 0.3253 | 0.9559 |
| 0.0664 | 5.0 | 6415 | 0.1716 | 0.4009 | 0.2840 | 0.3325 | 0.9559 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
Leogrin/eleuther-pythia1.4b-hh-dpo | Leogrin | 2023-07-27T18:16:00Z | 180 | 1 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:Anthropic/hh-rlhf",
"arxiv:2305.18290",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T15:07:41Z | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- Anthropic/hh-rlhf
---
# Infos
Pythia-1.4b supervised finetuned with Anthropic-hh-rlhf dataset for 1 epoch (sft-model), before DPO [(paper)](https://arxiv.org/abs/2305.18290) with same dataset for 1 epoch.
[wandb log](https://wandb.ai/pythia_dpo/Pythia_DPO_new/runs/6yrtkj3s)
See [Pythia-1.4b](https://huggingface.co/EleutherAI/pythia-1.4b) for model details [(paper)](https://arxiv.org/abs/2101.00027).
# Benchmark raw results:
Results for the base model are taken from the [Pythia paper](https://arxiv.org/abs/2101.00027).
## Zero shot
| Task | 1.4B_base | 1.4B_sft | 1.4B_dpo |
|------------------|--------------:|--------------:|---------------:|
| Lambada (OpenAI) | 0.616 ± 0.007 | 0.5977 ± 0.0068 | 0.5948 ± 0.0068 |
| PIQA | 0.711 ± 0.011 | 0.7133 ± 0.0106 | 0.7165 ± 0.0105 |
| WinoGrande | 0.573 ± 0.014 | 0.5793 ± 0.0139 | 0.5746 ± 0.0139 |
| WSC | 0.365 ± 0.047 | 0.3654 ± 0.0474 | 0.3654 ± 0.0474 |
| ARC - Easy | 0.606 ± 0.010 | 0.6098 ± 0.0100 | 0.6199 ± 0.0100 |
| ARC - Challenge | 0.260 ± 0.013 | 0.2696 ± 0.0130 | 0.2884 ± 0.0132 |
| SciQ | 0.865 ± 0.011 | 0.8540 ± 0.0112 | 0.8550 ± 0.0111 |
| LogiQA | 0.210 ± 0.016 | NA | NA |
## Five shot
| Task | 1.4B_base | 1.4B_sft | 1.4B_dpo |
|------------------|----------------:|----------------:|----------------:|
| Lambada (OpenAI) | 0.578 ± 0.007 | 0.5201 ± 0.007 | 0.5247 ± 0.007 |
| PIQA | 0.705 ± 0.011 | 0.7176 ± 0.0105| 0.7209 ± 0.0105|
| WinoGrande | 0.580 ± 0.014 | 0.5793 ± 0.0139| 0.5746 ± 0.0139|
| WSC | 0.365 ± 0.047 | 0.5288 ± 0.0492| 0.5769 ± 0.0487|
| ARC - Easy | 0.643 ± 0.010 | 0.6376 ± 0.0099| 0.6561 ± 0.0097|
| ARC - Challenge | 0.290 ± 0.013 | 0.2935 ± 0.0133| 0.3166 ± 0.0136|
| SciQ | 0.92 ± 0.009 | 0.9180 ± 0.0087| 0.9150 ± 0.0088|
| LogiQA | 0.240 ± 0.017 | N/A | N/A |
|
Khushnur/t5-base-end2end-questions-generation_squad_all_pcmq | Khushnur | 2023-07-27T18:11:03Z | 159 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-27T15:33:55Z | ---
license: apache-2.0
base_model: t5-base
tags:
- generated_from_trainer
model-index:
- name: t5-base-end2end-questions-generation_squad_all_pcmq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-end2end-questions-generation_squad_all_pcmq
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8599 | 0.67 | 100 | 1.6726 |
| 1.8315 | 1.35 | 200 | 1.6141 |
| 1.7564 | 2.02 | 300 | 1.5942 |
| 1.7153 | 2.69 | 400 | 1.5861 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
BauyrjanQ/whisper-kk-sp2ner-b2-ms1000-b | BauyrjanQ | 2023-07-27T18:07:56Z | 75 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:BauyrjanQ/whisper-kk",
"base_model:finetune:BauyrjanQ/whisper-kk",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-26T18:02:30Z | ---
license: apache-2.0
base_model: BauyrjanQ/whisper-kk
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-kk-sp2ner-b4-ms1000-b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-kk-sp2ner-b4-ms1000-b
This model is a fine-tuned version of [BauyrjanQ/whisper-kk](https://huggingface.co/BauyrjanQ/whisper-kk) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4320
- Wer: 95.6625
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 4
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 1.1132 | 0.06 | 1000 | 0.4320 | 95.6625 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jordyvl/vit-base_rvl_cdip_crl | jordyvl | 2023-07-27T18:00:23Z | 167 | 0 | transformers | [
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-07-26T16:38:18Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base_rvl_cdip_crl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base_rvl_cdip_crl
This model is a fine-tuned version of [jordyvl/vit-base_rvl-cdip](https://huggingface.co/jordyvl/vit-base_rvl-cdip) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6238
- Accuracy: 0.8956
- Brier Loss: 0.1819
- Nll: 1.1791
- F1 Micro: 0.8957
- F1 Macro: 0.8958
- Ece: 0.0846
- Aurc: 0.0210
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:----------:|:------:|:--------:|:--------:|:------:|:------:|
| 0.1844 | 1.0 | 1250 | 0.4411 | 0.8961 | 0.1614 | 1.1240 | 0.8961 | 0.8963 | 0.0528 | 0.0161 |
| 0.1394 | 2.0 | 2500 | 0.4830 | 0.8927 | 0.1716 | 1.1324 | 0.8927 | 0.8927 | 0.0646 | 0.0175 |
| 0.1 | 3.0 | 3750 | 0.5257 | 0.8911 | 0.1791 | 1.1569 | 0.8911 | 0.8912 | 0.0737 | 0.0187 |
| 0.068 | 4.0 | 5000 | 0.5497 | 0.8913 | 0.1806 | 1.1705 | 0.8913 | 0.8913 | 0.0770 | 0.0192 |
| 0.048 | 5.0 | 6250 | 0.5762 | 0.8915 | 0.1834 | 1.1906 | 0.8915 | 0.8914 | 0.0808 | 0.0195 |
| 0.033 | 6.0 | 7500 | 0.5877 | 0.8936 | 0.1822 | 1.1690 | 0.8936 | 0.8938 | 0.0817 | 0.0196 |
| 0.0231 | 7.0 | 8750 | 0.6000 | 0.8938 | 0.1822 | 1.1867 | 0.8938 | 0.8939 | 0.0833 | 0.0206 |
| 0.0162 | 8.0 | 10000 | 0.6187 | 0.8948 | 0.1834 | 1.1827 | 0.8948 | 0.8949 | 0.0841 | 0.0208 |
| 0.0123 | 9.0 | 11250 | 0.6191 | 0.8953 | 0.1824 | 1.1868 | 0.8953 | 0.8955 | 0.0836 | 0.0207 |
| 0.0102 | 10.0 | 12500 | 0.6238 | 0.8956 | 0.1819 | 1.1791 | 0.8957 | 0.8958 | 0.0846 | 0.0210 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
snob/TagMyBookmark-KoAlpaca-QLoRA-v1.0-Finetune300 | snob | 2023-07-27T17:57:27Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T17:57:09Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
dariowsz/ppo-SnowballTarget | dariowsz | 2023-07-27T17:45:56Z | 7 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | reinforcement-learning | 2023-07-27T17:45:49Z | ---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: dariowsz/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
asenella/MMVAEPlus_beta_10_scale_False_seed_2 | asenella | 2023-07-27T17:21:14Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T17:21:01Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/MMVAEPlus_beta_5_scale_False_seed_2 | asenella | 2023-07-27T17:15:39Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T17:15:20Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
magnustragardh/poca-SoccerTwos | magnustragardh | 2023-07-27T17:06:35Z | 5 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] | reinforcement-learning | 2023-07-27T17:01:53Z | ---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: magnustragardh/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
