
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
facebook/convnext-large-384
|
55a95313fa52934fa7b4d8e646aa0ac574eda4ef
|
2022-02-26T12:16:55.000Z
|
[
"pytorch",
"tf",
"convnext",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
facebook
| null |
facebook/convnext-large-384
| 85 | null |
transformers
| 4,900 |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (large-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-large-384")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-384")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
facebook/wav2vec2-xls-r-300m-en-to-15
|
eca5ea600a8570ea1744fe5bd13f8b1ce505a656
|
2022-05-26T22:27:20.000Z
|
[
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"multilingual",
"en",
"de",
"tr",
"fa",
"sv",
"mn",
"zh",
"cy",
"ca",
"sl",
"et",
"id",
"ar",
"ta",
"lv",
"ja",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"transformers",
"speech",
"xls_r",
"xls_r_translation",
"license:apache-2.0"
] |
automatic-speech-recognition
| false |
facebook
| null |
facebook/wav2vec2-xls-r-300m-en-to-15
| 85 | null |
transformers
| 4,901 |
---
language:
- multilingual
- en
- de
- tr
- fa
- sv
- mn
- zh
- cy
- ca
- sl
- et
- id
- ar
- ta
- lv
- ja
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- xls_r_translation
- automatic-speech-recognition
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
---
# Wav2Vec2-XLS-R-300M-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-300m-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-300m-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
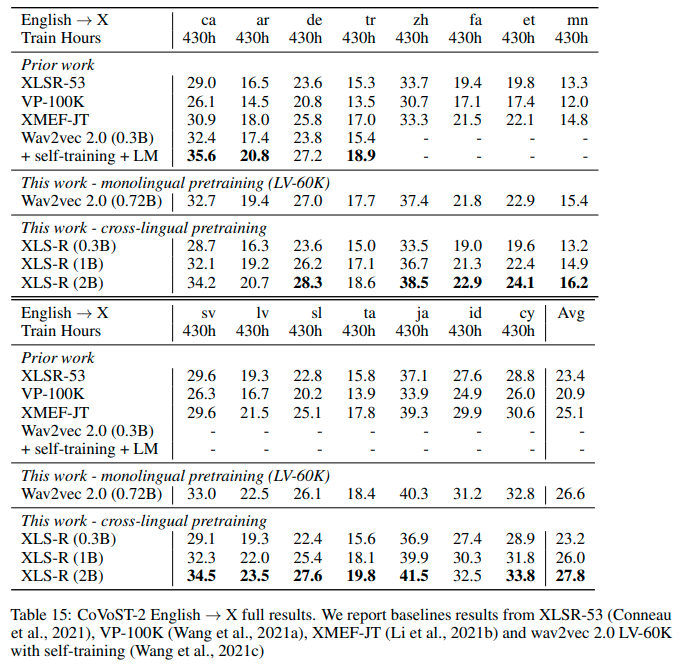
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
hfl/chinese-electra-small-discriminator
|
f59e9653eb2382d76ca1a45b782897158d828f26
|
2021-03-03T01:39:00.000Z
|
[
"pytorch",
"tf",
"electra",
"zh",
"arxiv:2004.13922",
"transformers",
"license:apache-2.0"
] | null | false |
hfl
| null |
hfl/chinese-electra-small-discriminator
| 85 | 1 |
transformers
| 4,902 |
---
language:
- zh
license: "apache-2.0"
---
**Please use `ElectraForPreTraining` for `discriminator` and `ElectraForMaskedLM` for `generator` if you are re-training these models.**
## Chinese ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants.
For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA.
ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
This project is based on the official code of ELECTRA: [https://github.com/google-research/electra](https://github.com/google-research/electra)
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
|
michaelbenayoun/vit-base-beans
|
b724a7366b1467f6f5e53b978b44c4c08d6c23cc
|
2021-12-17T09:17:23.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"dataset:cifar10",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
image-classification
| false |
michaelbenayoun
| null |
michaelbenayoun/vit-base-beans
| 85 | null |
transformers
| 4,903 |
---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
datasets:
- cifar10
metrics:
- accuracy
model-index:
- name: vit-base-beans
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: cifar10
type: cifar10
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.6224
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cifar10 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1333
- Accuracy: 0.6224
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1678 | 0.02 | 100 | 2.1333 | 0.6224 |
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.10.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.2
|
mrm8488/bert2bert_shared-spanish-finetuned-muchocine-review-summarization
|
266f7ece730f283e5f979c18056f53fc4896a31f
|
2021-05-07T09:26:36.000Z
|
[
"pytorch",
"encoder-decoder",
"text2text-generation",
"es",
"transformers",
"summarization",
"films",
"cinema",
"autotrain_compatible"
] |
summarization
| false |
mrm8488
| null |
mrm8488/bert2bert_shared-spanish-finetuned-muchocine-review-summarization
| 85 | null |
transformers
| 4,904 |
---
tags:
- summarization
- films
- cinema
language: es
widget:
- text: "Es la película que con más ansia he esperado, dado el precedente de las dos anteriores entregas, esta debía ser la joya de la corona, el mejor film jamás realizado… Pero cuando salí del cine estaba decepcionado, me leí el libro antes de ver la película (cosa que no hice con las otras dos) y sentí que Peter me falló. Le faltaba algo, habían obviado demasiadas cosas y no salía Saruman, algo incomprensible dada la importancia que se le dio en las anteriores películas. La película parecía incompleta y realmente lo estaba. Me pareció la peor de la trilogía. Volví a ver el film y esta vez en su versión extendida y mentalizado ya de que no podía ser igual que el libro y mi opinión cambio. Es la mejor de la trilogía en todos los aspectos y para mi gusto el mejor film que jamás se ha hecho. A pesar de sus casi 240 minutos el ritmo no decae sino que aumenta en algo que solo lo he visto hacer a Peter Jackson, las palabras de Tolkien cobra vida y con gran lirismo el film avanza hacía su clímax final. La impecable banda sonora te transporta los sentimientos que el maestro Jackson te quiere transmitir. Aquella noche de 2003 en el teatro Kodak de L.A los oscars dieron justicia a una trilogía que injustamente fue tratada hasta esa noche. En conjunto gano 17 oscars, pero en mi opinión se quedaron bastante cortos. El tiempo pondrá a esta trilogía como clásico imperecedero, una lección de cómo realizar una superproducción, los mensajes que transmiten, los bellos escenarios que presentan, un cuento al fin y al cabo pero convertido en obra de arte. Genialidad en todos los sentidos, no os dejéis engañar por los que duramente critican a esta trilogía y sino mirar lo que ellos llaman buen cine…"
---
|
nates-test-org/convit_base
|
ec61081b76678a0c3c53d4d6bd64305598a6da09
|
2021-10-29T04:40:37.000Z
|
[
"pytorch",
"timm",
"image-classification"
] |
image-classification
| false |
nates-test-org
| null |
nates-test-org/convit_base
| 85 | null |
timm
| 4,905 |
---
tags:
- image-classification
- timm
library_tag: timm
---
# Model card for convit_base
|
speechbrain/urbansound8k_ecapa
|
ac8b73ec8c5fd158447654a33101fe236e048bd9
|
2022-05-30T14:34:29.000Z
|
[
"en",
"dataset:Urbansound8k",
"arxiv:2106.04624",
"speechbrain",
"embeddings",
"Sound",
"Keywords",
"Keyword Spotting",
"pytorch",
"ECAPA-TDNN",
"TDNN",
"Command Recognition",
"audio-classification",
"license:apache-2.0"
] |
audio-classification
| false |
speechbrain
| null |
speechbrain/urbansound8k_ecapa
| 85 | 3 |
speechbrain
| 4,906 |
---
language: "en"
thumbnail:
tags:
- speechbrain
- embeddings
- Sound
- Keywords
- Keyword Spotting
- pytorch
- ECAPA-TDNN
- TDNN
- Command Recognition
- audio-classification
license: "apache-2.0"
datasets:
- Urbansound8k
metrics:
- Accuracy
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Sound Recognition with ECAPA embeddings on UrbanSoudnd8k
This repository provides all the necessary tools to perform sound recognition with SpeechBrain using a model pretrained on UrbanSound8k.
You can download the dataset [here](https://urbansounddataset.weebly.com/urbansound8k.html)
The provided system can recognize the following 10 keywords:
```
dog_bark, children_playing, air_conditioner, street_music, gun_shot, siren, engine_idling, jackhammer, drilling, car_horn
```
For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The given model performance on the test set is:
| Release | Accuracy 1-fold (%)
|:-------------:|:--------------:|
| 04-06-21 | 75.5 |
## Pipeline description
This system is composed of a ECAPA model coupled with statistical pooling. A classifier, trained with Categorical Cross-Entropy Loss, is applied on top of that.
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Perform Sound Recognition
```python
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(source="speechbrain/urbansound8k_ecapa", savedir="pretrained_models/gurbansound8k_ecapa")
out_prob, score, index, text_lab = classifier.classify_file('speechbrain/urbansound8k_ecapa/dog_bark.wav')
print(text_lab)
```
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (8cab8b0c).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/UrbanSound8k/SoundClassification
python train.py hparams/train_ecapa_tdnn.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1sItfg_WNuGX6h2dCs8JTGq2v2QoNTaUg?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
#### Referencing ECAPA
```@inproceedings{DBLP:conf/interspeech/DesplanquesTD20,
author = {Brecht Desplanques and
Jenthe Thienpondt and
Kris Demuynck},
editor = {Helen Meng and
Bo Xu and
Thomas Fang Zheng},
title = {{ECAPA-TDNN:} Emphasized Channel Attention, Propagation and Aggregation
in {TDNN} Based Speaker Verification},
booktitle = {Interspeech 2020},
pages = {3830--3834},
publisher = {{ISCA}},
year = {2020},
}
```
#### Referencing UrbanSound
```@inproceedings{Salamon:UrbanSound:ACMMM:14,
Author = {Salamon, J. and Jacoby, C. and Bello, J. P.},
Booktitle = {22nd {ACM} International Conference on Multimedia (ACM-MM'14)},
Month = {Nov.},
Pages = {1041--1044},
Title = {A Dataset and Taxonomy for Urban Sound Research},
Year = {2014}}
```
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
|
uer/t5-v1_1-small-chinese-cluecorpussmall
|
4695f4326f388432eed807b081822a18795ec17d
|
2022-07-15T08:22:12.000Z
|
[
"pytorch",
"tf",
"jax",
"mt5",
"text2text-generation",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
uer
| null |
uer/t5-v1_1-small-chinese-cluecorpussmall
| 85 | null |
transformers
| 4,907 |
---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "作为电子extra0的平台,京东绝对是领先者。如今的刘强extra1已经是身价过extra2的老板。"
---
# Chinese T5 Version 1.1
## Model description
This is the set of Chinese T5 Version 1.1 models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
**Version 1.1**
Chinese T5 Version 1.1 includes the following improvements compared to our Chinese T5 model:
- GEGLU activation in feed-forward hidden layer, rather than ReLU
- Dropout was turned off in pre-training
- no parameter sharing between embedding and classifier layer
You can download the set of Chinese T5 Version 1.1 models either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| ----------------- | :----------------------------: |
| **T5-v1_1-Small** | [**L=8/H=512 (Small)**][small] |
| **T5-v1_1-Base** | [**L=12/H=768 (Base)**][base] |
In T5 Version 1.1, spans of the input sequence are masked by so-called sentinel token. Each sentinel token represents a unique mask token for the input sequence and should start with `<extra_id_0>`, `<extra_id_1>`, … up to `<extra_id_99>`. However, `<extra_id_xxx>` is separated into multiple parts in Huggingface's Hosted inference API. Therefore, we replace `<extra_id_xxx>` with `extraxxx` in vocabulary and BertTokenizer regards `extraxxx` as one sentinel token.
## How to use
You can use this model directly with a pipeline for text2text generation (take the case of T5-v1_1-Small):
```python
>>> from transformers import BertTokenizer, MT5ForConditionalGeneration, Text2TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("uer/t5-v1_1-small-chinese-cluecorpussmall")
>>> model = MT5ForConditionalGeneration.from_pretrained("uer/t5-v1_1-small-chinese-cluecorpussmall")
>>> text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
>>> text2text_generator("中国的首都是extra0京", max_length=50, do_sample=False)
[{'generated_text': 'extra0 北 extra1 extra2 extra3 extra4 extra5'}]
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
The model is pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of T5-v1_1-Small
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5-v1_1_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5-v1_1_seq128_dataset.pt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--config_path models/t5-v1_1/small_config.json \
--output_model_path models/cluecorpussmall_t5-v1_1_small_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-3 --batch_size 64 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5-v1_1_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5-v1_1_seq512_dataset.pt \
--pretrained_model_path models/cluecorpussmall_t5-v1_1_small_seq128_model.bin-1000000 \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--config_path models/t5-v1_1/small_config.json \
--output_model_path models/cluecorpussmall_t5-v1_1_small_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-4 --batch_size 16 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_t5_from_uer_to_huggingface.py --input_model_path cluecorpussmall_t5_small_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 \
--type t5-v1_1
```
### BibTeX entry and citation info
```
@article{2020t5,
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
journal = {Journal of Machine Learning Research},
pages = {1-67},
year = {2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[small]:https://huggingface.co/uer/t5-v1_1-small-chinese-cluecorpussmall
[base]:https://huggingface.co/uer/t5-v1_1-base-chinese-cluecorpussmall
|
wietsedv/wav2vec2-large-xlsr-53-frisian
|
8c02c12454880a55cb031de9744245649fd0e70f
|
2021-03-28T20:09:35.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"fy-NL",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
wietsedv
| null |
wietsedv/wav2vec2-large-xlsr-53-frisian
| 85 | null |
transformers
| 4,908 |
---
language: fy-NL
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Frisian XLSR Wav2Vec2 Large 53 by Wietse de Vries
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fy-NL
type: common_voice
args: fy-NL
metrics:
- name: Test WER
type: wer
value: 16.25
---
# Wav2Vec2-Large-XLSR-53-Frisian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Frisian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "fy-NL", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("wietsedv/wav2vec2-large-xlsr-53-frisian")
model = Wav2Vec2ForCTC.from_pretrained("wietsedv/wav2vec2-large-xlsr-53-frisian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Frisian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "fy-NL", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("wietsedv/wav2vec2-large-xlsr-53-frisian")
model = Wav2Vec2ForCTC.from_pretrained("wietsedv/wav2vec2-large-xlsr-53-frisian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\'\“\%\‘\”]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:.2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 16.25 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
|
yuvraj/summarizer-cnndm
|
4dfc2c9a7a656985c0b7415509cfdd26550e8306
|
2020-12-11T22:04:58.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"transformers",
"summarization",
"autotrain_compatible"
] |
summarization
| false |
yuvraj
| null |
yuvraj/summarizer-cnndm
| 85 | null |
transformers
| 4,909 |
---
language: "en"
tags:
- summarization
---
# Summarization
## Model description
BartForConditionalGeneration model fine tuned for summarization on 10000 samples from the cnn-dailymail dataset
## How to use
PyTorch model available
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, pipeline
tokenizer = AutoTokenizer.from_pretrained("yuvraj/summarizer-cnndm")
AutoModelWithLMHead.from_pretrained("yuvraj/summarizer-cnndm")
summarizer = pipeline('summarization', model=model, tokenizer=tokenizer)
summarizer("<Text to be summarized>")
## Limitations and bias
Trained on a small dataset
|
zhiheng-huang/bert-base-uncased-embedding-relative-key-query
|
a3126b4d74e3edf3eea4280d186ac7ad4dbc4753
|
2021-05-20T09:45:59.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
zhiheng-huang
| null |
zhiheng-huang/bert-base-uncased-embedding-relative-key-query
| 85 | null |
transformers
| 4,910 |
Entry not found
|
kevinjesse/graphcodebert-MT4TS
|
ee7bbf8909df6ab4b82e3229dfff0b5b4c9cc8c0
|
2022-03-09T11:39:30.000Z
|
[
"pytorch",
"roberta",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
kevinjesse
| null |
kevinjesse/graphcodebert-MT4TS
| 85 | null |
transformers
| 4,911 |
Entry not found
|
hafidber/rare-puppers
|
aba4ab1fac86f7f7bb5958dd7e8c12ce14ec051b
|
2022-04-06T17:53:06.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
hafidber
| null |
hafidber/rare-puppers
| 85 | null |
transformers
| 4,912 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9552238583564758
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### samoyed

#### shiba inu

|
malteos/gpt2-wechsel-german-ds-meg
|
6961d2febd4a803e925a3acc7034548f32e6bc5c
|
2022-05-05T19:41:22.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"de",
"transformers",
"license:mit"
] |
text-generation
| false |
malteos
| null |
malteos/gpt2-wechsel-german-ds-meg
| 85 | null |
transformers
| 4,913 |
---
license: mit
language: de
widget:
- text: "In einer schockierenden Entdeckung fanden Wissenschaftler eine Herde Einhörner, die in einem abgelegenen, zuvor unerforschten Tal in den Anden lebten."
---
# Replication of [gpt2-wechsel-german](https://huggingface.co/benjamin/gpt2-wechsel-german)
- trained with [BigScience's DeepSpeed-Megatron-LM code base](https://github.com/bigscience-workshop/Megatron-DeepSpeed)
- 22hrs on 4xA100 GPUs (~ 80 TFLOPs / GPU)
- stopped after 100k steps
- less than a single epoch on `oscar_unshuffled_deduplicated_de` (excluding validation set; original model was trained for 75 epochs on less data)
- bf16
- zero stage 1
- tp/pp = 1
## Evaluation
| Model | PPL |
|---|---|
| `gpt2-wechsel-german-ds-meg` | **26.4** |
| `gpt2-wechsel-german` | 26.8 |
| `gpt2` (retrained from scratch) | 27.63 |
## License
MIT
|
ajtamayoh/NER_EHR_Spanish_model_Mulitlingual_BERT
|
8ff6b1072af538faea974122ed66e9870d9c1ec2
|
2022-06-14T16:29:31.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
ajtamayoh
| null |
ajtamayoh/NER_EHR_Spanish_model_Mulitlingual_BERT
| 85 | null |
transformers
| 4,914 |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: NER_EHR_Spanish_model_Mulitlingual_BERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NER_EHR_Spanish_model_Mulitlingual_BERT
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the DisTEMIST shared task 2022 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2603
- Precision: 0.5637
- Recall: 0.5801
- F1: 0.5718
- Accuracy: 0.9534
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 71 | 0.2060 | 0.5017 | 0.5540 | 0.5266 | 0.9496 |
| No log | 2.0 | 142 | 0.2163 | 0.5363 | 0.5433 | 0.5398 | 0.9495 |
| No log | 3.0 | 213 | 0.2245 | 0.5521 | 0.5356 | 0.5438 | 0.9514 |
| No log | 4.0 | 284 | 0.2453 | 0.5668 | 0.5985 | 0.5822 | 0.9522 |
| No log | 5.0 | 355 | 0.2433 | 0.5657 | 0.5579 | 0.5617 | 0.9530 |
| No log | 6.0 | 426 | 0.2553 | 0.5762 | 0.5762 | 0.5762 | 0.9536 |
| No log | 7.0 | 497 | 0.2603 | 0.5637 | 0.5801 | 0.5718 | 0.9534 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.2.0
- Tokenizers 0.12.1
|
malmarjeh/mbert2mbert-arabic-text-summarization
|
d575c9342bd733da408d31286672ec2fbe568b63
|
2022-06-29T12:54:31.000Z
|
[
"pytorch",
"encoder-decoder",
"text2text-generation",
"ar",
"transformers",
"Multilingual BERT",
"BERT2BERT",
"MSA",
"Arabic Text Summarization",
"Arabic News Title Generation",
"Arabic Paraphrasing",
"autotrain_compatible"
] |
text2text-generation
| false |
malmarjeh
| null |
malmarjeh/mbert2mbert-arabic-text-summarization
| 85 | null |
transformers
| 4,915 |
---
language:
- ar
tags:
- Multilingual BERT
- BERT2BERT
- MSA
- Arabic Text Summarization
- Arabic News Title Generation
- Arabic Paraphrasing
---
# An Arabic abstractive text summarization model
A BERT2BERT-based model whose parameters are initialized with mBERT weights and which has been fine-tuned on a dataset of 84,764 paragraph-summary pairs.
More details on the fine-tuning of this model will be released later.
The model can be used as follows:
```python
from transformers import BertTokenizer, AutoModelForSeq2SeqLM, pipeline
from arabert.preprocess import ArabertPreprocessor
model_name="malmarjeh/mbert2mbert-arabic-text-summarization"
preprocessor = ArabertPreprocessor(model_name="")
tokenizer = BertTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
pipeline = pipeline("text2text-generation",model=model,tokenizer=tokenizer)
text = "شهدت مدينة طرابلس، مساء أمس الأربعاء، احتجاجات شعبية وأعمال شغب لليوم الثالث على التوالي، وذلك بسبب تردي الوضع المعيشي والاقتصادي. واندلعت مواجهات عنيفة وعمليات كر وفر ما بين الجيش اللبناني والمحتجين استمرت لساعات، إثر محاولة فتح الطرقات المقطوعة، ما أدى إلى إصابة العشرات من الطرفين."
text = preprocessor.preprocess(text)
result = pipeline(text,
pad_token_id=tokenizer.eos_token_id,
num_beams=3,
repetition_penalty=3.0,
max_length=200,
length_penalty=1.0,
no_repeat_ngram_size = 3)[0]['generated_text']
result
>>> 'احتجاجات في طرابلس على خلفية مواجهات عنيفة بين الجيش اللبناني والمحتجين'
```
## Contact:
**Mohammad Bani Almarjeh**: [Linkedin](https://www.linkedin.com/in/mohammad-bani-almarjeh/) | <[email protected]>
|
gustavhartz/roberta-base-cuad-finetuned
|
b801aecb08c8e28c07b03e162226d93e804b6661
|
2022-06-27T11:58:31.000Z
|
[
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
gustavhartz
| null |
gustavhartz/roberta-base-cuad-finetuned
| 85 | null |
transformers
| 4,916 |
# Finetuned legal contract review QA model based 👩⚖️ 📑
Best model presented in the master thesis [*Exploring CUAD using RoBERTa span-selection QA models for legal contract review*](https://github.com/gustavhartz/transformers-legal-tasks) for QA on the Contract Understanding Atticus Dataset. Full training logic and associated thesis available through link.
Outperform the most popular HF cuad model [Rakib/roberta-base-on-cuad](hello.com) and is the best model for CUAD on Hugging Face 26/06/2022
| **Model name** | **Top 1 Has Ans F1** | **Top 3 Has Ans F1** |
|-----------------------------------------|----------------------|----------------------|
| gustavhartz/roberta-base-cuad-finetuned | 85.68 | 94.06 |
| Rakib/roberta-base-on-cuad | 81.26 | 92.48 |
For questions etc. go through the Github repo :)
### Citation
If you found the code of thesis helpful you can please cite it :)
```
@thesis{ha2022,
author = {Hartz, Gustav Selfort},
title = {Exploring CUAD using RoBERTa span-selection QA models for legal contract review},
language = {English},
format = {thesis},
year = {2022},
publisher = {DTU Department of Applied Mathematics and Computer Science}
}
```
|
alistairmcleay/UBAR-distilgpt2
|
f5d4fa573db863e37138ea73cb37e61a294850a9
|
2022-06-26T14:10:29.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"license:wtfpl"
] |
text-generation
| false |
alistairmcleay
| null |
alistairmcleay/UBAR-distilgpt2
| 85 | null |
transformers
| 4,917 |
---
license: wtfpl
---
|
ebelenwaf/canbert
|
f1bcf409d524839b6ab581dcc93f9635e5311e8e
|
2022-07-17T03:39:02.000Z
|
[
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
fill-mask
| false |
ebelenwaf
| null |
ebelenwaf/canbert
| 85 | null |
transformers
| 4,918 |
---
tags:
- generated_from_trainer
model-index:
- name: canbert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# canbert
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.12.0+cu113
- Tokenizers 0.12.1
|
tinkoff-ai/ruDialoGPT-small
|
aaf0936bedf44fcc834ee1ae91372af02f69f280
|
2022-07-19T20:27:35.000Z
|
[
"pytorch",
"gpt2",
"ru",
"arxiv:2001.09977",
"transformers",
"conversational",
"license:mit",
"text-generation"
] |
text-generation
| false |
tinkoff-ai
| null |
tinkoff-ai/ruDialoGPT-small
| 85 | null |
transformers
| 4,919 |
---
license: mit
pipeline_tag: text-generation
widget:
- text: "@@ПЕРВЫЙ@@ привет @@ВТОРОЙ@@ привет @@ПЕРВЫЙ@@ как дела? @@ВТОРОЙ@@"
example_title: "how r u"
- text: "@@ПЕРВЫЙ@@ что ты делал на выходных? @@ВТОРОЙ@@"
example_title: "wyd"
language:
- ru
tags:
- conversational
---
This generation model is based on [sberbank-ai/rugpt3small_based_on_gpt2](https://huggingface.co/sberbank-ai/rugpt3small_based_on_gpt2). It's trained on large corpus of dialog data and can be used for buildning generative conversational agents
The model was trained with context size 3
On a private validation set we calculated metrics introduced in [this paper](https://arxiv.org/pdf/2001.09977.pdf):
- Sensibleness: Crowdsourcers were asked whether model's response makes sense given the context
- Specificity: Crowdsourcers were asked whether model's response is specific for given context, in other words we don't want our model to give general and boring responses
- SSA which is the average of two metrics above (Sensibleness Specificity Average)
| | sensibleness | specificity | SSA |
|:----------------------------------------------------|---------------:|--------------:|------:|
| [tinkoff-ai/ruDialoGPT-small](https://huggingface.co/tinkoff-ai/ruDialoGPT-small) | 0.64 | 0.5 | 0.57 |
| [tinkoff-ai/ruDialoGPT-medium](https://huggingface.co/tinkoff-ai/ruDialoGPT-medium) | 0.78 | 0.69 | 0.735 |
How to use:
```python
import torch
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained('tinkoff-ai/ruDialoGPT-small')
model = AutoModelWithLMHead.from_pretrained('tinkoff-ai/ruDialoGPT-small')
inputs = tokenizer('@@ПЕРВЫЙ@@ привет @@ВТОРОЙ@@ привет @@ПЕРВЫЙ@@ как дела? @@ВТОРОЙ@@', return_tensors='pt')
generated_token_ids = model.generate(
**inputs,
top_k=10,
top_p=0.95,
num_beams=3,
num_return_sequences=3,
do_sample=True,
no_repeat_ngram_size=2,
temperature=1.2,
repetition_penalty=1.2,
length_penalty=1.0,
eos_token_id=50257,
max_new_tokens=40
)
context_with_response = [tokenizer.decode(sample_token_ids) for sample_token_ids in generated_token_ids]
context_with_response
```
|
nvidia/stt_ca_conformer_transducer_large
|
b07d20c46f0610ba8051db55674fcc36d438b7d7
|
2022-07-22T18:34:11.000Z
|
[
"nemo",
"ca",
"dataset:mozilla-foundation/common_voice_9_0",
"arxiv:2005.08100",
"automatic-speech-recognition",
"speech",
"audio",
"Transducer",
"Conformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"license:cc-by-4.0",
"model-index"
] |
automatic-speech-recognition
| false |
nvidia
| null |
nvidia/stt_ca_conformer_transducer_large
| 85 | 1 |
nemo
| 4,920 |
---
language:
- ca
library_name: nemo
datasets:
- mozilla-foundation/common_voice_9_0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
model-index:
- name: stt_ca_conformer_transducer_large
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 9.0
type: mozilla-foundation/common_voice_9_0
config: ca
split: test
args:
language: ca
metrics:
- name: Test WER
type: wer
value: 3.85
---
# NVIDIA Conformer-Transducer Large (Catalan)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech into lowercase Catalan alphabet including spaces, dashes and apostrophes, and is trained on around 1023 hours of Catalan speech data.
It is a non-autoregressive "large" variant of Conformer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_ca_conformer_transducer_large")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_ca_conformer_transducer_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16 kHz mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
The vocabulary we use contains 44 characters:
```python
[' ', "'", '-', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '·', 'à', 'á', 'ç', 'è', 'é', 'í', 'ï', 'ñ', 'ò', 'ó', 'ú', 'ü', 'ı', '–', '—']
```
Full config can be found inside the .nemo files.
### Datasets
All the models in this collection are trained on MCV-9.0 Catalan dataset, which contains around 1203 hours training, 28 hours of development and 27 hours of testing speech audios.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | Dev WER| Test WER| Train Dataset |
|---------|-----------------------|-----------------|--------|---------|-----------------|
| 1.11.0 | SentencePiece Unigram | 128 |4.43 | 3.85 | MCV-9.0 Train set|
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
Akashpb13/Swahili_xlsr
|
8aa8e010d6a3f1f049fa8fefd8ecc4de57ef00fe
|
2022-03-23T18:28:25.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sw",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"model_for_talk",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
Akashpb13
| null |
Akashpb13/Swahili_xlsr
| 84 | null |
transformers
| 4,921 |
---
language:
- sw
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- hf-asr-leaderboard
- model_for_talk
- mozilla-foundation/common_voice_8_0
- robust-speech-event
- sw
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: Akashpb13/Swahili_xlsr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: sw
metrics:
- name: Test WER
type: wer
value: 0.11763625454589981
- name: Test CER
type: cer
value: 0.02884228669922436
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: kmr
metrics:
- name: Test WER
type: wer
value: 0.11763625454589981
- name: Test CER
type: cer
value: 0.02884228669922436
---
# Akashpb13/Swahili_xlsr
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - hu dataset.
It achieves the following results on the evaluation set (which is 10 percent of train data set merged with dev datasets):
- Loss: 0.159032
- Wer: 0.187934
## Model description
"facebook/wav2vec2-xls-r-300m" was finetuned.
## Intended uses & limitations
More information needed
## Training and evaluation data
Training data -
Common voice Hausa train.tsv and dev.tsv
Only those points were considered where upvotes were greater than downvotes and duplicates were removed after concatenation of all the datasets given in common voice 7.0
## Training procedure
For creating the training dataset, all possible datasets were appended and 90-10 split was used.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000096
- train_batch_size: 16
- eval_batch_size: 16
- seed: 13
- gradient_accumulation_steps: 2
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 500
- num_epochs: 80
- mixed_precision_training: Native AMP
### Training results
| Step | Training Loss | Validation Loss | Wer |
|------|---------------|-----------------|----------|
| 500 | 4.810000 | 2.168847 | 0.995747 |
| 1000 | 0.564200 | 0.209411 | 0.303485 |
| 1500 | 0.217700 | 0.153959 | 0.239534 |
| 2000 | 0.150700 | 0.139901 | 0.216327 |
| 2500 | 0.119400 | 0.137543 | 0.208828 |
| 3000 | 0.099500 | 0.140921 | 0.203045 |
| 3500 | 0.087100 | 0.138835 | 0.199649 |
| 4000 | 0.074600 | 0.141297 | 0.195844 |
| 4500 | 0.066600 | 0.148560 | 0.194127 |
| 5000 | 0.060400 | 0.151214 | 0.194388 |
| 5500 | 0.054400 | 0.156072 | 0.192187 |
| 6000 | 0.051100 | 0.154726 | 0.190322 |
| 6500 | 0.048200 | 0.159847 | 0.189538 |
| 7000 | 0.046400 | 0.158727 | 0.188307 |
| 7500 | 0.046500 | 0.159032 | 0.187934 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.18.3
- Tokenizers 0.10.3
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id Akashpb13/Swahili_xlsr --dataset mozilla-foundation/common_voice_8_0 --config sw --split test
```
|
Frodnar/bee-likes
|
58dd1beead6c58c97840cae6cbd6c1ee298056f0
|
2021-07-02T14:47:21.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
Frodnar
| null |
Frodnar/bee-likes
| 84 | null |
transformers
| 4,922 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: bee-likes
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8333333134651184
---
# bee-likes
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### bee

