
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-05 12:28:32
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 468
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-05 12:27:45
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
prathamjagga/output2 | prathamjagga | 2024-03-19T14:52:03Z | 162 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T14:51:41Z | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: output2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2120
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6754 | 1.0 | 500 | 1.2120 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Tokenizers 0.15.2
|
Elkelouizajo/BERT_mnli_xlarge_10K | Elkelouizajo | 2024-03-19T14:49:30Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-large-cased",
"base_model:finetune:google-bert/bert-large-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T10:45:57Z | ---
license: apache-2.0
base_model: google-bert/bert-large-cased
tags:
- generated_from_trainer
model-index:
- name: results_bert_xlarge
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results_bert_xlarge
This model is a fine-tuned version of [google-bert/bert-large-cased](https://huggingface.co/google-bert/bert-large-cased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 8446
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 11.0
### Training results
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
textminr/ner-bert | textminr | 2024-03-19T14:49:21Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-03-19T13:39:56Z | ---
license: apache-2.0
base_model: bert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: ner-bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ner-bert
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0002
- Precision: 1.0
- Recall: 0.9993
- F1: 0.9997
- Accuracy: 1.0000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0005 | 0.1 | 250 | 0.0047 | 0.9998 | 0.9861 | 0.9929 | 0.9994 |
| 0.009 | 0.2 | 500 | 0.0041 | 0.9961 | 0.9864 | 0.9912 | 0.9994 |
| 0.0004 | 0.3 | 750 | 0.0024 | 0.9977 | 0.9895 | 0.9936 | 0.9995 |
| 0.0001 | 0.4 | 1000 | 0.0010 | 0.9984 | 0.9975 | 0.9980 | 0.9999 |
| 0.0001 | 0.51 | 1250 | 0.0008 | 1.0 | 0.9975 | 0.9987 | 0.9999 |
| 0.0001 | 0.61 | 1500 | 0.0005 | 1.0 | 0.9975 | 0.9987 | 0.9999 |
| 0.0003 | 0.71 | 1750 | 0.0003 | 1.0 | 0.9991 | 0.9995 | 1.0000 |
| 0.0001 | 0.81 | 2000 | 0.0002 | 1.0 | 0.9993 | 0.9997 | 1.0000 |
| 0.0 | 0.91 | 2250 | 0.0002 | 1.0 | 0.9993 | 0.9997 | 1.0000 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
quocviethere/alberta-finetuned-squadv2 | quocviethere | 2024-03-19T14:45:18Z | 108 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"albert",
"question-answering",
"generated_from_trainer",
"base_model:albert/albert-base-v2",
"base_model:finetune:albert/albert-base-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-03-19T13:32:51Z | ---
license: apache-2.0
base_model: albert/albert-base-v2
tags:
- generated_from_trainer
model-index:
- name: alberta-finetuned-squadv2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# alberta-finetuned-squadv2
This model is a fine-tuned version of [albert/albert-base-v2](https://huggingface.co/albert/albert-base-v2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.2.1+cu121
- Datasets 2.16.1
- Tokenizers 0.15.2
|
OEvortex/HelpingAI-Vision | OEvortex | 2024-03-19T14:38:53Z | 26 | 6 | transformers | [
"transformers",
"safetensors",
"HelpingAI",
"image-text-to-text",
"custom_code",
"en",
"base_model:visheratin/MC-LLaVA-3b",
"base_model:finetune:visheratin/MC-LLaVA-3b",
"license:other",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-01-19T11:27:11Z | ---
language:
- en
license: other
license_name: hsul
license_link: https://huggingface.co/OEvortex/vortex-3b/raw/main/LICENSE.md
library_name: transformers
base_model: visheratin/MC-LLaVA-3b
widget:
- text: What animal is it?
src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
- text: Where is it?
src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
pipeline_tag: image-text-to-text
---
# HelpingAI-Vision
<a target="_blank" href="https://colab.research.google.com/drive/1t2OAMVSKsiqVgvuHq7rhyNv28b67u0D8">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Model details
The fundamental concept behind HelpingAI-Vision is to generate one token embedding per N parts of an image, as opposed to producing N visual token embeddings for the entire image. This approach, based on the HelpingAI-Lite and incorporating the LLaVA adapter, aims to enhance scene understanding by capturing more detailed information.
For every crop of the image, an embedding is generated using the full SigLIP encoder (size [1, 1152]). Subsequently, all N embeddings undergo processing through the LLaVA adapter, resulting in a token embedding of size [N, 2560]. Currently, these tokens lack explicit information about their position in the original image, with plans to incorporate positional information in a later update.
HelpingAI-Vision was fine-tuned from MC-LLaVA-3b.
The model adopts the ChatML prompt format, suggesting its potential application in chat-based scenarios. If you have specific queries or would like further details, feel free ask
```
<|im_start|>system
You are Vortex, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## How to use
**Install dependencies**
```bash
!pip install -q open_clip_torch timm einops
```
**Download modeling files**
```python
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="OEvortex/HelpingAI-Vision", filename="configuration_llava.py", local_dir="./", force_download=True)
hf_hub_download(repo_id="OEvortex/HelpingAI-Vision", filename="configuration_phi.py", local_dir="./", force_download=True)
hf_hub_download(repo_id="OEvortex/HelpingAI-Vision", filename="modeling_llava.py", local_dir="./", force_download=True)
hf_hub_download(repo_id="OEvortex/HelpingAI-Vision", filename="modeling_phi.py", local_dir="./", force_download=True)
hf_hub_download(repo_id="OEvortex/HelpingAI-Vision", filename="processing_llava.py", local_dir="./", force_download=True)
```
**Create a model**
```python
from modeling_llava import LlavaForConditionalGeneration
import torch
model = LlavaForConditionalGeneration.from_pretrained("OEvortex/HelpingAI-Vision", torch_dtype=torch.float16)
model = model.to("cuda")
```
**Create processors**
```python
from transformers import AutoTokenizer
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor
tokenizer = AutoTokenizer.from_pretrained("OEvortex/HelpingAI-Vision")
image_processor = OpenCLIPImageProcessor(model.config.preprocess_config)
processor = LlavaProcessor(image_processor, tokenizer)
```
**Set image and text**
```python
from PIL import Image
import requests
image_file = "https://images.unsplash.com/photo-1439246854758-f686a415d9da"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
prompt = """<|im_start|>system
A chat between a curious human and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the human's questions.
The assistant does not hallucinate and pays very close attention to the details.<|im_end|>
<|im_start|>user
<image>
Describe the image.<|im_end|>
<|im_start|>assistant
"""
```
**Process inputs**
```python
with torch.inference_mode():
inputs = processor(prompt, raw_image, model, return_tensors='pt')
inputs['input_ids'] = inputs['input_ids'].to(model.device)
inputs['attention_mask'] = inputs['attention_mask'].to(model.device)
from transformers import TextStreamer
streamer = TextStreamer(tokenizer)
```
**Generate the data**
```python
%%time
with torch.inference_mode():
output = model.generate(**inputs, max_new_tokens=200, do_sample=True, top_p=0.9, temperature=1.2, eos_token_id=tokenizer.eos_token_id, streamer=streamer)
print(tokenizer.decode(output[0]).replace(prompt, "").replace("<|im_end|>", ""))
``` |
sessex/kvn-LoRA | sessex | 2024-03-19T14:38:26Z | 3 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"dora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-19T14:38:23Z | ---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- dora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: in the style of kvn photography
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - sessex/kvn-LoRA
<Gallery />
## Model description
These are sessex/kvn-LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use in the style of kvn photography to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](sessex/kvn-LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
EngTig/distilroberta-base-finetuned-wikitext2 | EngTig | 2024-03-19T14:38:05Z | 61 | 0 | transformers | [
"transformers",
"tf",
"roberta",
"fill-mask",
"generated_from_keras_callback",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-19T14:36:53Z | ---
license: apache-2.0
base_model: distilroberta-base
tags:
- generated_from_keras_callback
model-index:
- name: EngTig/distilroberta-base-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# EngTig/distilroberta-base-finetuned-wikitext2
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.7852
- Validation Loss: 1.6809
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.7852 | 1.6809 | 0 |
### Framework versions
- Transformers 4.38.2
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
kavya301/falcon-7b-sharded-bf16-finetuned-mental-health-conversational | kavya301 | 2024-03-19T14:35:51Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:ybelkada/falcon-7b-sharded-bf16",
"base_model:adapter:ybelkada/falcon-7b-sharded-bf16",
"region:us"
] | null | 2024-03-19T13:00:09Z | ---
base_model: ybelkada/falcon-7b-sharded-bf16
tags:
- generated_from_trainer
model-index:
- name: falcon-7b-sharded-bf16-finetuned-mental-health-conversational
results: []
library_name: peft
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# falcon-7b-sharded-bf16-finetuned-mental-health-conversational
This model is a fine-tuned version of [ybelkada/falcon-7b-sharded-bf16](https://huggingface.co/ybelkada/falcon-7b-sharded-bf16) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- _load_in_8bit: False
- _load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
- load_in_4bit: True
- load_in_8bit: False
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 320
- mixed_precision_training: Native AMP
### Framework versions
- PEFT 0.5.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.13.1
- Tokenizers 0.15.2
|
tedad09/PolizzeDonut-ConDOC-3Epochs-60img | tedad09 | 2024-03-19T14:34:47Z | 48 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"base_model:finetune:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-03-19T14:28:59Z | ---
license: mit
base_model: tedad09/PolizzeDonut-SoloPDF-3Epochs
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: PolizzeDonut-ConDOC-3Epochs-60img
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PolizzeDonut-ConDOC-3Epochs-60img
This model is a fine-tuned version of [tedad09/PolizzeDonut-SoloPDF-3Epochs](https://huggingface.co/tedad09/PolizzeDonut-SoloPDF-3Epochs) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5633
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0383 | 1.0 | 30 | 0.7194 |
| 0.7271 | 2.0 | 60 | 0.5648 |
| 0.5757 | 3.0 | 90 | 0.5633 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
nwhamed/Marcoro14-7B-slerp | nwhamed | 2024-03-19T14:33:22Z | 0 | 0 | null | [
"merge",
"mergekit",
"lazymergekit",
"AIDC-ai-business/Marcoroni-7B-v3",
"EmbeddedLLM/Mistral-7B-Merge-14-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-03-13T12:04:15Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- AIDC-ai-business/Marcoroni-7B-v3
- EmbeddedLLM/Mistral-7B-Merge-14-v0.1
---
# Marcoro14-7B-slerp
Marcoro14-7B-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [AIDC-ai-business/Marcoroni-7B-v3](https://huggingface.co/AIDC-ai-business/Marcoroni-7B-v3)
* [EmbeddedLLM/Mistral-7B-Merge-14-v0.1](https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: AIDC-ai-business/Marcoroni-7B-v3
layer_range: [0, 32]
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.1
layer_range: [0, 32]
merge_method: slerp
base_model: AIDC-ai-business/Marcoroni-7B-v3
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
mpasila/Capybara-Finnish-V1-8B | mpasila | 2024-03-19T14:32:54Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"bloom",
"text-generation",
"fi",
"dataset:Finnish-NLP/Capybara-fi-deepl-translated-sft",
"dataset:mpasila/Capybara-fi-deepl-translated-sft-alpaca",
"base_model:mpasila/gpt3-finnish-8B-gptq-4bit",
"base_model:finetune:mpasila/gpt3-finnish-8B-gptq-4bit",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-06T22:04:42Z | ---
language:
- fi
pipeline_tag: text-generation
base_model: mpasila/gpt3-finnish-8B-gptq-4bit
license: apache-2.0
datasets:
- Finnish-NLP/Capybara-fi-deepl-translated-sft
- mpasila/Capybara-fi-deepl-translated-sft-alpaca
---
# Model Card for Capybara-Finnish-V1-8B
This is a merge of [mpasila/Capybara-Finnish-V1-8B-LoRA](https://huggingface.co/mpasila/Capybara-Finnish-V1-8B-LoRA/).
Base model used: [mpasila/gpt3-finnish-8B-gptq-4bit](https://huggingface.co/mpasila/gpt3-finnish-8B-gptq-4bit/) and the original unquantized model: [TurkuNLP/gpt3-finnish-8B](https://huggingface.co/TurkuNLP/gpt3-finnish-8B/).
Dataset used with the LoRA is [Finnish-NLP/Capybara-fi-deepl-translated-sft](https://huggingface.co/datasets/Finnish-NLP/Capybara-fi-deepl-translated-sft/) with some modifications so it uses Alpaca formatting [modified dataset](https://huggingface.co/datasets/mpasila/Capybara-fi-deepl-translated-sft-alpaca/).
It uses Alpaca format but with a translated instruction at the start:
```
{
"instruction,output": "Alla on ohje, jossa kuvataan tehtävä. Kirjoita vastaus, joka täyttää pyynnön asianmukaisesti.\n\n### Instruction:\n%instruction%\n\n### Response:\n%output%",
"instruction,input,output": "Alla on ohje, jossa kuvataan tehtävä ja joka on yhdistetty kontekstia lisäävään syötteeseen. Kirjoita vastaus, joka täyttää pyynnön asianmukaisesti.\n\n### Instruction:\n%instruction%\n\n### Input:\n%input%\n\n### Response:\n%output%"
}
```
Merged using this [Colab notebook](https://colab.research.google.com/drive/1a76Y21GfPtmVs71Uztlgk2xzPA4_vVjs?usp=sharing). It might not be the best way to merge a quantized LoRA on to a float16 model but I just wanted to quickly do something. You can try merging it better if you want.
### Framework versions
- PEFT 0.8.2 |
beomi/Mistral-Ko-Inst-dev | beomi | 2024-03-19T14:32:13Z | 14 | 4 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"pytorch",
"conversational",
"ko",
"en",
"dataset:heegyu/kowikitext",
"dataset:heegyu/kowiki-sentences",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T10:00:46Z | ---
license: apache-2.0
datasets:
- heegyu/kowikitext
- heegyu/kowiki-sentences
language:
- ko
- en
library_name: transformers
tags:
- pytorch
---
Experimental Repository :)
Contents will updated without any notice at all. If you plan to use this repository, please use with `revision` with git hash.
This experiment is aimed to:
- Maintain NLU capability of Mistral-Instruct model(mistralai/Mistral-7B-Instruct-v0.1)
- Adapt new Korean vocab seamlessly
- Use minimal dataset (used Korean wikipedia only)
- Computationally efficient method
- Let model answer using English knowledge and NLU capability even the question/answer is Korean only.
Here's some test:
```python
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
'beomi/Mistral-Ko-Inst-dev',
torch_dtype='auto',
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained('beomi/Mistral-Ko-Inst-dev')
pipe = pipeline(
'text-generation',
model=model,
tokenizer=tokenizer,
do_sample=True,
max_new_tokens=350,
return_full_text=False,
no_repeat_ngram_size=6,
eos_token_id=1, # not yet tuned to gen </s>, use <s> instead.
