
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-04 18:27:18
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 468
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-04 18:26:45
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
kwang1993/wav2vec2-base-timit-demo | kwang1993 | 2021-12-21T04:54:44Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | https://huggingface.co/blog/fine-tune-wav2vec2-english
Use the processor from https://huggingface.co/facebook/wav2vec2-base |
vuiseng9/pegasus-arxiv | vuiseng9 | 2021-12-21T02:23:21Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | This model is developed with transformers v4.13 with minor patch in this [fork](https://github.com/vuiseng9/transformers/tree/pegasus-v4p13).
# Setup
```bash
git clone https://github.com/vuiseng9/transformers
cd transformers
git checkout pegasus-v4p13 && git reset --hard 41eeb07
# installation, set summarization dependency
# . . .
```
# Train
```bash
#!/usr/bin/env bash
export CUDA_VISIBLE_DEVICES=0,1,2,3
NEPOCH=10
RUNID=pegasus-arxiv-${NEPOCH}eph-run1
OUTDIR=/data1/vchua/pegasus-hf4p13/pegasus-ft/${RUNID}
mkdir -p $OUTDIR
python run_summarization.py \
--model_name_or_path google/pegasus-large \
--dataset_name ccdv/arxiv-summarization \
--do_train \
--adafactor \
--learning_rate 8e-4 \
--label_smoothing_factor 0.1 \
--num_train_epochs $NEPOCH \
--per_device_train_batch_size 2 \
--do_eval \
--per_device_eval_batch_size 2 \
--num_beams 8 \
--max_source_length 1024 \
--max_target_length 256 \
--evaluation_strategy steps \
--eval_steps 10000 \
--save_strategy steps \
--save_steps 5000 \
--logging_steps 1 \
--overwrite_output_dir \
--run_name $RUNID \
--output_dir $OUTDIR > $OUTDIR/run.log 2>&1 &
```
# Eval
```bash
#!/usr/bin/env bash
export CUDA_VISIBLE_DEVICES=3
DT=$(date +%F_%H-%M)
RUNID=pegasus-arxiv-${DT}
OUTDIR=/data1/vchua/pegasus-hf4p13/pegasus-eval/${RUNID}
mkdir -p $OUTDIR
python run_summarization.py \
--model_name_or_path vuiseng9/pegasus-arxiv \
--dataset_name ccdv/arxiv-summarization \
--max_source_length 1024 \
--max_target_length 256 \
--do_predict \
--per_device_eval_batch_size 8 \
--predict_with_generate \
--num_beams 8 \
--overwrite_output_dir \
--run_name $RUNID \
--output_dir $OUTDIR > $OUTDIR/run.log 2>&1 &
```
Although fine-tuning is carried out for 5 epochs, this model is the checkpoint @150000 steps, 5.91 epoch, 34hrs) with lowest eval loss during training. Test/predict with this checkpoint should give results below. Note that we observe model at 80000 steps is closed to published result from HF.
```
***** predict metrics *****
predict_gen_len = 210.0925
predict_loss = 1.7192
predict_rouge1 = 46.1383
predict_rouge2 = 19.1393
predict_rougeL = 27.7573
predict_rougeLsum = 41.583
predict_runtime = 2:40:25.86
predict_samples = 6440
predict_samples_per_second = 0.669
predict_steps_per_second = 0.084
``` |
Ayham/distilbert_gpt2_summarization_xsum | Ayham | 2021-12-20T20:31:56Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: distilbert_gpt2_summarization_xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_gpt2_summarization_xsum
This model is a fine-tuned version of [](https://huggingface.co/) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
quarter100/ko-boolq-model | quarter100 | 2021-12-20T13:23:04Z | 5 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | labeled by "YES" : 1, "NO" : 0, "No Answer" : 2
fine tuned by klue/roberta-large |
patrickvonplaten/wavlm-libri-clean-100h-base-plus | patrickvonplaten | 2021-12-20T12:59:01Z | 14,635 | 3 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wavlm",
"automatic-speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"wavlm_libri_finetune",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
- wavlm_libri_finetune
model-index:
- name: wavlm-libri-clean-100h-base-plus
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wavlm-libri-clean-100h-base-plus
This model is a fine-tuned version of [microsoft/wavlm-base-plus](https://huggingface.co/microsoft/wavlm-base-plus) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0819
- Wer: 0.0683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.8877 | 0.34 | 300 | 2.8649 | 1.0 |
| 0.2852 | 0.67 | 600 | 0.2196 | 0.1830 |
| 0.1198 | 1.01 | 900 | 0.1438 | 0.1273 |
| 0.0906 | 1.35 | 1200 | 0.1145 | 0.1035 |
| 0.0729 | 1.68 | 1500 | 0.1055 | 0.0955 |
| 0.0605 | 2.02 | 1800 | 0.0936 | 0.0859 |
| 0.0402 | 2.35 | 2100 | 0.0885 | 0.0746 |
| 0.0421 | 2.69 | 2400 | 0.0848 | 0.0700 |
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
patrickvonplaten/wav2vec2-common_voice-tr-demo | patrickvonplaten | 2021-12-20T12:54:39Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"speech-recognition",
"common_voice",
"generated_from_trainer",
"tr",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- tr
license: apache-2.0
tags:
- speech-recognition
- common_voice
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-common_voice-tr-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-common_voice-tr-demo
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the COMMON_VOICE - TR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3856
- Wer: 0.3556
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.7391 | 0.92 | 100 | 3.5760 | 1.0 |
| 2.927 | 1.83 | 200 | 3.0796 | 0.9999 |
| 0.9009 | 2.75 | 300 | 0.9278 | 0.8226 |
| 0.6529 | 3.67 | 400 | 0.5926 | 0.6367 |
| 0.3623 | 4.59 | 500 | 0.5372 | 0.5692 |
| 0.2888 | 5.5 | 600 | 0.4407 | 0.4838 |
| 0.285 | 6.42 | 700 | 0.4341 | 0.4694 |
| 0.0842 | 7.34 | 800 | 0.4153 | 0.4302 |
| 0.1415 | 8.26 | 900 | 0.4317 | 0.4136 |
| 0.1552 | 9.17 | 1000 | 0.4145 | 0.4013 |
| 0.1184 | 10.09 | 1100 | 0.4115 | 0.3844 |
| 0.0556 | 11.01 | 1200 | 0.4182 | 0.3862 |
| 0.0851 | 11.93 | 1300 | 0.3985 | 0.3688 |
| 0.0961 | 12.84 | 1400 | 0.4030 | 0.3665 |
| 0.0596 | 13.76 | 1500 | 0.3880 | 0.3631 |
| 0.0917 | 14.68 | 1600 | 0.3878 | 0.3582 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist | patrickvonplaten | 2021-12-20T12:53:43Z | 87 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- speech-recognition
- librispeech_asr
- generated_from_trainer
model-index:
- name: wav2vec2-librispeech-clean-100h-demo-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-librispeech-clean-100h-demo-dist
This model is a fine-tuned version of [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0572
- Wer: 0.0417
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.399 | 0.11 | 100 | 3.6153 | 1.0 |
| 2.8892 | 0.22 | 200 | 2.8963 | 1.0 |
| 2.8284 | 0.34 | 300 | 2.8574 | 1.0 |
| 0.7347 | 0.45 | 400 | 0.6158 | 0.4850 |
| 0.1138 | 0.56 | 500 | 0.2038 | 0.1560 |
| 0.248 | 0.67 | 600 | 0.1274 | 0.1024 |
| 0.2586 | 0.78 | 700 | 0.1108 | 0.0876 |
| 0.0733 | 0.9 | 800 | 0.0936 | 0.0762 |
| 0.044 | 1.01 | 900 | 0.0834 | 0.0662 |
| 0.0393 | 1.12 | 1000 | 0.0792 | 0.0622 |
| 0.0941 | 1.23 | 1100 | 0.0769 | 0.0627 |
| 0.036 | 1.35 | 1200 | 0.0731 | 0.0603 |
| 0.0768 | 1.46 | 1300 | 0.0713 | 0.0559 |
| 0.0518 | 1.57 | 1400 | 0.0686 | 0.0537 |
| 0.0815 | 1.68 | 1500 | 0.0639 | 0.0515 |
| 0.0603 | 1.79 | 1600 | 0.0636 | 0.0500 |
| 0.056 | 1.91 | 1700 | 0.0609 | 0.0480 |
| 0.0265 | 2.02 | 1800 | 0.0621 | 0.0465 |
| 0.0496 | 2.13 | 1900 | 0.0607 | 0.0449 |
| 0.0436 | 2.24 | 2000 | 0.0591 | 0.0446 |
| 0.0421 | 2.35 | 2100 | 0.0590 | 0.0428 |
| 0.0641 | 2.47 | 2200 | 0.0603 | 0.0443 |
| 0.0466 | 2.58 | 2300 | 0.0580 | 0.0429 |
| 0.0132 | 2.69 | 2400 | 0.0574 | 0.0423 |
| 0.0073 | 2.8 | 2500 | 0.0586 | 0.0417 |
| 0.0021 | 2.91 | 2600 | 0.0574 | 0.0412 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
patrickvonplaten/hubert-librispeech-clean-100h-demo-dist | patrickvonplaten | 2021-12-20T12:53:35Z | 10 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"hubert",
"automatic-speech-recognition",
"speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- speech-recognition
- librispeech_asr
- generated_from_trainer
model-index:
- name: hubert-librispeech-clean-100h-demo-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hubert-librispeech-clean-100h-demo-dist
This model is a fine-tuned version of [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0984
- Wer: 0.0883
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.9031 | 0.11 | 100 | 2.9220 | 1.0 |
| 2.6437 | 0.22 | 200 | 2.6268 | 1.0 |
| 0.3934 | 0.34 | 300 | 0.4860 | 0.4182 |
| 0.3531 | 0.45 | 400 | 0.3088 | 0.2894 |
| 0.2255 | 0.56 | 500 | 0.2568 | 0.2426 |
| 0.3379 | 0.67 | 600 | 0.2073 | 0.2011 |
| 0.2419 | 0.78 | 700 | 0.1849 | 0.1838 |
| 0.2128 | 0.9 | 800 | 0.1662 | 0.1690 |
| 0.1341 | 1.01 | 900 | 0.1600 | 0.1541 |
| 0.0946 | 1.12 | 1000 | 0.1431 | 0.1404 |
| 0.1643 | 1.23 | 1100 | 0.1373 | 0.1304 |
| 0.0663 | 1.35 | 1200 | 0.1293 | 0.1307 |
| 0.162 | 1.46 | 1300 | 0.1247 | 0.1266 |
| 0.1433 | 1.57 | 1400 | 0.1246 | 0.1262 |
| 0.1581 | 1.68 | 1500 | 0.1219 | 0.1154 |
| 0.1036 | 1.79 | 1600 | 0.1127 | 0.1081 |
| 0.1352 | 1.91 | 1700 | 0.1087 | 0.1040 |
| 0.0471 | 2.02 | 1800 | 0.1085 | 0.1005 |
| 0.0945 | 2.13 | 1900 | 0.1066 | 0.0973 |
| 0.0843 | 2.24 | 2000 | 0.1102 | 0.0964 |
| 0.0774 | 2.35 | 2100 | 0.1079 | 0.0940 |
| 0.0952 | 2.47 | 2200 | 0.1056 | 0.0927 |
| 0.0635 | 2.58 | 2300 | 0.1026 | 0.0920 |
| 0.0665 | 2.69 | 2400 | 0.1012 | 0.0905 |
| 0.034 | 2.8 | 2500 | 0.1009 | 0.0900 |
| 0.0251 | 2.91 | 2600 | 0.0993 | 0.0883 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
patrickvonplaten/sew-mid-100k-librispeech-clean-100h-ft | patrickvonplaten | 2021-12-20T12:53:26Z | 11 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"sew",
"automatic-speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
model-index:
- name: sew-mid-100k-librispeech-clean-100h-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sew-mid-100k-librispeech-clean-100h-ft
This model is a fine-tuned version of [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1976
- Wer: 0.1665
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.4274 | 0.11 | 100 | 4.1419 | 1.0 |
| 2.9657 | 0.22 | 200 | 3.1203 | 1.0 |
| 2.9069 | 0.34 | 300 | 3.0107 | 1.0 |
| 2.8666 | 0.45 | 400 | 2.8960 | 1.0 |
| 1.4535 | 0.56 | 500 | 1.4062 | 0.8664 |
| 0.6821 | 0.67 | 600 | 0.5530 | 0.4930 |
| 0.4827 | 0.78 | 700 | 0.4122 | 0.3630 |
| 0.4485 | 0.9 | 800 | 0.3597 | 0.3243 |
| 0.2666 | 1.01 | 900 | 0.3104 | 0.2790 |
| 0.2378 | 1.12 | 1000 | 0.2913 | 0.2613 |
| 0.2516 | 1.23 | 1100 | 0.2702 | 0.2452 |
| 0.2456 | 1.35 | 1200 | 0.2619 | 0.2338 |
| 0.2392 | 1.46 | 1300 | 0.2466 | 0.2195 |
| 0.2117 | 1.57 | 1400 | 0.2379 | 0.2092 |
| 0.1837 | 1.68 | 1500 | 0.2295 | 0.2029 |
| 0.1757 | 1.79 | 1600 | 0.2240 | 0.1949 |
| 0.1626 | 1.91 | 1700 | 0.2195 | 0.1927 |
| 0.168 | 2.02 | 1800 | 0.2137 | 0.1853 |
| 0.168 | 2.13 | 1900 | 0.2123 | 0.1839 |
| 0.1576 | 2.24 | 2000 | 0.2095 | 0.1803 |
| 0.1756 | 2.35 | 2100 | 0.2075 | 0.1776 |
| 0.1467 | 2.47 | 2200 | 0.2049 | 0.1754 |
| 0.1702 | 2.58 | 2300 | 0.2013 | 0.1722 |
| 0.177 | 2.69 | 2400 | 0.1993 | 0.1701 |
| 0.1417 | 2.8 | 2500 | 0.1983 | 0.1688 |
| 0.1302 | 2.91 | 2600 | 0.1977 | 0.1678 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.13.4.dev0
- Tokenizers 0.10.3
|
MMG/bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad2-es | MMG | 2021-12-20T08:10:24Z | 23 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"es",
"dataset:squad_es",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- squad_es
model-index:
- name: bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad2-es
results: []
language:
- es
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad2-es
This model is a fine-tuned version of [MMG/bert-base-spanish-wwm-cased-finetuned-sqac](https://huggingface.co/MMG/bert-base-spanish-wwm-cased-finetuned-sqac) on the squad_es dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2584
- {'exact': 63.358070500927646, 'f1': 70.22498384623977}
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Amalq/roberta-base-finetuned-schizophreniaReddit2 | Amalq | 2021-12-20T05:41:28Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-schizophreniaReddit2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-schizophreniaReddit2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 490 | 1.8093 |
| 1.9343 | 2.0 | 980 | 1.7996 |
| 1.8856 | 3.0 | 1470 | 1.7966 |
| 1.8552 | 4.0 | 1960 | 1.7844 |
| 1.8267 | 5.0 | 2450 | 1.7839 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
microsoft/unispeech-1350-en-168-es-ft-1h | microsoft | 2021-12-19T23:01:13Z | 33 | 0 | transformers | [
"transformers",
"pytorch",
"unispeech",
"automatic-speech-recognition",
"audio",
"es",
"dataset:common_voice",
"arxiv:2101.07597",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- es
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus Spanish
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Spanish phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-168-es-ft-1h"
sample = next(iter(load_dataset("common_voice", "es", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# -> gives:
