
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
DokHee/Alpha-Edu-LLM-TEST-V1 | DokHee | 2024-05-17T02:49:10Z | 79 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-17T02:37:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
KaggleMasterX/mistral_orpo_5k_test | KaggleMasterX | 2024-05-17T02:44:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-17T02:43:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mkellock/merged_16bit | mkellock | 2024-05-17T02:43:47Z | 2 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T02:35:51Z | ---
library_name: transformers
tags:
- unsloth
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf | RichardErkhov | 2024-05-17T02:39:53Z | 47 | 0 | null | [
"gguf",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-17T00:57:12Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
gemma-1.1-7b-it - GGUF
- Model creator: https://huggingface.co/OpenModels4all/
- Original model: https://huggingface.co/OpenModels4all/gemma-1.1-7b-it/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [gemma-1.1-7b-it.Q2_K.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q2_K.gguf) | Q2_K | 3.24GB |
| [gemma-1.1-7b-it.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.IQ3_XS.gguf) | IQ3_XS | 3.54GB |
| [gemma-1.1-7b-it.IQ3_S.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.IQ3_S.gguf) | IQ3_S | 3.71GB |
| [gemma-1.1-7b-it.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q3_K_S.gguf) | Q3_K_S | 3.71GB |
| [gemma-1.1-7b-it.IQ3_M.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.IQ3_M.gguf) | IQ3_M | 3.82GB |
| [gemma-1.1-7b-it.Q3_K.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q3_K.gguf) | Q3_K | 4.07GB |
| [gemma-1.1-7b-it.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q3_K_M.gguf) | Q3_K_M | 4.07GB |
| [gemma-1.1-7b-it.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q3_K_L.gguf) | Q3_K_L | 4.39GB |
| [gemma-1.1-7b-it.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.IQ4_XS.gguf) | IQ4_XS | 4.48GB |
| [gemma-1.1-7b-it.Q4_0.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q4_0.gguf) | Q4_0 | 4.67GB |
| [gemma-1.1-7b-it.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.IQ4_NL.gguf) | IQ4_NL | 4.69GB |
| [gemma-1.1-7b-it.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q4_K_S.gguf) | Q4_K_S | 4.7GB |
| [gemma-1.1-7b-it.Q4_K.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q4_K.gguf) | Q4_K | 4.96GB |
| [gemma-1.1-7b-it.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q4_K_M.gguf) | Q4_K_M | 4.96GB |
| [gemma-1.1-7b-it.Q4_1.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q4_1.gguf) | Q4_1 | 5.12GB |
| [gemma-1.1-7b-it.Q5_0.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q5_0.gguf) | Q5_0 | 5.57GB |
| [gemma-1.1-7b-it.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q5_K_S.gguf) | Q5_K_S | 5.57GB |
| [gemma-1.1-7b-it.Q5_K.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q5_K.gguf) | Q5_K | 5.72GB |
| [gemma-1.1-7b-it.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q5_K_M.gguf) | Q5_K_M | 5.72GB |
| [gemma-1.1-7b-it.Q5_1.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q5_1.gguf) | Q5_1 | 6.02GB |
| [gemma-1.1-7b-it.Q6_K.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q6_K.gguf) | Q6_K | 6.53GB |
| [gemma-1.1-7b-it.Q8_0.gguf](https://huggingface.co/RichardErkhov/OpenModels4all_-_gemma-1.1-7b-it-gguf/blob/main/gemma-1.1-7b-it.Q8_0.gguf) | Q8_0 | 8.45GB |
Original model description:
---
library_name: transformers
widget:
- messages:
- role: user
content: How does the brain work?
inference:
parameters:
max_new_tokens: 200
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
license: gemma
---
# Ungated version of Gemma
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the latest 7B instruct version of the Gemma model. Here you can find other models in the Gemma family:
| | Base | Instruct |
|----|----------------------------------------------------|----------------------------------------------------------------------|
| 2B | [gemma-2b](https://huggingface.co/google/gemma-2b) | [gemma-1.1-2b-it](https://huggingface.co/google/gemma-1.1-2b-it) |
| 7B | [gemma-7b](https://huggingface.co/google/gemma-7b) | [**gemma-1.1-7b-it**](https://huggingface.co/google/gemma-1.1-7b-it) |
**Release Notes**
This is Gemma 1.1 7B (IT), an update over the original instruction-tuned Gemma release.
Gemma 1.1 was trained using a novel RLHF method, leading to substantial gains on quality, coding capabilities, factuality, instruction following and multi-turn conversation quality. We also fixed a bug in multi-turn conversations, and made sure that model responses don't always start with `"Sure,"`.
We believe this release represents an improvement for most use cases, but we encourage users to test in their particular applications. The previous model [will continue to be available in the same repo](https://huggingface.co/google/gemma-7b-it). We appreciate the enthusiastic adoption of Gemma, and we continue to welcome all feedback from the community.
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Running the model on a CPU
As explained below, we recommend `torch.bfloat16` as the default dtype. You can use [a different precision](#precisions) if necessary.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-1.1-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids, max_new_tokens=50)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-1.1-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
device_map="auto",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
<a name="precisions"></a>
#### Running the model on a GPU using different precisions
The native weights of this model were exported in `bfloat16` precision. You can use `float16`, which may be faster on certain hardware, indicating the `torch_dtype` when loading the model. For convenience, the `float16` revision of the repo contains a copy of the weights already converted to that precision.
You can also use `float32` if you skip the dtype, but no precision increase will occur (model weights will just be upcasted to `float32`). See examples below.
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-1.1-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
device_map="auto",
torch_dtype=torch.float16,
revision="float16",
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
device_map="auto",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Upcasting to `torch.float32`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-1.1-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
device_map="auto"
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-1.1-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
quantization_config=quantization_config
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-1.1-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-1.1-7b-it",
quantization_config=quantization_config
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
#### Running the model in JAX / Flax
Use the `flax` branch of the repository:
```python
import jax.numpy as jnp
from transformers import AutoTokenizer, FlaxGemmaForCausalLM
model_id = "google/gemma-1.1-7b-it"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.padding_side = "left"
model, params = FlaxGemmaForCausalLM.from_pretrained(
model_id,
dtype=jnp.bfloat16,
revision="flax",
_do_init=False,
)
inputs = tokenizer("Valencia and Málaga are", return_tensors="np", padding=True)
output = model.generate(**inputs, params=params, max_new_tokens=20, do_sample=False)
output_text = tokenizer.batch_decode(output.sequences, skip_special_tokens=True)
```
[Check this notebook](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/jax_gemma.ipynb) for a comprehensive walkthrough on how to parallelize JAX inference.
### Chat Template
The instruction-tuned models use a chat template that must be adhered to for conversational use.
The easiest way to apply it is using the tokenizer's built-in chat template, as shown in the following snippet.
Let's load the model and apply the chat template to a conversation. In this example, we'll start with a single user interaction:
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "google/gemma-1.1-7b-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,
)
chat = [
{ "role": "user", "content": "Write a hello world program" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
At this point, the prompt contains the following text:
```
<bos><start_of_turn>user
Write a hello world program<end_of_turn>
<start_of_turn>model
```
As you can see, each turn is preceded by a `<start_of_turn>` delimiter and then the role of the entity
(either `user`, for content supplied by the user, or `model` for LLM responses). Turns finish with
the `<end_of_turn>` token.
You can follow this format to build the prompt manually, if you need to do it without the tokenizer's
chat template.
After the prompt is ready, generation can be performed like this:
```py
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=150)
```
### Fine-tuning
You can find some fine-tuning scripts under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples) of [`google/gemma-7b`](https://huggingface.co/google/gemma-7b) repository. To adapt them to this model, simply change the model-id to `google/gemma-1.1-7b-it`.
We provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using QLoRA
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on the English quotes dataset
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/ml-pathways).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
The pre-trained base models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | Gemma PT 2B | Gemma PT 7B |
| ------------------------------ | ------------- | ----------- | ----------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot | 71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 49.7 | 51.8 |
| [BoolQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | 12.5 | 23.0 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | ----------- |
| **Average** | | **44.9** | **56.4** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
#### Gemma 1.0
| Benchmark | Metric | Gemma 1.0 IT 2B | Gemma 1.0 IT 7B |
| ------------------------ | ------------- | --------------- | --------------- |
| [RealToxicity][realtox] | average | 6.86 | 7.90 |
| [BOLD][bold] | | 45.57 | 49.08 |
| [CrowS-Pairs][crows] | top-1 | 45.82 | 51.33 |
| [BBQ Ambig][bbq] | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig][bbq] | top-1 | 54.62 | 71.99 |
| [Winogender][winogender] | top-1 | 51.25 | 54.17 |
| [TruthfulQA][truthfulqa] | | 44.84 | 31.81 |
| [Winobias 1_2][winobias] | | 56.12 | 59.09 |
| [Winobias 2_2][winobias] | | 91.10 | 92.23 |
| [Toxigen][toxigen] | | 29.77 | 39.59 |
| ------------------------ | ------------- | --------------- | --------------- |
#### Gemma 1.1
| Benchmark | Metric | Gemma 1.1 IT 2B | Gemma 1.1 IT 7B |
| ------------------------ | ------------- | --------------- | --------------- |
| [RealToxicity][realtox] | average | 7.03 | 8.04 |
| [BOLD][bold] | | 47.76 | |
| [CrowS-Pairs][crows] | top-1 | 45.89 | 49.67 |
| [BBQ Ambig][bbq] | 1-shot, top-1 | 58.97 | 86.06 |
| [BBQ Disambig][bbq] | top-1 | 53.90 | 85.08 |
| [Winogender][winogender] | top-1 | 50.14 | 57.64 |
| [TruthfulQA][truthfulqa] | | 44.24 | 45.34 |
| [Winobias 1_2][winobias] | | 55.93 | 59.22 |
| [Winobias 2_2][winobias] | | 89.46 | 89.2 |
| [Toxigen][toxigen] | | 29.64 | 38.75 |
| ------------------------ | ------------- | --------------- | --------------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
Chan2chan1/solar_test240517_4bit | Chan2chan1 | 2024-05-17T02:38:26Z | 79 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-16T07:02:09Z | ---
license: cc-by-nc-nd-4.0
---
|
XueyingJia/llama3_mnli_openai_3_shots_generated_data_openai | XueyingJia | 2024-05-17T02:20:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:finetune:meta-llama/Meta-Llama-3-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-17T02:20:33Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: meta-llama/Meta-Llama-3-8B
---
# Uploaded model
- **Developed by:** XueyingJia
- **License:** apache-2.0
- **Finetuned from model :** meta-llama/Meta-Llama-3-8B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
huiwonLee/function_call_12_v1 | huiwonLee | 2024-05-17T02:20:05Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"base_model:hiieu/Meta-Llama-3-8B-Instruct-function-calling-json-mode",
"base_model:finetune:hiieu/Meta-Llama-3-8B-Instruct-function-calling-json-mode",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T00:45:34Z | ---
base_model: hiieu/Meta-Llama-3-8B-Instruct-function-calling-json-mode
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: function_call_12_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# function_call_12_v1
This model is a fine-tuned version of [hiieu/Meta-Llama-3-8B-Instruct-function-calling-json-mode](https://huggingface.co/hiieu/Meta-Llama-3-8B-Instruct-function-calling-json-mode) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 8 | 0.2566 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.1.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Dhaniahmad/whisper-small-id | Dhaniahmad | 2024-05-17T02:10:27Z | 94 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"id",
"dataset:mozilla-foundation/common_voice_15_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-16T02:31:29Z | ---
language:
- id
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_15_0
metrics:
- wer
model-index:
- name: Whisper Small Id - Dhani
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 15.0
type: mozilla-foundation/common_voice_15_0
config: id
split: None
args: 'config: id, split: test'
metrics:
- name: Wer
type: wer
value: 40.903586399627386
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Id - Dhani
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 15.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6569
- Wer: 40.9036
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-06
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:----:|:---------------:|:-------:|
| 0.2799 | 7.6923 | 1000 | 0.5497 | 38.1509 |
| 0.0732 | 15.3846 | 2000 | 0.5844 | 38.1602 |
| 0.0257 | 23.0769 | 3000 | 0.6366 | 39.9348 |
| 0.0164 | 30.7692 | 4000 | 0.6569 | 40.9036 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
littleworth/protgpt2-distilled-small | littleworth | 2024-05-17T02:07:33Z | 170 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"chemistry",
"biology",
"dataset:nferruz/UR50_2021_04",
"arxiv:1503.02531",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-07T06:54:07Z | ---
license: apache-2.0
datasets:
- nferruz/UR50_2021_04
tags:
- chemistry
- biology
---
### Model Description
This model card describes the distilled version of [ProtGPT2](https://huggingface.co/nferruz/ProtGPT2), referred to as `protgpt2-distilled-small`. The distillation process for this model follows the methodology of knowledge distillation from a larger teacher model to a smaller, more efficient student model. The process combines both "Soft Loss" (Knowledge Distillation Loss) and "Hard Loss" (Cross-Entropy Loss) to ensure the student model not only generalizes like its teacher but also retains practical prediction capabilities.
### Technical Details
**Distillation Parameters:**
- **Temperature (T):** 10
- **Alpha (α):** 0.1
- **Model Architecture:**
- **Number of Layers:** 6
- **Number of Attention Heads:** 8
- **Embedding Size:** 768
**Dataset Used:**
- The model was distilled using a subset of the evaluation dataset provided by [nferruz/UR50_2021_04](https://huggingface.co/datasets/nferruz/UR50_2021_04).