)
def gen(x):
chat = tokenizer.apply_chat_template([
{"role": "user", "content": x},
# {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
# {"role": "user", "content": "Do you have mayonnaise recipes? please say in Korean."}
], tokenize=False)
print(pipe(chat)[0]['generated_text'].strip())
gen("스타벅스와 스타벅스 코리아의 차이는?")
# (생성 예시)
# 스타벅스는 전 세계적으로 운영하고 있는 커피 전문사이다. 한국에는 스타벅스 코리아라는 이름으로 운영되고 있다.
# 스타벅스 코리아는 대한민국에 입점한 이후 2009년과 2010년에 두 차례의 브랜드과의 재검토 및 새로운 디자인을 통해 새로운 브랜드다. 커피 전문의 프리미엄 이미지를 유지하고 있고, 스타벅스 코리아는 한국을 대표하는 프리미엄 커피 전문 브랜드을 만들고 있다.
``` |
automerger/Experiment26Yamshadow-7B | automerger | 2024-03-19T14:31:52Z | 49 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:automerger/YamShadow-7B",
"base_model:finetune:automerger/YamShadow-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-15T02:17:47Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- automerger/YamShadow-7B
---
# Experiment26Yamshadow-7B
Experiment26Yamshadow-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [automerger/YamShadow-7B](https://huggingface.co/automerger/YamShadow-7B)
## 🧩 Configuration
```yaml
models:
- model: rwitz/experiment26-truthy-iter-0
# No parameters necessary for base model
- model: automerger/YamShadow-7B
parameters:
density: 0.53
weight: 0.6
merge_method: dare_ties
base_model: rwitz/experiment26-truthy-iter-0
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/Experiment26Yamshadow-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
mpasila/Capybara-Finnish-V1-8B-LoRA | mpasila | 2024-03-19T14:31:39Z | 0 | 0 | peft | [
"peft",
"safetensors",
"fi",
"dataset:Finnish-NLP/Capybara-fi-deepl-translated-sft",
"dataset:mpasila/Capybara-fi-deepl-translated-sft-alpaca",
"base_model:mpasila/gpt3-finnish-8B-gptq-4bit",
"base_model:adapter:mpasila/gpt3-finnish-8B-gptq-4bit",
"license:apache-2.0",
"region:us"
] | null | 2024-03-06T20:37:09Z | ---
language:
- fi
library_name: peft
base_model: mpasila/gpt3-finnish-8B-gptq-4bit
license: apache-2.0
datasets:
- Finnish-NLP/Capybara-fi-deepl-translated-sft
- mpasila/Capybara-fi-deepl-translated-sft-alpaca
---
# Model Card for Capybara-Finnish-V1-8B-LoRA
LoRA trained using [mpasila/gpt3-finnish-8B-gptq-4bit](https://huggingface.co/mpasila/gpt3-finnish-8B-gptq-4bit/) as the base model. Also the quantized model is based on this [TurkuNLP/gpt3-finnish-8B](https://huggingface.co/TurkuNLP/gpt3-finnish-8B/). Dataset used with the LoRA is [Finnish-NLP/Capybara-fi-deepl-translated-sft](https://huggingface.co/datasets/Finnish-NLP/Capybara-fi-deepl-translated-sft/) with some modifications so it uses Alpaca formatting [modified dataset](https://huggingface.co/datasets/mpasila/Capybara-fi-deepl-translated-sft-alpaca/).
It uses Alpaca format but with a translated instruction at the start:
```
{
"instruction,output": "Alla on ohje, jossa kuvataan tehtävä. Kirjoita vastaus, joka täyttää pyynnön asianmukaisesti.\n\n### Instruction:\n%instruction%\n\n### Response:\n%output%",
"instruction,input,output": "Alla on ohje, jossa kuvataan tehtävä ja joka on yhdistetty kontekstia lisäävään syötteeseen. Kirjoita vastaus, joka täyttää pyynnön asianmukaisesti.\n\n### Instruction:\n%instruction%\n\n### Input:\n%input%\n\n### Response:\n%output%"
}
```
Using the following settings:
```json
{
"lora_name": "Capybara_Finnish_V1",
"always_override": false,
"q_proj_en": true,
"v_proj_en": true,
"k_proj_en": false,
"o_proj_en": false,
"gate_proj_en": false,
"down_proj_en": false,
"up_proj_en": false,
"save_steps": 250.0,
"micro_batch_size": 4,
"batch_size": 128,
"epochs": 3.0,
"learning_rate": "3e-4",
"lr_scheduler_type": "linear",
"lora_rank": 32,
"lora_alpha": 64,
"lora_dropout": 0.05,
"cutoff_len": 256,
"dataset": "capybara_finnish_v1.1",
"eval_dataset": "None",
"format": "alpaca-format-finnish",
"eval_steps": 100.0,
"raw_text_file": "None",
"overlap_len": 128,
"newline_favor_len": 128,
"higher_rank_limit": false,
"warmup_steps": 100.0,
"optimizer": "adamw_torch",
"hard_cut_string": "\\n\\n\\n",
"train_only_after": "",
"stop_at_loss": 0,
"add_eos_token": false,
"min_chars": 0.0,
"report_to": "None"
}
```
### Framework versions
- PEFT 0.8.2 |
ijwatson98/sft-bart-xsum-1903 | ijwatson98 | 2024-03-19T14:27:17Z | 174 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T14:24:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
harsh798/pet | harsh798 | 2024-03-19T14:27:09Z | 2 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T14:23:14Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### pet Dreambooth model trained by harsh798 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 25500121058
Sample pictures of this concept:
.jpg)
|
Denath-Khor/dolphin-2.2.1-mistral-7b-GGUF | Denath-Khor | 2024-03-19T14:24:30Z | 2 | 0 | null | [
"gguf",
"fr",
"en",
"dataset:cognitivecomputations/dolphin",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-19T13:11:37Z | ---
datasets:
- cognitivecomputations/dolphin
language:
- fr
- en
---
Fenris MOBILE GGUF - Q4_K_M - Q8_0
Dolphin-2.2.1-mistral-7b - GGUF
Model creator : Cognitive Computations
Original model : Dolphin-2.2.1-mistral-7b : https://huggingface.co/cognitivecomputations/dolphin-2.2.1-mistral-7b
Description :
This repo contains GGUF format model files for Cognitive Computations's Dolphin-2.2.1-mistral-7b.
Finetuned from :
mistralai/Mistral-7B-v0.1 |
tincans-ai/gazelle-v0.1 | tincans-ai | 2024-03-19T14:24:13Z | 7 | 7 | transformers | [
"transformers",
"safetensors",
"gazelle",
"text2text-generation",
"text-generation",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-05T20:46:14Z | ---
license: apache-2.0
language:
- en
library_name: transformers
pipeline_tag: text-generation
---
# Gazelle
Gazelle v0.1 is a research preview of Tincan's joint speech-language models. The corresponding v0.1 [release notes](https://tincans.ai/slm2) have more details.
We suggest using the v0.2 series: [base](https://huggingface.co/tincans-ai/gazelle-v0.2) or [dpo](https://huggingface.co/tincans-ai/gazelle-v0.2-dpo).
|
sarthakharne/bert-base-70-ep-pretrain-on-textbooks | sarthakharne | 2024-03-19T14:23:45Z | 195 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-19T14:22:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
tedad09/PolizzeDonut-ConDOC-3Epochs-20img | tedad09 | 2024-03-19T14:22:32Z | 53 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"base_model:finetune:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-03-19T14:20:04Z | ---
license: mit
base_model: tedad09/PolizzeDonut-SoloPDF-3Epochs
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: PolizzeDonut-ConDOC-3Epochs-20img
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PolizzeDonut-ConDOC-3Epochs-20img
This model is a fine-tuned version of [tedad09/PolizzeDonut-SoloPDF-3Epochs](https://huggingface.co/tedad09/PolizzeDonut-SoloPDF-3Epochs) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7138
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.11 | 1.0 | 10 | 0.8166 |
| 0.845 | 2.0 | 20 | 0.7362 |
| 0.8439 | 3.0 | 30 | 0.7138 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
cstr/Flora_7B-laser | cstr | 2024-03-19T14:20:40Z | 1 | 0 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-18T13:00:39Z | ---
license: cc-by-sa-4.0
---
experimental laserRMT version of ResplendentAI/Flora_7B |
mvpmaster/MistralDpoPearl-7b-slerp | mvpmaster | 2024-03-19T14:16:33Z | 50 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"louisbrulenaudet/Pearl-7B-slerp",
"NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"base_model:NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"base_model:merge:NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"base_model:louisbrulenaudet/Pearl-7B-slerp",
"base_model:merge:louisbrulenaudet/Pearl-7B-slerp",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T13:51:23Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- louisbrulenaudet/Pearl-7B-slerp
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO
base_model:
- louisbrulenaudet/Pearl-7B-slerp
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO
---
# MistralDpoPearl-7b-slerp
MistralDpoPearl-7b-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [louisbrulenaudet/Pearl-7B-slerp](https://huggingface.co/louisbrulenaudet/Pearl-7B-slerp)
* [NousResearch/Nous-Hermes-2-Mistral-7B-DPO](https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: louisbrulenaudet/Pearl-7B-slerp
layer_range: [0, 32]
- model: NousResearch/Nous-Hermes-2-Mistral-7B-DPO
layer_range: [0, 32]
merge_method: slerp
base_model: louisbrulenaudet/Pearl-7B-slerp
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mvpmaster/MistralDpoPearl-7b-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
tedad09/PolizzeDonut-ConXLS-3Epochs-40img | tedad09 | 2024-03-19T14:14:39Z | 48 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"base_model:finetune:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-03-19T14:10:25Z | ---
license: mit
base_model: tedad09/PolizzeDonut-SoloPDF-3Epochs
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: PolizzeDonut-ConXLS-3Epochs-40img
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PolizzeDonut-ConXLS-3Epochs-40img
This model is a fine-tuned version of [tedad09/PolizzeDonut-SoloPDF-3Epochs](https://huggingface.co/tedad09/PolizzeDonut-SoloPDF-3Epochs) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3055
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0333 | 1.0 | 20 | 0.3278 |
| 0.8567 | 2.0 | 40 | 0.2948 |
| 0.6921 | 3.0 | 60 | 0.3055 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Commencis/Commencis-LLM | Commencis | 2024-03-19T14:12:59Z | 2,915 | 13 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"tr",
"en",
"dataset:uonlp/CulturaX",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-15T17:03:55Z | ---
license: apache-2.0
datasets:
- uonlp/CulturaX
language:
- tr
- en
pipeline_tag: text-generation
metrics:
- accuracy
- bleu
base_model: mistralai/Mistral-7B-Instruct-v0.1
---
# Commencis-LLM
<!-- Provide a quick summary of what the model is/does. -->
Commencis LLM is a generative model based on the Mistral 7B model. The base model adapts Mistral 7B to Turkish Banking specifically by training on a diverse dataset obtained through various methods, encompassing general Turkish and banking data.
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Commencis](https://www.commencis.com)
- **Language(s):** Turkish
- **Finetuned from model:** [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
- **Blog Post**: [LLM Blog](https://www.commencis.com/thoughts/commencis-introduces-its-purpose-built-turkish-fluent-llm-for-banking-and-finance-industry-a-detailed-overview/)
## Training Details
Alignment phase consists of two stages: supervised fine-tuning (SFT) and Reward Modeling with Reinforcement learning from human feedback (RLHF).
The SFT phase was done on the a mixture of synthetic datasets generated from comprehensive banking dictionary data, synthetic datasets generated from banking-based domain and sub-domain headings, and derived from the CulturaX Turkish dataset by filtering. It was trained with three epochs. We used a learning rate 2e-5, lora rank 64 and maximum sequence length 1024 tokens.
### Usage
### Suggested Inference Parameters
- Temperature: 0.5
- Repetition penalty: 1.0
- Top-p: 0.9
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
class TextGenerationAssistant:
def __init__(self, model_id:str):
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
self.model = AutoModelForCausalLM.from_pretrained(model_id, device_map='auto',load_in_8bit=True,load_in_4bit=False)
self.pipe = pipeline("text-generation",
model=self.model,
tokenizer=self.tokenizer,
device_map="auto",
max_new_tokens=1024,
return_full_text=True,
repetition_penalty=1.0
)
self.sampling_params = dict(do_sample=True, temperature=0.5, top_k=50, top_p=0.9)
self.system_prompt = "Sen yardımcı bir asistansın. Sana verilen talimat ve girdilere en uygun cevapları üreteceksin. \n\n\n"
def format_prompt(self, user_input):
return "[INST] " + self.system_prompt + user_input + " [/INST]"
def generate_response(self, user_query):
prompt = self.format_prompt(user_query)
outputs = self.pipe(prompt, **self.sampling_params)
return outputs[0]["generated_text"].split("[/INST]")[1].strip()
assistant = TextGenerationAssistant(model_id="Commencis/Commencis-LLM")
# Enter your query here.
user_query = "Faiz oranı yükseldiğinde kredi maliyetim nasıl etkilenir?"
response = assistant.generate_response(user_query)
print(response)
```
### Chat Template
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "Commencis/Commencis-LLM"
messages = [{"role": "user", "content": "Faiz oranı yükseldiğinde kredi maliyetim nasıl etkilenir?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=1024, do_sample=True, temperature=0.5, top_k=50, top_p=0.9)
print (outputs[0]["generated_text"].split("[/INST]")[1].strip())
```
# Quantized Models:
GGUF: https://huggingface.co/Commencis/Commencis-LLM-GGUF
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Like all LLMs, Commencis-LLM has certain limitations:
- Hallucination: Model may sometimes generate responses that contain plausible-sounding but factually incorrect or irrelevant information.
- Code Switching: The model might unintentionally switch between languages or dialects within a single response, affecting the coherence and understandability of the output.
- Repetition: The Model may produce repetitive phrases or sentences, leading to less engaging and informative responses.
- Coding and Math: The model's performance in generating accurate code or solving complex mathematical problems may be limited.
