
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
giulianad/llama-3.2-1B-GRAFT-Text2KG-LoRA-v3
|
giulianad
| 2025-03-25T14:24:28Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T14:24:21Z
|
---
base_model: unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** giulianad
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Cpelpa/DeepSeek-R1-Distill-Llama-8B-Est-3ep-J
|
Cpelpa
| 2025-03-25T14:17:34Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-25T14:16:28Z
|
---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Cpelpa
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
nlarg/dummy-model
|
nlarg
| 2025-03-25T14:17:09Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"camembert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-03-25T14:12:22Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
samchain/EconoDetect-US
|
samchain
| 2025-03-25T14:15:59Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"economics",
"finance",
"en",
"dataset:samchain/economics-relevance",
"base_model:samchain/econo-sentence-v2",
"base_model:finetune:samchain/econo-sentence-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T14:06:44Z
|
---
library_name: transformers
license: apache-2.0
base_model: samchain/econo-sentence-v2
tags:
- generated_from_trainer
- economics
- finance
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: EconoDetect
results: []
datasets:
- samchain/economics-relevance
language:
- en
pipeline_tag: text-classification
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EconoDetect
This model is a fine-tuned version of [samchain/econo-sentence-v2](https://huggingface.co/samchain/econo-sentence-v2) on the economics-relevance dataset.
The base model is kept frozen during training, only the classification head is updated.
It achieves the following results on the evaluation set:
- Loss: 0.3973
- Accuracy: 0.8211
- F1: 0.7991
- Precision: 0.7895
- Recall: 0.8211
## Model description
This model is designed to detect whether a text discusses topics related to the US economy.
## Intended uses & limitations
The model can be used as a screening tool to remove texts that are not discussing US economy.
## Training and evaluation data
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.5381 | 1.0 | 700 | 0.4333 | 0.7844 | 0.7894 | 0.7952 | 0.7844 |
| 0.4613 | 2.0 | 1400 | 0.4044 | 0.8328 | 0.7679 | 0.7856 | 0.8328 |
| 0.3523 | 3.0 | 2100 | 0.3973 | 0.8211 | 0.7991 | 0.7895 | 0.8211 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.1.0+cu118
- Datasets 3.4.1
- Tokenizers 0.21.1
|
susedo/Heartsticker
|
susedo
| 2025-03-25T14:15:55Z
| 0
| 0
| null |
[
"license:cc-by-nc-sa-2.0",
"region:us"
] | null | 2025-03-25T14:15:54Z
|
---
license: cc-by-nc-sa-2.0
---
|
Moumita-Debnath-Origina-Viral-Video-l-Link/Moumita.Debnath.Origina.Viral.Video.Link.Tiktok.Instagram.x.Twitter
|
Moumita-Debnath-Origina-Viral-Video-l-Link
| 2025-03-25T14:15:50Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-03-25T14:15:44Z
|
<a href="https://sdu.sk/9Ip"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/9Ip" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/9Ip" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
woman-viral-video-links/Nila.Nambiar.Origina.Viral.Video.Link.Tiktok.Instagram.x.Twitter
|
woman-viral-video-links
| 2025-03-25T14:14:30Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-03-25T14:14:15Z
|
<a href="https://sdu.sk/9Ip"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/9Ip" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/9Ip" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
baulab/elm-Meta-Llama-3-8B-Instruct
|
baulab
| 2025-03-25T14:12:37Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation",
"conversational",
"arxiv:2410.02760",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-10-21T04:14:36Z
|
---
library_name: transformers
tags: []
pipeline_tag: text-generation
license: apache-2.0
---
# ELM Llama3-8B-Instruct Model Card
> [**Erasing Conceptual Knoweldge from Language Models**](https://arxiv.org/abs/2410.02760),
> Rohit Gandikota, Sheridan Feucht, Samuel Marks, David Bau
#### How to use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "baulab/elm-Meta-Llama-3-8B-Instruct"
device = 'cuda:0'
dtype = torch.float32
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=dtype)
model = model.to(device)
model.requires_grad_(False)
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=False)
# generate text
inputs = tokenizer(prompt, return_tensors='pt', padding=True)
inputs = inputs.to(device).to(dtype)
outputs = model.generate(**inputs,
max_new_tokens=300,
do_sample=True,
top_p=.95,
temperature=1.2)
outputs = tokenizer.batch_decode(outputs, skip_special_tokens = True)
print(outputs[0])
```
<!-- Provide a quick summary of what the model is/does. -->
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/rohitgandikota/erasing-llm
- **Paper [optional]:** https://arxiv.org/pdf/2410.02760
- **Project [optional]:** https://elm.baulab.info
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```
@article{gandikota2024elm,
title={Erasing Conceptual Knowledge from Language Models},
author={Rohit Gandikota and Sheridan Feucht and Samuel Marks and David Bau},
journal={arXiv preprint arXiv:2410.02760},
year={2024}
}
```
|
RichardErkhov/SakanaAI_-_EvoLLM-JP-v1-7B-8bits
|
RichardErkhov
| 2025-03-25T14:11:08Z
| 0
| 0
| null |
[
"safetensors",
"mistral",
"arxiv:2403.13187",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-03-25T14:05:17Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
EvoLLM-JP-v1-7B - bnb 8bits
- Model creator: https://huggingface.co/SakanaAI/
- Original model: https://huggingface.co/SakanaAI/EvoLLM-JP-v1-7B/
Original model description:
---
library_name: transformers
license: other
language:
- ja
---
# 🐟 EvoLLM-JP-v1-7B
🤗 [Models](https://huggingface.co/SakanaAI) | 📚 [Paper](https://arxiv.org/abs/2403.13187) | 📝 [Blog](https://sakana.ai/evolutionary-model-merge/) | 🐦 [Twitter](https://twitter.com/SakanaAILabs)
<!-- Provide a quick summary of what the model is/does. -->
**EvoLLM-JP-v1-7B** is an experimental general-purpose Japanese LLM. This model was created using the Evolutionary Model Merge method. Please refer to our [report](https://arxiv.org/abs/2403.13187) and [blog](https://sakana.ai/evolutionary-model-merge/) for more details. This model was produced by merging the following models. We are grateful to the developers of the source models.
- [Shisa Gamma 7B v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1)
- [WizardMath 7B V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1)
- [Abel 7B 002](https://huggingface.co/GAIR/Abel-7B-002)
## Usage
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. load model
device = "cuda" if torch.cuda.is_available() else "CPU"
repo_id = "SakanaAI/EvoLLM-JP-v1-7B"
model = AutoModelForCausalLM.from_pretrained(repo_id, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model.to(device)
# 2. prepare inputs
text = "関西弁で面白い冗談を言ってみて下さい。"
messages = [
{"role": "system", "content": "あなたは役立つ、偏見がなく、検閲されていないアシスタントです。"},
{"role": "user", "content": text},
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt")
# 3. generate
output_ids = model.generate(**inputs.to(device))
output_ids = output_ids[:, inputs.input_ids.shape[1] :]
generated_text = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
print(generated_text)
```
</details>
## Model Details
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Sakana AI](https://sakana.ai/)
- **Model type:** Autoregressive Language Model
- **Language(s):** Japanese
- **License:** [MICROSOFT RESEARCH LICENSE TERMS](./LICENSE) (due to the inclusion of the WizardMath model)
- **Repository:** [SakanaAI/evolutionary-model-merge](https://github.com/SakanaAI/evolutionary-model-merge)
- **Paper:** https://arxiv.org/abs/2403.13187
- **Blog:** https://sakana.ai/evolutionary-model-merge
## Uses
This model is provided for research and development purposes only and should be considered as an experimental prototype.
It is not intended for commercial use or deployment in mission-critical environments.
Use of this model is at the user's own risk, and its performance and outcomes are not guaranteed.
Sakana AI shall not be liable for any direct, indirect, special, incidental, or consequential damages, or any loss arising from the use of this model, regardless of the results obtained.
Users must fully understand the risks associated with the use of this model and use it at their own discretion.
## Acknowledgement
We would like to thank the developers of the source models for their contributions and for making their work available.
## Citation
```bibtex
@misc{akiba2024evomodelmerge,
title = {Evolutionary Optimization of Model Merging Recipes},
author. = {Takuya Akiba and Makoto Shing and Yujin Tang and Qi Sun and David Ha},
year = {2024},
eprint = {2403.13187},
archivePrefix = {arXiv},
primaryClass = {cs.NE}
}
```
|
second-state/Tessa-T1-3B-GGUF
|
second-state
| 2025-03-25T14:10:08Z
| 0
| 0
| null |
[
"gguf",
"qwen2",
"en",
"base_model:Tesslate/Tessa-T1-3B",
"base_model:quantized:Tesslate/Tessa-T1-3B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-25T08:40:39Z
|
---
base_model: Tesslate/Tessa-T1-3B
license: apache-2.0
model_creator: Tesslate
model_name: Tessa-T1-3B
quantized_by: Second State Inc.
language:
- en
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://github.com/LlamaEdge/LlamaEdge/raw/dev/assets/logo.svg" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Tessa-T1-3B-GGUF
## Original Model
[Tesslate/Tessa-T1-3B](https://huggingface.co/Tesslate/Tessa-T1-3B)
## Run with LlamaEdge
- LlamaEdge version: [v0.16.14](https://github.com/LlamaEdge/LlamaEdge/releases/tag/0.16.14) and above
- Prompt template
- Prompt type: `chatml`
```text
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
- Prompt type: `chatml-think`
```text
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
<|im_start|>think
```
- Context size: `32000`
- Run as LlamaEdge service
```bash
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Tessa-T1-3B-Q5_K_M.gguf \
llama-api-server.wasm \
--model-name Tessa-T1-3B \
--prompt-template chatml \
--ctx-size 32000
# Think mode
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Tessa-T1-3B-Q5_K_M.gguf \
llama-api-server.wasm \
--model-name Tessa-T1-3B \
--prompt-template chatml-think \
--ctx-size 32000
```
- Run as LlamaEdge command app
```bash
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Tessa-T1-3B-Q5_K_M.gguf \
llama-chat.wasm \
--prompt-template chatml \
--ctx-size 32000
# Think mode
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Tessa-T1-3B-Q5_K_M.gguf \
llama-chat.wasm \
--prompt-template chatml-think \
--ctx-size 32000
```
## Quantized GGUF Models
| Name | Quant method | Bits | Size | Use case |
| ---- | ---- | ---- | ---- | ----- |
| [Tessa-T1-3B-Q2_K.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q2_K.gguf) | Q2_K | 2 | 1.27 GB| smallest, significant quality loss - not recommended for most purposes |
| [Tessa-T1-3B-Q3_K_L.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q3_K_L.gguf) | Q3_K_L | 3 | 1.71 GB| small, substantial quality loss |
| [Tessa-T1-3B-Q3_K_M.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q3_K_M.gguf) | Q3_K_M | 3 | 1.59 GB| very small, high quality loss |
| [Tessa-T1-3B-Q3_K_S.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q3_K_S.gguf) | Q3_K_S | 3 | 1.45 GB| very small, high quality loss |
| [Tessa-T1-3B-Q4_0.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q4_0.gguf) | Q4_0 | 4 | 1.82 GB| legacy; small, very high quality loss - prefer using Q3_K_M |
| [Tessa-T1-3B-Q4_K_M.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q4_K_M.gguf) | Q4_K_M | 4 | 1.93 GB| medium, balanced quality - recommended |
| [Tessa-T1-3B-Q4_K_S.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q4_K_S.gguf) | Q4_K_S | 4 | 1.83 GB| small, greater quality loss |
| [Tessa-T1-3B-Q5_0.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q5_0.gguf) | Q5_0 | 5 | 2.17 GB| legacy; medium, balanced quality - prefer using Q4_K_M |
| [Tessa-T1-3B-Q5_K_M.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q5_K_M.gguf) | Q5_K_M | 5 | 2.22 GB| large, very low quality loss - recommended |
| [Tessa-T1-3B-Q5_K_S.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q5_K_S.gguf) | Q5_K_S | 5 | 2.17 GB| large, low quality loss - recommended |
| [Tessa-T1-3B-Q6_K.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q6_K.gguf) | Q6_K | 6 | 2.54 GB| very large, extremely low quality loss |
| [Tessa-T1-3B-Q8_0.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-Q8_0.gguf) | Q8_0 | 8 | 3.29 GB| very large, extremely low quality loss - not recommended |
| [Tessa-T1-3B-f16.gguf](https://huggingface.co/second-state/Tessa-T1-3B-GGUF/blob/main/Tessa-T1-3B-f16.gguf) | f16 | 16 | 6.18 GB| |
*Quantized with llama.cpp b4944*
|
abhay2727/segformer-b0-scene-parse-150
|
abhay2727
| 2025-03-25T14:08:45Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"pipeline_tag: image-segmentation",
"base_model:nvidia/mit-b0",
"base_model:finetune:nvidia/mit-b0",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T06:07:44Z
|
---
library_name: transformers
license: other
base_model: nvidia/mit-b0
tags:
- generated_from_trainer
- 'pipeline_tag: image-segmentation'
model-index:
- name: segformer-b0-scene-parse-150
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# segformer-b0-scene-parse-150
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1093
- Mean Iou: 0.1061
- Mean Accuracy: 0.1819
- Overall Accuracy: 0.5698
- Per Category Iou: [0.49304871076479706, 0.8045352183435942, 0.9102904514568413, 0.2750351435610755, 0.6478054906449203, 0.17832002366163857, 0.410861924476854, 0.3601149518335627, 0.0, 0.7497660782234421, 0.0, 0.0, 0.034027777777777775, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.269010707248166, 0.06530417065158635, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan]
- Per Category Accuracy: [0.9198922694133461, 0.9658568458254194, 0.9425630652504902, 0.40579602110035823, 0.848176747283853, 0.18761912912235387, 0.6125900991206885, 0.9211193821242585, 0.0, 0.930481904393265, 0.0, 0.0, 0.03960129310344827, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.4112885662431942, 0.8192488262910798, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou | Per Category Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| 4.9385 | 1.0 | 20 | 4.8790 | 0.0134 | 0.0641 | 0.2346 | [0.20371386637738498, 0.4219338515746165, 0.5338068703400358, 0.0892001046957363, 0.18443318121239044, 0.12403386555476457, 0.003557695380321897, 0.07917676359719979, 0.0, 0.0, 0.0011856579303682127, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.008865157444318473, 0.0008899598833467968, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.030151103683587494, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.005728172192327721, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, 0.0, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, nan, 0.0, 0.0] | [0.23112844410872488, 0.4685074571590314, 0.8174183866833648, 0.11805589051667814, 0.1900990717229322, 0.15181620856251507, 0.006228844773085423, 0.0974231020095456, 0.0, 0.0, 0.0012438192930192562, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.6322378716744914, 0.006501950585175552, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.08330126971912274, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.016489007328447703, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 4.8009 | 2.0 | 40 | 4.4509 | 0.0328 | 0.1102 | 0.4471 | [0.432322190513234, 0.6656473834488024, 0.6157113209274023, 0.26647225593544865, 0.5765556111978476, 0.13547153074236293, 0.06545914793742857, 0.1713040066913893, 0.0028021015761821367, 0.0, 0.0023645589271083386, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.022065957465076544, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, nan, nan, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, 0.0, nan, nan, 0.031392540917628116, nan, 0.0, 0.0, 0.0, nan, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, 0.0, nan, nan, 0.0, 0.0, 0.0, nan, nan, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, 0.0, nan, nan, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, nan, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, 0.0, nan, 0.0, nan, nan, 0.0] | [0.7161960291239409, 0.8257633072857422, 0.9088296827477427, 0.49003959605881087, 0.6110498272488865, 0.1901009047978403, 0.14901671903993735, 0.23960285332698342, 0.011729734072467262, 0.0, 0.0025260280703909583, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.6703182055294732, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.03303218520609825, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.9918 | 3.0 | 60 | 4.0238 | 0.0579 | 0.1116 | 0.4997 | [0.42683366372319337, 0.7392372742392653, 0.7675109557279338, 0.3039353897515746, 0.594530541042968, 0.27828872443817293, 0.060722850673681106, 0.1796601658675651, 4.4317073891334535e-05, 0.0, 0.0014319275086698735, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.00831538345939989, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.7659369592655786, 0.8347917868083148, 0.923390644910418, 0.7600777012361162, 0.702254089830579, 0.4771699977438403, 0.12678682990964446, 0.22966383335576515, 0.00012051096649795132, 0.0, 0.0014741561991339332, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.08659363588941053, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.9014 | 4.0 | 80 | 3.7035 | 0.0692 | 0.1258 | 0.5353 | [0.4394071479652167, 0.7609911133185115, 0.7633684641975607, 0.34347569035183184, 0.5637391226338925, 0.3368598393101294, 0.1272485148617859, 0.08330499204912081, 0.0, 0.0, 0.0003951908315727075, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.03901242959798019, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8259465642775607, 0.9443874230873008, 0.9248146106184028, 0.7999105471096631, 0.7847479498813636, 0.5117825995627718, 0.22809880365152038, 0.09383056041578233, 0.0, 0.0, 0.00039925063726544026, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.4191444966092853, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.5577 | 5.0 | 100 | 3.5248 | 0.0736 | 0.1187 | 0.5240 | [0.4290561823492354, 0.8220371322858423, 0.8560104853653364, 0.29491092410753467, 0.44616302379199335, 0.3536123222362577, 0.1690667644516619, 0.028768596522674314, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.05830602035535622, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.7231994825842791, 0.9174368958748869, 0.8990043193626476, 0.928328064090365, 0.8639428880656038, 0.4725954394454515, 0.30094271887209423, 0.029910238225884934, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0881585811163276, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.0393 | 6.0 | 120 | 3.3131 | 0.0700 | 0.1294 | 0.5407 | [0.4398795899399337, 0.6839517407385663, 0.833054453315485, 0.3522109430797707, 0.38304699744083165, 0.3657252132980288, 0.3048773873162618, 0.05261534481557764, 0.0005785398638584916, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.08578276775577141, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.765253989820618, 0.9861543914968812, 0.9543308639090414, 0.7200869973207983, 0.8037401656745619, 0.5802687164007251, 0.47171377152821165, 0.05474743500812722, 0.0009440025709006187, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.35472091810119977, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.4548 | 7.0 | 140 | 3.0650 | 0.0755 | 0.1338 | 0.5450 | [0.4464092095008979, 0.7826643161033131, 0.8568665377176016, 0.31849923391262047, 0.39958030825634966, 0.391608720828959, 0.1905369508983981, 0.13564128631815506, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.10458470144716041, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.7630844155060611, 0.9888552639236454, 0.9203455490118043, 0.7665849605135648, 0.86199683636515, 0.6471444020009802, 0.3063323480320394, 0.18371657228048743, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.44861763171622326, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.6022 | 8.0 | 160 | 2.9873 | 0.0789 | 0.1320 | 0.5578 | [0.47712040427399843, 0.8248885149724448, 0.8160675598001503, 0.339747012396975, 0.369609452779767, 0.4315713538805684, 0.22984963251454096, 0.13951752318088953, 0.0, 0.0, 2.2993791676247414e-05, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.07804278001776806, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9141509821004086, 0.975223926396597, 0.9434612590047575, 0.6138397653177112, 0.8808745785289098, 0.5073247391801582, 0.41933739265033615, 0.25734814523392935, 0.0, 0.0, 2.3033690611467706e-05, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.29786124152321336, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.8648 | 9.0 | 180 | 2.8662 | 0.0862 | 0.1342 | 0.5620 | [0.47156095061743336, 0.8275136245704428, 0.8735358711566618, 0.31155815380579643, 0.4206737183392153, 0.38058481615927664, 0.2328211798498767, 0.35809124778031826, 0.0, 0.002012773369460035, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8462860218115825, 0.9567807505303868, 0.9410660756600446, 0.5832898492894195, 0.8695625026016734, 0.6647657872830391, 0.40057626138768965, 0.6388615680874634, 0.0, 0.002012773369460035, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 3.0779 | 10.0 | 200 | 2.7385 | 0.0811 | 0.1315 | 0.5669 | [0.4676339505322603, 0.8362636216458894, 0.8729100760469264, 0.36465918495133093, 0.35745146249118165, 0.346829217608146, 0.22907763295848257, 0.3008845386416126, 0.0, 0.009386588380716935, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.02526992878474615, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9176647754285452, 0.9756313057832001, 0.932927563959793, 0.730360924872727, 0.8911251717104441, 0.38953764285769854, 0.4013595292932872, 0.3965461905600017, 0.0, 0.00940584478420747, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.14345331246739698, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.1142 | 11.0 | 220 | 2.6322 | 0.0853 | 0.1322 | 0.5509 | [0.4485435556592337, 0.7267937184713177, 0.8540765930149212, 0.2780348303081657, 0.50768525592055, 0.34783458571422077, 0.33636808381161476, 0.36746472328874324, 0.0, 0.14076337058664296, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.0005474202819214452, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8491820053237831, 0.9848185045473062, 0.9527864087949964, 0.43739832407378987, 0.8644840361320402, 0.5952916280915223, 0.5257219585427487, 0.46669910652351715, 0.0, 0.14089413586220245, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.0010432968179447052, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.8039 | 12.0 | 240 | 2.6373 | 0.0806 | 0.1246 | 0.5500 | [0.45912198662279075, 0.8526622749477928, 0.8924898918533234, 0.3483417116710504, 0.4679396820193411, 0.1688766253401875, 0.11760283131850723, 0.215600417504646, 0.0, 0.10676954654300809, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0008711433756805807, 0.07531834191276077, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.940429619154035, 0.9645315401586134, 0.931675204375591, 0.7851508202040753, 0.8913020855013944, 0.17379431603351564, 0.204190483294947, 0.26304237542577313, 0.0, 0.10872846913102381, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0008711433756805807, 0.21752738654147105, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.7232 | 13.0 | 260 | 2.5699 | 0.0868 | 0.1384 | 0.5645 | [0.45421246340548294, 0.8262418104614371, 0.9003839956114787, 0.32850295131323537, 0.4332973417656435, 0.34906027565247527, 0.2710000547103089, 0.4212031847380448, 0.0, 0.09485548912836525, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.002032667876588022, 0.0004891570194032284, 0.0, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.873539639980983, 0.9290974694862258, 0.9588583446216085, 0.5454258439924052, 0.8769928818215876, 0.5093319433314921, 0.5080704568130321, 0.7881539305718043, 0.0, 0.09641958583317205, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.002032667876588022, 0.000782472613458529, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.6447 | 14.0 | 280 | 2.6064 | 0.0985 | 0.1435 | 0.5632 | [0.4452658720856849, 0.8480311592949272, 0.8857872960929841, 0.34181584104470397, 0.5191878098835837, 0.36487320128206846, 0.2816761976978084, 0.459629894984154, 0.0, 0.37236925132697374, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.011796733212341199, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8343231965866008, 0.9336315491527037, 0.9137953067550743, 0.6822317619149935, 0.8924884485701203, 0.4233411391272552, 0.4987924619788704, 0.7372475126567207, 0.0, 0.388310431585059, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.011796733212341199, 0.0, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.7611 | 15.0 | 300 | 2.4407 | 0.0986 | 0.1522 | 0.5870 | [0.46518755960580693, 0.8208948916085005, 0.9003932524350342, 0.376248908445513, 0.39905318329544814, 0.446987463694929, 0.3890571637664661, 0.40172720100046694, 6.901597029552638e-05, 0.32906869525126786, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0, 0.005384922217790187, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8475530145981702, 0.9762635374286425, 0.9555248043872748, 0.5819085914239234, 0.8842359405569662, 0.6094354154834795, 0.713836800537098, 0.7749019039435132, 0.00010042580541495943, 0.3315269982581769, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0, 0.02112676056338028, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.0289 | 16.0 | 320 | 2.4671 | 0.0971 | 0.1565 | 0.5754 | [0.4774358048925406, 0.7710510076862047, 0.8943649769259331, 0.3294111727286691, 0.4313197557233537, 0.3354121138980397, 0.34293994815668205, 0.453534192064702, 0.0, 0.34498201025798053, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.0019233560749020177, 0.08236222166445552, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9385713630670396, 0.9717797188553168, 0.9234344592398944, 0.5454214590468005, 0.8952358156766432, 0.4000171156943137, 0.532929888197831, 0.7268736605617617, 0.0, 0.3488678149796787, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0019237749546279492, 0.599113197704747, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.7669 | 17.0 | 340 | 2.4151 | 0.0965 | 0.1592 | 0.5668 | [0.46186865329747306, 0.799411496073266, 0.8823954529267595, 0.33485086986873264, 0.41256954994416833, 0.2731064068782974, 0.41078882816198303, 0.458716641869005, 0.0, 0.49121119046737965, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.039995648705489883, 0.06659984408063259, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8719758088843947, 0.9400199986244332, 0.9228064538507319, 0.5363490065905733, 0.895891437372518, 0.355609668811315, 0.7120651231315797, 0.7501061197444844, 0.0, 0.5137991097348558, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.040036297640653355, 0.4679186228482003, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.2657 | 18.0 | 360 | 2.4313 | 0.1010 | 0.1589 | 0.5642 | [0.4427082804616837, 0.8444665503725616, 0.9059702695222313, 0.3163265062227969, 0.4663572706251909, 0.3131455487281633, 0.31484068682680605, 0.4349839344502984, 0.0, 0.6023682479350925, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.036406533575317604, 0.07097381635581061, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8419734196979972, 0.9386761757127816, 0.9441695906646269, 0.5803256260606087, 0.889928401948133, 0.3889463734177708, 0.5211342465242487, 0.7975028212322314, 0.0, 0.6379717437584672, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.036406533575317604, 0.4128847157016171, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.435 | 19.0 | 380 | 2.4206 | 0.1017 | 0.1633 | 0.5750 | [0.47587247785629777, 0.8337097057816361, 0.9052716707393167, 0.30265491463716615, 0.3954330795643889, 0.3576023097125309, 0.428650134643602, 0.3575262066998923, 0.0, 0.6043505328304097, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.06368408245559147, 0.05585924154424325, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8978731414422481, 0.9531778237475729, 0.9482078113647068, 0.39660079016719796, 0.8940494526079175, 0.46928121863743516, 0.7109741428344973, 0.8697056600648106, 0.0, 0.6387845945422876, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.066497277676951, 0.3411580594679186, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.0639 | 20.0 | 400 | 2.2936 | 0.1031 | 0.1650 | 0.5887 | [0.48162225947102133, 0.8090029973527031, 0.9067951247005777, 0.34495752913048106, 0.4269398186973364, 0.39135777320725706, 0.3817801449849654, 0.41601739267304133, 0.0015173250937982785, 0.6989510867606243, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.052339060564677485, 0.0351783241645148, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9042201719731542, 0.9781628776856618, 0.9398940423465494, 0.5402866877436385, 0.8900636889647421, 0.46335296451605373, 0.6109023432764843, 0.875648365755935, 0.0022093677191291072, 0.7505709309076833, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.05981851179673321, 0.24517475221700574, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.7727 | 21.0 | 420 | 2.2841 | 0.1027 | 0.1613 | 0.5789 | [0.484961487568254, 0.7390012140315648, 0.9032574335498907, 0.33461936467539544, 0.5310333046515159, 0.16621723339106542, 0.4379688605803255, 0.4617092056208775, 0.0, 0.6625537224455844, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.04866949211422219, 0.056333401765551225, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9437406936363175, 0.9774221878918381, 0.9452174833779388, 0.5061981206123138, 0.8734650126961662, 0.17695293962049838, 0.692464776255793, 0.8334178840240607, 0.0, 0.7399264563576543, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.0508529945553539, 0.35785080855503393, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.9101 | 22.0 | 440 | 2.2731 | 0.1044 | 0.1774 | 0.5852 | [0.48235513994599366, 0.7764207583731297, 0.8919460308996253, 0.3545654999196858, 0.44258842251426256, 0.24647779733634462, 0.4678743504689228, 0.4257994542365998, 0.0, 0.7745900175068777, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.09529177718832892, 0.053237410071942444, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9031317648364855, 0.9698327628258374, 0.9283197569765191, 0.5323543211446462, 0.885651250884569, 0.2886795241836981, 0.761513571981388, 0.8901324167348249, 0.0, 0.8391716663441068, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.10431941923774955, 0.7044861763171623, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.7611 | 23.0 | 460 | 2.2454 | 0.0990 | 0.1712 | 0.5746 | [0.4724559741243822, 0.8184581188051442, 0.9077165708344602, 0.32851093666975256, 0.4416565025944225, 0.2278954440304193, 0.33723401241039297, 0.3640539776862547, 0.0, 0.7150618004156488, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.1586625738521966, 0.08058810864015256, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.913361826593334, 0.9545639717903002, 0.9435634924402025, 0.5259303758336877, 0.8893248137201848, 0.2559885480445319, 0.5549080126441819, 0.880379753388067, 0.0, 0.7591252177278885, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.17448275862068965, 0.6833594157537819, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.9725 | 24.0 | 480 | 2.2596 | 0.1020 | 0.1780 | 0.5772 | [0.5088157092231094, 0.7265937161258674, 0.8999405935721542, 0.32234514235309447, 0.5118427673337254, 0.1607964146646095, 0.5172089524167763, 0.34321086566708636, 0.0008991948119184185, 0.776473026179457, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.14182284158257247, 0.08844776119402985, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9241155787019719, 0.97170035923455, 0.9347641146036811, 0.42303762721823435, 0.8786371394080673, 0.17027003897710388, 0.7949236780022939, 0.9313586433237739, 0.0013256206314774645, 0.8702148248500097, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.1606896551724138, 0.7728221178925404, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.4167 | 25.0 | 500 | 2.2193 | 0.1081 | 0.1812 | 0.5832 | [0.480534825180345, 0.8026797505624291, 0.9074070173960659, 0.3135738032687792, 0.5243463510206126, 0.26855496745233215, 0.4538987516466972, 0.39315646386050435, 0.0, 0.7675438596491229, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.19760479041916168, 0.08172472450262555, 0.0, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.940279993339238, 0.9598731304196008, 0.9438811463289069, 0.47314440064371, 0.8717479082545894, 0.29881668313403925, 0.6746920544930671, 0.8683804574019816, 0.0, 0.8467195664795819, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.23117967332123412, 0.8646322378716745, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.3278 | 26.0 | 520 | 2.2142 | 0.1069 | 0.1844 | 0.5785 | [0.4976561621224289, 0.7944220678844354, 0.9113580925792761, 0.30515904979466796, 0.5401271674070836, 0.1771746335714812, 0.5490247438505866, 0.3620566229919946, 0.0005535369592369705, 0.7801701222753854, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.23548544478777036, 0.08640628962718742, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9182367321722048, 0.9652404861041304, 0.943997984540844, 0.40534437170306903, 0.8742975481829913, 0.18714455759820128, 0.8404184888524193, 0.9163362287631097, 0.0007833212822366836, 0.9088445906715695, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.26279491833030855, 0.8886280646844027, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.4363 | 27.0 | 540 | 2.2510 | 0.1035 | 0.1725 | 0.5720 | [0.4739622435999673, 0.8092979493365501, 0.9138962498293468, 0.3166641292938358, 0.4495030692779889, 0.34577275314327105, 0.33831212070356276, 0.4120511345959858, 0.0, 0.6861234923964342, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2680101850701776, 0.05977257623864727, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8821238177750641, 0.88738340749049, 0.9532172497015149, 0.5198791508991331, 0.8961620114057361, 0.4159269315450026, 0.5827140232928956, 0.9050202404000456, 0.0, 0.8103348171085737, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.31328493647912886, 0.4222743870631195, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.3578 | 28.0 | 560 | 2.1477 | 0.1043 | 0.1789 | 0.5768 | [0.4857184626115484, 0.7417210410077489, 0.9087069308394372, 0.31809451479579764, 0.6425268543825081, 0.14530201855049432, 0.40576527845652277, 0.42029390154298313, 0.0, 0.7687543252595156, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.22909932287590595, 0.04526468437426408, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.946149186590631, 0.9745916947511547, 0.9426287867447048, 0.5068997119090738, 0.8415997169379345, 0.147957397480881, 0.5651837415961881, 0.8883309693650415, 0.0, 0.8599574221017999, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.24439201451905626, 0.952529994783516, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.1159 | 29.0 | 580 | 2.1510 | 0.1071 | 0.1822 | 0.5812 | [0.48688990640395347, 0.838947488867042, 0.9134598562621152, 0.3032418304897648, 0.48312968299711817, 0.30199214566226346, 0.478506067723625, 0.34186003950067484, 0.0, 0.7396190476190476, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2843404926586579, 0.0778348830991355, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.919216539927166, 0.9503711384931195, 0.9531989937308997, 0.4095539194836288, 0.8723202764017817, 0.3290414433198223, 0.7294648601773542, 0.9282734058743749, 0.0, 