
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
sequence | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
mboth/distil-eng-quora-sentence | 0432d0fa4c983b9ecd6b95613882406eb273216d | 2021-07-09T06:00:21.000Z | [
"pytorch",
"distilbert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
] | sentence-similarity | false | mboth | null | mboth/distil-eng-quora-sentence | 4 | 1 | sentence-transformers | 18,800 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# mboth/distil-eng-quora-sentence
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('mboth/distil-eng-quora-sentence')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('mboth/distil-eng-quora-sentence')
model = AutoModel.from_pretrained('mboth/distil-eng-quora-sentence')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=mboth/distil-eng-quora-sentence)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
meghanabhange/Hinglish-Bert-Class | 30fe74ce635c67976b7fee2b9c8e4f03dac60c65 | 2021-05-19T23:12:59.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | meghanabhange | null | meghanabhange/Hinglish-Bert-Class | 4 | null | transformers | 18,801 | Entry not found |
mhu-coder/ConvTasNet_Libri1Mix_enhsingle | a7275d944176c8969495fe611c32520004aa070b | 2021-09-23T16:10:04.000Z | [
"pytorch",
"dataset:libri1mix",
"dataset:enh_single",
"asteroid",
"audio",
"ConvTasNet",
"audio-to-audio",
"license:cc-by-sa-4.0"
] | audio-to-audio | false | mhu-coder | null | mhu-coder/ConvTasNet_Libri1Mix_enhsingle | 4 | 1 | asteroid | 18,802 | ---
tags:
- asteroid
- audio
- ConvTasNet
- audio-to-audio
datasets:
- libri1mix
- enh_single
license: cc-by-sa-4.0
---
## Asteroid model `mhu-coder/ConvTasNet_Libri1Mix_enhsingle`
Imported from [Zenodo](https://zenodo.org/record/4301955#.X9cj98Jw0bY)
### Description:
This model was trained by Mathieu Hu using the librimix/ConvTasNet recipe in
[Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `enh_single` task of the Libri1Mix dataset.
### Training config:
```yaml
data:
n_src: 1
sample_rate: 16000
segment: 3
task: enh_single
train_dir: data/wav16k/min/train-100
valid_dir: data/wav16k/min/dev
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
main_args:
exp_dir: exp/train_convtasnet_f34664b9
help: None
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
n_src: 1
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
positional arguments:
training:
batch_size: 2
early_stop: True
epochs: 200
half_lr: True
num_workers: 4
```
### Results:
```yaml
si_sdr: 13.938355526049932
si_sdr_imp: 10.488574220190232
sdr: 14.567380104207393
sdr_imp: 11.064717304994337
sir: inf
sir_imp: nan
sar: 14.567380104207393
sar_imp: 11.064717304994337
stoi: 0.9201010933251715
stoi_imp: 0.1241812697846321
```
### License notice:
This work "ConvTasNet_Libri1Mx_enhsingle" is a derivative of [CSR-I (WSJ0) Complete](https://catalog.ldc.upenn.edu/LDC93S6A)
by [LDC](https://www.ldc.upenn.edu/), used under [LDC User Agreement for
Non-Members](https://catalog.ldc.upenn.edu/license/ldc-non-members-agreement.pdf) (Research only).
"ConvTasNet_Libri1Mix_enhsingle" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/)
by Mathieu Hu.
|
michaelrglass/dpr-ctx_encoder-multiset-base-kgi0-zsre | ab012f489c29f6c4edd8317b548a6845f222700f | 2021-04-20T18:21:38.000Z | [
"pytorch",
"dpr",
"transformers"
] | null | false | michaelrglass | null | michaelrglass/dpr-ctx_encoder-multiset-base-kgi0-zsre | 4 | null | transformers | 18,803 | Entry not found |
microsoft/deberta-xxlarge-v2-mnli | 095b3cb5ae735180e64199fe9b0f7b7015553a32 | 2021-02-11T02:05:00.000Z | [
"pytorch",
"deberta-v2",
"en",
"transformers",
"deberta",
"license:mit"
] | null | false | microsoft | null | microsoft/deberta-xxlarge-v2-mnli | 4 | null | transformers | 18,804 | ---
language: en
tags: deberta
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
## This model is DEPRECATED, please use [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli)
|
microsoft/unispeech-1350-en-168-es-ft-1h | e64faf70af36fe556a1916981a06c5dbccba2a09 | 2021-12-19T23:01:13.000Z | [
"pytorch",
"unispeech",
"automatic-speech-recognition",
"es",
"dataset:common_voice",
"arxiv:2101.07597",
"transformers",
"audio"
] | automatic-speech-recognition | false | microsoft | null | microsoft/unispeech-1350-en-168-es-ft-1h | 4 | null | transformers | 18,805 | ---
language:
- es
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus Spanish
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Spanish phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-168-es-ft-1h"
sample = next(iter(load_dataset("common_voice", "es", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# -> gives:
# b j e n i k e ɾ ɾ e ɣ a l o a s a β ɾ i ɾ p ɾ i m e ɾ o'
# for: Bien . ¿ y qué regalo vas a abrir primero ?
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *es*:
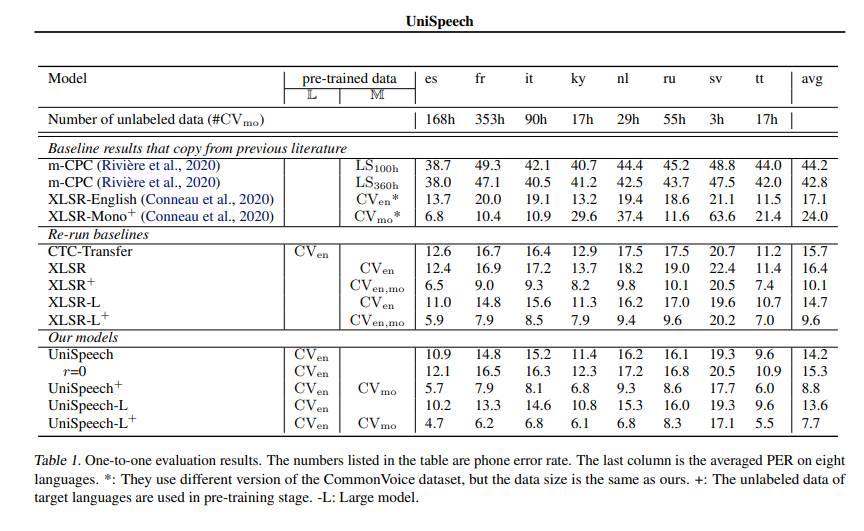 |
microsoft/unispeech-1350-en-17h-ky-ft-1h | 47f2558e5235c1ca19376d3fee08564055f29626 | 2021-12-19T23:00:00.000Z | [
"pytorch",
"unispeech",
"automatic-speech-recognition",
"ky",
"dataset:common_voice",
"arxiv:2101.07597",
"transformers",
"audio"
] | automatic-speech-recognition | false | microsoft | null | microsoft/unispeech-1350-en-17h-ky-ft-1h | 4 | null | transformers | 18,806 | ---
language:
- ky
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus Kyrgyz
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Kyrgyz phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-17h-ky-ft-1h"
sample = next(iter(load_dataset("common_voice", "ky", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *ky*:
 |
microsoft/unispeech-sat-large-sd | 1e451cf8fdaa17c25d2a08d70511a06b22488e40 | 2021-12-17T18:42:36.000Z | [
"pytorch",
"unispeech-sat",
"audio-frame-classification",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"transformers",
"speech"
] | null | false | microsoft | null | microsoft/unispeech-sat-large-sd | 4 | null | transformers | 18,807 | ---
language:
- en
datasets:
tags:
- speech
---
# UniSpeech-SAT-Large for Speaker Diarization
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [LibriMix dataset](https://github.com/JorisCos/LibriMix) using just a linear layer for mapping the network outputs.
# Usage
## Speaker Diarization
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForAudioFrameClassification
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-large-sd')
model = UniSpeechSatForAudioFrameClassification.from_pretrained('microsoft/unispeech-sat-large-sd')
# audio file is decoded on the fly
inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt")
logits = model(**inputs).logits
probabilities = torch.sigmoid(logits[0])
# labels is a one-hot array of shape (num_frames, num_speakers)
labels = (probabilities > 0.5).long()
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
midas/gupshup_h2e_mbart | b0e78f67817f90377719b4f12cba4186b816ec69 | 2021-11-14T02:08:45.000Z | [
"pytorch",
"mbart",
"text2text-generation",
"arxiv:1910.04073",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | midas | null | midas/gupshup_h2e_mbart | 4 | null | transformers | 18,808 | # Gupshup
GupShup: Summarizing Open-Domain Code-Switched Conversations EMNLP 2021
Paper: [https://aclanthology.org/2021.emnlp-main.499.pdf](https://aclanthology.org/2021.emnlp-main.499.pdf)
Github: [https://github.com/midas-research/gupshup](https://github.com/midas-research/gupshup)
### Dataset
Please request for the Gupshup data using [this Google form](https://docs.google.com/forms/d/1zvUk7WcldVF3RCoHdWzQPzPprtSJClrnHoIOYbzaJEI/edit?ts=61381ec0).
Dataset is available for `Hinglish Dilaogues to English Summarization`(h2e) and `English Dialogues to English Summarization`(e2e). For each task, Dialogues/conversastion have `.source`(train.source) as file extension whereas Summary has `.target`(train.target) file extension. ".source" file need to be provided to `input_path` and ".target" file to `reference_path` argument in the scripts.
## Models
All model weights are available on the Huggingface model hub. Users can either directly download these weights in their local and provide this path to `model_name` argument in the scripts or use the provided alias (to `model_name` argument) in scripts directly; this will lead to download weights automatically by scripts.
Model names were aliased in "gupshup_TASK_MODEL" sense, where "TASK" can be h2e,e2e and MODEL can be mbart, pegasus, etc., as listed below.
**1. Hinglish Dialogues to English Summary (h2e)**
| Model | Huggingface Alias |
|---------|-------------------------------------------------------------------------------|
| mBART | [midas/gupshup_h2e_mbart](https://huggingface.co/midas/gupshup_h2e_mbart) |
| PEGASUS | [midas/gupshup_h2e_pegasus](https://huggingface.co/midas/gupshup_h2e_pegasus) |
| T5 MTL | [midas/gupshup_h2e_t5_mtl](https://huggingface.co/midas/gupshup_h2e_t5_mtl) |
| T5 | [midas/gupshup_h2e_t5](https://huggingface.co/midas/gupshup_h2e_t5) |
| BART | [midas/gupshup_h2e_bart](https://huggingface.co/midas/gupshup_h2e_bart) |
| GPT-2 | [midas/gupshup_h2e_gpt](https://huggingface.co/midas/gupshup_h2e_gpt) |
**2. English Dialogues to English Summary (e2e)**
| Model | Huggingface Alias |
|---------|-------------------------------------------------------------------------------|
| mBART | [midas/gupshup_e2e_mbart](https://huggingface.co/midas/gupshup_e2e_mbart) |
| PEGASUS | [midas/gupshup_e2e_pegasus](https://huggingface.co/midas/gupshup_e2e_pegasus) |
| T5 MTL | [midas/gupshup_e2e_t5_mtl](https://huggingface.co/midas/gupshup_e2e_t5_mtl) |
| T5 | [midas/gupshup_e2e_t5](https://huggingface.co/midas/gupshup_e2e_t5) |
| BART | [midas/gupshup_e2e_bart](https://huggingface.co/midas/gupshup_e2e_bart) |
| GPT-2 | [midas/gupshup_e2e_gpt](https://huggingface.co/midas/gupshup_e2e_gpt) |
## Inference
### Using command line
1. Clone this repo and create a python virtual environment (https://docs.python.org/3/library/venv.html). Install the required packages using
```
git clone https://github.com/midas-research/gupshup.git
pip install -r requirements.txt
```
2. run_eval script has the following arguments.
* **model_name** : Path or alias to one of our models available on Huggingface as listed above.
* **input_path** : Source file or path to file containing conversations, which will be summarized.
* **save_path** : File path where to save summaries generated by the model.
* **reference_path** : Target file or path to file containing summaries, used to calculate matrices.
* **score_path** : File path where to save scores.
* **bs** : Batch size
* **device**: Cuda devices to use.