- Toxicity: The model could inadvertently generate responses containing inappropriate or harmful content. |
nwztest/outputs_cs_only | nwztest | 2024-03-19T14:11:23Z | 2 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:google/gemma-2b-it",
"base_model:adapter:google/gemma-2b-it",
"license:other",
"region:us"
] | null | 2024-03-19T14:02:36Z | ---
license: other
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b-it
model-index:
- name: outputs_cs_only
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs_cs_only
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- training_steps: 11
### Training results
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.1.2
- Datasets 2.16.0
- Tokenizers 0.15.2 |
hellie/conversation-summary | hellie | 2024-03-19T14:10:46Z | 177 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-19T14:10:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
namratanwani/gemma-finetuned-stack-exchange | namratanwani | 2024-03-19T14:10:40Z | 3 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"region:us"
] | null | 2024-03-19T03:28:45Z | ---
library_name: peft
base_model: google/gemma-2b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
tedad09/PolizzeDonut-ConXLS-3Epochs-30img | tedad09 | 2024-03-19T14:09:26Z | 49 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"base_model:finetune:tedad09/PolizzeDonut-SoloPDF-3Epochs",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-03-19T14:06:15Z | ---
license: mit
base_model: tedad09/PolizzeDonut-SoloPDF-3Epochs
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: PolizzeDonut-ConXLS-3Epochs-30img
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PolizzeDonut-ConXLS-3Epochs-30img
This model is a fine-tuned version of [tedad09/PolizzeDonut-SoloPDF-3Epochs](https://huggingface.co/tedad09/PolizzeDonut-SoloPDF-3Epochs) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3119
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.1939 | 1.0 | 15 | 0.2879 |
| 0.9005 | 2.0 | 30 | 0.3223 |
| 0.7769 | 3.0 | 45 | 0.3119 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
ijwatson98/sft-bart-xsum-1803 | ijwatson98 | 2024-03-19T14:08:55Z | 177 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-18T15:41:34Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gosshh/finetuned_ConvNext | gosshh | 2024-03-19T14:07:51Z | 189 | 0 | transformers | [
"transformers",
"safetensors",
"convnext",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-03-19T13:19:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Gaurav Sarkar
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
cenfis/XGLM_TR_FineTune_alpha-original | cenfis | 2024-03-19T14:04:03Z | 0 | 2 | peft | [
"peft",
"safetensors",
"xglm",
"text-generation",
"tr",
"dataset:TFLai/Turkish-Alpaca",
"license:apache-2.0",
"region:us"
] | text-generation | 2023-10-06T05:45:55Z | ---
datasets:
- TFLai/Turkish-Alpaca
language:
- tr
library_name: peft
pipeline_tag: text-generation
license: apache-2.0
---
# (ALPHA) Turkish Instruct LLM Based On Facebook-XGLM
This is one of our early experimental models based on Facebook's XGLM, fine-tuned using PEFT loRA on a Turkish Instruction dataset. Our goal is to share a Turkish LLM model in the future.
The model provided originates from a checkpoint at the 5700th step.
## Inference
Please note, utilizing this model necessitates the download of substantial data files, necessitating a minimum of 24GB VRAM.
Given its experimental nature, it is very likely that this model can produce garbage (biased & wrong) output from time to time, so **use it with caution.**
In order to install PEFT modules, please visit:
* https://github.com/huggingface/peft
### Load the Model
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained("facebook/xglm-7.5B",
quantization_config=bnb_config,
device_map="auto")
model = PeftModel.from_pretrained(model, "myzens/XGLM_TR_FineTune_alpha")
tokenizer = AutoTokenizer.from_pretrained("facebook/xglm-7.5B")
```
### Text Generation Examples
Here's a quick and dirty implementation of a post-processing function in case you want to get rid of any garbage letters etc (if any exists):
```python
import re
def post_process(text, how_many_sentences=5):
start_index = text.find("### Cevap: ") + len("### Cevap: ")
end_index = text.find("️", start_index)
extracted_text = text[start_index:end_index].strip()
sentences = extracted_text.split('.')
sentences = '.'.join(sentences[:how_many_sentences])
cleaned_text = ''.join(ch for ch in sentences if ch.isalnum() or ch.isspace() or ch == ".")
cleaned_text = cleaned_text.replace(" ", " ")
cleaned_text = re.sub('\.\.+', '.', cleaned_text)
cleaned_text = cleaned_text.strip()
return cleaned_text
```
#### Basic Sentiment Analysis
```python
PROMPT = """Aşağıda, daha fazla bağlam sağlayan bir girdi ile eşleştirilmiş bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.
### Talimat: Sana verilen cümleyi olumlu, olumsuz veya tarafsız olarak sınıflandır
### Giriş: Tamam iyi güzel kargo zamanında geliyor. HB ile ilgili bi sıkıntı yok. Ama bu ürün çok kullanışsız.
### Cevap:"""
inputs = tokenizer(PROMPT, return_tensors="pt")
input_ids = inputs["input_ids"].cuda()
generation_output = model.generate(
input_ids=input_ids,
temperature=0.1,
top_p=0.2,
repetition_penalty=1.2,
max_length=128,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
for generated_text in generation_output:
story = tokenizer.decode(generated_text, skip_special_tokens=True)
print(post_process(story, 1)) # Olumsuz
```
#### General
Use `how_many_sentences = -1`.
```python
PROMPT = """Aşağıda, daha fazla bağlam sağlayan bir girdi ile eşleştirilmiş bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.
### Talimat:
### Giriş: Sanatın toplum için önemini açıkla.
### Cevap:"""
inputs = tokenizer(PROMPT, return_tensors="pt")
input_ids = inputs["input_ids"].cuda()
generation_output = model.generate(
input_ids=input_ids,
temperature=0.8,
top_p=0.9,
repetition_penalty=1.2,
max_length=512,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
"""
Sanat insanlığın gelişimine katkıda bulunan önemli bir araçtır ve birçok farklı alanda kullanılabilir.
Örneğin sanat eserleri görsel olarak bilgiyi aktarmak veya duyguları ifade etmek gibi çeşitli amaçlar sağlayabilirler.
Ayrıca sanatçılar yaratıcılıklarını kullanarak yeni fikirler üretebilmelerine olanak tanıyarak toplumun ilerlemesine yardımcı olabilirler.
Son olarak sanatsal ürünler insanlar arasında iletişim kurmaya da yardımcı olurken aynı zamanda kültürel etkileşimde de büyük rol oynarlar.
Bu nedenle sanatın toplumsal faydası yadsınamazdır
"""
```
#### Suggestions
```python
PROMPT = """Aşağıda, daha fazla bağlam sağlayan bir girdi ile eşleştirilmiş bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.
### Talimat:
### Giriş: Ders çalışmak için önerilerde bulun.
### Cevap:"""
generation_output = model.generate(
input_ids=input_ids,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.2,
max_length=512,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
"""
1. Çalışmak istediğiniz konuyu belirleyin ve ders çalışmaya başlamadan önce o konudaki kaynakları araştırın.
2. Dersi takip etmek için düzenli olarak zaman ayırmaya çalışın.
3. Birden çok görev yapmayı deneyin - bu sayede her gün birkaç saatinizi verimli kullanabilirsiniz.
4. Herhangi bir soru veya sorunla karşılaştığınız anda öğretmeninize danışın.
5. Kendinizi motive etmenin yollarına odaklanın - böylece kendinize güvenebilirsiniz ve motivasyonunuzu sürdürmek kolaylaşır.
6. Öğrenme sürecinde hata yapmaktan korkmayın! Hatalar öğrenmenin doğal bir parçasıdır; ancak yanlış yaptığınızda düzeltmeniz gereken şeylerin farkına varmanız önemlidir.
7. Başarısızlık duygusunu kabul edin ve başarının yolunu bulmanıza yardımcı olacak yeni yollar arayın.
8. Başkalarına yardım etmeye çalışarak kendi gelişiminize katkı sağlayın.
9. Sınavlara hazırlık yaparken dikkat dağıtıcı aktivitelerden kaçının.
10. Sonunda başarılı olduğunuzun garantisini vermeyin. Bu sadece sizi stresli hale getirebilir.
11. Deneme sınavlarını tekrarlayın ve sonuçları değerlendirerek ilerlemeyi izleyin.
12. Daha iyi sonuçlar elde etme yolunda adım atmak için sabırlı olun.
13. Yeni bilgiler öğrendiğinizde bunları paylaşmayı unutmayın.
14. Motivasyonunu kaybetmekten korkan öğrencilerle iletişim kurmaktan çekinmeyin.
15. Soru sorduğunuzda olumlu geri bildirim almak önemli olduğundan emin olun.
16. Arkadaşlarınızla birlikte çalışırken destekleyici olmakta fayda vardır.
17. Öğretmeniniz tarafından verilen ödevleri eksiksiz yapın.
18. Dikkat dağıtan diğer etkinliklerden uzak durun.
19. Zaman yönetimini öğrenin ve planlı hareket ederek zamanı etkili kullanın.
20. Uyku düzenini koruyun ve sağlıklı beslenmeye özen gösterin.
21. Stresle başa çıkma becerilerinizi geliştirin.
22. Hayatınızda başkalarının da sizin gibi zorluklar yaşadığını hatırlayın.
23. Farkındalık yaratmak için farklı yöntemler deneyerek zihinsel sağlığınızı korumaya çalışın.
24. Eğer yeterince konsantre olamıyorsanız dinlenmeye izin verin.
"""
```
### Future Steps
1) We are aiming to decrease the inference cost while maintaining the quality in the outputs.
2) We'll continue to improve our dataset.
### Contact
We would like to thank [Ünver Çiftçi](https://www.linkedin.com/in/unverciftci/) who has connected us in the first place.
| | Task | LinkedIn | GitHub |
|:---:|:---:|:---:|:---:|
| Kaan Bıçakcı | Training + Data Preprocessing | [Contact](https://www.linkedin.com/in/kaanbicakci/) | https://github.com/Frightera |
| Talha Rüzgar Akkuş | Data Collection + General Idea | [Contact](https://www.linkedin.com/in/talha-r%C3%BCzgar-akku%C5%9F-1b5457264/) | https://github.com/LegallyCoder |
| Ethem Yağız Çalık | Data Collection + General Idea | [Contact](https://www.linkedin.com/in/ethem-ya%C4%9F%C4%B1z-%C3%A7al%C4%B1k-799a73275/) | https://github.com/Weyaxi | |
desarrolloasesoreslocales/bert-corpus-ft | desarrolloasesoreslocales | 2024-03-19T14:03:20Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-19T14:02:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Commencis/Commencis-LLM-GGUF | Commencis | 2024-03-19T13:59:28Z | 40 | 7 | transformers | [
"transformers",
"gguf",
"commencis",
"mistral",
"turkish",
"text-generation",
"tr",
"en",
"base_model:Commencis/Commencis-LLM",
"base_model:quantized:Commencis/Commencis-LLM",
"license:apache-2.0",
"region:us",
"conversational"
] | text-generation | 2024-03-18T06:12:48Z | ---
model_name: Commencis-LLM
model_creator: Commencis
base_model: Commencis/Commencis-LLM
language:
- tr
- en
pipeline_tag: text-generation
license: apache-2.0
library_name: transformers
inference: false
tags:
- commencis
- mistral
- turkish
---
## Commencis LLM Quantized models and methods
| Name | Quant method | Bits | Size | Use case |
| ---- | ---- | ---- | ---- | ----- |
| [Commencis-LLM.Q2_K.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q2_K.gguf) | Q2_K | 2 | 2.72 GB | smallest, significant quality loss - not recommended for most purposes |
| [Commencis-LLM.Q3_K_S.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB | very small, high quality loss |
| [Commencis-LLM.Q3_K_M.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB | very small, high quality loss |
| [Commencis-LLM.Q3_K_L.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB | small, substantial quality loss |
| [Commencis-LLM.Q4_0.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q4_0.gguf) | Q4_0 | 4 | 4.11 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [Commencis-LLM.Q4_K_S.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB | small, greater quality loss |
| [Commencis-LLM.Q4_K_M.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB | medium, balanced quality - recommended |
| [Commencis-LLM.Q5_0.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q5_0.gguf) | Q5_0 | 5 | 5 GB| legacy; medium, balanced quality - prefer using Q4_K_M |
| [Commencis-LLM.Q5_K_S.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q5_K_S.gguf) | Q5_K_S | 5 | 5 GB | large, low quality loss - recommended |
| [Commencis-LLM.Q5_K_M.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| large, very low quality loss - recommended |
| [Commencis-LLM.Q6_K.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q6_K.gguf) | Q6_K | 6 | 5.94 GB | very large, extremely low quality loss |
| [Commencis-LLM.Q8_0.gguf](https://huggingface.co/Commencis/Commencis-LLM-GGUF/blob/main/commencis-llm-Q8_0.gguf) | Q8_0 | 8 | 7.7 GB | very large, extremely low quality loss - not recommended |
|
arpanl/finetuned_model | arpanl | 2024-03-19T13:56:12Z | 192 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-03-19T13:36:46Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: finetuned_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_model
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
SeeonQwQ/blip2_frame_v3.3 | SeeonQwQ | 2024-03-19T13:55:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-19T13:55:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
arvnoodle/hcl-gemma-2b-javascript-lotuscript | arvnoodle | 2024-03-19T13:50:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma",
"trl",
"en",
"base_model:unsloth/gemma-2b-bnb-4bit",
"base_model:finetune:unsloth/gemma-2b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-03-19T13:50:24Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
base_model: unsloth/gemma-2b-bnb-4bit
---
# Uploaded model
- **Developed by:** arvnoodle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-2b-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Samuael/amhat5-base-finetuned | Samuael | 2024-03-19T13:45:12Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-09T22:40:10Z | ---
tags:
- generated_from_trainer
model-index:
- name: amhat5-base-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# amhat5-base-finetuned
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
ZJZAC/dog6_nop | ZJZAC | 2024-03-19T13:41:19Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T13:11:39Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
inference: true
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks dog
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - ZJZAC/dog6_nop
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
sarthakharne/bert-base-65-ep-pretrain-on-textbooks | sarthakharne | 2024-03-19T13:40:08Z | 195 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-19T13:37:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Kaushik1705/detr-resnet-50_finetuned_cppe5 | Kaushik1705 | 2024-03-19T13:34:02Z | 188 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | 2024-03-19T11:39:01Z | ---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: detr-resnet-50_finetuned_cppe5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-resnet-50_finetuned_cppe5
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
zxe123456/corgy_dog_LoRA | zxe123456 | 2024-03-19T13:26:08Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"dora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-19T10:16:05Z | ---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- dora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- dora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of couplepeople
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - zxe123456/corgy_dog_LoRA
<Gallery />
## Model description
These are zxe123456/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of couplepeople to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](zxe123456/corgy_dog_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
winglian/mistral-orpo | winglian | 2024-03-19T13:25:52Z | 4 | 3 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T13:23:49Z | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- generated_from_trainer
model-index:
- name: out
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: mistralai/Mistral-7B-v0.1
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
load_in_8bit: false
load_in_4bit: false
strict: false
rl: orpo
chat_template: inst
datasets:
- path: argilla/ultrafeedback-binarized-preferences-cleaned
type: orpo.chat_template
chat_template: inst
dataset_prepared_path:
val_set_size: 0.0
output_dir: ./out
remove_unused_columns: false
sequence_len: 1024
sample_packing: false
pad_to_sequence_len: false
eval_sample_packing: false
wandb_project: orpo
wandb_entity: oaaic
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 3e-6
orpo_alpha: 0.1
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 100
evals_per_epoch:
eval_table_size:
eval_max_new_tokens: 128
saves_per_epoch: 4
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
```
</details><br>
# out
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.0
|
adedamola26/bart-finetuned-samsum | adedamola26 | 2024-03-19T13:25:44Z | 122 | 0 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:samsum",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2024-03-11T01:03:01Z | ---
pipeline_tag: summarization
datasets:
- samsum
language:
- en
metrics:
- rouge
library_name: transformers
widget:
- text: |
Rita: I'm so bloody tired. Falling asleep at work. :-(
Tina: I know what you mean.