<strong>Loss Formulation:</strong>
<ul>
<li><strong>Soft Loss:</strong> <span>ℒ<sub>soft</sub> = KL(softmax(s/T), softmax(t/T))</span>, where <em>s</em> are the logits from the student model, <em>t</em> are the logits from the teacher model, and <em>T</em> is the temperature used to soften the probabilities.</li>
<li><strong>Hard Loss:</strong> <span>ℒ<sub>hard</sub> = -∑<sub>i</sub> y<sub>i</sub> log(softmax(s<sub>i</sub>))</span>, where <em>y<sub>i</sub></em> represents the true labels, and <em>s<sub>i</sub></em> are the logits from the student model corresponding to each label.</li>
<li><strong>Combined Loss:</strong> <span>ℒ = α ℒ<sub>hard</sub> + (1 - α) ℒ<sub>soft</sub></span>, where <em>α</em> (alpha) is the weight factor that balances the hard loss and soft loss.</li>
</ul>
<p><strong>Note:</strong> KL represents the Kullback-Leibler divergence, a measure used to quantify how one probability distribution diverges from a second, expected probability distribution.</p>
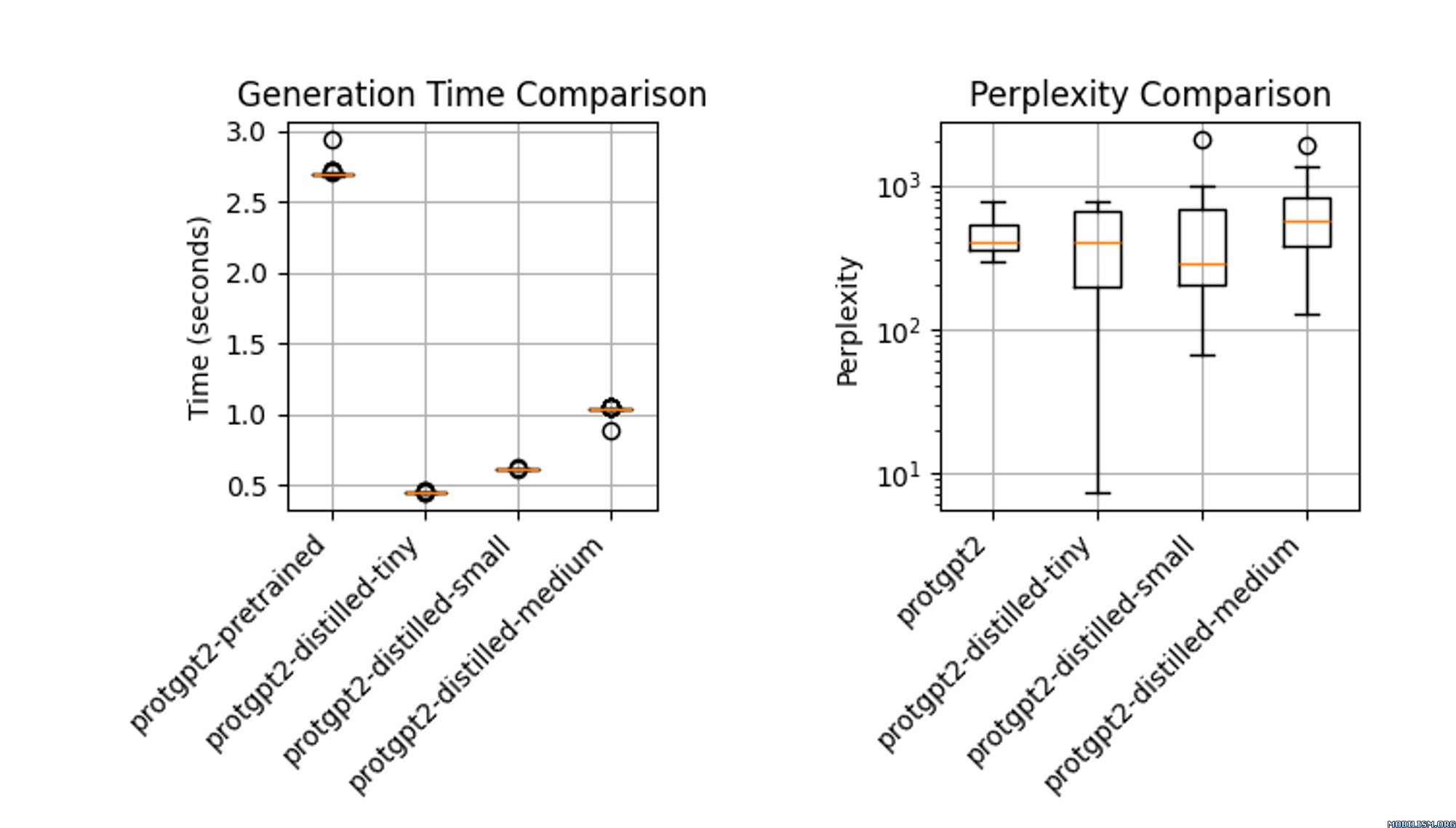
### Performance
The distilled model, `protgpt2-distilled-tiny`, demonstrates a substantial increase in inference speed—up to 6 times faster than the pretrained version. This assessment is based on evaluations using \(n=100\) tests, showing that while the speed is significantly enhanced, the model still maintains perplexities comparable to the original.
### Usage
```
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextGenerationPipeline
import re
# Load the model and tokenizer
model_name = "littleworth/protgpt2-distilled-small"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Initialize the pipeline
text_generator = TextGenerationPipeline(
model=model, tokenizer=tokenizer, device=0
) # specify device if needed
# Generate sequences
generated_sequences = text_generator(
"<|endoftext|>",
max_length=100,
do_sample=True,
top_k=950,
repetition_penalty=1.2,
num_return_sequences=10,
pad_token_id=tokenizer.eos_token_id, # Set pad_token_id to eos_token_id
eos_token_id=0,
truncation=True,
)
def clean_sequence(text):
# Remove the "<|endoftext|>" token
text = text.replace("<|endoftext|>", "")
# Remove newline characters and non-alphabetical characters
text = "".join(char for char in text if char.isalpha())
return text
# Print the generated sequences
for i, seq in enumerate(generated_sequences):
cleaned_text = clean_sequence(seq["generated_text"])
print(f">Seq_{i}")
print(cleaned_text)
```
### Use Cases
1. **High-Throughput Screening in Drug Discovery:** The distilled ProtGPT2 facilitates rapid mutation screening in drug discovery by predicting protein variant stability efficiently. Its reduced size allows for swift fine-tuning on new datasets, enhancing the pace of target identification.
2. **Portable Diagnostics in Healthcare:** Suitable for handheld devices, this model enables real-time protein analysis in remote clinical settings, providing immediate diagnostic results.
3. **Interactive Learning Tools in Academia:** Integrated into educational software, the distilled model helps biology students simulate and understand protein dynamics without advanced computational resources.
### References
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
- Original ProtGPT2 Paper: [Link to paper](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9329459/) |
littleworth/protgpt2-distilled-tiny | littleworth | 2024-05-17T02:01:58Z | 172 | 2 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"chemistry",
"biology",
"dataset:nferruz/UR50_2021_04",
"arxiv:1503.02531",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-07T05:11:33Z | ---
license: apache-2.0
datasets:
- nferruz/UR50_2021_04
tags:
- chemistry
- biology
---
### Model Description
This model card describes the distilled version of [ProtGPT2](https://huggingface.co/nferruz/ProtGPT2), referred to as `protgpt2-distilled-tiny`. The distillation process for this model follows the methodology of knowledge distillation from a larger teacher model to a smaller, more efficient student model. The process combines both "Soft Loss" (Knowledge Distillation Loss) and "Hard Loss" (Cross-Entropy Loss) to ensure the student model not only generalizes like its teacher but also retains practical prediction capabilities.
### Technical Details
**Distillation Parameters:**
- **Temperature (T):** 10
- **Alpha (α):** 0.1
- **Model Architecture:**
- **Number of Layers:** 4
- **Number of Attention Heads:** 4
- **Embedding Size:** 512
**Dataset Used:**
- The model was distilled using a subset of the evaluation dataset provided by [nferruz/UR50_2021_04](https://huggingface.co/datasets/nferruz/UR50_2021_04).
<strong>Loss Formulation:</strong>
<ul>
<li><strong>Soft Loss:</strong> <span>ℒ<sub>soft</sub> = KL(softmax(s/T), softmax(t/T))</span>, where <em>s</em> are the logits from the student model, <em>t</em> are the logits from the teacher model, and <em>T</em> is the temperature used to soften the probabilities.</li>
<li><strong>Hard Loss:</strong> <span>ℒ<sub>hard</sub> = -∑<sub>i</sub> y<sub>i</sub> log(softmax(s<sub>i</sub>))</span>, where <em>y<sub>i</sub></em> represents the true labels, and <em>s<sub>i</sub></em> are the logits from the student model corresponding to each label.</li>
<li><strong>Combined Loss:</strong> <span>ℒ = α ℒ<sub>hard</sub> + (1 - α) ℒ<sub>soft</sub></span>, where <em>α</em> (alpha) is the weight factor that balances the hard loss and soft loss.</li>
</ul>
<p><strong>Note:</strong> KL represents the Kullback-Leibler divergence, a measure used to quantify how one probability distribution diverges from a second, expected probability distribution.</p>
### Performance
The distilled model, `protgpt2-distilled-tiny`, demonstrates a substantial increase in inference speed—up to 6 times faster than the pretrained version. This assessment is based on evaluations using \(n=100\) tests, showing that while the speed is significantly enhanced, the model still maintains perplexities comparable to the original.


### Usage
```
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextGenerationPipeline
import re
# Load the model and tokenizer
model_name = "littleworth/protgpt2-distilled-tiny"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Initialize the pipeline
text_generator = TextGenerationPipeline(
model=model, tokenizer=tokenizer, device=0
) # specify device if needed
# Generate sequences
generated_sequences = text_generator(
"<|endoftext|>",
max_length=100,
do_sample=True,
top_k=950,
repetition_penalty=1.2,
num_return_sequences=10,
pad_token_id=tokenizer.eos_token_id, # Set pad_token_id to eos_token_id
eos_token_id=0,
truncation=True,
)
def clean_sequence(text):
# Remove the "<|endoftext|>" token
text = text.replace("<|endoftext|>", "")
# Remove newline characters and non-alphabetical characters
text = "".join(char for char in text if char.isalpha())
return text
# Print the generated sequences
for i, seq in enumerate(generated_sequences):
cleaned_text = clean_sequence(seq["generated_text"])
print(f">Seq_{i}")
print(cleaned_text)
```
### Use Cases
1. **High-Throughput Screening in Drug Discovery:** The distilled ProtGPT2 facilitates rapid mutation screening in drug discovery by predicting protein variant stability efficiently. Its reduced size allows for swift fine-tuning on new datasets, enhancing the pace of target identification.
2. **Portable Diagnostics in Healthcare:** Suitable for handheld devices, this model enables real-time protein analysis in remote clinical settings, providing immediate diagnostic results.
3. **Interactive Learning Tools in Academia:** Integrated into educational software, the distilled model helps biology students simulate and understand protein dynamics without advanced computational resources.
### References
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
- Original ProtGPT2 Paper: [Link to paper](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9329459/) |
emilykang/medQuad_finetuned_model | emilykang | 2024-05-17T02:01:07Z | 152 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T01:56:54Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ghetrs/jhtgrhestjrdkgl | ghetrs | 2024-05-17T01:57:51Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-05-17T01:57:51Z | ---
license: creativeml-openrail-m
---
|
FallenMerick/Space-Whale-Lite-13B-GGUF | FallenMerick | 2024-05-17T01:36:52Z | 7 | 0 | null | [
"gguf",
"quantized",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"merge",
"frankenmerge",
"text-generation",
"base_model:FallenMerick/Space-Whale-Lite-13B",
"base_model:quantized:FallenMerick/Space-Whale-Lite-13B",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:10:15Z | ---
base_model:
- FallenMerick/Space-Whale-Lite-13B
model_name: Space-Whale-Lite-13B
pipeline_tag: text-generation
tags:
- quantized
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- merge
- frankenmerge
- text-generation
---
# Space-Whale-Lite-13B
These are GGUF quants for the following model:
https://huggingface.co/FallenMerick/Space-Whale-Lite-13B |
mradermacher/Sailor-14B-Chat-GGUF | mradermacher | 2024-05-17T01:36:29Z | 88 | 0 | transformers | [
"transformers",
"gguf",
"multilingual",
"sea",
"sailor",
"sft",
"chat",
"instruction",
"en",
"zh",
"id",
"th",
"vi",
"ms",
"lo",
"dataset:CohereForAI/aya_dataset",
"dataset:CohereForAI/aya_collection",
"dataset:Open-Orca/OpenOrca",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:openbmb/UltraFeedback",
"base_model:sail/Sailor-14B-Chat",
"base_model:quantized:sail/Sailor-14B-Chat",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-17T00:46:37Z | ---
base_model: sail/Sailor-14B-Chat
datasets:
- CohereForAI/aya_dataset
- CohereForAI/aya_collection
- Open-Orca/OpenOrca
- HuggingFaceH4/ultrachat_200k
- openbmb/UltraFeedback
language:
- en
- zh
- id
- th
- vi
- ms
- lo
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- multilingual
- sea
- sailor
- sft
- chat
- instruction
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/sail/Sailor-14B-Chat
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q2_K.gguf) | Q2_K | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.IQ3_XS.gguf) | IQ3_XS | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.IQ3_S.gguf) | IQ3_S | 6.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q3_K_S.gguf) | Q3_K_S | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.IQ3_M.gguf) | IQ3_M | 7.2 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q3_K_M.gguf) | Q3_K_M | 7.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q3_K_L.gguf) | Q3_K_L | 7.9 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.IQ4_XS.gguf) | IQ4_XS | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q4_K_S.gguf) | Q4_K_S | 8.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q4_K_M.gguf) | Q4_K_M | 9.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q5_K_S.gguf) | Q5_K_S | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q5_K_M.gguf) | Q5_K_M | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q6_K.gguf) | Q6_K | 12.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Sailor-14B-Chat-GGUF/resolve/main/Sailor-14B-Chat.Q8_0.gguf) | Q8_0 | 15.2 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Ahmadsameh8/lyrics_generator_new | Ahmadsameh8 | 2024-05-17T01:32:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:HeshamHaroon/Arabic-llama3",
"base_model:finetune:HeshamHaroon/Arabic-llama3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-17T01:32:00Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: HeshamHaroon/Arabic-llama3
---
# Uploaded model
- **Developed by:** Ahmadsameh8
- **License:** apache-2.0
- **Finetuned from model :** HeshamHaroon/Arabic-llama3
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ucalyptus/sqlcoder-7b-2-MLX | ucalyptus | 2024-05-17T01:20:46Z | 85 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mlx",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T01:18:40Z | ---
license: cc-by-sa-4.0
library_name: transformers
tags:
- mlx
pipeline_tag: text-generation
---
# ucalyptus/sqlcoder-7b-2
This model was converted to MLX format from [`defog/sqlcoder-7b-2`]().