Please make sure you have downloaded the Gupshup dataset using the above google form and provide the correct path to these files in the argument's `input_path` and `refrence_path.` Or you can simply put `test.source` and `test.target` in `data/h2e/`(hinglish to english) or `data/e2e/`(english to english) folder. For example, to generate English summaries from Hinglish dialogues using the mbart model, run the following command
```
python run_eval.py \
--model_name midas/gupshup_h2e_mbart \
--input_path data/h2e/test.source \
--save_path generated_summary.txt \
--reference_path data/h2e/test.target \
--score_path scores.txt \
--bs 8
```
Another example, to generate English summaries from English dialogues using the Pegasus model
```
python run_eval.py \
--model_name midas/gupshup_e2e_pegasus \
--input_path data/e2e/test.source \
--save_path generated_summary.txt \
--reference_path data/e2e/test.target \
--score_path scores.txt \
--bs 8
```
Please create an issue if you are facing any difficulties in replicating the results.
### References
Please cite [[1]](https://arxiv.org/abs/1910.04073) if you found the resources in this repository useful.
[1] Mehnaz, Laiba, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle G. Lee, Anish Acharya, and Rajiv Shah. [*GupShup: Summarizing Open-Domain Code-Switched Conversations*](https://aclanthology.org/2021.emnlp-main.499.pdf)
```
@inproceedings{mehnaz2021gupshup,
title={GupShup: Summarizing Open-Domain Code-Switched Conversations},
author={Mehnaz, Laiba and Mahata, Debanjan and Gosangi, Rakesh and Gunturi, Uma Sushmitha and Jain, Riya and Gupta, Gauri and Kumar, Amardeep and Lee, Isabelle G and Acharya, Anish and Shah, Rajiv},
booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing},
pages={6177--6192},
year={2021}
}
```
|
midas/gupshup_h2e_t5 | ab85f7ba5e9f4c67cd55bd64257d789f37d23b01 | 2021-11-14T02:09:33.000Z | [
"pytorch",
"t5",
"text2text-generation",
"arxiv:1910.04073",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | midas | null | midas/gupshup_h2e_t5 | 4 | null | transformers | 18,809 | # Gupshup
GupShup: Summarizing Open-Domain Code-Switched Conversations EMNLP 2021
Paper: [https://aclanthology.org/2021.emnlp-main.499.pdf](https://aclanthology.org/2021.emnlp-main.499.pdf)
Github: [https://github.com/midas-research/gupshup](https://github.com/midas-research/gupshup)
### Dataset
Please request for the Gupshup data using [this Google form](https://docs.google.com/forms/d/1zvUk7WcldVF3RCoHdWzQPzPprtSJClrnHoIOYbzaJEI/edit?ts=61381ec0).
Dataset is available for `Hinglish Dilaogues to English Summarization`(h2e) and `English Dialogues to English Summarization`(e2e). For each task, Dialogues/conversastion have `.source`(train.source) as file extension whereas Summary has `.target`(train.target) file extension. ".source" file need to be provided to `input_path` and ".target" file to `reference_path` argument in the scripts.
## Models
All model weights are available on the Huggingface model hub. Users can either directly download these weights in their local and provide this path to `model_name` argument in the scripts or use the provided alias (to `model_name` argument) in scripts directly; this will lead to download weights automatically by scripts.
Model names were aliased in "gupshup_TASK_MODEL" sense, where "TASK" can be h2e,e2e and MODEL can be mbart, pegasus, etc., as listed below.
**1. Hinglish Dialogues to English Summary (h2e)**
| Model | Huggingface Alias |
|---------|-------------------------------------------------------------------------------|
| mBART | [midas/gupshup_h2e_mbart](https://huggingface.co/midas/gupshup_h2e_mbart) |
| PEGASUS | [midas/gupshup_h2e_pegasus](https://huggingface.co/midas/gupshup_h2e_pegasus) |
| T5 MTL | [midas/gupshup_h2e_t5_mtl](https://huggingface.co/midas/gupshup_h2e_t5_mtl) |
| T5 | [midas/gupshup_h2e_t5](https://huggingface.co/midas/gupshup_h2e_t5) |
| BART | [midas/gupshup_h2e_bart](https://huggingface.co/midas/gupshup_h2e_bart) |
| GPT-2 | [midas/gupshup_h2e_gpt](https://huggingface.co/midas/gupshup_h2e_gpt) |
**2. English Dialogues to English Summary (e2e)**
| Model | Huggingface Alias |
|---------|-------------------------------------------------------------------------------|
| mBART | [midas/gupshup_e2e_mbart](https://huggingface.co/midas/gupshup_e2e_mbart) |
| PEGASUS | [midas/gupshup_e2e_pegasus](https://huggingface.co/midas/gupshup_e2e_pegasus) |
| T5 MTL | [midas/gupshup_e2e_t5_mtl](https://huggingface.co/midas/gupshup_e2e_t5_mtl) |
| T5 | [midas/gupshup_e2e_t5](https://huggingface.co/midas/gupshup_e2e_t5) |
| BART | [midas/gupshup_e2e_bart](https://huggingface.co/midas/gupshup_e2e_bart) |
| GPT-2 | [midas/gupshup_e2e_gpt](https://huggingface.co/midas/gupshup_e2e_gpt) |
## Inference
### Using command line
1. Clone this repo and create a python virtual environment (https://docs.python.org/3/library/venv.html). Install the required packages using
```
git clone https://github.com/midas-research/gupshup.git
pip install -r requirements.txt
```
2. run_eval script has the following arguments.
* **model_name** : Path or alias to one of our models available on Huggingface as listed above.
* **input_path** : Source file or path to file containing conversations, which will be summarized.
* **save_path** : File path where to save summaries generated by the model.
* **reference_path** : Target file or path to file containing summaries, used to calculate matrices.
* **score_path** : File path where to save scores.
* **bs** : Batch size
* **device**: Cuda devices to use.
Please make sure you have downloaded the Gupshup dataset using the above google form and provide the correct path to these files in the argument's `input_path` and `refrence_path.` Or you can simply put `test.source` and `test.target` in `data/h2e/`(hinglish to english) or `data/e2e/`(english to english) folder. For example, to generate English summaries from Hinglish dialogues using the mbart model, run the following command
```
python run_eval.py \
--model_name midas/gupshup_h2e_mbart \
--input_path data/h2e/test.source \
--save_path generated_summary.txt \
--reference_path data/h2e/test.target \
--score_path scores.txt \
--bs 8
```
Another example, to generate English summaries from English dialogues using the Pegasus model
```
python run_eval.py \
--model_name midas/gupshup_e2e_pegasus \
--input_path data/e2e/test.source \
--save_path generated_summary.txt \
--reference_path data/e2e/test.target \
--score_path scores.txt \
--bs 8
```
Please create an issue if you are facing any difficulties in replicating the results.
### References
Please cite [[1]](https://arxiv.org/abs/1910.04073) if you found the resources in this repository useful.
[1] Mehnaz, Laiba, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle G. Lee, Anish Acharya, and Rajiv Shah. [*GupShup: Summarizing Open-Domain Code-Switched Conversations*](https://aclanthology.org/2021.emnlp-main.499.pdf)
```
@inproceedings{mehnaz2021gupshup,
title={GupShup: Summarizing Open-Domain Code-Switched Conversations},
author={Mehnaz, Laiba and Mahata, Debanjan and Gosangi, Rakesh and Gunturi, Uma Sushmitha and Jain, Riya and Gupta, Gauri and Kumar, Amardeep and Lee, Isabelle G and Acharya, Anish and Shah, Rajiv},
booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing},
pages={6177--6192},
year={2021}
}
```
|
milyiyo/minilm-finetuned-emotion | fb6005acdd6f3ab7088dec77ef0298616a41ba16 | 2022-01-16T00:37:00.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | milyiyo | null | milyiyo/minilm-finetuned-emotion | 4 | 1 | transformers | 18,810 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- f1
model-index:
- name: minilm-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: F1
type: f1
value: 0.931192
---
Based model: [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased)
Dataset: [emotion](https://huggingface.co/datasets/emotion)
These are the results on the evaluation set:
| Attribute | Value |
| ------------------ | -------- |
| Training Loss | 0.163100 |
| Validation Loss | 0.192153 |
| F1 | 0.931192 |
|
mimi/Waynehills-NLP-doogie | 4e1ec489b96e2feb40a3a1586bb6d03cd3f7a6b2 | 2022-01-06T08:02:38.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | mimi | null | mimi/Waynehills-NLP-doogie | 4 | null | transformers | 18,811 | ---
tags:
- generated_from_trainer
model-index:
- name: Waynehills-NLP-doogie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Waynehills-NLP-doogie
This model is a fine-tuned version of [KETI-AIR/ke-t5-base-ko](https://huggingface.co/KETI-AIR/ke-t5-base-ko) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9188
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 28.2167 | 0.06 | 1000 | 9.7030 |
| 10.4479 | 0.12 | 2000 | 7.5450 |
| 8.0306 | 0.19 | 3000 | 6.1969 |
| 6.503 | 0.25 | 4000 | 5.3015 |
| 5.5406 | 0.31 | 5000 | 4.6363 |
| 4.7299 | 0.38 | 6000 | 4.0431 |
| 3.9263 | 0.44 | 7000 | 3.6313 |
| 3.4111 | 0.5 | 8000 | 3.4830 |
| 3.0517 | 0.56 | 9000 | 3.3294 |
| 2.7524 | 0.62 | 10000 | 3.2077 |
| 2.5402 | 0.69 | 11000 | 3.1094 |
| 2.3228 | 0.75 | 12000 | 3.1099 |
| 2.1513 | 0.81 | 13000 | 3.0284 |
| 2.0418 | 0.88 | 14000 | 3.0155 |
| 1.8875 | 0.94 | 15000 | 3.0241 |
| 1.756 | 1.0 | 16000 | 3.0165 |
| 1.6489 | 1.06 | 17000 | 2.9849 |
| 1.5788 | 1.12 | 18000 | 2.9496 |
| 1.5368 | 1.19 | 19000 | 2.9500 |
| 1.4467 | 1.25 | 20000 | 3.0133 |
| 1.381 | 1.31 | 21000 | 2.9631 |
| 1.3451 | 1.38 | 22000 | 3.0159 |
| 1.2917 | 1.44 | 23000 | 2.9906 |
| 1.2605 | 1.5 | 24000 | 3.0006 |
| 1.2003 | 1.56 | 25000 | 2.9797 |
| 1.1987 | 1.62 | 26000 | 2.9253 |
| 1.1703 | 1.69 | 27000 | 3.0044 |
| 1.1474 | 1.75 | 28000 | 2.9216 |
| 1.0816 | 1.81 | 29000 | 2.9645 |
| 1.0709 | 1.88 | 30000 | 3.0439 |
| 1.0476 | 1.94 | 31000 | 3.0844 |
| 1.0645 | 2.0 | 32000 | 2.9434 |
| 1.0204 | 2.06 | 33000 | 2.9386 |
| 0.9901 | 2.12 | 34000 | 3.0452 |
| 0.9911 | 2.19 | 35000 | 2.9798 |
| 0.9706 | 2.25 | 36000 | 2.9919 |
| 0.9461 | 2.31 | 37000 | 3.0279 |
| 0.9577 | 2.38 | 38000 | 2.9615 |
| 0.9466 | 2.44 | 39000 | 2.9988 |
| 0.9486 | 2.5 | 40000 | 2.9133 |
| 0.9201 | 2.56 | 41000 | 3.0004 |
| 0.896 | 2.62 | 42000 | 2.9626 |
| 0.8893 | 2.69 | 43000 | 2.9667 |
| 0.9028 | 2.75 | 44000 | 2.9543 |
| 0.897 | 2.81 | 45000 | 2.8760 |
| 0.8664 | 2.88 | 46000 | 2.9894 |
| 0.8719 | 2.94 | 47000 | 2.8456 |
| 0.8491 | 3.0 | 48000 | 2.9713 |
| 0.8402 | 3.06 | 49000 | 2.9738 |
| 0.8484 | 3.12 | 50000 | 2.9361 |
| 0.8304 | 3.19 | 51000 | 2.8945 |
| 0.8208 | 3.25 | 52000 | 2.9625 |
| 0.8074 | 3.31 | 53000 | 3.0054 |
| 0.8226 | 3.38 | 54000 | 2.9405 |
| 0.8185 | 3.44 | 55000 | 2.9047 |
| 0.8352 | 3.5 | 56000 | 2.9016 |
| 0.8289 | 3.56 | 57000 | 2.9490 |
| 0.7918 | 3.62 | 58000 | 2.9621 |
| 0.8212 | 3.69 | 59000 | 2.9341 |
| 0.7955 | 3.75 | 60000 | 2.9167 |
| 0.7724 | 3.81 | 61000 | 2.9409 |
| 0.8169 | 3.88 | 62000 | 2.8925 |
| 0.7862 | 3.94 | 63000 | 2.9314 |
| 0.803 | 4.0 | 64000 | 2.9271 |
| 0.7595 | 4.06 | 65000 | 2.9263 |
| 0.7931 | 4.12 | 66000 | 2.9400 |
| 0.7759 | 4.19 | 67000 | 2.9501 |
| 0.7859 | 4.25 | 68000 | 2.9133 |
| 0.805 | 4.31 | 69000 | 2.8785 |
| 0.7649 | 4.38 | 70000 | 2.9060 |
| 0.7692 | 4.44 | 71000 | 2.8868 |
| 0.7692 | 4.5 | 72000 | 2.9045 |
| 0.7798 | 4.56 | 73000 | 2.8951 |
| 0.7812 | 4.62 | 74000 | 2.9068 |
| 0.7533 | 4.69 | 75000 | 2.9129 |
| 0.7527 | 4.75 | 76000 | 2.9157 |
| 0.7652 | 4.81 | 77000 | 2.9053 |
| 0.7633 | 4.88 | 78000 | 2.9190 |
| 0.7437 | 4.94 | 79000 | 2.9251 |
| 0.7653 | 5.0 | 80000 | 2.9188 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.5.0
- Tokenizers 0.10.3
|
mklucifer/DialoGPT-medium-DEADPOOL | 0550da6f5f3e109d635bbe8da5e87b2df05d7d38 | 2021-10-27T15:10:16.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | mklucifer | null | mklucifer/DialoGPT-medium-DEADPOOL | 4 | null | transformers | 18,812 | ---
tags:
- conversational
---
# DEADPOOL DialoGPT Model |
ml6team/distilbert-base-dutch-cased-toxic-comments | edf505d15afb6de3dbe994f13337c723495a4057 | 2022-01-20T08:21:12.000Z | [
"pytorch",
"distilbert",
"text-classification",
"nl",
"transformers",
"license:apache-2.0"
] | text-classification | false | ml6team | null | ml6team/distilbert-base-dutch-cased-toxic-comments | 4 | 5 | transformers | 18,813 | ---
language:
- nl
tags:
- text-classification
- pytorch
widget:
- text: "Ik heb je lief met heel mijn hart"
example_title: "Non toxic comment 1"
- text: "Dat is een goed punt, zo had ik het nog niet bekeken."