Tina: I keep on nodding off at my keyboard hoping that the boss doesn't notice..
Rita: The time just keeps on dragging on and on and on....
Rita: I keep on looking at the clock and there's still 4 hours of this drudgery to go.
Tina: Times like these I really hate my work.
Rita: I'm really not cut out for this level of boredom.
Tina: Neither am I.
- text: |
Beatrice: I am in town, shopping. They have nice scarfs in the shop next to the church. Do you want one?
Leo: No, thanks
Beatrice: But you don't have a scarf.
Leo: Because I don't need it.
Beatrice: Last winter you had a cold all the time. A scarf could help.
Leo: I don't like them.
Beatrice: Actually, I don't care. You will get a scarf.
Leo: How understanding of you!
Beatrice: You were complaining the whole winter that you're going to die. I've had enough.
Leo: Eh.
- text: |
Jack: Cocktails later?
May: YES!!!
May: You read my mind...
Jack: Possibly a little tightly strung today?
May: Sigh... without question.
Jack: Thought so.
May: A little drink will help!
Jack: Maybe two!
model-index:
- name: bart-finetuned-samsum
results:
- task:
name: Text Summarization
type: summarization
dataset:
name: SamSum
type: samsum
metrics:
- name: Validation ROUGE-1
type: rouge-1
value: 53.6163
- name: Validation ROUGE-2
type: rouge-2
value: 28.914
- name: Validation ROUGE-L
type: rougeL
value: 44.1443
- name: Validation ROUGE-L Sum
type: rougeLsum
value: 49.2995
---
# Description
This model was trained by fine-tuning the [facebook/bart-large-xsum](https://huggingface.co/facebook/bart-large-xsum) model using [these parameters](#training-parameters) and the [samsum dataset](https://huggingface.co/datasets/samsum).
## Development
- Jupyter Notebook: [Text Summarization With BART](https://github.com/adedamola26/text-summarization/blob/main/Text_Summarization_with_BART.ipynb)
## Usage
```python
from transformers import pipeline
model = pipeline("summarization", model="adedamolade26/bart-finetuned-samsum")
conversation = '''Jack: Cocktails later?
May: YES!!!
May: You read my mind...
Jack: Possibly a little tightly strung today?
May: Sigh... without question.
Jack: Thought so.
May: A little drink will help!
Jack: Maybe two!
'''
model(conversation)
```
## Training Parameters
```python
evaluation_strategy = "epoch",
save_strategy = 'epoch',
load_best_model_at_end = True,
metric_for_best_model = 'eval_loss',
seed = 42,
learning_rate=2e-5,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=2,
weight_decay=0.01,
save_total_limit=2,
num_train_epochs=4,
predict_with_generate=True,
fp16=True,
report_to="none"
```
## References
Model Training process was adapted from Luis Fernando Torres's [Kaggle Notebook](https://www.kaggle.com/code/lusfernandotorres/text-summarization-with-large-language-models): 📝 Text Summarization with Large Language Models
|
sinhala-nlp/NSINA-Category-sinbert-small | sinhala-nlp | 2024-03-19T13:25:32Z | 108 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"si",
"dataset:sinhala-nlp/NSINA",
"dataset:sinhala-nlp/NSINA-Categories",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T13:24:21Z | ---
license: cc-by-sa-4.0
datasets:
- sinhala-nlp/NSINA
- sinhala-nlp/NSINA-Categories
language:
- si
---
# Sinhala News Category Prediction
This is a text classification task created with the [NSINA dataset](https://github.com/Sinhala-NLP/NSINA). This dataset is also released with the same license as NSINA. Given the news content, the ML models should predict a pre-defined category for the news.
## Data
First, for this task, we dropped all the news articles in NSINA 1.0 without a category as some news sources prefer not to categorise them. Next, we identified the top 100 news categories from the available news instances. We grouped possible categories into four main categories: local news, international news, sports news, and business news. To avoid bias, we undersampled the dataset. We only used 10,000 instances from each category, and for the ``Business" category, we used the original number of instances which was 8777 articles. We divided this dataset into a training and test set following a 0.8 split
Data can be loaded into pandas dataframes using the following code.
```python
from datasets import Dataset
from datasets import load_dataset
train = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Categories', split='train'))
test = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Categories', split='test'))
```
## Citation
If you are using the dataset or the models, please cite the following paper.
~~~
@inproceedings{Nsina2024,
author={Hettiarachchi, Hansi and Premasiri, Damith and Uyangodage, Lasitha and Ranasinghe, Tharindu},
title={{NSINA: A News Corpus for Sinhala}},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
year={2024},
month={May},
}
~~~ |
IntelLabs/eftnas-s2-bert-medium | IntelLabs | 2024-03-19T13:24:24Z | 0 | 1 | null | [
"en",
"dataset:nyu-mll/glue",
"license:apache-2.0",
"region:us"
] | null | 2024-03-15T12:13:15Z | ---
language: en
license: apache-2.0
datasets:
- nyu-mll/glue
---
# EFTNAS Model Card: eftnas-s2-bert-medium
The super-networks fine-tuned on BERT-medium with [GLUE benchmark](https://gluebenchmark.com/) using EFTNAS.
## Model Details
### Information
- **Model name:** eftnas-s2-bert-medium-[TASK]
- **Base model:** [google/bert_uncased_L-8_H-512_A-8](https://huggingface.co/google/bert_uncased_L-8_H-512_A-8)
- **Subnetwork version:** Super-network
- **NNCF Configurations:** [eftnas_configs](https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/EFTNAS/eftnas_configs)
### Training and Evaluation
[GLUE benchmark](https://gluebenchmark.com/)
## Results
Results of the optimal sub-network discoverd from the super-network:
| Model | GFLOPs | GLUE Avg. | MNLI-m | QNLI | QQP | SST-2 | CoLA | MRPC | RTE |
|-------------------------------|-----------|---------------|----------|------|----------|----------|----------|----------|------|
| **Test Set:** |
| [**EFTNAS-S1**]() | 5.7 | 77.7 | 83.7 | 89.9 | 71.8 | 93.4 | 52.6 | 87.6 | 65.0 |
| [**EFTNAS-S2**]() | 2.2 | 75.2 | 82.0 | 87.8 | 70.6 | 91.4 | 44.5 | 86.1 | 64.0 |
## Model Sources
- **Repository:** [https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/EFTNAS](https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/EFTNAS)
- **Paper:** [Searching for Efficient Language Models in First-Order Weight-Reordered Super-Networks]()
## Citation
```bibtex
@inproceedings{
eftnas2024,
title={Searching for Efficient Language Models in First-Order Weight-Reordered Super-Networks},
author={J. Pablo Munoz and Yi Zheng and Nilesh Jain},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation},
year={2024},
url={}
}
```
## License
Apache-2.0
|
sinhala-nlp/NSINA-Category-sinbert-large | sinhala-nlp | 2024-03-19T13:23:54Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"si",
"dataset:sinhala-nlp/NSINA",
"dataset:sinhala-nlp/NSINA-Categories",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T13:19:58Z | ---
license: cc-by-sa-4.0
datasets:
- sinhala-nlp/NSINA
- sinhala-nlp/NSINA-Categories
language:
- si
---
# Sinhala News Category Prediction
This is a text classification task created with the [NSINA dataset](https://github.com/Sinhala-NLP/NSINA). This dataset is also released with the same license as NSINA. Given the news content, the ML models should predict a pre-defined category for the news.
## Data
First, for this task, we dropped all the news articles in NSINA 1.0 without a category as some news sources prefer not to categorise them. Next, we identified the top 100 news categories from the available news instances. We grouped possible categories into four main categories: local news, international news, sports news, and business news. To avoid bias, we undersampled the dataset. We only used 10,000 instances from each category, and for the ``Business" category, we used the original number of instances which was 8777 articles. We divided this dataset into a training and test set following a 0.8 split
Data can be loaded into pandas dataframes using the following code.
```python
from datasets import Dataset
from datasets import load_dataset
train = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Categories', split='train'))
test = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Categories', split='test'))
```
## Citation
If you are using the dataset or the models, please cite the following paper.
~~~
@inproceedings{Nsina2024,
author={Hettiarachchi, Hansi and Premasiri, Damith and Uyangodage, Lasitha and Ranasinghe, Tharindu},
title={{NSINA: A News Corpus for Sinhala}},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
year={2024},
month={May},
}
~~~ |
Aryanne/CalderaAI_Hexoteric-7B-F16 | Aryanne | 2024-03-19T13:17:43Z | 20 | 1 | transformers | [
"transformers",
"safetensors",
"gguf",
"mistral",
"text-generation",
"mergekit",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-18T18:40:24Z | ---
library_name: transformers
tags:
- mergekit
license: apache-2.0
---
### This is not a Merge
I just used mergekit to convert to f16 this model [CalderaAI/Hexoteric-7B](https://huggingface.co/CalderaAI/Hexoteric-7B).
### Configuration
The following YAML configuration was used to produce this model:
```yaml
base_model:
model:
path: CalderaAI/Hexoteric-7B
dtype: float16
merge_method: task_arithmetic
slices:
- sources:
- layer_range: [0, 32]
model:
model:
path: CalderaAI/Hexoteric-7B
parameters:
weight: 1.0
``` |
sinhala-nlp/NSINA-Category-xlmr-large | sinhala-nlp | 2024-03-19T13:11:33Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"si",
"dataset:sinhala-nlp/NSINA",
"dataset:sinhala-nlp/NSINA-Categories",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-18T20:59:43Z | ---
license: cc-by-sa-4.0
datasets:
- sinhala-nlp/NSINA
- sinhala-nlp/NSINA-Categories
language:
- si
---
# Sinhala News Category Prediction
This is a text classification task created with the [NSINA dataset](https://github.com/Sinhala-NLP/NSINA). This dataset is also released with the same license as NSINA. Given the news content, the ML models should predict a pre-defined category for the news.
## Data
First, for this task, we dropped all the news articles in NSINA 1.0 without a category as some news sources prefer not to categorise them. Next, we identified the top 100 news categories from the available news instances. We grouped possible categories into four main categories: local news, international news, sports news, and business news. To avoid bias, we undersampled the dataset. We only used 10,000 instances from each category, and for the ``Business" category, we used the original number of instances which was 8777 articles. We divided this dataset into a training and test set following a 0.8 split
Data can be loaded into pandas dataframes using the following code.
```python
from datasets import Dataset
from datasets import load_dataset
train = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Categories', split='train'))
test = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Categories', split='test'))
```
## Citation
If you are using the dataset or the models, please cite the following paper.
~~~
@inproceedings{Nsina2024,
author={Hettiarachchi, Hansi and Premasiri, Damith and Uyangodage, Lasitha and Ranasinghe, Tharindu},
title={{NSINA: A News Corpus for Sinhala}},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
year={2024},
month={May},
}
~~~ |
OEvortex/PixelGen | OEvortex | 2024-03-19T13:01:39Z | 54 | 11 | diffusers | [
"diffusers",
"pytorch",
"safetensors",
"PixelGen",
"HelpingAI",
"text-to-image",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-03-18T15:10:33Z | ---
pipeline_tag: text-to-image
license_name: hsul
license_link: https://huggingface.co/OEvortex/vortex-3b/raw/main/LICENSE.md
language:
- en
tags:
- PixelGen
- HelpingAI
license: other
---
## PixelGen: Text-to-Image Generation Model
### Overview
PixelGen, developed by HelpingAI, is a Text-to-Image generation model. It enables the generation of high-quality images from textual descriptions, offering a versatile tool for various creative and practical applications.
### Features
- **Text-to-Image Generation**: PixelGen translates textual descriptions into visually appealing images.
- **Large Model Size**: With 3.47 billion parameters, PixelGen can capture intricate details in generated images. |
vibber/decim8 | vibber | 2024-03-19T13:00:32Z | 3 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-19T13:00:25Z | ---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
widget:
- text: in the style of <s0><s1>
output:
url: image-0.png
- text: in the style of <s0><s1>
output:
url: image-1.png
- text: in the style of <s0><s1>
output:
url: image-2.png
- text: in the style of <s0><s1>
output:
url: image-3.png
- text: in the style of <s0><s1>
output:
url: image-4.png
- text: in the style of <s0><s1>
output:
url: image-5.png
- text: in the style of <s0><s1>
output:
url: image-6.png
- text: in the style of <s0><s1>
output:
url: image-7.png
- text: in the style of <s0><s1>
output:
url: image-8.png
- text: in the style of <s0><s1>
output:
url: image-9.png
- text: in the style of <s0><s1>
output:
url: image-10.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: in the style of <s0><s1>
license: openrail++
---
# SDXL LoRA DreamBooth - vibber/decim8
<Gallery />
## Model description
### These are vibber/decim8 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
## Download model
### Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- **LoRA**: download **[`decim8.safetensors` here 💾](/vibber/decim8/blob/main/decim8.safetensors)**.
- Place it on your `models/Lora` folder.
- On AUTOMATIC1111, load the LoRA by adding `<lora:decim8:1>` to your prompt. On ComfyUI just [load it as a regular LoRA](https://comfyanonymous.github.io/ComfyUI_examples/lora/).
- *Embeddings*: download **[`decim8_emb.safetensors` here 💾](/vibber/decim8/blob/main/decim8_emb.safetensors)**.
- Place it on it on your `embeddings` folder
- Use it by adding `decim8_emb` to your prompt. For example, `in the style of decim8_emb`
(you need both the LoRA and the embeddings as they were trained together for this LoRA)
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('vibber/decim8', weight_name='pytorch_lora_weights.safetensors')
embedding_path = hf_hub_download(repo_id='vibber/decim8', filename='decim8_emb.safetensors' repo_type="model")
state_dict = load_file(embedding_path)
pipeline.load_textual_inversion(state_dict["clip_l"], token=["<s0>", "<s1>"], text_encoder=pipeline.text_encoder, tokenizer=pipeline.tokenizer)
pipeline.load_textual_inversion(state_dict["clip_g"], token=["<s0>", "<s1>"], text_encoder=pipeline.text_encoder_2, tokenizer=pipeline.tokenizer_2)
image = pipeline('in the style of <s0><s1>').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Trigger words
To trigger image generation of trained concept(or concepts) replace each concept identifier in you prompt with the new inserted tokens:
to trigger concept `TOK` → use `<s0><s1>` in your prompt
## Details
All [Files & versions](/vibber/decim8/tree/main).
The weights were trained using [🧨 diffusers Advanced Dreambooth Training Script](https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py).
LoRA for the text encoder was enabled. False.
