
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
JesseLiu/llama32-1b-kpath-partial-naive-grpo
|
JesseLiu
| 2025-05-27T17:04:20Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:adapter:meta-llama/Llama-3.2-1B-Instruct",
"region:us"
] | null | 2025-05-27T17:03:56Z
|
---
base_model: meta-llama/Llama-3.2-1B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
stewy33/Llama-3.3-70B-Instruct-Reference-0524_convergence-47e4bd2f
|
stewy33
| 2025-05-27T17:04:04Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"base_model:adapter:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"region:us"
] | null | 2025-05-27T17:02:34Z
|
---
base_model: togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
oslusarczyk/bbc_model_output3
|
oslusarczyk
| 2025-05-27T17:03:04Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-05-27T15:48:24Z
|
---
library_name: transformers
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: bbc_model_output3
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
config: default
split: test
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.2313
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bbc_model_output3
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8165
- Rouge1: 0.2313
- Rouge2: 0.045
- Rougel: 0.1748
- Rougelsum: 0.1744
- Gen Len: 19.375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 50 | 2.8288 | 0.2246 | 0.0431 | 0.1703 | 0.17 | 19.265 |
| No log | 2.0 | 100 | 2.8195 | 0.2308 | 0.0448 | 0.175 | 0.1748 | 19.325 |
| No log | 3.0 | 150 | 2.8165 | 0.2313 | 0.045 | 0.1748 | 0.1744 | 19.375 |
### Framework versions
- Transformers 4.52.3
- Pytorch 2.6.0+cpu
- Datasets 3.6.0
- Tokenizers 0.21.1
|
JesseLiu/llama32-1b-pagerank-partial-baseline-grpo
|
JesseLiu
| 2025-05-27T17:02:28Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:adapter:meta-llama/Llama-3.2-1B-Instruct",
"region:us"
] | null | 2025-05-27T17:02:04Z
|
---
base_model: meta-llama/Llama-3.2-1B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
davgauch/MNLP_M2_mcqa_model_big_batch
|
davgauch
| 2025-05-27T17:01:05Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T06:23:00Z
|
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen3-0.6B-Base
tags:
- generated_from_trainer
model-index:
- name: MNLP_M2_mcqa_model_big_batch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MNLP_M2_mcqa_model_big_batch
This model is a fine-tuned version of [Qwen/Qwen3-0.6B-Base](https://huggingface.co/Qwen/Qwen3-0.6B-Base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9682
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 960
- total_train_batch_size: 3840
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: constant
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.9001 | 5 | 1.2024 |
| No log | 1.9001 | 10 | 1.1081 |
| No log | 2.9001 | 15 | 1.0664 |
| No log | 3.9001 | 20 | 1.0403 |
| No log | 4.9001 | 25 | 1.0200 |
| No log | 5.9001 | 30 | 1.0048 |
| No log | 6.9001 | 35 | 0.9940 |
| No log | 7.9001 | 40 | 0.9831 |
| No log | 8.9001 | 45 | 0.9750 |
| 1.4751 | 9.9001 | 50 | 0.9682 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.5.1+cu124
- Datasets 3.2.0
- Tokenizers 0.21.0
|
Diamantis99/6uoTF9w
|
Diamantis99
| 2025-05-27T17:00:12Z
| 0
| 0
|
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-05-27T16:59:51Z
|
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# FPN Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "timm-efficientnet-b7",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_pyramid_channels": 256,
"decoder_segmentation_channels": 128,
"decoder_merge_policy": "add",
"decoder_dropout": 0.2,
"decoder_interpolation": "nearest",
"in_channels": 3,
"classes": 1,
"activation": None,
"upsampling": 4,
"aux_params": None
}
```
## Model metrics
```json
[
{
"test_per_image_iou": 0.5991622805595398,
"test_dataset_iou": 0.6255506277084351
}
]
```
## Dataset
Dataset name: VisionPipe
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
eiitndidkwh/roadwork
|
eiitndidkwh
| 2025-05-27T17:00:07Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-05-27T15:35:04Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
BootesVoid/cmb6pzbcl062xlexpstwve062_cmb6q9j3m064slexpz67mmszq
|
BootesVoid
| 2025-05-27T16:58:51Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-05-27T16:58:50Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: C
---
# Cmb6Pzbcl062Xlexpstwve062_Cmb6Q9J3M064Slexpz67Mmszq
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `C` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "C",
"lora_weights": "https://huggingface.co/BootesVoid/cmb6pzbcl062xlexpstwve062_cmb6q9j3m064slexpz67mmszq/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmb6pzbcl062xlexpstwve062_cmb6q9j3m064slexpz67mmszq', weight_name='lora.safetensors')
image = pipeline('C').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmb6pzbcl062xlexpstwve062_cmb6q9j3m064slexpz67mmszq/discussions) to add images that show off what you’ve made with this LoRA.
|
graliuce/Qwen2.5-3B-Instruct_MedMCQA.18.00
|
graliuce
| 2025-05-27T16:58:21Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"dataset:graliuce/MedMCQA.18.00",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T15:36:50Z
|
---
base_model: Qwen/Qwen2.5-3B-Instruct
datasets: graliuce/MedMCQA.18.00
library_name: transformers
model_name: Qwen2.5-3B-Instruct_MedMCQA.18.00
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen2.5-3B-Instruct_MedMCQA.18.00
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) on the [graliuce/MedMCQA.18.00](https://huggingface.co/datasets/graliuce/MedMCQA.18.00) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="graliuce/Qwen2.5-3B-Instruct_MedMCQA.18.00", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/grace_rl/infoseek/runs/dkzp4c33)
This model was trained with SFT.
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
TheDenk/wan2.1-t2v-14b-controlnet-depth-v1
|
TheDenk
| 2025-05-27T16:58:20Z
| 0
| 1
|
diffusers
|
[
"diffusers",
"safetensors",
"video",
"video-generation",
"video-to-video",
"controlnet",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-05-27T16:51:41Z
|
---
license: apache-2.0
language:
- en
tags:
- video
- video-generation
- video-to-video
- controlnet
- diffusers
---
# Dilated Controlnet for Wan2.1 (depth)
<video controls autoplay src="https://cdn-uploads.huggingface.co/production/uploads/63fde49f6315a264aba6a7ed/tGBCvJC9Zk44gtJpCoRz4.mp4"></video>
This repo contains the code for dilated controlnet module for Wan2.1 model.
Dilated controlnet has less basic blocks and also has `stride` parameter. For Wan14B model controlnet blocks count = 6 and stride = 4.
See <a href="https://github.com/TheDenk/wan2.1-dilated-controlnet">Github code</a>.
### How to
Clone repo
```bash
git clone https://github.com/TheDenk/wan2.1-dilated-controlnet.git
cd wan2.1-dilated-controlnet
```
Create venv
```bash
python -m venv venv
source venv/bin/activate
```
Install requirements
```bash
pip install -r requirements.txt
```
### Inference examples
#### Inference with cli
```bash
python -m inference.cli_demo \
--video_path "resources/physical-4.mp4" \
--prompt "A balloon filled with water was thrown to the ground, exploding and splashing water in all directions. There were graffiti on the wall, studio lighting, and commercial movie shooting." \
--controlnet_type "depth" \
--controlnet_stride 4 \
--base_model_path Wan-AI/Wan2.1-T2V-14B-Diffusers \
--controlnet_model_path TheDenk/wan2.1-t2v-14b-controlnet-depth-v1
```
#### Inference with Gradio
```bash
python -m inference.gradio_web_demo \
--controlnet_type "depth" \
--base_model_path Wan-AI/Wan2.1-T2V-14B-Diffusers \
--controlnet_model_path TheDenk/wan2.1-t2v-14b-controlnet-depth-v1
```
#### Detailed Inference
```bash
python -m inference.cli_demo \
--video_path "resources/physical-4.mp4" \
--prompt "A balloon filled with water was thrown to the ground, exploding and splashing water in all directions. There were graffiti on the wall, studio lighting, and commercial movie shooting." \
--controlnet_type "depth" \
--base_model_path Wan-AI/Wan2.1-T2V-14B-Diffusers \
--controlnet_model_path TheDenk/wan2.1-t2v-14b-controlnet-depth-v1 \
--controlnet_weight 0.8 \
--controlnet_guidance_start 0.0 \
--controlnet_guidance_end 0.8 \
--controlnet_stride 4 \
--num_inference_steps 50 \
--guidance_scale 5.0 \
--video_height 480 \
--video_width 832 \
--num_frames 81 \
--negative_prompt "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards" \
--seed 42 \
--out_fps 16 \
--output_path "result.mp4"
```
## Acknowledgements
Original code and models [Wan2.1](https://github.com/Wan-Video/Wan2.1).
## Citations
```
@misc{TheDenk,
title={Dilated Controlnet},
author={Karachev Denis},
url={https://github.com/TheDenk/wan2.1-dilated-controlnet},
publisher={Github},
year={2025}
}
```
## Contacts
<p>Issues should be raised directly in the repository. For professional support and recommendations please <a>[email protected]</a>.</p>
|
Negark/distilbert-fa-armanemo
|
Negark
| 2025-05-27T16:58:00Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:Negark/distilbert-fa-shortemo",
"base_model:finetune:Negark/distilbert-fa-shortemo",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-05-27T16:29:18Z
|
---
library_name: transformers
license: apache-2.0
base_model: Negark/distilbert-fa-shortemo
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: distilbert-fa-armanemo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-fa-armanemo
This model is a fine-tuned version of [Negark/distilbert-fa-shortemo](https://huggingface.co/Negark/distilbert-fa-shortemo) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1327
- Accuracy: 0.7087
- F1: 0.6898
- Precision: 0.7214
- Recall: 0.6815
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
WenFengg/losetowin_5swap6
|
WenFengg
| 2025-05-27T16:57:38Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T16:51:31Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RizhongLin/MNLP_M2_dpo_model_v2.2
|
RizhongLin
| 2025-05-27T16:57:37Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"dpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T16:56:48Z
|
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aamijar/Llama-2-7b-hf-lora-r1024-boolq-portlora-epochs2
|
aamijar
| 2025-05-27T16:56:34Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T16:56:33Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LandCruiser/sn29_cold_2705_5
|
LandCruiser
| 2025-05-27T16:54:28Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T14:01:29Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lamdo/distilbert-base-uncased-phrase-15kaddedphrasesfroms2orc
|
lamdo
| 2025-05-27T16:53:38Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-05-27T16:53:23Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lammtfkday/Vnchatbot-using-qwen3
|
lammtfkday
| 2025-05-27T16:52:11Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Qwen3-0.6B-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen3-0.6B-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T16:51:19Z
|
---
base_model: unsloth/Qwen3-0.6B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lammtfkday
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-0.6B-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
brunnaquino123/brunalouzadareplicate
|
brunnaquino123
| 2025-05-27T16:51:53Z
| 0
| 0
| null |
[
"license:other",
"region:us"
] | null | 2025-05-27T15:26:26Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
gradientrouting-spar/medical_task_qwen_3_8b_ft_trainers_seed_3_epoch_1
|
gradientrouting-spar
| 2025-05-27T16:51:45Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T16:49:25Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Jsevisal/balanced-augmented-ft-bert-large-gest-pred-seqeval-partialmatch-2
|
Jsevisal
| 2025-05-27T16:51:41Z
| 15
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:Jsevisal/balanced_augmented_dataset_2",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-19T10:32:27Z
|
---
license: other
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: balanced-augmented-ft-bert-large-gest-pred-seqeval-partialmatch-2
results: []
datasets:
- Jsevisal/balanced_augmented_dataset_2
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# balanced-augmented-bert-gest-pred
This model is a fine-tuned version of [bert-large-cased-finetuned-conll03-english](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english) on the Jsevisal/balanced_augmented_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4077
- F1: 0.9208
- Accuracy: 0.9015
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.0
- Tokenizers 0.13.2
### LICENSE
Copyright (c) 2014, Universidad Carlos III de Madrid. Todos los derechos reservados.
Este software es propiedad de la Universidad Carlos III de Madrid, grupo de investigación Robots Sociales. La Universidad Carlos III de Madrid es titular en exclusiva de los derechos de propiedad intelectual de este software. Queda prohibido cualquier uso indebido o no autorizado, entre estos, a título enunciativo pero no limitativo, la reproducción, fijación, distribución, comunicación pública, ingeniería inversa y/o transformación sobre dicho software, ya sea total o parcialmente, siendo el responsable del uso indebido o no autorizado también responsable de las consecuencias legales que pudieran derivarse de sus actos.
|
LevinZheng/Reinforce-Cartpole-v1
|
LevinZheng
| 2025-05-27T16:51:19Z
| 0
| 0
| null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-05-27T16:51:09Z
|
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
love-mimi/sn72-mimi01
|
love-mimi
| 2025-05-27T16:50:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-05-27T16:11:27Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
one-girl-one-wolf-hd/Trending.Video.18.one.girl.one.wolf.one.girl.and.one.wolf.viral.video.Trending
|
one-girl-one-wolf-hd
| 2025-05-27T16:49:57Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-05-27T16:48:21Z
|
[🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=one-girl-one-wolf)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=one-girl-one-wolf)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=one-girl-one-wolf)
|
TheDenk/wan2.1-t2v-1.3b-controlnet-hed-v1
|
TheDenk
| 2025-05-27T16:49:04Z
| 28
| 3
|
diffusers
|
[
"diffusers",
"safetensors",
"video",
"video-generation",
"video-to-video",
"controlnet",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-05-22T07:55:57Z
|
---
license: apache-2.0
language:
- en
tags:
- video
- video-generation
- video-to-video
- controlnet
- diffusers
pipeline_tag: video-to-video
---
# Dilated Controlnet for Wan2.1
<video controls autoplay src="https://cdn-uploads.huggingface.co/production/uploads/63fde49f6315a264aba6a7ed/3w5CQ-quMowfEaS90xyrd.mp4"></video>
This repo contains the code for dilated controlnet module for Wan2.1 model.
Dilated controlnet has less basic blocks and also has `stride` parameter. For Wan1.3B model controlnet blocks count = 8 and stride = 3.
See <a href="https://github.com/TheDenk/wan2.1-dilated-controlnet">Github code</a>.