example_title: "Non toxic comment 2"
- text: "Wat de fuck zei je net tegen me, klootzak?"
example_title: "Toxic comment 1"
- text: "Rot op, vuile hoerenzoon."
example_title: "Toxic comment 2"
license: apache-2.0
metrics:
- Accuracy, F1 Score, Recall, Precision
---
# distilbert-base-dutch-toxic-comments
## Model description:
This model was created with the purpose to detect toxic or potentially harmful comments.
For this model, we finetuned a multilingual distilbert model [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the translated [Jigsaw Toxicity dataset](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge).
The original dataset was translated using the appropriate [MariantMT model](https://huggingface.co/Helsinki-NLP/opus-mt-en-nl).
The model was trained for 2 epochs, on 90% of the dataset, with the following arguments:
```
training_args = TrainingArguments(
learning_rate=3e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
gradient_accumulation_steps=4,
load_best_model_at_end=True,
metric_for_best_model="recall",
epochs=2,
evaluation_strategy="steps",
save_strategy="steps",
save_total_limit=10,
logging_steps=100,
eval_steps=250,
save_steps=250,
weight_decay=0.001,
report_to="wandb")
```
## Model Performance:
Model evaluation was done on 1/10th of the dataset, which served as the test dataset.
| Accuracy | F1 Score | Recall | Precision |
| --- | --- | --- | --- |
| 95.75 | 78.88 | 77.23 | 80.61 |
## Dataset:
Unfortunately we cannot open-source the dataset, since we are bound by the underlying Jigsaw license.
|
mmcquade11/autonlp-imdb-test-21134453 | 357f7eb72db04932822cc51da75b19199ebd1ca4 | 2021-10-18T17:47:59.000Z | [
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:mmcquade11/autonlp-data-imdb-test",
"transformers",
"autonlp",
"co2_eq_emissions"
] | text-classification | false | mmcquade11 | null | mmcquade11/autonlp-imdb-test-21134453 | 4 | null | transformers | 18,814 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- mmcquade11/autonlp-data-imdb-test
co2_eq_emissions: 38.102565360610484
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 21134453
- CO2 Emissions (in grams): 38.102565360610484
## Validation Metrics
- Loss: 0.172550767660141
- Accuracy: 0.9355
- Precision: 0.9362853135644159
- Recall: 0.9346
- AUC: 0.98267064
- F1: 0.9354418977079372
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/mmcquade11/autonlp-imdb-test-21134453
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("mmcquade11/autonlp-imdb-test-21134453", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("mmcquade11/autonlp-imdb-test-21134453", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
mofawzy/gpt-2-goodreads-ar | e00809551e44401ba29eb27d647d504bfbe78404 | 2021-05-23T09:53:17.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | mofawzy | null | mofawzy/gpt-2-goodreads-ar | 4 | null | transformers | 18,815 | ### Generate Arabic reviews sentences with model GPT-2 Medium.
#### Load model
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("mofawzy/gpt-2-medium-ar")
model = AutoModelWithLMHead.from_pretrained("mofawzy/gpt-2-medium-ar")
```
### Eval:
```
***** eval metrics *****
epoch = 20.0
eval_loss = 1.7798
eval_mem_cpu_alloc_delta = 3MB
eval_mem_cpu_peaked_delta = 0MB
eval_mem_gpu_alloc_delta = 0MB
eval_mem_gpu_peaked_delta = 7044MB
eval_runtime = 0:03:03.37
eval_samples = 527
eval_samples_per_second = 2.874
perplexity = 5.9285
```
#### Notebook:
https://colab.research.google.com/drive/1P0Raqrq0iBLNH87DyN9j0SwWg4C2HubV?usp=sharing
|
mohammed/wav2vec2-large-xlsr-arabic | acbe8be2e88637e63fc31d199de81b989e982600 | 2021-07-06T12:52:15.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"ar",
"dataset:common_voice",
"dataset:arabic_speech_corpus",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | mohammed | null | mohammed/wav2vec2-large-xlsr-arabic | 4 | 2 | transformers | 18,816 | ---
language: ar
datasets:
- common_voice
- arabic_speech_corpus
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Mohammed XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ar
type: common_voice
args: ar
metrics:
- name: Test WER
type: wer
value: 36.699
- name: Validation WER
type: wer
value: 36.699
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on Arabic using the `train` splits of [Common Voice](https://huggingface.co/datasets/common_voice)
and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
%%capture
!pip install datasets
!pip install transformers==4.4.0
!pip install torchaudio
!pip install jiwer
!pip install tnkeeh
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ar", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("mohammed/wav2vec2-large-xlsr-arabic")
model = Wav2Vec2ForCTC.from_pretrained("mohammed/wav2vec2-large-xlsr-arabic")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("The predicted sentence is: ", processor.batch_decode(predicted_ids))
print("The original sentence is:", test_dataset["sentence"][:2])
```
The output is:
```
The predicted sentence is : ['ألديك قلم', 'ليست نارك مكسافة على هذه الأرض أبعد من يوم أمس']
The original sentence is: ['ألديك قلم ؟', 'ليست هناك مسافة على هذه الأرض أبعد من يوم أمس.']
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice:
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# creating a dictionary with all diacritics
dict = {
'ِ': '',
'ُ': '',
'ٓ': '',
'ٰ': '',
'ْ': '',
'ٌ': '',
'ٍ': '',
'ً': '',
'ّ': '',
'َ': '',
'~': '',
',': '',
'ـ': '',
'—': '',
'.': '',
'!': '',
'-': '',
';': '',
':': '',
'\'': '',
'"': '',
'☭': '',
'«': '',
'»': '',
'؛': '',
'ـ': '',
'_': '',
'،': '',
'“': '',
'%': '',
'‘': '',
'”': '',
'�': '',
'_': '',
',': '',
'?': '',
'#': '',
'‘': '',
'.': '',
'؛': '',
'get': '',
'؟': '',
' ': ' ',
'\'ۖ ': '',
'\'': '',
'\'ۚ' : '',
' \'': '',
'31': '',
'24': '',
'39': ''
}
# replacing multiple diacritics using dictionary (stackoverflow is amazing)
def remove_special_characters(batch):
# Create a regular expression from the dictionary keys
regex = re.compile("(%s)" % "|".join(map(re.escape, dict.keys())))
# For each match, look-up corresponding value in dictionary
batch["sentence"] = regex.sub(lambda mo: dict[mo.string[mo.start():mo.end()]], batch["sentence"])
return batch
test_dataset = load_dataset("common_voice", "ar", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("mohammed/wav2vec2-large-xlsr-arabic")
model = Wav2Vec2ForCTC.from_pretrained("mohammed/wav2vec2-large-xlsr-arabic")
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
test_dataset = test_dataset.map(remove_special_characters)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 36.699%
## Future Work
One can use *data augmentation*, *transliteration*, or *attention_mask* to increase the accuracy.
|
mohsenfayyaz/bert-base-cased-toxicity | 20449e48fc48c477568c72f12b6159d86290ca43 | 2021-05-19T23:39:41.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | mohsenfayyaz | null | mohsenfayyaz/bert-base-cased-toxicity | 4 | null | transformers | 18,817 | Entry not found |
mohsenfayyaz/bert-base-uncased-offenseval2019-unbalanced | e2c36709fcd98f5761b8d3396354d0e515467ccf | 2021-05-19T23:41:35.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | mohsenfayyaz | null | mohsenfayyaz/bert-base-uncased-offenseval2019-unbalanced | 4 | null | transformers | 18,818 | Entry not found |
mohsenfayyaz/bert-base-uncased-toxicity-a | bc046871daaaba8d8c2ce7a10b2b4d7eb0ea46e2 | 2021-05-19T23:44:37.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | mohsenfayyaz | null | mohsenfayyaz/bert-base-uncased-toxicity-a | 4 | null | transformers | 18,819 | Entry not found |
mohsenfayyaz/xlnet-base-cased-offenseval2019-downsample | bd015b15113ade3ce9ebfbd7617a7d6ac898f973 | 2021-05-04T13:58:20.000Z | [
"pytorch",
"xlnet",
"text-classification",
"transformers"
] | text-classification | false | mohsenfayyaz | null | mohsenfayyaz/xlnet-base-cased-offenseval2019-downsample | 4 | null | transformers | 18,820 | Entry not found |
mollypak/bert-model-baby | 479f6cf68275cc5d09c3bf31fab1d57ab2e1407f | 2021-11-26T13:30:51.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | mollypak | null | mollypak/bert-model-baby | 4 | null | transformers | 18,821 | Entry not found |
momo/distilbert-base-uncased-finetuned-ner | 9a242b287e56e5a2a963b662f5aabb2a0f37cf11 | 2021-11-28T17:15:36.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | momo | null | momo/distilbert-base-uncased-finetuned-ner | 4 | null | transformers | 18,822 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9262123053131559
- name: Recall
type: recall
value: 0.9380243875153821
- name: F1
type: f1
value: 0.9320809248554913
- name: Accuracy
type: accuracy
value: 0.9839547555880344
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0617
- Precision: 0.9262
- Recall: 0.9380
- F1: 0.9321
- Accuracy: 0.9840
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2465 | 1.0 | 878 | 0.0727 | 0.9175 | 0.9199 | 0.9187 | 0.9808 |
| 0.0527 | 2.0 | 1756 | 0.0610 | 0.9245 | 0.9361 | 0.9303 | 0.9834 |
| 0.0313 | 3.0 | 2634 | 0.0617 | 0.9262 | 0.9380 | 0.9321 | 0.9840 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.8.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
monologg/kocharelectra-base-finetuned-goemotions | 6aad036b0a14d69fc4dce14d18eca945e4456925 | 2020-05-29T12:52:27.000Z | [
"pytorch",
"electra",
"transformers"
] | null | false | monologg | null | monologg/kocharelectra-base-finetuned-goemotions | 4 | null | transformers | 18,823 | Entry not found |
monologg/kocharelectra-base-generator | 019d26cdd8791eb28e2b67ff956b0fb441db4ffd | 2020-05-27T17:35:59.000Z | [
"pytorch",
"electra",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | monologg | null | monologg/kocharelectra-base-generator | 4 | null | transformers | 18,824 | Entry not found |
monologg/kocharelectra-small-finetuned-goemotions | e77adc04b5143e5989f09adff8fce8ac47d090b1 | 2020-05-29T12:56:37.000Z | [
"pytorch",
"electra",
"transformers"
] | null | false | monologg | null | monologg/kocharelectra-small-finetuned-goemotions | 4 | null | transformers | 18,825 | Entry not found |
monologg/koelectra-base-finetuned-goemotions | c505c12811b558c574420afdaa74aac8b3c31421 | 2020-05-18T20:19:16.000Z | [
"pytorch",
"electra",
"transformers"
] | null | false | monologg | null | monologg/koelectra-base-finetuned-goemotions | 4 | null | transformers | 18,826 | Entry not found |
monsoon-nlp/dv-muril | b67f178d9b0545a7652aad32f08d4ac2b5df7dca | 2021-05-20T00:01:51.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"dv",
"transformers",
"autotrain_compatible"
] | fill-mask | false | monsoon-nlp | null | monsoon-nlp/dv-muril | 4 | null | transformers | 18,827 | ---
language: dv
---
# dv-muril
This is an experiment in transfer learning, to insert Dhivehi word and
word-piece tokens into Google's MuRIL model.
