
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Team-PIXEL/pixel-base-finetuned-qnli | 066279a64f5529a4527e63b40bbcee9fa3e8f221 | 2022-07-15T02:52:20.000Z | [
"pytorch",
"pixel",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"model-index"
] | text-classification | false | Team-PIXEL | null | Team-PIXEL/pixel-base-finetuned-qnli | 5 | null | transformers | 17,600 | ---
language:
- en
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: pixel-base-finetuned-qnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QNLI
type: glue
args: qnli
metrics:
- name: Accuracy
type: accuracy
value: 0.8859600951857953
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pixel-base-finetuned-qnli
This model is a fine-tuned version of [Team-PIXEL/pixel-base](https://huggingface.co/Team-PIXEL/pixel-base) on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9503
- Accuracy: 0.8860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 15000
- mixed_precision_training: Apex, opt level O1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.5451 | 0.31 | 500 | 0.5379 | 0.7282 |
| 0.4451 | 0.61 | 1000 | 0.3846 | 0.8318 |
| 0.4567 | 0.92 | 1500 | 0.3543 | 0.8525 |
| 0.3558 | 1.22 | 2000 | 0.3294 | 0.8638 |
| 0.3324 | 1.53 | 2500 | 0.3221 | 0.8666 |
| 0.3434 | 1.83 | 3000 | 0.2976 | 0.8774 |
| 0.2573 | 2.14 | 3500 | 0.3193 | 0.8750 |
| 0.2411 | 2.44 | 4000 | 0.3044 | 0.8794 |
| 0.253 | 2.75 | 4500 | 0.2932 | 0.8834 |
| 0.1653 | 3.05 | 5000 | 0.3364 | 0.8841 |
| 0.1662 | 3.36 | 5500 | 0.3348 | 0.8797 |
| 0.1816 | 3.67 | 6000 | 0.3440 | 0.8869 |
| 0.1699 | 3.97 | 6500 | 0.3453 | 0.8845 |
| 0.1027 | 4.28 | 7000 | 0.4277 | 0.8810 |
| 0.0987 | 4.58 | 7500 | 0.4590 | 0.8832 |
| 0.0974 | 4.89 | 8000 | 0.4311 | 0.8783 |
| 0.0669 | 5.19 | 8500 | 0.5214 | 0.8819 |
| 0.0583 | 5.5 | 9000 | 0.5776 | 0.8850 |
| 0.065 | 5.8 | 9500 | 0.5646 | 0.8821 |
| 0.0381 | 6.11 | 10000 | 0.6252 | 0.8796 |
| 0.0314 | 6.41 | 10500 | 0.7222 | 0.8801 |
| 0.0453 | 6.72 | 11000 | 0.6951 | 0.8823 |
| 0.0264 | 7.03 | 11500 | 0.7620 | 0.8828 |
| 0.0215 | 7.33 | 12000 | 0.8160 | 0.8834 |
| 0.0176 | 7.64 | 12500 | 0.8583 | 0.8828 |
| 0.0245 | 7.94 | 13000 | 0.8484 | 0.8867 |
| 0.0124 | 8.25 | 13500 | 0.8927 | 0.8836 |
| 0.0112 | 8.55 | 14000 | 0.9368 | 0.8827 |
| 0.0154 | 8.86 | 14500 | 0.9405 | 0.8860 |
| 0.0046 | 9.16 | 15000 | 0.9503 | 0.8860 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
huggingtweets/thomastrainrek | d8e268125fe164d667b22ccef939c34cf0c1d604 | 2022-07-17T02:03:59.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/thomastrainrek | 5 | null | transformers | 17,601 | ---
language: en
thumbnail: http://www.huggingtweets.com/thomastrainrek/1658023434881/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1321337599332593664/tqNLm-HD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">thomas the trainwreck</div>
<div style="text-align: center; font-size: 14px;">@thomastrainrek</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from thomas the trainwreck.
| Data | thomas the trainwreck |
| --- | --- |
| Tweets downloaded | 1454 |
| Retweets | 34 |
| Short tweets | 40 |
| Tweets kept | 1380 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/15e6z8cg/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @thomastrainrek's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2967djo2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2967djo2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/thomastrainrek')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
JoonJoon/koelectra-base-v3-discriminator-finetuned-ner | 29e2af0578469824a76ee16a4f590ff7df003ccc | 2022-07-15T06:43:05.000Z | [
"pytorch",
"electra",
"token-classification",
"dataset:klue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | JoonJoon | null | JoonJoon/koelectra-base-v3-discriminator-finetuned-ner | 5 | null | transformers | 17,602 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: koelectra-base-v3-discriminator-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: klue
type: klue
args: ner
metrics:
- name: Precision
type: precision
value: 0.6665182546749777
- name: Recall
type: recall
value: 0.7350073648032546
- name: F1
type: f1
value: 0.6990893625537877
- name: Accuracy
type: accuracy
value: 0.9395764497172635
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# koelectra-base-v3-discriminator-finetuned-ner
This model is a fine-tuned version of [monologg/koelectra-base-v3-discriminator](https://huggingface.co/monologg/koelectra-base-v3-discriminator) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1957
- Precision: 0.6665
- Recall: 0.7350
- F1: 0.6991
- Accuracy: 0.9396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 438 | 0.2588 | 0.5701 | 0.6655 | 0.6141 | 0.9212 |
| 0.4333 | 2.0 | 876 | 0.2060 | 0.6671 | 0.7134 | 0.6895 | 0.9373 |
| 0.1944 | 3.0 | 1314 | 0.1957 | 0.6665 | 0.7350 | 0.6991 | 0.9396 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu102
- Datasets 1.14.0
- Tokenizers 0.10.3
|
jinwooChoi/hjw_small_25_32_0.0001 | 1a129cd10e36943e4395b70e1e439e74419667d6 | 2022-07-15T07:32:27.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers"
] | text-classification | false | jinwooChoi | null | jinwooChoi/hjw_small_25_32_0.0001 | 5 | null | transformers | 17,603 | Entry not found |
darragh/swinunetr-btcv-base | 2a60a8f819994b0210038531994703c7c7bd8e21 | 2022-07-15T21:01:42.000Z | [
"pytorch",
"en",
"dataset:BTCV",
"transformers",
"btcv",
"medical",
"swin",
"license:apache-2.0"
] | null | false | darragh | null | darragh/swinunetr-btcv-base | 5 | null | transformers | 17,604 | ---
language: en
tags:
- btcv
- medical
- swin
license: apache-2.0
datasets:
- BTCV
---
# Model Overview
This repository contains the code for Swin UNETR [1,2]. Swin UNETR is the state-of-the-art on Medical Segmentation
Decathlon (MSD) and Beyond the Cranial Vault (BTCV) Segmentation Challenge dataset. In [1], a novel methodology is devised for pre-training Swin UNETR backbone in a self-supervised
manner. We provide the option for training Swin UNETR by fine-tuning from pre-trained self-supervised weights or from scratch.
The source repository for the training of these models can be found [here](https://github.com/Project-MONAI/research-contributions/tree/main/SwinUNETR/BTCV).
# Installing Dependencies
Dependencies for training and inference can be installed using the model requirements :
``` bash
pip install -r requirements.txt
```
# Intended uses & limitations
You can use the raw model for dicom segmentation, but it's mostly intended to be fine-tuned on a downstream task.
Note that this model is primarily aimed at being fine-tuned on tasks which segment CAT scans or MRIs on images in dicom format. Dicom meta data mostly differs across medical facilities, so if applying to a new dataset, the model should be finetuned.
# How to use
To install necessary dependencies, run the below in bash.
```
git clone https://github.com/darraghdog/Project-MONAI-research-contributions pmrc
pip install -r pmrc/requirements.txt
cd pmrc/SwinUNETR/BTCV
```
To load the model from the hub.
```
>>> from swinunetr import SwinUnetrModelForInference
>>> model = SwinUnetrModelForInference.from_pretrained('darragh/swinunetr-btcv-tiny')
```
# Limitations and bias
The training data used for this model is specific to CAT scans from certain health facilities and machines. Data from other facilities may difffer in image distributions, and may require finetuning of the models for best performance.
# Evaluation results
We provide several pre-trained models on BTCV dataset in the following.
<table>
<tr>
<th>Name</th>
<th>Dice (overlap=0.7)</th>
<th>Dice (overlap=0.5)</th>
<th>Feature Size</th>
<th># params (M)</th>
<th>Self-Supervised Pre-trained </th>
</tr>
<tr>
<td>Swin UNETR/Base</td>
<td>82.25</td>
<td>81.86</td>
<td>48</td>
<td>62.1</td>
<td>Yes</td>
</tr>
<tr>
<td>Swin UNETR/Small</td>
<td>79.79</td>
<td>79.34</td>
<td>24</td>
<td>15.7</td>
<td>No</td>
</tr>
<tr>
<td>Swin UNETR/Tiny</td>
<td>72.05</td>
<td>70.35</td>
<td>12</td>
<td>4.0</td>
<td>No</td>
</tr>
</table>
# Data Preparation
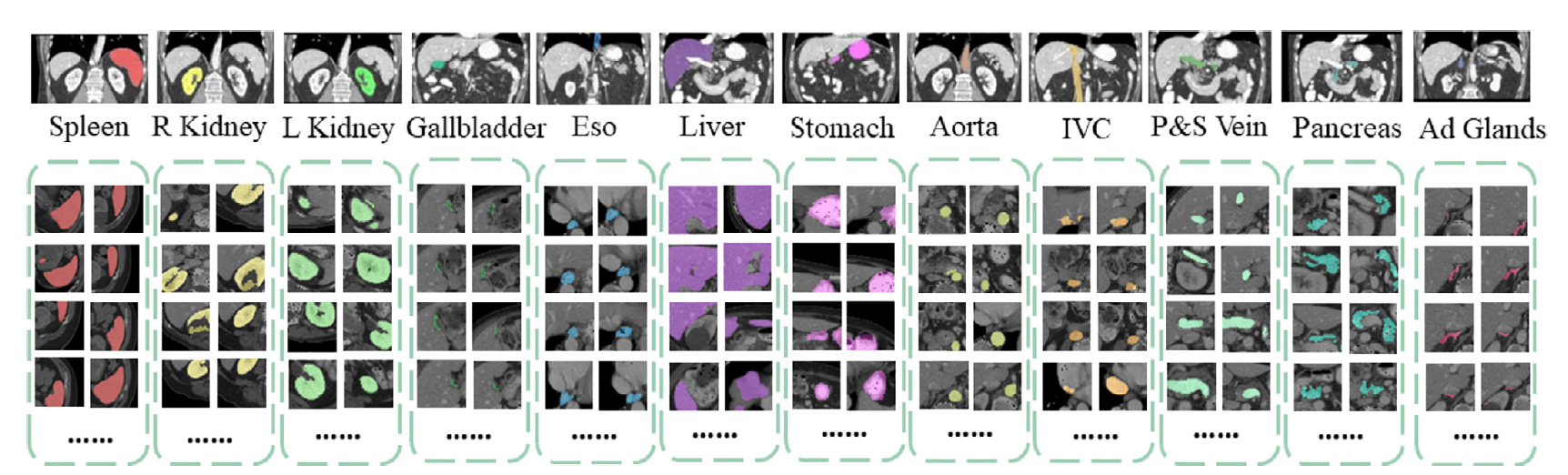
The training data is from the [BTCV challenge dataset](https://www.synapse.org/#!Synapse:syn3193805/wiki/217752).
- Target: 13 abdominal organs including 1. Spleen 2. Right Kidney 3. Left Kideny 4.Gallbladder 5.Esophagus 6. Liver 7. Stomach 8.Aorta 9. IVC 10. Portal and Splenic Veins 11. Pancreas 12.Right adrenal gland 13.Left adrenal gland.
- Task: Segmentation
- Modality: CT
- Size: 30 3D volumes (24 Training + 6 Testing)
# Training
See the source repository [here](https://github.com/Project-MONAI/research-contributions/tree/main/SwinUNETR/BTCV) for information on training.
# BibTeX entry and citation info
If you find this repository useful, please consider citing the following papers:
```
@inproceedings{tang2022self,
title={Self-supervised pre-training of swin transformers for 3d medical image analysis},
author={Tang, Yucheng and Yang, Dong and Li, Wenqi and Roth, Holger R and Landman, Bennett and Xu, Daguang and Nath, Vishwesh and Hatamizadeh, Ali},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={20730--20740},
year={2022}
}
@article{hatamizadeh2022swin,
title={Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images},
author={Hatamizadeh, Ali and Nath, Vishwesh and Tang, Yucheng and Yang, Dong and Roth, Holger and Xu, Daguang},
journal={arXiv preprint arXiv:2201.01266},
year={2022}
}
```
# References
[1]: Tang, Y., Yang, D., Li, W., Roth, H.R., Landman, B., Xu, D., Nath, V. and Hatamizadeh, A., 2022. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20730-20740).