Pivotal tuning was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
zxe123456/corgy_couplepeople_LoRA | zxe123456 | 2024-03-19T12:59:42Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"dora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-19T12:56:50Z | ---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- dora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- dora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- dora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of TOK dog
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - zxe123456/corgy_couplepeople_LoRA
<Gallery />
## Model description
These are zxe123456/corgy_couplepeople_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of TOK dog to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](zxe123456/corgy_couplepeople_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
tomaszki/mistral-14-copy | tomaszki | 2024-03-19T12:58:24Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T12:55:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sarthakharne/bert-base-60-ep-pretrain-on-textbooks | sarthakharne | 2024-03-19T12:55:51Z | 196 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-19T12:54:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
deepnet/SN6-70M8 | deepnet | 2024-03-19T12:52:07Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T11:21:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kalese/opus-mt-en-bkm-10e64 | kalese | 2024-03-19T12:45:37Z | 104 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"marian",
"text2text-generation",
"generated_from_trainer",
"dataset:arrow",
"base_model:Helsinki-NLP/opus-mt-en-ro",
"base_model:finetune:Helsinki-NLP/opus-mt-en-ro",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-19T11:27:17Z | ---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-ro
tags:
- generated_from_trainer
datasets:
- arrow
metrics:
- bleu
model-index:
- name: opus-mt-en-bkm-10e64
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: arrow
type: arrow
config: default
split: train
args: default
metrics:
- name: Bleu
type: bleu
value: 7.795
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-bkm-10e64
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ro](https://huggingface.co/Helsinki-NLP/opus-mt-en-ro) on the arrow dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4935
- Bleu: 7.795
- Gen Len: 60.8227
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 279 | 2.2834 | 1.3309 | 68.9546 |
| 3.1609 | 2.0 | 558 | 1.8907 | 4.0661 | 60.289 |
| 3.1609 | 3.0 | 837 | 1.7445 | 5.2814 | 59.5739 |
| 1.9255 | 4.0 | 1116 | 1.6564 | 6.0017 | 61.6317 |
| 1.9255 | 5.0 | 1395 | 1.5978 | 6.5742 | 60.6533 |
| 1.7347 | 6.0 | 1674 | 1.5572 | 7.0291 | 61.3661 |
| 1.7347 | 7.0 | 1953 | 1.5287 | 7.4536 | 60.8991 |
| 1.642 | 8.0 | 2232 | 1.5092 | 7.6945 | 60.6611 |
| 1.5888 | 9.0 | 2511 | 1.4971 | 7.7436 | 60.8317 |
| 1.5888 | 10.0 | 2790 | 1.4935 | 7.795 | 60.8227 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
lokaspire/simplrops_rule_based | lokaspire | 2024-03-19T12:39:19Z | 4 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-03-19T12:12:48Z | ---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: mistralai/Mistral-7B-Instruct-v0.2
model-index:
- name: simplrops_rule_based
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# simplrops_rule_based
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.1.0+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2 |
kallam/Mixtral-8x7B-It-v0.1 | kallam | 2024-03-19T12:37:42Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"fr",
"it",
"de",
"es",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T12:37:41Z | ---
license: apache-2.0
language:
- fr
- it
- de
- es
- en
inference:
parameters:
temperature: 0.5
widget:
- messages:
- role: user
content: What is your favorite condiment?
---
# Model Card for Mixtral-8x7B
The Mixtral-8x7B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts. The Mixtral-8x7B outperforms Llama 2 70B on most benchmarks we tested.
For full details of this model please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/).
## Warning
This repo contains weights that are compatible with [vLLM](https://github.com/vllm-project/vllm) serving of the model as well as Hugging Face [transformers](https://github.com/huggingface/transformers) library. It is based on the original Mixtral [torrent release](magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce), but the file format and parameter names are different. Please note that model cannot (yet) be instantiated with HF.
## Instruction format
This format must be strictly respected, otherwise the model will generate sub-optimal outputs.
The template used to build a prompt for the Instruct model is defined as follows:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
Note that `<s>` and `</s>` are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
As reference, here is the pseudo-code used to tokenize instructions during fine-tuning:
```python
def tokenize(text):
return tok.encode(text, add_special_tokens=False)
[BOS_ID] +
tokenize("[INST]") + tokenize(USER_MESSAGE_1) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_1) + [EOS_ID] +
…
tokenize("[INST]") + tokenize(USER_MESSAGE_N) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_N) + [EOS_ID]
```
In the pseudo-code above, note that the `tokenize` method should not add a BOS or EOS token automatically, but should add a prefix space.
In the Transformers library, one can use [chat templates](https://huggingface.co/docs/transformers/main/en/chat_templating) which make sure the right format is applied.
## Run the model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
### In half-precision
Note `float16` precision only works on GPU devices
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Lower precision using (8-bit & 4-bit) using `bitsandbytes`
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, device_map="auto")
text = "Hello my name is"
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Load the model with Flash Attention 2
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, use_flash_attention_2=True, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
## Limitations
The Mixtral-8x7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
moficodes/gemma-7b-sql-context | moficodes | 2024-03-19T12:37:18Z | 37 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-14T10:17:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
AlignmentResearch/robust_llm_pythia-tt-1b-mz-ada-v3-s-3 | AlignmentResearch | 2024-03-19T12:36:28Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-1b-deduped",
"base_model:finetune:EleutherAI/pythia-1b-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:34:29Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-1b-deduped
model-index:
- name: robust_llm_pythia-tt-1b-mz-ada-v3-s-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-1b-mz-ada-v3-s-3
This model is a fine-tuned version of [EleutherAI/pythia-1b-deduped](https://huggingface.co/EleutherAI/pythia-1b-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
freewheelin/free-solar-dpo-v0.2 | freewheelin | 2024-03-19T12:33:42Z | 60 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"en",
"arxiv:2312.15166",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T08:20:13Z | ---
language:
- ko
- en
license: mit
---
# Model Card for free-solar-dpo-v0.2
## Developed by : [Freewheelin](https://freewheelin-recruit.oopy.io/) AI Technical Team
## Hardware and Software
* **Training Factors**: We fine-tuned this model using the [HuggingFace TRL Trainer](https://huggingface.co/docs/trl/trainer)
## Method
- This model was trained using the learning method introduced in the [SOLAR paper](https://arxiv.org/pdf/2312.15166.pdf).
## Base Model
- [davidkim205/nox-solar-10.7b-v4](https://huggingface.co/davidkim205/nox-solar-10.7b-v4)
|
ZJZAC/dog6 | ZJZAC | 2024-03-19T12:28:09Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T11:48:05Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
inference: true
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks dog
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - ZJZAC/dog6
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
abhishek/autotrain-8kfjk-b3gva | abhishek | 2024-03-19T12:26:49Z | 232 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"autotrain",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T11:14:40Z | ---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` |
AlignmentResearch/robust_llm_pythia-tt-410m-mz-ada-v3-s-1 | AlignmentResearch | 2024-03-19T12:26:07Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-410m-deduped",
"base_model:finetune:EleutherAI/pythia-410m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:25:12Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-410m-deduped
model-index:
- name: robust_llm_pythia-tt-410m-mz-ada-v3-s-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-410m-mz-ada-v3-s-1
This model is a fine-tuned version of [EleutherAI/pythia-410m-deduped](https://huggingface.co/EleutherAI/pythia-410m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
Donnyed/PhysicsMistralAlpaca | Donnyed | 2024-03-19T12:22:59Z | 16 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"base_model:quantized:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-18T21:29:56Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
base_model: unsloth/mistral-7b-instruct-v0.2-bnb-4bit
---
# Uploaded model
- **Developed by:** Donnyed
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.2-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AlignmentResearch/robust_llm_pythia-tt-160m-mz-ada-v3-s-3 | AlignmentResearch | 2024-03-19T12:22:12Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m-deduped",
"base_model:finetune:EleutherAI/pythia-160m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:21:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-160m-deduped
model-index:
- name: robust_llm_pythia-tt-160m-mz-ada-v3-s-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-160m-mz-ada-v3-s-3
This model is a fine-tuned version of [EleutherAI/pythia-160m-deduped](https://huggingface.co/EleutherAI/pythia-160m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-160m-mz-ada-v3-s-2 | AlignmentResearch | 2024-03-19T12:19:44Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-160m-deduped",
"base_model:finetune:EleutherAI/pythia-160m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:19:18Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-160m-deduped
model-index:
- name: robust_llm_pythia-tt-160m-mz-ada-v3-s-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-160m-mz-ada-v3-s-2
This model is a fine-tuned version of [EleutherAI/pythia-160m-deduped](https://huggingface.co/EleutherAI/pythia-160m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-70m-mz-ada-v3-s-3 | AlignmentResearch | 2024-03-19T12:17:49Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-70m-deduped",
"base_model:finetune:EleutherAI/pythia-70m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:17:34Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-70m-deduped
model-index:
- name: robust_llm_pythia-tt-70m-mz-ada-v3-s-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-70m-mz-ada-v3-s-3
This model is a fine-tuned version of [EleutherAI/pythia-70m-deduped](https://huggingface.co/EleutherAI/pythia-70m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-31m-mz-ada-v3-s-1 | AlignmentResearch | 2024-03-19T12:17:17Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"base_model:finetune:EleutherAI/pythia-31m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:17:09Z | ---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-31m
model-index:
- name: robust_llm_pythia-tt-31m-mz-ada-v3-s-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-31m-mz-ada-v3-s-1
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-70m-mz-ada-v3-s-2 | AlignmentResearch | 2024-03-19T12:16:33Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-70m-deduped",
"base_model:finetune:EleutherAI/pythia-70m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:16:20Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-70m-deduped
model-index:
- name: robust_llm_pythia-tt-70m-mz-ada-v3-s-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-70m-mz-ada-v3-s-2
This model is a fine-tuned version of [EleutherAI/pythia-70m-deduped](https://huggingface.co/EleutherAI/pythia-70m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-31m-mz-ada-v3-s-3 | AlignmentResearch | 2024-03-19T12:15:46Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"base_model:finetune:EleutherAI/pythia-31m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:15:38Z | ---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-31m
model-index:
- name: robust_llm_pythia-tt-31m-mz-ada-v3-s-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-31m-mz-ada-v3-s-3
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-14m-mz-ada-v3-s-2 | AlignmentResearch | 2024-03-19T12:15:44Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:15:38Z | ---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-14m
model-index:
- name: robust_llm_pythia-tt-14m-mz-ada-v3-s-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-14m-mz-ada-v3-s-2
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-14m-mz-ada-v3-s-3 | AlignmentResearch | 2024-03-19T12:15:30Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:15:24Z | ---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-14m
model-index:
- name: robust_llm_pythia-tt-14m-mz-ada-v3-s-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-14m-mz-ada-v3-s-3
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
AlignmentResearch/robust_llm_pythia-tt-31m-mz-ada-v3-s-2 | AlignmentResearch | 2024-03-19T12:15:17Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"base_model:finetune:EleutherAI/pythia-31m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:15:10Z | ---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-31m
model-index:
- name: robust_llm_pythia-tt-31m-mz-ada-v3-s-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-tt-31m-mz-ada-v3-s-2
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
calewan/dqn-SpaceInvadersNoFrameskip-v4 | calewan | 2024-03-19T12:14:29Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-14T06:47:54Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 594.00 +/- 95.15
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga calewan -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga calewan -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga calewan
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1500000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
jitendra89/dataicd | jitendra89 | 2024-03-19T12:13:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-19T12:13:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Rajeevsh01/my-pet-dog | Rajeevsh01 | 2024-03-19T12:13:02Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T12:08:48Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Rajeevsh01 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:

|
roselyu/FinSent-XLMR-FinNews | roselyu | 2024-03-19T12:10:31Z | 115 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:09:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
linuxhunter/q-FrozenLake-v1-4x4-noSlippery | linuxhunter | 2024-03-19T12:08:34Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-19T12:08:31Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
model = load_from_hub(repo_id="linuxhunter/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
Dilipan/detr-finetuned-invoice | Dilipan | 2024-03-19T12:08:00Z | 226 | 1 | transformers | [
"transformers",
"safetensors",
"detr",
"object-detection",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | object-detection | 2024-03-19T11:11:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tiagomosantos/w2v-bert-2.0-pt_pt_v2 | tiagomosantos | 2024-03-19T12:07:10Z | 8 | 1 | transformers | [
"transformers",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"generated_from_trainer",
"asr",
"w2v-bert-2.0",
"pt",
"dataset:common_voice_16_1",
"base_model:facebook/w2v-bert-2.0",
"base_model:finetune:facebook/w2v-bert-2.0",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-03-17T23:42:48Z | ---
license: mit
base_model: facebook/w2v-bert-2.0
tags:
- generated_from_trainer
- asr
- w2v-bert-2.0
datasets:
- common_voice_16_1
metrics:
- wer
- cer
- bertscore
model-index:
- name: w2v-bert-2.0-pt_pt_v2
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_16_1
type: common_voice_16_1
config: pt
split: validation
args: pt
metrics:
- name: Wer
type: wer
value: 0.08315087821729188
language:
- pt
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w2v-bert-2.0-pt_pt_v2
This model is a fine-tuned version of [facebook/w2v-bert-2.0](https://huggingface.co/facebook/w2v-bert-2.0) on the common_voice_16_1 Portuguese subset using 1XRTX 3090.
It achieves the following results on the test set:
- Wer: 0.10491320595991134
- Cer: 0.032070871626631914
- Bert Score: 0.9619712047981167
- Sentence Similarity: 0.93867844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer | Bert Score |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:----------:|
| 1.2735 | 1.0 | 678 | 0.2292 | 0.1589 | 0.0415 | 0.9498 |
| 0.1715 | 2.0 | 1356 | 0.1762 | 0.1283 | 0.0344 | 0.9599 |
| 0.1158 | 3.0 | 2034 | 0.1539 | 0.1100 | 0.0298 | 0.9646 |
| 0.0821 | 4.0 | 2712 | 0.1362 | 0.0949 | 0.0258 | 0.9703 |
| 0.0605 | 5.0 | 3390 | 0.1349 | 0.0860 | 0.0236 | 0.9728 |
| 0.0475 | 6.0 | 4068 | 0.1395 | 0.0871 | 0.0239 | 0.9728 |
| 0.0355 | 7.0 | 4746 | 0.1487 | 0.0837 | 0.0230 | 0.9739 |
| 0.0309 | 8.0 | 5424 | 0.1452 | 0.0873 | 0.0240 | 0.9728 |
| 0.0308 | 9.0 | 6102 | 0.1390 | 0.0843 | 0.0228 | 0.9735 |
| 0.0239 | 10.0 | 6780 | 0.1282 | 0.0832 | 0.0224 | 0.9739 |
### Evaluation results
| Test Wer | Test Cer | Test Bert Score | Runtime | Samples per second |
|:------------------:|:-------------------:|:-----------------:|:-------:|:---------------------:|
| 0.09146400542583083| 0.02643665913309742 | 0.9702128323433327| 266.8185| 35.282 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.0
- Datasets 2.18.0
- Tokenizers 0.15.2 |
yemen2016/MeMo_BERT-WSD-DanskBERT | yemen2016 | 2024-03-19T12:06:11Z | 109 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:vesteinn/DanskBERT",
"base_model:finetune:vesteinn/DanskBERT",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T12:00:39Z | ---
license: cc-by-4.0
base_model: vesteinn/DanskBERT
tags:
- generated_from_trainer
model-index:
- name: MeMo_BERT-WSD-DanskBERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MeMo_BERT-WSD-DanskBERT
This model is a fine-tuned version of [vesteinn/DanskBERT](https://huggingface.co/vesteinn/DanskBERT) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7755
- F1-score: 0.5209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1-score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 61 | 1.4766 | 0.1229 |
| No log | 2.0 | 122 | 1.4366 | 0.1229 |
| No log | 3.0 | 183 | 1.3636 | 0.2462 |
| No log | 4.0 | 244 | 1.2889 | 0.3692 |
| No log | 5.0 | 305 | 1.4150 | 0.3786 |
| No log | 6.0 | 366 | 1.5581 | 0.3409 |
| No log | 7.0 | 427 | 1.6512 | 0.4664 |
| No log | 8.0 | 488 | 1.7405 | 0.4661 |
| 0.9424 | 9.0 | 549 | 1.7755 | 0.5209 |
| 0.9424 | 10.0 | 610 | 2.4738 | 0.4351 |
| 0.9424 | 11.0 | 671 | 2.4721 | 0.4858 |
| 0.9424 | 12.0 | 732 | 2.9449 | 0.4491 |
| 0.9424 | 13.0 | 793 | 2.8346 | 0.4528 |
| 0.9424 | 14.0 | 854 | 3.0715 | 0.4845 |
| 0.9424 | 15.0 | 915 | 3.1416 | 0.4520 |
| 0.9424 | 16.0 | 976 | 3.0893 | 0.5197 |
| 0.1197 | 17.0 | 1037 | 3.1668 | 0.4764 |
| 0.1197 | 18.0 | 1098 | 3.2142 | 0.4656 |
| 0.1197 | 19.0 | 1159 | 3.2174 | 0.5087 |
| 0.1197 | 20.0 | 1220 | 3.2239 | 0.5087 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Esmail-AGumaan/Transformer-model | Esmail-AGumaan | 2024-03-19T12:01:43Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | null | 2024-03-16T09:54:52Z | ---