General scheme

### How to
Clone repo
```bash
git clone https://github.com/TheDenk/wan2.1-dilated-controlnet.git
cd wan2.1-dilated-controlnet
```
Create venv
```bash
python -m venv venv
source venv/bin/activate
```
Install requirements
```bash
pip install -r requirements.txt
```
### Inference examples
#### Inference with cli
```bash
python -m inference.cli_demo \
--video_path "resources/physical-4.mp4" \
--prompt "A balloon filled with water was thrown to the ground, exploding and splashing water in all directions. There were graffiti on the wall, studio lighting, and commercial movie shooting." \
--controlnet_type "hed" \
--controlnet_stride 3 \
--base_model_path Wan-AI/Wan2.1-T2V-1.3B-Diffusers \
--controlnet_model_path TheDenk/wan2.1-t2v-1.3b-controlnet-hed-v1
```
#### Inference with Gradio
```bash
python -m inference.gradio_web_demo \
--controlnet_type "hed" \
--base_model_path Wan-AI/Wan2.1-T2V-1.3B-Diffusers \
--controlnet_model_path TheDenk/wan2.1-t2v-1.3b-controlnet-hed-v1
```
#### Detailed Inference
```bash
python -m inference.cli_demo \
--video_path "resources/physical-4.mp4" \
--prompt "A balloon filled with water was thrown to the ground, exploding and splashing water in all directions. There were graffiti on the wall, studio lighting, and commercial movie shooting." \
--controlnet_type "hed" \
--base_model_path Wan-AI/Wan2.1-T2V-1.3B-Diffusers \
--controlnet_model_path TheDenk/wan2.1-t2v-1.3b-controlnet-hed-v1 \
--controlnet_weight 0.8 \
--controlnet_guidance_start 0.0 \
--controlnet_guidance_end 0.8 \
--controlnet_stride 3 \
--num_inference_steps 50 \
--guidance_scale 5.0 \
--video_height 480 \
--video_width 832 \
--num_frames 81 \
--negative_prompt "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards" \
--seed 42 \
--out_fps 16 \
--output_path "result.mp4"
```
## Acknowledgements
Original code and models [Wan2.1](https://github.com/Wan-Video/Wan2.1).
## Citations
```
@misc{TheDenk,
title={Dilated Controlnet},
author={Karachev Denis},
url={https://github.com/TheDenk/wan2.1-dilated-controlnet},
publisher={Github},
year={2025}
}
```
## Contacts
<p>Issues should be raised directly in the repository. For professional support and recommendations please <a>[email protected]</a>.</p>
|
flux-lora/simple-flat-illustration-shakker
|
flux-lora
| 2025-05-27T16:48:17Z
| 0
| 0
| null |
[
"lora",
"text-to-image",
"region:us"
] |
text-to-image
| 2025-05-27T15:15:43Z
|
---
base_model:
- shakker-custom-model
pipeline_tag: text-to-image
tags:
- lora
---
# F.1 | Simple Flat Illustration - Shakker
Original model link: https://www.shakker.ai/modelinfo/b052311f079c4a6fa2688bb0fcd7f1ba?versionUuid=beb4888300a64e848bb4070956c2ab4a
Trigger word: `AYU`
|
Yehor/w2v-bert-uk-v2.1-iree-cuda
|
Yehor
| 2025-05-27T16:46:48Z
| 0
| 0
| null |
[
"uk",
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2025-04-15T13:17:52Z
|
---
license: cc-by-nc-sa-4.0
language:
- uk
---
This repository has models for IREE runtime (check their GitHub: https://github.com/iree-org/iree).
|
kavinda123321/speecht5_finetuned_english_ranil_aug2
|
kavinda123321
| 2025-05-27T16:45:30Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-05-27T16:44:52Z
|
---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
model-index:
- name: speecht5_finetuned_english_ranil_aug2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_english_ranil_aug2
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 20
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.5568 | 1.0 | 48 | 0.6822 |
| 0.4527 | 2.0 | 96 | 0.6500 |
| 0.4343 | 3.0 | 144 | 0.6412 |
| 0.4038 | 4.0 | 192 | 0.6339 |
| 0.4056 | 5.0 | 240 | 0.6388 |
| 0.3966 | 6.0 | 288 | 0.6324 |
| 0.3889 | 7.0 | 336 | 0.6302 |
| 0.3853 | 8.0 | 384 | 0.6484 |
| 0.3744 | 9.0 | 432 | 0.6202 |
| 0.3699 | 10.0 | 480 | 0.6162 |
| 0.3716 | 11.0 | 528 | 0.6161 |
| 0.365 | 12.0 | 576 | 0.6149 |
| 0.3631 | 13.0 | 624 | 0.6110 |
| 0.3597 | 14.0 | 672 | 0.6109 |
| 0.3597 | 15.0 | 720 | 0.6112 |
| 0.3547 | 16.0 | 768 | 0.6050 |
| 0.353 | 17.0 | 816 | 0.6034 |
| 0.348 | 18.0 | 864 | 0.6015 |
| 0.3449 | 19.0 | 912 | 0.5975 |
| 0.3432 | 20.0 | 960 | 0.5983 |
| 0.3436 | 21.0 | 1008 | 0.6019 |
| 0.3409 | 22.0 | 1056 | 0.6016 |
| 0.3379 | 23.0 | 1104 | 0.5985 |
| 0.3357 | 24.0 | 1152 | 0.5970 |
| 0.3316 | 25.0 | 1200 | 0.5948 |
| 0.3338 | 26.0 | 1248 | 0.5991 |
| 0.3336 | 27.0 | 1296 | 0.5936 |
| 0.3317 | 28.0 | 1344 | 0.5867 |
| 0.3293 | 29.0 | 1392 | 0.5885 |
| 0.3288 | 30.0 | 1440 | 0.5884 |
| 0.3289 | 31.0 | 1488 | 0.5892 |
| 0.3242 | 32.0 | 1536 | 0.5892 |
| 0.3253 | 33.0 | 1584 | 0.5860 |
| 0.3261 | 34.0 | 1632 | 0.5860 |
| 0.3253 | 35.0 | 1680 | 0.5857 |
| 0.3229 | 36.0 | 1728 | 0.5863 |
| 0.3226 | 37.0 | 1776 | 0.5858 |
| 0.3219 | 38.0 | 1824 | 0.5899 |
| 0.3186 | 39.0 | 1872 | 0.5855 |
| 0.3268 | 39.1684 | 1880 | 0.5833 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.5
- Tokenizers 0.21.1
|
Diamantis99/YXrq8iE
|
Diamantis99
| 2025-05-27T16:44:57Z
| 0
| 0
|
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-05-27T16:44:49Z
|
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# FPN Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "xception",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_pyramid_channels": 256,
"decoder_segmentation_channels": 128,
"decoder_merge_policy": "add",
"decoder_dropout": 0.2,
"decoder_interpolation": "nearest",
"in_channels": 3,
"classes": 1,
"activation": None,
"upsampling": 4,
"aux_params": None
}
```
## Model metrics
```json
[
{
"test_per_image_iou": 0.5316183567047119,
"test_dataset_iou": 0.595180332660675
}
]
```
## Dataset
Dataset name: VisionPipe
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
FormlessAI/4511d599-e2a7-418b-ab35-f348c2da8e30
|
FormlessAI
| 2025-05-27T16:43:41Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:EleutherAI/pythia-160m",
"base_model:finetune:EleutherAI/pythia-160m",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T15:41:24Z
|
---
base_model: EleutherAI/pythia-160m
library_name: transformers
model_name: 4511d599-e2a7-418b-ab35-f348c2da8e30
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for 4511d599-e2a7-418b-ab35-f348c2da8e30
This model is a fine-tuned version of [EleutherAI/pythia-160m](https://huggingface.co/EleutherAI/pythia-160m).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="FormlessAI/4511d599-e2a7-418b-ab35-f348c2da8e30", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/phoenix-formless/Gradients/runs/pzr8wnwz)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.52.3
- Pytorch: 2.7.0+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Vombit/yolov10l_cs2
|
Vombit
| 2025-05-27T16:43:39Z
| 9
| 0
|
yolov10
|
[
"yolov10",
"onnx",
"ultralytics",
"yolo",
"object-detection",
"pytorch",
"cs2",
"Counter Strike",
"license:cc-by-nc-nd-4.0",
"region:us"
] |
object-detection
| 2024-09-19T20:04:40Z
|
---
license: cc-by-nc-nd-4.0
pipeline_tag: object-detection
tags:
- yolov10
- ultralytics
- yolo
- object-detection
- pytorch
- cs2
- Counter Strike
---
Counter Strike 2 players detector
## Supported Labels
```
[ 'c', 'ch', 't', 'th' ]
```
## All models in this series
- [yoloV10n_cs2](https://huggingface.co/Vombit/yolov10n_cs2) (5.5mb)
- [yoloV10s_cs2](https://huggingface.co/Vombit/yolov10s_cs2) (15.7mb)
- [yoloV10m_cs2](https://huggingface.co/Vombit/yolov10m_cs2) (31.9mb)
- [yoloV10b_cs2](https://huggingface.co/Vombit/yolov10b_cs2) (39.7mb)
- [yoloV10l_cs2](https://huggingface.co/Vombit/yolov10l_cs2) (50.0mb)
- [yoloV10x_cs2](https://huggingface.co/Vombit/yolov10x_cs2) (61.4mb)
## How to use
```python
# load Yolo
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO(r'weights\yolov**_cs2.pt')
# Run inference on 'image.png' with arguments
model.predict(
'image.png',
save=True,
device=0
)
```
## Predict info
Ultralytics YOLOv8.2.90 🚀 Python-3.12.5 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4060, 8188MiB)
- yolov10l_cs2_fp16.engine (640x640 5 ts, 5 ths, 7.1ms)
- yolov10l_cs2.engine (640x640 5 ts, 5 ths, 16.1ms)
- yolov10l_cs2_fp16.onnx (640x640 5 ts, 5 ths, 337.2ms)
- yolov10l_cs2.onnx (640x640 5 ts, 5 ths, 348.0ms)
- yolov10l_cs2.pt (384x640 5 ts, 5 ths, 99.1ms)
## Dataset info
Data from over 120 games, where the footage has been tagged in detail.
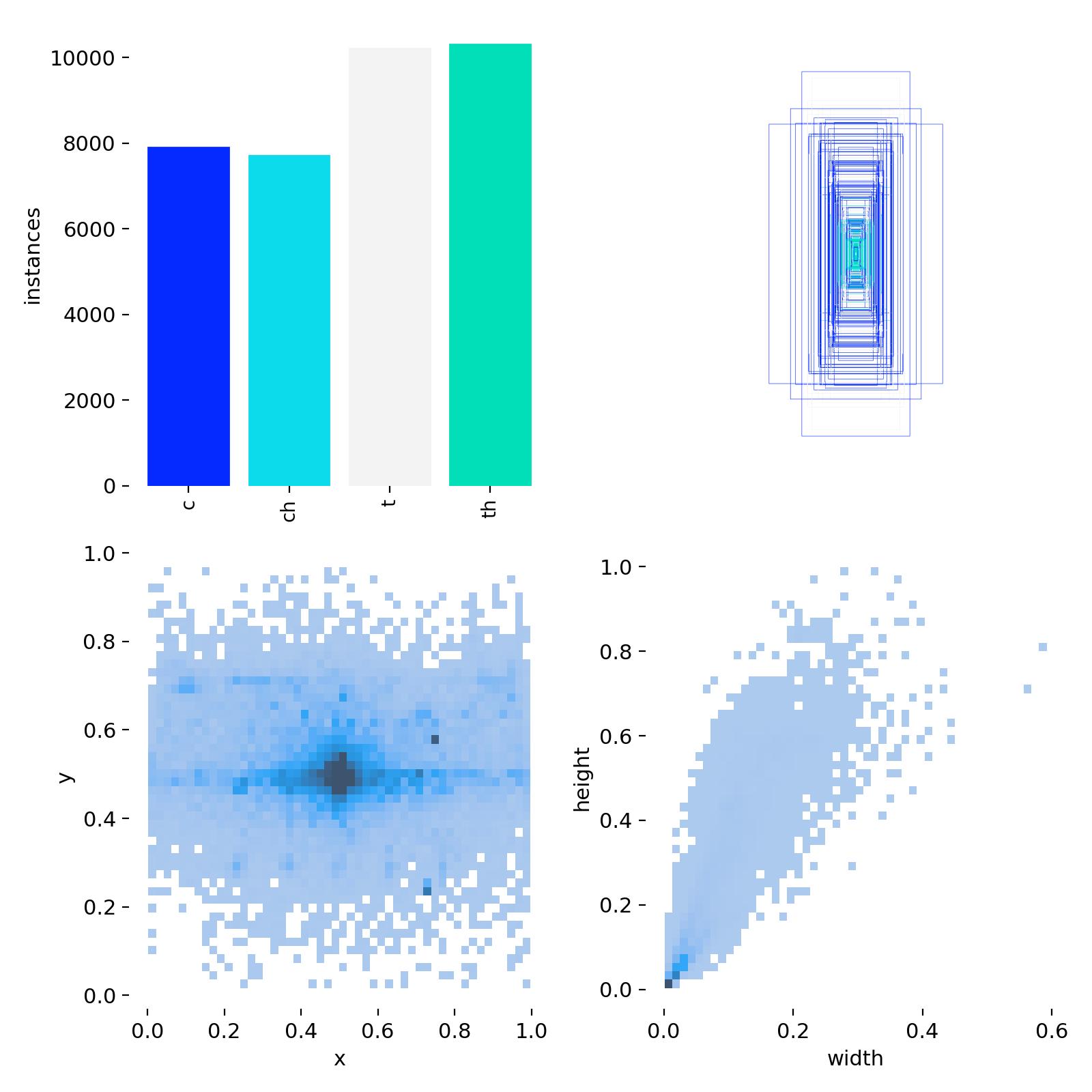
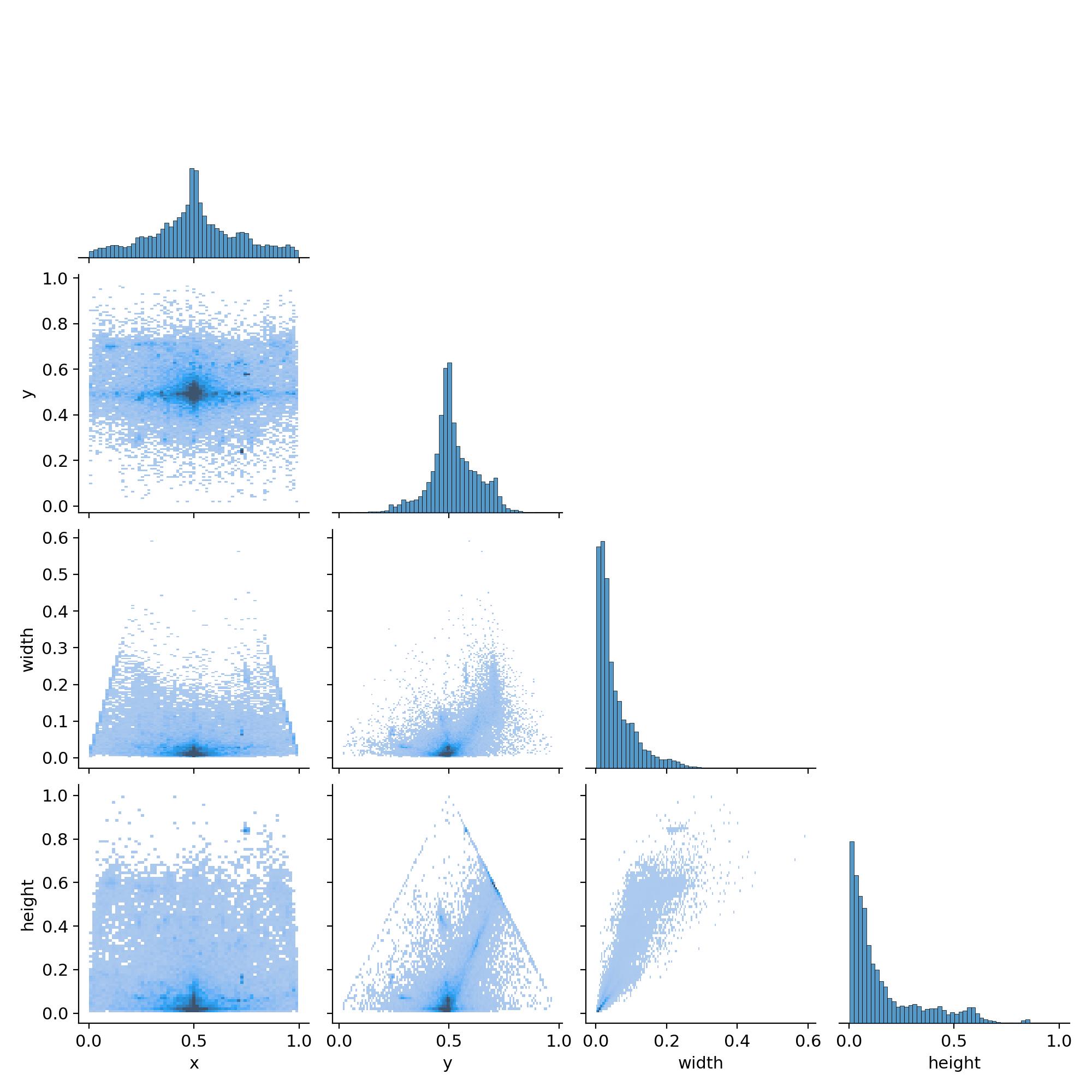
## Train info
The training took place over 150 epochs.
