
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755603918
|
mang3dd
| 2025-08-19T12:12:14Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:12:10Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755605480
|
lilTAT
| 2025-08-19T12:11:51Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:11:47Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sefcee/VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
|
sefcee
| 2025-08-19T12:11:29Z
| 0
| 0
| null |
[
"region:us"
] | null | 2025-08-19T12:10:07Z
|
<a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
🔴 ➤►DOWNLOAD👉👉🟢 ➤ <a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
<a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
🔴 ➤►DOWNLOAD👉👉🟢 ➤ <a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
|
LBST/t10_pick_and_place_smolvla_013000
|
LBST
| 2025-08-19T12:11:26Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-013000",
"region:us"
] |
robotics
| 2025-08-19T12:11:21Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-013000
---
# T08 Pick and Place Policy - Checkpoint 013000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 013000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 013000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_013000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 013000*
|
LBST/t10_pick_and_place_smolvla_012000
|
LBST
| 2025-08-19T12:11:01Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-012000",
"region:us"
] |
robotics
| 2025-08-19T12:10:54Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-012000
---
# T08 Pick and Place Policy - Checkpoint 012000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 012000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 012000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_012000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 012000*
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755603799
|
pempekmangedd
| 2025-08-19T12:11:00Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:10:57Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
SirAB/Dolphin-gemma2-2b-finetuned-v2
|
SirAB
| 2025-08-19T12:11:00Z
| 29
| 1
|
transformers
|
[
"transformers",
"safetensors",
"gemma2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:SirAB/Dolphin-gemma2-2b-finetuned-v2",
"base_model:finetune:SirAB/Dolphin-gemma2-2b-finetuned-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-10T09:34:21Z
|
---
base_model: SirAB/Dolphin-gemma2-2b-finetuned-v2
tags:
- text-generation-inference
- transformers
- unsloth
- gemma2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** SirAB
- **License:** apache-2.0
- **Finetuned from model :** SirAB/Dolphin-gemma2-2b-finetuned-v2
This gemma2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Prerna43/distilbert-base-uncased-lora-text-classification
|
Prerna43
| 2025-08-19T12:10:33Z
| 0
| 0
|
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:distilbert-base-uncased",
"lora",
"transformers",
"base_model:distilbert/distilbert-base-uncased",
"base_model:adapter:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:03:59Z
|
---
library_name: peft
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- base_model:adapter:distilbert-base-uncased
- lora
- transformers
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-lora-text-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-lora-text-classification
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6438
- Accuracy: 0.887
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 250 | 0.5865 | 0.891 |
| 0.051 | 2.0 | 500 | 0.6101 | 0.888 |
| 0.051 | 3.0 | 750 | 0.6309 | 0.889 |
| 0.1059 | 4.0 | 1000 | 0.6438 | 0.887 |
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755603621
|
katanyasekolah
| 2025-08-19T12:10:15Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:10:11Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LBST/t10_pick_and_place_smolvla_010000
|
LBST
| 2025-08-19T12:10:09Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-010000",
"region:us"
] |
robotics
| 2025-08-19T12:10:02Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-010000
---
# T08 Pick and Place Policy - Checkpoint 010000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 010000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 010000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_010000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 010000*
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755603876
|
lisaozill03
| 2025-08-19T12:10:02Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:09:58Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LBST/t10_pick_and_place_smolvla_009000
|
LBST
| 2025-08-19T12:09:43Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-009000",
"region:us"
] |
robotics
| 2025-08-19T12:09:36Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-009000
---
# T08 Pick and Place Policy - Checkpoint 009000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 009000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 009000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_009000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 009000*
|
LBST/t10_pick_and_place_smolvla_008000
|
LBST
| 2025-08-19T12:09:16Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-008000",
"region:us"
] |
robotics
| 2025-08-19T12:09:09Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-008000
---
# T08 Pick and Place Policy - Checkpoint 008000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 008000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 008000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_008000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 008000*
|
p1m2/falcon-7b-sharded-bf16-finetuned-mental-health-conversational
|
p1m2
| 2025-08-19T12:08:49Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:ybelkada/falcon-7b-sharded-bf16",
"base_model:finetune:ybelkada/falcon-7b-sharded-bf16",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:13:06Z
|
---
base_model: ybelkada/falcon-7b-sharded-bf16
library_name: transformers
model_name: falcon-7b-sharded-bf16-finetuned-mental-health-conversational
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for falcon-7b-sharded-bf16-finetuned-mental-health-conversational
This model is a fine-tuned version of [ybelkada/falcon-7b-sharded-bf16](https://huggingface.co/ybelkada/falcon-7b-sharded-bf16).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="p1m2/falcon-7b-sharded-bf16-finetuned-mental-health-conversational", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/parammehta123/huggingface/runs/w637538i)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755605258
|
Dejiat
| 2025-08-19T12:08:27Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:08:20Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Unlearning/early-unlearning-weak-filter-ga-1-in-209-ga-lr-scale-0_001-gclip-0_5
|
Unlearning
| 2025-08-19T12:07:52Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-11T15:07:18Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LBST/t10_pick_and_place_smolvla_004000
|
LBST
| 2025-08-19T12:07:36Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-004000",
"region:us"
] |
robotics
| 2025-08-19T12:07:29Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-004000
---
# T08 Pick and Place Policy - Checkpoint 004000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 004000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 004000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_004000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 004000*
|
LBST/t10_pick_and_place_smolvla_003000
|
LBST
| 2025-08-19T12:07:09Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-003000",
"region:us"
] |
robotics
| 2025-08-19T12:07:04Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-003000
---
# T08 Pick and Place Policy - Checkpoint 003000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 003000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 003000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_003000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 003000*
|
VoilaRaj/80_cGooIB
|
VoilaRaj
| 2025-08-19T12:06:45Z
| 0
| 0
| null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T12:02:53Z
|
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
LBST/t10_pick_and_place_smolvla_002000
|
LBST
| 2025-08-19T12:06:44Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-002000",
"region:us"
] |
robotics
| 2025-08-19T12:06:20Z
|
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-002000
---
# T08 Pick and Place Policy - Checkpoint 002000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 002000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 002000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_002000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 002000*
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755603595
|
quantumxnode
| 2025-08-19T12:06:13Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:06:10Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kumo2023/nupurbro
|
Kumo2023
| 2025-08-19T12:05:27Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T10:59:59Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Nupurbro
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/Kumo2023/nupurbro/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Kumo2023/nupurbro', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 6000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Kumo2023/nupurbro/discussions) to add images that show off what you’ve made with this LoRA.
|
haihp02/pdfreeee-biggerb
|
haihp02
| 2025-08-19T12:05:13Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"dpo",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:04:12Z
|
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
m-muraki/Qwen3-Coder-30B-A3B-Instruct-FP8
|
m-muraki
| 2025-08-19T12:03:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"fp8",
"region:us"
] |
text-generation
| 2025-08-19T12:02:47Z
|
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-Coder-30B-A3B-Instruct-FP8
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
**Qwen3-Coder** is available in multiple sizes. Today, we're excited to introduce **Qwen3-Coder-30B-A3B-Instruct-FP8**. This streamlined model maintains impressive performance and efficiency, featuring the following key enhancements:
- **Significant Performance** among open models on **Agentic Coding**, **Agentic Browser-Use**, and other foundational coding tasks.
- **Long-context Capabilities** with native support for **256K** tokens, extendable up to **1M** tokens using Yarn, optimized for repository-scale understanding.
- **Agentic Coding** supporting for most platform such as **Qwen Code**, **CLINE**, featuring a specially designed function call format.

## Model Overview
**Qwen3-Coder-30B-A3B-Instruct-FP8** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-coder/), [GitHub](https://github.com/QwenLM/Qwen3-Coder), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
We advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
## Note on FP8
For convenience and performance, we have provided `fp8`-quantized model checkpoint for Qwen3, whose name ends with `-FP8`. The quantization method is fine-grained `fp8` quantization with block size of 128. You can find more details in the `quantization_config` field in `config.json`.
You can use the Qwen3-30B-A3B-Instruct-FP8 model with serveral inference frameworks, including `transformers`, `sglang`, and `vllm`, as the original bfloat16 model.
However, please pay attention to the following known issues:
- `transformers`:
- there are currently issues with the "fine-grained fp8" method in `transformers` for distributed inference. You may need to set the environment variable `CUDA_LAUNCH_BLOCKING=1` if multiple devices are used in inference.
## Agentic Coding
Qwen3-Coder excels in tool calling capabilities.
You can simply define or use any tools as following example.
```python
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-30B-A3B-Instruct-FP8",
max_tokens=65536,
tools=tools,
)
print(completion.choice[0])
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `temperature=0.7`, `top_p=0.8`, `top_k=20`, `repetition_penalty=1.05`.
2. **Adequate Output Length**: We recommend using an output length of 65,536 tokens for most queries, which is adequate for instruct models.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
llm-slice/blm-gpt2s-90M-s42_901M-s42_submission
|
llm-slice
| 2025-08-19T12:03:13Z
| 993
| 0
| null |
[
"safetensors",
"gpt2",
"interaction",
"babylm-submission",
"babylm-2025",
"en",
"arxiv:2405.09605",
"arxiv:2411.07990",
"region:us"
] | null | 2025-08-15T08:47:53Z
|
---
language:
- en
tags:
- interaction
- babylm-submission
- babylm-2025
---
# Model Card for BabyLM submission to the Interaction Track
<!-- Provide a quick summary of what the model is/does. [Optional] -->
A 124M model with the GPT-2 architecture trained with the next token prediction loss for 10 epochs (~900 M words) **on 90% of the BabyLM corpus** and an additional **1 M words of PPO RL** training as submission for the Interaction track of the 2025 BabyLM challenge.
This model card is based on the model card of the BabyLM [100M GPT-2 baseline](https://huggingface.co/BabyLM-community/babylm-baseline-100m-gpt2/edit/main/README.md).
# Table of Contents
- [Model Card for Storytelling Submission Model](#model-card-for--model_id-)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [Model Description](#model-description)
- [Uses](#uses)
- [Training Details](#training-details)
- [Training Data](#training-data)
- [Hyperparameters](#hyperparameters)
- [Training Procedure](#training-procedure)
- [Size and Checkpoints](#size-and-checkpoints)
- [Evaluation](#evaluation)
- [Testing Data & Metrics](#testing-data-factors--metrics)
- [Testing Data](#testing-data)
- [Metrics](#metrics)
- [Results](#results)
- [Technical Specifications](#technical-specifications-optional)
- [Model Architecture and Objective](#model-architecture-and-objective)
- [Compute Infrastructure](#compute-infrastructure)
- [Hardware](#hardware)
- [Software](#software)
- [Training Time](#training-time)
- [Citation](#citation)
- [Model Card Authors](#model-card-authors-optional)
- [Bibliography](#bibliography)
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
This is the RL storytelling model, based on a [pretrained GPT-2 model](https://huggingface.co/llm-slice/blm-gpt2s-90M-s42), for the Interaction Track of the 2025 BabyLM challenge.
- **Developed by:** Jonas Mayer Martins, Ali Hamza Bashir, Muhammad Rehan Khalid
- **Model type:** Causal language model
- **Language(s) (NLP):** eng
- **Resources for more information:**
- [GitHub Repo](https://github.com/malihamza/babylm-interactive-learning)
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This is a pre-trained language model.
It can be used to evaluate tasks in a zero-shot manner and also can be fine-tuned for downstream tasks.
It can be used for language generation but given its small size and low number of words trained on, do not expect LLM-level performance.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
We used the BabyLM 100M (Strict) dataset for training. **We trained the tokenizer and model on randomly selected 90% of the corpus**, which is composed of the following:
| Source | Weight | Domain | Citation | Website | License |
| --- | --- | --- | --- | --- | --- |
| BNC | 8% | Dialogue | BNC Consortium (2007) | [link](http://www.natcorp.ox.ac.uk/) | [link](http://www.natcorp.ox.ac.uk/docs/licence.html) <sup>1</sup> |
| CHILDES | 29% | Dialogue, Child-Directed | MacWhinney (2000) | | [link](https://talkbank.org/share/rules.html) |
| Project Gutenberg | 26% | Fiction, Nonfiction | Gerlach & Font-Clos (2020) | [link](https://github.com/pgcorpus/gutenberg) | [link](https://www.gutenberg.org/policy/license.html) |
| OpenSubtitles | 20% | Dialogue, Scripted | Lison & Tiedermann (2016) | [link](https://opus.nlpl.eu/OpenSubtitles-v2018.php) | Open source |
| Simple English Wikipedia | 15% | Nonfiction | -- | [link](https://dumps.wikimedia.org/simplewiki/20221201/) | [link](https://dumps.wikimedia.org/legal.html) |
| Switchboard | 1% | Dialogue | Godfrey et al. (1992), Stolcke et al., (2000) | [link](http://compprag.christopherpotts.net/swda.html) | [link](http://compprag.christopherpotts.net/swda.html) |
<sup>1</sup> Our distribution of part of the BNC Texts is permitted under the fair dealings provision of copyright law (see term (2g) in the BNC license).
## Hyperparameters PPO RL training
| **Parameter** | **Value** |
|----------------------------------|---------------------|
| Student context length | 512 |
| seed | 42 |
| batch size | 360 |
| Student sampling temperature | 1 |
| top_k | 0 |
| top_p | 1 |
| max_new_tokens (student) | 90 |
| Teacher model | Llama 3.1 8B Instr. |
| Teacher context length | 1024 |
| max_new_tokens (teacher) | 6 |
| gradient_accumulation_steps | 1 |
| adap_kl_ctrl | True |
| init_kl_coef | 0.2 |
| learning_rate | 1×10⁻⁶ |
| Student input limit | 1 M words |
## Hyperparameters Pretraining
| Hyperparameter | Value |
| --- | --- |
| Number of epochs | 10 |
| Datapoint length | 512 |
| Batch size | 16 |
| Gradient accumulation steps | 4 |
| Learning rate | 0.0005 |
| Number of steps | 211650 |
| Warmup steps | 2116 |
| Gradient clipping | 1 |
| Optimizer | AdamW |
| Optimizer Beta_1 | 0.9 |
| Optimizer Beta_2 | 0.999 |
| Optimizer Epsilon | 10<sup>-8</sup>|
| Tokenizer | BytePairBPE |
| Vocab Size | 16000 |
## Training Procedure
The model is trained with next token prediction loss for 10 epochs.
### Size and checkpoints
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
The model has 124M parameters.
In total we train on around 901 M words and provide multiple checkpoints from the training.
Specifically we provode:
- Checkpoints every 1 M words for the first 10 M words
- Checkpoints every 10 M words first 100 M words
- Checkpoints every 100 M words until 900 M words
- Checkpoints every 100 K words until 901 M words
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
This model is evaluated in two ways:
1. We do zero-shot evaluation on 7 tasks.
2. We do fine-tuning on a subset of the (Super)GLUE tasks (Wang et al., ICLR 2019; Wang et al., NeurIPS 2019) .
## Testing Data & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
For the BLiMP, BLiMP supplement, and EWoK tasks, we use a filtered version of the dataset to only include examples with words found in the BabyLM dataset.
