
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-15 18:28:48
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 522
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-15 18:28:34
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
google/byt5-small | google | 2023-01-24T16:36:59Z | 1,451,674 | 64 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"ht",
"hu",
"hy",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"und",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:mc4",
"arxiv:1907.06292",
"arxiv:2105.13626",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
# ByT5 - Small
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-small).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-small` significantly outperforms [mt5-small](https://huggingface.co/google/mt5-small) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
## Example Inference
ByT5 works on raw UTF-8 bytes and can be used without a tokenizer:
```python
from transformers import T5ForConditionalGeneration
import torch
model = T5ForConditionalGeneration.from_pretrained('google/byt5-small')
input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + 3 # add 3 for special tokens
labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + 3 # add 3 for special tokens
loss = model(input_ids, labels=labels).loss # forward pass
```
For batched inference & training it is however recommended using a tokenizer class for padding:
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
model = T5ForConditionalGeneration.from_pretrained('google/byt5-small')
tokenizer = AutoTokenizer.from_pretrained('google/byt5-small')
model_inputs = tokenizer(["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt")
labels = tokenizer(["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt").input_ids
loss = model(**model_inputs, labels=labels).loss # forward pass
```
## Abstract
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.

|
google/byt5-base | google | 2023-01-24T16:36:53Z | 32,951 | 21 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"ht",
"hu",
"hy",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"und",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:mc4",
"arxiv:1907.06292",
"arxiv:2105.13626",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
# ByT5 - Base
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-base).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-base` significantly outperforms [mt5-base](https://huggingface.co/google/mt5-base) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
## Example Inference
ByT5 works on raw UTF-8 bytes and can be used without a tokenizer:
```python
from transformers import T5ForConditionalGeneration
import torch
model = T5ForConditionalGeneration.from_pretrained('google/byt5-base')
input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + 3 # add 3 for special tokens
labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + 3 # add 3 for special tokens
loss = model(input_ids, labels=labels).loss # forward pass
```
For batched inference & training it is however recommended using a tokenizer class for padding:
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
model = T5ForConditionalGeneration.from_pretrained('google/byt5-base')
tokenizer = AutoTokenizer.from_pretrained('google/byt5-base')
model_inputs = tokenizer(["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt")
labels = tokenizer(["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt").input_ids
loss = model(**model_inputs, labels=labels).loss # forward pass
```
## Abstract
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
 |
google/bigbird-pegasus-large-bigpatent | google | 2023-01-24T16:36:44Z | 785 | 39 | transformers | [
"transformers",
"pytorch",
"bigbird_pegasus",
"text2text-generation",
"summarization",
"en",
"dataset:big_patent",
"arxiv:2007.14062",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| summarization | 2022-03-02T23:29:05Z | ---
language: en
license: apache-2.0
datasets:
- big_patent
tags:
- summarization
---
# BigBirdPegasus model (large)
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
BigBird was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird).
Disclaimer: The team releasing BigBird did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BigBird relies on **block sparse attention** instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower compute cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
## How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BigBirdPegasusForConditionalGeneration, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google/bigbird-pegasus-large-bigpatent")
# by default encoder-attention is `block_sparse` with num_random_blocks=3, block_size=64
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-bigpatent")
# decoder attention type can't be changed & will be "original_full"
# you can change `attention_type` (encoder only) to full attention like this:
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-bigpatent", attention_type="original_full")
# you can change `block_size` & `num_random_blocks` like this:
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-bigpatent", block_size=16, num_random_blocks=2)
text = "Replace me by any text you'd like."
inputs = tokenizer(text, return_tensors='pt')
prediction = model.generate(**inputs)
prediction = tokenizer.batch_decode(prediction)
```
## Training Procedure
This checkpoint is obtained after fine-tuning `BigBirdPegasusForConditionalGeneration` for **summarization** on [big_patent](https://huggingface.co/datasets/big_patent) dataset.
## BibTeX entry and citation info
```tex
@misc{zaheer2021big,
title={Big Bird: Transformers for Longer Sequences},
author={Manzil Zaheer and Guru Guruganesh and Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Ontanon and Philip Pham and Anirudh Ravula and Qifan Wang and Li Yang and Amr Ahmed},
year={2021},
eprint={2007.14062},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
google/bert2bert_L-24_wmt_de_en | google | 2023-01-24T16:35:54Z | 843 | 8 | transformers | [
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"translation",
"en",
"de",
"dataset:wmt14",
"arxiv:1907.12461",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z | ---
language:
- en
- de
license: apache-2.0
datasets:
- wmt14
tags:
- translation
---
# bert2bert_L-24_wmt_de_en EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/bert24_de_en/1).
The model is an encoder-decoder model that was initialized on the `bert-large` checkpoints for both the encoder
and decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_de_en", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en")
sentence = "Willst du einen Kaffee trinken gehen mit mir?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Want to drink a kaffee go with me? .
```
|
facebook/xglm-7.5B | facebook | 2023-01-24T16:35:48Z | 4,749 | 57 | transformers | [
"transformers",
"pytorch",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-7.5B
XGLM-7.5B is a multilingual autoregressive language model (with 7.5 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-7.5B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-7.5B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-7.5B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-7.5B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
facebook/xglm-564M | facebook | 2023-01-24T16:35:45Z | 15,028 | 51 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-564M
XGLM-564M is a multilingual autoregressive language model (with 564 million parameters) trained on a balanced corpus of a diverse set of 30 languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-564M is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-564M development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-564M")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
facebook/xglm-2.9B | facebook | 2023-01-24T16:35:40Z | 557 | 8 | transformers | [
"transformers",
"pytorch",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-2.9B
XGLM-2.9B is a multilingual autoregressive language model (with 2.9 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-2.9B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-2.9B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-2.9B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-2.9B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
facebook/wmt21-dense-24-wide-x-en | facebook | 2023-01-24T16:35:35Z | 26 | 13 | transformers | [
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"translation",
"wmt21",
"multilingual",
"ha",
"is",
"ja",
"cs",
"ru",
"zh",
"de",
"en",
"arxiv:2108.03265",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- ha
- is
- ja
- cs
- ru
- zh
- de
- en
license: mit
tags:
- translation
- wmt21
---
# WMT 21 X-En
WMT 21 X-En is a 4.7B multilingual encoder-decoder (seq-to-seq) model trained for one-to-many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2108.03265) and first released in [this](https://github.com/pytorch/fairseq/tree/main/examples/wmt21) repository.
The model can directly translate text from 7 languages: Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de) to English.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
Since the model was trained with domain tags, you should prepend them to the input as well.
* "wmtdata newsdomain": Use for sentences in the news domain
* "wmtdata otherdomain": Use for sentences in all other domain
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/wmt21-dense-24-wide-x-en")
tokenizer = AutoTokenizer.from_pretrained("facebook/wmt21-dense-24-wide-x-en")
# translate German to English
tokenizer.src_lang = "de"
inputs = tokenizer("wmtdata newsdomain Ein Modell für viele Sprachen", return_tensors="pt")
generated_tokens = model.generate(**inputs)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "A model for many languages"
# translate Icelandic to English
tokenizer.src_lang = "is"
inputs = tokenizer("wmtdata newsdomain Ein fyrirmynd fyrir mörg tungumál", return_tensors="pt")
generated_tokens = model.generate(**inputs)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "One model for many languages"
```
See the [model hub](https://huggingface.co/models?filter=wmt21) to look for more fine-tuned versions.
## Languages covered
English (en), Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de)
## BibTeX entry and citation info
```
@inproceedings{tran2021facebook
title={Facebook AI’s WMT21 News Translation Task Submission},
author={Chau Tran and Shruti Bhosale and James Cross and Philipp Koehn and Sergey Edunov and Angela Fan},
booktitle={Proc. of WMT},
year={2021},
}
``` |
facebook/wmt21-dense-24-wide-en-x | facebook | 2023-01-24T16:35:31Z | 41 | 37 | transformers | [
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"translation",
"wmt21",
"multilingual",
"ha",
"is",
"ja",
"cs",
"ru",
"zh",
"de",
"en",
"arxiv:2108.03265",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- ha
- is
- ja
- cs
- ru
- zh
- de
- en
license: mit
tags:
- translation
- wmt21
---
# WMT 21 En-X
WMT 21 En-X is a 4.7B multilingual encoder-decoder (seq-to-seq) model trained for one-to-many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2108.03265) and first released in [this](https://github.com/pytorch/fairseq/tree/main/examples/wmt21) repository.
The model can directly translate English text into 7 other languages: Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de).
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
Since the model was trained with domain tags, you should prepend them to the input as well.
* "wmtdata newsdomain": Use for sentences in the news domain
* "wmtdata otherdomain": Use for sentences in all other domain
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/wmt21-dense-24-wide-en-x")
tokenizer = AutoTokenizer.from_pretrained("facebook/wmt21-dense-24-wide-en-x")
inputs = tokenizer("wmtdata newsdomain One model for many languages.", return_tensors="pt")
# translate English to German
generated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.get_lang_id("de"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Ein Modell für viele Sprachen."
# translate English to Icelandic
generated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.get_lang_id("is"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Ein fyrirmynd fyrir mörg tungumál."
```
See the [model hub](https://huggingface.co/models?filter=wmt21) to look for more fine-tuned versions.
## Languages covered
English (en), Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de)
## BibTeX entry and citation info
```
@inproceedings{tran2021facebook
title={Facebook AI’s WMT21 News Translation Task Submission},
author={Chau Tran and Shruti Bhosale and James Cross and Philipp Koehn and Sergey Edunov and Angela Fan},
booktitle={Proc. of WMT},
year={2021},
}
``` |
facebook/wav2vec2-xls-r-2b-22-to-16 | facebook | 2023-01-24T16:35:01Z | 32 | 14 | transformers | [
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2B-22-16 (XLS-R-Any-to-Any)
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on `{input_lang}` -> `{output_lang}` translation pairs
of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{input_lang}` to the following written languages `{output_lang}`:
`{input_lang}` -> `{output_lang}`
with `{input_lang}` one of:
{`en`, `fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`}
and `{output_lang}`:
{`en`, `de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-22-16).
You can select the target language, record some audio in any of the above mentioned input languages,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"en": 250004,
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-22-to-16", feature_extractor="facebook/wav2vec2-xls-r-2b-22-to-16")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
facebook/wav2vec2-xls-r-2b-21-to-en | facebook | 2023-01-24T16:34:58Z | 24 | 5 | transformers | [
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-2b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
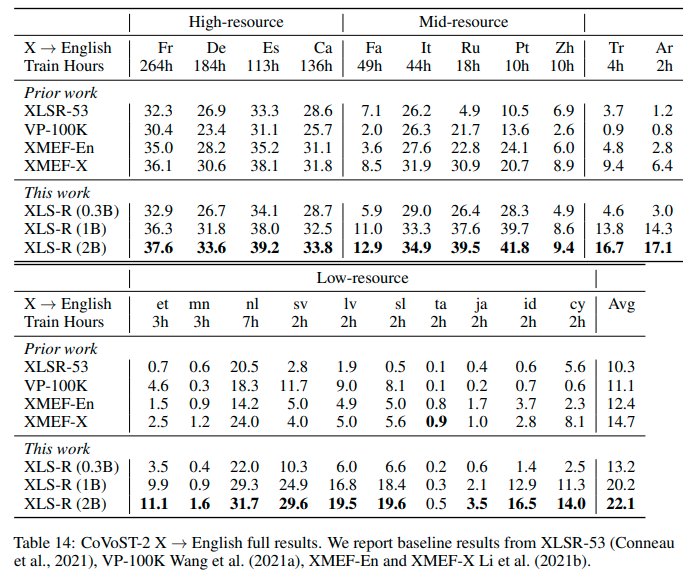
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
facebook/wav2vec2-xls-r-1b-21-to-en | facebook | 2023-01-24T16:34:50Z | 381 | 3 | transformers | [
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-1b`**](https://huggingface.co/facebook/wav2vec2-xls-r-1b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-1b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (1B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
facebook/s2t-wav2vec2-large-en-tr | facebook | 2023-01-24T16:32:38Z | 46 | 3 | transformers | [
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"audio",
"speech-translation",
"speech2text2",
"en",
"tr",
"dataset:covost2",
"dataset:librispeech_asr",
"arxiv:2104.06678",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- en
- tr
datasets:
- covost2
- librispeech_asr
tags:
- audio
- speech-translation
- automatic-speech-recognition
- speech2text2
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Common Voice 1
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_99989.mp3
- example_title: Common Voice 2
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_99986.mp3
- example_title: Common Voice 3
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_99987.mp3
---
# S2T2-Wav2Vec2-CoVoST2-EN-TR-ST
`s2t-wav2vec2-large-en-tr` is a Speech to Text Transformer model trained for end-to-end Speech Translation (ST).
The S2T2 model was proposed in [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/pdf/2104.06678.pdf) and officially released in
[Fairseq](https://github.com/pytorch/fairseq/blob/6f847c8654d56b4d1b1fbacec027f47419426ddb/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
## Model description
S2T2 is a transformer-based seq2seq (speech encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a pretrained [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html) as the encoder and a transformer-based decoder. The model is trained with standard autoregressive cross-entropy loss and generates the translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Turkish text translation.