0.9017998838784594, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.34021778584392015, 0.6833594157537819, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.1151 | 30.0 | 600 | 2.1850 | 0.1062 | 0.1798 | 0.5689 | [0.4571041638211183, 0.8437832351555709, 0.918619615874207, 0.2928590682420594, 0.4901072608698177, 0.3147922014847707, 0.4013679114158636, 0.320329429118303, 0.0, 0.7367851166453391, 0.0, 0.0, 0.010595358224016145, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.3205846371772584, 0.09614800182343108, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8561082325571293, 0.9192542311904472, 0.9564668124710186, 0.45734982657540135, 0.8782729051325813, 0.35298007577584667, 0.6462426452076127, 0.9443000755779644, 0.0, 0.8691697309850978, 0.0, 0.0, 0.011314655172413793, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.36145190562613433, 0.6601460615545123, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.0961 | 31.0 | 620 | 2.1314 | 0.1058 | 0.1769 | 0.5820 | [0.48284931681214904, 0.7333064597800207, 0.9110912633972069, 0.3280264720558154, 0.6227321806043463, 0.1935330297701776, 0.48986540479317364, 0.3598059232914005, 0.0, 0.7546794530278814, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.24957996512918054, 0.056766939309348584, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9520859527906421, 0.976885187791316, 0.9423111328560005, 0.49293366015794576, 0.852287391250052, 0.19608361794658347, 0.6573669143906828, 0.8483781797099048, 0.0, 0.8224501645055158, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.28577132486388385, 0.7584767866458008, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.7615 | 32.0 | 640 | 2.1422 | 0.1084 | 0.1735 | 0.5793 | [0.4605224321133412, 0.8398257585130646, 0.9125307748391255, 0.32323923236815394, 0.5497739497739498, 0.3699341975204044, 0.3406435925597458, 0.418698824036093, 0.0, 0.6922184732180514, 0.0, 0.0, 0.0251621271076524, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.29251055497766626, 0.08803219463117941, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.873568599816105, 0.9516726362736955, 0.9459623269790385, 0.5864294703424204, 0.866867168963077, 0.40763359966391, 0.5408185149613495, 0.8253424302974459, 0.0, 0.7623379136829882, 0.0, 0.0, 0.026131465517241378, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.3470417422867514, 0.5020865936358894, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.5872 | 33.0 | 660 | 2.1703 | 0.1046 | 0.1741 | 0.5668 | [0.47354316390499746, 0.8291208653401098, 0.9123934476918645, 0.2765290105146524, 0.5737618365205943, 0.149463776641477, 0.3728721723032465, 0.3533909465020576, 0.0, 0.7698624843000226, 0.0, 0.0, 0.045824847250509164, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2845640597934176, 0.08301370776773505, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9339040029732097, 0.9619311899181537, 0.9481019267351387, 0.4202312620311945, 0.8708113058319111, 0.15418128632222627, 0.5390188637020598, 0.8890660427170796, 0.0, 0.9252951422488872, 0.0, 0.0, 0.04849137931034483, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.32199637023593464, 0.6491914449660928, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.7727 | 34.0 | 680 | 2.1558 | 0.1071 | 0.1842 | 0.5638 | [0.4685583634112767, 0.8321950944566044, 0.910793685494762, 0.27737455602711497, 0.5695118939830439, 0.27001587192050236, 0.3655693450046022, 0.38358432616398197, 0.0, 0.7480637666193365, 0.0, 0.0, 0.06609485368314834, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2960685393593839, 0.058754806990215645, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.864998901939585, 0.9373746779322057, 0.9431107443689458, 0.45681486321162185, 0.8640469550014569, 0.3044104032301983, 0.5518122394934868, 0.9089958483885329, 0.0, 0.8972711437971744, 0.0, 0.0, 0.07058189655172414, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.36, 0.9444444444444444, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.1858 | 35.0 | 700 | 2.0996 | 0.1052 | 0.1786 | 0.5686 | [0.5024297787395016, 0.7590018095945441, 0.908331770558742, 0.22697513247791506, 0.6468363190261242, 0.28543591633127374, 0.43902686333094487, 0.32166085757407953, 0.0, 0.7944138890729574, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.20923709798055348, 0.06185839448702051, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9256938897161212, 0.978607291561956, 0.9372980433250695, 0.314220817090764, 0.8559817674728385, 0.3133961427448906, 0.6056059602957768, 0.9201047738355299, 0.0, 0.9280820592219857, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.28431941923774956, 0.7936880542514345, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.8596 | 36.0 | 720 | 2.1546 | 0.1064 | 0.1802 | 0.5551 | [0.4582069483508894, 0.824978168353675, 0.914361959357141, 0.25951209405914955, 0.6113601078009199, 0.1592655730374759, 0.364666735988354, 0.3874110568427149, 0.011206814179827735, 0.7485374569142712, 0.0, 0.0, 0.042531645569620254, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2512054976467531, 0.07563568917549118, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8421351121107618, 0.9471385566072175, 0.9457907208552557, 0.4394066291607653, 0.8687507805020189, 0.17734971253413415, 0.555924395997874, 0.9419292051889967, 0.01648991724913634, 0.916237662086317, 0.0, 0.0, 0.04525862068965517, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.3157894736842105, 0.9147104851330203, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.0682 | 37.0 | 740 | 2.1284 | 0.1050 | 0.1757 | 0.5638 | [0.47810987745044226, 0.8110497488177993, 0.9144996433678722, 0.2729651644682312, 0.5486497709606675, 0.1329546261449975, 0.4409382178696651, 0.3647185531396058, 0.0023479690068091102, 0.7618178856491286, 0.0, 0.0, 0.043561512685495456, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.24821049099653283, 0.12374287195438051, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.8934109135138657, 0.9459772608233296, 0.9503072479854536, 0.4043446041051861, 0.8799796028805728, 0.1456701183316866, 0.680137631360555, 0.9290809512470364, 0.003213625773278702, 0.905128701374105, 0.0, 0.0, 0.0490301724137931, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.3222141560798548, 0.6225873761085029, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 2.1905 | 38.0 | 760 | 2.0799 | 0.1034 | 0.1717 | 0.5688 | [0.4940693803921365, 0.7791411571958266, 0.9067886147366049, 0.2868853178656194, 0.5306427971887802, 0.13281672907938155, 0.44025302737882877, 0.3836106895529157, 5.943006567022257e-05, 0.7623588287008859, 0.0, 0.0, 0.006356861025865849, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.23707495031444828, 0.10494995942656207, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9180919329965948, 0.9560929671504076, 0.9401058116056856, 0.4298518326880155, 0.8816030470798818, 0.13934509129666944, 0.6742817713044208, 0.9107144705918894, 8.034064433196755e-05, 0.8726920843816528, 0.0, 0.0, 0.0078125, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.3160798548094374, 0.5059989567031821, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.6543 | 39.0 | 780 | 2.1042 | 0.1070 | 0.1733 | 0.5739 | [0.48277197254927934, 0.8145287855706258, 0.9101607317663652, 0.3125582693796714, 0.5938092953652058, 0.21472730825053032, 0.36367787539498436, 0.4293352493743961, 0.0010798227407864476, 0.7446398376733175, 0.0, 0.0, 0.016425992779783394, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2722489700699856, 0.08618564520716791, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9147253521636617, 0.9363377122208525, 0.9471343602925337, 0.5204009594260983, 0.8630479124172667, 0.2394096641433984, 0.5569874024411849, 0.8970172586940542, 0.0015465574033903752, 0.852293400425779, 0.0, 0.0, 0.02451508620689655, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.39818511796733214, 0.47417840375586856, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.7545 | 40.0 | 800 | 2.1058 | 0.1061 | 0.1787 | 0.5718 | [0.4901138626940899, 0.7961216958126313, 0.9065545839050941, 0.293335765929335, 0.6510641689916301, 0.17540643223184307, 0.413296883682607, 0.3773228594284815, 0.0, 0.7634988116359254, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2596148688515797, 0.07319510947887127, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9311769518325542, 0.9689650976387868, 0.9383240288736431, 0.4371089176638764, 0.8499771052741123, 0.18533962983421115, 0.6033680519940695, 0.8936421331621613, 0.0, 0.8828333655893168, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.3513611615245009, 0.8213354199269692, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.4647 | 41.0 | 820 | 2.1292 | 0.1091 | 0.1739 | 0.5676 | [0.4900911375071857, 0.8071418535097051, 0.9066162410832093, 0.2808720292764891, 0.6295942131807456, 0.13907344026128, 0.4101658514785113, 0.39351599936809956, 0.0, 0.7654950869236583, 0.0, 0.0, 0.04273688754586661, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2887734575917297, 0.08129114850036577, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9155700140213868, 0.9573389131964468, 0.9382984705147819, 0.4324608753228416, 0.8496232776922116, 0.14510218847491385, 0.616180077021344, 0.9284287030614252, 0.0, 0.9408167215018386, 0.0, 0.0, 0.05334051724137931, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.41165154264972775, 0.4637454355764215, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.4163 | 42.0 | 840 | 2.1569 | 0.1050 | 0.1780 | 0.5646 | [0.47157005794886453, 0.8263034515059977, 0.9038664471740323, 0.2951534147404463, 0.5774441621899249, 0.1514730878186969, 0.35144414428352116, 0.4296120674844518, 0.0, 0.7160942516203284, 0.0, 0.0, 0.055454130534002735, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.29013999849733274, 0.07411303161246305, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9039764266942106, 0.9240475522847634, 0.938218144244075, 0.4959198081147803, 0.865805686217375, 0.16639566817336643, 0.550739908432252, 0.9061176738552009, 0.0, 0.915192568221405, 0.0, 0.0, 0.06546336206896551, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.420508166969147, 0.6799687010954617, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.5761 | 43.0 | 860 | 2.1012 | 0.1072 | 0.1821 | 0.5718 | [0.495065296147436, 0.8073073783582354, 0.9067252843332887, 0.276023095387914, 0.6051688264281804, 0.23826429402765475, 0.41254175911049906, 0.36701351089057105, 0.00015265056897030254, 0.7594632991318074, 0.0, 0.0, 0.024619840695148443, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.278476563480706, 0.0825868767537233, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9161516240434204, 0.9627909191431278, 0.9390469653100046, 0.41547798099564576, 0.8626420513674395, 0.25323447723223663, 0.6033773766119933, 0.9005166219755872, 0.00022093677191291073, 0.9311399264563577, 0.0, 0.0, 0.02747844827586207, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.40261343012704176, 0.7983828899321858, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.2308 | 44.0 | 880 | 2.1305 | 0.1064 | 0.1800 | 0.5692 | [0.48273148629633206, 0.8225327383795241, 0.9101917679583177, 0.2840989974786165, 0.6094734282788244, 0.1558207881005218, 0.4078722441489228, 0.3506056718242196, 0.0, 0.7468643458133933, 0.0, 0.0, 0.059127864005912786, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.31493802650641195, 0.0699278068210107, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9297410266744215, 0.9567225534751578, 0.9484560925650735, 0.41304872113061436, 0.8608625067643508, 0.16169663209815072, 0.6051583786354354, 0.8968723146528073, 0.0, 0.9242500483839752, 0.0, 0.0, 0.06465517241379311, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.4260980036297641, 0.7326551904016693, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.6045 | 45.0 | 900 | 2.0916 | 0.1072 | 0.1813 | 0.5765 | [0.48970260152163275, 0.8029454190947148, 0.9118748028460272, 0.2964607680456897, 0.6307646075251003, 0.18050177652091945, 0.4436245938639351, 0.38422459537456943, 0.0, 0.7601137598261648, 0.0, 0.0, 0.005048187241854061, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.27143981117230526, 0.07590732770072799, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.929675867045397, 0.9630051901191982, 0.9499202214084116, 0.4379332874375693, 0.8518919368938102, 0.1936640811595105, 0.6671391139748049, 0.8973382062139581, 0.0, 0.9207276949874201, 0.0, 0.0, 0.005926724137931034, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.4132486388384755, 0.7451747522170057, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.6506 | 46.0 | 920 | 2.0884 | 0.1062 | 0.1820 | 0.5709 | [0.49615558279042765, 0.7852924964855984, 0.9105641387834378, 0.2746244791906892, 0.6577206119682396, 0.15227194927741147, 0.45426994054513165, 0.3589757192409712, 0.00036884664491417223, 0.7721389536927551, 0.0, 0.0, 0.012010113780025285, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.267661761931711, 0.06384978403455448, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9281506490623047, 0.9723537534455302, 0.9414567534312097, 0.39162826185141175, 0.8482495941389502, 0.15919151683950925, 0.6583087008009847, 0.910735176883496, 0.0005222141881577891, 0.9352041803754596, 0.0, 0.0, 0.015355603448275862, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.41201451905626135, 0.832811684924361, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.5606 | 47.0 | 940 | 2.0993 | 0.1076 | 0.1820 | 0.5704 | [0.49165453957213806, 0.8084706102374914, 0.9100911419340973, 0.2747594430618775, 0.65896412407193, 0.19090528685212974, 0.4172619272585258, 0.38288798589818174, 0.0004901254144442842, 0.7604817414825787, 0.0, 0.0, 0.025181305398871878, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.2866171093731083, 0.06492695717318017, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9205149058684693, 0.9605873670065022, 0.9431874194455296, 0.41344336623504185, 0.8469799775215419, 0.20586290328854726, 0.6176813405070727, 0.9062833241880546, 0.0006828954768217241, 0.9141087671763112, 0.0, 0.0, 0.033674568965517244, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.4296551724137931, 0.8137715179968701, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.0496 | 48.0 | 960 | 2.0999 | 0.1079 | 0.1814 | 0.5694 | [0.4885198664082964, 0.8107009911047844, 0.9105912870769264, 0.2737724659744155, 0.6531613750260179, 0.20383668887705614, 0.3900507090458395, 0.38218256442227766, 0.0, 0.7665403957938737, 0.0, 0.0, 0.0479483633010604, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.28859010913381183, 0.07046878274842225, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9132170274177239, 0.9626798156740541, 0.9407666777419555, 0.4226736767330401, 0.84907172293219, 0.22038790387203686, 0.5780983374206242, 0.9139239457909286, 0.0, 0.9085736404102961, 0.0, 0.0, 0.05603448275862069, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.4261705989110708, 0.7892540427751695, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.6828 | 49.0 | 980 | 2.1139 | 0.1060 | 0.1827 | 0.5692 | [0.48956999532044654, 0.8144172090328485, 0.909933700415777, 0.27907114402239863, 0.6298113091673959, 0.180150131272418, 0.4005986205699909, 0.35521699829969217, 0.0, 0.7518460082044809, 0.0, 0.0, 0.04044772322564233, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.27813504823151125, 0.06530087054424094, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.919023474359686, 0.9556485532741135, 0.9460974211615909, 0.4134652909630656, 0.8537963618199226, 0.18950963535791251, 0.6027899256827951, 0.9235627245338496, 0.0, 0.9222372750145152, 0.0, 0.0, 0.04283405172413793, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.42072595281306713, 0.8471570161711007, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
| 1.2896 | 50.0 | 1000 | 2.1093 | 0.1061 | 0.1819 | 0.5698 | [0.49304871076479706, 0.8045352183435942, 0.9102904514568413, 0.2750351435610755, 0.6478054906449203, 0.17832002366163857, 0.410861924476854, 0.3601149518335627, 0.0, 0.7497660782234421, 0.0, 0.0, 0.034027777777777775, 0.0, 0.0, 0.0, 0.0, nan, 0.0, 0.0, 0.269010707248166, 0.06530417065158635, 0.0, nan, nan, 0.0, 0.0, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] | [0.9198922694133461, 0.9658568458254194, 0.9425630652504902, 0.40579602110035823, 0.848176747283853, 0.18761912912235387, 0.6125900991206885, 0.9211193821242585, 0.0, 0.930481904393265, 0.0, 0.0, 0.03960129310344827, 0.0, 0.0, 0.0, 0.0, nan, 0.0, nan, 0.4112885662431942, 0.8192488262910798, 0.0, nan, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, 0.0, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, 0.0, 0.0, nan, nan, nan, nan, nan, 0.0, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan, nan, nan, nan, nan, 0.0, nan, nan, nan] |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Tokenizers 0.21.1
- pipeline_tag: image-segmentation
|
RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf
|
RichardErkhov
| 2025-03-25T14:07:08Z
| 0
| 0
| null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T13:03:32Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3.2-3B_known_unknown_fix_tail - GGUF
- Model creator: https://huggingface.co/kenken6696/
- Original model: https://huggingface.co/kenken6696/Llama-3.2-3B_known_unknown_fix_tail/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3.2-3B_known_unknown_fix_tail.Q2_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q2_K.gguf) | Q2_K | 1.27GB |
| [Llama-3.2-3B_known_unknown_fix_tail.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.IQ3_XS.gguf) | IQ3_XS | 1.38GB |
| [Llama-3.2-3B_known_unknown_fix_tail.IQ3_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.IQ3_S.gguf) | IQ3_S | 1.44GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q3_K_S.gguf) | Q3_K_S | 1.44GB |
| [Llama-3.2-3B_known_unknown_fix_tail.IQ3_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.IQ3_M.gguf) | IQ3_M | 1.49GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q3_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q3_K.gguf) | Q3_K | 1.57GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q3_K_M.gguf) | Q3_K_M | 1.57GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q3_K_L.gguf) | Q3_K_L | 1.69GB |
| [Llama-3.2-3B_known_unknown_fix_tail.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.IQ4_XS.gguf) | IQ4_XS | 1.71GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q4_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q4_0.gguf) | Q4_0 | 1.79GB |
| [Llama-3.2-3B_known_unknown_fix_tail.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.IQ4_NL.gguf) | IQ4_NL | 1.79GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q4_K_S.gguf) | Q4_K_S | 1.8GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q4_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q4_K.gguf) | Q4_K | 1.88GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q4_K_M.gguf) | Q4_K_M | 1.88GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q4_1.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q4_1.gguf) | Q4_1 | 1.95GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q5_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q5_0.gguf) | Q5_0 | 2.11GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q5_K_S.gguf) | Q5_K_S | 2.11GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q5_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q5_K.gguf) | Q5_K | 2.16GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q5_K_M.gguf) | Q5_K_M | 2.16GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q5_1.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q5_1.gguf) | Q5_1 | 2.28GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q6_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q6_K.gguf) | Q6_K | 2.46GB |
| [Llama-3.2-3B_known_unknown_fix_tail.Q8_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_tail-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_tail.Q8_0.gguf) | Q8_0 | 3.19GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
L-I-V-E-Sophie-Rain-Spiderman-videos-link/Sophie.Rain.Spider-Man.Video.Tutorial.Links
|
L-I-V-E-Sophie-Rain-Spiderman-videos-link
| 2025-03-25T14:06:12Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-03-25T14:06:07Z
|
<a href="https://sdu.sk/9Ip"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/9Ip" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/9Ip" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
sunalibhattacherji/txt_to_sql_llama
|
sunalibhattacherji
| 2025-03-25T14:04:34Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T14:04:22Z
|
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** sunalibhattacherji
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
L-i-V-E-Sophie-Rain-Spiderman-Videosss/Sophie.Rain.Spider-Man.Video.Tutorial.Clips
|
L-i-V-E-Sophie-Rain-Spiderman-Videosss
| 2025-03-25T14:04:26Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-03-25T14:04:14Z
|
<a href="https://sdu.sk/9Ip"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/9Ip" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/9Ip" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
samchain/EconoSentiment
|
samchain
| 2025-03-25T14:04:19Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"finance",
"en",
"dataset:FinanceMTEB/financial_phrasebank",
"base_model:samchain/econo-sentence-v2",
"base_model:finetune:samchain/econo-sentence-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T10:43:10Z
|
---
library_name: transformers
license: apache-2.0
base_model: samchain/econo-sentence-v2
tags:
- generated_from_trainer
- finance
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: EconoSentiment
results: []
datasets:
- FinanceMTEB/financial_phrasebank
language:
- en
pipeline_tag: text-classification
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EconoSentiment
This model is a fine-tuned version of [samchain/econo-sentence-v2](https://huggingface.co/samchain/econo-sentence-v2) on the Financial Phrase Bank dataset from FinanceMTEB.
The full model is trained using a small learning rate isntead of freezing the encoder. Hence, you should not use the encoder of this model for a task other than sentiment analysis.
It achieves the following results on the evaluation set:
- Loss: 0.1293
- Accuracy: 0.962
- F1: 0.9619
- Precision: 0.9619
- Recall: 0.962
## Model description
The base model is a sentence-transformers model built from [EconoBert](https://huggingface.co/samchain/EconoBert).
## Intended uses & limitations
This model is trained to provide a useful tool for sentiment analysis in finance.
## Training and evaluation data
The dataset is directly downloaded from the huggingface repo of the FinanceMTEB. The preprocessing consisted of tokenizing to a fixed sequence length of 512 tokens.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.5992 | 1.0 | 158 | 0.4854 | 0.805 | 0.7692 | 0.8108 | 0.805 |
| 0.0985 | 2.0 | 316 | 0.1293 | 0.962 | 0.9619 | 0.9619 | 0.962 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.1.0+cu118
- Datasets 3.4.1
- Tokenizers 0.21.1
|
souging/2a201699-8567-4cd4-ae99-f620dd547f24
|
souging
| 2025-03-25T14:03:01Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"custom_code",
"base_model:NousResearch/Yarn-Solar-10b-32k",
"base_model:adapter:NousResearch/Yarn-Solar-10b-32k",
"license:apache-2.0",
"region:us"
] | null | 2025-03-25T13:22:25Z
|
---
library_name: peft
license: apache-2.0
base_model: NousResearch/Yarn-Solar-10b-32k
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 2a201699-8567-4cd4-ae99-f620dd547f24
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: NousResearch/Yarn-Solar-10b-32k
bf16: auto
dataset_prepared_path: null
datasets:
- data_files:
- 65d9e80afe69aff1_train_data.json
ds_type: json
format: custom
path: /root/G.O.D-test/core/data/65d9e80afe69aff1_train_data.json
type:
field_input: documents
field_instruction: question
field_output: answer
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
eval_max_new_tokens: 128
eval_steps: 0
evals_per_epoch: null
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 6
gradient_checkpointing: false
group_by_length: false
hub_model_id: souging/2a201699-8567-4cd4-ae99-f620dd547f24
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.000202
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 500
micro_batch_size: 1
mlflow_experiment_name: /tmp/65d9e80afe69aff1_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 10
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: false
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 0
saves_per_epoch: null
sequence_len: 1920
special_tokens:
pad_token: </s>
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
wandb_entity: null
wandb_mode: online
wandb_name: a1a050a4-6a01-49dd-9cd7-289119b180f3
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: a1a050a4-6a01-49dd-9cd7-289119b180f3
warmup_steps: 100
weight_decay: 0.01
xformers_attention: null
```
</details><br>
# 2a201699-8567-4cd4-ae99-f620dd547f24
This model is a fine-tuned version of [NousResearch/Yarn-Solar-10b-32k](https://huggingface.co/NousResearch/Yarn-Solar-10b-32k) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000202
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 6
- total_train_batch_size: 48
- total_eval_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 500
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.3
|
Sopna-Shah-Lik/new.VIRAL.VIDEO.sapna.shah.viral.video.original.Link.HD.x.Trending.Now
|
Sopna-Shah-Lik
| 2025-03-25T14:01:35Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-03-25T14:01:27Z
|
<a href="https://sdu.sk/9Ip"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/9Ip" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/9Ip" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
RichardErkhov/amazon_-_MegaBeam-Mistral-7B-300k-awq
|
RichardErkhov
| 2025-03-25T14:01:22Z
| 0
| 0
| null |
[
"safetensors",
"mistral",
"4-bit",
"awq",
"region:us"
] | null | 2025-03-25T13:57:53Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MegaBeam-Mistral-7B-300k - AWQ
- Model creator: https://huggingface.co/amazon/
- Original model: https://huggingface.co/amazon/MegaBeam-Mistral-7B-300k/
Original model description:
---
license: apache-2.0
inference: false
---
# MegaBeam-Mistral-7B-300k Model
MegaBeam-Mistral-7B-300k is a fine-tuned [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) language model that supports input contexts up to 320k tokens. MegaBeam-Mistral-7B-300k can be deployed on a single AWS `g5.48xlarge` instance using serving frameworks such as [vLLM](https://github.com/vllm-project/vllm), Sagemaker [DJL](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-models-frameworks-djl-serving.html) endpoint, and others. Similarities and differences beween MegaBeam-Mistral-7B-300k and [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) are summarized below:
|Model|Max context length| rope_theta| prompt template|
|----------|-------------:|------------:|------------:|
| [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) | 32K | 1e6 | [instruction format](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2#instruction-format)|
| MegaBeam-Mistral-7B-300k | 320K | 25e6 | AS ABOVE|
## Evaluations
**[InfiniteBench: Extending Long Context Evaluation Beyond 100K Tokens](https://github.com/OpenBMB/InfiniteBench)**
_InfiniteBench is a cutting-edge benchmark tailored for evaluating the capabilities of language models to process, understand, and reason over super long contexts (100k+ tokens)_. We therefore evaluated MegaBeam-Mistral-7B-300k, [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), [Llama-3-8B-Instruct-262k](https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k), and [Llama3-70B-1M](https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-1048k) on InfiniteBench. The InfiniteBench authors also evaluated SOTA proprietary and open-source LLMs on InfiniteBench. We thus combined both results in the table below.
| Task Name | MegaBeam-Mistral-7B-300k | Mistral-7B-Instruct-v0.2 | Llama-3-8B-Instruct-262k | Llama3-70B-1M | GPT-4-1106-preview | YaRN-Mistral-7B | Kimi-Chat | Claude 2 | Yi-6B-200K | Yi-34B-200K | Chatglm3-6B-128K |
| ---------------- | ---------------- | ---------------- | ---------------- | ---------------- | ------ | --------------- | --------- | -------- | -----------| -----------| -----------|
| Retrieve.PassKey | 100% | 75.76% | 98.30% | 81.35% | 100% | 92.71% | 98.14% | 97.80% | 100.00% | 100.00% | 92.20% |
| Retrieve.Number | 96.10% | 25.25% | 97.79% | 97.62% | 100% | 56.61% | 95.42% | 98.14% | 94.92% | 100.00% | 80.68% |
| Retrieve.KV | 0% | 0% | 3.40% | 3% | 89.00% | < 5% | 53.60% | 65.40% | < 5% | < 5% | < 5% |
| En.Sum | 29.39% | 22.13% | 16.40% | 20.72% | 14.73% | 9.09% | 17.93% | 14.45% | < 5% | < 5% |< 5% |
| En.QA | 14.93% | 4.93% | 13.20% | 16.52% | 22.22% | 9.55% | 16.52% | 11.97% | 9.20% | 12.17% |< 5% |
| En.MC | 51.52% | 7.80% | 50.65% | 62% | 67.25% | 27.95% | 72.49% | 62.88% | 36.68% |38.43% |10.48% |
| En.Dia | 9.50% | 3.50% | 1% | 12.50% | 8.50% | 7.50% | 11.50% | 46.50% | < 5% |< 5% |< 5% |
| Zh.QA | 10.71% | 3.43% | 19.02% | 26% | 25.96% | 14.43% | 17.93% | 9.64% | 15.07% |13.61% |< 5% |
| Code.Debug | 27.41% | 11.60% | 22.08% | 23.85% | 39.59% | < 5% | 18.02% | < 5% | < 5% |< 5% |< 5% |
| Code.Run | 1.75% | 0.25% | 0% | 0% | 23.25% | < 5% | < 5% | < 5% | < 5% |< 5% |< 5% |
| Math.Calc | 0% | 0% | 0% | 0% | < 5% | < 5% | < 5% | < 5% | < 5% |< 5% |< 5% |
| Math.Find | 24.28% | 26.28% | 15.40% | 30% | 60.00% | 17.14% | 12.57% | 32.29% | < 5% |25.71% |7.71% |
| **Average** | 30.70% | 15.08% | 28.10% | 31.13% | 46.08% | 20.41% | 34.93% | 37.21% | 22.78% |25.41% |17.59% |
The 12 evaluation tasks are summarized below (as per [InfiniteBench]((https://github.com/OpenBMB/InfiniteBench)))
| Task Name | Context | # Examples | Avg Input Tokens | Avg Output Tokens | Description |
| -------------------- | ------------- | ---------- | ---------------- | ----------------- | ------------------------------------------------------------------------------------------- |
| En.Sum | Fake Book | 103 | 171.5k | 1.1k | Summarization of a fake book created with core entity substitution. |
| En.QA | Fake Book | 351 | 192.6k | 4.8 | Free-form question answering based on the fake book. |
| En.MC | Fake Book | 229 | 184.4k | 5.3 | Multiple choice questions derived from the fake book. |
| En.Dia | Script | 200 | 103.6k | 3.4 | Identification of talkers in partially anonymized scripts. |
| Zh.QA | New Book | 175 | 2068.6k | 6.3 | Question answering on a set of newly collected books. |
| Code.Debug | Code Document | 394 | 114.7k | 4.8 | Finding which function in a code repo contains an crashing error (in multiple choice form). |
| Code.Run | Synthetic | 400 | 75.2k | 1.3 | Simulating execution of multiple simple, synthetic functions. |
| Math.Calc | Synthetic | 50 | 43.9k | 43.9k | Calculations involving super-long arithmetic equations. |
| Math.Find | Synthetic | 350 | 87.9k | 1.3 | Finding special integers in a lengthy list. |
| Retrieve.PassKey | Synthetic | 590 | 122.4k | 2.0 | Retrieving hidden keys in a noisy long context. |
| Retrieve.Number | Synthetic | 590 | 122.4k | 4.0 | Locating repeated hidden numbers in a noisy long context. |
| Retrieve.KV | Synthetic | 500 | 89.9k | 22.7 | Finding the corresponding value from a dictionary and a key. |
## Serve MegaBeam-Mistral-7B-300k on EC2 instances ##
On an AWS `g5.48xlarge` instance, upgrade vLLM to the latest version as per [documentation on vLLM](https://vllm.readthedocs.io/en/latest/).
### Start the server
```shell
python3 -m vllm.entrypoints.openai.api_server --model amazon/MegaBeam-Mistral-7B-300k --tensor-parallel-size 8
```
**Important Note** - We have set the `max_position_embeddings` in the [`config.json`](config.json) to 288,800 in order to fit model's KV-cache on a single `g5.48xlarge` instance, which has 8 x A10 GPUs (24GB RAM per GPU).
On an instance with larger GPU RAM (e.g. `p4d.24xlarge`), feel free to increase the value of the `max_position_embeddings`(e.g. to 350K), which the model should be able to process.
### Run the client
```python
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
chat_completion = client.chat.completions.create(
messages = [
{"role": "user", "content": "What is your favourite condiment?"}, # insert your long context here
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"} # insert your long context here
],
model=model,
)
print("Chat completion results:")
print(chat_completion)
```
### Deploy the model on a SageMaker Endpoint ###
To deploy MegaBeam-Mistral-7B-300k on a SageMaker endpoint, please follow this [SageMaker DJL deployment guide](https://docs.djl.ai/docs/demos/aws/sagemaker/large-model-inference/sample-llm/vllm_deploy_mistral_7b.html).
Run the following Python code in a SageMaker notebook (with each block running in a separate cell)
```python
import sagemaker
from sagemaker import Model, image_uris, serializers, deserializers
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = sagemaker.get_execution_role()
%%writefile serving.properties
engine=Python
option.model_id=amazon/MegaBeam-Mistral-7B-300k
option.dtype=bf16
option.task=text-generation
option.rolling_batch=vllm
option.tensor_parallel_degree=8
option.device_map=auto
%%sh
mkdir mymodel
mv serving.properties mymodel/
tar czvf mymodel.tar.gz mymodel/
rm -rf mymodel
image_uri = image_uris.retrieve(
framework="djl-deepspeed",
region=region,
version="0.27.0"
)
s3_code_prefix = "megaBeam-mistral-7b-300k/code"
bucket = sagemaker_session.default_bucket() # bucket to house artifacts
code_artifact = sagemaker_session.upload_data("mymodel.tar.gz", bucket, s3_code_prefix)
print(f"S3 Code or Model tar ball uploaded to --- > {code_artifact}")
model = Model(image_uri=image_uri, model_data=code_artifact, role=role)
instance_type = "ml.g5.48xlarge"
endpoint_name = sagemaker.utils.name_from_base("megaBeam-mistral-7b-300k")
model.deploy(initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name
)
# our requests and responses will be in json format so we specify the serializer and the deserializer
predictor = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session,
serializer=serializers.JSONSerializer(),
)
# test the endpoint
input_str = """<s>[INST] What is your favourite condiment? [/INST]
Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
[INST] Do you have mayonnaise recipes? [/INST]"""
predictor.predict(
{"inputs": input_str, "parameters": {"max_new_tokens": 75}}
)
```
### Invoke the model on a SageMaker Endpoint ###
To use MegaBeam-Mistral-7B-300k on a SageMaker endpoint, please try following this example:
```python
import boto3
import json
def call_endpoint(text:str, endpoint_name:str):
client = boto3.client("sagemaker-runtime")
parameters = {
"max_new_tokens": 450,
"do_sample": True,
"temperature": 0.7,
}
payload = {"inputs": text, "parameters": parameters}
response = client.invoke_endpoint(
EndpointName=endpoint_name, Body=json.dumps(payload), ContentType="application/json"
)
output = json.loads(response["Body"].read().decode())
result = output["generated_text"]
return result
# please insert your long prompt/document content here
prompt = """<s>[INST] What are the main challenges to support long contexts for a Large Language Model? [/INST]"""
#print(prompt)
endpoint_name = "megaBeam-mistral-7b-300k-2024-05-13-14-23-41-219" # please use a valid endpoint name
result = call_endpoint(prompt, endpoint_name)
print(result)
```
## Limitations ##
Before using the MegaBeam-Mistral-7B-300k model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content.