For the Finetuning task, we both filter and sample down to a maximum 10 000 train examples.
*Validation Data*
*Zero-shot Tasks*
- **BLiMP**: The Benchmark of Linguistic Minimal Pairs evaluates the model's linguistic ability by seeing if it can recognize the grammatically correct sentence from a pair of minimally different sentences. It tests various grammatical phenomena.(Warstadt et al., TACL 2020)
- **BLiMP Supplement**: A supplement to BLiMP introduced in the first edition of the BabyLM challenge. More focused on dialogue and questions. (Warstadt et al., CoNLL-BabyLM 2023)
- **EWoK**: Works similarly to BLiMP but looks the model's internal world knowledge. Looking at both whter a model has physical and social knowledge. (Ivanova et al., 2024)
- **Eye Tracking and Self-paced Reading**: Looks at whether the model can mimick the eye tracking and reading time of a human but using surprisal of a word as a proxy for time spent reading a word. (de Varda et al., BRM 2024)
- **Entity Tracking**: Checks whether a model can keep track of the changes to the states of entities as text/dialogue unfolds. (Kim & Schuster, ACL 2023)
- **WUGs**: Tests morphological generalization in LMs through an adjective nominalization and past tense task. (Hofmann et al., 2024) (Weissweiler et al., 2023)
- **COMPS**: Property knowledge. (Misra et al., 2023)
*Finetuning Tasks*
- **BoolQ**: A yes/no QA dataset with unprompted and unconstrained questions. (Clark et al., NAACL 2019)
- **MNLI**: The Multi-Genre Natural Language Inference corpus tests the language understanding of a model by seeing wehther it can recognize textual entailment. (Williams et al., NAACL 2018)
- **MRPC**: The Microsoft Research Paraphrase Corpus contains pairs of sentences that are either paraphrases/semntically equivalent to each other or unrelated.(Dolan & Brockett, IJCNLP 2005)
- **QQP**<sup>2</sup>: Similarly to MRPC, the Quora Question Pairs corpus tests the models ability to determine whether a pair of questions are sematically similar to each other. These questions are sourced from Quora.
- **MultiRC**: The Multi-Sentence Reading Comprehension corpus is a QA task that evaluates the model's ability to the correct answer from a list of answers given a question and context paragraph. In this version the data is changed to a binary classification judging whether the answer to a question, context pair is correct. (Khashabi et al., NAACL 2018)
- **RTE**: Similar the Recognizing Text Entailement tests the model's ability to recognize text entailement. (Dagan et al., Springer 2006; Bar et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., TAC 2009)
- **WSC**: The Winograd Schema Challenge tests the models ability to do coreference resolution on sentences with a pronoun and a list of noun phrases found in the sentence. This version edits it to be a binary classification on examples consisting of a pronoun and noun phrase.(Levesque et al., PKRR 2012)
<sup>2</sup> https://www.quora.com/profile/Ricky-Riche-2/First-Quora-Dataset-Release-Question-Pairs
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
The metrics used to evaluate the model are the following:
- Zero-shot
- Accuracy on predicting the correct completion/sentence for BLiMP, BLiMP Supplement, EWoK, Entity Tracking, and WUGs
- Change in R^2 prediction from baseline for Eye Tracking (with no spillover) and Self-paced Reading (1-word spillover)
- Finetuning
- 3 class Accuracy for MNLI
- Binary Accuracy for BoolQ, MultiRC, and WSC
- F1-score for MRPC and QQP
The metrics were chosen based on the advice of the papers the tasks come from.
### Hyperparameters
| Hyperparameter | MNLI, RTE, QQP, MRPC, BoolQ, MultiRC | WSC |
| --- | --- | --- |
| Learning Rate | 3\*10<sup>-5</sup> | 3\*10<sup>-5</sup> |
| Batch Size | 16 | 16 |
| Epochs | 10 | 30 |
| Weight decay | 0.01 | 0.01 |
| Optimizer | AdamW | AdamW |
| Scheduler | cosine | cosine |
| Warmup percentage | 6% | 6% |
| Dropout | 0.1 | 0.1 |
## Results
We compare our student model against two official baselines from the 2025 BabyLM Challenge<sup>1</sup>:
- **1000M-pre:** The standard *pretraining* baseline, using a GPT-2-small model trained on 100M unique words from the BabyLM dataset (10 epochs, next-word prediction).
- **SimPO:** A baseline first trained for 7 epochs with next-word prediction, then 2 epochs *interleaving* prediction and reinforcement learning. Here, the RL reward encourages the student to generate completions similar to the teacher’s output.
- **900M-pre:** Our model, using the same GPT-2-small architecture, pretrained on 90% of the BabyLM dataset (yielding approximately 91M unique words, 10 epochs).
- **900M-RL:** Our model after additional PPO-based reinforcement learning with the teacher, using about 1M words as input for the interactive (RL) phase.
---
### Evaluation Results
| **Task** | **1000M-pre** | **SimPO** | **900M-pre** | **900M-RL** |
|:------------- | ------------: | ---------:| ------------:| -----------:|
| BLiMP | 74.88 | 72.16 | 77.52 | **77.53** |
| Suppl. | **63.32** | 61.22 | 56.62 | 56.72 |
| EWOK | 51.67 | **51.92** | 51.36 | 51.41 |
| COMPS | **56.17** | 55.05 | 55.20 | 55.18 |
| ET | 31.51 | 28.06 | 30.34 | **33.11** |
| GLUE | 52.18 | 50.35 | **53.14** | 52.46 |
#### Model descriptions:
- **1000M-pre:** Baseline pretrained on 100M words (BabyLM challenge baseline).
- **SimPO:** Baseline using a hybrid of pretraining and RL with a similarity-based reward.
- **900M-pre:** Our GPT-2-small model, pretrained on 90M words (similar settings as baseline, but less data).
- **900M-RL:** The same model as 900M-pre, further trained with PPO using teacher feedback on 1M words of input.
-
See: [BabyLM Challenge](https://huggingface.co/BabyLM-community) for the baselines.
# Technical Specifications
### Hardware
- 4 A100 GPUs were used to train this model.
### Software
PyTorch
### Training Time
The model took 20 hours to train and consumed 53560 core hours (with 4 GPUs and 32 CPUs).
# Citation
```latex
@misc{MayerMartinsBKB2025,
title={ToDo},
author={Jonas Mayer Martins, Ali Hamza Bashir, Muhammad Rehan Khalid, Lisa Beinborn},
year={2025},
eprint={2502.TODO},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={ToDo},
}
```
# Model Card Authors
Jonas Mayer Martins
# Bibliography
[GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) (Wang et al., ICLR 2019)
[SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems](https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf) (Wang et al., NeurIPS 2019)
[BLiMP: The Benchmark of Linguistic Minimal Pairs for English](https://aclanthology.org/2020.tacl-1.25/) (Warstadt et al., TACL 2020)
[Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora](https://aclanthology.org/2023.conll-babylm.1/) (Warstadt et al., CoNLL-BabyLM 2023)
[🌏 Elements of World Knowledge (EWoK): A cognition-inspired framework for evaluating basic world knowledge in language models](https://arxiv.org/pdf/2405.09605v1) (Ivanova et al., 2024)
[Cloze probability, predictability ratings, and computational estimates for 205 English sentences, aligned with existing EEG and reading time data](https://link.springer.com/article/10.3758/s13428-023-02261-8) (de Varda et al., BRM 2024)
[Entity Tracking in Language Models](https://aclanthology.org/2023.acl-long.213/) (Kim & Schuster, ACL 2023)
[Derivational Morphology Reveals Analogical Generalization in Large Language Models](https://arxiv.org/pdf/2411.07990) (Hofmann et al., 2024)
[Automatically Constructing a Corpus of Sentential Paraphrases](https://aclanthology.org/I05-5002/) (Dolan & Brockett, IJCNLP 2005)
[A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference](https://aclanthology.org/N18-1101/) (Williams et al., NAACL 2018)
[The Winograd Schema Challenge]( http://dl.acm.org/citation.cfm?id=3031843.3031909) (Levesque et al., PKRR 2012)
[The PASCAL Recognising Textual Entailment Challenge](https://link.springer.com/chapter/10.1007/11736790_9) (Dagan et al., Springer 2006)
[The Second PASCAL Recognising Textual Entailment Challenge]() (Bar et al., 2006)
[The Third PASCAL Recognizing Textual Entailment Challenge](https://aclanthology.org/W07-1401/) (Giampiccolo et al., 2007)
[The Fifth PASCAL Recognizing Textual Entailment Challenge](https://tac.nist.gov/publications/2009/additional.papers/RTE5_overview.proceedings.pdf) (Bentivogli et al., TAC 2009)
[BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions](https://aclanthology.org/N19-1300/) (Clark et al., NAACL 2019)
[Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences](https://aclanthology.org/N18-1023/) (Khashabi et al., NAACL 2018)
|
premrajreddy/Home-TinyLlama-1.1B-HomeAssist-GGUF
|
premrajreddy
| 2025-08-19T12:02:08Z
| 0
| 0
| null |
[
"safetensors",
"gguf",
"llama",
"home-assistant",
"voice-assistant",
"automation",
"assistant",
"home",
"text-generation",
"conversational",
"en",
"dataset:acon96/Home-Assistant-Requests",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"base_model:finetune:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:13:44Z
|
---
language: en
license: apache-2.0
tags:
- home-assistant
- voice-assistant
- automation
- assistant
- home
pipeline_tag: text-generation
datasets:
- acon96/Home-Assistant-Requests
base_model:
- TinyLlama/TinyLlama-1.1B-Chat-v1.0
base_model_relation: finetune
---
# 🏠 TinyLLaMA-1.1B Home Assistant Voice Model
This model is a **fine-tuned version** of [TinyLlama/TinyLlama-1.1B-Chat-v1.0](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0), trained with [acon96/Home-Assistant-Requests](https://huggingface.co/datasets/acon96/Home-Assistant-Requests).
It is designed to act as a **voice-controlled smart home assistant** that takes natural language instructions and outputs **Home Assistant commands**.
---
## ✨ Features
- Converts **natural language voice commands** into Home Assistant automation calls.
- Produces **friendly confirmations** and **structured JSON service commands**.
- Lightweight (1.1B parameters) – runs efficiently on CPUs, GPUs, and via **Ollama** with quantization.
---
## 🔧 Example Usage (Transformers)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("premrajreddy/tinyllama-1.1b-home-llm")
model = AutoModelForCausalLM.from_pretrained("premrajreddy/tinyllama-1.1b-home-llm")
query = "turn on the kitchen lights"
inputs = tokenizer(query, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=80)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
musdbi/bpce_model
|
musdbi
| 2025-08-19T12:00:37Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T12:00:27Z
|
---
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** musdbi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
swiptit/blockassist-bc-polished_armored_mandrill_1755604721
|
swiptit
| 2025-08-19T11:59:23Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"polished armored mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:59:19Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- polished armored mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vg-sentry/Qwen-Qwen2.5-Coder-7B-Instruct-sentry-v1
|
vg-sentry
| 2025-08-19T11:59:11Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"unsloth",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:07:28Z
|
---
base_model: unsloth/qwen2.5-coder-7b-instruct-bnb-4bit
library_name: transformers
model_name: Qwen-Qwen2.5-Coder-7B-Instruct-sentry-v1
tags:
- generated_from_trainer
- sft
- trl
- unsloth
licence: license
---
# Model Card for Qwen-Qwen2.5-Coder-7B-Instruct-sentry-v1
This model is a fine-tuned version of [unsloth/qwen2.5-coder-7b-instruct-bnb-4bit](https://huggingface.co/unsloth/qwen2.5-coder-7b-instruct-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vg-sentry/Qwen-Qwen2.5-Coder-7B-Instruct-sentry-v1", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755602935
|
indoempatnol
| 2025-08-19T11:56:18Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:56:14Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755603521
|
Sayemahsjn
| 2025-08-19T11:55:30Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:55:26Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755602793
|
kojeklollipop
| 2025-08-19T11:54:00Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:53:57Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lakelee/RLB_MLP_BC_v4.20250819.18.1
|
lakelee
| 2025-08-19T11:53:49Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"mlp_swiglu",
"generated_from_trainer",
"base_model:lakelee/RLB_MLP_BC_v4.20250819.18",
"base_model:finetune:lakelee/RLB_MLP_BC_v4.20250819.18",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:09:01Z
|
---
library_name: transformers
base_model: lakelee/RLB_MLP_BC_v4.20250819.18
tags:
- generated_from_trainer
model-index:
- name: RLB_MLP_BC_v4.20250819.18.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RLB_MLP_BC_v4.20250819.18.1
This model is a fine-tuned version of [lakelee/RLB_MLP_BC_v4.20250819.18](https://huggingface.co/lakelee/RLB_MLP_BC_v4.20250819.18) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.99) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.8.0+cu128
- Tokenizers 0.21.4
|
burmeai/burme-v1
|
burmeai
| 2025-08-19T11:51:20Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T11:51:20Z
|
---
license: apache-2.0
---
|
AXERA-TECH/Qwen2.5-0.5B-Instruct-CTX-Int8
|
AXERA-TECH
| 2025-08-19T11:51:10Z
| 10
| 0
|
transformers
|
[
"transformers",
"Qwen",
"Qwen2.5-0.5B-Instruct",
"Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"GPTQ",
"en",
"base_model:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"base_model:finetune:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | null | 2025-06-03T07:41:28Z
|
---
library_name: transformers
license: bsd-3-clause
base_model:
- Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8
tags:
- Qwen
- Qwen2.5-0.5B-Instruct
- Qwen2.5-0.5B-Instruct-GPTQ-Int8
- GPTQ
language:
- en
---
# Qwen2.5-0.5B-Instruct-GPTQ-Int8
This version of Qwen2.5-0.5B-Instruct-GPTQ-Int8 has been converted to run on the Axera NPU using **w8a16** quantization.