#### hoverfly

#### wasp

|
HScomcom/gpt2-MyLittlePony
|
30475d509fbf395c2a120673a3886f47bc3e4731
|
2021-05-21T10:09:36.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
HScomcom
| null |
HScomcom/gpt2-MyLittlePony
| 84 | 1 |
transformers
| 4,923 |
The model that generates the My little pony script
Fine tuning data: [Kaggle](https://www.kaggle.com/liury123/my-little-pony-transcript?select=clean_dialog.csv)
API page: [Ainize](https://ainize.ai/fpem123/GPT2-MyLittlePony)
Demo page: [End point](https://master-gpt2-my-little-pony-fpem123.endpoint.ainize.ai/)
### Model information
Base model: gpt-2 large
Epoch: 30
Train runtime: 4943.9641 secs
Loss: 0.0291
###===Teachable NLP===
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
Helsinki-NLP/opus-mt-ja-nl
|
c2caa48f4d8dc2123fbab467998cd32fe4d79a17
|
2020-08-21T14:42:47.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ja",
"nl",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ja-nl
| 84 | null |
transformers
| 4,924 |
---
language:
- ja
- nl
tags:
- translation
license: apache-2.0
---
### jpn-nld
* source group: Japanese
* target group: Dutch
* OPUS readme: [jpn-nld](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/jpn-nld/README.md)
* model: transformer-align
* source language(s): jpn jpn_Hani jpn_Hira jpn_Kana jpn_Latn
* target language(s): nld
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-nld/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-nld/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-nld/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.jpn.nld | 34.7 | 0.534 |
### System Info:
- hf_name: jpn-nld
- source_languages: jpn
- target_languages: nld
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/jpn-nld/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ja', 'nl']
- src_constituents: {'jpn_Hang', 'jpn', 'jpn_Yiii', 'jpn_Kana', 'jpn_Hani', 'jpn_Bopo', 'jpn_Latn', 'jpn_Hira'}
- tgt_constituents: {'nld'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-nld/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-nld/opus-2020-06-17.test.txt
- src_alpha3: jpn
- tgt_alpha3: nld
- short_pair: ja-nl
- chrF2_score: 0.534
- bleu: 34.7
- brevity_penalty: 0.938
- ref_len: 25849.0
- src_name: Japanese
- tgt_name: Dutch
- train_date: 2020-06-17
- src_alpha2: ja
- tgt_alpha2: nl
- prefer_old: False
- long_pair: jpn-nld
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-ko-ru
|
2050b5c2ba3981c9b135ff58febaca447efc75ad
|
2020-08-21T14:42:47.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ko",
"ru",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ko-ru
| 84 | null |
transformers
| 4,925 |
---
language:
- ko
- ru
tags:
- translation
license: apache-2.0
---
### kor-rus
* source group: Korean
* target group: Russian
* OPUS readme: [kor-rus](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/kor-rus/README.md)
* model: transformer-align
* source language(s): kor_Hang kor_Latn
* target language(s): rus
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/kor-rus/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/kor-rus/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/kor-rus/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.kor.rus | 30.3 | 0.514 |
### System Info:
- hf_name: kor-rus
- source_languages: kor
- target_languages: rus
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/kor-rus/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ko', 'ru']
- src_constituents: {'kor_Hani', 'kor_Hang', 'kor_Latn', 'kor'}
- tgt_constituents: {'rus'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/kor-rus/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/kor-rus/opus-2020-06-17.test.txt
- src_alpha3: kor
- tgt_alpha3: rus
- short_pair: ko-ru
- chrF2_score: 0.514
- bleu: 30.3
- brevity_penalty: 0.961
- ref_len: 1382.0
- src_name: Korean
- tgt_name: Russian
- train_date: 2020-06-17
- src_alpha2: ko
- tgt_alpha2: ru
- prefer_old: False
- long_pair: kor-rus
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-swc-fr
|
831ee59763b34c0bf2ecf27bcf966e74f16b2363
|
2021-09-11T10:47:54.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"swc",
"fr",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-swc-fr
| 84 | null |
transformers
| 4,926 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-swc-fr
* source languages: swc
* target languages: fr
* OPUS readme: [swc-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/swc-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/swc-fr/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/swc-fr/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/swc-fr/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.swc.fr | 28.6 | 0.470 |
|
JuliusAlphonso/distilbert-plutchik
|
034821c7b7614e228473d28b35ea937d5e1341e6
|
2021-06-19T22:06:23.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
JuliusAlphonso
| null |
JuliusAlphonso/distilbert-plutchik
| 84 | 1 |
transformers
| 4,927 |
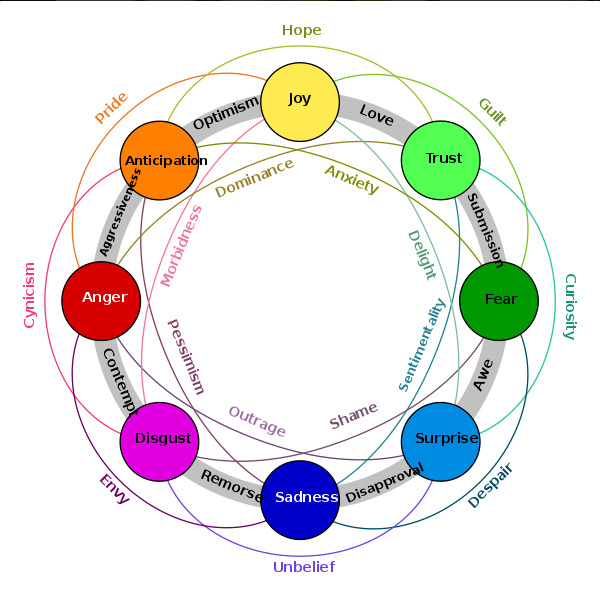
Labels are based on Plutchik's model of emotions and may be combined:
|
KoichiYasuoka/bert-base-japanese-upos
|
e9077f5b327b42da14e3c5d60f529331a68f9eed
|
2022-05-23T21:50:57.000Z
|
[
"pytorch",
"bert",
"token-classification",
"ja",
"dataset:universal_dependencies",
"transformers",
"japanese",
"pos",
"wikipedia",
"dependency-parsing",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
token-classification
| false |
KoichiYasuoka
| null |
KoichiYasuoka/bert-base-japanese-upos
| 84 | 1 |
transformers
| 4,928 |
---
language:
- "ja"
tags:
- "japanese"
- "token-classification"
- "pos"
- "wikipedia"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "cc-by-sa-4.0"
pipeline_tag: "token-classification"
widget:
- text: "国境の長いトンネルを抜けると雪国であった。"
---
# bert-base-japanese-upos
## Model Description
This is a BERT model pre-trained on Japanese Wikipedia texts for POS-tagging and dependency-parsing, derived from [bert-base-japanese-char-extended](https://huggingface.co/KoichiYasuoka/bert-base-japanese-char-extended). Every short-unit-word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech).
## How to Use
```py
import torch
from transformers import AutoTokenizer,AutoModelForTokenClassification
tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/bert-base-japanese-upos")
model=AutoModelForTokenClassification.from_pretrained("KoichiYasuoka/bert-base-japanese-upos")
s="国境の長いトンネルを抜けると雪国であった。"
p=[model.config.id2label[q] for q in torch.argmax(model(tokenizer.encode(s,return_tensors="pt"))["logits"],dim=2)[0].tolist()[1:-1]]
print(list(zip(s,p)))
```
or
```py
import esupar
nlp=esupar.load("KoichiYasuoka/bert-base-japanese-upos")
print(nlp("国境の長いトンネルを抜けると雪国であった。"))
```
## See Also
[esupar](https://github.com/KoichiYasuoka/esupar): Tokenizer POS-tagger and Dependency-parser with BERT/RoBERTa models
|
arbml/wav2vec2-large-xlsr-dialect-classification
|
7d2493de4078502088aebc858be597c98d2cb31d
|
2021-07-05T18:15:15.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"transformers"
] | null | false |
arbml
| null |
arbml/wav2vec2-large-xlsr-dialect-classification
| 84 | null |
transformers
| 4,929 |
Entry not found
|
andrejmiscic/simcls-scorer-cnndm
|
87f46dbe5b7337432287c0460b614ee0c8ec21c3
|
2021-10-16T20:39:39.000Z
|
[
"pytorch",
"roberta",
"feature-extraction",
"en",
"dataset:cnn_dailymail",
"arxiv:2106.01890",
"arxiv:1602.06023",
"transformers",
"simcls"
] |
feature-extraction
| false |
andrejmiscic
| null |
andrejmiscic/simcls-scorer-cnndm
| 84 | null |
transformers
| 4,930 |
---
language:
- en
tags:
- simcls
datasets:
- cnn_dailymail
---
# SimCLS
SimCLS is a framework for abstractive summarization presented in [SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization](https://arxiv.org/abs/2106.01890).
It is a two-stage approach consisting of a *generator* and a *scorer*. In the first stage, a large pre-trained model for abstractive summarization (the *generator*) is used to generate candidate summaries, whereas, in the second stage, the *scorer* assigns a score to each candidate given the source document. The final summary is the highest-scoring candidate.
This model is the *scorer* trained for summarization of CNN/DailyMail ([paper](https://arxiv.org/abs/1602.06023), [datasets](https://huggingface.co/datasets/cnn_dailymail)). It should be used in conjunction with [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn). See [our Github repository](https://github.com/andrejmiscic/simcls-pytorch) for details on training, evaluation, and usage.
## Usage
```bash
git clone https://github.com/andrejmiscic/simcls-pytorch.git
cd simcls-pytorch
pip3 install torch torchvision torchaudio transformers sentencepiece
```
```python
from src.model import SimCLS, GeneratorType
summarizer = SimCLS(generator_type=GeneratorType.Bart,
generator_path="facebook/bart-large-cnn",
scorer_path="andrejmiscic/simcls-scorer-cnndm")
article = "This is a news article."
summary = summarizer(article)
print(summary)
```
### Results
All of our results are reported together with 95% confidence intervals computed using 10000 iterations of bootstrap. See [SimCLS paper](https://arxiv.org/abs/2106.01890) for a description of baselines.
| System | Rouge-1 | Rouge-2 | Rouge-L |
|------------------|----------------------:|----------------------:|----------------------:|
| BART | 44.16 | 21.28 | 40.90 |
| **SimCLS paper** | --- | --- | --- |
| Origin | 44.39 | 21.21 | 41.28 |
| Min | 33.17 | 11.67 | 30.77 |
| Max | 54.36 | 28.73 | 50.77 |
| Random | 43.98 | 20.06 | 40.94 |
| **SimCLS** | 46.67 | 22.15 | 43.54 |
| **Our results** | --- | --- | --- |
| Origin | 44.41, [44.18, 44.63] | 21.05, [20.80, 21.29] | 41.53, [41.30, 41.75] |
| Min | 33.43, [33.25, 33.62] | 10.97, [10.82, 11.12] | 30.57, [30.40, 30.74] |
| Max | 53.87, [53.67, 54.08] | 29.72, [29.47, 29.98] | 51.13, [50.92, 51.34] |
| Random | 43.94, [43.73, 44.16] | 20.09, [19.86, 20.31] | 41.06, [40.85, 41.27] |
| **SimCLS** | 46.53, [46.32, 46.75] | 22.14, [21.91, 22.37] | 43.56, [43.34, 43.78] |
### Citation of the original work
```bibtex
@inproceedings{liu-liu-2021-simcls,
title = "{S}im{CLS}: A Simple Framework for Contrastive Learning of Abstractive Summarization",
author = "Liu, Yixin and
Liu, Pengfei",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-short.135",
doi = "10.18653/v1/2021.acl-short.135",
pages = "1065--1072",
}
```
|
bloomberg/KBIR
|
482e240f241d6a78157e5592e77d20e7536d4a81
|
2022-07-27T22:11:56.000Z
|
[
"pytorch",
"roberta",
"arxiv:2112.08547",
"transformers",
"license:apache-2.0"
] | null | false |
bloomberg
| null |
bloomberg/KBIR
| 84 | 1 |
transformers
| 4,931 |
---
license: apache-2.0
---
# Keyphrase Boundary Infilling with Replacement (KBIR)
The KBIR model as described in Learning Rich Representations of Keyphrases from Text (https://arxiv.org/pdf/2112.08547.pdf) builds on top of the RoBERTa architecture by adding an Infilling head and a Replacement Classification head that is used during pre-training. However, these heads are not used during the downstream evaluation of the model and we only leverage the pre-trained embeddings. Discarding the heads thereby allows us to be compatible with all AutoModel classes that RoBERTa supports.
We provide examples on how to perform downstream evaluation on some of the tasks reported in the paper.
## Downstream Evaluation
### Keyphrase Extraction
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KBIR")
model = AutoModelForTokenClassification.from_pretrained("bloomberg/KBIR")
from datasets import load_dataset
dataset = load_dataset("midas/semeval2017_ke_tagged")
```
Reported Results:
| Model | Inspec | SE10 | SE17 |
|-----------------------|--------|-------|-------|
| RoBERTa+BiLSTM-CRF | 59.5 | 27.8 | 50.8 |
| RoBERTa+TG-CRF | 60.4 | 29.7 | 52.1 |
| SciBERT+Hypernet-CRF | 62.1 | 36.7 | 54.4 |
| RoBERTa+Hypernet-CRF | 62.3 | 34.8 | 53.3 |
| RoBERTa-extended-CRF* | 62.09 | 40.61 | 52.32 |
| KBI-CRF* | 62.61 | 40.81 | 59.7 |
| KBIR-CRF* | 62.72 | 40.15 | 62.56 |
### Named Entity Recognition
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KBIR")
model = AutoModelForTokenClassification.from_pretrained("bloomberg/KBIR")
from datasets import load_dataset
dataset = load_dataset("conll2003")
```
Reported Results:
| Model | F1 |
|---------------------------------|-------|
| LSTM-CRF (Lample et al., 2016) | 91.0 |
| ELMo (Peters et al., 2018) | 92.2 |
| BERT (Devlin et al., 2018) | 92.8 |
| (Akbik et al., 2019) | 93.1 |
| (Baevski et al., 2019) | 93.5 |
| LUKE (Yamada et al., 2020) | 94.3 |
| LUKE w/o entity attention | 94.1 |
| RoBERTa (Yamada et al., 2020) | 92.4 |
| RoBERTa-extended* | 92.54 |
| KBI* | 92.73 |
| KBIR* | 92.97 |
### Question Answering
```
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KBIR")
model = AutoModelForQuestionAnswering.from_pretrained("bloomberg/KBIR")
from datasets import load_dataset
dataset = load_dataset("squad")
```
Reported Results:
| Model | EM | F1 |
|------------------------|-------|-------|
| BERT | 84.2 | 91.1 |
| XLNet | 89.0 | 94.5 |
| ALBERT | 89.3 | 94.8 |
| LUKE | 89.8 | 95.0 |
| LUKE w/o entity attention | 89.2 | 94.7 |
| RoBERTa | 88.9 | 94.6 |
| RoBERTa-extended* | 88.88 | 94.55 |
| KBI* | 88.97 | 94.7 |
| KBIR* | 89.04 | 94.75 |
## Any other classification task
As mentioned above since KBIR is built on top of the RoBERTa architecture, it is compatible with any AutoModel setting that RoBERTa is also compatible with.
We encourage you to try fine-tuning KBIR on different datasets and report the downstream results.
## Contact
For any questions contact [email protected]
|
dbernsohn/t5_wikisql_SQL2en
|
0807b341e3b442a8564a351b31460df88800d71b
|
2021-01-18T14:24:14.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
dbernsohn
| null |
dbernsohn/t5_wikisql_SQL2en
| 84 | null |
transformers
| 4,932 |
# t5_wikisql_SQL2en
---
language: en
datasets:
- wikisql
---
This is a [t5-small](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned version on the [wikisql dataset](https://huggingface.co/datasets/wikisql) for **SQL** to **English** **translation** text2text mission.
To load the model:
(necessary packages: !pip install transformers sentencepiece)
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("dbernsohn/t5_wikisql_SQL2en")
model = AutoModelWithLMHead.from_pretrained("dbernsohn/t5_wikisql_SQL2en")
```
You can then use this model to translate SQL queries into plain english.
```python
query = "SELECT people FROM peoples where age > 10"
input_text = f"translate SQL to English: {query} </s>"
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'].cuda(),
attention_mask=features['attention_mask'].cuda())
tokenizer.decode(output[0])
# Output: "What people are older than 10?"
```
The whole training process and hyperparameters are in my [GitHub repo](https://github.com/DorBernsohn/CodeLM/tree/main/SQLM)
> Created by [Dor Bernsohn](https://www.linkedin.com/in/dor-bernsohn-70b2b1146/)
|
inywer/DialoGPT-medium-leirbag
|
27ba149d0e4dbfd239716323d31c66ad9d4b7229
|
2021-10-06T02:28:28.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
inywer
| null |
inywer/DialoGPT-medium-leirbag
| 84 | null |
transformers
| 4,933 |
---
tags:
- conversational
---
# leirbag DialoGPT Model
|
ismgar01/vit-base-cats-vs-dogs
|
c1701cbf400293e32966a1f93b39011e095bb198
|
2021-11-08T09:10:58.000Z
|
[
"pytorch",
"vit",
"image-classification",
"dataset:cats_vs_dogs",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
image-classification
| false |
ismgar01
| null |
ismgar01/vit-base-cats-vs-dogs
| 84 | null |
transformers
| 4,934 |
---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
datasets:
- cats_vs_dogs
metrics:
- accuracy
model-index:
- name: vit-base-cats-vs-dogs
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: cats_vs_dogs
type: cats_vs_dogs
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9937357630979499
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-cats-vs-dogs
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cats_vs_dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0182
- Accuracy: 0.9937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 32
- eval_batch_size: 32
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1177 | 1.0 | 622 | 0.0473 | 0.9832 |
| 0.057 | 2.0 | 1244 | 0.0362 | 0.9883 |
| 0.0449 | 3.0 | 1866 | 0.0261 | 0.9886 |
| 0.066 | 4.0 | 2488 | 0.0248 | 0.9923 |
| 0.0328 | 5.0 | 3110 | 0.0182 | 0.9937 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.8.1+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
maxpe/bertin-roberta-base-spanish_semeval18_emodetection
|
9acb474fee50b951bc0c18c439b9c33abf4f6565
|
2021-10-27T15:21:12.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
| false |
maxpe
| null |
maxpe/bertin-roberta-base-spanish_semeval18_emodetection
| 84 | null |
transformers
| 4,935 |
# BERTIN-roBERTa-base-Spanish_SemEval18_Emodetection
This is a BERTIN-roBERTa-base-Spanish model trained on ~3500 tweets in Spanish annotated for 11 emotion categories in [SemEval-2018 Task 1: Affect in Tweets: SubTask 5: Emotion Classification](https://competitions.codalab.org/competitions/17751).
Run the classifier on the test set of the competition:
```python
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
from torch.utils.data import DataLoader
import torch
import pandas as pd
# choose GPU when available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained("bertin-project/bertin-roberta-base-spanish",model_max_length=512)
# build custom model with classification layer on top and a dropout layer before
class RobertaClass(torch.nn.Module):
def __init__(self):
super(RobertaClass, self).__init__()
self.l1 = AutoModel.from_pretrained("bertin-project/bertin-roberta-base-spanish",return_dict=False)
self.l2 = torch.nn.Dropout(0.3)
self.l3 = torch.nn.Linear(768, 11)
def forward(self, input_ids, attention_mask):
_, output_1= self.l1(input_ids=input_ids, attention_mask=attention_mask)
output_2 = self.l2(output_1)
output = self.l3(output_2)
return output
model_name="bertin-roberta-base-spanish_semeval18_emodetection/pytorch_model.bin"
model=RobertaClass()
model.load_state_dict(torch.load(model_name,map_location=torch.device(device)))
model.eval()
# run on more than 1 GPU
model = torch.nn.DataParallel(model)
model.to(device)
twnames=['anger','anticipation','disgust','fear','joy','love','optimism','pessimism','sadness','surprise','trust']