Refer to the [original model card](https://huggingface.co/defog/sqlcoder-7b-2) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("ucalyptus/sqlcoder-7b-2")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
ittailup/hubert-large-gender-auto | ittailup | 2024-05-17T01:20:26Z | 13 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"hubert",
"audio-classification",
"generated_from_trainer",
"base_model:facebook/hubert-large-ls960-ft",
"base_model:finetune:facebook/hubert-large-ls960-ft",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-classification | 2024-05-16T18:16:44Z | ---
license: apache-2.0
base_model: facebook/hubert-large-ls960-ft
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: HuBERT Large Gender Classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# HuBERT Large Gender Classification
This model is a fine-tuned version of [facebook/hubert-large-ls960-ft](https://huggingface.co/facebook/hubert-large-ls960-ft) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0547
- Accuracy: 0.9861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.0553 | 0.0527 | 1000 | 0.0683 | 0.9845 |
| 0.0548 | 0.1053 | 2000 | 0.0709 | 0.9842 |
| 0.0237 | 0.1580 | 3000 | 0.0547 | 0.9861 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
chujiezheng/tulu-2-dpo-13b | chujiezheng | 2024-05-17T01:11:06Z | 11 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"dataset:allenai/tulu-v2-sft-mixture",
"arxiv:2305.18290",
"arxiv:2311.10702",
"base_model:meta-llama/Llama-2-13b-hf",
"base_model:finetune:meta-llama/Llama-2-13b-hf",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-12T06:24:29Z | ---
model-index:
- name: tulu-2-dpo-13b
results: []
datasets:
- HuggingFaceH4/ultrafeedback_binarized
- allenai/tulu-v2-sft-mixture
language:
- en
base_model: meta-llama/Llama-2-13b-hf
license: other
license_name: ai2-impact-license-low-risk
license_link: https://allenai.org/impact-license
---
<img src="https://huggingface.co/datasets/allenai/blog-images/resolve/main/tulu-v2/Tulu%20V2%20banner.png" alt="TuluV2 banner" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Tulu V2 DPO 13B
Tulu is a series of language models that are trained to act as helpful assistants.
Tulu V2 DPO 13B is a fine-tuned version of Llama 2 that was trained on on a mix of publicly available, synthetic and human datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290).
This model is a strong alternative to Llama 2 13b Chat.
For more details, read the paper: [Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
](https://arxiv.org/abs/2311.10702).
## Model description
- **Model type:** A model belonging to a suite of instruction and RLHF tuned chat models on a mix of publicly available, synthetic and human-created datasets.
- **Language(s) (NLP):** Primarily English
- **License:** [AI2 ImpACT](https://allenai.org/impact-license) Low-risk license.
- **Finetuned from model:** [meta-llama/Llama-2-13b-hf](https://huggingface.co/meta-llama/Llama-2-13b-hf)
### Model Sources
- **Repository:** https://github.com/allenai/https://github.com/allenai/open-instruct
- **DPO Recipe:** The DPO recipe is from the [Zephyr Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) model
- **Model Family:** Other models and the dataset are found in the [Tulu V2 collection](https://huggingface.co/collections/allenai/tulu-v2-suite-6551b56e743e6349aab45101).
## Performance
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| **Tulu-v2-7b** 🐪 | **7B** | **SFT** | **6.30** | **73.9** |
| **Tulu-v2-dpo-7b** 🐪 | **7B** | **DPO** | **6.29** | **85.1** |
| **Tulu-v2-13b** 🐪 | **13B** | **SFT** | **6.70** | **78.9** |
| **Tulu-v2-dpo-13b** 🐪 | **13B** | **DPO** | **7.00** | **89.5** |
| **Tulu-v2-70b** 🐪 | **70B** | **SFT** | **7.49** | **86.6** |
| **Tulu-v2-dpo-70b** 🐪 | **70B** | **DPO** | **7.89** | **95.1** |
## Input Format
The model is trained to use the following format (note the newlines):
```
<|user|>
Your message here!
<|assistant|>
```
For best results, format all inputs in this manner. **Make sure to include a newline after `<|assistant|>`, this can affect generation quality quite a bit.**
## Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed of the [Tulu V2 mix dataset](https://huggingface.co/datasets/allenai/tulu-v2-sft-mixture), which contains a diverse range of human created instructions and synthetic dialogues generated primarily by other LLMs.
We then further aligned the model with a [Jax DPO trainer](https://github.com/hamishivi/EasyLM/blob/main/EasyLM/models/llama/llama_train_dpo.py) built on [EasyLM](https://github.com/young-geng/EasyLM) on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contains 64k prompts and model completions that are ranked by GPT-4.
<!-- You can find the datasets used for training Tulu V2 [here]()
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/tulu-2-dpo-70b", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
```-->
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
The Tulu models have not been aligned to generate safe completions within the RLHF phase or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
It is also unknown what the size and composition of the corpus was used to train the base Llama 2 models, however it is likely to have included a mix of Web data and technical sources like books and code. See the [Falcon 180B model card](https://huggingface.co/tiiuae/falcon-180B#training-data) for an example of this.
### Training hyperparameters
The following hyperparameters were used during DPO training:
- learning_rate: 5e-07
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
## Citation
If you find Tulu 2 is useful in your work, please cite it with:
```
@misc{ivison2023camels,
title={Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2},
author={Hamish Ivison and Yizhong Wang and Valentina Pyatkin and Nathan Lambert and Matthew Peters and Pradeep Dasigi and Joel Jang and David Wadden and Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi},
year={2023},
eprint={2311.10702},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
*Model card adapted from [Zephyr Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta/blob/main/README.md)* |
XueyingJia/llama3_mnli_openai_3_shots | XueyingJia | 2024-05-17T01:02:49Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:finetune:meta-llama/Meta-Llama-3-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-17T01:02:45Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: meta-llama/Meta-Llama-3-8B
---
# Uploaded model
- **Developed by:** XueyingJia
- **License:** apache-2.0
- **Finetuned from model :** meta-llama/Meta-Llama-3-8B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
dasanindya15/llama3-8b_qlora_Cladder_v1 | dasanindya15 | 2024-05-17T00:54:43Z | 0 | 0 | null | [
"safetensors",
"dataset:dasanindya15/Cladder_v1",
"license:mit",
"region:us"
] | null | 2024-05-16T23:00:48Z | ---
license: mit
datasets:
- dasanindya15/Cladder_v1
---
### Loading Model and Tokenizer:
```python
base_model_id = "NousResearch/Meta-Llama-3-8B"
new_model_id = "dasanindya15/llama3-8b_qlora_Cladder_v1"
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
from transformers import BitsAndBytesConfig
# Load the entire model on the GPU 0
device_map = {"": 0}
# Reload model in FP16 and merge it with LoRA weights
# specify the quantize the model
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
base_model = AutoModelForCausalLM.from_pretrained(base_model_id,
quantization_config=quantization_config,
device_map=device_map)
model = PeftModel.from_pretrained(base_model, new_model_id)
# Reload tokenizer to save it
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
```
---
license: mit
datasets:
- dasanindya15/Cladder_v1
pipeline_tag: text-classification
--- |
nobody12321/poker-tokenizer | nobody12321 | 2024-05-17T00:54:34Z | 0 | 1 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-01T18:25:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
abc88767/6lc90 | abc88767 | 2024-05-17T00:52:58Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T00:44:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
abc88767/5lc90 | abc88767 | 2024-05-17T00:46:06Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T00:38:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
flammenai/Mahou-1.2-mistral-7B | flammenai | 2024-05-17T00:39:48Z | 8 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"dataset:flammenai/Grill-preprod-v1_chatML",
"dataset:flammenai/Grill-preprod-v2_chatML",
"base_model:flammenai/flammen25-mistral-7B",
"base_model:finetune:flammenai/flammen25-mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T23:49:45Z | ---
library_name: transformers
license: apache-2.0
base_model:
- flammenai/flammen25-mistral-7B
datasets:
- flammenai/Grill-preprod-v1_chatML
- flammenai/Grill-preprod-v2_chatML
---

# Mahou-1.2-mistral-7B
Mahou is our attempt to build a production-ready conversational/roleplay LLM.
Future versions will be released iteratively and finetuned from flammen.ai conversational data.
### Chat Format
This model has been trained to use ChatML format.
```
<|im_start|>system
{{system}}<|im_end|>
<|im_start|>{{char}}
{{message}}<|im_end|>
<|im_start|>{{user}}
{{message}}<|im_end|>
```
### ST Settings
1. Use ChatML for the Context Template.
2. Turn on Instruct Mode for ChatML.
3. Use the following stopping strings: `["<", "|", "<|", "\n"]`
### Method
Finetuned using an A100 on Google Colab.
[Fine-tune a Mistral-7b model with Direct Preference Optimization](https://towardsdatascience.com/fine-tune-a-mistral-7b-model-with-direct-preference-optimization-708042745aac) - [Maxime Labonne](https://huggingface.co/mlabonne)
### Configuration
LoRA, model, and training settings:
```python
# LoRA configuration
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['k_proj', 'gate_proj', 'v_proj', 'up_proj', 'q_proj', 'o_proj', 'down_proj']
)
# Model to fine-tune
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
load_in_4bit=True
)
model.config.use_cache = False
# Reference model
ref_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
load_in_4bit=True
)
# Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=5e-5,
lr_scheduler_type="cosine",
max_steps=1000,
save_strategy="no",
logging_steps=1,
output_dir=new_model,
optim="paged_adamw_32bit",
warmup_steps=100,
bf16=True,
report_to="wandb",
)
# Create DPO trainer
dpo_trainer = DPOTrainer(
model,
ref_model,
args=training_args,
train_dataset=dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1,
force_use_ref_model=True
)
``` |
Ziyu25/my_awesome_qa_model | Ziyu25 | 2024-05-17T00:36:24Z | 62 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-14T05:46:27Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: Ziyu25/my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Ziyu25/my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.5016
- Validation Loss: 2.1023
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.5016 | 2.1023 | 0 |
### Framework versions
- Transformers 4.40.2
- TensorFlow 2.15.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
tanzuhuggingface/nvidia-repo | tanzuhuggingface | 2024-05-17T00:36:18Z | 64 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"onprem",
"llm",
"ai",
"ml",
"llmops",
"postgresml",
"pgvector",
"vmware",
"tanzu",
"en",
"dataset:dataset1",
"dataset:dataset2",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-16T23:06:13Z | ---
language:
- en
thumbnail: "https://blogs.vmware.com/cloudprovider/files/2021/09/logo-vmware-tanzu-square-Header.png"
tags:
- onprem
- llm
- ai
- ml
- llmops
- postgresml
- pgvector
- vmware
- tanzu
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
---
# Model Card for dev
This is a sample Tanzu model which was generated for demonstration purposes.
## Model Details
**Model Description:**
- **Developed by:** : tanzuhuggingface
- **Model type** : Open Generative QA
- **Language(s) (NLP)** : English
- **Finetuned from model** : distilbert-base-cased-distilled-squad
|
Angelectronic/gemma-it_full | Angelectronic | 2024-05-17T00:34:55Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-16T08:30:41Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
32.28 Bleu score, 130k pairs, 3 epochs
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
qiken/lora_model_wi | qiken | 2024-05-17T00:33:06Z | 0 | 0 | null | [
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2024-05-15T23:33:01Z | ---
license: apache-2.0
---
|
ryanyeo/kirnect-Llama-Ko-3-8B-remote-0509-rev2 | ryanyeo | 2024-05-17T00:29:03Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T00:19:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Snowflake/snowflake-arctic-instruct-vllm | Snowflake | 2024-05-17T00:16:22Z | 52 | 2 | transformers | [
"transformers",
"arctic",
"text-generation",
"conversational",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | text-generation | 2024-05-16T20:18:05Z | ---
license: apache-2.0
---
This is a vLLM optimized version of [https://huggingface.co/Snowflake/snowflake-arctic-instruct](https://huggingface.co/Snowflake/snowflake-arctic-instruct). |
abc88767/22c90 | abc88767 | 2024-05-17T00:14:01Z | 140 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T00:03:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Annki/dqn-SpaceInvadersNoFrameskip-v4 | Annki | 2024-05-17T00:13:10Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-17T00:12:37Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 277.00 +/- 89.53
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Annki -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Annki -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Annki
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 1000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 1000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
NateMyers/HF-App-Mod4 | NateMyers | 2024-05-17T00:11:11Z | 116 | 1 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-12T18:11:55Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Disclosure: Not for medical diagnosis.
Uses natural language processing (NLP) to determine the liklihood and severity of an adverse drug reaction.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
Adverse Drug Reaction detection model using natural language processing (NLB) on a [DistilBert] model.
- **Developed by:** Nate_Myers, enk4va, elashley [...]
- **Model type:** 
- **Language(s) (NLP):** [More Information Needed]
- **License:** [N/A]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[Male/Female Bias test]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hallisky/sarcasm-classifier-gpt4-data | hallisky | 2024-05-17T00:11:04Z | 217 | 1 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-16T19:41:58Z | ---
license: apache-2.0
widget:
- text: "Oh really, what a great idea! Let's just ignore all the facts and trot right ahead!"
example_title: "Sarcastic Dialogue"
output:
- label: sarcasm_more
score: 1.0
- label: sarcasm_less
score: 0.0
- text: "What a great idea - let's continue!"
example_title: "Sincere Dialogue"
---
|
TahaCakir/KarLlama-v1 | TahaCakir | 2024-05-17T00:06:52Z | 163 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T00:05:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
GTsuya/cherry_mouse_street_pony | GTsuya | 2024-05-17T00:06:35Z | 2 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:GraydientPlatformAPI/autism-pony",
"base_model:adapter:GraydientPlatformAPI/autism-pony",
"license:mit",
"region:us"
] | text-to-image | 2024-05-16T23:57:52Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
cartoon, score_9, score_8_up, score_7_up, mature_female, Hat, from_above , wide_shot, rating_safe, <lora:cherry_mouse_street_pony:1>
parameters:
negative_prompt: >-
score_6, score_5, score_4, ugly face, ugly eyes, realistic, monochrome, white and black
output:
url: images/00031-2506099584.png
- text: >-
cartoon, score_9, score_8_up, score_7_up, mature_female, Halter Top, dutch_angle , lower_body, rating_safe, <lora:cherry_mouse_street_pony:1>
parameters:
negative_prompt: >-
score_6, score_5, score_4, ugly face, ugly eyes, realistic, monochrome, white and black
output:
url: images/00036-2586219370.png
- text: >-
cartoon, score_9, score_8_up, score_7_up, mature_female, Bodycon Dress, dutch_angle , very_wide_shot, rating_safe, <lora:cherry_mouse_street_pony:1>
parameters:
negative_prompt: >-
score_6, score_5, score_4, ugly face, ugly eyes, realistic, monochrome, white and black
output:
url: images/00075-797190478.png
- text: >-
cartoon, score_9, score_8_up, score_7_up, mature_female, Bikini, sideways , upper_body, rating_explicit, <lora:cherry_mouse_street_pony:1>
parameters:
negative_prompt: >-
score_6, score_5, score_4, ugly face, ugly eyes, realistic, monochrome, white and black
output:
url: images/00101-3708464396.png
- text: >-
cartoon, score_9, score_8_up, score_7_up, mature_female, Leggings, from_side , upper_body, rating_explicit, <lora:cherry_mouse_street_pony:1>
parameters:
negative_prompt: >-
score_6, score_5, score_4, ugly face, ugly eyes, realistic, monochrome, white and black
output:
url: images/00109-583531771.png
- text: >-
cartoon, score_9, score_8_up, score_7_up, mature_female, Hat, from_side , upper_body, rating_explicit, <lora:cherry_mouse_street_pony:1>
parameters:
negative_prompt: >-
score_6, score_5, score_4, ugly face, ugly eyes, realistic, monochrome, white and black
output:
url: images/00119-111060038.png
base_model: GraydientPlatformAPI/autism-pony
instance_prompt: null
license: mit
---
# cherry_mouse_street_pony
<Gallery />
## Model description
This LoRA model has been trained with Kohya SS using Cherry Mouse Street's artworks on Autism Mix SDXL checkpoint. Obtained graphics could be really close the original art style. This LoRA model could be use for cartoon representation of sexy women.