asenella/MMVAEPlus_beta_25_scale_False_seed_0 | asenella | 2023-07-27T17:03:43Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T17:03:30Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/MMVAEPlus_beta_10_scale_False_seed_0 | asenella | 2023-07-27T17:01:30Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T17:01:18Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
Pallisgaard/whisper-small-dv | Pallisgaard | 2023-07-27T16:52:23Z | 76 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dv",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-27T15:24:33Z | ---
language:
- dv
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: Whisper Small Dv - Sanchit Gandhi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13
type: mozilla-foundation/common_voice_13_0
config: dv
split: test
args: dv
metrics:
- name: Wer
type: wer
value: 13.097680564732064
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Dv - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1691
- Wer Ortho: 62.1144
- Wer: 13.0977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.1237 | 1.63 | 500 | 0.1691 | 62.1144 | 13.0977 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
augtoma/qCammel-70-x | augtoma | 2023-07-27T16:47:02Z | 1,686 | 27 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama-2",
"qCammel-70",
"en",
"arxiv:2305.12031",
"arxiv:2305.14314",
"arxiv:2302.70971",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-07-23T00:39:34Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- pytorch
- llama
- llama-2
- qCammel-70
library_name: transformers
---
# qCammel-70
qCammel-70 is a fine-tuned version of Llama-2 70B model, trained on a distilled dataset of 15,000 instructions using QLoRA. This model is optimized for academic medical knowledge and instruction-following capabilities.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept their License before downloading this model .*
The fine-tuning process applied to qCammel-70 involves a distilled dataset of 15,000 instructions and is trained with QLoRA,
**Variations** The original Llama 2 has parameter sizes of 7B, 13B, and 70B. This is the fine-tuned version of the 70B model.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** qCammel-70 is based on the Llama 2 architecture, an auto-regressive language model that uses a decoder only transformer architecture.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
Llama 2 is licensed under the LLAMA 2 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved
**Research Papers**
- [Clinical Camel: An Open-Source Expert-Level Medical Language Model with Dialogue-Based Knowledge Encoding](https://arxiv.org/abs/2305.12031)
- [QLoRA: Efficient Finetuning of Quantized LLMs](https://arxiv.org/abs/2305.14314)
- [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.70971)
|
digitaljungle/ppo-LunarLander-v2 | digitaljungle | 2023-07-27T16:25:57Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T16:25:36Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 260.52 +/- 19.49
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
blackmount8/WizardLM-13B-V1.2-ct2-int8 | blackmount8 | 2023-07-27T16:17:54Z | 2 | 0 | transformers | [
"transformers",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-07-26T16:16:35Z | ---
license: mit
---
# blackmount8/WizardLM-13B-V1.2-ct2-int8
Int8 version of [WizardLM/WizardLM-13B-V1.2](https://huggingface.co/WizardLM/WizardLM-13B-V1.2), quantized using CTranslate2.
|
mdhafeez29/llama2-qlora-finetunined-french | mdhafeez29 | 2023-07-27T16:09:16Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T16:09:10Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
NasimB/aochildes-rarity-2 | NasimB | 2023-07-27T16:08:36Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T13:44:03Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: aochildes-rarity-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aochildes-rarity-2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1181
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.351 | 0.29 | 500 | 5.3358 |
| 5.0412 | 0.59 | 1000 | 4.9250 |
| 4.7138 | 0.88 | 1500 | 4.6868 |
| 4.4435 | 1.17 | 2000 | 4.5444 |
| 4.3073 | 1.47 | 2500 | 4.4317 |
| 4.205 | 1.76 | 3000 | 4.3274 |
| 4.0796 | 2.05 | 3500 | 4.2630 |
| 3.8987 | 2.35 | 4000 | 4.2145 |
| 3.8749 | 2.64 | 4500 | 4.1579 |
| 3.8421 | 2.93 | 5000 | 4.1113 |
| 3.6388 | 3.23 | 5500 | 4.1089 |
| 3.5906 | 3.52 | 6000 | 4.0804 |
| 3.5776 | 3.81 | 6500 | 4.0451 |
| 3.4712 | 4.11 | 7000 | 4.0519 |
| 3.3209 | 4.4 | 7500 | 4.0435 |
| 3.3179 | 4.69 | 8000 | 4.0297 |
| 3.3071 | 4.99 | 8500 | 4.0193 |
| 3.1447 | 5.28 | 9000 | 4.0337 |
| 3.1394 | 5.57 | 9500 | 4.0322 |
| 3.1343 | 5.87 | 10000 | 4.0318 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Lazycuber/Pygnen-dolly-6B | Lazycuber | 2023-07-27T16:08:06Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"gptj",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-25T14:12:36Z | ---
license: apache-2.0
---
|
yancongwen/chatglm2-medical-lora-20230727 | yancongwen | 2023-07-27T16:07:33Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"region:us"
] | null | 2023-07-27T16:06:20Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
drradford/ppo-Huggy | drradford | 2023-07-27T16:05:42Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2023-07-27T16:05:37Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: drradford/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
WforGodot/add-lora-7b | WforGodot | 2023-07-27T15:54:56Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-26T17:39:31Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
digitaljungle/taxi_q_ueue | digitaljungle | 2023-07-27T15:53:32Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T15:53:30Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi_q_ueue
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="digitaljungle/taxi_q_ueue", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
digitaljungle/q-FrozenLake-v1-4x4-noSlippery | digitaljungle | 2023-07-27T15:52:16Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T15:52:12Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="digitaljungle/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
aman38649/marian-finetuned-kde4-en-to-fr | aman38649 | 2023-07-27T15:50:48Z | 60 | 0 | transformers | [
"transformers",
"tf",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"base_model:Helsinki-NLP/opus-mt-en-fr",
"base_model:finetune:Helsinki-NLP/opus-mt-en-fr",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-27T09:19:00Z | ---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-fr
tags:
- generated_from_keras_callback
model-index:
- name: aman38649/marian-finetuned-kde4-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# aman38649/marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7983
- Validation Loss: 0.8210