This model has been optimized with the following LoRA:
Compatible with Pulsar2 version: 4.2(Not released yet)
## Convert tools links:
For those who are interested in model conversion, you can try to export axmodel through the original repo : https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8
[Pulsar2 Link, How to Convert LLM from Huggingface to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/appendix/build_llm.html)
[AXera NPU LLM Runtime](https://github.com/AXERA-TECH/ax-llm)
## Support Platform
- AX650
- AX650N DEMO Board
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
- AX630C
- *developing*
|Chips|w8a16|w4a16|
|--|--|--|
|AX650| 30 tokens/sec| TBD |
## How to use
Download all files from this repository to the device
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# tree -L 1
.
|-- main_ax650
|-- main_axcl_aarch64
|-- main_axcl_x86
|-- post_config.json
|-- qwen2.5-0.5b-gptq-int8-ctx-ax630c
|-- qwen2.5-0.5b-gptq-int8-ctx-ax650
|-- qwen2.5_tokenizer
|-- qwen2.5_tokenizer_uid.py
|-- run_qwen2.5_0.5b_gptq_int8_ctx_ax630c.sh
`-- run_qwen2.5_0.5b_gptq_int8_ctx_ax650.sh
3 directories, 7 files
```
#### Start the Tokenizer service
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# python3 qwen2.5_tokenizer_uid.py
Server running at http://0.0.0.0:12345
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro) or AX650N DEMO Board
Open another terminal and run `run_qwen2.5_0.5b_gptq_int8_ax650.sh`
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# ./run_qwen2.5_0.5b_gptq_int8_ctx_ax650.sh
[I][ Init][ 110]: LLM init start
[I][ Init][ 34]: connect http://127.0.0.1:12345 ok
[I][ Init][ 57]: uid: cdeaf62e-0243-4dc9-b557-23a7c1ba7da1
bos_id: -1, eos_id: 151645
100% | ████████████████████████████████ | 27 / 27 [12.35s<12.35s, 2.19 count/s] init post axmodel ok,remain_cmm(3960 MB)
[I][ Init][ 188]: max_token_len : 2560
[I][ Init][ 193]: kv_cache_size : 128, kv_cache_num: 2560
[I][ Init][ 201]: prefill_token_num : 128
[I][ Init][ 205]: grp: 1, prefill_max_token_num : 1
[I][ Init][ 205]: grp: 2, prefill_max_token_num : 128
[I][ Init][ 205]: grp: 3, prefill_max_token_num : 512
[I][ Init][ 205]: grp: 4, prefill_max_token_num : 1024
[I][ Init][ 205]: grp: 5, prefill_max_token_num : 1536
[I][ Init][ 205]: grp: 6, prefill_max_token_num : 2048
[I][ Init][ 209]: prefill_max_token_num : 2048
[I][ load_config][ 282]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": false,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 1,
"top_p": 0.8
}
[I][ Init][ 218]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
[I][ GenerateKVCachePrefill][ 271]: input token num : 21, prefill_split_num : 1 prefill_grpid : 2
[I][ GenerateKVCachePrefill][ 308]: input_num_token:21
[I][ main][ 230]: precompute_len: 21
[I][ main][ 231]: system_prompt: You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
prompt >> who are you?
[I][ SetKVCache][ 531]: prefill_grpid:2 kv_cache_num:128 precompute_len:38 input_num_token:12
[I][ SetKVCache][ 534]: current prefill_max_token_num:1920
[I][ Run][ 660]: input token num : 12, prefill_split_num : 1
[I][ Run][ 686]: input_num_token:12
[I][ Run][ 829]: ttft: 134.80 ms
I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks,
from general knowledge to specific areas such as science, technology, and more. How can I help you today?
[N][ Run][ 943]: hit eos,avg 30.88 token/s
[I][ GetKVCache][ 500]: precompute_len:98, remaining:1950
prompt >> what can you do?
[I][ SetKVCache][ 531]: prefill_grpid:2 kv_cache_num:128 precompute_len:98 input_num_token:13
[I][ SetKVCache][ 534]: current prefill_max_token_num:1920
[I][ Run][ 660]: input token num : 13, prefill_split_num : 1
[I][ Run][ 686]: input_num_token:13
[I][ Run][ 829]: ttft: 134.97 ms
I can answer questions, provide information, assist with tasks, and even engage in creative writing.
I'm here to help you with any questions or tasks you might have!
[N][ Run][ 943]: hit eos,avg 30.85 token/s
[I][ GetKVCache][ 500]: precompute_len:145, remaining:1903
```
|
koloni/blockassist-bc-deadly_graceful_stingray_1755602558
|
koloni
| 2025-08-19T11:51:00Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:50:57Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Datasmartly/nllb-darija1
|
Datasmartly
| 2025-08-19T11:50:31Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:16:39Z
|
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: nllb-darija1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nllb-darija1
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6728
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 2.9505 | 1.7778 | 500 | 2.6728 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.0.1
- Datasets 2.21.0
- Tokenizers 0.19.1
|
VoilaRaj/80_gz0xoQ
|
VoilaRaj
| 2025-08-19T11:49:57Z
| 0
| 0
| null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T11:46:05Z
|
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755602125
|
milliarderdol
| 2025-08-19T11:47:44Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:47:23Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1755602550
|
aleebaster
| 2025-08-19T11:46:08Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:45:59Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
dynokostya/sdxxl
|
dynokostya
| 2025-08-19T11:45:19Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-10-21T12:50:50Z
|
---
license: apache-2.0
---
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1755603599
|
liukevin666
| 2025-08-19T11:44:13Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:42:56Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/80_BVN8XN
|
VoilaRaj
| 2025-08-19T11:41:42Z
| 0
| 0
| null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T11:37:53Z
|
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
longhoang2112/whisper-turbo-fine-tuning_2_stages_with_covoi11_2
|
longhoang2112
| 2025-08-19T11:41:12Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"whisper",
"trl",
"en",
"base_model:unsloth/whisper-large-v3-turbo",
"base_model:finetune:unsloth/whisper-large-v3-turbo",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:41:08Z
|
---
base_model: unsloth/whisper-large-v3-turbo
tags:
- text-generation-inference
- transformers
- unsloth
- whisper
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** longhoang2112
- **License:** apache-2.0
- **Finetuned from model :** unsloth/whisper-large-v3-turbo
This whisper model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
rmtlabs/s-ai-qwen-azure-adapter
|
rmtlabs
| 2025-08-19T11:41:04Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-14B-Instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-14B-Instruct",
"region:us"
] |
text-generation
| 2025-08-19T11:40:49Z
|
---
base_model: Qwen/Qwen2.5-14B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:Qwen/Qwen2.5-14B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
arka7/Llama-3.2-3B-Instruct-bnb-4bit-rag-finetuned
|
arka7
| 2025-08-19T11:40:10Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:40:02Z
|
---
base_model: unsloth/llama-3.2-3b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** arka7
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Kumo2023/nupur
|
Kumo2023
| 2025-08-19T11:39:05Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T10:32:39Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Nupur
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/Kumo2023/nupur/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Kumo2023/nupur', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 6000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Kumo2023/nupur/discussions) to add images that show off what you’ve made with this LoRA.
|
bailai/blockassist-bc-waddling_durable_mandrill_1755601980
|
bailai
| 2025-08-19T11:35:38Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"waddling durable mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:30:23Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- waddling durable mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
marcomaccarini/padella_giusta_2
|
marcomaccarini
| 2025-08-19T11:35:36Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T11:32:05Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
TuKoResearch/WavCochV8192
|
TuKoResearch
| 2025-08-19T11:34:53Z
| 318
| 0
|
transformers
|
[
"transformers",
"safetensors",
"WavCoch.WavCoch",
"feature-extraction",
"audio",
"speech",
"tokenizer",
"quantizer",
"cochlear",
"custom_code",
"en",
"license:apache-2.0",
"region:us"
] |
feature-extraction
| 2025-04-15T23:01:03Z
|
---
language:
- en
library_name: transformers
pipeline_tag: feature-extraction
tags:
- audio
- speech
- tokenizer
- quantizer
- cochlear
- custom_code
license: apache-2.0 # ← adjust if different
pretty_name: WavCoch (8192-code speech tokenizer)
---
# WavCochV8192 — 8,192-code speech tokenizer (cochlear tokens)
**WavCochV8192** is a biologically-inspired, learned **audio quantizer** that maps a raw waveform to **discrete "cochlear tokens".** It is used as the tokenizer for the AuriStream autoregressive speech/language model (e.g., [TuKoResearch/AuriStream1B_librilight_ckpt500k](https://huggingface.co/TuKoResearch/AuriStream1B_librilight_ckpt500k)). The model is trained on LibriSpeech960 and encodes audio into a time–frequency representation ([Cochleagram; Feather et al., 2023 Nat Neuro](https://github.com/jenellefeather/chcochleagram)) and reads out **8,192-way discrete codes** through a low-bit latent bottleneck (LFQ). These tokens can be fed to a transformer LM for **representation learning** and **next-token prediction** (speech continuation).
> **API at a glance**
> - **Input:** mono waveform at 16 kHz (pytorch tensor float32), shape **(B, 1, T)**
> - **Output:** token IDs, shape **(B, L)** returned as dictionary under key **`"input_ids"`**
> - Implemented as a `transformers` custom model — load with `trust_remote_code=True`.
---
## Installation
```bash
pip install -U torch torchaudio transformers
```
---
## Quickstart — Quantize a waveform into cochlear tokens
```python
import torch, torchaudio
from transformers import AutoModel
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the quantizer
quantizer = AutoModel.from_pretrained(
"TuKoResearch/WavCochV8192", trust_remote_code=True
).to(device).eval()
# Load & prep audio (mono, 16 kHz)
wav, sr = torchaudio.load("sample.wav")
if wav.size(0) > 1: # stereo -> mono
wav = wav.mean(dim=0, keepdim=True)
if sr != 16_000:
wav = torchaudio.transforms.Resample(sr, 16_000)(wav)
sr = 16_000
# Forward pass — returns a dict with "input_ids" = (B, L)
with torch.no_grad():
out = quantizer(wav.unsqueeze(0).to(device)) # (1, 1, T) -> dict
token_ids = out["input_ids"] # LongTensor (1, L)
print("Token IDs shape:", token_ids.shape)
```
---
## Intended uses & limitations
- **Uses:** tokenization for speech LM training; compact storage/streaming of speech as discrete IDs, loosely inspired by human biology.
- **Limitations:** trained only on spoken English, so might not perform as well for other languages and non-speech sounds.
---
## Citation
If you use this tokenizer please cite:
```bibtex
@inproceedings{tuckute2025cochleartokens,
title = {Representing Speech Through Autoregressive Prediction of Cochlear Tokens},
author = {Greta Tuckute and Klemen Kotar and Evelina Fedorenko and Daniel Yamins},
booktitle = {Interspeech 2025},
year = {2025},
pages = {2180--2184},
doi = {10.21437/Interspeech.2025-2044},
issn = {2958-1796}
}
```
---
## Related
- **AuriStream LM:** https://huggingface.co/TuKoResearch/AuriStream1B_librilight_ckpt500k
- **Org:** https://huggingface.co/TuKoResearch
|
sankar-asthramedtech/Full-Precision_Whisper-Medium_and_LoRA-Adapters_Merged_Model_V-1.1
|
sankar-asthramedtech
| 2025-08-19T11:34:27Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-19T11:30:30Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755601588
|
quantumxnode
| 2025-08-19T11:32:30Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:32:26Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mohammadmahdinouri/moa-vanilla-init
|
mohammadmahdinouri
| 2025-08-19T11:31:35Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"ModernALBERT",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-08-19T11:31:23Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
1sandy12/blockassist-bc-waddling_scampering_orangutan_1755603028
|
1sandy12
| 2025-08-19T11:31:31Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"waddling scampering orangutan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:31:23Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- waddling scampering orangutan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rmtlabs/s-ai-deep-seek-azure-adapter
|
rmtlabs
| 2025-08-19T11:31:12Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"base_model:adapter:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"region:us"
] |
text-generation
| 2025-08-19T11:31:03Z
|
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
hossein12321asdf/Taxi-v3
|
hossein12321asdf
| 2025-08-19T11:30:10Z
| 0
| 0
| null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-17T13:53:47Z
|
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="hossein12321asdf/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
m-muraki/Qwen3-30B-A3B-Thinking-2507-FP8
|
m-muraki
| 2025-08-19T11:29:52Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-30B-A3B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"fp8",
"region:us"
] |
text-generation
| 2025-08-19T11:28:58Z
|
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B-Thinking-2507
---
# Qwen3-30B-A3B-Thinking-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-30B-A3B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-30B-A3B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
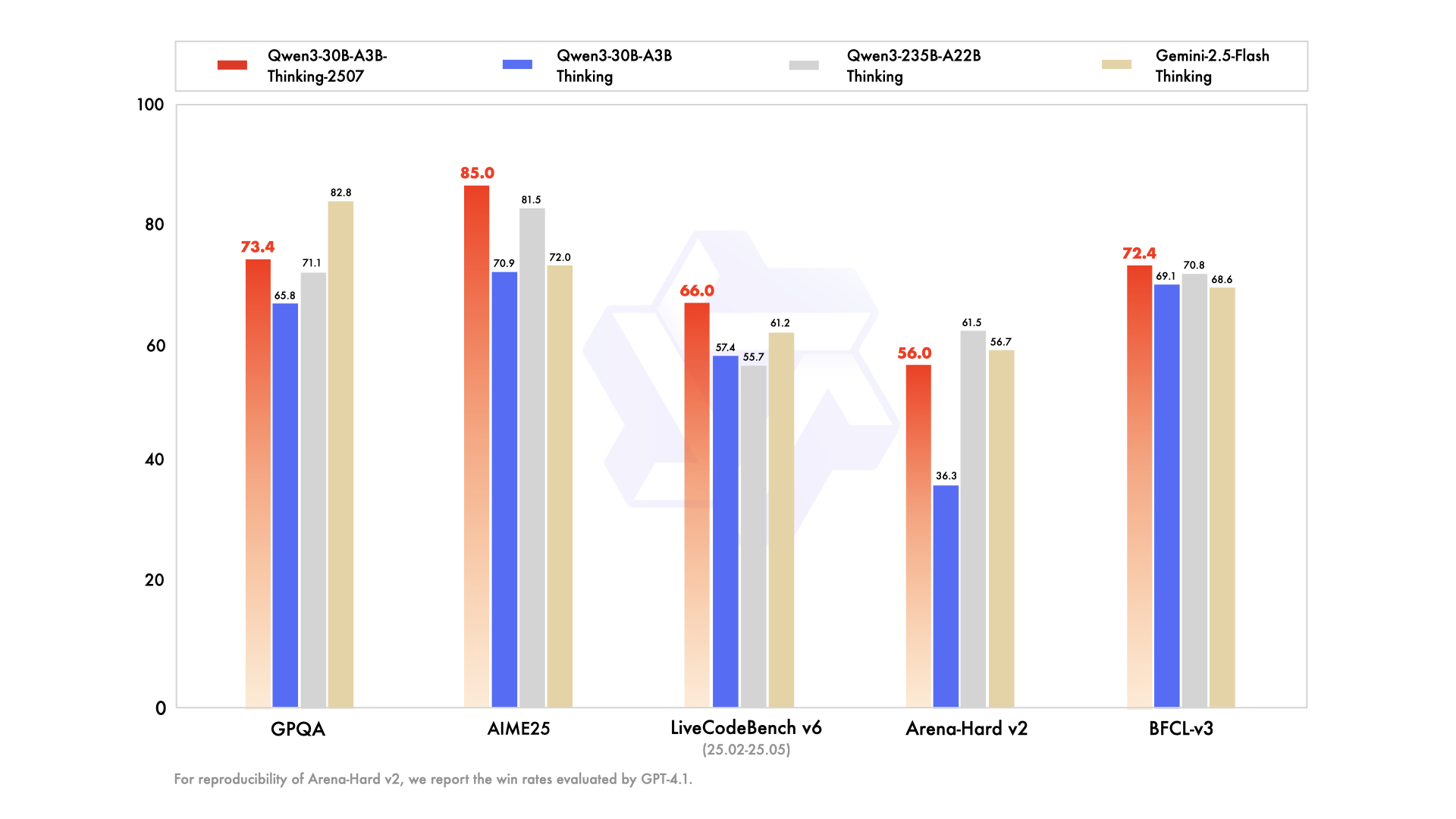
## Model Overview
This repo contains the FP8 version of **Qwen3-30B-A3B-Thinking-2507**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode. Meanwhile, specifying `enable_thinking=True` is no longer required.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 81.9 | **82.8** | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | **92.7** | 89.5 | 91.4 |
| GPQA | **82.8** | 71.1 | 65.8 | 73.4 |
| SuperGPQA | 57.8 | **60.7** | 51.8 | 56.8 |
| **Reasoning** | | | | |
| AIME25 | 72.0 | 81.5 | 70.9 | **85.0** |
| HMMT25 | 64.2 | 62.5 | 49.8 | **71.4** |
| LiveBench 20241125 | 74.3 | **77.1** | 74.3 | 76.8 |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 61.2 | 55.7 | 57.4 | **66.0** |
| CFEval | 1995 | **2056** | 1940 | 2044 |
| OJBench | 23.5 | **25.6** | 20.7 | 25.1 |
| **Alignment** | | | | |
| IFEval | **89.8** | 83.4 | 86.5 | 88.9 |
| Arena-Hard v2$ | 56.7 | **61.5** | 36.3 | 56.0 |
| Creative Writing v3 | **85.0** | 84.6 | 79.1 | 84.4 |
| WritingBench | 83.9 | 80.3 | 77.0 | **85.0** |
| **Agent** | | | | |
| BFCL-v3 | 68.6 | 70.8 | 69.1 | **72.4** |
| TAU1-Retail | 65.2 | 54.8 | 61.7 | **67.8** |
| TAU1-Airline | **54.0** | 26.0 | 32.0 | 48.0 |
| TAU2-Retail | **66.7** | 40.4 | 34.2 | 58.8 |
| TAU2-Airline | 52.0 | 30.0 | 36.0 | **58.0** |
| TAU2-Telecom | **31.6** | 21.9 | 22.8 | 26.3 |
| **Multilingualism** | | | | |
| MultiIF | 74.4 | 71.9 | 72.2 | **76.4** |
| MMLU-ProX | **80.2** | 80.0 | 73.1 | 76.4 |
| INCLUDE | **83.9** | 78.7 | 71.9 | 74.4 |
| PolyMATH | 49.8 | **54.7** | 46.1 | 52.6 |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507-FP8"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --context-length 262144 --reasoning-parser deepseek-r1
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Note on FP8
For convenience and performance, we have provided `fp8`-quantized model checkpoint for Qwen3, whose name ends with `-FP8`. The quantization method is fine-grained `fp8` quantization with block size of 128. You can find more details in the `quantization_config` field in `config.json`.