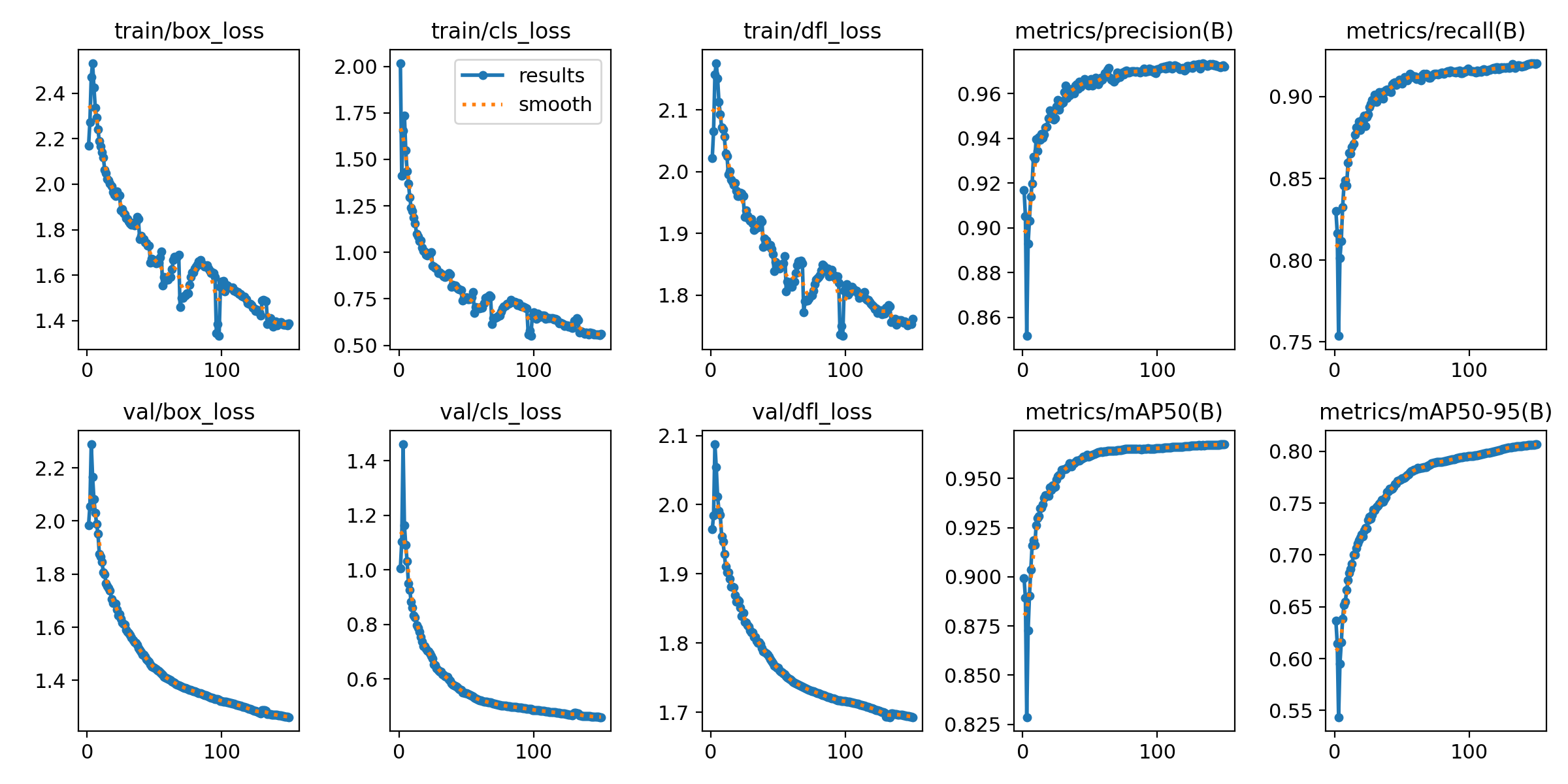
You can also support me with a cup of coffee: [donate](https://vombit.serveblog.net/donation)
|
jzilcov/prompt_complexity_classifier
|
jzilcov
| 2025-05-27T16:42:51Z
| 0
| 0
| null |
[
"safetensors",
"roberta",
"en",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:mit",
"region:us"
] | null | 2025-05-27T16:29:44Z
|
---
license: mit
language:
- en
base_model:
- distilbert/distilroberta-base
---
|
Vombit/yolov10s_cs2
|
Vombit
| 2025-05-27T16:42:49Z
| 11
| 0
|
yolov10
|
[
"yolov10",
"onnx",
"ultralytics",
"yolo",
"object-detection",
"pytorch",
"cs2",
"Counter Strike",
"license:cc-by-nc-nd-4.0",
"region:us"
] |
object-detection
| 2024-09-19T20:03:40Z
|
---
license: cc-by-nc-nd-4.0
pipeline_tag: object-detection
tags:
- yolov10
- ultralytics
- yolo
- object-detection
- pytorch
- cs2
- Counter Strike
---
Counter Strike 2 players detector
## Supported Labels
```
[ 'c', 'ch', 't', 'th' ]
```
## All models in this series
- [yoloV10n_cs2](https://huggingface.co/Vombit/yolov10n_cs2) (5.5mb)
- [yoloV10s_cs2](https://huggingface.co/Vombit/yolov10s_cs2) (15.7mb)
- [yoloV10m_cs2](https://huggingface.co/Vombit/yolov10m_cs2) (31.9mb)
- [yoloV10b_cs2](https://huggingface.co/Vombit/yolov10b_cs2) (39.7mb)
- [yoloV10l_cs2](https://huggingface.co/Vombit/yolov10l_cs2) (50.0mb)
- [yoloV10x_cs2](https://huggingface.co/Vombit/yolov10x_cs2) (61.4mb)
## How to use
```python
# load Yolo
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO(r'weights\yolov**_cs2.pt')
# Run inference on 'image.png' with arguments
model.predict(
'image.png',
save=True,
device=0
)
```
## Predict info
Ultralytics YOLOv8.2.90 🚀 Python-3.12.5 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4060, 8188MiB)
- yolov10s_cs2_fp16.engine (640x640 5 ts, 6 ths, 3.0ms)
- yolov10s_cs2.engine (640x640 5 ts, 6 ths, 4.5ms)
- yolov10s_cs2_fp16.onnx (640x640 5 ts, 6 ths, 80.4ms)
- yolov10s_cs2.onnx (640x640 5 ts, 6 ths, 76.6ms)
- yolov10s_cs2.pt (384x640 5 ts, 5 ths, 86.7ms)
## Dataset info
Data from over 120 games, where the footage has been tagged in detail.
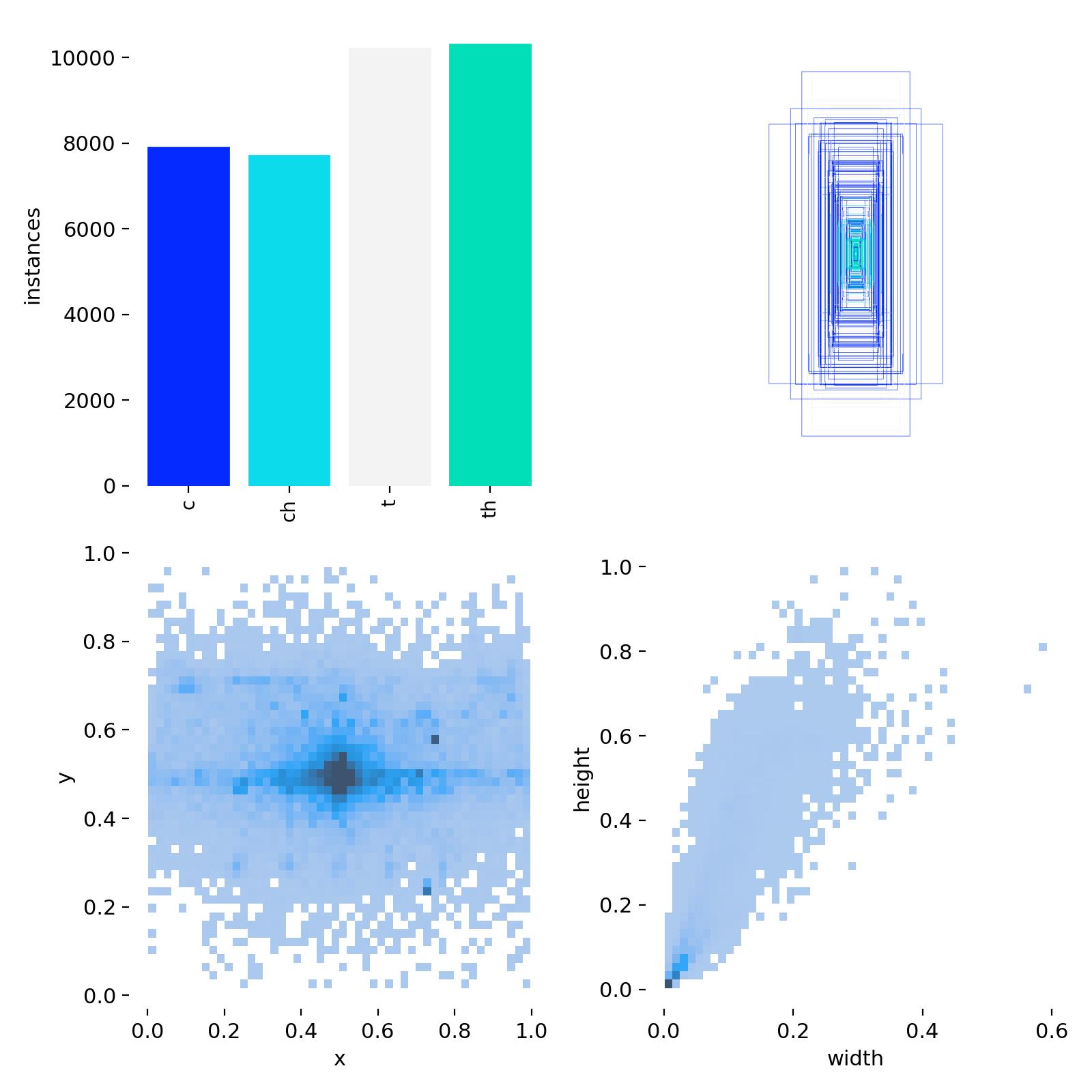
## Train info
The training took place over 150 epochs.
You can also support me with a cup of coffee: [donate](https://vombit.serveblog.net/donation)
|
othoi-113-viral-video-link-hd/othoiiii.viral.video.link.othoi.viral.video.link.1.13.second
|
othoi-113-viral-video-link-hd
| 2025-05-27T16:42:33Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-05-27T16:41:19Z
|
[🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=othoi)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=othoi)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=othoi)
|
Vombit/yolov10n_cs2
|
Vombit
| 2025-05-27T16:42:31Z
| 7
| 0
|
yolov10
|
[
"yolov10",
"onnx",
"ultralytics",
"yolo",
"object-detection",
"pytorch",
"cs2",
"Counter Strike",
"license:cc-by-nc-nd-4.0",
"region:us"
] |
object-detection
| 2024-09-19T20:02:38Z
|
---
license: cc-by-nc-nd-4.0
pipeline_tag: object-detection
tags:
- yolov10
- ultralytics
- yolo
- object-detection
- pytorch
- cs2
- Counter Strike
---
Counter Strike 2 players detector
## Supported Labels
```
[ 'c', 'ch', 't', 'th' ]
```
## All models in this series
- [yoloV10n_cs2](https://huggingface.co/Vombit/yolov10n_cs2) (5.5mb)
- [yoloV10s_cs2](https://huggingface.co/Vombit/yolov10s_cs2) (15.7mb)
- [yoloV10m_cs2](https://huggingface.co/Vombit/yolov10m_cs2) (31.9mb)
- [yoloV10b_cs2](https://huggingface.co/Vombit/yolov10b_cs2) (39.7mb)
- [yoloV10l_cs2](https://huggingface.co/Vombit/yolov10l_cs2) (50.0mb)
- [yoloV10x_cs2](https://huggingface.co/Vombit/yolov10x_cs2) (61.4mb)
## How to use
```python
# load Yolo
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO(r'weights\yolov**_cs2.pt')
# Run inference on 'image.png' with arguments
model.predict(
'image.png',
save=True,
device=0
)
```
## Predict info
Ultralytics YOLOv8.2.90 🚀 Python-3.12.5 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4060, 8188MiB)
- yolov10n_cs2_fp16.engine (640x640 5 ts, 5 ths, 2.6ms)
- yolov10n_cs2.engine (640x640 5 ts, 5 ths, 2.9ms)
- yolov10n_cs2_fp16.onnx (640x640 5 ts, 5 ths, 32.6ms)
- yolov10n_cs2.onnx (640x640 5 ts, 5 ths, 40.6ms)
- yolov10n_cs2.pt (384x640 5 ts, 5 ths, 124.3ms)
## Dataset info
Data from over 120 games, where the footage has been tagged in detail.
