
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-05 12:28:32
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 468
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-05 12:27:45
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
addy88/wav2vec2-assamese-stt | addy88 | 2021-12-19T16:55:56Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/addy88/wav2vec2-assamese-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/addy88/wav2vec2-assamese-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-bengali-stt | addy88 | 2021-12-19T16:52:02Z | 4 | 3 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-bengali-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-bengali-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-malayalam-stt | addy88 | 2021-12-19T16:36:31Z | 26 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-malayalam-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-malayalam-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-marathi-stt | addy88 | 2021-12-19T16:31:22Z | 21 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-marathi-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-marathi-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec-odia-stt | addy88 | 2021-12-19T15:56:01Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-odia-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-odia-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-urdu-stt | addy88 | 2021-12-19T15:47:47Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-urdu-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-urdu-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-nepali-stt | addy88 | 2021-12-19T15:36:06Z | 4 | 1 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-nepali-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-nepali-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
kco4776/soongsil-bert-wellness | kco4776 | 2021-12-19T15:23:09Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ## References
- [Soongsil-BERT](https://github.com/jason9693/Soongsil-BERT) |
addy88/wav2vec2-english-stt | addy88 | 2021-12-19T15:08:42Z | 17 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-english-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-english-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-kannada-stt | addy88 | 2021-12-19T13:35:26Z | 248 | 1 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-kannada-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-kannada-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
microsoft/unispeech-1350-en-90-it-ft-1h | microsoft | 2021-12-19T13:19:29Z | 28 | 0 | transformers | [
"transformers",
"pytorch",
"unispeech",
"automatic-speech-recognition",
"audio",
"it",
"dataset:common_voice",
"arxiv:2101.07597",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- it
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus ITALIAN
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Italian phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
sample = next(iter(load_dataset("common_voice", "it", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# => 'm ɪ a n n o f a tː o ʊ n o f f ɛ r t a k e n o n p o t e v o p r ɔ p r i o r i f j ʊ t a r e'
# for "Mi hanno fatto un\'offerta che non potevo proprio rifiutare."
```
## Evaluation
```python
from datasets import load_dataset, load_metric
import datasets
import torch
from transformers import AutoModelForCTC, AutoProcessor
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
ds = load_dataset("mozilla-foundation/common_voice_3_0", "it", split="train+validation+test+other")
wer = load_metric("wer")
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
# taken from
# https://github.com/microsoft/UniSpeech/blob/main/UniSpeech/examples/unispeech/data/it/phonesMatches_reduced.json
with open("./testSeqs_uniform_new_version.text", "r") as f:
lines = f.readlines()
# retrieve ids model is evaluated on
ids = [x.split("\t")[0] for x in lines]
ds = ds.filter(lambda p: p.split("/")[-1].split(".")[0] in ids, input_columns=["path"])
ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
def decode(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", sampling_rate=16_000)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, axis=-1)
batch["prediction"] = processor.batch_decode(pred_ids)
batch["target"] = processor.tokenizer.phonemize(batch["sentence"])
return batch
out = ds.map(decode, remove_columns=ds.column_names)
per = wer.compute(predictions=out["prediction"], references=out["target"])
print("per", per)
# -> should give per 0.06685252146070828 - compare to results below
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *it*:
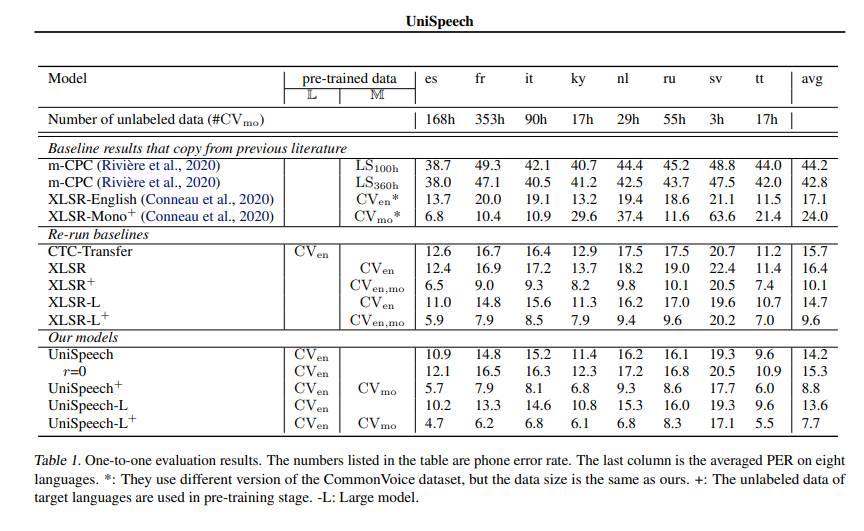 |
new5558/simcse-model-wangchanberta-base-att-spm-uncased | new5558 | 2021-12-19T13:01:31Z | 80 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"camembert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# new5558/simcse-model-wangchanberta-base-att-spm-uncased
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('new5558/simcse-model-wangchanberta-base-att-spm-uncased')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('new5558/simcse-model-wangchanberta-base-att-spm-uncased')
model = AutoModel.from_pretrained('new5558/simcse-model-wangchanberta-base-att-spm-uncased')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=new5558/simcse-model-wangchanberta-base-att-spm-uncased)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 5125 with parameters:
```
{'batch_size': 256, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 1e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 32, 'do_lower_case': False}) with Transformer model: CamembertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
rlagusrlagus123/XTC4096 | rlagusrlagus123 | 2021-12-19T11:19:34Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
tags:
- conversational
---
---
#12 epochs, each batch size 4, gradient accumulation steps 1, tail 4096.
#THIS SEEMS TO BE THE OPTIMAL SETUP. |
rlagusrlagus123/XTC20000 | rlagusrlagus123 | 2021-12-19T11:00:28Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
tags:
- conversational
---
---
#12 epochs, each batch size 2, gradient accumulation steps 2, tail 20000 |
NbAiLabArchive/test_w5_long_roberta_tokenizer | NbAiLabArchive | 2021-12-19T10:36:40Z | 41 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | Just for performing some experiments. Do not use. |
Langame/gpt2-waiting | Langame | 2021-12-19T09:02:26Z | 11 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"en",
"dataset:waiting-messages",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:04Z | ---
language:
- en # Example: en
license: mit # Example: apache-2.0 or any license from https://hf.co/docs/hub/model-repos#list-of-license-identifiers
tags:
- text-generation
datasets:
- waiting-messages # Example: common_voice. Use dataset id from https://hf.co/datasets
widget:
- text: 'List of funny waiting messages:'
example_title: 'Funny waiting messages'
---
# Langame/gpt2-waiting
This fine-tuned model can generate funny waiting messages.
[Langame](https://langa.me) uses these within its platform 😛.
|
Ayham/distilbert_gpt2_summarization_cnndm | Ayham | 2021-12-19T06:43:15Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: distilbert_gpt2_summarization_cnndm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_gpt2_summarization_cnndm
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Ayham/roberta_gpt2_summarization_xsum | Ayham | 2021-12-19T06:35:43Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: roberta_gpt2_summarization_xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta_gpt2_summarization_xsum
This model is a fine-tuned version of [](https://huggingface.co/) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Ayham/bert_gpt2_summarization_cnndm | Ayham | 2021-12-19T06:32:54Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: bert_gpt2_summarization_cnndm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_gpt2_summarization_cnndm
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Ayham/xlnet_gpt2_summarization_xsum | Ayham | 2021-12-19T04:50:11Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: xlnet_gpt2_summarization_xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet_gpt2_summarization_xsum
This model is a fine-tuned version of [](https://huggingface.co/) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
zaccharieramzi/UNet-OASIS | zaccharieramzi | 2021-12-19T02:07:02Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # UNet-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.unet import unet
model = unet(n_layers=4, layers_n_channels=[16, 32, 64, 128], layers_n_non_lins=2,)
model.load_weights('UNet-fastmri/model_weights.h5')
```
Using the model is then as simple as:
```python
model(zero_filled_recon)
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 29.8
- SSIM: 0.847
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/UNet-fastmri | zaccharieramzi | 2021-12-19T02:05:48Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # UNet-fastmri
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model can be used to reconstruct single coil fastMRI data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil knee data from Siemens scanner at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.unet import unet
model = unet(n_layers=4, layers_n_channels=[16, 32, 64, 128], layers_n_non_lins=2,)
model.load_weights('UNet-fastmri/model_weights.h5')
```
Using the model is then as simple as:
```python
model(zero_filled_recon)
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [fastMRI dataset](https://fastmri.org/dataset/).
| Contrast | PD | PDFS |
|----------|-------|--------|
| PSNR | 33.64 | 29.89 |
| SSIM | 0.807 | 0.6334 |
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/KIKI-net-OASIS | zaccharieramzi | 2021-12-19T01:59:51Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # KIKI-net-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.kiki_sep import full_kiki_net
from fastmri_recon.models.utils.non_linearities import lrelu
model = full_kiki_net(n_convs=16, n_filters=48, activation=lrelu)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 30.08
- SSIM: 0.853
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/CascadeNet-fastmri | zaccharieramzi | 2021-12-19T01:43:27Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # CascadeNet-fastmri
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model can be used to reconstruct single coil fastMRI data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil knee data from Siemens scanner at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.cascading import cascade_net
model = cascade_net()
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [fastMRI dataset](https://fastmri.org/dataset/).