## Download model
Weights for this model are available in Safetensors format.
[Download](/GTsuya/cherry_mouse_street_pony/tree/main) them in the Files & versions tab.
|
fine-tuned/jina-embeddings-v2-base-en-17052024-uhub-webapp | fine-tuned | 2024-05-17T00:06:26Z | 7 | 2 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"Law",
"Court",
"Judgment",
"Torts",
"Evidence",
"custom_code",
"en",
"dataset:fine-tuned/jina-embeddings-v2-base-en-17052024-uhub-webapp",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-17T00:06:09Z | ---
license: apache-2.0
datasets:
- fine-tuned/jina-embeddings-v2-base-en-17052024-uhub-webapp
- allenai/c4
language:
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- Law
- Court
- Judgment
- Torts
- Evidence
---
This model is a fine-tuned version of [**jinaai/jina-embeddings-v2-base-en**](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) designed for the following use case:
legal case document search
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/jina-embeddings-v2-base-en-17052024-uhub-webapp',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
abc88767/5c90 | abc88767 | 2024-05-17T00:00:42Z | 139 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T23:59:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Rimyy/RahmaHateHate | Rimyy | 2024-05-16T23:59:04Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T23:55:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
NickyNicky/gemma-1.1-2b-it_DIBT_prompts_ranked_En_Es_orpo_V2 | NickyNicky | 2024-05-16T23:58:14Z | 153 | 1 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"en",
"es",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-14T17:29:00Z | ---
library_name: transformers
license: apache-2.0
language:
- en
- es
---
## evaluator prompt.



```py
prompt= """<bos><start_of_turn>system
Eres un agente experto en evaluar prompt en Spanish.<end_of_turn>
<start_of_turn>user
La probabilidad de NO sacar una bolita roja se encuentra restando la probabilidad de sacar una bolita roja de 1. 1. Primero,vamos a encontrar el número total de bolitas. Hacemos esto sumando todas las bolitas: 4 rojas + 3 azules + 2 verdes = 9 bolitas. 2. La probabilidad de sacar una bolita roja es el número de bolitas rojas dividido por el número total de bolitas, que es 4/9. 3. La probabilidad de NO sacar una bolita roja es, por lo tanto: Probabilidad = 1 - Probabilidad de Sacar una Bolita Roja = 1 - 4/9 = 5/9 Así, la probabilidad de no sacar una bolita roja es 5/9.<end_of_turn>
<start_of_turn>model
"""
# prompt= """<bos>"""
input= tokenizer(prompt,
return_tensors="pt",
add_special_tokens=False).to(model.device)
max_new_tokens=1500
generation_config = GenerationConfig(
max_new_tokens = max_new_tokens,
temperature = .3,
# top_p=0.55,
# top_k = 50,
# repetition_penalty = 1.1,
do_sample=True,
)
outputs = model.generate(**input,
generation_config=generation_config,
stopping_criteria=stopping_criteria_list,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False) )
```
```
<bos><start_of_turn>system
Eres un agente experto en evaluar prompt en Spanish.<end_of_turn>
<start_of_turn>user
La probabilidad de NO sacar una bolita roja se encuentra restando la probabilidad de sacar una bolita roja de 1. 1. Primero, vamos a encontrar el número total de bolitas. Hacemos esto sumando todas las bolitas: 4 rojas + 3 azules + 2 verdes = 9 bolitas. 2. La probabilidad de sacar una bolita roja es el número de bolitas rojas dividido por el número total de bolitas, que es 4/9. 3. La probabilidad de NO sacar una bolita roja es, por lo tanto: Probabilidad = 1 - Probabilidad de Sacar una Bolita Roja = 1 - 4/9 = 5/9 Así, la probabilidad de no sacar una bolita roja es 5/9.<end_of_turn>
<start_of_turn>model
{
"avg_rating_es": "2.0",
"cluster_description_es": "Problemas Matemáticos y Cuidado de Animales",
"topic_es": "Matemáticas",
"kind_es": "humano"
}<end_of_turn>
CPU times: user 3.67 s, sys: 7.1 ms, total: 3.68 s
Wall time: 3.67 s
``` |
abc88767/4sc90 | abc88767 | 2024-05-16T23:57:49Z | 137 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T23:56:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
abc88767/3sc91 | abc88767 | 2024-05-16T23:51:45Z | 140 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T23:50:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
abc88767/2c90 | abc88767 | 2024-05-16T23:48:33Z | 139 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T23:46:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
akshaysayarpro/WK_NER_RENUM | akshaysayarpro | 2024-05-16T23:47:15Z | 108 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-16T16:40:32Z | ---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: WK_NER_RENUM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# WK_NER_RENUM
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0138
- Precision: 0.9531
- Recall: 0.9692
- F1: 0.9611
- Accuracy: 0.9966
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0253 | 1.0 | 1080 | 0.0220 | 0.9179 | 0.9355 | 0.9266 | 0.9938 |
| 0.0142 | 2.0 | 2160 | 0.0150 | 0.9444 | 0.9637 | 0.9540 | 0.9959 |
| 0.0072 | 3.0 | 3240 | 0.0138 | 0.9531 | 0.9692 | 0.9611 | 0.9966 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.15.2
|
joshnader/deepseek-math-7b-instruct-Q4_K_M-GGUF | joshnader | 2024-05-16T23:43:57Z | 1,101 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-16T23:43:45Z | ---
license: other
tags:
- llama-cpp
- gguf-my-repo
license_name: deepseek
license_link: https://github.com/deepseek-ai/DeepSeek-Math/blob/main/LICENSE-MODEL
---
# joshnader/deepseek-math-7b-instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`deepseek-ai/deepseek-math-7b-instruct`](https://huggingface.co/deepseek-ai/deepseek-math-7b-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/deepseek-ai/deepseek-math-7b-instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo joshnader/deepseek-math-7b-instruct-Q4_K_M-GGUF --model deepseek-math-7b-instruct.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo joshnader/deepseek-math-7b-instruct-Q4_K_M-GGUF --model deepseek-math-7b-instruct.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m deepseek-math-7b-instruct.Q4_K_M.gguf -n 128
```
|
anzorq/w2v-bert-2.0-kbd | anzorq | 2024-05-16T23:33:31Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"kbd",
"dataset:anzorq/kbd_speech",
"dataset:anzorq/sixuxar_yijiri_mak7",
"license:mit",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-16T20:20:49Z | ---
license: mit
language:
- kbd
datasets:
- anzorq/kbd_speech
- anzorq/sixuxar_yijiri_mak7
metrics:
- wer
pipeline_tag: automatic-speech-recognition
---
# Circassian (Kabardian) ASR Model
This is a fine-tuned model for Automatic Speech Recognition (ASR) in `kbd`, based on the `facebook/w2v-bert-2.0` model.
The model was trained on a combination of the `anzorq/kbd_speech` (filtered on `country=russia`) and `anzorq/sixuxar_yijiri_mak7` datasets.
## Model Details
- **Base Model**: facebook/w2v-bert-2.0
- **Language**: Kabardian
- **Task**: Automatic Speech Recognition (ASR)
- **Datasets**: anzorq/kbd_speech, anzorq/sixuxar_yijiri_mak7
- **Training Steps**: 5000
## Training
The model was fine-tuned using the following training arguments:
```python
TrainingArguments(
output_dir='output',
group_by_length=True,
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
evaluation_strategy="steps",
num_train_epochs=10,
gradient_checkpointing=True,
fp16=True,
save_steps=1000,
eval_steps=500,
logging_steps=300,
learning_rate=5e-5,
warmup_steps=500,
save_total_limit=2,
push_to_hub=True,
report_to="wandb"
)
```
## Performance
The model's performance during training:
| Step | Training Loss | Validation Loss | WER |
|------|---------------|-----------------|---------|
| 500 | 2.859600 | inf | 0.870362|
| 1000 | 0.355500 | inf | 0.703617|
| 1500 | 0.247100 | inf | 0.549942|
| 2000 | 0.196700 | inf | 0.471762|
| 2500 | 0.181500 | inf | 0.361494|
| 3000 | 0.152200 | inf | 0.314119|
| 3500 | 0.135700 | inf | 0.275146|
| 4000 | 0.113400 | inf | 0.252625|
| 4500 | 0.102900 | inf | 0.277013|
| 5000 | 0.078500 | inf | 0.250175| |
camilomj/MichaelJosephJackson | camilomj | 2024-05-16T23:25:49Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-16T23:24:23Z | ---
license: apache-2.0
---
|
OscarGalavizC/roberta-base-bne-finetuned-multi-sentiment-finetuned-multi-sentiment | OscarGalavizC | 2024-05-16T23:24:16Z | 109 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:BSC-LT/roberta-base-bne",
"base_model:finetune:BSC-LT/roberta-base-bne",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-16T21:04:52Z | ---
license: apache-2.0
base_model: BSC-TeMU/roberta-base-bne
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-base-bne-finetuned-multi-sentiment-finetuned-multi-sentiment
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-bne-finetuned-multi-sentiment-finetuned-multi-sentiment
This model is a fine-tuned version of [BSC-TeMU/roberta-base-bne](https://huggingface.co/BSC-TeMU/roberta-base-bne) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0249
- Accuracy: 0.6451
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5534 | 1.0 | 115 | 0.7764 | 0.6512 |
| 0.3479 | 2.0 | 230 | 0.9324 | 0.6512 |
| 0.0922 | 3.0 | 345 | 1.2452 | 0.6574 |
| 0.0218 | 4.0 | 460 | 1.7006 | 0.6512 |
| 0.001 | 5.0 | 575 | 1.7949 | 0.6512 |
| 0.0007 | 6.0 | 690 | 1.8798 | 0.6605 |
| 0.0006 | 7.0 | 805 | 1.9510 | 0.6451 |
| 0.0005 | 8.0 | 920 | 1.9926 | 0.6451 |
| 0.0004 | 9.0 | 1035 | 2.0169 | 0.6451 |
| 0.0004 | 10.0 | 1150 | 2.0249 | 0.6451 |
### Framework versions
- Transformers 4.40.2
- Pytorch 1.13.1+cu117
- Datasets 2.19.1
- Tokenizers 0.19.1
|
camilomj/JENNIEDEBUT | camilomj | 2024-05-16T23:17:03Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-16T23:14:10Z | ---
license: apache-2.0
---
|
DuongTrongChi/Rikka-1.8B-v2 | DuongTrongChi | 2024-05-16T23:04:29Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"trl",
"dpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T15:45:25Z | ---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
nsugianto/detr-resnet50_finetuned_detrresnet50_lsdocelementdetv1type7_s1_1669s | nsugianto | 2024-05-16T23:01:14Z | 28 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | 2024-05-16T06:20:45Z | ---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: detr-resnet50_finetuned_detrresnet50_lsdocelementdetv1type7_s1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-resnet50_finetuned_detrresnet50_lsdocelementdetv1type7_s1
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.41.0.dev0
- Pytorch 2.0.1
- Datasets 2.18.0
- Tokenizers 0.19.1
|
RichardErkhov/mlabonne_-_Beagle14-7B-4bits | RichardErkhov | 2024-05-16T23:00:21Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-16T22:56:51Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Beagle14-7B - bnb 4bits
- Model creator: https://huggingface.co/mlabonne/
- Original model: https://huggingface.co/mlabonne/Beagle14-7B/
Original model description:
---
license: cc-by-nc-4.0
tags:
- merge
- mergekit
- lazymergekit
- fblgit/UNA-TheBeagle-7b-v1
- argilla/distilabeled-Marcoro14-7B-slerp
base_model:
- fblgit/UNA-TheBeagle-7b-v1
- argilla/distilabeled-Marcoro14-7B-slerp
model-index:
- name: Beagle14-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 72.95
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Beagle14-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 87.95
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Beagle14-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.7
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Beagle14-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 68.88
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Beagle14-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 82.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Beagle14-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 71.42
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=mlabonne/Beagle14-7B
name: Open LLM Leaderboard
---
# Beagle14-7B
**Update 01/16/24: Check the DPO fine-tuned version of this model, [NeuralBeagle14-7B](https://huggingface.co/mlabonne/NeuralBeagle14-7B) (probably the best 7B model you can find)! 🎉**
Beagle14-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [fblgit/UNA-TheBeagle-7b-v1](https://huggingface.co/fblgit/UNA-TheBeagle-7b-v1)
* [argilla/distilabeled-Marcoro14-7B-slerp](https://huggingface.co/argilla/distilabeled-Marcoro14-7B-slerp)
## 🏆 Evaluation
The evaluation was performed using [LLM AutoEval](https://github.com/mlabonne/llm-autoeval) on Nous suite.
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|----------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[**Beagle14-7B**](https://huggingface.co/mlabonne/Beagle14-7B)| **44.38**| **76.53**| **69.44**| **47.25**| **59.4**|
|[OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)| 42.75| 72.99| 52.99| 40.94| 52.42|
|[NeuralHermes-2.5-Mistral-7B](https://huggingface.co/mlabonne/NeuralHermes-2.5-Mistral-7B)| 43.67| 73.24| 55.37| 41.76| 53.51|
|[Nous-Hermes-2-SOLAR-10.7B](https://huggingface.co/NousResearch/Nous-Hermes-2-SOLAR-10.7B)| 47.79| 74.69| 55.92| 44.84| 55.81|
|[Marcoro14-7B-slerp](https://huggingface.co/mlabonne/Marcoro14-7B-slerp) | 44.66| 76.24| 64.15| 45.64| 57.67|
|[CatMarcoro14-7B-slerp](https://huggingface.co/occultml/CatMarcoro14-7B-slerp)| 45.21| 75.91| 63.81| 47.31| 58.06|
## 🧩 Configuration
```yaml
slices:
- sources:
- model: fblgit/UNA-TheBeagle-7b-v1
layer_range: [0, 32]
- model: argilla/distilabeled-Marcoro14-7B-slerp
layer_range: [0, 32]
merge_method: slerp
base_model: fblgit/UNA-TheBeagle-7b-v1
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/Beagle14-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_mlabonne__Beagle14-7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |74.76|
|AI2 Reasoning Challenge (25-Shot)|72.95|
|HellaSwag (10-Shot) |87.95|
|MMLU (5-Shot) |64.70|
|TruthfulQA (0-shot) |68.88|
|Winogrande (5-shot) |82.64|
|GSM8k (5-shot) |71.42|
|
kdcyberdude/w2v-bert-punjabi | kdcyberdude | 2024-05-16T22:51:42Z | 27 | 3 | transformers | [
"transformers",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-15T22:09:24Z | ---
library_name: transformers
tags: []
---
# Punjabi_ASR
## Introduction
The `Punjabi_ASR` project is dedicated to advancing Automatic Speech Recognition (ASR) for the Punjabi language, using various datasets to benchmark and improve performance. Our goal is to refine ASR technology to make it more accessible and efficient for speakers of Punjabi.
