
question_slug
stringlengths 3
77
| title
stringlengths 1
183
| slug
stringlengths 12
45
| summary
stringlengths 1
160
⌀ | author
stringlengths 2
30
| certification
stringclasses 2
values | created_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| updated_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| hit_count
int64 0
10.6M
| has_video
bool 2
classes | content
stringlengths 4
576k
| upvotes
int64 0
11.5k
| downvotes
int64 0
358
| tags
stringlengths 2
193
| comments
int64 0
2.56k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
customers-who-never-order
|
Share My first DB Answer
|
share-my-first-db-answer-by-siyang3-lfj1
|
I learn database from a Standford tutorial.\n\nhttps://www.youtube.com/watch?v=D-k-h0GuFmE&list=PL6hGtHedy2Z4EkgY76QOcueU8lAC4o6c3\n\n select Name as Custom
|
siyang3
|
NORMAL
|
2015-02-25T22:49:28+00:00
|
2015-02-25T22:49:28+00:00
| 1,934 | false |
I learn database from a Standford tutorial.\n\nhttps://www.youtube.com/watch?v=D-k-h0GuFmE&list=PL6hGtHedy2Z4EkgY76QOcueU8lAC4o6c3\n\n select Name as Customers\n from Customers\n where Id not in\n (select CustomerId as Id from Orders);
| 6 | 0 |
[]
| 1 |
customers-who-never-order
|
Pandas | SQL | EASY | Customers Who Never Order | Easy Explained
|
pandas-sql-easy-customers-who-never-orde-giyn
|
First Approach\nSee the Accepted and Successful Submission Detail\n\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n \
|
Khosiyat
|
NORMAL
|
2023-09-17T10:58:43.161944+00:00
|
2023-10-01T17:32:47.159956+00:00
| 534 | false |
First Approach\n[See the Accepted and Successful Submission Detail](https://leetcode.com/submissions/detail/1051717047/)\n\n```\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n \n # Perform a left join between \'Customers\' and \'Orders\'\n merged = customers.merge(orders, left_on=\'id\', right_on=\'customerId\', how=\'left\')\n\n # Filter rows where \'customerId\' in \'Orders\' is null\n null_customerID = merged[merged[\'customerId\'].isnull()]\n \n # # We select the \'name\' column and rename the column from \'name\' to \'customers\' within the selected DataFrame. So, the resulting DataFrame will have a \'customers\' column containing the data from the original \'name\' column, but it does not change the original DataFrame. \n renamed_column = null_customerID[[\'name\']].rename(columns={\'name\': \'customers\'})\n\n return renamed_column\n```\n\nSecond Approach\n[See the Accepted and Successful Submission Detail](https://leetcode.com/submissions/detail/1051717306/)\n\n```\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n \n # First, extract customer id\n customer_id = customers[\'id\']\n # Then, extract the column named \'customerId\' from the orders DataFrame.\n orders_made_by_customer = orders[\'customerId\']\n\n # Extract names of customers whose IDs are not in the \'customerId\' column of \'Orders\'\n customer_notIn_orderList = customers[~customer_id.isin(orders_made_by_customer)]\n\n # We select the \'name\' column and rename the column from \'name\' to \'customers\' within the selected DataFrame. So, the resulting DataFrame will have a \'customers\' column containing the data from the original \'name\' column, but it does not change the original DataFrame. \n renamed_column = customer_notIn_orderList[[\'name\']].rename(columns={\'name\': \'customers\'})\n\n return renamed_column\n\n```\n\n**SQL**\n[See the Accepted and Successful Submission Detail](https://leetcode.com/submissions/detail/1061394161/)\n\n```\nSELECT name AS Customers\nFROM Customers \nWHERE Customers.id not in (\n SELECT customerId \n FROM Orders\n);\n```\n\n```\n-- Select the "name" column from the "Customers" table and rename it as "Customers"\nSELECT name AS Customers\n\n-- Specify the source table as "Customers" from which data will be retrieved\nFROM Customers \n\n-- Begin a conditional clause to filter rows\nWHERE Customers.id not in (\n -- Subquery: Select the "customerId" column from the "Orders" table\n SELECT customerId \n FROM Orders\n);\n-- Close the conditional clause\n```\n\n\n\n\n# Pandas & SQL | SOLVED & EXPLAINED LIST\n\n**EASY**\n\n- [Combine Two Tables](https://leetcode.com/problems/combine-two-tables/solutions/4051076/pandas-sql-easy-combine-two-tables/)\n\n- [Employees Earning More Than Their Managers](https://leetcode.com/problems/employees-earning-more-than-their-managers/solutions/4051991/pandas-sql-easy-employees-earning-more-than-their-managers/)\n\n- [Duplicate Emails](https://leetcode.com/problems/duplicate-emails/solutions/4055225/pandas-easy-duplicate-emails/)\n\n- [Customers Who Never Order](https://leetcode.com/problems/customers-who-never-order/solutions/4055429/pandas-sql-easy-customers-who-never-order-easy-explained/)\n\n- [Delete Duplicate Emails](https://leetcode.com/problems/delete-duplicate-emails/solutions/4055572/pandas-sql-easy-delete-duplicate-emails-easy/)\n- [Rising Temperature](https://leetcode.com/problems/rising-temperature/solutions/4056328/pandas-sql-easy-rising-temperature-easy/)\n\n- [ Game Play Analysis I](https://leetcode.com/problems/game-play-analysis-i/solutions/4056422/pandas-sql-easy-game-play-analysis-i-easy/)\n\n- [Find Customer Referee](https://leetcode.com/problems/find-customer-referee/solutions/4056516/pandas-sql-easy-find-customer-referee-easy/)\n\n- [Classes More Than 5 Students](https://leetcode.com/problems/classes-more-than-5-students/solutions/4058381/pandas-sql-easy-classes-more-than-5-students-easy/)\n- [Employee Bonus](https://leetcode.com/problems/employee-bonus/solutions/4058430/pandas-sql-easy-employee-bonus/)\n\n- [Sales Person](https://leetcode.com/problems/sales-person/solutions/4058824/pandas-sql-easy-sales-person/)\n\n- [Biggest Single Number](https://leetcode.com/problems/biggest-single-number/solutions/4063950/pandas-sql-easy-biggest-single-number/)\n\n- [Not Boring Movies](https://leetcode.com/problems/not-boring-movies/solutions/4065350/pandas-sql-easy-not-boring-movies/)\n- [Swap Salary](https://leetcode.com/problems/swap-salary/solutions/4065423/pandas-sql-easy-swap-salary/)\n\n- [Actors & Directors Cooperated min Three Times](https://leetcode.com/problems/actors-and-directors-who-cooperated-at-least-three-times/solutions/4065511/pandas-sql-easy-explained-step-by-step-actors-directors-cooperated-min-three-times/)\n\n- [Product Sales Analysis I](https://leetcode.com/problems/product-sales-analysis-i/solutions/4065545/pandas-sql-easy-product-sales-analysis-i/)\n\n- [Project Employees I](https://leetcode.com/problems/project-employees-i/solutions/4065635/pandas-sql-easy-project-employees-i/)\n- [Sales Analysis III](https://leetcode.com/problems/sales-analysis-iii/solutions/4065755/sales-analysis-iii-pandas-easy/)\n\n- [Reformat Department Table](https://leetcode.com/problems/reformat-department-table/solutions/4066153/pandas-sql-easy-explained-step-by-step-reformat-department-table/)\n\n- [Top Travellers](https://leetcode.com/problems/top-travellers/solutions/4066252/top-travellers-pandas-easy-eaxplained-step-by-step/)\n\n- [Replace Employee ID With The Unique Identifier](https://leetcode.com/problems/replace-employee-id-with-the-unique-identifier/solutions/4066321/pandas-sql-easy-replace-employee-id-with-the-unique-identifier/)\n- [Group Sold Products By The Date](https://leetcode.com/problems/group-sold-products-by-the-date/solutions/4066344/pandas-sql-easy-explained-step-by-step-group-sold-products-by-the-date/)\n\n- [Customer Placing the Largest Number of Orders](https://leetcode.com/problems/customer-placing-the-largest-number-of-orders/solutions/4068822/pandas-sql-easy-explained-step-by-step-customer-placing-the-largest-number-of-orders/)\n\n- [Article Views I](https://leetcode.com/problems/article-views-i/solutions/4069777/pandas-sql-easy-article-views-i/)\n\n- [User Activity for the Past 30 Days I](https://leetcode.com/problems/user-activity-for-the-past-30-days-i/solutions/4069797/pandas-sql-easy-user-activity-for-the-past-30-days-i/)\n\n- [Find Users With Valid E-Mails](https://leetcode.com/problems/find-users-with-valid-e-mails/solutions/4069810/pandas-sql-easy-find-users-with-valid-e-mails/)\n\n- [Patients With a Condition](https://leetcode.com/problems/patients-with-a-condition/solutions/4069817/pandas-sql-easy-patients-with-a-condition/)\n\n- [Customer Who Visited but Did Not Make Any Transactions](https://leetcode.com/problems/customer-who-visited-but-did-not-make-any-transactions/solutions/4072542/pandas-sql-easy-customer-who-visited-but-did-not-make-any-transactions/)\n\n\n- [Bank Account Summary II](https://leetcode.com/problems/bank-account-summary-ii/solutions/4072569/pandas-sql-easy-bank-account-summary-ii/)\n\n- [Invalid Tweets](https://leetcode.com/problems/invalid-tweets/solutions/4072599/pandas-sql-easy-invalid-tweets/)\n\n- [Daily Leads and Partners](https://leetcode.com/problems/daily-leads-and-partners/solutions/4072981/pandas-sql-easy-daily-leads-and-partners/)\n\n- [Recyclable and Low Fat Products](https://leetcode.com/problems/recyclable-and-low-fat-products/solutions/4073003/pandas-sql-easy-recyclable-and-low-fat-products/)\n\n- [Rearrange Products Table](https://leetcode.com/problems/rearrange-products-table/solutions/4073028/pandas-sql-easy-rearrange-products-table/)\n- [Calculate Special Bonus](https://leetcode.com/problems/calculate-special-bonus/solutions/4073595/pandas-sql-easy-calculate-special-bonus/)\n\n- [Count Unique Subjects](https://leetcode.com/problems/number-of-unique-subjects-taught-by-each-teacher/solutions/4073666/pandas-sql-easy-count-unique-subjects/)\n\n- [Count Unique Subjects](https://leetcode.com/problems/number-of-unique-subjects-taught-by-each-teacher/solutions/4073666/pandas-sql-easy-count-unique-subjects/)\n\n- [Fix Names in a Table](https://leetcode.com/problems/fix-names-in-a-table/solutions/4073695/pandas-sql-easy-fix-names-in-a-table/)\n- [Primary Department for Each Employee](https://leetcode.com/problems/primary-department-for-each-employee/solutions/4076183/pandas-sql-easy-primary-department-for-each-employee/)\n\n- [The Latest Login in 2020](https://leetcode.com/problems/the-latest-login-in-2020/solutions/4076240/pandas-sql-easy-the-latest-login-in-2020/)\n\n- [Find Total Time Spent by Each Employee](https://leetcode.com/problems/find-total-time-spent-by-each-employee/solutions/4076313/pandas-sql-easy-find-total-time-spent-by-each-employee/)\n\n- [Find Followers Count](https://leetcode.com/problems/find-followers-count/solutions/4076342/pandas-sql-easy-find-followers-count/)\n- [Percentage of Users Attended a Contest](https://leetcode.com/problems/percentage-of-users-attended-a-contest/solutions/4077301/pandas-sql-easy-percentage-of-users-attended-a-contest/)\n\n- [Employees With Missing Information](https://leetcode.com/problems/employees-with-missing-information/solutions/4077308/pandas-sql-easy-employees-with-missing-information/)\n\n- [Average Time of Process per Machine](https://leetcode.com/problems/average-time-of-process-per-machine/solutions/4077402/pandas-sql-easy-average-time-of-process-per-machine/)\n
| 5 | 0 |
['MySQL']
| 2 |
customers-who-never-order
|
Simple Python Pandas Solution ✅✅
|
simple-python-pandas-solution-by-lil_toe-cwcn
|
Code\n\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n never_o=pd.DataFrame()\n never_o[\'Cus
|
Lil_ToeTurtle
|
NORMAL
|
2023-08-16T09:07:11.057012+00:00
|
2023-08-16T09:07:11.057044+00:00
| 942 | false |
# Code\n```\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n never_o=pd.DataFrame()\n never_o[\'Customers\']=customers[~customers.id.isin(orders.customerId)][\'name\']\n return never_o\n```
| 5 | 0 |
['Pandas']
| 2 |
customers-who-never-order
|
MySQL Solution
|
mysql-solution-by-pranto1209-81qt
|
Code\n\n# Write your MySQL query statement below\nselect name as \'Customers\' from Customers\nwhere id not in (select customerid from Orders);\n
|
pranto1209
|
NORMAL
|
2023-01-12T22:23:46.480884+00:00
|
2023-03-13T16:06:36.427522+00:00
| 2,571 | false |
# Code\n```\n# Write your MySQL query statement below\nselect name as \'Customers\' from Customers\nwhere id not in (select customerid from Orders);\n```
| 5 | 0 |
['MySQL']
| 2 |
customers-who-never-order
|
Customers that dont order
|
customers-that-dont-order-by-niharika_so-js76
|
Intuition\nRequires Join\n\n# Approach\nFigure out which join is to be used and then where condition\n\n# Complexity\n- Time complexity:\nBegginer\n\n- Space co
|
niharika_solanki
|
NORMAL
|
2022-10-21T10:14:46.403884+00:00
|
2022-10-21T10:14:46.403918+00:00
| 1,231 | false |
# Intuition\nRequires Join\n\n# Approach\nFigure out which join is to be used and then where condition\n\n# Complexity\n- Time complexity:\nBegginer\n\n- Space complexity:\n4 lines\n\n# Code\n```\n/* Write your T-SQL query statement below */\nselect customers.name as Customers from customers\nleft join orders\non customers.id = orders.customerid\nwhere orders.customerid is null;\n```
| 5 | 0 |
['MS SQL Server']
| 0 |
customers-who-never-order
|
3 Simple Solutions (1. NOT IN, 2. NOT EXISTS, 3. LEFT JOIN)
|
3-simple-solutions-1-not-in-2-not-exists-ecvq
|
1. Using NOT IN\nselect name as Customers from customers c\nwhere c.id not in (select customerId from orders)\n\n2. Using NOT EXISTS\nselect name as Customers f
|
Einsatz
|
NORMAL
|
2022-07-14T15:12:21.323933+00:00
|
2022-07-14T15:12:21.323970+00:00
| 344 | false |
**1. Using NOT IN**\nselect name as Customers from customers c\nwhere c.id not in (select customerId from orders)\n\n**2. Using NOT EXISTS**\nselect name as Customers from customers c\nwhere not exists (select 1 from orders o where c.id = o.customerId)\n\n**3. LEFT JOIN**\nselect name as Customers from customers c\nleft join orders o\non c.id = o.customerId\nwhere o.customerId is null
| 5 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
Two Simple Solutions - Nested Query & Left Join
|
two-simple-solutions-nested-query-left-j-igg1
|
\n#Nested Query:\nSELECT name AS Customers FROM Customers \nWHERE id NOT IN ( SELECT customerId FROM orders );\n\n\n\n# Left Join\nSELECT c.name AS Customers \n
|
pruthashouche
|
NORMAL
|
2022-07-02T23:35:51.816161+00:00
|
2022-07-02T23:35:51.816207+00:00
| 285 | false |
```\n#Nested Query:\nSELECT name AS Customers FROM Customers \nWHERE id NOT IN ( SELECT customerId FROM orders );\n```\n\n```\n# Left Join\nSELECT c.name AS Customers \nFROM Customers c LEFT JOIN Orders o\nON c.id=o.CustomerId\nWHERE o.id is NULL;\n```\n\n**Please UpVote if it was Helpful :)**
| 5 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
Customers Who Never Order
|
customers-who-never-order-by-coolsand172-4a6q
|
\nSELECT\n name as Customers\nFROM \n Customers\nwhere \n id NOT IN (SELECT customerId FROM Orders);\n\nUpvote IF IT Help
|
coolsand1727
|
NORMAL
|
2022-06-21T09:25:34.443233+00:00
|
2022-06-21T09:25:34.443268+00:00
| 436 | false |
```\nSELECT\n name as Customers\nFROM \n Customers\nwhere \n id NOT IN (SELECT customerId FROM Orders);\n```\nUpvote IF IT Help
| 5 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
MYSQL Using || not in ||
|
mysql-using-not-in-by-smilyface_123-4tkq
|
\nselect c1.name as Customers \n from Customers c1\n Where c1.id not in ( select O.customerId \n from Orders O );\n\t\t\t\t\t \
|
smilyface_123
|
NORMAL
|
2022-04-20T17:35:44.866809+00:00
|
2022-04-20T17:35:44.866851+00:00
| 438 | false |
```\nselect c1.name as Customers \n from Customers c1\n Where c1.id not in ( select O.customerId \n from Orders O );\n\t\t\t\t\t \n\t\tIF Helpful Please Like And Upvoke\t\t\t \n```
| 5 | 0 |
['MS SQL Server']
| 0 |
customers-who-never-order
|
best easiest simplest mysql using subquery - 183. Customers Who Never Order
|
best-easiest-simplest-mysql-using-subque-olp2
|
\nselect name as Customers from customers where id NOT IN \n(select customerId from Orders);\n\n\n#pls upvote if you find solution easy to understand..Thanks..!
|
divyagoel1
|
NORMAL
|
2022-02-27T11:38:16.326508+00:00
|
2022-02-27T11:38:16.326550+00:00
| 294 | false |
```\nselect name as Customers from customers where id NOT IN \n(select customerId from Orders);\n\n\n#pls upvote if you find solution easy to understand..Thanks..!!\n```
| 5 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
Several ways to solve this type of questions - IN A NOT IN B
|
several-ways-to-solve-this-type-of-quest-fgxy
|
Genrally this type of questions contain more than one table (sometimes one table but comparing among fields), and the goal is to find records in table A but not
|
lisayang0620
|
NORMAL
|
2021-04-27T16:03:54.192254+00:00
|
2021-05-25T14:19:08.841110+00:00
| 355 | false |
Genrally this type of questions contain more than one table (sometimes one table but comparing among fields), and the goal is to find records in table A but not in table B. More complicated questions are looking for records in table A but not in table B with certian critera (e.g. range of time, overlaps, flags, distinct values).\n\nSimilar questions: 1084, 1581, 1809, 577, 1350, 1607, 607\n\nSimilar type of questions: \nhttps://leetcode.com/problems/customers-who-bought-products-a-and-b-but-not-c/discuss/1220534/four-solutions-for-this-type-of-questions-in-a-and-b-andnot-c\n\nSolution 1: Use left outer join\n```\nSELECT customers.Name as Customers\n FROM customers\n LEFT JOIN Orders\n ON customers.id = Orders.CustomerId\n WHERE customerId IS NULL\n```\n\nSolution 2: Put records not needed in a subquery. Then select records from table A WHERE the records are NOT IN/EXIST in the records selected by the subquery. \n```\nSELECT customers.Name as Customers\n FROM customers\n WHERE ID not in (SELECT CustomerId FROM Orders)\n```\nSolution 3: Create a flag using SUM(CASE WHEN). And select all records with the corresponding flag. \n```\nSELECT Name AS Customers\n FROM(\nSelect Customers.id, Name, SUM(CASE WHEN Customers.id = Orders.Customerid THEN 1 ELSE 0 END) AS score\n FROM Customers\n LEFT JOIN Orders\n ON Customers.id = Orders.CustomerId\n GROUP BY 1,2)a\n WHERE a.score = 0\n ```\n\nSolution 4: If there\'s a range or there are multiple records for one id, using GROUP BY + HAVING (criteria) to evaluate the aggregated results. This solution does not really apply to this question..
| 5 | 0 |
[]
| 0 |
customers-who-never-order
|
Easy and Simple Three Solutions 🚀 | Beginner-Friendly 🎓 | Beats 94.72% ⚡
|
easy-and-simple-three-solutions-beginner-4nnf
|
🎯Approach 1 Using NOT IN 🔍🖥️Code🧠Time Complexity Analysis
The subquery (SELECT customerId FROM Orders) runs in O(M).