| Contrast | PD | PDFS |
|----------|-------|--------|
| PSNR | 33.98 | 29.88 |
| SSIM | 0.811 | 0.6251 |
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/PDNet-fastmri | zaccharieramzi | 2021-12-19T01:32:10Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # PDNet-fastmri
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model can be used to reconstruct single coil fastMRI data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil knee data from Siemens scanner at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.pdnet import pdnet
model = pdnet()
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [fastMRI dataset](https://fastmri.org/dataset/).
| Contrast | PD | PDFS |
|----------|-------|--------|
| PSNR | 34.2 | 30.06 |
| SSIM | 0.818 | 0.9554 |
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
SoLID/sgd-output-plan-constructor | SoLID | 2021-12-18T21:00:54Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ## Schema Guided Dialogue Output Plan Constructor
|
s3h/mt5-small-finetuned-src-to-trg | s3h | 2021-12-18T20:34:32Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: mt5-small-finetuned-src-to-trg
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-src-to-trg
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 40 | nan | 0.1737 | 3.1818 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.6.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
zaccharieramzi/XPDNet-brain-af8 | zaccharieramzi | 2021-12-18T17:09:08Z | 0 | 0 | null | [
"arxiv:2010.07290",
"arxiv:2106.00753",
"region:us"
] | null | 2022-03-02T23:29:05Z | # XPDNet-brain-af8
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model was used to achieve the 2nd highest submission in terms of PSNR on the fastMRI dataset (see https://fastmri.org/leaderboards/).
It is a base model for acceleration factor 8.
The model uses 25 iterations and a medium MWCNN, and a big sensitivity maps refiner.
## Model description
For more details, see https://arxiv.org/abs/2010.07290.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct brain data from Siemens scanner at acceleration factor 8.
It was shown [here](https://arxiv.org/abs/2106.00753), that it can generalize well, although further tests are required.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
import tensorflow as tf
from fastmri_recon.models.subclassed_models.denoisers.proposed_params import get_model_specs
from fastmri_recon.models.subclassed_models.xpdnet import XPDNet
n_primal = 5
model_fun, model_kwargs, n_scales, res = [
(model_fun, kwargs, n_scales, res)
for m_name, m_size, model_fun, kwargs, _, n_scales, res in get_model_specs(n_primal=n_primal, force_res=False)
if m_name == 'MWCNN' and m_size == 'medium'
][0]
model_kwargs['use_bias'] = False
run_params = dict(
n_primal=n_primal,
multicoil=True,
n_scales=n_scales,
refine_smaps=True,
refine_big=True,
res=res,
output_shape_spec=True,
n_iter=25,
)
model = XPDNet(model_fun, model_kwargs, **run_params)
kspace_size = [1, 1, 320, 320]
inputs = [
tf.zeros(kspace_size + [1], dtype=tf.complex64), # kspace
tf.zeros(kspace_size, dtype=tf.complex64), # mask
tf.zeros(kspace_size, dtype=tf.complex64), # smaps
tf.constant([[320, 320]]), # shape
]
model(inputs)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_coils, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_coils, n_rows, n_cols]
smaps, # shape: [n_slices, n_coils, n_rows, n_cols]
shape, # shape: [n_slices, 2]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://arxiv.org/abs/2010.07290.
This section is WIP.
## Evaluation results
On the fastMRI validation dataset, the same model with a smaller sensitivity maps refiner gives the following results for 30 validation volumes per contrast:
| Contrast | T1 | T2 | FLAIR | T1-POST |
|----------|--------|--------|--------|---------|
| PSNR | 38.57 | 37.41 | 36.81 | 38.90 |
| SSIM | 0.9348 | 0.9404 | 0.9086 | 0.9517 |
Further results can be seen on the fastMRI leaderboards for the test and challenge dataset: https://fastmri.org/leaderboards/
## Bibtex entry
```
@inproceedings{Ramzi2020d,
archivePrefix = {arXiv},
arxivId = {2010.07290},
author = {Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
booktitle = {ISMRM},
eprint = {2010.07290},
pages = {1--4},
title = {{XPDNet for MRI Reconstruction: an application to the 2020 fastMRI challenge}},
url = {http://arxiv.org/abs/2010.07290},
year = {2021}
}
```
|
FarisHijazi/wav2vec2-large-xls-r-300m-turkish-colab | FarisHijazi | 2021-12-18T15:19:16Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 256
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.13.3
- Tokenizers 0.10.3
|
jcsilva/wav2vec2-base-timit-demo-colab | jcsilva | 2021-12-18T13:45:19Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7665
- Wer: 0.6956
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.052 | 0.8 | 100 | 3.0167 | 1.0 |
| 2.7436 | 1.6 | 200 | 1.9369 | 1.0006 |
| 1.4182 | 2.4 | 300 | 0.7665 | 0.6956 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
s-nlp/rubert-base-corruption-detector | s-nlp | 2021-12-18T09:28:50Z | 22 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"fluency",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language:
- ru
tags:
- fluency
---
This is a model for evaluation of naturalness of short Russian texts. It has been trained to distinguish human-written texts from their corrupted versions.
Corruption sources: random replacement, deletion, addition, shuffling, and re-inflection of words and characters, random changes of capitalization, round-trip translation, filling random gaps with T5 and RoBERTA models. For each original text, we sampled three corrupted texts, so the model is uniformly biased towards the `unnatural` label.
Data sources: web-corpora from [the Leipzig collection](https://wortschatz.uni-leipzig.de/en/download) (`rus_news_2020_100K`, `rus_newscrawl-public_2018_100K`, `rus-ru_web-public_2019_100K`, `rus_wikipedia_2021_100K`), comments from [OK](https://www.kaggle.com/alexandersemiletov/toxic-russian-comments) and [Pikabu](https://www.kaggle.com/blackmoon/russian-language-toxic-comments).
On our private test dataset, the model has achieved 40% rank correlation with human judgements of naturalness, which is higher than GPT perplexity, another popular fluency metric. |
nateraw/rare-puppers-demo | nateraw | 2021-12-17T22:48:47Z | 101 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2022-03-02T23:29:05Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers-demo
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9101123809814453
---
# rare-puppers-demo
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### husky

#### samoyed

#### shiba inu
 |
Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10 | Harveenchadha | 2021-12-17T20:14:16Z | 1,400 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"pa",
"arxiv:2107.07402",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
language: pa
#datasets:
#- Interspeech 2021
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
license: mit
model-index:
- name: Wav2Vec2 Vakyansh Punjabi Model by Harveen Chadha
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hi
type: common_voice
args: pa
metrics:
- name: Test WER
type: wer
value: 33.17
---
Fine-tuned on Multilingual Pretrained Model [CLSRIL-23](https://arxiv.org/abs/2107.07402). The original fairseq checkpoint is present [here](https://github.com/Open-Speech-EkStep/vakyansh-models). When using this model, make sure that your speech input is sampled at 16kHz.
**Note: The result from this model is without a language model so you may witness a higher WER in some cases.**
|
microsoft/unispeech-sat-base-plus-sd | microsoft | 2021-12-17T18:40:56Z | 407 | 0 | transformers | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-frame-classification",
"speech",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
tags:
- speech
---
# UniSpeech-SAT-Base for Speaker Diarization
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [LibriMix dataset](https://github.com/JorisCos/LibriMix) using just a linear layer for mapping the network outputs.
# Usage
## Speaker Diarization
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForAudioFrameClassification
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-base-plus-sd')
model = UniSpeechSatForAudioFrameClassification.from_pretrained('microsoft/unispeech-sat-base-plus-sd')
# audio file is decoded on the fly
inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt")
logits = model(**inputs).logits
probabilities = torch.sigmoid(logits[0])
# labels is a one-hot array of shape (num_frames, num_speakers)
labels = (probabilities > 0.5).long()
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
Eyvaz/wav2vec2-base-russian-modified-kaggle | Eyvaz | 2021-12-17T18:39:50Z | 5 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
name: wav2vec2-base-russian-modified-kaggle
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-russian-modified-kaggle
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1
- Datasets 1.13.3
- Tokenizers 0.10.3
|
cjrowe/afriberta_base-finetuned-tydiqa | cjrowe | 2021-12-17T18:21:22Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"sw",
"dataset:tydiqa",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
language:
- sw
tags:
- generated_from_trainer
datasets:
- tydiqa
model-index:
- name: afriberta_base-finetuned-tydiqa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# afriberta_base-finetuned-tydiqa
This model is a fine-tuned version of [castorini/afriberta_base](https://huggingface.co/castorini/afriberta_base) on the tydiqa dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3728
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 192 | 2.1359 |
| No log | 2.0 | 384 | 2.3409 |
| 0.8353 | 3.0 | 576 | 2.3728 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
microsoft/unispeech-sat-large-sv | microsoft | 2021-12-17T18:13:15Z | 240 | 4 | transformers | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-xvector",
"speech",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
datasets:
tags:
- speech
---
# UniSpeech-SAT-Large for Speaker Verification
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) using an X-Vector head with an Additive Margin Softmax loss
[X-Vectors: Robust DNN Embeddings for Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf)
# Usage
## Speaker Verification
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForXVector
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-large-sv')
model = UniSpeechSatForXVector.from_pretrained('microsoft/unispeech-sat-large-sv')
# audio files are decoded on the fly
inputs = feature_extractor(dataset[:2]["audio"]["array"], return_tensors="pt")
embeddings = model(**inputs).embeddings
embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
# the resulting embeddings can be used for cosine similarity-based retrieval
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
similarity = cosine_sim(embeddings[0], embeddings[1])
threshold = 0.89 # the optimal threshold is dataset-dependent
if similarity < threshold:
print("Speakers are not the same!")