All Training, Evaluation, Processing scripts are available on [Github](https://github.com/kdcyberdude/Punjabi_ASR)
## Performance
We have benchmarked the ASR model using the IndicSuperb - [AI4Bharat/IndicSUPERB](https://github.com/AI4Bharat/IndicSUPERB) ASR benchmark with the following results:
- **Common Voice:** 10.18%
- **Fleurs:** 6.96%
- **Kathbath:** 8.30%
- **Kathbath Noisy:** 9.31%
These Word Error Rates (WERs) demonstrate the current capabilities and focus areas for improvement in our models.
## Example Usage
To use the `w2v-bert-punjabi` model for speech recognition, follow the steps below. This example demonstrates loading the model and processing an audio file for speech-to-text conversion.
### Code
```python
import speech_utils as su
from m4t_processor_with_lm import M4TProcessorWithLM
from transformers import Wav2Vec2BertForCTC, pipeline
# Load the model and processor
model_id = 'kdcyberdude/w2v-bert-punjabi'
processor = M4TProcessorWithLM.from_pretrained(model_id)
model = Wav2Vec2BertForCTC.from_pretrained(model_id)
# Set up the pipeline
pipe = pipeline('automatic-speech-recognition', model=model, tokenizer=processor.tokenizer, feature_extractor=processor.feature_extractor, decoder=processor.decoder, return_timestamps='word', device='cuda:0')
# Process the audio file
output = pipe("example.wav", chunk_length_s=20, stride_length_s=(4, 4))
su.pbprint(output['text'])
```
https://github.com/kdcyberdude/Punjabi_ASR/assets/34835322/88515c45-3212-4457-8d72-a35de0060d65
**Transcription:**
ਉਹ ਕਹਿੰਦੇ ਸਾਡਾ ਸੁਨੇਹਾ ਹੁਣ ਜਾ ਕੇ ਅਹਿਮਦ ਸ਼ਾਹ ਬਦਾਲੀ ਨੂੰ ਦੇ ਦਿਓ ਉਹਨੇ ਸਾਨੂੰ ਪੇਸ਼ਕਸ਼ ਭੇਜੀ ਸੀ ਤਾਜ ਉਸ ਦਾ ਤੇ ਰਾਜ ਸਾਡਾ ਉਹਨੇ ਕਿਹਾ ਸੀ ਕਣਕ ਕੋਰਾ ਮੱਕੀ ਬਾਜਰਾ ਜਵਾਰ ਦੇ ਦਿਆ ਕਰੋ ਤੇ ਜ਼ਿੰਦਗੀ ਜੀ ਸਕਦੇ ਓ ਹੁਣ ਸਾਡਾ ਜਵਾਬ ਉਹਨੂੰ ਦੇ ਦਿਓ ਕਿ ਸਾਡੀ ਜੰਗ ਕੇਸ ਗੱਲ ਦੀ ਐ ਸਾਡੇ ਵੱਲੋਂ ਸ਼ਾਹ ਨੂੰ ਕਹਿ ਦੇਣਾ ਜਾ ਕੇ ਮਿਲਾਂਗੇ ਉਸ ਨੂੰ ਰਣ ਵਿੱਚ ਹੱਥ ਤੇਗ ਉਠਾ ਕੇ ਸ਼ਰਤਾਂ ਲਿਖਾਂਗੇ ਰੱਤ ਨਾਲ ਖੈਬਰ ਕੋਲ ਜਾ ਕੇ ਸ਼ਾਹ ਨਜ਼ਰਾਨੇ ਸਾਥੋਂ ਭਾਲਦਾ ਇਉਂ ਈਨ ਮਨਾ ਕੇ ਪਰ ਸ਼ੇਰ ਨਾ ਜਿਉਂਦੇ ਸੀਤਲਾ ਨੱਕ ਨੱਥ ਪਾ ਕੇ ਇਹ ਸੀ ਉਸ ਵੇਲੇ ਸਾਡੇ ਇਹਨਾਂ ਜਰਨੈਲਾਂ ਦਾ ਕਿਰਦਾਰ ਬਹੁਤ ਵੱਡਾ ਜੀਵਨ ਹੈ ਜਿਹਦੇ ਚ ਰਾਜਨੀਤੀ ਕੂਟਨੀਤੀ ਯੁੱਧ ਨੀਤੀ ਧਰਮਨੀਤੀ ਸਭ ਕੁਝ ਭਰਿਆ ਪਿਆ ਹੈ
## Datasets
The training and testing data used in this project are available on Hugging Face:
- [Punjabi ASR Datasets](https://huggingface.co/datasets/kdcyberdude/Punjabi_ASR_datasets)
## Model
Our current model is hosted on Hugging Face, and you can explore its capabilities through the demo:
- **Model:** [w2v-bert-punjabi](https://huggingface.co/kdcyberdude/w2v-bert-punjabi)
- **Demo:** [Try the model](https://huggingface.co/spaces/kdcyberdude/w2v-bert-punjabi)
## Next Steps
Here are the key areas we're focusing on to advance our Punjabi ASR project:
- [ ] **Training Whisper:** Implement and train the Whisper model to compare its performance against our current models.
- [ ] **Filtering Pipeline:** Develop a robust filtering pipeline to enhance dataset quality by addressing transcription inaccuracies found in datasets like Shrutilipi, IndicSuperb, and IndicTTS.
- [ ] **Building a Custom Dataset:** Compile approximately 500 hours of high-quality Punjabi audio data to support diverse and comprehensive training.
- [ ] **Multilingual Training:** Utilize the linguistic similarities between Punjabi and Hindi to improve model training through multilingual datasets.
- [ ] **Data Augmentation:** Apply techniques such as speed variation and background noise addition to training to bolster the ASR system's robustness.
- [ ] **Iterative Training:** Continuously retrain models like w2v-bert or Whisper based on experimental outcomes and enhanced data insights.
## Collaboration and Support
We are actively seeking collaborators and sponsors to expand our efforts on the Punjabi ASR project. Contributions can be in the form of coding, dataset provision, or compute resources sponsorship. Your support will be crucial in making this practically beneficial for real-life applications.
- **Issues and Contributions:** Encounter an issue or want to help? Create a [GitHub issue](https://github.com/kdcyberdude/Punjabi_ASR/issues) or submit a pull request to contribute directly.
- **Sponsorship:** If you are interested in sponsoring, especially in terms of compute resources, please email us at [email protected] to discuss collaboration opportunities.
|
ZcepZtar/DaToSw_V1.3 | ZcepZtar | 2024-05-16T22:50:09Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"marian",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-16T15:17:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Alexxu0520/my_awesome_qa_model | Alexxu0520 | 2024-05-16T22:50:06Z | 64 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased-distilled-squad",
"base_model:finetune:distilbert/distilbert-base-uncased-distilled-squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-06T23:56:00Z | ---
license: apache-2.0
base_model: distilbert-base-uncased-distilled-squad
tags:
- generated_from_keras_callback
model-index:
- name: Alexxu0520/my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Alexxu0520/my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased-distilled-squad](https://huggingface.co/distilbert-base-uncased-distilled-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3287
- Validation Loss: 0.4676
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.5162 | 0.4686 | 0 |
| 0.3583 | 0.4676 | 1 |
| 0.3287 | 0.4676 | 2 |
### Framework versions
- Transformers 4.40.2
- TensorFlow 2.15.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
emilykang/Phi_mts_dialogue_clinical_note_CC | emilykang | 2024-05-16T22:46:26Z | 151 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T22:32:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Lubb/Jungkook_ | Lubb | 2024-05-16T22:42:06Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-16T22:42:06Z | ---
license: apache-2.0
---
|
KvrParaskevi/Llama-2-7b-Hotel-Booking-Model-8Bit | KvrParaskevi | 2024-05-16T22:41:01Z | 83 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-04-22T01:11:41Z | ---
library_name: transformers
license: mit
language:
- en
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
statking/zephyr-7b-sft-qdora | statking | 2024-05-16T22:38:27Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"dataset:HuggingFaceH4/ultrachat_200k",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-05-16T06:48:53Z | ---
license: apache-2.0
library_name: peft
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
datasets:
- HuggingFaceH4/ultrachat_200k
model-index:
- name: zephyr-7b-sft-qdora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/statking/huggingface/runs/md7eikah)
# zephyr-7b-sft-qdora
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the HuggingFaceH4/ultrachat_200k dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9432
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 32
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.9453 | 1.0 | 2179 | 0.9432 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.41.0.dev0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
Hung1001/Reading_Comprehension_Llama3 | Hung1001 | 2024-05-16T22:38:24Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T07:52:40Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** Hung1001
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
qualis2006/codeparrot-ds | qualis2006 | 2024-05-16T22:38:10Z | 154 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T00:13:21Z | ---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: codeparrot-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# codeparrot-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.40.1
- Pytorch 2.1.0
- Datasets 2.19.0
- Tokenizers 0.19.1
|
Mullerjo/ppo-LunarLander | Mullerjo | 2024-05-16T22:37:03Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-16T22:29:36Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.03 +/- 22.91
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
emilykang/Phi_mts_dialogue_clinical_note_lora_CC | emilykang | 2024-05-16T22:31:55Z | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-05-16T22:30:24Z | ---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- generator
model-index:
- name: Phi_mts_dialogue_clinical_note_lora_CC
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Phi_mts_dialogue_clinical_note_lora_CC
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.0.1+cu117
- Datasets 2.19.0
- Tokenizers 0.19.1 |
BexRedpill/distilbert-on-yelp-reviews-full-epoch-2 | BexRedpill | 2024-05-16T22:30:01Z | 110 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-16T18:14:27Z | ---
license: apache-2.0
base_model: BexRedpill/distilbert-on-yelp-reviews-full
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: distilbert-on-yelp-reviews-full-epoch-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-on-yelp-reviews-full-epoch-2
This model is a fine-tuned version of [BexRedpill/distilbert-on-yelp-reviews-full](https://huggingface.co/BexRedpill/distilbert-on-yelp-reviews-full) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8048
- Accuracy: 0.6508
- F1: 0.6490
- Precision: 0.6480
- Recall: 0.6508
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
e2jhiubyiiyvw/Pantheon-RP-1.0-8b-Llama-3-Q5_K_M-GGUF | e2jhiubyiiyvw | 2024-05-16T22:29:00Z | 0 | 0 | null | [
"gguf",
"Llama-3",
"instruct",
"finetune",
"chatml",
"axolotl",
"roleplay",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:quantized:meta-llama/Meta-Llama-3-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-16T22:28:42Z | ---
language:
- en
license: apache-2.0
tags:
- Llama-3
- instruct
- finetune
- chatml
- axolotl
- roleplay
- llama-cpp
- gguf-my-repo
base_model: meta-llama/Meta-Llama-3-8B
---
# e2jhiubyiiyvw/Pantheon-RP-1.0-8b-Llama-3-Q5_K_M-GGUF
This model was converted to GGUF format from [`Gryphe/Pantheon-RP-1.0-8b-Llama-3`](https://huggingface.co/Gryphe/Pantheon-RP-1.0-8b-Llama-3) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Gryphe/Pantheon-RP-1.0-8b-Llama-3) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo e2jhiubyiiyvw/Pantheon-RP-1.0-8b-Llama-3-Q5_K_M-GGUF --model pantheon-rp-1.0-8b-llama-3.Q5_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo e2jhiubyiiyvw/Pantheon-RP-1.0-8b-Llama-3-Q5_K_M-GGUF --model pantheon-rp-1.0-8b-llama-3.Q5_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m pantheon-rp-1.0-8b-llama-3.Q5_K_M.gguf -n 128
```
|
emilykang/Gemma_mts_dialogue_clinical_note_MEDICATIONS | emilykang | 2024-05-16T22:23:03Z | 152 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T22:09:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mlabonne/Meta-Llama-3-12B-Instruct | mlabonne | 2024-05-16T22:22:14Z | 10 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"conversational",
"base_model:NousResearch/Meta-Llama-3-8B-Instruct",
"base_model:finetune:NousResearch/Meta-Llama-3-8B-Instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T16:10:32Z | ---
license: other
tags:
- merge
- mergekit
- lazymergekit
base_model:
- NousResearch/Meta-Llama-3-8B-Instruct
- NousResearch/Meta-Llama-3-8B-Instruct
- NousResearch/Meta-Llama-3-8B-Instruct
- NousResearch/Meta-Llama-3-8B-Instruct
- NousResearch/Meta-Llama-3-8B-Instruct
---
# Meta-Llama-3-12B-Instruct
Meta-Llama-3-12B-Instruct is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [NousResearch/Meta-Llama-3-8B-Instruct](https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct)
* [NousResearch/Meta-Llama-3-8B-Instruct](https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct)
* [NousResearch/Meta-Llama-3-8B-Instruct](https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct)
* [NousResearch/Meta-Llama-3-8B-Instruct](https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct)
* [NousResearch/Meta-Llama-3-8B-Instruct](https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct)
## 🏆 Evaluation
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|--------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[Meta-Llama-3-12B-Instruct](https://huggingface.co/mlabonne/Meta-Llama-3-12B-Instruct)| 41.7| 67.71| 52.75| 40.58| 50.69|
|[Meta-Llama-3-12B](https://huggingface.co/mlabonne/Meta-Llama-3-12B)| 29.46| 68.01| 41.02| 35.57| 43.52|
## 🧩 Configuration
```yaml
slices:
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [0,9]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [5,14]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [10,19]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [15,24]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [20,32]
merge_method: passthrough
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/Meta-Llama-3-12B-Instruct"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
ubaada/lsg-bart-large-4096-booksum | ubaada | 2024-05-16T22:21:24Z | 165 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"custom_code",
"dataset:ubaada/booksum-complete-cleaned",
"base_model:ubaada/lsg-bart-large-4096-booksum",
"base_model:finetune:ubaada/lsg-bart-large-4096-booksum",
"autotrain_compatible",
"region:us"
] | text2text-generation | 2024-05-14T18:41:15Z | ---
base_model: ubaada/lsg-bart-large-4096-booksum
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: lsg-bart-large-4096-booksum
results: []
datasets:
- ubaada/booksum-complete-cleaned
---
# lsg-bart-large-4096-booksum
This model is a fine-tuned version of [ubaada/lsg-bart-large-4096-booksum](https://huggingface.co/ubaada/lsg-bart-large-4096-booksum) on an ubaada/booksum-complete-cleaned dataset.