The outer query (SELECT FROM Customers WHER
|
bulbul_rahman
|
NORMAL
|
2025-03-16T18:13:58.506841+00:00
|
2025-03-16T18:13:58.506841+00:00
| 812 | false |
# 🎯Approach 1 Using NOT IN 🔍
# 🖥️Code
```mysql []
select
name AS Customers
FROM Customers WHERE Id
Not In
(
SELECT
customerId
FROM Orders
)
```
# 🧠Time Complexity Analysis
- **The subquery** (SELECT customerId FROM Orders) runs in **O(M)**.
- **The outer query** (SELECT FROM Customers WHERE Id NOT IN (...)) checks each Customers.Id against Orders.customerId.
- If customerId has no index, checking membership in an unsorted list takes O(M) per lookup.
- Since there are N rows in Customers, the total complexity is O(N * M).
# 📈Overall
- **Best Case** : If Orders.customerId is **indexed** and the DB optimizer uses a hash lookup, the check can run in **O(N log M)**.
- **Worst Case** : If **no index** exists, it results in **O(N * M)**.
- **Space Complexity** : **O(M)**.
# 🎯Approach 2 Using NOT EXISTS 🔄
# 🖥️Code
```mysql []
SELECT name AS Customers
FROM Customers c
WHERE NOT EXISTS (
SELECT
1 FROM
Orders o
WHERE o.customerId = c.Id
);
```
# 🧠Time Complexity Analysis
- **The correlated subquery** (SELECT 1 FROM Orders WHERE o.customerId = c.Id) runs for each row in Customers.
- If Orders.customerId is **indexed**, the subquery runs in O(log M) for each row in Customers, giving **O(N log M)**.
- If **no** **index** exists, the worst case is O(N * M).
# 📈Overall
- **Best Case** : With an index, O(N log M).
- **Worst Case** : If **no index** exists, it results in O(N * M).
- **Space Complexity** : O(1).
# 🎯Approach 3 Using LEFT JOIN 🛠️
# 🖥️Code
```mysql []
select
c.name AS Customers
from Customers c
Left join Orders o
on c.id = o.customerId
where o.customerId is null
```
# 🧠Complexity Analysis
- A **LEFT JOIN** merges the two tables:
- If Orders.customerId is indexed, the join runs in **O(N log M)**.
- If no index exists, it runs in **O(N * M)** (full table scan).
- **The WHERE** o.customerId IS NULL condition filters out matching records in O(N).
# 📈Overall
- **Best Case** : If Orders.customerId is indexed, the total time is **O(N log M)**.
- **Worst Case** : Without an index, it’s **O(N * M)**.
- **Space Complexity** : **O(N + M)**.
| 4 | 0 |
['MS SQL Server']
| 2 |
customers-who-never-order
|
✅Beats 64.11% 🔥|| 100% EASY TO FOLLOW 😊|| FAST & OPTIMIZED 🔥|| CLEAN QUERY WITH NOT EXISTS 😁
|
beats-6411-100-easy-to-follow-fast-optim-du2l
|
Problem StatementI was tasked with identifying all customers from the Customers table who have never placed an order. The result should include only the names o
|
ahmedzubayersunny
|
NORMAL
|
2025-03-14T09:52:49.297858+00:00
|
2025-03-14T09:52:49.297858+00:00
| 439 | false |
# Problem Statement
**I was tasked with identifying all customers from the Customers table who have never placed an order. The result should include only the names of these customers, and the output can be returned in any order.**
# Code - Solution
```mssql []
SELECT name AS Customers
FROM Customers c
WHERE NOT EXISTS (
SELECT 1
FROM Orders o
WHERE o.customerId = c.id
);
```
---
# Intuition
When I first approached this problem:
1. I realized that the key was to compare the id column in the Customers table with the customerId column in the Orders table.
2. To efficiently identify customers who never placed an order, I decided to use a subquery with the NOT EXISTS clause. This approach ensures that we only retrieve rows where no matching customerId exists in the Orders table.
3. The NOT EXISTS clause is particularly advantageous because it stops evaluating as soon as it finds a match, making it more efficient than alternatives like NOT IN.
# Approach
Here’s how I solved the problem step by step:
- I used the NOT EXISTS clause to filter out customers whose id exists in the Orders table under the customerId column.
- For each row in the Customers table, the subquery checks if there is a corresponding customerId in the Orders table.
- If no match is found, the customer is included in the result set.
The outer query selects only the name column of these customers and renames it to Customers for clarity.
- This approach avoids unnecessary computations and ensures correctness even if the Orders table contains NULL values in the customerId column.
**This method is clean, efficient, and leverages modern SQL optimizations for subqueries.**
---
# Complexity
- Time Complexity:
> $$O(n+m)$$
> n: Number of rows in the Customers table.
m: Number of rows in the Orders table.
The database engine optimizes the NOT EXISTS clause by using indexes (if available) or short-circuiting, resulting in linear time complexity relative to the size of both tables.
- Space Complexity:
> $$O(1)$$
> The subquery does not materialize its result; it only checks for existence.
No additional space is required beyond the input tables and the result set.
---
# **Explanation of the Code:**
**- Outer Query :**
Selects the name column from the Customers table and renames it to Customers.
Filters rows using the NOT EXISTS clause.
**- Subquery :**
Checks if there is any row in the Orders table where customerId matches the id of the current customer (c.id).
Returns TRUE if no such row exists, meaning the customer has never placed an order.
**- Efficiency :**
The NOT EXISTS clause is optimized by the database engine to stop evaluating as soon as a match is found, ensuring minimal computational overhead.
---
# **Some Extra Approches**
**1. `LEFT JOIN` Solution**
```
SELECT c.name AS Customers
FROM Customers c
LEFT JOIN Orders o ON c.id = o.customerId
WHERE o.customerId IS NULL;
```
**2. `NOT IN` Solution**
```
SELECT name AS Customers
FROM Customers
WHERE id NOT IN (
SELECT customerId
FROM Orders
);
```
---
# Please upvote to support me...! 😊
---
| 4 | 0 |
['Database', 'MySQL', 'MS SQL Server']
| 0 |
customers-who-never-order
|
MySQL Solution - Using Subquery
|
mysql-solution-using-subquery-by-ruch21-cfh9
|
Code
|
ruch21
|
NORMAL
|
2025-01-18T05:04:19.379036+00:00
|
2025-01-18T05:04:19.379036+00:00
| 838 | false |
# Code
```mysql []
# Write your MySQL query statement below
SELECT name AS Customers
FROM Customers
WHERE id NOT IN (
SELECT customerId
FROM Orders);
```
| 4 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
✅ Simple solution using LEFT JOIN ✅
|
simple-solution-using-left-join-by-angel-5tek
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \nUsed LEFT JOIN and then
|
angelin_silviya
|
NORMAL
|
2024-11-10T11:10:50.937435+00:00
|
2024-11-10T11:10:50.937461+00:00
| 1,016 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nUsed LEFT JOIN and then selected the NULL rows in order to filter the customers who never ordered.\n\n\n# Code\n```postgresql []\n-- Write your PostgreSQL query statement below\nSELECT \nname AS "Customers"\nFROM customers c\nLEFT JOIN orders o\nON c.id = o.customerId\nWHERE o.customerId IS NULL\n```
| 4 | 0 |
['PostgreSQL']
| 0 |
customers-who-never-order
|
Pandas-merge-Easy Solution
|
pandas-merge-easy-solution-by-kg-profile-xend
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time
|
KG-Profile
|
NORMAL
|
2024-04-19T17:59:57.042849+00:00
|
2024-04-19T17:59:57.042885+00:00
| 153 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n df=customers.merge(orders,how=\'left\',left_on=\'id\',right_on=\'customerId\')[[\'name\',\'customerId\']]\n df=df[df[\'customerId\'].isna()]\n return df[[\'name\']].rename(columns={\'name\':\'customers\'})\n```
| 4 | 0 |
['Pandas']
| 0 |
customers-who-never-order
|
💻Think like SQL Engine🔥Solve puzzle with 2 different ways✅
|
think-like-sql-enginesolve-puzzle-with-2-piqk
|
\n# Solution with LEFT OUTER JOIN\n\n/* Write your T-SQL query statement below */\nSELECT c.name Customers\nFROM Customers c \nLEFT OUTER JOIN Orders o ON c.id
|
k_a_m_o_l
|
NORMAL
|
2023-12-03T06:43:44.407710+00:00
|
2023-12-03T06:43:44.407735+00:00
| 485 | false |
\n# Solution with LEFT OUTER JOIN\n```\n/* Write your T-SQL query statement below */\nSELECT c.name Customers\nFROM Customers c \nLEFT OUTER JOIN Orders o ON c.id = o.customerId\nWHERE o.customerId IS NULL\n```\n# Solution with NOT IN\n```\n/* Write your T-SQL query statement below */\nSELECT name Customers\nFROM Customers \nWHERE id NOT IN (SELECT customerid FROM orders)\n```
| 4 | 0 |
['MySQL', 'MS SQL Server']
| 0 |
customers-who-never-order
|
||Easy MYSQL solution without join||
|
easy-mysql-solution-without-join-by-amma-tztk
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time
|
ammar_saquib
|
NORMAL
|
2023-10-26T19:19:16.911226+00:00
|
2023-10-26T19:19:16.911256+00:00
| 1,235 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Write your MySQL query statement below\nselect name as Customers from Customers where \nid not in(select customerId from orders);\n```
| 4 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
using isin() and negating it.
|
using-isin-and-negating-it-by-abdelazizs-zkz6
|
Intuition\n Describe your first thoughts on how to solve this problem. \n we just need to select the indicies which are not existing in the orders list\n# Appro
|
abdelazizSalah
|
NORMAL
|
2023-09-16T12:42:53.723550+00:00
|
2023-09-16T12:42:53.723574+00:00
| 254 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n* we just need to select the indicies which are not existing in the orders list\n# Approach\n<!-- Describe your approach to solving the problem. -->\n* First you have to know isin() function:\n * it takes a list as input, and loop over the calling object, and for each element, it check if this element exist in the provided list or not. \n * if it exist, it set its index to True, else it set it as False.\n * Then it return list of binary (or bool True, False or 1,0)\n* Then you have to know that we do not have isnotin() but to apply its logic, we use isin() then prefix it with **~** telda symbol. \n* Then you have to know rename() method, which we use it to change the name of the pd.Series column name.\n* Last function to know is .loc[firstParam, secondParam], it takes two parameters\n * firstParam: it should be a list of indicies, where you want to select.\n * secondParam: it should be a list of columns, that you want to select from. \n* Then now you are ready to solve the problem easily, by just \n 1. get the customers Id column.\n 2. then apply on it isin() \n 3. pass to isin(orders.customerId) to search for all the customers who did an order.\n 4. then use telda **~** to get the customers who did not order.\n 5. then pass this list to the first parameter of loc method.\n 6. then the second parameter should be the **name** column, to retrieve the name of the customers who did not order any thing.\n 7. then you have to use the rename method to change the column name from name to **Customers**.\n 8. Then just create a dataframe object, and put inside it this coulmn to match the return type of the functio\n 9. Then return that dataframe.\n# Code\n```\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n \n\n return pd.DataFrame(customers.loc[~customers.id.isin(orders.customerId), \'name\'].rename(\'Customers\'))\n```
| 4 | 0 |
['Pandas']
| 0 |
customers-who-never-order
|
Used two approach one using simple where and one using join
|
used-two-approach-one-using-simple-where-ur9n
|
upvote if you like the solution\n\n# best approach\nselect name as customers from customers\nwhere id not in (select customerId from orders);\n\n# using joins\n
|
toshiksirohi
|
NORMAL
|
2023-05-04T22:06:58.179904+00:00
|
2023-05-04T22:06:58.179947+00:00
| 909 | false |
# upvote if you like the solution\n\n# best approach\nselect name as customers from customers\nwhere id not in (select customerId from orders);\n\n# using joins\nSELECT customers.name AS customers\nFROM customers\nLEFT JOIN orders\nON customers.id = orders.customerId\nWHERE orders.customerId IS NULL;\n\n```
| 4 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
👇 MySQL 2 solutions | very easy 🔥 nested query | join
|
mysql-2-solutions-very-easy-nested-query-p9nf
|
\uD83D\uDE4B\uD83C\uDFFB\u200D\u2640\uFE0F Hello, here are my solutions to the problem.\nPlease upvote to motivate me post future solutions. HAPPY CODING \u2764
|
rusgurik
|
NORMAL
|
2022-08-25T16:16:45.505465+00:00
|
2022-08-25T16:16:45.505513+00:00
| 236 | false |
\uD83D\uDE4B\uD83C\uDFFB\u200D\u2640\uFE0F Hello, here are my solutions to the problem.\nPlease upvote to motivate me post future solutions. HAPPY CODING \u2764\uFE0F\nAny suggestions and improvements are always welcome.\nSolution 1: Join, long, not good \uD83E\uDD26\uD83C\uDFFB\u200D\u2640\uFE0F\n\u2705 Runtime: 591 ms, faster than 50.77% of MySQL.\n\n```\nselect name as Customers\nfrom Customers a\nleft join Orders b\non a.id = b.customerId\nwhere customerId is null\n```\nSolution 2: Nested query \uD83C\uDFAF\n\u2705 Runtime: 495 ms, faster than 69.10% of MySQL.\n\n```\nselect name as Customers \nfrom Customers \nwhere id not in (select customerId from Orders)\n```\nIf you like the solutions, please upvote \uD83D\uDD3C\nFor any questions, or discussions, comment below. \uD83D\uDC47\uFE0F
| 4 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
✅ Mysql | ✅ Beginner Friendly | Fully Explained | Sub Query Concept
|
mysql-beginner-friendly-fully-explained-8660p
|
Please Upvote If you like it :)\nConcept Of the Day - Subquery\n The subquery can be nested inside a SELECT, INSERT, UPDATE, or DELETE statement or inside anoth
|
vikramsinghgurjar
|
NORMAL
|
2022-07-12T17:20:29.754590+00:00
|
2022-07-12T19:18:21.612459+00:00
| 190 | false |
**Please Upvote If you like it :)**\nConcept Of the Day - **Subquery**\n* The subquery can be nested inside a SELECT, INSERT, UPDATE, or DELETE statement or inside another subquery.\n* A subquery is usually added within the WHERE Clause of another SQL SELECT statement.\n\nHere Subquery is present in where clause\n### Solution\n```\nselect name as Customers from Customers where id not in (select customerId from Orders)\n```
| 4 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
A solution using NOT IN || easy to understand
|
a-solution-using-not-in-easy-to-understa-72si
|
\tSELECT Name as Customers from Customers\n\tWHERE id NOT IN(SELECT customerId from Orders)
|
vinita645
|
NORMAL
|
2022-06-14T06:02:05.567966+00:00
|
2022-06-14T06:02:05.568016+00:00
| 274 | false |
\tSELECT Name as Customers from Customers\n\tWHERE id NOT IN(SELECT customerId from Orders)
| 4 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
🔴 MySQL Solution 🔴
|
mysql-solution-by-alekskram-92ck
|
Solution\n\nselect name as Customers\nfrom Customers\nleft join Orders on Orders.customerId = Customers.id\nwhere Orders.id is null\n\nBy using left join we can
|
alekskram
|
NORMAL
|
2022-04-18T13:36:38.346374+00:00
|
2022-04-18T13:36:38.346416+00:00
| 143 | false |
# Solution\n```\nselect name as Customers\nfrom Customers\nleft join Orders on Orders.customerId = Customers.id\nwhere Orders.id is null\n```\nBy using **left join** we can see customer, who has never make orders. Orders.id will be **null**, because **join** will not find rows for them in Orders.\nIf you find this **solution** and **explanation** helpful, please **upvote** it for others people.