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
microsoft/unispeech-sat-base-sv | microsoft | 2021-12-17T18:11:05Z | 200 | 0 | transformers | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-xvector",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2110.05752",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
datasets:
- librispeech_asr
tags:
- speech
---
# UniSpeech-SAT-Base for Speaker Verification
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 960 hours of [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) using an X-Vector head with an Additive Margin Softmax loss
[X-Vectors: Robust DNN Embeddings for Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf)
# Usage
## Speaker Verification
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForXVector
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-base-sv')
model = UniSpeechSatForXVector.from_pretrained('microsoft/unispeech-sat-base-sv')
# audio files are decoded on the fly
inputs = feature_extractor(dataset[:2]["audio"]["array"], return_tensors="pt")
embeddings = model(**inputs).embeddings
embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
# the resulting embeddings can be used for cosine similarity-based retrieval
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
similarity = cosine_sim(embeddings[0], embeddings[1])
threshold = 0.86 # the optimal threshold is dataset-dependent
if similarity < threshold:
print("Speakers are not the same!")
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
osanseviero/fastai_cat_vs_dog | osanseviero | 2021-12-17T14:27:39Z | 32 | 4 | generic | [
"generic",
"image-classification",
"region:us"
] | image-classification | 2022-03-02T23:29:05Z | ---
tags:
- image-classification
library_name: generic
---
# Dog vs Cat Image Classification with FastAI CNN
Training is based in FastAI [Quick Start](https://docs.fast.ai/quick_start.html). Example training
## Training
The model was trained as follows
```python
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
``` |
Rocketknight1/gbert-base-germaner | Rocketknight1 | 2021-12-17T14:04:59Z | 5 | 1 | transformers | [
"transformers",
"tf",
"tensorboard",
"bert",
"token-classification",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:04Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: Rocketknight1/gbert-base-germaner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Rocketknight1/gbert-base-germaner
This model is a fine-tuned version of [deepset/gbert-base](https://huggingface.co/deepset/gbert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0340
- Validation Loss: 0.0881
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 4176, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1345 | 0.0865 | 0 |
| 0.0550 | 0.0878 | 1 |
| 0.0340 | 0.0881 | 2 |
### Framework versions
- Transformers 4.15.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
patrickvonplaten/wavlm-libri-clean-100h-large | patrickvonplaten | 2021-12-17T13:40:58Z | 10,035 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wavlm",
"automatic-speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"wavlm_libri_finetune",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
- wavlm_libri_finetune
model-index:
- name: wavlm-librispeech-clean-100h-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wavlm-libri-clean-100h-large
This model is a fine-tuned version of [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0601
- Wer: 0.0491
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8069 | 0.34 | 300 | 0.7510 | 0.5809 |
| 0.2483 | 0.67 | 600 | 0.2023 | 0.1929 |
| 0.1033 | 1.01 | 900 | 0.1123 | 0.1028 |
| 0.0742 | 1.35 | 1200 | 0.0858 | 0.0771 |
| 0.057 | 1.68 | 1500 | 0.0722 | 0.0663 |
| 0.0421 | 2.02 | 1800 | 0.0682 | 0.0582 |
| 0.0839 | 2.35 | 2100 | 0.0630 | 0.0534 |
| 0.0307 | 2.69 | 2400 | 0.0603 | 0.0508 |
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
jamescalam/bert-stsb-cross-encoder | jamescalam | 2021-12-17T08:54:27Z | 1,081 | 1 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"text-classification",
"sentence-similarity",
"transformers",
"cross-encoder",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- transformers
- cross-encoder
---
# Augmented SBERT STSb
This is a [sentence-transformers](https://www.SBERT.net) cross encoder model.
It is used as a demo model within the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp), for the chapter on [In-domain Data Augmentation with BERT](https://www.pinecone.io/learn/data-augmentation/).
|
jamescalam/bert-stsb-aug | jamescalam | 2021-12-17T08:52:21Z | 4 | 1 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# Augmented SBERT STSb
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
It is used as a demo model within the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp), for the chapter on [In-domain Data Augmentation with BERT](https://www.pinecone.io/learn/data-augmentation/).
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('bert-stsb-aug')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('bert-stsb-aug')
model = AutoModel.from_pretrained('bert-stsb-aug')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2059 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 308,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
|
huggingtweets/bladeefan91 | huggingtweets | 2021-12-17T07:39:20Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/bladeefan91/1639726754777/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1470642032851009537/LWrcZk48_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">sweetie p1e</div>
<div style="text-align: center; font-size: 14px;">@bladeefan91</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from sweetie p1e.
| Data | sweetie p1e |
| --- | --- |
| Tweets downloaded | 2249 |
| Retweets | 351 |
| Short tweets | 547 |
| Tweets kept | 1351 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/cacbnxbr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bladeefan91's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2kupw7ab) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2kupw7ab/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bladeefan91')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
tabo/distilbert-base-uncased-finetuned-squad2 | tabo | 2021-12-17T07:22:42Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1606
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2306 | 1.0 | 5533 | 1.1557 |
| 0.9535 | 2.0 | 11066 | 1.1260 |
| 0.7629 | 3.0 | 16599 | 1.1606 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
nvidia/qdqbert-base-uncased | nvidia | 2021-12-17T06:31:27Z | 0 | 1 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | <!---
Copyright 2021 NVIDIA Corporation. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# QDQBERT base model (uncased)
## Model description
[QDQBERT](https://huggingface.co/docs/transformers/model_doc/qdqbert) model inserts fake quantization operations (pair of QuantizeLinear/DequantizeLinear operators) to (i) linear layer inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example bert-base-uncased), and perform Quantization Aware Training/Post Training Quantization.
In this model card, **qdqbert-base-uncased** corresponds to the **bert-base-uncased** model with QuantizeLinear/DequantizeLinear ops (**Q/DQ nodes**). Similarly, one can also use the QDQBERT model for qdqbert-large-cased corresponding to bert-large-cased, etc.
## How to run QDQBERT using Transformers
### Prerequisites
QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/main/tools/pytorch-quantization). To install Pytorch Quantization Toolkit, run
```
pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
```
### Set default quantizers
QDQBERT model inserts Q/DQ nodes to BERT by **TensorQuantizer** in Pytorch Quantization Toolkit. **TensorQuantizer** is the module for quantizing tensors, with **QuantDescriptor** defining how the tensor should be quantized. Refer to [Pytorch Quantization Toolkit userguide](https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html) for more details.
Before creating QDQBERT model, one has to set the default **QuantDescriptor** defining default tensor quantizers. Example:
```python
import pytorch_quantization.nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptor
# The default tensor quantizer is set to use Max calibration method
input_desc = QuantDescriptor(num_bits=8, calib_method="max")
# The default tensor quantizer is set to be per-channel quantization for weights
weight_desc = QuantDescriptor(num_bits=8, axis=((0,)))
quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
```
### Calibration
Calibration is the terminology of passing data samples to the quantizer and deciding the best scaling factors for tensors. After setting up the tensor quantizers, one can use the following example to calibrate the model:
```python
# Find the TensorQuantizer and enable calibration
for name, module in model.named_modules():
if name.endswith('_input_quantizer'):
module.enable_calib()
module.disable_quant() # Use full precision data to calibrate
# Feeding data samples
model(x)
# ...
# Finalize calibration
for name, module in model.named_modules():
if name.endswith('_input_quantizer'):
module.load_calib_amax()
module.enable_quant()
# If running on GPU, it needs to call .cuda() again because new tensors will be created by calibration process
model.cuda()
# Keep running the quantized model
# ...
```
### Export to ONNX
The goal of exporting to ONNX is to deploy inference by [TensorRT](https://developer.nvidia.com/tensorrt). Fake quantization will be broken into a pair of QuantizeLinear/DequantizeLinear ONNX ops. After setting the static member **TensorQuantizer** to use Pytorch’s own fake quantization functions, fake quantized model can be exported to ONNX, follow the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Example:
```python
from pytorch_quantization.nn import TensorQuantizer
TensorQuantizer.use_fb_fake_quant = True
# Load the calibrated model
...
# ONNX export
torch.onnx.export(...)