# load from hugging face dataset hub
testset_raw = load_dataset('sem_eval_2018_task_1','subtask5.spanish',split='test')
# remove old columns
testset=testset_raw.remove_columns(twnames+["ID"])
# tokenize
testset_tokenized = testset.map(lambda e: tokenizer(e['Tweet'], truncation=True, padding='max_length'), batched=True)
testset_tokenized=testset_tokenized.remove_columns("Tweet")
testset_tokenized.set_format(type='torch', columns=['input_ids', 'attention_mask'])
outfile="predicted_2018-E-c-Es-test-gold.txt"
MAX_LEN = 512
VALID_BATCH_SIZE = 8
# set batch size according to available RAM
# VALID_BATCH_SIZE = 1000
# set num_workers for parallel processing
inference_params = {'batch_size': VALID_BATCH_SIZE,
'shuffle': False,
# 'num_workers': 1
}
inference_loader = DataLoader(testset_tokenized, **inference_params)
open(outfile,"w").close()
with torch.no_grad():
# change lines for progress manager
# for _, data in tqdm(enumerate(inference_loader, 0),total=len(inference_loader)):
for _, data in enumerate(inference_loader, 0):
outputs = model(input_ids=data['input_ids'],attention_mask=data['attention_mask'])
fin_outputs=torch.sigmoid(outputs).cpu().detach().numpy().tolist()
pd.DataFrame(fin_outputs).to_csv(outfile,index=False,header=False,sep="\t",mode='a')
# # dataset from file (one text per line)
# from datasets import Dataset
# with open(linesoftextfile,"rb") as textfile:
# textdict={"text":[x.decode().rstrip("\n") for x in textfile.readlines()]}
# inference_dataset=Dataset.from_dict(textdict)
# del(textdict)
```
|
nateraw/pasta-pizza-ravioli
|
077bc96649cc6b8a35bc1471d2f82dc791cd8abe
|
2021-06-30T07:10:53.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
nateraw
| null |
nateraw/pasta-pizza-ravioli
| 84 | null |
transformers
| 4,936 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: pasta-pizza-ravioli
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9375
---
# pasta-pizza-ravioli
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### pasta

#### pizza

#### ravioli

|
pierreguillou/ner-bert-base-cased-pt-lenerbr
|
4ca0a39767b49788a93b59b632b19f614d12e26c
|
2021-12-29T19:32:39.000Z
|
[
"pytorch",
"bert",
"token-classification",
"pt",
"dataset:lener_br",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
pierreguillou
| null |
pierreguillou/ner-bert-base-cased-pt-lenerbr
| 84 | null |
transformers
| 4,937 |
---
language:
- pt
tags:
- generated_from_trainer
datasets:
- lener_br
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: checkpoints
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: lener_br
type: lener_br
metrics:
- name: F1
type: f1
value: 0.8926146010186757
- name: Precision
type: precision
value: 0.8810222036028488
- name: Recall
type: recall
value: 0.9045161290322581
- name: Accuracy
type: accuracy
value: 0.9759397808828684
- name: Loss
type: loss
value: 0.18803243339061737
widget:
- text: "Ao Instituto Médico Legal da jurisdição do acidente ou da residência cumpre fornecer, no prazo de 90 dias, laudo à vítima (art. 5, § 5, Lei n. 6.194/74 de 19 de dezembro de 1974), função técnica que pode ser suprida por prova pericial realizada por ordem do juízo da causa, ou por prova técnica realizada no âmbito administrativo que se mostre coerente com os demais elementos de prova constante dos autos."
- text: "Acrescento que não há de se falar em violação do artigo 114, § 3º, da Constituição Federal, posto que referido dispositivo revela-se impertinente, tratando da possibilidade de ajuizamento de dissídio coletivo pelo Ministério Público do Trabalho nos casos de greve em atividade essencial."
- text: "Dispõe sobre o estágio de estudantes; altera a redação do art. 428 da Consolidação das Leis do Trabalho – CLT, aprovada pelo Decreto-Lei no 5.452, de 1o de maio de 1943, e a Lei no 9.394, de 20 de dezembro de 1996; revoga as Leis nos 6.494, de 7 de dezembro de 1977, e 8.859, de 23 de março de 1994, o parágrafo único do art. 82 da Lei no 9.394, de 20 de dezembro de 1996, e o art. 6o da Medida Provisória no 2.164-41, de 24 de agosto de 2001; e dá outras providências."
---
## (BERT base) NER model in the legal domain in Portuguese (LeNER-Br)
**ner-bert-base-portuguese-cased-lenerbr** is a NER model (token classification) in the legal domain in Portuguese that was finetuned on 20/12/2021 in Google Colab from the model [pierreguillou/bert-base-cased-pt-lenerbr](https://huggingface.co/pierreguillou/bert-base-cased-pt-lenerbr) on the dataset [LeNER_br](https://huggingface.co/datasets/lener_br) by using a NER objective.
Due to the small size of BERTimbau base and finetuning dataset, the model overfitted before to reach the end of training. Here are the overall final metrics on the validation dataset (*note: see the paragraph "Validation metrics by Named Entity" to get detailed metrics*):
- **f1**: 0.8926146010186757
- **precision**: 0.8810222036028488
- **recall**: 0.9045161290322581
- **accuracy**: 0.9759397808828684
- **loss**: 0.18803243339061737
Check as well the [large version of this model](https://huggingface.co/pierreguillou/ner-bert-large-cased-pt-lenerbr) with a f1 of 0.908.
**Note**: the model [pierreguillou/bert-base-cased-pt-lenerbr](https://huggingface.co/pierreguillou/bert-base-cased-pt-lenerbr) is a language model that was created through the finetuning of the model [BERTimbau base](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the dataset [LeNER-Br language modeling](https://huggingface.co/datasets/pierreguillou/lener_br_finetuning_language_model) by using a MASK objective. This first specialization of the language model before finetuning on the NER task improved a bit the model quality. To prove it, here are the results of the NER model finetuned from the model [BERTimbau base](https://huggingface.co/neuralmind/bert-base-portuguese-cased) (a non-specialized language model):
- **f1**: 0.8716487228203504
- **precision**: 0.8559286898839138
- **recall**: 0.8879569892473118
- **accuracy**: 0.9755893153732458
- **loss**: 0.1133928969502449
## Blog post
[NLP | Modelos e Web App para Reconhecimento de Entidade Nomeada (NER) no domínio jurídico brasileiro](https://medium.com/@pierre_guillou/nlp-modelos-e-web-app-para-reconhecimento-de-entidade-nomeada-ner-no-dom%C3%ADnio-jur%C3%ADdico-b658db55edfb) (29/12/2021)
## Widget & App
You can test this model into the widget of this page.
Use as well the [NER App](https://huggingface.co/spaces/pierreguillou/ner-bert-pt-lenerbr) that allows comparing the 2 BERT models (base and large) fitted in the NER task with the legal LeNER-Br dataset.
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoModelForTokenClassification, AutoTokenizer
import torch
# parameters
model_name = "pierreguillou/ner-bert-base-cased-pt-lenerbr"
model = AutoModelForTokenClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = "Acrescento que não há de se falar em violação do artigo 114, § 3º, da Constituição Federal, posto que referido dispositivo revela-se impertinente, tratando da possibilidade de ajuizamento de dissídio coletivo pelo Ministério Público do Trabalho nos casos de greve em atividade essencial."
# tokenization
inputs = tokenizer(input_text, max_length=512, truncation=True, return_tensors="pt")
tokens = inputs.tokens()
# get predictions
outputs = model(**inputs).logits
predictions = torch.argmax(outputs, dim=2)
# print predictions
for token, prediction in zip(tokens, predictions[0].numpy()):
print((token, model.config.id2label[prediction]))
````
You can use pipeline, too. However, it seems to have an issue regarding to the max_length of the input sequence.
````
!pip install transformers
import transformers
from transformers import pipeline
model_name = "pierreguillou/ner-bert-base-cased-pt-lenerbr"
ner = pipeline(
"ner",
model=model_name
)
ner(input_text)
````
## Training procedure
### Notebook
The notebook of finetuning ([HuggingFace_Notebook_token_classification_NER_LeNER_Br.ipynb](https://github.com/piegu/language-models/blob/master/HuggingFace_Notebook_token_classification_NER_LeNER_Br.ipynb)) is in github.
### Hyperparameters
#### batch, learning rate...
- per_device_batch_size = 2
- gradient_accumulation_steps = 2
- learning_rate = 2e-5
- num_train_epochs = 10
- weight_decay = 0.01
- optimizer = AdamW
- betas = (0.9,0.999)
- epsilon = 1e-08
- lr_scheduler_type = linear
- seed = 7
#### save model & load best model
- save_total_limit = 2
- logging_steps = 300
- eval_steps = logging_steps
- evaluation_strategy = 'steps'
- logging_strategy = 'steps'
- save_strategy = 'steps'
- save_steps = logging_steps
- load_best_model_at_end = True
- fp16 = True
#### get best model through a metric
- metric_for_best_model = 'eval_f1'
- greater_is_better = True
### Training results
````
Num examples = 7828
Num Epochs = 10
Instantaneous batch size per device = 2
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 2
Total optimization steps = 19570
Step Training Loss Validation Loss Precision Recall F1 Accuracy
300 0.127600 0.178613 0.722909 0.741720 0.732194 0.948802
600 0.088200 0.136965 0.733636 0.867742 0.795074 0.963079
900 0.078000 0.128858 0.791912 0.838065 0.814335 0.965243
1200 0.077800 0.126345 0.815400 0.865376 0.839645 0.967849
1500 0.074100 0.148207 0.779274 0.895914 0.833533 0.960184
1800 0.059500 0.116634 0.830829 0.868172 0.849090 0.969342
2100 0.044500 0.208459 0.887150 0.816559 0.850392 0.960535
2400 0.029400 0.136352 0.867821 0.851398 0.859531 0.970271
2700 0.025000 0.165837 0.814881 0.878495 0.845493 0.961235
3000 0.038400 0.120629 0.811719 0.893763 0.850768 0.971506
3300 0.026200 0.175094 0.823435 0.882581 0.851983 0.962957
3600 0.025600 0.178438 0.881095 0.886022 0.883551 0.963689
3900 0.041000 0.134648 0.789035 0.916129 0.847846 0.967681
4200 0.026700 0.130178 0.821275 0.903226 0.860303 0.972313
4500 0.018500 0.139294 0.844016 0.875054 0.859255 0.971140
4800 0.020800 0.197811 0.892504 0.873118 0.882705 0.965883
5100 0.019300 0.161239 0.848746 0.888172 0.868012 0.967849
5400 0.024000 0.139131 0.837507 0.913333 0.873778 0.970591
5700 0.018400 0.157223 0.899754 0.864731 0.881895 0.970210
6000 0.023500 0.137022 0.883018 0.873333 0.878149 0.973243
6300 0.009300 0.181448 0.840490 0.900860 0.869628 0.968290
6600 0.019200 0.173125 0.821316 0.896559 0.857290 0.966736
6900 0.016100 0.143160 0.789938 0.904946 0.843540 0.968245
7200 0.017000 0.145755 0.823274 0.897634 0.858848 0.969037
7500 0.012100 0.159342 0.825694 0.883226 0.853491 0.967468
7800 0.013800 0.194886 0.861237 0.859570 0.860403 0.964771
8100 0.008000 0.140271 0.829914 0.896129 0.861752 0.971567
8400 0.010300 0.143318 0.826844 0.908817 0.865895 0.973578
8700 0.015000 0.143392 0.847336 0.889247 0.867786 0.973365
9000 0.006000 0.143512 0.847795 0.905591 0.875741 0.972892
9300 0.011800 0.138747 0.827133 0.894194 0.859357 0.971673
9600 0.008500 0.159490 0.837030 0.909032 0.871546 0.970028
9900 0.010700 0.159249 0.846692 0.910968 0.877655 0.970546
10200 0.008100 0.170069 0.848288 0.900645 0.873683 0.969113
10500 0.004800 0.183795 0.860317 0.899355 0.879403 0.969570
10800 0.010700 0.157024 0.837838 0.906667 0.870894 0.971094
11100 0.003800 0.164286 0.845312 0.880215 0.862410 0.970744
11400 0.009700 0.204025 0.884294 0.887527 0.885907 0.968854
11700 0.008900 0.162819 0.829415 0.887742 0.857588 0.970530
12000 0.006400 0.164296 0.852666 0.901075 0.876202 0.971414
12300 0.007100 0.143367 0.852959 0.895699 0.873807 0.973669
12600 0.015800 0.153383 0.859224 0.900430 0.879345 0.972679
12900 0.006600 0.173447 0.869954 0.899140 0.884306 0.970927
13200 0.006800 0.163234 0.856849 0.897204 0.876563 0.971795
13500 0.003200 0.167164 0.850867 0.907957 0.878485 0.971231
13800 0.003600 0.148950 0.867801 0.910538 0.888656 0.976961
14100 0.003500 0.155691 0.847621 0.907957 0.876752 0.974127
14400 0.003300 0.157672 0.846553 0.911183 0.877680 0.974584
14700 0.002500 0.169965 0.847804 0.917634 0.881338 0.973045
15000 0.003400 0.177099 0.842199 0.912473 0.875929 0.971155
15300 0.006000 0.164151 0.848928 0.911183 0.878954 0.973258
15600 0.002400 0.174305 0.847437 0.906667 0.876052 0.971765
15900 0.004100 0.174561 0.852929 0.907957 0.879583 0.972907
16200 0.002600 0.172626 0.843263 0.907097 0.874016 0.972100
16500 0.002100 0.185302 0.841108 0.907312 0.872957 0.970485
16800 0.002900 0.175638 0.840557 0.909247 0.873554 0.971704
17100 0.001600 0.178750 0.857056 0.906452 0.881062 0.971765
17400 0.003900 0.188910 0.853619 0.907957 0.879950 0.970835
17700 0.002700 0.180822 0.864699 0.907097 0.885390 0.972283
18000 0.001300 0.179974 0.868150 0.906237 0.886785 0.973060
18300 0.000800 0.188032 0.881022 0.904516 0.892615 0.972572
18600 0.002700 0.183266 0.868601 0.901290 0.884644 0.972298
18900 0.001600 0.180301 0.862041 0.903011 0.882050 0.972344
19200 0.002300 0.183432 0.855370 0.904301 0.879155 0.971109
19500 0.001800 0.183381 0.854501 0.904301 0.878696 0.971186
````
### Validation metrics by Named Entity
````
Num examples = 1177
{'JURISPRUDENCIA': {'f1': 0.7016574585635359,
'number': 657,
'precision': 0.6422250316055625,
'recall': 0.7732115677321156},
'LEGISLACAO': {'f1': 0.8839681133746677,
'number': 571,
'precision': 0.8942652329749103,
'recall': 0.8739054290718039},
'LOCAL': {'f1': 0.8253968253968254,
'number': 194,
'precision': 0.7368421052631579,
'recall': 0.9381443298969072},
'ORGANIZACAO': {'f1': 0.8934049079754601,
'number': 1340,
'precision': 0.918769716088328,
'recall': 0.8694029850746269},
'PESSOA': {'f1': 0.982653539615565,
'number': 1072,
'precision': 0.9877474081055608,
'recall': 0.9776119402985075},
'TEMPO': {'f1': 0.9657657657657657,
'number': 816,
'precision': 0.9469964664310954,
'recall': 0.9852941176470589},
'overall_accuracy': 0.9725722644643211,
'overall_f1': 0.8926146010186757,
'overall_precision': 0.8810222036028488,
'overall_recall': 0.9045161290322581}
````
|
prajjwal1/albert-base-v1-mnli
|
293306660f028a76fd36eb0991565b7843bffa8a
|
2021-10-05T17:54:14.000Z
|
[
"pytorch",
"albert",
"text-classification",
"arxiv:2110.01518",
"transformers"
] |
text-classification
| false |
prajjwal1
| null |
prajjwal1/albert-base-v1-mnli
| 84 | null |
transformers
| 4,938 |
If you use the model, please consider citing this paper
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
pucpr/clinicalnerpt-pharmacologic
|
e74bbc595ad467d1b3e9658db6f3fd87092900df
|
2021-10-13T09:33:40.000Z
|
[
"pytorch",
"bert",
"token-classification",
"pt",
"dataset:SemClinBr",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
pucpr
| null |
pucpr/clinicalnerpt-pharmacologic
| 84 | 4 |
transformers
| 4,939 |
---
language: "pt"
widget:
- text: "COMO ESQUEMA DE MEDICAÇÃO PARA ICC PRESCRITO NO ALTA, RECEBE FUROSEMIDA 40 BID, ISOSSORBIDA 40 TID, DIGOXINA 0,25 /D, CAPTOPRIL 50 TID E ESPIRONOLACTONA 25 /D."
- text: "ESTAVA EM USO DE FUROSEMIDA 40 BID, DIGOXINA 0,25 /D, SINVASTATINA 40 /NOITE, CAPTOPRIL 50 TID, ISOSSORBIDA 20 TID, AAS 100 /D E ESPIRONOLACTONA 25 /D."
datasets:
- SemClinBr
thumbnail: "https://raw.githubusercontent.com/HAILab-PUCPR/BioBERTpt/master/images/logo-biobertpr1.png"
---
<img src="https://raw.githubusercontent.com/HAILab-PUCPR/BioBERTpt/master/images/logo-biobertpr1.png" alt="Logo BioBERTpt">
# Portuguese Clinical NER - Pharmacologic
The Pharmacologic NER model is part of the [BioBERTpt project](https://www.aclweb.org/anthology/2020.clinicalnlp-1.7/), where 13 models of clinical entities (compatible with UMLS) were trained. All NER model from "pucpr" user was trained from the Brazilian clinical corpus [SemClinBr](https://github.com/HAILab-PUCPR/SemClinBr), with 10 epochs and IOB2 format, from BioBERTpt(all) model.
## Acknowledgements
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001.
## Citation
```
@inproceedings{schneider-etal-2020-biobertpt,
title = "{B}io{BERT}pt - A {P}ortuguese Neural Language Model for Clinical Named Entity Recognition",
author = "Schneider, Elisa Terumi Rubel and
de Souza, Jo{\~a}o Vitor Andrioli and
Knafou, Julien and
Oliveira, Lucas Emanuel Silva e and
Copara, Jenny and
Gumiel, Yohan Bonescki and
Oliveira, Lucas Ferro Antunes de and
Paraiso, Emerson Cabrera and
Teodoro, Douglas and
Barra, Cl{\'a}udia Maria Cabral Moro",
booktitle = "Proceedings of the 3rd Clinical Natural Language Processing Workshop",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.clinicalnlp-1.7",
pages = "65--72",
abstract = "With the growing number of electronic health record data, clinical NLP tasks have become increasingly relevant to unlock valuable information from unstructured clinical text. Although the performance of downstream NLP tasks, such as named-entity recognition (NER), in English corpus has recently improved by contextualised language models, less research is available for clinical texts in low resource languages. Our goal is to assess a deep contextual embedding model for Portuguese, so called BioBERTpt, to support clinical and biomedical NER. We transfer learned information encoded in a multilingual-BERT model to a corpora of clinical narratives and biomedical-scientific papers in Brazilian Portuguese. To evaluate the performance of BioBERTpt, we ran NER experiments on two annotated corpora containing clinical narratives and compared the results with existing BERT models. Our in-domain model outperformed the baseline model in F1-score by 2.72{\%}, achieving higher performance in 11 out of 13 assessed entities. We demonstrate that enriching contextual embedding models with domain literature can play an important role in improving performance for specific NLP tasks. The transfer learning process enhanced the Portuguese biomedical NER model by reducing the necessity of labeled data and the demand for retraining a whole new model.",
}
```
## Questions?
Post a Github issue on the [BioBERTpt repo](https://github.com/HAILab-PUCPR/BioBERTpt).
|
osanseviero/llama-horse-zebra
|
f133fc1416b4aa73a8ef5bb5869a0dc22f145a1d
|
2022-05-12T18:58:48.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"llama-leaderboard",
"model-index"
] |
image-classification
| false |
osanseviero
| null |
osanseviero/llama-horse-zebra
| 84 | null |
transformers
| 4,940 |
---
tags:
- image-classification
- pytorch
- huggingpics
- llama-leaderboard
inference: false
metrics:
- accuracy
model-index:
- name: llama-horse-zebras
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
# llama-horse-zebra
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### horse