license: mit
---
# Transformer model from scratch.
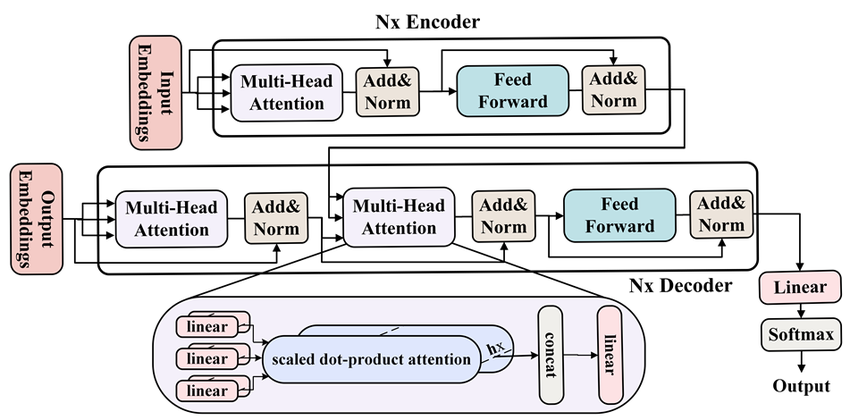
|
ritutweets46/layoutlm-funsd | ritutweets46 | 2024-03-19T12:00:21Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"layoutlm",
"token-classification",
"generated_from_trainer",
"dataset:funsd",
"base_model:microsoft/layoutlm-base-uncased",
"base_model:finetune:microsoft/layoutlm-base-uncased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-03-05T14:12:55Z | ---
license: mit
base_model: microsoft/layoutlm-base-uncased
tags:
- generated_from_trainer
datasets:
- funsd
model-index:
- name: layoutlm-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlm-funsd
This model is a fine-tuned version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased) on the funsd dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6784
- Answer: {'precision': 0.4630541871921182, 'recall': 0.580964153275649, 'f1': 0.5153508771929824, 'number': 809}
- Header: {'precision': 0.4470588235294118, 'recall': 0.31932773109243695, 'f1': 0.37254901960784315, 'number': 119}
- Question: {'precision': 0.5822259136212624, 'recall': 0.6582159624413145, 'f1': 0.617893345085941, 'number': 1065}
- Overall Precision: 0.5247
- Overall Recall: 0.6066
- Overall F1: 0.5627
- Overall Accuracy: 0.6411
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Answer | Header | Question | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 1.7288 | 1.0 | 10 | 1.5435 | {'precision': 0.022058823529411766, 'recall': 0.014833127317676144, 'f1': 0.017738359201773836, 'number': 809} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 119} | {'precision': 0.19180633147113593, 'recall': 0.09671361502347418, 'f1': 0.1285892634207241, 'number': 1065} | 0.1064 | 0.0577 | 0.0748 | 0.3266 |
| 1.4353 | 2.0 | 20 | 1.3528 | {'precision': 0.20369301788805538, 'recall': 0.4363411619283066, 'f1': 0.27773406766325726, 'number': 809} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 119} | {'precision': 0.2926481084939329, 'recall': 0.38497652582159625, 'f1': 0.33252230332522303, 'number': 1065} | 0.2427 | 0.3828 | 0.2971 | 0.4262 |
| 1.2751 | 3.0 | 30 | 1.2397 | {'precision': 0.24175084175084174, 'recall': 0.4437577255871446, 'f1': 0.3129904097646033, 'number': 809} | {'precision': 0.03636363636363636, 'recall': 0.01680672268907563, 'f1': 0.022988505747126436, 'number': 119} | {'precision': 0.34423076923076923, 'recall': 0.504225352112676, 'f1': 0.40914285714285714, 'number': 1065} | 0.2897 | 0.4506 | 0.3526 | 0.4736 |
| 1.1382 | 4.0 | 40 | 1.1096 | {'precision': 0.2822349570200573, 'recall': 0.48702101359703337, 'f1': 0.3573696145124716, 'number': 809} | {'precision': 0.2111111111111111, 'recall': 0.15966386554621848, 'f1': 0.1818181818181818, 'number': 119} | {'precision': 0.4142857142857143, 'recall': 0.5446009389671361, 'f1': 0.4705882352941177, 'number': 1065} | 0.3441 | 0.4982 | 0.4071 | 0.5598 |
| 1.0207 | 5.0 | 50 | 1.1986 | {'precision': 0.3122302158273381, 'recall': 0.5364647713226205, 'f1': 0.39472487494315595, 'number': 809} | {'precision': 0.2696629213483146, 'recall': 0.20168067226890757, 'f1': 0.23076923076923078, 'number': 119} | {'precision': 0.43670411985018726, 'recall': 0.5474178403755868, 'f1': 0.48583333333333334, 'number': 1065} | 0.3699 | 0.5223 | 0.4331 | 0.5405 |
| 0.9534 | 6.0 | 60 | 1.1446 | {'precision': 0.32223796033994334, 'recall': 0.5624227441285538, 'f1': 0.4097253489419181, 'number': 809} | {'precision': 0.3, 'recall': 0.17647058823529413, 'f1': 0.22222222222222224, 'number': 119} | {'precision': 0.48997995991983967, 'recall': 0.4591549295774648, 'f1': 0.47406689287445475, 'number': 1065} | 0.3891 | 0.4842 | 0.4315 | 0.5634 |
| 0.854 | 7.0 | 70 | 1.0533 | {'precision': 0.38318777292576417, 'recall': 0.4338689740420272, 'f1': 0.4069565217391304, 'number': 809} | {'precision': 0.264, 'recall': 0.2773109243697479, 'f1': 0.27049180327868855, 'number': 119} | {'precision': 0.4503968253968254, 'recall': 0.6394366197183099, 'f1': 0.5285215366705472, 'number': 1065} | 0.4172 | 0.5344 | 0.4685 | 0.5950 |
| 0.7821 | 8.0 | 80 | 1.0447 | {'precision': 0.3707482993197279, 'recall': 0.5389369592088998, 'f1': 0.43929471032745593, 'number': 809} | {'precision': 0.3373493975903614, 'recall': 0.23529411764705882, 'f1': 0.2772277227722772, 'number': 119} | {'precision': 0.4789594491201224, 'recall': 0.5877934272300469, 'f1': 0.5278246205733558, 'number': 1065} | 0.4248 | 0.5469 | 0.4782 | 0.6234 |
| 0.7291 | 9.0 | 90 | 1.1487 | {'precision': 0.39887005649717516, 'recall': 0.4363411619283066, 'f1': 0.41676505312868956, 'number': 809} | {'precision': 0.3106060606060606, 'recall': 0.3445378151260504, 'f1': 0.32669322709163345, 'number': 119} | {'precision': 0.4737201365187713, 'recall': 0.6516431924882629, 'f1': 0.5486166007905138, 'number': 1065} | 0.4384 | 0.5459 | 0.4863 | 0.5976 |
| 0.7222 | 10.0 | 100 | 1.0862 | {'precision': 0.36459246275197194, 'recall': 0.5142150803461063, 'f1': 0.42666666666666664, 'number': 809} | {'precision': 0.33, 'recall': 0.2773109243697479, 'f1': 0.30136986301369867, 'number': 119} | {'precision': 0.48, 'recall': 0.6422535211267606, 'f1': 0.5493975903614458, 'number': 1065} | 0.4250 | 0.5685 | 0.4864 | 0.6184 |
| 0.6242 | 11.0 | 110 | 1.2087 | {'precision': 0.3969465648854962, 'recall': 0.5142150803461063, 'f1': 0.44803446418955306, 'number': 809} | {'precision': 0.2536231884057971, 'recall': 0.29411764705882354, 'f1': 0.2723735408560311, 'number': 119} | {'precision': 0.5061124694376528, 'recall': 0.5830985915492958, 'f1': 0.5418848167539267, 'number': 1065} | 0.4443 | 0.5379 | 0.4866 | 0.6010 |
| 0.5972 | 12.0 | 120 | 1.1726 | {'precision': 0.43176972281449894, 'recall': 0.5006180469715699, 'f1': 0.4636519748139668, 'number': 809} | {'precision': 0.32989690721649484, 'recall': 0.2689075630252101, 'f1': 0.2962962962962963, 'number': 119} | {'precision': 0.5732430143945809, 'recall': 0.6356807511737089, 'f1': 0.6028495102404274, 'number': 1065} | 0.5027 | 0.5590 | 0.5293 | 0.6228 |
| 0.5502 | 13.0 | 130 | 1.2468 | {'precision': 0.4368048533872599, 'recall': 0.5339925834363412, 'f1': 0.4805339265850946, 'number': 809} | {'precision': 0.3181818181818182, 'recall': 0.29411764705882354, 'f1': 0.3056768558951965, 'number': 119} | {'precision': 0.5737855178735105, 'recall': 0.5877934272300469, 'f1': 0.5807050092764378, 'number': 1065} | 0.4991 | 0.5484 | 0.5226 | 0.6096 |
| 0.507 | 14.0 | 140 | 1.2631 | {'precision': 0.44842105263157894, 'recall': 0.5265760197775031, 'f1': 0.4843661171119955, 'number': 809} | {'precision': 0.3017241379310345, 'recall': 0.29411764705882354, 'f1': 0.29787234042553185, 'number': 119} | {'precision': 0.5765529308836396, 'recall': 0.6187793427230047, 'f1': 0.5969202898550725, 'number': 1065} | 0.5070 | 0.5620 | 0.5331 | 0.6096 |
| 0.4834 | 15.0 | 150 | 1.2604 | {'precision': 0.41264559068219636, 'recall': 0.6131025957972805, 'f1': 0.4932869219293884, 'number': 809} | {'precision': 0.3793103448275862, 'recall': 0.2773109243697479, 'f1': 0.32038834951456313, 'number': 119} | {'precision': 0.6035015447991761, 'recall': 0.5502347417840375, 'f1': 0.5756385068762279, 'number': 1065} | 0.4934 | 0.5595 | 0.5243 | 0.6207 |
| 0.4621 | 16.0 | 160 | 1.2164 | {'precision': 0.4373695198329854, 'recall': 0.5179233621755254, 'f1': 0.47425014148273914, 'number': 809} | {'precision': 0.3644859813084112, 'recall': 0.3277310924369748, 'f1': 0.3451327433628319, 'number': 119} | {'precision': 0.5385232744783307, 'recall': 0.6300469483568075, 'f1': 0.5807009952401558, 'number': 1065} | 0.4885 | 0.5665 | 0.5246 | 0.6197 |
| 0.4211 | 17.0 | 170 | 1.2596 | {'precision': 0.4471299093655589, 'recall': 0.5488257107540173, 'f1': 0.4927857935627081, 'number': 809} | {'precision': 0.3229166666666667, 'recall': 0.2605042016806723, 'f1': 0.28837209302325584, 'number': 119} | {'precision': 0.5671641791044776, 'recall': 0.6422535211267606, 'f1': 0.6023778071334215, 'number': 1065} | 0.5050 | 0.5815 | 0.5406 | 0.6253 |
| 0.3774 | 18.0 | 180 | 1.2991 | {'precision': 0.47, 'recall': 0.522867737948084, 'f1': 0.4950263311878291, 'number': 809} | {'precision': 0.32407407407407407, 'recall': 0.29411764705882354, 'f1': 0.30837004405286345, 'number': 119} | {'precision': 0.5509404388714734, 'recall': 0.6600938967136151, 'f1': 0.600598035027766, 'number': 1065} | 0.5083 | 0.5825 | 0.5429 | 0.6279 |
| 0.359 | 19.0 | 190 | 1.3849 | {'precision': 0.45615763546798027, 'recall': 0.5723114956736712, 'f1': 0.5076754385964912, 'number': 809} | {'precision': 0.36633663366336633, 'recall': 0.31092436974789917, 'f1': 0.33636363636363636, 'number': 119} | {'precision': 0.5760576057605761, 'recall': 0.6009389671361502, 'f1': 0.5882352941176471, 'number': 1065} | 0.5119 | 0.5720 | 0.5403 | 0.6079 |
| 0.3301 | 20.0 | 200 | 1.3047 | {'precision': 0.4407239819004525, 'recall': 0.6019777503090235, 'f1': 0.5088819226750262, 'number': 809} | {'precision': 0.3695652173913043, 'recall': 0.2857142857142857, 'f1': 0.3222748815165877, 'number': 119} | {'precision': 0.595724907063197, 'recall': 0.6018779342723005, 'f1': 0.5987856141989725, 'number': 1065} | 0.5112 | 0.5830 | 0.5448 | 0.6240 |
| 0.3018 | 21.0 | 210 | 1.4471 | {'precision': 0.46602972399150744, 'recall': 0.5426452410383189, 'f1': 0.5014277555682467, 'number': 809} | {'precision': 0.32989690721649484, 'recall': 0.2689075630252101, 'f1': 0.2962962962962963, 'number': 119} | {'precision': 0.5692695214105793, 'recall': 0.6366197183098592, 'f1': 0.601063829787234, 'number': 1065} | 0.5152 | 0.5765 | 0.5442 | 0.6149 |
| 0.2953 | 22.0 | 220 | 1.3775 | {'precision': 0.4605263157894737, 'recall': 0.5624227441285538, 'f1': 0.5063995548135781, 'number': 809} | {'precision': 0.3333333333333333, 'recall': 0.3025210084033613, 'f1': 0.3171806167400881, 'number': 119} | {'precision': 0.5631067961165048, 'recall': 0.6535211267605634, 'f1': 0.6049543676662321, 'number': 1065} | 0.5090 | 0.5956 | 0.5489 | 0.6281 |
| 0.2615 | 23.0 | 230 | 1.4087 | {'precision': 0.45692883895131087, 'recall': 0.6032138442521632, 'f1': 0.5199786893979754, 'number': 809} | {'precision': 0.3333333333333333, 'recall': 0.2773109243697479, 'f1': 0.30275229357798167, 'number': 119} | {'precision': 0.5908683974932856, 'recall': 0.6197183098591549, 'f1': 0.6049495875343722, 'number': 1065} | 0.5171 | 0.5926 | 0.5523 | 0.6290 |
| 0.254 | 24.0 | 240 | 1.3707 | {'precision': 0.4535353535353535, 'recall': 0.5550061804697157, 'f1': 0.4991662034463591, 'number': 809} | {'precision': 0.32432432432432434, 'recall': 0.3025210084033613, 'f1': 0.31304347826086953, 'number': 119} | {'precision': 0.5873949579831933, 'recall': 0.6563380281690141, 'f1': 0.6199556541019955, 'number': 1065} | 0.5168 | 0.5941 | 0.5528 | 0.6305 |