```
## Complete example
A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert](https://github.com/huggingface/transformers/tree/master/examples/research_projects/quantization-qdqbert) |
Jeska/BertjeWDialDataALL03 | Jeska | 2021-12-16T19:19:56Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
model-index:
- name: BertjeWDialDataALL03
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BertjeWDialDataALL03
This model is a fine-tuned version of [GroNLP/bert-base-dutch-cased](https://huggingface.co/GroNLP/bert-base-dutch-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9459
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 8.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.1951 | 1.0 | 1542 | 2.0285 |
| 2.0918 | 2.0 | 3084 | 1.9989 |
| 2.0562 | 3.0 | 4626 | 2.0162 |
| 2.0012 | 4.0 | 6168 | 1.9330 |
| 1.9705 | 5.0 | 7710 | 1.9151 |
| 1.9571 | 6.0 | 9252 | 1.9419 |
| 1.9113 | 7.0 | 10794 | 1.9175 |
| 1.8988 | 8.0 | 12336 | 1.9143 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
lewtun/xlm-roberta-base-finetuned-marc-en-hslu | lewtun | 2021-12-16T14:55:28Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: xlm-roberta-base-finetuned-marc-en-hslu
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc-en-hslu
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8826
- Mae: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1121 | 1.0 | 235 | 0.9400 | 0.5732 |
| 0.9487 | 2.0 | 470 | 0.8826 | 0.5 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
philschmid/deberta-v3-xsmall-emotion | philschmid | 2021-12-16T12:37:10Z | 3 | 1 | transformers | [
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
model-index:
- name: deberta-v3-xsmall-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.932
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-xsmall-emotion
This model is a fine-tuned version of [microsoft/deberta-v3-xsmall](https://huggingface.co/microsoft/deberta-v3-xsmall) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1877
- Accuracy: 0.932
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3683 | 1.0 | 500 | 0.8479 | 0.6975 |
| 0.547 | 2.0 | 1000 | 0.2881 | 0.905 |
| 0.2378 | 3.0 | 1500 | 0.2116 | 0.925 |
| 0.1704 | 4.0 | 2000 | 0.1877 | 0.932 |
| 0.1392 | 5.0 | 2500 | 0.1718 | 0.9295 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.1
- Datasets 1.15.1
- Tokenizers 0.10.3
|
llange/xlm-roberta-large-spanish | llange | 2021-12-16T11:24:16Z | 16 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | # Spanish XLM-R (from NLNDE-MEDDOPROF)
This Spanish language model was created for the MEDDOPROF shared task as part of the **NLNDE** team submission and outperformed all other participants in both sequence labeling tasks.
Details on the model, the pre-training corpus and the downstream task performance are given in the paper: "Boosting Transformers for Job Expression Extraction and Classification in a Low-Resource Setting" by Lukas Lange, Heike Adel and Jannik Strötgen.
The paper can be found [here](http://ceur-ws.org/Vol-2943/meddoprof_paper1.pdf).
In case of questions, please contact the authors as listed on the paper.
Please cite the above paper when reporting, reproducing or extending the results.
@inproceedings{lange-etal-2021-meddoprof,
author = {Lukas Lange and
Heike Adel and
Jannik Str{\"{o}}tgen},
title = {Boosting Transformers for Job Expression Extraction and Classification in a Low-Resource Setting},
year={2021},
booktitle= {{Proceedings of The Iberian Languages Evaluation Forum (IberLEF 2021)}},
series = {{CEUR} Workshop Proceedings},
url = {http://ceur-ws.org/Vol-2943/meddoprof_paper1.pdf},
}
## Training details
We use XLM-R (`xlm-roberta-large`, Conneau et al. 2020) as the main component of our models. XLM-R is a pretrained multilingual transformer model for 100 languages, including Spanish. It shows superior performance in different tasks across languages, and can even outperform
monolingual models in certain settings. It was pretrained on a large-scale corpus,
and Spanish documents made up only 2% of this data.
Thus, we explore further pretraining of this model and tune it towards Spanish
documents by pretraining a medium-size Spanish corpus with general
domain documents. For this, we use the [spanish corpus](https://github.com/josecannete/spanish-corpora) used to train the BETO model.
We use masked language modeling for pretraining and trained for three epochs
over the corpus, which roughly corresponds to 685k steps using a batch-size of 4.
## Performance
This model was trained in the context of the Meddoprof shared tasks and outperformed all other participants in both sequence labeling tasks. Our results (F1) in comparison with the standard XLM-R and the second-best system of the shared task are given in the Table.
More information on the shared task and other participants is given in this paper [here](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6393/3813).
The code for our NER models can be found [here](https://github.com/boschresearch/nlnde-meddoprof).
| | Meddoprof Task 1 (NER) | Meddoprof Task 2 (CLASS) |
|---------------------------------|------------------------|--------------------------|
| Second-best System | 80.0 | 76.4 |
| XLM-R (our baseline) | 79.2 | 77.6 |
| Our Spanish XLM-R (best System) | **83.2** | **79.1** |
## Purpose of the project
This software is a research prototype, solely developed for and published as part of the publication cited above. It will neither be maintained nor monitored in any way.
## License
The CLIN-X models are open-sourced under the CC-BY 4.0 license.
See the [LICENSE](LICENSE) file for details. |
Ayham/bert_gpt2_summarization_xsum | Ayham | 2021-12-16T06:59:13Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: bert_gpt2_summarization_xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_gpt2_summarization_xsum
This model is a fine-tuned version of [](https://huggingface.co/) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
oliverP/distilgpt2-finetuned-reddit-aita-text-gen | oliverP | 2021-12-16T02:15:33Z | 4 | 0 | transformers | [
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: distilgpt2-finetuned-reddit-aita-text-gen
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-reddit-aita-text-gen
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.0}
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.14.1
- TensorFlow 2.7.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
huggingtweets/ai_hexcrawl | huggingtweets | 2021-12-15T19:46:29Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/ai_hexcrawl/1639597537705/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1467327234365181953/gFho8YCv_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">AI Hexcrawl</div>
<div style="text-align: center; font-size: 14px;">@ai_hexcrawl</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from AI Hexcrawl.
| Data | AI Hexcrawl |
| --- | --- |
| Tweets downloaded | 1164 |
| Retweets | 42 |
| Short tweets | 2 |
| Tweets kept | 1120 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/vdxugbwr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ai_hexcrawl's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/r9ejkubu) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/r9ejkubu/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ai_hexcrawl')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Ayham/xlnet_gpt2_summarization_cnn_dailymail | Ayham | 2021-12-15T18:08:27Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: xlnet_gpt2_summarization_cnn_dailymail
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet_gpt2_summarization_cnn_dailymail
This model is a fine-tuned version of [](https://huggingface.co/) on the cnn_dailymail dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
nguyenvulebinh/spelling-oov | nguyenvulebinh | 2021-12-15T17:00:58Z | 672 | 1 | transformers | [
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ```python
from transformers import EncoderDecoderModel
from importlib.machinery import SourceFileLoader
from transformers.file_utils import cached_path, hf_bucket_url
import torch
import os
## Load model & tokenizer
cache_dir='./cache'
model_name='nguyenvulebinh/spelling-oov'
def download_tokenizer_files():
resources = ['envibert_tokenizer.py', 'dict.txt', 'sentencepiece.bpe.model']
for item in resources:
if not os.path.exists(os.path.join(cache_dir, item)):
tmp_file = hf_bucket_url(model_name, filename=item)
tmp_file = cached_path(tmp_file,cache_dir=cache_dir)
os.rename(tmp_file, os.path.join(cache_dir, item))
download_tokenizer_files()
spell_tokenizer = SourceFileLoader("envibert.tokenizer",os.path.join(cache_dir,'envibert_tokenizer.py')).load_module().RobertaTokenizer(cache_dir)
spell_model = EncoderDecoderModel.from_pretrained(model_name)
def oov_spelling(word, num_candidate=1):
result = []
inputs = spell_tokenizer([word.lower()])
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
inputs = {
"input_ids": torch.tensor(input_ids),
"attention_mask": torch.tensor(attention_mask)
}
outputs = spell_model.generate(**inputs, num_return_sequences=num_candidate)
for output in outputs.cpu().detach().numpy().tolist():
result.append(spell_tokenizer.sp_model.DecodePieces(spell_tokenizer.decode(output, skip_special_tokens=True).split()))
return result
oov_spelling('spacespeaker')
# output: ['x pây x pếch cơ']
``` |
NbAiLabArchive/test_w7 | NbAiLabArchive | 2021-12-15T14:14:41Z | 3 | 0 | transformers | [
"transformers",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | Just for performing some experiments. Do not use. |
aXhyra/presentation_sentiment_42 | aXhyra | 2021-12-15T13:28:22Z | 8 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_sentiment_42
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: sentiment
metrics:
- name: F1
type: f1
value: 0.7175864613336908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_sentiment_42
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6491
- F1: 0.7176
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6.923967812567773e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.4391 | 1.0 | 2851 | 0.6591 | 0.6953 |
| 0.6288 | 2.0 | 5702 | 0.6265 | 0.7158 |
| 0.4071 | 3.0 | 8553 | 0.6401 | 0.7179 |
| 0.6532 | 4.0 | 11404 | 0.6491 | 0.7176 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
raphaelmerx/marian-finetuned-en-map | raphaelmerx | 2021-12-15T12:54:46Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: marian-finetuned-en-map
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-en-map
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-map](https://huggingface.co/Helsinki-NLP/opus-mt-en-map) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.0542
- eval_bleu: 30.0673
- eval_runtime: 870.8596
- eval_samples_per_second: 14.467
- eval_steps_per_second: 0.226
- epoch: 2.29
- step: 17104
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
tlanfer/arc | tlanfer | 2021-12-15T12:14:18Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
title: ArcaneGAN
emoji: 🚀
colorFrom: blue
colorTo: blue
sdk: gradio
app_file: app.py
pinned: false
---
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio` or `streamlit`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
Path is relative to the root of the repository.