This BERT-based model currently performs better than dv-wave ELECTRA on
the Maldivian News Classification task https://github.com/Sofwath/DhivehiDatasets
## Training
- Start with MuRIL (similar to mBERT) with no Thaana vocabulary
- Based on PanLex dictionaries, attach 1,100 Dhivehi words to Malayalam or English embeddings
- Add remaining words and word-pieces from BertWordPieceTokenizer / vocab.txt
- Continue BERT pretraining
## Performance
- mBERT: 52%
- dv-wave (ELECTRA, 30k vocab): 89%
- dv-muril (10k vocab) before BERT pretraining step: 89.8%
- previous dv-muril (30k vocab): 90.7%
- dv-muril (10k vocab): 91.6%
CoLab notebook:
https://colab.research.google.com/drive/113o6vkLZRkm6OwhTHrvE0x6QPpavj0fn
|
monsoon-nlp/dv-wave | 2ba732ad89d9ead004e5fdc9941ddc829c2c6524 | 2020-12-11T21:51:38.000Z | [
"pytorch",
"tf",
"electra",
"dv",
"transformers"
] | null | false | monsoon-nlp | null | monsoon-nlp/dv-wave | 4 | null | transformers | 18,828 | ---
language: dv
---
# dv-wave
This is a second attempt at a Dhivehi language model trained with
Google Research's [ELECTRA](https://github.com/google-research/electra).
Tokenization and pre-training CoLab: https://colab.research.google.com/drive/1ZJ3tU9MwyWj6UtQ-8G7QJKTn-hG1uQ9v?usp=sharing
Using SimpleTransformers to classify news https://colab.research.google.com/drive/1KnyQxRNWG_yVwms_x9MUAqFQVeMecTV7?usp=sharing
V1: similar performance to mBERT on news classification task after finetuning for 3 epochs (52%)
V2: fixed tokenizers ```do_lower_case=False``` and ```strip_accents=False``` to preserve vowel signs of Dhivehi
dv-wave: 89% to mBERT: 52%
## Corpus
Trained on @Sofwath's 307MB corpus of Dhivehi text: https://github.com/Sofwath/DhivehiDatasets - this repo also contains the news classification task CSV
[OSCAR](https://oscar-corpus.com/) was considered but has not been added to pretraining; as of
this writing their web crawl has 126MB of Dhivehi text (79MB deduped).
## Vocabulary
Included as vocab.txt in the upload - vocab_size is 29874
|
moshew/bert-small-aug-sst2-distilled | 499849730805e6d6dba5eab7ba5c5bac42b18be7 | 2022-02-23T11:12:18.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
] | text-classification | false | moshew | null | moshew/bert-small-aug-sst2-distilled | 4 | null | transformers | 18,829 | Accuracy = 92 |
moussaKam/frugalscore_medium_roberta_bert-score | b73f9b7a9466c99166673f4ec146085f23bb4973 | 2022-02-01T10:51:17.000Z | [
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"transformers"
] | text-classification | false | moussaKam | null | moussaKam/frugalscore_medium_roberta_bert-score | 4 | null | transformers | 18,830 | # FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore | |
moussaKam/frugalscore_small_bert-base_mover-score | 3437e3adb217131a1af4c38127649b9f1f00cf14 | 2022-05-11T11:05:28.000Z | [
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"transformers"
] | text-classification | false | moussaKam | null | moussaKam/frugalscore_small_bert-base_mover-score | 4 | null | transformers | 18,831 | # FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore | |
mrm8488/RuPERTa-base-finetuned-spa-constitution | 2c2175a87fbdeef84c54e432495c32b74d4f79f0 | 2021-05-20T18:12:03.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | mrm8488 | null | mrm8488/RuPERTa-base-finetuned-spa-constitution | 4 | null | transformers | 18,832 | Entry not found |
mrm8488/bert-mini-wrslb-finetuned-squadv1 | a68eaa0039c5d956aa5740c5d5afe3afd5d1e227 | 2021-05-20T00:26:56.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | mrm8488 | null | mrm8488/bert-mini-wrslb-finetuned-squadv1 | 4 | null | transformers | 18,833 | Entry not found |
mrm8488/bert-small-wrslb-finetuned-squadv1 | e7aeb86ed58911ba91ce824e24207fe2a1b6d091 | 2021-05-20T00:34:10.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | mrm8488 | null | mrm8488/bert-small-wrslb-finetuned-squadv1 | 4 | null | transformers | 18,834 | Entry not found |
mrm8488/electricidad-small-discriminator | 2c4c04c7cd445ea978938e9618229fad7de2cbea | 2022-03-30T20:44:50.000Z | [
"pytorch",
"electra",
"pretraining",
"es",
"dataset:large_spanish_corpus",
"transformers",
"Spanish",
"Electra"
] | null | false | mrm8488 | null | mrm8488/electricidad-small-discriminator | 4 | 3 | transformers | 18,835 | ---
language: es
thumbnail: https://i.imgur.com/uxAvBfh.png
tags:
- Spanish
- Electra
datasets:
- large_spanish_corpus
---
## ELECTRICIDAD: The Spanish Electra [Imgur](https://imgur.com/uxAvBfh)
**ELECTRICIDAD** is a small Electra like model (discriminator in this case) trained on a [Large Spanish Corpus](https://github.com/josecannete/spanish-corpora) (aka BETO's corpus).
As mentioned in the original [paper](https://openreview.net/pdf?id=r1xMH1BtvB):
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer the paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
## Model details ⚙
|Param| # Value|
|-----|--------|
|Layers|\t12 |
|Hidden |256 \t|
|Params| 14M|
## Evaluation metrics (for discriminator) 🧾
|Metric | # Score |
|-------|---------|
|Accuracy| 0.94|
|Precision| 0.76|
|AUC | 0.92|
## Benchmarks 🔨
WIP 🚧
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("mrm8488/electricidad-small-discriminator")
tokenizer = ElectraTokenizerFast.from_pretrained("mrm8488/electricidad-small-discriminator")
sentence = "el zorro rojo es muy rápido"
fake_sentence = "el zorro rojo es muy ser"
fake_tokens = tokenizer.tokenize(sentence)
fake_inputs = tokenizer.encode(sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()[1:-1]]
# Output:
'''
el zorro rojo es muy ser 0 0 0 0 0 1[None, None, None, None, None, None]
'''
```
As you can see there is a **1** in the place where the model detected the fake token (**ser**). So, it works! 🎉
[Electricidad-small fine-tuned models](https://huggingface.co/models?search=electricidad-small)
## Acknowledgments
I thank [🤗/transformers team](https://github.com/huggingface/transformers) for answering my doubts and Google for helping me with the [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc) program.
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{mromero2020electricidad-small-discriminator,
title={Spanish Electra (small) by Manuel Romero},
author={Romero, Manuel},
publisher={Hugging Face},
journal={Hugging Face Hub},
howpublished={\url{https://huggingface.co/mrm8488/electricidad-small-discriminator}},
year={2020}
}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/scibert_scivocab-finetuned-CORD19 | 32d24a040bfbfe2558723fc76b7c18f61b9cc3a2 | 2021-05-20T00:48:35.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | mrm8488 | null | mrm8488/scibert_scivocab-finetuned-CORD19 | 4 | null | transformers | 18,836 | Entry not found |
mrm8488/t5-base-finetuned-math-linear-algebra-2d | 461e682b5f0577f892ed1373cdb3d0e626466585 | 2020-08-19T16:39:10.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mrm8488 | null | mrm8488/t5-base-finetuned-math-linear-algebra-2d | 4 | null | transformers | 18,837 | Entry not found |
mrshu/wav2vec2-large-xlsr-slovene | f935524ed90c6bd485855aadaa150f028fbc47b6 | 2021-07-06T13:25:51.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"sl",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | mrshu | null | mrshu/wav2vec2-large-xlsr-slovene | 4 | null | transformers | 18,838 | ---
language: sl
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Slovene
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice sl
type: common_voice
args: sl
metrics:
- name: Test WER
type: wer
value: 36.97
---
# Wav2Vec2-Large-XLSR-53-Slovene
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Slovene using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "sl", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("mrshu/wav2vec2-large-xlsr-slovene")
model = Wav2Vec2ForCTC.from_pretrained("mrshu/wav2vec2-large-xlsr-slovene")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Slovene test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "sl", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("mrshu/wav2vec2-large-xlsr-slovene")
model = Wav2Vec2ForCTC.from_pretrained("mrshu/wav2vec2-large-xlsr-slovene")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\«\»\)\(\„\'\–\’\—]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 36.97 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/drive/14uahdilysnFsiYniHxY9fyKjFGuYQe7p)
|
mse30/bart-base-finetuned-multinews | 3562810841c50072d210440e5624230687b5b9ee | 2021-10-09T03:19:09.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mse30 | null | mse30/bart-base-finetuned-multinews | 4 | null | transformers | 18,839 | Entry not found |
muhtasham/autonlp-Doctor_DE-24595545 | a46f143e53582e6376263fdb77d627bebbd70188 | 2021-10-22T11:59:58.000Z | [
"pytorch",
"bert",
"text-classification",
"de",
"dataset:muhtasham/autonlp-data-Doctor_DE",
"transformers",
"autonlp",
"co2_eq_emissions"
] | text-classification | false | muhtasham | null | muhtasham/autonlp-Doctor_DE-24595545 | 4 | null | transformers | 18,840 | ---
tags: autonlp
language: de
widget:
- text: "I love AutoNLP 🤗"
datasets:
- muhtasham/autonlp-data-Doctor_DE
co2_eq_emissions: 203.30658367993382
---
# Model Trained Using AutoNLP
- Problem type: Single Column Regression
- Model ID: 24595545
- CO2 Emissions (in grams): 203.30658367993382
## Validation Metrics
- Loss: 0.30214861035346985
- MSE: 0.30214861035346985
- MAE: 0.25911855697631836
- R2: 0.8455587614373526
- RMSE: 0.5496804714202881
- Explained Variance: 0.8476610779762268
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/muhtasham/autonlp-Doctor_DE-24595545
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("muhtasham/autonlp-Doctor_DE-24595545", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("muhtasham/autonlp-Doctor_DE-24595545", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
mwesner/bert-base-uncased | e33fba797781eed6a2ec06437ad1169958c8f373 | 2022-02-23T15:18:51.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | fill-mask | false | mwesner | null | mwesner/bert-base-uncased | 4 | null | transformers | 18,841 | ---
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased
results: []
---
# bert-base-uncased
This model was trained on a dataset of issues from github.