[2]: Hatamizadeh, A., Nath, V., Tang, Y., Yang, D., Roth, H. and Xu, D., 2022. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. arXiv preprint arXiv:2201.01266.
|
Jinchen/roberta-base-finetuned-mrpc | e1e575856446d6d7f99499bcd8288732da817d87 | 2022-07-15T13:15:54.000Z | [
"pytorch",
"roberta",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | Jinchen | null | Jinchen/roberta-base-finetuned-mrpc | 5 | null | transformers | 17,605 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: roberta-base-finetuned-mrpc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-mrpc
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2891
- Accuracy: 0.8925
- F1: 0.9228
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- total_eval_batch_size: 20
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- training precision: Mixed Precision
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5998 | 1.0 | 57 | 0.5425 | 0.74 | 0.8349 |
| 0.5058 | 2.0 | 114 | 0.3020 | 0.875 | 0.9084 |
| 0.3316 | 3.0 | 171 | 0.2891 | 0.8925 | 0.9228 |
| 0.1617 | 4.0 | 228 | 0.2937 | 0.8825 | 0.9138 |
| 0.3161 | 5.0 | 285 | 0.3193 | 0.8875 | 0.9171 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.3.2
- Tokenizers 0.12.1
|
clevrly/roberta-large-mnli-fer-finetuned | 0c7894eae6933bbbf3858723b33d8092805b7093 | 2022-07-22T20:30:58.000Z | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | clevrly | null | clevrly/roberta-large-mnli-fer-finetuned | 5 | null | transformers | 17,606 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-large-mnli-fer-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-mnli-fer-finetuned
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6940
- Accuracy: 0.5005
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7049 | 1.0 | 554 | 0.6895 | 0.5750 |
| 0.6981 | 2.0 | 1108 | 0.7054 | 0.5005 |
| 0.7039 | 3.0 | 1662 | 0.6936 | 0.5005 |
| 0.6976 | 4.0 | 2216 | 0.6935 | 0.4995 |
| 0.6991 | 5.0 | 2770 | 0.6940 | 0.5005 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Someman/xlm-roberta-base-finetuned-panx-de | cf83a59d0a275fc21ddbc23ecf7691346161c1c8 | 2022-07-16T05:50:27.000Z | [
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"dataset:xtreme",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | token-classification | false | Someman | null | Someman/xlm-roberta-base-finetuned-panx-de | 5 | null | transformers | 17,607 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8640345886904085
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1426
- F1: 0.8640
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2525 | 1.0 | 787 | 0.1795 | 0.8184 |
| 0.1283 | 2.0 | 1574 | 0.1402 | 0.8468 |
| 0.08 | 3.0 | 2361 | 0.1426 | 0.8640 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Someman/xlm-roberta-base-finetuned-panx-de-fr | bfdd3666597b998a34362838d77d958238e22ffe | 2022-07-16T07:25:13.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | token-classification | false | Someman | null | Someman/xlm-roberta-base-finetuned-panx-de-fr | 5 | null | transformers | 17,608 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1717
- F1: 0.8601
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2889 | 1.0 | 1073 | 0.1945 | 0.8293 |
| 0.1497 | 2.0 | 2146 | 0.1636 | 0.8476 |
| 0.093 | 3.0 | 3219 | 0.1717 | 0.8601 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Konstantine4096/bart-pizza-5K | 4fbd492c8cbed6ef5cfd65b124f9c7f5e125d210 | 2022-07-16T22:26:21.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | Konstantine4096 | null | Konstantine4096/bart-pizza-5K | 5 | null | transformers | 17,609 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bart-pizza-5K
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-pizza-5K
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1688
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0171 | 1.6 | 500 | 0.1688 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
MMVos/distilbert-base-uncased-finetuned-squad | 7e229c745a8c6aea4b1ce74f972bd69a0b57ae18 | 2022-07-18T12:16:01.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"dataset:squad_v2",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | question-answering | false | MMVos | null | MMVos/distilbert-base-uncased-finetuned-squad | 5 | null | transformers | 17,610 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.1814 | 1.0 | 8235 | 1.2488 |
| 0.9078 | 2.0 | 16470 | 1.3127 |
| 0.7439 | 3.0 | 24705 | 1.4214 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
davanstrien/vit-base-patch16-224-in21k-fine-tuned | d71d5458c6c0f6986cd74848f1d8758cd69de070 | 2022-07-20T17:18:39.000Z | [
"pytorch",
"tensorboard",
"vit",
"transformers"
] | null | false | davanstrien | null | davanstrien/vit-base-patch16-224-in21k-fine-tuned | 5 | null | transformers | 17,611 | Entry not found |
Kayvane/distilbert-base-uncased-wandb-week-3-complaints-classifier-256 | 88ba91c7588f1f13846521731b7e3f6dd0083f70 | 2022-07-19T06:29:12.000Z | [
"pytorch",
"distilbert",
"text-classification",
"dataset:consumer-finance-complaints",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | Kayvane | null | Kayvane/distilbert-base-uncased-wandb-week-3-complaints-classifier-256 | 5 | null | transformers | 17,612 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- consumer-finance-complaints
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: distilbert-base-uncased-wandb-week-3-complaints-classifier-256
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: consumer-finance-complaints
type: consumer-finance-complaints
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8234544620559604
- name: F1
type: f1
value: 0.8176243580045963
- name: Recall
type: recall
value: 0.8234544620559604
- name: Precision
type: precision
value: 0.8171438106054644
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-wandb-week-3-complaints-classifier-256
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the consumer-finance-complaints dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5453
- Accuracy: 0.8235
- F1: 0.8176
- Recall: 0.8235
- Precision: 0.8171
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.097565552226687e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 256
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.6691 | 0.61 | 1500 | 0.6475 | 0.7962 | 0.7818 | 0.7962 | 0.7875 |
| 0.5361 | 1.22 | 3000 | 0.5794 | 0.8161 | 0.8080 | 0.8161 | 0.8112 |
| 0.4659 | 1.83 | 4500 | 0.5453 | 0.8235 | 0.8176 | 0.8235 | 0.8171 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Ghostwolf/wav2vec2-large-xlsr-hindi | 757c05bcb11267d09a942180aeb1dd77f35bbb69 | 2022-07-26T16:48:59.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | false | Ghostwolf | null | Ghostwolf/wav2vec2-large-xlsr-hindi | 5 | null | transformers | 17,613 | |
RJ3vans/DeBERTaCMV1spanTagger | 054c74e31ea15fb78b7745cdc13c5d70158081a4 | 2022-07-19T16:24:58.000Z | [
"pytorch",
"deberta-v2",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | RJ3vans | null | RJ3vans/DeBERTaCMV1spanTagger | 5 | null | transformers | 17,614 | Entry not found |
abecode/t5-base-finetuned-emo20q-classification | 1ae994837532f5c27c347d90524050346e34e59d | 2022-07-19T18:56:13.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | abecode | null | abecode/t5-base-finetuned-emo20q-classification | 5 | null | transformers | 17,615 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-base-finetuned-emo20q-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-emo20q-classification
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3759
- Rouge1: 70.3125
- Rouge2: 0.0
- Rougel: 70.2083
- Rougelsum: 70.2083
- Gen Len: 2.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 280 | 0.3952 | 68.3333 | 0.0 | 68.2292 | 68.2812 | 2.0 |
| 0.7404 | 2.0 | 560 | 0.3774 | 70.1042 | 0.0 | 70.1042 | 70.1042 | 2.0 |
| 0.7404 | 3.0 | 840 | 0.3759 | 70.3125 | 0.0 | 70.2083 | 70.2083 | 2.0 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Siyong/MT_RN | 554b6a3111d14b1d3df95c9e46b89fbbfdfea1e8 | 2022-07-20T01:36:09.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | Siyong | null | Siyong/MT_RN | 5 | null | transformers | 17,616 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: run1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# run1
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6666
- Wer: 0.6375
- Cer: 0.3170
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 1.0564 | 2.36 | 2000 | 2.3456 | 0.9628 | 0.5549 |
| 0.5071 | 4.73 | 4000 | 2.0652 | 0.9071 | 0.5115 |
| 0.3952 | 7.09 | 6000 | 2.3649 | 0.9108 | 0.4628 |
| 0.3367 | 9.46 | 8000 | 1.7615 | 0.8253 | 0.4348 |
| 0.2765 | 11.82 | 10000 | 1.6151 | 0.7937 | 0.4087 |
| 0.2493 | 14.18 | 12000 | 1.4976 | 0.7881 | 0.3905 |
| 0.2318 | 16.55 | 14000 | 1.6731 | 0.8160 | 0.3925 |
| 0.2074 | 18.91 | 16000 | 1.5822 | 0.7658 | 0.3913 |
| 0.1825 | 21.28 | 18000 | 1.5442 | 0.7361 | 0.3704 |
| 0.1824 | 23.64 | 20000 | 1.5988 | 0.7621 | 0.3711 |
| 0.1699 | 26.0 | 22000 | 1.4261 | 0.7119 | 0.3490 |
| 0.158 | 28.37 | 24000 | 1.7482 | 0.7658 | 0.3648 |
| 0.1385 | 30.73 | 26000 | 1.4103 | 0.6784 | 0.3348 |
| 0.1199 | 33.1 | 28000 | 1.5214 | 0.6636 | 0.3273 |
| 0.116 | 35.46 | 30000 | 1.4288 | 0.7212 | 0.3486 |
| 0.1071 | 37.83 | 32000 | 1.5344 | 0.7138 | 0.3411 |
| 0.1007 | 40.19 | 34000 | 1.4501 | 0.6691 | 0.3237 |
| 0.0943 | 42.55 | 36000 | 1.5367 | 0.6859 | 0.3265 |
| 0.0844 | 44.92 | 38000 | 1.5321 | 0.6599 | 0.3273 |
| 0.0762 | 47.28 | 40000 | 1.6721 | 0.6264 | 0.3142 |
| 0.0778 | 49.65 | 42000 | 1.6666 | 0.6375 | 0.3170 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu113
- Datasets 2.0.0
- Tokenizers 0.12.1
|
commanderstrife/bc2gm_corpus-Bio_ClinicalBERT-finetuned-ner | a4367803bb4a087c0b8e0eac15862b08e0ad2697 | 2022-07-20T02:51:04.000Z | [
"pytorch",
"bert",
"token-classification",
"dataset:bc2gm_corpus",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | token-classification | false | commanderstrife | null | commanderstrife/bc2gm_corpus-Bio_ClinicalBERT-finetuned-ner | 5 | null | transformers | 17,617 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- bc2gm_corpus
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bc2gm_corpus-Bio_ClinicalBERT-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: bc2gm_corpus
type: bc2gm_corpus
args: bc2gm_corpus
metrics:
- name: Precision
type: precision
value: 0.7853881278538812
- name: Recall
type: recall
value: 0.8158102766798419
- name: F1
type: f1
value: 0.8003101977510663
- name: Accuracy
type: accuracy
value: 0.9758965601366187
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bc2gm_corpus-Bio_ClinicalBERT-finetuned-ner
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the bc2gm_corpus dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1505
- Precision: 0.7854
- Recall: 0.8158
- F1: 0.8003
- Accuracy: 0.9759
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0981 | 1.0 | 782 | 0.0712 | 0.7228 | 0.7948 | 0.7571 | 0.9724 |
| 0.0509 | 2.0 | 1564 | 0.0687 | 0.7472 | 0.8199 | 0.7818 | 0.9746 |
| 0.0121 | 3.0 | 2346 | 0.0740 | 0.7725 | 0.8011 | 0.7866 | 0.9747 |
| 0.0001 | 4.0 | 3128 | 0.1009 | 0.7618 | 0.8251 | 0.7922 | 0.9741 |
| 0.0042 | 5.0 | 3910 | 0.1106 | 0.7757 | 0.8185 | 0.7965 | 0.9754 |
| 0.0015 | 6.0 | 4692 | 0.1182 | 0.7812 | 0.8111 | 0.7958 | 0.9758 |
| 0.0001 | 7.0 | 5474 | 0.1283 | 0.7693 | 0.8275 | 0.7973 | 0.9753 |
| 0.0072 | 8.0 | 6256 | 0.1376 | 0.7863 | 0.8158 | 0.8008 | 0.9762 |
| 0.0045 | 9.0 | 7038 | 0.1468 | 0.7856 | 0.8180 | 0.8015 | 0.9761 |
| 0.0 | 10.0 | 7820 | 0.1505 | 0.7854 | 0.8158 | 0.8003 | 0.9759 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
huggingartists/rage-against-the-machine | 091efabcc80a94165cd155146cbc77a31804b783 | 2022-07-20T04:23:50.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"dataset:huggingartists/rage-against-the-machine",
"transformers",
"huggingartists",
"lyrics",
"lm-head",
"causal-lm"
] | text-generation | false | huggingartists | null | huggingartists/rage-against-the-machine | 5 | null | transformers | 17,618 | ---
language: en
datasets:
- huggingartists/rage-against-the-machine
tags:
- huggingartists
- lyrics
- lm-head
- causal-lm
widget:
- text: "I am"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/2158957823960c84c7890b8fa5e6d479.1000x1000x1.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rage Against the Machine</div>
<a href="https://genius.com/artists/rage-against-the-machine">
<div style="text-align: center; font-size: 14px;">@rage-against-the-machine</div>
</a>
</div>
I was made with [huggingartists](https://github.com/AlekseyKorshuk/huggingartists).