# b j e n i k e ɾ ɾ e ɣ a l o a s a β ɾ i ɾ p ɾ i m e ɾ o'
# for: Bien . ¿ y qué regalo vas a abrir primero ?
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *es*:
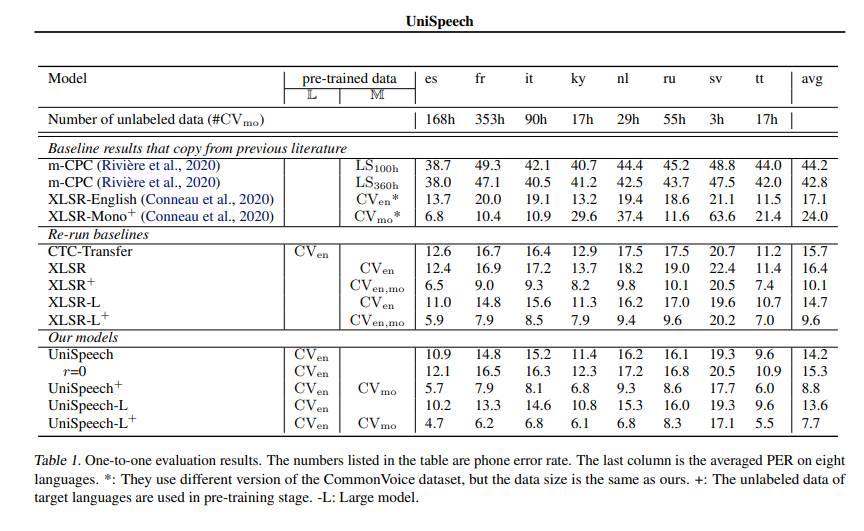 |
oseibrefo/distilbert-base-uncased-finetuned-cola | oseibrefo | 2021-12-19T19:40:54Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5497693861041112
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7595
- Matthews Correlation: 0.5498
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5275 | 1.0 | 535 | 0.5411 | 0.4254 |
| 0.3498 | 2.0 | 1070 | 0.4973 | 0.5183 |
| 0.2377 | 3.0 | 1605 | 0.6180 | 0.5079 |
| 0.175 | 4.0 | 2140 | 0.7595 | 0.5498 |
| 0.1322 | 5.0 | 2675 | 0.8412 | 0.5370 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
addy88/wav2vec2-assamese-stt | addy88 | 2021-12-19T16:55:56Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/addy88/wav2vec2-assamese-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/addy88/wav2vec2-assamese-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-bhojpuri-stt | addy88 | 2021-12-19T16:48:06Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-bhojpuri-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-bhojpuri-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-marathi-stt | addy88 | 2021-12-19T16:31:22Z | 21 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-marathi-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-marathi-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec-odia-stt | addy88 | 2021-12-19T15:56:01Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-odia-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-odia-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-rajsthani-stt | addy88 | 2021-12-19T15:52:16Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-rajsthani-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-rajsthani-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-urdu-stt | addy88 | 2021-12-19T15:47:47Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-urdu-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-urdu-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-tamil-stt | addy88 | 2021-12-19T15:43:45Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-tamil-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-tamil-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-telugu-stt | addy88 | 2021-12-19T15:39:58Z | 1,020 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-telugu-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-telugu-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-nepali-stt | addy88 | 2021-12-19T15:36:06Z | 4 | 1 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-nepali-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-nepali-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
nguyenvulebinh/envibert | nguyenvulebinh | 2021-12-19T14:20:51Z | 26 | 5 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"exbert",
"vi",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language: vi
tags:
- exbert
license: cc-by-nc-4.0
---
# RoBERTa for Vietnamese and English (envibert)
This RoBERTa version is trained by using 100GB of text (50GB of Vietnamese and 50GB of English) so it is named ***envibert***. The model architecture is custom for production so it only contains 70M parameters.
## Usages
```python
from transformers import RobertaModel
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
import os
cache_dir='./cache'
model_name='nguyenvulebinh/envibert'
def download_tokenizer_files():
resources = ['envibert_tokenizer.py', 'dict.txt', 'sentencepiece.bpe.model']
for item in resources:
if not os.path.exists(os.path.join(cache_dir, item)):
tmp_file = hf_bucket_url(model_name, filename=item)
tmp_file = cached_path(tmp_file,cache_dir=cache_dir)
os.rename(tmp_file, os.path.join(cache_dir, item))
download_tokenizer_files()
tokenizer = SourceFileLoader("envibert.tokenizer", os.path.join(cache_dir,'envibert_tokenizer.py')).load_module().RobertaTokenizer(cache_dir)
model = RobertaModel.from_pretrained(model_name,cache_dir=cache_dir)
# Encode text
text_input = 'Đại học Bách Khoa Hà Nội .'
text_ids = tokenizer(text_input, return_tensors='pt').input_ids
# tensor([[ 0, 705, 131, 8751, 2878, 347, 477, 5, 2]])
# Extract features
text_features = model(text_ids)
text_features['last_hidden_state'].shape
# torch.Size([1, 9, 768])
len(text_features['hidden_states'])
# 7
```
### Citation
```text
@inproceedings{nguyen20d_interspeech,
author={Thai Binh Nguyen and Quang Minh Nguyen and Thi Thu Hien Nguyen and Quoc Truong Do and Chi Mai Luong},
title={{Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={4263--4267},
doi={10.21437/Interspeech.2020-1896}
}
```
**Please CITE** our repo when it is used to help produce published results or is incorporated into other software.
# Contact
[email protected]
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh) |
addy88/wav2vec2-sanskrit-stt | addy88 | 2021-12-19T13:38:52Z | 264 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-sanskrit-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-sanskrit-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
addy88/wav2vec2-kannada-stt | addy88 | 2021-12-19T13:35:26Z | 248 | 1 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("addy88/wav2vec2-kannada-stt")
model = Wav2Vec2ForCTC.from_pretrained("addy88/wav2vec2-kannada-stt")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
``` |
new5558/simcse-model-wangchanberta-base-att-spm-uncased | new5558 | 2021-12-19T13:01:31Z | 80 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"camembert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# new5558/simcse-model-wangchanberta-base-att-spm-uncased
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('new5558/simcse-model-wangchanberta-base-att-spm-uncased')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('new5558/simcse-model-wangchanberta-base-att-spm-uncased')
model = AutoModel.from_pretrained('new5558/simcse-model-wangchanberta-base-att-spm-uncased')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=new5558/simcse-model-wangchanberta-base-att-spm-uncased)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 5125 with parameters:
```
{'batch_size': 256, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 1e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 32, 'do_lower_case': False}) with Transformer model: CamembertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
rlagusrlagus123/XTC4096 | rlagusrlagus123 | 2021-12-19T11:19:34Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
tags:
- conversational
---
---
#12 epochs, each batch size 4, gradient accumulation steps 1, tail 4096.
