
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Sebabrata/lmv2-g-pan-143doc-06-12 | 2c06639aac44ec6f299462ce11ffa7dd5d28fd87 | 2022-06-12T18:40:51.000Z | [
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"transformers",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible"
]
| token-classification | false | Sebabrata | null | Sebabrata/lmv2-g-pan-143doc-06-12 | 7 | null | transformers | 14,500 | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: lmv2-g-pan-143doc-06-12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lmv2-g-pan-143doc-06-12
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0443
- Dob Precision: 1.0
- Dob Recall: 1.0
- Dob F1: 1.0
- Dob Number: 27
- Fname Precision: 1.0
- Fname Recall: 0.9643
- Fname F1: 0.9818
- Fname Number: 28
- Name Precision: 0.9630
- Name Recall: 0.9630
- Name F1: 0.9630
- Name Number: 27
- Pan Precision: 1.0
- Pan Recall: 1.0
- Pan F1: 1.0
- Pan Number: 26
- Overall Precision: 0.9907
- Overall Recall: 0.9815
- Overall F1: 0.9860
- Overall Accuracy: 0.9978
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Dob Precision | Dob Recall | Dob F1 | Dob Number | Fname Precision | Fname Recall | Fname F1 | Fname Number | Name Precision | Name Recall | Name F1 | Name Number | Pan Precision | Pan Recall | Pan F1 | Pan Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-------------:|:----------:|:------:|:----------:|:---------------:|:------------:|:--------:|:------------:|:--------------:|:-----------:|:-------:|:-----------:|:-------------:|:----------:|:------:|:----------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 1.274 | 1.0 | 114 | 0.9098 | 0.9310 | 1.0 | 0.9643 | 27 | 0.1481 | 0.1429 | 0.1455 | 28 | 0.1639 | 0.3704 | 0.2273 | 27 | 0.8125 | 1.0 | 0.8966 | 26 | 0.4497 | 0.6204 | 0.5214 | 0.9143 |
| 0.7133 | 2.0 | 228 | 0.5771 | 0.9310 | 1.0 | 0.9643 | 27 | 0.2093 | 0.3214 | 0.2535 | 28 | 0.6562 | 0.7778 | 0.7119 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.6336 | 0.7685 | 0.6946 | 0.9443 |
| 0.4593 | 3.0 | 342 | 0.4018 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8276 | 0.8571 | 0.8421 | 28 | 0.9259 | 0.9259 | 0.9259 | 27 | 1.0 | 1.0 | 1.0 | 26 | 0.9273 | 0.9444 | 0.9358 | 0.9655 |
| 0.3011 | 4.0 | 456 | 0.2638 | 0.9643 | 1.0 | 0.9818 | 27 | 1.0 | 0.9286 | 0.9630 | 28 | 0.9259 | 0.9259 | 0.9259 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.9630 | 0.9630 | 0.9630 | 0.9811 |
| 0.2209 | 5.0 | 570 | 0.2108 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8621 | 0.8929 | 0.8772 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.9286 | 1.0 | 0.9630 | 26 | 0.9204 | 0.9630 | 0.9412 | 0.9811 |
| 0.1724 | 6.0 | 684 | 0.1671 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9286 | 0.9286 | 0.9286 | 28 | 0.8667 | 0.9630 | 0.9123 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9130 | 0.9722 | 0.9417 | 0.9844 |
| 0.1285 | 7.0 | 798 | 0.1754 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8929 | 0.8929 | 0.8929 | 28 | 0.9630 | 0.9630 | 0.9630 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.9455 | 0.9630 | 0.9541 | 0.9788 |
| 0.0999 | 8.0 | 912 | 0.1642 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9615 | 0.8929 | 0.9259 | 28 | 0.9630 | 0.9630 | 0.9630 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.9630 | 0.9630 | 0.9630 | 0.9811 |
| 0.0862 | 9.0 | 1026 | 0.1417 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8966 | 0.9286 | 0.9123 | 28 | 0.8966 | 0.9630 | 0.9286 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.9292 | 0.9722 | 0.9502 | 0.9788 |
| 0.0722 | 10.0 | 1140 | 0.1317 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9630 | 0.9286 | 0.9455 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.9545 | 0.9722 | 0.9633 | 0.9822 |
| 0.0748 | 11.0 | 1254 | 0.1220 | 0.9643 | 1.0 | 0.9818 | 27 | 1.0 | 0.8929 | 0.9434 | 28 | 1.0 | 0.9630 | 0.9811 | 27 | 0.9286 | 1.0 | 0.9630 | 26 | 0.9720 | 0.9630 | 0.9674 | 0.9833 |
| 0.0549 | 12.0 | 1368 | 0.1157 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8966 | 0.9286 | 0.9123 | 28 | 0.8667 | 0.9630 | 0.9123 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9052 | 0.9722 | 0.9375 | 0.9811 |
| 0.0444 | 13.0 | 1482 | 0.1198 | 0.9643 | 1.0 | 0.9818 | 27 | 1.0 | 0.8929 | 0.9434 | 28 | 0.9630 | 0.9630 | 0.9630 | 27 | 0.9630 | 1.0 | 0.9811 | 26 | 0.9720 | 0.9630 | 0.9674 | 0.9811 |
| 0.0371 | 14.0 | 1596 | 0.1082 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8966 | 0.9286 | 0.9123 | 28 | 0.8966 | 0.9630 | 0.9286 | 27 | 0.7879 | 1.0 | 0.8814 | 26 | 0.8824 | 0.9722 | 0.9251 | 0.9833 |
| 0.036 | 15.0 | 1710 | 0.1257 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9630 | 0.9286 | 0.9455 | 28 | 0.9630 | 0.9630 | 0.9630 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9459 | 0.9722 | 0.9589 | 0.9800 |
| 0.0291 | 16.0 | 1824 | 0.0930 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9643 | 0.9643 | 0.9643 | 28 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8667 | 1.0 | 0.9286 | 26 | 0.9386 | 0.9907 | 0.9640 | 0.9900 |
| 0.0267 | 17.0 | 1938 | 0.0993 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9286 | 0.9286 | 0.9286 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.9286 | 1.0 | 0.9630 | 26 | 0.9375 | 0.9722 | 0.9545 | 0.9844 |
| 0.023 | 18.0 | 2052 | 0.1240 | 0.9643 | 1.0 | 0.9818 | 27 | 0.7941 | 0.9643 | 0.8710 | 28 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8387 | 1.0 | 0.9123 | 26 | 0.8843 | 0.9907 | 0.9345 | 0.9800 |
| 0.0379 | 19.0 | 2166 | 0.1154 | 0.9643 | 1.0 | 0.9818 | 27 | 1.0 | 0.9286 | 0.9630 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.9286 | 1.0 | 0.9630 | 26 | 0.9545 | 0.9722 | 0.9633 | 0.9833 |
| 0.0199 | 20.0 | 2280 | 0.1143 | 0.9643 | 1.0 | 0.9818 | 27 | 1.0 | 0.9286 | 0.9630 | 28 | 0.8966 | 0.9630 | 0.9286 | 27 | 0.8667 | 1.0 | 0.9286 | 26 | 0.9292 | 0.9722 | 0.9502 | 0.9844 |
| 0.0256 | 21.0 | 2394 | 0.1175 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8667 | 0.9286 | 0.8966 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.9286 | 1.0 | 0.9630 | 26 | 0.9211 | 0.9722 | 0.9459 | 0.9811 |
| 0.0388 | 22.0 | 2508 | 0.0964 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8966 | 0.9286 | 0.9123 | 28 | 0.9310 | 1.0 | 0.9643 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9217 | 0.9815 | 0.9507 | 0.9855 |
| 0.0334 | 23.0 | 2622 | 0.1186 | 0.9643 | 1.0 | 0.9818 | 27 | 1.0 | 0.9286 | 0.9630 | 28 | 1.0 | 0.9630 | 0.9811 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9633 | 0.9722 | 0.9677 | 0.9833 |
| 0.0134 | 24.0 | 2736 | 0.1193 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9630 | 0.9286 | 0.9455 | 28 | 1.0 | 0.9630 | 0.9811 | 27 | 0.9286 | 1.0 | 0.9630 | 26 | 0.9633 | 0.9722 | 0.9677 | 0.9822 |
| 0.0157 | 25.0 | 2850 | 0.1078 | 1.0 | 1.0 | 1.0 | 27 | 0.9259 | 0.8929 | 0.9091 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9369 | 0.9630 | 0.9498 | 0.9833 |
| 0.0157 | 26.0 | 2964 | 0.0758 | 1.0 | 1.0 | 1.0 | 27 | 0.8929 | 0.8929 | 0.8929 | 28 | 1.0 | 1.0 | 1.0 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9459 | 0.9722 | 0.9589 | 0.9911 |
| 0.0096 | 27.0 | 3078 | 0.0766 | 1.0 | 1.0 | 1.0 | 27 | 0.8929 | 0.8929 | 0.8929 | 28 | 1.0 | 1.0 | 1.0 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9459 | 0.9722 | 0.9589 | 0.9889 |
| 0.0135 | 28.0 | 3192 | 0.0443 | 1.0 | 1.0 | 1.0 | 27 | 1.0 | 0.9643 | 0.9818 | 28 | 0.9630 | 0.9630 | 0.9630 | 27 | 1.0 | 1.0 | 1.0 | 26 | 0.9907 | 0.9815 | 0.9860 | 0.9978 |
| 0.012 | 29.0 | 3306 | 0.1153 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8966 | 0.9286 | 0.9123 | 28 | 0.8667 | 0.9630 | 0.9123 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9052 | 0.9722 | 0.9375 | 0.9822 |
| 0.0069 | 30.0 | 3420 | 0.1373 | 0.9643 | 1.0 | 0.9818 | 27 | 0.8966 | 0.9286 | 0.9123 | 28 | 0.9286 | 0.9630 | 0.9455 | 27 | 0.8966 | 1.0 | 0.9455 | 26 | 0.9211 | 0.9722 | 0.9459 | 0.9777 |
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Pennywise881/distilbert-base-uncased-finetuned-emotion | be547c9a781bdcfb7e76f890de325633573f8773 | 2022-06-13T12:11:59.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | Pennywise881 | null | Pennywise881/distilbert-base-uncased-finetuned-emotion | 7 | null | transformers | 14,501 | Entry not found |
ghadeermobasher/CRAFT-Original-PubMedBERT-512 | a2a603ac54cc1e98f85b198072b5295acffddb84 | 2022-06-14T00:10:03.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Original-PubMedBERT-512 | 7 | null | transformers | 14,502 | Entry not found |