Create your own bot based on your favorite artist with [the demo](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb)!
## How does it work?
To understand how the model was developed, check the [W&B report](https://wandb.ai/huggingartists/huggingartists/reportlist).
## Training data
The model was trained on lyrics from Rage Against the Machine.
Dataset is available [here](https://huggingface.co/datasets/huggingartists/rage-against-the-machine).
And can be used with:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/rage-against-the-machine")
```
[Explore the data](https://wandb.ai/huggingartists/huggingartists/runs/2lbi7kzi/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on Rage Against the Machine's lyrics.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/huggingartists/huggingartists/runs/10r0sf3w) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/huggingartists/huggingartists/runs/10r0sf3w/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingartists/rage-against-the-machine')
generator("I am", num_return_sequences=5)
```
Or with Transformers library:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("huggingartists/rage-against-the-machine")
model = AutoModelWithLMHead.from_pretrained("huggingartists/rage-against-the-machine")
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
|
lqdisme/test_squad | 9f2d7e3235da7299bdbce33e9e5deb8dac823bc6 | 2022-07-20T04:27:06.000Z | [
"pytorch",
"distilbert",
"feature-extraction",
"transformers"
] | feature-extraction | false | lqdisme | null | lqdisme/test_squad | 5 | null | transformers | 17,619 | Entry not found |
ryo0634/luke-base-comp-umls | 04b2e898e2f6f0bec9f74048f87b90a9c7221d0f | 2022-07-20T05:38:59.000Z | [
"pytorch",
"luke",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | ryo0634 | null | ryo0634/luke-base-comp-umls | 5 | null | transformers | 17,620 | Entry not found |
jordyvl/biobert-base-cased-v1.2_ncbi_disease-lowC-sm-first-ner | 2e2a35f2d4bd5f914ca4666d038fa4cb4c5e7087 | 2022-07-20T08:49:02.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | jordyvl | null | jordyvl/biobert-base-cased-v1.2_ncbi_disease-lowC-sm-first-ner | 5 | null | transformers | 17,621 | Entry not found |
tianying/bert-finetuned-ner | 4ecd1ad44a9b45d96f860c7a073323fdae4b5b02 | 2022-07-20T13:58:10.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | tianying | null | tianying/bert-finetuned-ner | 5 | null | transformers | 17,622 | Entry not found |
liton10/mt5-small-finetuned-amazon-en-es | bfb3714d65045c5f051eefe8e916d0b87c78c107 | 2022-07-20T10:03:33.000Z | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"transformers",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | summarization | false | liton10 | null | liton10/mt5-small-finetuned-amazon-en-es | 5 | null | transformers | 17,623 | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-amazon-en-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 9.2585
- Rouge1: 6.1835
- Rouge2: 0.0
- Rougel: 5.8333
- Rougelsum: 6.1835
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 24.1065 | 1.0 | 11 | 32.7123 | 7.342 | 1.5385 | 7.1515 | 7.342 |
| 22.6474 | 2.0 | 22 | 19.7137 | 6.1039 | 0.0 | 5.7143 | 6.1039 |
| 16.319 | 3.0 | 33 | 12.8543 | 6.1039 | 0.0 | 5.7143 | 6.1039 |
| 16.3224 | 4.0 | 44 | 10.1929 | 5.9524 | 0.0 | 5.7143 | 5.9524 |
| 15.0599 | 5.0 | 55 | 9.9186 | 5.9524 | 0.0 | 5.7143 | 5.9524 |
| 14.6053 | 6.0 | 66 | 9.3235 | 6.1835 | 0.0 | 5.8333 | 6.1835 |
| 14.4345 | 7.0 | 77 | 9.1621 | 6.1835 | 0.0 | 5.8333 | 6.1835 |
| 13.7973 | 8.0 | 88 | 9.2585 | 6.1835 | 0.0 | 5.8333 | 6.1835 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
jordyvl/biobert-base-cased-v1.2_ncbi_disease-CRF-first-ner | 2743f53bcf91adb11b6498e15d6be157218180f4 | 2022-07-20T14:09:50.000Z | [
"pytorch",
"tensorboard",
"bert",
"transformers"
] | null | false | jordyvl | null | jordyvl/biobert-base-cased-v1.2_ncbi_disease-CRF-first-ner | 5 | null | transformers | 17,624 | Entry not found |
Lvxue/distilled_test_0.99_formal | 76de46cb5e250490cd0f1dd585e4da81623d6e37 | 2022-07-22T20:00:29.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | Lvxue | null | Lvxue/distilled_test_0.99_formal | 5 | null | transformers | 17,625 | Entry not found |
ckadam15/distilbert-base-uncased-finetuned-squad | 389d2d4549011487e254c605f3390fc893bced15 | 2022-07-25T16:04:57.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | ckadam15 | null | ckadam15/distilbert-base-uncased-finetuned-squad | 5 | null | transformers | 17,626 | Entry not found |
furrutiav/beto_coherence_v2 | 639f8320999464f2b729f4d37c462e873980acde | 2022-07-21T20:23:27.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | furrutiav | null | furrutiav/beto_coherence_v2 | 5 | null | transformers | 17,627 | Entry not found |
gary109/ai-light-dance_singing3_ft_pretrain2_wav2vec2-large-xlsr-53 | 3468f5bec770d7eadb63aa5f6928ad27afa47433 | 2022-07-27T03:22:01.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"gary109/AI_Light_Dance",
"generated_from_trainer",
"model-index"
] | automatic-speech-recognition | false | gary109 | null | gary109/ai-light-dance_singing3_ft_pretrain2_wav2vec2-large-xlsr-53 | 5 | null | transformers | 17,628 | ---
tags:
- automatic-speech-recognition
- gary109/AI_Light_Dance
- generated_from_trainer
model-index:
- name: ai-light-dance_singing3_ft_pretrain2_wav2vec2-large-xlsr-53
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ai-light-dance_singing3_ft_pretrain2_wav2vec2-large-xlsr-53
This model is a fine-tuned version of [gary109/ai-light-dance_singing3_ft_pretrain2_wav2vec2-large-xlsr-53](https://huggingface.co/gary109/ai-light-dance_singing3_ft_pretrain2_wav2vec2-large-xlsr-53) on the GARY109/AI_LIGHT_DANCE - ONSET-SINGING3 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4279
- Wer: 1.0087
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.209 | 1.0 | 72 | 2.5599 | 0.9889 |
| 1.3395 | 2.0 | 144 | 2.7188 | 0.9877 |
| 1.2695 | 3.0 | 216 | 2.9989 | 0.9709 |
| 1.2818 | 4.0 | 288 | 3.2352 | 0.9757 |
| 1.2389 | 5.0 | 360 | 3.6867 | 0.9783 |
| 1.2368 | 6.0 | 432 | 3.3189 | 0.9811 |
| 1.2307 | 7.0 | 504 | 3.0786 | 0.9657 |
| 1.2607 | 8.0 | 576 | 2.9720 | 0.9677 |
| 1.2584 | 9.0 | 648 | 2.5613 | 0.9702 |
| 1.2266 | 10.0 | 720 | 2.6937 | 0.9610 |
| 1.262 | 11.0 | 792 | 3.9060 | 0.9745 |
| 1.2361 | 12.0 | 864 | 3.6138 | 0.9718 |
| 1.2348 | 13.0 | 936 | 3.4838 | 0.9745 |
| 1.2715 | 14.0 | 1008 | 3.3128 | 0.9751 |
| 1.2505 | 15.0 | 1080 | 3.2015 | 0.9710 |
| 1.211 | 16.0 | 1152 | 3.4709 | 0.9709 |
| 1.2067 | 17.0 | 1224 | 3.0566 | 0.9673 |
| 1.2536 | 18.0 | 1296 | 2.5479 | 0.9789 |
| 1.2297 | 19.0 | 1368 | 2.8307 | 0.9710 |
| 1.1949 | 20.0 | 1440 | 3.4112 | 0.9777 |
| 1.2181 | 21.0 | 1512 | 2.6784 | 0.9682 |
| 1.195 | 22.0 | 1584 | 3.0395 | 0.9639 |
| 1.2047 | 23.0 | 1656 | 3.1935 | 0.9726 |
| 1.2306 | 24.0 | 1728 | 3.2649 | 0.9723 |
| 1.199 | 25.0 | 1800 | 3.1378 | 0.9645 |
| 1.1945 | 26.0 | 1872 | 2.8143 | 0.9596 |
| 1.19 | 27.0 | 1944 | 3.5174 | 0.9787 |
| 1.1976 | 28.0 | 2016 | 2.9666 | 0.9594 |
| 1.2229 | 29.0 | 2088 | 2.8672 | 0.9589 |
| 1.1548 | 30.0 | 2160 | 2.6568 | 0.9627 |
| 1.169 | 31.0 | 2232 | 2.8799 | 0.9654 |
| 1.1857 | 32.0 | 2304 | 2.8691 | 0.9625 |
| 1.1862 | 33.0 | 2376 | 2.8251 | 0.9555 |
| 1.1721 | 34.0 | 2448 | 3.5968 | 0.9726 |
| 1.1293 | 35.0 | 2520 | 3.4130 | 0.9651 |
| 1.1513 | 36.0 | 2592 | 2.8804 | 0.9630 |
| 1.1537 | 37.0 | 2664 | 2.5824 | 0.9575 |
| 1.1818 | 38.0 | 2736 | 2.8443 | 0.9613 |
| 1.1835 | 39.0 | 2808 | 2.6431 | 0.9619 |
| 1.1457 | 40.0 | 2880 | 2.9254 | 0.9639 |
| 1.1591 | 41.0 | 2952 | 2.8194 | 0.9561 |
| 1.1284 | 42.0 | 3024 | 2.6432 | 0.9806 |
| 1.1602 | 43.0 | 3096 | 2.4279 | 1.0087 |
| 1.1556 | 44.0 | 3168 | 2.5040 | 1.0030 |
| 1.1256 | 45.0 | 3240 | 3.1641 | 0.9608 |
| 1.1256 | 46.0 | 3312 | 2.9522 | 0.9677 |
| 1.1211 | 47.0 | 3384 | 2.6318 | 0.9580 |
| 1.1142 | 48.0 | 3456 | 2.7298 | 0.9533 |
| 1.1237 | 49.0 | 3528 | 2.5442 | 0.9673 |
| 1.0976 | 50.0 | 3600 | 2.7767 | 0.9610 |
| 1.1154 | 51.0 | 3672 | 2.6849 | 0.9646 |
| 1.1012 | 52.0 | 3744 | 2.5384 | 0.9621 |
| 1.1077 | 53.0 | 3816 | 2.4505 | 1.0067 |
| 1.0936 | 54.0 | 3888 | 2.5847 | 0.9687 |
| 1.0772 | 55.0 | 3960 | 2.4575 | 0.9761 |
| 1.092 | 56.0 | 4032 | 2.4889 | 0.9802 |
| 1.0868 | 57.0 | 4104 | 2.5885 | 0.9664 |
| 1.0979 | 58.0 | 4176 | 2.6370 | 0.9607 |
| 1.094 | 59.0 | 4248 | 2.6195 | 0.9605 |
| 1.0745 | 60.0 | 4320 | 2.5346 | 0.9834 |
| 1.1057 | 61.0 | 4392 | 2.6879 | 0.9603 |
| 1.0722 | 62.0 | 4464 | 2.5426 | 0.9735 |
| 1.0731 | 63.0 | 4536 | 2.8259 | 0.9535 |
| 1.0862 | 64.0 | 4608 | 2.7632 | 0.9559 |
| 1.0396 | 65.0 | 4680 | 2.5401 | 0.9807 |
| 1.0581 | 66.0 | 4752 | 2.6977 | 0.9687 |
| 1.0647 | 67.0 | 4824 | 2.6968 | 0.9694 |