#THIS SEEMS TO BE THE OPTIMAL SETUP. |
NbAiLabArchive/test_w5_long_roberta_tokenizer | NbAiLabArchive | 2021-12-19T10:36:40Z | 41 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | Just for performing some experiments. Do not use. |
shreyasgite/wav2vec2-large-xls-r-300m-dementianet | shreyasgite | 2021-12-19T09:11:16Z | 78 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: wav2vec2-large-xls-r-300m-dementianet
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-dementianet
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3430
- Accuracy: 0.4062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 22
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3845 | 3.33 | 40 | 1.3556 | 0.3125 |
| 1.3659 | 6.67 | 80 | 1.3602 | 0.3125 |
| 1.3619 | 10.0 | 120 | 1.3569 | 0.3125 |
| 1.3575 | 13.33 | 160 | 1.3509 | 0.3125 |
| 1.3356 | 16.67 | 200 | 1.3599 | 0.3125 |
| 1.3166 | 20.0 | 240 | 1.3430 | 0.4062 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Ayham/roberta_gpt2_summarization_xsum | Ayham | 2021-12-19T06:35:43Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: roberta_gpt2_summarization_xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta_gpt2_summarization_xsum
This model is a fine-tuned version of [](https://huggingface.co/) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Ayham/xlnet_gpt2_summarization_xsum | Ayham | 2021-12-19T04:50:11Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: xlnet_gpt2_summarization_xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet_gpt2_summarization_xsum
This model is a fine-tuned version of [](https://huggingface.co/) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
yerevann/x-r-hy | yerevann | 2021-12-19T03:19:04Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-2b-armenian-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-2b-armenian-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-2b](https://huggingface.co/facebook/wav2vec2-xls-r-2b) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5166
- Wer: 0.7397
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 120
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 3.7057 | 2.38 | 200 | 0.7731 | 0.8091 |
| 0.5797 | 4.76 | 400 | 0.8279 | 0.7804 |
| 0.4341 | 7.14 | 600 | 1.0343 | 0.8285 |
| 0.3135 | 9.52 | 800 | 1.0551 | 0.8066 |
| 0.2409 | 11.9 | 1000 | 1.0686 | 0.7897 |
| 0.1998 | 14.29 | 1200 | 1.1329 | 0.7766 |
| 0.1729 | 16.67 | 1400 | 1.3234 | 0.8567 |
| 0.1533 | 19.05 | 1600 | 1.2432 | 0.8160 |
| 0.1354 | 21.43 | 1800 | 1.2780 | 0.7954 |
| 0.12 | 23.81 | 2000 | 1.2228 | 0.8054 |
| 0.1175 | 26.19 | 2200 | 1.3484 | 0.8129 |
| 0.1141 | 28.57 | 2400 | 1.2881 | 0.9130 |
| 0.1053 | 30.95 | 2600 | 1.1972 | 0.7910 |
| 0.0954 | 33.33 | 2800 | 1.3702 | 0.8048 |
| 0.0842 | 35.71 | 3000 | 1.3963 | 0.7960 |
| 0.0793 | 38.1 | 3200 | 1.4690 | 0.7991 |
| 0.0707 | 40.48 | 3400 | 1.5045 | 0.8085 |
| 0.0745 | 42.86 | 3600 | 1.4749 | 0.8004 |
| 0.0693 | 45.24 | 3800 | 1.5047 | 0.7960 |
| 0.0646 | 47.62 | 4000 | 1.4216 | 0.7997 |
| 0.0555 | 50.0 | 4200 | 1.4676 | 0.8029 |
| 0.056 | 52.38 | 4400 | 1.4273 | 0.8104 |
| 0.0465 | 54.76 | 4600 | 1.3999 | 0.7841 |
| 0.046 | 57.14 | 4800 | 1.6130 | 0.8473 |
| 0.0404 | 59.52 | 5000 | 1.5586 | 0.7841 |
| 0.0403 | 61.9 | 5200 | 1.3959 | 0.7653 |
| 0.0404 | 64.29 | 5400 | 1.5318 | 0.8041 |
| 0.0365 | 66.67 | 5600 | 1.5300 | 0.7854 |
| 0.0338 | 69.05 | 5800 | 1.5051 | 0.7885 |
| 0.0307 | 71.43 | 6000 | 1.5647 | 0.7935 |
| 0.0235 | 73.81 | 6200 | 1.4919 | 0.8154 |
| 0.0268 | 76.19 | 6400 | 1.5259 | 0.8060 |
| 0.0275 | 78.57 | 6600 | 1.3985 | 0.7897 |
| 0.022 | 80.95 | 6800 | 1.5515 | 0.8154 |
| 0.017 | 83.33 | 7000 | 1.5737 | 0.7647 |
| 0.0205 | 85.71 | 7200 | 1.4876 | 0.7572 |
| 0.0174 | 88.1 | 7400 | 1.6331 | 0.7829 |
| 0.0188 | 90.48 | 7600 | 1.5108 | 0.7685 |
| 0.0134 | 92.86 | 7800 | 1.7125 | 0.7866 |
| 0.0125 | 95.24 | 8000 | 1.6042 | 0.7635 |
| 0.0133 | 97.62 | 8200 | 1.4608 | 0.7478 |
| 0.0272 | 100.0 | 8400 | 1.4784 | 0.7309 |
| 0.0133 | 102.38 | 8600 | 1.4471 | 0.7459 |
| 0.0094 | 104.76 | 8800 | 1.4852 | 0.7272 |
| 0.0103 | 107.14 | 9000 | 1.5679 | 0.7409 |
| 0.0088 | 109.52 | 9200 | 1.5090 | 0.7309 |
| 0.0077 | 111.9 | 9400 | 1.4994 | 0.7290 |
| 0.0068 | 114.29 | 9600 | 1.5008 | 0.7340 |
| 0.0054 | 116.67 | 9800 | 1.5166 | 0.7390 |
| 0.0052 | 119.05 | 10000 | 1.5166 | 0.7397 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
zaccharieramzi/UNet-OASIS | zaccharieramzi | 2021-12-19T02:07:02Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # UNet-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.unet import unet
model = unet(n_layers=4, layers_n_channels=[16, 32, 64, 128], layers_n_non_lins=2,)
model.load_weights('UNet-fastmri/model_weights.h5')
```
Using the model is then as simple as:
```python
model(zero_filled_recon)
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 29.8
- SSIM: 0.847
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/KIKI-net-OASIS | zaccharieramzi | 2021-12-19T01:59:51Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # KIKI-net-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.kiki_sep import full_kiki_net
from fastmri_recon.models.utils.non_linearities import lrelu
model = full_kiki_net(n_convs=16, n_filters=48, activation=lrelu)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 30.08
- SSIM: 0.853
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/CascadeNet-OASIS | zaccharieramzi | 2021-12-19T01:47:21Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # CascadeNet-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.cascading import cascade_net
model = cascade_net()
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 32.0
- SSIM: 0.887
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/CascadeNet-fastmri | zaccharieramzi | 2021-12-19T01:43:27Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # CascadeNet-fastmri
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model can be used to reconstruct single coil fastMRI data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil knee data from Siemens scanner at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.cascading import cascade_net
model = cascade_net()
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [fastMRI dataset](https://fastmri.org/dataset/).
| Contrast | PD | PDFS |
|----------|-------|--------|
| PSNR | 33.98 | 29.88 |
| SSIM | 0.811 | 0.6251 |
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/PDNet-OASIS | zaccharieramzi | 2021-12-19T01:37:49Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # PDNet-OASIS
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- OASIS
---
This model can be used to reconstruct single coil OASIS data with an acceleration factor of 4.
## Model description
For more details, see https://www.mdpi.com/2076-3417/10/5/1816.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct single coil brain retrospective data from the OASIS database at acceleration factor 4.
It cannot be used on multi-coil data.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
from fastmri_recon.models.functional_models.pdnet import pdnet
model = pdnet()
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [OASIS dataset](https://www.oasis-brains.org/).
## Training procedure
The training procedure is described in https://www.mdpi.com/2076-3417/10/5/1816 for brain data.
This section is WIP.
## Evaluation results
This model was evaluated using the [OASIS dataset](https://www.oasis-brains.org/).
- PSNR: 33.22
- SSIM: 0.910
## Bibtex entry
```
@article{ramzi2020benchmarking,
title={Benchmarking MRI reconstruction neural networks on large public datasets},
author={Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
journal={Applied Sciences},
volume={10},
number={5},
pages={1816},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
```
|
zaccharieramzi/NCPDNet-multicoil-spiral | zaccharieramzi | 2021-12-19T01:01:43Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | # NCPDNet-multicoil-spiral
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This is a non-Cartesian multicoil MRI reconstruction model for spiral trajectories at acceleration factor 4.
The model uses 10 iterations and a small vanilla CNN.
## Model description
For more details, see https://hal.inria.fr/hal-03188997.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct multicoil knee data from Siemens scanner at acceleration factor 4 in a spiral acquisition setting.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
import tensorflow as tf
from fastmri_recon.models.subclassed_models.ncpdnet import NCPDNet
model = NCPDNet(
multicoil=True,
im_size=(640, 400),
dcomp=True,
refine_smaps=True,
)
kspace_shape = 1
inputs = [
tf.zeros([1, 1, kspace_shape, 1], dtype=tf.complex64),
tf.zeros([1, 2, kspace_shape], dtype=tf.float32),
tf.zeros([1, 1, 640, 320], dtype=tf.complex64),
(tf.constant([320]), tf.ones([1, kspace_shape], dtype=tf.float32)),
]
model(inputs)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_coils, n_kspace_samples, 1]
traj, # shape: [n_slices, n_coils, 2, n_kspace_samples]
smaps, # shape: [n_slices, n_coils, n_kspace_samples, n_coils]
(
output_shape, # shape: [n_slices, 1]
dcomp, # shape: [n_slices, n_kspace_samples]
)
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://hal.inria.fr/hal-03188997.
This section is WIP.
## Evaluation results
On the fastMRI validation dataset:
- PSNR: 40.68
- SSIM: 0.9255
## Bibtex entry
```
@unpublished{ramzi:hal-03188997,
TITLE = {{NC-PDNet: a Density-Compensated Unrolled Network for 2D and 3D non-Cartesian MRI Reconstruction}},
AUTHOR = {Ramzi, Zaccharie and G R, Chaithya and Starck, Jean-Luc and Ciuciu, Philippe},
YEAR = {2021},
MONTH = Sep,
}
```
|
SoLID/sgd-output-plan-constructor | SoLID | 2021-12-18T21:00:54Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ## Schema Guided Dialogue Output Plan Constructor
|
tasosk/bert-base-uncased-airlines | tasosk | 2021-12-18T20:20:24Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-airlines
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-airlines
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3458
- Accuracy: 0.9021
- F1: 0.9022
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 405 | 0.3230 | 0.8754 | 0.8750 |
| 0.4658 | 2.0 | 810 | 0.2738 | 0.8986 | 0.8985 |
| 0.2473 | 3.0 | 1215 | 0.2944 | 0.9110 | 0.9111 |
| 0.2498 | 4.0 | 1620 | 0.3322 | 0.8950 | 0.8949 |
| 0.2174 | 5.0 | 2025 | 0.3342 | 0.9021 | 0.9021 |
| 0.2174 | 6.0 | 2430 | 0.3526 | 0.8986 | 0.8985 |
| 0.2055 | 7.0 | 2835 | 0.3458 | 0.9021 | 0.9022 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
zaccharieramzi/UPDNet-knee-af8 | zaccharieramzi | 2021-12-18T18:08:29Z | 0 | 0 | null | [
"arxiv:2010.07290",
"region:us"
] | null | 2022-03-02T23:29:05Z | # UPDNet-knee-af8
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model was used to achieve the 9th highest submission in terms of PSNR on the fastMRI dataset (see https://fastmri.org/leaderboards/) (0.2dB behind the 2nd submission).
It is a base model for acceleration factor 8.
The model uses 25 iterations and a medium-ca-prelu U-net, and a medium sensitivity maps refiner.
## Model description
For more details, see https://arxiv.org/abs/2010.07290.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct knee data from Siemens scanner at acceleration factor 8.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
import tensorflow as tf
from fastmri_recon.models.subclassed_models.updnet import UPDNet
model = UPDNet(
multicoil=True,
n_dual=1,
primal_only=True,
n_layers=4,
n_iter=25,
channel_attention_kwargs={'dense': True},
refine_smaps=True,
non_linearity='prelu',
layers_n_channels=[16 * 2**i for i in range(4)],
)
kspace_size = [1, 1, 320, 320]
inputs = [
tf.zeros(kspace_size + [1], dtype=tf.complex64), # kspace
tf.zeros(kspace_size, dtype=tf.complex64), # mask
tf.zeros(kspace_size, dtype=tf.complex64), # smaps
]
model(inputs)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_coils, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_coils, n_rows, n_cols]
smaps, # shape: [n_slices, n_coils, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://arxiv.org/abs/2010.07290.
This section is WIP.
## Evaluation results
No evaluation available outside the one from the fastMRI leaderboard (id: `updnet_v3`).
## Bibtex entry
```
@inproceedings{Ramzi2020d,
archivePrefix = {arXiv},
arxivId = {2010.07290},
author = {Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
booktitle = {ISMRM},
eprint = {2010.07290},
pages = {1--4},
title = {{XPDNet for MRI Reconstruction: an application to the 2020 fastMRI challenge}},
url = {http://arxiv.org/abs/2010.07290},
year = {2021}
}
```
|
zaccharieramzi/UPDNet-knee-af4 | zaccharieramzi | 2021-12-18T18:08:04Z | 0 | 0 | null | [
"arxiv:2010.07290",
"region:us"
] | null | 2022-03-02T23:29:05Z | # UPDNet-knee-af4
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model was used to achieve the 9th highest submission in terms of PSNR on the fastMRI dataset (see https://fastmri.org/leaderboards/) (0.2dB behind the 2nd submission).
It is a base model for acceleration factor 4.
The model uses 25 iterations and a medium-ca-prelu U-net, and a medium sensitivity maps refiner.