See the [model hub](https://huggingface.co/models?filter=speech2text2) to look for other S2T2 checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
asr = pipeline("automatic-speech-recognition", model="facebook/s2t-wav2vec2-large-en-tr", feature_extractor="facebook/s2t-wav2vec2-large-en-tr")
translation = asr(librispeech_en[0]["file"])
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoder
from datasets import load_dataset
import soundfile as sf
model = SpeechEncoderDecoder.from_pretrained("facebook/s2t-wav2vec2-large-en-tr")
processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-tr")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Evaluation results
CoVoST-V2 test results for en-tr (BLEU score): **17.5**
For more information, please have a look at the [official paper](https://arxiv.org/pdf/2104.06678.pdf) - especially row 10 of Table 2.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2104-06678,
author = {Changhan Wang and
Anne Wu and
Juan Miguel Pino and
Alexei Baevski and
Michael Auli and
Alexis Conneau},
title = {Large-Scale Self- and Semi-Supervised Learning for Speech Translation},
journal = {CoRR},
volume = {abs/2104.06678},
year = {2021},
url = {https://arxiv.org/abs/2104.06678},
archivePrefix = {arXiv},
eprint = {2104.06678},
timestamp = {Thu, 12 Aug 2021 15:37:06 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-06678.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
facebook/s2t-wav2vec2-large-en-ca | facebook | 2023-01-24T16:32:32Z | 6 | 2 | transformers | [
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"audio",
"speech-translation",
"speech2text2",
"en",
"ca",
"dataset:covost2",
"dataset:librispeech_asr",
"arxiv:2104.06678",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- en
- ca
datasets:
- covost2
- librispeech_asr
tags:
- audio
- speech-translation
- automatic-speech-recognition
- speech2text2
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Common Voice 1
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Common Voice 2
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_99989.mp3
- example_title: Common Voice 3
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_9999.mp3
---
# S2T2-Wav2Vec2-CoVoST2-EN-CA-ST
`s2t-wav2vec2-large-en-ca` is a Speech to Text Transformer model trained for end-to-end Speech Translation (ST).
The S2T2 model was proposed in [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/pdf/2104.06678.pdf) and officially released in
[Fairseq](https://github.com/pytorch/fairseq/blob/6f847c8654d56b4d1b1fbacec027f47419426ddb/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
## Model description
S2T2 is a transformer-based seq2seq (speech encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a pretrained [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html) as the encoder and a transformer-based decoder. The model is trained with standard autoregressive cross-entropy loss and generates the translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Catalan text translation.
See the [model hub](https://huggingface.co/models?filter=speech2text2) to look for other S2T2 checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
asr = pipeline("automatic-speech-recognition", model="facebook/s2t-wav2vec2-large-en-ca", feature_extractor="facebook/s2t-wav2vec2-large-en-ca")
translation = asr(librispeech_en[0]["file"])
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoder
from datasets import load_dataset
import soundfile as sf
model = SpeechEncoderDecoder.from_pretrained("facebook/s2t-wav2vec2-large-en-ca")
processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-ca")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Evaluation results
CoVoST-V2 test results for en-ca (BLEU score): **34.1**
For more information, please have a look at the [official paper](https://arxiv.org/pdf/2104.06678.pdf) - especially row 10 of Table 2.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2104-06678,
author = {Changhan Wang and
Anne Wu and
Juan Miguel Pino and
Alexei Baevski and
Michael Auli and
Alexis Conneau},
title = {Large-Scale Self- and Semi-Supervised Learning for Speech Translation},
journal = {CoRR},
volume = {abs/2104.06678},
year = {2021},
url = {https://arxiv.org/abs/2104.06678},
archivePrefix = {arXiv},
eprint = {2104.06678},
timestamp = {Thu, 12 Aug 2021 15:37:06 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-06678.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
facebook/s2t-small-mustc-en-ru-st | facebook | 2023-01-24T16:32:26Z | 12 | 1 | transformers | [
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"audio",
"speech-translation",
"en",
"ru",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- en
- ru
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-MUSTC-EN-RU-ST
`s2t-small-mustc-en-ru-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Russian text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-mustc-en-ru-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-mustc-en-ru-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-mustc-en-ru-st is trained on English-Russian subset of [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 8,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
MuST-C test results for en-ru (BLEU score): 15.3
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/s2t-small-mustc-en-ro-st | facebook | 2023-01-24T16:32:22Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"audio",
"speech-translation",
"en",
"ro",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- en
- ro
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-MUSTC-EN-RO-ST
`s2t-small-mustc-en-ro-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Romanian text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-mustc-en-ro-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-mustc-en-ro-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-mustc-en-ro-st is trained on English-Romanian subset of [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 8,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
MuST-C test results for en-ro (BLEU score): 21.9
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/s2t-small-mustc-en-pt-st | facebook | 2023-01-24T16:32:19Z | 6 | 2 | transformers | [
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"audio",
"speech-translation",
"en",
"pt",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- en
- pt
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-MUSTC-EN-PT-ST
`s2t-small-mustc-en-pt-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Portuguese text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-mustc-en-pt-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-mustc-en-pt-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-mustc-en-pt-st is trained on English-Portuguese subset of [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 8,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
MuST-C test results for en-pt (BLEU score): 28.1
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/s2t-small-covost2-es-en-st | facebook | 2023-01-24T16:31:55Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"audio",
"speech-translation",
"es",
"en",
"dataset:covost2",
"arxiv:2010.05171",
"arxiv:1912.06670",
"arxiv:1904.08779",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- es
- en
datasets:
- covost2
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-COVOST2-ES-EN-ST
`s2t-small-covost2-es-en-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end Spanish speech to English text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-covost2-es-en-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-covost2-es-en-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=48_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-covost2-es-en-st is trained on Spanish-English subset of [CoVoST2](https://github.com/facebookresearch/covost).
CoVoST is a large-scale multilingual ST corpus based on [Common Voice](https://arxiv.org/abs/1912.06670), created to to foster
ST research with the largest ever open dataset
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using character based SentencePiece vocab.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
CoVOST2 test results for es-en (BLEU score): 22.31
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/s2t-small-covost2-ca-en-st | facebook | 2023-01-24T16:31:36Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"audio",
"speech-translation",
"ca",
"en",
"dataset:covost2",
"arxiv:2010.05171",
"arxiv:1912.06670",
"arxiv:1904.08779",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- ca
- en
datasets:
- covost2
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-COVOST2-CA-EN-ST
`s2t-small-covost2-ca-en-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end Catalan speech to English text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-covost2-ca-en-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-covost2-ca-en-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=48_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-covost2-ca-en-st is trained on Catalan-English subset of [CoVoST2](https://github.com/facebookresearch/covost).
CoVoST is a large-scale multilingual ST corpus based on [Common Voice](https://arxiv.org/abs/1912.06670), created to to foster
ST research with the largest ever open dataset
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using character based SentencePiece vocab.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
CoVOST2 test results for ca-en (BLEU score): 17.85
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/s2t-medium-mustc-multilingual-st | facebook | 2023-01-24T16:31:33Z | 6,629 | 6 | transformers | [
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"audio",
"speech-translation",
"en",
"de",
"nl",
"es",
"fr",
"it",
"pt",
"ro",
"ru",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"license:mit",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language:
- en
- de
- nl
- es
- fr
- it
- pt
- ro
- ru
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
pipeline_tag: automatic-speech-recognition
license: mit
---
# S2T-MEDIUM-MUSTC-MULTILINGUAL-ST
`s2t-medium-mustc-multilingual-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Multilingual Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to French text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
the target language id is forced as the first generated token. To force the target language id as the first
generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
example shows how to transate English speech to French and German text using the `facebook/s2t-medium-mustc-multilingual-st`
checkpoint.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
# translate English Speech To French Text
generated_ids = model.generate(
input_ids=inputs["input_features"],
attention_mask=inputs["attention_mask"],
forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"]
)
translation_fr = processor.batch_decode(generated_ids)
# translate English Speech To German Text
generated_ids = model.generate(
input_ids=inputs["input_features"],
attention_mask=inputs["attention_mask"],
forced_bos_token_id=processor.tokenizer.lang_code_to_id["de"]
)
translation_de = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-medium-mustc-multilingual-st is trained on [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 10,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for multilingual ASR. For multilingual models, target language ID token
is used as target BOS.
## Evaluation results
MuST-C test results (BLEU score):
| En-De | En-Nl | En-Es | En-Fr | En-It | En-Pt | En-Ro | En-Ru |
|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|
| 24.5 | 28.6 | 28.2 | 34.9 | 24.6 | 31.1 | 23.8 | 16.0 |
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
``` |
facebook/blenderbot-90M | facebook | 2023-01-24T16:29:11Z | 4,767 | 3 | transformers | [
"transformers",
"pytorch",
"blenderbot-small",
"text2text-generation",
"convAI",
"conversational",
"facebook",
"en",
"dataset:blended_skill_talk",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language:
- en
thumbnail:
tags:
- convAI
- conversational
- facebook
license: apache-2.0
datasets:
- blended_skill_talk
metrics:
- perplexity
---
# 🚨🚨**IMPORTANT**🚨🚨
**This model is deprecated! Please use the identical model** **https://huggingface.co/facebook/blenderbot_small-90M instead**
## Model description
+ Paper: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/1907.06616)
+ [Original PARLAI Code](https://parl.ai/projects/recipes/)
### Abstract
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, both asking and answering questions, and displaying knowledge, empathy and personality appropriately, depending on the situation. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter neural models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
|
facebook/bart-large-xsum | facebook | 2023-01-24T16:28:59Z | 11,853 | 35 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"bart",
"text2text-generation",
"summarization",
"en",
"arxiv:1910.13461",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| summarization | 2022-03-02T23:29:05Z | ---
tags:
- summarization
language:
- en
license: mit
model-index:
- name: facebook/bart-large-xsum
results:
- task:
type: summarization
name: Summarization
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 25.2697
verified: true
- name: ROUGE-2
type: rouge
value: 7.6638
verified: true
- name: ROUGE-L
type: rouge
value: 17.1808
verified: true
- name: ROUGE-LSUM
type: rouge
value: 21.7933
verified: true
- name: loss
type: loss
value: 3.5042972564697266
verified: true
- name: gen_len
type: gen_len
value: 27.4462
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: xsum
type: xsum
config: default
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 45.4525
verified: true
- name: ROUGE-2
type: rouge
value: 22.3455
verified: true
- name: ROUGE-L
type: rouge
value: 37.2302
verified: true
- name: ROUGE-LSUM
type: rouge
value: 37.2323
verified: true
- name: loss
type: loss
value: 2.3128726482391357
verified: true
- name: gen_len
type: gen_len
value: 25.5435
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: train
metrics:
- name: ROUGE-1
type: rouge
value: 24.7852
verified: true
- name: ROUGE-2
type: rouge
value: 5.2533
verified: true
- name: ROUGE-L
type: rouge
value: 18.6792
verified: true
- name: ROUGE-LSUM
type: rouge
value: 20.629
verified: true
- name: loss
type: loss
value: 3.746837854385376
verified: true
- name: gen_len
type: gen_len
value: 23.1206
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 24.9158
verified: true
- name: ROUGE-2
type: rouge
value: 5.5837
verified: true
- name: ROUGE-L
type: rouge
value: 18.8935
verified: true
- name: ROUGE-LSUM
type: rouge
value: 20.76
verified: true
- name: loss
type: loss
value: 3.775235891342163
verified: true
- name: gen_len
type: gen_len
value: 23.0928
verified: true
---
### Bart model finetuned on xsum
docs: https://huggingface.co/transformers/model_doc/bart.html
finetuning: examples/seq2seq/ (as of Aug 20, 2020)
Metrics: ROUGE > 22 on xsum.
variants: search for distilbart
paper: https://arxiv.org/abs/1910.13461 |
allenai/wmt19-de-en-6-6-base | allenai | 2023-01-24T16:28:48Z | 30 | 0 | transformers | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"allenai",
"de",
"en",
"dataset:wmt19",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z |
---
language:
- de
- en
thumbnail:
tags:
- translation
- wmt19
- allenai
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt19 transformer](https://github.com/jungokasai/deep-shallow/) for de-en.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
2 models are available:
* [wmt19-de-en-6-6-big](https://huggingface.co/allenai/wmt19-de-en-6-6-big)
* [wmt19-de-en-6-6-base](https://huggingface.co/allenai/wmt19-de-en-6-6-base)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt19-de-en-6-6-base"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, nicht wahr?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | transformers
-------|---------
wmt19-de-en-6-6-base | 38.37
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt19-de-en-6-6-base $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
allenai/wmt16-en-de-dist-6-1 | allenai | 2023-01-24T16:28:45Z | 28 | 1 | transformers | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt16",
"allenai",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z |
---
language:
- en
- de
thumbnail:
tags:
- translation
- wmt16
- allenai
license: apache-2.0
datasets:
- wmt16
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-dist-6-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-dist-6-1 | 27.4 | 27.11
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-dist-6-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
allenai/wmt16-en-de-dist-12-1 | allenai | 2023-01-24T16:28:42Z | 44 | 1 | transformers | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt16",
"allenai",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z |
---
language:
- en
- de
thumbnail:
tags:
- translation
- wmt16
- allenai
license: apache-2.0
datasets:
- wmt16
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-dist-12-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-dist-12-1 | 28.3 | 27.52
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-dist-12-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
allenai/wmt16-en-de-12-1 | allenai | 2023-01-24T16:28:39Z | 22 | 1 | transformers | [
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt16",
"allenai",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z |
---
language:
- en
- de
thumbnail:
tags:
- translation
- wmt16
- allenai
license: apache-2.0
datasets:
- wmt16
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-12-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-12-1 | 26.9 | 25.75
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-12-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
allenai/unifiedqa-v2-t5-small-1251000 | allenai | 2023-01-24T16:28:33Z | 12 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
# Further details: https://github.com/allenai/unifiedqa |
allenai/unifiedqa-v2-t5-large-1363200 | allenai | 2023-01-24T16:28:30Z | 321 | 4 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
# Further details: https://github.com/allenai/unifiedqa
|
allenai/unifiedqa-v2-t5-large-1251000 | allenai | 2023-01-24T16:28:27Z | 12 | 1 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
# Further details: https://github.com/allenai/unifiedqa
|
allenai/unifiedqa-v2-t5-base-1363200 | allenai | 2023-01-24T16:28:24Z | 308 | 2 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
# Further details: https://github.com/allenai/unifiedqa
|
allenai/unifiedqa-v2-t5-base-1251000 | allenai | 2023-01-24T16:28:21Z | 90 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
# Further details: https://github.com/allenai/unifiedqa |
allenai/unifiedqa-v2-t5-3b-1251000 | allenai | 2023-01-24T16:28:15Z | 67 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
# Further details: https://github.com/allenai/unifiedqa
|
allenai/t5-small-squad2-question-generation | allenai | 2023-01-24T16:27:47Z | 501 | 43 | transformers | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
A simple question-generation model built based on SQuAD 2.0 dataset.