ghadeermobasher/CRAFT-Original-BlueBERT-512 | 0b44315fd69bdb62c3fb14fcab5a5a7b7e164a6f | 2022-06-14T00:04:33.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Original-BlueBERT-512 | 7 | null | transformers | 14,503 | Entry not found |
ghadeermobasher/CRAFT-Modified-BlueBERT-384 | 0df9d8c07d8c723f1874ff26b17ec78a4c0c5304 | 2022-06-13T23:06:51.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Modified-BlueBERT-384 | 7 | null | transformers | 14,504 | Entry not found |
ghadeermobasher/CRAFT-Modified-SciBERT-512 | da1423b23942111e7ceb3f6c2353b6791484706e | 2022-06-14T00:21:12.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Modified-SciBERT-512 | 7 | null | transformers | 14,505 | Entry not found |
ghadeermobasher/BioNLP13-Modified-BlueBERT-512 | 80badaa39d6ece2d64a3fdea9a7c8ee198f730b5 | 2022-06-13T22:12:03.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13-Modified-BlueBERT-512 | 7 | null | transformers | 14,506 | Entry not found |
ghadeermobasher/BioNLP13-Modified-SciBERT-384 | 77cb621ddbd3418d994893d14388b4a472b4c073 | 2022-06-13T22:48:32.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13-Modified-SciBERT-384 | 7 | null | transformers | 14,507 | Entry not found |
ghadeermobasher/BIONLP13CG-CHEM-Chem-Original-BlueBERT-512 | 34f8acb500117515630cc5b4ed7abe2e7771b43e | 2022-06-13T23:22:35.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BIONLP13CG-CHEM-Chem-Original-BlueBERT-512 | 7 | null | transformers | 14,508 | Entry not found |
ghadeermobasher/BIONLP13CG-CHEM-Chem-Original-BioBERT-512 | 3842c6ea9603dac545628123747dfba84073431e | 2022-06-13T23:23:10.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BIONLP13CG-CHEM-Chem-Original-BioBERT-512 | 7 | null | transformers | 14,509 | Entry not found |
ghadeermobasher/BIONLP13CG-CHEM-Chem-Original-SciBERT-384 | 9aa2162c1d9610eb91e370c6523199007cbfbb04 | 2022-06-13T23:59:39.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BIONLP13CG-CHEM-Chem-Original-SciBERT-384 | 7 | null | transformers | 14,510 | Entry not found |
Hermite/DialoGPT-large-hermite | e4af5007c1efeda83fd40e055f11c50f4e6dd6de | 2022-06-14T16:16:12.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | false | Hermite | null | Hermite/DialoGPT-large-hermite | 7 | null | transformers | 14,511 | ---
tags:
- conversational
---
# Hermite DialoGPT Model |
Happyb/distilbert-base-uncased-finetuned-emotion | 0826a4676cd5a297d60e0b40881abfec881f100a | 2022-06-15T07:57:51.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | Happyb | null | Happyb/distilbert-base-uncased-finetuned-emotion | 7 | null | transformers | 14,512 | Entry not found |
ghadeermobasher/BioNLP13CG-Chem-Modified-BioBERT-384 | 2bd86a9d4e034d5012c718a94a0e80df252dd905 | 2022-06-15T10:04:38.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Chem-Modified-BioBERT-384 | 7 | null | transformers | 14,513 | Entry not found |
ghadeermobasher/BioNLP13CG-Chem-Original-BioBERT-384 | d6089c5f7961d7341c62d73e621f10f1c3d720d4 | 2022-06-15T10:35:46.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Chem-Original-BioBERT-384 | 7 | null | transformers | 14,514 | Entry not found |
ghadeermobasher/BioNLP13CG-Chem-Modified-PubMedBERT-384 | f706088251988b27578eb636cae174db586339e8 | 2022-06-15T10:46:53.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Chem-Modified-PubMedBERT-384 | 7 | null | transformers | 14,515 | Entry not found |
ghadeermobasher/BioNLP13CG-Chem-Modified-PubMedBERT-512 | 32b807834ca64acf5b5fd0a7b4dcf9eb54869bc5 | 2022-06-15T12:25:06.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Chem-Modified-PubMedBERT-512 | 7 | null | transformers | 14,516 | Entry not found |
microsoft/swinv2-large-patch4-window12-192-22k | 1695b54afb11e8358082d0a586a0c7b041311a7c | 2022-07-09T06:00:31.000Z | [
"pytorch",
"swinv2",
"transformers"
]
| null | false | microsoft | null | microsoft/swinv2-large-patch4-window12-192-22k | 7 | null | transformers | 14,517 | Entry not found |
ghadeermobasher/BioNLP13CG-Chem-Original-PubMedBERT-512 | 6b903647bf77de58a8d581978b1cfa48a9aa36bf | 2022-06-15T23:08:09.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Chem-Original-PubMedBERT-512 | 7 | null | transformers | 14,518 | Entry not found |
eslamxm/mbert2mbert-finetune-fa | e96f0b9ecdcf7420c36f4b64d0ed87a78d845043 | 2022-06-16T05:28:50.000Z | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:pn_summary",
"transformers",
"summarization",
"fa",
"mbert",
"mbert2mbert",
"Abstractive Summarization",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
]
| summarization | false | eslamxm | null | eslamxm/mbert2mbert-finetune-fa | 7 | null | transformers | 14,519 | ---
tags:
- summarization
- fa
- mbert
- mbert2mbert
- Abstractive Summarization
- generated_from_trainer
datasets:
- pn_summary
model-index:
- name: mbert2mbert-finetune-fa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbert2mbert-finetune-fa
This model is a fine-tuned version of [](https://huggingface.co/) on the pn_summary dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- num_epochs: 5
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ali2066/sentence_bert-base-uncased-finetuned-SENTENCE | b3e8cf12312a11aa7a86d4b896b12b8a80318bbd | 2022-06-16T11:57:45.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | ali2066 | null | ali2066/sentence_bert-base-uncased-finetuned-SENTENCE | 7 | null | transformers | 14,520 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: sentence_bert-base-uncased-finetuned-SENTENCE
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentence_bert-base-uncased-finetuned-SENTENCE
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4834
- Precision: 0.8079
- Recall: 1.0
- F1: 0.8938
- Accuracy: 0.8079
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 13 | 0.3520 | 0.8889 | 1.0 | 0.9412 | 0.8889 |
| No log | 2.0 | 26 | 0.3761 | 0.8889 | 1.0 | 0.9412 | 0.8889 |
| No log | 3.0 | 39 | 0.3683 | 0.8889 | 1.0 | 0.9412 | 0.8889 |
| No log | 4.0 | 52 | 0.3767 | 0.8889 | 1.0 | 0.9412 | 0.8889 |
| No log | 5.0 | 65 | 0.3834 | 0.8889 | 1.0 | 0.9412 | 0.8889 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
|
Suva/uptag-url-model-v2 | 0ceb50d5e0a0fc646fa0a68df7b62eb74185124b | 2022-06-22T05:48:40.000Z | [
"pytorch",
"t5",
"text2text-generation",
"dataset:arxiv",
"transformers",
"license:mit",
"autotrain_compatible"
]
| text2text-generation | false | Suva | null | Suva/uptag-url-model-v2 | 7 | null | transformers | 14,521 | ---
datasets:
- arxiv
widget:
- text: "summarize: We describe a system called Overton, whose main design goal is to support engineers in building, monitoring, and improving production
machinelearning systems. Key challenges engineers face are monitoring fine-grained quality, diagnosing errors in sophisticated applications, and
handling contradictory or incomplete supervision data. Overton automates the life cycle of model construction, deployment, and monitoring by providing a set of novel high-level, declarative abstractions. Overton's vision is to shift developers to these higher-level tasks instead of lower-level machine learning tasks.
In fact, using Overton, engineers can build deep-learning-based applications without writing any code in frameworks like TensorFlow. For over a year,
Overton has been used in production to support multiple applications in both near-real-time applications and back-of-house processing.
In that time, Overton-based applications have answered billions of queries in multiple languages and processed trillions of records reducing errors
1.7-2.9 times versus production systems."
license: mit
---
## Usage:
```python
abstract = """We describe a system called Overton, whose main design goal is to support engineers in building, monitoring, and improving production
machine learning systems. Key challenges engineers face are monitoring fine-grained quality, diagnosing errors in sophisticated applications, and
handling contradictory or incomplete supervision data. Overton automates the life cycle of model construction, deployment, and monitoring by providing a
set of novel high-level, declarative abstractions. Overton's vision is to shift developers to these higher-level tasks instead of lower-level machine learning tasks.
In fact, using Overton, engineers can build deep-learning-based applications without writing any code in frameworks like TensorFlow. For over a year,
Overton has been used in production to support multiple applications in both near-real-time applications and back-of-house processing. In that time,
Overton-based applications have answered billions of queries in multiple languages and processed trillions of records reducing errors 1.7-2.9 times versus production systems.