`pinned`: _boolean_
Whether the Space stays on top of your list. |
MMG/bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad | MMG | 2021-12-15T12:03:20Z | 32 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"es",
"dataset:squad_es",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- squad_es
model-index:
- name: bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad
results: []
language:
- es
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad
This model is a fine-tuned version of [MMG/bert-base-spanish-wwm-cased-finetuned-sqac](https://huggingface.co/MMG/bert-base-spanish-wwm-cased-finetuned-sqac) on the squad_es dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5325
- {'exact_match': 60.30274361400189, 'f1': 77.01962587890856}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
honeyd3wy/kobart-titlenaming-v0.1 | honeyd3wy | 2021-12-15T11:44:58Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ```python
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
model = BartForConditionalGeneration.from_pretrained('honeyd3wy/kobart-titlenaming-v0.1')
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v2')
``` |
aXhyra/presentation_hate_31415 | aXhyra | 2021-12-15T11:24:57Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_hate_31415
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7729508817074093
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_hate_31415
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8632
- F1: 0.7730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.436235805743952e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 31415
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.363 | 1.0 | 282 | 0.4997 | 0.7401 |
| 0.2145 | 2.0 | 564 | 0.5071 | 0.7773 |
| 0.1327 | 3.0 | 846 | 0.7109 | 0.7645 |
| 0.0157 | 4.0 | 1128 | 0.8632 | 0.7730 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
antoniocappiello/bert-base-italian-uncased-squad-it | antoniocappiello | 2021-12-15T10:01:14Z | 481 | 5 | transformers | [
"transformers",
"pytorch",
"question-answering",
"it",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
language: it
widget:
- text: "Quando nacque D'Annunzio?"
context: "D'Annunzio nacque nel 1863"
---
# Italian Bert Base Uncased on Squad-it
## Model description
This model is the uncased base version of the italian BERT (which you may find at `dbmdz/bert-base-italian-uncased`) trained on the question answering task.
#### How to use
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='antoniocappiello/bert-base-italian-uncased-squad-it')
# nlp(context="D'Annunzio nacque nel 1863", question="Quando nacque D'Annunzio?")
# {'score': 0.9990354180335999, 'start': 22, 'end': 25, 'answer': '1863'}
```
## Training data
It has been trained on the question answering task using [SQuAD-it](http://sag.art.uniroma2.it/demo-software/squadit/), derived from the original SQuAD dataset and obtained through the semi-automatic translation of the SQuAD dataset in Italian.
## Training procedure
```bash
python ./examples/run_squad.py \
--model_type bert \
--model_name_or_path dbmdz/bert-base-italian-uncased \
--do_train \
--do_eval \
--train_file ./squad_it_uncased/train-v1.1.json \
--predict_file ./squad_it_uncased/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./models/bert-base-italian-uncased-squad-it/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
--do_lower_case \
```
## Eval Results
| Metric | # Value |
| ------ | --------- |
| **EM** | **63.8** |
| **F1** | **75.30** |
## Comparison
| Model | EM | F1 score |
| -------------------------------------------------------------------------------------------------------------------------------- | --------- | --------- |
| [DrQA-it trained on SQuAD-it](https://github.com/crux82/squad-it/blob/master/README.md#evaluating-a-neural-model-over-squad-it) | 56.1 | 65.9 |
| This one | **63.8** | **75.30** | |
flboehm/reddit-bert-text4 | flboehm | 2021-12-15T08:41:48Z | 11 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: reddit-bert-text4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# reddit-bert-text4
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4763
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.1071 | 1.0 | 978 | 2.6170 |
| 2.6788 | 2.0 | 1956 | 2.5332 |
| 2.6112 | 3.0 | 2934 | 2.4844 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
hiiamsid/hit5-base | hiiamsid | 2021-12-15T04:12:27Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"hindi",
"hi",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
language: ["hi"]
tags:
- hindi
license: mit
---
This is a smaller version of the [google/mt5-base](https://huggingface.co/google/mt5-base) model with only hindi embeddings left.
* The original model has 582M parameters, with 237M of them being input and output embeddings.
* After shrinking the `sentencepiece` vocabulary from 250K to 25K (top 25K Hindi tokens) the number of model parameters reduced to 237M parameters, and model size reduced from 2.2GB to 0.9GB - 42% of the original one.
## Citing & Authors
- Model : [google/mt5-base](https://huggingface.co/google/mt5-base)
- Reference: [cointegrated/rut5-base](https://huggingface.co/cointegrated/rut5-base) |
huggingtweets/d_greetest | huggingtweets | 2021-12-15T02:04:34Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/d_greetest/1639533869820/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1387092178753687567/43vkVfBK_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Greetest</div>
<div style="text-align: center; font-size: 14px;">@d_greetest</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Greetest.
| Data | Greetest |
| --- | --- |
| Tweets downloaded | 629 |
| Retweets | 265 |
| Short tweets | 34 |
| Tweets kept | 330 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3kz7im60/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @d_greetest's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1h67ju9y) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1h67ju9y/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/d_greetest')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/iuditg | huggingtweets | 2021-12-15T01:36:57Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/iuditg/1639532212187/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1457774258063437824/VgJyJ_c2_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">uditgoenka.eth</div>
<div style="text-align: center; font-size: 14px;">@iuditg</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from uditgoenka.eth.
| Data | uditgoenka.eth |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 993 |
| Short tweets | 450 |
| Tweets kept | 1807 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1r2lhfr0/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @iuditg's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/iswph9y4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/iswph9y4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/iuditg')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ssmadha/gpt2-finetuned-scientific-articles | ssmadha | 2021-12-14T20:47:55Z | 21 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-finetuned-scientific-articles
results: []
---
This repository is the submission for the final project for BF510 [Institutional Racism in Health and Science](http://irhs.bu.edu/) for Shariq Madha.
To see Jupyter detailing how this model was produced, as well as the motivation behind it, go [here](https://github.com/ssmadha/BF510-final-project/).
To try this out yourself, enter a prompt in the textbox to the right and hit compute (it may take a minute for the first to process, but subsequent results should be quick).
# gpt2-finetuned-scientific-articles
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on scientific articles about algorithmic bias.
It achieves the following results on the evaluation set:
- Loss: 2.3793
## Model description
This model is a casual language modeling GPT2 fine-tuned on scientific articles about algorithmic bias, in an attempt to showcase an example about correcting for algorithmic bias.
## Intended uses & limitations
This model is intended for prompts about algorithms and bias. Other prompts will yield results, but they are less likely to be influenced by the fine-tuning.
## Training and evaluation data
This model is trained on fully freely accessible articles obtained from a PubMed Central search on algorithmic bias. The pmc_result_algorithmicbias.txt file contains the list of PMC's used. Due to technical and time limitations, only fine-tuned on the introduction sections, but training on other sections is planned.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5293 | 1.0 | 1071 | 2.3892 |
| 2.4821 | 2.0 | 2142 | 2.3793 |
### Framework versions
- Transformers 4.14.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.10.3
|
Rocketknight1/test-model-tf | Rocketknight1 | 2021-12-14T19:25:51Z | 4 | 0 | transformers | [
"transformers",
"tf",
"bert",
"feature-extraction",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: test-model-tf
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# test-model-tf
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.14.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
clampert/multilingual-sentiment-covid19 | clampert | 2021-12-14T18:57:07Z | 111 | 5 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"sentiment-analysis",
"multilingual",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
pipeline_tag: text-classification
language: multilingual
license: apache-2.0
tags:
- "sentiment-analysis"
- "multilingual"
widget:
- text: "I am very happy."
example_title: "English"
- text: "Heute bin ich schlecht drauf."
example_title: "Deutsch"
- text: "Quel cauchemard!"
example_title: "Francais"
- text: "ฉันรักฤดูใบไม้ผลิ"
example_title: "ภาษาไทย"
---
# Multi-lingual sentiment prediction trained from COVID19-related tweets
Repository: [https://github.com/clampert/multilingual-sentiment-analysis/](https://github.com/clampert/multilingual-sentiment-analysis/)
Model trained on a large-scale (18437530 examples) dataset of
multi-lingual tweets that was collected between March 2020
and November 2021 using Twitter’s Streaming API with varying
COVID19-related keywords. Labels were auto-general based on
the presence of positive and negative emoticons. For details
on the dataset, see our IEEE BigData 2021 publication.
Base model is [sentence-transformers/stsb-xlm-r-multilingual](https://huggingface.co/sentence-transformers/stsb-xlm-r-multilingual).
It was finetuned for sequence classification with `positive`
and `negative` labels for two epochs (48 hours on 8xP100 GPUs).