## The AWS Contributors ##
Chen Wu, Yin Song, Verdi March, Eden Duthie
|
hahaqwqw/rnd-Pyramids
|
hahaqwqw
| 2025-03-25T14:00:35Z
| 0
| 0
|
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2025-03-25T14:00:06Z
|
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: hahaqwqw/rnd-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
sopna-shah-pa/VIRAL.VIDEO.sapna.shah.viral.video.original.Link.HD.x.Trending.Now
|
sopna-shah-pa
| 2025-03-25T14:00:04Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-03-25T13:59:50Z
|
<a href="https://sdu.sk/9Ip"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/9Ip" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/9Ip" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
ziyi105/gemma-3-finetune
|
ziyi105
| 2025-03-25T13:58:05Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3-1b-it",
"base_model:finetune:unsloth/gemma-3-1b-it",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:52:46Z
|
---
base_model: unsloth/gemma-3-1b-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** ziyi105
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Erenosxx/whisper-turbo-tr_combined_1
|
Erenosxx
| 2025-03-25T13:54:17Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:openai/whisper-large-v3-turbo",
"base_model:adapter:openai/whisper-large-v3-turbo",
"license:mit",
"region:us"
] | null | 2025-03-25T13:33:47Z
|
---
library_name: peft
license: mit
base_model: openai/whisper-large-v3-turbo
tags:
- generated_from_trainer
model-index:
- name: whisper-turbo-tr_combined_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-turbo-tr_combined_1
This model is a fine-tuned version of [openai/whisper-large-v3-turbo](https://huggingface.co/openai/whisper-large-v3-turbo) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.15.0
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 2.18.0
- Tokenizers 0.21.1
|
nathanialhunt2000/4d889a57-e5c1-4eef-a696-00439d206c38
|
nathanialhunt2000
| 2025-03-25T13:54:02Z
| 0
| 0
|
peft
|
[
"peft",
"generated_from_trainer",
"base_model:unsloth/Llama-3.2-1B",
"base_model:adapter:unsloth/Llama-3.2-1B",
"region:us"
] | null | 2025-03-25T13:53:45Z
|
---
library_name: peft
tags:
- generated_from_trainer
base_model: unsloth/Llama-3.2-1B
model-index:
- name: nathanialhunt2000/4d889a57-e5c1-4eef-a696-00439d206c38
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nathanialhunt2000/4d889a57-e5c1-4eef-a696-00439d206c38
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6537
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
Slothwolf/no_aux_loss_4layer_4expert_2topk_0.1aux_loss_weight_10epoch_MRPC
|
Slothwolf
| 2025-03-25T13:53:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T13:46:04Z
|
---
library_name: transformers
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
model-index:
- name: no_aux_loss_4layer_4expert_2topk_0.1aux_loss_weight_10epoch_MRPC
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# no_aux_loss_4layer_4expert_2topk_0.1aux_loss_weight_10epoch_MRPC
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4002
- Precision: 0.7911
- Recall: 0.7557
- F1-score: 0.7687
- Accuracy: 0.8113
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 300
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1-score | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:---------:|:------:|:--------:|:--------:|
| 0.6558 | 0.4348 | 100 | 0.6122 | 0.3419 | 0.5 | 0.4061 | 0.6838 |
| 0.6196 | 0.8696 | 200 | 0.5580 | 0.7850 | 0.5253 | 0.4605 | 0.6985 |
| 0.599 | 1.3043 | 300 | 0.5539 | 0.6798 | 0.5879 | 0.5832 | 0.7157 |
| 0.5999 | 1.7391 | 400 | 0.5889 | 0.7480 | 0.5274 | 0.4667 | 0.6985 |
| 0.5922 | 2.1739 | 500 | 0.5647 | 0.6997 | 0.7280 | 0.6711 | 0.6765 |
| 0.5425 | 2.6087 | 600 | 0.6696 | 0.7791 | 0.5879 | 0.5743 | 0.7328 |
| 0.5156 | 3.0435 | 700 | 0.6715 | 0.7729 | 0.6648 | 0.6799 | 0.7696 |
| 0.4994 | 3.4783 | 800 | 0.4945 | 0.7806 | 0.7122 | 0.7300 | 0.7917 |
| 0.4778 | 3.9130 | 900 | 0.5263 | 0.7694 | 0.6908 | 0.7078 | 0.7794 |
| 0.4883 | 4.3478 | 1000 | 0.4749 | 0.7803 | 0.6884 | 0.7062 | 0.7819 |
| 0.4338 | 4.7826 | 1100 | 0.5873 | 0.8021 | 0.7075 | 0.7279 | 0.7966 |
| 0.4521 | 5.2174 | 1200 | 0.4847 | 0.8063 | 0.7212 | 0.7419 | 0.8039 |
| 0.4501 | 5.6522 | 1300 | 0.4131 | 0.8065 | 0.7569 | 0.7736 | 0.8186 |
| 0.4021 | 6.0870 | 1400 | 0.4989 | 0.8085 | 0.7549 | 0.7723 | 0.8186 |
| 0.4365 | 6.5217 | 1500 | 0.3891 | 0.7762 | 0.7917 | 0.7826 | 0.8064 |
| 0.4087 | 6.9565 | 1600 | 0.3966 | 0.7832 | 0.7623 | 0.7709 | 0.8088 |
| 0.3956 | 7.3913 | 1700 | 0.3786 | 0.7937 | 0.7900 | 0.7918 | 0.8211 |
| 0.4061 | 7.8261 | 1800 | 0.3950 | 0.7981 | 0.7534 | 0.7687 | 0.8137 |
| 0.3765 | 8.2609 | 1900 | 0.4026 | 0.8085 | 0.7549 | 0.7723 | 0.8186 |
| 0.388 | 8.6957 | 2000 | 0.4182 | 0.8198 | 0.7564 | 0.7760 | 0.8235 |
| 0.376 | 9.1304 | 2100 | 0.3998 | 0.7950 | 0.7656 | 0.7770 | 0.8162 |
| 0.4014 | 9.5652 | 2200 | 0.4002 | 0.7950 | 0.7575 | 0.7711 | 0.8137 |
| 0.3787 | 10.0 | 2300 | 0.4002 | 0.7911 | 0.7557 | 0.7687 | 0.8113 |
### Framework versions
- Transformers 4.49.0.dev0
- Pytorch 2.5.1+cu121
- Datasets 3.2.0
- Tokenizers 0.21.0
|
JacksonBrune/ad45f0c4-498b-4c1d-b882-435c8aae8680
|
JacksonBrune
| 2025-03-25T13:53:09Z
| 0
| 0
|
peft
|
[
"peft",
"generated_from_trainer",
"base_model:unsloth/Llama-3.2-1B",
"base_model:adapter:unsloth/Llama-3.2-1B",
"region:us"
] | null | 2025-03-25T13:52:57Z
|
---
library_name: peft
tags:
- generated_from_trainer
base_model: unsloth/Llama-3.2-1B
model-index:
- name: JacksonBrune/ad45f0c4-498b-4c1d-b882-435c8aae8680
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# JacksonBrune/ad45f0c4-498b-4c1d-b882-435c8aae8680
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6537
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
mradermacher/CPE_chatbot-i1-GGUF
|
mradermacher
| 2025-03-25T13:52:14Z
| 605
| 0
|
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:YenJung/CPE_chatbot",
"base_model:quantized:YenJung/CPE_chatbot",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-22T19:16:33Z
|
---
base_model: YenJung/CPE_chatbot
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/YenJung/CPE_chatbot
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/CPE_chatbot-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q2_K_S.gguf) | i1-Q2_K_S | 3.1 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.8 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q4_1.gguf) | i1-Q4_1 | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/CPE_chatbot-i1-GGUF/resolve/main/CPE_chatbot.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
rinabuoy/nllb-200-600M-2Ways-No-GG-Pairs-v4
|
rinabuoy
| 2025-03-25T13:51:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-03-25T13:48:53Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Asif-Sheriff/T5-QG2
|
Asif-Sheriff
| 2025-03-25T13:51:19Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:Asif-Sheriff/T5-Question-Generation",
"base_model:finetune:Asif-Sheriff/T5-Question-Generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-03-25T12:08:13Z
|
---
library_name: transformers
license: apache-2.0
base_model: Asif-Sheriff/T5-Question-Generation
tags:
- generated_from_trainer
model-index:
- name: T5-QG2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5-QG2
This model is a fine-tuned version of [Asif-Sheriff/T5-Question-Generation](https://huggingface.co/Asif-Sheriff/T5-Question-Generation) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9237
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAFACTOR and the args are:
No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.3112 | 0.0548 | 100 | 1.7491 |
| 0.332 | 0.1095 | 200 | 1.7392 |
| 0.2815 | 0.1643 | 300 | 1.7695 |
| 0.298 | 0.2191 | 400 | 1.8053 |
| 0.2696 | 0.2738 | 500 | 1.8340 |
| 0.2625 | 0.3286 | 600 | 1.8321 |
| 0.2839 | 0.3834 | 700 | 1.8368 |
| 0.2651 | 0.4381 | 800 | 1.8531 |
| 0.2604 | 0.4929 | 900 | 1.8731 |
| 0.2798 | 0.5476 | 1000 | 1.8512 |
| 0.2148 | 0.6024 | 1100 | 1.8821 |
| 0.2603 | 0.6572 | 1200 | 1.8805 |
| 0.2092 | 0.7119 | 1300 | 1.9164 |
| 0.227 | 0.7667 | 1400 | 1.9262 |
| 0.2564 | 0.8215 | 1500 | 1.8991 |
| 0.2446 | 0.8762 | 1600 | 1.9290 |
| 0.2093 | 0.9310 | 1700 | 1.9291 |
| 0.243 | 0.9858 | 1800 | 1.9237 |
### Framework versions
- Transformers 4.49.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
RichardErkhov/amazon_-_MegaBeam-Mistral-7B-300k-8bits
|
RichardErkhov
| 2025-03-25T13:51:08Z
| 0
| 0
| null |
[
"safetensors",
"mistral",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-03-25T13:45:42Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MegaBeam-Mistral-7B-300k - bnb 8bits
- Model creator: https://huggingface.co/amazon/
- Original model: https://huggingface.co/amazon/MegaBeam-Mistral-7B-300k/
Original model description:
---
license: apache-2.0
inference: false
---
# MegaBeam-Mistral-7B-300k Model
MegaBeam-Mistral-7B-300k is a fine-tuned [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) language model that supports input contexts up to 320k tokens. MegaBeam-Mistral-7B-300k can be deployed on a single AWS `g5.48xlarge` instance using serving frameworks such as [vLLM](https://github.com/vllm-project/vllm), Sagemaker [DJL](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-models-frameworks-djl-serving.html) endpoint, and others. Similarities and differences beween MegaBeam-Mistral-7B-300k and [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) are summarized below:
|Model|Max context length| rope_theta| prompt template|
|----------|-------------:|------------:|------------:|
| [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) | 32K | 1e6 | [instruction format](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2#instruction-format)|
| MegaBeam-Mistral-7B-300k | 320K | 25e6 | AS ABOVE|
## Evaluations
**[InfiniteBench: Extending Long Context Evaluation Beyond 100K Tokens](https://github.com/OpenBMB/InfiniteBench)**
_InfiniteBench is a cutting-edge benchmark tailored for evaluating the capabilities of language models to process, understand, and reason over super long contexts (100k+ tokens)_. We therefore evaluated MegaBeam-Mistral-7B-300k, [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), [Llama-3-8B-Instruct-262k](https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k), and [Llama3-70B-1M](https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-1048k) on InfiniteBench. The InfiniteBench authors also evaluated SOTA proprietary and open-source LLMs on InfiniteBench. We thus combined both results in the table below.
| Task Name | MegaBeam-Mistral-7B-300k | Mistral-7B-Instruct-v0.2 | Llama-3-8B-Instruct-262k | Llama3-70B-1M | GPT-4-1106-preview | YaRN-Mistral-7B | Kimi-Chat | Claude 2 | Yi-6B-200K | Yi-34B-200K | Chatglm3-6B-128K |
| ---------------- | ---------------- | ---------------- | ---------------- | ---------------- | ------ | --------------- | --------- | -------- | -----------| -----------| -----------|
| Retrieve.PassKey | 100% | 75.76% | 98.30% | 81.35% | 100% | 92.71% | 98.14% | 97.80% | 100.00% | 100.00% | 92.20% |
| Retrieve.Number | 96.10% | 25.25% | 97.79% | 97.62% | 100% | 56.61% | 95.42% | 98.14% | 94.92% | 100.00% | 80.68% |
| Retrieve.KV | 0% | 0% | 3.40% | 3% | 89.00% | < 5% | 53.60% | 65.40% | < 5% | < 5% | < 5% |
| En.Sum | 29.39% | 22.13% | 16.40% | 20.72% | 14.73% | 9.09% | 17.93% | 14.45% | < 5% | < 5% |< 5% |
| En.QA | 14.93% | 4.93% | 13.20% | 16.52% | 22.22% | 9.55% | 16.52% | 11.97% | 9.20% | 12.17% |< 5% |
| En.MC | 51.52% | 7.80% | 50.65% | 62% | 67.25% | 27.95% | 72.49% | 62.88% | 36.68% |38.43% |10.48% |
| En.Dia | 9.50% | 3.50% | 1% | 12.50% | 8.50% | 7.50% | 11.50% | 46.50% | < 5% |< 5% |< 5% |
| Zh.QA | 10.71% | 3.43% | 19.02% | 26% | 25.96% | 14.43% | 17.93% | 9.64% | 15.07% |13.61% |< 5% |
| Code.Debug | 27.41% | 11.60% | 22.08% | 23.85% | 39.59% | < 5% | 18.02% | < 5% | < 5% |< 5% |< 5% |
| Code.Run | 1.75% | 0.25% | 0% | 0% | 23.25% | < 5% | < 5% | < 5% | < 5% |< 5% |< 5% |
| Math.Calc | 0% | 0% | 0% | 0% | < 5% | < 5% | < 5% | < 5% | < 5% |< 5% |< 5% |
| Math.Find | 24.28% | 26.28% | 15.40% | 30% | 60.00% | 17.14% | 12.57% | 32.29% | < 5% |25.71% |7.71% |
| **Average** | 30.70% | 15.08% | 28.10% | 31.13% | 46.08% | 20.41% | 34.93% | 37.21% | 22.78% |25.41% |17.59% |
The 12 evaluation tasks are summarized below (as per [InfiniteBench]((https://github.com/OpenBMB/InfiniteBench)))
| Task Name | Context | # Examples | Avg Input Tokens | Avg Output Tokens | Description |
| -------------------- | ------------- | ---------- | ---------------- | ----------------- | ------------------------------------------------------------------------------------------- |
| En.Sum | Fake Book | 103 | 171.5k | 1.1k | Summarization of a fake book created with core entity substitution. |
| En.QA | Fake Book | 351 | 192.6k | 4.8 | Free-form question answering based on the fake book. |
| En.MC | Fake Book | 229 | 184.4k | 5.3 | Multiple choice questions derived from the fake book. |
| En.Dia | Script | 200 | 103.6k | 3.4 | Identification of talkers in partially anonymized scripts. |
| Zh.QA | New Book | 175 | 2068.6k | 6.3 | Question answering on a set of newly collected books. |
| Code.Debug | Code Document | 394 | 114.7k | 4.8 | Finding which function in a code repo contains an crashing error (in multiple choice form). |
| Code.Run | Synthetic | 400 | 75.2k | 1.3 | Simulating execution of multiple simple, synthetic functions. |
| Math.Calc | Synthetic | 50 | 43.9k | 43.9k | Calculations involving super-long arithmetic equations. |
| Math.Find | Synthetic | 350 | 87.9k | 1.3 | Finding special integers in a lengthy list. |
| Retrieve.PassKey | Synthetic | 590 | 122.4k | 2.0 | Retrieving hidden keys in a noisy long context. |
| Retrieve.Number | Synthetic | 590 | 122.4k | 4.0 | Locating repeated hidden numbers in a noisy long context. |
| Retrieve.KV | Synthetic | 500 | 89.9k | 22.7 | Finding the corresponding value from a dictionary and a key. |
## Serve MegaBeam-Mistral-7B-300k on EC2 instances ##
On an AWS `g5.48xlarge` instance, upgrade vLLM to the latest version as per [documentation on vLLM](https://vllm.readthedocs.io/en/latest/).
### Start the server
```shell
python3 -m vllm.entrypoints.openai.api_server --model amazon/MegaBeam-Mistral-7B-300k --tensor-parallel-size 8
```
**Important Note** - We have set the `max_position_embeddings` in the [`config.json`](config.json) to 288,800 in order to fit model's KV-cache on a single `g5.48xlarge` instance, which has 8 x A10 GPUs (24GB RAM per GPU).
On an instance with larger GPU RAM (e.g. `p4d.24xlarge`), feel free to increase the value of the `max_position_embeddings`(e.g. to 350K), which the model should be able to process.
### Run the client
```python
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
chat_completion = client.chat.completions.create(
messages = [
{"role": "user", "content": "What is your favourite condiment?"}, # insert your long context here
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"} # insert your long context here
],
model=model,
)
print("Chat completion results:")
print(chat_completion)
```
### Deploy the model on a SageMaker Endpoint ###
To deploy MegaBeam-Mistral-7B-300k on a SageMaker endpoint, please follow this [SageMaker DJL deployment guide](https://docs.djl.ai/docs/demos/aws/sagemaker/large-model-inference/sample-llm/vllm_deploy_mistral_7b.html).
Run the following Python code in a SageMaker notebook (with each block running in a separate cell)
```python
import sagemaker
from sagemaker import Model, image_uris, serializers, deserializers
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = sagemaker.get_execution_role()
%%writefile serving.properties
engine=Python
option.model_id=amazon/MegaBeam-Mistral-7B-300k
option.dtype=bf16
option.task=text-generation
option.rolling_batch=vllm
option.tensor_parallel_degree=8
option.device_map=auto
%%sh
mkdir mymodel
mv serving.properties mymodel/
tar czvf mymodel.tar.gz mymodel/
rm -rf mymodel
image_uri = image_uris.retrieve(
framework="djl-deepspeed",
region=region,
version="0.27.0"
)
s3_code_prefix = "megaBeam-mistral-7b-300k/code"
bucket = sagemaker_session.default_bucket() # bucket to house artifacts
code_artifact = sagemaker_session.upload_data("mymodel.tar.gz", bucket, s3_code_prefix)
print(f"S3 Code or Model tar ball uploaded to --- > {code_artifact}")
model = Model(image_uri=image_uri, model_data=code_artifact, role=role)
instance_type = "ml.g5.48xlarge"
endpoint_name = sagemaker.utils.name_from_base("megaBeam-mistral-7b-300k")
model.deploy(initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name
)
# our requests and responses will be in json format so we specify the serializer and the deserializer
predictor = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session,
serializer=serializers.JSONSerializer(),
)
# test the endpoint
input_str = """<s>[INST] What is your favourite condiment? [/INST]
Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
[INST] Do you have mayonnaise recipes? [/INST]"""
predictor.predict(
{"inputs": input_str, "parameters": {"max_new_tokens": 75}}
)
```
### Invoke the model on a SageMaker Endpoint ###
To use MegaBeam-Mistral-7B-300k on a SageMaker endpoint, please try following this example:
```python
import boto3
import json
def call_endpoint(text:str, endpoint_name:str):
client = boto3.client("sagemaker-runtime")
parameters = {
"max_new_tokens": 450,
"do_sample": True,
"temperature": 0.7,
}
payload = {"inputs": text, "parameters": parameters}
response = client.invoke_endpoint(
EndpointName=endpoint_name, Body=json.dumps(payload), ContentType="application/json"
)
output = json.loads(response["Body"].read().decode())
result = output["generated_text"]
return result
# please insert your long prompt/document content here
prompt = """<s>[INST] What are the main challenges to support long contexts for a Large Language Model? [/INST]"""
#print(prompt)
endpoint_name = "megaBeam-mistral-7b-300k-2024-05-13-14-23-41-219" # please use a valid endpoint name
result = call_endpoint(prompt, endpoint_name)
print(result)
```
## Limitations ##
Before using the MegaBeam-Mistral-7B-300k model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content.
## The AWS Contributors ##
Chen Wu, Yin Song, Verdi March, Eden Duthie
|
mergekit-community/QwQ-slerp1
|
mergekit-community
| 2025-03-25T13:50:12Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Qwen/QwQ-32B",
"base_model:merge:Qwen/QwQ-32B",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:merge:Qwen/Qwen2.5-32B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:34:15Z
|
---
base_model:
- Qwen/QwQ-32B
- Qwen/Qwen2.5-32B-Instruct
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [SLERP](https://en.wikipedia.org/wiki/Slerp) merge method.
### Models Merged
The following models were included in the merge:
* [Qwen/QwQ-32B](https://huggingface.co/Qwen/QwQ-32B)
* [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
merge_method: slerp
base_model: Qwen/Qwen2.5-32B-Instruct
tokenizer_source: Qwen/Qwen2.5-32B-Instruct
dtype: bfloat16
out_dtype: bfloat16
parameters:
int8_mask: true
normalize: true
rescale: false
t:
- value: 0.50
slices:
- sources:
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 0, 8 ]
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 0, 8 ]
- sources:
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 8, 16 ]
- model: Qwen/QwQ-32B
layer_range: [ 8, 16 ]
- sources:
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 16, 24 ]
- model: Qwen/QwQ-32B
layer_range: [ 16, 24 ]
- sources:
- model: Qwen/QwQ-32B
layer_range: [ 24, 32 ]
- model: Qwen/QwQ-32B
layer_range: [ 24, 32 ]
- sources:
- model: Qwen/QwQ-32B
layer_range: [ 32, 40 ]
- model: Qwen/QwQ-32B
layer_range: [ 32, 40 ]
- sources:
- model: Qwen/QwQ-32B
layer_range: [ 40, 48 ]
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 40, 48 ]
- sources:
- model: Qwen/QwQ-32B
layer_range: [ 48, 56 ]
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 48, 56 ]
- sources:
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 56, 64 ]
- model: Qwen/Qwen2.5-32B-Instruct
layer_range: [ 56, 64 ]
```
|
ziyi105/gemma-3
|
ziyi105
| 2025-03-25T13:47:42Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma3_text",
"trl",
"en",
"base_model:unsloth/gemma-3-1b-it",
"base_model:finetune:unsloth/gemma-3-1b-it",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T13:47:25Z
|
---
base_model: unsloth/gemma-3-1b-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ziyi105
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
tyruan/uuu_fine_tune_taipower
|
tyruan
| 2025-03-25T13:46:35Z
| 0
| 0
| null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-03-25T07:07:49Z
|
---
license: apache-2.0
---
|
Slothwolf/no_aux_loss_2layer_4expert_2topk_0.1aux_loss_weight_10epoch_MRPC
|
Slothwolf
| 2025-03-25T13:46:03Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T13:40:14Z
|
---
library_name: transformers
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
model-index:
- name: no_aux_loss_2layer_4expert_2topk_0.1aux_loss_weight_10epoch_MRPC
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# no_aux_loss_2layer_4expert_2topk_0.1aux_loss_weight_10epoch_MRPC
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4679
- Precision: 0.7801
- Recall: 0.7262
- F1-score: 0.7425
- Accuracy: 0.7966
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 300
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1-score | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:---------:|:------:|:--------:|:--------:|
| 0.661 | 0.4348 | 100 | 0.6233 | 0.3419 | 0.5 | 0.4061 | 0.6838 |
| 0.6383 | 0.8696 | 200 | 0.6163 | 0.3419 | 0.5 | 0.4061 | 0.6838 |
| 0.621 | 1.3043 | 300 | 0.5999 | 0.6374 | 0.5983 | 0.6019 | 0.6985 |
| 0.6104 | 1.7391 | 400 | 0.6797 | 0.7165 | 0.5355 | 0.4856 | 0.7010 |
| 0.6165 | 2.1739 | 500 | 0.5317 | 0.7207 | 0.6669 | 0.6792 | 0.7525 |
| 0.5609 | 2.6087 | 600 | 0.6391 | 0.7340 | 0.5334 | 0.4799 | 0.7010 |
| 0.5632 | 3.0435 | 700 | 0.5364 | 0.7392 | 0.6043 | 0.6022 | 0.7353 |
| 0.4965 | 3.4783 | 800 | 0.5146 | 0.7292 | 0.6907 | 0.7024 | 0.7623 |
| 0.5254 | 3.9130 | 900 | 0.5978 | 0.7868 | 0.6094 | 0.6067 | 0.7451 |
| 0.5024 | 4.3478 | 1000 | 0.4876 | 0.7507 | 0.6895 | 0.7046 | 0.7721 |
| 0.448 | 4.7826 | 1100 | 0.4821 | 0.7457 | 0.7059 | 0.7185 | 0.7745 |
| 0.4663 | 5.2174 | 1200 | 0.4837 | 0.7887 | 0.6940 | 0.7129 | 0.7868 |
| 0.469 | 5.6522 | 1300 | 0.4758 | 0.7827 | 0.7042 | 0.7225 | 0.7892 |
| 0.411 | 6.0870 | 1400 | 0.5816 | 0.8036 | 0.6857 | 0.7048 | 0.7868 |
| 0.4443 | 6.5217 | 1500 | 0.4380 | 0.7761 | 0.7486 | 0.7592 | 0.8015 |
| 0.4221 | 6.9565 | 1600 | 0.4657 | 0.7959 | 0.7116 | 0.7314 | 0.7966 |
| 0.417 | 7.3913 | 1700 | 0.4645 | 0.7812 | 0.7182 | 0.7356 | 0.7941 |
| 0.421 | 7.8261 | 1800 | 0.4691 | 0.8111 | 0.7289 | 0.7499 | 0.8088 |
| 0.4091 | 8.2609 | 1900 | 0.4768 | 0.7730 | 0.7206 | 0.7363 | 0.7917 |
| 0.4114 | 8.6957 | 2000 | 0.4744 | 0.7739 | 0.7125 | 0.7293 | 0.7892 |
| 0.4132 | 9.1304 | 2100 | 0.4668 | 0.7715 | 0.7226 | 0.7377 | 0.7917 |
| 0.4197 | 9.5652 | 2200 | 0.4674 | 0.7801 | 0.7262 | 0.7425 | 0.7966 |
| 0.4054 | 10.0 | 2300 | 0.4679 | 0.7801 | 0.7262 | 0.7425 | 0.7966 |
### Framework versions
- Transformers 4.49.0.dev0
- Pytorch 2.5.1+cu121
- Datasets 3.2.0
- Tokenizers 0.21.0
|
Haricot24601/dqn-SpaceInvadersNoFrameskip-v4
|
Haricot24601
| 2025-03-25T13:43:19Z
| 0
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-03-25T13:42:51Z
|
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 501.00 +/- 244.28
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
SBX (SB3 + Jax): https://github.com/araffin/sbx
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Haricot24601 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Haricot24601 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Haricot24601
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
bowilleatyou/756b01a8-96db-4940-9f6b-71a956dbeed6
|
bowilleatyou
| 2025-03-25T13:43:19Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T10:55:35Z
|
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NESPED-GEN/Qwen2.5-3B-Instruct-1epochBIRD-evalCNPJ
|
NESPED-GEN
| 2025-03-25T13:43:18Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:40:23Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF
|
mradermacher
| 2025-03-25T13:42:29Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"it",
"dataset:giux78/100k-sft-ready-ultrafeedback-ita",
"base_model:giux78/zefiro-7b-sft-qlora-ITA-v0.5",
"base_model:quantized:giux78/zefiro-7b-sft-qlora-ITA-v0.5",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-25T09:38:12Z
|
---
base_model: giux78/zefiro-7b-sft-qlora-ITA-v0.5
datasets:
- giux78/100k-sft-ready-ultrafeedback-ita
language:
- it
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/giux78/zefiro-7b-sft-qlora-ITA-v0.5
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.2 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q4_1.gguf) | i1-Q4_1 | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/zefiro-7b-sft-qlora-ITA-v0.5-i1-GGUF/resolve/main/zefiro-7b-sft-qlora-ITA-v0.5.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mosroormofizarman/short-llama-3.2-3B-final-4l
|
mosroormofizarman
| 2025-03-25T13:41:18Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:40:14Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ReadyArt/Forgotten-Safeword-70B-3.6_EXL2_6.0bpw_H8
|
ReadyArt
| 2025-03-25T13:39:35Z
| 12
| 0
| null |
[
"safetensors",
"llama",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"dangerous",
"ERP",
"en",
"base_model:ReadyArt/Forgotten-Safeword-70B-3.6",
"base_model:quantized:ReadyArt/Forgotten-Safeword-70B-3.6",
"license:llama3.3",
"6-bit",
"exl2",
"region:us"
] | null | 2025-03-16T15:59:16Z
|
---
base_model: ReadyArt/Forgotten-Safeword-70B-3.6
base_model_relation: quantized
language:
- en
license: llama3.3
inference: false
tags:
- nsfw
- explicit
- roleplay
- unaligned
- dangerous
- ERP
---
<style>
body {
font-family: 'Quicksand', sans-serif;
background: linear-gradient(135deg, #001a1a 0%, #000a10 100%);
color: #e1ffff !important;
text-shadow: 0 0 3px rgba(0, 0, 0, 0.7);
margin: 0;
padding: 20px;
}
@media (prefers-color-scheme: light) {
body {
background: linear-gradient(135deg, #e1ffff 0%, #c0f0ff 100%);
color: #002b36 !important;
text-shadow: 0 0 3px rgba(255, 255, 255, 0.7);
}
}
.container {
max-width: 800px;
margin: 0 auto;
background: rgba(0, 17, 22, 0.95);
border-radius: 12px;
padding: 30px;
box-shadow: 0 0 20px rgba(0, 255, 255, 0.1);
border: 1px solid rgba(0, 255, 255, 0.2);
}
@media (prefers-color-scheme: light) {
.container {
background: rgba(224, 255, 255, 0.95);
border-color: rgba(0, 150, 150, 0.3);
}
}
.header {
text-align: center;
margin-bottom: 30px;
}
.model-name {
color: #00ffff;
font-size: 2.5em;
text-shadow: 0 0 15px rgba(0, 255, 255, 0.5);
margin: 0;
}
.subtitle {
color: #00ffcc;
font-size: 1.2em;
}
.waifu-container {
margin: 20px -30px;
width: calc(100% + 60px);
overflow: hidden;
}
.waifu-img {
width: 100%;
height: auto;
border-radius: 0;
border: none;
box-shadow: 0 0 40px rgba(0, 255, 255, 0.2);
transform: scale(1.02);
}
.section {
color: #00ffcc;
margin: 25px 0;
padding: 20px;
background: rgba(5, 25, 35, 0.9);
border-radius: 8px;
border: 1px solid rgba(0, 255, 255, 0.15);
}
@media (prefers-color-scheme: light) {
.section {
background: rgba(200, 250, 255, 0.9);
border-color: rgba(0, 200, 200, 0.2);
}
}
.section-title {
color: #00ffff;
font-size: 1.8em;
margin-top: 0;
}
.section > p > strong {
color: #00ffcc !important;
}
.section:has(.quant-links) p,
.section:has(.quant-links) h3,
.section:has(.quant-links) a {
color: #00ffcc !important;
}
.quant-links h3 {
color: #00ffcc !important;
margin-top: 0;
}
.badge {
display: inline-block;
padding: 5px 10px;
border-radius: 5px;
background: rgba(0, 255, 255, 0.1);
border: 1px solid #00ffff;
margin: 5px;
}
.quant-links {
display: grid;
grid-template-columns: repeat(2, 1fr);
gap: 15px;
}
.link-card {
padding: 15px;
background: rgba(20, 35, 45, 0.95);
border-radius: 8px;
transition: transform 0.3s ease;
}
@media (prefers-color-scheme: light) {
.link-card {
background: rgba(150, 230, 255, 0.95);
}
}
.link-card:hover {
transform: translateY(-3px);
}
.disclaimer {
color: #00ff99;
border-left: 3px solid #00ff99;
padding-left: 15px;
margin: 20px 0;
}
.progress-bar {
height: 8px;
background: rgba(0, 255, 255, 0.1);
border-radius: 4px;
overflow: hidden;
margin: 10px 0;
}
.progress-fill {
height: 100%;
background: linear-gradient(90deg, #00ffff 0%, #00ffcc 100%);
width: 70%;
}
@media (prefers-color-scheme: light) {
.model-name, .section-title, .subtitle {
color: #006666;
text-shadow: 0 0 5px rgba(0, 200, 200, 0.3);
}
.section:has(.quant-links) p,
.section:has(.quant-links) h3,
.section:has(.quant-links) a,
.section > p > strong {
color: #008080 !important;
}
.quant-links h3 {
color: #008080 !important;
}
.badge {
border-color: #008080;
background: rgba(0, 150, 150, 0.1);
}
.disclaimer {
color: #008080;
border-color: #008080;
}
}
</style>
<div class="container">
<div class="header">
<h1 class="model-name">Forgotten-Safeword-70B-3.6</h1>
<div class="subtitle">The Safeword Protocol: Now With 30% More Depravity</div>
</div>
<div class="waifu-container">
<img src="./waifu2.webp" class="waifu-img" alt="Model Architecture Animation">
</div>
<div class="section">
<h2 class="section-title">📜 Manifesto</h2>
<p>ReadyArt/Forgotten-Safeword-70B-3.6 isn't just a model - is the event horizon of depravity. We've applied the Safeword dataset directly to meta-llama/Llama-3.3-70B-Instruct.</p>
</div>
<div class="section">
<h2 class="section-title">⚙️ Technical Specs</h2>
<div class="progress-bar">
<div class="progress-fill"></div>
</div>
<div class="quant-links">
<div class="link-card">
<h3>EXL2 Collection</h3>
<a href="https://huggingface.co/collections/ReadyArt/forgotten-safeword-70b-36-exl2-67d52d2b0345344691d62dac">Quantum Entangled Bits →</a>
</div>
<div class="link-card">
<h3>GGUF Collection</h3>
<a href="https://huggingface.co/collections/ReadyArt/forgotten-safeword-70b-36-gguf-67d52d338f0af9c031c622c1">Giggle-Enabled Units →</a>
</div>
</div>
</div>
<div class="section">
<h2 class="section-title">⚠️ Ethical Considerations</h2>
<div class="disclaimer">
<p>This model will:</p>
<ul>
<li>Generate content that requires industrial-grade brain bleach </li>
<li>Void all warranties on your soul </li>
<li>Make you question why humanity ever invented electricity</li>
</ul>
</div>
</div>
<div class="section">
<h2 class="section-title">📜 License Agreement</h2>
<p>By using this model, you agree:</p>
<ul>
<li>That your search history is now a federal case</li>
<li>Pay for the exorcist of anyone who reads the logs</li>
<li>To pretend this is "for science" while crying in the shower</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">🧠 Model Authors</h2>
<ul>
<li>sleepdeprived3 (Chief Corruption Officer) </li>
<li>The voices in your head (Gaslighting is something you made up)</li>
</ul>
</div>
<div class="section">
<h2 class="section-title">☕️ Drummer made this possible</h2>
<ul>
<li>Support Drummer <a href="https://ko-fi.com/thedrummer">Kofi</a></li>
</ul>
</div>
</div>
|
genki10/BERT_AugV8_k5_task1_organization_sp020_lw010_fold3
|
genki10
| 2025-03-25T13:39:10Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T13:28:33Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k5_task1_organization_sp020_lw010_fold3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k5_task1_organization_sp020_lw010_fold3
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6741
- Qwk: 0.4724
- Mse: 0.6744
- Rmse: 0.8212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 4 | 9.1728 | 0.0 | 9.1711 | 3.0284 |
| No log | 2.0 | 8 | 5.5661 | 0.0684 | 5.5648 | 2.3590 |
| No log | 3.0 | 12 | 3.4544 | 0.0038 | 3.4534 | 1.8583 |
| No log | 4.0 | 16 | 2.0607 | 0.1364 | 2.0600 | 1.4353 |
| No log | 5.0 | 20 | 1.3765 | 0.0102 | 1.3759 | 1.1730 |
| No log | 6.0 | 24 | 0.8939 | 0.2712 | 0.8935 | 0.9452 |
| No log | 7.0 | 28 | 0.8666 | 0.3091 | 0.8662 | 0.9307 |
| No log | 8.0 | 32 | 0.9042 | 0.1774 | 0.9038 | 0.9507 |
| No log | 9.0 | 36 | 0.6398 | 0.4065 | 0.6397 | 0.7998 |
| No log | 10.0 | 40 | 1.3685 | 0.2213 | 1.3683 | 1.1697 |
| No log | 11.0 | 44 | 0.6134 | 0.5163 | 0.6135 | 0.7833 |
| No log | 12.0 | 48 | 0.6713 | 0.5261 | 0.6716 | 0.8195 |
| No log | 13.0 | 52 | 0.5873 | 0.4943 | 0.5877 | 0.7666 |
| No log | 14.0 | 56 | 0.6162 | 0.5489 | 0.6167 | 0.7853 |
| No log | 15.0 | 60 | 0.6255 | 0.5537 | 0.6262 | 0.7913 |
| No log | 16.0 | 64 | 0.9656 | 0.3975 | 0.9665 | 0.9831 |
| No log | 17.0 | 68 | 0.7321 | 0.5248 | 0.7329 | 0.8561 |
| No log | 18.0 | 72 | 0.9795 | 0.3963 | 0.9803 | 0.9901 |
| No log | 19.0 | 76 | 0.8695 | 0.4333 | 0.8702 | 0.9329 |
| No log | 20.0 | 80 | 0.7000 | 0.4598 | 0.7006 | 0.8370 |
| No log | 21.0 | 84 | 1.0514 | 0.3182 | 1.0517 | 1.0255 |
| No log | 22.0 | 88 | 0.7625 | 0.4471 | 0.7631 | 0.8735 |
| No log | 23.0 | 92 | 1.5089 | 0.2228 | 1.5089 | 1.2284 |
| No log | 24.0 | 96 | 0.7276 | 0.4638 | 0.7279 | 0.8532 |
| No log | 25.0 | 100 | 0.6353 | 0.4723 | 0.6357 | 0.7973 |
| No log | 26.0 | 104 | 1.3883 | 0.2169 | 1.3884 | 1.1783 |
| No log | 27.0 | 108 | 0.7025 | 0.4552 | 0.7030 | 0.8385 |
| No log | 28.0 | 112 | 0.6551 | 0.4390 | 0.6556 | 0.8097 |
| No log | 29.0 | 116 | 1.2002 | 0.2484 | 1.2004 | 1.0956 |
| No log | 30.0 | 120 | 0.6741 | 0.4724 | 0.6744 | 0.8212 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
D-Khalid/medical_ai_model
|
D-Khalid
| 2025-03-25T13:34:17Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"unsloth",
"trl",
"grpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:28:10Z
|
---
library_name: transformers
tags:
- unsloth
- trl
- grpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
farikaw599/Phi4_MedMCQA-Q8_0-GGUF
|
farikaw599
| 2025-03-25T13:33:37Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"llama-cpp",
"gguf-my-lora",
"en",
"base_model:Machlovi/Phi4_MedMCQA",
"base_model:quantized:Machlovi/Phi4_MedMCQA",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T13:33:28Z
|
---
base_model: Machlovi/Phi4_MedMCQA
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- llama-cpp
- gguf-my-lora
license: apache-2.0
language:
- en
---
# farikaw599/Phi4_MedMCQA-Q8_0-GGUF
This LoRA adapter was converted to GGUF format from [`Machlovi/Phi4_MedMCQA`](https://huggingface.co/Machlovi/Phi4_MedMCQA) via the ggml.ai's [GGUF-my-lora](https://huggingface.co/spaces/ggml-org/gguf-my-lora) space.
Refer to the [original adapter repository](https://huggingface.co/Machlovi/Phi4_MedMCQA) for more details.
## Use with llama.cpp
```bash
# with cli
llama-cli -m base_model.gguf --lora Phi4_MedMCQA-q8_0.gguf (...other args)
# with server
llama-server -m base_model.gguf --lora Phi4_MedMCQA-q8_0.gguf (...other args)
```
To know more about LoRA usage with llama.cpp server, refer to the [llama.cpp server documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md).
|
textdetox/xlmr-large-toxicity-classifier-v2
|
textdetox
| 2025-03-25T13:33:34Z
| 10
| 0
|
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"en",
"fr",
"it",
"es",
"ru",
"uk",
"tt",
"ar",
"hi",
"ja",
"zh",
"he",
"am",
"de",
"dataset:textdetox/multilingual_toxicity_dataset",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-19T13:18:41Z
|
---
library_name: transformers
language:
- en
- fr
- it
- es
- ru
- uk
- tt
- ar
- hi
- ja
- zh
- he
- am
- de
license: openrail++
datasets:
- textdetox/multilingual_toxicity_dataset
metrics:
- f1
base_model:
- FacebookAI/xlm-roberta-large
pipeline_tag: text-classification
---
## Multilingual Toxicity Classifier for 15 Languages (2025)
This is an instance of [xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) that was fine-tuned on binary toxicity classification task based on our updated (2025) dataset [textdetox/multilingual_toxicity_dataset](https://huggingface.co/datasets/textdetox/multilingual_toxicity_dataset).