"""
```
### Using Transformers🤗
```python
model_name = "Suva/uptag-url-model-v2"
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_ids = tokenizer.encode("summarize: " + abstract, return_tensors="pt", add_special_tokens=True)
generated_ids = model.generate(input_ids=input_ids,num_beams=5,max_length=100,repetition_penalty=2.5,length_penalty=1,early_stopping=True,num_return_sequences=3)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in generated_ids]
print(preds)
# output
["Overton: Building, Deploying, and Monitoring Machine Learning Systems for Engineers",
"Overton: A System for Building, Monitoring, and Improving Production Machine Learning Systems",
"Overton: Building, Monitoring, and Improving Production Machine Learning Systems"]
``` |
ahujaniharika95/tinyroberta-squad2-finetuned-squad | f77b0bb37f9aa05439b0c8499e23183420743a81 | 2022-07-06T10:22:19.000Z | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | ahujaniharika95 | null | ahujaniharika95/tinyroberta-squad2-finetuned-squad | 7 | null | transformers | 14,522 | Entry not found |
raedinkhaled/vit-base-mri | e2a64e0c1a6c11c8082fe295384cb75ff0c37330 | 2022-06-18T03:33:44.000Z | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"dataset:imagefolder",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| image-classification | false | raedinkhaled | null | raedinkhaled/vit-base-mri | 7 | null | transformers | 14,523 | ---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-mri
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: mriDataSet
type: imagefolder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9827025893699549
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-mri
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the mriDataSet dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0453
- Accuracy: 0.9827
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.04 | 0.3 | 500 | 0.0828 | 0.9690 |
| 0.0765 | 0.59 | 1000 | 0.0623 | 0.9750 |
| 0.0479 | 0.89 | 1500 | 0.0453 | 0.9827 |
| 0.0199 | 1.18 | 2000 | 0.0524 | 0.9857 |
| 0.0114 | 1.48 | 2500 | 0.0484 | 0.9861 |
| 0.008 | 1.78 | 3000 | 0.0566 | 0.9852 |
| 0.0051 | 2.07 | 3500 | 0.0513 | 0.9874 |
| 0.0008 | 2.37 | 4000 | 0.0617 | 0.9874 |
| 0.0021 | 2.66 | 4500 | 0.0664 | 0.9870 |
| 0.0005 | 2.96 | 5000 | 0.0639 | 0.9872 |
| 0.001 | 3.25 | 5500 | 0.0644 | 0.9879 |
| 0.0004 | 3.55 | 6000 | 0.0672 | 0.9875 |
| 0.0003 | 3.85 | 6500 | 0.0690 | 0.9879 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
S2312dal/M6_MLM_cross | 9bcb2dd7d6af60627df2196447c05127c26fc9d5 | 2022-06-18T09:44:44.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | S2312dal | null | S2312dal/M6_MLM_cross | 7 | null | transformers | 14,524 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- spearmanr
model-index:
- name: M6_MLM_cross
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# M6_MLM_cross
This model is a fine-tuned version of [S2312dal/M6_MLM](https://huggingface.co/S2312dal/M6_MLM) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0197
- Pearson: 0.9680
- Spearmanr: 0.9098
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 25
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 8.0
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|
| 0.0723 | 1.0 | 131 | 0.0646 | 0.8674 | 0.8449 |
| 0.0433 | 2.0 | 262 | 0.0322 | 0.9475 | 0.9020 |
| 0.0015 | 3.0 | 393 | 0.0197 | 0.9680 | 0.9098 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
nestoralvaro/mt5-small-test-ged-mlsum_max_target_length_10 | 6d4cf4355e64adb57bff92e6bc5c81e31b0d9461 | 2022-06-19T06:39:24.000Z | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"dataset:mlsum",
"transformers",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| summarization | false | nestoralvaro | null | nestoralvaro/mt5-small-test-ged-mlsum_max_target_length_10 | 7 | null | transformers | 14,525 | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
datasets:
- mlsum
metrics:
- rouge
model-index:
- name: mt5-small-test-ged-mlsum_max_target_length_10
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: mlsum
type: mlsum
args: es
metrics:
- name: Rouge1
type: rouge
value: 74.8229
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-test-ged-mlsum_max_target_length_10
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the mlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3341
- Rouge1: 74.8229
- Rouge2: 68.1808
- Rougel: 74.8297
- Rougelsum: 74.8414
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 0.5565 | 1.0 | 33296 | 0.3827 | 69.9041 | 62.821 | 69.8709 | 69.8924 |
| 0.2636 | 2.0 | 66592 | 0.3552 | 72.0701 | 65.4937 | 72.0787 | 72.091 |
| 0.2309 | 3.0 | 99888 | 0.3525 | 72.5071 | 65.8026 | 72.5132 | 72.512 |
| 0.2109 | 4.0 | 133184 | 0.3346 | 74.0842 | 67.4776 | 74.0887 | 74.0968 |
| 0.1972 | 5.0 | 166480 | 0.3398 | 74.6051 | 68.6024 | 74.6177 | 74.6365 |
| 0.1867 | 6.0 | 199776 | 0.3283 | 74.9022 | 68.2146 | 74.9023 | 74.926 |
| 0.1785 | 7.0 | 233072 | 0.3325 | 74.8631 | 68.2468 | 74.8843 | 74.9026 |
| 0.1725 | 8.0 | 266368 | 0.3341 | 74.8229 | 68.1808 | 74.8297 | 74.8414 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Emanuel/mdeberta-v3-base-finetuned-pos | c54d6d34c3964462b7637acd8e5ebff833f6baf8 | 2022-06-18T21:15:47.000Z | [
"pytorch",
"deberta-v2",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
]
| token-classification | false | Emanuel | null | Emanuel/mdeberta-v3-base-finetuned-pos | 7 | null | transformers | 14,526 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: mdeberta-v3-base-finetuned-pos
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mdeberta-v3-base-finetuned-pos
This model is a fine-tuned version of [microsoft/mdeberta-v3-base](https://huggingface.co/microsoft/mdeberta-v3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0887
- Acc: 0.9814
- F1: 0.8861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 439 | 0.0965 | 0.9749 | 0.8471 |
| 0.3317 | 2.0 | 878 | 0.0815 | 0.9783 | 0.8702 |
| 0.0775 | 3.0 | 1317 | 0.0780 | 0.9812 | 0.8825 |
| 0.0568 | 4.0 | 1756 | 0.0769 | 0.9809 | 0.8827 |
| 0.0444 | 5.0 | 2195 | 0.0799 | 0.9811 | 0.8885 |
| 0.0339 | 6.0 | 2634 | 0.0834 | 0.9813 | 0.8821 |
| 0.0278 | 7.0 | 3073 | 0.0845 | 0.9817 | 0.8843 |
| 0.0222 | 8.0 | 3512 | 0.0866 | 0.9814 | 0.8863 |
| 0.0222 | 9.0 | 3951 | 0.0885 | 0.9814 | 0.8862 |
| 0.0188 | 10.0 | 4390 | 0.0887 | 0.9814 | 0.8861 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
huggingtweets/notch | 9bee1a8e6ab9317c7a5d18f07a63263a3d1816a1 | 2022-06-19T17:55:17.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/notch | 7 | null | transformers | 14,527 | ---
language: en
thumbnail: http://www.huggingtweets.com/notch/1655661312216/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1523817638706700288/tVCx9ZP1_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Notch</div>
<div style="text-align: center; font-size: 14px;">@notch</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Notch.
| Data | Notch |
| --- | --- |
| Tweets downloaded | 3248 |
| Retweets | 62 |
| Short tweets | 307 |
| Tweets kept | 2879 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/6thbin0e/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @notch's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/tffryipu) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/tffryipu/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/notch')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Danastos/nq_squad_bert_el_4 | 96d23632566dbf347e7dc6cad41e903e134a4e27 | 2022-06-20T09:42:30.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | Danastos | null | Danastos/nq_squad_bert_el_4 | 7 | null | transformers | 14,528 | Entry not found |
huggingtweets/bts_twt | 9a4efb54896c52baf1e2624151be5c2f15e69d5a | 2022-06-19T23:54:57.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/bts_twt | 7 | null | transformers | 14,529 | ---
language: en
thumbnail: http://www.huggingtweets.com/bts_twt/1655682892675/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1522592324785557504/yllnHgtN_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">방탄소년단</div>
<div style="text-align: center; font-size: 14px;">@bts_twt</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 방탄소년단.
| Data | 방탄소년단 |
| --- | --- |
| Tweets downloaded | 3217 |
| Retweets | 379 |
| Short tweets | 1284 |
| Tweets kept | 1554 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/db6x6xue/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bts_twt's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/28y0ojch) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/28y0ojch/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bts_twt')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Danastos/nq_squad_bert_el_3 | c8ab7c65d252f907fa7051d5992b788c93dd95cf | 2022-06-20T11:31:29.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | Danastos | null | Danastos/nq_squad_bert_el_3 | 7 | null | transformers | 14,530 | Entry not found |
skpawar1305/wav2vec2-base-finetuned-digits | c65994478dfea3b393d65cf17a4ad646aad70418 | 2022-06-22T05:07:10.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"audio-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| audio-classification | false | skpawar1305 | null | skpawar1305/wav2vec2-base-finetuned-digits | 7 | null | transformers | 14,531 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: wav2vec2-base-finetuned-digits
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-digits
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0605
- Accuracy: 0.9846
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4808 | 1.0 | 620 | 0.3103 | 0.9696 |
| 0.1877 | 2.0 | 1240 | 0.1043 | 0.9791 |
| 0.1478 | 3.0 | 1860 | 0.0727 | 0.9827 |
| 0.1611 | 4.0 | 2480 | 0.0644 | 0.9842 |
| 0.0993 | 5.0 | 3100 | 0.0605 | 0.9846 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
skylord/swin-finetuned-food101 | 490c9d67095b36fb709dbd553946e8eb5d97390c | 2022-06-20T14:20:56.000Z | [
"pytorch",
"tensorboard",
"swin",
"image-classification",
"dataset:food101",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| image-classification | false | skylord | null | skylord/swin-finetuned-food101 | 7 | null | transformers | 14,532 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- food101
metrics:
- accuracy
model-index:
- name: swin-finetuned-food101
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: food101
type: food101
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9214257425742575
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-finetuned-food101
This model is a fine-tuned version of [microsoft/swin-base-patch4-window7-224](https://huggingface.co/microsoft/swin-base-patch4-window7-224) on the food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2779
- Accuracy: 0.9214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5646 | 1.0 | 1183 | 0.3937 | 0.8861 |
| 0.3327 | 2.0 | 2366 | 0.3024 | 0.9124 |
| 0.1042 | 3.0 | 3549 | 0.2779 | 0.9214 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Jeevesh8/std_0pnt2_bert_ft_cola-69 | 414b4919d011a6053f839c1c1b6ea5c2a25cf6b6 | 2022-06-21T13:28:15.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | Jeevesh8 | null | Jeevesh8/std_0pnt2_bert_ft_cola-69 | 7 | null | transformers | 14,533 | Entry not found |
Jeevesh8/std_0pnt2_bert_ft_cola-66 | fd95196498775ff6edc971ca4443e105f9b37e12 | 2022-06-21T13:28:47.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | Jeevesh8 | null | Jeevesh8/std_0pnt2_bert_ft_cola-66 | 7 | null | transformers | 14,534 | Entry not found |
M-Chimiste/MiniLM-L-12-StackOverflow | 639ac83b7ba0d4708906c3e8c20cb582c03230bf | 2022-06-21T14:05:35.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | M-Chimiste | null | M-Chimiste/MiniLM-L-12-StackOverflow | 7 | null | transformers | 14,535 | ---
license: apache-2.0
---
# Cross-Encoder for MS Marco
This model is a generic masked language model fine tuned on stack overflow data. It's base pre-trained model was the cross-encoder/ms-marco-MiniLM-L-12-v2 model.
The model can be used for creating vectors for search applications. It was trained to be used in conjunction with a knn search with OpenSearch for a pet project I've been working on. It's easiest to create document embeddings with the flair package as shown below.