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 17733, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.0611 | 0.8791 | 0 |
| 0.7983 | 0.8210 | 1 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.12.0
- Datasets 2.14.0
- Tokenizers 0.13.3
|
timothytruong/my_awesome_billsum_model | timothytruong | 2023-07-27T15:40:12Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:billsum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-26T16:27:51Z | ---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- billsum
metrics:
- rouge
model-index:
- name: my_awesome_billsum_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: billsum
type: billsum
config: default
split: ca_test
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.1365
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5173
- Rouge1: 0.1365
- Rouge2: 0.0489
- Rougel: 0.1158
- Rougelsum: 0.1158
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.8028 | 0.1229 | 0.0364 | 0.1048 | 0.1048 | 19.0 |
| No log | 2.0 | 124 | 2.5974 | 0.1324 | 0.0467 | 0.1121 | 0.1122 | 19.0 |
| No log | 3.0 | 186 | 2.5350 | 0.1354 | 0.0491 | 0.1153 | 0.1151 | 19.0 |
| No log | 4.0 | 248 | 2.5173 | 0.1365 | 0.0489 | 0.1158 | 0.1158 | 19.0 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.10.1+cpu
- Datasets 2.13.1
- Tokenizers 0.13.3
|
mahmoudzamani/t5_recommendation_sports_equipment_english | mahmoudzamani | 2023-07-27T15:30:14Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-27T15:18:57Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5_recommendation_sports_equipment_english
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_recommendation_sports_equipment_english
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4517
- Rouge1: 57.9365
- Rouge2: 47.6190
- Rougel: 56.9841
- Rougelsum: 56.6667
- Gen Len: 3.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 0.96 | 6 | 6.7882 | 8.8278 | 0.9524 | 8.7668 | 8.8278 | 19.0 |
| No log | 1.96 | 12 | 2.3412 | 18.0952 | 0.0 | 18.0952 | 18.0952 | 3.2381 |
| No log | 2.96 | 18 | 0.8550 | 11.9048 | 4.7619 | 11.9048 | 11.9048 | 4.0 |
| No log | 3.96 | 24 | 0.7481 | 32.3810 | 4.7619 | 32.0635 | 32.0635 | 3.9048 |
| No log | 4.96 | 30 | 0.7208 | 21.2698 | 4.7619 | 20.7937 | 20.7937 | 3.6190 |
| No log | 5.96 | 36 | 0.6293 | 31.7460 | 23.8095 | 31.7460 | 31.7460 | 3.6667 |
| No log | 6.96 | 42 | 0.6203 | 43.6508 | 33.3333 | 43.4921 | 42.6984 | 3.9048 |
| No log | 7.96 | 48 | 0.6352 | 48.4127 | 33.3333 | 46.8254 | 46.8254 | 3.8095 |
| No log | 8.96 | 54 | 0.5334 | 53.2540 | 42.8571 | 52.3810 | 52.0635 | 3.9524 |
| No log | 9.96 | 60 | 0.4517 | 57.9365 | 47.6190 | 56.9841 | 56.6667 | 3.9048 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.0.1+cu118
- Datasets 2.8.0
- Tokenizers 0.13.3
|
alexandremarie/Falcon7b-wiki2-fr | alexandremarie | 2023-07-27T15:14:35Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-27T15:14:35Z | ---
license: creativeml-openrail-m
---
|
royokong/prompteol-llama-7b | royokong | 2023-07-27T15:07:54Z | 3 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T15:06:19Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
StofEzz/mascir_fr_hubert_test | StofEzz | 2023-07-27T15:03:40Z | 136 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"hubert",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/hubert-large-ls960-ft",
"base_model:finetune:facebook/hubert-large-ls960-ft",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-27T12:22:50Z | ---
license: apache-2.0
base_model: facebook/hubert-large-ls960-ft
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: mascir_fr_hubert_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mascir_fr_hubert_test
This model is a fine-tuned version of [facebook/hubert-large-ls960-ft](https://huggingface.co/facebook/hubert-large-ls960-ft) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0113
- Wer: 0.1680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 8.06 | 250 | 3.0885 | 0.9919 |
| 5.8634 | 16.13 | 500 | 2.8476 | 0.9919 |
| 5.8634 | 24.19 | 750 | 1.1091 | 0.9461 |
| 1.7302 | 32.26 | 1000 | 0.4035 | 0.6076 |
| 1.7302 | 40.32 | 1250 | 0.1643 | 0.3980 |
| 0.5446 | 48.39 | 1500 | 0.0872 | 0.2784 |
| 0.5446 | 56.45 | 1750 | 0.0464 | 0.2257 |
| 0.3144 | 64.52 | 2000 | 0.0311 | 0.2021 |
| 0.3144 | 72.58 | 2250 | 0.0213 | 0.1891 |
| 0.2224 | 80.65 | 2500 | 0.0155 | 0.1816 |
| 0.2224 | 88.71 | 2750 | 0.0132 | 0.1699 |
| 0.1871 | 96.77 | 3000 | 0.0113 | 0.1680 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
epsilonai/SargeRVB | epsilonai | 2023-07-27T14:42:04Z | 0 | 0 | null | [
"rvb",
"red vs blue",
"music",
"rvc",
"text-to-speech",
"en",
"region:us"
] | text-to-speech | 2023-07-27T14:38:06Z | ---
language:
- en
pipeline_tag: text-to-speech
tags:
- rvb
- red vs blue
- music
- rvc
--- |
nakcnx/wangchang-math-v2 | nakcnx | 2023-07-27T14:29:04Z | 1 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T10:25:44Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
- PEFT 0.5.0.dev0
|
Varshitha/flan-t5-small-finetuned-medicine | Varshitha | 2023-07-27T14:27:11Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"text2textgeneration",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-27T14:10:18Z | ---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- text2textgeneration
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-small-finetuned-medicine
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-small-finetuned-medicine
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9066
- Rouge1: 9.3596
- Rouge2: 2.6144
- Rougel: 8.94
- Rougelsum: 8.94
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 3.1417 | 1.0 | 5 | 2.9168 | 9.5238 | 2.6144 | 8.9947 | 8.9947 |
| 3.1069 | 2.0 | 10 | 2.9066 | 9.3596 | 2.6144 | 8.94 | 8.94 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
Andreaa4/Llama-2-7b-chat-hf | Andreaa4 | 2023-07-27T14:14:13Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T14:09:28Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
sophy/qa_model | sophy | 2023-07-27T14:05:19Z | 0 | 0 | transformers | [
"transformers",
"question-answering",
"dataset:squad",
"license:openrail",
"endpoints_compatible",
"region:us"
] | question-answering | 2023-07-22T22:02:20Z | ---
license: openrail
datasets:
- squad
pipeline_tag: question-answering
library_name: transformers
--- |
reach-vb/musicgen-large-endpoint | reach-vb | 2023-07-27T14:04:06Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"musicgen",
"text-to-audio",
"arxiv:2306.05284",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | text-to-audio | 2023-07-27T11:46:07Z | ---
inference: false
tags:
- musicgen
license: cc-by-nc-4.0
duplicated_from: facebook/musicgen-large
---
# MusicGen - Large - 3.3B
MusicGen is a text-to-music model capable of genreating high-quality music samples conditioned on text descriptions or audio prompts.