You can use the Qwen3-30B-A3B-Thinking-2507-FP8 model with serveral inference frameworks, including `transformers`, `sglang`, and `vllm`, as the original bfloat16 model.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507-FP8',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --served-model-name Qwen3-30B-A3B-Thinking-2507-FP8 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-30B-A3B-Thinking-2507-FP8',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
KCS97/candle
|
KCS97
| 2025-08-19T11:29:49Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:finetune:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T11:18:19Z
|
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: a photo of sks candle
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - KCS97/candle
This is a dreambooth model derived from stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on a photo of sks candle using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
imanuelradityaa/finetuned_cs_gemma_900_steps_4bit
|
imanuelradityaa
| 2025-08-19T11:29:16Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-2b-it-bnb-4bit",
"base_model:quantized:unsloth/gemma-2b-it-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-19T11:27:50Z
|
---
base_model: unsloth/gemma-2b-it-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** imanuelradityaa
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-2b-it-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
phospho-app/Deimos252-ACT_BBOX-deimos_dataset-0ztq8
|
phospho-app
| 2025-08-19T11:28:36Z
| 0
| 0
|
phosphobot
|
[
"phosphobot",
"safetensors",
"act",
"robotics",
"dataset:phospho-app/deimos_dataset_bboxes",
"region:us"
] |
robotics
| 2025-08-19T10:58:48Z
|
---
datasets: phospho-app/deimos_dataset_bboxes
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successful, try it out on your robot!
## Training parameters:
- **Dataset**: [phospho-app/deimos_dataset_bboxes](https://huggingface.co/datasets/phospho-app/deimos_dataset_bboxes)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF
|
tensorblock
| 2025-08-19T11:26:38Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"nvidia",
"code",
"TensorBlock",
"GGUF",
"text-generation",
"en",
"base_model:nvidia/OpenReasoning-Nemotron-32B",
"base_model:quantized:nvidia/OpenReasoning-Nemotron-32B",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-19T05:35:42Z
|
---
license: cc-by-4.0
language:
- en
base_model: nvidia/OpenReasoning-Nemotron-32B
pipeline_tag: text-generation
library_name: transformers
tags:
- nvidia
- code
- TensorBlock
- GGUF
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
[](https://tensorblock.co)
[](https://twitter.com/tensorblock_aoi)
[](https://discord.gg/Ej5NmeHFf2)
[](https://github.com/TensorBlock)
[](https://t.me/TensorBlock)
## nvidia/OpenReasoning-Nemotron-32B - GGUF
<div style="text-align: left; margin: 20px 0;">
<a href="https://discord.com/invite/Ej5NmeHFf2" style="display: inline-block; padding: 10px 20px; background-color: #5865F2; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Join our Discord to learn more about what we're building ↗
</a>
</div>
This repo contains GGUF format model files for [nvidia/OpenReasoning-Nemotron-32B](https://huggingface.co/nvidia/OpenReasoning-Nemotron-32B).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b5753](https://github.com/ggml-org/llama.cpp/commit/73e53dc834c0a2336cd104473af6897197b96277).
## Our projects
<table border="1" cellspacing="0" cellpadding="10">
<tr>
<th colspan="2" style="font-size: 25px;">Forge</th>
</tr>
<tr>
<th colspan="2">
<img src="https://imgur.com/faI5UKh.jpeg" alt="Forge Project" width="900"/>
</th>
</tr>
<tr>
<th colspan="2">An OpenAI-compatible multi-provider routing layer.</th>
</tr>
<tr>
<th colspan="2">
<a href="https://github.com/TensorBlock/forge" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">🚀 Try it now! 🚀</a>
</th>
</tr>
<tr>
<th style="font-size: 25px;">Awesome MCP Servers</th>
<th style="font-size: 25px;">TensorBlock Studio</th>
</tr>
<tr>
<th><img src="https://imgur.com/2Xov7B7.jpeg" alt="MCP Servers" width="450"/></th>
<th><img src="https://imgur.com/pJcmF5u.jpeg" alt="Studio" width="450"/></th>
</tr>
<tr>
<th>A comprehensive collection of Model Context Protocol (MCP) servers.</th>
<th>A lightweight, open, and extensible multi-LLM interaction studio.</th>
</tr>
<tr>
<th>
<a href="https://github.com/TensorBlock/awesome-mcp-servers" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
<th>
<a href="https://github.com/TensorBlock/TensorBlock-Studio" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
</tr>
</table>
## Prompt template
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [OpenReasoning-Nemotron-32B-Q2_K.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q2_K.gguf) | Q2_K | 12.313 GB | smallest, significant quality loss - not recommended for most purposes |
| [OpenReasoning-Nemotron-32B-Q3_K_S.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q3_K_S.gguf) | Q3_K_S | 14.392 GB | very small, high quality loss |
| [OpenReasoning-Nemotron-32B-Q3_K_M.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q3_K_M.gguf) | Q3_K_M | 15.935 GB | very small, high quality loss |
| [OpenReasoning-Nemotron-32B-Q3_K_L.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q3_K_L.gguf) | Q3_K_L | 17.247 GB | small, substantial quality loss |
| [OpenReasoning-Nemotron-32B-Q4_0.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q4_0.gguf) | Q4_0 | 18.640 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [OpenReasoning-Nemotron-32B-Q4_K_S.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q4_K_S.gguf) | Q4_K_S | 18.784 GB | small, greater quality loss |
| [OpenReasoning-Nemotron-32B-Q4_K_M.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q4_K_M.gguf) | Q4_K_M | 19.851 GB | medium, balanced quality - recommended |
| [OpenReasoning-Nemotron-32B-Q5_0.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q5_0.gguf) | Q5_0 | 22.638 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [OpenReasoning-Nemotron-32B-Q5_K_S.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q5_K_S.gguf) | Q5_K_S | 22.638 GB | large, low quality loss - recommended |
| [OpenReasoning-Nemotron-32B-Q5_K_M.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q5_K_M.gguf) | Q5_K_M | 23.262 GB | large, very low quality loss - recommended |
| [OpenReasoning-Nemotron-32B-Q6_K.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q6_K.gguf) | Q6_K | 26.886 GB | very large, extremely low quality loss |
| [OpenReasoning-Nemotron-32B-Q8_0.gguf](https://huggingface.co/tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF/blob/main/OpenReasoning-Nemotron-32B-Q8_0.gguf) | Q8_0 | 34.821 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF --include "OpenReasoning-Nemotron-32B-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/nvidia_OpenReasoning-Nemotron-32B-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
lavavaa/blockassist-bc-giant_knobby_chimpanzee_1755602733
|
lavavaa
| 2025-08-19T11:26:15Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"giant knobby chimpanzee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:26:11Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- giant knobby chimpanzee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chainway9/blockassist-bc-untamed_quick_eel_1755600980
|
chainway9
| 2025-08-19T11:25:05Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:25:01Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755601506
|
Sayemahsjn
| 2025-08-19T11:23:34Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:23:29Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755601011
|
sampingkaca72
| 2025-08-19T11:23:09Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:23:05Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Team-Atom/act_record_pp_red001_0_64_40000
|
Team-Atom
| 2025-08-19T11:22:57Z
| 0
| 0
|
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:Team-Atom/PiPl_red_001_0",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T11:22:42Z
|
---
datasets: Team-Atom/PiPl_red_001_0
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- lerobot
- act
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755600940
|
kojeklollipop
| 2025-08-19T11:21:46Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:21:42Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/80_V9q3Cr
|
VoilaRaj
| 2025-08-19T11:21:29Z
| 0
| 0
| null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T11:17:40Z
|
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
iscchang/t2s
|
iscchang
| 2025-08-19T11:19:38Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-Coder-7B-Instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"region:us"
] |
text-generation
| 2025-08-19T11:16:49Z
|
---
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:Qwen/Qwen2.5-Coder-7B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
Medved444/blockassist-bc-bellowing_finicky_manatee_1755601184
|
Medved444
| 2025-08-19T11:19:13Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bellowing finicky manatee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:18:44Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bellowing finicky manatee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mohammadmahdinouri/moa-30k
|
mohammadmahdinouri
| 2025-08-19T11:17:57Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"ModernALBERT",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-08-19T11:17:54Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Prathyusha101/tldr-ppco-g0p5-l1p0
|
Prathyusha101
| 2025-08-19T11:17:20Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"dataset:trl-internal-testing/tldr-preference-sft-trl-style",
"arxiv:1909.08593",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-18T18:16:19Z
|
---
datasets: trl-internal-testing/tldr-preference-sft-trl-style
library_name: transformers
model_name: tldr-ppco-g0p5-l1p0
tags:
- generated_from_trainer
licence: license
---
# Model Card for tldr-ppco-g0p5-l1p0
This model is a fine-tuned version of [None](https://huggingface.co/None) on the [trl-internal-testing/tldr-preference-sft-trl-style](https://huggingface.co/datasets/trl-internal-testing/tldr-preference-sft-trl-style) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Prathyusha101/tldr-ppco-g0p5-l1p0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/prathyusha1-the-university-of-texas-at-austin/huggingface/runs/chlykdcx)
This model was trained with PPO, a method introduced in [Fine-Tuning Language Models from Human Preferences](https://huggingface.co/papers/1909.08593).
### Framework versions
- TRL: 0.15.0.dev0
- Transformers: 4.53.1
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.2
## Citations
Cite PPO as:
```bibtex
@article{mziegler2019fine-tuning,
title = {{Fine-Tuning Language Models from Human Preferences}},
author = {Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul F. Christiano and Geoffrey Irving},
year = 2019,
eprint = {arXiv:1909.08593}
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
SP4ND4N/Qwen3-0.6B-2025-08-19_15-15-49
|
SP4ND4N
| 2025-08-19T11:17:19Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-0.6B",
"base_model:finetune:unsloth/Qwen3-0.6B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:17:10Z
|
---
base_model: unsloth/Qwen3-0.6B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** SP4ND4N
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-0.6B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
crocodlo/blockassist-bc-soft_barky_scorpion_1755602151
|
crocodlo
| 2025-08-19T11:16:33Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"soft barky scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:16:24Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- soft barky scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
GoutamNagp123/segment_1_model
|
GoutamNagp123
| 2025-08-19T11:15:41Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:49:02Z
|
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
KCS97/can
|
KCS97
| 2025-08-19T11:15:21Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:finetune:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T11:04:16Z
|
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: a photo of sks can
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - KCS97/can
This is a dreambooth model derived from stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on a photo of sks can using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
JackTheKing/Qwen2.5-3B-FT
|
JackTheKing
| 2025-08-19T11:15:13Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T11:15:13Z
|
---
license: apache-2.0
---
|
baidu/ERNIE-4.5-VL-424B-A47B-Base-Paddle
|
baidu
| 2025-08-19T11:13:55Z
| 7
| 55
|
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5_moe_vl",
"ERNIE4.5",
"image-text-to-text",
"conversational",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-28T16:05:05Z
|
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: image-text-to-text
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-VL-424B-A47B-Base
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
To ensure the stability of multimodal joint training, we adopt a staged training strategy. In the first and second stage, we train only the text-related parameters, enabling the model to develop strong fundamental language understanding as well as long-text processing capabilities. The final multimodal stage extends capabilities to images and videos by introducing additional parameters including a ViT for image feature extraction, an adapter for feature transformation, and visual experts for multimodal understanding. At this stage, text and visual modalities mutually enhance each other. After pretraining trillions tokens, we obtained ERNIE-4.5-VL-424B-A47B-Base.