Example use:
```python
from transformers import T5Config, T5ForConditionalGeneration, T5Tokenizer
model_name = "allenai/t5-small-squad2-question-generation"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("shrouds herself in white and walks penitentially disguised as brotherly love through factories and parliaments; offers help, but desires power;")
run_model("He thanked all fellow bloggers and organizations that showed support.")
run_model("Races are held between April and December at the Veliefendi Hippodrome near Bakerky, 15 km (9 miles) west of Istanbul.")
```
which should result in the following:
```
['What is the name of the man who is a brotherly love?']
['What did He thank all fellow bloggers and organizations that showed support?']
['Where is the Veliefendi Hippodrome located?']
```
|
allenai/t5-small-squad11 | allenai | 2023-01-24T16:27:41Z | 16 | 1 | transformers | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
---
SQuAD 1.1 question-answering based on T5-small.
Example use:
```python
from transformers import T5Config, T5ForConditionalGeneration, T5Tokenizer
model_name = "allenai/t5-small-next-word-generator-qoogle"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("Who is the winner of 2009 olympics? \n Jack and Jill participated, but James won the games.")```
which should result in the following:
```
['James']
```
|
allenai/led-large-16384-arxiv | allenai | 2023-01-24T16:27:02Z | 2,522 | 31 | transformers | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"dataset:scientific_papers",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
datasets:
- scientific_papers
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
This is the official *led-large-16384* checkpoint that is fine-tuned on the arXiv dataset.*led-large-16384-arxiv* is the official fine-tuned version of [led-large-16384](https://huggingface.co/allenai/led-large-16384). As presented in the [paper](https://arxiv.org/pdf/2004.05150.pdf), the checkpoint achieves state-of-the-art results on arxiv
## Evaluation on downstream task
[This notebook](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing) shows how *led-large-16384-arxiv* can be evaluated on the [arxiv dataset](https://huggingface.co/datasets/scientific_papers)
## Usage
The model can be used as follows. The input is taken from the test data of the [arxiv dataset](https://huggingface.co/datasets/scientific_papers).
```python
LONG_ARTICLE = """"for about 20 years the problem of properties of
short - term changes of solar activity has been
considered extensively . many investigators
studied the short - term periodicities of the
various indices of solar activity . several
periodicities were detected , but the
periodicities about 155 days and from the interval
of @xmath3 $ ] days ( @xmath4 $ ] years ) are
mentioned most often . first of them was
discovered by @xcite in the occurence rate of
gamma - ray flares detected by the gamma - ray
spectrometer aboard the _ solar maximum mission (
smm ) . this periodicity was confirmed for other
solar flares data and for the same time period
@xcite . it was also found in proton flares during
solar cycles 19 and 20 @xcite , but it was not
found in the solar flares data during solar cycles
22 @xcite . _ several autors confirmed above
results for the daily sunspot area data . @xcite
studied the sunspot data from 18741984 . she found
the 155-day periodicity in data records from 31
years . this periodicity is always characteristic
for one of the solar hemispheres ( the southern
hemisphere for cycles 1215 and the northern
hemisphere for cycles 1621 ) . moreover , it is
only present during epochs of maximum activity (
in episodes of 13 years ) .
similarinvestigationswerecarriedoutby + @xcite .
they applied the same power spectrum method as
lean , but the daily sunspot area data ( cycles
1221 ) were divided into 10 shorter time series .
the periodicities were searched for the frequency
interval 57115 nhz ( 100200 days ) and for each of
10 time series . the authors showed that the
periodicity between 150160 days is statistically
significant during all cycles from 16 to 21 . the
considered peaks were remained unaltered after
removing the 11-year cycle and applying the power
spectrum analysis . @xcite used the wavelet
technique for the daily sunspot areas between 1874
and 1993 . they determined the epochs of
appearance of this periodicity and concluded that
it presents around the maximum activity period in
cycles 16 to 21 . moreover , the power of this
periodicity started growing at cycle 19 ,
decreased in cycles 20 and 21 and disappered after
cycle 21 . similaranalyseswerepresentedby + @xcite
, but for sunspot number , solar wind plasma ,
interplanetary magnetic field and geomagnetic
activity index @xmath5 . during 1964 - 2000 the
sunspot number wavelet power of periods less than
one year shows a cyclic evolution with the phase
of the solar cycle.the 154-day period is prominent
and its strenth is stronger around the 1982 - 1984
interval in almost all solar wind parameters . the
existence of the 156-day periodicity in sunspot
data were confirmed by @xcite . they considered
the possible relation between the 475-day (
1.3-year ) and 156-day periodicities . the 475-day
( 1.3-year ) periodicity was also detected in
variations of the interplanetary magnetic field ,
geomagnetic activity helioseismic data and in the
solar wind speed @xcite . @xcite concluded that
the region of larger wavelet power shifts from
475-day ( 1.3-year ) period to 620-day ( 1.7-year
) period and then back to 475-day ( 1.3-year ) .
the periodicities from the interval @xmath6 $ ]
days ( @xmath4 $ ] years ) have been considered
from 1968 . @xcite mentioned a 16.3-month (
490-day ) periodicity in the sunspot numbers and
in the geomagnetic data . @xcite analysed the
occurrence rate of major flares during solar
cycles 19 . they found a 18-month ( 540-day )
periodicity in flare rate of the norhern
hemisphere . @xcite confirmed this result for the
@xmath7 flare data for solar cycles 20 and 21 and
found a peak in the power spectra near 510540 days
. @xcite found a 17-month ( 510-day ) periodicity
of sunspot groups and their areas from 1969 to
1986 . these authors concluded that the length of
this period is variable and the reason of this
periodicity is still not understood . @xcite and +
@xcite obtained statistically significant peaks of
power at around 158 days for daily sunspot data
from 1923 - 1933 ( cycle 16 ) . in this paper the
problem of the existence of this periodicity for
sunspot data from cycle 16 is considered . the
daily sunspot areas , the mean sunspot areas per
carrington rotation , the monthly sunspot numbers
and their fluctuations , which are obtained after
removing the 11-year cycle are analysed . in
section 2 the properties of the power spectrum
methods are described . in section 3 a new
approach to the problem of aliases in the power
spectrum analysis is presented . in section 4
numerical results of the new method of the
diagnosis of an echo - effect for sunspot area
data are discussed . in section 5 the problem of
the existence of the periodicity of about 155 days
during the maximum activity period for sunspot
data from the whole solar disk and from each solar
hemisphere separately is considered . to find
periodicities in a given time series the power
spectrum analysis is applied . in this paper two
methods are used : the fast fourier transformation
algorithm with the hamming window function ( fft )
and the blackman - tukey ( bt ) power spectrum
method @xcite . the bt method is used for the
diagnosis of the reasons of the existence of peaks
, which are obtained by the fft method . the bt
method consists in the smoothing of a cosine
transform of an autocorrelation function using a
3-point weighting average . such an estimator is
consistent and unbiased . moreover , the peaks are
uncorrelated and their sum is a variance of a
considered time series . the main disadvantage of
this method is a weak resolution of the
periodogram points , particularly for low
frequences . for example , if the autocorrelation
function is evaluated for @xmath8 , then the
distribution points in the time domain are :
@xmath9 thus , it is obvious that this method
should not be used for detecting low frequency
periodicities with a fairly good resolution .
however , because of an application of the
autocorrelation function , the bt method can be
used to verify a reality of peaks which are
computed using a method giving the better
resolution ( for example the fft method ) . it is
valuable to remember that the power spectrum
methods should be applied very carefully . the
difficulties in the interpretation of significant
peaks could be caused by at least four effects : a
sampling of a continuos function , an echo -
effect , a contribution of long - term
periodicities and a random noise . first effect
exists because periodicities , which are shorter
than the sampling interval , may mix with longer
periodicities . in result , this effect can be
reduced by an decrease of the sampling interval
between observations . the echo - effect occurs
when there is a latent harmonic of frequency
@xmath10 in the time series , giving a spectral
peak at @xmath10 , and also periodic terms of
frequency @xmath11 etc . this may be detected by
the autocorrelation function for time series with
a large variance . time series often contain long
- term periodicities , that influence short - term
peaks . they could rise periodogram s peaks at
lower frequencies . however , it is also easy to
notice the influence of the long - term
periodicities on short - term peaks in the graphs
of the autocorrelation functions . this effect is
observed for the time series of solar activity
indexes which are limited by the 11-year cycle .
to find statistically significant periodicities it
is reasonable to use the autocorrelation function
and the power spectrum method with a high
resolution . in the case of a stationary time
series they give similar results . moreover , for
a stationary time series with the mean zero the
fourier transform is equivalent to the cosine
transform of an autocorrelation function @xcite .
thus , after a comparison of a periodogram with an
appropriate autocorrelation function one can
detect peaks which are in the graph of the first
function and do not exist in the graph of the
second function . the reasons of their existence
could be explained by the long - term
periodicities and the echo - effect . below method
enables one to detect these effects . ( solid line
) and the 95% confidence level basing on thered
noise ( dotted line ) . the periodogram values are
presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] because
the statistical tests indicate that the time
series is a white noise the confidence level is
not marked . ] . ] the method of the diagnosis
of an echo - effect in the power spectrum ( de )
consists in an analysis of a periodogram of a
given time series computed using the bt method .
the bt method bases on the cosine transform of the
autocorrelation function which creates peaks which
are in the periodogram , but not in the
autocorrelation function . the de method is used
for peaks which are computed by the fft method (
with high resolution ) and are statistically
significant . the time series of sunspot activity
indexes with the spacing interval one rotation or
one month contain a markov - type persistence ,
which means a tendency for the successive values
of the time series to remember their antecendent
values . thus , i use a confidence level basing on
the red noise of markov @xcite for the choice of
the significant peaks of the periodogram computed
by the fft method . when a time series does not
contain the markov - type persistence i apply the
fisher test and the kolmogorov - smirnov test at
the significance level @xmath12 @xcite to verify a
statistically significance of periodograms peaks .
the fisher test checks the null hypothesis that
the time series is white noise agains the
alternative hypothesis that the time series
contains an added deterministic periodic component
of unspecified frequency . because the fisher test
tends to be severe in rejecting peaks as
insignificant the kolmogorov - smirnov test is
also used . the de method analyses raw estimators
of the power spectrum . they are given as follows
@xmath13 for @xmath14 + where @xmath15 for
@xmath16 + @xmath17 is the length of the time
series @xmath18 and @xmath19 is the mean value .
the first term of the estimator @xmath20 is
constant . the second term takes two values (
depending on odd or even @xmath21 ) which are not
significant because @xmath22 for large m. thus ,
the third term of ( 1 ) should be analysed .
looking for intervals of @xmath23 for which
@xmath24 has the same sign and different signs one
can find such parts of the function @xmath25 which
create the value @xmath20 . let the set of values
of the independent variable of the autocorrelation
function be called @xmath26 and it can be divided
into the sums of disjoint sets : @xmath27 where +
@xmath28 + @xmath29 @xmath30 @xmath31 + @xmath32 +
@xmath33 @xmath34 @xmath35 @xmath36 @xmath37
@xmath38 @xmath39 @xmath40 well , the set
@xmath41 contains all integer values of @xmath23
from the interval of @xmath42 for which the
autocorrelation function and the cosinus function
with the period @xmath43 $ ] are positive . the
index @xmath44 indicates successive parts of the
cosinus function for which the cosinuses of
successive values of @xmath23 have the same sign .
however , sometimes the set @xmath41 can be empty
. for example , for @xmath45 and @xmath46 the set
@xmath47 should contain all @xmath48 $ ] for which
@xmath49 and @xmath50 , but for such values of
@xmath23 the values of @xmath51 are negative .
thus , the set @xmath47 is empty . . the
periodogram values are presented on the left axis
. the lower curve illustrates the autocorrelation
function of the same time series . the
autocorrelation values are shown in the right axis
. ] let us take into consideration all sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } which
are not empty . because numberings and power of
these sets depend on the form of the
autocorrelation function of the given time series
, it is impossible to establish them arbitrary .
thus , the sets of appropriate indexes of the sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } are
called @xmath54 , @xmath55 and @xmath56
respectively . for example the set @xmath56
contains all @xmath44 from the set @xmath57 for
which the sets @xmath41 are not empty . to
separate quantitatively in the estimator @xmath20
the positive contributions which are originated by
the cases described by the formula ( 5 ) from the
cases which are described by the formula ( 3 ) the
following indexes are introduced : @xmath58
@xmath59 @xmath60 @xmath61 where @xmath62 @xmath63
@xmath64 taking for the empty sets \{@xmath53 }
and \{@xmath41 } the indices @xmath65 and @xmath66
equal zero . the index @xmath65 describes a
percentage of the contribution of the case when
@xmath25 and @xmath51 are positive to the positive
part of the third term of the sum ( 1 ) . the
index @xmath66 describes a similar contribution ,
but for the case when the both @xmath25 and
@xmath51 are simultaneously negative . thanks to
these one can decide which the positive or the
negative values of the autocorrelation function
have a larger contribution to the positive values
of the estimator @xmath20 . when the difference
@xmath67 is positive , the statement the
@xmath21-th peak really exists can not be rejected
. thus , the following formula should be satisfied
: @xmath68 because the @xmath21-th peak could
exist as a result of the echo - effect , it is
necessary to verify the second condition :
@xmath69\in c_m.\ ] ] . the periodogram values
are presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] to
verify the implication ( 8) firstly it is
necessary to evaluate the sets @xmath41 for
@xmath70 of the values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath71 $ ] are positive and the
sets @xmath72 of values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath43 $ ] are negative .