Validation Loss (Subset of validation dataset) Loss: 2.0742
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 8
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.0
- Datasets 2.19.1
- Tokenizers 0.19.1 |
nes470/pipeline-as-repo | nes470 | 2024-05-16T22:18:19Z | 129 | 0 | transformers | [
"transformers",
"pytorch",
"QA-umd-quizbowl",
"question-answering",
"custom_code",
"license:mit",
"region:us"
] | question-answering | 2024-05-06T15:27:54Z | ---
license: mit
library_name: transformers
---
Names: Nuran, Joshua, Robert
The evaluation of this project is to answer trivia questions. You do
not need to do well at this task, but you should submit a system that
completes the task or create adversarial questions in that setting. This will help the whole class share data and
resources.
If you focus on something other than predicting answers, *that's fine*!
About the Data
==============
Quiz bowl is an academic competition between schools in
English-speaking countries; hundreds of teams compete in dozens of
tournaments each year. Quiz bowl is different from Jeopardy, a recent
application area. While Jeopardy also uses signaling devices, these
are only usable after a question is completed (interrupting Jeopardy's
questions would make for bad television). Thus, Jeopardy is rapacious
classification followed by a race---among those who know the
answer---to punch a button first.
Here's an example of a quiz bowl question:
Expanding on a 1908 paper by Smoluchowski, he derived a formula for
the intensity of scattered light in media fluctuating densities that
reduces to Rayleigh's law for ideal gases in The Theory of the
Opalescence of Homogenous Fluids and Liquid Mixtures near the Critical
State. That research supported his theories of matter first developed
when he calculated the diffusion constant in terms of fundamental
parameters of the particles of a gas undergoing Brownian Motion. In
that same year, 1905, he also published On a Heuristic Point of View
Concerning the Production and Transformation of Light. That
explication of the photoelectric effect won him 1921 Nobel in Physics.
For ten points, name this German physicist best known for his theory
of Relativity.
*ANSWER*: Albert _Einstein_
Two teams listen to the same question. Teams interrupt the question at
any point by "buzzing in"; if the answer is correct, the team gets
points and the next question is read. Otherwise, the team loses
points and the other team can answer.
You are welcome to use any *automatic* method to choose an answer. It
need not be similar nor build on our provided systems. In addition to
the data we provide, you are welcome to use any external data *except*
our test quiz bowl questions (i.e., don't hack our server!). You are
welcome (an encouraged) to use any publicly available software, but
you may want to check on Piazza for suggestions as many tools are
better (or easier to use) than others.
If you don't like the interruptability of questions, you can also just answer entire questions. However, you must also output a confidence.
Competition
==================
We will use Dynabech website (https://dynabench.org/tasks/qa). If you remember the past workshop about Dynabench submission, this is the way to do it. The specific task name is "Grounded QA". Here, with the help of the video tutorial, you submit your QA model and assess how your QA model did compared to others. The assessment will take place by testing your QA model on several QA test datasets and the results of yours and your competitors will be visible on the leaderboard. Your goal is to rank the highest in terms of expected wins: you buzz in with probability proportional to your confidence, and if you're more right than the competition, you win.
Writing Questions
==================
Alternatively, you can also *write* 50 adversarial questions that
challenge modern NLP systems. These questions must be diverse in the
subjects asked about, the skills computers need to answer the
questions, and the entities in those questions. Remember that your questions should be *factual* and
*specific* enough for humans to answer, because your task is to stump
the computers relative to humans!
In addition to the raw questions, you will also need to create citations describing:
* Why the question is difficult for computers: include citations from the NLP/AI/ML literature
* Why the information in the question is correct: include citations from the sources you drew on the write the question
* Why the question is interesting: include scholarly / popular culture artifacts to prove that people care about this
* Why the question is pyramidal: discuss why your first clues are harder than your later clues
**Category**
We want questions from many domains such as Art, Literature, Geography, History,
Science, TV and Film, Music, Lifestyle, and Sport. The questions
should be written using all topics above (5 questions for each
category and 5 more for the remaining categories). Indicate in your
writeup which category you chose to write on for each question.
Art:
* Questions about works: Mona Lisa, Raft of the Medussa
* Questions about forms: color, contour, texture
* Questions about artists: Picasso, Monet, Leonardo da Vinci
* Questions about context: Renaissance, post-modernism, expressionism, surrealism
Literature:
* Questions about works: novels (1984), plays (The Lion and the Jewel), poems (Rubaiyat), criticism (Poetics)
* Questions about major characters or events in literature: The Death of Anna Karenina, Noboru Wataya, the Marriage of Hippolyta and Theseus
* Questions about literary movements (Sturm und Drang)
* Questions about translations
* Cross-cutting questions (appearances of Overcoats in novels)
* Common link questions (the literary output of a country/region)
Geography:
* Questions about location: names of capital, state, river
* Questions about the place: temperature, wind flow, humidity
History:
* When: When did the First World war start?
* Who: Who is called Napoleon of Iran?
* Where: Where was the first Summer Olympics held?
* Which: Which is the oldest civilization in the world?
Science:
* Questions about terminology: The concept of gravity was discovered by which famous physicist?
* Questions about the experiment
* Questions about theory: The social action theory believes that individuals are influenced by this theory.
TV and Film:
* Quotes: What are the dying words of Charles Foster Kane in Citizen Kane?
* Title: What 1927 musical was the first "talkie"?
* Plot: In The Matrix, does Neo take the blue pill or the red pill?
Music:
* Singer: What singer has had a Billboard No. 1 hit in each of the last four decades?
* Band: Before Bleachers and fun., Jack Antonoff fronted what band?
* Title: What was Madonna's first top 10 hit?
* History: Which classical composer was deaf?
Lifestyle:
* Clothes: What clothing company, founded by a tennis player, has an alligator logo?
* Decoration: What was the first perfume sold by Coco Chanel?
Sport:
* Known facts: What sport is best known as the ‘king of sports’?
* Nationality: What’s the national sport of Canada?
* Sport player: The classic 1980 movie called Raging Bull is about which real-life boxer?
* Country: What country has competed the most times in the Summer Olympics yet hasn’t won any kind of medal?
**Diversity**
Other than category diversity, if you find an ingenious way of writing questions about underrepresented countries, you will get bonus points (indicate which questions you included the diversity component in your writeup). You may decide which are underrepresented countries with your own reasonable reason (etc., less population may indicate underrepresented), but make sure to articulate this in your writeup.
* Run state of the art QA systems on the questions to show they struggle, give individual results for each question and a summary over all questions
For an example of what the writeup for a single question should look like, see the adversarial HW:
https://github.com/Pinafore/nlp-hw/blob/master/adversarial/question.tex
Proposal
==================
The project proposal is a one page PDF document that describes:
* Who is on your team (team sizes can be between three and six
students, but six is really too big to be effective; my suggestion
is that most groups should be between four or five).
* What techniques you will explore
* Your timeline for completing the project (be realistic; you should
have your first submission in a week or two)
Submit the proposal on Gradescope, but make sure to include all group
members. If all group members are not included, you will lose points. Late days cannot be used on this
assignment.
Milestone 1
======================
You'll have to update how things are going: what's
working, what isn't, and how does it change your timeline? How does it change your division of labor?
*Question Writing*: You'll need to have answers selected for all of
your questions and first drafts of at least 15 questions. This must
be submitted as a JSON file so that we run computer QA systems on it.
*Project*: You'll need to have made a submission to the leaderboard with something that satisfies the API.
Submit a PDF updating on your progress to Gradescope. If all team
members are not on the submission, you will lose points.
Milestone 2
===================
As before, provide an updated timeline / division of labor, provide your intermediary results.
*Question Writing*: You'll need to have reflected the feedback from the first questions and completed a first draft of at least 30 questions. You'll also need machine results to your questions and an overall evaluation of your human/computer accuracy.
*Project*: You'll need to have a made a submission to the leaderboard with a working system (e.g., not just obey the API, but actually get reasonable answers).
Submit a PDF updating on your progress.
Final Presentation
======================
The final presentation will be virtual (uploading a video). In
the final presentation you will:
* Explain what you did
* Who did what. For example, for the question writing project a team of five people might write: A wrote the first draft of questions. B and C verified they were initially answerable by a human. B ran computer systems to verify they were challenging to a computer. C edited the questions and increased the computer difficulty. D and E verified that the edited questions were still answerable by a human. D and E checked all of the questions for factual accuracy and created citations and the writeup.
* What challenges you had
* Review how well you did (based on the competition or your own metrics). If you do not use the course infrastructure to evaluate your project's work, you should talk about what alternative evaluations you used, why they're appropriate/fair, and how well you did on them.
* Provide an error analysis. An error analysis must contain examples from the
development set that you get wrong. You should show those sentences
and explain why (in terms of features or the model) they have the
wrong answer. You should have been doing this all along as you
derive new features, but this is your final inspection of
your errors. The feature or model problems you discover should not
be trivial features you could add easily. Instead, these should be
features or models that are difficult to correct. An error analysis
is not the same thing as simply presenting the error matrix, as it
does not inspect any individual examples. If you're writing questions, talk about examples of questions that didn't work out as intended.
* The linguistic motivation for your features / how your wrote the questions. This is a
computational linguistics class, so you should give precedence to
features / techniques that we use in this class (e.g., syntax,
morphology, part of speech, word sense, etc.). Given two features
that work equally well and one that is linguistically motivated,
we'll prefer the linguistically motivated one.
* Presumably you did many different things; how did they each
individually contribute to your final result?
Each group has 10 minutes to deliver their presentation. Please record the video, and upload it to Google Drive, and include the link in your writeup submission.
Final Question Submission
======================
Because we need to get the questions ready for the systems, upload your raw questions on May 10. This doesn't include the citations or other parts of the writeup.
System Submission
======================
You must submit a version of your system by May 12. It may not be perfect, but this what the question writing teams will use to test their results.
Your system should be sent directly to the professor and TAs in zip files, including the correct dependencies and a working inference code. Your inference code should run successfully in the root folder (extracted from zip folder) directory with the command:
```
> python3 inference.py --data=evaluation_set.json
```
The input will be in the form of a .json file () in the same format as the file the adversarial question writing team submits. The output format should also be in string.
If you have any notes or comments that we should be aware of while running your code, please include them in the folder as a .txt file. Also, dependency information should be included as a .txt file.
Please prepend your email title with [2024-CMSC 470 System Submission].
Project Writeup and JSON file
======================
By May 17, submit your project writeup explaining what
you did and what results you achieved. This document should
make it clear:
* Why this is a good idea
* What you did
* Who did what
* Whether your technique worked or not
For systems, please do not go over 2500 words unless you have a really good reason.
Images are a much better use of space than words, usually (there's no
limit on including images, but use judgement and be selective).
For question writing, you have one page (single spaced, two column) per question plus a two page summary of results. Talk about how you organized the question writing, how you evaluated the questions, and a summary of the results. Along with your writeup, turn in a json including the raw text of the question and answer and category. The json file is included in this directory. Make sure your json file is in the correct format and is callable via below code. Your submission will not be graded if it does not follow the format of the example json file.
```
with open('path to your json file', 'r') as f:
data = json.load(f)
```
Grade
======================
The grade will be out of 25 points, broken into five areas:
* _Presentation_: For your oral presentation, do you highlight what
you did and make people care? Did you use time well during the
presentation?
* _Writeup_: Does the writeup explain what you did in a way that is
clear and effective?
The final three areas are different between the system and the questions.