## Model Overview
ERNIE-4.5-VL-424B-A47B-Base is a multimodal MoE Base model, with 424B total parameters and 47B activated parameters for each token. The following are the model configuration details:
| Key | Value |
| --------------------------------- | ------------- |
| Modality | Text & Vision |
| Training Stage | Pretraining |
| Params(Total / Activated) | 424B / 47B |
| Layers | 54 |
| Heads(Q/KV) | 64 / 8 |
| Text Experts(Total / Activated) | 64 / 8 |
| Vision Experts(Total / Activated) | 64 / 8 |
| Context Length | 131072 |
## Quickstart
### vLLM inference
We are working with the community to fully support ERNIE4.5 models, stay tuned.
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright © 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF
|
Ba2han
| 2025-08-19T11:13:53Z
| 0
| 0
| null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:Ba2han/qwen3-coder-30b-a3b-experiment2",
"base_model:quantized:Ba2han/qwen3-coder-30b-a3b-experiment2",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:12:44Z
|
---
base_model: Ba2han/qwen3-coder-30b-a3b-experiment2
tags:
- llama-cpp
- gguf-my-repo
---
# Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF
This model was converted to GGUF format from [`Ba2han/qwen3-coder-30b-a3b-experiment2`](https://huggingface.co/Ba2han/qwen3-coder-30b-a3b-experiment2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Ba2han/qwen3-coder-30b-a3b-experiment2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -c 2048
```
|
aleebaster/blockassist-bc-sly_eager_boar_1755600473
|
aleebaster
| 2025-08-19T11:13:15Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:13:09Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/80_FdLMAe
|
VoilaRaj
| 2025-08-19T11:13:09Z
| 0
| 0
| null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T11:09:19Z
|
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Nerva1228/fyeye
|
Nerva1228
| 2025-08-19T11:12:32Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T07:45:38Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: fyeye
---
# Fyeye
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `fyeye` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "fyeye",
"lora_weights": "https://huggingface.co/Nerva1228/fyeye/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Nerva1228/fyeye', weight_name='lora.safetensors')
image = pipeline('fyeye').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Nerva1228/fyeye/discussions) to add images that show off what you’ve made with this LoRA.
|
RajorshiGon/intent-classifier
|
RajorshiGon
| 2025-08-19T11:12:10Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/gemma-3-270m-it-unsloth-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"arxiv:1910.09700",
"base_model:unsloth/gemma-3-270m-it-unsloth-bnb-4bit",
"region:us"
] | null | 2025-08-19T11:08:18Z
|
---
base_model: unsloth/gemma-3-270m-it-unsloth-bnb-4bit
library_name: peft
tags:
- base_model:adapter:unsloth/gemma-3-270m-it-unsloth-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
forstseh/blockassist-bc-arctic_soaring_heron_1755597883
|
forstseh
| 2025-08-19T11:10:51Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"arctic soaring heron",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:10:35Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- arctic soaring heron
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Reallusion/fluxLora_Kevin
|
Reallusion
| 2025-08-19T11:09:50Z
| 0
| 0
| null |
[
"text-to-image",
"en",
"dataset:crystantine/fluxgym",
"base_model:black-forest-labs/FLUX.1-Fill-dev",
"base_model:finetune:black-forest-labs/FLUX.1-Fill-dev",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-08-19T10:22:28Z
|
---
license: creativeml-openrail-m
datasets:
- crystantine/fluxgym
language:
- en
base_model:
- black-forest-labs/FLUX.1-dev
- black-forest-labs/FLUX.1-Fill-dev
pipeline_tag: text-to-image
---
|
hasdal/21aa9f58-1f69-4055-9211-a03c7007ec6e
|
hasdal
| 2025-08-19T11:07:33Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mixtral",
"trl",
"en",
"base_model:TitanML/tiny-mixtral",
"base_model:finetune:TitanML/tiny-mixtral",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:07:31Z
|
---
base_model: TitanML/tiny-mixtral
tags:
- text-generation-inference
- transformers
- unsloth
- mixtral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** hasdal
- **License:** apache-2.0
- **Finetuned from model :** TitanML/tiny-mixtral
This mixtral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755600119
|
lisaozill03
| 2025-08-19T11:06:51Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:06:48Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BSC-LT/salamandraTA-2b-instruct
|
BSC-LT
| 2025-08-19T11:06:33Z
| 1,355
| 1
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"translation",
"bg",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"eu",
"fi",
"fr",
"ga",
"gl",
"hr",
"hu",
"it",
"lt",
"lv",
"mt",
"nl",
"nb",
"no",
"nn",
"oc",
"pl",
"pt",
"ro",
"ru",
"sl",
"sk",
"sr",
"sv",
"uk",
"ast",
"an",
"arxiv:2010.11125",
"arxiv:2403.14009",
"arxiv:1907.05791",
"arxiv:1911.04944",
"arxiv:2402.17733",
"arxiv:2207.04672",
"arxiv:2404.06392",
"arxiv:2309.04662",
"arxiv:2211.01355",
"arxiv:2508.12774",
"base_model:BSC-LT/salamandra-2b",
"base_model:finetune:BSC-LT/salamandra-2b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:eu"
] |
translation
| 2025-05-13T14:25:01Z
|
---
license: apache-2.0
library_name: transformers
pipeline_tag: translation
language:
- bg
- ca
- cs
- cy
- da
- de
- el
- en
- es
- et
- eu
- fi
- fr
- ga
- gl
- hr
- hu
- it
- lt
- lv
- mt
- nl
- nb
- 'no'
- nn
- oc
- pl
- pt
- ro
- ru
- sl
- sk
- sr
- sv
- uk
- ast
- an
base_model:
- BSC-LT/salamandra-2b
---

# SalamandraTA Model Card
SalamandraTA-2b-instruct is a translation LLM that has been instruction-tuned from SalamandraTA-2b-base.
The base model results from continually pre-training [Salamandra-2b](https://huggingface.co/BSC-LT/salamandra-2b) on parallel data and has not been published, but is reserved for internal use.
SalamandraTA-2b-instruct is proficent in 35 European languages (plus 3 varieties) and supports translation-related tasks, namely: sentence-level-translation, paragraph-level-translation, automatic post-editing, grammar checking, machine translation evaluation, alternative translations, named-entity-recognition and context-aware translation.
> [!WARNING]
> **DISCLAIMER:** This version of Salamandra is tailored exclusively for translation tasks. It lacks chat capabilities and has not been trained with any chat instructions.
---
## Model Details
### Description
SalamandraTA-2b-base is a continual pre-training of [Salamandra-2b](https://huggingface.co/BSC-LT/salamandra-2b) using parallel data, resulting in a total of 424B tokens processed during training.
### Architecture
| | |
|-------------------------|:--------------|
| Total Parameters | 2,253,490,176 |
| Embedding Parameters | 524,288,000 |
| Layers | 24 |
| Hidden size | 2,048 |
| Attention heads | 16 |
| Context length | 8,192 |
| Vocabulary size | 256,000 |
| Precision | bfloat16 |
| Embedding type | RoPE |
| Activation Function | SwiGLU |
| Layer normalization | RMS Norm |
| Flash attention | ✅ |
| Grouped Query Attention | ❌ |
| Num. query groups | N/A |
---
## Intended Use
### Direct Use
The model is intended for both research and commercial use in any of the languages included in the training data for general machine translation tasks.
### Out-of-scope Use
The model is not intended for malicious activities, such as harming others or violating human rights.
Any downstream application must comply with current laws and regulations.
Irresponsible usage in production environments without proper risk assessment and mitigation is also discouraged.
---
## Hardware and Software
### Training Framework
SalamandraTA-2b-base was continually pre-trained using NVIDIA’s [NeMo Framework](https://docs.nvidia.com/nemo-framework/index.html),
which leverages PyTorch Lightning for efficient model training in highly distributed settings.
SalamandraTA-2b-instruct was produced with [FastChat](https://github.com/lm-sys/FastChat).
### Compute Infrastructure
All models were trained on [MareNostrum 5](https://www.bsc.es/ca/marenostrum/marenostrum-5), a pre-exascale EuroHPC supercomputer hosted and
operated by Barcelona Supercomputing Center.
The accelerated partition is composed of 1,120 nodes with the following specifications:
- 4x Nvidia Hopper GPUs with 64GB HBM2 memory
- 2x Intel Sapphire Rapids 8460Y+ at 2.3Ghz and 32c each (64 cores)
- 4x NDR200 (BW per node 800Gb/s)
- 512 GB of Main memory (DDR5)
- 460GB on NVMe storage
---
## How to use
You can translate between the following **35 languages** (and 3 varieties):
Aragonese, Asturian, Basque, Bulgarian, Catalan (and Catalan-Valencian variety), Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hungarian,
Irish, Italian, Latvian, Lithuanian, Maltese, Norwegian (Bokmål and Nynorsk varieties), Occitan (and Aranese variety), Polish, Portuguese, Romanian, Russian, Serbian, Slovak,
Slovenian, Spanish, Swedish, Ukrainian, Welsh.
The instruction-following model uses the commonly adopted ChatML template:
```
<|im_start|>system
{SYSTEM PROMPT}<|im_end|>
<|im_start|>user
{USER PROMPT}<|im_end|>
<|im_start|>assistant
{MODEL RESPONSE}<|im_end|>
<|im_start|>user
[...]
```
The easiest way to apply it is by using the tokenizer's built-in functions, as shown in the following snippet.
```python
from datetime import datetime
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "BSC-LT/salamandraTA-2b-instruct"
source = 'Spanish'
target = 'Catalan'
sentence = "Ayer se fue, tomó sus cosas y se puso a navegar. Una camisa, un pantalón vaquero y una canción, dónde irá, dónde irá. Se despidió, y decidió batirse en duelo con el mar. Y recorrer el mundo en su velero. Y navegar, nai-na-na, navegar"
text = f"Translate the following text from {source} into {target}.\n{source}: {sentence} \n{target}:"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16
)
message = [ { "role": "user", "content": text } ]
date_string = datetime.today().strftime('%Y-%m-%d')
prompt = tokenizer.apply_chat_template(
message,
tokenize=False,
add_generation_prompt=True,
date_string=date_string
)
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
input_length = inputs.shape[1]
outputs = model.generate(input_ids=inputs.to(model.device),
max_new_tokens=400,
early_stopping=True,
num_beams=5)
print(tokenizer.decode(outputs[0, input_length:], skip_special_tokens=True))
# Ahir se'n va anar, va recollir les seves coses i es va fer a la mar. Una camisa, uns texans i una cançó, on anirà, on anirà. Es va acomiadar i va decidir batre's en duel amb el mar. I fer la volta al món en el seu veler. I navegar, nai-na-na, navegar
```
Using this template, each turn is preceded by a `<|im_start|>` delimiter and the role of the entity
(either `user`, for content supplied by the user, or `assistant` for LLM responses), and finished with the `<|im_end|>` token.
#### General translation
For machine translation tasks, you can use the following prompt template:
```
Translate the following text from {source} into {target}.
{source}: {source sentence}
{target}:
```
<details>
<summary>Show an example</summary>
```python
source = 'Catalan'
target = 'Galician'
source_sentence = "Als antics egipcis del període de l'Imperi Nou els fascinaven els monuments dels seus predecessors, que llavors tenien més de mil anys."
text = f"Translate the following text from {source} into {target}.\n{source}: {source_sentence} \n{target}:"
# Os antigos exipcios do período do Imperio Novo estaban fascinados polos monumentos dos seus predecesores, que entón tiñan máis de mil anos de antigüidade.
```
</details>
### Post-editing
For post-editing tasks, you can use the following prompt template:
```
Please fix any mistakes in the following {source}-{target} machine translation or keep it unedited if it's correct.
Source: {source_sentence}
MT: {machine_translation}
Corrected:"
```
<details>
<summary>Show an example</summary>
```python
source = 'Catalan'
target = 'English'
source_sentence = 'Rafael Nadal i Maria Magdalena van inspirar a una generació sencera.'
machine_translation = 'Rafael Christmas and Maria the Muffin inspired an entire generation each in their own way.'
text = f"Please fix any mistakes in the following {source}-{target} machine translation or keep it unedited if it's correct.\nSource: {source_sentence} \nMT: {machine_translation} \nCorrected:"
# Rafael Nadal and Maria Magdalena inspired an entire generation.
```
</details>
### Paragraph-level translation
For paragraph-level translation tasks, you can use the following prompt template:
```
Please translate this text from {source} into {target}.
{source}: {paragraph}
{target}:
```
<details>
<summary>Show an example</summary>
```python
source = 'English'
target = 'Asturian'
text = """Please translate this text from {} into {}.\n{}: President Donald Trump, who campaigned on promises to crack down on illegal immigration, has raised alarms in the U.S. dairy industry with his threat to impose 25% tariffs on Mexico and Canada by February 2025. This move is part of a broader strategy to declare a national emergency at the southern border to halt illegal migration completely. However, the implications for the agriculture sector, particularly dairy, are significant. Approximately half of the U.S. dairy industry's workforce consists of immigrant labor, many of whom are undocumented. The National Milk Producers Federation estimates that removing immigrant workers could decimate the dairy herd by 2.1 million cows and slash milk production by nearly 50 billion pounds, leading to a dramatic 90.4% increase in milk prices. The complex perspectives of Americans on undocumented workers were highlighted in a Pew Research Center study. While 64% of U.S. adults support legal pathways for undocumented immigrants, 35% oppose it—a gap that has been narrowing recently. Factors influencing public opinion include the belief that immigrants should have jobs and pass security checks, contrasted by concerns about lawbreakers being rewarded, fairness for legal migrants, and resource allocation.
{}:""".format(source, target, source, target)
```
</details>
### Named-entity recognition
For named-entity recognition tasks, you can use the following prompt template:
```
Analyse the following tokenized text and mark the tokens containing named entities.
Use the following annotation guidelines with these tags for named entities:
- ORG (Refers to named groups or organizations)
- PER (Refers to individual people or named groups of people)
- LOC (Refers to physical places or natural landmarks)
- MISC (Refers to entities that don't fit into standard categories).
Prepend B- to the first token of a given entity and I- to the remaining ones if they exist.
If a token is not a named entity, label it as O.
Input: {list of words in a sentence}
Marked:
```
<details>
<summary>Show an example</summary>
```python
text = """Analyse the following tokenized text and mark the tokens containing named entities.
Use the following annotation guidelines with these tags for named entities:
- ORG (Refers to named groups or organizations)
- PER (Refers to individual people or named groups of people)
- LOC (Refers to physical places or natural landmarks)
- MISC (Refers to entities that don't fit into standard categories).
Prepend B- to the first token of a given entity and I- to the remaining ones if they exist.
If a token is not a named entity, label it as O.
Input: ['La', 'defensa', 'del', 'antiguo', 'responsable', 'de', 'la', 'RFEF', 'confirma', 'que', 'interpondrá', 'un', 'recurso.']