| 1.0549 | 68.0 | 4896 | 2.6439 | 0.9807 |
| 1.0607 | 69.0 | 4968 | 2.6822 | 0.9771 |
| 1.05 | 70.0 | 5040 | 2.7011 | 0.9607 |
| 1.042 | 71.0 | 5112 | 2.5766 | 0.9713 |
| 1.042 | 72.0 | 5184 | 2.5720 | 0.9747 |
| 1.0594 | 73.0 | 5256 | 2.7176 | 0.9704 |
| 1.0425 | 74.0 | 5328 | 2.7458 | 0.9614 |
| 1.0199 | 75.0 | 5400 | 2.5906 | 0.9987 |
| 1.0198 | 76.0 | 5472 | 2.5534 | 1.0087 |
| 1.0193 | 77.0 | 5544 | 2.5421 | 0.9933 |
| 1.0379 | 78.0 | 5616 | 2.5139 | 0.9994 |
| 1.025 | 79.0 | 5688 | 2.4850 | 1.0313 |
| 1.0054 | 80.0 | 5760 | 2.5803 | 0.9814 |
| 1.0218 | 81.0 | 5832 | 2.5696 | 0.9867 |
| 1.0177 | 82.0 | 5904 | 2.6011 | 1.0065 |
| 1.0094 | 83.0 | 5976 | 2.6166 | 0.9855 |
| 1.0202 | 84.0 | 6048 | 2.5557 | 1.0204 |
| 1.0148 | 85.0 | 6120 | 2.6118 | 1.0033 |
| 1.0117 | 86.0 | 6192 | 2.5671 | 1.0120 |
| 1.0195 | 87.0 | 6264 | 2.5443 | 1.0041 |
| 1.0114 | 88.0 | 6336 | 2.5627 | 1.0049 |
| 1.0074 | 89.0 | 6408 | 2.5670 | 1.0255 |
| 0.9883 | 90.0 | 6480 | 2.5338 | 1.0306 |
| 1.0112 | 91.0 | 6552 | 2.5615 | 1.0142 |
| 0.9986 | 92.0 | 6624 | 2.5566 | 1.0415 |
| 0.9939 | 93.0 | 6696 | 2.5728 | 1.0287 |
| 0.9954 | 94.0 | 6768 | 2.5617 | 1.0138 |
| 0.9643 | 95.0 | 6840 | 2.5890 | 1.0145 |
| 0.9892 | 96.0 | 6912 | 2.5918 | 1.0119 |
| 0.983 | 97.0 | 6984 | 2.5862 | 1.0175 |
| 0.988 | 98.0 | 7056 | 2.5873 | 1.0147 |
| 0.9908 | 99.0 | 7128 | 2.5973 | 1.0073 |
| 0.9696 | 100.0 | 7200 | 2.5938 | 1.0156 |
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.9.1+cu102
- Datasets 2.3.3.dev0
- Tokenizers 0.12.1
|
huggingtweets/hotwingsuk | b3b6666d4a33270169525ff28f135fcfcc34e3cf | 2022-07-22T03:26:48.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/hotwingsuk | 5 | null | transformers | 17,629 | ---
language: en
thumbnail: http://www.huggingtweets.com/hotwingsuk/1658460403599/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1280474754214957056/GKqk3gAm_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">HotWings</div>
<div style="text-align: center; font-size: 14px;">@hotwingsuk</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from HotWings.
| Data | HotWings |
| --- | --- |
| Tweets downloaded | 2057 |
| Retweets | 69 |
| Short tweets | 258 |
| Tweets kept | 1730 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3opu8h6o/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hotwingsuk's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/bzf76pmf) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/bzf76pmf/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hotwingsuk')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sudo-s/exper5_mesum5 | 97e53fb419c9c283bba70e7520acb1e0ad4387c3 | 2022-07-22T15:29:30.000Z | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | image-classification | false | sudo-s | null | sudo-s/exper5_mesum5 | 5 | null | transformers | 17,630 | ---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: exper5_mesum5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# exper5_mesum5
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the sudo-s/herbier_mesuem5 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0181
- Accuracy: 0.8142
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.7331 | 0.23 | 100 | 4.7080 | 0.1130 |
| 4.4246 | 0.47 | 200 | 4.4573 | 0.1598 |
| 4.2524 | 0.7 | 300 | 4.2474 | 0.2 |
| 4.0881 | 0.93 | 400 | 4.0703 | 0.2290 |
| 3.8605 | 1.16 | 500 | 3.9115 | 0.2763 |
| 3.7434 | 1.4 | 600 | 3.7716 | 0.3349 |
| 3.5978 | 1.63 | 700 | 3.6375 | 0.3544 |
| 3.5081 | 1.86 | 800 | 3.5081 | 0.3840 |
| 3.2616 | 2.09 | 900 | 3.3952 | 0.4308 |
| 3.2131 | 2.33 | 1000 | 3.2817 | 0.4509 |
| 3.1369 | 2.56 | 1100 | 3.1756 | 0.4710 |
| 3.0726 | 2.79 | 1200 | 3.0692 | 0.5107 |
| 2.8159 | 3.02 | 1300 | 2.9734 | 0.5308 |
| 2.651 | 3.26 | 1400 | 2.8813 | 0.5728 |
| 2.6879 | 3.49 | 1500 | 2.7972 | 0.5781 |
| 2.5625 | 3.72 | 1600 | 2.7107 | 0.6012 |
| 2.4156 | 3.95 | 1700 | 2.6249 | 0.6237 |
| 2.3557 | 4.19 | 1800 | 2.5475 | 0.6302 |
| 2.2496 | 4.42 | 1900 | 2.4604 | 0.6556 |
| 2.1933 | 4.65 | 2000 | 2.3963 | 0.6456 |
| 2.0341 | 4.88 | 2100 | 2.3327 | 0.6858 |
| 1.793 | 5.12 | 2200 | 2.2500 | 0.6858 |
| 1.8131 | 5.35 | 2300 | 2.1950 | 0.6935 |
| 1.8358 | 5.58 | 2400 | 2.1214 | 0.7136 |
| 1.8304 | 5.81 | 2500 | 2.0544 | 0.7130 |
| 1.602 | 6.05 | 2600 | 1.9998 | 0.7325 |
| 1.5487 | 6.28 | 2700 | 1.9519 | 0.7308 |
| 1.4782 | 6.51 | 2800 | 1.8918 | 0.7361 |
| 1.4397 | 6.74 | 2900 | 1.8359 | 0.7544 |
| 1.3278 | 6.98 | 3000 | 1.7930 | 0.7485 |
| 1.4241 | 7.21 | 3100 | 1.7463 | 0.7574 |
| 1.3319 | 7.44 | 3200 | 1.7050 | 0.7663 |
| 1.2584 | 7.67 | 3300 | 1.6436 | 0.7686 |
| 1.088 | 7.91 | 3400 | 1.6128 | 0.7751 |
| 1.0303 | 8.14 | 3500 | 1.5756 | 0.7757 |
| 1.0075 | 8.37 | 3600 | 1.5306 | 0.7822 |
| 0.976 | 8.6 | 3700 | 1.4990 | 0.7858 |
| 0.9363 | 8.84 | 3800 | 1.4619 | 0.7781 |
| 0.8869 | 9.07 | 3900 | 1.4299 | 0.7899 |
| 0.8749 | 9.3 | 4000 | 1.3930 | 0.8018 |
| 0.7958 | 9.53 | 4100 | 1.3616 | 0.8065 |
| 0.7605 | 9.77 | 4200 | 1.3367 | 0.7982 |
| 0.7642 | 10.0 | 4300 | 1.3154 | 0.7911 |
| 0.6852 | 10.23 | 4400 | 1.2894 | 0.8 |
| 0.667 | 10.47 | 4500 | 1.2623 | 0.8148 |
| 0.6119 | 10.7 | 4600 | 1.2389 | 0.8095 |
| 0.6553 | 10.93 | 4700 | 1.2180 | 0.8053 |
| 0.5725 | 11.16 | 4800 | 1.2098 | 0.8036 |
| 0.567 | 11.4 | 4900 | 1.1803 | 0.8083 |
| 0.4941 | 11.63 | 5000 | 1.1591 | 0.8107 |
| 0.4562 | 11.86 | 5100 | 1.1471 | 0.8024 |
| 0.5155 | 12.09 | 5200 | 1.1272 | 0.8172 |
| 0.5062 | 12.33 | 5300 | 1.1206 | 0.8095 |
| 0.4552 | 12.56 | 5400 | 1.1030 | 0.8142 |
| 0.4553 | 12.79 | 5500 | 1.0918 | 0.8148 |
| 0.4055 | 13.02 | 5600 | 1.0837 | 0.8118 |
| 0.4484 | 13.26 | 5700 | 1.0712 | 0.8148 |
| 0.3635 | 13.49 | 5800 | 1.0657 | 0.8124 |
| 0.4054 | 13.72 | 5900 | 1.0543 | 0.8124 |
| 0.3201 | 13.95 | 6000 | 1.0508 | 0.8148 |
| 0.3448 | 14.19 | 6100 | 1.0409 | 0.8166 |
| 0.3591 | 14.42 | 6200 | 1.0371 | 0.8142 |
| 0.3606 | 14.65 | 6300 | 1.0345 | 0.8160 |
| 0.3633 | 14.88 | 6400 | 1.0281 | 0.8136 |
| 0.373 | 15.12 | 6500 | 1.0259 | 0.8124 |
| 0.3417 | 15.35 | 6600 | 1.0215 | 0.8112 |
| 0.3429 | 15.58 | 6700 | 1.0204 | 0.8148 |
| 0.3509 | 15.81 | 6800 | 1.0181 | 0.8142 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ai4bharat/IndicXLMv2-alpha-QA | e9b34813364166204fa9f2aa5a5b3b2f8b0da389 | 2022-07-22T14:22:58.000Z | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | ai4bharat | null | ai4bharat/IndicXLMv2-alpha-QA | 5 | null | transformers | 17,631 | Entry not found |
cyr19/distilbert-base-uncased_2-epochs-squad | fb53da82b07f65ca8150147a205431731d9c90db | 2022-07-22T16:17:30.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | cyr19 | null | cyr19/distilbert-base-uncased_2-epochs-squad | 5 | null | transformers | 17,632 | learning_rate:
- 1e-5
train_batchsize:
- 16
epochs:
- 2
weight_decay
- 0.01
optimizer
- Adam
datasets:
- squad
metrics
- EM:10.307414104882
- F1:42.10389032370503
|
huggingtweets/aoc-kamalaharris | 05ad2c1d3bbbdbe0a17a284e54fcba435c4014bd | 2022-07-23T04:44:34.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/aoc-kamalaharris | 5 | null | transformers | 17,633 | ---
language: en
thumbnail: http://www.huggingtweets.com/aoc-kamalaharris/1658551469874/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1377062766314467332/2hyqngJz_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/923274881197895680/AbHcStkl_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Kamala Harris & Alexandria Ocasio-Cortez</div>
<div style="text-align: center; font-size: 14px;">@aoc-kamalaharris</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Kamala Harris & Alexandria Ocasio-Cortez.
| Data | Kamala Harris | Alexandria Ocasio-Cortez |
| --- | --- | --- |
| Tweets downloaded | 3206 | 3245 |
| Retweets | 829 | 1264 |
| Short tweets | 8 | 126 |
| Tweets kept | 2369 | 1855 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1fpjb3ip/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @aoc-kamalaharris's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/wftrlnh5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/wftrlnh5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/aoc-kamalaharris')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/kremlinrussia_e | e48343e61aa78d240c67d0b316622e91bac48fac | 2022-07-23T05:48:32.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/kremlinrussia_e | 5 | null | transformers | 17,634 | ---
language: en
thumbnail: http://www.huggingtweets.com/kremlinrussia_e/1658555307462/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/501717583846842368/psd9aFLl_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">President of Russia</div>
<div style="text-align: center; font-size: 14px;">@kremlinrussia_e</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from President of Russia.