## Usage with Transformers
```python
from flair.data import Sentence
from flair.embeddings import TransformerDocumentEmbeddings
sentence = Sentence("Text to be embedded.")
model = TransformerDocumentEmbeddings("model-name")
model.embed(sentence)
embeddings = sentence.embedding
```
|
davidcechak/DNADeberta_finehuman_nontata_promoters | b3a1bfa6462a9d28d7d346eb7c48ee2168e2aae0 | 2022-06-22T21:00:19.000Z | [
"pytorch",
"deberta",
"text-classification",
"transformers"
]
| text-classification | false | davidcechak | null | davidcechak/DNADeberta_finehuman_nontata_promoters | 7 | null | transformers | 14,536 | Entry not found |
shahma/distilbert-base-uncased-finetuned-squad | 99b1eae9dec0fc17d01bc4879ce330fa5521454e | 2022-06-22T07:22:39.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| question-answering | false | shahma | null | shahma/distilbert-base-uncased-finetuned-squad | 7 | null | transformers | 14,537 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Elron/deberta-v3-large-hate | db034e2f0af5354009dfb05671a6253a4aad7641 | 2022-06-22T09:47:20.000Z | [
"pytorch",
"deberta-v2",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
]
| text-classification | false | Elron | null | Elron/deberta-v3-large-hate | 7 | null | transformers | 14,538 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: deberta-v3-large
results: []
---
# deberta-v3-large-sentiment
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on an [tweet_eval](https://huggingface.co/datasets/tweet_eval) dataset.
## Model description
Test set results:
| Model | Emotion | Hate | Irony | Offensive | Sentiment |
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| deberta-v3-large | **86.3** | **61.3** | **87.1** | **86.4** | **73.9** |
| BERTweet | 79.3 | - | 82.1 | 79.5 | 73.4 |
| RoB-RT | 79.5 | 52.3 | 61.7 | 80.5 | 69.3 |
[source:papers_with_code](https://paperswithcode.com/sota/sentiment-analysis-on-tweeteval)
## Intended uses & limitations
Classifying attributes of interest on tweeter like data.
## Training and evaluation data
[tweet_eval](https://huggingface.co/datasets/tweet_eval) dataset.
## Training procedure
Fine tuned and evaluated with [run_glue.py]()
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6362 | 0.18 | 100 | 0.5481 | 0.7197 |
| 0.4264 | 0.36 | 200 | 0.4550 | 0.8008 |
| 0.4174 | 0.53 | 300 | 0.4524 | 0.7868 |
| 0.4197 | 0.71 | 400 | 0.4586 | 0.7918 |
| 0.3819 | 0.89 | 500 | 0.4368 | 0.8078 |
| 0.3558 | 1.07 | 600 | 0.4525 | 0.8068 |
| 0.2982 | 1.24 | 700 | 0.4999 | 0.7928 |
| 0.2885 | 1.42 | 800 | 0.5129 | 0.8108 |
| 0.253 | 1.6 | 900 | 0.5873 | 0.8208 |
| 0.3354 | 1.78 | 1000 | 0.4244 | 0.8178 |
| 0.3083 | 1.95 | 1100 | 0.4853 | 0.8058 |
| 0.2301 | 2.13 | 1200 | 0.7209 | 0.8018 |
| 0.2167 | 2.31 | 1300 | 0.8090 | 0.7778 |
| 0.1863 | 2.49 | 1400 | 0.6812 | 0.8038 |
| 0.2181 | 2.66 | 1500 | 0.6958 | 0.8138 |
| 0.2159 | 2.84 | 1600 | 0.6315 | 0.8118 |
| 0.1828 | 3.02 | 1700 | 0.7173 | 0.8138 |
| 0.1287 | 3.2 | 1800 | 0.9081 | 0.8018 |
| 0.1711 | 3.37 | 1900 | 0.8858 | 0.8068 |
| 0.1598 | 3.55 | 2000 | 0.7878 | 0.8028 |
| 0.1467 | 3.73 | 2100 | 0.9003 | 0.7948 |
| 0.127 | 3.91 | 2200 | 0.9066 | 0.8048 |
| 0.1134 | 4.09 | 2300 | 0.9646 | 0.8118 |
| 0.1017 | 4.26 | 2400 | 0.9778 | 0.8048 |
| 0.085 | 4.44 | 2500 | 1.0529 | 0.8088 |
| 0.0996 | 4.62 | 2600 | 1.0082 | 0.8058 |
| 0.1054 | 4.8 | 2700 | 0.9698 | 0.8108 |
| 0.1375 | 4.97 | 2800 | 0.9334 | 0.8048 |
| 0.0487 | 5.15 | 2900 | 1.1273 | 0.8108 |
| 0.0611 | 5.33 | 3000 | 1.1528 | 0.8058 |
| 0.0668 | 5.51 | 3100 | 1.0148 | 0.8118 |
| 0.0582 | 5.68 | 3200 | 1.1333 | 0.8108 |
| 0.0869 | 5.86 | 3300 | 1.0607 | 0.8088 |
| 0.0623 | 6.04 | 3400 | 1.1880 | 0.8068 |
| 0.0317 | 6.22 | 3500 | 1.2836 | 0.8008 |
| 0.0546 | 6.39 | 3600 | 1.2148 | 0.8058 |
| 0.0486 | 6.57 | 3700 | 1.3348 | 0.8008 |
| 0.0332 | 6.75 | 3800 | 1.3734 | 0.8018 |
| 0.051 | 6.93 | 3900 | 1.2966 | 0.7978 |
| 0.0217 | 7.1 | 4000 | 1.3853 | 0.8048 |
| 0.0109 | 7.28 | 4100 | 1.4803 | 0.8068 |
| 0.0345 | 7.46 | 4200 | 1.4906 | 0.7998 |
| 0.0365 | 7.64 | 4300 | 1.4347 | 0.8028 |
| 0.0265 | 7.82 | 4400 | 1.3977 | 0.8128 |
| 0.0257 | 7.99 | 4500 | 1.3705 | 0.8108 |
| 0.0036 | 8.17 | 4600 | 1.4353 | 0.8168 |
| 0.0269 | 8.35 | 4700 | 1.4826 | 0.8068 |
| 0.0231 | 8.53 | 4800 | 1.4811 | 0.8118 |
| 0.0204 | 8.7 | 4900 | 1.5245 | 0.8028 |
| 0.0263 | 8.88 | 5000 | 1.5123 | 0.8018 |
| 0.0138 | 9.06 | 5100 | 1.5113 | 0.8028 |
| 0.0089 | 9.24 | 5200 | 1.5846 | 0.7978 |
| 0.029 | 9.41 | 5300 | 1.5362 | 0.8008 |
| 0.0058 | 9.59 | 5400 | 1.5759 | 0.8018 |
| 0.0084 | 9.77 | 5500 | 1.5679 | 0.8018 |
| 0.0065 | 9.95 | 5600 | 1.5683 | 0.8028 |
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.9.0
- Datasets 2.2.2
- Tokenizers 0.11.6
|
Mizew/EN-RSK | f2987afdddc608581d83c6608acab260d60d76ea | 2022-06-24T11:13:10.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"en",
"es",
"dataset:Mizew/autotrain-data-rusyn2",
"transformers",
"autotrain",
"translation",
"co2_eq_emissions",
"autotrain_compatible"
]
| translation | false | Mizew | null | Mizew/EN-RSK | 7 | null | transformers | 14,539 | ---
tags:
- autotrain
- translation
language:
- en
- es
datasets:
- Mizew/autotrain-data-rusyn2
co2_eq_emissions: 19.740487511182447
---
# Model Trained Using AutoTrain
- Problem type: Translation
- Model ID: 1018434345
- CO2 Emissions (in grams): 19.740487511182447
## Validation Metrics
- Loss: 0.9978321194648743
- SacreBLEU: 13.8459
- Gen len: 6.0588
## Description
This is a model for the Pannonian Rusyn language, Albeit the data i trained it on also had a bit of Carpathian Rusyn in it, so don't expect the translator give out pure pannonian. and also it's not very good. |
Andyrasika/xlm-roberta-base-finetuned-panx-de | aaf44df2e6344b404767765111c63730d2508c37 | 2022-06-23T04:54:40.000Z | [
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"dataset:xtreme",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
]
| token-classification | false | Andyrasika | null | Andyrasika/xlm-roberta-base-finetuned-panx-de | 7 | 1 | transformers | 14,540 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8588964027959312
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1383
- F1: 0.8589
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2631 | 1.0 | 525 | 0.1596 | 0.8218 |
| 0.1296 | 2.0 | 1050 | 0.1353 | 0.8479 |
| 0.0821 | 3.0 | 1575 | 0.1383 | 0.8589 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
domenicrosati/scibert-finetuned-DAGPap22 | 0825f92bc5c449474af271ace8b20b7113e4ce70 | 2022-06-23T10:50:32.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"model-index"
]
| text-classification | false | domenicrosati | null | domenicrosati/scibert-finetuned-DAGPap22 | 7 | null | transformers | 14,541 | ---
tags:
- text-classification
- generated_from_trainer
model-index:
- name: scibert-finetuned-DAGPap22
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scibert-finetuned-DAGPap22
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
cjbarrie/autotrain-atc | 3e964ae123603afbfea619e575e8578b4f7b2832 | 2022-06-23T08:00:44.000Z | [
"pytorch",
"distilbert",
"text-classification",
"en",
"dataset:cjbarrie/autotrain-data-traintest-sentiment-split",
"transformers",
"autotrain",
"co2_eq_emissions"
]
| text-classification | false | cjbarrie | null | cjbarrie/autotrain-atc | 7 | null | transformers | 14,542 | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- cjbarrie/autotrain-data-traintest-sentiment-split
co2_eq_emissions: 2.288443953210163
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1024534822
- CO2 Emissions (in grams): 2.288443953210163
## Validation Metrics
- Loss: 0.5510443449020386
- Accuracy: 0.7619047619047619
- Precision: 0.6761363636363636
- Recall: 0.7345679012345679
- AUC: 0.7936883912336109
- F1: 0.7041420118343196
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/cjbarrie/autotrain-traintest-sentiment-split-1024534822
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("cjbarrie/autotrain-traintest-sentiment-split-1024534822", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("cjbarrie/autotrain-traintest-sentiment-split-1024534822", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
cjbarrie/autotrain-atc2 | b0088256bc6edcee5b56c6233d9cf9109f3e5a52 | 2022-06-23T08:01:58.000Z | [
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:cjbarrie/autotrain-data-traintest-sentiment-split",
"transformers",
"autotrain",
"co2_eq_emissions"
]
| text-classification | false | cjbarrie | null | cjbarrie/autotrain-atc2 | 7 | null | transformers | 14,543 | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- cjbarrie/autotrain-data-traintest-sentiment-split
co2_eq_emissions: 3.1566482249518177
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1024534825
- CO2 Emissions (in grams): 3.1566482249518177
## Validation Metrics
- Loss: 0.5167999267578125
- Accuracy: 0.7523809523809524
- Precision: 0.7377049180327869
- Recall: 0.5555555555555556
- AUC: 0.8142525600535937
- F1: 0.6338028169014086
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/cjbarrie/autotrain-traintest-sentiment-split-1024534825
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("cjbarrie/autotrain-traintest-sentiment-split-1024534825", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("cjbarrie/autotrain-traintest-sentiment-split-1024534825", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
vaibhavagg303/Bart_for_summarization_2 | 89dc8fb1e6e026f1259c9fe5f0aecd9eddc849c8 | 2022-06-23T17:59:26.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | vaibhavagg303 | null | vaibhavagg303/Bart_for_summarization_2 | 7 | null | transformers | 14,544 | Entry not found |
AlekseyKorshuk/books-short-model | 68fb5e2050ce8960f8b067e53c4b8b9a0499f3ba | 2022-06-24T10:10:19.000Z | [
"pytorch",
"gptj",
"text-generation",
"transformers"
]
| text-generation | false | AlekseyKorshuk | null | AlekseyKorshuk/books-short-model | 7 | 1 | transformers | 14,545 | Entry not found |