## Citation
If you use our model your work, please cite:
```
@inproceedings{lampert2021overcoming,
title={Overcoming Rare-Language Discrimination in Multi-Lingual Sentiment Analysis},
author={Jasmin Lampert and Christoph H. Lampert},
booktitle={IEEE International Conference on Big Data (BigData)},
year={2021},
note={Special Session: Machine Learning on Big Data},
}
```
Enjoy!
|
evandrodiniz/autonlp-api-boamente-417310793 | evandrodiniz | 2021-12-14T18:39:10Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"unk",
"dataset:evandrodiniz/autonlp-data-api-boamente",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- evandrodiniz/autonlp-data-api-boamente
co2_eq_emissions: 9.446754273734577
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 417310793
- CO2 Emissions (in grams): 9.446754273734577
## Validation Metrics
- Loss: 0.25755178928375244
- Accuracy: 0.9407114624505929
- Precision: 0.8600823045267489
- Recall: 0.95
- AUC: 0.9732501264968797
- F1: 0.9028077753779697
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/evandrodiniz/autonlp-api-boamente-417310793
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("evandrodiniz/autonlp-api-boamente-417310793", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("evandrodiniz/autonlp-api-boamente-417310793", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
huggingtweets/_luisinhobr-bryan_paula_-luanaguei | huggingtweets | 2021-12-14T18:17:37Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/_luisinhobr-bryan_paula_-luanaguei/1639505852811/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1390224220643278850/LcIZLss-_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1407505852580442113/U6iWBRLs_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1459704723506872320/gLulTAzG_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">luisfer nando & Dj Cigarro Solto & ajax de uva verde</div>
<div style="text-align: center; font-size: 14px;">@_luisinhobr-bryan_paula_-luanaguei</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from luisfer nando & Dj Cigarro Solto & ajax de uva verde.
| Data | luisfer nando | Dj Cigarro Solto | ajax de uva verde |
| --- | --- | --- | --- |
| Tweets downloaded | 2313 | 3232 | 2237 |
| Retweets | 351 | 645 | 467 |
| Short tweets | 492 | 586 | 598 |
| Tweets kept | 1470 | 2001 | 1172 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/39qoxauq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_luisinhobr-bryan_paula_-luanaguei's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/30onq8vd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/30onq8vd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_luisinhobr-bryan_paula_-luanaguei')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Rocketknight1/model_card_test2 | Rocketknight1 | 2021-12-14T17:50:16Z | 6 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: model_card_test2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# model_card_test2
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0031
- Train Accuracy: 1.0
- Validation Loss: 0.0000
- Validation Accuracy: 1.0
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.4647 | 0.6406 | 0.0057 | 1.0 | 0 |
| 0.0031 | 1.0 | 0.0000 | 1.0 | 1 |
### Framework versions
- Transformers 4.14.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
Rocketknight1/model-card-callback-test-new | Rocketknight1 | 2021-12-14T17:49:02Z | 11 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Rocketknight1/model-card-callback-test-new
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Rocketknight1/model-card-callback-test-new
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0031
- Train Accuracy: 1.0
- Validation Loss: 0.0000
- Validation Accuracy: 1.0
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.4647 | 0.6406 | 0.0057 | 1.0 | 0 |
| 0.0031 | 1.0 | 0.0000 | 1.0 | 1 |
### Framework versions
- Transformers 4.14.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
huggingtweets/exp-twt456 | huggingtweets | 2021-12-14T13:59:42Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1442763644606029828/CeUlNL6L_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1468633629274218502/LGrXJ5Fg_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1446914192825454592/cGOslAWZ_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Zeneca_33 🍌 & Jacob Martin & TΞtranodΞ (💎, 💎) & dcbuilder.eth 🦇🔊🐼 (3,3)(🧋,🧋)┻┳🦀</div>
<div style="text-align: center; font-size: 14px;">@dcbuild3r-tetranode-thenftattorney-zeneca_33</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Zeneca_33 🍌 & Jacob Martin & TΞtranodΞ (💎, 💎) & dcbuilder.eth 🦇🔊🐼 (3,3)(🧋,🧋)┻┳🦀.
| Data | Zeneca_33 🍌 | Jacob Martin | TΞtranodΞ (💎, 💎) | dcbuilder.eth 🦇🔊🐼 (3,3)(🧋,🧋)┻┳🦀 |
| --- | --- | --- | --- | --- |
| Tweets downloaded | 3250 | 3250 | 3247 | 3250 |
| Retweets | 7 | 58 | 736 | 318 |
| Short tweets | 537 | 390 | 555 | 646 |
| Tweets kept | 2706 | 2802 | 1956 | 2286 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1562a0v6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dcbuild3r-tetranode-thenftattorney-zeneca_33's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/18w54tsa) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/18w54tsa/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dcbuild3r-tetranode-thenftattorney-zeneca_33')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
juliusco/distilbert-base-uncased-finetuned-covdistilbert | juliusco | 2021-12-14T09:08:34Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:covid_qa_deepset",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- covid_qa_deepset
model-index:
- name: distilbert-base-uncased-finetuned-covdistilbert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-covdistilbert
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the covid_qa_deepset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 457 | 0.5125 |
| 0.5146 | 2.0 | 914 | 0.4843 |
| 0.2158 | 3.0 | 1371 | 0.4492 |
| 0.1639 | 4.0 | 1828 | 0.4760 |
| 0.1371 | 5.0 | 2285 | 0.4844 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
|
winvoker/bert-base-turkish-cased-ner-tf | winvoker | 2021-12-14T08:43:51Z | 5 | 3 | transformers | [
"transformers",
"tf",
"bert",
"token-classification",
"tr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z |
---
language: tr
widget:
- text: "Mustafa Kemal Atatürk 19 Mayıs 1919'da Samsun'a çıktı."
---
# Turkish Named Entity Recognition (NER) Model
## This repository is cloned from https://huggingface.co/akdeniz27/bert-base-turkish-cased-ner. This is the tensorflow version.
This model is the fine-tuned model of "dbmdz/bert-base-turkish-cased"
using a reviewed version of well known Turkish NER dataset
(https://github.com/stefan-it/turkish-bert/files/4558187/nerdata.txt).
# Fine-tuning parameters:
```
task = "ner"
model_checkpoint = "dbmdz/bert-base-turkish-cased"
batch_size = 8
label_list = ['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC']
max_length = 512
learning_rate = 2e-5
num_train_epochs = 3
weight_decay = 0.01
```
# How to use:
```
model = AutoModelForTokenClassification.from_pretrained("winvoker/bert-base-turkish-cased-ner-tf")
tokenizer = AutoTokenizer.from_pretrained("winvoker/bert-base-turkish-cased-ner-tf")
ner = pipeline('ner', model=model, tokenizer=tokenizer, aggregation_strategy="first")
ner("<your text here>")
```
Pls refer "https://huggingface.co/transformers/_modules/transformers/pipelines/token_classification.html" for entity grouping with aggregation_strategy parameter.
# Reference test results:
* accuracy: 0.9933935699477056
* f1: 0.9592969472710453
* precision: 0.9543530277931161
* recall: 0.9642923563325274
Evaluation results with the test sets proposed in ["Küçük, D., Küçük, D., Arıcı, N. 2016. Türkçe Varlık İsmi Tanıma için bir Veri Kümesi ("A Named Entity Recognition Dataset for Turkish"). IEEE Sinyal İşleme, İletişim ve Uygulamaları Kurultayı. Zonguldak, Türkiye."](https://ieeexplore.ieee.org/document/7495744) paper.
* Test Set Acc. Prec. Rec. F1-Score
* 20010000 0.9946 0.9871 0.9463 0.9662
* 20020000 0.9928 0.9134 0.9206 0.9170
* 20030000 0.9942 0.9814 0.9186 0.9489
* 20040000 0.9943 0.9660 0.9522 0.9590
* 20050000 0.9971 0.9539 0.9932 0.9732
* 20060000 0.9993 0.9942 0.9942 0.9942
* 20070000 0.9970 0.9806 0.9439 0.9619
* 20080000 0.9988 0.9821 0.9649 0.9735
* 20090000 0.9977 0.9891 0.9479 0.9681
* 20100000 0.9961 0.9684 0.9293 0.9485
* Overall 0.9961 0.9720 0.9516 0.9617 |
huggingtweets/alterhuss-zainabverse | huggingtweets | 2021-12-14T07:46:28Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1467618648961527812/jtH0RZpT_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1468367771746672643/21w6R4SP_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Alter Huss & Zainab</div>
<div style="text-align: center; font-size: 14px;">@alterhuss-zainabverse</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Alter Huss & Zainab.
| Data | Alter Huss | Zainab |
| --- | --- | --- |
| Tweets downloaded | 3229 | 3246 |
| Retweets | 125 | 95 |
| Short tweets | 1004 | 426 |
| Tweets kept | 2100 | 2725 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/8ibzokov/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @alterhuss-zainabverse's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3d8wr9hg) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3d8wr9hg/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/alterhuss-zainabverse')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
justinqbui/bertweet-covid-vaccine-tweets-finetuned | justinqbui | 2021-12-14T06:54:39Z | 5 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
tags:
model-index:
- name: bertweet-covid--vaccine-tweets-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets
This model is a fine-tuned version of [justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets](https://huggingface.co/justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets) which was finetuned by using [this google fact check](https://huggingface.co/datasets/justinqbui/covid_fact_checked_google_api) ~3k dataset size and webscraped data from [polifact covid info](https://huggingface.co/datasets/justinqbui/covid_fact_checked_polifact) ~ 1200 dataset size and ~1200 tweets pulled from the CDC with tweets containing the words covid or vaccine.
It achieves the following results on the evaluation set (20% from the dataset randomly shuffled and selected to serve as a test set):
- Validation Loss: 0.267367
- Accuracy: 91.1370%
To use the model, use the inference API.
Alternatively, to run locally
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("justinqbui/bertweet-covid-vaccine-tweets-finetuned")
model = AutoModelForSequenceClassification.from_pretrained("justinqbui/bertweet-covid-vaccine-tweets-finetuned")
```
## Model description
This model is a fine-tuned version of pretrained version [justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets](https://huggingface.co/justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets). Click on [this](https://huggingface.co/justinqbui/bertweet-covid19-base-uncased-pretraining-covid-vaccine-tweets) to see how the pre-training was done.
This model was fine-tuned with a dataset of ~5500. A web scraper was used to scrape polifact and a script was used to pull from the google fact check API. Because ~80% of both these datasets were either false or misleading, I pulled about ~1200 tweets from the CDC related to covid and labelled them as true. ~30% of this dataset is considered true and the rest false or misleading. Please see the published datasets above for more detailed information.