## Model description
For more details, see https://arxiv.org/abs/2010.07290.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct knee data from Siemens scanner at acceleration factor 4.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
import tensorflow as tf
from fastmri_recon.models.subclassed_models.updnet import UPDNet
model = UPDNet(
multicoil=True,
n_dual=1,
primal_only=True,
n_layers=4,
n_iter=25,
channel_attention_kwargs={'dense': True},
refine_smaps=True,
non_linearity='prelu',
layers_n_channels=[16 * 2**i for i in range(4)],
)
kspace_size = [1, 1, 320, 320]
inputs = [
tf.zeros(kspace_size + [1], dtype=tf.complex64), # kspace
tf.zeros(kspace_size, dtype=tf.complex64), # mask
tf.zeros(kspace_size, dtype=tf.complex64), # smaps
]
model(inputs)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_coils, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_coils, n_rows, n_cols]
smaps, # shape: [n_slices, n_coils, n_rows, n_cols]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://arxiv.org/abs/2010.07290.
This section is WIP.
## Evaluation results
No evaluation available outside the one from the fastMRI leaderboard (id: `updnet_v3`).
## Bibtex entry
```
@inproceedings{Ramzi2020d,
archivePrefix = {arXiv},
arxivId = {2010.07290},
author = {Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
booktitle = {ISMRM},
eprint = {2010.07290},
pages = {1--4},
title = {{XPDNet for MRI Reconstruction: an application to the 2020 fastMRI challenge}},
url = {http://arxiv.org/abs/2010.07290},
year = {2021}
}
```
|
zaccharieramzi/XPDNet-brain-af4 | zaccharieramzi | 2021-12-18T17:10:04Z | 0 | 0 | null | [
"arxiv:2010.07290",
"arxiv:2106.00753",
"region:us"
] | null | 2022-03-02T23:29:05Z | # XPDNet-brain-af4
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model was used to achieve the 3rd highest submission in terms of PSNR on the fastMRI dataset (see https://fastmri.org/leaderboards/).
It is a base model for acceleration factor 4.
The model uses 25 iterations and a medium MWCNN, and a big sensitivity maps refiner.
## Model description
For more details, see https://arxiv.org/abs/2010.07290.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct brain data from Siemens scanner at acceleration factor 4.
It was shown [here](https://arxiv.org/abs/2106.00753), that it can generalize well, although further tests are required.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
import tensorflow as tf
from fastmri_recon.models.subclassed_models.denoisers.proposed_params import get_model_specs
from fastmri_recon.models.subclassed_models.xpdnet import XPDNet
n_primal = 5
model_fun, model_kwargs, n_scales, res = [
(model_fun, kwargs, n_scales, res)
for m_name, m_size, model_fun, kwargs, _, n_scales, res in get_model_specs(n_primal=n_primal, force_res=False)
if m_name == 'MWCNN' and m_size == 'medium'
][0]
model_kwargs['use_bias'] = False
run_params = dict(
n_primal=n_primal,
multicoil=True,
n_scales=n_scales,
refine_smaps=True,
refine_big=True,
res=res,
output_shape_spec=True,
n_iter=25,
)
model = XPDNet(model_fun, model_kwargs, **run_params)
kspace_size = [1, 1, 320, 320]
inputs = [
tf.zeros(kspace_size + [1], dtype=tf.complex64), # kspace
tf.zeros(kspace_size, dtype=tf.complex64), # mask
tf.zeros(kspace_size, dtype=tf.complex64), # smaps
tf.constant([[320, 320]]), # shape
]
model(inputs)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_coils, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_coils, n_rows, n_cols]
smaps, # shape: [n_slices, n_coils, n_rows, n_cols]
shape, # shape: [n_slices, 2]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://arxiv.org/abs/2010.07290.
This section is WIP.
## Evaluation results
On the fastMRI validation dataset, the same model with a smaller sensitivity maps refiner gives the following results for 30 validation volumes per contrast:
| Contrast | T1 | T2 | FLAIR | T1-POST |
|----------|--------|--------|--------|---------|
| PSNR | 41.56 | 40.68 | 39.60 | 42.53 |
| SSIM | 0.9506 | 0.9554 | 0.9321 | 0.9683 |
Further results can be seen on the fastMRI leaderboards for the test and challenge dataset: https://fastmri.org/leaderboards/
## Bibtex entry
```
@inproceedings{Ramzi2020d,
archivePrefix = {arXiv},
arxivId = {2010.07290},
author = {Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
booktitle = {ISMRM},
eprint = {2010.07290},
pages = {1--4},
title = {{XPDNet for MRI Reconstruction: an application to the 2020 fastMRI challenge}},
url = {http://arxiv.org/abs/2010.07290},
year = {2021}
}
```
|
zaccharieramzi/XPDNet-brain-af8 | zaccharieramzi | 2021-12-18T17:09:08Z | 0 | 0 | null | [
"arxiv:2010.07290",
"arxiv:2106.00753",
"region:us"
] | null | 2022-03-02T23:29:05Z | # XPDNet-brain-af8
---
tags:
- TensorFlow
- MRI reconstruction
- MRI
datasets:
- fastMRI
---
This model was used to achieve the 2nd highest submission in terms of PSNR on the fastMRI dataset (see https://fastmri.org/leaderboards/).
It is a base model for acceleration factor 8.
The model uses 25 iterations and a medium MWCNN, and a big sensitivity maps refiner.
## Model description
For more details, see https://arxiv.org/abs/2010.07290.
This section is WIP.
## Intended uses and limitations
This model can be used to reconstruct brain data from Siemens scanner at acceleration factor 8.
It was shown [here](https://arxiv.org/abs/2106.00753), that it can generalize well, although further tests are required.
## How to use
This model can be loaded using the following repo: https://github.com/zaccharieramzi/fastmri-reproducible-benchmark.
After cloning the repo, `git clone https://github.com/zaccharieramzi/fastmri-reproducible-benchmark`, you can install the package via `pip install fastmri-reproducible-benchmark`.
The framework is TensorFlow.
You can initialize and load the model weights as follows:
```python
import tensorflow as tf
from fastmri_recon.models.subclassed_models.denoisers.proposed_params import get_model_specs
from fastmri_recon.models.subclassed_models.xpdnet import XPDNet
n_primal = 5
model_fun, model_kwargs, n_scales, res = [
(model_fun, kwargs, n_scales, res)
for m_name, m_size, model_fun, kwargs, _, n_scales, res in get_model_specs(n_primal=n_primal, force_res=False)
if m_name == 'MWCNN' and m_size == 'medium'
][0]
model_kwargs['use_bias'] = False
run_params = dict(
n_primal=n_primal,
multicoil=True,
n_scales=n_scales,
refine_smaps=True,
refine_big=True,
res=res,
output_shape_spec=True,
n_iter=25,
)
model = XPDNet(model_fun, model_kwargs, **run_params)
kspace_size = [1, 1, 320, 320]
inputs = [
tf.zeros(kspace_size + [1], dtype=tf.complex64), # kspace
tf.zeros(kspace_size, dtype=tf.complex64), # mask
tf.zeros(kspace_size, dtype=tf.complex64), # smaps
tf.constant([[320, 320]]), # shape
]
model(inputs)
model.load_weights('model_weights.h5')
```
Using the model is then as simple as:
```python
model([
kspace, # shape: [n_slices, n_coils, n_rows, n_cols, 1]
mask, # shape: [n_slices, n_coils, n_rows, n_cols]
smaps, # shape: [n_slices, n_coils, n_rows, n_cols]
shape, # shape: [n_slices, 2]
])
```
## Limitations and bias
The limitations and bias of this model have not been properly investigated.
## Training data
This model was trained using the [fastMRI dataset](https://fastmri.org/dataset/).
## Training procedure
The training procedure is described in https://arxiv.org/abs/2010.07290.
This section is WIP.
## Evaluation results
On the fastMRI validation dataset, the same model with a smaller sensitivity maps refiner gives the following results for 30 validation volumes per contrast:
| Contrast | T1 | T2 | FLAIR | T1-POST |
|----------|--------|--------|--------|---------|
| PSNR | 38.57 | 37.41 | 36.81 | 38.90 |
| SSIM | 0.9348 | 0.9404 | 0.9086 | 0.9517 |
Further results can be seen on the fastMRI leaderboards for the test and challenge dataset: https://fastmri.org/leaderboards/
## Bibtex entry
```
@inproceedings{Ramzi2020d,
archivePrefix = {arXiv},
arxivId = {2010.07290},
author = {Ramzi, Zaccharie and Ciuciu, Philippe and Starck, Jean-Luc},
booktitle = {ISMRM},
eprint = {2010.07290},
pages = {1--4},
title = {{XPDNet for MRI Reconstruction: an application to the 2020 fastMRI challenge}},
url = {http://arxiv.org/abs/2010.07290},
year = {2021}
}
```
|
jcsilva/wav2vec2-base-timit-demo-colab | jcsilva | 2021-12-18T13:45:19Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7665
- Wer: 0.6956
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.052 | 0.8 | 100 | 3.0167 | 1.0 |
| 2.7436 | 1.6 | 200 | 1.9369 | 1.0006 |
| 1.4182 | 2.4 | 300 | 0.7665 | 0.6956 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
flboehm/reddit-bert-text_5 | flboehm | 2021-12-18T12:05:58Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: reddit-bert-text5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# reddit-bert-text5
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5749
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.0257 | 1.0 | 945 | 2.6167 |
| 2.7138 | 2.0 | 1890 | 2.5529 |
| 2.6363 | 3.0 | 2835 | 2.5463 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
s-nlp/rubert-base-corruption-detector | s-nlp | 2021-12-18T09:28:50Z | 22 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"fluency",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language:
- ru
tags:
- fluency
---
This is a model for evaluation of naturalness of short Russian texts. It has been trained to distinguish human-written texts from their corrupted versions.
Corruption sources: random replacement, deletion, addition, shuffling, and re-inflection of words and characters, random changes of capitalization, round-trip translation, filling random gaps with T5 and RoBERTA models. For each original text, we sampled three corrupted texts, so the model is uniformly biased towards the `unnatural` label.
Data sources: web-corpora from [the Leipzig collection](https://wortschatz.uni-leipzig.de/en/download) (`rus_news_2020_100K`, `rus_newscrawl-public_2018_100K`, `rus-ru_web-public_2019_100K`, `rus_wikipedia_2021_100K`), comments from [OK](https://www.kaggle.com/alexandersemiletov/toxic-russian-comments) and [Pikabu](https://www.kaggle.com/blackmoon/russian-language-toxic-comments).
On our private test dataset, the model has achieved 40% rank correlation with human judgements of naturalness, which is higher than GPT perplexity, another popular fluency metric. |
Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10 | Harveenchadha | 2021-12-17T20:14:16Z | 1,400 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"pa",
"arxiv:2107.07402",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
language: pa
#datasets:
#- Interspeech 2021
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
license: mit
model-index:
- name: Wav2Vec2 Vakyansh Punjabi Model by Harveen Chadha
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hi
type: common_voice
args: pa
metrics:
- name: Test WER
type: wer
value: 33.17
---
Fine-tuned on Multilingual Pretrained Model [CLSRIL-23](https://arxiv.org/abs/2107.07402). The original fairseq checkpoint is present [here](https://github.com/Open-Speech-EkStep/vakyansh-models). When using this model, make sure that your speech input is sampled at 16kHz.
**Note: The result from this model is without a language model so you may witness a higher WER in some cases.**
|
Eyvaz/wav2vec2-base-russian-modified-kaggle | Eyvaz | 2021-12-17T18:39:50Z | 5 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
name: wav2vec2-base-russian-modified-kaggle
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-russian-modified-kaggle
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1
- Datasets 1.13.3
- Tokenizers 0.10.3
|
microsoft/unispeech-sat-base-sd | microsoft | 2021-12-17T18:39:23Z | 38 | 0 | transformers | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-frame-classification",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2110.05752",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
datasets:
- librispeech_asr
tags:
- speech
---
# UniSpeech-SAT-Base for Speaker Diarization
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 960 hours of [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [LibriMix dataset](https://github.com/JorisCos/LibriMix) using just a linear layer for mapping the network outputs.