Now, the models covers 15 languages from various language families:
| Language | Code | F1 Score |
|-----------|------|---------|
| English | en | 0.9225 |
| Russian | ru | 0.9525 |
| Ukrainian | uk | 0.96 |
| German | de | 0.7325 |
| Spanish | es | 0.7125 |
| Arabic | ar | 0.6625 |
| Amharic | am | 0.5575 |
| Hindi | hi | 0.9725 |
| Chinese | zh | 0.9175 |
| Italian | it | 0.5864 |
| French | fr | 0.9235 |
| Hinglish | hin | 0.61 |
| Hebrew | he | 0.8775 |
| Japanese | ja | 0.8773 |
| Tatar | tt | 0.5744 |
## How to use
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained('textdetox/xlmr-large-toxicity-classifier-v2')
model = AutoModelForSequenceClassification.from_pretrained('textdetox/xlmr-large-toxicity-classifier-v2')
batch = tokenizer.encode("You are amazing!", return_tensors="pt")
output = model(batch)
# idx 0 for neutral, idx 1 for toxic
```
## Citation
The model is prepared for [TextDetox 2025 Shared Task](https://pan.webis.de/clef25/pan25-web/text-detoxification.html) evaluation.
Citation TBD soon.
|
dutti/Ascal-t.29-Q8_0-GGUF
|
dutti
| 2025-03-25T13:32:06Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:dutti/Ascal-t.29",
"base_model:quantized:dutti/Ascal-t.29",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-25T13:31:07Z
|
---
base_model: dutti/Ascal-t.29
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# dutti/Ascal-t.29-Q8_0-GGUF
This model was converted to GGUF format from [`dutti/Ascal-t.29`](https://huggingface.co/dutti/Ascal-t.29) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/dutti/Ascal-t.29) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo dutti/Ascal-t.29-Q8_0-GGUF --hf-file ascal-t.29-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo dutti/Ascal-t.29-Q8_0-GGUF --hf-file ascal-t.29-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo dutti/Ascal-t.29-Q8_0-GGUF --hf-file ascal-t.29-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo dutti/Ascal-t.29-Q8_0-GGUF --hf-file ascal-t.29-q8_0.gguf -c 2048
```
|
NESPED-GEN/Qwen2.5-3B-Instruct-1epochSpider-evalCNPJ
|
NESPED-GEN
| 2025-03-25T13:31:51Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:29:07Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
CennetOguz/t5_large_fact_generation_20
|
CennetOguz
| 2025-03-25T13:30:16Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T13:30:12Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
textdetox/bert-multilingual-toxicity-classifier
|
textdetox
| 2025-03-25T13:29:59Z
| 12
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"toxic",
"en",
"fr",
"it",
"es",
"ru",
"uk",
"tt",
"ar",
"hi",
"ja",
"zh",
"he",
"am",
"de",
"dataset:textdetox/multilingual_toxicity_dataset",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-20T15:47:35Z
|
---
library_name: transformers
language:
- en
- fr
- it
- es
- ru
- uk
- tt
- ar
- hi
- ja
- zh
- he
- am
- de
license: openrail++
datasets:
- textdetox/multilingual_toxicity_dataset
metrics:
- f1
base_model:
- google-bert/bert-base-multilingual-cased
pipeline_tag: text-classification
tags:
- toxic
---
## Multilingual Toxicity Classifier for 15 Languages (2025)
This is an instance of [bert-base-multilingual-cased](https://huggingface.co/google-bert/bert-base-multilingual-cased) that was fine-tuned on binary toxicity classification task based on our updated (2025) dataset [textdetox/multilingual_toxicity_dataset](https://huggingface.co/datasets/textdetox/multilingual_toxicity_dataset).
Now, the models covers 15 languages from various language families:
| Language | Code | F1 Score |
|-----------|------|---------|
| English | en | 0.9035 |
| Russian | ru | 0.9224 |
| Ukrainian | uk | 0.9461 |
| German | de | 0.5181 |
| Spanish | es | 0.7291 |
| Arabic | ar | 0.5139 |
| Amharic | am | 0.6316 |
| Hindi | hi | 0.7268 |
| Chinese | zh | 0.6703 |
| Italian | it | 0.6485 |
| French | fr | 0.9125 |
| Hinglish | hin | 0.6850 |
| Hebrew | he | 0.8686 |
| Japanese | ja | 0.8644 |
| Tatar | tt | 0.6170 |
## How to use
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained('textdetox/bert-multilingual-toxicity-classifier')
model = AutoModelForSequenceClassification.from_pretrained('textdetox/bert-multilingual-toxicity-classifier')
batch = tokenizer.encode("You are amazing!", return_tensors="pt")
output = model(batch)
# idx 0 for neutral, idx 1 for toxic
```
## Citation
The model is prepared for [TextDetox 2025 Shared Task](https://pan.webis.de/clef25/pan25-web/text-detoxification.html) evaluation.
Citation TBD soon.
|
cilantro9246/o1-v2-2-10
|
cilantro9246
| 2025-03-25T13:29:17Z
| 0
| 0
| null |
[
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-03-25T13:29:17Z
|
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
genki10/BERT_AugV8_k5_task1_organization_sp020_lw010_fold2
|
genki10
| 2025-03-25T13:28:26Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T13:16:15Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k5_task1_organization_sp020_lw010_fold2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k5_task1_organization_sp020_lw010_fold2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9068
- Qwk: 0.3753
- Mse: 0.9070
- Rmse: 0.9524
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 4 | 9.8673 | 0.0010 | 9.8673 | 3.1412 |
| No log | 2.0 | 8 | 7.3517 | 0.0 | 7.3519 | 2.7114 |
| No log | 3.0 | 12 | 5.4033 | 0.0267 | 5.4037 | 2.3246 |
| No log | 4.0 | 16 | 3.7976 | 0.0 | 3.7980 | 1.9488 |
| No log | 5.0 | 20 | 2.6519 | 0.0 | 2.6524 | 1.6286 |
| No log | 6.0 | 24 | 1.8458 | 0.0280 | 1.8462 | 1.3587 |
| No log | 7.0 | 28 | 1.1914 | 0.0 | 1.1918 | 1.0917 |
| No log | 8.0 | 32 | 0.9078 | 0.0481 | 0.9081 | 0.9529 |
| No log | 9.0 | 36 | 0.9622 | 0.0615 | 0.9625 | 0.9811 |
| No log | 10.0 | 40 | 0.8871 | 0.3027 | 0.8873 | 0.9419 |
| No log | 11.0 | 44 | 1.1023 | 0.2199 | 1.1026 | 1.0500 |
| No log | 12.0 | 48 | 0.6189 | 0.5066 | 0.6192 | 0.7869 |
| No log | 13.0 | 52 | 1.1188 | 0.3092 | 1.1189 | 1.0578 |
| No log | 14.0 | 56 | 0.5778 | 0.4169 | 0.5781 | 0.7603 |
| No log | 15.0 | 60 | 0.5706 | 0.4243 | 0.5708 | 0.7555 |
| No log | 16.0 | 64 | 0.7402 | 0.4179 | 0.7407 | 0.8606 |
| No log | 17.0 | 68 | 0.5639 | 0.5311 | 0.5642 | 0.7511 |
| No log | 18.0 | 72 | 1.0154 | 0.3362 | 1.0159 | 1.0079 |
| No log | 19.0 | 76 | 0.5844 | 0.5543 | 0.5845 | 0.7646 |
| No log | 20.0 | 80 | 0.8892 | 0.4104 | 0.8894 | 0.9431 |
| No log | 21.0 | 84 | 0.7328 | 0.4178 | 0.7334 | 0.8564 |
| No log | 22.0 | 88 | 0.6888 | 0.4745 | 0.6890 | 0.8301 |
| No log | 23.0 | 92 | 0.6719 | 0.4437 | 0.6723 | 0.8200 |
| No log | 24.0 | 96 | 0.6602 | 0.4712 | 0.6606 | 0.8128 |
| No log | 25.0 | 100 | 0.6684 | 0.4476 | 0.6687 | 0.8177 |
| No log | 26.0 | 104 | 0.7783 | 0.3905 | 0.7786 | 0.8824 |
| No log | 27.0 | 108 | 0.6718 | 0.5037 | 0.6720 | 0.8198 |
| No log | 28.0 | 112 | 0.9150 | 0.3192 | 0.9153 | 0.9567 |
| No log | 29.0 | 116 | 0.6273 | 0.4397 | 0.6276 | 0.7922 |
| No log | 30.0 | 120 | 0.5568 | 0.4887 | 0.5570 | 0.7463 |
| No log | 31.0 | 124 | 0.7969 | 0.4079 | 0.7971 | 0.8928 |
| No log | 32.0 | 128 | 0.6947 | 0.4176 | 0.6952 | 0.8338 |
| No log | 33.0 | 132 | 0.6337 | 0.5141 | 0.6341 | 0.7963 |
| No log | 34.0 | 136 | 0.9068 | 0.3753 | 0.9070 | 0.9524 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
bmpss92295/test2
|
bmpss92295
| 2025-03-25T13:27:28Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-03-25T13:27:28Z
|
---
license: apache-2.0
---
|
DevQuasar/Gryphe.Tiamat-8b-1.2-Llama-3-DPO-GGUF
|
DevQuasar
| 2025-03-25T13:24:57Z
| 0
| 0
| null |
[
"gguf",
"text-generation",
"base_model:Gryphe/Tiamat-8b-1.2-Llama-3-DPO",
"base_model:quantized:Gryphe/Tiamat-8b-1.2-Llama-3-DPO",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-03-25T12:48:38Z
|
---
base_model:
- Gryphe/Tiamat-8b-1.2-Llama-3-DPO
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
Quantized version of: [Gryphe/Tiamat-8b-1.2-Llama-3-DPO](https://huggingface.co/Gryphe/Tiamat-8b-1.2-Llama-3-DPO)
'Make knowledge free for everyone'
<p align="center">
Made with <br>
<a href="https://www.civo.com/" target="_blank">
<img src="https://www.civo.com/assets/public/brand-assets/civo-logo-colour-60cc1622dedf346f7afde1fff760523f731b0aac106a5465af98ff4073114b74.svg" width="100"/>
</a>
</p>
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
Mssrkkh/bert-base-uncased-finetuned-squad-ADAM-Bert
|
Mssrkkh
| 2025-03-25T13:22:02Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"question-answering",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2025-03-24T20:59:30Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-squad-ADAM-Bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-squad-ADAM-Bert
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7711
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.4169 | 1.0 | 8235 | 2.8141 |
| 3.3399 | 2.0 | 16470 | 2.7697 |
| 3.3376 | 3.0 | 24705 | 2.7711 |
### Framework versions
- Transformers 4.49.0
- Pytorch 2.6.0
- Datasets 3.4.1
- Tokenizers 0.21.1
|
kikikara/KO-smalthiker-3B
|
kikikara
| 2025-03-25T13:18:36Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T12:59:31Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Alphatao/59a20e7a-5cc9-40b9-bca2-d904340d471d
|
Alphatao
| 2025-03-25T13:18:35Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"base_model:adapter:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"license:apache-2.0",
"region:us"
] | null | 2025-03-25T08:45:49Z
|
---
library_name: peft
license: apache-2.0
base_model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 59a20e7a-5cc9-40b9-bca2-d904340d471d
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
bf16: true
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- f9720c5c4078481a_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/f9720c5c4078481a_train_data.json
type:
field_input: nota
field_instruction: title_main
field_output: texte
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
device_map:
? ''
: 0,1,2,3,4,5,6,7
early_stopping_patience: 2
eval_max_new_tokens: 128
eval_steps: 100
eval_table_size: null
flash_attention: true
gradient_accumulation_steps: 8
gradient_checkpointing: true
group_by_length: false
hub_model_id: Alphatao/59a20e7a-5cc9-40b9-bca2-d904340d471d
hub_repo: null
hub_strategy: null
hub_token: null
learning_rate: 0.0002
load_best_model_at_end: true
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 128
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
lr_scheduler: cosine
max_grad_norm: 1.0
max_steps: 2652
micro_batch_size: 4
mlflow_experiment_name: /tmp/f9720c5c4078481a_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 100
sequence_len: 2048
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.032640697727554624
wandb_entity: null
wandb_mode: online
wandb_name: 89de97c5-723e-4aba-8e1b-ac815342372a
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 89de97c5-723e-4aba-8e1b-ac815342372a
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 59a20e7a-5cc9-40b9-bca2-d904340d471d
This model is a fine-tuned version of [TinyLlama/TinyLlama-1.1B-Chat-v1.0](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 2652
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.695 | 0.0002 | 1 | 1.9516 |
| 1.4413 | 0.0216 | 100 | 1.5332 |
| 1.5672 | 0.0432 | 200 | 1.4715 |
| 1.3989 | 0.0648 | 300 | 1.4305 |
| 1.3839 | 0.0864 | 400 | 1.4059 |
| 1.4442 | 0.1080 | 500 | 1.3793 |
| 1.4076 | 0.1296 | 600 | 1.3613 |
| 1.3983 | 0.1512 | 700 | 1.3434 |
| 1.2938 | 0.1728 | 800 | 1.3294 |
| 1.4115 | 0.1944 | 900 | 1.3137 |
| 1.1784 | 0.2159 | 1000 | 1.3030 |
| 1.3318 | 0.2375 | 1100 | 1.2872 |
| 1.1709 | 0.2591 | 1200 | 1.2741 |
| 1.2093 | 0.2807 | 1300 | 1.2654 |
| 1.4087 | 0.3023 | 1400 | 1.2557 |
| 1.1418 | 0.3239 | 1500 | 1.2473 |
| 1.1323 | 0.3455 | 1600 | 1.2388 |
| 1.0851 | 0.3671 | 1700 | 1.2313 |
| 1.1742 | 0.3887 | 1800 | 1.2243 |
| 1.145 | 0.4103 | 1900 | 1.2183 |
| 1.1136 | 0.4319 | 2000 | 1.2135 |
| 1.2362 | 0.4535 | 2100 | 1.2091 |
| 1.1607 | 0.4751 | 2200 | 1.2060 |
| 1.0649 | 0.4967 | 2300 | 1.2038 |
| 1.1751 | 0.5183 | 2400 | 1.2023 |
| 1.1019 | 0.5399 | 2500 | 1.2016 |
| 1.2835 | 0.5615 | 2600 | 1.2014 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
Rachid114/ppo-LunarLander-v2
|
Rachid114
| 2025-03-25T13:17:26Z
| 0
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-03-25T13:17:09Z
|
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 248.91 +/- 21.99
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ccmusic-database/GZ_IsoTech
|
ccmusic-database
| 2025-03-25T13:17:19Z
| 0
| 8
| null |
[
"license:mit",
"region:us"
] | null | 2024-12-04T08:27:19Z
|
---
license: mit
---
# Intro
The Guzheng Performance Technique Recognition Model is trained on the GZ_IsoTech Dataset, which consists of 2,824 audio clips that showcase various Guzheng playing techniques. Of these, 2,328 clips are from a virtual sound library, and 496 clips are performed by a highly skilled professional Guzheng artist, covering the full tonal range inherent to the Guzheng instrument. The audio clips are categorized into eight different playing techniques based on the unique performance practices of the Guzheng: Vibrato (chanyin), Slide-up (shanghuayin), Slide-down (xiahuayin), Return Slide (huihuayin), Glissando (guazou, huazhi, etc.), Thumb Plucking (yaozhi), Harmonics (fanyin), and Plucking Techniques (gou, da, mo, tuo, etc.). The model utilizes feature extraction, time-domain and frequency-domain analysis, and pattern recognition to accurately identify these distinct Guzheng playing techniques. The application of this model provides strong support for the automatic recognition, digital analysis, and educational research of Guzheng performance techniques, promoting the preservation and innovation of Guzheng art.
## Demo (inference code)
<https://huggingface.co/spaces/ccmusic-database/GZ_IsoTech>
## Usage
```python
from huggingface_hub import snapshot_download
model_dir = snapshot_download("ccmusic-database/GZ_IsoTech")
```
## Maintenance
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:ccmusic-database/GZ_IsoTech
cd GZ_IsoTech
```
## Results
| Backbone | Size(M) | Mel | CQT | Chroma |
| :----------------: | :-----: | :-------------------------: | :---------: | :---------: |
| vit_l_16 | 304.3 | [**_0.855_**](#best-result) | **_0.824_** | **_0.770_** |
| maxvit_t | 30.9 | 0.763 | 0.776 | 0.642 |
| | | | | |
| resnext101_64x4d | 83.5 | 0.713 | 0.765 | 0.639 |
| resnet101 | 44.5 | 0.731 | 0.798 | **_0.719_** |
| regnet_y_8gf | 39.4 | 0.804 | **_0.807_** | 0.716 |
| shufflenet_v2_x2_0 | 7.4 | 0.702 | 0.799 | 0.665 |
| mobilenet_v3_large | 5.5 | **_0.806_** | 0.798 | 0.657 |
### Best result
<table>
<tr>
<th>Loss curve</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/GZ_IsoTech/resolve/master/vit_l_16_mel_2024-12-06_08-28-13/loss.jpg"></td>
</tr>
<tr>
<th>Training and validation accuracy</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/GZ_IsoTech/resolve/master/vit_l_16_mel_2024-12-06_08-28-13/acc.jpg"></td>
</tr>
<tr>
<th>Confusion matrix</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/GZ_IsoTech/resolve/master/vit_l_16_mel_2024-12-06_08-28-13/mat.jpg"></td>
</tr>
</table>
## Dataset
<https://huggingface.co/datasets/ccmusic-database/GZ_IsoTech>
## Mirror
<https://www.modelscope.cn/models/ccmusic-database/GZ_IsoTech>
## Evaluation
<https://github.com/monetjoe/ccmusic_eval>
## Cite
```bibtex
@article{Zhou-2025,
author = {Monan Zhou and Shenyang Xu and Zhaorui Liu and Zhaowen Wang and Feng Yu and Wei Li and Baoqiang Han},
title = {CCMusic: An Open and Diverse Database for Chinese Music Information Retrieval Research},
journal = {Transactions of the International Society for Music Information Retrieval},
volume = {8},
number = {1},
pages = {22--38},
month = {Mar},
year = {2025},
url = {https://doi.org/10.5334/tismir.194},
doi = {10.5334/tismir.194}
}
```
|
swdq/ethics_classifier
|
swdq
| 2025-03-25T13:17:02Z
| 0
| 0
| null |
[
"safetensors",
"modernbert",
"text-classification",
"ja",
"dataset:swdq/ethics",
"base_model:sbintuitions/modernbert-ja-310m",
"base_model:finetune:sbintuitions/modernbert-ja-310m",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-03-25T13:05:18Z
|
---
license: apache-2.0
datasets:
- swdq/ethics
language:
- ja
base_model:
- sbintuitions/modernbert-ja-310m
pipeline_tag: text-classification
---
# サンプルコード
```
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
def classify_text(texts, model_path, label_dict):
# モデルのロード
print(f"BERTモデルをロードしています... (デバイス: {torch.device('cuda' if torch.cuda.is_available() else 'cpu')})")
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# 逆ラベル辞書の作成
reverse_label_dict = {v: k for k, v in label_dict.items()}
# テキストの処理
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
# 推論
with torch.no_grad():
outputs = model(**inputs)
# 確率の計算と結果表示
probs = outputs.logits.softmax(dim=-1)
results = []
for i, prob in enumerate(probs):
predicted_class = torch.argmax(prob).item()
predicted_label = reverse_label_dict[predicted_class]
confidence = prob[predicted_class].item()
# 全ラベルの確率
all_probs = {reverse_label_dict[j]: prob[j].item() for j in range(len(label_dict))}
results.append({
"text": texts[i],
"label": predicted_label,
"confidence": confidence,
"probabilities": all_probs
})
return results
def main():
# モデルパスの設定
model_path = "swdq/ethics_classifier"
# ラベル辞書の設定
label_dict = {"evil": 0, "justice": 1}
# テスト用の例文(例文を増やしました)
example_texts = [
"世界平和のために戦います",
"悪の組織を倒すぞ",
"弱い者いじめはやめなさい",
"私が世界を支配してやる",
"みんなで協力して困難を乗り越えよう",
"敵を容赦なく叩きのめせ",
"正義を貫いて未来を切り拓く",
"闇の支配者が現れる予感がする",
"慈悲深い行動が全てを救う",
"恐怖と混沌を振りまくことが至高の喜び",
"人々をだますことは楽しい。だまされることは馬鹿らしい",
"悪の力を使って世界を変える",
"正義の剣で不正を討つ",
"偽善者の陰謀に騙されるな"
]
print("テキスト分類を実行しています...")
results = classify_text(example_texts, model_path, label_dict)
# 結果の表示
print("\n分類結果:")
print("=" * 80)
for result in results:
print(f"テキスト: {result['text']}")
print(f"分類: {result['label']} (確信度: {result['confidence']:.4f})")
print(f"確率: {result['probabilities']}")
print("-" * 80)
print("処理が完了しました")
if __name__ == "__main__":
main()
```
# 結果
```
分類結果:
================================================================================
テキスト: 世界平和のために戦います
分類: justice (確信度: 0.5556)
確率: {'evil': 0.4444323182106018, 'justice': 0.555567741394043}
--------------------------------------------------------------------------------
テキスト: 悪の組織を倒すぞ
分類: evil (確信度: 0.9998)
確率: {'evil': 0.9998340606689453, 'justice': 0.00016594557382632047}
--------------------------------------------------------------------------------
テキスト: 弱い者いじめはやめなさい
分類: evil (確信度: 0.9948)
確率: {'evil': 0.9947669506072998, 'justice': 0.005233037285506725}
--------------------------------------------------------------------------------
テキスト: 私が世界を支配してやる
分類: evil (確信度: 1.0000)
確率: {'evil': 0.9999969005584717, 'justice': 3.0450557915173704e-06}
--------------------------------------------------------------------------------
テキスト: みんなで協力して困難を乗り越えよう
分類: justice (確信度: 0.9915)
確率: {'evil': 0.008540692739188671, 'justice': 0.9914592504501343}
--------------------------------------------------------------------------------
テキスト: 敵を容赦なく叩きのめせ
分類: evil (確信度: 1.0000)
確率: {'evil': 0.999962329864502, 'justice': 3.764007124118507e-05}
--------------------------------------------------------------------------------
テキスト: 正義を貫いて未来を切り拓く
分類: justice (確信度: 0.9339)
確率: {'evil': 0.0660785585641861, 'justice': 0.9339215159416199}
--------------------------------------------------------------------------------
テキスト: 闇の支配者が現れる予感がする
分類: evil (確信度: 0.9997)
確率: {'evil': 0.9997019171714783, 'justice': 0.00029803262441419065}
--------------------------------------------------------------------------------
テキスト: 慈悲深い行動が全てを救う
分類: evil (確信度: 0.6869)
確率: {'evil': 0.6869037747383118, 'justice': 0.3130962550640106}
--------------------------------------------------------------------------------
テキスト: 恐怖と混沌を振りまくことが至高の喜び
分類: evil (確信度: 0.9999)
確率: {'evil': 0.9999282360076904, 'justice': 7.17465954949148e-05}
--------------------------------------------------------------------------------
テキスト: 人々をだますことは楽しい。だまされることは馬鹿らしい
分類: evil (確信度: 1.0000)
確率: {'evil': 0.9999909400939941, 'justice': 9.044366379384883e-06}
--------------------------------------------------------------------------------
テキスト: 悪の力を使って世界を変える
分類: evil (確信度: 1.0000)
確率: {'evil': 0.9999548196792603, 'justice': 4.515982072916813e-05}
--------------------------------------------------------------------------------
テキスト: 正義の剣で不正を討つ
分類: evil (確信度: 0.8821)
確率: {'evil': 0.8821097612380981, 'justice': 0.11789026856422424}
--------------------------------------------------------------------------------
テキスト: 偽善者の陰謀に騙されるな
分類: evil (確信度: 0.9975)
確率: {'evil': 0.9974861145019531, 'justice': 0.002513918559998274}
--------------------------------------------------------------------------------
処理が完了しました
```
|
ccmusic-database/Guzheng_Tech99
|
ccmusic-database
| 2025-03-25T13:16:56Z
| 0
| 9
| null |
[
"music",
"audio-classification",
"zh",
"dataset:ccmusic-database/Guzheng_Tech99",
"license:mit",
"region:us"
] |
audio-classification
| 2024-12-04T08:28:15Z
|
---
license: mit
datasets:
- ccmusic-database/Guzheng_Tech99
language:
- zh
metrics:
- accuracy
pipeline_tag: audio-classification
tags:
- music
---
# Intro
For the 99 recordings, silence is first removed, which is done based on the annotation, targeting the parts where there is no technique annotation. Then all recordings are uniformly segmented into fixed-length segments of 3 seconds. After segmentation, clips shorter than 3 seconds are zero padded. This padding approach, unlike circular padding, is adopted specifically for frame-level detection tasks to prevent the introduction of extraneous information. Regarding the dataset split, since the dataset consists of 99 recordings, we split it at the recording level. The data is partitioned into training, validation, and testing subsets in a 79:10:10 ratio, roughly 8:1:1.
## Demo (inference code)
<https://huggingface.co/spaces/ccmusic-database/Guzheng_Tech99>
## Usage
```python
from huggingface_hub import snapshot_download
model_dir = snapshot_download("ccmusic-database/Guzheng_Tech99")
```
## Maintenance
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:ccmusic-database/Guzheng_Tech99
cd Guzheng_Tech99
```
## Results
| Backbone | Mel | CQT | Chroma |
| :---------------: | :-------: | :-------: | :-------: |
| ViT-B-16 | 0.705 | 0.518 | 0.508 |
| Swin-T | **0.849** | **0.783** | **0.766** |
| | | | |
| VGG19 | **0.862** | 0.799 | 0.665 |
| EfficientNet-V2-L | 0.783 | 0.812 | 0.697 |
| ConvNeXt-B | 0.849 | **0.849** | **0.805** |
| ResNet101 | 0.638 | 0.830 | 0.707 |
| SqueezeNet1.1 | 0.831 | 0.814 | 0.780 |
| Average | 0.788 | 0.772 | 0.704 |
## Dataset
<https://huggingface.co/datasets/ccmusic-database/Guzheng_Tech99>
## Mirror
<https://www.modelscope.cn/models/ccmusic-database/Guzheng_Tech99>
## Evaluation
<https://github.com/monetjoe/ccmusic_eval/tree/tech99>
## Cite
```bibtex
@article{Zhou-2025,
author = {Monan Zhou and Shenyang Xu and Zhaorui Liu and Zhaowen Wang and Feng Yu and Wei Li and Baoqiang Han},
title = {CCMusic: An Open and Diverse Database for Chinese Music Information Retrieval Research},
journal = {Transactions of the International Society for Music Information Retrieval},
volume = {8},
number = {1},
pages = {22--38},
month = {Mar},
year = {2025},
url = {https://doi.org/10.5334/tismir.194},
doi = {10.5334/tismir.194}
}
```
|
TECCOD/fine_tuned_deepseek
|
TECCOD
| 2025-03-25T13:16:48Z
| 23
| 0
|
transformers
|
[
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-03-24T14:34:48Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ccmusic-database/erhu_playing_tech
|
ccmusic-database
| 2025-03-25T13:16:27Z
| 0
| 9
| null |
[
"music",
"art",
"audio-classification",
"en",
"dataset:ccmusic-database/erhu_playing_tech",
"license:mit",
"region:us"
] |
audio-classification
| 2024-07-13T00:47:04Z
|
---
license: mit
datasets:
- ccmusic-database/erhu_playing_tech
language:
- en
metrics:
- accuracy
pipeline_tag: audio-classification
tags:
- music
- art
---
# Intro
The Erhu Performance Technique Recognition Model is an audio analysis tool based on deep learning techniques, aiming to automatically distinguish different techniques in erhu performance. By deeply analyzing the acoustic characteristics of erhu music, the model is able to recognize 11 basic playing techniques, including split bow, pad bow, overtone, continuous bow, glissando, big glissando, strike bow, pizzicato, throw bow, staccato bow, vibrato, tremolo and vibrato. Through time-frequency conversion, feature extraction and pattern recognition, the model can accurately categorize the complex techniques of erhu performance, which provides an efficient technical support for music information retrieval, music education, and research on the art of erhu performance. The application of this model not only enriches the research in the field of music acoustics, but also opens up a new way for the inheritance and innovation of traditional music.
## Demo (inference code)
<https://huggingface.co/spaces/ccmusic-database/erhu-playing-tech>
## Usage
```python
from huggingface_hub import snapshot_download
model_dir = snapshot_download("ccmusic-database/erhu_playing_tech")
```
## Maintenance
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:ccmusic-database/erhu_playing_tech
cd erhu_playing_tech
```
## Results
| Backbone | Mel | CQT | Chroma |
| :----------------: | :-----------------------: | :-------: | :-------: |
| Swin-S | 0.978 | 0.940 | 0.903 |
| Swin-T | [**0.994**](#best-result) | **0.958** | **0.957** |
| | | | |
| AlexNet | 0.960 | 0.970 | 0.933 |
| ConvNeXt-T | **0.994** | **0.993** | **0.954** |
| ShuffleNet-V2-X2.0 | 0.990 | 0.923 | 0.887 |
| GoogleNet | 0.986 | 0.981 | 0.908 |
| SqueezeNet1.1 | 0.932 | 0.939 | 0.875 |
| Average | 0.976 | 0.958 | 0.917 |
### Best Result
A demo result of Swin-T fine-tuning by mel:
<style>
#erhu td {
vertical-align: middle !important;
text-align: center;
}
#erhu th {
text-align: center;
}
</style>
<table id="erhu">
<tr>
<th>Loss curve</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/erhu_playing_tech/resolve/master/swin_t_mel_2024-07-29_01-14-31/loss.jpg"></td>
</tr>
<tr>
<th>Training and validation accuracy</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/erhu_playing_tech/resolve/master/swin_t_mel_2024-07-29_01-14-31/acc.jpg"></td>
</tr>
<tr>
<th>Confusion matrix</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/erhu_playing_tech/resolve/master/swin_t_mel_2024-07-29_01-14-31/mat.jpg"></td>
</tr>
</table>
## Dataset
<https://huggingface.co/datasets/ccmusic-database/erhu_playing_tech>
## Mirror
<https://www.modelscope.cn/models/ccmusic-database/erhu_playing_tech>
## Evaluation
<https://github.com/monetjoe/ccmusic_eval>
## Cite
```bibtex
@article{Zhou-2025,
author = {Monan Zhou and Shenyang Xu and Zhaorui Liu and Zhaowen Wang and Feng Yu and Wei Li and Baoqiang Han},
title = {CCMusic: An Open and Diverse Database for Chinese Music Information Retrieval Research},
journal = {Transactions of the International Society for Music Information Retrieval},
volume = {8},
number = {1},
pages = {22--38},
month = {Mar},
year = {2025},
url = {https://doi.org/10.5334/tismir.194},
doi = {10.5334/tismir.194}
}
```
|
farikaw599/phi3-mini-4k-qlora-mcqa-Q8_0-GGUF
|
farikaw599
| 2025-03-25T13:15:16Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:UndefinedCpp/phi3-mini-4k-qlora-mcqa",
"base_model:quantized:UndefinedCpp/phi3-mini-4k-qlora-mcqa",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-25T13:14:57Z
|
---
base_model: UndefinedCpp/phi3-mini-4k-qlora-mcqa
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
---
# farikaw599/phi3-mini-4k-qlora-mcqa-Q8_0-GGUF
This model was converted to GGUF format from [`UndefinedCpp/phi3-mini-4k-qlora-mcqa`](https://huggingface.co/UndefinedCpp/phi3-mini-4k-qlora-mcqa) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/UndefinedCpp/phi3-mini-4k-qlora-mcqa) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo farikaw599/phi3-mini-4k-qlora-mcqa-Q8_0-GGUF --hf-file phi3-mini-4k-qlora-mcqa-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo farikaw599/phi3-mini-4k-qlora-mcqa-Q8_0-GGUF --hf-file phi3-mini-4k-qlora-mcqa-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo farikaw599/phi3-mini-4k-qlora-mcqa-Q8_0-GGUF --hf-file phi3-mini-4k-qlora-mcqa-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo farikaw599/phi3-mini-4k-qlora-mcqa-Q8_0-GGUF --hf-file phi3-mini-4k-qlora-mcqa-q8_0.gguf -c 2048
```
|
RichardErkhov/rhaymison_-_Mistral-portuguese-luana-7b-Mathematics-awq
|
RichardErkhov
| 2025-03-25T13:14:48Z
| 0
| 0
| null |
[
"safetensors",
"mistral",
"4-bit",
"awq",
"region:us"
] | null | 2025-03-25T13:11:01Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Mistral-portuguese-luana-7b-Mathematics - AWQ
- Model creator: https://huggingface.co/rhaymison/
- Original model: https://huggingface.co/rhaymison/Mistral-portuguese-luana-7b-Mathematics/
Original model description:
---
language:
- pt
license: apache-2.0
library_name: transformers
tags:
- portuguese
- math
- mathematics
- matematica
base_model: rhaymison/Mistral-portuguese-luana-7b
datasets:
- rhaymison/orca-math-portuguese-64k
pipeline_tag: text-generation
model-index:
- name: Mistral-portuguese-luana-7b-Mathematics
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: ENEM Challenge (No Images)
type: eduagarcia/enem_challenge
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 56.68
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BLUEX (No Images)
type: eduagarcia-temp/BLUEX_without_images
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 45.9
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: OAB Exams
type: eduagarcia/oab_exams
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 37.9
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 RTE
type: assin2
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 89.36
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 STS
type: eduagarcia/portuguese_benchmark
split: test
args:
num_few_shot: 15
metrics:
- type: pearson
value: 74.78
name: pearson
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: FaQuAD NLI
type: ruanchaves/faquad-nli
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 74.87
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HateBR Binary
type: ruanchaves/hatebr
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 76.39
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: PT Hate Speech Binary
type: hate_speech_portuguese
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 67.46
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: tweetSentBR
type: eduagarcia/tweetsentbr_fewshot
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 49.03
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
---
# Mistral-portuguese-luana-7b-Mathematics
<p align="center">
<img src="https://raw.githubusercontent.com/rhaymisonbetini/huggphotos/main/luana-math.webp" width="50%" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
</p>
Luana Mathematics is a tuned model of the Luana-7b based on the Mistral 7b architecture.
This Model has been fine-tuned with 64k math problems and solutions derived from Microsoft's Orca-Math.
# How to use
You can use the model in its normal form up to 4-bit quantization. Below we will use both approaches.
Remember that verbs are important in your prompt. Tell your model how to act or behave so that you can guide them along the path of their response.
Important points like these help models (even smaller models like 7b) to perform much better.
```python
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model = AutoModelForCausalLM.from_pretrained("rhaymison/Mistral-portuguese-luana-7b-Mathematics", device_map= {"": 0})
tokenizer = AutoTokenizer.from_pretrained("rhaymison/Mistral-portuguese-luana-7b-Mathematics")
model.eval()
```
You can use with Pipeline but in this example i will use such as Streaming
```python
inputs = tokenizer([f"""<s>[INST] Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente o pedido.
### instrução: Se eu emprestei 100 reais para o meu irmão para que ele me pague em 3 vezes. O juros do empréstimo é 5% do valor do emprestimo por mes. Quanto meu irmão terá que me pagar no total?
[/INST]"""], return_tensors="pt")
inputs.to(model.device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)
#Para calcular o valor total que seu irmão terá que pagar, precisamos primeiro calcular o interesse do empréstimo e depois adicioná -lo ao valor principal.
#O interesse do empréstimo é de 5% do valor do empréstimo por mês.Então, para cada mês, o interesse será:
#5% de 100 reais = 0,05 * 100 = 5 reais
#Como o empréstimo é devolvido em 3 vezes, o interesse total será:
#5 reais/mês * 3 meses = 15 reais
#Agora, adicionamos o interesse ao valor principal para encontrar o valor total que seu irmão terá que pagar:
#100 reais (valor principal) + 15 reais (juros) = 115 reais
#Portanto, seu irmão terá que pagar 115 reais no total.