It achieves the following results on the evaluation set:
- Loss: 1.2437
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
Masked language model trained on github issue data with token length of 128.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 2.205 | 1.0 | 9303 | 1.7893 |
| 1.8417 | 2.0 | 18606 | 1.7270 |
| 1.7103 | 3.0 | 27909 | 1.6650 |
| 1.6014 | 4.0 | 37212 | 1.6052 |
| 1.523 | 5.0 | 46515 | 1.5782 |
| 1.4588 | 6.0 | 55818 | 1.4836 |
| 1.3922 | 7.0 | 65121 | 1.4289 |
| 1.317 | 8.0 | 74424 | 1.4414 |
| 1.2622 | 9.0 | 83727 | 1.4322 |
| 1.2123 | 10.0 | 93030 | 1.3651 |
| 1.1753 | 11.0 | 102333 | 1.3636 |
| 1.1164 | 12.0 | 111636 | 1.2872 |
| 1.0636 | 13.0 | 120939 | 1.3705 |
| 1.021 | 14.0 | 130242 | 1.3013 |
| 0.996 | 15.0 | 139545 | 1.2756 |
| 0.9625 | 16.0 | 148848 | 1.2437 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.9.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
naram92/all-mpnet-base-v2-finetuned-mydata | 929ddedf2036b9e05ecdfa7a99be03335d212939 | 2021-10-07T20:47:30.000Z | [
"pytorch",
"tensorboard",
"mpnet",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | naram92 | null | naram92/all-mpnet-base-v2-finetuned-mydata | 4 | null | transformers | 18,842 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: all-mpnet-base-v2-finetuned-mydata
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-mpnet-base-v2-finetuned-mydata
This model is a fine-tuned version of [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 416 | 4.5566 |
| 5.5599 | 2.0 | 832 | 3.9093 |
| 4.1188 | 3.0 | 1248 | 3.6204 |
| 3.6951 | 4.0 | 1664 | 3.4622 |
| 3.4406 | 5.0 | 2080 | 3.3143 |
| 3.4406 | 6.0 | 2496 | 3.2054 |
| 3.3001 | 7.0 | 2912 | 3.1572 |
| 3.2002 | 8.0 | 3328 | 3.0510 |
| 3.1467 | 9.0 | 3744 | 3.0717 |
| 3.0763 | 10.0 | 4160 | 3.0017 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
nateraw/my-cool-timm-model-3 | a108f8ba0274ad6bb6bc65cbf8962d2d587145f4 | 2021-11-15T20:08:55.000Z | [
"pytorch",
"tensorboard",
"dataset:cats_vs_dogs",
"timm",
"image-classification",
"generated_from_trainer",
"model-index"
] | image-classification | false | nateraw | null | nateraw/my-cool-timm-model-3 | 4 | null | timm | 18,843 | ---
tags:
- image-classification
- timm
- generated_from_trainer
datasets:
- cats_vs_dogs
model-index:
- name: my-cool-timm-model-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my-cool-timm-model-3
This model is a fine-tuned version of [resnet18](https://huggingface.co/resnet18) on the cats_vs_dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2455
- Acc1: 94.4175
- Acc5: 100.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc1 | Acc5 |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-----:|
| 0.5152 | 0.14 | 10 | 0.2455 | 94.4175 | 100.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
nateraw/resnet18-random-classifier-123 | 20db6d9c301bdd7f04fa609d86923d60c8e62a6c | 2021-11-23T04:45:37.000Z | [
"pytorch",
"timm",
"image-classification"
] | image-classification | false | nateraw | null | nateraw/resnet18-random-classifier-123 | 4 | null | timm | 18,844 | ---
tags:
- image-classification
- timm
library_tag: timm
---
# Model card for resnet18-random-classifier-123 |
nateraw/timm-resnet18-beans-test | 237d6489fe22f45af47a74ef76b36cfdab4ebe1b | 2021-09-04T00:55:46.000Z | [
"pytorch",
"tensorboard",
"dataset:beans",
"timm",
"image-classification",
"generated_from_trainer"
] | image-classification | false | nateraw | null | nateraw/timm-resnet18-beans-test | 4 | null | timm | 18,845 | ---
tags:
- image-classification
- timm
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model_index:
- name: timm-resnet18-beans-test
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
args: default
metric:
name: Accuracy
type: accuracy
value: 0.3609022556390977
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# timm-resnet18-beans-test
This model is a fine-tuned version of [resnet18](https://huggingface.co/resnet18) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2126
- Accuracy: 0.3609
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10
### Training results
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0
- Datasets 1.11.1.dev0
- Tokenizers 0.10.3
|
nates-test-org/cait_s24_224 | 95705783329ab8d3d4bd6efeca8decacaa99fb1e | 2021-10-29T04:22:26.000Z | [
"pytorch",
"timm",
"image-classification"
] | image-classification | false | nates-test-org | null | nates-test-org/cait_s24_224 | 4 | null | timm | 18,846 | ---
tags:
- image-classification
- timm
library_tag: timm
---
# Model card for cait_s24_224 |
ncoop57/neo-code-py | 21bb94ddd2e530911c755ab8028f3532fd3ce999 | 2022-01-29T19:45:07.000Z | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] | text-generation | false | ncoop57 | null | ncoop57/neo-code-py | 4 | null | transformers | 18,847 | Entry not found |
negfir/distilbert-base-uncased-finetuned-squad | ae4c5650bf98af6c6a7a4f004e725efb32606272 | 2022-03-24T01:39:12.000Z | [
"pytorch",
"tensorboard",
"bert",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | question-answering | false | negfir | null | negfir/distilbert-base-uncased-finetuned-squad | 4 | null | transformers | 18,848 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.2789 | 1.0 | 5533 | 1.2200 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.4
- Tokenizers 0.11.6
|
neuralspace-reverie/indic-transformers-te-distilbert | a838c2b0925d58d0ddfc404e72581004b004f352 | 2020-12-11T21:57:36.000Z | [
"pytorch",
"tf",
"distilbert",
"fill-mask",
"te",
"transformers",
"MaskedLM",
"Telugu",
"DistilBERT",
"Question-Answering",
"Token Classification",
"Text Classification",
"autotrain_compatible"
] | fill-mask | false | neuralspace-reverie | null | neuralspace-reverie/indic-transformers-te-distilbert | 4 | null | transformers | 18,849 | ---
language:
- te
tags:
- MaskedLM
- Telugu
- DistilBERT
- Question-Answering
- Token Classification
- Text Classification
---
# Indic-Transformers Telugu DistilBERT
## Model description
This is a DistilBERT language model pre-trained on ~2 GB of monolingual training corpus. The pre-training data was majorly taken from [OSCAR](https://oscar-corpus.com/).
This model can be fine-tuned on various downstream tasks like text-classification, POS-tagging, question-answering, etc. Embeddings from this model can also be used for feature-based training.
## Intended uses & limitations
#### How to use
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('neuralspace-reverie/indic-transformers-te-distilbert')
model = AutoModel.from_pretrained('neuralspace-reverie/indic-transformers-te-distilbert')
text = "మీరు ఎలా ఉన్నారు"
input_ids = tokenizer(text, return_tensors='pt')['input_ids']
out = model(input_ids)[0]
print(out.shape)
# out = [1, 5, 768]
```
#### Limitations and bias
The original language model has been trained using `PyTorch` and hence the use of `pytorch_model.bin` weights file is recommended. The h5 file for `Tensorflow` has been generated manually by commands suggested [here](https://huggingface.co/transformers/model_sharing.html).
|
neurocode/IsRoBERTa | c343f2f15b450839451f86752cb3252be83c176b | 2021-05-20T18:50:32.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"is",
"dataset:Icelandic portion of the OSCAR corpus from INRIA",
"dataset:oscar",
"transformers",
"autotrain_compatible"
] | fill-mask | false | neurocode | null | neurocode/IsRoBERTa | 4 | null | transformers | 18,850 | ---
language: is
datasets:
- Icelandic portion of the OSCAR corpus from INRIA
- oscar
---
# IsRoBERTa a RoBERTa-like masked language model
Probably the first icelandic transformer language model!
## Overview
**Language:** Icelandic
**Downstream-task:** masked-lm
**Training data:** OSCAR corpus
**Code:** See [here](https://github.com/neurocode-io/icelandic-language-model)
**Infrastructure**: 1x Nvidia K80
## Hyperparameters
```
per_device_train_batch_size = 48
n_epochs = 1
vocab_size = 52.000
max_position_embeddings = 514
num_attention_heads = 12
num_hidden_layers = 6
type_vocab_size = 1
learning_rate=0.00005
```
## Usage
### In Transformers
```python
from transformers import (
pipeline,
AutoTokenizer,
AutoModelWithLMHead
)
model_name = "neurocode/IsRoBERTa"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
>>> fill_mask = pipeline(
... "fill-mask",
... model=model,
... tokenizer=tokenizer
... )
>>> result = fill_mask("Hann fór út að <mask>.")
>>> result
[
{'sequence': '<s>Hann fór út að nýju.</s>', 'score': 0.03395755589008331, 'token': 2219, 'token_str': 'Ġnýju'},
{'sequence': '<s>Hann fór út að undanförnu.</s>', 'score': 0.029087543487548828, 'token': 7590, 'token_str': 'Ġundanförnu'},
{'sequence': '<s>Hann fór út að lokum.</s>', 'score': 0.024420788511633873, 'token': 4384, 'token_str': 'Ġlokum'},
{'sequence': '<s>Hann fór út að þessu.</s>', 'score': 0.021231256425380707, 'token': 921, 'token_str': 'Ġþessu'},
{'sequence': '<s>Hann fór út að honum.</s>', 'score': 0.0205782949924469, 'token': 1136, 'token_str': 'Ġhonum'}
]
```
## Authors
Bobby Donchev: `contact [at] donchev.is`
Elena Cramer: `elena.cramer [at] neurocode.io`
## About us
We bring AI software for our customers live
Our focus: AI software development
Get in touch:
[LinkedIn](https://de.linkedin.com/company/neurocodeio) | [Website](https://neurocode.io)
|
nickmuchi/minilm-finetuned-emotion_nm | 9b1f91ecb6ce61015ac5e61aa50b768c92c05fb9 | 2022-01-17T08:15:50.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | nickmuchi | null | nickmuchi/minilm-finetuned-emotion_nm | 4 | null | transformers | 18,851 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- f1
model-index:
- name: minilm-finetuned-emotion_nm
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: F1
type: f1
value: 0.9322805793931607
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# minilm-finetuned-emotion_nm
This model is a fine-tuned version of [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1918
- F1: 0.9323
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.3627 | 1.0 | 250 | 1.0048 | 0.5936 |
| 0.8406 | 2.0 | 500 | 0.6477 | 0.8608 |
| 0.5344 | 3.0 | 750 | 0.4025 | 0.9099 |
| 0.3619 | 4.0 | 1000 | 0.3142 | 0.9188 |
| 0.274 | 5.0 | 1250 | 0.2489 | 0.9277 |
| 0.2225 | 6.0 | 1500 | 0.2320 | 0.9303 |
| 0.191 | 7.0 | 1750 | 0.2083 | 0.9298 |
| 0.1731 | 8.0 | 2000 | 0.1969 | 0.9334 |
| 0.1606 | 9.0 | 2250 | 0.1928 | 0.9362 |
| 0.1462 | 10.0 | 2500 | 0.1918 | 0.9323 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
nicktien/TaipeiQA_v1 | 6f3dfb6e69bb2d8e168ca01bc5f897ceb60d5bc9 | 2022-01-04T11:34:30.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | nicktien | null | nicktien/TaipeiQA_v1 | 4 | null | transformers | 18,852 | ---
widget:
- text: "所有權人接獲古蹟公告後,如不服指定程序該如何處理?"
---
# TaipeiQA
|
nielsr/tapex-large-finetuned-tabfact | fa24859010fc8e07cca3824aaa0847db2e344140 | 2022-01-17T13:39:28.000Z | [
"pytorch",
"bart",
"text-classification",
"en",
"dataset:tab_fact",
"arxiv:2107.07653",
"transformers",
"tapex",
"license:apache-2.0"
] | text-classification | false | nielsr | null | nielsr/tapex-large-finetuned-tabfact | 4 | null | transformers | 18,853 | ---
language: en
tags:
- tapex
license: apache-2.0
datasets:
- tab_fact
inference: false
---
TAPEX-large model fine-tuned on WTQ. This model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. Original repo can be found [here](https://github.com/microsoft/Table-Pretraining).