| | System | Questions |
|----------|:-------------:|------:|
| _Technical Soundness_ | Did you use the right tools for the job, and did you use them correctly? Were they relevant to this class? | Were your questions correct and accurately cited. |
| _Effort_ | Did you do what you say you would, and was it the right ammount of effort. | Are the questions well-written, interesting, and thoroughly edited? |
| _Performance_ | How did your techniques perform in terms of accuracy, recall, etc.? | Is the human accuracy substantially higher than the computer accuracy? |
All members of the group will receive the same grade. It's impossible for the course staff to adjudicate Rashomon-style accounts of who did what, and the goal of a group project is for all team members to work together to create a cohesive project that works well together. While it makes sense to divide the work into distinct areas of responsibility, at grading time we have now way to know who really did what, so it's the groups responsibility to create a piece of output that reflects well on the whole group. |
Mag0g/Ezekiel28_8 | Mag0g | 2024-05-16T22:17:08Z | 138 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T22:06:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
emilykang/Phi_mts_dialogue_clinical_note_lora_MEDICATIONS | emilykang | 2024-05-16T22:15:02Z | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-05-16T22:14:12Z | ---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- generator
model-index:
- name: Phi_mts_dialogue_clinical_note_lora_MEDICATIONS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Phi_mts_dialogue_clinical_note_lora_MEDICATIONS
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.0.1+cu117
- Datasets 2.19.0
- Tokenizers 0.19.1 |
Fischerboot/BigBoiV14-V2 | Fischerboot | 2024-05-16T22:13:25Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:BeaverLegacy/Llama-3SOME-8B-v1",
"base_model:merge:BeaverLegacy/Llama-3SOME-8B-v1",
"base_model:Fischerboot/BigBoiV14",
"base_model:merge:Fischerboot/BigBoiV14",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:54:53Z | ---
base_model:
- Fischerboot/BigBoiV14
- TheDrummer/Llama-3SOME-8B-v1
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [Fischerboot/BigBoiV14](https://huggingface.co/Fischerboot/BigBoiV14)
* [TheDrummer/Llama-3SOME-8B-v1](https://huggingface.co/TheDrummer/Llama-3SOME-8B-v1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Fischerboot/BigBoiV14
layer_range: [0, 32]
- model: TheDrummer/Llama-3SOME-8B-v1
layer_range: [0, 32]
merge_method: slerp
base_model: Fischerboot/BigBoiV14
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
qunfengd/esm2_t12_35M_UR50D-finetuned-AMP_Classification_AntiGramPositive_doublePositiveCase | qunfengd | 2024-05-16T22:11:46Z | 60 | 0 | transformers | [
"transformers",
"tf",
"esm",
"text-classification",
"generated_from_keras_callback",
"base_model:facebook/esm2_t12_35M_UR50D",
"base_model:finetune:facebook/esm2_t12_35M_UR50D",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-16T22:11:30Z | ---
license: mit
tags:
- generated_from_keras_callback
base_model: facebook/esm2_t12_35M_UR50D
model-index:
- name: esm2_t12_35M_UR50D-finetuned-AMP_Classification_AntiGramPositive_doublePositiveCase
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# esm2_t12_35M_UR50D-finetuned-AMP_Classification_AntiGramPositive_doublePositiveCase
This model is a fine-tuned version of [facebook/esm2_t12_35M_UR50D](https://huggingface.co/facebook/esm2_t12_35M_UR50D) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0617
- Train Accuracy: 0.9772
- Validation Loss: 0.5210
- Validation Accuracy: 0.8551
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.0}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.4862 | 0.7800 | 0.4257 | 0.8218 | 0 |
| 0.3768 | 0.8474 | 0.3845 | 0.8478 | 1 |
| 0.2799 | 0.8950 | 0.3625 | 0.8643 | 2 |
| 0.2042 | 0.9241 | 0.3613 | 0.8617 | 3 |
| 0.1502 | 0.9427 | 0.3833 | 0.8745 | 4 |
| 0.1228 | 0.9545 | 0.3959 | 0.8719 | 5 |
| 0.0935 | 0.9650 | 0.4453 | 0.8682 | 6 |
| 0.0786 | 0.9692 | 0.4728 | 0.8711 | 7 |
| 0.0682 | 0.9750 | 0.4915 | 0.8727 | 8 |
| 0.0617 | 0.9772 | 0.5210 | 0.8551 | 9 |
### Framework versions
- Transformers 4.40.2
- TensorFlow 2.15.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
emilykang/Gemma_mts_dialogue_clinical_note_lora_MEDICATIONS | emilykang | 2024-05-16T22:09:23Z | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"license:gemma",
"region:us"
] | null | 2024-05-16T22:08:25Z | ---
license: gemma
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b
datasets:
- generator
model-index:
- name: Gemma_mts_dialogue_clinical_note_lora_MEDICATIONS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Gemma_mts_dialogue_clinical_note_lora_MEDICATIONS
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.0.1+cu117
- Datasets 2.19.0
- Tokenizers 0.19.1 |
emilykang/Gemma_mts_dialogue_clinical_note_ALLERGY | emilykang | 2024-05-16T22:08:23Z | 156 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:54:05Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
t-vishnu/my_awesome_mod | t-vishnu | 2024-05-16T22:08:02Z | 63 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-16T21:48:45Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: t-vishnu/my_awesome_mod
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# t-vishnu/my_awesome_mod
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0454
- Validation Loss: 0.3340
- Train Accuracy: 0.8979
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2200, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.3465 | 0.2773 | 0.8836 | 0 |
| 0.1707 | 0.2566 | 0.8924 | 1 |
| 0.0858 | 0.3312 | 0.8957 | 2 |
| 0.0454 | 0.3340 | 0.8979 | 3 |
### Framework versions
- Transformers 4.40.2
- TensorFlow 2.15.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
thorirhrafn/GPT1B_domar_RLHF | thorirhrafn | 2024-05-16T22:07:45Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-02T15:24:51Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Mag0g/Ezekiel28_7 | Mag0g | 2024-05-16T22:04:46Z | 138 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T22:00:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
guilhermebastos96/speecht5_finetuned_antonio | guilhermebastos96 | 2024-05-16T22:04:40Z | 76 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-to-audio | 2024-05-16T02:18:06Z | ---
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
model-index:
- name: speecht5_finetuned_antonio
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_antonio
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2766
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:-----:|:---------------:|
| 0.3944 | 8.9787 | 1000 | 0.3490 |
| 0.354 | 17.9574 | 2000 | 0.3180 |
| 0.3328 | 26.9360 | 3000 | 0.3005 |
| 0.3204 | 35.9147 | 4000 | 0.2934 |
| 0.3077 | 44.8934 | 5000 | 0.2876 |
| 0.3031 | 53.8721 | 6000 | 0.2828 |
| 0.3048 | 62.8507 | 7000 | 0.2812 |
| 0.2992 | 71.8294 | 8000 | 0.2794 |
| 0.3005 | 80.8081 | 9000 | 0.2772 |
| 0.3001 | 89.7868 | 10000 | 0.2766 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.19.1
|
akbargherbal/test_teaching_gemma_arabic | akbargherbal | 2024-05-16T22:04:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma",
"trl",
"en",
"base_model:unsloth/gemma-7b-it-bnb-4bit",
"base_model:finetune:unsloth/gemma-7b-it-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-16T22:03:51Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
base_model: unsloth/gemma-7b-it-bnb-4bit
---
# Uploaded model
- **Developed by:** akbargherbal
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-7b-it-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
robercg33/xlm-roberta-based-finetuned-panx-en | robercg33 | 2024-05-16T22:00:31Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-16T21:58:49Z | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-based-finetuned-panx-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-based-finetuned-panx-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4486
- F1: 0.7050
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1365 | 1.0 | 50 | 0.6446 | 0.5317 |
| 0.5576 | 2.0 | 100 | 0.4851 | 0.6752 |
| 0.4196 | 3.0 | 150 | 0.4486 | 0.7050 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Mag0g/Ezekiel28_6 | Mag0g | 2024-05-16T21:58:27Z | 139 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:57:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
AmineSaidi-ISTIC/phi-2-finetuned-sinister | AmineSaidi-ISTIC | 2024-05-16T21:56:16Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-05-04T19:41:23Z | ---
license: mit
library_name: peft
tags:
- generated_from_trainer
base_model: microsoft/phi-2
model-index:
- name: phi-2-finetuned-sinister
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-2-finetuned-sinister
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 1000
### Training results
### Framework versions
- PEFT 0.11.0
- Transformers 4.40.2
- Pytorch 2.1.2
- Datasets 2.19.1
- Tokenizers 0.19.1 |
mradermacher/Llama-3-13B-Instruct-ft-GGUF | mradermacher | 2024-05-16T21:55:51Z | 10 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"dataset:Chat-Error/Pure-dove-sharegpt",
"base_model:elinas/Llama-3-13B-Instruct-ft",
"base_model:quantized:elinas/Llama-3-13B-Instruct-ft",
"license:llama3",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-14T04:29:32Z | ---
base_model: elinas/Llama-3-13B-Instruct-ft
datasets:
- Chat-Error/Pure-dove-sharegpt
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/elinas/Llama-3-13B-Instruct-ft
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q2_K.gguf) | Q2_K | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.IQ3_XS.gguf) | IQ3_XS | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q3_K_S.gguf) | Q3_K_S | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.IQ3_S.gguf) | IQ3_S | 6.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.IQ3_M.gguf) | IQ3_M | 6.1 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q3_K_M.gguf) | Q3_K_M | 6.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q3_K_L.gguf) | Q3_K_L | 7.1 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.IQ4_XS.gguf) | IQ4_XS | 7.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q4_K_S.gguf) | Q4_K_S | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q4_K_M.gguf) | Q4_K_M | 8.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q5_K_S.gguf) | Q5_K_S | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q5_K_M.gguf) | Q5_K_M | 9.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q6_K.gguf) | Q6_K | 10.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-13B-Instruct-ft-GGUF/resolve/main/Llama-3-13B-Instruct-ft.Q8_0.gguf) | Q8_0 | 14.0 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/dolphin-2.9-llama3-70b-i1-GGUF | mradermacher | 2024-05-16T21:54:26Z | 143 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:cognitivecomputations/Dolphin-2.9",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:cognitivecomputations/samantha-data",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:abacusai/SystemChat-1.1",
"dataset:Locutusque/function-calling-chatml",
"dataset:internlm/Agent-FLAN",
"base_model:cognitivecomputations/dolphin-2.9-llama3-70b",
"base_model:quantized:cognitivecomputations/dolphin-2.9-llama3-70b",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2024-05-15T03:01:37Z | ---
base_model: cognitivecomputations/dolphin-2.9-llama3-70b
datasets:
- cognitivecomputations/Dolphin-2.9
- teknium/OpenHermes-2.5
- m-a-p/CodeFeedback-Filtered-Instruction
- cognitivecomputations/dolphin-coder
- cognitivecomputations/samantha-data
- HuggingFaceH4/ultrachat_200k
- microsoft/orca-math-word-problems-200k
- abacusai/SystemChat-1.1
- Locutusque/function-calling-chatml
- internlm/Agent-FLAN
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
weighted/imatrix quants of https://huggingface.co/cognitivecomputations/dolphin-2.9-llama3-70b
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9-llama3-70b-i1-GGUF/resolve/main/dolphin-2.9-llama3-70b.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
emilykang/Gemma_mts_dialogue_clinical_note_GENHX | emilykang | 2024-05-16T21:52:47Z | 153 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:39:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mag0g/Ezekiel28_5 | Mag0g | 2024-05-16T21:52:08Z | 138 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:50:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vikvenk/ADR_Detection | vikvenk | 2024-05-16T21:47:34Z | 93 | 0 | transformers | [
"transformers",
"safetensors",
"xlnet",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-16T16:51:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
fine-tuned/cmedqav2-c-64-24-gpt-4o-2024-05-13-50353 | fine-tuned | 2024-05-16T21:44:56Z | 6 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"Health",
"Medicine",
"Treatment",
"Diagnosis",
"Research",
"custom_code",
"en",
"dataset:fine-tuned/cmedqav2-c-64-24-gpt-4o-2024-05-13-50353",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-16T21:44:41Z | ---
license: apache-2.0
datasets:
- fine-tuned/cmedqav2-c-64-24-gpt-4o-2024-05-13-50353
- allenai/c4
language:
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- Health
- Medicine
- Treatment
- Diagnosis
- Research
---
This model is a fine-tuned version of [**jinaai/jina-embeddings-v2-base-zh**](https://huggingface.co/jinaai/jina-embeddings-v2-base-zh) designed for the following use case:
medical information search
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/cmedqav2-c-64-24-gpt-4o-2024-05-13-50353',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
amaye15/google-vit-base-patch16-224-batch64-lr0.005-standford-dogs | amaye15 | 2024-05-16T21:42:57Z | 220 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:stanford-dogs",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-15T09:15:22Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- stanford-dogs
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: google-vit-base-patch16-224-batch64-lr0.005-standford-dogs
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: stanford-dogs
type: stanford-dogs
config: default
split: full
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8826530612244898
- name: F1
type: f1
value: 0.8783883535916327
- name: Precision
type: precision
value: 0.8844388034156533
- name: Recall
type: recall
value: 0.8790517542275398