#### llama

#### zebra

|
ybelkada/japanese-roberta-question-answering
|
4306006321c17a1a8d040201db2cd1e4de61e54e
|
2022-04-08T11:38:39.000Z
|
[
"pytorch",
"roberta",
"question-answering",
"ja",
"dataset:SkelterLabsInc/JaQuAD",
"transformers",
"extractive-qa",
"license:cc-by-sa-3.0",
"autotrain_compatible"
] | null | false |
ybelkada
| null |
ybelkada/japanese-roberta-question-answering
| 84 | null |
transformers
| 4,941 |
---
license: cc-by-sa-3.0
language: ja
tags:
- question-answering
- extractive-qa
pipeline_tag:
- None
datasets:
- SkelterLabsInc/JaQuAD
metrics:
- Exact match
- F1 score
---
# RoBERTa base Japanese - JaQuAD
## Description
A Japanese Question Answering model fine-tuned on [JaQuAD](https://huggingface.co/datasets/SkelterLabsInc/JaQuAD).
Please refer [RoBERTa base Japanese](https://huggingface.co/rinna/japanese-roberta-base) for details about the pre-training model.
The codes for the fine-tuning are available [on this notebook](https://huggingface.co/ybelkada/japanese-roberta-question-answering/blob/main/roberta_ja_qa.ipynb)
## Usage
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
question = 'アレクサンダー・グラハム・ベルは、どこで生まれたの?'
context = 'アレクサンダー・グラハム・ベルは、スコットランド生まれの科学者、発明家、工学者である。世界初の>実用的電話の発明で知られている。'
model = AutoModelForQuestionAnswering.from_pretrained(
'ybelkada/japanese-roberta-question-answering')
tokenizer = AutoTokenizer.from_pretrained(
'ybelkada/japanese-roberta-question-answering')
inputs = tokenizer(
question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score.
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score.
# 1 is added to `answer_end` because the index pointed by score is inclusive.
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
# answer = 'スコットランド'
```
## License
The fine-tuned model is licensed under the [CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/) license.
## Miscellaneous
The Q&A widget does not work on that model. Tried also with ```Pipeline``` and I was able to reproduce the error, needs a further investigation
|
Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned
|
9dca1cc8c6eede5293bcf45bb78f56d49a959a57
|
2022-05-26T12:42:28.000Z
|
[
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"fi",
"dataset:mozilla-foundation/common_voice_9_0",
"arxiv:2006.11477",
"transformers",
"finnish",
"generated_from_trainer",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
Finnish-NLP
| null |
Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned
| 84 | 3 |
transformers
| 4,942 |
---
license: apache-2.0
language: fi
metrics:
- wer
- cer
tags:
- automatic-speech-recognition
- fi
- finnish
- generated_from_trainer
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_9_0
model-index:
- name: wav2vec2-base-fi-voxpopuli-v2-finetuned
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 9
type: mozilla-foundation/common_voice_9_0
args: fi
metrics:
- name: Test WER
type: wer
value: 5.93
- name: Test CER
type: cer
value: 1.40
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: FLEURS ASR
type: google/fleurs
args: fi_fi
metrics:
- name: Test WER
type: wer
value: 13.99
- name: Test CER
type: cer
value: 6.07
---
# Wav2Vec2-base-fi-voxpopuli-v2 for Finnish ASR
This acoustic model is a fine-tuned version of [facebook/wav2vec2-base-fi-voxpopuli-v2](https://huggingface.co/facebook/wav2vec2-base-fi-voxpopuli-v2) for Finnish ASR. The model has been fine-tuned with 276.7 hours of Finnish transcribed speech data. Wav2Vec2 was introduced in
[this paper](https://arxiv.org/abs/2006.11477) and first released at [this page](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec#wav2vec-20).
This repository also includes Finnish KenLM language model used in the decoding phase with the acoustic model.
## Model description
[Wav2vec2-base-fi-voxpopuli-v2](https://huggingface.co/facebook/wav2vec2-base-fi-voxpopuli-v2) is Facebook AI's pretrained model for Finnish speech. It is pretrained on 14.2k hours of unlabeled Finnish speech from [VoxPopuli V2 dataset](https://github.com/facebookresearch/voxpopuli/) with the wav2vec 2.0 objective.
This model is fine-tuned version of the pretrained model for Finnish ASR.
## Intended uses & limitations
You can use this model for Finnish ASR (speech-to-text) task.
### How to use
Check the [run-finnish-asr-models.ipynb](https://huggingface.co/Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned/blob/main/run-finnish-asr-models.ipynb) notebook in this repository for an detailed example on how to use this model.
### Limitations and bias
This model was fine-tuned with audio samples which maximum length was 20 seconds so this model most likely works the best for quite short audios of similar length. However, you can try this model with a lot longer audios too and see how it works. If you encounter out of memory errors with very long audio files you can use the audio chunking method introduced in [this blog post](https://huggingface.co/blog/asr-chunking).
A vast majority of the data used for fine-tuning was from the Finnish Parliament dataset so this model may not generalize so well to very different domains like common daily spoken Finnish with dialects etc. In addition, audios of the datasets tend to be adult male dominated so this model may not work as well for speeches of children and women, for example.
The Finnish KenLM language model used in the decoding phase has been trained with text data from the audio transcriptions and from a subset of Finnish Wikipedia. Thus, the decoder's language model may not generalize to very different language, for example to spoken daily language with dialects (because especially the Wikipedia contains mostly formal Finnish language). It may be beneficial to train your own KenLM language model for your domain language and use that in the decoding.
## Training data
This model was fine-tuned with 276.7 hours of Finnish transcribed speech data from following datasets:
| Dataset | Hours | % of total hours |
|:------------------------------------------------------------------------------------------------------------------------------ |:--------:|:----------------:|
| [Common Voice 9.0 Finnish train + evaluation + other splits](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) | 10.80 h | 3.90 % |
| [Finnish parliament session 2](https://b2share.eudat.eu/records/4df422d631544ce682d6af1d4714b2d4) | 0.24 h | 0.09 % |
| [VoxPopuli Finnish](https://github.com/facebookresearch/voxpopuli) | 21.97 h | 7.94 % |
| [CSS10 Finnish](https://github.com/kyubyong/css10) | 10.32 h | 3.73 % |
| [Aalto Finnish Parliament ASR Corpus](http://urn.fi/urn:nbn:fi:lb-2021051903) | 228.00 h | 82.40 % |
| [Finnish Broadcast Corpus](http://urn.fi/urn:nbn:fi:lb-2016042502) | 5.37 h | 1.94 % |
Datasets were filtered to include maximum length of 20 seconds long audio samples.
## Training procedure
This model was trained on a Tesla V100 GPU, sponsored by Hugging Face & OVHcloud.
Training script was provided by Hugging Face and it is available [here](https://github.com/huggingface/transformers/blob/main/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py). We only modified its data loading for our custom datasets.
For the KenLM language model training, we followed the [blog post tutorial](https://huggingface.co/blog/wav2vec2-with-ngram) provided by Hugging Face. Training data for the 5-gram KenLM were text transcriptions of the audio training data and 100k random samples of cleaned [Finnish Wikipedia](https://huggingface.co/datasets/wikipedia) (August 2021) dataset.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-04
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: [8-bit Adam](https://github.com/facebookresearch/bitsandbytes) with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
The pretrained `facebook/wav2vec2-base-fi-voxpopuli-v2` model was initialized with following hyperparameters:
- attention_dropout: 0.094
- hidden_dropout: 0.047
- feat_proj_dropout: 0.04
- mask_time_prob: 0.082
- layerdrop: 0.041
- activation_dropout: 0.055
- ctc_loss_reduction: "mean"
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.575 | 0.33 | 500 | 0.7454 | 0.7048 |
| 0.5838 | 0.66 | 1000 | 0.2377 | 0.2608 |
| 0.5692 | 1.0 | 1500 | 0.2014 | 0.2244 |
| 0.5112 | 1.33 | 2000 | 0.1885 | 0.2013 |
| 0.4857 | 1.66 | 2500 | 0.1881 | 0.2120 |
| 0.4821 | 1.99 | 3000 | 0.1603 | 0.1894 |
| 0.4531 | 2.32 | 3500 | 0.1594 | 0.1865 |
| 0.4411 | 2.65 | 4000 | 0.1641 | 0.1874 |
| 0.4437 | 2.99 | 4500 | 0.1545 | 0.1874 |
| 0.4191 | 3.32 | 5000 | 0.1565 | 0.1770 |
| 0.4158 | 3.65 | 5500 | 0.1696 | 0.1867 |
| 0.4032 | 3.98 | 6000 | 0.1561 | 0.1746 |
| 0.4003 | 4.31 | 6500 | 0.1432 | 0.1749 |
| 0.4059 | 4.64 | 7000 | 0.1390 | 0.1690 |
| 0.4019 | 4.98 | 7500 | 0.1291 | 0.1646 |
| 0.3811 | 5.31 | 8000 | 0.1485 | 0.1755 |
| 0.3955 | 5.64 | 8500 | 0.1351 | 0.1659 |
| 0.3562 | 5.97 | 9000 | 0.1328 | 0.1614 |
| 0.3646 | 6.3 | 9500 | 0.1329 | 0.1584 |
| 0.351 | 6.64 | 10000 | 0.1342 | 0.1554 |
| 0.3408 | 6.97 | 10500 | 0.1422 | 0.1509 |
| 0.3562 | 7.3 | 11000 | 0.1309 | 0.1528 |
| 0.3335 | 7.63 | 11500 | 0.1305 | 0.1506 |
| 0.3491 | 7.96 | 12000 | 0.1365 | 0.1560 |
| 0.3538 | 8.29 | 12500 | 0.1293 | 0.1512 |
| 0.3338 | 8.63 | 13000 | 0.1328 | 0.1511 |
| 0.3509 | 8.96 | 13500 | 0.1304 | 0.1520 |
| 0.3431 | 9.29 | 14000 | 0.1360 | 0.1517 |
| 0.3309 | 9.62 | 14500 | 0.1328 | 0.1514 |
| 0.3252 | 9.95 | 15000 | 0.1316 | 0.1498 |
### Framework versions
- Transformers 4.19.1
- Pytorch 1.11.0+cu102
- Datasets 2.2.1
- Tokenizers 0.11.0
## Evaluation results
Evaluation was done with the [Common Voice 7.0 Finnish test split](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0), [Common Voice 9.0 Finnish test split](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) and with the [FLEURS ASR Finnish test split](https://huggingface.co/datasets/google/fleurs).
This model's training data includes the training splits of Common Voice 9.0 but most of our previous models include the Common Voice 7.0 so we ran tests for both Common Voice versions. Note: Common Voice doesn't seem to fully preserve the test split as fixed between the dataset versions so it is possible that some of the training examples of Common Voice 9.0 are in the test split of the Common Voice 7.0 and vice versa. Thus, Common Voice test result comparisons are not fully accurate between the models trained with different Common Voice versions but the comparison should still be meaningful enough.
### Common Voice 7.0 testing
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned --dataset mozilla-foundation/common_voice_7_0 --config fi --split test
```
This model (the first row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models and their parameter counts:
| | Model parameters | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-------------------------------------------------------|------------------|---------------|------------------|---------------|------------------|
|Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned | 95 million |5.85 |13.52 |1.35 |2.44 |
|Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish | 300 million |4.13 |**9.66** |0.90 |1.66 |
|Finnish-NLP/wav2vec2-xlsr-300m-finnish-lm | 300 million |8.16 |17.92 |1.97 |3.36 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm | 1000 million |5.65 |13.11 |1.20 |2.23 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2 | 1000 million |**4.09** |9.73 |**0.88** |**1.65** |
### Common Voice 9.0 testing
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned --dataset mozilla-foundation/common_voice_9_0 --config fi --split test
```
This model (the first row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models and their parameter counts:
| | Model parameters | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-------------------------------------------------------|------------------|---------------|------------------|---------------|------------------|
|Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned | 95 million |5.93 |14.08 |1.40 |2.59 |
|Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish | 300 million |4.13 |9.83 |0.92 |1.71 |
|Finnish-NLP/wav2vec2-xlsr-300m-finnish-lm | 300 million |7.42 |16.45 |1.79 |3.07 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm | 1000 million |5.35 |13.00 |1.14 |2.20 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2 | 1000 million |**3.72** |**8.96** |**0.80** |**1.52** |
### FLEURS ASR testing
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned --dataset google/fleurs --config fi_fi --split test
```
This model (the first row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models and their parameter counts:
| | Model parameters | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-------------------------------------------------------|------------------|---------------|------------------|---------------|------------------|
|Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned | 95 million |13.99 |17.16 |6.07 |6.61 |
|Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish | 300 million |12.44 |**14.63** |5.77 |6.22 |
|Finnish-NLP/wav2vec2-xlsr-300m-finnish-lm | 300 million |17.72 |23.30 |6.78 |7.67 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm | 1000 million |20.34 |16.67 |6.97 |6.35 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2 | 1000 million |**12.11** |14.89 |**5.65** |**6.06** |
## Team Members
- Aapo Tanskanen, [Hugging Face profile](https://huggingface.co/aapot), [LinkedIn profile](https://www.linkedin.com/in/aapotanskanen/)
- Rasmus Toivanen, [Hugging Face profile](https://huggingface.co/RASMUS), [LinkedIn profile](https://www.linkedin.com/in/rasmustoivanen/)
Feel free to contact us for more details 🤗
|
Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish
|
72cda0634358fb4cb11da6c09cea9fad6f0cf073
|
2022-05-26T12:37:37.000Z
|
[
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"fi",
"dataset:mozilla-foundation/common_voice_9_0",
"arxiv:2006.11477",
"transformers",
"finnish",
"generated_from_trainer",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
Finnish-NLP
| null |
Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish
| 84 | null |
transformers
| 4,943 |
---
license: apache-2.0
language: fi
metrics:
- wer
- cer
tags:
- automatic-speech-recognition
- fi
- finnish
- generated_from_trainer
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_9_0
model-index:
- name: wav2vec2-large-uralic-voxpopuli-v2-finnish
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 9
type: mozilla-foundation/common_voice_9_0
args: fi
metrics:
- name: Test WER
type: wer
value: 4.13
- name: Test CER
type: cer
value: 0.92
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: FLEURS ASR
type: google/fleurs
args: fi_fi
metrics:
- name: Test WER
type: wer
value: 12.44
- name: Test CER
type: cer
value: 5.77
---
# Wav2vec2-large-uralic-voxpopuli-v2 for Finnish ASR
This acoustic model is a fine-tuned version of [facebook/wav2vec2-large-uralic-voxpopuli-v2](https://huggingface.co/facebook/wav2vec2-large-uralic-voxpopuli-v2) for Finnish ASR. The model has been fine-tuned with 276.7 hours of Finnish transcribed speech data. Wav2Vec2 was introduced in
[this paper](https://arxiv.org/abs/2006.11477) and first released at [this page](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec#wav2vec-20).
This repository also includes Finnish KenLM language model used in the decoding phase with the acoustic model.
## Model description
[Wav2vec2-large-uralic-voxpopuli-v2](https://huggingface.co/facebook/wav2vec2-large-uralic-voxpopuli-v2) is Facebook AI's pretrained model for uralic language family (Finnish, Estonian, Hungarian) speech. It is pretrained on 42.5k hours of unlabeled Finnish, Estonian and Hungarian speech from [VoxPopuli V2 dataset](https://github.com/facebookresearch/voxpopuli/) with the wav2vec 2.0 objective.
This model is fine-tuned version of the pretrained model for Finnish ASR.
## Intended uses & limitations
You can use this model for Finnish ASR (speech-to-text) task.
### How to use
Check the [run-finnish-asr-models.ipynb](https://huggingface.co/Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish/blob/main/run-finnish-asr-models.ipynb) notebook in this repository for an detailed example on how to use this model.
### Limitations and bias
This model was fine-tuned with audio samples which maximum length was 20 seconds so this model most likely works the best for quite short audios of similar length. However, you can try this model with a lot longer audios too and see how it works. If you encounter out of memory errors with very long audio files you can use the audio chunking method introduced in [this blog post](https://huggingface.co/blog/asr-chunking).
A vast majority of the data used for fine-tuning was from the Finnish Parliament dataset so this model may not generalize so well to very different domains like common daily spoken Finnish with dialects etc. In addition, audios of the datasets tend to be adult male dominated so this model may not work as well for speeches of children and women, for example.
The Finnish KenLM language model used in the decoding phase has been trained with text data from the audio transcriptions and from a subset of Finnish Wikipedia. Thus, the decoder's language model may not generalize to very different language, for example to spoken daily language with dialects (because especially the Wikipedia contains mostly formal Finnish language). It may be beneficial to train your own KenLM language model for your domain language and use that in the decoding.
## Training data
This model was fine-tuned with 276.7 hours of Finnish transcribed speech data from following datasets:
| Dataset | Hours | % of total hours |
|:------------------------------------------------------------------------------------------------------------------------------ |:--------:|:----------------:|
| [Common Voice 9.0 Finnish train + evaluation + other splits](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) | 10.80 h | 3.90 % |
| [Finnish parliament session 2](https://b2share.eudat.eu/records/4df422d631544ce682d6af1d4714b2d4) | 0.24 h | 0.09 % |
| [VoxPopuli Finnish](https://github.com/facebookresearch/voxpopuli) | 21.97 h | 7.94 % |
| [CSS10 Finnish](https://github.com/kyubyong/css10) | 10.32 h | 3.73 % |
| [Aalto Finnish Parliament ASR Corpus](http://urn.fi/urn:nbn:fi:lb-2021051903) | 228.00 h | 82.40 % |
| [Finnish Broadcast Corpus](http://urn.fi/urn:nbn:fi:lb-2016042502) | 5.37 h | 1.94 % |
Datasets were filtered to include maximum length of 20 seconds long audio samples.
## Training procedure
This model was trained on a Tesla V100 GPU, sponsored by Hugging Face & OVHcloud.
Training script was provided by Hugging Face and it is available [here](https://github.com/huggingface/transformers/blob/main/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py). We only modified its data loading for our custom datasets.
For the KenLM language model training, we followed the [blog post tutorial](https://huggingface.co/blog/wav2vec2-with-ngram) provided by Hugging Face. Training data for the 5-gram KenLM were text transcriptions of the audio training data and 100k random samples of cleaned [Finnish Wikipedia](https://huggingface.co/datasets/wikipedia) (August 2021) dataset.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-04
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: [8-bit Adam](https://github.com/facebookresearch/bitsandbytes) with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
The pretrained `facebook/wav2vec2-large-uralic-voxpopuli-v2` model was initialized with following hyperparameters:
- attention_dropout: 0.094
- hidden_dropout: 0.047
- feat_proj_dropout: 0.04
- mask_time_prob: 0.082
- layerdrop: 0.041
- activation_dropout: 0.055
- ctc_loss_reduction: "mean"
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.9421 | 0.17 | 500 | 0.8633 | 0.8870 |
| 0.572 | 0.33 | 1000 | 0.1650 | 0.1829 |
| 0.5149 | 0.5 | 1500 | 0.1416 | 0.1711 |
| 0.4884 | 0.66 | 2000 | 0.1265 | 0.1605 |
| 0.4729 | 0.83 | 2500 | 0.1205 | 0.1485 |
| 0.4723 | 1.0 | 3000 | 0.1108 | 0.1403 |
| 0.443 | 1.16 | 3500 | 0.1175 | 0.1439 |
| 0.4378 | 1.33 | 4000 | 0.1083 | 0.1482 |
| 0.4313 | 1.49 | 4500 | 0.1110 | 0.1398 |
| 0.4182 | 1.66 | 5000 | 0.1024 | 0.1418 |
| 0.3884 | 1.83 | 5500 | 0.1032 | 0.1395 |
| 0.4034 | 1.99 | 6000 | 0.0985 | 0.1318 |
| 0.3735 | 2.16 | 6500 | 0.1008 | 0.1355 |
| 0.4174 | 2.32 | 7000 | 0.0970 | 0.1361 |
| 0.3581 | 2.49 | 7500 | 0.0968 | 0.1297 |
| 0.3783 | 2.66 | 8000 | 0.0881 | 0.1284 |
| 0.3827 | 2.82 | 8500 | 0.0921 | 0.1352 |
| 0.3651 | 2.99 | 9000 | 0.0861 | 0.1298 |
| 0.3684 | 3.15 | 9500 | 0.0844 | 0.1270 |
| 0.3784 | 3.32 | 10000 | 0.0870 | 0.1248 |
| 0.356 | 3.48 | 10500 | 0.0828 | 0.1214 |
| 0.3524 | 3.65 | 11000 | 0.0878 | 0.1218 |
| 0.3879 | 3.82 | 11500 | 0.0874 | 0.1216 |
| 0.3521 | 3.98 | 12000 | 0.0860 | 0.1210 |
| 0.3527 | 4.15 | 12500 | 0.0818 | 0.1184 |
| 0.3529 | 4.31 | 13000 | 0.0787 | 0.1185 |
| 0.3114 | 4.48 | 13500 | 0.0852 | 0.1202 |
| 0.3495 | 4.65 | 14000 | 0.0807 | 0.1187 |
| 0.34 | 4.81 | 14500 | 0.0796 | 0.1162 |
| 0.3646 | 4.98 | 15000 | 0.0782 | 0.1149 |
| 0.3004 | 5.14 | 15500 | 0.0799 | 0.1142 |
| 0.3167 | 5.31 | 16000 | 0.0847 | 0.1123 |
| 0.3249 | 5.48 | 16500 | 0.0837 | 0.1171 |
| 0.3202 | 5.64 | 17000 | 0.0749 | 0.1109 |
| 0.3104 | 5.81 | 17500 | 0.0798 | 0.1093 |
| 0.3039 | 5.97 | 18000 | 0.0810 | 0.1132 |
| 0.3157 | 6.14 | 18500 | 0.0847 | 0.1156 |
| 0.3133 | 6.31 | 19000 | 0.0833 | 0.1140 |
| 0.3203 | 6.47 | 19500 | 0.0838 | 0.1113 |
| 0.3178 | 6.64 | 20000 | 0.0907 | 0.1141 |
| 0.3182 | 6.8 | 20500 | 0.0938 | 0.1143 |
| 0.3 | 6.97 | 21000 | 0.0854 | 0.1133 |
| 0.3151 | 7.14 | 21500 | 0.0859 | 0.1109 |
| 0.2963 | 7.3 | 22000 | 0.0832 | 0.1122 |
| 0.3099 | 7.47 | 22500 | 0.0865 | 0.1103 |
| 0.322 | 7.63 | 23000 | 0.0833 | 0.1105 |
| 0.3064 | 7.8 | 23500 | 0.0865 | 0.1078 |
| 0.2964 | 7.97 | 24000 | 0.0859 | 0.1096 |
| 0.2869 | 8.13 | 24500 | 0.0872 | 0.1100 |
| 0.315 | 8.3 | 25000 | 0.0869 | 0.1099 |
| 0.3003 | 8.46 | 25500 | 0.0878 | 0.1105 |
| 0.2947 | 8.63 | 26000 | 0.0884 | 0.1084 |
| 0.297 | 8.8 | 26500 | 0.0891 | 0.1102 |
| 0.3049 | 8.96 | 27000 | 0.0863 | 0.1081 |
| 0.2957 | 9.13 | 27500 | 0.0846 | 0.1083 |
| 0.2908 | 9.29 | 28000 | 0.0848 | 0.1059 |
| 0.2955 | 9.46 | 28500 | 0.0846 | 0.1085 |
| 0.2991 | 9.62 | 29000 | 0.0839 | 0.1081 |
| 0.3112 | 9.79 | 29500 | 0.0832 | 0.1071 |
| 0.29 | 9.96 | 30000 | 0.0828 | 0.1075 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu102
- Datasets 2.2.2
- Tokenizers 0.11.0
## Evaluation results
Evaluation was done with the [Common Voice 7.0 Finnish test split](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0), [Common Voice 9.0 Finnish test split](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) and with the [FLEURS ASR Finnish test split](https://huggingface.co/datasets/google/fleurs).
This model's training data includes the training splits of Common Voice 9.0 but most of our previous models include the Common Voice 7.0 so we ran tests for both Common Voice versions. Note: Common Voice doesn't seem to fully preserve the test split as fixed between the dataset versions so it is possible that some of the training examples of Common Voice 9.0 are in the test split of the Common Voice 7.0 and vice versa. Thus, Common Voice test result comparisons are not fully accurate between the models trained with different Common Voice versions but the comparison should still be meaningful enough.
### Common Voice 7.0 testing
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish --dataset mozilla-foundation/common_voice_7_0 --config fi --split test
```
This model (the second row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models and their parameter counts:
| | Model parameters | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-------------------------------------------------------|------------------|---------------|------------------|---------------|------------------|
|Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned | 95 million |5.85 |13.52 |1.35 |2.44 |
|Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish | 300 million |4.13 |**9.66** |0.90 |1.66 |
|Finnish-NLP/wav2vec2-xlsr-300m-finnish-lm | 300 million |8.16 |17.92 |1.97 |3.36 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm | 1000 million |5.65 |13.11 |1.20 |2.23 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2 | 1000 million |**4.09** |9.73 |**0.88** |**1.65** |
### Common Voice 9.0 testing
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish --dataset mozilla-foundation/common_voice_9_0 --config fi --split test
```
This model (the second row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models and their parameter counts:
| | Model parameters | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-------------------------------------------------------|------------------|---------------|------------------|---------------|------------------|
|Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned | 95 million |5.93 |14.08 |1.40 |2.59 |
|Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish | 300 million |4.13 |9.83 |0.92 |1.71 |
|Finnish-NLP/wav2vec2-xlsr-300m-finnish-lm | 300 million |7.42 |16.45 |1.79 |3.07 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm | 1000 million |5.35 |13.00 |1.14 |2.20 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2 | 1000 million |**3.72** |**8.96** |**0.80** |**1.52** |
### FLEURS ASR testing
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish --dataset google/fleurs --config fi_fi --split test
```
This model (the second row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models and their parameter counts:
| | Model parameters | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-------------------------------------------------------|------------------|---------------|------------------|---------------|------------------|
|Finnish-NLP/wav2vec2-base-fi-voxpopuli-v2-finetuned | 95 million |13.99 |17.16 |6.07 |6.61 |
|Finnish-NLP/wav2vec2-large-uralic-voxpopuli-v2-finnish | 300 million |12.44 |**14.63** |5.77 |6.22 |
|Finnish-NLP/wav2vec2-xlsr-300m-finnish-lm | 300 million |17.72 |23.30 |6.78 |7.67 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm | 1000 million |20.34 |16.67 |6.97 |6.35 |
|Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2 | 1000 million |**12.11** |14.89 |**5.65** |**6.06** |
## Team Members
- Aapo Tanskanen, [Hugging Face profile](https://huggingface.co/aapot), [LinkedIn profile](https://www.linkedin.com/in/aapotanskanen/)
- Rasmus Toivanen, [Hugging Face profile](https://huggingface.co/RASMUS), [LinkedIn profile](https://www.linkedin.com/in/rasmustoivanen/)
Feel free to contact us for more details 🤗
|
lgodwangl/sent_chineses
|
04493d425c3208347b9bf368f864d8c9a2deda7f
|
2022-07-11T22:04:50.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
lgodwangl
| null |
lgodwangl/sent_chineses
| 84 | null |
transformers
| 4,944 |
Entry not found
|
czearing/article-title-generator
|
511d2f366414670c9d01631dd6484c2f810f5c3e
|
2022-06-28T20:08:16.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
czearing
| null |
czearing/article-title-generator
| 84 | 1 |
transformers
| 4,945 |
---
license: mit
---
## Article Title Generator
The model is based on the T5 language model and trained using a large collection of Medium articles.
## Usage
Example code:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("czearing/article-title-generator")
model = AutoModel.from_pretrained("czearing/article-title-generator")
```
## License
MIT
|
Jeevesh8/goog_bert_ft_cola-5
|
35852e6ca1901ddbb5307dc9aea597c42c241812
|
2022-06-29T17:31:47.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
Jeevesh8
| null |
Jeevesh8/goog_bert_ft_cola-5
| 84 | null |
transformers
| 4,946 |
Entry not found
|
knkarthick/TOPIC-SUMMARY
|
dd97e38f6bef8952181b7c5e8d4d514af813c1b6
|
2022-07-11T05:49:54.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
knkarthick
| null |
knkarthick/TOPIC-SUMMARY
| 84 | null |
transformers
| 4,947 |
Entry not found
|
AhmedSSoliman/MarianCG-NL-to-Code
|
6336d7b6b6b03cbc7a9f9135ee687e660a47a69f
|
2022-06-29T15:53:49.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
AhmedSSoliman
| null |
AhmedSSoliman/MarianCG-NL-to-Code
| 83 | null |
transformers
| 4,948 |
---
widget:
- text: "create array containing the maximum value of respective elements of array `[2, 3, 4]` and array `[1, 5, 2]"
- text: "check if all elements in list `mylist` are identical"
- text: "enable debug mode on flask application `app`"
- text: "getting the length of `my_tuple`"
- text: 'find all files in directory "/mydir" with extension ".txt"'
---
# MarianCG: A TRANSFORMER MODEL FOR AUTOMATIC CODE GENERATION
This model is to improve the solving of the code generation problem and implement a transformer model that can work with high accurate results. We implemented MarianCG transformer model which is a code generation model that can be able to generate code from natural language. This work declares the impact of using Marian machine translation model for solving the problem of code generation. In our implementation we prove that a machine translation model can be operated and working as a code generation model.Finally, we set the new contributors and state-of-the-art on CoNaLa reaching a BLEU score of 30.92 in the code generation problem with CoNaLa dataset.
CoNaLa Dataset for Code Generation is available at
https://huggingface.co/datasets/AhmedSSoliman/CoNaLa
This is the model is avialable on the huggingface hub https://huggingface.co/AhmedSSoliman/MarianCG-NL-to-Code
```python
# Model and Tokenizer
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# model_name = "AhmedSSoliman/MarianCG-NL-to-Code"
model = AutoModelForSeq2SeqLM.from_pretrained("AhmedSSoliman/MarianCG-NL-to-Code")
tokenizer = AutoTokenizer.from_pretrained("AhmedSSoliman/MarianCG-NL-to-Code")
# Input (Natural Language) and Output (Python Code)
NL_input = "create array containing the maximum value of respective elements of array `[2, 3, 4]` and array `[1, 5, 2]"
output = model.generate(**tokenizer(NL_input, padding="max_length", truncation=True, max_length=512, return_tensors="pt"))
output_code = tokenizer.decode(output[0], skip_special_tokens=True)
```
This model is available in spaces using gradio at: https://huggingface.co/spaces/AhmedSSoliman/MarianCG-NL-to-Code
---
Tasks:
- Translation
- Code Generation
- Text2Text Generation
- Text Generation
---
|
Finnish-NLP/roberta-large-finnish
|
4efd90ea2c50928d27bd43a20a19b956852288d4
|
2022-06-13T16:13:07.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"fi",
"dataset:Finnish-NLP/mc4_fi_cleaned",
"dataset:wikipedia",
"arxiv:1907.11692",
"transformers",
"finnish",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Finnish-NLP
| null |
Finnish-NLP/roberta-large-finnish
| 83 | 1 |
transformers
| 4,949 |
---
language:
- fi
license: apache-2.0
tags:
- finnish
- roberta
datasets:
- Finnish-NLP/mc4_fi_cleaned
- wikipedia
widget:
- text: "Moikka olen <mask> kielimalli."
---
# RoBERTa large model for Finnish
Pretrained RoBERTa model on Finnish language using a masked language modeling (MLM) objective. RoBERTa was introduced in
[this paper](https://arxiv.org/abs/1907.11692) and first released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/roberta). This model is case-sensitive: it
makes a difference between finnish and Finnish.
## Model description
Finnish RoBERTa is a transformers model pretrained on a large corpus of Finnish data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model
randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict
the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one
after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to
learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of the Finnish language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the RoBERTa model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Finnish-NLP/roberta-large-finnish')
>>> unmasker("Moikka olen <mask> kielimalli.")
[{'sequence': 'Moikka olen hyvä kielimalli.',
'score': 0.1535797119140625,
'token': 767,
'token_str': ' hyvä'},
{'sequence': 'Moikka olen paras kielimalli.',
'score': 0.04795042425394058,
'token': 2888,
'token_str': ' paras'},
{'sequence': 'Moikka olen huono kielimalli.',
'score': 0.04251479730010033,
'token': 3217,
'token_str': ' huono'},
{'sequence': 'Moikka olen myös kielimalli.',
'score': 0.027469098567962646,
'token': 520,
'token_str': ' myös'},
{'sequence': 'Moikka olen se kielimalli.',
'score': 0.013878575526177883,
'token': 358,
'token_str': ' se'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('Finnish-NLP/roberta-large-finnish')
model = RobertaModel.from_pretrained('Finnish-NLP/roberta-large-finnish')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
tokenizer = RobertaTokenizer.from_pretrained('Finnish-NLP/roberta-large-finnish')
model = TFRobertaModel.from_pretrained('Finnish-NLP/roberta-large-finnish', from_pt=True)
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model contains a lot of unfiltered content from the internet, which is far from
neutral. Therefore, the model can have biased predictions.
## Training data
This Finnish RoBERTa model was pretrained on the combination of five datasets:
- [mc4](https://huggingface.co/datasets/mc4), the dataset mC4 is a multilingual colossal, cleaned version of Common Crawl's web crawl corpus. We used the Finnish subset of the mC4 dataset
- [wikipedia](https://huggingface.co/datasets/wikipedia) We used the Finnish subset of the wikipedia (August 2021) dataset
- [Yle Finnish News Archive](http://urn.fi/urn:nbn:fi:lb-2017070501)
- [Finnish News Agency Archive (STT)](http://urn.fi/urn:nbn:fi:lb-2018121001)
- [The Suomi24 Sentences Corpus](http://urn.fi/urn:nbn:fi:lb-2020021803)
Raw datasets were cleaned to filter out bad quality and non-Finnish examples. Together these cleaned datasets were around 78GB of text.
## Training procedure
### Preprocessing
The texts are tokenized using a byte version of Byte-Pair Encoding (BPE) and a vocabulary size of 50265. The inputs of
the model take pieces of 512 contiguous token that may span over documents. The beginning of a new document is marked
with `<s>` and the end of one by `</s>`
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
Contrary to BERT, the masking is done dynamically during pretraining (e.g., it changes at each epoch and is not fixed).
### Pretraining
The model was trained on TPUv3-8 VM, sponsored by the [Google TPU Research Cloud](https://sites.research.google/trc/about/), for 2 epochs with a sequence length of 128 and continuing for one more epoch with a sequence length of 512. The optimizer used is Adafactor with a learning rate of 2e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and \\(\epsilon = 1e-6\\), learning rate warmup for 1500 steps and linear decay of the learning rate after.
## Evaluation results
Evaluation was done by fine-tuning the model on downstream text classification task with two different labeled datasets: [Yle News](https://github.com/spyysalo/yle-corpus) and [Eduskunta](https://github.com/aajanki/eduskunta-vkk). Yle News classification fine-tuning was done with two different sequence lengths: 128 and 512 but Eduskunta only with 128 sequence length.
When fine-tuned on those datasets, this model (the first row of the table) achieves the following accuracy results compared to the [FinBERT (Finnish BERT)](https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1) and to our previous [Finnish RoBERTa-large](https://huggingface.co/flax-community/RoBERTa-large-finnish) trained during the Hugging Face JAX/Flax community week:
| | Average | Yle News 128 length | Yle News 512 length | Eduskunta 128 length |
|----------------------------------------|----------|---------------------|---------------------|----------------------|
|Finnish-NLP/roberta-large-finnish |88.02 |94.53 |95.23 |74.30 |
|TurkuNLP/bert-base-finnish-cased-v1 |**88.82** |**94.90** |**95.49** |**76.07** |
|flax-community/RoBERTa-large-finnish |87.72 |94.42 |95.06 |73.67 |
To conclude, this model improves on our previous [Finnish RoBERTa-large](https://huggingface.co/flax-community/RoBERTa-large-finnish) model trained during the Hugging Face JAX/Flax community week but is still slightly (~ 1%) losing to the [FinBERT (Finnish BERT)](https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1) model.
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/).
## Team Members
- Aapo Tanskanen, [Hugging Face profile](https://huggingface.co/aapot), [LinkedIn profile](https://www.linkedin.com/in/aapotanskanen/)
- Rasmus Toivanen [Hugging Face profile](https://huggingface.co/RASMUS), [LinkedIn profile](https://www.linkedin.com/in/rasmustoivanen/)
- Tommi Vehviläinen [Hugging Face profile](https://huggingface.co/Tommi)
Feel free to contact us for more details 🤗
|
HHousen/household-rooms
|
c80d9567f40da3d988bb01232ee66bc11c2a941f
|
2022-02-12T06:21:05.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
HHousen
| null |
HHousen/household-rooms
| 83 | null |
transformers
| 4,950 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: household-rooms
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8482142686843872
---
# household-rooms
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### bathroom