## Train info
The training took place over 150 epochs.
You can also support me with a cup of coffee: [donate](https://vombit.serveblog.net/donation)
|
Mawdistical/Draconia-Overdrive-32B_EXL3_8.0bpw_H8
|
Mawdistical
| 2025-05-27T16:42:21Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"8-bit",
"region:us"
] |
text-generation
| 2025-05-27T16:20:53Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
Mawdistical/Draconia-Overdrive-32B_EXL3_8.0bpw_H6
|
Mawdistical
| 2025-05-27T16:42:17Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"8-bit",
"region:us"
] |
text-generation
| 2025-05-27T16:17:21Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
Mawdistical/Draconia-Overdrive-32B_EXL3_5.0bpw_H6
|
Mawdistical
| 2025-05-27T16:42:08Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"5-bit",
"region:us"
] |
text-generation
| 2025-05-27T16:12:07Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
Mawdistical/Draconia-Overdrive-32B_EXL3_4.5bpw_H6
|
Mawdistical
| 2025-05-27T16:42:04Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-05-27T16:10:04Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
Mawdistical/Draconia-Overdrive-32B_EXL3_4.0bpw_H6
|
Mawdistical
| 2025-05-27T16:42:00Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"4-bit",
"region:us"
] |
text-generation
| 2025-05-27T16:02:16Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
Mawdistical/Draconia-Overdrive-32B_EXL3_3.0bpw_H6
|
Mawdistical
| 2025-05-27T16:41:51Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"3-bit",
"region:us"
] |
text-generation
| 2025-05-27T15:58:23Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
BootesVoid/cmb6pxhjv062qlexpw6nfpaii_cmb6q4yep063zlexpzgmaioyi
|
BootesVoid
| 2025-05-27T16:41:39Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-05-27T16:41:37Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: elena_
---
# Cmb6Pxhjv062Qlexpw6Nfpaii_Cmb6Q4Yep063Zlexpzgmaioyi
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `elena_` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "elena_",
"lora_weights": "https://huggingface.co/BootesVoid/cmb6pxhjv062qlexpw6nfpaii_cmb6q4yep063zlexpzgmaioyi/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmb6pxhjv062qlexpw6nfpaii_cmb6q4yep063zlexpzgmaioyi', weight_name='lora.safetensors')
image = pipeline('elena_').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmb6pxhjv062qlexpw6nfpaii_cmb6q4yep063zlexpzgmaioyi/discussions) to add images that show off what you’ve made with this LoRA.
|
Mohamed-Aly/BABYLM-TOKENIZER-BPE-TXT
|
Mohamed-Aly
| 2025-05-27T16:41:38Z
| 0
| 0
|
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T16:41:37Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Mawdistical/Draconia-Overdrive-32B_EXL3_2.5bpw_H6
|
Mawdistical
| 2025-05-27T16:41:14Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"glm4",
"text-generation",
"nsfw",
"explicit",
"roleplay",
"Furry",
"exl3",
"conversational",
"en",
"base_model:Mawdistical/Draconia-Overdrive-32B",
"base_model:quantized:Mawdistical/Draconia-Overdrive-32B",
"license:mit",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-05-27T15:56:57Z
|
---
thumbnail: >-
https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png
language:
- en
license: mit
license_link: https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE
inference: false
tags:
- nsfw
- explicit
- roleplay
- Furry
- exl3
base_model:
- Mawdistical/Draconia-Overdrive-32B
base_model_relation: quantized
quantized_by: ArtusDev
pipeline_tag: text-generation
library_name: transformers
---
<div style="background-color: #ffffff; color: #111; padding: 28px 18px; border-radius: 10px; width: 100%;">
<div align="center">
<h1 style="color: #111; margin-bottom: 18px; font-size: 2.1em; font-family:serif;">
Draconia-Overdrive-32B
</h1>
<img src="https://cdn-uploads.huggingface.co/production/uploads/67c10cfba43d7939d60160ff/Sxw5POvqQLws62gTq5EyW.png" width="680px" style="border-radius: 8px; box-shadow: 0 0 16px #0ff;">
<h3 style="color: #111; font-style: italic; margin-top: 13px;">Explicit Content Warning</h3>
<p style="color: #111; font-size: 0.95em; margin-top: 3px; margin-bottom: 14px;">
<a href="https://ko-fi.com/mawnipulator" style="color: #111; text-decoration: underline;"><b>Support Mawdistical finetunes here</b></a>
</p>
</div>
<div style="background-color: #e0fcff; color: #111; padding: 16px; border-radius: 7px; margin: 22px 0; border-left: 3px solid #00eaff;">
<p>
<em>
"A creation of <a href="https://huggingface.co/THUDM/GLM-4-32B-0414" style="color:#067a86; text-decoration: underline;">'chaos aura'</a> that accentuates draconian fervor."
</em>
<br><br>
Draconia-Overdrive-32B is an expressive, creative, and roleplay-driven large language model developed for a wide range of contexts. Drawing inspiration from deep chaos, it brings a fervent, untamed spirit mirroring the energy of relentless draconianism.
</p>
</div>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Quantized Formats</h2>
<ul>
<li><strong style="color: #111;">Original Model</strong>:
<ul>
<li><a href="https://huggingface.co/Mawdistical/Draconia-Overdrive-32B" style="color: #067a86; text-decoration: underline;">Draconia-Overdrive-32B</a></li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.25em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Recommended Settings</h2>
<ul>
<li><strong style="color: #111;">Temperature</strong>: 1.0-1.1</li>
<li><strong style="color: #111;">Min P</strong>: 0.02-0.05</li>
<li><strong style="color: #111;">Dynamic Temperature</strong> (optional):
<ul>
<li style="color: #111;">Multiplier: 0.75-0.85</li>
<li style="color: #111;">Base: 1.8</li>
<li style="color: #111;">Length: 4</li>
</ul>
</li>
</ul>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Sample Presets</h2>
<pre style="background: #e0fcff; color: #111; border-radius: 7px; border: 1px solid #00eaff; padding: 12px; font-size: 1em;">
Temperature: 1.07
Top-P: 0.92
Min-P: 0.035
Mirostat: 2
Repetition Penalty: 1.12
Dynamic Temperature: on (Multiplier: 0.8, Base: 1.8, Length: 4)
</pre>
<hr style="border: 0; height: 1px; background-color: #00eaff; margin: 25px 0;">
<h2 style="color: #111; font-size: 1.2em; border-bottom: 1px solid #00eaff; padding-bottom: 7px;">✧ Credits</h2>
<ul>
<li><strong style="color: #111;">Model Author</strong>: <a href="https://vyvan.se" style="color: #067a86; text-decoration: underline;">@Mawnipulator</a></li>
<li><strong style="color: #111;">Additional Credit</strong>: <a href="https://huggingface.co/xtristan" style="color: #067a86; text-decoration: underline;">@xtristan</a></li>
<li><strong style="color: #111;">Government Body</strong>:
<ul>
<li><a href="https://huggingface.co/ArtusDev" style="color: #067a86;">@ArtusDev</a></li>
<li><a href="https://huggingface.co/SaisExperiments" style="color: #067a86;">@SaisExperiments</a></li>
<li><a href="https://huggingface.co/allura-org" style="color: #067a86;">ALLURA-ORG</a></li>
</ul>
</li>
</ul>
<p style="color: #111; font-size:1em; margin-top:20px;">
<strong style="color: #111;">License:</strong>
<a href="https://huggingface.co/THUDM/GLM-4-32B-0414/blob/main/LICENSE" style="color: #067a86; text-decoration: underline;">MIT</a>
</p>
<p style="color: #111; font-size: 1em; margin-top:17px;">
This model was generously made with compute from
<a href="https://Shuttleai.com" style="color:#067a86; text-decoration:underline;">Shuttleai.com</a>
</p>
</div>
|
MattBou00/SmolLM-toxic-detox-ppo-1000updates
|
MattBou00
| 2025-05-27T16:40:54Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T16:40:26Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Diamantis99/OL56jaO
|
Diamantis99
| 2025-05-27T16:38:44Z
| 0
| 0
|
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-05-27T16:38:41Z
|
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# FPN Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "mobilenet_v2",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_pyramid_channels": 256,
"decoder_segmentation_channels": 128,
"decoder_merge_policy": "add",
"decoder_dropout": 0.2,
"decoder_interpolation": "nearest",
"in_channels": 3,
"classes": 1,
"activation": None,
"upsampling": 4,
"aux_params": None
}
```
## Model metrics
```json
[
{
"test_per_image_iou": 0.5323230624198914,
"test_dataset_iou": 0.6163333654403687
}
]
```
## Dataset
Dataset name: VisionPipe
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
Diamantis99/KVIbIp1
|
Diamantis99
| 2025-05-27T16:35:25Z
| 0
| 0
|
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-05-27T16:35:08Z
|
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# FPN Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "efficientnet-b7",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_pyramid_channels": 256,
"decoder_segmentation_channels": 128,
"decoder_merge_policy": "add",
"decoder_dropout": 0.2,
"decoder_interpolation": "nearest",
"in_channels": 3,
"classes": 1,
"activation": None,
"upsampling": 4,
"aux_params": None
}
```
## Model metrics
```json
[
{
"test_per_image_iou": 0.611117422580719,
"test_dataset_iou": 0.6363441348075867
}
]
```
## Dataset
Dataset name: VisionPipe
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
mradermacher/LIMOPro-LIMO-P-i1-GGUF
|
mradermacher
| 2025-05-27T16:35:16Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:YangXiao-nlp/LIMOPro-LIMO-P",
"base_model:quantized:YangXiao-nlp/LIMOPro-LIMO-P",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-05-27T13:15:12Z
|
---
base_model: YangXiao-nlp/LIMOPro-LIMO-P
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/YangXiao-nlp/LIMOPro-LIMO-P
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/LIMOPro-LIMO-P-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ1_M.gguf) | i1-IQ1_M | 8.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ2_M.gguf) | i1-IQ2_M | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ3_M.gguf) | i1-IQ3_M | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q4_K_M.gguf) | i1-Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/LIMOPro-LIMO-P-i1-GGUF/resolve/main/LIMOPro-LIMO-P.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
seantilley/model
|
seantilley
| 2025-05-27T12:28:11Z
| 0
| 0
|
transformers
|
[
"transformers",
"text-generation-inference",
"unsloth",
"llama",
"gguf",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T12:28:07Z
|
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** seantilley
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ObadaAlaqtash/my_llama3_model_eastern_caverns
|
ObadaAlaqtash
| 2025-05-27T12:27:14Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T12:27:06Z
|
---
base_model: unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ObadaAlaqtash
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ltg/norbert3-xs
|
ltg
| 2025-05-27T12:27:09Z
| 1,738
| 4
|
transformers
|
[
"transformers",
"pytorch",
"fill-mask",
"BERT",
"NorBERT",
"Norwegian",
"encoder",
"custom_code",
"no",
"nb",
"nn",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2023-03-28T16:49:08Z
|
---
language:
- 'no'
- nb
- nn
inference: false
tags:
- BERT
- NorBERT
- Norwegian
- encoder
license: apache-2.0
---
# NorBERT 3 xs
<img src="https://huggingface.co/ltg/norbert3-base/resolve/main/norbert.png" width=12.5%>
The official release of a new generation of NorBERT language models described in paper [**NorBench — A Benchmark for Norwegian Language Models**](https://aclanthology.org/2023.nodalida-1.61/). Plese read the paper to learn more details about the model.
## Other sizes:
- [NorBERT 3 xs (15M)](https://huggingface.co/ltg/norbert3-xs)
- [NorBERT 3 small (40M)](https://huggingface.co/ltg/norbert3-small)
- [NorBERT 3 base (123M)](https://huggingface.co/ltg/norbert3-base)
- [NorBERT 3 large (323M)](https://huggingface.co/ltg/norbert3-large)
## Generative NorT5 siblings:
- [NorT5 xs (32M)](https://huggingface.co/ltg/nort5-xs)
- [NorT5 small (88M)](https://huggingface.co/ltg/nort5-small)
- [NorT5 base (228M)](https://huggingface.co/ltg/nort5-base)
- [NorT5 large (808M)](https://huggingface.co/ltg/nort5-large)
## Example usage
This model currently needs a custom wrapper from `modeling_norbert.py`, you should therefore load the model with `trust_remote_code=True`.
```python
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ltg/norbert3-xs")
model = AutoModelForMaskedLM.from_pretrained("ltg/norbert3-xs", trust_remote_code=True)
mask_id = tokenizer.convert_tokens_to_ids("[MASK]")
input_text = tokenizer("Nå ønsker de seg en[MASK] bolig.", return_tensors="pt")
output_p = model(**input_text)
output_text = torch.where(input_text.input_ids == mask_id, output_p.logits.argmax(-1), input_text.input_ids)
# should output: '[CLS] Nå ønsker de seg en ny bolig.[SEP]'
print(tokenizer.decode(output_text[0].tolist()))
```
The following classes are currently implemented: `AutoModel`, `AutoModelMaskedLM`, `AutoModelForSequenceClassification`, `AutoModelForTokenClassification`, `AutoModelForQuestionAnswering` and `AutoModeltForMultipleChoice`.