secondly , a percentage of the contribution of the
sum of products of positive values of @xmath25 and
@xmath51 to the sum of positive products of the
values of @xmath25 and @xmath51 should be
evaluated . as a result the indexes @xmath65 for
each set @xmath41 where @xmath44 is the index from
the set @xmath56 are obtained . thirdly , from all
sets @xmath41 such that @xmath70 the set @xmath73
for which the index @xmath65 is the greatest
should be chosen . the implication ( 8) is true
when the set @xmath73 includes the considered
period @xmath43 $ ] . this means that the greatest
contribution of positive values of the
autocorrelation function and positive cosines with
the period @xmath43 $ ] to the periodogram value
@xmath20 is caused by the sum of positive products
of @xmath74 for each @xmath75-\frac{m}{2k},[\frac{
2m}{k}]+\frac{m}{2k})$ ] . when the implication
( 8) is false , the peak @xmath20 is mainly
created by the sum of positive products of
@xmath74 for each @xmath76-\frac{m}{2k},\big [
\frac{2m}{n}\big ] + \frac{m}{2k } \big ) $ ] ,
where @xmath77 is a multiple or a divisor of
@xmath21 . it is necessary to add , that the de
method should be applied to the periodograms peaks
, which probably exist because of the echo -
effect . it enables one to find such parts of the
autocorrelation function , which have the
significant contribution to the considered peak .
the fact , that the conditions ( 7 ) and ( 8) are
satisfied , can unambiguously decide about the
existence of the considered periodicity in the
given time series , but if at least one of them is
not satisfied , one can doubt about the existence
of the considered periodicity . thus , in such
cases the sentence the peak can not be treated as
true should be used . using the de method it is
necessary to remember about the power of the set
@xmath78 . if @xmath79 is too large , errors of an
autocorrelation function estimation appear . they
are caused by the finite length of the given time
series and as a result additional peaks of the
periodogram occur . if @xmath79 is too small ,
there are less peaks because of a low resolution
of the periodogram . in applications @xmath80 is
used . in order to evaluate the value @xmath79 the
fft method is used . the periodograms computed by
the bt and the fft method are compared . the
conformity of them enables one to obtain the value
@xmath79 . . the fft periodogram values are
presented on the left axis . the lower curve
illustrates the bt periodogram of the same time
series ( solid line and large black circles ) .
the bt periodogram values are shown in the right
axis . ] in this paper the sunspot activity data (
august 1923 - october 1933 ) provided by the
greenwich photoheliographic results ( gpr ) are
analysed . firstly , i consider the monthly
sunspot number data . to eliminate the 11-year
trend from these data , the consecutively smoothed
monthly sunspot number @xmath81 is subtracted from
the monthly sunspot number @xmath82 where the
consecutive mean @xmath83 is given by @xmath84 the
values @xmath83 for @xmath85 and @xmath86 are
calculated using additional data from last six
months of cycle 15 and first six months of cycle
17 . because of the north - south asymmetry of
various solar indices @xcite , the sunspot
activity is considered for each solar hemisphere
separately . analogously to the monthly sunspot
numbers , the time series of sunspot areas in the
northern and southern hemispheres with the spacing
interval @xmath87 rotation are denoted . in order
to find periodicities , the following time series
are used : + @xmath88 + @xmath89 + @xmath90
+ in the lower part of figure [ f1 ] the
autocorrelation function of the time series for
the northern hemisphere @xmath88 is shown . it is
easy to notice that the prominent peak falls at 17
rotations interval ( 459 days ) and @xmath25 for
@xmath91 $ ] rotations ( [ 81 , 162 ] days ) are
significantly negative . the periodogram of the
time series @xmath88 ( see the upper curve in
figures [ f1 ] ) does not show the significant
peaks at @xmath92 rotations ( 135 , 162 days ) ,
but there is the significant peak at @xmath93 (
243 days ) . the peaks at @xmath94 are close to
the peaks of the autocorrelation function . thus ,
the result obtained for the periodicity at about
@xmath0 days are contradict to the results
obtained for the time series of daily sunspot
areas @xcite . for the southern hemisphere (
the lower curve in figure [ f2 ] ) @xmath25 for
@xmath95 $ ] rotations ( [ 54 , 189 ] days ) is
not positive except @xmath96 ( 135 days ) for
which @xmath97 is not statistically significant .
the upper curve in figures [ f2 ] presents the
periodogram of the time series @xmath89 . this
time series does not contain a markov - type
persistence . moreover , the kolmogorov - smirnov
test and the fisher test do not reject a null
hypothesis that the time series is a white noise
only . this means that the time series do not
contain an added deterministic periodic component
of unspecified frequency . the autocorrelation
function of the time series @xmath90 ( the lower
curve in figure [ f3 ] ) has only one
statistically significant peak for @xmath98 months
( 480 days ) and negative values for @xmath99 $ ]
months ( [ 90 , 390 ] days ) . however , the
periodogram of this time series ( the upper curve
in figure [ f3 ] ) has two significant peaks the
first at 15.2 and the second at 5.3 months ( 456 ,
159 days ) . thus , the periodogram contains the
significant peak , although the autocorrelation
function has the negative value at @xmath100
months . to explain these problems two
following time series of daily sunspot areas are
considered : + @xmath101 + @xmath102 + where
@xmath103 the values @xmath104 for @xmath105
and @xmath106 are calculated using additional
daily data from the solar cycles 15 and 17 .
and the cosine function for @xmath45 ( the period
at about 154 days ) . the horizontal line ( dotted
line ) shows the zero level . the vertical dotted
lines evaluate the intervals where the sets
@xmath107 ( for @xmath108 ) are searched . the
percentage values show the index @xmath65 for each
@xmath41 for the time series @xmath102 ( in
parentheses for the time series @xmath101 ) . in
the right bottom corner the values of @xmath65 for
the time series @xmath102 , for @xmath109 are
written . ] ( the 500-day period ) ] the
comparison of the functions @xmath25 of the time
series @xmath101 ( the lower curve in figure [ f4
] ) and @xmath102 ( the lower curve in figure [ f5
] ) suggests that the positive values of the
function @xmath110 of the time series @xmath101 in
the interval of @xmath111 $ ] days could be caused
by the 11-year cycle . this effect is not visible
in the case of periodograms of the both time
series computed using the fft method ( see the
upper curves in figures [ f4 ] and [ f5 ] ) or the
bt method ( see the lower curve in figure [ f6 ] )
. moreover , the periodogram of the time series
@xmath102 has the significant values at @xmath112
days , but the autocorrelation function is
negative at these points . @xcite showed that the
lomb - scargle periodograms for the both time
series ( see @xcite , figures 7 a - c ) have a
peak at 158.8 days which stands over the fap level
by a significant amount . using the de method the
above discrepancies are obvious . to establish the
@xmath79 value the periodograms computed by the
fft and the bt methods are shown in figure [ f6 ]
( the upper and the lower curve respectively ) .
for @xmath46 and for periods less than 166 days
there is a good comformity of the both
periodograms ( but for periods greater than 166
days the points of the bt periodogram are not
linked because the bt periodogram has much worse
resolution than the fft periodogram ( no one know
how to do it ) ) . for @xmath46 and @xmath113 the
value of @xmath21 is 13 ( @xmath71=153 $ ] ) . the
inequality ( 7 ) is satisfied because @xmath114 .
this means that the value of @xmath115 is mainly
created by positive values of the autocorrelation
function . the implication ( 8) needs an
evaluation of the greatest value of the index
@xmath65 where @xmath70 , but the solar data
contain the most prominent period for @xmath116
days because of the solar rotation . thus ,
although @xmath117 for each @xmath118 , all sets
@xmath41 ( see ( 5 ) and ( 6 ) ) without the set
@xmath119 ( see ( 4 ) ) , which contains @xmath120
$ ] , are considered . this situation is presented
in figure [ f7 ] . in this figure two curves
@xmath121 and @xmath122 are plotted . the vertical
dotted lines evaluate the intervals where the sets
@xmath107 ( for @xmath123 ) are searched . for
such @xmath41 two numbers are written : in
parentheses the value of @xmath65 for the time
series @xmath101 and above it the value of
@xmath65 for the time series @xmath102 . to make
this figure clear the curves are plotted for the
set @xmath124 only . ( in the right bottom corner
information about the values of @xmath65 for the
time series @xmath102 , for @xmath109 are written
. ) the implication ( 8) is not true , because
@xmath125 for @xmath126 . therefore ,
@xmath43=153\notin c_6=[423,500]$ ] . moreover ,
the autocorrelation function for @xmath127 $ ] is
negative and the set @xmath128 is empty . thus ,
@xmath129 . on the basis of these information one
can state , that the periodogram peak at @xmath130
days of the time series @xmath102 exists because
of positive @xmath25 , but for @xmath23 from the
intervals which do not contain this period .
looking at the values of @xmath65 of the time
series @xmath101 , one can notice that they
decrease when @xmath23 increases until @xmath131 .
this indicates , that when @xmath23 increases ,
the contribution of the 11-year cycle to the peaks
of the periodogram decreases . an increase of the
value of @xmath65 is for @xmath132 for the both
time series , although the contribution of the
11-year cycle for the time series @xmath101 is
insignificant . thus , this part of the
autocorrelation function ( @xmath133 for the time
series @xmath102 ) influences the @xmath21-th peak
of the periodogram . this suggests that the
periodicity at about 155 days is a harmonic of the
periodicity from the interval of @xmath1 $ ] days
. ( solid line ) and consecutively smoothed
sunspot areas of the one rotation time interval
@xmath134 ( dotted line ) . both indexes are
presented on the left axis . the lower curve
illustrates fluctuations of the sunspot areas
@xmath135 . the dotted and dashed horizontal lines
represent levels zero and @xmath136 respectively .
the fluctuations are shown on the right axis . ]
the described reasoning can be carried out for
other values of the periodogram . for example ,
the condition ( 8) is not satisfied for @xmath137
( 250 , 222 , 200 days ) . moreover , the
autocorrelation function at these points is
negative . these suggest that there are not a true
periodicity in the interval of [ 200 , 250 ] days
. it is difficult to decide about the existence of
the periodicities for @xmath138 ( 333 days ) and
@xmath139 ( 286 days ) on the basis of above
analysis . the implication ( 8) is not satisfied
for @xmath139 and the condition ( 7 ) is not
satisfied for @xmath138 , although the function
@xmath25 of the time series @xmath102 is
significantly positive for @xmath140 . the
conditions ( 7 ) and ( 8) are satisfied for
@xmath141 ( figure [ f8 ] ) and @xmath142 .
therefore , it is possible to exist the
periodicity from the interval of @xmath1 $ ] days
. similar results were also obtained by @xcite for
daily sunspot numbers and daily sunspot areas .
she considered the means of three periodograms of
these indexes for data from @xmath143 years and
found statistically significant peaks from the
interval of @xmath1 $ ] ( see @xcite , figure 2 )
. @xcite studied sunspot areas from 1876 - 1999
and sunspot numbers from 1749 - 2001 with the help
of the wavelet transform . they pointed out that
the 154 - 158-day period could be the third
harmonic of the 1.3-year ( 475-day ) period .
moreover , the both periods fluctuate considerably
with time , being stronger during stronger sunspot
cycles . therefore , the wavelet analysis suggests
a common origin of the both periodicities . this
conclusion confirms the de method result which
indicates that the periodogram peak at @xmath144
days is an alias of the periodicity from the
interval of @xmath1 $ ] in order to verify the
existence of the periodicity at about 155 days i
consider the following time series : + @xmath145
+ @xmath146 + @xmath147 + the value @xmath134
is calculated analogously to @xmath83 ( see sect .
the values @xmath148 and @xmath149 are evaluated
from the formula ( 9 ) . in the upper part of
figure [ f9 ] the time series of sunspot areas
@xmath150 of the one rotation time interval from
the whole solar disk and the time series of
consecutively smoothed sunspot areas @xmath151 are
showed . in the lower part of figure [ f9 ] the
time series of sunspot area fluctuations @xmath145
is presented . on the basis of these data the
maximum activity period of cycle 16 is evaluated .
it is an interval between two strongest
fluctuations e.a . @xmath152 $ ] rotations . the
length of the time interval @xmath153 is 54
rotations . if the about @xmath0-day ( 6 solar
rotations ) periodicity existed in this time
interval and it was characteristic for strong
fluctuations from this time interval , 10 local
maxima in the set of @xmath154 would be seen .
then it should be necessary to find such a value
of p for which @xmath155 for @xmath156 and the
number of the local maxima of these values is 10 .
