
question_slug
stringlengths 3
77
| title
stringlengths 1
183
| slug
stringlengths 12
45
| summary
stringlengths 1
160
⌀ | author
stringlengths 2
30
| certification
stringclasses 2
values | created_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| updated_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| hit_count
int64 0
10.6M
| has_video
bool 2
classes | content
stringlengths 4
576k
| upvotes
int64 0
11.5k
| downvotes
int64 0
358
| tags
stringlengths 2
193
| comments
int64 0
2.56k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
find-duplicate-subtrees
|
Solution in C++
|
solution-in-c-by-ashish_madhup-7j2n
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time
|
ashish_madhup
|
NORMAL
|
2023-02-28T12:55:51.246357+00:00
|
2023-02-28T12:55:51.246405+00:00
| 251 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\nclass Solution {\npublic:\n string f(TreeNode* root,vector<TreeNode*>&ans, map<string,int> &mp){\n if(!root) return "%";\n string l = f(root->left,ans,mp);\n string r = f(root->right,ans,mp);\n string s = to_string(root->val) +"%"+l+"%"+r;\n if(mp[s]==1){\n ans.push_back(root);\n }\n mp[s]++;\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> ans;\n map<string,int> mp;\n if(!root) return ans;\n f(root,ans,mp);\n return ans;\n }\n};\n```
| 5 | 0 |
['C++']
| 1 |
find-duplicate-subtrees
|
JAVA Solution || Easy
|
java-solution-easy-by-sanjay1305-prwc
|
\nclass Solution {\n Map<String,Integer> map=new HashMap<>();\n List<TreeNode> res=new ArrayList<>();\n public List<TreeNode> findDuplicateSubtrees(Tre
|
sanjay1305
|
NORMAL
|
2023-02-28T03:55:18.571656+00:00
|
2023-02-28T08:59:31.790543+00:00
| 774 | false |
```\nclass Solution {\n Map<String,Integer> map=new HashMap<>();\n List<TreeNode> res=new ArrayList<>();\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n helper(root);\n return res;\n }\n public String helper(TreeNode root){\n if(root==null) return "";\n String left= helper(root.left);\n String right= helper(root.right);\n String curr= root.val +" "+left +" "+ right;\n map.put(curr, map.getOrDefault(curr, 0)+ 1);\n if(map.get(curr) == 2)\n res.add(root);\n return curr;\n }\n}\n```
| 5 | 0 |
['Depth-First Search', 'Binary Tree', 'Java']
| 0 |
find-duplicate-subtrees
|
Python DFS with Hashing
|
python-dfs-with-hashing-by-hong_zhao-ma5m
|
python []\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n\n hmap = defaultdict(int)\n
|
hong_zhao
|
NORMAL
|
2023-02-28T00:35:32.444707+00:00
|
2023-02-28T00:35:32.444751+00:00
| 1,665 | false |
```python []\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n\n hmap = defaultdict(int)\n res = []\n def dfs(node):\n if not node: return \'\'\n l, r = dfs(node.left), dfs(node.right)\n struct = f\'l{l}{node.val}{r}r\'\n hmap[struct] += 1\n if hmap[struct] == 2:\n res.append(node)\n return struct\n dfs(root)\n return res\n```
| 5 | 0 |
['Python3']
| 1 |
find-duplicate-subtrees
|
🥳【Python3】🔥 Easy Solution - Compare Serialisations of TreeNodes
|
python3-easy-solution-compare-serialisat-v44k
|
Approach\nSerialize each TreeNode and compare with memorized TreeNode serialization. Please see comments in code.\n\nExample of serialization. For the tree in e
|
yimingdai
|
NORMAL
|
2023-02-28T00:15:20.289554+00:00
|
2023-02-28T00:23:17.853289+00:00
| 1,450 | false |
## Approach\nSerialize each TreeNode and compare with memorized TreeNode serialization. Please see comments in code.\n\nExample of serialization. For the tree in example one, each tree is serialized into the following form:\n```\n4,#,#,\n2,4,#,#,#,\n4,#,#,\n2,4,#,#,#,\n4,#,#,\n3,2,4,#,#,#,4,#,#,\n1,2,4,#,#,#,3,2,4,#,#,#,4,#,#,\n```\n\n## Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n res = [] # store all root TreeNodes\n dic = {} # memo: map serialized data to root TreeNode\n \n self.find(root, dic, res)\n return res\n \n \n def find(self, root, dic, res):\n if not root:\n return\n \n # find left and right duplicate subtrees\n self.find(root.left, dic, res)\n self.find(root.right, dic, res)\n # serialize a new subtree for every TreeNode\n data = []\n self.serialize(root, data)\n data = \'\'.join(data)\n # only add one TreeNode for each duplication\n if dic.get(data, 0) == 1:\n res.append(root)\n # update memo dictionary\n dic[data] = dic.get(data, 0) + 1\n \n\n def serialize(self, root, data):\n if not root:\n data.append(\'#,\')\n return\n # preorder serialization\n data.append(str(root.val))\n data.append(\',\')\n self.serialize(root.left, data)\n self.serialize(root.right, data)\n```\n\n## **Congratulations on your FINAL question for February!!!**
| 5 | 0 |
['Tree', 'Depth-First Search', 'Recursion', 'Python3']
| 0 |
find-duplicate-subtrees
|
Golang O(n) solution with map
|
golang-on-solution-with-map-by-tuanbiebe-lnb5
|
\nfunc PrettyPrint(data interface{}) {\n\tvar p []byte\n\t// var err := error\n\tp, err := json.MarshalIndent(data, "", "\\t")\n\tif err != nil {\n\t\tfmt.Pr
|
tuanbieber
|
NORMAL
|
2022-03-14T10:36:25.633733+00:00
|
2022-03-14T10:36:25.633762+00:00
| 356 | false |
```\nfunc PrettyPrint(data interface{}) {\n\tvar p []byte\n\t// var err := error\n\tp, err := json.MarshalIndent(data, "", "\\t")\n\tif err != nil {\n\t\tfmt.Println(err)\n\t\treturn\n\t}\n\tfmt.Printf("%s \\n", p)\n}\n\nfunc findDuplicateSubtrees(root *TreeNode) []*TreeNode {\n var res []*TreeNode\n \n record := make(map[string][]*TreeNode)\n \n debugInfo := serialize(root, record)\n \n for _, value := range record {\n if len(value) > 1 {\n res = append(res, value[0])\n }\n }\n \n PrettyPrint(debugInfo)\n \n return res\n}\n\nfunc serialize(root *TreeNode, record map[string][]*TreeNode) string {\n if root == nil {\n return ""\n }\n \n left := serialize(root.Left, record)\n right := serialize(root.Right, record)\n \n key := "[" + left + "," + fmt.Sprintf("%v", root.Val) + "," + right + "]"\n \n record[key] = append(record[key], root)\n\n return key\n}\n```
| 5 | 1 |
['Go']
| 3 |
find-duplicate-subtrees
|
Python O(n) simple . beats 97%
|
python-on-simple-beats-97-by-ketansomvan-o8bt
|
\n\tdef dfs(self,root):\n if not root:\n return \' \'\n n=str(root.val)+","+self.dfs(root.left)+","+self.dfs(root.right)\n if n
|
ketansomvanshi007
|
NORMAL
|
2022-01-04T13:23:13.069928+00:00
|
2022-01-04T13:24:52.867569+00:00
| 653 | false |
```\n\tdef dfs(self,root):\n if not root:\n return \' \'\n n=str(root.val)+","+self.dfs(root.left)+","+self.dfs(root.right)\n if n in self.s and n not in self.counted:\n self.counted.add(n)\n self.ans.append(root)\n return n\n self.s.add(n)\n return n\n \n \n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n self.s=set()\n self.ans=[]\n self.counted=set()\n self.dfs(root)\n return self.ans\n```
| 5 | 0 |
['Depth-First Search', 'Python']
| 0 |
find-duplicate-subtrees
|
Clean Javascript Post-Order solution
|
clean-javascript-post-order-solution-by-4y6y9
|
\nvar findDuplicateSubtrees = function(root) {\n let seen = {};\n let output = [];\n \n traverse(root);\n \n return output; \n \n functi
|
Adetomiwa
|
NORMAL
|
2021-11-15T23:24:09.564188+00:00
|
2021-11-15T23:24:09.564223+00:00
| 642 | false |
```\nvar findDuplicateSubtrees = function(root) {\n let seen = {};\n let output = [];\n \n traverse(root);\n \n return output; \n \n function traverse(node){\n if(!node) return "null";\n \n let left = traverse(node.left);\n let right = traverse(node.right);\n \n let key = `${node.val}-${left}-${right}`;\n \n seen[key] = (seen[key] || 0) + 1;\n if(seen[key] == 2) output.push(node);\n \n return key;\n }\n};\n```
| 5 | 0 |
['Depth-First Search', 'JavaScript']
| 2 |
find-duplicate-subtrees
|
C# HashCode
|
c-hashcode-by-dana-n-kt86
|
I ended up using hash codes here and it worked well enough to get accepted. It is not guaranteed to be unique, in order for that you need to do deep comparision
|
dana-n
|
NORMAL
|
2021-11-12T18:52:37.808198+00:00
|
2023-02-28T20:52:06.135799+00:00
| 314 | false |
I ended up using hash codes here and it worked well enough to get accepted. It is not guaranteed to be unique, in order for that you need to do deep comparision. Some of the solutions serialize the tree into a string which seems to work well. In terms of performance, this solution is pretty dang fast!\n\n```cs\npublic IList<TreeNode> FindDuplicateSubtrees(TreeNode root) {\n var map = new Dictionary<int, List<TreeNode>>();\n int f(TreeNode n) {\n if (n == null) {\n return 0;\n }\n int hash = HashCode.Combine(n.val, f(n.left), f(n.right));\n if (!map.TryGetValue(hash, out var list)) {\n map.Add(hash, list = new List<TreeNode>());\n }\n list.Add(n);\n return hash;\n }\n f(root);\n var res = new List<TreeNode>();\n foreach (var pair in map.Where(p => p.Value.Count > 1)) {\n res.Add(pair.Value.First());\n }\n return res;\n}\n```
| 5 | 0 |
[]
| 2 |
find-duplicate-subtrees
|
Easy O(N) Java solution
|
easy-on-java-solution-by-anweban-7c9n
|
\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String,TreeNode> map = new HashMap<>();\n postOrderTrav
|
anweban
|
NORMAL
|
2021-05-25T17:04:16.733067+00:00
|
2021-05-25T17:04:16.733109+00:00
| 455 | false |
```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String,TreeNode> map = new HashMap<>();\n postOrderTraversal(root, map, new StringBuilder());\n \n List<TreeNode> res = new ArrayList<>();\n for(TreeNode tree : map.values()){\n if(tree != null) res.add(tree);\n }\n return res;\n }\n public void postOrderTraversal(TreeNode root, Map<String,TreeNode> map, StringBuilder sb){\n if(root == null){\n sb.append("#|");\n return;\n }\n \n StringBuilder left = new StringBuilder();\n StringBuilder right = new StringBuilder();\n \n postOrderTraversal(root.left,map,left);\n postOrderTraversal(root.right,map,right);\n sb.append(left.toString());\n sb.append(right.toString());\n sb.append(String.valueOf(root.val)+"|");\n \n String key = sb.toString();\n if(!map.containsKey(key))\n map.put(key,null);\n else\n map.put(key,root); \n }\n \n}\n```
| 5 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
Python O(N) Hashmap Solution
|
python-on-hashmap-solution-by-wei_lun-yfd4
|
We ask the question : FOR EACH SUBTREE, WHAT ARE ITS ROOTS?\n\n2. In other words, we want to keep track of {subtree1: [root1, root2, ...], ...}, where root1 and
|
wei_lun
|
NORMAL
|
2020-10-07T13:19:05.736433+00:00
|
2020-10-07T13:19:05.736484+00:00
| 523 | false |
1. We ask the question : **FOR EACH SUBTREE, WHAT ARE ITS ROOTS?**\n\n2. In other words, we want to keep track of **{subtree1: [root1, root2, ...], ...}**, where root1 and root2 are the roots of subtree1, in `sub_roots_map`\n\n3. During the `preorder` traversal, we shall return the **string representation of the subtree (since subtree is the key and hence must be hashable)** rooted at `root`, then update `sub_roots_map` accordingly\n\n<br>\n\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n \n # KEEP TRACK OF {SUBTREE: [ROOT1, ROOT2, ...]} - {STR: [TREENODE, TREENODE, ...]}\n sub_roots_map = defaultdict(list)\n \n # START A PRE-ORDER TRAVERSAL TO FILL UP THE MAP\n self.preorder(root, sub_roots_map)\n \n # RETURN ANY ROOT FOR SUBTREES WITH MULTIPLE ROOTS\n return [root[0] for sub, root in sub_roots_map.items() if len(root) > 1]\n\n\n def preorder(self, root, sub_roots_map):\n if not root:\n return "null"\n \n # OBTAIN THE STRING REPRESENTATION OF THIS SUBTREE\n sub =f"{root.val},{self.preorder(root.left, sub_roots_map)},{self.preorder(root.right, sub_roots_map)}"\n \n # SAVE IT TO OUR MAP\n sub_roots_map[sub].append(root)\n \n # RETURN THE STRING REPRESENTATION OF THIS SUBTREE\n return sub\n```
| 5 | 0 |
['Python']
| 0 |
find-duplicate-subtrees
|
c# DFS
|
c-dfs-by-finefurrydove-nqw1
|
\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * public int val;\n * public TreeNode left;\n * public TreeNode right;\n
|
FineFurryDove
|
NORMAL
|
2020-09-29T17:25:16.056152+00:00
|
2020-09-29T17:25:16.056201+00:00
| 334 | false |
```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * public int val;\n * public TreeNode left;\n * public TreeNode right;\n * public TreeNode(int val=0, TreeNode left=null, TreeNode right=null) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\npublic class Solution {\n public IList<TreeNode> FindDuplicateSubtrees(TreeNode root) {\n var res = new List<TreeNode>();\n if (root == null) return res;\n var dict = new Dictionary<string, int>(); // the string representation and the occurences\n DFS(root, res, dict);\n return res;\n }\n \n public string DFS(TreeNode root, IList<TreeNode> res, Dictionary<string, int> dict) {\n if (root == null) return "#";\n var serial = root.val + "," + DFS(root.left, res, dict) + "," + DFS(root.right, res, dict);\n \n if (dict.ContainsKey(serial)) {\n dict[serial] += 1;\n // only add to the result at the second time, otherwise, there is duplicate. cannot use hashset here because there are different node\n if (dict[serial] == 2) res.Add(root);\n } else {\n dict[serial] = 1;\n }\n \n return serial;\n }\n}\n```
| 5 | 0 |
['Depth-First Search']
| 1 |
find-duplicate-subtrees
|
Java Simple DFS
|
java-simple-dfs-by-arunvt1983-l6ia
|
\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode(int x)
|
arunvt1983
|
NORMAL
|
2019-10-31T14:00:02.311963+00:00
|
2019-10-31T14:00:02.312016+00:00
| 719 | false |
```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode(int x) { val = x; }\n * }\n */\nclass Solution {\n Map<String,Integer> subTrees = new HashMap<>();\n List<TreeNode> duplicates = new ArrayList<>();\n\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n traverse(root);\n return duplicates;\n }\n \n \n \n private String traverse(TreeNode node){\n if(node == null)\n return "";\n String left = traverse(node.left);\n String right = traverse(node.right);\n String res = node.val+"#"+left+"#"+right;\n subTrees.put(res,subTrees.getOrDefault(res,0)+1);\n if(subTrees.get(res) == 2)\n duplicates.add(node);\n return res;\n }\n}\n```
| 5 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
652: Solution with step by step explanation
|
652-solution-with-step-by-step-explanati-oszh
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n1. Create an empty dictionary freq to store the frequency of each subtree
|
Marlen09
|
NORMAL
|
2023-03-19T06:00:13.245502+00:00
|
2023-03-19T06:00:13.245536+00:00
| 151 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Create an empty dictionary freq to store the frequency of each subtree.\n2. Define a helper function traverse(node) to traverse the binary tree recursively and get the string representation of each subtree:\n - If the current node is None, return an empty string.\n - Traverse the left and right subtrees recursively by calling traverse(node.left) and traverse(node.right) respectively, and store the results in left and right.\n - Combine the string representations of left, right, and node.val to form the string representation of the current subtree subtree.\n - Update the frequency of subtree in the dictionary freq by incrementing its value by 1.\n - If the frequency of subtree is 2, append the current node to the result list res.\n - Return subtree.\n4. Call traverse(root) to traverse the binary tree and update the frequency of each subtree in the dictionary.\n5. Create an empty list res to store the duplicate subtree nodes.\nIterate through the items in freq:\n - If the frequency of the current subtree is greater than 1, append the corresponding node to res.\n6. Return res.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n # Step 1: Create a dictionary to store the frequency of each subtree\n freq = {}\n res = []\n # Step 2: Define a function called "traverse" to get the string representation of a subtree\n def traverse(node):\n # If node is None, return an empty string\n if not node:\n return ""\n # Get the string representation of left and right subtrees recursively\n left = traverse(node.left)\n right = traverse(node.right)\n # Combine the string representations to form the string representation of the current subtree\n subtree = left + "," + right + "," + str(node.val)\n # Update the frequency of the current subtree in the dictionary\n freq[subtree] = freq.get(subtree, 0) + 1\n # If the frequency of the current subtree is 2, add it to the result list\n if freq[subtree] == 2:\n res.append(node)\n # Return the string representation of the current subtree\n return subtree\n \n # Step 3: Traverse the tree recursively and update the frequency of each subtree in the dictionary\n traverse(root)\n \n # Step 4: Return the list of subtrees which have a frequency greater than 1\n return res\n```
| 4 | 0 |
['Python3']
| 0 |
find-duplicate-subtrees
|
📌📌Python3 || ⚡42 ms, faster than 97.10% of Python3
|
python3-42-ms-faster-than-9710-of-python-xq38
|
\n\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n map = {}\n res = set()\n
|
harshithdshetty
|
NORMAL
|
2023-02-28T14:19:00.764021+00:00
|
2023-02-28T14:19:00.764053+00:00
| 1,824 | false |
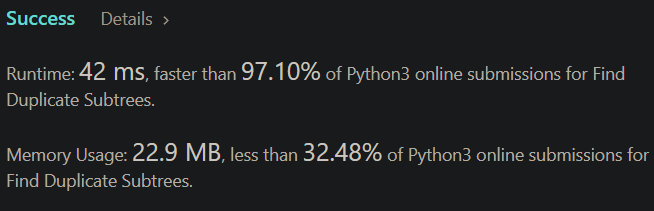\n```\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n map = {}\n res = set()\n def check(node):\n if not node:\n return \'#\'\n s = \'\'\n if not node.left and not node.right:\n s += str(node.val)\n map[s] = map.get(s,0)+1\n if map[s]==2:\n res.add(node)\n return s\n s = s + str(node.val)\n s = s + "," + check(node.left)\n s = s+ "," + check(node.right)\n map[s] = map.get(s,0)+1\n if map[s]==2:\n res.add(node)\n return s\n \n check(root)\n return res\n```\nThe given code finds all the duplicate subtrees in a given binary tree. Here\'s a step-by-step explanation of the code:\n1. Define a class named Solution.\n1. Define a function findDuplicateSubtrees that takes the root of the binary tree as input and returns a list of nodes that are duplicate.\n1. Create a dictionary named \'map\' that will store the subtree string and its frequency.\n1. Create a set named \'res\' that will store the duplicate subtrees.\n1. Define a nested function named \'check\' that takes a node as input and returns a string.\n1. If the node is None, return a string \'#\'. This represents a null node in the subtree string.\n1. Create an empty string \'s\'.\n1. If the node has no children (i.e., it is a leaf node), append its value to \'s\' as a string.\n1. Add the subtree string \'s\' to the dictionary \'map\' with its frequency increased by 1.\n1. If the frequency of the subtree \'s\' in the dictionary is 2, add the current node to the set \'res\'.\n1. Return the subtree string \'s\'.\n1. If the node has children, append the value of the node to \'s\' as a string.\n1. Recursively call the \'check\' function on the left and right subtrees of the node.\n1. Append the result of calling the \'check\' function on the left and right subtrees to \'s\' with \',\' as a separator.\n1. Add the subtree string \'s\' to the dictionary \'map\' with its frequency increased by 1.\n1. If the frequency of the subtree \'s\' in the dictionary is 2, add the current node to the set \'res\'.\n1. Return the subtree string \'s\'.\n1. Call the \'check\' function with the root of the binary tree as input.\n1. Return the set \'res\' containing the duplicate subtrees.