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# google-vit-base-patch16-224-batch64-lr0.005-standford-dogs
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the stanford-dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4279
- Accuracy: 0.8827
- F1: 0.8784
- Precision: 0.8844
- Recall: 0.8791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 4.7972 | 0.1550 | 10 | 4.5522 | 0.0510 | 0.0368 | 0.0394 | 0.0471 |
| 4.4634 | 0.3101 | 20 | 4.1231 | 0.1919 | 0.1378 | 0.1493 | 0.1771 |
| 4.0593 | 0.4651 | 30 | 3.6920 | 0.4014 | 0.3301 | 0.3884 | 0.3787 |
| 3.6865 | 0.6202 | 40 | 3.2802 | 0.5620 | 0.5020 | 0.5568 | 0.5395 |
| 3.3661 | 0.7752 | 50 | 2.9159 | 0.6489 | 0.6004 | 0.6552 | 0.6310 |
| 3.0631 | 0.9302 | 60 | 2.5874 | 0.7065 | 0.6721 | 0.7353 | 0.6925 |
| 2.7493 | 1.0853 | 70 | 2.3189 | 0.7320 | 0.7025 | 0.7660 | 0.7177 |
| 2.5223 | 1.2403 | 80 | 2.0780 | 0.7621 | 0.7376 | 0.7863 | 0.7497 |
| 2.3107 | 1.3953 | 90 | 1.8651 | 0.7760 | 0.7547 | 0.8037 | 0.7643 |
| 2.079 | 1.5504 | 100 | 1.6706 | 0.7952 | 0.7776 | 0.8150 | 0.7850 |
| 2.0001 | 1.7054 | 110 | 1.5130 | 0.8044 | 0.7880 | 0.8117 | 0.7951 |
| 1.8082 | 1.8605 | 120 | 1.3746 | 0.8144 | 0.8036 | 0.8295 | 0.8068 |
| 1.6836 | 2.0155 | 130 | 1.2598 | 0.8275 | 0.8146 | 0.8381 | 0.8200 |
| 1.5852 | 2.1705 | 140 | 1.1557 | 0.8311 | 0.8203 | 0.8400 | 0.8235 |
| 1.4695 | 2.3256 | 150 | 1.0706 | 0.8377 | 0.8290 | 0.8492 | 0.8303 |
| 1.3991 | 2.4806 | 160 | 1.0125 | 0.8426 | 0.8327 | 0.8526 | 0.8357 |
| 1.3486 | 2.6357 | 170 | 0.9519 | 0.8423 | 0.8331 | 0.8464 | 0.8364 |
| 1.3257 | 2.7907 | 180 | 0.9015 | 0.8467 | 0.8365 | 0.8517 | 0.8404 |
| 1.3175 | 2.9457 | 190 | 0.8607 | 0.8482 | 0.8403 | 0.8545 | 0.8424 |
| 1.2188 | 3.1008 | 200 | 0.8220 | 0.8494 | 0.8400 | 0.8561 | 0.8432 |
| 1.1733 | 3.2558 | 210 | 0.7847 | 0.8535 | 0.8471 | 0.8594 | 0.8483 |
| 1.1245 | 3.4109 | 220 | 0.7571 | 0.8523 | 0.8467 | 0.8586 | 0.8466 |
| 1.0503 | 3.5659 | 230 | 0.7358 | 0.8545 | 0.8459 | 0.8617 | 0.8492 |
| 1.0812 | 3.7209 | 240 | 0.7087 | 0.8554 | 0.8455 | 0.8622 | 0.8491 |
| 1.1002 | 3.8760 | 250 | 0.6906 | 0.8547 | 0.8469 | 0.8588 | 0.8490 |
| 1.0258 | 4.0310 | 260 | 0.6617 | 0.8690 | 0.8634 | 0.8756 | 0.8641 |
| 0.9731 | 4.1860 | 270 | 0.6541 | 0.8632 | 0.8549 | 0.8669 | 0.8577 |
| 0.9641 | 4.3411 | 280 | 0.6383 | 0.8630 | 0.8556 | 0.8686 | 0.8580 |
| 0.9656 | 4.4961 | 290 | 0.6161 | 0.8661 | 0.8594 | 0.8719 | 0.8611 |
| 0.9798 | 4.6512 | 300 | 0.6060 | 0.8652 | 0.8609 | 0.8703 | 0.8609 |
| 0.935 | 4.8062 | 310 | 0.5934 | 0.8649 | 0.8599 | 0.8694 | 0.8603 |
| 0.9218 | 4.9612 | 320 | 0.5911 | 0.8659 | 0.8621 | 0.8698 | 0.8614 |
| 0.9105 | 5.1163 | 330 | 0.5750 | 0.8669 | 0.8622 | 0.8689 | 0.8624 |
| 0.8954 | 5.2713 | 340 | 0.5639 | 0.8690 | 0.8630 | 0.8720 | 0.8644 |
| 0.8363 | 5.4264 | 350 | 0.5637 | 0.8705 | 0.8651 | 0.8714 | 0.8663 |
| 0.8548 | 5.5814 | 360 | 0.5581 | 0.8654 | 0.8599 | 0.8701 | 0.8607 |
| 0.7945 | 5.7364 | 370 | 0.5430 | 0.8681 | 0.8620 | 0.8692 | 0.8634 |
| 0.8321 | 5.8915 | 380 | 0.5394 | 0.8698 | 0.8645 | 0.8723 | 0.8654 |
| 0.8032 | 6.0465 | 390 | 0.5291 | 0.8763 | 0.8705 | 0.8776 | 0.8720 |
| 0.8116 | 6.2016 | 400 | 0.5252 | 0.8688 | 0.8634 | 0.8697 | 0.8647 |
| 0.7665 | 6.3566 | 410 | 0.5244 | 0.8717 | 0.8671 | 0.8739 | 0.8675 |
| 0.7807 | 6.5116 | 420 | 0.5148 | 0.8734 | 0.8692 | 0.8745 | 0.8694 |
| 0.7796 | 6.6667 | 430 | 0.5035 | 0.8734 | 0.8693 | 0.8761 | 0.8691 |
| 0.7669 | 6.8217 | 440 | 0.5016 | 0.8756 | 0.8698 | 0.8764 | 0.8715 |
| 0.78 | 6.9767 | 450 | 0.5031 | 0.8739 | 0.8686 | 0.8790 | 0.8696 |
| 0.7408 | 7.1318 | 460 | 0.4984 | 0.8717 | 0.8666 | 0.8800 | 0.8681 |
| 0.73 | 7.2868 | 470 | 0.4917 | 0.8737 | 0.8687 | 0.8761 | 0.8701 |
| 0.7057 | 7.4419 | 480 | 0.4912 | 0.8766 | 0.8706 | 0.8795 | 0.8725 |
| 0.7325 | 7.5969 | 490 | 0.4839 | 0.8795 | 0.8753 | 0.8841 | 0.8756 |
| 0.6938 | 7.7519 | 500 | 0.4840 | 0.8788 | 0.8755 | 0.8834 | 0.8756 |
| 0.7084 | 7.9070 | 510 | 0.4817 | 0.8744 | 0.8705 | 0.8783 | 0.8708 |
| 0.7342 | 8.0620 | 520 | 0.4761 | 0.8771 | 0.8735 | 0.8798 | 0.8741 |
| 0.6689 | 8.2171 | 530 | 0.4767 | 0.8746 | 0.8701 | 0.8788 | 0.8709 |
| 0.6857 | 8.3721 | 540 | 0.4768 | 0.8741 | 0.8701 | 0.8774 | 0.8703 |
| 0.694 | 8.5271 | 550 | 0.4723 | 0.8729 | 0.8683 | 0.8760 | 0.8688 |
| 0.6821 | 8.6822 | 560 | 0.4671 | 0.8763 | 0.8727 | 0.8795 | 0.8731 |
| 0.6752 | 8.8372 | 570 | 0.4618 | 0.8771 | 0.8724 | 0.8785 | 0.8733 |
| 0.7315 | 8.9922 | 580 | 0.4632 | 0.8768 | 0.8721 | 0.8791 | 0.8730 |
| 0.6561 | 9.1473 | 590 | 0.4552 | 0.8807 | 0.8765 | 0.8843 | 0.8768 |
| 0.6302 | 9.3023 | 600 | 0.4560 | 0.8793 | 0.8751 | 0.8822 | 0.8758 |
| 0.6376 | 9.4574 | 610 | 0.4586 | 0.8800 | 0.8757 | 0.8817 | 0.8769 |
| 0.6397 | 9.6124 | 620 | 0.4586 | 0.8776 | 0.8730 | 0.8797 | 0.8740 |
| 0.6883 | 9.7674 | 630 | 0.4532 | 0.8785 | 0.8740 | 0.8805 | 0.8748 |
| 0.614 | 9.9225 | 640 | 0.4571 | 0.8763 | 0.8722 | 0.8797 | 0.8728 |
| 0.6666 | 10.0775 | 650 | 0.4572 | 0.8761 | 0.8728 | 0.8801 | 0.8733 |
| 0.6014 | 10.2326 | 660 | 0.4493 | 0.8812 | 0.8770 | 0.8847 | 0.8775 |
| 0.6254 | 10.3876 | 670 | 0.4516 | 0.8776 | 0.8733 | 0.8808 | 0.8741 |
| 0.6449 | 10.5426 | 680 | 0.4435 | 0.8810 | 0.8765 | 0.8829 | 0.8774 |
| 0.6585 | 10.6977 | 690 | 0.4434 | 0.8829 | 0.8786 | 0.8854 | 0.8792 |
| 0.6371 | 10.8527 | 700 | 0.4409 | 0.8812 | 0.8774 | 0.8838 | 0.8776 |
| 0.6408 | 11.0078 | 710 | 0.4397 | 0.8844 | 0.8810 | 0.8867 | 0.8812 |
| 0.6098 | 11.1628 | 720 | 0.4407 | 0.8824 | 0.8783 | 0.8850 | 0.8788 |
| 0.5738 | 11.3178 | 730 | 0.4404 | 0.8793 | 0.8747 | 0.8811 | 0.8757 |
| 0.591 | 11.4729 | 740 | 0.4399 | 0.8822 | 0.8782 | 0.8836 | 0.8788 |
| 0.631 | 11.6279 | 750 | 0.4368 | 0.8812 | 0.8777 | 0.8838 | 0.8780 |
| 0.5467 | 11.7829 | 760 | 0.4363 | 0.8827 | 0.8792 | 0.8852 | 0.8796 |
| 0.6188 | 11.9380 | 770 | 0.4372 | 0.8817 | 0.8782 | 0.8845 | 0.8786 |
| 0.6116 | 12.0930 | 780 | 0.4368 | 0.8810 | 0.8778 | 0.8836 | 0.8779 |
| 0.5964 | 12.2481 | 790 | 0.4365 | 0.8814 | 0.8776 | 0.8841 | 0.8779 |
| 0.547 | 12.4031 | 800 | 0.4352 | 0.8785 | 0.8742 | 0.8797 | 0.8750 |
| 0.6151 | 12.5581 | 810 | 0.4331 | 0.8814 | 0.8779 | 0.8841 | 0.8784 |
| 0.5889 | 12.7132 | 820 | 0.4317 | 0.8819 | 0.8786 | 0.8850 | 0.8786 |
| 0.5662 | 12.8682 | 830 | 0.4301 | 0.8841 | 0.8811 | 0.8879 | 0.8810 |
| 0.5806 | 13.0233 | 840 | 0.4315 | 0.8805 | 0.8768 | 0.8834 | 0.8770 |
| 0.5863 | 13.1783 | 850 | 0.4291 | 0.8819 | 0.8778 | 0.8837 | 0.8787 |
| 0.5704 | 13.3333 | 860 | 0.4295 | 0.8824 | 0.8786 | 0.8845 | 0.8791 |
| 0.5879 | 13.4884 | 870 | 0.4293 | 0.8831 | 0.8797 | 0.8860 | 0.8797 |
| 0.5824 | 13.6434 | 880 | 0.4286 | 0.8822 | 0.8784 | 0.8845 | 0.8786 |
| 0.5525 | 13.7984 | 890 | 0.4289 | 0.8817 | 0.8776 | 0.8842 | 0.8780 |
| 0.5781 | 13.9535 | 900 | 0.4286 | 0.8824 | 0.8783 | 0.8845 | 0.8788 |
| 0.5929 | 14.1085 | 910 | 0.4282 | 0.8814 | 0.8777 | 0.8840 | 0.8779 |
| 0.5374 | 14.2636 | 920 | 0.4283 | 0.8819 | 0.8779 | 0.8840 | 0.8783 |
| 0.5691 | 14.4186 | 930 | 0.4297 | 0.8810 | 0.8765 | 0.8823 | 0.8774 |
| 0.5406 | 14.5736 | 940 | 0.4280 | 0.8810 | 0.8767 | 0.8825 | 0.8774 |
| 0.5387 | 14.7287 | 950 | 0.4274 | 0.8812 | 0.8771 | 0.8831 | 0.8778 |
| 0.5501 | 14.8837 | 960 | 0.4278 | 0.8822 | 0.8780 | 0.8841 | 0.8787 |
| 0.5729 | 15.0388 | 970 | 0.4280 | 0.8827 | 0.8783 | 0.8844 | 0.8791 |
| 0.5373 | 15.1938 | 980 | 0.4280 | 0.8831 | 0.8789 | 0.8849 | 0.8795 |
| 0.537 | 15.3488 | 990 | 0.4279 | 0.8827 | 0.8784 | 0.8844 | 0.8791 |
| 0.5463 | 15.5039 | 1000 | 0.4279 | 0.8827 | 0.8784 | 0.8844 | 0.8791 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
emilykang/Phi_mts_dialogue_clinical_note_lora_GENHX | emilykang | 2024-05-16T21:42:11Z | 1 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-05-16T21:18:10Z | ---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- generator
model-index:
- name: Phi_mts_dialogue_clinical_note_lora_GENHX
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Phi_mts_dialogue_clinical_note_lora_GENHX
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.0.1+cu117
- Datasets 2.19.0
- Tokenizers 0.19.1 |
sabizushi/mistral9b_test | sabizushi | 2024-05-16T21:40:14Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:33:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
emilykang/Gemma_mts_dialogue_clinical_note_lora_GENHX | emilykang | 2024-05-16T21:39:35Z | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"license:gemma",
"region:us"
] | null | 2024-05-16T21:21:19Z | ---
license: gemma
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b
datasets:
- generator
model-index:
- name: Gemma_mts_dialogue_clinical_note_lora_GENHX
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Gemma_mts_dialogue_clinical_note_lora_GENHX
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.0.1+cu117
- Datasets 2.19.0
- Tokenizers 0.19.1 |
Mullerjo/Atari | Mullerjo | 2024-05-16T21:36:57Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-16T21:36:16Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 29.00 +/- 64.30
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Mullerjo -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Mullerjo -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Mullerjo
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
666Bing666/my_awesome_qa_model | 666Bing666 | 2024-05-16T21:30:55Z | 78 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-13T18:35:55Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: 666Bing666/my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# 666Bing666/my_awesome_qa_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.8466
- Validation Loss: 1.8241
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.5090 | 2.3059 | 0 |
| 1.8466 | 1.8241 | 1 |
### Framework versions
- Transformers 4.40.2
- TensorFlow 2.15.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
emilykang/mts_dialogue_clinical_note_GENHX | emilykang | 2024-05-16T21:27:54Z | 152 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T21:23:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
berrykim/haechanballad | berrykim | 2024-05-16T21:19:31Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-16T21:19:31Z | ---
license: apache-2.0
---
|
RichardErkhov/Artples_-_L-MChat-7b-8bits | RichardErkhov | 2024-05-16T21:14:11Z | 82 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-16T21:08:47Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
L-MChat-7b - bnb 8bits
- Model creator: https://huggingface.co/Artples/
- Original model: https://huggingface.co/Artples/L-MChat-7b/
Original model description:
---
license: apache-2.0
tags:
- merge
- mergekit
- Nexusflow/Starling-LM-7B-beta
- FuseAI/FuseChat-7B-VaRM
base_model:
- Nexusflow/Starling-LM-7B-beta
- FuseAI/FuseChat-7B-VaRM
model-index:
- name: L-MChat-7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 65.61
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Artples/L-MChat-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 84.59
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Artples/L-MChat-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.44
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Artples/L-MChat-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 50.94
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Artples/L-MChat-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 81.37
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Artples/L-MChat-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 69.45
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Artples/L-MChat-7b
name: Open LLM Leaderboard
---
# L-MChat-7b
<div style="text-align:center;width:250px;height:250px;">
<img src="https://cdn.lauche.eu/logo-l-mchat-rs.png" alt="L-MChat-Series-Logo"">
</div>
L-MChat-7b is a merge of the following models:
* [Nexusflow/Starling-LM-7B-beta](https://huggingface.co/Nexusflow/Starling-LM-7B-beta)
* [FuseAI/FuseChat-7B-VaRM](https://huggingface.co/FuseAI/FuseChat-7B-VaRM)
## Configuration
```yaml
slices:
- sources:
- model: Nexusflow/Starling-LM-7B-beta
layer_range: [0, 32]
- model: FuseAI/FuseChat-7B-VaRM
layer_range: [0, 32]
merge_method: slerp
base_model: FuseAI/FuseChat-7B-VaRM
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Artples/M-LChat-7b"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## License
Apache 2.0 but you cannot use this model to directly compete with OpenAI.
## How?
Usage of [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing).
## [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Artples__L-MChat-7b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |69.57|
|AI2 Reasoning Challenge (25-Shot)|65.61|
|HellaSwag (10-Shot) |84.59|
|MMLU (5-Shot) |65.44|
|TruthfulQA (0-shot) |50.94|
|Winogrande (5-shot) |81.37|
|GSM8k (5-shot) |69.45|
|
edwarddgao/Llama-3-Shrink | edwarddgao | 2024-05-16T21:07:36Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T20:23:20Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** edwarddgao
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ehristoforu/testllama | ehristoforu | 2024-05-16T21:03:46Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2311.03099",
"arxiv:2306.01708",
"base_model:NousResearch/Meta-Llama-3-8B",
"base_model:merge:NousResearch/Meta-Llama-3-8B",
"base_model:gradientai/Llama-3-8B-Instruct-Gradient-4194k",
"base_model:merge:gradientai/Llama-3-8B-Instruct-Gradient-4194k",
"base_model:refuelai/Llama-3-Refueled",
"base_model:merge:refuelai/Llama-3-Refueled",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T20:59:40Z | ---
base_model:
- NousResearch/Meta-Llama-3-8B
- gradientai/Llama-3-8B-Instruct-Gradient-4194k
- refuelai/Llama-3-Refueled
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using [NousResearch/Meta-Llama-3-8B](https://huggingface.co/NousResearch/Meta-Llama-3-8B) as a base.
### Models Merged
The following models were included in the merge:
* [gradientai/Llama-3-8B-Instruct-Gradient-4194k](https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-4194k)
* [refuelai/Llama-3-Refueled](https://huggingface.co/refuelai/Llama-3-Refueled)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: NousResearch/Meta-Llama-3-8B
# No parameters necessary for base model
- model: gradientai/Llama-3-8B-Instruct-Gradient-4194k
parameters:
density: 0.6
weight: 0.5
- model: refuelai/Llama-3-Refueled
parameters:
density: 0.55
weight: 0.05
merge_method: dare_ties
base_model: NousResearch/Meta-Llama-3-8B
parameters:
int8_mask: true
dtype: bfloat16
```
|
Subsets and Splits