The tokenizer requires the emoji library to be installed.
```
!pip install nltk emoji
```
## Intended uses & limitations
The intended use of this model is to detect if the contents of a covid tweet is potentially false or misleading. This model is not an end all be all. It has many limitations. For example, if someone makes a post containing an image, but has attached a satirical image, this model would not be able to distinguish this. If a user links a website, the tokenizer allocates a special token for links, meaning the contents of the linked website is completely lost. If someone tweets a reply, this model can't look at the parent tweets, and will lack context.
This model's dataset relies on the crowd-sourcing annotations being accurate. This data is only accurate of up until early December 2021. For example, it probably wouldn't do very ell with tweets regarded the new omicron variant.
Example true inputs:
```
Covid vaccines are safe and effective. -> 97% true
Vaccinations are safe and help prevent covid. -> 97% true
```
Example false inputs:
```
Covid vaccines will kill you. -> 97% false
covid vaccines make you infertile. -> 97% false
```
## Training and evaluation data
This model was finetuned by using [this google fact check](https://huggingface.co/datasets/justinqbui/covid_fact_checked_google_api) ~3k dataset size and webscraped data from [polifact covid info](https://huggingface.co/datasets/justinqbui/covid_fact_checked_polifact) ~ 1200 dataset size and ~1200 tweets pulled from the CDC with tweets containing the words covid or vaccine.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-5
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
-
### Training results
| Training Loss | Epoch | Validation Loss | Accuracy |
|:-------------:|:-----:|:---------------:|:--------:|
| 0.435500 | 1.0 | 0.401900 | 0.906893 |
| 0.309700 | 2.0 | 0.265500 | 0.907789 |
| 0.266200 | 3.0 | 0.216500 | 0.911370 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Shushant/NepNewsBERT | Shushant | 2021-12-14T06:44:31Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | # NepNewsBERT
## Masked Language Model for nepali language trained on nepali news scrapped from different nepali news website. The data set contained about 10 million of nepali sentences mainly related to nepali news.
## Usage
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("Shushant/NepNewsBERT")
model = AutoModelForMaskedLM.from_pretrained("Shushant/NepNewsBERT")
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer,
)
from pprint import pprint
pprint(fill_mask(f"तिमीलाई कस्तो {tokenizer.mask_token}.")) |
BigSalmon/MrLincoln13 | BigSalmon | 2021-12-14T01:32:00Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:04Z | Informal to Formal:
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelWithLMHead.from_pretrained("BigSalmon/MrLincoln13")
```
```
https://huggingface.co/spaces/BigSalmon/GPT2_Most_Probable (The model for this space changes over time)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
informal english: meteors are much harder to see, because they are only there for a fraction of a second.
Translated into the Style of Abraham Lincoln: meteors are not ( easily / readily ) detectable, lasting for mere fractions of a second.
informal english:
```` |
huggingtweets/empressrandom | huggingtweets | 2021-12-13T22:46:44Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1046186115647115264/wc7kB-PY_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Random Empress Theresa</div>
<div style="text-align: center; font-size: 14px;">@empressrandom</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Random Empress Theresa.
| Data | Random Empress Theresa |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 29 |
| Short tweets | 34 |
| Tweets kept | 3187 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/m6jr1ywy/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @empressrandom's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/h29snzrp) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/h29snzrp/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/empressrandom')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/punk4156 | huggingtweets | 2021-12-13T22:42:15Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/punk4156/1639435330741/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1468633623922368516/wRptFCHW_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">4156</div>
<div style="text-align: center; font-size: 14px;">@punk4156</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 4156.
| Data | 4156 |
| --- | --- |
| Tweets downloaded | 3249 |
| Retweets | 627 |
| Short tweets | 523 |
| Tweets kept | 2099 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1x7ge00q/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @punk4156's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/jr4fidjd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/jr4fidjd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/punk4156')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Jeska/BertjeWDialDataALLQonly09 | Jeska | 2021-12-13T22:05:20Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
model-index:
- name: BertjeWDialDataALLQonly09
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BertjeWDialDataALLQonly09
This model is a fine-tuned version of [GroNLP/bert-base-dutch-cased](https://huggingface.co/GroNLP/bert-base-dutch-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9043
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.2439 | 1.0 | 871 | 2.1102 |
| 2.1235 | 2.0 | 1742 | 2.0785 |
| 2.0709 | 3.0 | 2613 | 2.0689 |
| 2.0033 | 4.0 | 3484 | 2.0565 |
| 1.9386 | 5.0 | 4355 | 2.0290 |
| 1.8909 | 6.0 | 5226 | 2.0366 |
| 1.8449 | 7.0 | 6097 | 1.9809 |
| 1.8078 | 8.0 | 6968 | 2.0177 |
| 1.7709 | 9.0 | 7839 | 2.0289 |
| 1.7516 | 10.0 | 8710 | 1.9645 |
| 1.7354 | 11.0 | 9581 | 1.9810 |
| 1.7073 | 12.0 | 10452 | 1.9631 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
jordanhagan/DialoGPT-medium-NegaNetizen | jordanhagan | 2021-12-13T21:38:57Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language:
- en # Example: fr
tags:
- conversational # Example: audio
- gpt2 # Example: automatic-speech-recognition
datasets:
- Discord transcripts
---
### About NegaNetizen
Trained on conversations from a friend for use within their discord server.
### How to use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained('jordanhagan/DialoGPT-medium-NegaNetizen')
# Let's chat for 5 lines
for step in range(5):
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("NNR: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
godiec/diam | godiec | 2021-12-13T19:12:32Z | 72 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2022-03-02T23:29:05Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: diam
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9775280952453613
---
# diam
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### bunny

#### moon

#### sun

#### tiger
 |
aXhyra/demo_hate_42 | aXhyra | 2021-12-13T19:09:34Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: demo_hate_42
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7772939485986298
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# demo_hate_42
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8697
- F1: 0.7773
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.320702985778492e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 282 | 0.4850 | 0.7645 |
| 0.3877 | 2.0 | 564 | 0.5160 | 0.7856 |
| 0.3877 | 3.0 | 846 | 0.6927 | 0.7802 |
| 0.1343 | 4.0 | 1128 | 0.8697 | 0.7773 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/demo_emotion_1234567 | aXhyra | 2021-12-13T18:21:16Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: demo_emotion_1234567
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: emotion
metrics:
- name: F1
type: f1
value: 0.7348035780583043
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# demo_emotion_1234567
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9818
- F1: 0.7348
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.551070618629693e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 204 | 0.7431 | 0.6530 |
| No log | 2.0 | 408 | 0.6943 | 0.7333 |
| 0.5176 | 3.0 | 612 | 0.8456 | 0.7326 |
| 0.5176 | 4.0 | 816 | 0.9818 | 0.7348 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/demo_irony_1234567 | aXhyra | 2021-12-13T17:57:42Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: demo_irony_1234567
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: irony
metrics:
- name: F1
type: f1
value: 0.685764300192161
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# demo_irony_1234567
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2905
- F1: 0.6858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.7735294032820418e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 358 | 0.5872 | 0.6786 |
| 0.5869 | 2.0 | 716 | 0.6884 | 0.6952 |
| 0.3417 | 3.0 | 1074 | 0.9824 | 0.6995 |
| 0.3417 | 4.0 | 1432 | 1.2905 | 0.6858 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/demo_irony_31415 | aXhyra | 2021-12-13T17:54:43Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: demo_irony_31415
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: irony
metrics:
- name: F1
type: f1
value: 0.685764300192161
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# demo_irony_31415
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2905
- F1: 0.6858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.7735294032820418e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 358 | 0.5872 | 0.6786 |
| 0.5869 | 2.0 | 716 | 0.6884 | 0.6952 |
| 0.3417 | 3.0 | 1074 | 0.9824 | 0.6995 |
| 0.3417 | 4.0 | 1432 | 1.2905 | 0.6858 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/demo_irony_42 | aXhyra | 2021-12-13T17:51:38Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: demo_irony_42
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: irony
metrics:
- name: F1
type: f1
value: 0.685764300192161
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# demo_irony_42
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2905
- F1: 0.6858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.7735294032820418e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 358 | 0.5872 | 0.6786 |
| 0.5869 | 2.0 | 716 | 0.6884 | 0.6952 |
| 0.3417 | 3.0 | 1074 | 0.9824 | 0.6995 |
| 0.3417 | 4.0 | 1432 | 1.2905 | 0.6858 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
ykliu1892/translation-en-pt-t5-finetuned-Duolingo-Subtitles | ykliu1892 | 2021-12-13T17:37:09Z | 5 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
tags:
- generated_from_trainer
model-index:
- name: translation-en-pt-t5-finetuned-Duolingo-Subtitles
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# translation-en-pt-t5-finetuned-Duolingo-Subtitles
This model is a fine-tuned version of [ykliu1892/translation-en-pt-t5-finetuned-Duolingo-Subtitles](https://huggingface.co/ykliu1892/translation-en-pt-t5-finetuned-Duolingo-Subtitles) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.0932
- eval_bleu: 28.4269
- eval_gen_len: 8.816
- eval_runtime: 1404.5946
- eval_samples_per_second: 106.792
- eval_steps_per_second: 3.338
- epoch: 0.52
- step: 28000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
huggingtweets/floristree92 | huggingtweets | 2021-12-13T17:11:06Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/floristree92/1639415459410/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1427988024646717441/3WW-7dhn_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">tea and oranges</div>
<div style="text-align: center; font-size: 14px;">@floristree92</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from tea and oranges.