To load it and run inference, you can do the following:
```
from transformers import BartTokenizer, BartForSequenceClassification
import pandas as pd
tokenizer = BartTokenizer.from_pretrained("nielsr/tapex-large-finetuned-tabfact")
model = BartForSequenceClassification.from_pretrained("nielsr/tapex-large-finetuned-tabfact")
# create table
data = {'Actors': ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], 'Number of movies': ["87", "53", "69"]}
table = pd.DataFrame.from_dict(data)
# turn into dict
table_dict = {"header": list(table.columns), "rows": [list(row.values) for i,row in table.iterrows()]}
# turn into format TAPEX expects
# define the linearizer based on this code: https://github.com/microsoft/Table-Pretraining/blob/main/tapex/processor/table_linearize.py
linearizer = IndexedRowTableLinearize()
linear_table = linearizer.process_table(table_dict)
# add sentence
sentence = "George Clooney has 69 movies"
joint_input = sentence + " " + linear_table
# encode
encoding = tokenizer(joint_input, return_tensors="pt")
# forward pass
outputs = model(**encoding)
# print prediction
logits = outputs.logits
print(logits.argmax(-1))
``` |
nlokam/ada_V.3 | 71f5ff3fc3f53a732a63c306cd2cc5345bf08929 | 2022-01-26T23:28:36.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | nlokam | null | nlokam/ada_V.3 | 4 | null | transformers | 18,854 | ---
tags:
- conversational
---
# Ada model |
nlpunibo/multiplechoice | fd25a3e80d41807805a965cd70aa06b7cbc2b244 | 2021-03-18T12:08:51.000Z | [
"pytorch",
"distilbert",
"multiple-choice",
"transformers"
] | multiple-choice | false | nlpunibo | null | nlpunibo/multiplechoice | 4 | null | transformers | 18,855 | Entry not found |
nouamanetazi/wav2vec2-xls-r-300m-ar | b6c8ec432be0f6ef61181f1d3d0d14286661fb8d | 2022-03-23T18:35:04.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ar",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | nouamanetazi | null | nouamanetazi/wav2vec2-xls-r-300m-ar | 4 | 1 | transformers | 18,856 | ---
language:
- ar
license: apache-2.0
tags:
- ar
- automatic-speech-recognition
- common_voice
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
datasets:
- common_voice
model-index:
- name: XLS-R-300M - Arabic
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: ar
metrics:
- name: Test WER
type: wer
value: 1.0
- name: Test CER
type: cer
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-ar
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the COMMON_VOICE - AR dataset.
It achieves the following results on the evaluation set:
- eval_loss: 3.0191
- eval_wer: 1.0
- eval_runtime: 252.2389
- eval_samples_per_second: 30.217
- eval_steps_per_second: 0.476
- epoch: 1.0
- step: 340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
#### Evaluation Commands
Please use the evaluation script `eval.py` included in the repo.
1. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id nouamanetazi/wav2vec2-xls-r-300m-ar --dataset speech-recognition-community-v2/dev_data --config ar --split validation --chunk_length_s 5.0 --stride_length_s 1.0
``` |
nuriafari/my_model | 5c18bb546b16689d4492d5af4f75001a41e23793 | 2022-01-20T20:06:26.000Z | [
"pytorch",
"tensorboard",
"perceiver",
"text-classification",
"dataset:financial_phrasebank",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | nuriafari | null | nuriafari/my_model | 4 | null | transformers | 18,857 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- recall
- accuracy
- precision
model-index:
- name: my_model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
args: sentences_50agree
metrics:
- name: Recall
type: recall
value: 0.874936448490344
- name: Accuracy
type: accuracy
value: 0.865979381443299
- name: Precision
type: precision
value: 0.8280314825660291
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_model
This model is a fine-tuned version of [deepmind/language-perceiver](https://huggingface.co/deepmind/language-perceiver) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3732
- Recall: 0.8749
- Accuracy: 0.8660
- Precision: 0.8280
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- distributed_type: tpu
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Recall | Accuracy | Precision |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|:---------:|
| 0.1421 | 1.0 | 273 | 0.3732 | 0.8749 | 0.8660 | 0.8280 |
| 0.1036 | 2.0 | 546 | 0.3732 | 0.8749 | 0.8660 | 0.8280 |
| 0.1836 | 3.0 | 819 | 0.3732 | 0.8749 | 0.8660 | 0.8280 |
| 0.0423 | 4.0 | 1092 | 0.3732 | 0.8749 | 0.8660 | 0.8280 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.9.0+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
oemga38/distilbert-base-uncased-finetuned-cola | 3f82c9cabf04434948a580424b8ce84194013020 | 2022-02-17T21:51:01.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | oemga38 | null | oemga38/distilbert-base-uncased-finetuned-cola | 4 | null | transformers | 18,858 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5570389007427182
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7475
- Matthews Correlation: 0.5570
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5251 | 1.0 | 535 | 0.5304 | 0.4272 |
| 0.3474 | 2.0 | 1070 | 0.4874 | 0.5136 |
| 0.2356 | 3.0 | 1605 | 0.6454 | 0.5314 |
| 0.1699 | 4.0 | 2140 | 0.7475 | 0.5570 |
| 0.1244 | 5.0 | 2675 | 0.8525 | 0.5478 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
ogpat23/Jules-Chatbot | 78727165f5b83c2758d83398c644bc239ce5ad74 | 2022-05-13T16:43:30.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | ogpat23 | null | ogpat23/Jules-Chatbot | 4 | null | transformers | 18,859 | ---
tags:
- conversational
---
# Chat bot based on Pulp fiction Character Jules
# Model trained on Pytorch framework uisng Pulp fiction dialogue script dataset from kaggle
|
osanseviero/torch | edbb1f63aaaa010d7903261d243958363ce19ac2 | 2021-06-15T20:00:08.000Z | [
"pytorch",
"transformers"
] | null | false | osanseviero | null | osanseviero/torch | 4 | null | transformers | 18,860 | example |
oumeima/finetuned-bert-mrpc | 63d0302ab1d8709b53bf0e216b486d95647ede77 | 2021-08-22T11:35:18.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | text-classification | false | oumeima | null | oumeima/finetuned-bert-mrpc | 4 | null | transformers | 18,861 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model_index:
- name: finetuned-bert-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metric:
name: F1
type: f1
value: 0.9003322259136212
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-bert-mrpc
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5280
- Accuracy: 0.8529
- F1: 0.9003
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5704 | 1.0 | 230 | 0.4204 | 0.7917 | 0.8542 |
| 0.3391 | 2.0 | 460 | 0.4157 | 0.8456 | 0.8955 |
| 0.1923 | 3.0 | 690 | 0.5280 | 0.8529 | 0.9003 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
p208p2002/gpt2-squad-nqg-hl | dcd6fb9f156e726555c22ea22ae8c4e599fd34b9 | 2021-05-23T10:53:50.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"dataset:squad",
"arxiv:1606.05250",
"arxiv:1705.00106",
"transformers",
"question-generation"
] | text-generation | false | p208p2002 | null | p208p2002/gpt2-squad-nqg-hl | 4 | null | transformers | 18,862 | ---
datasets:
- squad
tags:
- question-generation
widget:
- text: "Harry Potter is a series of seven fantasy novels written by British author, [HL]J. K. Rowling[HL]."
---
# Transformer QG on SQuAD
HLQG is Proposed by [Ying-Hong Chan & Yao-Chung Fan. (2019). A Re-current BERT-based Model for Question Generation.](https://www.aclweb.org/anthology/D19-5821/)
**This is a Reproduce Version**
More detail: [p208p2002/Transformer-QG-on-SQuAD](https://github.com/p208p2002/Transformer-QG-on-SQuAD)
## Usage
### Input Format
```
C' = [c1, c2, ..., [HL], a1, ..., a|A|, [HL], ..., c|C|]
```
### Input Example
```
Harry Potter is a series of seven fantasy novels written by British author, [HL]J. K. Rowling[HL].
```
> # Who wrote Harry Potter?
## Data setting
We report two dataset setting as Follow
### SQuAD
- train: 87599\\\\t
- validation: 10570
> [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250)
### SQuAD NQG
- train: 75722
- dev: 10570
- test: 11877
> [Learning to Ask: Neural Question Generation for Reading Comprehension](https://arxiv.org/abs/1705.00106)
## Available models
- BART
- GPT2
- T5
## Expriments
We report score with `NQG Scorer` which is using in SQuAD NQG.
If not special explanation, the size of the model defaults to "base".
### SQuAD
Model |Bleu 1|Bleu 2|Bleu 3|Bleu 4|METEOR|ROUGE-L|
---------------------------------|------|------|------|------|------|-------|
BART-HLSQG |54.67 |39.26 |30.34 |24.15 |25.43 |52.64 |
GPT2-HLSQG |49.31 |33.95 |25.41| 19.69 |22.29 |48.82 |
T5-HLSQG |54.29 |39.22 |30.43 |24.26 |25.56 |53.11 |
### SQuAD NQG
Model |Bleu 1|Bleu 2|Bleu 3|Bleu 4|METEOR|ROUGE-L|
---------------------------------|------|------|------|------|------|-------|
BERT-HLSQG (Chan et al.) |49.73 |34.60 |26.13 |20.33 |23.88 |48.23 |
BART-HLSQG |54.12 |38.19 |28.84 |22.35 |24.55 |51.03 |
GPT2-HLSQG |49.82 |33.69 |24.71 |18.63 |21.90 |47.60 |
T5-HLSQG |53.13 |37.60 |28.62 |22.38 |24.48 |51.20 | |
pablouribe/beto-copus-overfitted | 9881fea25969b4a4f9f8966d314ed3591017cc52 | 2022-01-18T20:05:59.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | pablouribe | null | pablouribe/beto-copus-overfitted | 4 | null | transformers | 18,863 | Entry not found |
patrickvonplaten/prophetnet-decoder-clm-large-uncased | 2ce2c5641eac02f7d99ec103a40210c176bd5a78 | 2020-10-21T10:06:17.000Z | [
"pytorch",
"prophetnet",
"text-generation",
"transformers"
] | text-generation | false | patrickvonplaten | null | patrickvonplaten/prophetnet-decoder-clm-large-uncased | 4 | null | transformers | 18,864 | Entry not found |
patrickvonplaten/prophetnet-large-uncased-cnndm_old | 56bafad907302360edf943682ab0641da695f217 | 2020-10-16T12:55:25.000Z | [
"pytorch",
"prophetnet",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | patrickvonplaten | null | patrickvonplaten/prophetnet-large-uncased-cnndm_old | 4 | null | transformers | 18,865 | Entry not found |
patrickvonplaten/prophetnet-large-uncased-standalone | 62441c2f0f93fff06d7dbd6930bc473cfabaa527 | 2020-10-21T10:13:29.000Z | [
"pytorch",
"prophetnet",
"transformers"
] | null | false | patrickvonplaten | null | patrickvonplaten/prophetnet-large-uncased-standalone | 4 | null | transformers | 18,866 | Entry not found |
patrickvonplaten/wav2vec2-large-lv60h-100h-2nd-try | 38dfd9c80bcbe9f43a36447e1aec30dd5d12415a | 2021-03-03T13:02:06.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"arxiv:2006.11477",
"transformers"
] | automatic-speech-recognition | false | patrickvonplaten | null | patrickvonplaten/wav2vec2-large-lv60h-100h-2nd-try | 4 | null | transformers | 18,867 | Fine-tuning of `wav2vec2-large-lv60` on 100h of Librispeech training data. Results are a bit worse than those reported in the Appendix in Table 3 of the original [paper](https://arxiv.org/pdf/2006.11477.pdf).