| 4 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
easy to understand
|
easy-to-understand-by-saurabht462-m8s8
|
```\nselect c.name as \'Customers\'\nfrom Customers as c\nwhere (select count(*) from Orders where Orders.customerID=c.id)=0;
|
saurabht462
|
NORMAL
|
2021-12-01T14:41:16.900674+00:00
|
2021-12-01T14:41:16.900707+00:00
| 184 | false |
```\nselect c.name as \'Customers\'\nfrom Customers as c\nwhere (select count(*) from Orders where Orders.customerID=c.id)=0;
| 4 | 0 |
[]
| 0 |
customers-who-never-order
|
left join simple
|
left-join-simple-by-prayaga74-5r3x
|
select customers.name as customers from customers left join orders on Customers.Id=Orders.CustomerId\nwhere orders.Id is null
|
prayaga74
|
NORMAL
|
2020-12-08T19:56:03.527523+00:00
|
2020-12-08T19:56:03.527564+00:00
| 278 | false |
select customers.name as customers from customers left join orders on Customers.Id=Orders.CustomerId\nwhere orders.Id is null
| 4 | 0 |
[]
| 0 |
customers-who-never-order
|
[MySQL] Simple Solution | Beats 100% in Less Space | Self-Explanatory
|
mysql-simple-solution-beats-100-in-less-iv5yg
|
\n# Write your MySQL query statement below\nselect\n c.Name as \'Customers\'\nfrom Customers c\nwhere not exists (select o.CustomerId\nfrom Orders o\nwhere c
|
ravireddy07
|
NORMAL
|
2020-09-10T04:13:15.317094+00:00
|
2020-09-10T04:16:23.516833+00:00
| 343 | false |
```\n# Write your MySQL query statement below\nselect\n c.Name as \'Customers\'\nfrom Customers c\nwhere not exists (select o.CustomerId\nfrom Orders o\nwhere c.Id = o.CustomerId);\n```
| 4 | 0 |
[]
| 0 |
customers-who-never-order
|
New simple Solution
|
new-simple-solution-by-mehdistudie-qllg
|
\nselect Name as \'Customers\' from Customers \nwhere Id not in (select distinct CustomerId from Orders);\n
|
mehdistudie
|
NORMAL
|
2018-04-30T16:50:35.409006+00:00
|
2018-04-30T16:50:35.409006+00:00
| 328 | false |
```\nselect Name as \'Customers\' from Customers \nwhere Id not in (select distinct CustomerId from Orders);\n```
| 4 | 0 |
[]
| 1 |
customers-who-never-order
|
Just a solution
|
just-a-solution-by-greedythief-h8jo
|
select Name as Customers from Customers where Customers.id not in (select CustomerId from Orders);
|
greedythief
|
NORMAL
|
2015-01-21T02:57:50+00:00
|
2015-01-21T02:57:50+00:00
| 1,381 | false |
select Name as Customers from Customers where Customers.id not in (select CustomerId from Orders);
| 4 | 0 |
[]
| 2 |
customers-who-never-order
|
A very simple solutions (Beats 100%/Runtime: 474 ms )
|
a-very-simple-solutions-beats-100runtime-tx8u
|
select Name as Customers from Customers where id not in(select CustomerId from Orders);
|
koyomi
|
NORMAL
|
2016-09-02T12:45:39.936000+00:00
|
2016-09-02T12:45:39.936000+00:00
| 1,440 | false |
select Name as Customers from Customers where id not in(select CustomerId from Orders);
| 4 | 1 |
[]
| 0 |
customers-who-never-order
|
Using "distinct" beats 99% of the solutions
|
using-distinct-beats-99-of-the-solutions-spi2
|
select \n Name \n from \n (\n select \n c.Name, \n o.CustomerId\n from Customers c \n left join (select distinct Cus
|
wyddfrank
|
NORMAL
|
2016-01-03T00:44:34+00:00
|
2016-01-03T00:44:34+00:00
| 1,964 | false |
select \n Name \n from \n (\n select \n c.Name, \n o.CustomerId\n from Customers c \n left join (select distinct CustomerId from Orders) o \n on c.Id=o.CustomerId \n ) t \n where t.CustomerId is null\n ;
| 4 | 0 |
[]
| 5 |
customers-who-never-order
|
Using one subQuery
|
using-one-subquery-by-mantosh_kumar04-8nep
|
\n\n# Code\nmysql []\n# Write your MySQL query statement below\nselect name as Customers from Customers \nwhere id not in (select customerId from Orders );\n\n
|
mantosh_kumar04
|
NORMAL
|
2024-10-09T15:40:25.011476+00:00
|
2024-10-09T15:40:25.011515+00:00
| 399 | false |
\n\n# Code\n```mysql []\n# Write your MySQL query statement below\nselect name as Customers from Customers \nwhere id not in (select customerId from Orders );\n```\n\n
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
MySQL Clean Solution || 2-Approach Detail Explanation
|
mysql-clean-solution-2-approach-detail-e-bx5s
|
OVERVIEW\n\n\n\n# Code\nWAY-1\n\n# Write your MySQL query statement below\nSELECT name AS Customers FROM Customers\nWHERE id NOT IN (\n SELECT customerId FRO
|
Shree_Govind_Jee
|
NORMAL
|
2024-05-28T04:25:27.860296+00:00
|
2024-05-28T04:25:27.860324+00:00
| 944 | false |
# OVERVIEW\n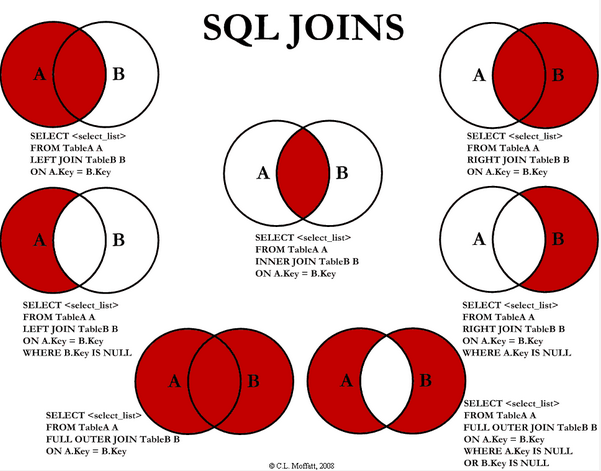\n\n\n# Code\n**WAY-1**\n```\n# Write your MySQL query statement below\nSELECT name AS Customers FROM Customers\nWHERE id NOT IN (\n SELECT customerId FROM Orders\n);\n```\n\n---\n\n**WAY-2**\n```\nSELECT c.name AS Customers FROM Customers c\nLEFT JOIN Orders o\nON c.id = o.customerId\nWHERE o.customerId IS NULL;\n```
| 3 | 0 |
['Database', 'MySQL']
| 1 |
customers-who-never-order
|
Simple LEFT JOIN With Explained Approach✔
|
simple-left-join-with-explained-approach-uaea
|
Approach\nLEFT JOIN Orders ON Customers.id = Orders.customerId, This part performs a LEFT JOIN between the "Customers" table and the "Orders" table based on the
|
iamsubrat1
|
NORMAL
|
2023-12-31T11:29:39.191889+00:00
|
2023-12-31T11:29:39.191919+00:00
| 1,069 | false |
# Approach\n**LEFT JOIN Orders ON Customers.id = Orders.customerId**, This part performs a LEFT JOIN between the **"Customers"** table and the **"Orders"** table based on the condition that the "*id"* column in the **"Customers"** table matches the *"customerId*" column in the **"Orders"** table. A LEFT JOIN returns all rows from the left table (Customers) and the matched rows from the right table (Orders). If there is no match, NULL values are returned for columns from the right table.\n\n**WHERE Orders.CustomerId IS NULL** This is a condition applied to the result of the LEFT JOIN. It filters the rows where there is no matching order for a customer. In other words, it selects only those customers who have not placed any orders.\n\n#### *PLEASE UPVOTE IF IT HEPLS*\n\n# Code\n```\nSELECT Customers.name as Customers FROM Customers LEFT JOIN \nOrders ON Customers.id=Orders.customerId\nWHERE Orders.CustomerId is NULL\n\n```
| 3 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
Easy to understand Solution for Beginners using Pandas.
|
easy-to-understand-solution-for-beginner-6fkd
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\nchanged name of id and name column to customerId and Customers to merge t
|
gauravbisht126
|
NORMAL
|
2023-08-04T18:57:33.233677+00:00
|
2023-08-05T18:12:18.488422+00:00
| 182 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nchanged name of id and name column to customerId and Customers to merge the table order to customers on column customerId merge is same as merge in mysql you have to define the merge type whether outer inner left right etc. then filtered replaced null values with 0 to represent that customer have 0 orders using fillna() which is used to fill in your data inplace of null. after that we save our filtered out data in a new dataframe and return customers column from it\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n customers.rename(columns={"id":"customerId","name":"Customers"}, inplace=True)\n new_df = pd.merge(customers,orders,how="left", on="customerId")\n new_df["id"].fillna(0, inplace=True)\n df = new_df[(new_df["id"]==0)]\n return df[["Customers"]]\n```
| 3 | 0 |
['Database', 'Python3', 'Pandas']
| 0 |
customers-who-never-order
|
[Pandas || LEFT ANTI JOIN]
|
pandas-left-anti-join-by-tejkiran_v-cw8o
|
Left anti join selects only the rows that are present in left dataFrame as per the join-condition.\n\nIn other words, \nleft-anti-join == (left-join AND .isna
|
tejkiran_v
|
NORMAL
|
2023-08-04T18:01:18.208392+00:00
|
2023-08-04T18:01:18.208426+00:00
| 864 | false |
Left anti join selects only the rows that are present in left dataFrame as per the join-condition.\n\nIn other words, \n`left-anti-join == (left-join AND .isna())`\n\nHere we are using the pandas\' inbuilt `_merge` indicator\n# Code\n```\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n\n joined_df = pd.merge(customers, orders, left_on="id", right_on="customerId", how="outer", indicator=True)\n \n return joined_df[joined_df["_merge"] == "left_only"][["name"]].rename(columns={"name": "Customers"})\n\n```
| 3 | 0 |
['Pandas']
| 1 |
customers-who-never-order
|
An easy to understand solution
|
an-easy-to-understand-solution-by-delete-4gt0
|
Code\n\nSELECT name as Customers FROM Customers WHERE id NOT IN (SELECT customerId FROM Orders); \n
|
deleted_user
|
NORMAL
|
2023-07-25T08:21:29.495687+00:00
|
2023-07-25T08:21:54.587183+00:00
| 787 | false |
# Code\n```\nSELECT name as Customers FROM Customers WHERE id NOT IN (SELECT customerId FROM Orders); \n```
| 3 | 0 |
['Oracle']
| 0 |
customers-who-never-order
|
SQL Server CLEAN & EASY
|
sql-server-clean-easy-by-rhazem13-4shy
|
\n/* Write your T-SQL query statement below */\nSELECT name AS Customers\nFROM Customers\nWHERE id NOT IN (SELECT customerId FROM Orders)\n
|
rhazem13
|
NORMAL
|
2023-03-08T15:46:35.353929+00:00
|
2023-03-08T15:46:35.353965+00:00
| 1,616 | false |
```\n/* Write your T-SQL query statement below */\nSELECT name AS Customers\nFROM Customers\nWHERE id NOT IN (SELECT customerId FROM Orders)\n```
| 3 | 0 |
[]
| 0 |
customers-who-never-order
|
Easy SQL Query
|
easy-sql-query-by-yashwardhan24_sharma-xjx0
|
Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time
|
yashwardhan24_sharma
|
NORMAL
|
2023-03-01T05:59:09.606611+00:00
|
2023-03-01T05:59:09.606659+00:00
| 2,178 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Write your MySQL query statement below\n\n\nSELECT name AS Customers FROM Customers WHERE id not in (SELECT customerId FROM Orders);\n```
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
Easy MySQL || beginner solution
|
easy-mysql-beginner-solution-by-nikhil_m-4w64
|
\n# Code\n\nselect name as Customers\nfrom Customers c\nwhere id not in (select customerId from Orders);\n
|
nikhil_mane
|
NORMAL
|
2022-11-05T17:16:46.530443+00:00
|
2022-11-05T17:16:46.530492+00:00
| 1,637 | false |
\n# Code\n```\nselect name as Customers\nfrom Customers c\nwhere id not in (select customerId from Orders);\n```
| 3 | 0 |
['MySQL', 'MS SQL Server']
| 0 |
customers-who-never-order
|
Simple one line solution | mysql
|
simple-one-line-solution-mysql-by-gauri_-echu
|
SELECT name AS Customers FROM Customers WHERE id NOT IN ( Select customerId From Orders);\n\n#header is Customer in the required output ,thus using as in the qu
|
gauri_ajgar
|
NORMAL
|
2022-10-22T10:16:03.448587+00:00
|
2022-10-22T10:16:03.448631+00:00
| 309 | false |
SELECT name AS Customers FROM Customers WHERE id NOT IN ( Select customerId From Orders);\n\n#header is Customer in the required output ,thus using as in the query.
| 3 | 0 |
[]
| 0 |
customers-who-never-order
|
mysql not in
|
mysql-not-in-by-hailey_lai-uso5
|
select name as customers\nfrom customers\nwhere id not in (select customerid from orders)
|
Hailey_lai
|
NORMAL
|
2022-10-05T13:25:00.328417+00:00
|
2022-10-05T13:25:00.328466+00:00
| 799 | false |
select name as customers\nfrom customers\nwhere id not in (select customerid from orders)
| 3 | 0 |
['MySQL']
| 2 |
customers-who-never-order
|
You can do it with both sub query and join
|
you-can-do-it-with-both-sub-query-and-jo-vibu
|
/ Write your T-SQL query statement below /\n\nselect Customers.name as Customers\nfrom Customers\nleft join Orders on Customers.id= Orders.customerId\nwhere Ord
|
Shahzaib_Arshad
|
NORMAL
|
2022-09-25T21:52:26.376710+00:00
|
2022-09-25T21:52:26.376781+00:00
| 561 | false |
/* Write your T-SQL query statement below */\n\nselect Customers.name as Customers\nfrom Customers\nleft join Orders on Customers.id= Orders.customerId\nwhere Orders.customerId is null\n\n \n-- sub query \nSELECT c.Name as Customers\nFROM Customers c\nWHERE c.id not in (\nSELECT o.CustomerId FROM Orders o\n);
| 3 | 0 |
[]
| 1 |
customers-who-never-order
|
Simple Solution With Each step Explanation
|
simple-solution-with-each-step-explanati-g7qm
|
select name as Customers from Customers where id not in (select customerId from Orders);\n\n\nname as Customers: We are creating a Alias name for name in Custom
|
ramakm
|
NORMAL
|
2022-09-03T11:41:09.588306+00:00
|
2022-09-03T11:41:30.606275+00:00
| 375 | false |
```select name as Customers from Customers where id not in (select customerId from Orders);```\n\n\nname as Customers: We are creating a Alias name for name in Customer Table as Customers.\n\n(select customerId from Orders): First Select Customerid from Orders.\n\nThen check with Customer Table. So, as My final result is from Customer table. \n\n where id not in: This will give the result which ids are not in Orders table.\n \n \n Give it a upvote if you like this solution.\n\n\n
| 3 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
MsSQL one liner | Simple | Easy
|
mssql-one-liner-simple-easy-by-rishithar-wyi0
|
\nselect name as Customers from Customers where id not in (select customerId from Orders);\n
|
RishithaRamesh
|
NORMAL
|
2022-08-16T07:17:57.463136+00:00
|
2022-08-16T07:17:57.463189+00:00
| 631 | false |
```\nselect name as Customers from Customers where id not in (select customerId from Orders);\n```
| 3 | 0 |
['MS SQL Server']
| 0 |
customers-who-never-order
|
Faster Than 99.67% | Subquery
|
faster-than-9967-subquery-by-manishbaswa-lr0c
|
\nselect name as customers from Customers where id not in (select customerId from Orders);\n\n
|
manishbaswal6
|
NORMAL
|
2022-08-05T18:24:52.617102+00:00
|
2022-08-05T18:25:36.543504+00:00
| 279 | false |
```\nselect name as customers from Customers where id not in (select customerId from Orders);\n\n```
| 3 | 0 |
[]
| 0 |
customers-who-never-order
|
easy 2-liner sql solution
|
easy-2-liner-sql-solution-by-dhruvraj_05-vvi6
|
\n SELECT Name AS Customers FROM CUSTOMERS LEFT JOIN ORDERS ON ORDERS.CustomerID = Customers.Id\n WHERE Orders.CustomerID IS NULL
|
Dhruvraj_05
|
NORMAL
|
2022-07-29T04:36:14.131268+00:00
|
2022-07-29T04:36:14.131308+00:00
| 546 | false |
\n* SELECT Name AS Customers FROM CUSTOMERS LEFT JOIN ORDERS ON ORDERS.CustomerID = Customers.Id\n* WHERE Orders.CustomerID IS NULL
| 3 | 0 |
['Oracle']
| 0 |
customers-who-never-order
|
SQL | LEFT JOIN
|
sql-left-join-by-madsteins-wg3r
|
\nSELECT NAME AS \'CUSTOMERS\'FROM CUSTOMERS LEFT JOIN ORDERS\nON CUSTOMERS.ID = ORDERS.CUSTOMERID\nWHERE ORDERS.CUSTOMERID IS NULL\n
|
MadSteins
|
NORMAL
|
2022-05-29T20:17:59.730753+00:00
|
2022-05-29T20:17:59.730800+00:00
| 283 | false |
```\nSELECT NAME AS \'CUSTOMERS\'FROM CUSTOMERS LEFT JOIN ORDERS\nON CUSTOMERS.ID = ORDERS.CUSTOMERID\nWHERE ORDERS.CUSTOMERID IS NULL\n```
| 3 | 0 |
['MySQL']
| 1 |
customers-who-never-order
|
✅ [Accepted] Solution for MySQL | Clean & Simple Code
|
accepted-solution-for-mysql-clean-simple-k86w
|
\nSELECT name AS Customers FROM Customers \nWHERE id NOT IN (SELECT customerId FROM Orders);\n
|
axitchandora
|
NORMAL
|
2022-05-15T16:23:03.315949+00:00
|
2022-05-23T10:50:43.096599+00:00
| 272 | false |
```\nSELECT name AS Customers FROM Customers \nWHERE id NOT IN (SELECT customerId FROM Orders);\n```
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
Simple SQL query
|
simple-sql-query-by-sathwikamadarapu-b0ob
|
```\nselect c.name as Customers\nfrom Customers c\nwhere c.id Not In (select customerId from Orders );
|
SATHWIKAMADARAPU
|
NORMAL
|
2022-05-02T11:53:18.864593+00:00
|
2022-05-02T11:53:18.864638+00:00
| 256 | false |
```\nselect c.name as Customers\nfrom Customers c\nwhere c.id Not In (select customerId from Orders );
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
183. Customers Who Never Order
|
183-customers-who-never-order-by-shubham-jvnx
|
\nselect name as customers from customers AS c\nleft join orders AS O\nON c.ID = o.customerID where o.customerId is null;\n
|
shubham_pcs2012
|
NORMAL
|
2022-04-20T05:39:14.531618+00:00
|
2022-04-20T05:39:14.531645+00:00
| 306 | false |
```\nselect name as customers from customers AS c\nleft join orders AS O\nON c.ID = o.customerID where o.customerId is null;\n```
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
Easy Solution using Sub-query
|
easy-solution-using-sub-query-by-tejaspr-kng2
|
Approach\n Since we have the CustomerId column as a foreign key in the Orders table, we need to find all those customers whose Id is not present in CustomerId c
|
tejaspradhan
|
NORMAL
|
2021-07-12T17:33:07.193116+00:00
|
2021-07-12T17:34:58.229191+00:00
| 238 | false |
**Approach**\n* Since we have the CustomerId column as a foreign key in the Orders table, we need to find all those customers whose Id is not present in CustomerId column of Orders table. \n* This in turn means that they haven\'t ordered anything.\n* So, first we write a sub-query to find all the CustomerIds present in the orders table (Find customers who have ordered something)\n* Then we filter those Ids from the Customers table which are not a part of the above list of Ids.\n\n\n**QUERY**\n\n```\nselect Name as Customers from Customers C where C.Id not in (select CustomerId from Orders);\n```
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
A very intuitive and simple solution. Memory: 0B, less than 100.00%
|
a-very-intuitive-and-simple-solution-mem-25eu
|
```\nSELECT Name as Customers \nFROM Customers\nWHERE id not in (SELECT CustomerId FROM Orders)
|
m-d-f
|
NORMAL
|
2021-02-18T12:04:35.542903+00:00
|
2021-02-18T12:04:35.542942+00:00
| 223 | false |
```\nSELECT Name as Customers \nFROM Customers\nWHERE id not in (SELECT CustomerId FROM Orders)
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
MySQL, LEFT JOIN()
|
mysql-left-join-by-leovam-x73d
|
\n# Write your MySQL query statement below\nSELECT\n c.name AS customers\nFROM\n customers AS c\nLEFT JOIN \n orders AS o\nON o.customerid = c.id\nWHER
|
leovam
|
NORMAL
|
2021-01-20T04:03:59.763792+00:00
|
2021-01-20T04:03:59.763842+00:00
| 331 | false |
```\n# Write your MySQL query statement below\nSELECT\n c.name AS customers\nFROM\n customers AS c\nLEFT JOIN \n orders AS o\nON o.customerid = c.id\nWHERE\n o.customerid IS NULL\n\n```
| 3 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
SELECT name AS Customers FROM Customers WHERE id NOT IN ( SELECT customerId FROM Orders );
|
select-name-as-customers-from-customers-730tm
|
Code
|
Vishal1431
|
NORMAL
|
2025-02-03T18:49:35.628642+00:00
|
2025-02-03T18:49:35.628642+00:00
| 342 | false |
# Code
```mysql []
SELECT name AS Customers FROM Customers
WHERE id NOT IN (
SELECT customerId FROM Orders
);
```
| 2 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
Left Join
|
left-join-by-ramsingh27-8enw
|
IntuitionApproachComplexity
Time complexity:
Space complexity:
Code
|
Ramsingh27
|
NORMAL
|
2024-12-24T07:41:22.242008+00:00
|
2024-12-24T07:41:22.242008+00:00
| 413 | false |
# Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```mysql []
# Write your MySQL query statement below
select name as Customers from customers c
left join orders o
on c.id = o.customerId
where o.id is null;
```
| 2 | 0 |
['MySQL']
| 0 |
customers-who-never-order
|
2 solutions ( 1 more faster code)
|
2-solutions-1-more-faster-code-by-devdis-d0ie
|
Code\nmssql []\n-- \u2B50 1. using left join concept\nSELECT C.n[ame AS Customers \nFROM Customers AS C LEFT JOIN Orders AS O\nON C.id = O.customerId \nWHERE O.