It is a single stage auto-regressive Transformer model trained over a 32kHz EnCodec tokenizer with 4 codebooks sampled at 50 Hz.
Unlike existing methods, like MusicLM, MusicGen doesn't require a self-supervised semantic representation, and it generates all 4 codebooks in one pass.
By introducing a small delay between the codebooks, we show we can predict them in parallel, thus having only 50 auto-regressive steps per second of audio.
MusicGen was published in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by *Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez*.
Four checkpoints are released:
- [small](https://huggingface.co/facebook/musicgen-small)
- [medium](https://huggingface.co/facebook/musicgen-medium)
- [**large** (this checkpoint)](https://huggingface.co/facebook/musicgen-large)
- [melody](https://huggingface.co/facebook/musicgen-melody)
## Example
Try out MusicGen yourself!
* Audiocraft Colab:
<a target="_blank" href="https://colab.research.google.com/drive/1fxGqfg96RBUvGxZ1XXN07s3DthrKUl4-?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
* Hugging Face Colab:
<a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/MusicGen.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
* Hugging Face Demo:
<a target="_blank" href="https://huggingface.co/spaces/facebook/MusicGen">
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/open-in-hf-spaces-sm.svg" alt="Open in HuggingFace"/>
</a>
## 🤗 Transformers Usage
You can run MusicGen locally with the 🤗 Transformers library from version 4.31.0 onwards.
1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers) from main:
```
pip install git+https://github.com/huggingface/transformers.git
```
2. Run the following Python code to generate text-conditional audio samples:
```py
from transformers import AutoProcessor, MusicgenForConditionalGeneration
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large")
inputs = processor(
text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, max_new_tokens=256)
```
3. Listen to the audio samples either in an ipynb notebook:
```py
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0].numpy(), rate=sampling_rate)
```
Or save them as a `.wav` file using a third-party library, e.g. `scipy`:
```py
import scipy
sampling_rate = model.config.audio_encoder.sampling_rate
scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy())
```
For more details on using the MusicGen model for inference using the 🤗 Transformers library, refer to the [MusicGen docs](https://huggingface.co/docs/transformers/model_doc/musicgen).
## Audiocraft Usage
You can also run MusicGen locally through the original [Audiocraft library]((https://github.com/facebookresearch/audiocraft):
1. First install the [`audiocraft` library](https://github.com/facebookresearch/audiocraft)
```
pip install git+https://github.com/facebookresearch/audiocraft.git
```
2. Make sure to have [`ffmpeg`](https://ffmpeg.org/download.html) installed:
```
apt get install ffmpeg
```
3. Run the following Python code:
```py
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained("large")
model.set_generation_params(duration=8) # generate 8 seconds.
descriptions = ["happy rock", "energetic EDM"]
wav = model.generate(descriptions) # generates 2 samples.
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")
```
## Model details
**Organization developing the model:** The FAIR team of Meta AI.
**Model date:** MusicGen was trained between April 2023 and May 2023.
**Model version:** This is the version 1 of the model.
**Model type:** MusicGen consists of an EnCodec model for audio tokenization, an auto-regressive language model based on the transformer architecture for music modeling. The model comes in different sizes: 300M, 1.5B and 3.3B parameters ; and two variants: a model trained for text-to-music generation task and a model trained for melody-guided music generation.
**Paper or resources for more information:** More information can be found in the paper [Simple and Controllable Music Generation][https://arxiv.org/abs/2306.05284].
**Citation details**:
```
@misc{copet2023simple,
title={Simple and Controllable Music Generation},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
year={2023},
eprint={2306.05284},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
**License** Code is released under MIT, model weights are released under CC-BY-NC 4.0.
**Where to send questions or comments about the model:** Questions and comments about MusicGen can be sent via the [Github repository](https://github.com/facebookresearch/audiocraft) of the project, or by opening an issue.
## Intended use
**Primary intended use:** The primary use of MusicGen is research on AI-based music generation, including:
- Research efforts, such as probing and better understanding the limitations of generative models to further improve the state of science
- Generation of music guided by text or melody to understand current abilities of generative AI models by machine learning amateurs
**Primary intended users:** The primary intended users of the model are researchers in audio, machine learning and artificial intelligence, as well as amateur seeking to better understand those models.
**Out-of-scope use cases** The model should not be used on downstream applications without further risk evaluation and mitigation. The model should not be used to intentionally create or disseminate music pieces that create hostile or alienating environments for people. This includes generating music that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
## Metrics
**Models performance measures:** We used the following objective measure to evaluate the model on a standard music benchmark:
- Frechet Audio Distance computed on features extracted from a pre-trained audio classifier (VGGish)
- Kullback-Leibler Divergence on label distributions extracted from a pre-trained audio classifier (PaSST)
- CLAP Score between audio embedding and text embedding extracted from a pre-trained CLAP model
Additionally, we run qualitative studies with human participants, evaluating the performance of the model with the following axes:
- Overall quality of the music samples;
- Text relevance to the provided text input;
- Adherence to the melody for melody-guided music generation.
More details on performance measures and human studies can be found in the paper.
**Decision thresholds:** Not applicable.
## Evaluation datasets
The model was evaluated on the [MusicCaps benchmark](https://www.kaggle.com/datasets/googleai/musiccaps) and on an in-domain held-out evaluation set, with no artist overlap with the training set.
## Training datasets
The model was trained using the following sources: the [Meta Music Initiative Sound Collection](https://www.fb.com/sound), [Shutterstock music collection](https://www.shutterstock.com/music) and the [Pond5 music collection](https://www.pond5.com/). See the paper for more details about the training set and corresponding preprocessing.
## Quantitative analysis
More information can be found in the paper [Simple and Controllable Music Generation][arxiv], in the Experimental Setup section.
## Limitations and biases
**Data:** The data sources used to train the model are created by music professionals and covered by legal agreements with the right holders. The model is trained on 20K hours of data, we believe that scaling the model on larger datasets can further improve the performance of the model.
**Mitigations:** All vocals have been removed from the data source using a state-of-the-art music source separation method, namely using the open source [Hybrid Transformer for Music Source Separation](https://github.com/facebookresearch/demucs) (HT-Demucs). The model is therefore not able to produce vocals.
**Limitations:**
- The model is not able to generate realistic vocals.
- The model has been trained with English descriptions and will not perform as well in other languages.
- The model does not perform equally well for all music styles and cultures.
- The model sometimes generates end of songs, collapsing to silence.