# Usage
## Speaker Diarization
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForAudioFrameClassification
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-base-sd')
model = UniSpeechSatForAudioFrameClassification.from_pretrained('microsoft/unispeech-sat-base-sd')
# audio file is decoded on the fly
inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt")
logits = model(**inputs).logits
probabilities = torch.sigmoid(logits[0])
# labels is a one-hot array of shape (num_frames, num_speakers)
labels = (probabilities > 0.5).long()
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
microsoft/unispeech-sat-large-sv | microsoft | 2021-12-17T18:13:15Z | 240 | 4 | transformers | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-xvector",
"speech",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
datasets:
tags:
- speech
---
# UniSpeech-SAT-Large for Speaker Verification
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) using an X-Vector head with an Additive Margin Softmax loss
[X-Vectors: Robust DNN Embeddings for Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf)
# Usage
## Speaker Verification
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForXVector
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-large-sv')
model = UniSpeechSatForXVector.from_pretrained('microsoft/unispeech-sat-large-sv')
# audio files are decoded on the fly
inputs = feature_extractor(dataset[:2]["audio"]["array"], return_tensors="pt")
embeddings = model(**inputs).embeddings
embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
# the resulting embeddings can be used for cosine similarity-based retrieval
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
similarity = cosine_sim(embeddings[0], embeddings[1])
threshold = 0.89 # the optimal threshold is dataset-dependent
if similarity < threshold:
print("Speakers are not the same!")
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
microsoft/unispeech-sat-base-sv | microsoft | 2021-12-17T18:11:05Z | 200 | 0 | transformers | [
"transformers",
"pytorch",
"unispeech-sat",
"audio-xvector",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2110.05752",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- en
datasets:
- librispeech_asr
tags:
- speech
---
# UniSpeech-SAT-Base for Speaker Verification
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 960 hours of [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) using an X-Vector head with an Additive Margin Softmax loss
[X-Vectors: Robust DNN Embeddings for Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf)
# Usage
## Speaker Verification
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForXVector
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-base-sv')
model = UniSpeechSatForXVector.from_pretrained('microsoft/unispeech-sat-base-sv')
# audio files are decoded on the fly
inputs = feature_extractor(dataset[:2]["audio"]["array"], return_tensors="pt")
embeddings = model(**inputs).embeddings
embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
# the resulting embeddings can be used for cosine similarity-based retrieval
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
similarity = cosine_sim(embeddings[0], embeddings[1])
threshold = 0.86 # the optimal threshold is dataset-dependent
if similarity < threshold:
print("Speakers are not the same!")
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
Guan-Ting/StyleSpeech-MelGAN-vocoder-16kHz | Guan-Ting | 2021-12-17T13:37:11Z | 0 | 5 | null | [
"region:us"
] | null | 2022-03-02T23:29:04Z | ### The MelGAN vocoder for StyleSpeech
#### About StyleSpeech
* StyleSpeech or Meta-StyleSpeech is a model for Multi-Speaker Adaptive Text-to-Speech Generation
* The StyleSpeech model can be trained by official implementation (https://github.com/KevinMIN95/StyleSpeech).
#### About MelGAN vocoder
* This MelGAN vocoder is used to transform the mel-spectrogram back to the waveform.
* StyleSpeech is based on 16k Hz sampling rate, and there is no available 16k Hz multi-speaker vocoder.
* Thus I train this vocoder from scratch using Libri-TTS train-100 hour dataset. The training pipeline is the same as the official MelGAN (https://github.com/descriptinc/melgan-neurips).
* The synthesized sounds are close to the official demo with good quality.
#### Usage
* Please follow the official MelGAN (https://github.com/descriptinc/melgan-neurips) to load pre-trained checkpoint and convert your mel-spectrogram back to the waveform.
#### Training Details
* GPU: RTX 2080Ti
* Training epoch: 3000
|
ivanlau/language-detection-fine-tuned-on-xlm-roberta-base | ivanlau | 2021-12-17T10:33:13Z | 13,130 | 16 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:common_language",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- common_language
metrics:
- accuracy
model-index:
- name: language-detection-fine-tuned-on-xlm-roberta-base
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: common_language
type: common_language
args: full
metrics:
- name: Accuracy
type: accuracy
value: 0.9738386718094919
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# language-detection-fine-tuned-on-xlm-roberta-base
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [common_language](https://huggingface.co/datasets/common_language) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1886
- Accuracy: 0.9738
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.1 | 1.0 | 22194 | 0.1886 | 0.9738 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
### Notebook
[notebook](https://github.com/IvanLauLinTiong/language-detector/blob/main/xlm_roberta_base_commonlanguage_language_detector.ipynb) |
llange/xlm-roberta-large-spanish-clinical | llange | 2021-12-17T10:27:39Z | 3 | 1 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2112.08754",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | # CLIN-X-ES: a pre-trained language model for the Spanish clinical domain
Details on the model, the pre-training corpus and the downstream task performance are given in the paper: "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain" by Lukas Lange, Heike Adel, Jannik Strötgen and Dietrich Klakow.
The paper can be found [here](https://arxiv.org/abs/2112.08754).
In case of questions, please contact the authors as listed on the paper.
Please cite the above paper when reporting, reproducing or extending the results.
@misc{lange-etal-2021-clin-x,
author = {Lukas Lange and
Heike Adel and
Jannik Str{\"{o}}tgen and
Dietrich Klakow},
title = {CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain},
year={2021},
eprint={2112.08754},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2112.08754}
}
## Training details
The model is based on the multilingual XLM-R transformer `(xlm-roberta-large)`, which was trained on 100 languages and showed superior performance in many different tasks across languages and can even outperform monolingual models in certain settings (Conneau et al. 2020).
Even though XLM-R was pre-trained on 53GB of Spanish documents, this was only 2% of the overall training data. To steer this model towards the Spanish clinical domain, we sample documents from the Scielo archive (https://scielo.org/)
and the MeSpEn resources (Villegas et al. 2018). The resulting corpus has a size of 790MB and is highly specific for the clinical domain.
We initialize CLIN-X using the pre-trained XLM-R weights and train masked language modeling (MLM) on the Spanish clinical corpus for 3 epochs which roughly corresponds to 32k steps. This allows researchers and practitioners to address
the Spanish clinical domain with an out-of-the-box tailored model.
## Results for Spanish concept extraction
We apply CLIN-X-ES to five Spanish concept extraction tasks from the clinical domain in a standard sequence labeling architecture similar to Devlin et al. 2019 and compare to a Spanish BERT model called BETO. In addition, we perform experiments with an improved architecture `(+ OurArchitecture)` as described in the paper linked above. The code for our model architecture can be found [here](https://github.com/boschresearch/clin_x).
| | Cantemist | Meddocan | Meddoprof (NER) | Meddoprof (CLASS) | Pharmaconer |
|------------------------------------------|-----------|----------|-----------------|-------------------|-------------|
| BETO (Spanish BERT) | 81.30 | 96.81 | 79.19 | 74.59 | 87.70 |
| CLIN-X (ES) | 83.22 | 97.08 | 79.54 | 76.95 | 90.05 |
| CLIN-X (ES) + OurArchitecture | **88.24** | **98.00** | **81.68** | **80.54** | **92.27** |
### Results for English concept extraction
As the CLIN-X-ES model is based on XLM-R, the model is still multilingual and we demonstrate the positive impact of cross-language domain adaptation by applying this model to five different English sequence labeling tasks from i2b2.
We found that further transfer from related concept extraction is particularly helpful in this cross-language setting. For a detailed description of the transfer process and all other models, we refer to our paper.
| | i2b2 2006 | i2b2 2010 | i2b2 2012 (Concept) | i2b2 2012 (Time) | i2b2 2014 |
|------------------------------------------|-----------|-----------|---------------|---------------|-----------|
| BERT | 94.80 | 85.25 | 76.51 | 75.28 | 94.86 |
| ClinicalBERT | 94.8 | 87.8 | 78.9 | 76.6 | 93.0 |
| CLIN-X (ES) | 95.49 | 87.94 | 79.58 | 77.57 | 96.80 |
| CLIN-X (ES) + OurArchitecture | 98.30 | 89.10 | 80.42 | 78.48 | **97.62** |
| CLIN-X (ES) + OurArchitecture + Transfer | **89.50** | **89.74** | **80.93** | **79.60** | 97.46 |
## Purpose of the project
This software is a research prototype, solely developed for and published as part of the publication cited above. It will neither be maintained nor monitored in any way.
## License
The CLIN-X models are open-sourced under the CC-BY 4.0 license.
See the [LICENSE](LICENSE) file for details. |
llange/xlm-roberta-large-english-clinical | llange | 2021-12-17T10:27:20Z | 44 | 2 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2112.08754",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | # CLIN-X-EN: a pre-trained language model for the English clinical domain
Details on the model, the pre-training corpus and the downstream task performance are given in the paper: "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain" by Lukas Lange, Heike Adel, Jannik Strötgen and Dietrich Klakow.
The paper can be found [here](https://arxiv.org/abs/2112.08754).
In case of questions, please contact the authors as listed on the paper.
Please cite the above paper when reporting, reproducing or extending the results.
@misc{lange-etal-2021-clin-x,
author = {Lukas Lange and
Heike Adel and
Jannik Str{\"{o}}tgen and
Dietrich Klakow},
title = {CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain},
year={2021},
eprint={2112.08754},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2112.08754}
}
## Training details
The model is based on the multilingual XLM-R transformer `(xlm-roberta-large)`, which was trained on 100 languages and showed superior performance in many different tasks across languages and can even outperform monolingual models in certain settings (Conneau et al. 2020).
We train the CLIN-X model on clinical Pubmed abstracts (850MB) filtered
following Haynes et al. (2005). Pubmed is used with the courtesy of the U.S. National Library of Medicine
We initialize CLIN-X using the pre-trained XLM-R weights and train masked language modeling (MLM) on the Spanish clinical corpus for 3 epochs which roughly corresponds to 32k steps. This allows researchers and practitioners to address
the English clinical domain with an out-of-the-box tailored model.
## Results for Spanish concept extraction
We apply CLIN-X-EN to five different English sequence labeling tasks from i2b2 in a standard sequence labeling architecture similar to Devlin et al. 2019 and compare to BERT and ClinicalBERT. In addition, we perform experiments with an improved architecture `(+ OurArchitecture)` as described in the paper linked above. The code for our model architecture can be found [here](https://github.com/boschresearch/clin_x).
| | i2b2 2006 | i2b2 2010 | i2b2 2012 (Concept) | i2b2 2012 (Time) | i2b2 2014 |
|-------------------------------|-----------|-----------|---------------------|------------------|-----------|
| BERT | 94.80 | 82.25 | 76.51 | 75.28 | 94.86 |
| ClinicalBERT | 94.8 | 87.8 | 78.9 | 76.6 | 93.0 |
| CLIN-X (EN) | 96.25 | 88.10 | 79.58 | 77.70 | 96.73 |
| CLIN-X (EN) + OurArchitecture | **98.49** | **89.23** | **80.62** | **78.50** | **97.60** |
## Purpose of the project
This software is a research prototype, solely developed for and published as part of the publication cited above. It will neither be maintained nor monitored in any way.
## License
The CLIN-X models are open-sourced under the CC-BY 4.0 license.
See the [LICENSE](LICENSE) file for details. |
digio/Twitter4SSE | digio | 2021-12-17T09:01:29Z | 17 | 7 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"Pytorch",
"Sentence Transformers",
"Transformers",
"sentence-similarity",
"en",
"arxiv:2110.02030",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
language:
- en
pipeline_tag: sentence-similarity
tags:
- Pytorch
- Sentence Transformers
- Transformers
license: "apache-2.0"
---
# Twitter4SSE
This model maps texts to 768 dimensional dense embeddings that encode semantic similarity.
It was trained with Multiple Negatives Ranking Loss (MNRL) on a Twitter dataset.
It was initialized from [BERTweet](https://huggingface.co/vinai/bertweet-base) and trained with [Sentence-transformers](https://www.sbert.net/).
## Usage
The model is easier to use with sentence-trainsformers library
```
pip install -U sentence-transformers
```
```
from sentence_transformers import SentenceTransformer
sentences = ["This is the first tweet", "This is the second tweet"]
model = SentenceTransformer('digio/Twitter4SSE')
embeddings = model.encode(sentences)
print(embeddings)
```
Without sentence-transfomer library, please refer to [this repository](https://huggingface.co/sentence-transformers) for detailed instructions on how to use Sentence Transformers on Huggingface.