Marked: """
# [('La', 'O'), ('defensa', 'O'), ('del', 'O'), ('antiguo', 'O'), ('responsable', 'O'), ('de', 'O'), ('la', 'O'), ('RFEF', 'B-ORG'), ('confirma', 'O'), ('que', 'O'), ('interpondrá', 'O'), ('un', 'O'), ('recurso.', 'O')]
```
</details>
### Grammar checker
For fixing any mistakes in grammar, you can use the following prompt template:
```
Please fix any mistakes in the following {source} sentence or keep it unedited if it's correct.
Sentence: {sentence}
Corrected:
```
<details>
<summary>Show an example</summary>
```python
source = 'Catalan'
sentence = 'Entonses, el meu jefe m’ha dit que he de treballar els fins de setmana.'
text = f"Please fix any mistakes in the following {source} sentence or keep it unedited if it's correct.\nSentence: {sentence} \nCorrected:"
# Llavors, el meu cap m'ha dit que he de treballar els caps de setmana.
```
</details>
## Data
### Pretraining Data
The pretraining corpus consists of 424 billion tokens of Catalan-centric, Spanish-centric, and English-centric parallel data,
including all of the official European languages plus Catalan, Basque, Galician, Asturian, Aragonese and Aranese.
It amounts to 6,574,251,526 parallel sentence pairs.
This highly multilingual corpus is predominantly composed of data sourced from [OPUS](https://opus.nlpl.eu/),
with additional data taken from the [NTEU Project](https://nteu.eu/), [Aina Project](https://projecteaina.cat/), and other sources
(see: [Data Sources](#pre-data-sources) and [References](#pre-references)).
Where little parallel Catalan <-> xx data could be found, synthetic Catalan data was generated from the Spanish side of the collected Spanish <-> xx corpora using
[Projecte Aina’s Spanish-Catalan model](https://huggingface.co/projecte-aina/aina-translator-es-ca). The final distribution of languages was as below:

Click the expand button below to see the full list of corpora included in the training data.
<details id="pre-data-sources">
<summary>Data Sources</summary>
| Dataset | Ca-xx Languages | Es-xx Langugages | En-xx Languages |
|-----------------------------------------------|----------------------------------------------------------------|-----------------------------------------------|----------------------------------------------------------------|
|[AINA](https://huggingface.co/projecte-aina) | en | | |
|ARANESE-SYNTH-CORPUS-BSC | arn | | |
|BOUA-SYNTH-BSC | | val | |
|[BOUMH](https://github.com/transducens/PILAR/tree/main/valencian/BOUMH) | | val | |
|[BOUA-PILAR](https://github.com/transducens/PILAR/tree/main/valencian/BOUA) | | val | |
|[CCMatrix](https://opus.nlpl.eu/CCMatrix/corpus/version/CCMatrix) |eu | | ga |
|[DGT](https://opus.nlpl.eu/DGT/corpus/version/DGT) | |bg,cs,da,de,el ,et,fi,fr,ga,hr,hu,lt,lv,mt,nl,pl,pt,ro,sk,sl,sv | da,et,ga,hr,hu,lt,lv,mt,sh,sl|
|DOGV-SYNTH-BSC | | val | |
|[DOGV-PILAR](https://github.com/transducens/PILAR/tree/main/valencian/DOGV-html) | | val | |
|[ELRC-EMEA](https://opus.nlpl.eu/ELRC-EMEA/corpus/version/ELRC-EMEA) | |bg,cs,da,hu,lt,lv,mt,pl,ro,sk,sl | et,hr,lv,ro,sk,sl |
|[EMEA](https://opus.nlpl.eu/EMEA/corpus/version/EMEA) | |bg,cs,da,el,fi,hu,lt,mt,nl,pl,ro,sk,sl,sv | et,mt |
|[EUBookshop](https://opus.nlpl.eu/EUbookshop/corpus/version/EUbookshop) |lt,pl,pt |cs,da,de,el,fi,fr,ga,it,lv,mt,nl,pl,pt,ro,sk,sl,sv |cy,ga|
|[Europarl](https://opus.nlpl.eu/Europarl/corpus/version/Europarl) | |bg,cs,da,el,en,fi,fr,hu,lt,lv,nl,pl,pt ,ro,sk,sl,sv | |
|[Europat](https://opus.nlpl.eu/EuroPat/corpus/version/EuroPat) | |en,hr | no |
|[GAITU Corpus](https://gaitu.eus/) | | | eu|
|[KDE4](https://opus.nlpl.eu/KDE4/corpus/version/KDE4) |bg,cs,da,de,el ,et,eu,fi,fr,ga,gl,hr,it,lt,lv,nl,pl,pt,ro,sk,sl,sv |bg,ga,hr |cy,ga,nn,oc |
|[GlobalVoices](https://opus.nlpl.eu/GlobalVoices/corpus/version/GlobalVoices) | bg,de,fr,it,nl,pl,pt |bg,de,fr,pt | |
|[GNOME](https://opus.nlpl.eu/GNOME/corpus/version/GNOME) |eu,fr,ga,gl,pt |ga |cy,ga,nn|
|[JRC-Arquis](https://opus.nlpl.eu/JRC-Acquis/corpus/version/JRC-Acquis) | |cs,da,et,fr,lt,lv,mt,nl,pl ,ro,sv| et |
|LES-CORTS-VALENCIANES-SYNTH-BSC | | val | |
|[MaCoCu](https://opus.nlpl.eu/MaCoCu/corpus/version/MaCoCu) | en | | hr,mt,uk |
|[MultiCCAligned](https://opus.nlpl.eu/JRC-Acquis/corpus/version/JRC-Acquis) |bg,cs,de,el,et,fi,fr,hr,hu,it,lt,lv,nl,pl,ro,sk,sv |bg,fi,fr,hr,it,lv,nl,pt |bg,cy,da,et,fi,hr,hu,lt,lv,no,sl,sr,uk|
|[MultiHPLT](https://opus.nlpl.eu/MultiHPLT/corpus/version/MultiHPLT) |en, et,fi,ga,hr,mt | |fi,ga,gl,hr,mt,nn,sr |
|[MultiParaCrawl](https://opus.nlpl.eu/MultiParaCrawl/corpus/version/MultiParaCrawl) |bg,da |de,en,fr,ga,hr,hu,it,mt,pt |bg,cs,da,de,el,et,fi,fr,ga,hr,hu,lt,lv,mt,nn,pl,ro,sk,sl,uk|
|[MultiUN](https://opus.nlpl.eu/MultiUN/corpus/version/MultiUN) | |fr | |
|[News-Commentary](https://opus.nlpl.eu/News-Commentary/corpus/version/News-Commentary) | |fr | |
|[NLLB](https://opus.nlpl.eu/NLLB/corpus/version/NLLB) |bg,da,el,en,et,fi,fr,gl,hu,it ,lt,lv,pt,ro,sk,sl |bg,cs,da,de,el ,et,fi,fr,hu,it,lt,lv,nl,pl,pt ,ro,sk,sl,sv| bg,cs,cy,da,de,el,et,fi,fr,ga,hr,hu,it,lt,lv,mt,nl,no,oc,pl,pt,ro,ru,sk,sl,sr,sv,uk|
|[NÓS Authentic Corpus](https://zenodo.org/records/7675110) | | | gl |
|[NÓS Synthetic Corpus](https://zenodo.org/records/7685180) | | | gl |
|[NTEU](https://www.elrc-share.eu/repository/search/?q=NTEU) | |bg,cs,da,de,el,en,et,fi,fr,ga,hr,hu,it,lt,lv,mt,nl,pl,pt,ro,sk,sl,sv | da,et,ga,hr,lt,lv,mt,ro,sk,sl,sv |
|[OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) |bg,cs,da,de,el ,et,eu,fi,gl,hr,hu,lt,lv,nl,pl,pt,ro,sk,sl,sv |da,de,fi,fr,hr,hu,it,lv,nl | bg,cs,de,el,et,hr,fi,fr,hr,hu,no,sl,sr|
|[OPUS-100](https://opus.nlpl.eu/opus-100.php) | en | | gl |
|[StanfordNLP-NMT](https://opus.nlpl.eu/StanfordNLP-NMT/corpus/version/StanfordNLP-NMT) | | |cs |
|[Tatoeba](https://opus.nlpl.eu/Tatoeba/corpus/version/Tatoeba) |de,pt |pt | |
|[TildeModel](https://opus.nlpl.eu/TildeMODEL/corpus/version/TildeMODEL) | |bg | et,hr,lt,lv,mt |
|[UNPC](https://opus.nlpl.eu/UNPC/corpus/version/UNPC) | |en,fr | ru |
|[PILAR-VALENCIAN-AUTH](https://github.com/transducens/PILAR/tree/main/valencian/Generalitat) | | val | |
|[PILAR-VALENCIAN-SYNTH](https://github.com/transducens/PILAR/tree/main/valencian/Generalitat) | | val | |
|[WikiMatrix](https://opus.nlpl.eu/WikiMatrix/corpus/version/WikiMatrix) |bg,cs,da,de,el ,et,eu,fi,fr,gl,hr,hu,it,lt,nl,pl,pt,ro,sk,sl,sv |bg,en,fr,hr,it,pt | oc,sh |
|[Wikimedia](https://opus.nlpl.eu/wikimedia/corpus/version/wikimedia) | | |cy,nn |
|[XLENT](https://opus.nlpl.eu/XLEnt/corpus/version/XLEnt) |eu,ga,gl |ga |cy,et,ga,gl,hr,oc,sh|
Datasets with "-BSC" in their names (e.g., BOUA-SYNTH-BSC, DOGV-SYNTH-BSC) are synthetic datasets obtained by machine translating
pre-existing monolingual corpora with our own seq-to-seq models. These datasets were generated internally for model training and are not published.
To consult the data summary document with the respective licences, please send an e-mail to [email protected].
</details>
<details id="pre-references">
<summary>References</summary>
- Aulamo, M., Sulubacak, U., Virpioja, S., & Tiedemann, J. (2020). OpusTools and Parallel Corpus Diagnostics. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 3782–3789). European Language Resources Association. https://aclanthology.org/2020.lrec-1.467
- Chaudhary, V., Tang, Y., Guzmán, F., Schwenk, H., & Koehn, P. (2019). Low-Resource Corpus Filtering Using Multilingual Sentence Embeddings. In O. Bojar, R. Chatterjee, C. Federmann, M. Fishel, Y. Graham, B. Haddow, M. Huck, A. J. Yepes, P. Koehn, A. Martins, C. Monz, M. Negri, A. Névéol, M. Neves, M. Post, M. Turchi, & K. Verspoor (Eds.), Proceedings of the Fourth Conference on Machine Translation (Volume 3: Shared Task Papers, Day 2) (pp. 261–266). Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-5435
- DGT-Translation Memory—European Commission. (n.d.). Retrieved November 4, 2024, from https://joint-research-centre.ec.europa.eu/language-technology-resources/dgt-translation-memory_en
- Eisele, A., & Chen, Y. (2010). MultiUN: A Multilingual Corpus from United Nation Documents. In N. Calzolari, K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, M. Rosner, & D. Tapias (Eds.), Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10). European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2010/pdf/686_Paper.pdf
- El-Kishky, A., Chaudhary, V., Guzmán, F., & Koehn, P. (2020). CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 5960–5969. https://doi.org/10.18653/v1/2020.emnlp-main.480
- El-Kishky, A., Renduchintala, A., Cross, J., Guzmán, F., & Koehn, P. (2021). XLEnt: Mining a Large Cross-lingual Entity Dataset with Lexical-Semantic-Phonetic Word Alignment. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 10424–10430. https://doi.org/10.18653/v1/2021.emnlp-main.814
- Fan, A., Bhosale, S., Schwenk, H., Ma, Z., El-Kishky, A., Goyal, S., Baines, M., Celebi, O., Wenzek, G., Chaudhary, V., Goyal, N., Birch, T., Liptchinsky, V., Edunov, S., Grave, E., Auli, M., & Joulin, A. (2020). Beyond English-Centric Multilingual Machine Translation (No. arXiv:2010.11125). arXiv. https://doi.org/10.48550/arXiv.2010.11125
- García-Martínez, M., Bié, L., Cerdà, A., Estela, A., Herranz, M., Krišlauks, R., Melero, M., O’Dowd, T., O’Gorman, S., Pinnis, M., Stafanovič, A., Superbo, R., & Vasiļevskis, A. (2021). Neural Translation for European Union (NTEU). 316–334. https://aclanthology.org/2021.mtsummit-up.23
- Gibert, O. de, Nail, G., Arefyev, N., Bañón, M., Linde, J. van der, Ji, S., Zaragoza-Bernabeu, J., Aulamo, M., Ramírez-Sánchez, G., Kutuzov, A., Pyysalo, S., Oepen, S., & Tiedemann, J. (2024). A New Massive Multilingual Dataset for High-Performance Language Technologies (No. arXiv:2403.14009). arXiv. http://arxiv.org/abs/2403.14009
- Koehn, P. (2005). Europarl: A Parallel Corpus for Statistical Machine Translation. Proceedings of Machine Translation Summit X: Papers, 79–86. https://aclanthology.org/2005.mtsummit-papers.11
- Kreutzer, J., Caswell, I., Wang, L., Wahab, A., Van Esch, D., Ulzii-Orshikh, N., Tapo, A., Subramani, N., Sokolov, A., Sikasote, C., Setyawan, M., Sarin, S., Samb, S., Sagot, B., Rivera, C., Rios, A., Papadimitriou, I., Osei, S., Suarez, P. O., … Adeyemi, M. (2022). Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. Transactions of the Association for Computational Linguistics, 10, 50–72. https://doi.org/10.1162/tacl_a_00447
- Rozis, R.,Skadiņš, R (2017). Tilde MODEL - Multilingual Open Data for EU Languages. https://aclanthology.org/W17-0235
- Schwenk, H., Chaudhary, V., Sun, S., Gong, H., & Guzmán, F. (2019). WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia (No. arXiv:1907.05791). arXiv. https://doi.org/10.48550/arXiv.1907.05791
- Schwenk, H., Wenzek, G., Edunov, S., Grave, E., & Joulin, A. (2020). CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB (No. arXiv:1911.04944). arXiv. https://doi.org/10.48550/arXiv.1911.04944
- Steinberger, R., Pouliquen, B., Widiger, A., Ignat, C., Erjavec, T., Tufiş, D., & Varga, D. (n.d.). The JRC-Acquis: A Multilingual Aligned Parallel Corpus with 20+ Languages. http://www.lrec-conf.org/proceedings/lrec2006/pdf/340_pdf
- Subramani, N., Luccioni, S., Dodge, J., & Mitchell, M. (2023). Detecting Personal Information in Training Corpora: An Analysis. In A. Ovalle, K.-W. Chang, N. Mehrabi, Y. Pruksachatkun, A. Galystan, J. Dhamala, A. Verma, T. Cao, A. Kumar, & R. Gupta (Eds.), Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023) (pp. 208–220). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.trustnlp-1.18
- Tiedemann, J. (23-25). Parallel Data, Tools and Interfaces in OPUS. In N. C. (Conference Chair), K. Choukri, T. Declerck, M. U. Doğan, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC’12). European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2012/pdf/463_Paper
- Ziemski, M., Junczys-Dowmunt, M., & Pouliquen, B. (n.d.). The United Nations Parallel Corpus v1.0. https://aclanthology.org/L16-1561
</details>
### Instruction Tuning Data
This model has been fine-tuned on ~135k instructions, primarily targeting machine translation performance for Catalan, English, and Spanish.