| 4 | 0 |
['Tree', 'Depth-First Search', 'Python', 'Python3']
| 1 |
find-duplicate-subtrees
|
O(n) Solution | Very Easy to Understand
|
on-solution-very-easy-to-understand-by-c-gh82
|
1.Perform a depth-first search (DFS) traversal of the binary tree.\n2.For each node visited during the traversal, generate a unique string representation of the
|
cOde_Ranvir25
|
NORMAL
|
2023-02-28T12:45:23.151848+00:00
|
2023-02-28T12:45:23.151889+00:00
| 512 | false |
**1.Perform a depth-first search (DFS) traversal of the binary tree.\n2.For each node visited during the traversal, generate a unique string representation of the subtree rooted at that node using a subtree serialization technique.**\n**3.Store the string representation in a hash map along with the node that is the root of the subtree.**\n**4.If a string representation already exists in the hash map, it means we have found a duplicate subtree. Add its root node to a list of duplicate subtree roots.**\n**5.Return the list of duplicate subtree roots.**\n\n```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n HashMap<String,Integer>map=new HashMap<>();\n List<TreeNode>ans=new ArrayList<>();\n traverse(map,ans,root);\n return ans;\n }\n public String traverse(HashMap<String,Integer>map,List<TreeNode>list,TreeNode root){\n if(root==null){\n return "#";\n }\n String ans=root.val+","+traverse(map,list,root.left)+","+traverse(map,list,root.right);\n map.put(ans,map.getOrDefault(ans,0)+1);\n if(map.get(ans)==2){\n list.add(root);\n }\n return ans;\n }\n}\n```\n# UpVoting Is Much Appreciated
| 4 | 0 |
['Java']
| 1 |
find-duplicate-subtrees
|
Easy Solution Java|| 80% faster Solution
|
easy-solution-java-80-faster-solution-by-3is6
|
Intuition\n Describe your first thoughts on how to solve this problem. Using HashMap\n\n# Approach\n Describe your approach to solving the problem. \n\n# Comple
|
Soumyabehera123
|
NORMAL
|
2023-02-28T04:26:17.948094+00:00
|
2023-02-28T04:26:17.948125+00:00
| 991 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->Using HashMap\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:18ms || Beats 80% of Solution\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n List<TreeNode> res=new ArrayList<>();\n HashMap<String,Integer> hm=new HashMap<>();\n helper(res,root,hm);\n return res;\n }\n public String helper(List<TreeNode> res,TreeNode root,HashMap<String,Integer> hm){\n if(root==null)\n return "";\n String left=helper(res,root.left,hm);\n String right=helper(res,root.right,hm);\n int currroot=root.val;\n String stringformed=currroot+"$"+left+"$"+right;\n if(hm.getOrDefault(stringformed,0)==1){\n res.add(root);\n }\n hm.put(stringformed,hm.getOrDefault(stringformed,0)+1);\n return stringformed;\n }\n}\n```
| 4 | 0 |
['Java']
| 1 |
find-duplicate-subtrees
|
PHP - easy understanding / Beats 100%
|
php-easy-understanding-beats-100-by-ting-nfsa
|
Explain\n\nSave the structure as string while travel the nodes.\n\n# Code\n\nclass Solution {\n\n /**\n * @param TreeNode $root\n * @return TreeNode[
|
tinghaolai
|
NORMAL
|
2023-02-28T03:09:11.146228+00:00
|
2023-02-28T03:09:11.146275+00:00
| 290 | false |
# Explain\n\nSave the structure as string while travel the nodes.\n\n# Code\n```\nclass Solution {\n\n /**\n * @param TreeNode $root\n * @return TreeNode[]\n */\n function findDuplicateSubtrees($root) {\n $this->subTrees = [];\n $this->result = [];\n $this->runNode($root);\n\n return $this->result;\n }\n\n function runNode($node) {\n if (!$node) {\n return \'null\';\n }\n\n $leftString = $this->runNode($node->left);\n $rightString = $this->runNode($node->right);\n $string = \'v-\' . $node->val . \'l-\' . $leftString . \'r-\' . $rightString;\n if (empty($this->subTrees[$string])) {\n $this->subTrees[$string] = [\n \'count\' => 1,\n \'tree\' => $node,\n ];\n } else {\n $this->subTrees[$string][\'count\']++;\n // put into answer only at second times\n if ($this->subTrees[$string][\'count\'] === 2) {\n $this->result[] = $node;\n }\n }\n\n return $string;\n }\n}\n```
| 4 | 0 |
['PHP']
| 1 |
find-duplicate-subtrees
|
[C++] || Postorder Traversal + Map
|
c-postorder-traversal-map-by-rahul921-02se
|
\nclass Solution {\npublic:\n unordered_map<string,int> dp ;\n vector<TreeNode*> ans ;\n \n string solve(TreeNode * root){\n if(!root) return
|
rahul921
|
NORMAL
|
2022-08-07T13:08:26.850322+00:00
|
2022-08-07T13:08:26.850357+00:00
| 481 | false |
```\nclass Solution {\npublic:\n unordered_map<string,int> dp ;\n vector<TreeNode*> ans ;\n \n string solve(TreeNode * root){\n if(!root) return "" ;\n \n string left = solve(root->left) ;\n string right = solve(root->right) ;\n \n string code = to_string(root->val) + " " + left + " " + right ;\n if(dp[code] == 1) ans.push_back(root) ;\n dp[code]++ ;\n \n return code ;\n }\n \n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n string dummy = solve(root) ;\n return ans ;\n }\n};\n```
| 4 | 0 |
['C']
| 0 |
find-duplicate-subtrees
|
C++ | Easy to understand
|
c-easy-to-understand-by-dhakad_g-2jjo
|
\nclass Solution {\npublic:\n unordered_map<string, int> mp;\n vector<TreeNode*> ans;\n string dfs(TreeNode *p)\n {\n if(!p) return "";\n
|
dhakad_g
|
NORMAL
|
2022-06-28T14:27:36.482545+00:00
|
2022-06-28T14:27:36.482590+00:00
| 317 | false |
```\nclass Solution {\npublic:\n unordered_map<string, int> mp;\n vector<TreeNode*> ans;\n string dfs(TreeNode *p)\n {\n if(!p) return "";\n string res = to_string(p->val) + "|" + dfs(p->left) + "|" + dfs(p->right);\n mp[res] ++;\n if(mp[res] == 2) ans.push_back(p);\n return res;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n dfs(root);\n return ans;\n }\n};\n```
| 4 | 0 |
['Depth-First Search', 'C']
| 0 |
find-duplicate-subtrees
|
Java | HashMap
|
java-hashmap-by-meerasuthar1122-bd36
|
\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n
|
MeeraSuthar1122
|
NORMAL
|
2022-04-06T15:09:39.039097+00:00
|
2022-04-06T15:09:39.039132+00:00
| 700 | false |
```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n Set<TreeNode> set;\n Map<String, TreeNode> map;\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n set = new HashSet<>();\n map = new HashMap<>();\n traverse(root);\n List<TreeNode> ans = new LinkedList<>();\n for (TreeNode node : set) {\n ans.add(node);\n }\n return ans;\n }\n \n public String traverse(TreeNode root) {\n if (root == null) {\n return "";\n }\n String left = traverse(root.left);\n String right = traverse(root.right);\n String cur = left +" "+ right +" "+ root.val;\n if (map.containsKey(cur)) {\n set.add(map.get(cur));\n } else {\n map.put(cur, root);\n }\n \n return cur;\n }\n}\n```
| 4 | 0 |
['Java']
| 0 |
find-duplicate-subtrees
|
Python, simple
|
python-simple-by-sadomtsevvs-wmeb
|
\ndef findDuplicateSubtrees(self, root: Optional[TreeNode]) -> list[Optional[TreeNode]]:\n\n result = []\n paths = defaultdict(int)\n\t\n def get_path(
|
sadomtsevvs
|
NORMAL
|
2022-02-25T23:58:24.849885+00:00
|
2022-02-25T23:58:24.849912+00:00
| 435 | false |
```\ndef findDuplicateSubtrees(self, root: Optional[TreeNode]) -> list[Optional[TreeNode]]:\n\n result = []\n paths = defaultdict(int)\n\t\n def get_path(node):\n if not node:\n return "None"\n else:\n path = str(node.val)\n path += \'.\' + get_path(node.left)\n path += \'.\' + get_path(node.right)\n paths[path] += 1\n if paths[path] == 2:\n result.append(node)\n return path\n\t\t\n get_path(root)\n return result\n```
| 4 | 0 |
['Python']
| 0 |
find-duplicate-subtrees
|
Post Order Traversal | Unordered_Map | C++
|
post-order-traversal-unordered_map-c-by-njegq
|
\nclass Solution {\npublic:\n unordered_map<string, int> mp;\n vector<TreeNode*> result;\n string calc(TreeNode *root) {\n if (root == nullptr)
|
ajay_5097
|
NORMAL
|
2021-11-14T10:47:46.122468+00:00
|
2021-11-14T10:47:46.122509+00:00
| 214 | false |
```\nclass Solution {\npublic:\n unordered_map<string, int> mp;\n vector<TreeNode*> result;\n string calc(TreeNode *root) {\n if (root == nullptr) return to_string(\'#\');\n string node = "";\n string left = calc(root->left);\n string right = calc(root->right);\n node += left + ":" + to_string(root->val) + ":" + right + \':\';\n if (mp[node] == 1) {\n result.push_back(root);\n }\n ++mp[node];\n return node;\n }\n \n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n calc(root);\n return result;\n }\n};\n```
| 4 | 0 |
[]
| 1 |
find-duplicate-subtrees
|
C++ || Great Question || Conceptual ||
|
c-great-question-conceptual-by-kundankum-urne
|
\tclass Solution {\n\tpublic:\n vector res;\n vector findDuplicateSubtrees(TreeNode root) {\n unordered_map m;\n solve(root,m);\n ret
|
kundankumar4348
|
NORMAL
|
2021-10-21T05:25:47.696798+00:00
|
2021-10-21T05:25:47.696846+00:00
| 250 | false |
\tclass Solution {\n\tpublic:\n vector<TreeNode*> res;\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string,int> m;\n solve(root,m);\n return res;\n }\n \n string solve(TreeNode* root,unordered_map<string,int>& m){\n if(!root) return "x";\n string l=solve(root->left,m);\n string r=solve(root->right,m);\n string temp=to_string(root->val)+" "+l+" "+r+" ";\n m[temp]++;\n if(m[temp]==2)\n res.push_back(root);\n return temp;\n }\n\t};
| 4 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
[Java] [O(N) time][beats 98.52%] Clean Code with Explanation + Merkle Tree
|
java-on-timebeats-9852-clean-code-with-e-qjy1
|
To find if the duplicate exists or not in the subtree we need a good way of converting a sub-tree to some canonical format.\n\nThis canonical representation (i.
|
stb_satybald
|
NORMAL
|
2021-09-26T12:52:01.494954+00:00
|
2021-09-26T15:04:28.894970+00:00
| 378 | false |
To find if the duplicate exists or not in the subtree we need a good way of converting a sub-tree to some `canonical format`.\n\nThis canonical representation (i.e. which allows it to be identified in a unique way) can be a string representation of the \npost order traversal of sub-tree. For example, our unique representation of the tree - `left-subtree` - `node.val` - `right-subtree`.\n\n**The catch**: when working with string in java it\'s quite easy to make O(N^2) from O(N) by [inefficiently](https://stackoverflow.com/questions/58309852/why-is-the-complexity-of-simple-string-concatenation-on2) concatenating strings.\n\nTime: O(N)\nSpace: O(N)\n\nRuntime: 10 ms, faster than 96.72% of Java\n\n```java\nclass Solution {\n private final String NULL = new String(new byte[]{0x0});\n private final String DELIMITER = new String(new byte[]{0x1});\n private Map<String, Integer> map;\n private List<TreeNode> ans;\n \n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n this.map = new HashMap<>();\n this.ans = new ArrayList<>();\n dfs(root);\n return ans;\n }\n \n private String dfs(final TreeNode node) {\n if (node == null) {\n return NULL;\n }\n \n String left = dfs(node.left),\n right = dfs(node.right);\n \n StringBuilder sb = new StringBuilder();\n sb.append(left)\n .append(right) \n .append(node.val)\n .append(DELIMITER);\n \n String key = sb.toString();\n \n map.merge(key, 1, Integer::sum);\n if (map.get(key) == 2) {\n ans.add(node);\n }\n \n return key;\n }\n \n}\n```\n\n\n**Merkle Tree Approach**\n\nCompute a hash function on top of key to reduce space as serializing a full binary tree path might be expensive.\n\n\nAdopted from [here](https://leetcode.com/problems/find-duplicate-subtrees/discuss/1203500/Java-Merkle-Tree-using-String-HashCode)\n\nRuntime: 5 ms, faster than 98.52% of Java \n\n```\nclass Solution {\n private final String NULL = new String(new byte[]{0x0});\n private Map<String, Integer> map;\n private List<TreeNode> ans;\n \n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n this.map = new HashMap<>();\n this.ans = new ArrayList<>();\n dfs(root);\n return ans;\n }\n \n private String dfs(final TreeNode node) {\n if (node == null) {\n return NULL;\n }\n \n String left = dfs(node.left),\n right = dfs(node.right);\n \n StringBuilder sb = new StringBuilder();\n sb.append(left)\n .append(right) \n .append(node.val);\n \n String key = getHash(sb.toString());\n \n map.merge(key, 1, Integer::sum);\n if (map.get(key) == 2) {\n ans.add(node);\n }\n \n return key;\n }\n \n private String getHash(String value) {\n return String.valueOf(value.hashCode());\n }\n}\n```\n\nPlease don\'t forget to **Up Vote** if you like the solution \u30C4\n\n
| 4 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
[Python3] DFS with comments
|
python3-dfs-with-comments-by-ssshukla26-y2zf
|
\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.lef
|
ssshukla26
|
NORMAL
|
2021-08-24T21:32:58.908469+00:00
|
2021-08-24T21:32:58.908500+00:00
| 673 | false |
```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\n\nfrom collections import defaultdict\n\nclass Solution:\n \n def traverse(self, node: TreeNode, dups: Dict, subs: Set) -> Tuple:\n \n # If node not null\n if node:\n \n # Get left subtree\n l_subtree = self.traverse(node.left, dups, subs)\n \n # Get right subtree\n r_subtree = self.traverse(node.right, dups, subs)\n \n # Make current subtree\n subtree = (node.val, l_subtree, r_subtree)\n \n # Increament the duplicated variable, this stores\n # number of occurrence of a subtree\n dups[subtree] = dups[subtree] + 1\n \n # If subtree occurs twice store it to a list.\n # Here comparing number of occurrence excatly to 2 has some\n # benifits. As each tree node is different object, using\n # a set also doesn\'t work.\n if dups[subtree] == 2:\n subs.add(node)\n \n # Return the newly formed subtree\n return subtree\n \n # Return None\n return None\n \n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n dups = defaultdict(lambda: 0)\n res = set()\n self.traverse(root, dups, res)\n return list(res)\n```
| 4 | 0 |
['Depth-First Search', 'Python', 'Python3']
| 0 |
find-duplicate-subtrees
|
Java solution | Simple Logic using map
|
java-solution-simple-logic-using-map-by-vy2f8
|
Approach- make a string of subtree element ,chekh if that string is already present in map,if not return a default value 0 ,it tells that the given subtree is n
|
kuldeepmishra007k
|
NORMAL
|
2021-07-16T13:10:11.125483+00:00
|
2022-02-27T15:39:31.293298+00:00
| 469 | false |
Approach- make a string of subtree element ,chekh if that string is already present in map,if not return a default value 0 ,it tells that the given subtree is not present in map.And further we insert that subtree in map with an increased value by 1.If we get a value equal to 1 , then the subtree has duplicate already and we add that in the list.\n\n\n```\nclass Solution {\n List<TreeNode> list=new ArrayList<>();\n Map<String,Integer> map=new HashMap<>();\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n helper(root);\n return list;\n }\n public String helper(TreeNode root){\n if(root==null){\n return "#";\n }\n String leftsub=helper(root.left);\n String rightsub=helper(root.right);\n String subtree=root.val+" "+left+right; //full subtree \n int frequency=map.getOrDefault(subtree,0); //checking existence of subree in map \n if(frequency==1){ //means the subtree has a duplicate already\n list.add(root);\n }\n map.put(subtree,frequency+1); //inserting the subtree into the map\n return subtree;\n }\n}
| 4 | 0 |
['Java']
| 2 |
find-duplicate-subtrees
|
Clean and simple C++
|
clean-and-simple-c-by-arpit-satnalika-dapy
|
\nunordered_map<string,int> hashmap;\nstring dfs(TreeNode *root,vector<TreeNode*> &v)\n{\n\tif(root==NULL)\n\t\treturn "#";\n\tstring left=dfs(root->left,v);\n\
|
arpit-satnalika
|
NORMAL
|
2020-12-21T14:04:45.398400+00:00
|
2020-12-21T14:04:45.398441+00:00
| 163 | false |
```\nunordered_map<string,int> hashmap;\nstring dfs(TreeNode *root,vector<TreeNode*> &v)\n{\n\tif(root==NULL)\n\t\treturn "#";\n\tstring left=dfs(root->left,v);\n\tstring right=dfs(root->right,v);\n\tstring str;\n\tstr=to_string(root->val)+","+left+ ","+right;\n\thashmap[str]++;\n\tif(hashmap[str]==2)\n\t\tv.push_back(root);\n\treturn str;\n}\nvector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n\tvector<TreeNode*> v;\n\tdfs(root,v);\n\treturn v;\n}\n```
| 4 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
8 lines python solution beats 85%
|
8-lines-python-solution-beats-85-by-luol-zdb2
|
\'\'\'\nclass Solution:\n\n def findDuplicateSubtrees(self, root):\n dic=collections.defaultdict(list)\n def inorder(root):\n if not
|
luolingwei
|
NORMAL
|
2019-06-27T12:48:15.359664+00:00
|
2019-06-27T12:48:15.359694+00:00
| 407 | false |
\'\'\'\nclass Solution:\n\n def findDuplicateSubtrees(self, root):\n dic=collections.defaultdict(list)\n def inorder(root):\n if not root:return \'#\'\n strings=str(root.val)+inorder(root.left)+inorder(root.right)\n dic[strings].append(root)\n return strings\n inorder(root)\n return [nodes[0] for nodes in dic.values() if len(nodes)>1]\n\'\'\'
| 4 | 0 |
[]
| 3 |
find-duplicate-subtrees
|
JavaScript Merkle tree - Based in Subtree of Another Tree
|
javascript-merkle-tree-based-in-subtree-tinbp
|
Based in https://leetcode.com/problems/subtree-of-another-tree\n\nSimilarly to Subtree of Another Tree (and @awice \'s answer), we generate the hash of every su
|
grs
|
NORMAL
|
2018-11-13T11:45:58.804342+00:00
|
2018-11-13T11:45:58.804381+00:00
| 573 | false |
Based in https://leetcode.com/problems/subtree-of-another-tree\n\nSimilarly to Subtree of Another Tree (and [@awice \'s answer](https://leetcode.com/problems/subtree-of-another-tree/discuss/102741/Python-Straightforward-with-Explanation-(O(ST)-and-O(S+T)-approaches))), we generate the hash of every subtree (known as Merkle tree). We store this hash and and of the nodes that led to it. At the end we return those hashes that have been set more than once.\n\n```\nconst crypto = require(\'crypto\');\n\nfunction hash(str) {\n return crypto.createHash(\'sha256\').update(str).digest(\'hex\');\n}\n\n/**\n * Definition for a binary tree node.\n * function TreeNode(val) {\n * this.val = val;\n * this.left = this.right = null;\n * }\n */\n/**\n * @param {TreeNode} root\n * @return {TreeNode[]}\n */\nvar findDuplicateSubtrees = function(root) {\n const merkleNodes = new Map();\n merkle(root, merkleNodes);\n const duplicates = [];\n for (const [count, node] of merkleNodes.values()) {\n if (count > 1) {\n duplicates.push(node);\n }\n }\n return duplicates;\n};\n\nfunction merkle(node, merkleNodes) {\n if (!node) {\n return \'\';\n }\n \n const left = merkle(node.left, merkleNodes);\n const right = merkle(node.right, merkleNodes);\n const treeHash = hash(`${left}${node.val}${right}`);\n \n const previousMerkleNode = merkleNodes.get(treeHash) || [0, node];\n previousMerkleNode[0] += 1;\n merkleNodes.set(treeHash, previousMerkleNode);\n \n return treeHash;\n}\n```
| 4 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
Java | Post order traversal | 10 lines
|
java-post-order-traversal-10-lines-by-ju-whvh
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time
|
judgementdey
|
NORMAL
|
2023-02-28T21:50:53.101330+00:00
|
2023-03-22T21:36:01.974848+00:00
| 61 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n List<TreeNode> ans = new ArrayList<>();\n Map<String, Integer> map = new HashMap<>();\n\n private String postOrder(TreeNode node) {\n if (node == null) return " ";\n\n var s = postOrder(node.left) + " " + postOrder(node.right) + " " + node.val;\n map.put(s, map.getOrDefault(s, 0) + 1);\n if (map.get(s) == 2) ans.add(node);\n \n return s;\n }\n\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n postOrder(root);\n return ans;\n }\n}\n```\nIf you like my solution, please upvote it!
| 3 | 0 |
['Depth-First Search', 'Java']
| 0 |
find-duplicate-subtrees
|
📌📌 C++ || DFS || Hashmap || Faster || Easy To Understand 🤷♂️🤷♂️
|
c-dfs-hashmap-faster-easy-to-understand-8ol13
|
Using DFS && Hashmap\n\n Time Complexity :- O(N)\n\n Space Complexity :- O(N)\n\n\nclass Solution {\npublic:\n \n // declare an unordered map\n \n u
|
__KR_SHANU_IITG
|
NORMAL
|
2023-02-28T08:05:51.114345+00:00
|
2023-02-28T08:05:51.114390+00:00
| 532 | false |
* ***Using DFS && Hashmap***\n\n* ***Time Complexity :- O(N)***\n\n* ***Space Complexity :- O(N)***\n\n```\nclass Solution {\npublic:\n \n // declare an unordered map\n \n unordered_map<string, int> mp;\n \n // declare a res array\n \n vector<TreeNode*> res;\n \n // function for finding duplicate subtree\n \n string dfs(TreeNode* root)\n {\n // base case\n \n if(root == NULL)\n {\n return "";\n }\n \n // find the subtree for the curr node and store in str\n \n string str = "";\n \n str += to_string(root -> val);\n \n // provide delimeter\n \n str += "#";\n \n // call for left subtree\n \n string left = dfs(root -> left);\n \n str += left;\n \n // provide delimeter\n \n str += "#";\n \n // call for right subtree\n \n string right = dfs(root -> right);\n \n str += right;\n \n // increment the count of str\n \n mp[str]++;\n \n // if we found duplicate subtree then include the root into result\n \n if(mp[str] == 2)\n {\n res.push_back(root);\n }\n \n // return str\n \n return str;\n }\n \n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n \n dfs(root);\n \n return res;\n }\n};\n```
| 3 | 0 |
['Tree', 'Depth-First Search', 'C', 'C++']
| 0 |
find-duplicate-subtrees
|
C# and TypeScript Solution . ❇️✅
|
c-and-typescript-solution-by-arafatsabbi-nzfo
|
\u2B06\uFE0FLike|\uD83C\uDFAFShare|\u2B50Favourite\n# Approach\n1. Traverse the tree in postorder and get a unique identifier for each subtree.\n2. Use a dictio
|
arafatsabbir
|
NORMAL
|
2023-02-28T06:12:38.239666+00:00
|
2023-02-28T06:12:38.239718+00:00
| 239 | false |
# \u2B06\uFE0FLike|\uD83C\uDFAFShare|\u2B50Favourite\n# Approach\n1. Traverse the tree in postorder and get a unique identifier for each subtree.\n2. Use a dictionary to count the number of times each subtree occurs in the tree.\n3. Return all subtrees with more than one occurrence.\n\n# Runtime & Memory\n\n\n# Complexity\n- Time complexity:\nO(N^2) to traverse the tree and count the number of subtrees.\n\n- Space complexity:\nO(N^2) to keep the entire tree.\n\n# C# Code\n```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * public int val;\n * public TreeNode left;\n * public TreeNode right;\n * public TreeNode(int val=0, TreeNode left=null, TreeNode right=null) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\npublic class Solution \n{\n public IList<TreeNode> FindDuplicateSubtrees(TreeNode root) \n {\n var result = new List<TreeNode>();\n var visited = new Dictionary<string, int>();\n Traverse(root, visited, result);\n return result;\n }\n\n private string Traverse(TreeNode node, Dictionary<string, int> visited, List<TreeNode> result)\n {\n if (node == null)\n return "#";\n\n var left = Traverse(node.left, visited, result);\n var right = Traverse(node.right, visited, result);\n\n var key = $"{node.val},{left},{right}";\n if (visited.ContainsKey(key))\n {\n if (visited[key] == 1)\n result.Add(node);\n visited[key]++;\n }\n else\n {\n visited.Add(key, 1);\n }\n\n return key;\n }\n}\n```\n\n# TypeScript Code\n```\n/**\n * Definition for a binary tree node.\n * class TreeNode {\n * val: number\n * left: TreeNode | null\n * right: TreeNode | null\n * constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {\n * this.val = (val===undefined ? 0 : val)\n * this.left = (left===undefined ? null : left)\n * this.right = (right===undefined ? null : right)\n * }\n * }\n */\n\nfunction findDuplicateSubtrees(root: TreeNode | null): Array<TreeNode | null> {\n const result: Array<TreeNode | null> = [];\n const visited: Map<string, number> = new Map();\n traverse(root, visited, result);\n return result;\n};\n\nfunction traverse(node: TreeNode | null, visited: Map<string, number>, result: Array<TreeNode | null>): string {\n if (node === null) return \'#\';\n\n const left = traverse(node.left, visited, result);\n const right = traverse(node.right, visited, result);\n\n const key = `${node.val},${left},${right}`;\n if (visited.has(key)) {\n if (visited.get(key) === 1) result.push(node);\n visited.set(key, visited.get(key) + 1);\n } else {\n visited.set(key, 1);\n }\n\n return key;\n}\n```
| 3 | 0 |
['Hash Table', 'Tree', 'Binary Tree', 'TypeScript', 'C#']
| 0 |
find-duplicate-subtrees
|
📌 Python Concise DFS Solution With Detailed Explaination | ⚡ Fastest Solution 🚀
|
python-concise-dfs-solution-with-detaile-5pi1
|
\uD83D\uDD3C IF YOU FIND THIS POST HELPFUL PLEASE UPVOTE \uD83D\uDC4D\n\nSolution:\n\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNo
|
pniraj657
|
NORMAL
|
2023-02-28T05:15:59.607830+00:00
|
2023-02-28T05:15:59.607862+00:00
| 427 | false |
**\uD83D\uDD3C IF YOU FIND THIS POST HELPFUL PLEASE UPVOTE \uD83D\uDC4D**\n\n**Solution:**\n```\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n # create a dictionary to store subtrees\n subTrees = defaultdict(list)\n \n # define a DFS function to traverse the binary tree and find duplicate subtrees\n def dfs(node):\n # if the node is empty, return \'null\'\n if not node:\n return \'null\'\n \n # create a string representation of the current node and its subtrees\n s = \',\'.join([str(node.val), dfs(node.left), dfs(node.right)])\n \n # if the string representation is already in subTrees, then it\'s a duplicate subtree\n if len(subTrees[s]) == 1:\n # add the root node of one of the duplicate subtrees to the result list\n res.append(node)\n \n # add the current node to the list of nodes with the same string representation\n subTrees[s].append(node)\n \n # return the string representation of the current node and its subtrees\n return s\n \n # initialize an empty result list\n res = []\n \n # traverse the binary tree and find duplicate subtrees\n dfs(root)\n \n # return the root nodes of all the duplicate subtrees\n return res\n```\n\n**For Detailed Explaination Read this Blog:**\nhttps://www.python-techs.com/2023/02/find-duplicate-subtrees-in-binary-tree.html\n\n**Thank you for reading! \uD83D\uDE04 Comment if you have any questions or feedback.**
| 3 | 0 |
['Depth-First Search', 'Python', 'Python3']
| 0 |
find-duplicate-subtrees
|
python3 , HashMap + store duplicates with same height
|
python3-hashmap-store-duplicates-with-sa-kj9i
|
Intuition\nThe idea is to for duplicates subTrees to exist there will be nodes in tress with duplicates values. For two subtrees to be duplicate at two nodes wi
|
Code-IQ7
|
NORMAL
|
2023-02-28T04:37:40.326469+00:00
|
2023-02-28T04:37:40.326499+00:00
| 205 | false |
# Intuition\nThe idea is to for duplicates subTrees to exist there will be nodes in tress with duplicates values. For two subtrees to be duplicate at two nodes will have -\n1. same heights\n2. same Tree structure\n\nWe need to take care of edge cases where two nodes might be at same heights but they might have different structure. We need to track all nodes as well.\n\n# Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n # check is two trees are having same structure\n def isSame(self,root1,root2):\n if root1 is None and root2 is None:\n return True\n if root1 is None or root2 is None:\n return False\n return self.isSame(root1.left,root2.left) and self.isSame(root1.right,root2.right) and root1.val == root2.val\n\n\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n #stores every node with its values & its height\n self.nodeMap = defaultdict(list)\n # stores unique( taken set) nodes which are duplicates in Tree\n ans = defaultdict(set)\n\n def traverseAndMap(root):\n if root is None:\n return 0\n l = traverseAndMap(root.left)\n r = traverseAndMap(root.right)\n height = max(l,r)\n duplicate = False\n # if this value at this height is seen\n if (root.val,height) in self.nodeMap:\n for node in self.nodeMap[(root.val,height)]:\n if self.isSame(root,node): # if duplicates with other node already found\n ans[(root.val,height)].add(node)\n duplicate = True\n break\n if not duplicate: # node with this structure is not seen\n self.nodeMap[(root.val,height)].append(root) \n return height + 1\n\n traverseAndMap(root)\n result = []\n for k in ans:\n for node in ans[k]:\n result.append(node)\n return result\n\n\n\n```
| 3 | 0 |
['Python3']
| 0 |
find-duplicate-subtrees
|
Find Duplicate Subtree || Easy to understand || beginner's Friendly😉🤗
|
find-duplicate-subtree-easy-to-understan-e3yp
|
Intuition\nBy reading this qston first things which came to my mind was mapping.So, here is its implementation :\n\n# Approach\n- make a helper function ans pas
|
abhix2910
|
NORMAL
|
2023-02-28T04:09:08.689022+00:00
|
2023-02-28T04:09:08.689060+00:00
| 850 | false |
# Intuition\nBy reading this qston first things which came to my mind was mapping.So, here is its implementation :\n\n# Approach\n- make a helper function ans pass the root and an answer vector.\n- first check the base case if root is null or not if yes then return a "#",\n- declare a string and inside that string keep on adding the the values of nodes in a postorder traversal method\n- and keep on incresing the frequency of s in map\n- if frewuency is 2 then push it inside the answer vector\n- return that string s.\n\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\nclass Solution {\npublic:\n map<string,int> mp;\n string solve(TreeNode* root,vector<TreeNode*>& res)\n {\n if(!root)\n return "#";\n string s=solve(root->left,res)+ \',\' +solve(root->right,res)+ \',\' +to_string(root->val);\n mp[s]++;\n if(mp[s]==2)\n res.push_back(root);\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> ans;\n solve(root,ans);\n return ans;\n }\n};\n```\nHope u guys like it and upvote\uD83E\uDDD1\u200D\uD83D\uDCBB //Happy Coding
| 3 | 0 |
['Tree', 'Binary Tree', 'C++']
| 1 |
find-duplicate-subtrees
|
Java
|
java-by-akash2023-v05e
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time
|
Akash2023
|
NORMAL
|
2023-02-28T03:54:35.995060+00:00
|
2023-02-28T03:54:35.995111+00:00
| 796 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n List<TreeNode> res;\n HashMap<String, Integer> serialCount;\n String pos(TreeNode root)\n {\n\t if(root == null) return "#";\n\t String serial = root.val + "," + pos(root.left) + pos(root.right);\n\t int freq = serialCount.getOrDefault(serial, 0);\n\t serialCount.put(serial, ++freq);\n\t if (freq == 2) res.add(root);\n\t return serial;\n }\n public List<TreeNode> findDuplicateSubtrees (TreeNode root){\n\t res = new LinkedList<>();\n\t serialCount = new HashMap<>();\n\t pos(root);\n\t return res;\n } \n}\n```
| 3 | 0 |
['Java']
| 0 |
find-duplicate-subtrees
|
✅✅ C++|| Simplest Solution
|
c-simplest-solution-by-ashvani_gurjar-emb0
|
\n# Complexity\n- Time complexity: O(N2)\n Add your time complexity here, e.g. O(n) \n\n- Space complexity: O(N)\n Add your space complexity here, e.g. O(n) \n\
|
Ashvani_Gurjar
|
NORMAL
|
2023-02-28T03:53:02.912843+00:00
|
2023-02-28T03:53:02.912898+00:00
| 453 | false |
\n# Complexity\n- Time complexity: O(N2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\n #include<bits/stdc++.h>\nclass Solution {\n public:\n string solution(TreeNode*root, vector<TreeNode*>&ans,unordered_map<string,int>&m){\n if(root == NULL) return "";\n string s = solution(root->left,ans,m) + "," + solution(root->right,ans,m) + "," + to_string(root->val);\n m[s]++;\n if(m[s] == 2) \n ans.push_back(root);\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*>ans;\n unordered_map<string,int>m;\n solution(root,ans,m);\n return ans;\n \n }\n};\n```
| 3 | 0 |
['C++']
| 1 |
find-duplicate-subtrees
|
Simple solution using postorder traversal.