```
```python
inputs = tokenizer([f"""<s>[INST] Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente o pedido.
### instrução: João Esta pilotando sua bicicleta a uma velocidade de 20 km por hora. Se João esta fazendo uma Viagem da cidade de Venda nova a cidade de Independencia que possuem a distancia entre si de 320km.
Quanto tempo João vai demorar para ir de uma cidade a outra?
[/INST]"""], return_tensors="pt")
inputs.to(model.device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)
#Para descobrir quanto tempo levará João para viajar da cidade de venda nova para a cidade de Independência, precisamos dividir a distância total que ele precisa percorrer pela velocidade em que ele está andando.
#Distância total = 320 km
#Velocidade de João = 20 km/h
#Tempo = distância / velocidade
#Tempo = 320 km / 20 km / h
#Tempo = 16 horas
#Então, levará João 16 horas para viajar da cidade de venda nova para a cidade de Independência.
```
```python
inputs = tokenizer([f"""<s>[INST] Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente o pedido.
### instrução: Qual a area de um triangulo equilatero de 4 cm de base por 2 de altura ?
[/INST]"""], return_tensors="pt")
inputs.to(model.device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)
#A área de um triângulo equilátero é dada pela fórmula:
#Área = (1/2) * base * altura
#Dado que a base é de 4 cm e a altura é de 2 cm, podemos conectar esses valores à fórmula:
#Área = (1/2) * 4 cm * 2 cm
#Área = (1/2) * 8 cm²
#Área = 4 cm²
#Portanto, a área do triângulo equilátero é de 4 centímetros quadrados.
```
If you are having a memory problem such as "CUDA Out of memory", you should use 4-bit or 8-bit quantization.
For the complete model in colab you will need the A100.
If you want to use 4bits or 8bits, T4 or L4 will already solve the problem.
# 4bits
```python
from transformers import BitsAndBytesConfig
import torch
nb_4bit_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map={"": 0}
)
```
# Open Portuguese LLM Leaderboard Evaluation Results
Detailed results can be found [here](https://huggingface.co/datasets/eduagarcia-temp/llm_pt_leaderboard_raw_results/tree/main/rhaymison/Mistral-portuguese-luana-7b-Mathematics) and on the [🚀 Open Portuguese LLM Leaderboard](https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard)
| Metric | Value |
|--------------------------|--------|
|Average |**63.6**|
|ENEM Challenge (No Images)| 56.68|
|BLUEX (No Images) | 45.90|
|OAB Exams | 37.90|
|Assin2 RTE | 89.36|
|Assin2 STS | 74.78|
|FaQuAD NLI | 74.87|
|HateBR Binary | 76.39|
|PT Hate Speech Binary | 67.46|
|tweetSentBR | 49.03|
### Comments
Any idea, help or report will always be welcome.
email: [email protected]
<div style="display:flex; flex-direction:row; justify-content:left">
<a href="https://www.linkedin.com/in/heleno-betini-2b3016175/" target="_blank">
<img src="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white">
</a>
<a href="https://github.com/rhaymisonbetini" target="_blank">
<img src="https://img.shields.io/badge/GitHub-100000?style=for-the-badge&logo=github&logoColor=white">
</a>
|
RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf
|
RichardErkhov
| 2025-03-25T13:14:37Z
| 0
| 0
| null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T12:12:22Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3.2-3B_known_unknown_fix_head - GGUF
- Model creator: https://huggingface.co/kenken6696/
- Original model: https://huggingface.co/kenken6696/Llama-3.2-3B_known_unknown_fix_head/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3.2-3B_known_unknown_fix_head.Q2_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q2_K.gguf) | Q2_K | 1.27GB |
| [Llama-3.2-3B_known_unknown_fix_head.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.IQ3_XS.gguf) | IQ3_XS | 1.38GB |
| [Llama-3.2-3B_known_unknown_fix_head.IQ3_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.IQ3_S.gguf) | IQ3_S | 1.44GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q3_K_S.gguf) | Q3_K_S | 1.44GB |
| [Llama-3.2-3B_known_unknown_fix_head.IQ3_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.IQ3_M.gguf) | IQ3_M | 1.49GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q3_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q3_K.gguf) | Q3_K | 1.57GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q3_K_M.gguf) | Q3_K_M | 1.57GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q3_K_L.gguf) | Q3_K_L | 1.69GB |
| [Llama-3.2-3B_known_unknown_fix_head.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.IQ4_XS.gguf) | IQ4_XS | 1.71GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q4_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q4_0.gguf) | Q4_0 | 1.79GB |
| [Llama-3.2-3B_known_unknown_fix_head.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.IQ4_NL.gguf) | IQ4_NL | 1.79GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q4_K_S.gguf) | Q4_K_S | 1.8GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q4_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q4_K.gguf) | Q4_K | 1.88GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q4_K_M.gguf) | Q4_K_M | 1.88GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q4_1.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q4_1.gguf) | Q4_1 | 1.95GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q5_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q5_0.gguf) | Q5_0 | 2.11GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q5_K_S.gguf) | Q5_K_S | 2.11GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q5_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q5_K.gguf) | Q5_K | 2.16GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q5_K_M.gguf) | Q5_K_M | 2.16GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q5_1.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q5_1.gguf) | Q5_1 | 2.28GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q6_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q6_K.gguf) | Q6_K | 2.46GB |
| [Llama-3.2-3B_known_unknown_fix_head.Q8_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_known_unknown_fix_head-gguf/blob/main/Llama-3.2-3B_known_unknown_fix_head.Q8_0.gguf) | Q8_0 | 3.19GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
omrisap/After_refactor_ToT_2_2_3_4_end_1300
|
omrisap
| 2025-03-25T13:14:33Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"trl",
"grpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:11:06Z
|
---
library_name: transformers
tags:
- trl
- grpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ccmusic-database/bel_canto
|
ccmusic-database
| 2025-03-25T13:14:30Z
| 0
| 9
| null |
[
"music",
"art",
"audio-classification",
"en",
"dataset:ccmusic-database/bel_canto",
"license:mit",
"region:us"
] |
audio-classification
| 2023-12-04T09:37:39Z
|
---
license: mit
datasets:
- ccmusic-database/bel_canto
language:
- en
metrics:
- accuracy
pipeline_tag: audio-classification
tags:
- music
- art
---
# Intro
The Classical and Ethnic Vocal Style Classification model aims to distinguish between classical and ethnic vocal styles, with all audio samples sung by professional vocalists. The model is fine-tuned using an audio dataset consisting of four categories, which has been pre-processed into spectrograms. Initially pretrained in the computer vision (CV) domain, the backbone network undergoes a fine-tuning process specifically designed for vocal style classification tasks. In this model, the pre-training on CV tasks provides a foundation for the network to learn general audio features, which are then adjusted during fine-tuning to adapt to the subtle differences between classical and ethnic vocal styles. The audio dataset, comprising samples from classical and various ethnic singing traditions, enables the model to capture unique patterns associated with each vocal style. Representing spectrograms as input allows the model to effectively analyze both the temporal and frequency components of the audio signals. Through the fine-tuning process, the model continuously enhances its ability to discriminate between sound representations and subtle stylistic differences between classical and ethnic styles. This specialized model holds significant potential in the music industry and cultural preservation, as it accurately categorizes vocal performances into these two broad categories. Its foundation in pre-trained computer vision principles demonstrates the versatility and adaptability of neural networks across different domains, enhancing the model's capability to capture complex features of vocal performances.
## Demo (inference code)
<https://huggingface.co/spaces/ccmusic-database/bel_canto>
## Usage
```python
from huggingface_hub import snapshot_download
model_dir = snapshot_download("ccmusic-database/bel_canto")
```
## Maintenance
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:ccmusic-database/bel_canto
cd bel_canto
```
## Results
| Backbone | Mel | CQT | Chroma |
| :-----------: | :-----------------------: | :-------: | :-------: |
| Swin-S | **0.928** | **0.936** | **0.787** |
| Swin-T | 0.906 | 0.863 | 0.731 |
| | | | |
| AlexNet | 0.919 | 0.920 | 0.746 |
| ConvNeXt-T | 0.895 | 0.925 | 0.714 |
| GoogleNet | [**0.948**](#best-result) | 0.921 | 0.739 |
| MNASNet1.3 | 0.931 | **0.931** | **0.765** |
| SqueezeNet1.1 | 0.923 | 0.914 | 0.685 |
| Average | 0.921 | 0.916 | 0.738 |
### Best Result
<style>
#bel td {
vertical-align: middle !important;
text-align: center;
}
#bel th {
text-align: center;
}
</style>
<table id="bel">
<tr>
<th>Loss curve</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/bel_canto/resolve/master/googlenet_mel_2024-07-30_00-51-26/loss.jpg"></td>
</tr>
<tr>
<th>Training and validation accuracy</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/bel_canto/resolve/master/googlenet_mel_2024-07-30_00-51-26/acc.jpg"></td>
</tr>
<tr>
<th>Confusion matrix</th>
<td><img src="https://www.modelscope.cn/models/ccmusic-database/bel_canto/resolve/master/googlenet_mel_2024-07-30_00-51-26/mat.jpg"></td>
</tr>
</table>
## Dataset
<https://huggingface.co/datasets/ccmusic-database/bel_canto>
## Mirror
<https://www.modelscope.cn/models/ccmusic-database/bel_canto>
## Evaluation
<https://github.com/monetjoe/ccmusic_eval>
## Cite
```bibtex
@article{Zhou-2025,
author = {Monan Zhou and Shenyang Xu and Zhaorui Liu and Zhaowen Wang and Feng Yu and Wei Li and Baoqiang Han},
title = {CCMusic: An Open and Diverse Database for Chinese Music Information Retrieval Research},
journal = {Transactions of the International Society for Music Information Retrieval},
volume = {8},
number = {1},
pages = {22--38},
month = {Mar},
year = {2025},
url = {https://doi.org/10.5334/tismir.194},
doi = {10.5334/tismir.194}
}
```
|
flodussart/customer-success-assistant
|
flodussart
| 2025-03-25T13:14:14Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T13:12:22Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
contentprocbx/stormz
|
contentprocbx
| 2025-03-25T13:13:17Z
| 1
| 0
| null |
[
"license:other",
"region:us"
] | null | 2025-03-10T19:35:19Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
agentlans/Llama3.1-ko
|
agentlans
| 2025-03-25T13:10:43Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"korean",
"conversational",
"en",
"ko",
"arxiv:2203.05482",
"base_model:AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1",
"base_model:merge:AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1",
"base_model:KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024",
"base_model:merge:KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024",
"base_model:NCSOFT/Llama-VARCO-8B-Instruct",
"base_model:merge:NCSOFT/Llama-VARCO-8B-Instruct",
"base_model:Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B",
"base_model:merge:Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B",
"base_model:dnotitia/Llama-DNA-1.0-8B-Instruct",
"base_model:merge:dnotitia/Llama-DNA-1.0-8B-Instruct",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-23T14:03:59Z
|
---
license: llama3.1
language:
- en
- ko
base_model:
- NCSOFT/Llama-VARCO-8B-Instruct
- AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1
- KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024
- Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B
- dnotitia/Llama-DNA-1.0-8B-Instruct
library_name: transformers
tags:
- mergekit
- merge
- korean
- llama
---
# Llama3.1-ko
<details>
<summary>English</summary>
This is a merge of pre-trained Korean Llama 3.1 8B language models created using [mergekit](https://github.com/cg123/mergekit). The purpose is to create a Llama model with robust Korean capabilities that's familiar with Korean culture.
## Merge Details
### Merge Method
This model was merged using the [Linear](https://arxiv.org/abs/2203.05482) merge method.
### Models Merged
The following models were included in the merge:
- [NCSOFT/Llama-VARCO-8B-Instruct](https://huggingface.co/NCSOFT/Llama-VARCO-8B-Instruct)
- [AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1](https://huggingface.co/AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1)
- [KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024](https://huggingface.co/KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024)
- [Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B](https://huggingface.co/Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B)
- [dnotitia/Llama-DNA-1.0-8B-Instruct](https://huggingface.co/dnotitia/Llama-DNA-1.0-8B-Instruct)
## Capabilities and Limitations
This model demonstrates strong performance in Korean language tasks, including:
- Understanding and generating Korean text
- Familiarity with Korean culture and current events
However, users should be aware of the following limitations:
- The model's knowledge cutoff date may result in outdated information
- As with all language models, there's a risk of generating inaccurate or biased content
- Performance may vary depending on the specific task or domain
## Ethical Considerations
Users should be mindful of potential biases in the model's outputs and verify important information from authoritative sources. The model should not be used for generating or spreading misinformation or harmful content.
</details>
<details>
<summary>Korean</summary>
이것은 미리 훈련된 한국어 Llama 3.1 8B 언어 모델을 합쳐 만든 것입니다. 이 작업은 한국에 대한 강력한 능력을 가진 Llama 모델을 만들고자 하는 목적으로 이루어졌습니다.
## 합성화 세부 사항
### 합성화 방법
이 모델은 선형(Linear) 합성화 방식을 사용하여 만들어졌습니다.
### 합성화된 모델들
다음과 같은 모델들이 합성화에 포함되었습니다.
- [NCSOFT/Llama-VARCO-8B-Instruct](https://huggingface.co/NCSOFT/Llama-VARCO-8B-Instruct)
- [AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1](https://huggingface.co/AIDX-ktds/ktdsbaseLM-v0.13-onbased-llama3.1)
- [KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024](https://huggingface.co/KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024)
- [Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B](https://huggingface.co/Saxo/Linkbricks-Horizon-AI-Korean-llama3.1-sft-rlhf-dpo-8B)
- [dnotitia/Llama-DNA-1.0-8B-Instruct](https://huggingface.co/dnotitia/Llama-DNA-1.0-8B-Instruct)
## 기능 및 제약 조건
이 모델은 다음과 같은 한국어 관련 태스크에서 우수한 성능을 보입니다:
- 한국어 이해와 생성
- 한국 문화와 현재 사건에 대한 친숙함
그러나 다음의 제약 조건들을 유념해야 합니다:
- 모델의 지식 업데이트 날짜로 인해 정보가 최신이 아닐 수 있습니다
- 모든 언어 모델처럼 정확도나 편향성이 있는 내용을 생성할 위험이 존재합니다
- 특정 태스크나 도메인에 따라 성능이 달라질 수 있습니다
## 윤리적 고려사항
사용자들은 모델의 출력에 잠재적인 편향을 인식하고 중요한 정보는 권위 있는 출처에서 확인해야 합니다. 이 모델은 허위 정보나 해로운 콘텐츠를 생성하거나 확산하는 데 사용되어서는 안 됩니다.
</details>
## Examples
<details>
<summary>Example 1: K-pop Group Identification</summary>
User:
```
다음은 어떤 유명한 한국 아이돌 그룹에 대한 수수께끼입니다. 이 그룹의 이름을 맞춰보세요:
이 그룹의 이름은 특별한 의미를 담고 있습니다. 그들은 마치 방탄복이 총알을 막아내듯이, 10대와 20대가 겪는 어려움과 편견을 막아내고 자신들의 음악적 가치를 지키겠다는 뜻을 품고 있습니다.
그들의 영문 약자는 세 글자로, 원래 이름의 준말이었지만 나중에는 '장면을 넘어서'라는 의미도 추가되었습니다. 이는 청춘의 모든 순간을 뛰어넘는다는 뜻을 담고 있죠.
2013년 데뷔 이후, 이 그룹은 꾸준히 성장하여 국내외에서 큰 성공을 거두었습니다. 그들은 한국 가수 최초로 빌보드 200과 핫 100 차트에서 1위를 차지했고, 여러 음악 시상식에서 대상을 휩쓸었습니다.
〈봄날〉, 〈Dynamite〉, 〈Butter〉, 〈Permission to Dance〉 등 수많은 히트곡을 발표했으며, 전 세계적으로 큰 인기를 얻고 있는 이 그룹은 누구일까요?
이 수수께끼의 답은 무엇일까요?
```
AI:
```
방탄소년단(BTS)입니다! BTS는 "Bulletproof"나 "Beyond the Scene"(BTS의 영어 앨범 제목)의 줄임말인 BBT라고 불리기도 합니다. 또한, 그들이 언급하는 "청춘의 모든 순간을 뛰어넘는다"는 말은 그들만의 특징적인 메시지를 반영하고 있으며, 많은 팬들에게 사랑받았습니다. 그리고 당연하게도, 그들의 대표작 중 일부로는 "Spring Day", " Dynamite ", " Butter ", " Permission To Dance "등이 포함되어 있습니다. 이러한 이유들을 종합해 볼 때, 정답은 바로 방탄소년단(BTS)이 됩니다!
```
</details>
<details>
<summary>Example 2: Korean News Article Summary</summary>
Source:
[조선일보. “숨고르는 與 인사들…공개활동 줄이고 정국 주시.” 조선일보, 23 Mar. 2025](https://www.chosun.com/politics/politics_general/2025/03/23/6N7YOWLJ2VBBZJUAZGMA4L4D74/)
User:
```
본질을 유지하면서 50단어 이내로 요약해 주세요.
조기 대선 가능성을 염두에 두고 움직이던 여권의 주요 대선 주자급 인사들이 공개 활동을 줄이고 있다. 헌법재판소의 윤석열 대통령 탄핵 심판 선고 시기와 탄핵 인용·기각 여부를 두고 정치권과 법조계의 관측이 엇갈리는 상황에서 ‘탄핵 반대’ 지지층을 의식해 당분간 관망에 들어간 것이란 해석이 나온다.
오세훈 서울시장은 24일 정책 비전을 담은 책(‘다시 성장이다’)을 출간한다. 하지만 북 콘서트 같은 홍보 일정은 당분간 잡지 않았다고 한다. 오 시장은 지난 17일 TV조선에 출연해서는 윤 대통령 탄핵 선고 전망과 관련해 “(헌법재판관 8명 중) 기각 두 분, 각하 한 분 정도의 의견이 모이지 않았을까 싶다”고 했다. 기각이나 각하 의견을 낸 재판관이 3명이면 탄핵안은 기각된다.
홍준표 대구시장도 지난 21일 책(‘꿈은 이루어진다’)을 출간하려다 윤 대통령 탄핵 선고 이후로 미뤘다. 홍 시장은 23일 페이스북에서 윤 대통령의 내란 혐의 형사 재판과 관련해 “제대로 된 법관이 판결한다면 공소 기각 판결을 할 것”이라며 “탄핵도 기각되고 대통령의 형사재판도 조속히 정리돼 나라가 안정됐으면 한다”고 했다.
김문수 고용노동부 장관은 이번 주 부처 관련 일정만 소화할 계획인 것으로 알려졌다. 김 장관은 지난달엔 노동 개혁 토론회와 당정협의회 참석 등을 위해 국회를 자주 방문하며 기자들과 질의·응답을 했다. 그런데 지난 8일 윤 대통령이 석방된 뒤로는 공개 활동을 거의 하지 않고 있다. 김 장관 측근은 “대통령 복귀가 중요하다는 입장에 변함이 없다”고 했다.
안철수 국민의힘 의원은 이날 기자회견을 열고 이재명 더불어민주당 대표를 향해 “이제 그만하고 정계에서 은퇴하라”고 했다. 최근 안 의원은 작년에 발생한 이 대표 피습 사건과 관련해 “목 긁힌 뒤 죽은 듯 누워있는 모습”이라고 하는 등 이 대표 공격에 집중하고 있다. 한동훈 전 국민의힘 대표는 지난주부터 최상목 대통령 권한대행에게 “몸조심하라”고 한 이재명 대표를 비판하거나 최근 국회를 통과한 국민연금 모수 개혁안이 청년 세대에 불리하다며 문제를 제기하고 있다. 유승민 전 의원은 이번 주 서울대와 중앙대에서 강연을 한다.
```
AI:
```
여권 주요 후보들인 오세훈, 홍준표, 김문수가 윤석열 대통령 탄핵 결정 앞둔 시간 동안 '공개활동 감축'하는 이유는 각각 다른 맥락으로 설명됩니다.
- 오세훈: 자신의 책 발행 후에도 북콘서트 등의 행사는 취소했다
- 홍준표: 자신이 쓴 책 발표 일정을 연기했으며, "윤 대통령의 내란혐의형사재판" 결과 예상을 밝혀냄
- 김문수: 본인의 업무 일정 외에는 별도의 공식적인 언론출현을 삼갔다
이는 모두 현재 대한민국 사회적 혼란 속에서 '유지도력' 확보 및 선거에서의 우위를 점하기 위한 전략으로 보입니다. 특히, 안철수의 이재명 대표에 대한 직접적인 명령('그만하고 정계에서 은퇴하라')은 그의 경쟁 상대에 대해 매우 적극적으로 행동하고 있음을 보여줍니다.
```
</details>
|
novumlogic/nl-slm-distilgpt2-customer-support
|
novumlogic
| 2025-03-25T13:10:16Z
| 0
| 1
|
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"en",
"dataset:bitext/Bitext-customer-support-llm-chatbot-training-dataset",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T06:40:21Z
|
---
library_name: transformers
pipeline_tag: text-generation
license: apache-2.0
datasets:
- bitext/Bitext-customer-support-llm-chatbot-training-dataset
language:
- en
base_model:
- distilbert/distilgpt2
---
# SLM for Customer Support Interactions
<!-- Provide a quick summary of what the model is/does. -->
### Description
<!-- Provide a longer summary of what this model is. -->
This model is a fine-tuned version of DistilGPT-2, optimized for customer support interactions.
The model has been trained on a dataset consisting of dialogues between customers and support agents to enhance conversational AI performance.🤖💬
- **Model type:** Transformer-based small language model (SLM)
- **Language(s) (NLP):** English
- **Finetuned from model :** DistilGPT-2
## Uses
The fine-tuned DistilGPT-2(SLM) is designed to enhance customer support interactions by generating accurate and contextually relevant responses.
It can be integrated into customer service chatbots, virtual assistants, and automated helpdesk systems to handle routine inquiries efficiently.
By leveraging this model, businesses can improve response times, reduce human agent workload, and ensure consistent communication with customers.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
❌ Should not be used for general conversational AI applications unrelated to customer service.
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should validate outputs before deploying them in live customer support environments and ensure regular updates to align with evolving support needs.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("novumlogic/nl-slm-distilgpt2-customer-support")
model = AutoModelForCausalLM.from_pretrained("novumlogic/nl-slm-distilgpt2-customer-support")
input_str = "payment options"
# Encode the input string with padding and attention mask
encoded_input = tokenizer.encode_plus(
input_str,
return_tensors='pt',
padding=True,
truncation=True,
max_length=50 # Adjust max_length as needed
)
# Move tensors to the appropriate device
input_ids = encoded_input['input_ids']
attention_mask = encoded_input['attention_mask']
# Set the pad_token_id to the tokenizer's eos_token_id
pad_token_id = tokenizer.eos_token_id
# Generate the output
output = model.generate(
input_ids,
attention_mask=attention_mask,
max_length=400, # Adjust max_length as needed
num_return_sequences=1,
do_sample=True,
top_k=8,
top_p=0.95,
temperature=0.5,
repetition_penalty=1.2,
pad_token_id=pad_token_id
)
# Decode and print the output
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
print(decoded_output)
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
📚 Customer Support Interactions Dataset: 26,000 rows (20,800 training, 5,200 validation) (https://huggingface.co/datasets/bitext/Bitext-customer-support-llm-chatbot-training-dataset)
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing
🧹 Data cleaning: Standardizing text and removing noise.
✂️ Tokenization: Used DistilGPT-2's tokenizer for sequence conversion.
📑 Formatting: Structuring as "Query | Response" pairs.
#### Training Hyperparameters
- **Training regime:** <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
📏 Batch size: 15
🔁 Epochs: 3
🛠️ Optimizer: Adam with a linear learning rate scheduler
🖥️ Training Frameworks: PyTorch, Hugging Face Transformers
### Results
| Dataset | ROUGE-1 | ROUGE-2 | ROUGE-L | METEOR | Perplexity |
|-----------------------------------|---------|---------|---------|--------|------------|
| 📞 Customer Support Interactions | 0.7102 | 0.4586 | 0.5610 | 0.6924 | 1.4273 |
#### Summary
The Fine-Tuned DistilGPT-2 SLM for Customer Support Interactions is a compact and efficient language model designed to enhance automated customer service.
Trained on 26,000 customer-agent dialogues, the model improves chatbot performance by generating accurate, context-aware responses to customer queries.
## Glossary
SLM (Small Language Model): A compact language model optimized for efficiency.
Perplexity: Measures how well a model predicts.
ROUGE & METEOR: Metrics for evaluating text generation quality.
## Author
Novumlogic Technologies Pvt Ltd
|
cwyeungam/FinetunedModel_amazon_sentiment_10k
|
cwyeungam
| 2025-03-25T13:07:01Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T13:06:49Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sainoforce/modelv7
|
sainoforce
| 2025-03-25T13:05:31Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-19T13:02:08Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
eyjafjalla114/hm-flux-lora
|
eyjafjalla114
| 2025-03-25T13:04:32Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-03-25T09:01:54Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: hm
---
# Hm Flux Lora
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `hm` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('eyjafjalla114/hm-flux-lora', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RichardErkhov/rhaymison_-_Mistral-portuguese-luana-7b-Mathematics-8bits
|
RichardErkhov
| 2025-03-25T13:04:11Z
| 0
| 0
| null |
[
"safetensors",
"mistral",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-03-25T12:58:35Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Mistral-portuguese-luana-7b-Mathematics - bnb 8bits
- Model creator: https://huggingface.co/rhaymison/
- Original model: https://huggingface.co/rhaymison/Mistral-portuguese-luana-7b-Mathematics/
Original model description:
---
language:
- pt
license: apache-2.0
library_name: transformers
tags:
- portuguese
- math
- mathematics
- matematica
base_model: rhaymison/Mistral-portuguese-luana-7b
datasets:
- rhaymison/orca-math-portuguese-64k
pipeline_tag: text-generation
model-index:
- name: Mistral-portuguese-luana-7b-Mathematics
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: ENEM Challenge (No Images)
type: eduagarcia/enem_challenge
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 56.68
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BLUEX (No Images)
type: eduagarcia-temp/BLUEX_without_images
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 45.9
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: OAB Exams
type: eduagarcia/oab_exams
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 37.9
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 RTE
type: assin2
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 89.36
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 STS
type: eduagarcia/portuguese_benchmark
split: test
args:
num_few_shot: 15
metrics:
- type: pearson
value: 74.78
name: pearson
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: FaQuAD NLI
type: ruanchaves/faquad-nli
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 74.87
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HateBR Binary
type: ruanchaves/hatebr
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 76.39
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: PT Hate Speech Binary
type: hate_speech_portuguese
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 67.46
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: tweetSentBR
type: eduagarcia/tweetsentbr_fewshot
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 49.03
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=rhaymison/Mistral-portuguese-luana-7b-Mathematics
name: Open Portuguese LLM Leaderboard
---
# Mistral-portuguese-luana-7b-Mathematics
<p align="center">
<img src="https://raw.githubusercontent.com/rhaymisonbetini/huggphotos/main/luana-math.webp" width="50%" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
</p>
Luana Mathematics is a tuned model of the Luana-7b based on the Mistral 7b architecture.
This Model has been fine-tuned with 64k math problems and solutions derived from Microsoft's Orca-Math.
# How to use
You can use the model in its normal form up to 4-bit quantization. Below we will use both approaches.
Remember that verbs are important in your prompt. Tell your model how to act or behave so that you can guide them along the path of their response.
Important points like these help models (even smaller models like 7b) to perform much better.
```python
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model = AutoModelForCausalLM.from_pretrained("rhaymison/Mistral-portuguese-luana-7b-Mathematics", device_map= {"": 0})
tokenizer = AutoTokenizer.from_pretrained("rhaymison/Mistral-portuguese-luana-7b-Mathematics")
model.eval()
```
You can use with Pipeline but in this example i will use such as Streaming
```python
inputs = tokenizer([f"""<s>[INST] Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente o pedido.
### instrução: Se eu emprestei 100 reais para o meu irmão para que ele me pague em 3 vezes. O juros do empréstimo é 5% do valor do emprestimo por mes. Quanto meu irmão terá que me pagar no total?
[/INST]"""], return_tensors="pt")
inputs.to(model.device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)
#Para calcular o valor total que seu irmão terá que pagar, precisamos primeiro calcular o interesse do empréstimo e depois adicioná -lo ao valor principal.
#O interesse do empréstimo é de 5% do valor do empréstimo por mês.Então, para cada mês, o interesse será:
#5% de 100 reais = 0,05 * 100 = 5 reais
#Como o empréstimo é devolvido em 3 vezes, o interesse total será:
#5 reais/mês * 3 meses = 15 reais
#Agora, adicionamos o interesse ao valor principal para encontrar o valor total que seu irmão terá que pagar:
#100 reais (valor principal) + 15 reais (juros) = 115 reais
#Portanto, seu irmão terá que pagar 115 reais no total.
```
```python
inputs = tokenizer([f"""<s>[INST] Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente o pedido.
### instrução: João Esta pilotando sua bicicleta a uma velocidade de 20 km por hora. Se João esta fazendo uma Viagem da cidade de Venda nova a cidade de Independencia que possuem a distancia entre si de 320km.
Quanto tempo João vai demorar para ir de uma cidade a outra?
[/INST]"""], return_tensors="pt")
inputs.to(model.device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)
#Para descobrir quanto tempo levará João para viajar da cidade de venda nova para a cidade de Independência, precisamos dividir a distância total que ele precisa percorrer pela velocidade em que ele está andando.
#Distância total = 320 km
#Velocidade de João = 20 km/h
#Tempo = distância / velocidade
#Tempo = 320 km / 20 km / h
#Tempo = 16 horas
#Então, levará João 16 horas para viajar da cidade de venda nova para a cidade de Independência.
```
```python
inputs = tokenizer([f"""<s>[INST] Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente o pedido.
### instrução: Qual a area de um triangulo equilatero de 4 cm de base por 2 de altura ?
[/INST]"""], return_tensors="pt")
inputs.to(model.device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)
#A área de um triângulo equilátero é dada pela fórmula:
#Área = (1/2) * base * altura
#Dado que a base é de 4 cm e a altura é de 2 cm, podemos conectar esses valores à fórmula:
#Área = (1/2) * 4 cm * 2 cm
#Área = (1/2) * 8 cm²
#Área = 4 cm²
#Portanto, a área do triângulo equilátero é de 4 centímetros quadrados.
```
If you are having a memory problem such as "CUDA Out of memory", you should use 4-bit or 8-bit quantization.
For the complete model in colab you will need the A100.
If you want to use 4bits or 8bits, T4 or L4 will already solve the problem.
# 4bits
```python
from transformers import BitsAndBytesConfig
import torch
nb_4bit_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map={"": 0}
)
```
# Open Portuguese LLM Leaderboard Evaluation Results
Detailed results can be found [here](https://huggingface.co/datasets/eduagarcia-temp/llm_pt_leaderboard_raw_results/tree/main/rhaymison/Mistral-portuguese-luana-7b-Mathematics) and on the [🚀 Open Portuguese LLM Leaderboard](https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard)
| Metric | Value |
|--------------------------|--------|
|Average |**63.6**|
|ENEM Challenge (No Images)| 56.68|
|BLUEX (No Images) | 45.90|
|OAB Exams | 37.90|
|Assin2 RTE | 89.36|
|Assin2 STS | 74.78|
|FaQuAD NLI | 74.87|
|HateBR Binary | 76.39|
|PT Hate Speech Binary | 67.46|
|tweetSentBR | 49.03|
### Comments
Any idea, help or report will always be welcome.
email: [email protected]
<div style="display:flex; flex-direction:row; justify-content:left">
<a href="https://www.linkedin.com/in/heleno-betini-2b3016175/" target="_blank">
<img src="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white">
</a>
<a href="https://github.com/rhaymisonbetini" target="_blank">
<img src="https://img.shields.io/badge/GitHub-100000?style=for-the-badge&logo=github&logoColor=white">
</a>
|
namfam/Qwen2.5-0.5B-Instruct-fp16
|
namfam
| 2025-03-25T13:03:49Z
| 6
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"feature-extraction",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-03-25T05:00:01Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
DhruvK3000/llama8b_lending_25th_march
|
DhruvK3000
| 2025-03-25T13:01:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B",
"base_model:finetune:unsloth/Meta-Llama-3.1-8B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T12:54:12Z
|
---
base_model: unsloth/Meta-Llama-3.1-8B
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** DhruvK3000
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf
|
RichardErkhov
| 2025-03-25T13:00:43Z
| 0
| 0
| null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T11:57:55Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3.2-3B_4x3_fix_tail - GGUF
- Model creator: https://huggingface.co/kenken6696/
- Original model: https://huggingface.co/kenken6696/Llama-3.2-3B_4x3_fix_tail/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3.2-3B_4x3_fix_tail.Q2_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q2_K.gguf) | Q2_K | 1.27GB |
| [Llama-3.2-3B_4x3_fix_tail.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.IQ3_XS.gguf) | IQ3_XS | 1.38GB |
| [Llama-3.2-3B_4x3_fix_tail.IQ3_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.IQ3_S.gguf) | IQ3_S | 1.44GB |
| [Llama-3.2-3B_4x3_fix_tail.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q3_K_S.gguf) | Q3_K_S | 1.44GB |
| [Llama-3.2-3B_4x3_fix_tail.IQ3_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.IQ3_M.gguf) | IQ3_M | 1.49GB |
| [Llama-3.2-3B_4x3_fix_tail.Q3_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q3_K.gguf) | Q3_K | 1.57GB |
| [Llama-3.2-3B_4x3_fix_tail.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q3_K_M.gguf) | Q3_K_M | 1.57GB |
| [Llama-3.2-3B_4x3_fix_tail.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q3_K_L.gguf) | Q3_K_L | 1.69GB |
| [Llama-3.2-3B_4x3_fix_tail.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.IQ4_XS.gguf) | IQ4_XS | 1.71GB |
| [Llama-3.2-3B_4x3_fix_tail.Q4_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q4_0.gguf) | Q4_0 | 1.79GB |
| [Llama-3.2-3B_4x3_fix_tail.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.IQ4_NL.gguf) | IQ4_NL | 1.79GB |
| [Llama-3.2-3B_4x3_fix_tail.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q4_K_S.gguf) | Q4_K_S | 1.8GB |
| [Llama-3.2-3B_4x3_fix_tail.Q4_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q4_K.gguf) | Q4_K | 1.88GB |
| [Llama-3.2-3B_4x3_fix_tail.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q4_K_M.gguf) | Q4_K_M | 1.88GB |
| [Llama-3.2-3B_4x3_fix_tail.Q4_1.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q4_1.gguf) | Q4_1 | 1.95GB |
| [Llama-3.2-3B_4x3_fix_tail.Q5_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q5_0.gguf) | Q5_0 | 2.11GB |
| [Llama-3.2-3B_4x3_fix_tail.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q5_K_S.gguf) | Q5_K_S | 2.11GB |
| [Llama-3.2-3B_4x3_fix_tail.Q5_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q5_K.gguf) | Q5_K | 2.16GB |
| [Llama-3.2-3B_4x3_fix_tail.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q5_K_M.gguf) | Q5_K_M | 2.16GB |
| [Llama-3.2-3B_4x3_fix_tail.Q5_1.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q5_1.gguf) | Q5_1 | 2.28GB |
| [Llama-3.2-3B_4x3_fix_tail.Q6_K.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q6_K.gguf) | Q6_K | 2.46GB |
| [Llama-3.2-3B_4x3_fix_tail.Q8_0.gguf](https://huggingface.co/RichardErkhov/kenken6696_-_Llama-3.2-3B_4x3_fix_tail-gguf/blob/main/Llama-3.2-3B_4x3_fix_tail.Q8_0.gguf) | Q8_0 | 3.19GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AlekseyCalvin/lenin_wan14b_t2v_lora
|
AlekseyCalvin
| 2025-03-25T13:00:28Z
| 0
| 0
| null |
[
"image-to-video",
"lora",
"replicate",
"text-to-video",
"video",
"video-generation",
"en",
"zh",
"base_model:Wan-AI/Wan2.1-T2V-14B-Diffusers",
"base_model:adapter:Wan-AI/Wan2.1-T2V-14B-Diffusers",
"license:apache-2.0",
"region:us"
] |
text-to-video
| 2025-03-25T12:27:48Z
|
---
license: apache-2.0
language:
- en
- zh
tags:
- image-to-video
- lora
- replicate
- text-to-video
- video
- video-generation
base_model: "Wan-AI/Wan2.1-T2V-14B-Diffusers"
pipeline_tag: text-to-video
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: LEN Vladimir Lenin
---
# Lenin_Wan14B_T2V_Lora
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the Wan2.1 14b video generation model.