|
DevDish
|
NORMAL
|
2024-09-20T11:07:03.859493+00:00
|
2024-09-20T11:07:03.859514+00:00
| 38 | false |
# Code\n```mssql []\n-- \u2B50 1. using left join concept\nSELECT C.n[ame AS Customers \nFROM Customers AS C LEFT JOIN Orders AS O\nON C.id = O.customerId \nWHERE O.customerId IS NULL]()\n\n-- \u2B50 2. more optimised/faster code\nSELECT name AS Customers \nFROM Customers \nWHERE id NOT IN (SELECT customerId FROM Orders )\n```
| 2 | 0 |
['MS SQL Server']
| 1 |
customers-who-never-order
|
Customers Who Never Order
|
customers-who-never-order-by-tejdekiwadi-edps
|
Intuition\nThe goal is to find customers who have not placed any orders. By joining the customers table with the orders table using a LEFT JOIN and filtering fo
|
tejdekiwadiya
|
NORMAL
|
2024-06-28T20:07:04.063970+00:00
|
2024-06-28T20:07:04.064004+00:00
| 529 | false |
# Intuition\nThe goal is to find customers who have not placed any orders. By joining the `customers` table with the `orders` table using a LEFT JOIN and filtering for records where there is no corresponding `customerId` in the `orders` table, we can identify these customers.\n\n# Approach\n1. **LEFT JOIN**: Perform a LEFT JOIN between the `customers` and `orders` tables on the condition that the `id` column in the `customers` table matches the `customerId` column in the `orders` table. This ensures that all rows from the `customers` table are included, regardless of whether there is a matching row in the `orders` table.\n \n2. **Filter Null Values**: Use a `WHERE` clause to filter the results where `orders.customerId` is `NULL`. This condition identifies customers who do not have any corresponding entries in the `orders` table.\n\n# Complexity\n- **Time Complexity**:\n The time complexity depends on the database implementation and indexing. However, in general, for a join operation:\n - Without indexes: The complexity can be approximately (O(n times m)), where (n) is the number of rows in the `customers` table and (m) is the number of rows in the `orders` table.\n - With indexes: The complexity can be significantly reduced, approximately (O(n \\log m)) if the `orders.customerId` column is indexed.\n\n- **Space Complexity**:\n The space complexity is primarily determined by the space needed to store the result set, which in the worst case could be (O(n)) where (n) is the number of rows in the `customers` table, assuming no customer has placed an order. Additional space is required for intermediate results during the join operation, but this is usually managed efficiently by the database engine.\n\nHere is the SQL query for reference:\n\n```sql\nSELECT name AS Customers\nFROM customers\nLEFT JOIN orders ON customers.id = orders.customerId\nWHERE orders.customerId IS NULL;\n```\n\n# Summary\n- **Intuition**: Identify customers who have not placed any orders by finding rows in the `customers` table that do not have matching rows in the `orders` table.\n- **Approach**: Use a LEFT JOIN to include all customers and filter out those who have placed orders using a `WHERE` clause.\n- **Complexity**: Dependent on indexing, with time complexity ranging from (O(n times m)) to (O(n log m)) and space complexity mainly based on the result set size.
| 2 | 0 |
['Database', 'MySQL']
| 0 |
customers-who-never-order
|
🚀🚀beats 85% || ✅✅Easy approach
|
beats-85-easy-approach-by-u23cs159-k2qv
|
\n\n\n# Intuition\n Describe your first thoughts on how to solve this problem. \n\uD83C\uDFAFImagine you run a store and want to identify which of your customer
|
u23cs159
|
NORMAL
|
2024-06-07T09:40:51.422921+00:00
|
2024-06-07T09:40:51.422950+00:00
| 886 | false |
\n\n\n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\uD83C\uDFAFImagine you run a store and want to identify which of your customers have never made a purchase. By comparing your customer list with your order records, you can easily find those customers who haven\'t placed any orders. This is crucial for targeted marketing and understanding customer behavior.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1) \uD83D\uDCCB Create DataFrames: Start by creating DataFrames for the customers and orders tables.\n2) \uD83D\uDD17 Merge DataFrames: Perform a right join on the customers DataFrame with the orders DataFrame using the customerId as the key. This will ensure that all customers are included, even those who haven\'t placed any orders.\n3) \uD83D\uDD0D Identify Non-Ordering Customers: Filter the merged DataFrame to find rows where the orders ID is NaN, indicating customers who never placed any orders.\n4) \u2705 Prepare Final Result: Extract the names of these customers and rename the column to Customers for the final output.\n\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(NlogN)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(N)\n\n# Code\n```\nimport pandas as pd\n\ndef find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:\n customers[\'customerId\'] = customers[\'id\']\n df = pd.merge(left=orders,right=customers,on=\'customerId\',how=\'right\')\n return df[(df.id_x.isna())][[\'name\']].rename(columns={\'name\':\'Customers\'})\n```
| 2 | 0 |
['Python3', 'Pandas']
| 0 |
find-duplicate-subtrees
|
Java Concise Postorder Traversal Solution
|
java-concise-postorder-traversal-solutio-rsvj
|
We perform postorder traversal, serializing and hashing the serials of subtrees in the process. We can recognize a duplicate subtree by its serialization.\n\n\n
|
compton_scatter
|
NORMAL
|
2017-07-30T03:06:07.745000+00:00
|
2020-12-06T00:05:41.850378+00:00
| 79,332 | false |
We perform postorder traversal, serializing and hashing the serials of subtrees in the process. We can recognize a duplicate subtree by its serialization.\n\n```\npublic List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n List<TreeNode> res = new LinkedList<>();\n postorder(root, new HashMap<>(), res);\n return res;\n}\n\npublic String postorder(TreeNode cur, Map<String, Integer> map, List<TreeNode> res) {\n if (cur == null) return "#"; \n String serial = cur.val + "," + postorder(cur.left, map, res) + "," + postorder(cur.right, map, res);\n map.put(serial, map.getOrDefault(serial, 0) + 1);\n if (map.get(serial) == 2) res.add(cur);\n return serial;\n}\n```\n\nThe above time complexity is O(n^2). We can improve this to O(n) by replacing full serializations with serial ids instead.\n\n```\nclass Solution {\n int curId = 1;\n\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String, Integer> serialToId = new HashMap<>();\n Map<Integer, Integer> idToCount = new HashMap<>();\n List<TreeNode> res = new LinkedList<>();\n postorder(root, serialToId, idToCount, res);\n return res;\n }\n \n private int postorder(TreeNode root, Map<String, Integer> serialToId, Map<Integer, Integer> idToCount, List<TreeNode> res) {\n if (root == null) return 0;\n int leftId = postorder(root.left, serialToId, idToCount, res);\n int rightId = postorder(root.right, serialToId, idToCount, res);\n String curSerial = leftId + "," + root.val + "," + rightId;\n int serialId = serialToId.getOrDefault(curSerial, curId);\n if (serialId == curId) curId++;\n serialToId.put(curSerial, serialId);\n idToCount.put(serialId, idToCount.getOrDefault(serialId, 0) + 1);\n if (idToCount.get(serialId) == 2) res.add(root);\n return serialId;\n }\n \n}\n```
| 459 | 11 |
[]
| 117 |
find-duplicate-subtrees
|
O(n) time and space, lots of analysis
|
on-time-and-space-lots-of-analysis-by-st-wu1s
|
First the basic version, which is O(n2) time and gets accepted in about 150 ms:\n\n def findDuplicateSubtrees(self, root):\n def tuplify(root):\n
|
stefanpochmann
|
NORMAL
|
2017-07-30T04:17:32.670000+00:00
|
2018-10-06T15:10:14.065220+00:00
| 51,182 | false |
First the basic version, which is O(n<sup>2</sup>) time and gets accepted in about 150 ms:\n\n def findDuplicateSubtrees(self, root):\n def tuplify(root):\n if root:\n tuple = root.val, tuplify(root.left), tuplify(root.right)\n trees[tuple].append(root)\n return tuple\n trees = collections.defaultdict(list)\n tuplify(root)\n return [roots[0] for roots in trees.values() if roots[1:]]\n\nI convert the entire tree of nested `TreeNode`s to a tree of nested `tuple`s. Those have the advantage that they already support hashing and deep comparison (for the very unlikely cases of hash collisions). So then I can just use each subtree's `tuple` version as a key in my dictionary. And equal subtrees have the same key and thus get collected in the same list.\n\nOverall this costs only O(n) memory (where n is the number of nodes in the given tree). The string serialization I've seen in other posted solutions costs O(n^2) memory (and thus also at least that much time).\n\n<br>\n\n# So far only O(n<sup>2</sup>) time\n\nUnfortunately, tuples don't cache their own hash value (see [this](https://mail.python.org/pipermail/python-dev/2003-August/037424.html) for a reason). So if I use a tuple as key and thus it gets asked for its hash value, it will compute it again. Which entails asking its content elements for *their* hashes. And if they're tuples, then they'll do the same and ask *their* elements for *their* hashes. And so on. So asking a tuple tree root for its hash traverses the entire tree. Which makes the above solution only O(n^2) time, as the following test demonstrates. It tests linear trees, and doubling the height quadruples the run time, exactly what's expected from a quadratic time algorithm.\n\nThe code:\n```\nfrom timeit import timeit\nimport sys\nsys.setrecursionlimit(5000)\n\ndef tree(height):\n if height:\n root = TreeNode(0)\n root.right = tree(height - 1)\n return root\n\nsolution = Solution().findDuplicateSubtrees\nfor e in range(5, 12):\n root = tree(2**e)\n print(timeit(lambda: solution(root), number=1000))\n```\nThe printed times:\n```\n0.0661657641567657\n0.08246562780375502\n0.23728608832718473\n0.779312441896731\n2.909226393471882\n10.919695348072757\n43.52919811329259\n```\n\n<br>\n\n# Caching hashes\n\nThere's an easy way to add caching, though. Simply wrap each tuple in a `frozenset`, which *does* cache its hash value:\n\n def findDuplicateSubtrees(self, root):\n def convert(root):\n if root:\n result = frozenset([(root.val, convert(root.left), convert(root.right))])\n trees[result].append(root)\n return result\n trees = collections.defaultdict(list)\n convert(root)\n return [roots[0] for roots in trees.values() if roots[1:]]\n\nRunning the above test again now shows O(n) behaviour as expected, doubling of size causing doubling of run time:\n```\n0.06577755770063994\n0.056785410167764075\n0.14042076531958228\n0.22786156533737006\n0.4496169916643781\n0.932876339417438\n1.8611131309331435\n```\nAnd it's much faster than the original version using only tuples. That said, both solutions get accepted by LeetCode in about 150 ms, since the test suite's trees are sadly pretty small and simple.\n\n---\n\nThat of course doesn't mean that the solution is now O(n) time. Only that it's apparently O(n) time for such linear trees. But there's a catch. If two subtrees have the same hash value, then they'll still get fully compared. There are two cases:\n1. **Different trees having the same hash value**, i.e., hash collisions. LeetCode uses 64-bit Python and thus hash collisions are very unlikely unless you have a huge number of subtrees. The largest tree in the test suite has 5841 subtrees. The probability of having no collisions for 5841 different values is about 99.9999999999078%:\n ```\n >>> reduce(lambda p, i: p * (2**64 - i) / 2**64, range(5841), 1.0)\n 0.999999999999078\n ```\n Even if all 5841 subtrees were different and all of the test suite's 167 test cases were like that, then we'd still have about a 99.99999998460193% chance to not have any hash collisions anywhere:\n ```\n >>> 0.999999999999078**167\n 0.9999999998460193\n ```\n Also, I could of course use a stronger hashing algorithm, like SHA256.\n\n2. **Equal trees having the same hash value**. Well duh, obviously equal trees have the same hash value. So how big of a problem is that? How many equal trees can we have, and of what sizes? In the above case of the whole tree being linear, there are *no* equal subtrees at all (except for the trivial empty subtrees, but they don't matter). So let's go to the other extreme end, a [perfect tree](https://en.wikipedia.org/wiki/Binary_tree#Types_of_binary_trees). Then there are *lots* of equal trees. There are n subtrees but only about log<sup>2</sup>(n) *different* subtrees, one for each height. Subtrees of the same height are all equal. So pretty much *every* subtree is a duplicate and thus shares the hash with a previous subtree and thus will get completely compared to the previous one. So how costly is it to traverse all subtrees completely (in separate traversals)? The whole tree has n nodes. Its two subtrees have about n/2 nodes each, so about n nodes together (actually n-1 because they don't contain the root). The next level has 4 trees with about n/4 nodes each, again adding n nodes overall. And so on. We have log<sub>2</sub>(n) levels, so overall this takes O(n log n) time. We can again test this, doubling the size of a tree makes the run time a bit worse than double:\n ```\n def tree(height):\n if height:\n root = TreeNode(0)\n root.left = tree(height - 1)\n root.right = tree(height - 1)\n return root\n\n solution = Solution().findDuplicateSubtrees\n for e in range(10, 17):\n root = tree(e)\n print(timeit(lambda: solution(root), number=100))\n ```\n The printed times:\n ```\n 0.10957473965829807\n 0.22831256388730117\n 0.48625792412907487\n 1.010916041039311\n 2.131317089557299\n 4.5137782403671025\n 9.616743290368206\n ```\n The last two trees have 15 and 16 levels, respectively. If the solution does take Θ(n log n) time for perfect trees, then we expect it to take 2 * 16/15 as long for the tree with 16 levels as for the tree with 15 levels. And it did: 4.51 * 2 * 16/15 is about 9.62. (If you find that suspiciously accurate, you're right: I actually ran the whole test 50 times and used the averages).\n\n So is the `frozenset` solution O(n log n) time? Nope. Sadly not. It's still only O(n<sup>2</sup>). Remember how the original tuple solution took O(n<sup>2</sup>) time for linear trees? And how caching the hashes improved that to O(n), because there were no duplicate subtrees whose equal hashes would cause expensive deep comparison? Well, all we have to do to create the same nightmare scenario again is to have *two* such linear subtrees under a common root node. Then while the left subtree only takes O(n), the right subtree takes O(n<sup>2</sup>). Demonstration again:\n ```\n def tree(height):\n if height:\n root = TreeNode(0)\n root.right = tree(height - 1)\n return root\n\n solution = Solution().findDuplicateSubtrees\n for e in range(5, 12):\n root = TreeNode(0)\n root.left = tree(2**e)\n root.right = tree(2**e)\n print(timeit(lambda: solution(root), number=1000))\n ```\n The printed times:\n ```\n 0.1138048859928981\n 0.19950686963173872\n 0.5518468952197122\n 1.8595846431294971\n 6.7689327267056605\n 26.291197508748162\n 106.77212851917264\n ```\n<br>\n\n# O(n) time and space\n\nFortunately, @Danile showed an [O(n) time solution](https://discuss.leetcode.com/topic/97790/no-string-hash-python-code-o-n-time-and-space) and it's pretty simple. Here's my implementation using their idea:\n\n def findDuplicateSubtrees(self, root, heights=[]):\n def getid(root):\n if root:\n id = treeid[root.val, getid(root.left), getid(root.right)]\n trees[id].append(root)\n return id\n trees = collections.defaultdict(list)\n treeid = collections.defaultdict()\n treeid.default_factory = treeid.__len__\n getid(root)\n return [roots[0] for roots in trees.values() if roots[1:]]\n\nThe idea is the same as Danile's: Identify trees by numbering them. The first unique subtree gets id 0, the next unique subtree gets id 1, the next gets 2, etc. Now the dictionary keys aren't deep nested structures anymore but just ints and triples of ints.\n\nRunning the "perfect trees" test again:\n```\n0.05069159040252735\n0.09899985757750773\n0.19695348072759256\n0.39157652084085726\n0.7962228593508778\n1.5419999122629369\n3.160187444826308\n```\nAnd the "linear trees" test again:\n```\n0.034597848759331834\n0.05386034062412301\n0.12324202869723078\n0.22538750035305155\n0.46485619835306713\n0.8654176554613617\n1.7437530910788834\n```\nAnd the "two parallel linear trees" test again:\n```\n0.05274439729745809\n0.0894428275852537\n0.18871220620853896\n0.3264557892339413\n0.7091321061762685\n1.3789991725072908\n2.7934804751983546\n```\nAll three tests now show nice doubling of the times, as expected from O(n).\n\nThis solution gets accepted in about 100 ms, and the best time I got from a handful of submissions was 92 ms.\n\n<br>\n\n# Revisiting the probability calculation for hash collisions\n\nAbove I calculated the probability 99.9999999999078% using *floats*. Which of course have rounding errors. So can we trust that calculation? Especially since we're multiplying so many special factors, all being close to 1? Turns out that yes, that's pretty accurate.\n\nWe can do the calculation using integers, which only round down. Just scale the "probability" by 10<sup>30</sup> or so:\n```\n>>> p = 10**30\n>>> for i in range(5841):\n p = p * (2**64 - i) // 2**64\n\n>>> p\n999999999999075407566135201054\n```\nSince those divisions round down, this gives us a lower bound for the true value. And if we instead work with *negative* numbers, then the divisions effectively round *up* and we get an *upper* bound for the true value:\n```\n>>> p = -10**30\n>>> for i in range(5841):\n p = p * (2**64 - i) // 2**64\n\n>>> -p\n999999999999075407566135206894\n```\nComparing those two bounds we can see that the true probability is 99.999999999907540756613520...%. So of the previous result 99.9999999999078% using floats, only that last digit was wrong.\n\nUsing this value in the subsequent calculation again, we get a 99.99999998455928% chance for not having any collisions anywhere even if all 167 test cases had 5841 subtrees without duplicates:\n```\n>>> 0.99999999999907540756613520**167\n0.9999999998455928\n```
| 385 | 7 |
[]
| 22 |
find-duplicate-subtrees
|
[C++] [Java] Clean Code with Explanation
|
c-java-clean-code-with-explanation-by-al-ncds
|
Description\n\nGiven the root of a binary tree, return all duplicate subtrees.\n\nFor each kind of duplicate subtrees, you only need to return the root node of
|
alexander
|
NORMAL
|
2017-07-30T03:25:45.643000+00:00
|
2020-08-23T00:09:12.270276+00:00
| 38,338 | false |
## Description\n\nGiven the `root` of a binary tree, return all `duplicate subtrees`.\n\nFor each kind of duplicate subtrees, you only need to return the root node of any one of them.\n\nTwo trees are duplicate if they have the same structure with the same node values.\n\n\n## Analysis\n\n- A unique sub-tree can be uniquely identified by its serialized string;\n- using post order traversal we can gradualy collect all unique tree-serializations with their associated nodes, with 1 traversal;\n- then you can see if there is any serialization is associated with more than 1 sub-tree nodes, then you know there is duplicated sub-tree nodes;\n\n\n## Solutions\n\n### C++\n```\nclass Solution {\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string, vector<TreeNode*>> map;\n vector<TreeNode*> dups;\n serialize(root, map);\n for (auto it = map.begin(); it != map.end(); it++)\n if (it->second.size() > 1) dups.push_back(it->second[0]);\n return dups;\n }\nprivate:\n string serialize(TreeNode* node, unordered_map<string, vector<TreeNode*>>& map) {\n if (!node) return "";\n string s = "(" + serialize(node->left, map) + to_string(node->val) + serialize(node->right, map) + ")";\n map[s].push_back(node);\n return s;\n }\n};\n```\n\n### Java\n```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String, List<TreeNode>> map = new HashMap<String, List<TreeNode>>();\n List<TreeNode> dups = new ArrayList<TreeNode>();\n serialize(root, map);\n for (List<TreeNode> group : map.values())\n if (group.size() > 1) dups.add(group.get(0));\n return dups;\n }\n\n private String serialize(TreeNode node, Map<String, List<TreeNode>> map) {\n if (node == null) return "";\n String s = "(" + serialize(node.left, map) + node.val + serialize(node.right, map) + ")";\n if (!map.containsKey(s)) map.put(s, new ArrayList<TreeNode>());\n map.get(s).add(node);\n return s;\n }\n}\n```\n\n## Question\n\nBeing lazy, can anyone come up with strict proof why serialization would be uniquely identify an tree structure?