|
simple-solution-using-postorder-traversa-tifu
|
\n\n# Complexity\n- Time complexity:O(N^2)\n Add your time complexity here, e.g. O(n) \n\n- Space complexity:O(N)\n Add your space complexity here, e.g. O(n) \n
|
ShivamDubey55555
|
NORMAL
|
2023-02-28T03:39:52.229691+00:00
|
2023-02-28T03:39:52.229780+00:00
| 301 | false |
\n\n# Complexity\n- Time complexity:$$O(N^2)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:$$O(N)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\n #include<bits/stdc++.h>\nclass Solution {\n public:\n string solution(TreeNode*root, vector<TreeNode*>&ans,unordered_map<string,int>&m){\n if(root == NULL) return "";\n string s = solution(root->left,ans,m) + "," + solution(root->right,ans,m) + "," + to_string(root->val);\n m[s]++;\n if(m[s] == 2) \n ans.push_back(root);\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*>ans;\n unordered_map<string,int>m;\n solution(root,ans,m);\n return ans;\n \n }\n};\n```
| 3 | 0 |
['C++']
| 1 |
find-duplicate-subtrees
|
C++ Solution || >90% Runtime and Memory
|
c-solution-90-runtime-and-memory-by-0nea-xuy2
|
\n# Code\n\nclass Solution {\npublic:\n unordered_map<string, pair<int, int>> mp;\n int id;\n vector<TreeNode*> res;\n vector<TreeNode*> findDuplica
|
0neAnd0nlyBOI
|
NORMAL
|
2023-02-28T02:28:02.003778+00:00
|
2023-02-28T02:28:02.003812+00:00
| 645 | false |
\n# Code\n```\nclass Solution {\npublic:\n unordered_map<string, pair<int, int>> mp;\n int id;\n vector<TreeNode*> res;\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n id = 1;\n postOrder(root);\n return res;\n }\n\n string postOrder(TreeNode* root)\n {\n if(root == NULL)\n return "0";\n string left = postOrder(root->left);\n string right = postOrder(root->right);\n string cur = left + ","+ to_string(root->val)+","+right;\n if(mp.find(cur) == mp.end())\n {\n mp[cur] = {id++, 1};\n }\n else\n {\n ++mp[cur].second;\n if(mp[cur].second == 2)\n res.push_back(root);\n }\n return to_string(mp[cur].first);\n }\n};\n```\n\nPlease feel free to upvote the solution! Thanks!
| 3 | 0 |
['C++']
| 1 |
find-duplicate-subtrees
|
HashMap & PostorderTraversal
|
hashmap-postordertraversal-by-brijesh20m-zgko
|
\n# Code\n\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeN
|
brijesh20M
|
NORMAL
|
2023-02-28T02:10:32.526608+00:00
|
2023-02-28T02:10:32.526652+00:00
| 132 | false |
\n# Code\n```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n Set<TreeNode> set;\n Map<String, TreeNode> map;\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n set = new HashSet<>();\n map = new HashMap<>();\n traverse(root);\n List<TreeNode> ans = new LinkedList<>();\n for (TreeNode node : set) {\n ans.add(node);\n }\n \n return ans;\n }\n \n public String traverse(TreeNode root) {\n if (root == null) {\n return "";\n }\n String left = traverse(root.left);\n String right = traverse(root.right);\n String cur = left +" "+ right +" "+ root.val;\n if (map.containsKey(cur)) {\n set.add(map.get(cur));\n } else {\n map.put(cur, root);\n }\n \n return cur;\n }\n}\n```
| 3 | 0 |
['Java']
| 1 |
find-duplicate-subtrees
|
Swift | Set
|
swift-set-by-upvotethispls-nxzi
|
Set (accepted answer)\n\nclass Solution {\n func findDuplicateSubtrees(_ root: TreeNode?) -> [TreeNode?] {\n var set = Set<Int>()\n var result
|
UpvoteThisPls
|
NORMAL
|
2023-02-28T00:45:59.961833+00:00
|
2024-04-16T18:45:00.051095+00:00
| 107 | false |
**Set (accepted answer)**\n```\nclass Solution {\n func findDuplicateSubtrees(_ root: TreeNode?) -> [TreeNode?] {\n var set = Set<Int>()\n var result = [TreeNode?]()\n \n func dfs(_ node: TreeNode?) -> Int {\n guard let node else { return 0 }\n let hashValue = [node.val, dfs(node.left), dfs(node.right)].hashValue\n if !set.insert(hashValue).inserted, set.insert(-hashValue).inserted {\n result.append(node)\n }\n return hashValue\n }\n \n dfs(root)\n return result\n }\n}\n```
| 3 | 0 |
['Swift']
| 1 |
find-duplicate-subtrees
|
The simplest C# solution with Stack and Postorder traversal
|
the-simplest-c-solution-with-stack-and-p-zqgv
|
Approach\nPostorder traversal.\n\n# Complexity\n- Time complexity: O(n)\n\n- Space complexity: O(n)\n\n# Code\n\npublic class Solution {\n public IList<TreeN
|
dyfilatov
|
NORMAL
|
2022-12-12T15:09:22.686226+00:00
|
2022-12-12T15:10:30.456483+00:00
| 212 | false |
# Approach\nPostorder traversal.\n\n# Complexity\n- Time complexity: O(n)\n\n- Space complexity: O(n)\n\n# Code\n```\npublic class Solution {\n public IList<TreeNode> FindDuplicateSubtrees(TreeNode root) {\n var stack = new Stack<TreeNode>();\n var visited = new Dictionary<TreeNode, string>();\n var duplicates = new Dictionary<string, List<TreeNode>>();\n stack.Push(root);\n \n while(stack.Count != 0){\n var top = stack.Peek();\n if(top.left != null && !visited.ContainsKey(top.left)){\n stack.Push(top.left);\n continue;\n }\n \n if(top.right != null && !visited.ContainsKey(top.right)){\n stack.Push(top.right);\n continue;\n }\n \n var newStructure = $"{top.val}";\n if(top.left != null && visited.ContainsKey(top.left)){\n newStructure = $"{visited[top.left]} < {newStructure}";\n }\n \n if(top.right != null && visited.ContainsKey(top.right)){\n newStructure = $"{newStructure} > {visited[top.right]}";\n }\n \n visited.Add(stack.Pop(), newStructure);\n if(duplicates.ContainsKey(newStructure)){\n duplicates[newStructure].Add(top);\n } else {\n duplicates.Add(newStructure, new List<TreeNode>(){top});\n }\n \n }\n \n return duplicates.Values.Where(v => v.Count > 1).Select(v => v[0]).ToList();\n }\n \n}\n```
| 3 | 0 |
['Stack', 'C#']
| 0 |
find-duplicate-subtrees
|
Python O(N) using hashmap simply and easy
|
python-on-using-hashmap-simply-and-easy-u9ebv
|
Similar to LC297 preorder serialization binary tree, recursively serialize every node, using a hashmap to record every serialized string, if there is duplicat
|
JessicaWestside
|
NORMAL
|
2022-07-04T01:39:00.184459+00:00
|
2022-07-04T01:39:00.184502+00:00
| 355 | false |
Similar to LC297 `preorder serialization binary tree`, recursively serialize every node, using a hashmap to record every serialized string, if there is duplicate, record it.\nTime Complexity O(n)\n```\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n res = []\n map = defaultdict(int)\n def dfs(node):\n if node is None:\n return \'#\'\n path = str(node.val) + \'#\' + dfs(node.left)+ \'#\' + dfs(node.right)\n map[path] += 1\n if map[path] == 2:\n res.append(node)\n return path\n dfs(root)\n return res\n```
| 3 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
C++ | Clean And Easy Solution
|
c-clean-and-easy-solution-by-jayesh2604-2o18
|
\nclass Solution\n{\nprivate:\n map<string, vector<TreeNode *>> mp;\n string postOrder(TreeNode *root)\n {\n if (!root)\n {\n
|
jayesh2604
|
NORMAL
|
2022-05-28T15:26:31.123177+00:00
|
2022-05-28T15:26:31.123216+00:00
| 432 | false |
```\nclass Solution\n{\nprivate:\n map<string, vector<TreeNode *>> mp;\n string postOrder(TreeNode *root)\n {\n if (!root)\n {\n return "";\n }\n string leftAns = postOrder(root->left);\n string rightAns = postOrder(root->right);\n string currentString = "L" + leftAns + to_string(root->val) + "R" + rightAns;\n mp[currentString].push_back(root);\n return currentString;\n }\n\npublic:\n vector<TreeNode *> findDuplicateSubtrees(TreeNode *root)\n {\n postOrder(root);\n vector<TreeNode *> ans;\n for (auto [key, value] : mp)\n {\n if (value.size() > 1)\n {\n ans.push_back(value[0]);\n }\n }\n return ans;\n }\n};\n```
| 3 | 0 |
['C++']
| 0 |
find-duplicate-subtrees
|
Python | Hashmap | DFS | Simple Solution
|
python-hashmap-dfs-simple-solution-by-ak-578t
|
\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.lef
|
akash3anup
|
NORMAL
|
2022-05-21T20:43:39.203635+00:00
|
2022-05-21T20:43:39.203676+00:00
| 516 | false |
```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def dfs(self, root, lookup, duplicates):\n if not root:\n return \'.\'\n subtree = str(root.val) + \'-\' + self.dfs(root.left, lookup, duplicates) + \'-\' + self.dfs(root.right, lookup, duplicates) \n if subtree in lookup:\n if lookup[subtree] == 1:\n duplicates.append(root)\n lookup[subtree] += 1\n else:\n lookup[subtree] = 1\n return subtree\n \n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]: \n lookup, duplicates = {}, []\n self.dfs(root, lookup, duplicates)\n return duplicates\n```\n\n***If you liked the above solution then please upvote!***
| 3 | 0 |
['Depth-First Search', 'Python']
| 0 |
find-duplicate-subtrees
|
c++ easy solution with Hashmap.
|
c-easy-solution-with-hashmap-by-prashant-95sa
|
\nclass Solution {\npublic:\n vector<TreeNode*> d;\n unordered_map<string, int> mp;\n \n string postorder(TreeNode* root) {\n if(!root) retur
|
Prashant830
|
NORMAL
|
2022-04-25T07:52:42.675337+00:00
|
2022-04-25T07:52:42.675366+00:00
| 182 | false |
```\nclass Solution {\npublic:\n vector<TreeNode*> d;\n unordered_map<string, int> mp;\n \n string postorder(TreeNode* root) {\n if(!root) return "";\n \n string left = postorder(root->left);\n string right = postorder(root->right);\n \n string current = to_string(root->val) + "L" + left + "R" + right;\n mp[current]++;\n if(mp[current] == 2)\n d.push_back(root);\n \n return current;\n }\n \n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n postorder(root);\n return d;\n }\n};\n```
| 3 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
C++ DFS string and hashmap
|
c-dfs-string-and-hashmap-by-adbnemesis-9imt
|
The main idea is to store the tree as a string and keep incrementing it.\n\n```\nclass Solution {\n \npublic:\n \n string help(TreeNode root, unordered
|
adbnemesis
|
NORMAL
|
2022-02-22T10:48:51.106515+00:00
|
2022-02-22T10:48:51.106546+00:00
| 182 | false |
The main idea is to store the tree as a string and keep incrementing it.\n\n```\nclass Solution {\n \npublic:\n \n string help(TreeNode* root, unordered_map<string, int>& um,vector<TreeNode*>& ans){\n if(root == NULL){\n return " ";\n };\n string s = to_string(root->val) + " "+ help(root->left,um,ans)+ " "+ help(root->right,um,ans);\n if(um[s]++ == 1){\n ans.push_back(root);\n }\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string,int> um;\n \n vector<TreeNode*> ans;\n help(root,um,ans);\n return ans;\n }\n};
| 3 | 0 |
[]
| 1 |
find-duplicate-subtrees
|
Easy HashMap based solution
|
easy-hashmap-based-solution-by-pratosh-1r95
|
\nclass Solution {\n List<TreeNode> res = new ArrayList<>();\n HashMap<String, Integer> map = new HashMap<>();\n \n public List<TreeNode> findDuplic
|
pratosh
|
NORMAL
|
2022-02-10T15:02:50.327787+00:00
|
2022-02-10T15:10:28.870207+00:00
| 491 | false |
```\nclass Solution {\n List<TreeNode> res = new ArrayList<>();\n HashMap<String, Integer> map = new HashMap<>();\n \n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n find(root);\n return res;\n }\n \n String find(TreeNode root){\n if(root==null) return "";\n \n int cur = root.val;\n String left = find(root.left);\n String right = find(root.right);\n String temp = cur+","+left+","+right;\n \n if(map.getOrDefault(temp, 0) == 1)\n res.add(root);\n map.put(temp, map.getOrDefault(temp, 0)+1);\n\t\t\n return temp; \n }\n}\n```
| 3 | 0 |
['Java']
| 0 |
find-duplicate-subtrees
|
JAVA || EASY SOLUTION || HASHMAP || FAST
|
java-easy-solution-hashmap-fast-by-anike-3xhg
|
\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n
|
aniket7419
|
NORMAL
|
2022-02-03T18:09:46.426265+00:00
|
2022-02-03T18:09:46.426408+00:00
| 107 | false |
```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n \n \n \n HashMap<String,Integer> map=new HashMap<>();\n List<TreeNode> result=new ArrayList<>();\n String visit(TreeNode node){\n if (node==null) return "";\n int cur=node.val;\n String left=visit(node.left);\n String right =visit(node.right);\n String rep=cur+","+left+","+right;\n if (map.getOrDefault(rep,0)==1)\n result.add(node);\n map.put(rep,map.getOrDefault(rep,0)+1);\n return rep;\n }\n \n \n \n\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n visit(root);\n return result;\n }\n \n } \n}\n```
| 3 | 1 |
[]
| 0 |
find-duplicate-subtrees
|
Simpe postorder recursive Java solution
|
simpe-postorder-recursive-java-solution-25sho
|
\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String, Integer> map = new HashMap<>();\n List<TreeNode
|
KorabeL
|
NORMAL
|
2021-12-08T13:15:39.780869+00:00
|
2021-12-08T13:15:39.780909+00:00
| 230 | false |
```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String, Integer> map = new HashMap<>();\n List<TreeNode> list = new LinkedList<>();\n helper(root, map, list);\n return list;\n }\n\n private String helper(TreeNode root, Map<String, Integer> map, List<TreeNode> list) {\n if(root == null) return "#";\n\n String key = helper(root.left, map, list) + "#" +\n helper(root.right, map, list) + "#" +\n root.val;\n\n map.put(key, map.getOrDefault(key, 0) + 1);\n if(map.get(key) == 2) list.add(root);\n\n return key;\n }\n}\n```
| 3 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
python dfs
|
python-dfs-by-gasohel336-xjga
|
```\nfrom typing import List\nfrom collections import defaultdict\nclass TreeNode:\n def init(self, val=0, left=None, right=None):\n self.val = val\n
|
gasohel336
|
NORMAL
|
2021-07-30T14:10:20.489891+00:00
|
2021-07-30T14:10:20.489944+00:00
| 228 | false |
```\nfrom typing import List\nfrom collections import defaultdict\nclass TreeNode:\n def __init__(self, val=0, left=None, right=None):\n self.val = val\n self.left = left\n self.right = right\n\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n\n seen = defaultdict(int)\n output = []\n\n def dfs(node):\n if not node:\n return\n subtree = tuple([dfs(node.left), node.val, dfs(node.right)])\n if seen[subtree] == 1:\n output.append(node)\n seen[subtree] += 1\n return subtree\n\n dfs(root)\n return output
| 3 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
Simple C++ solution using unordered_map
|
simple-c-solution-using-unordered_map-by-tqju
|
\nclass Solution {\npublic:\n unordered_map<string,int> mp;\n vector<TreeNode*> ans;\n \n string dfs(TreeNode* root)\n {\n if(root==NULL)\
|
Amey_Joshi
|
NORMAL
|
2021-07-16T04:10:10.173088+00:00
|
2021-07-16T04:10:10.173148+00:00
| 165 | false |
```\nclass Solution {\npublic:\n unordered_map<string,int> mp;\n vector<TreeNode*> ans;\n \n string dfs(TreeNode* root)\n {\n if(root==NULL)\n return "#";\n \n string left=dfs(root->left);\n string right=dfs(root->right);\n \n string key=left+" "+right+" "+to_string(root->val);\n mp[key]++;\n \n if(mp[key]==2)\n ans.push_back(root);\n \n return key;\n \n }\n \n \n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n dfs(root);\n return ans;\n }\n};\n```
| 3 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
C++ solution using string and hashmap
|
c-solution-using-string-and-hashmap-by-m-7l67
|
Create a hashmap storing vector of TreeNodes with a string as a key. The string can uniquely identify the subtree because we are using "(" and ")" values to mar
|
maitreya47
|
NORMAL
|
2021-06-22T00:02:35.407797+00:00
|
2021-06-22T00:17:43.802202+00:00
| 508 | false |
Create a hashmap storing vector of TreeNodes with a string as a key. The string can uniquely identify the subtree because we are using "(" and ")" values to mark each left and right subtree recursively , so even if the node values are same, the structure is checked if and only if the parans too are same.\nFor example: 000 can match with 000 but (((0)0)0) will reject (0(0(0))) and only match with (((0)0)0).\n(((0)0)0) tree is as follows:- [0, 0, null, 0, null].\nNow, we maintain a hashmap to keep track of all the strings and keep adding vectors of TreeNodes to them. Atlast, if any string is has 2 or more vectors, then it is present more than 1 time, hence we return that vector of TreeNodes.\n```\nclass Solution {\n string inorder(unordered_map<string, vector<TreeNode*>> &A, TreeNode* root)\n {\n if(root==NULL)\n return "";\n string s = "(" + inorder(A, root->left) + to_string(root->val) + inorder(A, root->right) + ")";\n A[s].push_back(root);\n return s;\n }\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> ret;\n unordered_map<string, vector<TreeNode*>> A; //vector of TreeNodes so as to keep pushing\n\t\t//the TreeNodes and at last compare if more than 1 TreeNodes when traversed, give the same\n\t\t//string check more than one by vector.size()\n if(root==NULL)\n return ret;\n inorder(A, root);\n for(auto it=A.begin(); it!=A.end(); it++)\n if(it->second.size()>1) ret.push_back(it->second[0]);\n return ret;\n }\n};\n```
| 3 | 0 |
['String', 'C', 'C++']
| 1 |
find-duplicate-subtrees
|
Sumple C++ soln | Hashing | Serialization
|
sumple-c-soln-hashing-serialization-by-s-r5u0
|
\n string helper(TreeNode* root,vector<TreeNode*> &ans, unordered_map<string, int>&m ){\n if(!root)\n return "# ";\n string node=to_
|
sneha_pandey_
|
NORMAL
|
2021-05-17T13:54:30.594042+00:00
|
2021-05-17T13:54:30.594081+00:00
| 346 | false |
```\n string helper(TreeNode* root,vector<TreeNode*> &ans, unordered_map<string, int>&m ){\n if(!root)\n return "# ";\n string node=to_string(root->val)+" ";\n node+=helper(root->left, ans,m);\n node+=helper(root->right, ans,m);\n if(m.count(node) && m[node]==1){\n ans.push_back(root);\n m[node]++;\n }\n else if(!m.count(node)){\n m[node]=1;\n }\n return node;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> ans;\n unordered_map<string, int> m;\n helper(root, ans, m);\n return ans;\n }\n```
| 3 | 0 |
['C']
| 1 |
find-duplicate-subtrees
|
Java || Tree + Hashing || 2 solutions || 4ms || beats 99% in both time and memory
|
java-tree-hashing-2-solutions-4ms-beats-70maw
|
\n\t// O(n^2) O(n)\n\tpublic List findDuplicateSubtrees1(TreeNode root) {\n\n\t\tList ans = new ArrayList();\n\t\tHashMap map = new HashMap<>();\n\t\tfindDuplic
|
LegendaryCoder
|
NORMAL
|
2021-05-16T14:31:27.119777+00:00
|
2021-05-16T14:31:27.119810+00:00
| 332 | false |
\n\t// O(n^2) O(n)\n\tpublic List<TreeNode> findDuplicateSubtrees1(TreeNode root) {\n\n\t\tList<TreeNode> ans = new ArrayList<TreeNode>();\n\t\tHashMap<String, Integer> map = new HashMap<>();\n\t\tfindDuplicateSubtrees1(root, ans, map);\n\t\treturn ans;\n\t}\n\n\t// O(n^2) O(n)\n\tpublic StringBuilder findDuplicateSubtrees1(TreeNode root, List<TreeNode> ans, HashMap<String, Integer> map) {\n\n\t\tif (root == null)\n\t\t\treturn new StringBuilder("#");\n\n\t\tStringBuilder left = findDuplicateSubtrees1(root.left, ans, map);\n\t\tStringBuilder right = findDuplicateSubtrees1(root.right, ans, map);\n\n\t\tStringBuilder sb = new StringBuilder();\n\t\tsb.append(root.val);\n\t\tsb.append("_");\n\t\tsb.append(left);\n\t\tsb.append("_");\n\t\tsb.append(right);\n\n\t\tString key = sb.toString();\n\t\tint freq = map.getOrDefault(key, 0);\n\t\tif (freq == 1) {\n\t\t\tans.add(root);\n\t\t\tmap.put(key, 2);\n\t\t} else if (freq == 0)\n\t\t\tmap.put(key, 1);\n\n\t\treturn sb;\n\t}\n\n\tint currId = 1;\n\n\t// O(n) O(n)\n\tpublic List<TreeNode> findDuplicateSubtrees2(TreeNode root) {\n\n\t\tList<TreeNode> ans = new ArrayList<>();\n\t\tHashMap<String, Integer> serial2Id = new HashMap<>();\n\t\tHashMap<Integer, Integer> freq = new HashMap<>();\n\t\tfindDuplicateSubtrees2(root, serial2Id, freq, ans);\n\t\treturn ans;\n\t}\n\n\t// O(n) O(n)\n\tpublic int findDuplicateSubtrees2(TreeNode root, HashMap<String, Integer> serial2Id, HashMap<Integer, Integer> map,\n\t\t\tList<TreeNode> ans) {\n\n\t\tif (root == null)\n\t\t\treturn 0;\n\n\t\tint left = findDuplicateSubtrees2(root.left, serial2Id, map, ans);\n\t\tint right = findDuplicateSubtrees2(root.right, serial2Id, map, ans);\n\t\tStringBuilder sb = new StringBuilder();\n\t\tsb.append(root.val);\n\t\tsb.append("_");\n\t\tsb.append(left);\n\t\tsb.append("_");\n\t\tsb.append(right);\n\n\t\tString serial = sb.toString();\n\t\tint id = serial2Id.getOrDefault(serial, currId++);\n\t\tint freq = map.getOrDefault(id, 0);\n\t\tserial2Id.put(serial, id);\n\n\t\tif (freq == 1) {\n\t\t\tans.add(root);\n\t\t\tmap.put(id, 2);\n\t\t} else if (freq == 0)\n\t\t\tmap.put(id, 1);\n\n\t\treturn id;\n\t}
| 3 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
Java, dfs with serializing and stringbuilder beats 98.7%
|
java-dfs-with-serializing-and-stringbuil-h3j5
|
```\npublic List findDuplicateSubtrees(TreeNode root) {\n List ans = new ArrayList<>();\n if (root == null) {\n return ans;\n }\
|
amethystave
|
NORMAL
|
2021-02-24T21:59:57.692169+00:00
|
2021-02-24T21:59:57.692223+00:00
| 444 | false |
```\npublic List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n List<TreeNode> ans = new ArrayList<>();\n if (root == null) {\n return ans;\n }\n \n // serial to id map\n Map<String, Integer> serialToId = new HashMap<>();\n // id to count map\n Map<Integer, Integer> count = new HashMap<>();\n dfs(serialToId, count, ans, root);\n \n return ans;\n }\n \n private int dfs(Map<String, Integer> serialToId, Map<Integer, Integer> count, List<TreeNode> ans, TreeNode n) {\n if (n == null) {\n return 0;\n }\n \n int left = dfs(serialToId, count, ans, n.left);\n int right = dfs(serialToId, count, ans, n.right);\n StringBuilder sb = new StringBuilder();\n String serial = sb.append(n.val).append(",").append(left).append(",").append(right).toString();\n int id = serialToId.computeIfAbsent(serial, k -> serialToId.size() + 1);\n count.put(id, count.getOrDefault(id, 0) + 1);\n if (count.get(id) == 2) {\n ans.add(n);\n }\n \n return id;\n }
| 3 | 0 |
['Java']
| 0 |
find-duplicate-subtrees
|
Time & Space Beating 99%. The Reasoning behind Hashing: Rabin Karp
|
time-space-beating-99-the-reasoning-behi-1rql
|
This problem is quite simple and straightforward indeed. We are to find the "equal" binary trees among all the subtrees.\n\nFirst, how do we define an "equality
|
maristie
|
NORMAL
|
2021-01-13T13:16:30.281154+00:00
|
2021-01-13T15:23:18.836325+00:00
| 207 | false |