| Data | President of Russia |
| --- | --- |
| Tweets downloaded | 3197 |
| Retweets | 1 |
| Short tweets | 38 |
| Tweets kept | 3158 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1nplalk6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @kremlinrussia_e's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3jz3samc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3jz3samc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/kremlinrussia_e')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
planhanasan/test-trainer | 6f8a5204d700486a3493645adcfb6506328d9dcd | 2022-07-27T00:09:44.000Z | [
"pytorch",
"tensorboard",
"camembert",
"fill-mask",
"ja",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | planhanasan | null | planhanasan/test-trainer | 5 | null | transformers | 17,635 | ---
license: apache-2.0
language:
- ja
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: test-trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-trainer
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Someman/pegasus-samsum | 23c750d73ac94da41bf70cd039749d6804c0d45d | 2022-07-23T13:20:32.000Z | [
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"dataset:samsum",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | Someman | null | Someman/pegasus-samsum | 5 | null | transformers | 17,636 | ---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6902 | 0.54 | 500 | 1.4884 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Siyong/M_RN_LM | 36b173c09a7b925cd1f4e8c047f4d31fc0b716ab | 2022-07-23T16:51:20.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | Siyong | null | Siyong/M_RN_LM | 5 | null | transformers | 17,637 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: MilladRN
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MilladRN
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4355
- Wer: 0.4907
- Cer: 0.2802
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 4000
- num_epochs: 750
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:------:|:-----:|:---------------:|:------:|:------:|
| 3.3347 | 33.9 | 2000 | 2.2561 | 0.9888 | 0.6087 |
| 1.3337 | 67.8 | 4000 | 1.8137 | 0.6877 | 0.3407 |
| 0.6504 | 101.69 | 6000 | 2.0718 | 0.6245 | 0.3229 |
| 0.404 | 135.59 | 8000 | 2.2246 | 0.6004 | 0.3221 |
| 0.2877 | 169.49 | 10000 | 2.2624 | 0.5836 | 0.3107 |
| 0.2149 | 203.39 | 12000 | 2.3788 | 0.5279 | 0.2802 |
| 0.1693 | 237.29 | 14000 | 1.8928 | 0.5502 | 0.2937 |
| 0.1383 | 271.19 | 16000 | 2.7520 | 0.5725 | 0.3103 |
| 0.1169 | 305.08 | 18000 | 2.2552 | 0.5446 | 0.2968 |
| 0.1011 | 338.98 | 20000 | 2.6794 | 0.5725 | 0.3119 |
| 0.0996 | 372.88 | 22000 | 2.4704 | 0.5595 | 0.3142 |
| 0.0665 | 406.78 | 24000 | 2.9073 | 0.5836 | 0.3194 |
| 0.0538 | 440.68 | 26000 | 3.1357 | 0.5632 | 0.3213 |
| 0.0538 | 474.58 | 28000 | 2.5639 | 0.5613 | 0.3091 |
| 0.0493 | 508.47 | 30000 | 3.3801 | 0.5613 | 0.3119 |
| 0.0451 | 542.37 | 32000 | 3.5469 | 0.5428 | 0.3158 |
| 0.0307 | 576.27 | 34000 | 4.2243 | 0.5390 | 0.3126 |
| 0.0301 | 610.17 | 36000 | 3.6666 | 0.5297 | 0.2929 |
| 0.0269 | 644.07 | 38000 | 3.2164 | 0.5 | 0.2838 |
| 0.0182 | 677.97 | 40000 | 3.0557 | 0.4963 | 0.2779 |
| 0.0191 | 711.86 | 42000 | 3.5190 | 0.5130 | 0.2921 |
| 0.0133 | 745.76 | 44000 | 3.4355 | 0.4907 | 0.2802 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.0+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
Isaacks/swin-tiny-patch4-window7-224-finetuned-cars | acd01546297f68e862e88f83357caad1e6f5873c | 2022-07-23T18:53:15.000Z | [
"pytorch",
"tensorboard",
"swin",
"image-classification",
"dataset:imagefolder",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | image-classification | false | Isaacks | null | Isaacks/swin-tiny-patch4-window7-224-finetuned-cars | 5 | null | transformers | 17,638 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-cars
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9135135135135135
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-cars
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2192
- Accuracy: 0.9135
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4522 | 1.0 | 13 | 0.3636 | 0.8432 |
| 0.3308 | 2.0 | 26 | 0.2472 | 0.9027 |
| 0.2714 | 3.0 | 39 | 0.2192 | 0.9135 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
clevrly/xlnet-base-rte-finetuned | d8bfe91c16102b467e48b52d18a14aa1890f316b | 2022-07-25T05:45:31.000Z | [
"pytorch",
"tensorboard",
"xlnet",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | clevrly | null | clevrly/xlnet-base-rte-finetuned | 5 | null | transformers | 17,639 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: xlnet-base-rte-finetuned
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: rte
metrics:
- name: Accuracy
type: accuracy
value: 0.703971119133574
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet-base-rte-finetuned
This model is a fine-tuned version of [xlnet-base-cased](https://huggingface.co/xlnet-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6688
- Accuracy: 0.7040
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 311 | 0.9695 | 0.6859 |
| 0.315 | 2.0 | 622 | 2.2516 | 0.6498 |
| 0.315 | 3.0 | 933 | 2.0439 | 0.7076 |
| 0.1096 | 4.0 | 1244 | 2.5190 | 0.7040 |
| 0.0368 | 5.0 | 1555 | 2.6688 | 0.7040 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
circulus/kobart-style-v1 | 92ae63f4807c8f47be33ed018114766e45ad5703 | 2022-07-25T06:46:04.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | circulus | null | circulus/kobart-style-v1 | 5 | null | transformers | 17,640 | KoBART 기반 언어 스타일 변환
- Smilegate AI 의 SmileStyle 데이터 셋을 통해 훈련된 모델 입니다. (https://github.com/smilegate-ai/korean_smile_style_dataset)
- 사용방법은 곧 올리도록 하겠습니다. |
wisejiyoon/bert-base-finetuned-sts | 85b8a8854820e720492ccfb0e0e75abfe69183fe | 2022-07-25T05:29:55.000Z | [
"pytorch",
"bert",
"text-classification",
"dataset:klue",
"transformers",
"generated_from_trainer",
"model-index"
] | text-classification | false | wisejiyoon | null | wisejiyoon/bert-base-finetuned-sts | 5 | null | transformers | 17,641 | ---
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- pearsonr
model-index:
- name: bert-base-finetuned-sts
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: klue
type: klue
args: sts
metrics:
- name: Pearsonr
type: pearsonr
value: 0.9000373376026184
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-finetuned-sts
This model is a fine-tuned version of [klue/bert-base](https://huggingface.co/klue/bert-base) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4582
- Pearsonr: 0.9000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearsonr |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 183 | 0.5329 | 0.8827 |
| No log | 2.0 | 366 | 0.4549 | 0.8937 |
| 0.2316 | 3.0 | 549 | 0.4656 | 0.8959 |
| 0.2316 | 4.0 | 732 | 0.4651 | 0.8990 |
| 0.2316 | 5.0 | 915 | 0.4582 | 0.9000 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
jonatasgrosman/exp_w2v2r_en_vp-100k_accent_us-0_england-10_s870 | ec520e9d7a001347421d9727a9185ad4b968675d | 2022-07-25T05:24:06.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"en",
"dataset:mozilla-foundation/common_voice_7_0",
"transformers",
"license:apache-2.0"
] | automatic-speech-recognition | false | jonatasgrosman | null | jonatasgrosman/exp_w2v2r_en_vp-100k_accent_us-0_england-10_s870 | 5 | null | transformers | 17,642 | ---
language:
- en
license: apache-2.0
tags:
- automatic-speech-recognition
- en
datasets:
- mozilla-foundation/common_voice_7_0
---
# exp_w2v2r_en_vp-100k_accent_us-0_england-10_s870
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (en)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
jinwooChoi/SKKU_SA_HJW_base_9_a | 812017d1513a91eb7b54d1684debc94034cfcffa | 2022-07-25T07:17:52.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers"
] | text-classification | false | jinwooChoi | null | jinwooChoi/SKKU_SA_HJW_base_9_a | 5 | null | transformers | 17,643 | Entry not found |
jinwooChoi/SKKU_AP_SA_KBT6 | bb4adcf23d6aaf39ef717fe99f6d733a854df1db | 2022-07-25T08:37:32.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | jinwooChoi | null | jinwooChoi/SKKU_AP_SA_KBT6 | 5 | null | transformers | 17,644 | Entry not found |
jinwooChoi/SKKU_AP_SA_KBT7 | 7e2c3b0d542857b325a8be34caac1aaecab1564a | 2022-07-25T08:55:59.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | jinwooChoi | null | jinwooChoi/SKKU_AP_SA_KBT7 | 5 | null | transformers | 17,645 | Entry not found |
relbert/relbert-roberta-large-conceptnet-hc-average-prompt-d-nce | 976d287994700d7eac7aa515de07b7a3c5fbe3d0 | 2022-07-27T10:58:34.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | relbert | null | relbert/relbert-roberta-large-conceptnet-hc-average-prompt-d-nce | 5 | null | transformers | 17,646 | Entry not found |
Frikallo/Dodo82J | 6d69158f52459e4ee395ff9d2872d965ed579b90 | 2022-07-26T08:24:41.000Z | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-generation | false | Frikallo | null | Frikallo/Dodo82J | 5 | null | transformers | 17,647 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Dodo82J
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Dodo82J
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001372
- train_batch_size: 1
- eval_batch_size: 8
- seed: 3064995158
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.9.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ZedTheUndead/solar_bloom | 4715121ce007544bd9f45794115863083d08768d | 2022-07-26T16:01:58.000Z | [
"pytorch",
"jax",
"bloom",
"feature-extraction",
"ak",
"ar",
"as",
"bm",
"bn",
"ca",
"code",
"en",
"es",
"eu",
"fon",
"fr",
"gu",
"hi",
"id",
"ig",
"ki",
"kn",
"lg",
"ln",
"ml",
"mr",
"ne",
"nso",
"ny",
"or",
"pa",
"pt",
"rn",
"rw",
"sn",
"st",
"sw",
"ta",
"te",
"tn",
"ts",
"tum",
"tw",
"ur",
"vi",
"wo",
"xh",
"yo",
"zh",
"zhs",
"zht",
"zu",
"arxiv:1909.08053",
"arxiv:2110.02861",
"arxiv:2108.12409",
"transformers",
"license:bigscience-bloom-rail-1.0",
"text-generation"
] | text-generation | false | ZedTheUndead | null | ZedTheUndead/solar_bloom | 5 | null | transformers | 17,648 | |
aemami1/distilbert-base-uncased-finetuned-wnli | 115408304dc486dc7461dbef0d29db8c265863a2 | 2022-07-26T17:02:48.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | aemami1 | null | aemami1/distilbert-base-uncased-finetuned-wnli | 5 | null | transformers | 17,649 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-wnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: wnli
metrics:
- name: Accuracy
type: accuracy
value: 0.5492957746478874
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-wnli
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6950
- Accuracy: 0.5493