| 255 | 6 |
[]
| 27 |
find-duplicate-subtrees
|
Python easy understand solution
|
python-easy-understand-solution-by-lee21-edsi
|
`````\ndef findDuplicateSubtrees(self, root):\n def trv(root):\n if not root: return "null"\n struct = "%s,%s,%s" % (str(root.val),
|
lee215
|
NORMAL
|
2017-07-30T10:41:47.454000+00:00
|
2018-10-23T19:17:59.280825+00:00
| 31,354 | false |
`````\ndef findDuplicateSubtrees(self, root):\n def trv(root):\n if not root: return "null"\n struct = "%s,%s,%s" % (str(root.val), trv(root.left), trv(root.right))\n nodes[struct].append(root)\n return struct\n \n nodes = collections.defaultdict(list)\n trv(root)\n return [nodes[struct][0] for struct in nodes if len(nodes[struct]) > 1]
| 204 | 13 |
[]
| 26 |
find-duplicate-subtrees
|
Python solution explained in two steps - for beginners
|
python-solution-explained-in-two-steps-f-2qy6
|
Lets divide the problem into two:\n\nOverview: We need to somehow serialize the tree for every node in the tree. Then in a hash map (dict), we need to increment
|
ikna
|
NORMAL
|
2021-11-11T05:01:30.073865+00:00
|
2021-11-11T05:03:20.666887+00:00
| 7,468 | false |
Lets divide the problem into two:\n\n**Overview**: We need to somehow serialize the tree for every node in the tree. Then in a hash map (dict), we need to increment the count when serialization from another matches the existing key in hmap. \n\n```\n\t\t\t1\n\t\t2 3\n```\nIf we serialize from each node, the output is as follows ( I am doing preorder serialization)\n\nfrom node with value 2: ```2,#,#``` \nfrom node with value 3: ```3,#,# ```\nfrom node with value 1: ```1,2,#,#,3,#,#```\n\n```plain\n\t\t\t1\n\t\t2 1\'\n\t\t\t 2\'\n\t\t\n```\nIf we serialize from each node, the output is as follows ( I am doing preorder serialization)\n\nfrom node with value 2\': ```2\',#,#``` (MATCHED)\nfrom node with value 1\': ```1\',2\',#,#,# ```\nfrom node with value 2: ```2,#,#``` (MATCHED)\nfrom node with value 1: ```1,2,#,#,1\',2\',#,#,#```\n\n**So step 1**: lets just generate this preorder serialization \n\n```\ndef serialization(node, path):\n\tif node is None: return \'#\'\n\t\n\tpath = \',\'.join([str(node.val), serialization(node.left, path), serialization(node.right, path)])\n\t\n\treturn path\n\t\nserialization(root,\'\')\n\t\n```\n\n**Step 2**: now in the above step, lets build hmap with key as path and value as the number of times it appears\n\n```\nhmap = {}\ndef serialization(node, path):\n\tif node is None: return \'#\'\n\t\n\tpath = \',\'.join([str(node.val), serialization(node.left, path), serialization(node.right, path)])\n\tif path in hmap:\n\t\thmap[path] += 1\n\telse:\n\t\thmap[path] = 1\n\t\n\treturn path\n\t\nserialization(root,\'\')\n```\n\n**Final Solution:**\n\nwe collect all the paths for which hmap[path] == 2 (which means it is repeated atleast once)\n\n```\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n \n res = []\n \n hmap = {}\n \n def recurse(node, path):\n if node is None:\n return \'#\'\n \n path += \',\'.join([str(node.val), recurse(node.left, path), recurse(node.right, path)])\n \n if path in hmap:\n hmap[path] += 1\n if hmap[path] == 2:\n res.append(node)\n else:\n hmap[path] = 1\n \n \n return path\n \n recurse(root, \'\')\n #print(hmap) I SUGGEST YOU PRINT THIS - TO UNDERSTAND WHAT IS HAPPENING.\n return res\n```\n\nPlease upvote if you like my explanation.
| 159 | 1 |
['Python']
| 11 |
find-duplicate-subtrees
|
Java || Easy Approach with Explanation || HashMap || Postorder
|
java-easy-approach-with-explanation-hash-6hx9
|
\nclass Solution \n{\n HashMap<String, Integer> map= new HashMap<>();//String -- frequency//it store the string at every instant when we visit parent after v
|
swapnilGhosh
|
NORMAL
|
2021-07-29T14:38:48.524727+00:00
|
2021-07-29T14:39:40.957368+00:00
| 8,749 | false |
```\nclass Solution \n{\n HashMap<String, Integer> map= new HashMap<>();//String -- frequency//it store the string at every instant when we visit parent after visiting its children //it also calculates the frequency of the String in the tree\n ArrayList<TreeNode> res= new ArrayList<>();//it contain the list of dublicate nodes \n \n public List<TreeNode> findDuplicateSubtrees(TreeNode root) \n {\n Mapper(root);\n return res;//returning the list containing a node of dublicate subtree\n }\n \n public String Mapper(TreeNode root)\n {//we are doing postorder traversal because we want to first deal with children and then the parent \n if(root == null)//when we reach to the null ,we return N to tell that i am null and unique \n return "N";\n \n String left= Mapper(root.left);//recursing down the left subtree and knowing about the left child //LEFT\n String right= Mapper(root.right);//recursing down the hright subtree and knowing abou the right child //RIGHT\n \n //ROOT\n String curr= root.val +" "+left +" "+ right;//after knowing about the left and right children//parent forms their own string //space is added to disinguish the string of same reapeatating root value ex- 11 N , 1 1N\n \n map.put(curr, map.getOrDefault(curr, 0)+ 1);//counting the frequency of string \n \n if(map.get(curr) == 2)//only the dublicate string node are added to the ArrayList \n res.add(root);\n \n return curr;//returning to the parent to that i am present, and here is my string with the informationn of my left and right child \n }\n}//Please do Upvote, it helps a lot \n```
| 136 | 2 |
['Depth-First Search', 'Recursion', 'Java']
| 3 |
find-duplicate-subtrees
|
✅ Java | Easy | HashMap | With Explanation
|
java-easy-hashmap-with-explanation-by-ka-a6tv
|
The basic intuition is to find the duplicate subtrees of the given tree. So here we just used a hashmap and we can use preorder or postorder traversal to form t
|
kalinga
|
NORMAL
|
2023-02-28T01:39:09.540183+00:00
|
2023-02-28T01:39:09.540219+00:00
| 10,168 | false |
**The basic intuition is to find the duplicate subtrees of the given tree. So here we just used a hashmap and we can use preorder or postorder traversal to form the subtrees of string type and will check if they are already present in hashmap. If they are not present then we will simply insert into hashmap and keep on counting the number of occurences. If its present atleast 1 time we add the root into the list.**\n```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n List<TreeNode> res=new ArrayList<>();\n HashMap<String,Integer> hm=new HashMap<>();\n helper(res,root,hm);\n return res;\n }\n public String helper(List<TreeNode> res,TreeNode root,HashMap<String,Integer> hm){\n if(root==null)\n return "";\n String left=helper(res,root.left,hm);\n String right=helper(res,root.right,hm);\n int currroot=root.val;\n String stringformed=currroot+"$"+left+"$"+right;\n if(hm.getOrDefault(stringformed,0)==1){\n res.add(root);\n }\n hm.put(stringformed,hm.getOrDefault(stringformed,0)+1);\n return stringformed;\n }\n}\n```\n\n
| 124 | 0 |
['Tree', 'Depth-First Search', 'Recursion', 'Binary Tree', 'Java']
| 6 |
find-duplicate-subtrees
|
8 lines C++
|
8-lines-c-by-zefengsong-bwu1
|
\nclass Solution {\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string, int>m;\n vector<TreeNode*>res;\
|
zefengsong
|
NORMAL
|
2017-10-15T05:10:58.973000+00:00
|
2018-10-17T15:00:36.163674+00:00
| 12,067 | false |
```\nclass Solution {\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string, int>m;\n vector<TreeNode*>res;\n DFS(root, m, res);\n return res;\n }\n \n string DFS(TreeNode* root, unordered_map<string, int>& m, vector<TreeNode*>& res){\n if(!root) return "";\n string s = to_string(root->val) + "," + DFS(root->left, m, res) + "," + DFS(root->right, m, res);\n if(m[s]++ == 1) res.push_back(root);\n return s;\n }\n};\n```
| 105 | 2 |
['C++']
| 13 |
find-duplicate-subtrees
|
✌️🟢C++ EASIEST SOLUTION WITH COMPLETE EXPLANATION EASY TO UNDERSTAND
|
c-easiest-solution-with-complete-explana-pbxr
|
Intuition\nThe problem asks to find duplicate subtrees in a given binary tree. Two trees are considered duplicate if they have the same structure and node value
|
suryansh_639
|
NORMAL
|
2023-02-28T00:25:05.899447+00:00
|
2023-02-28T04:45:50.666285+00:00
| 14,941 | false |
# Intuition\nThe problem asks to find duplicate subtrees in a given binary tree. Two trees are considered duplicate if they have the same structure and node values. The task is to return any one of the duplicate subtrees.\n\nTo solve this problem, we can use a post-order traversal of the binary tree and serialize the subtrees. For each subtree, we can serialize its left and right children recursively and append its own value. By serializing the subtrees in this way, we can represent each subtree as a unique string. We can then use a hash table to keep track of the frequency of each serialized subtree. If the frequency of a serialized subtree is greater than 1, it means that the subtree is a duplicate. We can add the root node of the duplicate subtree to a vector and return it as the result.\n\nTherefore, by using a post-order traversal and serializing the subtrees, we can efficiently find the duplicate subtrees in the given binary tree.\n\n# Approach\nTo solve the problem of finding duplicate subtrees in a binary tree, we can use a post-order traversal of the binary tree and serialize each subtree.\n\nThe steps to solve the problem are as follows:\n\n1. Create a hash table to store the frequency of each serialized subtree and a vector to store the duplicate subtrees.\n2. Traverse the binary tree using a post-order traversal. For each subtree, serialize its left and right children recursively and append its own value to create a unique string representation of the subtree.\n3. Add the serialized subtree to the hash table and update its frequency. If the frequency of the serialized subtree is equal to 2, add the root node of the subtree to the vector of duplicate subtrees.\n4. Return the vector of duplicate subtrees.\n\nBy using this approach, we can efficiently find the duplicate subtrees in the binary tree by using a hash table to store the frequency of each serialized subtree. This approach has a time complexity of O(n), where n is the number of nodes in the binary tree, and a space complexity of O(n) to store the serialized subtrees and the hash table.\n\n# Complexity\nTime Complexity:\n\nThe time complexity of the serializeSubtrees function is O(n), where n is the number of nodes in the binary tree.\nThe time complexity of the entire algorithm is also O(n), because the serializeSubtrees function is called once for each node in the binary tree.\n\nSpace Complexity:\n\nThe space complexity of the serializeSubtrees function is O(n), because the function creates a string for each subtree in the binary tree.\nThe space complexity of the findDuplicateSubtrees function is O(n), because it creates an unordered map to store the serialized subtrees and their frequency, and a vector to store the duplicate subtrees.\nTherefore, the overall space complexity of the algorithm is O(n).\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\n class Solution {\npublic:\n // Serialize subtrees and check for duplicates using a post-order traversal\n string serializeSubtrees(TreeNode* node, unordered_map<string, int>& subtrees, vector<TreeNode*>& duplicates) {\n if (!node) return "#"; // Null nodes are represented by \'#\'\n \n string left = serializeSubtrees(node->left, subtrees, duplicates);\n string right = serializeSubtrees(node->right, subtrees, duplicates);\n \n string s = left + "," + right + "," + to_string(node->val); // Serialize the current subtree\n \n if (subtrees[s] == 1) duplicates.push_back(node); // If a duplicate subtree is found, add to the vector\n \n subtrees[s]++;\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string, int> subtrees; // Store serialized subtree and its frequency\n vector<TreeNode*> duplicates; // Store duplicate subtrees\n \n serializeSubtrees(root, subtrees, duplicates); // Traverse the tree and serialize subtrees\n \n return duplicates;\n }\n \n};\n\n\n//\uD83D\uDC47PLEASE UPVOTE IF YOU LIKED MY APPROACH\n```
| 95 | 3 |
['C++']
| 8 |
find-duplicate-subtrees
|
simple c++ solution | unordered-map | 97% faster
|
simple-c-solution-unordered-map-97-faste-7e8q
|
\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0)
|
xor09
|
NORMAL
|
2021-02-14T05:05:58.783908+00:00
|
2021-02-14T05:05:58.783941+00:00
| 5,624 | false |
```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\nclass Solution {\npublic:\n vector<TreeNode*> vec;\n unordered_map<string,int> ump;\n string solve(TreeNode* root){\n if(!root) return "$";\n string left = solve(root->left);\n string right = solve(root->right);\n string s = to_string(root->val) +"$"+left+"$"+right;\n if(ump[s]==1){\n vec.push_back(root);\n }\n ump[s]++;\n return s;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n if(!root) return vec;\n solve(root);\n return vec;\n }\n};\n```\nPlease **UPVOTE**
| 68 | 1 |
['C']
| 6 |
find-duplicate-subtrees
|
Python, O(N) Merkle Hashing Approach
|
python-on-merkle-hashing-approach-by-awi-h16z
|
We'll assign every subtree a unique merkle hash. You can find more information about Merkle tree hashing here: https://discuss.leetcode.com/topic/88520/python
|
awice
|
NORMAL
|
2017-07-30T03:43:28.023000+00:00
|
2017-07-30T03:43:28.023000+00:00
| 11,340 | false |
We'll assign every subtree a unique *merkle* hash. You can find more information about Merkle tree hashing here: https://discuss.leetcode.com/topic/88520/python-straightforward-with-explanation-o-st-and-o-s-t-approaches\n\n```\ndef findDuplicateSubtrees(self, root):\n from hashlib import sha256\n def hash_(x):\n S = sha256()\n S.update(x)\n return S.hexdigest()\n\n def merkle(node):\n if not node:\n return '#'\n m_left = merkle(node.left)\n m_right = merkle(node.right)\n node.merkle = hash_(m_left + str(node.val) + m_right)\n count[node.merkle].append(node)\n return node.merkle\n\n count = collections.defaultdict(list)\n merkle(root)\n return [nodes.pop() for nodes in count.values() if len(nodes) >= 2]\n```
| 61 | 1 |
[]
| 10 |
find-duplicate-subtrees
|
Clean Codes🔥🔥|| Full Explanation✅|| Depth First Search✅|| C++|| Java|| Python3
|
clean-codes-full-explanation-depth-first-yn8v
|
Intuition :\n- Here we have to find all the subtrees in a binary tree that occur more than once and return their roots.\n Describe your first thoughts on how to
|
N7_BLACKHAT
|
NORMAL
|
2023-02-28T02:20:02.011222+00:00
|
2023-03-01T02:28:41.612228+00:00
| 7,853 | false |