| Data | tea and oranges |
| --- | --- |
| Tweets downloaded | 2510 |
| Retweets | 1363 |
| Short tweets | 109 |
| Tweets kept | 1038 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2fuokdip/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @floristree92's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1e0xd79p) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1e0xd79p/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/floristree92')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Ayham/robertagpt2_xsum4 | Ayham | 2021-12-13T12:46:02Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
model-index:
- name: robertagpt2_xsum4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robertagpt2_xsum4
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
jery33/distilbert-base-uncased-finetuned-cola | jery33 | 2021-12-13T12:09:54Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5373281885173845
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7637
- Matthews Correlation: 0.5373
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5306 | 1.0 | 535 | 0.5156 | 0.4063 |
| 0.3524 | 2.0 | 1070 | 0.5249 | 0.5207 |
| 0.2417 | 3.0 | 1605 | 0.6514 | 0.5029 |
| 0.1762 | 4.0 | 2140 | 0.7637 | 0.5373 |
| 0.1252 | 5.0 | 2675 | 0.8746 | 0.5291 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
li666/wav2vec2-large-xls-r-300m-zh-CN-colab | li666 | 2021-12-13T11:30:47Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-zh-CN-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-zh-CN-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
MoritzLaurer/MiniLM-L6-mnli | MoritzLaurer | 2021-12-13T10:36:43Z | 6,095 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"zero-shot-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | ---
language:
- en
tags:
- text-classification
- zero-shot-classification
metrics:
- accuracy
widget:
- text: "I liked the movie. [SEP] The movie was good."
---
# MiniLM-L6-mnli
## Model description
This model was trained on the [MultiNLI](https://huggingface.co/datasets/multi_nli) dataset.
The base model is MiniLM-L6 from Microsoft, which is very fast, but a bit less accurate than other models.
## Intended uses & limitations
#### How to use the model
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name = "MoritzLaurer/MiniLM-L6-mnli"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
premise = "I liked the movie"
hypothesis = "The movie was good."
input = tokenizer(premise, hypothesis, truncation=True, return_tensors="pt")
output = model(input["input_ids"].to(device)) # device = "cuda:0" or "cpu"
prediction = torch.softmax(output["logits"][0], -1).tolist()
label_names = ["entailment", "neutral", "contradiction"]
prediction = {name: round(float(pred) * 100, 1) for pred, name in zip(prediction, label_names)}
print(prediction)
```
### Training data
[MultiNLI](https://huggingface.co/datasets/multi_nli).
### Training procedure
MiniLM-L6-mnli-binary was trained using the Hugging Face trainer with the following hyperparameters.
```
training_args = TrainingArguments(
num_train_epochs=5, # total number of training epochs
learning_rate=2e-05,
per_device_train_batch_size=32, # batch size per device during training
per_device_eval_batch_size=32, # batch size for evaluation
warmup_ratio=0.1, # number of warmup steps for learning rate scheduler
weight_decay=0.06, # strength of weight decay
fp16=True # mixed precision training
)
```
### Eval results
The model was evaluated using the (matched) test set from MultiNLI. Accuracy: 0.814
## Limitations and bias
Please consult the original MiniLM paper and literature on different NLI datasets for potential biases.
### BibTeX entry and citation info
If you want to cite this model, please cite the original MiniLM paper, the respective NLI datasets and include a link to this model on the Hugging Face hub. |
jiangjiechen/loren | jiangjiechen | 2021-12-13T09:31:16Z | 0 | 0 | null | [
"arxiv:2012.13577",
"region:us"
] | null | 2022-03-02T23:29:04Z | `LOREN` is an interpretable fact verification model trained on [FEVER](https://fever.ai), which aims to predict the veracity of a textual claim against a trustworthy knowledge source such as Wikipedia.
`LOREN` also decomposes the verification and makes accurate and faithful phrase-level veracity predictions without any phrasal veracity supervision.
This repo hosts the following pre-trained models for `LOREN`:
- `fact_checking/`: the verification models based on BERT (large) and RoBERTa (large), respectively.
- `mrc_seq2seq/`: the generative machine reading comprehension model based on BART (base).
- `evidence_retrieval/`: the evidence sentence ranking models, which are copied directly from [KGAT](https://github.com/thunlp/KernelGAT).
More technical details can be found at [this GitHub Repo](https://github.com/jiangjiechen/LOREN).
Please check out our AAAI 2022 paper for more details: "[LOREN: Logic-Regularized Reasoning for Interpretable Fact Verification](https://arxiv.org/abs/2012.13577)". |
ydshieh/_flax-vision-encoder-decoder-vit-gpt2-coco-en | ydshieh | 2021-12-13T09:19:17Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | Found. Redirecting to https://cdn-lfs.hf.co/ydshieh/_flax-vision-encoder-decoder-vit-gpt2-coco-en/b2d266b24f2abf01c089cee5263cc2ea1710774992359f558f2a1c2e7249dab4?response-content-disposition=inline%3B+filename*%3DUTF-8%27%27README.md%3B+filename%3D%22README.md%22%3B&response-content-type=text%2Fmarkdown&Expires=1739268995&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTczOTI2ODk5NX19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5oZi5jby95ZHNoaWVoL19mbGF4LXZpc2lvbi1lbmNvZGVyLWRlY29kZXItdml0LWdwdDItY29jby1lbi9iMmQyNjZiMjRmMmFiZjAxYzA4OWNlZTUyNjNjYzJlYTE3MTA3NzQ5OTIzNTlmNTU4ZjJhMWMyZTcyNDlkYWI0P3Jlc3BvbnNlLWNvbnRlbnQtZGlzcG9zaXRpb249KiZyZXNwb25zZS1jb250ZW50LXR5cGU9KiJ9XX0_&Signature=f7awv44WHmA818C-8a66waCYuOxYok0OwPAyGs5hgLSmaxDqYr5MB7V%7EOr%7ERbF3hmcbEOFyWoNHnzi4B4YTODKPRFqamCDuM6dB2QpUlr0nEkOSAFwM9NGkrLzvm7C9nQb5Pkzm27-JSmglvaVvZ9CZZrheQAr5MOfXL6tTZUPZU4RaA4ZfXAmg9U5VfTUYcDZOwmkVxDJM5sXjHFQdyAYxa2Vep8V7YyhavuN1LQKmOsf7XRVH3Wi5z8AE9WqVtwfGaTZD8Wj2cU55WwBX8pAmt768hNR34Qf-z7mwRHeq5-tF%7ED2KAdH64pAKJE38YQhEx6-G8oy8wrtuJ4d3QnA__&Key-Pair-Id=K3RPWS32NSSJCE |
M-FAC/bert-mini-finetuned-qnli | M-FAC | 2021-12-13T08:16:16Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2107.03356",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | # BERT-mini model finetuned with M-FAC
This model is finetuned on QNLI dataset with state-of-the-art second-order optimizer M-FAC.
Check NeurIPS 2021 paper for more details on M-FAC: [https://arxiv.org/pdf/2107.03356.pdf](https://arxiv.org/pdf/2107.03356.pdf).
## Finetuning setup
For fair comparison against default Adam baseline, we finetune the model in the same framework as described here [https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) and just swap Adam optimizer with M-FAC.
Hyperparameters used by M-FAC optimizer:
```bash
learning rate = 1e-4
number of gradients = 1024
dampening = 1e-6
```
## Results
We share the best model out of 5 runs with the following score on QNLI validation set:
```bash
accuracy = 83.90
```
Mean and standard deviation for 5 runs on QNLI validation set:
| | Accuracy |
|:----:|:-----------:|
| Adam | 83.85 ± 0.10 |
| M-FAC | 83.70 ± 0.13 |
Results can be reproduced by adding M-FAC optimizer code in [https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) and running the following bash script:
```bash
CUDA_VISIBLE_DEVICES=0 python run_glue.py \
--seed 8276 \
--model_name_or_path prajjwal1/bert-mini \
--task_name qnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 1e-4 \
--num_train_epochs 5 \
--output_dir out_dir/ \
--optim MFAC \
--optim_args '{"lr": 1e-4, "num_grads": 1024, "damp": 1e-6}'
```
We believe these results could be improved with modest tuning of hyperparameters: `per_device_train_batch_size`, `learning_rate`, `num_train_epochs`, `num_grads` and `damp`. For the sake of fair comparison and a robust default setup we use the same hyperparameters across all models (`bert-tiny`, `bert-mini`) and all datasets (SQuAD version 2 and GLUE).
Our code for M-FAC can be found here: [https://github.com/IST-DASLab/M-FAC](https://github.com/IST-DASLab/M-FAC).
A step-by-step tutorial on how to integrate and use M-FAC with any repository can be found here: [https://github.com/IST-DASLab/M-FAC/tree/master/tutorials](https://github.com/IST-DASLab/M-FAC/tree/master/tutorials).
## BibTeX entry and citation info
```bibtex
@article{frantar2021m,
title={M-FAC: Efficient Matrix-Free Approximations of Second-Order Information},
author={Frantar, Elias and Kurtic, Eldar and Alistarh, Dan},
journal={Advances in Neural Information Processing Systems},
volume={35},
year={2021}
}
```
|
Subsets and Splits