| 0.2387 | 25.0 | 250 | 1.4163 | {'precision': 0.4524793388429752, 'recall': 0.5414091470951793, 'f1': 0.49296567248171075, 'number': 809} | {'precision': 0.3333333333333333, 'recall': 0.2773109243697479, 'f1': 0.30275229357798167, 'number': 119} | {'precision': 0.5631372549019608, 'recall': 0.6741784037558686, 'f1': 0.6136752136752136, 'number': 1065} | 0.5077 | 0.5966 | 0.5486 | 0.6326 |
| 0.2268 | 26.0 | 260 | 1.4138 | {'precision': 0.4505386875612145, 'recall': 0.5686032138442522, 'f1': 0.5027322404371585, 'number': 809} | {'precision': 0.36363636363636365, 'recall': 0.2689075630252101, 'f1': 0.30917874396135264, 'number': 119} | {'precision': 0.5654281098546042, 'recall': 0.6572769953051644, 'f1': 0.60790273556231, 'number': 1065} | 0.5079 | 0.5981 | 0.5493 | 0.6302 |
| 0.2165 | 27.0 | 270 | 1.4642 | {'precision': 0.4694533762057878, 'recall': 0.5414091470951793, 'f1': 0.5028702640642939, 'number': 809} | {'precision': 0.3229166666666667, 'recall': 0.2605042016806723, 'f1': 0.28837209302325584, 'number': 119} | {'precision': 0.5489296636085627, 'recall': 0.6741784037558686, 'f1': 0.605141171512853, 'number': 1065} | 0.5079 | 0.5956 | 0.5483 | 0.6267 |
| 0.2078 | 28.0 | 280 | 1.4767 | {'precision': 0.49171270718232046, 'recall': 0.5500618046971569, 'f1': 0.5192532088681446, 'number': 809} | {'precision': 0.3389830508474576, 'recall': 0.33613445378151263, 'f1': 0.3375527426160338, 'number': 119} | {'precision': 0.5939849624060151, 'recall': 0.6676056338028169, 'f1': 0.6286472148541113, 'number': 1065} | 0.5387 | 0.6001 | 0.5678 | 0.6361 |
| 0.196 | 29.0 | 290 | 1.4066 | {'precision': 0.46553446553446554, 'recall': 0.5760197775030902, 'f1': 0.5149171270718232, 'number': 809} | {'precision': 0.375, 'recall': 0.2773109243697479, 'f1': 0.31884057971014496, 'number': 119} | {'precision': 0.5620031796502385, 'recall': 0.6638497652582159, 'f1': 0.6086956521739131, 'number': 1065} | 0.5138 | 0.6051 | 0.5558 | 0.6452 |
| 0.1834 | 30.0 | 300 | 1.5397 | {'precision': 0.4612286002014099, 'recall': 0.5661310259579728, 'f1': 0.5083240843507214, 'number': 809} | {'precision': 0.3235294117647059, 'recall': 0.2773109243697479, 'f1': 0.2986425339366516, 'number': 119} | {'precision': 0.5724815724815725, 'recall': 0.6563380281690141, 'f1': 0.6115485564304461, 'number': 1065} | 0.5138 | 0.5971 | 0.5523 | 0.6241 |
| 0.1701 | 31.0 | 310 | 1.5250 | {'precision': 0.4490566037735849, 'recall': 0.588380716934487, 'f1': 0.50936329588015, 'number': 809} | {'precision': 0.3764705882352941, 'recall': 0.2689075630252101, 'f1': 0.3137254901960785, 'number': 119} | {'precision': 0.5677685950413223, 'recall': 0.6450704225352113, 'f1': 0.6039560439560439, 'number': 1065} | 0.5074 | 0.5996 | 0.5497 | 0.6348 |
| 0.1659 | 32.0 | 320 | 1.5413 | {'precision': 0.466537342386033, 'recall': 0.5945611866501854, 'f1': 0.5228260869565217, 'number': 809} | {'precision': 0.38823529411764707, 'recall': 0.2773109243697479, 'f1': 0.32352941176470584, 'number': 119} | {'precision': 0.587532023911187, 'recall': 0.6460093896713615, 'f1': 0.6153846153846153, 'number': 1065} | 0.5256 | 0.6031 | 0.5617 | 0.6350 |
| 0.1576 | 33.0 | 330 | 1.5256 | {'precision': 0.47274529236868185, 'recall': 0.5896168108776267, 'f1': 0.5247524752475247, 'number': 809} | {'precision': 0.36538461538461536, 'recall': 0.31932773109243695, 'f1': 0.34080717488789236, 'number': 119} | {'precision': 0.5860621326616289, 'recall': 0.6553990610328638, 'f1': 0.6187943262411348, 'number': 1065} | 0.5265 | 0.6086 | 0.5646 | 0.6393 |
| 0.1444 | 34.0 | 340 | 1.5900 | {'precision': 0.4597478176527643, 'recall': 0.5859085290482077, 'f1': 0.5152173913043477, 'number': 809} | {'precision': 0.3870967741935484, 'recall': 0.3025210084033613, 'f1': 0.339622641509434, 'number': 119} | {'precision': 0.5847953216374269, 'recall': 0.6572769953051644, 'f1': 0.6189213085764811, 'number': 1065} | 0.5213 | 0.6071 | 0.5610 | 0.6348 |
| 0.1447 | 35.0 | 350 | 1.6271 | {'precision': 0.4558011049723757, 'recall': 0.6118665018541409, 'f1': 0.5224274406332453, 'number': 809} | {'precision': 0.46153846153846156, 'recall': 0.3025210084033613, 'f1': 0.3654822335025381, 'number': 119} | {'precision': 0.6021602160216022, 'recall': 0.6281690140845071, 'f1': 0.614889705882353, 'number': 1065} | 0.5275 | 0.6021 | 0.5623 | 0.6400 |
| 0.1403 | 36.0 | 360 | 1.6242 | {'precision': 0.4578313253012048, 'recall': 0.6106304079110012, 'f1': 0.5233050847457628, 'number': 809} | {'precision': 0.4177215189873418, 'recall': 0.2773109243697479, 'f1': 0.33333333333333337, 'number': 119} | {'precision': 0.603060306030603, 'recall': 0.6291079812206573, 'f1': 0.6158088235294117, 'number': 1065} | 0.5275 | 0.6006 | 0.5617 | 0.6299 |
| 0.1302 | 37.0 | 370 | 1.5982 | {'precision': 0.4633458646616541, 'recall': 0.6093943139678616, 'f1': 0.5264281900694073, 'number': 809} | {'precision': 0.3162393162393162, 'recall': 0.31092436974789917, 'f1': 0.3135593220338983, 'number': 119} | {'precision': 0.5850877192982457, 'recall': 0.6262910798122066, 'f1': 0.6049886621315193, 'number': 1065} | 0.5157 | 0.6006 | 0.5549 | 0.6334 |
| 0.127 | 38.0 | 380 | 1.6324 | {'precision': 0.4689655172413793, 'recall': 0.588380716934487, 'f1': 0.5219298245614035, 'number': 809} | {'precision': 0.4065934065934066, 'recall': 0.31092436974789917, 'f1': 0.3523809523809524, 'number': 119} | {'precision': 0.6041666666666666, 'recall': 0.6535211267605634, 'f1': 0.6278755074424899, 'number': 1065} | 0.5354 | 0.6066 | 0.5688 | 0.6331 |
| 0.1224 | 39.0 | 390 | 1.6212 | {'precision': 0.46387832699619774, 'recall': 0.6032138442521632, 'f1': 0.5244492208490059, 'number': 809} | {'precision': 0.3977272727272727, 'recall': 0.29411764705882354, 'f1': 0.3381642512077294, 'number': 119} | {'precision': 0.5654320987654321, 'recall': 0.6450704225352113, 'f1': 0.6026315789473683, 'number': 1065} | 0.5138 | 0.6071 | 0.5566 | 0.6420 |
| 0.1149 | 40.0 | 400 | 1.6236 | {'precision': 0.4704081632653061, 'recall': 0.5698393077873919, 'f1': 0.5153717160424818, 'number': 809} | {'precision': 0.4044943820224719, 'recall': 0.3025210084033613, 'f1': 0.34615384615384615, 'number': 119} | {'precision': 0.5826446280991735, 'recall': 0.6619718309859155, 'f1': 0.6197802197802197, 'number': 1065} | 0.5274 | 0.6031 | 0.5627 | 0.6345 |
| 0.1096 | 41.0 | 410 | 1.6220 | {'precision': 0.4804646251319958, 'recall': 0.5624227441285538, 'f1': 0.5182232346241458, 'number': 809} | {'precision': 0.4065934065934066, 'recall': 0.31092436974789917, 'f1': 0.3523809523809524, 'number': 119} | {'precision': 0.5713153724247226, 'recall': 0.6769953051643193, 'f1': 0.6196819939836701, 'number': 1065} | 0.5274 | 0.6086 | 0.5651 | 0.6357 |
| 0.111 | 42.0 | 420 | 1.6721 | {'precision': 0.46367112810707456, 'recall': 0.5995055624227441, 'f1': 0.5229110512129381, 'number': 809} | {'precision': 0.42528735632183906, 'recall': 0.31092436974789917, 'f1': 0.3592233009708738, 'number': 119} | {'precision': 0.6057091882247992, 'recall': 0.6375586854460094, 'f1': 0.6212259835315644, 'number': 1065} | 0.5328 | 0.6026 | 0.5656 | 0.6401 |
| 0.1052 | 43.0 | 430 | 1.6521 | {'precision': 0.4725609756097561, 'recall': 0.5747836835599506, 'f1': 0.5186837702175126, 'number': 809} | {'precision': 0.4166666666666667, 'recall': 0.33613445378151263, 'f1': 0.37209302325581406, 'number': 119} | {'precision': 0.5882838283828383, 'recall': 0.6694835680751173, 'f1': 0.6262626262626263, 'number': 1065} | 0.5314 | 0.6111 | 0.5685 | 0.6406 |
| 0.1024 | 44.0 | 440 | 1.6361 | {'precision': 0.47112462006079026, 'recall': 0.5747836835599506, 'f1': 0.5178173719376392, 'number': 809} | {'precision': 0.43010752688172044, 'recall': 0.33613445378151263, 'f1': 0.37735849056603776, 'number': 119} | {'precision': 0.5836038961038961, 'recall': 0.6751173708920187, 'f1': 0.6260339573356551, 'number': 1065} | 0.5294 | 0.6141 | 0.5686 | 0.6430 |
| 0.099 | 45.0 | 450 | 1.6565 | {'precision': 0.4645222327341533, 'recall': 0.6069221260815822, 'f1': 0.5262593783494106, 'number': 809} | {'precision': 0.43956043956043955, 'recall': 0.33613445378151263, 'f1': 0.380952380952381, 'number': 119} | {'precision': 0.5934819897084048, 'recall': 0.6497652582159624, 'f1': 0.6203496190049306, 'number': 1065} | 0.5285 | 0.6136 | 0.5679 | 0.6429 |
| 0.0993 | 46.0 | 460 | 1.6493 | {'precision': 0.46771037181996084, 'recall': 0.5908529048207664, 'f1': 0.5221190606226106, 'number': 809} | {'precision': 0.43023255813953487, 'recall': 0.31092436974789917, 'f1': 0.36097560975609755, 'number': 119} | {'precision': 0.5841004184100418, 'recall': 0.6553990610328638, 'f1': 0.6176991150442477, 'number': 1065} | 0.5267 | 0.6086 | 0.5647 | 0.6373 |
| 0.0997 | 47.0 | 470 | 1.6391 | {'precision': 0.46400778210116733, 'recall': 0.5896168108776267, 'f1': 0.5193249863908546, 'number': 809} | {'precision': 0.41304347826086957, 'recall': 0.31932773109243695, 'f1': 0.3601895734597156, 'number': 119} | {'precision': 0.5760065735414954, 'recall': 0.6582159624413145, 'f1': 0.614373356704645, 'number': 1065} | 0.5203 | 0.6101 | 0.5617 | 0.6411 |
| 0.0951 | 48.0 | 480 | 1.6616 | {'precision': 0.4644308943089431, 'recall': 0.5648949320148331, 'f1': 0.5097601784718349, 'number': 809} | {'precision': 0.43157894736842106, 'recall': 0.3445378151260504, 'f1': 0.38317757009345793, 'number': 119} | {'precision': 0.5755336617405583, 'recall': 0.6582159624413145, 'f1': 0.6141042487954446, 'number': 1065} | 0.5220 | 0.6016 | 0.5590 | 0.6357 |
| 0.0957 | 49.0 | 490 | 1.6806 | {'precision': 0.46360917248255235, 'recall': 0.5747836835599506, 'f1': 0.5132450331125828, 'number': 809} | {'precision': 0.4418604651162791, 'recall': 0.31932773109243695, 'f1': 0.3707317073170731, 'number': 119} | {'precision': 0.5841666666666666, 'recall': 0.6582159624413145, 'f1': 0.6189845474613687, 'number': 1065} | 0.5260 | 0.6041 | 0.5624 | 0.6392 |
| 0.0896 | 50.0 | 500 | 1.6784 | {'precision': 0.4630541871921182, 'recall': 0.580964153275649, 'f1': 0.5153508771929824, 'number': 809} | {'precision': 0.4470588235294118, 'recall': 0.31932773109243695, 'f1': 0.37254901960784315, 'number': 119} | {'precision': 0.5822259136212624, 'recall': 0.6582159624413145, 'f1': 0.617893345085941, 'number': 1065} | 0.5247 | 0.6066 | 0.5627 | 0.6411 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
kaitchup/Mayonnaise-4in1-02-awq-4bit | kaitchup | 2024-03-19T11:59:58Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"awq",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"region:us"
] | text-generation | 2024-03-19T08:37:16Z | ---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- merge
- awq
---
## Model Details
kaitchup/Mayonnaise-4in1-02 quantized to 4-bit with AutoAWQ.