This problem is quite simple and straightforward indeed. We are to find the "equal" binary trees among all the subtrees.\n\nFirst, how do we define an "equality" between two binary trees? It can be defined recursively: two trees are equal if and only if their root node has the same value and their respective left and right subtrees are equal (including `null`).\n\nNext, if we can decide whether two trees are equal now, how to tackle the problem? It\'s trivial to scan all the subtrees (amounting to n, where n is the total number of nodes), and maintain all the distinct subtrees. Output the subtrees that occur more than once.\n\nThe most important step is to efficiently decide whether two trees are distinct or equal. It is intuitive to use hashing. Generally, hashing avoids costly comparison between objects and reduces time complexity to O(1) on average. But here is a binary tree which has a recursive structure. We cannot afford computing the same substructure (subtree) repeatedly.\n\nThe key to overcoming this difficulty is rolling hash in Rabin Karp algorithm. We can use precomputed hashing of other subtrees to calculate its own hash. The basic idea is similar to dynamic programming or caching, where results of solved duplicate subproblems can be reused. Let\'s suppose a hash value is stored in each subtree which will be computed only once during execution. By definition, we need to compute the hash by the value of root node and the hash of two subtrees. Note that left and right subtrees should be distinguished.\n\n```\nint h = root.val + CONST * root.left.hashCode() + CONST * CONST * root.right.hashCode();\n```\n\nHere is an example of hashing method. `CONST` can be any value, but for efficiency a prime number is desired.\n\nAs long as we have the crucial hashing method now, we can make use of another powerful weapon, *hash table*, to crack the original problem now.\n\n```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n var newRoot = new HashableTreeNode(root);\n \n var subtrees = new HashMap<HashableTreeNode, Integer>();\n traverse(newRoot, subtrees);\n \n return subtrees.entrySet().stream()\n .filter(entry -> entry.getValue() > 1)\n .map(entry -> entry.getKey().original)\n .collect(Collectors.toList());\n }\n \n private void traverse(HashableTreeNode root, Map<HashableTreeNode, Integer> subtrees) {\n subtrees.merge(root, 1, (oldVal, val) -> oldVal + 1);\n if (root.left != null) traverse(root.left, subtrees);\n if (root.right != null) traverse(root.right, subtrees);\n }\n}\n\nclass HashableTreeNode extends TreeNode {\n private static final int BASE = 201;\n private int hash = 0;\n \n HashableTreeNode left;\n HashableTreeNode right;\n TreeNode original;\n \n HashableTreeNode(TreeNode node) {\n val = node.val;\n original = node;\n if (node.left != null) left = new HashableTreeNode(node.left);\n if (node.right != null) right = new HashableTreeNode(node.right);\n }\n \n @Override\n public int hashCode() {\n int h = hash;\n if (h == 0) {\n h = (val + BASE)\n + 31 * ((left == null) ? 0 : left.hashCode())\n + 31 * 31 * ((right == null) ? 0 : right.hashCode());\n hash = h;\n }\n return h;\n }\n \n @Override\n public boolean equals(Object obj) {\n if (obj == null) return false;\n if (obj == this) return true;\n if (!(obj instanceof HashableTreeNode)) return false;\n \n var node = (HashableTreeNode)obj;\n return val == node.val && Objects.equals(left, node.left) && Objects.equals(right, node.right);\n }\n}\n```
| 3 | 0 |
[]
| 1 |
find-duplicate-subtrees
|
Java / HashMap / recursive
|
java-hashmap-recursive-by-zc-3618e4cb-aj8g
|
java\nclass Solution {\n Map<String, Integer> map = new HashMap<>();\n List<TreeNode> res = new ArrayList<>();\n public List<TreeNode> findDuplicateSub
|
zc-3618e4cb
|
NORMAL
|
2020-10-17T07:50:59.187849+00:00
|
2020-10-17T07:50:59.187884+00:00
| 265 | false |
```java\nclass Solution {\n Map<String, Integer> map = new HashMap<>();\n List<TreeNode> res = new ArrayList<>();\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n traverse(root);\n return res;\n }\n \n private String traverse(TreeNode node) {\n if (node == null) {\n return "";\n }\n \n String curr = new StringBuilder()\n .append(node.val).append(":")\n .append(traverse(node.left)).append(",")\n .append(traverse(node.right)).append(";")\n .toString();\n \n int count = map.getOrDefault(curr, 0);\n if (count == 1) {\n res.add(node);\n }\n map.put(curr, count+1);\n \n return curr;\n }\n}\n```
| 3 | 0 |
['Recursion']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
O(n logn) | Detailed Explanation
|
on-logn-detailed-explanation-by-khaufnak-50xq
|
A hard question = Lots of observation + data structures \n\nLet\'s figure out observations and then find out data structure to implement them.\n\n>Observation 0
|
khaufnak
|
NORMAL
|
2020-07-05T07:21:49.295543+00:00
|
2020-08-18T17:09:11.550068+00:00
| 10,670 | false |
A hard question = Lots of observation + data structures \n\nLet\'s figure out observations and then find out data structure to implement them.\n\n>Observation 0: Well, we know that if we could get smallest digit to the left, then we will be able to make number smaller than we currently have. In that sense, a sorted number(Ascending) will already be smallest. \n\nSo, let\'s take pen and paper and try to find smallest number we can form for this:\n\n```"4321", k = 4```\n\nSo, let\'s try to move 1 to left most postion. From now on, I\'ll call the current digit we are moving to left as ```d```:\n```"4321", k = 4```\n```"4312", k = 3```\n```"4132", k = 2```\n```"1432", k = 1```\nHmm, we can clearly observe: \n\n>Observation 1: when we move a digit to left, other digit are shifted to right. i.e 432 got shifted to right by 1.\n\nBut, wait. What if there was another digit to right of ```d```?\n```"43219", k = 4```\n```"43129", k = 3```\n```"41329", k = 2```\n```"14329", k = 1```\n\nWell, location of 9 didn\'t change. Therefore, we can make some correction to our above observation. \n\n>Corrected observation 1: Only digits to the left of ```d``` get their position shifted.\n\nAlright, what\'s next?\n\nBut what if the ```k``` was really small and we couldn\'t move 1 to left most?\n```"43219", k = 2```\n```"43129", k = 1```\n```"41329", k = 0```\n\nHmm, something is fishy, we clearly didn\'t reach smallest number here. Smallest for ```k=2``` would be ```24319```.\n\nWe can observe here, that we should choose smallest ```d``` that is in the reach of ```k```. \n\n>Observation 2: Choose first smallest ```d``` that is in reach of ```k```. \n\nIf we combine all the observation, we can see that we will iterate from left to right and try to place digits 0 through 9.\nLet\'s work through a bigger example:\n\n```"9438957234785635408", k = 23```\n\nWe will start from left. Let\'s try to place 0 here. ```0``` is within reach of ```k```, ```0``` is 17 shifts away to right. So, we will get:\n```"0943895723478563548", k = 6```\n\nObserve that all the number got shifted to right except the once to the right of ```d``` (8, here). \n\nNow, let\'s move to next position:\nLet\'s try to place 0 here, again. But wait, we don\'t 0 left, so try 1, which is not there also. So let\'s try 2, 2 is 8 distance away from this position. ```8 > k```, so we cannot choose 2. Let\'s try 3, 3 is 2 distance away. 2 < k, therefore let\'s choose 3.\n\n```"0394895723478563548", k = 4```\n\nand we can continue like this.\n\n>For observation 1, to calculate the correct number of shifts, we will need to also store how many elements before ```d``` already shifted. We will use segment tree for this.\n>For observation 2, We will use queue to choose latest occurence of each digit.\n\n\n```\nclass Solution {\n public String minInteger(String num, int k) {\n //pqs stores the location of each digit.\n List<Queue<Integer>> pqs = new ArrayList<>();\n for (int i = 0; i <= 9; ++i) {\n pqs.add(new LinkedList<>());\n }\n\n for (int i = 0; i < num.length(); ++i) {\n pqs.get(num.charAt(i) - \'0\').add(i);\n }\n String ans = "";\n SegmentTree seg = new SegmentTree(num.length());\n\n for (int i = 0; i < num.length(); ++i) {\n // At each location, try to place 0....9\n for (int digit = 0; digit <= 9; ++digit) {\n // is there any occurrence of digit left?\n if (pqs.get(digit).size() != 0) {\n // yes, there is a occurrence of digit at pos\n Integer pos = pqs.get(digit).peek();\n\t\t\t\t\t// Since few numbers already shifted to left, this `pos` might be outdated.\n // we try to find how many number already got shifted that were to the left of pos.\n int shift = seg.getCountLessThan(pos);\n // (pos - shift) is number of steps to make digit move from pos to i.\n if (pos - shift <= k) {\n k -= pos - shift;\n seg.add(pos); // Add pos to our segment tree.\n pqs.get(digit).remove();\n ans += digit;\n break;\n }\n }\n }\n }\n return ans;\n }\n\n class SegmentTree {\n int[] nodes;\n int n;\n\n public SegmentTree(int max) {\n nodes = new int[4 * (max)];\n n = max;\n }\n\n public void add(int num) {\n addUtil(num, 0, n, 0);\n }\n\n private void addUtil(int num, int l, int r, int node) {\n if (num < l || num > r) {\n return;\n }\n if (l == r) {\n nodes[node]++;\n return;\n }\n int mid = (l + r) / 2;\n addUtil(num, l, mid, 2 * node + 1);\n addUtil(num, mid + 1, r, 2 * node + 2);\n nodes[node] = nodes[2 * node + 1] + nodes[2 * node + 2];\n }\n\n // Essentialy it tells count of numbers < num.\n public int getCountLessThan(int num) {\n return getUtil(0, num, 0, n, 0);\n }\n\n private int getUtil(int ql, int qr, int l, int r, int node) {\n if (qr < l || ql > r) return 0;\n if (ql <= l && qr >= r) {\n return nodes[node];\n }\n\n int mid = (l + r) / 2;\n return getUtil(ql, qr, l, mid, 2 * node + 1) + getUtil(ql, qr, mid + 1, r, 2 * node + 2);\n }\n }\n\n}\n```\n\nIf you don\'t know about segment tree. This is simplest segment tree and you can look up ```sum of ranges using segment tree``` on Google and you will find million articles. You can also use Balanced BST, BIT (Thanks @giftwei for suggestion) to get same complexity.\n\n
| 307 | 3 |
['Java']
| 20 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
The constraint was not very helpful... [C++/Python] Clean 56ms O(n2) solution
|
the-constraint-was-not-very-helpful-cpyt-yays
|
1 <= num.length <= 30000\n1 <= k <= 10^9\n\nGiven these two constraints, how could leetcode expect someone to know that O(n2) and O(n2logn) would pass the OJ?\n
|
lichuan199010
|
NORMAL
|
2020-07-05T04:15:42.175031+00:00
|
2020-07-07T22:24:42.355787+00:00
| 5,774 | false |
1 <= num.length <= 30000\n1 <= k <= 10^9\n\nGiven these two constraints, how could leetcode expect someone to know that O(n2) and O(n2logn) would pass the OJ?\nIt was not hard to figure out the bubble sort as a naive solution (pick the smallest possible number and move to the front) and think about fast return with sorted digits if k >= n*(n-1)//2 (when all numbers can be rearranged freely), but I spent the last hour trying to implement a clever solution, but failed...\nI think BIT or segment tree will do, but didn\'t manage to get them right.\n\nI would suggest either make the constraint less daunting, or reinforce the constraint as claimed...\nWell, I guess maybe sometimes we just need to be bold enough and jump off the cliff to realize it was just a pit...\n\nUsually, I would think the total number of computation acceptable would be below 10^8. So, if n > 10000, I would hesitate to try O(n2).\n\n--------------------\nWow, so many people voted up, so I attached a solution below, beat 100% in Python (56ms in total).\nThis is an O(n2) solution just for fun.\n\n\tclass Solution:\n\t\tdef minInteger(self, num: str, k: int) -> str:\n\t\t # base case\n\t\t if k <= 0: return num\n\t\t # the total number of swaps if you need to reverse the whole string is n*(n-1)//2.\n\t\t\t# therefore, if k is >= this number, any order is achievable.\n\t\t\tn = len(num)\n\t\t\tif k >= n*(n-1)//2: \n\t\t\t\treturn "".join(sorted(list(num)))\n \n\t\t # starting from the smallest number\n\t\t\tfor i in range(10):\n\t\t\t # find the smallest index\n\t\t\t\tind = num.find(str(i))\n\t\t\t\t# if this index is valid\n\t\t\t\tif 0 <= ind <= k:\n\t\t\t\t # move the digit to the front and deal with the rest of the string recursively.\n\t\t\t\t\treturn str(num[ind]) + self.minInteger(num[0:ind] + num[ind+1:], k-ind)\n\nTo copy and paste:\n\n\tclass Solution:\n\t\tdef minInteger(self, num: str, k: int) -> str:\n\t\t\tif k <= 0: return num\n\t\t\tn = len(num)\n\t\t\tif k >= n*(n-1)//2: \n\t\t\t\treturn "".join(sorted(list(num)))\n\n\t\t\t# for each number, find the first index\n\t\t\tfor i in range(10):\n\t\t\t\tind = num.find(str(i))\n\t\t\t\tif 0 <= ind <= k:\n\t\t\t\t\treturn str(num[ind]) + self.minInteger(num[0:ind] + num[ind+1:], k-ind)\n\t\t\t\t\t\nC++ version by @wanli2019. Thank you.\n\n\tclass Solution {\n\tpublic:\n\t\tstring minInteger(string num, int k) {\n\t\t\tif(k <= 0) \n\t\t\t\treturn num;\n\t\t\tint n = num.size();\n\t\t\tif(k>=n*(n+1)/2){ \n\t\t\t\tsort(num.begin(), num.end());\n\t\t\t\treturn num;\n\t\t\t}\n\t\t\tfor(int i=0; i<10; i++){\n\t\t\t\tint idx = num.find(to_string(i));\n\t\t\t\tif(idx>=0 && idx<=k)\n\t\t\t\t\treturn num[idx]+minInteger(num.substr(0,idx)+num.substr(idx+1), k-idx);\n\t\t\t}\n\t\t\treturn num;\n\t\t}\n\t};
| 97 | 0 |
[]
| 12 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python] 17 lines O(nlogn) solution
|
python-17-lines-onlogn-solution-by-qqwqe-uf7i
|
The idea is quite straightforward: \nIn each round, pick the smallest number within k distance and move it to the front.\nFor each number, we save its indexes i
|
qqwqert007-2
|
NORMAL
|
2020-07-05T08:13:14.048747+00:00
|
2020-07-05T08:15:34.291457+00:00
| 3,192 | false |
The idea is quite straightforward: \n`In each round, pick the smallest number within k distance and move it to the front.`\nFor each number, we save its indexes in a deque.\nIn each round, we check from 0 to 9 to see if the nearest index is within k distance.\nBut here comes the tricky part:\n`The index of a number may change due to the swaps we made in the previous rounds.`\nFor example, if 3 numbers after `num[i]` are moved to the front,\nthen the index of `num[i]` becomes `i + 3` in the new array.\nSo we need a data structure to store the indexes of picked numbers,\nto support fast calculation of the new index of each remaining number.\nBIT, Segment Tree and Balanced Binary Search Tree can do this.\nHere I use `sortedcontainers`, which is an implementation of Balanced Binary Search Tree.\n\n```\nfrom collections import defaultdict, deque\nfrom sortedcontainers import SortedList\nfrom string import digits\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n d = defaultdict(deque)\n for i, a in enumerate(num):\n d[a].append(i)\n ans, seen = \'\', SortedList()\n for _ in range(len(num)):\n for a in digits:\n if d[a]:\n i = d[a][0]\n ni = i + (len(seen) - seen.bisect(i))\n dis = ni - len(seen)\n if dis <= k:\n k -= dis\n d[a].popleft()\n ans += a\n seen.add(i)\n break\n return ans\n```
| 38 | 0 |
[]
| 8 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python] bytedance interview question
|
python-bytedance-interview-question-by-y-ftql
|
Idea\nGreedily select the smallest number we can reach, and push it all the way to the front.\n\nComplexity\n- time: O(n^2)\n- space: O(n)\n\nPython\n\nclass So
|
yanrucheng
|
NORMAL
|
2020-07-05T04:03:28.080097+00:00
|
2020-07-05T04:03:28.080165+00:00
| 5,500 | false |
**Idea**\nGreedily select the smallest number we can reach, and push it all the way to the front.\n\n**Complexity**\n- time: O(n^2)\n- space: O(n)\n\n**Python**\n```\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n num = [*map(int, num)]\n if k >= (len(num) ** 2) // 2:\n return \'\'.join(map(str, sorted(num)))\n \n res = []\n q = [(v, i) for i, v in enumerate(num)]\n while k and q:\n idx, (v, i) = min(enumerate(q[:k + 1]), key=lambda p:p[1])\n k -= idx\n del q[idx]\n res += v,\n \n res += [v for v, _ in q]\n return \'\'.join(map(str, res))\n```\n\nPlease please don\'t downvote unless necessary bro.
| 37 | 18 |
[]
| 8 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Java Bubblesort 16 lines with detailed explanation easy to understand
|
java-bubblesort-16-lines-with-detailed-e-sk5n
|
\n\n\nclass Solution {\n public String minInteger(String num, int k) {\n char[] ca = num.toCharArray();\n helper(ca, 0, k);\n return new
|
funbam
|
NORMAL
|
2020-07-05T04:01:11.746599+00:00
|
2020-07-05T05:37:43.624050+00:00
| 3,177 | false |
\n\n```\nclass Solution {\n public String minInteger(String num, int k) {\n char[] ca = num.toCharArray();\n helper(ca, 0, k);\n return new String(ca);\n }\n \n public void helper(char[] ca, int I, int k){\n if (k==0 || I==ca.length) return;\n int min = ca[I], minIdx = I;\n for (int i = I+1; i<Math.min(I+k+1, ca.length); i++)\n if (ca[i]<min){\n min=ca[i];\n minIdx=i;\n }\n char temp = ca[minIdx];\n for (int i = minIdx; i>I; i--) ca[i]=ca[i-1];\n ca[I] = temp;\n helper(ca, I+1, k-(minIdx-I));\n }\n}\n```\n\nTime : \u041E(n^2), In the worst case, k will be very large, and it becomes bubble sort.\n\nHappy Coding!
| 30 | 5 |
[]
| 9 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[C++] O(N log N) Fenwick/BIT solution 196ms (with explanation)
|
c-on-log-n-fenwickbit-solution-196ms-wit-wcj1
|
\nclass Solution {\n vector<pair<int, int>> resort;\n \n priority_queue<int, vector<int>, greater<int>> nums[10];\n int used[30001];\n int n;\n
|
jt3698
|
NORMAL
|
2020-07-05T04:20:59.986562+00:00
|
2020-07-05T04:58:41.747875+00:00
| 3,176 | false |
```\nclass Solution {\n vector<pair<int, int>> resort;\n \n priority_queue<int, vector<int>, greater<int>> nums[10];\n int used[30001];\n int n;\n int getSum(int index) {\n int sum = 0;\n while (index > 0) { \n sum += used[index];\n index -= index & (-index); \n } \n return sum; \n } \n \n void updateBIT(int index, int val) \n { \n while (index <= n) \n { \n used[index] += val;\n index += index & (-index); \n } \n }\n \npublic:\n string minInteger(string num, int k) {\n memset(used, 0, sizeof(used));\n \n int ctr = 0;\n n = num.size();\n for (int i = 0; i < n; i++) {\n nums[num[i] - \'0\'].push(i + 1);\n }\n string res;\n while (ctr < n && k > 0) {\n for (int i = 0; i <= 9; i++) {\n if (!nums[i].empty()) {\n int cur = nums[i].top();\n \n int holes = getSum(cur - 1);\n int act = cur - holes;\n if (act - 1 <= k) {\n res += (\'0\' + i);\n k -= (act - 1);\n updateBIT(cur, 1);\n nums[i].pop();\n break;\n }\n }\n }\n ctr++;\n }\n \n for(int i = 0; i <= 9; i++) {\n while (!nums[i].empty()) {\n resort.emplace_back(nums[i].top(), i);\n nums[i].pop();\n }\n }\n \n sort(resort.begin(), resort.end());\n for (auto &p : resort) {\n res += (\'0\' + p.second);\n }\n return res;\n }\n};\n```\n\n# General Idea:\nWe greedily take the smallest digit in the range of remaining ```k``` from the current index we are filling (start from 1st position) and swap it all the way left to the current index. We make sure that we have the right updated cost to take a digit by using BIT to store how many digits have been taken to the left of that digit. The actual cost of taking that digit to the current index is its position subtracted by how many digits have been taken to the left of this digit.\n\nThe remaining digts not taken is then put to the back of the answer string.\n\n# Explanation of getting the actual cost of taking a digit and swapping it all the way to the current index:\nWhen there are no swaps done, the cost of taking a digit and swapping it to the first position is its position (subtracted by 1). Say we take the digit in position ```x``` for the first index. When we move to the next index (2nd position), the cost for all digits in front of ```x``` (to the left) is still its position (since they were all shifted right during the swapping and their distance from the current index stays the same). However, all digits to the right of ```x``` will cost less (since the current index is closer by 1, but their positions have not changed). \n\nThis continues for the rest and the actual cost of taking a digit ```x``` to the current index is its position subtracted by how many digits to the left of ```x``` has been taken. We keep track of this efficiently using the Fenwick tree.\n\n# Implementation:\nIn the code above, I first store the positions for each digit in priority queues (Can be done in a vector and sorted after as well). \n\nThen, while I am still taking digits (```ctr < n```) and I still have remaining swaps (```k > 0```), I will look for the smallest affordable digit by looking at each priority queue for each digit, then if the furthest left untaken digit\'s actual cost is affordable, I will take it and update the Fenwick tree.\n\nThe last sorting using ```resort``` empties out the priority queues since they are filled with digits that have not been taken and I will append them to the string according to their positions since their ordering stays the same throughout all the swapping.\n\n
| 23 | 4 |
[]
| 4 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Largest Number Possible After At Most K Swaps
|
largest-number-possible-after-at-most-k-j0mum
|
Hi guys, a solution to this problem is provided here in the link.\nSolution Link:-https://www.pepcoding.com/resources/data-structures-and-algorithms-in-java-lev
|
sanjeevpep1coding
|
NORMAL
|
2020-09-04T11:24:28.001160+00:00
|
2020-09-04T11:24:28.001194+00:00
| 12,925 | false |
Hi guys, a solution to this problem is provided here in the link.\nSolution Link:-https://www.pepcoding.com/resources/data-structures-and-algorithms-in-java-levelup/recursion-and-backtracking/largest-number-at-most-k-swaps-official/ojquestion\nFree resources Link:-https://www.pepcoding.com/resources/online-java-foundation\nYouTube Link:-https://www.youtube.com/channel/UC7rNzgC2fEBVpb-q_acpsmw\nSHARE AND SUBSCRIBE if you LIKE it.\nThanks.