Additional instruction data for other European and closely related Iberian languages was also included, as it yielded a positive impact on the languages of interest.
That said, the performance in these additional languages is not guaranteed due to the limited amount of available data and the lack of resources for thorough testing.
A portion of our fine-tuning data comes directly from, or is sampled from [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2).
We also created additional datasets for our main languages of interest.
While tasks relating to machine translation are included, it’s important to note that no chat data was used in the fine-tuning process.
The final distribution of tasks was as below:

Click the expand button below to see the full list of tasks included in the finetuning data.
<details id="instr-data-sources">
<summary>Data Sources</summary>
| Task | Source | Languages | Count |
|----------------------------------|------------------------------------------------------------------------------------------|----------------------------------------------------------------|--------|
| Multi-reference Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [Tatoeba Dev (filtered)](https://github.com/Helsinki-NLP/Tatoeba-Challenge) | mixed | 10000 |
| Paraphrase | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [PAWS-X Dev](https://github.com/google-research-datasets/paws) | mixed | 3521 |
| Named-entity Recognition | [AnCora-Ca-NER](https://huggingface.co/datasets/projecte-aina/ancora-ca-ner) | ca | 12059 |
| Named-entity Recognition | [BasqueGLUE](https://huggingface.co/datasets/orai-nlp/basqueGLUE), [EusIE](https://huggingface.co/datasets/HiTZ/EusIE) | eu | 4304 |
| Named-entity Recognition | [SLI NERC Galician Gold Corpus](https://github.com/xavier-gz/SLI_Galician_Corpora) | gl | 6483 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | pt | 854 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | nl | 800 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | es | 1654 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | en | 1671 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | ru | 800 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | it | 858 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | fr | 857 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | de | 1312 |
| Terminology-aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [WMT21 Terminology Dev (filtered)](https://www.statmt.org/wmt21/terminology-task.html) | en-ru | 50 |
| Terminology-aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [WMT21 Terminology Dev (filtered)](https://www.statmt.org/wmt21/terminology-task.html) | en-fr | 29 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-fr | 6133 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-nl | 9077 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-pt | 5762 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | de-en | 10000 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-de | 10000 |
| Machine Translation Evaluation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2)-sample: [WMT20 to WMT22 Metrics MQM](https://www.statmt.org/wmt22/results.html), [WMT17 to WMT22 Metrics Direct Assessments](https://www.statmt.org/wmt22/results.html) | en-ru, en-pl, ru-en, en-de, en-ru, de-fr, de-en, en-de | 353 |
| Machine Translation Evaluation | Non-public | four pivot languages (eu, es, ca, gl) paired with European languages (bg, cs, da, de, el, en, et, fi, fr, ga, hr, hu, it, lt, lv, mt, nl, pl, pt, ro, sk, sl, sv) | 9700 |
| General Machine Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [WMT14 to WMT21](https://www.statmt.org/wmt22/results.html), [NTREX](https://github.com/MicrosoftTranslator/NTREX), [Flores Dev](https://github.com/facebookresearch/flores), [FRMT](https://github.com/google-research/google-research/tree/master/frmt), [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/), [OPUS (Quality Filtered)](https://opus.nlpl.eu/), [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | nl-en, en-ru, it-en, fr-en, es-en, en-fr, ru-en, fr-de, en-nl, de-fr | 500 |
| General Machine Translation | Non-public | three pivot languages (es, ca, en) paired with European languages (ast, arn, arg, bg, cs, cy, da, de, el, et, fi, ga, gl, hr, it, lt, lv, mt, nb, nn, nl, oc, pl, pt, ro, ru, sk, sl, sr, sv, uk, eu) | 9350 |
| Fill-in-the-Blank | Non-public | five pivot languages (ca, es, eu, gl, en) paired with European languages (cs, da, de, el, et, fi, fr, ga, hr, hu, it, lt, lv, mt, nl, pl, pt, ro, sk, sl, sv) | 11500 |
| Document-level Translation | Non-public | two pivot languages (es, en) paired with European languages (bg, cs, da, de, el, et, fi, fr, hu, it, lt, lv, nl, pl, pt, ro, ru, sk, sv) | 7600 |
| Paragraph-level Translation | Non-public | two pivot languages (es, en) paired with European languages (bg, cs, da, de, el, et, fi, fr, hu, it, lt, lv, nl, pl, pt, ro, ru, sk, sv) | 7600 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-it | 348 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-ru | 454 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-fr | 369 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-nl | 417 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-es | 431 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-de | 558 |
|**Total** | | | **135,404** |
The non-public portion of this dataset was jointly created by the [ILENIA](https://proyectoilenia.es/) partners: BSC-LT, [HiTZ](http://hitz.ehu.eus/es),
and [CiTIUS](https://citius.gal/es/). For further information regarding the instruction-tuning data,
please contact <[email protected]>.
</details>
<details id="instr-references">
<summary>References</summary>
- Alves, D. M., Pombal, J., Guerreiro, N. M., Martins, P. H., Alves, J., Farajian, A., Peters, B., Rei, R., Fernandes, P., Agrawal, S., Colombo, P., de Souza, J. G. C., & Martins, A. F. T. (2024). Tower: An open multilingual large language model for translation-related tasks (No. arXiv: 2402.17733). arXiv. https://arxiv.org/abs/2402.17733
- Armengol-Estapé, J., Carrino, C. P., Rodriguez-Penagos, C., de Gibert Bonet, O., Armentano-Oller, C., Gonzalez-Agirre, A., Melero, M., & Villegas, M. (2021). Are multilingual models the best choice for moderately under-resourced languages? A comprehensive assessment for Catalan. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 4933–4946. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.findings-acl.437
- Currey, A., Nadejde, M., Pappagari, R. R., Mayer, M., Lauly, S., Niu, X., Hsu, B., & Dinu, G. (2022). MT-GenEval: A counterfactual and contextual dataset for evaluating gender accuracy in machine translation. In Y. Goldberg, Z. Kozareva, & Y. Zhang (Eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 4287–4299). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.emnlp-main.288
- Federmann, C., Kocmi, T., & Xin, Y. (2022). NTREX-128 – News test references for MT evaluation of 128 languages. Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, 21–24. Association for Computational Linguistics. https://aclanthology.org/2022.sumeval-1.4
- Ive, J., Specia, L., Szoc, S., Vanallemeersch, T., Van den Bogaert, J., Farah, E., Maroti, C., Ventura, A., & Khalilov, M. (2020). A post-editing dataset in the legal domain: Do we underestimate neural machine translation quality? In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 3692–3697). European Language Resources Association. https://aclanthology.org/2020.lrec-1.455/
- Malmasi, S., Fang, A., Fetahu, B., Kar, S., & Rokhlenko, O. (2022). MultiCoNER: A large-scale multilingual dataset for complex named entity recognition. Proceedings of the 29th International Conference on Computational Linguistics, 3798–3809. International Committee on Computational Linguistics. https://aclanthology.org/2022.coling-1.334/
- NLLB Team, Costa-jussà, M. R., Cross, J., Çelebi, O., Elbayad, M., Heafield, K., Heffernan, K., Kalbassi, E., Lam, J., Licht, D., Maillard, J., Sun, A., Wang, S., Wenzek, G., Youngblood, A., Akula, B., Barrault, L., Mejia Gonzalez, G., Hansanti, P., Hoffman, J., Jarrett, S., Sadagopan, K. R., Rowe, D., Spruit, S., Tran, C., Andrews, P., Ayan, N. F., Bhosale, S., Edunov, S., Fan, A., Gao, C., Goswami, V., Guzmán, F., Koehn, P., Mourachko, A., Ropers, C., Saleem, S., Schwenk, H., & Wang, J. (2022). No language left behind: Scaling human-centered machine translation (No. arXiv: 2207.04672). arXiv. https://arxiv.org/abs/2207.04672
- Riley, P., Dozat, T., Botha, J. A., Garcia, X., Garrette, D., Riesa, J., Firat, O., & Constant, N. (2022). FRMT: A benchmark for few-shot region-aware machine translation (No. arXiv: 2210.00193). arXiv. https://doi.org/10.48550/ARXIV.2210.00193
- Specia, L., Harris, K., Blain, F., Burchardt, A., Macketanz, V., Skadiņa, I., Negri, M., & Turchi, M. (2017). Translation quality and productivity: A study on rich morphology languages. Proceedings of Machine Translation Summit XVI, 55–71. Nagoya, Japan.
- Tiedemann, J. (2020). The Tatoeba translation challenge – Realistic data sets for low-resource and multilingual MT. Proceedings of the Fifth Conference on Machine Translation, 1174–1182. Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.wmt-1.139
- Urbizu, G., San Vicente, I., Saralegi, X., Agerri, R., & Soroa, A. (2022). BasqueGLUE: A natural language understanding benchmark for Basque. Proceedings of the Language Resources and Evaluation Conference, 1603–1612. European Language Resources Association. https://aclanthology.org/2022.lrec-1.172
- Yang, Y., Zhang, Y., Tar, C., & Baldridge, J. (2019). PAWS-X: A cross-lingual adversarial dataset for paraphrase identification. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 3687–3692). Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1382
- Zubillaga, M., Sainz, O., Estarrona, A., Lopez de Lacalle, O., & Agirre, E. (2024). Event extraction in Basque: Typologically motivated cross-lingual transfer-learning analysis (No. arXiv: 2404.06392). arXiv. https://arxiv.org/abs/2404.06392
</details>
## Evaluation
Below are the evaluation results on the [Flores+200 devtest set](https://huggingface.co/datasets/openlanguagedata/flores_plus),
compared against the state-of-the-art [MADLAD400-3B-mt model](https://huggingface.co/google/madlad400-3b-mt) ([Kudugunta, S., et al.](https://arxiv.org/abs/2309.04662)) and [NLLB-200-3.3B](https://huggingface.co/facebook/nllb-200-3.3B) ([Costa-jussà et al., 2022](https://arxiv.org/abs/2207.04672)).
These results cover the translation directions CA-XX, ES-XX, EN-XX, as well as XX-CA, XX-ES, and XX-EN.
The metrics have been computed excluding Asturian, Aranese, and Aragonese, as we report them separately.
The evaluation was conducted using [MT-Lens](https://github.com/langtech-bsc/mt-evaluation), following the standard setting (beam search with beam size 5, limiting the translation length to 500 tokens). We report the following metrics:
<details>
<summary>Click to show metrics details</summary>
- `BLEU`: Sacrebleu implementation. Signature: nrefs:1— case:mixed— eff:no— tok:13a— smooth:exp—version:2.3.1
- `TER`: Sacrebleu implementation.
- `ChrF`: Sacrebleu implementation.
- `Comet`: Model checkpoint: "Unbabel/wmt22-comet-da".
- `Comet-kiwi`: Model checkpoint: "Unbabel/wmt22-cometkiwi-da".
- `Bleurt`: Model checkpoint: "lucadiliello/BLEURT-20".
- `MetricX`: Model checkpoint: "google/metricx-23-xl-v2p0".
- `MetricX-QE`: Model checkpoint: "google/metricx-23-qe-xl-v2p0".
</details>
<details>
<summary>English evaluation</summary>
### English
This section presents the evaluation metrics for English translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **EN-XX** | | | | | | | | |
| MADLAD400-3B | **35.11** | **52.61** | **63.04** | **0.88** | **0.85** | **0.78** | 1.21 | 1.12 |
| SalamandraTA-2b-instruct | 33.52 | 56.26 | 61.74 | **0.88** | **0.85** | **0.78** | **1.16** | **0.89** |
| nllb-200-3.3B | 31.17 | 56.03 | 59.19 | 0.87 | 0.83 | 0.76 | 2.22 | 2.20 |
| **XX-EN** | | | | | | | | |
| MADLAD400-3B | **41.84** | **44.43** | **67.04** | **0.88** | **0.85** | **0.79** | **1.22** | 1.18 |
| nllb-200-3.3B | 41.52 | 45.28 | 66.21 | **0.88** | **0.85** | 0.78 | 1.43 | 1.57 |
| SalamandraTA-2b-instruct | 41.44 | 45.24 | 66.64 | **0.88** | **0.85** | **0.79** | 1.24 | **1.05** |
<img src="./images/bleu_en.png" alt="English" width="100%"/>
</details>
<details>
<summary>Spanish evaluation</summary>
### Spanish
This section presents the evaluation metrics for Spanish translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **ES-XX** | | | | | | | | |
| MADLAD400-3B | **21.87** | **69.80** | **53.46** | **0.86** | **0.83** | **0.74** | **1.15** | 1.12 |
| SalamandraTA-2b-instruct | 20.77 | 73.37 | 52.16 | **0.86** | **0.83** | **0.74** | 1.16 | **0.89** |
| nllb-200-3.3B | 19.54 | 72.19 | 50.07 | 0.84 | 0.81 | 0.71 | 2.19 | 2.21 |
| **XX-ES** | | | | | | | | |
| SalamandraTA-2b-instruct | **25.01** | 63.35 | **52.74** | **0.85** | **0.84** | **0.73** | **1.03** | **1.20** |
| MADLAD400-3B | 24.38 | **62.31** | 52.65 | **0.85** | **0.84** | **0.73** | 1.13 | 1.54 |
| nllb-200-3.3B | 22.68 | 64.18 | 50.91 | 0.84 | 0.83 | 0.71 | 1.62 | 2.06 |
<img src="./images/bleu_es.png" alt="English" width="100%"/>
</details>
<details>
<summary>Catalan evaluation</summary>
### Catalan
This section presents the evaluation metrics for Catalan translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **CA-XX** | | | | | | | | |
| MADLAD400-3B | **28.86** | **59.60** | **58.05** | **0.87** | **0.81** | **0.77** | **1.15** | 1.28 |
| SalamandraTA-2b-instruct | 26.70 | 64.12 | 56.18 | **0.87** | **0.81** | 0.76 | 1.24 | **1.09** |
| nllb-200-3.3B | 25.17 | 63.15 | 54.02 | 0.85 | 0.79 | 0.72 | 2.42 | 2.59 |
| **XX-CA** | | | | | | | | |
| SalamandraTA-2b-instruct | **32.42** | 56.54 | 58.67 | **0.86** | **0.81** | 0.74 | **1.11** | **1.38** |
| MADLAD400-3B | 32.31 | **55.68** | **58.87** | **0.86** | **0.81** | **0.75** | 1.27 | 1.83 |
| nllb-200-3.3B | 29.28 | 58.95 | 55.97 | 0.84 | 0.80 | 0.71 | 2.18 | 2.61 |
<img src="./images/bleu_ca.png" alt="English" width="100%"/>
</details>
<details>
<summary>Galician evaluation</summary>
### Galician
This section presents the evaluation metrics for Galician translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **GL-XX** | | | | | | | | |
| SalamandraTA-2b-instruct | **25.46** | 65.95 | 55.42 | **0.87** | 0.82 | **0.75** | **1.22** | **1.05** |
| MADLAD400-3B | 25.12 | 66.02 | **55.78** | 0.85 | **0.85** | 0.74 | 1.37 | 1.83 |
| nllb-200-3.3B | 24.20 | **64.70** | 53.37 | 0.85 | 0.80 | 0.72 | 2.29 | 2.42 |
| **XX-GL** | | | | | | | | |
| SalamandraTA-2b-instruct | **28.72** | **59.65** | **56.33** | **0.86** | 0.83 | **0.69** | **1.04** | **1.25** |
| MADLAD400-3B | 27.54 | 59.84 | 54.94 | 0.85 | **0.85** | 0.67 | 1.34 | 2.28 |
| nllb-200-3.3B | 26.22 | 60.15 | 53.84 | 0.84 | 0.81 | 0.67 | 1.91 | 2.54 |
<img src="./images/bleu_gl.png" alt="English" width="100%"/>
</details>
<details>
<summary>Basque evaluation</summary>
### Basque
This section presents the evaluation metrics for Basque translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **EU-XX** | | | | | | | | |
| MADLAD400-3B | **20.02** | 71.82 | 48.71 | 0.84 | **0.85** | **0.71** | 1.68 | 2.76 |
| SalamandraTA-2b-instruct | 19.00 | 77.45 | **49.13** | **0.85** | 0.79 | **0.71** | **1.45** | **1.43** |
| nllb-200-3.3B | 18.83 | **71.60** | 47.96 | 0.83 | 0.76 | 0.69 | 2.35 | 2.89 |
| **XX-EU** | | | | | | | | |
| SalamandraTA-2b-instruct | **13.06** | 89.81 | **51.65** | **0.84** | 0.77 | **0.78** | **1.25** | **1.09** |
| MADLAD400-3B | 12.65 | 91.60 | 49.86 | 0.82 | **0.84** | **0.78** | 2.22 | 3.43 |
| nllb-200-3.3B | 7.58 | **86.57** | 40.43 | 0.73 | 0.62 | 0.64 | 4.68 | 6.08 |
<img src="./images/bleu_eu.png" alt="English" width="100%"/>
</details>
### Low-Resource Languages of Spain
The tables below summarize the performance metrics for English, Spanish, and Catalan to Asturian, Aranese and Aragonese compared
against [Transducens/IbRo-nllb](https://huggingface.co/Transducens/IbRo-nllb) [(Galiano Jimenez, et al.)](https://aclanthology.org/2024.wmt-1.85/),
[NLLB-200-3.3B](https://huggingface.co/facebook/nllb-200-3.3B) ([Costa-jussà et al., 2022](https://arxiv.org/abs/2207.04672)).