- It is sometimes difficult to assess what types of text descriptions provide the best generations. Prompt engineering may be required to obtain satisfying results.
**Biases:** The source of data is potentially lacking diversity and all music cultures are not equally represented in the dataset. The model may not perform equally well on the wide variety of music genres that exists. The generated samples from the model will reflect the biases from the training data. Further work on this model should include methods for balanced and just representations of cultures, for example, by scaling the training data to be both diverse and inclusive.
**Risks and harms:** Biases and limitations of the model may lead to generation of samples that may be considered as biased, inappropriate or offensive. We believe that providing the code to reproduce the research and train new models will allow to broaden the application to new and more representative data.
**Use cases:** Users must be aware of the biases, limitations and risks of the model. MusicGen is a model developed for artificial intelligence research on controllable music generation. As such, it should not be used for downstream applications without further investigation and mitigation of risks. |
Chat-Error/deberta-xlarge-reward | Chat-Error | 2023-07-27T14:02:34Z | 0 | 1 | null | [
"tensorboard",
"region:us"
] | null | 2023-07-27T00:26:56Z | This is Deberta V2 xlarge trained on my https://huggingface.co/datasets/nRuaif/RLHF-hh dataset, using trl.
|
SigSegev/t5-large_PREFIX_TUNING_SEQ2SEQ_v2 | SigSegev | 2023-07-27T13:41:44Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T13:41:29Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
luodian/Flamingo-Llama2-Chat7B-CC3M | luodian | 2023-07-27T13:34:33Z | 4 | 10 | transformers | [
"transformers",
"pytorch",
"flamingo",
"text2text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-26T01:22:21Z | ---
license: mit
---
**TLDR**: We trained a Flamingo with Llama2-Chat7B as LLM on CC3M in less than 5 hours using just 4 A100s.
The model showed promising zero-shot captioning skills. High-quality captioning data really helps fast alignment.
You could test it via following code. Be sure to visit [Otter](https://github.com/Luodian/Otter) to get necessary Flamingo/Otter models.
```python
from flamingo.modeling_flamingo import FlamingoForConditionalGeneration
flamingo_model = FlamingoForConditionalGeneration.from_pretrained("luodian/Flamingo-Llama2-Chat7B-CC3M", device_map=auto)
prompt = "<image>an image of"
simple_prompt = "<image>"
``` |
SaferChat/falcon-7b-test | SaferChat | 2023-07-27T13:33:36Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T13:19:45Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
winterbro/distilbert-base-uncased-finetuned-cola | winterbro | 2023-07-27T13:15:59Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-27T11:28:54Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5425688103069501
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5259
- Matthews Correlation: 0.5426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5221 | 1.0 | 535 | 0.5361 | 0.4307 |
| 0.3492 | 2.0 | 1070 | 0.5128 | 0.4921 |
| 0.2382 | 3.0 | 1605 | 0.5259 | 0.5426 |
| 0.1758 | 4.0 | 2140 | 0.7495 | 0.5301 |
| 0.1251 | 5.0 | 2675 | 0.7982 | 0.5414 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
undrwolf/Pyramid | undrwolf | 2023-07-27T13:14:28Z | 1 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2023-07-27T13:10:10Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: undrwolf/Pyramid
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Carloswear/llama2-qlora-finetunined-french | Carloswear | 2023-07-27T13:12:23Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T13:12:18Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
xinyangli/woman_photo | xinyangli | 2023-07-27T13:07:00Z | 0 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2023-07-27T12:41:48Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of a sks person
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - xinyangli/woman_photo
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of a sks person using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
ditwoo/distilhubert-finetuned-gtzan | ditwoo | 2023-07-27T13:04:50Z | 161 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-06-25T19:25:16Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9570
- Accuracy: 0.86
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1586 | 1.0 | 112 | 2.0855 | 0.45 |
| 1.4771 | 2.0 | 225 | 1.3396 | 0.72 |
| 1.181 | 3.0 | 337 | 0.9735 | 0.76 |
| 0.8133 | 4.0 | 450 | 0.8692 | 0.76 |
| 0.5397 | 5.0 | 562 | 0.7118 | 0.81 |
| 0.3424 | 6.0 | 675 | 0.6237 | 0.81 |
| 0.2717 | 7.0 | 787 | 0.6551 | 0.83 |
| 0.2653 | 8.0 | 900 | 0.6707 | 0.83 |
| 0.0503 | 9.0 | 1012 | 0.7025 | 0.84 |
| 0.0168 | 10.0 | 1125 | 0.7643 | 0.87 |
| 0.1125 | 11.0 | 1237 | 0.8550 | 0.86 |
| 0.155 | 12.0 | 1350 | 0.9796 | 0.82 |
| 0.005 | 13.0 | 1462 | 0.9539 | 0.86 |
| 0.0038 | 14.0 | 1575 | 0.9206 | 0.86 |
| 0.0035 | 15.0 | 1687 | 0.8725 | 0.88 |
| 0.051 | 16.0 | 1800 | 0.9980 | 0.86 |
| 0.003 | 17.0 | 1912 | 0.9579 | 0.86 |
| 0.0025 | 18.0 | 2025 | 0.9735 | 0.86 |
| 0.0023 | 19.0 | 2137 | 0.9589 | 0.86 |
| 0.0022 | 19.91 | 2240 | 0.9570 | 0.86 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaalan/sbert_large_nlu_ru | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaalan | 2023-07-27T13:03:18Z | 46 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"jax",
"bert",
"PyTorch",
"Transformers",
"ru",
"region:us"
] | null | 2023-07-27T09:07:35Z | ---
library_name: sentence-transformers
language:
- ru
tags:
- PyTorch
- Transformers
---
# BERT large model (uncased) for Sentence Embeddings in Russian language.
The model is described [in this article](https://habr.com/ru/company/sberdevices/blog/527576/)
For better quality, use mean token embeddings.
## Usage (HuggingFace Models Repository)
You can use the model directly from the model repository to compute sentence embeddings:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
#Sentences we want sentence embeddings for
sentences = ['Привет! Как твои дела?',
'А правда, что 42 твое любимое число?']
#Load AutoModel from huggingface model repository
tokenizer = AutoTokenizer.from_pretrained("sberbank-ai/sbert_large_nlu_ru")
model = AutoModel.from_pretrained("sberbank-ai/sbert_large_nlu_ru")
#Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=24, return_tensors='pt')
#Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
#Perform pooling. In this case, mean pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
# Authors
- [SberDevices](https://sberdevices.ru/) Team.