Model was trained on *librispeech-clean-train.100* with following hyper-parameters:
- 2 GPUs Titan RTX
- Total update steps 17500
- Batch size per GPU: 16 corresponding to a *total batch size* of ca. ~750 seconds
- Adam with linear decaying learning rate with 3000 warmup steps
- dynamic padding for batch
- fp16
- attention_mask was used during training
Check: https://wandb.ai/patrickvonplaten/huggingface/reports/Project-Dashboard--Vmlldzo0OTI0OTc?accessToken=8azw8iyxnbiqd4ytxcgm4hbnfh3x1b2c9l2eyfqfzdqw7l0icreljc9qpx0rkl6f
*Result (WER)* on Librispeech test:
| "clean" | "other" |
|---|---|
| 4.0 | 10.3 | |
patrickvonplaten/xprophetnet-large-uncased-standalone | 0d7d60dded4dc2bfab2a94e93ce37f8c84ca7028 | 2020-10-21T10:16:36.000Z | [
"pytorch",
"xlm-prophetnet",
"transformers"
] | null | false | patrickvonplaten | null | patrickvonplaten/xprophetnet-large-uncased-standalone | 4 | null | transformers | 18,868 | Entry not found |
patrickvonplaten/xprophetnet-large-wiki100-cased-xglue-ntg_old | 4961a704b0cb659647dc3638667a1e50ceee329c | 2020-10-16T13:09:59.000Z | [
"pytorch",
"xlm-prophetnet",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | patrickvonplaten | null | patrickvonplaten/xprophetnet-large-wiki100-cased-xglue-ntg_old | 4 | null | transformers | 18,869 | Entry not found |
pedropei/question-intimacy | 5bf8c6ee2fda92df206c18ff224cbe68daf3f10b | 2021-05-20T19:25:02.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"en",
"transformers"
] | text-classification | false | pedropei | null | pedropei/question-intimacy | 4 | null | transformers | 18,870 | ---
language:
- en
inference: false
---
|
pere/norwegian-roberta-base-highlr | ff287ff8b5ebf47a90f4d4643bb4235426421c58 | 2021-11-30T12:18:13.000Z | [
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | pere | null | pere/norwegian-roberta-base-highlr | 4 | null | transformers | 18,871 | Same as norwegian-roberta-base but with higher learning rate and batch size |
pertschuk/bert-large-uncased-msmarco | 59a906252f66ae8fd75f5101f2620721c75d4146 | 2021-05-20T02:30:02.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
] | null | false | pertschuk | null | pertschuk/bert-large-uncased-msmarco | 4 | null | transformers | 18,872 | Entry not found |
peterhsu/distilbert-base-uncased-finetuned-imdb | 3d57bdbae75489a6ee2a5e6e2b1f121db0fd3610 | 2022-02-17T08:47:04.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"dataset:imdb",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | peterhsu | null | peterhsu/distilbert-base-uncased-finetuned-imdb | 4 | null | transformers | 18,873 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4718
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.707 | 1.0 | 157 | 2.4883 |
| 2.572 | 2.0 | 314 | 2.4240 |
| 2.5377 | 3.0 | 471 | 2.4355 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
pierric/test-EsperBERTo-small | 0694fd56a2c6cf15aa79588683c9694c8adc1bb3 | 2021-05-20T19:29:19.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"esperanto",
"transformers",
"autotrain_compatible"
] | fill-mask | false | pierric | null | pierric/test-EsperBERTo-small | 4 | null | transformers | 18,874 | ---
language: esperanto
thumbnail: https://huggingface.co/blog/assets/EsperBERTo-thumbnail-v2.png
---
## EsperBERTo: RoBERTa-like Language model trained on Esperanto
**Companion model to blog post https://huggingface.co/blog/how-to-train** 🔥
### Training Details
- current checkpoint: 566000
- machine name: `galinette`
|
pietrotrope/emotion_final | 48576b1661384f5e8709528742b7bcab0cbf23ca | 2021-12-11T11:14:26.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | pietrotrope | null | pietrotrope/emotion_final | 4 | null | transformers | 18,875 | Entry not found |
pinecone/bert-mrpc-cross-encoder | 97c588b361e8b941feb04135e2069fd23770559f | 2021-12-30T12:12:14.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | pinecone | null | pinecone/bert-mrpc-cross-encoder | 4 | null | transformers | 18,876 | # MRPC Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
poom-sci/distilbert-qa | 380e060bfb3f6d6263b92ebba3b52523d92df162 | 2021-11-12T04:45:13.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | poom-sci | null | poom-sci/distilbert-qa | 4 | null | transformers | 18,877 | Entry not found |
pooyaphoenix/distilbert-base-uncased-finetuned-cola | 56f8d4d780bdab0c8a274c24d2f26adf359526b1 | 2021-11-01T10:54:03.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | pooyaphoenix | null | pooyaphoenix/distilbert-base-uncased-finetuned-cola | 4 | null | transformers | 18,878 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5226700639354173
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7904
- Matthews Correlation: 0.5227
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.528 | 1.0 | 535 | 0.5180 | 0.4003 |
| 0.3508 | 2.0 | 1070 | 0.5120 | 0.5019 |
| 0.2409 | 3.0 | 1605 | 0.6374 | 0.5128 |
| 0.1806 | 4.0 | 2140 | 0.7904 | 0.5227 |
| 0.1311 | 5.0 | 2675 | 0.8824 | 0.5227 |
### Framework versions
- Transformers 4.12.2
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
prajjwal1/albert_new | 8d4d574c1b91b33ca2d4a65e39fc703be05058c4 | 2021-05-26T19:57:27.000Z | [
"pytorch",
"albert",
"multiple-choice",
"transformers"
] | multiple-choice | false | prajjwal1 | null | prajjwal1/albert_new | 4 | null | transformers | 18,879 | Entry not found |
prao/distilbert-base-uncased-finetuned-ner | 0820a3265f4f40cb2a9ca5bb7927d4ae80197ce9 | 2021-08-03T07:15:20.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | false | prao | null | prao/distilbert-base-uncased-finetuned-ner | 4 | null | transformers | 18,880 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model_index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metric:
name: Accuracy
type: accuracy
value: 0.9842883695807584
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0586
- Precision: 0.9293
- Recall: 0.9385
- F1: 0.9339
- Accuracy: 0.9843
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2436 | 1.0 | 878 | 0.0670 | 0.9190 | 0.9240 | 0.9215 | 0.9815 |
| 0.0505 | 2.0 | 1756 | 0.0591 | 0.9252 | 0.9351 | 0.9301 | 0.9836 |
| 0.0304 | 3.0 | 2634 | 0.0586 | 0.9293 | 0.9385 | 0.9339 | 0.9843 |
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
qarib/bert-base-qarib60_860k | b98c86a1175b24fde6c1802277a1eca7244d5e34 | 2021-05-20T03:48:03.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"ar",
"dataset:arabic_billion_words",
"dataset:open_subtitles",
"dataset:twitter",
"arxiv:2102.10684",
"transformers",
"tf",
"bert-base-qarib60_860k",
"qarib",
"autotrain_compatible"
] | fill-mask | false | qarib | null | qarib/bert-base-qarib60_860k | 4 | null | transformers | 18,881 | ---
language: ar
tags:
- pytorch
- tf
- bert-base-qarib60_860k
- qarib
datasets:
- arabic_billion_words
- open_subtitles
- twitter
metrics:
- f1
widget:
- text: " شو عندكم يا [MASK] ."
---
# QARiB: QCRI Arabic and Dialectal BERT
## About QARiB
QCRI Arabic and Dialectal BERT (QARiB) model, was trained on a collection of ~ 420 Million tweets and ~ 180 Million sentences of text.
For tweets, the data was collected using twitter API and using language filter. `lang:ar`. For text data, it was a combination from
[Arabic GigaWord](url), [Abulkhair Arabic Corpus]() and [OPUS](http://opus.nlpl.eu/).
### bert-base-qarib60_860k
- Data size: 60Gb
- Number of Iterations: 860k
- Loss: 2.2454472
## Training QARiB
The training of the model has been performed using Google’s original Tensorflow code on Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
See more details in [Training QARiB](https://github.com/qcri/QARiB/blob/main/Training_QARiB.md)
## Using QARiB
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you. For more details, see [Using QARiB](https://github.com/qcri/QARiB/blob/main/Using_QARiB.md)
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>>from transformers import pipeline
>>>fill_mask = pipeline("fill-mask", model="./models/data60gb_86k")
>>> fill_mask("شو عندكم يا [MASK]")
[{'sequence': '[CLS] شو عندكم يا عرب [SEP]', 'score': 0.0990147516131401, 'token': 2355, 'token_str': 'عرب'},
{'sequence': '[CLS] شو عندكم يا جماعة [SEP]', 'score': 0.051633741706609726, 'token': 2308, 'token_str': 'جماعة'},
{'sequence': '[CLS] شو عندكم يا شباب [SEP]', 'score': 0.046871256083250046, 'token': 939, 'token_str': 'شباب'},
{'sequence': '[CLS] شو عندكم يا رفاق [SEP]', 'score': 0.03598872944712639, 'token': 7664, 'token_str': 'رفاق'},
{'sequence': '[CLS] شو عندكم يا ناس [SEP]', 'score': 0.031996358186006546, 'token': 271, 'token_str': 'ناس'}]
>>> fill_mask("قللي وشفيييك يرحم [MASK]")
[{'sequence': '[CLS] قللي وشفيييك يرحم والديك [SEP]', 'score': 0.4152909517288208, 'token': 9650, 'token_str': 'والديك'},
{'sequence': '[CLS] قللي وشفيييك يرحملي [SEP]', 'score': 0.07663793861865997, 'token': 294, 'token_str': '##لي'},
{'sequence': '[CLS] قللي وشفيييك يرحم حالك [SEP]', 'score': 0.0453166700899601, 'token': 2663, 'token_str': 'حالك'},
{'sequence': '[CLS] قللي وشفيييك يرحم امك [SEP]', 'score': 0.04390475153923035, 'token': 1942, 'token_str': 'امك'},
{'sequence': '[CLS] قللي وشفيييك يرحمونك [SEP]', 'score': 0.027349254116415977, 'token': 3283, 'token_str': '##ونك'}]
>>> fill_mask("وقام المدير [MASK]")
[
{'sequence': '[CLS] وقام المدير بالعمل [SEP]', 'score': 0.0678194984793663, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقام المدير بذلك [SEP]', 'score': 0.05191086605191231, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقام المدير بالاتصال [SEP]', 'score': 0.045264165848493576, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقام المدير بعمله [SEP]', 'score': 0.03732728958129883, 'token': 40486, 'token_str': 'بعمله'},
{'sequence': '[CLS] وقام المدير بالامر [SEP]', 'score': 0.0246378555893898, 'token': 29124, 'token_str': 'بالامر'}
]
>>> fill_mask("وقامت المديرة [MASK]")
[{'sequence': '[CLS] وقامت المديرة بذلك [SEP]', 'score': 0.23992691934108734, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقامت المديرة بالامر [SEP]', 'score': 0.108805812895298, 'token': 29124, 'token_str': 'بالامر'},
{'sequence': '[CLS] وقامت المديرة بالعمل [SEP]', 'score': 0.06639821827411652, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقامت المديرة بالاتصال [SEP]', 'score': 0.05613093823194504, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقامت المديرة المديرة [SEP]', 'score': 0.021778125315904617, 'token': 41635, 'token_str': 'المديرة'}]
```
## Training procedure
The training of the model has been performed using Google’s original Tensorflow code on eight core Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
## Eval results
We evaluated QARiB models on five NLP downstream task:
- Sentiment Analysis
- Emotion Detection
- Named-Entity Recognition (NER)
- Offensive Language Detection
- Dialect Identification
The results obtained from QARiB models outperforms multilingual BERT/AraBERT/ArabicBERT.
## Model Weights and Vocab Download
From Huggingface site: https://huggingface.co/qarib/bert-base-qarib60_860k
## Contacts
Ahmed Abdelali, Sabit Hassan, Hamdy Mubarak, Kareem Darwish and Younes Samih
## Reference
```
@article{abdelali2021pretraining,
title={Pre-Training BERT on Arabic Tweets: Practical Considerations},
author={Ahmed Abdelali and Sabit Hassan and Hamdy Mubarak and Kareem Darwish and Younes Samih},
year={2021},
eprint={2102.10684},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
quarter100/BoolQ_dain_test | 13eedaf1113b2d64e95404ecaafabaa3a9cf3bc1 | 2021-12-27T02:02:43.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | quarter100 | null | quarter100/BoolQ_dain_test | 4 | null | transformers | 18,882 | Entry not found |
quarter100/ko-boolq-model | 0b90e8781f0e35d8c978876130ad1fcb7c11b5a0 | 2021-12-20T13:23:04.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | quarter100 | null | quarter100/ko-boolq-model | 4 | 1 | transformers | 18,883 | labeled by "YES" : 1, "NO" : 0, "No Answer" : 2
fine tuned by klue/roberta-large |
redwoodresearch/classifier_12aug_50k_labels | b35b588233377a36955ceee0ddf4c7ba40631471 | 2021-09-21T02:58:41.000Z | [
"pytorch",
"deberta",
"text-classification",
"transformers"
] | text-classification | false | redwoodresearch | null | redwoodresearch/classifier_12aug_50k_labels | 4 | null | transformers | 18,884 | Entry not found |
researchaccount/sa_sub2 | 4238d72dca3b2519d8aea4e4edeb866c9aaa9503 | 2021-05-20T04:21:46.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"transformers"
] | text-classification | false | researchaccount | null | researchaccount/sa_sub2 | 4 | null | transformers | 18,885 | ---
language: en
widget:
- text: "USER USER USER USER لاحول ولاقوه الا بالله 💔 💔 💔 💔 HASH TAG متي يصدر قرار العشرين ! ! ! ! ! !"