as it can be seen in the lower part of figure [ f9
] this is for the case of @xmath157 ( in this
figure the dashed horizontal line is the level of
@xmath158 ) . figure [ f10 ] presents nine time
distances among the successive fluctuation local
maxima and the horizontal line represents the
6-rotation periodicity . it is immediately
apparent that the dispersion of these points is 10
and it is difficult to find even few points which
oscillate around the value of 6 . such an analysis
was carried out for smaller and larger @xmath136
and the results were similar . therefore , the
fact , that the about @xmath0-day periodicity
exists in the time series of sunspot area
fluctuations during the maximum activity period is
questionable . . the horizontal line represents
the 6-rotation ( 162-day ) period . ] ] ]
to verify again the existence of the about
@xmath0-day periodicity during the maximum
activity period in each solar hemisphere
separately , the time series @xmath88 and @xmath89
were also cut down to the maximum activity period
( january 1925december 1930 ) . the comparison of
the autocorrelation functions of these time series
with the appriopriate autocorrelation functions of
the time series @xmath88 and @xmath89 , which are
computed for the whole 11-year cycle ( the lower
curves of figures [ f1 ] and [ f2 ] ) , indicates
that there are not significant differences between
them especially for @xmath23=5 and 6 rotations (
135 and 162 days ) ) . this conclusion is
confirmed by the analysis of the time series
@xmath146 for the maximum activity period . the
autocorrelation function ( the lower curve of
figure [ f11 ] ) is negative for the interval of [
57 , 173 ] days , but the resolution of the
periodogram is too low to find the significant
peak at @xmath159 days . the autocorrelation
function gives the same result as for daily
sunspot area fluctuations from the whole solar
disk ( @xmath160 ) ( see also the lower curve of
figures [ f5 ] ) . in the case of the time series
@xmath89 @xmath161 is zero for the fluctuations
from the whole solar cycle and it is almost zero (
@xmath162 ) for the fluctuations from the maximum
activity period . the value @xmath163 is negative
. similarly to the case of the northern hemisphere
the autocorrelation function and the periodogram
of southern hemisphere daily sunspot area
fluctuations from the maximum activity period
@xmath147 are computed ( see figure [ f12 ] ) .
the autocorrelation function has the statistically
significant positive peak in the interval of [ 155
, 165 ] days , but the periodogram has too low
resolution to decide about the possible
periodicities . the correlative analysis indicates
that there are positive fluctuations with time
distances about @xmath0 days in the maximum
activity period . the results of the analyses of
the time series of sunspot area fluctuations from
the maximum activity period are contradict with
the conclusions of @xcite . she uses the power
spectrum analysis only . the periodogram of daily
sunspot fluctuations contains peaks , which could
be harmonics or subharmonics of the true
periodicities . they could be treated as real
periodicities . this effect is not visible for
sunspot data of the one rotation time interval ,
but averaging could lose true periodicities . this
is observed for data from the southern hemisphere
. there is the about @xmath0-day peak in the
autocorrelation function of daily fluctuations ,
but the correlation for data of the one rotation
interval is almost zero or negative at the points
@xmath164 and 6 rotations . thus , it is
reasonable to research both time series together
using the correlative and the power spectrum
analyses . the following results are obtained :
1 . a new method of the detection of statistically
significant peaks of the periodograms enables one
to identify aliases in the periodogram . 2 . two
effects cause the existence of the peak of the
periodogram of the time series of sunspot area
fluctuations at about @xmath0 days : the first is
caused by the 27-day periodicity , which probably
creates the 162-day periodicity ( it is a
subharmonic frequency of the 27-day periodicity )
and the second is caused by statistically
significant positive values of the autocorrelation
function from the intervals of @xmath165 $ ] and
@xmath166 $ ] days . the existence of the
periodicity of about @xmath0 days of the time
series of sunspot area fluctuations and sunspot
area fluctuations from the northern hemisphere
during the maximum activity period is questionable
. the autocorrelation analysis of the time series
of sunspot area fluctuations from the southern
hemisphere indicates that the periodicity of about
155 days exists during the maximum activity period
. i appreciate valuable comments from professor j.
jakimiec ."""
from transformers import LEDForConditionalGeneration, LEDTokenizer
import torch
tokenizer = LEDTokenizer.from_pretrained("allenai/led-large-16384-arxiv")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
global_attention_mask = torch.zeros_like(input_ids)
# set global_attention_mask on first token
global_attention_mask[:, 0] = 1
model = LEDForConditionalGeneration.from_pretrained("allenai/led-large-16384-arxiv", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids, global_attention_mask=global_attention_mask).sequences
summary = tokenizer.batch_decode(sequences)
```
|
ViktorDo/DistilBERT-POWO_Scratch | ViktorDo | 2023-01-24T16:26:31Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-01-24T15:00:39Z | ---
tags:
- generated_from_trainer
model-index:
- name: DistilBERT-POWO_Scratch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBERT-POWO_Scratch
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.9068
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 5
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 40
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.104 | 0.18 | 200 | 5.9641 |
| 5.6973 | 0.36 | 400 | 5.5992 |
| 5.5464 | 0.54 | 600 | 5.4564 |
| 5.377 | 0.72 | 800 | 5.3606 |
| 5.2162 | 0.9 | 1000 | 5.2674 |
| 5.1499 | 1.08 | 1200 | 5.2080 |
| 5.1313 | 1.26 | 1400 | 5.1447 |
| 5.0138 | 1.44 | 1600 | 5.1041 |
| 4.9509 | 1.62 | 1800 | 5.0572 |
| 4.9598 | 1.8 | 2000 | 5.0185 |
| 4.9581 | 1.98 | 2200 | 5.0109 |
| 4.8458 | 2.16 | 2400 | 4.9608 |
| 4.953 | 2.34 | 2600 | 4.9482 |
| 4.7448 | 2.52 | 2800 | 4.9211 |
| 4.8574 | 2.71 | 3000 | 4.9093 |
| 4.8402 | 2.89 | 3200 | 4.8980 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
SZTAKI-HLT/mT5-small-HunSum-1 | SZTAKI-HLT | 2023-01-24T16:21:41Z | 11 | 1 | transformers | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"summarization",
"hu",
"dataset:SZTAKI-HLT/HunSum-1",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| summarization | 2023-01-06T10:17:13Z | ---
language:
- hu
pipeline_tag: summarization
inference:
parameters:
num_beams: 5
length_penalty: 2
max_length: 128
encoder_no_repeat_ngram_size: 4
no_repeat_ngram_size: 3
datasets:
- SZTAKI-HLT/HunSum-1
metrics:
- rouge
---
# Model Card for mT5-small-HunSum-1
The mT5-small-HunSum-1 is a Hungarian abstractive summarization model, which was trained on the [SZTAKI-HLT/HunSum-1 dataset](https://huggingface.co/datasets/SZTAKI-HLT/HunSum-1).
The model is based on [google/mt5-small]([google/mt5-small](https://huggingface.co/google/mt5-small)).
## Intended uses & limitations
- **Model type:** Text Summarization
- **Language(s) (NLP):** Hungarian
- **Resource(s) for more information:**
- [GitHub Repo](https://github.com/dorinapetra/summarization)
## Parameters
- **Batch Size:** 16
- **Learning Rate:** 5e-5
- **Weight Decay:** 0.01
- **Warmup Steps:** 3000
- **Epochs:** 10
- **no_repeat_ngram_size:** 3
- **num_beams:** 5
- **early_stopping:** False
- **encoder_no_repeat_ngram_size:** 4
## Results
| Metric | Value |
| :------------ | :------------------------------------------ |
| ROUGE-1 | 36.49 |
| ROUGE-2 | 9.50 |
| ROUGE-L | 23.48 |
## Citation
If you use our model, please cite the following paper:
```
@inproceedings {HunSum-1,
title = {{HunSum-1: an Abstractive Summarization Dataset for Hungarian}},
booktitle = {XIX. Magyar Számítógépes Nyelvészeti Konferencia (MSZNY 2023)},
year = {2023},
publisher = {Szegedi Tudományegyetem, Informatikai Intézet},
address = {Szeged, Magyarország},
author = {Barta, Botond and Lakatos, Dorina and Nagy, Attila and Nyist, Mil{\'{a}}n Konor and {\'{A}}cs, Judit},
pages = {231--243}
}
``` |
SZTAKI-HLT/Bert2Bert-HunSum-1 | SZTAKI-HLT | 2023-01-24T16:21:16Z | 5 | 2 | transformers | [
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"hubert",
"bert",
"summarization",
"hu",
"dataset:SZTAKI-HLT/HunSum-1",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-01-07T10:35:58Z | ---
datasets:
- SZTAKI-HLT/HunSum-1
language:
- hu
metrics:
- rouge
pipeline_tag: text2text-generation
inference:
parameters:
num_beams: 5
length_penalty: 2
max_length: 128
no_repeat_ngram_size: 3
early_stopping: True
tags:
- hubert
- bert
- summarization
---
# Model Card for Bert2Bert-HunSum-1
The Bert2Bert-HunSum-1 is a Hungarian abstractive summarization model, which was trained on the [SZTAKI-HLT/HunSum-1 dataset](https://huggingface.co/datasets/SZTAKI-HLT/HunSum-1).
The model is based on [SZTAKI-HLT/hubert-base-cc](https://huggingface.co/SZTAKI-HLT/hubert-base-cc).
## Intended uses & limitations
- **Model type:** Text Summarization
- **Language(s) (NLP):** Hungarian
- **Resource(s) for more information:**
- [GitHub Repo](https://github.com/dorinapetra/summarization)
## Parameters
- **Batch Size:** 13
- **Learning Rate:** 5e-5
- **Weight Decay:** 0.01
- **Warmup Steps:** 16000
- **Epochs:** 15
- **no_repeat_ngram_size:** 3
- **num_beams:** 5
- **early_stopping:** True
## Results
| Metric | Value |
| :------------ | :------------------------------------------ |
| ROUGE-1 | 28.52 |
| ROUGE-2 | 10.35 |
| ROUGE-L | 20.07 |
## Citation
If you use our model, please cite the following paper:
```
@inproceedings {HunSum-1,
title = {{HunSum-1: an Abstractive Summarization Dataset for Hungarian}},
booktitle = {XIX. Magyar Számítógépes Nyelvészeti Konferencia (MSZNY 2023)},
year = {2023},
publisher = {Szegedi Tudományegyetem, Informatikai Intézet},
address = {Szeged, Magyarország},
author = {Barta, Botond and Lakatos, Dorina and Nagy, Attila and Nyist, Mil{\'{a}}n Konor and {\'{A}}cs, Judit},
pages = {231--243}
}
``` |
cmdshiftenter/distilbert-base-uncased-finetuned-emotion | cmdshiftenter | 2023-01-24T16:06:29Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-01-24T14:35:09Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: train
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9240228561413785
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2164
- Accuracy: 0.924
- F1: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8345 | 1.0 | 250 | 0.2964 | 0.909 | 0.9074 |
| 0.2422 | 2.0 | 500 | 0.2164 | 0.924 | 0.9240 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
BobMcDear/regnety_3200mf | BobMcDear | 2023-01-24T16:05:40Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:59Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnety_4000mf | BobMcDear | 2023-01-24T16:05:33Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:42:00Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnetx_1600mf | BobMcDear | 2023-01-24T16:05:08Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:42:01Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnety_6400mf | BobMcDear | 2023-01-24T16:05:00Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:42:02Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnety_16gf | BobMcDear | 2023-01-24T16:04:52Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:51Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnetx_16gf | BobMcDear | 2023-01-24T16:04:45Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:52Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnetx_12gf | BobMcDear | 2023-01-24T16:04:31Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:42:04Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnety_32gf | BobMcDear | 2023-01-24T16:04:24Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:49Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnety_200mf | BobMcDear | 2023-01-24T16:03:45Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:42:06Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
LarryAIDraw/7thtwamMixedmodel_7thtwam10 | LarryAIDraw | 2023-01-24T16:03:25Z | 0 | 6 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-01-24T09:36:28Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/4870/7thtwam-mixedmodel |
BobMcDear/regnety_12gf | BobMcDear | 2023-01-24T16:03:23Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:45Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnetx_800mf | BobMcDear | 2023-01-24T16:03:08Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:46Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
BobMcDear/regnety_600mf | BobMcDear | 2023-01-24T16:02:59Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-01-24T14:41:50Z | Please refer to [flaim](https://github.com/bobmcdear/flaim) for sample usage and more information.
|
arputtick/GPT_Neo_muslim_travel | arputtick | 2023-01-24T15:55:27Z | 40 | 0 | transformers | [
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"en",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-11-07T16:37:52Z | ---
language: en
license: openrail
pipeline_tag: text-generation
---
# GPT-Neo 1.3B - Muslim Traveler
## Model Description
GPT-Neo 1.3B-Muslim Traveler is finetuned on EleutherAI's GPT-Neo 1.3B model.
## Training data
The training data consists of travel texts written by ancient muslim travelers. See 'combined.txt' file in the model repository.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='arputtick/GPT_Neo_muslim_travel')
>>> generator("> You wake up.", do_sample=True, min_length=50)
[{'generated_text': '> You wake up"\nYou get out of bed, don your armor and get out of the door in search for new adventures.'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
### BibTeX entry and citation info
The model is made using the following software:
```bibtex
@software{gpt-neo,
author = {Black, Sid and
Leo, Gao and
Wang, Phil and
Leahy, Connor and
Biderman, Stella},
title = {{GPT-Neo: Large Scale Autoregressive Language
Modeling with Mesh-Tensorflow}},
month = mar,
year = 2021,
note = {{If you use this software, please cite it using
these metadata.}},
publisher = {Zenodo},
version = {1.0},
doi = {10.5281/zenodo.5297715},
url = {https://doi.org/10.5281/zenodo.5297715}
}
``` |
SorinAbrudan/q-FrozenLake-v1-4x4-noSlippery | SorinAbrudan | 2023-01-24T15:41:08Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T15:41:04Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="SorinAbrudan/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
khaled5321/worm | khaled5321 | 2023-01-24T15:15:07Z | 12 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Worm",
"region:us"
]
| reinforcement-learning | 2023-01-24T15:15:01Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Worm
library_name: ml-agents
---
# **ppo** Agent playing **Worm**
This is a trained model of a **ppo** agent playing **Worm** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Worm
2. Step 1: Write your model_id: khaled5321/worm
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
alphahg/kobigbird-pure2-93753787 | alphahg | 2023-01-24T15:14:56Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"big_bird",
"question-answering",
"generated_from_trainer",
"dataset:custom_squad_v2",
"endpoints_compatible",
"region:us"
]
| question-answering | 2023-01-24T13:55:52Z | ---
tags:
- generated_from_trainer
datasets:
- custom_squad_v2
model-index:
- name: kobigbird-pure2-93753787
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobigbird-pure2-93753787
This model is a fine-tuned version of [monologg/kobigbird-bert-base](https://huggingface.co/monologg/kobigbird-bert-base) on the custom_squad_v2 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 3.4619
- eval_runtime: 26.5163
- eval_samples_per_second: 45.406
- eval_steps_per_second: 0.717
- epoch: 0.99
- step: 21
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 2
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Schwarzschild009/q-Taxi-v3 | Schwarzschild009 | 2023-01-24T15:11:10Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T14:06:49Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Schwarzschild009/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
javiervela/dqn-SpaceInvadersNoFrameskip-v4 | javiervela | 2023-01-24T15:05:18Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-12-24T09:44:16Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 544.50 +/- 73.26
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga javiervela -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga javiervela -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga javiervela
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Kenemo/ppo-LunarLander-v2-10Msteps | Kenemo | 2023-01-24T15:00:29Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T14:56:09Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 278.51 +/- 17.32
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AllaNBarakat/xlm-roberta-base-fintuned-panx-de | AllaNBarakat | 2023-01-24T14:52:43Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-01-24T14:35:48Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-fintuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: train
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8647266113447767
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-fintuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1357
- F1: 0.8647
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2577 | 1.0 | 525 | 0.1719 | 0.8077 |
| 0.1254 | 2.0 | 1050 | 0.1362 | 0.8558 |
| 0.081 | 3.0 | 1575 | 0.1357 | 0.8647 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
FacebookAI/xlm-mlm-enro-1024 | FacebookAI | 2023-01-24T14:50:13Z | 111 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"xlm",
"fill-mask",
"multilingual",
"en",
"ro",
"arxiv:1901.07291",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:04Z | ---
language:
- multilingual
- en
- ro
license: cc-by-nc-4.0
---
# xlm-mlm-enro-1024
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Technical Specifications](#technical-specifications)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
10. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
The XLM model was proposed in [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample, Alexis Conneau. xlm-mlm-enro-1024 is a transformer pretrained using a masked language modeling (MLM) objective for English-Romanian. This model uses language embeddings to specify the language used at inference. See the [Hugging Face Multilingual Models for Inference docs](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) for further details.