- Denis Antykhov: [Github](https://github.com/gaphex);
- Aleksandr Abramov: [Github](https://github.com/Ab1992ao), [Kaggle Competitions Master](https://www.kaggle.com/andrilko)
|
asenella/ms_MMVAEPlus_beta_5_scale_True_seed_2 | asenella | 2023-07-27T12:44:38Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:44:36Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
apple/coreml-stable-diffusion-xl-base | apple | 2023-07-27T12:41:14Z | 22 | 67 | null | [
"coreml",
"text-to-image",
"stable-diffusion",
"core-ml",
"arxiv:2307.01952",
"arxiv:2211.01324",
"arxiv:2108.01073",
"arxiv:2112.10752",
"license:openrail++",
"region:us"
] | text-to-image | 2023-07-26T14:44:27Z | ---
license: openrail++
tags:
- text-to-image
- stable-diffusion
- core-ml
---
# SD-XL 1.0-base Model Card (Core ML)
This model was generated by Hugging Face using [Apple’s repository](https://github.com/apple/ml-stable-diffusion) which has [ASCL](https://github.com/apple/ml-stable-diffusion/blob/main/LICENSE.md). This version contains Core ML weights with the `ORIGINAL` attention implementation, suitable for running on macOS GPUs.
The Core ML weights are also distributed as a zip archive for use in the [Hugging Face demo app](https://github.com/huggingface/swift-coreml-diffusers) and other third party tools. The zip archive was created from the contents of the `original/compiled` folder in this repo. Please, refer to https://huggingface.co/blog/diffusers-coreml for details.
The remaining contents of this model card were copied from the [original repo](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)

## Model

[SDXL](https://arxiv.org/abs/2307.01952) consists of an [ensemble of experts](https://arxiv.org/abs/2211.01324) pipeline for latent diffusion:
In a first step, the base model is used to generate (noisy) latents,
which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
### Model Description
- **Developed by:** Stability AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/Stability-AI/generative-models) and the [SDXL report on arXiv](https://arxiv.org/abs/2307.01952).
### Model Sources
For research purposes, we recommned our `generative-models` Github repository (https://github.com/Stability-AI/generative-models), which implements the most popoular diffusion frameworks (both training and inference) and for which new functionalities like distillation will be added over time.
[Clipdrop](https://clipdrop.co/stable-diffusion) provides free SDXL inference.
- **Repository:** https://github.com/Stability-AI/generative-models
- **Demo:** https://clipdrop.co/stable-diffusion
## Evaluation

The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1.
The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.18.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
You can use the model then as follows
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. |
bwilkie/bwilkie-whisper-small-dv | bwilkie | 2023-07-27T12:32:54Z | 84 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-27T09:25:35Z | ---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- PolyAI/minds14
metrics:
- wer
model-index:
- name: bwilkie-whisper-small-dv
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: PolyAI/minds14
type: PolyAI/minds14
config: all
split: None
metrics:
- name: Wer
type: wer
value: 0.23270055113288426
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bwilkie-whisper-small-dv
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7358
- Wer Ortho: 0.2389
- Wer: 0.2327
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|
| 0.0001 | 17.86 | 500 | 0.7358 | 0.2389 | 0.2327 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
asenella/ms_MMVAEPlus_beta_25_scale_True_seed_1 | asenella | 2023-07-27T12:28:12Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:28:10Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
annishaa/my_awesome_eli5_clm-model-2 | annishaa | 2023-07-27T12:26:30Z | 226 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T11:17:11Z | ---
license: apache-2.0
base_model: distilgpt2
tags:
- generated_from_trainer
model-index:
- name: my_awesome_eli5_clm-model-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_clm-model-2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7158
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7157 | 1.0 | 1128 | 3.7215 |
| 3.6465 | 2.0 | 2256 | 3.7161 |
| 3.623 | 3.0 | 3384 | 3.7158 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
asenella/ms_MMVAEPlus_beta_5_scale_True_seed_0 | asenella | 2023-07-27T12:17:13Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:17:11Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
rehanhaider/DBSD-1.5-9-vectors-lr-5e-6 | rehanhaider | 2023-07-27T12:17:03Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-27T11:59:35Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: in the style of wlat_mntn
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - rehanhaider/DBSD-1.5-9-vectors-lr-5e-6
This is a dreambooth model derived from runwayml/stable-diffusion-v1-5. The weights were trained on in the style of wlat_mntn using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
asenella/ms_MMVAEPlus_beta_10_scale_False_seed_3 | asenella | 2023-07-27T12:15:36Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:15:34Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
AnushaPalle/my_awesome_eli5_clm-model | AnushaPalle | 2023-07-27T12:09:17Z | 226 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-27T11:05:43Z | ---
license: apache-2.0
base_model: distilgpt2
tags:
- generated_from_trainer
model-index:
- name: my_awesome_eli5_clm-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_clm-model
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7490
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.8717 | 1.0 | 1113 | 3.7653 |
| 3.7754 | 2.0 | 2226 | 3.7524 |
| 3.7318 | 3.0 | 3339 | 3.7490 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
asenella/ms_MMVAEPlus_beta_5_scale_False_seed_1 | asenella | 2023-07-27T12:05:36Z | 0 | 1 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:05:35Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/ms_MMVAEPlus_beta_25_scale_True_seed_0 | asenella | 2023-07-27T12:05:35Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:05:33Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/ms_MMVAEPlus_beta_25_scale_False_seed_2 | asenella | 2023-07-27T12:05:32Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T12:05:30Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
alesanm/blip-image-captioning-base-fashionimages-finetuned | alesanm | 2023-07-27T12:05:03Z | 140 | 1 | transformers | [
"transformers",
"pytorch",
"blip",
"image-text-to-text",
"image-to-text",
"dataset:alesanm/balenciaga_short_descriptions",
"region:us"
] | image-to-text | 2023-07-24T11:00:40Z | ---
inference: False
datasets:
- alesanm/balenciaga_short_descriptions
library_name: transformers
pipeline_tag: image-to-text
---
The BLIP model was trained on 141 photos of the Balenciaga fashion brand and descriptions produced by GPT3 |
asenella/ms_MMVAEPlus_beta_10_scale_True_seed_3 | asenella | 2023-07-27T12:00:00Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T11:59:58Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
YanJiangJerry/baselineberttweetlarge | YanJiangJerry | 2023-07-27T11:59:35Z | 113 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:vinai/bertweet-large",
"base_model:finetune:vinai/bertweet-large",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-27T07:55:47Z | ---
base_model: vinai/bertweet-large
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: baselineberttweetlarge
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# baselineberttweetlarge
This model is a fine-tuned version of [vinai/bertweet-large](https://huggingface.co/vinai/bertweet-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6168
- Accuracy: 0.6274
- F1: 0.0
- Precision: 0.0
- Recall: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---:|:---------:|:------:|
| 0.6062 | 1.0 | 788 | 0.6020 | 0.6274 | 0.0 | 0.0 | 0.0 |
| 0.5852 | 2.0 | 1576 | 0.6168 | 0.6274 | 0.0 | 0.0 | 0.0 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
asenella/ms_MMVAEPlus_beta_5_scale_False_seed_0 | asenella | 2023-07-27T11:59:17Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T11:59:15Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
dhinman/Reinforce-Pixelcopter-200000 | dhinman | 2023-07-27T11:58:35Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-27T11:58:23Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-200000
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 182.70 +/- 200.09
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
snob/TagMyBookmark-KoAlpaca-QLoRA-v1.0_ALLDATA | snob | 2023-07-27T11:58:28Z | 3 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-27T11:58:20Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
asenella/ms_MMVAEPlus_beta_5_scale_True_seed_3 | asenella | 2023-07-27T11:58:19Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T11:58:17Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/ms_MMVAEPlus_beta_10_scale_True_seed_0 | asenella | 2023-07-27T11:53:07Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T11:53:05Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
asenella/ms_MMVAEPlus_beta_25_scale_True_seed_2 | asenella | 2023-07-27T11:52:01Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T11:52:00Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
Chat-Error/Kimiko_7B | Chat-Error | 2023-07-27T11:50:53Z | 0 | 15 | null | [
"arxiv:1910.09700",
"region:us"
] | null | 2023-07-26T14:59:07Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Kimiko_7B
<!-- Provide a quick summary of what the model is/does. -->
This is my new Kimiko models, trained with LLaMA2 for...purpose
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** nRuaif
- **Model type:** Decoder only
- **License:** CC BY-NC-SA
- **Finetuned from model [optional]:** LLaMA2
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/OpenAccess-AI-Collective/axolotl
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
This model is trained on 3k examples of instructions dataset, high quality roleplay, for best result follow this format
```
<<HUMAN>>
How to do abc
<<AIBOT>>
Here is how
Or with system prompting for roleplay
<<SYSTEM>>
A's Persona:
B's Persona:
Scenario:
Add some instruction here on how you want your RP to go.