## Cite us
```bibtex
@inproceedings{samuel-etal-2023-norbench,
title = "{N}or{B}ench {--} A Benchmark for {N}orwegian Language Models",
author = "Samuel, David and
Kutuzov, Andrey and
Touileb, Samia and
Velldal, Erik and
{\O}vrelid, Lilja and
R{\o}nningstad, Egil and
Sigdel, Elina and
Palatkina, Anna",
booktitle = "Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)",
month = may,
year = "2023",
address = "T{\'o}rshavn, Faroe Islands",
publisher = "University of Tartu Library",
url = "https://aclanthology.org/2023.nodalida-1.61",
pages = "618--633",
abstract = "We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.",
}
```
|
ltg/norbert3-base
|
ltg
| 2025-05-27T12:26:28Z
| 1,966
| 7
|
transformers
|
[
"transformers",
"pytorch",
"fill-mask",
"BERT",
"NorBERT",
"Norwegian",
"encoder",
"custom_code",
"no",
"nb",
"nn",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2023-03-02T21:38:09Z
|
---
language:
- 'no'
- nb
- nn
inference: false
tags:
- BERT
- NorBERT
- Norwegian
- encoder
license: apache-2.0
---
# NorBERT 3 base
<img src="https://huggingface.co/ltg/norbert3-base/resolve/main/norbert.png" width=12.5%>
The official release of a new generation of NorBERT language models described in paper [**NorBench — A Benchmark for Norwegian Language Models**](https://aclanthology.org/2023.nodalida-1.61/). Plese read the paper to learn more details about the model.
## Other sizes:
- [NorBERT 3 xs (15M)](https://huggingface.co/ltg/norbert3-xs)
- [NorBERT 3 small (40M)](https://huggingface.co/ltg/norbert3-small)
- [NorBERT 3 base (123M)](https://huggingface.co/ltg/norbert3-base)
- [NorBERT 3 large (323M)](https://huggingface.co/ltg/norbert3-large)
## Generative NorT5 siblings:
- [NorT5 xs (32M)](https://huggingface.co/ltg/nort5-xs)
- [NorT5 small (88M)](https://huggingface.co/ltg/nort5-small)
- [NorT5 base (228M)](https://huggingface.co/ltg/nort5-base)
- [NorT5 large (808M)](https://huggingface.co/ltg/nort5-large)
## Example usage
This model currently needs a custom wrapper from `modeling_norbert.py`, you should therefore load the model with `trust_remote_code=True`.
```python
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ltg/norbert3-base")
model = AutoModelForMaskedLM.from_pretrained("ltg/norbert3-base", trust_remote_code=True)
mask_id = tokenizer.convert_tokens_to_ids("[MASK]")
input_text = tokenizer("Nå ønsker de seg en[MASK] bolig.", return_tensors="pt")
output_p = model(**input_text)
output_text = torch.where(input_text.input_ids == mask_id, output_p.logits.argmax(-1), input_text.input_ids)
# should output: '[CLS] Nå ønsker de seg en ny bolig.[SEP]'
print(tokenizer.decode(output_text[0].tolist()))
```
The following classes are currently implemented: `AutoModel`, `AutoModelMaskedLM`, `AutoModelForSequenceClassification`, `AutoModelForTokenClassification`, `AutoModelForQuestionAnswering` and `AutoModeltForMultipleChoice`.
## Cite us
```bibtex
@inproceedings{samuel-etal-2023-norbench,
title = "{N}or{B}ench {--} A Benchmark for {N}orwegian Language Models",
author = "Samuel, David and
Kutuzov, Andrey and
Touileb, Samia and
Velldal, Erik and
{\O}vrelid, Lilja and
R{\o}nningstad, Egil and
Sigdel, Elina and
Palatkina, Anna",
booktitle = "Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)",
month = may,
year = "2023",
address = "T{\'o}rshavn, Faroe Islands",
publisher = "University of Tartu Library",
url = "https://aclanthology.org/2023.nodalida-1.61",
pages = "618--633",
abstract = "We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.",
}
```
|
root4k/Dolphin-Mistral-24B-Venice
|
root4k
| 2025-05-27T12:26:23Z
| 0
| 0
|
mlx
|
[
"mlx",
"safetensors",
"mistral",
"text-generation",
"conversational",
"base_model:cognitivecomputations/Dolphin-Mistral-24B-Venice-Edition",
"base_model:quantized:cognitivecomputations/Dolphin-Mistral-24B-Venice-Edition",
"license:apache-2.0",
"4-bit",
"region:us"
] |
text-generation
| 2025-05-27T11:38:46Z
|
---
license: apache-2.0
base_model: cognitivecomputations/Dolphin-Mistral-24B-Venice-Edition
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
|
ltg/norbert3-large
|
ltg
| 2025-05-27T12:25:45Z
| 1,262
| 5
|
transformers
|
[
"transformers",
"pytorch",
"fill-mask",
"BERT",
"NorBERT",
"Norwegian",
"encoder",
"custom_code",
"no",
"nb",
"nn",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2023-03-02T20:27:09Z
|
---
language:
- 'no'
- nb
- nn
inference: true
tags:
- BERT
- NorBERT
- Norwegian
- encoder
license: apache-2.0
---
# NorBERT 3 large
<img src="https://huggingface.co/ltg/norbert3-base/resolve/main/norbert.png" width=12.5%>
The official release of a new generation of NorBERT language models described in paper [**NorBench — A Benchmark for Norwegian Language Models**](https://aclanthology.org/2023.nodalida-1.61/). Plese read the paper to learn more details about the model.
## Other sizes:
- [NorBERT 3 xs (15M)](https://huggingface.co/ltg/norbert3-xs)
- [NorBERT 3 small (40M)](https://huggingface.co/ltg/norbert3-small)
- [NorBERT 3 base (123M)](https://huggingface.co/ltg/norbert3-base)
- [NorBERT 3 large (323M)](https://huggingface.co/ltg/norbert3-large)
## Generative NorT5 siblings:
- [NorT5 xs (32M)](https://huggingface.co/ltg/nort5-xs)
- [NorT5 small (88M)](https://huggingface.co/ltg/nort5-small)
- [NorT5 base (228M)](https://huggingface.co/ltg/nort5-base)
- [NorT5 large (808M)](https://huggingface.co/ltg/nort5-large)
## Example usage
This model currently needs a custom wrapper from `modeling_norbert.py`, you should therefore load the model with `trust_remote_code=True`.
```python
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ltg/norbert3-large")
model = AutoModelForMaskedLM.from_pretrained("ltg/norbert3-large", trust_remote_code=True)
mask_id = tokenizer.convert_tokens_to_ids("[MASK]")
input_text = tokenizer("Nå ønsker de seg en[MASK] bolig.", return_tensors="pt")
output_p = model(**input_text)
output_text = torch.where(input_text.input_ids == mask_id, output_p.logits.argmax(-1), input_text.input_ids)
# should output: '[CLS] Nå ønsker de seg en ny bolig.[SEP]'
print(tokenizer.decode(output_text[0].tolist()))
```
The following classes are currently implemented: `AutoModel`, `AutoModelMaskedLM`, `AutoModelForSequenceClassification`, `AutoModelForTokenClassification`, `AutoModelForQuestionAnswering` and `AutoModeltForMultipleChoice`.
## Cite us
```bibtex
@inproceedings{samuel-etal-2023-norbench,
title = "{N}or{B}ench {--} A Benchmark for {N}orwegian Language Models",
author = "Samuel, David and
Kutuzov, Andrey and
Touileb, Samia and
Velldal, Erik and
{\O}vrelid, Lilja and
R{\o}nningstad, Egil and
Sigdel, Elina and
Palatkina, Anna",
booktitle = "Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)",
month = may,
year = "2023",
address = "T{\'o}rshavn, Faroe Islands",
publisher = "University of Tartu Library",
url = "https://aclanthology.org/2023.nodalida-1.61",
pages = "618--633",
abstract = "We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.",
}
```
|
lisabdunlap/balanced_sft_long-1e4_e15
|
lisabdunlap
| 2025-05-27T12:24:26Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/Qwen3-8B",
"base_model:finetune:unsloth/Qwen3-8B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T12:23:34Z
|
---
base_model: unsloth/Qwen3-8B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lisabdunlap
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-8B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
majdab4/dummy-model
|
majdab4
| 2025-05-27T12:23:34Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"camembert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-05-27T12:23:01Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ChevellaShyam/emotion-transformer-model
|
ChevellaShyam
| 2025-05-27T12:23:27Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-05-27T12:22:26Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sayantan0013/Qwen3-0.6B-SFT
|
sayantan0013
| 2025-05-27T12:22:06Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T12:21:50Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mvsamsonov/speecht5_finetuned_voxpopuli_nl
|
mvsamsonov
| 2025-05-27T12:22:03Z
| 5
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:voxpopuli",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-05-25T05:55:45Z
|
---
library_name: transformers
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_nl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_nl
This model was trained from scratch on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4590
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.6863 | 0.8607 | 200 | 0.6124 |
| 0.5721 | 1.7230 | 400 | 0.5167 |
| 0.5396 | 2.5853 | 600 | 0.4984 |
| 0.5289 | 3.4476 | 800 | 0.4868 |
| 0.5172 | 4.3098 | 1000 | 0.4815 |
| 0.5169 | 5.1721 | 1200 | 0.4771 |
| 0.5108 | 6.0344 | 1400 | 0.4740 |
| 0.5086 | 6.8951 | 1600 | 0.4715 |
| 0.5042 | 7.7574 | 1800 | 0.4699 |
| 0.4939 | 8.6197 | 2000 | 0.4678 |
| 0.4965 | 9.4820 | 2200 | 0.4667 |
| 0.5004 | 10.3443 | 2400 | 0.4644 |
| 0.4906 | 11.2066 | 2600 | 0.4617 |
| 0.4889 | 12.0689 | 2800 | 0.4612 |
| 0.493 | 12.9295 | 3000 | 0.4601 |
| 0.4893 | 13.7918 | 3200 | 0.4599 |
| 0.4894 | 14.6541 | 3400 | 0.4600 |
| 0.4922 | 15.5164 | 3600 | 0.4594 |
| 0.491 | 16.3787 | 3800 | 0.4599 |
| 0.482 | 17.2410 | 4000 | 0.4590 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Emmzyel/Emmzy_Wealth
|
Emmzyel
| 2025-05-27T12:21:32Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-05-27T12:21:32Z
|
---
license: apache-2.0
---
|
abhikapoor909/vitmodel
|
abhikapoor909
| 2025-05-27T12:21:21Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-27T12:20:22Z
|
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** abhikapoor909
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AlphaSurgeMaleEnhancement/AlphaSurgeMaleEnhancement
|
AlphaSurgeMaleEnhancement
| 2025-05-27T12:20:46Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-05-27T12:11:12Z
|
## What Is Alpha Surge Male Enhancement?
**[Alpha Surge Male Enhancement](https://www.diginear.com/2PGQH1JJ/ZDFM5CX/)** is a dietary supplement designed specifically for men looking to boost their sexual health, energy levels, and overall vitality. Available in gummy form, it provides a refreshing alternative to conventional capsules or tablets, which can be cumbersome or unappealing for some users. The product is marketed as a natural, non-GMO, and gluten-free formula, crafted in FDA-registered and GMP-certified facilities in the United States. This emphasis on quality manufacturing ensures that users receive a product that meets high safety and efficacy standards.
The core promise of Alpha Surge Male Enhancement is to enhance male performance by addressing common issues such as erectile dysfunction, low libido, and reduced stamina. By promoting better blood flow, supporting testosterone production, and boosting energy, the supplement aims to help men feel more confident and capable in intimate moments. Additionally, its holistic approach extends beyond sexual health, contributing to overall well-being, including improved mood, reduced stress, and enhanced physical endurance.
## **[👉Hurry Up!! (Official Website) 😊 Order Now👈](https://www.diginear.com/2PGQH1JJ/ZDFM5CX/)**
## Key Ingredients in Alpha Surge Male Enhancement
The effectiveness of Alpha Surge Male Enhancement lies in its carefully curated blend of natural ingredients, each selected for its potential to support male health. Here’s a closer look at the primary components that drive the supplement’s benefits:
Horny Goat Weed (Epimedium): A staple in traditional Chinese medicine, Horny Goat Weed contains icariin, a compound known to boost nitric oxide levels. This enhances blood flow, which is crucial for achieving stronger, longer-lasting erections and improving libido. Its fatigue-fighting properties also make it a valuable addition for men seeking sustained energy during physical activities.
Tongkat Ali: This herbal remedy is renowned for supporting healthy testosterone levels, which can enhance energy, libido, and muscle strength. By addressing hormonal imbalances, Tongkat Ali helps men feel more youthful and vigorous.
Ashwagandha Extract: As an adaptogenic herb, Ashwagandha reduces stress and cortisol levels, promoting a calm and focused mindset. This indirectly supports sexual performance by alleviating anxiety, which can hinder intimate moments. It may also contribute to testosterone production, further boosting vitality.
L-Arginine HCl: An amino acid that increases nitric oxide production, L-Arginine improves blood circulation, supporting better stamina and erectile function. Its role in vasodilation makes it a key player in enhancing physical performance, both in the gym and the bedroom.
Maca Root Extract: Known as a Peruvian superfood, Maca Root boosts libido and endurance without relying on stimulants like caffeine. It provides a natural energy lift, helping men combat fatigue and perform at their best.
Beet Root Powder: Rich in nitrates, Beet Root Powder supports vasodilation, improving blood flow and endurance. This ingredient enhances both sexual and athletic performance, making it a versatile addition to the formula.
These ingredients work synergistically to create a comprehensive formula that targets multiple aspects of male health, from circulation and hormone balance to energy and emotional well-being.
## How Does Alpha Surge Male Enhancement Work?
The science behind Alpha Surge Male Enhancement revolves around its ability to address the root causes of male performance issues. **[Arthro MD+](https://www.diginear.com/2PGQH1JJ/Z9MTN5X/)** Poor blood flow, low testosterone, and high stress are common culprits behind reduced libido and stamina. By incorporating ingredients that enhance nitric oxide production, such as L-Arginine and Horny Goat Weed, the supplement promotes better blood circulation to the genital area, which is essential for achieving and maintaining erections.
Additionally, Alpha Surge Male Enhancement supports testosterone production through ingredients like Tongkat Ali and Ashwagandha. Testosterone is a critical hormone for male vitality, influencing everything from sexual desire to muscle mass and energy levels. By fostering a healthy hormonal balance, the supplement helps men feel more confident and capable.
The inclusion of adaptogens like Ashwagandha also sets Alpha Surge Male Enhancement apart. Stress and anxiety can significantly impact sexual performance, creating a vicious cycle of doubt and dissatisfaction. By reducing cortisol levels, Ashwagandha promotes a calmer state of mind, allowing men to focus on the moment and enjoy intimate experiences without psychological barriers.
## **[👉Hurry Up!! (Official Website) 😊 Order Now👈](https://www.diginear.com/2PGQH1JJ/ZDFM5CX/)**
## Benefits of Alpha Surge Male Enhancement
Users of Alpha Surge Male Enhancement report a range of benefits that contribute to both sexual and overall health. These include:
Enhanced Libido: The supplement’s aphrodisiac ingredients, such as Horny Goat Weed and Maca Root, ignite sexual desire, helping men overcome age-related declines in libido.