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 0.6929 | 0.5211 |
| No log | 2.0 | 80 | 0.6951 | 0.4789 |
| No log | 3.0 | 120 | 0.6950 | 0.5493 |
| No log | 4.0 | 160 | 0.6966 | 0.5352 |
| No log | 5.0 | 200 | 0.6966 | 0.5352 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
leokai/distilroberta-base-finetuned-marktextepoch_35 | 9991df368e068cc7b562bab558d6c60ad4428c8a | 2022-07-27T06:17:44.000Z | [
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | leokai | null | leokai/distilroberta-base-finetuned-marktextepoch_35 | 5 | null | transformers | 17,650 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-finetuned-marktextepoch_35
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-marktextepoch_35
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0029
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 35
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.5158 | 1.0 | 1500 | 2.3385 |
| 2.4312 | 2.0 | 3000 | 2.2620 |
| 2.3563 | 3.0 | 4500 | 2.2279 |
| 2.3249 | 4.0 | 6000 | 2.2165 |
| 2.2515 | 5.0 | 7500 | 2.2246 |
| 2.2178 | 6.0 | 9000 | 2.1714 |
| 2.1822 | 7.0 | 10500 | 2.1461 |
| 2.1501 | 8.0 | 12000 | 2.1388 |
| 2.1342 | 9.0 | 13500 | 2.1085 |
| 2.1141 | 10.0 | 15000 | 2.1090 |
| 2.0833 | 11.0 | 16500 | 2.1130 |
| 2.0769 | 12.0 | 18000 | 2.0969 |
| 2.0474 | 13.0 | 19500 | 2.0823 |
| 2.0364 | 14.0 | 21000 | 2.0893 |
| 2.0269 | 15.0 | 22500 | 2.0501 |
| 1.9814 | 16.0 | 24000 | 2.0667 |
| 1.9716 | 17.0 | 25500 | 2.0570 |
| 1.9611 | 18.0 | 27000 | 2.0530 |
| 1.9557 | 19.0 | 28500 | 2.0590 |
| 1.9443 | 20.0 | 30000 | 2.0381 |
| 1.9229 | 21.0 | 31500 | 2.0433 |
| 1.9192 | 22.0 | 33000 | 2.0468 |
| 1.8865 | 23.0 | 34500 | 2.0361 |
| 1.914 | 24.0 | 36000 | 2.0412 |
| 1.867 | 25.0 | 37500 | 2.0165 |
| 1.8724 | 26.0 | 39000 | 2.0152 |
| 1.8644 | 27.0 | 40500 | 2.0129 |
| 1.8685 | 28.0 | 42000 | 2.0183 |
| 1.8458 | 29.0 | 43500 | 2.0082 |
| 1.8653 | 30.0 | 45000 | 1.9939 |
| 1.8584 | 31.0 | 46500 | 2.0015 |
| 1.8396 | 32.0 | 48000 | 1.9924 |
| 1.8399 | 33.0 | 49500 | 2.0102 |
| 1.8363 | 34.0 | 51000 | 1.9946 |
| 1.83 | 35.0 | 52500 | 1.9908 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Evelyn18/roberta-base-spanish-squades-becasIncentivos1 | 2e3736b2be6313a3f611dbcd3ae03a2107ec2c46 | 2022-07-27T03:13:04.000Z | [
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"dataset:becasv2",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | question-answering | false | Evelyn18 | null | Evelyn18/roberta-base-spanish-squades-becasIncentivos1 | 5 | null | transformers | 17,651 | ---
tags:
- generated_from_trainer
datasets:
- becasv2
model-index:
- name: roberta-base-spanish-squades-becasIncentivos1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-spanish-squades-becasIncentivos1
This model is a fine-tuned version of [IIC/roberta-base-spanish-squades](https://huggingface.co/IIC/roberta-base-spanish-squades) on the becasv2 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1943
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 11
- eval_batch_size: 11
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 6 | 2.1580 |
| No log | 2.0 | 12 | 1.7889 |
| No log | 3.0 | 18 | 1.8939 |
| No log | 4.0 | 24 | 2.1401 |
| No log | 5.0 | 30 | 2.1943 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
olemeyer/zero_shot_issue_classification_bart-large-32-b | 8b2e6fd7a9395ab2a7fb1d602fa9174e4dfff673 | 2022-07-27T14:09:29.000Z | [
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | olemeyer | null | olemeyer/zero_shot_issue_classification_bart-large-32-b | 5 | null | transformers | 17,652 | Entry not found |
sheikh/layoutlmv2-finetuned-SLR-test | 07a4fb6b8ca6e8e3a0c16437605ad1cb4e64c9cd | 2022-07-27T06:09:01.000Z | [
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"transformers",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | sheikh | null | sheikh/layoutlmv2-finetuned-SLR-test | 5 | null | transformers | 17,653 | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: layoutlmv2-finetuned-SLR-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-SLR-test
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 8
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Doohae/lassl-electra-720k | d6c886a960ea9d852122abd22d4e39dc51a54f0d | 2022-07-27T06:24:17.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
] | null | false | Doohae | null | Doohae/lassl-electra-720k | 5 | null | transformers | 17,654 | Entry not found |
lisaterumi/genia-biobert-ent2 | db354c3d694a090a36b49fa6c2f6603a2e985787 | 2022-07-27T14:02:12.000Z | [
"pytorch",
"bert",
"token-classification",
"en",
"dataset:Genia",
"transformers",
"autotrain_compatible"
] | token-classification | false | lisaterumi | null | lisaterumi/genia-biobert-ent2 | 5 | null | transformers | 17,655 | ---
language: "en"
widget:
- text: "Point mutation of a GATA-1 site at -230 reduced promoter activity by 37%."
- text: "Electrophoretic mobility shift assays indicated that the -230 GATA-1 site has a relatively low affinity for GATA-1."
- text: "Accordingly, the effects of the constitutively active PKCs were compared to the effects of mutationally activated p21ras."
- text: "Activated Src and p21ras were able to induce CD69 expression."
datasets:
- Genia
---
# Genia-BioBERT-ENT-v2
Nesta versão, as entidades descontinuas são marcadas como uma só.
Exemplo:
```
[['alpha', '-', 'globin'], [17, 18, 22]]
[['beta', '-', 'globin'], [20, 21, 22]]
```
Viram:
```
[['alpha', '-', 'and', 'beta', '-', 'globin'], [17, 18, 19, 20, 21, 22]]
```
Treinado com codigo Thiago no [Colab](https://colab.research.google.com/drive/1lYXwcYcj5k95CGeO2VyFciXwQI6hVD4M#scrollTo=6xIR5mAhZ8TV).
Metricas:
```
precision recall f1-score support
0 0.92 0.93 0.93 17388
1 0.96 0.96 0.96 34980
accuracy 0.95 52368
macro avg 0.94 0.95 0.94 52368
weighted avg 0.95 0.95 0.95 52368
F1: 0.9509454289528652 Accuracy: 0.9509242285365108
```
Parâmetros:
```
nclasses = 3
nepochs = 50 (parou na 10a. epoca pelo early stop)
batch_size = 32
batch_status = 32
learning_rate = 3e-5
early_stop = 5
max_length = 200
checkpoint: dmis-lab/biobert-base-cased-v1.2
```
## Citation
```
coming soon
```
|
jaeyeon/korean-aihub-learning-math-8batch | 9e32cad5ca4f927cd4944bc99b0f54cc10c1ab60 | 2022-07-28T06:51:16.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | jaeyeon | null | jaeyeon/korean-aihub-learning-math-8batch | 5 | null | transformers | 17,656 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: korean-aihub-learning-math-8batch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# korean-aihub-learning-math-8batch
This model is a fine-tuned version of [kresnik/wav2vec2-large-xlsr-korean](https://huggingface.co/kresnik/wav2vec2-large-xlsr-korean) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1867
- Wer: 0.5315
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 20 | 33.1529 | 1.0 |
| No log | 2.0 | 40 | 28.0161 | 1.0 |
| No log | 3.0 | 60 | 8.7324 | 1.0 |
| No log | 4.0 | 80 | 4.9786 | 1.0 |
| 21.6269 | 5.0 | 100 | 4.5335 | 1.0 |
| 21.6269 | 6.0 | 120 | 4.4517 | 1.0 |
| 21.6269 | 7.0 | 140 | 4.4068 | 1.0 |
| 21.6269 | 8.0 | 160 | 4.3210 | 1.0 |
| 21.6269 | 9.0 | 180 | 4.0041 | 0.9932 |
| 4.1788 | 10.0 | 200 | 3.0921 | 0.9712 |
| 4.1788 | 11.0 | 220 | 2.1650 | 0.8603 |
| 4.1788 | 12.0 | 240 | 1.6135 | 0.7192 |
| 4.1788 | 13.0 | 260 | 1.3842 | 0.6466 |
| 4.1788 | 14.0 | 280 | 1.2872 | 0.5918 |
| 1.205 | 15.0 | 300 | 1.2234 | 0.5808 |
| 1.205 | 16.0 | 320 | 1.2694 | 0.6 |
| 1.205 | 17.0 | 340 | 1.2287 | 0.5575 |
| 1.205 | 18.0 | 360 | 1.1776 | 0.5877 |
| 1.205 | 19.0 | 380 | 1.2418 | 0.5671 |
| 0.2825 | 20.0 | 400 | 1.2469 | 0.5616 |
| 0.2825 | 21.0 | 420 | 1.2203 | 0.5425 |
| 0.2825 | 22.0 | 440 | 1.2270 | 0.5863 |
| 0.2825 | 23.0 | 460 | 1.1930 | 0.5548 |
| 0.2825 | 24.0 | 480 | 1.1242 | 0.5521 |
| 0.1831 | 25.0 | 500 | 1.2245 | 0.5575 |
| 0.1831 | 26.0 | 520 | 1.2276 | 0.5342 |
| 0.1831 | 27.0 | 540 | 1.1641 | 0.5205 |
| 0.1831 | 28.0 | 560 | 1.1727 | 0.5329 |
| 0.1831 | 29.0 | 580 | 1.1885 | 0.5534 |
| 0.14 | 30.0 | 600 | 1.1867 | 0.5315 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
SharpAI/mal_tls-bert-base-w1q8 | 775ab52526a78dc9fd35fe1c012cf7db00038a2d | 2022-07-28T07:05:48.000Z | [
"pytorch",
"tf",
"bert",
"text-classification",
"transformers",
"generated_from_keras_callback",
"model-index"
] | text-classification | false | SharpAI | null | SharpAI/mal_tls-bert-base-w1q8 | 5 | null | transformers | 17,657 | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal_tls-bert-base-w1q8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal_tls-bert-base-w1q8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
dnikolic/wav2vec2-xlsr-530-serbian-colab | 8d46a78014020bcf9329eb7e204abb0b115c6e43 | 2022-07-28T14:16:28.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | dnikolic | null | dnikolic/wav2vec2-xlsr-530-serbian-colab | 5 | null | transformers | 17,658 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-xlsr-530-serbian-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xlsr-530-serbian-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Framework versions
- Transformers 4.20.0
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
BramVanroy/bert-base-dutch-cased-hebban-reviews5 | fc8ac9a45b3f6c5c6e259beaa4e87b898883ba8c | 2022-07-29T09:52:36.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"nl",
"dataset:BramVanroy/hebban-reviews",
"transformers",
"sentiment-analysis",
"dutch",
"text",
"license:mit",
"model-index"
] | text-classification | false | BramVanroy | null | BramVanroy/bert-base-dutch-cased-hebban-reviews5 | 5 | null | transformers | 17,659 | ---
datasets:
- BramVanroy/hebban-reviews
language:
- nl
license: mit
metrics:
- accuracy
- f1
- precision
- qwk
- recall
model-index:
- name: bert-base-dutch-cased-hebban-reviews5
results:
- dataset:
config: filtered_rating
name: BramVanroy/hebban-reviews - filtered_rating - 2.0.0
revision: 2.0.0
split: test
type: BramVanroy/hebban-reviews
metrics:
- name: Test accuracy
type: accuracy
value: 0.6071005917159763
- name: Test f1
type: f1
value: 0.6050857981600024
- name: Test precision
type: precision
value: 0.6167698094913165
- name: Test qwk
type: qwk
value: 0.7455315835020534
- name: Test recall
type: recall
value: 0.6071005917159763
task:
name: sentiment analysis
type: text-classification
tags:
- sentiment-analysis
- dutch
- text
widget:
- text: Wauw, wat een leuk boek! Ik heb me er er goed mee vermaakt.
- text: Nee, deze vond ik niet goed. De auteur doet zijn best om je als lezer mee
te trekken in het verhaal maar mij overtuigt het alleszins niet.