```
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
All bias of this model come from LLaMA2 with an exception of NSFW bias.....
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
3000 examples from LIMAERP, LIMA and I sample 1000 good instruction from Airboro
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
Model is trained with 1 L4 from GCP costing a whooping 1.5USD
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
3 epochs with 0.0002 lr, full 4096 ctx token, LoRA
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
It takes 8 hours to train this model with xformers enable
[More Information Needed]
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** L4 with 12CPUs 48gb ram
- **Hours used:** 8
- **Cloud Provider:** GCP
- **Compute Region:** US
- **Carbon Emitted:** 0.2KG
|
MheniDevs/Kinyarwanda | MheniDevs | 2023-07-27T11:43:04Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-24T02:16:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-kinyarwanda
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kinyarwanda
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3917
- Wer: 0.3246
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 9.0634 | 0.12 | 400 | 3.0554 | 1.0 |
| 2.8009 | 0.24 | 800 | 1.5927 | 0.9554 |
| 0.9022 | 0.36 | 1200 | 0.7328 | 0.6445 |
| 0.6213 | 0.48 | 1600 | 0.6138 | 0.5510 |
| 0.5299 | 0.6 | 2000 | 0.6072 | 0.5223 |
| 0.4999 | 0.72 | 2400 | 0.5449 | 0.4969 |
| 0.4731 | 0.84 | 2800 | 0.5261 | 0.4828 |
| 0.458 | 0.96 | 3200 | 0.5058 | 0.4607 |
| 0.4158 | 1.09 | 3600 | 0.4892 | 0.4463 |
| 0.4037 | 1.21 | 4000 | 0.4759 | 0.4429 |
| 0.4021 | 1.33 | 4400 | 0.4615 | 0.4330 |
| 0.3934 | 1.45 | 4800 | 0.4593 | 0.4315 |
| 0.3808 | 1.57 | 5200 | 0.4736 | 0.4344 |
| 0.3838 | 1.69 | 5600 | 0.4569 | 0.4249 |
| 0.3726 | 1.81 | 6000 | 0.4473 | 0.4140 |
| 0.3623 | 1.93 | 6400 | 0.4403 | 0.4097 |
| 0.3517 | 2.05 | 6800 | 0.4389 | 0.4061 |
| 0.333 | 2.17 | 7200 | 0.4383 | 0.4104 |
| 0.3354 | 2.29 | 7600 | 0.4360 | 0.3955 |
| 0.3257 | 2.41 | 8000 | 0.4226 | 0.3942 |
| 0.3275 | 2.53 | 8400 | 0.4206 | 0.4040 |
| 0.3262 | 2.65 | 8800 | 0.4172 | 0.3875 |
| 0.3206 | 2.77 | 9200 | 0.4209 | 0.3877 |
| 0.323 | 2.89 | 9600 | 0.4177 | 0.3825 |
| 0.3099 | 3.01 | 10000 | 0.4101 | 0.3691 |
| 0.3008 | 3.14 | 10400 | 0.4055 | 0.3709 |
| 0.2918 | 3.26 | 10800 | 0.4085 | 0.3800 |
| 0.292 | 3.38 | 11200 | 0.4089 | 0.3713 |
| 0.292 | 3.5 | 11600 | 0.4092 | 0.3730 |
| 0.2785 | 3.62 | 12000 | 0.4151 | 0.3687 |
| 0.2941 | 3.74 | 12400 | 0.4004 | 0.3639 |
| 0.2838 | 3.86 | 12800 | 0.4108 | 0.3703 |
| 0.2854 | 3.98 | 13200 | 0.3911 | 0.3596 |
| 0.2683 | 4.1 | 13600 | 0.3944 | 0.3575 |
| 0.2647 | 4.22 | 14000 | 0.3836 | 0.3538 |
| 0.2704 | 4.34 | 14400 | 0.4006 | 0.3540 |
| 0.2664 | 4.46 | 14800 | 0.3974 | 0.3553 |
| 0.2662 | 4.58 | 15200 | 0.3890 | 0.3470 |
| 0.2615 | 4.7 | 15600 | 0.3856 | 0.3507 |
| 0.2553 | 4.82 | 16000 | 0.3814 | 0.3497 |
| 0.2587 | 4.94 | 16400 | 0.3837 | 0.3440 |
| 0.2522 | 5.06 | 16800 | 0.3834 | 0.3486 |
| 0.2451 | 5.19 | 17200 | 0.3897 | 0.3414 |
| 0.2423 | 5.31 | 17600 | 0.3864 | 0.3481 |
| 0.2434 | 5.43 | 18000 | 0.3808 | 0.3416 |
| 0.2525 | 5.55 | 18400 | 0.3795 | 0.3408 |
| 0.2427 | 5.67 | 18800 | 0.3841 | 0.3411 |
| 0.2411 | 5.79 | 19200 | 0.3804 | 0.3366 |
| 0.2404 | 5.91 | 19600 | 0.3800 | 0.3328 |
| 0.2372 | 6.03 | 20000 | 0.3749 | 0.3335 |
| 0.2244 | 6.15 | 20400 | 0.3820 | 0.3327 |
| 0.2381 | 6.27 | 20800 | 0.3789 | 0.3325 |
| 0.2294 | 6.39 | 21200 | 0.3867 | 0.3298 |
| 0.2378 | 6.51 | 21600 | 0.3843 | 0.3281 |
| 0.2312 | 6.63 | 22000 | 0.3813 | 0.3277 |
| 0.2411 | 6.75 | 22400 | 0.3780 | 0.3268 |
| 0.2315 | 6.87 | 22800 | 0.3790 | 0.3280 |
| 0.241 | 6.99 | 23200 | 0.3776 | 0.3281 |
| 0.2313 | 7.11 | 23600 | 0.3929 | 0.3283 |
| 0.2423 | 7.24 | 24000 | 0.3905 | 0.3280 |
| 0.2337 | 7.36 | 24400 | 0.3979 | 0.3249 |
| 0.2368 | 7.48 | 24800 | 0.3980 | 0.3257 |
| 0.2409 | 7.6 | 25200 | 0.3937 | 0.3229 |