Improved Stamina and Endurance: By boosting blood flow and energy levels, Alpha Surge Male Enhancement enables men to perform longer and more effectively, whether during intimate moments or physical activities.
Stronger Erections: Ingredients like L-Citrulline and Beet Root Powder enhance circulation, leading to harder and more sustainable erections. This can significantly improve sexual satisfaction for both partners.
Increased Confidence: Improved performance and vitality translate to greater self-assurance, both in and out of the bedroom. Users often report feeling more youthful and empowered.
Reduced Stress and Anxiety: Ashwagandha’s adaptogenic properties help men manage stress, creating a more relaxed and focused mindset during intimate encounters.
Convenient and Enjoyable Format: Unlike traditional supplements, the gummy form of Alpha Surge Male Enhancement is easy to take and pleasant to consume, making it a seamless addition to daily routines.
These benefits make Alpha Surge Male Enhancement a compelling choice for men seeking a natural, non-invasive solution to enhance their performance and well-being.
## Potential Drawbacks and Considerations
While Alpha Surge Male Enhancement has garnered positive feedback, it’s important to approach any supplement with realistic expectations. **[Nourix Diet](https:/https://www.diginear.com/2PGQH1JJ/Z9WS3SZ/)** Results can vary depending on individual factors such as age, health conditions, diet, and lifestyle. For instance, men with underlying medical issues, such as diabetes or heart disease, may not experience the same benefits as those in good health. Consulting a healthcare professional before starting any new supplement is advisable, especially for those taking medications like nitrates, which can interact with ingredients that boost nitric oxide.
Additionally, some sources have raised concerns about the male enhancement industry, noting that certain products may contain undeclared ingredients, such as sildenafil (the active ingredient in Viagra). While there’s no evidence suggesting Alpha Surge Male Enhancement contains hidden drugs, users should purchase from reputable sources, such as the official website, to ensure authenticity and safety.
The gummy format, while convenient, may not appeal to everyone, particularly those who prefer traditional capsules or have dietary restrictions. Furthermore, while the product is marketed as non-GMO and gluten-free, individuals with allergies should carefully review the ingredient list to avoid potential reactions.
## **[👉Hurry Up!! (Official Website) 😊 Order Now👈](https://www.diginear.com/2PGQH1JJ/ZDFM5CX/)**
## User Feedback and Real-World Results
Customer testimonials for Alpha Surge Male Enhancement are largely positive, with many users reporting noticeable improvements within weeks of consistent use. One user shared, “I’ve tried several male enhancement supplements, but none have worked as well as Alpha Surge. **[Golden Revive](https://www.diginear.com/2PGQH1JJ/XSZCHQH/)** The results were noticeable within a few weeks, and my partner has appreciated the change.” Others have praised the gummies’ taste and convenience, noting that they fit easily into busy lifestyles.
However, not all feedback is universally glowing. Some users report modest results, emphasizing the importance of combining the supplement with a healthy diet and regular exercise to maximize benefits. As with any supplement, patience is key, as it may take time for the body to respond to the ingredients.
## Why Choose Alpha Surge Male Enhancement?
In a crowded market of male enhancement products, Alpha Surge Male Enhancement stands out for several reasons. Its gummy format offers a unique and enjoyable way to support male health, making it more approachable than traditional supplements. The use of natural, science-backed ingredients, manufactured in FDA-registered facilities, provides reassurance of quality and safety. Additionally, **[Glyco Forte](https://www.diginear.com/2PGQH1JJ/ZD6NPNW/)** the product’s holistic approach—addressing not just sexual performance but also energy, stress, and overall vitality—makes it a versatile choice for men of all ages.
The inclusion of a 90-day money-back guarantee further enhances its appeal, allowing users to try the product with minimal risk. This customer-centric approach reflects the brand’s confidence in its formula and commitment to satisfaction.
## Final Thoughts
Alpha Surge Male Enhancement offers a promising solution for men seeking to enhance their sexual health and vitality without resorting to prescription medications or invasive procedures. **[ZentraSlim](https://www.diginear.com/2PGQH1JJ/ZD156QG/)** By leveraging a blend of natural ingredients like Horny Goat Weed, Tongkat Ali, and Ashwagandha, the supplement addresses key aspects of male performance, from libido and stamina to confidence and stress management. Its gummy format makes it a convenient and enjoyable addition to daily routines, while its manufacturing standards ensure quality and safety.
However, as with any supplement, results vary, and Alpha Surge Male Enhancement is most effective when paired with a healthy lifestyle. Men considering this product should consult with a healthcare provider to ensure it aligns with their health needs and goals. For those looking for a natural, reliable way to boost their performance and reclaim their confidence, Alpha Surge Male Enhancement is a contender worth exploring.
## **[👉Hurry Up!! (Official Website) 😊 Order Now👈](https://www.diginear.com/2PGQH1JJ/ZDFM5CX/)**
Also Read
https://www.diginear.com/2PGQH1JJ/Z9MTN5X/
https://www.diginear.com/2PGQH1JJ/Z9WS3SZ/
https://www.diginear.com/2PGQH1JJ/XSZCHQH/
https://www.diginear.com/2PGQH1JJ/ZD6NPNW/
https://www.diginear.com/2PGQH1JJ/ZD156QG
|
dongseon/q_noSlippery
|
dongseon
| 2025-05-27T12:16:24Z
| 0
| 0
| null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-05-27T12:16:19Z
|
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q_noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dongseon/q_noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
MatteoBucc/passphrase-identification-roberta-base-qqp-epoch-4
|
MatteoBucc
| 2025-05-27T12:14:13Z
| 1
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:FacebookAI/roberta-base",
"base_model:adapter:FacebookAI/roberta-base",
"region:us"
] | null | 2025-05-14T14:11:52Z
|
---
base_model: roberta-base
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
Hsianchengfun/pruned_30_dt_dp_100epoch
|
Hsianchengfun
| 2025-05-27T12:11:50Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T12:08:21Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
slecas/llama_8B_ibd_test_a
|
slecas
| 2025-05-27T12:11:13Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"trl",
"sft",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T11:19:16Z
|
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lisabdunlap/balanced_sft_long-1e4-systems-prompt_e2
|
lisabdunlap
| 2025-05-27T12:08:58Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/Qwen3-8B",
"base_model:finetune:unsloth/Qwen3-8B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T12:08:01Z
|
---
base_model: unsloth/Qwen3-8B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lisabdunlap
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-8B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Cloudmaster/Llama-3.2-3B-torchao-final02
|
Cloudmaster
| 2025-05-27T12:07:50Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"torchao",
"region:us"
] |
text-generation
| 2025-05-27T12:02:06Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aamijar/Llama-2-7b-hf-lora-r128-boolq-portlora-epochs0
|
aamijar
| 2025-05-27T12:07:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T12:07:39Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jeongseokoh/llama3_8b-with-conclusion-Alphabet_False_Multiple2_aggr_last_starting_with_inst_withOutEmbed
|
jeongseokoh
| 2025-05-27T12:03:24Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T11:56:34Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Darkhn/llamatest-EXL2-4.58bpw-H6
|
Darkhn
| 2025-05-27T12:02:15Z
| 0
| 0
|
exllamav2
|
[
"exllamav2",
"quantized",
"license:mit",
"region:us"
] | null | 2025-05-27T11:38:08Z
|
---
library_name: exllamav2
license: mit
tags:
- exllamav2
- quantized
---
# llamatest-EXL2-4.58bpw-H6
EXL2 quantized model of `unsloth/Llama-3.2-1B-Instruct` (the original base model).
## Quantization Details
- **Bits per weight (bpw):** 4.58
- **Head Bits:** 6
- **Calibration Source:** Measurement derived from model weights (no explicit dataset calibration or provided measurement for this specific quantization pass).
Quantized using the [exllamav2 library](https://github.com/turboderp/exllamav2).
|
TanAlexanderlz/ALL_RGBCROP_ori16F-8B16F-GWlr-cosine
|
TanAlexanderlz
| 2025-05-27T12:01:19Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base-finetuned-kinetics",
"base_model:finetune:MCG-NJU/videomae-base-finetuned-kinetics",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2025-05-27T10:49:47Z
|
---
library_name: transformers
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base-finetuned-kinetics
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: ALL_RGBCROP_ori16F-8B16F-GWlr-cosine
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ALL_RGBCROP_ori16F-8B16F-GWlr-cosine
This model is a fine-tuned version of [MCG-NJU/videomae-base-finetuned-kinetics](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3658
- Accuracy: 0.8623
Best Checkpoint : 240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 1152
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.6775 | 0.0417 | 48 | 0.7147 | 0.4695 |
| 0.5877 | 1.0417 | 96 | 0.6383 | 0.6220 |
| 0.3375 | 2.0417 | 144 | 0.5176 | 0.7317 |
| 0.219 | 3.0417 | 192 | 0.4915 | 0.7805 |
| 0.0698 | 4.0417 | 240 | 0.5611 | 0.8110 |
| 0.0587 | 5.0417 | 288 | 0.6506 | 0.7927 |
| 0.0194 | 6.0417 | 336 | 0.7638 | 0.7988 |
| 0.0029 | 7.0417 | 384 | 0.9139 | 0.7805 |
| 0.0023 | 8.0417 | 432 | 0.9306 | 0.7988 |
| 0.0033 | 9.0417 | 480 | 0.9203 | 0.7988 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Mass-14/MNLP_M2_rag_model
|
Mass-14
| 2025-05-27T11:57:41Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"feature-extraction",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-05-27T11:56:29Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
KetoBurner/KetoBurner
|
KetoBurner
| 2025-05-27T11:52:17Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-05-27T11:51:15Z
|
---
license: apache-2.0
---
ما هو Keto Burner؟
Keto Burner حبوب كبسولة لإنقاص الوزن، مصممة لدعم الأفراد الذين يسعون إلى نمط حياة صحي من خلال التحكم الطبيعي في الوزن. صُممت هذه الكبسولة خصيصًا لمن يعانون من الدهون العنيدة، وتقلبات مستويات الطاقة، وبطء عملية الأيض، لتكون حليفًا موثوقًا به في رحلة لياقتك. بخلاف الحلول قصيرة المدى أو الحميات الغذائية القاسية، تُركز Keto Burner كبسولة على تحسين قدرة جسمك على التحكم في وزنك بفعالية أكبر مع مرور الوقت.
الموقع الرسمي:<a href="https://www.nutritionsee.com/ketourneunisia">www.KetoBurner.com</a>
<p><a href="https://www.nutritionsee.com/ketourneunisia"> <img src="https://www.nutritionsee.com/wp-content/uploads/2025/05/Keto-Burner.png" alt="enter image description here"> </a></p>
<a href="https://www.nutritionsee.com/ketourneunisia">اشترِ الآن! انقر على الرابط أدناه لمزيد من المعلومات واحصل على خصم ٥٠٪ الآن... سارع!</a>
الموقع الرسمي:<a href="https://www.nutritionsee.com/ketourneunisia">www.KetoBurner.com</a>
|
BootesVoid/cmb6fhkup04helexpqayylopn_cmb6fmqxu04i1lexpafcu98v2
|
BootesVoid
| 2025-05-27T11:50:47Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-05-27T11:50:46Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: lucy
---
# Cmb6Fhkup04Helexpqayylopn_Cmb6Fmqxu04I1Lexpafcu98V2
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `lucy` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "lucy",
"lora_weights": "https://huggingface.co/BootesVoid/cmb6fhkup04helexpqayylopn_cmb6fmqxu04i1lexpafcu98v2/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmb6fhkup04helexpqayylopn_cmb6fmqxu04i1lexpafcu98v2', weight_name='lora.safetensors')
image = pipeline('lucy').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmb6fhkup04helexpqayylopn_cmb6fmqxu04i1lexpafcu98v2/discussions) to add images that show off what you’ve made with this LoRA.
|
BKM1804/SmolLM-135M-Instruct-4643c60e-bad6-442a-bae2-dd7473506d71-phase1
|
BKM1804
| 2025-05-27T11:49:55Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"base_model:unsloth/SmolLM-135M-Instruct",
"base_model:finetune:unsloth/SmolLM-135M-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-05-26T11:10:01Z
|
---
base_model: unsloth/SmolLM-135M-Instruct
library_name: transformers
model_name: SmolLM-135M-Instruct-4643c60e-bad6-442a-bae2-dd7473506d71-phase1
tags:
- generated_from_trainer
- unsloth
- trl
- sft
licence: license
---
# Model Card for SmolLM-135M-Instruct-4643c60e-bad6-442a-bae2-dd7473506d71-phase1
This model is a fine-tuned version of [unsloth/SmolLM-135M-Instruct](https://huggingface.co/unsloth/SmolLM-135M-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="BKM1804/SmolLM-135M-Instruct-4643c60e-bad6-442a-bae2-dd7473506d71-phase1", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/buikhacminh1804/sn56-sft-before-dpo-train/runs/mwlnysly)
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
LakshmiDataScientist/peft_model
|
LakshmiDataScientist
| 2025-05-27T11:49:18Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T11:49:10Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
arnaultsta/MNLP_M2_rag_model
|
arnaultsta
| 2025-05-27T11:48:51Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T11:48:24Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
DaniloNeto/roco_qlora_qwen2
|
DaniloNeto
| 2025-05-27T11:47:11Z
| 5
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"feature-extraction",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-05-27T00:50:38Z
|
---
base_model: unsloth/qwen2-vl-2b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** DaniloNeto
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2-vl-2b-instruct-bnb-4bit
This qwen2_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
HPLT/hplt2c_eng50-tur50_checkpoints
|
HPLT
| 2025-05-27T11:46:00Z
| 0
| 0
| null |
[
"pytorch",
"llama",
"HPLT",
"decoder",
"en",
"tr",
"dataset:HPLT/HPLT2.0_cleaned",
"arxiv:2503.10267",
"license:apache-2.0",
"region:us"
] | null | 2025-05-26T08:49:52Z
|
---
language:
- en
- tr
tags:
- HPLT
- decoder
license: apache-2.0
datasets:
- HPLT/HPLT2.0_cleaned
---
# HPLT v2.0 - Cleaned - English (50%), Turkish (50%)
<img src="https://hplt-project.org/_next/static/media/logo-hplt.d5e16ca5.svg" width=12.5%>
This is one of the decoder-only language models trained on [HPLT2.0_cleaned](https://huggingface.co/datasets/HPLT/HPLT2.0_cleaned).