## Model Description
- **Developed by:** Guillaume Lample, Alexis Conneau, see [associated paper](https://arxiv.org/abs/1901.07291)
- **Model type:** Language model
- **Language(s) (NLP):** English-Romanian
- **License:** license: cc-by-nc-4.0
- **Related Models:** [xlm-clm-enfr-1024](https://huggingface.co/xlm-clm-enfr-1024), [xlm-clm-ende-1024](https://huggingface.co/xlm-clm-ende-1024), [xlm-mlm-enfr-1024](https://huggingface.co/xlm-mlm-enfr-1024), [xlm-mlm-ende-1024](https://huggingface.co/xlm-mlm-ende-1024)
- **Resources for more information:**
- [Associated paper](https://arxiv.org/abs/1901.07291)
- [GitHub Repo](https://github.com/facebookresearch/XLM)
- [Hugging Face Multilingual Models for Inference docs](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings)
# Uses
## Direct Use
The model is a language model. The model can be used for masked language modeling.
## Downstream Use
To learn more about this task and potential downstream uses, see the Hugging Face [fill mask docs](https://huggingface.co/tasks/fill-mask) and the [Hugging Face Multilingual Models for Inference](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) docs.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
# Training
The model developers write:
> In all experiments, we use a Transformer architecture with 1024 hidden units, 8 heads, GELU activations (Hendrycks and Gimpel, 2016), a dropout rate of 0.1 and learned positional embeddings. We train our models with the Adam op- timizer (Kingma and Ba, 2014), a linear warm- up (Vaswani et al., 2017) and learning rates varying from 10^−4 to 5.10^−4.
See the [associated paper](https://arxiv.org/pdf/1901.07291.pdf) for links, citations, and further details on the training data and training procedure.
The model developers also write that:
> If you use these models, you should use the same data preprocessing / BPE codes to preprocess your data.
See the associated [GitHub Repo](https://github.com/facebookresearch/XLM#ii-cross-lingual-language-model-pretraining-xlm) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The model developers evaluated the model on the [WMT'16 English-Romanian](https://huggingface.co/datasets/wmt16) dataset using the [BLEU metric](https://huggingface.co/spaces/evaluate-metric/bleu). See the [associated paper](https://arxiv.org/pdf/1901.07291.pdf) for further details on the testing data, factors and metrics.
## Results
For xlm-mlm-enro-1024 results, see Tables 1-3 of the [associated paper](https://arxiv.org/pdf/1901.07291.pdf).
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications
The model developers write:
> We implement all our models in PyTorch (Paszke et al., 2017), and train them on 64 Volta GPUs for the language modeling tasks, and 8 GPUs for the MT tasks. We use float16 operations to speed up training and to reduce the memory usage of our models.
See the [associated paper](https://arxiv.org/pdf/1901.07291.pdf) for further details.
# Citation
**BibTeX:**
```bibtex
@article{lample2019cross,
title={Cross-lingual language model pretraining},
author={Lample, Guillaume and Conneau, Alexis},
journal={arXiv preprint arXiv:1901.07291},
year={2019}
}
```
**APA:**
- Lample, G., & Conneau, A. (2019). Cross-lingual language model pretraining. arXiv preprint arXiv:1901.07291.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
More information needed. This model uses language embeddings to specify the language used at inference. See the [Hugging Face Multilingual Models for Inference docs](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) for further details. |
FacebookAI/xlm-mlm-en-2048 | FacebookAI | 2023-01-24T14:50:04Z | 1,953 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"xlm",
"fill-mask",
"exbert",
"en",
"arxiv:1901.07291",
"arxiv:1911.02116",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:04Z | ---
language: en
tags:
- exbert
license: cc-by-nc-4.0
---
# xlm-mlm-en-2048
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [Model Card Authors](#model-card-authors)
9. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
The XLM model was proposed in [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau. It’s a transformer pretrained with either a causal language modeling (CLM) objective (next token prediction), a masked language modeling (MLM) objective (BERT-like), or
a Translation Language Modeling (TLM) object (extension of BERT’s MLM to multiple language inputs). This model is trained with a masked language modeling objective on English text.
## Model Description
- **Developed by:** Researchers affiliated with Facebook AI, see [associated paper](https://arxiv.org/abs/1901.07291) and [GitHub Repo](https://github.com/facebookresearch/XLM)
- **Model type:** Language model
- **Language(s) (NLP):** English
- **License:** CC-BY-NC-4.0
- **Related Models:** Other [XLM models](https://huggingface.co/models?sort=downloads&search=xlm)
- **Resources for more information:**
- [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau (2019)
- [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/pdf/1911.02116.pdf) by Conneau et al. (2020)
- [GitHub Repo](https://github.com/facebookresearch/XLM)
- [Hugging Face XLM docs](https://huggingface.co/docs/transformers/model_doc/xlm)
# Uses
## Direct Use
The model is a language model. The model can be used for masked language modeling.
## Downstream Use
To learn more about this task and potential downstream uses, see the Hugging Face [fill mask docs](https://huggingface.co/tasks/fill-mask) and the [Hugging Face Multilingual Models for Inference](https://huggingface.co/docs/transformers/v4.20.1/en/multilingual#xlm-with-language-embeddings) docs. Also see the [associated paper](https://arxiv.org/abs/1901.07291).
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
# Training
More information needed. See the [associated GitHub Repo](https://github.com/facebookresearch/XLM).
# Evaluation
More information needed. See the [associated GitHub Repo](https://github.com/facebookresearch/XLM).
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@article{lample2019cross,
title={Cross-lingual language model pretraining},
author={Lample, Guillaume and Conneau, Alexis},
journal={arXiv preprint arXiv:1901.07291},
year={2019}
}
```
**APA:**
- Lample, G., & Conneau, A. (2019). Cross-lingual language model pretraining. arXiv preprint arXiv:1901.07291.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model. See the [Hugging Face XLM docs](https://huggingface.co/docs/transformers/model_doc/xlm) for more examples.
```python
from transformers import XLMTokenizer, XLMModel
import torch
tokenizer = XLMTokenizer.from_pretrained("xlm-mlm-en-2048")
model = XLMModel.from_pretrained("xlm-mlm-en-2048")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
<a href="https://huggingface.co/exbert/?model=xlm-mlm-en-2048">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
dobis-lks/sloth-animal | dobis-lks | 2023-01-24T14:47:03Z | 1 | 1 | diffusers | [
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"animal",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-01-24T14:41:44Z | ---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: a photo of sloth animal in the Acropolis
---
# DreamBooth model for the sloth concept trained by dobis-lks on the dobis-lks/test dataset.
This is a Stable Diffusion model fine-tuned on the sloth concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of sloth animal**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `animal` images for the animal theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('dobis-lks/sloth-animal')
image = pipeline().images[0]
image
```
|
summervent/russian-spellchecking2 | summervent | 2023-01-24T14:45:44Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-01-24T14:36:37Z | ---
tags:
- generated_from_trainer
model-index:
- name: russian-spellchecking2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# russian-spellchecking2
This model is a fine-tuned version of [UrukHan/t5-russian-spell](https://huggingface.co/UrukHan/t5-russian-spell) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Tokenizers 0.13.2
|
keras-sd/decoder-tflite | keras-sd | 2023-01-24T14:41:02Z | 0 | 0 | keras | [
"keras",
"tflite",
"decoder",
"stable diffusion",
"v1.4",
"text-to-image",
"license:apache-2.0",
"region:us"
]
| text-to-image | 2022-12-27T00:33:48Z | ---
license: apache-2.0
library_name: keras
pipeline_tag: text-to-image
tags:
- decoder
- stable diffusion
- v1.4
---
This repository hosts the TFLite version of `decoder` part of [KerasCV Stable Diffusion](https://github.com/keras-team/keras-cv/tree/master/keras_cv/models/stable_diffusion).
Stable Diffusion consists of `text encoder`, `diffusion model`, `decoder`, and some glue codes to handl inputs and outputs of each part. The TFLite version of `decoder` in this repository is built not only with the `decpder` itself but also TensorFlow operations that takes `latent` from `diffusion model` and generates final images.
TFLite conversion was based on the `SavedModel` from [this repository](https://huggingface.co/keras-sd/tfs-text-encoder/tree/main), and TensorFlow version `>= 2.12-nightly` was used.
- NOTE: [Dynamic range quantization](https://www.tensorflow.org/lite/performance/post_training_quant#optimizing_an_existing_model) was used.
- NOTE: TensorFlow version `< 2.12-nightly` will fail for the conversion process.
- NOTE: For those who wonder how `SavedModel` is constructed, find it in [keras-sd-serving repository](https://github.com/deep-diver/keras-sd-serving). |
khaled5321/RND-PyramidsTraining | khaled5321 | 2023-01-24T14:40:39Z | 6 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2023-01-24T14:39:30Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: khaled5321/RND-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Ashraf-kasem/gpt2_fine_tune_with_callback_PolynomialDecay_from_local | Ashraf-kasem | 2023-01-24T14:40:18Z | 17 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-01-17T12:04:41Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: Ashraf-kasem/gpt2_fine_tune_with_callback_PolynomialDecay_from_local
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Ashraf-kasem/gpt2_fine_tune_with_callback_PolynomialDecay_from_local
This model is a fine-tuned version of [Ashraf-kasem/gpt2_fine_tune_with_callback_PolynomialDecay_from_local](https://huggingface.co/Ashraf-kasem/gpt2_fine_tune_with_callback_PolynomialDecay_from_local) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.4591
- Validation Loss: 4.1433
- Epoch: 49
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 231100, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.0567 | 3.4196 | 0 |
| 2.0328 | 3.4604 | 1 |
| 2.0056 | 3.5015 | 2 |
| 1.9789 | 3.5125 | 3 |
| 1.9530 | 3.5556 | 4 |
| 1.9285 | 3.5970 | 5 |
| 1.9051 | 3.6428 | 6 |
| 1.8823 | 3.6087 | 7 |
| 1.8607 | 3.6300 | 8 |
| 1.8402 | 3.6607 | 9 |
| 1.8202 | 3.7323 | 10 |
| 1.8014 | 3.7363 | 11 |
| 1.7832 | 3.7573 | 12 |
| 1.7660 | 3.7414 | 13 |
| 1.7493 | 3.7810 | 14 |
| 1.7330 | 3.8443 | 15 |
| 1.7175 | 3.8305 | 16 |
| 1.7029 | 3.8547 | 17 |
| 1.6887 | 3.8189 | 18 |
| 1.6753 | 3.8725 | 19 |
| 1.6622 | 3.9050 | 20 |
| 1.6498 | 3.9306 | 21 |
| 1.6376 | 3.9670 | 22 |
| 1.6262 | 3.9569 | 23 |
| 1.6150 | 3.9473 | 24 |
| 1.6044 | 3.9695 | 25 |
| 1.5943 | 3.9193 | 26 |
| 1.5844 | 3.9739 | 27 |
| 1.5751 | 4.0273 | 28 |
| 1.5660 | 4.0224 | 29 |
| 1.5574 | 4.0163 | 30 |
| 1.5491 | 4.0466 | 31 |
| 1.5413 | 4.0520 | 32 |
| 1.5342 | 4.0640 | 33 |
| 1.5270 | 4.0616 | 34 |
| 1.5199 | 4.0611 | 35 |
| 1.5133 | 4.0884 | 36 |
| 1.5073 | 4.0827 | 37 |
| 1.5015 | 4.0972 | 38 |
| 1.4962 | 4.0991 | 39 |
| 1.4908 | 4.0989 | 40 |
| 1.4858 | 4.1078 | 41 |
| 1.4814 | 4.1295 | 42 |
| 1.4773 | 4.1142 | 43 |
| 1.4730 | 4.1200 | 44 |
| 1.4699 | 4.1270 | 45 |
| 1.4664 | 4.1425 | 46 |
| 1.4637 | 4.1392 | 47 |
| 1.4612 | 4.1365 | 48 |
| 1.4591 | 4.1433 | 49 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.0
- Datasets 2.8.0
- Tokenizers 0.13.2
|
keras-sd/text-encoder-tflite | keras-sd | 2023-01-24T14:39:01Z | 0 | 0 | keras | [
"keras",
"tflite",
"text encoder",
"stable diffusion",
"v1.4",
"text-to-image",
"license:apache-2.0",
"region:us"
]
| text-to-image | 2022-12-27T00:26:41Z | ---
license: apache-2.0
library_name: keras
pipeline_tag: text-to-image
tags:
- text encoder
- stable diffusion
- v1.4
---
This repository hosts the TFLite version of `text encoder` part of [KerasCV Stable Diffusion](https://github.com/keras-team/keras-cv/tree/master/keras_cv/models/stable_diffusion).