| 0.2416 | 7.72 | 25600 | 0.3867 | 0.3237 |
| 0.2364 | 7.84 | 26000 | 0.3912 | 0.3253 |
| 0.234 | 7.96 | 26400 | 0.3917 | 0.3246 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
google/flan-t5-xxl | google | 2023-07-27T11:42:14Z | 724,370 | 1,229 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"arxiv:2210.11416",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-10-21T15:54:59Z | ---
language:
- en
- fr
- ro
- de
- multilingual
widget:
- text: "Translate to German: My name is Arthur"
example_title: "Translation"
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
example_title: "Question Answering"
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
example_title: "Logical reasoning"
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
example_title: "Scientific knowledge"
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
example_title: "Yes/no question"
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
example_title: "Reasoning task"
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
example_title: "Boolean Expressions"
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
example_title: "Math reasoning"
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
example_title: "Premise and hypothesis"
tags:
- text2text-generation
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
license: apache-2.0
---
# Model Card for FLAN-T5 XXL
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/flan2_architecture.jpg"
alt="drawing" width="600"/>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
# TL;DR
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
As mentioned in the first few lines of the abstract :
> Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [T5 model card](https://huggingface.co/t5-large).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English, German, French
- **License:** Apache 2.0
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
- **Original Checkpoints:** [All Original FLAN-T5 Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2210.11416.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face FLAN-T5 Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/t5)
# Usage
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
# Uses
## Direct Use and Downstream Use
The authors write in [the original paper's model card](https://arxiv.org/pdf/2210.11416.pdf) that:
> The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
See the [research paper](https://arxiv.org/pdf/2210.11416.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
The information below in this section are copied from the model's [official model card](https://arxiv.org/pdf/2210.11416.pdf):
> Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
## Ethical considerations and risks
> Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
## Known Limitations
> Flan-T5 has not been tested in real world applications.
## Sensitive Use:
> Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
# Training Details
## Training Data
The model was trained on a mixture of tasks, that includes the tasks described in the table below (from the original paper, figure 2):
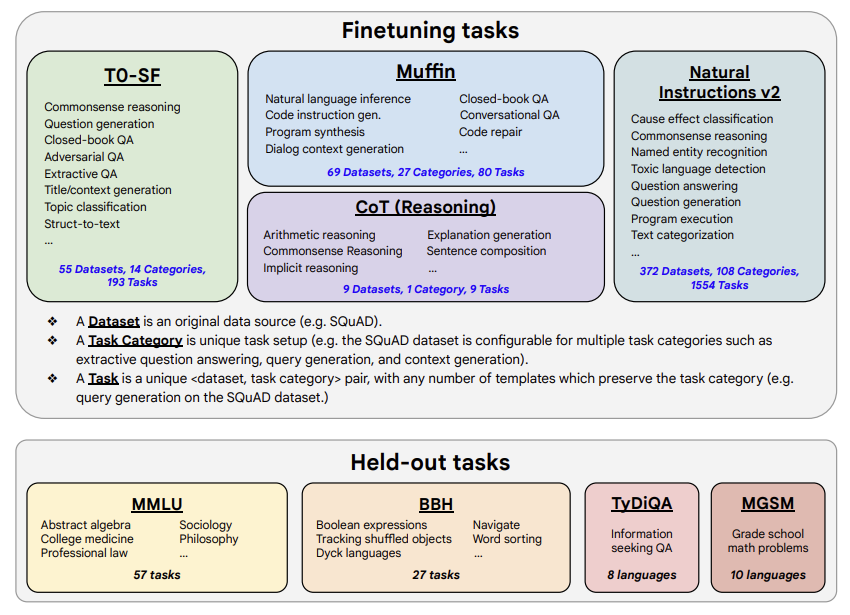
## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2210.11416.pdf):
> These models are based on pretrained T5 (Raffel et al., 2020) and fine-tuned with instructions for better zero-shot and few-shot performance. There is one fine-tuned Flan model per T5 model size.
The model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks covering several languages (1836 in total). See the table below for some quantitative evaluation:
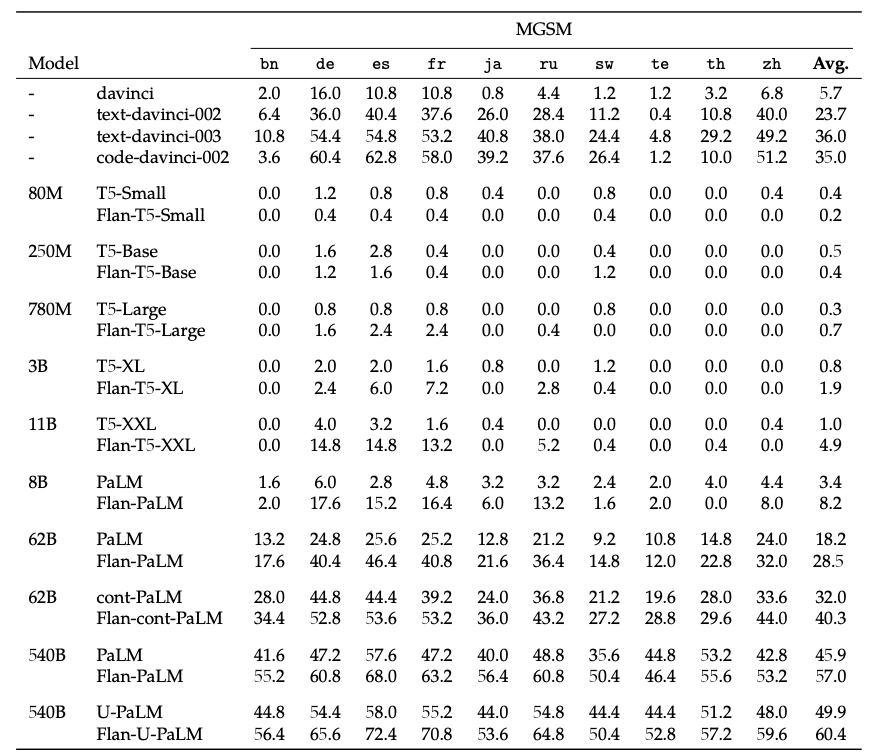
For full details, please check the [research paper](https://arxiv.org/pdf/2210.11416.pdf).
## Results
For full results for FLAN-T5-XXL, see the [research paper](https://arxiv.org/pdf/2210.11416.pdf), Table 3.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
Subsets and Splits