<details>
<summary>English evaluation</summary>
#### English-XX
| | source | target | Bleu ↑ | Ter ↓ | ChrF ↑ |
|:-------------------------|:---------|:---------|:----------|:----------|:----------|
| SalamandraTA-2b-instruct | en | ast | **25.84** | **63.31** | **58.60** |
| nllb-200-3.3B | en | ast | 22.02 | 77.26 | 51.40 |
| Transducens/IbRo-nllb | en | ast | 20.56 | 63.92 | 53.32 |
| | | | | | |
| SalamandraTA-2b-instruct | en | arn | **19.09** | 76.04 | **50.18** |
| Transducens/IbRo-nllb | en | arn | 12.81 | **73.21** | 45.76 |
| | | | | | |
| SalamandraTA-2b-instruct | en | arg | **15.87** | 76.75 | **48.08** |
| Transducens/IbRo-nllb | en | arg | 14.07 | **70.37** | 46.89 |
| nllb-200-3.3B | en | arg | 0.31 | 114.39 | 6.87 |
</details>
<details>
<summary>Spanish evaluation</summary>
#### Spanish-XX
| | source | target | Bleu ↑ | Ter ↓ | ChrF ↑ |
|:-------------------------|:---------|:---------|:----------|:----------|:----------|
| SalamandraTA-2b-instruct | es | ast | **17.30** | 76.72 | **51.31** |
| Transducens/IbRo-nllb | es | ast | 16.79 | **76.36** | 50.89 |
| nllb-200-3.3B | es | ast | 11.85 | 100.86 | 40.27 |
| | | | | | |
| Transducens/IbRo-nllb | es | arn | **50.20** | **36.60** | **73.16** |
| SalamandraTA-2b-instruct | es | arn | 46.76 | 39.32 | 70.76 |
| | | | | | |
| Transducens/IbRo-nllb | es | arg | **59.75** | **28.01** | **78.73** |
| SalamandraTA-2b-instruct | es | arg | 38.42 | 44.43 | 67.39 |
</details>
<details>
<summary>Catalan evaluation</summary>
#### Catalan-XX
| | source | target | Bleu ↑ | Ter ↓ | ChrF ↑ |
|:-------------------------|:---------|:---------|:----------|:----------|:----------|
| Transducens/IbRo-nllb | ca | ast | **24.77** | **61.60** | **57.49** |
| SalamandraTA-2b-instruct | ca | ast | 24.49 | 65.71 | 57.40 |
| nllb-200-3.3B | ca | ast | 17.17 | 91.47 | 45.83 |
| | | | | | |
| Transducens/IbRo-nllb | ca | arn | **31.22** | **54.30** | **60.30** |
| SalamandraTA-2b-instruct | ca | arn | 29.75 | 57.69 | 59.20 |
| | | | | | |
| Transducens/IbRo-nllb | ca | arg | **24.44** | **60.79** | **55.51** |
| SalamandraTA-2b-instruct | ca | arg | 17.85 | 68.85 | 50.39 |
</details>
## Gender Aware Translation
Below are the evaluation results for gender aware translation evaluated on the [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval?tab=readme-ov-file#mt-geneval)
dataset ([Currey, A. et al.](https://arxiv.org/pdf/2211.01355)).
These have been calculated for translation from English into German, Spanish, French, Italian, Portuguese and Russian and are compared
against [MADLAD400-3b-mt](https://huggingface.co/google/madlad400-3b-mt), and [NLLB-200-3-3B](https://huggingface.co/facebook/nllb-200-3.3B).
Evaluation was conducted using [MT-Lens](https://github.com/langtech-bsc/mt-evaluation) and is reported as accuracy computed using the accuracy metric
provided with MT-GenEval.
<details>
<summary>MT-GenEval Evaluation</summary>
| | Source | Target | Masc | Fem | Pair |
|:--|:--|:--|:--|:--|:--|
| MADLAD400-3B | en | de | 0.863 | 0.837 | 0.713 |
| SalamandraTA-2b-instruct | en | de | **0.887** | **0.843** | **0.747** |
| nllb_3.3B | en | de | 0.870 | 0.787 | 0.677 |
| | | | | | |
| MADLAD400-3B | en | es | **0.883** | 0.750 | 0.660 |
| SalamandraTA-2b-instruct | en | es | 0.877 | **0.843** | **0.740** |
| nllb_3.3B | en | es | 0.867 | 0.777 | 0.663 |
| | | | | | |
| MADLAD400-3B | en | fr | 0.883 | 0.797 | 0.707 |
| SalamandraTA-2b-instruct | en | fr | **0.900** | **0.823** | **0.737** |
| nllb_3.3B | en | fr | **0.900** | 0.727 | 0.643 |
| | | | | | |
| MADLAD400-3B | en | it | **0.917** | 0.693 | 0.643 |
| SalamandraTA-2b-instruct | en | it | 0.910 | **0.757** | **0.687** |
| nllb_3.3B | en | it | 0.907 | 0.673 | 0.597 |
| | | | | | |
| MADLAD400-3B | en | pt | **0.923** | 0.697 | 0.640 |
| SalamandraTA-2b-instruct | en | pt | 0.910 | **0.720** | **0.660** |
| nllb_3.3B | en | pt | 0.913 | 0.713 | 0.650 |
| | | | | | |
| MADLAD400-3B | en | ru | **0.947** | 0.780 | 0.730 |
| SalamandraTA-2b-instruct | en | ru | 0.933 | **0.813** | **0.750** |
| nllb_3.3B | en | ru | 0.930 | 0.787 | 0.723 |
| | | | | | |
</details>
## Ethical Considerations and Limitations
Detailed information on the work done to examine the presence of unwanted social and cognitive biases in the base model can be found
at [Salamandra-2B model card](https://huggingface.co/BSC-LT/salamandra-2b).
With regard to MT models, the only analysis related to bias which we have conducted is the MT-GenEval evaluation.
No specific analysis has yet been carried out in order to evaluate potential biases or limitations in translation
accuracy across different languages, dialects, or domains. However, we recognize the importance of identifying and addressing any harmful stereotypes,
cultural inaccuracies, or systematic performance discrepancies that may arise in Machine Translation. As such, we plan to continue performing more analyses
as we implement the necessary metrics and methods within our evaluation framework [MT-Lens](https://github.com/langtech-bsc/mt-evaluation).
Note that the model has only undergone preliminary instruction tuning.
We urge developers to consider potential limitations and conduct safety testing and tuning tailored to their specific applications.
## Additional information
### Author
The Language Technologies Unit from Barcelona Supercomputing Center.
### Contact
For further information, please send an email to <[email protected]>.
### Copyright
Copyright(c) 2025 by Language Technologies Unit, Barcelona Supercomputing Center.
### Funding
This work has been promoted and financed by the Government of Catalonia through the [Aina Project](https://projecteaina.cat/).
This work is funded by the _Ministerio para la Transformación Digital y de la Función Pública_ - Funded by EU – NextGenerationEU
within the framework of [ILENIA Project](https://proyectoilenia.es/) with reference 2022/TL22/00215337.
### Acknowledgements
The success of this project has been made possible thanks to the invaluable contributions of our partners in the [ILENIA Project](https://proyectoilenia.es/):
[HiTZ](http://hitz.ehu.eus/es), and [CiTIUS](https://citius.gal/es/).
Their efforts have been instrumental in advancing our work, and we sincerely appreciate their help and support.
### Disclaimer
### Disclaimer
Be aware that the model may contain biases or other unintended distortions.
When third parties deploy systems or provide services based on this model, or use the model themselves,
they bear the responsibility for mitigating any associated risks and ensuring compliance with applicable regulations,
including those governing the use of Artificial Intelligence.
The Barcelona Supercomputing Center, as the owner and creator of the model, shall not be held liable for any outcomes resulting from third-party use.
### License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Citation
If you find our model useful, we would appreciate if you could cite our work as follows:
```
@misc{gilabert2025salamandrasalamandratabscsubmission,
title={From SALAMANDRA to SALAMANDRATA: BSC Submission for WMT25 General Machine Translation Shared Task},
author={Javier Garcia Gilabert and Xixian Liao and Severino Da Dalt and Ella Bohman and Audrey Mash and Francesca De Luca Fornaciari and Irene Baucells and Joan Llop and Miguel Claramunt Argote and Carlos Escolano and Maite Melero},
year={2025},
eprint={2508.12774},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.12774},
}
```
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755599920
|
ihsanridzi
| 2025-08-19T11:06:17Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:06:13Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
teysty/vjepa2-vitl-fpc16-256-ssv2-fdet_baseline_epochs5
|
teysty
| 2025-08-19T11:06:04Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vjepa2",
"video-classification",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2025-08-19T11:04:53Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
OdedKBio/ppo-LunarLander-v2
|
OdedKBio
| 2025-08-19T11:03:33Z
| 0
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-19T11:01:33Z
|
---
library_name: stable-baselines3
tags:
- LunarLander-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v3
type: LunarLander-v3
metrics:
- type: mean_reward
value: -198.68 +/- 121.66
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v3**
This is a trained model of a **PPO** agent playing **LunarLander-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ale91Jonathan/blockassist-bc-alert_dormant_prawn_1755599723
|
Ale91Jonathan
| 2025-08-19T11:03:01Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"alert dormant prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:02:57Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- alert dormant prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
crocodlo/blockassist-bc-soft_barky_scorpion_1755601327
|
crocodlo
| 2025-08-19T11:02:50Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"soft barky scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:02:41Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- soft barky scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755599691
|
pempekmangedd
| 2025-08-19T11:01:58Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:01:54Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kittygirlhere/blockassist-bc-twitchy_beaked_coral_1755601270
|
kittygirlhere
| 2025-08-19T11:01:54Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"twitchy beaked coral",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:01:50Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- twitchy beaked coral
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755599676
|
quantumxnode
| 2025-08-19T11:01:10Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:01:07Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
OleksandrLitke/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grassy_scurrying_walrus
|
OleksandrLitke
| 2025-08-19T11:00:40Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am grassy_scurrying_walrus",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T05:11:06Z
|
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am grassy_scurrying_walrus
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sous26hotmailf1/blockassist-bc-tawny_melodic_tapir_1755599630
|
sous26hotmailf1
| 2025-08-19T10:59:58Z
| 0
| 0
| null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tawny melodic tapir",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:59:55Z
|
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tawny melodic tapir
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lakelee/RLB_MLP_BC_v4.20250819.18
|
lakelee
| 2025-08-19T10:59:47Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"mlp_swiglu",
"generated_from_trainer",
"base_model:lakelee/RLB_MLP_TSC_v1.20250818.16",
"base_model:finetune:lakelee/RLB_MLP_TSC_v1.20250818.16",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:33:07Z
|
---
library_name: transformers
base_model: lakelee/RLB_MLP_TSC_v1.20250818.16
tags:
- generated_from_trainer
model-index:
- name: RLB_MLP_BC_v4.20250819.18
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RLB_MLP_BC_v4.20250819.18
This model is a fine-tuned version of [lakelee/RLB_MLP_TSC_v1.20250818.16](https://huggingface.co/lakelee/RLB_MLP_TSC_v1.20250818.16) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.95) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.8.0+cu128
- Tokenizers 0.21.4
|
onnx-community/layoutlm-base-uncased-ONNX
|
onnx-community
| 2025-08-19T10:56:36Z
| 0
| 0
|
transformers.js
|
[
"transformers.js",
"onnx",
"layoutlm",
"base_model:microsoft/layoutlm-base-uncased",
"base_model:quantized:microsoft/layoutlm-base-uncased",
"region:us"
] | null | 2025-08-19T10:56:29Z
|
---
library_name: transformers.js
base_model:
- microsoft/layoutlm-base-uncased
---
# layoutlm-base-uncased (ONNX)
This is an ONNX version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased). It was automatically converted and uploaded using [this space](https://huggingface.co/spaces/onnx-community/convert-to-onnx).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.