- text: Ik vind het niet slecht maar de schrijfstijl trekt me ook niet echt aan. Het
wordt een beetje saai vanaf het vijfde hoofdstuk
---
# bert-base-dutch-cased-hebban-reviews5
# Dataset
- dataset_name: BramVanroy/hebban-reviews
- dataset_config: filtered_rating
- dataset_revision: 2.0.0
- labelcolumn: review_rating0
- textcolumn: review_text_without_quotes
# Training
- optim: adamw_hf
- learning_rate: 5e-05
- per_device_train_batch_size: 64
- per_device_eval_batch_size: 64
- gradient_accumulation_steps: 1
- max_steps: 5001
- save_steps: 500
- metric_for_best_model: qwk
# Best checkedpoint based on validation
- best_metric: 0.736704788874575
- best_model_checkpoint: trained/hebban-reviews5/bert-base-dutch-cased/checkpoint-2000
# Test results of best checkpoint
- accuracy: 0.6071005917159763
- f1: 0.6050857981600024
- precision: 0.6167698094913165
- qwk: 0.7455315835020534
- recall: 0.6071005917159763
## Confusion matric

## Normalized confusion matrix

# Environment
- cuda_capabilities: 8.0; 8.0
- cuda_device_count: 2
- cuda_devices: NVIDIA A100-SXM4-80GB; NVIDIA A100-SXM4-80GB
- finetuner_commit: 8159b4c1d5e66b36f68dd263299927ffb8670ebd
- platform: Linux-4.18.0-305.49.1.el8_4.x86_64-x86_64-with-glibc2.28
- python_version: 3.9.5
- toch_version: 1.10.0
- transformers_version: 4.21.0
|
BramVanroy/robbert-v2-dutch-base-hebban-reviews5 | 6df31850ee3c01a8f3bb2df32f997f7dbfb1d543 | 2022-07-29T09:55:19.000Z | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"nl",
"dataset:BramVanroy/hebban-reviews",
"transformers",
"sentiment-analysis",
"dutch",
"text",
"license:mit",
"model-index"
] | text-classification | false | BramVanroy | null | BramVanroy/robbert-v2-dutch-base-hebban-reviews5 | 5 | null | transformers | 17,660 | ---
datasets:
- BramVanroy/hebban-reviews
language:
- nl
license: mit
metrics:
- accuracy
- f1
- precision
- qwk
- recall
model-index:
- name: robbert-v2-dutch-base-hebban-reviews5
results:
- dataset:
config: filtered_rating
name: BramVanroy/hebban-reviews - filtered_rating - 2.0.0
revision: 2.0.0
split: test
type: BramVanroy/hebban-reviews
metrics:
- name: Test accuracy
type: accuracy
value: 0.624457593688363
- name: Test f1
type: f1
value: 0.625518585787774
- name: Test precision
type: precision
value: 0.6295608657909847
- name: Test qwk
type: qwk
value: 0.7517620387343015
- name: Test recall
type: recall
value: 0.624457593688363
task:
name: sentiment analysis
type: text-classification
tags:
- sentiment-analysis
- dutch
- text
widget:
- text: Wauw, wat een leuk boek! Ik heb me er er goed mee vermaakt.
- text: Nee, deze vond ik niet goed. De auteur doet zijn best om je als lezer mee
te trekken in het verhaal maar mij overtuigt het alleszins niet.
- text: Ik vind het niet slecht maar de schrijfstijl trekt me ook niet echt aan. Het
wordt een beetje saai vanaf het vijfde hoofdstuk
---
# robbert-v2-dutch-base-hebban-reviews5
# Dataset
- dataset_name: BramVanroy/hebban-reviews
- dataset_config: filtered_rating
- dataset_revision: 2.0.0
- labelcolumn: review_rating0
- textcolumn: review_text_without_quotes
# Training
- optim: adamw_hf
- learning_rate: 5e-05
- per_device_train_batch_size: 64
- per_device_eval_batch_size: 64
- gradient_accumulation_steps: 1
- max_steps: 5001
- save_steps: 500
- metric_for_best_model: qwk
# Best checkedpoint based on validation
- best_metric: 0.7480754124116261
- best_model_checkpoint: trained/hebban-reviews5/robbert-v2-dutch-base/checkpoint-3000
# Test results of best checkpoint
- accuracy: 0.624457593688363
- f1: 0.625518585787774
- precision: 0.6295608657909847
- qwk: 0.7517620387343015
- recall: 0.624457593688363
## Confusion matric

## Normalized confusion matrix

# Environment
- cuda_capabilities: 8.0; 8.0
- cuda_device_count: 2
- cuda_devices: NVIDIA A100-SXM4-80GB; NVIDIA A100-SXM4-80GB
- finetuner_commit: 8159b4c1d5e66b36f68dd263299927ffb8670ebd
- platform: Linux-4.18.0-305.49.1.el8_4.x86_64-x86_64-with-glibc2.28
- python_version: 3.9.5
- toch_version: 1.10.0
- transformers_version: 4.21.0
|
asparius/combined | c5f5fee480c4e291731caf8fbe11c262e5e1eb09 | 2022-07-29T15:04:34.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | asparius | null | asparius/combined | 5 | null | transformers | 17,661 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: combined
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# combined
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4197
- Accuracy: 0.8898
- F1: 0.8934
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Anas2000/balu | f04f8d2d1743a7b0307d72c0b629e748319a91fc | 2022-07-29T15:23:03.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | false | Anas2000 | null | Anas2000/balu | 5 | null | transformers | 17,662 | Entry not found |
susghosh/distilbert-base-uncased-finetuned-imdb | 0c300106cd32c3c8d916154893928d5cbf912279 | 2022-07-29T16:32:48.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"dataset:imdb",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | susghosh | null | susghosh/distilbert-base-uncased-finetuned-imdb | 5 | null | transformers | 17,663 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7341
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.9667 | 1.0 | 156 | 2.7795 |
| 2.8612 | 2.0 | 312 | 2.6910 |
| 2.8075 | 3.0 | 468 | 2.7044 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bthomas/testModel2 | 690cfba3e73a4f8607757ba5dd2c4a4ca9207557 | 2022-07-29T16:52:33.000Z | [
"pytorch",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | bthomas | null | bthomas/testModel2 | 5 | null | transformers | 17,664 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: testModel2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.875
- name: F1
type: f1
value: 0.9134125636672327
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testModel2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5316
- Accuracy: 0.875
- F1: 0.9134
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 459 | 0.3961 | 0.8235 | 0.8723 |
| 0.5362 | 2.0 | 918 | 0.4021 | 0.8627 | 0.9070 |
| 0.313 | 3.0 | 1377 | 0.5316 | 0.875 | 0.9134 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.3.2
- Tokenizers 0.11.0
|
hadidev/Vit_roberta_urdu | 65d7a66879ccf4dd69e1ee15f2bb0c48ebf3dfc2 | 2022-07-29T22:43:27.000Z | [
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"transformers",
"license:gpl-3.0"
] | null | false | hadidev | null | hadidev/Vit_roberta_urdu | 5 | null | transformers | 17,665 | ---
license: gpl-3.0
---
|
13048909972/wav2vec2-common_voice-tr-demo | 92c68c2dd3aeb0c9eb5fe79f57bd09e522a1cbbc | 2021-12-09T02:15:30.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | false | 13048909972 | null | 13048909972/wav2vec2-common_voice-tr-demo | 4 | null | transformers | 17,666 | Entry not found |
18811449050/bert_cn_finetuning | dd8621ee740c6bc4fbbc25f24757723bf3a50cf5 | 2021-05-18T17:03:47.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | 18811449050 | null | 18811449050/bert_cn_finetuning | 4 | null | transformers | 17,667 | Entry not found |
AIDA-UPM/bertweet-base-multi-mami | aac32459c38bd7a29ed8aa079172a0c7a12e794c | 2021-12-29T11:45:41.000Z | [
"pytorch",
"roberta",
"text-classification",
"en",
"transformers",
"misogyny",
"license:apache-2.0"
] | text-classification | false | AIDA-UPM | null | AIDA-UPM/bertweet-base-multi-mami | 4 | null | transformers | 17,668 | ---
pipeline_tag: text-classification
tags:
- text-classification
- misogyny
language: en
license: apache-2.0
widget:
- text: "Women wear yoga pants because men don't stare at their personality"
example_title: "Misogyny detection"
---
# bertweet-base-multi-mami
This is a Bertweet model: It maps sentences & paragraphs to a 768 dimensional dense vector space and classifies them into 5 multi labels.
# Multilabels
label2id={
"misogynous": 0,
"shaming": 1,
"stereotype": 2,
"objectification": 3,
"violence": 4,
},
|
AK/ak_nlp | ef5cc2479fb4388e9a49bcbfad935e73b9bccf21 | 2021-05-20T11:39:02.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | AK | null | AK/ak_nlp | 4 | null | transformers | 17,669 | Entry not found |
Ahren09/distilbert-base-uncased-finetuned-cola | a635cfbf7441a808025f10a0d82c6b87a00d6d2f | 2021-11-28T02:27:26.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | Ahren09 | null | Ahren09/distilbert-base-uncased-finetuned-cola | 4 | null | transformers | 17,670 | Entry not found |
AkshaySg/gramCorrection | 04edb6a4c1ef4f02eaf8d315231f9c5500501929 | 2021-07-15T08:56:11.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | AkshaySg | null | AkshaySg/gramCorrection | 4 | null | transformers | 17,671 | Entry not found |
Aleksandar/bert-srb-base-cased-oscar | 583a406adc3e9c1eccdf1fc72d3375a06a3e8004 | 2021-09-22T12:19:20.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | fill-mask | false | Aleksandar | null | Aleksandar/bert-srb-base-cased-oscar | 4 | null | transformers | 17,672 | ---
tags:
- generated_from_trainer
model_index:
- name: bert-srb-base-cased-oscar
results:
- task:
name: Masked Language Modeling
type: fill-mask
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-srb-base-cased-oscar
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0
- Datasets 1.11.0
- Tokenizers 0.10.1
|
Aleksandar/distilbert-srb-ner-setimes | 2b1db306808207f82b5242ffe53fb8d441d3df7b | 2021-09-22T12:19:29.000Z | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | token-classification | false | Aleksandar | null | Aleksandar/distilbert-srb-ner-setimes | 4 | null | transformers | 17,673 | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model_index:
- name: distilbert-srb-ner-setimes
results:
- task:
name: Token Classification
type: token-classification
metric:
name: Accuracy
type: accuracy
value: 0.9665376552169005
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-srb-ner-setimes
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1838
- Precision: 0.8370
- Recall: 0.8617
- F1: 0.8492
- Accuracy: 0.9665
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 104 | 0.2319 | 0.6668 | 0.7029 | 0.6844 | 0.9358 |
| No log | 2.0 | 208 | 0.1850 | 0.7265 | 0.7508 | 0.7385 | 0.9469 |
| No log | 3.0 | 312 | 0.1584 | 0.7555 | 0.7937 | 0.7741 | 0.9538 |
| No log | 4.0 | 416 | 0.1484 | 0.7644 | 0.8128 | 0.7879 | 0.9571 |
| 0.1939 | 5.0 | 520 | 0.1383 | 0.7850 | 0.8131 | 0.7988 | 0.9604 |
| 0.1939 | 6.0 | 624 | 0.1409 | 0.7914 | 0.8359 | 0.8130 | 0.9632 |
| 0.1939 | 7.0 | 728 | 0.1526 | 0.8176 | 0.8392 | 0.8283 | 0.9637 |
| 0.1939 | 8.0 | 832 | 0.1536 | 0.8195 | 0.8409 | 0.8301 | 0.9641 |
| 0.1939 | 9.0 | 936 | 0.1538 | 0.8242 | 0.8523 | 0.8380 | 0.9661 |
| 0.0364 | 10.0 | 1040 | 0.1612 | 0.8228 | 0.8413 | 0.8319 | 0.9652 |
| 0.0364 | 11.0 | 1144 | 0.1721 | 0.8289 | 0.8503 | 0.8395 | 0.9656 |
| 0.0364 | 12.0 | 1248 | 0.1645 | 0.8301 | 0.8590 | 0.8443 | 0.9663 |
| 0.0364 | 13.0 | 1352 | 0.1747 | 0.8352 | 0.8540 | 0.8445 | 0.9665 |
| 0.0364 | 14.0 | 1456 | 0.1703 | 0.8277 | 0.8573 | 0.8422 | 0.9663 |
| 0.011 | 15.0 | 1560 | 0.1770 | 0.8314 | 0.8624 | 0.8466 | 0.9665 |
| 0.011 | 16.0 | 1664 | 0.1903 | 0.8399 | 0.8537 | 0.8467 | 0.9661 |
| 0.011 | 17.0 | 1768 | 0.1837 | 0.8363 | 0.8590 | 0.8475 | 0.9665 |
| 0.011 | 18.0 | 1872 | 0.1820 | 0.8338 | 0.8570 | 0.8453 | 0.9667 |
| 0.011 | 19.0 | 1976 | 0.1855 | 0.8382 | 0.8620 | 0.8499 | 0.9666 |
| 0.0053 | 20.0 | 2080 | 0.1838 | 0.8370 | 0.8617 | 0.8492 | 0.9665 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0
- Datasets 1.11.0
- Tokenizers 0.10.1
|
Alerosae/SocratesGPT-2 | 38449e4d6b86ddf4db3a010aef572eee4a899bac | 2021-12-20T12:36:38.000Z | [
"pytorch",
"gpt2",
"feature-extraction",
"en",
"transformers",
"text-generation"
] | text-generation | false | Alerosae | null | Alerosae/SocratesGPT-2 | 4 | null | transformers | 17,674 | ---
language: "en"
tags:
- text-generation
pipeline_tag: text-generation
widget:
- text: "The Gods"
- text: "What is"
---
This is a fine-tuned version of GPT-2, trained with the entire corpus of Plato's works. By generating text samples you should be able to generate ancient Greek philosophy on the fly!