## Citing & Authors
The official paper [Exploiting Twitter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings](https://arxiv.org/abs/2110.02030) will be presented at EMNLP 2021. Further details will be available soon.
```
@inproceedings{di-giovanni-brambilla-2021-exploiting,
title = "Exploiting {T}witter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings",
author = "Di Giovanni, Marco and
Brambilla, Marco",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.780",
pages = "9902--9910",
}
```
The official code is available on [GitHub](https://github.com/marco-digio/Twitter4SSE)
|
jamescalam/bert-stsb-gold | jamescalam | 2021-12-17T08:57:06Z | 2 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# Gold-only BERT STSb
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
It is used as a demo model within the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp), for the chapter on [In-domain Data Augmentation with BERT](https://www.pinecone.io/learn/data-augmentation/).
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('bert-stsb-gold')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('bert-stsb-gold')
model = AutoModel.from_pretrained('bert-stsb-gold')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 360 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 36,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
|
huggingtweets/bladeefan91 | huggingtweets | 2021-12-17T07:39:20Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/bladeefan91/1639726754777/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1470642032851009537/LWrcZk48_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">sweetie p1e</div>
<div style="text-align: center; font-size: 14px;">@bladeefan91</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from sweetie p1e.
| Data | sweetie p1e |
| --- | --- |
| Tweets downloaded | 2249 |
| Retweets | 351 |
| Short tweets | 547 |
| Tweets kept | 1351 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/cacbnxbr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bladeefan91's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2kupw7ab) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2kupw7ab/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bladeefan91')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
tabo/distilbert-base-uncased-finetuned-squad2 | tabo | 2021-12-17T07:22:42Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1606
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2306 | 1.0 | 5533 | 1.1557 |
| 0.9535 | 2.0 | 11066 | 1.1260 |
| 0.7629 | 3.0 | 16599 | 1.1606 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
baffo32/t5-base-ptmap | baffo32 | 2021-12-16T23:38:12Z | 16 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"t5",
"text2text-generation",
"summarization",
"translation",
"en",
"fr",
"ro",
"de",
"dataset:c4",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | translation | 2022-03-02T23:29:05Z | ---
language:
- en
- fr
- ro
- de
datasets:
- c4
tags:
- summarization
- translation
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
Pretraining Dataset: [C4](https://huggingface.co/datasets/c4)
Other Community Checkpoints: [here](https://huggingface.co/models?search=t5)
Paper: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)
Authors: *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*
## Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

|
huggingtweets/musingsofyouth | huggingtweets | 2021-12-16T22:50:23Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/musingsofyouth/1639695018349/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1274909495869804544/3UJtcEdD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Autumn Youth</div>
<div style="text-align: center; font-size: 14px;">@musingsofyouth</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Autumn Youth.
| Data | Autumn Youth |
| --- | --- |
| Tweets downloaded | 3241 |
| Retweets | 89 |
| Short tweets | 129 |
| Tweets kept | 3023 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wunn2a4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @musingsofyouth's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/22xo4w9e) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/22xo4w9e/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/musingsofyouth')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
airKlizz/mt5-small-wikinewssum-test | airKlizz | 2021-12-16T16:18:08Z | 8 | 0 | transformers | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-wikinewssum-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-wikinewssum-test
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9354
- Rouge1: 6.8433
- Rouge2: 2.5498
- Rougel: 5.6114
- Rougelsum: 6.353
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| No log | 1.0 | 661 | 3.2810 | 6.4161 | 2.403 | 5.3674 | 6.0329 |
| No log | 2.0 | 1322 | 3.1515 | 6.9291 | 2.6826 | 5.6839 | 6.4359 |
| No log | 3.0 | 1983 | 3.0565 | 6.7939 | 2.6113 | 5.6133 | 6.3126 |
| No log | 4.0 | 2644 | 2.9815 | 6.0279 | 2.1637 | 4.9892 | 5.5962 |
| No log | 5.0 | 3305 | 2.9645 | 6.3926 | 2.339 | 5.2716 | 5.9443 |
| 3.9937 | 6.0 | 3966 | 2.9476 | 6.4739 | 2.3615 | 5.3473 | 6.0089 |
| 3.9937 | 7.0 | 4627 | 2.9405 | 6.615 | 2.4309 | 5.4493 | 6.1445 |
| 3.9937 | 8.0 | 5288 | 2.9354 | 6.8433 | 2.5498 | 5.6114 | 6.353 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
mateocolina/xlm-roberta-base-finetuned-marc-en | mateocolina | 2021-12-16T14:39:14Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: xlm-roberta-base-finetuned-marc-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9276
- Mae: 0.5366
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0992 | 1.0 | 235 | 0.9340 | 0.5122 |
| 0.945 | 2.0 | 470 | 0.9276 | 0.5366 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
TomO/xlm-roberta-base-finetuned-marc-en | TomO | 2021-12-16T14:31:13Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: xlm-roberta-base-finetuned-marc-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9237
- Mae: 0.5122
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1089 | 1.0 | 235 | 0.9380 | 0.4878 |
| 0.9546 | 2.0 | 470 | 0.9237 | 0.5122 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
NbAiLabArchive/test_w5_long | NbAiLabArchive | 2021-12-16T12:46:14Z | 33 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | Just for performing some experiments. Do not use. |
philschmid/deberta-v3-xsmall-emotion | philschmid | 2021-12-16T12:37:10Z | 3 | 1 | transformers | [
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
model-index:
- name: deberta-v3-xsmall-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.932
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-xsmall-emotion
This model is a fine-tuned version of [microsoft/deberta-v3-xsmall](https://huggingface.co/microsoft/deberta-v3-xsmall) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1877
- Accuracy: 0.932
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3683 | 1.0 | 500 | 0.8479 | 0.6975 |
| 0.547 | 2.0 | 1000 | 0.2881 | 0.905 |
| 0.2378 | 3.0 | 1500 | 0.2116 | 0.925 |
| 0.1704 | 4.0 | 2000 | 0.1877 | 0.932 |
| 0.1392 | 5.0 | 2500 | 0.1718 | 0.9295 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.1
- Datasets 1.15.1
- Tokenizers 0.10.3
|
llange/xlm-roberta-large-spanish | llange | 2021-12-16T11:24:16Z | 16 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | # Spanish XLM-R (from NLNDE-MEDDOPROF)
This Spanish language model was created for the MEDDOPROF shared task as part of the **NLNDE** team submission and outperformed all other participants in both sequence labeling tasks.
Details on the model, the pre-training corpus and the downstream task performance are given in the paper: "Boosting Transformers for Job Expression Extraction and Classification in a Low-Resource Setting" by Lukas Lange, Heike Adel and Jannik Strötgen.
The paper can be found [here](http://ceur-ws.org/Vol-2943/meddoprof_paper1.pdf).
In case of questions, please contact the authors as listed on the paper.
Please cite the above paper when reporting, reproducing or extending the results.
@inproceedings{lange-etal-2021-meddoprof,
author = {Lukas Lange and
Heike Adel and
Jannik Str{\"{o}}tgen},
title = {Boosting Transformers for Job Expression Extraction and Classification in a Low-Resource Setting},
year={2021},
booktitle= {{Proceedings of The Iberian Languages Evaluation Forum (IberLEF 2021)}},
series = {{CEUR} Workshop Proceedings},
url = {http://ceur-ws.org/Vol-2943/meddoprof_paper1.pdf},
}
## Training details
We use XLM-R (`xlm-roberta-large`, Conneau et al. 2020) as the main component of our models. XLM-R is a pretrained multilingual transformer model for 100 languages, including Spanish. It shows superior performance in different tasks across languages, and can even outperform
monolingual models in certain settings. It was pretrained on a large-scale corpus,
and Spanish documents made up only 2% of this data.
Thus, we explore further pretraining of this model and tune it towards Spanish
documents by pretraining a medium-size Spanish corpus with general
domain documents. For this, we use the [spanish corpus](https://github.com/josecannete/spanish-corpora) used to train the BETO model.
We use masked language modeling for pretraining and trained for three epochs
over the corpus, which roughly corresponds to 685k steps using a batch-size of 4.
## Performance
This model was trained in the context of the Meddoprof shared tasks and outperformed all other participants in both sequence labeling tasks. Our results (F1) in comparison with the standard XLM-R and the second-best system of the shared task are given in the Table.
More information on the shared task and other participants is given in this paper [here](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6393/3813).
The code for our NER models can be found [here](https://github.com/boschresearch/nlnde-meddoprof).
| | Meddoprof Task 1 (NER) | Meddoprof Task 2 (CLASS) |
|---------------------------------|------------------------|--------------------------|
| Second-best System | 80.0 | 76.4 |
| XLM-R (our baseline) | 79.2 | 77.6 |
| Our Spanish XLM-R (best System) | **83.2** | **79.1** |
## Purpose of the project
This software is a research prototype, solely developed for and published as part of the publication cited above. It will neither be maintained nor monitored in any way.
## License
The CLIN-X models are open-sourced under the CC-BY 4.0 license.
See the [LICENSE](LICENSE) file for details. |
huggingtweets/ai_hexcrawl | huggingtweets | 2021-12-15T19:46:29Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/ai_hexcrawl/1639597537705/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1467327234365181953/gFho8YCv_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">AI Hexcrawl</div>
<div style="text-align: center; font-size: 14px;">@ai_hexcrawl</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from AI Hexcrawl.