#### bedroom

#### dining room

#### kitchen

#### living room

|
Helsinki-NLP/opus-mt-ko-de
|
23a6fdbbed8020e0c787c25c7aeeb9f435963fe6
|
2021-09-10T13:54:01.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ko",
"de",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ko-de
| 83 | null |
transformers
| 4,951 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-ko-de
* source languages: ko
* target languages: de
* OPUS readme: [ko-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ko-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/ko-de/opus-2020-01-20.zip)
* test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ko-de/opus-2020-01-20.test.txt)
* test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ko-de/opus-2020-01-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ko.de | 30.2 | 0.523 |
|
Helsinki-NLP/opus-mt-ru-es
|
717eeb22c5017551f217849d8b5e2cf91398e336
|
2021-09-10T14:02:21.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ru",
"es",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ru-es
| 83 | null |
transformers
| 4,952 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-ru-es
* source languages: ru
* target languages: es
* OPUS readme: [ru-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ru-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-21.zip](https://object.pouta.csc.fi/OPUS-MT-models/ru-es/opus-2020-01-21.zip)
* test set translations: [opus-2020-01-21.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ru-es/opus-2020-01-21.test.txt)
* test set scores: [opus-2020-01-21.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ru-es/opus-2020-01-21.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newstest2012.ru.es | 26.1 | 0.527 |
| newstest2013.ru.es | 28.2 | 0.538 |
| Tatoeba.ru.es | 49.4 | 0.675 |
|
Muennighoff/SGPT-5.8B-weightedmean-nli-bitfit
|
1aea373089cef8598efd159039b525a06e7ebbcc
|
2022-06-18T20:14:43.000Z
|
[
"pytorch",
"gptj",
"feature-extraction",
"arxiv:2202.08904",
"sentence-transformers",
"sentence-similarity"
] |
sentence-similarity
| false |
Muennighoff
| null |
Muennighoff/SGPT-5.8B-weightedmean-nli-bitfit
| 83 | 2 |
sentence-transformers
| 4,953 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# SGPT-5.8B-weightedmean-nli-bitfit
## Usage
For usage instructions, refer to our codebase: https://github.com/Muennighoff/sgpt
## Evaluation Results
For eval results, refer to the eval folder or our paper: https://arxiv.org/abs/2202.08904
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 93941 with parameters:
```
{'batch_size': 6}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 9394,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0001
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 9395,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: GPTJModel
(1): Pooling({'word_embedding_dimension': 4096, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
|
baykenney/bert-base-gpt2detector-topk40
|
07f08704e25e432c02d081f85a94fb92beed3cb3
|
2021-05-19T12:10:12.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
baykenney
| null |
baykenney/bert-base-gpt2detector-topk40
| 83 | null |
transformers
| 4,954 |
Entry not found
|
colorfulscoop/bert-base-ja
|
bba3cc734a1a068222249c4634ff4ea06bb07605
|
2021-09-23T13:46:05.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"ja",
"dataset:wikipedia",
"transformers",
"license:cc-by-sa-4.0",
"fill-mask"
] |
fill-mask
| false |
colorfulscoop
| null |
colorfulscoop/bert-base-ja
| 83 | null |
transformers
| 4,955 |
---
language: ja
datasets: wikipedia
pipeline_tag: fill-mask
widget:
- text: 得意な科目は[MASK]です。
license: cc-by-sa-4.0
---
# BERT base Japanese model
This repository contains a BERT base model trained on Japanese Wikipedia dataset.
## Training data
[Japanese Wikipedia](https://ja.wikipedia.org/wiki/Wikipedia:データベースダウンロード) dataset as of June 20, 2021 which is released under [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/) is used for training.
The dataset is splitted into three subsets - train, valid and test. Both tokenizer and model are trained with the train split.
## Model description
The model architecture is the same as BERT base model (hidden_size: 768, num_hidden_layers: 12, num_attention_heads: 12, max_position_embeddings: 512) except for a vocabulary size.
The vocabulary size is set to 32,000 instead of an original size of 30,522.
For the model, `transformers.BertForPreTraining` is used.
## Tokenizer description
[SentencePiece](https://github.com/google/sentencepiece) tokenizer is used as a tokenizer for this model.
While training, the tokenizer model was trained with 1,000,000 samples which were extracted from the train split.
The vocabulary size is set to 32,000. A `add_dummy_prefix` option is set to `True` because words are not separated by whitespaces in Japanese.
After training, the model is imported to `transformers.DebertaV2Tokenizer` because it supports SentencePiece models and its behavior is consistent when `use_fast` option is set to `True` or `False`.
**Note:**
The meaning of "consistent" here is as follows.
For example, AlbertTokenizer provides AlbertTokenizer and AlbertTokenizerFast. Fast model is used as default. However, the tokenization behavior between them is different and a behavior this mdoel expects is the verions of not fast.
Although `use_fast=False` option passing to AutoTokenier or pipeline solves this problem to force to use not fast version of the tokenizer, this option cannot be passed to config.json or model card.
Therefore unexpected behavior happens when using Inference API. To avoid this kind of problems, `transformers.DebertaV2Tokenizer` is used in this model.
## Training
Training details are as follows.
* gradient update is every 256 samples (batch size: 8, accumulate_grad_batches: 32)
* gradient clip norm is 1.0
* Learning rate starts from 0 and linearly increased to 0.0001 in the first 10,000 steps
* The training set contains around 20M samples. Because 80k * 256 ~ 20M, 1 epochs has around 80k steps.
Trainind was conducted on Ubuntu 18.04.5 LTS with one RTX 2080 Ti.
The training continued until validation loss got worse. Totally the number of training steps were around 214k.
The test set loss was 2.80 .
Training code is available in [a GitHub repository](https://github.com/colorfulscoop/bert-ja).
## Usage
First, install dependecies.
```sh
$ pip install torch==1.8.0 transformers==4.8.2 sentencepiece==0.1.95
```
Then use `transformers.pipeline` to try mask fill task.
```sh
>>> import transformers
>>> pipeline = transformers.pipeline("fill-mask", "colorfulscoop/bert-base-ja", revision="v1.0")
>>> pipeline("専門として[MASK]を専攻しています")
[{'sequence': '専門として工学を専攻しています', 'score': 0.03630176931619644, 'token': 3988, 'token_str': '工学'}, {'sequence': '専門として政治学を専攻しています', 'score': 0.03547220677137375, 'token': 22307, 'token_str': '政治学'}, {'sequence': '専門として教育を専攻しています', 'score': 0.03162326663732529, 'token': 414, 'token_str': '教育'}, {'sequence': '専門として経済学を専攻しています', 'score': 0.026036914438009262, 'token': 6814, 'token_str': '経済学'}, {'sequence': '専門として法学を専攻しています', 'score': 0.02561848610639572, 'token': 10810, 'token_str': '法学'}]
```
Note: specifying a `revision` option is recommended to keep reproducibility when downloading a model via `transformers.pipeline` or `transformers.AutoModel.from_pretrained` .
## License
Copyright (c) 2021 Colorful Scoop
All the models included in this repository are licensed under [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
**Disclaimer:** The model potentially has possibility that it generates similar texts in the training data, texts not to be true, or biased texts. Use of the model is at your sole risk. Colorful Scoop makes no warranty or guarantee of any outputs from the model. Colorful Scoop is not liable for any trouble, loss, or damage arising from the model output.
---
This model utilizes the following data as training data
* **Name:** ウィキペディア (Wikipedia): フリー百科事典
* **Credit:** https://ja.wikipedia.org/
* **License:** [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/)
* **Link:** https://ja.wikipedia.org/
|
danyaljj/gpt2_question_generation_given_paragraph_answer
|
ee45d524ee2eb7ac062b15a8ad66f1065bf9ad01
|
2021-06-17T18:27:47.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
danyaljj
| null |
danyaljj/gpt2_question_generation_given_paragraph_answer
| 83 | null |
transformers
| 4,956 |
Sample usage:
```python
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("danyaljj/gpt2_question_generation_given_paragraph_answer")
input_ids = tokenizer.encode("There are two apples on the counter. A: apples Q:", return_tensors="pt")
outputs = model.generate(input_ids)
print("Generated:", tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Which should produce this:
```
Generated: There are two apples on the counter. A: apples Q: What is the name of the counter
```
|
ibombonato/vit-age-classifier
|
bc39c91226024da05693ce11422eb79d6c538443
|
2022-02-10T22:06:51.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
ibombonato
| null |
ibombonato/vit-age-classifier
| 83 | null |
transformers
| 4,957 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: vit-age-classifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8364999890327454
---
# vit-age-classifier
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
|
juanfiguera/ice_cream
|
c16725e9d0943dd5ddbb2230569f8dd5b7f59836
|
2021-09-10T02:59:58.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
juanfiguera
| null |
juanfiguera/ice_cream
| 83 | null |
transformers
| 4,958 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: ice_cream
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.5166666507720947
---
# ice_cream
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### chocolate ice cream