| 16 | 24 |
[]
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
A simple C++ O(n) solution - 100ms
|
a-simple-c-on-solution-100ms-by-user2009-dy4h
|
\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n const int n = num.size();\n string res;\n res.reserve(n);\n
|
user2009j
|
NORMAL
|
2020-07-07T01:30:11.199031+00:00
|
2020-07-07T01:30:11.199140+00:00
| 2,416 | false |
```\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n const int n = num.size();\n string res;\n res.reserve(n);\n vector<int> q(10, n);\n for (int i = 0; i < n; ++i) {\n const int d = num[i] - \'0\';\n if (q[d] == n)\n q[d] = i;\n }\n vector<bool> used(n);\n vector<int> q_used(10);\n for (int i = 0; i < n; ++i) {\n for (int d = 0; d < 10; ++d) {\n if (q[d] == n)\n continue;\n const int c = q[d] - q_used[d];\n \n if (c <= k) {\n k -= c;\n res.push_back(\'0\' + d);\n used[q[d]] = true;\n for (int d1 = 0; d1 < 10; ++d1) {\n if (q[d1] > q[d])\n q_used[d1]++;\n }\n while (q[d] < n) {\n if (used[q[d]])\n ++q_used[d];\n if (num[++q[d]] == \'0\' + d)\n break;\n }\n break;\n }\n }\n }\n return res;\n }\n};\n```
| 16 | 2 |
[]
| 4 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Detailed C++ Segment Tree Solution (88ms, might not be optimal)
|
detailed-c-segment-tree-solution-88ms-mi-uzin
|
Here is my first post on leetcode. I would like to share my segment tree solution to this problem. My time complexity is O(nlognlogn) so it might not be the opt
|
yao_yin
|
NORMAL
|
2020-07-05T06:45:17.421302+00:00
|
2020-07-05T18:39:32.619430+00:00
| 1,643 | false |
Here is my first post on leetcode. I would like to share my segment tree solution to this problem. My time complexity is **O(nlognlogn)** so it might not be the optimal solution.\n\nWell, let us analyze this problem. If we want to construct the mininal number, we need to force the leftmost digit as small as possible. So we can go though the string from left to right, pick the smallest one while the swap operation number does not exceeding the threshold(at first it is **K**). And we do the same operation for the next digit, until we run out our operations.\n\nWe can easily find a O(n^2) algorithm following this idea. But it is not YOUXIU (good) enough, we need to optimize it.\n\nIn general, we use three steps to pick digits from left to right. \n\n1. Calculate the right most index(**1-based**) we can pick in the threshold;\n2. Pick the smallest one(among smallest ones we choose the left most one), and declare that it has been picked so we can not pick it again;\n3. Update the threshold.\n\nWe can use Segment Tree. I won\'t talk about basic knowledge of segment tree(without lazy-tag) in this post, just to show how to use it in this problem.\n\nFirst let\'s talk about the threshold. Threshold here means the largest index that we can pick. We can use the prefix sum to calculate it.\nFor instance,\n```\noriginal string: "1 2 4 3 5 6 7", original k = 3;\nuse/not state: 1 1 1 1 1 1 1 (1: not been used, 0: used);\nprefix sum: 1 2 3 4 5 6 7 ;\n```\nSo the largest index we can pick is 4 = k + 1;\nAnother instance:\n```\noriginal string: "1 4 2 5 6 7", k = 2;\nuse/not state: 0 1 0 1 1 1 (1: not been used, 0: used);\nprefix sum: 0 1 1 2 3 4; \n```\nSo the largest index we can pick is 5 since presum[5] = 3 = k + 1;\n\nAt this point, we can design the tree node;\n```\ntypedef long long ll;\nstruct Node {\n ll l,r;\n ll minv, idx, sum;\n\t/* minv: min value in [l...r] in the original string;\n\t idx: the index of minv;\n\t\tsum: sum of use/not use in [l...r] period;*/\n} tree[4*N];\n```\nAnd we can write the push_up method carefully.\n```\nvoid push_up(Node& a, Node& b, Node & c) {\n // Use information from b and c to update Node a, b.idx is always <= c.idx\n if(b.minv <= c.minv) {\n a.minv = b.minv;\n a.idx = b.idx;\n } else {\n a.minv = c.minv;\n a.idx = c.idx;\n }\n a.sum = b.sum + c.sum;\n}\nvoid push_up(ll u) {\n push_up(tree[u], tree[2*u], tree[2*u+1]);\n}\n```\nWe can use binary search to find the right most idx that we can pick;\n```\nint get_idx(int presum, int len) {\n // O(lognlogn)\n int l = 1;\n int r = len;\n int res = len; // If we can not find it, we should return the last index\n while(l <= r) {\n int mid = (l + r) / 2;\n if(query(1, 1, mid).sum >= presum) {\n res = mid;\n r = mid - 1;\n } else {\n l = mid + 1;\n }\n }\n return res;\n}\n```\nAfter we pick one, we should declare that this number has been picked and we should not pick it again by setting it to 10 and set the use/not use state to 0 and we should update our threshold. Details are in the code.\n\nFull code:\n```\ntypedef long long ll;\nconst int N =30010;\nll w[N];\nll st[N];\n\nstruct Node {\n ll l,r;\n ll minv, idx, sum;\n} tree[4*N];\n\nvoid push_up(Node& a, Node& b, Node & c) {\n if(b.minv <= c.minv) {\n a.minv = b.minv;\n a.idx = b.idx;\n } else {\n a.minv = c.minv;\n a.idx = c.idx;\n }\n a.sum = b.sum + c.sum;\n}\n\nvoid push_up(ll u) {\n push_up(tree[u], tree[2*u], tree[2*u+1]);\n}\n\nvoid build(ll u, ll l, ll r) {\n tree[u].l = l;\n tree[u].r = r;\n if(l == r) {\n ll b = w[l];\n tree[u].minv = b;\n tree[u].idx = l;\n tree[u].sum = st[l];\n } else {\n ll mid = (l + r) / 2;\n build(2*u, l, mid);\n build(2*u+1, mid+1, r);\n push_up(u);\n }\n}\n\nvoid update(ll u, ll idx, ll x) {\n if(tree[u].l == tree[u].r) {\n tree[u].minv = x;\n tree[u].sum = 0;\n st[tree[u].l] = 0;\n } else {\n ll mid = (tree[u].l + tree[u].r)/2;\n if(idx <= mid) update(2*u, idx, x);\n else update(2*u+1, idx, x);\n push_up(u);\n }\n}\n\nNode query(ll u, ll l, ll r) {\n if(tree[u].l >= l && tree[u].r <= r) {\n return tree[u];\n } else {\n ll mid = (tree[u].l + tree[u].r)/2;\n if(l > mid) {\n return query(2*u+1, l, r);\n } else if (r <= mid) {\n return query(2*u, l, r);\n } else {\n auto left = query(2*u, l, r);\n auto right = query(2*u+1, l, r);\n Node res;\n push_up(res, left, right);\n return res;\n }\n }\n}\n\nint get_idx(int presum, int len) {\n int l = 1;\n int r = len;\n int res = len;\n while(l <= r) {\n int mid = (l + r) / 2;\n if(query(1, 1, mid).sum >= presum) {\n res = mid;\n r = mid - 1;\n } else {\n l = mid + 1;\n }\n }\n return res;\n}\n\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n int n = num.size();\n if(k > n*(n-1)/2) {\n sort(num.begin(), num.end());\n return num;\n }\n return solve(num, k);\n }\n void init(string & num) {\n // build the SegTree;\n int n = num.size();\n memset(tree, 0, sizeof tree);\n for(int i = 1; i <= n; i ++) w[i] = num[i-1] - \'0\';\n for(int i = 1; i <= n; i ++) st[i] = 1;\n build(1, 1, n);\n }\n string solve(string & num, int k) {\n init(num);\n string res;\n while(k) {\n int max_sum = min(k+1, (int)num.size());\n int threshold = get_idx(max_sum, num.size());\n Node curr = query(1, 1, threshold);\n if(curr.minv == 10) break;\n res.push_back(curr.minv + \'0\');\n update(1, curr.idx, 10);\n k -= query(1, 1, curr.idx).sum;\n }\n for(int i = 1; i <= num.size(); i ++) {\n if(st[i] == 1) {\n\t\t\t// unused digits\n res.push_back(num[i-1]);\n }\n }\n return res;\n }\n};\n```\nThe time complexity is O(nlognlogn), space complexity is O(n).\nThanks for reading.\n\n\n\n\n
| 15 | 0 |
[]
| 4 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Java] 27ms O(NlogN) Fenwick/BIT solution
|
java-27ms-onlogn-fenwickbit-solution-by-4wszg
|
Had the rough idea during the contest but got stuck at how to update INDEX using BIT. Checked @tian-tang-6\'s answer and this tutorial: https://www.hackerearth.
|
caohuicn
|
NORMAL
|
2020-07-05T07:25:44.599779+00:00
|
2020-07-05T07:25:44.599826+00:00
| 957 | false |
Had the rough idea during the contest but got stuck at how to update INDEX using BIT. Checked @tian-tang-6\'s answer and this tutorial: https://www.hackerearth.com/practice/data-structures/advanced-data-structures/fenwick-binary-indexed-trees/tutorial/, realized that instead of updating INDEX, we should: \n1. Initialize BIT with 1 for all indices, which is the character count;\n2. Update the count to 0 ( count--) when a character at index i is swapped to the beginning.\n\n```\n public String minInteger(String num, int k) {\n char[] cs = num.toCharArray();\n int n = cs.length;\n StringBuilder sb = new StringBuilder();\n IntegerBIT bit = new IntegerBIT(n);\n for (int i = 1; i <= n; i++) {\n bit.update(i, 1);\n }\n Deque<Integer>[] dq = new ArrayDeque[10];\n for (int i = 0; i < 10; i++) {\n dq[i] = new ArrayDeque<>();\n }\n for (int i = 0; i < n; i++) {\n dq[cs[i] - \'0\'].offerLast(i);\n }\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < 10; j++) {\n Integer index = dq[j].peekFirst();\n if (!dq[j].isEmpty() && bit.query(index) <= k) {\n //number of \'1\'s before index is the number of swaps\n k -= bit.query(index);\n //index in string is represented in BIT at index + 1\n bit.update(index + 1, -1);\n dq[j].pollFirst();\n sb.append((char)(\'0\' + j));\n break;\n }\n }\n }\n return sb.toString();\n }\n\n public static class IntegerBIT {\n int n;\n int[] data;\n\n public IntegerBIT(int n) {\n this.n = n;\n data = new int[n + 1];//1 based\n }\n\n /**\n * Queries sum of A[1]..A[x] inclusive. A is the underlying array this BIT represents.\n */\n public int query(int x) {\n int sum = 0;\n for (; x > 0 ; x -= x & (-x)) {\n sum += data[x];\n }\n return sum;\n }\n\n /**\n * Queries sum of A[i]..A[j] inclusive\n */\n public int query(int i, int j) {\n return query(i) - query(j - 1);\n }\n\n /**\n * Updates A[i] by d\n */\n public void update(int i, int d) {\n for (; i <= n; i += i & (-i)) {\n data[i] += d;\n }\n }\n }\n```\n
| 10 | 0 |
['Binary Indexed Tree']
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
My screencast
|
my-screencast-by-cuiaoxiang-gyt8
|
https://www.youtube.com/watch?v=1wjYXKeGtOc
|
cuiaoxiang
|
NORMAL
|
2020-07-05T04:37:36.984462+00:00
|
2020-07-05T04:37:36.984516+00:00
| 925 | false |
https://www.youtube.com/watch?v=1wjYXKeGtOc
| 10 | 1 |
[]
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
C++ Preprocess (120 ms)
|
c-preprocess-120-ms-by-votrubac-f4ig
|
The first function is just a greedy brute-force algorithm that checks for the minimal character within K, and bubbles it up.\n\nIt\'s O(n * n) so you will get T
|
votrubac
|
NORMAL
|
2020-07-05T05:23:52.961720+00:00
|
2020-07-05T12:00:31.027165+00:00
| 2,010 | false |
The first function is just a greedy brute-force algorithm that checks for the minimal character within K, and bubbles it up.\n\nIt\'s O(n * n) so you will get TLE. I saw folks solved it using logarithmic structures, but all I got is this silly idea.\n\nI think that we first need to reduce K. Obviously, if K is large, we would move all zeros, ones, and so on to the front. We can get positions of a given number in one scan, and we do it for each digit `\'0\' - \'9\'`. Note that we need to quit as soon as the next smallest character cannot be moved to the front, and do brute-force for reduced K.\n\n\n```cpp\nstring minInteger(string num, int k) {\n string pre;\n preprocess(pre, num, k);\n while (k > 0 && !num.empty()) {\n auto pos = 0;\n for (auto i = 1; i < num.size() && i <= k; ++i)\n if (num[i] < num[pos]) \n pos = i;\n pre += num[pos];\n k -= pos;\n num = num.substr(0, pos) + num.substr(pos + 1);\n }\n return pre + num;\n}\nvoid preprocess(string &pre, string &num, int &k) {\n for (auto n = \'0\'; n < \'9\'; ++n) {\n vector<int> pos;\n for (auto i = 0; i < num.size(); ++i)\n if (num[i] == n)\n pos.push_back(i);\n if (!pos.empty() && k < pos[0])\n break;\n int cnt = 0; \n for (auto i = 0; i < pos.size() && pos[i] <= k + cnt; ++i) {\n k -= pos[i] - cnt;\n ++cnt; \n }\n pre += string(cnt, n);\n string num1;\n for (auto ch : num) {\n if (ch == n && cnt > 0)\n --cnt;\n else\n num1 += ch;\n }\n swap(num, num1);\n }\n}\n```
| 9 | 2 |
[]
| 3 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
C++ | O(NlogN) | Binary Search with logic
|
c-onlogn-binary-search-with-logic-by-agr-t0q6
|
\n```\n/ \nWe take 10 queues for digits 0 to 9 and store their occurence(index in the original string) in the queues (clearly all the queues are sorted by defau
|
agrims
|
NORMAL
|
2020-09-03T12:00:08.086061+00:00
|
2020-09-03T12:01:45.392230+00:00
| 1,466 | false |
\n```\n/** <Greedy Approach>\nWe take 10 queues for digits 0 to 9 and store their occurence(index in the original string) in the queues (clearly all the queues are sorted by default) \nNow we want the most significant digit to be the smallest so we try all the 0-9 digits at position i .\nSuppose we want to place any digit j in range [0,9] at a position i we do a binay search on all the 10 queues to find the number of digits \nwith index smaller than the current chosen digits index then we will check if the swaps are less than or equal to the current k value if yes\nwe put the current digit in new string and go for the (i+1)th place else we will continue to check for digit j+1 .\nBelow is the implementation\n*/\nint bs(vector<int> &v,int l,int r,int key){\n\n if(l>r) return l;\n int mid=l+(r-l)/2;\n\n if(v[mid]>key) return bs(v,l,mid-1,key);\n return bs(v,mid+1,r,key);\n}\nstring minInteger(string num, int k) {\n int n=num.size();\n\t //trivial case\n if(k>=(n*(n-1))/2){\n sort(num.begin(),num.end());\n return num;\n }\n\t //queues\n vector<vector<int> >v(10);\n for(int i=0;i<n;++i){\n v[num[i]-\'0\'].push_back(i);\n }\n\t //head for every queue to store the queue state\n vector<int> head(10);\n string ans="";\n vector<bool> visit(n);\n for(int i=0;i<n && k>0;++i){\n for(int j=0;j<10;++j){\n\n if(head[j]<v[j].size()){\n\n\t\t\t\t// total count of digits with smaller index than the current chosen digit\n int idx=0;\n\t\t\t\t//binary search on all the 10 queues\n for(int l=0;l<10;++l){\n if(l!=j){\n idx+=bs(v[l],0,head[l]-1,v[j][head[j]]);\n }\n else\n idx+=head[l];\n }\n// cout<<k<<" "<<idx<<" "<<j<<"\\n";\n if(k>=(v[j][head[j]]-idx)){\n\n ans.push_back((char)(j+\'0\'));\n visit[v[j][head[j]]]=true;\n k-=(v[j][head[j]]-idx);\n ++head[j];\n break;\n }\n }\n }\n }\n\t// appending the remaining string\n for(int i=0;i<n;++i) if(!visit[i]) ans.push_back(num[i]);\n \n return ans;\n\n}
| 6 | 0 |
[]
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Beats 100% on memory [EXPLAINED]
|
beats-100-on-memory-explained-by-r9n-hozw
|
Intuition\nThe problem involves rearranging digits of a number to form the smallest possible integer by making at most k adjacent swaps.\n\n# Approach\nThe appr
|
r9n
|
NORMAL
|
2024-09-26T18:38:04.455133+00:00
|
2024-09-26T18:38:04.455162+00:00
| 35 | false |
# Intuition\nThe problem involves rearranging digits of a number to form the smallest possible integer by making at most k adjacent swaps.\n\n# Approach\nThe approach is to iteratively find the smallest digit within the range allowed by k, bring it to the current position, and repeat this process until k is exhausted or all positions are processed.\n\n# Complexity\n- Time complexity:\nO(n2) in the worst case, where n is the length of the number.\n\n- Space complexity:\nO(n) for storing the digits.\n\n# Code\n```csharp []\npublic class Solution {\n public string MinInteger(string num, int k) {\n char[] digits = num.ToCharArray();\n int n = digits.Length;\n\n for (int i = 0; i < n && k > 0; i++) {\n // Find the smallest digit within the next k positions\n int minIndex = i;\n for (int j = i + 1; j < n && j <= i + k; j++) {\n if (digits[j] < digits[minIndex]) {\n minIndex = j;\n }\n }\n\n // If a smaller digit is found, move it to the front\n if (minIndex != i) {\n // The number of swaps needed to move the minIndex to the current position\n int swapsNeeded = minIndex - i;\n if (swapsNeeded <= k) {\n // Perform the swaps\n char minChar = digits[minIndex];\n for (int j = minIndex; j > i; j--) {\n digits[j] = digits[j - 1];\n }\n digits[i] = minChar;\n \n // Decrease k by the number of swaps performed\n k -= swapsNeeded;\n }\n }\n }\n\n return new string(digits);\n }\n}\n\n```
| 5 | 0 |
['C#']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Python. Straight Forward Short Greedy Algorithm.