|
Alexander-Learn/bert-finetuned-squad | 4a8f1adebf1f241f0f14682ea3d44f950b31dabc | 2022-01-29T09:16:44.000Z | [
"pytorch",
"tensorboard",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | Alexander-Learn | null | Alexander-Learn/bert-finetuned-squad | 4 | null | transformers | 17,675 | Entry not found |
Alireza1044/albert-base-v2-cola | 7b3d1e47bc6ad26f49e79ccd3bfb56bf1179528e | 2021-07-25T16:25:10.000Z | [
"pytorch",
"tensorboard",
"albert",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | text-classification | false | Alireza1044 | null | Alireza1044/albert-base-v2-cola | 4 | null | transformers | 17,676 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model_index:
- name: cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE COLA
type: glue
args: cola
metric:
name: Matthews Correlation
type: matthews_correlation
value: 0.5494768667363472
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cola
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7552
- Matthews Correlation: 0.5495
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
### Training results
### Framework versions
- Transformers 4.9.0
- Pytorch 1.9.0+cu102
- Datasets 1.10.2
- Tokenizers 0.10.3
|
Alireza1044/albert-base-v2-qqp | 529530efc4e7a27c184e280e7e31dc1177c2c229 | 2021-07-28T02:04:17.000Z | [
"pytorch",
"albert",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | text-classification | false | Alireza1044 | null | Alireza1044/albert-base-v2-qqp | 4 | null | transformers | 17,677 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model_index:
- name: qqp
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QQP
type: glue
args: qqp
metric:
name: F1
type: f1
value: 0.8722569490623753
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qqp
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3695
- Accuracy: 0.9050
- F1: 0.8723
- Combined Score: 0.8886
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
### Training results
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.10.2
- Tokenizers 0.10.3
|
Alireza1044/bert_classification_lm | e44960e937ebbd66268001dc99b679e195ece584 | 2021-07-09T08:50:58.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | Alireza1044 | null | Alireza1044/bert_classification_lm | 4 | null | transformers | 17,678 | A simple model trained on dialogues of characters in NBC series, `The Office`. The model can do a binary classification between `Michael Scott` and `Dwight Shrute`'s dialogues.
<style type="text/css">
.tg {border-collapse:collapse;border-spacing:0;}
.tg td{border-color:black;border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg th{border-color:black;border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;
font-weight:normal;overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:top}
</style>
<table class="tg">
<thead>
<tr>
<th class="tg-c3ow" colspan="2">Label Definitions</th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-c3ow">Label 0</td>
<td class="tg-c3ow">Michael</td>
</tr>
<tr>
<td class="tg-c3ow">Label 1</td>
<td class="tg-c3ow">Dwight</td>
</tr>
</tbody>
</table> |
Amalq/distilbert-base-uncased-finetuned-cola | a94ca7df7aa7c1bb797bd84249e125e2c9fa1937 | 2022-02-11T20:25:53.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | Amalq | null | Amalq/distilbert-base-uncased-finetuned-cola | 4 | null | transformers | 17,679 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5335074704896392
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7570
- Matthews Correlation: 0.5335
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5315 | 1.0 | 535 | 0.5214 | 0.4009 |
| 0.354 | 2.0 | 1070 | 0.5275 | 0.4857 |
| 0.2396 | 3.0 | 1605 | 0.6610 | 0.4901 |
| 0.1825 | 4.0 | 2140 | 0.7570 | 0.5335 |
| 0.1271 | 5.0 | 2675 | 0.8923 | 0.5074 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
Anamika/autonlp-fa-473312409 | 30f4541f49f67d3887c5f2161a2513c6a2741e55 | 2022-01-04T20:08:00.000Z | [
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:Anamika/autonlp-data-fa",
"transformers",
"autonlp",
"co2_eq_emissions"
] | text-classification | false | Anamika | null | Anamika/autonlp-fa-473312409 | 4 | null | transformers | 17,680 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- Anamika/autonlp-data-fa
co2_eq_emissions: 25.128735714898614
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 473312409
- CO2 Emissions (in grams): 25.128735714898614
## Validation Metrics
- Loss: 0.6010786890983582
- Accuracy: 0.7990650945370823
- Macro F1: 0.7429662929144928
- Micro F1: 0.7990650945370823
- Weighted F1: 0.7977660363770382
- Macro Precision: 0.7744390888231261
- Micro Precision: 0.7990650945370823
- Weighted Precision: 0.800444194278352
- Macro Recall: 0.7198278524814119
- Micro Recall: 0.7990650945370823
- Weighted Recall: 0.7990650945370823
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/Anamika/autonlp-fa-473312409
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("Anamika/autonlp-fa-473312409", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Anamika/autonlp-fa-473312409", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
Andrija/SRoBERTa-F | 0756a2b34ebbb89e8e344e90b6945f207c4633cd | 2021-10-07T18:53:58.000Z | [
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"hr",
"sr",
"dataset:oscar",
"dataset:srwac",
"dataset:leipzig",
"dataset:cc100",
"dataset:hrwac",
"transformers",
"masked-lm",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | Andrija | null | Andrija/SRoBERTa-F | 4 | null | transformers | 17,681 | ---
datasets:
- oscar
- srwac
- leipzig
- cc100
- hrwac
language:
- hr
- sr
tags:
- masked-lm
widget:
- text: "Ovo je početak <mask>."
license: apache-2.0
---
# Transformer language model for Croatian and Serbian
Trained on 43GB datasets that contain Croatian and Serbian language for one epochs (9.6 mil. steps, 3 epochs).
Leipzig Corpus, OSCAR, srWac, hrWac, cc100-hr and cc100-sr datasets
Validation number of exampels run for perplexity:1620487 sentences
Perplexity:6.02
Start loss: 8.6
Final loss: 2.0
Thoughts: Model could be trained more, the training did not stagnate.
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `Andrija/SRoBERTa-X` | 80M | Fifth | Leipzig Corpus, OSCAR, srWac, hrWac, cc100-hr and cc100-sr (43 GB of text) | |
Andrija/SRoBERTa-L | 41be36386505953338c6ab26986c2b1225e09dda | 2021-08-19T14:11:38.000Z | [
"pytorch",
"roberta",
"fill-mask",
"hr",
"sr",
"dataset:oscar",
"dataset:srwac",
"dataset:leipzig",
"transformers",
"masked-lm",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | Andrija | null | Andrija/SRoBERTa-L | 4 | null | transformers | 17,682 | ---
datasets:
- oscar
- srwac
- leipzig
language:
- hr
- sr
tags:
- masked-lm
widget:
- text: "Ovo je početak <mask>."
license: apache-2.0
---
# Transformer language model for Croatian and Serbian
Trained on 6GB datasets that contain Croatian and Serbian language for two epochs (500k steps).
Leipzig, OSCAR and srWac datasets
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `Andrija/SRoBERTa-L` | 80M | Third | Leipzig Corpus, OSCAR and srWac (6 GB of text) | |
AndyJ/prompt_finetune | 9f06e8b528686a6bbd412ca861e1eceaf3e58902 | 2022-02-17T01:25:00.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | AndyJ | null | AndyJ/prompt_finetune | 4 | null | transformers | 17,683 | Entry not found |
AnonARR/qqp-bert | 4e29cc176eba764a341e5bf18854c634a1334e73 | 2021-11-15T21:25:04.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | AnonARR | null | AnonARR/qqp-bert | 4 | null | transformers | 17,684 | Entry not found |
Anonymous/ReasonBERT-RoBERTa | e913515bb4824cc3dc93bc9b043d7ae5b779fccb | 2021-05-23T02:34:08.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | Anonymous | null | Anonymous/ReasonBERT-RoBERTa | 4 | null | transformers | 17,685 | Pre-trained to have better reasoning ability, try this if you are working with task like QA. For more details please see https://openreview.net/forum?id=cGB7CMFtrSx
This is based on roberta-base model and pre-trained for text input |
AnonymousSub/AR_SDR_HF_model_base | 2ca620015458f285b6d37b67e14f7c477afd6f98 | 2022-01-11T21:48:47.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/AR_SDR_HF_model_base | 4 | null | transformers | 17,686 | Entry not found |
AnonymousSub/AR_rule_based_hier_quadruplet_epochs_1_shard_1 | 2e3de1d312bfc6095360785a4bd7b9fa5b0fdab4 | 2022-01-10T22:20:52.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/AR_rule_based_hier_quadruplet_epochs_1_shard_1 | 4 | null | transformers | 17,687 | Entry not found |
AnonymousSub/AR_rule_based_roberta_bert_quadruplet_epochs_1_shard_1 | 89e8b8ff7aab0d9767610cd76694d424725a6e1e | 2022-01-06T13:53:01.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/AR_rule_based_roberta_bert_quadruplet_epochs_1_shard_1 | 4 | null | transformers | 17,688 | Entry not found |
AnonymousSub/AR_rule_based_roberta_only_classfn_twostage_epochs_1_shard_1 | 32aa0f629e8dd7d331b0f22bd345d113b548d47d | 2022-01-06T10:19:21.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/AR_rule_based_roberta_only_classfn_twostage_epochs_1_shard_1 | 4 | null | transformers | 17,689 | Entry not found |
AnonymousSub/EManuals_BERT_copy | 1f3bfe85464f66377abab7d403eb90f664a09d37 | 2022-01-23T03:44:19.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/EManuals_BERT_copy | 4 | null | transformers | 17,690 | Entry not found |
AnonymousSub/SR_rule_based_hier_triplet_epochs_1_shard_1 | fb39f389cfcf22f3cde561453ab656b95a8b6e0e | 2022-01-11T01:14:35.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/SR_rule_based_hier_triplet_epochs_1_shard_1 | 4 | null | transformers | 17,691 | Entry not found |
AnonymousSub/SR_rule_based_only_classfn_twostage_epochs_1_shard_1 | 8829254d3f63c7a9f304a91ead7811db3a23b484 | 2022-01-10T22:14:11.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | AnonymousSub | null | AnonymousSub/SR_rule_based_only_classfn_twostage_epochs_1_shard_1 | 4 | null | transformers | 17,692 | Entry not found |
AnonymousSub/T5_pubmedqa_question_generation | f463c14de6e70fdec1c8daa698f7199ef50a1472 | 2022-01-06T10:01:25.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | AnonymousSub | null | AnonymousSub/T5_pubmedqa_question_generation | 4 | null | transformers | 17,693 | Entry not found |
AnonymousSub/cline-emanuals-s10-AR | b4c05723f2022daa35316b543f1f7813349672ab | 2021-10-03T02:09:14.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | AnonymousSub | null | AnonymousSub/cline-emanuals-s10-AR | 4 | null | transformers | 17,694 | Entry not found |
AnonymousSub/cline-s10-AR | a313ffbe5b5a453fec3991c5861a8986efffdda2 | 2021-10-03T02:14:07.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | AnonymousSub | null | AnonymousSub/cline-s10-AR | 4 | null | transformers | 17,695 | Entry not found |
AnonymousSub/cline-techqa | 1e0d8e7e3b9e7ab2bc0b87c623627928083b4114 | 2021-09-30T19:09:50.000Z | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | AnonymousSub | null | AnonymousSub/cline-techqa | 4 | null | transformers | 17,696 | Entry not found |
AnonymousSub/cline | ece0cf3cc921815593993dcf910c1198a5f99cf1 | 2021-09-29T17:30:05.000Z | [
"pytorch",
"roberta",
"transformers"
] | null | false | AnonymousSub | null | AnonymousSub/cline | 4 | null | transformers | 17,697 | Entry not found |
AnonymousSub/cline_wikiqa | 4d2dd09531dbe97daa8650264c5bb24e5718394b | 2022-01-23T00:39:46.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | AnonymousSub | null | AnonymousSub/cline_wikiqa | 4 | null | transformers | 17,698 | Entry not found |
AnonymousSub/consert-s10-SR | d830184228681879c0104fd630930403466487e3 | 2021-10-05T14:11:09.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | AnonymousSub | null | AnonymousSub/consert-s10-SR | 4 | null | transformers | 17,699 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.