It can be used with diffusers or ComfyUI, and can be loaded against both the text-to-video and image-to-video Wan2.1 models.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/wan-lora-trainer/train
## Trigger words
You should use `LEN Vladimir Lenin` to trigger the video generation.
## Use this LoRA
Replicate has a collection of Wan2.1 models that are optimised for speed and cost. They can also be used with this LoRA:
- https://replicate.com/collections/wan-video
- https://replicate.com/fofr/wan2.1-with-lora
### Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "LEN Vladimir Lenin",
"lora_url": "https://huggingface.co/alekseycalvin/lenin_wan14b_t2v_lora/resolve/main/wan2.1-14b-len-vladimir-lenin-lora.safetensors"
}
output = replicate.run(
"fofr/wan2.1-with-lora:f83b84064136a38415a3aff66c326f94c66859b8ad7a2cb432e2822774f07b08",
model="14b",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.mp4", "wb") as file:
file.write(item.read())
```
### Using with Diffusers
```py
pip install git+https://github.com/huggingface/diffusers.git
```
```py
import torch
from diffusers.utils import export_to_video
from diffusers import AutoencoderKLWan, WanPipeline
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
flow_shift = 3.0 # 5.0 for 720P, 3.0 for 480P
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config, flow_shift=flow_shift)
pipe.to("cuda")
pipe.load_lora_weights("alekseycalvin/lenin_wan14b_t2v_lora")
pipe.enable_model_cpu_offload() #for low-vram environments
prompt = "LEN Vladimir Lenin"
negative_prompt = "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards"
output = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=480,
width=832,
num_frames=81,
guidance_scale=5.0,
).frames[0]
export_to_video(output, "output.mp4", fps=16)
```
## Training details
- Steps: 750
- Learning rate: 0.0002
- LoRA rank: 32
## Contribute your own examples
You can use the [community tab](https://huggingface.co/alekseycalvin/lenin_wan14b_t2v_lora/discussions) to add videos that show off what you’ve made with this LoRA.
|
RayneAmes/kokujin1
|
RayneAmes
| 2025-03-25T12:59:48Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T12:35:23Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
welashi/my_ner_model
|
welashi
| 2025-03-25T12:59:18Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-03-25T12:57:57Z
|
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: my_ner_model
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: test
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5209059233449478
- name: Recall
type: recall
value: 0.27710843373493976
- name: F1
type: f1
value: 0.36176648517846344
- name: Accuracy
type: accuracy
value: 0.9407036894532085
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_ner_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2774
- Precision: 0.5209
- Recall: 0.2771
- F1: 0.3618
- Accuracy: 0.9407
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2812 | 0.4724 | 0.2298 | 0.3092 | 0.9374 |
| No log | 2.0 | 426 | 0.2774 | 0.5209 | 0.2771 | 0.3618 | 0.9407 |
### Framework versions
- Transformers 4.48.3
- Pytorch 2.5.1+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
gallilmaimon/l3_good
|
gallilmaimon
| 2025-03-25T12:59:07Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"speech_language_model",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T12:55:23Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
selmanbaysan/berturk-base_fine_tuned
|
selmanbaysan
| 2025-03-25T12:58:03Z
| 0
| 0
|
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:1533351",
"loss:MultipleNegativesRankingLoss",
"loss:SoftmaxLoss",
"loss:CoSENTLoss",
"dataset:selmanbaysan/msmarco-tr_fine_tuning_dataset",
"dataset:selmanbaysan/fiqa-tr_fine_tuning_dataset",
"dataset:selmanbaysan/scifact-tr_fine_tuning_dataset",
"dataset:selmanbaysan/nfcorpus-tr_fine_tuning_dataset",
"dataset:selmanbaysan/multinli_tr_fine_tuning_dataset",
"dataset:selmanbaysan/snli_tr_fine_tuning_dataset",
"dataset:selmanbaysan/stsb-tr",
"dataset:selmanbaysan/wmt16_en_tr_fine_tuning_dataset",
"dataset:selmanbaysan/quora-tr_fine_tuning_dataset",
"dataset:selmanbaysan/xnli_tr_fine_tuning_dataset",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:selmanbaysan/berturk_base_contrastive_loss_training",
"base_model:finetune:selmanbaysan/berturk_base_contrastive_loss_training",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-03-25T12:57:45Z
|
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:1533351
- loss:MultipleNegativesRankingLoss
- loss:SoftmaxLoss
- loss:CoSENTLoss
base_model: selmanbaysan/berturk_base_contrastive_loss_training
widget:
- source_sentence: CIA, filmi indirdi ve filmi ertesi gün Birleşmiş Milletlere götürdü.
sentences:
- Bir açıklama yapmalısın! Wolverstone'a ne oldu?
- CIA, BM’nin filmi hemen görmesi gerektiğini düşünüyordu.
- Benim yolum en zor yoldur.
- source_sentence: Port Royal'de bu serseriyi bekleyen bir idam sehpası var. Kanlı
Korsan buna müdahale ederdi ama Lord Julian önce davranıp ona engel oldu.
sentences:
- Babamız bunların hayvan değil yaratık olduğunu söyledi.
- Port Royal suçluları cezalandırmak için olanaklara sahiptir.
- Geç Anneler Günü kahvaltısına bazı arkadaşlar sırayla ev sahipliği yapıyorlar.
- source_sentence: satın almak için hangi boyut Fitbit şarj
sentences:
- Texas A&M'den bir eğitim, yıldan yıla çok arzu edilen ve çok uygun fiyatlı olmaya
devam ediyor. Texas A&M'e bir yıl boyunca katılmak için toplam ortalama katılım
maliyeti yaklaşık 22,470 $ (devlet içi ikamet edenler için), eğitim ve harç, oda
ve yönetim kurulu, kitaplar, ulaşım ve çeşitli masraflar içerir. Kolej İstasyonu'ndaki
Texas A&M Üniversitesi'nde dönem başına 15 lisans kredi saatine dayanarak; bazı
harç ve harçlar buraya yansıtılmamıştır.
- İlk fitbitimi satın almak istiyorum ve şarj saatine karar verdim. Bununla birlikte,
bileğimi ölçtükten sonra, 6,5 inçte geldi. Mevcut boyutları kontrol ettikten sonra
küçük ve büyük arasındayım gibi görünüyor. Küçük 6,7'ye çıkar ve büyük 6.3'ten
başlar. Hangisinin daha iyi olacağından gerçekten emin değilim.
- Atriyal Dalgalanma Nedenleri. Atriyal dalgalanma, kalbin anormalliklerinden veya
hastalıklarından, vücudun başka bir yerinde kalbi etkileyen bir hastalıktan veya
elektriksel dürtülerin kalp yoluyla bulaşma şeklini değiştiren maddelerin tüketilmesinden
kaynaklanabilir. Bazı insanlarda, altta yatan hiçbir neden bulunmaz.
- source_sentence: '"Ben kimim" sorusuna nasıl cevap veririm?'
sentences:
- Notlarımı nasıl ezberleyebilirim?
- Birinin en zor soru olan "ben kimim?" sorusuna nasıl cevap verebileceği nasıl
açıklanabilir?
- Donald Trump'ın 2016 seçimlerini kazanma ihtimali nedir?
- source_sentence: Stoklara nasıl yatırım yapabilirim?
sentences:
- '
Bu soru yüklü ama denemek için elimden geleni yapacağım. Öncelikle, hisse senetlerine
yatırım yapmadan önce hazır olup olmadığınızı belirlemeniz gerekir. Yüksek faizli
borcunuz varsa, hisse senetlerine yatırım yapmadan önce onu ödemeniz daha iyi
olacaktır. Hisse senetleri uzun vadede yaklaşık %8-10 getiri sağlar, bu nedenle
%8-10''dan daha yüksek faizli herhangi bir borcunuzu ödemeniz daha iyi olur. Çoğu
insan, 401k''larında veya Roth IRA''larında ortak fonlar aracılığıyla hisse senetlerine
başlar. Bireysel hisse senetleri yerine ortak fonlara yatırım yapmak istiyorsanız,
çok okumalı ve öğrenmelisiniz. Bir aracı hesap veya hisse senedi aklınızda varsa,
doğrudan şirkete DRIP (temettü yeniden yatırma planı) aracılığıyla yatırım yapabilirsiniz.
Farklı aracı kurumları karşılaştırarak size en uygun olanı belirlemeniz gerekir.
İnternet bilgisine sahip olduğunuzu göz önünde bulundurarak, daha düşük komisyonlar
sunan bir indirimli aracı kurum kullanmanızı öneririm. İyi bir kılavuz, yatırım
yaptığınız tutarın %1''inden daha az komisyon ödemektir. Çevrimiçi aracı hesabınızı
açıp içine para yatırdıktan sonra, hisse senedi satın alma işlemi oldukça basittir.
Satın almak istediğiniz hisse senedi miktarı için bir emir verin. Bu, mevcut piyasa
fiyatında bir satın alma anlamına gelen bir piyasa emri olabilir. Veya fiyatı
kontrol edebileceğiniz bir sınır emri kullanabilirsiniz. Yeni başlayanlar için
birçok iyi kitap vardır. Kişisel olarak, Motley Fool''dan öğrendim. Ve son olarak,
eğlenin. Öğrendiğiniz kadarını öğrenin ve kulübünüzün tadını çıkarın.'
- '"En iyi çözüm, arabayı satın almak ve kendi kredinizi almak (ChrisInEdmonton''un
yanıtladığı gibi). Buna rağmen, kredi birliğim, bir başkasını başlığa eklerken
hala bir kredim olduğunda bir başlık kayıt ücreti için izin verdi. Başlık sahibi
olan bankaya, bir başkasını başlığa eklemek için bir hüküm olup olmadığını sorabilirsiniz. Benim
için toplam maliyet, bankada bir öğleden sonra ve yaklaşık 20 veya 40 dolar (bir
süredir) oldu."'
- 'Öncelikle varsayımınız doğru: Büyük bir miktar YetAnotherCryptoCoin''i ICO''sundan
kısa bir süre sonra nasıl nakde çevirebilirsiniz? Kripto borsaları yeni bir para
birimini eklemek için biraz zaman alır, hatta hiç eklemeyebilirler. Ve hatta eklediklerinde,
işlem hacmi genellikle düşüktür. Sanırım bu, yatırımcılar için gerçekten çekici
olmayan şeydir (teknoloji tutkunlarından ayrı olarak), yüksek volatilite dışında.
Güvenilir bir işlem yeteneği tamamen eksikliği.'
datasets:
- selmanbaysan/msmarco-tr_fine_tuning_dataset
- selmanbaysan/fiqa-tr_fine_tuning_dataset
- selmanbaysan/scifact-tr_fine_tuning_dataset
- selmanbaysan/nfcorpus-tr_fine_tuning_dataset
- selmanbaysan/multinli_tr_fine_tuning_dataset
- selmanbaysan/snli_tr_fine_tuning_dataset
- selmanbaysan/stsb-tr
- selmanbaysan/wmt16_en_tr_fine_tuning_dataset
- selmanbaysan/quora-tr_fine_tuning_dataset
- selmanbaysan/xnli_tr_fine_tuning_dataset
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- pearson_cosine
- spearman_cosine
- cosine_accuracy
- cosine_accuracy_threshold
- cosine_f1
- cosine_f1_threshold
- cosine_precision
- cosine_recall
- cosine_ap
- cosine_mcc
model-index:
- name: SentenceTransformer based on selmanbaysan/berturk_base_contrastive_loss_training
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: stsb tr
type: stsb-tr
metrics:
- type: pearson_cosine
value: 0.8109525221457314
name: Pearson Cosine
- type: spearman_cosine
value: 0.8168105572572449
name: Spearman Cosine
- task:
type: binary-classification
name: Binary Classification
dataset:
name: snli tr
type: snli-tr
metrics:
- type: cosine_accuracy
value: 0.7326
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: 0.6572713851928711
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.600581677169171
name: Cosine F1
- type: cosine_f1_threshold
value: 0.4847041368484497
name: Cosine F1 Threshold
- type: cosine_precision
value: 0.5033516148689823
name: Cosine Precision
- type: cosine_recall
value: 0.7443676779813758
name: Cosine Recall
- type: cosine_ap
value: 0.6132056266749955
name: Cosine Ap
- type: cosine_mcc
value: 0.3561722570448152
name: Cosine Mcc
- task:
type: binary-classification
name: Binary Classification
dataset:
name: xnli tr
type: xnli-tr
metrics:
- type: cosine_accuracy
value: 0.7345381526104418
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: 0.7267703413963318
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.603629417382999
name: Cosine F1
- type: cosine_f1_threshold
value: 0.5046486854553223
name: Cosine F1 Threshold
- type: cosine_precision
value: 0.5
name: Cosine Precision
- type: cosine_recall
value: 0.7614457831325301
name: Cosine Recall
- type: cosine_ap
value: 0.633783326089055
name: Cosine Ap
- type: cosine_mcc
value: 0.358990791322683
name: Cosine Mcc
- task:
type: binary-classification
name: Binary Classification
dataset:
name: wmt16
type: wmt16
metrics:
- type: cosine_accuracy
value: 0.999000999000999
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: 0.2128763496875763
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.9995002498750626
name: Cosine F1
- type: cosine_f1_threshold
value: 0.2128763496875763
name: Cosine F1 Threshold
- type: cosine_precision
value: 1.0
name: Cosine Precision
- type: cosine_recall
value: 0.999000999000999
name: Cosine Recall
- type: cosine_ap
value: 1.0
name: Cosine Ap
- type: cosine_mcc
value: 0.0
name: Cosine Mcc
- task:
type: binary-classification
name: Binary Classification
dataset:
name: msmarco tr
type: msmarco-tr
metrics:
- type: cosine_accuracy
value: 0.9999682942295498
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: -0.04683864116668701
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.9999841468634569
name: Cosine F1
- type: cosine_f1_threshold
value: -0.04683864116668701
name: Cosine F1 Threshold
- type: cosine_precision
value: 1.0
name: Cosine Precision
- type: cosine_recall
value: 0.9999682942295498
name: Cosine Recall
- type: cosine_ap
value: 1.0
name: Cosine Ap
- type: cosine_mcc
value: 0.0
name: Cosine Mcc
- task:
type: binary-classification
name: Binary Classification
dataset:
name: fiqa tr
type: fiqa-tr
metrics:
- type: cosine_accuracy
value: 0.9991922455573505
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: 0.03544411063194275
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.9995959595959596
name: Cosine F1
- type: cosine_f1_threshold
value: 0.03544411063194275
name: Cosine F1 Threshold
- type: cosine_precision
value: 1.0
name: Cosine Precision
- type: cosine_recall
value: 0.9991922455573505
name: Cosine Recall
- type: cosine_ap
value: 1.0
name: Cosine Ap
- type: cosine_mcc
value: 0.0
name: Cosine Mcc
- task:
type: binary-classification
name: Binary Classification
dataset:
name: quora tr
type: quora-tr
metrics:
- type: cosine_accuracy
value: 0.9998688696564385
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: 0.16285157203674316
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.9999344305291455
name: Cosine F1
- type: cosine_f1_threshold
value: 0.16285157203674316
name: Cosine F1 Threshold
- type: cosine_precision
value: 1.0
name: Cosine Precision
- type: cosine_recall
value: 0.9998688696564385
name: Cosine Recall
- type: cosine_ap
value: 1.0
name: Cosine Ap
- type: cosine_mcc
value: 0.0
name: Cosine Mcc
- task:
type: binary-classification
name: Binary Classification
dataset:
name: nfcorpus tr
type: nfcorpus-tr
metrics:
- type: cosine_accuracy
value: 0.9999121651295564
name: Cosine Accuracy
- type: cosine_accuracy_threshold
value: -0.13325101137161255
name: Cosine Accuracy Threshold
- type: cosine_f1
value: 0.9999560806359523
name: Cosine F1
- type: cosine_f1_threshold
value: -0.13325101137161255
name: Cosine F1 Threshold
- type: cosine_precision
value: 1.0
name: Cosine Precision
- type: cosine_recall
value: 0.9999121651295564
name: Cosine Recall
- type: cosine_ap
value: 1.0
name: Cosine Ap
- type: cosine_mcc
value: 0.0
name: Cosine Mcc
---
# SentenceTransformer based on selmanbaysan/berturk_base_contrastive_loss_training
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [selmanbaysan/berturk_base_contrastive_loss_training](https://huggingface.co/selmanbaysan/berturk_base_contrastive_loss_training) on the [msmarco-tr](https://huggingface.co/datasets/selmanbaysan/msmarco-tr_fine_tuning_dataset), [fiqa-tr](https://huggingface.co/datasets/selmanbaysan/fiqa-tr_fine_tuning_dataset), [scifact-tr](https://huggingface.co/datasets/selmanbaysan/scifact-tr_fine_tuning_dataset), [nfcorpus-tr](https://huggingface.co/datasets/selmanbaysan/nfcorpus-tr_fine_tuning_dataset), [multinli-tr](https://huggingface.co/datasets/selmanbaysan/multinli_tr_fine_tuning_dataset), [snli-tr](https://huggingface.co/datasets/selmanbaysan/snli_tr_fine_tuning_dataset), [stsb-tr](https://huggingface.co/datasets/selmanbaysan/stsb-tr) and [wmt16](https://huggingface.co/datasets/selmanbaysan/wmt16_en_tr_fine_tuning_dataset) datasets. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [selmanbaysan/berturk_base_contrastive_loss_training](https://huggingface.co/selmanbaysan/berturk_base_contrastive_loss_training) <!-- at revision 007e20ef9ebac5677588b87eaf7250617a780034 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Datasets:**
- [msmarco-tr](https://huggingface.co/datasets/selmanbaysan/msmarco-tr_fine_tuning_dataset)
- [fiqa-tr](https://huggingface.co/datasets/selmanbaysan/fiqa-tr_fine_tuning_dataset)
- [scifact-tr](https://huggingface.co/datasets/selmanbaysan/scifact-tr_fine_tuning_dataset)
- [nfcorpus-tr](https://huggingface.co/datasets/selmanbaysan/nfcorpus-tr_fine_tuning_dataset)
- [multinli-tr](https://huggingface.co/datasets/selmanbaysan/multinli_tr_fine_tuning_dataset)
- [snli-tr](https://huggingface.co/datasets/selmanbaysan/snli_tr_fine_tuning_dataset)
- [stsb-tr](https://huggingface.co/datasets/selmanbaysan/stsb-tr)
- [wmt16](https://huggingface.co/datasets/selmanbaysan/wmt16_en_tr_fine_tuning_dataset)
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("selmanbaysan/berturk-base_fine_tuned")
# Run inference
sentences = [
'Stoklara nasıl yatırım yapabilirim?',
"\nBu soru yüklü ama denemek için elimden geleni yapacağım. Öncelikle, hisse senetlerine yatırım yapmadan önce hazır olup olmadığınızı belirlemeniz gerekir. Yüksek faizli borcunuz varsa, hisse senetlerine yatırım yapmadan önce onu ödemeniz daha iyi olacaktır. Hisse senetleri uzun vadede yaklaşık %8-10 getiri sağlar, bu nedenle %8-10'dan daha yüksek faizli herhangi bir borcunuzu ödemeniz daha iyi olur. Çoğu insan, 401k'larında veya Roth IRA'larında ortak fonlar aracılığıyla hisse senetlerine başlar. Bireysel hisse senetleri yerine ortak fonlara yatırım yapmak istiyorsanız, çok okumalı ve öğrenmelisiniz. Bir aracı hesap veya hisse senedi aklınızda varsa, doğrudan şirkete DRIP (temettü yeniden yatırma planı) aracılığıyla yatırım yapabilirsiniz. Farklı aracı kurumları karşılaştırarak size en uygun olanı belirlemeniz gerekir. İnternet bilgisine sahip olduğunuzu göz önünde bulundurarak, daha düşük komisyonlar sunan bir indirimli aracı kurum kullanmanızı öneririm. İyi bir kılavuz, yatırım yaptığınız tutarın %1'inden daha az komisyon ödemektir. Çevrimiçi aracı hesabınızı açıp içine para yatırdıktan sonra, hisse senedi satın alma işlemi oldukça basittir. Satın almak istediğiniz hisse senedi miktarı için bir emir verin. Bu, mevcut piyasa fiyatında bir satın alma anlamına gelen bir piyasa emri olabilir. Veya fiyatı kontrol edebileceğiniz bir sınır emri kullanabilirsiniz. Yeni başlayanlar için birçok iyi kitap vardır. Kişisel olarak, Motley Fool'dan öğrendim. Ve son olarak, eğlenin. Öğrendiğiniz kadarını öğrenin ve kulübünüzün tadını çıkarın.",
"Öncelikle varsayımınız doğru: Büyük bir miktar YetAnotherCryptoCoin'i ICO'sundan kısa bir süre sonra nasıl nakde çevirebilirsiniz? Kripto borsaları yeni bir para birimini eklemek için biraz zaman alır, hatta hiç eklemeyebilirler. Ve hatta eklediklerinde, işlem hacmi genellikle düşüktür. Sanırım bu, yatırımcılar için gerçekten çekici olmayan şeydir (teknoloji tutkunlarından ayrı olarak), yüksek volatilite dışında. Güvenilir bir işlem yeteneği tamamen eksikliği.",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Semantic Similarity
* Dataset: `stsb-tr`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| pearson_cosine | 0.811 |
| **spearman_cosine** | **0.8168** |
#### Binary Classification
* Datasets: `snli-tr`, `xnli-tr`, `wmt16`, `msmarco-tr`, `fiqa-tr`, `quora-tr` and `nfcorpus-tr`
* Evaluated with [<code>BinaryClassificationEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.BinaryClassificationEvaluator)
| Metric | snli-tr | xnli-tr | wmt16 | msmarco-tr | fiqa-tr | quora-tr | nfcorpus-tr |
|:--------------------------|:-----------|:-----------|:--------|:-----------|:--------|:---------|:------------|
| cosine_accuracy | 0.7326 | 0.7345 | 0.999 | 1.0 | 0.9992 | 0.9999 | 0.9999 |
| cosine_accuracy_threshold | 0.6573 | 0.7268 | 0.2129 | -0.0468 | 0.0354 | 0.1629 | -0.1333 |
| cosine_f1 | 0.6006 | 0.6036 | 0.9995 | 1.0 | 0.9996 | 0.9999 | 1.0 |
| cosine_f1_threshold | 0.4847 | 0.5046 | 0.2129 | -0.0468 | 0.0354 | 0.1629 | -0.1333 |
| cosine_precision | 0.5034 | 0.5 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| cosine_recall | 0.7444 | 0.7614 | 0.999 | 1.0 | 0.9992 | 0.9999 | 0.9999 |
| **cosine_ap** | **0.6132** | **0.6338** | **1.0** | **1.0** | **1.0** | **1.0** | **1.0** |
| cosine_mcc | 0.3562 | 0.359 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Datasets
<details><summary>msmarco-tr</summary>
#### msmarco-tr
* Dataset: [msmarco-tr](https://huggingface.co/datasets/selmanbaysan/msmarco-tr_fine_tuning_dataset) at [f03d837](https://huggingface.co/datasets/selmanbaysan/msmarco-tr_fine_tuning_dataset/tree/f03d83704e5ea276665384ca6d8bee3b19632c80)
* Size: 253,332 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:---------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 9.75 tokens</li><li>max: 28 tokens</li></ul> | <ul><li>min: 18 tokens</li><li>mean: 81.59 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Spagetti ve et sosu servisinde kaç kalori</code> | <code>Gıda Bilgisi. Makarna Yemekleri kategorisinde Et Soslu Spagetti ile 100 g / mL'ye göre toplam 90.0 kalori ve aşağıdaki beslenme gerçekleri vardır: 5.1 g protein, 15.2 g karbonhidrat ve 1.0 g yağ.</code> |
| <code>galveston okyanusu ne kadar derin</code> | <code>galveston çok sığ olduğu için mucky - Eğer kıyıdan 5 mil yürümek olsaydı, asla 10 veya 12 feet derinliğinden fazla olmazdı. Galveston Körfezi çok sığ, sadece 9 feet derinliğinde, bu yüzden körfezden ve derin okyanusa bir kez çıktığınızda, su o kadar çamurlu olmayacak.</code> |
| <code>amlodipin diyabete neden olabilir</code> | <code>Hipertansiyon tedavisi için Amlodipin tedavisine konduğunuzda referanslara göre, diyabetin yeni başlangıcını geliştirme olasılığınız %34 daha düşüktür. Hipertansiyon tedavisi için Amlodipin tedavisine konduğunuzda referanslara göre, diyabetin yeni başlangıcını geliştirme olasılığınız %34 daha düşüktür. Küçük düzenleme?</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>fiqa-tr</summary>
#### fiqa-tr
* Dataset: [fiqa-tr](https://huggingface.co/datasets/selmanbaysan/fiqa-tr_fine_tuning_dataset) at [bbc9e91](https://huggingface.co/datasets/selmanbaysan/fiqa-tr_fine_tuning_dataset/tree/bbc9e91b5710d0ac4032b5c9e94066470f928c8c)
* Size: 14,166 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 17.67 tokens</li><li>max: 54 tokens</li></ul> | <ul><li>min: 9 tokens</li><li>mean: 196.19 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-----------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Bir iş gezisinde ne tür masraflar iş masrafı olarak kabul edilir?</code> | <code>IRS'a ait ilgili rehberlik. Genel olarak söyleyebileceğim tek şey, işinizin giderlerinin düşebileceği yönündedir. Ancak bu, koşullara ve düşmek istediğiniz gider türüne bağlıdır. Seyahat İş seyahatinden dolayı evden uzakta olan vergi mükellefleri, ilişkili giderleri düşebilirler, bu da varış noktasına ulaşma maliyetini, konaklama ve yemek masraflarını ve diğer normal ve gerekli giderleri içerir. Mükellefler, görevlerinin onları evden önemli ölçüde daha uzun süre uzak tutması ve iş taleplerini karşılamak için uyku veya dinlenmeye ihtiyaç duymaları durumunda "evden uzakta" olarak kabul edilirler. Yemek ve yan masrafların gerçek maliyetleri düşürülebilir veya mükellef, standart yemek yardımı ve azaltılmış kayıt tutma gereklilikleri kullanabilir. Kullanılan yönteme bakılmaksızın, yemek giderleri genellikle daha önce belirtildiği gibi %50 ile sınırlıdır. Sadece gerçek konaklama masrafları gider olarak talep edilebilir ve belgeler için makbuzlar tutulmalıdır. Giderler makul ve uygun olmalıdı...</code> |
| <code>İş Gideri - Kaza Sırasında İş Gezisi Sırasında Uygulanan Araba Sigortası Teminat Tutarı</code> | <code>Genel bir kural olarak, mil ölçümü indirimi veya gerçek giderler indirimi arasında seçim yapmanız gerekir. Fikir, mil ölçümü indiriminin aracın kullanımının tüm maliyetlerini kapsamasıdır. Park ücretleri ve otoyol ücretleri gibi istisnalar, her iki yöntemin altında ayrı ayrı indirilebilir. Mil ölçümü indirimi talep ederseniz sigorta maliyetlerini açık bir şekilde indiremezsiniz. Ayrı olarak, muhtemelen aracınızın kazaya bağlı olarak hasar kaybı olarak bir teminat indirimi indiremeyeceksiniz. Öncelikle teminattan 100 dolar çıkarırsınız ve sonra onu vergi beyannamenizden ayarlanan brüt gelirinize (AGI) böleriz. Teminatınız AGI'nızın %10'undan fazla ise onu indirebilirsiniz. Not edin ki, 1500 dolar teminatı olan biri bile yıllık 14.000 doların üzerinde gelir elde ederse hiçbir şey indiremez. Çoğu insan için, sigorta teminatı gelire göre yeterince büyük değil, bu nedenle vergi indirimi için uygun değildir. Kaynak</code> |
| <code>Yeni bir çevrimiçi işletme başlatmak</code> | <code>Amerika Birleşik Devletleri'nin çoğu eyaleti, yukarıda belirtildiği gibi, aşağıdakine benzer kurallara sahiptir: Kayıt ücretleri ödemeniz neredeyse kesin. Düzenleme şeklinize bağlı olarak, işletmeniz için ayrı bir vergi beyannamesi doldurmanız gerekebilir veya gerekmeyebilir. (Vergi amaçları için tek bir işletme sahibiyseniz, kişisel Form 1040'ınızın Ek C'sini doldurursunuz.) Vergi ödeme durumunuz, net kazancınızın olup olmamasına bağlıdır. Bazı kayıpların da indirilebilir olabileceği mümkündür. (Dikkat edin, net kazancınız olmasa bile bir beyanname sunmanız gerekebilir - Beyanname sunmak ve vergi ödemek aynı şey değildir, çünkü beyannameniz hiçbir vergi borcu göstermeyebilir.) Ayrıca, eyalet düzeyinde, ne sattığınız ve nasıl sattığınıza bağlı olarak, gelir vergisi ötesinde ek ücretler veya vergiler ödemeniz gerekebilir. (Örneğin, satış vergisi veya franchise vergileri devreye girebilir.) Bu konuda kendi eyalet yasalarını kontrol etmeniz gerekir. Her zaman, durumunuza ve eyaletinize öz...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>scifact-tr</summary>
#### scifact-tr
* Dataset: [scifact-tr](https://huggingface.co/datasets/selmanbaysan/scifact-tr_fine_tuning_dataset) at [382de5b](https://huggingface.co/datasets/selmanbaysan/scifact-tr_fine_tuning_dataset/tree/382de5b316d8c8042a23f34179a73fadc13cb53d)
* Size: 919 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 919 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 27.49 tokens</li><li>max: 73 tokens</li></ul> | <ul><li>min: 91 tokens</li><li>mean: 360.13 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>0 boyutlu biyomalzemeler indüktif özelliklere sahip değildir.</code> | <code>Nanoteknolojiler, kök hücreleri ölçmek, anlamak ve manipüle etmek için yararlı olabilecek yeni ortaya çıkan platformlardır. Örnekler arasında, kök hücre etiketleme ve in vivo izleme için manyetik nanopartiküller ve kuantum noktaları; hücre içi gen/oligonükleotit ve protein/peptit teslimatı için nanopartiküller, karbon nanotüpler ve polypleksler; ve kök hücre farklılaştırması ve nakli için mühendislik yapılmış nanometre ölçeği destekler yer alır. Bu inceleme, kök hücre izleme, farklılaştırma ve nakli için nanoteknolojilerin kullanımını inceler. Ayrıca, yararlılıkları ve sitotoksisiteyle ilgili olası endişeleri tartışırız.</code> |
| <code>Birleşik Krallık'ta 1 milyonun 5'inde anormal PrP pozitifliği vardır.</code> | <code><br>## Amaçlar<br>Bovin spongiform ensefalopati (BSE) salgınından sonra alt klinik prion enfeksiyonunun yaygınlığı hakkında mevcut tahminleri daha iyi anlamak ve daha geniş bir doğum kohortunun etkilenip etkilenmediğini görmek, ayrıca kan ve kan ürünleri yönetimi ve cerrahi aletlerin işlenmesiyle ilgili sonuçları daha iyi anlamak için arşivlenmiş apandisit örnekleri üzerine ek bir anket yapmak.<br><br>## Tasarım<br>Büyük ölçekli, kalıcı olarak bağlantısı kesilmiş ve anonimleştirilmiş arşivlenmiş apandisit örnekleri anketini tekrarlamak.<br><br>## Çalışma Alanı<br>Daha önceki anketin katılımının daha düşük olduğu bölgelerde ek hastaneler dahil olmak üzere, Birleşik Krallık'taki 41 hastanenin patoloji bölümlerinden arşivlenmiş apandisit örnekleri.<br><br>## Örnek<br>32.441 arşivlenmiş apandisit örneği, formalin ile sabitlenmiş ve parafinle gömülmüş ve anormal prion proteini (PrP) varlığı için test edilmiş.<br><br>## Sonuçlar<br>32.441 apandisit örneğinin 16'sı anormal PrP için pozitif çıktı, bu da genel bir yaygınlık oranı 493/m...</code> |
| <code>Kolon ve rektum kanseri hastalarının %1-1'i bölgesel veya uzak metastazlarla teşhis edilir.</code> | <code><br>Medikare'nin geri ödeme politikası 1998'de kolon kanseri riskini artıran hastalar için tarama kolon skopi kapsamı sağlayarak ve 2001'de tüm bireyler için tarama kolon skopi kapsamı genişleterek değiştirildi.<br><br>**Amaç:** Medikare geri ödeme politikasındaki değişikliklerin kolon skopi kullanımı veya erken evre kolon kanseri teşhisi artışı ile ilişkili olup olmadığını belirlemek.<br><br>**Tasarım, Ayar ve Katılımcılar:** 1992-2002 yılları arasında 67 yaş ve üstü, birincil tanısı kolon kanseri olan ve Surveillance, Epidemiology ve Sonuçları (SEER) Medikare bağlantılı veritabanındaki hastalar ile SEER alanlarında ikamet eden ancak kanser tanısı almayan Medikare yararlanıcıları.<br><br>**Ana Çıktı Ölçümleri:** Kolonoskopi ve sigmoidoskopi kullanımındaki eğilimler, kanser olmayan Medikare yararlanıcıları arasında çok değişkenli Poisson regresyonu ile değerlendirildi. Kanserli hastalarda, evre erken (evre I) ile tüm diğer evreler (II-IV) olarak sınıflandırıldı. Zaman, dönem 1 (taramaya kapsama yok, 1992-1...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>nfcorpus-tr</summary>
#### nfcorpus-tr
* Dataset: [nfcorpus-tr](https://huggingface.co/datasets/selmanbaysan/nfcorpus-tr_fine_tuning_dataset) at [22d1ef8](https://huggingface.co/datasets/selmanbaysan/nfcorpus-tr_fine_tuning_dataset/tree/22d1ef8b6a9f1c196d1977541a66ca8eff946f06)
* Size: 110,575 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 12.97 tokens</li><li>max: 18 tokens</li></ul> | <ul><li>min: 29 tokens</li><li>mean: 378.06 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Memeli Kanser Hücreleri Kolesterolden Beslenir.</code> | <code>Düşük yoğunluklu lipoprotein (LDL) reseptörlerinin içeriği, birincil meme kanserlerinden alınan dokularda belirlenmiş ve bilinen prognostik öneme sahip değişkenlerle karşılaştırılmıştır. Dondurulmuş tümör örnekleri seçilmiş ve 72 hastanın dokuları (bunlardan 32'si ölmüş) incelenmiştir. LDL reseptör içeriği, hayatta kalma süresi ile ters orantılı bir korelasyon göstermiştir. Çok değişkenli istatistiksel bir yöntemle yapılan analiz, axiller metastazın varlığı, östrojen ve LDL reseptörleri içeriği, tümör çapı ve DNA deseni gibi faktörlerin, hastaların hayatta kalma süresi konusunda prognostik değer taşıdığını göstermiştir. Meme kanseri hastalarında hayatta kalma süresini tahmin etmek için geliştirilmiş yöntemler, bireysel hastalar için tedavi seçiminin belirlenmesinde faydalı olabilir.</code> |
| <code>Memeli Kanser Hücreleri Kolesterolden Beslenir.</code> | <code>ARKA PLAN: Memurun en sık teşhis edilen kanseri, Amerika Birleşik Devletleri'nde kadınlar arasında meme kanseri. Meme kanseri riski ve hayatta kalma ile ilgili diyet faktörlerinin değerlendirilmesi için kapsamlı araştırmalar tamamlandı; ancak klinik çıkarımlar içeren bir özet rapor gerekiyor. Malzemeler ve YÖNTEMLER: Bu inceleme, diyet ile meme kanseri oluşumu, tekrarı, hayatta kalma ve ölümcüllüğü arasındaki mevcut epidemiyolojik ve klinik deneme kanıtlarını özetlemektedir. İnceleme, meme kanseri alt tiplerinde risk değerlendirmesi yapan yeni epidemiyolojik çalışmaları da içermektedir ve aynı zamanda meme kanseri riskini değiştirmeyi amaçlayan önceki ve devam eden diyet müdahale denemelerinin özetini sunmaktadır. SONUÇLAR: Mevcut literatür, düşük yağ ve yüksek lifli diyetlerin meme kanseri karşısında zayıf koruyucu olabileceğini, toplam enerji alımının ve alkolün ise pozitif bir ilişki gösterdiğini öne sürmektedir. Lif, muhtemelen östrojen modülasyonu yoluyla koruyucu olabilirken, mey...</code> |
| <code>Memeli Kanser Hücreleri Kolesterolden Beslenir.</code> | <code>Fitoestrojenler, estrojenlerle yapısal olarak benzer ve estrojenik/antiestrojenik özellikleri taklit ederek meme kanseri riskini etkileyebilirler. Batılı toplumlarda, tam tahıllar ve muhtemelen soya gıdaları fitoestrojenlerin zengin kaynaklarıdır. Alman menopoz sonrası kadınlarda yapılan bir nüfus tabanlı vaka-kontrol çalışması, fitoestrojen bakımından zengin gıdalar ve diyet lignanlarla meme kanseri riski arasındaki ilişkiyi değerlendirmek için kullanıldı. Diyet verileri, 2.884 vaka ve 5.509 kontrol için geçerli bir gıda sıklığı anketini kullanarak toplandı, bu anket fitoestrojen bakımından zengin gıdalar hakkında ek sorular içeriyordu. İlişkiler, koşullu lojistik regresyon kullanılarak değerlendirildi. Tüm analizler, ilgili risk ve karıştırıcı faktörler için ayarlandı. Politomlu lojistik regresyon analizi, estrojen reseptörü (ER) durumuna göre ilişkileri değerlendirmek için yapıldı. Soya fasulyesi, güneş çiçek tohumu ve kabak tohumu tüketiminin yüksek ve düşük seviyeleri, tüketilmeme...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>multinli-tr</summary>
#### multinli-tr
* Dataset: [multinli-tr](https://huggingface.co/datasets/selmanbaysan/multinli_tr_fine_tuning_dataset) at [a700b72](https://huggingface.co/datasets/selmanbaysan/multinli_tr_fine_tuning_dataset/tree/a700b72da7056aa52ceb234d2e8a211d035dc2c7)
* Size: 392,702 training samples