Stable Diffusion consists of `text encoder`, `diffusion model`, `decoder`, and some glue codes to handl inputs and outputs of each part. The TFLite version of `text encoder` in this repository is built not only with the `text encoder` itself but also TensorFlow operations that generates `context` and `unconditional context`. These output should be passed down to the `diffusion model` which is hosted in [this repository](https://huggingface.co/keras-sd/diffusion-model-tflite/tree/main).
TFLite conversion was based on the `SavedModel` from [this repository](https://huggingface.co/keras-sd/tfs-text-encoder/tree/main), and TensorFlow version `>= 2.12-nightly` was used.
- NOTE: [Dynamic range quantization](https://www.tensorflow.org/lite/performance/post_training_quant#optimizing_an_existing_model) was used.
- NOTE: TensorFlow version `< 2.12-nightly` will fail for the conversion process.
- NOTE: For those who wonder how `SavedModel` is constructed, find it in [keras-sd-serving repository](https://github.com/deep-diver/keras-sd-serving). |
threite/bert-finetuned-ner | threite | 2023-01-24T14:32:13Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-01-24T13:30:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9485085819030161
- name: Recall
type: recall
value: 0.9579266240323123
- name: F1
type: f1
value: 0.9531943397806245
- name: Accuracy
type: accuracy
value: 0.9919979751567306
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0176
- Precision: 0.9485
- Recall: 0.9579
- F1: 0.9532
- Accuracy: 0.9920
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.003 | 1.0 | 1756 | 0.0180 | 0.9397 | 0.9461 | 0.9429 | 0.9908 |
| 0.0013 | 2.0 | 3512 | 0.0163 | 0.9456 | 0.9566 | 0.9511 | 0.9919 |
| 0.0006 | 3.0 | 5268 | 0.0176 | 0.9485 | 0.9579 | 0.9532 | 0.9920 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.1
- Datasets 2.7.1
- Tokenizers 0.13.1
|
IshitaSingh/t5-small-finetuned-xsum | IshitaSingh | 2023-01-24T14:28:19Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-01-23T17:04:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
config: default
split: train
args: default
metrics:
- name: Rouge1
type: rouge
value: 28.3594
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4785
- Rouge1: 28.3594
- Rouge2: 7.7695
- Rougel: 22.2562
- Rougelsum: 22.262
- Gen Len: 18.8329
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.716 | 1.0 | 12753 | 2.4785 | 28.3594 | 7.7695 | 22.2562 | 22.262 | 18.8329 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
|
wooihen/ppo-PyramidsRND1 | wooihen | 2023-01-24T14:23:50Z | 7 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2023-01-24T14:23:44Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: wooihen/ppo-PyramidsRND1
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
newwater/a2c-PandaReachDense-v2 | newwater | 2023-01-24T13:30:39Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T13:29:03Z | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.90 +/- 0.67
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
javiervela/Reinforce-Pixelcopter-PLE-v0 | javiervela | 2023-01-24T13:27:24Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T13:27:21Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 19.90 +/- 12.01
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Unterwexi/Reinforce-pixelcopterV2 | Unterwexi | 2023-01-24T13:06:23Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T13:05:53Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixelcopterV2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 90.30 +/- 78.30
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
huggingtweets/btc-eth-vitalikbuterin | huggingtweets | 2023-01-24T12:52:32Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-01-24T12:47:16Z | ---
language: en
thumbnail: http://www.huggingtweets.com/btc-eth-vitalikbuterin/1674564747266/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/977496875887558661/L86xyLF4_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1292159368943693824/JXYCQur0_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1258321209730760705/1hkrHoOT_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">vitalik.eth & BTC Times & ETH Zürich</div>
<div style="text-align: center; font-size: 14px;">@btc-eth-vitalikbuterin</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from vitalik.eth & BTC Times & ETH Zürich.
| Data | vitalik.eth | BTC Times | ETH Zürich |
| --- | --- | --- | --- |
| Tweets downloaded | 3243 | 3241 | 3246 |
| Retweets | 241 | 1215 | 1023 |
| Short tweets | 123 | 35 | 34 |
| Tweets kept | 2879 | 1991 | 2189 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/d3n8pkg2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @btc-eth-vitalikbuterin's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/x6co1yfz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/x6co1yfz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/btc-eth-vitalikbuterin')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Schwarzschild009/q-FrozenLake-v1-4x4-noSlippery | Schwarzschild009 | 2023-01-24T12:44:10Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T12:44:07Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Schwarzschild009/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
StatsGary/xlm-roberta-base-finetuned-panx-de | StatsGary | 2023-01-24T12:36:58Z | 7 | 1 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-01-20T16:20:24Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: train
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8654677896653767
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1405
- F1: 0.8655
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2495 | 1.0 | 787 | 0.1764 | 0.8184 |
| 0.1299 | 2.0 | 1574 | 0.1427 | 0.8562 |
| 0.0771 | 3.0 | 2361 | 0.1405 | 0.8655 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
stablemobile/fuatuzumcu | stablemobile | 2023-01-24T12:28:55Z | 5 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-01-24T12:27:06Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: fuatuzumcu
---
### fuatuzumcu Dreambooth model trained by stablemobile with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
fuatuzumcu (use that on your prompt)

|
tim-binding/dqn-SpaceInvadersNoFrameskip-v4 | tim-binding | 2023-01-24T12:21:39Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T12:21:01Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 597.00 +/- 225.89
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga tim-binding -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga tim-binding -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga tim-binding
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
sprenkamp/distilbert-base-uncased-finetuned-squad | sprenkamp | 2023-01-24T12:16:41Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2023-01-24T09:05:00Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1596
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.224 | 1.0 | 5533 | 1.1606 |
| 0.9626 | 2.0 | 11066 | 1.1240 |
| 0.7619 | 3.0 | 16599 | 1.1596 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
huggingtweets/btc-doveywan-eth | huggingtweets | 2023-01-24T12:08:10Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-01-24T11:44:34Z | ---
language: en
thumbnail: http://www.huggingtweets.com/btc-doveywan-eth/1674562085261/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1616618733556101124/oXxgxm8O_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1292159368943693824/JXYCQur0_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1258321209730760705/1hkrHoOT_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Dovey "Rug The Fiat" Wan & BTC Times & ETH Zürich</div>
<div style="text-align: center; font-size: 14px;">@btc-doveywan-eth</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Dovey "Rug The Fiat" Wan & BTC Times & ETH Zürich.
| Data | Dovey "Rug The Fiat" Wan | BTC Times | ETH Zürich |
| --- | --- | --- | --- |
| Tweets downloaded | 3244 | 3241 | 3246 |
| Retweets | 311 | 1215 | 1023 |
| Short tweets | 264 | 35 | 34 |
| Tweets kept | 2669 | 1991 | 2189 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/fjov15tq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @btc-doveywan-eth's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/n69s58ct) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/n69s58ct/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/btc-doveywan-eth')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
AmirMesbah/q-Taxi-v3 | AmirMesbah | 2023-01-24T12:03:14Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T12:03:12Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="AmirMesbah/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
stevaras2/dqn-SpaceInvadersNoFrameskip-v4 | stevaras2 | 2023-01-24T11:48:26Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T11:47:49Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 569.50 +/- 94.77
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga stevaras2 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga stevaras2 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga stevaras2
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
MrFitzmaurice/roberta-finetuned-topic-5 | MrFitzmaurice | 2023-01-24T11:35:27Z | 0 | 0 | adapter-transformers | [
"adapter-transformers",
"pytorch",
"tensorboard",
"roberta",
"code",
"NLP",
"text-classification",
"en",
"region:us"
]
| text-classification | 2023-01-12T08:07:19Z | ---
language:
- en
metrics:
- accuracy
library_name: adapter-transformers
pipeline_tag: text-classification
tags:
- code
- NLP
--- |
jfiekdjdk/gpt2-furry-prompt-gen | jfiekdjdk | 2023-01-24T11:25:22Z | 4 | 1 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-01-23T15:26:16Z | ### WARNING: this model is overfitting!!! |
maneprajakta/m2m100_418M-test | maneprajakta | 2023-01-24T11:15:01Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"dataset:dataset",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-01-24T08:49:56Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- dataset
metrics:
- bleu
model-index:
- name: m2m100_418M-test
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: dataset
type: dataset
config: uptycs
split: train
args: uptycs
metrics:
- name: Bleu
type: bleu
value: 29.9962
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# m2m100_418M-test
This model is a fine-tuned version of [facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M) on the dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9953
- Bleu: 29.9962
- Gen Len: 41.6441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| 0.3804 | 1.0 | 1267 | 0.9953 | 29.9962 | 41.6441 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
newwater/ppo-SnowballTarget | newwater | 2023-01-24T10:58:20Z | 3 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
]
| reinforcement-learning | 2023-01-24T10:58:13Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: newwater/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
csebuetnlp/banglabert_small | csebuetnlp | 2023-01-24T10:49:22Z | 75 | 2 | transformers | [
"transformers",
"pytorch",
"electra",
"pretraining",
"bn",
"endpoints_compatible",
"region:us"
]
| null | 2023-01-24T10:01:21Z | ---
language:
- bn
licenses:
- cc-by-nc-sa-4.0
---
# BanglaBERT (small)
This repository contains the pretrained discriminator checkpoint of the model **BanglaBERT (small)**. This is an [ELECTRA](https://openreview.net/pdf?id=r1xMH1BtvB) discriminator model pretrained with the Replaced Token Detection (RTD) objective. Finetuned models using this checkpoint achieve state-of-the-art results on many of the NLP tasks in bengali.
For finetuning on different downstream tasks such as `Sentiment classification`, `Named Entity Recognition`, `Natural Language Inference` etc., refer to the scripts in the official GitHub [repository](https://github.com/csebuetnlp/banglabert).