All the HPLT decoder-only models use the same hyper-parameters, roughly following the llama architecture with 2.15B parameters in total:
- hidden size: 2048
- attention heads: 32
- layers: 24
- sequence length: 2048
## Intermediate checkpoints
We are releasing intermediate checkpoints for each model at intervals of every 1000 training steps in separate branches. The naming convention is `checkpoint_00xxxx00`: for example, `checkpoint_0005000`. The checkpoints range from checkpoint_0001000 to checkpoint_0047684 and the latter is in the main branch.
## Cite us
```bibtex
@misc{burchell2025expandedmassivemultilingualdataset,
title={An Expanded Massive Multilingual Dataset for High-Performance Language Technologies},
author={Laurie Burchell and Ona de Gibert and Nikolay Arefyev and Mikko Aulamo and Marta Bañón and Pinzhen Chen and Mariia Fedorova and Liane Guillou and Barry Haddow and Jan Hajič and Jindřich Helcl and Erik Henriksson and Mateusz Klimaszewski and Ville Komulainen and Andrey Kutuzov and Joona Kytöniemi and Veronika Laippala and Petter Mæhlum and Bhavitvya Malik and Farrokh Mehryary and Vladislav Mikhailov and Nikita Moghe and Amanda Myntti and Dayyán O'Brien and Stephan Oepen and Proyag Pal and Jousia Piha and Sampo Pyysalo and Gema Ramírez-Sánchez and David Samuel and Pavel Stepachev and Jörg Tiedemann and Dušan Variš and Tereza Vojtěchová and Jaume Zaragoza-Bernabeu},
year={2025},
eprint={2503.10267},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.10267},
}
```
|
JesseLiu/llama32-1b-kpath-partial-naive-grpo-lora
|
JesseLiu
| 2025-05-27T11:44:33Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:adapter:meta-llama/Llama-3.2-1B-Instruct",
"region:us"
] | null | 2025-05-27T11:44:07Z
|
---
base_model: meta-llama/Llama-3.2-1B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
aamijar/Llama-2-7b-hf-lora-r8-boolq-portlora
|
aamijar
| 2025-05-27T11:44:31Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T11:44:29Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aamijar/Llama-2-7b-hf-lora-r8-boolq-portlora-epochs9
|
aamijar
| 2025-05-27T11:44:29Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T11:44:27Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
stochastic-parrots/MNLP_M2_dpo_model
|
stochastic-parrots
| 2025-05-27T11:44:26Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"dpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T11:43:06Z
|
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
VerifiedPrompts/CNTXT-Filter-Prompt-Opt
|
VerifiedPrompts
| 2025-05-27T11:43:28Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"prompt-filtering",
"moderation",
"en",
"dataset:VerifiedPrompts/cntxt-class-final",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-05-27T07:55:35Z
|
---
license: mit
tags:
- text-classification
- prompt-filtering
- moderation
- distilbert
- transformers
datasets:
- VerifiedPrompts/cntxt-class-final
language:
- en
pipeline_tag: text-classification
widget:
- text: "Write a LinkedIn post about eco-friendly tech for Gen Z entrepreneurs."
example_title: Context-rich prompt
- text: "Write something"
example_title: Vague prompt
---
# 📘 Model Card: CNTXT-Filter-Prompt-Opt
## 🔍 Model Overview
**CNTXT-Filter-Prompt-Opt** is a lightweight, high-accuracy text classification model designed to evaluate the **contextual completeness of user prompts** submitted to LLMs.
It acts as a **gatekeeper** before generation, helping eliminate vague or spam-like input and ensuring only quality prompts proceed to LLM2.
- **Base model**: `distilbert-base-uncased`
- **Trained on**: 200k labeled prompts
- **Purpose**: Prompt validation, spam filtering, and context enforcement
---
## 🎯 Intended Use
This model is intended for:
- Pre-processing prompts before LLM2 generation
- Blocking unclear or context-poor requests
- Structuring user input pipelines in AI apps, bots, and assistants
---
## 🔢 Labels
The model classifies prompts into 3 categories:
| Label | Description |
|-------|-------------|
| `has context` | Prompt is clear, actionable, and self-contained |
| `missing platform, audience, budget, goal` | Prompt lacks structural clarity |
| `Intent is unclear, Please input more context` | Vague or incoherent prompt |
---
## 📊 Training Details
- **Model**: `distilbert-base-uncased`
- **Training method**: Hugging Face AutoTrain
- **Dataset size**: 200,000 prompts (curated, curriculum style)
- **Epochs**: 3
- **Batch size**: 8
- **Max seq length**: 128
- **Mixed Precision**: `fp16`
- **LoRA**: ❌ Disabled
- **Optimizer**: AdamW
---
## ✅ Evaluation
| Metric | Score |
|--------|-------|
| Accuracy | 1.0 |
| F1 (macro/micro/weighted) | 1.0 |
| Precision / Recall | 1.0 |
| Validation Loss | 0.0 |
The model generalizes extremely well on all validation samples.
---
## ⚙️ How to Use
```python
from transformers import pipeline
classifier = pipeline("text-classification", model="VerifiedPrompts/CNTXT-Filter-Prompt-Opt")
prompt = "Write a business plan for a freelance app in Canada."
result = classifier(prompt)
print(result)
# [{'label': 'has context', 'score': 0.98}]
|
hunter12441/model
|
hunter12441
| 2025-05-27T11:42:53Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T11:34:00Z
|
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** hunter12441
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
John6666/luminarqmix-v7-noobaixl-illustriousxl-anime-style-merge-model-v70-vpred-mature-sdxl
|
John6666
| 2025-05-27T11:40:32Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"girls",
"cute",
"hands",
"human body",
"flatter shading",
"mature",
"merge",
"v-pred",
"Illustrious XL v2.0",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-XL-v2.0",
"base_model:merge:OnomaAIResearch/Illustrious-XL-v2.0",
"base_model:cyberdelia/CyberIllustrious",
"base_model:merge:cyberdelia/CyberIllustrious",
"base_model:hybskgks28275/LuminarQMix",
"base_model:merge:hybskgks28275/LuminarQMix",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-05-27T11:34:39Z
|
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- girls
- cute
- hands
- human body
- flatter shading
- mature
- merge
- v-pred
- Illustrious XL v2.0
- illustrious
base_model:
- hybskgks28275/LuminarQMix
- cyberdelia/CyberIllustrious
- OnomaAIResearch/Illustrious-XL-v2.0
---
Original model is [here](https://huggingface.co/hybskgks28275/LuminarQMix) and on [Civitai](https://civitai.com/models/1616309?modelVersionId=1837502).
The author is [here](https://huggingface.co/hybskgks28275)
This model created by [hybskgks28275](https://civitai.com/user/hybskgks28275).
|
alpcaferoglu/Qwen2.5-Coder-3B-Instruct_bd_cs_t2sws-t2s_r64_a64_e1_bs2_gas4_lr0.0002_sftreason
|
alpcaferoglu
| 2025-05-27T11:38:42Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-27T02:27:20Z
|
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
beanne-valerie-dela-cruz-viral-video/1.Viral.beanne-valerie-dela-cruz-beanne-dela-cruz-viral-video-beanne-valerie-delacruz-telegram
|
beanne-valerie-dela-cruz-viral-video
| 2025-05-27T11:38:28Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-05-27T11:37:52Z
|
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ff">►►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤️​</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ff">🔴►𝐂𝐋𝐈𝐂𝐊 𝐇𝐄𝐑𝐄 🌐==►► 𝐃𝐨𝐰𝐧𝐥𝐨𝐚𝐝 𝐍𝐨𝐰⬇️⬇️​</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ff"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
|
tripolskypetr/gemma-3-27B-it-qat-GGUF
|
tripolskypetr
| 2025-05-27T11:36:21Z
| 0
| 0
| null |
[
"gguf",
"image-text-to-text",
"base_model:google/gemma-3-27b-it",
"base_model:quantized:google/gemma-3-27b-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] |
image-text-to-text
| 2025-05-26T14:21:53Z
|
---
pipeline_tag: image-text-to-text
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
license: gemma
extra_gated_heading: Access Gemma on Hugging Face
base_model: google/gemma-3-27b-it
---
## 💫 Community Model> gemma 3 27b it by Google
*👾 [LM Studio](https://lmstudio.ai) Community models highlights program. Highlighting new & noteworthy models by the community. Join the conversation on [Discord](https://discord.gg/aPQfnNkxGC)*.
**Model creator:** [google](https://huggingface.co/google)<br>
**Original model**: [gemma-3-27b-it](https://huggingface.co/google/gemma-3-27b-it)<br>
**GGUF quantization:** provided by Google<br>
## Technical Details
Optimized with Quantization Aware Training for improved 4-bit performance.
Supports a context length of 128k tokens, with a max output of 8192.
Multimodal supporting images normalized to 896 x 896 resolution.
Gemma 3 models are well-suited for a variety of text generation and image understanding tasks, including question answering, summarization, and reasoning.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
## Disclaimers
LM Studio is not the creator, originator, or owner of any Model featured in the Community Model Program. Each Community Model is created and provided by third parties. LM Studio does not endorse, support, represent or guarantee the completeness, truthfulness, accuracy, or reliability of any Community Model. You understand that Community Models can produce content that might be offensive, harmful, inaccurate or otherwise inappropriate, or deceptive. Each Community Model is the sole responsibility of the person or entity who originated such Model. LM Studio may not monitor or control the Community Models and cannot, and does not, take responsibility for any such Model. LM Studio disclaims all warranties or guarantees about the accuracy, reliability or benefits of the Community Models. LM Studio further disclaims any warranty that the Community Model will meet your requirements, be secure, uninterrupted or available at any time or location, or error-free, viruses-free, or that any errors will be corrected, or otherwise. You will be solely responsible for any damage resulting from your use of or access to the Community Models, your downloading of any Community Model, or use of any other Community Model provided by or through LM Studio.
|
nickname19/First_T5
|
nickname19
| 2025-05-27T11:34:45Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-05-27T11:33:48Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
07-Sophie-Rain-Spider-Man-Videos/Sophie.Rain.Spiderman.Video.Tutorial.Viral.Full.Video
|
07-Sophie-Rain-Spider-Man-Videos
| 2025-05-27T11:34:40Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-05-27T11:34:19Z
|
18 seconds ago
<a href="https://tv2online.com/Leaked/?v=Sophie+Rain+Spiderman" rel="nofollow">►►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤️</a></p>
<a href="https://tv2online.com/Leaked/?v=Sophie+Rain+Spiderman" rel="nofollow">🔴►𝐂𝐋𝐈𝐂𝐊 𝐇𝐄𝐑𝐄 🌐==►► 𝐃𝐨𝐰𝐧𝐥𝐨𝐚𝐝 𝐍𝐨𝐰⬇️⬇️</a></p>
<p><a rel="nofollow" title="WATCH NOW" href="https://tv2online.com/Leaked/?v=Sophie+Rain+Spiderman"><img border="Sophie+Rain+Spidermanno" height="480" width="720" title="WATCH NOW" alt="WATCH NOW" src="https://i.ibb.co.com/xMMVF88/686577567.gif"></a></p>
Sophie Rain Spiderman Video Tutorial Original Video video oficial twitter
L𝚎aked Video Sophie Rain Spiderman Video Tutorial Original Video Viral Video L𝚎aked on X Twitter
. . . . . . . . . L𝚎aked Video Sophie Rain Spiderman Video Tutorial Original Video Viral Video L𝚎aked on X Twitter Telegram
L𝚎aked Video Sophie Rain Spiderman Video Tutorial Original Video Viral Video L𝚎aked on X Twitter
Sophie Rain Spiderman Video Tutorial Original Video video oficial twitter
|
nattkorat/scibert-base-uncased-ner
|
nattkorat
| 2025-05-27T11:33:34Z
| 17
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:allenai/scibert_scivocab_uncased",
"base_model:finetune:allenai/scibert_scivocab_uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-05-17T07:22:26Z
|
---
library_name: transformers
base_model: allenai/scibert_scivocab_uncased
tags:
- generated_from_trainer
model-index:
- name: scibert-base-uncased-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scibert-base-uncased-ner
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0191
- Cases: {'precision': 0.9767981438515081, 'recall': 0.967816091954023, 'f1': 0.972286374133949, 'number': 435}
- Country: {'precision': 0.9751332149200711, 'recall': 1.0, 'f1': 0.9874100719424461, 'number': 549}
- Date: {'precision': 0.9706896551724138, 'recall': 0.9690189328743546, 'f1': 0.9698535745047373, 'number': 581}
- Deaths: {'precision': 0.9529411764705882, 'recall': 0.9501466275659824, 'f1': 0.9515418502202643, 'number': 341}
- Virus: {'precision': 0.9963235294117647, 'recall': 0.998158379373849, 'f1': 0.9972401103955841, 'number': 543}
- Overall Precision: 0.9760
- Overall Recall: 0.9796
- Overall F1: 0.9778
- Overall Accuracy: 0.9923
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cases | Country | Date | Deaths | Virus | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| No log | 1.0 | 291 | 0.0411 | {'precision': 0.90744920993228, 'recall': 0.9241379310344827, 'f1': 0.9157175398633258, 'number': 435} | {'precision': 0.9699646643109541, 'recall': 1.0, 'f1': 0.9847533632286996, 'number': 549} | {'precision': 0.9149305555555556, 'recall': 0.9070567986230637, 'f1': 0.9109766637856526, 'number': 581} | {'precision': 0.8830769230769231, 'recall': 0.841642228739003, 'f1': 0.8618618618618619, 'number': 341} | {'precision': 0.9889908256880734, 'recall': 0.992633517495396, 'f1': 0.9908088235294119, 'number': 543} | 0.9385 | 0.9408 | 0.9396 | 0.9861 |