|
python-straight-forward-short-greedy-alg-0sq3
|
A greedy approach will do the job.\nIterate the index i from the left to right. Each iteration do a swap in a greedy way, i.e. swap num[i] with the smallest num
|
caitao
|
NORMAL
|
2020-07-05T19:05:24.560186+00:00
|
2020-07-05T19:06:36.165209+00:00
| 664 | false |
A greedy approach will do the job.\nIterate the index i from the left to right. Each iteration do a swap in a greedy way, i.e. swap num[i] with the smallest number within num[i+1:]\n\n```\nclass Solution:\n \'\'\' greedy approach. start from the left side, \n\t and everytime pick the smallest number on the right side that is able to swap, then do the swap\n \'\'\'\n def minInteger(self, num: str, k: int) -> str:\n min_num = sorted(list(num))\n min_num = \'\'.join(min_num)\n i = 0\n to_find = 0\n while num != min_num and k > 0 and i < len(num):\n indx = num.find(str(to_find), i)\n while indx != -1:\n if indx - i <= k: # able to swap\n num = num[:i] + num[indx] + num[i:indx] + num[indx+1:] # the swap\n k -= (indx - i)\n i += 1\n to_find = 0 # restart the to_find variable\n indx = num.find(str(to_find), i)\n else:\n break\n to_find += 1\n return num\n```
| 5 | 0 |
[]
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Java][NlogN][Binary Tree]
|
javanlognbinary-tree-by-mayank12559-afl0
|
Store indexes of all digits in a list.\n Start putting from 0 to 9 whichever satisfy the condition first.\n Condition is satisfied if number of swaps remaining
|
mayank12559
|
NORMAL
|
2020-07-05T04:18:37.992710+00:00
|
2020-07-05T04:34:21.390867+00:00
| 1,023 | false |
* Store indexes of all digits in a list.\n* Start putting from 0 to 9 whichever satisfy the condition first.\n* Condition is satisfied if number of swaps remaining (k) >= number of swaps required (val - count) => `k >= val - count`\n* `val = index of the digit`\n* ` count = number of elements used before that index`\n* To find the number of elements used , maintain a Binary Tree with left count.\n\n\n\n\n```\nclass Solution { \n class TreeNode{\n TreeNode left;\n TreeNode right;\n int val;\n int leftcount;\n TreeNode(int val){\n this.val = val;\n }\n }\n int count;\n public String minInteger(String num, int k) {\n int n = num.length();\n List<Integer> al[] = new ArrayList[10];\n for(int i=0;i<10;i++){\n al[i] = new ArrayList();\n }\n for(int i=n-1;i>=0;i--){\n al[num.charAt(i) - 48].add(i);\n }\n Set<Integer> hs = new HashSet();\n StringBuilder sb = new StringBuilder("");\n TreeNode root = null;\n while(n-- > 0 && k > 0){\n for(int ind=0;ind<10;ind++){\n if(al[ind].size() == 0){\n continue ;\n }\n int val = al[ind].get(al[ind].size()-1);\n count = 0;\n search(root, val);\n if(k >= val - count){\n sb.append(ind);\n root = add(root, val);\n al[ind].remove(al[ind].size()-1);\n hs.add(val);\n k -= val-count;\n break ;\n }\n }\n }\n for(int i=0;i<num.length();i++){\n if(!hs.contains(i)){\n sb.append(num.charAt(i));\n }\n }\n return sb.toString();\n }\n \n private void search(TreeNode root, int val){\n if(root == null){\n return ;\n }\n if(val < root.val){\n search(root.left, val);\n }else{\n count += 1+root.leftcount;\n search(root.right, val);\n }\n }\n \n private TreeNode add(TreeNode root, int val){\n if(root == null){\n return new TreeNode(val);\n }\n if(val < root.val){\n root.left = add(root.left, val);\n root.leftcount += 1;\n }else{\n root.right = add(root.right, val);\n }\n return root;\n }\n}\n```
| 5 | 1 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Java TreeMap headMap().size() Time complexity is not O(1)
|
java-treemap-headmapsize-time-complexity-18q2
|
I was surprised that no one consider using treemap at first, but found out I didn\'t quite understand the time complexity of treemap api.\nImplemente the idea o
|
wooohs
|
NORMAL
|
2020-10-22T23:25:33.822721+00:00
|
2020-10-22T23:27:24.326711+00:00
| 906 | false |
I was surprised that no one consider using treemap at first, but found out I didn\'t quite understand the time complexity of treemap api.\nImplemente the idea of this [post](https://leetcode.com/problems/minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits/discuss/720548/O(n-logn)-or-Detailed-Explanation) using treemap, but got TLE\n\nheadMap().size() complexity is O(k) not O(1): https://stackoverflow.com/questions/14750374/what-is-complexity-of-size-for-treeset-portion-view-in-java\n\n```\n public String minInteger(String num, int k) {\n Queue<Integer>[] qArr = new ArrayDeque[10];\n char[] arr = num.toCharArray();\n int n = num.length();\n \n for (int d = 0; d < 10; d++) {\n qArr[d] = new ArrayDeque<>();\n }\n \n for (int i = 0; i < n; i++) {\n qArr[arr[i] - \'0\'].offer(i);\n }\n TreeSet<Integer> treeSet = new TreeSet<>();\n \n StringBuilder res = new StringBuilder();\n for (int i = 0; i < n; i++) {\n for (int d = 0; d < 10; d++) {\n Queue<Integer> q = qArr[d];\n if (q.isEmpty()) {\n continue;\n }\n int idx = q.peek();\n int numLessOrEqual = treeSet.headSet(idx).size();\n int requiredSteps = idx - numLessOrEqual; \n if (k >= requiredSteps) {\n q.poll();\n k -= requiredSteps;\n res.append(d);\n treeSet.add(idx);\n break;\n }\n }\n }\n \n return res.toString();\n \n }\n```
| 4 | 0 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
EASY CPP || SLIDING WINDOW
|
easy-cpp-sliding-window-by-beenbuggy-7k7x
|
\n\n# Code\n\nclass Solution {\npublic:\n string minInteger(string a, int k) {\n int n=a.length();\n int req=(n+1)*n/2; // upper limit fo
|
SprihaAnand
|
NORMAL
|
2023-08-06T08:59:10.582913+00:00
|
2023-08-06T08:59:10.582937+00:00
| 603 | false |
\n\n# Code\n```\nclass Solution {\npublic:\n string minInteger(string a, int k) {\n int n=a.length();\n int req=(n+1)*n/2; // upper limit for the number of swaps that is also less than 10^9 lowering our time complexity\n if(k>req){ // that means we can try all swaps so returning minimum of all these by sorting \n sort(a.begin(),a.end()); \n return a;\n }\n for(int i=0;i<n-1 && k>0;i++){\n //iterate in a window of size k \n int pos=i;\n int j;\n for(j=i+1;j<n;j++){\n //out of window bound\n if(j-i>k){break;}\n //else if we actually wanna swap, we do\n if(a[j]<a[pos]){pos=j;}\n }\n //now assuming we swapped we have pos=j\n char temp;\n for(j=pos;j>i;j--){\n //we are swapping a[j] and a[j-1] finally we will have a[pos] swapped with a[i]\n temp=a[j];\n a[j]=a[j-1];\n a[j-1]=temp;\n }\n //now update k value and do over if we wanna change the second most significant element to\n k-=pos-i;\n }\n return a;\n }\n};\n```
| 3 | 0 |
['C++']
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[python] 3 solutions with thought process when being asked during interviews
|
python-3-solutions-with-thought-process-ax73f
|
Binary Search\nIn order to construct the minimum number, we want to find the minimum digit within the window of size of k, which determine the range of digits t
|
jandk
|
NORMAL
|
2021-08-07T16:34:28.434083+00:00
|
2021-08-08T02:04:32.251058+00:00
| 471 | false |
### Binary Search\nIn order to construct the minimum number, we want to find the minimum digit within the window of size of *k*, which determine the range of digits that can be moved.\nThe naive solution I came up first is to find out the minimum digit adhoc, which takes many unnecessary comparision. Because the digit is limited from 0 to 9, we can iterate from 0 to 9 to pick the first digit that is within the window. \nThe key point is that the index of digits after the moved one have to be updated accordingly after moving. For example, `4203 => 0423`, the index of `3` changed from `3` to `2` since we won\'t consider `0` by excluding it. In another word, the *num* bacomes `423`. However, all digits before `0` are not changed. \nSo each time we get the index of digit from 0 to 9, we have to update it with the *offset* that is the number of moved digits that appear before it.\nSo we can use binary search to find the number of moved indices that is smaller than each index we want to pick. If the `index - offset <= k`, we can pick that digit and move on to next digit.\nOne improvement is that we can quickly return the sorted *num* if *k* is larger than *n^2* since the complexity is O(N^2) for sorting algorithm based on comparision. Then we can append each digit from 0 to 9 instead of actual sorting it, which takes linear time.\n\n```python\ndef minInteger(self, num: str, k: int) -> str:\n\tn = len(num)\n num = list(num)\n res = []\n\n counter = defaultdict(deque)\n for i, c in enumerate(num):\n\t\tcounter[int(c)].append(i)\n\tif k >= n**2:\n\t\treturn \'\'.join(sorted(num))\n\n\tused = []\n for _ in range(n):\n\t\tfor i in range(10):\n\t\t\tif counter[i]:\n\t\t\t\tindex = counter[i][0]\n offset = bisect.bisect_left(used, index)\n if index - offset <= k:\n\t\t\t\t\tk -= index - offset\n res.append(i)\n used.insert(offset, counter[i].popleft())\n break\n\treturn \'\'.join(map(str, res))\n```\nNote, since `insert` takes linear time, the complexity is actual N^2, while it\'d be NlgN if you use SortedList or Binary Search Tree.\n\n*Time Complexity* = **O(NlgN)**\n*Space Complexity* =**O(N)**\n\n### Binary Indexed Tree\nThe idea is the same, but with a different data structure, binary indexed tree, to query the number of indices of moved digits that is smaller than current index. Binary Indexed Tree is more balanced natually than binary search tree written by manually. \nActually, BIT is quite easy to wirte and use if you are familiar with the template of BIT.\n\n```python\ndef minInteger(self, num: str, k: int) -> str:\n\tn = len(num)\n num = list(num)\n res = []\n\n counter = defaultdict(deque)\n for i, c in enumerate(num):\n\t\tcounter[c].append(i)\n\tif k >= n**2:\n\t\treturn \'\'.join(sorted(num))\n\n\t# bit template, will always be the same when you use it\n\tbit = [0] * (n + 1)\n def query(i):\n\t\ttotal = 0\n while i:\n\t\t\ttotal += bit[i]\n i -= i & -i\n\t\treturn total\n \n\tdef update(i, value):\n\t\twhile i < len(bit):\n\t\t\tbit[i] += value\n\t\t\ti += i & -i\n\n\tfor _ in range(n):\n\t\tfor i in \'0123456789\':\n\t\t\tif counter[i]:\n\t\t\t\tindex = counter[i][0]\n offset = query(index)\n if index - offset <= k:\n\t\t\t\t\tk -= index - offset\n res.append(i)\n counter[i].popleft()\n update(index + 1, 1)\n break\n\treturn \'\'.join(res)\n```\n\n### Segment Tree\nSame idea with different data structure, the only difference between Segment Tree and Binary Indexed Tree here is Segement Tree is more flexible supporting customized merge function, such as range minimum/maximum/sum, while BIT supports limited functions, most of cases is sum. for this problem, both works.\n```python\ndef minInteger(self, num: str, k: int) -> str:\n\tn = len(num)\n num = list(num)\n res = []\n\n counter = defaultdict(deque)\n for i, c in enumerate(num):\n\t\tcounter[c].append(i)\n\tif k >= n**2:\n\t\treturn \'\'.join(sorted(num))\n\n\t# segment tree template, modify for use cases\n\theight = ceil(log(n, 2))\n leaf = 2 ** height - 1\n st = [0] * (2 ** (height + 1) - 1)\n \n def query(i, j):\n\t\ti, j = i + leaf, j + leaf\n total = 0\n while i <= j:\n\t\t\tif not i % 2:\n\t\t\t\ttotal += st[i]\n i += 1\n\t\t\tif j % 2:\n\t\t\t\ttotal += st[j]\n j -= 1\n\t\t\ti = (i - 1) // 2\n j = j // 2 - 1 \n\t\treturn total\n \n\tdef update(i, value):\n\t\ti += leaf\n while i >= 0:\n\t\t\tst[i] += value\n if i % 2:\n\t\t\t\ti = (i - 1) // 2\n\t\t\telse:\n\t\t\t\ti = i // 2 - 1\n \n\tfor _ in range(n):\n\t\tfor i in \'0123456789\':\n\t\t\tif counter[i]:\n\t\t\t\tindex = counter[i][0]\n offset = query(index)\n if index - offset <= k:\n\t\t\t\t\tk -= index - offset\n res.append(i)\n counter[i].popleft()\n update(index + 1, 1)\n break\n\treturn \'\'.join(res)\n```\n\n\n
| 3 | 0 |
[]
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Java super easy Insertion Sort O(N^2) w/ explanation
|
java-super-easy-insertion-sort-on2-w-exp-aupf
|
In the window of length k, the optimal solution is when the smallest integer in the window is occupying the MSB. So, for each position, find the minimum element
|
varkey98
|
NORMAL
|
2020-08-27T18:38:36.370419+00:00
|
2020-08-27T19:01:32.121652+00:00
| 635 | false |
In the window of length k, the optimal solution is when the smallest integer in the window is occupying the MSB. So, for each position, find the minimum element in that window, perform the swaps and update the MSB.\n```\npublic String minInteger(String num, int k) \n{\n\tchar[] arr=num.toCharArray();\n\tint n=arr.length;\n\tfor(int i=0;i<n;++i)\n\t{\n\t\tint pos=i;\n\t\tfor(int j=i+1;j<n&&j<=i+k;++j)\n\t\t\tif(arr[pos]>arr[j])\n\t\t\t\tpos=j;\n\t\tchar temp=arr[pos];\n\t\twhile(pos!=i)// the swaps are being performed.\n\t\t{\n\t\t\tarr[pos]=arr[pos-1];\n\t\t\t--k;\n\t\t\t--pos;\n\t\t}\n\t\tarr[pos]=temp;\n\t}\n\treturn new String(arr);\n}\n\t```
| 3 | 0 |
['Java']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python] O(n) 10 deques with 1 stack
|
python-on-10-deques-with-1-stack-by-yupi-n14f
|
Idea\n\nThe first digit of the output should be the minimum of the first k + 1 digits in num, i.e., min(num[:k+1]). Similarly, the i-th digit of the output shou
|
yupingso
|
NORMAL
|
2020-07-14T09:00:57.395980+00:00
|
2020-07-15T10:02:21.394370+00:00
| 427 | false |
# Idea\n\nThe first digit of the output should be the minimum of the first `k + 1` digits in `num`, i.e., `min(num[:k+1])`. Similarly, the `i`-th digit of the output should be `min(num[i:i+k+1])`, where we assume\n* The digits of `num` are swapped in-place. That is, `num[:i]` are already the first `i` digits of the output.\n* `k` is the remaining number of moves, which decreases as more and more digits are swapped.\n\nIf we swap digits one by one, we will end up with a `O(n^2)` algorithm because there will be a maximum of `O(n^2)` swaps needed. Therefore, we need a more efficient way to swap the digits.\n\nInstead of actually swapping *adjacent* digits, assume we store all the digits of interest (`num[i:i+k+1]`) as a **sequence** in a data structure `D`, which supports the following 4 operations:\n1. `push(x)`: Push `x` to the end of `D`.\n2. `pop()`: Pop the last element of `D`.\n3. `pop_min()`: Pop the minimum digit in `D`. If there are multiple ones, return the first one.\n4. `get_min_position()`: Get the position of the minimum digit in `D`. Here the *position* is the 0-based index in the sequence.\n\nThen, we can solve the problem this way.\n\n```py\ndef minInteger(self, num: str, k: int) -> str:\n data = D() # Empty sequence\n output = \'\' # Output string\n for i in range(len(num)):\n\t # Make sure data contains the (k + 1) digits of interest\n\t while data.count < k + 1:\n\t\t x = next_digit_in_num()\n\t\t data.push(x)\n\t\twhile data.count > k + 1:\n\t\t data.pop()\n\t\t# data.get_min_position() is the number of swaps to move the minimum digit to\n\t\t# the desired position (output[i])\n\t\tk -= data.get_min_position()\n\t\t# Find the minimum number in data\n\t\tx = data.pop_min()\n\t\t# x is the i-th digit of output\n\t\toutput += x\n\treturn output\n```\n\nBy `next_digit_in_num()`, we mean to find the first digit in `num` which is neither in `output` nor `data`.\n\n# Achieving O(n)\n\nThe remaining question is how to implement `D` efficiently. It\'s easier to explain with an example. Suppose in some iteration `data` contains `[1, 0, 2, 1, 0]`. We store 2 attributes for each element `x` in `data`:\n* `x.index`: The index of `x` in the input string `num`.\n* `x.moves`: The number of elements preceding `x` in `data` that are **greater than** `x`. It will become clear later why this is called *moves*.\n\nSince there are only 10 possible digits (`0` to `9`), we can store these elements in 10 lists, one per digit:\n```py\n# The tuples stand for (index, moves)\ndigits[0] = [(1, 1), (4, 3)]\ndigits[1] = [(0, 0), (3, 1)]\ndigits[2] = [(2, 0)]\n...\n```\n\nThis way, all the 4 operations of `D` can be done in `O(1)` time.\n1. `push(x)`: To calculate `x.moves`, we only need to count the total number of elements in `digits[x+1]`, ..., `digits[9]`. Then, simply append `x` as well as its index to `digits[x]`.\n2. `pop()`: Compare the last element of `digits[x]` for `x in range(10)` and pop the one with minimum index.\n3. `pop_min()`: Find the minimum `x` with non-empty `digits[x]` and remove the first element of `digits[x]`. **Note that we don\'t need to update any `moves` attributes of the remaining elements in `data`**, because all the elements after `x` should be greater than or equal to `x`.\n4. `get_min_position()`: Find the minimum `x` with non-empty `digits[x]`, and return `x.moves`. **`x.moves` will be exactly its position in the sequence** because all the elements preceding `x` should be greater than `x`. In other words, `x.moves` is the **number of moves** required to swap `x` all the way to the front of the sequence.\n\n# Complete code\n\n```py\nfrom collections import deque, namedtuple\n\nDigit = namedtuple(\'Digit\', [\'index\', \'moves\'])\n\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n n = len(num)\n remain_num = [(i, ord(x) - ord(\'0\')) for i, x in enumerate(num)][::-1]\n digits = [deque() for _ in range(10)]\n count = 0 # Number of elements in digits\n output = []\n for _ in range(n):\n # Ensure digits has (k + 1) elements (unless insufficient)\n while remain_num and count < k + 1:\n index, x = remain_num.pop()\n # moves: Number of elements before x that are greater than x\n moves = sum(map(len, digits[x+1:])) \n digits[x].append(Digit(index, moves))\n count += 1\n while count > k + 1:\n # Find digit with maximum index\n d = max((digit[-1], i) for i, digit in enumerate(digits) if digit)[1]\n x = digits[d].pop()\n remain_num.append((x.index, d))\n count -= 1\n # Find the minimum element in the list\n d = min(i for i, digit in enumerate(digits) if digit)\n x = digits[d].popleft()\n count -= 1\n k -= x.moves\n output.append(d)\n return \'\'.join(chr(ord(\'0\') + d) for d in output)\n```\n\n# Analysis of time complexity\n\nLet `r1[i]` and `r2[i]` be the number of iterations of the first and second while loop, in the `i`-th iteration of the for loop. We will show that `sum(r1) + sum(r2) = O(n)`, where `n` is the length of the input string `num`.\n\nIn the first iteration of the for loop (`i = 0`), since `k >= 1`, `r1[0] = k + 1` and `r2[0] = 0`.\n\nTo find the upper bound of `r1[i]` and `r2[i]` for `i > 0`, we need to define some terms first. Let `T0[i]` be the moment right before entering the `i`-th iteration of the for loop, and `T1[i]` be the moment at the end of the `i`-th iteration. We use `k[i]` to denote the value of `k` in the code at `T0[i]`, and similarly `count[i]` for the value of `count` at `T0[i]`.\n\nNow assume `i > 0`. Observe that if `count[i] <= k[i] - 1`, then `count` must be no greater than `k` *right before `digits[d].popleft()` is called in the previous iteration*, which means that `remain_num` must be empty in previous iteration, and hence in `T0[i]`. This observation shows that we either have `count[i] >= k[i]` or `remain_num` is empty in `T0[i]`, which proves that `r1[i] <= 1` for all `i > 0`. Therefore, `sum(r1) <= n`.\n\nIn `T1[i-1]`, it\'s clear that `count <= k` (because of the `count -= 1`), which is equivalent to `count[i] <= k[i-1]`. As a result,\n```py\n(*) r2[i] <= count - (k[i] + 1)\n <= k[i-1] - (k[i] + 1)\n```\n\nNow we claim that `sum(r2) <= 2n`. Let `j` be the minimum `i` with `k[i] < n - 1`. If such `i` doesn\'t exist, then `r2[i] = 0` for all `i > 0` (because `count` is always at most `n`) and we\'re done. Otherwise, by `(*)`,\n```py\nsum(r2[j+1:n]) <= k[j] - k[n-1] - 1 <= k[j] <= n\n```\nCombining all the results,\n```py\nsum(r2) = r2[0] + sum(r2[0:j]) + r2[j] + sum(r2[j+1:n])\n = r2[j] + sum(r2[j+1:n])\n <= n + n\n```\nwhich proves the claim.
| 3 | 0 |
[]
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python] O(N*log(N)) BinarySearch solution
|
python-onlogn-binarysearch-solution-by-k-vg8s
|
In this post I will focus on stepping through my thought process in solving this question and only post the full solution at the end. So a word of warning: long
|
k0dl3
|
NORMAL
|
2020-07-11T08:20:07.677510+00:00
|
2020-07-11T08:20:07.677556+00:00
| 277 | false |
In this post I will focus on stepping through my thought process in solving this question and only post the full solution at the end. So a word of warning: **long post**. But hopefully some may find this useful :) You can also practice implementing after reading analysis instead of refering to the full solution.\n\n**Initial Analysis**\n1) Understand the questions first, realize that *optimal is just the sorted array of digits given* and that greedily making permissible moves of smallest digit to the front will always be optimal. I.e. no movement of digits near the end of the number will yield as large a decrease as *decreasing the leading (leftmost) digit*.\n2) Look for bounds, `1 <= num.length <= 30000`, and `1 <= k <= 10^9` suggests we cannot use O(k) solution and need faster than O(N^2) to AC. The bounds also give some hints to what\'s permissible in solution, in this case, O(N\\*log(N)) will be ok. (And generally is the case except for very large bounds, hard to distinguish between O(N) vs O(N\\*log(N)) solution timings - unless you\'re using python T.T)\n\n**First-pass *(horribly wrong)***\n- Insight 1: Index of digit determines least number of swaps needed to move it to the front\n- Insight 2: Number of digits moved before will decrease this cost proportionately (wrong)\n- So we can do *O(N)* scan while keeping counter for number of previously moved digits?\n- Since we need to move smaller digits first, if we have a sorted list of digits by index per digit, then doing repeated greedy scans from `0` to `9` always picking from smaller digit first will give us the order of digits to move? (also actually wrong)\n- That\'s not too bad, we can init queues for each digit type and push index of each digit as we encounter them by scanning through `num` once with O(N) time and space (number of digit types is constant) then pop them as we consider each digit O(1) time.\n\n*code, code, code, Run, Failed!* :O\n\n**Ofc, LC-hard, not so easy - Second Try**\n- Does not pass first test case, seems like we are missing caveat from Insight 1&2. Not the case that number of digits previously moved discounts the next move proportionately, rather:\n- Insight 3: Number of digits with indices smaller than current digit\'s index will discount number of swaps to move current digit to front\n- So we have to not only keep track of how many moves-to-front we\'ve made but at which indices we\'ve made them from\n- Naive Solution:\n - Keep list of moved digit indices\n - Scan through list when computing next move feasibility (cost) and count number of smaller indices for discount\n - O(N) scan per digit => O(N^2) overall, TLE (oops)\n- Have to think of better way to store and lookup number of indices smaller than current\n - This is the actual issue in this problem\n\n**Abstract the problem a bit -> Reduce to a familiar classic problem**\n- Given a list of numbers, find how many are smaller than a given query\n- We have a time-budget of O(log(N)) -> What algos do we know that can do this? BinarySearch\n- Problem: BinarySearch only works when the given list of numbers are already sorted.\n - Time cost incurred to sort again: O(N\\*log(N)) => TLE\n- **Insight 4** (what needed to click for me to solve this):\n - Instead of thinking of *the* (single) list of previously moved digits, we know that the order in which we move a certain type of digit (say all `0`s moved so far) have strictly increasing indices!\n - In other words, we already have 10 sorted lists of previously moved indices and we can just do multiple searches for each type of digit previously moved and take the sum as total \'discount\' for currently considered move.\n - If we just store a \'taken\' index for which index we have already taken for this digit type and increment this each time we move a digit to the front rather than using queues, we can reuse sorted arrays for each digit type with `digit[i][:taken[i]+1]` (this store indices of previously moved digits of type `i`)\n- Time analysis:\n - 10\\*O(log(N)) ~ O(log(N)) => AC :) at least on time\n\n**Yay! AC?**\n- Nope...\n- Failed Testcase:\n - "294984148179"\n11\n- Output:\n - "124499488179"\n- Expected:\n - "124498948179"\n- Notice that in this case, our solution chose to move the third \'4\' rather than the first \'8\' ahead by 1 position\n- Stepping through algo to debug:\n - We notice that after [1244]99848179, we move \'up\' (retain) \'9\' in what\'s currently at index 5, thereafter, as per our greedy strategy, we look for more digits of type \'9\' to move, which is in the next position, and so we end up with [124499]848179 and then restart from \'0\' and end up moving \'4\' up one position since with `k=1` left, that is the next most optimal choice we have\n- Insight 5 (last one, I promise): When it is impossible to move up any digit smaller than at the current index, we need to consider moving smaller digits into the next position instead and restart from \'0\'\n- With this last modification, our solution will restart the greedy scan from \'0\' after [12449]9848179 and consider moving up \'8\' with the last swap instead of retaining \'9\' and moving \'4\'.\n- But does this restart hurt our time?\n - Each time we choose to move a digit, we reduce the number of digits we have to look at by 1\n - For each choice of digit movement, we consider moving up at most 10 digits (0-9 and only if our current digit is 9) and to compute each digit\'s cost, we do at most 10\\*O(log(N))\n - Worst case: 100\\*O(log(N)) per digit in given `num` string ~ O(N\\*log(N)) time complexity, should be ok.\n- AC :D\n\nThanks for reading, hopefully stepping through my approach was helpful to some of you!\n\n**TL;DR:** realize we need to find how many digits we\'ve moved prior (smaller than) current digit\'s index in O(log(N)) time, use BinarySearch, problem: sorted array of previously moved digits\' index? No problem, we are already picking them in sorted order for each type `0-9`, just whack with 10xBinarySearch, still asymptotically overall O(N\\*log(N)) solution => AC :)\n\n**A bit lengthly solution, but with comments and debugging output to help with understanding**\n```python\n# Turn on for debugging output\nDEBUG = False\n\n# Generic binary search to return insertion index\ndef binarySearch(arr, s, t, n):\n m = (s+t)//2\n if (s == t):\n return s\n if (arr[m] > n):\n return binarySearch(arr, s, m, n)\n else:\n return binarySearch(arr, m+1, t, n)\n \nclass Solution:\n def __init__(self):\n self.digits = dict()\n self.taken = [-1 for i in range(10)]\n \n # Compute how much it costs to move this digit to the front\n def cost(self, cur):\n discount = 0\n\t\t# Sum previously moved digits with index less than cur for each type\n for i in range(10):\n discount += binarySearch(self.digits[i], 0, self.taken[i]+1, cur)\n\t\t\t\n if (DEBUG):\n if (self.taken[i] >= 0):\n print(f"{i}: [{self.digits[i][:self.taken[i]+1]}] search:{cur} discount:{binarySearch(self.digits[i],0,self.taken[i]+1,cur)}")\n return cur - discount\n \n def minInteger(self, num: str, k: int) -> str:\n if (DEBUG):\n print(f"Testcase: [{num}] k={k}")\n \n # Keep sorted arrays (by index) for each occurance of digits\n self.digits = {i:[] for i in range(10)}\n for i,n in enumerate(num):\n self.digits[int(n)].append(i)\n \n extracted = set()\n head = "" # constructed \'front\' of string\n \n # Terminating conditions:\n # 1) No more swaps left\n # 2) We have sorted our array\n while k > 0 and len(head) < len(num):\n i = 0\n # Scan each digit occurances from smalled (0) to largest (9) in order\n # to greedily make best permissible moves to front\n while i < 10:\n # Sanity check that we still have digits not yet moved to front\n while k > 0 and len(self.digits[i]) and self.taken[i]+1 < len(self.digits[i]):\n # Get number of swaps to move current digit to front\n\t\t\t\t\tcurCost = self.cost(self.digits[i][self.taken[i]+1])\n \n if (DEBUG):\n print(f"move to head:{i}@{self.digits[i][self.taken[i]+1]} cost: {curCost}")\n \n # If we can move this digit, move it\n if (curCost <= k):\n self.taken[i] += 1\n k -= curCost\n extracted.add(self.digits[i][self.taken[i]])\n head += str(i)\n \n if (DEBUG):\n print(f"[{head}]",end="")\n for j in range(len(num)):\n if j in extracted:\n continue\n print(num[j],end="")\n print(f" k={k}")\n # Otherwise, no further digit of this kind could possible be moved\n # since our self.digits[i] array is sorted (move onto the next digit)\n else:\n break\n # When we move a digit \'for free\', we reset our search as a previously seen\n # not-possible but more optimal (smaller) digit could now be moved to front\n if (curCost == 0):\n i = 0\n # remember to increment our search onto the next smallest digit\n i += 1\n \n # Parse and output final answer\n for i in range(len(num)):\n if i in extracted:\n continue\n head += num[i]\n return head\n```
| 3 | 1 |
[]
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
C++ easy solution
|
c-easy-solution-by-klimkina-h4iu
|
\nclass Solution {\npublic:\n void helper(char *array, int k, int start, int n){\n if (k == 0 or start >= n) // no moves left, done modifying the stri
|
klimkina
|
NORMAL
|
2020-07-05T15:28:12.449918+00:00
|
2020-07-05T15:28:12.449943+00:00
| 398 | false |
```\nclass Solution {\npublic:\n void helper(char *array, int k, int start, int n){\n if (k == 0 or start >= n) // no moves left, done modifying the string\n return; \n int min_idx = start; // position of the closest min digit within k\n for(int i = start+1; i < min(n, start + k + 1); i++)\n if (array[i] < array[min_idx])\n min_idx = i;\n\t\t// found a smaller digit within k steps\n if (min_idx > start){ \n char temp = array[min_idx]; // memorize the min\n for(int j = min_idx; j > start; j--) //shift all digits\n array[j] = array[j-1];\n array[start] = temp; // update the first digit\n k -= (min_idx - start); // reduce k\n }\n return helper(array, k, start+1, n); // go to the next digit\n }\n string minInteger(string num, int k) {\n int n = num.length();\n\t\t// worst case digits in number in reverse sorted order, need (n-1) steps to move last to front, then (n-2) mooving new last and so on\n\t\t// so we need max (n-1) + (n-2)+... + 1 = (n-1)*n/2 to sort\n if (k >= (n*(n-1)) / 2){ \n sort(num.begin(),num.end());\n return num;\n }\n \n helper(&num[0], k, 0, n); // strings in c++ already array of chars\n return num;\n }\n};\n```
| 3 | 1 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Java] O(n^2) Easy to understand
|
java-on2-easy-to-understand-by-marvinbai-6g6k
|
\nclass Solution {\n public String minInteger(String num, int k) {\n int n = num.length();\n int[] nums = new int[n];\n for(int i = 0; i
|
marvinbai
|
NORMAL
|
2020-07-05T09:31:34.273150+00:00
|
2020-07-05T11:26:39.729900+00:00
| 208 | false |
```\nclass Solution {\n public String minInteger(String num, int k) {\n int n = num.length();\n int[] nums = new int[n];\n for(int i = 0; i < n; i++) nums[i] = Character.getNumericValue(num.charAt(i));\n helper(nums, k);\n StringBuilder sb = new StringBuilder();\n for(int i = 0; i < n; i++) {\n sb.append(nums[i] + "");\n }\n return sb.toString();\n }\n \n private void helper(int[] nums, int k) {\n int n = nums.length;\n for(int i = 0; i < n && k > 0; i++) {\n int index = i;\n for(int j = i + 1; j < n; j++) {\n if(k < j - i) break;\n if(nums[j] < nums[index]) {\n index = j;\n }\n }\n for(int j = index; j > i; j--) {\n swap(nums, j, j - 1);\n }\n k -= (index - i);\n }\n }\n \n private void swap(int[] arr, int a, int b) {\n int tmp = arr[a];\n arr[a] = arr[b];\n arr[b] = tmp;\n }\n}\n```\n\nThe essence lies within the helper function. The idea is to get the smallest digit to the front as best as it could (withing k_curr steps).