**Note**: This model was pretrained using a specific normalization pipeline available [here](https://github.com/csebuetnlp/normalizer). All finetuning scripts in the official GitHub repository uses this normalization by default. If you need to adapt the pretrained model for a different task make sure the text units are normalized using this pipeline before tokenizing to get best results. A basic example is given below:
## Using this model as a discriminator in `transformers` (tested on 4.11.0.dev0)
```python
from transformers import AutoModelForPreTraining, AutoTokenizer
from normalizer import normalize # pip install git+https://github.com/csebuetnlp/normalizer
import torch
model = AutoModelForPreTraining.from_pretrained("csebuetnlp/banglabert_small")
tokenizer = AutoTokenizer.from_pretrained("csebuetnlp/banglabert_small")
original_sentence = "আমি কৃতজ্ঞ কারণ আপনি আমার জন্য অনেক কিছু করেছেন।"
fake_sentence = "আমি হতাশ কারণ আপনি আমার জন্য অনেক কিছু করেছেন।"
fake_sentence = normalize(fake_sentence) # this normalization step is required before tokenizing the text
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = model(fake_inputs).logits
predictions = torch.round((torch.sign(discriminator_outputs) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
print("\n" + "-" * 50)
[print("%7s" % int(prediction), end="") for prediction in predictions.squeeze().tolist()[1:-1]]
print("\n" + "-" * 50)
```
## Benchmarks
* Zero-shot cross-lingual transfer-learning
| Model | Params | SC (macro-F1) | NLI (accuracy) | NER (micro-F1) | QA (EM/F1) | BangLUE score |
|----------------|-----------|-----------|-----------|-----------|-----------|-----------|
|[mBERT](https://huggingface.co/bert-base-multilingual-cased) | 180M | 27.05 | 62.22 | 39.27 | 59.01/64.18 | 50.35 |
|[XLM-R (base)](https://huggingface.co/xlm-roberta-base) | 270M | 42.03 | 72.18 | 45.37 | 55.03/61.83 | 55.29 |
|[XLM-R (large)](https://huggingface.co/xlm-roberta-large) | 550M | 49.49 | 78.13 | 56.48 | 71.13/77.70 | 66.59 |
|[BanglishBERT](https://huggingface.co/csebuetnlp/banglishbert) | 110M | 48.39 | 75.26 | 55.56 | 72.87/78.63 | 66.14 |
* Supervised fine-tuning
| Model | Params | SC (macro-F1) | NLI (accuracy) | NER (micro-F1) | QA (EM/F1) | BangLUE score |
|----------------|-----------|-----------|-----------|-----------|-----------|-----------|
|[mBERT](https://huggingface.co/bert-base-multilingual-cased) | 180M | 67.59 | 75.13 | 68.97 | 67.12/72.64 | 70.29 |
|[XLM-R (base)](https://huggingface.co/xlm-roberta-base) | 270M | 69.54 | 78.46 | 73.32 | 68.09/74.27 | 72.82 |
|[XLM-R (large)](https://huggingface.co/xlm-roberta-large) | 550M | 70.97 | 82.40 | 78.39 | 73.15/79.06 | 76.79 |
|[sahajBERT](https://huggingface.co/neuropark/sahajBERT) | 18M | 71.12 | 76.92 | 70.94 | 65.48/70.69 | 71.03 |
|[BanglishBERT](https://huggingface.co/csebuetnlp/banglishbert) | 110M | 70.61 | 80.95 | 76.28 | 72.43/78.40 | 75.73 |
|[BanglaBERT (small)](https://huggingface.co/csebuetnlp/banglabert_small) | 13M | 69.29 | 76.75 | 73.41 | 63.30/69.65 | *70.38* |
|[BanglaBERT](https://huggingface.co/csebuetnlp/banglabert) | 110M | 72.89 | 82.80 | 77.78 | 72.63/79.34 | 77.09 |
|[BanglaBERT (large)](https://huggingface.co/csebuetnlp/banglabert_large) | 335M | 71.94 | 83.41 | 79.20 | 76.10/81.50 | **78.43** |
The benchmarking datasets are as follows:
* **SC:** **[Sentiment Classification](https://aclanthology.org/2021.findings-emnlp.278)**
* **NER:** **[Named Entity Recognition](https://multiconer.github.io/competition)**
* **NLI:** **[Natural Language Inference](https://github.com/csebuetnlp/banglabert/#datasets)**
* **QA:** **[Question Answering](https://github.com/csebuetnlp/banglabert/#datasets)**
## Citation
If you use this model, please cite the following paper:
```
@inproceedings{bhattacharjee-etal-2022-banglabert,
title = "{B}angla{BERT}: Language Model Pretraining and Benchmarks for Low-Resource Language Understanding Evaluation in {B}angla",
author = "Bhattacharjee, Abhik and
Hasan, Tahmid and
Ahmad, Wasi and
Mubasshir, Kazi Samin and
Islam, Md Saiful and
Iqbal, Anindya and
Rahman, M. Sohel and
Shahriyar, Rifat",
booktitle = "Findings of the Association for Computational Linguistics: NAACL 2022",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-naacl.98",
pages = "1318--1327",
abstract = "In this work, we introduce BanglaBERT, a BERT-based Natural Language Understanding (NLU) model pretrained in Bangla, a widely spoken yet low-resource language in the NLP literature. To pretrain BanglaBERT, we collect 27.5 GB of Bangla pretraining data (dubbed {`}Bangla2B+{'}) by crawling 110 popular Bangla sites. We introduce two downstream task datasets on natural language inference and question answering and benchmark on four diverse NLU tasks covering text classification, sequence labeling, and span prediction. In the process, we bring them under the first-ever Bangla Language Understanding Benchmark (BLUB). BanglaBERT achieves state-of-the-art results outperforming multilingual and monolingual models. We are making the models, datasets, and a leaderboard publicly available at \url{https://github.com/csebuetnlp/banglabert} to advance Bangla NLP.",
}
```
If you use the normalization module, please cite the following paper:
```
@inproceedings{hasan-etal-2020-low,
title = "Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for {B}engali-{E}nglish Machine Translation",
author = "Hasan, Tahmid and
Bhattacharjee, Abhik and
Samin, Kazi and
Hasan, Masum and
Basak, Madhusudan and
Rahman, M. Sohel and
Shahriyar, Rifat",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.207",
doi = "10.18653/v1/2020.emnlp-main.207",
pages = "2612--2623",
abstract = "Despite being the seventh most widely spoken language in the world, Bengali has received much less attention in machine translation literature due to being low in resources. Most publicly available parallel corpora for Bengali are not large enough; and have rather poor quality, mostly because of incorrect sentence alignments resulting from erroneous sentence segmentation, and also because of a high volume of noise present in them. In this work, we build a customized sentence segmenter for Bengali and propose two novel methods for parallel corpus creation on low-resource setups: aligner ensembling and batch filtering. With the segmenter and the two methods combined, we compile a high-quality Bengali-English parallel corpus comprising of 2.75 million sentence pairs, more than 2 million of which were not available before. Training on neural models, we achieve an improvement of more than 9 BLEU score over previous approaches to Bengali-English machine translation. We also evaluate on a new test set of 1000 pairs made with extensive quality control. We release the segmenter, parallel corpus, and the evaluation set, thus elevating Bengali from its low-resource status. To the best of our knowledge, this is the first ever large scale study on Bengali-English machine translation. We believe our study will pave the way for future research on Bengali-English machine translation as well as other low-resource languages. Our data and code are available at https://github.com/csebuetnlp/banglanmt.",
}
```
|
morit/xlm-t-roberta-base-mnli-xnli | morit | 2023-01-24T10:42:43Z | 5 | 2 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"ar",
"bg",
"de",
"el",
"en",
"es",
"tr",
"th",
"ur",
"hi",
"zh",
"vi",
"fr",
"ru",
"sw",
"dataset:xnli",
"dataset:multi_nli",
"arxiv:1911.02116",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-01-24T09:11:51Z | ---
license: mit
datasets:
- xnli
- multi_nli
language:
- ar
- bg
- de
- el
- en
- es
- tr
- th
- ur
- hi
- zh
- vi
- fr
- ru
- sw
metrics:
- accuracy
---
# XLM-T-ROBERTA-BASE-MNLI-XNLI
## Model description
This model takes the XLM-Roberta-base model which has been continued to pre-traine on a large corpus of Twitter in multiple languages.
It was developed following a similar strategy as introduced as part of the [Tweet Eval](https://github.com/cardiffnlp/tweeteval) framework.
The model is further finetuned on the MNLI dataset and also on the xnli dataset.
## Intended Usage
This model was developed to do Zero-Shot Text Classification in the realm of Hate Speech Detection. It is finetuned on the whole xnli train set containing 15 different languages like:
**ar, bg ,de , en, el , es, fr, hi, ru, sw, th, tr, ur, vi, zh**
Since the base model was pre-trained on 100 different languages it has shown some effectiveness in other languages. Please refer to the list of languages in the [XLM Roberta paper](https://arxiv.org/abs/1911.02116)
### Usage with Zero-Shot Classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="morit/xlm-t-roberta-base-mnli-xnli")
```
## Training
This model was pre-trained on set of 100 languages, as described in the original paper. It was then fine-tuned on the task of NLI on the concatenated MNLI train set. Finally, it was trained for one additional epoch on only XNLI data where the translations for the premise and hypothesis are shuffled such that the premise and hypothesis for each example come from the same original English example but the premise and hypothesis are of different languages.
The following hyper-parameters were chosen:
- learning rate: 2e-5
- batch size: 32
- max sequence: length 128
using one GPU (NVIDIA GeForce RTX 3090)
## Evaluation
The model was evaluated on all the test sets of the xnli dataset resulting in the following accuracies:
| ar | bg | de | el | en | es | fr | hi| ru | sw | th | tr |ur | vi | zh |
|-----|-----|-----|----|----|----|----|----|----|----|----|----|----|----|----|
|0.776|0.804|0.796|0.791|0.851|0.813|0.806|0.757|0.783|0.716|0.765|0.780|0.705|0.795|0.782| |
lewtun/dummy-trl-model | lewtun | 2023-01-24T10:42:37Z | 4 | 1 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"trl",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| reinforcement-learning | 2023-01-24T10:42:24Z | ---
license: apache-2.0
tags:
- trl
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/lvwerra/trl) that has been fine-tuned with reinforcement learning to guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="lewtun/dummy-trl-model")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("lewtun/dummy-trl-model")
model = AutoModelForCausalLMWithValueHead.from_pretrained("lewtun/dummy-trl-model")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
summervent/russian-spellchecking | summervent | 2023-01-24T10:40:07Z | 3 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-01-22T10:56:20Z | ---
tags:
- generated_from_trainer
model-index:
- name: russian-spellchecking
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# russian-spellchecking
This model is a fine-tuned version of [UrukHan/t5-russian-spell](https://huggingface.co/UrukHan/t5-russian-spell) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Tokenizers 0.13.2
|
ludsil/taxi | ludsil | 2023-01-24T10:38:49Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T10:38:46Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.62
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="ludsil/taxi", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ludsil/q-FrozenLake-v1-4x4-noSlippery | ludsil | 2023-01-24T10:31:17Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T10:31:14Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="ludsil/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kostasang/ppo-Pyramids | kostasang | 2023-01-24T10:24:33Z | 1 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2023-01-24T10:24:25Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: kostasang/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
fedihch/InvoiceReceiptClassifier_LayoutLMv3 | fedihch | 2023-01-24T10:06:30Z | 51 | 1 | transformers | [
"transformers",
"pytorch",
"layoutlmv3",
"feature-extraction",
"image-classification",
"es",
"en",
"multilingual",
"license:other",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-08-16T12:58:41Z | ---
language:
- es
- en
- multilingual
license: other
tags:
- image-classification
pipeline_tag: image-classification
widget:
- src: https://upserve.com/media/sites/2/Bill-from-Mezcalero-in-Washington-D.C.-photo-by-Alfredo-Solis-1-e1507226752437.jpg
example_title: receipt
- src: https://templates.invoicehome.com/invoice-template-us-neat-750px.png
example_title: invoice
---
**InvoiceReceiptClassifier_LayoutLMv3** is a fine-tuned LayoutLMv3 model that classifies a document to an invoice or receipt.
## Quick start: using the raw model
```python
from transformers import (
AutoModelForSequenceClassification,
AutoProcessor,
)
from PIL import Image
from urllib.request import urlopen
model = AutoModelForSequenceClassification.from_pretrained("fedihch/InvoiceReceiptClassifier_LayoutLMv3")
processor = AutoProcessor.from_pretrained("fedihch/InvoiceReceiptClassifier_LayoutLMv3")
input_img_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/0/0b/ReceiptSwiss.jpg/1024px-ReceiptSwiss.jpg"
with urlopen(input_img_url) as testImage:
input_img = Image.open(testImage).convert("RGB")
encoded_inputs = processor(input_img, padding="max_length", return_tensors="pt")
outputs = model(**encoded_inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
id2label = {0: "invoice", 1: "receipt"}
print(id2label[predicted_class_idx])
```
|
jwright94/dqn-SpaceInvadersNoFrameskip-v4 | jwright94 | 2023-01-24T09:52:17Z | 2 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-01-24T08:45:50Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 449.00 +/- 125.50
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jwright94 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jwright94 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jwright94
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 75000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
kostasang/ppo-SnowballTarget | kostasang | 2023-01-24T09:48:58Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
]
| reinforcement-learning | 2023-01-24T09:48:50Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: kostasang/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
morit/XLM-T-full-xnli | morit | 2023-01-24T09:41:27Z | 21 | 2 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"zero-shot-classification",
"de",
"dataset:xnli",
"arxiv:1911.02116",
"arxiv:2104.12250",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| zero-shot-classification | 2023-01-19T12:15:38Z | ---
license: mit
datasets:
- xnli
language:
- de
metrics:
- accuracy
pipeline_tag: zero-shot-classification
---
# XLM-ROBERTA-BASE-XNLI
## Model description
This model takes the XLM-Roberta-base model which has been continued to pre-traine on a large corpus of Twitter in multiple languages.
It was developed following a similar strategy as introduced as part of the [Tweet Eval](https://github.com/cardiffnlp/tweeteval) framework.
The model is further finetuned on all of the languages of the XNLI train set
## Intended Usage
This model was developed to do Zero-Shot Text Classification in the realm of Hate Speech Detection. It is finetuned on the whole xnli train set containing 15 different languages like:
**ar, bg ,de , en, el , es, fr, hi, ru, sw, th, tr, ur, vi, zh**
Since the base model was pre-trained on 100 different languages it has shown some effectiveness in other languages. Please refer to the list of languages in the [XLM Roberta paper](https://arxiv.org/abs/1911.02116)
### Usage with Zero-Shot Classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="morit/XLM-T-full-xnli")
```
## Training
This model was pre-trained on a set of 100 languages and follwed further training on 198M multilingual tweets as described in the original [paper](https://arxiv.org/abs/2104.12250). Further it was trained on the full train set of XNLI dataset which is a machine translated version of the MNLI dataset. It was trained on 5 epochs of the XNLI train set and evaluated on the XNLI eval dataset at the end of every epoch to find the best performing model. The model which had the highest accuracy on the eval set was chosen at the end.

- learning rate: 2e-5
- batch size: 32
- max sequence: length 128
using a GPU (NVIDIA GeForce RTX 3090)
# Evaluation
The model was evaluated on all the test sets of the xnli dataset resulting in the following accuracies:
| ar | bg | de | el | en | es | fr | hi| ru | sw | th | tr |ur | vi | zh |
|-----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|
| 0.749 | 0.787 | 0.774 | 0.774 | 0.831 | 0.796 | 0.785 | 0.734 | 0.761 | 0.701 | 0.757 | 0.758 | 0.704 | 0.778 | 0.774 |
|
NotoriousYang/Mybot | NotoriousYang | 2023-01-24T09:04:44Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-01-24T09:04:44Z | ---
license: creativeml-openrail-m
---
|
sayakpaul/mit-b0-finetuned-pets | sayakpaul | 2023-01-24T08:55:19Z | 8 | 1 | keras | [
"keras",
"tf",
"segformer",
"vision",
"image-segmentation",
"dataset:oxford_pets",
"license:other",
"region:us"
]
| image-segmentation | 2023-01-24T08:19:53Z | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- oxford_pets
widget:
- src: >-
https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: Dog
- src: >-
https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Cat
library_name: keras
---
# sayakpaul/mit-b0-finetuned-pets
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on the [Oxford Pets](https://www.robots.ox.ac.uk/~vgg/data/pets/) dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1481
- Validation Loss: 0.1962
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 6e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.2821 | 0.2146 | 0 |
| 0.2090 | 0.1983 | 1 |
| 0.1920 | 0.2002 | 2 |
| 0.1805 | 0.1868 | 3 |
| 0.1716 | 0.1920 | 4 |
| 0.1651 | 0.1850 | 5 |
| 0.1537 | 0.1943 | 6 |
| 0.1570 | 0.1842 | 7 |
| 0.1462 | 0.1833 | 8 |
| 0.1481 | 0.1962 | 9 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.10.1
- Tokenizers 0.13.2 |
Subsets and Splits