Chemsseddine/bert2gpt2_med_v3 | 22c8a6ba607098b04ce1ce3b9b46d318b40450ea | 2022-06-30T20:11:24.000Z | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
]
| text2text-generation | false | Chemsseddine | null | Chemsseddine/bert2gpt2_med_v3 | 7 | null | transformers | 14,546 | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bert2gpt2_med_v3
results: []
---
<img src="https://huggingface.co/Chemsseddine/bert2gpt2_med_fr/resolve/main/logobert2gpt2.png" alt="Map of positive probabilities per country." width="200"/>
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert2gpt2_med_v3
This model is a fine-tuned version of [Chemsseddine/bert2gpt2_med_v2](https://huggingface.co/Chemsseddine/bert2gpt2_med_v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5474
- Rouge1: 31.8871
- Rouge2: 14.4411
- Rougel: 31.6716
- Rougelsum: 31.579
- Gen Len: 22.8412
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 2.5621 | 1.0 | 900 | 1.9724 | 30.3731 | 13.8412 | 29.9606 | 29.9716 | 22.6353 |
| 1.3692 | 2.0 | 1800 | 1.9634 | 29.6409 | 13.7674 | 29.5202 | 29.5207 | 22.5059 |
| 0.8308 | 3.0 | 2700 | 2.1431 | 30.9317 | 14.5594 | 30.8021 | 30.7287 | 22.6118 |
| 0.4689 | 4.0 | 3600 | 2.2970 | 30.1132 | 14.6407 | 29.9657 | 30.0182 | 23.3235 |
| 0.2875 | 5.0 | 4500 | 2.3787 | 30.9378 | 14.7108 | 30.861 | 30.9097 | 22.7529 |
| 0.1564 | 6.0 | 5400 | 2.4137 | 30.5338 | 13.9702 | 30.1252 | 30.1975 | 23.1588 |
| 0.1007 | 7.0 | 6300 | 2.4822 | 30.872 | 14.9353 | 30.835 | 30.7694 | 23.0529 |
| 0.0783 | 8.0 | 7200 | 2.4974 | 29.9825 | 14.1702 | 29.7507 | 29.7271 | 23.1882 |
| 0.0504 | 9.0 | 8100 | 2.5175 | 31.96 | 15.0705 | 31.9669 | 31.9839 | 23.0588 |
| 0.0339 | 10.0 | 9000 | 2.5474 | 31.8871 | 14.4411 | 31.6716 | 31.579 | 22.8412 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
SoDehghan/supmpn-bert-base-uncased | 7cd19c922cfcf0b5bf0538eeba43a3910460a8ae | 2022-06-27T06:39:52.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers",
"license:apache-2.0"
]
| feature-extraction | false | SoDehghan | null | SoDehghan/supmpn-bert-base-uncased | 7 | null | transformers | 14,547 | ---
license: apache-2.0
---
|
Parsa/LD50-prediction | a51d10706addebc0f9dd713ce331b06553cac454 | 2022-06-27T02:34:13.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | Parsa | null | Parsa/LD50-prediction | 7 | null | transformers | 14,548 | Toxicity LD50 prediction (regression model) based on <a href = "https://tdcommons.ai/single_pred_tasks/tox/"> Acute Toxicity LD50 </a> dataset.
For now, for the purpose of prediction, download the model. In the future, an easy colab notebook will be available. |
Moo/kogpt2-proofreader | df3a61eed6bdac4f500db4a5a013532a4101e86e | 2022-06-27T03:25:43.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"license:apache-2.0"
]
| text-generation | false | Moo | null | Moo/kogpt2-proofreader | 7 | null | transformers | 14,549 | ---
license: apache-2.0
---
|
chisun/mt5-small-finetuned-amazon-en-es-accelerate2 | 7640cd720dd3d34b001f132400d5e19464217e86 | 2022-06-27T08:49:35.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | chisun | null | chisun/mt5-small-finetuned-amazon-en-es-accelerate2 | 7 | null | transformers | 14,550 | Entry not found |
BritishLibraryLabs/distilbert-base-cased-fine-tuned-blbooksgenre | f8f28c9933c6bf233a206edd39133aecdeabff9a | 2022-06-27T10:08:45.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"dataset:blbooksgenre",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| fill-mask | false | BritishLibraryLabs | null | BritishLibraryLabs/distilbert-base-cased-fine-tuned-blbooksgenre | 7 | null | transformers | 14,551 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- blbooksgenre
model-index:
- name: distilbert-base-cased-fine-tuned-blbooksgenre
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-fine-tuned-blbooksgenre
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the blbooksgenre dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9631
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.2575 | 1.0 | 6226 | 2.1388 |
| 2.0548 | 2.0 | 12452 | 2.0312 |
| 1.988 | 3.0 | 18678 | 1.9631 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
elliotthwang/t5-small-finetuned-xlsum-chinese-tradition | 2017b16a84971fd58dcc91eea99c36213188cd3e | 2022-06-27T21:51:47.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"dataset:xlsum",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| text2text-generation | false | elliotthwang | null | elliotthwang/t5-small-finetuned-xlsum-chinese-tradition | 7 | null | transformers | 14,552 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xlsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xlsum-chinese-tradition
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xlsum
type: xlsum
args: chinese_traditional
metrics:
- name: Rouge1
type: rouge
value: 0.8887
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xlsum-chinese-tradition
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2061
- Rouge1: 0.8887
- Rouge2: 0.0671
- Rougel: 0.889
- Rougelsum: 0.8838
- Gen Len: 6.8779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.4231 | 1.0 | 2336 | 1.2586 | 0.711 | 0.0528 | 0.7029 | 0.7053 | 7.3368 |
| 1.378 | 2.0 | 4672 | 1.2281 | 0.9688 | 0.05 | 0.9574 | 0.9656 | 7.0392 |
| 1.3567 | 3.0 | 7008 | 1.2182 | 0.9534 | 0.1035 | 0.9531 | 0.9472 | 6.7437 |
| 1.3339 | 4.0 | 9344 | 1.2096 | 0.9969 | 0.0814 | 0.9969 | 0.9938 | 7.4503 |
| 1.3537 | 5.0 | 11680 | 1.2072 | 0.8429 | 0.0742 | 0.8372 | 0.838 | 6.8049 |
| 1.3351 | 6.0 | 14016 | 1.2061 | 0.8887 | 0.0671 | 0.889 | 0.8838 | 6.8779 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
annahaz/xlm-roberta-base-finetuned-misogyny | a9560f18d77d2d75cee28c8aa48a8891b6b5b42d | 2022-06-27T21:20:05.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
]
| text-classification | false | annahaz | null | annahaz/xlm-roberta-base-finetuned-misogyny | 7 | null | transformers | 14,553 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: xlm-roberta-base-finetuned-misogyny
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-misogyny
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7913
- Accuracy: 0.8925
- F1: 0.8280
- Precision: 0.8240
- Recall: 0.8320
- Mae: 0.1075
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Mae |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|:------:|
| 0.328 | 1.0 | 828 | 0.3477 | 0.8732 | 0.7831 | 0.8366 | 0.7359 | 0.1268 |
| 0.273 | 2.0 | 1656 | 0.2921 | 0.8910 | 0.8269 | 0.8171 | 0.8369 | 0.1090 |
| 0.2342 | 3.0 | 2484 | 0.3222 | 0.8834 | 0.8176 | 0.7965 | 0.8398 | 0.1166 |
| 0.2132 | 4.0 | 3312 | 0.3801 | 0.8852 | 0.8223 | 0.7933 | 0.8534 | 0.1148 |
| 0.1347 | 5.0 | 4140 | 0.5474 | 0.8955 | 0.8314 | 0.8346 | 0.8282 | 0.1045 |
| 0.1187 | 6.0 | 4968 | 0.5853 | 0.8886 | 0.8137 | 0.8475 | 0.7825 | 0.1114 |
| 0.0968 | 7.0 | 5796 | 0.6378 | 0.8916 | 0.8267 | 0.8223 | 0.8311 | 0.1084 |
| 0.0533 | 8.0 | 6624 | 0.7397 | 0.8831 | 0.8191 | 0.7899 | 0.8505 | 0.1169 |
| 0.06 | 9.0 | 7452 | 0.8112 | 0.8861 | 0.8224 | 0.7987 | 0.8476 | 0.1139 |
| 0.0287 | 10.0 | 8280 | 0.7913 | 0.8925 | 0.8280 | 0.8240 | 0.8320 | 0.1075 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.9.0+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Aalaa/distilgpt2-finetuned-wikitext2 | 07feec3d0c88d587837f3fa540a80396941cd091 | 2022-06-28T21:26:23.000Z | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-generation | false | Aalaa | null | Aalaa/distilgpt2-finetuned-wikitext2 | 7 | null | transformers | 14,554 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6421
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7602 | 1.0 | 2334 | 3.6669 |
| 3.653 | 2.0 | 4668 | 3.6472 |
| 3.6006 | 3.0 | 7002 | 3.6421 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
gciaffoni/wav2vec2-large-xls-r-300m-it-colab6 | f4ba7cb076ced73066eb8d9ddf6a3742908b3854 | 2022-07-22T14:59:43.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
]
| automatic-speech-recognition | false | gciaffoni | null | gciaffoni/wav2vec2-large-xls-r-300m-it-colab6 | 7 | null | transformers | 14,555 | Entry not found |
Lamine/bert-finetuned-ner2 | 09782e547f3a7ddba31ab82dda1f2c7275828bf0 | 2022-06-28T09:22:42.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | Lamine | null | Lamine/bert-finetuned-ner2 | 7 | null | transformers | 14,556 | Entry not found |
okite97/distilbert-base-uncased-finetuned-emotion | 7bedf2fd1abab1e601f7997982fa206d33c86bcf | 2022-07-23T00:06:28.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | okite97 | null | okite97/distilbert-base-uncased-finetuned-emotion | 7 | null | transformers | 14,557 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9325
- name: F1
type: f1
value: 0.9328468818264821
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1659
- Accuracy: 0.9325
- F1: 0.9328
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1057 | 1.0 | 250 | 0.1865 | 0.9275 | 0.9275 |
| 0.1059 | 2.0 | 500 | 0.1659 | 0.9325 | 0.9328 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
dexay/fNER | 6bc65d0d8f0c0491a1fc3b047e4a18fbaff65717 | 2022-06-29T06:28:17.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | dexay | null | dexay/fNER | 7 | null | transformers | 14,558 | Entry not found |
cwkeam/m-ctc-t-large-lid | 697f6693403448e004f80f3be1fb769c0a95500e | 2022-06-29T08:11:14.000Z | [
"pytorch",
"mctct",
"en",
"dataset:librispeech_asr",
"dataset:common_voice",
"arxiv:2111.00161",
"transformers",
"speech",
"license:apache-2.0"
]
| null | false | cwkeam | null | cwkeam/m-ctc-t-large-lid | 7 | null | transformers | 14,559 | ---
language: en
datasets:
- librispeech_asr
- common_voice
tags:
- speech
license: apache-2.0
---
# M-CTC-T
Massively multilingual speech recognizer from Meta AI. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
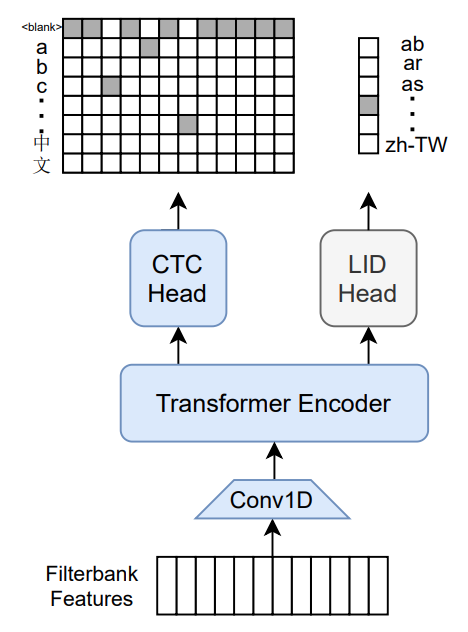
The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl .
## Citation
[Paper](https://arxiv.org/abs/2111.00161)
Authors: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
```
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
```
Additional thanks to [Chan Woo Kim](https://huggingface.co/cwkeam) and [Patrick von Platen](https://huggingface.co/patrickvonplaten) for porting the model from Flashlight to PyTorch.
# Training method
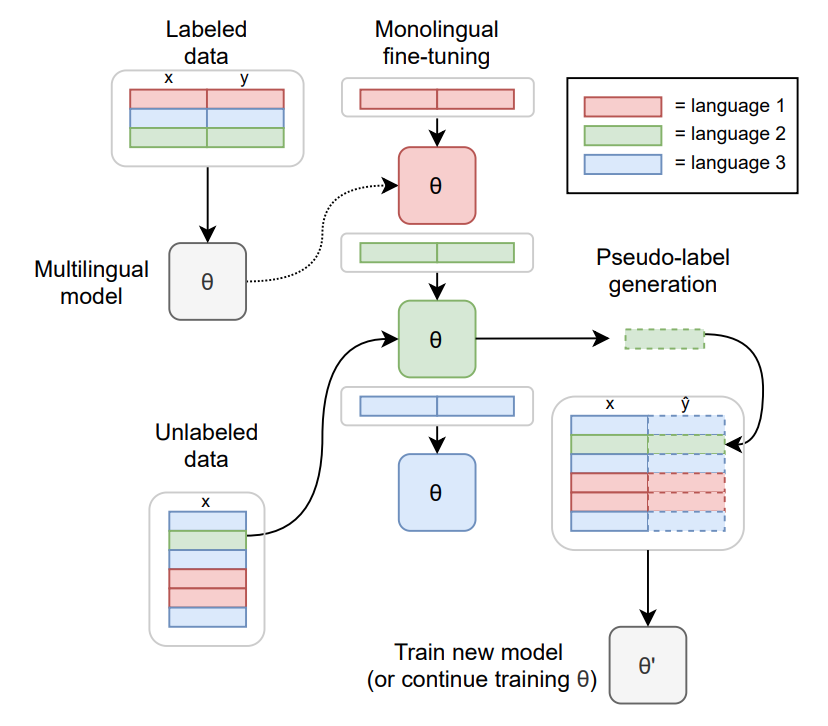 TO-DO: replace with the training diagram from paper
For more information on how the model was trained, please take a look at the [official paper](https://arxiv.org/abs/2111.00161).
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/mctct-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/mctct-large")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_features = processor(ds[0]["audio"]["array"], return_tensors="pt").input_features
# retrieve logits
logits = model(input_features).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
Results for Common Voice, averaged over all languages:
*Character error rate (CER)*:
| Valid | Test |
|-------|------|
| 21.4 | 23.3 |
|
Abonia/finetuning-sentiment-model-3000-samples | 6c78e5636149b7510d4e2d296f284e753edaab19 | 2022-06-29T15:27:48.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:imdb",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | Abonia | null | Abonia/finetuning-sentiment-model-3000-samples | 7 | null | transformers | 14,560 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8766666666666667
- name: F1
type: f1
value: 0.877076411960133
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2991
- Accuracy: 0.8767
- F1: 0.8771
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Shivagowri/vit-snacks | 7d4c06f4fbeb0f5ee3486808ace75b48769a2cf1 | 2022-06-30T06:56:00.000Z | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"dataset:snacks",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| image-classification | false | Shivagowri | null | Shivagowri/vit-snacks | 7 | null | transformers | 14,561 | ---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
datasets:
- snacks
metrics:
- accuracy
model-index:
- name: vit-snacks
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: Matthijs/snacks
type: snacks
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9392670157068063
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-snacks
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the Matthijs/snacks dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2754
- Accuracy: 0.9393
## Model description
upload any image of your fave yummy snack
## Intended uses & limitations
there are only 20 different varieties of snacks
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8724 | 0.33 | 100 | 0.9118 | 0.8670 |
| 0.5628 | 0.66 | 200 | 0.6873 | 0.8471 |
| 0.4421 | 0.99 | 300 | 0.4995 | 0.8691 |
| 0.2837 | 1.32 | 400 | 0.4008 | 0.9026 |
| 0.1645 | 1.65 | 500 | 0.3702 | 0.9058 |
| 0.1604 | 1.98 | 600 | 0.3981 | 0.8921 |
| 0.0498 | 2.31 | 700 | 0.3185 | 0.9204 |
| 0.0406 | 2.64 | 800 | 0.3427 | 0.9141 |
| 0.1049 | 2.97 | 900 | 0.3444 | 0.9173 |
| 0.0272 | 3.3 | 1000 | 0.3168 | 0.9246 |
| 0.0186 | 3.63 | 1100 | 0.3142 | 0.9288 |
| 0.0203 | 3.96 | 1200 | 0.2931 | 0.9298 |
| 0.007 | 4.29 | 1300 | 0.2754 | 0.9393 |
| 0.0072 | 4.62 | 1400 | 0.2778 | 0.9403 |
| 0.0073 | 4.95 | 1500 | 0.2782 | 0.9393 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ghadeermobasher/BioRed-Dis-Original-PubMedBERT-512 | 761e217fdc90f4759a8020cf4d67cf0d9a84cd56 | 2022-06-29T17:56:15.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Original-PubMedBERT-512 | 7 | null | transformers | 14,562 | Entry not found |
Jeevesh8/goog_bert_ft_cola-2 | e5be45949b6c392ca7e1e9e2f895636dc4a1950a | 2022-06-29T17:31:48.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | Jeevesh8 | null | Jeevesh8/goog_bert_ft_cola-2 | 7 | null | transformers | 14,563 | Entry not found |
Gansukh/dlub-2022-mlm-full | e816312e88c9f162b19bfece769a1658a79ed254 | 2022-06-30T03:59:08.000Z | [
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
]
| fill-mask | false | Gansukh | null | Gansukh/dlub-2022-mlm-full | 7 | null | transformers | 14,564 | ---
tags:
- generated_from_trainer
model-index:
- name: dlub-2022-mlm-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dlub-2022-mlm-full
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 8.4321
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 9.7318 | 1.0 | 21 | 9.4453 |
| 9.3594 | 2.0 | 42 | 9.1713 |
| 9.1176 | 3.0 | 63 | 9.0082 |
| 8.9335 | 4.0 | 84 | 8.8166 |
| 8.7735 | 5.0 | 105 | 8.7055 |
| 8.6841 | 6.0 | 126 | 8.6051 |
| 8.6166 | 7.0 | 147 | 8.5337 |
| 8.5258 | 8.0 | 168 | 8.4790 |
| 8.5259 | 9.0 | 189 | 8.4290 |
| 8.4628 | 10.0 | 210 | 8.4321 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
ricardo-filho/bert_base_tcm_0.5 | f9f26c02cd00dec16d30adb04aa000421b35e6a2 | 2022-06-30T19:37:41.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
]
| token-classification | false | ricardo-filho | null | ricardo-filho/bert_base_tcm_0.5 | 7 | null | transformers | 14,565 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: bert_base_tcm_0.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_base_tcm_0.5
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0165
- Criterio Julgamento Precision: 0.7708
- Criterio Julgamento Recall: 0.8740
- Criterio Julgamento F1: 0.8192
- Criterio Julgamento Number: 127
- Data Sessao Precision: 0.7692
- Data Sessao Recall: 0.8571
- Data Sessao F1: 0.8108
- Data Sessao Number: 70
- Modalidade Licitacao Precision: 0.9002
- Modalidade Licitacao Recall: 0.9651
- Modalidade Licitacao F1: 0.9315
- Modalidade Licitacao Number: 430
- Numero Exercicio Precision: 0.8578
- Numero Exercicio Recall: 0.8698
- Numero Exercicio F1: 0.8637
- Numero Exercicio Number: 215
- Objeto Licitacao Precision: 0.4245
- Objeto Licitacao Recall: 0.5488
- Objeto Licitacao F1: 0.4787
- Objeto Licitacao Number: 82
- Valor Objeto Precision: 0.76
- Valor Objeto Recall: 0.8444
- Valor Objeto F1: 0.8
- Valor Objeto Number: 45
- Overall Precision: 0.8098
- Overall Recall: 0.8834
- Overall F1: 0.8450
- Overall Accuracy: 0.9960
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Criterio Julgamento Precision | Criterio Julgamento Recall | Criterio Julgamento F1 | Criterio Julgamento Number | Data Sessao Precision | Data Sessao Recall | Data Sessao F1 | Data Sessao Number | Modalidade Licitacao Precision | Modalidade Licitacao Recall | Modalidade Licitacao F1 | Modalidade Licitacao Number | Numero Exercicio Precision | Numero Exercicio Recall | Numero Exercicio F1 | Numero Exercicio Number | Objeto Licitacao Precision | Objeto Licitacao Recall | Objeto Licitacao F1 | Objeto Licitacao Number | Valor Objeto Precision | Valor Objeto Recall | Valor Objeto F1 | Valor Objeto Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------------------:|:--------------------------:|:----------------------:|:--------------------------:|:---------------------:|:------------------:|:--------------:|:------------------:|:------------------------------:|:---------------------------:|:-----------------------:|:---------------------------:|:--------------------------:|:-----------------------:|:-------------------:|:-----------------------:|:--------------------------:|:-----------------------:|:-------------------:|:-----------------------:|:----------------------:|:-------------------:|:---------------:|:-------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.0257 | 1.0 | 3996 | 0.0197 | 0.7724 | 0.8819 | 0.8235 | 127 | 0.7033 | 0.9143 | 0.7950 | 70 | 0.8820 | 0.9558 | 0.9174 | 430 | 0.8932 | 0.9721 | 0.9310 | 215 | 0.32 | 0.4878 | 0.3865 | 82 | 0.4722 | 0.7556 | 0.5812 | 45 | 0.7679 | 0.8978 | 0.8278 | 0.9952 |
| 0.0159 | 2.0 | 7992 | 0.0212 | 0.7883 | 0.8504 | 0.8182 | 127 | 0.7097 | 0.9429 | 0.8098 | 70 | 0.8551 | 0.9605 | 0.9047 | 430 | 0.9539 | 0.9628 | 0.9583 | 215 | 0.2484 | 0.4756 | 0.3264 | 82 | 0.5797 | 0.8889 | 0.7018 | 45 | 0.7552 | 0.9009 | 0.8216 | 0.9942 |
| 0.0099 | 3.0 | 11988 | 0.0177 | 0.7868 | 0.8425 | 0.8137 | 127 | 0.7439 | 0.8714 | 0.8026 | 70 | 0.8841 | 0.9581 | 0.9196 | 430 | 0.9414 | 0.9721 | 0.9565 | 215 | 0.3333 | 0.5976 | 0.4279 | 82 | 0.6557 | 0.8889 | 0.7547 | 45 | 0.7882 | 0.9061 | 0.8430 | 0.9957 |
| 0.0075 | 4.0 | 15984 | 0.0165 | 0.7708 | 0.8740 | 0.8192 | 127 | 0.7692 | 0.8571 | 0.8108 | 70 | 0.9002 | 0.9651 | 0.9315 | 430 | 0.8578 | 0.8698 | 0.8637 | 215 | 0.4245 | 0.5488 | 0.4787 | 82 | 0.76 | 0.8444 | 0.8 | 45 | 0.8098 | 0.8834 | 0.8450 | 0.9960 |