| 3 | 0 |
[]
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[C++] O(nlogn) solution using segment tree
|
c-onlogn-solution-using-segment-tree-by-60l9g
|
I applied the greedy approach where I will move the smallest possible digit to the leftmost unfixed position. Instead of updating all the ununsed indices to the
|
svashish
|
NORMAL
|
2020-07-05T07:36:15.991854+00:00
|
2020-07-05T07:36:15.991888+00:00
| 212 | false |
I applied the greedy approach where I will move the smallest possible digit to the leftmost unfixed position. Instead of updating all the ununsed indices to the left, I used a segement tree to find the number of digits on the right side of each digit which crossed over the current digit and go left. This brought down the complexity to O(nlogn).\n \n void update_seg_tree(vector<int>& seg_tree,int idx,int sidx,int ssrt, int send)\n {\n if(idx<ssrt or idx>send) return;\n \n if(ssrt==send)\n {\n seg_tree[sidx]=1;\n return;\n }\n \n int smid=(ssrt+send)/2;\n update_seg_tree(seg_tree,idx,2*sidx+1,ssrt,smid);\n update_seg_tree(seg_tree,idx,2*sidx+2,smid+1,send);\n \n seg_tree[sidx]=seg_tree[2*sidx+1]+seg_tree[2*sidx+2];\n }\n \n int calcte_seg_tree(vector<int>& seg_tree,int srt,int end,int sidx,int ssrt, int send)\n {\n if(end<ssrt or srt>send) return 0;\n \n if(ssrt>=srt and send<=end) return seg_tree[sidx];\n \n int smid=(ssrt+send)/2;\n int left = calcte_seg_tree(seg_tree,srt,end,2*sidx+1,ssrt,smid);\n int rigt = calcte_seg_tree(seg_tree,srt,end,2*sidx+2,smid+1,send);\n \n return left+rigt;\n }\n \npublic:\n string minInteger(string num, int k) {\n \n int n = num.size();\n \n //Calculating the height of the segment tree(starting from 0)\n int height=0;\n \n int p=n-1;\n while(p)\n {\n p/=2;\n height++;\n }\n \n //For a tree of height h, the total number of nodes till height h is 2*(2^h)-1\n vector<int> seg_tree(2*(1<<height)-1,0);\n \n list<int> lst[10];\n \n for(int i=0;i<n;i++)\n {\n lst[num[i]-\'0\'].push_back(i);\n }\n \n string ans;\n \n for(int i=0;i<n;i++)\n {\n int digit=-1;\n int kminus=0;\n for(int j=0;j<10;j++)\n {\n if(!lst[j].empty())\n {\n int pos=lst[j].front();\n int right_shift=calcte_seg_tree(seg_tree,pos,n-1,0,0,n-1);\n \n if(pos+right_shift-i<=k)\n {\n kminus=pos+right_shift-i;\n digit=j;\n break;\n }\n }\n }\n \n ans.push_back(\'0\'+digit);\n \n update_seg_tree(seg_tree,lst[digit].front(),0,0,n-1);\n \n k-=kminus;\n \n lst[digit].pop_front();\n }\n \n return ans;\n }
| 3 | 0 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Javascript] specific bubble sorting problem with limited steps k
|
javascript-specific-bubble-sorting-probl-e7cq
|
\n/**\n * @param {string} num\n * @param {number} k\n * @return {string}\n \n Idea is based on bubble sorting with limited steps k\n \n */\n\nvar minInteger = f
|
alanchanghsnu
|
NORMAL
|
2020-07-05T04:06:27.364744+00:00
|
2020-07-05T04:06:27.364793+00:00
| 295 | false |
```\n/**\n * @param {string} num\n * @param {number} k\n * @return {string}\n \n Idea is based on bubble sorting with limited steps k\n \n */\n\nvar minInteger = function(num, k) {\n if (num.length == 1)\n return num;\n \n let nums = num.split(\'\');\n let i = 0, j = 0;\n \n while (k && i < num.length-1) {\n// step 0: if leading zero, check the next digit\n if (nums[i] == \'0\') {\n i++;\n j++;\n continue;\n }\n \n// step 1: find the min digit \n let p = j, steps = 0;\n while (nums[p] !== \'0\' && j < nums.length && steps <= k) {\n if (nums[j] < nums[p])\n p = j;\n j++;\n steps++;\n }\n \n// step 2: nums[i] is the current minimum digit --> check next digit\n if (p == i) {\n i++;\n j = i;\n continue;\n }\n \n// step 3: move the min digit to i\n for (; p > i; p--) {\n [nums[p], nums[p-1]] = [nums[p-1], nums[p]];\n k--;\n }\n \n i++;\n j = i;\n \n }\n \n return nums.join(\'\');\n};\n```
| 3 | 0 |
['JavaScript']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Concise JavaScript solution
|
concise-javascript-solution-by-seriously-40dv
|
\nvar minInteger = function(num, k) {\n var arr = num.split("");\n var n = arr.length;\n\t\tfor (var i = 0; i < n-1 && k > 0; ++i) \n {\n
|
seriously_ridhi
|
NORMAL
|
2020-07-05T04:05:33.344264+00:00
|
2020-07-05T04:11:59.038490+00:00
| 297 | false |
```\nvar minInteger = function(num, k) {\n var arr = num.split("");\n var n = arr.length;\n\t\tfor (var i = 0; i < n-1 && k > 0; ++i) \n {\n var pos = i; \n for (var j = i+1; j < n ; ++j) \n {\n if (j - i > k) \n break; \n \n if (arr[j] < arr[pos]) \n pos = j; \n }\n var temp;\n for (var j = pos; j>i; --j) \n { \n temp=arr[j]; \n arr[j]=arr[j-1]; \n arr[j-1]=temp; \n }\n k -= pos-i; \n }\n return arr.join("");\n};\n```\n
| 3 | 0 |
['JavaScript']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python3] brute force
|
python3-brute-force-by-ye15-juve
|
Algo\nScan through the string. At each index, look for the smallest element behind it within k swaps. Upon finding such minimum, swap it to replece the current
|
ye15
|
NORMAL
|
2020-07-05T04:03:11.567689+00:00
|
2020-07-05T04:10:57.467902+00:00
| 688 | false |
Algo\nScan through the string. At each index, look for the smallest element behind it within k swaps. Upon finding such minimum, swap it to replece the current element, and reduce k to reflect the swaps. Do this for all element until k becomes 0. \n\n`O(N^2)` time & `O(N)` space \n```\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n n = len(num)\n if k >= n*(n-1)//2: return "".join(sorted(num)) #special case\n \n #find smallest elements within k swaps \n #and swap it to current position \n num = list(num)\n for i in range(n):\n if not k: break \n #find minimum within k swaps\n ii = i\n for j in range(i+1, min(n, i+k+1)): \n if num[ii] > num[j]: ii = j \n #swap the min to current position \n if ii != i: \n k -= ii-i\n for j in range(ii, i, -1):\n num[j-1], num[j] = num[j], num[j-1]\n return "".join(num)\n```
| 3 | 1 |
['Python3']
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
c++ | easy | segment tree
|
c-easy-segment-tree-by-venomhighs7-cuki
|
\n# Code\n\ntypedef long long ll;\nconst int N =30010;\nll w[N];\nll st[N];\n\nstruct Node {\n ll l,r;\n ll minv, idx, sum;\n} tree[4*N];\n\nvoid push_up(
|
venomhighs7
|
NORMAL
|
2022-10-11T04:11:08.079523+00:00
|
2022-10-11T04:11:08.079564+00:00
| 1,273 | false |
\n# Code\n```\ntypedef long long ll;\nconst int N =30010;\nll w[N];\nll st[N];\n\nstruct Node {\n ll l,r;\n ll minv, idx, sum;\n} tree[4*N];\n\nvoid push_up(Node& a, Node& b, Node & c) {\n if(b.minv <= c.minv) {\n a.minv = b.minv;\n a.idx = b.idx;\n } else {\n a.minv = c.minv;\n a.idx = c.idx;\n }\n a.sum = b.sum + c.sum;\n}\n\nvoid push_up(ll u) {\n push_up(tree[u], tree[2*u], tree[2*u+1]);\n}\n\nvoid build(ll u, ll l, ll r) {\n tree[u].l = l;\n tree[u].r = r;\n if(l == r) {\n ll b = w[l];\n tree[u].minv = b;\n tree[u].idx = l;\n tree[u].sum = st[l];\n } else {\n ll mid = (l + r) / 2;\n build(2*u, l, mid);\n build(2*u+1, mid+1, r);\n push_up(u);\n }\n}\n\nvoid update(ll u, ll idx, ll x) {\n if(tree[u].l == tree[u].r) {\n tree[u].minv = x;\n tree[u].sum = 0;\n st[tree[u].l] = 0;\n } else {\n ll mid = (tree[u].l + tree[u].r)/2;\n if(idx <= mid) update(2*u, idx, x);\n else update(2*u+1, idx, x);\n push_up(u);\n }\n}\n\nNode query(ll u, ll l, ll r) {\n if(tree[u].l >= l && tree[u].r <= r) {\n return tree[u];\n } else {\n ll mid = (tree[u].l + tree[u].r)/2;\n if(l > mid) {\n return query(2*u+1, l, r);\n } else if (r <= mid) {\n return query(2*u, l, r);\n } else {\n auto left = query(2*u, l, r);\n auto right = query(2*u+1, l, r);\n Node res;\n push_up(res, left, right);\n return res;\n }\n }\n}\n\nint get_idx(int presum, int len) {\n int l = 1;\n int r = len;\n int res = len;\n while(l <= r) {\n int mid = (l + r) / 2;\n if(query(1, 1, mid).sum >= presum) {\n res = mid;\n r = mid - 1;\n } else {\n l = mid + 1;\n }\n }\n return res;\n}\n\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n int n = num.size();\n if(k > n*(n-1)/2) {\n sort(num.begin(), num.end());\n return num;\n }\n return solve(num, k);\n }\n void init(string & num) {\n int n = num.size();\n memset(tree, 0, sizeof tree);\n for(int i = 1; i <= n; i ++) w[i] = num[i-1] - \'0\';\n for(int i = 1; i <= n; i ++) st[i] = 1;\n build(1, 1, n);\n }\n string solve(string & num, int k) {\n init(num);\n string res;\n while(k) {\n int max_sum = min(k+1, (int)num.size());\n int threshold = get_idx(max_sum, num.size());\n Node curr = query(1, 1, threshold);\n if(curr.minv == 10) break;\n res.push_back(curr.minv + \'0\');\n update(1, curr.idx, 10);\n k -= query(1, 1, curr.idx).sum;\n }\n for(int i = 1; i <= num.size(); i ++) {\n if(st[i] == 1) {\n res.push_back(num[i-1]);\n }\n }\n return res;\n }\n};\n```
| 2 | 0 |
['C++']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Java | Simple implementation | Detailed explanation
|
java-simple-implementation-detailed-expl-7ux4
|
\nclass Solution {\n public static String minInteger(String num, int k) {\n char[] array = num.toCharArray(); // returns a newly allocated character a
|
BoiMax
|
NORMAL
|
2022-08-17T11:27:31.990498+00:00
|
2022-08-17T11:27:31.990527+00:00
| 713 | false |
```\nclass Solution {\n public static String minInteger(String num, int k) {\n char[] array = num.toCharArray(); // returns a newly allocated character array.\n int length = array.length;\n int pointer = 0; // the index replaced at most K times by the smallest possible digit\n while (k > 0 && pointer < length) {\n int minDigit = array[pointer] - \'0\', minIndex = pointer;\n int limit = Math.min(length - 1, pointer + k); // when k is too large -> pointer + k is too large, run out\n // of range -> min(length-1, pointer+k)\n for (int i = pointer + 1; i <= limit; i++) {\n // take smallest digit from position: pointer -> limit\n int temp = array[i] - \'0\';\n if (temp < minDigit) {\n minDigit = temp; // smallest digit\n minIndex = i; // smallest digit\'s index\n }\n }\n k -= (minIndex - pointer); // swapping times needed to move smallest digit to pointer position\n char c = array[minIndex]; // smallest digit: c (char)\n // move c = array[minIndex] to be array[pointer]: line 21 -> 23\n for (int i = minIndex - 1; i >= pointer; i--)\n array[i + 1] = array[i];\n array[pointer] = c;\n pointer++; // continue with next array[pointer]\n }\n return new String(array);\n }\n}\n```
| 2 | 0 |
['Java']
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Segment tree and Queue
|
segment-tree-and-queue-by-shiraj2802-udns
|
\tclass SegmentTree {\n\t\tpublic:\n\t\tvector arr;\n\t\tint n;\n\t\tSegmentTree(int n) {\n\t\t\tthis->n=n;\n\t\t\tarr = vector(4n);\n\t\t}\n\t\tvoid add(int i)
|
shiraj2802
|
NORMAL
|
2022-08-08T17:38:15.247497+00:00
|
2022-08-08T17:38:15.247539+00:00
| 378 | false |
\tclass SegmentTree {\n\t\tpublic:\n\t\tvector<int> arr;\n\t\tint n;\n\t\tSegmentTree(int n) {\n\t\t\tthis->n=n;\n\t\t\tarr = vector<int>(4*n);\n\t\t}\n\t\tvoid add(int i) {\n\t\t\taddUtil(0,n-1,i,0);\n\t\t}\n\n\t\tint addUtil(int l, int r, int ind, int node) {\n\t\t\tif(l == r && l == ind){\n\t\t\t\tarr[node]++;\n\t\t\t\treturn arr[node];\n\t\t\t}\n\t\t\tif(ind < l || ind > r)\n\t\t\t\treturn arr[node];\n\t\t\tint m = l + (r-l)/2;\n\t\t\tint le = addUtil(l,m,ind,2*node+1);\n\t\t\tint ri = addUtil(m+1,r,ind,2*node+2);\n\t\t\tarr[node] = le+ri;\n\t\t\treturn arr[node];\n\t\t}\n\n\t\tint getSum(int ql, int qr, int l, int r, int node) {\n\t\t\tif(l >= ql && r <= qr)\n\t\t\t\treturn arr[node];\n\t\t\tif(r < ql || l > qr)\n\t\t\t\treturn 0;\n\t\t\tint m = l + (r-l)/2;\n\t\t\treturn arr[node] = getSum(ql,qr,l,m,2*node+1) + getSum(ql,qr,m+1,r,2*node+2);\n\t\t}\n\t};\n\n\tclass Solution {\n\tpublic:\n\t\tstring minInteger(string num, int k) {\n\t\t\tint n = num.size();\n\t\t\tvector<queue<int>> arr(10);\n\t\t\tSegmentTree *tree = new SegmentTree(n);\n\n\t\t\tfor(int i = 0; i < n; i++) {\n\t\t\t\tarr[num[i]-\'0\'].push(i);\n\t\t\t}\n\n\t\t\tstring ans;\n\t\t\tfor(int i = 0; i < num.size(); i++) {\n\t\t\t\tfor(int digit = 0; digit <= 9; digit++) {\n\t\t\t\t\tif(arr[digit].size() != 0) {\n\t\t\t\t\t\tint pos = arr[digit].front();\n\t\t\t\t\t\tint shift = tree->getSum(0,pos,0,n,0);\n\t\t\t\t\t\tif(pos-shift <= k) {\n\t\t\t\t\t\t\tk -= pos-shift;\n\t\t\t\t\t\t\ttree->add(pos);\n\t\t\t\t\t\t\tarr[digit].pop();\n\t\t\t\t\t\t\tans.push_back(digit+\'0\');\n\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\treturn ans;\n\t\t}\n\t};
| 2 | 0 |
['Tree']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
C++ Time O(n) , Space O(n)
|
c-time-on-space-on-by-aholtzman-f6mr
|
// The solution is base on:\n// 1) position queue for each digit\n// 2) The entries that removed before the first psition for each digit\n// 3) The next digit t
|
aholtzman
|
NORMAL
|
2021-12-21T15:43:25.686737+00:00
|
2021-12-21T15:49:28.914818+00:00
| 682 | false |
// The solution is base on:\n// 1) position queue for each digit\n// 2) The entries that removed before the first psition for each digit\n// 3) The next digit to add to the return string is the lowest digit which the position minus removed entries not greater than k;\n// 4) Update return string; ( time n)\n// 5) Update removed entries for each digit; (time 10xn)\n// 6) calculate the removed entries for the entry that moved to queue front (for the digit that added to return string); (time nx10)\n// Return to (3)\n// Time complexity ~n*22 which is O(n)\n```\ntemplate <class T>\nclass simple_queue \n{\n int out_ix;\n vector<T> q;\npublic:\n simple_queue() : out_ix(0) {}\n ~simple_queue() { /* delete [] q;*/ }\n void push(T t) { q.push_back(t); }\n T pop(void) { return q[out_ix++]; }\n T front(void) { return q[out_ix]; }\n bool empty(void) { return (out_ix == q.size());}\n};\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n int n = num.length();\n string ans(n,\'-\');\n ans[n] = \'\\0\';\n int i = 0;\n int first = 0;\n int start = 0;\n bool found = true;\n vector<simple_queue<int>> pos(10);\n vector<int> first_pos_sub(10,0);\n\n for(int j=0; j<n; j++)\n pos[num[j]-\'0\'].push(j);\n \n while (found == true && i<n)\n {\n found = false;\n while(first<=9 && pos[first].empty()) first++; \n for (int d = first; d<=9 && !found; d++)\n {\n while (!pos[d].empty() && pos[d].front() - first_pos_sub[d] <= k)\n {\n // cout << d << ", " << k << ", " << pos[d].front()- first_pos_sub[d] << endl;\n found = true;\n int p = pos[d].pop();\n k -= (p -first_pos_sub[d]);\n ans[i++] = \'0\'+d;\n for (int d1 = first; d1<=9; d1++)\n {\n if (!pos[d1].empty() && pos[d1].front() > p) first_pos_sub[d1]++;\n }\n num[p] = \'-\';\n if (!pos[d].empty())\n {\n for (int j=p+1; j<pos[d].front(); j++)\n {\n if (num[j] == \'-\') first_pos_sub[d]++;\n }\n }\n\n if (d != first) break;\n }\n }\n }\n return ans;\n }\n};\n```
| 2 | 0 |
[]
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python] O(n) time and O(1) space complexity
|
python-on-time-and-o1-space-complexity-b-mg0n
|
\nclass Solution:\n def minInteger(self, num, k):\n ln=len(num)\n optimizedNums=0\n YJSP=1145141919810\n a={\'0\':YJSP,\'1\':YJSP
|
tztanjunjie
|
NORMAL
|
2020-10-03T17:06:42.428347+00:00
|
2020-10-03T17:06:42.428377+00:00
| 689 | false |
```\nclass Solution:\n def minInteger(self, num, k):\n ln=len(num)\n optimizedNums=0\n YJSP=1145141919810\n a={\'0\':YJSP,\'1\':YJSP,\'2\':YJSP,\'3\':YJSP,\'4\':YJSP,\'5\':YJSP,\'6\':YJSP,\'7\':YJSP,\'8\':YJSP,\'9\':YJSP}\n for i in range(ln):\n if i<a[num[i]]:a[num[i]]=i \n while k>0 and optimizedNums<ln:\n for i in a:\n if a[i]-optimizedNums<=k:\n num=num[:optimizedNums]+i+num[optimizedNums:a[i]]+num[a[i]+1:]\n k-=a[i]-optimizedNums\n for j in a:\n if a[j]<a[i]:a[j]+=1 \n for j in range(a[i]+1,ln):\n if num[j]==i:\n a[i]=j\n break\n else:\n a[i]=YJSP\n break\n optimizedNums+=1\n return num\n```
| 2 | 2 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Python] Detailed comments with explanation, using bsearch only
|
python-detailed-comments-with-explanatio-tisc
|
The O(N*logN) solution requires a bit of leap of faith and view the problem from a different angle. I\'ve also left in my first attempt that TLEs which would gi
|
algomelon
|
NORMAL
|
2020-07-12T18:11:43.135360+00:00
|
2020-07-12T18:18:43.734131+00:00
| 229 | false |
The `O(N*logN)` solution requires a bit of leap of faith and view the problem from a different angle. I\'ve also left in my first attempt that TLEs which would give some motivation to the `O(N*logN)`\nsolution.\n\nThe key to understanding the solution is viewing it as a selection problem instead of a swapping problem. You have n position to fill with the best digit possible, from n candidate digits. For each position i, you have n - i candidate digits to choose from such that the digit chosen must not be too far away from index i. \n\n```\nfrom sortedcontainers import SortedList\n\nclass Solution:\n # O(N*LogN) solution\n def minInteger(self, num: str, k: int) -> str: \n smaller_digit_indexes = collections.defaultdict(collections.deque)\n A = [int(d) for d in num]\n for i in range(len(A)):\n smaller_digit_indexes[A[i]].append(i)\n \n result = \'\'\n pulled_to_front_indexes = SortedList()\n # This problem requires a leap of faith. Instead of thinking how we could replace\n # each individual digit at index i by swapping, let\'s view it as a selecting problem\n # where we continously try to select the smallest digit possible, from all that are\n # available, and add them into a result list.\n n = len(A)\n for _ in range(n):\n # Given n digits that are available for selection, we\'ve so far selected len(result)\n # number of digits and is now looking for the best digit to add to result. Since\n # we want the smallest digit possible, we go through digit 0-9 (at a constant loop cost\n # of 10) and stop at the first available digit.\n for d in range(0, 10):\n if len(smaller_digit_indexes[d]) == 0:\n continue\n \n # Okay, we have `d` that we could potentially add to result. To build some intuition,\n # let\'s forget about all the swapping business and simply imagine we\'ve so far pulled \n\t\t\t\t# len(result) digits out of A, each digit pulled out leaving a hole in A, and the \n # remaining digits in A remains in-place in their original index. And, `d`, the potential \n # candidate for selection is at A[j]. In other words, in each iteration of the loop\n # (from 0 to n - 1), we are looking to see if the first digit in those that remain in A\n # could be replaced by `d` at A[j]. If so, we simply pull `d` out of its position at j\n # and place it into `result`.\n j = smaller_digit_indexes[d][0]\n \n # Now the question is, could we possibly choose `d` at its original index j given the\n # constraint that we cannot touch digits that are more than k digits away? (Here k\n # digits away means number of digits between some start and some end, inclusive, minus 1)\n # Well we could if the number of digits from `d` at the j original index j, to the \n # first digit remaining in A that we\'ve not yet pulled out (and put into `result`) is <= k.\n # Why? Because if you were to do the swapping process step by step, you\'ll notice that\n # other than digits we\'ve pulled and put into `result`, the remaining digits\n # in A have remained in the same relative order, except for the holes. We only need to\n # deduct for the holes they are between the first digit of A and j, to arrive at the \n # true distance\n nb_moved_to_front = pulled_to_front_indexes.bisect_right(j)\n dist = j - nb_moved_to_front\n if dist == 0 or dist <= k:\n # dist == 0 means `d` happens to be the first digit remaining in A\n result += str(d)\n pulled_to_front_indexes.add(j)\n smaller_digit_indexes[d].popleft()\n k -= dist\n break\n\n return result\n\n # First O(N^2) attempt that will LTE\n def minInteger2(self, num: str, k: int) -> str:\n def bubble_up(A, i, j):\n t = A[j]\n for x in range(j, i, -1):\n A[x] = A[x - 1]\n A[i] = t\n \n \n A = [int(d) for d in num]\n \n i = 0\n while i < len(A) and k > 0:\n # Given A[i], let\'s see if we can find the smallest possible A[j] such that j - i <= k.\n # That is, the smallest possible A[j], k-swap distance away that we could swap with A[i] \n # and get a smallest possible number\n j = i + 1\n min_digit_idx = None\n while j < len(A) and j - i <= k:\n if A[j] < A[i]:\n if min_digit_idx is None or A[j] < A[min_digit_idx]:\n min_digit_idx = j\n j += 1\n \n if min_digit_idx != None:\n bubble_up(A, i, min_digit_idx)\n k -= min_digit_idx - i\n \n i += 1\n \n return \'\'.join([str(d) for d in A])\n```\n
| 2 | 0 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
[Java][中文视频] Fenwick Tree O(nlogn) Solution
|
javazhong-wen-shi-pin-fenwick-tree-onlog-hj2w
|
Video:\nhttps://www.youtube.com/watch?v=GYin0E1ENWM\n\nclass Solution {\n public String minInteger(String num, int k) {\n int n = num.length();\n
|
zzzyq
|
NORMAL
|
2020-07-09T15:55:06.848785+00:00
|
2020-07-09T15:55:06.848828+00:00
| 314 | false |
Video:\nhttps://www.youtube.com/watch?v=GYin0E1ENWM\n```\nclass Solution {\n public String minInteger(String num, int k) {\n int n = num.length();\n FenwickTree ft = new FenwickTree(n);\n for(int i = 0; i < n; i++) {\n ft.update(i, 1);\n }\n Queue[] arr = new Queue[10];\n for(int i = 0; i < 10; i++) arr[i] = new LinkedList<>();\n for(int i = 0; i < n; i++) {\n arr[num.charAt(i) - \'0\'].offer(i);\n }\n int idx = 0;\n String res = "";\n while(idx < n) {\n for(int i = 0; i < 10; i++) {\n if(arr[i].size() > 0) {\n int bestIdx = (int)arr[i].peek();\n int cost = ft.getSum(bestIdx) - 1;\n if(cost <= k) {\n res += (char)(\'0\' + i);\n arr[i].poll();\n k -= cost;\n if(bestIdx < n - 1) ft.update(bestIdx + 1, -1);\n break;\n } else continue;\n }\n }\n idx += 1;\n }\n return res; \n }\n}\n\nclass FenwickTree {\n int[] tree;\n public FenwickTree(int n) {\n this.tree = new int[n + 1];\n }\n \n private int getNext(int x) {\n return x + (x & (-x));\n }\n \n private int getParent(int x) {\n return x - (x & (-x));\n }\n \n public void update(int idx, int diff) {\n idx += 1;\n while(idx < tree.length) {\n tree[idx] += diff;\n idx = getNext(idx);\n }\n return;\n }\n \n public int getSum(int idx) {\n idx += 1;\n int sum = 0;\n while(idx > 0) {\n sum += tree[idx];\n idx = getParent(idx);\n }\n return sum;\n }\n}\n```