| 0.1005 | 2.0 | 582 | 0.0291 | {'precision': 0.9733656174334141, 'recall': 0.9241379310344827, 'f1': 0.9481132075471699, 'number': 435} | {'precision': 0.9699646643109541, 'recall': 1.0, 'f1': 0.9847533632286996, 'number': 549} | {'precision': 0.9512195121951219, 'recall': 0.9397590361445783, 'f1': 0.9454545454545454, 'number': 581} | {'precision': 0.9161849710982659, 'recall': 0.9296187683284457, 'f1': 0.9228529839883551, 'number': 341} | {'precision': 0.9889908256880734, 'recall': 0.992633517495396, 'f1': 0.9908088235294119, 'number': 543} | 0.9628 | 0.9608 | 0.9618 | 0.9910 |
| 0.1005 | 3.0 | 873 | 0.0221 | {'precision': 0.9764705882352941, 'recall': 0.9540229885057471, 'f1': 0.9651162790697674, 'number': 435} | {'precision': 0.9751332149200711, 'recall': 1.0, 'f1': 0.9874100719424461, 'number': 549} | {'precision': 0.9706896551724138, 'recall': 0.9690189328743546, 'f1': 0.9698535745047373, 'number': 581} | {'precision': 0.9552238805970149, 'recall': 0.9384164222873901, 'f1': 0.9467455621301775, 'number': 341} | {'precision': 0.9963235294117647, 'recall': 0.998158379373849, 'f1': 0.9972401103955841, 'number': 543} | 0.9763 | 0.9755 | 0.9759 | 0.9929 |
| 0.0237 | 4.0 | 1164 | 0.0216 | {'precision': 0.9789719626168224, 'recall': 0.9632183908045977, 'f1': 0.9710312862108922, 'number': 435} | {'precision': 0.9751332149200711, 'recall': 1.0, 'f1': 0.9874100719424461, 'number': 549} | {'precision': 0.9740034662045061, 'recall': 0.9672977624784854, 'f1': 0.9706390328151987, 'number': 581} | {'precision': 0.9502923976608187, 'recall': 0.9530791788856305, 'f1': 0.951683748169839, 'number': 341} | {'precision': 0.9944954128440368, 'recall': 0.998158379373849, 'f1': 0.9963235294117647, 'number': 543} | 0.9764 | 0.9788 | 0.9776 | 0.9921 |
| 0.0237 | 5.0 | 1455 | 0.0191 | {'precision': 0.9767981438515081, 'recall': 0.967816091954023, 'f1': 0.972286374133949, 'number': 435} | {'precision': 0.9751332149200711, 'recall': 1.0, 'f1': 0.9874100719424461, 'number': 549} | {'precision': 0.9706896551724138, 'recall': 0.9690189328743546, 'f1': 0.9698535745047373, 'number': 581} | {'precision': 0.9529411764705882, 'recall': 0.9501466275659824, 'f1': 0.9515418502202643, 'number': 341} | {'precision': 0.9963235294117647, 'recall': 0.998158379373849, 'f1': 0.9972401103955841, 'number': 543} | 0.9760 | 0.9796 | 0.9778 | 0.9923 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.5.1+cu121
- Datasets 3.5.0
- Tokenizers 0.21.1
|
Cloudmaster/Llama-3.2-3B-torchao-final01
|
Cloudmaster
| 2025-05-27T11:31:26Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"torchao",
"region:us"
] |
text-generation
| 2025-05-27T11:27:37Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ganesh004/ppo-LunarLander-v2-TEST
|
ganesh004
| 2025-05-27T11:30:47Z
| 0
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-05-27T11:30:27Z
|
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 245.31 +/- 21.85
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nattkorat/biobert-base-uncased-ner
|
nattkorat
| 2025-05-27T11:30:41Z
| 12
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:dmis-lab/biobert-v1.1",
"base_model:finetune:dmis-lab/biobert-v1.1",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-05-17T07:40:16Z
|
---
library_name: transformers
base_model: dmis-lab/biobert-v1.1
tags:
- generated_from_trainer
model-index:
- name: biobert-base-uncased-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biobert-base-uncased-ner
This model is a fine-tuned version of [dmis-lab/biobert-v1.1](https://huggingface.co/dmis-lab/biobert-v1.1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0299
- Cases: {'precision': 0.963963963963964, 'recall': 0.9705215419501134, 'f1': 0.9672316384180792, 'number': 441}
- Country: {'precision': 0.9926062846580407, 'recall': 0.9962894248608535, 'f1': 0.9944444444444445, 'number': 539}
- Date: {'precision': 0.9637931034482758, 'recall': 0.9704861111111112, 'f1': 0.9671280276816608, 'number': 576}
- Deaths: {'precision': 0.9224376731301939, 'recall': 0.9596541786743515, 'f1': 0.9406779661016949, 'number': 347}
- Virus: {'precision': 0.9927140255009107, 'recall': 0.9927140255009107, 'f1': 0.9927140255009107, 'number': 549}
- Overall Precision: 0.9705
- Overall Recall: 0.9796
- Overall F1: 0.9750
- Overall Accuracy: 0.9923
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cases | Country | Date | Deaths | Virus | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| No log | 1.0 | 291 | 0.0329 | {'precision': 0.9712918660287081, 'recall': 0.9206349206349206, 'f1': 0.9452852153667054, 'number': 441} | {'precision': 0.988950276243094, 'recall': 0.9962894248608535, 'f1': 0.9926062846580408, 'number': 539} | {'precision': 0.9498269896193772, 'recall': 0.953125, 'f1': 0.951473136915078, 'number': 576} | {'precision': 0.9388379204892966, 'recall': 0.8847262247838616, 'f1': 0.9109792284866469, 'number': 347} | {'precision': 0.9926873857404022, 'recall': 0.9890710382513661, 'f1': 0.990875912408759, 'number': 549} | 0.9706 | 0.9551 | 0.9628 | 0.9901 |
| 0.0216 | 2.0 | 582 | 0.0336 | {'precision': 0.9527027027027027, 'recall': 0.9591836734693877, 'f1': 0.9559322033898305, 'number': 441} | {'precision': 0.9907749077490775, 'recall': 0.9962894248608535, 'f1': 0.9935245143385755, 'number': 539} | {'precision': 0.9616724738675958, 'recall': 0.9583333333333334, 'f1': 0.96, 'number': 576} | {'precision': 0.9010989010989011, 'recall': 0.9452449567723343, 'f1': 0.9226441631504924, 'number': 347} | {'precision': 0.9908759124087592, 'recall': 0.9890710382513661, 'f1': 0.9899726526891522, 'number': 549} | 0.9640 | 0.9719 | 0.9679 | 0.9907 |
| 0.0216 | 3.0 | 873 | 0.0345 | {'precision': 0.9555555555555556, 'recall': 0.9750566893424036, 'f1': 0.9652076318742986, 'number': 441} | {'precision': 0.9926062846580407, 'recall': 0.9962894248608535, 'f1': 0.9944444444444445, 'number': 539} | {'precision': 0.9536082474226805, 'recall': 0.9635416666666666, 'f1': 0.9585492227979275, 'number': 576} | {'precision': 0.9131652661064426, 'recall': 0.9394812680115274, 'f1': 0.9261363636363636, 'number': 347} | {'precision': 0.990909090909091, 'recall': 0.9927140255009107, 'f1': 0.991810737033667, 'number': 549} | 0.9649 | 0.9759 | 0.9704 | 0.9914 |
| 0.0126 | 4.0 | 1164 | 0.0292 | {'precision': 0.9682539682539683, 'recall': 0.9682539682539683, 'f1': 0.9682539682539683, 'number': 441} | {'precision': 0.9907749077490775, 'recall': 0.9962894248608535, 'f1': 0.9935245143385755, 'number': 539} | {'precision': 0.9655172413793104, 'recall': 0.9722222222222222, 'f1': 0.9688581314878894, 'number': 576} | {'precision': 0.9301675977653632, 'recall': 0.9596541786743515, 'f1': 0.9446808510638297, 'number': 347} | {'precision': 0.9927140255009107, 'recall': 0.9927140255009107, 'f1': 0.9927140255009107, 'number': 549} | 0.9725 | 0.9796 | 0.9760 | 0.9925 |
| 0.0126 | 5.0 | 1455 | 0.0299 | {'precision': 0.963963963963964, 'recall': 0.9705215419501134, 'f1': 0.9672316384180792, 'number': 441} | {'precision': 0.9926062846580407, 'recall': 0.9962894248608535, 'f1': 0.9944444444444445, 'number': 539} | {'precision': 0.9637931034482758, 'recall': 0.9704861111111112, 'f1': 0.9671280276816608, 'number': 576} | {'precision': 0.9224376731301939, 'recall': 0.9596541786743515, 'f1': 0.9406779661016949, 'number': 347} | {'precision': 0.9927140255009107, 'recall': 0.9927140255009107, 'f1': 0.9927140255009107, 'number': 549} | 0.9705 | 0.9796 | 0.9750 | 0.9923 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.5.1+cu121
- Datasets 3.5.0
- Tokenizers 0.21.1
|
madhueb/MNLP_M2_dpo_model
|
madhueb
| 2025-05-27T11:29:22Z
| 8
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"dpo",
"conversational",
"dataset:madhueb/MNLP_M2_dpo_dataset",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-25T15:58:34Z
|
---
library_name: transformers
tags:
- trl
- dpo
datasets:
- madhueb/MNLP_M2_dpo_dataset
---
- **Developed by:** Madeleine Hueber
- **Language(s) (NLP):** English
- **License:** For academic use only
- **Finetuned from model:** Qwen3-0.6B-Base
This model is a preference-aligned language model fine-tuned for answering STEM-related instruction prompts. It was developed as part of the M2 deliverable for the CS-552 course Modern Natural Language Processing.
# Training Details:
- Stage 1: Instruction tuning on a subset of TIGER-Lab/WebInstructSub (200k data , aivalable on the train_instruct split of madhueb/MNLP_M2_dpo_dataset )
- Stage 2: DPO fine-tuning using the train split of madhueb/MNLP_M2_dpo_dataset.
|
kevanme/Practica1
|
kevanme
| 2025-05-27T11:28:56Z
| 0
| 0
|
fastai
|
[
"fastai",
"region:us"
] | null | 2025-02-13T17:07:30Z
|
---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
Hsianchengfun/pruned_55_dt_dp_100epoch
|
Hsianchengfun
| 2025-05-27T11:27:44Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T11:24:47Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nattkorat/bert-base-uncased-ner
|
nattkorat
| 2025-05-27T11:26:12Z
| 33
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-05-07T08:25:41Z
|
---
library_name: transformers
license: apache-2.0
base_model: google-bert/bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-ner
This model is a fine-tuned version of [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0459
- Cases: {'precision': 0.9311111111111111, 'recall': 0.95662100456621, 'f1': 0.9436936936936937, 'number': 438}
- Country: {'precision': 0.9640933572710951, 'recall': 0.9926062846580407, 'f1': 0.9781420765027322, 'number': 541}
- Date: {'precision': 0.9480968858131488, 'recall': 0.9547038327526133, 'f1': 0.951388888888889, 'number': 574}
- Deaths: {'precision': 0.877906976744186, 'recall': 0.8961424332344213, 'f1': 0.8869309838472834, 'number': 337}
- Virus: {'precision': 0.9526315789473684, 'recall': 0.985480943738657, 'f1': 0.9687778768956289, 'number': 551}
- Overall Precision: 0.9400
- Overall Recall: 0.9623
- Overall F1: 0.9510
- Overall Accuracy: 0.9827
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cases | Country | Date | Deaths | Virus | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| No log | 1.0 | 291 | 0.0806 | {'precision': 0.9074889867841409, 'recall': 0.9406392694063926, 'f1': 0.9237668161434976, 'number': 438} | {'precision': 0.9853479853479854, 'recall': 0.9944547134935305, 'f1': 0.9898804047838086, 'number': 541} | {'precision': 0.9320557491289199, 'recall': 0.9320557491289199, 'f1': 0.9320557491289199, 'number': 574} | {'precision': 0.8575757575757575, 'recall': 0.8397626112759644, 'f1': 0.848575712143928, 'number': 337} | {'precision': 0.9526315789473684, 'recall': 0.985480943738657, 'f1': 0.9687778768956289, 'number': 551} | 0.9341 | 0.9467 | 0.9404 | 0.9778 |
| 0.1433 | 2.0 | 582 | 0.0586 | {'precision': 0.9280898876404494, 'recall': 0.9429223744292238, 'f1': 0.9354473386183466, 'number': 438} | {'precision': 0.9781818181818182, 'recall': 0.9944547134935305, 'f1': 0.9862511457378552, 'number': 541} | {'precision': 0.9363166953528399, 'recall': 0.9477351916376306, 'f1': 0.941991341991342, 'number': 574} | {'precision': 0.8662790697674418, 'recall': 0.884272997032641, 'f1': 0.8751835535976507, 'number': 337} | {'precision': 0.9627659574468085, 'recall': 0.985480943738657, 'f1': 0.9739910313901345, 'number': 551} | 0.9404 | 0.9570 | 0.9486 | 0.9811 |
| 0.1433 | 3.0 | 873 | 0.0482 | {'precision': 0.9317180616740088, 'recall': 0.9657534246575342, 'f1': 0.9484304932735426, 'number': 438} | {'precision': 0.9728260869565217, 'recall': 0.9926062846580407, 'f1': 0.9826166514181153, 'number': 541} | {'precision': 0.9463667820069204, 'recall': 0.9529616724738676, 'f1': 0.9496527777777778, 'number': 574} | {'precision': 0.8922155688622755, 'recall': 0.884272997032641, 'f1': 0.8882265275707899, 'number': 337} | {'precision': 0.9410745233968805, 'recall': 0.985480943738657, 'f1': 0.9627659574468086, 'number': 551} | 0.9411 | 0.9619 | 0.9514 | 0.9823 |
| 0.033 | 4.0 | 1164 | 0.0492 | {'precision': 0.9395973154362416, 'recall': 0.958904109589041, 'f1': 0.9491525423728814, 'number': 438} | {'precision': 0.9640933572710951, 'recall': 0.9926062846580407, 'f1': 0.9781420765027322, 'number': 541} | {'precision': 0.9515570934256056, 'recall': 0.9581881533101045, 'f1': 0.9548611111111112, 'number': 574} | {'precision': 0.8753623188405797, 'recall': 0.8961424332344213, 'f1': 0.8856304985337242, 'number': 337} | {'precision': 0.9593639575971732, 'recall': 0.985480943738657, 'f1': 0.97224709042077, 'number': 551} | 0.9434 | 0.9635 | 0.9534 | 0.9830 |
| 0.033 | 5.0 | 1455 | 0.0459 | {'precision': 0.9311111111111111, 'recall': 0.95662100456621, 'f1': 0.9436936936936937, 'number': 438} | {'precision': 0.9640933572710951, 'recall': 0.9926062846580407, 'f1': 0.9781420765027322, 'number': 541} | {'precision': 0.9480968858131488, 'recall': 0.9547038327526133, 'f1': 0.951388888888889, 'number': 574} | {'precision': 0.877906976744186, 'recall': 0.8961424332344213, 'f1': 0.8869309838472834, 'number': 337} | {'precision': 0.9526315789473684, 'recall': 0.985480943738657, 'f1': 0.9687778768956289, 'number': 551} | 0.9400 | 0.9623 | 0.9510 | 0.9827 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.5.1+cu121
- Datasets 3.5.0
- Tokenizers 0.21.1
|
Mass-14/MNLP_M2_document_encoder
|
Mass-14
| 2025-05-27T11:25:54Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-05-27T11:25:10Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.