| 0.0044 | 5.0 | 19980 | 0.0185 | 0.8271 | 0.8661 | 0.8462 | 127 | 0.8529 | 0.8286 | 0.8406 | 70 | 0.8991 | 0.9535 | 0.9255 | 430 | 0.9720 | 0.9674 | 0.9697 | 215 | 0.4324 | 0.5854 | 0.4974 | 82 | 0.6545 | 0.8 | 0.7200 | 45 | 0.8390 | 0.8978 | 0.8674 | 0.9962 |
| 0.0053 | 6.0 | 23976 | 0.0191 | 0.8168 | 0.8425 | 0.8295 | 127 | 0.8148 | 0.9429 | 0.8742 | 70 | 0.8896 | 0.9558 | 0.9215 | 430 | 0.9589 | 0.9767 | 0.9677 | 215 | 0.4032 | 0.6098 | 0.4854 | 82 | 0.7255 | 0.8222 | 0.7708 | 45 | 0.8249 | 0.9092 | 0.8650 | 0.9959 |
| 0.0029 | 7.0 | 27972 | 0.0226 | 0.8102 | 0.8740 | 0.8409 | 127 | 0.8 | 0.9143 | 0.8533 | 70 | 0.8926 | 0.9279 | 0.9099 | 430 | 0.9579 | 0.9535 | 0.9557 | 215 | 0.4519 | 0.5732 | 0.5054 | 82 | 0.7647 | 0.8667 | 0.8125 | 45 | 0.8374 | 0.8927 | 0.8641 | 0.9960 |
| 0.0016 | 8.0 | 31968 | 0.0231 | 0.8268 | 0.8268 | 0.8268 | 127 | 0.7215 | 0.8143 | 0.7651 | 70 | 0.8838 | 0.9372 | 0.9097 | 430 | 0.9498 | 0.9674 | 0.9585 | 215 | 0.4952 | 0.6341 | 0.5561 | 82 | 0.8085 | 0.8444 | 0.8261 | 45 | 0.8354 | 0.8906 | 0.8621 | 0.9964 |
| 0.0023 | 9.0 | 35964 | 0.0248 | 0.8321 | 0.8583 | 0.8450 | 127 | 0.8056 | 0.8286 | 0.8169 | 70 | 0.8969 | 0.9302 | 0.9132 | 430 | 0.9671 | 0.9581 | 0.9626 | 215 | 0.5 | 0.5976 | 0.5444 | 82 | 0.8085 | 0.8444 | 0.8261 | 45 | 0.8540 | 0.8875 | 0.8704 | 0.9963 |
| 0.001 | 10.0 | 39960 | 0.0260 | 0.8308 | 0.8504 | 0.8405 | 127 | 0.8286 | 0.8286 | 0.8286 | 70 | 0.8989 | 0.9302 | 0.9143 | 430 | 0.9717 | 0.9581 | 0.9649 | 215 | 0.51 | 0.6220 | 0.5604 | 82 | 0.8298 | 0.8667 | 0.8478 | 45 | 0.8586 | 0.8896 | 0.8738 | 0.9963 |
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
bayartsogt/roberta-base-ner-demo | 360bf2fa1dc6706fd41bfa7aebc0d81b649bba82 | 2022-07-01T03:54:37.000Z | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"mn",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
]
| token-classification | false | bayartsogt | null | bayartsogt/roberta-base-ner-demo | 7 | null | transformers | 14,566 | ---
language:
- mn
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-ner-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-ner-demo
This model is a fine-tuned version of [bayartsogt/mongolian-roberta-base](https://huggingface.co/bayartsogt/mongolian-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0833
- Precision: 0.8885
- Recall: 0.9070
- F1: 0.8976
- Accuracy: 0.9752
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1666 | 1.0 | 477 | 0.0833 | 0.8885 | 0.9070 | 0.8976 | 0.9752 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Buyandelger/roberta-base-ner-demo | 340861dd9df933fb38018ea4707e4e99bc7a19fc | 2022-07-01T03:58:26.000Z | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"mn",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
]
| token-classification | false | Buyandelger | null | Buyandelger/roberta-base-ner-demo | 7 | null | transformers | 14,567 | ---
language:
- mn
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-ner-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-ner-demo
This model is a fine-tuned version of [bayartsogt/mongolian-roberta-base](https://huggingface.co/bayartsogt/mongolian-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0771
- Precision: 0.8802
- Recall: 0.8951
- F1: 0.8876
- Accuracy: 0.9798
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0336 | 1.0 | 477 | 0.0771 | 0.8802 | 0.8951 | 0.8876 | 0.9798 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
ryo0634/luke-base-embedding_predictor-20181220 | 36f636cf99cf99b41cef5e1fc9d0a776509aaa55 | 2022-07-02T02:05:02.000Z | [
"pytorch",
"luke",
"transformers"
]
| null | false | ryo0634 | null | ryo0634/luke-base-embedding_predictor-20181220 | 7 | null | transformers | 14,568 | Entry not found |
jdang/distilbert-base-uncased-finetuned-emotion | 444bf7c533e794cfcb533e69940d1f9583428c82 | 2022-07-05T13:44:29.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | jdang | null | jdang/distilbert-base-uncased-finetuned-emotion | 7 | null | transformers | 14,569 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9205
- name: F1
type: f1
value: 0.9206916294520199
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2235
- Accuracy: 0.9205
- F1: 0.9207
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8546 | 1.0 | 250 | 0.3252 | 0.906 | 0.9028 |
| 0.2551 | 2.0 | 500 | 0.2235 | 0.9205 | 0.9207 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.11.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Neha2608/xlm-roberta-base-finetuned-panx-all | 26ae3b70c603e85c5c72bc621a9c1b4def0eaa15 | 2022-07-02T13:00:24.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
]
| token-classification | false | Neha2608 | null | Neha2608/xlm-roberta-base-finetuned-panx-all | 7 | null | transformers | 14,570 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1752
- F1: 0.8557
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3 | 1.0 | 835 | 0.1862 | 0.8114 |
| 0.1552 | 2.0 | 1670 | 0.1758 | 0.8426 |
| 0.1002 | 3.0 | 2505 | 0.1752 | 0.8557 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
tner/bertweet-large-tweetner-2020 | 4e520fd9e826a156d07241f339f517f80c0bdfe1 | 2022-07-08T06:26:08.000Z | [
"pytorch",
"roberta",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | tner | null | tner/bertweet-large-tweetner-2020 | 7 | null | transformers | 14,571 | Entry not found |
tner/roberta-base-tweetner-2020 | c0060e794a826edf75563297e7f2843ddfed172a | 2022-07-07T23:33:14.000Z | [
"pytorch",
"roberta",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | tner | null | tner/roberta-base-tweetner-2020 | 7 | null | transformers | 14,572 | Entry not found |
tner/twitter-roberta-base-dec2021-tweetner-2020 | 3a2e4d3c587b2d1d5384cda8aefe4303dc72a3ab | 2022-07-07T10:10:13.000Z | [
"pytorch",
"roberta",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | tner | null | tner/twitter-roberta-base-dec2021-tweetner-2020 | 7 | null | transformers | 14,573 | Entry not found |
Siqi/marian-finetuned-kde4-en-to-fr-2 | bf3d1b9a994b9940e1ef9c04e68ddc309e76d9c8 | 2022-07-03T22:53:13.000Z | [
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"dataset:kde4",
"transformers",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| translation | false | Siqi | null | Siqi/marian-finetuned-kde4-en-to-fr-2 | 7 | null | transformers | 14,574 | ---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-fr-2
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
args: en-fr
metrics:
- name: Bleu
type: bleu
value: 52.932594546181996
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr-2
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8559
- Bleu: 52.9326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
lucataco/DialoGPT-med-geoff | f88dd8a09183ca91d7d7faee9b1ec7b05ea6d465 | 2022-07-03T23:34:44.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | false | lucataco | null | lucataco/DialoGPT-med-geoff | 7 | null | transformers | 14,575 | ---
tags:
- conversational
---
# Geoff Dialog GPT Model Medium 12
# Trained on discord channels:
# Dragalia, casuo chat |
seoyoung/BART_BaseModel | 124805b36e098f4ac80eea296427ef3dab351261 | 2022-07-03T23:56:13.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | seoyoung | null | seoyoung/BART_BaseModel | 7 | null | transformers | 14,576 | Entry not found |
Aktsvigun/bart-base_xsum_705525 | 9fb92ecac6636726a30a88c5099cf8e3f407eda8 | 2022-07-07T14:40:13.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | Aktsvigun | null | Aktsvigun/bart-base_xsum_705525 | 7 | null | transformers | 14,577 | Entry not found |
ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-256-5 | b92efbdfe808fea3753114c32a02ddbd859f25ff | 2022-07-04T10:10:03.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-256-5 | 7 | null | transformers | 14,578 | Entry not found |
ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-256-13 | a4809225781534924edb548911af014854a317ef | 2022-07-04T10:33:54.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-256-13 | 7 | null | transformers | 14,579 | Entry not found |
ghadeermobasher/BioRed-Dis-Original-PubMedBERT-256-5 | 6447e25ad4935f2d4029d8f48de311effcb8d50d | 2022-07-04T10:27:56.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Original-PubMedBERT-256-5 | 7 | null | transformers | 14,580 | Entry not found |
ghadeermobasher/BioRed-Dis-Original-PubMedBERT-256-13 | d47320335c3d46c7eec4337963ccd7f26779deb6 | 2022-07-04T10:41:18.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Original-PubMedBERT-256-13 | 7 | null | transformers | 14,581 | Entry not found |
ghadeermobasher/BioRed-Dis-Original-PubMedBERT-384-8 | 1e0387d2d04e341524f9cb26d516dab22675acdf | 2022-07-04T11:26:29.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Original-PubMedBERT-384-8 | 7 | null | transformers | 14,582 | Entry not found |
ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-384-8 | c5dd08b17a5e819f4c1e5d974531c7f6e784405b | 2022-07-04T11:27:34.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-384-8 | 7 | null | transformers | 14,583 | Entry not found |
ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-320-8 | 31600a9a620376161afb870ce4384a99a2e94f8d | 2022-07-04T13:22:27.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Modified-PubMedBERT-320-8 | 7 | null | transformers | 14,584 | Entry not found |
ghadeermobasher/BioRed-Dis-Original-PubMedBERT-128-32 | e8ff09638cc4b825bf5515f7ca7678ec3a81d561 | 2022-07-04T13:25:51.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Dis-Original-PubMedBERT-128-32 | 7 | null | transformers | 14,585 | Entry not found |
ghadeermobasher/BioRed-Chem-Modified-PubMedBERT-128-32 | bfed117b82bc3ace83f5effec561d8fecc773ee3 | 2022-07-04T13:28:21.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Chem-Modified-PubMedBERT-128-32 | 7 | null | transformers | 14,586 | Entry not found |
ghadeermobasher/BioRed-Chem-Modified-PubMedBERT-128-10 | 09d3a512a5fb4520875a4fec0e944eab165e558f | 2022-07-04T14:32:15.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioRed-Chem-Modified-PubMedBERT-128-10 | 7 | null | transformers | 14,587 | Entry not found |
Samlit/rare-puppers | 3d83792ec87f8aacd2bfbed6031163cd1fc6ebf6 | 2022-07-04T16:51:00.000Z | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
]
| image-classification | false | Samlit | null | Samlit/rare-puppers | 7 | null | transformers | 14,588 | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.4285714328289032
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### Marcelle Lender doing the Bolero in Chilperic

#### Moulin Rouge: La Goulue - Henri Toulouse-Lautrec

#### Salon at the Rue des Moulins - Henri de Toulouse-Lautrec

#### aristide bruant - Henri de Toulouse-Lautrec

#### la goulue - Henri de Toulouse-Lautrec
 |
moonzi/finetuning-sentiment-model-3000-samples | 3a53d8f03fbb657d7f3e1db14e52dd9d077a5d4a | 2022-07-05T03:13:53.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | moonzi | null | moonzi/finetuning-sentiment-model-3000-samples | 7 | null | transformers | 14,589 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3288
- Accuracy: 0.8467
- F1: 0.8544
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Tokenizers 0.12.1
|
tho-clare/autotrain-Text-Generate-1089139622 | 23d9365c2c3d9338483eeb354824d5795fe7ff48 | 2022-07-05T14:47:38.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:tho-clare/autotrain-data-Text-Generate",
"transformers",
"autotrain",
"co2_eq_emissions",
"autotrain_compatible"
]
| text2text-generation | false | tho-clare | null | tho-clare/autotrain-Text-Generate-1089139622 | 7 | null | transformers | 14,590 | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- tho-clare/autotrain-data-Text-Generate
co2_eq_emissions: 7.2566545568791945
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1089139622
- CO2 Emissions (in grams): 7.2566545568791945
## Validation Metrics
- Loss: 2.4398036003112793
- Rouge1: 15.4155
- Rouge2: 6.5786
- RougeL: 12.3257
- RougeLsum: 13.9424
- Gen Len: 19.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/tho-clare/autotrain-Text-Generate-1089139622
``` |
annahaz/distilbert-base-multilingual-cased-finetuned-misogyny-sexism | 8acdcc2fbd12061fd495878997cef0df30e801bf | 2022-07-06T02:53:18.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | annahaz | null | annahaz/distilbert-base-multilingual-cased-finetuned-misogyny-sexism | 7 | null | transformers | 14,591 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: distilbert-base-multilingual-cased-finetuned-misogyny-sexism
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-multilingual-cased-finetuned-misogyny-sexism
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0013
- Accuracy: 0.9995
- F1: 0.9995
- Precision: 0.9989
- Recall: 1.0
- Mae: 0.0005
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Mae |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|:------:|
| 0.301 | 1.0 | 1759 | 0.3981 | 0.8194 | 0.8268 | 0.7669 | 0.8968 | 0.1806 |
| 0.2573 | 2.0 | 3518 | 0.2608 | 0.8887 | 0.8902 | 0.8463 | 0.9389 | 0.1113 |
| 0.1818 | 3.0 | 5277 | 0.1608 | 0.9418 | 0.9426 | 0.8965 | 0.9937 | 0.0582 |
| 0.1146 | 4.0 | 7036 | 0.0667 | 0.9793 | 0.9787 | 0.9652 | 0.9926 | 0.0207 |
| 0.0829 | 5.0 | 8795 | 0.0292 | 0.9924 | 0.9921 | 0.9875 | 0.9968 | 0.0076 |
| 0.059 | 6.0 | 10554 | 0.0221 | 0.9939 | 0.9937 | 0.9916 | 0.9958 | 0.0061 |
| 0.0434 | 7.0 | 12313 | 0.0177 | 0.9954 | 0.9953 | 0.9916 | 0.9989 | 0.0046 |
| 0.0165 | 8.0 | 14072 | 0.0014 | 0.9995 | 0.9995 | 0.9989 | 1.0 | 0.0005 |
| 0.0144 | 9.0 | 15831 | 0.0008 | 0.9995 | 0.9995 | 0.9989 | 1.0 | 0.0005 |
| 0.012 | 10.0 | 17590 | 0.0013 | 0.9995 | 0.9995 | 0.9989 | 1.0 | 0.0005 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.9.0+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Sayan01/tiny-bert-qqp-128-distilled | a0ac7b8ebf3b8d77db29e8561970ca3d104d4b45 | 2022-07-08T01:27:24.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | Sayan01 | null | Sayan01/tiny-bert-qqp-128-distilled | 7 | null | transformers | 14,592 | Entry not found |
sumitrsch/Indic-bert_multiconer22_hi | 7f88bc1db8075fcd2496af0fe0f121ac87519f56 | 2022-07-06T10:00:34.000Z | [
"pytorch",
"albert",
"token-classification",
"transformers",
"license:afl-3.0",
"autotrain_compatible"
]
| token-classification | false | sumitrsch | null | sumitrsch/Indic-bert_multiconer22_hi | 7 | 1 | transformers | 14,593 | ---
license: afl-3.0
---
Put this model path in variable best_model_path in first cell of given colab notebook for testing semeval multiconer task. https://colab.research.google.com/drive/17WyqwdoRNnzImeik6wTRE5uuj9QQnkXA#scrollTo=nYtUtmyDFAqP |
paola-md/recipe-distilbert-is | 1d03c901c6d880f8fec8975c7c1d7345b3d3d85e | 2022-07-07T08:34:16.000Z | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| fill-mask | false | paola-md | null | paola-md/recipe-distilbert-is | 7 | null | transformers | 14,594 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: recipe-distilbert-is
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# recipe-distilbert-is
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0558
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.9409 | 1.0 | 1 | 4.0558 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ltrctelugu/tree_topconstituents | 3340ffb20aa6891279480a2e9712f918a0511db7 | 2022-07-06T23:02:06.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | ltrctelugu | null | ltrctelugu/tree_topconstituents | 7 | null | transformers | 14,595 | hello
|
Aktsvigun/bart-base_aeslc_3878022 | 6513a339d9a39a1a2f410b7d96a939f8d4c07e5f | 2022-07-07T15:18:11.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | Aktsvigun | null | Aktsvigun/bart-base_aeslc_3878022 | 7 | null | transformers | 14,596 | Entry not found |
Aktsvigun/bart-base_aeslc_9467153 | f4149ea0ec1f254b7cac5feca95a4d36fcbfb325 | 2022-07-07T15:34:51.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | Aktsvigun | null | Aktsvigun/bart-base_aeslc_9467153 | 7 | null | transformers | 14,597 | Entry not found |
huggingtweets/joviex | e19e1e8d6d791d8cc441b8da39d84a223405d9fa | 2022-07-07T01:05:09.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/joviex | 7 | null | transformers | 14,598 | ---
language: en
thumbnail: http://www.huggingtweets.com/joviex/1657155904240/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1481464434123894785/YmWpO9TE_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">lɐǝɹ sı ǝʌıʇɔǝdsɹǝd</div>
<div style="text-align: center; font-size: 14px;">@joviex</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from lɐǝɹ sı ǝʌıʇɔǝdsɹǝd.
| Data | lɐǝɹ sı ǝʌıʇɔǝdsɹǝd |
| --- | --- |
| Tweets downloaded | 3248 |
| Retweets | 36 |
| Short tweets | 259 |
| Tweets kept | 2953 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2xrk357z/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @joviex's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/25r2lx70) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/25r2lx70/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/joviex')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aktsvigun/bart-base_aeslc_5537116 | 3253455e50ab652b693b76bb1924d3aa386a830b | 2022-07-07T15:06:11.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | Aktsvigun | null | Aktsvigun/bart-base_aeslc_5537116 | 7 | null | transformers | 14,599 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.