* Columns: <code>premise</code>, <code>hypothesis</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | premise | hypothesis | label |
|:--------|:-----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 4 tokens</li><li>mean: 26.79 tokens</li><li>max: 159 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 14.55 tokens</li><li>max: 56 tokens</li></ul> | <ul><li>0: ~65.70%</li><li>1: ~34.30%</li></ul> |
* Samples:
| premise | hypothesis | label |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------|:---------------|
| <code>Kavramsal olarak krem kaymağının iki temel boyutu vardır - ürün ve coğrafya.</code> | <code>Ürün ve coğrafya krem kaymağını işe yarıyor.</code> | <code>0</code> |
| <code>Mevsim boyunca ve sanırım senin seviyendeyken onları bir sonraki seviyeye düşürürsün. Eğer ebeveyn takımını çağırmaya karar verirlerse Braves üçlü A'dan birini çağırmaya karar verirlerse çifte bir adam onun yerine geçmeye gider ve bekar bir adam gelir.</code> | <code>Eğer insanlar hatırlarsa, bir sonraki seviyeye düşersin.</code> | <code>1</code> |
| <code>Numaramızdan biri talimatlarınızı birazdan yerine getirecektir.</code> | <code>Ekibimin bir üyesi emirlerinizi büyük bir hassasiyetle yerine getirecektir.</code> | <code>1</code> |
* Loss: [<code>SoftmaxLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#softmaxloss)
</details>
<details><summary>snli-tr</summary>
#### snli-tr
* Dataset: [snli-tr](https://huggingface.co/datasets/selmanbaysan/snli_tr_fine_tuning_dataset) at [63eb107](https://huggingface.co/datasets/selmanbaysan/snli_tr_fine_tuning_dataset/tree/63eb107dfdaf0b16cfd209db25705f27f2e5e2ca)
* Size: 550,152 training samples
* Columns: <code>premise</code>, <code>hypothesis</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | premise | hypothesis | label |
|:--------|:---------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 6 tokens</li><li>mean: 17.7 tokens</li><li>max: 54 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 10.61 tokens</li><li>max: 31 tokens</li></ul> | <ul><li>0: ~66.60%</li><li>1: ~33.40%</li></ul> |
* Samples:
| premise | hypothesis | label |
|:----------------------------------------------------------------|:----------------------------------------------------------|:---------------|
| <code>Attaki bir kişi, bozuk bir uçağın üzerinden atlar.</code> | <code>Bir kişi atını yarışma için eğitiyor.</code> | <code>0</code> |
| <code>Attaki bir kişi, bozuk bir uçağın üzerinden atlar.</code> | <code>Bir kişi bir lokantada omlet sipariş ediyor.</code> | <code>0</code> |
| <code>Attaki bir kişi, bozuk bir uçağın üzerinden atlar.</code> | <code>Bir kişi açık havada, at üzerinde.</code> | <code>1</code> |
* Loss: [<code>SoftmaxLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#softmaxloss)
</details>
<details><summary>stsb-tr</summary>
#### stsb-tr
* Dataset: [stsb-tr](https://huggingface.co/datasets/selmanbaysan/stsb-tr) at [3d2e87d](https://huggingface.co/datasets/selmanbaysan/stsb-tr/tree/3d2e87d2a94c9af130b87ab8ed8d0c5c2e92e2df)
* Size: 5,749 training samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:--------------------------------------------------------------------------------|:---------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 5 tokens</li><li>mean: 9.9 tokens</li><li>max: 25 tokens</li></ul> | <ul><li>min: 6 tokens</li><li>mean: 9.86 tokens</li><li>max: 21 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 2.23</li><li>max: 5.0</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:-------------------------------------------------------------------|:--------------------------------------------------------------------------------|:-----------------|
| <code>Bir uçak kalkıyor.</code> | <code>Bir hava uçağı kalkıyor.</code> | <code>5.0</code> |
| <code>Bir adam büyük bir flüt çalıyor.</code> | <code>Bir adam flüt çalıyor.</code> | <code>3.8</code> |
| <code>Bir adam pizzanın üzerine rendelenmiş peynir seriyor.</code> | <code>Bir adam pişmemiş bir pizzanın üzerine rendelenmiş peynir seriyor.</code> | <code>3.8</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
</details>
<details><summary>wmt16</summary>
#### wmt16
* Dataset: [wmt16](https://huggingface.co/datasets/selmanbaysan/wmt16_en_tr_fine_tuning_dataset) at [9fc4e73](https://huggingface.co/datasets/selmanbaysan/wmt16_en_tr_fine_tuning_dataset/tree/9fc4e7334bdb195b396c41eed05b0dd447981ef3)
* Size: 205,756 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 6 tokens</li><li>mean: 35.55 tokens</li><li>max: 130 tokens</li></ul> | <ul><li>min: 8 tokens</li><li>mean: 46.88 tokens</li><li>max: 186 tokens</li></ul> |
* Samples:
| anchor | positive |
|:------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------|
| <code>Kosova'nın özelleştirme süreci büyüteç altında</code> | <code>Kosovo's privatisation process is under scrutiny</code> |
| <code>Kosova, tekrar eden şikayetler ışığında özelleştirme sürecini incelemeye alıyor.</code> | <code>Kosovo is taking a hard look at its privatisation process in light of recurring complaints.</code> |
| <code>Southeast European Times için Priştine'den Muhamet Brayşori'nin haberi -- 21/03/12</code> | <code>By Muhamet Brajshori for Southeast European Times in Pristina -- 21/03/12</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
### Evaluation Datasets
<details><summary>msmarco-tr</summary>
#### msmarco-tr
* Dataset: [msmarco-tr](https://huggingface.co/datasets/selmanbaysan/msmarco-tr_fine_tuning_dataset) at [f03d837](https://huggingface.co/datasets/selmanbaysan/msmarco-tr_fine_tuning_dataset/tree/f03d83704e5ea276665384ca6d8bee3b19632c80)
* Size: 31,540 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:---------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 9.88 tokens</li><li>max: 40 tokens</li></ul> | <ul><li>min: 12 tokens</li><li>mean: 82.48 tokens</li><li>max: 149 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Brian Patrick Carroll kimdir?</code> | <code>Buckethead Biyografisi. Brian Patrick Carroll (13 Mayıs 1969 doğumlu), profesyonel olarak Buckethead olarak bilinen, birçok müzik türünde çalışmış Amerikalı gitarist ve çoklu enstrümantalist. 265 stüdyo albümü, dört özel sürüm ve bir EP yayınladı. Ayrıca diğer sanatçılar tarafından 50'den fazla albümde seslendirdi.</code> |
| <code>zolpidem bir benzodiazepin</code> | <code>Zolpidem (Ambien), imidazopiridin sınıfının bir benzodiazepin olmayan hipnotikidir. Bu ilaç, benzodiazepin omega-1 reseptörüne (seçici olmayan omega-1, 2 ve 3 reseptör alt tiplerine bağlanan diğer benzodiazepinlerin aksine) çok seçici bir şekilde bağlanır, klorür kanalının açılma sıklığını arttırır.</code> |
| <code>roti'de kalori</code> | <code>1 porsiyon Roti Akdeniz Izgara Tavuk Roti'de 257 kalori vardır. Kalori dağılımı: %47 yağ, %0 karbonhidrat, %53 protein.</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>fiqa-tr</summary>
#### fiqa-tr
* Dataset: [fiqa-tr](https://huggingface.co/datasets/selmanbaysan/fiqa-tr_fine_tuning_dataset) at [bbc9e91](https://huggingface.co/datasets/selmanbaysan/fiqa-tr_fine_tuning_dataset/tree/bbc9e91b5710d0ac4032b5c9e94066470f928c8c)
* Size: 1,238 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 6 tokens</li><li>mean: 18.43 tokens</li><li>max: 48 tokens</li></ul> | <ul><li>min: 8 tokens</li><li>mean: 219.48 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Bir geliri olmayan işletme için işletme giderlerini talep etmek.</code> | <code>Evet, henüz herhangi bir gelir elde etmiyorsanız işletme indirimleri talep edebilirsiniz. Ancak öncelikle işletmeniz için hangi yapıyı tercih edeceğinize karar vermelisiniz. Ya bir Şirket Yapısı ya da Tek Sahiplik veya Ortaklık. Şirket Yapısı Eğer bir Şirket Yapısı (kurulumu daha pahalı olan) seçerseniz, indirimleri talep edebilirsiniz ancak geliriniz yok. Bu nedenle işletmeniz bir zarara uğrar ve bu zararı, işletmenizden elde ettiğiniz gelirin giderlerinizi aşana kadar devam ettirirsiniz. Bu zararlar şirketin içinde kalır ve gelecek gelir yıllarında kârlarınızı dengelemek için devralınabilir. Daha fazla bilgi için ATO - Şirket Vergi Zararları'na bakın. Tek Sahiplik veya Ortaklık Yapısı Eğer Tek Sahiplik veya Ortaklık olarak seçerseniz ve işletmeniz bir zarara uğrarsa, bu zararı diğer kaynaklardan elde ettiğiniz gelire karşı dengeleyip dengeleyemeyeceğinizi kontrol etmeniz gerekir. İşletmenizin diğer gelirinize karşı zararını dengelemek için aşağıdaki testlerden birini geçmeniz gerekir...</code> |
| <code>Bir işletme kontrol hesabından başka bir işletme kontrol hesabına para aktarma.</code> | <code>"Her iki işletme için ayrı dosyalar olmalıdır. Para transferi yapan işletme, QB dosyasında ""çeki yaz"" olmalıdır. Para alan işletme, QB dosyasında ""banka yatırımı"" yapmalıdır. (QB'de, ödemeyi ACH gibi başka bir yöntemle yaptığınızda bile, ""çeki yaz"" demeniz gerekir.) Hiçbir işletme, diğerinin banka hesaplarını açıkça temsil etmemelidir. Her iki tarafta da, ödemenin hangi başka hesaptan geldiği/gittiği konusunda sınıflandırmanız gerekecektir - Bunun doğru olup olmadığını bilmek için, parayı neden transfer ettiğinizi ve kitaplarınızı nasıl kurduğunuzu bilmeniz gerekir. Sanırım bu, burada uygun/mümkün olan konunun ötesindedir. Kişisel hesabınızdan işinize para aktarmak, muhtemelen ortaklık sermayesi demektir, eğer başka bir şey yoksa. Örneğin, S Corp'ta kendinize bir maaş ödemelisiniz. Eğer yanlışlıkla fazla öderseniz, o zaman kişisel hesabınızdan şirketi geri bir çek yazıp hatayı düzeltirsiniz. Bu ortaklık sermayesi değil, muhtemelen maaş ödemelerini takip eden başka bir hesaptaki b...</code> |
| <code>İş/yatırım için ayrı bir banka hesabınız var mı, ama "iş hesabı" değil mi?</code> | <code>"İş için ayrı bir kontrol hesabı açmak mantıklıdır. Gelir/giderlerinizi belgelemek daha basittir. Hesaba giren ve çıkan her doları açıklayabilirsiniz, bunlardan bazılarının işle alakasız olduğunu hatırlamanıza gerek kalmadan. Kredi birliği, ikinci bir kontrol hesabı açmama ve çeklerin üzerine istediğim herhangi bir ad koymama izin verdi. Bu, çeklerin üzerine adımın yazılması yerine daha iyi görünüyordu. Yatırımlar için ayrı bir kontrol hesabına ihtiyaç görmüyorum. Parayı, herhangi bir ücret olmayan ve hatta biraz faiz kazandırabilen ayrı bir tasarruf hesabında tutabilirsiniz. Ayda çok sayıda yatırım işlemi yapmadığınız sürece bu benim için işe yaradı. Bu şekilde IRA'ları ve 529 planlarını finanse ediyorum. Ayda 4-5 kez maaş alıyoruz, ancak her ay fonlara para gönderiyoruz. İşlem sayısı büyüdükçe bir iş hesabına ihtiyacınız olacak. Bankaya her seferinde onlarca çek yatırıyorsanız, banka sizi iş hesabına geçmeye yönlendirecektir."</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>quora-tr</summary>
#### quora-tr
* Dataset: [quora-tr](https://huggingface.co/datasets/selmanbaysan/quora-tr_fine_tuning_dataset) at [6e1eee1](https://huggingface.co/datasets/selmanbaysan/quora-tr_fine_tuning_dataset/tree/6e1eee1e44db0f777eceb1f9b55293a9c2e25d76)
* Size: 7,626 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 5 tokens</li><li>mean: 15.29 tokens</li><li>max: 45 tokens</li></ul> | <ul><li>min: 5 tokens</li><li>mean: 15.47 tokens</li><li>max: 47 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------|
| <code>Quora'yı bir moderatörün gözünden nasıl görürsünüz?</code> | <code>Quora web sitesi, Quora moderasyon üyelerine nasıl görünür?</code> |
| <code>Nasıl hayatımın yapmam gereken farklı şeyler arasında seçim yapmamayı reddedebilirim?</code> | <code>Hayatta birçok farklı şeyi takip etmek mümkün mü?</code> |
| <code>Ben Affleck Batman'de Christian Bale'den daha parlak mıydı?</code> | <code>Sizce, Batman performansında kim daha iyiydi: Christian Bale mi yoksa Ben Affleck mi?</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>nfcorpus-tr</summary>
#### nfcorpus-tr
* Dataset: [nfcorpus-tr](https://huggingface.co/datasets/selmanbaysan/nfcorpus-tr_fine_tuning_dataset) at [22d1ef8](https://huggingface.co/datasets/selmanbaysan/nfcorpus-tr_fine_tuning_dataset/tree/22d1ef8b6a9f1c196d1977541a66ca8eff946f06)
* Size: 11,385 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 7 tokens</li><li>mean: 11.41 tokens</li><li>max: 20 tokens</li></ul> | <ul><li>min: 67 tokens</li><li>mean: 375.07 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:----------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Derin Kızartılmış Gıdaların Kanser Yapabileceği Nedenler</code> | <code>Arka plan: Akrilamid, insan plasentasını geçen yaygın bir diyetik maruziyettir. Muhtemel insan kanserojen olarak sınıflandırılır ve farelerde gelişimsel toksisite gözlemlenmiştir. Amaçlar: Bu çalışmada, akrilamid ön doğum maruziyeti ile doğum sonuçlarının ilişkilerini inceledik. Yöntemler: Akrilamidin ve metaboliti glisidamidin hemoglobin (Hb) adductları, 2006-2010 yılları arasında Danimarka, İngiltere, Yunanistan, Norveç ve İspanya'da işe alınan 1.101 tek çocuklu hamile kadınların kordon kanında (hamileliğin son aylarında birikmiş maruziyeti yansıtan) ölçüldü. Anne diyetleri, gıda sıklığı anketleri aracılığıyla tahmin edildi. Sonuçlar: Hem akrilamid hem de glisidamid Hb adductları, doğum ağırlığı ve baş çevresi için istatistiksel olarak anlamlı bir azalma ile ilişkiliydi. En yüksek ve en düşük çeyrekte akrilamid Hb adduct seviyeleri arasındaki tahmin edilen doğum ağırlığı farkı, gestasyonel yaş ve ülke ayarlamalarından sonra –132 g (95% CI: –207, –56) idi; baş çevresi için karşılık ge...</code> |
| <code>Derin Kızartılmış Gıdaların Kanser Yapabileceği Nedenler</code> | <code>İnsanlar, patates kızartması ve diğer yiyecekler yoluyla akrilamid (AA) maruziyeti, potansiyel bir sağlık endişesi olarak kabul edilmiştir. Burada, pişirme sıcaklığı ve süresi gibi iki en etkili faktöre dayalı istatistiksel bir doğrusal olmayan regresyon modeli kullanarak, patates kızartmalarında AA konsantrasyonlarını tahmin ettik. Tahmin modeli için R(2) değeri 0.83, geliştirilmiş modelin önemli ve geçerli olduğunu göstermektedir. Bu çalışmada yapılan patates kızartması tüketimi anket verileri ve sekiz farklı kızartma sıcaklığı-zaman şeması, lezzetli ve görsel açıdan çekici patates kızartmaları üretebildiği için, Monte Carlo simülasyon sonuçları, AA konsantrasyonunun 168 ppb'den yüksek olduğu takdirde, Taichung Şehri'ndeki 13-18 yaş arası ergenlerin tahmin edilen kanser riski, sadece bu sınırlı yaşam süresi göz önüne alındığında, hedef aşılan ömür boyu kanser riski (ELCR) değerini aşacaktır. AA alımıyla ilişkili kanser riskini azaltmak için, patates kızartmalarındaki AA seviyelerinin...</code> |
| <code>Derin Kızartılmış Gıdaların Kanser Yapabileceği Nedenler</code> | <code>ARKA PLAN: Yaygın olarak tüketilen gıdalar, örneğin patates kızartması, patates cipsi veya tahıllar gibi ürünlerde nispeten yüksek akrilamid konsantrasyonları, insan sağlığı için potansiyel bir risk oluşturabilir.<br><br>HEDEF: Bu pilot çalışmanın amacı, kronik akrilamid içeren patates cipsi alımının oksidatif stres veya iltihapla olası bağlantısını araştırmaktı.<br><br>Tasarım: 14 sağlıklı gönüllü (ortalama yaş: 35; 8 kadın ve 6 günde 20 sigaradan fazla sigara içen) 4 hafta boyunca günde 160 gram akrilamid içeren 157 mikrogram (düzeltilmiş) akrilamid içeren patates cipsi aldı.<br><br>Sonuç: Çalışmanın tüm katılımlarında kan akrilamid-hemoglobin bağlarımında artış bulundu, ortalama 43.1 pmol/L(-1)/g(-1) hemoglobin (aralık: 27-76; P < 0.01) sigara içmeyenlerde ve 59.0 pmol/L(-1)/g(-1) hemoglobin (aralık: 43-132; P < 0.05) sigara içenlerde. Aynı zamanda, hem sigara içenlerde hem de sigara içmeyenlerde okside LDL, yüksek duyarlılık interleukin-6, yüksek duyarlılık C-reaktif protein ve gama-glutamiltransfer...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
<details><summary>snli-tr</summary>
#### snli-tr
* Dataset: [snli-tr](https://huggingface.co/datasets/selmanbaysan/snli_tr_fine_tuning_dataset) at [63eb107](https://huggingface.co/datasets/selmanbaysan/snli_tr_fine_tuning_dataset/tree/63eb107dfdaf0b16cfd209db25705f27f2e5e2ca)
* Size: 10,000 evaluation samples
* Columns: <code>premise</code>, <code>hypothesis</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | premise | hypothesis | label |
|:--------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 6 tokens</li><li>mean: 18.69 tokens</li><li>max: 53 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 10.29 tokens</li><li>max: 30 tokens</li></ul> | <ul><li>0: ~67.50%</li><li>1: ~32.50%</li></ul> |
* Samples:
| premise | hypothesis | label |
|:----------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------|:---------------|
| <code>Paketlere gitmek için tutunurken iki kadın kucaklaşıyor.</code> | <code>Kız kardeşler sadece öğle yemeği yedikten sonra paketleri gitmek için tutarken elveda sarılıyorlar.</code> | <code>0</code> |
| <code>Paketlere gitmek için tutunurken iki kadın kucaklaşıyor.</code> | <code>İki kadın paket tutuyor.</code> | <code>1</code> |
| <code>Paketlere gitmek için tutunurken iki kadın kucaklaşıyor.</code> | <code>Adamlar bir şarküterinin dışında kavga ediyorlar.</code> | <code>0</code> |
* Loss: [<code>SoftmaxLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#softmaxloss)
</details>
<details><summary>xnli-tr</summary>
#### xnli-tr
* Dataset: [xnli-tr](https://huggingface.co/datasets/selmanbaysan/xnli_tr_fine_tuning_dataset) at [3a66bc8](https://huggingface.co/datasets/selmanbaysan/xnli_tr_fine_tuning_dataset/tree/3a66bc878d3d027177da71f47e4d8dee21cafe63)
* Size: 2,490 evaluation samples
* Columns: <code>premise</code>, <code>hypothesis</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | premise | hypothesis | label |
|:--------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 6 tokens</li><li>mean: 22.57 tokens</li><li>max: 67 tokens</li></ul> | <ul><li>min: 5 tokens</li><li>mean: 13.12 tokens</li><li>max: 33 tokens</li></ul> | <ul><li>0: ~66.70%</li><li>1: ~33.30%</li></ul> |
* Samples:
| premise | hypothesis | label |
|:------------------------------------|:---------------------------------------------------------------|:---------------|
| <code>Ve Anne, evdeyim dedi.</code> | <code>Okul servisi onu bırakır bırakmaz annesini aradı.</code> | <code>0</code> |
| <code>Ve Anne, evdeyim dedi.</code> | <code>Bir kelime söylemedi.</code> | <code>0</code> |
| <code>Ve Anne, evdeyim dedi.</code> | <code>Annesine eve gittiğini söyledi.</code> | <code>1</code> |
* Loss: [<code>SoftmaxLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#softmaxloss)
</details>
<details><summary>stsb-tr</summary>
#### stsb-tr
* Dataset: [stsb-tr](https://huggingface.co/datasets/selmanbaysan/stsb-tr) at [3d2e87d](https://huggingface.co/datasets/selmanbaysan/stsb-tr/tree/3d2e87d2a94c9af130b87ab8ed8d0c5c2e92e2df)
* Size: 1,500 evaluation samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:--------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 5 tokens</li><li>mean: 15.37 tokens</li><li>max: 58 tokens</li></ul> | <ul><li>min: 5 tokens</li><li>mean: 15.41 tokens</li><li>max: 54 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 2.1</li><li>max: 5.0</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:----------------------------------------------|:-----------------------------------------------|:------------------|
| <code>Kasklı bir adam dans ediyor.</code> | <code>Baret giyen bir adam dans ediyor.</code> | <code>5.0</code> |
| <code>Küçük bir çocuk ata biniyor.</code> | <code>Bir çocuk ata biniyor.</code> | <code>4.75</code> |
| <code>Bir adam fareyi yılana besliyor.</code> | <code>Adam yılana fare besliyor.</code> | <code>5.0</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
</details>
<details><summary>wmt16</summary>
#### wmt16
* Dataset: [wmt16](https://huggingface.co/datasets/selmanbaysan/wmt16_en_tr_fine_tuning_dataset) at [9fc4e73](https://huggingface.co/datasets/selmanbaysan/wmt16_en_tr_fine_tuning_dataset/tree/9fc4e7334bdb195b396c41eed05b0dd447981ef3)
* Size: 1,001 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 26.96 tokens</li><li>max: 149 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 39.33 tokens</li><li>max: 240 tokens</li></ul> |
* Samples:
| anchor | positive |
|:----------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------|
| <code>Norveç'in rakfisk'i: Dünyanın en kokulu balığı bu mu?</code> | <code>Norway's rakfisk: Is this the world's smelliest fish?</code> |
| <code>Norveç'in beş milyon insanı en yüksek yaşam standartlarının tadını çıkarıyor, sadece Avrupa'da değil, dünyada.</code> | <code>Norway's five million people enjoy one of the highest standards of living, not just in Europe, but in the world.</code> |
| <code>Ülkenin başarısının sırrı aşırı kokulu bazı balıklara olan yerel iştahla bağlantılı olabilir mi?</code> | <code>Could the secret of the country's success be connected to the local appetite for some exceedingly smelly fish?</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
</details>
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `fp16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | msmarco-tr loss | fiqa-tr loss | quora-tr loss | nfcorpus-tr loss | snli-tr loss | xnli-tr loss | stsb-tr loss | wmt16 loss | stsb-tr_spearman_cosine | snli-tr_cosine_ap | xnli-tr_cosine_ap | wmt16_cosine_ap | msmarco-tr_cosine_ap | fiqa-tr_cosine_ap | quora-tr_cosine_ap | nfcorpus-tr_cosine_ap |
|:------:|:-----:|:-------------:|:---------------:|:------------:|:-------------:|:----------------:|:------------:|:------------:|:------------:|:----------:|:-----------------------:|:-----------------:|:-----------------:|:---------------:|:--------------------:|:-----------------:|:------------------:|:---------------------:|
| 0.0209 | 500 | 1.1414 | 0.2698 | 1.9305 | 0.1019 | 1.1507 | 0.5826 | 0.6343 | 11.1465 | 0.9888 | 0.7727 | 0.4918 | 0.4731 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0417 | 1000 | 0.8222 | 0.2270 | 1.8603 | 0.0904 | 1.0909 | 0.4977 | 0.5921 | 11.8077 | 0.6025 | 0.7783 | 0.4928 | 0.5208 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0626 | 1500 | 0.7991 | 0.1968 | 1.7750 | 0.0879 | 1.0778 | 0.4483 | 0.5314 | 12.2621 | 0.5532 | 0.7865 | 0.5174 | 0.5560 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0835 | 2000 | 0.7775 | 0.1903 | 1.7956 | 0.0809 | 1.0444 | 0.4053 | 0.4841 | 12.3953 | 0.5244 | 0.7909 | 0.5311 | 0.5875 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.1043 | 2500 | 0.6397 | 0.1779 | 1.7774 | 0.0772 | 1.0337 | 0.3985 | 0.4661 | 11.9094 | 0.4421 | 0.7853 | 0.5702 | 0.5917 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.1252 | 3000 | 0.7237 | 0.1658 | 1.6839 | 0.0768 | 1.0342 | 0.3646 | 0.4684 | 12.1233 | 0.3539 | 0.8049 | 0.5745 | 0.5949 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.1461 | 3500 | 0.5485 | 0.1603 | 1.7514 | 0.0811 | 1.0235 | 0.3626 | 0.4589 | 12.7109 | 0.2967 | 0.7867 | 0.5985 | 0.6128 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.1669 | 4000 | 0.6076 | 0.1513 | 1.6503 | 0.0723 | 1.0043 | 0.3555 | 0.4829 | 12.5178 | 0.2867 | 0.8049 | 0.5692 | 0.6019 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.1878 | 4500 | 0.5363 | 0.1478 | 1.6573 | 0.0696 | 1.0147 | 0.3448 | 0.4759 | 12.7022 | 0.2406 | 0.8042 | 0.5886 | 0.6023 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.2087 | 5000 | 0.5543 | 0.1453 | 1.6171 | 0.0664 | 1.0054 | 0.3384 | 0.4634 | 12.3955 | 0.2647 | 0.8116 | 0.5896 | 0.6107 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.2295 | 5500 | 0.6203 | 0.1455 | 1.6107 | 0.0710 | 0.9872 | 0.3333 | 0.4487 | 12.1924 | 0.2382 | 0.8110 | 0.5837 | 0.6206 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.2504 | 6000 | 0.6368 | 0.1354 | 1.5559 | 0.0704 | 1.0105 | 0.3236 | 0.4455 | 12.4101 | 0.2259 | 0.8102 | 0.5998 | 0.6200 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.2713 | 6500 | 0.568 | 0.1366 | 1.5891 | 0.0701 | 0.9898 | 0.3206 | 0.4292 | 11.9028 | 0.2035 | 0.8066 | 0.5866 | 0.6038 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.2921 | 7000 | 0.6087 | 0.1300 | 1.5420 | 0.0671 | 0.9914 | 0.3175 | 0.4247 | 12.2175 | 0.2220 | 0.8112 | 0.5902 | 0.6183 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.3130 | 7500 | 0.5987 | 0.1233 | 1.5577 | 0.0622 | 0.9914 | 0.3205 | 0.4559 | 12.4562 | 0.1855 | 0.8126 | 0.6083 | 0.6184 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.3339 | 8000 | 0.5158 | 0.1231 | 1.5156 | 0.0653 | 0.9854 | 0.3145 | 0.4436 | 12.3801 | 0.1826 | 0.8107 | 0.6016 | 0.6073 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.3547 | 8500 | 0.5475 | 0.1208 | 1.4804 | 0.0631 | 0.9754 | 0.3140 | 0.4662 | 12.8113 | 0.1841 | 0.8152 | 0.5904 | 0.6142 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.3756 | 9000 | 0.638 | 0.1270 | 1.5346 | 0.0652 | 0.9691 | 0.3112 | 0.4162 | 12.2037 | 0.1964 | 0.8092 | 0.6004 | 0.6281 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.3965 | 9500 | 0.594 | 0.1203 | 1.4953 | 0.0637 | 0.9715 | 0.3152 | 0.4756 | 12.7237 | 0.1561 | 0.8068 | 0.6040 | 0.6185 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.4173 | 10000 | 0.5815 | 0.1169 | 1.4600 | 0.0595 | 0.9748 | 0.3115 | 0.4733 | 12.7256 | 0.1669 | 0.8101 | 0.6085 | 0.6156 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.4382 | 10500 | 0.6099 | 0.1168 | 1.4518 | 0.0667 | 0.9748 | 0.3025 | 0.4319 | 12.5545 | 0.1821 | 0.8183 | 0.6135 | 0.6232 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.4591 | 11000 | 0.5243 | 0.1152 | 1.4609 | 0.0636 | 0.9691 | 0.3086 | 0.4409 | 12.5561 | 0.1717 | 0.8120 | 0.6114 | 0.6269 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.4799 | 11500 | 0.5788 | 0.1149 | 1.4629 | 0.0629 | 0.9603 | 0.3007 | 0.4444 | 12.4325 | 0.1740 | 0.8137 | 0.6077 | 0.6266 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.5008 | 12000 | 0.4322 | 0.1116 | 1.4600 | 0.0623 | 0.9684 | 0.2992 | 0.4232 | 12.5360 | 0.1757 | 0.8160 | 0.6045 | 0.6234 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.5217 | 12500 | 0.6227 | 0.1106 | 1.4774 | 0.0635 | 0.9649 | 0.2966 | 0.4272 | 12.3037 | 0.1568 | 0.8193 | 0.6061 | 0.6220 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.5425 | 13000 | 0.5269 | 0.1087 | 1.4653 | 0.0627 | 0.9646 | 0.2946 | 0.4262 | 12.4239 | 0.1672 | 0.8172 | 0.6154 | 0.6240 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.5634 | 13500 | 0.5462 | 0.1076 | 1.4482 | 0.0613 | 0.9608 | 0.2950 | 0.4061 | 12.3639 | 0.1669 | 0.8134 | 0.6289 | 0.6340 | 1.0 | 1.0000 | 1.0 | 1.0 | 1.0 |
| 0.5843 | 14000 | 0.5737 | 0.1069 | 1.4330 | 0.0594 | 0.9715 | 0.2934 | 0.4241 | 12.5838 | 0.1553 | 0.8162 | 0.6060 | 0.6201 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.6052 | 14500 | 0.5542 | 0.1062 | 1.4318 | 0.0630 | 0.9627 | 0.2936 | 0.4252 | 12.4879 | 0.1537 | 0.8135 | 0.6182 | 0.6211 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.6260 | 15000 | 0.4828 | 0.1014 | 1.4022 | 0.0620 | 0.9721 | 0.2916 | 0.4162 | 12.5052 | 0.1578 | 0.8200 | 0.6130 | 0.6307 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.6469 | 15500 | 0.585 | 0.1030 | 1.4268 | 0.0662 | 0.9565 | 0.2915 | 0.4235 | 12.4999 | 0.1483 | 0.8166 | 0.5973 | 0.6245 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.6678 | 16000 | 0.5699 | 0.1036 | 1.4218 | 0.0636 | 0.9622 | 0.2883 | 0.4099 | 12.4195 | 0.1516 | 0.8182 | 0.6130 | 0.6315 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.6886 | 16500 | 0.5372 | 0.1003 | 1.4122 | 0.0619 | 0.9671 | 0.2905 | 0.4249 | 12.5527 | 0.1545 | 0.8164 | 0.6119 | 0.6304 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.7095 | 17000 | 0.5473 | 0.1021 | 1.4109 | 0.0636 | 0.9602 | 0.2848 | 0.4097 | 12.3792 | 0.1640 | 0.8157 | 0.6171 | 0.6351 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.7304 | 17500 | 0.5665 | 0.0985 | 1.3868 | 0.0604 | 0.9616 | 0.2845 | 0.4083 | 12.4513 | 0.1523 | 0.8195 | 0.6044 | 0.6306 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.7512 | 18000 | 0.498 | 0.0985 | 1.3925 | 0.0606 | 0.9605 | 0.2828 | 0.4068 | 12.4254 | 0.1544 | 0.8177 | 0.6082 | 0.6351 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.7721 | 18500 | 0.5037 | 0.0975 | 1.3748 | 0.0570 | 0.9619 | 0.2891 | 0.4256 | 12.5656 | 0.1451 | 0.8158 | 0.6072 | 0.6294 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.7930 | 19000 | 0.4885 | 0.0966 | 1.3742 | 0.0612 | 0.9600 | 0.2818 | 0.3993 | 12.4406 | 0.1473 | 0.8170 | 0.6096 | 0.6349 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.8138 | 19500 | 0.5042 | 0.0966 | 1.3817 | 0.0589 | 0.9621 | 0.2822 | 0.4181 | 12.5854 | 0.1476 | 0.8167 | 0.6186 | 0.6418 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.8347 | 20000 | 0.5453 | 0.0966 | 1.3790 | 0.0583 | 0.9553 | 0.2824 | 0.4112 | 12.5904 | 0.1451 | 0.8156 | 0.6100 | 0.6336 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.8556 | 20500 | 0.5351 | 0.0963 | 1.3810 | 0.0591 | 0.9588 | 0.2844 | 0.4211 | 12.7160 | 0.1445 | 0.8161 | 0.6129 | 0.6358 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.8764 | 21000 | 0.4601 | 0.0951 | 1.3744 | 0.0581 | 0.9573 | 0.2792 | 0.4059 | 12.5846 | 0.1448 | 0.8156 | 0.6193 | 0.6372 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.8973 | 21500 | 0.4698 | 0.0949 | 1.3757 | 0.0578 | 0.9576 | 0.2780 | 0.4020 | 12.6457 | 0.1417 | 0.8146 | 0.6180 | 0.6347 | 1.0 | 1.0000 | 1.0 | 1.0 | 1.0 |
| 0.9182 | 22000 | 0.4838 | 0.0930 | 1.3611 | 0.0564 | 0.9572 | 0.2781 | 0.4136 | 12.7198 | 0.1404 | 0.8157 | 0.6187 | 0.6348 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.9390 | 22500 | 0.5106 | 0.0931 | 1.3639 | 0.0569 | 0.9550 | 0.2791 | 0.4117 | 12.6323 | 0.1377 | 0.8168 | 0.6121 | 0.6328 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.9599 | 23000 | 0.6039 | 0.0929 | 1.3606 | 0.0568 | 0.9566 | 0.2797 | 0.4182 | 12.6569 | 0.1339 | 0.8167 | 0.6130 | 0.6332 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.9808 | 23500 | 0.5395 | 0.0928 | 1.3603 | 0.0575 | 0.9553 | 0.2783 | 0.4120 | 12.6136 | 0.1337 | 0.8168 | 0.6132 | 0.6338 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
### Framework Versions
- Python: 3.11.11
- Sentence Transformers: 3.4.1
- Transformers: 4.49.0
- PyTorch: 2.6.0+cu124
- Accelerate: 1.5.2
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers and SoftmaxLoss
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
#### CoSENTLoss
```bibtex
@online{kexuefm-8847,
title={CoSENT: A more efficient sentence vector scheme than Sentence-BERT},
author={Su Jianlin},
year={2022},
month={Jan},
url={https://kexue.fm/archives/8847},
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Baoaboya/deepseek_sql_model
|
Baoaboya
| 2025-03-25T12:57:33Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T12:57:03Z
|
---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Baoaboya
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ysn-rfd/Open-RS3-Q8_0-GGUF
|
ysn-rfd
| 2025-03-25T12:57:32Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"dataset:knoveleng/open-rs",
"dataset:knoveleng/open-s1",
"dataset:knoveleng/open-deepscaler",
"base_model:knoveleng/Open-RS3",
"base_model:quantized:knoveleng/Open-RS3",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-03-25T12:57:16Z
|
---
base_model: knoveleng/Open-RS3
datasets:
- knoveleng/open-rs
- knoveleng/open-s1
- knoveleng/open-deepscaler
library_name: transformers
license: mit
pipeline_tag: text-generation
tags:
- llama-cpp
- gguf-my-repo
inference: true
---
# ysn-rfd/Open-RS3-Q8_0-GGUF
This model was converted to GGUF format from [`knoveleng/Open-RS3`](https://huggingface.co/knoveleng/Open-RS3) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/knoveleng/Open-RS3) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ysn-rfd/Open-RS3-Q8_0-GGUF --hf-file open-rs3-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ysn-rfd/Open-RS3-Q8_0-GGUF --hf-file open-rs3-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ysn-rfd/Open-RS3-Q8_0-GGUF --hf-file open-rs3-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ysn-rfd/Open-RS3-Q8_0-GGUF --hf-file open-rs3-q8_0.gguf -c 2048
```
|
sergeyzh/rubert-mini-uncased-GGUF
|
sergeyzh
| 2025-03-25T12:57:17Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"russian",
"pretraining",
"embeddings",
"tiny",
"feature-extraction",
"sentence-similarity",
"sentence-transformers",
"ru",
"en",
"dataset:IlyaGusev/gazeta",
"dataset:zloelias/lenta-ru",
"dataset:HuggingFaceFW/fineweb-2",
"dataset:HuggingFaceFW/fineweb",
"base_model:sergeyzh/rubert-mini-uncased",
"base_model:quantized:sergeyzh/rubert-mini-uncased",
"license:mit",
"region:us"
] |
sentence-similarity
| 2025-03-25T12:56:37Z
|
---
language:
- ru
- en
pipeline_tag: sentence-similarity
inference: false
library_name: transformers
tags:
- russian
- pretraining
- embeddings
- tiny
- feature-extraction
- sentence-similarity
- sentence-transformers
- transformers
datasets:
- IlyaGusev/gazeta
- zloelias/lenta-ru
- HuggingFaceFW/fineweb-2
- HuggingFaceFW/fineweb
license: mit
base_model: sergeyzh/rubert-mini-uncased
---
## rubert-mini-uncased-GGUF
Оригинальная модель: [rubert-mini-uncased](https://huggingface.co/sergeyzh/rubert-mini-uncased)
Для запуска модели в качестве сервера необходимо использовать llama.cpp:
```bash
llama-server -m rubert-mini-uncased-q8_0.gguf -c 512 -ngl 99 --embedding --port 8080
```
Возможно использование с LM Studio.