# Intuition :\n- Here we have to find all the subtrees in a binary tree that occur more than once and return their roots.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Detail Explanation to Approach :\n- Here we are using a `depth-first search` approach to traverse the tree and encode each subtree into a string using a preorder traversal.\n- The encoding includes the value of the current node and the encoding of its left and right subtrees, separated by a special character ("#").\n- **For example,** the subtree consisting of just the root node with value `1` would be encoded as `"1##"` (with two "#" characters to indicate that there are no left or right subtrees).\n```\nfinal String encoded = root.val + "#" + encode(root.left, count,ans)\n + "#" + encode(root.right, count, ans);\n```\n**OR YOU CAN WRITE IT AS**\n```\nString left = encode(root.left, count, ans);\nString right = encode(root.right, count, ans);\nfinal String encoded = root.val + "#" + left + "#" + right;\n```\n- The encoding is then added to a HashMap that counts the number of occurrences of each subtree.\n- If the encoding already exists in the map, its count is incremented by 1 using the `Integer::sum` function. \n- If it doesn\'t exist, a new entry is added with a count of 1. This ensures that each subtree encoding is counted exactly once in the map.\n```\ncount.merge(encoded, 1, Integer::sum);\n```\n- If a subtree\'s encoding appears more than once (i.e., its count in the HashMap is 2), its root is added to a result list. \n```\nif (count.get(encoded) == 2)//duplicate subtree\n ans.add(root);//add the roots\n```\n- Finally, return the list of duplicate subtrees.\n```\nreturn ans;\n```\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity :\n- Time complexity : O(n^2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity : O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Please Upvote\uD83D\uDC4D\uD83D\uDC4D\n```\nThanks for visiting my solution.\uD83D\uDE0A\n\n```\n*Let\'s Code it Up .\nThere may be minor syntax difference in C++ and Python*\n# Codes [C++ |Java |Python3] : With Comments\n\n```C++ []\nclass Solution {\n public:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> ans;\n unordered_map<string, int> count;\n encode(root, count, ans);\n return ans;\n }\n\n private:\n string encode(TreeNode* root, unordered_map<string, int>& count,\n vector<TreeNode*>& ans) {\n if (root == nullptr)\n return "";\n\n const string encoded = to_string(root->val) + "#" +\n encode(root->left, count, ans) + "#" +\n encode(root->right, count, ans);\n //# for encoding null left and right childs\n if (++count[encoded] == 2)//duplicate subtree\n ans.push_back(root);//add the roots\n return encoded;\n }\n};\n```\n```Java []\nclass Solution \n{\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) \n {\n List<TreeNode> ans = new ArrayList<>();\n Map<String, Integer> count = new HashMap<>();\n\n encode(root, count, ans);\n return ans;\n }\n private String encode(TreeNode root, Map<String, Integer> count, List<TreeNode> ans)\n {\n if (root == null)\n return "";\n \n final String encoded = root.val + "#" + encode(root.left, count, ans) + "#" + encode(root.right, count, ans);//# for encoding null left and right childs\n count.merge(encoded, 1, Integer::sum);\n //used to add the encoding to the count map. If the encoding already exists in the map, its count is incremented by 1 using the Integer::sum function. If it doesn\'t exist, a new entry is added with a count of 1. This ensures that each subtree encoding is counted exactly once in the map.\n if (count.get(encoded) == 2)//duplicate subtree\n ans.add(root);//add the roots\n return encoded;\n }\n}\n```\n```Python []\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n ans = []\n count = collections.Counter()\n\n def encode(root: Optional[TreeNode]) -> str:\n if not root:\n return \'\'\n\n encoded = str(root.val) + \'#\' + \\\n encode(root.left) + \'#\' + \\\n encode(root.right)\n count[encoded] += 1\n if count[encoded] == 2:\n ans.append(root)\n return encoded\n\n encode(root)\n return ans\n```\n# Please Upvote\uD83D\uDC4D\uD83D\uDC4D\n\n\n
| 59 | 0 |
['Depth-First Search', 'Python', 'C++', 'Java', 'Python3']
| 5 |
find-duplicate-subtrees
|
No string hash, Python code, O(n) time and space
|
no-string-hash-python-code-on-time-and-s-u0rg
|
\n def findDuplicateSubtrees(self, root):\n self.type_id_gen = 0\n duplicated_subtrees = []\n type_to_freq = defaultdict(int)\n t
|
danile
|
NORMAL
|
2017-07-31T03:30:05.685000+00:00
|
2018-10-21T03:13:17.473252+00:00
| 9,866 | false |
```\n def findDuplicateSubtrees(self, root):\n self.type_id_gen = 0\n duplicated_subtrees = []\n type_to_freq = defaultdict(int)\n type_to_id = {}\n \n def dfs(node):\n if not node:\n return -1\n type_id_left, type_id_right = (dfs(ch) for ch in (node.left, node.right))\n tree_type = (node.val, type_id_left, type_id_right)\n freq = type_to_freq[tree_type]\n if freq == 0:\n type_id = self.type_id_gen\n self.type_id_gen += 1\n type_to_id[tree_type] = type_id\n elif freq == 1:\n type_id = type_to_id[tree_type]\n duplicated_subtrees.append(node)\n else:\n type_id = type_to_id[tree_type] \n type_to_freq[tree_type] += 1\n return type_id\n \n dfs(root)\n return duplicated_subtrees \n```\n@StefanPochmann, I'm not sure about the time complexity of string or your tuple hash. For each time we wanna get the hash value of a string, should we regard the action as O(1) or O(length of string)? If it is the latter, then the total time complexity would be O(n ^ 2), given tree is a linked list, which conflicts with the time of actual execution of those solutions; otherwise, in what way that Python makes the operation of string with different length has the same time complexity? Thanks!
| 57 | 1 |
[]
| 5 |
find-duplicate-subtrees
|
Javascript Postorder DFS
|
javascript-postorder-dfs-by-fbecker11-4w5d
|
\nvar findDuplicateSubtrees = function(root) {\n const map = new Map(), res = []\n dfs(root, map, res)\n return res\n};\n\nfunction dfs(root, map, res){\n i
|
fbecker11
|
NORMAL
|
2020-09-27T14:36:33.602608+00:00
|
2020-09-27T14:36:33.602655+00:00
| 2,528 | false |
```\nvar findDuplicateSubtrees = function(root) {\n const map = new Map(), res = []\n dfs(root, map, res)\n return res\n};\n\nfunction dfs(root, map, res){\n if(!root) return \'#\'\n const subtree = `${root.val}.${dfs(root.left,map,res)}.${dfs(root.right, map,res)}`\n map.set(subtree,(map.get(subtree)||0) + 1)\n if(map.get(subtree) === 2){\n res.push(root)\n }\n return subtree\n}\n```
| 35 | 0 |
['Depth-First Search', 'JavaScript']
| 8 |
find-duplicate-subtrees
|
C++ easy traversing solution with comments
|
c-easy-traversing-solution-with-comments-119c
|
PLEASE UPVOTE IF IT HELPS A BIT\n```\n\nclass Solution {\npublic:\n vector ans;\n unordered_mapmymap;\n string helper(TreeNode root)\n {\n if
|
code77777
|
NORMAL
|
2022-01-05T13:19:57.104949+00:00
|
2022-01-05T13:19:57.104995+00:00
| 2,309 | false |
**PLEASE UPVOTE IF IT HELPS A BIT**\n```\n\nclass Solution {\npublic:\n vector<TreeNode*> ans;\n unordered_map<string, int>mymap;\n string helper(TreeNode* root)\n {\n if(root == NULL) return "";\n \n string l= helper(root->left);\n string r= helper(root->right);\n string s = "(" + l + to_string(root->val) + r + ")"; //make unique string of each subtree\n if(mymap[s]!=-1) mymap[s]++; // if string is not present insert and increase count\n \n if(mymap[s]>1) // if same string found more than one time we got same subtrees\n {\n ans.push_back(root);\n mymap[s]=-1; // no need to insert again\n }\n return s; \n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n helper(root);\n return ans;\n }\n};
| 32 | 0 |
['C']
| 4 |
find-duplicate-subtrees
|
C++ 15ms (< 99.76%)
|
c-15ms-9976-by-huahualeetcode-z4vk
|
Running Time: 15 ms (< 99.76%)\nC++\nUse \n(root.val << 32) | (id(root.left) << 16) | id(root.right) \nas a 64 bit key, supports up to 65535 unique nodes\n\n\nC
|
huahualeetcode
|
NORMAL
|
2018-01-01T00:43:22.517000+00:00
|
2019-05-08T04:16:44.201849+00:00
| 3,898 | false |
Running Time: 15 ms (< 99.76%)\n```C++\nUse \n(root.val << 32) | (id(root.left) << 16) | id(root.right) \nas a 64 bit key, supports up to 65535 unique nodes\n```\n\n```C++\nclass Solution {\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<long, pair<int,int>> counts; \n vector<TreeNode*> ans;\n function<int(TreeNode*)> getId = [&](TreeNode* r) {\n if (!r) return 0;\n long key = (static_cast<long>(static_cast<unsigned>(r->val)) << 32) |\n (getId(r->left) << 16) | getId(r->right); \n auto& p = counts[key];\n if (p.second++ == 0)\n p.first = counts.size();\n else if (p.second == 2)\n ans.push_back(r);\n return p.first; \n };\n getId(root);\n return ans;\n }\n};\n```
| 23 | 3 |
[]
| 11 |
find-duplicate-subtrees
|
Python code easy to understand, postorder traversal + serialization
|
python-code-easy-to-understand-postorder-zz29
|
\n# Definition for a binary tree node.\n# class TreeNode(object):\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# s
|
kitt
|
NORMAL
|
2017-07-30T04:10:28.898000+00:00
|
2017-07-30T04:10:28.898000+00:00
| 2,775 | false |
```\n# Definition for a binary tree node.\n# class TreeNode(object):\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nclass Solution(object):\n def postorder(self, node):\n """\n :type node: TreeNode\n :rtype: str\n """\n if not node:\n return '#'\n tree_str = self.postorder(node.left) + self.postorder(node.right) + str(node.val)\n if self.tree_str_count[tree_str] == 1:\n self.result.append(node)\n self.tree_str_count[tree_str] += 1\n return tree_str\n \n def findDuplicateSubtrees(self, root):\n """\n :type root: TreeNode\n :rtype: List[TreeNode]\n """\n self.tree_str_count, self.result = collections.defaultdict(int), []\n self.postorder(root)\n return self.result\n```
| 22 | 4 |
[]
| 3 |
find-duplicate-subtrees
|
Post-order Traversal + Post-order/Pre-order Serialization
|
post-order-traversal-post-orderpre-order-w5c7
|
We can serialize subtrees while traversing the tree, and then compare the serializations to see if there are duplicates.\n\nThe post-order traversal is natural
|
gracemeng
|
NORMAL
|
2018-05-04T09:06:13.376240+00:00
|
2021-05-12T20:22:15.474114+00:00
| 2,917 | false |
We can serialize subtrees while traversing the tree, and then compare the serializations to see if there are duplicates.\n\nThe post-order traversal is natural here.\n\nAs for the construction of the serialization string, we can apply either the pre-order or the post-order. The in-order is inappropriate here because trees as shown below will have the same serializations if in-order.\n```\n 0\n /\n 0\n```\n\n```\n 0\n \\\n 0\n```\n\nSince we only need to return the root node of any one of duplicate subtrees of the same kind, we utilize a dictionary that maps a serialization string to its appearances. And we add a subtree root to result only if its serialization string appears once.\n\n\n****\n```\nclass Solution {\n \n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n List<TreeNode> result = new ArrayList<>();\n Map<String, Integer> serialToCnt = new HashMap<>();\n encode(root, result, serialToCnt);\n return result;\n }\n \n private String encode(TreeNode root, List<TreeNode> result, Map<String, Integer> serialToCnt) {\n if (root == null) {\n return "";\n }\n \n // String serial = encode(root.left, result, serialToCnt) + "," + encode(root.right, result, serialToCnt) + "," + root.val;\n String serial = root.val + encode(root.left, result, serialToCnt) + "," + encode(root.right, result, serialToCnt);\n \n serialToCnt.put(serial, serialToCnt.getOrDefault(serial, 0) + 1);\n if (serialToCnt.get(serial) == 2) {\n // Return once for each kind of duplicate subtrees\n result.add(root);\n }\n \n return serial;\n }\n}\n```
| 21 | 2 |
[]
| 5 |
find-duplicate-subtrees
|
Easy + Clean + Straightforward Python Recursive
|
easy-clean-straightforward-python-recurs-j58t
|
\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n \n seen = collections.defaultdict(int)\n res =
|
pythagoras_the_3rd
|
NORMAL
|
2021-04-27T05:16:00.520547+00:00
|
2021-04-27T05:18:12.054781+00:00
| 2,410 | false |
```\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n \n seen = collections.defaultdict(int)\n res = []\n \n def helper(node):\n if not node:\n return\n sub = tuple([helper(node.left), node.val, helper(node.right)])\n if sub in seen and seen[sub] == 1:\n res.append(node)\n seen[sub] += 1\n return sub\n \n helper(root)\n return res\n```
| 20 | 0 |
['Recursion', 'Python', 'Python3']
| 3 |
find-duplicate-subtrees
|
Verbose Java solution, tree traversal
|
verbose-java-solution-tree-traversal-by-0831z
|
Idea is to traverse the tree and serialize each sub-tree to a string and put them into a HashMap. The first time we put null as the value and later we put the r
|
shawngao
|
NORMAL
|
2017-07-30T03:10:06.693000+00:00
|
2018-10-08T07:39:29.931539+00:00
| 7,959 | false |
Idea is to traverse the tree and serialize each sub-tree to a string and put them into a HashMap. The first time we put ```null``` as the value and later we put the real node as the value. Then at last, every entry in the map with not null value, is an answer.\nAn optimization is to start searching from the ```first possible``` start node which has both left and right sub-trees. Think about why tree node with only one sub-tree can't be a valid start point?\n```\npublic class Solution {\n Map<String, TreeNode> map = new HashMap<>();\n \n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n List<TreeNode> result = new ArrayList<>();\n if (root == null) return result;\n \n traverse(first(root));\n \n for (TreeNode node : map.values()) {\n if (node != null) {\n result.add(node);\n }\n }\n \n return result;\n }\n \n private TreeNode first(TreeNode root) {\n if (root == null) return null;\n if (root.left != null && root.right != null) return root;\n if (root.left != null) return first(root.left);\n return first(root.right);\n }\n \n private void traverse(TreeNode root) {\n if (root == null) return;\n \n String s = path(root);\n if (map.containsKey(s)) {\n map.put(s, root);\n }\n else {\n map.put(s, null);\n }\n \n traverse(root.left);\n traverse(root.right);\n }\n \n private String path(TreeNode root) {\n if (root == null) return "#";\n return root.val + "," + path(root.left) + "," + path(root.right);\n }\n}\n```
| 18 | 0 |
[]
| 7 |
find-duplicate-subtrees
|
C++ || Easy and Concise Inorder Traversal
|
c-easy-and-concise-inorder-traversal-by-hw5k3
|
\nstring inorder(TreeNode* root, unordered_map<string, int>& mp, vector<TreeNode*>& res) \n{\n if(!root)\n return "";\n\n s
|
suniti0804
|
NORMAL
|
2021-06-08T04:57:05.930396+00:00
|
2021-06-08T04:57:05.930442+00:00
| 1,994 | false |
```\nstring inorder(TreeNode* root, unordered_map<string, int>& mp, vector<TreeNode*>& res) \n{\n if(!root)\n return "";\n\n string str = "(";\n str += inorder(root -> left, mp, res);\n str += to_string(root -> val);\n str += inorder(root -> right, mp, res);\n str += ")";\n\n if(mp[str] == 1)\n res.push_back(root);\n \n mp[str]++;\n\n return str;\n}\n \nvector<TreeNode*> findDuplicateSubtrees(TreeNode* root) \n{\n\tunordered_map<string, int> mp;\n\tvector<TreeNode*> res;\n\tinorder(root, mp, res);\n\treturn res;\n}\t\t\n \n```
| 17 | 0 |
['C', 'C++']
| 2 |
find-duplicate-subtrees
|
Optimised and simple solution in JavaScript.