#### vanilla ice cream

|
kiri-ai/distiluse-base-multilingual-cased-et
|
4cc7064dcd075214b9417ad6092e5769c1119570
|
2020-12-11T21:48:24.000Z
|
[
"pytorch",
"distilbert",
"feature-extraction",
"et",
"transformers"
] |
feature-extraction
| false |
kiri-ai
| null |
kiri-ai/distiluse-base-multilingual-cased-et
| 83 | null |
transformers
| 4,959 |
---
language: et
---
## Model Description
This model is based off **Sentence-Transformer's** `distiluse-base-multilingual-cased` multilingual model that has been extended to understand sentence embeddings in Estonian.
## Sentence-Transformers
This model can be imported directly via the SentenceTransformers package as shown below:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('kiri-ai/distiluse-base-multilingual-cased-et')
sentences = ['Here is a sample sentence','Another sample sentence']
embeddings = model.encode(sentences)
print("Sentence embeddings:")
print(embeddings)
```
## Fine-tuning
The fine-tuning and training processes were inspired by [sbert's](https://www.sbert.net/) multilingual training techniques which are available [here](https://www.sbert.net/examples/training/multilingual/README.html). The documentation shows and explains the step-by-step process of using parallel sentences to train models in a different language.
### Resources
The model was fine-tuned on English-Estonian parallel sentences taken from [OPUS](http://opus.nlpl.eu/) and [ParaCrawl](https://paracrawl.eu/).
|
manueltonneau/clinicalcovid-bert-base-cased
|
feaed908d09e54f65f098c04b09b51584626c096
|
2020-06-02T11:52:31.000Z
|
[
"pytorch",
"transformers"
] | null | false |
manueltonneau
| null |
manueltonneau/clinicalcovid-bert-base-cased
| 83 | null |
transformers
| 4,960 |
Entry not found
|
mariagrandury/roberta-base-finetuned-sms-spam-detection
|
ed7a6c34f9a6041c3a0881fea29eb27e0838dd27
|
2022-02-22T11:54:07.000Z
|
[
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"dataset:sms_spam",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] |
text-classification
| false |
mariagrandury
| null |
mariagrandury/roberta-base-finetuned-sms-spam-detection
| 83 | 1 |
transformers
| 4,961 |
---
license: mit
tags:
- generated_from_trainer
datasets:
- sms_spam
metrics:
- accuracy
model-index:
- name: roberta-base-finetuned-sms-spam-detection
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: sms_spam
type: sms_spam
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.998
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-sms-spam-detection
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the sms_spam dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0133
- Accuracy: 0.998
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0363 | 1.0 | 250 | 0.0156 | 0.996 |
| 0.0147 | 2.0 | 500 | 0.0133 | 0.998 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
mrm8488/t5-base-finetuned-wikiSQL-sql-to-en
|
88935a5332548e7660ee2f1a9f9f846ef4020800
|
2020-12-11T21:56:17.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"arxiv:1910.10683",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
mrm8488
| null |
mrm8488/t5-base-finetuned-wikiSQL-sql-to-en
| 83 | 1 |
transformers
| 4,962 |
---
language: en
datasets:
- wikisql
---
# T5-base fine-tuned on WikiSQL for SQL to English translation
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned on [WikiSQL](https://github.com/salesforce/WikiSQL) for **SQL** to **English** **translation** task.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Details of the Dataset 📚
Dataset ID: ```wikisql``` from [Huggingface/NLP](https://huggingface.co/nlp/viewer/?dataset=wikisql)
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| wikisql | train | 56355 |
| wikisql | valid | 14436 |
How to load it from [nlp](https://github.com/huggingface/nlp)
```python
train_dataset = nlp.load_dataset('wikisql', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('wikisql', split=nlp.Split.VALIDATION)
```
Check out more about this dataset and others in [NLP Viewer](https://huggingface.co/nlp/viewer/)
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this Colab Notebook](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) created by [Suraj Patil](https://github.com/patil-suraj), so all credits to him!
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL-sql-to-en")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL-sql-to-en")
def get_explanation(query):
input_text = "translate Sql to English: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "SELECT COUNT Params form model where location=HF-Hub"
get_explanation(query)
# output: 'How many parameters form model for HF-hub?'
```
Play with it in a Colab:
<img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg">
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
nates-test-org/convit_tiny
|
6627075ee4777ed2a2bac509b900c115ef003e25
|
2021-10-29T04:46:42.000Z
|
[
"pytorch",
"timm",
"image-classification"
] |
image-classification
| false |
nates-test-org
| null |
nates-test-org/convit_tiny
| 83 | null |
timm
| 4,963 |
---
tags:
- image-classification
- timm
library_tag: timm
---
# Model card for convit_tiny
|
persiannlp/mt5-large-parsinlu-sentiment-analysis
|
0a6e33f37de3e8ae666e2eb5a9ca1ed33042e248
|
2021-09-23T16:20:21.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"fa",
"multilingual",
"dataset:parsinlu",
"transformers",
"sentiment",
"sentiment-analysis",
"persian",
"farsi",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
text2text-generation
| false |
persiannlp
| null |
persiannlp/mt5-large-parsinlu-sentiment-analysis
| 83 | null |
transformers
| 4,964 |
---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- sentiment
- sentiment-analysis
- mt5
- persian
- farsi
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Sentiment Analysis (آنالیز احساسات)
This is a mT5 model for sentiment analysis.
Here is an example of how you can run this model:
```python
import torch
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
import numpy as np
model_name_or_path = "persiannlp/mt5-large-parsinlu-sentiment-analysis"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
def model_predict(text_a, text_b):
features = tokenizer( [(text_a, text_b)], padding="max_length", truncation=True, return_tensors='pt')
output = model(**features)
logits = output[0]
probs = torch.nn.functional.softmax(logits, dim=1).tolist()
idx = np.argmax(np.array(probs))
print(labels[idx], probs)
def run_model(context, query, **generator_args):
input_ids = tokenizer.encode(context + "<sep>" + query, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model(
"یک فیلم ضعیف بی محتوا بدون فیلمنامه . شوخی های سخیف .",
"نظر شما در مورد داستان، فیلمنامه، دیالوگ ها و موضوع فیلم لونه زنبور چیست؟"
)
run_model(
"فیلم تا وسط فیلم یعنی دقیقا تا جایی که معلوم میشه بچه های املشی دنبال رضان خیلی خوب و جذاب پیش میره ولی دقیقا از همونجاش سکته میزنه و خلاص...",
"نظر شما به صورت کلی در مورد فیلم ژن خوک چیست؟"
)
run_model(
"اصلا به هیچ عنوان علاقه نداشتم اجرای می سی سی پی نشسته میمیرد روی پرده سینما ببینم دیالوگ های تکراری هلیکوپتر ماشین آلندلون لئون پاپیون آخه چرااااااااااااااا همون حسی که توی تالار وحدت بعد از نیم ساعت به سرم اومد امشب توی سالن سینما تجربه کردم ،حس گریز از سالن....... (ノಠ益ಠ)ノ ",
" نظر شما در مورد صداگذاری و جلوه های صوتی فیلم مسخرهباز چیست؟"
)
run_model(
" گول نخورید این رنگارنگ مینو نیست برای شرکت گرجیه و متاسفانه این محصولش اصلا مزه رنگارنگی که انتظار دارید رو نمیده ",
" نظر شما در مورد عطر، بو، و طعم این بیسکویت و ویفر چیست؟"
)
run_model(
"در مقایسه با سایر برندهای موجود در بازار با توجه به حراجی که داشت ارزانتر ب",
" شما در مورد قیمت و ارزش خرید این حبوبات و سویا چیست؟"
)
run_model(
"من پسرم عاشق ایناس ولی دیگه به خاطر حفظ محیط زیست فقط زمانهایی که مجبور باشم شیر دونه ای میخرم و سعی میکنم دیگه کمتر شیر با بسته بندی تتراپک استفاده کنم ",
"نظر شما به صورت کلی در مورد این شیر چیست؟"
)
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
|
persiannlp/parsbert-base-parsinlu-multiple-choice
|
a97e11816584b3eea9b17eeaff63dc00ec824a47
|
2021-09-23T16:20:53.000Z
|
[
"pytorch",
"jax",
"bert",
"multiple-choice",
"fa",
"multilingual",
"dataset:parsinlu",
"transformers",
"parsbert",
"persian",
"farsi",
"license:cc-by-nc-sa-4.0",
"text-classification"
] |
text-classification
| false |
persiannlp
| null |
persiannlp/parsbert-base-parsinlu-multiple-choice
| 83 | null |
transformers
| 4,965 |
---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- multiple-choice
- parsbert
- persian
- farsi
pipeline_tag: text-classification
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Multiple-Choice Question Answering (مدل برای پاسخ به سوالات چهار جوابی)
This is a parsbert-based model for multiple-choice question answering.
Here is an example of how you can run this model:
```python
from typing import List
import torch
from transformers import AutoConfig, AutoModelForMultipleChoice, AutoTokenizer
model_name = "persiannlp/parsbert-base-parsinlu-multiple-choice"
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForMultipleChoice.from_pretrained(model_name, config=config)
def run_model(question: str, candicates: List[str]):
assert len(candicates) == 4, "you need four candidates"
choices_inputs = []
for c in candicates:
text_a = "" # empty context
text_b = question + " " + c
inputs = tokenizer(
text_a,
text_b,
add_special_tokens=True,
max_length=128,
padding="max_length",
truncation=True,
return_overflowing_tokens=True,
)
choices_inputs.append(inputs)
input_ids = torch.LongTensor([x["input_ids"] for x in choices_inputs])
output = model(input_ids=input_ids)
print(output)
return output
run_model(question="وسیع ترین کشور جهان کدام است؟", candicates=["آمریکا", "کانادا", "روسیه", "چین"])
run_model(question="طامع یعنی ؟", candicates=["آزمند", "خوش شانس", "محتاج", "مطمئن"])
run_model(
question="زمینی به ۳۱ قطعه متساوی مفروض شده است و هر روز مساحت آماده شده برای احداث، دو برابر مساحت روز قبل است.اگر پس از (۵ روز) تمام زمین آماده شده باشد، در چه روزی یک قطعه زمین آماده شده ",
candicates=["روز اول", "روز دوم", "روز سوم", "هیچکدام"])
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
|
sreeramajay/pollution
|
6e4c26a68b8195ef8003d249813d79934b149b94
|
2021-07-03T07:05:10.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
sreeramajay
| null |
sreeramajay/pollution
| 83 | 1 |
transformers
| 4,966 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: pollution
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.7129629850387573
---
# pollution
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### air pollution

#### land pollution

#### water pollution

|
thak123/goan-fish-fry
|
f6aac0b124bd6f6f2e2c57cc4920927d35762bb3
|
2021-07-02T10:46:53.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
thak123
| null |
thak123/goan-fish-fry
| 83 | null |
transformers
| 4,967 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: goan-fish-fry
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.4583333432674408
---
# goan-fish-fry
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### king fish fry

#### mackerel fry

#### pomfret fry

#### prawn fish fry

#### squid fish fry

|
vivekRahul/animal_classifier_huggingface
|
aed061da9fc2e8c7c0fc54061e80d0688fb91d20
|
2021-07-25T06:02:38.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
vivekRahul
| null |
vivekRahul/animal_classifier_huggingface
| 83 | null |
transformers
| 4,968 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: animal_classifier_huggingface
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9910714030265808
---
# animal_classifier_huggingface
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### cat