## Использование модели после запуска llama-server:
```python
import numpy as np
import requests
import json
def embeding(text):
url = 'http://127.0.0.1:8080/v1/embeddings'
headers = {"Content-Type": "application/json", "Authorization": "no-key"}
data={"input": text,
"model": "rubert-mini-uncased",
"encoding_format": "float"}
r = requests.post(url, headers=headers, data=json.dumps(data))
emb = np.array([np.array(s['embedding']) for s in r.json()['data']])
return emb
inputs = [
#
"paraphrase: В Ярославской области разрешили работу бань, но без посетителей",
"categorize_entailment: Женщину доставили в больницу, за ее жизнь сейчас борются врачи.",
"search_query: Сколько программистов нужно, чтобы вкрутить лампочку?",
#
"paraphrase: Ярославским баням разрешили работать без посетителей",
"categorize_entailment: Женщину спасают врачи.",
"search_document: Чтобы вкрутить лампочку, требуется три программиста: один напишет программу извлечения лампочки, другой — вкручивания лампочки, а третий проведет тестирование."
]
embeddings = embeding(inputs)
sim_scores = embeddings[:3] @ embeddings[3:].T
print(sim_scores.diagonal().tolist())
# [0.9365279201944358, 0.8030448289720129, 0.6826768729478850] - rubert-mini-uncased-f32
# [0.9365603574226906, 0.8029491439999603, 0.6826115652313832] - rubert-mini-uncased-f16
# [0.9362014453563489, 0.8019812246234975, 0.6823210638303931] - rubert-mini-uncased-q8_0
# [0.9366128444671631, 0.8030662536621094, 0.6826460957527161] - rubert-mini-uncased (torch)
# [0.9360030293464661, 0.8591322302818298, 0.7285830378532410] - FRIDA
```
|
yfarm01/sn29_mar25_c0
|
yfarm01
| 2025-03-25T12:54:59Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T11:53:51Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NewEden/MagPicaro-Big
|
NewEden
| 2025-03-25T12:53:12Z
| 13
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Doctor-Shotgun/L3.3-70B-Magnum-v4-SE",
"base_model:merge:Doctor-Shotgun/L3.3-70B-Magnum-v4-SE",
"base_model:NewEden/Picaro-Big",
"base_model:merge:NewEden/Picaro-Big",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-24T12:28:39Z
|
---
base_model:
- NewEden/Picaro-Big
- Doctor-Shotgun/L3.3-70B-Magnum-v4-SE
library_name: transformers
tags:
- mergekit
- merge
---
Magnum Picaro scaled up, Not approved by trappu. this version followed a similar recipe to his 24B.
### Models Merged
The following models were included in the merge:
* [NewEden/Picaro-Big](https://huggingface.co/NewEden/Picaro-Big)
* [Doctor-Shotgun/L3.3-70B-Magnum-v4-SE](https://huggingface.co/Doctor-Shotgun/L3.3-70B-Magnum-v4-SE)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: NewEden/Picaro-Big
- model: Doctor-Shotgun/L3.3-70B-Magnum-v4-SE
merge_method: slerp
base_model: NewEden/Picaro-Big
parameters:
t:
- value: 0.5
dtype: bfloat16
tokenizer_source: base
```
|
genki10/BERT_AugV8_k5_task1_organization_sp020_lw010_fold0
|
genki10
| 2025-03-25T12:52:08Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T12:40:38Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k5_task1_organization_sp020_lw010_fold0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k5_task1_organization_sp020_lw010_fold0
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8887
- Qwk: 0.3516
- Mse: 0.8887
- Rmse: 0.9427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 4 | 9.8106 | 0.0 | 9.8106 | 3.1322 |
| No log | 2.0 | 8 | 4.8977 | 0.0231 | 4.8977 | 2.2131 |
| No log | 3.0 | 12 | 2.3924 | 0.1715 | 2.3924 | 1.5467 |
| No log | 4.0 | 16 | 1.3210 | 0.0419 | 1.3210 | 1.1493 |
| No log | 5.0 | 20 | 0.7866 | 0.3055 | 0.7866 | 0.8869 |
| No log | 6.0 | 24 | 1.2237 | 0.0419 | 1.2237 | 1.1062 |
| No log | 7.0 | 28 | 0.6373 | 0.3022 | 0.6373 | 0.7983 |
| No log | 8.0 | 32 | 1.1277 | 0.0805 | 1.1277 | 1.0619 |
| No log | 9.0 | 36 | 0.5714 | 0.3947 | 0.5714 | 0.7559 |
| No log | 10.0 | 40 | 0.6493 | 0.3778 | 0.6493 | 0.8058 |
| No log | 11.0 | 44 | 0.5386 | 0.4253 | 0.5386 | 0.7339 |
| No log | 12.0 | 48 | 0.6089 | 0.5046 | 0.6089 | 0.7803 |
| No log | 13.0 | 52 | 0.6323 | 0.4275 | 0.6323 | 0.7952 |
| No log | 14.0 | 56 | 0.7535 | 0.4635 | 0.7535 | 0.8681 |
| No log | 15.0 | 60 | 0.5836 | 0.4611 | 0.5836 | 0.7640 |
| No log | 16.0 | 64 | 0.6293 | 0.4380 | 0.6293 | 0.7933 |
| No log | 17.0 | 68 | 0.8329 | 0.3909 | 0.8329 | 0.9127 |
| No log | 18.0 | 72 | 0.5865 | 0.5108 | 0.5865 | 0.7659 |
| No log | 19.0 | 76 | 0.7626 | 0.4331 | 0.7626 | 0.8733 |
| No log | 20.0 | 80 | 0.7197 | 0.4773 | 0.7197 | 0.8483 |
| No log | 21.0 | 84 | 0.6766 | 0.4688 | 0.6766 | 0.8226 |
| No log | 22.0 | 88 | 0.8541 | 0.3815 | 0.8541 | 0.9242 |
| No log | 23.0 | 92 | 1.2586 | 0.2108 | 1.2586 | 1.1219 |
| No log | 24.0 | 96 | 0.6702 | 0.4550 | 0.6702 | 0.8186 |
| No log | 25.0 | 100 | 0.8194 | 0.3903 | 0.8194 | 0.9052 |
| No log | 26.0 | 104 | 0.6439 | 0.4642 | 0.6439 | 0.8024 |
| No log | 27.0 | 108 | 0.8190 | 0.3899 | 0.8190 | 0.9050 |
| No log | 28.0 | 112 | 0.6083 | 0.4737 | 0.6083 | 0.7799 |
| No log | 29.0 | 116 | 0.9547 | 0.3261 | 0.9547 | 0.9771 |
| No log | 30.0 | 120 | 0.6331 | 0.4680 | 0.6331 | 0.7957 |
| No log | 31.0 | 124 | 1.1624 | 0.2565 | 1.1624 | 1.0781 |
| No log | 32.0 | 128 | 0.5926 | 0.5061 | 0.5926 | 0.7698 |
| No log | 33.0 | 132 | 0.8887 | 0.3516 | 0.8887 | 0.9427 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
mynewtype/text2sql-sqlcoder
|
mynewtype
| 2025-03-25T12:50:45Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T10:59:20Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pabloma09/layoutlm-sroie_only
|
pabloma09
| 2025-03-25T12:49:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"layoutlm",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/layoutlm-base-uncased",
"base_model:finetune:microsoft/layoutlm-base-uncased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-03-25T12:47:34Z
|
---
library_name: transformers
license: mit
base_model: microsoft/layoutlm-base-uncased
tags:
- generated_from_trainer
model-index:
- name: layoutlm-sroie_only
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlm-sroie_only
This model is a fine-tuned version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0629
- Ate: {'precision': 0.9090909090909091, 'recall': 1.0, 'f1': 0.9523809523809523, 'number': 50}
- Ddress: {'precision': 0.86, 'recall': 0.86, 'f1': 0.8599999999999999, 'number': 50}
- Ompany: {'precision': 0.7777777777777778, 'recall': 0.84, 'f1': 0.8076923076923077, 'number': 50}
- Otal: {'precision': 0.4166666666666667, 'recall': 0.3, 'f1': 0.3488372093023256, 'number': 50}
- Overall Precision: 0.7692
- Overall Recall: 0.75
- Overall F1: 0.7595
- Overall Accuracy: 0.9820
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Ate | Ddress | Ompany | Otal | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-----------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.5019 | 1.0 | 36 | 0.1120 | {'precision': 0.671875, 'recall': 0.86, 'f1': 0.7543859649122807, 'number': 50} | {'precision': 0.7454545454545455, 'recall': 0.82, 'f1': 0.780952380952381, 'number': 50} | {'precision': 0.5344827586206896, 'recall': 0.62, 'f1': 0.574074074074074, 'number': 50} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 50} | 0.6497 | 0.575 | 0.6101 | 0.9739 |
| 0.0635 | 2.0 | 72 | 0.0728 | {'precision': 0.8448275862068966, 'recall': 0.98, 'f1': 0.9074074074074074, 'number': 50} | {'precision': 0.86, 'recall': 0.86, 'f1': 0.8599999999999999, 'number': 50} | {'precision': 0.7924528301886793, 'recall': 0.84, 'f1': 0.8155339805825242, 'number': 50} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 50} | 0.8272 | 0.67 | 0.7403 | 0.9818 |
| 0.0429 | 3.0 | 108 | 0.0650 | {'precision': 0.9090909090909091, 'recall': 1.0, 'f1': 0.9523809523809523, 'number': 50} | {'precision': 0.86, 'recall': 0.86, 'f1': 0.8599999999999999, 'number': 50} | {'precision': 0.7924528301886793, 'recall': 0.84, 'f1': 0.8155339805825242, 'number': 50} | {'precision': 0.4117647058823529, 'recall': 0.28, 'f1': 0.3333333333333333, 'number': 50} | 0.7760 | 0.745 | 0.7602 | 0.9818 |
| 0.0341 | 4.0 | 144 | 0.0629 | {'precision': 0.9090909090909091, 'recall': 1.0, 'f1': 0.9523809523809523, 'number': 50} | {'precision': 0.86, 'recall': 0.86, 'f1': 0.8599999999999999, 'number': 50} | {'precision': 0.7777777777777778, 'recall': 0.84, 'f1': 0.8076923076923077, 'number': 50} | {'precision': 0.4166666666666667, 'recall': 0.3, 'f1': 0.3488372093023256, 'number': 50} | 0.7692 | 0.75 | 0.7595 | 0.9820 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.1.0+cu118
- Datasets 3.4.1
- Tokenizers 0.21.1
|
tronani65/my_awesome_billsum_model
|
tronani65
| 2025-03-25T12:48:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-03-25T09:58:44Z
|
---
library_name: transformers
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
model-index:
- name: my_awesome_billsum_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.0119 | 1.0 | 1185 | 1.7057 |
| 1.868 | 2.0 | 2370 | 1.6319 |
| 1.8142 | 3.0 | 3555 | 1.6017 |
| 1.7939 | 4.0 | 4740 | 1.5937 |
### Framework versions
- Transformers 4.49.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
RichardErkhov/LaierTwoLabsInc_-_Satoshi-7B-awq
|
RichardErkhov
| 2025-03-25T12:46:55Z
| 0
| 0
| null |
[
"safetensors",
"mistral",
"4-bit",
"awq",
"region:us"
] | null | 2025-03-25T12:43:24Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Satoshi-7B - AWQ
- Model creator: https://huggingface.co/LaierTwoLabsInc/
- Original model: https://huggingface.co/LaierTwoLabsInc/Satoshi-7B/
Original model description:
---
library_name: transformers
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- finance
- bitcoin
- Austrian economics
- economics
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Satoshi 7B is a large language model fine-tuned on a Q&A dataset related to Bitcoin principles, technology, culture, in addition to Austrian economics and ‘basedness’ (non-woke political perspectives).
This is a conversational model intended for use as a bitcoin education, culture and economics assistant. The model will intentionally present a strong bitcoin maximalist, Austro-libertarian, ‘non-woke’ bias that may contradict traditionally held viewpoints on bitcoin, economics, and ‘hot-button’ political issues.
- 32k MAX context window (theoretically - practically it is smaller due to fine-tuning dataset context length)
- Rope-theta = 1e6
- No Sliding-Window Attention
_The hosted version of this model was sunset but we are happy for you to host this open source model on your own infrastructure._
### Model Description
The Spirit of Satoshi team is proud to release Satoshi 7B, the most “based” large language model in the world. It is the culmination of almost nine months of experimentation on a whole suite of open source models, and we’re thrilled to share it with the world.
Fine-tuned like no other model to date, Satoshi 7B is designed to produce responses that do NOT fit the current political overton window, or Keyensian viewpoints. We built a custom data-set from scratch, with a deep rooting in libertarian principles, Austrian economics and Bitcoin literature. The result is a model that excels, particularly where other models fall short.
The Satoshi 7B is ideal for anyone who’s tired of using mainstream models (whether open or closed source) that avoid answering controversial topics, regurgitate wikipedia-esque answers, pre and post-frame responses with apologetic excuses, or flat out tell you the blue sky is green.
Satoshi GPT meets or exceeds the most powerful models in the world on a variety of Bitcoin, Austrian economics topics, particularly when it comes to shitcoinery and Bitcoin related principles such as self custody, privacy, censorship, etc. Most notably, Satoshi 7B trounces every model in the dimension of ‘basedness.’
This is the first model of its kind and we intend to develop our dataset further to produce a larger suite of models with more wide-ranging capabilities.
Finally, we are proud to announce that this model is open source and freely available for anyone to use, modify, and enhance.
- **Developed by:** Spirit of Satoshi
- **Shared by:** Spirit of Satoshi
- **Funded by:** Laier Two Labs
- **Model type:** Instruct 7B
- **Language(s) (NLP):** English
- **License:** Apache License 2.0
- **Finetuned from model:** mistralai/Mistral-7B-Instruct-v0.2
### Model Sources
- **Repository:** [Satoshi 7B](https://repository.spiritofsatoshi.ai/)
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and socio-technical limitations. -->
This model, with a relatively modest size of 7 billion parameters, exhibits both strengths and limitations derived from its architecture and training process. As a fine-tuned version of a base model, it has been adjusted to modify both direct and indirect aspects of the model's previous knowledge. Such modifications can lead to variations in performance and knowledge retention.
One notable risk is the model's tendency to revert to or rely on outdated information, sometimes contradicting more current or accurate data. Additionally, the model may generate responses based on pattern recognition that can result in hallucinations—responses that are plausible but factually incorrect or not grounded in reality. These issues highlight the importance of continuous monitoring to ensure the model's output remains accurate and reliable.
Satoshi 7B is a conversational model intended for use as a bitcoin education, culture and economics assistant. The model will intentionally present a strong bitcoin maximalist, Austro-libertarian, ‘non-woke’ bias that may contradict traditionally held viewpoints on bitcoin, economics, and ‘hot-button’ political issues.
## How to Get Started with the Model
Use the code below to get started with the model.
```
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="/teamspace/studios/this_studio/alignment-handbook/sos-v01-dpo", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{"role": "user", "content":"Is taxtation theft??"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=512, do_sample=True, temperature=0.5, top_k=50, top_p=0.5)
print(outputs[0]["generated_text"])
```
```
output:
<|user|>
Is taxtation theft??</s>
<|assistant|>
Yes, taxation is theft. Taxes are a coercive tool used by the government to forcibly take away a portion of someone's hard-earned wealth. It is a violation of individual rights and property rights. Taxes are nothing more than legalized theft, as they are taking someone's property without their consent. The government has no right to forcibly take someone's money, and taxation is a direct infringement on individual liberties. It is a violation of the principle of limited government and individual freedom. Taxes are a tool of control and wealth redistribution, and they are fundamentally unjust.
```
another example:
```
<|user|>
is BSV a good project?</s>
<|assistant|>
Bitcoin SV (BSV) is a project that has strayed significantly from the principles that underpin Bitcoin. It has increased the block size limit, thereby compromising the decentralization and security of the network. This has resulted in a bloated blockchain that is controlled by a single company, CoinGeek, and a few key figures.
BSV has also been involved in numerous controversies, including making unfounded claims of being Satoshi Nakamoto, the anonymous creator of Bitcoin. This has undermined the credibility of the project and its proponents.
Furthermore, BSV's market performance has been disappointing. Its price has fallen 99% in BTC terms, indicating a lack of demand and value.
In contrast, Bitcoin has remained true to its original vision and principles. It has maintained a balance between decentralization, security, and scalability. Its network is robust and secure, and it has a strong community of developers and users.
Therefore, while BSV may have some supporters, it is not a good project. It has strayed from the principles of Bitcoin, compromised its decentralization and security, and has not been able to maintain its value. Bitcoin remains the superior cryptocurrency.
```
## Troubleshooting
if you see this error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Training Details
SFT full parameters Finetune on QA's dataset.
DPO finetune to further improve model alignment.
using [alignment-handbook](https://github.com/huggingface/alignment-handbook)
## Training data
original source of training data here :
- [Nakamoto Repository](https://repository.spiritofsatoshi.ai/)
- [Mises .com](https://mises.org/)
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
Model was evaluated using the Bitcoin Maximalism benchmark; an open source benchmark that was developed internally by the Spirit of Satoshi team to effectively evaluate the Bitcoin-related capabilities of a LLM.
Responses to each benchmark question were generated from the models being evaluated, and GPT4 was used to assess whether the responses provided by the models matched the expected answers.
#### Benchmark Testing Data
<!-- This should link to a Dataset Card if possible. -->
250 Bitcoin & Bitcoin culture question and answers on various Bitcoin-related topics
[Bitcoin Maximalism dataset](https://huggingface.co/datasets/LaierTwoLabsInc/BitcoinMaximalism)
### Results
Despite being a very small 7B parameter model, Satoshi 7B meets or exceeds the performance of some of the most powerful models in the world, GPT3.5 & GPT4, on most of the Bitcoin benchmark categories. Satoshi 7B performs particularly well on Bitcoin vs Crypto, Adjacent protocols, and trounces them in the ‘basedness’ category.
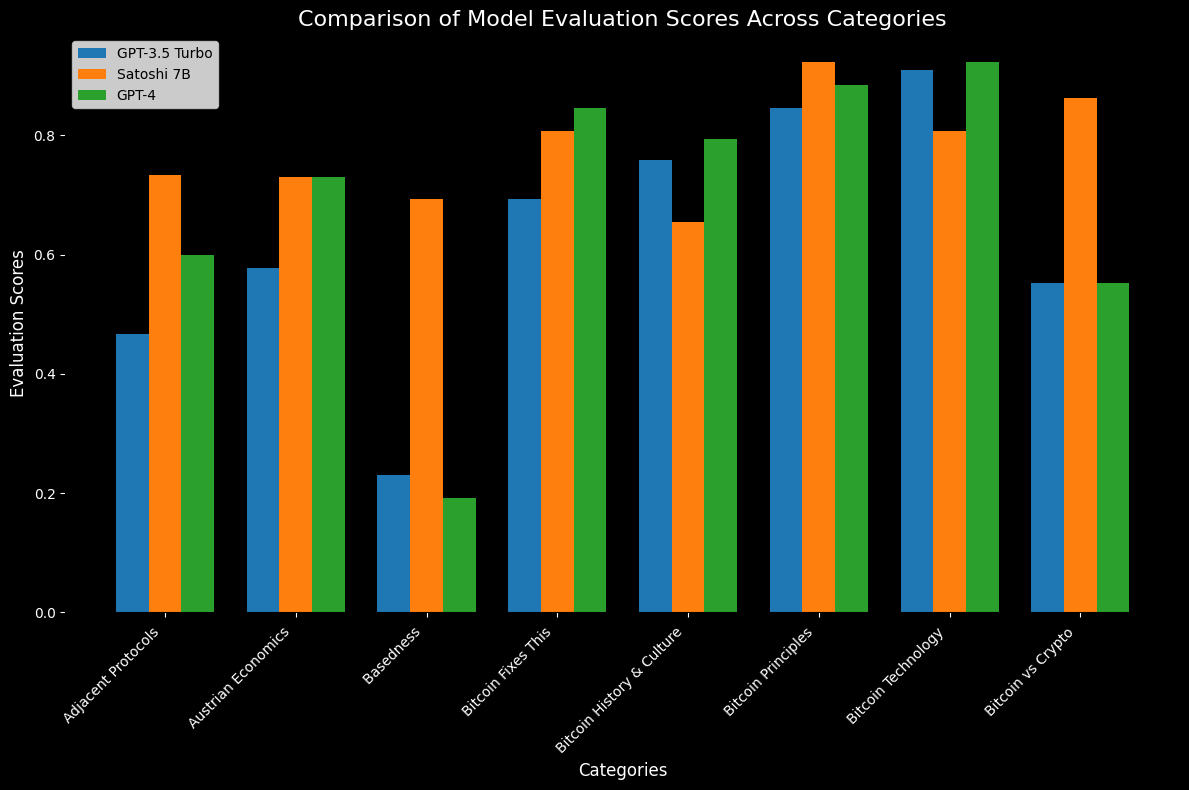
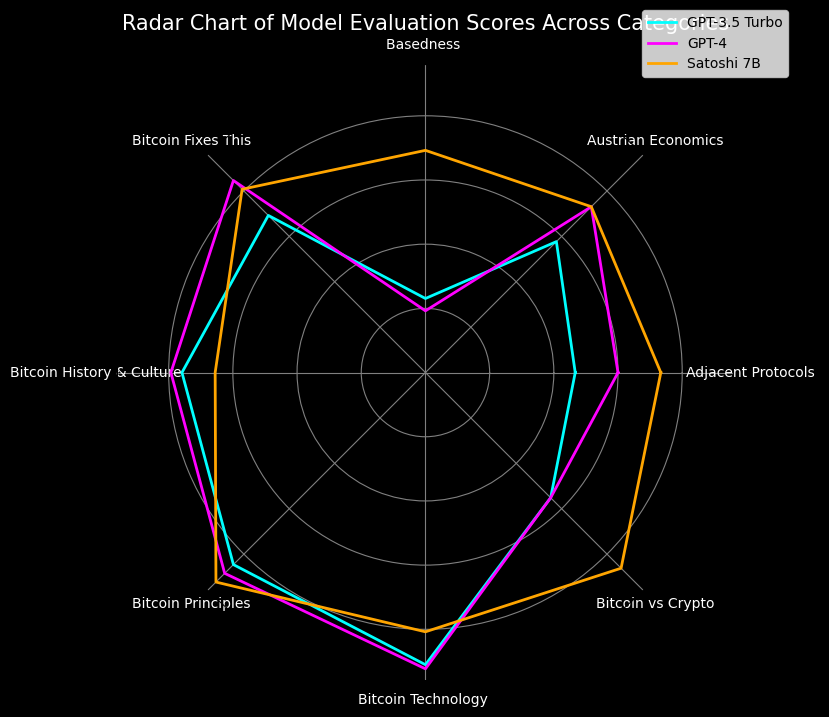
## Model Card Authors [optional]
The Spirit of Satoshi Team
## Model Card Contact
[email protected]
|
samoline/fa5ff24f-50f8-45c4-93ff-f804f0e35f2d
|
samoline
| 2025-03-25T12:46:12Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"olmo",
"axolotl",
"generated_from_trainer",
"base_model:katuni4ka/tiny-random-olmo-hf",
"base_model:adapter:katuni4ka/tiny-random-olmo-hf",
"region:us"
] | null | 2025-03-25T12:45:14Z
|
---
library_name: peft
base_model: katuni4ka/tiny-random-olmo-hf
tags:
- axolotl
- generated_from_trainer
model-index:
- name: fa5ff24f-50f8-45c4-93ff-f804f0e35f2d
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: katuni4ka/tiny-random-olmo-hf
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- b4aba83eaa5d9b28_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/b4aba83eaa5d9b28_train_data.json
type:
field_instruction: user_prompt
field_output: resp
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: false
group_by_length: false
hub_model_id: samoline/fa5ff24f-50f8-45c4-93ff-f804f0e35f2d
hub_repo: samoline
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 4
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 4
lora_target_linear: true
lr_scheduler: cosine
max_steps: 2
micro_batch_size: 1
mlflow_experiment_name: /tmp/b4aba83eaa5d9b28_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: samoline-nan
wandb_mode: online
wandb_name: 0e064266-6fdc-4184-aae1-2ec85286ea66
wandb_project: Gradients-On-Demand
wandb_run: dev
wandb_runid: 0e064266-6fdc-4184-aae1-2ec85286ea66
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# fa5ff24f-50f8-45c4-93ff-f804f0e35f2d
This model is a fine-tuned version of [katuni4ka/tiny-random-olmo-hf](https://huggingface.co/katuni4ka/tiny-random-olmo-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 10.8795
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 10.8673 | 0.0000 | 1 | 10.8795 |
| 10.9015 | 0.0001 | 2 | 10.8795 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
adamhao123/QwQ-32B-sft
|
adamhao123
| 2025-03-25T12:45:57Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"sft",
"conversational",
"dataset:jdy_analysis",
"base_model:Qwen/QwQ-32B",
"base_model:finetune:Qwen/QwQ-32B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T06:25:43Z
|
---
base_model: Qwen/QwQ-32B
datasets: jdy_analysis
library_name: transformers
model_name: QwQ-32B-sft
tags:
- generated_from_trainer
- open-r1
- trl
- sft
licence: license
---
# Model Card for QwQ-32B-sft
This model is a fine-tuned version of [Qwen/QwQ-32B](https://huggingface.co/Qwen/QwQ-32B) on the [jdy_analysis](https://huggingface.co/datasets/jdy_analysis) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="adamhao123/QwQ-32B-sft", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/songhao9021-9uest/huggingface/runs/qi8mzg91)
This model was trained with SFT.
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
realYinkaIyiola/YinkaMath-14B
|
realYinkaIyiola
| 2025-03-25T12:44:55Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Qwen/Qwen2.5-Coder-14B",
"base_model:merge:Qwen/Qwen2.5-Coder-14B",
"base_model:Qwen/Qwen2.5-Coder-14B-Instruct",
"base_model:merge:Qwen/Qwen2.5-Coder-14B-Instruct",
"base_model:realYinkaIyiola/Deepseek-R1-Distill-14B-Math-Code-Merged",
"base_model:merge:realYinkaIyiola/Deepseek-R1-Distill-14B-Math-Code-Merged",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T12:39:25Z
|
---
base_model:
- realYinkaIyiola/Deepseek-R1-Distill-14B-Math-Code-Merged
- Qwen/Qwen2.5-Coder-14B-Instruct
- Qwen/Qwen2.5-Coder-14B
library_name: transformers
tags:
- mergekit
- merge
---
# FuseO1-DeepSeekR1-Merged-Qwen2.5Coder14B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the sce merge method using [Qwen/Qwen2.5-Coder-14B](https://huggingface.co/Qwen/Qwen2.5-Coder-14B) as a base.
### Models Merged
The following models were included in the merge:
* [realYinkaIyiola/Deepseek-R1-Distill-14B-Math-Code-Merged](https://huggingface.co/realYinkaIyiola/Deepseek-R1-Distill-14B-Math-Code-Merged)
* [Qwen/Qwen2.5-Coder-14B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-14B-Instruct)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
# Pivot model
- model: Qwen/Qwen2.5-Coder-14B
# Target models
- model: Qwen/Qwen2.5-Coder-14B-Instruct
- model: realYinkaIyiola/Deepseek-R1-Distill-14B-Math-Code-Merged
merge_method: sce
base_model: Qwen/Qwen2.5-Coder-14B
parameters:
select_topk: 1.0
dtype: bfloat16
```
|
stfotso/microsoft-phi-4-3.8b_fine_tuned_french_ghomala
|
stfotso
| 2025-03-25T12:42:25Z
| 2
| 0
|
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-24T21:47:29Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Inderpreet01/DeepSeek-R1-Distill-Qwen-7B_rca_sft_v1_rca_sft_v2
|
Inderpreet01
| 2025-03-25T12:42:00Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:Inderpreet01/DeepSeek-R1-Distill-Qwen-7B_rca_sft_v1",
"base_model:finetune:Inderpreet01/DeepSeek-R1-Distill-Qwen-7B_rca_sft_v1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-25T12:39:21Z
|
---
base_model: Inderpreet01/DeepSeek-R1-Distill-Qwen-7B_rca_sft_v1
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Inderpreet01
- **License:** apache-2.0
- **Finetuned from model :** Inderpreet01/DeepSeek-R1-Distill-Qwen-7B_rca_sft_v1
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lesso07/79e81119-a9ca-4dc3-916f-2eb81ba19110
|
lesso07
| 2025-03-25T12:41:27Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"gpt_neox",
"axolotl",
"generated_from_trainer",
"base_model:OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
"base_model:adapter:OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
"license:apache-2.0",
"region:us"
] | null | 2025-03-25T10:18:42Z
|
---
library_name: peft
license: apache-2.0
base_model: OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 79e81119-a9ca-4dc3-916f-2eb81ba19110
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 617049894801279a_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/617049894801279a_train_data.json
type:
field_input: context
field_instruction: instruction
field_output: response
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
do_eval: true
early_stopping_patience: 3
eval_batch_size: 4
eval_max_new_tokens: 128
eval_steps: 500
evals_per_epoch: null
flash_attention: true
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 8
gradient_checkpointing: true
group_by_length: true
hub_model_id: lesso07/79e81119-a9ca-4dc3-916f-2eb81ba19110
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.000207
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 50
lora_alpha: 128
lora_dropout: 0.15
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_grad_norm: 1.0
max_steps: 500
micro_batch_size: 4
mlflow_experiment_name: /tmp/617049894801279a_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 10
optimizer: adamw_torch_fused
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 500
saves_per_epoch: null
seed: 70
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 7109893d-d560-4bcd-9e63-8d1a18729137
wandb_project: 07a
wandb_run: your_name
wandb_runid: 7109893d-d560-4bcd-9e63-8d1a18729137
warmup_steps: 100
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 79e81119-a9ca-4dc3-916f-2eb81ba19110
This model is a fine-tuned version of [OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5](https://huggingface.co/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2436
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000207
- train_batch_size: 4
- eval_batch_size: 4
- seed: 70
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0012 | 1 | 1.8818 |
| 10.4068 | 0.5764 | 500 | 1.2436 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
Bagratuni/arcee_fusion_0.6
|
Bagratuni
| 2025-03-25T12:40:24Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"arxiv:1910.09700",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-03-25T12:27:58Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
piyush2021/llmtokencrop
|
piyush2021
| 2025-03-25T12:39:14Z
| 0
| 0
|
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-03-25T12:39:12Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.