| 2 | 1 |
[]
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Python NlogN Fenwick/BIT solution
|
python-nlogn-fenwickbit-solution-by-nate-dysn
|
python\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n n = len(num)\n mp = defaultdict(deque)\n for i,v in enumerate
|
nate17
|
NORMAL
|
2020-07-05T09:41:45.701339+00:00
|
2020-07-06T03:26:31.889417+00:00
| 168 | false |
```python\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n n = len(num)\n mp = defaultdict(deque)\n for i,v in enumerate(num):\n mp[v].append(i)\n res = ""\n def lowbit(x):\n return x & (-x)\n def query(x):\n sums = 0\n while x:\n sums += arr[x]\n x -= lowbit(x)\n return sums\n def update(x,delta):\n while x <= n:\n arr[x] += delta\n x += lowbit(x)\n\n arr = [0]*(n+1)\n for i in range(n):\n update(i+1,1)\n\n for i in range(n):\n for v in "0123456789":\n if mp[v]:\n idx = mp[v][0]\n cnt = query(idx)\n if cnt > k: continue\n mp[v].popleft()\n k -= cnt\n res += v\n update(idx+1,-1)\n break\n return res\n\n```
| 2 | 0 |
[]
| 1 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Python Bisect O(nlgn) Pass! [SO HARD]
|
python-bisect-onlgn-pass-so-hard-by-wsy1-zco1
|
\tclass Solution:\n\t\tdef minInteger(self, num: str, k: int) -> str:\n\n\t\t\tnum = list(num)\n\t\t\tsmall = sorted(list(num))\n\n\t\t\tif k > len(num) ** 2:\n
|
wsy19970125
|
NORMAL
|
2020-07-05T05:15:18.710672+00:00
|
2020-07-05T05:18:15.728148+00:00
| 196 | false |
\tclass Solution:\n\t\tdef minInteger(self, num: str, k: int) -> str:\n\n\t\t\tnum = list(num)\n\t\t\tsmall = sorted(list(num))\n\n\t\t\tif k > len(num) ** 2:\n\t\t\t\treturn \'\'.join(small)\n\n\t\t\td = defaultdict(list)\n\t\t\tfor i in range(len(num)):\n\t\t\t\td[num[i]].append(i)\n\n\t\t\tindexs = []\n\t\t\tfor char in sorted(d.keys()):\n\t\t\t\tindexs += d[char]\n\n\t\t\tdone = []\n\t\t\thead = 0\n\n\t\t\twhile k > 0 and indexs:\n\t\t\t\tif num == small:\n\t\t\t\t\treturn \'\'.join(num)\n\t\t\t\tfor i in range(len(indexs)):\n\t\t\t\t\tpre = bisect.bisect(done, indexs[i])\n\t\t\t\t\tnewi = indexs[i] + len(done) - pre\n\t\t\t\t\tif newi >= head and newi - head <= k:\n\t\t\t\t\t\tbisect.insort(done, indexs[i])\n\t\t\t\t\t\tnum = num[:head] + [num[newi]] + num[head:newi] + num[newi + 1:]\n\t\t\t\t\t\tk -= newi - head\n\t\t\t\t\t\thead += 1\n\t\t\t\t\t\tindexs.pop(i)\n\t\t\t\t\t\tbreak\n\n\t\t\treturn \'\'.join(num)
| 2 | 1 |
[]
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Efficient JS Solution - Greedy + No Segment tree - O(10n)
|
efficient-js-solution-greedy-no-segment-5hfvk
|
Pro tip: love Lil Xie! \uD83D\uDC9C\n\n# Brief explanation\n- We will generate the result from left to right. For each position, we will also greedily choose th
|
CuteTN
|
NORMAL
|
2024-01-10T11:59:37.274912+00:00
|
2024-01-10T12:44:23.624387+00:00
| 244 | false |
Pro tip: love Lil Xie! \uD83D\uDC9C\n\n# Brief explanation\n- We will generate the result from left to right. For each position, we will also greedily choose the smallest digit possible.\n- Suppose we want to move digit `d` from the position `j` of num to the position `i` of the result. We will calculate how many swaps needed to do this by these observations\n - Every indices `k` such that `k < j` and `num[k] <= num[j]` must move to some indices before `i` in the answer, if this is not the case, we are wasting some swaps and doesn\'t improve the result lexicographical order. So we\'ll only care about those indices `k` such that `num[k] > num[j]` and perform the swapping operation with them.\n - Watch out! There are some of those numbers were actually chosen during the process. So keep track of the used digits, we will not swap with them either.\n\nThose are not formal proof, but just a small explanation on the approach. It requires some intuition to fully grasp the ideas. In addition, don\'t forget the pro tip: love Lil Xie! \uD83D\uDC9C\n\n# Complexity\n- Let `n = num.length`; `d = number of distinct digits = 10`\n- Time complexity: $$O(nd)$$\n- Space complexity: $$O(n + d)$$\n\n# Code\n```js\n// pre[i] is number of indices j in num such that j<i and num[j]>num[i]\nconst pre = new Uint32Array(1e5);\n\n// first[d] is the index of the first occurrence of the digit d\nconst first = new Int32Array(10)\n// link[i] is the smallest index j such that num[i] == num[j]. if such index does not exist, it is conventionally defined as -1.\nconst links = new Uint32Array(1e5);\n\n// In the first iteration, counters[d] is the number of the digit d found so far in num\n// In the last iteration, coutners[d] is the number of the digit d that are chosen in the result \nconst counters = new Uint32Array(10);\n\n/**\n * @param {string} num\n * @param {number} k\n * @return {string}\n */\nvar minInteger = function (num, k) {\n let n = num.length;\n counters.fill(0);\n\n for (let i = 0; i < n; ++i) {\n let d = num.charCodeAt(i) - 48;\n ++counters[d];\n\n pre[i] = 0;\n for (let j = d + 1; j < 10; ++j) pre[i] += counters[j];\n }\n\n first.fill(-1);\n for (let i = n - 1; i >= 0; --i) {\n let d = num.charCodeAt(i) - 48;\n links[i] = first[d];\n first[d] = i;\n }\n\n let res = "";\n counters.fill(0);\n for (let i = 0; i < n; ++i) {\n let steps = 2e9;\n\n let d = 0;\n for (; d < 10; ++d) {\n if (first[d] >= 0) {\n steps = pre[first[d]] - counters[d];\n if (steps <= k) {\n for (let dd = 0; dd < d; ++dd) ++counters[dd];\n first[d] = links[first[d]];\n k -= steps;\n res += String.fromCharCode(d + 48);\n break;\n }\n }\n }\n }\n\n return res;\n};\n```
| 1 | 0 |
['Greedy', 'Counting', 'JavaScript']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
C++ | Most Intuitive
|
c-most-intuitive-by-mukulgupta1357-06ud
|
\n# Code\n\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n int n = num.size();\n if(k > n*(n+1)/2)\n {\n
|
mukulgupta1357
|
NORMAL
|
2023-08-13T11:07:43.984531+00:00
|
2023-08-13T11:07:43.984556+00:00
| 195 | false |
\n# Code\n```\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n int n = num.size();\n if(k > n*(n+1)/2)\n {\n sort(num.begin(), num.end());\n }\n\n for(int i=0;i<n && k >0;i++)\n {\n int pos = i;\n for(int j=i+1;j<n;j++)\n {\n if(j-i > k)\n break;\n if(num[j] < num[pos])\n pos = j;\n }\n\n while(pos > i)\n {\n swap(num[pos], num[pos-1]);\n pos--;\n k--;\n }\n }\n return num;\n }\n};\n```
| 1 | 0 |
['Sliding Window', 'C++']
| 2 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
Python Sliding Window + AVL Tree Solution | Easy to Understand
|
python-sliding-window-avl-tree-solution-a73tk
|
Approach\n Describe your approach to solving the problem. \nMaintain a window of size k in a AVL Tree, pop out the minimum element in the index in O(log(n)) tim
|
hemantdhamija
|
NORMAL
|
2023-01-06T05:08:50.933493+00:00
|
2023-01-06T05:08:50.933534+00:00
| 168 | false |
# Approach\n<!-- Describe your approach to solving the problem. -->\nMaintain a window of size ```k``` in a AVL Tree, pop out the minimum element in the index in $$O(log(n))$$ time, find its index, decrement ```k``` accordingly until ```k``` becomes ```0```.\n\n# Complexity\n- Time complexity: $$O(n * log(n))$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```python []\nfrom sortedcontainers import SortedList\n\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n sz, window = len(num), SortedList()\n remainedIndices, poppedIndices = SortedList(range(sz)), []\n while k > 0:\n while len(window) < k + 1 and len(window) < len(remainedIndices):\n idx = remainedIndices[len(window)]\n window.add((num[idx], idx))\n if not window:\n break\n index = window.pop(0)[1]\n k -= remainedIndices.bisect_left(index)\n remainedIndices.remove(index)\n poppedIndices.append(index)\n for idx in remainedIndices[k + 1: len(window)]:\n window.remove((num[idx], idx))\n poppedSet = set(poppedIndices)\n return "".join(num[idx] for idx in poppedIndices) + "".join(num[idx] for idx in range(sz) if idx not in poppedSet)\n```
| 1 | 0 |
['String', 'Greedy', 'Binary Search Tree', 'Sliding Window', 'Python3']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
C++ || Segment tree || Explained solution
|
c-segment-tree-explained-solution-by-raj-c1ap
|
```\n/\n\nswap any two adjacent digits atmost k times -> minimum integer formed after this??\n\nwill greedy approach works here ?\n\nbringing all smaller no\' a
|
Rajdeep_Nagar
|
NORMAL
|
2022-10-06T16:29:34.867131+00:00
|
2022-10-06T16:29:34.867173+00:00
| 115 | false |
```\n/*\n\nswap any two adjacent digits atmost k times -> minimum integer formed after this??\n\nwill greedy approach works here ?\n\nbringing all smaller no\' ahead as possible as\n \n \n(bring that smallest no. here which is towards right of it and can be brought here within k steps) () () ()...\n\n\nValue of k decreases..\n\n(.)(bring that smallest no. here which is towards right of it and can be brought here within remaining k steps) () () () () () ...\n\nValue of k decreases..\n\nand so on till k>0\n\n\nNOTE:\n\n7683(1)67 => (1)768367\n\n\nby doing this, index of all no\'s toward left of (1) increases by 1\n\n\n O(n*n), for each position i, check minimum digit within the range (among next k digits) , and put that minimum digit at this position\n\n O(n logn) , for each position i, we check Is it possible to place any digit [0-9] at this position, let we can place \'3\' at this position , and index of this \'3\' is idx, so no. of swaps we needs to do to bring \'3\' from index idx towards left to index i = idx- (no of digits from [0,idx] that have already used)\n\nif we are at index i, it means we are already done with [0...i-1]\n\n\n let num= 872124652 , k=20\n\n S.T = 0 0 0 0 0 0 0 0 0\n \n num= 872124652\n for i=0, 872124652 => ans=1(87224652)\n nextIdx=3, alreadyUsed=0, countSwap=3-0=3, k=k-3=17\n S.T = 0 0 0 1 0 0 0 0 0\n \n num= 872124652\n for i=1, 1|87224652 => ans=12(8724652)\n nextIdx=2, alreadyUsed=0, countSwap=2-0=2, k=17-2=15\n S.T = 0 0 1 1 0 0 0 0 0\n \n num= 872124652\n for i=2, 12|8724652 => ans=122(874652)\n nextIdx=4, alreadyUsed=2, countSwap=4-2=2, k=15-2=13\n S.T = 0 0 1 1 1 0 0 0 0\n\n num= 87212465(2)\n for i=3, 122|874652 => ans=1222(87465)\n nextIdx=8, alreadyUsed=3, countSwap=8-3=5, k=13-5=8\n S.T = 0 0 1 1 1 0 0 0 1\n\nnum= 87212(4)652\n for i=4, 1222|87465 => ans=12224(8765)\n nextIdx=5, alreadyUsed=3, countSwap=5-3=2, k=8-2=6\n S.T = 0 0 1 1 1 1 0 0 1\n \n num= 8721246(5)2\n for i=5, 12224|8765 => ans=122245(876)\n nextIdx=7, alreadyUsed=4, countSwap=7-4=3, k=6-3=3\n S.T = 0 0 1 1 1 1 0 1 1\n \n num= 872124(6)52\n for i=5, 122245|876 => ans=1222456(87)\n nextIdx=6, alreadyUsed=4, countSwap=6-4=2, k=3-2=1\n S.T = 0 0 1 1 1 1 1 1 1\n \n num= 8(7)2124652\n for i=5, 1222456|87 => ans=12224567(8)\n nextIdx=1, alreadyUsed=0, countSwap=1-0=1, k=1-1=0\n S.T = 0 1 1 1 1 1 1 1 1\n \n k=0\n \n return ans=122245678 \n\n\n\n to keep track of how many digits have been used in range [0....idx] we use segment tree\n\n let we shifting digit at index i1 or using digit at index i1 at any left side index , than we update our segment tree by adding 1 at index i1 in the segment tree \n\n*/\n\nclass Solution {\npublic:\n string minInteger(string num, int k) {\n \n int n=num.length();\n \n if(k>n*n){\n sort(num.begin(),num.end());\n \n return num;\n }\n \n \nunordered_map<int,deque<int>>mp;\n \nint arr[n];\n \n for(int i=0;i<n;i++){\n arr[i]=0;\n }\n \nint *st=constructST(arr,n);\n \n for(int i=0;i<n;i++){\n mp[num[i]-\'0\'].push_back(i);\n }\n \n string ans;\n \n for(int i=0;i<n;i++){\n \n for(int d=0;d<=9;d++){\n \n if(mp[d].size()>0){\n \n int nextIdx=mp[d].front();\n \n // no. of digits that already used\n int alreadyUsed=getsum(st,0,0,n-1,0,nextIdx);\n \n int countSwap=nextIdx-alreadyUsed;\n \n if(k>=countSwap){\n ans+=to_string(d);\n mp[d].pop_front();\n k-=countSwap;\n update(st,0,0,n-1,nextIdx,1);\n break;\n }\n }\n }\n }\n \n \n \n return ans;\n \n }\n \n \n \nvoid update(int *st,int si,int sl,int sr,int pos,int diff)\n{\nif(sl>pos || sr<pos)\nreturn ;\nst[si]=st[si]+diff;\nif(sl!=sr){\nint mid=(sl+sr)/2;\nupdate(st,2*si+1,sl,mid,pos,diff);\nupdate(st,2*si+2,mid+1,sr,pos,diff);\n}}\n\n\n\nint getsum(int *st,int si,int sl,int sr,int l,int r)\n{\nif(l<=sl && r>=sr)\nreturn st[si];\nif(l>sr || r<sl)\nreturn 0;\nint mid=(sl+sr)/2;\nreturn (getsum(st,2*si+1,sl,mid,l,r)+\ngetsum(st,2*si+2,mid+1,sr,l,r));\n}\n\n\n\nint constructSTUL(int *st,int si,int arr[],int l,int r){\nif(l==r){\nst[si]=arr[l];\nreturn arr[l];\n}\nint mid=(l+r)/2;\n\nst[si]=(constructSTUL(st,2*si+1,arr,l,mid)\n+ constructSTUL(st,2*si+2,arr,mid+1,r));\nreturn st[si];\n}\n\n\n\nint *constructST(int arr[],int n){\n\nint h=(int)(ceil(log2(n)));\nint max_size_st=2*(int)pow(2,h)-1;\nint *st=new int[max_size_st];\n\nconstructSTUL(st,0,arr,0,n-1);\n\nreturn st;\n}\n\n};
| 1 | 0 |
['Tree', 'C']
| 0 |
minimum-possible-integer-after-at-most-k-adjacent-swaps-on-digits
|
O(nlogn): Segment tree + binary search
|
onlogn-segment-tree-binary-search-by-sha-2ip5
|
For a given swap count k, if we are currently at index i of our array nums, we wish to find the minimum element in nums that is <= k swaps away from index i, an
|
shaunakdas88
|
NORMAL
|
2022-06-21T13:12:33.660780+00:00
|
2022-06-21T20:23:41.390422+00:00
| 231 | false |
For a given swap count `k`, if we are currently at index `i` of our array `nums`, we wish to find the minimum element in `nums` that is `<= k` swaps away from index `i`, and bubble it up to `i`\'s position, eating up some number of swaps along the way. We repeatedly do this until we have either:\n- exhausted all swaps\n- exhausted all digits in `nums`\n\nThe fact that we are trying to find a minimum value within some prescribed interval range should immediately suggest we leverage a segment tree (`min` is binary, associative operation), where the minimum value stored for an internal/parent node is the minimum of the minimum values stored by it\'s two children:\n```\nparent min = min(left child min, right child min)\n```\n\nThere are a couple of subtleties to be mindful of, which we discuss below.\n\n**ACCEPTABLE INDEX INTERVAL**\nSuppose we have performed a bunch of swaps so far. How do we determine which range of original indexes in `nums` we should be searching our segment tree for the next round of swaps, if we have `k` swaps left? \n\nLet\'s maintain a sorted list `free` of the original indexes of unused values in `nums`, throughout the swapping rounds (by unused, we simply mean the value at this original index has not been bubbled up towards the front yet). Then, the index interval `[free[0], free[k]]` is certainly what we care about (note, if `k > len(free)`, then right-hand endpoint will be `free[n-1]`). This is because we are guaranteed everything we removed from `free` during prior rounds, will precede `free[0]` in our final semi-sorted result, and so the corresponding digits for `free[0], free[1], ..., free[k]` should currently be contiguous after those earlier swaps were performed. By restricting to the first `k+1` such, we are ensured we don\'t go beyond `k` swaps for this upcoming round.\n\nHowever, we want to make sure, when searching our segment tree for the minimum value in this interval `[free[0], free[k]]`, we don\'t take into account any indexes in this interval that were previously used. We treat this next.\n\n**"DELETION" OF NODES**\nWhenever we have used an original index `i`, we want to make sure it won\'t be eligible in future swapping rounds. How can we easily achieve this? Since our segment tree is keeping track of minimums over index subintervals of `nums`, we should:\n- search for the segment tree node corresponding to the index `i` we just used\n- set the min value for this tree node to infinity\n- parent back up, using the same update rule we did during building of the tree (i.e. `parent min = min(left child min, right child min)`)\n\nBy doing this, whenever we later search for a minimum value in some prescribed index range `[a, b]` which contains previously used index `i`, we know `nums[i]` will no longer contribute to this answer since we artificially made it too large in our tree, effectively deleting it from the segment tree (for the purpose of lookups).\n\nWe now know:\n- which subinterval to restrict our segment tree search for a min value; it will depending on the number of remaining swaps `k` and our maintained sorted list of currently free/unused indexes\n- how to avoid re-using previously used indexes that fall into such a search interval; "delete" the corresponding leaf node from the segment tree by updating the value to something large, and propagate this update to ancestor nodes\n\nSo we can easily get the minimum we care about. But once we have it and swapped it forward, how do we know how many swaps are remaining after?\n\n\n**UPDATING REMAINING SWAPS: BINARY SEARCH**\nAs we\'ve vaguely discussed so far, our segment tree is returning the minimum free value within a restricted index interval of interest (the restriction being the number of swaps we have remaining). Although this gives us the next value to bubble up, it yields no information about how many swaps actually got used, hence gives us no way to update the remaining swaps after this round.\n\nRather than returning the minimum free value within some interval `[free[0], free[k]]`, our segment tree should return the _index of_ the minimum free value within that interval. Suppose we get free index `j`, then we know at most `j - free[0]` swaps were performed, and we simply need to deduct the number of indexes in `[free[0], j]` that were already used/swapped in prior rounds. \n\nFor this, let\'s just maintain a complementary sorted list to `free`, call it `used`. We can easily binary search for the number of elements in range `[free[0], j]` that are in `used`, denote this value `u`. Then this means the number of swaps we used to bubble up `nums[j]` was precisely:\n```\nj - free[0] - u\n```\nand that\'s what we update our remaining swap count `k` to for the next round.\n\n**CODE**\n```\nfrom sortedcontainers import SortedList\n\n\nclass Solution:\n def minInteger(self, num: str, k: int) -> str:\n n = len(num)\n \n # CORNER CASE: able to handle the worst case scenario of sorting a reverse sorted list\n if k >= n * (n - 1) // 2:\n return "".join(sorted(num))\n \n nums = [int(x) for x in num]\n \n # segment tree data structures and methods\n min_val = [float("inf")] * 4 * n\n min_index = [float("inf")] * 4 * n\n \n def build(node: int, l: int, r: int):\n # CASE 1: arrived at a leaf node\n if l == r:\n min_val[node] = nums[l]\n min_index[node] = l\n return\n # CASE 2: still at an internal node, recurse down\n mid = (l + r) // 2\n left_child = 2 * node + 1\n right_child = left_child + 1\n build(left_child, l, mid)\n build(right_child, mid + 1, r)\n update(node)\n \n def update(node: int):\n """\n update rule for internal/parent node in segment tree. In case, minima for children\n is a tie, left child wins, since this results in fewer swaps to move corresponding digit in nums forward.\n """\n left_child = 2 * node + 1\n right_child = left_child + 1\n if min_val[left_child] <= min_val[right_child]:\n winner = left_child\n else:\n winner = right_child\n min_val[node] = min_val[winner]\n min_index[node] = min_index[winner]\n \n def lookup(node: int, l: int, r: int, desired_l: int, desired_r: int):\n """\n Return\'s the index in nums of the currently smallest value in range [desired_l, desired_r]\n """\n # CASE 1: out of bounds\n if l > desired_r or r < desired_l:\n return None\n # CASE 2: containment of node\'s interval [l,r] inside of [desired_l, desired_r]\n if desired_l <= l and r <= desired_r:\n return min_index[node]\n\t\t # CASE 3: intersection of node\'s interval [l, r] with [desired_l, desired_r]\n mid = (l + r) // 2\n left_child = 2 * node + 1\n right_child = left_child + 1\n left_res = lookup(left_child, l, mid, desired_l, desired_r)\n right_res = lookup(right_child, mid + 1, r, desired_l, desired_r)\n if left_res is None:\n return right_res\n if right_res is None:\n return left_res\n if nums[left_res] <= nums[right_res]:\n return left_res\n else:\n return right_res\n \n def delete(node: int, l: int, r: int, target: int):\n """\n Update\'s segment tree leaf corresponding to index target in nums to be infinity, \n and updates parent node values on the way back up recursive call stack\n """\n # CASE 1: out of bounds\n if l > target or r < target:\n return\n # CASE 2: at the target leaf\n if l == r:\n min_val[node] = float("inf")\n nums[target] = float("inf")\n return\n # CASE 3: internal node whose interval [l, r] contains target\n mid = (l + r) // 2\n if target <= mid:\n left_child = 2 * node + 1\n delete(left_child, l, mid, target)\n else:\n right_child = 2 * node + 2\n delete(right_child, mid + 1, r, target)\n update(node)\n \n # STEP 1: build the segment tree\n build(0, 0, n-1)\n \n \n # STEP 2: While we have swaps available, greedily pick the smallest allowed value possible\n # to swap into current position in our result\n res = []\n free = SortedList([i for i in range(n)])\n used = SortedList()\n while k > 0 and len(res) < n:\n # Find allowed range of indexes in the original array to search for a free minimum\n left_index = free[0]\n r = min(k, len(free) - 1)\n right_index = free[r]\n # Get the index of the swapped in element in nums, update our final result, and "delete" from segment tree\n next_index = lookup(0, 0, n - 1, left_index, right_index) \n res.append(str(nums[next_index]))\n delete(0, 0, n - 1, next_index)\n # Determine precisely how many swaps occurred to bubble up nums[next_index]\n intervening_that_were_used = used.bisect_right(next_index) - used.bisect_right(left_index)\n swaps = next_index - left_index - intervening_that_were_used\n k -= swaps\n # Update our sorted lists of used and unused elements\n free.remove(next_index)\n used.add(next_index)\n \n # STEP 3: any indices i which were not used, tack on nums[i] IN ORDER, since no more swaps allowed\n for i in range(n):\n if nums[i] == float("inf"):\n continue\n res.append(str(nums[i]))\n return "".join(res)\n```\n\n\n\n
| 1 | 0 |
[]
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.