#### dog

#### elephant

#### lion

#### tiger

|
hamedkhaledi/persain-flair-pos
|
1b18d8db47f93b5efc969cad8718dcd4a6748108
|
2022-03-27T22:26:53.000Z
|
[
"pytorch",
"fa",
"dataset:UPC-2017",
"flair",
"token-classification",
"sequence-tagger-model"
] |
token-classification
| false |
hamedkhaledi
| null |
hamedkhaledi/persain-flair-pos
| 83 | 1 |
flair
| 4,969 |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language: fa
datasets:
- UPC-2017
widget:
- text: "تمام ایران یک تابستان تنوری را تجربه میکند ."
---
## Persian Part-of-Speech Tagging in Flair
This is the part-of-speech tagging model for Persian that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **??** (UPC-2017)
List of Tags in UPC:
| **tag** | **meaning** |
|:--------:|:-----------------------:|
| ADJ | adjective |
| ADJ_CMPR | Comparative adjective |
| ADJ_INO | Participle adjective |
| ADJ_SUP | Superlative adjective |
| ADJ_VOC | Vocative adjective |
| ADV | Adverb |
| ADV_COMP | Adverb of comparison |
| ADV_I | Adverb of interrogation |
| ADV_LOC | Adverb of location |
| ADV_NEG | Adverb of negation |
| ADV_TIME | Adverb of time |
| CLITIC | Accusative marker |
| CON | Conjunction |
| DELM | Delimiter |
| DET | Determiner |
| FW | Foreign Word |
| INT | Interjection |
| N_PL | Plural noun |
| N_SING | Singular noun |
| NUM | Numeral |
| N_VOC | Vocative noun |
| P | Preposition |
| PREV | Preverbal particle |
| PRO | Pronoun |
| SYM | Symbol |
| V_AUX | Auxiliary verb |
| V_PA | Past tense verb |
| V_PP | Past participle verb |
| V_PRS | Present tense verb |
| V_SUB | Subjunctive verb |
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("hamedkhaledi/persain-flair-pos")
# make example sentence
sentence = Sentence("تمام ایران یک تابستان تنوری را تجربه میکند .")
tagger.predict(sentence)
# print result
print(sentence.to_tagged_string())
```
This yields the following output:
```
تمام <DET> ایران <N_SING> یک <NUM> تابستان <N_SING> تنوری <ADJ> را <CLITIC> تجربه <N_SING> میکند <V_PRS> . <DELM>
```
|
mojians/E2E-QA-Mining
|
7f23cc4e5b8ba5ebb90d79fa2c7ab629708fa69d
|
2022-04-10T02:34:53.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"dataset:squad",
"transformers",
"question-generation",
"question-answer mining",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
mojians
| null |
mojians/E2E-QA-Mining
| 83 | 1 |
transformers
| 4,970 |
---
datasets:
- squad
tags:
- question-generation
- question-answer mining
widget:
- text: "context: The English name 'Normans' comes from the French words Normans/Normanz, plural of Normant, modern French normand, which is itself borrowed from Old Low Franconian Nortmann 'Northman' or directly from Old Norse Norðmaðr, Latinized variously as Nortmannus, Normannus, or Nordmannus (recorded in Medieval Latin, 9th century) to mean 'Norseman, Viking'. generate questions and answers:"
inference:
parameters:
min_length: 50
license: mit
---
# Model name
## Model description
This model mines the question-answer pairs from a given context in an end2end fashion. It takes a context as an input and generates a list of questions and answers as an output. It is based on a pre-trained `t5-small` model and uses a prompt enigneering technique to train.
#### How to use
The model takes the context (with prompt) as an input sequence and will generate question-answer pairs as an output sequence. The max sequence length is 512 tokens. Inputs should be organized into the following format:
```
context: context text here. generate questions and answers:
```
The input sequence can then be encoded and passed as the `input_ids` argument in the model's `generate()` method.
You can try out the demo in the [E2E-QA-mining space app](https://huggingface.co/spaces/mojians/E2E-QA-mining)
#### Limitations and bias
The model is limited to generating questions in the same style as those found in [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), The generated questions can potentially be leading or reflect biases that are present in the context. If the context is too short or completely absent, or if the context and answer do not match, the generated question is likely to be incoherent.
## Training data
The model was fine-tuned on a dataset made up of several well-known QA datasets ([SQuAD](https://rajpurkar.github.io/SQuAD-explorer/))
## Source and Citation
Please find our code and cite us in this repo [https://github.com/jian-mo/E2E-QA-Mining](https://github.com/jian-mo/E2E-QA-Mining)
|
jaygala24/finetuned-vit-base-patch16-224-upside-down-detector
|
6d3e260801fa016711309ddda6a6a0f73a5c0c10
|
2022-04-02T15:24:57.000Z
|
[
"pytorch",
"vit",
"image-classification",
"transformers",
"accelerator",
"license:apache-2.0",
"model-index"
] |
image-classification
| false |
jaygala24
| null |
jaygala24/finetuned-vit-base-patch16-224-upside-down-detector
| 83 | null |
transformers
| 4,971 |
---
license: apache-2.0
tags:
- accelerator
metrics:
- accuracy
model-index:
- name: finetuned-vit-base-patch16-224-upside-down-detector
results: []
widget:
- src: https://huggingface.co/jaygala24/finetuned-vit-base-patch16-224-upside-down-detector/resolve/main/original.jpg
example_title: original
- src: https://huggingface.co/jaygala24/finetuned-vit-base-patch16-224-upside-down-detector/resolve/main/upside_down.jpg
example_title: upside_down
---
# finetuned-vit-base-patch16-224-upside-down-detector
This model is a fine-tuned version of [vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the custom image orientation dataset adapted from the [beans](https://huggingface.co/datasets/beans) dataset. It achieves the following results on the evaluation set:
- Accuracy: 0.8947
## Training and evaluation data
The custom dataset for image orientation adapted from [beans](https://huggingface.co/datasets/beans) dataset contains a total of 2,590 image samples with 1,295 original and 1,295 upside down. The model was fine-tuned on the train subset and evaluated on validation and test subsets. The dataset splits are listed below:
| Split | # examples |
|:----------:|:----------:|
| train | 2068 |
| validation | 133 |
| test | 128 |
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-04
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 32
- num_epochs: 5
### Training results
| Epoch | Accuracy |
|:----------:|:----------:|
| 0 | 0.8609 |
| 1 | 0.8835 |
| 2 | 0.8571 |
| 3 | 0.8941 |
| 4 | 0.8941 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.9.0+cu111
- Pytorch/XLA 1.9
- Datasets 2.0.0
- Tokenizers 0.12.0
|
yangy50/garbage-classification
|
9bfbbceba2d807df5c8c6f1546ffa48086eb28b2
|
2022-04-25T22:55:50.000Z
|
[
"pytorch",
"vit",
"image-classification",
"arxiv:2010.11929",
"transformers"
] |
image-classification
| false |
yangy50
| null |
yangy50/garbage-classification
| 83 | null |
transformers
| 4,972 |
# Garbage Classification
## Overview
### Backgroud
Garbage classification refers to the separation of several types of different categories in accordance with the environmental impact of the use of the value of the composition of garbage components and the requirements of existing treatment methods.
The significance of garbage classification:
1. Garbage classification reduces the mutual pollution between different garbage, which is beneficial to the recycling of materials.
2. Garbage classification is conducive to reducing the final waste disposal volume.
3. Garbage classification is conducive to enhancing the degree of social civilization.
### Dataset
The garbage classification dataset is from Kaggle. There are totally 2467 pictures in this dataset. And this model is an image classification model for this dataset. There are 6 classes for this dataset, which are cardboard (393), glass (491), metal (400), paper(584), plastic (472), and trash(127).
### Model
The model is based on the [ViT](https://huggingface.co/google/vit-base-patch16-224-in21k) model, which is short for the Vision Transformer. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929), which was introduced in June 2021 by a team of researchers at Google Brain. And first released in [this repository](https://github.com/rwightman/pytorch-image-models). I trained this model with PyTorch. I think the most different thing between using the transformer to train on an image and on a text is in the tokenizing step.
There are 3 steps to tokenize the image:
1. Split an image into a grid of sub-image patches
2. Embed each patch with a linear projection
3. Each embedded patch becomes a token, and the resulting sequence of embedded patches is the sequence you pass to the model.
I trained the model with 10 epochs, and I use Adam as the optimizer. The accuracy on the test set is 95%.
## Huggingface Space
Huggingface space is [here](https://huggingface.co/yangy50/garbage-classification).
## Huggingface Model Card
Huggingface model card is [here](https://huggingface.co/yangy50/garbage-classification/tree/main).
## Critical Analysis
1. Next step: build a CNN model on this dataset and compare the accuracy and training time for these two models.
2. Didn’t use the Dataset package to store the image data. Want to find out how to use the Dataset package to handle image data.
## Resource Links
[vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k)
[Garbage dataset](https://huggingface.co/cardiffnlp/twitter-roberta-base)
[An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
## Code Demo
[Code Demo](https://github.com/yuechen-yang/garbage-classification) is inside this repo
## Repo
In this repo
## Video Recording
|
naver/splade-cocondenser-selfdistil
|
0f718e09b0540c68c15c5c2b50de731b6e89090a
|
2022-05-11T08:02:55.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"en",
"dataset:ms_marco",
"arxiv:2205.04733",
"transformers",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
naver
| null |
naver/splade-cocondenser-selfdistil
| 83 | 5 |
transformers
| 4,973 |
---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
datasets:
- ms_marco
---
## SPLADE CoCondenser SelfDistil
SPLADE model for passage retrieval. For additional details, please visit:
* paper: https://arxiv.org/abs/2205.04733
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) |
| --- | --- | --- |
| `splade-cocondenser-selfdistil` | 37.6 | 98.4 |
## Citation
If you use our checkpoint, please cite our work:
```
@misc{https://doi.org/10.48550/arxiv.2205.04733,
doi = {10.48550/ARXIV.2205.04733},
url = {https://arxiv.org/abs/2205.04733},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
```
|
nateraw/vit-base-food101
|
977c7a15b0a1d5775c412d99325894474f695b74
|
2022-05-10T03:40:35.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers"
] |
image-classification
| false |
nateraw
| null |
nateraw/vit-base-food101
| 83 | null |
transformers
| 4,974 |
Entry not found
|
YSU/aspram
|
1d31728083d761274b65cd8e6d0b520eaea453ba
|
2022-05-19T12:24:13.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"hy",
"hy-AM",
"hye",
"dataset:mozilla-foundation/common_voice_9_0",
"dataset:google/fleurs",
"dataset:mc4",
"transformers",
"mozilla-foundation/common_voice_9_0",
"google/fleurs",
"license:apache-2.0"
] |
automatic-speech-recognition
| false |
YSU
| null |
YSU/aspram
| 83 | 2 |
transformers
| 4,975 |
---
language:
- hy
- hy-AM
- hye
license: apache-2.0
tags:
- automatic-speech-recognition
- hy
- mozilla-foundation/common_voice_9_0
- google/fleurs
models:
- facebook/wav2vec2-xls-r-2b
datasets:
- mozilla-foundation/common_voice_9_0
- google/fleurs
- mc4
task_categories:
- automatic-speech-recognition
- speech-processing
task_ids:
- speech-recognition
---
# Automatic SPeech Recognition for ArMenian
TODO Model details
|
drhyrum/bert-tiny-torch-vuln
|
753c3cb70db0705e814b400330028ad5335246d3
|
2022-07-07T19:17:08.000Z
|
[
"pytorch",
"bert",
"en",
"arxiv:1908.08962",
"arxiv:2110.01518",
"transformers",
"BERT",
"MNLI",
"NLI",
"transformer",
"pre-training",
"license:mit"
] | null | false |
drhyrum
| null |
drhyrum/bert-tiny-torch-vuln
| 83 | 1 |
transformers
| 4,976 |
---
language:
- en
license:
- mit
tags:
- BERT
- MNLI
- NLI
- transformer
- pre-training
---
The following model is a Pytorch pre-trained model obtained from converting Tensorflow checkpoint found in the [official Google BERT repository](https://github.com/google-research/bert).
This is one of the smaller pre-trained BERT variants, together with [bert-mini](https://huggingface.co/prajjwal1/bert-mini) [bert-small](https://huggingface.co/prajjwal1/bert-small) and [bert-medium](https://huggingface.co/prajjwal1/bert-medium). They were introduced in the study `Well-Read Students Learn Better: On the Importance of Pre-training Compact Models` ([arxiv](https://arxiv.org/abs/1908.08962)), and ported to HF for the study `Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics` ([arXiv](https://arxiv.org/abs/2110.01518)). These models are supposed to be trained on a downstream task.
If you use the model, please consider citing both the papers:
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{DBLP:journals/corr/abs-1908-08962,
author = {Iulia Turc and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {Well-Read Students Learn Better: The Impact of Student Initialization
on Knowledge Distillation},
journal = {CoRR},
volume = {abs/1908.08962},
year = {2019},
url = {http://arxiv.org/abs/1908.08962},
eprinttype = {arXiv},
eprint = {1908.08962},
timestamp = {Thu, 29 Aug 2019 16:32:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1908-08962.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Config of this model:
- `prajjwal1/bert-tiny` (L=2, H=128) [Model Link](https://huggingface.co/prajjwal1/bert-tiny)
Other models to check out:
- `prajjwal1/bert-mini` (L=4, H=256) [Model Link](https://huggingface.co/prajjwal1/bert-mini)
- `prajjwal1/bert-small` (L=4, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-small)
- `prajjwal1/bert-medium` (L=8, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-medium)
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
Twitter: [@prajjwal_1](https://twitter.com/prajjwal_1)
|
arminmehrabian/distilgpt2-finetuned-wikitext2-agu
|
596eefbc2b8f3f223849e9afff5abe16c5b69cc5
|
2022-07-30T04:08:38.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-generation
| false |
arminmehrabian
| null |
arminmehrabian/distilgpt2-finetuned-wikitext2-agu
| 83 | 1 |
transformers
| 4,977 |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-wikitext2-agu
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2-agu
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3055
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 3.7357 | 1.0 | 13655 | 3.6781 |
| 3.5721 | 2.0 | 27310 | 3.5302 |
| 3.4961 | 3.0 | 40965 | 3.4658 |
| 3.4406 | 4.0 | 54620 | 3.4242 |
| 3.4043 | 5.0 | 68275 | 3.3943 |
| 3.3789 | 6.0 | 81930 | 3.3726 |
| 3.3576 | 7.0 | 95585 | 3.3538 |
| 3.3389 | 8.0 | 109240 | 3.3389 |
| 3.3151 | 9.0 | 122895 | 3.3270 |
| 3.314 | 5.0 | 136545 | 3.3226 |
| 3.3044 | 6.0 | 163854 | 3.3124 |
| 3.2931 | 7.0 | 191163 | 3.3078 |
| 3.2874 | 8.0 | 218472 | 3.3055 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
nielsr/donut-base
|
905659914224a88ac7f934281c333befd3fbd649
|
2022-07-26T09:09:36.000Z
|
[
"pytorch",
"vision-encoder-decoder",
"transformers"
] | null | false |
nielsr
| null |
nielsr/donut-base
| 83 | null |
transformers
| 4,978 |
Entry not found
|
ckb/c-deobfuscate-mt
|
2afcaa6025db3e1fad3d276ec71949eda6b26483
|
2022-07-29T02:49:31.000Z
|
[
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false |
ckb
| null |
ckb/c-deobfuscate-mt
| 83 | null |
transformers
| 4,979 |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: c-deobfuscate-mt
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# c-deobfuscate-mt
This model is a fine-tuned version of [Salesforce/codet5-base](https://huggingface.co/Salesforce/codet5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.5207
- eval_bleu: 65.8038
- eval_gen_len: 266.6
- eval_runtime: 13.5258
- eval_samples_per_second: 1.109
- eval_steps_per_second: 0.148
- epoch: 40.0
- step: 960
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Amrrs/south-indian-foods
|
757e34748641041c8c7a88c2235fb3cdab6ceacb
|
2021-07-20T18:22:24.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
Amrrs
| null |
Amrrs/south-indian-foods
| 82 | null |
transformers
| 4,980 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: south-indian-foods
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.875
---
# south-indian-foods
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### dosai

#### idiyappam

#### idli

#### puttu

#### vadai

|
Davlan/bert-base-multilingual-cased-finetuned-amharic
|
90283498970edd0fe6af2f094f5f25d61e525ebd
|
2021-06-02T12:37:53.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"am",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
Davlan
| null |
Davlan/bert-base-multilingual-cased-finetuned-amharic
| 82 | null |
transformers
| 4,981 |
Hugging Face's logo
---
language: am
datasets:
---
# bert-base-multilingual-cased-finetuned-amharic
## Model description
**bert-base-multilingual-cased-finetuned-amharic** is a **Amharic BERT** model obtained by replacing mBERT vocabulary by amharic vocabulary because the language was not supported, and fine-tuning **bert-base-multilingual-cased** model on Amharic language texts. It provides **better performance** than the multilingual Amharic on named entity recognition datasets.
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on Amharic corpus using Amharic vocabulary.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/bert-base-multilingual-cased-finetuned-amharic')
>>> unmasker("የአሜሪካ የአፍሪካ ቀንድ ልዩ መልዕክተኛ ጄፈሪ ፌልትማን በአራት አገራት የሚያደጉትን [MASK] መጀመራቸውን የአሜሪካ የውጪ ጉዳይ ሚንስቴር አስታወቀ።")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on [Amharic CC-100](http://data.statmt.org/cc-100/)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| mBERT F1 | am_bert F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 0.0 | 60.89
### BibTeX entry and citation info
By David Adelani
```
```
|
Helsinki-NLP/opus-mt-fr-id
|
03aa1793243ef305e007d30388744fb59b95051b
|
2021-09-09T21:54:31.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"fr",
"id",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-fr-id
| 82 | null |
transformers
| 4,982 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-fr-id
* source languages: fr
* target languages: id
* OPUS readme: [fr-id](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-id/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-id/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-id/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-id/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.fr.id | 37.2 | 0.636 |
|
Helsinki-NLP/opus-mt-it-ar
|
894b5e96a86f86b7ac1594fc14b247df05e0ee1e
|
2020-08-21T14:42:46.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"it",
"ar",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-it-ar
| 82 | null |
transformers
| 4,983 |
---
language:
- it
- ar
tags:
- translation
license: apache-2.0
---
### ita-ara
* source group: Italian
* target group: Arabic
* OPUS readme: [ita-ara](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-ara/README.md)
* model: transformer
* source language(s): ita
* target language(s): ara
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-07-03.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-ara/opus-2020-07-03.zip)
* test set translations: [opus-2020-07-03.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-ara/opus-2020-07-03.test.txt)
* test set scores: [opus-2020-07-03.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-ara/opus-2020-07-03.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ita.ara | 21.9 | 0.517 |
### System Info:
- hf_name: ita-ara
- source_languages: ita
- target_languages: ara
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-ara/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['it', 'ar']
- src_constituents: {'ita'}
- tgt_constituents: {'apc', 'ara', 'arq_Latn', 'arq', 'afb', 'ara_Latn', 'apc_Latn', 'arz'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ita-ara/opus-2020-07-03.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ita-ara/opus-2020-07-03.test.txt
- src_alpha3: ita
- tgt_alpha3: ara
- short_pair: it-ar
- chrF2_score: 0.517
- bleu: 21.9
- brevity_penalty: 0.95
- ref_len: 1161.0
- src_name: Italian
- tgt_name: Arabic
- train_date: 2020-07-03
- src_alpha2: it
- tgt_alpha2: ar
- prefer_old: False
- long_pair: ita-ara
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-ja-ru
|
46386a5e83ca1df32e809077547aea08198f9317
|
2020-08-21T14:42:47.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ja",
"ru",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ja-ru
| 82 | null |
transformers
| 4,984 |
---
language:
- ja
- ru
tags:
- translation
license: apache-2.0
---
### jpn-rus
* source group: Japanese
* target group: Russian
* OPUS readme: [jpn-rus](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/jpn-rus/README.md)
* model: transformer-align
* source language(s): jpn jpn_Bopo jpn_Hani jpn_Hira jpn_Kana jpn_Latn jpn_Yiii
* target language(s): rus
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-rus/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-rus/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-rus/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.jpn.rus | 23.2 | 0.441 |
### System Info:
- hf_name: jpn-rus
- source_languages: jpn
- target_languages: rus
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/jpn-rus/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ja', 'ru']
- src_constituents: {'jpn_Hang', 'jpn', 'jpn_Yiii', 'jpn_Kana', 'jpn_Hani', 'jpn_Bopo', 'jpn_Latn', 'jpn_Hira'}
- tgt_constituents: {'rus'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-rus/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/jpn-rus/opus-2020-06-17.test.txt
- src_alpha3: jpn
- tgt_alpha3: rus
- short_pair: ja-ru
- chrF2_score: 0.441
- bleu: 23.2
- brevity_penalty: 0.9740000000000001
- ref_len: 70820.0
- src_name: Japanese
- tgt_name: Russian
- train_date: 2020-06-17
- src_alpha2: ja
- tgt_alpha2: ru
- prefer_old: False
- long_pair: jpn-rus
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-vi-fr
|
d2d4e2e848ae77f77103428f6fe797bd5f9904e8
|
2020-08-21T14:42:51.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"vi",
"fr",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-vi-fr
| 82 | null |
transformers
| 4,985 |
---
language:
- vi
- fr
tags:
- translation
license: apache-2.0
---
### vie-fra
* source group: Vietnamese
* target group: French
* OPUS readme: [vie-fra](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-fra/README.md)
* model: transformer-align
* source language(s): vie
* target language(s): fra
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-fra/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-fra/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-fra/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.vie.fra | 34.2 | 0.544 |
### System Info:
- hf_name: vie-fra
- source_languages: vie
- target_languages: fra
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-fra/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['vi', 'fr']
- src_constituents: {'vie', 'vie_Hani'}
- tgt_constituents: {'fra'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-fra/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-fra/opus-2020-06-17.test.txt
- src_alpha3: vie
- tgt_alpha3: fra
- short_pair: vi-fr
- chrF2_score: 0.544
- bleu: 34.2
- brevity_penalty: 0.955
- ref_len: 11519.0
- src_name: Vietnamese
- tgt_name: French
- train_date: 2020-06-17
- src_alpha2: vi
- tgt_alpha2: fr
- prefer_old: False
- long_pair: vie-fra
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
LeBenchmark/wav2vec2-FR-3K-large
|
84bcdf4e561f53723623cd139dc70462380072ae
|
2021-11-26T20:35:33.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"feature-extraction",
"fr",
"transformers",
"license:apache-2.0"
] |
feature-extraction
| false |
LeBenchmark
| null |
LeBenchmark/wav2vec2-FR-3K-large
| 82 | null |
transformers
| 4,986 |
---
language: "fr"
thumbnail:
tags:
- wav2vec2
license: "apache-2.0"
---
# LeBenchmark: wav2vec2 large model trained on 3K hours of French speech
LeBenchmark provides an ensemble of pretrained wav2vec2 models on different French dataset containing spontaneous, read and broadcasted speech. For more information on the different benchmark that can be used to evaluate the wav2vec2 models, please refer to our paper at: [Task Agnostic and Task Specific Self-Supervised Learning from Speech with LeBenchmark](https://openreview.net/pdf?id=TSvj5dmuSd)
## Model and data descriptions
We release four different models that can be found under our HuggingFace organisation. Two different wav2vec2 architectures *Base* and *Large* are coupled with our small (*S*) and medium (*M*) corpus. A larger one shoud come later. In short:
- [wav2vec2-FR-M-Large](#): Large wav2vec2 trained on 2.9K hours of French speech (1.8K Males / 1.0K Females / 0.1K unknown).
- [wav2vec2-FR-M-Base](https://huggingface.co/LeBenchmark/wav2vec2-FR-M-base): Base wav2vec2 trained on 2.9K hours of French speech (1.8K Males / 1.0K Females / 0.1K unknown).
- [wav2vec2-FR-S-Large](https://huggingface.co/LeBenchmark/wav2vec2-FR-S-large): Large wav2vec2 trained on 1K hours of French speech (0.5K Males / 0.5K Females).
- [wav2vec2-FR-S-Base](https://huggingface.co/LeBenchmark/wav2vec2-FR-S-base): Base wav2vec2 trained on 1K hours of French speech (0.5K Males / 0.5K Females).
## Intended uses & limitations
Pretrained wav2vec2 models are distributed under the apache-2.0 licence. Hence, they can be reused extensively without strict limitations. However, benchmarks and data may be linked to corpus that are not completely open-sourced.
## Fine-tune with Fairseq for ASR with CTC
As our wav2vec2 models were trained with Fairseq, then can be used in the different tools that they provide to fine-tune the model for ASR with CTC. The full procedure has been nicely summarized in [this blogpost](https://huggingface.co/blog/fine-tune-wav2vec2-english).
Please note that due to the nature of CTC, speech-to-text results aren't expected to be state-of-the-art. Moreover, future features might appear depending on the involvement of Fairseq and HuggingFace on this part.
## Integrate to SpeechBrain for ASR, Speaker, Source Separation ...
Pretrained wav2vec models recently gained in popularity. At the same time [SpeechBrain toolkit](https://speechbrain.github.io) came out, proposing a new and simpler way of dealing with state-of-the-art speech & deep-learning technologies.
While it currently is in beta, SpeechBrain offers two different ways of nicely integrating wav2vec2 models that were trained with Fairseq i.e our LeBenchmark models!
1. Extract wav2vec2 features on-the-fly (with a frozen wav2vec2 encoder) to be combined with any speech related architecture. Examples are: E2E ASR with CTC+Att+Language Models; Speaker Recognition or Verification, Source Separation ...
2. *Experimental:* To fully benefit from wav2vec2, the best solution remains to fine-tune the model while you train your downstream task. This is very simply allowed within SpeechBrain as just a flag needs to be turned on. Thus, our wav2vec2 models can be fine-tuned while training your favorite ASR pipeline or Speaker Recognizer.
**If interested, simply follow this [tutorial](https://colab.research.google.com/drive/17Hu1pxqhfMisjkSgmM2CnZxfqDyn2hSY?usp=sharing)**
## Referencing LeBenchmark
```
Reference to come
```
|
Narrativa/mbart-large-50-finetuned-opus-en-pt-translation
|
6558673ba6383ba816acf621d9cc6be5751460f6
|
2021-06-21T11:07:11.000Z
|
[
"pytorch",
"mbart",
"text2text-generation",
"en",
"pt",
"dataset:opus100",
"dataset:opusbook",
"arxiv:2008.00401",
"arxiv:2004.11867",
"transformers",
"translation",
"autotrain_compatible"
] |
translation
| false |
Narrativa
| null |