|
optimised-and-simple-solution-in-javascr-yydu
|
\n# Approach\n1) Define a recursive function to traverse the binary tree. The function should take a node as input and return a string representation of the sub
|
AdiCoder95
|
NORMAL
|
2023-02-28T03:33:04.884287+00:00
|
2023-02-28T03:33:04.884331+00:00
| 620 | false |
\n# Approach\n1) Define a recursive function to traverse the binary tree. The function should take a node as input and return a string representation of the subtree rooted at that node.\n2) In the "traverse" function, if the node is null, return a special symbol to represent it.\n3) Construct a string representation of the subtree rooted at the current node. The representation should include the node\'s value and the string representations of its left and right subtrees.\n4) Create a hash map to store the subtrees and their counts. The keys of the hash map should be the string representations of the subtrees, and the values should be the number of times each subtree has been seen.\n5) Get the count of the subtree from the hash map. If the count is 1, it means we\'ve seen this subtree before and it\'s a duplicate. Add the current node to the result array.\n6) Increment the count of the subtree in the hash map.\n7) Return the string representation of the subtree from the traverse function.\n8) Start the traversal from the root node of the binary tree.\n9) Return the array of duplicate subtrees.\n\n**By following this approach, we can traverse the binary tree and keep track of the subtrees that have been seen before. We can then return an array of root nodes for all the duplicate subtrees.**\n\n\n\n\n\n# Complexity\n- Time complexity:\n\nThe time complexity of this code is O(n^2) in the worst case, where n is the number of nodes in the binary tree. This is because the traverse function is called recursively for each node in the tree, and for each node, it constructs a string representation of the subtree rooted at that node, which takes O(n) time in the worst case. The hash map lookup and insertion take O(1) time on average, but in the worst case, when all the subtrees are unique, the hash map can contain up to n entries, so the overall time complexity is O(n^2).\n\nHowever, we can improve the time complexity of this code to O(n) by using a post-order traversal instead of a pre-order traversal. In a post-order traversal, we visit the left subtree, then the right subtree, and then the root node. By doing this, we can construct the string representation of each subtree by concatenating the string representations of its left and right subtrees, and then the root node\'s value. This way, we don\'t need to construct the string representation of the same subtree multiple times, and we can do the duplicate check and hash map lookup in O(1) time.\n\nWith this optimization, the time complexity of the code becomes O(n), which is optimal because we need to visit each node in the tree at least once.\n\n- Space complexity:\n\nThe space complexity of this code is O(n), where n is the number of nodes in the binary tree. This is because we need to store the string representations of all the subtrees in the hash map, and in the worst case, when all the subtrees are unique, the hash map can contain up to n entries. Additionally, the recursive call stack can go up to the height of the tree, which is O(log n) in the average case for a balanced binary tree, and O(n) in the worst case for a degenerate binary tree. Therefore, the overall space complexity is O(n) in the worst case.\n\n# Code\n```\nfunction findDuplicateSubtrees(root) {\n // Create a hash map to store the subtrees and their counts\n const map = new Map();\n // Create an array to store the duplicate subtrees\n const result = [];\n\n // Traverse the binary tree recursively\n function traverse(node) {\n // If the node is null, return a special symbol to represent it\n if (!node) return \'#\';\n\n // Construct a string representation of the subtree rooted at the current node\n const subtree = `${node.val},${traverse(node.left)},${traverse(node.right)}`;\n // Get the count of the subtree from the hash map, default to 0 if not found\n const count = map.get(subtree) || 0;\n\n // If the count is 1, it means we\'ve seen this subtree before and it\'s a duplicate\n if (count === 1) {\n // Add the current node to the result array\n result.push(node);\n }\n\n // Increment the count of the subtree in the hash map\n map.set(subtree, count + 1);\n\n // Return the string representation of the subtree\n return subtree;\n }\n\n // Start the traversal from the root node\n traverse(root);\n\n // Return the array of duplicate subtrees\n return result;\n}\n\n```
| 11 | 0 |
['Hash Table', 'Binary Tree', 'JavaScript']
| 1 |
find-duplicate-subtrees
|
🧐Look at once 💻 🔥Solutions in Java 📝, Python 🐍, and C++ 🖥️ with Video Explanation 🎥
|
look-at-once-solutions-in-java-python-an-badv
|
Intuition\n Describe your first thoughts on how to solve this problem. \nTo find duplicate subtrees, we can traverse the binary tree using depth-first search (D
|
Vikas-Pathak-123
|
NORMAL
|
2023-02-28T03:15:17.303000+00:00
|
2023-02-28T03:15:17.303045+00:00
| 1,385 | false |
# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nTo find duplicate subtrees, we can traverse the binary tree using depth-first search (DFS) and store the subtree\'s serialized representation in a map, where the key is the serialized string, and the value is a list of tree nodes that represent the same subtree.\n\nTo serialize a subtree, we can use a pre-order traversal approach and represent null nodes as "#". The serialized string of the subtree\'s root node will be the concatenation of its value, left subtree, and right subtree in pre-order traversal.\n\nOnce we have stored all the subtrees\' serialized representations, we can iterate over the map and add the nodes that represent the duplicate subtrees to the result list.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Initialize an empty map, where the key is a string representation of the subtree, and the value is a list of nodes representing that subtree.\n2. Traverse the binary tree using DFS. For each node, do the following:\n- a. Serialize the node\'s subtree.\n- b. If the serialized string is already in the map, add the node to the list of nodes representing that subtree.\n- c. Otherwise, add the serialized string to the map with the node as the only node representing that subtree.\n3. Initialize an empty list to store the nodes representing duplicate subtrees.\n4. Iterate over the map, and for each key-value pair, add the first node in the list of nodes representing that subtree to the result list.\n5. Return the result list.\n6. \n# Video reference\n<iframe width="560" height="315" src="https://www.youtube.com/embed/rsx_QjNOtyU" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>\n\n\n\n\n# Please Upvote\uD83D\uDC4D\uD83D\uDC4D\n```\nThanks for visiting my solution.\uD83D\uDE0A\n```\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nWe are traversing the entire binary tree once and performing a constant amount of work for each node. Therefore, the time complexity of this algorithm is $$O(n)$$, where n is the number of nodes in the binary tree.\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nWe are using a map to store the serialized representations of the subtrees, which can have up to n keys and values. Therefore, the space complexity of this algorithm is $$O(n)$$.\n\n\n# Code\n``` java []\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String, List<TreeNode>> map = new HashMap<>();\n traverse(root, map);\n List<TreeNode> result = new ArrayList<>();\n for (Map.Entry<String, List<TreeNode>> entry : map.entrySet()) {\n List<TreeNode> nodes = entry.getValue();\n if (nodes.size() > 1) {\n result.add(nodes.get(0));\n }\n }\nreturn result;\n}\n\n\nprivate String traverse(TreeNode node, Map<String, List<TreeNode>> map) {\n if (node == null) {\n return "#";\n }\n String left = traverse(node.left, map);\n String right = traverse(node.right, map);\n String serialized = node.val + "," + left + "," + right;\n List<TreeNode> nodes = map.getOrDefault(serialized, new ArrayList<>());\n nodes.add(node);\n map.put(serialized, nodes);\n return serialized;\n}\n}\n```\n\n```python []\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n def traverse(node, map):\n if not node:\n return "#"\n left = traverse(node.left, map)\n right = traverse(node.right, map)\n serialized = str(node.val) + "," + left + "," + right\n nodes = map.setdefault(serialized, [])\n nodes.append(node)\n return serialized\n\n map = {}\n traverse(root, map)\n result = []\n for nodes in map.values():\n if len(nodes) > 1:\n result.append(nodes[0])\n return result\n\n```\n```C++ []\nclass Solution {\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<string, vector<TreeNode*>> map;\n traverse(root, map);\n vector<TreeNode*> result;\n for (auto entry : map) {\n vector<TreeNode*> nodes = entry.second;\n if (nodes.size() > 1) {\n result.push_back(nodes[0]);\n }\n }\n return result;\n }\n\n string traverse(TreeNode* node, unordered_map<string, vector<TreeNode*>>& map) {\n if (node == nullptr) {\n return "#";\n }\n string left = traverse(node->left, map);\n string right = traverse(node->right, map);\n string serialized = to_string(node->val) + "," + left + "," + right;\n vector<TreeNode*>& nodes = map[serialized];\n nodes.push_back(node);\n return serialized;\n }\n};\n\n```\n\n# Please Comment\uD83D\uDC4D\uD83D\uDC4D\n```\nThanks for visiting my solution comment below.\uD83D\uDE0A\n```\n
| 11 | 0 |
['Hash Table', 'Depth-First Search', 'Python', 'C++', 'Java']
| 1 |
find-duplicate-subtrees
|
Best Python Solution (not serializing entire tree!!!)
|
best-python-solution-not-serializing-ent-bvj5
|
Most python solutions are serializing the entire tree into a string and using that as a unique key. That makes it O(n^2) space complexity. This is a much better
|
mcmar
|
NORMAL
|
2021-06-03T21:52:16.637264+00:00
|
2021-06-03T21:52:16.637296+00:00
| 1,277 | false |
Most python solutions are serializing the entire tree into a string and using that as a unique key. That makes it `O(n^2)` space complexity. This is a much better solution that is `O(n)` space complexity. Instead, I map each `(node.val, left_id, right_id)` to a new unique id that I return for the parent to use. Now each key is a finite length of `3` ints. You could simplify this a lot by just blindly hashing `(node.val, left_id, right_id)`, but you can\'t be guaranteed that you won\'t get a hash conflict. The solution to that is to rely on python\'s `dict` to handle hash conflicts for you by mapping each one to a unique int.\n```\n# need to walk trees, preorder, inorder, postorder\n# need to store unique subtrees somewhere Map/Set\n# need unique key for subtree hash(key left + key right + val)\n# handle hash conflicts?\n# use hashmap to store monotonic id for (key left + key right + val)\n# parent uses left child\'s mono id + right child\'s mono id + val\n\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n subtrees = {}\n mono_id = 1\n visited = set()\n res = []\n def helper(node: TreeNode) -> int:\n nonlocal mono_id\n if not node:\n return 0\n left_id = helper(node.left)\n right_id = helper(node.right)\n key = (node.val, left_id, right_id)\n if key in subtrees:\n # already seen this unique subtree\n if key not in visited:\n # first time re-visiting this unique subtree\n visited.add(key)\n res.append(node)\n else:\n # first time seeing this unique subtree\n subtrees[key] = mono_id\n mono_id += 1\n return subtrees[key]\n helper(root)\n return res\n```
| 11 | 0 |
['Python']
| 1 |
find-duplicate-subtrees
|
Easy Java Solution 100% faster || With Algorithm in steps || Super Easy to understand
|
easy-java-solution-100-faster-with-algor-l87q
|
\n\n# Intuition\n Describe your first thoughts on how to solve this problem. \nThe intuition behind this solution is to use depth-first search (DFS) to traverse
|
Yaduttam_Pareek
|
NORMAL
|
2023-02-28T02:36:42.349485+00:00
|
2023-02-28T02:36:42.349515+00:00
| 1,697 | false |
\n\n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe intuition behind this solution is to use depth-first search (DFS) to traverse the binary tree and store information about each subtree in a map. Specifically, we create a custom node class called MyTreeNode that stores a hash value, the node value, and the left and right child nodes. The hash value is computed using a hashing function that takes into account the node value and the hash values of its left and right child nodes.\n\nWe maintain a map called countMap that keeps track of the frequency of each MyTreeNode object. If the frequency of a MyTreeNode object is 2, it means that we have found a duplicate subtree, so we add the corresponding node to a list called duplicates.\n\n# Algorithm\n<!-- Describe your approach to solving the problem. -->\n1. Create a class called MyTreeNode to store information about each subtree, including a hash value, node value, and left and right child nodes.\n\n2. Create an empty map called countMap to keep track of the frequency of each MyTreeNode object.\n\n3. Create an empty list called duplicates to store the duplicate nodes.\n\n4. Define a recursive function called dfs that takes a TreeNode object as input and returns a MyTreeNode object. The function should perform the following steps:\n\n a. If the input node is null, return null.\n\n b. Recursively call the dfs function on the left and right child nodes of the input node, and store the results in left and right, respectively.\n\n c. Compute the hash value of the subtree rooted at the input node using a hashing function that takes into account the node value and the hash values of its left and right child nodes.\n\n d. Create a new MyTreeNode object with the computed hash value, node value, left child, and right child.\n\n e. Increment the count of the MyTreeNode object in countMap by 1.\n\n f. If the count of the MyTreeNode object in countMap is 2, it means that we have found a duplicate subtree, so add the input node to duplicates.\n\n g. Return the MyTreeNode object.\n\n5. Call the dfs function on the root of the binary tree.\n\n6. Return the duplicates list.\n\n\n# Complexity\n- Time complexity:\nThe **time complexity** of the algorithm is **O(n^2) in the worst case**, where n is the number of nodes in the binary tree. This is because the algorithm needs to compute the hash value of each subtree and compare it with the hash values of all the other subtrees, which takes O(n) time per subtree. In the worst case, there could be n nodes in the tree, and each node could be the root of a subtree with n nodes, so the total number of subtrees to be processed would be O(n^2).\n\n- Space complexity:\nThe **space complexity** of the algorithm is also **O(n^2) in the worst case**, where n is the number of nodes in the binary tree. This is because the algorithm needs to store the hash values of all the subtrees in a hash map, and in the worst case, there could be n nodes in the tree, and each node could be the root of a subtree with n nodes, so the total number of subtrees to be stored would be O(n^2). In addition, the recursion stack could also have a maximum depth of n in the worst case, which would contribute an additional O(n) space complexity.\n\n\n\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\n\n//2L4LnRnRn\n// 2\n//(4LnRn) (n)\n// \n// 2\n// 4 (n)\n// (n) (n)\n\nclass Solution {\n\n private Map<MyTreeNode, Integer> countMap = new HashMap<>();\n private List<TreeNode> duplicates = new LinkedList<>();\n\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n dfs(root);\n return duplicates;\n }\n\n private MyTreeNode dfs(TreeNode node) {\n if(node == null) {\n return null;\n }\n\n MyTreeNode left = dfs(node.left);\n MyTreeNode right = dfs(node.right);\n\n int prime = 31;\n int hash = 1;\n hash = hash * prime + node.val;\n if(left != null) {\n hash = hash * prime + left.hash;\n }\n\n if(right != null) {\n hash = hash * prime + right.hash;\n }\n\n MyTreeNode myNode = new MyTreeNode(hash, node.val, left, right);\n int count = countMap.getOrDefault(myNode, 0) + 1;\n countMap.put(myNode, count);\n if(count == 2) {\n duplicates.add(node);\n }\n\n return myNode;\n }\n\n private class MyTreeNode {\n private int hash;\n private int val;\n private MyTreeNode left;\n private MyTreeNode right;\n\n public MyTreeNode(int h, int v, MyTreeNode l, MyTreeNode r) {\n this.hash = h;\n this.val = v;\n this.left = l;\n this.right = r;\n }\n\n @Override\n public int hashCode() {\n return hash;\n }\n\n @Override\n public boolean equals(Object o) {\n MyTreeNode node = (MyTreeNode) o;\n return this.hash == node.hash && this.val == node.val && equals(node.left, this.left) && equals(node.right, this.right);\n }\n\n private boolean equals(MyTreeNode a, MyTreeNode b) {\n if(a == null && b == null) {\n return true;\n }\n\n if(a == null || b == null) {\n return false;\n }\n\n return a.equals(b);\n }\n }\n\n}\n```
| 10 | 0 |
['Java']
| 0 |
find-duplicate-subtrees
|
Simple C++ Solution || O(n) || postOrder
|
simple-c-solution-on-postorder-by-samaha-70r9
|
\n# Complexity\n- Time complexity:O(n)\n Add your time complexity here, e.g. O(n) \n\n- Space complexity:O(n)\n Add your space complexity here, e.g. O(n) \n\n#
|
samahakal04
|
NORMAL
|
2022-11-07T07:32:03.939198+00:00
|
2022-11-07T07:32:03.939247+00:00
| 1,403 | false |
\n# Complexity\n- Time complexity:O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\nclass Solution {\npublic:\n unordered_map<string,int>mp;\n vector<TreeNode *>res;\n\n string solve(TreeNode *root){\n if(!root) return "";\n\n string left = solve(root->left);\n string right = solve(root->right);\n\n string curr = to_string(root->val) + " " + left + " " + right;\n\n if(mp[curr] == 1){\n res.push_back(root);\n }\n mp[curr]++;\n return curr;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n string dummy = solve(root);\n return res;\n }\n};\n```\n# upvote if it\'s help you HAPPY CODING :)
| 9 | 1 |
['String', 'Tree', 'Binary Tree', 'C++']
| 4 |
find-duplicate-subtrees
|
Go 12ms 100% map solution
|
go-12ms-100-map-solution-by-tjucoder-2kte
|
go\nfunc findDuplicateSubtrees(root *TreeNode) []*TreeNode {\n\thashAll := map[string]int{}\n\tduplicate := []*TreeNode{}\n\tdfs(root, hashAll, &duplicate)\n\tr
|
tjucoder
|
NORMAL
|
2020-09-12T18:03:52.983083+00:00
|
2020-09-12T18:03:52.983129+00:00
| 506 | false |
```go\nfunc findDuplicateSubtrees(root *TreeNode) []*TreeNode {\n\thashAll := map[string]int{}\n\tduplicate := []*TreeNode{}\n\tdfs(root, hashAll, &duplicate)\n\treturn duplicate\n}\n\nfunc dfs(node *TreeNode, hashAll map[string]int, duplicate *[]*TreeNode) string {\n\tif node == nil {\n\t\treturn "nil"\n\t}\n lString := dfs(node.Left, hashAll, duplicate)\n rString := dfs(node.Right, hashAll, duplicate)\n buildString := fmt.Sprintf("(%s)(%v)(%s)", lString, node.Val, rString)\n\thashAll[buildString]++\n\tif hashAll[buildString] == 2 {\n\t\t*duplicate = append(*duplicate, node)\n\t}\n return buildString\n}\n```
| 9 | 0 |
['Go']
| 0 |
find-duplicate-subtrees
|
easy peasy recursive preorder solution
|
easy-peasy-recursive-preorder-solution-b-coo7
|
\tdef findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n if root is None:\n return []\n self.mp = {}\n self.rs = [
|
lostworld21
|
NORMAL
|
2019-09-22T00:37:59.388511+00:00
|
2019-09-22T00:37:59.388549+00:00
| 2,106 | false |
\tdef findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n if root is None:\n return []\n self.mp = {}\n self.rs = []\n self.preorder(root)\n return self.rs\n \n def preorder(self, root):\n if root:\n ls = str(root.val) + "-" + self.preorder(root.left) + "-" + self.preorder(root.right)\n count = self.mp.get(ls, 0)\n if count == 1:\n self.rs.append(root)\n \n self.mp[ls] = count + 1\n return ls\n else:\n return "#"
| 9 | 0 |
['Tree', 'Depth-First Search', 'Python', 'Python3']
| 3 |
find-duplicate-subtrees
|
C++ O(n) time & space - 8ms beats 100% and scales to 2^64 unique nodes
|
c-on-time-space-8ms-beats-100-and-scales-q4h5
|
This solution builds up on the fantastic work of @Danile, @StefanPochman. This C++ implmentation uses a bitset that encodes the root\'s value in the most signif
|
v1s1on
|
NORMAL
|
2019-01-26T03:08:54.552773+00:00
|
2019-01-26T03:08:54.552821+00:00
| 1,285 | false |
This solution builds up on the fantastic work of @Danile, @StefanPochman. This C++ implmentation uses a bitset that encodes the root\'s value in the most significant bits, followed by a concatenation of the left\'s node id and the right node\'s id. Since these node id\'s are actually just an incremened counter we can have as many unique ids as supported by the counter\'s underlying type. Unlike other C++ solutions which used a long or some other 64-bit primitive POD, I used bitset which is able to acomodate 64 bits for both left and right child node ids and the full 32 bits for the root\'s value. This allows the solution to scale well beyond 2^16 nodes.\n\nHere\'s the 8ms submission that seems to currently beat 100%.\n\n```\nclass Solution {\npublic:\n using id_type = bitset<8*(2*sizeof(uint64_t) + sizeof(int))>;\n const int ValByteOffset = 16*sizeof(uint64_t);\n const int IdByteOffset = 8*sizeof(uint64_t);\n \n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n unordered_map<id_type, pair<uint64_t, int>> tree_map;\n vector<TreeNode*> result;\n getId(root, tree_map, result);\n return result;\n }\n \nprivate:\n uint64_t getId(TreeNode* root, unordered_map<id_type, pair<uint64_t, int>>& tree_map, vector<TreeNode*>& result)\n {\n if (root == nullptr) return 0UL;\n \n id_type id = id_type(root->val) << ValByteOffset | id_type(getId(root->left, tree_map, result)) << IdByteOffset | id_type(getId(root->right, tree_map, result));\n auto it = tree_map.find(id);\n if (it == tree_map.end())\n it = tree_map.insert({id, {tree_map.size() + 1, 0}}).first;\n \n if (++it->second.second == 2)\n result.push_back(root);\n\n return it->second.first;\n }\n};\n```
| 9 | 1 |
[]
| 2 |
find-duplicate-subtrees
|
Python solution
|
python-solution-by-zitaowang-z424
|
\nclass Solution(object):\n def findDuplicateSubtrees(self, root):\n """\n :type root: TreeNode\n :rtype: List[TreeNode]\n """\n
|
zitaowang
|
NORMAL
|
2018-11-13T17:58:24.932135+00:00
|
2018-11-13T17:58:24.932180+00:00
| 897 | false |
```\nclass Solution(object):\n def findDuplicateSubtrees(self, root):\n """\n :type root: TreeNode\n :rtype: List[TreeNode]\n """\n def helper(root):\n if not root:\n return "None,"\n l = helper(root.left)\n r = helper(root.right)\n encode = str(root.val)+","+l+r\n if encode not in dic:\n dic[encode] = 1\n else:\n dic[encode] += 1\n if dic[encode] == 2:\n res.append(root)\n return encode\n\t\t\t\t\t\t\n res = []\n dic = {}\n helper(root)\n return res\n```
| 8 | 0 |
[]
| 3 |
find-duplicate-subtrees
|
Java - Super easy postorder with HashMap<String, TreeNode> solution
|
java-super-easy-postorder-with-hashmapst-3lwy
|
No fancy tricks, just a post order traversal.\nUse HashMap to store the founded subtree and its root node. Use postorder traversal to get the left and right sub
|
wei-cheng
|
NORMAL
|
2017-07-30T19:30:04.198000+00:00
|
2018-08-26T23:19:51.213985+00:00
| 2,479 | false |
No fancy tricks, just a post order traversal.\nUse HashMap<String, TreeNode> to store the founded subtree and its root node. Use postorder traversal to get the left and right subtree and form the full subtree string with the current node. If the subtree is found first time, put <postorder string, null>. If the subtree is found again, put <postorder string, node> . Finally, go through the HashMap to get those not-null value.\n```\npublic List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n if(root == null) return new LinkedList<>();\t\n\t\n\tHashMap<String, TreeNode> map = new HashMap<>();\n\t\n\thelper(root, map);\n\t\n\tList<TreeNode> res = new LinkedList<>();\t\n\t\n\tfor(Map.Entry<String, TreeNode> e : map.entrySet()){\n\t if(e.getValue() != null) res.add(e.getValue());\n\t}\n\t\n\treturn res;\n \n}\n\npublic String helper(TreeNode node, HashMap<String, TreeNode> map){\n\t//leaves node\n if(node.left == null && node.right == null){\n\t\tString str = "" + node.val;\n\t\tif(!map.containsKey(str))\t\t\t\n\t\t map.put(str, null);\n\t\telse\n map.put(str, node);\t\t\t\n\t\t\n\t\treturn str;\n\t}\n\t//post order\n\tString left = "";\n\tif(node.left != null)\n\t left = helper(node.left, map);\t\n\t\n\tString right = "";\n\tif(node.right != null)\n\t right = helper(node.right, map);\n\t\n\t//new subtree found, put null; subtree found again, put the subtree's root node.\n\tString str = left +" # "+ right +" # "+ node.val; \n\tif(!map.containsKey(str))\t\t\n\t map.put(str, null);\n\telse\n map.put(str, node);\t\t\n\t\t\n\treturn str;\n}\n```\nEasy to understand? Any suggestion on efficiency?