---
Sub 2 |
researchaccount/sa_sub4 | 02294b3482cc2cf5b50bc4e941cac566e4efc151 | 2021-05-20T04:24:52.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"transformers"
] | text-classification | false | researchaccount | null | researchaccount/sa_sub4 | 4 | null | transformers | 18,886 | ---
language: en
widget:
- text: "USER USER USER USER لاحول ولاقوه الا بالله 💔 💔 💔 💔 HASH TAG متي يصدر قرار العشرين ! ! ! ! ! !"
---
Sub 4 |
rexxar96/autonlp-sentiment-analysis-456211724 | a3e9927d761166cf8dbeecb688dfe603e947f1de | 2021-12-29T14:47:09.000Z | [
"pytorch",
"distilbert",
"text-classification",
"unk",
"dataset:rexxar96/autonlp-data-sentiment-analysis",
"transformers",
"autonlp",
"co2_eq_emissions"
] | text-classification | false | rexxar96 | null | rexxar96/autonlp-sentiment-analysis-456211724 | 4 | null | transformers | 18,887 | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- rexxar96/autonlp-data-sentiment-analysis
co2_eq_emissions: 22.28263989637389
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 456211724
- CO2 Emissions (in grams): 22.28263989637389
## Validation Metrics
- Loss: 0.23710417747497559
- Accuracy: 0.9119100357812234
- Precision: 0.8882611424984307
- Recall: 0.9461718488799733
- AUC: 0.974790366001874
- F1: 0.9163024121741946
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/rexxar96/autonlp-sentiment-analysis-456211724
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("rexxar96/autonlp-sentiment-analysis-456211724", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("rexxar96/autonlp-sentiment-analysis-456211724", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
rg089/bert_newspaper_source | 66c0c84ba893f71dfaae01eff834b3764d00e0ac | 2021-11-27T19:06:53.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | rg089 | null | rg089/bert_newspaper_source | 4 | 1 | transformers | 18,888 | Entry not found |
ricardo-filho/sbertimbau-large-nli-sts | bb1b5669743b2ea4422fac018757eabf643d1ecb | 2021-08-13T13:58:12.000Z | [
"pytorch",
"bert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
] | sentence-similarity | false | ricardo-filho | null | ricardo-filho/sbertimbau-large-nli-sts | 4 | null | sentence-transformers | 18,889 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 356 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 143,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 64, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
riyadhctg/distilbert-base-uncased-finetuned-cola | 5726807d8579447ea2cea1b3bdc36131c4d3b65c | 2021-08-30T07:04:19.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | text-classification | false | riyadhctg | null | riyadhctg/distilbert-base-uncased-finetuned-cola | 4 | null | transformers | 18,890 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model_index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metric:
name: Matthews Correlation
type: matthews_correlation
value: 0.5526838482765232
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7691
- Matthews Correlation: 0.5527
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5247 | 1.0 | 535 | 0.5390 | 0.4315 |
| 0.353 | 2.0 | 1070 | 0.5273 | 0.4994 |
| 0.2386 | 3.0 | 1605 | 0.6391 | 0.5089 |
| 0.17 | 4.0 | 2140 | 0.7691 | 0.5527 |
| 0.1348 | 5.0 | 2675 | 0.8483 | 0.5472 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
rjbownes/BBC-GQA | eb5db0066b3ff1adfd64bd52252c009467781263 | 2021-06-23T13:57:11.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | rjbownes | null | rjbownes/BBC-GQA | 4 | null | transformers | 18,891 | Entry not found |
rjbownes/lovelace-generator | cb10dfa02542b04276eac89632469e79a9813cd6 | 2021-06-23T13:59:02.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | rjbownes | null | rjbownes/lovelace-generator | 4 | null | transformers | 18,892 | Entry not found |
rtoguchi/t5-small-finetuned-en-to-ro-fp16_off-lr_2e-7-weight_decay_0.001 | 81a8b19fb4e53d4ea7eee35d3ae763e0498df25c | 2021-12-03T19:24:15.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"dataset:wmt16",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | rtoguchi | null | rtoguchi/t5-small-finetuned-en-to-ro-fp16_off-lr_2e-7-weight_decay_0.001 | 4 | null | transformers | 18,893 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: t5-small-finetuned-en-to-ro-fp16_off-lr_2e-7-weight_decay_0.001
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: wmt16
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 4.7258
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-en-to-ro-fp16_off-lr_2e-7-weight_decay_0.001
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wmt16 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4943
- Bleu: 4.7258
- Gen Len: 18.7149
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-07
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| 1.047 | 1.0 | 7629 | 1.4943 | 4.7258 | 18.7149 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
saattrupdan/alvenir-wav2vec2-base-cv8-da | 98d042a658f0779dc2c391c912c60b31d58062d7 | 2022-03-22T10:52:55.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"da",
"dataset:common_voice_8_0",
"transformers",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | saattrupdan | null | saattrupdan/alvenir-wav2vec2-base-cv8-da | 4 | null | transformers | 18,894 | ---
language:
- da
license: apache-2.0
tasks:
- automatic-speech-recognition
datasets:
- common_voice_8_0
metrics:
- wer
model-index:
- name: alvenir-wav2vec2-base-cv8-da
results:
- task:
type: automatic-speech-recognition
dataset:
type: mozilla-foundation/common_voice_8_0
args: da
name: Danish Common Voice 8.0
metrics:
- type: wer
value: 39.86
- task:
type: automatic-speech-recognition
dataset:
type: Alvenir/alvenir_asr_da_eval
name: Alvenir ASR test dataset
metrics:
- type: wer
value: 34.12
---
# Alvenir-Wav2vec2-base-CV8-da
## Model description
This model is a fine-tuned version of the Danish acoustic model [Alvenir/wav2vec2-base-da](https://huggingface.co/Alvenir/wav2vec2-base-da) on the Danish part of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), containing ~6 crowdsourced hours of read-aloud Danish speech.
## Performance
The model achieves the following WER scores (lower is better):
| **Dataset** | **WER without LM** | **WER with 5-gram LM** |
| :---: | ---: | ---: |
| [Danish part of Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0/viewer/da/train) | 46.05 | 39.86 |
| [Alvenir test set](https://huggingface.co/datasets/Alvenir/alvenir_asr_da_eval) | 41.08 | 34.12 | |
sabhi/t5-base-qa-qg | fb6c39f225ed9cd4c929d26c4eceb586a07bfede | 2021-09-07T07:24:12.000Z | [
"pytorch",
"t5",
"text2text-generation",
"dataset:squadv1",
"arxiv:1910.10683",
"transformers",
"question-generation",
"autotrain_compatible"
] | text2text-generation | false | sabhi | null | sabhi/t5-base-qa-qg | 4 | 1 | transformers | 18,895 | ---
datasets:
- squadv1
tags:
- question-generation
---
## T5 for multi-task QA and QG
This is multi-task [t5-base](https://arxiv.org/abs/1910.10683) model trained for question answering and answer aware question generation tasks.
For question generation the answer spans are highlighted within the text with special highlight tokens (`<hl>`) and prefixed with 'generate question: '. For QA the input is processed like this `question: question_text context: context_text </s>`
You can play with the model using the inference API. Here's how you can use it
For QG
`generate question: <hl> 42 <hl> is the answer to life, the universe and everything. </s>`
For QA
`question: What is 42 context: 42 is the answer to life, the universe and everything. </s>`
For more deatils see [this](https://github.com/sabhi27/question_generation) repo.
### Model in action 🚀
You'll need to clone the [repo](https://github.com/sabhi27/question_generation).
[](https://colab.research.google.com/github/sabhi27/question_generation/blob/master/question_generation.ipynb)
```python3
from pipelines import pipeline
nlp = pipeline("multitask-qa-qg", model="sabhi/t5-base-qa-qg")
# to generate questions simply pass the text
nlp("42 is the answer to life, the universe and everything.")
=> [{'answer': '42', 'question': 'What is the answer to life, the universe and everything?'}]
# for qa pass a dict with "question" and "context"
nlp({
"question": "What is 42 ?",
"context": "42 is the answer to life, the universe and everything."
})
=> 'the answer to life, the universe and everything'
``` |
sambotx4/scamantha | 50e6f9cff1c54fff11cf0a93af1da81a1a3a6278 | 2021-08-12T10:20:43.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | sambotx4 | null | sambotx4/scamantha | 4 | null | transformers | 18,896 | ---
tags:
- conversational
---
# Scamantha |
sammy786/wav2vec2-xlsr-sakha | 06627f367db2d01f1b1ae79f55c0d8a1d4f0411b | 2022-03-24T11:56:16.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sah",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"model_for_talk",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | sammy786 | null | sammy786/wav2vec2-xlsr-sakha | 4 | null | transformers | 18,897 | ---
language:
- sah
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
- sah
- robust-speech-event
- model_for_talk
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: sammy786/wav2vec2-xlsr-sakha
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: sah
metrics:
- name: Test WER
type: wer
value: 36.15
- name: Test CER
type: cer
value: 8.06
---
# sammy786/wav2vec2-xlsr-sakha
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - sah dataset.
It achieves the following results on evaluation set (which is 10 percent of train data set merged with other and dev datasets):
- Loss: 21.39
- Wer: 30.99
## Model description
"facebook/wav2vec2-xls-r-1b" was finetuned.
## Intended uses & limitations
More information needed
## Training and evaluation data
Training data -
Common voice Finnish train.tsv, dev.tsv and other.tsv
## Training procedure
For creating the train dataset, all possible datasets were appended and 90-10 split was used.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000045637994662983496
- train_batch_size: 16
- eval_batch_size: 16
- seed: 13
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 500
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Step | Training Loss | Validation Loss | Wer |
|------|---------------|-----------------|----------|
| 200 | 4.541600 | 1.044711 | 0.926395 |
| 400 | 1.013700 | 0.290368 | 0.401758 |
| 600 | 0.645000 | 0.232261 | 0.346555 |
| 800 | 0.467800 | 0.214120 | 0.318340 |
| 1000 | 0.502300 | 0.213995 | 0.309957 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.10.3
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id sammy786/wav2vec2-xlsr-sakha --dataset mozilla-foundation/common_voice_8_0 --config sah --split test
``` |
sanayAI/sanay-bert | 06568bd76ad0c78facfc2b0d72561d3824d56397 | 2021-05-20T04:44:48.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | sanayAI | null | sanayAI/sanay-bert | 4 | null | transformers | 18,898 | Entry not found |
sanchit-gandhi/wav2vec2-2-gpt2-no-adapter | 9e51a4203878c4120fa76a6bb780d8e44f080b51 | 2022-02-22T18:18:09.000Z | [
"pytorch",
"tensorboard",
"speech-encoder-decoder",
"automatic-speech-recognition",
"dataset:librispeech_asr",
"transformers",
"generated_from_trainer",
"model-index"
] | automatic-speech-recognition | false | sanchit-gandhi | null | sanchit-gandhi/wav2vec2-2-gpt2-no-adapter | 4 | null | transformers | 18,899 | ---
tags:
- generated_from_trainer
datasets:
- librispeech_asr
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model was trained from scratch on the librispeech_asr dataset.
It achieves the following results on the evaluation set:
- Loss: 5.2453
- Wer: 1.9070
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.6407 | 0.28 | 500 | 6.3882 | 1.9939 |
| 5.6351 | 0.56 | 1000 | 6.1492 | 2.0010 |
| 5.4896 | 0.84 | 1500 | 5.8014 | 1.9549 |
| 4.9941 | 1.12 | 2000 | 5.7117 | 1.9888 |
| 5.1524 | 1.4 | 2500 | 5.5260 | 1.3353 |
| 4.8291 | 1.68 | 3000 | 5.4030 | 1.9694 |
| 4.6539 | 1.96 | 3500 | 5.3507 | 1.9606 |
| 4.351 | 2.24 | 4000 | 5.4178 | 1.9678 |
| 4.1189 | 2.52 | 4500 | 5.2799 | 1.9154 |
| 3.9921 | 2.8 | 5000 | 5.2453 | 1.9070 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.