| Data | AI Hexcrawl |
| --- | --- |
| Tweets downloaded | 1164 |
| Retweets | 42 |
| Short tweets | 2 |
| Tweets kept | 1120 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/vdxugbwr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ai_hexcrawl's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/r9ejkubu) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/r9ejkubu/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ai_hexcrawl')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Jeska/VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly09 | Jeska | 2021-12-15T16:50:47Z | 16 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly09
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly09
This model is a fine-tuned version of [outputDAQonly09/](https://huggingface.co/outputDAQonly09/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4978
- Accuracy: 0.9031
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 330 | 3.9692 | 0.2249 |
| 4.3672 | 2.0 | 660 | 3.1312 | 0.4031 |
| 4.3672 | 3.0 | 990 | 2.5068 | 0.5658 |
| 3.1495 | 4.0 | 1320 | 2.0300 | 0.6600 |
| 2.2491 | 5.0 | 1650 | 1.6517 | 0.7450 |
| 2.2491 | 6.0 | 1980 | 1.3604 | 0.7943 |
| 1.622 | 7.0 | 2310 | 1.1328 | 0.8327 |
| 1.1252 | 8.0 | 2640 | 0.9484 | 0.8611 |
| 1.1252 | 9.0 | 2970 | 0.8212 | 0.8757 |
| 0.7969 | 10.0 | 3300 | 0.7243 | 0.8830 |
| 0.5348 | 11.0 | 3630 | 0.6597 | 0.8867 |
| 0.5348 | 12.0 | 3960 | 0.5983 | 0.8857 |
| 0.3744 | 13.0 | 4290 | 0.5635 | 0.8976 |
| 0.2564 | 14.0 | 4620 | 0.5437 | 0.8985 |
| 0.2564 | 15.0 | 4950 | 0.5124 | 0.9013 |
| 0.1862 | 16.0 | 5280 | 0.5074 | 0.9022 |
| 0.1349 | 17.0 | 5610 | 0.5028 | 0.9049 |
| 0.1349 | 18.0 | 5940 | 0.4876 | 0.9077 |
| 0.0979 | 19.0 | 6270 | 0.4971 | 0.9049 |
| 0.0763 | 20.0 | 6600 | 0.4941 | 0.9022 |
| 0.0763 | 21.0 | 6930 | 0.4957 | 0.9049 |
| 0.0602 | 22.0 | 7260 | 0.4989 | 0.9049 |
| 0.0504 | 23.0 | 7590 | 0.4959 | 0.9040 |
| 0.0504 | 24.0 | 7920 | 0.4944 | 0.9031 |
| 0.0422 | 25.0 | 8250 | 0.4985 | 0.9040 |
| 0.0379 | 26.0 | 8580 | 0.4970 | 0.9049 |
| 0.0379 | 27.0 | 8910 | 0.4949 | 0.9040 |
| 0.0351 | 28.0 | 9240 | 0.4971 | 0.9040 |
| 0.0321 | 29.0 | 9570 | 0.4967 | 0.9031 |
| 0.0321 | 30.0 | 9900 | 0.4978 | 0.9031 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
NbAiLabArchive/test_w7 | NbAiLabArchive | 2021-12-15T14:14:41Z | 3 | 0 | transformers | [
"transformers",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | Just for performing some experiments. Do not use. |
harshit345/xlsr-53-wav2vec-greek | harshit345 | 2021-12-15T13:13:37Z | 4 | 1 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"el",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language: el
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: V XLSR Wav2Vec2 Large 53 - greek
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice el
type: common_voice
args: el
metrics:
- name: Test WER
type: wer
value: 18.996669
- name: Test CER
type: cer
value: 5.781874
---
# Wav2Vec2-Large-XLSR-53-greek
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on greek using the [Common Voice](https://huggingface.co/datasets/common_voice) and [CSS10 Greek: Single Speaker Speech Dataset](https://www.kaggle.com/bryanpark/greek-single-speaker-speech-dataset).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "el", split="test[:2%]") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
processor = Wav2Vec2Processor.from_pretrained("vasilis/wav2vec2-large-xlsr-53-greek") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model = Wav2Vec2ForCTC.from_pretrained("vasilis/wav2vec2-large-xlsr-53-greek") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
| Reference | Prediction |
| ------------- | ------------- |
| ΤΟ ΒΑΣΙΛΌΠΟΥΛΟ, ΠΟΥ ΜΟΙΆΖΕΙ ΛΕΟΝΤΑΡΆΚΙ ΚΑΙ ΑΕΤΟΥΔΆΚΙ | ΤΟ ΒΑΣΙΛΌΠΟΥΛΟ ΠΟΥ ΜΙΑΣΕ ΛΙΟΝΤΑΡΑΚΉ ΚΑΙ ΑΪΤΟΥΔΆΚΙ |
| ΣΥΝΆΜΑ ΞΕΠΡΌΒΑΛΑΝ ΑΠΌ ΜΈΣΑ ΑΠΌ ΤΑ ΔΈΝΤΡΑ, ΔΕΞΙΆ, ΑΡΜΑΤΩΜΈΝΟΙ ΚΑΒΑΛΑΡΈΟΙ. | ΣΥΝΆΜΑ ΚΑΙ ΤΡΌΒΑΛΑΝ ΑΠΌ ΜΈΣΑ ΑΠΌ ΤΑ ΔΈΝΤΡΑ ΔΕΞΙΆ ΑΡΜΑΤΩΜΈΝΟΙ ΚΑΒΑΛΑΡΈΟΙ |
| ΤΑ ΣΥΣΚΕΥΑΣΜΈΝΑ ΒΙΟΛΟΓΙΚΆ ΛΑΧΑΝΙΚΆ ΔΕΝ ΠΕΡΙΈΧΟΥΝ ΣΥΝΤΗΡΗΤΙΚΆ ΚΑΙ ΟΡΜΌΝΕΣ | ΤΑ ΣΥΣΚΕΦΑΣΜΈΝΑ ΒΙΟΛΟΓΙΚΆ ΛΑΧΑΝΙΚΆ ΔΕΝ ΠΕΡΙΈΧΟΥΝ ΣΙΔΗΡΗΤΙΚΆ ΚΑΙ ΟΡΜΌΝΕΣ |
| ΑΚΟΛΟΥΘΉΣΕΤΕ ΜΕ! | ΑΚΟΛΟΥΘΉΣΤΕ ΜΕ |
| ΚΑΙ ΠΟΎ ΜΠΟΡΏ ΝΑ ΤΟΝ ΒΡΩ; | Ε ΠΟΎ ΜΠΟΡΏ ΝΑ ΤΙ ΕΒΡΩ |
| ΝΑΙ! ΑΠΟΚΡΊΘΗΚΕ ΤΟ ΠΑΙΔΊ | ΝΑΙ ΑΠΟΚΡΊΘΗΚΕ ΤΟ ΠΑΙΔΊ |
| ΤΟ ΠΑΛΆΤΙ ΜΟΥ ΤΟ ΠΡΟΜΉΘΕΥΕ. | ΤΟ ΠΑΛΆΤΙ ΜΟΥ ΤΟ ΠΡΟΜΉΘΕΥΕ |
| ΉΛΘΕ ΜΉΝΥΜΑ ΑΠΌ ΤΟ ΘΕΊΟ ΒΑΣΙΛΙΆ; | ΉΛΘΑ ΜΕΊΝΕΙ ΜΕ ΑΠΌ ΤΟ ΘΕΊΟ ΒΑΣΊΛΙΑ |
| ΠΑΡΑΚΆΤΩ, ΈΝΑ ΡΥΆΚΙ ΜΟΥΡΜΟΎΡΙΖΕ ΓΛΥΚΆ, ΚΥΛΏΝΤΑΣ ΤΑ ΚΡΥΣΤΑΛΛΈΝΙΑ ΝΕΡΆ ΤΟΥ ΑΝΆΜΕΣΑ ΣΤΑ ΠΥΚΝΆ ΧΑΜΌΔΕΝΤΡΑ. | ΠΑΡΑΚΆΤΩ ΈΝΑ ΡΥΆΚΙ ΜΟΥΡΜΟΎΡΙΖΕ ΓΛΥΚΆ ΚΥΛΏΝΤΑΣ ΤΑ ΚΡΥΣΤΑΛΛΈΝΙΑ ΝΕΡΆ ΤΟΥ ΑΝΆΜΕΣΑ ΣΤΑ ΠΥΚΡΆ ΧΑΜΌΔΕΝΤΡΑ |
| ΠΡΆΓΜΑΤΙ, ΕΊΝΑΙ ΑΣΤΕΊΟ ΝΑ ΠΆΡΕΙ Ο ΔΙΆΒΟΛΟΣ | ΠΡΆΓΜΑΤΗ ΕΊΝΑΙ ΑΣΤΕΊΟ ΝΑ ΠΆΡΕΙ Ο ΔΙΆΒΟΛΟΣ |
## Evaluation
The model can be evaluated as follows on the greek test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "el", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("vasilis/wav2vec2-large-xlsr-53-greek") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model = Wav2Vec2ForCTC.from_pretrained("vasilis/wav2vec2-large-xlsr-53-greek") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]' # TODO: adapt this list to include all special characters you removed from the data
normalize_greek_letters = {"ς": "σ"}
# normalize_greek_letters = {"ά": "α", "έ": "ε", "ί": "ι", 'ϊ': "ι", "ύ": "υ", "ς": "σ", "ΐ": "ι", 'ϋ': "υ", "ή": "η", "ώ": "ω", 'ό': "ο"}
remove_chars_greek = {"a": "", "h": "", "n": "", "g": "", "o": "", "v": "", "e": "", "r": "", "t": "", "«": "", "»": "", "m": "", '́': '', "·": "", "’": "", '´': ""}
replacements = {**normalize_greek_letters, **remove_chars_greek}
resampler = {
48_000: torchaudio.transforms.Resample(48_000, 16_000),
44100: torchaudio.transforms.Resample(44100, 16_000),
32000: torchaudio.transforms.Resample(32000, 16_000)
}
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
for key, value in replacements.items():
batch["sentence"] = batch["sentence"].replace(key, value)
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler[sampling_rate](speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}".format(100 * wer.compute(predictions=[" ".join(list(entry)) for entry in result["pred_strings"]], references=[" ".join(list(entry)) for entry in result["sentence"]])))
```
**Test Result**: 18.996669 %
## Training
The Common Voice train dataset was used for training. Also all of `CSS10 Greek` was used using the normalized transcripts.
During text preprocessing letter `ς` is normalized to `σ` the reason is that both letters sound the same with `ς` only used as the ending character of words. So, the change can be mapped up to proper dictation easily. I tried removing all accents from letters as well that improved `WER` significantly. The model was reaching `17%` WER easily without having converged. However, the text preprocessing needed to do after to fix transcrtiptions would be more complicated. A language model should fix things easily though. Another thing that could be tried out would be to change all of `ι`, `η` ... etc to a single character since all sound the same. similar for `o` and `ω` these should help the acoustic model part significantly since all these characters map to the same sound. But further text normlization would be needed.
|
tlanfer/arc | tlanfer | 2021-12-15T12:14:18Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
title: ArcaneGAN
emoji: 🚀
colorFrom: blue
colorTo: blue
sdk: gradio
app_file: app.py
pinned: false
---
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio` or `streamlit`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
Path is relative to the root of the repository.
`pinned`: _boolean_
Whether the Space stays on top of your list. |
MMG/bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad | MMG | 2021-12-15T12:03:20Z | 32 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"es",
"dataset:squad_es",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_trainer
datasets:
- squad_es
model-index:
- name: bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad
results: []
language:
- es
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-spanish-wwm-cased-finetuned-sqac-finetuned-squad
This model is a fine-tuned version of [MMG/bert-base-spanish-wwm-cased-finetuned-sqac](https://huggingface.co/MMG/bert-base-spanish-wwm-cased-finetuned-sqac) on the squad_es dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5325
- {'exact_match': 60.30274361400189, 'f1': 77.01962587890856}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
honeyd3wy/kobart-titlenaming-v0.1 | honeyd3wy | 2021-12-15T11:44:58Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ```python
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
model = BartForConditionalGeneration.from_pretrained('honeyd3wy/kobart-titlenaming-v0.1')
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v2')
``` |
aXhyra/presentation_hate_1234567 | aXhyra | 2021-12-15T11:31:02Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_hate_1234567
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7679568806891273
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_hate_1234567
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8438
- F1: 0.7680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.436235805743952e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 1234567
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6027 | 1.0 | 282 | 0.5186 | 0.7209 |
| 0.3537 | 2.0 | 564 | 0.4989 | 0.7619 |
| 0.0969 | 3.0 | 846 | 0.6405 | 0.7697 |
| 0.0514 | 4.0 | 1128 | 0.8438 | 0.7680 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/presentation_hate_31415 | aXhyra | 2021-12-15T11:24:57Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_hate_31415
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7729508817074093
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_hate_31415
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8632
- F1: 0.7730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.436235805743952e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 31415
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.363 | 1.0 | 282 | 0.4997 | 0.7401 |
| 0.2145 | 2.0 | 564 | 0.5071 | 0.7773 |
| 0.1327 | 3.0 | 846 | 0.7109 | 0.7645 |
| 0.0157 | 4.0 | 1128 | 0.8632 | 0.7730 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/presentation_hate_42 | aXhyra | 2021-12-15T11:18:17Z | 15 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_hate_42
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7692074096568478
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_hate_42
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8711
- F1: 0.7692
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.436235805743952e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5207 | 1.0 | 282 | 0.4815 | 0.7513 |
| 0.3047 | 2.0 | 564 | 0.5557 | 0.7510 |
| 0.2335 | 3.0 | 846 | 0.6627 | 0.7585 |
| 0.0056 | 4.0 | 1128 | 0.8711 | 0.7692 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/presentation_emotion_42 | aXhyra | 2021-12-15T10:36:30Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_emotion_42
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: emotion
metrics:
- name: F1
type: f1
value: 0.732897530282475
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_emotion_42
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0989
- F1: 0.7329
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.18796906442746e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3703 | 1.0 | 408 | 0.6624 | 0.7029 |
| 0.2122 | 2.0 | 816 | 0.6684 | 0.7258 |
| 0.9452 | 3.0 | 1224 | 1.0001 | 0.7041 |
| 0.0023 | 4.0 | 1632 | 1.0989 | 0.7329 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Azuris/DialoGPT-medium-senorita | Azuris | 2021-12-15T10:31:51Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:04Z | ---
tags:
- conversational
---
|
aXhyra/presentation_irony_42 | aXhyra | 2021-12-15T10:10:19Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_irony_42
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: irony
metrics:
- name: F1
type: f1
value: 0.6745358521762839
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_irony_42
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9344
- F1: 0.6745
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.1637764704815665e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6675 | 1.0 | 90 | 0.5988 | 0.6684 |
| 0.5872 | 2.0 | 180 | 0.6039 | 0.6742 |
| 0.3953 | 3.0 | 270 | 0.8549 | 0.6557 |
| 0.0355 | 4.0 | 360 | 0.9344 | 0.6745 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
hiiamsid/hit5-base | hiiamsid | 2021-12-15T04:12:27Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"hindi",
"hi",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
language: ["hi"]
tags:
- hindi
license: mit
---
This is a smaller version of the [google/mt5-base](https://huggingface.co/google/mt5-base) model with only hindi embeddings left.