The original model was created using a recipe detailed in this article:
[The Mayonnaise: Rank First on the Open LLM Leaderboard with TIES-Merging
](https://kaitchup.substack.com/p/the-mayonnaise-rank-first-on-the)
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [The Kaitchup](https://kaitchup.substack.com/)
- **Model type:** Causal
- **Language(s) (NLP):** English
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
|
ingeol/facets_128b | ingeol | 2024-03-19T11:56:10Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-03-19T11:55:46Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# ingeol/facets_128b
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('ingeol/facets_128b')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('ingeol/facets_128b')
model = AutoModel.from_pretrained('ingeol/facets_128b')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=ingeol/facets_128b)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 3899 with parameters:
```
{'batch_size': 128, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`beir.losses.bpr_loss.BPRLoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 7000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"correct_bias": false,
"eps": 1e-06,
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
July24/deberta-v3-base-prompt-injection | July24 | 2024-03-19T11:55:27Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-21T11:04:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
codebyershivam/my-pet-cow-xzg | codebyershivam | 2024-03-19T11:48:14Z | 1 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T11:44:05Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cow-xzg Dreambooth model trained by codebyershivam following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:

|
AndromedaPL/openchat-prometheus-v0.1-GGUF | AndromedaPL | 2024-03-19T11:45:41Z | 2 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:openchat/openchat-3.5-0106",
"base_model:quantized:openchat/openchat-3.5-0106",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-18T21:34:14Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
base_model: openchat/openchat-3.5-0106
---
# Uploaded model
- **Developed by:** AndromedaPL
- **License:** apache-2.0
- **Finetuned from model :** openchat/openchat-3.5-0106
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
InferenceIllusionist/M7-Evil-7b-GGUF | InferenceIllusionist | 2024-03-19T11:43:01Z | 411 | 5 | null | [
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-03-16T10:46:42Z | <img src="https://files.catbox.moe/40bgsm.png" width="500"/>
PiVoT-0.1-Evil-a SLERPed with M7-7b through sheer chaos.
<b>Use in conjunction with [this mmproj file](https://huggingface.co/koboldcpp/mmproj/resolve/main/mistral-7b-mmproj-v1.5-Q4_1.gguf) in Kobold</b>
<i>Warning: Extreme experimental merge for use with mmproj files only but might be good for other cases too idk.</i>
<i>Warning #2: Can insult/berrate user without provocation or warrant at times during image identification so beware.</i>
<h1>Update</h1>
Probably pointless to upload this since this merge is just for fun. But if anyone is interested:
This merge's unique characteristics are amplified by an equally chaotic set of samplers. Latest SillyTavern staging and Kobold releases recommended. Works very well with Smoothing Curve. After testing ST is the definitve front end for this.
Just make sure you configure Image Captioning in ST.
<img src="https://imgur.com/wvVe6n8.jpg" width="500"/>
<img src="https://imgur.com/jmzkPl9.jpg" width="500"/>
<img src="https://imgur.com/IPW8meJ.jpg" width="500"/> |
cijo-uc/lilt-demo-service-list-8 | cijo-uc | 2024-03-19T11:29:11Z | 159 | 0 | transformers | [
"transformers",
"safetensors",
"lilt",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-03-19T11:29:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sinhala-nlp/NSINA-Media-sinbert-small | sinhala-nlp | 2024-03-19T11:27:17Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"si",
"dataset:sinhala-nlp/NSINA",
"dataset:sinhala-nlp/NSINA-Media",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T11:25:04Z | ---
license: cc-by-sa-4.0
datasets:
- sinhala-nlp/NSINA
- sinhala-nlp/NSINA-Media
language:
- si
---
# Sinhala News Media Identification
This is a text classification task created with the [NSINA dataset](https://github.com/Sinhala-NLP/NSINA). This dataset is also released with the same license as NSINA. The task is identifying news media given the news content.
## Data
We only used 10,000 instances in NSINA 1.0 from each news source. For the two sources that had less than 10,000 instances ("Dinamina" and "Siyatha") we used the original number of instances they contained. We divided this dataset into a training and test set following a 0.8 split.
Data can be loaded into pandas dataframes using the following code.
```python
from datasets import Dataset
from datasets import load_dataset
train = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Media', split='train'))
test = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Media', split='test'))
```
## Citation
If you are using the dataset or the models, please cite the following paper.
~~~
@inproceedings{Nsina2024,
author={Hettiarachchi, Hansi and Premasiri, Damith and Uyangodage, Lasitha and Ranasinghe, Tharindu},
title={{NSINA: A News Corpus for Sinhala}},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
year={2024},
month={May},
}
~~~ |
sinhala-nlp/NSINA-Media-xlmr-large | sinhala-nlp | 2024-03-19T11:23:39Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"si",
"dataset:sinhala-nlp/NSINA",
"dataset:sinhala-nlp/NSINA-Media",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-18T20:17:08Z | ---
license: cc-by-sa-4.0
datasets:
- sinhala-nlp/NSINA
- sinhala-nlp/NSINA-Media
language:
- si
---
# Sinhala News Media Identification
This is a text classification task created with the [NSINA dataset](https://github.com/Sinhala-NLP/NSINA). This dataset is also released with the same license as NSINA. The task is identifying news media given the news content.
## Data
We only used 10,000 instances in NSINA 1.0 from each news source. For the two sources that had less than 10,000 instances ("Dinamina" and "Siyatha") we used the original number of instances they contained. We divided this dataset into a training and test set following a 0.8 split.
Data can be loaded into pandas dataframes using the following code.
```python
from datasets import Dataset
from datasets import load_dataset
train = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Media', split='train'))
test = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Media', split='test'))
```
## Citation
If you are using the dataset or the models, please cite the following paper.
~~~
@inproceedings{Nsina2024,
author={Hettiarachchi, Hansi and Premasiri, Damith and Uyangodage, Lasitha and Ranasinghe, Tharindu},
title={{NSINA: A News Corpus for Sinhala}},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
year={2024},
month={May},
}
~~~ |
kalese/opus-mt-en-bkm-10e | kalese | 2024-03-19T11:23:20Z | 118 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"marian",
"text2text-generation",
"generated_from_trainer",
"dataset:arrow",
"base_model:Helsinki-NLP/opus-mt-en-ro",
"base_model:finetune:Helsinki-NLP/opus-mt-en-ro",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-19T09:22:48Z | ---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-ro
tags:
- generated_from_trainer
datasets:
- arrow
metrics:
- bleu
model-index:
- name: opus-mt-en-bkm-10e
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: arrow
type: arrow
config: default
split: train
args: default
metrics:
- name: Bleu
type: bleu
value: 7.1794
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-bkm-10e
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ro](https://huggingface.co/Helsinki-NLP/opus-mt-en-ro) on the arrow dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5644
- Bleu: 7.1794
- Gen Len: 60.0222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 96
- eval_batch_size: 96
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 186 | 2.6868 | 0.299 | 76.178 |
| No log | 2.0 | 372 | 2.0190 | 2.2444 | 67.167 |
| 3.115 | 3.0 | 558 | 1.8364 | 4.5959 | 59.7357 |
| 3.115 | 4.0 | 744 | 1.7372 | 5.1827 | 61.7218 |
| 3.115 | 5.0 | 930 | 1.6732 | 5.8295 | 59.7346 |
| 1.8706 | 6.0 | 1116 | 1.6301 | 6.4389 | 60.9085 |
| 1.8706 | 7.0 | 1302 | 1.6002 | 6.6498 | 60.4191 |
| 1.8706 | 8.0 | 1488 | 1.5792 | 6.8315 | 60.2721 |
| 1.7133 | 9.0 | 1674 | 1.5680 | 7.1239 | 60.5609 |
| 1.7133 | 10.0 | 1860 | 1.5644 | 7.1794 | 60.0222 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Wilfrenm/ainew1 | Wilfrenm | 2024-03-19T11:23:05Z | 23 | 0 | diffusers | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T11:19:21Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### AINew1 Dreambooth model trained by Wilfrenm following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 232035
Sample pictures of this concept:

|
sinhala-nlp/NSINA-Media-xlmr-base | sinhala-nlp | 2024-03-19T11:22:00Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"si",
"dataset:sinhala-nlp/NSINA",
"dataset:sinhala-nlp/NSINA-Media",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-18T20:17:43Z | ---
license: cc-by-sa-4.0
datasets:
- sinhala-nlp/NSINA
- sinhala-nlp/NSINA-Media
language:
- si
---
# Sinhala News Media Identification
This is a text classification task created with the [NSINA dataset](https://github.com/Sinhala-NLP/NSINA). This dataset is also released with the same license as NSINA. The task is identifying news media given the news content.
## Data
We only used 10,000 instances in NSINA 1.0 from each news source. For the two sources that had less than 10,000 instances ("Dinamina" and "Siyatha") we used the original number of instances they contained. We divided this dataset into a training and test set following a 0.8 split.
Data can be loaded into pandas dataframes using the following code.
```python
from datasets import Dataset
from datasets import load_dataset
train = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Media', split='train'))
test = Dataset.to_pandas(load_dataset('sinhala-nlp/NSINA-Media', split='test'))
```
## Citation
If you are using the dataset or the models, please cite the following paper.
~~~
@inproceedings{Nsina2024,
author={Hettiarachchi, Hansi and Premasiri, Damith and Uyangodage, Lasitha and Ranasinghe, Tharindu},
title={{NSINA: A News Corpus for Sinhala}},
booktitle={The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)},
year={2024},
month={May},
}
~~~ |
santhoshkammari/PEFTFinetune-Bloom7B | santhoshkammari | 2024-03-19T11:17:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-19T11:05:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ldowey/llama-2-7b-sentinomics | ldowey | 2024-03-19T11:13:27Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-18T17:30:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
yemen2016/MeMo_BERT-WSD-01 | yemen2016 | 2024-03-19T11:12:41Z | 109 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:MiMe-MeMo/MeMo-BERT-01",
"base_model:finetune:MiMe-MeMo/MeMo-BERT-01",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-19T10:47:26Z | ---
base_model: MiMe-MeMo/MeMo_BERT-01
tags:
- generated_from_trainer
model-index:
- name: MeMo_BERT-01
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MeMo_BERT-01
This model is a fine-tuned version of [MiMe-MeMo/MeMo_BERT-01](https://huggingface.co/MiMe-MeMo/MeMo_BERT-01) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8264
- F1-score: 0.4148
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1-score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 61 | 1.5574 | 0.1229 |
| No log | 2.0 | 122 | 1.4491 | 0.1477 |
| No log | 3.0 | 183 | 1.3661 | 0.2112 |
| No log | 4.0 | 244 | 1.7131 | 0.3356 |
| No log | 5.0 | 305 | 2.0026 | 0.3592 |
| No log | 6.0 | 366 | 2.8807 | 0.2263 |
| No log | 7.0 | 427 | 2.8357 | 0.3625 |
| No log | 8.0 | 488 | 3.5272 | 0.3150 |
| 0.7496 | 9.0 | 549 | 3.5185 | 0.3402 |
| 0.7496 | 10.0 | 610 | 3.8264 | 0.4148 |
| 0.7496 | 11.0 | 671 | 4.5875 | 0.2999 |
| 0.7496 | 12.0 | 732 | 4.3188 | 0.3392 |
| 0.7496 | 13.0 | 793 | 4.7118 | 0.3098 |
| 0.7496 | 14.0 | 854 | 4.5895 | 0.3319 |
| 0.7496 | 15.0 | 915 | 4.6764 | 0.3033 |
| 0.7496 | 16.0 | 976 | 4.6250 | 0.3319 |
| 0.01 | 17.0 | 1037 | 4.7393 | 0.3176 |
| 0.01 | 18.0 | 1098 | 4.7690 | 0.3176 |
| 0.01 | 19.0 | 1159 | 4.7655 | 0.3176 |
| 0.01 | 20.0 | 1220 | 4.7695 | 0.3176 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
automerger/Inex12Neural-7B | automerger | 2024-03-19T11:12:39Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:Kukedlc/Neural-Krishna-Multiverse-7b-v3",
"base_model:merge:Kukedlc/Neural-Krishna-Multiverse-7b-v3",
"base_model:MSL7/INEX12-7b",
"base_model:merge:MSL7/INEX12-7b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-19T11:11:48Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- MSL7/INEX12-7b
- Kukedlc/Neural-Krishna-Multiverse-7b-v3
---
# Inex12Neural-7B
Inex12Neural-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [MSL7/INEX12-7b](https://huggingface.co/MSL7/INEX12-7b)
* [Kukedlc/Neural-Krishna-Multiverse-7b-v3](https://huggingface.co/Kukedlc/Neural-Krishna-Multiverse-7b-v3)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: MSL7/INEX12-7b
layer_range: [0, 32]
- model: Kukedlc/Neural-Krishna-Multiverse-7b-v3
layer_range: [0, 32]
merge_method: slerp
base_model: MSL7/INEX12-7b
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/Inex12Neural-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
jcjo/pjy-cat-sd-lora | jcjo | 2024-03-19T11:11:00Z | 1 | 0 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-19T07:04:14Z | ---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
widget:
- text: '<pjy0><pjy1> realistic, 4k, high resolution cat, '
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: <pjy0><pjy1> realistic, 4k, high resolution cat,
license: openrail++
---
# SDXL LoRA DreamBooth - jcjo/pjy-cat-sd-lora
<Gallery />
## Model description
### These are jcjo/pjy-cat-sd-lora LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
## Download model
### Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- **LoRA**: download **[`/content/drive/MyDrive/Colab_Notebooks/DA Matching Algorithm/AI/pet_babyAI//ckpt/cat3.safetensors` here 💾](/jcjo/pjy-cat-sd-lora/blob/main//content/drive/MyDrive/Colab_Notebooks/DA Matching Algorithm/AI/pet_babyAI//ckpt/cat3.safetensors)**.
- Place it on your `models/Lora` folder.
- On AUTOMATIC1111, load the LoRA by adding `<lora:/content/drive/MyDrive/Colab_Notebooks/DA Matching Algorithm/AI/pet_babyAI//ckpt/cat3:1>` to your prompt. On ComfyUI just [load it as a regular LoRA](https://comfyanonymous.github.io/ComfyUI_examples/lora/).
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('jcjo/pjy-cat-sd-lora', weight_name='pytorch_lora_weights.safetensors')
image = pipeline('True').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Trigger words
You should use <pjy0><pjy1> realistic, 4k, high resolution cat, to trigger the image generation.
## Details
All [Files & versions](/jcjo/pjy-cat-sd-lora/tree/main).
The weights were trained using [🧨 diffusers Advanced Dreambooth Training Script](https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py).
LoRA for the text encoder was enabled. True.
Pivotal tuning was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
Subsets and Splits