Narrativa/mbart-large-50-finetuned-opus-en-pt-translation
| 82 | 1 |
transformers
| 4,987 |
---
language:
- en
- pt
datasets:
- opus100
- opusbook
tags:
- translation
metrics:
- bleu
---
# mBART-large-50 fine-tuned onpus100 and opusbook for English to Portuguese translation.
[mBART-50](https://huggingface.co/facebook/mbart-large-50/) large fine-tuned on [opus100](https://huggingface.co/datasets/viewer/?dataset=opus100) dataset for **NMT** downstream task.
# Details of mBART-50 🧠
mBART-50 is a multilingual Sequence-to-Sequence model pre-trained using the "Multilingual Denoising Pretraining" objective. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
mBART-50 is a multilingual Sequence-to-Sequence model. It was created to show that multilingual translation models can be created through multilingual fine-tuning.
Instead of fine-tuning on one direction, a pre-trained model is fine-tuned many directions simultaneously. mBART-50 is created using the original mBART model and extended to add extra 25 languages to support multilingual machine translation models of 50 languages. The pre-training objective is explained below.
**Multilingual Denoising Pretraining**: The model incorporates N languages by concatenating data:
`D = {D1, ..., DN }` where each Di is a collection of monolingual documents in language `i`. The source documents are noised using two schemes,
first randomly shuffling the original sentences' order, and second a novel in-filling scheme,
where spans of text are replaced with a single mask token. The model is then tasked to reconstruct the original text.
35% of each instance's words are masked by random sampling a span length according to a Poisson distribution `(λ = 3.5)`.
The decoder input is the original text with one position offset. A language id symbol `LID` is used as the initial token to predict the sentence.
## Details of the downstream task (NMT) - Dataset 📚
- **Homepage:** [Link](http://opus.nlpl.eu/opus-100.php)
- **Repository:** [GitHub](https://github.com/EdinburghNLP/opus-100-corpus)
- **Paper:** [ARXIV](https://arxiv.org/abs/2004.11867)
### Dataset Summary
OPUS-100 is English-centric, meaning that all training pairs include English on either the source or target side. The corpus covers 100 languages (including English). Languages were selected based on the volume of parallel data available in OPUS.
### Languages
OPUS-100 contains approximately 55M sentence pairs. Of the 99 language pairs, 44 have 1M sentence pairs of training data, 73 have at least 100k, and 95 have at least 10k.
## Dataset Structure
### Data Fields
- `src_tag`: `string` text in source language
- `tgt_tag`: `string` translation of source language in target language
### Data Splits
The dataset is split into training, development, and test portions. Data was prepared by randomly sampled up to 1M sentence pairs per language pair for training and up to 2000 each for development and test. To ensure that there was no overlap (at the monolingual sentence level) between the training and development/test data, they applied a filter during sampling to exclude sentences that had already been sampled. Note that this was done cross-lingually so that, for instance, an English sentence in the Portuguese-English portion of the training data could not occur in the Hindi-English test set.
## Test set metrics 🧾
We got a **BLEU score of 20.61**
## Model in Action 🚀
```sh
git clone https://github.com/huggingface/transformers.git
pip install -q ./transformers
```
```python
from transformers import MBart50TokenizerFast, MBartForConditionalGeneration
ckpt = 'Narrativa/mbart-large-50-finetuned-opus-en-pt-translation'
tokenizer = MBart50TokenizerFast.from_pretrained(ckpt)
model = MBartForConditionalGeneration.from_pretrained(ckpt).to("cuda")
tokenizer.src_lang = 'en_XX'
def translate(text):
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs.input_ids.to('cuda')
attention_mask = inputs.attention_mask.to('cuda')
output = model.generate(input_ids, attention_mask=attention_mask, forced_bos_token_id=tokenizer.lang_code_to_id['pt_XX'])
return tokenizer.decode(output[0], skip_special_tokens=True)
translate('here your English text to be translated to Portuguese...')
```
Created by: [Narrativa](https://www.narrativa.com/)
About Narrativa: Natural Language Generation (NLG) | Gabriele, our machine learning-based platform, builds and deploys natural language solutions. #NLG #AI
|
Narrativa/mbart-large-50-finetuned-opus-pt-en-translation
|
764997c29e8d47c7d23c77fb0339a75a0d2fd722
|
2021-06-21T11:16:19.000Z
|
[
"pytorch",
"mbart",
"text2text-generation",
"pt",
"en",
"dataset:opus100",
"dataset:opusbook",
"arxiv:2008.00401",
"arxiv:2004.11867",
"transformers",
"translation",
"autotrain_compatible"
] |
translation
| false |
Narrativa
| null |
Narrativa/mbart-large-50-finetuned-opus-pt-en-translation
| 82 | null |
transformers
| 4,988 |
---
language:
- pt
- en
datasets:
- opus100
- opusbook
tags:
- translation
metrics:
- bleu
---
# mBART-large-50 fine-tuned onpus100 and opusbook for Portuguese to English translation.
[mBART-50](https://huggingface.co/facebook/mbart-large-50/) large fine-tuned on [opus100](https://huggingface.co/datasets/viewer/?dataset=opus100) dataset for **NMT** downstream task.
# Details of mBART-50 🧠
mBART-50 is a multilingual Sequence-to-Sequence model pre-trained using the "Multilingual Denoising Pretraining" objective. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
mBART-50 is a multilingual Sequence-to-Sequence model. It was created to show that multilingual translation models can be created through multilingual fine-tuning.
Instead of fine-tuning on one direction, a pre-trained model is fine-tuned many directions simultaneously. mBART-50 is created using the original mBART model and extended to add extra 25 languages to support multilingual machine translation models of 50 languages. The pre-training objective is explained below.
**Multilingual Denoising Pretraining**: The model incorporates N languages by concatenating data:
`D = {D1, ..., DN }` where each Di is a collection of monolingual documents in language `i`. The source documents are noised using two schemes,
first randomly shuffling the original sentences' order, and second a novel in-filling scheme,
where spans of text are replaced with a single mask token. The model is then tasked to reconstruct the original text.
35% of each instance's words are masked by random sampling a span length according to a Poisson distribution `(λ = 3.5)`.
The decoder input is the original text with one position offset. A language id symbol `LID` is used as the initial token to predict the sentence.
## Details of the downstream task (NMT) - Dataset 📚
- **Homepage:** [Link](http://opus.nlpl.eu/opus-100.php)
- **Repository:** [GitHub](https://github.com/EdinburghNLP/opus-100-corpus)
- **Paper:** [ARXIV](https://arxiv.org/abs/2004.11867)
### Dataset Summary
OPUS-100 is English-centric, meaning that all training pairs include English on either the source or target side. The corpus covers 100 languages (including English). Languages were selected based on the volume of parallel data available in OPUS.
### Languages
OPUS-100 contains approximately 55M sentence pairs. Of the 99 language pairs, 44 have 1M sentence pairs of training data, 73 have at least 100k, and 95 have at least 10k.
## Dataset Structure
### Data Fields
- `src_tag`: `string` text in source language
- `tgt_tag`: `string` translation of source language in target language
### Data Splits
The dataset is split into training, development, and test portions. Data was prepared by randomly sampled up to 1M sentence pairs per language pair for training and up to 2000 each for development and test. To ensure that there was no overlap (at the monolingual sentence level) between the training and development/test data, they applied a filter during sampling to exclude sentences that had already been sampled. Note that this was done cross-lingually so that, for instance, an English sentence in the Portuguese-English portion of the training data could not occur in the Hindi-English test set.
## Test set metrics 🧾
We got a **BLEU score of 26.12**
## Model in Action 🚀
```sh
git clone https://github.com/huggingface/transformers.git
pip install -q ./transformers
```
```python
from transformers import MBart50TokenizerFast, MBartForConditionalGeneration
ckpt = 'Narrativa/mbart-large-50-finetuned-opus-pt-en-translation'
tokenizer = MBart50TokenizerFast.from_pretrained(ckpt)
model = MBartForConditionalGeneration.from_pretrained(ckpt).to("cuda")
tokenizer.src_lang = 'pt_XX'
def translate(text):
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs.input_ids.to('cuda')
attention_mask = inputs.attention_mask.to('cuda')
output = model.generate(input_ids, attention_mask=attention_mask, forced_bos_token_id=tokenizer.lang_code_to_id['en_XX'])
return tokenizer.decode(output[0], skip_special_tokens=True)
translate('here your Portuguese text to be translated to English...')
```
Created by: [Narrativa](https://www.narrativa.com/)
About Narrativa: Natural Language Generation (NLG) | Gabriele, our machine learning-based platform, builds and deploys natural language solutions. #NLG #AI
|
SkelterLabsInc/bert-base-japanese-jaquad
|
7bd5402cab37743c5c989e0773e92cf8089a8c5a
|
2022-02-04T02:39:25.000Z
|
[
"pytorch",
"bert",
"question-answering",
"ja",
"dataset:SkelterLabsInc/JaQuAD",
"arxiv:2202.01764",
"transformers",
"extractive-qa",
"license:cc-by-sa-3.0",
"autotrain_compatible"
] | null | false |
SkelterLabsInc
| null |
SkelterLabsInc/bert-base-japanese-jaquad
| 82 | 1 |
transformers
| 4,989 |
---
license: cc-by-sa-3.0
language: ja
tags:
- question-answering
- extractive-qa
pipeline_tag:
- None
datasets:
- SkelterLabsInc/JaQuAD
metrics:
- Exact match
- F1 score
---
# BERT base Japanese - JaQuAD
## Description
A Japanese Question Answering model fine-tuned on [JaQuAD](https://huggingface.co/datasets/SkelterLabsInc/JaQuAD).
Please refer [BERT base Japanese](https://huggingface.co/cl-tohoku/bert-base-japanese) for details about the pre-training model.
The codes for the fine-tuning are available at [SkelterLabsInc/JaQuAD](https://github.com/SkelterLabsInc/JaQuAD)
## Evaluation results
On the development set.
```shell
{"f1": 77.35, "exact_match": 61.01}
```
On the test set.
```shell
{"f1": 78.92, "exact_match": 63.38}
```
## Usage
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
question = 'アレクサンダー・グラハム・ベルは、どこで生まれたの?'
context = 'アレクサンダー・グラハム・ベルは、スコットランド生まれの科学者、発明家、工学者である。世界初の>実用的電話の発明で知られている。'
model = AutoModelForQuestionAnswering.from_pretrained(
'SkelterLabsInc/bert-base-japanese-jaquad')
tokenizer = AutoTokenizer.from_pretrained(
'SkelterLabsInc/bert-base-japanese-jaquad')
inputs = tokenizer(
question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score.
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score.
# 1 is added to `answer_end` because the index pointed by score is inclusive.
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
# answer = 'スコットランド'
```
## License
The fine-tuned model is licensed under the [CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/) license.
## Citation
```bibtex
@misc{so2022jaquad,
title={{JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension}},
author={ByungHoon So and Kyuhong Byun and Kyungwon Kang and Seongjin Cho},
year={2022},
eprint={2202.01764},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
SriramSridhar78/sriram-car-classifier
|
acd0d25f394630bd42d8588bf95cee633f7fdff3
|
2022-01-26T16:04:18.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
SriramSridhar78
| null |
SriramSridhar78/sriram-car-classifier
| 82 | 1 |
transformers
| 4,990 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: sriram-car-classifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8271908164024353
---
# sriram-car-classifier
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### AM_General_Hummer_SUV_2000

#### Acura_Integra_Type_R_2001

#### Acura_RL_Sedan_2012

#### Acura_TL_Sedan_2012

#### Acura_TL_Type-S_2008

#### Acura_TSX_Sedan_2012

#### Acura_ZDX_Hatchback_2012

#### Aston_Martin_V8_Vantage_Convertible_2012

#### Aston_Martin_V8_Vantage_Coupe_2012

#### Aston_Martin_Virage_Convertible_2012

#### Aston_Martin_Virage_Coupe_2012

#### Audi_100_Sedan_1994

#### Audi_100_Wagon_1994

#### Audi_A5_Coupe_2012

#### Audi_R8_Coupe_2012

#### Audi_RS_4_Convertible_2008

#### Audi_S4_Sedan_2007

#### Audi_S4_Sedan_2012

#### Audi_S5_Convertible_2012

#### Audi_S5_Coupe_2012

#### Audi_S6_Sedan_2011

#### Audi_TTS_Coupe_2012

#### Audi_TT_Hatchback_2011

#### Audi_TT_RS_Coupe_2012

#### Audi_V8_Sedan_1994

#### BMW_1_Series_Convertible_2012

#### BMW_1_Series_Coupe_2012

#### BMW_3_Series_Sedan_2012

#### BMW_3_Series_Wagon_2012

#### BMW_6_Series_Convertible_2007

#### BMW_ActiveHybrid_5_Sedan_2012

#### BMW_M3_Coupe_2012

#### BMW_M5_Sedan_2010

#### BMW_M6_Convertible_2010

#### BMW_X3_SUV_2012

#### BMW_X5_SUV_2007

#### BMW_X6_SUV_2012

#### BMW_Z4_Convertible_2012

#### Bentley_Arnage_Sedan_2009

#### Bentley_Continental_Flying_Spur_Sedan_2007

#### Bentley_Continental_GT_Coupe_2007

#### Bentley_Continental_GT_Coupe_2012

#### Bentley_Continental_Supersports_Conv._Convertible_2012

#### Bentley_Mulsanne_Sedan_2011

#### Bugatti_Veyron_16.4_Convertible_2009

#### Bugatti_Veyron_16.4_Coupe_2009

#### Buick_Enclave_SUV_2012

#### Buick_Rainier_SUV_2007

#### Buick_Regal_GS_2012

#### Buick_Verano_Sedan_2012

#### Cadillac_CTS-V_Sedan_2012

#### Cadillac_Escalade_EXT_Crew_Cab_2007

#### Cadillac_SRX_SUV_2012

#### Chevrolet_Avalanche_Crew_Cab_2012

#### Chevrolet_Camaro_Convertible_2012

#### Chevrolet_Cobalt_SS_2010

#### Chevrolet_Corvette_Convertible_2012

#### Chevrolet_Corvette_Ron_Fellows_Edition_Z06_2007

#### Chevrolet_Corvette_ZR1_2012

#### Chevrolet_Express_Cargo_Van_2007

#### Chevrolet_Express_Van_2007

#### Chevrolet_HHR_SS_2010

#### Chevrolet_Impala_Sedan_2007

#### Chevrolet_Malibu_Hybrid_Sedan_2010

#### Chevrolet_Malibu_Sedan_2007

#### Chevrolet_Monte_Carlo_Coupe_2007

#### Chevrolet_Silverado_1500_Classic_Extended_Cab_2007

#### Chevrolet_Silverado_1500_Extended_Cab_2012

#### Chevrolet_Silverado_1500_Hybrid_Crew_Cab_2012

#### Chevrolet_Silverado_1500_Regular_Cab_2012

#### Chevrolet_Silverado_2500HD_Regular_Cab_2012

#### Chevrolet_Sonic_Sedan_2012

#### Chevrolet_Tahoe_Hybrid_SUV_2012

#### Chevrolet_TrailBlazer_SS_2009

#### Chevrolet_Traverse_SUV_2012

#### Chrysler_300_SRT-8_2010

#### Chrysler_Aspen_SUV_2009

#### Chrysler_Crossfire_Convertible_2008

#### Chrysler_PT_Cruiser_Convertible_2008

#### Chrysler_Sebring_Convertible_2010

#### Chrysler_Town_and_Country_Minivan_2012

#### Daewoo_Nubira_Wagon_2002

#### Dodge_Caliber_Wagon_2007

#### Dodge_Caliber_Wagon_2012

#### Dodge_Caravan_Minivan_1997

#### Dodge_Challenger_SRT8_2011

#### Dodge_Charger_SRT-8_2009

#### Dodge_Charger_Sedan_2012

#### Dodge_Dakota_Club_Cab_2007

#### Dodge_Dakota_Crew_Cab_2010

#### Dodge_Durango_SUV_2007

#### Dodge_Durango_SUV_2012

#### Dodge_Journey_SUV_2012

#### Dodge_Magnum_Wagon_2008

#### Dodge_Ram_Pickup_3500_Crew_Cab_2010

#### Dodge_Ram_Pickup_3500_Quad_Cab_2009

#### Dodge_Sprinter_Cargo_Van_2009

#### Eagle_Talon_Hatchback_1998

#### FIAT_500_Abarth_2012

#### FIAT_500_Convertible_2012

#### Ferrari_458_Italia_Convertible_2012

#### Ferrari_458_Italia_Coupe_2012

#### Ferrari_California_Convertible_2012

#### Ferrari_FF_Coupe_2012

#### Fisker_Karma_Sedan_2012

#### Ford_E-Series_Wagon_Van_2012

#### Ford_Edge_SUV_2012

#### Ford_Expedition_EL_SUV_2009

#### Ford_F-150_Regular_Cab_2007

#### Ford_F-150_Regular_Cab_2012

#### Ford_F-450_Super_Duty_Crew_Cab_2012

#### Ford_Fiesta_Sedan_2012

#### Ford_Focus_Sedan_2007

#### Ford_Freestar_Minivan_2007

#### Ford_GT_Coupe_2006

#### Ford_Mustang_Convertible_2007

#### Ford_Ranger_SuperCab_2011

#### GMC_Acadia_SUV_2012

#### GMC_Canyon_Extended_Cab_2012

#### GMC_Savana_Van_2012

#### GMC_Terrain_SUV_2012

#### GMC_Yukon_Hybrid_SUV_2012

#### Geo_Metro_Convertible_1993

#### HUMMER_H2_SUT_Crew_Cab_2009

#### HUMMER_H3T_Crew_Cab_2010

#### Honda_Accord_Coupe_2012

#### Honda_Accord_Sedan_2012

#### Honda_Odyssey_Minivan_2007

#### Honda_Odyssey_Minivan_2012

#### Hyundai_Accent_Sedan_2012

#### Hyundai_Azera_Sedan_2012

#### Hyundai_Elantra_Sedan_2007

#### Hyundai_Elantra_Touring_Hatchback_2012

#### Hyundai_Genesis_Sedan_2012

#### Hyundai_Santa_Fe_SUV_2012

#### Hyundai_Sonata_Hybrid_Sedan_2012

#### Hyundai_Sonata_Sedan_2012

#### Hyundai_Tucson_SUV_2012

#### Hyundai_Veloster_Hatchback_2012

#### Hyundai_Veracruz_SUV_2012

#### Infiniti_G_Coupe_IPL_2012

#### Infiniti_QX56_SUV_2011

#### Isuzu_Ascender_SUV_2008

#### Jaguar_XK_XKR_2012

#### Jeep_Compass_SUV_2012

#### Jeep_Grand_Cherokee_SUV_2012

#### Jeep_Liberty_SUV_2012

#### Jeep_Patriot_SUV_2012

#### Jeep_Wrangler_SUV_2012

#### Lamborghini_Aventador_Coupe_2012

#### Lamborghini_Diablo_Coupe_2001

#### Lamborghini_Gallardo_LP_570-4_Superleggera_2012

#### Lamborghini_Reventon_Coupe_2008

#### Land_Rover_LR2_SUV_2012

#### Land_Rover_Range_Rover_SUV_2012

#### Lincoln_Town_Car_Sedan_2011

#### MINI_Cooper_Roadster_Convertible_2012

#### Maybach_Landaulet_Convertible_2012

#### Mazda_Tribute_SUV_2011

#### McLaren_MP4-12C_Coupe_2012

#### Mercedes-Benz_300-Class_Convertible_1993

#### Mercedes-Benz_C-Class_Sedan_2012

#### Mercedes-Benz_E-Class_Sedan_2012

#### Mercedes-Benz_S-Class_Sedan_2012

#### Mercedes-Benz_SL-Class_Coupe_2009

#### Mercedes-Benz_Sprinter_Van_2012

#### Mitsubishi_Lancer_Sedan_2012

#### Nissan_240SX_Coupe_1998

#### Nissan_Juke_Hatchback_2012

#### Nissan_Leaf_Hatchback_2012

#### Nissan_NV_Passenger_Van_2012

#### Plymouth_Neon_Coupe_1999

#### Porsche_Panamera_Sedan_2012

#### Ram_C_V_Cargo_Van_Minivan_2012

#### Rolls-Royce_Ghost_Sedan_2012

#### Rolls-Royce_Phantom_Drophead_Coupe_Convertible_2012

#### Rolls-Royce_Phantom_Sedan_2012

#### Scion_xD_Hatchback_2012

#### Spyker_C8_Convertible_2009

#### Spyker_C8_Coupe_2009

#### Suzuki_Aerio_Sedan_2007

#### Suzuki_Kizashi_Sedan_2012

#### Suzuki_SX4_Hatchback_2012

#### Suzuki_SX4_Sedan_2012

#### Tesla_Model_S_Sedan_2012

#### Toyota_4Runner_SUV_2012

#### Toyota_Camry_Sedan_2012

#### Toyota_Corolla_Sedan_2012

#### Toyota_Sequoia_SUV_2012

#### Volkswagen_Beetle_Hatchback_2012

#### Volkswagen_Golf_Hatchback_1991

#### Volkswagen_Golf_Hatchback_2012

#### Volvo_240_Sedan_1993

#### Volvo_C30_Hatchback_2012

#### Volvo_XC90_SUV_2007

#### smart_fortwo_Convertible_2012

|
ajrae/bert-base-uncased-finetuned-mrpc
|
561654da12001407e33f5118cc2d980143030e07
|
2022-02-21T21:19:06.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
ajrae
| null |
ajrae/bert-base-uncased-finetuned-mrpc
| 82 | null |
transformers
| 4,991 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8578431372549019
- name: F1
type: f1
value: 0.9003436426116839
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4520
- Accuracy: 0.8578
- F1: 0.9003
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.4169 | 0.8039 | 0.8639 |
| No log | 2.0 | 460 | 0.4299 | 0.8137 | 0.875 |
| 0.4242 | 3.0 | 690 | 0.4520 | 0.8578 | 0.9003 |
| 0.4242 | 4.0 | 920 | 0.6323 | 0.8431 | 0.8926 |
| 0.1103 | 5.0 | 1150 | 0.6163 | 0.8578 | 0.8997 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
akhooli/mbart-large-cc25-ar-en
|
903e7a58186a74ce3aed12f6d1c891e27ade277a
|
2020-12-11T21:32:04.000Z
|
[
"pytorch",
"mbart",
"text2text-generation",
"ar",
"en",
"transformers",
"translation",
"license:mit",
"autotrain_compatible"
] |
translation
| false |
akhooli
| null |
akhooli/mbart-large-cc25-ar-en
| 82 | 1 |
transformers
| 4,992 |
---
tags:
- translation
language:
- ar
- en
license: mit
---
### mbart-large-ar-en
This is mbart-large-cc25, finetuned on a subset of the OPUS corpus for ar_en.
Usage: see [example notebook](https://colab.research.google.com/drive/1I6RFOWMaTpPBX7saJYjnSTddW0TD6H1t?usp=sharing)
Note: model has limited training set, not fully trained (do not use for production).
Other models by me: [Abed Khooli](https://huggingface.co/akhooli)
|
b25mayank3/shirt_identifier
|
2b37de74691a740e005ea610f5decfa610c6d13b
|
2021-07-21T20:29:09.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
b25mayank3
| null |
b25mayank3/shirt_identifier
| 82 | null |
transformers
| 4,993 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: shirt_identifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.6875
---
# shirt_identifier
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### Big Check shirt

#### Formal Shirt

#### casual shirt

#### denim shirt

|
bayartsogt/mongolian-roberta-base
|
9e6b882a3b2e208f1e7741407e4f0e350fa3a3cc
|
2021-07-07T00:52:33.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
bayartsogt
| null |
bayartsogt/mongolian-roberta-base
| 82 | null |
transformers
| 4,994 |
Entry not found
|
birgermoell/roberta-swedish-scandi
|
3c3b9c6fee15853aa9fe9f472190ab82a180927d
|
2021-09-23T13:42:48.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"roberta",
"feature-extraction",
"sv",
"dataset:mc4",
"transformers",
"translate",
"license:cc-by-4.0"
] |
feature-extraction
| false |
birgermoell
| null |
birgermoell/roberta-swedish-scandi
| 82 | null |
transformers
| 4,995 |
---
language: sv
license: cc-by-4.0
tags:
- translate
datasets:
- mc4
widget:
- text: Meningen med livet är <mask>
---
# Svensk Roberta
## Description
Swedish Roberta model trained on the MC4 dataset. The model performance needs to be assessed
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
|
deepset/covid_bert_base
|
defac006e33937242fe54122c275fbc86794223f
|
2021-05-19T15:31:18.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
deepset
| null |
deepset/covid_bert_base
| 82 | 4 |
transformers
| 4,996 |
Entry not found
|
frgfm/rexnet1_5x
|
af5a939881795422fa97771e8a06b33e19f2dcab
|
2022-07-20T00:54:55.000Z
|
[
"pytorch",
"onnx",
"dataset:frgfm/imagenette",
"arxiv:2007.00992",
"transformers",
"image-classification",
"license:apache-2.0"
] |
image-classification
| false |
frgfm
| null |
frgfm/rexnet1_5x
| 82 | null |
transformers
| 4,997 |
---
license: apache-2.0
tags:
- image-classification
- pytorch
- onnx
datasets:
- frgfm/imagenette
---
# ReXNet-1.5x model
Pretrained on [ImageNette](https://github.com/fastai/imagenette). The ReXNet architecture was introduced in [this paper](https://arxiv.org/pdf/2007.00992.pdf).
## Model description
The core idea of the author is to add a customized Squeeze-Excitation layer in the residual blocks that will prevent channel redundancy.
## Installation
### Prerequisites
Python 3.6 (or higher) and [pip](https://pip.pypa.io/en/stable/)/[conda](https://docs.conda.io/en/latest/miniconda.html) are required to install Holocron.
### Latest stable release
You can install the last stable release of the package using [pypi](https://pypi.org/project/pylocron/) as follows:
```shell
pip install pylocron
```
or using [conda](https://anaconda.org/frgfm/pylocron):
```shell
conda install -c frgfm pylocron
```
### Developer mode
Alternatively, if you wish to use the latest features of the project that haven't made their way to a release yet, you can install the package from source *(install [Git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) first)*:
```shell
git clone https://github.com/frgfm/Holocron.git
pip install -e Holocron/.
```
## Usage instructions
```python
from PIL import Image
from torchvision.transforms import Compose, ConvertImageDtype, Normalize, PILToTensor, Resize
from torchvision.transforms.functional import InterpolationMode
from holocron.models import model_from_hf_hub
model = model_from_hf_hub("frgfm/rexnet1_5x").eval()
img = Image.open(path_to_an_image).convert("RGB")
# Preprocessing
config = model.default_cfg
transform = Compose([
Resize(config['input_shape'][1:], interpolation=InterpolationMode.BILINEAR),
PILToTensor(),
ConvertImageDtype(torch.float32),
Normalize(config['mean'], config['std'])
])
input_tensor = transform(img).unsqueeze(0)
# Inference
with torch.inference_mode():
output = model(input_tensor)
probs = output.squeeze(0).softmax(dim=0)
```
## Citation
Original paper
```bibtex
@article{DBLP:journals/corr/abs-2007-00992,
author = {Dongyoon Han and
Sangdoo Yun and
Byeongho Heo and
Young Joon Yoo},
title = {ReXNet: Diminishing Representational Bottleneck on Convolutional Neural
Network},
journal = {CoRR},
volume = {abs/2007.00992},
year = {2020},
url = {https://arxiv.org/abs/2007.00992},
eprinttype = {arXiv},
eprint = {2007.00992},
timestamp = {Mon, 06 Jul 2020 15:26:01 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007-00992.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Source of this implementation
```bibtex
@software{Fernandez_Holocron_2020,
author = {Fernandez, François-Guillaume},
month = {5},
title = {{Holocron}},
url = {https://github.com/frgfm/Holocron},
year = {2020}
}
```
|
google/bert_uncased_L-6_H-256_A-4
|
67ada51801f40684c01ca3f20c97a35fa7a67d36
|
2021-05-19T17:33:36.000Z
|
[
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"transformers",
"license:apache-2.0"
] | null | false |
google
| null |
google/bert_uncased_L-6_H-256_A-4
| 82 | null |
transformers
| 4,998 |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
gsarti/opus-tatoeba-eng-pol
|
e7460fa29a5d6e992cfd8a442c6127d4f1c6dda1
|
2021-10-18T13:48:19.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"pl",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
gsarti
| null |
gsarti/opus-tatoeba-eng-pol
| 82 | null |
transformers
| 4,999 |
---
language:
- en
- pl
tags:
- translation
license: apache-2.0
---
### OPUS Tatoeba English-Polish
*This model was obtained by running the script [convert_marian_to_pytorch.py](https://github.com/huggingface/transformers/blob/master/src/transformers/models/marian/convert_marian_to_pytorch.py) with the flag `-m eng-pol`. The original models were trained by [Jörg Tiedemann](https://blogs.helsinki.fi/tiedeman/) using the [MarianNMT](https://marian-nmt.github.io/) library. See all available `MarianMTModel` models on the profile of the [Helsinki NLP](https://huggingface.co/Helsinki-NLP) group.*
* source language name: English
* target language name: Polish
* OPUS readme: [README.md](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-pol/README.md)
* model: transformer
* source language code: en
* target language code: pl
* dataset: opus
* release date: 2021-02-19
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2021-02-19.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-pol/opus-2021-02-19.zip/eng-pol/opus-2021-02-19.zip)
* Training data:
* eng-pol: Tatoeba-train (59742979)
* Validation data:
* eng-pol: Tatoeba-dev, 44146
* total-size-shuffled: 44145
* devset-selected: top 5000 lines of Tatoeba-dev.src.shuffled!
* Test data:
* Tatoeba-test.eng-pol: 10000/64925
* test set translations file: [test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-pol/opus-2021-02-19.zip/eng-pol/opus-2021-02-19.test.txt)
* test set scores file: [eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-pol/opus-2021-02-19.zip/eng-pol/opus-2021-02-19.eval.txt)
* BLEU-scores
|Test set|score|
|---|---|
|Tatoeba-test.eng-pol|47.5|
* chr-F-scores
|Test set|score|
|---|---|
|Tatoeba-test.eng-pol|0.673|
### System Info:
* hf_name: eng-pol
* source_languages: en
* target_languages: pl
* opus_readme_url: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-pol/opus-2021-02-19.zip/README.md
* original_repo: Tatoeba-Challenge
* tags: ['translation']
* languages: ['en', 'pl']
* src_constituents: ['eng']
* tgt_constituents: ['pol']
* src_multilingual: False
* tgt_multilingual: False
* helsinki_git_sha: 70b0a9621f054ef1d8ea81f7d55595d7f64d19ff
* transformers_git_sha: 7c6cd0ac28f1b760ccb4d6e4761f13185d05d90b
* port_machine: databox
* port_time: 2021-10-18-15:11
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.