* The original model has 582M parameters, with 237M of them being input and output embeddings.
* After shrinking the `sentencepiece` vocabulary from 250K to 25K (top 25K Hindi tokens) the number of model parameters reduced to 237M parameters, and model size reduced from 2.2GB to 0.9GB - 42% of the original one.
## Citing & Authors
- Model : [google/mt5-base](https://huggingface.co/google/mt5-base)
- Reference: [cointegrated/rut5-base](https://huggingface.co/cointegrated/rut5-base) |
huggingtweets/cabelobssb | huggingtweets | 2021-12-15T02:29:00Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/cabelobssb/1639535335803/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1221820584570519552/G_6GC8Em_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Cabelob</div>
<div style="text-align: center; font-size: 14px;">@cabelobssb</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Cabelob.
| Data | Cabelob |
| --- | --- |
| Tweets downloaded | 3158 |
| Retweets | 303 |
| Short tweets | 300 |
| Tweets kept | 2555 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2u8zt14c/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @cabelobssb's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2r13iux3) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2r13iux3/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/cabelobssb')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Elron/bleurt-large-512 | Elron | 2021-12-15T01:57:26Z | 2,480 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | ## BLEURT
Pytorch version of the original BLEURT models from ACL paper ["BLEURT: Learning Robust Metrics for Text Generation"](https://aclanthology.org/2020.acl-main.704/) by
Thibault Sellam, Dipanjan Das and Ankur P. Parikh of Google Research.
The code for model conversion was originated from [this notebook](https://colab.research.google.com/drive/1KsCUkFW45d5_ROSv2aHtXgeBa2Z98r03?usp=sharing) mentioned [here](https://github.com/huggingface/datasets/issues/224).
## Usage Example
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("Elron/bleurt-large-512")
model = AutoModelForSequenceClassification.from_pretrained("Elron/bleurt-large-512")
model.eval()
references = ["hello world", "hello world"]
candidates = ["hi universe", "bye world"]
with torch.no_grad():
scores = model(**tokenizer(references, candidates, return_tensors='pt'))[0].squeeze()
print(scores) # tensor([0.9877, 0.0475])
```
|
huggingtweets/anvers1158 | huggingtweets | 2021-12-15T01:08:56Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/anvers1158/1639530531829/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1305932428607922177/Rh6HaRlW_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">YugenSSBU</div>
<div style="text-align: center; font-size: 14px;">@anvers1158</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from YugenSSBU.
| Data | YugenSSBU |
| --- | --- |
| Tweets downloaded | 257 |
| Retweets | 16 |
| Short tweets | 19 |
| Tweets kept | 222 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2qmptuy4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @anvers1158's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2erdua3k) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2erdua3k/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/anvers1158')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
aXhyra/presentation_sentiment_1234567 | aXhyra | 2021-12-14T23:23:42Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_sentiment_1234567
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: sentiment
metrics:
- name: F1
type: f1
value: 0.71829420028644
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_sentiment_1234567
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0860
- F1: 0.7183
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.2792011721188e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.3747 | 1.0 | 11404 | 0.6515 | 0.7045 |
| 0.6511 | 2.0 | 22808 | 0.7334 | 0.7188 |
| 0.0362 | 3.0 | 34212 | 0.9498 | 0.7195 |
| 1.0576 | 4.0 | 45616 | 1.0860 | 0.7183 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
aXhyra/presentation_sentiment_31415 | aXhyra | 2021-12-14T22:46:29Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: presentation_sentiment_31415
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: sentiment
metrics:
- name: F1
type: f1
value: 0.71829420028644
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# presentation_sentiment_31415
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0860
- F1: 0.7183
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.2792011721188e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.3747 | 1.0 | 11404 | 0.6515 | 0.7045 |
| 0.6511 | 2.0 | 22808 | 0.7334 | 0.7188 |
| 0.0362 | 3.0 | 34212 | 0.9498 | 0.7195 |
| 1.0576 | 4.0 | 45616 | 1.0860 | 0.7183 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Kookly/Kooklybots | Kookly | 2021-12-14T22:08:04Z | 0 | 0 | null | [
"region:us"
] | null | 2022-03-02T23:29:04Z | from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("r3dhummingbird/DialoGPT-medium-joshua")
model = AutoModelForCausalLM.from_pretrained("r3dhummingbird/DialoGPT-medium-joshua") |
ssmadha/gpt2-finetuned-scientific-articles | ssmadha | 2021-12-14T20:47:55Z | 21 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-finetuned-scientific-articles
results: []
---
This repository is the submission for the final project for BF510 [Institutional Racism in Health and Science](http://irhs.bu.edu/) for Shariq Madha.
To see Jupyter detailing how this model was produced, as well as the motivation behind it, go [here](https://github.com/ssmadha/BF510-final-project/).
To try this out yourself, enter a prompt in the textbox to the right and hit compute (it may take a minute for the first to process, but subsequent results should be quick).
# gpt2-finetuned-scientific-articles
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on scientific articles about algorithmic bias.
It achieves the following results on the evaluation set:
- Loss: 2.3793
## Model description
This model is a casual language modeling GPT2 fine-tuned on scientific articles about algorithmic bias, in an attempt to showcase an example about correcting for algorithmic bias.
## Intended uses & limitations
This model is intended for prompts about algorithms and bias. Other prompts will yield results, but they are less likely to be influenced by the fine-tuning.
## Training and evaluation data
This model is trained on fully freely accessible articles obtained from a PubMed Central search on algorithmic bias. The pmc_result_algorithmicbias.txt file contains the list of PMC's used. Due to technical and time limitations, only fine-tuned on the introduction sections, but training on other sections is planned.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5293 | 1.0 | 1071 | 2.3892 |
| 2.4821 | 2.0 | 2142 | 2.3793 |
### Framework versions
- Transformers 4.14.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.10.3
|
svsokol/opus-mt-ru-en-finetuned-en-to-ru | svsokol | 2021-12-14T19:53:09Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"dataset:wmt16",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
model-index:
- name: opus-mt-ru-en-finetuned-en-to-ru
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-ru-en-finetuned-en-to-ru
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ru-en](https://huggingface.co/Helsinki-NLP/opus-mt-ru-en) on the wmt16 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Rocketknight1/test-model-tf | Rocketknight1 | 2021-12-14T19:25:51Z | 4 | 0 | transformers | [
"transformers",
"tf",
"bert",
"feature-extraction",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2022-03-02T23:29:04Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: test-model-tf
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# test-model-tf
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.14.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
S34NtheGuy/DialoGPT-medium-Mona | S34NtheGuy | 2021-12-14T18:49:19Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:04Z | ---
tags:
- conversational
---
# DialoGPT chat bot model using discord messages as data |
evandrodiniz/autonlp-api-boamente-417310793 | evandrodiniz | 2021-12-14T18:39:10Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"unk",
"dataset:evandrodiniz/autonlp-data-api-boamente",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- evandrodiniz/autonlp-data-api-boamente
co2_eq_emissions: 9.446754273734577
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 417310793
- CO2 Emissions (in grams): 9.446754273734577
## Validation Metrics
- Loss: 0.25755178928375244
- Accuracy: 0.9407114624505929
- Precision: 0.8600823045267489
- Recall: 0.95
- AUC: 0.9732501264968797
- F1: 0.9028077753779697
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/evandrodiniz/autonlp-api-boamente-417310793
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("evandrodiniz/autonlp-api-boamente-417310793", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("evandrodiniz/autonlp-api-boamente-417310793", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
evandrodiniz/autonlp-api-boamente-417310788 | evandrodiniz | 2021-12-14T18:38:02Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"unk",
"dataset:evandrodiniz/autonlp-data-api-boamente",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- evandrodiniz/autonlp-data-api-boamente
co2_eq_emissions: 6.826886567147602
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 417310788
- CO2 Emissions (in grams): 6.826886567147602
## Validation Metrics
- Loss: 0.20949310064315796
- Accuracy: 0.9578392621870883
- Precision: 0.9476190476190476
- Recall: 0.9045454545454545
- AUC: 0.9714032720526227
- F1: 0.9255813953488372
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/evandrodiniz/autonlp-api-boamente-417310788
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("evandrodiniz/autonlp-api-boamente-417310788", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("evandrodiniz/autonlp-api-boamente-417310788", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
huggingtweets/_luisinhobr-bryan_paula_-luanaguei | huggingtweets | 2021-12-14T18:17:37Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/_luisinhobr-bryan_paula_-luanaguei/1639505852811/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1390224220643278850/LcIZLss-_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1407505852580442113/U6iWBRLs_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1459704723506872320/gLulTAzG_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">luisfer nando & Dj Cigarro Solto & ajax de uva verde</div>
<div style="text-align: center; font-size: 14px;">@_luisinhobr-bryan_paula_-luanaguei</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from luisfer nando & Dj Cigarro Solto & ajax de uva verde.
| Data | luisfer nando | Dj Cigarro Solto | ajax de uva verde |
| --- | --- | --- | --- |
| Tweets downloaded | 2313 | 3232 | 2237 |
| Retweets | 351 | 645 | 467 |
| Short tweets | 492 | 586 | 598 |
| Tweets kept | 1470 | 2001 | 1172 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/39qoxauq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_luisinhobr-bryan_paula_-luanaguei's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/30onq8vd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/30onq8vd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_luisinhobr-bryan_paula_-luanaguei')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Rocketknight1/model-card-callback-test-new | Rocketknight1 | 2021-12-14T17:49:02Z | 11 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Rocketknight1/model-card-callback-test-new
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Rocketknight1/model-card-callback-test-new
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0031
- Train Accuracy: 1.0
- Validation Loss: 0.0000
- Validation Accuracy: 1.0
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.4647 | 0.6406 | 0.0057 | 1.0 | 0 |
| 0.0031 | 1.0 | 0.0000 | 1.0 | 1 |
### Framework versions
- Transformers 4.14.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
huggingtweets/lucca | huggingtweets | 2021-12-14T17:24:28Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/lucca/1639502663568/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1453506838608191495/27SY-TWi_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">lucca</div>
<div style="text-align: center; font-size: 14px;">@lucca</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from lucca.
| Data | lucca |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 43 |
| Short tweets | 718 |
| Tweets kept | 2486 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3u9l56fn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @lucca's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/qxkw0i4f) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/qxkw0i4f/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/lucca')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
algolet/bert-large-chinese | algolet | 2021-12-14T10:00:38Z | 45 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | <p>Chinese Bert Large Model</p>
<p>bert large中文预训练模型</p>
#### 训练语料
中文wiki, 2018-2020海量新闻语料 |
juliusco/distilbert-base-uncased-finetuned-covdistilbert | juliusco | 2021-12-14T09:08:34Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:covid_qa_deepset",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- covid_qa_deepset
model-index:
- name: distilbert-base-uncased-finetuned-covdistilbert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-covdistilbert
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the covid_qa_deepset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 457 | 0.5125 |
| 0.5146 | 2.0 | 914 | 0.4843 |
| 0.2158 | 3.0 | 1371 | 0.4492 |
| 0.1639 | 4.0 | 1828 | 0.4760 |
| 0.1371 | 5.0 | 2285 | 0.4844 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
|
huggingtweets/alterhuss-zainabverse | huggingtweets | 2021-12-14T07:46:28Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1467618648961527812/jtH0RZpT_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1468367771746672643/21w6R4SP_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Alter Huss & Zainab</div>
<div style="text-align: center; font-size: 14px;">@alterhuss-zainabverse</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Alter Huss & Zainab.
| Data | Alter Huss | Zainab |
| --- | --- | --- |
| Tweets downloaded | 3229 | 3246 |
| Retweets | 125 | 95 |
| Short tweets | 1004 | 426 |
| Tweets kept | 2100 | 2725 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/8ibzokov/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @alterhuss-zainabverse's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3d8wr9hg) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3d8wr9hg/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/alterhuss-zainabverse')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Subsets and Splits