| 8 | 1 |
[]
| 5 |
find-duplicate-subtrees
|
C++ Easy solution | Beats 95% | unordered map | post order traversal
|
c-easy-solution-beats-95-unordered-map-p-q49i
|
Approach\n Store a node\'s value + it\'s child values recursively in form of string. check if this string already exists in unordered map. \nIf this string exis
|
Jaswanth_9989
|
NORMAL
|
2023-02-28T07:16:15.021538+00:00
|
2023-02-28T07:16:15.021566+00:00
| 1,979 | false |
# Approach\n Store a node\'s value + it\'s child values recursively in form of string. check if this string already exists in unordered map. \nIf this string exists in map, push the node into v(answer vector).\nelse add this string into map. \n<!-- Describe your approach to solving the problem. -->\n\n# Code\n```\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode() : val(0), left(nullptr), right(nullptr) {}\n * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}\n * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}\n * };\n */\nclass Solution {\npublic:\n unordered_map<string,int> s;\n vector<TreeNode*> v;\n string fun(TreeNode* root)\n {\n string r1="",r2="";\n if(root->right!=NULL)\n {\n r2=r2+fun(root->right);\n } \n if(root->left!=NULL)\n {\n r1=r1+fun(root->left);\n } \n string r=to_string(root->val)+","+r1+","+r2;\n if(s.find(r)!=s.end())\n {\n if(s[r]==1)\n {\n v.push_back(root);\n } \n s[r]++;\n }\n else\n {\n s[r]=1;\n }\n return r;\n }\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n string k=fun(root);\n return v;\n }\n};\n```
| 7 | 1 |
['C++']
| 0 |
find-duplicate-subtrees
|
Python | DFS, Dictionary | O(n) time, O(n) space
|
python-dfs-dictionary-on-time-on-space-b-gw0n
|
\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.lef
|
Kiyomi_
|
NORMAL
|
2022-05-07T13:21:43.096955+00:00
|
2022-05-16T06:58:14.297938+00:00
| 1,437 | false |
```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:\n seen = defaultdict(int)\n dup = []\n \n def find(root):\n if root is None: \n return "#" # at leaf node, add # to key\n \n l = find(root.left)\n r = find(root.right)\n \n k = str(root.val) + "." + l + "." + r + "." # essential to add special char to distinguish value \n # e.g. 1, 11 or 11, 1\n seen[k] += 1\n \n if seen[k] == 2:\n dup.append(root)\n \n return k # return key to save to seen\n \n find(root)\n return dup\n```
| 7 | 0 |
['Tree', 'Depth-First Search', 'Python', 'Python3']
| 3 |
find-duplicate-subtrees
|
Easy java dfs code
|
easy-java-dfs-code-by-legit_123-tgky
|
Uniquely identify each subtree by a String key , and if that key occurs more than once , then the subtree to which that key is mapped is a duplicate subtree \n\
|
legit_123
|
NORMAL
|
2021-10-06T05:04:03.797876+00:00
|
2021-10-06T05:04:03.797927+00:00
| 1,191 | false |
Uniquely identify each subtree by a String key , and if that key occurs more than once , then the subtree to which that key is mapped is a duplicate subtree \n\n```\n/**\n * Definition for a binary tree node.\n * public class TreeNode {\n * int val;\n * TreeNode left;\n * TreeNode right;\n * TreeNode() {}\n * TreeNode(int val) { this.val = val; }\n * TreeNode(int val, TreeNode left, TreeNode right) {\n * this.val = val;\n * this.left = left;\n * this.right = right;\n * }\n * }\n */\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n HashMap<String,Pair> map = new HashMap();\n \n dfs(root,map);\n \n List<TreeNode> list = new ArrayList();\n for(String key : map.keySet()){\n Pair pair = map.get(key);\n if(pair.count>1) list.add(pair.node);\n }\n \n return list;\n }\n \n private String dfs(TreeNode node ,HashMap<String,Pair> map){\n if(node==null) return "N";\n \n String left = dfs(node.left,map);\n String right = dfs(node.right,map);\n \n String curr = node.val+"#"+left+"#"+right;\n \n if(map.containsKey(curr)){\n map.get(curr).count++;\n }else{\n map.put(curr,new Pair(node));\n }\n \n return curr;\n }\n}\n\nclass Pair{\n TreeNode node;\n int count;\n \n public Pair(TreeNode node){\n this.node = node;\n this.count = 1;\n }\n}\n```
| 7 | 0 |
['Depth-First Search', 'Java']
| 3 |
find-duplicate-subtrees
|
[c++] easy to understand hashing based solution
|
c-easy-to-understand-hashing-based-solut-aezi
|
\nclass Solution {\npublic:\n \n unordered_map<string,vector<TreeNode*>>mp;\n \n string recurs(TreeNode* root)\n {\n if(root==NULL)\n
|
SJ4u
|
NORMAL
|
2021-06-30T05:26:56.190153+00:00
|
2021-06-30T05:28:06.463703+00:00
| 1,027 | false |
```\nclass Solution {\npublic:\n \n unordered_map<string,vector<TreeNode*>>mp;\n \n string recurs(TreeNode* root)\n {\n if(root==NULL)\n return "";\n string a=recurs(root->left);\n string b=recurs(root->right);\n \n string temp="";\n temp+=to_string(root->val)+"-"+a+"-"+b;\n mp[temp].push_back(root);\n return temp;\n }\n\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> res;\n\n recurs(root);\n \n for(auto x:mp)\n {\n if(x.second.size()>1)\n res.push_back(x.second[0]);\n }\n return res;\n }\n};\n```
| 7 | 0 |
['Depth-First Search', 'C', 'C++']
| 1 |
find-duplicate-subtrees
|
🗓️ Daily LeetCoding Challenge February, Day 28
|
daily-leetcoding-challenge-february-day-nw46h
|
This problem is the Daily LeetCoding Challenge for February, Day 28. Feel free to share anything related to this problem here! You can ask questions, discuss wh
|
leetcode
|
OFFICIAL
|
2023-02-28T00:00:19.128545+00:00
|
2023-02-28T00:00:19.128614+00:00
| 7,930 | false |
This problem is the Daily LeetCoding Challenge for February, Day 28.
Feel free to share anything related to this problem here!
You can ask questions, discuss what you've learned from this problem, or show off how many days of streak you've made!
---
If you'd like to share a detailed solution to the problem, please create a new post in the discuss section and provide
- **Detailed Explanations**: Describe the algorithm you used to solve this problem. Include any insights you used to solve this problem.
- **Images** that help explain the algorithm.
- **Language and Code** you used to pass the problem.
- **Time and Space complexity analysis**.
---
**📌 Do you want to learn the problem thoroughly?**
Read [**⭐ LeetCode Official Solution⭐**](https://leetcode.com/problems/find-duplicate-subtrees/solution) to learn the 3 approaches to the problem with detailed explanations to the algorithms, codes, and complexity analysis.
<details>
<summary> Spoiler Alert! We'll explain this 0 approach in the official solution</summary>
</details>
If you're new to Daily LeetCoding Challenge, [**check out this post**](https://leetcode.com/discuss/general-discussion/655704/)!
---
<br>
<p align="center">
<a href="https://leetcode.com/subscribe/?ref=ex_dc" target="_blank">
<img src="https://assets.leetcode.com/static_assets/marketing/daily_leetcoding_banner.png" width="560px" />
</a>
</p>
<br>
| 6 | 1 |
[]
| 47 |
find-duplicate-subtrees
|
short c++ solution
|
short-c-solution-by-sandeep_003-2w8j
|
\n unordered_map<string,int> m;\n vector<TreeNode*> v;\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n solve(root);\n return v;
|
sandeep_003
|
NORMAL
|
2021-08-25T07:18:06.661544+00:00
|
2021-08-25T07:18:06.661590+00:00
| 419 | false |
```\n unordered_map<string,int> m;\n vector<TreeNode*> v;\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n solve(root);\n return v;\n }\n string solve(TreeNode* root)\n {\n if(root==nullptr) return "#";\n string s="";\n s=s+to_string(root->val)+\',\';\n s=s+solve(root->left);\n s=s+solve(root->right);\n m[s]++;\n if(m[s]==2)\n {\n v.push_back(root);\n } \n return s;\n }\n```
| 6 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
Java Easy to Understand Solution with Explanation
|
java-easy-to-understand-solution-with-ex-c9ag
|
Intuition consists of 3 steps:\n\n1) Create a signature for each node. \n2) Add node to the result if you have already seen that signature before.\n3) Make sure
|
kamaci
|
NORMAL
|
2021-06-13T08:29:49.859866+00:00
|
2021-06-13T08:29:49.859909+00:00
| 1,182 | false |
Intuition consists of 3 steps:\n\n1) Create a signature for each node. \n2) Add node to the result if you have already seen that signature before.\n3) Make sure to add prefix for sub-left tree and sub-right tree representations in order to avoid some cases at which signature are same but trees are not duplicate.\n\n```\nclass Solution {\n public List<TreeNode> findDuplicateSubtrees(TreeNode root) {\n Map<String, Integer> map = new HashMap<>();\n List<TreeNode> result = new ArrayList<>();\n traverse(root, map, result);\n return result;\n }\n \n public String traverse(TreeNode node, Map<String, Integer> map, List<TreeNode> result) {\n if (node == null) {\n return "#";\n }\n String key = new StringBuilder()\n .append("l")\n .append(traverse(node.left, map, result))\n .append(node.val)\n .append("r")\n .append(traverse(node.right, map, result))\n .toString();\n int freq = map.getOrDefault(key, 0);\n if (freq == 1) {\n result.add(node);\n }\n map.put(key, freq + 1);\n return key;\n }\n}\n```
| 6 | 0 |
['Depth-First Search', 'Java']
| 0 |
find-duplicate-subtrees
|
EASY JAVASCRIPT SOLUTION!!
|
easy-javascript-solution-by-hanseaston-vs28
|
\nvar findDuplicateSubtrees = function(root) {\n const rtn = [];\n\t// Map keeping track of the subtrees\n const map = new Map();\n const helper = root
|
hanseaston
|
NORMAL
|
2020-07-03T04:44:46.653136+00:00
|
2020-07-03T04:47:33.787402+00:00
| 359 | false |
```\nvar findDuplicateSubtrees = function(root) {\n const rtn = [];\n\t// Map keeping track of the subtrees\n const map = new Map();\n const helper = root => {\n\t // Use "#" to represent null nodes\n if (!root) return "#";\n\t\t// Adding "." is necessary, for ex, differentiating "1" and "11"\n let subtree = root.val.toString() + "." + helper(root.left) + "." + helper(root.right);\n\t\t// If not saved, save\n if (!map[subtree]) {\n map[subtree] = 1;\n\t\t // If encountered once already, store the result\n } else if (map[subtree] === 1) {\n rtn.push(root);\n\t\t\t// Adding once more is necessary because we want to make sure we only add duplicates once\n map[subtree]++;\n } \n return subtree;\n }\n helper(root);\n return rtn;\n};\n```
| 6 | 0 |
[]
| 0 |
find-duplicate-subtrees
|
[Python] Serialization (Easy Understanding)
|
python-serialization-easy-understanding-p20sf
|
\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.righ
|
ruifeng_wang
|
NORMAL
|
2020-02-23T01:59:20.868071+00:00
|
2020-02-23T01:59:20.868131+00:00
| 602 | false |
```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nfrom collections import defaultdict\n\nclass Solution:\n def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:\n \n # from leaf to root algorithm\n """\nAn Efficient solution based on tree serialization and hashing. The idea is to serialize subtrees as strings and store the strings in hash table. Once we find a serialized tree (which is not a leaf) already existing in hash-table, we return true.\nBelow The implementation of above idea.\n """\n self.pathCount=defaultdict(int)\n self.res=[]\n self.serialization(root)\n return self.res\n \n def serialization(self, node):\n if not node:\n return \'*\'\n path = str(node.val) + self.serialization(node.left) + self.serialization(node.right)\n if self.pathCount[path] == 1:\n self.res.append(node)\n self.pathCount[path] += 1\n \n return path\n\n\n```
| 6 | 3 |
['Python3']
| 4 |
find-duplicate-subtrees
|
C++, 19 ms, O(n^2), sort by subtree height
|
c-19-ms-on2-sort-by-subtree-height-by-ze-vfbi
|
If two subtrees are the same, they have to have same height. The idea is to sort subtrees by its height using post order traversal, and then to work on each gro
|
zestypanda
|
NORMAL
|
2017-07-30T17:22:29.758000+00:00
|
2017-07-30T17:22:29.758000+00:00
| 1,206 | false |
If two subtrees are the same, they have to have same height. The idea is to sort subtrees by its height using post order traversal, and then to work on each group with the same height. \n\nThe run time is O(n^2), the same as the string serialization solution. The analysis is as below. It takes O(n) time to sort subtrees into groups. It takes O(m) time to check whether two trees are the same, with m is the total node number in the tree. For a group with the same height, there are O(k^2) same tree comparisons, and k is the number of subtrees in the group. For height i, assuming there are ki subtrees, so there are about n/ki nodes in each subtree. The run time for this group is O(ki^2) x O(n/ki) = O(nki). The sum of all ki, i.e. all nodes, is n, so the total run time is O(n^2). \n\nI have tried to incorporate the total nodes for each subtree, because the same subtree will also have the same amount of nodes, however it didn't improve the run time due to performance of hash table. The comparison to check whether it is the same tree is still potentially time consuming. If anyone have good optimization, please leave a comment. Thanks!\n```\nclass Solution {\npublic:\n vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {\n vector<TreeNode*> ans;\n if (root == NULL) return ans;\n vector<vector<TreeNode*>> height(1, vector<TreeNode*>());\n find_height(height, root);\n for (int i = 1; i < height.size(); i++) {\n for (int j = 0; j < height[i].size(); j++) {\n if (height[i][j] == NULL) continue;\n bool exist = false;\n for (int k = j+1; k < height[i].size(); k++) {\n if (sametree(height[i][j], height[i][k])) {\n height[i][k] = NULL;\n exist = true;\n }\n }\n if (exist) ans.push_back(height[i][j]);\n } \n }\n return ans;\n }\nprivate:\n int find_height(vector<vector<TreeNode*>>& height, TreeNode* p) {\n if (p == NULL) return 0;\n int left = find_height(height, p->left), right = find_height(height, p->right), h = max(left, right)+1;\n if (h == height.size()) \n height.push_back({p});\n else \n height[h].push_back(p);\n return h;\n }\n bool sametree(TreeNode* p, TreeNode* q) {\n if (p == NULL && q == NULL) return true;\n if (p == NULL || q == NULL) return false;\n if (p->val != q->val) return false;\n return sametree(p->left, q->left) && sametree(p->right, q->right);\n }\n};\n```
| 6 | 0 |
[]
| 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.